|
| 1 | +# 哈弗曼编码 |
| 2 | + |
| 3 | +## 1. 哈夫曼编码(Huffman Coding) |
| 4 | + |
| 5 | +>哈夫曼编码,又称为霍夫曼编码,它是现代压缩算法的基础 |
| 6 | + |
| 7 | +问题引入:假设要把字符串`【ABBBCCCCCCCCDDDDDDEE】`转成二进制编码进行传输,怎么办? |
| 8 | + |
| 9 | +可以转成ASCII编码(65~69,1000001~1000101),但是有点冗长,如果希望编码更短呢? |
| 10 | + |
| 11 | +可以先约定5个字母对应的二进制 |
| 12 | + |
| 13 | +| A | B | C | D | E | |
| 14 | +| ---- | ---- | ---- | ---- | ---- | |
| 15 | +| 000 | 001 | 010 | 011 | 100 | |
| 16 | + |
| 17 | +- 对应的二进制编码:`000`**001001001**`010010010010010010010010`**011011011011011011**100100 |
| 18 | +- 一共20个字母,转成了60个二进制位 |
| 19 | + |
| 20 | +>如果我们不按照固定位数进行编码,压缩效率会更高。但是这样会存在一些问题,比如有些字母的二进制位可能是其他编码的`前缀`,在解析的时候会存在问题 |
| 21 | + |
| 22 | +如果使用哈夫曼编码,可以压缩至41个二进制位,约为原来长度的`68.3%` |
| 23 | + |
| 24 | +先计算出每个字母的出现频率(权值,这里直接用出现次数),`【ABBBCCCCCCCCDDDDDDEE】` |
| 25 | + |
| 26 | +| A | B | C | D | E | |
| 27 | +| ---- | ---- | ---- | ---- | ---- | |
| 28 | +| 1 | 3 | 8 | 6 | 2 | |
| 29 | + |
| 30 | +利用这些权值,构建一棵哈夫曼树(又称为霍夫曼树、最优二叉树) |
| 31 | + |
| 32 | +>那么如何构建一棵哈夫曼树呢?(假设有n个权值) |
| 33 | +> |
| 34 | +>1. 以权值作为根节点构建 n 棵二叉树,组成森林 |
| 35 | +>2. 在森林中选出 2 个根节点最小的树合并,作为一棵新树的左右子树,且新树的根节点为其左右子树根节点之和 |
| 36 | +>3. 从森林中删除刚才选取的 2 棵树,并将新树加入森林 |
| 37 | +>4. 重复 2、3 步骤,直到森林只剩一棵树为止,该树即为哈夫曼树 |
| 38 | + |
| 39 | +## 1.2 编码实例 |
| 40 | + |
| 41 | +我们对上面出现的字母进行哈夫曼树构建 |
| 42 | + |
| 43 | +1. 首先组成森林 |
| 44 | + |
| 45 | +  |
| 46 | + |
| 47 | +2. 找到两个根结点最小的树`A、E`,组成一棵新树,新树根结点的值为`1 + 2 = 3` |
| 48 | + |
| 49 | + 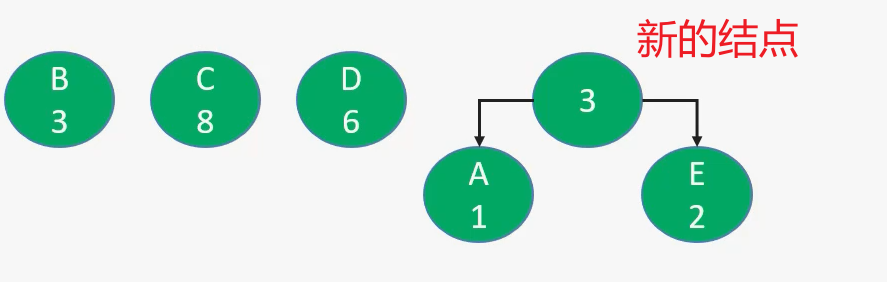 |
| 50 | + |
| 51 | +3. 以此类推 |
| 52 | + |
| 53 | + 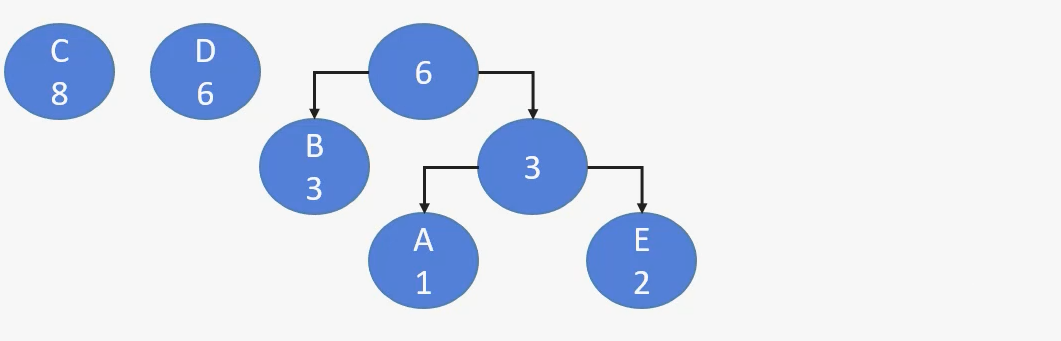 |
| 54 | + |
| 55 | + 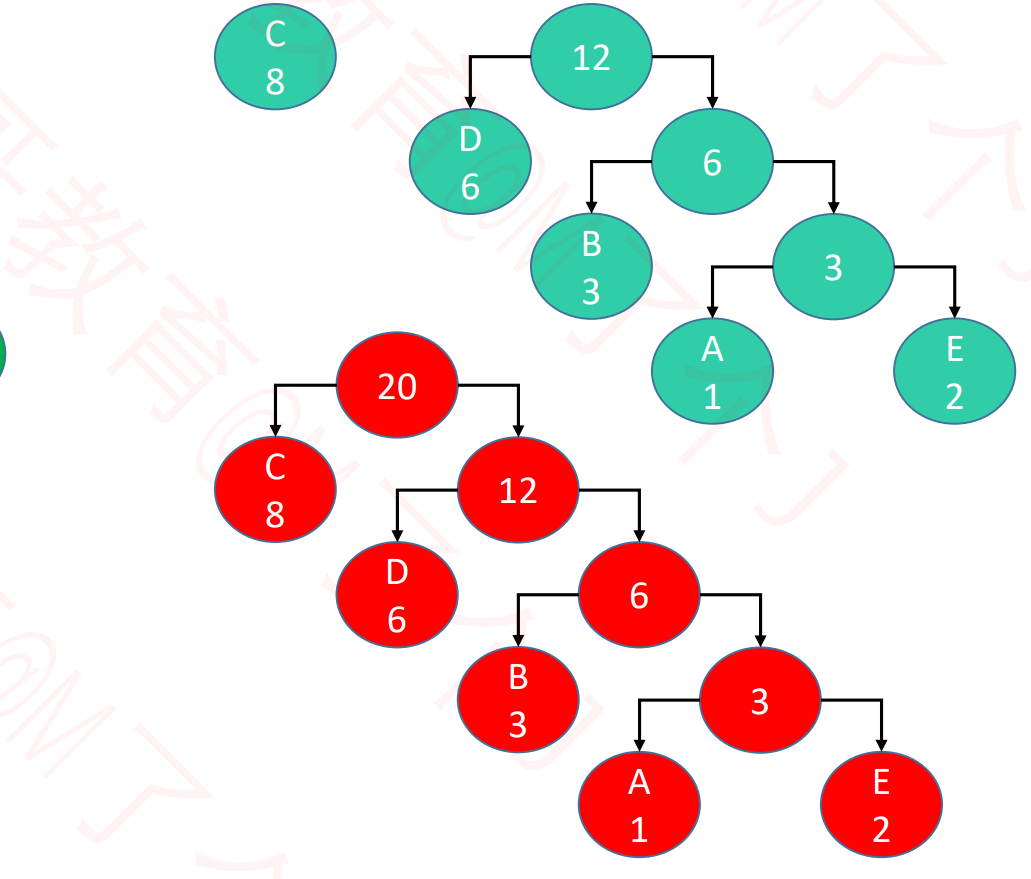 |
| 56 | + |
| 57 | +接下来构建哈夫曼编码 |
| 58 | + |
| 59 | +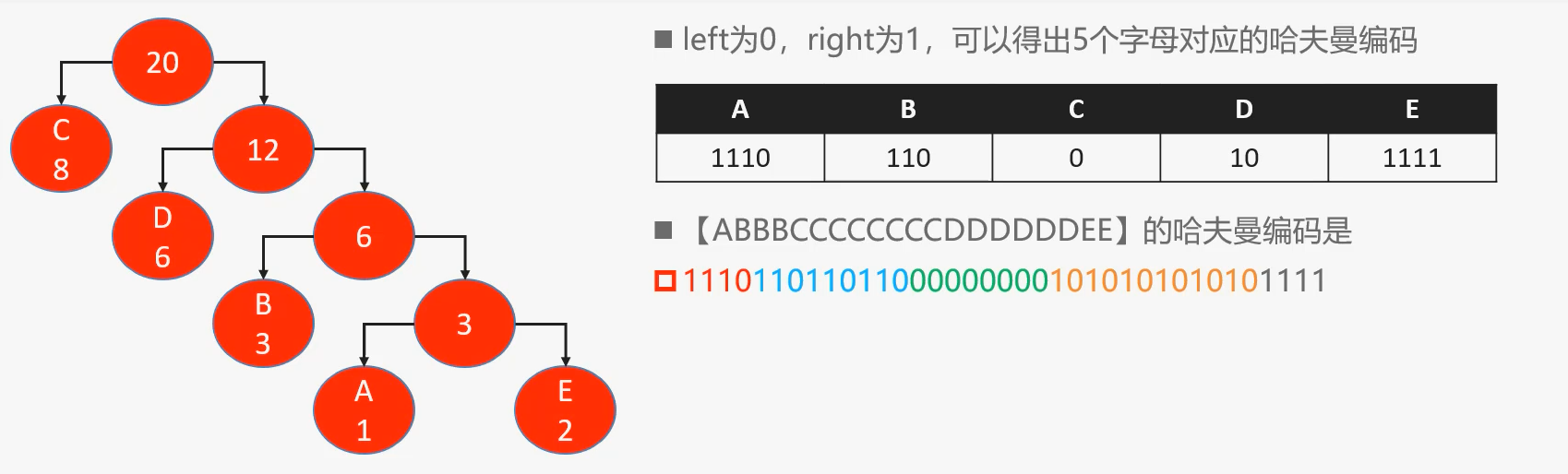 |
| 60 | + |
| 61 | +通过哈夫曼编码的编码有以下特点: |
| 62 | + |
| 63 | +- 出现次数比较多的字母,会用较少bit位来表示 |
| 64 | +- 任意一个字母的编码都不会是其他字母编码的前缀,这个特点让解码时不会出现歧义 |
| 65 | + |
| 66 | +总结: |
| 67 | + |
| 68 | +- n个权值构建出现的哈夫曼树拥有`n`个叶子结点 |
| 69 | +- 每个哈夫曼编码都不是其他哈弗曼编码的前缀(因为我们要编码的结点都是`叶子结点`,而我们的编码其实是根结点到叶子节点的具体路径,**当然不会产生冲突**) |
| 70 | +- 哈夫曼树是`带权路径长度最短的树`,**权值较大的结点离根节点较近** |
| 71 | +- 带权路径长度:树中所有的叶子结点的权值乘上其到根结点的路径长度。**与最终的哈夫曼编码长度成正比关系** |
| 72 | + |
| 73 | +## 1.3 实现哈弗曼编码 |
| 74 | + |
| 75 | +```java |
| 76 | +package com.fx.huffman; |
| 77 | + |
| 78 | +import java.util.Comparator; |
| 79 | +import java.util.HashMap; |
| 80 | +import java.util.PriorityQueue; |
| 81 | +import java.util.Scanner; |
| 82 | + |
| 83 | +/** |
| 84 | + * 哈夫曼编码 |
| 85 | + * |
| 86 | + * @author eureka |
| 87 | + * @since 2023/6/23 13:29 |
| 88 | + */ |
| 89 | + |
| 90 | +class HuffmanNode { |
| 91 | + int data; |
| 92 | + char c; |
| 93 | + HuffmanNode left; |
| 94 | + HuffmanNode right; |
| 95 | +} |
| 96 | + |
| 97 | +class MyComparator implements Comparator<HuffmanNode> { |
| 98 | + public int compare(HuffmanNode x, HuffmanNode y) { |
| 99 | + return x.data - y.data; |
| 100 | + } |
| 101 | +} |
| 102 | + |
| 103 | +public class Huffman { |
| 104 | + |
| 105 | + public static void printCode(HuffmanNode root, String s) { |
| 106 | + if (root.left == null && root.right == null && Character.isLetter(root.c)) { |
| 107 | + System.out.println(root.c + ":" + s); |
| 108 | + return; |
| 109 | + } |
| 110 | + assert root.left != null; |
| 111 | + printCode(root.left, s + "0"); |
| 112 | + printCode(root.right, s + "1"); |
| 113 | + } |
| 114 | + |
| 115 | + public static void main(String[] args) { |
| 116 | + Scanner sc = new Scanner(System.in); |
| 117 | + |
| 118 | + System.out.print("Enter the input string: "); |
| 119 | + String inputString = sc.nextLine(); |
| 120 | + |
| 121 | + HashMap<Character, Integer> freqMap = new HashMap<>(); |
| 122 | + |
| 123 | + for (int i = 0; i < inputString.length(); i++) { |
| 124 | + char c = inputString.charAt(i); |
| 125 | + if (Character.isLetter(c)) { |
| 126 | + freqMap.put(c, freqMap.getOrDefault(c, 0) + 1); |
| 127 | + } |
| 128 | + } |
| 129 | + |
| 130 | + PriorityQueue<HuffmanNode> pq |
| 131 | + = new PriorityQueue<>(new MyComparator()); |
| 132 | + |
| 133 | + for (char c : freqMap.keySet()) { |
| 134 | + HuffmanNode hn = new HuffmanNode(); |
| 135 | + hn.c = c; |
| 136 | + hn.data = freqMap.get(c); |
| 137 | + hn.left = null; |
| 138 | + hn.right = null; |
| 139 | + pq.add(hn); |
| 140 | + } |
| 141 | + |
| 142 | + while (pq.size() > 1) { |
| 143 | + |
| 144 | + HuffmanNode x = pq.peek(); |
| 145 | + pq.poll(); |
| 146 | + |
| 147 | + HuffmanNode y = pq.peek(); |
| 148 | + pq.poll(); |
| 149 | + |
| 150 | + HuffmanNode f = new HuffmanNode(); |
| 151 | + f.data = x.data + y.data; |
| 152 | + f.c = '-'; |
| 153 | + f.left = x; |
| 154 | + f.right = y; |
| 155 | + pq.add(f); |
| 156 | + } |
| 157 | + |
| 158 | + HuffmanNode root = pq.peek(); |
| 159 | + |
| 160 | + printCode(root, ""); |
| 161 | + } |
| 162 | +} |
| 163 | +``` |
| 164 | + |
| 165 | +测试 |
| 166 | + |
| 167 | +```java |
| 168 | +Enter the input string: aaaaabbbbccd |
| 169 | +a:0 |
| 170 | +d:100 |
| 171 | +c:101 |
| 172 | +b:11 |
| 173 | + |
| 174 | +Enter the input string: ABBBCCCCCCCCDDDDDDEE |
| 175 | +C:0 |
| 176 | +D:10 |
| 177 | +B:110 |
| 178 | +A:1110 |
| 179 | +E:1111 |
| 180 | +``` |
| 181 | + |
| 182 | + |
| 183 | + |
| 184 | + |
| 185 | + |
| 186 | + |
| 187 | + |
| 188 | + |
| 189 | + |
| 190 | + |
| 191 | + |
| 192 | + |
| 193 | + |
| 194 | + |
| 195 | + |
| 196 | + |
| 197 | + |
| 198 | + |
| 199 | + |
| 200 | + |
| 201 | + |
| 202 | + |
| 203 | + |
| 204 | + |
| 205 | + |
0 commit comments