|
| 1 | +> 通过startup.sh启动Tomcat后会发生什么呢? |
| 2 | +
|
| 3 | +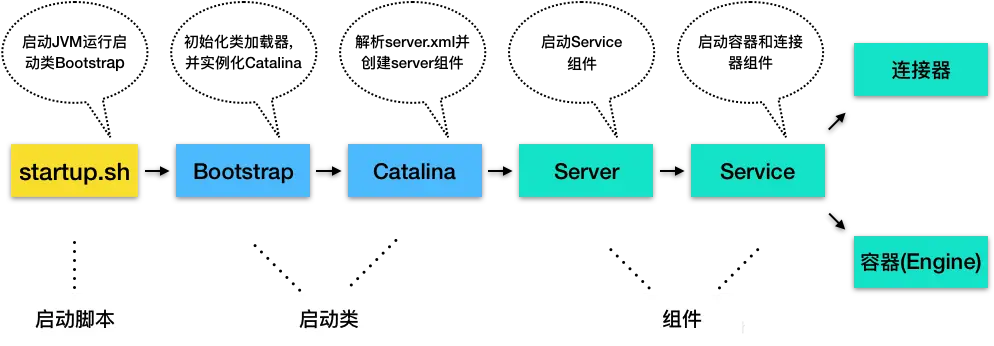 |
| 4 | +1. Tomcat也是Java程序,因此startup.sh脚本会启动一个JVM运行Tomcat的启动类Bootstrap |
| 5 | +2. Bootstrap主要负责初始化Tomcat的类加载器,并创建Catalina |
| 6 | +3. Catalina是个启动类,解析server.xml、创建相应组件,并调用Server#start |
| 7 | +4. Server组件负责管理Service组件,会调用Service#start |
| 8 | +5. Service组件负责管理连接器和顶层容器Engine,因此会调用连接器和Engine的start() |
| 9 | + |
| 10 | +这些启动类或组件不处理具体的请求,它们主要是“管理”,管理下层组件的生命周期,并给下层组件分配任务,即路由请求到应负责的组件。 |
| 11 | +# Catalina |
| 12 | +主要负责创建Server,并非直接new个Server实例就完事了,而是: |
| 13 | +- 解析server.xml,将里面配的各种组件创建出来 |
| 14 | +- 接着调用Server组件的init、start方法,这样整个Tomcat就启动起来了 |
| 15 | + |
| 16 | +Catalina还需要处理各种“异常”,比如当通过“Ctrl + C”关闭Tomcat时, |
| 17 | + |
| 18 | +> Tomcat会如何优雅停止并清理资源呢? |
| 19 | +
|
| 20 | +因此Catalina在JVM中注册一个 **关闭钩子**。 |
| 21 | +```java |
| 22 | +public void start() { |
| 23 | + // 1. 如果持有的Server实例为空,就解析server.xml创建出来 |
| 24 | + if (getServer() == null) { |
| 25 | + load(); |
| 26 | + } |
| 27 | + // 2. 如果创建失败,报错退出 |
| 28 | + if (getServer() == null) { |
| 29 | + log.fatal(sm.getString("catalina.noServer")); |
| 30 | + return; |
| 31 | + } |
| 32 | + |
| 33 | + // 3.启动Server |
| 34 | + try { |
| 35 | + getServer().start(); |
| 36 | + } catch (LifecycleException e) { |
| 37 | + return; |
| 38 | + } |
| 39 | + |
| 40 | + // 创建并注册关闭钩子 |
| 41 | + if (useShutdownHook) { |
| 42 | + if (shutdownHook == null) { |
| 43 | + shutdownHook = new CatalinaShutdownHook(); |
| 44 | + } |
| 45 | + Runtime.getRuntime().addShutdownHook(shutdownHook); |
| 46 | + } |
| 47 | + |
| 48 | + // 监听停止请求 |
| 49 | + if (await) { |
| 50 | + await(); |
| 51 | + stop(); |
| 52 | + } |
| 53 | +} |
| 54 | +``` |
| 55 | +## 关闭钩子 |
| 56 | +若需在JVM关闭时做一些清理,比如: |
| 57 | +- 将缓存数据刷盘 |
| 58 | +- 清理一些临时文件 |
| 59 | + |
| 60 | +就可以向JVM注册一个关闭钩子,其实就是个线程,JVM在停止之前会尝试执行该线程的run()。 |
| 61 | + |
| 62 | +Tomcat的**关闭钩子** 就是CatalinaShutdownHook: |
| 63 | +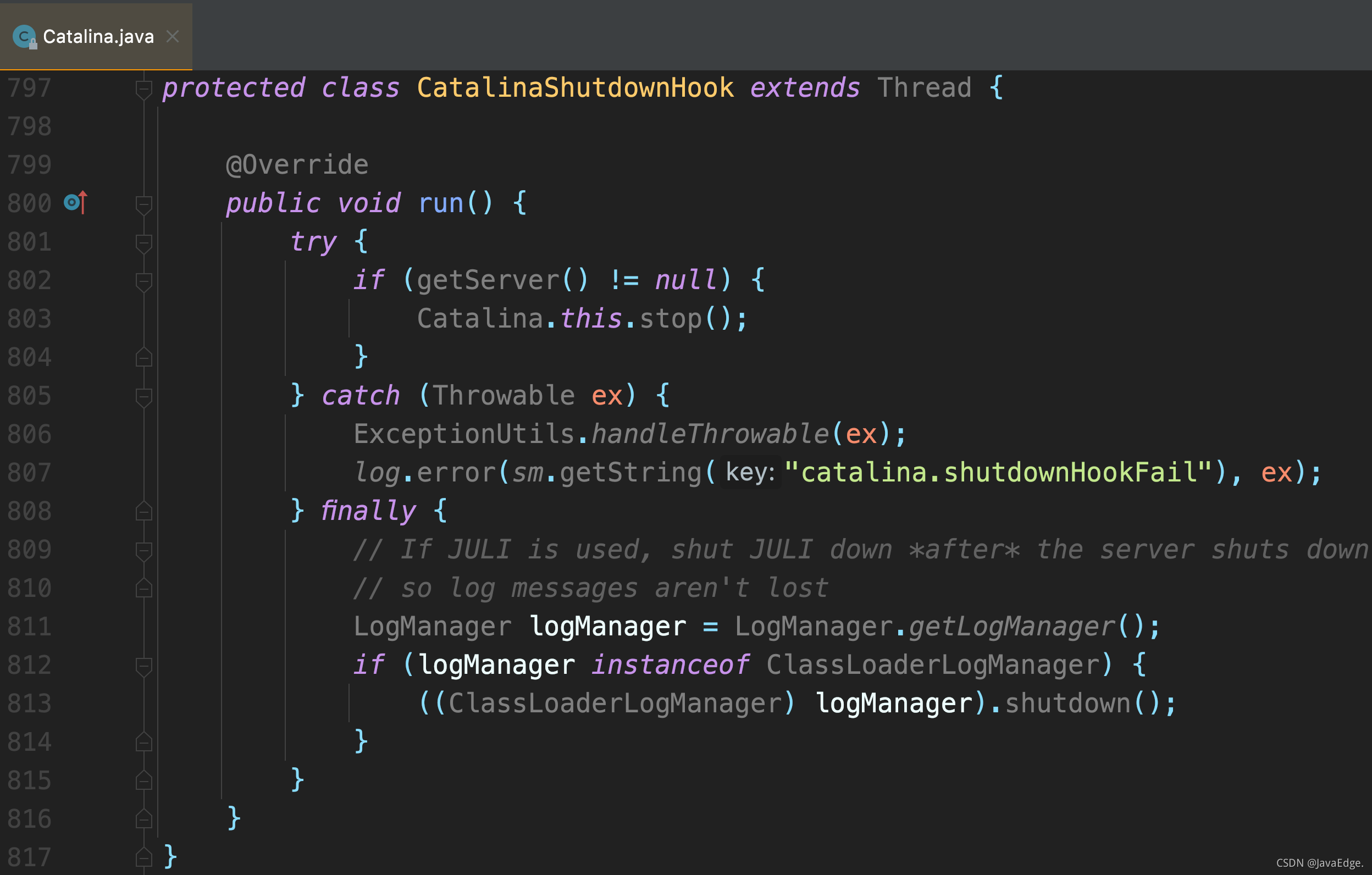 |
| 64 | + |
| 65 | +Tomcat的“关闭钩子”实际上就执行了Server#stop,会释放和清理所有资源。 |
| 66 | +# Server组件 |
| 67 | +Server组件具体实现类StandardServer。 |
| 68 | + |
| 69 | +Server继承了LifecycleBase,它的生命周期被统一管理 |
| 70 | + |
| 71 | +它的子组件是Service,因此它还需要管理Service的生命周期,即在启动时调用Service组件的启动方法,在停止时调用它们的停止方法。Server在内部维护了若干Service组件,它是以数组来保存的,那Server是如何添加一个Service到数组中的呢? |
| 72 | +```java |
| 73 | +@Override |
| 74 | +public void addService(Service service) { |
| 75 | + |
| 76 | + service.setServer(this); |
| 77 | + |
| 78 | + synchronized (servicesLock) { |
| 79 | + // 长度+1的数组并没有一开始就分配一个很长的数组 |
| 80 | + // 而是在添加的过程中动态地扩展数组长度,当添加一个新的Service实例时 |
| 81 | + // 会创建一个新数组并把原来数组内容复制到新数组,节省内存 |
| 82 | + Service results[] = new Service[services.length + 1]; |
| 83 | + |
| 84 | + // 复制老数据 |
| 85 | + System.arraycopy(services, 0, results, 0, services.length); |
| 86 | + results[services.length] = service; |
| 87 | + services = results; |
| 88 | + |
| 89 | + // 启动Service组件 |
| 90 | + if (getState().isAvailable()) { |
| 91 | + try { |
| 92 | + service.start(); |
| 93 | + } catch (LifecycleException e) { |
| 94 | + // Ignore |
| 95 | + } |
| 96 | + } |
| 97 | + |
| 98 | + // 触发监听事件 |
| 99 | + support.firePropertyChange("service", null, service); |
| 100 | + } |
| 101 | + |
| 102 | +} |
| 103 | +``` |
| 104 | + |
| 105 | +Server组件还需要启动一个Socket来监听停止端口,所以才能通过shutdown命令关闭Tomcat。 |
| 106 | +上面Catalina的启动方法最后一行代码就是调用Server#await。 |
| 107 | + |
| 108 | +在await方法里会创建一个Socket监听8005端口,并在一个死循环里接收Socket上的连接请求,如果有新的连接到来就建立连接,然后从Socket中读取数据;如果读到的数据是停止命令“SHUTDOWN”,就退出循环,进入stop流程。 |
| 109 | + |
| 110 | +# Service组件 |
| 111 | +Service组件的具体实现类StandardService |
| 112 | +```java |
| 113 | +public class StandardService extends LifecycleBase implements Service { |
| 114 | + //名字 |
| 115 | + private String name = null; |
| 116 | + |
| 117 | + //Server实例 |
| 118 | + private Server server = null; |
| 119 | + |
| 120 | + //连接器数组 |
| 121 | + protected Connector connectors[] = new Connector[0]; |
| 122 | + private final Object connectorsLock = new Object(); |
| 123 | + |
| 124 | + //对应的Engine容器 |
| 125 | + private Engine engine = null; |
| 126 | + |
| 127 | + //映射器及其监听器 |
| 128 | + protected final Mapper mapper = new Mapper(); |
| 129 | + protected final MapperListener mapperListener = new MapperListener(this); |
| 130 | +``` |
| 131 | + |
| 132 | +StandardService继承了LifecycleBase抽象类,此外StandardService中还有一些我们熟悉的组件,比如Server、Connector、Engine和Mapper。 |
| 133 | + |
| 134 | +Tomcat支持热部署,当Web应用的部署发生变化,Mapper中的映射信息也要跟着变化,MapperListener就是监听器,监听容器的变化,并把信息更新到Mapper。 |
| 135 | + |
| 136 | +## Service启动方法 |
| 137 | +```java |
| 138 | +protected void startInternal() throws LifecycleException { |
| 139 | + |
| 140 | + // 1. 触发启动监听器 |
| 141 | + setState(LifecycleState.STARTING); |
| 142 | + |
| 143 | + // 2. 先启动Engine,Engine会启动它子容器 |
| 144 | + if (engine != null) { |
| 145 | + synchronized (engine) { |
| 146 | + engine.start(); |
| 147 | + } |
| 148 | + } |
| 149 | + |
| 150 | + // 3. 再启动Mapper监听器 |
| 151 | + mapperListener.start(); |
| 152 | + |
| 153 | + // 4.最后启动连接器,连接器会启动它子组件,比如Endpoint |
| 154 | + synchronized (connectorsLock) { |
| 155 | + for (Connector connector: connectors) { |
| 156 | + if (connector.getState() != LifecycleState.FAILED) { |
| 157 | + connector.start(); |
| 158 | + } |
| 159 | + } |
| 160 | + } |
| 161 | +} |
| 162 | +``` |
| 163 | +Service先后启动Engine、Mapper监听器、连接器。 |
| 164 | +内层组件启动好了才能对外提供服务,才能启动外层的连接器组件。而Mapper也依赖容器组件,容器组件启动好了才能监听它们的变化,因此Mapper和MapperListener在容器组件之后启动。 |
| 165 | +# Engine组件 |
| 166 | +最后我们再来看看顶层的容器组件Engine具体是如何实现的。Engine本质是一个容器,因此它继承了ContainerBase基类,并且实现了Engine接口。 |
| 167 | + |
| 168 | +```java |
| 169 | +public class StandardEngine extends ContainerBase implements Engine { |
| 170 | +} |
| 171 | +``` |
| 172 | +Engine的子容器是Host,所以它持有了一个Host容器的数组,这些功能都被抽象到了ContainerBase,ContainerBase中有这样一个数据结构: |
| 173 | +```java |
| 174 | +protected final HashMap<String, Container> children = new HashMap<>(); |
| 175 | +``` |
| 176 | +ContainerBase用HashMap保存了它的子容器,并且ContainerBase还实现了子容器的“增删改查”,甚至连子组件的启动和停止都提供了默认实现,比如ContainerBase会用专门的线程池来启动子容器。 |
| 177 | +```java |
| 178 | +for (int i = 0; i < children.length; i++) { |
| 179 | + results.add(startStopExecutor.submit(new StartChild(children[i]))); |
| 180 | +} |
| 181 | +``` |
| 182 | +所以Engine在启动Host子容器时就直接重用了这个方法。 |
| 183 | +## Engine自己做了什么? |
| 184 | +容器组件最重要的功能是处理请求,而Engine容器对请求的“处理”,其实就是把请求转发给某一个Host子容器来处理,具体是通过Valve来实现的。 |
| 185 | + |
| 186 | +每个容器组件都有一个Pipeline,而Pipeline中有一个基础阀(Basic Valve)。 |
| 187 | +Engine容器的基础阀定义如下: |
| 188 | + |
| 189 | +```java |
| 190 | +final class StandardEngineValve extends ValveBase { |
| 191 | + |
| 192 | + public final void invoke(Request request, Response response) |
| 193 | + throws IOException, ServletException { |
| 194 | + |
| 195 | + // 拿到请求中的Host容器 |
| 196 | + Host host = request.getHost(); |
| 197 | + if (host == null) { |
| 198 | + return; |
| 199 | + } |
| 200 | + |
| 201 | + // 调用Host容器中的Pipeline中的第一个Valve |
| 202 | + host.getPipeline().getFirst().invoke(request, response); |
| 203 | + } |
| 204 | + |
| 205 | +} |
| 206 | +``` |
| 207 | +把请求转发到Host容器。 |
| 208 | +处理请求的Host容器对象是从请求中拿到的,请求对象中怎么会有Host容器? |
| 209 | +因为请求到达Engine容器前,Mapper组件已对请求进行路由处理,Mapper组件通过请求URL定位了相应的容器,并且把容器对象保存到请求对象。 |
| 210 | + |
| 211 | +所以当我们在设计这样的组件时,需考虑: |
| 212 | +- 用合适的数据结构来保存子组件,比如 |
| 213 | +Server用数组来保存Service组件,并且采取动态扩容的方式,这是因为数组结构简单,占用内存小 |
| 214 | +ContainerBase用HashMap来保存子容器,虽然Map占用内存会多一点,但是可以通过Map来快速的查找子容器 |
| 215 | +- 根据子组件依赖关系来决定它们的启动和停止顺序,以及如何优雅的停止,防止异常情况下的资源泄漏。 |
| 216 | + |
| 217 | +# 总结 |
| 218 | +- Server 组件, 实现类 StandServer |
| 219 | +- 继承了 LifeCycleBase |
| 220 | +- 子组件是 Service, 需要管理其生命周期(调用其 LifeCycle 的方法), 用数组保存多个 Service 组件, 动态扩容数组来添加组件 |
| 221 | +- 启动一个 socket Listen停止端口, Catalina 启动时, 调用 Server await 方法, 其创建 socket Listen 8005 端口, 并在死循环中等连接, 检查到 shutdown 命令, 调用 stop 方法 |
| 222 | +- Service 组件, 实现类 StandService |
| 223 | +- 包含 Server, Connector, Engine 和 Mapper 组件的成员变量 |
| 224 | +- 还包含 MapperListener 成员变量, 以支持热部署, 其Listen容器变化, 并更新 Mapper, 是观察者模式 |
| 225 | +- 需注意各组件启动顺序, 根据其依赖关系确定 |
| 226 | +- 先启动 Engine, 再启动 Mapper Listener, 最后启动连接器, 而停止顺序相反. |
| 227 | +- Engine 组件, 实现类 StandEngine 继承 ContainerBase |
| 228 | +- ContainerBase 实现了维护子组件的逻辑, 用 HaspMap 保存子组件, 因此各层容器可重用逻辑 |
| 229 | +- ContainerBase 用专门线程池启动子容器, 并负责子组件启动/停止, "增删改查" |
| 230 | +- 请求到达 Engine 之前, Mapper 通过 URL 定位了容器, 并存入 Request 中. Engine 从 Request 取出 Host 子容器, 并调用其 pipeline 的第一个 valve |
0 commit comments