\n",
+ "\n",
+ "\n",
+ " \n",
+ "
\n",
+ "
"
+ ],
+ "text/plain": [
+ " sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) \\\n",
+ "145 6.7 3.0 5.2 2.3 \n",
+ "146 6.3 2.5 5.0 1.9 \n",
+ "147 6.5 3.0 5.2 2.0 \n",
+ "148 6.2 3.4 5.4 2.3 \n",
+ "149 5.9 3.0 5.1 1.8 \n",
+ "\n",
+ " class \n",
+ "145 2 \n",
+ "146 2 \n",
+ "147 2 \n",
+ "148 2 \n",
+ "149 2 "
+ ]
+ },
+ "execution_count": 9,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "df.tail()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6076c300",
+ "metadata": {},
+ "source": [
+ "### 결측치 유무 확인하기"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 16,
+ "id": "c78a1cc1",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "| \n", + " | sepal length (cm) | \n", + "sepal width (cm) | \n", + "petal length (cm) | \n", + "petal width (cm) | \n", + "class | \n", + "
|---|---|---|---|---|---|
| 145 | \n", + "6.7 | \n", + "3.0 | \n", + "5.2 | \n", + "2.3 | \n", + "2 | \n", + "
| 146 | \n", + "6.3 | \n", + "2.5 | \n", + "5.0 | \n", + "1.9 | \n", + "2 | \n", + "
| 147 | \n", + "6.5 | \n", + "3.0 | \n", + "5.2 | \n", + "2.0 | \n", + "2 | \n", + "
| 148 | \n", + "6.2 | \n", + "3.4 | \n", + "5.4 | \n", + "2.3 | \n", + "2 | \n", + "
| 149 | \n", + "5.9 | \n", + "3.0 | \n", + "5.1 | \n", + "1.8 | \n", + "2 | \n", + "
\n",
+ "\n",
+ "\n",
+ " \n",
+ "
\n",
+ "
"
+ ],
+ "text/plain": [
+ " sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) \\\n",
+ "0 False False False False \n",
+ "1 False False False False \n",
+ "2 False False False False \n",
+ "3 False False False False \n",
+ "4 False False False False \n",
+ "\n",
+ " class \n",
+ "0 False \n",
+ "1 False \n",
+ "2 False \n",
+ "3 False \n",
+ "4 False "
+ ]
+ },
+ "execution_count": 16,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "df.isnull()[:5]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "e5b79a65",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "sepal length (cm) 0\n",
+ "sepal width (cm) 0\n",
+ "petal length (cm) 0\n",
+ "petal width (cm) 0\n",
+ "class 0\n",
+ "dtype: int64"
+ ]
+ },
+ "execution_count": 11,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "df.isnull().sum()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3ce4eef2",
+ "metadata": {},
+ "source": [
+ "### 수치데이터 특성보기"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 17,
+ "id": "8f9f14f7",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "| \n", + " | sepal length (cm) | \n", + "sepal width (cm) | \n", + "petal length (cm) | \n", + "petal width (cm) | \n", + "class | \n", + "
|---|---|---|---|---|---|
| 0 | \n", + "False | \n", + "False | \n", + "False | \n", + "False | \n", + "False | \n", + "
| 1 | \n", + "False | \n", + "False | \n", + "False | \n", + "False | \n", + "False | \n", + "
| 2 | \n", + "False | \n", + "False | \n", + "False | \n", + "False | \n", + "False | \n", + "
| 3 | \n", + "False | \n", + "False | \n", + "False | \n", + "False | \n", + "False | \n", + "
| 4 | \n", + "False | \n", + "False | \n", + "False | \n", + "False | \n", + "False | \n", + "
\n",
+ "\n",
+ "\n",
+ " \n",
+ "
\n",
+ "
"
+ ],
+ "text/plain": [
+ " sepal length (cm) sepal width (cm) petal length (cm) \\\n",
+ "count 150.000000 150.000000 150.000000 \n",
+ "mean 5.843333 3.057333 3.758000 \n",
+ "std 0.828066 0.435866 1.765298 \n",
+ "min 4.300000 2.000000 1.000000 \n",
+ "25% 5.100000 2.800000 1.600000 \n",
+ "50% 5.800000 3.000000 4.350000 \n",
+ "75% 6.400000 3.300000 5.100000 \n",
+ "max 7.900000 4.400000 6.900000 \n",
+ "\n",
+ " petal width (cm) class \n",
+ "count 150.000000 150.000000 \n",
+ "mean 1.199333 1.000000 \n",
+ "std 0.762238 0.819232 \n",
+ "min 0.100000 0.000000 \n",
+ "25% 0.300000 0.000000 \n",
+ "50% 1.300000 1.000000 \n",
+ "75% 1.800000 2.000000 \n",
+ "max 2.500000 2.000000 "
+ ]
+ },
+ "execution_count": 17,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "df.describe()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "953ea783",
+ "metadata": {},
+ "source": [
+ "### 변수분포 시각화"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "76afd2e0",
+ "metadata": {},
+ "source": [
+ "[seaborn 알아보기](https://github.com/rrkcl7733/playground/blob/main/Python_Study/_Seaborn_%ED%95%9C%EB%B2%88%EC%97%90_%EC%A0%9C%EB%8C%80%EB%A1%9C_%EB%B0%B0%EC%9A%B0%EA%B8%B0.ipynb)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 18,
+ "id": "a76fb660",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import seaborn as sns"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 20,
+ "id": "11bd22ef",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAvcAAALFCAYAAABHzcwdAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjQuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8rg+JYAAAACXBIWXMAAAsTAAALEwEAmpwYAAEAAElEQVR4nOyddXgc19WH35lZ3tWKmSWLzMwUcJiZmdNw2iZp86VN06Zt2iRt0jAzMzoMjmNmlixZzLDSMsz3x8orrVe2JWtF9rzPoyeZu3fu3F3fuXPm3t85R5BlGQUFBQUFBQUFBQWFkY841B1QUFBQUFBQUFBQUAgPinGvoKCgoKCgoKCgcJCgGPcKCgoKCgoKCgoKBwmKca+goKCgoKCgoKBwkKAY9woKCgoKCgoKCgoHCYpxr6CgoKCgoKCgoHCQMOTGvSAItwiCsEkQhI2CILwuCIJuX/WPOeYYGVD+lL/B+OsTythU/gbxr08oY1P5G8S/PqGMTeVvEP8OGYbUuBcEIRW4EZgqy/JYQALO2dc5jY2Ng9E1BYU+o4xNheGKMjYVhivK2FRQCD9DvnIPqAC9IAgqwABUD3F/FBQUFBQUFBQUFEYkQ2rcy7JcBfwLKAdqgDZZlhfvWU8QhKsEQVgpCMLKhoaGwe6mgsJeUcamwnBFGZsKwxVlbCooDCyCLA+dDEkQhGjgXeBsoBV4G3hHluVX9nbO1KlT5ZUrVw5OBxUOdYS+VFbG5vChZHspWzcXI0kihaPzyMrNGOouhRtlbCoEqK6qZcuGHVitNnLzsigYnYtKpRqq7ihj8yChubGFLRu301DfRHpmCkVj8zEYDUPdrf7Qp7E5khmyu7+TI4FSWZYbAARBeA+YDezVuFdQUFDYF5s2bOOKc27G2mEDIDomkqdff4j8wtwh7pmCQviprqzlpiv/wLbNxQBIksRjL/yDWfOnDXHPFEYylrZ2/vXXx/jkvS4xxR1/upFzLj4VURwOim6FfTHU/0LlwExBEAyCIAjAEcCWIe6TgoLCCObd1z8JGPYALc1tfPPFT0PYIwWFgWPT+q0Bwx7A6/Xy7789jqW1fQh7pTDSKd5eGmTYAzz89yep2FU1RD1S6AtDrblfBrwDrAY2dPbnqaHsUzhwtbXidTiGuhsKCoccXq+XnTvKQsrLdlYMfmcUFAaB1lZLSFlNVR125Rmk0A862q0hZQ6HE5vVPgS9UegrQ71yjyzL98iyXCjL8lhZli+UZdk51H3qD662FqyVpVh2bkX2eYe6OwoKhxSSJHHaOSeElB913MLB74yCwiCQV5CDf+O7i1POOo64+Jgh6pHCwUBGVhoGoz6orGhsHinpSUPUI4W+MOTG/cGGo6EObVwCkkaLq611qLujoHDIMXfBdG6+82pMEUYio8zc+ZebmTZr4lB3S0FhQBgzroCHnvwLKWlJaLQazr34NM675DQkSRrqrimMYLJy0nn8pQcYPb4ASZJYeORs/vrQH4iMNA911xR6wVA71B5U+DxuPA4busQk8PlwtbWgjY4d6m4pKBxSxMRFc9k153H8yYsQRIGExLih7pKCwoCh1qg5/Oh5TJw6FqfDRXxi7FBGylE4iJg0dRxPv/Jv2tutxMRGodPrhrpLCr1EmQHCiKejHZXOgCCISHoDzuZGZFkO2TJVUFAYeBKT44e6CwoKg0ZMbPRQd0HhICQiMoKIyIih7oZCH1GM+zDitnYg6vxvtqJKDQj4XC4krXZoO6ag0AuaGprZuG4rVZW1ZGanMXZCIZFRXVuwXq+XLRt3sGXjdvR6HWMnFpKVExw/vrqylo3rttDU2EJ+YS5jJhSg0w3+as/WTTvYvGEboiQyZnwheQU5g94HBYVwU7KjjE3rtuJyuxk9toCisXn7XDwq2V7GhrVbaGxoIicvi7z8bHYW76KqspasnHTGjC8IuscVFLrTUNfIhnVbqa2uJzs3gzETCjGbTSH1SraXsXH9FjxuL6PHF5BXkM3q5evZsmkHWq2GsRMKGTuhaAi+waGLYtyHEY/diiaya/VE0unw2q2Kca8w7Glv7+DB+5/g43e/DJRdfeNFXHXDRag1agBWL1/P1RfchsfjdxRPSIzj6dceJHtUJgB1NfXcdt09bFq3NdDG/f+9m+NPPnIQvwlsWLuFy8++CYfD75sfYTbx7BsPUzgmb1D7oaAQTnZsLeGys2+mrTM6jkar4dnXH2LClLE91q8oq+TeO//FmpUbAmXX33oZ7735KTVVdQBcfdPFXHXDhajV6oH/AgojitaWNv72f//hmy9+DJTd9PuruOTqc4L8ObZvKeGys2/C0uYPvWo0GvjHI3dz89V343F7AL9U8j9P/5UJk8cM7pc4hFEcasOELMt4HXYkTZchL6q1eOy2fZyloDA82LljV5BhD/DM/15lV2klAA67gyf+82LAsAeor2tk5bJ1geOtm4qDDHuAB+59lPq6xgHseTCyLPPOqx8FDHuAdksHX3/+w6D1QUFhIPjx218Dhj2Ay+ni5WffxuPx9Fh/y6biIMMe4IWn3uDoEw4LHD/z6CuUlypxyxVCKdleFmTYAzz+8AtUlAWPl++++jlg2AOcevZxvPTMWwHDHvyZblcsXTOwHVYIQjHuw4TP5UQQJYRub7SiRoPXqcSEVRj+2Gyh49Tr9WLvLHe63NRW14fUaW5s6WrDGvoi29ZiwekYvOi2Pp+PivLqkPKqitpB64OCwkBQVxN6/1VV1O7VuO/pnrZ22NBoNYFjr9eL3a48oxRC6Wn8uJwu7HvM5zV7PBdi46JpbGgOObenMoWBQzHuw8Seq/YAolqjJLNSGBFkZqcRExfskJdflEtaZgoAkZERnHPxqSHnTZkxIfD/OXlZAQnPbk48/SiSkhMGoMc9I0kSZ55/Ukj5MScdPmh9UFAYCBYumhtSdvZFp/To01JVUUNKaiL6PaKbzJgzhY1ru5LAF44eRVpGavg7qzDiycpOJ2IPff2kaeMwGHR8/N5iXnr6LVYtX88RR80LqvPem59x4mlHh7Q3Y/bkAe2vQjCK5j5MeBx2hD10i6Jajc/tUiLmKAx7UlKTeOyFf/Lov59h3apNzFkwnatuuIjomKhAnWNOODwgBTCbTdx0x9WMndjlJBUZHckdf7qRd177iKqKWuYfPoujjj8sxOAfaGbNm8of7ruFZx59BUklcd2tlzFl+vhB7YOCQriZOGUMf//v3TzywDO4nC4uvfY85h8+M6Tebt8Xm9XG3x7+A88/8TqlJeUsOHI2Z55/Ek/992UizCbmLpzBVTdcSFS04lCrEEp6VipPvPwv/vvPp9i8YTsLj5zN+ZeewY2X30VpSXmg3mMv/pP7//NHHv3XM7icbs6/7HSmz56M0+Hk7dc+xmjUc+UNFzJZmYMHFUGW5aHuQ5+YOnWqvHLlyqHuRggdu0oQNRrUEZHB5eWlmEcVhqzqK4wI+vRGNlzHZl+w2x20t7UTGR2Jttv2fXca65tQa9QhUTa+//oXbr3mbuYfPov4xFhWLF1DS1Mrb3/+LAlJgx+WsqmxGVEQiY6NGvRrDwKH3NhU8NPa0obH491rBtofv1nKby67AwCNRs0lV59LZk4aM2ZPIiEpIXCPR0VHBkl0wogyNg8ibFY7He0dRMdE8d1XS7j9unuCPk9JS+L1j58CZHw+mdhuO8DlZVWotWqSB3H3dj8cMqusysp9mPA6naiMoSGiRLUan9OhGPcKIwK9Xheylb8ncQk9J2azW+143B6+/fKnQJkkSbhc7rD2sbfExvVs/CgojGSioiP3+bm9m1ba5XLz1CMvIYoiH333CtC7e1xBYTcGox6DUQ/0rMNvaW7D6XT2KL/MyFIkX0OForkPA7Is43U5ENWhqyCiSo3XNXgOhQoKQ0VuQVbISuCpZx83qJp7BYVDnZz8rJBdtxNOO4okJambQj/JL8hBpZKCys656FQlC/gwRDHuw4Ds9SAgBEXK2Y2gUuN1Ksa9wsFPXkEOT77ybyZPn0BsfAyXXnMel193Piq1skGooDBY5BXk8NSrDzJt5kRi42O4+KpzuOamiwdKgqNwCFEwZhSPv/QA4yYWEZcQwzU3X8K5F5+CKCqm5HBDeeqGAa/TGeJMuxtRrVIi5igcEgiCwJTp43nshb9jszmIjYtWHMkVFIaASdPG8cjzf8dmtRMTG6UYXwphQZIkZsyZwlOvFuGwO4hR5vhhi2LchwGfy4m4N+NepcbtsvT4mYLCwYjBaMBgNAx1NxQUDmkMBj0Gg36ou6FwEGI0GTCalDl+OKMY92HA63Qgqnre8hRU/nCYCgojHbfLzYZ1W1i+ZDURkSamz55MXkHOUHdLQeGQYeumHSxbshqn08WM2ZMYM6EQlUp5jCv0n6bGFtat2siGtZsZVZDD5OnjSU5JHOpuKRwgyqwQBva1ci9IErLPi+zzIShbowojmOVLV3Pdxb9nd/hcc2QEz7/1X/IKFQNfQWGg2bJxO5eceWMgGs7jksTTrz3I1JkTh7ZjCiMel9PFC0++zotPvRkomz1/Gn//z91Exew7OpPC8ESxNsOA1+VEUO3FuBcERGX1XmGEY7PZefyhF+ieF8PS1s7KZWuHrlMKCocQP36zNCjMpdfr5cWn38Tj9gxhrxQOBsrLKnn5mbeDyn75cQUlxWVD0yGFfqMY92HA53Ih7sW4BxBUKnwuxbhXGLl4PV4sbe0h5R3t1iHojYLCoUdra6jvVktzG16fbwh6o3Aw4XZ78PUwjlxOxW4ZqSjGfT+RfT5/KMx96B5FSaWs3CuMaCLMJi668uygMlEUGTO+kGf+9wqPPPAMa1ZuwK2sIiooDAiHL5obUnb2BSfz9isf8dD9T7D8lzXY7UpkNoX909FhZckPy/jXff/jteffRavTMm3WpKA6ickJZOdmDFEPFfqLornvJz63C0Gl2mc4KEGlUhJZKYx4jjh6HoIg8PKzbxEVHcklV53Dg397nO1bSgB49rFXeerVfzN99uQh7qmCwsHH+CljePS5v/PUIy9htzm44PIz+O6rJXz9+Q8APP/E6/zn6b9y2FGhLwEKCt356tMfuOd3/wgcJyYn8J+n7+Pzj77hmy9+YvKM8Vx0+VkkKQ61IxbFuO8nPpdzn5Ic6JTlKCv3CiOc6NgoTj/3BI46fiFqtYoXn3ojYNgD+Hw+XnzyDSZPG68krlJQCDNarYb5R8xi6qyJ+Lw+vv7ih4Bhv5tH//0sU2dOJMJsGqJeKgx3GuobefjvTwSV1dXUU1VRwy13XsMV11+AwahHvZcgIQojA+UJ3E+8+9HbA4gqFW6HfZ91FBRGCrsNB0tbR8hnbZYOvD6fMrEoKAwQu2PXW9ttIZ9ZO2x4Pd7B7pLCCMLr8eKwOxFFkbSMZNpa22lrteByuRFFkcgo81B3USEMKM/gfuJzOfeptwcQJDU+t3uQeqSgMDgcdtRcXn62K8KCSq3iulsu5e1XPqS0pJy5h81kyvTxmCMjAnXaWi2sXrGBn75dSs6oTOYsnNFnXWddbQMrlq5l1bK1jJs0mhlzppCalhS276WgMJS4XW42rN3Cd1/9jFanZcERsxFFkW+//BGnw8XYiYWUl1VSNLaAUflZFG8vC5x76TXnKqELD3E2rd/GD9/8grXDxmFHzWHCpDGoNV0LkAlJ8dz2x2uxtHawY9tOYuOiiYqJpKBo1KD3VZnLBw7FuO8nPpcTUaPdZx1BpUJWjHuFg4zxk0bzxEsP8Ozjr2Gz2rnht5dz753/orqyFoC3X/2I3//pRs6/9HQAZFnmw7c/51/3PRZoI/X5d3nm9YdITU/u1TXtNjuPPPAMH73zBQDvvv4JM+dO4Z+P3kNUtGLUKIx81qzcwJXn3RoIO/vCk29ww+2X8/SjrwB+R/Zb/3Atv7n0Dh5+6j7efvUj6usaOe+S0zls0Zyh7LrCELN5wzYuPfMGHA6/j98rz77NEy8/wKx50wJ1RFFEluG/DzwdKEtIjOOYEw8f1L4qc/nAokTL6Sdel2v/K/eiiCz7kH3KdqnCwYNGq2H2guk89uI/ee7N/2C3OQKG/W7+9+9nqa2uA6Cmup7HHno+6POqihq2ddPt749dpZWBh8Fufv15FaUl5Qf4LRQUhg8ej4eXnn4rKJ+Ey+mirKSCxOR4wO/bsnLpGgrH5PH2qx/xr8f/xEvv/o/Tzjme6NioIeq5wnDg5++WBQx78C+oPP/EG7i6heKur2vgf/9+Lui8+rpGtm4qHrR+gjKXDzTKyn0/8blde81Ouxt/IisVPrcbSSsNUs8UFAYHrVYDgKcHra/L5cbr9cdP9nm9PYbK7EsSnp6u4S9XQnAqjHxkn4zNGqqldzpdQQ6ODocLjVaNzWpHklSBe1Dh0KanUKg2qw2ftyuGvc8r4+whfv1gz6HKXD6wKCv3/SAQ417a/zuSX3evRMxROHjJK8jGFGEMKjv/0tNJSkkAICklgfMuOS3o8wizibzCnF5fIyMrlWkzJwaVZY/KJCs7/cA6raAwjFBr1Jx/2RlBZYIgUDA6l8ry6kDZzLlT2Lh2KxdcfqZi2CsEmHf4zJCw3BdeeRY6vS5wnJgczyVXnxNUR2/Qk1+Y26tr7NhawpP/fYm7b7uf779eQrslNLBCb1Dm8oFFWbnvBz63C0Had4z73QgqSXGqVTio0Wg13PjbK1n2yyqqKmqZOXcKo8cVIEn+3SqVSsUFl59JckoiH7z9OQWjczn34tP65FBrjozgnn/8lk/eW8y3i39m1rypnHLWccQnxg3U11JQGFRmzp3KQ0/+hZeefguVWsWi4xagVquZMnMCsixz9PGHsW1zMQ/870/MnDdlqLurMIwYN3E0T736IC899QYWSwcXXXkWs+ZNDaojCAJnnHcicfExvPPaR2TnZnL+ZWcwqiB7v+2Xluzi8nNuobWlDYAP3/mCe/7+W04/94Q+91WZywcWobu274AbEYRZwAXAPCAZsAMbgU+BV2RZbuv3RTqZOnWqvHLlynA11y/cHRZsNZUYktP2W9fR1IBKb0Cf0DvHQYVhwf7f2roxnMbmUPD15z9y6zV3UzQ2j7iEWNav3ozH4+G9xS+QnBqcDMVhd6DWqAOG/4FgtznQ6bW9erk+CFHG5kHOk/99kWVLVrN6+XpEUWDStPEsOGI25158Kj5ZHs4r9srYHGI8bg9en2+/Y8ThcKBSqVDtx29wN599+DV33PiXoLLY+Bje/uwZ4hJiD7i/gziXHzIPi36v3AuC8DlQDXwI/BWoB3RAPnAY8KEgCA/KsvxRf6813PC5XIi9kOQAnZp7RZajcPDi63QY37JxB7AD8OvxfT5fSN3u28QHit7Q/zYUFIYrmzdsZ+WvawHw+WDF0jUkJscHhTVUUOgJlVrVK+NOp+vbHNpdu78bt8uNTw4t7wvKXB5+wiHLuVCW5cY9yjqA1Z1//xYEYa/7LIIgFABvdivKAf5PluWHw9C3AcXrciLsJ4HVbgRJhdcR6iiloHCwkFeYS4TZFKTBvOiqs4NW7R3tNuq3VVCxagdRqXGkTR5FZIqyDasw8mivb6Vm/U4aiqtIHptF4uhMjDHhSwB01gUn893in4PKTj7z2LC1rzCyaK9voXp9KY0DNN56Q8HoUegNeuy2rqScV1x/AQmJ8YPaD4X902/jfk/DXhAEc/d2ZVlu7sH4737+NmBi57kSUAW8399+DQY+l3O/2Wl3I6pUuBXNvcJBTHZuBk+/9hDvvP4x2zcXc8pZxwUS8IA/LNvOnzey8cNfAKhaU0zJT+s5/PazMMVHDWHPFRT6ht1i49dnP6dllz/Ma9XaEjKmFzD1/CNQhUkuM3n6eB5/8Z+88vy7iILABZefycQpY8PStsLIwj/evthjvBUy9YIjUA3iTk5eYQ7PvvEwb770PmWlFZxx3onMWzhz0K6v0HvC5lArCMLVwL349fa7hfwy/pX43nIEUCLL8q5w9Wsg8blcSHpDr+oKkkpxqFU46Bk9Lp+7x96Kx+0JkQ/Ymi1s+Xx5UJmjzUZrZaNi3CuMKNprmwOG1m7Kl2+jYNFUotPDs4qp1+uYs3AGM+b6nWZ7q4tWOPjoebxtpWDRlLCNt94ydkIhox/4PV6PV5GIDWPCOVvcDozZ1yp9LzgHeH3PQkEQrgKuAsjI6Fuq+oHE53Yh9nLCFVQqZI8HWZYPVQfAg5LhOjaHEkEQepz0ZVECWUZSq4hKi8fe1oGtuZ1wOPUrhKKMzYFjb2N2IKb2g9GoV8Zm35B9e5sjh2buFEURUaNEUh/OhHPWKAEOWFQuCIIGOAm4c8/PZFl+CngK/J71B3qNcCLLMj6Pe7/ZaXcjCAKCJCJ73AjqYRvlQKGPDMexOZzYtG4rP3zzC6tXrGfKjInMvvgwNq/cxFs/LSc3J4NZR40nKlXR3A8EytgcOMxJMZiTY7HUNAXKJp29kLqtFax950eSxmRhyI5n+fJ1fP3590ycOp6jj19I9qhMWppbWbZkNR+/9yU5ozI5/pRFFI7Jw2a1s2r5Ot5741Mio82ccuaxTJg85qBcDFLGZt8wJ4eOt/Sp+cg+mXXv/kRbTRNZM4pILMxAG6Ef0L5s2bidT97/irKd5Zx0+jHMmDOFqOhg7X9zUwvLf1nDpx98RUSEkRNOO5qZc6cEJJoKA09YQmECCIIwCXgeWAYE8h/LsnxjL88/GbheluWj9lVvuITN8rqcWHZswZTZe9WRtaocU3o2KoNx/5UVhgNKSLd+UF1Ryx033cvaVZsCZZOnjWfeYTP5zz+fAiAmNoqX3vsfGVn7DyerEIQyNocYS20zFSu3U7elnLzDJ1D6y2ZqN/kVpZGZCSxp2MUH734RqJ+Znc4zrz/I4s9+4IF7Hw2UR5hNvPL+Y5SWlHPzVX8MlKvUKl5691HGTigavC8VHpSxOQB0H29pk0cRNyqVH//7Pi5rV1baCafPo2DRwOU+KNlexkWnXx8UNOHOe2/i3IuDkxN+9O4X/PHW+wPHao2a/73wD2bOGfK8DAffm/JeCOdr1JPAt8CvwKpuf73lXHqQ5AxXfG4XorpvejNRUsJhKhw6FG8vDTLsAVavWE9iSpdGtLmple1bdg521xQU+o05KYYxJ8zksNvOxBgbGTDsAbSZsXz0/uKg+rtKK9iyqZgnHn4hqLzd0sGWTTt45n+vBJV73B5++VExehX8dB9v+UdMpqOhLciwB9j06TJsLe0D1oetm3aEZKR94uEXaKjr2lFobbHw6nPvBtVxu9wsW9IXc1Chv4RTluORZfnWAzlREAQDsAi4Ooz9GVB8Llevw2DuRslSq3Aw0Bu/EX9s+553BUVJZMqMCTTUNVJeVrXXegoKIwFB9Esu4/PTsNQ042zfhzp1Lzvle9fwC4HPDkZ5jkJ/2Mu8OcjTqX94hl5UpZIYO7EIu83Bts3F+/AbUBgIwrly/50gCFcJgpAsCELM7r/enCjLsk2W5dhwZrIdaLxOZ6+daXcjSCq8buf+KyooDENcdieVa4v56ZEPWP7ClzSWVIcYJds27+Aff36EK869BYNRz8QpY4I+v/KGC2msawJZZuKUsfz27uspGD1qML+GgkJYaa9roWZDKbLXR8a0fAoWTcG5q4mTTlkUVC8jK42isXlcc9PFQeURZhOyLHPB5WcGlReNzWNUfhY3X/VHbrv2Hpb/shqXS9n5PVSx1Daz6ZNf+e7Bt9n+zWoiEqLQGIOTP40+bjqGmIgB60PhmDwizKagsqtuvIj4xC6/qahoM1ffeCHX33Y5Op2O1PRkfnv3b5h7uBIyczAJ58r9eZ3/7e4Q29dQmCMGn8vZa2fa3YgqFT6XsnKvMDKp3VDKr891aYjLV27n8NvPJCYrCYCynRVcce6ttLVaALjs7Jt5/MV/sm7NZtYsX8dhR8+jvraRf933GACrlq8n6ttfmX/ErMH/MgoKYcDZbmfZ81/SXFYLQGNJNbG5KRQumkJR1FwmTB/PV599F3CoTUxO4MTTjyYhMY733/6cuPgYckZl8tc/PsTocQU8+ORf+PT9r4iKMTPvsJncdOUfAtf65osfeeb1h5g2a9JQfV2FIcLeZuWXJz8NONQ2FleTOjGXhbeczq7lW2mr7nKoHVAEmatuuJAd20ppqGtk0rTxxMZFhVRzOd385x9PBY5//OYXXnj7kYHtm0IQYTPuZVnODldbIwGf24laF9mncwSVGp/NOkA9UlAYONx2J5u/XBFU5vN4qd9eGTDut28pCRj2u7nl6rv5+IdXuO6WS6mqqOHkIy4K+ry1pY3tW3aSmZ0+sF9AQWEAsNQ1Bwz73TSVVDPxjHnEZieTMSqD0889IejzqOhIps6ayKcffMWqZev46B3/C/OKpWs44bRFPPTkXwD/vdMdWZb56J0vFOP+EMRS0xwUKQf8iaxGHzeDCafNG7R+bNm4g3//9XHSMlKIiY3i6UdfxmDQM2XGRBI6V+9tVhsvPPVm0Hkej5elP69i/OQxPTWrMACETZYjCML1giBEdTuOFgThunC1P9zwuRSHWoWRjyzLeNyeXtUVhdDporsOePf/5+ZlMWveVEwRRgRRREbAbrUDAlIPodAkScTpdCkZnBWGLbIs4/V6Q8oltYrE0ZnozMHJDEWVhNcTXN/tcgfp57duLqaqogYArVbDjDmTiY2NCdwLKpXU4/UUDj326m7R6ZPR09jcE5/X2+kL1YXH7elTnpHdzwCDUY/BaEClUiFJImL3DgoCkkpCrVEzbdYkxk30R3uSJP+53e+D3bgVRUPYCedMcaUsy//bfSDLcosgCFcCj4XxGsOCrhj3fXWo9WepVRJZKQwHNq7bwpsvf0DZzgrOOPdE5h42k9i46B7rqvVaio6bztKnPg2USWoVCQVdISwLx4zid/fcwLpVG6mpquOsC05mxuzJvPXCeyxdsppjjlvIJVefw+PdooUctmgOdruTay+6HYNBz5nnn8zMeVPQarUD9r0VFPpCS3k9JT9toLWigazZo0kdn4M+yoSlppnKVdtx2xykTc5DUkts+2o1k85eSO2mXax69RsSCtKJHJPOL7+s4pP3FzNmQhGnn3sCBUW5XHfLpfzfb//B3MNmMH7SGJoamqkor+aFi97AaDJw6tnHs3HdFqoq/DsDoihy0mlHD/GvoTAURCTHEp2RQEt5faAse84YfB4vK1/5mrbqJnLmjCV5XDb6yOBQ226Hk/qtlWz/bi0anYa8wyciRBn4+ftfefeNT8nNy+SsC05hzPiC/fZj9Lh8fn/PDaxavo76uiYuuPwMisbkEZcQG6hjMOj5zW2Xs3HdFn75YTmR0WZ+d89vmDB5LO+8/jEfvPkZ+UW5nHn+SZgijHzx8bd8t/hnZs2bxgmnHUV2rpLULByEM879emCC3NmgIAgSsF6W5bDuwwyHmLhelxNL8VZMGX1XIrWXFRNVOL7PzrgKQ8JBG695+9YSLjz1euw2e6Ds5juv5rJrztvrOR6ni4bianYt24IuwkD6tAJiOyU5ANs3FnPpuTcFhUo756JT+HXJaspKygG4+KqzKSwaxTeLf6ZoTB5JqQn84Za/BeqLosijz/+duQtnhPPrHowctGNzONFe28I3/3wDl60rEELhUVPIPWwiPz78Hu11LYHyhMJ0Co6eSvG3a6nZUAqAOS2OZW3VvPtW10txTFw0L7/3P6KiI1m3aiPbt+7kyf+8yOXXn8+j/3o2UE+SJB566j4+eW8xRpOBk888hvGTRo+EjLXK2Awz9tYOypZuxtlhx1LbQlRaPDFZiax4cTFuR5caYMxJsxh97PSgxcPKNcX88uQngWNjrJnKeJH/PfR8V5nJwCvvP05uftY++7Fj604uOPW6/T43Pvvwa+648S+BY0mS+Pt/7+a31/8pUHbcyUfS3NjCr91CZOYV5vDkK/8mLr5XsVgOhENmVTWc0XK+BN4SBOEIQRAOxx+z/ov9nDMi8bmcfZbk7EZUqRVpjsKQs31LSdAEDfDs/16lvrZxr+eotBqSx2Qx87JjmXjmgiDDHmDH1pKQGMjvv/kZhy2aEzh+8ak3iY+L4cEn7uWcS07lzZc+CKrv8/n46dtfD/BbKSiEl9bqxiDDHmD7t2tpq2wMMuwB6rdWIIpiwLAH0OfEByWyAmhubKF4WykRZhPjJo/h/Tc/ZcacyXzzxY9B9bxeLyt/XYPL5SI9K4XJ08aPBMNeYQCw1Daz4cNfKPt1C852G8Xfr6W1siHIsAfY9uVK7N3i3HtdHrZ9HRxfPqIoleefeiOozNphY9uW4v32Y9vm4pDnxnOPvUZ9XUPg2Ga18+Ie7Xu9Xlb8uoaY2KhAWUZWapBhD/6Xh90LQQr9I5zG/e+Bb4Brges7//93YWx/2OB1OvssydmNqFJ09wpDjySF6nnVGjWi2PeFDa/Hg9ftQZRCpxOVWhWiB92dglwURVQ9aIjVmgO7txQUwo3QeT9EpceTPC4bjVGHKIl7vU8EUQheG5RB6kE7v/teEQUBtVqNx+Pt0XBXqVSUbC+jw6IEYjgU8TjdyD4ZoXPO1Bh16CKNqPXaHqW9giQGC/QFAWnPceWTexxrPT0T9qSnOV6tUQf5YwmCgEajCa2nVuH1+oLq9fYaCn0nbL+iLMs+WZafkGX5DFmWT5dl+UlZlvfv5TEC8bn6HuN+N4JKjU+JVawwxBSOySM6Jjja029uuzxIO7k/vB4vdVvLWfL4x3z/8Lvk5mSS2C3eMcC5F5/GV5/9EDiet3AG2aMyATAaDZx/6RlB9TVaDfOVeMgKw4So9Hgmnb0QY6wZe2sH2bNHM+WCI7C3W4nOSAiqmzVrNJHJsWTN6lKiWnfUcv6FpwbVy8hKI7/QHyE6wmzi2lsuYdkvq1l03IKgelqthjETCqmtqeeIY+YP0DdUGI50NLax5fPlfPvAW6x583vUBi2Tzz2M2Oxk7C0dpIzPITozMcSRe+yJszBEd8W5l9QShUdNDapj2VbNdTdfElQWExdN4Zj95xspGpu/3+eG3qDjit9cEFRHp9MyZcbEoGhqO4t3ccyJhwfVmzJjAtm5mfvth8L+6bfmXhCEj4GngC9kWXbv8VkOcAlQJsvyc/26UCfDQZ/XXlaMpNWhjjD3+VxnSxOCpMKYooT+GwEc1NrRHVtL+HbxEsrLKll03AImT5+AeY8EJfuiYUcV3z34diA54diTZ+E0qVm2fC2lOyuYt3AGeXnZrF61gdWrNjB5ynhmzJ5ETlFX6ov2diurfl3L4s9+wGjSc8TR85g+e3JgdV9hrxzUY3O4YKlt5pt/vInb3iXNyZk3jqaSapLGZAICHY1tpIzLJrEoA0N0BLaWduq3VlC7eRexuSmYsuJZt2Er33+9hKIxecw/YnaQ06DNamftqo2sWbGe9Kw0lv+yBqNRz+z509hZvIvJ08czbmLRSLonlLHZDzxOF8tfWEzlmi6ZTOExU6lYtQNrQ1eez+Rx2Yw9aRY1G0ppr28ldeIo4vNS0e6R2Mrj9tC8s4byldtR6zSkTR6FKtrI6uXr+fqLH8nMTuewo+aQV9C7lETbt5bwXbfnxpTpE0ISW9ntDtav3sQXH39LZJSZRcctIC0zlRVL1/DtFz+Rm5/FwkVzMBoN/PrzSpb+vIrJ08YxZ8F00jJS+vHr7ZdDRnMfDuM+CbgVOB1oBhoAHZANFAOPyrL8YT/7GWA4TARt2zehjYlD0un7fK673YLX5SQiM3cAeqYQZpSH1D5Y+/YPbP9mTeB49PEz2PzpMiKSoolIjKF20y5A5pg/X4Qptm85IRT2izI2B4GKVdtZ+vRnQWWiJJJ/5BS2frkCtV6LIdrEjCuOJSolbi+tHHIoY7MftFY1svgvrwSV7Z5b9+TIu84jZo8dJIV9csgY9/32zpFluRa/tv53giBkAcmAHdguy7Ktv+0PR3wuF8IBOtQKKhW+jvb9V1RQGKa4nS5EUUKlC9ZV7tZQJk0ahSragMvqoK2yocf4+NYOK1qttkfNvYLCcEHsQYcsqiRkn19x6rY7sThdPY7x3XS0W9HptTjsTnR6bYje2Wa1o1JJaLTB95Pd5kAQBXQ6JSzsoYQgCAiigOyTg8pCK4IoCng9HnweH2pdqM59f1itNjRq9T79nJxOFx2WDqJjo/a5e+RwOJF9MnqDbq91FAaPsD5ZZVkuA8rC2eZww+fxICMjiPt3PukJJVqOwkjF2WGnZkMp279dg9akp+CoKUhqCa/bb+iodBrSzp3Ncy+9T1V5DUceO5+5FyzAENOlAa2tqefLj7/lg7c+Z1RBNhdfdQ5jJxQO1VdSUNgnUWlxGGPNWJu6tMKjFkygfOW2ruOFEzDGh+5MVZZX88l7i5GRcdid/PjNUorG5XPB5Wcyemw+TY3NfPvlz7zx0vukpCVx2TXnMXHqWKwdVpb8sIIXn3oDrU7L5dedz7RZk9Bq+268KYw8TAmR5B02MWhX1OPxEjcqhcbi6kBZzpyxyD4fy579AktdCzlzxpI2OQ9D9P6llfW1jXz1+Q+89/onZOakc8nV5zB+0uiQemtWbuCtVz5ky8btzF0wg+NPXUTR2PygOk6ni5W/ruGZ/72K0+Hk4qvOYc6CaZgiei/xVAg/YYtzP1gM9Raex2alo6IUY+qBJVqQZZmO0mKix01C2Mdqj8KwQNle7sbOJRtZ+fLXgWNthIGZlx1DQ3EVHocLb3ok1192BzZrV6i0My84idv+cD0Ggw6328ODf3ucV597J/C50WTg1Q8eJycvazC/ysGAMjYHCUttM7WbyrDUNpNYmIHb7qS9vhVrowVzcgyiSiLv8ImouxnfdpudP9x6P/V1jSQmxQU5lZsjI3j1w8f5/qtf+Pdfu3I8qjVqXn7vf1RV1HLbtf8X1Idn33iYabMmDfyXDQ/K2Own9jYrDTsqqdtSTkxmIolFGSAI1G0pp7msloSCdMxJMXz7r7fwuroyjBceM41xJ80ORHnqCZ/Px2MPPsdTj7wcKNPptLz64RPkFXbp7nds3ck1F95OQ31ToGz2/Gnc/58/Eh0TFShb/stqrjj3lqBrPPjEvRx5bLCD+DDhkJHlKNZlH/E6HQcc4x46t9w6M9X2BtknU/zDOn54+D1Wv/k99jYlJJrC4OOyOdi2ODgmsbPdRvOuOsaeOIuJZy5gZ0l5kGEP8MFbn1NavAuAupp63nz5g6DPrR02ireXoqAwXDEnxZB/xGSmnn8kKq2ala98Q8mPG2iramTrFyvY+OEvWBstQedUVdTw9ec/dMav/ynoM0tbO9s2l/DCHrHA3S43WzZs542X3gvpw1ef/xhSpnDwoo80kjG1gGkXLiJ3/nhM8VGY4iLJnTeOaRcuInN6IZba5iDDHmDHN2uwte5b9ltf28DLz7wdVOZwONm2pSSorGRHWZBhD/DLjyvY2Tmf7+brz39gT1557h3crt7ZOAoDgyJ47SNepwPxAGPc70ZUqfG5nEia/Wsp17z9A/Vby0mfmo+lppmv/voq8286jahUxXlLYeCRZRmLpR2NSoVKp8EQG0HS9Hx8TjflP25GpVPjdrrB5+tRP6/TaVGrVbS1WlCpVGi1GmJjo5k0bRz1tY2sXrEedT9elhUUBhKv25/DQdOpIxY6Y3B7HC7aOxMICWJo3HtJpUKlkvC4PWg0ahyO4ERYKpWEXq8jOiaS6bMnI0kS+UW5ZOdlEhkVKvExm40D8fUUhjGyLOO2OZG06p5zJfRQJmlUgZj4e0NSSej0WowRBqbOmEhjQzOrlq1Do1Hj8/lob+/AYDCg7mE+lyQJlUqF0+nC6XBijowgwmxCo9Uwa+5UVGqJpT+txBxpRhAFOtqtSJKk6PCHgLAZ94IgzAH+BGR2tisAsizLvYuvNELwOZ2I/UyyI6pUvYp1X7t5F1VrdjD53MNR6zTEj0rFFB/Fj/99n0V3nYc+UpnwFQaOqvIaPnjncz774GuKxuZx8ZVns2r5ep555GkizCYuuvws9PFmfnj4PbxOF7nHTyY1PYmqitpAG1f+5kI+/+gbvvzkO+YsnM5DT/6F775ewpLvlpGanswf/3orhWPzhvBbKij0TGNJNVs+X057fSs5c8cSn5dGW1UjUenxtFZ0ZeQsWDQJY3xU0LlpGSlcfPW5fPXpd5x2zgm89sK7gc+ycjOoqarjd/fcwKpla/nhm6XEJ8Qyefp4Xn76LU44/Sgsbe0s/2U14H9BPuyouYPynRWGB+31rez8eSOVq3cQm5NMwaLJRKcHR8WJTo9HHxOBvblrpX7cybMxRO1b6x6fEMefH/g9y5es5qfvfiUxOZ677r2ZzJx0Hrr/Cb754icmzxjPeRefxtgJhWxctzVw7hnnn4goCNx81R+pKq/mjPNO4ohj5hNhjuDLT77D5XJxyVXnMHvBND55bzEvPvUm5qgIrr7hIqbOmthjciuFgSFsmntBELYCtwCrgEDyKlmWm/Z60gEw1Pq8th2b0UTHojqAMJi7cTY3IWo0GJJS91pHlmUW3/cqaZNHET8quF7Z0i3YWiwsuOn0fWrrFPrNIasddTqd/Ol3D/DpB18BkJqezJkXnMTD9z8ZqCOKIg8/fi/1H/jlOpJGQ84Fc1m1YgNVFdXMmDOFJT8s48O3vwick5uXxbhJo/ngLX94Qb1Bz4tv/ofC8QWD+O0OCg7ZsTkYtFY28PXf38Dn6crDmDN3LA07qkgem4WkVmG3WEkZm03cqBR0PaysNze1sGbFRmpr6oiKjmTF0jVERvlzo3zx8bccc+LhPP/E64H6KrWK6265lEf/9SyPPPs31q3ehFanZfb86YwZWfeHMjb7gdvh4tdnPqNmY1mgTBth4Mjfn40xrmtXp7Wykao1O/C43Dja7ZiTYlBpVeQumLDPqDY+n4///vNpnnv8ta72tRp+d88N/OWufwfKEpMTePipv7BmxQaKt5cyYcpYcvOzuPTMG4MkN397+A/cdfNfg65xz99/y9/v+Q9OZ+fuliDw/Fv/ZfL08Qf8u4SJQ8ZgCqcsp02W5c/D2N6wQ5Zl/8p9P2UEolqFz+nYZ536bRV4nG7ickMTOmTMKGDt2z9S8uN6Ri2c0K++KCj0RHVlLZ992OU8e/ZFp/De658E1fH5fKxds5m8+EisDW14XS6avt3MpbedjaRWsXrF+iDDHvw6zu6OVnabneJtpYpxrzCsaKtqDDLsAXYt28qohRPY9tUqJI0KbYSBwqOm9mjYA8TERnPEMfMA2La5mMcefI7GhhbsNjtnnn8SH74TfG943B5sVjuiKLBx3TZ+c/sVA/PlFIY11sa2IMMe/P5NltrmIOO+rbqRTZ8uQ6XToDFo2bVsC5JKImV8LsbYvSfYrKtp4LXn3w0qczpd1Nc27lGvHktbOxdcfmag7KN3vggy7DOz0/jpu19DrvHB258xceo4li3xL/zIsszSn1YOB+P+kKHfxr0gCJM7//c7QRAeAN4DAgJDWZZX9/cawwXZ278wmLsRVGq8HR37rFPy4wZSxmX3GN9WFEUKjpjMuvd+InXSKEWeo7BXnB12RJW01xjIHZZ2HFYnccnBPhy79fHxiXFMmjoWo9GA0WQkKjqS2QumYbPaWfLDcowmA+aEGAwpMbTuqEZr0kHnmNXsRb4mScGrSlqdlpaGZkRJIrIztbm1w4bH4wmsdCooDCZid72xAAkF6UQkRiOo/GPX6/LgtNgQVRKOdhsagw5REnE5XbQ2tWKKisBhd2I06bF22NHoNLS2WLDb/A7ndpsDk8lAc2NL0HUjzEYEUexRo9zebgVZDskGqnBwIUoigihiSogkNjuZjvpWGkuqg8ckfu28IIpkzBmNOkJPw9pSrE1tiJKE2+6POa8xho4jtVqFwWQI8QORJJHcvCzGTCikbGcF61dvCsm9sGc4Vv84DrU/IiJMWCzBNk5E50twS3Mrer0Ond7fN4/Hg6Wtg4gI4z7j7Sv0jXCs3P97j+Op3f5fBg4PwzWGBV6nA0mj7TmhRB8Q1X6H2r3hdrio3VTGjMuO2WsdY5yZxKIM1r//MzMuObpf/VE4+LC3dlC+cjvF369FZzYy9sRZxOenIXYa1l6PlxVLVvPEIy9RW1PPKacdw/GnHkl6Tjrgl+H87eE/8uO3S/n155W0NLdx/a2XsuLXtXz9+Y+YIozccsfVFI3J5+9/+g8Oh5OzzjyeqUdMCDh/ZedmcPwpR/LpB107AEefcBirV2wIHGfnpKPWqrnozBvQG/TccOvl+ASZJx5+EUtbOxdecSZHHb+QmNjoQfz1FA51otPjMcaa8TjdFB03nao1xdSsLyVpbBZ5h09i50/rmXnFsWz4YAmNJdWkTBiFoTCJ1196j+z8bHbuKOPXJasYPb6AmXOmsGb5ev7yrzu565b7sFntfLv4J669+RL+/dfHA9eMS4hBUqm49c5rmDB5TKDcZrXx0/fLeOo/L+Hxerny+gtYcORsxcg/SDElRDHz8qOpXl9K3dZyIpNjmXrhkUQmxwbVi8pKIO2M6Tz+xGtUVtZy4slHcsyFh9FcXsumj3/F43RTeNQUUieOQmvqkhHHJcRyw+1X8Oc7HgiUpWWkMGHKWMp2VrBsySryi3K59193kDsqK+iaRePySUpJoLa6HoD6ukYWHDmbT95bjN3uVyNIksQ5F53KjVfcFTgvwmxi8vQJPPbQ83z49udkZadzzS2XEBMTxUvPvMWP3y5l6oyJXHLNORQUjQr3T3pIEk7NfY4syzv3V9ZfhlKf52hqwG1pQRef1K92ZFmmo6yY6DETe9wFKF+5jR3frmXcybP32Y7H6WbFS18x/8ZTiVZSUA8EI1Y7uvXLlax//+fAsSAKHP7bs4nN9o/d9Ss2cMm5N+Nxd4VSu/TKs7nxjquRVBIOu4M/3nY/iz/9HoCo6EjOu/R0Hnvwua42BYHb776OB+79X6Dsbw//kRNOXRQ4rq9tZM3KDWzZuJ3R4/IpKMqjdHsZq1esJzU9ieS0JG666o94vX4JxK13XcND9z9J93np7vtv48zzTgrvDzTyGbFjc6TQXteMpbaFX5/5HG+3+yRzRiG5CyfyyxMf4+gMTVxw2mzufeAxsvOyqK6sCXJCjEuI4diTjuSjd77ggUfv4ftvfiElNYnpsyfRbung+69/QSVJaHUannvidTxuD4+9+A9mz58OwM/fLeO6S34X1LcHn/wLRx4zfxB+hQNCGZv9wG138suTn1K3tTxQpjXpOeKOczB1k+VsXL2ZS865CZezKzjHeRedyuzkbGrXd4UXnn7JUWTN7EpQ5Xa7eenptwCo3FWNOSqCnLws3n39Y9au3BioF5cQw6sfPEFyamJQ/0pLyln561pqq+uZPnsS4yeNoay0guVLVuF0uZk5ZwoFRbls3rid5UtWYzQZmL1gGq+/8H5QKGStVsPNd17NP/70SKAsOTWRl959lMTkAbNnFM39AfAOMHmPsreBKWG8xpDidToQ1P339hYEAVGtwet0otIbQj6vWlsSMML2hUqrJmNGIeve/YmFt5ze734pHBw4LFa2f7smqEz2ybTsqg2Mqx3bSoMMe4A3Xv2IM88/ibTsNKqr6oIS78ycO4VP318c3KYsU15WRVR0JK0tbQC89vw7HHnsfHQ6f5jXhKQ4jj7hMI4+4bDAeZk5aSw8Zi7WdiuXn3NzwLCPiY2isryGPRccXnn2HY454XBlpVJhUIlIjKGloiHIsAcoX7GN7LnjAoY9QLvPxY7tpRx+zHwWf/pdUP3G+mYMBj1trRZcLjd3/OnGwGc1VXWsWbGOkh3lAckOwNqVGwPG/ScfBN93AG+9/AGHHzV3n46TCiMTa5MlyLAHv7yyvaY5yLgv3rYzyLAHeOfNTzn+2X8GGffbv11D2qQ8VFq/5KW8tJInHn4Bp9NFXEIM1nYbF115dpBhD/5xW1pSHmLcZ+dmkJ0bnMSzaEweRWOCo55NmjqOSVPHAf5sze++/nHwd3K6aG0Ozg9RU1VHWWnlQBr3hwzh0NwXAmOASEEQTuv2kRk4qIKb+hx2JGN4DIzdse7Zw7j3+XzUbt7FlPN6p2ZKHpNF5eod1G2tILEwPSx9UxiZ+LxenB0OBAG0Rl2Q8QGg6qa71+lDcyyYI02BUGUajRqdThvYarVabZgjI0LOMej1gYgIAHHxsah6iL/cEyqVRExsVODY4XCiN+jQ6bTMO3wWBqOen79fRkxsVI8xlxUUBhqd2Uj2nDHUb6sIJKpS6TRI6uAxbo4yc/q5JxIZFYEoivh8vqDPd/uZaDvvQVmWaW5s6ZTJCUGGPYApokvHHJ8QLMcAiE+MUwz7gxRRJSFKIhFJMcRmJ9HR0Er99kokTfAcqNOFmlemCCO4g8eeLsKIIHUtWKs1aiIiTcRptcyYM5nG+mYEQUCSpMBCy260e/HV6i3NTa2o1SrUGjVGk5G21mBjfk//KwCdVgmXGQ7CMTsUACcAUcCJ3f4mA1eGof1hg9fpQArDyj2AoFbjdYbq7lsrGtAYdOgiQlf0e0KURLJmFLHhg59DVjz3xO1y887rH/N/v/07Lzz5Opa2fWeyUxg5tNe1sPrN71l836useu1bRh8/I+hzXZSR2KzkwHHRmHxS05OD6tx0+xUkpPpXTFLTk7n+tssCny39aSXnXHxqkEERFR1JUmpCwDBRqSQuvOJMVKreGeJavY6LLj8r8DJgs9rJyErjN7dfTmnxLpYtWcUJpy7iN7dfEXC+UlAYDGSfTP32SjZ8sISajWUkFmUGIpONWjiB6nU7mXze4YgqiaSjxvP8s2/x3eKfqKqo4ewLTwlqa/rsSezYtpNpsyaRV5hDTVUtjz30PGcddwW3XXsPV1x/AUkpXSuVMbFRTJw6NnB8zAmHo+82/tUaNWddcPLA/gAKQ4YpPpKZlx+LOTmGqnV+VfO0CxdhTgl+ySsam0dmVlpQ2U23X0HNr9sCx4IoUHj0VKRuc3JGVhr/97fbmTVvKj99+yvNTS1kj0rn/MvOCGprwRGzyc3LOqDv0NTYwmsvvMu5J17FJWfcwOYN2/jjX28LqpObnxWyK7DouIVkH+A1FYIJp+Z+lizLS8PS2D4YKn2e7PPRsmkNpqxR/XaoBXBZWpG9Xkzp2UHlW75YQfOuOvL6EOJS9smsfPVrppx7OEljsnqsY2lr5+oLbkMQBCZOGcvO4l3s3LGLJ1/5F9mjMvvzVQ5mRoR21G13suTxj6nfXhkoi81JZswJM2kpr0dr0hGXm4o5OSbovOJNJaxeuYHGhiYmThnL+MljMEV27UxZLB1sWLOZDWu3kDMqk472Dlqa22ioa0Kr06DX6ygqyqV4005cbjf5mRmMysskc0rvw1q63W42rNzE6hXr0eq0ZOdlct0lvw+qc9e9N3POxace4K9z0DIixuZIpaW8nm/+8QY+b9cqaPbcscRkJFK+YisNO6pInZBL8rzRXHf1XVRXdiVuO+uCk5k0bTylxbtIzUhGo1YjigITp44jISmOh+5/IqB5Bn98+0eevZ/VK9ZjNpuYNG084yeNDurP1k07WLV8PT6vl8nTxzN6XEFYnkMDhDI2+0FP87nGoOXIO8/F1C1ZWktFPWUlFewoK6exvokxY/NJNJpJLkinYVslHqeb+FGpRGclBi3KeDwe/nXfY0HhMFVqFa988DgNtY1s2bid7FEZTJwy9oDlMW+/+lFQzHyAp197EIC1qzaRnJLApGnjMBgNrF+ziW2bisnNz2LC5LEkJMX11GS4GLY3TbgJ5173eYIgnLtHWRuwUpblD8N4nSHB67AjqjVhm1BFlRq3zRZSXr+1gri80Nj2+0IQBTKmFbLx419JHJ0Z0kePx8ONV9xFSnoyZ19wMoIgcNhRc/nlxxVcef6tvPnJ08TGx+yldYXhjrXJEvQgAGjaWYPP66PomGl7PW/UmFxGjcnd6+dms4k5C6YzZ8F0LG3tnHfS1ZSXVRFhNuF2uXE4nFx2xdmMsmtx21w0lW7GV9pI2vhcpF7KaNRqNZNnTWTyrIkAPP7Q8yF1XnvxPY4/dZGiuVcYNNqqm4IMe4Bdv25Ba9DRsKMKgKp1JUijk4IMe4C3XvmQE05dxPGnHBnSbk1VHW++9EFQmcftoamxhRv2Ede+cEwehWOUTM6HAj3N5y6bE0ttS5Bxb6luYscbP6HSqcmMMFD30WoaVBLpf76YUQv2vjhYX9fEO68F6989bg8l28s48bSjWHDkvgN57I+OdmtIHH2A5b+s5obfXsmMOcFumIctmsthi5QMzOEmnKI9LTAR2NH5Nx6IAS4XBOHhMF5nSPA6HYhhTJ0sajR4XcGJrHxeH02lNUSm9v3NNSE/DYfFSv22ypDPXnr6LRx2J2edf1KQ4T97/jSmz57MXbf+bb+SHoXhi6iSEHvQuas0fX93t9sd1Nc2BOnowW+Ex3Zqf9stHYEYyeYIE84OO26Hv74xxky7pYPqXdW43W76SlRMZEhZfGIs6gP4LgoKvcVptWPv5qPS072jNelw2Z0IgkDS6EzyjpgUIhebPG0851x8apBmvjsarYao6NAxbjDoaahvok2RSh6SyD4Ze2sHLptjn/O5paWNipIKbB1WpE4HWY/DjbXBH9BAY9D2eG53NBo1kZERZOWkc/aFp3DksfNRa9QYDPp9ntdbVGpVj34i0Uo440ElnMb9KOBwWZYfkWX5EeBIoAg4FTgqjNcZEjwOG2KY9PYAgqRC9nqRuzmwtFU1oo3Qo+nB2XG/7YkC6VPy2fLZsqDyhromnn3sVS68/MweHbBOPO1oqitq+OLjb/v+JRSGBab4qBCNfdLoTMypoRPsvti8YTu3XfN/nLroEv7v9r9TvK0r4oLeoOPq31yIJHU9OGLiohmVmorX5Y8mYoiJgPx4rr34d5x14lU88KdHKd1e1qc+TJ81KcjJVpIkrr7hoh6dxxQU+ovH5aFy9Q6++cebfPXXV9m6eCX2NivRmYlEJAXvZuYfMZnaTWVMOHM+HqebsqWb8Va1cuKpR6FSq7j1rmswGPV8+v5X/PefT7N1046Q68XGRXP73dcHlWXnZuDzeTnzmMu46LTr+f7rJSFRUBQOXqzNFjZ+9Atf/uUVvnvwHZzttpAd1+QJOdS0tXL79X/mnFOu4Z7f/pN2PETtsRA48cz5+01qGRcfw1/+fScTp47ji4+/pbysit//328oHJsflu+j02m58sbgZ0VUdCQz5xw0gRNHBOHU3G8Dpsuy3NZ5HAksk2W5UBCENbIsTwrHdYZKn9e+czuS0YQ6TNFyAKxV5ZjSs1EZ/Dfjju/XUbupjIIj94wo2jt8Xh/Lnv+S+TecEoh7/5e7/k27pYMzz997nPDtW0p44ck3+OSHV9Hq+v5icRAzYrSjLquD5l11tFY2YIyLJDY7CUN0aHSbvVFdWct5J18TlDEzvyiXp197kOiYKAC2fr2KqqYmdlZWodfpyIhPIG/sKBq3V+Lz+ZCTzVx+0W1B6clPPPUo7r7/tj45xO4s3sW6VZuw2eyMn1jE6PEFQQ8KBWAEjc3hTN22Cn54KFhCMPmchYxaOJGOhlaadtbgsNiIzkrEEG2io76NpU99GtipAkhfOA45wcj99z7CrtKundPEpHhefv+xIGdZ8EeF2rR+K5vWbSMmLhqtVsPvfvPnoEglz7/9CFOmjx+gbz3gKGOzl8g+mfXv/8y2r1YFygRRYMZlx2JtaPVnPzbqEBPMXHPVHbQ0twXqFY4exX+fuA9nbWtgjMZkJu13x9bt9vDAvY/yxkvvB8pUKolXPniC0ePCY+B7vV62bNzO+jWb0et1TJg8lpy8YeHbp2juD4B/AmsFQfge/w84H/ibIAhG4Ot9nTgS8DjsaKLDq0sX1Wq8TkfAuG8qqcacdOBbV6Ikkjopl61frmDWlcfTUNfE5x99w1/+dcc+z8svyiUlPYm3X/uYC/bwmFcYGWiMOpJGZ5I0+sAm0F1llUGGPfhf+ip3VRMdE4WtpZ2dP6yno6GNGLUK2ddOrbcOs6imbvMuOhraEGdmBhn2AJ999A1XXHse2QXBjuP7ImdUJjmKk7fCIFC3pTykrPiH9WRML8IUHxWkcQawVDcHGfYAFd9vIOXkqUGGPUBdbQPlu6pCjHudTsuU6ROYMn0CLc2tnHPCVSEhCNet2jiSjXuFXmJv66Dkpw1BZbJPxlLdyObPlqPSqvG6PEQfNTbIsAfYurmYqsoapszp22JgQ10j777xSVCZx+OleHtp2Ix7SZIYO6GIsROKwtKeQt8JmyxHluVngdnAB51/c2VZfkaWZassy78N13WGAp/Xg+z1IqjUYW1XVGnwOrriGzftrMGc1DcpxZ6kjM2mdnM5tuZ2Xn/xXWbMmdxjfPI9OfG0o3ju8deU7eARjM1mp7K0irY9HgK9wdDDyrokSej0OmzN7YCALsq/a+V1ewLOhvooEwmFaWTPGYNBr0Oj1XD0CYdx4RVnkV+US2RUxAHtBjnabdhaOxRfEIUBpScJgz4qAmkvumWxh7jcolrCHG3moivPYsYehpZGo8bW3I7bHhr2GPxZOuMTQ32sonvwPVEYmexrLpPUKnTmUK270LlT6XG6kWUZvSF0flapJPQGPc31zVSWVQUtrHQ0tGGpbe6xP1qdlpiYKPIKcrjg8jM59qQj0Go1mEy9C7+tMDIIdxYMEWgAmoFRgiD0Kj+2IAhRgiC8IwjCVkEQtgiCMCvM/eoXXocdURO+SDm7ETUavE6/ce+0OnB02P265X6g0qpJHJ3B1q9X8c7rn3D4Ub3zQs/MTiclNZFPP/iqX9dXGBq2bdjOH2/+G6cdcynXXfp7Vv6yZv8ndSMnL4sTTz86qOzSq8/FuqWKz//0Ikue+IjCRVPQdTOGUibmIqklKleXUL5iGzlZGfzu/35D8bZS3nntY7JzM7jv33eSktn76E8ep5vyldv4+v7X+fLel9n82TLsrR19+i4KCr0lPi8VnbnLqBElkcKjpoQkDAKo2VhK7eZdJBR0xRaX1CoyT5vBfx9+jjdf+gCfT+b2u69Ho9Ww6LiFfPbB16z4YSVLnvyUxpLqkDYNRgO/ue3yINlZYnJCILOnwsjF43RTvmKPuawteC7TmvRMOH1+kFgkIikmJGxxlFbPUcctDCq79Mpz6LDZuOzcmzn92Mu5/+6H2bm1lOIf1vHdg2/z7QNvseHDX2ivC96RjY2L5t5/3UH+6Fzee+MTtm4u5rY/Xk/hWCUa08FEODX3/wDOBjYBu2OIybIs713s3XXui8BPsiw/IwiCBjDIstzaU92h0Oc5Gutxt7ehi0/cf+U+4HU5cdTXElU4jtpNZWz48BcmnD6v3+3aWztY9srXfFy+iRvvuLrX521av4333/yUD755aTjHUB5MRoR2tKm+mRuvuJMN67YGyowmAy+//SijRu891GVIOw3NbFy3larKGjKz0lDV29j17brA55JaxbzfnExLeR2SRo3ObOCXJz8NfB5/2Ghuu+vveDxdEoMTTjuKP/39t2h6mXWwJw30xDPmk3+AfigHMSNibA536rZW0LC9AgQB2etDpdOgMerInRdsXDfurOGHh97B6/aSNWs0prhIvB4vusw4rr3qTurrGgN1U9OTufmOq/nqsx9Y/Ol3REaZue93v6FpeTGL7jqPiMRg6aXH42HLxu1s3ViM0WRgzIQCMrNHdLZxZWwCdVvL+eHh94LKJp65gPwjgt0PvW4PLeX1tFb6E1jGZCWhMelo2VWHpboJQ6yZmMxEmppa2bJpO9VVdWRlpxOTEM1FZ9wQJOk67azjmBmZiqWyazxOOH0uBYumBo7dbjf33/Nf3nn1o0CZJEm8+sHjjB7f+xwlI5RDxrAJp+b+FKBAluWe9x/3giAIZvz6/EsAZFl2AcNKG+KxW8MaBnM3olqNz+1C9vlo3lUXou88UPRRJpptHSyY0PtEWACjx+Xz1isfsmLpGqbPVoypkULVruogwx7A2mGjrKS8T8Z9bHxMIMZxW3UTX77xctDnXrcHl80ZeFCsei04wlJda2uQYQ/w2Qdfc+3Nl5Ley9X7hm0VIWUlP20ga/ZoND1sTSso9Ie6LeVs/XKFfzFDEJB9PiKSokmfko/G0CUna69txuv2j+2ypZsBfwjalNOmBRn2AFUVNezYtpPFn34HQFurhVaHHY/TjaWuJcS4V6lUjJs4mnETgxNXKYxs6rb2MJf9uJ6sWUVBc5mkVhGXm0JcbvAcmViYQWJhRuA4LcpEWm7XrtF7r34c4qvx0XtfcsR9dwYZ97uWbSNz1mh0nbKbhromPnjrs6DzvF4vxTvKDgXj/pAhnLKcncCBiNJz8Et5nhcEYY0gCM90OuEGEAThKkEQVgqCsLKhoSEcfe0TXrsdURt+w0IQRESVGq/LSVNpLRGJUWFpt7mplY2VFcQ4xD5plgVBYMGRs3nthdAEFAo9M9RjE/wxsrU9rIwbTfsOibYvVBoVal1om6puZcZYc9BnOo0GnU7LCacexaXXnMuY8YVEx0ah26Mdr8eDtcmCs8POnuzW9XfHEGMOSp+u0DuGw9gc7hii/eNNlmVkn3/D2Rhrxuv2YG22BHxLVD3cC5JK6vEeE0URqTPs8NSZE7ns2vNISE9AlMQe76lDkUNhbO4eW90xxpp7neBvf/SUSyE2PgafPXhtVB9lRKXuMs20Oi1x8TEUjc3n0mvO5aTTj0Zv0O81N4PCyCScxr0Nf7ScJwVB+O/uv16cpwImA493hsu0AkHhXWRZfkqW5amyLE+Nj48PY5f3jyzLeJ12pAFYuQcQNVq8Djst5fWYEsOT5OHXn1cSnREPPh/O+r45V86aO5XlS9aErEYp9MxQjs3dZBdkcd1NlwSVHb5oLnmjcw64TWNcJBPOCHaZSRqdGRRXOXlcFtqILmewREMEt999PevXbOLlZ98mKSWevz10V5DDYHtdC6te+YbP/+8Fvn3gLWo378Ln68oEmpCfhr7bQ1GUREYfN61HDbTCvhkOY3O4k1CQhi6qy6gRVRK5C8bzzT/f4PP/e5G1b31PR1MbUenxxOelBp075sSZ5I0dxTkXnRpUfvZFp/DzD8u4+Y6rUatVvPjUmzz40LMkHD+RyJT+BUw4WDgUxmZCfjr6PcZW0XHTw2bcF47Jo6hb1mJBELj9ruvoKO16WZLUEnmHT0Kl7TLuY+Oiufefvyc9M5VXnnuH1Ss2cPMdV1E0elRY+qUwPAin5v7insplWX5xP+clAb/KspzVeTwPuEOW5eN7qj/Y+jyPw05H6Q6M6VkD0r6zuQmfLPD1Q58y55oTw6J1v/v2vzP/iFnEoMFrd5G4cEyfzn/pmbcYP2k0V/7mwn73ZYQzYrSjbc1tbFq7hfKyKuISYhkzvoDkjOR+telxumgpr8dS24LObCA6MxHDHivrltpmWisa8Hm8tIkeLjn35qCt4qOPO4w///v3GAx6PG4Py1/4kspVXcl9BFHkyDvPITq9K1xge10LLRX1eF0eItPiiE5PUHxAQhkxY3O4017fQsuuerxuD4bYCJY//yX21q5stflHTmbCafOw1LfQUlaHs8NOREIUsTnJeFwelr/zHR06geY2C7GRZuKMJnSZcTzwl/+xYe2WQDt6g543P32KrJyMnrpxMKGMzU66z2VRafFEpceHbS5r3lVHefEuqpqbaW+3kpGeTKSoJSk3tXNO9hCZFk9cbkpQAkunw8l9d/6bD9/7MlAmiiIvvPEfJs446MOvHjIPkrAth8my/KIgCHogQ5blbX04r1YQhApBEAo6zzsC2ByufvUXr92GqB24xE6iRo2jvpmIhOiw3PTVVbV0tFtJS09G9so0/LQFj92FSt/7nYe5C2fw/BOvc/l15/eY1VZh+BEZE8nsw2cyO4xtqrQa4vPSiM9L22sdc1IM5s5Mnh+88WmIBvSrL37g2psvJqcgG0dLB5Wrg7N2yj4fltqWIOM+IjE6RJesoDBQRCREE5HgH28lP24IMuwBSn/ZRP4Rk4hMiiFyj6y1bdsqaFi9EwC9ADa5gXKg8LIjggx7ALvNTtnOikPBuFfoZCDnMktNM9vf/gUAUYTK5RVUiQJZf7kkxCG8O7VVdXz6UXDqIZ/PR0lx2aFg3B8yhM1yEwThRGAt8EXn8URBED7a50ld3AC8KgjCemAi8Ldw9au/eOxWRPVAGvdafB4nxvjwxDVesXQt+UW5CKKIqJbQJUXRvr2mT21k52agUkmsWrZu/5UVDipcNgcdDW2BRD3NDU1sWb+Nip3+BD0ej4fqilrq60J1smZzqMY0Ni46EKNZ0qjQRYTGUtbohyYrss/jwet04NvjhUShC1n24XU58bqHVYyDsGFracfW7P+zNlmITI2j8OhpRHaTnxliIoJkDd0JWjTp3AQXBAGDyYC+h9wRERHhy3Cu0IXPu/te9gx1V0KwtXZgbbIEyQ/3xO1w0VrZQHt9y17r7El3h+/d8Qn1USYkzb5dH/V6HQlJoVIos9lES1ML27aUUFdT3+t+9AWn00VVeQ3NTb3/ngoHRjiFrH8CpgPfA8iyvFYQhF6lpZRleS0wdX/1hgKvzYbaPHAJRUS1BlEEU0JUWNpb/stqDj+qK5ymIS2W1nVlRI3LQBB7tzMgCAKz50/j3dc/YdqsSfs/QeGgoLGkmtVvfEdrRQPxBanEzC/i8f+8yNIfV5CemcKtd13L1k07ePbx1zCZDNx617UsOm4BBqPfYC8YncekqeNYs9KfcdGvAb2W5HS/PEgfZWLi2Qv59emuSA3x+WlEpYcm8Rlo3B0WrFXl+JwOVBFmDElpqPRKEpfueF1OHA21OJsbEUQJQ0oaGnN0IMHOSMZldbBr+VZqNpURnZFAyQ/r8TjdZE4vRFSJRKbGkZCfRvEP65hw2ry9RmoyJ8aQf+Rktn+9OlBWdNx0skZl8JvfXsED9z4aKD/imPnk9iFTs0Lv8NisWKvK8dqtSAYjxpSMQNb3ocRtd1Kxagfr3/8Zj9PNqIUTyD9iEobo4Fw2LRX1bP1yJZWrd6AzGxh70hzSJuWi3s+iR1R6PLHZyTSVdi7eCTDp7IU9LqB0JyElgdvvupbbrv9TIODG2PGFJKQkcMvVd7N6xQZG5Wdz2x+uZc7CGQf+A+xB2c4KHnvwORZ/+j1JKQncde/NzF4wDZUSLGFACKfmfpksyzMEQVjT6RiLIAjrZVkO6z7PYOrzZFmmZdMajOlZiNLADcD6dRvwiGb0MVH9aqemup5//OkRrr7xQoRucpqmZcVET8rCmNF7I6rd0sEfbv0bX/36zqHsRX/IaEc7Glr56v7Xcdv8kWwzF03ksdfeCRjqAGqNmit/cyGPPfhcoOypVx9k5twpgePKsko2r9+OpbWdrNwMxk4qRGfocrr1uj20VDTQXtuMxqgnOjMhRMc/0Hgcdiw7toDctZIm6QxE5OQjjpwHzYCOTVmWsddW4WioDSqPyMlHbTLv5ayRQ/W6En5+/GPGnTKHDR8sCfos7/BJVKzcRsaMIjJnFBKZErtPeaLT6qClvB5bswVjrJno9ATqm1p47KHnyM7NwOFwotGoKS+t4vTzTmDytINe+jBo86bX5cRSvAXZ07ViL6jUmEcVDVgQjN5Su3kXP/73/aCy8afOofDoaYFjj9vNqle/ZdevwRKueTecQvKYrP1ew9bSTsuuOlx2F+akGKLS4/eaXbk7TruTTWu3UFpSjinCSHZeJrdf/yfKdnaF7zSaDDz35n8oGpu/3/b2ez2nkz/c8jcWf/p9oEwURV796AnGjBvU8JuK5v4A2CgIwnmAJAhCHnAj8EsY2x90fC4ngigNqGHvcbqxt9kxZ/Z/9XLVsnXkFWYHGfYAhvRYLFuq+mTcR5hNFI3J48tPvuP0c0/od98UhjcdDW0Bwx7Aa9YGGfYAbpcbjyd423v18nVBxn1aVhppWXvX6EtqFXE5ycTl9M/Ztz/4nM4gwx7A67Dhc7tGknE/oMgeD86WppByj816cBj3G0vRRxnp6EEGUbupjLi8VCpWbKXwqCn79TvSGnUkFQXr6CvXVPHJe4tD6k6bNfFQMO4HDZ/LGWTYA8geNz6Xc8iN+/ptlSFlO5dsImfeuMBOkLXRQtWa4pB6ltrmXhn3huiIkJ2A3qDVa5k8ayKTZ00EYOlPK4IMe/DnSiktqQiLcV9f28RXn/0QVObz+SgrqRhs4/6QIZxPshuAPwBO4HXgS+AvYWx/0PHYbUgD6EwLfqPK45ERZQ97V+T1jlXLgg2t3egSI2nfXo27zYY6svfSg5nzpvL+W58pxv1BTH1dIw67E70xeJyrETBHRmBpaw8q33MLNTk1EWuTBVmWMURHIEoi9jYrHqfbH195P/rPgUKWZXydOnFRrQlyVu9RViKKIS/FvcHrcoHs81/jYHI+F0UkrRaPxx1crPYbTHv+voD/WAZRoxkW0Y18Xi+25nZEScIQE2wARSREU27fhsbUtaukMxtIn5pPVHo8ukgjmTMK2XOhz2Gx4XY40ZmN+4xZbzAa0Bv02G3BuRwizH03xBT2jrCXhTdBkvC53cg+L6JKHbjnvS4nyPKg3K/GODP6KCPpU/KR1CpqNpWhjzIhdguFqdZpMMREoDHoiM9PxW13Ub5iGxqDFmuzBXubFY1eGwhaMFCYIkxotBpczmDfmqioCFqaWmlv7yAmLhrTAeZO0Rt0xCfEhoTYNkcqPigDRTij5djwG/d/CFebQ43HZkXUDGxWzI6GVmREkPvnCNTc3EpDfRNpPWQCFSQRfUoMbVuriZvR+1i24yaO5uVn36a8rJKMfazGKow8nE4X33+1hPvv+Q8tTa0cdfxCzjv7BHa8+TMAzb/u4IbfXs5f//hw4JyFR86mtHhX4DgjK438rAy+vPdlfF4foxZOIGlMFstf+BJHm5WU8TmMP23ugD+Y9sTnduForMfRWAcI6BOT0UTHIXUmcpF0ejRRMbhamwPnGJLTETW9f5GXfV5cllZsVRXIXg+ayGj0SalIA5DsbigQJQl9YirtpduhU7opanWoDEb/79vU0CnZETCkpCN7Pdjra0CW0cUmoItPDBj9Q4GtuZ2ti1dS8uMGVBoVY0+ZTeaMooDzdvLYLLZ/sxpREjHEmjFEmUgoSKf4+7UUf7+O1EmjMESZKFu6hdHHTScqNZ7azbtY9do32JrbSSzKYOKZC3qMW79l0w7eff0Trrn5Yh762xOB8iOPmU9eoaK5DyeSVosuPilIPqZLSsXnctFRtgOf2x3wqfHYrNhrK5G9XjQx8ejjkwZ08S5uVApZs8ZQ/N1aPC4P6VPzGLVgIqpuxr0hOoJJZy9k+zdr2PLFCrQmPYXHTscYF8nSpz+jubQ2kHMkeVwW0gD5uxSMzuWqGy7k0X89Gyg76fRj0Bl0XHT69ewqrWTytPHc+ZebKCjqezz8uPgY7rrvFm656o8Bnf+seVMpVGLrDxj91twLgvAxgTgBociyfFK/LrAHg6lrtpRsRR0ROaDOOVs+X4HWpCUuVY9Xm7D/E/bCt1/+zLrVGzn25CN7/Nxrd9H06w7Sz5iJqO79BPHGyx+QlZ3ODb+94oD7NoI5aDX3a1dt5KLTrg8qO/HkRVxyxok4Wjr8ERd0KppxUV5WRXRMJJlJSdSXVlPb1opGrSZGpSMxIZYNH3Sp7/KPnEzZ0s24rA4AUifmMvOyYwc1CZWjuQFb5a6gMmNGDtqorpcMr9uN12FD9rgRNTpUOn2fHEXd1nbaS4Ij/mpi4jCmZiAIg7KCP+BjU5ZlvA47XocdQRSR9AYkjTbk99UnpmCvqw4615CSji4usU/XCydbvlgRoqWf95uTSR7bZVx3NLTSWtGASqfBbXeytJujN0D2nDHUb6skPj+VgqOnsvjPrwSy2ILfeJt3/clBjo9Njc1cfPoNlJdVcvwpRzH/iJk01DcRnxBLflEOuXmHhHE/qPOmz+vBa++U1am1IAq0F28NqqMyRiCIAu52S6BMF5+EPil1wHaZajaV8dMjHwSVjTt5NkXHTu/Wdy+rXvuO0iUbA2UTz1zAzp83YKnpWnyQ1Crm33hqSCK1cNLS1MLGdVupLK8hLjGWtIwULj7tehyOLrlmXkEOz77xMFExfQ8y4na52balhNKScqKiIigckxeU4HCQGPotxUEiHE/cf4WhjWGHLMt47Da0cQducPeG9oZWzMnZgOzXAR+gYbBq+Tryi3L3+rmk16CJNtJeXEtkUe8niNnzpvLEwy9y/W2XKTHvDyJKS8pDyr784geOmTGdmp+60kwc/ruzmXvYTKzNFr7/9ztYmyyIgAeoB0zzxqGNMOBstwFQv62C2JxkajaUAlC1rgR7Wwem+KiB/1L471tXc6hW3N3WEmTcS2o1kvrAo2B5HY6QMldLM/qEZKQ+7AAMZwRBQKU3BEUR2vP3FbU6PA57yLnOlia0MXEI4uBH1nHZHJQtDU2VUr+9Msi4N8VHBcblli9WhNSv3VRG0ugsKtcUkzNnTJBhD9BYXI2tpYPIbsZ9TVUd5WV+rfWnHyzm0w/8uvvHXvznoWLYDzqipELs5gfi7LYjtxuPtR1dQnKQce9qbUYXn4igGhjpYMP2UM196dLN5C4YH9DcO9pslK8IfhHRGHVBhj34AxF0NLQOqHEfHRvNvMNnBY5//OaXIMMeYMe2ndRU1x2Qca/WqBk7oZCxEwr73VeF/dNv416W5R/2X2vkMRjOtD6PF3tLB7ooE8g2BNmNLPTdMLDZ7OwsLufoEw/bZz1DRhyWzZWYC1N6vVqRkZWG3qBj+S9retTzK4xMoqJDnSLT0pPxtHcZaqJahUavxVLbjKRRY4yPRGXSocuMA6+P9i1VaI063PauB4Ax1oy1qesBaojae4zwgUAQBCS9Ho+tI6hc0oU3zGVPjreSRjMkxuxgIggCksEQ+H1ljxuxh5ckSac/4IWK/iJpVJiTY2ivC3aWNcREIPvkQEhg2SdjbbYg+3zoo0O1v8bYSGytHRjjzEgqFWq9loxpBWiMOtqqG2ksqUG1h+7eYDRw9U0XU1NVx+JPvgsYR5FRitZ+sBB72IETVCrkPWLgi1rdgO6ymXrIXWNOiUWURNrrWxFEAbVOiyk+iraqLi26IAqotGo8zmB/F42xZ8mfraUdj8uDIcqIShs+KZw50ozBqOfYE48gJj6aspIKlv68EqNJCRk8ElCWYveCx2YdcGdaa1M7ugg9kiQhCxL4Dkx3v3HdVjKyUtDsJzqAOtqIIInYK0NXNvfFrHlTef/NTw+obwrDk8LRo5gybULgWKWSuOnWy2ne5F/RF0SB2Vcex8pXv+aLP73Etw+8QcrCMXxftYOb/nA/v7//YeoT1UhRenwefxIotV5L8rgcWiv8Ca4EQWDCGfPQmQc3lKo2Jj5IYiOo1Kgjo8J6DUlvRDJ0MwgFAUNKxiERbUcbHRdwZJS9XgRJFaSvF0QJXVzCkDnVSioVhUdPC3qpNMVH4mizsfXLFTg77Dg77GxdvJIv//wyX/zpZSS1isjULv28pJZIm5JHw44qxpwwE0NMBONPm0v1+hK2fL4ch8XGzMuOwdjNUXf9ms389rp7ePI/L7J25QZu+v1VmCMjuPDyM8kZlTWYP8EhjaQ3oDZHBZUZUtLx2LvtMAki+sSUAc3ZEJ+fHpSdVqVVU3DEJDZ8+Atf/OklvvzzS+z8eT3jT5+HKHWZYvXbKxh70qygtjJmFGJODfbv8Lo9lK/Yxld/fY0v7nmRpU9/hqU2dNfiQMnNz+Kue2/ml59W8PQjL1Oxq4q//+du0jMHbvdAIXyELc79YDFYumZrdTmyzxe0lR9uajaW0rC9ioxpBQg+f3g+3wFIBZ74z4tEx0QyYcrY/da117TgqGkl5bjeJ6faHfN+8dK3ieghC+lBzEGruW8srmbDdyuxqGXsDieJUVGkxMcSlRqPvc2KOTGGNW9+R1Op31FNHxPBDq2dF557O6idf//3/0iRjMiyTGxOClVrdqCPNiF7fYgqifb6ViaeOR+tUd9TNwYMj8OB12HzrzTr9APi6Opzu/DYbcher/8aOv1gGrRDOjY9Tgdee9fvC+B12JFlGUmnR6Ub3H/vnrDUNFG/owqnxYbL5qT4+7XIPpnZV58AAvzyxCeBuuNOmYO9tYPItDhkrw99lAmHxYbGoKWtrpn0iXksvu8VZF/X8zI2J4l5N5yKRq+lrqaec0+6msb6LuMqwmzikWfvZ1RBNubIQ2rlfsjnTZ/H7b83PR4krQ5Jp8fncfvHqM83aGPU2mShtbIBr9tLZEosTTtrWPnK10F15lx3EoboCCy1zf7oOdER7FyygbicFOwWKxqDDmtTGwkFGSR0k+U07azhm3++GdRW2pQ8pl9ydJDT7oGys3gXZx93Bc5uEXRyRmXy/Fv/JTo2qt/tDxGK5v5Qx2Ozotnj7T/ctNe1oIv0r2rKSIhy31O8e7xeNq7bysVXnd2r+rrEKDqKa3HUt6FL6N2LRITZxJjxhXz+0TecdcHJfe6jwvCjva6ZhlU7Af/2XQPVNKkkjr33EhILM2irbgoY9gARmfF89fKrIe2sX70Zm02Ls93GxDPns/PnjSF18g+fNOjGvUqnQ6Ub2Mg1olqDZggjwgwlKq0O1R4vTMMtUpAxLpLS57+kpbw+qLylvA5nN/mZWq/F3tpByY/rKVg0la1fBuvv1ToN8TkpQYY9QNPOWuwtHWj0Wqor64IMe/Avirjd7kPNsB8WiCo1mojg55uk0Q66P4wx1owx1i+B9Hq8rHgpNPdB5artzLj0GKLT4wGo2bSL4u/WUfzduuC2YszQzbjfU3YGULW6GOepc1HFHbg/UaBfu6qCDHvwG/y1NfUj2bg/ZOi3cT/Y0XIGg91RIqT4pAG9TnttK4lF6f4DQfKHw5Rl6MPq346tO4mOiez1irogChgz42ldX07SkeN6fZ3Z86fx9qsfKcb9CMLjdGFr7kBUSRjjzHg9XizVTYCMKTHGH4N5agEqjYrm8npcVgeyz0dbdSOCJKE16XF2+I0gt8VOdnYGVRXBGUsTE+Jwb/HrRXtKl26INaPS998A9rpcgZjVgyV9kb1evG4XgiggDXBI3OGO7PP6Y/ojICMjCgKiRjss4tnvDVGSiM5ICBj30RkJJI3JJG5UKoII2ggDtZvKcDvcxI1KQWPQ9jiGI5KiUem0jD5uOm3VTVSv24ksy2hN+kCse3NkBCqVhKdTogZ+WVpk1MhP+DUS8DgdyG43glod8tI5lMg+GWtTGz6vD0NMBNEZ/ghSiUWZIMtUrSshMi0et8OFrbkdlUaFxqjtUXOvNQV/L21E6IKJKT4qxA/kQImMDn1BMBj1h3LG+hGFEi2nB3xOB4IoDagez9fpzKWP6jTKBQEQQfaC0Pt/ljUrNpAzKrNP19anxtBRuhVncwfamN69FIwZX8Crz73Dlo3bw5KxTmFgaa9vZd27P1G9rgSVVs2sq46nZkMpO3/agCxD4bHTKDx6Ghs/Worb7iRlQg5Fx0zj+3+/g62lndicZCacOZ/lL3wJMrSU1HDhhaeyetUGbFa/wZ9flEt2QiJVG+oAcNtdJI7OpG6zP0yiIApMOG0uEf2IlCPLPlyWNmyVu5C9HiS9EWNaZlAEl4HA43Bgq6nA094GooghOQ1NVMyAOtgPV7xOJ/a6alytTSCIaGPi/BlA9Qa0sQmB/AHDDUEUyF0wnso1xaROyMHn9bH1y1UIi1eROaMIr8dL2qRRuB0uVrz4FV6PhwmnzycmJ5nmnTUAiCqJomOn8/P/PsTZbiMmK4lxp85h/Qc/M/m8wwPJsTKy07jlrmt54N5HA9e/7pZLycrN6LFvCuHDZWnFVl2Oz+VC1GgxpGaErNoPBU6rg9KfN7Lpk1/xejxkTi9k1IIJuOxOtn65AkEUyZ49hvhRKSx9+jNqN5Wh1mmYfN4RTDh9Hqte+zbQVs7csZiTg8NGRqUnkDQ2i9qNZQAIosikcxeiNYVnlzQ3P4vzLzuDV597J1B2559vIi0jNJeOwvBD0dz3gLOlCWdzI/rE5AG7hrWxjfUfLKHo6GmBMsHTgSzpkaXe3Zwy8Psb7uWEUxeRkBTft+uXNeCxOkg6over9x+/9yWSSsU999/ep2uNYIZcO3og+Lw+1r71PcU/rAdAbdAw5viZrH37x0CdsSfPZuOHXfHpi46dxo5v1watFsWNSmH8qXOxtbSjjTAQlRpHVW09JdvL0Om05BflYtJqaatsxOf1+RP6iAKt5Q24bA4iEqOJzUlC6sdKu8dmxVK8JahMMhiJyM4bMENbln1YqypwNTcElUfk5KM2DZuV2EEbm7baKhz1NUFlu2PbmzJy0URF7+XM4UF7fQvV63ey7p2fgspHHzcdUa0Kug8Apl20CLVei+yT0Zr1/Pr0ZzgstsDnCQXpTDhzPuakGCRV1wKQzWpnx9YSaqrrSUiKp6Ao91CNLDJoY9Njt9K+czuyt9uOiaQiIid/wBcA9kf1hp38/L+PgsoKFk2hYtV2bM3+zN8xWYkY46OoWBGcM2PqhUfisNjwujxIKommslqKjplGXG6wYe2wWGmtbMRlc2JOiiYyJS4QDSocWNra2balhKaGZtIykskrzEUbxog8Q8Dw3WoMM2F7OgqCkAfcD4wGAvtHsiznhOsag4XHZkUc4Eg57XWtGKKDtZiyICH4PMi93DCoqazF43YfUCIIQ3osDT9vxdnUjja2d5rQuQtn8OffP8Dtf7juUH1ojQic7TYqVu0IHCePzaZua0VQHa9rz8hMQsg2cGNxNQgCGVMLAmU5ozJDdoqMMcEGb39W6vfE63KGltms+NzuATPufW4P7rYeYmU77MPJuB8UfB5PUCbf3XhdTgS1GldH27A37k3xUVSt2xlS3tFoQdKETrZbvljBwltPxxAVwa7lW4MMe/DnclCpVUGGPfglCxOmjGWCEjF40PC6XEGGPYDs9eB1OYfcuG8srg4pq1pXQmxOcsC4jxuVSknnIkx3rI1t/twL3dZe0yfnhRj3OrORpNEDJ5MxR0YwbebEAWtfYeAIZyjM54HH8ee3OQx4CXg5jO0PGh67dcAdbyy1zeij9rgpBQlkd88n9MCalRvIzcs+IN2rIIkYsxNoXlXa63OiY6IoHJPHJ++HOgUpDB9UOg3mlK4oT60VjZiTg6M+iSpxn8fgDweoMfT9PrA2ttFa2YDTGproqTf4fD7cNivujvYe48YLKlVIuc/rwWO34XU66Wk30ufz4els0+ve9z0mSBJiD7pd6RB0nt2dmXZPRJUa2eNF0ujweTz4fF7c1g7c1g58ngML6TtQCIJAbHao/5TWpEPXg37YnByDWucf9z3pmg3REQiSEkV6ONDzC77QY7nX68VtbcfVbun0HxlYTAlRIWXm5NigPCDWJgsRSaEvx5JGHeLJqDX3/LLS0dBGa5V/9V5BYTfhnKH0six/g1/qs0uW5T8Bh4ex/UEh4Ew7wE45ltqWkJV7BBWC3PsH45oVG8jJyzrgPhjSYnC3WbHXtvb6nAVHzua159/t0YBSGB6odRrGnTwnEOfbUtNE/KhUDLHdsji220ka07UCX7d5F0XHTgtqZ9JZC4lI6P2qrMftpuzXzSy+71UW3/cqPz3yPq3dkrP0Bq/TiaOumvaSrbTv3Ianox1NVHB8Z2NqJlK3nA4eh5320mIsOzbTtmMTzubGoNU8r8uFo74GS8k22nduw1q+E7fNutc+iJKEITktKAmTyhiBpD/0HMkEUUQXmxDkfyRpdSDLiGo1steDvbYKZ0sT7SXbaC/ZirVqF267bR+tDj5ZM4rQdVtMMcREoDHoEESByNSunU+1QUv+EZMDjrJRafFkTOvauRJEkbzDJ/Lrs5/TUhEchUdh8JF0enQJwfJZXWJyIDzrbjwOO876Wtp3bqejdDvWyjLc1uBEd+EmIT+dqPQuuazaoCX/yElYG7uMe0ttM+NPnYuk7rq/kkZn+hdnuq3Z5c4fR1RasPTW4/Kwc8lGFv/1VRb/5RV++t+HtFX3LYeNwsFLOPe1HYI/3dsOQRB+A1QBCWFsf1DYnZl2QJ1pvT5sTRb0IVkLO+9m2etfxd8HlrZ2aqrrSM868IQSgihiyk2ieWUJKcdP7tUOQOGYPDweL8uWrFYy1g5j4nJTOPKOc7HUNqPSqolMjWPudSfRVtWI7PMRmRaPPtJIW9VuvWYM+mgTyWOzsbd2YIw1Y06N7ZN+s7WikeUvdO3qNJfVse6dH5l9zYmoe5ml1mPrwNHQFZHH0ViLPiUNU3S+36G2M2b1bmSfF3ttFd7dGWl9PmxVu5B0OtTGiK42u2nGPdZ2nE31SLpMRLHn9Q21MQJzXhFepwNRFJF0+qBETYcKsizj7rCgjfVP5aJag6hS4XXYUUdEBv6tdAnJ/qAAsoy7rQVJq0M9xLKI7kSmxnHE7WfRWt2I7JXRGHW4HU4iU+LImFZAa0UDXo+HyNQ4YjojmgDoIgxMOnshGdMKaCqtRVJJ7PhuLbbmdla+/DULbj4NjWH4RGc51PC5nHjdLozp2fg8HkSVXyrmc7uComp57TYcDd3mgA4LTo0GUedPIjkQmOIjmXfdybRWN+JzezEnxxCRGM0RvzvbH5FMFIlMjcUYY+bIO8+jvbYZlV5LVFocokrFwptPp72+FX2Uiah0/3zdndaKela+3BUzv6mkmvUfLGHWFcei0gxPJ3eFwSOcxv3NgAG4EfgL/lX7i8PY/qDgsdsGPjNtYxvaCH3Q2zoAgtBNd7/vCWfd6k1k5WSgUvVvYtIlR2Hd1YCtvBFj5v6dcgVB4PCj5/LCU28oxv0wx5wcEyTH0UcaiUoN9s/QFQZH89hT09kXrA2tIWV1W8pxtllR97BF3RMeW+hqmrOxgYicfCRNqN7d5/HgtoRe1+t0BIx7r8Me8rm7vQ2fy4m4j0Q2qmGSjGkokb1eXK3N+Dp9H1TGCJDlkH8nr92GpNPh7Vyxd7e34YtNQBxGkXSMcZEY9xL/25y092SFWpMer8fDls+XB5W3lNdjb+1QjPshxOt24W5pwt0SvGKtMUcFae49PewkedrbkGMTQT9w97g+2oQ+OjginSk+ElN88DiMTIn1ByToRkJBOgkF6Xttu6O+NaSsZsNOnBZbWOLcK4xswmbcy7K8AqBz9f5GWZbbw9X2YOKxWREHWG/fVtMccsMHCOju992H1Ss2kNsPSU7gcoJARF4Szat2Ykjvnaf9rLlT+fDtLyjeXsqo/Ox+90Hh4EBrDpWtmBIi+xTnvic5nKTT96i9BxBECUmrR9Lp/Dp5WcbV1oKo6rpmdwlP9+scimEt+4ogiqj0Blydxr3P5URlMqMSOg19wN1hQdRo8XSTOkk6PQzg7udgo4sI3YXQmQ09xsVXGDxEye9/o4mOQZBUyF6/A/ie93ZPPnSiVo8wSDkzBoKeNPjm5Jiw5BVRGPmETXMvCMJUQRA2AOuBDYIgrBMEYcQt7XrttoF3pq1uwhizlwg1ggrBt2/dvdPlYtumYrLzwhNDWRMbgahR076jZv+VAbVGzeFHz+OZR18Jy/UVDg6i0uLInFkUOBZVElPOPaJHw2hvqIymIAdOQZLQxSXuNXGVqFJhSM3A63TgqK/B0ViPJiom6CVB0ptQGbpePARRQp+QMqxWlYcrgiiiS0hC6DSWfG4X6ohIBEnl/73ra5DUGlQGE7LXP28JKjXa6Li9Sp5GIpEpcYxaOCFwLIgiUy84MtRvSmFQkXR6DKkZuNpacNTX4GprxZCSgWQInnMkgzHIZ0aQJHTxicM2R0NviE5PIH1qV84ZSS0x+ZzDBz0buMLwJJyvrc8B18my/BOAIAhz8UfQGR/GawwofmdaG9rYvoeW7Att1U1kdTOCgvogSIhyqIygO5s3bCcpNQF9mLYTd6/et67bhSk3EbEXUp/DFs3mD7f+jcryaiWphQLgX92ceOYCsmeP8ce5T4gOidKzP1R6I8b0HLwOG7LP55fGGPbuyCp7vdgbarukN7IPR30NapM5IK9T6fUY0rPx2W34fD4knR71PtpUCEalN2IeVYjX4UAQRTwOe5AUytXWgsoUgTEjB2QZSadDdZA5H2uMOsaeNIv0qfk42+2Y4iMx7yGjUBh8ZK8HW1U5ss/vQC973NiqyzEbTdAtzKna4E9+53XakX0+v0+IcWS/mOnMBiafcxi588fjsjmJSIzap7xM4dAinMZ9+27DHkCW5Z8FQRhR0hzZ4w+RJwzgdr3T6sDjdKHbS1gr/2aKDLIvKFpHd9YsX09uH7PS7g91pAGVWY9lazVRY/eu89uNwWhgwZFzeOLhF7jvwbvC2heFkYvWqCMhP61fbah0OlS63umYfV6PP4vsHnhdDtR0PbxVWh0Mo7T0Iw1Jq0PS6pBlGXtdaPxut8VCRPaoIejZ4KEx6IgfdeABDBTCj8/tChj2u5G9XnwuV8gOvEpvGPLY9+FGa9L3e75VODgJ577pckEQnhQEYaEgCAsEQXgM+F4QhMmCIEwO43UGDI/dhqjRHVDc+N5iqW7CFBu592sIAggSwl7i3ft8Ptat3khuQfi17qbcRNo2VuBze/dfGTjquAV8//UvlJaUh70vCsMDh8VKU1kt7fWtgxb+VPb58NhteGxWfF6Pf0fN6cDdmbyqO4IoIel6jsPeV7xuF26bFa/zwOLzHwrIPh8qY6i/UE9lwx2P20NrVSMtFfW4HQMf91whPPjc7sB96l+I2+NZKggjWku/L6yNbTSV1WJrGVHrpgpDQDjvgImd/71nj/LZ+NMxDPuY937jfmCdUVrLG4LijfeELEjgc4MYqv0v3l6K0WQkKjr83vDqCD2aGCOWbVVEjd2/nt9gNHDU8Qt58G+P88iz94e9PwpDS3NZHUuf+RRrowWVVs3kcw4jfWo+knrgHpxetxtnQy2OxjrAbzTq4pPo2LUTZB+iRoMpIzcg1fFr7tNpL90BPh8A6siYfUp5esJtbaejfCey240gShjSMtFERg/oi/5Iw+t0YK2uQBsVg6jW4HP7DWJRqx1xxr29tYPNny2n5Kf1IEPyuGwmnbUAUxizKyuEH4/NSkd5CT6XC0QRQ1om+qRU7LWVgTr6pLQBz1Mz2Ph8PmrW72T5S1/htjnRRRqZdfmxxCur9gp7IWwr97IsH7aPv2Fv2MPgONO2VDVgjN9PCntBheDreeV+9fL15A5ghBpjdgJtmyrxeX29qn/EMfPYsnE7y5asHrA+KQw+zg47y19aHEi44nG6Wf7i4gFPkuK1dQQMewCPtcMf/abT8c3ncmGtKAvKgqo2RmAeVYQpaxQROQUYU9P7tHLvc7uwdhr24I+dby0v7TGE5qGMq7UFr82K125DbY5Cl5CMPjEFtcncYwjT4UzD9kpKflwfyAJas6GU8hXbhrZTCvvE5/FgrSj1G/bgz2lRXgqSiD4xJTAeXS1NgZCsBwvtdS0sfeZz3J1ZaB1tVpY+85mygq+wV8IZLSdREIRnBUH4vPN4tCAIl4er/cHA67AhDmCMe7fdhbPNiiEkeVUwsiD5M9XuIYOQgVXL15M3AJKc3agj9Kgj9HQU1+6/MqDRaDjzvJP46x8fxO3q+YVEYeThsFix9GDIW5tC9e3hxNND5liPtSNoJd7rtOPzBI81lU6PxhyF2hTRZ0mOz+0OkfuA3GVEKPjj3bc1I+n0eGxWnE31OOprsNdV42xqwNNh2X8jw4i6bRUhZZVrivEoc9iwxedx9yiZk91u7HXVgfHoddjwug+ue9fWZMHnCZbLOiw27K0j66VaYfAIp+b+BeBLYHfolO34E1uNCGSvF5/bPaBZKFsq6jHGRyFK+/vZO51qCV49r9xVheyTiU8c2Gg+xqx42jZV9FpjPWnaOKJjonj6f0pozJGEz+ulraaJptIaHO3BK10agw59VKjUYs8sieHphwe3zepPIKfToTIY0SUko0tIRhMZjaTTBz3URbUGcY8Y6j63G7e1A4/Djiz78DiduCxtuNstePdjpAuSqseM1EqozG6IIipjBD6Xw5/9NyISfWIKhtRMDCkZaKJi8dhtfr8IryfgN+G2dQTtsoQDe2sHjTtraK9tRvYdmB9ITGZiSFl8XtqASs4U+ocoST3ek4KkxpiejSEtC2N6FqJWh6hS47Z24LK0BXbgfB4P7o52XO1teHfnbfB6/f49dhs+b+98zfqL2+6kubyO1sqGXr9M6iKNIa4FKp0GrUkJe6nQM+GcyeJkWX5LEIQ7AWRZ9giCMDh3SxjwOOyIGu2Aamyby2qJiO+FVl4QkDulOd0z1a5cto5RBdkDrgNWRxsRRBF7ZTOG9P2HexMEgfMuPZ37/vAgC4+czehxBQPaP4X+47I7Kf5+HZs+/hXZ58OcFMPMK44jKs3/4qiPMjHtokUsefwjvJ0O1oXHTMOcsv8sxn3B63RgrdyFx+rfXjZk5CBqdTjq/TkXJL0RfWIKHWU7/CcIAobk9KCXcI/d5tfhOp0gCJgyR+ForMXT4W9zt4Rkb+EvJa0WQ1oW1vKdgd0yfVLqQafb7Q+CIKCJjMZtaUVlNONsafTveNisuDujFalMZiSdzh/lS/bhbKwHQNIbMKVn+xNb9ZOm0lp+eeoT7C0dSGqJSWctJGNmIao+voglFmUSm51MU6l/nBljzeTMHaP4WAxjRLUGY1oW7WXFgftUl5iCqJKwVZcje70IkoQhJROPy4m9sgxk2X9eejbO1iZczY2Af0waUtJx1Nfhbm8FQBMZjT45bUCluR0Nrax+4ztqN+0CIGtWEWNPmr3ffAkRSTFMPH0+a9/9EeTOPAsXHqn4iCjslXAa91ZBEGLpVDEKgjATGNg9/DDi7TTuBwpZhubSOrLnjuldfUGF4HMhS10Gxspl6zh80dyB6mIAQRAwpMfStrmyV8Y9QExsFOdcdAq3XXsPb332DBHmkeVgd6jRUl7Pxg9/CRxbapvZ8MHPzLrqeFQav6GUWJTBorvOp6OxDW2EHnNyDGpt+Ha2ZFnG2dwYMOwBZKcDV7dU8l67FVdbM/rk9ECSJFtDLZLBgKTR4vN6sdVW+g178GdKtXYEDHug0yA17TO2vcYchSpvNF6XE1GlRtLp9poV91DFZWlFExOPz+nAY+tApTfgbu6a4j0dFiSdHlFSBTk4eu027I11GFMzEPYS3rc3ODvsrHhpMfYWvxTB6/ay8tVviEqPJyYrqU9tmeIjmXPtCVhqmvF5fZiTY5SEVCMAlcmMOW80PpcTUaVC9sm0l3U508teL9aqMoypmYEXAJ/bhdfpCBj24B+TzuZGfG5noMyfr8GMFBveBYzuVKzcHjDsAcqWbiE+P43sWfu2C1RqFTkLxhGXn4qjzYoxxkyEEtNeYR+EU5ZzK/ARkCsIwhLgJeCGMLY/oHjt1h7T1IcLa2MbiELvs3XuEQ6ztqaBjnYrKWmh28kDgS45CldzB25L7x2Tps+eTOHoUfz+xnvxDtIWp8KBYW0Mfe+u21KOs6PLiVQQBMzJMaSMyyY2Kymshj34wyq6u8WoF1TqHiU0HmsHXrs1kBHVZ+8KiSl7PXjau/TeqggzHmuo/ru7sd8TgiAgder2VQajYtjvgc/t9uvqRQF3hwVJq+vRadFrsyITKpVxW9qQPf2bExwWG5aa5pDyjqYD0/vrzEYSCtJJGp2pGPYjBEEQAv41KoMJn8cVMOwD+HzI3cpEjbZHrb67wxKUDRv843Sg8Hq8VK4tCSmv39K7UNIqtZqYjERSxuUQmRrXC3mvwqFM2FbuZVleLQjCAqAAvzpsmyzvJVj7HgiCUAa0A17AI8vy1HD1q7d4HHY0kdED1n5jSTWRyTG93/YVVLDbqVYQWPXrWvILcxAGKaW7IIroU6OxbKshdlpur88768KT+e8/n+avf3yYu/92q7LNHSY8bg8ddS14XB5M8ZG9ekl0WGx0NLah0qgwJUaj6qYn7klPH52VhEbfv90r2efD63Qg+7yIGi1SDz4sXpcLn9uJIEqozVFIWh2itjO/hKSCluD6qsho1AYjKlMEIOBorAdBwG1tR5BUSHojXrvfEddrtaIyGEMcc/saGlPBj9+J0YkgCGjjkxBEETE2HtnlChj63ZF0+h7veZXR1KNfQ1/QGHUYoiNCIoQYOseyw2Kjo6EVlVaNKTEar8tNR30rokoiIiEKVZhfThWGHkGlQVCr0UbF+nPEyDLO1iYElQpdQjLgX82XegiUodIbQ4x+lcmEz+3G63IiiCKSVtevZ66zw05bdRNet4fI1FgSC9Np2VUXVCc2V8nwrhB+wmbcC4JwJvCFLMubBEH4IzBZEIT7ZFnubYzEw2RZbtx/tfAjyzJehx0pvm9bu32hYUcVSaP3Hzs+gCD4Q2LKbmRBw/Jf1zBn/vQB619P6NNiaV5WTMzkbIRerhKoVCquvflSHrz/cf7x50f4/T03KAZ+P3F22Nn6xQq2fbMaZDAnxzDryuOITNm7Y3VbdSNLn/oMS20zCFBwxGQKj5kWcMCKzkggZ+5Ydv68EfAbThPPmI+6H8a9z+vB2dSAvbYakBHVakyZo4IMa4/NSvuu4s6wkwLGjGzc7W242vwWvToyGl1iMo46vxZaE+NfodqthxdUaoxpmf6Y9C4nCCKmzBysFaXIXi9euxVdYjLuDgu+zge3pDegMu0n/KxCCB6HHeuuEjRRMbjaWlCbo/wOyp0vUurIaHTxSTga/JG1JK0OdWQ07vZWf11LK+DfkdEnJPd7YUIfaWTaxYtY8vjHeJz+daPRJ8wgMiWW1qpGlj71Ke11LQiCQN6Rk/C5vRR/vw6A7DljGHvS7AFxCFcYOnwqNYbEVKzV5f4VfFHEmJKB1+3yj8vdc0Zktn9Xr3OXT1Cp0cUlYK3uipok6Q2oDCYsO7cGZH66+ER08UkHlBTPUtfC5k9+DYRYjUqLZ9I5h1G1bifttf4dqLhRKSSNzurnr6CgEEo4Nfd3y7L8tiAIc4GjgX8BjwMzwniNAcHndiGIYr9XlvaGraUDZ7sdY1zfEk/JggrB66S+sZ2W5lbSMpIHpH97Q2XQoorQY61oxJSV0Ovz9AYdN//+av77wNPcdfN9/Pmfv0ejrJodMM1ldWz7uusd2VLTzObPljP9kqOQesjE6PV42PL5Cr9hDyDDtq9Xk1CYTvJYfxhVXYSB8afPJ3vOGNx2F6aEKEx9HJ8h17XbsddWBY59bjfWqnIicvIQJZU/TnXVrkA8eVGjxtNhCZJ3uNtaUOlT0SemIMsykt6AdVfXVrbscWOrqUAXm4C9pgJkH9aKUkzZ+chejz+ihlaPmJGDz+lAAEStHpVeiSrRF2SfD0d9LTJ+p2fZ60X2uAOGPXT+WyX5/63AP496rO3o4pMQBDGwgyNpdWFzUkwoSGfRXef5/UBMesxJMSAKbPpkKe11/hdEWZbZ/tVqxp48O3Be6ZJNJI3OJH1Kflj6oTA8kLxu2qvKQe6U4fh8WKvL0cUmBDT3sseNraocbXQsaoMJWZaRfV6cLS1EZOfjc9oBAVGjxVZTETDsARwNdaiMZjTmvs+NjcVVQbkTWisbKPt1M/NvOoWO+jZEUcCcFIO2t1JdBYU+EE6Nx25B5fHA47Isfwj01qKTgcWCIKwSBOGqMPapVwx08qqG7RVEpcUh9nHlSu5cuV/561ryCnJCwv8NBvqUaNq31/T5PKPJwK13XkNdbSOXnHkDtdX1A9C7Q4OAkd6Nui3luDpCdaQArg4H/8/eeYc5dlR5+60blKVW5xwmB+eIsQEbk7EJZglLTv5MhiUak3NOXkwwYRdYYGGBJSwZDAYb4zD22DOe8cTOOXcr64b6/rjd6lZLM9PTebrv+zx6ZlSqe1VqlW6de+qc3+k/2FHQPtmfH+/i8Xso31RLze7mRRv2QF5y2jRWKoGckkKUlplnyKu+AGaiUKfZSiXJjI048fVFYvDtTAZlVoiRtCykZeIJl6AFQiiqiu4P4I2W4YmWuYb9ApCWhRGfQJvStZ/Wt5+LmUqSGR9x9O5Hh53cBkVF0TT0YAhPuGRJr61CCMLVpdSe1UJZczWaVyebSDPwSKFuvZnK5u0WjLTPr3aHy5mDbWRnDPtco+3sfM9uyqSRtp3Tw88MD2LExxEC9FAEPeTkXMzO35mmWLz+fBjrKFzzhg53IaSgekcjldsaXMPeZdlYSuO+RwhxK/B84LdCCO9pnP8KKeWFwNOANwghHjf7RSHEDUKIPUKIPUNDQ0s4ZAcztXxKOVJC/4FOoo0LyMAXGkiDB+59iO075x/3vpT4qkvIDMcwE4WG26nw+ry85s0vY8dZ23j+06/nj7+5fekHuMos99wECFdFC9oqttShB4pLNeoBH5Vb6wvagxURRtr6GG7tI5tIk05nOHzwGPffu4/BgcVHxBWrEaEGw064zsQYtmWhzJKXtNIpVH9hmITi8eYSZhWtiP68xwOKmtPCV3TPstanOFNZzNwUqooWDGNl0mj+AFYmXZB8CDiKRbMKgGnBEOoKOyE8AS8VReKWNZ+el1hZ2jj/3cdiGIbBscOt3H/PQ/R0uzcKi2Exc9NMJclMjGHEYwhNLzDkKaLI5FxT8h0FejCclzivqCpqsDAXqVi8/nyYlhWeTdmmWjzhlXc2jI2O89D9D/PwQ4eIxwpv0l3WH0tp3D8fp4jVU6WU40AZ8M75HCil7J36dxD4OXDpnNe/IaW8WEp5cWXl0stUWemkYzAsA5O9I0jbJli+gJhfITBMKCsL0Ni8Okk3QlXwVZcQbx04deciKIrC05/5BN7wtlfy+Y9/lZve8lFik+unqt5yz02AspYaNl2+O/fcHw1y1jMejeYpHlWneTR2X3tZXtJsy2W7mOgZ5rZP/5i/fObH3P/LO/j6F7/D859+Pa983pt4ybNfxyMPH13UOBWPD+8sGTnF68VbWk7s+BESHceJtR4hUFOfC3+zsxn0SEleVWgtHEGoWs4bZ6ZS+GblwghFxV/bSKKn01HPGerHV1WzbL/fM5nFzE2hKPirap1kxCmjXvV4827OtGAYFCWnVqL6/OiR6JKNf75oHp1dT73EKfQzRfOjd5GcVb2z7rzNVG4rvOGdL+lUmh9/7xfO7+X5b+aF197A3vv2L2rcG5mFzs1sbIJY68z1xEwlCdQ2zRj4QhCoa0TO2rERikqwvjmv4Luie5zwsdn9VJVATZ1zwzCFp7QCrYgDYj6UtdRQc1ZL7nmwooQtjz0nT9hgJWhv7eT1r7iRlz7nDbzoma/hQzd+loE+dyd9vSPmW4V02QYgRBBQpJSxqf//CfiIlPL3xfpffPHFcs+ePUs6hvFD+/BV1S5LaM7B396L6tWo3t64oOO7W48zPDyGN7I4r9NiyI7GiR3upf7ZlywqOTaTzvDT//41B/cf5rO3fJDzLjp7CUe5LJzWh12OuTlNNp0l1jeKmTEIV0fnJd2XHI0RG3TUQxKjk9z9zd/mXgtesZWb3vfZvP6XPeZivviNjxIMLmyr2IjHSPV3o4dLkFKiBULEO47nbZsLVSfUsgVp246nzOubUthJgVBQvV6ktLFSaaS0HSUdTcdKJ7FNE0X3kOzpyFWddE4qiGzdhVbEs7yOWZG5aWUdjXChKFjpFEJRsC0TLAsznXK+ayOL8HjQfMFVCYGysib3fveP+EqC6D4PQhEMHe9l9zWXgi1RNI1ITSmeE+x0zYf9Dx7kxc96XV5bU0sD3/vZLZRVLJ/K2hnKssxNM5Mm3nYUO5u/i+yvb0JRVKRtIxSF9MgggbomhADbtFA9HlSvD9syc+E5isd3QulrK5vBymSm8nd8Cw6H7br/CBN9I4Qqo0jLRkrJeM8I5z/3sacdortQpJTc/Olv8B9f+2Fe+ye++F6ufc6TV2QMa4wNo+6xFmptVwM/nzIaNeCHJzLslwNpW9iGsSzb+tlEmpHWPnY9deHKnnv3HuYJV19Ix0Bh7PFKoZcGsQ2L7FgCb9nCi1N5fV5e/Mp/4cE9D/OmV9/EG972al7wsmcv3UDXMR6fh/JNp6fmFCgLEyhzbgIe+f29ea+NThbGlu6550Emx2MLNu5tI4OZTORiswP1zQXxsNIysE0D7yzZWVGkrLyq599oK1NqN0Yinm/YA0iJbc6vjLvL6aF6PKgeD7ZhFN5UTWGlnZwl36YTqzctJ5lEir4D7Zjp/Gtkw3mb2XrV+UvyHn09hZ7OzvZuRkfGXeN+hZCmWWDYA0jDIDGYrxVvG9m8awyAomoogVOvX6rHuySOvtH2AQ7/6f68tlBlCeY1j8ITXJnq16lkmjv+cndB+4N79m9U437DsOrGvZSyFThvtd7fmoq3Xw65xp6HWok2Vi5YX3locITOzgECfg+aamBaq7PLIoTAVxslfnxgUcb9NOdffDZ1DTXc8vlv09XZw9vf+3pXLnOZqd7VTO9DrbnnZeFCz/+Fl5xDSXThxXwU3YseLcMTiToqKR4vqCrMLmgmlFPeSFtGFjudwrZtNK8P1TfjDVY0HaGoSHv2OcWCpOpcToOpGHzVH0DRPQghMFNJVK8PY3ICb2kFVjaN6nGMFtuyprykjlrOcuZEeII+Krc30LevNa89WBFdsveoqSvcOW1oqqO0fPGJ6C7zQ2iaEzs/x8AvqHo8dY0xU0lHQcvjyc3LlaS0uXDOVO9qRvOtXAihP+Djiqsu5ejh/N/GGbBr7rJINnyJMzO9PMm0lmHR89DxoomN8+Xg/iM0NtWRyliEAqtbMdNfW0qibQBpL80NRlVNBe/64Bv5x+338qkP/TurHR623qk9u4XqXTN1FkpVLy+7/vm551XVFbztPa8nsECvPTja0YqmkehsJdndQbyjlWBDixOXDU48bH1jXtz2XMx0imRPB7G2o05cbfsxjFmKOqrXS7CxZSZpTgiCDc15NwAuS4+iKHhKSrGSTqXg1EAv0rJQdB3NH8A2TeIdrZjJBLaRJdnbyeSxR4i1HmHy+CHMItVslwrNo3POMx6d26UC2HrVeUWNq4Wybcdm3v7e1+eShcOREB/93LspryhbsvdwOTma10egrjFPstpXVevk28yKuQ82tmDEJpg8etCZf0cfwUicvEL1clCxpZ7Gi2ekVyO1ZWx9/HkrWllWCMF1L7iGHbu35tqufspjuOTRF6zYGFxWh1WPuT9dljquOdHdDkIseXXarj1HGG7rZ9NluxZ0vC0lt978XS5/3CU0NpTj0RW6BhYmybVUjPzzCOWXbcNfu3R/q2Qiyec//jWuue7JvObNL1uy8y4RaybmfinIJFLEB8aRUhKuLkWqgrbjncTjSZqa66iuXZwxlJ0YJ95xLK9N9fnxVlTnvG3ZsRFCm7ahncAYT48MkezJl/H0RMsJNDTn4lSllFjZjBPrrelOFcmNt/OzonPTtm1SfV1kRvKVTfy1DZipJMa4I9fqq6xBC4aIt+fPA0+0jGBDy7JW2E6Ox50KtR6dSE3pklekNbIGbcc7GR+bpK6xmoZGt7LoCViWuWkbBrG2I+ihSM5hoAb8pHq68ZSWz7y5opLq7847VvF4iWzdueI7fNlUhvjAGJZpEa6K4ousThG10ZEx2lu70DWN5i1NRCKL34E/Q9kwC8Wqh+WsNmYqhSe6tIa9ZVh07jnC5ivOWvA5err6UFWVaFkJqbRFWWT11UB8NVHirYNLatwHggHe9M7r+eQHbmbLthae+LTHnfoglwXhDfrxbs43qnedvXRFfYrq3KdT2NkM6cGZWgnTuvfFsIp4eM1kHGkaMLXDJoRA8/rgJDsALkuMZRWtSWAmE1jpme/MTMQRRXZCjXgMaVnLatwHoiEC0eUzWnSPzvZdqyNJ7OJUwLbSqby8j0B9M7aRzbu++KoKiz3a2YyTkL/Cxr3H76Ws5fRypZaDsvJSysrd3JCNxIYOy5FSYmVSS66S0/PQcQLlkTwpwtPl4QcfoXlTAwKBZYNh2QR8qxua46uJkuwcRlr2qTufBtHSEl73b6/gw+/+DJ3t3ac+wGVNouiFvyN1SiM9h1BACDLjoxixyTyNdAAtUBgWpAVDefJ0LiuPZdtoocJ8DNXrw87O0rkPhVH1wu9KD0WWrQK4y8ZAmYq5n41QlAJd+2I3kMqU6paLy0ZhQxv3djaDUNQlXXTMjEHnfYepmRXffLpkDYMjjxynefOMfGYqbRMOru5Gi+r3oIV8JHsKK6YulpYtTVzz7Cfzzjd8GPMknl2XtYvqD+Rr0ms6/uo6jNiE06AoBBuaiXe1kehsJdZ2hNRgL9asKrRqIIQ+K0RO9frwlVWumHScSyFmOkWi7TBaIJhXyEqPRJ1Y5ylFJC0QQg+XoPmDeMpm1zvw4auqWVavvcv6R9F0go0tTh0MAAS2hEB940xej6KgeLz4a+qZjsAQmkawoQVF2/CBCi4biA0926fVHpaS7geOEa6O4i9ZeGzd0UdaKa8sIxCYCaFIpi0qoh4GRk6/UuxS4quJEj/eT7Bp6WXvrn7KY9j34EG+/dUfrsX4e5dToHqcwjB6uATbMlE9PlSfj5Jtux0PvaqQ6OlEzlK7yIwMoYciOc1pzecnUNeEXVaJlDaK1+eE4LisClJK0sMD2Nksic42/LUNiPIqFE3DtiyMiTH81U7suZlOYcYn0avrCNY24CuvnFJN8hVInbq4LAQ9GCaybRd2NotQVWzbJtF5HF951dSNpiTZ20WoZSuRbSVO0rfHsyw1bFxc1jIb27hPJpZUKcdIZenae5Ttjz9/Ued56IEDtGzOL3qVNWxUFTyaIGuuXhK0r6aEob/3YWdNlBNUSF0oQghedv3z+dh7v8CTn34lm7Y2L+n5XZYfRdNQ5oRvqF6fI5mYTGAnC0ufzw3NUXW9aGiHy8ojLQszPqM0kupzwuYCdY0YsRhGbBxjcnymv2Hgq6pFqOpGKyrmskLM1qHPTIwhDYP0UH9en2I69y4uG4kNvU9qpRKoS6io0HHfYaL1FXhDC5flGx0dZ3hohPoiSgzJtLXqoTmKruEtD5HoGDp15wVQXlHKNdc9iQ+9+7OuPOY6QNo2ZipJdtIJzdECIXyVNfiqavFX16EFQ46U3Sxsw8BIxMjGJrCKFa2RMndOM5VE2kubA7KRsTJpsrEJzEQc27IQqooemdZyFwTqmwnUN6NoHvTSQhlIvSS6EZWLXFYJRfegeH34q+ty15Tp+HozmXDmcmZ1VeZcXFaDDeu5l1JipVJ4y5dGCzmTSNO3v40dT1ycfuyDex6mZXMTahEt3FTaJhzQGJlY3WqcvpoosWP9hLcVqhIsBVc/+TH88449/PaXf+aaZz9pWd7DZfmRUpIdH3XkZgGEQqh5M/HOVpgyyL1llXm691Y2S7K7AyPu3AwIXSfcsi3nBZZSkp0YI9HVBlM3f4H6JrylFW5M9yIxEnHi7UeRU0XHPGUVBKrr8ZVVYSYS+KpqSPV1YU/lSKj+IP7aRlJ9XQBo4QieSHS1hu+yEdE9eMsrSfV25ZoCdU0YqQTp6TZFIdyy1ZHQdHHZIGzY1dDOZkARS5Zk03n3Icqaq/AEFh4fbBgmB/Y9wpbtLUVfT2Us/D6V1bZhvFURjLEERnx5PCKKovDCl13H5z/+NRLx5St+47K8WJk0iVma9Z6SKMm+rpxhD5AZHUIaMwm1ZiKWM+yBqS33AeRU0qadzTg3C7N2dZI9nfmKPC6njW2aJHs7c4Y9QHZ0GDOdRPX5CDZvwYhN5Ax7cHY+kRJfTT3Bxk2EmjYveQ6Ti8vJkJl0LlRsmmRfF+psZRzbJtHVXhD+5+Kyntmwxr2ZTCzZQpSeTNF/qIOqHY2n7nwSDh04SmlZKeFwcQlNKSGdsQgHVnfDRShKLrF2udi6YxPbd27mW1/5/rK9h8vyIk0jzwhXPF7sTGGYzexFd7aG9TRmMp6TX7VNM+/mIHcO0124F4O0raI1Bqa/G0UIrCL5EmYqgRmfJDs+hqJu2I1gl1VCmtm8a4zTKPNuUsGJwbctV4XNZeOwoY17ZYmM+457HqF8Uy26b+Hx+xK495972bZj80n7pdZA3D2Ar66M+LH+ZY2Lv+4F1/A/3/8lPV19p+7sUoCVyZCdnMCIx1bF+FV0D7O3max0Kk9KMddvVlK7FihUmdIj0ZxcraLphdK1Qjjv5bJghKqhBQvDFqYTF6W00cIlBa9rgRBmMjErLt/FZeWYe41xGhWEpuXi8H1VtaiBkKtz77Kh2MDGfXxJPPfpySSDR7qp3Fa/qPO0t3ZhmRY19SfPAUimLcJ+bdVrKOslfhCC9MDEqTsvkLLyKFc/5bF84eNfW7b3WK+YyQSTxw4Sbz9KrPUwie4O7FnhLyuB4vESatqcM8bNRAx/TcNMAq0Q+Osa0XwzCehaMIS3YuY3oAaCeMsqckmaqtdLqGlLTutaKCpBNxxk0SiqSqCuAcU7daMlBP6aBlR/ADOVZPLYIQTO9zONXlIKQuKJRNGLGP4uLsuN4gsQrG/OXWOEqhJsaMFMxEkN9JIe7CM91I+/ssbVuXfZUGzI2S5t2/EiLoFB0H73I5RvXpzXHuCfd9zHjt1bEKcw2y0bDNMm4FdJpKyT9l1OhBD468uYPNyLvya6bO/zlGsfzwfe8Sn23refCy45Z9neZz0hLYvkQE/e1rQxOY5ZWo6nZOU83EIIPJEo6tbd2KaBoumoXi/all1YhlNATvX68tRVFE0nUNOAt7QCKSWqx1uwKOvhiKN1bRgouobqcQ37pUDzB4hs2YmVnfluQDo5D6YjN6hHShxPqD+AqntBgK+00q0+67IqqKqKWlqO4vXlrgfYkszwwEwnKUn2dqIFgm69BZcNw4b03E/r2y9WXSM9kWDoaA9V2wplK0+Hrs5exkcnaNo0v5j9RNqiZA2E5vjrSkn1jGKll88j7PV6uO4FT+eTH7wZ25U8nBe2bWElC+Oni8lKrgSq14seDKFOeYUVXUcPhNB8/qKyiUJR0PwB9EDwhN421TN1TtewX1IULf+7kZaNmYznXjcmJ0gP9mEl42iBAJo/4Br2LquOHgjiLYmiB0LYZuF65Mbcu2w0NqRxbyRiqL6Fa9FP0373I1RsqUVbhFa+BP5+2z/Zfc521HnebCRTFpHQ6hv3iq7hqyph8sjyxsRfevmFmKbJ//3sD8v6PusFRdWKxkAvxZyfi21kMWKTZCfHsTIZbNN0NOonxjHTqYKcDCklZjpFdmIcIxFzF9w1jlBVPCVlebUJPKXlqF7/iod5ubgUwzIMspMTpEeGyE5OoGiFhSlVf8CNuXfZUKy+hbgKmPHJRWveJsfiDB3vZddTLl7UeY4faSMRS9CyuWnex5iWxLIkAZ9KMr16oTkAgaYKxh9sJ3pWI6KINv9SoCgKL3jps/nSp27l6qc8lnCkuJqQi4NQFPyVNViZtKNwIgS+qlo0f2Gy6mKwMmniHcdzCjd6tBwBZMdHpgYiCG/alvdbM+MxYu1HcwoXntIKArX17sK7RhFCoIfDxDtakVM3Yqo/gB6OEms7Sqh5i5vv4LJqWJZJZmyYdH9Prs1f20CgcRPJng6wbRSPl2B9sxtz77Kh2HCee2nbmMkkqn9xXsy2fzxM5dZ6NM/CjRLTMLnt93dw3kVno5xmiFAiZVGyBrz3esSPGvAQb1+eirXTbN7azFnn7uSWz397Wd9nvaD6/IRbthHZuovItt34q2qXfHEz4pN50pWa1ztj2ANI6STyTin12IZBoqc9T7ouOzaMlSqUv3RZG9imSXp4MGfYA1ipJLaRwcpmMOKTqzg6l42OlUyS7u/Na0v196DoHkq27Xauf1t2FlXhcnFZz2w4495MxFC9XoSy8DjR2MAY411DVG5dnELOXXfcR6QkTG199Wkfu1aMe4BgSyUT+zqWVRYT4Dn/eg2//eWfObj/8LK+z3pB0TS0QPCEse2LxZyji17s+7ezmVxir7StvCJIuT6uRv2aZVp8YC5WJo3i9WEW0b53cVkppGXgBLfObpRI00D1+twkWpcNy4Yz7rOTE6iLCE+QEo7d/hDVu5tR9YXfIPR09fHQAwe48NKFKcCYlsQ0JeHA6iezecrDIATJjuFlfZ9wJMS//Ou1vP8dn8Iw3Fjt1WZuaFuxBHUtGEZMhdwITc+TUpwmJ7/osmZw8iLGMDPpovkbmj+InUq6EpguK4qUEjOVJDMxhhGPoeiFjjqhqnm1M1xcNiIbyriXUpKdHFvUFt3wsR4yiTRlLafvbZ8mHk/wy5/+nosfdT7+RYQHxZMmpZHV90oIIQhtrWH0gTbkMivaXP64SwgE/Nx683eX9X1cTo0eDOGrqIZp+VZFwV9Tnysqo/r8+KtrUaYLUKkqgbqmmcReRSHQ0Jync++y+hiJGJPHHiHecZxE2xH0YBht+kZOCLzlVdiGga+iGr3IzZqLy3JhTE4wefQREh3HibUeJhsbJ9DYkudACDa0oLthOC4bnLUR17FCWKkkAjFTROc0MbMmR//6II0XbT/tGPlpUukMP/nBr9i0pYn6xtoFnWOaeMqiMeJBUwWmtbwhMafCUx5C9WpMHuqlZHfDsr2PEIKXXv98PvbeL3D5lZdw4SXnLtt7uZwcRffgr6nHU1YBUmIbBsmeDnzlVSAEdjZDoruDyNaduYRZzR8gvHkHtpGd0lJ3PWxrCduySPZ1w6yb9HjHcUJbdiCqakEIpwKoEKhLICfs4jJfrGyWRE8Hs8NwMoP9eDZvJ9SyDWkZCE1HL1IF28Vlo7GhrsyZsWEnTGCB8cetd+wjVBklXBVd0PHjY5P88D9/RnlFGbvP3bGgc8xGSoinTMrWiPc+vKOO8Yc6MBPLq6deWlbCy294Ae98w4cYHhw59QEuy4ZQFDSfH80fQFoGtpElPdRPerCP7PhoXsz9NIqmofkDrmG/BpGWVTTG3k6l0ENh9GAI3R9w8jhcw95lBZG2hSySn2ObJnoggCdc4hr2Li5TbJirs7QtsuOj6OGFSWCOtPYzfKyPunM3nfaxlmXxwH37+d63fkzTpgbOu+isU1ainS+TcZOyEg/K0udLnjZayEegsZyhfxxe9uTacy/YzeVXXsobX3UTyaSrtrIWUIpIImqhSG7L3GXto2gankhpQbvqc+UuXVYXRdNRixjvqhtf7+JSwIYx7tOjw6g+/4Iy51PjcR75w300Xbpj3tKXqVSattYu/vqnf/C1m7/LgX2HuOqJV7Bj55YlM+zBSaxNpS0qogsvpLWUBDdXY6WyjO/vXPb3esZ1T6asPMqbX/0e0unVqb7qMoPmCxBsbMkluKmBIIG6hlzMvcvaRygK/qpatOCUE0RRCNQ1FjWqXFxWEkXTCDa0oPqcuShUlWDT5mUpzuficqazIWLupWWRHuzDX1132sdmEmke+tkdVO9qIlSRrwyRSmcY6h9mZHiUsZFxxsdjTE7EmJyYxDQtyspLqawq53FXP5podHFFs07GeMygrtLHWMzAMFc39l4oguh5zYzecxQt6CW8pWb53ksIXvb/ns93bv0RN7zobfz7tz9BtNRV71gthKLgLa1AC4SRtoXi8aCoG+ISs65QfT5CLVuwsxmEoqJ4PMsipericro4OTvbnZwdVXW99i4uJ2BDrLzJvm5UX+C0KykmRmPs/987KW2upnJLHYlEio62Ljpau+jq7CUeS1BaVkKkJEwwGKSqqozmzQ2EQgF8ft+SeuhPhmlJxuMGjdV+2nqSc1V/VxzVpxO9aDOje1qxsxaRnXXLZhyoqsorX/tC/vfHv+F5T7ueT978Pi5+1HnL8l4u88ONpT/zUVQVxfXWu6xBFE1zq826uJyCdf8LSQ8Pko2NE6xrmvcxti3p3XectrsO4qkp4VB3F7/9251MjE9SVV1BZXUlj7r8QqKlEYRYG5FNk3ETr67QWOOjayDNMoe8nxI95KPski2MP9hOum+M8ku3ooWWJ25XURSe+8JnsHX7Jt75+g9y8WXn87p/ewWbt7Usy/u5uLi4uLi4uKxV1q1xb2UzpAZ6MeKTBGrqEaeI+00l0nQf66T/UCfZvgmS2SwHezvRe/xU11Ry7vm7KassQ13DChFDY1kqSj1saQgwMJIhlrROfdAyogW8lD9qG4m2Qbp/tYdAfRmhzVX4qqMonqWfeudfdDY7z9rGn3//d17xvDfT1FLPE5/2OC6+7Hy27diM1+d6lF1cXFxcXFzWN+vKuE8PD5LszU/k1EtKaTt4mPvufhBm1VdqqagkWmTbuTLoIdEUISKg8aza/HCSRGzVQ15OxVAMKmtLaK6d+WyWZfOXX+1lbDi2auNSpcBsHyTRPlT09THNotdvslSRTI+9+jIO7jvMFz7x9ZP227ZzM1/73mepqq5Ymjd2cXFxcXFxcVlFxHJLFi41QoghoKPYay+57pml77jh+vru/v7M4eOtKcM0pWGYfp8nKHURLAGEow6P3FpVK8oCIWHapsyapkwaacu0VrkS1AKxpVQVIQrc9KFIQNTWV6gAP/3+n9L9vSPLWz52niiKIsqCEbXUH1JDXr/i1T3Kg13HUv9z/18nT3SMlNIvhFiw5qVACF3zenTVo6uKpilCVYVQlayZTHUMHTxuWBmzyGHDUsqnzvs9TjI3l5AKYHiZ32MpcMe5tMwd51qcmyfjTPg7u2NcGnxSyrPn23mec/NM+Nwnwx3/6lMBHDqd6+aZzBln3J8uQog9UsqLV3scy4n7GTcOZ8rfwR3n0nKmjPNEnAnjd8e4NCzHGM+Ez30y3PGvPuvhM5wOazeA3MXFxcXFxcXFxcXltHCNexcXFxcXFxcXF5d1wkYw7r+x2gNYAdzPuHE4U/4O7jiXljNlnCfiTBi/O8alYTnGeCZ87pPhjn/1WQ+fYd6s+5h7FxcXFxcXFxcXl43CRvDcu7i4uLi4uLi4uGwIXOPexcXFxcXFxcXFZZ3gGvcuLi4uLi4uLi4u64RlN+6FEKoQYq8Q4tdFXrtKCDEhhHhw6vGB5R6Pi4uLi4uLi4uLy3pFW4H3eAvwCBA5wet3SCmvXYFxuLi4uLi4uLi4uKxrltVzL4RoAK4BvrVU53zqU58qAffhPlbicVq4c9N9rODjtHDnpvtYwcdp4c5N97GCjw3DcnvuvwS8CwifpM+jhRAPAb3AO6SUB+Z2EELcANwA0NTUtAzDdHFZGO7cdFmruHPTZa3izk0Xl+Vl2Tz3QohrgUEp5f0n6fYA0CylPA/4MvCLYp2klN+QUl4spby4srJy6Qfr4rJA3LnpslZx56bLWsWdmy4uy8tyhuVcATxTCNEO/Ai4Wgjx/dkdpJSTUsr41P9/C+hCiIplHJOLi4uLi4uLi4vLumXZwnKklDcBN4GjioMTcvOS2X2EEDXAgJRSCiEuxbnZGFmuMZ1J2JaJmYiTGR1G0XQ8ZeVo/iBCiNUemouLywZG2rZzbRobBgTesgq0YBAhXGVll7WLkYyTHRvBNgxnzgZCKNpKaIq4uKw8Kz6zhRCvBZBSfh14LvA6IYQJpIB/lVJuqKSHE2HEJkl0tuaeZ8aGiWzZiRYIruKoXFxcNjpmIkas7WjueXZ8hPDmHeihk6VWubisHmYyQez4EZA2AMbkOMHGTXhLy1d5ZC4uy8OKGPdSytuB26f+//VZ7bcAt6zEGM4kbMskPdiX3yglRiLmGvcuLi6rhpSS9MhQQXtmfMQ17l3WLEYinjPsp0kN9qFHSlBU13vvsv5wZ/Vaxd3AcDkDSSaSfPOW76NqKte/4SX4fN7VHpLLUlPs0uRerlzWNCeYoO68dVmnuMb9GkRRNXxVtSS62mYahUAPup4xl7WLbdu86dU3oaoqRtbk+OE2vviNj632sFyWECEEvopKjNh4Xrsb3uCyltGDYVJC5DnN/FW1bsy9y7rFndlrFD0SJdS8hczoMELX8ZVWoPoDqz0sF5cT8n//+0fGRie48YNvwjItPvTuz3LfP/dyyaMvWO2huSwhWjBMeNN20qNDCATe8ko3XNBlTaP6A0S27CA9OoycTqgNRVZ7WC4uy4Zr3K9RFFXFU1KKp6R0tYfi4nJKbNvm1pu/ywtffh2KoqB4FJ58zeP5zjd+5Br36wyhKOjhCHrYNY5czgyEEGiBEKFAaLWH4uKyIrjaZS4uLoui/Z5H+PXH/ouGSJQdu7fm2i+9/AIeuHcfY6Pjqzc4FxcXFxeXDYZr3Lu4uCyYvgPt7PvZHbT39fP4ph2YsVTuNb/fx+5zdvD32/65iiN0cXFxcXHZWLjGvYuLy4KQtmTvj29n02PP4c59+/A3ljO2tz2vz7kX7OK2P9yxOgN0cXFxcXHZgLjGvYuLy4LoP9COUBT6YhNUVlcQ3VpLsnsUK2Pk+uw6ewf33/MQlmWt4khdXFxcXFw2Dq5xv0aQUiJt1wByOXM4fufD1J7dwkMPHGDz1mYUXcVbESbZMZzrU1pWQqQkzOGDx1dxpC5LibRtpG2fuqOLywohpUS6DgQXlxyucb/KyKnKs/GO40weP0JmbATbNE59oIvLKmKkswwe6qRiWz37HzzIpi1NAHgrIyS6hvP6bt2xiQf37F+NYbosIbZpkp0YI9Z6hFj7MYz4pGvku6w6ZjpFqr+HyeOHSPZ1Y6bTqz0kF5dVxzXuVxkrlSTWegRjchwrlSDR1UZ2Yny1h+XiclL6D3QQqStndGwCy7QorywDwFsRJt0/gbRnisVs3trM/fc+tFpDdVkizCknhJmMY8YnibUewUwmVntYLhsY2zRIdLWRHurHSqdID/WT6GrFNs3VHpqLy6riGverjJGM51XNA0gP9rnee5c1Te/+Vsqaq3nk4cM0b2pACAGA4tFQ/TrZ0Viu7+ZtzRx46NBqDdVlCZC2TXpooKA9Ozm+8oNxcZnCSqexUsn8tlQSK5M6wREuLhsD17hfZaaNojwUBSjS7uKyBpBSMnCwk7KWag7uP0J9U23e657SIOmBydzzmtoqxscnGR+bWOmhuiwlSuFyUfT65eKyQgil+PwTwjVtXDY27i9gldECIYSi5rX5q+tQNLd4sMvaJDYwBgJ80RBHHjlOU3N93ut6JEB6aMaQVxSFls2NHNx/ZKWH6rJECEXBX1kzp1Ggl0RXZTwuLgCK14ceLslr0yNRFK93lUbk4rI2cC3IFcK2TISiFHgUNH+A8JYdTsy9YeApiaK7JbJd1jCDh7uINlYy2D+MoipEopG81/WSAPG2wby2hqY6Dh88xuWPu2Qlh+qyhGjBEOHNO8hOjiGEgh6Jonp8qz0slw3I9HqqqBqB+iaMeAwzEUMPhtFCERTVNW1cNjbuL2CZsTJpMmMjZCfG0PxBfBXVaIFAXh/NH0DzB05wBheXtcXg4W5K6so5eug4DU11BaEZatCLnTGwMgaqVwcc4/7A/sOrMVyXJUIoCnoojOr3Y8RjJHs7AYG/uhY9GEao6inP4eKyGKxshuzYKJnxETS/H19FDVogiFrmhbKK1R6ei8uawQ3LWUakZZHs73ESZDNpsuMjxNqOYGUyqz00F5cFIaVk+FgPJfUVHD3URl1ddUEfIQR62E92NJ5ra2yu48jBYys5VJdlwozHSHQcdxIXUwni7cccYQAXl2VE2japgV5SAz1T6+kYsbYjmBlX+tLFZS6ucb+MWEYWY2Isr01appvJ73LGkhyZxLZs/CVBjh1ppa6xtmg/LewnOzojk1hbV01vdz/ZTHalhuqyDEgpSY8MFbRnx0ZWYTQuGwnHa58/z6RlYaXd9dTFZS6ucb+cCOE8CppdhQmXM5Ph1j5K6itIJtOMjU5QWVVWtJ8W8pIdm/Hm6h6dyuoK2lu7VmqoLsuAEKJosr9wY5xdlhkhBBRRwXGVcVxcCnF/FcuI6vHim6MwofoDqD7/Ko3IxWVxDB/vJVxdSntrJzV1VSgniLPWQv484x6gvrGWo4dbV2KYLsuIt6ySPKleIfCUFr/Jc3FZKhSPF391/k6h4vO766mLSxFcd8syIoTAW16F5g9gJGKoPj96MIyiexZ0Pts0HMUdxU1cc1kdRlr7aHn0bh66535qaqtO2E8LeTEmU0gpcztVNbWVtB7rWKmhuiwRtmmCELkbOS0YchS+4pMIBHo4jOoPrvIoXdY7Qgi8ZRWoXj9GYhLV63cSvD0epLSRloVQVdeT7+LCChj3QggV2AP0SCmvnfOaAG4Gng4kgVdIKR9Y7jGtJKquo5aU4ikpXfA5rGzGUdwZHUbx+vBX16EHXblMl5XFMkxi/WOEq6IcP9rBpi1NJ+yr6BpCVbESGbSQI5dY11DDIweOrtRwXRaJbWTJTIyRGR5EaBqB6jq0UNiRwQyG3GuQy4qjaDqekiieWfUVzHSK9FA/ZjyGFgo7Cjp+15vvsrFZiVvctwCPnOC1pwHbph43AF9bgfGcUUjbJjXYT3qgF9vIYsYnibUewXSTiFxWmPGuIQJlYVRdo6O1i5raypP210I+shMzpeFr66tdz/0ZRGZ8jFRvF3Y2g5VMEGs7iplMnvpAF5cVwjYM4u3HyI6NYBtZsmMjxDuPYxvGag/NxWVVWVbjXgjRAFwDfOsEXZ4FfE863A1EhRDF5Tc2KLaRJTs6nN8obVchwGXFGe0YIFxdytjYBKZpFRSvmosW9GBMzhiD1TWV9PcOYhjmcg/VZZHYpkFmeKCg3XQlL13WEFYmjZ3Nl5a2M2msrCuP6bKxWW7P/ZeAdwH2CV6vB2bLZ3RPteUhhLhBCLFHCLFnaKhQhm1dIwRCdRUC1iobaW6OtPYRqorS3tpFbX3VKVWf1IAXY3zGuNc9OmXlUbo7e5d7qC4scm4KUbQolZvv47IULNV1UyjF10F3fXTZ6CzbL0AIcS0wKKW8/2TdirTJggYpvyGlvFhKeXFl5clDAdYbqseLv6Yhr03x+lDdmMI1wUaam6Pt/URqymg/3kll1amrQWoBL8ZEfhhHXX017cc7l2uILrNYzNxUVA1/Tb6fRagamhtn77IELNV1U/H68JSW57V5SstRvL7FDtHF5YxmORNqrwCeKYR4OuADIkKI70spXzKrTzfQOOt5A7Bh3HqWYYBlIjxelBN4IAA8JaUoHg9mIo7q8aIFQ6ge7wqO1GWjY6QypCYSBMrDtB/vZMv2llMeowa9GLH88DFX6/7MQQ9FCG/egZmMIzQdzR9A0fQT9rdNE5An7ePispQoqkqguh5PJIqZSqL5A2iB4Akleq1sBiklmmv8u6xzls24l1LeBNwEIIS4CnjHHMMe4FfAG4UQPwIeBUxIKfuWa0xriWxsgvRAL1Ymg14SxVdeiXYCOTlF0/CES/CES1Z4lC4uDmOdg4SroiiKQmd7D5c/7pJTHqP6PFhpA9uyUaZCy6prKmk7RVKtlJL08CDZ8VEUXSdQ24DqLsYrjlAUR2rQ6yMzPkqs/ShCUQnU1KOHI7kQHWlZZGMTpPp7QEp8lTWOQ0J3jXyX5UfxePB4PCdVpLNNEyM+QXqgD9uy8JZV4ImWobka+S7rlBUPTBNCvFYI8dqpp78FWoFjwDeB16/0eFYDMxEn3n4cM5lAWibZ0WFSA31Tni8Xl7XHaMcAoapSJsYnMQzjlMm0AEIRaH4P5izvfU1dFW0nCcuRUpLoaic7OoynJIrQNCaPH8LKuAlyq0V2YoxUXxfSMLAzaeIdx/NUc4xknERnK3Y2g21kSfZ2YsQnVnHELi75mMk4ic42rEwaaRqkB/vIjo+t9rBcXJaNFSliJaW8Hbh96v9fn9UugTesxBjWEmY6BTI/x9iYHMfKpFE0N6bVZe0x0tZPuCpKZ3sPNbWnTqadRg06xaw8UWdXqrq2ks72nhP2Tw8PYKYSBGobEIqCFggiEMS72ohs2Tnv93VZGmzLJD0yWNBuxCbQQ2EAshPjBa+nh4fwlJS6Cbgua4JiKk/ZsWG8ZeVuiKvLusRNKV8FimX4C0U9Yea/i8tqM9YxQLimlM72biqqyk99wBSqz4MZm/G6R0tLSCZTxGOJgr5WJkN6sA9/VU3eb0EviSItC2PC9bStNEKIojH0YlbIjVok/Eb1eMBVLHFZIwil0I8pNN2doy7rFndmrwKqP4DqD+S1+apr0ea0ubisBTKJNJlEmkBpmI62bqqqT62UM43q92DEZkI4hBAn9N4n+zrRI6UouievXQiBt7SM5EAvzmafy0ohFBV/dS2zhc2EqqGHZsKy9Eg0XzZTCLwV1e4ui8uaQQuGHGN+Fv6qmqI3pi4u64FThuUIIS4GHgvUASngYeDPUsrRZR7bGY1lWchsBoSC5stPBtR8fgINLVjJBLaRdYz9QKFhL6XENgyEUtx7th6wbZuhwRF8Pi8ls+K4U8k0E+OTREsj+PxuMuVqMtYxQKS6FCEEnR09nHP+rnkfqwY8pPvH89qqayrpaOti9znbc21mIo6ZTBJsaC5+Hn8QRocxE/FcOIjLyqAFw0S27sBIJqZCpUJoPj+2kQWca1No8w7nWiUliseD6vNjmwbSlii67hr6K8D42ASZTJbKqvI89bVYLEEilqC8ohTdsz7XEWlZ2JaJomq5G03LyCAtG0XT0YMhQs1bnMq1UoKqoYXcENj5kIgniU3GKS2P4vV6TthvZHgU25JUVs9/Z9dl+TihcS+EeAXwZqANuB84jCNp+RjgRiHEw8D7pZSuaPUczGSC9OgwxvgoQtfxV9WiRUpQ1Zk/t+4PoJ/EU28bWdKjw2SGBxCqir+mEU8ksq5iWHu7+/nR937Oz/7711RWlfO2976ORz/2Eo4dbuXmz3yTvffu41FXXMgb33E923dtWe3hblhG2/sJVUVJZ7KMj4xTVnFiVYq5aAEvZjw/GbaiqpyujnzPfXKgB0+07CRFaQR6uITM6JBr3K8wQgjHoA84xpBtGqSGBzHjk6g+P5nRYUDiLa3AymbQQhGsTJpUfw/SMvGWV+Etq3Bjm5cJI2vwzzv28LmPf5WRoVH+5YXX8q8vv466+hoeuHcfn/v4Vzl+pJ0nXXMl17/+xbRsblrtIS8pZipJsr8bMx5HC4UIVNc7c7S/ByubQQ+X4KusmWrrzs1Jze8D5cTGqgvs23uQL3zi6zzy8BGufMKjee1bXs7mbS15feLxBH/5/R18+XPfwsgavOp1L+ba5zyJsvL5rxMuS8/JPPdB4AopZarYi0KI84FtgGvcz8KyLNKjw2RHnap7MmOR6Goj1LIVNRKd93kyY6OkBxzJf2lZJDqPo2zesW4MG9u2+dH3fs53bv0RALHJOG9+9Xv4r59/lbfe8D4GB4YBuP3Pd3H8aAff/emXTyvW22XpGGnrp7Sxkt6ufsory1BPoCFdDNXvwUo42tLT3tvqOVr3ZjKBlU7hq6w+6bm0UJhEVzvSsopWT3VZGYzYJKneLvzVdaQGZm7S0kP9+KvrwDJJ9MzInaYH+xCKgr+qdjWGu+555MBR3vTqm3Iha9+59UcoisJ1z7+G1770HaTTGQB+9ZPfMzo8zue+8iECwfUhAWlls8TbjzoeecCMTRJPp9EjJVhpx3QxJsbQg2GSvTOmijsnT01nezeve9k7iU06yci//7+/0NszwFe/82kiJTN2yN579/O+t38y9/xzH/sKJaVhnvXcp634mF1mOGHMvZTyKycy7Kdef1BKedvyDOvMRWYzGOOFEUunI+VnmyaZ0cKS3GYitqixrSWGBkf42X//Oq/Ntm262ntyhv00XR09dHVumNpma46xjkHC1aV0dfac9parUBWErmEls7m2qpoKOtu6c89TQ/14IqWnLBmvqBqqz0825sosrhZSSjKjw6h+f1EFEiMeQxYpPJ4ZGcI2jZUY4obj6KHjBbkoP/nBrxgYGMwZ9tPc+de76esdWMnhLSuO/Gr+vLKNLGLWLrlQ1aLrrzsnT05HW3fOsJ9m3wMH6Onuz2u77Y93FBz7k+//imw2W9DusnLMJ+Z+E/AmoGV2fynlM5dvWGcwQkHoOjJjzWmev6dRCIGi69jZ/Avz3ISgMxmfz0tlVXnBxSMQKgxVEkIQCKwPT9OZRmoigWWY+EqCdLX1UF5RdtrnUAMezHgKLeiEZVTVVNDV4dys2dksZmySYFPLvM6lB0Jkx0fxRk9/HC6LRwiB4vVixiYRvsLf6oni64XuKpMsF6FwYex4VXUFXk9hyEkwFMDnWz/hUScL45tG2nZxhTrdVXQ6GYFg4e/b4/Xg9+fPn7r6moJ+DU11p7XD67L0zGdm/wJoB74MfH7Ww6UIms9XsNWneLyo/vkbp0JVne3t2QoVuo4WXD8JQCXRCG977+vyLsKbtzazZVsz//qyZ+f1fcVrXkjLlvUVJ3qmMNrWT6S2DCEEXR09VC0gWUr1ezDiMzeqJdEIyUSSZCJJemQQLRye982vGgxixCeRtn3qzi7LgresEtsyUb3e/O9NUVD9AaRpzFE8EgRq6lHcxX5ZOPvcnWzeOpOIrigKb3vv62hsrueKKy/N6/u297yO+sb1E4qien14y6vy2rzlVZiZWY4xKVEDwSJzss6dkydh6/ZNPPmax+e1vfHtr6axuT6v7aonXU60tCT33Ofz8qJX/otr3K8y8ylilZZS/vuyj2QdoUVKCLVsxcqkEYqK6vejTyejWeZUzLAGUiJtC0XTCzwLjkLFTsxUEqGqaP4Aqnd9qcY8+rGX8F8//ypHD7USjgQ569yd1DfW8rq3voorn3A5vd0D1DXVcPY5O0+ape+yfIy09ROqjCKBnu5+nnLt4095zFxUn55XpVZRFKpqKuju6KVSxgnUNsz7XIqqoXq8GIkYnnDJqQ9wWXL0QJDI1t3YpkFo0zasbAZs29lttCz0UARvWQVmKom0LOfa5cr8Lhv1TbXc8p+f5uD+Q8QmE2zbuZldZ29H1zU+9Jl3cXDfYYYHR9m0tYnd5+xY7eEuKUJV8VfV4imJIi0boaqoPh+2YeIJhbFNE9XrQwsE0TZvd6rC2xaqP+hKT5+CkmiYd3/ozTzjOU9msH+Ypk0NnHXu9gKjffvOLXz3p1/m4P4jGKbJrrO2sWP31lUatcs08zHubxZCfBD4I5C7HZZSPrBsozrTMU2ykxNkx4ZRNB1/XSPStrHSKRK9nVjJBFowhCdaTrK3E08kir+6DtU34913FCqCaIHgKn6Q5UXXNc69YDfnXrA7r720rIQrrnrUKo3KZTYjrb3UnNXM2Og4iiqKhk2dCtWfX8gKoKqmktjgANX1ZShFwgdOfr4gxuSEa9yvEkYqiTExRmZ4EAR4K6rxlJSi+fJ3J9ebM2It09BUS0NToUe+uqaS6prKVRjRymFlUiT7e5x1NRDEX1OPHoqgzdotl5aFEZ8k2eeo5fjKq1A03Sm25nJCKqrKuPKJl5+y36atzWzaWlzG2GV1mI9xfw7wUuBqYHovXE49d5mDlJL0yGBOLcc2siQ6jqNs2Um84xjSNAFH19vOZvGWVpAZHcK2bcJNm10VEJc1g7QlY52DbHvCBRw6fJyqqoUZCarfQ2ZoMq+tvKKUiGajhyMnOOrEaIEA6aF+wA3VWg3MRIz0YF/ueXqgF0XTC4x7F5flxkwniXe2IacSY81kgnhXG+GW7XnGvZlKkOhqyz1PT0tMV9et+JhdXFaC+Rj31wGbpZRu6vM8sA2D7OhIYXs2kzPsZ/pmEZrzFZixCSwji6a6C6TL2mCyfxRP0IfH76Wns4/yyoXpFqs+D2YiPzl86+Z6/B51QXkkiseLtGysbMbVTl9hLMvCmBgraDcmx/GVr28Pscvaw8pkcob9NNIwsLLpfOM+mSg4NjM6jLe8ct0WiHTZ2MwnofYhILrM41g3CEVBKVLS+lQeeaFqJ8z8d3FZDUba+ojUOKo0ne09VFQuTKFG9etYqSzSnpHrO393C4eP9SyocqkQAtUfwIhNnrqzy5KiquqcxEQHxeveZLmsPCdKiFXUfL9lMaU5xeM5pfyui8uZynxmdjVwSAjxByHEr6Yfyz2wMxVF0/DXNea1qT4/iteHtyK/SI+3rBJjSrM7UNfoeiFd1hTDx3oJVzve+p7OPioXWERMKAqKR8NMTnvvJS01Uf655+CCx6b5/bnfjsvK4iktz1PJEaqG5zQK9Lm4LBWqz4+3LH/HyFtRlZe/BqAHQyiz11ch8FfXu2GwLuuW+YTlfHDZR7GGsS0TaZoIVUPRiv+5rGwGpCNXKU0DxeMjsnUXVjrlZO/7A6geL0pVDZ5wBMvITnm/BGog6GTzn+GZ+7FYgrGRMSIl4TxZLJczl+Hjvex40kVYlsVA/9CCw3JgKqk2nkYP+fCrIIXC8ePdmKaFpp3+Aqv6AmRGh/Mq37osHmlb2IYxtQNZ6KG3bRtF0wm2bMFOp0GA6vWvm8rZZwJ9vQNYlk1tXdWGlBuUloVtGghFRdF1fFU1aOEI0sgidA+aP1CwVqteH+FN27DSKUctx+dHLVKnwWXlmbYdSqIRSqKnn4PlUpz5GPedQJ+UMg0ghPDjePPXPWYykVO3Ubw+gg3N6MGZRcy2TDJjI6T7e5HSdjxaQGZ8FH91Hd7S8rx4PkXTUcIlrLcIv0f2H+HjH/gS+x44wNbtm3j/J97OBZecs9rDclkEmXiK9ESCYEWEgb4hwiUh9EUoS6j+mbj7sGaTsgThSIjRkTGqqitO+3yKriMUFSudOuNvjNcKZjpNaqAHY2IMoekE6pvwhEty4YJmOkVmZJDM6DAIga+yBm9pubvjuEJMjE/yq5/9ga9+4T/IZg1e8qrn8qJX/su6V8OZjZlOkezrwoxNougeAg3NgCA90IuVTqH6/ARqi++Cq16fq+C0xji4/wgff/8X2b/3INt2bOZ9n3gbF1zs2g5LwXzCcn7CjEoOgDXVtq6xDYN4x3GsqUQcO5Mm3nYsr4y1mYiT6u1C2hZISXZ0GKGoCKGQ6uvGTBSWZ19vDA+N8vbXfYB9DxwA4NiRNt74qnfT1dGzyiNzWQwjrX1E6spRFIXurj6qFhiSM43q1THjaQSSoAopy5E8HRooTD6f9zl9fsxEbFHjcnGQtk16sC+XLCtNg0THccxUMtfHmBgnMzIEUoJtkx7o3RDXuLXC3vv289mP3EIinsTIGvzn1/+bv/zhjtUe1ophWxbJng7MqVwb28g6a3IqgZV26mhY6RTxrjbMdOpkp3JZAwwNjvDW17yP/Xud8Myjh1t54yvfTfdU9XKXxTEf416brZQz9f91Lw5rZTPYRr5AkLQtJwRnimIJfUZ8MqcAkp0cX9YxrgV6u/rp7urLa4tNxulyf6BnNINHuonUOgm0vV19lFUsPCQHprXuUwRUSdYGG0FJSYTB/uGFn9Pnx4i7SbVLgW0aZMcLb7SmnRm2YZCdLKKS4+Y9rBh3/PXugrZf/M9vSafSRXqvP2wjW+RmUhZUq5amkeeEc1mb9Hb309czkNcWm4zT1enaDkvBfIz7ISHEM6efCCGeBSx8RT5DEKoKRWJ5Z2fhq0UUIhTdg2040lxzk3rWI6FIEN1TGGhUUuLG4J7JDB7uIlrvhMt0dfZRvmjj3vHchzRJynJ+V5FomIH+oUWc04+ZiCOlPHVnl5PiJD0XuZ5NX+9UtfjrrkrOirFpS2Fdh207thS9/q5HhKI4ld3ntp9inXZZm4TCQTS98HuKuLbDkjAf4/61wHuEEJ1CiE7gRuCG5R3W6qN6ffhrGvLavBXVeYuZForkJ50pCnoogpVKIHR9Q1TQbGqp59/e/Zq8tpf/vxewaatbYOhMxUhniQ2MEZ6Swezp6qNisWE5Pg922iCgQtpy2qKlJQwuwrhXtKm4e9dLt2iUqRj72ajBEGrAyWdQFAVfWWWeSo6i6+ih9X+NWytcceWl1DXU5J6HwkFe9MrnbJikWtXjLZijekkU5nx+X2XNhnCsnek0tTTwlnflm5KvfO0LXdthiTjl7a2U8jhwmRAiBAgp5YYIchVC4C0rRwsEsLNZFF1H9QXyPAKaz0948w6sdBIpJYrXh7RMwpt3IDUN27KQqSSKx/HmKyfQiIapYhzSRvV48hbQtY6maTznX6/h7HN30tPdR1V1JTvP2kog6CY5nqkMH+0hUlOGqqkYhsnI8Bil5YsPyykp9+dCcgBKSiMM3b3wmHuYiruPx9zqqEuAHoo4Kl+ZNEJVHdWRqeuVbZqgqoQ2bcXKZhAIFI8XoWmYmTQCp7iYq1y0fGza2sy3/vuLHH7kOJZpsnXHZjZvbV7tYa0onkgUdetOrEwGoWlo/gDSlmj+oJP7JhRHmU7TMFOOMo7i8aIWqT1zIqRlYRlZhKK4yeLLiK5rPO/Fz+DcC3bT091PdU0FO3ZvJRBwr+VLwQmNeyHES4AfSiltACllfM7rW4BaKeWdJzjeB/wd8E69z0+llB+c0+cq4JfAdF3o/5VSfmRBn2QZUFQNJRiG4In7qF4vqteLmUqSHh4kOzYCAnwVVSBUFE0l0z2ClUoidJ1gfTN6uCS3CNqmSXZilFRfD9K28JSU4q+pP6Oy+oPBABdcco6rkLNO6D/USclUSE5/3yClZSULkqucjVAVqjZXkMzaTG8YlpZGGB4eRcqiEXDzQvX5MOKTzu/NZVEIIdACQbRA/gXPTCVJTSfbKgq+imoUj4fM8ABCVcmMOTdovvKq3Gsuy0NDUx0NTXWrPYxVQygKWiCEFpipbJ2dHCfZ24WdzaB4vQTqmjATkyT7upGmiRYI4q9tRJ9HNWwrkybZ14MxOYZQVPy1DXijZa4e/jIRcG2HZeNknvtyYK8Q4n7gfmAI8AFbgStx4u7ffZLjM8DVUsq4EEIH7hRC/E5KOTcr6A4p5bUL/gRrhOzkONmxqVQECemhAQL1TWRGhnKZ/HJKgSeydVdOvs9KJUn2dM6cZ2IMoXsI1Da4XjCXVWHgkU62PNa52PZ09S24Mu1cypuiDMSyKCHnsuP1+VAVhXgsTjhy6oW3GI7e/Yird7+MZMdGcio6TKnqBBqaUbw+0oMzyfTp4QEUnw9f2caRZnRZXYxkgkRXG9JyYv3sTAYrlSTVP6PWZiYTpPq6UJq3ntSDL6UkNTSAMZU4Lm1HnUf1etFDrv66y5nFCWPupZQ3AxcC/w1UAk+Yet4DvFRK+S9SyqMnOV7O8vbrU491mflmWyZGEWUcIx5DzA3DkRJ7luKOmUoUHJcdH0Ga5lIP08XllKQnEyRHY4RrnDCc3q7+RSvlAPi9CpZpk4ln8tpLy6IMDiw8P19oGgiR95tyWTqsbLao6pdtGFjFrl1jI26Cs8uKYWfTOcN+mrnqOeAY+Ke6RtimgTExWnisK6vpcgZy0oRaKaUlpfyTlPJDUsrXSCn/TUp5q5Sy82THTSOEUIUQDwKDwJ+klPcU6fZoIcRDQojfCSHOOsF5bhBC7BFC7BkaWngC3rIhFFRvYZyY6vUh58hpAnkZ/8Vi8FWvP1c4xmVts+bn5mnSf7CT0qYqlKn5193ZuySe+1BAIzGRxkoZee0lpZFFad0LIdB8foz4hkgFOi2WYm4KRSkaIihUFUUvjEfW/EF3B8XllCzVdVNRCz3xxeaf0PRThtYIRUUpMtdVbWOoEbmsL5bVgpy6OTgfaAAuFUKcPafLA0CzlPI84MvAL05wnm9IKS+WUl5cWbn2tnwVRcFbVlFgtKs+P56SfMPIU1aB6p+5EdCCIdTZFTaFgr+m3o3xO0NY63PzdOnb30pp00z8em93/5IY9+GASiJpYqXyvWeRkvCiPPcAis/nFrMqwlLMTUXT8FVW56vkeH0IVUPRdZRZYQ5C0/CULk5VyWVjsFTXTcXnx1dZk9cmNB09Es1rC9Q2nDLpXlFVAjUNIGbMIjUQQg2cJOnOxWWNsiJisFLKcSHE7cBTgYdntU/O+v9vhRBfFUJUSCnXjI6+bRjYpoHQNNRZXnYzlUBaNorXi6p70ENhQi3bsNJJhCJQPD5s00ANBAlt2QmWiVBVVK8/p7hjppJIyyLYuAk7m0XaFprPf1oyXsmxGNlkGn8khDfsHGeaJj1dfVimRWVNBUMDIyiKQn1jLXoRXVkXFwDbsuk/2MlFL74agGzWYGx0gmjZ4uQOFQE+j0oma2Ol8neySqKRRclhgqOYkx7oO3VHlwWhhyKENm3DSqccrXHd42RA6zrBUNip6zGlFoYQOdUSO5tBSomqe9aNsyIxOomRyuAvCeMNLVz0IB6L0987iC/gp6GxllQyRU93Px6PTkNTXW7nzOXkqLqOp6wSPRzBtqwpRToveiiMGS1DmiaK14cWDGHbNnY65cxJjzfvxnQaPRSmZNsuzHTKUYzy+U+ocLdWsS2bxPAE0rYJlJegeVZnzU+n0vR096NpGg1NtaiqSmwyTn/fIIGAn/rG2lUZ10Zh2b51IUQlYEwZ9n7gicCn5/SpAQaklFIIcSnOTsLitPGWECMRJ9HVhp3NIDSdUGMLis9PdnyM1EAP2LaTiV/XCEIhPdyPMTGGv7qOzMgwZjKeU5cw4zGsTJpAQzNaIIQxOU6qvxtpWag+P4H6ZjyR+RtRtm3Tf6Cd+773ZzKxJJGaMi59xZMRET8//M7P+I+v/RDTMLn6KY+ltr6aH33v57zs+ufz0uufR3nF0iRIuqwvho/34isJ4As7O0l9PQOUlkcXraMd8KukszbCoxaE5ZSWRmg92r6o8yu6Z6p6dBbVVWpZFvRgCBSF9GAfejCMmYyTHR8FBJ7Scke1aHIcoaoIzYNQBKmBXpASLVxCsK7xjFIAm4ttWfQ81Mr9P7iNbCJNSUMll778yZQ2nr7XufVYOx97zxfYc89DBEMB3nrTa2lv7eL73/4JXq+H17/tVfzLC691i/nMEzuddNRyjCyK7iFQ34iUCsmejqn1NYC/vhkzNk56qN+Zk6EIgZr6AmUocJwFZ6pOfjqW5NhfH+LQH/dgWxZNl+zk7Gc+mlDFytaj6O7s5eZPf4M//uZ2NF3jhje+lKue/Bg++p7Ps++BA4QjIW780Jt5yrWPx+t1r9nLwSndA0IIrxDiRUKI9wghPjD9mMe5a4G/CiH2AffhxNz/WgjxWiHEa6f6PBd4WAjxEPDvwL/KNZKNZWWzxDuO55JwpGkQaz+ONZV5z1TSjplMkBkcxJwcx5gYQ/UHMVNJx7CHnLqEHilBWiaJjuNY6WTuwgNgpVMkezuxisTnn4hY3yh3ff3XZGJJACb7R7n7P3/P/Xc/yK03fxcjayCl5Lbf/x3TNCkri/IfX/she+5+aAn/Si7rie69xyjfNONN6esZWJp4e79GOmuheHSszJyY+7IShgYXt1EnhHD07t3QnGXFmBjDSiSwLXPKsAeQOZWwbGwSoWoIRXHUSqYu5WZsgvTI4BmdaDvRM8Ld3/wt2YRTMG2ie4g93/8T2eTpFVBLpzN85fP/wZ57nOtwIp7kY+/9AmVlUQAymSxf/OTX2f/gI0s6/vWKkYiT6G7Hnlo7bSNLoqsdRVNmra9J7EzKUXaanpPxSTKjQ9hFkm/PZIaP9XLwt/dgmxZI6Lz3EF33HV7RMUgp+dXP/sAffv1XpJQYWYOvfOE/uPeuB3h4al7HJuO8722f4PDBYys6to3EfPb+fgk8CzCBxKzHSZFS7pNSXiClPFdKefa0fr2U8utSyq9P/f8WKeVZUsrzpJSXSSnvWvhHWVpsI4s08w0RpI1VJONeSjOnKKEFgxjxycI+szL67UzhOaxUEjs7f+M+MTKJbeVfmKRpc+8/9xb03fPPBzn7/F0A3Hn7XCVSFxfngtzz4DEqtsxoaHd39VK+yOJVAEG/SjpjIzQFpESaM7+FSCREPJ4imzVOcoZTo/r8GK5xv2zYhoExOY5WEsWMFV7fzHgMPVKCmYwji4iiZcfHzmgFsPjweMHNyVjHIKnx+AmOKM7o8Bh/+UNhaZhUOv8m4cC+lTXIzlRsI1OolmNZOWMfQPF4cnLUszFiE3n91gODh7oK2jrvO4yRXrnPGZuM87tf/rmg/fDBY1RW5+fkdLZ3r9SwNhzzCctpkFI+ddlHssYQquYk1sh8A1rRCv9kUoLmD+QMdNXrw0ol8883K4ZSFIn1E7qOchrhD9Px9bOxDJNt52wqaN+0tYnOdkf3d9dZ2+f9Hi4bh7GOAYQQBCtm9Jy7O/vYtGVxpcAVAV5dIZO1EQhUr46VyqJNzV8hFEqiYUYGR6htqDnF2U6M6vOTHhpY1FhdToKqovoC2KkEij8AyXyjVvX5yU6OowdDRdVKVH8AoZ65ceTToWp5bZEAuv/0KpiGQkG2bG/hyCPH89rnhiY0NW/cQlWnw2wRi5lGkdduZ42ihdWUWflv64WShsKE9rJNNagrmGsXCPg569yddLTlG+519dVMjOU7BsqXQGbZpTjzudreJYTYcOXDVK+XQH1jXpu/ug7VH0QLzypoIQS+iio80XKEpmFMTuAtLc/LuNeCoZzH31teherzoeep6AgCtQ2nFecXqS1j51MumTUMwfnPu5LLHncxO3ZvzbWXlpVw7gW7OXzwGFu2t3DFVZfO+z1cNg6de45Qua0+zzBbCqWcgM9JpJ1G8WpYc7xIpWUlDA4uLtVG8XixTSf53WXpmVYEs7IZ9GAkz0GheDyO4pdtoeienJDANEJRCVTX5SnunGmU1Few9crzcs+FIrjoxU8gUHp6cfGRaJh3f/jNecb845/8GHq7+3PPL7jkXM67qKgqtMschM+Lrzr/RshXXYth5e+yqL5AniqdUFT8VTVFnXVnMtU7m4g2zOSBeMN+tl51PsoK3lhrusbLb3gBJdEZO2n3uTu49IoLsWaFQV1z3ZPybBWXpUWcKA5SCLEfp+iUBmwDWnGqzgqcGlXnrtQgZ3PxxRfLPXv2rMh7SdvGSqewspkpaUsfiqphZtLY6RS2ZaF6fbmy1mYqgZXNOl56RUVmM44etKZjGVkUTUP1Od4CK+tU0rNNE9XrQw0ET1shwUhlmegdJj2ZIFhRQqS2HFVTGRwY5uihVkzTpKq6gu7OXgSCXedup77hxBnqtm1z+OAxJidiNDTVudnszlyfNys5N5cSaUt+/Z5vcdYzZhKvMtksb37Ve3jLjf/vtHaU5lJV6kHXFcYnHaM70TmEpyxMsKki1+e23/+dHbu38sSnPW5RnyPV34OvsgZPyYbwBq3K3Mxd41QV2zQRUiJ0HWkYU4nNNqrXg1A0rHQKaVsoPj/aGZxMO002kWaid4RMPEmoMkqktpzUeJxsIoUvEsQfnX+V5eNH2+lo7SIUCbFtx2YmJyZpPdZBSTSCbUs8usa2XZvxT8kmZzJZutp7kEgam+rw+df033NF56aZdtZRaZoITUNoOqqmY6VT2JaJ6vGi+vxYmQxWOunMUZ8fPRBEWlbO8aZ6vWf0Deg0iZFJxjoHsS2baEMFkZqlFdCwbZuujh6SyTT19TVEosVvcLvae2g91oHu0dm2YxMVVeUcP9pOZ1s34ZIw23ZuJhqN0NbayWDfEOWVZWzdXhh5sMRsmCIcJ7ttvXbFRrFGEYqCFggWZNRrXh/MWaysTIbUYH+uTLuntBykJDsxhr+6Hm95ZZ6RpHq8qJ7T29Kdi+735MVIT1NVXUFVdQXtR9q5+bPf5LY/3omiKDzvX6/lVa99EbXNhUZ7LJbgNz//I1/61K0kEylaNjfywU+9k4sedV5BX5f1xfDxHlRdy1NU6OsZpKyydFGGPTie+3hqJtZa0bUCOcxINMzAIuUwwdG8NuKTG8W4X3GsTJrUQF+uGre3vAp/lRNKlZoYJzPSBoAeKSVQ24A+e4dzHeAJ+qjcVg84N8R9D7dx73f/SDaRxl8a4rJXP43KrfXzOteWbS1s2daSe15aVkIykeJLn7qVf96xB01Tee6Ln8lLX/08PF4Pt978XX72378G4JpnP4k3vfPV1NYvPIxtPSENg0RX25RxrxNq3ITi86OE8o1OzedD882s21Y2Q6q/l+y4s2voKavEX12bJ3l9ppGeTHL0rw9y9C97kbak7rwtnP/cxxKqjC7J+RPxJD//8W+4+dPfIJPJcvb5u/joZ29kSxGjvLGlnsaW/N/D1u2b8gz4v//lbj560+cY6B+itKyE93z0rTzp6Ve6UrBLwAn/glLKDillB/Cx6f/Pblu5IZ4ZZCdGc4Y9OGXYlSnjPdXfXbRU+3Lzx9/czm1/dJK3bNvmxz/8VdGEW4AD+w7xifd/iWTCSTxqb+3iMx/5MoP9a6bkgMsy0fbPg1TtzI+t7+3uWxKlHH+xsJw5haxKS0uWxLh3K9UuL9mJsZxhD5AZGcRIxDHiMTIjg7l2Y3KM7MRokTOsHyYHRrnrG7/JqeekxuL88xu/ITm2sPln2za/+tkf+OcdjgfbNC1+9N2fs/e+/dz7jwf46Q//DyklUkp+/fM/8tc//mPJPsuZjJVJE+s4nkvWlqZBvPN4UeGLuRiT4znDHiA7OoRRJFn8TGLoaDdH/vwA0nYiMnofOk7HvYeW7PwH9x/mMx+5hUzGcdA8/OAjfOUL/0mmiEjIqTh2uJUPvOOTuWv/2OgE73/7Jzm4300mXwrmc3uUF/wnhFCBi5ZnOGcm0rbIzjLsp7HSqZyBb2VOTzJtsaQSSW77c+ECcPdd9xft3z2VcDubRx4+Sn/fYJHeLusFM2vSs/cYVTsa8tp7uvpy8nwLxasrWJZkttqc4tELtO5LykoY6l98eQvF68POZrHPYFWWtYq0rFnylzMYsQnMIkok2YmxAhWT9URyJObIDc4iPZk8bfWcaUaGRvnH7fcUtD/0wAGOHWkvaP/9r/+y7mQcF4JtZGHO30Fa1imV56SUZMcL12xjYnwph7fiDB0pXMe77j+6ZGo5XZ29BW1/u+0uRofHT/tcvT0DjI7kH5dOZ+judAsSLgUnNO6FEDcJIWLAuUKIyalHDBjEkcd0mUYoaMHCeEvV40UajiGjaCu71ef1+zjv/N0F7btPoJZTUVWYZV9TV5WXFOOy/uh96Djh6rICNZDuzl7KKxcX3uL3KWSMOWpT3sKwnGg0wujIGLa9OB10V+9+GVGKX+O0QLBoeKEWcIperVd8kUBB9K7m1fEEFxYLH4qE2XHWtoL2LdtaqK6pKGi/5LIL3NAFptVy5nwRQiBOkSgrhCg+n4u0nUlEixRVq9hSh7pEVWqL7ebuPGsbocjp/93KKkrx+fKvHYqiUFHlFtlcCk4WlvNJKWUY+KyUMjL1CEspy6WUN63gGNc8Qgi8pRV5ZapVnz9Xil2PlKIFCqXUlhNFUbju+U+ntq4q17Zz91auuPKSov13nb2d615wTe65x+vhXR98E82bGor2d1kftN75MNW7Ggvae7sHqKgsvOE7HfxelWx2jnGvq0jLQs6q0aDrOj6/l/HRiUW9H0zp3buhOUuOEAJvWRXKLJUc1R9AD0XQQ+E8JRJF1/GWVRSVxFwvhGtLOfe6x+SeC0Vw8YufsODYZr/fywtffl2eYXPO+Tu56FHncfmVl7Jt5+Zce1NLA9c8+0kLHvt6QvX5ClTtAnVN86qG7C0tz5PIVHw+9Eh0qYe4olTtbKR800wuhj8aZOuV5y3ZjeBZ5+zgqc+8Ovc8GArwzve/gXC4sNLvqdi5eytvf+/rc2MTQvC6t77SleteIk6mlnPhyQ6UUj6wLCM6BculSGKbJlY243j/vL6cLr2VzWAbBkJVwZbYpqMKofkLZSvNTBorlUQIgfB6kdksQlEdlR2tUNt+oSRGJ0lPJPCG/KdcTLpauzl2uA1d12hormNsZAx/wE+0spTB/mFKohGaWhwJxOGhUQ4dOMrY6DjNmxoJhYOkkimqqisZGRkFCXW1VZixNIqmEqqKok3p5/b1DDA0OEJpWQmNzfNLKjsDWNdqOcnRGH/46Pe57PqnoWozibPpTJZ/u/49vOXGG/LqM5wuWxoCjE0aeTH3AOP7Oym7eDPaLC/nj//rF7zgpc9m51mLk0Yz0ymyo8OUbF/3UoIrMjenr4sA0jIRioptZBFCcZS/NA0rm3ZifKWcUiLxLVosYC0ibUlsaBwjmSZQGkYP+Bhr7ycdT+GPOsaNvyREsHxmt3Ogf4iBviGipREam+sZHRmnt7ufUDhAU0sD6pyE9UMHjnLsSBter4ftu7ZQUVVOV3sPmXQW27ZIJtNs2tJI3UlUz9YAK3rdlLaNkYhhTyk26cHQvK9bVjaLlU4hhEDx+dZ8Mm18aJxMPIU/GiJQGsa2bOKDYxgZg2B5BF84QGoiwWTfKLZpEakty5uPsxnsHaS7o5dgKMCmHZvweAptFCklXe09jI9PUl1TQXVtFZPjkxw70k48Fqd5cyPNmwqdQ+CEdrYd78Tj1dm2YzOlRcI8U4kUBw8coaerj5raKnadvY1w5PTkZU+T9etxmMPJ9mo+P/WvD7gYeAjnD3MucA/wmBMcd8ZhpdPEu9uwkk7Sq7eiGl9lDXYmRbyjNbeo+apqyIwMIaUk2NiMJxydOUcmTbK3M1e90VNajr+mfskvFgOHOrn7278jE0uh+zxc8vInUXfelhPemTdubqBxcwOP7DvM21//QY4eaUPTVJ73kmfRfryTB/c8zHs//jae9oyrqags4zFXPYrxsQm++40f851bf4RlWew6extPfNqVfPmz3+Kqqy/nuisfw/A9x9h29fnsfOolPLTvEDe+6cOMjowTCgf56GffzVVPvqJg4XJZW7T/8yBV2xvyDHuA/p5+yivKFmXYC5yY+6xRGBesToXmzDbuS6JhhgaGF23cq14fViaDbZrrTsN6pbHSKeJdbejhEoz4JHowjJmMYyacuHJPaTmq10+q3ylWo0eiBGob16VhbxomnfceYu+PbscyTAKlYS568dU8+LM72PTo3ez5/p8xkhk8QR+Xvfqp1Oxu4cE9D/P2132AocERQuEgn7nlg3zyAzfT1dGDx+vhbe95Lc9+3tMJBB1HUUdbF5/58JfZc89DCCH48Gdu5PY/35mraHvlEy6nuraS/xkc4V0feKMrVQwYhoEdnyTZ24m0LISqEqhvxhudX2iH6vGgFilwtdawbZueB49z3/f+hJnO4g37ufy1z2C0tY/9v/gHtmUTri7l0f/v6UQbKvGXnNyTfmDvI9z09k/QfrwTTdd4/ZtfzvNe/ExKyqO5PoZh8uff3s6H3v05UskUFVVlfO6rH+bCS87lwktProT+0P0H+NzHv8JD9x9ACMGznvtUXvb/ns/WHZvz+vmDfi669DwuutRV5VtqThaW83gp5eOBDuBCKeXFUsqLgAuAYys1wOVGSkl6ZCBn2ANkhgechW3KsAcnaTY10IuntBxpGiS7O/ISybLjY3ll2bNjI5jxpc28T4xOcve3HMMewEhnufvbvyc2UJgYNJtkIsnXb/4uR484UnWmafHf3/lfLrnsAlKpNO9/+yc5NvUawP4HH+HbX/0B1lRC3CMPH+WRh4+w6+xt3P6Xuzg2Moge8HLktr10tXbzrjd+KJcYE48leNebP0JHa2EZbJe1g5SS1rsOUL27sAJtT1c/5YtUyvF6FAxLUmxjUExVqZ1NSTSyJIo5btz90iClTWqo30lONLJII4u0rJxhD841TtoWTIXfGJPjZGep6awnJntH2PNff8YynPUgORbjwZ/8nR1PvJADv74bI+nsbmQTaf75zd/R297DTf/2MYamirNdevmF3PK5b9PV4SQ8ZjNZPvXBf+fIIadSrW3b/O+Pfsueex4CIFIS5ujh1pxhD07iYjAU4N67HuC2P9yxYp99TZNJk+jpyCVvS8si0d2Osc5+/7H+Me759u8wpxJjM7EUI8d7eehnd2BPhTjGBsZ48Kd/P2XybGwixpc+fSvtxzsB58b13z//bQ7uP5LXr+1YB+956ydIJR17Y3hwlBvf9BEGB06uoJfNZvm///0DD91/AHDWml/85Hfs23vw9D+4y4KZj2tup5Ry//QTKeXDwPnLNqIVRlomxmRhrK9tZHOG/UxnOet1A3sqWVbaFtnJIpn3saW9wKTGE2Ti+coUtmmRHD35+4wOjnL3XYVRVIlEEkVRkFLmVUg8dqi1oO8D9+1n99k7ALjr7geI1DrG30DvIGNzYqWNrEFfr6uys5YZPtaLEIJwdWHSbE9XH2WzPDgLwYm3L66Wono0zOScpNrSEgb6Fm/cgxt3vxRI08KITaL5A5iJOKovgJksVIKxMum8uGVjYowThXqeySRGCteI2MAYSImVzV8njFSGoYERerpmVD+2bG8pKvE33ScRT/LXP84Y7Ft3bOLgvkIJw8MHj9GyuYk//+5vrloOYJuFajnYtqOis45Ijk7mjPhpjFSh/OTgoS6y8UL1qtmMDo1x790PFrR3z1HC6esZyDn4phnoG2L4FNXEhwZGuOcfhap8B/a5EpcryXyM+0eEEN8SQlwlhLhSCPFN4JHlHthKIRS1aIa8oulF1R6mk8SEqs1s+wsFPVQYJ6YFTz/J5GR4Q340b35cnBDilFtwJaUlnHVOYZJKIOjPLRCV1TPJk01Fkmh37t5Ke6tzp3/BebuJDzmLXXllWW5beRo3433t03bXAap3NRVNeuzq7F309+fzKmSN4kae4ilUzCktKzmlR2i+aH6nmJXLwhGqihYIYmXSqP5A7t+5qB5vzskBoIcj6zKR1l9SuEYESsNOBXI1f51QdY3SsmjeDXJf9wAtWwp3ySqrHCUcf8CXVzCwq72naGGgzVub6enq47IrLnLVcgCh6bmdo5lGseLqdMuNryRY8LvSvIWfsbS5Cj1w8rC4SEmYXUWUmapr8pV2iinoRUtLiJaWFLTPpqyilN3n7ixo37pj2avPusxiPleHVwIHgLcA/wYcnGpbFwhFwVdZ41wkptDDJSheL8GGlrwLh6+yxtF6FoJAXSPa1GKXU8uZFWuqBkLooaWVkQxVlnDxy56UW0yEEJz/gquKel9nE46GefM7rs/7UV71pCs4eqgVIQRvfOf1bN0+Ewt3zvm7edLTr8w9L68s4/IrL+X+e/exbfsmztuylfREgtpzNtG8pZEPf+bGXGKtoii8+8NvZvOW5qX86C5LiJk16Nl7jOqdxROhersXH5bj96pF4+0BlCJhOdHSEoYGR4qG8ZwuiteHbWSxTePUnV2KIhQFf3Udtmmi+YMgJarHO+caF3TyMqYcBIrPj75OqwOX1JWz+5pH5Z6rHo1z/+UxHP3LXnY+5RKEMuX0URQufskTaNzSyEc+9248UwbYn3/3N9749lcRDM3cIL30+ufnckw0TeNFr/wXauurARgcGGbbzs15Kjnbdm7G6/NSUVnK0571xGX/zGcCwuvHX5PvjArUNhRUkD/TidSUcf7zrswZ+IqqEG2sZMuVM7Hvut/LBS94PJ7AyT97aWUp73zf6wnPkq98zvOexq45DsAt25t5+3tfn3tPj9fDRz/3buoaTl4Z2e/38fwXP5OaWUp9F112HudesO5FDtYUJ1TLWasslyKJlc1gZdIIRUH1Ouo2UkrMZAI7m0HRPU6FQNNwFjghQNoomo6dzSKljTLlxXLifpdWIWca27KJDYySHI3hKwkSqSlD1eeXOHjsUCudHT0EgwEqqsrp6x2grDzK5m3N+Hw+0skUrYfaGB+fpKa+molYnHQqTXlFKUMDo5iWSXNLPb6Ms7hFasvwBv2Ypkl7axd9PYNUVpWxeWtzblE7w1mXajmd9x3m6F/2cs6zryh4LZVK89bXvJ+3vOv/LSqhdvemEF39KYpJ11uGyeSBbqqvPjuv/ZbPfYtP3vy+vEVnoaT6e/BV1uBZp8YmKzQ3c9dFoWCbhqMfbttTTg8BSIQQSFuien2o3vWXTGuZFvHBMbLxNKpXIxvPECiP4I8GmegdJhNL4Qn5sbIGuteDlOAN+QhURDjyyHF6uwcoq4iyY/cWhgZG6enqoyQaJpXM4PM7fy/do5GIJ1EVBdu2saVky9YWTNOk9VgHlmURCAXIpDJs3tpc1Ku6hljWueko2GURqobq9WFkU4isiWVmHQELrw99javeLAQzYzDeM0R6IkmgLEy0sZJMIsNkzzBGKkOoIkK0serUJ5riyMFjdHX0Eo6E2Lp9E2VF6pqk0xnajnUwMjxGXX01LVuaMA1nvU8kkjQ21Z1wLh46cJT21i48Hg+btzXRsrmJgf4herv6CUeCNG9uRNeX3kY6BetvW/EEnNAqFEL8j5Ty+UKI/UDBEi2lPHm69BmG6vEWqDwY8UkSHa1TSWMKwcZmtHCEzMgQ6enkWsvKlWRX/QECdU3oy1gIQ1EVSuoqKKkrLGxyMo4cOs7bXvMBOtu7URSFV772hbzihn+lpNTZXZgYmeDnP/4N//6Fb2MaJhVVZXz25g9QWlrC5z/+tVxZ9IsvO593vPf17N69I3duTdPYun0TW4tsI7usPdrvfoTK7cXrF/R291NRtTilHI8usGxZ1LCHfK17MSukoay8lIG+oSUx7lVfACM2sZ6N+xWh6HUxESfV152LwddCEVSvl/RwhmD9/DTGzxSMTJbjf9vH/l/chbRt/NEQV7z2WkKVJXTff4T7ppJs9YCXS17yRPb8158dx0skQOXTzuPGt36c8bEJPF4P7/nIW7j2uieTSqZ462veT09XH4qi8IkvvZdv3fJ9jh1pQwjBC176bF7zlpcTLXN2Wte4Ib+iGIk48Y5jSNMEIfDXN6EgiPd2OjedikKwrhmrJLqu1Npsy6bnoeO5pG494OXy11zLwMEODv/pfqQtCZSFufSVT6Fq26lr0zzy8FHe+pr30dvdj6qqvObNL+PFr3puwbXX5/Oy6+wZj/7keIzvfevHfOsrP8C2bRqa6vjirR9lx+58lbO24518+KbPceAhJ2/kuhc8nee96Jm89bXvZ6BvCE1TeeM7rucFL3123m6Wy9JxshX8LVP/Xgs8o8hjXWNlMiQ6pwx7AGmT6GrHSiZID/Q6cX26J2fYA1ipJNmxkTWX6JROpbnls9+is92RrLNtm29/9QcceHgmweXIwWN84dO3Yk6pQQwPjvLFT9/K3f+4P2fYA+y5+0H+dttdK/sBXJaMTCLN8LEeKrbWFX29p6ufiopFxtt7ThySAyAQqF5PYWjOEsbdq343qXa5MGLjecm1ZnwSoahYycS6U8sZ7xpm3//eiZy6pqfG49z/w78w0TPMPd/5Y049x0hm2POD22i4wDFyIjvr+cBNn2V8zMlNymayfPjdn+PIoeN8/uNfzSXS7ti9hT//7m85tTIpJT/63s/Zt/fASn/UNY9tGiS62hzDHkBKFKGQ6OmcSaq1bRK9Hdjp5OoNdBmI9Y9y75z5Ntrez6E/7HFqTODULdn/83+Qmkyc7FQk4kk+97Gv5EQ0LMviq1/8Tx45cPSU4zj48BG+8eX/ytk43Z293Pzpb+QUdabP95Mf/DJn2AP8/Me/5Z67HmBkaBRwFPu+9KlbOXTw1O/psjBOJoU5ner/BMAjpeyY/ViZ4a0etmnk5LVySIk9VdBF0fXc/2djJmKFx60y42OT3POPQrWcno4ZNYfZajnT2FJyz117C9rvLaK843Jm0LP3GKXN1WhFCpYA9HT2UlaxOG+3z3PiZNppFG9hUm1JNLwkcpgAiseLNM11p5qx2liWhRkvopqTTqJ4vRgT4+tKLSc5UpiYPdY5SGJkImfwT5NNpFGnflemLgrUn6SUdHf1cd8/H8y17di9LScZOJsjjxQqlm10bNMsWHOlbYMsppazvvJtkmOxgvlmFpG8HGntIzN58hub8bEJ9hRRy+mdpe50InqK9LnnrgcYH5v5nSRiSf5+2z8L+rUd6yjI5errGTjle7osjPnsvbcAtwohjgsh/kcI8SYhxPnLO6zVR9F0hFK4radMxfLZhpGXXDaNGgw51WzXEJGSMOdfck5Be11Dde7/s5NfZnNRkWIVF1yyriKyNhSd9x2mcuuJKwh3dfVRuchkWkcp5+S7V4pXxyySVNu/RBKqQgjXe78MqFMqOgXtXj92NoMeLllXajn+0sIQsUhduaOUM+dz6gEv9pRXWbcoqjhVV1/NeRfN5JocP9LGWefuKOi3ZVvLIke+/lBULU92FXDC+grUcpRlyXdbTfzRUKFajq+IWk5TFd6Qv6B9NpFohHMvLExuramvLtJ7Tp8idsL5F51NSXRGLTAQ8nPZYy4u6Ne8uTFXD2eauQo9LkvHKY17KeUHpJRXA2cDdwLvBApFTNcZqtdLsLFl1oVDEGhoRg0E8ZZXOaXWTRMtODOpFa8XX2nFmpMoCwT9/NuNN+QtNs9/ybPYfc7MorJt12ZueP1LcheQcCTEW95+PZc/5mLOOX9Xrt+us7dx9ZPXTXHiDUUmkWa0vZ+yTSdWO+jr7qd8kTG+Po+KYZ7CuPeoWMl8L1xpeZTBJdK6hym9+5gribnU6CWlqL4ZA0L1O8a+4vHiia6vHIdoYyW7n35pLg3PE/By8YufQEl9BRe9+Opcboqqa1z4gqvo3OMUAhp/uJMPfuzt+APO30lRFN71gTeybecW3vWBN+RkMvc/+AhPufbqPAWSa657EudduHvlPuQZgqLrBBta8pxulmkRqG2cWaenlOyUIrKtZzLh6tKC+VY6Ry3HG/Jz7nMeiz968pylcDjIjR98Y55U60uvfz67dhfKY85l9znbeeErnpN7Xl5Zxtvf+zoCwZm/t6Zp/OvLr2PTLOnXq5/yWC69/EICU78HIQTXv+HF7CgiyemyNJxSLUcI8T7gCiAE7MUx8O+YFbZzouN8wN8BL07i7k+llB+c00cANwNPB5LAK6SUJ435WEpFEts0sTNpJCA0DWkYCEVB8fpQVBUpJVYm7XjpNQ3V50MIBcvIYKfT2JY1tf1vIG0bxeMD20IoAsXjm9HBL4JlmMQGxsgm0gTLIwQrnOSp5GiMid4RQBIsLyETT6HqKuGaMnSfB9u2aT3URn/vIOVVZXj8XkaGxqioLCWVSDExOkHTpgYaimjV9/cO0tnRQzgcwrJMujv7KK8sZVNzPdZkBiXkpa29m4mxCeoaa9E9GrHJBKVlJXS294CUbNnWQuPUuft6Buju7CVaVoKqqgwPjlJRWUrTpga0k3z2sZFx2lu70HSNaKlTmTQQCLBpSxP+U8h4rTDrSi2n/e6DtP3jAGdde1nR1+PxBO9640d40zuvX7D3VRGwsyVER9/JC6lkx+JkJ5KUXTgj9ZdKpfnWLf/FLf/56QJn3EKwshlS/b1Ed527rrzJUyyzIkkWO5vJqYdJ28bKpEEIpGmAUJwveyqJEdtG8frRzmC1HCOdJTYwhm1aWIaJmTEIV5fiiwQZ7x7CMk1UTcXMms612LTQfB4s02I8nWRsIobf7yUVSxIpCVNZUsrAxCj9/cOUlIZJJ9MEggF2nbWN8fFJOjt6EDhF//xBP+lUmnA4xKatzUyMT3L8SDuqqlBWUUo2a9CyuRGhKLQf78QyLZo3N56w2Fwmk6X9eCeTEzHqm2qpqz+5fOESs6xz00gksI2M48n3+bGkhGzaWb91HTw+dE3DyqSRlomie9e8ilNyLEZ8aALd5yFcXYrm1YkNjpMci+EL+QnXlGIaFuNdg6QnEgTKwpQ2V5MajxPrHyObzBCqKKF8Uw2xyTjtxzsxTJOWTY2UVZSSnkwSGxxDUVXC1aV4Al4O7DtEd0cv4ZIwm7Y1UVtb6Lk3DJOOti5Gh8epqaukqaWBgb5Bjh1uIxZL0NRSz+5zdhCbiNHW2oVlWrRsbqS0PMrxo+20H+/E4/WwZdsm6hqq6enqo7uzl0hJmE1bmvD5V3y9X3cLwYmYj4bicwAT+A3wN+BuKWV6HsdlgKullHEhhA7cKYT4nZTy7ll9ngZsm3o8Cvja1L/LjpVJk+juwEzE8NfUkxkdzsXzeaJlBGoaUDweNJ8fZnmprGyG9GA/mVHHwyg0nWB9E1Y6RXqwDyvtGDV6uIRAfVOB0gQ4CgzH/voQD//yLqSUeII+HvO6Z6J6dfb+6K8MH+/lnGdfwd7/+RvxwXEAmi/bybnXPZZ/3LmH9779E6RSaXSPzvVveDG//cWfGR4a5XVvfSW33vxdfD4vX/jqhzlvTihOTV0VNXVV/PWPd/K+t3+S2GQcVVV53VtfwaPPOZt/3P8QX7/le9i2TUk0wmvf8nK+9Klbqayu4Evf+Bjbd23JnWvf3oO8+dU3gRC84oYX8LUvfic3pg9+8h087VlPRC8i0dne2sW73/JRHtl/hHe87/V875v/k4uzfvGrnssNb3oppWXRhX+xLieke+8xyjfVnvD1nq5+KqvLF2UIez0K2VN47WFK635OlVq/34cQgthknEiRokGni6J7cnky60nBZbkxU0ni7UdzccvBxk2kBvvwlJRiTI7nrnFaKIIeDJEacCpbqoEgocZNZ+TfOjWR4OFf3kU2mUb1aHTe64gN+EtDXPD8qzj0xz1UbK5l8Eg3NbubOfynB5C2Tai2FPusaj70ns+TzWTx+by85i0v5ze//BOveePL+PBNnyMeS6BpKi+9/vncfeceHveEy3nRK56DR9e58c0fyYWiPeu5T+O1b3k57a1dfOjGz3DkkeMAXPaYi3jqM65mz90P8uCeh3OCBjvP2sanv/yBPA8pODfpP/j2T/nal76DbduUlpXw79/+JOcVCcU408hOjjtJtVN5bb7aRhRFIdnb6VSQF8KZr5m0I3yBU5At1LIVPVhYaHItMNY5yJ1f/RWpcSeXZdvVF9BwwRbu+MqvMNNZhKJwycueiJHO8tBP/o5t2WhenUte9iTGugY59Ic9IMEXCXDWSx7PLbd8l9v+4FQ73r57C5/47E20/+IexrsdsYK6i3eg76ripn/7GMODowgheP5Ln8WLXv4cNm2dqU+TzWT55U9/zyc/8CVM0yIYCvCpm9/PPf94gO//x08AqKqu4BNfeh/f//ZPuP3P/wBg97k7uPGDb+KD7/oM7cedwpdXPfEK3vLuG9iyrYX6xhOvQS5Lx3zCci7ESaq9F3gSsF8Icec8jpNSyunMK33qMXeb4FnA96b63g1EhRAr8s1nYxOYiRiqz4+ZSuYl6mTHRzGTxTPOzWQiZ9gDSNMgPdTvqEWkZ7yVRmzihFUyJ7qH2f+Lf+QSz7KJNA/+9G/0H2hn+Hgv0cZKxjoHcoY9QMfdh2g/2sEH3/0ZUinn3srIGnzzy//FNc9+Eol4kv/42g+59jlPZmhwhC9+6lYmxgpLph891Mon3v8lYpPOV2NZFrd87tuM2xm++u/fyWXBT4xP8qPv/ZynXPt4ujt7+fZXf0A2k8299rH3fJ7RkXGe+S9P4Zu3fD9vTB+68TO5arZz+b+f/YGD+w7zqCsu4vY/35WXQPmD//gpB/cfKXqcy+KwDJPBQ12UbT6xB6+nq4/yRSbTej0Kxini7WF2Iav8S0JZRWlBIuJCEUKg+QNu3P1pIC2LZH9PzrBXvT6M2ARIG2kaedc4Mz7pXMOEs4xYyQTZibFVGfdiGWnrp+2uA5Q2V+cMe4DUWJxjtz/E5seew5Hb9tJw/lYO/XFPLrkxsL02Z9iDowv+jS//F69+7Yv4zEduIR5z1hHTtPjOrT/iCU99HLfe/F0O7DvMrV/+Xl6OyS9/+juOHWnjN7/4U86wB7j7zvtJJFKkU+k8pbJDB47yq5/+viCB+fDBY3zlC/+Ru5aPjU7wkZs+n1PuOVMxM2mSvV15ghWqrs0Y9uDczGcyOcMenDmd6Gpfk0XtjEyWfT+/M2fYAxz9y16GW/tyCbPStkmMTPLg//wN23K+UzNjcP8PbsM27dwl1Ehl2HPvQznDHuDIweP8/H9+i5GZ+exl5zTw5c9+i+FBR7lGSsmPv/cLjhzOT+I+frSdj733C5im8/dOxJN88MbP5KkBDg4M89Uv/gebt83cFFRWlvO/P/pNzrAHuP3P/+CBe/ct6m/lcnqc0rgXQpwNvAR4OfACoBv4y3xOLoRQhRAPAoPAn6SU98zpUg90zXrePdU29zw3CCH2CCH2DA0tzcJvxJwLnerzYxUx5M0TSGkVy8I/4Y1AEVUJcLbgijF0tAdwqiGOthdmkQ8PjOSM8tx7mBbGVBLX6PAYobAT//rQ3oOMjxbeXIwMjxZVJClmUHW0dVM9lUBzz10PMDnhjHt8bJJDB48BoHv0omMa7C+UNEynM9x5u7Nxs3XHJh5+8JGCPsVUe9YyyzE3l4PBI92EKqN4/Cfenu7u6KV8CWQwDfPUaimKqiBUBTtr5rWXlpUwuESKOTAliRk7s42ahbKQuWlbFmZi5vqk+vyYyQSq11/0Omdl0iizlJeMyYkzUi1nsncYoSgFSd4Aox0DqLoT522ZZt79aCyVyhn206SSKSQwNDiS1y6lJJN2nEj9PQPse6BQJScWS/DAvQ8VtPd1DzihkXO48/Z7SKfyc1eKJaUfPXScifG1k3+ykLkpi6nlWDZzy1rLueo5gJ3N5JKd1xLGlDTxXOYq4dimlZO8nCabzOQVsPSVhDhYRM7ynn/uxV81U53e0hX2F1l75+Y7DfQPFfyWR4fHCIbz8xn2P/hI3q7+hZeew977Cg35Q/OQ2nRZOuaT+flpIAz8O7BLSvl4KeUH5nNyKaUlpTwfaAAunbpRmE2x/f9iBbO+IaW8WEp5cWXl0mRXe8LOZLfSKdQi6g/aCRJy5mbrA456RJFPooWKhxYEpgpH5SOomiosNN49TFlLoYe1sqaioMiEpqloU+o85ZVlOU/R+RedRWlZScE5KirLi2a8Vxdpa9nSRH+Ps1A8+jEXUxJ1xl1aWsKuqUSYbCZbdEzFsuB9Pi+Pu/pywFlszrlgV0Gf+sYVjQ1dNMsxN5eDvn1tlLacXA2hu7OXyiIKH6eDI4M5vzoPilfDTBYq5vT1LZ08muoPOPK0Z6DBuVgWMjcVVc0TCTDTKbRAEGvq37moXh92dsbhoUfOTLWckvoKpG2j+Quv7+WbarAMx3upalretT7s8xdU4w4E/QickIXZCCHw+pyb65o5qjnThMJBLr7s/IL22oZqmloKVa4ed/VluSq3ub51hb/zHbu35IpirQUWMjeFphUo1BVTyxGi0KxRvCfPgVstPEFf0YKCc5VwFFVFKPmf0xP0Yc367aXG45w1q+DUNJddcSGpgfHcc9WQnHNBYcJ2dW2+DVBTW1XwW55tY0xz3oVncXjK2Qdw390PcdGl5xWcf3eRsbksH/MJy7lGSvkZKeVdUsoF7WtJKceB24GnznmpG2ic9bwB6GUF0MNRtFDEWbT8AZRZcaKe0vKiCxk4Rr+3YuZHoOg6vqpapGWhzroh0CNR9FAxIx6iDeWc9y+Pzf1YvWE/5z/vcVTvbqJyRwMTPcOUNlYSrpkJkdh0+Vk0b2viY5+5MVfRzev18Jo3v5xf//xPhCMhXvXaF/Lr//0j1bWVvO3dryVS5CZi645NvOcj/5Yz1DVd499uvIGo0Hnz216dq+pXVh7lBS95Fn/8zV9p2dzIq17/IvQpD10kGuZ9n3g7FVVl/Oqnv+eGN70sb0wf+dy7adnSWPDeANc+50mce+FZ3HvXXh73hMtzKhFCCF5+wwvYfe7Oose5LI7eh9soP4lxL4Henn4qKhenlOP1KPPy3AOoReLuS8tK6OtZGjlMmJG0tVLrq6jNciFUlUBN/YzkbyaNHokiFAWh6fnXuHCJo94x5SnVguEztiJw+aZaNj/2HEbb+2m+bFfOgA+WR9hy5bm0/n0fO550EV17j7HrqZegTFVWTh3r5yOffhe+KaPdH/Bzw5texn987b+58QNvyjk+NF3j1a9/Mbf97u+84e2v5uzzdvKaN700F38shOC5L3wG23Zs4unPemKektljHv8ofD4vgWCAJzz1cbn2EweNvQABAABJREFUs8/fxTP+5akFBtiO3Vt5843/L3ctL68s4wOfeAclJcXXozMFzesjUN+EUKeNdIGVNQnUN+VCwxAKiteLv2bGYBaqRrChZU3KY2peD+c8+zEEyqduqAXsePJFlG+pRQ84c0rRVEJVUS54wVUomvOdaj4PF734CahePff9e0M+Lrr0PJ76jKtz5991znaue97T8QRn8gYnDnbypndcn3PAKYrCi1/13DzvOzhyrB/81Dty6344EuIjn70Rj8eTe8+auipe92+voLtjxmybnIhx3Quenlex/klPv5ILihj8LsvHKdVyFnxiISoBQ0o5LoTwA38EPi2l/PWsPtcAb8RRy3kU8O9SyktPdt4lV8vJpp08HFXBymQQiorq9aEW8dDPPs5Kp7AtE9Xjc+JRpe0UtjIMxNQFRlFPopZjWvlqOeXOhTc2OE6sfxSJJFAaJjE8ierRiDZU4J9KMmw91EZf7wAVleUIBYb6R6iuqyKTSjMxNkFDUx1+Rcc2LWy/RndPP6qmUl9bDbEM3oiPnuFRerr7KSuP0lRXTXYkjr8iQv/QCBMTMWobqskaJolEkqaWBiqKaJ/39w7S09VHtLQEVVMYHhwlWlaCtCVDgyPU1lc7Cg9zFp/xsQk6cmo5JVNqOX5atjTlFsk1wrpQy4kNjvOXz/yYy65/2gm9qqOj43zoxs/w+re+asHvoyqwvTlE5ymUcqZJ9oyg+j2Et86k2Qz0D/Gn397Oxz5/04LHMZf08CBaIIi/al0lci3r3LSNrHM9VFVUr3dGLQfn+ieEQHi8qNp0MT95SoWw1SI1kSDWP4pQFSI1ZSfUATczWWID49jSJhtLgQShKRipLP5oCEUVGCkDK5tF83sxUhm8QT+WbTOZSTMRi+MP+jGyWYJ+P1F/kHg2zcj4BKqmkkwkCQYD7Ni9NSeR2dHWTfvxTnx+x3i3LIvN21qIx+JTajkqZeVRDMOkZVODo5bT2oVlmjRvakTVVFqPtpNOZ2je1JjblTWyBm2tncQm4tQ31lBTxJu/jCzr3DRTSayso5aj+vzYgMyksI0siuZB+PyoijKllmOheDxFhS3WEqnxeE4tJ1RdihSSsbYBkqMxfJEAkdpSdL+Xsa4hMpNJ/KVhyltqSE4miPWOTKnlRChrqSERT9De2oVhmDRvaqC0LEomlppSy1EIVzvnOrDvMD1dfYQjIVo2NVDbULhrbpomHW3djI2MU11XRWNTHWMj4xw5dJzYZJymTQ1s37mFeCw+NS8dFadoaQk9XX20Hm1H93jYtmsz5eVr4sb/zNtWXCDLeSWuBb4rhFBxdgj+R0r5ayHEawGklF8Hfotj2B/DkcJ85TKOpwBF01C0kKMO0XYsV81Sj0QdpRu9uIGvaBpKqHjmveqZn1KEqqlE6/O3bWOD49z7n79npK2fc5/zGPb+9+25+Pz687dwwQuuIlAaZvPOTTRtaaD17w/z0E//jpSSfl3j7Gc+msCEwbG99zJ8rIfqq87ii9/8L1qPOQWFL7rkXF72jKcx9M8jbHrM2Tz2GY+m/2AHf/vUTxwpT1Xh0lc+hd1XXTqvrfVp9Z2Z59X89If/x+c++hVs28bn8/K5r32Yx1396LzjoqUlRC+a2SJ2s+eXl4GDHZS2VJ/0O+3p7KOqquKEr88Hr0edVzLtNKpXx0rM0bovizI8OIJtSxRlaa7Dqj+AEZtcb8b9sqLonpz3HkAoKtI0ibUfy8U9a8EwwcaWE+5yrgUm+0b4x62/JtbvJPpW7Wjkkpc+MSc9PBvN68EfDbH/F3eSiafRfHouudYT9HHRi5/A3d/+HXJKreSiFz+Be//zDxipLIqm8ujrn0b9uVvzzlkJbCp4pxmaNzWQTqV506tvysXKP+Xax/PO97+Rxz6+uGTt2ec5u5tDAyN88oM387tf3QY4BYFu+c9PsWP3VnSPzvadW4oef6aj+QO5sFkpJdb4CImuDpy7MUGwoQU1WnbC0Nq1iD8aytOn79xzmPu++ycsw7mR3n3toyjfWscdN/8caUsUTeUxr38mfQ+3cfQvDwLOHH3MG55FxeZazpqzA+4N+/GGZ25q775zD+98w4dzeRjXveDpvOYtr6BuTiErTdOcgmqz5OhLy6M86oqL8vqFwiHOPi8/zLa+sdZd21eRZau2JKXcJ6W8QEp5rpTybCnlR6bavz5l2E8r6rxBSrlFSnmOlHLF3Z7StkkPDeSVqTcmxzETxZNhl5O+fa2MtPVT2lTF8PG+vMTbngePM9I6U1pgsneUB3/yt1wssWWYHLltL76SIMPHegiUR/jnvodzhj3A/ffto2N8BM2r03bnw4y09nH/9/+cU36wLZv7vvsnYrNUek6H1qPtfObDX85l06fTGd7/9k/S1+uWmF5N+g60U9pw8rjW7s4+yhZZmXa+MpjTKD5PQcy9x6Pj9/sZHV461RXN58dMJQrKt7vMHyllnlwwgJmInVARbC0gpaTtnwdzhj3A4OEuBg51nfCYsc4B2u46SFlLvmpONpHm0O/vo+4cx1Q3Mwb7f/EPGi9y4oht0+Le7/6J+NDpJW9nM1m+/dUf5CXB/uHXf2Xf3sJk27ns23swZ9iDs+v1jS9/j0ymMCl4vTItaZ1L1ZOSRHd7bpfpTGS0vZ+9P74dy3ASgKWUHPi/u7GNmaRa27QY6xrMGfYwpbr349vJJk/+2YcGhvnSp76Rl2D98x//loP7Di39h3FZNU5o3Ash/k8I8asTPVZykMuJtPPVIaaZLfm2UgwedhadSG0Z412FcccTPTMKNOmJQuUKRVOY7HPkrQJVJex96GBBn0OHWwmUObsOydFYQQa+ZZhkJhcWnzw0MFLQNjY6wdicktMuK4dt2wwf7aG0qTBhejZdHT1ULlIpx6vPP94enIRaq4g6SXllKf19Sxd3L1QV1ePFTK78Dfu6wbaLGvKr4QSZL5ZhMvBIoSTvcOuJ07oSI5O5Y+cy1jVIpGbmN5IcjeGdpRxipDJk4qd37YzHE0UlAmc7ZU5EMbnhB+7bT3xy7X4nS400jQK1nOnq8WcqmViKTKzQ/pi75s9V1AFH2cmYU/l7LmNjkzzycKHk9FJJELusDU7muf8c8PmTPNYFQtXQIkW2aFdhS692yis01jVE+ea6gtejTTNbZoGycGGYhZRE652EyETfGI9+1PkF5zjn7O0khp0FLFhRkkvQmUb3efBHF7bNXlNXhaLkT6mq6goqqhaXpOmycMY6BvGGA3iCJw8X6+7spaJ68Uo5pxOWo+gq0raxjblymNGicn6LQfU5oTkuC0OoKnokWtB+ItGAtYDm0ak/rzA0pWp78WR/gFBlFCBPYnCais11jHXNGEDh/8/eWYdHdbR9+J51jbs7wbVAKYVSo9Rdqbu7fPX2rb8V6u7uLm+dGsVaHALE3T2bZGW+PzZZ2OyGBOJw7uvKBTs7c86c3dk5z5l5nt8TGey1u6q3GDHsZPI1a4DVr/vNqNFpfmp7kz7K1+Fn9n4zCAgansmaBgKh1W0Lpu1EpUKlHX7Bs73FEGjyctEBd8C1Kdj7e9X6iU8Lz4hD101MiadORAiTuyS4BIiJU1xodie6Ne6llIt39DeYnRxIhBAYQyO8VCD0oeFozH3PkLmzRI1LInZKGg0l1QRGhxAU3+FKISBt3kTCUrb9+KxRIUw/82DPTUhvNZK+/xTqS2uIm5qOra6JSalp7LWdgX/IofOI1ppxOZ2MPnQ6YanRzDx3gUd2S2vSM/O8BZ4b3M6SkpbIPY/8nycoNiQ0iAeeuM1HEk5h8KjIKiAofsefv9PppKKsktB+ccvp/cq9QKA26HC2dPW7D+z3fAd7st59f6EPDvWSydQFhaLpJvZouJAwPdNLajBxxmgiRvlKD3YSnBjJ6AXTqcgqJG2/iW41INwLIZmHTKNis3t31RBoZvzRsyhdlwu4/Z1nnrcAc8jOfR5arYbTzz+B0ePd7j1CCE4/9wS/MsFdGT95LGdecJJnQSVzTBpnXXgy2hFs2O4sap0eS0IKQuVepBIqNZaElBGZJbmT4IRIpp66v8dHXq3VMOmkuai0GjR693erMxsITY1m/NH7bBuj4QFMOmEOWkP3YiDgXjy58oYLiEtwLyBqNGrOvXQh4yaN2mE7hZFFj2o5Qoh04H5gDOD5xUgpUwa2a/4ZKEUSl8OBs60VoVKh1us9k8VgU15SwdZNOUgpSYiPgfpWtEY9zWonpWWVBAZaSclIwmIxI6WkqaKOtiYbGqMOW20TbY02NGEWCotKcTicRMZFUJhfglarITw8hJzsAiwWM6nJCaha7BiDLag1atqbWzEEmrF0BJq1NdloKK3B0W4nIDIEc1jvVuiklOTnFlFXW09IWDA1VbU0dUTVJyT53lQL80vIzy3EbDGRmp5EQOCwMhZGvFrOr499RHhGHOFpvhrZnZQUl/HYfc9x7qULd/k8KhVkJlrI76VSTidNOeUYY0MwRm9TUsjLKWTVyrXcdOcVu9yfrkgpacrPJihzwrBUdNkFhmRsuhwOnO1tCCFQ6/QI9dDMkztDe0srTRV1CLUKa0QQmi669K2NLTSU1iCEwGl3IF0u9FYTUoC0O7Hb2rBEBKMPMFJfVEV7cyv6ABMuuwPpkrTbHdTamqkoryIoPBi73U5wSBCJKfFs3phNYX4JYREhjB6b7pEg7srGdZvJ2ZqPwWhg1OhUj+HVleqqWrK35OF0OElOSyA4JIj83ELabG3EJ8b6aNm3tNjI2ZxHTU0dcQkxJKcmDEYegkEfm862NlwOOyqtpteiFsOJxoo6mipq0Rh1BEaHotKoqM2vpLm6HkOAmYDoULRmPXX5FbTUNWEJCyQ4IYL62jq2bMx132OTYkkb2/OOTycb124mN6eAgAALY8ZnEBAUQG52AaXF5YRHhJCclkR7Wzsb12+hsryauIRoxozPoNXWRvaWPJobm0lMjic+KZbqqhpytuThcLhISUskMtp/jFd+biEFecVedswgo6jlbMerwB3AY8A83Io2u90H1KmcM5Tk5xZy3SV3ehJCJKXEc91FZ9Gmktx6+yPYWtyG0ylnHcslV51NYHAA1shgUAnWffYXhSs3Ez4zg1c/+4pV/67nsuvO5b47F1Fc6F4FzRybzox9pvD6C+8z76DZnHz4wRR+9y9jDp/BqAOneLb5Wmqb+Oe9nylZ7U5Hrbca2ffyowlJ6FlOTQhBUko8NdUWFt3/PJ99+C3gTs7yzOsPMWm7xC1rV23k4jOu92S+XXDUAdxw22V9XkFWcONyOqnOLSd9/8k7rFdcUEp4H3dX9NqdC6btRKXX4mj2DgALDQ2ivKR//T+FEGgMJuxNDeiDlPG1q7jnyZH1cKQzGfwmBQS3j/3yN37AHBZAc1U9FVlFgHvOm3P5MQSnuo3sdls7m75dzqb/LQcgODGCmAmpVGwtptTs5KF7n8HlcqFWq7ng8tNZ/NMSTj3rWO76v4exdyQaOufiUznzgpMIDgny6sPKpau59pI7PEHkM2ZP5cY7LvfSCQe369zNV93LqpXrALcayZMv39+tKk5TUzOvPvsOLz71lvua9DoWvXgv+8zdodr0iESt16PWD2+5y+6ozi3ltyc/8/jKp8wZT3haLMtf/x6X0z2njj5kLyzhgSx/60e3KJBKxZTz5vP6W5/w2cffAWC2mHji+XvZa/aUHs/574q1XHrWjZ6EVGecfyLjJmZy81X34nA4EUJw9f9diFaj5cG7nwTcuRoWPX8P3331M1998j3g1r5/+rUH+e/dT3my3sYlxPDky/eTmpHkdc6VS1dz6dk30tLstmNOPuNoLrnmXIL8JvVU6Cu9UcsxSil/wr3Kny+lvBPYv4c2CrvAz//7wyvTW15OIatysnn7/c89hj3Au699wqaN2+rV5pdTuHIzaq2GoqY6Vv27noSkWApyizyGPbjTPwshsFjN/PLDH1TZ3cfc8NVS6ktqPPVqcks9hj24A3w2fLUUR3vvg5Q2rt3sMewBmhqbefCuJ2nsCPZqaW7hsfue9Rj2AN9+/hPr12b5HEth16jJL8cUbOlxm7Ywv4TQsL5pEBt06l5npt0etUGLo8nbLccaaKG1tY3m5v4NaldccxS6UrmlmMrNRZiCrR7DHjrmvG+W4uiIB6kvrvQY9gAxE1JY/9USAibE8/D9z3oUwpxOJ688+w5nnH8ij9z7jMewB3jl2XfYtH6L1/mbmlp49bl3vNShlv6xkjX/+Krl/P37Co9hD1BcWMrH733lOXdXtmzK8Rj2AG1t7dxx/YNUlFf5ra8w+Nhb21n90e9eQbAarYZ/3//VY9gDbPxuOba65m2iQC4XmzZs9Rj2AM1NLTx0z1PUVGy7l/ujob6RB+543CvTrFql5u7/ewSHw52JWUrJY/c/T2PTtjoOu4PNm7I9hn1nvT9++dtj2IP7IfTTD772ygpeV1vPf25+xGPYA7z3xmds2uD9e1DoP3pj3LcKdz7nLUKIy4QQxwA7lt5Q2CX8qSb8++86/G2UVFVsU6Zp7VC3MQSayM51KygkJMexJSvXp11hfjERUe5V2qqqGo+/3vaR+P7k3Kpzy7DbdhyFvz2VFb7KOZvWbfEY9w31Taxf6ydiv59XbPdkKjcXERjb84p8QX5Rn4Oe9ToVjp3wt+/EvXLfdVwJwsJDKCvuX797jdGMvbGBnlwRFfYc6our0Bh1tDX5PkhW55Ti6FBzam3wVipxOVwgob6hyWMQddLW1o7L5aK2xnce7apIUldbx6b1W33q5ecW+ZT5W/hY8fcq2vyopoD3PaKTivIq6ut81eEUhgZ7Sxu1Bd5S0WqdhvZmXzlLZ5dxVlvvKxCQtTHba8HMH42NTT5jTqPTeBn74Dbc7e3eY8tm8+5XZFQ42VvyfM6xfMkq2rd7sG1saPKrAOVvjCr0D70x7q8CTMAVwFTgdODMAezTHsvcA2f5lM3ZdwZ6Pyuvcdslh+jMbmurbWJspjvbxKb1W5g4daxPu9SMZIoK3Hr5sbGRbu1vgZdPvT+DMGZCMnpL730Z/fmM7rPfdIJDgwAIDg1k33kzfOokJHcf7Kawc1RkFREY07PRXlxQ2uegZ8NOatx3ojbqcNrcGU63JyQsiJKi/s2PIDoCDV0jWANboX8JTYnG3tKGIcBXHS1mYqpHZcoc6u3LLlQClUZNSGCAJ9tsJ9YACy6Xi9h4b1cglUpFfJJ37Et4RBh77zvN59wZo31dbabP8nW3OHDBXIwm//NybHy0j399WkYy4Yp62bBBZzUSNTbJq6ytqdUjV92JUAnUWu/4lkg/0sUzZk0hNGLHbochIcHMmuPtmtXU2ExYl3YarcYnONtq9XZdLiooYfykMT7nOPiw/dBvF9sSEhrM1OkTferFKUmuBowejXsp5XIpZRPQAFwhpTxWSvn3wHdtz2P2fjM48rj5ngn5oPlzSLKGsPC4w0lKTQDAYNBz673XMGrMtsCZkKQoxh6xNwhBcLuKE08+gpqqOnQ6LfvMdRvQQggOPfpAyorLkVJy/qULMTbY0Rh0zDjrEAKit034IclRjDl0hmdVPzQ1hlEHTUW1E8Fzo8dlcP1tl6Lr+IFnjE7lyhsvwGh034j0ej0XX3UWYzpUIrQ6LVfeeIHntULfcLlcVOeW9bhy39Jio6mpuc9+j3qdCrt9F1bu1SqESoWz1dvlKyQ0mOJ+VswRQqAxKpKYCtsIS40m48ApVOeVkbLveM+cF5YaQ8YBk1Gp3a8DY0KZfubBHrWS8o0FTD11f6qWbeG+/95EULDb+A8JC+bCK8/kjRfe5//uvsqTwdtsMXHbfdcyZnyXzKF6HSedcQwTprgXYjQaNQvPOZ7J03ylCqfNnMTJZxztUcfZ78BZHHrUAd1eW1pGMv955P88Dx9x8dHc/fCNio/zMEKj1TDuyFkExbvHiUqjxhoZzNSFB2AMdhvSWoOOqacdQFB8OFqTO67AEGhmzKTRXHvTRZ57bFp6ElffeAHWHkQpjCYDV998EekdsRo6vY6U1AQefPJ2z4OfNcDCg0/eTmJKPBarO+g1MiqccRMzuebmi9Dq3L+DlLRE9t53GieedqTHbtl//mzmHz7P65xmi4kb77qClLREd/8Nem6552pGjUlHYWDojVrONNxBtZ0jph44R0q5coD75pfhqEiyI1xOFw2lNTRX1aO3GgmMCUNr7N4Huq6yloKcIkASGx+Do8GG1qQlv7ySwvwiAgIDSE9PIjYpFntbO/XF1bQ1tGAKsSCle5vPEB5AZXUtDocDs8VEQV4xarWaiMhQiovKMBoNJCbEomp3ojcb/EpfupxOmirqcNidWMIC0HWzOrQjnE4nBXnFtDTbiI2P9ntTqa9roLiwFKPJQHxiLJrhFaw3YtVyagsq+OuFr9jr9IN2WG9zVg5vvfQhp5593C6fSyUgM2nnlXI6acgqISAjCl3otvGxdXMuWeu3cu2tF+9yv/xhb2rE0dJEQMqIl30bsWNzuNBQVkN9cRXSJTGHBSDUKpxtdhztDjQ6De22NgIig7F25H+QUtJUWUd7SxsavRanw4larcLlclHX3EJtTR1qnYayskrCwkNJy0hmy6ZsiotKCQsLJmN0Gg31TRR0zuOjkj3qYJXlleRmF6I36MkYnYLR6F+rvK2tncK8IhxOJwmJsZjMO87HIqWkML+EhvoGomIiCRscsQJlbHZgq2+moaQap91JQEyIR42uK3VFldSX1qA16AhOjEBvNlBbUImtrhGdxUhwfDhCqKgrrqKt0YYxyEJgbCgu6SI3K4/mZhtxCdGER4djq2+mvqQKl8NFYHQI5m7Omb05l6LCUiwWEykZyWhVajas30xJcRnhEaFkZKYSHhnGpvVbqKmuIyYukqSUhI77ehEtza3ExkcRFBxIW1sbBXnFuJwu4hJjMHczLmur6ygpLsNsMZOQFOuTF2cQ2O3EYLqjN5bUK8AlUsrfAYQQs3Eb+xMGsmO7C6Xrcvnr+a/d7i/AqIOnMnrBDHR+DPyGshr+evYLmsrrACgMDWD25UexcvUGbrj8bto70orPP3wel111No2bStjw9VLAvW0389wFnnTogWFBbN6UwzknXkl5mdvPMyU9kf0O3IdXnn2HeQfP5tZ7r+lW016lVnut5u8KarWa5I4dh+4IDAroVh5OYdep3FpMYEzPrjZFeSV93qbX76JLTidqgxZ7czu67boRHh7CL/3scw/u5HStVeVIl8uzSquw51FTUMGyV7/zZPQ2BJoZe8RMqrNLaalp8ATXagw65lxxDGEpbhcXa4T/wPMAp5N/PlzH3Tc9jJSSkLBgLr/+PO65+VGcTrev9OnnncDmTTks/cO9Lnb0CQu4+uaLCA4JIjwynPBI//KB26PX60gb1XsVaiEECUmxQPdSuAoDQ3NVPX+/8h3VOW43WL3FyJwrjvHJFl6VXcJvT3yKo83to5609xiixiSy9NXvPBnkRy+YjjnUyoq3fgLc3+v0s+aTMH0UGeO2rX43Vdax5MVvqC1wJwE0BJjY9/JjCI73Hlsrl67m4jOup7XVHe904ulHM3psOv+5+RFPgPY5F5/KwnOPJ3Os9+q6+76e6FWm1+tJ78W4DA4N8rjmKgwsvbm7NXYa9gBSyj8AJSKnFzTXuGXW5HZqBlnfr6ShxL9aQfG/Wz2GPbhl2koKy3j4nmc8hj3A/776haysHI9hDyBdkhVv/URzlTuIS0rJJ+996THsAXK25ON0OrEGWPjl+z/YsGZTf12qwjCjcnMxAdE9r9Ll5xX2S/KqXXHJ6URl0OLoEtAYEGSlpbnFS12hPxBqNWqdHkezMoXtyZRvzPcY9uAWFKjcXERAdIiXao6jtZ01n/yOvZug1U7yc4u477ZFnmDtw44+iEX3P+8x7AHefOlD9po5yfP6sw+/9VJHU9i9qNhS7DHswZ07JuvHlV6BsXZbG6s++s1j2IM7QdXKd3/2GPYAG79dRmt9i+e1lJKV7/zkI35RkVXoMezBLbaRvXi1l6JSfX0D99/xuMewB7BYTPz3P0951Xvl2XfYvDF7Vy9fYYjpjXG/TAjxvBBiPyHEXCHEM8CvQogpQoieBVX3YOwtbX6j3jvVbbqy/UTQSUtrG0UFJT7lNdV1vueztdHe4j5fW1s7/y5f51OnqKCE8Ej3EmlFuRKpvjsipaQqu6R3Sjl5xURG9VHjXqfG3qeVex2OJu/fiRAqwiPC+j1TLYDaaKa9QZHE3JOpK/JdYGksq8XpR+63rqiqR6Wwupp6L9lLg1FPfZ1vbEdbm/dDQvV2EpgKuxeNpb7315rcMpzbGfJ2Wzv1XcaiWqvxksbspKtajqPNTnuXxY+6Qt9xXZVT6jWumxqb2dpFSU+tUftdSKmq3LGspsLwpTfG/SQgA3ciqzuB0cAs4BHg4YHq2O6AMdBCQJT3qqhQCSzh/n3gYif7ZpcLslqZNG2cT3lcQrQn2KsTc1gAxiB3EI7BoGfBkb7BVumjUijMdz8sJKXE9+5CFEYUzVUNIKVfBZDtcblclJWUExbRd6Uc+y7IYHaiNup8tO4BQiNC/D7Y9hWNyaTo3e/hRI7ynfvCUmNQ63w9VeMmp6K3+veB7yQqJsITVAtQWV7d4Q6zDY1G7aM+Ep+ouMvsroSm+irGxU3N8ATFglstJ2aitztLa0Ozj5+8UKlQdVHLMQaZMQV7B89GjPJVm0uYluGV6yQkNJg5+8/0qtNQ1+iTVVan13WbKVlh+NMbtZx5O/hTklntAL3VyPSz57uzyAI6k56Z5x3arbtE5OhEUudOQAiBEILkfcYSnRjF1Tde6JFGM1tM3HjHFYwdl8HeFxy2TaotPJCZ5x6KIWBbOueDDtuPw44+yJ0qXq3m2JMPcwfXqlTccPtljBk/4oMKFfxQlV1MYFxYj2nmy0srMZvNfqVWdwaDTrVLCaw6UenUSClxdVk1DQsLpiC/uE99838+PdLpxNnW+7wNCrsX4RlxpM6Z4I67EG4DPjQ1mrIN+Yw6aApqrdvID0+PJXP+Xqh7CPSPiYvi0efu9hhIy5b8w//dfZXHwA8MCuDuh29i/Wp3sh+zxcR/Hr7Jr+Slwu5BWGoMYw6d4VmEi5mYSso+Y73mZY1Ww9jDZhLW8SCg1moITohgxjnzsUS4DXyd2cDeFxxGaHK05yHTFBrA3ucf5lnM85wzLYbM+dM88URxU9NJmO6t0GQ0GrjyxgsYP2m0+7XJyOjxGdz10I0e+daQ0CDu/u9NjJvo3VZh5NAbtZxI4D4gRkq5QAgxBthbSvnyYHSwKyMxsr6tsQVbXRNak8GjSb89tvom6ourcbTZCYgJBZcLKd0ygfWl1WiNelqFi9LySixmE+mZKeg71GuaaxqxN9toU0FeXiGNDU0kpSSQmpGEEIJWWytFBaWoNSpCQkMoL63AYNQTlxAzFJHqPmRvySMvuwCzxX1doX60e4eQEan6sOyNH9DoNMT52QnanqV//cPin5Zw5HHzd/lcfVXK6aR+UzGBmbHoQrbdrApyC1mxdDU3/+eqPh3bH7bKcnTWAAxhkf1+7EFiRI7NwaSxoo6GkmpUGjWBcWGYuhhC9jY7DSXVgKSt0YbL5cIUbEWt14KUSKcLc2gALqeL+uIq2ppbsUYEExAT0u3cWVleRXVVLcGhQURGhVOQW0hpcQVBwQGMGptOfV0DZSUVmC0mr1XR3OwCcrbmYTQaSB+VQngf8050R3NTC1s25VBZXkVMXBRpmSleeuT9hDI2O2iuaaQ2vxyXw0lQXFi3IhVV2SXUl9agM+gISojAGhFEa2MLrXVNaM0GzCEBNDe1sGntZirKq4hLiCZjbLrf787ldNJUWY90uTCHBaLRaf2cERrrGykpKcdkMhKXEIMQguwteVSUVREcEugTSLuzFOQVkb05D61OS3pmCpFRPQeMDwKKWs52vIZbHeeWjtebgfeBITHuRyJ6qwm91b+LRHN1gzuiPtvtfqDRa5lz5bEIleC3RZ8gpWTsEXuz9tM/POmoG/fKYPKJ+2GwmjCHWKl0tHPP/z3M4h//Atzbac+89hDTZ03GYDSQNirZc77AoB1r4A4mK5et4eLTr/ME9uw9Zy/u/u+Nw2USGLFUbS1m1EFTe6xXkFtEeD8E0/ZFKacTjdHtd7+9cR8eGUZRYSlSQg+bELtwPhPt9XUj2bhX2AE1+eUsfvwTj+9yUFw4sy48zEsdTKvXorcY+OuFr6krdAsPaE165l55LCGJ7nHR2tjCqg8WU7DcnR1WqFTMvuRIoscl+T1veGSYl2GekBxPQvI2FyB/6mBr/93ABQuvpbnJHYs1ccpYHnjiNmL7OcGPraWV1198n+cWveYpu+PB6znmxEOHxULP7kZTZT1/vfg1dR0Brl3HVicl63JZ8vxXOO1un/rwjFimnHIAgdEhGDrsBltLK6+98B7PP/66p91dD93IUScc4vPdqdRqH3dgf1gDrYzqoomfmp5EanrSTl9rVzaszeKC0671ZMsdNSaNR5+7W3FDG0R684sOk1J+ALgApJQOwLnjJgq9pTq31GPYgztIZv2XSyhenYO9tZ34aRls+WWVx7AHKFy+2XMzAti4Nstj2AO0t7Xz4J1P+A3oGi40NjbzyL3PeEXsL/ltORvW+KZYV+g9bU02WuubvTIOd0duTmGfM9P2VSmnE5VBh73Re/XfaDKi1+sGJEW5xmTGYWtGOpWpbHfD6XCQ9cNKr6DEuqJKKjYX+dSt2FzkNZfaW9rI+mElTofD067TsAeQLhcr3/6J1obmfulra2sbzy56zWPYA6z+Zz2r/1nfL8ffnpyteV6GPcCDdzxBQV7/u74pQOWWIo9hD+6xten7FZ6xBWCra2LdZ395DHtwK53V5ntn587ekudl2APcf/uiYfnd2dvtvPrcux7DHiBrw1aW/71q6Dq1B9Ib475ZCBFKR354IcRM3ImsFPqBlhpfSb764ipcHROAIcBMS7Uf1YXGbTcDf8o5udn5XjeM4UZzYzM5W/J8ypXo/L5RnVNKQHT3bgOdSKAov5iI6L7tkhj6qJTTicakw97g69oTGRVOfp6vUdZXhEqFWm/E3jR8H4AVdg1nu8PLYO+kscx3bmks91WrqS2o8KiLtDX6jsmW2kbsth1LY/aWlma3m0xXigp8ldP6Sm2N7227tbXNywhT6D/8ja26wkqcbduM+/aWNr/12rpIA9fVjpzvzmZr9Svxmru1YAh6s+fSG+P+GuALIFUI8SfwBnD5gPZqDyIozte4ip+WgSHQvR1Xm19OeLrvVpZlu2Qqicm+yg/7z9+3z/rlA0loWDAHHbqfT3lPSa8UdkzFluJeJR+rrakD8KQW31X6Gkzbidqow9HcRscagoewyFAKcvvfuAf36n17vSJFuLuhMxlI2MtXLCA83VdJJDzNd25NnJ7pychtiQjy8dKNyIzHENi3300nQcGBHHKkry7FuIn9L3YQFx+N0eidaTwyOpzoGMU1bSAIS/NVmkmYPsojggFgCrESPT7Zp541Isjrdayf7y46NpLo2OH33QUEWllw1IE+5dNmTByC3uy59EYt5x9gLm75ywuBsVLKNQPdsT2FkORoJp24Hxq9tkO1IY20/SYRNzGNhGkZlG3KJ3pCCqGpbv9LndnAzHMXEBS3zZ1i9Ph0/vPwTVgD3P7Ke+87jUuvOXcgAqX6Da1Oy7mXnMbseW5JLovVzB33X6co+PSRqi1FBMb0bNzn5xYRFRPRo6JOT+j7KIPZiUqjRqUROLusiEZFhQ/Yio/GbMbeWE9PogIKI4/EmaNJnJEJwq1AMv7offxKE4amxjD+6H1QazUIIUickUnizNGe94Niw5h57gKPQRaWFsPkE/fzkhbsCyqVihMXHsXBh81DCIHRZOT62y9j/KQx/XL87UlMiefxl+4jKsadITU1PYlHn73bk/dEoX8JTYlhwjGz3cpLAhJnZJI00/t71Rp0ZB48lYjMeM/rSSfMISTFO94iKSWeRS/e61FjSstI5uFn7upzdvGB4sjj5nPEsfNRqVQYDHquvPECJk31lfRWGDh6o5ZzAvCdlLJRCHErMAW4p8Po31G7eNyr/FG4/fVfkFI+3qXOfsDnQGdGhU+klHfv6LjDLbK+pKiMrI3ZOOwO0kYlk5yagJSS+uIqGstq0Oh1BMWH+0hWbU9LXSON5XW4HE4MAUZsdS0gJQ3CQW52AQaDnowxaVg0OjQGHeYQ/0GxJUVl2GytRMdEYDK7V/63bMhmy6ZsNGo1GWPSSEpP9NsWoKa6lqwN2dTW1JOYHEtGZirabiLt+4uWZhtlJeXoDfp+DyDrB0aU6oOj3cHn1z7HrAsP80j5dcdnH3xLVWW15+FqV1CrICPRQkEflXI6adxaijkxAkPkNo3nxoYm3nr5Axa9eF+/B9UCNBcXYI5NQGvpOUZhmDGixmZ/4bQ7qC+uoqmiDr3VRFBceLca9A67g5bqBlRqFebQQITK+yNrqq6nvqgKrVmPy+5ESjCHWgmI9N3xbK5ppL6ugfyiEmprG0hIiiVjdAo63TYj397WTn1RJY1NzRTX1FBSXE54ZBhjxmX4aIh3pdXWSklxOTqdltj4aPJzi9ialYNarSZjdGq/zo1VFdXU1TYQFh5CUIj/nCt9ZI8cm/6QLklzdT0upwtTaAAarYaavHLqS6oQKkFQXDhBceG0NrXQXFGHWq8lKDYch91OfVE1zZV1GALNBMaFozcbqCyvor6u0fPd2eqbqSuqxN7ShjUqhMDYUL8umbnZBWzNykWj1ZAxOpWo6HC2bMohL6cQa4CZUWPSsVhMZG3MpriwjPCIUEaNSUVKSdaGrVRV1hKXEEXG6DQMBr2fK/Wlra2NkqIyNBoNsfHRwyVoW1HL2Y7bpJQfCiFmA/NxJ656FpjRQzsHcK2U8h8hhBVYKYT4QUq5oUu936WUh+90z4cBeTmFXH7O/5GfWwi4V59ffOcxwvUmfnvyM1wdGeXC0mKYee4Cn4QTAM1V9fz1wteelNFqrZrxx8ymuLaGm279L7YWt+GUnpnCohfuIX4Hq7IxcVFer9esWMcl59zk8cuLiYvi8efuYdR4X4mr2uo6Hrjjcb778hcAhBA8+uzdHLBgzs5+LDuFyWwkpR+i8xWgJq8Mc3hgj4Y9uGMy0jJ8t4N3Br1O3S8uOZ2ojTrsjS1exr01wAxCUFNVMyBuZhqThfa62pFo3O+RFK/J4e+XvvF4byVMz2TyiXPRW3wNfI1W061qSENZDb8/+RnxUzMoWrWVpoo6dxu9lv2uPo6QJO+51C5cPPnEa3z96feAe3586Kk7mH/4PMAtP5jz21oKV2dTaHbw2APPe9qecNqRXHLNOYSGBdMdBqOBlDT3wsvGdZs575SraWxoAtwuGc+8/lC/uSyGRYQSNkxXfHc33EkrgzyvK7cU8+dzX3oy15uCrR0a9lEYLO4FOSklhcs3s/yNHzzt0uZOZNzRs7zUmGz1TSx//QfKNuR3nEvFvpcdSdSYJK8+bFibxfmnXuMZT2kZyVx50wVcfcGtODpslCOOm8/4iaO57/ZFnnann3cC4RGhPHrfc56yux66kaNPXNCrHV+9Xk9yaveLiQoDS28epTrDuA8DnpVSfg70uCcppSztXN2XUjYCG4HdSgfp7z9WeAx7cKd1fuulD9j6+1qPYQ9QtbWEmi7R751U55Z5DHsAp91JbUkVH3z2ncewB9iyKYd/lq/tdd+cDicfvfOlV8BNSVEZf/z6t9/6mzdlewx7cE8w/7n1USrKfAPTFIYnlVuKe+WSI3E/mHZuz+8q/eVv34nGqMde33UXQBATG0lu9sC45mjNFtobahXXnBFAS20j/777i1dYRsGyTdQXV+30scrW59Ha2AICj2EPbrWyTf/zVjQB9/zbadiDe36899bHKCtxz+uN5XWs+fRPLJMSeOaxV73afvj2F2ze6Btg6A+Xy8X7b33uMcQAigtL+f0X//O2wsjB5XKR88c6j2EP7jFdstY7oLq5qp5/3//Vq2zr4tUdORm2UVtQ6THswa3k9M97v3iJbTgcDt5+5WOv8TR6XAb//c9THsMe3MIFj9z7jNfx33zpQ9ravN0kH7jzCU+Ge4XhTW+M+2IhxPPAicA3Qgh9L9t5EEIkAZOBpX7e3lsIsVoI8a0QYmw37S8QQqwQQqyorBw+xmZ+TqFP2eZNOdi73BjAv+oCuH/cXWl3OsjL9TVmSgp7r6DQ3t7O5s25PuU53RhJtX6i8WuqamluHr6KO8OB4TQ2K7MKe2Xc11bXIZFYArp3FesNhn7yt+9Ebdbj8PM7iYyOYOvmvH47z/aodDqESo2juannyiOM4TQ2+wO7rd1HRQSgbTtjqbc0lNagMxlobfCd3+pLqj1qOZ3U1fqqKtXV1tPc0R97SyvS5aKltdXHIAKoremdKpPd7mDTui0+5dl+5vKRzO42NnuD0+6gsdyfYlOd12u7rR1Hm92nXtdx3u7nt9Bc2eDVtr3dTlaXB8uIqDCKC8q8ylRqld9x297u3Q9bi43mpv6RgVUYWHpjpJ8I/A84REpZB4QA1/f2BEIIC/AxcJWUsusM9w+QKKWcCDwJfObvGFLKF6SU06SU08LDh0+Co5mzp/mUHXn8fAK324brJCDa//ZwcIJvtLvFbOLgg+f6lE/ciYAUo8nIYUcc4FM+e65/b6qk5HjUarVX2Yx9phAROXw+7+HIcBmbLqeTmvxyAmN71q3P2ZpPTGxUn4NpDfr+dctR6TW4nC5cXW4oMXFRbM3ylQvsLzRmK+11/a+lP9QMl7HZX5iCLYR1CYoVKpWPskhviBqXjK2+ya2G04WkmaM9ajmdJCTHotF4z4+T95rgkZI1hQViCDQToNF7ZZ4F91yckNy7TWu9XsdRJxziUz5n/1m9aj9S2N3GZm/Q6nXE+skaHj3W23XFFGJ1Z6rfDrVWjTXcOz7CGhXs40EeNzUd/XZKTiaTkaOO9x5PK5et5oBD9vUqq66oISHJW03KaDKiVnmP+dT0pD7v+CoMDr1Ry2mRUn4ipdzS8bpUSvl9T+0AhBBa3Ib921LKT/wcu0FK2dTx/28ArRBiYPJuDwCT9xrPdbdegslsRKNRc8pZx3Lw4fNI3XcCcVPTQbjVbaafdbBfIx4gJDmSaQsPRGvSI4QgfloGarWaKckpHH38IajVaixWM7fcczUTpuycgsK8g/fh1DOPQaPVYDQauOzqc5g2078cVdqoZBa9cI8nqdHe+07jpjuvxGzxn1lXYXhRW1CBIdDcKxWP3C35/ZIFuL/dcgQCjdnXNScqJpLiwlLs7b6rWf2B1mKhvb4WKfvvWhT6H61Rz9TT9iciw22EGIMt7HPJET6GUG8IT4thwtGzqc4tZdTBU9EYdAiVIHXOeBJmZPrUT8tI5vGX7vMExk6fNZlb770Ga4eUrCnIwj4XHUH9mgJu+8/VZI5zxzXFJ8by36duZ9wE32N2x/7z9+X08070zNtX3XQhU2dM2OlrVBh+xExIJXXOBFRqFWqdhtELpnvGcyd6i5GZZx9CaIdijjksgNmXHIW1S/xIUFw4M887FH1HFtuYCSmMPWImmi4xVwcduh+nnn0cGo0ao8nIAfPncOEVZzLv4NkAhIQGsfecvXjwydsZP8mtFJWQFMdTr9zP9NlTPA+rE6aM5f7HbyU4JKjfPxeF/qdHtZxdPrB7WfB1oEZKeVU3daKAcimlFEJMBz7CvZLfbaeGW2R9U1U9JQWlOF0uomMjCIp2G8cOuwNbTSNqncZvIO321JfW0FLTgHS60AUYMQSYwAlaq4Hysiq0Ws0u69na2+0U5hahVquJT4nrMWK9qqKapqYWIiJDPYo7ezAjRvVh43fLqS0oJ21uz1rC99/xBJOmjiU5bdeDnXRaQXKMiaLynXeJ2BEtRdVoTHosad4BjW+/+jGnn3c8GZmp/Xo+z3lLCjFGxaILCBqQ4w8AI2Zs9jf21nZa65vRGHQYO1YppUtSV1RJQ2k1GoOO4PgITF1UxRrKaqgrqkQ6XeitJuytbZhDA9FbDUgXICXGYCvqLiv029PT/Nje3Epbo40mRzvV1bUEhwTuktKNw+GgtLgctVpNdGxkn3fZBpk9dmx2pa6wktrCClwOJwExoYSnxVJfVkNLdQNCCMwRgVjDgvy2bbe10Vbfgtasx2Dt/l7cUteEs82OMdiCpht1O7vdQVmJ93hqtbVSXlaJ0WggomOxp7G+kerqOgICrYSEuvtVU1VLQ0MToeEhnofZEcyI+iH1hd6o5ewq+wCnA2uFEKs6ym4GEgCklM8BxwMXCyEcgA04eUeG/XCjoayG3574jJYOf8qNei1zrzqO0OQoNFoN1sju1RE6qS2o4O+Xv/VkqVNp1My68HBiOhJbJCT1LQZZq9OSMqr3qiiKksLIpHxTgd9kZ11xOp0U5BVxqJ/EOTuDoZ+VcjrRmPW01/n6dMbGR5G1YeuAGfcai5W2mqqRZNzvsWgNOp8dqorNhfz2xGdIl3tMBiVEsM+Fh2MOdasg1RZWsPixj2lvaQNAbzWSvv9kVr71E3OvPo7g+N65GvQ0P+rMBnRmA1YgOm7XEwxpNBriE3cr/Yk9jpr8cpa88DXNHRnm1VoNsy46gr9f+tqT4dgQaGLulccSGOPrsKAz6tEZe5adNO1AZrsTrdZ3PBmMBp8EmNZAK9ZA74fikLBgQnag9KQwPBkw4VEp5R9SSiGlnCClnNTx942U8rkOwx4p5VNSyrFSyolSyplSyr8Gqj8DQfnGAo9hD26lhc0//YNzuyj0nqjOLfVKP+1yONnw7VK3koOCQi9wOZ3U5Jb5zXbclcKCUgIDrei7ZDvcWYx6FW0DYNyrzYYOtxzvZ/z4hFg2rN3c7+frRGu2Ym9qwOUnGF5heNPe0sbqj//wGPYAdQUV1ORtUyjLW7LBY9iDW+CgpaYRtU5L7p9d1ZkVFPpOxeZCj2EP7oDazT/9Q2Dstnm6tb6FkjW7V7C0wvBgWGQVGKk0VfoqzDSUVHvJYPaEP7WGlqoGz5O9gkJPVOeWYQy29srfPjsrh5j4qB7r9YRRr8Zu7/9NNrVOg1CBs8V7/McnxpCXXeij3tBfCLUajclCW+3uF1i7u+Noa6e52ncu7lTWkVJSV+Qrl9lS24ghwER9cSXSNWI2jBVGCC01vkp4zVX1HleyThrKfBV0FBT6imLc94GoMb5JRZJnj9up1OTBCb7bwfHTMjCHKUl1FHpH+caCXq3aA2RtzN7l+I3tMQzQyj2Axmykvc77oVen1xEVE0HWht7phe8KWmsAbTWViub9CMMQaCZppq/YQKdylBCC5L193w9NiqK+pJrkWWN9stcqKPSV8DRft6r4aRlUbinyKoudNDCuhgp7Nopx3wdCU2OYcur+6Ex61Fo1mYfsRdwU3+yvOyIsLYapp+2P3mpCpVaRNGsMyfuMHS6pmhVGAGXr8whO6Nm4l8CWrBziE/rmy6tRuw0hp3NgjGC1WU97na/ufFJyPKtXrh+QcwKoDUZwuXZLzfvdGZVKRfq8SaTsOw6hUmEINDPz/EMJTty2cBI1NolxR81Co9eiMejIOHAKDaXVjDl0BlFjk4au8wq7LWFpsUw6YQ46swGVRk3q3AnETk4jdc4E1FoNWqOeSSfuR3h6XM8HU1DYSQYyoHZEIl0uHLYWnK02VBoNaqMZtc7/SrzOqCdtzgRiJqQgXRJ7SxsVmwpQqdUEJUQQ0IuAWr3ZSOTYZAJjwnC5XOjMRgK7SZm+K9QVV1FXWLFTfVIYObS3tNJQWtMrffvK8iqQEBjct10ho15NW/vAyUZqrQaa833dKFJHJfHZ+99y2jnHMxDiIUIItAFBtFaVobXsWOFqT0JKibO1BYfNhlCp0BhNqPV9i9nob0whVpJnjSM4IRKtUUdoYqSXJKAhwMToQ/YicXomQgiESuByujCFWGmqrKdicxEuh4PA2DCC4sK91Glaahupza+gvdmGNTqEoPgIH7lBheGF096Os6UZl8OB2mBAYzQhVN2rIA0ExkAz0eNT0JmNuBwOghIiCI4LJzg2nKRZYxBCdKukZ2topia3jOaqevRWMyFJEVgjlHu3Qu9RZqgutDfU0VywLWGO2mzBmpCCStu9q40pyEJ1Xhm/PvqRJ7Oh3mpk7lXHEdSD0dVYUcfvT33mSYEuVCrmXHE0kZm+Lj87y672SWHkUL6xkMDYsB3K93Wyaf0W4hJj+yyrZzSoaB8Af/tO1CY9ztZ2XHYHqu2MqLDwEIRakJtdQEpa338f/tBaA2guzMXZ1jrsDNihwtHSRGPOZuhwVxJaLdbkDDQG4xD3bBsVWYX8/uRnHpeqwJhQ9rnkSCxh2xL/CCE86jmdNJTWsPiJT7DVundrVBo1c6861uNSYatrYumr/6Ny8zZXipnnLiBhr1EDfUkKu4jL3k5zYS6Opm0+7+b4JPTBg3vfayirYfHj/seWOaT7BRaXw0XuH+tY98UST1nMhBQmn7zfDtspKGyP4vuxHU57Oy0lBd5lzU04bDtWrnG5XGz9ZZVXyvK2Rhula3rOqlmdU+ox7MG9c7Du87+wt/YtoLYvfVIYOZSszfEbt+GP9Ws3k5AY03PFHjDp1bS19z5ofGcRQqC1GGiv7SqJKRg1Jo2//xg4TWyhUqG1BmKrLOu58h6AdDmxlZd6DHsAabd7GU5DTXtLK6s//t0rVqK+pJra/PIdtHJTsbnQY3yBW61s03fLcdrd82ZdUZWXYQ/w7we/0uLHbUxheOBotfmMz5aSQpztbd20GBgqsop8xtbGb5d5xlZ31BVVsPHbZV5lJWty/AaFKyh0h2Lcb4/LhfQjhSedOzZkpFN6yVl20lTlq+DQlTY/kpfNNY1eRvmu0Jc+KYwMpEtSti6P0OSe1W9cUrJpXVaf8yYAGA3qAQum7URjNdJe7WtAjR0/iqV/rsRhH7iHC21gEPa6WlztimKVdElcdt/PwV/ZUOFod2Cr9X3YaGvqOcFaS43vGGuqrPcYYHabr0HY1mTr8/ysMHD4u19Lp9NLKnUwaPEzJpurGno07h1tdpx+5jd7y+A+nCiMbBTjfjtUWh26wK5+bQK1Ycfb82qtmpR9x/uU9yYKPiTJ1zBL3Xe8O0ttH+hLnxRGBjV5ZWiNOoy9SGJSkFeM3mAgMDiwx7o7Qq9T4XRKBvo+qbEaaav2vTkGhwQRFh7CymWrB+zcKrUGTUAALRUlA3aOkYJKo0Ef4uvOoBlGMQnGADPJs8d5FwoIiu/ZDSMyM96nLHXOBHQm95wfEBWCSu19m4ybko4xuOffnMLQoNYb6BqUo7EGot6Ba+1AEDnKz9jad7xnbHWHJTLYZzdWY9AREN1/sXgKuz+Kcb8dQqVyp6APDgUhUOkNWJPTUBt6NrRjxqcw4ZjZaE16DAEmpi08kDA/UlhdCU6KYO8LDsMUGoBGryVz/jSSZ43tj8vZ5T4pjAyKVm0lNKV3qe3XrdpAUorvzWZnGWiXnE40Zj3ONjsuP7r2k/eawNef/cBAKlbqAkOw19fibOt59Xd3Rx8UgiEiGqFSI7RazPHJaE3Dx7gVKkHa3AlkHDAZtU6DOTyAfS46oldZZ0NTophx9nyMwVZ0JgNjD5/ppXgWGBvGvpcfTUB0KGqtmqRZYxh/1CwloHYYozYYsSane4x8XVAo5ph4hHpwA2pDU6KYcc4hGIMsaA0699iamtFjO1OQhcmnzCNqfDIqjZqg+HBmXXAoIYl9lzBW2HMQI03Tedq0aXLFioHzuQW337vLYUeo1Kg0OzeJt9Q1IYTwSVTRE62NLbjsToxBll5rLpcUlLDu342UlVaQlJLA+MmjCQ4PoaG0huq8MlwOJ6HJUejMBveDy072SYGdijwdjLHZiZSSb257lcyDp2HthQLS3Tc/wvS9J5OU2rdA1LgIAw6Hi8aWgTfwm7aWYYwPxRjd9fokb778IceceCjTZk4asPO31dUg7XasyTsnbztIDOrYlFListsRQqDSanf5OAOJy+Wita4ZtVaN3tr7nc+Gshqqc0pxtjsISYokOCHSZw5ua2qltbEZW00jjRV1BMSEEJIYidag9z1efSPrVm8iL6eAmNgoxk0cTVjEHrXqOizmTZfDgXQ5UWm0iCGSlm4or6W5qg7pkhiDrQTFhPX6/t7W0oatrhG92djtvTt3cz7rV2+krrae9MxUxk8di8k8fALdhyF7TEILZfnBD0KlQq3znbR7g6kXLhL+MOzEzQigqqyK+29/gsW/bIuov+zqczjxxMNY/OjHnuyMXdUfFHYP6gorcTldWCKCeqxbW1NPRVkl8f3gb28yqKmoGRx/Y02AkbbKBj/GvWC/A/fhndc/YfT4UZgH6GamCwiiubiA9sZ6dNa+uTONdIQQ3UoCDxdUKhWmkJ1zF2oorebXxz72ZApXqVXMvfJYwjO8tcddLif/vvcLFVnbgmunnLI/aXMneNWz2+28/erHPPvYq56yBUcewC33XE1A4PBxZdoTcC/MDZ2J01Baw6+PfeQZW0KlYu5VxxKR0Ttde71Jj97UvR1SkF3IdZfdyZasbSIZDzx2C4cee3DfOq6wW6C45YxQtmzM8TLsAV545i3ysws9hj24I/Szvl+J00+gsMLIJX/ZJsLT43ola/nPstWkpieh7uO2tFYjUKnA7hic3T5tkIm2qkbc6be8iU+MJWNUKs88+gr2HgLUdhWhUmEIDaelKB/pGvidCoXBp3xTocf4AnA5XWz4drlP0GN9UZWXYQ+w5tM/aO4iUFCQV8yLT77hVfbtFz+RsyW/n3uuMNwpzyrwGlvS5WLjt0v7LRh747rNXoY9wKMPPE9ZkaL0paAY9yMWW7PNp6y9rR2bzddHuKWmEZdzcJUCFAYOl8tFwbIsvwFb/ljy+woyRvc9kNpsVGNrG7xxpNZpUWnVtNf7l6Kdc8DeCODBO5+kpHBgbmgakxmV3kBLaVHPlRVGHLb6rnKrYKtr9FErcbT5xn44Wtt9HgJaba04HL4Pgi0tO5ZTVtj92N6w76SltqnfFtpamn2PX1NTR1sfZbQVdg8U436EkpgajzXA2wVo4uSxxCX46pinzZ2AVj+8t9QVek/FxgJ0Zj3msJ4TmpSXVVJRUdVnX3sAi1FDW9vgrmBrA020lfmXb1WpVBx2zEEkpyXwwJ1PcP/tT/D1Zz+Ss7UAl6v/dhcMoeG019fS3qjIyO5uRI72/V2kzZ2Aros7REBUCGqdt4tHzIQUHzeguIQYRo/zjtEIDgkkMbnvwewKIwt/iy9pcyf2qJbTW1IzktF0SV549LHziY7vWRpZYfdHMe5HKKmjU3jqpfvZa8YkrAEWDjvyQG675xqikmOYed6hmMMCMQSYmHT8HGImKvKXuxNbf1tL5OjEXtX97acljBk3qs8uOQAWk4aWQVy5B9AFm2mtqMefaw6AECqmTp/IhVecwfjJo8nPLeSFJ1/n+kvv5LuvfukXPXyhVmMIj6K5IHdY6bsr9J3Q5GhmXXAYloggDAEmJhw7m9jJvgHUAdEhzL3iWMJSY9Ca9KTsO56Jx+2LpsuiSWBQAPctupXDjj4Ia4CFWXOn88zr/yU2vneqVgq7DyFdx9Yxs72UmPrK2EmjefLF+xg9Np3AoABOO/NYzjj/JHTKQp4CilrOiKexvpGGukZCI0IwGLetCLQ12ZAuF4YARSGnDwwL1Yftaalt4n93v8GMsw9Bo9+xakl7u53rL72Dk884luDQoD6d16hXERdppKRicKUhJZL6NQWETE1BY+194Gx5WSV/Ll5Ga0srl11/LhGRfU8931Zbg7PVRkDqqCFT39iOYTc2RzJtzTZcDlePimL21nbsre0YrEZUO3hgbm9rp662HmuABaNpj1MvUcbmdvR2bO0qddV12JpsRMRGoNYMrtznCGSPUcsZ8juUQt+wBlqJTYzxMuwB9BajYtjvhmz9dRURoxJ6NOwB/vx1KdGxUX027AECzBpaWgc/qFQg0IWYsZX4ZlveEZFR4Rx70qFkjk3n/tsep7Qfgsx0QcEIlYrmojxG2qKIwo7Zkdzg9mgNOkxBlh0a9gA6vY6IqPA90bBX6EJvx9auEhQaRHRitGLYK3ihGPcKCiMEe2s7OX+sI3Zyz25W9nY7X3/2I9NnTemXcweYtdhsQ6MYowu1YiurpTvXnO4RTJk+gdnzZvDwvc9SV9s3n3khBIbwSBy2FmxlxX06loKCgoKCwkChGPcKCiOErYtXExQf3qtcCj9+9xthESHExPU9uMqgU6FSQZt9aBSXNEY9Qq2ivbppl9qPnZDJuImZPPXwK332wXdnsY6hva4GW6UiOaegoKCgMPxQjHsFhRGA3dZG1g8rSdwrs8e61VW1fPP5T8w9YFa/nDvQqqVpiFbtO9GFBdBcWL3L7WfOnoparebj977sc19Uag3G6FhaK8tpraro8/EUFBQUFBT6E8W4V1AYAWz83wpCEiN7lL90uVy8/MzbTJkxoV987QUQbNXQ1DK0SdD0oVbaqhtxtvrqjfcGIVQccsQ8/v59JRvXbelzf1QaLaboWGwVpYqBr6CgoKAwrBgw414IES+E+EUIsVEIsV4IcaWfOkII8YQQYqsQYo0Qon8chIcAl8tFdU4pG75ZStYPK6ktUG74Cv1DU2U92YvXkLT3mB7rfvbht9haWpnZT772gRYN7XaJY5Cy0naHSq1CH2qlOb9yl49hNBk5+LD9ePnpt2nxkwRup/uk1XkMfFtleZ+Pp9B/OB1OqrJLWP/132z+8R/qinZ93Cgo7Cp1RZVs/ukf1n/1N5Vbi3H6SXCmoDAQaHqusss4gGullP8IIazASiHED1LKDdvVWQCkd/zNAJ7t+HfEUZVdwuLHPkZ2JM9R6zTMu/YEQhIjh7hnCiMZKSUr3v6J+KnpGKymHdb987fl/PHrUk47+/h+k2oMC9ZR17Brq+X9jSEqkIYNxVhSIlBpd23qSk5LJDEll3de/ZjzLlvY5z65Dfw4bGXFSKcDY2QMQuwxamvDlqotxSx+4hNPDLbWqGfetccTFBc+tB1T2GOoK6rkl0c+wm5rA2D9138z5/JjiBrTuxwlCgp9YcBW7qWUpVLKfzr+3whsBGK7VDsKeEO6+RsIEkKMuGwfLqeLLT/+6zHsAZztDkrW5AxhrxR2B3L+WIettrHH5Ccrl63hgzc/47iTD8ds2fFDQG8JsmiQEmyDnLiqO9Q6LdogE005fdsVm3vgPmRt2MqKpav7pV8qrRZjdBztdTW0FBcoMplDjKPdzoZvl3mJK9ltbZRvKhy6TinscVRsKvQY9gBI2PjNUhztw2OxRGH3ZlB87oUQScBkYGmXt2KB7WfcInwfABBCXCCEWCGEWFFZOfy2V6WUtDX5bvO3NfZ9619heDOQY7OhtIa1n/5J5sHTUKm7/6ku/esf3njxfY49+TBCw0P65dxqlSAqVE9t/fC6ERljgrEVV+Pc/qa5k+h0Wg49+kDefPEDaqrq+qVfKo0GU0wcDlszTXlbka6h334f7vPmQCGdLtr9zMf2lsFNwKbQPXvC2LS3+mazbmtuxeUcHoslCrs3A27cCyEswMfAVVLKhq5v+2nis+wlpXxBSjlNSjktPHz4bauqNWrS503yKY+bkjb4nVEYVAZqbLY3t/L7M5+TPHvcDoNof/hmMe+9/inHn3oEkdERXu9p1AKTQY3FpMZkUKNR985dRADxkQaabM4hk7/sDrVOiyEyiPr1Rey87v02omOjmDJjIs889gp2e/8ECwuVGmNULBJo2LoJZ/uuP4D0B8N93hwotEY9GQd2iTkREKm4Qwwb9oSxGZEZ72PhjDpoKjqjfmg6pDBoCCHuFEJcN5R9GEife4QQWtyG/dtSyk/8VCkC4rd7HQeUDGSfBorIMQnMOGc+m/63ArVWw5hDZxCaOuI8jBSGAY42O78/8zkhCZFEj/VvkDicTt597RPWr97EyWccTWBwIABGvYogq5YAswYhwO6QuFwSlUqg06hwSUlTi5PGFgdNLQ5cXexjjVoQF2EAAbXDxNe+K4aoIBo2FtOcX4U5cdcNg+l7T6K8pJw3Xnyfcy4+jf5wlRdCYAiLwF5fR8OWjZjjk9AFBPX9wAo7RcyEFPY64yCyfliJzmRgzKEzlPgnhUElJCmKOZcfw4avl9Le0krGgVOImZAy1N1S2EMYMONeuKPKXgY2Sikf7abaF8BlQoj3cAfS1kspSweqTwOJzmQgcfpoYsangEqFVq8d6i4pjEDaW1r54+kv0Br1pOw7zm+dmuo6nl30KiqVilPOOha9QU+gRUNYkA61StDU4qC8ug27H4UbjUZg1KsJC9QSF2Ggtd2Jrc2FyyXRaVVYjBoamh3UNQ5Pwx7cBrQlNZKGjcVozHr0PciDdn8cFYcceSAfvPUZ77/5GSedfnS/Gfi6oGBUej3NRfnYA+oxRcch1Ep6+MFCbzGSPGsscZPTECoVGmU+Vhhk1Bo1UWMSCUuLweV0KSv2uzFCiDOA63BvJ68Bsrd773zgAkAHbAVOl1K2CCFOAO4AnLht3zlCiLHAqx11VcBxUspd0m4eyJX7fYDTgbVCiFUdZTcDCQBSyueAb4BDcV9wC3D2APZnUNAqP2CFXaSuqJI/n/+K4PgIUueM91FdcUnJH7/8zUfvfsnU6ZOYuc8kQgL1hAXpsDsk9Y32HoNfHQ5Jo8NBYzMIAXqdCp1GhVolaG93UdRowzW8PHH8otZrsaRFUbemgMBx8RgiAnfpODqdluNOOYKP3/mSlqYWTj/vBLS6/jEENUYT5tgEWmuqqMtahyk6Dl1QiKKmM4go87HCUKPpp/lEYXjSYZDfAuwjpawSQoQAV2xX5RMp5Ysdde8BzgWeBG4H5kspi4UQQR11LwIel1K+LYTQAbu8IjRgxr2U8g/8+9RvX0cClw5UHxQURgKtDS1s/N9y8pZsIHXOBKJGJ3i973K5WLViHV98/B1SwnkXnkByYhgBZi0tbU4qatpp3wXfeCmhtc1F6zBRw9lZtBYD1vQoGjYU0VbViDU9apckMo1GAyeefhT/++oX7rrpYRaeewKZY/snXkao1RjDI3G02mitLMNWXoIhLBJdUAgqzYB6RSooKCgoDDz7Ax9JKasApJQ1XRZwxnUY9UGABfhfR/mfwGtCiA+ATrf1JcAtQog43A8Fu5xxUbm7KCgMMk67g6aKOqrzyihZk0NFVhGRo+KZtvBA9GYDDqeT6soaCnOLyM8toLKsjOSUGC6++EgiIwJxOCXNNifFFTb2dOEFjdlAwJg4bMU1VP62EUNEIPqIALQBJtRGLT2sL3jQ6XQccezBZG3YysvPvIXFamHG7KmMGp1KTFwUer2ub/00GFFHx+FstdHeUEtLWREaowmN2YrGZEatN6DS6votP4GCgoKCwqAg2LG6w2vA0VLK1UKIs4D9AKSUFwkhZgCHAauEEJOklO8IIZZ2lP1PCHGelPLnXerUSNNkFkJUAvk70SQMqBqg7gwXlGscGKqklIf0tvKOxubDJ9wwOj4k2q8AfVl9ZasDtf706w8Tas2Od+Eaa5uxNSuSfv5QCRWabvzayxpqXQ4//kZSSiGE8JkEBcLHypY42yXOfglG0Ot1qozkJGNP9RJnzf23qbnFhe/477exOUiMhDlK6WP/YJBS+g8Y8kMvx+ZIuO4dofR/6AkDNu3MvNkbOtxyPgX2llJWb+eW0ySlfFgIUQWMAWpxu6IXSynPEkKkSimzO47xL2639AYgV7pvTIuAPCnlol3p14hbuZdS7pQ8hhBihZRy2kD1ZzigXOPwYGfH5q4QOgI+Bxh+31d3GhXDrZ9daWxqBvrez8EYmztiuH/OoPSxvxBCrNiZ+r0ZmyPhuneE0v+hp+Ma+tWwB5BSrhdC3AssFkI4gX+BvO2q3IY7x1M+sBawdpT/VwiRjnvl/ydgNXATsFAIYQfKgLt3tV8jzrhXUFBQUFBQUFBQGA5IKV8HXu/mvWeBZ/2UH+un+v0df31GcfBUUFBQUFBQUFBQ2E3YE4z7F4a6A4OAco17DiPlc1D62b+MlH52x0jov9LH/mEg+jgSrntHKP0fenaHa+g1Iy6gVkFBQUFBQUFBQUHBP3vCyr2CgoKCgoKCgoLCHoFi3CsoKCgoKCgoKCjsJijGvYKCgoKCgoKCgsJugmLcKygoKCgoKCgoKAwzhBCHCCGyhBBbhRA39bqdElCroKCgoKCgoKCgMHwQQqiBzcBBQBGwHDhFSrmhp7ZKEisFBQUFBQUFBQWFPlCzZsWpwH1AAlAA3BwyYdo7fTjkdGCrlDIHQAjxHnAU0KNxP+Lccg455BAJKH/K32D87RTK2FT+BvFvp1DGpvI3iH87hTI2lb9B/BswOgz7F4FEQHT8+2JH+a4SCxRu97qoo6xHhty4F0KMEkKs2u6vQQhxVXf1q6qqBrF3Cgq9RxmbCsMVZWwqDFeUsamwm3AfYOpSZuoo31WEn7JePaQMuVuOlDILmAQe/6Ji4NOh7JOCgoKCgoKCgoJCL0nYyfLeUATEb/c6DijpTcMhX7nvwgFAtpQyf6g7ojA4OBwOykorqK2pG+quKADNTS2UlpRjs7UOdVcUFBQUFEYoUkrKSyuprqod6q4MFgU7Wd4blgPpQohkIYQOOBn4ojcNh5txfzLwbtdCIcQFQogVQogVlZWVQ9AthYGguLCUR+55hqPmnc7Coy/h1x//xN5uH+pu7RS709hcu2ojl5x1I4fPPY3rLrmDzRuzh7pLCn1gdxqbCrsXytjcvakoq+K5x1/nmIPO5KRDz+OrT7+npcU21N0aaG4GWrqUtXSU7xJSSgdwGfA/YCPwgZRyfW/aDhspzI6nkhJgrJSyvLt606ZNkytWrBi8jikMCE6nk8fuf443XvzAUyaE4I1PnmbilLFD2DMv/Pm7dctIHptFhaWcesSF1NXWe8pS0hJ55YPHCQkNHsKeKXTDHjM2FUYcytjcw3nr5Q956O6nvMqef/sR9p49bYh65GGnxubOMgBqObvMkPvcb8cC4J8dGfYKuw9VFTV88t7XXmVSSrZm5Qwn436PoTCvyMuwB8jZmk9xQali3CsoKCgo9IrGhiY+fOdLn/Klf6wcDsb9gNJhyA+JMd+V4eSWcwp+XHIUdk8MJgORUeE+5QGBAUPQGwWzxexTptGoMVm6Bv8rKICzvZ36LRtwORxD3RUFBYVhhE6vIy4hxqc8KiZiCHqz5zIsVu6FECbcGbguHOq+KAwOgYFWrr31Ej5+90vSMlKw2+1kbdzKmPEZQ921PZLU9ESOP/UIPtpuxeWiK88iISnOq15zcwslhWVodRriEmLQaIbFFOJDa2sbxQWlCJUgPiEGrU471F3arXA01eO0teBobkQXqOzsKCjsrpQWl1Ff10hEZBghYf5/63a7ncL8ElxOF3EJ0Zx36Wks/XMl7W3tAERGhTNj1pTB7PYez7C4M0spW4DQoe6HwuASFBxIdVUtP333OgaDnguvPBODQT/U3dojMVvMXH7deRwwf1/KyyqJjY9hzPgMtNptU0RBXhEP3f0Uv/20BK1Oy3mXLuSUM48lKHh47baUFpfz9CMv8+Un36NSqTjx9KM475KFhEcqU0x/4Wh1qyk52xRVJQWF3RGn08lvPy/hjusfoq62nvjEWB54/FbGTx7jVa+qsprXnn+Pt1/5GJfLxYIjD+DKGy/grU+fZfPGrej1OkaPz/BZKFIYWIaFca+w59Hc3MLLz7zNqhXrAPdK6+MPvkBKWiLzDp49xL3bMwkODWKf/Wb4fc/lcvHRO1/y209LALC323n2sVcZOz6DOQfMGsxu9sgv3//BFx//D3DfoN597RPGTxzN4ccePMQ9231w2dtQ6Q242tuGuisKCgoDQO7WAq69+A4cdrfrXWF+MTdefjdvfvYsodut4C9fsspLGOObz39k9Lh0zrzgZDLHpg16vxXcDCefe4U9AHu7neVLVvHvsjX89dtyn/cL8oqGoFcKPdFQ38j3X//qU7763w1er7M35/LS02/xf1few4/fLvYJ0h1onE4n3375k0/5rz/+Oaj92N1x2e2o9QZc9pElXaugoNA7igtLPYZ9J0WFpWzdnMtzj7/OzVffy9I/V/LHr0t92n7z+U+0dbjkKAwNinGvMKisXLaac0++krWrN5GWkeTzfli44joxHDGZjIybmOlTnpy6LfleYX4xFy68jiceepGvP/uBay66nc8//G4wu4larWbKXhN8ysdPGuOntsKuIh0OVDqdElCroLCb4s+/3hpgYdlf//DMo6/w1Sffc81Ft5OU4puAdcr0CeiUOKd+QQjxihCiQgixbmfaKca9wqDhcDg823cvP/0W515yGiaz0fP+rDl7MdaPAakw9Oj0Os655DSCggM9ZVOmT2TK9G2GdNaGbCrKq7zaPbvoVUqLB1fd9ojj5hMTF+V5nZqexNwDh5fr0EhHOh2otDqkU1m5V1DYHUnNSOKiq87yvFapVFx36yV8+v42CevGhiacDgfpmamessiocI49+TCEGFBJ+T2J14BDdraR4nOvMGhIl6S93b1V195u55F7n+XOB2+gpbmFoOBARo1JIzY+eoh7qdAdY8Zl8Pbnz5G7NR+9QUfaqGRCw0I877tcTp82TocTl8s1mN0kLSOZVz94guwteaiEIHVUsl/ZVYVdQ0qJdDo7jHvf71xBQWHkYzIZOeuCk5g9dzpVVTXExkVTmF9MVUWNV723X/2YNz55mtLicpxOJ6npSV6LK3sSH1y0yCeJ1YnPXdUn3Xsp5W9CiKSdbacY9wqDhlanZeG5J7Lsr3+BbQE6r3zwOFOnT/Sq63Q6aWm2YbaYUKmUDabhQnxiDPGJvhrGABmjU7EGWGhsaPKUnXnBSUTHRg5W9zxEx0YSFByIUIHBYBj08+/OSJcTVCqEWo10OpFSKqt0Cgq7ISaziTETRmGztWGxmFCpVRhNRmwtNk+d8y5dSHJqgpeL5p5Ih2H/ItCZHCYRePGDixbRVwN/V1CMe4VBZfrek3nylft559WPMRgNLDzneCZ08YfO3pLH+29+xt+/r2Df/ffm+FOP2OMnjpFAUkoCL737GB+/+yWbNmRzzIkLmLP/rEF/OGtuauHP35bx6rPvotWqOfeShUzfZwpGo2Lk9wfS6USo1G6DXqVCupwItXIrUVDY3cjamM07r37EvyvWcdChcznq+AW8/N5jfPDWF+RlF3D8qUcwe55/hbU9kPvYZth3YuooV4x7hd0bk9nI3ANmsc/c6ahUKh/Dr6qimmsvuoOcrXkA5OUU8s/yNTz7+kNe/t4Kw5PR4zK45Z5rcDqcaLRDM70s++sfrrv4Ds/ry8/9P154+1Fmzp46JP3Z3XAb9+7frVC5V+9RjHsFhd2KkuIyLjnjeiorqgF48ck3ydqwlYeevJ27HrphSOf4YUp3K5BDsjKpfDMK/UpDfSNZG7OprqwhLiGa9MxU9HqdT73uMpvm5RZ5DPtO1q/eRH5ukWLcD0NKi8vYsikXu91OakYySSnxCCGGbNJ3Op2898anPuXffP6DYtz3E97GvUrxu1dQGGG4XC62ZOWQn12INcBCxphUr/gpgNwt+R7DvpPfflpCUUEpGaNTFcPelwLcrjj+ygcd5dtR6Deampp5btFrvPXKR56y/zx8E0cef0ivfXK13UwYiqzW8CMvp5DLz/k/8nMLAQgItPLiO48yelzGkPVJpVIRGOSbMddfmcKuIV2Kca+gMJJZ9tc/XHLWjR4d+9nzZnDXQzcSHrFNilrr556rVqvRaNSD1s8Rxs14+9wDtHSU7zJCiHeB/YAwIUQRcIeU8uWe2imRigr9RvbmPC/DHuD+Ox6nqKCk18dITkvkgPn7epUdcdx8EpPj+6WPCv3Hn4uXegx7cO/avPv6pziH0NgTQnDymcegVm+7Aen0Og4+bN6Q9Wl3QzrdAbXQYdz7UUlSUFAYntTVNnD/HU94Jaj645elbFy32ateakYyk7vkDDn9vBOIT4odlH6ONDqCZs8H8gHZ8e/5/aCWc4qUMlpKqZVSxvXGsAdl5V6hH/GXjbSl2ealntITAQEWbrzzCg48dC7r12xi/KQxTJ0+0UsPX2F4kL05z6ds47rN2NsdqI1Dt7ozccpYXv/oSf5cvAy1RsOsuXsxdvyoIevP7oZ0uRCiY11IWblXUBhRtDS3UJDrmwm+tqbO63VoWDD3PXYzy/9exeaNW5my10QmTxuPVqvsondHhyE/6MGz/lCMe4V+IyEpFr1BT1trm6csbVQK0TE7J4UYFRPBYUcfxGFHH9TfXVToR2bvN4OP3vnSq+zI4+ZjMOqHqEdu1Go1E6aMZcKUsUPaj92VTilMACFUyEHOY6CgoLDrhIaHcOCCOfzvq1+8yv1lmo2Nj1Zyz4xQFONeoc/U1tSxbvUmtmblcvt917Ju9UY+eOsLrrjxfAIDA/jyk+8ZO2EUYydmYjBsM/za29pZtyaLdas3EhwcyMSpY0lIihvCK1HYEQ6Hgw1rNrN29UbMZiOZ4zK45paLeeaRV3A4HBx/2pHM2Gcq33z+I5UV1YwZl8G4iaMxmvpXgrK2po51qzaydXMeiclxjJ88xstXVGFgkU7nthgaxS1HQWFEodfruPSac2hutvHHL38TFBzITXddQWxcFH/88jdbsnKJT4xlwuQxRESF7dI5nE4nG9duZs2qjRgMeiZOHUtqepJPPWUuHzgU416hT7S3tfPa8+/z6nPbdqLmHz6Ptz9/jv+76j/kbt0WKP7fp+9k/uHbfJ//XLyMK8+/xfM6LiGG5996mPhExadvOLJi6WouPv16j099SFgwL7+3iAMXzMHpcKHRqLnqglvJ2rDV0+aeR2/myOPm91sf2traeeXZd3n9hfc8ZYcdfSA3/+dqrAGWfjuPQvdIl2tbQK0QiluOgsIIIyk1gUeeuZOy0kqMRgOh4cG88MQbPP/EG546BxwyhzsfvIHAIOtOH/+f5Wu48LRrcTjcc0NwSCAvv/c4aaOSPXWUuXxgUQJqd3NsLTY2b8ome3Me7W3t/X78/LwiPnrnC046/WjOv/x0Fp5zPEv//IecLXlehj3Aw/c8TXVVLQB1NfU8et+zXu8XFZSwYU1Wv/dRoe/YWlp5btFrXsGyNVW1rFi6irj4GBKT49iSletl2AM8cs/TVJRVepXV1dSzcd1mCvKKkVLS0mwja2M22VvysLfbd9iP/NxC3nzpA6+yrz/7kZyt+X28QoXeogTUKiiMfNrb7bTaWmlra6cgt4iXnn7b6/2fvvuNnC15O33c1tY2XnryLY9hD1BbU8/Sv1Z61VPm8oFlWKzcCyGCgJeAcbijjM+RUi4Z0k7tBhQXlvLofc/ywzeLUalUnHj60Zx/2cJ+3fZqb7Nz8VVn8drz71FRXkVQcCDnXHwKNlurT926mnra290PGO3tdmqq63zqNG+X1lph+GC326nqonkM7u+0E1uz73fXUN9E+3YGe9aGrdx81b1sycrBaDRw7a2XkJddwFuvfIRarebUs4/jnItPJTQs2G8/Wm1tuPz4eLf6GW8KA4TLiejMU6EE1CoojDi2ZOVw69X3sXH9FvR6Hfc+dotflTObbefvxw67g4ryKp/ymo6FvU6UuXxgGS4r948D30kpM4GJwMYh7s9uwXdf/cwP3ywG3Ekr3nv9E5Yv+bdfz2G2mnjpmbc9P+a62nqefuQVEpPjfZJcnHTG0UREun34wiJCOOXMY7zeV6vVZGSm9mv/FPqHgEArp559nE/5tJmTPf9PyUhE1yVh2TEnHUpUdATgzoNw3+2Pk5dbyOhxGVisZu655VGCQ4MAt5/mmy99wMqlq7vtR3xiDKPGeI+RiMgwRSp1EJEuF6jcPvdCqEAJqFVQGDHYWmwseuB5Nq7fArjdY378djHjJ432qhcSFuw3yLYnLFYzp551HEII0jNTPG62M2dP86oXGGQlLSPZqywiMoxgJVmlF0KIeCHEL0KIjUKI9UKIK3vTbshX7oUQAcAc4CwAKWU70P/+I3sYra1tfP/Vrz7lf/22nEOPOrDH9hvWZvHtFz9TUVbJYcccxJTpE7BYzJ73a6vrWPbXP9TU1Ps8kbe1tQOS5954mCf++yIlRaUcd/LhHHvy4R79cZVKxfGnHoFGo+HDt78gMjqcK244n9Hj0vt03QoDx8GH7YfD7uTNlz8gINDKFdefz/iJmZ73MzJTeeKl+3hu0asUFpRyyBHzOP7UIz0PeTVVtYSFB3PeJaexdvVGxk3MJDI6HPt2esvgTrBy8GH7+e1DcEgQ9z9+G68+9y5//rqUyXtN4MIrziQqJmLArlvBG+lyekthKm45CgojhpqaOv74ZalX2fdf/8rTrz7A99/8yuIf/2LClLFcfOVZxMRF+bTP2rCV77/+lfzcQhYceQB77T2ZgEBvv/w5B+zNfeZb+PG7xVgsZm666wrGdXl4qK2p57BjDmLNvxtYvXIdmWPTmTV3OjW1df1+zSMcB3CtlPIfIYQVWCmE+EFKuWFHjYbcuAdSgErgVSHERGAlcKWUsrmzghDiAuACgISEnX+S3BPR63VMmzHRJzHFuO2Mse7I2rCVs0+8EluHi8y3X/zEA0/c5nkokFLy8Xtf8cRDL3LuJadhNBq83HBUKhUBgVYyx6bz/JsP09raRkhokE+W2qiYSC666ixOWHgkBoMe83YPDyOFPWlshoWHcsb5J3L4sQeh1Wp9gp4K80u47foHyByTxn4HJPPbT38THhFGSloiQggCAqxERoXz7KLXth0zIoSb7vReiOgpw21aRjJ3PnA99XUNWAMt6PVDK705XBmoseleud8uoFZZuVfYSfakeXO4YbVYyByT5lm5B/fOPkJw673XcPl152EJsHgp23WSszWfc0++iob6RsD9UHDrPddw4ulHedXbsG4z/3fVPZ7X3375M69/9CRjJ2yzP4KCA3n+8ddJzUhm3sH7krs1n0fvfZb3v36xvy950JiQOPdU4D4gASgAbl6Tv7ivSaxKgdKO/zcKITYCscCwN+41wBTgcinlUiHE48BNwG2dFaSULwAvAEybNk0OSS9HGEIIjjnpMH787jdKi8sBGDNhFLPmTEdKSX5uESVFpQSHBJOcloDBoKfV1kpudgEr/l7tMew7efaxV9lnvxkEBlopLS7nxSffBODrz37g8hvOo6GuEafLhVajISIqnOS0RADMFhNmi4kdERoWMgCfwOAwksdmc1MLOVvzaWpsJiEpjth431Uaf4SE+veH37xxK/sdMItpMybR0tLC9H2m8PwTb3DIkQcQExtJc7ONj9/9yqtNVUUNldv5Z46fNJoZ+0zpsQ9anZYwRTJthwzU2HQnsepwy1GpkE7FuFfYOUbyvDncqautJ3drAXaHg6SUeI8rbCcBQVZuuusKLj7zBlo64qSOOHY+o8elo9XueF7dtH6Lx7Dv5JnHXmHW3L2oKKvC6XSSkBzLS0+/5VWnva2dv/9Y6WXcJyTFctv913Hbtfezfs0mhBBcf/tlJKeOzIe9DsP+RaDT4EkEXpyQOJe+GvidCCGSgMnA0h6qDgvjvggoklJ2dvYj3Ma9Qh9JG5XM6x89RfaWPDQaNSnpSYRHhPLXb8u5+oJbsdlaEUJw5Y0XcPQJC3jn9U94/fn3OPUsX99qp9OFlO45WErpCYRxOpw4nS5efvYd7O121Go1/3f3lai6rNIrDC9qa+p5+pGX+eCtzwH3KsrTrz3o43e5MwQGBwBw4xV3A2ANsHD3f28E2Xnvln4DqELCgnn2jf+i0WhIzUgiLHzkPuztEWwnhYlKhZSKca+gMBwoLS7jzpv+y5LfVgCQkBTHohfv8fFt1+n1nHXhyTgcTjQaDRarCZWq5xBMf/P3MScdyu3XPcCKjlipExcehdPh8Km3vXoOuHf4Dzl8HhmjUygrriA8MpSU9CSfuK0RxH1sM+w7MXWU99m4F0JYgI+Bq6SUDT3VH/KAWillGVAohOjMD38APWw3KPSeqJgI9pk7nRn7TCU8IpTyskpuu/Z+jxuNlJJFDzzP+rVZvPDEGxx+3MFMnTmRhCRvrfnzLzsdbYfvdHRsJGddeDIAhx97MM8tes0jYeh0Orn/9sfJzfaWwVQYXmxYm+Ux7MG92vPwPc/Q3NSyy8esr2vkw7e/8LxubGjiqYdfRnQEX0bHRnLmBSd5tQkKDmTshFFkjklj1JhUxbAfAUjp3sKHTrccxedeQWE4sOyvfz2GPUBBXhEfv/uVl1He2NDEfbcv4plHX+WFJ97gmUdf4aG7nmLTdm463ZE5Jh1rgIXpsyZzyBH7E5cYQ0Cg1WPYA3zx0Xccc9JhXu00GjV7z5nW9XBodVrSMpKZNG0c6Zmpfl2BRhDdbTn0eStCCKHFbdi/LaX8pDdthsPKPcDlwNtCCB2QA5w9xP3ZbamrbaDSj6RhY30ji164h4/f/YoH73ySgw6bS0xsFD98s5jDjj6Qtas38s5rH3PepQuZvd8MTjrjaGLjo2loaPIxCJ1OJ5UV1WSMVpRvhitdtecB1q7aQEN9Y49uVN3hTyoze0sedTX1RMdEolKpOPTog7AGWPj1hz9JSI7jmJMO5a/Fy/ngrc8xGPWcecHJzJo7Hat15MVf7Cm43XI61oUUtRwFhWHDej95Ypb+sRKbrRWz2T2vNzQ0sm6VryBhWUlFj8dPzUjioafu4NXn3mXjus0cc8IC9F1W2ltb27C12Ljnkf/jy0+/x2o1c/SJhzHKjxJebnYBH7z5GYt/WsJee09i4bknkD4qpbeXO9wowO2K4698lxFuH8iXgY1Sykd7227IV+4BpJSrpJTTpJQTpJRHSylre26lsCuEhQUTFx/tVSaEICI6nFuuuY/ff/mbwvxiXnnmHf5dvobrb7+U/9zyKB++9QVZG7Zy/aV3suLvfwkLD+XoEw/lgPn7EtRFukqr0yrqJcOcmLhon7KZs6cSFLLrMmSxfo45bmImYRFun0+73cF7r3/Ks4teQ6hUbN2Uw4a1W7jv9kVs3ZzLutWbuP7SO/lnB1KYCsMAl9wmhalSKQG1CgrDhCl7jfcpm3fwbEwmo+d1cHAgM/aZ6lMvLiGmx+Nv2rCVK867mWV//UN+bhFPPvwyFWVVXm0tVjNqjZo7b3yIttY2CvNLuPycm3wePOrrGrj1mvt4+9WPKSoo4dP3v+HKc2+m3M/C0wjhZqDr1ndLR3lf2Ac4HdhfCLGq4+/QnhoNl5V7hT5SWVFN1oYtNDY0k5yaQMboVFQqFetWb2LLxmy0ei0xcVHkZhdwybXn0N7u4M4bHsRg0HPzPVdTmFfsswL/7Rc/s+CoA32yhn7w9pfMPXAfAGLjo3noqdu5/tK7qK9rwGQ2cvd/byIpRdEdH86MGZ/BZdeey3OPv4bD4SQpNYErb7iA9as3UVFWRUx8FKNGp2E0Gbzarf5nPVuzctDr9WSOS8doNLB5YzYOh4OU9CQuufpsXnjqTRx2BzFxUdxwx+UU5BWy7K+VhIQGkb05l5ZmGyv+XsX5l5/BFx9959O3P39bhk6vo6G+kbSMZFIzkgbpU1HoCbd/vQQ6YmqEACmRUvqoYSkoKPQfDfWNZG3YSmV5NbEJ7vnZYPSen6fOmMgxJx/Gp+997X49fSJHHn+I12/TZDZxzc0Xcd0ld1KQV4RGo+biq84msxcy1Fs2ZnP4MQcRHRuFw+FAq9Xw/de/cOOdl7NhTRZSSlLTk3njpQ9wOJysWrHO0zY3uwCn00VuTj6BgQEEhwSytssOQlFhKfm5RURGhffloxoS1uQvfmdC4lzof7WcP/BMuL1HMe53A8rLKrn1mvtY+uc/gNu/7enXHkKr03DlebfQ2NAEuP3vjz5hAc89/jrjJmby1mfPEBBoJSEpjv999YvPcQ1GvcfPfnu6Zg+dOXsa7339IpXlVYSEBhOfGKPc6Ic51gALZ198CvvP35eWZhuRMeG88+onvPrctnnopjuv4KQzjvbkJvj7jxVced4tnniNpNQELr3mbK6/9C7PMd/45ClmzdmLhoZGEhJj+e6rX3nq4Zc8xzztnONpaGgia8NWGhsasQb4ut+oVCpuuuJuamvqMZqMvPTOo4yfPGYgPw6F3uKSIFTb1HKE6DDwXSDUQ9w5BYXdk5bmFl588k1ef/F9T9nN/7mKExce5RUIGx4Zxk13XMGpZx6Lw+EgPjHWR4Me3Hlqpu89iUOO3B+AosISbM02r1w2/ggLD2FrVi6fvv8NABqthkefvZv7b19ESZFblc8aYOHaWy5m7aptoZPhkWEYjHouOO0aTybcm/9zlTtmR3qLJel02p35aIYVHYZ8vyjj9JV+c8sRQkwTQlwthPivEOJuIcSJQgglOm4Q2LRui8ewB3dU+juvfcyn73/jMezBLTmZlJrA6eedQEFeMbnZBQQFBaJSqQiPCCUl3dtd7MSFRxMcGuQVva7Rajj2ZO9gGYDYuCgmTR1HQlKsYtiPELRaLWmjkpkwZQyV5dVehj3Ao/c/R0FeEeDOLvvKc+965TPIyy6grKQCS4d/fGNDEx+/+xVBIUGER4bR2NjCM4++4nXM917/lHkHuXd9Pnr7S044zfvmZDIbCQsPobamHnBnU3z52bc7EqMpDDXS5fIESHeiuOYoKAwsOVvyvQx7gEfueYaC3CKfukaTgVFj0hg7IdO/YV9Tx323L8IlJRmZKURGRfDXb8t9cuL4o7Gx2Wu13WIx88+y1R7DHtz3gVUr1nkp9Fx6zTk8/uALHsMe4NvPf+KYk7y9S+YdPJuUESqFOdzo88q9EOIs4AogF3cCqizAAMwGbhRCrANuk1Iq8ikDRF1tvU+ZdLnI3pzneX32RadQVFDCLVffR3BoIGddcDIOu4NzTr6Cm+68kprqOubsvzf7H7wv1VU1xCXEsHLpagICLdz54PWUlVQgVIIZs6Z4adUq7B501S4GtzZxY7374bCxsYnCPN8bSXlZJZHR4TQ1NrPX3pMZMy6D80+9mrKSCm6843If6TSn08mosemcf9lCYuNjGDMug2dee5BlS/7FYDSQmBzHPbd4xwxtzcqltbXVJ3BLYfCRLpc7iHZ7hGLcKygMJHV1vsqHbW3tNDY2+6m9Y2wtrVx+/fl8++VP3HDZ3YRHhHLJtecge7Em19zkfb6QsCCKCkt96m3JyuX+Rbfw609/YTabSBuVTHmpty/9vyvWcvp5JzB7v5msX7ORjMw0pkwfT0BQwE5fk4Iv/eGWYwb2kVLa/L0phJgEpNPHiGGF7kny86QbmxDDjH2msmFtFumZKZSXVfLDN4sBd+KgJ/77IoteuIetWXlcctaNvPD2I/zflfeg0agJCLRSVVnDpKnj+HfFWn7/+W+u+r8LOfvCU5RV+d2UuIQYLFYzTdvdLGLiojzpx6OjIznw0P14/fn3vNpljknnrZc/AuCk04/mhsvu8hj0AUFWQkKDqKmu89QPCQsmKTmOA+bvu+3ciTHMmjsdgD8XL6OxoQm9XodWp6WpsZkjj19AYKAy4Q8HpNxO474DoRKKYo6CwgASnxiLyWz0JJ3qLOucn3cGS4CZ77/5lZ++/Q1wL9DcecNDPP3agz227fSF1+q0GAx6CnKLOOG0o/ix41idHHXCIYwam86osW4//ob6RmbNnc6fv27LvSSEwBpgYcY+UzlwwZydvg6FHdNntxwp5dPdGfYd76+SUv7U1/ModM/osen89+k7CQkLxmI1c+eDN5CQFEe73cG9j93MQYfux+If//Jpl70lH5VKRXtbOy3NLTz+4r0EBQdSWVHNlOkTmHvgLNav3sQV159PQ10jb738IRvWZvn4yCmMfBKSYnnylQc8D4pjJ2by6HN3e2UrPPLY+Rx+zMGo1WqsARau/r+LsARYMJmNaLQaqiurvVbqi4vKuO62Sz3bs+mZKVx36yU01DfRHROnjOHxl+5j4XkncPQJC7j30Zs54tiDBuiqFXYa1zaNew/Kyr2CwoCSmBzHU6884BGqGD9pNA8/c6dP/FtvKC+t5OfvvI1xKSWF+cU9tm1psfHwM3dyzkWncPixB3PTXVcSHhnKFTecj9FkRKvTcuYFJ7P/Qfuy5t8NvP7C+3zw1udUlFdx+XXnMatD6z4sIoR7Hv0/JkxSYqkGin4LqBVCJOPWq0/a/rhSyiP76xwK/tHpdcw/fB6Tp42jtKSCS868weNrr1areerVB4iNj2bzxmyvdk6n02OMGQwGps2cxLtfvUDWhq289fKHPP7gC1xz80U8/cgrtLa2ec71yvuPM0EJcNztmDp9Aq9/9CT1dY2EhgZh7eKvmZ6Zwu33X8vp552ITqchNSMZKSWffP8aLqeLNau8c8+Fh4Ww+Ke/SM9MYd782RTll/Dbz39z/mULu+1DWUkld1z/oMfVTKVS8dxbDxMdu/MrVAr9j5fGfQdCMe4VFAacaTMn8fpHT9HQ0EhIiO/83FtMZiOR0REUd3GnsQZYemwbEGDlzpseoriwzFN2zc0Xc+LCIzn0qANxOV1ExUbwz7K1XLjwWo+PfWBQAK+8/zgPPnkHxYWlmMwmRVFvgOlPtZzPcAvtfwkoM/0QEBEVztef/egVROt0OnnnlY+4/b5rOeuEyz0poDNGp1JT7U4nsOCoA0jLdCeOCAsPwZYcR3lZJXEJMWzemOMx7MHth/3J+18rxv1uSnBIEMEhQZ7XVRXVlJVWYA2wkJAUh8FoYPR2kmlCCM/WsMPpZMr0CfyzbA3gXuX535e+KkynnnkM69dswmwxk5AU6xVQu3zJv14xJC6XixeeeINJU8b6yL4pDD7S38q9SijGvYLCIBAcGkRwaFCfjhEbF81VN13IjZff7VncmzB5DGPGj6K8tJLKiiqCggP96t5XVdV4GfYA777+CUcef4jnPtDa2sYLT73hFTxbX9fA0j9XsvDcEwhUfOoHhf407lullE/04/EUdoFOg317KitrMJoMXHvLJdTVNmC2GEkblUJlRTXPvflfMsekE7TdDy4+IYanXn2A4oJS3nnNN9Oxv+ymCrsf61Zv4rpL7qCkqAyjycjNd1/JgiMP8FJP2p6klHjufOB6NqzbTEN9IxFRYX7rrVy2hscffAG9Xsd1t1/GUcfN9xju/gLHqqtqsdsdGIw+bykMNtKPWo5QuaUwFRQURgT7HTSL5996mLycAixWC2PGZVBTXcf5p1xNZUU11gALdz10A/MOnu2RQgZw2J0+x6qva8De3r5dHQc1lb52yPaxVwoDT38a948LIe4Avgc8S71Syn+6b6LQ3+w7b29ef8FbMuuUM4/hhSff9NKyN5mNPPnKA+w1c5Lf48TERhETG4XN1spPXfzzjjvliH7vt8Lwoq62ntuve4CSIvcqja3Fxm3XPUB6Zgpjxo/qtl1SaoLHb7+qoprE5Djyt5NrS0yOoyi/BHCrPdx7y6Nkjkll4pRxAEyfNYXnFr3mFdex8Ozje7VlrDDw+FPLEUIgXb43fQUFheGJXq9nxj5TPZlqy0srOfeUq6iqqAHccpY3XH43H37zslcSwfTMZDRaDQ67w1N26lnHER65bSHHbDFx+LEHs+iB573OOXZC9/cNhf6nP4378XSkyGWbW47seK0wSEzoCEh85tFXaGm2cfZFpzB2YiYP3Pmkp87RJx5KaFgwLz31JiuXrubgQ/cjJT2RrVm5fPfVz6xfk8WCI/Zn1py9mDp9Ig8+dTsvPP4GTpeLCy4/gxmzJg/hFSoMBlUVNWzdnOtTXlxQukPj/t/la/jfV7+Ql1PI/vP35cEnb+ftVz9m6R8rmbHPFFLSk3j6kZe92hQVlHqM+/ETM3nqlft5+tFXqa9r4MzzT2L/Q/b1dyqFIcDtc9/VLUfxuVdQGMlUlFd5DPtOXE4X1VU1/Pz976xctoYD5u/L7P1m8PxbD/P0I69SUlTKCacdyZHHHeLlWtnY0ITL5eTKmy7g43e+wmI1s/Dc46korxrsy9qj6U/j/hggRUqpZJsZQgwGPfMO2oe9Zk7C6XQSGBRAbXUtGaNTWL1yPWMnZNLe1s7Lz7wNwJLfV/Dlx/9j0Qv3cPEZ13t+gH/+upRzL13IZdeew4IjDmD23BlIKf0mxVDY/QgMCiAyKpzyLi5YYZGh3bSA9WuzuPrC2zzbr3/9tpxzLzmNO+6/jqYOfeSzjt8W99FJeMS2VR+dXse+++/NlOkTsDscBAUF9tMVKfQL0p9ajuJzr6AwkgkOCfSRQj7htCO597ZF5G7NB+Cvxcs46oQF3HLP1Tzz+oO02dr8+v8bTUasAVaefuQV9tlvOraWVu6//XHuX3TrYF2OAv1r3K8GgoCKfjymQger/1lPQV4x4ZEhWCxm6mrqCQ0PIcwagKOxFVOolYDIEI8/bGfW0PKySnK3FnD2hafw5+JlBIUE8vLTb3sduzC/mC1ZOT5P1m+8+D7HnngoJrOR7K35SJckJS3BawtOYfckPDKUexfdzPIlq3C5XOh0WoJDgzCbTfzvq18wGPRkjE4lOjbS02bzhmxSM5I5ee/JOBwOXE4XX33yPQceMoeamjoio8K5++EbuXDh9dha3Oq5p551LKPGpPqc39xDGnSFocFfQK0Qis69gsJQ0NTUTM7mPBobm4lPjCUhKZbWxhYaSmtwOV0ERAVjCva/IFeYV0xBfjFWq5mU9CTuX3QrG9dtxu5woNVqiU+I4f03P/Nq88VH33Hm+SeSNioFk8l/EJTdbufzD7+lrraerz/9wVOetXEraaOSycspJDAogJS0RMwWU799Fgre9KdxHwlsEkIsx9vnXpHC7COLf/qLm674D2aziZPPOIZnFr2Kw+5ApVJxxZVnEVkHtqoGZp1/KDETtxlK2ZtzueqC28jPLQRg4tRxXHbtOT7GPYB0+deub2xs5rpL7/Skpk7PTOGRZ+8iKUVJEb2709TQzOvPv+dRSzr7olNY8ttyfvrud8DtH3/TXVd4dOwDgiyER4byzKOvAG7fy8uvP4/CghJuuOwu1Go1N//nKi655mwa6hvRarVYLCYlMdpIQkrf70tZuVdQGHTqaut56uGX+eCtzwG3lOWTL91Hw5KtVGxy3/PNoQHMvvRIAmO8F+RWr1zPJWdtk8w+/tQjmXvgTF546k0cdgdCCO568Aa/5+0xzY2UfnPhOB1Ozj/1Go8E56lnH8fFV55FYLCinjMQ9DmJ1Xbcgds15z7gke3+FPpATnY+j9zzDM1NLRx+7MG89MxbnmAWl8vFE4+/RtD0VIwhVpa98QPN1W61ESkln334LTXVtcw/fB4HHLIvWeu3UF1VyyFHeodBxMRFkZAUS3iEt8vF6eeewKYNWzyGPcCWTTn876tfB/aiFXYJp9NJbXUdbW2994yrq2ugtKjcpzx3Sz733/G4lwzqq8+9y+hxGZ7Xy/76h1XL13leq1VqvvnsR8/r5qYWPnjzc3KzCzz9e/CuJ2lsaOLFJ9/kmUdf4aG7n2LT+q07dZ0KQ4fL5fQNqFV87hUUBp2N6zZ7DHtw+7o/eNeTSN02dZvm6gayF6/F5XLR3tKK3dZGY30j99/5uJdk9kfvfMGWTbkkJsVx5HHzGT9pNOvXZZGUEud1zgPm74vZvGPZMq1Ox9EnLvAq02jdeVEqK6o9Ze+8+jGbNipz/0DRnyv3BUCplLIVQAhhxL2a3yNCiDygEXACDinltH7s14ikpqqW77/+lfDIUPJy3E/hao3aK/00uA38dVuzqWitZO5ek2hrsmEODaCtrZ3WljZOO/s4vvvqF3Q6LRdddRZbN+cSFR3BORefyrrVG0lMjic8MozqqhqeeOFevvviJ7Kycjjw4H2ZPW8m99/lq2669M+VXHjFGYPyOSj0jvzcQj5483N++HYx4yeN5rxLF3oZ4l1xOBws+X0FLz31FhXllRx61EEcetSBHmWE2po6ykt9JU+7PjjkbM3z/L/Tr977/XwcdrvndXtbu8+qTmWFEmg1YnBJHylMhEA6FbUcBYXBxF+A6sb1W9Cc7u3SWLGliNK1eaz55HfUOg1Jh09j49rNPm21Wi2jxqaxbMm/ZGSmEp8Yy5z99+bv31eQtXEr02ZOJi4hhrq6BmLio7vtl63FxvIlq7jqpgtZ8fcqzBYT4yePYdWKtQSHBHrdVyqVINsBoz9X7j/EO3mVs6Ost8yTUk5SDHs333/zK/fdvoitm3MZNzETAFtLK8Eh3gGGOr0Oh93Jh+9/xeuffoUwuJ/XDAY9qRlJPPf46+RlF7B5YzaLHniejFEpLP7xL95/8zPa2+389tMSnn3sVUKDg8l67WdGtRk5adIMNP+WUPL7OuYcsLdP3w5Q1EuGFU1Nzdx3++O8+fKHlJVU8MM3i7lw4XUUFZR02+bf5Wu58vxb+HfFWooLy3jxqTf58J0vcDjcu0IRkWEkpyX6tDMY9F6vM7d7gIiM8I3FGD9pNFuytqnumC0mLxk1gLgd3CgUhhfS5fTjc69SfO4VFAaZ0NBgn7JpMychWr3n1+ixifz7wa80ltdSV1hJwU9rmNkhgbk9Gq2Gbz77kbKSCn77eQmvPf8urbZWvvvyZ9rb7bz50gd89M4XXkkO/WGxmomJi+LJ/75EXW09W7Nyefg/TxMZHeGjyBOrzP0DRn8a95rtlXI6/u8/241CtxTkFfHdlz/T2NDE+Zefzlsvf8gFV5xBfGIsn3/4LedfdjohHRHq1gALl1x9Np9/9C3HnnwYe82awq+//s2GdZtpbW3jm89/8Dn+siX/ct/jt2KxmFm1Yh0NDU3c8+jNBOv0ONrstNQ0Up1TiqPNTu6fG5g+fSKHHnWAp/1BC+Yy76DZg/VxKPSC4oIylvy23Kusrrbe4w7jj62bc32M7E/f/4aCPLcmfVxSLDfffaUnYNZoNHDLf64mZ0seACqVipPPPIbJ08Z52oebLFx9wwWeJFcJSbFcctXZrPlnPeBW4Lnn0ZtZ8fcqAPR6Hf/3n6vIGJ226xevMLi4pNuY3x4lQ62CwqBjtzs54/wT0eq0gDuJ4P4Hz8aaFAEdz9+RoxMwBJhpqd6WHLBmSzEXXrzQs3ij1Wm5/Prz+fHbxV7Hr6qoobqqlhNPP4q99p7MWReeTHtbO/X1jTvsl0ql4rhTDmfK9AmsW72J3OwCTjv7OKbPmkxcgtuY1+l13HTnFYxS5v4Boz/dciqFEEdKKb8AEEIcBfR2z0UC3wshJPC8lPKF7d8UQlwAXACQkLD7BnJu2ZTN+addS02VO7tbUHAgZ190KjdfdS9X3XQhYeEhhEWE8PYXz5GzJY/lS1bx5ssfst+B+5C1YQufvPc1AGq1mlc+eJxgP0/2QcGBjB6bzjtfPE9ZaTmBQQHEJ8ZSti7Pp65ar8WqMzB/1AQOum+6u6y+FaNU+9TdUxkOY1On1/gkFgEwGLp/ttb7yTIbEGhBp9tWXlNbz+z9ZhAUEojL6WJLVg4ZmanEXRELQPaWPK9AbKfK/dBw5vknIlQqqsqraa5t4InH7qA0rwSD0BClNrHohXspL6vAYjGTkBznpZGs0H8MxNiUfqQwhVB87hV2juEwb4507O3t/Pbz35x1wUkIlYry0kpee+F93v7sWRJvXYjL6cIcYmXZa//zaqe3mKiqq2Pi5DEcdOhcpJRERIWyasU6n3MIIXj6kVc8r8+/bCHGjmziOyIxOZ5FL95LYV4xWp2GhKQ49Hodr3/8FCVFZZgtZhKSYr2y3yr0L/15V70IuFkIUSCEKABupOPH2wv2kVJOARYAlwoh5mz/ppTyBSnlNCnltPDw8H7s8vDif1//6jHswb36mrM1n6DgQJ56+GUSkuOYMHks4SEhpCUnkru1gH3mTmfWnL0ICw/xGElOp5M7rn+AY08+DI1m24/HZDYyemw64JY6HD9pDAlJcQghCIwPJyje+7Mdd8RMWhuacTbaqP59E9W/b6JiTR75SzcOwqcxMhgOYzMuIZbzLl3oVTZ91hRSM1K6bZOenkxMXJRX2UWXn0l4xwNhaXE59978KB++/QUvPvkmLz/zNh+89TnmADNOp5Pm5hbW/LOelctWe9oXV1bx689LqKttQEpJUWEJ/33weRqLqqhfspXyvzax5uM/0DklidHRRIaFKob9ADIQY9NvEish3Ea/gkIvGQ7z5kikrclGY0Ud7bY2EqIicTqcvPjUW7zwxBvunf3zT8as0xMUG0ZIQgR6i5FRB0/zipOJO2ACix58gcKCEqSUNNQ18vmH33Hymcd4nWv2fjNY9te/XmVvvfxRr3/rVquZMeMzSB+V4llMCgkNZtzE0SSnJiiG/QDTbyv3UspsYKYQwgIIKeWO926825Z0/FshhPgUmA781l99Gyls2ZTjU1ZWUs51t15CYnIcqRnJ1BSU88+7v9BcVc+xJyzgkQee44uPvmPC5DFcc8vFLHrgeRx2B0WFZWRn5XLngzeQn1eEvd1OQICVpX+u5KDD9vM5jynIwqwLD6dqawnNVfVYIoIoXLmZ1R//TuykNMLSYtn84z8A1BX6BloqDB1arYZTzzqO8RMzWbd6E8mpCUycOs7jvuUPix3uuusaNufmUVVVy/jxmejKm3G02dGbjbQ022josv16ylnHsm7VRr765HuMJiMnn3E09vZtuwV2p5PzLl3I2698REV5FXvvO40TFh6JcztbcOyRe7Pm0z8pXZuLMcjC1FPmETUuCZUy0Y8MpAtUvmo5is+9gsLAUrmlmBVv/0hjWS2hKdGMXrAXN1x0FoW11VTX1JKRmoTIr8Nha/NqF5YWw/7Xn0jllmLUOg2uMDNHHjefNas28NJTbxEaHsypZx1H2qgUZu4zlfVrs0hNTyI4JJDzTrna61g2Wyu2ltbBvGyFXaTPy2ZCiIViOydMKWXT9oa9ECJVCNGtk7YQwiyEsHb+HzgY8N0f2gNY0EWiEuDI4xew//x9Sc1IxlbfzJIXvqYmt4zAycnceNU9FOQVA7Dm3w188t5XHHK4+xhzD9ibH779jVuvvR+XS/LD17/yxH9fZK8Zk7o9vyUskKSZo4kYm8jSV76jZHUO0iUp+mcL9pY2LOHuYN6kvUf3/8Ur9Img4AD23X9vLr76bA458gCv5FL+sEYEk//REszrq8lo0VPz1SqMOh2GALfSQmRMONNmTPTUj4qJwOV08dkH3+JwON1ylk+9RVDINo1iq9XM4w++4FFxWPL7ClatWIdWCgwBJiIzE6jIKqR0rTvA1lbXxJ/PfUVdkaKYMFLoduVeMe4VFAaMxopafn/6cxrL3Dv71TmlrPpgMSanwLy1lnSHicbfNmMNCcAc7q0br1KpCE2OJvPgaaTvN4nwmHA2b8rmj1+WIqWkqqKGJ//7EiqVYO6Bs7jk6rOZf/g8wiPDfFxwuiYuVBi+9MeeeCjwrxDiFSHEpUKIE4UQZwgh7hZCLAYeAnyFtLcRCfwhhFgNLAO+llJ+1w/9GnHMmDWVK2+8AKPJiNFo4NJrzmGfuXt53m+pbqC5yh0YU9vS5KVBDpCzJZ/Y+Cj2O3AWaRkprF+zCYDffvyLiVPHcc2NFzJ15qRuz99UWU/ekg0UrdjC+KNmETl6my9k6bpcIsckMvpQt+/9ll9XUV+sGGUjleD4CPa+4DA0ei0tVQ0kzsgkc/5eqDvcuCwWM7fcczX77j8TgAMOmcMfvy71Oc7GtZvJ+3sjG79bTllxOa4uRt6fi5dhSYogenwycVPTMAZ6y7RJKakrqmTjd8vZ/PO/1BUpu0LDmu587hW3HAWFXcLRZqciq5B1Xy0h+/c1NJTV+tRpqqzH0eotQ9xc3Uj81AzS5k0iIiOeKafuz5gF02mubGDzz/+y8bvlVOWU4nJ6/zYrS6v45fs/vcqklBQVlHqVJacm8PTrD3oCb6fPmsx9i24hKNhbsU9heNJntxwp5eNCiKeA/YF9gAmADdgInC6l7F6yw90+B5i4ozp7CsGhQZxz8aksOOpAkJLo2EivVTKtUY9Ko8blcGIy+Aa1GE1Gpk6fyN9/ruT5J173lKekJ3LWwuMo/XMDqi4yWZ201Dby1/NfeRlXow6eSmNFHS3VDVgjg0naewxLX/6Wpsp6AHRmA/OuOZ7AWF8JRIXhjVqrIX5KOmGpMTjb7RiDLag13tNBakYyDz99J5UVNRiNenK35HuyC3YSHRXBP+/9gqO1HePevj7+kdHhVGcVUrFsK7l/rid2cioRo+KpyCr01LHVNbH+y78B0Bh0zLvmeIITIgbgqhX6inRJH+MelVDcchQUdpGStbn8/dI3ntfGEAv7XXU81oggT5la62uqZRw4mX/e/dlzPwaYetoBbPpuuSeZpVAJ5lx5LJGj4j11zBYjMXFRFOYXex0vIMDic45pMybx+odP0tDQRFh4MCazaZevU2Fw6ZdoNimlU0r5g5TyTinlhVLKq6SUz/dk2Cv4IoQgJjaSmLgon+1vS0QQE45xeziJ8iaOOuZgr/evvv58rFod1ZXbtGTNFhOH7b8va175nsqsIkrWuP36W2obqcoppamyjqbKOqpySn1WTbMXryF+SjpqrZqxR+zNvx8s9ppI2ptbqdzqPUEojCyMgWYs4UE+hr3nfZORhKRYgoICOfv8k7y2aZNTExg3JsOTj9xsk8zad1uaCpVKxeWXnUXtmm3TQPG/2YSnx3peR2TG01he53ntaG2nbH1eP12dQn/jdsvp4nOvqOUoKOwSrY0trPnkd68yW00TtQXltNS479GN5bVI6SJt3kQyD57G6AXTyThgMtaIYK/7McC6L5YQPT7Z81q6JFnfr8Dp2JZkLi4xlitvvMAroHXS1HFkdohtdCUoJJCEpFjFsB9h9KcUpsIAo1KrSJk9lpCkSJqq6skMmM5hx82nrLCM8JBgGlbmsmHFr9x65YXUCzsuJJZ2Qc2f27LRtTXaqCko589nvgAg44ApbPhmGenzJvmcz9nuIHJ0AokzR2MKttDeZPOpY29p8ylT2P2QTidtq4t49vn7KCwuRa/XER0cQmteBSqNGtrsyIZWLjv3NA47eD+aWlqICQ8jNjKcf//0TjFuDgtg9ILp6AOM2GqbyPp+pdf7bc1KwNawxY9bDkKAlEgpff3xFRQUusXldGG3tfuUtze38eMD79La0IJGr2WvMw7CEh7Eus//coseWI1MPmk/tEY99u0CaO22NjQduvedtDXZkE4XbKecN/fAvXn+zYfJzSnAarWQOSaNlI7s5Aq7B4pxP8LQ6HWEpcYQlhoDQAJJlK7L5fenPvfUKfpxNRGZ8Uw4dl9+euBdLy3ymAkpLHnxa2x1zYxesBfrvliCs0MfXaPX4mize+omzhxNeEasZ1V31AFTWPnuz9s6IyA8I24gL1dhEOiNUaYx6AhLj2Hdu+5VpjagQcCEo2djCrZi+X/2zjtMrqr8459zp89s770mm56QTgoh9N6bomBB7CjFCmJBRERBsCJWLD8VRBAQRFE6BFII6W177216O78/7mays7ObbJLZbDuf59knO2fuPffczbn3vvc97/t9M1PIW1jK9r/qIlcGoJVmAiXZ5C4oo+m9SgASc1LprGqmt6kTv9tHwZJYb1HeIM+TYmIhpYyS1QN9tfGggR9j+CsUihGxJTuoOGMxO5/dEGnTDBohfwBvnxvQY/LDoTDbnngtEj/v6/fw7l9foXTNvIiKHUDZKfNp2l5Fcn4GBrOR7tpWKk5fjNESbfBbLBZWrFnCijVLTsBZKsYDZdwfB6FQiG1bdvH4/z2Ns8/JlR+4mGUrT8LusB1x357GDmrf3k1XTSvFK2eTO68Es8NKZ1UzB17dhgyFKV45h5ZdNciQpHTtfNJLo0N1OqtbqN+8D7PdEtN/+74GuqpbWPHhc2h6rwpnRw8Vpy/G6/Lgaj9YrU5EDPsDL29l/sWrad5RjbO9h+KVcyhZNTcqXCN/yQzQBPte3IIlwcrcC04mtVhlzk8EXF19NG+vpn7zPjJnFlC0bBZJuWmH3WfX9n384/Hnqa6s49Krz2PVKctGLC2ur9AIFl6+luo3dmKyW5h15hKEJnBkJBPyBzBaY+dhV00ryz+0iJ6GdnLmFlOyei6dVc30tXSTUZZL9uwiHOlJ7P33JowWE/MuXo0waLzz6L/x9bspO2UBWRUFmGyxfSvGgXAYhlao5VBojlB1CxSKUSOEoHTtfIwWE5WvbsORnkzFWUvY9IcXo7bra+6KSYz19bvJrCigp6EdV0cfRctnkTO3mJw5xdRs2EXQG2D5h84mqSyH117awON//AeOBAdXffBiFi2Zp3TmpzhxM+6FEBbgCqBkcL9SyrvidYyJxs5te7nhfZ8nOBDP9vKLb/LgL7/D6WePqPwJ6Jnvrz7098ibefu+BmafvZS8xTN4+cEn9Hq9QOPWShZdcQrv/f01at/Zw+lfvJq0AWO6r7mTDb9+HldHL/MvXhVzjJSCTFp319K4tZLVn7gAKQRv/+p5ytbMw5pkx9vnRmgCoekPZb/bx9bHXyFrViFrP3MJSTlpMd5ca6Kd8lMWULh0JsJgwDTEG6AYH4L+IDuf3kDNhl0AtO9rpO6dPay/9UrsqYnD7lO5r5qPvf9mnP0uADa8vokvfv2zXHfDVcNub7SaMZqN7Prn22TPKSYcCiHDkg2/fj6yMlS4rCJmv6TcNLLnFpO3oBSjxczu599h13NvD4yzgcatlZz+5avJX3QNwiDoa+7ipR88TnjgmmreUcOqG8+ncGls34oTi5Ry5C81JYepUBwL9pQEZp21lNLV89BMBjy9rsj97yCaUUMIEXUNmqxmuqpbQErSS3OoeWsnyfnpvP2bFyLXYtu+BlLOnc+tn/lmZL9/PfM/fvf4j1m0dN4JOT/F+BBPz/0/gF5gM/qq/ZTntZc2RAz7g/zu4T+zet0yrMOo2Rykt6kjYtgDFCyZidFqxtnSzeyzlnHglfci4TFte+tJLcqmu7aV9n0NEeO+p7ETV4eeTNNd10bh0grqN+ux9Wa7heKT57D9ydeZefpJODv6MJqNFK+YTe2mvcw9byU7/vEmdRv3suiKUwj6/IQCIWwpDuzpSbjaexEIEnNShw3XMNuPXH5aceJwtfdQ8/auqDZvnxtney+9jZ0YLUaSctOxJBxaUdqz60DEsD/IIz/6PaeuW4nRG8KemkBSblqkuFQ4EKT6jZ343T7qN+/DnpqINdkRFfIVDuurTQcrGJusZsrXLcDT04+v143ZYaVpW2XUMX1OD731HZHwnLY99TEPtt3/2kjOvBJMVvNx/qUUx0VYj7cf7p4ghAbh0DA7KRSKI9Hf1kN/Wzcmqxmz3cL8i1fhdXoIB0IYTAYsSXYWXrGWbU+8jpQSzWhg0VWnsuMfb0RsCWuyg7a99VEv2anlOfzhd3+POlYoFOLV/72pjPspTjyN+wIp5blx7G/Cow3zkNMMGjD6uNPS1fNwdfay4+m3ALAk2Jh/8Sq2Pj5QoPdgLOvB34n5lcatlWTNLmTeRSeTmJVKd30bO59+iznnr6Tq9R24B2SxUgoyKVs9n73/2cyss5aQXJCJp8fJjmfeAqkvEc69YCU1G3bh7XWx9tOXRGndKyYoMQmOMP/i1bz5i2fxDySn5i8qY8n7T8eWkjCwyzBzVxPUvLmTlrf2IjTByo+cQ+GyWYe2HRRrLaWMMcK9PS7cXX3Mu+hkwsEwMhxmz783s+jyU9jw6+cRQjDn/BUE/UGcbT3Djn9oPPdIY1WceKQ8TNiNph3es69QKIalo6qZ1378VCQxtnBZBfmLynj3ry9HQnFmnb2UpPx05l6wknAohDAYEJqIchLqdsKQe+UIaTDqnjr1iWeA5JtCiAVx7G/Cs/a0kzEO0Z/9yCfej3WY2OPBJOdnYEtxIITAnpZI296GyHc+p4em7dV6oqqArIoCuuvbMJgMZA2SEEzOzyAxOzXyuW1PPX0t3STlpVP16naKVs7GaDERGpQg29PQjtFiInNmPgde2YY1yc57f3s1EgYkpWT3vzZStHwWoUCIjX/4D96+aO+uYuLhyEymbM38yOesWYU0vlcZMewBGt+roqumJfJ59twZJCVHh+xcf/0V9OzU9edlWLLpj/+NSK2ZbBbmnrcisq2nx0lSThpGq5mCpTMpXjkboQn6WrrZ+cwGdj//Dnte2EThkpn0terSrFJK9rywiaJB4TvWJHtUnYSsWYW6+s4g5py3QnntJwAyPIxSzgBCCKTy3CsUR0XA4+O9J16LUryp37QPV4deW6Z0zTwyKwrY++/NeDr62fnsBnY/v5Fdz27AYDZidhxaRff2ucmeVTDgYNTprmzmuo9Gh1oaTUbWnbF67E9OMa4ct+deCLEd3Tw0Ah8RQlShh+UIQEopFx7vMSYq8xbO4reP/Yhn//5v+vudXHzluSxZduT3m4SMZNZ97nKatlXhd8fK/vU2djLvwpVUnLGYtj0NzDztJIpWzI5KXk3KSWPFR/Rk2a7aVnLnFZM9txhHahJLPnAGu59/h5adNZSumUd/azeNW/VwiJ7GdoRmYMWHziYUCEWFVQBR3lh3Vz9+lxdrUnRVUcXEwmgyMveClaSX5tK49QDFJ89h8//9L2Y7Z0df5PeymSX86i8/5IVnXqK6so5zzl+Pobqbnr5D1RGDvgA+pydSTCVnfgmnfPYSat7ajTXZTuacQpYk2tjzwiZCgSAphVksvmY9bXvrcXf1k16aQ09jB0k5h15Cw8EQSXnp5C0qI6Ugk8IlM6OKtaQWZXHabVdR984evH1uSlbNidLFV4wjUsZo3EcQmipkpVAcJQGPj5661uhGode0ScrLoHl7NUl56Zx01ToCQyrUbvnz/1h14/k0vVeJs72P/JPKSMhNZ/1tV1H79m4Cbh8lq+aSWJjBL/54P//42/MkJDi48PKzmb9o9gk8S8V4EI+wnAvj0MekRNM0Fi2Zx6IlRx+7lpyXTnJeOs07amJ0vvMXlVG2dj6awUD+ovIR+0gvySG9JCeqrXVvPW//+vnI5z0vbGLu+Sto3VNP0OsnOTedPf/eTOO7+znttqti5C9NdkvEwE8tzsKarAz7yYA9NZHSNfMoXTOPUDBE885aat7cGbVNcl561OfZc2cye64e697X3MW/X/xT1PeWRDu2lEP//yaLmdz5peTO16UqG949wDu/+3fk+/f+9ipzz19J2756TBYzu/+1kdTCrKgXRpPVTFpxNkXLZg17HkII0ktzSC/NGfZ7xfhxWM+9SqhVKI4ac6KdnPklNL57KBcpb2EZ+195j459eoFIb5+bnvp2ll57etS+mqZhTXaw+JrTYvrNKMuN+rzqlGWsGlRgUDH1OW7jXkpZCyCE+IOU8rrB3wkh/gBcN+yOCgDSSnOYd+HJ7H7+HYRBY8GlazDbrTTvqsFkNtPX0oXBZCS1KIuUgkwCHh/d9e24O/uwpiSQWpgZlSjZsr065hhN26vJqijAaDHh6uyPGFvO9l5W3XgB7/zuBXxOD9YkO7PPWc6u594mISuFpR84UyXPTkIMRgOzz1pKf0sXnVXNaAaNueevjCRjD0didiqrP34B7zz6b321JtnBqo9fgKfbSfveBiyJNlIKs7ANetlrHmauNe+sYe55K3C26XKqqcXZvPnIs4D+srDyI+eQkJkS93NWnAAOY9yjqtQqFEeN0WRkwcWryZpViK/PjTAYSC3M5PWBIpMH8bu8hAJBzHYLfrcPW4qDZR84E5PVTOO2KgJuH4k5qaQWZkZEEBTTm3gm1Ea5r4UQBmBpHPufklgcVuact5zCpTPxOb288fAzBDx+Vt14Pq/+4qmIIe7ISOLkj51P+94Gtj35emT/GesXseDSNZGYZEtSbIloa5KdgiUzqXxlG53VzZF2zaiRO7+EM2+/Fl+/G0uijXAoTMaMPOxpiVgTVbnpyUpSbhqnfPYSXB19GMxGEjJTomIxhyI0Qd7CMs66/Vp8/R6sKQ7a9tRFeebzF89g6bWnR+bFcKs61iQ7la9up7OqGQSs+PA5nPnV9+Hr018eR5LmVEx8DpdQq8fcK+NeoTha3N39bH3slUiI7JL3n4ZmNMQIFphsFk699Up8/R7sqQkYLSY2/Pp5Og40Afo1uOZTF5G3sOyEn4Ni4nHcCbVCiK8KIfqBhUKIvoGffqANXR5TcQQ0g4Gk3HRadtbgd3mZcfoi9r+0lZSCTOact5yKM5cgQ5KOA014nZ6oJJoDL79HX0tX5HPOvOKoolZC05hz7nKMVlOUYe9IT4p4ch1piaQVZ+NISyIxM4W04mxl2E8BzHYrqUVZJOWkHdawH4wjPYm0kmxkKMy7j70S9V3juwdwDki2uTr7SC/LjSoupRk0ChbPOPRQkrD9ydcJBUKkFWcrw36SI8OHqUCrCZDKuFcohuLq7KW/rZtQMBjznc/pZevjr0blvgV9QcpOWUD+4hnMOW8FpWvmkT2nCKPFTGpBJjlzikjKSaO7vj1i2IMuWLDlry/j7XfHHEcx/YhHWM53ge8KIb4rpfxqHMY0belt7gT0+GmTxUxfcxd7/qVX7iw/dSFCCDqrmph11lJqNuyiv0VPftSrh+qk5Gdy2heuoqOymZA/SHp5LmlF2YRCIU77wlV0VrdgTbCRXparwiMUIxL0BaLmFcDM0xdT+dp26t7Zg8FsYtbZS1l0xVqc7X3IcBizw0rdpr1RHn1PrytKsUkxiZHhESX0hArLUSii8Lu91Ly1mx1Pv0koEKR0zTzmnLsCR3pSZJtQIIC7qz9qv5DfT2pxFl3VzTS+ewB7ehLzLjwZn9MTtd3Q+zOAp7ufkF/dbxXxlcJ8XAixZMhPuRAinqE/U5q8BfpyWuvuOgJePw1b9iOlJOD1s+eFTViT7PTUt7P9H29QvELPdrcm20kcpEYCkJyXQfkpC6g4YzHpJTkITWA0Gcmckc/ss5bqGfTZqTHHVygOYnZYyZiRF/lsT08iFAhSu2E3MiwJev3sfPotfP0e9v13CwdeeY/tT71BSkEmHZWHvEm5C8qwDmjrKyY3ekLtSGo5AhlSUpgKxUE6q5rZ+vgrBH0BZFhS9dqOSIG/g1iTHJScPCeqzWSzsOdfG+mq0VV03J19bP7Tf7EmR6+mD1dksnjFbCWCoQDiG3P/M2AJsA1dBnMB8B6QLoT4pJTy3yPtOBCfvwlolFJOO/Wdjsom2vY1YDQbmXfhybi7+2naWhmzXVddG7PPWU7IHyQcCjH/klVYHDYqX36P7DlF9LV04+lxkjW7iPSyHEwWpQ0+XfD2u+msbKKjsomkvHQyyvLw9Dhp3VOHJclO9qyiGLWcvpauiGxl9uwi7BmJdFW30lPfRkphJmVr52Mwm2jdXUvBSeUROdXB+NxeHOlJuLv7mX32UlKKsjDbLQQ9fnIXlJJalEXI6wcV5jXpObzOvfLcKxSDad/fGNNWs2E3M9YvighVaAaNGaefRNAfpPbtPViT7TgykiOr8gcJB0N4upxRbamFmaz51EVs+evLeLr7KVo+iznnr8RgVP5URXyN+xrgBinlTgAhxFzgi8C3gb8DIxr3wOeB3UDSYbaZknRUNfH6z56OFByypSaw/PqzcXf34+rsi9rWYNTY/fw72FISWPbBM9j57AY6DjQx++xlvPP7/+Dp1i/+PS9sYsWHz6bk5Lkn/HwUJ55QMMS+/77Lnn9tjLSll+WSkJVC7QbdU2RJtHHarVeRlJsG6OXOX3no75E542zvIeAJ0Lq7NtJH4fJZJGQkkXbucjSTkcSctJg5mZiVSsUtS5DhMM6OXt746dMULp2JNclB294Gqt/cSfm6KVvqYnpxmLAcNIEMKeNeoTjIcDlGSblpGMzRZld3bRu9jR3MOmspfpeH3qaOGIlqALMjujimZjCQt7CMtNIcQv4A1mSHMuwVEeIZljP7oGEPIKXcBSyWUlYdbichRAFwAfCrOI5lQuHu7qe9som+li7CQ7xbnVUtUZVEPd1Otj7+CsUr9AqzB0nKTSMcDBEOhnB19OLtc0eSaQxmY8RIO8i2v7+Op1dVl50OuNp7YmoldFY1k5CRHPns6/fQOahCbXddW9ScSc7LiDLsAeo37SW9LBcQWBJsFC2viJmT1kQb9pQEHGlJJOekkTW7kOo3d7H7Xxvpqm1hybWnYx1GwUkx+TiS5x5VoVahiGBNtkeFvxqtZvIWluF3+eisaaG7rg1XVz/bn3yD7ro29rywkarXd1D16g7mXxxdQbZw2SwQgv7WbtoPNOHq7D10nEQ7jvRkZdgroojnbNgrhPg58JeBz9cA+4QQFuBwGR4PAl8CRpTSEEJ8HPg4QFFRUVwGe6LoONDEG794Fl+/G4PJwOJrTqNo5WyMJv1PP1zyS9Drx2A2svKj5xLw+HB19uHrc7P3xS2RbQbLZEkpY/vwBdQy+QlgIszNcCg87P/10OrDg+fa0Hk33BxCgrvbye7n30EzGph34cnMu3gVAZcPYRD4+j30NXeRf5K+uTVJ117uWd+O3+klMSeV5PyM4z4/xbER97l5uAq1qoiV4iiYCPfNsaa3sZPsOUUULZ8Vub8GPD7e/s3ztO1tAHTZy4AvuvKsu1tPsF1wyWqC/iAGk4HOqmZ8/W7e/MWzhPxBzA4rqz52PtlzpubfTnH8xNNz/2HgAHAzcAtQNdAWAGJLqAFCiAuBNinl5uG+P4iU8hEp5TIp5bLMzMw4Dnls8fa52PDbf+EbkKYKBUJs+tOL9DV1RrZJK8lFaNHesMJlFWz580u88fNnMCfYcHb0ceCVbTBgfxktJuzpSRGPqGbQMJiiC1fMPH0xtmSVyDjWTIS56chIJndBaVSbJdFOKHBIek1oGmnFOciwRIYlttRENOOhOeN3ebGnR0fFpZXk0NPQDugvk9ufeoOQP8iu595m5zMbqHxlG5kVBVH7WJPs5Mwppmj5LFILs9BG0EVXjD3xnpvhcEjPphoGFXOvOBomwn1zrMmaXciBV95j57Mb2PXPt6l+Ywc+p5f2/Y26il1JDu37GylZFR0+qxkNGMwGtv/jTXY//w47nn6L7ro2hKYR8uv3dL/Ly4ZfP4+rq2+4QysU8fPcSyk9wP0DP0NxDtMGsAa4WAhxPmAFkoQQf5RSfjBe4xpPvH1u3ENilJHg7uqPaMxnzMxl9ScvYt+LW/D1uyk5eS7BQABfvy575WzvxWg2MvP0k2jZWYsjI5mcucX4nR7W3XQZ+/73Lk07alj+oXOofXs3zvYeytYuoHBZRcxLg2JqYrKaOemqU0kpyKB+834yynIpP3URvQ3tJOWmYUtJZN6FKwl4fbzxi2eQ4TClq+ex+Jr11G/eh6fHidGsV0ps21dP+/5GcueXYLJa2PX821HHMtutJOelY06wMff8FaSVjFz1VjHFCB/Gc6+KWCkUUaSV5LDuc5ex+/mN+F1eFly2mvqN+1hw6RpadtWi2QwULZtF0/ZKZp21lOYd1ViTHOQtLMOWmsjM006ieWcNKQWZlK9byJuPPBPVv8/pwdvrwpE27VIVFaMgbsa9EGIN8E2geHC/UsoRy6UN6OJ/dWD/9cAXpophD2BJsGFNduAdEvtuGyQN2NfcxVu/fI6MslwSc9LY88JGZqxfhMluIeD2YU2wUrW/Eb/LS8YMXQFl6+OvsP7WK0gpzGTZB88g6AtgslnIW1RGOBCKKmKlmB4kZqUw/+LVzDprKUaLCc1gIL00h8JlFWhGA53Vzbzy0N8jqz/N22tYePlaZChMcl4G1W/tIiknlTWfvgSkxO/y8vIPn4hsf5CEjCRO/+LVaAZDTGKYYmojwyHECKXthaaBVDH3CsVBDEYDOXOKySjPQ4bCmGwWvL1uNv3hxajtQr4Afc3VZFbk60Wt/vYKp3zmUhZeeQozz1iMJdGKq72PoCc6lNJks2BRKmSKEYjnmvmvgQeAtcDyQT/TFltKAis/fE4kCVEIwcLL10ZJEnZWtVBwUjmZFfkk56ZTdspCGt+rIm9BKanF2aQWZbPs2jMIB4I0bN5PZ2Uzs89ZTkqBvpSpGQyY7VaE0LXslWE/fRFCYLZb0QYZYCabBYPJSM3buylft5B5F57M3AtWMvP0k2g/0EgoGKJhy34AFl2xDrPNgtluJSEzhcXvW4/ROiCnKmD2OctIKcrS+1SG/fRDypHVclRYjkIRg7fPTWdVMx0HmnC299Dw7oGo71t31lJ+6kIQgoYtB2jf10D5KQtJLc7CYDCQkJGMyWIhMTuVxe8/LbIabzAZWPHhs6NEExSKwcTzCd0rpXz+WHeWUr4MvBy30UwQsmYXctYd1+Lq6MOSaCMxJy2STAtgS3Hg7u6nbuNeAMx2CwsuXUtKUSaOND2uPjE7lTNvfz+u9j5MDgtJ2WlRqiUKxZHImlHA7n9tpL9V10+2pycNhNXk4Ot3k5CZElU5ESB/YTnrb7kCZ3sP1kQ7yUUZWGy28Ri+YgJwuCJWQiXUKhRRuDp7efu3L0RU7SyJdhZetoaWHTWRbaSU9NS3c+ZX3qeH4FpNJOWkYbJG16gxmIyUrp5HRnke3l4X9rREErNUIUrFyMTTuH9JCPF9dE37SF1kKeWWkXeZ+gghSMxKHfFCDPoCkYsfwO/20bD1AHmLSqMkBBMyUkjISBnr4SqmKK7u/ohhD3rVw/6WLsrWzD/sfmnF2ZH8kJHwubzIcBirWiKe0sjwyDr3uhTmMIpLCsU0pW1fY9Sz3dfvpmVXLanF2XTX6tVnhaaRt6gcR3pSjHMlFAzhd3ow2cwYLWYMRgMp+RmgFMgUoyCexv3KgX+XDWqTwOlxPMaUw9sTq0XfU9/O3he3kJSTRsHiGZFqdgrFsdJd1xbT1lnVggzLY068Dvr8NO2oYcc/3iQUCDL7nGUULq1QRv5URY6sc6+kMBWKaPqbO2PaumtbWfHRc6l+YydGk5HC5RWkl+TEbNfX0sXe/2ymcWslqcVZLLh4NWnDbKdQjEQ81XKGlbtUHJ7hdMCzZhXQurOWff/ZgslmoXDJzHEYmWIqkb+wjKatlVFtx6uo1FHZzIZfPhf5/O5fXsZoNlO6WlVGnorIcBhGlDYVgETK8MiKOgrFNCKtLA+IVvkuWKIb8xmluSPu5/f42Pyn/9K+vxGA1l11dNW0cuZX3k9iVsoYjlgxlYjbXVgIkS2E+LUQ4vmBz3OFEDfEq//JQE9jB7Vv76Zu096oEIjDkV6aw4JLVkc0xzNm5JGUk4bf7WX+JatxtvVQv3kfzo6eMRy5YqLj7OylYct+at7aRVdta0yl4yORPaeY8nUL9bAKASUnzyF/UXnUNr5+Dy27aql+Yyete+vxe3wj9KbTtC22+PSBV7ZG6esrpg6HD8sRoKmkWoXiIJnlecw+ZxmaQTezcueXULJ67shJ6QO4O/oihv1BAm7fqG0KhQLiG5bzO+C3wB0Dn/cBf0VX0ZnydNa08MoPnyDo0+WqLIl21t9yOcl5h4+PMzuszDpnGQVLZtBZ3UrDu/vZ9dzbLLpiHduefD1SidaRnsQpn7uMpGyVRDPdcLb38tpP/0F/Sxegx2muu+nSo6pOaE9N4KSr1zFj/SJA4shIwThI8cbv8bPjmbeofHVbpG3+JauZffbSKPWdwdiSHbHHSUtS9RWmKlKOmFALA3H3oTAMP10UimmFs6OXrtpWZp29DCEE3fVtuDp6j/gMN5gMaEZDVBV6QIloKI6KeK6fZkgpHwPCAFLKIDAthI/D4TAHXtoaMexBT54ZzrM5HJqmkZidRlJuGm176smaVUjDu/ujLm5XZx8dQ97mFdODrpqWiGEPugd125NvHNGzPhSD0UhyXjrJeRlRhj1Af0tnlGEPsPOZDfS39ozYX+6C0ijpVc1oYNYZS0Z8GVBMbg7nuQf9pVN57hUKnfZ99bTtqWf38++w67m3ad5ezd7/bD7ifduRlcK8C0+OastdWBoloa1QHIl4eu5dQoh0BsreCCFOBnrj2P+ERYbksEtmzvajO/204mxO/+I1uLt6efexV2K+9/SMVOhXMZXx9btj2tzdfXopclt86hoEPP6YNhkOE/TFth8kpSCT075wNV01LYQDIdJKskkpyorLeBQTEBmGw63KaBoyPC38OQrFEXEPI5bh6XYS9AUwH+a+rWka5esWkFqURW9TJ470JNJKcrAkKBlixeiJp3F/K/A0UC6EeAPIBK6MY/8TFoPJQNnaBXTVtGJLcRAOSXz97piY5tGQUpBBSkEGvU1dbH/qjajvMmfmx2vIiknEcAZz2Zr5UVKpx0tCVgpmhxW/yxtpS8xJxXGEIin6SoDyKE0HdM/94cJylGKOQnGQrJn5HHhpK5YEG5rJgKfbSdHyWdgHVagfCbPdSs7cYnLmFp+AkSqmIvFUy9kihDgVmIUunbBXShk4wm6Tnu66Vpp31ODISOLkG86jdW8dBqOR7DlFZByHMV68cjYBr58DL23FZLOw8PK1SgprmpJanM2qj1/Ae397FV+/h/J1Cyk7ZcFhQySCvgCd1c0076jBmuwgZ24xoUCIlh3VyHCYnPmlpJVkow2onyRkJHPKZy9l699epau6hew5hSy8bK2StVQAerEdPeZeee4VitGQWZHP6k9eRNveeoJeP1mzCkktViubihPDcRv3QojLR/iqQgiBlPLvx3uMiUp3XRv/+8HjhAJBPQH2idf0hyBQ/cYO1t921bAatqPBnprIgotXM2PdQjSjhjUpNnlRMT0wmowULplJ5sx8woEg1pSEiFE+Es07q3nrkUMylXv+tZGZp53Ezmc3ALD7XxtZf+uVZM449AKaXprDus9egt/tw5JgxWgxx/SrmKYMGPaHjbkXGijPvUIBQG9zF+/87gWCXj20seatXay68XySc9VKp2LsiYfn/qLDfCfRK9ZOSVp21hDyB0kvz6VlZ03EsAcIBUI0vVd5zMY96CXd7WmJ8RiqYgowWi+6z+llx9NvRbX5XV7CoXAk6VGGJZWvvBdl3AOYbBZMcYrjV0wdZPgwBawGUGE5CsUh2vbURwz7g+z9zxayZhdhcajClIqx5biNeynlR+IxkMlIYODCNZiMenLj0O+HSVJUKMYaKcNRyk2R9nAYoQnkgP3l9/iRUh5Rd1mhQOovhodFqeUoFBGGswlC/kCMxKVCMRaoUoLHQe78UhDQcaCJnPklMd8XLJ5x4gelmPZYE+3MOmtpVJtm0DDZLFEPlhmnLlKGvWJUHCmZFgAhVMy9QjFA1uzCmPtr2bqFw9YHUSjiTTzVcqYdaaU5rPvcZez51yZcHb0su+4sKl/bjtFsZM45y0kvG7nEtEIxlhQtq8BoNnHg5fewpyVQceZSwqEQGTPykOEws85aRmaFUl9SjI5RheVoGjKkjHuFAiBzZh6rP3kh+/77LkGvn9K183WHoEJxAlDG/XFgMBrImVNM5owCZDiM0WKiaHkFQggMJvWnVYwf1iQHZWvnU7i8As2gYTDq8zGzPB+JxGhW1Q4Vo0cP6Tq8514IFZajUBzEaDaTv6icrIpCwuGwirNXnFDGUi0H4IhqOUIIK/AqYBkYz9+klN843nGdSAwmAwdrrh80mvpauuhv7cZoMZOcn64kBRXjgmmI4o1hUGVaX7+H3qZOAl4fiVmpJOWmnejhKSYLo/DcownluVcohmCyRd+DXZ299DZ1oWmCpLx07KlKNEMRfyaCWo4POF1K6RRCmIDXhRDPSyk3xGFs40JHZROv/ujJSFJj7sJSln3gDGzJRy5eoVCcCDy9Lrb85SUa3z0A6Eb/upsuU4XSFMMymph7ITTC4Slf2kShOGZ6Gjt49cdP4h2oXpuUm8aaT15EYnbqOI9MMdUYd7UcqetHOgc+mgZ+5Mh7TGwCHh/vPfFalFpJ87Zquta2kb9QGfeKiUF3XWvEsAdd2eHdx15h/S2XY7ar5WNFNFKGQTuS514D5blXKIZFSkn1Gzsjhj1AX3MXzTuqlXGviDtxDQwXQlwAzAMi1oGU8q5R7GcANgMzgJ9KKd8e8v3HgY8DFBUVxXPIcSfg9dPb2BHT7u1xDrO1YrIzmebmYLx97pi2vuZOAl6/Mu6nCHGdm+EQHMlzr2n6S4BCcQQm633zeAiHwnRUNsW0d9e1jcNoFFOduElhCiEeBq4BbgIEcBVQPJp9pZQhKeVJQAGwQggxf8j3j0gpl0kpl2VmZsZryGOCJdFG/knlMe3qzXxqMpnm5mASslJi2vIXlWFRuSFThnjOTT0sZxRFrELKuFccmcl63zweDEYDxctnxbQrBR3FWBBPnfvVUsrrgW4p5beAVUDh0XQgpewBXgbOjeO4TigGo5E5560gq6JA/2w2svia9aQWZ43zyBSKQ6QVZbH02tMxWvQE8IyZ+cy7cBVGpfKkGIZR6dxrmtK5VygOQ/7iGZSsmgtCX+mqOHMJmQO2gkIRT+L5JPcM/OsWQuQBncARX0mFEJlAQErZI4SwAWcC34vjuE44STlprPnURbi6+jGajTgyklWxIMWEwmgxU3bKArLnFBH0BXGkJ2KyWcZ7WIoJigyFjhhzL1SFWoXisDjSk1hy7enMOmspQtNIyExCMxjGe1iKKUg8jftnhRApwPeBLehJsb8axX65wKMDcfca8JiU8tk4jmtcMNkspOQrY0kxcRFCkJCZMt7DUEwCRheWozz3CsWRMJqMJOelj/cwFFOceBr390kpfcATQohn0ZNqvUfaSUq5DVgcx3EoFAqFIo7IcBhhOHJYDuEwUsopu1Lpc3rw9rlJyklDHEk9SKFQKMaJeBr3bwFLAAaMfJ8QYsvBNoVCoVBMUsIhhPHwjwshhF7oSsojF7yaZMiwZPvTb3Lg5fcwWc3YUhyc8tlLsSTYxntoCoVCEUM8KtTmAPmATQixGF0pByAJUNIbCoVCMcmR4bDumT8CYiCpVoxi28mCDEveefTf9DZ2sOL6szDZLVS+up0Nv/kX6266dMquUigUislLPDz35wAfRpexfGBQex9wexz6VygUCsU4IsOh0RmxQtPlMKeQ6NK2p16np6GdhZetwTCgJlW2dj6b/+9/NG+vJm9h2TiPUKFQKKKJR4XaR9ETYq+QUj4RhzEpFAqFYgIhw+FReePFFJPDrNmwm7qNe1l8zfqIYQ+gGTSKV85m13NvK+NeoVBMOOK5dvqGEOLXQojnAYQQc4UQN8Sxf4VCoVCMA0cbljMV6KptZetjLzPvwpMxDyMTmzEjD3dXP931qsKoQqGYWMTTuP8t8AKQN/B5H3BzHPtXKBQKxTigh+WM4nGhaVOiSq3P5eXNh59lxmknkZCRPOw2mqaRM7eY6jd3neDRKRQKxeGJp3GfIaV8DAgDSCmDwNRw4SgUCsV0Jhw+YhErmBpa91JKNj76b9LKciKVxkcic1YBDZv3IcPyBI1OoVAojkw8jXuXECIdvXgVQoiTgd449q9QKBSKcUAvYjXKsJzQ5Dbua9/eTV9LF2Wr5x1xW0daEgaLic6a5hMwMoVCoRgd8TTubwWeBsqFEG8AvwduimP/CoVCoTjByHB49Nr1mgaT2HPvc3nZ+rdXmXXmEjSjYVT7ZJTl0ri1coxHplAoFKMnbsa9lHILcCqwGvgEMG+g+qxCoVAoJikHk2lHI4Wph+VM3pj7nc9uILM8n8Ts1FHvk1aSQ/P26mM6XjAYpLO9i+bGVnxe3zH1oVAoFEOJmxqxEMIKfBpYix6a85oQ4mEppTdex1AoFArFiUUvSjU6L7bQBOFQcIxHNDa4u53UbtjF8uvOOqr9EnNS8fQ48fQ4saUkDLtNOBzmpX+/zn+ee4Xa6np6uvvo73PicrpxJNgxmYw4+10sXrGQW77yCebMr4jHKSkUimlKPEuN/B7oB3488Pn9wB+Aq+J4DIVCoVCcQGToKCrOTuKY+70vbiZ7bjFmh/Wo9tM0jdSiLFp311Gyam7M9709fXz+xjvo6e5lzakrWLhkLomJDuwOOwmJDrSBv63P52fDa5v4+Adu4/Zv38x5F58Rl/NSKBTTj3ga97OklIsGfX5JCPFeHPtXKBQKxQlG99yPzrgXmkbY7x/jEcWfgNdPzZu7WHrt6ce0f0pBJi27amOM+4A/wKc//GVy8rL41M0fjhjyw2GxmDn1zNWUzyrlu19/iLT0VFauWXJM41EoFNObeCbUvjugkAOAEGIl8EYc+1coFArFCeZoPPeTtYhV3Tt7SCnMwJpkP6b9U4qyaNtbj5TRkpgP/+hRDAaNaz54yWEN+8EUFOZyw6c/wFc+/226u3qOaTwKhWJ6E0/jfiXwphCiRghRA7wFnCqE2C6EUIm1CoVCMQmRodCoqtMCoBkmZVhO5WvbyZlXcsz725IdAPS3dkfamhpa+MujT/LBj145qmTkwcxdUMGSFQu5/+6fHfOYFArF9CWeYTnnxrEvhUKhUEwAji6hdvLF3Pc2deLpcZFWlH3MfQghSCnMpG1fA0k5aQD88id/YN0Zq0hNSzmmPi+58lzu/MK97HhvN/MXzTnmsSkUiulHPKUwaw/3M9J+QohCIcRLQojdQoidQojPx2tMCoVCoTg+ZCg0qgJWMDnDcmo27CJ7diFiFBV4D0dyXgZte+oB6O7q4YVnXuLMc9cdc382m5WLLjubB+55+LjGpVAoph/xDMs5VoLAbVLKOcDJwGeEELGSAwqFQqE44YSDQTCM1rifXGE5Miyp27iXrFmFx91XSkEG7fsbkVLy5F+fY/HyBSQlJx5Xn2vWr6S+tpFNbyttCoVCMXrG3biXUjYPFMBCStkP7Abyx3dUhyfoceNpbcZZV42/tydG1zkcCuHv68FZX42ntYmgxz1OI1UoJh9Btwt3cwPOhhr8/X1H7QmW4TABZz+uxlpcTfUEXM6YREfF6JGh4OilMIUAKZFychSy6qxuRjMYcGQkHXdf1oNx923dPPHnZ1i7fuVx92k0GjjvojP4xUO/O+6+piohvw9vZzvOuiq8ne2E/MMXA4u+r/ROqpdQheJoGXfjfjBCiBJgMfD2kPaPCyE2CSE2tbe3j8vYDhL0eumv2oentRF/TyfO2gP4e7qitvH3duOsOYC/uxNPaxP9VXsJej3jNGLFWDKR5uZUIOhx01e5F297C/6uDpzV+wj09x9dH24n/VV78XW24+topb9yL0G3a4xGPHGJ19zU1XJGGXMvBMIwebz3dRv3kjkz/6gTXodDCEFKQQZb/7uJYDBEeUXJ8Q8QWLVuGQf21bBr+7649DcRiNfcDAeDuBvrcDfW4u/pwt1Yi7uxPsbhFvS46asafF/Zj7+/73hPQ6GYsEwY414IkQA8AdwspYy66qSUj0gpl0kpl2VmZo7PAAcIed3IITcOT0sToYCu7RwOBPC0NkZ9L0MhQp7pZ1xMBybS3JwKBJx9MMTr62lrIjxKY1FKibejbWhrzAv4dCBec1MGgwjD6Ix7mDyhOTIsadiyn8yZ8VsoTs5LZ/87u1ixeklcXhgAjEYjZ5xzCr/5+Z/i0t9EIF5zM+z3EujvjWoL9PcQ9kV77wOufghH31e8bU2TtpqyQnEkJoRxL4QwoRv2f5JS/n28x3NYhlvelxIizRLCsduoqACFYhSMdH0dTRfh2JCQyRImMhEJH01YDgxUqZ34RlNHZRNGixlH+vGH5BwkKT8D0edj2cpFR974KFh3+ireem0TTQ0tce13sjNSuF1M+zDbSRke9NxWKKYW427cC9298Wtgt5TygfEez5Ew2Owxms/WzGw0kwkAzWTGmpUbvZPQMNpii6OEw6GIx38kwqHQsMaKQjGVkKEQMhzC6EgEoj2e1swctFF6joUQWDOyYtotKenIcHjUKwCKQ8jQUXruDQbCwYn/d67buJeMOHrtAZraOzBqGpnJyXHt12a3svrU5fzpt3+La7+THYPFqj+TB7fZHRgsVqQ8dL2bHIl6PsggrJm5aEajfu9R9wXFFCOeOvfHyhrgOmC7EGLrQNvtUsrnxm9II2O02kgsm4Wvs42Qz4slLQNzYkrUEqw5KQlEIYGeLoTJjCUtA4PVFtVPwNmHt6ONsM+LKTlV/xl0kwoHA/j7evF1tCKMRmxZuRgdiXFb6lUoJgLhUJBAXy/ejlaEZsCSlUNCSTm+znZkKIQ5NR2jI+Go+jTY7DgKS/F1dYAQWNIzQEB/TSUy6MeSnoUpKQXDwAu5YmSklMjg6GPu4WBYzsT23IdDYRq27GfRlafEtd/Nb28lwazhbe3FlGg78g5Hwelnn8LddzzAp2/5KI6EY6ukO9XQjCbs+UX4e7oIupwYHQmYU9IJ+314O1oJedyYU9MxJaWSUDwDX2fbwH0lDaPdga+3G29bi+4UyMrBlJB4VHNdoZiojLvnXkr5upRSSCkXSilPGviZkIb9QUx2B46CEpLKZmFNy4x47Q/i7+3B09IImoGwz4uz5gChQYo5AbcLZ20lgb4eQj4v3rZmfO2tuuTcoD7cDTWEvB6Czn76q/ZNy6RAxdQm0NeLq76akMdN0NWPq3o/IZ9XvxY0gbupjoDz6BJqQ243rvoa9BC5MK7aKoJuF0FnLyGvR0++6+0+UjcK9AJWaOKownLEJAjLadtbjyXRhj31+KQqByOBLRu3k5Sbhqc5/vMrIzONOfMrePKv/4x735OVcCCAu76WQG8PmsFIoLcbd0Mt3s52/D1dhHxePC2NeNub8bQ2Eg4GBu4rDQTdLly1lYQ8LoJuJ86aAwRczvE+JYUiLkwEz/2kIBwKEvK4CQeDaCYz4YAfGQrpy4J2B5qmEXA5CXk9CKOJhOIZBF39CCEI+X0EvR6Mdl0qTU/KjV4G9Pd0YsnIQjMaCQeDeDtaY8YQdPVjOkovpkJxIgkHA4Q8HsKhIAaLFc1kJuTzEA740UwWDBYr4YCfkM+LMBiGf2EVGubkFGQ4jNGeQMjjwt9v0q83swWDzTZiUSUpJd6udqyZ2SAEQgiMdgdBtwuDxUrI5wXA196CJSUVzai894dDBoJohqN7TAiDgXAgMEYjig81G3aRWVEQ1z4b6poIh8OklWTT824NUsq4r7Seed46fvvwn3n/hy/HcBShUlOVkM+LOT0DzWRGBvyYTZm6FObQ52t3J/bCUqTfh5QSU2IK/r6emP4CvT0YTGaCXg/CYMBotcc47xSKyYAy7kdBOBTC09KEr7MNc6q+5Bc8+IYvBAnFZaAZcNVWIcMh7LkFOGv2R5J4jHYHWnJqpL9hDROhHXoQiBE8ZUeT1KZQnGDCwQCuhloCAw9Ng9WGOTkVT2tTZBtbdh7+3m5CA9KwpoRkzMmpEU+6NSMb/0DIG4ApKRWEwFm9P9KHo7gcy6DraSjm5FQ8LQ3IgZUwzWTGlp2HZ7BilaYxNLZfEUs4GDiqeHs4GHM/cT33Aa+f5m3VLLv+rLj2++7G7ZRXlGJ0WJEhSdDpjXtoTvnMEhISE/jvv17j7AvWx7XvSYkQyEAQV1N9pMmalYuwOaI2s2Rk42tvidx30DQc+UUEhxj4RkcCvft3RxS7DI4EEgrLMJjNY3oaCkW8UdbiEQiHQoTcLnyduryewWw5ZNijx5cGfT783Z3IUBBTYrIe6zsoOz/odulymH4/4VAIzWrFlJqOOSUNa2YORrtDT8q1WAHQDAZs2XlR4xCaQU8KUigmKEGPO2LYAxHD3pSYjDUzB1Nisv45KSWyTcDZeygfRQhdaUWGsecX4ygsxZiQQKA3WsbS3VhLyB+diB4KBAi4XYR8PkIed8SwBwZWCnxRiem2nHw0Y7RvQ79GfUdlmIaDAUJ+35RV4wkH/Ajj0XvuZXDieu7rN+8nuSADi8Ma1363vLONGTNLEEJgTk/A29wT1/4PcvYFp/Lrn/1p2hZmCweDBD1u3UMfDuNtb466x3jbWjBoIur5enC13ZKWMSCAYcbX3TWQwK9jSkzWZXQHXcshl5OQCodVTEKU5/4wBD1u3M0NkXAaiJbYMjoSMToSCLldhAeq4mlms67VPYSQXzcufF0dhDwujI4ETClpuJsaMCUmY0pMRhvkmdcsNhwFpQRcfbphn5iEwWwZw7NVKI6PoQadBOy5hfh7u/C2t2C0O7DnFsYo1gijCWtmDsJkAqFhzcjG09qEDIWw5US/5OrHCUZVrQ24nPg62/D3dqOZTFgzctAsliit65Dfiy2ngLDPgzEhGZMj2rMX9LhxtzQS7O/FYLNjzys87Mu0DIcJ9PfhbqojHAxgTs3AlpmNwRJfg3G8CQcCiKMMy9EMRgIT2LivfOU98hfPiGufXV09dLR3UVCkK6WZUx24m7pIrMg9wp5Hz0lL5/PkX5/j7Te2cPLapXHvfyITdDnxtLcQ6OtFs1iwZecOc48pQIZCBD1uwj3dmFLTAH1V0HswUT8lDWE0YE5OJdDXq4fvJSZFrRAeJBQ8vKKdQjERUZ77EQgHAjhrKwk6+/Ql/IGQmcHhMqbEJLxtzQOx8LohEHS7MCXGyqAZbQ48rY2RYlZBlxNvWwuW1HQCfd16ss+gONVAbxeuhmqCzj69Em7NAZVQq5jQGCyDQhCEhsFsxtPeEpm3QbcLb0eLvsQ9KDTNaLNjzy3AlpGNZjDgbqrXXxRkOKbwDIDB5oiEioQCAd2w7+kCKQn7/bib6rCkZkTtY0pIwpqWgT23EHNiUpQiRjgYxFVfQ3CgGE7I46Z/ILF3JIIeN87aA4QDfpASf1c73o7WKedNDft9MSscR0IYjBM25r6zqhlvn5v0kpy49rt10w7KZxZHJFst6Yl4W3rGZD5omsa5F53OL370aNz7nsiEAgHcLY366qAQhH1ehNF06B6jaZF7jGYyE/Z5QQgC3Z1oJpPuMBi4r/i7OxDoz2V7Tj627DyMNgem5LSY4xqt8Q2tUihOBMpzj+6ND3pcBN0uhGbAaHcMvN2nopkthP1+HPnFBD0u/L3dOIrKCPm8yHAYR2GpvoxvMGIvKNFvOAYjpoRE3M0NCASWjCzCwUBUqAAcWvI+qIvv6+7E6EhAM1vwdbUPbDPI4Hc7MSXGr+CKQnG8BL0egm4nhCUGuwNH8QzCkYRxoSfUDvLiCpMZhMCanokwGNBsDiQDVWU1oeejaFrEqPd1d2LLLcTb3owMBjHYHFjTMwm6nPi8HoyOhMMo3wgQYElNP6x6S9jvI+R1R7VpJjMhrxd/Xy+a0YDRnhDllY/E7g7C192JNTNnSq2whfy+o07iF0ajvroyBgmlx8uuf20kf/EMhBbfcW16+z1mzSmPfDbYzGgmI/4uJ5b0+IdTrlyzlH8+9R82bdjKspNPinv/ExF9dVxiy8mPVE2WwSAmRwIGq41wSE/+Dno9hIMBbNl5yFAIYTIN+7Lp7+nGnJoRMd6FENgys5HBAIG+HoRmwJZbEKOjr1BMBpRxj65C01+1L/JZGI04imcgQyHcDbWRdlNSCva8Qlz1NZEwHNDjd0UoiLulIRJrLzQDjoISgm4Xvq4O7LnDKzMYrDbczfXIQTefhJIZaCYb4SFxxSprXzGRCHrc9FftjSg/2fOL8XW0Rnm8bdl5eP0+vRCS0Yg5MRlXfXXke3t+Mf21dYeuG4MBW2ZOJAk37PcRcPZhzS5ABnzIUIiAqx9/dycA5tR0NJMp5loRBqOumAP4+3owmw6TEGcw6CtzB72sQsOSloGz9kBkE81kJrGsImLgD6cgo5nMU04jO+z3IVJGTl4eDiEEwmggHPBPqBed7ro2uqqambFuQVz7dbk8VB+o47yLTotqN6cn4G7sGhPj3mg0cOFlZ/Hgvb/gD0/+bMK9RI0FwqC/ZHtaGiNtCaUzAaKS9s0paSCj22w5BQiTKeo5O9z1arBYSSgsJRTwIzRtQs1fheJomPZhOTIUwtPahDUrB0dhKY6iUiwZ2RAK4utsj9o20NdDOBCIMuwBAs5+Aq7+qCRaGQ4RdPXj7+lEMxgIBfyYU9Kj9rOkZegxrZoBa1Yu1qxcTEkpeFqasOXmRlXU00zmqOQfheJIhEN64lnQ6xmT8IBAf2+MpOvQUBZvR5v+sAXMyWlREq9G+4DXffB1EwoRDg6qiCoElvRMNIMBzWLBmJikh+AM4O/txpIeXZH2YIKut70Fb3sLMhjEnJSirzJ43ISHePENZgu2nEMv3+akgaT4QYQD/qiwOIPdHlOYzp5XeNQhLBMZGQ4PSJgevVNBl0AdOazpRCOl5N3HXqFoxWwMpvj+H23dvJ2SsgJMQxRVLOmJeBq6Rtjr+Dl57TJ6unv5779eG7NjTCjCYbwDwhaD24au3Pl7uhAi+n7nbWuODtUTAmtW9rAqOLoEpk0Z9opJzdR5Eh0jUkpdJqujDW9bi25MpGUQGkF2Ug4TAwy6akbMtqEwtuw8hGYk5NNDCIwOB1JKNKNJTwqUElNCEt72FpASoz1BDwcyWUiaMVvXzRcaBpt9yiXrKcaOkNeDq7FWV3YSAltWHpaMzKPWLD8c4UC0t3w4xRgZCmJKSkYzmzFYbRHVKTgomThMbLYMRxJvNYsF6ffhbmmEcBjNYsGeU3BolSwcxtfVTkLxDEIBH5qmoVntaJqGo7AU0I39QF8vnrYm/RpzJODIL8Fg1a8nIQSWtHSMNjshvxeD2UqgtnKYYR16kTGYLSSUzNBrX4RCGK1WDEPk9yY7IZ8XzWQasabA4dDMFkIeDwyTfzQe1G7Yja/fTe6Ckrj3vfGtd5k5qyym3ZyWQM+2WkK+AAZL/FddNU3jqg9cwn13/Zg161dgs03t54McuN4HMzQ5/1B79HYyHMKUkKQ/d6XUjXrT1P57KaY3095zj6YR6O8l6Bqogiklvs52NIMhxjMnjKaBN/3oJVDNbMY8XCJOQiL+3h5c9VV425pxN9biaW7EaLPjqqvSQ36Ephs8A97LoNupP1SNRow2B5bUDMwpacqwV4waGQ7rSWYHJVulxNPaGPeE7MGSlqAbvAwJDzAnp6FZrdgyc9AstmgZTFf/sMnnmtmCq6EGT3M9hMO4m+ojD/Wwz4evuwPzoH5kKIxmMWPLyMaSlonJ7sBgtWFJTceSmk44GMDT2njoGnM58XS0Rr2MaAN5Mta0TIyOBCwZ0asBAAZrdOytwWzBnJyKNS0Doz1hyoVGhDxuNPOx3XcMFuuwqmHjgbO9h61/e5WKM5dEKZLFA5fLw77dVZRXlMR8JwzamHvv5y6ooLS8iIe+98iYHWOiYDBbYu4XmtmCNiTkTjNbolYDQZe5DAX1ZHtPc71eIb6rfcolwCsUB5n2xr0MBgj2xz6Egi4n5pR0TEkpCIMRY0Iijvwi3C1NOIpKMdjsCKMRS0YWBpudsN+LNTMHzWRGM1uwZecR8nowp6RiTk3X+3Akklg2M+KtFJohJpEPBsIdBiXfhgIBfD1d9NdW4mltIjhMMp9CcRAZChLo641pHy4J9Hgw2RNwFJWhWfQHbCjgx55bMKBmY4zEw4uw/gCVwQAGiyVyPRgsNgwWK9acfDSTCc1iwVFUqvdnsSKMppgk9IPnYUxIHLguk0goKsNoHTnpLeSJPe9Abzf+3h76aw7g6+6IitkXQmBJTceanae/0FttJJTOxGifXol1AWc/BsuxhSYY7Q5CHhcBZ3+cR3V0BDw+Xv/Z0xStmE1iVkrc+9/yznuUlBVisQ7/dzJnJuGqax/2u3jxvusv44Vn/sdrL20Y0+OMN5rJhC0779Dz1O5ABv3Y84owJSbpQhaJydhzCwfi8wfuQylpGKw2hkTq4O/rPmyivUIxmZn2YTlC0z30Q0MMhNGEp7VRf7AXl+Hr7cE5sFTvanDrBTOSUjBYrISDQXweD76uDkxJybqntL0FW1YupsRkLKkZyKAeWy8MBuSAR0uGQ8OGSRhsdoRBf++SUuLv6tA9j+hGibeznaTyWcqbrxgWoRkw2Oy6jOsg4h1DKgwGLClpmBKSADkgIXkAU2ISRpstYthZs3Ii2/t7e0CAOTmFcCCAq76ahOIZWGfMBSEiMetGWwJShgkP80IiTCYM9gSSymchjEY04+FDHoY7bz1EqJ2gq59AXw+W9EzdKBjw7BrMFuzZeVjTMkETcQ1nmgxIKQk4+4atMzAahKZhzczBWXuA5Ip5Md7VE0EoEOSNh58hMSuV/EWxYTPx4I1X3mHO/IoRv7dmJtG+p4lwIIRmGptk64REBzd+9jpuv+U7/PrPD1IxSLVnqmG0O7Bbi5GZPjAYCXk9OKv3Y05Nx5aTStDtxFlXqdfNMBgxJ9sIuJzgckbuQ5G+bI4plwCvUBxkWnvuw8EAIZ8Ha2Z2VKEWg92hv9FLicFmRzNbMAxOlAuHMVhsmGx6bK/BaNQNck3g7+7E39OFwWRGM5kxmMwIoUsCHkwSNNjskSTAcMCPcZDUnDAYsGfnR2464YAfT1tz1LhlMBB3L6xi6iAMBuw5+YeSUtGXpQ32sYkJ1wYMbIPVjjk1nUB/L76uDsKBAI6C4ojxLYTAmp5F2O/H19VBoL8XU3IqUuheucHJqAazGaNFj2M3D0mEs+cWYrLpCa1HMuxBT341JRxazhcGg55g6zrkVfZ1tusVL4eem8k07Qx7GFjlERyXUW60OzAmJOoypyeYcCjEW798DilhxvpFYxIy1d7WRWN9C+UVpSNuo5mNmFPsuBs74378wcycXcb7r7+Mj3/gVt7bsnNMjzXeyICfUMCPDPhBE9hy8vB3d+BurMXf3akXqwuHD92H/D5suYX4+w9d78JgxJaVG1W3RqGYSky/p9YAIZ8XZ121XlTKaMSRX4QMS4RBL74TDgQiy3mawYg1IxtTYhLhYFA32ofE4/t7ujElpyE0DSGErq7hcWFJTY85tmYwYsvJx5yShgwFsZjMyFAQGQ5jsFiH8cjHxgWqWEHF4TDaHSTNmEPI542sTo25kosmMNrsGMx5+vwUQtesH4SnvQVr5oAnXwg9L2CEJHXQjXxbdp7u6Q8FMZqtaEepO20wW3AUlRDyevSEeKFFyVwqYvH3dMUlj8DkSMTb2T6iFPBYEA6F2fDrf+Fzeph34clx17Q/yKv/fZO5CyowGg/v/bXkpOCsbCWhJDaPI54sX7UYs8XMZz/yFa79yOV85JPXYh0hXGiyEnD20V9zIHLPcBSVEQz4SSgu15/NRhO+vh4sqemYExKRoZDunLPZMSUkEPJmDjxnbccccqZQTAamrXHv7+uJVIslGMRVV4UtJx9r2kC58AHbXUo5IM2nYbQPX8xFX4LOwlkTbTAkls8a8fiawYA2iuIwmsmMNTMH7yDvvTAYYpL7FIqhDP+iOHaEPG7cTXVRbYGebhLLZ+nefZMZS2p6zFy22YoO26/BbI6RrJNS6gVqDIZRGaCa0YSWoHv5Q34fmsFIOHwoFM+ckj6sLN50REqJv7cr8hJ2PGgWK+GAn3AwMKpVluNFhiXvPPpv3J19zLt4FZphbDyzAX+AV/+3gas/ePERt7VmJ9O/t4mQx4/BNrZzbNGSedxx9y089sd/8Pgfn+b6j1/Dle+/iITEya/kpIfx1UQ5A8IBP2G3C+cg2WqDzTFwzxhivGta5B6gUEx1xt24F0L8BrgQaJNSzj9Rxw0Ok+gV6O/FNlAtFvTqm76uDgJ9PRgdCVgzsjGO4DU0ORJJKJmBt7NNN/bTszHGIQxCDFTz1Mxm/F2dekhPWgZGq4q3V0wshuatAIR8Hj3EzWjU53JGFprFEj2Xj/IFJOTz4u1sI9DXizEhEWtG1mETaodiMFtIKJ2Jv7tzIHE+VU+cV/G3gB6SI6XUVUeOEyEEBqtN/zsnH10xrKNFSsnm//svfU2dLLh0NYYjeNSPh7de30x2TgbpmbEqaUPRjAasWUn0H2ghZcHhX2TjQXpGKp+6+cPUVtfzwj9f5lc/+SPvu/5SPvyJ909qIz8cCsbcYzzNDSSUVRDs7yXocmJ0JOi5cEqjXjHNGXfjHvgd8BPg9yfyoKakZAL9vUPaUiK/h4NBXA01hAbkA/1+H0FnP4nls0csfGFOSolIdcUzxlMzmbGmZWJJzZhycnuKqYNmGiZx1e5ADAoHOt65HA4GD4XTAf4uH8H+vhGvy5EwWm0YcwuQUqpragj+3u64SnsazFaCbteYGvdSSt7968t0VDWz8LI1cS9UNZhQKMQ/n/o3Z5yzbtT72ArS6d1RT/K8wjELExpKcWkhH//sdbS3dvDMk//hovUf4Kt33czZF6w/IcePN5rRqK8EDSqOZknLwN1YhwyFMFis+Lq7CPT1kVhecUJWihSKicq4Z5NIKV8Fxk4IeARMiclRxrwxMQlz0qGHT8jvixj2BwkH/EesuiiEGDNjQRkhiomMwWbTK70OzFPNZMaRVzRsQuqxzuWQz3sonG6A0VyXI6GuqVgCfT1xWXU8iMFiiXuNhcFIKdn6+Cu07qlnwSWrMZrH1qh77X8bcCQ4KCodfR6BKdmOZjLirus48sZxJjM7g49+8v18/Kbruf87P+POL9yLzxubPD7R0YwmEgpLEAeNdiEwOhIJ+7y6pLWrXxeb8HkmVHVkhWI8GHfjfjQIIT4uhNgkhNjU3h4fzWCD2YKjsJSkGXNInDGHhKLyqASbkR76J8rropgcjMXcnKxoBiPWzCySZs4lsXw2STNmx9VIBEZUt1CqF7Ecy9wMB/yE/f4YwYDjQbNYCXncYyICEA6H2fyn/9K6u46Fl63BZB3bmHaX081Tjz/PutNXHdV+QggcpZl0v1c7bmIIM2aVcsfdt9Dc2MKHr7qJzvYT7lOLcKz3TaM9QX9ml88maeZctBGSYo+lqrJCMZWYFFeAlPIRKeUyKeWyzMzMuPWrDRS6MNkdaIbo+EyDxYI5PfpYpsRkpS2viGKs5uZkRQgNo9WGyZEwJtrmBrMFc9qQ6zIpWSlfDMOxzM1Afy8Guz2+YYVGI2gaYV98vcVBf4A3H36W7ro2Fl62dswNewn88Td/o2JOOTl5R698Y8nU60G4qk68NOhBbDYrH7/pesorSrn2kk9SfaB2XMZxPPdNg9mMyZGA0WrDYLHFVIc3p6Shqee0YpozEWLuJyRCM2DPysWckETQ7cRgtWN0JKo4PoViHNHrQAxclx51XcYbf28PRlv8ky4NVuvAfTQ+RpezvZc3Hn4GW4qDBZesRhvD5NmDvPzv16murOUDH7nymPYXQpA4K4+uzZXYCtIwWMZnzgohuOTKc8nITONDV97E/T//FstXLR6XsRwvmsGAPa8AU3IKIY8Lg82hOxYMKjleMb1Rxv1h0ExmzMnmMVd5UCgUo0czmTGnmDGnqOsynshQiICrH0taxpE3PkoMVhuB/r7j7ltKSd07e3n3sZcpWj6L/JPKT0jexIY3NvPU48/zvg9dhuk4YvrNKQ4sWcm0v7GX7NPmjWvOx5pTV5CalsJtn/o6n7n1Bq6+7pJJmYOimcxYUtIg5cjKRQrFdGHcw3KEEH8G3gJmCSEahBA3jPeYFAqFYrrh7+3GaLVFVTaOF0abg4Cz97jizfvbenjtJ0+x49m3WHDJagoWzxhzYzQYCvHUY8/x1z88xZXXXkRqWspx95lYkUvI6aXzncpxL0Y4d0EFX/r6TfzhN49z88e/Nq5x+AqFIn6Mu+deSvn+8R6DQqFQTGeklHjaW4atqB0PNJMJzWQm0Ndz1Cuhfc1d7H1xMw1bDlC4dCYVZywZs+JUBwmGQry7cTtPPfYcdoeND3zkChISj1x0cDQITSNlcQndW2pofWknGSfPxGgfv5yR7NxMbv/W53n6iRe45Izr+cBHr+Ca6y4jLT1l3MakUCiOj3E37hUKhUIxfoSDQdwtDQhNwzBCkb54YE5Jxd1Ur1dOHqLGI6UkFAgR8Pjw9bvpb+2hu7aV5l01eHtc5MwvYfmHzsJsi58RHJaSQCCAz+PD2e+iq6uX5sYWKvfVsHPbXjKy0lh9ynLKKkrivkKgmYykLS/DeaCFhqc2Yi9Mx56fhinFgdFuRjMZQRs7WeWhmMwmrnj/haxdv5J/PfM/zn/kfcxfNJuVa5Yyc3YZeQU5pKWl4Eh0YLGY0ZQ6lUIxoRHjvSx4tAgh2oGjSfHPAE68uPCJRZ3j2NAhpTx3tBsfw9w8FibL/7UaZ3wZOs64zM2kxASt+vWXItmUPr9/TB4IB4uFWcxmAZC5eMXmcFg/1IUL12dct+qS4pH2DYVDMhz359TECS43jRAGVdfVwe82vDIuD2jtCJrPYRkO76x//d0RvrYeTbX5Ud43J8t1OhJq/ONPBrDnaO6bk5lJZ9wfLUKITVLKZeM9jrFEneP0YbL8HdQ448tkGedITIbxqzHGh7EY42Q478Ohxj/+TIVzOBrU2ppCoVAoFAqFQjFFUMa9QqFQKBQKhUIxRZgOxv0j4z2AE4A6x+nDZPk7qHHGl8kyzpGYDONXY4wPYzHGyXDeh0ONf/yZCucwaqZ8zL1CoVAoFAqFQjFdmA6ee4VCoVAoFAqFYlqgjHuFQqFQKBQKhWKKoIx7hUKhUCgUCoViiqCMe4VCoVAoFAqFYoqgjHuFQqFQKBQKhWKKMOmM+3PPPVcC6kf9nIifo0LNTfVzAn+OCjU31c8J/Dkq1NxUPyfwZ9ow6Yz7jo6O8R6CQjEsam4qJipqbiomKmpuKhTxZ9IZ9wqFQqFQKBQKhWJ4lHGvUCgUCoVCoVBMEYxj1bEQohD4PZADhIFHpJQPDdlmPfAPoHqg6e9SyrvGakzTkb6efmprGjAYNIrLCnE47CNuGwgEqatuoK+3n9z8bHLyskZ9nIa6JtpaOkjLSKWoJB9NU++NitHR0tRG1f4ajCYjMypKSctIPeI+B+dbemYaRSX5CCFOwEgVirGlp7uXuppGTCYjJWWF2Ow2AJxOF7VVDWiaIBAIIoCi0gKSU5LGd8AKhWJCMmbGPRAEbpNSbhFCJAKbhRD/kVLuGrLda1LKC8dwHNOWupoGvvHF+9j8znsAnHvR6dx6+6eGNdo9bi9P/OVZHrjn5wQDQTKy0njwke+wcPHcIx7nzVfe4Yuf/Rb9fU5sNivfuu9LnHn+qRiNYzm9FFOBndv2cPcdP2Tntj0AnHXeqXzmCzdQNqN4xH1ef/ltvnzTXZH5dtf3v8yZ55+KwWA4UcNWKOJOdWUdd9x6Dzu27gbg0qvP56YvfIxAIMB9d/2YlNRkOtu7eeW/bwKwePkC7vr+VyguLRjPYSsUignImLlXpZTNUsotA7/3A7uB/LE6niKWfz75n4hhD/CvZ/7H229sHnbbfXsque9bPyYYCALQ0dbFt778fXq6ew97jKb6Zr78uW/T3+cEwOPxcvut91BbVR+ns1BMVcLhMM888ULEsAf4z/OvsPGtd0fcp6G+KWLYw6H5VqPmm2ISEw6HeeLPz0QMe4CnHnuOLRu38eZrG3nj5XfIyEqPGPYA727czjN/f2E8hqtQKCY4JyR2QghRAiwG3h7m61VCiPeEEM8LIeadiPFMB7xeHy+/+EZM+8YNW4fdvqmhJaZt/94qujp7Dnuc9vZOenv6otqCgSAtze2jHqtietLT3cc7b8Ya8tvfHbq4d4iOtq6IYX+QgD9Aa4uab4rJi7PfxSsvvhnTvu3dXezYupvc/GyqD9TFfP/Ki2/icXtPxBAnPFJKZDg83sNQKCYEY27cCyESgCeAm6WUfUO+3gIUSykXAT8Gnhqhj48LITYJITa1t6uH+GiwWi2sOXVFTPviZQuG3X64UJ2SskJSUpMPe5z09DQSEh1RbQaDgczs9KMY7eRFzc1jJyk5gcXLY+fj3IWzRtwnPSMVR0J03ojRaCAza3rMt6NBzc3JgyPBzslrl8W0z1s4iznzKmhtbh82/Gb1uuVYbZYTMcS4MhZz01lbSV/lniNvqFBMA8bUuBdCmNAN+z9JKf8+9HspZZ+U0jnw+3OASQiRMcx2j0gpl0kpl2VmZo7lkKcUF11xLhVzyyOfV69bzsmnxD5AACpml/OZ2z4aSUxMTErgG9/7EmnpKYc9RkFxHt954HYsFjOgG1p3fvc2SsuK4nMSExw1N48do9HIpVedT0n5obmycu1Slq9aPOI+hcX53D14vpmMfOPeL1IyTebb0aDm5uTBYDBwzfWXUjroWjj9nFNYumIhq9evYO7CWTidLpauXBT5fuasUi696rxJmUw+FnMz4Owj5HHHpS+FYrIjpBybol1Cv+M8CnRJKW8eYZscoFVKKYUQK4C/oXvyRxzUsmXL5KZNm8ZiyBOa5sZWGuqaSExOpLS8KGLcHImG+iYq99VgNBqZMauE7JyRFXCc/U727DxAd1cvhSV5zJ47c1THCIfD1FU30NLcRkZmGsVlRZhMUyKZ9qiemtNhbna0d1FbXY/FYqG0vBBHguOw24fDYWqr62lv7SQrO4Oi0oIYJaW6mgYq99dgMhqZMauMhEQHNZV1+Px+iksLychMG6bPBlqb28nISqO4tHCqzLejQc3NSUB9bSPNjW2kpidTUlqIyWwadrva6gaqK2tJTknC6/Fid9gpLS8iKTkR0FV0qivrMBoN+Lx+hBAUl8VeGxOEcZmb3TveRYZDpC5YOilfeBQnhGkzMcbyibgGuA7YLoTYOtB2O1AEIKV8GLgS+JQQIgh4gPcdzrCfrmx7dxefu+GrdHX2oGkan/j8h7juhitJSEw47H41VfV85fPfZte2vQCcesZqbv/258nNz4nZ1u1y89c//IMff/9XhMNhklOS+NGv7xkxjGcwmqZRUl4U5YFVTD0O7K3mtk9/g+oDtQBcePnZ3PKVT5CZHbPYBuhG+H+ee4Wv3XoPPp8fi8XMPQ/ewRnnrosy8ItKCigq0UMO2lo6+M7XHuCfT70IQNmMEu7/+bcoryiJbK9pGqXlRVFeToViorHhjc3c+ok7cfa7MBoNfOkbN3Hp1edjtUaH0WzdvIM7brmH+tpGQFc1+8ytH40Y9gApqcmjuhdPV/R4+xAIgQyFEEqpTTHNGUu1nNellEJKuVBKedLAz3NSyocHDHuklD+RUs6TUi6SUp4spYzNKJrm9Pb0cfft90cSW8PhMD//4W/Zs6vyiPs+88QLEcMe4JX/vslbr4+kllPFQ997hPBAQlJvTx/f+NJ9dB8hoVYxPQgEgvzxN3+LGPYAz/7932zdvGPEfWqrGyKGPYDP5+eOW+6hrqZhxH3e3bQ9YtgDVB2o4c+/e4JgMBiHs1AoTgytLe3ccfN3cPa7AAgGQ3z36w9Rtb8majuPy8MffvVYxLAHXdXsvS07T+RwJz0yFAJNQzOakMHAeA9HoRh3VKWhCU5Pdx97dh2IaW9tbjvsfl6vj9df3hDTvuWdbcNu39zYGtNWU1lH9xGkMBXTA1e/i7de2xjTPtzcPEh7a0fEsD+I1+ujo61rxH1279gX0/bma5twOVUsrWLy0NXZTXtbZ1SblJKWpuj7dmdHN1s3xb4gVw55CVAcHhkKohmMCIOBcCg03sNRKMYdZdxPcFJTk5kzLzb2/UjVY61WC+tOXx3TPjghazB5BdkxbWUziklNO7xajmJ6kJDkYPW65THts4eZmwfJysmMCUGw2axkHEbZZu6CWKWcNetXxCjkKBQTmfSMNLKGhKsJIcjJj77PpmelsnjFwpj9yytKx3R8Uw0ZCoKmITRN/12hmOYo436Ck5SSyNfuuY2MLD1xymAw8NkvfoxZc2cccd8LLjuLhUsOlQ4445xTOHnN0mG3nTmrnFtv/1SkymdaegrfvO9LpKalHP9JKCY9RqORD370KmYMMjouvfp8Tlo6f8R9ikry+c4P78BmswK6YX/PD+84bEXNxcsWcPFV50Y+z5xdxvuvv0xVO1ZMKrKyM7jnwTtITNLzoowmI3fcfQvlM0uitrPZbFz30asoKSuMtF142VmctPTIlcEVh5ChEEIzgGbQQ3QUimnOmKnljBXTVfWhpamNxvpmEpMTKCktxHwYtZyDygrBQJCcvCy6OroxGA0kpyTR1NCCzW6jfGZxjNKJs9/F7h376O7qpaAol3BY4nK6SEtPo7mxhVAoxIxZpRQWx6/Q8P49VdRU1eNIsDFrzgzSJ5b6w7RSJAn4A1RX1dHR3kVOTibFZYWRl72DdHV0U1vTgMVipqSsCLvDFvV9d3cPe3dV0tfdR1FpAeUVJezavo/WpjZy8rOYM7+CPTv3U1/bREpqEhWzy2M8+W2tHezfU4XP66O8ooTi0kIUMUyruTkZkVKya8c+2lraSU5Owu32YHfYEEJgNBjp6+snOSWJ0vIiujq6qaqsxWKxkJjkwO8PUDajhGAwQPWBOoQmKC0vRtME1QfqCAaDlJQVjpjMPhIBf4Dqyjo6OrrIzc2iuKwwRr0qDpzwuenv6cLb2Y4wGDAlJGHNOPzKtmLaotRyFBOLnLysI4bigB47f9dXf8Abr7wD6IWoHvjFt/H7/Fx3+Wfo6ugG4Ir3Xchnv/gx0jNSAXA6XTz6y7/yi4ceBfSiKp+97QZ+dN8vSUxK4Lobr+b+u3/GzNll3PX9LzNv4ezjPqdNG7byhc98MzKm8y85k8/c9tG4vjwoRoff7+fpv73Ad772Q0KhEGaLme89dCdnnLcuaru0jFTSBubMUFqb2/nVz/7IX3//FKDXSrj7/q/ylc9/G4/bi91h454f3sGdX7g3UmX2musv5fobr6GwKG+gjzbu+fpDvPTv1wEoKMzloV/fw8xZZWN05grF2PDmq+9w+83f4cbPXsdX778bt8uD0Wjknh/ezj1ff4iegXym933oMj59y0fIL8jh8zd+LZJce+d3buVv//cMu3fuB2DBSXM4/9Kz+N43fwRA6YxiHnj4rpjVgJEI+AM89fjz3HPng4eu8R9/nTPOOSX+J3+CkeEwQtMQQtNVcxSKaY4Ky5libNzwbsSwB10O8/E/Pc2ff/f3iBEN8MRfnmX3jkNKOvt3V0UMewCX082ffvsE51x0Om2tHWx4bROLly1g/54qXvzXq8c9zq6uHn76wK+jxvTcP15k5yB1H8WJo6ayPmLYA/h9fu784r1RKh5HYtf2vRHDHqC/z8mPv/8rTjtrLQCnnb2WB7/3SMSwB/jr759i785DSbnvbtweMewBGuqb+eOvHycQUHG0islDS1MbX7vtXk4/+xT++Ju/4XZ5ADjl9JN59JePRQx7gL88+iS7tu/jL48+GbneMrPS2be3KmLYA2zfupvG+uZI1fDqA7U89dhzjHb1vepAbew1ftt3qa9riss5jycyHAJNgCZUWI5CgTLupxw73ostv/3OG1tiVEsAmhsOKTe0tsSWAG+oayIzWw+Z2L1zP2UzigHYunH7cY+zu7OHXdv3x7QPVZNQnBja2zojD/2DOPtdUS9fR2K4OXRgXzX5hXpdhbyCHGoq64Y5dkfk9727YyVeN761FbdLqeUoJg893b10tneRlpFCU0NLpL1sRjF7dg5z32ts5Z233o18Liot4MCeqpjtqvbXkF+YG/m84fXNeD2+UY2pva0zInV8EGe/a0rIHctQCCEGEmqV516hUMb9VGPJ8ljlhfVnrSYhMVZtpKA4L/J7XkFsYavymSU01jcDcNLS+ewakCk8ee2y4x5nVnYGS4ZRiRj84FKcOHJys2KqZ6akJh9VTO9wc2jewtlU7te18Wsq64ZV18kdpCAyf1FsuNepZ64mIfHwlXAViolERmYaOXlZtDS1RxX3271jHyctnRezfUFxHqeeeUjdrHJfDXPmV8RsN2vODGqr6yOfTztrDTa7dVRjys3LwjikknNKajKZh1GvmiyEwyEQA2E5ynOvUCjjfqqxdMVCLnvfBZHPS5Yv5JKrzuf9H7qC0gHPu8Fg4BOfu555Cw/JDlbMLuOr3745YuBl52Ry5Qcu4j/PvcLM2WXMXzSb3Tv2cfLaZaw/a81xjzMxKYFPfO76iEqEwWDguo9dxcLFc467b8XRU1JeyHcfvCOSIJucksT3fnznsAb7SCxYNJtP3/KRiAGRV5DDZ794A5vf3grAxg1b+fyXPx4x5o0mI5++9aNRUq8nLZ3PNdddGikfv+CkOVz9wUtiEnsViolMRlY69/7oTjZueJdrPnhJRBZz8zvb+MANV0XyioxGA5+97QbmLqjgivdfyKIB9anenj5mzi7jlNNPjvR5xrnryC/KjRTGWr5qMRdefvaox1RcVsh3H/waNvuha/y+n3w96uV60hIKIzQBmoYcsjqhUExHlFrOFMTj9lJbXU8wGKKoJD9SxvzAvmqq9teSkGAnOzeLxoZm0jNSKZtRgs1uJRgMUlfTSF9vP9k5mTidLrxuL+mZqTTUNROWkpmzSknPiJ+izYG91TTUNWF32CifVUp6+vDJmuPEtFIkkVJSX9tIV2cPWdkZwxr2TY0tVB+ow2q1UD6zhJQhdRB6unvZv7eK/j4X+YU5zJozg/raRjo7usnITKOgKI/9e6poqG8mKTmBOfNnYR/iefR6fdRW1eP3+ykqKSA5Jemoz6W1pZ3qA7VomkbZzBIyJpYKUzyYVnNzstLS1EZbawc2mwWXy43FYgEJRpMBt8uDI8FBcVkBbS0d1FTVYzQZSUh0EAwECYXCGI16USaL1UJxaQFCCGqrGwgGQxSX5JM4cG8fCbfbQ9W+Grq6eigoyqOkrJCGuqbDXuNx4ITPTWddFZrRhDAaCDj7SSqLrZehUKDUchSTGZvdGhP+sH3rbj51/Rfp6+0HYN3pq3Ak2Hn+6f/yqZs/zPU3XoMjwR6Jqx9KXkH8w2WGjun8S8/ki1/7zESTw5w2CCEoKimgqGR4Hfo9O/fz6Q9/KVJhds2pK/j6d78Q8fz1dPfxsx/+lr88+iQANruNn/3ueyxduShKAWnm7DJmzh5Z/cZqtYyqjsNIVO2v5eaP30FNlR6+MHfhLO770dcpOoy+vkIxFoxG5Wz3jn186kNfiuS3rD1tJeUzS3n0kb8AsHDxXL770J3YHXpo5eEKxw3G6XTx25//H7/8yR8BsFjMPPTL77D61BUjXuOTFRkOg6aB0JAh5blXKFRYzjTA7XLzw3t+HjGiAV7931uUV5QA8PMHf0flvupxH9NzT73Izu1KLWciEvAH+O0v/hwx7AHeeOUdtm46lFy9d9f+iGEP4HF7+Pbt90cpg5wI/vnUvyOGPcCubXt59aUNJ3QMCsVo8Pn8/PInf4xKXH/9pbex262RULRt7+7irdc2HnXf+/dURQz7g8f6xpfuo6214zB7TU5kOIwQAqFpIJVxr1Ao434a0NfrZOf2fTHtXo8vUsCkva1zQoyptTlWcUUx/rhcHt7bvDOm/cD+msjvw82hqgO19PU6Y9rHilAoFKU6cpDBLyEKxUTB5XSxbUvsddXV2YMj4ZAIwvatu466745hrsfWlnZ6e/qH2XqSM9hzr2LuFQpl3E8HUtOTOeW0lTHtdruN8IDH40Sr1Iw0pqm2XDxVSExycPo5a2PaFyw6lABdUJQX8/3SFYtIy0gZy6FFYTAYOOv89THtp5x2cuzGCsU4k5ScyGlnx15XGVlpUfUgVq1dftR95xfmRhLTDzKjonRKqOMM5ZDnXijjXqFAGffTAovFwqdu/jBzF+jSaiaziQ/ecBVvv7kFR4Kdex68Y9RVDsdyTJ/78o2Rz4qJhcFg4JoPXsryVYsjnz/yyWtZtOSQrN+sOTO44+5bsFjMgF5B8yvf+hwJCSdWxvKMc07hrPNPBfQ8gsuuOZ+TTzl++VaFIt4YjUau/cgVLFmxaOCzgY9++lpCwRBSSoQQXP2Bi1m+6qSj7ntGRSnfvv+rEXWcgsJc7vrBl0lJPfoE9YmOlLrnXghN9+IrFNMcpZYzjag6UKsr09ht5OZl0d3dS3JKUiTZsb/PyYG91fR095KVm4nP46Xf6SIvL5u21k6klMyoKCEnLxspJVX7a6mvbSQxOZGZs0ojqjxHoqmhhcr9NRiNBgqL8+nr7cdmt1JYnI/ROKFyvJUiyRBqqxuor2nAbDFTOrOYzMxoL2BdTQP791TT19dPUUk+c+ZXUH2gjtaWNnJysyivKI0Y/wdprG+m6kAtRqORGRUlR6WtPxJul4f62kY0TaOwJB+r1XLcfU4w1NycxFQdqKWupgGT0YjZasZqs9Ld2YPZbMLmsOLsc5OWnkIwGMLn8+H3+imvKCU7N3NU/ff19nNgbzVer2/gvizJycs+UapRJ3xu9uzehi0nD2Ew4qytJG3B0uPqTzFlUWo5iqnF1s07+OR1X4iUQT/t7LV87e5bIxVo+3r7+ckPfsVffv8UMOBJ/9KNeD1e7vvmTyJl0QsKc/nxb++lvbWTz370K/gHKt9eevX53PLVT5CalnLYcezfU8WnP/SlSDXTirnlPPDzu1Q4ziRg1459fPKDX4gkyC5evpDvPnQHefm6nF71gVp++sPf8u9nXwKgYk45F11+Nvd/5+eRPr72nVu57JoLMA1o4e/dXcmnrv9CJFF37sJZfP8n36SwODbE52iwO2zHpbijUIwVm9/Zxqev/yIejxeA089ZS3JyEk8+9hwAC5fMY/bcGezesY81p67g4YceBaC0vJAHf3kPpYOKYg1HT3cvD33vEZ7487MAmC1mfvKb705FOdgIMhwGoYEQIGVk1UOhmK6osJxpgNPp4oF7fh4x7AFe+vfr7Nq+J/J53+7KiGEPujrKP5/8T8QDepCG+mae+8eLPPzg7yKGPcBTjz3H3l0HDjsOKSVP/OWZiGEPsG9XJa+//M7xnJ7iBOD3+fnNz/4UpXzz7sZtbHlnW+Tz3j2VEcMe4PSz1/LQ9x6J6ufeb/6I2gElm1AoxF9//2SUAs+ubXt5+3XlYVZMTfp6+7nvmz+KGPYA/3vhdfKLDuU8bduyk7T0FHbv2EcwGIqsOlVX1vO/f792xGPs3XUgYtiDfu3e9ZUf0NXZfZi9JjdSDsTcC6Eb+So0RzHNUcb9NMDZ52LvrsqY9rbWQ2oKHe1dMd8bDAb276mKaX934/DKI50dh394+Hx+3t24I6Z9l5K/nPC43R52vLcnpr26si7ye1dHT9R3oVCIYDC6FHwwEIy8IPi8/mEVePYc4SVRoZisOPtd7Bvmnuob5CgB6O7qxe6w09bSHlUo7r1NsffPoXS2x96HG+qboxJ0pxxhCZruqVdJtQqFMu6nBWnpKZw+jCJDSVlh5PfC4vyYZUyT2cTi5Qtj9jv7gvUkJCXEtA8uVDQcVquF8y4+I6Z97akrDrufYvxJSk7k7AvWx7QvWjw38ntBUbTiUjAYInHIPElMSiBnoOiV3WHjnItOj+lz5ZolcRixQjHxSEtP4dQzV8W026zRVZozs9Pp6+2nsCSf9kFOmNPPOeWIxygsGV61aqoWB9TzBiWRcGqh6Qm2CsU0Rhn30wCzxcyNN10XUWSwWi186eufZe6CQyW6K2aXcc+Dd0SMsRkVpZx9wXoa6hq56Ipz0DQNTdO47H0XsP7MNXzuSx9jzny9UqIjwc5dP/gKFXPKjziWsy5YzwWXnoUQAoPBwPU3Xs2yY1CCUJxYNE3jymsv4tQzVwP6i9+nbvkIC5fMj2yzYNFsvvSNmyL63Nve3cV3HridrIEE2eycTH74i7spGCS7ev4lZ3L2BacBulLIRz55LUsH5qlCMdWw2qzc9IWPsXBAZcpmt/H5L91Ic1MroN+r3//hy9m+dTc3fPoDWG1WwuEwmqZxzXWXsnrdkR0hFXNmcPf9X41ch3PmzeSr3/78CVetOmEMxNsfdE4JTaiwHMW0Z8zUcoQQhcDvgRwgDDwipXxoyDYCeAg4H3ADH5ZSbjlcv1Nd9aGpoYX9e6uQUpKdm0VLYytmi5mZs8siRtKx0t/voqmhBYvFTEdbJ3XVDaRlpjJnXkVEhaGhrglnv4usnEz6evvx+/xk52XpBVEkFBTnRdROenv7aGlsw55gp3AYjfOR8Hq8NNQ1YzIbCfgD1FY34EiwM3N2GekZabhdHvbvraK1uZ3c/Gxmzi7FOsSzdYKY0ooknR3d7N9TibPfRUl5EeUzS46YhLZ31wGam9owmYwUFufFJEJ3d/WyddN2+nr7KSkvYsFJc2hv66S7s4e0jBTSM9Ko3FdDbXUDySmJzJxTjtVqobGuCYPRSEFRXiTZ9nhoqGviwN5qNE1j5uxScgeSfqcQU3puTka8Xi/791bTWN9CYpKDcDCEZtAwGo1IoKerl/TMNCpml6EJQVNjK0aTEZAYjUZ8Xj8GgyGi115YnEcoFKKhthkh9DoS5iFKUwfp7Ohi3+4qXE43peVFlFeURO7lPT199PfoqwDlFaVxub6OwAmdm+FggN69O0go1p1LrsY6EgpLMdqn6MuM4niYNlnWY3mVB4HbpJRbhBCJwGYhxH+klINL7Z0HzBz4WQn8fODfaUnl/ho++5Gv0FjfDEBWdgbXXH8pP/7+r5i/aDbf/+k3j6vYVGKig1lzynnqsef45pe/T3jAu3HJVefxuS99jMysjKhCRGnpKZHfk4eRuUxOTiI5+eg1k602KzNmlbLlnW188rov4PX6AFi1bjnf+t6XeO4fL/Lgvb+IbP/Vuz7PVR+4eKLJZE5q2ls7+NZXfsCr/3sLAIvFzM9//32WnXzSiPu88+YWbvnEnZHY3VlzdQ/hQVWaro5u7v3mQ/zrGT2p1mgy8pPf3MvqdcvJztFfHl9/+W0+d8NXI7H4511yBl/+xk3MmFUWt3Pbv6eKT1x3WyRRt7A4n5/89t4jqowoFMdKMBjkycee57t3Phhp+8BHrmDv7krOu/gM7rnzQUIhfc5f8b4LueWrnxiVmpPRaKS8ouSw27S2tPP1L9zLW6/pBrLVauHhP/6AGRWl/Obnf+Zv//c0oK++3f/wXZwxitCeyUREKWcAIYQKy1FMe8YsLEdK2XzQCy+l7Ad2A0ODsi8Bfi91NgApQogTWyp1AvHi869GDHuAttYOGuubySvIYcd7e0ZMZD0a9u+t5gd3/yxi2AP84/Hn2b1j/3H3fTT097v4wXd+FjHsAd56dSOV+2v40X2/jNr2+9/+KbXVDSd0fFOdXTv2RQx70BP67vvWj+nrHb40vdPp5re/+EtUUt7eXQfYsvGQWs6eXQcihj3oybN33/FARKWjs6OLb99+f1SS7fP/+O+wyd7Hwz/+9nyUAk99bSMv/+eNuB5DoRhMbXUD37/rJ1Ftf370Sa7+4CX87Ie/jRj2AE/85Vn2DpNUe6zs3LY3YtgDeL0+HrjnYWqrGyKGPUA4HObbX/0BLU1tcTv2hGCgOm0EoamEWsW054TE3AshSoDFwNtDvsoH6gd9biD2BQAhxMeFEJuEEJva29uHfj1l2Pne7pi22uoGcnKz9N9rjt/A7evpG9aA6zqC0k28cfW7qNpfEzuOzu6oFw/QjcTe7r4TNLKjY7LOzeH+vysP1OJyuofdvr+3j5rK2pj2+tqmQ30OI7WnhwbofbqcbpobW2PHEkeJvlAoxLZ3d8W0T0dFpsk6Nycjvd19BAPBqLZwOExYSjqHUSLrjuP9tqOtM6atcl81blfstdzV2UN/vytuxz5W4jk3pZSgDfLcq5h7hWLsjXshRALwBHCzlHKohTZc/FNMEoCU8hEp5TIp5bLMzNFV6JuMnHneqTFtJy2dz97dujTgoiVzY74/WvIKc7J2+R8AAHssSURBVCifWRLVZjQaTngRqfSMVM46f31Me35BbozCSlp6CnkFEzNmerLOzeLS2P/vM89bR3pG6rDbZ+dmceqZa2LaF54051Cfw8yhtetXkpmlF0pLz0xj1SnLor4XQgw7lmPFYDBwwSVnxbSfNoxa1FRnss7NyUheQQ5pQ66dhEQHHpc7SrgAiFRNjhfDhZudfcF60jPSMBgMUe3zFs0mO+f4K0AfL/GcmzLGc6+kMBWKMTXuhRAmdMP+T1LKvw+zSQNQOOhzAdA0zHbTglXrlvPhT7wPo8mI0WjgsmvOp7Ojm1AwxG13fJqFi+cd9zFy87K5857bmDlHj3FOz0zjOz+8nfknzT7uvo8Gk9nEDZ/+AGvX6ykWjgQ7X//uF5g9byYP/fI7kdyC4tICfvjI3eTkZZ3Q8U115i6Yxbfu+3LkRWrVuuV88vMfHjFhT9M0Lr36fE4/5xSEEFitFj75+Q9FSaXOmjuDe39050C5e11+77Y7Po3NridDOxx2vvT1myL7JKck8b0f3UnF7COrLB0N689azfuuvxSDwYDRZOSGT3+AlauVvKZi7MjJy+LBX9wdeVHNK8jh07d8hL88+hSfvPnDEWWxtPQU7v/Zt+KaYzJv4WzuvOe2iDrOKaefzEc+eS0l5YXc//NvRXKn5i2azTe/98XI9TllkGG9Mu1BhKa3KRTTmFGp5QghUoE8wAPUyFFkqwwo4TwKdEkpbx5hmwuAz6Kr5awEfiSlPKzW11RXfQgEgjQ1NCMlZGal09rSjslkpK21g6p9NSSnJjNnfgWFxaNTp6mpqufA3ioMRiNZ2Rk01jXhSLRTUJhHd1cPSSlJlM0oHpNz6WjrZO/uSvr7nJSWFzFzdhmaFv0+6XZ5aGlqxWK1RCULd7Z30d3VS1pGCmnpw3uTTwBTWpGkva2THVt309/nZMbsUmbPnRn1/9Pb28eOrXuor20kJTWZ2fNm4PP52bvzABarhYVL5pKblx3Tb3NjC26Xl+y8zGHl95z9TlqbO7An2IbdPx4EA0Ea6pvQNI28gpypmIw9pefmZKWrs4eujh66OrtpamgmKSUJGQ6RmJyEzWZFM2g0N7Zit9uYNXfGiCtlI9HY0MK+XQcIhULMmFUWVauksb4Zn9dHTl42doct0t7S3Iazz0V2TgaJJ8awP6Fz09/Xg6etGXuOvhri7WjDlJCENUM5hBQxKLUcIUQy8Bng/YAZaAesQLYQYgPwMynlSyPtD6wBrgO2CyG2DrTdDhQBSCkfBp5DN+wPoEthfuR4TmYqYDIZKS49dMMum1HM80+/yO033xNJylq9bjm3f/vmI4bS7N6xjxuvvTUSY5+bn83FV5zLL370KIuXL+R7P74zEs8fb9paOrjzC9+NJHoZjQZ+9uh9nLw2OizD7rBRNiRMCPQVhaladGUi0NrSzh233MM7b+rKs0aTkZ/97j5OXrs0ss1/n3+Vb33lBxx0AJxz4Wkg4YV/6pf9zNllPPjI3THFy44kO5mQmEBCYmwRtHhiNBkpKVPqOIoTS0pqEi8+/wp33/FApO3iK86hsb6Z/KI8ujq6ef1lPfXstLPX8vV7bhv1fa66so7PfPjLNNTpi9uJSQn88v9+yNwFFQAjKqnl5GbBVJapkBIxSC1HheUoFIcPy/kberLrKVLKWVLKtQMxcoXAvcAlQogbRtpZSvm6lFJIKRdKKU8a+HlOSvnwgGHPgErOZ6SU5VLKBVJK5VoaQm11Aw/c83CU2sKbr25k1/Z9h90vHA7z2B//EZU829zYisvpIjkliXc3bmPXtrFLMty1Y1+UgkMwGOK73/gRPT29Y3ZMxejZtX1vxLAH3dP9/bt+Qm+vnhaze+d+Hrz3EQav7L3w7EvMmF0a+bx/TxVb3jmklqNQTHfqamJVc55+4gVWrl3G03/7F4uWHgqtfOnfr7Nn14FR9/3GK+9EDHuA/j4nf/n9k1HPhumILoV5yCErVFiOQjGy515KGZuVdui7zcDmMRmRIgq3y01rc6yawEiShQcJBILDylu2trSTnplKb08fXZ098RpmDL3dsUZ8fU0DHqeHlJTkMTuuYnT0DKM+VFvTgNvlITk5CVe/i55h/g8DQxRBGgZJtyoU0x1nvwufzx/THgzq143fH4hqH+46HInh1MX27tpPwB/AYDPE7jBNiE2oRXnuFdOeUSXUCiEWCiEuFkJcfvBnrAem0MnNzz4mhRGLxcwlV50b0z5zdjl1A5rxZTPHJtYeoGQYBYdzLzpDhdpMEIZT2Dj3wtPIyND/f/IKc1kwSAkH9NCqodUtFy+bP3aDVCgmGbn5OVGFAAFsdhsyHMZsMWMcpF4jhKCkbPRKUaecdnJM28VXnovVNi7VuycOUsZ47pVxr5juHNG4F0L8BvgNcAVw0cDPhWM8LsUAKanJ3PTFj7FiQO0jIyuNux/4KguXHNmoOv2cU7j+xqsxmozYbFY++qlr2bV9LwmJCXzngdsjsZpjwex5M7nvx18nLT0FIQRnnHMKn/jc9SOqsShOLHPmV3Dvj+4kNS0ZIQRnnX8qN950PSazCYC8/Gxu+9qnWbx8AQDZuZnc+6M7cTvdGAwGEhId3P7tm1m4+PjlWRWKqUJ6Rio/+Nm3mLdIVx8rLM7npi/cwOsvv8N9P/5GpFZJRlYaDzx811EpRS1evpBbb/8kNrsNo8nIB2+4kjPPXTcm5zGZkEPVcjQVc69QHFEtRwixS0o5YZ7g01X1oaenj8a6Jqw2K+1N7TTVN5ORnY49wU5TUyvZOVnIsKSjvZPcgmxc/W5cLjcFRbn0dvdjMGrY7XaqK+uwO2xk52ZSW11PekYac+bNJC0jlY62Lvbs3EdXVw8lZUXMnjtjVMa4y+lmz879NDY0k56RisVqoamhhdKyItIyUgkGg2TnZE5GD9OUViRpa+2gtroBv9dHZk4G5TNLonSxfT4/e3cdoLurB5vNysxZpXR19tLa3I7BaKC4NJ/u7j727txPMBBi5uxSTGYTB/bV4OxzUliSz6w5ZdRUNdDS1EZufjYzZpZQvb+O2uo6kpKTmLuggtyiqZztN2ZM6bk5mWiqb2bXjn10tHWRnpVGKBgiLT2F5JREurv7aKhtIiMzjYVL5mKz2WhtacfusJGWnsK7G7dTdaAGq9VKfmEuvb39zJ1fgdvtYf/uSgxGA7PnVRAOh9m76wBmi4ns3CwSEuzk5GXT0dbB7h378Xi8zKgopWJOeXSIyvhwQuemp7WJkM+LJU3X7w/09xL2B0gojp/cqGLKMO4Xx4liNPpwbwkh5kopY8s+Kk4YKSlJ2O02fv+Lv/CjH/wq0n7BZWfR2tzOpg1b+dhnPsjzT/+XlqY2bv7qJ/jZ/b8BIfjclz5GOBTmh999mGBQT76qmFPOkhUL+cujT3LeJWfwuS/eyL3f/BGvvPhmpO/7fvINzr3o9MOOKxgM8rf/e4b7v/OzYcd0x3du5eoPXDwRHjiKQbQ0tfGlz36LrZt3AHrxp5/89l7WnHpIifY//3yZ22/5DqCHENx9/1e566s/iMQUF5UUcNHlZ/PTB34DwCP/9wA//O4v2LJxW2Sfb9//FX56/28ilWk/8sn3s+H1zezeoSeEn7x6Cd/63peUga+YlHR39PDoL//Knx99MtJ2zfWXUl/bxIrVS3jwuw9H2i+64hy+/PXPRuQrX/7PG9z6yTsj9+SZs8u4/mNX89pLG/jhdx+OVIv+wtc+zW9+/n+RHKnEpAR+9ZcHaWlq4/M33s6BvdWAXjvkkT89wNIVh2pPTAeGJtQiNEah1q1QTGlGE3P/KLqBv1cIsU0IsV0IoSQyxoHqvdX87KHfRbX988n/REJ2/vjrxznnwtMIhUI8/sd/cNb5p+Jxe3D1u3nyr89FHiIA+3ZXRvTjn//Hf9m760CUYQ/w3a8/SGtz22HHVFfdwEP3PTLimO7/9k+pr208pvNVjB27duyLGPYAoVCI++76SUTNqKmxlXu/+aPI98tXncSTjz0XlSxYV9OAz+fHMrC6097aETHsQS8L/+P7fsXHb7ou0vboI39l/ZmrI583vLmFPTtHrxiiUEwk9u2p5C+/fyqq7W9/eoZLrz6PXzz0aFT7M0+8wP59NQC0t3by0wd+E3VP3r+nCr/fz4bXN0UM+6zsDGqrG6LED/r7nDz51+c4sK86YtgDBPwBfvKDX+F2e+J7khMcKaMTaoWSwlQoRmXc/wZdr/5cDsXbXzSWg1IMT3+fk+AQtRI4pMTg9fowDiQ8NjW2kpGVDoAEmptaY/YL+P2RokXDqe90d/XidnsPOyZnv/uIYzr4oFJMHPp6YlU6Guub8Q78f3tcnqg5kZGVHvG+D6anuzdSGdPZ74r5vq21I0rTPhwOExry4O3rHb1iiEIxkejr6WdoaGsoFCIUDOMZxsju79OvKafTOez11NvTT+cgQz4tI3VYtbR9uw8M239ddQNez+Hv2VOOcFivSnsQIZQUpmLaMxrjvk5K+bSUslpKWXvwZ8xHpoihsDifwiFKDIlJCRHjeuassogO8mlnrWHD67paqcViYv2Za2L6s9lthMNhLBYzJeVFGI3RcmprTl1Jdk7mYceUX5QbU8Ro8JhmzZ1Bbv7YVCFVHDtlM0piQqUuuvxs0jP1F8LsvEyWr1oc+W7zhvc45fRYtY78wtyIV7GopCCmAvG6M1axecPWyOfMrHScfYdeAgwGA6XlY6fapFCMJcWl+aSlp0S1Zedm4nK6mD1vZlS71WqheKDwYH5hrl4UbggFRXksXnpILOHAvmrmD1GtArjsmguGvTdfds35pKalxLRPZWRYDkmoVWo5CsVojPs9Qoj/E0K8X0lhji/ZBdnc+9CdkZt/xZxybvnqJ3j8T0+zcs0SrvrARbz43Cucc9FpzJxdxoF91bz/w5dTX9NIflEuF1x6JgaDgcysdL70jc/yr2f+R0l5ET/93fdYcNIcfvKbeykoykMIwennrOWLX/9MVBnz4UjPSOX+n3+LpSsWATBr7qExrTplGff88A5SUpWu/URjzvyZ3P/zb5GVnYHBYODiK8/lI5+8NiJ1mZCgq+EcDKGx2iycc8FpXPexqzCZTaSkJvONe79IWkYqiUkJWCxm+vr6uefBO8jNz0YIwfozV/PRT13Lzu16sbQFi+fyvR9/ne6OLoQQ5Bfk8MDPvsXshbPG7e+gUBwPFfNmcu9DdzJnvm7Iz180mw/deA3PPvkfvvT1z7Lm1JUAlM4o5qe/+x6lM/QXWbPZzNUfvDhyT87ISuNr37mVt17dxOLlC/n4TddjsZix2ayUlBVy6+2fxJFgx2az8pnbPsra9SuZu2AW9/zwDtLSUzCajLzv+su4/H0XTrv8JhWWo1DEMhq1nN8O0yyllB8dmyEdnomm+lBb3cDuHfsIBIJUzC5j1twZY37M3u5eutq7SU5JQjMZcPa7SEtPxePx4vV4ycxKp7u7l1AwREZWGrXVDRgNBgqK8mhr7cBiteBw2Ojs6CYhMYGU1CQA3D1O2hpa8Xi9pKenkpafiXFAGvFIuJxuurt6SEpKJCzDkTEd6eVggjOlFUlamtqoq20k4A+QnplC+cyyGB17j8dLZ3sXjgQ7qWkpBINB2po7MJqNZGXr6hRVB2oJhUKUlhfh7/fQ0NyGz+clPT2N7NxM3B4vvT19JKcmk5jowO1y09akK4Zk5WWNx6lPBab03JyItLd2sGv7Pro6uykuLWTugoqIAlhLY6seopbowOV0YzebCXb0Y0lLImiE5LTkYZ0cHo+H+tomLBYzFosFg1EjMyuDcDhMS3MbBk0jO1e/Rlqa25BhSU5eVpQx297agT8QICs7M+b6HSdO6Nzsr96PwW7H5EgEIOT3421rJmX2gmPuUzFlmTZvvkc07icaE+khVbm/ho9feyvtbZ2AXjjqV395kEVL5h1hz4mHp8/F2799gbbddZG2FR8+m5KTJ4wK6ngwZQ2o5sZWbv7E19i9XVet0TSNh375HU4dlOx6tLh7nGz41XN0HGiKtK268XwKl45dPYVpzJSdmxORzo5uvv7Fe3ntfxsibd+678tcds35UduFQ2H2/mcz2596I9JWsmouJ119Kmab5YSNd5w5oXOzr2ofpoQEjHY9tyccCOBubiB17qJj7lMxZZk2xv1oilg9KoRIGfQ5daCw1bTnrVc3Rgx70HXBf/eLPxMYUmJ8MtDb0BFl2ANsffxVXF2xibaKyc+u7Xsjhj3oia733fUTerp6j7nPnvr2KMMe4N2/voynx3nMfSoUE4H9eyqjDHuAH9z9U5oaWqLanG3d7Hzmrai2mrd20dfUiWKMkEMSajWVUKtQjCbmfqGUsufgByllN7B45M2nD8OpHdTVNBIYRj1mohPw+GLa/C4voUn4oqI4Mv3DKdu0tOP1HrvSxnBzyNfvITQJrweFYjDDKUH19znxDFGmCfqChEOxhmXA649pU8QHGR4ac6/pSbYKxTRmNMa9JoRIPfhBCJHG6IpfTXlWDyr4c5CrP3jJpIwzT8xJQxuilpO3sAx7WuI4jUgxlpTPLIlRtrnsmgsi8qnHQlJOGmJIn4XLZ2FNSRhhD4ViclBSXhSp53CQ1aeuIHdIzogjPYnk/OhryGS3kJiVMtZDnL7IoUWsdM/9ZAs5VijiyWiM+/uBN4UQ3xZC3AW8Cdw3tsOaHJy0dD533/9VMrPSSUxK4KYvfIzTzzllvId1TCTnpbPupktJzs9AMxooXjmbRVecMuqEWsXkYva8mfzoV/dQXFqA1Wrh/R+6nOtvvBqj8djf25MLMjjlpktIyk3DZDNRumYe8y48OVJ7QaGYrJTPLOHnv/8+c+bNxGwxc/4lZ/Llb9yE3WGP2s6SaOPkj55H3sIyNKOB9PI81t10KQmZKeMz8GnAUCnMiBdfGfeKacwRn7pSyt8LITYBp6MnI1wupdw15iObBDgS7Fx85bmsPnUFoWCIrJyMEypD1tfSRVdNK+7ufhKzU0kvzcGeesjTLqWkp76d7rpWhMFAWnE2yXnDe2aFEGTNKuS0264k4PVjTbJjGKWh19vdx45te6itrie/IJd5i2aRkXnsHmDF2GMyGVl3xioWLp6Lx6srLA017ANeH121bfQ1dWJLSSCtJDtqfg1F0zTCiRbEkgI8Hd2ImZmYkqyHHYeUku76dnpqW9GMBtJKskFodNW0EPIHSCnKIq0oG6FNmzwoxQRECMHcWeXcd9/tuF1u0jJSSEhJonFbJe6OPhJz0kgtzsbisJKcn8HJHzsPT68TV1svXdUteHrdpBVnY0898iqWlJI9O/eza/s+jCYD8xfOobyiZOxPcrIiJUIM8VNqmi6ROSr/pUIx9RjRehNCJEgpnQADxnyMQT94m+lMRmbaCT+mq7OPdx97hdZdh+qJzT1/BXPOXxExyjurm3nlh08QCuglzs12C+tvvZKUgpELU5ntVsz2wxtkgwn4A/zh14/xyI//EGm76Ipz+Mq3PkdiogrHmOikpCWTwvB1CGrf3suWP/8v8jlrVgErbzgPW5Jj2O1bm9u47dPfYOd7eyJt333oa1xw6VkjHr+jSp+j4aA+Rxdcspr9L23F26dXNRaaxqk3X05WRcFRn5tCES88fS7+v733DpPkqu7331PVeXLaiZtzXq1WOQsQQhIIRAaRjMHYRNvYP4y/TuCEMTKYYJlsYUwSiCCJJCGhvAorbc47Oznnmc5V9/dH9fRMz/SknemZ6Zn7Ps/sdldX3TrdffrWqXvP+dxnv/1r2k82JrfteM0VnHv8CMEeR3Rg+22Xs+XmSzBdJqbLRfPBcxy89/Hk/pU713DJu27ClxsY1/5oDr14jPe+5WNEI06efn5BHt/8wRfYtHV9Bt5Z9qPsMWk5OHn32DaYExyk0SxxJrut/ZmIfE5ErhWR5NVcRNaJyHtF5NfAzZk3UZOO3saOlMAe4MRvXqC3oRNw1E9OP3IwGdgDRIMRmg+dm1M76mob+MZX/i9l2y9+/GtqT+tFjLOZwc4+Dt33RMq29pON9DVNrPpx4uiZlMAe4LOf/jLtbZ1p97fiFqd+80IysHd53URDkWRgD86F+/iD+4nrwm7NAtLX2JkS2IPT367cN7IK7bEHn2WwvReAwY5ejvzsqZT9Ww6fp7+5e9LzWJbFd795bzKwB+jvG+DRh56a5KjlzdhFrAAQ0UW1mmXNhCP3SqmXicgtwB8BVyUKaWPASeAB4F1KqdaJjtdklnhkfLBjx62kuo2yFEOd42UNh0eZ5opQKIxlWeO2DwVDc3oezfxix+LE0yh8pNs2THAoOG5bX08/kfB4FR0AZdkMdfcnn5seN7HQ+PaDPYPODYCu/9AsEOn623g4ijmqnkTZdrL/tWLxlIGVYaZSzbEsa5y8JjgLWGkmQKnxI/eJtByNZrkyaUKaUupBpdTblVJrlFL5SqkSpdSVSql/0oH9wpJXXoQ7kLooSvGacvLKHWEj022y/tpd446r3jO3K+jWrKoaN11cXFrE6rU6jSKbCRTnUbVrXco20+Miv2LiFLR1G9fgHhOAv/r1r6SiMv0qtC6vmw3XjSw0ExkIkls2PkVow3W7ZpQqptHMNfkVxZie1LGw8q2r6KoduQwWriwjp9Tx35yS/HGpZG6fh/zyIibD4/Hwpne8dtz2l2WpUEOmUUqlDe4RcdJyNJpliq42yVKKV5dz5ftvo2xjDYHiPGr2buSiN9+Af5TsYOWONVz0puvJry6hoLqUy95zM6XrK+fUjqLiQv71C3/DK2+7gbz8XK667jK+8u3PUFVdMafn0cwvLq+H3a+/hnXX7MAd8FK6vorrPnIH+ZUTB/ebtq7n7ns+y449W8kvyOPtf/AG3v/hd4wL+EdTtWsde954Lb78ADmlBeSVF3HF+24lt7wQb16Ana+7ihq9wq1mgcmvLOa6j9xB6foq3AEv667ZwfZXX4GYQqA4j1WXbOay99yMN9eRQXb7vex9+8tYc+U2AkV5rNi8kms/+rrk4MtkXHP9ZXzi7z9C2YoSqldW8i9f+H/suXhHpt9idpII7Mem5Tha9zq41yxfMqZRl1jF9jagXSk1rmcSkeuBnwG1iU0/UUp9KlP2LDaGOvvoPNdCsHuAotXllKypwO330NPQQefZZlCK0vVVFK1KHfWMDIToOt9CX2MnnuoiQusKaHINkbu6ABVwvs6+pk46zzZjuF0M+KG11IXH7WLAjFP37El8+QFEhP7mLnLKCildV0mgOO+CbdqweS3/eNcn6evpI68gD79fj7LON51tXRx+8Rgnj56mZnU1u/duY+W6lZMeM9DeS9fZZsL9Q5SsraRobTku90ggnldexN633MC2Wy/H7fOgBJ5/6kUOHjhKbk6APft2Ul5SRNeZZqyYRcn6StZVVvLp//dRwqEwhUWFBAw35585Tn9LF/mVJRSvWUG4L0hXbSuBolxK11ex6WV7WXXJZsQwksHRii012HEbf0H64l2NJlP0t/XQdbaZyGCIknWVFK0ux+V2IQZsfNlFWLE47oAXZdus2reFoa5+CleWoVCc33+cgcEh2oKDDAaDeAs8NFW4WL2uiJh3etWdRSWFvO09r+eVr74R0zQoLEpf8K5JX0wLODn3Oi1Hs4zJpAD1t4EvAfdMss/jSqnbMmjDoiTUM8jTX3+Q7vMjK9zufesNlK6r4nef/QFW1FnR03SbXP9nb6BkrTPaHo/FOfGb5zn52xfYcOslfP5f/4unn3wh2cb7/+RO7nzX63jkcz8iFoyw8o2X88E/+mviiRVCc/Ny+OJXPs3AqSZO/+7F5HFlm2q4+O038uy3fj3epvWT2zSM1+thRcXEKjyazBGLxvjBPT/lv7808lO77IqL+Ke7PsmKqvQpMYMdvTz+xfsY7Bipy7j8fbewaswouWGaBBKzQY8/9DQfft8nsRMjYsUlhXzqrz5C68OHAdh44x7aTtQniwZXbF6JrzCH+v0jRbarLt2CO+Dl7KMHASisKePqP3nNuMXSvFm4EJwm+xlo7+WxL9xHcFQtyFV//Gr8Rbkc+MGj9NQ5ue/Ve9ZjWxYth88n91t/3S7CgyGerD/Dk0+9wBVX7+P/vv3j5OuXXbWXz/zn31FcWjgtW0pKpx7lX/Yoe7wMJjjSuXrkXrOMmVZajoiYIlIlIquG/6Y6Rin1GDC5NMAypbepMyWIBjh835P0Nncmg2gAK2Zx7smjyeeD7b2ceugAAAOGlRLYA3zza9+nsb6VWDDCqsu38sPv/yIZ2IOzhPqTT71A17mmlOM6TjXS29CR3qamyW3SLDy1p87zza9+L2Xb/qdf5MyJiZWReurbUwJ7gEP3Pk54YHxRLMBg/yBf+/J3koE9QHdXL2eaGpO5yJ4cX4oaSNnG6pTAHqD+2RMpqWG9jR30NnZM8Q41mvmhp64tJbAHOPiTxxlo7UkG9uDclI4O7AHOPX4Y34Zyvvfdn/GyV17Dvd/7Rcrr+588wJlTc6tWttxR6fLtAXRajmaZM2VwLyIfBtqA3+Ko5DwA3D9H579CRA6KyC9FZPskNrxfRJ4Xkec7OrI/EEgn6xeLRFOC6GFC3SPqNlYsnlxSOxJJo2QSixONOts9uT46OsbfW3V3duMJjB8VtdKoQUzHpuXOYvDNaCRKLI1PhYLhCY9J971Gg2HsNAof4PhCd3fvuO0Dg8GkYoiyUqXnJpKiG3sOLXOZGRaDb2Yb6dRsooPhpArOMOl8W9mKWDyGZVmYppkiZzlMKDTxb3I5MWe+adtpF7gTER3ca5Y10xm5/yiwWSm1XSm1M/E3XoZl5hwAViuldgNfBH460Y5Kqa8qpfYppfaVlWV/6kd+5XjlhVWXbCF3ReG4fddduzP5OLesgKLVTprFiuKicbmY+y7dRWVVOQD1Tx3n9W+8ZVx71914JfYY6Uq330t+VckF2bTcWQy+uXJNDZdctidlW0FhPus2rpnwmPyqEgwz9ee/4fpdKQXZoykqK+ZNb3tNyjYRYev6tUSHnIBFTMF0j+QVRwaCSfWQYXJXFGLFR/zPdJsUVOrVjDPBYvDNbKNoZdm4YHHjDXvIqyjG5R2pR4lHnFW8R1O4sgxfFHbs3MLxI6e4+LLdKa/nF+Sxbv3qzBmfRcyVbzo592nCGJ2Wo1nmyPBI8IQ7iDwCvEIpNX6ob6rGRdYA96crqE2z73lgn1Iq/Yo3Cfbt26eef/75mZqy6Og818LR+5+mv7mLVZduYf01O/Hm+mk5cp6jDzwDCra+6lKqdq/D4x+RvOxr6ebUQy/Qdb6NFS/bzre+9gOOHTnF9Tdewdve/XpWr19J27F6jvziacouWsuZrnb+5xs/wutx874/uZOSiEFheTEDbT00HzxL4coVbL/1MorXVFywTUuYNPO9E7OQvnn62Fm+f899PPrwU2zdvpH3ffBOdl8y8U2YshUdZ5o48vOnGOrqZ/3VO1l9xTZyxuS+j6atoY1f3f87vv/dn5Kfn8cHPvIuNlZXcfSnT2NFY2y95TJ8eX5OPvQi0aEwKzZXU717A6d+9yJd51ooXV/Fxhv30HqsnvNPHSWvoogdt11B6YaqTHwkS52s8c1swrZtOk41cuRnTxHqHWL9dbtYfdkWAkV5tByt4+RvnmegrZuavZtYuXcDJ377At3n26jauZY1V27j9KMHsYv8/OaJZ1i5rob68008+eh+tu/azPs/+i527Nqy0G9xPpg334wNDRBsqidQlSoeEOnuxPT58a+YW3U4TdYzI9/MZiYM7kXkzxIPtwObcdJxkqvRKKXumrLxSYJ7EakA2pRSSkQuBe7FGcmf9G4j2y5SkcEQXeda6DzbTF5FMWUbq8lNjGbGozHikRjeHH/KaFE0GAbl5DCnw7YsIkMR3H4P0WiU/p4B+nr6eGH/QdpaO7j4kt3s3LOFQE4Ab66fzrZOTNOkqLSI8ICTRmF6XEQGw9jRGF3nW+mtb6egpgxfQQ6h3kFySvLpqW9PBGkrE/rmisGOPtqO1+MOeFmxeSWF1aXz8TEuFFkVQMWiMbrau8kvyiOQM/kS98ljwk7qlS8/QGtzOy8+d4hTJ86yfddWdu7agtU9ROeZZvLKCyndVEOkP0h7Uzsej4vSmnIUMNDajbLsxCyP0HW2maGefkrXVVJQXcZgRw/h/hC+fD955cUEewYIdg/g8XvJrywhL83skGZKsso3FyM99e20n2zAisVZsWUlxWsqMAxnFDgWjmLF4vjyAnTXtdFxuomhrj5H1UkM+lu66GvuorCmFG9BLrGhEN3n2yheU0F+ZTHewhyCoRCBnADBoSA5uTn4fOkHRKKRKIdfOs6zTx2goDCfS6/cy4bNa+fzo5hr5i+4H+gn2NpIoDJ1TYFITxeGyz1uu2bZs2yC+8nUcoaH8OoTf57EH8CU6zqLyPeA64FSEWkE/g5wAyil7gbeAPyxiMSBEPCWqQL7bMO2bc7+/hBHfvF0clvx2nKu+sCr8Rfk4vK4caXRAJ9qwR7DNPEnpoRdbhfN55v56Af+Jrmy4be+9gP+/p8/zh1vfzUApeUjAbgvbyToM10GL/7gCRpfOJ3cVrN3A2WbVvLU3fcTGXRWmT32wH6u+pNXY7hcPP7F+5Lfvifg5YY/fyMFSzvAzxrcHjcVNeUzO8bnwe3z0Nfbzz/9zX/w+1HL3L/57a9hX34lfefbMUyDPW+8jgM/eCTl+9/8ios5/DPnmEvffRPHHtifLNQ9zYvsuuNq6p49SV+iaHblvk1Eh8K0Ha8HHLnNaz/yOnJK8mf79jWaadNT384jn/tRcuVZuf8ZrvvY65MLTw3/LnqbOnnmG79ksL0XgFgoykBbD92jFq/acP1uOk410tfcBcDaK7dz0Zuvo6TUWRNiKmngZ558gQ+95xPJ54VFBXzrh19g/aasDvDnBaXscRr3kMi511KYmmXMhDn3Sql/UEr9A3Bs+PGobcenalgp9ValVKVSyq2UqlFKfUMpdXcisEcp9aVEHv9updTlSqmnpmoz2xjq6OPYL59N2dZd20ZfU9ecnufEsTPjliz/0ue/SVNt0wRHOAy09qQE9gDNh2qxorFkYD/MkZ89TfuJ+pTbumgwQvvpyc+hyQ7OnalLCewBfvh/v8C9ysmHL9+2mtqnj437/qPBSDIX2YrGxynwnPjVc2x6+d7k84bnT1G6fiQNZ6CtR6vlaOad5kPnkoE9OGlqpx4+MK4eqbehIxnYA+SWFqQE9uCo5FTtHlmlu/apowy09TIdhgaH+PLnvpl6zp4+Djx3eJrvZJkzYc69gbJ0cK9ZvkynoPavprlNMwbbsrHj49VH0m2bDdE0aiNDA0Hi8cnLJKw0doghWLHxx8WCkXHbAOJp1CU02Uc6ZQ+lFPFEsOPyutN+11YsjuFyimjtNBfTeCSGaaYu3jN2gs6aQKFHo8kUkaHxqjWRgdA4FRx7TF+YTiXHtsaPHltT9L3DxOIW/X3j1ceCQ6E0e2vGopSaYOTe0AW1mmXNhMG9iLxKRL4IVIvIf476+zYw4+La5UhOaT7VF61P2ebJ8ZFfWTyn59m4aS0erydl21vuvJ3q1dWTHpdXXkTeitSFUnLLCgkU5Y1TjNj0ir3jVE1EhLKNk59Dkx2sWbeSqpqKlG27L9qOa8AJ6NuO1VGzd2PK6yJCoDgvqZbjyw+MU1xafflWGg6cSj7Prywm1DMSzLi8bgqqtFqOZn6p2bN+3LaNN+5JyroOU1BdmqKSY8XjePNSpYRXbF1Jd93IGiFFK8vG9asTUViYz7ve9+aUbYZhcNG+KTUoNEy1Qq0eNNAsXybLuW8GXgBek/h/mAHgTzNp1FLB5XGz+45ryK8opuH5UxStLmfLTfvILSuc0/Ns27uVr3zjX/jmf3+PpsZWXvO6m3jlrTfg8ky+ALG/IIcrP3Abp3/3Im0nGqjYtoqi1eWcf+Y4l73nZs4+fphw3xAbb9xDzUUbQWDfnS/j1MMv4s31s/WWSyleM7Mcb83ipLxyBf/5jX/mu9+8l+eefonrX3Eld7zxFsJn2zHCcfxFuVTvXkdOSR71z5/C9LjYeP1uxDDY9IqLMV0GYhpc9YFXc/KhAwx19lGzdyPVe9ZT+9RRckoLqNi2mrVXbaP1eD25KwrJryxh6837dHCvmXeK11Vw9Qdv59iD+7EiMXbcfiVlm8YPVJSsq+Taj7yWkw8dIBaMYrhMrvyj2zj72CG6zrVSsX01FVtX0/jiaXJKC6jcvoYN1+/Cmzv9FZZvuvV6TNPkf791L6Vlxbzvw+9g267Nc/l2ly7KdmQvxyCGXsRKs7yZjhSmWym1aFaZyUbVB6UU0aEILp8L0zU+4O4400Tr0Tosy2LFxmraTzaQW1aALz+X1qPn8eT4KN+6mvItK9O07tDf0k1vRw+xeJy83AAdp5qIR2OUbayhr6ULOxqnZF0l7aca8eb4qNi+moKqUoa6B+ipayPUN0SgMJei1WW4PB48OT7i0Rh23BpX4BsNRjBcRtpi4CVG1iqShAdDdJ5uovXYebx5ASq2raZsQ2rw0tfcReuxOoa6+qncsYbSdVXgMggOBcnNyyEeitJxuom243XkV5eyYmMNA+29tB+vwxXwUbFtFcq2aT1SRzwao3LbagJl+fQ1dRENRsgrK6R4dTkun4dYKIrb70lq60eHwhgeFy735DegmgnJWt+cT2zLoqu2jZbD5zDdLip3rE0ZkIhFYnTXttBxuom88iIG2nuIDoYoXluJy+Oiv7WHYM8gJWsrCPcN4S/KxeV1EwvHsMJR8qqK8BfkESjKw4rGcQc8ScWdmTLQP4jb7cI3RQFuFjBvvhlqbyEeCuIrSdXKj4eCRHt7KNi49YLa1SxZlo1azmRSmIeZRBVnjhaymjFL7SLVebaZJ778M6LBCLtffw2Hf/okhtvFRW++nuf+5zfJ/dw+D1f98atZsXl8gD/Q3ssjd/2IcO8QO197lTMaNbwCqcDu11/LoZ88jmEabH/1FRz6yRN48/xc97HXc+RnT9J8qDbZ1upLt7D3bTfi9nnGnWcZkrUBVO1TR3nunt8mn3tyfFzzwdspWefoPg+09fDI535EuD+Y3OeSd72CtVc4C0Xbts3xXz7L0V88A4DhMtl9x9W8+MPfJ/d3+zxsfuU+jiTUchC4/L2vYv83f50cNbvozdez8YY9mXyry5Ws9c35pO1EA4994SfJOg/TbXLDx99E8eryxOv1PPlfv2DzTRdz6uEXU2qLdr3+Go7+/OlkDdLWV13KuSeOsPbKbdQ/d5JgYqXuzTddzI7XXInpMtEA8+ibwdYm7GgEb3GqYpsVCRPp6qBg04QL32uWJ8smuJ9siOE24NXArxJ/b0/8PYijSa+ZA7pqW5xRzvIieurbsS2bzS/fy+nfvZiyXywcpeNsc9o2euvbCfcO4c31E+odHAnsARQ0vXSWso01WDGLwfZe/IW5RAYcXebRgT1A3bMnUtQhNNnHUM8AJ36derGMDoXprhtR+ehpaE8J7AEO3/ckob4hp43Ofo7/8rnkaxXbVnP+mVSRrFg4SiwYHslJVnDuicOsH7WC8ZGfP81Q9/iCQY0m01hxi1MPHUgp4LZiFs0Hzyafd5xqRNk2VjQ+TjTg/NPHqNw5Ikd57vHDrLx4I2d+fyil/uTUQy8y1NGbuTeimRBl25BmpkREp+VoljcTzokrpeoAROQqpdRVo176hIg8CXwq08YtB4aVQgyXSTwRlJseV2qAnsBOsw1IyrcZLjPtcVY0hjuhix+PxjDdCXWTeNy5jx0zP5NORUeTPai4TTyNgtJoVZp0ik1WNJ68ICrbTpGSM9zmhG0Op9oAxCNxzNEFiLG4vshqFoxYeLzKV2yU6lM8GkcMI63SkzWqr3T2dZ7bsTjGKAUoZdvYaVR0NPPABDr3GKL7Hc2yZjrJgTkicvXwExG5EsjJnEnLi5I1FYhh0NfcSel6J2XizCMHWXt1qlqCGELJhqp0TVBQXYrpcRHqHSSvomjcxFP17vW0n2wEoLCmjMGOPgyXSdHKFeSPUcApXlOhVwzNcnLLCthwbWrWnGEaFK0ayTUurCkbpwyy+aaL8RfmAhAoyWf1FSP5qm3H6ll58aaU/cUQAkV5REeNeK69Yhtnf38o+XzjDbsJFOeh0cw3pstk040XpW4UqN6zIfl0xaYarGgcb64fGTMCvHLfZlqOnE8+X3P5NppeOsvKS7fQcmRkxrPmog3klupF2BaCidRynJF7PUilWb5Mp6D2YuCbQEFiUy/wB0qpA5k1LT1LLXfUjtu0nain7tnjePP8FK0q5+xjh1m5bxOGCLVPHcUd8LHxht2Ub12Jy5M+F76rtoXaJ48ihkHZpmpqnzxKNBRl/TU76KlrZ6Cth3VX76DhwGkE2PTyvZSsq2SgrYdzTxyh9VgdVTvXsubK7eSXT0/GbRmQtXnNAx29tByu5fzTx/DlB9h440WUb12VUuzXda6Fkw8fYLCtl/XX7qRq93r8BSP37UNd/TQ8f5K6/ScoWlPO+mt20lPXTu1TR/Hk+Nh440WgFCcfegErGmfdNTspqC6h9sljRAaClG2uoWbPBgJFOrjPAFnrm/NJNBSl7XgdJ3/zAi6fmy037aNsY3XyxjYaDtNxspnW4+cpXl1BwwunCPcNsfKSzeSWFVC//wSDHX3U7N3gzIzGLAqrS2k+eJae+nZWX76VVZds1j6eyrz55mDdWQyPF3de6s2VUorB2tMU7bw4/ci+ZrmybJxhyuA+uaNIfmL/vil3ziBL8SLVU99O44tnCPUNsnLfJgqqy0DBYGs34YEgyhTcLheNL57GX5BH1a61ycLIYfqaOmk8eJbB9l5qLtpA6foqTI8Ll8dNPBpDxMB0m8QiMQzTSCn+UrYiHo3h8rp1R5hK1gdQkaEwpstM0eoejRW3sC0bt9dNT0MHrUfP013XRtnGaso21jDU1cdAWw/evAAlaxzFkN7GDgyPi5K1FRSvKic8GMSO2wQKc+lr7qL54Fn6Wrup2b2esk01M5IF1EybrPfN+WR0HwhO8Nd9vpXWI+fJLS+kp76DWCjC2qu3Y7rd9NS3ER0MU7y2Em+uj7ZjdXTXtVG9ZwMlayvwFeQw2N5L24kGus42U77NUTPTQT4wj745cP40pi+AO3f85z5Qe5qi7ReNm5HRLGuWTYAzYc69iNyplPpfEfmzMdsBUErdlWHblgW9TZ08cte9ydU/zz91jCvedwtiGjx19/3J/VxeN1tvvoTDP3uK888c5eo/uZ2iVSsAR/nk0c//mMiAs6ph3TPH2fvWG9lwnZOaMVqy0p0myBNDtDrOEsWbM7msnukyMV0mg519PP/dh+k57xTdNr14hpq9G/EX5HD6kZcAyCkrpGrnGk7/znluelzc+PE3Jf1wsKOXx/7zJ4R6naLc+v0n2P36a9j8iosz8+Y0mmkyVra3+3wbj3zuXrbfdjnPf+fhpCJOoCiP0797MSXVbMdrruDUQweIBiPUP3uSXa+7mjVXbOO5e35L17kWAOqfO8maK7ax9y03THgjrZl7lG2PW3BxGEfr3tLBvWZZMpnXD8/P503wp5kDus41JwP7YdpPNXDsgf0p2+KRGJGhMC6fh1CvM3o6TE9DezKwH+bIz58i1DuYOcM1S4q+pq5kYD9M44HTFK8bWbV2qKM3Zc0DKxqn/VRj8nlvY2cysB/m6AP7Gerqz5DVGs2F0XzwLC6Pi3DfUDKwR5xZzOgY1ZxzTxyhetSKtsce3M9AR28ysB/m/NPHGNSqOfOKk3M/QRijFXM0y5jJ1HL+O/HwM0qp8DzZs+ywrfRpUenUTJRtj545GbV9fBvKspluypVGM+FFcIwLjfUpZY34abo2lGVNslqGRrMwWHFnRNce5bOSTjoMpy+WUeo4tmXDBOo46fpiTQaxJ1DLITFyb+miWs3yZDrzVUdE5EkR+VcRuUVECqY+RDNdStZWYIxZ/KR4TQVbbr4kZZthGvgLcomFIrgDXgqqRxbtKKwpHTcVvOXmS3T+p2ba5FeVkDemkHrFZmdF2mG8eQHsUXKaTvH2yKJqBdWluAPelDY2vfxirZajWXRU71lPdChMTnF+Mq1DKYXhMsepSK25YluKNv6ml+0ht6xg3O+lcudacrXS2LyilEqrcw/DaTl65F6zPJlWQa2IrAKuAa4CbgF6lVJ7MmtaepZaYZhSiq7aFs48cpBg9wAbrt9N+bbVCM7qiWcePYg3L8DKfZuoffoY3oCPdVdtp2xTTUo73efbOPvYIfpbull79Xaqdq7Dl9C211wwy6posau2lbpnT9Bd28KKLauo3r2O7vOt1O0/SfGaCtZcsZVgVz+nH3kJX16ADTfuoXRdVUrOa099O2cfP0xvYwdrr9xG1c51SXlNzZyyrHxzrrEti84zzZx/9jila6toOVJLNBhm8yv24Ql4OfvYIQY7+1h/zU4Kqko498QReho6WHvFNqp2OT7d39LN+f3HaD/RQPWeDay8eBO5ZXrsi3n0zd7jh/BXVGG4x9eMBVua8FdU4cnT34kmybIpqJ2OFGYNTmB/HbAb6AaeUEr9S+bNG082XKSiwTDtJxup23+c3LJCVl2yOVl0mI7uujbaTtYTD8UprC6hv62HwfYe1l61neLV5ZhuN2IIsYiziIoxwUiFUgrbsvUy6HPHkgmgbMui61wr558+hm1ZrLt6ByA0PH+Soa5+qvdupHzLSnKK84lFori9IxdLK+4sVDU8/W1ZFiKi/XBhWTK+ORNCfUO0Hauj4cBpileXU7N3IwVVJVMfmMC2LLpqW6l96ih23Gblvk0Eu/ooWlVOQU1p0u+VrbDtER+ezKetuKV9PZV5882eoy8RqF6F4RqfYRxqa8FXUoansPiC2tYsSZZNcD9hzv0o6oHngH9WSn0gw/YsCRpeOM0L3304+fzc44e58S/fnPYi1NPQwaN33Us8MrL65/bbLqf54Dnqnj3B9R97PSs2O6kP6ZRuRiMi+iKjSUtXbSuP3nVvMmc+p7SA04+8RCxRPNhy5Dw7X3sVW2++JCWwB8b5lGlO7mPaDzWZwLYsTj98gBO/eQGAlsO11D51jBv+/A3klExvEamu2lYe/dzI76D+uRPsvuMafvfvP+SaD72Wyu1rAEdBzDRGfHgyn9a+vnAoNbVajkazHJlOzv1FwD3A20TkaRG5R0Tem2G7spZw/xBH738mZVssHKWnvj3t/l21LSmBPUDdsyeo3LUWFJx57FDa4zSamVC3/3hKMayIJAP7YU49dICBtp75Nk2jmRZDXf2cevjFlG3B7n76mjqn3cb5Z1J/ByhoP9lA8epyTj10ACuNkIFmcaKUgsnUcnRBrWYZM+XIvVLqoIicBc7ipOfcCVwLfCPDtmUlSg3/M+6VCQ6YqJHEaIRWX9DMAWpMXVm6dDylFEpL22gWK2qCrnVGbaTzewDRxZfZRuI6OaFajpbC1Cxjphy5F5HngaeB1wEngGuVUmsybFfW4i/IYestl6Vsc3ndFK5Mn3NfsrZinDrDqku30HK4FoD1iYWoNJrZsPqyLSnZhiLjFy7beONF5Jfr/FTN4iSnNJ+NN+xO2eYvzJlRzv3qy7aOy7ot37KS7rpWNr18r06xySKUbcMEKTngpOXY8fg8WqTRLB6mk3P/KqVUx9S7LW+UUogItm2zat8mvLk+ap88St6KQtZcuZ3CUdKVoylatYLr//wNtB49TzQYoWh1OYNtPZRvXcn6a3ZRsr5q5By2SptfONF2zdJj2M8mfH2MLwzvX7Kukus/9npaj9VjK5vSjdWUbaqmbv8Jhjr7WLlvMxVbV6VvQ/uXZhFgmCabX3Ex+VUl1O8/QfG6SlZfupmc0hE1FNu2Uwq9xz4vXlfByz/xVk7+5gVsy6Jy51p6G9q55kOvpSzR1071G9MsEmwbmSglB5y0HB3ca5Yp00nLuaDAXkS+CdwGtCuldqR5XYAv4EhrBoF3K6UOXMi5Fgrbtuk618LZ3x8iv6qE3LICap86hul2se6aHVz1J6/G5Z7GUuQKgl0DDHUPULq+ik03XgSG0H6ygaf+6+d483Oo2bOB2meOkVOcz5ortlG0soz+lm7qnj1Bx6lGVu7bRNWuddMuLNNkF121rZx74jBDXf2sv3onK7auwpszslpssHuApkNnaXj+FGUbq1m1bzP9rd2cffwwOSX5rL1yO1YsTl9LF9g2JWsrWLGlhks2vSLZRn9bD0cf2E/bsTqqL9pA+dZVdJ1rpm7/CUrWVbLmsq0p6ytoNPONvzCXdVftYN1VqZeUwa5+2o7XUf/sSQJFeay5chvRwRBnnziM2+9lw3W7UXGbM48dxDAM1l+/m9J1lRimSd/qcs48cYhw3xDtJxsI9QVZf+1OyresTFmRWbO4ULaNTKDYBSCmgR3Rwb1meTKdkfsL5dvAl3CKcdPxKmBj4u8y4L8S/2cN3efbePSuexHD5OKtq3jm679MvtZy6BxXffA1VO1YO2kbPfVtPHrXj7ASiwO1n6jnkne+ApfXzdNfezC5X8Pzp9h+2+Uc/umT1O0/znUfvYOnv/YAgx19AHSebaartpV9d74Ml2caNxSarKGnoZ1H77oXK+ZcqNpPNLDvzpcn5CwhHolx+GdPUrf/BAD9Ld2IaXDs/v3JNuqfPcnWWy6l5dA5wFHHueKPbmXlRRsBpxD8ma89QG+jU5zYebaZim2rEUPoPNNM55lm6p49wY0ffxO5pVo3WrO4aHz+FIfue2Lk+Yun2frKS2g/3uDMXK2p4NBPRr3+0hmu/9M3YLpNfvfZH7HjNVfwwv/9LrkyePuJei55102svWLbvL8XzfRQtjXhAlYAYpi6oFazbJmOWs4FoZR6DEcTfyJuB+5RDs8AhSJSmSl7MkHrkVqUrVh37Q7OP30s5TWlVMqqhhPRea41GdgPc+zBZ+mqa03ZZsctwv1B3H4v0aEwvY0dycB+mPrnTozbpsl+es63JQP7YY49uJ/wQBCAoc4+6p49kXytatc6zj99PGV/KxYnHo6lrIZc+8RR7ETBWX9LdzKwH6b1WB1Fq8uTz8O9Q/Q3d83Nm9Jo5oiB9l5OP5KqomNF49iJ9RiKVpfTfrIx9SAF558+Rm9DB4bLIDoUTgb2wxz/5bNEh8KZNl9zgShlT5o+5Uhh6pF7zfJkwpF7EbljsgOVUj+Z5bmrgYZRzxsT21rS2PJ+4P0Aq1atmuVp547hKUFl2Yg5vpOZbMpwZJ90x0laFR2REZWTCbV9da7ovDIvvpnmOxVjlEqECIIklW6UnT5nWAxS1EJSfHa6fqP9K2tYrP3mXCMiE/ils81J30jzezCNRKfKuCJbSPSx2t0zwlz4pppMBhNn5H7sDZtGs1yYLPp89SR/t83BudN1m2mFzpRSX1VK7VNK7SsrK5uDU88NlTvWYLhMap88wtorUnNAxTCo2r1uyjZK11biGrM41fbbLqd0fXXKNtPtwpsXIB6O4isIUFhTNk4lYt1VO8jRy5/PK/Phm8VrK3CNUbbZftsVeHP9AOSUFbD26hH/az50jrVXbU/Z3+XzYLpd2FZCGk4cfxkuNsyvKKZkbUXKMdV71tN1buReO6ckf0bKJJqFZbH2m3NNblkBW15xcco2t9+LGIJSip6GdmchwDFqUWsu30rRqhUopXD7veP74Vsv1zn3GWJOfHMaOfc6LUezXJF0etdz1rjIGuD+CQpq/xt4VCn1vcTzk8D1SqlxI/ejWUzLqCul6K5tpe7Zk/iLc8lbUUjD86cw3S5WXbKJFZtWYbimHr3vrmuj4flTBLsHWH35Vso2VCMGdJxupm7/cbx5Acq3rqLxwGlySvKp2buBgqpSBtp6aDp0js4zTVTvXk/51lUEivLm4Z0vG+ZtGfWp6K5vp+H5kwS7Blh92RZKN1bj8XuTrwd7Bmk7XkfTwbOUbqimcscahjr6qNt/gkBJHiv3biIaDFO3/wS2bbP6ks2UbqzB4x+5aRjs6KX50DnaTzVStXMtJeur6K1vp/HFMxSvLqd6zwbyK7VU5iJh0fjmYiDYO0jHyQYaDpwhUJRLzd6NxIIRzj97HI/fy+rLt4FS1D1zHDEN1ly2heK1lYghdJ9vo+ngGfIriumpayc8EEz0w1W4fd6pT64Zy7z4ZqS7k2hvN74VFWlfV0oxWHuGoh0XTWsWXbMsWDZzcdMK7kXkVmA7kBzGUEp9ahrHrWHi4P5W4EM4ajmXAf+plLp0qjaX+kVKs6jQAZRmsaJ9U7NYmRffDHe2Exvsx1eafg0ZgMG6cxRs2obh9ky4j2ZZsWyC+ynVckTkbiAA3AB8HXgD8Ow0jvsecD1QKiKNwN8BbgCl1N3AgziB/RkcKcz3XNA70Gg0Go1Gs6xQtjVlDZCYJnY8roN7zbJjOlKYVyqldonIIaXUP4jI54Api2mVUm+d4nUFfHCadmo0Go1Go9EAoCxrynQbMc2sX8iq7UQ9xx7YjzcvwM7brySvvGihTdJkAdNJRAsl/g+KSBUQAyYXb9doNBqNRqPJEGqqFWoZHrmPzZNFc093XRtPf+1ByjbV4Mnx8fBnf0BPfftCm6XJAqYT3N8vIoXAZ4EDwHng+xm0SaPRaDQajWZClGXBBJLQw4jpytrgXinFC999mHVX72DFphpW7dvExuv38PiXf0aob2ihzdMscqYT3P+bUqpXKfVjYDWwBfjHzJql0Wg0Go1Gkx5lTy8tx45lZ3DffrKBaDBC+daRdQDKNlZTsW01z3z9QZSdOaVDTfYzneD+6eEHSqmIUqpv9DaNRqPRaDSa+WQ6wb1hurBjkXmyaG458+ghqnatHbcg4epLtxANRTj9yEsLY5gmK5jwlyEiFSJyMeAXkYtEZG/i73oc9RyNRqPRaDSaeUdZk69QCyAuF3Y0+0buY6EIbcfrnMXXxiCGsPnlezn6wDMEuwcWwDpNNjCZWs4rgXcDNcBdo7b3A5/MoE0ajUaj0Wg0E+KM3JuT7mO43Nix6DxZNHc0H66lsKYMty+9hGegKI/qXet46d7HuPL9t86zdZpsYMLgXin1P8D/iMjrE/n2Go1Go9FoNAvOtKQwXS6UFXeUdbJoldrGF89Qsq5y0n1W7tvEs//zG3rq2ylaNfFCXprlyXS8/UkR+YaI/BJARLaJyHszbJdGo9FoNBpNeqYRsIsIhsuVVaP3tmXRfrye4rUVk+5nul2svHgTR+5/Zp4s02QT0wnuvwX8GqhKPD8FfCxTBmk0Go1Go9FMhFLKWaF2GqPx4vZgRcLzYNXc0HWuFV9hLt4c35T7Vu5YQ9fZZgbaezNvmCarmE5wX6qU+iFgAyil4oCVUas0Go1Go9Fo0mE7xbRjlWTSYbg9WOHQlPstFlqP1VG0qmxa+5puFxXbVnPm9wczbJUm25hOcD8kIiWAAhCRy4G+jFql0Wg0Go1GkwbbshBzejn0psdLPJg9iz61HqujaOX0c+grtq+mbv8JbEuPuWpGmM6v48+AnwPrReRJ4B7gwxm1SqPRaDQajSYNyopPqZQzjOnzEQ8OotTiX/QpGorQ39JFflXJtI8JFOXhLwjQdqw+g5Zpso3JpDABUEodEJHrgM2AACeVUtknHKvRaDQajSbrmc4CVsOIyw0IVjiEy7+4l+jpONlIQVUppmt6Ny7DlG2opv65k1TuXJshyzTZxpS/DhHxAR8BPg38A/DBxDaNRqPRaDSaeUXFpz9yLyK48/IJtTWjFnnqStuJegpqSmd8XOnGapqP1GJbdgas0mQj07n1vQfYDnwR+BKwDfhOJo3KZux4DDseX2gzNJolhbIs7FgsK6bWlxt2PK77PM28Mh2N+9F4CopQVpye4weJ9HRl0LLZ0Xa8nqKV0yumHY0vL4AvP4fOs80ZsEqTjUyZlgNsVkrtHvX8ERHRpdljsOMxon29hNtbwDDwl1fhyStAzJlNr2k0mlRiQ4OEWpuwIiE8hcX4SlZgevXk4UJjWxax/l5CbU5A4VtRiaegEMOczmVFo7lwlBWHGVxbJXFNtiJhgs0NeAqKFt2iVqHeQcL9QfJWFF3Q8cVrymk+XMuKTTVzbJkmG5mOd7+YUMgBQEQuA57MnEnZSWygj2BTHXYsih0JM1R/jtjQ4EKbpdFkNfFwiIHaU8SHBlDxOJHOdoItTYt+en05EB8aYKihFjsawY5GCDaeJzbQv9BmaZYBdjx+QcG56fVhuN3EhwYyYNXsaDteT9GqMsSYWt4zHcWry2k9en5ujdJkLdMZYrkMeKeIDJdirwKOi8hhQCmldmXMuixB2Tbhro5x26P9vXjyCxbAIo1maWBFwo6m9Shi/T1YsSpcpn+BrNIAadMbIl2dzqjoNPTHNZoLZSZqOWMxfX5igwO48xbXtbnlSC2FM5DAHEteRRHB7gHC/UP48nMuqI1TJ85y/PApAjkB9l66i5LSC5tF0Cw80wnub864FdmOCIbLg0Wqlq7pdi+QQRrN0iDt6JwxvcVrNJnFdHsYK5tmeDz6u9FkHDsex/RdWGqe6fURG1xcI/e2ZdN6vJ6L33bjBbdhGAaFNWW0n2xg1SVbZnRsX28/f/2n/8yxwyfZvG0DoWCIv/2Lf+XKay/hQx//Q9auX3XBdmkWhulIYdbNhyHZjIjgKysnNtALiYI/MUzc+YULapdGk+24fH5Mfw5WaOTGOVBRo3PuFwGewmLC3R0jMysieEtmrvSh0cyU2YzcG14vVmf7HFs0O7rOtThFsXmzk+osrC6h9fjMgvuhwSB/8OaPsmbdSv7pPz6Jy+WEhaFQmEd/+yTveN2fcPsbX8UH/+w9BHIWt5SoZgRd+TRHuAI55K/fQiw4iIiBK5CDmC7seBzDpT9mjWYy7Fg0MQOWOttluD3krl5HPDiEHY3g8udgBi5sylkztwz3efHgICgwAwFMt2ehzdIsA+x4/ILFKsR0oZS9qK7NjS+epmRdxazbKVy5guO/fHZGx/z9//dvVFaX8+Z3vDZl1s3v9/Gq17yMK6+9lB9/7xfcfuM7+eQ//ik3vOKqWdupyTwZLRcXkZtF5KSInBGRT6R5/XoR6RORlxJ/f5tJezKJiOAK5OAvLcedl0+0p4v+00fpP3uCaH8vSmn9WY1mLHYsRqi9lb5Tx+g/fZxITxe2lSqraHq8eAuL8a+oxJ2Xj6EVqBYNLn8AT0ExYhoM1Z2j7/QxQh2tWDG9zqEmcyhrFsG9CIbb49TzLAKUrWh44TSlG6pn3VZOaT7RYIRgz/TEPB596EkOvXiMt77rdROm0xUU5vEHf/w23vGHb+Qzf/cF/vhdf0ntGZ3QsdjJWHAvIibwZeBVONr4bxWRbWl2fVwptSfx96lM2TNfKKWIdLYT7mxztLkjYQbPnyEeCi60aRrNoiPa30OotRFlxbFjUYYaaokHh6Y+ULNoiAeHGGo4jx2LouJxQi2NToqiRpMBlFKouDUrmWnD7cGOLo7gvv1UI26fh9zS2Rf4igiFNaV0nmmcct9YLM5n/v6LvOWdr8XjmXrGbeuOTfzdZ/6C6poK3nHHB/mrj/0jp46fnbXNmsyQyZH7S4EzSqlzSqko8H3g9gyeb1Fgx2JEujvHbbdCoQWwRqNZvNiWRSSNylSsv28BrNFcKNH+3nHbIl2dKFvLlWrmHmVZYAgiFx6+GC43ViQyh1ZdOGcefYnybavnrL38qhLaTzVNud/P7/0VhcUF7Ni9ddptu1wuXnnbDfzTXX+Fx+vhj+78c974qvfy1S/ew8EXjhCNRGdjumYOyWTCWTXQMOp5I46s5liuSCyK1Qx8XCl1dOwOIvJ+4P0Aq1Yt7qptMQzE7UJFUi9sejGrpUk2+eZiQ0QwPF6scOqNrzGNUSTN1MyXb5ppvi/T64FZBF+apc1sfFPF47NeKM1wu7AXQVrOQFsP7acauew9r5yzNguqSjn9uxcn3ceyLL72pe/wjve+8YLOEcgJcNtrX8GrXn0jJ4+d4dBLx7n/vt/S0tTGhk1ruOyqi7np1hvYtnPTBbWvmT2ZDO7TJXCNXTv+ALBaKTUoIrcAPwU2jjtIqa8CXwXYt2/fol5/3nC5CFSuZPD8mZFtHh8uv64yX4pkk28uNsQw8JVVEBvoG1GZMl2LTn86W5kv33TnFRDuaHNWDQUQwVdSriUxNRMyG9+047FZD5aJy401uLCLTCqlOPCDR1l58SZcnrmTzc5dUUCod5DIYAhvbvq1QB7+1ePk5Oawaev6WZ3LNE227dzMtp2bAYiEI9SerefY4VN8+A8+wco11XzyUx+b9Xk0MyeTwX0jsHLU8xqc0fkkSqn+UY8fFJGviEipUmp8XksWoJTCjkUxfX7yNmxFxWMggunxppXui4fDKNvCcHvSauIPtydiYGjNfM0SJKm4EgoihoHpD+Dy+bHCYZSyMbw+jGmsRKls27noG0ZScceKOlPEwyPL8cSCWNNtczrY8RjKtjHc7lmlCSx2RvoipxgRIB4aAgQxXeSt20g8EgErjsufgyuQgx2LOd+hW2vfa+YOFY8hsx65d2PHFi4tRynF0fufIdg9wOaX753Ttg3DoKCqhM4zTVTv2ZB2n+98/Ye87OZr5vS8AF6fly3bN7Jl+0Zuf+PNPPHIft77lo/x53/9x7z2TbfM+fk0E5PJ4P45YKOIrAWagLcAbxu9g4hUAG1KKSUil+LUAIxf9jALsGNRIt2dhDpa8ZWUY8ejRHu7MVxu/BVViOlKym5ZlkV8sJ9QaxN2JII7vwBfWQXunNxke1Y0SqSrnXBnO2KaBCpr8OQX6vQezZJiWGXKlZC3tGMxwp3thNpbUJaFt7gUb0kZLt/Eq9FakTChjlaiPV0YbjeB6jVYoSHC7a0g4F9Rhbg9hFrqseNxPEUleEtW4J7FbJqybWIDfQSbG7DjMTxFpfjLypek/r4VixLp6iDc0YaYBoGVa7GGBol0toOAt7gMKxLG9HixYlGUUliRMMGWRpRl4Sspw1tanjZ9R6OZKXMycm+6UJaFsu30C+VlkL7mLg795AkG2nvYefuVGObcnz+/qoT20+mD+5PHztDY0MLeS3bO+XlHY5om1738SjZtXc9//tvXCIcjvOWdr8voOTUjZMyrlVJx4EPAr4HjwA+VUkdF5AMi8oHEbm8AjiRy7v8TeItSKitTG6L9fYTamjHdHuxYlGhPFyRGu4YazqcogNjBIYbqzyVy/hSx/l5CbU3JkUaAaG8X4Y5WUDYqHtMqIpplQSw4SLC53pn1UjaRrnaivd0T7q9s2wnsuzud31s8TnxogFBrE8q2UJZFsKUBOxLCjsVBKaLdnUR7OrHtC5enjYeCDNaddfT5lSLa3eEoZGVn9zUp0d5uwu0tTl9kgx0OE25vSX6+4Y5WXP4A4c525+bGthlqqE1+h+HONiI9WTkZq1mE2LE5CO7FmXGyY/NXAGrF4rzwfw/zyOd+hL8ol4vefP2EaTOzpaCqlPaT6RVzvn/PfVxzw+WY8zRQWFldzp/99R9z9+e/zaMPPTkv59RkWOdeKfWgUmqTUmq9UuqfEtvuVkrdnXj8JaXUdqXUbqXU5UqppzJpT6ZQtp1UyHHl5hNLox5hRUaKBq1oOJljPEx8cAA76kwT2vE4ke40KiLBhc0R1GgyTXxo/LLw0d7ulBvf0djxmHMjncDlzyGeZmn5eCiYslx9tLcHe4I2p8PYImDA0eifx2BhPnD6opHA3FNYRKy/Z9x+8eAQpt9PPBTEjsfHvR7t7sCOa+17zexxgvvZJx0Ybves+oCZYNs2T/33/fQ1d3PJO1/Bqn2bMF2ZC67zK4oYbO8hFkpNPRoaDPLr+x/h6uvTaZtkjrIVJfzRR9/F33z8X2lqaJnXcy9Xlm6S6HwikpyOV1YcSZMfP3rhnXTLZovpQhLTc05e6/jpfZ13r1nqGK7xqRuG25P8bYxFjNR6FBWPpf2dGC53StBpuN2z08lOE1wYbk/a33Y2I4aB4fEmn9uxSDLnfjSG2+189qaZNs3B8Hi1eo5mTrDjUYw5CIwNl2ve8u5PPfQiob4htt1yKW5f5tPTDJdJfkUxHWdSyhx58GcPsWX7RoqK51+0YMOmtdx06w188mP/OKtZU8300L3tHCAi+ErLwDCI9vXgKy5Ned30+jD9OSPPfX5cgdyUffzlVbgS+4hp4q+ohFFFaIbbgysnL4PvQqNZeFw5uanBowi+sooJpe8Ml5tA1YiUnhUJ48rNg1EBppguDK/PSRNJtOkvr0xbxD5dzEAAc0wdQKBq5aJZzn6uEMPAv6Ii2RfFB/rxFBSl3MSIaWJ4vCjLxvQFQKmUGwLn867SKwtr5oS5GrkX0z3hjOBcEh4IcvyXz7Lp5Xszkl8/EQXVpbSfHFEjV0rxg3t+yjU3zO+o/WhuuuU6BgeD/Oh/f75gNiwXltaVaI5QtuV0IIYJhqDi8ZSCWHAKaB2VDA9iGLgCuY5CTiyKwiB37SasSCihAJKTIoXp8gfwV6/CDgWxLctR0wmkFveNtBcDAdPrxfQsvWI9TeZQto0di4EhmGlGWzOFHYslVKDcMx7Jdufkkrt6PfFQEKVsXD4/ZiDXUbqxHGWpsSPz7rx88jdsIR4OY5gmpj+H/EAu8dAQgmAGckDZGDVrULaFmWhzNpgeL7lrNmAlfsMunx9zicrdDvdFWBZKDEQgd+3GZHqh4XKj4nFyVq8HFOJy4y0uxQqFUMrC9C7dz0Yz/6h4DJmDm2hH6z7zI/cnHzrAik01BApn1+fMlMKaMmqfHlk26OihE/T29iVlKxcCwzC4871v5K5/+govf9W1lJQVL5gtSx0d3I/BCocItjYR6+/FcHvwlZU7ijUiBGpW4/LnEB3oI9jkFP15CorwVVRjGAaxni7CnW3OaGNpOVYoSDw0hL+8GtPtSbk5cPsDMMkFz45FiXZ3EOnudEbPKmuQAtesF+/QLA+SCjLdnYjpIlC1MuNqS0rZxPr7CTbXYcdiuPOLCFRUp+S6T4VtWcRDQUKtjSjbxlteiSseJ9TSiB2L4srNw19enaIsJeLcXA/PhsXDISI9Xc7qtwK+0nK8RaV4x8yozRbT48UcPUK9RLHCYSJd7aAUIkKkpwsRA29JqTNTEshF3B6G6s6AUvhKy/GVrsBTWLTQpmuWGMq2Ewo3s+/HxOXGGspsHVs8Gqf2iSPsedN1GT1POvIrixnq6Evq3f/gnp9yzfWXz5kM8IVSs7KSy6/Zx+c/81U+/e+fWFBbljI6LWcUyrKSgT04AXawuQFvUQlWJMxg7RniwUGG6s4mp/ijfT2E21qIDg4k1G0U2Dbh9hZcgRxUPE6wqY74DItho8PBiVKOXY11Wi1HMy2UUkS6OhwFGZw6kKGGWuKhYEbPa4VCDNadcWYLgFh/D8GEas10iQcHCTbVOUvMK4XL42OovjZZqBofHCDU0ogVm7g4MzbQT6SzDUfaxfktxof6J9xfMznRvi5ifT0YLrdTXKsUyrYId7Th8uc4ykTRiNP3KUW4o5VoX+9Cm61ZgtixqFOfNgfrJsxHQW3Ti6fJXVE476P2AIZpJFNz+nr7efjXj3P1AqbkjOa2193E7x96ihNHTy+0KUsWHdyPwo7H0irdDMvbKdvCCo9fsjra1+2kz4whHg5hJAptrRksdT1WoSLZXoZHGTRLAxWPEekZv1xExoP7ND4e6+9JBvvTYazSjXPsGGWp4GBSWWostm0T6xuv5hJN87vWTI0VjRLt68EVyCU2OP4GyQqHMDxeRy1nVA1CpKdzRjd1Gs10sGPROatrcbTu46gMFnfWPnWUiq2rpt4xQxStWkHLkfP85PsPsOuibeQXLI66vUDAz6vvuIl/+9SXlqR88GJAB/ejEMNAXOOL7EaPEqRLazDcHjDGjyQM56JCenWNie2Q5E1BSnvLIAVAMwcYJoZ3vK9kWm0p/W9jZnn3Y+1OV4Q5Wllq3PGGkfa963qVC8NRI/I6QVWaug1xe1BWHMPtSbmJM71+rY6jmXPsWCztNfpCEBFHRWuCgYLZEuoboruunZL1VRlpfzoUrymn5eh5/u9bP+bGV879irSz4eobLqe5sYWnHntuoU1ZkujedxSG20NOdepdtisnFytRdOMtXYEZyMHMSZ1iC1Svwh3ITVWQcLsxXM7IgDnDYjsxTPzlVSkXR8PjS8kz1mgmwjBNAhXVKWpLps+fVGPKFC5/AHdufsq2QNXqGd1UuHPyUm5irVgMV15qm/6Kaly+iX9P3qKSlBsNcblxF+j87wvBcLnwl1VgRSO4clL7OOfGzQARDK83maoohomvdMWcpE5oNKOxo5E5rTsz3O4ZzarPhMYDpylZV5lRPfupCBTlEY3GWFdZwdr1CzeDkA6Xy+S1b7qFz/3TV7Q0ZgbQ1ZkJrFgMOxpB3B7yN27DCocQ00RcLpRl4y0pQ0zDUYWoXoUVDqMsy9G3N02UUuSs3wyxKCDgcoFlkbtuE2K6Eyk9IcTlwo7HE7rbMZRlOTJy8RhKKUyPF8Plwp2TS/6GLc4xhoHh9TvLukejehl3zZS4cvLI37A14T8mpj+QEb9RiVWYUcq5OV65htjQYPK34crJIR4OOYpTbhcurx8rHHYWNDIM3IGchKpP1AkSPV78azdhxKMo5QSXnoIirKIgKh7H8Ppw+QNY0UhiFM+Fy+vDjsWwohHENHDn5pO7dlNSaUpcbtyB8Tc2diyGbcUx3O60AYOyLaxo1FG8WiazZsqysGJRx2c8HmdtANMkb+1GVNwiZ+1GUDaCoBAQhSuvEFE2eRu2OUomHg8unx8rEkn0aZ602vcazUyxopE5UcoZRtye5ODdXNPw/Ckqtq/OSNvTxVaKc+2tXLNr14LaMRF7L9nFbx54lAd/+hC33XHTQpuzpNDBPc7Kr+GONidX1zDwlVXgKSh2Cmob65J5pb7ScqJ93bjzCpxiskAOls9PpLOdQGUN8VDQWS1TBG9JGXY0QnxoAH95FbFQCLc/QLizzRl98PrwlawgHglhuj2E21tRtoU7vxD/ikpcAUc+0+UPEA+HCDbVEx/qR1wuAlWr8eQX6AumZkJEJOk/mcKOx4h0dRJqbwGl8FZUY7pMQi1NKCuOKycXX3kVwaY67Ijj84HqVYTbmokPDSIuFznVq4kO9DnFv+JoqovLzUBLA9g27oIivMUlBJsbUPEYrkAOvopqQk31WJEwhsdLTs1qQu0txAcHENOFv6IaZcUJtTkLuPjKKjDcnqSuvVKK2GA/wcbz2LEYpj+HnJrVKZ+VFQkTbGki1t/jrDtRWYO3oDijakMLjRUOMdTSSHygDzFd5KxcQ6S7E09RKbG+blyBXOL9PUR7up0+rrg0kQPtRllxcLnw5BUQ7+/FGugn2NYEto2nsAR/RaVOjdLMGjsaxZ03d3njhtuddrXp2RLuH6K3qYOtt1w6523PhGefPEBnJMjGkI1KqF0tJkSEO95yG//52a9x063X4/Hqgcu5YtlHh5ZlEe3tHinCs23Cbc3YsQjBxvPJH74djRBsbcRbssJRh7DiuAK5RDpaHb1cK060pxNQoGwinW24/AGUZTuKO4VFhNqakvl9diRMqL0ZT16h016i+CzW30u4uyM5TaUsi2BLQ1LtQ8XjDNWfzUiHpNHMhPjQIKG2JkeVBoXL4yHYWOcEeonXw+0tyVxtb3EZ4baWlMLw2NBgUtUHZRNqa3bSOxL+H+vrIdbfl7woxYNDhFqakmk2hstFuLMtWYirLEedynmSUG9pbyE+NFKoa0fCDJ4fUfWxQkMM1Z9LrmCrlHJu9vt7Em0m1KpCS1etStnOZx8f6AOc+oloXw9K2VjBAeLBIex4zBm8GO7jutpx+QNEujsxvD6i3Z1OioPpIpi4OQOI9nYR6erUhXOaWWPHonOWcw9OHZsVmftradPBc5SsWdiUnGg0xr3f+wW7r9yNshTR7sUpyLF563oqqsr5/j0/XWhTlhTLPrhX8SixNLJtdiyalN8b2Wg7En04+fnDnYKnoDityk48FEwW99nRaPLYkXPHnfSEMcT6e5MSXXY8RnwgjUpFhvIENZrpEh3jl+lUceKDA0n9edPnSwmyXYFc4ukUWBIj8sPEBvpxjao3sUIjyiyunDxi/ePbGKuAMVpBx4okZBvHnHP4927HY0T7use/lyV8Q+2855HPyJWTR2ygH29hCdG+XqePSwT+o7HCIQyvBysUxPT5nfVB0ozQR3q6kuICGs2FMJwCaMxhcG96PFiR8JzfeDY8f4qS9ZVz2uZMuf8nv2ZFRRmr1q3EX1nIwOnWBbVnMl735lv4+pe/Q3/fwNQ7a6bFsg/uxXClVdcQ05VSkDiyv/OR2QmFCHCCeDOtuo0nWWSWXr5L0iqJmB5fUiVEDDO9SsUSW+Zek32MXZwqnS8b7pHfgLOi88iF2Y5F0ypAjVaZAmexqNF61GK6kjNddiya/vc75rc7uqBd0oymiWEmf9timGnVqsw5DCoWG2KYKd+FHYtierzEI2FMr5d4JJj+u3J7nFoIj6OWY3h9YI8P4k2fX6cRamaFnagFmUs/EsPEME3sORwsiwyF6T7fSvGaijlrc6acPX2e3z/8FDfedBUA/upihmrbsWOLU562ZmUluy/ewd1f+PZCm7JkWPa9rel24yutgFEdhun1IS43vvJUCStvcSnxxIqMw1POhsdLfLAfT0FRSj6u4fYghukUFvpzsC0Lb0lZSnu+0hVOwdkofWjEwFdemQyCDLebwBgFH3d+YUZzqTWa6eDOzccYVaSr7DiuMWo5vvIqIr3OKHiwpRF/RU3yNSsUxJ1fkPq78XidIvZhjXTDwFNYnLIInL+ymnC7MwoV7evBt6Iy5UbclZObssiV4XbjyS9MPjd9frzFqb/FQPXK5A26ozZUk6o2FMjFDCxdtSrD5XKUwobTnwb78RSXEulow1tSjjU4iLeweFwfh2GAYSRGUxWeAue7SlEHEwN/edWSrlfQZB47Eknpb+YKw+uf0wUimw+epWh1OS7PwgzA9fT08ZW7vsUrbrme3LzErKnfg6c4l4HTLQti03S4/Q2v4uf3/orz5xoW2pQlgWRbHuS+ffvU888/PydtKdvGGs6Bj8exI+GExnwAd8BR5LBCoYTGsxvEwI5FHOWaWBRlWxi+AFhxFI6WvRUOgQhmIpfPGXn3YlsxZzZA2SgrnnjsTDOavgB2NIKybVw+f0oKAjjTkVY45KQrmI7yyVxOTWomZEbVR3Ppm9mCFY1ghUMjN6m27Ty3LUdhxu1FJVJeDLcH5fUhsYijTGWYTkBtmAlVH8H0+bHjMeywM1VueL0YphsrEkqMEHsRnx+iEWf2zHCBxwOxKFYkjJgmpt+PIMTDIQSnTXPM6L4dj2OFg9jxGKbHh+nzo2zLUeAxXZgeD/FwKKk25PL7086gLSBz7puj+xlH396DbcUT6l4u7EgMw+vCjjgKQpgmWBZiuhIzKL6k9K+IgRUOJvu0lAEMzVInI/1muLOd2EAfvrLyCzYsHdH+XlQ8Tu6qdXPS3u8//xOK11ZQvmXlnLQ3E/p6+/m3T32JTVvWc9nVF6e8FusL0nvwPDV3XIaxgLUAk/Hr+x+hob6Zu+/5bKaKfxdXRXEGWba5HXY0SqizjUhnO6DwFpfhK6/EHHUBNz3ecRJ4yrKI9HUTam7ElZuHEQ4ll2R3FxTiX1GVHFV35+YRDw0xVF+bCDxc5NSsxlNQPN5xJ9Gwnw/lE43mQhj9G7HjcaID3YTampIzVoHKGoLN9cngPmflWtx5BePacY1K8TE9XhgzSu7yjwSHsaFBhhrPO6pTbjc5NWtw5ebjzk1V0UiXKjeM4XJhjJpliAeHGGyodW7wXW5yalbjzivAtYyC0uF+RgyDoaZ6px7CMAhU1uDKy8cyo4TbW5z6BRG8RSXYloWYJr7S8nGflZbs1cwlViSUkRtslz9AsLlxTtRkwv1Bus63svFlF82RddOnrraRL/3719m2azOXXrV33OvuggDughz6jjZQtHvNvNs3HV528zV8+pN38dsHf89Nt16/0OZkNcs2LSc22E+ks43hpe0j3R3E+scXjI0lHg46iiC25ShFdHUki/Nifb1Ee0cK8ex4nMFEYA+OksdgnVa60SxN4qEhgs31ycJxKzREqK05qWxjx6IM1p2Zla60FY0yWHd2RHUqFmNg1PMLwY7FGKw/m8y7VfGY8ztdhkXrjmpOy0ihs20TbKrHCocc5aLholuliHR34vL5ifZ0JdWKNJpM4UhSZyAtx+1BXC5iaYr7Z0r9cycoWVcxryk5ccvi/vt+y7//41e48rpLueKaSya8ScnbVEn/sSaivYtT+cvlcnHne9/Av/zt5+ntmToe00zMsg3uRytDJLf1dk153PAF31HLGX/xj/X3JvN97Vg0baGOlaHlrjWahSSdr8eHBnCNWkBKWdZ4FaqZnCMWTRbojmy0Z/WbsmPRlIJdwEmZW4a/UzseJ9o/vm+0Y/G0imDDAVc6JR2NZq4YThlLV9Q9F3jyCwi3tcxKNUcpxbknjlCxdf4Wrjpx7Ax/9xef4eCBo9z5B69n645Nk+5v+j3kbqyg7ZGj2NHFqV61cfM69l62m09/8i4tnzsLlm1w70qzYqVrGgVzw7nuo9VyUl73+ZOFY2KaaYvI0ivnaDTZTTr9acPjHSP3KrMqrBTTTKtiNZsaFDHNlIL6kTaX3+9UTDNtfrwYBqZvfFqg4fagYnGdU6/JKHZi5fdM/SZdufnOehbN9Y5s9QUElZ1nmolHYhSuLJt651nS3d3LV/7jW3z1i/dw6ZV7ueMtt1JQND7dMR2BmhI8hTm0Pnx40arn3PHmWzhx9BQ/+f79C21K1rJsg3tPQVFKcC5uN56ikimPc/kDuPMLk2o5o/N6xXThK1mBkQgUTI+XQM2alOO9JSv0hVCzJDGHfxvDiOCvqCbUOqLQ4K+qmTQXfspzeH0EqlLVo/wV1eMKZmfaZk516mibr6wirRzmUscwTQKVNSAjlwZ3bj6m34+3uDRFgtfwekEEcZmp37tGM8fEg0PjpHfnEhHBX1GFFYnQd/ooPUcOOOl+adahmYjjv3qO6os2ZHQV2Lhl8av7f8ff/cW/4fV6eM8fvZXN22Z+zrwtVRgeFy2/eol46MJnUjOFx+Ph/R95J//xL//NwReOLLQ5WcnyG5pKYPr85K3fnMx/N73jFTXSYbg95NSsxgqvwLYs3PmFTqqAbePy+3H5U2cEPPkFmBu3YUUjGKYL0+/HMJftx65Zwri8PgKVK7EShZam14fh8ZK/bgNWLIbpds9a71wShZwufwArsaCNy+dPq7E/EzwFRZheX6JNF6YvkFxrYrnhzskjf+NWR53LcNSHDJcb0+0hb80m4uEgYhiIaaDiFrlFG5dV4bFm/okN9s9qUGA6iGniX+Fo0yvbItLTTf/Zk+Rv2DLlNbvrXAu9De1svHFPxuw7e6qW//naD/F43Lzt3XdQVFJ4wW2JCPnbahg610bzL15gxXVb8ZVfeHuZoKq6gvd84K185A//mq9//z/YuHlu1IyWCxmNMkXkZuALgAl8XSn1r2Nel8TrtwBB4N1KqQOZtGk06dRwpoPhcmPkTi8NQMTQSjeaZYPp9Y6/SXa757SjEcPAFcjBxfjUusXUZjbj8vnTBuyuQABXQPdlmvlDKUWsvw9/RdXUO88RYpj4SsoId7YzVF9L7pqJR8dty+L5/3uYNVdsw8yAxGRvTz8//t4vOPzSCa592eVs3bFpTmYHRITc9RW48wO0PXKMvI0VFO1Zg5iLJ6Fj10XbeOOdr+F9b/1TvvD1f2b33u0LbVLWkLFvUURM4MvAq4BtwFtFZNuY3V4FbEz8vR/4r0zZo9FoNBqNJruIDw0k112Yb7wlZVjRCOGOtrSvK6V48Qe/x+31UL51Vdp9LpS+3n5+9L8/5//9+b8Qtyze84G3sm3n5jlP+/GW5VNyxUbCHf00/vx5Qs3jC+oXksuu3Mud730jH3z3/8e37v4e8fjiLARebGRy5P5S4IxS6hyAiHwfuB04Nmqf24F7lFO98oyIFIpIpVJq8S6jptFoNBqNJuMopQi1NjkrWWcwl30iRAT/ikqCzQ0YbjfeUXV50VCEl37wKF21rey64+o5sS8UCnPs8Cn2P/kCxw6dZOuOTbzzfW8ivyBv6oNngel1U7h7NZH2fjqePIkrz0fh9hr81cWzSqOcK3bv3c4nP/VRvvPNe/nx937Bez7wNm669Xry8pfuquGzJZPBfTUweh3hRuCyaexTDaQE9yLyfpyRfVatmtu7Y41mNmjf1CxWtG9qFivT8U07Hqf/zHFUPIansHhB153wFpcw1FBLqLWJof4YZ585S+vxZnJXFLL+2l2E+4YI902uHd/V2cPpk7VYlkU8HiMWiRMMhRgcGKKns5euTmfE3OvzsHJNNa+59UY8Xi/Bzn6CnbPX4J82lblYvSHaHjnqLAPkMSHHAz43uA0wDSj0I7mZkSWdjDvedAvHjpzii5/9Ov/wic/idrvYtG0DK1dXUVpWQm5eDjfdej0bNq2dd9sWG5IpHVEReSPwSqXUHyaevwO4VCn14VH7PAD8i1LqicTzh4G/VEq9MEm7HUDdDEwpBTov4C1kE/o9ZoZOpdTN0935AnzzQsiW71rbObeMtXMx+uZkZMPnrG2cG3xKqR3T3Xki37xk107//d/62rbG1pZwOBI1TdNc0HwMv9dr1FRWeAEaDjdz4KGj8b7QwLTkdGzbdpmmWwyZXMtTKVsx/xMUE5Lr8ZHr84+z6EhznfWD559YUJkdEcPwuHzj7jC6Bppbm3vONKU5pBQ4MZN+M5vJ5Mh9I7By1PMaoPkC9klBKTUjEVkReV4ptW8mx2Qb+j0uDmbqmxdCNnwOoO2ca2Zr53z45mRkw+esbZwbROT5mew/lW+uYPG97+JdsPvtr5n2/ovN/pky1v43AZ9aQHsuhMR7WBaBPWRW5/45YKOIrBURD/AW4Odj9vk58E5xuBzo0/n2Go1Go9FoNBrNhZGxkXulVFxEPgT8GkcK85tKqaMi8oHE63cDD+LIYJ7BkcJ8T6bs0Wg0Go1Go9FoljoZ1blXSj2IE8CP3nb3qMcK+GAmbQC+muH2FwP6PS4fsuVz0HbOLdli50Rkg/3axrkhEzZmw/ueDG3/wrMU3sO0yVhBrUaj0Wg0Go1Go5lfFl7AVKPRaDQajUaj0cwJOrjXaDQajUaj0WiWCEs+uBcRU0ReFJH7F9qWTJBY1fdeETkhIsdF5IqFtmmuEZE/FZGjInJERL4nIr6Ftmm+EZGVIvJI4js+KiIfXWib0iEiPhF5VkQOJuz8h4W2aTKyoX8QkfMiclhEXpqpzOBCk0V+mw1+sKj7+kz00yJys4icFJEzIvKJubBzPhGRb4pIu4gcWWhbLoRs+f1ORLZdj+aSJR/cAx8Fji+0ERnkC8CvlFJbgN0ssfcqItXAR4B9iYVRTBxZ1eVGHPhzpdRW4HLggyKybYFtSkcEuFEptRvYA9yckLldrGRL/3CDUmpPFmplZ4vfZoMfLNq+PhP9tIiYwJeBVwHbgLcuUt+ZjG8D2aytni2/34nItuvRnLGkg3sRqQFuBb6+0LZkAhHJB64FvgGglIoqpXoX1KjM4AL8IuICAkyx0NlSRCnVopQ6kHg8gHNhr15Yq8ajHAYTT92Jv0VZtb/U+4fFQDb4bTb4QZb09XPdT18KnFFKnVNKRYHvA7fPss15RSn1GNC90HZcKNnw+52MbLoezTVLOrgHPg/8JWAvsB2ZYh3QAXwrMaX8dRHJWWij5hKlVBPw70A90IKz0NlvFtaqhUVE1gAXAfsX2JS0JFIcXgLagd8qpRalnWRP/6CA34jICyLy/oU25kJZxH77eRa/Hyzqvj5D/XQ10DDqeSNZFFguNRbx73dSsuh6NKcs2eBeRG4D2pVSLyy0LRnEBewF/kspdREwBGRdXuJkiEgRzmjNWqAKyBGROxfWqoVDRHKBHwMfU0r1L7Q96VBKWUqpPUANcKmI7Fhgk8aRZf3DVUqpvTjpCR8UkWsX2qCZslj9Nov8YFH39RnqpyXNtmUx6rrYWKy/3+mQDdejTLBkg3vgKuA1InIeZzrvRhH534U1ac5pBBpH3Ynei3MBWEq8HKhVSnUopWLAT4ArF9imBUFE3Dgd7HeVUj9ZaHumIpE28CiLM+c0a/oHpVRz4v924D6cdIWsYZH7bbb4wWLv6zPRTzcCK0c9r2EZpmQuNIv89zttFvn1aM5ZssG9UuqvlFI1Sqk1OIU9v1NKLakRX6VUK9AgIpsTm14GHFtAkzJBPXC5iARERHDe46IpJJsvEu/9G8BxpdRdC23PRIhImYgUJh77cS76JxbUqDRkS/8gIjkikjf8GLgJyBrljcXut9niB1nQ12ein34O2Cgia0XEg/P9/HyWbWpmwGL//U5FtlyPMoFroQ3QzJoPA99NdH7ngPcssD1zilJqv4jcCxzAqdx/kWW2jHSCq4B3AIcT+YMAn1RKPbhwJqWlEvifhNKFAfxQKbVo5QWzgHLgPucaiwv4P6XUrxbWpBmRLX6bDSzavj4T/bRSKi4iHwJ+jaO+802l1NFZGzuPiMj3gOuBUhFpBP5OKfWNhbVqRmT773fZXo9EKZ3CptFoNBqNRqPRLAWWbFqORqPRaDQajUaz3NDBvUaj0Wg0Go1Gs0TQwb1Go9FoNBqNRrNE0MG9RqPRaDQajUazRNDBvUaj0Wg0Go1Gs0TQwf0iRUSuF5Fxkk0TbZ+D871WRLaNev6oiOybxnGVc2FPQo82myT+lj0X6osiUpWQzUv3WtLvROSTo7avEZFp6buLyMdE5J0ztStNOx8SkUUjN7hcEZF3i0jVNPb7toi8Ybrb58Au7Z8aYPY+Oo3jPpDOZ0b7nYjsEZFbRr329yLy8Wm0LSLyOxHJn6ldadp6KLFasWaB0cG9ZpjXAtum2ikNfwZ8bbYnV0p1AC0ictVs29IsbpRSzUqp6VzgPjn1LqmIiAv4A+D/ZmzYeL4JfGQO2tHMjncDUwZOC4D2T80w7yaDPqqUulspdc8Uu+0Bbplin3TcAhxUSvVfwLFj+Q7wJ3PQjmaW6OD+AkmsHPmAiBwUkSMi8ubE9otF5Pci8oKI/FpEKhPbHxWRz4vIU4n9L01svzSx7cXE/5snO28aG74pIs8ljr89sf3dIvITEfmViJwWkX8bdcx7ReRUwp6viciXRORK4DXAZ0XkJRFZn9j9jSLybGL/ayYw4/XArxJtmyLy7yJyWEQOiciHE9vPi8g/i8jTIvK8iOxNfDZnReQDo9r6KfD26b5/zeQslI+KyIMisivx+EUR+dvE40+LyB+OGW3yi8j3E/7yA8Cf2P6vgD/hj99NNG0mfPaoiPxGnBUHx3IjcEApFU+0syExmnRQRA6IyHpxZhx+LyI/TPj2v4rI2xO+fnjY/5VSQeD88OegmT2J7/6EiPxP4ju/V0QCidfG+aU4o5z7cBZveinhL3+b6POOiMhXRZwVvqZ5/sl8/zNj+ztxVlz94bB/ish+Edmn/XPpMt8+KiIrROSFxOPdIqJEZFXi+dmEDyZH4RM2HBSRp4EPJrZ5gE8Bb07Y8OZE89sSvn1ORCa6EXw78LNR9rwz8b4Pish3Etu+LSL/JSKPJNq6TpzY47iIfHtUWz8H3jrDj1yTCZRS+u8C/nCC2q+Nel4AuIGngLLEtjfjrKoH8Ojw/sC1wJHE43zAlXj8cuDHicfXA/enOW9yO/DPwJ2Jx4XAKSAHZxThXMImH1AHrMQZWTgPFCdsfRz4UuL4bwNvGHWeR4HPJR7fAjyUxpa1wAujnv8x8ONR76c48f954I8Tj/8DOATkAWVA+6jjq4HDC/3dLpW/BfTRT+BcdPJxlpD/dWL7I8BmYM2otv9s1Pl34axuuS/xfHBUm2sSr+1JPP/hsO+POfc/AB8e9Xw/8LrEYx8QSNjdi7N6oRdoAv4hsc9Hgc+POv6vgT9f6O9yqfwlvkcFXJV4/k3g49Pwy32j2ige9fg7wKsTj7/NqD5s1D7fBt4wjXOM6+8Stv134vEO7Z9L/2+BfPQoTn/5IZw+8+3AauDpxOt/D3w88fgQcF3i8WcZ6UvfTeJ6PuqYpxI+VAp0Ae40564D8hKPtwMngdLR7yNh9/cBAW4H+oGdOAPELwz7fWLf00DJQn+Py/3PheZCOQz8u4h8BifAeVxEduBcAH6buFE3gZZRx3wPQCn1mIjki0ghTpD7PyKyEadDcc/AhpuA18hIXp0PWJV4/LBSqg9ARI7hdBSlwO+VUt2J7T8CNk3S/k8S/7+A0+GNpRLoGPX85cDdKjEqNXyeBD9P/H8YyFVKDQADIhIWkUKlVC/QzuKcfs9WFspHH8dJF6gFHgBekRj5WqOUOikia0btey3wn4lzHhKRQ5O0W6uUeinxeDKfPA4gInlAtVLqvkT74cR2gOeUUi2J52eB3ySOPwzcMKq9dmDLFO9XMzMalFJPJh7/L46v/IrJ/XI0N4jIX+IEwsU4gdEvpnHezVOcI11/dzXwBQCl1BHtn8uG+fbRp4CrcPrDfwZuxgmkHx+9k4gUAIVKqd8nNn0HeNUk7T6glIoAERFpB8qBxjH7FCeux+DMLN2rlOqEcdfwXyillIgcBtqUUocTNh3F8fWXEvsNX8e7JrFLk2F0cH+BKKVOicjFOKM8/yIivwHuA44qpa6Y6LA0zz8NPKKUel0i6Hl0BmYI8Hql1MmUjSKXAZFRmyyc73ra09cJhtsYPn4sIZwbitH2jH2PY9uyx9hmj2rbl2hTMwcsoI8+hzNNfQ74Lc5N5ftwAp7pnHMixvp0urSH0T45mb+P9cHR/jna17VPzj3pfEyY3C8BEBEf8BWcUdIGEfl7UvugSQ+f4hzp+ruZ9JnaP5cO8+2jjwPX4AzC/Qz4/xLnHCtYMNk1Nh3p4oCxxEXEUErZU7Q/nWs4aJ9cFOic+wtEnMr4oFLqf4F/B/biTGeVicgViX3cIrJ91GHDOc9XA32JkfUCnGlXcKbVZsKvgQ8P5/OJyEVT7P8scJ2IFIlT2PX6Ua8N4IzQzoRTpI5O/Qb4QKJtRKR4hu1tAqalOKGZmoXyUaVUFGgA3gQ8g3Ph+jhjRqESPEaiziIxq7Br1GsxEZnJTBY4o6IbEnb0A40i8tpE+97h3NkZoH1y7lk17H84+blPMLlfju6bhoOkThHJxUm3mS5T+X46nsDxY8RRE9s56jXtn0uX+fbRx4A7gdOJILsbZ1DmydE7JWa4+xL9M6TWqF3INRyc97Uu8fhh4E0iUgIzv4YnYpEKnFRczQKig/sLZyfwrIi8hJP3+I+JoOYNwGdE5CDONNWVo47pEZGngLuB9ya2/RvOqOqTONN8M+HTOCkSh8QpUPz0ZDsrpZpwpvz2Aw8Bx4C+xMvfB/5CnALI9RM0Mba9IeCsiGxIbPo6UJ+w5yDwthm+nxtw0jg0c8NC+ujjOFO3wcTjGtIH9/8F5CbSHf4S5wZ0mK/i+NJ30xw3Eb/Emdoe5h3ARxLtP4Vz4ZkJV+H8VjRzx3HgXYnvpBj4ryn88tvA3Qk/juCocx3GKcB/bronnYbvp+MrOAHdIZzR1EOM9JnaP5cu8+qjSqnziYePJf5/AuhVSvWk2f09wJfFKagdPUL+CE4B7eiC2unwAE6dB0qpo8A/Ab9PvMe7ZtAOwMXAM8OpuZqFQ5SayQyP5kIRkUdxCmKeX2A7cpVSg4nR9ftwCoLum0V7rwMuVkr9vzmw7THg9gk6NE2GWSw+OltE5D7gL5VSp2fZzkXAnyml3jE3lmkSaV33K6V2LLQt00FETJwixHBi0ONhYFMi0LvQNrV/LmKyzUdniziKUfcopV4xB219Afi5Uurh2VummQ0653758fci8nKcqcPf4IwsXDBKqfuGp/Bmg4iUAXfpwF4zB3wCp3BxVsETTq3A38zeHE0WEwAeSaTfCI7q1wUH9gm0f2oWDUqpFnEkXPPV7LXuj+jAfnGgR+41Go1Go9FoNJolgs6512g0Go1Go9Folgg6uNdoNBqNRqPRaJYIOrjXaDQajUaj0WiWCDq412g0Go1Go9Folgg6uNdoNBqNRqPRaJYI/z+3G1reoCkjXgAAAABJRU5ErkJggg==\n",
+ "text/plain": [
+ "| \n", + " | sepal length (cm) | \n", + "sepal width (cm) | \n", + "petal length (cm) | \n", + "petal width (cm) | \n", + "class | \n", + "
|---|---|---|---|---|---|
| count | \n", + "150.000000 | \n", + "150.000000 | \n", + "150.000000 | \n", + "150.000000 | \n", + "150.000000 | \n", + "
| mean | \n", + "5.843333 | \n", + "3.057333 | \n", + "3.758000 | \n", + "1.199333 | \n", + "1.000000 | \n", + "
| std | \n", + "0.828066 | \n", + "0.435866 | \n", + "1.765298 | \n", + "0.762238 | \n", + "0.819232 | \n", + "
| min | \n", + "4.300000 | \n", + "2.000000 | \n", + "1.000000 | \n", + "0.100000 | \n", + "0.000000 | \n", + "
| 25% | \n", + "5.100000 | \n", + "2.800000 | \n", + "1.600000 | \n", + "0.300000 | \n", + "0.000000 | \n", + "
| 50% | \n", + "5.800000 | \n", + "3.000000 | \n", + "4.350000 | \n", + "1.300000 | \n", + "1.000000 | \n", + "
| 75% | \n", + "6.400000 | \n", + "3.300000 | \n", + "5.100000 | \n", + "1.800000 | \n", + "2.000000 | \n", + "
| max | \n", + "7.900000 | \n", + "4.400000 | \n", + "6.900000 | \n", + "2.500000 | \n", + "2.000000 | \n", + "
"
+ ]
+ },
+ "metadata": {
+ "needs_background": "light"
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "sns.pairplot(df, hue='class');"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 30,
+ "id": "fce3ff85",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAX4AAAEGCAYAAABiq/5QAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjQuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8rg+JYAAAACXBIWXMAAAsTAAALEwEAmpwYAABRqElEQVR4nO3dd3hb1fnA8e/Rli3vPeLYjjOcnRCSQEIgbMoqs4xCaSmUljJKKaVAW0oXpS0FSn9QRgeQssps2JuQMLL3Ho5HvLe1pfP7Q7Jjx5Is25LlcT7P4yfR8R3nWvare894j5BSoiiKoowdmlhXQFEURRlaKvAriqKMMSrwK4qijDEq8CuKoowxKvAriqKMMbpYV6C79PR0WVhYGOtqKIqijBhr166tl1Jm9GefYRX4CwsLWbNmTayroSiKMmIIIcr6u49q6lEURRljVOBXFEUZY6IW+IUQk4UQG7p9tQohbo7W+RRFUZTwRK2NX0q5E5gNIITQApXAK9E6n6IoykC5XC4qKiqw2+2xrkpQJpOJ/Px89Hr9oI81VJ27JwF7pZT97oRQFEWJtoqKChISEigsLEQIEevq9CKlpKGhgYqKCoqKigZ9vKEK/JcAzwb6hhDiWuBagIKCgiGqztgkpWTX9r3s2r4Xo8lA6fRJjBufF+tqKUrM2e32YRv0AYQQpKWlUVdXF5HjRT3wCyEMwDnAzwJ9X0r5GPAYwLx581Sq0CjasHYL11x2C06HE4CcvCweffpPFE1QH7iKMlyDfqdI1m8oRvWcAayTUtYMwbmUIJxOJ0/8bVlX0Ac4VFnDV6vWxbBWiqLEwlAE/ksJ0syjDB2H3Ul5WWWv8uqq2hjURlFGh7vvvps//elPsa5Gv0U18Ash4oBTgJejeR6lbwmJFi689Oxe5fOPnRuD2iiKEktRDfxSSquUMk1K2RLN8yjhOe3spVx7wxWY48ykZ6by27/cway5U2NdLUUZMZ566ilmzpzJrFmzuOKKK3p87/HHH+foo49m1qxZXHDBBVitVgBefPFFpk+fzqxZs1iyZAkAW7duZf78+cyePZuZM2eye/fuIb0OMZyWXpw3b55UuXqiy+v1UltTj06nIz0jNarncbvdGAyGqJ1DGZ7cbjdI0OmHVSqwkLZv305paWnIbbZu3cr555/PypUrSU9Pp7GxkYceegiLxcKtt95KQ0MDaWlpANx1111kZWVxww03MGPGDN5++23y8vJobm4mOTmZG264gYULF3L55ZfjdDrxeDyYzeYB1VMIsVZKOa8/1zty3hklIjQaDdk5mVE9x5aNO3j+6VfYt7uMCy49m+NPOoa0KH7IKMODy+li/ZrNPP3Ei9isNi7/zoUsWDSXuPi4WFctIj788EMuvPBC0tPTAUhN7fk7vWXLFu666y6am5tpb2/ntNNOA2DRokVcddVVXHzxxZx//vkAHHPMMfz2t7+loqKC888/n4kTJw7ptahcPUpE7d65j+9eejOvvfg2mzds5+6f3scrz7/JcHqyVKJj04ZtXHPZLXzywSq++nw9N11zJ1+OolFjUsqQQyqvuuoqHn74YTZv3swvf/nLrlnAjz76KL/5zW8oLy9n9uzZNDQ0cNlll/H6669jNps57bTT+PDDD4fqMgAV+JUI27V9L9YOW4+yJx9ZRm11ZCaeKMPXB29/2usD/pknXsTpdAbZY2Q56aSTeOGFF2hoaACgsbGxx/fb2trIycnB5XKxbNmyrvK9e/eyYMEC7rnnHtLT0ykvL2ffvn0UFxdz4403cs4557Bp06YhvRbV1KNElFar7VWm1+sRmsjeY9jtDnZt30t5WSVpGalMmVpCckpSRM+h9I/RaOxdZjKiEaPj/nLatGnceeedHH/88Wi1WubMmUP3haN+/etfs2DBAsaPH8+MGTNoa2sD4Cc/+Qm7d+9GSslJJ53ErFmzuPfee3nmmWfQ6/VkZ2fzi1/8YkivRXXuKhF1YF85V110A431TV1ld/32Fi7+5rkRO4eUktdefItf/OQPXWUXXHoWt9zxfRISLRE7j9I/mzds46qLbsTldAG+maZ/f+ZPLFzcr37HmAinc3c4UJ27yrBUWDyOJ/7zFz5+fyUHD1Rw4qnHcdSCWRE9R+XBQ9x790M9yl56djnnXHA6c46eEdFzKeGbPquUf734EO+/9Sk2q51TzzyBmWq48LCkAr8ScSWTiyiZPPgMgsG0d3T06kcAaGlpjdo5lb4JIZgxeyozZqtgP9yNjsY3ZUzJzslkUumEHmVGo4EClWlUUcKiAr8y4iSnJPHbv9zJPH8T0rjxeTz8z3spKhkf45opysigmnqUEWly6QT++o97aahvxJJgITUtOdZVUpQRQwV+ZcSKt8QRbxkds0JHA4/Hw8Z1W3n52Tew2mxceOnZzDl6BmazKdZVU46gmnoURYmIzRu2c/U3bub1l97m/Tc/4borbmXNFxtiXa0R5e2332by5MmUlJRw7733Ru08KvArihIRH7y9Ao/H06PsqSde6BrXr4Tm8Xi4/vrreeutt9i2bRvPPvss27Zti8q5VFOPMiyUl1Wyd9cBtDotEycXk50b3URyytAQDO/lDAfK0dSArboSr8uJRm/AnJ2HMSVtUMf86quvKCkpobi4GIBLLrmE1157jalTIz88VgV+JeZ2btvDtZffQlOjb9mG4pLxPPjEbxlfNC7GNVP64+TTl/DMky/2uOu/8pqL0Bv0MaxV5DmaGuioKAPpBcDrcvpew6CCf2VlJePGHf6dz8/P58svvxxcZYNQgV+JKa/Xy/NPv9oV9AH27Slj1aerVeAfYabPnsI/XniQ1154kw6rjfO/cdaonEltq67sCvpdpBdbdeWgAn+g9DnRWgBeBX4lppwOJ1s37ehVvnP73hjURhkMrVbLnHkzmDNv9AX77ryuwNlGg5WHKz8/n/Ly8q7XFRUV5ObmDuqYwajOXSWmTGYTZ3791F7li4+fH4PaKErfNPrAq8oFKw/X0Ucfze7du9m/fz9Op5PnnnuOc845Z1DHDEYFfiXmTvna8Zx/6VloNBoMRgPX3fQtjpof2cRuihIp5uw8ODLVtND4ygdBp9Px8MMPc9ppp1FaWsrFF1/MtGnTBnXMYFRaZmVYcDqcVFVUo9FqyBuXEzCvv6JES3/TMkdjVE84VFpmZdjavWMfH723krL95Zx8+hKOWjCLxKSEkPsYjAYKJxSEfY66mnq+XLWeFR99wYzZpSw5cSEFhfmDrfqo1dTYzJovNvLhOysomVLECScvYsLEwlhXa8QypqQNSaCPFhX4lYg6sK+cay77EY0NzQD876V3uPPXN/ONK8+L2DmcDidP/N8ynv3XywC89dr7vPL8Gzzy1B/JzEqP2HlGCyklLz/3Bg/+4bGusuf+/Sr/eOFBxhVEp/NQGd5UG78SUTu27u4K+p0e/vM/qK2pj9g5yg9W8fxTr/Yo271jH3t3HYjYOUaTQ5U1PPbQUz3Kag7VskuNnBqzonrHL4RIBp4ApgMS+I6U8vNonlOJrSOn7AO43W6k1xtg64GRXok3wPG8Ac49WDWHatm7uwwhBBMmFfb5ROH1etm3p4yKg1WkpCZTMqko5onkvF6JO8DPJho/L2VkiHZTz4PA21LKC4UQBkClUhzlJpeWEG+Jo6Pd2lV29Q8uJzM7I2LnyC/I4Wvnnsybr73fVZabn03xpMKInQNg3+4ybvzuHRw8UAH4Vha7/9F7KCwO3hex8pOvuPnau7ry03zr2ku49oYrYroWcE5eJldcfRH/eOQ/XWWJSQlMnDIhxF7KaBa1wC+ESASWAFcBSCmdwOBmOCjDXsnkIp549gFeXPYa+3aXcf6lZ3Lc0oURnYFoMpu48bZrmDZzMm//70Pmzp/FuRedTk5uVsTOAfDGq+91BX2APTv38/F7q7jqe4EDf21NPXffdl+PpGT/fuw5lp66mLkxnMGq1Wq5/NsXkF+Qy6svvkXptIlccOlZFBarmdFjVTTv+IuBOuCfQohZwFrgJillR/eNhBDXAtcCFBSEP6pDGb6mzZzM1Bk/weP2oNNH51csNz+bCy8/h5PPPAFLfFzE76i9Xi9rvthAbn42J52+BK/Hw/tvfcr6NZu56nuXBNyntbmNutqGXuX1tZHr3xiojKx0LrzsbL5+0RloddqopQJQBu473/kOy5cvJzMzky1btkT1XNHs3NUBc4FHpJRzgA7g9iM3klI+JqWcJ6Wcl5ERueYAJbaEEFEL+gB7du3ntut/xRnHfoOrv3ETa7/cGNHjazQaLvv2BZx46mJefm45r7/0Dl8792S+ftHpQffJyEpj8tSezSdCCMYNo7WAdXqdCvrD1FVXXcXbb789JOeKZuCvACqklJ3p5f6L74NAUQaltbmNn996L598sAqv18uObXv4wVU/Zf/egxE9j81q55l//JeOdittre388+/P4nAEzy2flJzIr+67vasJxZIQz+8euJMJEe57UGKv7MsdLL/jSV647gGW3/EkZV/2zjfVX0uWLCE1NTUCtetb1G7JpJTVQohyIcRkKeVO4CQgOqsKKGPKoaoatm7cgclkoHT6ZA7sO0hTYwtl+8sp6scksFC8Xi//e/mdXuXvvfkxp599YtD9ps6YxL/++1eqq2pJSEpQ4+RHobIvd7Bm2ft4nG4ArI1trFnmG2gwfsGUWFYtbNEe1XMDsMw/omcf8O0on29M2bNrP1+sWENNdR2Ljp/PrLnTMceN/vVNzXEmbr79eyQkxLN54w5OOHUR6empJCSGnh3cHxqNhuKS8az+fH2P8uKSwj73TU1LITUtJWJ1UYaXza+t7Ar6nTxON5tfW6kCP4CUcgPQrxwSSnj27y3ju5fc3DVZ6t+PPc8fH/4lp4W4Gx0tMjLTqDlUxwP3/r2rrHT6RH73wF0RPc953ziTN197n7bWdgCSU5I45WvHR/QcyshjbWzrV/lwpFI2jFBbNu7sNUP2wfseZ/6iuaSkJsekTkNlz679vLjstR5l27fsZt/usojmn5k6YxJPvfw3dm3fixCCKVNL+pVPSBmd4lITAgb5uNTIPXFGm0rZMEK5nL2nRFitNjzu0T8b0+1y4w5wndFY1DspOZH0zFQyMtNITE4Ma5+tm3bw9v8+5MtV62htGTl3gUp4Zpy7CK2h5z2z1qBjxrmLBnXcSy+9lGOOOYadO3eSn5/Pk08+OajjhaLu+EeoKdMmojfoewS7b3/vUtIzR27GwHAVTRjPohMWsPLjw+uRpmWkUjK5KKLnObD3ILf+8G52bfPltJk5Zyq/e+AuCgqDD8/86N3PuP2m32Cz2gC46nuX8K1rLyEtXbX5jxad7fibX1uJtbGNuNQEZpy7aNDt+88++2wkqhcWFfhHqNLpk3jiP3/hH4/+h6qKai658jxOPHVxrKs1JJJTk7jxtmsomVTIio++YMrUiXzjynOZVBrZFARv/+/DrqAPsGn9Nj798HO++Z0LA25/cH85v//lg11BH+Bff3+O+cfMYfHShRGtmxJb4xdMGTEduYGowD9CCSGYc/QM/jzzV7jdHuLizWHvW1fbgF6vJzklvKaLgairqaO93cq48XnodOH9mtXXNaLVaEhJS+5z29JpEymdNpFvXXsJCYkWjMbwlr1ra+vA1mElLSM15GIvXq+Xz1f0XhRozRcbggb+xoZmqqtqe5XXVNf1Wa/29g6s7VZS0lLQR3Him6KAauMf8QxGQ9hBv662gX88+h8uOv07XHbO93j3jY+x2+0RrY/T6eSDd1Zw3RW3ccV51/P7Xz7Iru17Qu7T2NDEM0++yEVnXM2l53yPN155r0eSt1DSM1LDCvpSSlZ/vp5rL/sR551yFX/41cOUl1UG3V6j0XDiab2foBafsCDoPpnZGQHz3+T3MZZ/3epNfP/K2zjvlKv43c//Qtn+8pDbK8pgqcA/hrz/1ic88Pu/09jQTMXBKm79wS/ZuDayc+o2rNnCrd//Jbt37qO1pY0Xn3mdZf98CYcjeH6+Tz/4nPvueZiGukaqKqr52c2/YcPayOYq2bVjL9dd+RO2btpJW2s7z/37ZR594N84Q9TrpNOXcPxJx3a9Pu2spSwKsQh8bn42d/z65q7UzUajgVt/fj1TZ0wKus/eXQe47pu3snHtFtpa23np2eX8+bePYLNF9gNZUbpTz5RjRFtrO88dsXgJwFer1rJgUeQyaezdfaBXTv43Xn2fK797MRMm9e58tdsdPP/0a73KP3r3s5BBtr/27S7rNernjVff43s3fStoZ21+QS6/f+guDu6vQAjB+KJxfT5dLVw8j8efvZ+Kg1UkJydTOmNiyKau/XvLsNsdPco+fm8lhyprKC4ZH+bVKUr/qMA/RugNenJyM9m/p6xHeaRHAcXF9Q6MqWnJGE3GgNvrdFryCnLYuqlnrpOcvNAplg9V1rBh7Ra2b9lFwfh8Zs2bxsTJxUG3D7QYSnJKIiZT6GYiiyWeqTMmh9zmSEUTxlM0IbygHRffu16WhPiw+ywUZSBUU88YYTIZueaHV/TImJmWkcqCY4+K6HmmzphM8cSeQe+HP746aDu3TqfjiqsvwtAt0CWnJLHkxOCjYBwOJ8899Qo/veEe/vX357jnjj/xmzvup6LsUNB98sblUDp9Yo+y7//o2xFdIGYgJpVO4Ohj5vQo+9HPriNvXE6MaqTESnl5OUuXLqW0tJRp06bx4IMPRu1cQkoZtYP317x58+SaNb1HUiiR4fV62bFlN9u27sJsMjFt5uSozETdtX0PWzbupKW5hZJJxcydPzPk8oNSSnZs28P2zTvR6/VMmzmZ4hAzcLds2M6VF/4Qt6tnvpS//P3XnHT6koD7fPzeSlatWE1qWgo2q42EBAuff7aG3/7lDrJzMgd0nZFSXVXL1k07qKtpYMKkQqbNnBzwSUCJnu3bt1NaWhrTOhw6dIhDhw4xd+5c2traOOqoo3j11VeZOnVq1zaB6imEWCul7FdqHNXUM4ZoNBqmzpzM1Jn9a7ror0mlJUwqLQl7eyFE1/DMcDidzl5BH8BmcwTY2sdud7Bx7RaWnrIYg9FAY2MzO7ftjsps3/5KS0+hoDCfxKREcvOzVNAfAd549T0euu9xqqtqyc7N5MbbruHMr58yqGPm5OSQk+N70ktISKC0tJTKysoegT9SVOBXRpzxxQUcfcycHpkzk1OSQua9nzCxkFlzp/Pog//G6/WSmp7Cnb+5hezc2N7t26x2XnjmNR649+94PB6SU5J44PHfMPfomTGtlxLcG6++x69u/yN2/43GocoafnX7HwEGHfw7HThwgPXr17NgQfDhw4Oh2viVESctPYUf3/l9Lrz0bLJyMlhy4kLuf/SekE8Mra1tPPfUK3i9XgAa65v456PPYuuI7bDJ3Tv28uff/l/XSKjmphZ+cesfaKxvimm9lOAeuu/xrqDfyW5z8NB9j0fk+O3t7VxwwQU88MADJCZGZ5KluuNX+uR2u2ltacdiievRCRtLU2dM5vZ7ivhOzeUkpyRhCdGHAHCosveM2h1bd9Pc3EJicuisiq0tbQghIr6uLxBwpu/BAxU0NbaQqvL7DEuB3rNQ5f3hcrm44IILuPzyyzn//PMHfbxgVOBXQtq/p4xl/3yJT95fxex50/nu9d9k8tTw2++jyWAwkB/m6JecvN5NOqXTJ5KcnBR0n7bWdj5+fyWPP/wMOq2W7930LRafsCBkR3V/BWpqKijMJyUteL2U2MrOzeRQZU3A8sGQUnL11VdTWlrKLbfcMqhj9UU19ShBtTa38fOf/IEXnnmNmuo63ln+ET/41m0Bf+mHu8lTS7j+x99Bo/H9yqemp3DXb24Jebf/5ap13Pmj33Fg70H27NrPT66/m/WrN0e0XhOnTODHd/2gK29QckoSv/7T7WoFr2HsxtuuwWTuOS/FZDZy423XDOq4K1eu5Omnn+bDDz9k9uzZzJ49mzfffHNQxwxG3fErQZUfrGTTuq09yupqGziwr7zPCVbDjcUSz7e/dylLT1lMa0sbeQU55OQGvwYpJS8+03tG8f9eeZfFSyPX4WaOM3HZVedz7HFH09zUSl5+FrlqDP+w1tmBG+lRPYsXL2aohterwK8EZTQa0Gg0XR2inY6824mF+tp6NqzbxoG95WTlpDN9VmmfC60bjIawUzcLIcjITO9VnpkV+fUO9Ho9E6cEn3WsDD9nfv2UiI3giQUV+JWgCgrzufKai/nX35/rKlt66uKwFhyPJrfbzYvL/scjD/yrq+zYJfP4+e9ujeiM14u+eQ5vL/+wK5Gb2Wzi9LNG/5rGyuinAr8SlMFo4Nvfu5Sj5s9i+9bdFJeMZ9ZR00jqYxRMtO3ctpcnH/lPj7JVn65h1/a9EQ38M+dM5an/Psy6NZvQCA1z5s8Me5KZMvJIKRFCxLoaQUWyGUgFfiWklLRksnMyEQLS0lJIz0jtcx+bzcGubbtpa+ugsDif/ILgSxUOhM1qx2DQc9FlZxNniUN6JW++9j4dHbaQ+7ndbg7ur6C9rYPc/Ow+E9QJISgozkej1SA0os+8+srIZTKZaGhoIC0tbVgGfyklDQ0NmEymiByvz8AvhJgHHAfkAjZgC/C+lLIxIjVQhrUP31nB3T/9I81NLcTFm/npL27g9HNOxhwXuJ2/rraeZ//9Cv969Fncbg8FhXn8+s8/Y868GRGr0/gJ4/jxXT/g4T89SUNdI2azie/84DImTC4Muo+1w8ZLzy3ngXv/jsvpIjc/m/sf/XXIXPkVB6v4w91/5ZMPVgG+fPy33PH9EdexrfQtPz+fiooK6ur6Xi0tVkwmE/n5+RE5VtAkbUKIq4Abgf3AWqAWMAGTgEX4PgB+LqU8GJGaoJK0DTe7tu3h2m/+mMaG5q4ynV7Hk//5C3PmB04p8OE7n3HztXf2KJu3cDb3P3IPyamRGZteV1PPZedeR82hw3+kGo2G55Y/xpQgTTHr12zmWxf8sEfZjDlTefSpPwadmPXvx57nz7/9vx5lv/j9rVx42dmDvAJFiZyBJGkLNY4/HlgkpbxASvk7KeUTUsqHpZQ3SimPAv4CjJkGT6fTibWPpoRYsHZYaWpsjsqxqw/V9gj6AG6Xm8qK4OmPD1VW9ypb99Um6usaIlav+vrGHkEffJlHD1UFn19QVdG7XpvXb+t1fd2P9+E7K3qVf/bxl/2rrKIMQ0GbeqSUfwu1o5RyQ18HF0IcANoAD+Du76fScODxeFi3ehNP/m0Z9XWNXHbVBSw9dTEpEbp7HSiv18uqT1fz9JMvUF/TyFnnn8JJpx9HQWHvNV8HKj09FUtCPO1tHV1lGo0mZA77jOzeQyBLp08iOTU5YvVKSUkmNS25V9DODDD8sut7Wb2/VzKpKGhHtUaj4ZglR7N+Tc8JW/MWzu53fRVluOlz5q4QokgIcb8Q4mUhxOudX/04x1Ip5eyRGPQBtm3aybWX/ZhVn65m1/a93P3T+3j/rU9iXS3WfLmRG797B59/uobdO/fxl9//nTdeeT+i55g6awq3/+qmrvw8Wq2Wm267JmhzCsC0GZM598Izul4npyRx8+3XhtUpHK60tGTuuOsGTP5VvTQaDdff8C1yAwT3TpOnlvDt6y7tep2QaOHnv/sxySnBP8BPP2tpj/QUs+ZOY8mJx0TgChQltvpciEUIsRF4EtgMdM3kkVL2Gf38d/zzpJT14VRmOLbxP/XEC/zp1z0ffvILcvnP/x4Nmecl2p5+4gX+eES9UtNTeOq/D1NQFJkOIACX08XWTTuoqqghMyuNKdNKsCSGHs7ZWN/Ezu17aG1pp7B4XMRz+zRX1vPJgy+TPKeQZmsHCXFx2HfXMuf8xeRM772ubyer1cb+PWW0trSRX5DLuPF9jzZqqGtk/96DCCEoKhlPalpyBK9EUQYvWgux2KWUDw2wThJ4Vwghgb9LKR87cgMhxLXAtQAFBZFfDWqwzObew6csCfHotLEdCRsoS2ZcnBm9Xh/R8zicTlwuD06XE6fLjcvt6XMfp9OF3ebAYXfgcrlxudzo9ZH7eWm0GowpFuzSQ5vdjkarxZwWj0an7aNiHpKlgThdPGaPBo/LjbaPeqVlpJIWwacVRRkOwvlrfFAI8UvgXaArCbWUcl0Y+y6SUlYJITKB94QQO6SUn3bfwP9h8Bj47vjDr/rQmDNvBolJCbS2tHWV/eBH38aSEB/DWkHp1Im92rm/e/3l5ORHbqih2+3mv8te5/7fPdpVdtHl53DLHdcRbwl8/dVVtfz4+79g84btgK8Z5qEnfseSkyLXRBKXlkhdqpY//uzerrJTzzieWecdF3QfW0s7X/3zbWp3VvgKBBxzzZmMmztmxicoSpdwAv8M4ArgRA439Uj/65CklFX+f2uFEK8A84FPQ+81vJRMLuIfzz/I5ytW09jQwuIT5jNjTuSXQuuvNI2Re/90B+s3bqO+rpH5C+eQ4hA4rXYMcZGZ5HHwQCUP/fGJHmUvLnudcy86g5lBfgbbt+zqCvrg64S+9+6HmDG7lJQINZNUVVbz8F/+0aPs3bc+4dLvXEhGbuCO5+by+sNBH0DC+uc+Ir04B3Ny5PPsK8pwFk7gPw8ollI6+3NgIUQ8oJFStvn/fypwzwDqGHOTSieEndxrqNhaOzj4wueMS0lgYlIejW9uwhZnZPopR2OIULp4a4c14Nq2ba3tQfdpbW1j3Pg8TjtrKRqthvIDlXz47grs9uDr4faXzWpHSskFl55NanoyToeT5a+8R1trW9B9nNbeK23Z26x4nL2vrzu300V7XQtCCOIzktBFsMlKUWIlnN/ijUAyvglc/ZEFvOKf/qwD/iOlfLufx1CCSM733dlam9qwNvkCXuGx0zAnRq4JKjc/h+KS8ezbU9ZVlpBooaAweOfxhIlFnHzGEp558kXsdgeTp5Zwzx9vJz0zcu3kOblZ3H7PTTz+16eoLK8mIdHC1ddfTmGI7JyJ2akIjQbZLdNo/tyJmFKC3+13NLSy5fVVlH21A4GgaPE0pn5tAXEpsc1VpCiDFc5CLFnADiHEO/0Zziml3CelnOX/mial/O3gq6t0SinI5Jhrz8ScYkGj01Jy/ExKls5CaCKXZyQ1LZn7Hv4lxx4/HyEE02eX8n//vo9x44PnrGlrbuWfjz7bdYe/c9selr/8Lk57vx4YQ3K5XDzx16epLPdNymprbeev9z0R8hxJ+ekcd/05WDKTERpBwfwpzDj32JB38FUb91L25Q6Qvlwp+1ZsoWZ7xCaqK0rMhHPH/8uo10LpN61ex7i5E8koycPjcmNOtqDRRn5BtUmlE7j/kXtobmohIdHS57qzFWVVvcpWfvIV9bWNxPfRIe71eEHQtUpWMLW19VSU95w97PF4qKw4FLRJTqPRkD2tkJN++g3cTjemBDNaXfBff+mVlK/d3au8cuNeio6dFrJ+AB63x5fcbRgm/FKUcAL/QeCQlNIOIIQw43sKUIYBU2Lk1n8NJi7eTFy8OaxtA03UmjSlmMQQHxguh5PaHeXs/nADOpOeSSfOIb0kF4028PDMpKREkpITaWlu7VGelh66OanpYC17V2ymubyOomOnkjuzOGjHrtAIMibmUb+35wdZ+oTQGTqtTW1UbvA9KaQWZVO8aFpXs5yiDBfh3CK+SLeJW/jSL7wYneooI93EkkJO/9rSrtdx8WZ+fPt1JKcnB92ndkc5Kx/5H7U7y6nauI9PHniZhv29c+t0ys3P5u77bkPXbdz+92++ipJJhUH3aa1p4pMHXmLfis00Hqhm7X8+ZPfHG3utLtZd5pQC4tMTu14nZKeQWpgddHuP2832t1az/vmPaTxQzZ6PNvDJg6/QXt8SdB9FiYVw7vh13Uf0SCmdQojes4cUBfA0Wbno5KWcc+4ptLd3kJ2RTs1n27HNnBKwU9Tj9rDz/Z5TQqSUVG7YS0ZJ8Jm1J5x8LM+/+QSV5YdIz0iluKQw5FNJS0UdTmvPkUW73l9H8eLpWNJ7z8CWUrLno/XkTC/CaPEd197SwYEvt5E5KXDntrW+jX2f9czt42iz0lJZH/AcihIr4QT+OiHEOVLK1wGEEOcCYaVgUMYeoRHsf2991+tWwBBvCtnWrQ0w4zZQWXfS6yXVEIchMQ2TMQ5tH1P/RIB+g1Bt8EIIhFbLno839iifcHzgdNS+A+IfOdRzdnOgcytKLIUT+K8DlgkhHva/rsA3oUtReknISsGYYMbRdjiFdekZRwdtS9fqtJScMKvHaBmNTkvW1OBDM6WUlK/exeqn3usqKz5uBjPPWxR08lryuAzMKRZsTYfnIEw9cwFxqcGHZpacMIvK9Xu6lrwTGg3j508Jun18WhKTT5nL9rdWd5VZMpJIyguePE5RYqHPJG1dGwph8W8ffJbMIA3HJG1K/xzavJ+m8lrsLR3YWjpIGZ9Fe20zsy44rqvJpDuv18vm11dhijfTWFaLVq8lKTcNrVFPyZLAd9ftdc28+5tluB2uHuUn3nox6SXBO19bqhqo2rSP1kMN5M2aQMak/IB16qqbx0PD/mrKV+9EaLWMO2oiqUXZIUcd2Vut1O6qoGrTXlLGZZIzo4jEbJXrR4meiCZpE0J8E9+kKy+AlLL9iO9PAHKklJ8NpLIjiZSSjvoWvG4PcWmJ6AyRTYQ2UFJKKiuqcdgd5ORmhT3yJprsbTb2frqJokXTSchOpXr7Qaq3HmDaWQsDB363h5qtZWh1OvLmTMDr8bJ/1daQAdxld/UK+gAOa+iFcpJy00jKDb3ObncarZbUwixMljgQEJ+e2OdQU1NiHAXzJlEwL/iSjoFYG9tw2RyYUywRS7mhKMGEaupJA9YLIdbiW3qxDt/SiyXA8fja+W+Peg1jzGlzsH/lVra8vgqP003+nBJmnLeYhMzkmNbL2mFl+Svvcf/vHsHaYeO4Exfyk5//kMLiyC3EMhBJuakUL57Brg/W47I5SC/J5egrTsGUFHjYqc6gZ+rXFnBw9U42v7ISodVQdOw08ucET5ERl2ohMS+d1srDXU0anRZLiJFDA2FtamPHO2vY++kmhBBMOmkOE0+aizkpcrOjvR4PVZv2sXbZhzjabaQWZjHvmyerIaBKVAW9fZFSPgjMBZ4FMoCT/K8rgSv8SzL2nuEyyjTur2bjfz/tyulSsX4P+1ZsRnpjm0h066ad/ObO+7uWg1zx4Rf8+7HncAXIrTOUPC4PW5d/gcvmG0FTv6eKyo17CdWi2F7bTMW63Ugp8bo97P10E86O4Ll93DYnJcfP7BpaGZ+eyMzzFuF2RG52MPiarfZ8vBHplXg9Xna8u5aaHZGdudtS2cDnj72Jo933PjYeqGHNsg8C5hZSlEgJ+dwqpfRIKd+TUt4tpfyelPJmKeXfI7nA+nDXVNZ7HdeDq3d0/aHGyt5dB3qVvfvGxzTWNw19Zbppr2vuVVa1cS+OVmvA7d1OFwfX7OxVXh0iNUJ7Qyvrn/0IU1IcpWfMJ3NSPlte/5y26shdu/RKyr7a0au8csPeiJ0DfD+vI/vZGvdXY2vuCLKHogyeSjXYh7huE3g6JednoDMFb+d32hzU7apg/6qtxKUkULiwNOTEn4HIDLC2bcnkIuITgs/kdTmc1O2u5MDKrRgsZoqOmUpqUXZE0woYA5w/ITsVvSnw1A+tTkdqYRbN5T0XT0/ODz4SxhhvQmfUU7VxH1Ub93U7d+g+jubKespX76Spoo7xR08mq3R80JnPQiNIK86hfk/PmbupBZkhz9FfgX5epsQ49GY1VUaJHjXAuA/pxbmkFed0vdaZDEw9c0HIDt5Dm/ax8pH/UbVxH3s+3shHf/4vTQf7m9w0tGkzJ7Nw8VFdr81mEzff/j0sQRZIAajZdpDPHn6tq7nqo/v/S2OAJ5rBSCnIJHdWcddrjU7L3G+cgCE+cIel0AgmLJnVI2gnZKeSPW180HNYslKYds4x0O3zqvCYUuIygk+Saqtt5pMHXmb726up3nKAL//5DntXbArZZFe4oBRT8uGfZ3x6InmzI7uMZFJeOsWLp3e9FhrBUZefpDKAKlEV9nDOoTBch3PaWtppqWzA43STkJNKYlZK0G2dVjvv3/sc7bXNPcrnXLKUiSfMimi9Guob2b1jHx3tVopKxlNcEjxYuhxOPg7wATTj64soPf3oiNbL3malpaoBV4edhOxUEnNS+3yqaK9rpqWqAY1WS1JeWsjA11LVwKrHljN+/pSu5RPrdlcy+ZSjyJ4a+GdQsW43qx57o0eZVq/j9LuvJD6t91Ndp476FpqrGhBCkJSXRnxq8G0Hymm101JRj73dRkJGMom5aVFJuKeMTlFZc1cIYQQuAAq7by+lHJGLqgyEOcmCOSnMVZqCfY5G4QM2LT2VtMWDHCMehXqZEuIwTe5f8jiX3YXL5kSj1eAOI4VzW00TW17/vEfZpJPn9uucQPD3yy8+PYn4KKdbMMSZyAiSBkJRoiGc24rXgHMBN9DR7UsJwBBvYtqZC3qUafW6PrM6RpveaGDKGT3v7DU6LZmlsV/gvm53JZ8+9DJf/esdvnjyLVY+ujxkE1R8RlKv1MiWzOSQY/ST8tN79QFMOW1eyJm7ijJa9dnUI4TYIqWcHnKjCBmuTT395bQ5qNtZwf5VWzAnWyg8dhppEe7cHQiXw0ndrkr2f7YFQ4KZomOnklaUE9Oc8V63l9VPv0fZl9t7lM8491hKz5gfdD9rUxuHthygfO0uMibmMe6oSX3OkG2uqOPg6p00Haxj/IIpZE8N3rmrKCNFVJp6gFVCiBlSys19b6oAGMxG8mZPIG/28FqnV280kDujiNwZRf3az2l14GizYogz9Tlypr9cTictVb1z/rUcagi5X1xKArmzikktzEJvNoaV/TI5P0NNjFIUQqds2IyvBVQHfFsIsQ9w4BtLIaWUIdIUKqNF08Ea1j77EY37q0nITmHe5SeRMTFy7dHGOBN5syf0Gs6Z1UcTVN2eKja+/CmN+6qJT09i9kVLyJlR1GdKBUVRQrfxnwWcDZyBL03Dqf7XneXKKGdv7WDV42/S6F8Upa26iRV/e5222shOEkvKSSd/bglCCDQ6LcXHzcAUYtH4jsZW1v7nAxr3+erVUd/CF0+8SeOB4Iu3KIpyWNA7fillGYAQ4mkpZY80zEKIp1GpmUe9joZWOup6rh7ltjtpr2shITP4kNb+cDtdbHvrS7Q6HVNOPxqkpHLjXkCSM60wcL3qW2it6tkU5HF5aK9tIb04tp3oijIShNPG32P4hBBCCxwVZFtlFNGbjWh0WrzunguLBJuM1amlsp6qTftoq2v2pT+emBc046RGpyU5P4MDn2+jYf/hBdSLFwUfT6A3GdEZ9b0ydPZVL0VRfII29QghfiaEaANmCiFa/V9tQC2+IZ7KKGdOtlB6xBDQwmOnhcxO2VbTyMcPvMzm11ZxYNU2Vj7yPw6u3hV0e41GQ8kJs9CbjV1l8WmJZE8vDLqPJTuFqWcu7FGWf9RE4jPV8oaKEo5QTT2/B34vhPi9lPJnQ1gnZZjoqG/h0OYDTD/3WDxON1q9lvq9h2ivawk6s7apvB5HW8+EbFteX0XerOKgq3Cljs/ipJ9+g5bKejRaLcn56SEnTdkaWjm4ekePejWW1WBrbCMpSy16oih9Caep50UhxJFTIluAMillnzmA/U1Da4BKKeVZA6hjzNnbrbRWNfpSNmSnhDV0sL2+mbbqZrQGHUm5aSFXehooR4eN1qpG3A4nlsyUsNYI6GhopbW6Ea1OS2JuGqYQSd28XknjgepenaaTTwk+Q1Z6vb2P4/H2ykB5pMTs1LBXqpJeSXN5Xa+RQBOOUwPNFCUc4QT+/8OXh38TvqGcM4CNQJoQ4jop5bt97H8TsB2IfJKTIWBtamPN0+9Tva0MAKPFzJIbv05KQVbQfRoP1vDpg6/g7PDlVM+eXsi8CCfesjW3s+75j6lcvwcAfZyRJTecR1pR8IlizeV1fPrXV7D7UyRnTMpn/rdODZqrJiEjiZzphRzacuBwWVZKyACdkJXSq/198slzg97tD0R8RhIF8yZxcM3hJiRzqoXEXHW3ryjhCGfQ8wFgjpRynpTyKGA2sAU4Gbgv1I5CiHzgTOCJwVUzdhr2HeoK+gCOdhvb3voKd5AFT9wuN9uWf9kV9AGqtxygYd+hgNsPVOPB2q6gD+CyOtj86kpcQfLceNwedn2wrivoA9TtqqBud0XQc+jNRuZ84wRmnHssKeOzmHLaPBZdd1bIIO60OZh29jHkzy0htSib0jOOxu1wdi3MEgk6g54Z5y1i1gXHkTI+i0knzWHJ9V+PSgI1RRmNwrnjnyKl3Nr5Qkq5TQgxR0q5L4yp/g8AtwFBb3WFENcC1wIUFMQ+b8yR2mp6j1lv3F+N2+ZEp+/943PbnAHHkx+ZrXOwrA2tvcqaympw2RwBc997nC7qA3z4tFSGniFryUimeMkMcmYVY7SYMYcYXw9ga2xj438/JSkvHVNiHLs/2ojH4aLkhNkRXUs2Pi2JyaccRckJs9HoNDFNO6EoI004d/w7hRCPCCGO93/9H7DLn7Wz94rXfkKIs4BaKeXaUAeXUj7mf5qYl5Ex/KbTpwRYeCNvdgkGS+AgZog3BczZnjwusteWECA1dM6MoqApFfRmI/lzetcrrY/kcfV7q/j8sTd47zfL+Ozh10KujAVg8efEb6msp2b7Qdx2J9nTCyOe6qGTVq9VQV9R+imcwH8VsAe4GfgRsM9f5gKWhthvEXCOEOIA8BxwohDimYFXNTZSi3KYdtbCrvzoGZPymLh0dtDUABqthkknzSFjUl7X62lnLSS1KCfg9gOlNxuYeOJsNDot4F8AZfYENBptwO2FEBQtmta1wInQCKacdhTpE4LXq72+hdVPv0ftzgqkV9J0sJYvHn+DpiM6VbtLHpfB7IuPR6vX+l9nMvO8RSEXrlEUZWgNyUIsQogTgFv7GtUzXLNzej0e2mub8bg9xKcnYeg25jwYp81BR30LWp0WS2YyGm3ggDxQez7ZxO6P1pM/pwQhNLTWNFK7o5xTf/5N4kK0wbv8M281Wg2WzGS0uuD1OrStjBUPvdKrfOF3z6Bg3uSg+0mvpL2uGbfDRVxqIsYgT0eKogxetBZiWQTcDYyn50IsxcH2GW00Wi2JOcFzvQdiMBsxjAt/fVZbczt1e6po2HeI1MIsMibmhRwFZLSYaKtuYvtbq7vKksdloDOEfkv1JgMpYTY7GUwGNFoNXk/PIZr6Pj74hEYEbIpSFGV4CKdz90l8TTxrAU8f2wYkpfwY+Hgg+44FLruTza+t5MDnh3PS582ewNFXnoohLnCQTSnMIik3jRZ/zhqhEcw8/7iIdqAm5Wcw5bR5bHvzq66ygvmTVWpjRRnhwgn8LVLKt6JekzGsraapR9AHqNywlymnNZIWpG/AkpbE4uvPpelgLW6Hk8SctIh3IOsMOiYcP4vkgiysja2YkuJJG58VMmWDoijDXziB/yMhxB+Bl/Hl4wdASrkuarUaY7weD/HpiYxfUIr0ehEaDQdX78TjDv2AFZ+WGHKh8EgwJ8WTP8wWlFEUZXDCCfydC8h27zyQwImRr87YZElPYcKSWWx5bSVejy/wTzt7YVgpGBRFUfqrz8AvpQw1ZFOJAKfNxtb/fd7ViSq9XrYt/4K8WRMwJ0Uu1YGiKAqEMY5fCJElhHhSCPGW//VUIcTV0a/a2OFoteE5IgWE1+PF3toRoxrFhr21A0e7LdbVUJRRL5ymnn8B/wTu9L/eBTyPb7SPEgHm5Hh0JgPubnl2tHodccmRS+o2nNnbrBxcvZMd76xBq9cy/ZxjyZ1VjN7YO/WEoiiDF87M3XQp5QuAF8CfinlAwzqVwCwZyRzz3TPQ+4du6kwGFl59OpYx0sZ/aPMBNrzwCfaWDjrqW/nyH2/TsDeySe0URTksnDv+DiFEGr4OXYQQC/Hl41ciKGd6Eaf87DLsrR2YEuOwZCTHukpDwuNys+eTjb3KKzfuJXvq+BjUSFFGv3AC/y3A68AEIcRKIAO4MKq1CpPb5abpQA0N+6owWuJIL8kd0TNGLRlJXUnOosHr8dJ4sIaGPVXoTHrSJ+SRlNu/GcmRJjQa4tMSaSqr6VEeybULFEXpKZxRPeuEEMcDk/EtxLJTShk0K+dQqtl6gJWPLu96HZeayPE3n6+GQQZRt7uCTx96Ben15WcyxJtYesuFJOWlx6xOnUntqjbt61rU3RBvImdGUczqpCijXdDAL4Q4P8i3JgkhkFK+HKU6hcXRbmPjy5/1KLM2ttJUVqMCfwBup4ttb37VFfQBnB12anaWxzTwA6QV53DSbRfTVFaL0GlJHZ8V8ycRRRnNQt3xnx3iexLfTN6Y8bo9PVa56uR2BF6Baqzzery9FkEHcA6D4ZNCCFIKskIuZ6koSuQEDfxSym8PZUX6y5QUz8Sls9m6/IuuMqERKoFYEAazkYknzmHtsg96lGdOGX6rnimKEl3hdO4OS50Li2j0WvZ+sglzsoXp5xxDcoAVsxSfvNkTkB4vO99fiz7OyPSzjgm5OLuiKKPTkCzEEq6BLsTiaLOi0esCrjUbS44OOxqtJux6eT0eXFYHOrMx5AIpg65Xu81XrzAWlFEUZXiLykIsI4ExIS7WVejB1tJBxdpd7PpwA6bEOKadtZDMyfkhV+FqOdTA7g/Wc2jrAbKmjGPyyUdFrdPVaInO+reKoowMAxnVAxDzUT3DWfmaXWx48RMAOupbWPHXV1n6k4tILw68sLm91coXT7xFS2U9AAc+3079niqW3nqxyn2vKErEjdhRPcOVo93Grg96LlUgpaRhX3XQwN9e19wV9A+XtdBW06QCv6IoETdiR/UMVxqtBkO8CWtjW4/yUO38Wn3gtyFYuaIoymCEk6QNIcSZQojbhBC/6PyKdsVGKr3ZyIxzj/XNcfYzJsSRPiHwEooACVnJFB83o0dZwfwpJGSP3PQTiqIMX33eUgohHgXigKXAE/jy9HwVcqcxLnPyOJbechH1eyoxxJtIn5hHYk7wmag6o4FpZy0ke9p4msvrSMpLJ704B4MadaMoShT0OZxTCLFJSjmz278W4GUp5amRrsxAh3MqiqKMVQMZzhlOU0/nnH6rECIXcAEqg5aiKMoIFU7v4XIhRDLwR2AdvhE9T0SzUoqiKEr0hBP475NSOoCXhBDLARPQOzuaEhMetxuvR6I36mNdFUVRRohwAv/nwFwA/weAQwixrrMsGCGECfgUMPrP818p5S8HV12lk5SS+r1V7Hx3LR0NrZScMJO8WSWYEofXLGZFUYafUDN3s4E8wCyEmMPhAYqJ+Eb59MUBnCilbBdC6IHPhBBvSSm/6GtHpW9N5XV88sDLXYuXrF32IW6Hi8knHxXjmimKMtyFuuM/DbgKyAfu71beCtzR14Glb7hQu/+l3v81fDLCjXDNB2u6gn6nne+upeDoKWq2r6IoIYWauftv4N9CiAuklC8N5OBCCC2wFigB/ial/DLANtcC1wIUFKjc8OHSBJjVqzXo0GjDmpOnKMoYFk6UWCmEeFII8RaAEGKqEOLqcA4upfRIKWfje2qYL4SYHmCbx6SU86SU8zIy1CIq4Uodn4UxoWeWzRlfX6QybyqK0qdwOnf/6f+60/96F/A88GS4J5FSNgshPgZOB7b0s45KAInZqZxw8wVUbyvD2txOzvQi0ovVoiqKovQtnMCfLqV8QQjxMwAppVsI4elrJyFEBuDyB30zcDLwh8FVV+kuKS895gulK4oy8oQT+DuEEGn4O2aFEAuBljD2y8HXR6DF16T0gpRy+YBrqiiKokREOIH/FuB1YIIQYiWQgS9RW0hSyk3AnMFVT1EURYm0PgO/lHKdEOJ4YDK+sfw7pZSuqNdMURRFiYpw0jKbgB8Ai/E196wQQjwqpVRpGxRFUUagcJp6ngLagL/6X18KPA1cFK1KKYqiKNETTuCfLKWc1e31R0KIjdGqkKIoihJd4UzgWu8fyQOAEGIBsDJ6VVIURVGiKZw7/gXAlUKIg/7XBcB2IcRmfCl5ZkatdoqiKErEhRP4T496LRRFUZQhE85wzrKhqIiiKIoyNFQqR0VRlDFGBX5FUZQxRgV+RVGUMUYFfkVRlDFGBX5FUZQxRgV+RVGUMUYFfkVRlDFGBX5FUZQxRgV+RVGUMUYFfkVRlDFGBX5FUZQxRgV+RVGUMUYFfkVRlDFGBX5FUZQxRgV+RVGUMUYFfkVRlDEmaoFfCDFOCPGREGK7EGKrEOKmaJ1LURRFCV84Sy8OlBv4sZRynRAiAVgrhHhPSrktiudUFEVR+hC1O34p5SEp5Tr//9uA7UBetM6nKIqihGdI2viFEIXAHODLAN+7VgixRgixpq6ubiiqoyjDjtftxuN0IL3eWFdl0LwuJx6nEyllrKuiBBHNph4AhBAW4CXgZill65Hfl1I+BjwGMG/ePPWboowpUkrcHe1YK8vwOB0YkpIxZ+aiNZljXbV+83o8OJsbsdVUgldiysjCmJqORm+IddWUI0T1jl8IoccX9JdJKV+O5rkUZSTyOOy07d+Fx2EHKXE2N9FxqByvxxPrqvWbu6MNa2UZ0u1Gej3YaqpwtrbEulpKANEc1SOAJ4HtUsr7o3UeRRnJPHZfwO/O3daK1+WMUY0Gztna3KvM0ViH9I68D7HRLpp3/IuAK4AThRAb/F9fi+L5FGXE0Wh7/wkKrRahGXlTbLQGY+8yownEyLuW0S5qbfxSys8AEa3jK8pooDXHobck4Wo/3CRizhkXMIgOd/rEZOz1NUi321cgNJjSM/E9/CvDSdQ7dxVFCU6j0xM/bjxumxWvy4XWZEJnjot1tQZEZzKTUDwFj90K0ovWFDdir2W0U4FfUSLM47DjcTrR6HRojUaERhtye6HV+ka+CA0anb7P7YczjU6H1BtAetHo9GHt43E48DgdaLRatEYTQjtyr3+kUIFfUSLI1d5K24E94B+Pb87Ow5iWgUYb+E/N63HjqK/FVlPlK9BoSCgsQW9JHKoqR4zH6aCj4gDu9jYANEYTCeMnhBya6ra207Z/D9Ljax4ypmVizsoJ+0NDGRjV66IoEeJ1uegoP9AV9AFs1ZW+kTtBeOy2w0EfwOulo/wAXpcrijWNDld7a1fQB/A67DiaGoJO5PJ63HRUlXcFfQBHQy0emzXqdR3rVOBXRiwpvXhcTmQ/xrx7PR68rv7NKvW6XXjdfQdir8cdcBhmqKGZnQFen5CEMTUDrcmM1+XE2y0YDrZeQ8Xd3g4aDYbkVAwp6QitDld7a48Pwu6kx4PH2tGr3DMCP/RGGtXUo4xIHrsNW101rtZmtKZ44nJy0cVZgm7fNUO2ugKvw4EhJQ1TWiZaY/DRM163G2dLE/baQyDAnJWLPjEFTZA2aI1Oh8ZgxOt09CjXGoLPXNUaDMTljsPZ3IjT2oE+IRFDSioaXfA/Ta/Hg6u1yfekIMGUmYMhKSXkPkNBn5SM1mjE0dQA0uubtRuizV5odejiE3B3tPUoD/XzUiJD3fErI47X46ajsgxnUwPS48Hd0Urbvt2+2a9BeOw23wxZawfS48ZRX4OtpipkbhxXeyvWyjLfHbjTSUf5gV5BqjvfCJ0iRGf7tBDE5RWEbOP2SrAeqsTtr5ezudF35xzigcTd3uprDnI68bqcWCvLfHfWMSaEwFZThdfpwOtyYa+r7jU5rTuNVktc7jg03QK9KSsXrRoJFHXqjl8ZcbxOJ+6O9h5l0uvB47D7JgwF0JkSAQRCo0F6PTibGzBn5QTcR0qJo6F30kBnUwOGxOSgddPHW0gsKcXrciC0Ot8olRDj2L0OO0jfh4/Q6ZFuF662Ft8oF33gDk5Hc2PvsoZ6DEkpMR0zHyg9g6OxHmNKatCRSjpzHIkTpuBxOhEaje/nNQInr400KvArI49GA0L0upsMFTCERoMpPQs0GqTHg0avx9XeFnRWqRDCdyd6RBO0JoyJVVqDIezmCqHREJc/HrwSr8uJxmTCbbOFDOBavYEjW8E1RkPEg77L2oHHZsXrdKA1mdGa49GZAn+wdtarV5nB0OfMXY3eEPVEbh67DVdHO9LrQRdvQWeOHxYTy9x2G25rO9LjQRdnQRcXhxiCmc4q8CsjjtZgxJyVi626sqtMn5AUsklF6HS+O+luzUG+GbLBA44xLQNnc1PXHTkaDYaklMFfQDcag9GXmbPbSBZTVi4iyJMLgD4xCXtj3eFOU6HBkJQa0Xq5bVZsVeW4rYefrEwZ2YjMHLRB2ux18RaEVnu4s10IXydvjAOs22albd+uHqOHEoonxXzIrNtu89WrWwe9pWgihoSkqJ9bBX5lxBFCYEzLQGuOx2O3ojUY0cbFhxz77bXbe/UB2Gur0Mdb0MXFB9xHH2chsWQybmsHINDFxUd8JqrXYe81fNFeV40+IRFtkM5qV1sr5oxs38gkKREaDc7WZgwJkQtkHoe9R9AHsNfXoE9MQhufEHAft7UdU3rW4XpptTiaG9AnJMY0+Lva23oEfQBbzSF0cfExnSzn7mjvEfQBbNVV6OIsQQcQRIoK/Mqw4HW78TjsviYWo6nPX3yNVofQaHxNBFod9PEHHKgTV3o8fQ7r1OiN6My+vgFNmM03HqcDr9OJ0GrRmkwhH90Ddi57vb5e3xDHd7U0+Zq7AKREZ0lEShkywLrtNjwOOxqtDq3JHHIUUMB6SYkMWS8nzsY6QPiydEmJNi7e1yQXw8B/ZHDtLJMydDIx34IyDoRGG9YM7H7XK8CQXel2+Z8wVeBXRjm33U5H+X48Nl+Duj4phbic/JCJypwtTXRUHPA1KwiBOSsPQ0oa2iAdolqTqVe/gCE5NWSbvcdhp6OirGskjz4hyTdKJ8Q+ro422g/s9f9RC8y5+ZhS0oMOadQaTb4+i26BVp+QFLJehqQUX+Dvdi3GlLSQQd/V1kp7+f6uIGjKzMaQloFOH/g8nakTus+R0MVb0IQY/mpISvYHftk1KsmUlhnzzlp9QpJvhFE3xvTMkDcXbpuV9rI9eJ2+ORim9CxMmdkRnVGsi+/9RGdMzxySWcuq+1yJKSklzqb6rqAP4GppCjls0mWz0lF58HBQkhJbdYUvOVgQeksilvET0MVZEDo9xrRMjOmZQT8owPfh0r0errYWXG3BFxbpnLl7+E5OYqsqx2O3Bd1HSrCMK0IXn4DQ6TGkpmNISUfK4MNMpceDOSvX92RkMGLKzAmZ897jdGI9VN7jztdeW43XGrxe+ngL8QUT0Fn89UpJw5yVhy7EB5I+zrdPZ73i8sajj2Dz00Dp4uKwjC/xPeXoDcTlFqBPDN5XIz0erNWVXUEffM1c7gjPKNaZ47EUTeyqlzknH2NyZPtqgp57SM4yRnndboQQKulUKF5vwGDqam/DmJIecBfpcgV8fO/+hxqIITEZrSkO6XUj9MagnZTg+0ByBRie6GptxZSWGXAfr9vVa/IWgMflDPqH5nXasVaWYUjPxJCUgqO1GefBvSRMmAJBYqyrpQmX3Up8Tj4gsFZXodXrMaSkowlwd+11uwJ++PS12IshIRGt2YTX7UbTx88LfMnmjMkp6C2+PoD+TCiL5t+K0GgxJCWjs1hAyj7vqL0eT8AbD6/DAYG7NwZYLw2GhCRfH1MY9YokFfijwOty4mhpwlFfi9DpicvK8d05qQUpetNo0Cck9QpMuiAdiOAb7y50usN53zsPFcaQQN8onr63E0KgS0js1cGpswSvl0anR6M39AqooerV+T1nfS2de2kMRkSIoGlISUPvTcFeVwNSYs7IBI0uYND31cs3n+DIzu2wfl46A1pd/4Za9ifge5xOnM0NOBrr0RiMmLNyfE9lUegTCJYor/d2WnTxFtxtPSfFhWrmGoxw6xXRcw75GccAR3MTtqpyvE4HHms7bft347aqxFOBCCF8bfPdhmLqE5K67hoD0RqNmLPyfG3jvqP4hhqGaLYZCJ05rscsUl2cxddXEIRG75+52+2u1Zydhy7EMFOdOQ5TZk7Xa+GfzaoLMZwTgW8IqL+z1lpVTqipvlqDEXPuOES3AGNMz4r5DFkppW8GdXUlXqcDd3srbft2hWwaGwpCqyUuO7/HBDpjWgZa0+iZUazu+CPM63bhqK/pVe62tqMP0Jmj+BfwKJrkG9WjEWgMptC5apwObNWVviYX/52hs6XJ11kWoWDm9Xqx19egNZrQJyQhhMBjt+ForAs5zlpvSSBxYql/VI+uz5moGr0eU3oWeksiXo8brcHY55BRZ3NTgLIGX2d1kHMZEpLQFE/y573ve1TPUPC6nNgbansWSonHbov5Ai46cxwJE0rxOu3+UT2ja50AFfgjrbOd8ogm6JG8uMZQ0Oj1QVMU9CIE0uvpNVIjkqNHNBoNQqvDeUR6BENq4H6H7rQGE1pDiDv2I8+l06EJ8YRzpEDNQEIbvKmnk848vFbE6mzTP7LJrq/30ety4bZ14HU5fT/ruLioNJf0Zwb2SKOaeiJMo9Vhzs7rUebLQqju9iNFazRhysjuWRZvQWsM3qQyEMaUtJ7jz0XkZ+4OhDEp9Yh6CUxhfCANNxq9gbic/F5lIZPaedxYD5XTfmAP1sqDtO3fhaO+NuQoKKU3dccfBXpLIgnFk3F3tCG0OvSWhJC/zEr/CCEwpWeii4vHbe1AazT5xphHuI3f2d6KOSvXlzNfCDQ6HW5rx5BMqQ9Fn5BIQtFEXB1tIH0d4doRemNhSExBU2TA1dGGxmDwXUuI/g2P3d7rKcxWewh9UkrIvhSlJxX4o0BoNOgtCSE7KJXB0ej0aE1xCK0ejU4b8SRfUkq8NhvOjtquZjrp9aAfBnf84Lu5iHWumUgQWi36hMSwx/sHnK8gZcj02kpvKvArI5Kro432sn2+8fwaDfF5431piSPUzi+EwJiajrujrUewGaoJNkpggWYUa03mkLOpld5UG78y4nhdTjoOHk4/4Fundn/IhVgGQp+QiDm3AKHT+eZj5I0POY5fiT6twUhC0STfPA+hQZ+UQnxBccxHKI006qeljDhetyvw2rZOZ8SGc4KvOcmcnokxKRkQEe9DiAWvx4PQaGKeKnkwdHHxWApLkB43Gp1OjZgbgKgFfiHEP4CzgFop5fRonUcZe4RWh9DqemU3jFZgjvYiIUPB43TgbGnC2dSA1mTGmJ6FPkg66pFAo9XCKBpXP9Si2dTzL+D0KB5fGaO0BiPx4wp7DGk0Z+eFHA0ylkkpsdfXYjtUgcduw9ncSPu+XbhjPENWiZ2o3fFLKT8VQhRG6/jK2KZPSCJx4lS8TqcvF43JpB75g/A6HTiOmCErvR7fDFk1BHJMinkbvxDiWuBagIKCghjXRhkphBC+oKUCV9+ECLxG8Qhu51cGJ+ajeqSUj0kp50kp52VkZMS6Oooy6vjWKO45m9w3Q3b4pG9QhlbM7/gVRYk+Y0oaWoMRZ3sLOqMJnSURbZTSDCvDnwr8ijIGaHQ6DEnJGJKSY10VZRiIWlOPEOJZ4HNgshCiQghxdbTOpSiKooQvmqN6Lo3WsRVFUZSBi3nnrqIoijK0VOBXFEUZY1TgVxRFGWNU4FcURRljhDxiNl8sCSHqgLIB7p4O1EewOiPJWL52GNvXr6597Oq8/vFSyn7Nfh1WgX8whBBrpJTzYl2PWBjL1w5j+/rVtY/Na4fBXb9q6lEURRljVOBXFEUZY0ZT4H8s1hWIobF87TC2r19d+9g14OsfNW38iqIoSnhG0x2/oiiKEgYV+BVFUcaYERX4hRDjhBAfCSG2CyG2CiFuCrCNEEI8JITYI4TYJISYG4u6RlqY136CEKJFCLHB//WLWNQ10oQQJiHEV0KIjf5r/1WAbUbl+w5hX/+ofO87CSG0Qoj1QojlAb43at976PPaB/S+j7R8/G7gx1LKdUKIBGCtEOI9KeW2btucAUz0fy0AHvH/O9KFc+0AK6SUZ8WgftHkAE6UUrYLIfTAZ0KIt6SUX3TbZrS+7xDe9cPofO873QRsBxIDfG80v/cQ+tphAO/7iLrjl1IeklKu8/+/Dd8PI++Izc4FnpI+XwDJQoicIa5qxIV57aOS/71s97/U+7+OHJUwKt93CPv6Ry0hRD5wJvBEkE1G7XsfxrUPyIgK/N0JIQqBOcCXR3wrDyjv9rqCURYgQ1w7wDH+JoG3hBDThrZm0eN/3N0A1ALvSSnH1PsexvXDKH3vgQeA2wBvkO+P5vf+AUJfOwzgfR+RgV8IYQFeAm6WUrYe+e0Au4yau6M+rn0dvrwds4C/Aq8OcfWiRkrpkVLOBvKB+UKI6UdsMqrf9zCuf1S+90KIs4BaKeXaUJsFKBvx732Y1z6g933EBX5/G+dLwDIp5csBNqkAxnV7nQ9UDUXdoq2va5dStnY2CUgp3wT0Qoj0Ia5mVEkpm4GPgdOP+Naofd+7C3b9o/i9XwScI4Q4ADwHnCiEeOaIbUbre9/ntQ/0fR9RgV8IIYAnge1SyvuDbPY6cKW/p38h0CKlPDRklYyScK5dCJHt3w4hxHx872/D0NUyOoQQGUKIZP//zcDJwI4jNhuV7zuEd/2j9b2XUv5MSpkvpSwELgE+lFJ+84jNRuV7H861D/R9H2mjehYBVwCb/e2dAHcABQBSykeBN4GvAXsAK/Dtoa9mVIRz7RcC3xdCuAEbcIkcHVOzc4B/CyG0+H6xX5BSLhdCXAej/n2H8K5/tL73AY2h976XSLzvKmWDoijKGDOimnoURVGUwVOBX1EUZYxRgV9RFGWMUYFfURRljFGBX1EUZYxRgV8Z1fzZC3tlNQxjv1whxH+DfO9jIcQ8///v6FZeKITYEubxbxZCXNnfegU4zg+FEKN6+KISeSrwK0oAUsoqKeWFYWx6R9+b9CSE0AHfAf7T74r19g/gxggcRxlDVOBXYkoIES+EeMOfZGqLEOIb/vKjhBCfCCHWCiHe6cy26L/bfkAIscq//Xx/+Xx/2Xr/v5P7OO+bQoiZ/v+vF/485kKIXwshvtv97l0IYRZCPCd8ud6fB8z+8nsBs/DlQV/mP7RWCPG48OXNf9c/0/ZIJwLrpJRu/3FKhBDv+38G64QQE/xPKp8IIV4QQuwSQtwrhLhc+PLybxZCTACQUlqBA50/B0UJhwr8SqydDlRJKWdJKacDbwtfTqK/AhdKKY/Cd1f72277xEspjwV+4P8e+FIYLJFSzgF+Afyuj/N+ChwnhEjEt9bBIn/5YmDFEdt+H7BKKWf663EUgJTydsAmpZwtpbzcv+1E4G9SymlAM3BBgHMvAron3lrm32cWcCzQmW5gFr5c7DPwzdqeJKWcjy9F7w3d9l8DHNfH9SpKl5GWskEZfTYDfxJC/AFYLqVcIXyZJ6cD7/nTkGg5HAwBngWQUn4qhEj057FJwJfWYCK+zIz6Ps67Al8TyX7gDeAUIUQcUCil3Cl8qa87LQEe8p9zkxBiU4jj7pdSbvD/fy1QGGCbHHzrKSB8i+rkSSlf8R/f7i8HWN2Zc0YIsRd417//ZmBpt+PVAlP6uF5F6aICvxJTUspdQoij8OVa+b0Q4l3gFWCrlPKYYLsFeP1r4CMp5Xn+oP1xH6deDcwD9gHvAenANfS8Ew91zmAc3f7vwd8sdAQbYPL/P1BK4UDH8nZ77aXn367Jf0xFCYtq6lFiSgiRi68Z5RngT8BcYCeQIYQ4xr+NXvRcYKKzH2AxvkyMLUASUOn//lV9nVdK6cS3eMfFwBf4ngBupXczD/iahS73n3M6MLPb91z+pqn+2A6U+OvRClQIIb7uP77R/+TRH5OAsEYTKQqowK/E3gzgK3/G0TuB3/iD8oXAH4QQG4EN+Nq+OzUJIVYBjwJX+8vuw/fEsBJf01A4VgA1/g7SFfjyuAcK/I8AFn8Tz23AV92+9xiwqVvnbjjewtd81OkK4Eb/8VcB2f04Fvj6DN7v5z7KGKaycyojihDiY+BWKeWaWNdlMIQQrwC3SSl3D/I4c4BbpJRXRKZmylig7vgVJTZux9fJO1jpwM8jcBxlDFF3/IqiKGOMuuNXFEUZY1TgVxRFGWNU4FcURRljVOBXFEUZY1TgVxRFGWP+Hw41HryS8ZheAAAAAElFTkSuQmCC\n",
+ "text/plain": [
+ "
"
+ ]
+ },
+ "metadata": {
+ "needs_background": "light"
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "sns.scatterplot(data=df, x='sepal width (cm)', y='petal length (cm)', hue='class');"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 31,
+ "id": "ffe81dec",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAX4AAAEGCAYAAABiq/5QAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjQuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8rg+JYAAAACXBIWXMAAAsTAAALEwEAmpwYAAAaNUlEQVR4nO3de5QV5Znv8e9PwIABRrkkgi0iGg0i9xZC8DJqHC/xkBlhzmiMLqI5rMzkKB7HeDRZo4nGjCaTLE1MwsEwM1EZPRo1chjxkoWORifRBrkjElFCo44EjUIEBXzOH7sgTduX6ma/u7t3/T5r9WLvXVXP+7yUPlS/9da7FRGYmVlx7NfRCZiZWWW58JuZFYwLv5lZwbjwm5kVjAu/mVnBdO/oBBoaMGBADB06tKPTMDPrMhYtWvT7iBjYlmM6VeEfOnQodXV1HZ2GmVmXIWl9W4/xUI+ZWcG48JuZFUyywi/paElLGvy8I+myVO2ZmVk+ycb4I2INMAZAUjdgI/BAqvbMzNprx44d1NfXs3379o5OpVk9e/akpqaGHj167HOsSt3cPRV4KSLafBPCzCy1+vp6+vTpw9ChQ5HU0el8SESwefNm6uvrOfzww/c5XqXG+M8F7mpqg6QZkuok1W3atKlC6ZiZ/cn27dvp379/pyz6AJLo379/2X4jSV74Je0PTAHubWp7RMyOiNqIqB04sE1TUc3MyqazFv3dyplfJa74zwQWR8R/VaAtMzNrRSXG+M+jmWEeS++pBSuTxd62dWey2AC9eqf7z/OEM0cki93VPXrv0mSx/+KvRyeL3RG+8Y1v0Lt3b6644oqOTqVNkl7xSzoAOA24P2U7ZmaWX9LCHxHvRkT/iHg7ZTtmZpVw++23M2rUKEaPHs0FF1yw17bbbruN4447jtGjRzN16lTeffddAO69916OPfZYRo8ezYknngjAypUrmTBhAmPGjGHUqFGsXbu2ov3wk7tmZjmsXLmSG264gYULF7J06VJuueWWvbafc845PPfccyxdupThw4czZ84cAK677joeeeQRli5dyrx58wCYNWsWM2fOZMmSJdTV1VFTU1PRvrjwm5nlsHDhQqZNm8aAAQMA6Nev317bV6xYwQknnMDIkSOZO3cuK1eW7q9NnjyZ6dOnc9ttt7Fr1y4AJk2axLe//W1uuukm1q9fT69evSraFxd+M7McIqLFKZXTp0/n1ltvZfny5Vx77bV75tzPmjWLb33rW2zYsIExY8awefNmPv/5zzNv3jx69erF6aefzsKFCyvVDcCF38wsl1NPPZV77rmHzZs3A/Dmm2/utX3Lli0MGjSIHTt2MHfu3D2fv/TSS0ycOJHrrruOAQMGsGHDBtatW8ewYcO49NJLmTJlCsuWLatoXzrVevxmZp3ViBEj+PrXv85JJ51Et27dGDt2LA2/OOr6669n4sSJHHbYYYwcOZItW7YA8NWvfpW1a9cSEZx66qmMHj2aG2+8kTvvvJMePXpw8MEHc80111S0L4qIijbYktra2vAXsZSX5/E3zfP4m1fEefyrV69m+PDhHZ1Gq5rKU9KiiKhtSxwP9ZiZFYwLv5lZwbjwm5kVjAu/mVnBuPCbmRWMC7+ZWcF4Hr+ZWSNvrVpC7CzfdGV1785Bx4xpdb+HH36YmTNnsmvXLr70pS9x1VVXlS2HhnzFb2bWSDmLft54u3bt4itf+QoLFixg1apV3HXXXaxataqseezmwm9m1gk8++yzHHnkkQwbNoz999+fc889lwcffDBJWy78ZmadwMaNGzn00EP3vK+pqWHjxo1J2nLhNzPrBJpaPifVF8C78JuZdQI1NTVs2LBhz/v6+noGDx6cpC0XfjOzTuC4445j7dq1vPzyy7z//vvcfffdTJkyJUlbns7ZCaRcQTOlN199N2n8bVvfTxb7zdcWJYsNsG1LutwPOapvstjQeVfQrCR171726Zyt6d69O7feeiunn346u3bt4qKLLmLEiDSryLrwm5k1kmfOfQpnnXUWZ511VvJ2PNRjZlYwLvxmZgXjwm9mVjBJC7+kAyX9XNILklZLmpSyPTMza13qm7u3AA9HxDRJ+wMHJG7PzMxakazwS+oLnAhMB4iI94F0c9zMzCyXlFf8w4BNwL9IGg0sAmZGxB8b7iRpBjADYMiQIQnTMTPL58ErZ/PeO+V7TuUjfQ/gc9+Z0eI+F110EfPnz+djH/sYK1asKFvbTUk5xt8dGAf8JCLGAn8EPrS4dETMjojaiKgdOHBgwnTMzPIpZ9HPG2/69Ok8/PDDZW23OSkLfz1QHxG/yd7/nNI/BGZm1siJJ55Iv379KtJWssIfEa8DGyQdnX10KpDmWwXMzCy31LN6LgHmZjN61gFfTNyemZm1Imnhj4glQG3KNszMrG385K6ZWcG48JuZNfKRvuV91jRPvPPOO49JkyaxZs0aampqmDNnTllzaMjLMpuZNdLanPsU7rrrroq15St+M7OCceE3MysYF34zs4Jx4TczKxgXfjOzgvGsnhyeWrAyafxtW3emi70lXex+g9N+vcIzj7yULPYhR41MFhug36CeyWKfcOaIZLGtGFz4zcwaOXn8X7L592+VLV7/AQfx+KJftLjPhg0buPDCC3n99dfZb7/9mDFjBjNnzixbDg258JuZNVLOop83Xvfu3fne977HuHHj2LJlC+PHj+e0007jmGOOKWsu4DF+M7NOYdCgQYwbV1q5vk+fPgwfPpyNGzcmacuF38ysk3nllVd4/vnnmThxYpL4LvxmZp3I1q1bmTp1KjfffDN9+/ZN0oYLv5lZJ7Fjxw6mTp3K+eefzznnnJOsHRd+M7NOICK4+OKLGT58OJdffnnStlz4zcwa6T/goIrHe/rpp7njjjtYuHAhY8aMYcyYMTz00ENlzWM3T+c0M2uktTn3KRx//PFEREXa8hW/mVnBuPCbmRWMC7+ZGVRsmKW9ypmfC7+ZFV7Pnj3ZvHlzpy3+EcHmzZvp2bM8i/+1enNXUi1wAjAY2AasAH4ZEW+WJQMzsw5WU1NDfX09mzZt6uhUmtWzZ09qamrKEqvZwi9pOnAp8DKwCFgD9ASOB/63pBXAP0TE78qSiZlZB+nRoweHH354R6dRMS1d8X8UmBwR25raKGkM8AnAhd/MrAtptvBHxI9aOjAilrQWXNIrwBZgF7AzImrbmJ+ZmZVZnjH+w4FLgKEN94+IKTnbODkift+u7MzMrOzyPLn7C2AO8P+AD5JmY2ZmyeUp/Nsj4gftjB/Ao5IC+D8RMbvxDpJmADMAhgwZ0s5mzMwsrzyF/xZJ1wKPAu/t/jAiFuc4dnJEvCrpY8Bjkl6IiCcb7pD9YzAboLa2tnNOojUzqyJ5Cv9I4ALgFP401BPZ+xZFxKvZn29IegCYADzZ8lGdT++3Xk/bwEEHJwvdq3e6dfi2bd2ZLDbAp08fmSz2gZvrk8UG6LGjPA/aNG1EwthWBHmqwl8BwyLi/bYElvRRYL+I2JK9/gvgunbkaGZmZZSn8C8FDgTeaGPsjwMPSNrdzr9FxMNtjGFmZmWWp/B/HHhB0nPsPcbf4nTOiFgHjN639MzMrNzyFP5rk2dhZmYVk6fw/w54LSK2A0jqRem3ADMz64LyLMt8L3s/uLUr+8zMzLqgPIW/e8MZPdnr/dOlZGZmKeUp/Jsk7bmRK+lzgNfeMTProvKM8X8ZmCvp1ux9PaUHuszMrAtqtfBHxEvApyT1BhQRW9KnZWZmqTQ71CPpC5L2bI+IrQ2LvqQjJB2fOkEzMyuvlq74+wPPS1pE6asXN1H66sUjgZMojfNflTxDMzMrq5a+geuWbFz/FGAyMIrSl62vBi7wd+2amXVNLY7xR8Qu4LHsx8zMqkCe6ZxmZlZFXPjNzArGhd/MrGBanccv6SPAVGBow/0jwl+qYmbWBeV5cvdB4G1KUzrfa2VfMzPr5PIU/pqIOCN5JmZmVhF5xvifkZTuW6/NzKyimr3il7QciGyfL0paR2moR0BExKjKpFj99lu2Olns99/Zniz2gYcelCx2ahO+/NmOTsGsw7Q01HN2xbIwM7OKaWnJhvUAku6IiL2WYZZ0B16a2cysS8ozxj+i4RtJ3YDxadIxM7PUWlqW+WpJW4BRkt7JfrYAb1Ca4mlmZl1Qs4U/Iv4xIvoA342IvtlPn4joHxFXVzBHMzMrozzz+O+VNK7RZ28D6yNiZ2sHZ0NDdcDGiPANYzOzDpan8P8YGAcsozSVcySwFOgv6csR8Wgrx8+ktIZ/331J1MzMyiPPzd1XgLERURsR44ExwArgM8B3WjpQUg3wWeCn+5ammZmVS57C/8mIWLn7TUSsovQPwbocx94MXAl80NwOkmZIqpNUt2nTphwhzcxsX+Qp/Gsk/UTSSdnPj4EXs1U7dzR3kKSzgTciYlFLwSNidvbbRO3AgQPblr2ZmbVZnsI/HfgtcBnwv4B12Wc7gJNbOG4yMEXSK8DdwCmS7mx/qmZmVg6t3tyNiG3A97Kfxra2cNzVwNUAkv4cuCIivtCuLM3MrGzyfBHLZOAbwGHs/UUsw9KlZWZmqeSZzjmH0hDPImBXexqJiCeAJ9pzrJmZlVeewv92RCxInomZmVVEnsL/uKTvAvfT4KsXI2JxsqzMzCyZPIV/YvZnbYPPAjil/OmYmVlqeWb1tDRl08zMuphW5/FL+rikOZIWZO+PkXRx+tTMzCyFPA9w/SvwCDA4e/8ipYe5zMysC8pT+AdExD1k6+1kSzG3a1qnmZl1vDw3d/8oqT+lG7pI+hSl9fg7leXzn04Wu3vfnsliAxxw6EHJYvdNnHtKI8+e3NEpmFWlPIX/cmAecISkp4GBwLSkWZmZWTJ5ZvUslnQScDSlL2JZExHNrsppZmadW7OFX9I5zWw6ShIRcX+inMzMLKGWrvj/WwvbgtKTvGZm1sU0W/gj4ouVTMTMzCojz3ROMzOrIi78ZmYF48JvZlYw7ZnVA+BZPWZmXZRn9ZiZFYxn9ZiZFUyeJRuQ9FlgBLBn4ZeIuC5VUmZmlk6e9fhnAX8DXEJpyYa/Bg5LnJeZmSWSZ1bPpyPiQuCtiPgmMAk4NG1aZmaWSp7Cvy37811Jg4EdwOHpUjIzs5TyjPHPl3Qg8F1gMaUZPT9NmZSZmaWTp/B/JyLeA+6TNJ/SDd7tadMyM7NU8gz1/OfuFxHxXkS83fCz5kjqKelZSUslrZT0zX1J1MzMyqOlJ3cPBg4BekkaS2lGD0Bf4IAcsd8DTomIrZJ6AL+StCAifr2vSZuZWfu1NNRzOjAdqAG+3+Dzd4CvtRY4IgLYmr3tkf1Eu7I0M7OyaenJ3Z8BP5M0NSLua09wSd2ARcCRwI8i4jdN7DMDmAEwZMiQ9jRjZmZtoNKFeQs7lIZ8bgAGR8SZko4BJkXEnNyNlGYFPQBcEhErmtuvtrY26urq8oY1Mys8SYsiorYtx+S5ufsvwCPA4Oz9i8BlbWkkIv4APAGc0ZbjzMys/PIU/gERcQ/wAUBE7AR2tXaQpIHZlT6SegGfAV5of6pmZlYOeebx/1FSf7Ibs5I+Bbyd47hBlO4RdKP0D8w9ETG/3ZmamVlZ5Cn8lwPzgCMkPQ0MBKa1dlBELAPG7lt6ZmZWbq0W/ohYLOkk4GhKc/nXRMSO5JmZmVkSrRZ+ST2BvwOOpzTc85SkWRHhZRvMzLqgPEM9twNbgB9m788D7qC0Lr+ZmXUxeQr/0RExusH7xyUtTZWQmZmllWc65/PZTB4AJE0Enk6XkpmZpZTnin8icKGk32XvhwCrJS2ntCTPqGTZmZlZ2eUp/H7a1sysiuSZzrm+EomYmVll5BnjNzOzKuLCb2ZWMC78ZmYF48JvZlYwLvxmZgXjwm9mVjAu/GZmBePCb2ZWMC78ZmYFk2fJBjNro9/+6LpksY/8yjXJYgO8dOePk8VW337JYg+bcm6y2NXGV/xmZgXjwm9mVjAu/GZmBePCb2ZWMC78ZmYF48JvZlYwyQq/pEMlPS5ptaSVkmamasvMzPJLOY9/J/D3EbFYUh9gkaTHImJVwjbNzKwVya74I+K1iFicvd4CrAYOSdWemZnlU5ExfklDgbHAb5rYNkNSnaS6TZs2VSIdM7NCS174JfUG7gMui4h3Gm+PiNkRURsRtQMHDkydjplZ4SUt/JJ6UCr6cyPi/pRtmZlZPiln9QiYA6yOiO+nasfMzNom5RX/ZOAC4BRJS7KfsxK2Z2ZmOSSbzhkRvwKUKr6ZmbWPn9w1MysYF34zs4Jx4TczKxgXfjOzgnHhNzMrGBd+M7OCUUR0dA571NbWRl1dXUen8SHr5t2dNP6wKecmjZ9K6r+Xn95+e7LY53xyULLYAM+/9lay2H/YvjNZbICTD0+3dMpBnxyfLHZq6tsvWex9qQGSFkVEbVuO8RW/mVnBuPCbmRWMC7+ZWcG48JuZFYwLv5lZwbjwm5kVjAu/mVnBuPCbmRWMC7+ZWcG48JuZFYwLv5lZwbjwm5kVjAu/mVnBuPCbmRWMC7+ZWcG48JuZFYwLv5lZwbjwm5kVTLLCL+mfJb0haUWqNszMrO1SXvH/K3BGwvhmZtYOyQp/RDwJvJkqvpmZtY8iIl1waSgwPyKObWGfGcAMgCFDhoxfv359snzMzKqNpEURUduWYzr85m5EzI6I2oioHThwYEenY2ZW9Tq88JuZWWW58JuZFUzK6Zx3Af8JHC2pXtLFqdoyM7P8uqcKHBHnpYptZmbt56EeM7OCceE3MysYF34zs4Jx4TczK5ikT+62laRNQHsf3R0A/L6M6XQlRe47FLv/7ntx7e7/YRHRpqdfO1Xh3xeS6tr62HK1KHLfodj9d9+L2XfYt/57qMfMrGBc+M3MCqaaCv/sjk6gAxW571Ds/rvvxdXu/lfNGL+ZmeVTTVf8ZmaWgwu/mVnBdKnCL+lQSY9LWi1ppaSZTewjST+Q9FtJyySN64hcyy1n3/9c0tuSlmQ/13REruUmqaekZyUtzfr+zSb2qcrzDrn7X5XnfjdJ3SQ9L2l+E9uq9txDq31v13lPtjpnIjuBv4+IxZL6AIskPRYRqxrscybwiexnIvCT7M+uLk/fAZ6KiLM7IL+U3gNOiYitknoAv5K0ICJ+3WCfaj3vkK//UJ3nfreZwGqgbxPbqvncQ8t9h3ac9y51xR8Rr0XE4uz1Fkp/GYc02u1zwO1R8mvgQEmDKpxq2eXse1XKzuXW7G2P7KfxrISqPO+Qu/9VS1IN8Fngp83sUrXnPkff26VLFf6Gsi9yHwv8ptGmQ4ANDd7XU2UFsoW+A0zKhgQWSBpR2czSyX7dXQK8ATwWEYU67zn6D1V67oGbgSuBD5rZXs3n/mZa7ju047x3ycIvqTdwH3BZRLzTeHMTh1TN1VErfV9Mad2O0cAPgV9UOL1kImJXRIwBaoAJko5ttEtVn/cc/a/Kcy/pbOCNiFjU0m5NfNblz33OvrfrvHe5wp+Ncd4HzI2I+5vYpR44tMH7GuDVSuSWWmt9j4h3dg8JRMRDQA9JAyqcZlIR8QfgCeCMRpuq9rw31Fz/q/jcTwamSHoFuBs4RdKdjfap1nPfat/be967VOGXJGAOsDoivt/MbvOAC7M7/Z8C3o6I1yqWZCJ5+i7p4Gw/JE2gdH43Vy7LNCQNlHRg9roX8BnghUa7VeV5h3z9r9ZzHxFXR0RNRAwFzgUWRsQXGu1Wlec+T9/be9672qyeycAFwPJsvBPga8AQgIiYBTwEnAX8FngX+GLl00wiT9+nAX8raSewDTg3quPR7EHAzyR1o/Qf9j0RMV/Sl6Hqzzvk63+1nvsmFejcf0g5zruXbDAzK5guNdRjZmb7zoXfzKxgXPjNzArGhd/MrGBc+M3MCsaF36patnrhh1Y1zHHcYEk/b2bbE5Jqs9dfa/D5UEkrcsa/TNKFbc2riTj/U1JVT1+08nPhN2tCRLwaEdNy7Pq11nfZm6TuwEXAv7U5sQ/7Z+DSMsSxAnHhtw4l6aOS/j1bZGqFpL/JPh8v6T8kLZL0yO7VFrOr7ZslPZPtPyH7fEL22fPZn0e30u5DkkZlr59Xto65pOslfanh1bukXpLuVmmt9/8L9Mo+vxHopdI66HOz0N0k3abSuvmPZk/aNnYKsDgidmZxjpT0y+zvYLGkI7LfVP5D0j2SXpR0o6TzVVqXf7mkIwAi4l3gld1/D2Z5uPBbRzsDeDUiRkfEscDDKq1J9ENgWkSMp3RVe0ODYz4aEZ8G/i7bBqUlDE6MiLHANcC3W2n3SeAESX0pfdfB5Ozz44GnGu37t8C7ETEqy2M8QERcBWyLiDERcX627yeAH0XECOAPwNQm2p4MNFx4a252zGjg08Du5QZGU1qLfSSlp7aPiogJlJbovaTB8XXACa3012yPrrZkg1Wf5cA/SboJmB8RT6m08uSxwGPZMiTd+FMxBLgLICKelNQ3W8emD6VlDT5BaWXGHq20+xSlIZKXgX8HTpN0ADA0ItaotPT1bicCP8jaXCZpWQtxX46IJdnrRcDQJvYZROn7FFDpS3UOiYgHsvjbs88Bntu95oykl4BHs+OXAyc3iPcG8MlW+mu2hwu/daiIeFHSeEprrfyjpEeBB4CVETGpucOaeH898HhE/FVWtJ9openngFpgHfAYMAD4H+x9Jd5Sm815r8HrXWTDQo1sA3pmr5taUripWB80eP8Be/+/2zOLaZaLh3qsQ0kaTGkY5U7gn4BxwBpgoKRJ2T49tPcXTOy+D3A8pZUY3wb+DNiYbZ/eWrsR8T6lL+/478CvKf0GcAUfHuaB0rDQ+VmbxwKjGmzbkQ1NtcVq4Mgsj3eAekl/mcX/SPabR1scBeSaTWQGLvzW8UYCz2Yrjn4d+FZWlKcBN0laCiyhNPa921uSngFmARdnn32H0m8MT1MaGsrjKeC/shukT1Fax72pwv8ToHc2xHMl8GyDbbOBZQ1u7uaxgNLw0W4XAJdm8Z8BDm5DLCjdM/hlG4+xAvPqnNalSHoCuCIi6jo6l30h6QHgyohYu49xxgKXR8QF5cnMisBX/GYd4ypKN3n31QDgH8oQxwrEV/xmZgXjK34zs4Jx4TczKxgXfjOzgnHhNzMrGBd+M7OC+f/KvzKQxYp0xwAAAABJRU5ErkJggg==\n",
+ "text/plain": [
+ "
"
+ ]
+ },
+ "metadata": {
+ "needs_background": "light"
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "sns.histplot(data=df, x='sepal width (cm)', y='petal length (cm)', hue='class');"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git "a/EDA/Lv5_EDA_\353\215\260\354\235\264\355\204\260 \353\266\210\353\237\254\354\230\244\352\270\260 \353\260\217 \355\231\225\354\235\270.assets/image-20220507215302976.png" "b/EDA/Lv5_EDA_\353\215\260\354\235\264\355\204\260 \353\266\210\353\237\254\354\230\244\352\270\260 \353\260\217 \355\231\225\354\235\270.assets/image-20220507215302976.png"
new file mode 100644
index 0000000..f33cda6
Binary files /dev/null and "b/EDA/Lv5_EDA_\353\215\260\354\235\264\355\204\260 \353\266\210\353\237\254\354\230\244\352\270\260 \353\260\217 \355\231\225\354\235\270.assets/image-20220507215302976.png" differ
diff --git "a/EDA/Lv5_EDA_\353\215\260\354\235\264\355\204\260 \353\266\210\353\237\254\354\230\244\352\270\260 \353\260\217 \355\231\225\354\235\270.assets/image-20220507225405518.png" "b/EDA/Lv5_EDA_\353\215\260\354\235\264\355\204\260 \353\266\210\353\237\254\354\230\244\352\270\260 \353\260\217 \355\231\225\354\235\270.assets/image-20220507225405518.png"
new file mode 100644
index 0000000..1a5c92d
Binary files /dev/null and "b/EDA/Lv5_EDA_\353\215\260\354\235\264\355\204\260 \353\266\210\353\237\254\354\230\244\352\270\260 \353\260\217 \355\231\225\354\235\270.assets/image-20220507225405518.png" differ
diff --git "a/EDA/Lv5_EDA_\353\215\260\354\235\264\355\204\260 \353\266\210\353\237\254\354\230\244\352\270\260 \353\260\217 \355\231\225\354\235\270.md" "b/EDA/Lv5_EDA_\353\215\260\354\235\264\355\204\260 \353\266\210\353\237\254\354\230\244\352\270\260 \353\260\217 \355\231\225\354\235\270.md"
new file mode 100644
index 0000000..40d00d5
--- /dev/null
+++ "b/EDA/Lv5_EDA_\353\215\260\354\235\264\355\204\260 \353\266\210\353\237\254\354\230\244\352\270\260 \353\260\217 \355\231\225\354\235\270.md"
@@ -0,0 +1,122 @@
+# Lv5_EDA_데이터 불러오기 및 확인
+
+
+
+### 데이터를 n번째 행까지만 불러오기
+
+```python
+# 예) 데이터를 3번째 행까지만 불러오기
+
+import pandas as pd
+
+train_3 = pd.read_csv('data/train.csv', nrows=3)
+```
+
+
+
+### 데이터의 n번째 행을 컬럼으로 지정하여 불러오기
+
+```python
+# 예) 데이터의 2번째 행을 컬럼으로 지정
+import pandas as pd
+
+train = pd.read_csv('data/train.csv',header = 1)
+test = pd.read_csv('data/test.csv',header = 1)
+```
+
+
+
+### 원하는 컬럼을 index로 지정하여 불러오기
+
+```python
+train_index = pd.read_csv('data/train.csv',index_col = 'index')
+test_index = pd.read_csv('data/test.csv',index_col = 'index')
+```
+
+
+
+
+
+### 데이터에서 결측치를 제외하고 불러오기
+
+```python
+# na_filter=False 옵션으로 결측치를 제외한다.
+# 데이터를 결측치를 제외하고 불러오기
+import pandas as pd
+
+train_notnull = pd.read_csv('data/train.csv',na_filter =False)
+test_notnull = pd.read_csv('data/test.csv',na_filter =False)
+
+# 확인
+train_notnull.isnull().sum()
+```
+
+
+
+### 데이터에서 뒤에서 n개의 행 제외하고 불러오기
+
+```python
+import pandas as pd
+
+
+train_skipfooter = pd.read_csv('data/train.csv' , skipfooter=5 )
+test_skipfooter = pd.read_csv('data/test.csv' , skipfooter=5 )
+```
+
+
+
+### 데이터의 인코딩 형식을 맞춰서 불러오기
+
+'내가 불러오고자 하는 데이터의 encoding과 python encoding의 설정이 맞지 않는 경우'
+
+```python
+import pandas as pd
+
+train = pd.read_csv('train.csv',encoding = 'cp949')
+```
+
+
+
+### 데이터를 불러올 때 컬럼명을 지정해서 불러오기
+
+```python
+import pandas as pd
+
+
+train_names = pd.read_csv('data/train.csv',names=['인덱스','카테고리','텍스트'])
+test_names = pd.read_csv('data/test.csv',names=['인덱스','카테고리','텍스트'])
+```
+
+
+
+
+
+### index는 제외하고 데이터 저장하기
+
+'dataframe을 to_csv 메서드로 저장할 때 인덱스도 데이터에 포함되어 저장되고 인덱스가 추가로 생긴다. 따라서 원래 인덱스는 제외하고 저장해야 한다. '
+
+
+
+```python
+import pandas as pd
+
+train.to_csv('data/train.csv',index = False)
+test.to_csv('data/test.csv',index = False)
+```
+
+
+
+### value_counts(): 어떤 컬럼의 unique한 value들을 count
+
+```python
+# train 데이터에서 category 컬럼의 고유값의 개수를 출력
+train['category'].value_counts()
+```
+
+```python
+2 13362
+1 13337
+0 13301
+Name: category, dtype: int64
+```
+
diff --git a/Kfold.assets/image-20220425220747620.png b/Kfold/Kfold.assets/image-20220425220747620.png
similarity index 100%
rename from Kfold.assets/image-20220425220747620.png
rename to Kfold/Kfold.assets/image-20220425220747620.png
diff --git a/Kfold.assets/image-20220425221031508.png b/Kfold/Kfold.assets/image-20220425221031508.png
similarity index 100%
rename from Kfold.assets/image-20220425221031508.png
rename to Kfold/Kfold.assets/image-20220425221031508.png
diff --git a/Kfold.assets/image-20220425221430406.png b/Kfold/Kfold.assets/image-20220425221430406.png
similarity index 100%
rename from Kfold.assets/image-20220425221430406.png
rename to Kfold/Kfold.assets/image-20220425221430406.png
diff --git a/Kfold.md b/Kfold/Kfold.md
similarity index 97%
rename from Kfold.md
rename to Kfold/Kfold.md
index 6a8e40b..c7ec127 100644
--- a/Kfold.md
+++ b/Kfold/Kfold.md
@@ -1,62 +1,62 @@
-# Kfold
-
-## K-fold
-
-**Hold-out**
-
-- Hold-out은 단순하게 Train 데이터를 (train, valid)라는 이름의 2개의 데이터로 나누는 작업
-
-- 보통 train : valid = 8:2 혹은 7:3의 비율로 데이터를 나눔
-- Hold-out의 문제점은 **데이터의 낭비**
-- 단순하게 trian과 test로 분할하게 된다면, 20%의 데이터는 모델이 학습할 기회도 없이, 예측만하고 버려지게 된다.
-
-**교차검증**
-
-
-
-- "모든 데이터를 최소한 한 번씩 다 학습하게 하자!"
-
-- 그래서 valid 데이터를 겹치지 않게 나누어 K개의 데이터셋을 만들어 낸다.
-- 클래스가 편중될 가능성이 있어서 `shuffle=True`로 분할하기전에 섞기 때문에 편중될 확률이 줄어들기는 한다.
-
-https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.KFold.html?highlight=kfold#sklearn.model_selection.KFold
-
-```python
-X = train.drop(columns = ['index','quality'])
-y = train['quality']
-
-kf = KFold(n_splits = 5, shuffle = True, random_state = 0)
-# shuffle=True면 random_state지정해줘야함
-model = RandomForestClassifier(random_state = 0)
-valid_scores = []
-test_predictions = []
-
-for train_idx, valid_idx in kf.split(X,y) :
- X_tr = X.iloc[train_idx]
- y_tr = y.iloc[train_idx]
-
- X_val = X.iloc[valid_idx]
- y_val = y.iloc[valid_idx]
-
- model.fit(X_tr, y_tr)
-
- valid_prediction = model.predict(X_val)
- score = accuracy_score(y_val, valid_prediction)
- valid_scores.append(score)
- print(score)
-print('평균 점수 : ', np.mean(valid_scores))
-
-```
-
-## StratifiedKFold
-
-**불균형한 분포도를 가진 레이블 데이터를 위한 방식**
-
-금융거래 사기 분류 모델에서 전체 데이터중 정상 거래 건수는 95% 사기인 거래건수는 5% 라면, 앞서 설명한 일반적인 교차 검증으로 데이터를 분할했을 때, 사기 거래 건수가 고루 분할 되지 못하고 한 분할에 몰릴 수 있다. 이때 데이터 클래스 별 분포를 고려해서 데이터 폴드 세트를 만드는 방법이 StratifiedKFold
-
-https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.StratifiedKFold.html
-
-This cross-validation object is a variation of KFold that returns stratified folds. The folds are made by preserving the percentage of samples for each class.
-
-
-
+# Kfold
+
+## K-fold
+
+**Hold-out**
+
+- Hold-out은 단순하게 Train 데이터를 (train, valid)라는 이름의 2개의 데이터로 나누는 작업
+
+- 보통 train : valid = 8:2 혹은 7:3의 비율로 데이터를 나눔
+- Hold-out의 문제점은 **데이터의 낭비**
+- 단순하게 trian과 test로 분할하게 된다면, 20%의 데이터는 모델이 학습할 기회도 없이, 예측만하고 버려지게 된다.
+
+**교차검증**
+
+
+
+- "모든 데이터를 최소한 한 번씩 다 학습하게 하자!"
+
+- 그래서 valid 데이터를 겹치지 않게 나누어 K개의 데이터셋을 만들어 낸다.
+- 클래스가 편중될 가능성이 있어서 `shuffle=True`로 분할하기전에 섞기 때문에 편중될 확률이 줄어들기는 한다.
+
+https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.KFold.html?highlight=kfold#sklearn.model_selection.KFold
+
+```python
+X = train.drop(columns = ['index','quality'])
+y = train['quality']
+
+kf = KFold(n_splits = 5, shuffle = True, random_state = 0)
+# shuffle=True면 random_state지정해줘야함
+model = RandomForestClassifier(random_state = 0)
+valid_scores = []
+test_predictions = []
+
+for train_idx, valid_idx in kf.split(X,y) :
+ X_tr = X.iloc[train_idx]
+ y_tr = y.iloc[train_idx]
+
+ X_val = X.iloc[valid_idx]
+ y_val = y.iloc[valid_idx]
+
+ model.fit(X_tr, y_tr)
+
+ valid_prediction = model.predict(X_val)
+ score = accuracy_score(y_val, valid_prediction)
+ valid_scores.append(score)
+ print(score)
+print('평균 점수 : ', np.mean(valid_scores))
+
+```
+
+## StratifiedKFold
+
+**불균형한 분포도를 가진 레이블 데이터를 위한 방식**
+
+금융거래 사기 분류 모델에서 전체 데이터중 정상 거래 건수는 95% 사기인 거래건수는 5% 라면, 앞서 설명한 일반적인 교차 검증으로 데이터를 분할했을 때, 사기 거래 건수가 고루 분할 되지 못하고 한 분할에 몰릴 수 있다. 이때 데이터 클래스 별 분포를 고려해서 데이터 폴드 세트를 만드는 방법이 StratifiedKFold
+
+https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.StratifiedKFold.html
+
+This cross-validation object is a variation of KFold that returns stratified folds. The folds are made by preserving the percentage of samples for each class.
+
+
+
diff --git a/RandomForest.md b/RandomForest.md
deleted file mode 100644
index e722c0f..0000000
--- a/RandomForest.md
+++ /dev/null
@@ -1,81 +0,0 @@
-# RandomForest & 'criterion' 옵션
-
-```python
-from sklearn.ensemble import RandomForestRegressor
-model = RandomForestRegressor()
-```
-
-
-
-#### RandomForest란?
-
-https://www.analyticsvidhya.com/blog/2021/06/understanding-random-forest/
-
-여러 개의 의사결정나무를 만들어서 이들의 평균으로 예측의 성능을 높이는 방법이며, 이러한 기법을 앙상블(Ensemble) 기법이라고 한다.
-
-주어진 하나의 데이터로부터 여러 개의 랜덤 데이터셋을 추출해, 각 데이터셋을 통해 모델을 여러 개 만들 수 있다.
-
-의사 결정 나무는 가지치기(오차를 크게 할 위험이 높거나 부적절한 추론규칙을 가지고 있는 가지 또는 불필요한 가지를 제거하는 단계)를 함에도 불구하고 overfitting(학습 데이터를 과하게 학습해 실제 데이터에서는 정확도가 떨어지는 현상)되는 경향이 있어 일반화 성능이 좋지 않다.
-
-이를 보완하기 위해 앙상블 기법을 사용하는 것이다.
-
-
-
-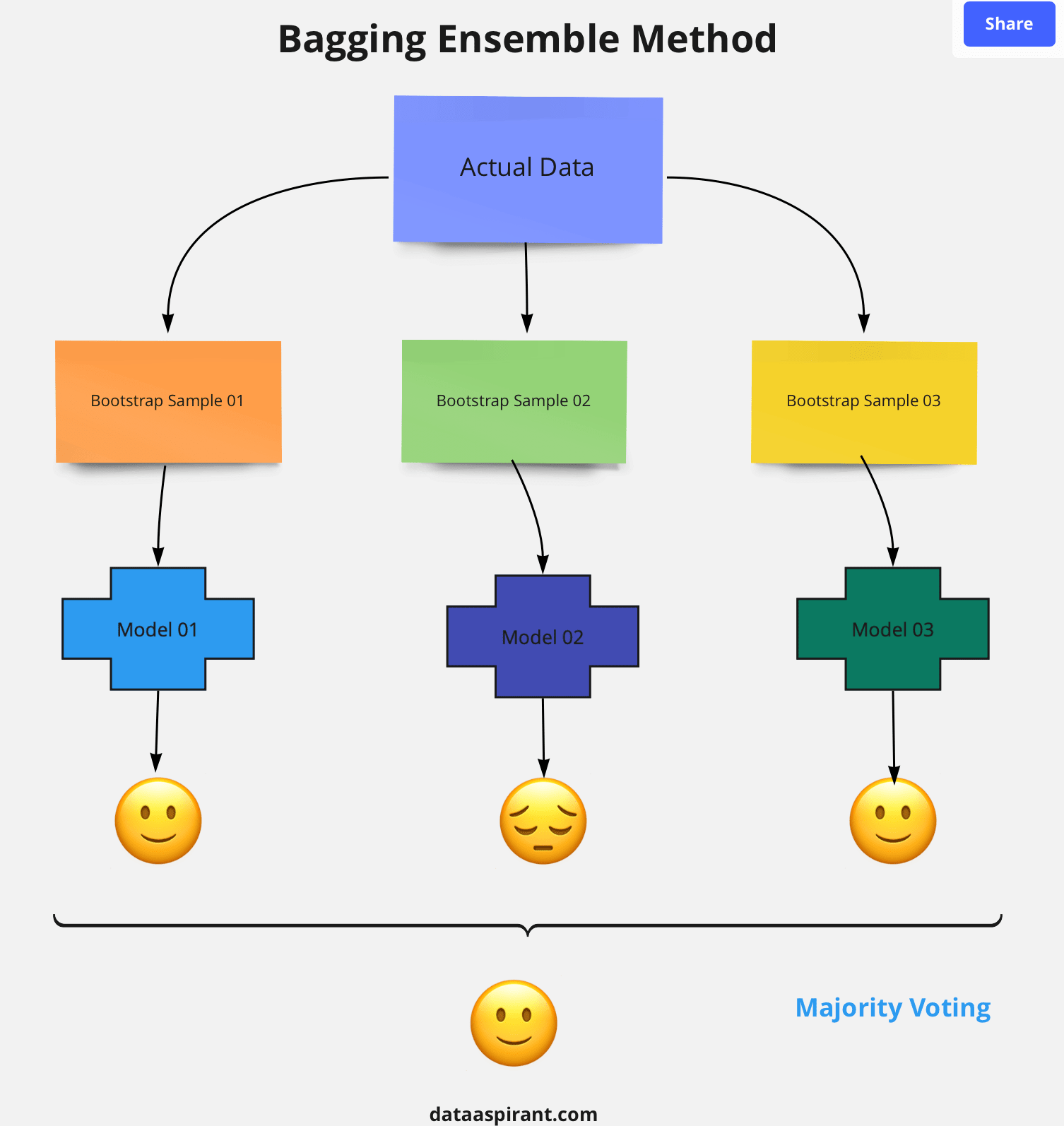
-
-*bootstrap: 표본에서 재표본을 여러번 추출하여 표본에 대해 더 자세히 알고자 하는 데 사용됨
-
-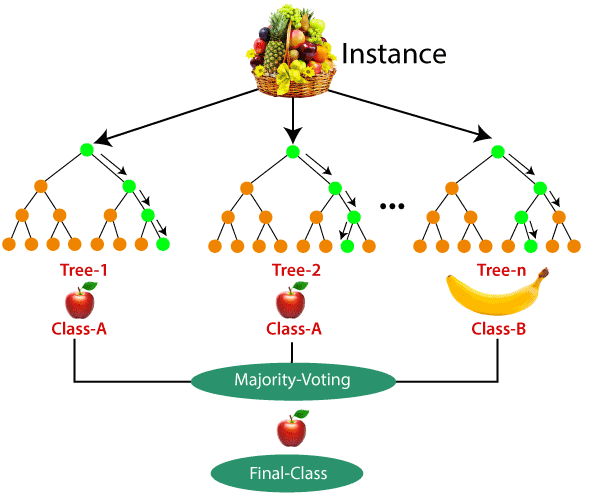
-
-
-
-## RandomForestRegressor()의 criterion 옵션
-
-"랜덤포레스트 모듈의 옵션 중 criterion 옵션을 통해 어떤 평가척도를 기준으로 훈련할 것인지 정할 수 있습니다.
-
-따릉이 대회의 평가지표는 RMSE 입니다. RMSE 는 MSE 평가지표에 루트를 씌운 것으로서, 모델을 선언할 때 criterion = ‘mse’ 옵션으로 구현할 수 있습니다."
-
-
-
-### RandomForestRegressor()
-
-랜덤포레스트 회귀 분석
-
-
-
-### model = RandomForestRegressor(criterion = 'mse')
-
-- RMSE(Root Mean Squared Error): 예측값과 실제값을 뺀 후 제곱시킨 값들을 모두 더하고 n으로 나눈 후 루트를 씌운다. 쉽게 말해 오차의 제곱에 대한 평균으로, 이 값이 작을 수록 원본과의 오차가 적은 것이므로 추측한 값의 정확성이 높은 것이다. (criterion의 디폴트 값으로, "squared_error"로 용어 변경됨.)
-
-## RandomForestClassfier
-
-### 사이킷런 모델
-
-https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
-
-- **n_estimators** : 모델에서 사용할 트리 갯수(학습시 생성할 트리 갯수)
-- **criterion** : 분할 품질을 측정하는 기능 (default : gini)
- - [지니와 엔트로피](https://wyatt37.tistory.com/9)
- - 결론
- - 시간을 투자해서 더 나은 성능을 원하면 엔트로피
- - 준수한 성능과 빠른 계산을 원하면 지니
- - 그떄마다 좋은 성능을 나타내는 것이 다름
-- **max_depth** : 트리의 최대 깊이
-- min_samples_split : 내부 노드를 분할하는데 필요한 최소 샘플 수 (default : 2)
-- min_samples_leaf : 리프 노드에 있어야 할 최소 샘플 수 (default : 1)
-- min_weight_fraction_leaf : min_sample_leaf와 같지만 가중치가 부여된 샘플 수에서의 비율
-- **max_features** : 각 노드에서 분할에 사용할 특징의 최대 수
-- max_leaf_nodes : 리프 노드의 최대수
-- min_impurity_decrease : 최소 불순도
-- min_impurity_split : 나무 성장을 멈추기 위한 임계치
-- **bootstrap** : 부트스트랩(중복허용 샘플링) 사용 여부
-- oob_score : 일반화 정확도를 줄이기 위해 밖의 샘플 사용 여부
- - Out-Of-Bag (OOB)
- - 일반적으로 훈련 샘플의 63%만 샘플링 되고 나머지 37%의 데이터는 훈련에 쓰이지 않는다.
-- **n_jobs** :적합성과 예측성을 위해 병렬로 실행할 작업 수
-- **random_state** : 난수 seed 설정
- - [random_state](https://miinkang.tistory.com/19)
- - **데이터를 섞을때 일관적이게 섞고 싶을 때 사용하는 것**이 seed
-- verbose : 실행 과정 출력 여부
-- warm_start : 이전 호출의 솔루션을 재사용하여 합계에 더 많은 견적가를 추가
-- class_weight : 클래스 가중치
\ No newline at end of file
diff --git "a/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509193258492-16520923797381.png" "b/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509193258492-16520923797381.png"
new file mode 100644
index 0000000..10bc1ca
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509193258492-16520923797381.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509193258492.png" "b/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509193258492.png"
new file mode 100644
index 0000000..10bc1ca
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509193258492.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509201840918-16520951224432.png" "b/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509201840918-16520951224432.png"
new file mode 100644
index 0000000..dcf6243
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509201840918-16520951224432.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509201840918.png" "b/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509201840918.png"
new file mode 100644
index 0000000..dcf6243
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509201840918.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509204421788-16520966629473.png" "b/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509204421788-16520966629473.png"
new file mode 100644
index 0000000..a812152
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509204421788-16520966629473.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509204421788.png" "b/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509204421788.png"
new file mode 100644
index 0000000..a812152
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201.assets/image-20220509204421788.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201_LGBM.md" "b/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201_LGBM.md"
new file mode 100644
index 0000000..f6d025b
--- /dev/null
+++ "b/\353\252\250\353\215\270\353\247\201/Lv1_\353\252\250\353\215\270\353\247\201_LGBM.md"
@@ -0,0 +1,111 @@
+# 모델링
+
+
+
+## train_test_split()
+
+머신러닝 모델의 결과
+
+
+
+머신러닝 모델에 train 데이터를 학습시킨 후 test데이터를 모델로 예측했을 경우 성능이 낮게 나오는 경우가 발생하는데 이를 overfitting 이라고 한다.
+
+overfit은 모델이 학습데이터에 지나치게 의존되어 있어서 다른 데이터(test)에 대해서는 예측율이 현저히 떨어지는 현상이다.
+
+이러한 현상을 방지하기 위해 train test로 구분되어 있는 데이터에서 train을 train과 validation으로 나눈 다음 학습 중간중간 validation데이터로 학습한 모델을 평가하여 모델이 학습된 정도를 평가하고 overfit이 발생하여 성능이 떨어지기 시작하면 학습을 종료시킨다.
+
+
+
+```python
+# 라이브러리 로딩
+from sklearn.model_selection import train_test_split
+
+#train_test_split() 메소드를 이용해 train/validation 데이터 나누기
+x_train,x_valid, y_train, y_valid = train_test_split(train_x, train['category'])
+
+# x_train,x_valid,y_train,y_valid 사이즈 확인
+
+print('x_train 데이터 사이즈', x_train.shape)
+print('x_valid 데이터 사이즈', x_valid.shape)
+print('y_train 데이터 사이즈', y_train.shape)
+print('y_valid 데이터 사이즈', y_valid.shape)
+```
+
+
+
+### test_size
+
+- test data(validation data) 구성의 비율을 나타냅니다. train_size의 옵션과 반대 관계에 있는 옵션 값이며, 주로 test_size 파라미터를 지정 해줍니다. test_size = 0.2 로 지정 하면 전체 데이터 셋의 20%를 test(validation) 셋으로 지정하겠다는 의미입니다. default 값은 0.25 입니다.
+
+ ```python
+ x_train,x_valid, y_train, y_valid = train_test_split(train_x, train['category'], test_size=0.2)
+ ```
+
+
+
+### shuffle
+
+- 데이터를 split 하기 이전에 섞을지 말지 여부에 대해 지정해주는 파라미터 입니다. default = True 입니다.
+
+### stratify
+
+- stratify값을 target 값으로 지정해주면 target의 class 비율을 유지 한 채로 데이터 셋을 split 하게 됩니다.
+
+```python
+x_train,x_valid, y_train, y_valid = train_test_split(train_x, train['category'], stratify=train['category'])
+```
+
+
+
+
+
+
+
+## LGBM
+
+```python
+# LightGBM을 이용해 학습 및 검증 진행
+from lightgbm import LGBMRegressor
+
+model = LGBMRegressor()
+model.fit(x_train,y_train, eval_set = [(x_train,y_train),(x_valid,y_valid)])
+```
+
+
+
+### eval_metric
+
+- eval_metric = "원하는 평가산식" 을 정해주면 학습을 진행하며 지정한 평가 산식과 검증 데이터 셋을 이용해 결과 값을 출력
+
+ '**l1**': absolute loss
+
+ '**l2**': square loss
+
+ '**rmse**': root square loss
+
+ '**auc**': area under the ROC curve
+
+ [참고문헌](https://lightgbm.readthedocs.io/en/latest/Parameters.html#metric-parameters)
+
+
+
+### verbose
+
+- 일정한 값(숫자)을 지정해주면 n_estimators를 기준으로 지정해준 값마다 결과 값을 출력
+
+```python
+# LightGBM을 이용해 학습 및 검증 진행
+from lightgbm import LGBMRegressor
+
+#모델 정의
+model = LGBMRegressor()
+
+#평가 산식을 AUC로 설정, n_estimators 기준 5번 마다 결과값 출력하게 모델 학습.
+model.fit(train_x,train['category'], eval_set = [(x_train,y_train),(x_valid,y_valid)], eval_metric = 'auc' ,verbose = 5)
+```
+
+
+
+
+
+[참고문헌](https://deep-deep-deep.tistory.com/159)
\ No newline at end of file
diff --git "a/\353\252\250\353\215\270\353\247\201/Lv2_\353\252\250\353\215\270\353\247\201_RandomForest.assets/325745-Bagging-ensemble-method.png" "b/\353\252\250\353\215\270\353\247\201/Lv2_\353\252\250\353\215\270\353\247\201_RandomForest.assets/325745-Bagging-ensemble-method.png"
new file mode 100644
index 0000000..438f131
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/Lv2_\353\252\250\353\215\270\353\247\201_RandomForest.assets/325745-Bagging-ensemble-method.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/Lv2_\353\252\250\353\215\270\353\247\201_RandomForest.assets/33019random-forest-algorithm2.png" "b/\353\252\250\353\215\270\353\247\201/Lv2_\353\252\250\353\215\270\353\247\201_RandomForest.assets/33019random-forest-algorithm2.png"
new file mode 100644
index 0000000..03a7320
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/Lv2_\353\252\250\353\215\270\353\247\201_RandomForest.assets/33019random-forest-algorithm2.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/Lv2_\353\252\250\353\215\270\353\247\201_RandomForest.md" "b/\353\252\250\353\215\270\353\247\201/Lv2_\353\252\250\353\215\270\353\247\201_RandomForest.md"
new file mode 100644
index 0000000..4ba3fb5
--- /dev/null
+++ "b/\353\252\250\353\215\270\353\247\201/Lv2_\353\252\250\353\215\270\353\247\201_RandomForest.md"
@@ -0,0 +1,81 @@
+# RandomForest & 'criterion' 옵션
+
+```python
+from sklearn.ensemble import RandomForestRegressor
+model = RandomForestRegressor()
+```
+
+
+
+#### RandomForest란?
+
+https://www.analyticsvidhya.com/blog/2021/06/understanding-random-forest/
+
+여러 개의 의사결정나무를 만들어서 이들의 평균으로 예측의 성능을 높이는 방법이며, 이러한 기법을 앙상블(Ensemble) 기법이라고 한다.
+
+주어진 하나의 데이터로부터 여러 개의 랜덤 데이터셋을 추출해, 각 데이터셋을 통해 모델을 여러 개 만들 수 있다.
+
+의사 결정 나무는 가지치기(오차를 크게 할 위험이 높거나 부적절한 추론규칙을 가지고 있는 가지 또는 불필요한 가지를 제거하는 단계)를 함에도 불구하고 overfitting(학습 데이터를 과하게 학습해 실제 데이터에서는 정확도가 떨어지는 현상)되는 경향이 있어 일반화 성능이 좋지 않다.
+
+이를 보완하기 위해 앙상블 기법을 사용하는 것이다.
+
+
+
+
+
+*bootstrap: 표본에서 재표본을 여러번 추출하여 표본에 대해 더 자세히 알고자 하는 데 사용됨
+
+
+
+
+
+## RandomForestRegressor()의 criterion 옵션
+
+"랜덤포레스트 모듈의 옵션 중 criterion 옵션을 통해 어떤 평가척도를 기준으로 훈련할 것인지 정할 수 있습니다.
+
+따릉이 대회의 평가지표는 RMSE 입니다. RMSE 는 MSE 평가지표에 루트를 씌운 것으로서, 모델을 선언할 때 criterion = ‘mse’ 옵션으로 구현할 수 있습니다."
+
+
+
+### RandomForestRegressor()
+
+랜덤포레스트 회귀 분석
+
+
+
+### model = RandomForestRegressor(criterion = 'mse')
+
+- RMSE(Root Mean Squared Error): 예측값과 실제값을 뺀 후 제곱시킨 값들을 모두 더하고 n으로 나눈 후 루트를 씌운다. 쉽게 말해 오차의 제곱에 대한 평균으로, 이 값이 작을 수록 원본과의 오차가 적은 것이므로 추측한 값의 정확성이 높은 것이다. (criterion의 디폴트 값으로, "squared_error"로 용어 변경됨.)
+
+## RandomForestClassfier
+
+### 사이킷런 모델
+
+https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
+
+- **n_estimators** : 모델에서 사용할 트리 갯수(학습시 생성할 트리 갯수)
+- **criterion** : 분할 품질을 측정하는 기능 (default : gini)
+ - [지니와 엔트로피](https://wyatt37.tistory.com/9)
+ - 결론
+ - 시간을 투자해서 더 나은 성능을 원하면 엔트로피
+ - 준수한 성능과 빠른 계산을 원하면 지니
+ - 그떄마다 좋은 성능을 나타내는 것이 다름
+- **max_depth** : 트리의 최대 깊이
+- min_samples_split : 내부 노드를 분할하는데 필요한 최소 샘플 수 (default : 2)
+- min_samples_leaf : 리프 노드에 있어야 할 최소 샘플 수 (default : 1)
+- min_weight_fraction_leaf : min_sample_leaf와 같지만 가중치가 부여된 샘플 수에서의 비율
+- **max_features** : 각 노드에서 분할에 사용할 특징의 최대 수
+- max_leaf_nodes : 리프 노드의 최대수
+- min_impurity_decrease : 최소 불순도
+- min_impurity_split : 나무 성장을 멈추기 위한 임계치
+- **bootstrap** : 부트스트랩(중복허용 샘플링) 사용 여부
+- oob_score : 일반화 정확도를 줄이기 위해 밖의 샘플 사용 여부
+ - Out-Of-Bag (OOB)
+ - 일반적으로 훈련 샘플의 63%만 샘플링 되고 나머지 37%의 데이터는 훈련에 쓰이지 않는다.
+- **n_jobs** :적합성과 예측성을 위해 병렬로 실행할 작업 수
+- **random_state** : 난수 seed 설정
+ - [random_state](https://miinkang.tistory.com/19)
+ - **데이터를 섞을때 일관적이게 섞고 싶을 때 사용하는 것**이 seed
+- verbose : 실행 과정 출력 여부
+- warm_start : 이전 호출의 솔루션을 재사용하여 합계에 더 많은 견적가를 추가
+- class_weight : 클래스 가중치
\ No newline at end of file
diff --git "a/\353\252\250\353\215\270\353\247\201/Lv4_\353\252\250\353\215\270\353\247\201_XGBoost.md" "b/\353\252\250\353\215\270\353\247\201/Lv4_\353\252\250\353\215\270\353\247\201_XGBoost.md"
new file mode 100644
index 0000000..ea8dc76
--- /dev/null
+++ "b/\353\252\250\353\215\270\353\247\201/Lv4_\353\252\250\353\215\270\353\247\201_XGBoost.md"
@@ -0,0 +1,106 @@
+# 모델링
+
+## GBM
+
+- 부스팅 알고리즘은 여러 개의 weak learner를 순차적으로 학습하면서 각 단계별로 잘못 예측된 데이터에 대해 가중치를 부여해 오류를 개선해 나가는 학습 방식
+
+
+
+- 각 **Iteration(step)**에서 잘못 예측된 데이터에 대하여 가중치를 부여한 예측 결정 기준을 결합해 최종 예측 결정 기준을 만듬
+- GBM(Gradient Boost Machine)도 AdaBoost와 유사하게 동작하지만 가중치 업데이트의 방식이 **경사 하강법(Gradient descent)**을 사용하는 것이 차이점
+- GBM은 RandomForest보다 나은 예측 성능을 보이는 경우가 많지만 수행 시간이 오래 걸린다는 단점이 있음 빠른 수행 시간을 요구하는 경우에는 RandomForest를 사용
+
+### GBM 하이퍼 파라미터 튜닝
+
+- loss : 경사 하강법에서 사용할 비용 함수를 지정. 기본값은 'devidence'
+- learning_rate : GBM이 학습을 진행할 때마다 적용하는 학습률 기본값(0.1), weak learner가 순차적으로 오류 값을 보정해 나가는 데 적용하는 계수로 0 ~ 1 사이의 값,
+- n_estimators : weak learner의 개
+- subsample : weak learner가 학습에 사용하는 데이터 샘플링의 비율, 기본값은 1.
+
+[참고문헌](https://kimdingko-world.tistory.com/181)
+
+
+
+## XGBoost
+
+### Boosting
+
+- 여러 개의 성능이 높지 않은 모델을 조합해서 사용하는 Ensemble 기법 중 하나
+- 약한 예측 모형들의 학습 에러에 가중치를 두고, 순차적으로 다음 학습 모델에 반영하여 강한 예측모형을 만드는 것이다.
+
+
+
+### XGBoost
+
+- XGBoost는 Extreme Gradient Boosting의 약자
+- Boosting 기법을 이용하여 구현한 알고리즘은 Gradient Boost 가 대표적인데 이 알고리즘을 병렬 학습이 지원되도록 구현한 라이브러리가 XGBoost
+- Regression, Classification 문제를 모두 지원하며, 성능과 자원 효율이 좋아서, 인기 있게 사용되는 알고리즘
+
+### XGBoost의 장점
+
+- 기존 모델(GBM) 대비 빠른 수행시간
+ - 병렬 처리로 학습, 분류 속도가 빠르다.
+- 과적합 규제(Regularization)
+ - 표준 GBM의 경우 과적합 규제기능이 없으나, XGBoost는 자체에 과적합 규제 기능으로 강한 내구성 지닌다.
+- 분류와 회귀영역에서 뛰어난 예측 성능 발휘
+- Early Stopping(조기 종료) 기능이 있음
+- 다양한 옵션을 제공하며 Customizing이 용이
+- 결측치를 내부적으로 처리
+
+[참고문헌](https://wooono.tistory.com/97)
+
+[참고문헌](https://xgboost.readthedocs.io/en/latest/python/python_api.html)
+
+
+
+
+
+## LGBM
+
+- Tree 기반 학습 알고리즘
+- 기존의 다른 Tree 기반 학습 알고리즘과 달리 Tree 구조가 수평적으로 확장하지 않고 수직적으로 확장함
+
+
+
+- 장점 :
+ - 대용량 데이터 처리
+ - 효율적인 메모리 사용
+ - 빠른 속도
+ - GPU 지원
+
+- 단점 : 과적합 우려가 다른 Tree 알고리즘 대비 높아서 데이터의 양이 적을 경우 사용 자제
+
+[참고문헌](https://nicola-ml.tistory.com/51)
+
+
+
+
+
+## stratified k-fold
+
+- 데이터가 편향되어 있을 경우 k-fold 교차검증을 사용하면 성능 평가가 잘 되지 않을 수 있음, 이를 해결하기 위해 stratified k-fold 방법을 사용
+
+### 
+
+[참고문헌](https://jinnyjinny.github.io/deep%20learning/2020/04/02/Kfold/)
+
+
+
+### Voting Classifier
+
+- 여러 개의 모델을 결합하여 예측 결과를 도출하는 앙상블 기법
+
+### Hard Voting
+
+- 여러 모델을 생성하고 그 결과들을 집계하여 가장 많은 표를 얻는 클래스를 최종 예측값으로 정하는 것
+
+
+
+### Soft Voting
+
+- 앙상블에 사용되는 모든 분류기가 클래스의 확률을 예측할 수 있을 때 사용 가능
+- 각 분류기의 예측을 평균해서 확률이 가장 높은 클래스로 예측
+
+
+
+[참고문헌](https://nonmeyet.tistory.com/entry/Python-Voting-Classifiers%EB%8B%A4%EC%88%98%EA%B2%B0-%EB%B6%84%EB%A5%98%EC%9D%98-%EC%A0%95%EC%9D%98%EC%99%80-%EA%B5%AC%ED%98%84)
\ No newline at end of file
diff --git "a/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502182813214-16514836948861.png" "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502182813214-16514836948861.png"
new file mode 100644
index 0000000..59197e0
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502182813214-16514836948861.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502182813214.png" "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502182813214.png"
new file mode 100644
index 0000000..59197e0
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502182813214.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502192706129-16514872272064.png" "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502192706129-16514872272064.png"
new file mode 100644
index 0000000..957821b
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502192706129-16514872272064.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502192706129.png" "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502192706129.png"
new file mode 100644
index 0000000..957821b
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502192706129.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502204434249-16514918755535.png" "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502204434249-16514918755535.png"
new file mode 100644
index 0000000..be54d60
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502204434249-16514918755535.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502204434249.png" "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502204434249.png"
new file mode 100644
index 0000000..be54d60
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502204434249.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502204626358-16514919876396.png" "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502204626358-16514919876396.png"
new file mode 100644
index 0000000..721376d
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502204626358-16514919876396.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502204626358.png" "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502204626358.png"
new file mode 100644
index 0000000..721376d
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502204626358.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502205115616-16514922766947.png" "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502205115616-16514922766947.png"
new file mode 100644
index 0000000..77104cf
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502205115616-16514922766947.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502205115616.png" "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502205115616.png"
new file mode 100644
index 0000000..77104cf
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/image-20220502205115616.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/img-16514852894803.png" "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/img-16514852894803.png"
new file mode 100644
index 0000000..3008db9
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/img-16514852894803.png" differ
diff --git "a/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/img.png" "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/img.png"
new file mode 100644
index 0000000..3008db9
Binary files /dev/null and "b/\353\252\250\353\215\270\353\247\201/\353\252\250\353\215\270\353\247\201.assets/img.png" differ
diff --git "a/\354\240\204\354\262\230\353\246\254/Lv3_\354\240\204\354\262\230\353\246\254_Scaling.md" "b/\354\240\204\354\262\230\353\246\254/Lv3_\354\240\204\354\262\230\353\246\254_Scaling.md"
new file mode 100644
index 0000000..78346a0
--- /dev/null
+++ "b/\354\240\204\354\262\230\353\246\254/Lv3_\354\240\204\354\262\230\353\246\254_Scaling.md"
@@ -0,0 +1,194 @@
+# 전처리- 이상치
+
+## 이상치
+
+> 패턴에서 벗어난 값, 중심에서 많이 벗어난 값
+
+- 평균에 막대한 영향을 미침
+- [1,2,3,4,5] 의 평균은 3이지만, [1,2,3,4,100]의 평균은 22 => 하지만 중위수는 3으로 같음
+- 따라서 평균으로 값을 나타내기보다 중위수로 요약값을 나타내는 것이 더 결과를 잘 반영하는 경우도 있음
+- 이상치 데이터는 모델의 성능을 크게 떨어트림
+
+
+
+## 이상치 탐지 방법 - IQR
+
+> IQR이란, Interquartile range의 약자로써 Q3 - Q1를 의미한다.
+>
+> Q3 - Q1: 사분위수의 상위 75% 지점의 값과 하위 25% 지점의 값 차이
+
+.assets/img-16508985826691.png)
+
+Q1 - 1.5 * IQR : 최소 제한선, Q3 + 1.5 * IQR :최대 제한선
+
+ 최소 제한선과 최대 제한선을 넘어가는 값들을 이상치라고 한다.
+
+```python
+from collections import Counter
+def detect_outliers(df, n, features):
+ outlier_indices = []
+ for col in features:
+ Q1 = np.percentile(df[col], 25)
+ Q3 = np.percentile(df[col], 75)
+ IQR = Q3 - Q1
+ outlier_step = 1.5 * IQR
+ outlier_list_col = df[(df[col] < Q1 - outlier_step) | (df[col] > Q3 + outlier_step)].index
+ outlier_indices.extend(outlier_list_col)
+ outlier_indices = Counter(outlier_indices)
+ multiple_outliers = list(k for k, v in outlier_indices.items() if v > n)
+
+return multiple_outliers
+
+Outliers_to_drop = detect_outliers(df_train, 2, ["변수명"])
+```
+
+출처: https://hong-yp-ml-records.tistory.com/15 [HONG YP's Data Science BLOG]
+
+
+
+
+
+
+
+## 수치형 데이터 정규화
+
+> 의사결정 나무나, 랜덤포레스트 같은 “트리 기반의 모델”들은 대소 비교를 통해서 구분하기 때문에, 숫자의 단위에 크게 영향을 받지 않습니다.
+>
+> 하지만 Logistic Regression, Lasso 등과 같은 “평활 함수 모델”들은 숫자의 크기와 단위에 영향을 많이 받습니다. 출처: 데이콘
+
+[데이터 평활](https://min23th.tistory.com/20) : 시계열 데이터에서 발생하는 무작위적인 변화량으로 인해 생기는 효과를 줄이기 위해 사용되는 기법
+
+[Logistic Regression](https://ko.wikipedia.org/wiki/%EB%A1%9C%EC%A7%80%EC%8A%A4%ED%8B%B1_%ED%9A%8C%EA%B7%80) : 독립 변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는데 사용되는 통계 기법이다.
+
+
+
+### Scaler
+
+- StandardScaler : 평균을 제거하고 데이터를 단위 분산으로 조정한다. 그러나 이상치가 있다면 평균과 표준편차에 영향을 미쳐 변환된 데이터의 확산은 매우 달라지게 된다. 따라서 이상치가 있는 경우 균형 잡힌 척도를 보장할 수 없다.
+
+```python
+from sklearn.preprocessing import StandardScaler
+standardScaler = StandardScaler()
+print(standardScaler.fit(train_data))
+train_data_standardScaled = standardScaler.transform(train_data)
+```
+
+- MaxAbsScaler : 절대값이 0~1사이에 매핑되도록 한다. 즉 -1~1 사이로 재조정한다. 양수 데이터로만 구성된 특징 데이터셋에서는 MinMaxScaler와 유사하게 동작하며, 큰 이상치에 민감할 수 있다.
+
+```python
+from sklearn.preprocessing import MaxAbsScaler
+maxAbsScaler = MaxAbsScaler()
+print(maxAbsScaler.fit(train_data))
+train_data_maxAbsScaled = maxAbsScaler.transform(train_data)
+```
+
+- RobustScaler : 아웃라이어의 영향을 최소화한 기법이다. 중앙값(median)과 IQR(interquartile range)을 사용하기 때문에 StandardScaler와 비교해보면 표준화 후 동일한 값을 더 넓게 분포시킨다.
+
+```python
+from sklearn.preprocessing import RobustScaler
+robustScaler = RobustScaler()
+print(robustScaler.fit(train_data))
+train_data_robustScaled = robustScaler.transform(train_data)
+```
+
+[출처](https://mkjjo.github.io/python/2019/01/10/scaler.html)
+
+
+
+### Min Max Scailing
+
+> 변수의 크기가 상대적으로 값이 너무 작거나, 큰 경우 해당 변수가 Target에 미치는 영향력이 제대로 표현되지 않을 수 있음
+>
+> 이러한 문제를 해결하기 위해 변수의 값의 범위를 0부터 1로 변경하고 최솟값을 0, 최댓값을 1로 해서 값들의 분포를 나타내는 것
+>
+> 이때 이상치에 따라 scailing의 값이 변하므로 이상치에 매우 민감하고, 이상치를 처리해주는 것이 매우 중요
+>
+> 이상치가 있는 경우 변환된 값이 매우 좁은 범위에 몰려있을 수 있음
+
+- 공식 :
+
+.assets/image-20220425205122523-16508986033022.png)
+
+
+
+
+
+- 예제 코드:
+
+```python
+from sklearn.preprocessing import MinMaxScaler
+
+# scaler로 MinMaxScaler()함수를 불러온다.
+scaler = MinMaxScaler()
+
+# scaler를 학습시켜야함
+# train데이터에 []을 더 붙여주는 이유는 scaler.fit의 인자는 2d array로 받기 때문이다.
+scaler.fit(train[['fixed acidity']])
+
+# 학습된 scaler로 새로운 컬럼을 만든다.
+train['Scaled fixed acidity'] = scaler.transform(train[['fixed acidity']])
+
+
+
+# 위의 방법을 fit_transform으로 한꺼번에 써줄 수 있다.
+
+
+train['스케일된 컬럼명']=scaler.fit_transform(train['컬럼명']) #에러 발생
+'''
+ValueError: Expected 2D array, got 1D array instead:
+array=[5.6 8.8 7.9 ... 7.8 6.6 7. ].
+Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
+'''
+# 이 오류는 2d array를 인자로 받아야 하는데, 리스트는 1d array이기 때문에 오류가 난다.
+# 해결책은 안에 []를 더 넣어 붙인다!
+
+
+train['Scaled 컬럼명']=scaler.fit_transform(train[['컬럼명']])
+```
+
+
+
+
+
+
+
+## One-Hot Encoding
+
+> 컴퓨터는 문자 데이터를 학습할 수 없으므로 문자로 되어있는 feature를 컴퓨터가 읽어서 학습할 수 있도록 인코딩해야 한다.
+
+
+
+### 단어 집합
+
+- 서로 다른 단어들의 집합
+- 기본적으로 단어의 변형 형태도 다른 단어로 간주한다. (book, books 서로 다른 단어)
+
+
+
+### 원-핫 인코딩
+
+- 단어 집합의 크기만큼 각 단어별로 고유한 정수를 부여한다. (각 단어의 인덱스가 됨)
+- 표현하고 싶은 단어의 인덱스에 1을 부여하고, 다른 인덱스에는 0을 부여하는 벡터 표현 방식
+
+```python
+[[0. 0. 1. 0. 0. 0. 0. 0.] # 인덱스 2의 원-핫 벡터
+ [0. 0. 0. 0. 0. 1. 0. 0.] # 인덱스 5의 원-핫 벡터
+ [0. 1. 0. 0. 0. 0. 0. 0.] # 인덱스 1의 원-핫 벡터
+ [0. 0. 0. 0. 0. 0. 1. 0.] # 인덱스 6의 원-핫 벡터
+ [0. 0. 0. 1. 0. 0. 0. 0.] # 인덱스 3의 원-핫 벡터
+ [0. 0. 0. 0. 0. 0. 0. 1.]] # 인덱스 7의 원-핫 벡터
+
+[[1,0]
+[0,1]]
+```
+
+
+
+### 단점
+
+- 단어의 개수가 늘어날수록 이를 벡터로 표현하기 위해 필요한 저장 공간이 증가하게된다. 또한 벡터로 저장할 때 하나만 1이 부여되고 나머지는 0이 부여되기 때문에 부여된 저장 공간을 비효율적으로 사용한다.
+- 단어의 유사도를 표현하지 못함
+
+
+
+[출처](https://wikidocs.net/22647)
diff --git "a/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv.4).ipynb" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv.4).ipynb"
new file mode 100644
index 0000000..aaf0f4e
--- /dev/null
+++ "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv.4).ipynb"
@@ -0,0 +1,1149 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "1a9e5648",
+ "metadata": {},
+ "source": [
+ " ## 다중공선성\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "675799a6",
+ "metadata": {},
+ "source": [
+ "- 공선성(collinearity): 하나의 독립변수가 다른 하나의 독립변수로 잘 예측되는 경우, 또는 서로 상관이 높은 경우
\n", + "\n", + "- 다중공선성(multicollinearity): 하나의 독립변수가 다른 여러 개의 독립변수들로 잘 예측되는 경우
\n", + "\n", + "##### **(다중)공선성이 있으면:**\n", + "\n", + "- 계수 추정이 잘 되지 않거나 불안정해져서 데이터가 약간만 바뀌어도 추정치가 크게 달라질 수 있다
\n", + "- 계수가 통계적으로 유의미하지 않은 것처럼 나올 수 있다
\n", + "---\n", + "- 분산팽창계수(VIF, Variance Inflation Factor)를 구하여 판단\n", + "- 엄밀한 기준은 없으나 보통 10보다 크면 다중공선성이 있다고 판단(5를 기준으로 하기도 함)
\n", + "---\n", + "- 변수 정규화
\n", + "- 변수 제거
\n", + "- PCA(주성분 분석)" + ] + }, + { + "cell_type": "code", + "execution_count": 21, + "id": "8a49ea2b", + "metadata": {}, + "outputs": [], + "source": [ + "import pandas as pd\n", + "from sklearn.model_selection import train_test_split\n", + "import statsmodels.api as sm" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "188aa7a9", + "metadata": {}, + "outputs": [], + "source": [ + "df = pd.read_csv('https://gist.githubusercontent.com/euphoris/f8cc761601d81d8ca077a9fcacf355b5/raw/46f23ba0efdbf315fcf9536b83a7c417590cd259/crab.csv')" + ] + }, + { + "cell_type": "code", + "execution_count": 3, + "id": "6421626d", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n",
+ "
\n",
+ "\n",
+ "
\n",
+ "\n",
+ "
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors assume that the covariance matrix of the errors is correctly specified." + ], + "text/plain": [ + "\n",
+ "\"\"\"\n",
+ " OLS Regression Results \n",
+ "=======================================================================================\n",
+ "Dep. Variable: y R-squared (uncentered): 0.827\n",
+ "Model: OLS Adj. R-squared (uncentered): 0.823\n",
+ "Method: Least Squares F-statistic: 214.8\n",
+ "Date: Sun, 01 May 2022 Prob (F-statistic): 3.39e-51\n",
+ "Time: 12:25:41 Log-Likelihood: -42.203\n",
+ "No. Observations: 138 AIC: 90.41\n",
+ "Df Residuals: 135 BIC: 99.19\n",
+ "Df Model: 3 \n",
+ "Covariance Type: nonrobust \n",
+ "==============================================================================\n",
+ " coef std err t P>|t| [0.025 0.975]\n",
+ "------------------------------------------------------------------------------\n",
+ "sat 0.1028 0.010 10.381 0.000 0.083 0.122\n",
+ "weight 0.0755 0.071 1.063 0.290 -0.065 0.216\n",
+ "width 0.0051 0.006 0.802 0.424 -0.008 0.018\n",
+ "==============================================================================\n",
+ "Omnibus: 13.620 Durbin-Watson: 1.891\n",
+ "Prob(Omnibus): 0.001 Jarque-Bera (JB): 5.772\n",
+ "Skew: 0.247 Prob(JB): 0.0558\n",
+ "Kurtosis: 2.128 Cond. No. 67.4\n",
+ "==============================================================================\n",
+ "\n",
+ "Notes:\n",
+ "[1] R² is computed without centering (uncentered) since the model does not contain a constant.\n",
+ "[2] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n",
+ "\"\"\""
+ ]
+ },
+ "execution_count": 33,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "results.summary()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "28b67782",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 31,
+ "id": "a3001e17",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from statsmodels.stats.outliers_influence import variance_inflation_factor"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 34,
+ "id": "1efe76df",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "['sat', 'weight', 'width']"
+ ]
+ },
+ "execution_count": 34,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "model.exog_names"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 38,
+ "id": "337b2c37",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "
\n",
+ "\n",
+ "
\n",
+ "\n",
+ "
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors assume that the covariance matrix of the errors is correctly specified." + ], + "text/plain": [ + "\n",
+ "\"\"\"\n",
+ " OLS Regression Results \n",
+ "=======================================================================================\n",
+ "Dep. Variable: y R-squared (uncentered): 0.822\n",
+ "Model: OLS Adj. R-squared (uncentered): 0.818\n",
+ "Method: Least Squares F-statistic: 208.4\n",
+ "Date: Sun, 01 May 2022 Prob (F-statistic): 1.85e-50\n",
+ "Time: 12:41:40 Log-Likelihood: -43.939\n",
+ "No. Observations: 138 AIC: 93.88\n",
+ "Df Residuals: 135 BIC: 102.7\n",
+ "Df Model: 3 \n",
+ "Covariance Type: nonrobust \n",
+ "==============================================================================\n",
+ " coef std err t P>|t| [0.025 0.975]\n",
+ "------------------------------------------------------------------------------\n",
+ "x1 1.5318 0.151 10.157 0.000 1.234 1.830\n",
+ "x2 -0.0417 0.423 -0.099 0.922 -0.878 0.795\n",
+ "x3 0.7329 0.311 2.358 0.020 0.118 1.348\n",
+ "==============================================================================\n",
+ "Omnibus: 2.864 Durbin-Watson: 1.824\n",
+ "Prob(Omnibus): 0.239 Jarque-Bera (JB): 2.467\n",
+ "Skew: 0.222 Prob(JB): 0.291\n",
+ "Kurtosis: 2.519 Cond. No. 11.2\n",
+ "==============================================================================\n",
+ "\n",
+ "Notes:\n",
+ "[1] R² is computed without centering (uncentered) since the model does not contain a constant.\n",
+ "[2] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n",
+ "\"\"\""
+ ]
+ },
+ "execution_count": 55,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "model = sm.OLS(y_train, X_train_scale)\n",
+ "results = model.fit()\n",
+ "results.summary()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 56,
+ "id": "ab03a742",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "
\n", + "\n", + "- 다중공선성(multicollinearity): 하나의 독립변수가 다른 여러 개의 독립변수들로 잘 예측되는 경우
\n", + "\n", + "##### **(다중)공선성이 있으면:**\n", + "\n", + "- 계수 추정이 잘 되지 않거나 불안정해져서 데이터가 약간만 바뀌어도 추정치가 크게 달라질 수 있다
\n", + "- 계수가 통계적으로 유의미하지 않은 것처럼 나올 수 있다
\n", + "---\n", + "- 분산팽창계수(VIF, Variance Inflation Factor)를 구하여 판단\n", + "- 엄밀한 기준은 없으나 보통 10보다 크면 다중공선성이 있다고 판단(5를 기준으로 하기도 함)
\n", + "---\n", + "- 변수 정규화
\n", + "- 변수 제거
\n", + "- PCA(주성분 분석)" + ] + }, + { + "cell_type": "code", + "execution_count": 21, + "id": "8a49ea2b", + "metadata": {}, + "outputs": [], + "source": [ + "import pandas as pd\n", + "from sklearn.model_selection import train_test_split\n", + "import statsmodels.api as sm" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "188aa7a9", + "metadata": {}, + "outputs": [], + "source": [ + "df = pd.read_csv('https://gist.githubusercontent.com/euphoris/f8cc761601d81d8ca077a9fcacf355b5/raw/46f23ba0efdbf315fcf9536b83a7c417590cd259/crab.csv')" + ] + }, + { + "cell_type": "code", + "execution_count": 3, + "id": "6421626d", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "
\n",
+ "\n",
+ "\n",
+ " \n",
+ "
\n",
+ "
"
+ ],
+ "text/plain": [
+ " crab sat y weight width color spine\n",
+ "168 169 3 1 2.750 26.1 3 3\n",
+ "169 170 4 1 3.275 29.0 3 3\n",
+ "170 171 0 0 2.625 28.0 1 1\n",
+ "171 172 0 0 2.625 27.0 4 3\n",
+ "172 173 0 0 2.000 24.5 2 2"
+ ]
+ },
+ "execution_count": 3,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "df.tail()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "d41407be",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "X = df[['sat', 'weight', 'width']]\n",
+ "y = df['y']\n",
+ "X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.2, random_state=1)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 32,
+ "id": "42d90f79",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model = sm.OLS(y_train, X_train)\n",
+ "results = model.fit()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 33,
+ "id": "d9175811",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "| \n", + " | crab | \n", + "sat | \n", + "y | \n", + "weight | \n", + "width | \n", + "color | \n", + "spine | \n", + "
|---|---|---|---|---|---|---|---|
| 168 | \n", + "169 | \n", + "3 | \n", + "1 | \n", + "2.750 | \n", + "26.1 | \n", + "3 | \n", + "3 | \n", + "
| 169 | \n", + "170 | \n", + "4 | \n", + "1 | \n", + "3.275 | \n", + "29.0 | \n", + "3 | \n", + "3 | \n", + "
| 170 | \n", + "171 | \n", + "0 | \n", + "0 | \n", + "2.625 | \n", + "28.0 | \n", + "1 | \n", + "1 | \n", + "
| 171 | \n", + "172 | \n", + "0 | \n", + "0 | \n", + "2.625 | \n", + "27.0 | \n", + "4 | \n", + "3 | \n", + "
| 172 | \n", + "173 | \n", + "0 | \n", + "0 | \n", + "2.000 | \n", + "24.5 | \n", + "2 | \n", + "2 | \n", + "
| Dep. Variable: | y | R-squared (uncentered): | 0.827 | \n", + "
|---|---|---|---|
| Model: | OLS | Adj. R-squared (uncentered): | 0.823 | \n", + "
| Method: | Least Squares | F-statistic: | 214.8 | \n", + "
| Date: | Sun, 01 May 2022 | Prob (F-statistic): | 3.39e-51 | \n", + "
| Time: | 12:25:41 | Log-Likelihood: | -42.203 | \n", + "
| No. Observations: | 138 | AIC: | 90.41 | \n", + "
| Df Residuals: | 135 | BIC: | 99.19 | \n", + "
| Df Model: | 3 | \n", + " | |
| Covariance Type: | nonrobust | \n", + " |
| coef | std err | t | P>|t| | [0.025 | 0.975] | \n", + "|
|---|---|---|---|---|---|---|
| sat | 0.1028 | 0.010 | 10.381 | 0.000 | 0.083 | 0.122 | \n", + "
| weight | 0.0755 | 0.071 | 1.063 | 0.290 | -0.065 | 0.216 | \n", + "
| width | 0.0051 | 0.006 | 0.802 | 0.424 | -0.008 | 0.018 | \n", + "
| Omnibus: | 13.620 | Durbin-Watson: | 1.891 | \n", + "
|---|---|---|---|
| Prob(Omnibus): | 0.001 | Jarque-Bera (JB): | 5.772 | \n", + "
| Skew: | 0.247 | Prob(JB): | 0.0558 | \n", + "
| Kurtosis: | 2.128 | Cond. No. | 67.4 | \n", + "
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors assume that the covariance matrix of the errors is correctly specified." + ], + "text/plain": [ + "
\n",
+ "\n",
+ "\n",
+ " \n",
+ "
\n",
+ "
"
+ ],
+ "text/plain": [
+ " 컬럼 VIF\n",
+ "0 sat 2.313813\n",
+ "1 weight 39.859206\n",
+ "2 width 35.791751"
+ ]
+ },
+ "execution_count": 38,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "pd.DataFrame({'컬럼': column, 'VIF': variance_inflation_factor(model.exog, i)} \n",
+ " for i, column in enumerate(model.exog_names))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "22c58180",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "54bd3d12",
+ "metadata": {},
+ "source": [
+ "### 정규화 하면?"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 53,
+ "id": "36738053",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from sklearn.preprocessing import MinMaxScaler"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 54,
+ "id": "eb69f62b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ss = MinMaxScaler()\n",
+ "X_train_scale = ss.fit_transform(X_train)\n",
+ "X_test_scale = ss.transform(X_test)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 55,
+ "id": "e33ee183",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "| \n", + " | 컬럼 | \n", + "VIF | \n", + "
|---|---|---|
| 0 | \n", + "sat | \n", + "2.313813 | \n", + "
| 1 | \n", + "weight | \n", + "39.859206 | \n", + "
| 2 | \n", + "width | \n", + "35.791751 | \n", + "
| Dep. Variable: | y | R-squared (uncentered): | 0.822 | \n", + "
|---|---|---|---|
| Model: | OLS | Adj. R-squared (uncentered): | 0.818 | \n", + "
| Method: | Least Squares | F-statistic: | 208.4 | \n", + "
| Date: | Sun, 01 May 2022 | Prob (F-statistic): | 1.85e-50 | \n", + "
| Time: | 12:41:40 | Log-Likelihood: | -43.939 | \n", + "
| No. Observations: | 138 | AIC: | 93.88 | \n", + "
| Df Residuals: | 135 | BIC: | 102.7 | \n", + "
| Df Model: | 3 | \n", + " | |
| Covariance Type: | nonrobust | \n", + " |
| coef | std err | t | P>|t| | [0.025 | 0.975] | \n", + "|
|---|---|---|---|---|---|---|
| x1 | 1.5318 | 0.151 | 10.157 | 0.000 | 1.234 | 1.830 | \n", + "
| x2 | -0.0417 | 0.423 | -0.099 | 0.922 | -0.878 | 0.795 | \n", + "
| x3 | 0.7329 | 0.311 | 2.358 | 0.020 | 0.118 | 1.348 | \n", + "
| Omnibus: | 2.864 | Durbin-Watson: | 1.824 | \n", + "
|---|---|---|---|
| Prob(Omnibus): | 0.239 | Jarque-Bera (JB): | 2.467 | \n", + "
| Skew: | 0.222 | Prob(JB): | 0.291 | \n", + "
| Kurtosis: | 2.519 | Cond. No. | 11.2 | \n", + "
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors assume that the covariance matrix of the errors is correctly specified." + ], + "text/plain": [ + "
\n",
+ "\n",
+ "\n",
+ " \n",
+ "
\n",
+ "
"
+ ],
+ "text/plain": [
+ " 컬럼 VIF\n",
+ "0 x1 2.325643\n",
+ "1 x2 25.897343\n",
+ "2 x3 24.825742"
+ ]
+ },
+ "execution_count": 56,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "pd.DataFrame({'컬럼': column, 'VIF': variance_inflation_factor(model.exog, i)} \n",
+ " for i, column in enumerate(model.exog_names))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "de8f617f",
+ "metadata": {},
+ "source": [
+ "#### 정규화를 거치면 수치가 다르게 나타날 수 있다."
+ ]
+ },
+ {
+ "attachments": {
+ "image.png": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAA/QAAAKtCAYAAACJ0yXpAAAgAElEQVR4nOzdf4xT5534+zd72Stzl954JCrZV6TlVFTCs6HFiErYSrQdo6kWU7rBIyJhK1GpSXaJJ9kmHtgN47BZ4gkV2MluOoYqwUmUyEYKGpOWjJGK5hB9iWzuN7njaUHjXBXl0GYkWypXPtmgi6+K6vuH7RmPxz9nIGS6n5eENJzjc/z4/HjO83l+nRWlUqmEEEIIIYQQQgghlpW/utcJEEIIIYQQQgghRPckoBdCCCGEEEIIIZYhCeiFEEIIIYQQQohlSAJ6IYQQQgghhBBiGZKAXgghhBBCCCGEWIYkoBdCCCGEEEIIIZYhCeiFEEIIIYQQQohlSAL6L4Gu6/znf/4nfX19rFixgp6eHnbt2sUHH3zQ0fYffPABe/fuRVEUVqxYgdVq5d///d/Rdf0up1wIIYQQQgghxFdVdwH9jSzqRRX1k0UGksU8mYsq6sUs3e2hSP5jFfVihnxxcV99Z1TToZK90dkWU1NT9PX18corr/D3f//3jI+PE4vFMJvN7Nq1i2eeeabl9i+88AJ9fX386U9/4qWXXmJ8fJx//Md/ZGJiAqvVytTU1B34XUIIIYQQQgghlpsVpVKpVL8wf3oAszuBK55jbI9pbsXlEVbYAnAkRel528K96VkSr0eIXSgH7Mb1TjxPenE9YCyvn4kzcL+HBEFSpWEa7KGJPPFHzHjOuIh9NoZ7bTc/USN5PEEWsOzy41zf7HNF8h+nmP6i0Tozm/ssGGfTAcF0ieGtrb9Z13X6+vr427/9W06ePLlg/W9/+1t++MMf8s///M+88MILC9a/9dZbPPPMM7z//vt85zvfWbB+//79jI+Po2kaRqOxdWKEEEIIIYQQQvxFuXNd7m+mGdney8DBMbIGC7ZNCrkLQwxstOA5k+9uXzNxBlasYMXsv3IQDQk899cuX8HA6Xb7zpM5OMTQwSEyLVvVddRj29jmaPSvXCHQrbfeeotCoTAbzP/hD3/g6NGjxONxAL7zne8Qi8X4z//8z4bd53/605/ys5/9bDaYj8fjHD16lD/84Q8AnDx5ko0bN/If//Efi0idEEIIIYQQQojlbGX1j2qrfK2E28wKd/lvVzzHmNJ8R/nzowQug+OEysR+S3nhkw4GFA/xMyrh3W5MzTefb7WC81gIe/X/xSzJw1FUwPF4EOe3DbMfNSqGRnuYM6MxWfmz8EURaPZ5E67XChReq912DO/GfSSabNHOW2+9xXPPPQeUg/kHH3yQb37zm+i6zqVLlzh58iQPPfQQ3/jGN3jvvff48Y9/PLvte++9h9FoxO0un4B//dd/JRaLsWnTJk6ePMn4+DgbN27kySef5LnnnmvYwi+EEEIIIYQQ4i/XbEDPagVHv6P8d24a9Woe0wMOes3lRcrq1jsy3d+LCVAvqmR2mVEMRbQL46QAk8nYNIxuyGjDe6DaIV8nc9zDUOV/6oyB0DE/1g57mGvnY7MBefj1BEP9zSoWiujXJud3ub+hNR3rf6ugo+tgMDb/bb/5zW/4/PPP+fDDD4nFYnz3u9/lgw8+4Pr16yiKMtty/41vfIPr16/P23Zqaor77ruPDz/8EIATJ05w8eJFvv/97/PjH/+Y999/n40bN3L//fcv2FYIIYQQQgghxF++2YDetDPExM7y39rr2/jWE3nsh2J1Y+hb7Gmrn+Srkww8PcjmM4Ozi019w8QOO+lmhHdRz6N9MknmI5Xx12LEr+Yx7QwStKUIHBpisyWK+1EfO/osWCybsaxrHFTrH47geSIJJjfuh+LEz/jxv24l+rilwefLXe7LXfvbG3H2MEL7Mf3/8i//Mvv33/3d3wHlWetrx7x//vnnDbf97W9/i9PpnJ9KXec3v/kNvb29APzXf/1XZwkWQgghhBBCCPEXZWWjhfnPVABS13PQqD07HSN8PAVr7Hj32irBugHrU2N8ulcj85FGAehR7FjXGSjqOrpu6Dioz77uZPPBDACmB9wEEwF8uywYgYGdCSIvBRg9Pkj8OLApxGTGj7V2B8U86s997DuYQMNG8GyUYdMOuOQh/oSDfDZM6JAb65rG3z+cLDA0b8a+hWl37g/hUIwtey40mG+Qt956i7179/KLX/xidtmVK1d49tln533uhRdeWNCNvjrJ3p///Gf27Nkzu+13v/vd5okQQgghhBBCCPEXqUFAnyF1rvxX/l2VzHPW+cEywPkIQ+eB3TE8e23kzw3h+Xlmbn2ly/48/af49I1V7VNU1FF2RpjoM6GsWUWPsdKWruvl7u9rHfhOpPC9XKBwU0fLG1D0IhgNUMwQ+YmP8Ok0GoDJwfDbYwxvNQBuYmkDPXsGiLziYfMrHpStPkJnR3E1qLMo5rNM527N/p2dAeujA7Pr7Y/58beZ5b7e1NQUzzzzDL/4xS9mx8YfPXqU++67j4cffrjt9j/96U/585//zPvvv4/RaOTzzz/n6NGjvPLKK90lRAghhBBCCCHEsrcgoC9eiBGaApPJRH4qROyCD2t/XQf158YpHLQz23JtVoC5gP5WsRzMWx8dxrNRQdmiYDZvRiHZNkH5s94Fk/O1tTtG7l03JoMV+/dg8CMnvqd9+B91ohh1shdVcvTQa3MxeimH50yU6KtRoj1WrA2C+XJ3+oWCDw3QYl7Atn7605/idrtng/l4PM6JEyf44IMP2m77wQcf8Mtf/pJLly7NBvM7duzgH/7hH+ZNpieEEEIIIYQQ4r+H+e+h11UCfdsYmfIylnEQs3pImNzE0jHc62j/HvqK9IsrsB+uzIy/J0fkB0Plielu55i+mCXf4j30+uUo0Uv1U9EVmIyPEJ+y4n7Ow+aeutXzuv4vSA0jK+wE2o53b/Qe+lWYLRbMBjCsNmJY2d176GtVJ8L77LPPuO+++xgfH+ef/umf+OCDD9i0aVPb7X/84x/zN3/zN/zsZz8D4MEHH8RqtfLWW291ngghhBBCCCGEEH8xZlvo9atxAo97iEyB87VhXJsUrPFxUu44nv4iuTej+BuOuK9xU0e/DYVbtQuNKP1OnACFSQoXs7R6c7xxqxf/VijqOsXZpTmM6RHiUwoOt5eBmqC81Szz3TFg2uLAVMyTSU9TwMzmPktXk/m18t577/HQQw9x3333AeXX0L3wwgsdBfPV7U+fPg2UW/Y///xzef+8EEIIIYQQQvw3NhuiT77tJ3IZbE+NM/p4uWO5sidK4noe1yGNQgdhc/qVHuyHwfH8GBOqkZ5vGwETzgP+ckCfT5L7OE8P7YLwNOEeO4EFyxPs25hg3+z/288y37UbKkGHh0TDXgQGlO0hQt8DS5MJ9ZrRdX32FXYAv//977vqKv/5559z5coVAC5dusTDDz88b6Z8IYQQQgghhBD/vcwG9I7DSca3m3H21Q4qN2B7boLso3kMaw2tX1tXw2ix4+hrMDjd5CT0a+fC5Qs/iPVYiFDT9dUu+POX5k8PtBh/n8Bz/wo89Yur4+87SBUYse31Nxwq0In619B1G5DXvgLv3/7t3xaZCiGEEEIIIYQQfwnmOtGvtuLsa/wh49rOwt0q7fwo4Zn6ge7z9oj9cS+2pvGsMteq31Ce+EcLA3qD4iR0zN5VWlmjNOktkCJ2PEyq6Xatxu03ZjQa2b9/P1euXOH9999H1/Wugvof/vCHbNy4kZMnT6Lr9fMMCCGEEEIIIYT476TdqPhFybwzUjPnfSMuYntaBfSLUx1/f2ckiRxsMSt/5ZV9nfrggw/42c9+NjvD/YMPPsjU1BTf//73O9r2m9/8JvF4HIDvfOc7895jL4QQQgghhBDiv5/uAvr1LiZUG5gtDVfbnilQeKqzXRmWFMwbcRycYGJ/D71djmVva62LaKFAtO0HDV23zv/2t7/F7Xbz+eef84c//KGrbX//+9/z+eefc9999/Hb3/62i28WQgghhBBCCPGXaP5r68RdU22N/+Y3v8nnn3/OunXrOnr/fNWPf/xjfvnLX7Jx40YuXbrExYsXO2rdF0IIIYQQQgjxl0kC+i/R9evXee+991i3bh0PP/xw19u/9957XL9+nYcffph169bdhRQKIYQQQgghhFguJKAXQgghhBBCCCGWob+61wkQQgghhBBCCCFE9ySgF0IIIYQQQgghliEJ6IUQQgghhBBCiGVIAnohhBBCCCGEEGIZkoBeCCGEEEIIIYRYhiSgF0IIIYQQQgghliEJ6IUQQgghhBBCiGVIAnohhBBCCCGEEGIZkoBeCCGEEEIIIYRYhiSgF0IIIYQQQgghliEJ6IUQQgghhBBCiGVIAnohhBBCCCGEEGIZkoBeCCGEEEIIIYRYhiSgF0IIIYQQQgghliEJ6IUQQgghhBBCiGVIAnohhBBCCCGEEGIZkoBeCCGEEEIIIYRYhiSgF0IIIYQQQgghliEJ6IUQQgghhBBCiGVIAnohhBBCCCGEEGIZkoBeCCGEEEIIIYRYhiSgF0IIIYQQQgghliEJ6IUQQgghhBBCiGVIAnohhBBCCCGEEGIZkoBeCCGEEEIIIYRYhiSgF0IIIYQQQgghliEJ6IUQQgghhBBCiGVIAnohhBBCCCGEEGIZkoBeCCGEEEIIIYRYhiSgF0IIIYQQQgghliEJ6IUQQgghhBBCiGVIAnohhBBCCCGEEGIZkoBeCCGEEEIIIYRYhiSgF0IIIYQQQgghliEJ6IUQQgghhBBCiGVIAnohhBBCCCGEEGIZkoBeCCGEEEIIIYRYhiSgF0IIIYQQQgghliEJ6IUQQgghhBBCiGVIAnohhBBCCCGEEGIZkoBeCCGEEEIIIYRYhiSgF0IIIYQQQgghliEJ6IUQQgghhBBCiGVIAnohhBBCCCGEEGIZkoBeCCGEEEIIIYRYhiSgF0IIIYQQQgghliEJ6IUQQgghhBBCiGVIAnohhBBCCCGEEGIZkoBeCCGEEEIIIYRYhiSgF0IIIYQQQgghlqH/5YUXXnihmw2Kus7tlQZWLqYq4HYR/b9uYzCs7G67oo5+k+63+0oqkv/4f/A//2+N4tcUvv6/Lc906J+opK7c69+wWEv57Xfq/OlkL6a4cr1Ij/J1DN1seiOL+n9eQfv/elDWdLVl+Zsr507/azPm/31p99Sir4Ml/IbiTIb/8X9l70D6l3Aui3kyl/4n2cWcv1pf0rks6jo3i0WKtw0Y/tfFJhbmjpnOKrOZ1fcyS17isSsfEzAYbn91flPXlno+qvnQIravHv//ZxXm/2M1Szpsiz2X1ftwUWlYQh5cr9NjcVNH/3+LFIt3ozxzF89lNd0YmJfsO3kNLMWdTMdiy6lL2fYvqowrhLgnSo18Fiu5cJVin9WvSJWCUAqmG25VKt3KlSYTp0qhY6FS6NVYaTyTm78+HSxBsJRqsnkzubirxO5YKdf+ow3SVCgVCrc6+GChlHojVBr/3WK+ZPbLSrmPJkoTaqN/k6XcrVKpVMqVYrsp0eo45lKl2Kv+krffUXI8YCqBUrL1O0qu/aFSLL2oo9DoS9qmI3WkvN4VX/id1XXzt231++f/m/yszTn53Xj5Omr7b7z0aZNdFNKVa/FX9Z9o/tsL2XZp7uD8daR8L7W6H3JxV+Pjnw6WgBJHGm+ZU0+V/HsdJUe/o+To95b8b0yUcn+q+eYW57WjlNec+8bXQcWtQmk6PVGa1AqlBWe74W+4VSoUCo3/fVHz+5odlwaq53P6j43S3+Zc/ulWKZdNlSbUiVIqW/cbPouVXG3OX60v/1wWSqlXfSXXVqW8/3n/lJJtt680qi7m/FePWaPnQxuz93Tze3beN1WOWe2xmXcc2xy71mrvv2a/qVCa7iAvq7++Zv0pV0rFgyVvn6Vkqj/+e4Nd5uXN8os25+NPudLEG5VnSb+j5NjrL52ad96r+22y/a1C6dNMJf/T6u7i6vFf7LO59vy1Opd/ulX6NDNRSmVzpVt/qltXvQ/r0/BFk3ykUHsft8+DZ93KlSbVidLER7m57Wu/u8WxKFwaLfl220rKgvuQkrLVVfK9Ov+ebpGIyvO1Wpao/w1tzmXp09L4sVApdOxUKVWoW9XmXDbNZ1pt99Fo+Zp7Znxx10fVrQ7OZTfX4h+nS6nqvZvJNXk2dV9OXcq2SyrjCiFEqVS6c9WB1+N4bAGKTwbxPqhg0DWSh60MromQesOFqeMdZYj8YIhE7aLcNNzI4vlBdN4nXS9N4NvSem/5s17MZwfIvetuk4Yi2vkhNIsf5/qOE1tHRz22Dc+ZRutcxD4bw7229R60M/vY9kgUDTA94KDX3IvDDHCLzMkhEieHCOwdY+INF0qTfaRfXIH9cIsvOZKi9HyzrZei1e+fzxXPMbanxRm5kWHoYKCD7wxiP+BseCyKWpKhgwk4Yse/s7Pfmz2zjW1Njl05zZ3sJc3ICjuNUx8kVRrG1lFquqed9mB3x8mvt+Hd5cDwSYLYT6KEXwsyeXEYa0fNUHmSz3oIX61bvDPExFPWztJxboh9T4RR8+X/m/qGib0bxLGmxUYzCbz3e+bf+1VHUpSe7/6oVc9nMF1iuNV31ylORfDsHiRxbW6Zqc9P5I0QrnVdJ2NRFn8udZJPWthxMo+pz8vwG04c64yz67SLKonTEQYdY2R/lWV0p7HZjmAmzkDDc5LAc/8KPDVLOr+nm9+zUG45LwKFm5UFtwroug4YuNV87y3kiT9ixnOmch1s7XS7LAnHtib38XwLr68sUZeDfefysN6Ga/8wdqUHKKB9pJJ8M4DnzVGix5KMH7AurXW4KY34T+x43smjbPXi6jeQPRtj35thoi9Noj7X+nvr72EAZfcoY6/5sLa4ZGrlzw3h+XmmbqmL0K99dJKTLLgP13s5dW4U74bWRyz9Sk+TZ2Bnz+EFbqgEHR4Su2MdlCXm6OcGsfwoQt7kwPv8KZx9CrN34nUV9UycyNPbGMuOkz3hpPVhrT5fF/kbyJM5OEQAF7E9XmxtzmH1PgQoVG+8mwV0vXLsVxpbp/e2jnpBBaO324TOT/VZL2Z3o6eCj/HCKM4Or0Wolq9ULPvdOJQik2978Hx9kMSvhrGtbrVluVxKB2XOBelveA8AWPG/HcLZeeFYCCGamgvoryUJn82W/y5MoqExfiJMrqe8yLKrVaBbRD3hIX94mon9ltmljl29GFb4iD3twr+p0yRZ8b47Nq+gmH3TiT0xQPBdL5aa5YaWGXBZLq/BbRZZEFwsF6euRBlYC5Ai1LODkQafulXQ0XUwGI3lglVRJfJIFA0noY9i+LfUPan0LJEnehl8c4DwrkLTgrjB6MCxVUO9rMF6Gw5lFbc0lfQ1ULY6UIzNC0P50wMLHp4Jt5kV7sova1loN+F6rUDhtaa7J3fGS+8TDUO2+bb4KRR8zdfPjOHduK9x8Ff9ruupef/XL0eJXtKBApO/a/31w8kCQ/Xxo8EI5Bt9vAkTlr5ezPOqzYwtC9EdHf+mdRMZ4s/GyeNjPDOKczVAEM/hFdhfDJCcGsbaYTCjz6ioF+oWPlRs+NkFrkUZ/FEY1eTA+7wT08wYI2+OsO3J3g4Lw058xxzzA74Niyz1/Gnuz+JMhtTvCmQ/a7PNTALv9kESeQXXkSDeBw1opyMEXw8zsKuHVLqzCpl7dy41MmfzgI3Aq6fwPVC3us+F3Zwl+aRKZCrL6M4Wv2a1gvNYCHv1/8UsycNRVMDxeBDnt+euZqPSOsjKa5OVvwrcKkLjGyFNuKeuMuzoDnqOAgSJxVt+xR1mw18o0CIXInWshx1HFy4vXoiWg/lNw6QuBRcGC1cjbNs4iHowivp4s6CkUcVgAPuK6pIgqVKLYOnjOP538vDUONOvOsuH+4iHwAo7I4eSZJ6zNr2Oix+P4PlRmLTJgfdVH+71RdJvBgicGWQzPZ0HtTe1clA3j4OOcpKbKoHqfXjAh/22SuiVKPv2KPSmh7F1UAtifXQYz8aemiVGlA7KDQvcrv2PTvbiJLkb0+htNtOujpEHbIdGOfWUpW6tA5fNTPb8IOrJDNkTzs4rem+3/8gC+RzT81NH8niCLICWqv8wiSfMCyrnE0/0knii8p8jKUr9i0hHl4wPBZhQa+7CGyojj4ygmsyYuwjmuRZl8JEc/uyn+DZUlh0IoB524HrJhvaSo8WzuYh+QYUji/gBNzXU1W6m3xjAXLfK0E36hRCihblQw6hg3VLJzm4USJJHsVqxVlodWmecBlZ9zUQhV67Rnc0UbxbQMXf9AJ0NcAFuJBl7O49yM8ZY2ktoezc5YAb17QxMxVCvufEuuuW9e6uMRoxGgB5WNfnMiLOHkdoWg2KxUtAxo6xr8DuNCkqlFFUoNi8SWZ+aYOJ7I6ywBeCxMBPP22Zb7b2vTFRaqJoEpqsVHP0OgNlKgHJPgfLqRRWGFmOlAWOLigduVo7qJkOTh7DG5KXKb0ykyDxvw1xtse/Aqp7q+VsKO4G3u2xJqTn+5KZRr+a7OP5mlIeAMynUixr2h3pATzF+AcCGsetzt5iWoCLqGwGSgPfEGKd2GQEXvTe/heeMn+hldwctpHY8B/x3oBeDxvTl8l+TWh5dC7KtYUtP3VbnI8Tz4Dgxzli1grLPiWJYxY6fBxi75MdWXzZv5J6dSyuul5yM/iTJ4MZvEeu3snmrHeVrUNBSpDOZcmWfyUFoe5t2UqMN74HqmdDJHPcwVPmfOmMgdMzfYWutxvg71WMfJnJ2CEfDikET1mMhQg33YcHEZMM1X2W3GgRfRT1Hoe2WBoz9Diq5MdqFNBoKtn6l8kxpXTmIScEOJC6pqNft2I1QSI+jAmxt1bpaJPVugDTge2Oc0e3lb3Fst2L8QS+DZ6KMX3PTTbtr294bDWhnwoTzYD02xtgBK+DDvtqO/cUAobPejvanbB/E3+X3NlL83WS58viShkYWtcOeG9ZdQZyv7iP5dC/fijuwWm3lnhpfaKQuT5K5kEbDhOOYs4MeCxraJYAEk78r4l5Xe/aj+H8w3rK6uZidLJ97Eqgf6bjXVlvsGzGgbA8R+l6LHXZayapPk7qoNr/evtaLfYup6bVsWGvFUfMM0s/GUQHTXiuGj1XUL4BPtLbJyGdUkrs9RDfULjXicA6Qt6XJvOS4az3nWLmKHmObHg1CCLEEcwH9GguOvkopdSZPhCy9Nse8jLQV2/4Yzkdc9D7iwfc9M3yhoZ5OYnh1jNBiAumbGukzEQKHEiivTvDp9zLs67ewbWeQ4NMebOvaVc8XSb/oI7QxxsSTMTxH4jjecKO0GWQQfWYb6tdafOABP7GXnV0MIWjOe2IC94YeeqtdNY0OPEdsRA5HGbBN4901gOXr1U/nyCYSRC8DW4MMbr87/bRMO0NM7Cz/Xa0EsB+KdVgYa1yrf1d927yg1hug+GGUyPnKf6ZChE67iO0Zo7QHarvgNtPoOrA+FSO0884ku5na46+9vo1vPZFfePwvN90a97FxJm94Cf/oW4Rnlyt434jirW+pvSuyZM7nAR+uvmrxRcGx2w1n4qhXNIa3Lm64x4Ku2O1MJYhWehkk3hkncKLc0pM9vY3B15tvpt8ot2MZjbUtewbMihXIoN1o1y5Xdi/PpWXvONmHVJLnk6jnMmQvJ8nOrnQx+rQT53YHSttut3m0TybJfKQy/lqM+NU8pp1BgrYUgUNDbLZEcT/qY0efBYtlM5Z1jYJMnfSLHvadB9OjbuzvxEk86ydqjTboOq3gPODHqWdJ/DxM5JKGcb0L32EfDhPkT0cX7P3uadBboEOGfh+xR2N43hlhW08cW78De78F8xcaqQ9VUhez5DHhjvtbdBm24vv1RLmHQFFlaNU2wngJ/7q2h0h+7rzWW+sm9KtJ9CfC7FDmriDWezn15vzebvPp6JXI0NxTe37MKOuBCyr5G+2OwFLpZD9KAlY8/dVQ14DtRwOYXsyQyExT3NM8CGypqKMXAQod9tzTUc/Gyn/mRxm74MarTmCrthS32nSDl/GsA/V8kuSFBJlraZKzw3h6cb06iHO7E8f69qFe8cIYo5XzEn49ga/fXdOLSSN9oVVQq5E4OTIb8EePRfD2DzNcKjEMcLnSADDLiG1vpVI1nyZ+JkWuCKyx4NrlnMs3muZfNS6MMHChUR/Fim6GMdxMEzkWBawMPWIh89K3Oi5vGI1m0G8tOOfFLwqwyXyXhr0IIcSXo3F4W7yFjl7uFtlAtas41LSirnEQVDWGPskwmbsFOHAdHO26Rbd4IcCOZ6OoN3pwP+pnOPMpDhOAwqmsnfSZKKM7Few3enA8Psr4kQbdpG7nSR7x4L2wmehpN451NsKX7NhdGrHXhiv7q1fuLu5sm0JDB7WsC8eXNqJYHTjmtVYasD2fIvdghOArEcaOD1FbfDU94MT36ij+R51fTkt5pbty6poGmODjCNsOlVvZbrWpEHfuD+FoEbe1657b1oxWbjFZszCAKH4Sxbt7hAw2Qr8aZPIJD3G3hx6iBPdYWp4/g9GBox+4nWP6Qpb8vBaxu6HahXZha3j+s3JRMXU9B42KO+kY4eMpWGPHu9dW/l3rnIRUjUD1PlxlZvMmC8aVxfI45NWLbCNYUOBrpkhxCsBMT81Xme7vBUDN56Hp6Omq2m7FUD42Q2j3dxFc3Uwzsn+INDYcfRrq+QChCyrRxx2s+rD1ppatXkyMkDg7Rna7D4sRyCeJvZ0BrNgt3VemfWnn8kYW9Upu9r+mB5y4H2icq2kZlfJtbGZzX+P7Ivu6k80HM5V9uQkmAvh2lT87sDNB5KUAo8cHiR8HNoWYzPjntTQWZ1Qiz+5j6IwGW4MkTgxj2g4pd5x9fXmyL4cI7LZirH0S3Uwzst1OoBosXFBJnE0x9lFstuu/nk2h6u1b5cpylZZNmP4sD1trj3+K2PFbFFoOwbHifs7D5p7mn7AsmJ9Bwf12FtueGOE3E6iXooSrQ1jW23DtH8X7rAdnB4EcAPl85VxNk8vT4BKaGyJXOzxO2RliQguQnZqkfAltxo1zpZkAACAASURBVLrBiOFm+RneuBeSCWufE95JMpZI4t3ixLQS9KsxoicBfFg3AJ90lvT5Ws0vUquIfgNAwVx7bKu9Dq7n0Wl4J81TO8QFgCMpcutDTcZkN6ad9uE9mcfU50C5qBI+HMV5LoijmCfSdKtKt/zZdFtwPjrcuHzx2SRqZRiQeaOjwbVEeQz/4TB5nLh2TZI448FzyEjiSPWiDJIqOVAbHlsd9ZAHzxkw7Y8RvX+UHYcCuNy0KA+V5c8P4nJGSNcsGzrkIHh2nOGtNU/e340zejxHT23+1W7Y3KxOylSAniH8mIvAZbAdieDbpEB1iF86RI+zRaUBYHjIQ/Cwk8Drm4nsLec5xZkkwcNhnE9+2tGcDndV9RjSboirEEIs1DCg16+kUVExfpTHu35hbh8/MkD6a1Raq+1ob0ZJNaixz5yPkJzSgFvYDqgEW7V8Vxj6A4xdCjTubr3ShG3PMLY9w8SKOnpdl8PijSypCwkihwNkrKMkz1cn7ykXrpSjHlzmb2E/EsS324ljw/zHyLyu/otkXFsJCBdQ5hdaWzD1+Rjt8zHKXKukYbWRL/eNJhlS58p/5Std1q3VSW46YH/Mj7/jyafmq52Mp5lcttL11gjoOrrBiHFllvizQwR+nkQDbEfC+Hba4KyGZgsQcfcyOTNJ6kCjNv0y61MTTDxFzWRgC1vE7qxqhUH99VFz/N9VyTxnXVjgOB9h6DywO4Znr6FuMslqF935/L++xcBikrnSuGAoxt1TP4beiLLahLHSFbtwJcbIO40mGaq4GmVg1z4S18rXwPj+AkMbdxB5opdMPsVom2839HmJ7I0z8OYgvWcG560rFySBmW5+z5d4Lq8l2Obotk25yUSNRR1lZ4SJPhPKmlX0VPNkXS+PHV7rwHcihe/lAoWbOlregKIXwWigOBXBuz9M/HI51eVJESsTT+2JkTL04HFFCLs3E3Yr2J4KkXi1PHlq/lyIwGVwvfEpY3sV9PNDWJxhgmeGSFYeR+qLA61bRucdk8nZid3iH00T3V3bspskcjDZZgcKO570dzz0pDb/6rF5CNqaV+2WJ/sDDEZajTDSM2rleoiTTEdw7aoPgTLEj2aIA8GH/Dj1ucpXoNxj7vKCK4iJW41zA2V3gOA7kwSO78B8vHZNu14F7dQMI2iYpjtrwRj6DSYMX3cSOmYHNNSDEZqf/TzJgx68x1XyJjexN2JYztrZ/OwI2zZqxM7saPHNnU+oWKvR5J35iyN43QGSebC9HGTs8SIj/XYCR3fgXDk8N79FA/qHYXz7Q8Sv5sHkJnzQjXOdjVjWjuedANusGmOZU7gabVxUGf1JhDQuRjNRfJsM5M8HcTlHCDwTxZX2zfXymIozMhWv5F+2jp7hNV+Erhebl3GKedKnQwQOlSdoVPaOEXveVr6Hq2W2ng6q3A1Whs8lCD/twfJEtvwkX+/Ef2SasT13Y5JgIYT48jTIPjXGXh9n+FiQ5KsxMnv8Cwqfc+OwAYrkagsiBjNc8ZA0jTG83YHrkEJPtSW/XfesjlsBa9TMfl1MRwlfMuN5J8dYtRWmqKMXDRiNRmzPjZPbmyb+epSRuAl7pXU/8/NtDJ3r7msbz7BvwvnyRPNWfj1N9HgKfXuKwru2ebXSzWdCbeEOdv+vp5+LEpoCZb2CNhUies7L6M5hSqVhoP1M+osfutBlt/3KhFnlMZoWHA8ZuXXGgf/lUYJ7LOWH/dZhUjkbkZezbN5vpXFQnkc9GSNT7c5dmKwEUFH8P1DLLfRfaDheSbVtX+5OfYVBWfFCjNAUmEwm8lMhYhd8WPvrSvzPjVM4aKfcwqGjPABUZ6a/rVe6FpaDY8taCxaTmV6bAa2TbpL1tviY+HW5taX1uTdg2ARMTaLNgK0SBGm/K1fAuNZ1crU2GUN/wI8TyJ9OtQ7oH3Dg/LYJfWeUU5WC32h6HMOTSRz7baw62e77FVxvTDK9M0rkdJKsDhgtuPYH8PV1f7d9qeey41axWo1byJrPLt1CtfvsJjubGSS93Yf/KT+e7QrGG1nUi7nymNldo6RyHuKvRxl9O0qP1TqbF2jXEoCLgf7ynWbsc+IhTDijkdte/ozj+TGGzUm2Pdm+C37mbAQVK9ZNGTLHw8SecNTMp1KeWE5rOQQnRfCxbURbVajOvgFiccOOWo8x1xh7PQomE6Z8nujrYwzv8tblQ3MTsRpWAzcUygNEKm5WOhpv9xHqs2B+wILJ3IvdoM1rfZ212sbwrzPY3gkRP50p54VrHfie9eF6YCkjgWuGEbR83hswrgFIoc0A1cqU69Plio0NSkfPvcZj6L2VyuY0xZYBvQlHvxXOGhk9E8W9DnhGZXKlh8DtIdzrsow13bb9hIqNNJro1/Q9GxZMFF9KMPZMuTQ2fGEay8kU5v29qC82b5k2bnHQu3oIZXeI2Ak/tjVQbeCw7oqQuO3GZQKuN9j4appoHjjgw7upfM5N270M7hohfVYlM1MT0O86VZn0zYCRNCOLGKrS8A0U+QT7rAPldJgc+OOjBNr0smtpjQ1/fBr/20X0mzRuOFpjJXSsfe+PO+7bOxg80PkbFIQQotaCIop2OkCAIKkDO9h8xYrvRTtqtTa0IQPWuqA//aKH1Ho7jj7T/NnztRS0qk9uUhjNnfHSe97ZcJZQVs5l7cadIcbrxjgveG2dyYb7eRu1vfCse8cYe7R5shppPsN+9bV71Vfz6KSrPRgKk8SOxslsclO4kaIHMD7kxbv1KzZVip4k+ESEPF7GzrpQ+3cQecKHPR0rF2paqO+hMG92/Q56aIARx8EJJvbXLf4kXi689w8z9pxjwQO959uVAsfuKNouw7ya/qKeR7sOlu0Wbl3T0NeZZ2fjnzuPRtCGGDpOE0Ys/T4sq2910fKwUFHXKepFaHUcdZXgwXD5+J93ELN6CD/mZXP98V/Vg3G2z2xdZdJsD4NycKycG8JztFy8bzdcYmmsONxWmEoQO6/hflwBMiROJAAr9o1fRkuIgvdXOby1uds6J6Gkk6Kuoz/6KZ8+3oN5TbHFWxKMWHb5Gd3lX1pSvuxzudKA0ai3nSOiqtVr3AxKtSWzVoHJ+AjxqSbd0NcolWeFFX+6xLyjV+09UA36q3nx86fmf+9qK6CRu0E5kJvRyoHpOvPsfW+02HEoTUePz7keJ3gwA5tCRI45cf1ghH2PjtB7wdF+23mT0pXlrqhk843eXlHVJP+aHW/tZVR1Lxi/Xs2/GtHeHGLfebAeSxAp+rAf3ofnxd4Fz+W5iVgBk5PQr+eqlmffuGDz4D+gkHzWw8hVgFsLen7MWmnCsTeEY2/TpN1FRuz9XjgZZTSh4t/qwIBOMl6uwPF9r5NZKZfO0B8il6WmpGTA+tQY47eL6LqZkJYjajRi/CS8cFujEb3Bmy4aavVaztUOQpoGhpqzvdqC64AFbuYxaTl8RiNGchSOhQjVzuRvsDJ88RbDtdsWdfS8Rs5ow0aebL4H5YFq2aumcs9oohfIzxveoJPTAMzzJ+acN+lbq4ktm2s41MDkYviYH2XlAN5dNkzVn6Gnib6eQseCq8UrMBv6OMK2QzR/daKukbwAjgOd77Ko6xQNMumdEOLemVck0S8E8DwL4XS59l85EmbM5mJgdZLYM9Y2mVWR/Mcpcqa6AuA6B97HK8vSBYZatY5VZjbvrLtWm1nQu7HaiLEy5o1mY9g6Vn69iTr7ap4ihStJkpXWtp5+Bw7ypC+U2wWsG8rdMasTaC29i32lQuGLSjHtbT/bLq2aLfgHbCsIYCL4UabhQ1C/GifwuIdIHmwv+3A9YMX6spsxdxyPLc9kpeW7sYU9FBbOrt+OAdMWx8Ja6lWVdiRjL/a+Butrti8ftyLZ0wGGDodrJiGao2z3E3w5iHvD3HaOYyVKx9qlL0/nb85KEdzdi/9ytq5PwDCpUuPumrPHfwqcrw3j2qRgjY+Tcsfx9BfJvRnF3/K6KHdfRJ8/9Y/h6xac/eXqMO1ip13mK+Nyb2fLQ2dyGo43P6VdKGTdE8D98gDxJ+z0nu7F/Mdp1Ktg2h/E29HrK1PEjodJAblskswMkJvG8lKbd6bXaniM5lpPhy+VCJr02ZmcZ+/520X0mSyT2sI5yIv5LNmZIgWtiP2J9kXIe3cu289QrV0cmps0sgnj1nJL5vz8OIcxPUJ8SsHh9lZezVn51jswZAnA2ufBxhBDuwfIPWFBPx9FxcRwn5VVXYx4KX4SZXDnPhKY8B3xYusvEH40iuedAPanvR3M0l7TmgzMTabZ6u0VlfzrdhH9ZvmdL0ajoTLRLIDC5r4OZ9O+nUc97sVzKAkmP6H9NmxECCbtBA672FEIM3qkzd1YmQBu/kSSBno2OnGaATTU+uEcRZ389SzTuYVTxunXM2g3IKcZ8T7WyY8o086PEp4pkr2QQbudQ+uP8Wlf622M230Et0YJHN9G7yUHChrq5TxsDeHtMB8of291VvksOrfQ/jjAWGZhz8OmGt2jH4fpsQVgV4xPE26Ma6yEjoVqKrTKGleK1SZQZehkuyEf1ATzRbTzUcInI4ydm/9cUbZ68T7tw7enrqxW3fZGmvDTXkKn659HgMmC+9kokQM1V+Z6B+7toJ7x4z1qwL/VgHY2yNAUmPY7sTc9BeWJLR2V14Ri3rxgeGM3lEdD5Yn7at2YJn5wCJVh7AecKOtdTKg2+Fpv+6D6to56geZlzBbrU2+HCV+qvC3kmj43bMTk5NTF8eZ5ij5N6mKS4tVseXJBKs+267dwHku1nW9JCCHamX1UZV8fwHG4yND5sbmWo3VuYmkDQz/xEdqUJNjyAayjHtvG2K4cY88UiFZbzmtfP/Z1M47+Jq8fnpVHPeIhfHX+UgdxBh+phFJfaKiXvY3HfS5aecwbDcawLU0lyL2pkTwTIXE6g7bWivvRIbwLuu/OBRytWs5aM9NjrHmH+LU00wYHvYoDh2LEstWO8nUzjnU0mB25yOTbfiKXwfbUOLFK9z5lTxS1uIodP4mi3W72mrivFv3cEA53hPx6F8G4F5vFwuZ1oGU0tKtxQk+H8WRyGD6K4aormFcrIZp1g632Qmg+J8L8lj1zv5leAKMF2/cUzGvtKA1LE/OP/+jj5aBR2RMlcT2P65BGod3Rn0ngrYz9H1Un8GHGwlxwBpAxJMne7uQVhHPjcqHcKtlRsWyti+jFU6zaHSB6USWLCcczMUaPODtswagb17zehkPpxbCkvhHAdZWxSqt19FcqgQcdczM5V91I4lMGWlbaKFv92G+3C+i/audysZrN9J5g38YE+2b/v5hXHDaxyU/sVzn2PREmfBBAwfXqGIE+A/rpzndjMKzi1k2wHUkQ2mkEjLhPqNwyhFl1yIv25l2cMb8a8HUzg3e96+OEDyXJm5yEzgdxrAawMXx6DK1/gOhMq55iZbPDJh4fLb/L22xh3gzmZDBcyFKsncPjagTr9wItZgsxYekLdBWEZN4Zme3+b3rAQW8n16vByvC5CXhsH4Hz5Qkcq13HOw3Ga7+3mocpX1/qE6xIOlnpbH+2+kpcJ/4D7afUXer3Zo462HwojekBN55jfuxbFIwUyV9NkTofJ+COMnp+jMzbrrprLkN4p52hyyYcj48S2bMZi8VCj55lWtNQT/oZOWhHuz2J+py1kjMpeE+Mk/2Jl/ChgdmhCcruUcaOtc/L9UuV14S26n2wyOOQfjtSmUMjyuhpL7Y9NW9p6kj9xKv1gnX/t+BSJ+aeFVusOFaZ6d1gxlA7/0WD4WwGxUmoX0f7eK7EZVxvxbrFikfZjGUt6C0n5RRCiPZmQxLLngiZ3SZM9bn0OhchteGUKc2tbtL1aIuPiV+327jNOHSojL2rW/Zx3SRAVblpuJHF84MGhbfZcY93m0b0kW+x77yC64Aby9U4+xwxMr/qosWxYybc75bmDSlorNHrjgw4DicZ327GOa+ywYBl7yk+3R5ENzUpmraZ/6DcM6Bek8m47oDsVIQ84DoSYbgmKLf2KVj7HBhzUbYdjZOdic2Nz+xIB9fngpa9RhqNXG1+/G3PTZB9NI9hbQdzUQCtWgJnJ/5rqvU1lG7Tsgtg2ODl1BUvo7pOcaWxzXvTK9a6GSu1v3IXJZ8ksMdDAhPKetCOexjoiRE94MBUWzFjchBQJ+a1tKwy92IxGZjXK2gmTutw8F6eyyLa+SGGzrQa6tKuUqqqXffZahf82mVtXgt5xoN5xcJwsLYCTdkZYuKzYLmVu82EcU2tcxPNOMBUMwneagve104BaVrNiZ1v2VW6yVtMWgXvi7m213sZvWSm+ICz/KaFqnUuTmVzBHUTJvKNx8DXu38zjr6GV9DCvOoBL0nVRm0flR5lc/lVZbX38uXWs4oDmGZfFdrA5Q5aptc4GE5+il/XKXbRK8/2fInS8x19tEs62dd9uF7MwHoF5VqSfY8Osur1IO4GcwsUtSRDBxOVSsnGE7c5+h10doFnSB5KAy7C5+qG7PQ5cT+1A+MKOyPvjJE65iqPja+ayZK6DDBI8DXfXF5ismHaYMNhuUXm3D6SmSw6c/NZzL5p43q511KPYsfa9pXBd5NO5hVP+fhvd+LMJIm7PSjGBMGuXuXbouzRqHyJEUufo8WrHpurrYDtTp7EY1Z8MwGSapPhAUIIUTFXnFttujOTcdwsoOutM/y7MmP7OgfDzzXObhd016oyL2xlm3slXzOdFirKk6mhqWx+eRzzeaDfT/AlH5ZLEDk/wthVjdGdjbPpateuZu7aa01WW3E264lhMjWvla+ZBb1zd6aLbiOWTT5MREi8GiBi8OKwWTAbyt2mJ9MxgkcBnJha9MaY7a7ZzAYX/p13eEx4i+NvXNvNHTrXbb2pu5H+OneqG/aizGRQP5okeSZM7HT5vd/Ol5OMPV4k/CMXgUPbML/hxLfHhaPPjqPPgnEJBbcFvgLn0vHYcM2wkkbyFGn1Pu/Ke+FbbB//qD6gb9/lv5EFr7JcufRhVYZmFZDtrFa6z8/WNsgda15F1VjrMcDKg02O/EpTy7xrgeprEVuYfaYYTFgXMfnj3XRP8xF0tA9TpNNJYq9FykO4tvoYPz2K5aN9bHskgmfjGME9Hnw7HdgfcmBdW5faPg/DTYeqleWLzI0Rb8iCdb8JTiYYfTmK8ScO7OvKV1YxnyV1NliuZNy6GaX+9K21YN8KicujBA8p+B6xVbYtoGUyJF8JkARM6xs94w0Y11lxtJk/p6m21177cfD61STJ87XHf5iJt4PYZ8IMbB9ixGkm+oAbz7MDePqdC4//slQg97s8+es5CuXRO0II0dQdDauNax3oZwYZaDMZU+MZ4pdoTbddruqVu0mrrwww8Eqrz7maT6Yyj0b6igHHRi/m1RacxxyMHhyk968rr8Fa7yWyp/lekieHWsy+W3k10VfpPaU1s6B/FRh3hlDjBgafDTPoWtiWanrAzeibkZrZrhea312zgSP2ux4QL14Hr+NaZPoNxk5bd+8xQ47Ek/uI5E1Y9gSJHJqboXv41xlsJ4OEX40QeTFJ6q9TzSuy7rnFn8vok9ta9yRYSpfwpowLhzLcKZVAe+lDDKrDYhoHitU5TZas+jqvpoLlMcB34Ktaqr4WsVVKvuxnSrUS+E7NhXPXGNE/CuI5mIb1Tnyv+gnsr/TsWXeKyStOIi8FGD0dZvC0Ruwz58LyweuDbHu91Xd0MmTFiPOYSswwiP+Vfez4+cJPKLtDpBoOSbDiP5eCJz0MHfWQPLpgS5wHxhitvPnnjmp77bW/Bwx/TOE/GCFvsuA+Nkr4mcrxX+NnPOsk/tIQgeNxwod6cOx0dVA+67bL/b1gwXfpFp7bhq/+LSKEuOdWlEqlUjcbFHUdvvR3ote53eKVI19hxRtZMldy3OpRsD+gNDyGnb6/dem9HMqTGE5/AeZFTASof6IymVvctotyI4t6pfLKqy2tWhTrFdH1HFpGK3chXWWmd4OCqdW1c1NHv93BrjvtSt5QeRLGHGY293X5Gp7qsWg42VBlIrVOLCn9ZYu+Dlr+htaKlcmWer5tb9sSo9/Iw2pTywJRUdfQbyvdtXgW82TS0xQWc/5q3aVz2fl7oJfaCl7NR3rotVnbtDDeYUu4hua7C79hdlK8du7y8a9MiteJrp8pi86TW+yr23NZvQ8XlYYu8uCbOvnbhtbPjaJO/gYY19ZUEnVz/LvphVA/cWGPwub1Smf5+U2d/Mzctj3KZixrF1meuJPXQEs6+etgXNfiGN0ukteLmNbcw7nmF1s2nX298vIq0wohvjq6DuiFEEIIIYQQQghx7/3VvU6AEEIIIYQQQgghuicBvRBCCCGEEEIIsQxJQC+EEEIIIYQQQixDEtALIYQQQgghhBDLkAT0QgghhBBCCCHEMiQBvRBCCCGEEEIIsQxJQC+EEEIIIYQQQixDEtALIYQQQgghhBDLkAT0QgghhBBCCCHEMiQBvRBCCCGEEEIIsQxJQC+EEEIIIYQQQixDEtALIYQQQgghhBDLkAT0QgghhBBCCCHEMiQBvRBCCCGEEEIIsQxJQC+EEEIIIYQQQixDEtALIYQQQgghhBDLkAT0QgghhBBCCCHEMrSIgL6IrusUF/FlRV2neHsRGwLcLqLri/nWr4LFHzMAburoN+/BtndE+99enMmgfpxf+Jllfc7nLPq6X8K5K+o69/zQfQXO35KOQ1G/Y+lfSjoWu+2S8tt6i70Wi/c6/1mEr8B1uzRLeN4s5bcv5Vlzp475Hbxn76ivarqWrebX+B3N95azJV5zS3p23rxD5Y97Ufa952VmIRZnRalUKtUu0K+pJM9nyBWBNRZcu5woxpoPzMQZuH+Mgc/GcK+tLiyi62A0GubtvKjrsNqIYSVAmpEVdkiXGN5a86HbRfSbze98Q3X7yyOssEGqNIyt2Yfn7cuwID0L3NTRO8j4DUYjbfZU1iyNDY/ZnOJMhuQFFe0GGNZasPc5sZrm1qdfXIGdFKXnm/7ypjrZtjiTIfW7Qgd766HXZsXU0cGoaPPbAfKnBzCfHSD3rhtT7YpOznnVtSThs+A64ERp89HMz7cxdK7dDl2Efu3D2u5jDeVJPutB7YsR2gnxR8xoz9Zd9x1Y/HnPE3/EzNiuHGN7TO0/vhRFHb3Y5F7r5vzdFR0eh2KRosGw4B5vel3erXTc0W2b5LeL1PpabJ7G/OkBzNeGGmynkTyeINvuize48O9sd0frpN+MMm3x4t1qbP6xe/msKXZWwJ1NQ0M62YuT5BqtMm/GsaHy2zvIc5tawj3bdX71cYRtcYXYy05Ml0dY8bKy5Hvtzt2zi9PsGHScrttF9JsLy1KNFUm/OMD4g2ME+7p5KH/FXR7B/raV5AknTe/mptd4F/leR+W/Du7trmSI/GCIRLuP7Qwx8dTiSh9VS7sXun/uZH6+jdi6GKGdJtIvriC0vtW2RfIfp5j+otE6M5v7LBi5+2XfO7mdEPfavKKDdtqD/dk8Ow75cG8xkP8wyjZLGO/ZcYa3tsjUZhJ479cYmlcIyJN4ooNAZirKwKFK9nY7x/TFAj19vZgrKXO9NIFvS5tfoWeJvzRE4Pgkhuq2uWnU4mb8R0IE9lgaPhjSr/RgP9xm37iILaZg1CHttAf74SKDR7zYthjQrycJWAcxn0hxalebjPS2RuLQIEPHk2goOA8ECR12Y1ndXRqKM5NkPtZrU4V6MEJyu49QX21h2sgqa21A37xQbnyoReE6n2TosTCZ6v9z03Aji+cH0dmPuF6awNfNj8inGDpYxPqUE6XN89e6d4yxR1t8IB2ix9mmhetGFvVKfdF6rsJDn1HRWtXyLvLcNa+M6L4CorOKjSb7vpEm/LSX0OkseYD1TvxHQgT3WNpWfuVPD2B2tyvStLvvygW3QKNVRzp5GBfJng4wdDhM8lp5ibLdT/DlIO4NnRfgtHNhEp80WLHGjnevrXmBFMifG8Lz80yDNVb8b4dwNr39ywFs6kaDVR0FwDWuJQmfbRxWm/vKz4F7Rbs4RKRo7+D3FNDODRG/7Wod0N/DZ03+rLeDax6CLQORLAnHNlL7QzhqDol2cYiIrZNrXiN5cJDB2TwnxOhLLpSmFQhl7fKJVsdN/0Rlsj6b/Fov9i0mDLd11Bm94XZdp6NNANT8XutuPwvUVdQUbgEU0PW532VY3SoXqPNxmJ6OK7FjBJMOgs//BQXzAFvdeI8MEJ1y4t9UXVgXAN6YRkdnOq2irqksM2/GsaHzr8m8OdD6+feFhnrZu+BcdHwt0ejesOJ9dwxPi21Sx3rY0a72r2m+bcT+uBdb00uu3NgQvtpsfatnT+MKxZ5v27GuNVDU25R56valHttGyDCMZ2NP3boiSl/jfBQoVwQeYlENLney/CTEV83co/xGghG3TvB3E3jXV5b1ObGtG+Bb+yM4M/67c7Fv8THx60roVq11fbuLAHomwb4+H7mfxEjdcsxrPS7OqISfdLD5QoTUG64FtZS250uUnm+173J6WtEvR4leqjy8tRQAseNhyn9VMtdmGxdVIu48gewEvtkHkQPXtw2seCqGb1erY15EPWTHlw+SzMVQ0Bg76MTxpIHM2wt/ayvGrV78tYXIqTBjADkFx4FWaehB2WKtC+B01KMDTK7z4G1WMDU5CLxrn/0dhRu3yn+u7qGnsjPDauDjTn9BEfVX5cqA5KUgjv4voYBzLcE2RwrfMUdNj4D6Co9mFn/uirqKumWcwkF73RpDy+CxkWrFRu6Ml97zTqbfGMBcWTd/Wd2+ixlGdtoZ7xsn8ycnppWgX40ytMuBd2WG2O4Orr5dp+Z9XyOGlj/IxnCpxPC8ZRpx17cY39A+oM2f8eI4vIrgmQLjm4xwWydzJoCvz4vhoxiuDvOfnm9bsdZVwugXRxj4yIxnb+siuak/wNhDdQtnxvBuTLZpOTKgbLRyq651I3t6G8HbDvw7O0s7AEYF+TTfvwAAIABJREFU64KgXSP55D6KD/mbb/dxhG2H5gLU3BUoZD1se7O6pFxAan5+FZwH/DhbJC1dHCLSLv0A11RiZ0EtqmiPe5v30LmHzxrTnjFKe1rtvNKy2AH7Y/55+XVnx6lI+kUP3rx3Xp5jP2REO+ZoWQmn9A8z/EDlP5/E2fYkjKpuLJVF5nXNt9UujDBSW4DOTaNawotqNWye9wErW+d+RquH4edaXW3l+2ewy37C+QvBuuDOgYMwA4+EZ5e4XppgoMP96X/MQYc5eeZsBMPTyb/AIETB84wD5V0V36bqtVlEu5IhM1uJ2YPzmBOuZ8hcryzaoHQV0FufmmDiqRYfqPRWqbcw384x9pNektunie6en+MZFlTQa6ivt+6ZpE1B29qcRvn2DZWRRyZRHvW22pDN7mGGK88O/eIIA5dtjD3nqFx1PfQ2vfw01KMj83oX5K6oWF5efE9AZfsg/m63va2jXmCRw37vXPlJiK+auYD+WpYo9rlgvkLpG8D1WLk7uHUNLUTx/0BlVc2S3BXwPNtFam7k0EihzQBrgWKeTHqaAsAnGiwoqhVRT/iY3JMg9ZxtQaHEsNbBcDzBrYdcRC+77kjX03qGtZuxbql0V19dzqYtW6yVwk5PubW4Wa2lYRU9pgK5G0WoSX3xCx3MSusM5lqM8PEdRP7orZwXK94TMbLfHiI25aqp2e6OPhVlaHcI5d1JApcGcP4IEm/4sTU890YsfY7Zgl1ZhsyzJlYprTLpcjc27dwQg88mKCgKq4DcFQ3lyVPEnq8tYFavq+Y1x9o7XjyXBhlPQvAxL9GLUbwtWlnTr/RgT9f3PqjVQ+iYpYMCpx3Pgf+fvbcNceLcG7h/PvjACFtIwBsSsOAUC0YsOIsFE9oPO7IHNosHNosFEyx4Ugs1q1AThbqpHzxZCzaxYHcVrLGgZIVKIhzZCEd29oOHRFA2grIRlE6hCwkcIQMVduARfD4k2c17Jrtrrfc9P5B2J/Nyzcw113X934O9u5Ov9d1tsmKxrMP002fBAuh9wMZNWC2W5T7XalsV/V6CsB5l/qx7+RlZdvqZvJBj0w8zRPZ3EKqqtDn3mljMkrzlxn2u25vLkTg7zeiFJfy7Kv1kowXpQJRIbhOhmyE8XxtbJlu2y02LyNyjEHwkdu8/goUmb86Xm1ru2nAgtt1yw/k19Jsgb+ukImnBZgfyQP0XjK6Qfipj6zTe7/KT/KWTnam8QCr21pombBu7aMe0LBMHw1iuzZK468N3SiR9Vu7er97BuaYjp11sqPM289QLkc8TRE7bif3ur4RzSfjPT5H9nxiJL+Wmeb+Wuj6+KQtA/4BsaNxrFJrU66N88MzAt9GOVY59whYJuYviZtN/em+ObV+U2aoC7aVK7oFKaZOd/l2Oum+7+MzI2TSUW1OAjeTdMM6Oiuks6fMiow/eRmDBm0f41I3vbymUkzJuC4AF56HKXPsiT/ZehsxzHftOF/JArRJ9rSNOA4O25r7aNG7nKWYhta1AwtLNQ61I7mSIpXSJULsP6LCfSBcFVctx+1GOkG0THZdeDXNHsTgFT3fgGmicT1ohEfh3redkWYG+8P471gfXa/1kYvIXY0Wg3yLiIcHCc3DWTO764wypXQ7CHYV5AC/hX0Ks6L3KWsvG4TX+9V6U90A6Wo61qbkS2dsJtG2bmEwpBPfICLrK/MMcGoBaoHmRpVF8XsR9rHmBtUyfk+F9RaJqEfbUDzxdXY5fFVjA0VG7XrdQ6HGxA04C19yM7t/B6MEArv+BkqowfVdg8ma0o1BUfJAm/ZWfRO176XPhPphj4oFKcJdxt1vtaZZMLkP6+hRTzySiP+cJfmKB/fOkvvfj+58pHF8F8O1zIX3sxNGpLzyfR3k0SqDDArG8X5yxv6v41F/xVi08r/JM/X0H4dslJvdVB1wZ3zdeHC00x/qiwtTxLwj97mbmxjjureC4PIbPsYP0uUkih9zt2+r0ETzxliK71/HdvQ20Fyp82N9kfRWsdrhbpEjzl9rEvUhdiEUTO4Pl2FrDrdJRLgTJnEiQaOh7mbMVy/GyO62O/gjs1iaxjE3vQa5DnHV3iuSzOQIHHd13XU/0eTK3JPq/XIfF1dMcik1mtNM3vLEaW6pTvJ8iea+AjgXHyCjubeuxWCpSeAauoTYKilcauZsRQscTCCfTJA9KCCNpCl43DtlH5GwI3x5bm3nhz59rurvpLqECnWxrHakNM2nhWablc6RHRpmsFWo3y3i+GiWRK+Lf9mcsyjXy2RSeTw35XbwVZNtqnoNO9rthPFeXGB4ZxUGcsZEsrrMzTB7qHoJURb0RIJCPMJsq4TsdY/Tj8fau048yJD9yk6xTUmhkfwwTuZwk/aQI25x4Bn2EzgbK57k/wYavBObvulCq4VLbnPi/jBE9URMepKukv58g9ssMSuU8Tfvcn2DDOZFff3GSq4aOVfqg9p8pwuemSN7OU0TEud+N73iEQE04THEuRvjUFPH7KradXkIXYgQHap69sAPXwb1knkzi/qTmSd+fQB5R2HHYi3vATulOBNc/tKawUDWnoCytuIOvhuLvC2AR6aZiVa9HCUtu3NenSB2RV9YzHcjdjhNv6/YO4DCUD6iuHTmF3Eigp2PWhJYnc8uD68LqT5Hy2tngbdz6ZsNcTUz+t1Ij0HsIn4vjHhpFOxdAsoD2ZJrosQUi2agBt65Gi5vOphaxed7TybJmssGfVr8fI3jRxWTWT+6AG//1DImDTvxVoeu+TuhS8/kEAfK/F6Ht0r+I+hTsHzcP6h1d+GqvYXB9qv9RttQv1Rvcl1nSNLQ+YKMFS8UVyzIYYVYNkX80T2EJGPQQviB2SIxURn2eAnuowRJVFkiUoiGRapnSgwTpZxLy2QzRXbWLYAvOE0l+PVokd2eG5O04JXtngV6dS5H+KkCirmErsW7LE+xLjQIOxNrJb6OIuA2UOoFKbFaQ3I+x93AURe8ncOwKha9kbJXnJe6bJFNQmDoTY/h/hmEgwpV/jSM3ur5dC7L3Xuep2lBM7TL1sWmFx+AYab3nmt9di7Z7ziYQp41df63YHC6k4/MsvPRiq3mu6uMM7PcZ63nOIJMdXe57cYHTyH43iu/eGKm7ze7DrmOTZVfIZauHA+krCKezBPfUCGgvs8ykIHBmDcL48xkSN/34z+nk5pSyxReNhRahwi2FPANKxFbo99LEbT7SDd4d1YVtXdK0zmdC+SVK4VDCwJivkvrHXgK/yYQOexB1hfiQg6ljaZJHa0JxllZiigWLBb1VXHWLcyt3wfrxAsrcAvaP5Mq4UyR1xEPokopwYIzI3TyenZX76pMI/iuP+9YUkcMSX7yw4j03Q+JgfY98G3MNL1WUPm/3MBMD+U8y12LE7q38rWbp6qKrvyyAJDZ8mxasdlDO+Nj7U2XTH53VCsXfFwArJQ2jnuErvFBIXXLi+lwo94fSUo8neJMUUR+DZZsRD5l69LkInl+cpHIRnJX3FzwyzagYIvHpTEfvhzIa+Z9DDJ/SCN0JIu+C1BMZ11CBxE8RvDubH3Tx2Ty5PWN171P92YdrWmLmdr48/2oqSrZUn9T4UZLAERX/8RnyF62UclOMeV24N86TqXolCRqaIBO5HcVhAf1pHL/TRWhbiSsjNSe7pRA7FqEgRkiqk1g22uF5HN+nCaT0DPlrVqCEOpeltGXlOO32GNKXKmPTs5Skahsk1Mv5GkW+DdFhYyqvwifVu1RJnA7Tf3WJyaHKNzbgQf5olA8upvHvWQl1KTzOkXsJlk39qxbol3QdNndOiKzdDeM7KZDIJnFmfbgGv4C7VzoI9Q48yqwBg4+dxsjyzqgoN9MEvkrUf5baApk5BUubhMaF3zLwzEWB9qNaO7S5FFOfuPD1afT+Odvw/vKasiy/vglc14Vsgtj3GbrnJDAx+etQIzYKSCdmye9Lk7ydZvqBju1TmVjhCs51VN5vslqwNAh7+Rth/N55hrMK7q0C7htTfDHoYm8uQuSkv8P1bbgPBgl8HmTamWg5iKrXgwTvBUlcbfNFrqP7Tf6RAhTIPooiNw1MGWLHRpneSNlSeFAn/lOG5nV+jvSFNLlF4A8n43ORlhpiYaMN1qE0i/ZUQd3iKccMlxbIzC203tEiIu8XoaSQfyG3FupfpImdLhC905iddoHUpQmyG8ueGdIWG+zyET7kwiMX8R904xIKKLenSBUjJM526XB7/CRu+7FsbTPZ2mQCF2UC5zXUFyA2LJKdX5co1biBtoohB2OL6xVqY9M0lO+UtnFya353+8MkG5RQQp+AhrHrr5ldPsKDEj6vlfg5Py7bEvlbMYJflog8MJi/Yb1c7osKsWNfEH3hJ3VnfHlBXUdf4zduwX1yhvQBFzueBgmOuLC+yJC8ECP3aZLZfattlY5yOcz8NwmSFpVE1eJLCfW/LXbvIOQZVSKWyTF1Osbw6VKTEK5cm0B9D9gXRd5uIIzgeYLYdyKhXOe4agB9Lk4g5yV1ryrIuPEM9DMqhkkM1QgyNyOMPtxENeGSvTGuuh0fyXC7vK/nbHXMseE+k8J1zlanTFrBgmNknMTIOPGiitZXK/K85blmzX2+tTAg7Z7FY1+9EmrHSIDxgUqrnk6j3G+3p0bmjoLNViQ1F8E90tudqLfixLeBfHqUNJSVB+9HemtsU2hBBUOJMKusbxUQrZin+OFo/Tyz1cnoiA/1BdBOoH+pkrubZurHCDP4mMpewVPpV85vFRa2hfB/5CB+OEzgyCjuGmV74bmCZA3V39ViGj4OIFfnRYu0fL4VVOSvFPwVa7ZlYJzERRWrJ4HylYQsAEh4T9SMFXv8BL4KMfwkz5WR2mccR5V+ZeZwzTd2v0iafgKfihWjhQVppPYbzBE/PUX/2V8Zr4S8WQbGiRxP0n8pSXDfSriWfasL5XmtgltD+y9Y3qsfmew2EfR6r6rGPBOrofgshe39cMvvVV/MkjgfJnxbJDIXL48HWxNkhDF84gckW3gItk2g2pIcuYdpHCNB3F0VQqDdjhEuREk3zl2PU0x9l6U89koNIYs5lF/AVkygPAoi9RSmqZL8KY74Sib8WRqAJRXsHxk5VkcrquTzBco6gDwqQE4hrebJL+qU1BKu05EelRomJv+3abIDW7bLjNpcjB6ubilr35YRZKLPnFib5sEwrg3NOacjXWLo8z/62HFBYPJBmkA1ycdWD1ceOEj9GEd92dn4IAxGyVwM8YXzAxIjAXz7ylpIvZgjfX2KpO5hKhttttBW+X0eZa6zatGQ29ZLhcR5kei5fqLX0gT2NAq1LsK1CZj0HJtgWaAXtkDOm8b2yzjuQQ/hrdblWK1si8vZt8kwV6LeUKJRKoCnBw1MU9IiA6wsruvOxPRxP8mDCdSmiaHh3gGw4bn6K/LTLPOFErruwH1SIVLrIbDRgjzYytnBgs2AWxuCBbH2ml3KVjWiv9TQa7wpulysJjatSPESbQXqNb+7Nkooo9evkv3nhpoqDynsGxpjoqvbIg2Zfm14ruURf44QOeYhVNiE/WOZUF7BYzRD/LLloD0rVtkWhz9JMXU2zOQcyMcT5E90zijfxFY3k/cK5G7PoDxXKeDAd7NActfqF/jqDT++6zJTD2QECysWX4pMP5igZXrNNQt5Otl/BghZr/BrCwHL/8OscavHyywTB7+gdHaegIHFnfpEoeiJ1StRWgkyn8eYrRW2uiWj6oKwuUVca6v9bPWx2m99rjHQ5zt7UrTKWdKCLR7iJXedUkjos0NORcVZY9UtW6UdB2XkqkC/qdVsU+FRnOgdP/HL4D87RW5oHMmo8fN5nLEvS0RzmZUcIfcn2HDe4PHUJ7HtXharV1TUm9B/vPfz2T524/ZOMnlHJjxUzt6fuxEjmh0n2uk7ep4mfFvFcyJDdKiSM6embJ3jwCSZoSDp6zGmzs8gXVsRdvVXRURbvRpQGorg/NjPsB4meNyHu2U/crHjw/qXZpFkPETJPQW5ZXvLnhzNePANNvhj7XIT2dOP/+864RNBfIMOLLWrzMU8mUcOXFutdZUA7FtdcKdFuNZjlSLOyncs4TnpxXViDPFsgGFJoDCXInIygfdsyLiF+f4EG5wt66O0oJ8Np6hRGBWZ/lzCd9eK9/gkuXzZO1DXNHTBgjgySaaQJX4+wvD/DOO4sMDM0TccfvXbNIEvk/iuqc1eVZ+GSbRJQKndjhO1R4gfS+E/n8LXQzJl9acxvihFmc+uJE3O/nMDUWNHkzw2xrQGWBw4PxZxnIvCyxyqxYG0W8C6vx+HDYzVEngDvMWQTBOT1dLs2L2Ywv++r0udzIYYly1ekq+bAmEM4Tg6w+tWizuLA8+3NcPDNg+zCi0XM+JIlNmhELk7MyhPcpWyGpYWLuT12HZFiQo6uYflYaP0OMHEYwfj3v46zWB3ty2d7A9hEociqEet6ANuAjcyJA50cD4WGrTgZJnwZhCdMvKWem1uK5dKmyTj/ixO+pR75T28UEhdcuM+btzdvmumVyO8Upn+ci++Z2NkLna37C2jZUnervFSeJIjd7d+F/dgQ/mSxWlGu/bPBvYnylmVa8tWNSAzzdhn080/rEM92EbW692tleYqD724vlmQDkVJHur9uoLoJjqooT7sPF3r77cX6C0WC7Z9cXJXnQaqCrRhow1pxL8uWaLV22P4vCpjWcVwhvy1Uw418FwUSWQNJCLseKocsc89TH6YIPNNY+WK1lhtIuQKDYqpImrW1mpmaaB7X2tVD7heCWWMaim4tznXNPV5VSF0iYYqGVQydXdR7xgaA+vnaItTxv/3OMpz74rnxKJC8qaH0fNG1Ekq8VMh7OcLuPfB1E2JwPcy6W8NKNJ+S/HFUBjLdGbVyVrfOFqJAnKXxL9t2OYnmd9E+KSM6K7EjR8KEM0FKxbvNuwKMHO1YVtj2TqLiPvoZMdqEFWE3eNkCk6mzsQYc4yxNOAnci6Kf3eXN7QRILdi5NZU0tdjxG/Pk7ubLVtPAc60O7a2ERLj9wo4L0WIHdvB2EsZ/9ko0UNSuZ8sqqTIk5KtLUqOelAXwdlh/BQPJMiJ0ySuhfF9pyHu8uC7VRN2Y4Q947x+Pd602Vjddhvey3k8Gy01YZHlEs3LHh82J/5zM/jP6ug1I4K4L0hwsCb5ZieMhkj9Ns0Xgz7UIxnivVT3eakQ+TLD2K0o7l39jF12E7wuNYUntUK9+QV7T1tIZFdb+cqB/5dZ/KwoQpqSw1aQDv/Krx2DlBp4paNpOsJm00fe5P8ezcuubsJ5h1Ju6u0YKXqsg1zBWE1sD9EBR+tBROh9cS7uC9aVeCreyDChDzN2opeSOjr5n/x40sPl+F0Bgj+MITt9jAkJJke6PAu9SC5bwN4gsIsDfvyV0iiZUouyRNt8hM/E8XweRrg4hot54icDLJxJMWnARasZjfytOFM3kqRv1kzi25x4BkfxHfG3nDT1p9OEjwRJ9IWYvxtsKuHVEUGkf/dS+8nt6TR7j+i4apPDtOuflRIzHev3VspW6VqXGvPV5lk6x8+ByvycUnEb01AfqqgbHYx93d/5xGt9d41eJXqR/JMC6n/tBM55/7ykOKusB9tUJnE1bJHxHyjHoe+dk3tMoFdPXX/QVObVEtomEUNFxF4VSZ/x4f8J/P9O1yVmMkSj1VZTyT3X4L950q88JM636UsvssSO+MoJIbOTuI14rLShOBcj8GWI3KcJMpeN9x/bgI/AMT+Bn0Ri+0UEXSV9NsjkYIyM4dwTvdG61GhvLtRvY65p6vOVOP1VVclYzRy92U3gbJT+g2GsP4/hIsPkkSCFs+nuCqiKwja8OUGm8nw9F1PkB124/5sgfsaLo836WfvPBL79k3AyTbKTgns1vCyhaZXvTVOZ10V2rPZcFpmI6kBf5SAibPcS/Ze3pYVSN1ybu4frbbShvWzhWbgcblZE+cGP72M3+uMMgZ3Nuy7zCkBCECiXJB3qZ+bjBFPXokgVbWlZuWaQjTbko5PIR6MU52L4vf24Xy6QOeoAm4gHGXdteeRObG+uiGDb6cZ/zkuwp5C4dUToti6osFFo3q82+WYbSo8TTHw41SWERCd/I8zY8QTCyXmUr40pYYFyZRCPj8yRFMoeAZAYvxHD53QxvJggfmIlJ1HDgWS/8+G5AKE7SUPJ/zrToAhpQe6nD5qUumUylfLQJdQHWfIaLKkK2edgG7qCku6QXvT3eZS5AupDdSUk7kGW/O8igVtXelEfmJj8pWj+bLVsm9juCqX5FWGvgeKjECFcbQT6cvxfu3iyak3stmSjWN3GBLE/Dw3lZD9775WzrFddT4U946QfWPAfCBH/KIm/00j7QiEiJxn9PUmwFF8xdfWtuOHa7TLNdm8B57dpUkKI4D47WZz4v0yRPtEhC3OH+0gfceBfHCN+LkV02raifX5ZJH8vTmjQgVKXtAaKN3xI3iyuc6neXZ7fGuVJxHez235dMq1utCAPqqS+m8CyzYlLtIJgx7VTNPD8V//uBIuMfC/FxHcAItKgozwBbRZx73b8uTFn3erBdrB0rhsvVZTFdqOVBfnkLA5bfc/MfWen/1RD/Q2bA/kjO9Vn6vi0i1IGKnXJR1GkKIlcELlXYaBPRCZbjnHcIuF2VJYSm0Wk3RLy+/1YWjxd/f4E/c5J7F/HWLjqxbHqha1G+kg/w7dEgucXiB9w9PYNb3Yz+ThF7GQA15dZVJsD98EwykXjSoGwc0MLS10NrayCa+TdnGtqUUl/36GWdcs5WkD6Js28LUx4n53R5TGniyCgZ5n42MWkGCU9XfNe+5yM313AdmyUyB1na280LUv0tIJ0LU9kcG2zQ2vPjB1kLsjssFP+fkYCqxfoEbBsXUdDxB8qyn0VsOE4l2Zmnb127FtdKPkOCVQFG/I3UcLpHSiPiwR2VgenFJnHOt4aj0N1LkHK5iawHXiSZvK+h9gNb6W8IVRDMzAUH13XCGwD40RPz7BjLkfxqAPbVgeuXQqpORX/ts7Pu1BUkZoqkVTKzrYU8gBsSOeisBpPiz8DixPfYUfHsaVwM8NEx+p7Raa9Er4HLqI3KxWJjLI4je9jH+r+GRLf1qw3tnpJPLYR/myC+ICrpdeU9p8o4bsSiccR5HV8vstVaFqwpAKfN2zc5mFWWXn30m6ZTfYdOGxCnRGmVfDQildudYQUsO+UkXYPY3c4EN+mm7+JyRppFuhfqqRPpnH8Mt7mo5WQBq3s6PmDLsf/taWvSxyptSE1XDFN6PNYbx9ftRTW8zSxW83LodJjFZ7NMPl9oVkw2t7K88CCfDJD4aytSaNp2R0g+axSsXPRWPOENsn5pKOzzLb8xYLzxBUyJ64Yu0Bb8uQuFRnLjuNuqKlNnw3H0DjhI2Fcj/JM7quJpN4XQSmIOFZrGn2hEJGjCN/46G8piToM1oPvhdrsqm3o4IWyTMXa3xojtXBX9+7WJUQCjezPcTIvGrerZAAasmiXWUW2180O5IGav9fyzfZyzDKt6rWD9E2B1990P7rYTnNZZYuH6FwBy5bVta6uhnX7VjRtEfYEmHkWQFxzebhycsCFs462FtaubHYSvJoh2Og6bJBIV5f7N8CfOde0U5CrGYCKlamBzS78hzopSIvkTqZZ6nmOtiAdmmTm0KTx+xCcBO8WCNhsze3pc+C/utA+J77FSURpPXP1SmvPjGaKN5q2MP1ZGwXuzVYls2BFmauT+06m/8ImJu/Mtswr4dgXYXzniqW8KlgAdfXKm9rVrk/9UR50gn9TmpPh1oyFNocL6eeFupwIuesT5Ld4kCU7AjqFuQSJ/zjxXaodn2wkvw8hWYOMbq9kmD+VxnkyUg4P2CYxSpjknRzyARFBL5D5OUwkZzMm0D+cZuKZDc9AP3YB9KJC4loWpze+HAfvPxMg+ncfYxtjBEccWNEpPM2g/O4gsL+q/tUoPMshj/SqDhZxnwj2eIxx2ilwCo+hlG8tmNZXy8kSs3pIDOzA3iEsSd7XSc1mw3NWobDF0caS3oEtXqYeyK3nrM0yEaX9Gt3ySYRZpcfrGWC5Ck0LMuesDDdu3OxAHlidmaDRK9cwiyl8Hwconkqvewimicl60WY4sLCjEsvdMzUlilpTrV+8Rmwy4V96Xe5VSmFZRKTdLdqwW6LtcGZvY/s0mKCpG8sl7dqyTs+tJSKOgzai09O4t3mb4gi1R9Mk0ja8jfHdfeIarIMr1x4+EjRrjv6pCIgfSSz90bhdQlI8bY6xIrbsfkuUNK2jC6HQV4k3tPTj+2bcUDzoMu/t6G41flVuQ6evo3v4xOpYrTC/xqsiriqspgVbHW/Wg+J/A2uZa9qFFe2WmN3f5tD3jHj5rGGO7hHB1j43wF8fG57LJUqXeztqOaHgxk3YigpKvkigRcJMYasTeTWuxx3Gwubo7gq1Y+EuF6OP4+Re+BEr87V9c4nIqWF8Vc+AfaME7qUb3O39JC67yJ4exlGtQ39qnkRVSLG4idyLEvjKjf1IEdtON75TUWbOT/HBIwP3ZbNQOhdm2FsO27PtdDP6ZYZ0TWI4y75J8vemCJ/z4/pHniI2HAPD+L6t+cb0eZRLAeSzbXren7XObEAcHGe8ZfhC27eGval/tEoS3BvC1tUbOt7OnNWBpio0KzTqVt8aWgG1WEQtlGhTldrE5K3TRqBP4Xt/A405r+toUSam7A4cY/SzWIcDPT3H3LZmDQP2GjR8685GC+KgxvTxUVqkZKthvZ5bK2x4LirwQ4yA00f2uYhzUGRTxW1Q3OMncDpDdOhNTATd+5pnej2zGf8Z1Lp6d1p0vC1aW657ZqMFeVAh9tkoHb/4qoVCsCENrPN77BORX7ZJaLhMuVya+13qQv9HeBsu972zhrnmTfR5YLVz9F+KbR5mT1rfeKjW6pV55VK+6Y39xPvWeQm/5n7hRD7iIX5Pw1OpbmEbipIc6pZnPE9RiDAT1eGgAAAgAElEQVQ+7Wa8zZBp+SRI4nGQRN3WSV7XWjb3jPP6dYuDt7iJ/uLumu3c8kmAyU8CtPMV0bMKia/chFt0jj93nVmPZbuM3OjF2DMGvt1uIX9/QRz7Zwn39f41p7ztPGUq/BXmgJ0BMn/40PvejGHAxGQ92PD6dcth+a9HTTmXd49K5s03ZCXsyEsNDaOl12qOqdRJX3ub/6R7/wv3D13ToK82K65BVvPuaq7ZKXusiQF0DU1fH0vPWt7Hao9ddb9rxWr7oq6hvVpdH+7tMuvY3//CY8kbZy33vobxat2e+Tp+swD8No3vgMrY3DjOtZxyvdsF8DzO8DGYTBuscHF/gg3O+XdAUNRI/UNGPTb/51ZFeBPv6G2yxvtZ05j6UkPb+JbXH6sdj9YyjpmYvEXeHYHexMTExMTExOTP4FWWib8nkS5G11RF4s2ho5zsJz04T9RIybJ3RaB/GGPvVQfJi+53JNGuiYmJydvHFOhNTExMTExMTP43864I9CYmJiYmPWMK9CYmJiYmJiYmJiYmJiYm7yD/z9tugImJiYmJiYmJiYmJiYmJSe+YAr2JiYmJiYmJiYmJiYmJyTuIKdCbmJiYmJiYmJiYmJiYmLyDmAK9iYmJiYmJiYmJiYmJick7iCnQm5iYmJiYmJiYmJiYmJi8g5gCvYmJiYmJiYmJiYmJiYnJO4gp0JuYmJiYmJiYmJiYmJiYvIOYAr2JiYmJiYmJiYmJiYmJyTuIKdCbmJiYmJiYmJiYmJiYmLyDmAK9iYmJiYmJiYmJiYmJick7iCnQm5iYmJiYmJiYmJiYmJi8g5gCvYmJiYmJiYmJiYmJiYnJO4gp0JuYmJiYmJiYmJiYmJiYvIOYAr2JiYmJiYmJiYmJiYmJyTuIKdCbmJiYmJiYmJiYmJiYmLyD/OkCva5p6K/W4USvdDRNf6vnWcu96JrGejQfdDRNY1WnWq9n+Nb4i9z7qs+1hvav6dgG3tI3sF5tWC/W+k2u+ln8Be59TfwV2v9SQ3u52oPX9i2t+r332OZ211m/uaRH/grvnbdx/+s49oLh5/hG73MN38/b6H/rNu+UT7am+W+19776Y1fb/9a535qYmPyl6CLQa2R/jhG/r3U5TfOEtDLg5pj6W4h0ESBLzGol9nB1jc39uJe9P+bKfzyMYf0yRXF1p1rhYQyrNUa23e8v8ihzeZqfgLF70V+2Gj6LpL604r+15tbDYgq/1U9qsd3v04xuGGW61e/t7l3X0LTu/4xMqLqB83ReSGjk5xTyL3q49w7tX25zt/fejYdT7P3bFLnquVbTF7u9u3U7tsVEXkwTqn6XBp6F3vIdre17rqNbG16q5OZSxL+PEfs+RuznFMqjYu+LE71Ibi5HsenAVXyTtc+wcnzds3ilG/t+jPTFunMZuOuXBr9hw9dcQ/tf5MneipffW837yz7tNq80UmT6sw2M3mh+R9kfrFh/aNOCVxr5uWmmvo8R+z5O6r5aP56v4jvM/biX0O0iLd+7QTq2uXnvNt9aL/22/fNr4s8YQztSHveVhn+5xXKPLd4OVdYC7e7fgPCyWkFuLeN2lWKaUE/zxzqsGV7kUR62HjN764vr3K6eMTLv6BQf1vSdh0X0F/n6/lQZf4q3/KtcS7a+925rHr3DsYZYbf9bj35rYmLyl2Vj559LqLdDTL/y4N9jab/bYgr/+yqh1+M4gfJgZUc9/prxPTraXRXNkDZVp/gww8IfDZvf24Frtw1dU1B6XMKrt0KMnYyRfg7iUJDI+Qje7YLxEzxPsVeGzPK9GeBlnukzIcLfp1EBEHGfiBA97cXRZ/S6aWK38u1/3+zCf8hJh7eyaoq3/Ni9qa77RbKvGd/TaY8c8c9CdDrTkqqQ/TzD62/bPd08KXkvZF8zvrlrk4BK+4/nkT+yN/3mOTtLYLeRs7Tpi/Z+5O0WeKWh3KVjb9QeThE4FGH6SRHbTi+hS1MEP+n2xsoKsJbPbF+U2aOSkcbXs5jC/36S0d+TeLdUtr3SULt9ly+yxI75id7Ilxc7Ngfe43GmTvTS74pMf2bHd7P5F8+1X0keFLscr5H70c/o2TyOEQ/uT11INh314TypUyH2PpOYvJkgsMvgN/1CISI3PIuO++dRHhcaNtrpH3Bg6fYMH8UZPVV5k68KLMyVsA7swF4ZdQ31RS3P9NkQ4e/nEarHFhZQ9H6CZ6KEDzhavovsD1Zcp7vdnIdEp+ew5vbr5H70MXo2j/NggOEBCZtQ3l58ojC5P4DPESZ5NYBkdFzslZdZJgY9KB+FCRyQsOhFcpd9OE6Nkk4HkTp1m+X+r9PfMH7rmoJqwKJZvDGK/dYohV+82Hpsuno7Rurp8l9kAK7FiN2rbNrswn+o2/dTg77Awj3IbF1AP2Cj062vzxgKnb7/hrM29MXyuB/fIyO+t7KXdDSBtMUGL1WUTsJ4qzGvsWW3/M3vppgm9HmMXIv9paMJovt6eYs6+RthQqdjzAsN4/8rDfVuB4XDwyn2nqqfBQqPoZT3sffn2q0eov8OYGhWeJ5i73mxh77YYS5CIngtirvDibL/3GBgDIo0rK00sj/HybRS4G/3ENxntL9rKOf2EszL7LADO4MkPsux15tY6dP7osjb2z85/dEU/oMr83f45ykCu7vNfEWUMz5iTyp/FhZQXlhrvqNOz61I+rgPZaDXfsY691sTE5N3kc4C/XOFxC1QdAX1sJ8elg6rRGN+emJlMITygOiIUfjF2/PZ9LshXEcKRO4USGwF9WYQ94Af4UECj5HF/KookjoiE94YIfnfGaTNwIsc02cCyEcEctc8xiZTi4i0WyB/Yy8pW5LxAQuQZ1pOYftlHFkU2y/IapUBpXlUVGYuxihYy5scI0Hc29pf2nYgyesDnRqXZWKDy8BNSAT+PUug05n+uYFuZ1oCNlX/eKWjVb0etKX2B30aJrGKRfQK5QVBVBjH95F1ZfN2sSzQd+N5HN/HCaR0hpLTSikbxfepG/2BwvjuTktpHe2ugjNdItSo49j4JtQ37ZqRY2KfB2UwTm7JjU0AfVEhdsSD+1Ua5Rupo0Cwgg3vL6+p/3pzxKR+EnfjxIqVZ6tmoEVP0G6HcV8ViT9O4q5V6Ax44ESE4A0frqEQ4uPJ+t/Xi+cp9soZAufkmvFPRxxoLUjXsTvA7L8rvX9xmtH3k4xeM6hIAFhM8cVAgMI/EmSW5IowXGnBokLsiEz/3SkyV5vHFOe3r3n9badzl9vzRtv/aAr/MYioC3i3Nvw24MZ7NMD0Zx/g/8nF/NftFtYq6e9TlEezEvPPQL0zSWyx0m+6LPLVG2HCH8dZuuBe7q/ykBO75wPid/1M7mv3FlXin7tI7pohU7CjnHQjn7GhnpMN9vu1Y/1QqlF0SEiKp36H9zrMAU1oKGfCxEfG8d8LE7qVYHKky4y+5jF0Bc90geSBNmfq0Bf9P8x2URqvM6801LsWvI/jjDb2c6G38VefiyAfL68/JguT+D71YXk2g7/D3LvMVpnxbxw1G1TSRxTSg17G6/q73fC6TPtvAZ4JFMDgO5Xw/5LE17h5MYn/o7QxI82ZTsr6VgiIH0ksNSjS8zf2EnklE9zXw6kA16nESr+7nzPep3+bxj+UQLxaM39/7EPo+v5suM/P4q78Vbwxiv3mKFdSXkPvSVs0pihsYh37rYmJybtJe4FeyzJxMIzl2iyJuz58p0TSZ+UOi9gwrg3hui2R48snYyGroGzOo0KHga1+MARQr4/ywW8iNqhYu42ikvghxvDFEv5d5VZLh+MknomEbuTwnDBm6Syq8+X2Px/H2WIgV3MKyhJYP3QhbRHgUYLI9VEm//CvLMY2S3jPRZjfFCJx3ENwl4ELb3YgDzjY9B9QtrmQB2zAJrIoiE4ZudOiuqIMAOBFiTRFREkqKxcA+19sfJdtHabX5wtkAYtahD22snuis7afeRh9g20Th8YItluItkVHuRqmcC7NzFC5t1uGIiQuD/PBxTSBq56uwuAmqwXLer2nFwVUNJZ0Viw/rwos4Gj77LS7ccLvhVk4415e/AhbZMbPR1A+jKN8NYl7te17miH9yI3La+26a/7RFEVPpq2wLh4YY8zrIvfcoEC/qJIhhZjX8W5pFoe0fAZlzrLiiQGAC9+JoHEPnVa8KKCSQV0EtlB2/c8uUAJ42mpU1FEuBpg/kCLzjbNJcBO2yIxPp1j61EP8vufNCz09tx/QdXI4EBuF+WVExO2QaxmWVMWKuLuqPNIo3YXi1n6kqqXM3rkPbeqzQFGjUNdCndJLG5a+DuLwoxRThSjxtBsR8J+fIvs/06RPynjehOKoBZbtMvJ2KM7FiV6fJrcIICJ/FSQwUlUoVVx2X5bQNAE2WrDUeTvoFO8niJ4Kk9oaI3PZi7iY4otBF3vvRYgc9+Fs8R38Jbk/wYbasf9MqMsB9YrsRkqP268oNlnWOv5qKDcnVtYfuyJMnevHPbKXaTuV8bdJVF6hMv8vn20uTOiViD6nwmk/8irapj7PwCMd9QXLa4FuCBZLs9Lo5aZWu64TArbdcoPAraHfBHlbs7fIqlmcZvR934r3wf7amVBHuRwkfyRFfKisNLMMVd7fVQXfWaNKPZ2FXApuWcm98CL+CePG2vutiYnJu0qzQP9KI3czQuh4AuFkmuRBCWEkTcHrxiH7iJwN4dvTyl2v1nWq7Ga3Ml2WUHM5cla1YWHVDR31cQrPR9He72wxS/pOAP907egm4Br0kft+HvWEZKAdORIXVLwH7YQvK/haWGcKj3PkXoJlU39ZoNd1ctixNrqQCpuwkkP/MzKS1C4GFotMkWdHNyVADcXbIXw/tnLeqrKECvjX2k6KFJ6BZVu7BYJO9sYUpSE3pXOTZPdFcO4Z5/Xr8fLPnayM2gKZOaVJcF5WvLxRcmS/s+PL1SuNxAEP8pcZ5i96kP+0NbRO9naCgq1Aak7Ff8hP8hffspWl7VEvC2Bx0bQWFjZhoVDOe7CqhYPK9NkIS+fTTNZaZe/rhC41723b4obLCtmvnThbuGVrczMk8RM2YvVCI31tEtdBL4kfEgQGm72OSr/Nk3toNe6JYYjyO9C2bWIypRDcIyPoKvMPc+VYbrXVqKhRfF7EfaxZmF+mz8nwviLRqrKrhnKMd4cmdVHorL39wC430QE3wX/YCZ8cRd5mQ6jMOHoxj3I9zNhPMpN3OqlKLDgGZMqjWZHiJcg7qgrO7tj2RbhydxiXrOAfcmClwPy1FMXBOFcG2n+ExXyG3L7QiivzZgl5ZJT5p1fwfGLo0is8KyxbRfWauO5SnetRa7TbY0hnIfLDFcLbraDNM3VMxv0khfLtSt/IXBhj9CY1YTka6ZOjhK4r6FKA4Lc5fq0+s60eruRdKJciRAa+YF6QGT2dYHJ/wzN9q2NoC2rG/uKNUezPux1grVNkN6L9kYanrX9bO3lylzzIp1aenuR0U/wXxL6Rsb1QmJjrfhZ9MUvq5yjha1bGb88jPw6x9+NR/GdC+EecdV47nU+UJX0NnHtmiN9S8Rw2sgore+KFW/72ZhXpdejzZG5J9H+5jm7jW7wkX5f9xsphMbU/5sndKeL+sX7slQZ92Iey5M/KBkMcEsSuBxg/kSF6KYv72w5juYmJickaqRHoi6SOeAhdUhEOjBG5m8ezszIZ9UkE/5XHfWuKyGGJL15Y8Z6bIdE1/rWKyPCRIN4tWfSTU8Zbp2dQrsu479Vc5/d5lLml9lahKosqKeyEGlYjwntWuFuk2PloQCf7zwDRD8PkLtqJD3rw/6Qwdbje1db1eZBgrXVsu0SAMDP/CeL8ZGX41v8zQ5IAke3dbnqd0ZfQqtZZQF/MkXlWKv/R7hm+VFH6vCxcHaWTTlxYc9zrEvpLsLexlGn/iRG86CD8YArhrAPPkR1krnoRu2R+EEQ30UEN9WEOdS7EFAGiAxVLeVXxshpq4xr/6KDSWFSZR2S0cSEpbMKCSvEFZStnB+Jf70V5r3aLh+g1kUQ1Ts6gQKbfjxG86CJ+x0Vc8jHxkcL4HktXK4vN4ULyJlF+89a5S6tzSVK7XIRXE7LyMk/82DBhYmQO6sS/j60kJ2vjci8emmTm8Rd4pAyjX/pw764oE/UiuVtxorfB968rhqym6o0A/twY6bte8kdc+E7ZSZ1xY6vpT717ZFS9jzQWtNbyWfUdTGb95A648V/PkDjoxH+iIsi2UWYIAuR/L9LeQbaI+hTsHzf3Z11TUHbPUDrZOaDFiDfmatuPIBH8dw7XzTjxIzL+ufxy4inbTpnhz/wkcl6chh/3EksaaC/bhNosldA0rXJfFctinwP/1V/x/ZYjo5YAF+5DERybO48B6vMUng9rFcki4k6IXg5jzVpRs4ABJZKaT8Eja8UqWp9TZEkFPu90dBHl5hSuI7/i31MZpy1VLxmF3LfOZa+ROtfi8o7Ix64wc8qOaGlxrxttyEcnkY9G0X4roDd4Sb2xMbRHlgp5snMFym9cp/ikgHjQaPifpaMiu1icWoNAX2P9bxX2sagyT3/9tbfswPMfFXFAxrlYZKqtz6GOcnqY8A0FVXAz+mWQzONKyM32K/z6qcLUmQjy8TT6VhnvmRkig53DuLLfB5l0RsgdL+D/sDoPGHuH3XPlvFn0e2niNh/pBs/GqndkvTdVPVo+g3JHJ58VkN2sKKn0IvknJRwHA+xoviL6Iw87Gj2LNtsRi2ECf1OWx/nCY3CMtLjwbynGDoaxnM8Q2edjYtDD8P8XJ3G6fr758+nSb01MTN5ZaoYWG+4zKVznbNhaCmoWHCPjJEbGiRdVtL7GgSBD4vtYOXFPJdaxeaDsjeKtKSY+9VOoXTgt5sk91CtWoQ5sNBon1urCWeJng3zxQGb2tgdbH4zfThD+TKb/1iiRc5N4d7Y51uIm+K80vk93MHoiyKjTSimbJPZ9DvmX2dW7Ka8S7XEWBQXhnop/m4i+OE/uYUWMamdZA9i4CavF8kaS7q1QZOGWDfuphqu8KpK9FMZ3bAF/VsGzRYBzCpFjw3zgSBK5EGV8qP1EZNnjX1ayZPUQU/gInliTw3SZ2rjGp9Mo99vst1FYsybeezrZEEMvYBE0+Ga8HJLyQmFirkPSRHSKdyL4/jHNjosZ3LtsOP6VweeUUS9PMTnUpQG7AsTPK7ide1EOe3FLMH9nmvhtiNwymIRpGQ31TpzQsRC5T6+gXPQivjKaUVnEfX4W9XiO9F2F/MN58nlwOOxYhqLkLkjdrVSaSvrSGP4LFiL3gkh9AtJFhaVjw0iSk7ELMcYHerqhGqreRyXU/zaOeRr5G2H83nmGswrurQLuG1Nld+dchMhJfwdh1ob7YJDA50GmnYnmGHRAvR4keC9I4mqbr3STFcua/C/X0v4KG204D4zjPDC+hnZUeJEjexcUS5biYbF5fL8ZYfThJqqJpxwPapPKrZCbSxC+X65cYjlwheSgwev/v2CtuPsLz6DLDAS6wsxPbjwjMyTuFvEcqM8p0j1/iA37hzbUZ0V0VuLltWd5FnbZO44x9Qn1jFGbW2Xdx9BqSEArWuZCEbAMyiiXxsohV9ucuEQrwhZpbaEvbxPDgpyAfCpJ+mRj+EQFm0zgokzgYtnjg1YKmyqviijf+/FdFIll3di2wuQvWfaODFM6HyW8X8LSpV1LJQ2tVUEKwdLx0sCKAaYtVnY4O43hOaZOxxg+XWqac5RrE6jv0Sa5nYA4FMX9QiX3RMDudGEVBKKDedSHOUDAvrMfseeJWsb3jbfiMaShfKdQNwu/Ukl/F2LsdA75qkL8gAiIjN9JY/lyFLvDweTNJAEjYZcmJiYmPVA3lAubbYaEYMHWsJjaLBNWbJRqNkm7ZeyG3GDb8Ns0weMFIrcbEj45KwuL+zqh8x2O3+JARqGkUecarP23ACOujvep3p1keuMYC3e8OKrHbpaJ/DvP6N08lnbCfAVx3ySZQo7UHQX1eQEcPpKFJNKfnmhUJfnTPJELEZIXpskeGMdZs1Bra1mDtu6WdXTQjBvLcFvh4w2EWbEE6PcnCd6yEHmcxruzMuP2OfBfXWB4LsWC2F6YLz5SWKjpiPnfAeZR5gqoD8vlqoTdPgKrCQOsDWXY1EEgtYnssKkUGi3xLwqoOBANWLdbx9DbkKpus5VQik6oj4q4b84vZ1YW902SfpxCeeVA6HIsCEhfz5Dfp5C+k0N9DvaBcTLnZMQeZETtdgj38RjFDwMELxdILrtK11h4oXNfBIQtEp5Dq8jwD+hP4sRyMolcELl6+eX+pFD42AarKFpUpup9VGT6wUSdzS3/o48dFwQmH6QJVHNabPVw5YGD1I9x1Jd0FE6EwSiZiyG+cH5AYiSAb1954asXc6SvT5HUPUxlo8jtPGW6LqY7u0+vvv0dMlW3xYLrsB9nh76l3ooz822UyO1JEo+8zblIPo8xW5OAq9gnsFKHwoLlj2m+KHqYPeDDfcSBXRCwWARYbP6WbVs9pH6r9eMqoj4G5zEP8ieUc5t0uSP15hQTQ34Kx2TcQ1GUfR3eVRucX6cY/buHHc4dyJ9K8DDNzO8OwjcjHZVq9Qn1jFHNrbLeY6hli4x2sxISAC0yfwODjYJl54Sq+qdhZiUREJBPzuKwteo4GSKf7yXeTmAtLIBjtY7j1e++zc9bRBwkURfBWd1nUSX1yRKjcwpLLxbQ2sRb9DR3VmhtRddIH5HwP/eTeBxBrngxifuvMC9OETg6Rdp5paWysExFqfLDKKM/LKHezUJN1YFy9vT2bbLtihIVdHIPy+F7pccJJh47GPf214RyWdgktRPoy16SIesVfh1pfr+dEyZacB5qzHsiEdzlbt51JE5pSKhZ6wgIu1Is/Eb9/L2oktnlIDxQdbmvhADVnmujiGPAR6KQrFd2WiQCv/yKb7GIsEVgWeHQu0ZhjXTptyYmJu8sy1PdmiYRoUbQaMKBRwlj3Vz9/9nuroovFMIHfKjH5ol3zAjeAZuEPDRK/E4Y97IrooZyawr3vmBHlz3xYILZgy1+2GhBGqpOETakc1Fo5+prW70Asl6o10N80ReicNSNlHcQ/F6ui7tsR627ZflECqFLNGT6pmOccess2+XcCsmRDhmPAeGTCJnG1XIlu70guelHQ8eCsFkmrDiw17yD0oMpJm5WzQki0mCUKDq5hwXsOyVEwcoOpw0edXkIa8KB81CB0O0sgV0rzzt3N0Hhm2iP1u3VIuD85kqTwGXZ6aGcK9tDvOQuu1x3qEtr2SbjPSqvuhWWgQDxuQiOZaFRR/stz7xalRisiJIDcZuHWQWW00A1Ji0ywv5Ey5JMwicRZlvGPQvYBqpJ/9Z/geU4OsProy1+sDjwfFvjzt147zWII1Fmh0Lk7sygPMlVrMIW5LMZorvalx4ztpju7D69+va3zlTdGWtna9lv04RPQ+RekOGP5pG+msB1d7xlXoUqtoEAwRrPi+KNNPy//cgDTtCyxH/KlEM+SvNNzs/ih/3YzmfIfessf68vMig3PcidlMiN7T1ZIHrHg22XRmTEge9IP5lrxrJdL9PnZFwpENRU8rkiwvEwk7b6RGWWLTJiw3MoJ9QrVwigQ1UT9XaMFPWut+s7hjYnuq2W8jOWQb9T6TSYqPx3uZxdlS3l8W2FAsl/7CA9tEB8f20gmfCGvNBEduxPoTzQ8G4pXyF3L4lNsxL/LtsxKZ7z6xKlVt9dB1qHv1mQz+VRWyS2s+wOkOjqJFWrVKlUtmkSotsrQsV9wbqs9MUbGSb0YcZOGHnvGtnvRvFcFElk11JhyWDZxLq5Q0L2Srj/pRD+pJo3SSd7Nwmeqa7zt/iJB7FNCTrLch/VKT1Ok9/cITFiA7pWRN9oe8NekyYmJu8qywL9WgSwZTrVTn+4IqE53pdxtEtU8yROaCSM+o9MD6WxWiHiOx0hPuIjLEwy5oT5n0ME8hFSF4zXMs3fmiL2Y4KZmvhPtjnxDPoInK6x+LWitsQa5YRbaklj0/vdS75pTxXmC2XriPqsWqZJJYPKwvkxkk/ysH+SZBvXafXWGL6TAolseZJyn0uRMxjHVetuCSxbT9ec6Xs1/JZm4lSIyRs64qBYtmm8KrAwp9P/VZDwmUCddt9xOMnsYSrPnrIFbg0sZz2nnMgrv6hiH4jSuYiigPxlDIfTx5glwfhBG8VbMYLnHcSyxjLkLscHVqheu2ALEDWcu6I11VI6v1ZL6WyWiJ7rEKKia6yUfNYpPF2gUAKr04CJrk9crt2t3g4xdjxGfrMH96AL8T0oqRmUL1MUP4xw5dr4ymJli4d4qUS88XzZKFY3zJRCLdyVuy/Oi3NTRC4lSN/MrghxNgfykI/A8QD+na3OoDI/p7CkF8k/KaD/oZJ56WbqeItdW9A1QR0AHqIDjtaLRcGGNOLvSRG0tsV0Pb23v5qpWkfT9NaZsnvhhUL4QBDOZ8olo7ZFiN124fEKpK8Fkbq8dO2pwjz99eEQFonRw9XEoRYy3zUkiNzjJWJ3Ef7BRfyQjfnzUWa+ChM1YNnSnsQJDIbhfKbiRWDBfS7F2KAL199VUlfHcRrOeK1TfJhhoaocyc9TaJhihX3j+D5s9RCK5E6G4NP2An3xUYgQrjqBfr3H0LXRpnTaMhVBvanUl9DQbp1NG4E+I2Eo5bwY6Vd58ouVge+/edKPVJYGo2Q6lnStYsNzOEjwdJS0FKJfSxI9LxC6M1vuE4vTjL7fJoa+z4KltopEJzp4yUE5lwS0Vtz8ZXmRJXbER+h3NzPZSdxtPQiM0Kpsaj3NSfFAOhBG/tiH//0UkYM2itcn8F10MPXA+AqoWwm6dr8vl+Ws9LnyeidPEZHgvxeIttL8ls+4Dv3WxMTkXWV903PUlktrSZ5peQy93QJDyxI9No3tQo4rQ2v3Txf2jJO+KRA6MYz9PjgPBUjdDna06qygk/vOjTs7TPxihsntNYvSlyrZmzGCkneoSOoAACAASURBVI9QXU37HBP2fsINSmvbTpkddmCLhNvhwPWRgctrajnW/cPo8mLGss1DUPEAVsTTItaNFtAas9HrZL+X8Zy3ErqTXHGn63Mux3EFrs+SPPQuTOxpxpx+SmcU8tMNdb9faWR/9OHZp5POBpuFnYcxrE5qKi800E2IpWz54v4UE/dFpEEHdsCyzY3Dpne0agOw1Ut8DsIn/biOlbDu8xGei3dwb6xSdnNUb02UrU9bJNyOskXJss2N5Ohe6q0zOgu5DNyC7G/eckmxbW6CJ2p2Kabw2UeZbjhSrLhbWrY5cTlceAZ6iFt4MoXv7yq+xyVm6oTmIKCR+8FH/+dxfk1XrTGNC/IK1vI1V5PfoXjTh3TeSuSHBNFpcTnjOrpGfm6K0KCb/G2F8doxbLNE9JyA/jBXTkaIBXHAg8vej432VQJqkQ4lSbby+KmSjWJ1r2Q//6ux6vYvpvC/n2T09x5q1zegP43jGwijn0yTPFAds0S8VzMIJ78gcE4ifbazB0n+5l72kuH1iTilV9VeU9O/dDvioNjg8i3ivxgnf8SH/fgSjgNh0pfdBvqcSvpcDP1UmsSBmjG2z8n43QXEM6nuQlodOurjHLm24Qsl5qcn0E+2V7o3J9hcoWNivnUYQ9eOivJTqkOAUIn53urZdqZPxH3OjfZbbuWam0Wk3RKSV6R/mwhat3ClMsJghPRTPz6nlTwywcsJYyVrAbR5Et9VEqC2YUlVyH5urM57K8VNLY79s8zW+Qg1ekaUK9tQ6UuFxwr5oo3Ig9warOfN6Pcn6HdOYv86xsJV77IyePV0D/9pWb5wi4dEVmDi1Mr8HZmbrFnrGSPltbOhgzbBU5dQz4J8chbbsmeThDRkRZTKa73lfAqt1h7r2G9NTEzeTdZXoG+ondrMJjp6eVmcRJTZdW2S5ZMgV7JBrvR8ZI70qSz+exncjZnp+0Sch4KM3f6AxL0YnuWFlMR44TXd0z8V2+a3XW53o5W8HU3JagScX6XIHbbRFFZYieNqF5dY54Zai1pOdbiS9LCGzS78h5xvxg3seY6p4hiZhsoCAGy04Nzvw3U8SX4xiNSrwNAoxDbR7CpaRzeBHhC2e4n+y0tvRRc7x46uDZ38T35898ZIXF4geCCM7fZKbOUyNg+J169JdD2f0cR2oKl5siOjJFpawC1IQ26cx41Un1gtRZSb0/UZw6sIFhxD44QPh3HdyTG+u2aBvM1N8ESbXmCgDwBli1un360NipFimtDnnRfzTewMkjjvxtbGS6r0WIVnM0x+X2guRdgt23Gv7V9HhO0+ph6MYtvS0IKNIp7zs5XwEaMna3MfNjfRf7d4x1vdRNO/9vj9inivLbS2CPY58J7rNTlgq1jgWsq5G9oU7wRaJdhcIXPOynCPLVqm2xhaWxWklsICvMjj+1uT/01N2b0qZS8D9eIs3jYVYqTdMtYaD4V2HiWFx1DK+9j7c/NvnrOzBHYDlobcHq1olSCuJQLS0QQLR7uPpE2065M1dE+qaBzLdpl6tZgD95lxHLUpOM7Y2bG9koxxOSFesUnxu5b3LuwJMPMsgLht/UqGqndCpLcnGR9oc87dEvJ7O5rHhq1uxqfdjDfdoHE80+0UbRXv17ptVc+mVbDqfquT+06m/2p/2RvCsOeQiYnJX423WkDjr40D6agN/+U4o9v9DbVsdYp34kzecuI786dnuutOn7Hkhk0IIv27l5otSLslZve3OeY9cW3utJ3YJhGw+Zn8UUY83FBz96VK+uIkqT2jHUqoLVHStI7rL6HPsmKp/d/KKx31YYrp82EmX3hJ3B5H3qwjbRxj+KO9yKeCBA/IXUt5rQWL003gSz/hH0ViDe9SX1SInYygnki8wfwCNqRPnfguxkkPhHE3xI1rj+JM/mQjcLWTQvJPwiYT/qXXpXol3KCdl9RuibZ2bPtavT46s6RpaJ0sbRvbZPMGQMC2HiXSakratcVI1u53kNYJNst018WsYQytrQrSQFu1hr21YkmUZGSDpdPEwXHGWyauba9Msa/Jrfsdoes3UOsVJZQ9slZznTW9dwviWpIpt8HicCG3zfP0fxmdQkH9/9m7/9A2rv3/8898N59FWdJFhlyQllzoXFKoQguRaSESzR+W8YUo5EJkUohEC6nSQmu30MgJfGo1fEiVFlIphdZuoY1aaJECDVbghihwQxT45iJlv+1agRSruw1VoAEJrhcP35qNdjeQ/UOyLcv6aTtttZ/XA0pjSTOa0Zw5M+9z3ucM3B2gZNJ6TigR+cPrq1BmbVrY42TFey5P4qMwY65j5BYd1Vl5fy2SufUAx8EA4Tvp1o+v60dtJzf8HezwMpVPMH06gntbmuIuFx5jWzXdDwf+NyLMXfU1LxFbrXhGMsReHCXW5iuWe2Z61WYisz+U+TTjzwbJPD/K2OvXKew3aj0RFhxHz/Pz/hzJL+IEXQfgjVmybz+mkHqHl6k7KaZPRfAYaQp1w1Jsz3gJHE9TOLqROTM6c7yZZm5HhIn9Bgd+2IZrxGBbbXzitr1BxpJ5Qq16cZppMinj5mgx3KAbHbOkfkNbrRgjJsnja4dvrLKmV3ZzWawePDdjjL7YriZYmrW7u/rPcfg64e1Weuiu/d2EXdWniLR0usXrG61DN7EsdtwHIstDA6oTAm7K1z4+OzyEMwuPKRtpre7OAR/Rf/T6SNIm/kh1UE2n1Hdo9aSAx/u9vmbPsP9NWfF+XGThfUubRlUR6QdbHj169KjdByqmSWUTey4qpgmb0Su6WRP2dLueRRPzIWzoZrvO5v2uG5h46neY9Ggj+10xa+N02/bo/Q7W/TtuZNKwTZpwbIPWfT7XJtrrefs3q8zWTfS3Wb/hun+LP8TkYxvwR9j+RROT36deWPdx36Rt3uxrtHSyyXXves+f37HM1/s9yt+m3Uduwnb89ufeesvfH+OeQUQej44BvYiIiIiIiIj88fyX33sDRERERERERKR3CuhFRERERERE+pACehEREREREZE+pIBeREREREREpA8poBcRERERERHpQwroRURERERERPqQAnoRERERERGRPqSAXkRERERERKQPKaAXERERERER6UMK6EVERERERET6kAJ6ERERERERkT6kgF5ERERERESkDymgFxEREREREelDCuhFRERERERE+pACehEREREREZE+pIBeREREREREpA8poBcRERERERHpQ48hoK9gmiaVZu+YJpWHm/QtponZ7Ese47Kbtv0PK5jr3fjN9EfZjsX1HsvWZW1d27C4vkU3UhYb17Pe8rWZ2/Bbn1dLy67/3FpnOd7AMf9D+r32ZyP1yB+iDlpvPbKJ9Y+IiIjIOm1+QH8/RXAgSOp+4xs5YgMDxL7fjC8pk3ptgOClcstP5N7bwpb3cutatsUau9v+iolpNvuv7rbv+xgDAzGabV1tJZRvp0l+EiP24dJ/0ySv5ilv5t1jp+1YLJK/kSK+tA1fpcjcLm/CDWye6b8OM137LXMfNR6PIukPY6Tv1i9Tofx9hvz9um9vWdZ6l/togIGPWh+RzS9Pa76hq/JVWWz26/e4DZUy+RvNytJG9mUjy66jbiinmfjrBOkytXLQ7nxq8a0djvmK1eW1Zw/L5C7EGH9xmGHPbuxbtmB/dpjhv44y/mGS3EaLTk3r/SmTPj7MxOUNfFHLMkMX9VkbXS5bvFxfF7b6L01xPduw3npkE+sfERERkfXaWv9H+fIEgU/yqz7gez+BkQwQ+6H+VSehr6N4bVANtLLM/Vp7a34OE5O5XIbMjtpr9kE8T3ezOUXSH6YotHzfivvVIC5rN+vqhUnuqzjZ+SZvPe0jdNDoek3lS0Hsp0p4jG0rL/5aJHMrSPbRJK5OK7iXZuKVICnLKP7DHjzP1HbWLJK5HCb8SgXf5+eJtt2mMskX7QQurn3H9/XPzLzUaX9M8p8EGX2/gOOQD+8+N05bheL3s6TemWD4JydTFxOM7bG0XkWlTD43x0LDywNPuXHurGBey8Dp1tufPzkB+0J4d61sU+bsMDMjc8QP22svPei4Hy2Pa43jUP13PCb3k4z+OUCqyVu+ZImZI7b2yy8WSJ6eILwcsBh4T0SInvLj2L6O7ZnPEPHMMPrLDP6d3SzQujyBjch3JSafa7VsjjNb3ISbvudnppTA12L3K/fzZH9qLEF2BoccWB+aFK8VMVv06pu34sRvmk3eceA74aX7MxqgU3ltYzHHmREfGVeEyNkZHDusWLdT7ZleLFG4NE3YOYXnUobJva3Pp43uj3k/Q3Ejvfc9l5mq4qUJxk9WG+eM/SEi5yL4n25Tb7Qw8JQTZ7uy/mOS4TcquFf9FmXSxwNkhhJED3Y4xxqV00y8HCPf5C3nm+tYn4iIiMhjsiqgZ7FIZrufuS9HqYVMWLZXSJ3NYD1cF0gBluWgukLxTp78ctA0gPesF+7lyd+rvfS00WVAP4DxnBPLj0mGL9mY+XcPVqBwYZiUbYbJIQOj5b3g6uCtmANIEPswW31hh5vgURfN2wIsGM86efDr6lcLF4aJPPQQOtjNttd5Ocb1d+tC91tn2NIxkq/uQ/rsATIvZJk77aJxVz2HgoT9Ydz7YqQXpvC2bNiw4f/2Ef5Vr+WJOQdJXIsTKw9UXypmAffarbgcxvulQfzODN4ddW8M+eBEhNCFAO79Exh3pla/v2olsyQ+WH1DXLqTwXGuxMyRlj/AKsV8hsxyzG4yZ0Lqtd2kXqv/lI/RlmuoHddihjMvlvFl/DgA88YZRss+rh9xYG/5G26kPDXY6Wfmkb/hxRzhLT62PdUpMCiTesNDeGuEmX9dwbkDmM+TPD2G5w0L+a99PP7Qoll5gmqwHsVouwEuJh89YrLx5ftJRv9cxN5mWTOf4Ex9A+OvRTL3gsyWJnF22GLLzkGczzU0BvyYZPh0Bc8Jb4elN9EPGcK3xsnmgqsb87ZasFoNXEejRIpbcF/LM7m3dSXxu+9PY8NJpW54xcIDYBuNKtcmcL9RInK1ROJJKF4M4R0KYvkuga+HRgEA69Oe9teQbc37+NfdkPHQpHjNiv9OnNHGbbVseouyiIiIyLptXfvKNgas1rpApZamuX0Aq7XZjYwV19FQ9WZ1vkDuZpbs3Qr2Z9x4hpzYLA3racuKY8iDY1sObhi4hzzYgG3/hMwuN56hdpHD6qDc8hOAA+dzjuoLTxhrAuT6ZW3PeRoCI5PKRfDssrdYZqPCuLeEAR+J5V6vCuY8GC5by2217NyNwUx1rGwv95U/Zknf9uL2D3T8aOH2NGVftmWwbhwZZ9zvJn+3TUBv8xL9R32gUSTp+wtFwwZdJsaW7uTJL9+ML1D8V0OP9v0ko3+eabOG2nG1lZlmG4NDHlxAuTwN/zaIZ6hdK8tGylNnlVsZ0rYg0Wc6fPB2gsg3o0z9GlzpodzhxH82wuy2CRLHfYT29Pjl94tkSWEUKvh3rt0Ls5Alc8Nay6xpU8jMBUrQY293zXypYymwHYxyva4xrXJtgm2f2bCYJmaH7AzLTieehkDMXEzBiIP1ntHZr2PEbrb5QLNsnl1OxmxBpj7xYDvqwqjvZX5Yofh9nKkvbIx97mj73ZuyP4sLmGa7UmvBam3+fuWnWVJkGbwP7KxlIvnrc04iDUsUSXwU48CnCwT3VMuQ89U4iZ8MJi7k8Z3o1CSzel3LmVv/KpC+3aTklOaA8R7W2Z1tVitNL3siIiIifxBrA/p1qtw6g+dQht2v+vEO2Vm4GsH9iknw0pVVqaRLva7V1OuNhESNVgfl2/4J0Cloa6MyS/aSk8HXHlf/5yRXFiZwU9/hY8NzJEj4jXHCW8ME9zsxlm6wKybF2zNMvxMm/2aceE89XEWS70d4cC7N1Nt1N9K3Kkx8tvbTtp1e+DxD7m0XriZpruaNK8wQJNxLqnqlyOwlH4Pnul/E/XKI0N6lv8okvztD9OoUsfu1RomF2fWNme3KJpenVYokToexn/4ZT8MpEH97mMwTdWm9lQp57Aw0HgfLNgbIU+l5QgOT9NdTuF/yk/gowdhIcE1AvnBvlvz3A7XMmtXRTP6TYSaIcv1NJyyalLBgqatFirXjY90XJLi3ftmG9OdKhbyNVY0iSwFzq2EQhR8y2H7KM/5iEh6WmMPRJjujUYXZ3AxOZ3AdGQ02nGejddtaJHNyGl6P4unUmrHDy9SdNMnPpjk2EiBzq67E7nLh2XeA4OUC/ud6jRp72x/rTg/mxXFGmw6bqHkmROKct8n6yqS+iOHd7yV8Lon/Wz/GkRkeLWXaNMtAup8jfXWMYLJ+vyy4RwLkP5yleMLZQ0OQncEhJ5ZfAZx43hjEaPy5chEGvjB+g2wVERERkT+WTQroiyROhRn88gFT+2u3vUM+PM+O8pdP0wT3rqQFL/W6WrcNbnJAX69S61l9QAWwYFK4MUsJWErd7riGm2nitgDpht7P5TTwdr2Xv8ySuVHXg/hjkbX9mI2ZEFW2Q+eZfTZN4lyUwKkUueWJ4Qxch70ETmSZ3W903zm/WCD+1gHCxMi+VCH+YYzl3W+Rcm8cneLKnWP4nFlGXwvgfa6WMVApk78UJ3oZAn8/j69V73wTlVyGxIiXsSdXXlv6LQu/AE0CuAcLJubyxi7wYJOekNC7jZenZQ+LJF8bJrwjQfbVtSGN/9QMEy5WWnmedjJGmCv/DOF6YeV8qfzzCjOMEelqKMuK4oUxgvlx0tf8FN5wE3jHTuq0F1tdTWDsHyfUYlx/xcyQWZoWsbxA6ZndHVLuV9SnP5f/VcKx39NDb3mezNclgh9niQxZusjOaLCYJf2VncDVhp7h5XO1Nja/6cIG3hMhVvJNclROTsOqBqc2djjxv3se/7vdb25HPe2PDe+566w3Mb/4TYjQLxHS17x4RgYJvGeQfrfDcJP7RVLYmWj4kOWJAbhWpkwvmR3NMqgatnG+CDYPnfOPNluRK5/GKA3Q83wrIiIiIpthbUD/0xWmPiwxwALF73JwJIKblZ63Jat70UzMf4H1idUBut1m0NiF6O72JnhDCuSvAeUM2dMePJYFit/na5PtVVO328szfSrGgVMLa8bqZr4+Q/EJ4GAUz9Nr00YthpfofZP89/Wjxx1Ezzq67j2y7vIy9qmXsS4/35xJ8WqcibcmyO87T+ZTP8bDbuehNvCeu07xeJ70tQyF72cpFMDhsGPdHyX/cf1Qim6USX12BvfR0qqb+KXGneKaWaItWEc8ZD4aZfSj+tc9eI6OEzq4knKf/aCHoG7dNlqeqswfkkTeCpF6Mkb2S3/TgGbbQEOKr9VL6O9pAvt2M3oixKhrgIXcDLEP83i+vd5mHoXGLy+S/myc4MdWIjdDOLdbcH6a4cFbB3A6XYx/HGNyqMt1LXlujOwd4GFl+ckH7RoD6tkOTjF3EKhUqNTKUru6wbwcJ2qZID20vkbA/BdhYvvDLDQOT7iR4My9bYCP6JCj4XxvNalikSxA0xT8pYk7200k2Er98Jv2ut0f48cMs6VetgHsz3pw7ADMIqlzxxj7wkYsN4lzOzgvX2fhRR+OGweInJ0i+FyL47GVzekt/36a4XeaTSe52oNiBigx+tcYHKxlkIiIiIj8J7AqoLcYXqJ+Eyx2HM84ce4LsPuZAYpmlECbmcLBie+kH/eJcYz3xzjgtFC6kSJyMoH//YnfPA2yci1B1DnFFONMXxrHc6S+h62aut06DKyQe2+MiYHz/HxobbQU/Og6k20aJKx7g20aLKoBwtxTQRYWGnrn76aJXWo9v39TLXqEzMsTeI/HKD81RujzEjPLcw+4CJ6on6yvecr9EstOJ76jG78xLl6o9fAdWl0SlgK4XGWC6Kp3nIz943rnBo0dHsIZB/YeMgXWY2PlCco3pol8GGP6Jweh0xnmjjh6Gn9vHJwiW8qTupqheLcEjgAzpRmcPZxYlR/ixPIeEvkQnqXltjsIfjnHgRsZSs/baDXPRe7DYcLXqv9+UAQIMXxzG5TmyPxQxvaMh/BXiSa9o0WSrx0jXpscs3QHFgoBhr+qBmC5u2DsDTF1qUPi/Hya8GszBL4uYr0cI/YjPQ23qNw6w9jxAc7/5Fvbq9w4geUqzSfLBCfOjK/FMgO1iTtbTSS4cb3sT/GnPPkfe1z/n6sBffHyBBM/eleXmR0eIv8oMHo5A+1mq9/pwEOGBZNVc32Y/yrBIXf314Q9QWa+DfS2A1t/y0HvBgfeCPU087+IiIjIZloV0K8NRuvGvR5tfwtmHEmQN5Ikvg4T+MDE2OMjcKmA75nfeEahxRyRkxnGP8syZqmQ2B8i6Urgf7LzomCS+2AU36cGidzascXdKl6OkWIp2K5/rJ9J5sIEub0Gxv9b/V2We8OsBs5WvV2t2JsnmFqHxojfiOBYHtJQwbxXYLa4NEv2AIbTgbHLx/UMLE/H1ebxai0dTlD61t/yBt28FibgLzL+XRxnr52rXW1P972a67Kh8lRlHRjA+eYVFkYcWNc7yMW2scYVywsRrr/Q9B1sQ0vjpi0Y+6N4Gx4l4Tg4ufJYuoHzDD45sLzsyiRqZZJr1m3H89oktlpAvM2ewLGU2rG19vg2AHJNHw8GVB/7dvAAs29kyYxYqPxYe3zZ/ALpNg+4XGL+8wyjh6cwklmCPT+esJbq/bCCudjFZAWr9qmmy4a6tXMONNfr/hgHQ70/pWNp2Zdm+Pmlhhdrs9sbQx54WB2AQmM9AmBz4tk/SvxqGO9yxoZJ5tI03oOh7uvWrdUytrpObeJumtglenokYcUsU9lq62luUREREZE/mo7hRS+P/bE94yV41k9oPc/GBpgvkLlTqo45/2mulvpffWRY8aco45fyFPAz9e2BFhubJ/ayj4wvRWavBQiROBfAPXKMB5eiBNs1LszniL0RYOIXL1dyU3h7CNgalW9PMIF7OaCvf6zfwEgUL0Xy31f/XuoNY4cDz5ADFk1MmgQGvdhuLD+fvHh5gvHjMQo7fHhH3BhPwEIxS+a1FOWnIpz/enLlhnanj/jCAvHG9eWiDHhZnsRvNUuLG2KTwlcTHHinSDCXYbLXxgpo8bi3Op3GUVfK5HNzLMzPYZIn8WGMLLBwpwjzCSZeCZO/7yL0baT52NuNlKc6lj1+gnsaJpRbj4bAcuHeLMUFk21/XntU2infmCbyWYL0xdxKL7fNgWd/gLHjY2v2a+mRYZX7ebLlbVis1i4zDFbGPps/ZpjF0uJJGc2ZPyQJvxpgdug66Xerj3G0LD2+7H6Z6bYBvUnuwyCBkyW8f88ytZGxzd/HGHCFO3/udJZHjb39T3oIvtru+JSYeWU36Z0Bgm2HIm1wfx6WyXwTJfl5inj9xHwYuI4GGX9jrO3EfOb3ccKnzjCdt+B5tjbzwa9FMvcs+N+IEH67MVvAIHAqQvxQgLBlinEXzH41wVghQurj3o/F6jq1ifk8EydpeA591fJwsaUZ8h+WmLtRoIxB6B9zRFs+YMBkLpch/bBA4X7tvKut48FIlGyXj98UEREReZw2bZZ7gNxHA7hpclMLLM0UTbv06K0mxe/zmDiILsVxOwx8J67jAwaMMIbVghVzbY/e/RTHhkaZ23+FxLsrz3A3jiTIWiY49moU42oET5N71sqtMwy6prC/HWPuS/9yMLw5ao/1WyyQ+ijG9M3qBHme10OEDq1NvW7/G/boh2kCfysSuLPAlVVBWggwyX8UYPDlOD+nl7IRWjy2aqD6jOlmk/i1Yv4zyvg3Nqby5/Gue8xF3eOqmumUdm15QOn7PAUG8J711F6z4z4a5Tqwzb6bsM2CxcqmlqdWVk0ot4YDX+Z6w+SAec7YBwk3ZMLbnvGw2w7sdOJ1OHA/2/02lC8GcJ4bIPJRgmjSWJmhvmJSuDHNxIiXwuXmDTDmzQjDl0ZbZGQ0791fUrg4zHAvdcPDIulzCSxvzZHpcYgClRxnnncz9acQsUICf7vU8G7sneTRo8nlBqTR5YyQ6jj5mUN1j1Js9NCkmJ9jofm7gNm5wXTD+2OSfstJcDFM6sIc55+sW7726LzwQQfZzwtMHWxSoG/H8D4/gyed5dH+hv2sFEmdDOA5aaHwqXdV/WDZO0n6ooWJEwew3wLX0TFSl0NNn5zRlVNutpxq94HGR+dZ8Zy8vpwhAk6c+wcwnAYD9dkUa+bwALYbeM96Me/lV+qfHQbO55w4/QaDuwwwexwiJSIiIvIYLAf0+U+Gmbi89gP1414b+d6/zthza19vrjruuC1rwxjvXuz0Eb1Rwrpz7Y21cSjK9UOtF7XsHePKT2MYux5X8mWFzPseEn9OM5N2YjEzxA56iFiL1Rm7HxOzWCB3aJRE055kK879XlzHe51xujvWFyJcz2x0LWXyJ9M8+HYST9OGICfOkQF2t2wkapydvAcbKE/rY8Ux5Gl4zclk6RGTHZctdzmevEzmYhL3Gz8T3NtwxC1WHPsnCb8axn01z+RzvZ6HtYarHpeqalI3bDXwf3llfWPQLS7GLv3M2K4engbxuMxniHgS2M96Wp5jAyOtG0KATdifAvnPyoznxnA1Zh5ttWDsHWP8jXHctwtMHVx7BMuFLLnD46Qag3kAi4HPf4BRV57Cp941x9/6QojzuRDn17XdDZplQCxp9ui8LmbHb6mba1HTp1tUyH/gYfDLwWqm12Oe30NERERkOaA3RiaZfKbZR1qHE/ZmaekPFjDNds/xatELvAmaBV9dLonR8/jaDh6UKNzKUCwWKFgHMe6Xse+rjaHeMYjDUSazWBuDumbZTr8hXaU9W11exl4LEv7EIPaqa9XM9JX7GWInIxRPJNbM5P/HYmW3y4Pnd5h0av3lqY3f8fwAG859LgKfxkkPhfE2PDbSvB1n6gsbY1+2zEGGhw9YMM02Za/N9v+G+27d9Ud6fJibwIn1NnZUbWx/DBwv2Ygmk3h3+XDuqP+NK5i3E0x9asPfNLF/KgAAIABJREFUIhXe5nDj8k8xdcnJxMHV80BU5vMkPp3C9nqcNqXmP5EKpVIR7g5QMmmfkSYiIiKyCZZvzZbGyW6ExerBczPG6IuxNp/yEf3H2B88iNyY6u8wzfhdB67nnQw6HXiPT5E4vBu3YbCtVKTkmuFKk/TW7n5DJ6Gvo51T2Xd4mbqTYvpUBI+RplCXum17xkvgeJrCUWdv6cyboll6eSspAn/eQtt5rtv13P2B/BHOD8ebaeZ2RJjYb3Dgh224Rgy21cYUb9sbZCyZJzTUoh94u4FnMcn4i2unv1vRfPu72vdnQiTOebvrUa1/wkHbJ3BsXPnCKHb/ytSMqcbyeNHOFj9tJogM497SaQx+hOyjyQ0F/a3Z8H2Zx/pZhPBQiPQPZYy9HmzzGXJ3bTgOjjKWzDM21OKX3xMifcdg+v1RHL4CPONht/0BxWs5iru8jL2VIP+65/FnQ/Sccv97sOL9uMjC+5aNzYMiIiIi0qUtjx49evR7b8R6VEyTisXKejr01rtsxTRhu3Vl3PE6VEyTSrPZsH8LtRmqu5/UrOZhBXORx9dzvGhibl3fsdzUbVjnZIQbKYubZV3bUCsPsI4y8YdSwTTXUT43YwLKP5Ju92d5csX1ZURUTLM6E8RmlPnHXbd0pYJpVtZxDqx3OREREZHN07cBvYiIiIiIiMh/Zv/l994AEREREREREemdAnoRERERERGRPqSAXkRERERERKQPKaAXERERERER6UMK6EVERERERET6kAJ6ERERERERkT6kgF5ERERERESkDymgFxEREREREelDCuhFRERERERE+pACehEREREREZE+pIBeREREREREpA8poBcRERERERHpQwroRURERERERPqQAnoRERERERGRPqSAXkRERERERKQPKaAXERERERER6UMK6EVERERERET6kAJ6ERERERERkT6kgF5ERERERESkDymgFxEREREREelDCuhFRERERERE+pACehEREREREZE+pIBeREREREREpA8poBcRERERERHpQwroRURERERERPqQAnoRERERERGRPqSAXkRERERERKQPKaAXERERERER6UMK6EVERERERET6kAJ6ERERERERkT6kgF5ERERERESkDymgFxEREREREelDCuhFRERERERE+pACehEREREREZE+pIBeREREREREpA8poBcRERERERHpQwroRURERERERPqQAnoRERERERGRPqSAXkRERERERKQPKaAXERERERER6UMK6EVERERERET6kAJ6ERERERERkT6kgF5ERERERESkDymgFxEREREREelDCuhFRERERERE+pACehEREREREZE+pIBeREREREREpA8poBcRERERERHpQwroRURERERERPqQAnoRERERERGRPqSAXkRERERERKQPKaAXERERERER6UMK6EVERERERET6kAJ6ERERERERkT6kgF5ERERERESkDymgFxEREREREelDCuhFRERERERE+pACehEREREREZE+pIBeREREREREpA8poBcRERERERHpQwroRURERERERPqQAnoRERERERGRPqSAXkRERERERKQPKaAXERERERER6UMK6EVERERERET6kAJ6ERERERERkT6kgF5ERERERESkDymgFxEREREREelDCuhFRERERERE+pACehEREREREZE+pIBeREREREREpA8poBcRERERERHpQwroRURERERERPqQAnoRERERERGRPqSAXkRERERERKQPKaAXERERERER6UMK6EVERERERET6kAJ6ERERERERkT6kgF5ERERERESkDymgFxEREREREelDCuhFRERERERE+pACehEREREREZE+pIBeREREREREpA8poBcRERERERHpQwroRURERERERPrQ//Af//Ef/9HbIhVMcxEsFrY2e/thBfO/P8RiafJuu/d6/K6KafJwq4Wt62iSqJgmi1joejM24TtX6fl3eEw6bceiifn/WLD8jz2+9xta77FcWnZdx/MPsO/mjxmyd4qY/2bH/j/3svMVyt//V/7b/16k8oTBn/6nDWzEfIHM/3qH4v+5Dfv/sr15ffCYVe7n+a//W4Hi/z2AscPS48Jl8jf/G4V7FQaMP9Hj0is28jv8XsuyUoZ6KwcmhRtZ7mz0N+vVoon5f1WoVNj8evMPUI5bWd8x2mQdfp+lc3BNXbSJv2vL7+gbG6l3N7HO7ln1HqxSAQvz1fryD3iedGfpdzTZZrezvYcdWP/1tqZWf7HVwuL/0d05/TjP/Zb787CC+d8XH089u3S93Yzys4Fr9/rrkg2ch+ve3vWXWfnPZ8ujR48eNXujYpqw3bo2ULqfZPTPM4z+MoN/Z5MFb51hiwuyjyZx9fJeMy2/K8eZLW7IPWJybzcrqlcm+aKdmUMlZo7Y1r5dMTErABas1vrTrsvvXF5+LYvVWj2RO/4OFcq3M2RuFigtr8uC/Rk3niEntp7uoiuYZmXlu+t12I7ce1twk+XRu2vfbffexpkUbsxSanh14Ck3zp0WypcnCNwLcP1Ne/tj2UT+k2ESTyaIHoTki3aKx3svQy33/W6a2M0BgkddWHtb5RrlW0lmUhlStxdw7PXifXkU766Vtebe24L7FPiSK/tu3ooTv2k2WZsD3wkvRnXNJF+0E7gIkZZluUL5+yxzvw6w27VU3paOSd1rt86wxRWGwwlK3/ppeQSWPkek+3Mf2p5LbLVi3Q7lC6PY/Sk43aIsPqxQvptnrvSAbfZBnE/XnQf3k4z+OUCqy+1a+n2t+4IE99Yd4Va/w8MK5mKrHajVB49j2TaWyk0k9wjPtZV/d38OVOvBcDe/2Tq2r575z2nCHydIX8xRbHjP2OvD6x8j/LoHW5ubnMr9PNmfFpq80305rtzPkbo0Q+ZyfmU7djrxjYwyesjVY33cZBvnC+TvVLA5HRjW1SurP171x6j1fjV4Yjfu52wdbyAr9/Jkiwuwzc7gHgerNqPD77N0DtbXRd0s14uW31FOM/FyjHw3K3kmROKct/V2fD/N8DupLlbkI/qPMZxN3jF/zDBbWrlW1W1ox3p3uf5+2kfooNHTskufSx8PEPuh0/Y7CX0dxdvNAVmqIw8nKJ2DsaV/1x3PzSyLFdOkda1Xx2KtK6Mmua/iZOcbPrPDTfCoi8J7W3Cf8pH4ZRqO2wlc9JFocv9aMYsU8kUWGMB43omxfeW9ZtfblvtwL08BB84nV/Z0PfVuq3O/a3fTxC4Vln+H+nuSlvuz0XP2YYXiD1nKlt04d9lWxw/1ZanVupe2ecnTPnykSP248pLjUAivpf21u3IvT7ZsWVuX0aIuafzeRk/7CB3c1uV52ESP9xp1W1v7zuZlVqRei1uhHLGBbgPmhsq0mAUg8WGM6r+suF8N4uoqwmkI5ObnMDGZy2XI7Ki99sRu3M+1WHz5pFnLeW6W2bebXYJrFgskT40T+miOgaHdUMiw4AgR/zKK98lutr2qfC1C4JOG24tfi2RuuZgpJfB1qiHvpZl4JUjKMor/sAfPM7UfziySuRwm/EoF3+fnia664LdxP0WwXQNMPTNH/IssSyFhMQeQIPZh9Ug2uzC0/+7Wx2OVNRV8gZRnmPheD8YTKx9zvpnAudMGi0UyLSM9YD5H7K0g0QsVBk9EiJ7y46hdnCtmhuJi500vXxjFfmm0t4vafJ6JqwaBoxtp5DDJvONl+IPc8iuZaymm3wvjT2ZJHGl93CvFNBMnm/3aEdxvDmLm5ljAZK5ZzN+4DWeHGy4i1WMSpvcLS+XXpZu9EgsmdFuAypeC1WC9iY7nM1C5PU3g8Dipuyuv2YZCTH8ZxdfDOb28vtrv60sGCHZzMf8+xoAr3OLN2u/4GJYtXo6tugGqqjbqtNcuIOghCNgE5uVxHH+bpmzzEHz3PN4hY7nYmPcyZC4mmX5rmJnCFQqfelsWKfNmhOGmZaibclwh/9Eo3uNpygC7XHiMbcADil/FGP8qxrjNS/TqDKE964nqi6SPHyP4Uaa6fmx43k0wc9rT8RRpvV8NOt2YL+aZfmWU8Yt1TSY2D6G215iGclKaAyD7foDhr2qvPRMi8WLnzYO6RrkmOgZQD02K1zJkuvkia7D9+w9NMte6WZOnZdBZuDjMcJeBX6Pl+vu0uyGg7555P0PmWqdPWQk+XPmrfHli7T0LAD6iXw50/s7NKouUSb1WDZg6Wf37VihenWCicbnDiS6vxY3nIYCB7+MZ4m86e2icL5J6ZZjRr6rnku2lBNmv/XR3JJcaStcKu7asfr1V43Wj+TwTJ8M9/A4bs+Z6uyvI+ctTBJ/uoW5c2uYlp924mWDi1MpLkX0hvK3q7cU8Mb+Xicu1I9mxLmvxvY3anJMtGxs7WmmoW0sBvPRuExI4LBjPOnnwa+3P55xcP1z//gBG1+fzAsXv86y0kw3gPeuFe3ny92ov7djGYKuAfqefmUdrb3Nz720harO3+V6T9EkPocUY2Qf+2vaaFL4Yw3PoDKncJK4u98F2MMr1g6tfq1ybYNtJO0bHc90kffYAmReyzJ12rWnJ9hwKEvaHce+LkV6YwrvRbuBGFoPB5x6wFH45n7uOr/79J4x1pNi2r5iqgXPz94IfXV9Hy3SR+MtuZvZcIVuykznpxXPaRvGs57dLD96Ayo0ogQ9ysDfC9cuTeHZA5W6S4L4ASf84nuevENzVfFnboTgLC/G6V7JEBw5wBmA+Q8TTReNKgwemibkdYIEHAKQI/HkLga7XUCT1Raz272mmL4bwvtrdLY51X5jrmbFVrxW+GWb8K3DsbHc+U23I2j9OqmzgOx0h+IKF4oVpIl/EGD00QDbXSyt5bU/uVn+9YrkE3TTz7PJxPdP4LSaZD0Y50+mmewPLlm+vvgGqiuDuGNA384DitRxFnExudn3TRvGHGcqA650pzr/paHjXg89lp3B1nMxneQqfelseyzVlaD7DmRfPkOmmHN+eJng8TXnPGDMXo/h21dcgFYrfBHG/nGTi6DSefKhpj23bffxinAMfZbANBZncb6OcOkP8vWGCjs43hmvP9Qb3Zwg+e6zD+W6SPull/GIZ43CU6OtOLPfSxN6JEftbAHs+S2hPFzti343HvruLD3aw3GCyor6XtKmGa37xq1H+8srSXvs4X5wh2G3j3d5JHj2abP3+cg+j0WWQRl2W0QIPHrb/aOledtXfKxlXC8z+1O0XQutrbuugEYCHJeZuFCjbHHie7VC/1tmcsljPw+S31WtfI/PGGUbfa9Xosnq/K6ZJxTRZeNDuuyrkPwhw4KMctqEgU2/6MSo54qfCpN4ahB3dB2nFr8YZ/aqIcTiEjxSxbwKMuxwkjhgdtgHAhvNslOjy3yWyX1YbZh2HQwSfrzseT3e3PeVf5la/UNcLXcw1WWAjFjOEl663J8ZwP8wQ/SjOsSMGu3u4f15W1/iTe6/6UiT3iMk9ZfK5DJncHGv7Jar12cTlMsbhEGNPm6S/iBP72ziOn1rfNwHwXIiFhep1onQxyO7XUnBwitmvA9VzfasV6pp7NpvR0HkFBlal10uPmheZ+0VmAePXCmBZnYr2sMQcDkaXP2zB9pwHG1C+ESf6TZL8fTD2BQm+6sdlq6Y5By4DvxaBdq3kBt4TIbwA8wVy3+WZ/eEB9ucGcbvqU817qY1MFkpAu5PZzJL+bDeRn/x1jQ9WHK9OMPHpIJnbk7jWk/JU+/70hRhO/2zDDV+c0F8zbFvV81XBnAfD1TotzbJzNwYzmIt019N5v0gKE2+tS2FVa3zj8bDYcA7Z4GGZzDdRkhfyFDHwHA0SPOzCtjXP9F+rQeGDIvByDz/DRi2nbdecnmj+udsppktR4ulqinnw3DS5PyVJn/Tga3KD8EdTuBWnDPjeCi7f0Fh2+Rl/NUDyvTTleVqW5cp8kdlVqY/FlUvQDg/hzHXGug0oAUhx7NkUx1a9ZsMxtBv7VmqZJ43J0HUeFkkdDxC4CLaXgniuxUm+NsyxrVeIHnV0LL6WnU48q25K8+SPA3jxOBtuah4sYJrmcipm8eo0yTJ4Pr3CzOu1gHDIi2HZxoFPwszcDOFqjBPbKjJXq3by12Ypvu1ce1N/MYB9S2ClB2WHA89Q45cUKX7QxddtYFnXu4949G7tj3KKgH2U5NMLzN3IUPml3ZI2vOeusyrsN9OMDxxgeo+dgfW2iC39Li2tTUN0Horg/fgY6bd285ekB6fThdsYgF+LZG/Nkr+Wo4gNz1lv20C6sQyZl5JkANvBEBP7ajfJxQwTn6XXLFsuZKup3L5AQzAPYMF4aZzgy0nO3M5SuB/C2UtvSiVD/FQaCDL97flq3XR4NwtGgNTxOLkjvTc49ex+mvhnZdgTZebbpQYJD26ryYAvTvRqntCeZr9uXTkp50ldzVCcB3YYePb7WD41b3WVCL/i5RjX1zOE62GF8t0MidMTRC8UYG+EK6cg4g1zzPgL6bNTRF7y4OhpbMTSsCOwP+vBsQMoF8m2XaZ2rwGk8nNUjtgw22QZrVZk9mattk5lyb/rwt4y42pzLXdCLDVY7AuTWOpJv5987N+/lpXdLk9D3V9VLk93uY5qlmmbPteqSpbEOzlgjPjfp/BuB/DgdVoZdoyT+uoKxSMdMjsAKJK5kAbbJOe/juDBi+XmMGfeGGTgjW62t+7eFyhfDTNTy7Iq/GLB8XGox+yoCnP5WsPHxQzZeT++Tr3Q9W5GCPy1TSNNw/CV4sUYsTI4z84wc8IJjOHe7sb9XpjopWDP2SotteuYuDtD7LMy7D/P9W+D1fs/Jwz44oQv5Ai2q1u2Lg2xNcnkamu/nKGwONZbvb5O6+u8ElmtaUBvfpcha7ORvZYlMuLBsifIzLe1G7L7MwSfXXvzk//IzeC3Hma+ShC2PaBwKUbIeYWJ7xJ4RiaZfAb4MUnmVueNqtw6g+dQht2v+vEODbBwNYLbXyF0dYaxnlMbq0Fy2/k9Fk1KWHGvWbUV65+g8GtXo7qaKn4zxlghQurjxhsjP+FvJ3ADluXIxobnSJDwG+OEt4YJ7neujKmsmBRvzzD9Tpj8m3HiXVYy+Zsz2GwlUjeKBHcZ2EbCzOyrvZmLMrCm0y5PbN8gM0MzxL8OY68UmDkXwnl1gvzXHjz/PokDKFzI9NSssmF1vSflC6PY7zb/WLmQJX9wYuUmf4cTz6FRZn88j++FHr/zpxJLfbH1Y/sWHgDbWizT6UII+N6/zliLLBP7k24gRfF+fS9wkeKPVP9uU47bpj5arBjOQQxKFDv1ei2r7ykpkPSME8dN+OtaL0hjIwtUx37fL5C5HCf+8TTpu2AbipD6dBLnXQfm/gnir+zmyjdBwm8G8bicXd5oV8i9N8bEbbCdCBFobNT44AADH6ykYprz1d4Jq7U+ZdSC3XACeYrzHccdrP72f8aZvlr74+o08X8GiLzQsN1LPVsNg/aWGtGcbyaIHixTvgZgx1p/HGrlpvoZ26YsC8D9QjUd+ccYxzwxevZjnhmAESc9tX8A7HASPbvS57QcOO8fIzpU3xziWJvv8HSQKwUPmatp0tdS5O/mSC+f87vxfTyOd78Xz64e0gbuJRl7Iw64mDgdXel9vlVpGtDbHG5cpMh9OkX8oIPAnrr5FyplMh9FiAPs9fR+0/djnnQZeN230hP5pIfAS5D6JsPc3UlcbRqh2w1H6dpSgPqUnfr+WKu9NtvGw/bXvfLVcXze6YbrgEHw2+ucP1x3fJfqxINRrr/Zax5De8VvRvnLyyu/g3E4SvbTEK4d4L5pIXh0gtTJA6ROAriIfpcl1CrDb5WlYUe1nsEdYJZK1QbSp43m+TnzGVKf1f79TYrMSQ+e5QyR9g2pq+qX21GiF3wkjszw6Ai0T81tptcsqpqlDALzAQ+Whj/ON+sJXW1TyuKmc+DLXMcFFC4MM/5Fi4+ZZm2Ip52B+jrVZuAAMtfK3fXLmgXy14CXBtltAdjN4AjwjRP/vwcYuD2xcnybqJgmZrnAbD5L+ptppq8WYVeQ6GswffIMB+xJvK+PETjoxul0YOxoMr9VvXsppj9Y2vI40c+CeN9duYdaGkPfUrlAptxmTPmq4Ssmhe/SgJPAyNL5bcH1t1Fs7+WXG7c2JUNyp4/4wgLxJlkf5Xx16I3nkGe5sd065GOMONO1RrJOtY95I0rkK8Bmw1ZOEXonietLP4Z6y6UPrC2mizmip2eZuJhg4XCYmC/D5N66CeIWm0UyeTJf55j8JIvv6eorrqMRwt8NEL8Zw3fEg+dpYFs3IWCe6dencH9dJDpS+84hH56nDvCXc2lGv/b1OFFHieJN2H28zVI7XXj3B0hcLuB/feW2tXIrSfxakInkSlX0YMHENFmelKul+TzJ9ycI5RzEL0ziWvPZbQxYrWt6KW2HzjP7bJrEuSiBUylyyzexBq7DXgInsszuN7ob13UvSeTkINM5F/FDYZIjCfxP1k0mM9DkWN7OkLg1yXTOV7uBdxE8HSY/ECfzvg//kAcHsO2f3WzAxjwoFcjdKNVSvSuUfyhhvBRsm+5YvJvC91RdEIGB8QxEPw8zkBuoppq1y9ZYWk8hBbcHKM6Dc0ee+IsTyxePltkJz4VYKIw1eWM1S5tyYxsJMmZLMX3Sy/BPQbxPDVD6bprYRWB/BH83N6P/foWFk+76b8R6P9XdfAar1PeUbKvduGeJvDxMvNZDv8bDPNOH3IRvAzYH/rNTxN6uTVy2J8SVO26m3wkT+SLO+I04thPXuxgOYZL/KIDvVA52jRE/2eTzr05x/YiDgaeqZ4ZjbxAbZ0hdmqGwfwyHFSinSXydB5y4HT3UIveSBA+fIY+LaDJAxj/OmcMHqJybInykLtOgvmer3mKRzLUM1qPA/AILIx48vxrYuzmJN7IskL9RTV0PJn8mun+A7NkBDnSTIQBAhczfpygDY/sGG37zZhlGdUuaJpUdboKv1pXD3EI1cN7jXf06gGlS2W7FsrVhHhWbA+9LkzQdLPDLLJlaxsFyL2oL5q1pgi+Nkyrb8CcT+AqjbHF2OBv2jBH/ssCBV+IccyYbMlVqdgWZuTDWe2NHpVLt/bcP1NXlNuxPAWTaZuKssqZxpMGONsOkdjkZBaYvznDlnr+Wmm6SSc8A4N3Z7hzJE39lmlx9Wvu9JAFXgPhbcfwHI3i62Pxepfx2tvhZzoIx9geJvO7A8vwgnhHvqonorC+EmPlpjPLtNFeuzZKvuAl2Fcw3Zx0JM5vxUTGaTodH+uwYccB70Mvs5WmCx91kv/bX6s8y5c+aLAZUfoyv1C9/H2f2tQBJf4AB4kSOdM5kWrWNOz14Rjp9qkU67/256vXhWpEyBTKe4c493PU2UhY3RZErn8aYM7Pk7prw0Ir/8xkG/9xmEZsTz35IXp1h5nIQ10EbYFK4EGca4PVqQ2ab0LZqsdYw8JS9Vv8vncsGB94IYXzVIaC/MYHdV+sI2OUieHaKyVe9GFYIHvIRfz/C9GcTBD4DCDLzr/OtMw7nM4SPBEhhYywZx/7xAcKnfIxuTRA/0X4S0Y7DTppvPeZ8dV/t9dtkM3ADqXtlTLoapLbiZhi3PUBxZIaZp6ovxd8eJnEvQ2FfgtK5tfeupfvVo2TdXveedaDaWHl7gsEtLbI6odpA+8kYx06mKOIiejWBcc7N6DcB3PczhE9MEtjfqhfnt7DSSLfuSRLl//dWn9pmntjLPjK+FJkXXHDpAB6Xh1Ky04Wl2pNdXErRB2CB0j2w7y81tC5HOm5UpWzH/qfVVb99pwGVdhOhFcjcaZwXHTBzZMtOrH+PEbsJjkPN2q0Ngp/OkBvZzV8uj+EfMqCYIfnZAt6/J1ZVnMnTo+SeoEVvg0nhaprUxSniX5Vxno6SueZbnpCtW9ZdXsY+9dI5NGzjXorxIyEsySy+vQbOcxncrgMUk3Emh9pUrdutDFBkYRFY2u75EkXseOcbJrk73d2mrIzDXmuh6QR1FqwjHjKfjZMDrLuq6baWnc71paH+Gww8OYjzOSuWn1gze/4alQxXvvDiO3SFxLUyviNOxv5xffl4VGe5b2Jr45MR1mGHl6ncDJY3Joh9caY22ZMNx6vnmTnXvjFj2XyR2fzSdlQo/1BgYYcd79kobhaYTZ4hebubFdVPSFmozfBdpnCj3PoGx+Ii+NkMThy4n3OsvXHc4WLs8+uMnSuSv5ljwWgTzFdMCjfiRE5GSf5Qhr1jXLkwhbfZjcyfB/EMrZQOy1CQ6aNJRr8aZ/fF8VUfdZ2eZmwPcL/T/pfJvDfGsVMpioDrdIyxIy582wsE/jZNzL+b7P1Zsvs6rWfJAypb3YS/dYNZZPb78srkWq0aAzay7GKGxLk8EMQ7YmC1Nm/Da+n2NOEPymCbxDfSWPsXyV0r0jjBVlWHdNdaNkWj6o3K0uSLvVnqRV3lYZn85RniX8SqPV4YBL+8wtQRA/OygWekFnK2HDpiwXH0PD8fDJG5liFzM1MNFLDi2OvBPeTBu69JGf8tuQKETqwzOd/qJZT0M+NPcsz4C/ERg22lOTI/lGFvhPDhNrVNZYGFMoCD3Utj1J904n4WkteK1UbvJR3Ldvdsz3jYbaeaBVMbE2wxBmC+SObCdJvJ8QYwLAXiH1L3xI8lzSeDLN2p/j/+9jCZJ1hjOSNmPk/y9BiBT6rpvlMpD7lX3AS+CeC+P0vkbLh5Q8LDAsnjE4Q/Sa/ULwddcKlI0RVm2r+b2fuzZE90O569yZCZHuS/W8pSSZO9PVHt4V6ec6ILGymLq9Q1GjcqzTV5cUme5AfVYR7VcmJS6ZiIZRA4FSGZDxP7m51VOUw2P4mTrSfc3EzW/RFmcyHsTxvYGu4hrLu8hL70Evq8gjlfpHB/AGfTYN4k9+EYwXNJCmWwvRQjdMSL4Uow5wqQfGcY508z5L/0NVk2z/RfJ3qeY6ddtuG6bLUu18vWXX4yzqrrAAAgAElEQVTGnrdjWaxrpNo3hm+/gWXNc0/Aur3dBI5exs5We+4X7iQ48039cKAKuQ99DJ/Kgc1D5OIMoT1W+DLLzI5jjH0UJ/K0j8D+wc3ay3VYGeqosfXSynLRMK+FGX05DkfiJN6tTci2d5JMwcb44QNMWLKcP9TqkmwQOB0hfugAx44H8e16QObCGRJbp0iPOHHsW2Dhc1qkeDdy4j1pYfD1cazvj3HAaaF0I0Xk5Az+98OtbwrKWaY/SK6kh/1aJFNxMekfxHM2iP0ZBzbLALufpPnF6Ukf5wsLFL5PEHONw6ezZB+sfURc+7EuFsx7s1hHYmQ/bfM4ox1OomcbWiw7PTajmTWPtwGoUPgqyIFXcjg/Ti/Pim4cSVDYcYbAaz5iF9qkHe4KEDkdx/e3Y0y86sOoZEi8n4CP03j2OHAvLBCHak9fp+3basUYMUkeH2VpJF7pToaFHbWbsprlmfyXrQ6gG1X2hbnuNAALnpPXcdjq+rie9JG6V4blW7YyxTvgesuH54VqZkGnm5PixWnO7A9SesuDd3+UzMEonnaNMr08OmlJu0coPekjmvYRXTQxH9LwiJ4q254o0bNgbTbj5BfjDDemGJ7O8uhdP1Am+V23AX2GMy9mqpPqLaubeGhNyn1t3OkDKxZKzN7s0HRisUEpQ3574yOeAIrEfX/h2FWoji9MrHpaQWcGvi9nmTsYZ/pCmoIJWB34Xg8z1q5BaxUb7r0GD2weQuemiBxxYAGMg1NkSz6mzxVwv+mE22vTtZs94SHl/8vqkRq2CLPNJoTcyLLLiiTfCBArg+vcGMaFYYYv17JLurGY48zrE+QA37lxPGuKWbvH7zRO8NSdag+7i9DCQs+NmU2zXh7OMfPGONNlG55Xp5g8PYanduhXTV7aZOjIqsdnbbUzuD/A4P4mjcGL5so1p8l52nqDLTiB/J0iZVy1eqBIsTpov4sJVGu+DjF8s10rTfunExhHEmStuwmfnCJ5LcPyufZOh3PNMojndRuxz84QeLHC2PP2aibRNbC9Hqj+zvfaLL9O7ncSK+Nxb6W7HxO8rDo5ZDcNo/ZnPdif7fSpMqnjXgLflGHvJNe/DmJsBePTDA+2HuDYV1nKWKDZvPhbHXj2WXlwcXX9wt5JsiUX0+cKDL7upJvJuNo9KaClVbPO58l8na+lGudJXC4w9q4Hx/0y3Y5a32hZXNGh0XgNG/5vH+Gn2WPvTCov/czPR2CbBUpHZ5g5bK1mbNVY9k5yPe8ifi5J8na1gjT2jRF607fqc21tt1Z7gn+qDsuwLc+nUM0aGGh3vW02dK2jZvWvFefQbqwnDXxnE8RP1J5I9KSfRMHJ6CcpeKma4br2MlDB7PZpEXU8pwEsWHcAZCneB5aGH92rZXy0GqLSzHNjXP/HWMNjW2dwv9TwuYcG0Z9+Jsq25eFCAzYHkMFcrJuBsFxiDmDER+hEtUOkfCHbENBbcL0d47x1Ac9L1awIALYa+M5dx3s8T9HixIqJsT9K9HnaZoM9HnVDHUVaWA7orfuCRK9N4GwIrixPBzl/p/OkIJa9k2Tv+MjdzJK9vw3PO1kie2rjZiy1sYdddg85385S2hMn+sUo4QsLDL4dJnipgG9N4FfnmSAz/6jbzltn2HLOYPxEY89Am4vjViuOvYPVi72z1+e9A1hwvR7FRZ7pvw53aO304TlR96fVwPlcj19ob9YiacExMkGi5MTVUItaRya5Upjs8GwDC653sxQO58jkspQsHsI3IssBl6V2x9rVobR5if6jvgWnXHtufKLLSVLatxovBZrLj7MDjKcGsZ2rGy81nyVz0YfnXBdfB3AvSfhkiehVH7Y9JpFDDgJvDLZ//IzNU+057Ymlfcv/0kSULcadmvfSpK+B8+mVIKNxRu9t9t218emrMweW0jJbt/Ta8H1ea4RrtuUtN3xl3Gkvmj/uxSDwzhSFwwbBg951XkCtOA6FmDoUWs/CAFhGopR+oe6cqWCaFbAMEnhnEComlaUZ6Z/YvXJMdzoYPRHF/aeGLdrlxLDCgDGIYbVg/bHJuPaNLAtUH30YqAUZUabfdlJ5r5vHWdXMZwi/GODMreqjl6I9T2hUneDJ0+3zqbEzOLSSAWaxWjG7DVDaPcLJ4mHixizjTy7V5ZVa+nWxblywFWPIR+lfY1i2Lp2T3T8+q15Pjy3a4yGwB/IXE1y566/OwHw7xdQlYI8bR6eZ2bfXZRjASpZBk5niOzH2T5LYP0mip6WseD/Oc90IE/48Vn1kmM2B//QVIv++Sb2aFROzUqHysMXaWqQH9/787hY920sNqlTLZKurs+/9ONHnLQRer0tn3u4g+OXPjJ42saxprKz75sNxiocsq8ZDV8wyxXvg2O/gwd0i5pP25fq41XAti+ElenbtNah4o5rq7XxpksCzDfcLdSnwxQtRorfB+2Uc38UDHDsVIjaSYbKbAGLTyuJKYL6kt2PZ5UR4+Ej84lndYGXzEDzraTtlc1tWB84R4Nrs/8fe/Yc4de+Pn3/6XXeJy9wlA17ILF4wxYIRBSMWTLj+4RnmA0b8gBksmGDBxhZsxkJNFK6TygebaUEnFtoZC62x0JIRKhPhykToMEf4tiTdbZkULJPuVnoKFRKoSw7bYT27HyH7R5KZTHJOfsyMtnM/rwfIvZ3k/Mj5+X69f7zeLBh+HLYC+TvQ2GvAUnOuka6Y5B0BbPtHUZ+MYmu45Axdp/hLEfvfPVAqULI7cb9VpnyWhpe5h9FKhda7qf6+a1dZacc7FIKPkkykVSIHFGzoZKaqQwjCL/U8IKnDtK2Nlis27C43PiBzPUnuRBxPH2izKaYA99C+9pV4fR5CZ6s5awaXctZUj7BtWz1/jEH5QYbMD2A7ZFGmWKqIMCj+uECxqJEvOQkeNf+6FUPXMQyj6yl+hYDG0M7mxL0bQCNzNQ3HIvi6GcPXaKsLzzEnzu8zzMymiH2QqWa83+vD5XKiDEWoVLoLWh2HQoy/uAXt1jTD58L4n3PN1NJYecpoeZ2BnnqSVWs7PZkyUcvlmgK6elbrRR2dDuPzO6l3TddzJD9ZYNdrITxLtY7drcK+04N/u5P8vRnUWzEmZ6sZ791DLlw7FI6cr9DlqVwDN6Evptsk9yky/eouMo3d9g8EiA94ib3vJXnKwfy1cWbOxBjv4vrRf0gSHorBtfp0TXZ8V9KMDHnx/rtG+uYoHtPAshowG4/yZEsDePevQwKY+pzI27Oo91uDosKDaoBmP9WwF7WM3svzkOfNszIP+PANsFwTbaJagNXJfZok+9iOt/EasmRHuTDH3JmmP/84xeAbSRgaZfofrXNs18e9t+zD38OM/71E5twgIz/0MA96LTHfvNZ63IxSgcIjg7Jm4H29y8mnNgNPNTLvxYher3ZnXMHhInAuyeT5xvPuJnDFDfXkUk1Ba3trWPZxjrFX/cTuVrtNZ+/VspfXMt93SoZUuj9GKBAjU6q2YmeudzuPcquu56c2aW2yClCWWGSmb2bfWasM+yXN6aFhkhbJNB2HIiRvjtemArUttcSYbnNvgNHAPpqrU017y1hyE7wYYPzlKU4f3MXUngGKD1QKOAhfDnVM3tQyPWq9lW9VmeLrFad+xr8Mdz/93mYHyplxMq+NY+vrkKSrG59F8H6Wa8gbU+X/7GcmO627lGPq8xTTs/PV5GTAxGuDqC4XvmNBgsc97ccO1z3Ok7wSI/F5puU+dx4IEboQIXys6V7c5iNyluVedg095+zbOs7lUTtuBoVbMaKXEg3JHxu2fThC/FqcwE7ztdgPhIgcWG6hrldA5IxqQO88PELEorJJ/3qMYGCKkiNM+KgPZU+c5L0YsWPD2D7o3IF/fa/FtVhOhGeunth1maGX0H5coNgyrZyO9p2GThHNHuoiwaAT5YQPZsc4/YpBoC/LWAl81+dJnXC2z12yw0fkvM+kd4G5TvdaPZjXv04QPlMbrtbEsTtA9KNJImaJgksqk5cnSc2mm+5FJ55TIUbeCBPYv/K6th8OEz+QJHZ1kF1fKTjRUL+pViiHjq4iKjWdtrWB2VCQHUFil5NkLo3h9+TY9dfqNIw4AsROdPlUq+Ws4UAWta95v3WyP1TLXYrJcNOl/B7Nhm7gP9q+Yiv5lpfkN7mmnhN+UlrX/WOEMAvvSuQvROGgRUDf58R3xWc+P+xijrF/95PcGmT0hA/fkJ/YdtDyGtoPaWKHwvBmhumzbvOAR8+R/CS73HpSVMkyT6E2nuqJppJ76CeltUlu0TMD9cIWBq82/dnnIn1oFwOb7bgOePE5e22BhdIv88xblfH+sss08Mu934+XNq1OvVjUyFzIsOWERTBm1vW/xvhmjCPHkthPjhI87EM5HsOJxrymUbgdw/sGq5x1oBca6ifpNl3vysy39B1zErqepPBGkIFzT3CdiJH5uJsWI43MlQTGxeVhCgD0eRidXcB5OU2ntkb9qziDd4YbujGuA7Pu8x2Yz0PeKm51jy8x0O5Fid72kzK7huotC0stPctTWK5QT4Zp34X3kMnnHeiPVNRZs7HaDXMgb27YuccZws7lYR5mnAcieJ92G6rqZN70cuSjEs7jcVKnGobTGCXUjyKMXfCilufQ3m3OCVAfE27RRb3lGK5xWRvwWwnnqRvMfBDqKX+HMRvF/W8JSjhQ3k6SuuTrLgiyUD839Xl9/R8vkDw+0DAv9Sgz5SjeTr1V1kwj+cYwyYcOAh9nmDzlXu6dYujkPw/jez3BkSsK5es+7NjxnIq0Hu96NvwXj5j0/GqwmGfyzVqA/EEYt8U5cBxPot7cwvDFJOpsARwKkakJ4qspAK9JvbutYh5QLM3R3Hqecu/3W7egtr22G6xo4VVQarelc68P11/tOF/qp914JuObMRRPjBwOXIeO4L8yzABQ1rLkvpomenuS6AdxsrNmyWkbPM4wsucIkyUnvjOjRIaUpUpP/ReVzOdJYv4kM+/Oo/7DpAxTnxbsstdkKJytbXdd/W4UJTBJaYef+FQIj8vFvqWy0xTjbyYI5ovYvk21adyot1BbzUNvRiPz8QQ5PMTvjFfzk2wdJfWFxuCbNlwv9neYqu/PxEC7O9aSC2HZk5au5oWP3Oy72KbXpsOFcrG7+QKcJ+JM3Jln5HaCMcBxdIL4KTd2Wzc9GrvvFdRVb4XvE/gORsk5FEIfTBJ4ycWunf2Uf1xA01Qmz40RPahhfKsy2tgz9FGa4EvDTJUcuE5EGH/dhXP/AMYPBYq/zpP8PEbw0wmy/yww0ficsrkZvTsHr5wmdk9FozrjROp6pPsKwka/qIy916Yy+GmtK/0KNjxvp5gpnyb0fm34wA4/E7eTPTcIqu8Mo77T5Zcbn192F56XnPRT61HndLJv+wD2RfPfsiKJ5VA9O3+14WxgqxN3n/WjT7sbJfqhhvdyisiBZ966JjaA3otrdg8hi8QnpXsTxDbHWPhiZdZf9yEn7kMKfredTQcz5M9aJDezu/Duf9KQtMxN6qhZ1+Fc07jetbChXKlQudLpe7nexkgDxQd58qZJ34CtW9i3Hi25a7HDR+S82QclMtdjcGlheQ5vANwo290oh/zs27oJ79084b3m10L+w0Gid1v/XnwA5UKQwU9bP2tNsFKtXNKuz1m2TLj3K60tvNt9jGd+7nEMr5PAZwuYVbDS5yJwpdfMr+ukJWN9Vbsa/xXzkLfodQqkNmotC38os66ADoWYOrei+6Tp8INHU7SfYLCuQP6jEhBi/PpoS3ZhxQWFu0HSn+YovKv0VoBZyzE0W7bPQ+RemVF770GhbShO+oN+tENhAu2GN3W9wuq5MepBVF8/dru9YaYU85k+AIz6HNxtuu0qQ0rLFIHmSpTuAXg5MuReOdTEZsc9dAQvU6RzBTTaz2vfjdLdOCOfqoBKaI+X+bes1lhNurdwcgJ90eiylTvH2KY23YovedlkUpm3pszIq0322eW13dLCa6Jk+fKtvqtyQDijMXG4cT8jgE761X6GP42Ruh/G06aypHQ/xWQJeDvFzOXm95qC/9Auys4g6YsZ8v/oNUGrRSVRTeH7SUqA//Ikow0t6fWyk72YZPC9KQqPUstjlLvQ/l0A4CRwPYP9dSe+hqDAefwGC0fB9rjdM3Idr8UO48hjnk0m22mt6KxW/i4nEFtpC84hBWdDln/XyQxzBxqr6vtxuqsBWeP9mOsmuLO5Cf9TY/j7LAvswru3l/KdRe+2Bm2n32tSKmSrs9K8EefG2eUj5DjgwHVAwWXkeeHVDPM/6bC/YZrU3DRTJeDtNAuN98Ch6n0cOthP/79PMnlbJXa0acaprQqjmZ+J6DoGa0wQXO+haNEbCsB3GFqHHjjxXZuj+K6Obqx+H5Yqn1eo9gg93ZS7ppvnF6ZxQDdJLEsWcUeOqX9PkAbS9jTB9WxEEhuWZfFhucu5BbNEXS/uwzObInVvmNjhpoeZUSKTUeFwqM2FZ8dVmxbtX4H3lQiR1RSinpTR2x789mP6WlbXJss8mHXhcuB0e1A/S5E5GsPXNAbQeJRhZhZ8r1ufSefQKKO7zT6xDowHLMaNOt0KykaZpuPpE8q63v7c9JI8a0XG+mXa49Xs3GpVE/sULZPIdtsl/3ntw3o/R1y4zzjgoyTjF9zwuoJ35wA2ymj5POpHMdKA45SnzTazpK4m2rR2tTuGvS1rW0UwX1sSz1mrRHe9039UmS+CXqg+y/RCFvW+HZbmttaYv6/yhH52eSxylhwKMnqi/ZksGXTId+LG966H2MU0kVdPUz4bWEp2ZZTypD8ZJw14XumxMsaC42CIyOE8iXsa+cUuOtH2FDBXZwDpdUq47jIjr/4azX5WnUXGims1Q/i64sC5xw3kmf4ogdLvr92bgK6RzU2TvAfgwdVujBHgcHnxMEXukzgxV5hhj3ephb78Sxb15kT1Pj/jbv9syaVIXG3Trm2SzNa1N4yDSdIfxJi0hVA8LgZs1SFC87kU8fcAfDi6yiXS6VnZdD763PhMul7bOl6S63gtruM4ctiF/8woSrtjpevgsC8NU1s/Nhx7e++FZtm7rUEvUwVXr+U0uetxYjsarmVdYz6fIXExAzhWJBReXm6K3Ccxos4IPreLfdv7a8tlmfqwNqXlIbflvvZSNu3or0727Xe37cFlPAaaz3UvZSwT+q8F5vPNSX11NKsGuufOieukAz4v4XH3NrWl+Ndl8mitTRn2/jDD71sv2Jg0YsneCJkHA8QvKjh9ZfrrtaTFBdTH/QTeiLMw5V/1mMye7PAzd6H/D73QzWuVl5nVVNvsCspXCYZftkp4BV1nizXJMm/GbOoR91sZFhxxooedHHncj7KnWltZzVIfYOTyAqlj1mfSvlNBsWhV71Wn49g+4/ZKruNzxPrsQMf5bHrX50RZnGLk5XZH2+LesbKKLvfrr5rYx/pXWXTJ/5fZBzu+Kyop2wiR90cYbuldUs8M3mYKPjJMXmg35rvd/q9l2ZVs9k4JEddP4fYggw0tdK3dGJOMKElo10W44/XfTfdiG+5/ZMhuDhO6lmTE39TmuMNHZGqcWIeKg65t8zGeSdE/4GW6b737YLWfAWRtVn+dZT6K0m7JzsN7Vs/91jTTv40QvRpj+K7Jm2KHn/GvkoRNK5gb7A6T+dZG9EKMscARk16A9dk2OgzhujdJtM2c42Zd8u1Hx1GnbIycS7Ren1THPE98OllNnthRp2dlD+djsx3nkIKyzeyduY7X4rr29jKbnaVJu2Saz8DzfO4C1bL4VxA6FWUskGk9Fjt8RNITxA81PZ92h8l8ZRA+M07i1SO0lEIdLgJX0kyeei6leJgdY3i2fX9c0ylL16inLvd/CAf+zzTKH7D2qZLFv4xNlUql8mxWXcuOCbB5jUnezNau67DKRDyGrmOsogZvLdvc0Ayd+qlcl+RHfxKrPp/rkbiwkxXTtrTR83Vcm1ru9+q0TJ2yx3edqKddrfzjAuqDomXeiI57vB77YLriEvncAuVeks4ZOnpJW0q41+/ch2tb+2toLfv/zH47yy3o3VwHDUt1n6ivIUt4Jy373/DM6XnZDlYe0x5ax7u9jp+WyFzyc+RTJ9Ntxzx3trpz1LtVX2ddnuO1vjeM2owJ/S+aTXFZ05IMsx+n24VzFQXeambweaqr2sKAy4Vza4ff0O0zu215yEDXi2h5rZqzZcsAu0zmJm+33+uRWM185bXn5Sqf489Dt7+/1zJp/T5se/31uK5e7+nVLrcy8V/394Sh6+ilAgvFJ7XrcAD7Wlrfe7l+ur2X6P1abvss6fK90/P9s5qyRnXBWnmtTS82IWqeYUAvhBBC/FdioF50MvjpPsbvTRN5pklDhRBCCCEkoBdCCCHWz+MSpT6HtKYIIYQQ4rmQgF4IIYQQQgghhNiA/tsfvQNCCCGEEEIIIYTonQT0QgghhBBCCCHEBiQBvRBCCCGEEEIIsQFJQC+EEEIIIYQQQmxAEtALIYQQQgghhBAbkAT0QgghhBBCCCHEBiQBvRBCCCGEEEIIsQFJQC+EEEIIIYQQQmxAEtALIYQQQgghhBAbkAT0QgghhBBCCCHEBiQBvRBCCCGEEEIIsQFJQC+EEEIIIYQQQmxAEtALIYQQQgghhBAbkAT0QgghhBBCCCHEBiQBvRBCCCGEEEIIsQH9D//xH//xH89ta08N9P/7KTbb5ue2yfVloOuLYLOx9l9goOvrcSxWv0+GrvN0s43Nq6jWMXSdRWys/VSu5Ziudtn1PI/reSzWtBerv54WdfT/z4btf1rFVlf729fzWbCG/V83f4Zn2+MC6v/2AO3/7ce51db7cv/XFgb+176e76XSd/+d//3/0DD+4uSv/3OP+/yn1+73rfG3r/Z8We6jzpaBAfp6OIH6jyrZB6vb/9Uv++e4Zur7r/+PAwz8L20OmqGjLxoYhrFu74zaild93kCncD/Lg1/aLLuoo/8/Bkbz83lN93sPx20NDF1n0TDAonyy9Hmv56PtPVctF1RXuz6/y3iU57//n5taj/Ma3xerfe+upcwnhPiTqzxPuXgF4pXsc9xkOXejMn4zWyl3v0Qle3O8MvOTyUe/pip+/JXUr6vbl+I/IxXlrZlKcWld63AsOu3TbwuVOXXB5PdnK3GoxHPtV//k9ycmfy1WUsep+KeKPe9ui47HtM1+rvZ89Lrc7+XKz/lsZaFYrrQeDatj0eY6Wi/FmUpkKFKZKVbWdD1lL1Ph8mqW7OI6+M8nlSf/afL3dXwWdNr/J78tVLKZVGXiynhl/Mp4ZWJqppItdP9E6IrV7ynOVCJDSkXp8C/yz+7vpSflcqVcNrkWc/EKNB2Ln2Yq47Xf3fLvnz+vXO54qtK4F+XcDetlr4xXbuTKlfo1QNtnyZNKuTBXSX1QX3aiksrMV4pmj5ba94vfzlXm1M7/5n+1XMmKY9XVP9NVtft97X97ccrfcj7qf/NPFc3PV9fq2/ZXUr82/n+TY/DbQiWrzld+NvmB2csm+/+fT7o6RqbLNm63uFDJqnOVudxC07Ht5ppZ+b1O/yzXU7/+TcoA9f03e349KUxX4qeUisvRui3HbqUSujxdWVjzI6T9eav8Z7EyX3tuTUzNVRZ+W7H3lThtlm33+yzu925ZrvfbierzrF7GWbXl8z6aMbsOZyqjHX67pXb33K+pih/WtYxanPKbH+c1vf9WW/7qrswnhNiYVtbvPcyQuFPoXAuw00/kqLPhD3km/y1K2uy7R8eZO+tuu7rS3SjBD/Odt9vFupqVf8oQvQX+Ux7sXS1hoN2Lorki+Hb0tCmgWns9X2z+6wD7DrlgUUN9pPe2vu8mCZ+KM/VDCcfuANGPJon8vbtfAsDDNIMKZCujeLpdZrHA1OUosasZNACc+M7HGb8UwNXX7XY7XEtbvYS6Pie90MhcTWO2ZfvBEKEDvWxRI3PuNKFbRXbtGYDfNdTHbiZupwjv7dSitrbrqM70evrLLrz7Hdie6mizGvrTNit4qpG+OEL0agath/OY/3CQ6F2zT/yMfxmm012of50gfGacqR9KAKu7dh9NMfy3oMlzxU9KmyawvcPyTzXSF04TvvuEI8eG8XjcuGwlCj+oTLwbwv/XIMmb4/g6rQfQ7kQZuZAg8xCchyPEr8UJ7OyiVdWhEPvC2+YLRaZf3UVmsfOqqkqkXx8geNtP6tdpAts6fP1xnuiFmPmuvasQOWq9qKFliF4wfaoD4J8KEjrQfvPGj1PE3oiQuF8y2QGFyLUJ4idcrDySOuqVQYK326+7ug9Fpk84LD6tH6vO61m5rpXvs+KD6v8m3xpE/QuAm8hn4/gsNmvoOgZQrp/TJ2V0XQdsPOluV2rM36vusynG25y3ZbXn1/sqtbsQ5e0U05eV9s/d7xL0e8yvmfbHu2Yxz+Srw4zc1pb/5lCIXL/B+DGn9XJt+M6Mo7RZ1LXV4oP69X88RfBUl2/A7xMo7ig5nPjPTxA75MJRu0CNUgH17iSpS8MkM+PM5yLmz0LLZ1ddnGwlZPmp8X2C4cNRMituGyehL+a4cdz6QNSvPYBy/WJbLKPrtR+w2d7m3Lcpx3Xz3H+qo86qYLf+Xb0a8/Uz1u2XSxmiryQwLUnujpC65qPDlbt2zftQXIDHBYL/llz6iv/dOcJWi9+NEryvrGJf11YGF0JsfCsDersT9/72hdTCrUFGDG9TQO8m9MU0wabvZq/0c0Q36MTuDjL6D1/n7XaxrpU01FtpmDVQH4YIdRVYaSzchsJRDQ70XvjQZscYawyEftdQvwmRrYzS89oeJgm+lMKdyVL29FPOjRM86MP4VmW0w3lavRLpNxRim+NM/zaDeyvwOM/U5TDKGzbyn/m7e9HUrqXCrUHSjmlGD9mBAlNKGscXoyhOJ5a/QM+R/CRLtepDIwvwWYLEV7VVtw3M+3Hud7cGCO8NM7+9cwDSKP9+kCOPgiz8FOmD7ckAACAASURBVF4KgPXZGL7DUZwPJvBZFSLXUeH2IIO5MOOHGq6erVvYt99hffyWGKgXvYRLcTLFFE40pi/4ujqPhq6i7p+hfKE5GLV1rIQxvhvDd1xFuZnnyWEHNgxK9xOEjvsw7vZw7W4LMF0JrPzb9wn2uVPMfJyg2F/9k5YDs9qq/IdBhh8FWciHV1RgKIcDhM/Hyb2j4D2RsC6U13/PbBTvG0Xi94qktoN2O4LvUAjbtyn8nQJqPc/00rVspsy8Zvnh2u2PUC6vLD5m3+3nyFUY3t3+ieQ4lqRcrhZEs1f6OfIeuC7PkT27r/oFmx0wCdTrHqUJHQoyVXLivzJD/KSXARuAQTGXIvZmlERAoUiW1InGfXHg/7hM+WPrVRdvh9j1unW4VGVHuTDH3Jnq/T82C6HrcwR2Vj8t3Bpk5BNQ3q4+n/pfNL+yB/YoDOzpsKklORL9XlaEw+8dof89gDipqW7XA2Cgz6qozb/qVHdLa5+McOR9FcehEKOHHZTSYyTfGSTk6iIoB9gbYDSwj/7GbTs73bsl0m/4GLldwnk8TvyUB9vDKSbfTZLwD9OfyzLawzO4Oy5cFu/20q8LK//QUNGs5SyW+WmeHMCZCZJXfE3POwXfUSfGrSNMfpOl8CiC2+wZsNmOc0jB9UClUHLgOrSLgSca6jcaOFwoe+zWz29DJX44SqbkIXwzQeSYEyOXJPpqjOTLQVz5LJG9pntuWoGVfn0X6ddr/3E5S2XIasMmnhZZuF+ghEKvpa/10Hi/LiswpYyQNFug2e+1Y7539Bk0Hpiw7yP4j1EaS7OjTV8Z2A48tFh+FY0+VdVnhSdTJtr8Ltz8XH65EOIPtjKg3+pCOeRqu8CWr8GxufVVZLO3vqD6t3S3E7ZtbpQOBeMtX3e3rmU6uXeCxLammPtshuDJGM67cZROQdj3WTIOB8VbKtrJUM9BuPvsHHNnG/7wdYxNHzh7D+YxUG/GKF7JMHO4urT9cJzUx0d44XqG8E1/Vy+okjYP6Cw8HMVjUujR8irqE+h/0Yt7mw2+TxH/fJiJ30O460HQVjeBK3Hmt0RJnfNbFCaa1K6lLV+DusOLcsgBbCGHitOjtD/fNif79j+hXP2Pamv7Hjfu2ou9f1u7QqUd1yGFlVdxnvw5B1ucvdR551E/yzH6YXZFMGgfCjHieYHU/Ri+48+8vr/KEyRyvuv+FcsepkhcPcLkb6FqxQxuQtdTFF6Mkvq+i/O4pR+7vdfCgI56M8aWSwvED9ePjw3HoVEmLqu8cFMlvL+5kNy9Qi5D/rCXYH+nb5Yo5HL4j6UteiPY8JwawX9p2rpQDoBG6v0ER66XCe2t7rX7tSSpn5xEb+Xxn+/Q8rGokbmQxfcgybDFNkKvRWvBcTeewNPqfhUfA50qFDbbsNsb7pdFFfVzgBCKp2mbt4MMbApWC/1ve8Bmp7poCb1WAC08KGHY7TgaWoTqLdjN8rfjTJXA9/Ec06+tfALaD0eYnh1g2Blk6twUIyd66EHUNRuO/QoOSpQ+qv7F6VZQagFl/Z1id9WfT3Vuwl9WW9H0hyqZe3mKBth3+xgecmHfXO3BMnjX7Lc7cF8ZZ9x0f1w4mF/F74ib9LBqU5ECYKgkL2WAEJNf3MC/FTi+i7IzSPpcklw3x/vFI4ycD/TWUvhwhsnPSzA0wcwX4dpzWMG3w8YW3ySxdJbIgV29rBGAzEdRMpafxvGe95m8Yw0W8rXqkNsq2ccB/G16rNQ5DoWIHJgi8dERXF8p7HrJjc81ABQpzObJPlApAM5TQev3mMPH+Jf72PfyAMHbXmKfTRN4NMYmTwwOxkh9EcBBybQnGd/nGCsBZ2LE673YDo8ycWWeF15Jk/lWa3h2pwn+bRNB4mQrYZyHxxl/qc2P29nubC5f90vqPQ2GHN1fB/oC2fuq9TO+3sOsi1Wpn42h/aX5r08wrQN1+Bj/cmXDkH53hP5/n8Q90N/V9qqSRP5Nxbr42qa3gs2B+5ADHueYvDROajZN7qETz3EfoQtxQvtrR+UhQJbU1QRZ7HhfC9H8OF6NLf12en5lCyH+JawqI4d3+8B670dXFEd3rxT9+yni5yKk+qJkpgK4+/xkHg/j2zNI8N040ROepS50KyzmGDszjvd6GvcnfmKfK6ROrq6LYJ1WyMHOIzjoWARrkif33gDB/MrXhvOQH+X1LPPX/Sgd31B5Uh9oBE4OEPtYJXhFaXmpFR/kyS+Cfcu+akBvGOQZoL85CLJtoZ88xvOopq+/FIFqJQDQUBDv2cN51O+HCffY9d3o7YSZWu6ma+EZdgUsfZshcyZEqrESq8+L72SesW81InvXdm2bM9Afg93eGnFv6bPDY331LT2/TBG//ITxexMrKiNyRpTJli/bcexwkL2nop0ImFaoabPTpPd6ibULih/lyNwLE5pqLCXZ8A4FyV+dRzvv7qKyTkOdSqK3q4ToeghKiYU7APnlLt3dWiyQfCNIogSea+FqkNfI4ULZMwD2pqfE9ykm6q1+t8eZ+NpP/O+d97OQq3Y89e6xOELbPQwfg/SdebRH4Nm2vGwvXeWfDYP8h8P43sw0PLejnD4QJzs7CrqKOmu2nBPf+Qg+vUD6wwSTX2nYd/gJXwqjOKB0q6t2xbX7MV/trn3Gv1yJvV0heBLSn6uWFbydGei1nnJls/EDeokFAHv/ipZ924ATN5D/pYRO7wH9qFnL48rdouXl9kuayffqZy/J+EchfG+PUqlU20xz72zCe8lkXVsVxr8qErw7w/RshtzDPJlH9U7UdpTXbhD3H8G/9xlX6PbZTIPQ8mJjC26t9X+zHRt23Kci1YqaUo6p21mKBrDVhf+YD2f94fJN97tgFOar3bj3Oum61Dc7xvBsm47yx1MUv2hfUWTfpqBY9iTYgnNIwYkTe4cSbOH7aQCU3e0bqlbSyM226zbVobeCoRLbE0W/kiTzwTT2zQb69ynCh33o96x6VwghxNr0GNCX0B4ALQUB8/E7TzTglVXvW8t27TvaN/mXbo/gvziJZgswclmlcMxVKyDbcL81Q2EozeS7Idyvluk/kWBmqqGgr+dJvOJn4sUE2WMenO4EqsfL4E9JUhd95hUAHWmod1QibzUE5fXa68cL6G3qgHmkMY+T4eZCt20LdjRKHVvnDHLvhBl/MUb++gDJIT+hT1QmX3OtCBq8r0SINAbKO92EiTHzdQTP35d/tPH1DNOEibd0f3vGjFpL/e+1EtvjAuqD2qDyxwttujIv0+6nyZwJk1oRLeks5FTUrQ29E1Zw47vgwffxFKEDAZy1O0X/eoqJO35GPuhUmKt2G24/kAS66cK+QuMYvadFFnAxbPFV7WEaBqJN67ex5S+glkrQKRT9LMLgVyuvUf+7KZxTQRI/VP+7+ABcxxq/4cDlcZO+0xxIa6h30rg9sVVVXhg/Jhk5GoNrWUJGksTV5TNv3uXehnIxQ+zVYbx7ZgieG8a3vXYkdI3MrTESeTcTtzuMC32kkWaAaNNJsv2lH2ZLdDyKWxViqqPW26SNv7QZgtLo4QL1nsKZb/PE/97d2MjSN0nib51m8htwnpom9ZbJcksthw1+yTByJkoON6PXhlHPxRg7Pkz/3RSRL+cIU2LqZbPg246jlpugWDaLtgBDY/4OwAB2i5wOncZOd+4CvkqlDONvZijtHWXufhzFrpN/P8i+czHitwPMvF2h8rbFb1/MMXbYS6weOM2qpO9kmf42RX0Ai17Iouq9j7Uo3RpmINBpqAG1illgoL/h/ncw8CKAWn1/dAro6z02lsTJ/upkvN3Y8N0eQg4Yuz3N9A8+wrvt8LREZipFHnB7XKu6/zuNpW4Z2/9YJXYiSBoH4akkAx8cIXbJz/DmFMnzCg7Tko9B6bssC7/X/tPuRDkeRjH7ankB9X61O7/5+6MXWeKvDJLcXBtfvdfDqAPGrsaIH0oR9fRj/JIhcT0NuAkecsPSU6DW+t9QFijdG8Hvm6RxREH0okL8zgyjBxr286cZJq4W6besTDTI3k8BED64r/PzyWR4jznrd57xKE/2pzK2o6OMdpMnoqCiPrJo8TdUZq6XgDDKS02f1t9tjRXqZkO8VuP7HGOlYbIn3UvlT/veECOvnWa8UCKyVBHkJXg+8gx6JrWXrQ9ffGZ5jIQQf4R1mnNkPcfvVAtJ08e6HOfXwHE0TvrgOA6L6Nu+28/olJ/Rj0toi/algrjxTQLl2DhbTiTJXqt13dseIPXASeLNEN5zMH+9927CxjdTTBbjTB5s2J/fNOa/y9Nf1ii3a6nYbF4735VSjuS7EU5/qzB314+jD0bvpoi9rLDvzjDxKxMEdlssa/cR+WeG4MFdDJ+PMOzpp5ybJnE1j/LFHL7n/fT/MY8KFO9niQ8p2HSN/He1joplrXOg9DhD4lKR8XvN52+B9Edj5DZXk0y5t7Vea+6zKRKvD/KCawLFuaUaQBcGCH3ZRTIyzIehrFnjGL3HKmP3rRMP2jY7at2zV+l4jOmmMfS2Phs6o4z+DtXcBGpLt1H3a0nG7/vwKiqhkz72MU/m8yQzxEm/1mNyHl0j80mUkQt5lJsqyRNOjG5bmPrchL/4meCPKpnZPPn7GoXHdlzOAfadmaF80NWxhYfNrLL3hE7u0yTZx91+P0/+fueul/k7k0tjqvOfZcidceOxvMhKqO/HSdycJvNDterBfyVF8nw3hTid/PthglemKJTAc3mS2FseQo4FvIEpoi+5mL6SRj1vFW3b8L4cx3M1xuSrIdz3JpeGLADwOE/ywmkSgOMffhSLHWqpcOxRNamkzkKt/qc+xAig8GvtO4Us6n07A3uU5eRqT41qK5zHyz47gB33S24gw3xJR7ubIP1jmfmfWrdZujtO7Bvw3/yZ6VNO9HtRXL4E8dtRMrWLSX1nuGVsfFf6nChD1RCz+EClsA69iCy1jKF34ejrx3dlHC+g3Y8yea9pGZtC6IMQUy8nGdmTZqTxswNxJl9z031ftXoOhM7fXM5/oJO7GiZ0rXrdOk4miJzw4fSkWPAEmbo4iPunafI3/SZr6T4ZY6OuEgW2VaJwv9r9XrkM2BRid+LkjsUY873QUJHhwHctSbhdC6+hMvHqJDn8TOSThPfaKN2L4/eNEXsriT8XXh6O9v0UY99PWScMfJgi8V4JHKP4h9o/MRqT8XVW7eVh67O3TLumfxVnsJsKq0YWLf75j2KMlSyeLw9zqA+pJfArkTm3XEndrWpySpPzvtNN2BFn5l4IT23YmfEwTequA9chCZ+FEM9GjwF9Ee0r2HfO/OX17MbvaGi3rbe7xGanq175fQ6cDS1CtgMh0t+GcTTXsm/1EJlaILK0nBPfFd+KZS0t5ki8NYHrYn5lgbs+LvHRFNn32rTQOJzscpiMk31cRMOFs01Aqc1OMLV5hIV7AVz187FVIf5lgeHZAnarYL7GeXSCbDFP+p6K9rAIriDTxWncz2nI+DIDdWqcfR9MwJuTpN9QCOzwETlfa/d+NEX2vek2y2tMnQsxfTKF1lIIam3ZaLHZSeDmz/gfF8g/KPKk34l3t7Pj3K/WGeKt+d+dI7y/iy82Dkd4VGLSfBQmAAM7FLhfRoeGAE6nXAS/p4uTaTGGvjouGaiNTW7Zgz43kX8W8N/PkPlOQ2MA5e0s44ecPVSK6WQu+Bi5WsJ1JsKN4jRKbZdtB0IrgjzzLvfL7DsVAjtN29k62+ZCQaW88iCi/1aEY95nnzW50eMMyWt5cESIv6YSeydG/PMAM69ZBdUOdjmKZB734zsfJ3YuRDenvcqO3QHlkhP/B9Mkz1YTTTpPpCj8zUv0UhbluAdbm+DMtn+U1Bcagy8nOe2e4nS9S389URXgPHWDmYutQ4Hq1jpkpXB7kMGGbtXJNwZbkmmp7wyjvgPxXIXRekC/zYX3AKQ/GiE0ECe0u0z6yhjgIHTARenrfUTNumtT6xmDn+GhWu6TQz6CJEjkNYqHq99R3p5mdCDD4Bu9dcF3HB1n7ihg2TOixmardnF/oFHCUzs+GloewE9X6UQsxtCHavk8coZJQA84j99g/oGP5PUUmYfVG8d1NEzsjFXLeKuuZ75pVLsW3Id2Yb/QVHm1PUCq4Gb4wzScrCYEbX37dk7GaKrr/BdWWmessB0YZe6Bn8zdDIXHgG0A92Efyo4O2/ohR7IEnA8vVaA5DocYOTZG7o5K/lFDQH/sBgs3hxkwazFfzDF28jQZwH9tpMPwPpNEkF2I5yotCRIbE3Euq84EcvqOnxumuUha99/4ZozwuRzgJ/GGyfOlnicEgBL6I6shNNYsk1PafYzf14md87LJV73KHLsDjFzJMnroWSUz7t5aK0mFEH9OvQX0RplySbGeIuZZ0csUUWqJvSx8U0s404ulh7odxzZq3ZlVFKspiYwyhdkCAyc7rHexQPINPxMvTpJfdeI0F55TRaJ3c4T3epZeSPnZFMV/jLftJuw8mWLObB8323Efrr/EqsmbsDqmDjf+U3/sVCfG13GisyNM5sLYnqbwXZzC85n5eOgWTzWmXh8k+NMI2evWAUM3bFtduAaKaH0DK4J541GebGkA/xcVGjvquU9NM93pGmneRrfTAfbA4VbwvZwkc9G3XFh8rJL+yIfv3LMYP9/IjvNQgPCh1S+vvJEke3l5yigMHe3HebR6t4x+J/t2OnEdn2OuMQ3imp4FTRxulMPDJO/F8C21wumodybxHY20uRbteE5F8DQOEWmjY7fdp9XKqckSeK4FGT3uZeGTYaZeDzKyNcWExXRgjhPTVE7UW9B0dLMxKtsD/PxTADb3rwjenCeSaMds2Jp2y/73MDfUetfa5VbUAZMu3M7jN/i5GGLq8xTTswWKmgZOJ/4zYYZfCRI4YP58bB5D+0RTyT0E5wEFZ7sAv4nnrTLls8tZ8f0fL5A8Xk1w1hwkrLwH3UTuzmG8cprYpVoX8x0+IukJ4ods8FKZ8tn6OlZu09bnZkXSwkdatfv79oGlwMPu8qI4u5gidrX2KgT3Qv52ipmHgeoML9+nmbgD7PXi6mKqxrWw7/YTue5frgzv1aJWnQKtp41Wp0uz7R9FfTK64ro1dJ3iL0Xsf/dAqUDJ7sRduzYaA3Kb3Y6t2+dHF2PB2+swiaFtAO+xEI19pPSlG9hJ4KefCQD9jTtgd7ALKP1SQqfeu0inqEHL0JbNW+i3m0xj91gl9nKQsW/AcTLFeMfeB+0SQVozLUfa7NhtrUM4q8knsyTeHGZq6R1sPn2kPhtj+JUxcjgITI130ZvOQaDpHV5n6DrGZrvlkCArtp0B4lM+4ia9EADYHeLnn+g+L0F1Zygt2nA87/K3EGJD6C2g16H/lMIuiwdkY3dGMCj9UKBolNG+zeG6YD33Zkd2hbjmwmj3XjmwnOymUenWMAN3hrt78Xaa17ubeb9LGWKBEFPbJ8ne7HKKN1M2lNcTuDxBRuwpRk86KN1JELnmIpHrNkDVKdyZJPFhipn7heW2tB0e/ENBwpciS62epp4a6IvLHenKv8yjlXW2/K3dvNq1LdfmTy/8CtpPEyQe9VOdgk5j4doI0z8U4PgE04ctlv8uQfC4yvAdtdrD4a0UiVe8DL76hJlroeWeBybqc1+n+qLMz0aWs/WvQWFqkPGm6Z70r+IMml1bfXbs6BTuz8OedagA+3Ue9X7txtI18g812D1CpNNUWjuCxC4n8b8Sw3Z9BC/zJC+EWbicZqKbhFiN2wUwShR+KKL9NkD4SncVKyu6YhpFCoUi5af9eLsIymzbXUsti5kLI4xcLeA47kN5yUk/ZbRvVU7fLuG6fIPU2w0XhMVYzuLtELvu+WqtUk0shwY5CV6KkzwWJGabYMQD859GCRfipD/o4gg0DhGxoN2PUjxp3W13xVzuB+IkXnNDn5v4ByFyLyeZ9L+AejnLvGUSqS5b0FoClGowb5k8rMmKFu5GDg+B8x4C5zuvo7YAvmtzK/JP1Pch9P5cb9Oe9VUDFqP+DOir9zox2FJ7+22xW/Qs26owmvmZUUNHN5pmC+izY29YRyP3oSAeokSPD1N83YV+L4mKg9FDbrasqot8NRv2jJYl91DnieYg+lWiwzJughcDjL88xemDu5jaM1Dtoo+D8OVQ+7wRdfUx1lTf4QUdnmhlhm/PWyb2MnSNQt5kKFTt2WH8rmF4Os8es7IiqrPm4U31YF7/OkH4zDhTP7QeeMfuANGPJok0J3jc6mb8SpvwtDxP6r0p8/nOa+o9DOqBaPyVQZJPan0CarkJ/FNZy/wnALn3+7u475pa93coBA6DejtC6D0bkQM2tDtxot+D44wPb9sGfp3CrTgj5xKoJXCcvIF6vZvnfDURpFIb/87APpSd69tVs3nqyOpwEzuhxrLY0xLq1RDBixlKOPBdy5A80WPFdT2Z5RczqCuuGQeuo8OEz0QIHe4m30n1mYtJLwQAfkjyggeT2StouO+qsypoLA+vcZ6fY+GK9VBNLa+iFjXyD2sVP79rZL8pUNweJv3xH5PMWgjxfPQW0DsURm+adV21YR9S0O6MMYYd1wFvrRXFxsBuBffBILt2Aj2OUVqx/u3PukWxrj4NjBW/9Uv4qcbUhSilkyrzp1xrTzayPUDyPsQuhPC+Wab/aJDY/SSBrlpXDPLv+fDljpC8nmViZ0OBZ1EjdztBxB0kumIu7TxjA/uINZV9HLsVdg0A29z4XC683czJrGvkv9PhxfGlY2nf4Sei+oF+nJec9G+2g95aLCrdPo335QV8/0w1JPFxEriZxXbhNKErTjLvKqbHt3QriDuQw3slTaGrscLdyJO9C2ljAePEcvKd4iMNbs+zYARMkiYWSCuD1Rf6GgJ6m11B+SrN2HvL95VtmxdXV8nAbHjezpC2RYkcHSCHh9DraTLnPR0LJMvbBXDiHnJVg+CtTnz7XVglbC/dDjLwcvNk2048Q0621J4Nrpf8KD20shY+DHLklyAL5ZnWihw9TyKwj+CnPzNzqvaMaJ6qrcbow7pVqg3bgVEyt21Ezx9h4BvwnAqTvhvB001F0Q6F0GvtK8Cy5WjbOZVtfTaKhRIcCDNza3Rpu87jN5j/0sHwGxqhkx5sJasWTRd+dc46+dKPU227ftvs7TJOm4/l7m1MbW07Vq1Zf6R6a61FD456T4IVuRj2Rkj9s8jp1xMkLgBUhy3EDtnQb61mJzJMXqhP2ubEM1Qd/tDp+DqOJ1FvbmH4YhJ1tgAOhcjUBPGjXV799THW9fXtVtjl7MdmWaFdIvPmCwx/3madOzxEXup2Othuu3K3dlkH4PsEvoNRcg6F0AeTBF5ysWtnP+UfF9A0lclzY0QPahjfqozuX9+u0I6/9jf0MChRuA8c2oUy5Ky9R524XnKg32mzjr3jjF+x+lRDvTBpMpWfk9D1GQqvhkhcHF763Hl8gukr7fMA5d8fZt85FXDgezdN6h+9vT+Xxr9b9Xbqmh3nkK9NQtky8781P3MM1AtuBt8v1cqpqYZpU7tk5Bk7vI/YN+A8HGb0FRe7druwlfJomoZ6a5IR3ySpa/NkzZKKmlhKQNdMywKt7wX7wRhzjnp1mBv3fh/9zn047Y3vNLNawWovCdtinnx9jnvbAK79bty+AXbtdOJoWwUlhNjolooh3bbCNFoeA2Uyf2lX2owDvD3AJtOEoxYv73XTZv2Pphj+W5sx25udBD5bMO26tVq2nQHG/xnouTsb5MlczBH6KouvOTN9nxPPqQgjd18g9VUC/1LLoJvRYoXWfg7NSubzwDawN41ztmTSBdhxfJxs0SQfwmYn/mtzmKUzWlr2aBy16MS1joObtVvjjL8YIPD5JOk3leq18ThD8pqTwMkUiU9DKGd6mRane+6zc8ydtfjwUTdrsOM5f4Ps+Rvrt902HMdTVCqpzl/seuokHa2Qw380Zd4rw+7Gd9RD9FEXWfvXwP73CDdyEXo7isCjNKG/xSgOOdvMaaHgblf+3eYnmVsgsc3VMgbZPhRnrp6YzbL1147rkILlFbolZ/UJ0OlaMHuGr2FMLe27O8c8m0zWaz5Pu9m7JR1ofq+srMDtLcFZa0+COufRceZ+jVd7ONnsLTMBdsfDaMXqeVyiudqslQ3XqRssnJxAXzRPQmbKordbZw6Ui3PMNY4t3jLArp0D2GhsRS8x1S7ob1hf+67cVkFtVamQrWZ6fyPOjbPLV4fjgAPXAQWXkeeFVzPM/6TD/sYM+bW56us5H0z0Dyko29qEu10dw/bn0Hk0QsQy03sOw+q3b/cxrmrEfikwr5Xpd3pxb+98AbrfGmfiJxXnuRC+TmP1n6kS+QtRYktT8pl85a8KylDjtHU2lMtpJvo1lLOBtj34LP2QYeIb4FiKuXRjz4RqI1bkZRfePSPkrmTIv+XuqpfLwB43brOZgfrMe23ZtrlRVlW2rU2XuZpFH6UJvhSmdDHD3Nk/dpilEGL1lh6HnrcrVN5+3ptfXRKaNeeg+S/Bhfusg9DHSYZ3hpryDxiU7iWZuOMhePm5Z7rrQpfJDc30OXGt13j0pyXU98OcvmYjkUvhyQUZfCWG/ZqX7LkRytfmSA1pRI8qHNFTJN9SWlrqn5Qtxi0vMW9NFnV2vIfDhF6PMfligtCBxumJDEr3E0Qva0Q++zMXREIkvjTpWtmD5eEHG8EaxtTq9qUs7t0zn02i/VzW5iwTnuZSJK5mrRfc6SdytKlCyaKnyHP3HPfDvlNBWbepTTsFKW2CWsDh8uIhTe56nNiOMMMeb3Uudl1jPp8hcTEDOHA5LAoUe/yE/2HeE6yu/Jg/6ZhmG/btbpSeciW4CV9fh+dop3sFF/7zvi6qX71EPjBLgtegMdjv8xBeS8+AHW6GHTB5J0b0qo3wQVe1MsooUsjnUT9NkAMcpzzWlaNNnG4Fxaxho0Ml6nOlF9FKJbRiGYsJRoUQG8Af3sHxmUzttSZr6HLf4JIKLgAAIABJREFUgf1gjLkXB9apG3jHreG7lif1foyw5zS5xcYM009wHQ0Se5Cxnr5OYHyXJPGtl9SDCJ6twPYkM8YIR9wjuD+YJnXCCTgZv5cheSHGxFde4kP1q7k6DEV9f5jh99ttxc/4lx3mQreyVSGmuhjYCnQ9PdrGYz86QeH2JLF3FZx3G3JB4MB1NEjkboHQOneZXV8xvJs6tVebtTJvVGtoLSLM3JerzrbSwLr1fFXuTRI1yei+5LK3NaA3U5t2rquZUjqoVlhUWynb1hn+V7U3QuYrCJ2KMhbItM5j35jk0MzsGMOzLUutYJk34r+yTvcKcbxdBfRpTu9Jc7rdV9bcvb+B3cf4/RS2czESF4ZpnTzPie98ivE2s3I0M+9RVBdf5Y6us91hsr8HMfr+bGVxIUQvNlUqlcpz29pTA32R59tqYZbQ6E/BQNfX41jU5nTtVDGyqNeS+a3PsTB0HWPVXUlXrKm7/V/XZdeyzT+rNVxPizo6vWfyhTVcB2t4FlTHZ6/iOn6Wz4I/4tnWrJ5Rv9ekVPXl/rIL735Hz/dS6bssC7+zch73fxVNiUEtrSIT9qrPV4v6Oehnl8dtks/DWj156WrO3eqXXa9rppp4tEjn323oJbQfFyg+AejH6XbhtLpXuz3nrDXvw+rPWy+/vcWa7vfl895xZo416DoHR6/3Xbf33KKO/lhjXitTvV6cDPyJcnys9r1r6Dr8iX6HEGL9PN+AXgghhBBCCCGEEOviv/3ROyCEEEIIIYQQQojeSUAvhBBCCCGEEEJsQBLQCyGEEEIIIYQQG5AE9EIIIYQQQgghxAYkAb0QQgghhBBCCLEBSUAvhBBCCCGEEEJsQBLQCyGEEEIIIYQQG5AE9EIIIYQQQgghxAYkAb0QQgghhBBCCLEBSUAvhBBCCCGEEEJsQBLQCyGEEEIIIYQQG5AE9EIIIYQQQgghxAYkAb0QQgghhBBCCLEBSUAvhBBCCCGEEEJsQBLQCyGEEEIIIYQQG5AE9EIIIYQQQgghxAYkAb0QQgghhBBCCLEBSUAvhBBCCCGEEEJsQBLQCyGEEEIIIYQQG5AE9EIIIYQQQgghxAYkAb0QQgghhBBCCLEBSUAvhBBCCCGEEEJsQBLQCyGEEEIIIYQQG5AE9EIIIYQQQgghxAYkAb0QQgghhBBCCLEBSUAvhBBCCCGEEEJsQBLQCyGEEEIIIYQQG5AE9EIIIYQQQgghxAYkAb0QQgghhBBCCLEBSUAvhBBCCCGEEEJsQBLQCyGEEEIIIYQQG5AE9EIIIYQQQgghxAYkAb0QQgghhBBCCLEBSUAvhBBCCCGEEEJsQBLQCyGEEEIIIYQQG5AE9EIIIYQQQgghxAYkAb0QQgghhBBCCLEBSUAvhBBCCCGEEEJsQBLQCyGEEEIIIYQQG5AE9EIIIYQQQgghxAYkAb0QQgghhBBCCLEBSUAvhBBCCCGEEEJsQBLQCyGEEEIIIYQQG5AE9EIIIYQQQgghxAYkAb0QQgghhBBCCLEBSUAvhBBCCCGEEEJsQBLQCyGEEEIIIYQQG5AE9EIIIYQQQgghxAYkAb0QQgghhBBCCLEBSUAvhBBCCCGEEEJsQBLQCyGEEEIIIYQQG9AqAnoDXdcx1mPrizr64nqs6Fla4+99aqDr63K0MHSd1azK0HWMp6ve6Prs/5rO9SrPwToe+38Jazke63Sv6j+qqPdVCo97W854lEe9r6L+qPe+UaNE/r6Ker/AKpb+c3hcWN3vr//270q93z9tljV0Hb2Lf2u9+3o576u9tiy2TOk7FfV+nlKvP2Itx3w12zG7rru45o1HefN9/LM+N/+Q8sJq3//rWE4SQgghOthUqVQqPS3xaIrhv00z/Os0gW1r23junU14yVJ522P6ufG4QP7bPPM/FDEA2zYX+9xePDvta9uwmW/G2OSBbGWUFXvT6fcaJfL3ZlAf6mAbwHVQwbfX0Xm9PSsx9fIA08eKTJ9wtH5suZ/V5bRzFUYPtFm9YWDYbNiat3prmIE7wxS/CGCy1a73se25fqpT+CqD+l0RAzvOgwrKASdLZ3m119xajv1TA30R7PbmI9Iq/+Eg0budvuVn/Msw7nZfKWWIvpIg32FN7rMpxo+anI3vJhm8yMrtfDfJ4JST1DUfjjUcj0736kr1gMDWcvxy72zCewniueXrUf8mSfIr87DDfjBE6IC9eh0G0nC5cR90cp8myVoGcHa8r4XwLE4x/LcgaeLWv31RIz+rVu9jgK1OvB6lzbNGp3B/nqLlMVg2sEfBtbWLLzb7ZoxNnlj1Nw+py/+/+Rw8NdB+yFKy7cK9w4Ftc8Nnj2q//XhqxT1sWAYbDefMYtn6fR683ekH+El1vGd1tPsZMt/Vn/Feho95cNR2wfy8mzO7ttp8m7FNXmIr9rH+tzjZSgjt5QGCt61/Q/UYtl7j1sfNbPnu2PrsK89r43bMrut2n9VYPttX/Zyo3o8Lruo92zNDp/RLgaLNhWtb6+/t9hnU2zurg9W+e9axnCSEEEJ00lxEQP9ukvCpOFM/lHDsDhD9aJLI33t8OS8VJpr5SWnTBLZ3WP6pRvrCacJ3n3Dk2DAejxuXrUThB5WJd0P4/xokeXMcX9v16Gj3koxdTTJzv8CWAyFCFyJEjrlagtZV+2WKoCeG8Uac0N+d2HSNzCU3I1snyd7091aY0PNMvhEkfqtAyeEicC7J5HkPz6DqooFB4VaM6KUEmYfVvzgPR4hfixPYuW5Hqb3FHGNDftQ9McIn3NiNEvmPg7guDpPJRHB3vRslMueCJH5o+NPvGgCRf1PZ0vBny4C40XcJ+rss1LpPTTN9ss0XcuP0+7oovD/V0WbtBB4kGW5XCLRZXBVPddRZVm7nqY76qLtW3XUrCD9KE+oioKkztAzRC61PC4DAF0FClsGZgXYvStQysPSTOhHqcP50cldDBC+k0Uw+dR4fJ3U9gqclIC+QVgaJtV13VTxXYdQioC/djRL8sLkKp4vKnxrj+0mCx0dI1+5fdoS4cXeCUNv7t0T6dauAvE2lxxI7yoU55s5Yfa6jvjfM2GyHnV/Mkwj4iN4trfjzyI4Q07M38Ld9vteD71Yxz6aVf2+sDDDqvZzKPKl9/ETX0fugtxdDjkR/PfhfTWVtffnuLFVSfDfJ4MXavfK0yAIAyeVn3O5ItfLObCXNFYbFBXhcIPhvyaWv+N+dI9zzb6kro92NMvXU32NAb5D/MMjwm3kcQ062PC2yUBgg+PENxo86e9wHg4UHWfjKycJiAEef1feq7wv1UBfvgpZFrSteu3q3CCGEEOtsZUD/MEnwpRTuTJayp59ybpzgQR/Gtyqj+3so7WwLMF0JrPzb9wn2uVPMfJyg2F/9k5YDs5JQ/sMgw4+CLOTDuBpeyMrhAOHzcXLvKHhPJJjPRSwKvQaFD4ModwaInZ8mnrah3UkQ8e8ie/NnZk5VCwkrWga1LACpqwmq/6/Wumf5Iw3U60FKlxaYO+Na3sdju7BtCpN6009kb5tjtIJGMrCP1N4ZsmUv/XqW8RNefE/nUf/htixnrmgZflpkgTKFVwZJ1s/q0XHmzg5YbrV0O4RyaQvx22Vm9trhqU7+dozwoRC2b1P4u2pZ0MhcTVMAoMz8T6DdmyDxqHaSd/qJtCmUabdixF5K8uQD39LvVA57GPC/QHI2xMTRbguGDpRL03gb/mLMxhh4GaI34yiNBTurgLiB/lsRuqxO0e4nSf/Y7gt5WLFnbbeMVphn/jerz/vZ5Wm46hsLly0VGH7GL3e52T+Q41iScjnZ8BeN1Cv7GLnrZt+L7QrHDvwflyl/DPD/s/f+oU2de+D/a1/6hRQ6OAUvJODAc/GCKRNMcWDC9Y8e6YWmdGCCgyZs4KIDTTeYicJs9A+XOugSB3eNwmYUHKkwaQq3NIWVnv7hJREmjeBohMmOsEICE3JghQa+gt8/krRJmp+17m6fz/P6R3tyfjznnOc8z/P+nSTUO8wEZoJqEm/pERkkYK3R8QXSX9ixXUxhHPBx86oX54FSv9UzzPw7QOArP7ZfCyQXx7FWCQdWfPl8U+EnOdnL8BfN7hxY11AX1ZqNSnuW23WVwNAY8ZyM47wX2wuV0FdRTo3K9KXGsbYxZNvPhFCqPk9zG8ocHXXyWBsW+uZkbnvxz+WwfjxD9KoDs0EnfduL/aMozrNWfkl4thRxG3l0XQeDRNEgbsQyGSK0ebYsyVth4k/AfMKH552Kce9AhW/BrKdo8d8kzqmDcU4BjukY/a92Sx1gxqEuYSXDtDJGFIXx78dR9kClQsRzfQnXATDtr3OKLhN9gyb62r2kUSHwfXkcKpB/XlJp9PTSW+orhh7g4Q5v6alKbBbUgop22kO7org+58d+Syb62wz2kuKr8CSKZ8BNeCHZwTwK+mKQwG0n4yeTBC7GiV1zIG8zW5T2XVPRduLC30zx2sbcIhAIBALBblMx1RVQbwXITiaYHypOxdJQkNg3w/z9egLvLccrWYszqQTpIRvu3lZ75sikUjiOx6uE+S0MWE+O4bg8Q2bNh6Wu0GnA/HGMzEkJqXQO48kpwmsz2BZS5E7KGAHD3n4sh/PFHXqKIqn5sIWieN6LbAAaTvgGut80ks8WLa+ba+f1PDom5IaWge0UlqMEsiESCXtxESTZCX53k+F/REicvomjgXWvpWW4SwJyDX5ME7s6jfPfG3gOGTb3t4yGCKa78d/z4/i0HRthL/LhstJBJ78IuX39WA6Xeoup+Qvv7pEgp5OFigVggfy6EamnMy8BgyRVvIcMkXszyPshNufFfqYTzwwddTYCGJlZDGAdbH5k7pEf/8Y8+QuNhHYPnquGNr+fPFo6TbrhY5Potlg2XZKR+nF/No699Od41b4m5Dp+Mq+dcr6Gn7NkobWAuCmklXi6QmIOOORGqV3MX7bxxmVwTBfDOjbf+ZpeUiplWMkVkCTjljVz05JZg64SvZgCo4/Yf0LVSh/JiufaPH09NmyfBwjNeeqHuuwS5fvpBO1emHAOLJMzzJy3AF5s5fbOttde2wc+fC3d0xtTFjjr00tfw1CDHOn7KUDB84mjNNZLWE6PMfbRNIGFNBmdLQH7i2F6v6h8TjL2877Nfq/dGyNWUqplfi4gT/rqWvgNsp3QZP3vVJKlhqPlNvR8Kdxio8WOjZAwDyiY6SZV+rvPqqDsBciRu1HcS7YoKJXv57CXpR+8VIcqSJhHnNgPSECayL+OEa/b54vhAdqcn7FzcfKyTDeQfawhn71J7JJSMUaWrf4WfHdC2Ft1JT3FxPsBpDtLxBbduC/KJK4qbYx5OsmFCLZzv2wK8wCGAx7GTp/CsZDGd6j1PFRYSxG7FiAwJxNO3cS1TyP+4TFs/0oSvOrHfcS4e555JbolCUnI7wKBQCD4E1Ah0KdJfWHCna6ePOUBB8pHSVauO1B2OiM+myZ4ZYPQwlSVtj1V8BPZtrOEcb+R5IKKNuqqq+XXFmeIH7IRaGpB3hLmyxh6qq3Vhr2W0gIK6C4uq/oHlLbdJ61nYtjfc9D3nhvvOyb4XUO9m8Dw7xlC9SwqDUj/dwLTByvV3gb7FRyDp0imp3A0Eih7pOKCqZAjNTtDcq0Ae8w4jtuRWy40ChQegam39twGut+E9Hq70Z3lhSmUF6IZsw1loD3hxDgS5ObiMDZFxTNkppcsK3fi5Aaj3BzYQYcr6GSWowQ+CaF/GGf1FoTfVehb9jN1xYNyQGq5sNPuevFmgizF87gvh3G+M4611fN8lCD6babpLubjPuwt+4XM8Flf+3GXBiOWASPoGonZOJnnpTjkE1aMXcCDNs9TpkIIr4zxzW9AVdxCM9ZWi2qER/nOk0I9Vwm8f4oERrxXPNs9cPZbUeTubQqz9L2pTdVFfHKK1Eiw9Xf8JF0cf47209dIefgvO3yeJv5Uo1o10ZnL9O6jk/kxAVhwD5afkgHru06Mn6eJp1cpjO5QiFnX0V8AemthVb0zgfZm498buyAbkPYArJJ7DpS/i/WyoCzRW/nNnZ5iadRM7z+KGwu6TvbZCum0inpvmsiCBke8TLkg9kkEp5zAfsaFY1Chz7yVW0A64sF3BHLLEYI34mR0GeWMD+9xMxIpJlo/nSK6XmpnBm0NrHvTRP7lL/bBRgqk3aKQJvKenbHKUIULp7BeSaJeAn1RpdbnY5OnUcbe1XBrv2yFvr3IEHm3j8BcvsIjSsH9mQszvfQ1G/te6KTvBfGfi2G4kGDmfQuG4wmyLjtmxd2GMF2g8AqJ7vQ5P86LMdRCP95PxklnlOK4h4zj1i/YliMEr9g4lTagHA8Su95hKJxAIBAIBH8BtgT6NY0VZJy1FhVDNxJacdG1g+QuhSdRxkYCcC2JpxAl/OVWPG99l3sDysUEgQ+d2A7O4z7nxL6vtKLQNRJ3JwinLUzday/GdJPnCWJ3srguKnUn9MLvRUv9RpW5fYvNOMuuCkXBHoWgquF/kmYluwEoOC5MdWSdhxzaY5CP17rGd9MtgfZcp6mN81mcU4NetAE/nuMyG8tRjl2M4FuYwXto60Y28jq6DltJr8xYzkAgkcJ3xFph2U4xHwfvFfP2a7Vkgw0d9PUGgkDZbZYKa3qPGc+tX3A/S5PU8oAN+8kg5j0diiJPorhPTjD9AOxnvHhmMzjeLvabcTWDayFG+Fw/wwtgHR0nOu1h+x3qZG77Gb6o41/woRyC+E8KtqEssW+DuN6uv7I1n1hi6Z+tm2hqy5oTx/3WG7ib7VKbIGw9xcSQg+RAGO+ggcwNN5aFIMk7JYXYiw3yuo6hhVSuZeLwqBftOVj2pIm+598Ukjc04IN22g9aJlX6X4LkoyDWtlxmdbSFCGMfBkjkjChX44TqhVt8EGapJimWNjeG91wKDo0Tcqj4L0/gcPWSuOMrWjMb5fTYY0QBVD1PnvpfWfleLA29RSy4PnPT38QRpbOEeI1jw6spoD8HkDFVnt8oYwPiz3K0GDmA7fHmjuks/qcmbJebHWVAHgoReqdlI5H+1ui5SSjHfRhvhAm874QrHqxSlsSXASKA9aoTC2xlaH+rH2Vg670Xlv383VEK09hvx/vvmwTOFIU57wkHkSthwjcmOHVjAvAw89uWp5N2143NNb1pjVcXo8xfXUH9rHx2jZXlJNkmqScKP6+U+lOclUwB195Cc0F6F8nNhRiby2G5tIR6RUHS04Rd/fgvB4mNzjP+8iXjjfr8uk4WM3Kl90KXjLwf1ColrtxCuZ0jftaB/4aGYXSM4OLWeEuPBd9/MthnIwRPWzj1vBfX5Dyx9+up540oJ7x4r06TGqlQnD6bZupbC2OzzechadDPzYMBTPvqK2qNA16mBryEdI3suukPFuY15q+XQgxbhJ4JBAKBQPAqbAn0XdsznL8SukbiWz9jF9Iot1SiozKFdq2FPRa83/+C+4lKYjFNelkj81zCLJvoPzNP/qgZqUFcXE0jSN0OEr2bRH3cjeOaSvRE/Sk980gFsqQehapdHAFIEv7EyXQXpbh0uWF27fRChMQjDdjAel4l2MR6Vcaw4wdfQP3Gy8ponOSVklA+5EA56OTvF2PYE1txjNNXnKTepCJpkoT9wjyJURt9T3z4jtvofZ5k5t9h0kdnWGo7dr2C52lSi6BKKXKn5e2Lp3tBnA+7oeTGaf4xXDf2PL0cI/CgWG5JGr3JzGAb1z7gIbrgJlY3K72EPORlasjL1IsCeqHG/X1dI72YIPJ1kHncRFJbCbmsl1RW9/vxHDQTPR3Ae9aJ/VDJ4vQ0QXi2uVW+6r4epkk0W9htyz1RFO5okbU7Nxdi6mgM7WrRZdY+IIPFzvRDV9EFf/YUfbOnSnsH65+koDL/rR3H8Xliizkcoxa8P2wlyCpmmG7rLolfVzf/H5tL4T1kbTy2vMgQvxgmNBsl9RQwKvimpwiOthEioacJn3UTupshh5XgjQC+Ix5MP9twf+en3zxDaFbF10gRuX8Y7/tG1O/G8FyUiV+2b4UyUCC3EOTUZRWw4x1ppD7s0KOiJQakQQUFih4/D+ql6ts9amPoJdmAsSdEaBLIrxD7Yroq+Vf9JH5NWEww3SBRm2EwRDIOp86GCWzGtRtRPp3nZpPcIbwowDtelu77kPf20lv+5tf1ogLA0I/7agz3lQJ5PU/u1wJyV1lTm2L63DS5Q+MsLQdReorW6bGLUdQzZTValDElWvfSRXQSd8Obf4XnVIKD9qIgDU2SwlZSIPcwyervmVIyRp3VlIpaiqFfLad2SauoG8W8GZt980VR8La9018cxyQLtsPAwgo5vZTTJL9SN8kjh9wETtpwKDk879uxGbKocxHiuSCxq52Iu0bsV+LYJo0NEs9JmI+PEzs+TjSnofc0FmalkSDxn5w4zDH6DpqADbTFHMqteXxHmowCHY6/gBCsBQKBQPB/JFtisVGmz6iRrbXEP8+iYUZue8Gqk7hgZ+zLHOYzPm5mZ1BK6wRDyd2xTH2X+y2kAwquA0q7F66DAfmgDetzA4auaWLfRrFZQ9tjK9dVYtdkQpP9hO4k8B6x18T+2QjcqSw/U6gWwg0meOwmYZxhfEjBcVGmt2wJb6nEMCKbjWi52mjjLNmfwfxWs0WWRmY5h/OraoFJPurE8YFGjq24dM9XS9uFwn12pu5nSc/Noz7VyGLGfS/LzKGd2TG02Sjzl0IE56aIPXJtT2ZUY13N9RjYyskuIf0+zamcg6VRN/azZkyG0jNcS9GUthbQNVRmYH+aIDCn4TifJDRUKpdXUbbOPDpFcshH4rswkWvzWO60n/CpPRqVX9OKCRrvhAnfr/2tlLRRAu1pHJslUtEHLNgcOUI/54odoHyvpXJU9dDuRZgY8pD9RME+FEIdqYkpb/dO5qKEHoHxfBDPYoCJktXQ0yjUoEvG9OYKKax4JgOMn24nXKSEJGHqypPb72DqbhTvYQMg47qTQX7HT+BHBccRQ5OkeEYc1+ME1xwEvhjG9AXIRxTkNyH7WCWTA4wK4z/EGrefJMHKRJT1GAmx9HG7/kQVipRy2bq6lF3Wk2hrbI3Zz0rhDgfqKNTqUD+G3odvBFibJlkj0O828vEQSyNB9Ocamt6LvNdYFSq1GfNekdiuWIGi02CHUjb6NY2VHHB2GEUCMGM/rsDCDOmnZYHew5RqJ9soU/+jKKHbwJAXLxEiXweJfGjvKHnb9sSCKhPvqdtc/qNnjxGtKf9nNNuwEidyzoNp3YP5eZzQ54DRg/XtHKl3/E08PIw4bv2C8iTFSjZPoWDGfkEleKjCLb5LQhlsnfTfsMfYVh8zGFv1RQnrZ0tkP9ZI/6iR7zbR/x8zLSuGSjKWTpL1QsucLrvLbiv7BAKBQCCoT8Uy1Iz1ZBZ/jUUtvRgj+1moA/d2CeVslOQV85ZFoaCjPVlBK+Wfo1em/4BcdFWudHxuuoBtQNP6xAaMhx14DjvgfADPV076j0+QrMoAXSD1VYDYySDax70UBux47yaJjTYT2QxYRqsz7Kc+d5PcX4odr7QcaElaZTg3H/GQPZcgdcay1a5HKrHcOKHDzY7sxfQPSGd1qjKy5zSSxjarMHUZsRyvE6vcKc+mCVyG4H0fwwdXsJyZwLYtM3g1xgEvvoGKZt9NwP9bcq3VU0S/TRYtbo2sTWX2Oojm82yzqaVC9NphPu+v8wYqrPSHvMzfqvm5tmydJGP/eGozCRcA++34zislS1uzBgKY6B8wN0gSZUA+aGFj2zksWFRHg/OVkjYCRqNCsirGW2M1BeY28xjwbJrAhSyhBQfGQzrB42bcZ/u3XPbb5dk03o8i5LASco3jfmeV6HvTnHp/jN67Uw3KkBmwfrbCy0vl2vXl0JCavY6G+OXnEFTlwZBxfaPhMNR6F0lYP77JUvnPPQoBdQkvpu1hFj3WUkjGDJF706SfZdGyJuSDHuxXHXgb5qOosKSXKCoBjJgH+jC15UH0KkjYBj1wI8pUXMV3RMGATmK6+BV439lJyExrjCMhlkZ0MssrpRjy5pgOKi1CDtJE7H7iJa8dS814UfgtQ2IxDQYFX3njHguhyVDtidCW/UQW6mXuh83s/T0SJgAtW/QAooD2swo4kPdQGmdk+gdsaDfqNHc9xcQZPymMeM8ECRkMzCyE8Z8JYJkLlrLUt8NWhYZyNYTxRB6/FbYqNoxvjl1VydMP+Uj8UMB9NrDp2SAP+Zi5HkQxgC2fx7s2g+fgqfpKTj3FzFxyK5zhpzTpGsWFfbDRWFUk9fkbLcIythNs4WlEj4z5HzrJdVO1MP88g/oY+i+95GXl/nvMKANmtLkwcZpY3p8mCM+C47y97fGsoOcodBlfc9lYgUAgEAh2h4plpwHlozBmq5sxKcb4+0Zys2F818yEU0pH7viGfeXSRxqJC2OMfZnBeMKO8o5ML3m0H1VO3cthvnKT2KWKKfOwj3x+eyGo7D0PfQt2Vm852VaEravdKdeA5bgbxzkf6k/jWA8DFMh868GRGCa+qGAwgO+rMRSrmzFDjKnjrab/ottk1lgjLu5T8JwubUvl8ddbGFa2bMBD+KAN91mJ2GU3xtwM4U9DmK8lWyQiLMUffuQlKodx7jNQeJYg+OkUyrVkR0J6ZQI0dI0VLY/eLbfnZv1cJTDqK+ZJ2A/sDxKes+FwGUjc8WFp8Yr0Jyor9FeXX5IsOE+XhJI1ieQXiSZnKFnyy8m8WlCVDf+VKaA9TpOuE36xSX6F2Bd9RBrWqzZgPFyZ26GAntPIZLJbObRLSrB6Vit5yIvyjo+x/RECAwZWbvsJ5EMk/klLDxH9pyjewWKOi6KFUcI+GWds0IbtXY34rfE6NdhrKZC5G2DsXBg1B9YrYbyHwHAoSORkCuftCE5ZJZhaoa6/TRdbtetbXapWgWcwYGg77rxRzXAJechDaMjT8gxbVIckQI7p90y479V687RHsdRjgcxiGu3nj7S4AAAgAElEQVRFFm0wxi8DzY+RhrwEj0QJfHmMvvsKMhrqgxwcCeFpM2QmWfb++C1TDBV6kWX1QIjM9VovpUoyxJVjbSUEDKZeMt60/2zFnlvvqxhq9tV/TBfL+h2tiO/eb8d33l49ZgHJfFGgt4x48FR2kR4JQ3mmk2zYzxiJ3PDi7FrBLmWIfAkM2bHuo6niUH8YxjPqJ/4UjO+H8Y1IGAgSv5LEdnmCYwdThObm8bWpRyuPQ72ltBbdveWs6b2lTBfd9EpS3fcgDY4z//N48Rl0VSeANUgShvUmGSwNMv2HN8g3+v3JNMfOFrA1EYCtl17y8lLt1uI3MHO884oNZbLLQY4981d/40/jHFNo8O2WqoxgayzQP0/jv0Dd+9kssVrZ/5cz5JDx/bBKqKFerBgikXiRIbNW6oWlc2wMhkiOdnbfAoFAIBC8CtV2pH0uossQuODB9kme3hE3geXoVjbcDsl87Wb4mZvV/Dzm2lVJKZGP+/ZWXXi6ygnbqin0AF2NFzf1KOg6htqaMnoWDRO2LgAd9UI/x+7bmb+7ZUk2HBkn8aOEZ9RP9OAMnqaSX9FtcuZ4lplP80TLyoXK+/ibqQ33RRnXdRWu+PFYx8jvseO+WMw70AppZIrMvTD+MzZOPdAwvt3esekvTPRfrCnSZDSjHDQBMpZBM+ajrasyF55EcQ8EKFxIMLN5TRnXrSSGC6fwTlpIXG0eNpG5d4xjJHl5Pkr+RfmdVTzDggl5UG6ZNyF924l/rnqbMgjh95yEobRYMxP+tXOBqzES1hMezM0UCWsSyS/aKYhVFozjbAw5cJor1Fe/TROYnad7JMLNyZraynsdxFIGJq74cd8G6ZAHdcFVJ+lfLRqJyTCFi4lqj5QeK+OLq8hX4o0X/VUY6O3KspoD68fzxC6VPXxkHLdWWNrr5NQzD64jBnL1XJihwopeH315AufnjVKObbeWV7G5SK+goKN3nIK//vi0G6S/m9h0bTe+rTTIul/bHAvjc0vwwSkCCyoaIJ8IEbvua1uZl7jhZ0tVJmMdlOkz0KI6gRVfPt/wXUGWmQ/7ODXbZiOARi7njckR/8hU4bK+xYS9t+o81ZZhCftkgqnnTsa+nUAFjAM+5q97kGke2iMdsCCvF70UEtfL3isGrJcSLP1/xT7uONwsxGN3KVvJ61q+uyTkQQWF3VRevm500stxWLOjYd0UvvWsBmisPh3H2ij05Y6PY/cbKDF+14BaZZ2EcmEJ46ZXlAXLUC+yRaa3UkFS7132yNgn7ejP0mxG8O+RsRy2YHHJ9O+XQe8wtl8gEAgEgldgm4hkOOAi9B8X2x0aO0VHy6RwjMS2C/MAkgX7iBX/WmWk9y6xrhJ45xTaRzcJnVGQe6CwphK+HCJ9xE+0ZIlULiTJXjWWytxUNO2wl5mfS8vVdhdnPQ2UDYe9LP3QzvFmXJPzuCbbvF4F0j993Ez5uNnBMZbPsrz8rPV+uRY5uQwH3ER+dGLcW3P3XTKOa0s0chivf7IGz9BoJ/SDvd4vVVg+XmLp4yY7rE3jfGumelsugf+D8PY44d+LN16sxVxDTZKv1Fe9OL5X6NvmPlLBoKP1wjqXIOjS8FSWlKrAN6kRtf+dwGyWWG1yx312xm/Za+rQt0LGdWcVV72fesy4Jts/m/FElGQmjHyg1jInoVxZ4pfSXw3VGuXyew3I5Zpl26i1ltdQJ8dCbtaDydVR1oXNXATcdTY5tkGVgsqcDRUYR2d42cia96CZV0qJPQrjiV/w6TqFthUORlzfv6z/3tvidZTsc3DzcRRnjaIte89D30f1nnXrTPtlF/xtlJKuejp6ZkCPQjCdJWCsdcWu7uOtqe9RUltxAALY3tja0tJlvZJmY+ZzlaASwtCwOoOZ0KT5Dy/vVngQIZR24TJFmH7gZvyIAUgTnVzB9b6JwDcJnJMNPEdOBJi50MCfrBR6VU2tV1QHSFY851sUxWxQIaHwcALlnSj9iRWmhoRDv0AgEAh2h9cY6SlhG/Li+ShA5B9hPFW1aAvklsP4r2j47rxy9PZ2ehSCc0EC507x9wtlidSIedRP8laF9arNpD4tWc+j680XhVVun/9HYcC4dxdsQBUl7RpfSmqdKKlTpH7cn41Tb+nbUJx9s2/botJ2MbZjN9NNDAZ6jRorj3M49m2v3VxYy5DJGultWELtf4mhjjD/52Uz2Von7JExAIUeGWWww2SdtQqvXWZ3w0japb4QXkXbY56Olllh5bearb82GhMkrCd9TcqqlZKu1hPoS+zkmRmMzWqqt32W5h4lDWjkoZSsmzRzC/NxH/Ztlu0/U8I2nczdIGPnkgzPqvgIo7w/hvE7D3zjZsYeQ70kEXtXwf5JmMhlF5baMI7uXqRaj7wyvU3CD/5gCr9l0dDozeVBROgLBAKBYJd4rSJm0R08QuCqgjxX6fJqxDzixjeXwdNplto2MRxwEUq4CJVda1+HMAhIexX0e2M467h+VuK4uoS3aYK7/3sxSArK/TDO98JN97N8HCM0sstCYwvLcLvEXSbeaGHydEy3iC2V7ISWC4QnHfS9q2GoSK6WfaxS2OfBc1nF14llZ7+DpQu9YulYg1RTcaMjRkIsjexqc+rTJRUVB6/Jzf/ViXPqYJxTzXZpmrS0kk5d7l8HZUH7dStHWniUdEh12MR2gkfrCfQNPEkqaDle7RbPEoS/A8+yiuuAARgncT2A87gDRqObITyeeBLTF36Cs1ZmTtd49V228UbTJH0NynX+wUhDU2j5EIY/7TctEAgEgr8ib7x8+fJl690qKWaj3ol1o9Cpi+PWgcXa4f+TSXDn97vrLdF1CjtQTBR0HXbqIbBbz35dR6c6edMfz5/nXbZDZdKvXWlzRSm+jtml96c/UVnJtpP9vJrCWprkz3kw9aMc6FA9UciRTq2Sb1pp4E/O8wzq42zn91++9zf7sB3u0Lrc5NjahHQN6WrdZ9o6VxvnqWWnfa3UqlL1ipoa8G0d+grPvBPaTQL6B3qH7XSO+vOy0znjrzXXCAQCgeCvzQ4EeoFAIBAIBAKBQCAQCAT/a/6f/3UDBAKBQCAQCAQCgUAgEHSOEOgFAoFAIBAIBAKBQCD4CyIEeoFAIBAIBAKBQCAQCP6CCIFeIBAIBAKBQCAQCASCvyBCoBcIBAKBQCAQCAQCgeAviBDoBQKBQCAQCAQCgUAg+AsiBHqBQCAQCAQCgUAgEAj+ggiBXiAQCAQCgUAgEAgEgr8gQqAXCAQCgUAgEAgEAoHgL4gQ6AUCgUAgEAgEAoFAIPgLIgR6gUAgEAgEAoFAIBAI/oIIgV4gEAgEAoFAIBAIBIK/IEKgFwgEAoFAIBAIBAKB4C+IEOgFAoFAIBAIBAKBQCD4CyIEeoFAIBAIBAKBQCAQCP6CCIFeIBAIBAKBQCAQCASCvyBCoBcIBAKBQCAQCAQCgeAvyGsQ6Avouk6h3i+6TuHFLlxiXUdf3/nhBV1Hr9fANo7blfb/kRRypJfT5Orc727ez06f6Q4uhF7vQi8K9bf/L1jf4bN4lXt4hW/iD3t3zdjpvTfqD380/6v+9we9d/2Jirqsknlec461NOqyivpEb+eC6Porvq/14jkKLxq3qVPK50mv7f7725Xn1opCjvSyivowV3febad9Le+99NxfSxcvt385wy48jabs/vsokHu4O/2wfL5G66fXe+zr4n/Upp2Oi3+W+UQgEAg65I2XL1++3NUzrk3jfGsG568zuPZW/pBi4g0bpF4yfqSdE+WYfs/EzPEsM6PGql9Sn7+BjSQvL1nrHqk/UUkspskWQNpvQxmwIkutz9ucTttfwYsC+jpIkqHlrumvj+Gfa7WXg9APXiztXHvX3kczWj3TAvqTNMn0Cpm1AmDA9HY/lnesmPd0eKW7TkyzTrLfu6i60oMJ3rBC8uU49XvFDvdtk/TXx/ATYuljC6nP3yC0v9P+9WrtavVNABTWCxh6avvgTr+HXWaH996wP9SgP4gSvd/OYl3CdtqDVWq9ZxWN2q+niH6bbCmoSEc9eI50etH23nt9Onvvqc/fwHYZgjXjRe6uE5MrDldat2Fz3xOxlu8LoPAsTQYzln1bfbayHcpi/TZtnSBHOrVKvtEF3uzDdthIunROx3SDZ/FCJ/NQJXlf23yP0n4btqOtx6/deG5AaRx3Eye4vY+Vf6t5roWGgpRhcy5Ktbr3mvtotV81OqnbUZL1BN0DDnwjcot708ksr5Bt40qmg0pbc8nO34dG4ss4Gcw4ztuRt45k+j0T7ntN+mEnNJivtbkw8Sd19u8y4/i01J6Gc30LniYIz1JzX+1T0DUyTwqYDsgYa9c4bbdpN9cjOx8X251PBAKB4M9GV+UfuTk/7q/TVTs4rsaQp92Ef6rcasF3J4TdCEUNdZLV30s/PV9FR2c1paKWJ1hTP8qB13QHVRRIfa7gWO4j8LELi1Qg9zCK+2wA59w8vsOtBeoy25/FBhrAp8dQ36zY/LaP2DV788H/YZjeNoUVy8kZZt5vskMqRK+9mcY7R+Jcxft6kWWVPJkPjhEtv+2REEsft2hImQcTvGEN1PlhnOTLYGvh61kc/4de4hvDOBxWbIfNGHIZMstTBD90YBqNcvNak4VEjUCUf6zBz/NMfZmlt7TNfNyHvc3bAdAySQBWn4J1f5sHNRAOygvJgq6itrBDaLN+xi6ESTwFechH8FoQ14HmfbLeN1mk8htswnqG6St+Al8miv0XGfv5IKHLLsw9LY6takgC/wdh6rWkipGiUmOL8kK4DkYF7/sWGj6BpwnCs/WO7FzoNuztx3K48u1lmFbGiJ6cYul9c8X2XuRtDdJIXBhj7MsEGjL28yGmrjqQu2r3q8O6RuJCAvP34yhNBI7evXWewrME/rNjhBc02G/HNzlF6HhnS+6dC/zFBXbtlx+wvrG17UqSbLvfDzmSC8XvjnszqM9cuPY12lcj/uExnLdLPfbkDEu3HJ0LG89VgoqbeKPfSwJwM/T/hvGc9BN/Wu9XGfuVm8QuKWx1xTSRf/k3r7lRvAWilfPGSIhYh4rMzkkR7t3+/orUUQq8FgpoC3789+r8dMWG16KT/DlfWjPUI0NcOdbgHqoJpl4yXveZdtiPN/Loug4GiWrZNEf6gp8AQWw7FHwrz7UbStT84xgTBT/uT1+pMZBL4r9QwPKxvc7Y14RnCfwfeoj91kefCTY0lZxliplbXiydzC0AT1dJAjzW4EiTp/swwrGLtG/QqOCV51KBQCD4E1O9JF3XUHtcrN5yYiptMvQUiE+qSCdWiZ4wbe5q2FzBFNAep0lvauF7sU/a4Vma9LPSpgNymwJ95eI/z8rPoC1MEV4riW6VWv16PI0RuNxP9Pcp7OUJZcCO1ejk77dUPIfttCsDGAcDzByt2LCuEnjLCediBAcrZz1Dy3Pqv2WhzStry9H6mvjNHdKArckORpTLM5t7FPQ8Gy+Arm56yyuULglItdUejozz8uV41SZ9bozed9PEvgwXJ+HSu9pOmvCoE+2DVVbPmCsENwX7qBff5RQTgzbcX62Q/LTB9GyQ6T+8sSVIH7ag1OxikoA23R0LT6IELsL4JYmJc2H67/iwtPNqnqsElRCGz9z0925tLrzVnmWosOjHdjZLcCFLbB9o93zYBzwYfozhaGa5qPNNljG0bHeO+FmFQFeQmd/msewBnqeZvuJFOWsgfcfRvhVC6sf92XhTxYm+PIFzm7tiL/Lh7UK7NjfGqYINX9NrylhqlXDPVSbeW0F+39NuywEw7LWgbD7nAplvo8wP2bHfT6Jd8OBpqFgpkPrcjSfnIZGNIaMxc8GO7aKENqk0VkZU3wh9VqXi+m2wnmJi1EP2wwTZaRmezeAbsuHv0QgNdrLq3ilGLJMhQs12OWCEdtxaX+RIXHbg/C6Hcb8MT+O4RwNIs8G6i2jt9hjO2xryCR8O4oRvOxk7+gvzJzsUo/Y6iObnMfcOM8E483k/8j0PfR/F4bN58heKgrjW4PDCwwnsRwOkjAq+6RD+EQvGHuBFgdxTlegFD4HLx7B3raB+Vl8x1S0rKDuW/uoJowFsb5S3NBPM67w/TcV/I7HTxuwAI45v8uS/qdiUCtFrnwBAvx/kmKuhuqUChfEWCjFTQ8WSAWlQ2TZnVFEpuX8xTO8XdTwR1jRWAMiS12l3Ot815BEfvpHqbanPQ0S7zK9oSS6g/icKQOJ+EKXtsSVNeHQY7YNVtM25XUe9aMd+QSZzvf21FusZolcC8Nk40uQYYUsM3+EGR7/QURfZmQv/K82lAoFA8Odmu42pq5teSaoYjHPFf3p6kaR6o56E9aSvuKh4niF1P0nyaQHT2zaUAQtGQ815mlK5+NfJL0JuXz+W8uBu6m1yLGDoRiKL/hyo0BAX1nWMkqHNxXf5XJUa+gKZuzFm9stwbwbvkLcD66aOOhsBjMwsBrC2mDBzj/z4N+bJX2gktHvwXG2uRDBIEoaSdS+el5HfBLKraG+NcfPOOErFwWXLkeXjGKGRdpYGBZKLESzvj7e2UqxlSD5w4Lxnrv/se6x4PnEQmM2Q+9RSf2FiMGIZMIKeIf5thNhiMc5S2u/Ae9mLUj7oKcAGeV1HLz+DyvM8z5C4HWDsmo7n3gzj/zQw/MUw9neS+P8dxDNoRmppcZUZPuvrzJ0RAI3YV2GGr+fxHCo+fMvpKLGfZfx30zjOt7A1bPsm2+RRjOB3TqZ+92xZTPZYcE0GWen2EzvnwHeozXOV30MTcrlI6T1UImEeUDBXbSugLmRQjC362x4zykD1kTxK4zd2I+9kFVvQySzHiHwdZqbLS2Lah/lZGOdAH/HjPryfuFEO1PSbpzGCl02Ef/VgMQJY8FyLkPpbmNhHCp62LNQ1Hkv1MPWjHNh6w9q9IIG3wmRPl76LQx4i11P0fhXDO+h5RQthO8jYz/uwv8ih3ggSmU4QfwDWQYXhMz58x4vfdO5uafdUjPCXya3QgRc6mYdJ0vcTxL6JkHgKxpEQiWkvfOvEfm6CYdM09jNe3CO2ivAbDfVuAozj3LwTRMGO4f4xJu6qaCc7U+IUXct76Qag+A31lr+D7t4WIVAFkt8HSAGe6zOEjld8fV0GjAfsjE9Hyb45TORiFPXMFHYJwIL3hyW8gP5UJbFQDP0y7LVgH1I2Q782n1ur9peF0RdZVpcz5JCxDsqle5KazGml91e56UHhlQX65FU3x243/r16HimgP13Z8t4DeLa1DpCOBlhSvSUl3QRqw7PuQCG21aLS+9BJ340SnU2Q0YG9Cp6PPLiOFNu6+T5OT7E0aqb3H9WjbeHnkgWZGZLpEPaB7U++aPV3EOvU5b0VT6K4P5lG01RSpfFV3i+jPZUJpTu1U1ejfefBfX+M+QQEP/AQXY42UW5W8Egl9mCcSKpybpdQPhrDJsdQL9txtBqjX+hkFqMEPgmhfxhn5jMrhncnGB7pJ3luiuBJe8cheS3Z6VwqEAgEf3LacRpti8KDCZTjKn2nXdgHTOQXgtg+1PHMzjN+ZGvI19Iq6gb0/sOGZZubaeXiP0fuBmTMNpQWgsQmex0Eb6kMW4+hnrZjfhOy6SjxnJ3orXataVV3hf5EJXp5jNBzD/F0DL4eRrGoRSFwwEyrsHjtrhdvJshSPI/7chjnO+OtXYUfJYh+W9dJeRPzcR/2hsKERvTsMNroL/zy/tbSP3NjmL7LCfIV2nPlg3FcB9i2gGlE4UGY4D0vwcdB7JuTbY7pHyeYqd15jxGzMcn8fQ3XaB0R5IXG/GwcyzuBFlaGNOEhO+q7UUJ3gpgMBbSFIF6Lm7FUrMJ1d5rgeym6K1zoCo8ieM6EmX5mwHU2yHzGgbl0q9bPlsiMxIlcdWK2F5BHvIS/92HdbQPoWorEghfPdOUzNmAbdJP+cgXtvOX1CGiFAmlMW0LM5qW76SVN4X+W+ydDetGI4uj8rrW0Svq4t8PnpRP/sBfnghllyI3ncpLQEWNxPDjkY/5XN6l7UaJnbXiWMwzH89wsCXB6Jk3iuJOpygX6HgXHGSexdA7P/hZjU4+MfdKOXumxVI8DcoVAr5P5MYFjZKrqu5AGHHgdMdI5T2cKjWy+qASjMnFfyXOnKRrR92ycmgXziJPxS5CenSHgiDJ/rcarZiGCfwEc0248R4AXGeJnhgk8AuPbLoLxAN7j5uK48+k8mcFpghcChG/4SdywEEwlGd9jAD1DehE40UefAaCPvqPAvTQZHVqodHcRnVzpfcmmBmNjjxnLILCYLSbgqvBaS3/txP5JolqNbVQI1syH3PFx7H53A4XqlnJgK87cQ/iHP8Jdvj65n1RyPzX+XTpZ+ZeOOnkMdz2Xe8CwR6a/R4Y17TULWDniH1hwfpdDPqIgvwkb9wO4b08xP50kVjk3vdWPMlD7dDXiNyZK7zLHxI04ngHXtjGoeG65DcXwBhud5N474CbyvZPN3AfracIuOzMfhPG2q5CtobCmEjl3Cv+vdubvjmPfB+ZvxnCb+0hMtiFMvyi0ldug/sXTRD70Er6rYRgdIzibwfF2qQccGWcp4yD+dRDnwWEK++x4v5rBd+SP8EoSCASCvy67JNBrxC4H6L+1wdRQaeAdcKAcdPL36wk8R7Zce7OP06TXQeruryPQV1Kc9PT1jQY/l2LdqLTGGjCfvMkvJzTSP2rkAdtIkmCt1a0lGaIuDxN3UzDkxXt6nkx5MfrZEpkTCWLX/PTbE3DExfjtGJ5tIQU6mdt+hi/q+Bd8KIcg/pOCbShL7NsgrrfrL2HMJ5ZY+mfrFjZaY5avrWfBLFcvOeR9MixXx9/LFgWlzSQ0+mIA5wcqw7Mq5lSY8GZoQAOXe4NCYCGA+4SNvjk3vhP2TQuV/ixB7GqYtGWKmTMtrAwPE4QeeIin7JuWXstoiGC6m0gqjGtfuXdtX+waDrkJ3nYS3W/EUKe3S287GJ92MP5NjsxzA+YOOkplAsMNDfigwY5rGnFM+GvemeHNXljMkYPmAur9IO5/Ras2WT6O4X7mbn79Axa8BJj/rw/rP7durPDfeWbwEuwgr0VhLV2Mdy3+Re6nDNnKjvRbhsRCEt5r41zLM4RyHmIdL0Y11HsJvGdi1QKAvkpyWUWilz5rpVdQiXVQJvPkr1W0oSphmAHzkJfQkLfoovwCCi/A0AWF9SxY5Jr3I9FrAvWKm2Pfljb9rgHVFuTiNcw4T9d4GTRA1/XSWFZAfw79/6jpFVIvJlQCrmNESn25ab9DK0boaBk07FhyKsGKPAjZx2A+0aRBT1WmZ3NwPMZ8vCTAXLAz9uYwkckE6U8tW66rn5W8isq+qwYr3rsruIxm5DpaT+ltF6GEi9B6jsxPeUzlBfu6XhQUDsqlOcOIfBC4F2G4N9KksdspxswmSy71UXz/UunOrhZ/vGzjjXJyvbpHGzFbLXAvzfxiCt8R67Y5pPBgmugicMiGuVLhk0sQ+iRB7tA4S8tBFAn0/xbd9wNXYrgSnpKFvQM2lS8raGtg3VuRK+VFltVtB9SPHd8p1ksveXlp58ePJ/L4KwfmLoncbCkR3evm6TyR74r9eKncj5/HOfU3J9Fz0/hHx7f6calfbLnc66Q+d+O+B8YzMcI9Ptxfujn2Xpab//ZteYgBnq+W2kvoVlJaxQ+tUhg1trE22UpimFsO4/3IT/bEEolL2/tkSx6EOXY6hFrox/vJTbJnFIylsUQemSKZVYlcCTP8t2EYCHLzP+Mo9bwRD9vxH7Ez9Z0H66bRQCf13RTxE2NEmikcDRbcV6M4vzEXQ1hqkcw4LsVwfBYl9zSLoR2Pgd2kIkdPc8OJQCAQ/HnYLuJsDmZ5tB9TMBrERk0sO7UDnY7+G0hvVg+8JqNMrRnQ9oEPXzuT3vM0qUVQpRS50/J2C+69IM6H3WwmNFlvlEBLJXY5VXSzk1zc/H64jYub8XyTwH1Hqi8E7rfjvW7Hex0KeqE6/mpdI72YIPJ1kHncRFI3cZQsyNZLKqv7/XgOmomeDuA968R+qDShN0wAVp/0wzSJhjkFLLgve7CdOEbutAu7tZvs8jyR2RzB70Kdx9zlUkQnAwTugudOgvEjBrSWmfiLGA55mcm4ydxPoD5Mo2oZ9D1m5L/1453LV7kZN8QoY2MG7RlYy9b4FxqZn8B0tMlk32aG8UoSe2x4TlrbshjJg+OMv138f+au2jgrQRevFudo9TFVG/dnkOBZi+tLdnz/SeA+2ofzvA+ntZd8aobwl2mU75dKLsLtYcglmfhOw27ezK6B6W3zlvDcbUfuijZxmy2jEftyAvnCCkqH6zR9LkwgGyIxUtPwx3EiX6QojgWWbXHZ6dvOupUjso9V8nsU+moDKgHH1SW8h5u3p++4l/GBUlueTKM+qPw1h3qlNploK9pJztSH48xWPHHTfvdUJZZy4LDESDzwYjliJ/RD2Qm7lJir2aX2mDADqrZC5pmdXgny99Wi67HFWP2NdFeGZO1MmAymXjLe0FXZiHmgD+nXLbfjVkgGUBdTUOmmbupDeceN3WzCsNeMsh/0xfrHW05HCH5vI3DZRt9jH+OjZYWkjrYQY+LLOBpWgjdqEnSt54vWXLlvU4EpHbLQD6TSOXTYEug/CLPURsJCPa2WEu3FUX/Uce0FfU1FbdD2irvAVZP3AzqIu34Y4djFToXu7VVYcs9WWCl/74WiEqd3r53QpA3yK8S+mG6ScDNJsDKpax2ahoz19BbvV1sh88yBvBe0H1eKSpDafjzkJTQgI8kG+GmaU5/4iC7nwOgifMGFa4+Z7BM7/nt+jt3PMJMOtvE8qtGX40SOWLF+lyB5WakvMFcdoJGYjRC7FkNFwf9NFl+7Xou1HPEQm/Mg7Wtg5DAqeK8reK/paM9Bbtg2C767YU4N/p2/X1c2w/pW/+ZhqWmG+MrKB22Gf8ztsPKIQCAQ/F9E1RRpkO2EXDoYTJjftmA56ilBiS0AACAASURBVKbv7V40PYS7adIxC44LLmznx5Cvehm2GMguxwleiOG66t+RMKPNRpm/FCI4N0XskWt7rG/tQmitGCNfVh9IUp7pj3I4VBfukTHMRgOGHgkDuRbp4LbK0LRPRdzc0wSBOQ3H+SShIbm4WKgoW2cenSI55CPxXZjItXksd15PPKzx+E1+OZoh9ThLvlDAPORHvVJpvSzGZzb10SikiXzgJngflLNB1Ap39eokPQ1c7st0SZgHXJgHdngze12Evlc5Zu0jelTBsidLcjFJ98g8N2uFu0pqE+q1w5ty21YP6YCymeyx+79NdtxrRkHdlkxJ/y0Lx22tv49GcX9tXL9odUkTX1DRnmbB7GYmO1OKB++Aw16WbjXboYAaB8f+Zr25mGDuVD7ISiuvjFqeTeP9aAb3HW17duOjAWJNFpGWj5fqVHUoZ5qONc00begxQVpDw1pVqkp7DOb3FZSyQN9dO6oYsV9b6qj6QsVVkfbAys81GZ/XNFYw4xlUNvNgNO53BVJ3ImTPRUnsj2AqWYY7GmskO77vPSTeCzMsh7e27/dw85obmUaZUdpIRFbvcl1Aj1RUXD3WyGHFWHrWoBCcjmH6tlh2rB0MgyFevgwVa0s3DC/R6X3/F34ZBfbU9IMeK+ML82R7h4ncC3PqXnjb0d7/JKpd6AH292M/Auqsj1MfrWL/B2QWokQB6wU7FtrLKLNFmuhkFIwyMhrRySje4z5c37/EBRXu+PXYad6PEi901MXWarpqlG1Jy6JnjxGt2RZMvWR8FFibJtlUoM+RWc7Vr5RRotrVvwajg+D3HlJ1+nHs3zX92OrGd768rrBiNeRQT4SIXfdh3QNgwfefDPbZCHE8OIww3eTS20kTnZxn/GoGZcFM4Gt3w4SKWzcHPDfj/C5N9FATi/4ehYBqxtQ07lzC2LC6RAUGCblVn9nn4ubPDvQnaVayG/TKtqoSkw1OjHzQwsbvLXarol7lkdfIP4YZOy/K1gkEgr8WVeKcdMRTYz0vuvWpAzFCJ5sPb/JojLQ8TexOAPcXOvIhB+7K2KhOeDZN4DIE7/sYPriC5cwEtsVxrM002XsVvOcrlpBr0yTopn9AwVqlFW6Ukb1Mncy8ACQJ9Q5DretgiU0r/SEv87WCT23ZOknG/vFU9WJ/vx3feaW6BGBDTPQPmFtYkXVSc4mKGsAZ0g9rFmaD9k0BvS4GC+6rM7j3VSSMW8+R+WmVbCkSotvUh2W/hHJhCbNx62Tler+d0KyOr3ziJr+M6OSeZVgtGAlMykiV/aFLQhmkerFTSuSmP4gSzfQ1trzrKaLfrtL3uqwARgvKkJPoQgD7pvBYTJZoH/G9/gRnRguOk6+WPKk1WbRHIA82eoA66a/cOK7LxFLjWDoqjzTNqUE32tkk0Z1meK9Tdi/7GPKZmiRfNWX3JKuC590o6lPXVgK8NZWZew6c19roLG1aOKstjBK2QQ/D36po728J4bn7M8RPOIm0cdnCgzC+b20EH1sw7vESmuzH/XkfaoduuvKJm/zy+/hmCBPdJvoPV4wHPTLKoFKdKbwU++1+ECV6X29YnUSv+3spLv3+KqsFMLLK6n3gUD+ycWfZrXOznrZcu+vWWJd6S54xxSz55VSlyclehr8A09/qvQwLvoVVTFf9BL+bwJ8D9tvx3goS3MF3mLkRwP8ALJMzRLu89J/z4/3cRuJSe55EdSnoFLraOLpOlZPy8XqhTvLRKorzwtKZ8t/dmMxmTAagS9oav7sk5EEFZVuSPyvjL1+ydfWysr3zxHPyiZv8shHcKj3aK2N7W67rgVdxFJ7/vMRTuc+6jv4CTAPeYuLDdTbvsXGm/TIFUp978b8V5pcBCVkOI1u9BA8nCDYcN4vtsJ/3FBU3bzQpwwjQLClfU8VPA0qlHZuoPJEOmDFlNXqrYp2K5YyzRgczL11V+xsPKxhbzrnFNduquZRksx1eFHOEGPYIU75AIPi/j5Yx9PqaitZOaSLA+LYdz6QLX6c1SCt5rhIY9cG1ZHEBvT9IeM6Gw2Ug0U6JsecZ1MfQ/4/KjRKW455S/HUWKTXR1NnLIEkYXhTQ19tYPm6rV/sq1JYArEN+hdgXfURa1hFupQkv1uEuHG0eIybtL8X/rqeJfOQmuAx9Q/aS63WWzMIY8xkYvjrDVEWJMeunefLbrKJZZj7sIzFUXQJxs8XN+s3zDOrjchoejZUfa4tNmRn/zFRXOC5oCfwL3bhPNnhipVrh3aOtBPrKbOWlOPJfTSiTzWtZg4z7cpDocTcBwxRjVli57cebCRL/dxvi/GaM+FY7tIcamgbD19pM4lfTn/PPVtDyOt1vNSuB2AEFjcyigvl6ncbkVMKfnMKfVoilbjapP77tpGTuBhg7F8NwYQX10xaWrGYYFQLfN7/X5GQvw7Wm3D12vFdD9L8foPf2GDaSTJ31kb2aaF5usMwhDzPfu5vsUPomasZYachLcLIf98Veop/YIDXF2LkswbnWpQZzCwEcdpXhlFpKXGnBdzfGitWG8luM6FVX+1U6toWtpEnfrxw9TdgHTbBv+4dT0BL4L8ThMzOeo9vT2WUfl36/YqsQ6GWUUTssTnDqg0KxbF0O7FcdWGi72GYVm9nUG5C5e4yxbxv+XKLaS6a3VRC8ZMZxMYb9YiuhtwkvcqhfenBfTIDRS/CkBYshvBkG0P+4ZDluepIad/XsKupPRXu074cNnB00J7ccIXgjRuJeqrrU334rng/G8J5xFUtjblIS3irK0aYfJuue2zRox4T8epPjGYzIb62wcidB4kGGifJ2yYx1yMMv+ZnNEIlNSs9NfxglcHmCyML2IofykI/gtWDTsnq8yJG44sbzrUwsVYrj3+ciOquhWPtxTt4k8qnS/Nve66oRjmtYm8b5VpMgmkbHP5jgjUqDQ8dkiCkh+qoUCcWEiDPH6yjJoI05t4C24CdhKCXZrCJZKplbDAvN6LBRqgBgHLqJmmhSDUNfJbmcoFCRAyabSZB+toF9MkmzkVogEAj+zOxalnuA1Fe92Ejysm5MYLEuLk0mvcKTKO6BAIULCWZGtxZ4rltJDBdO4Z20kLjawpHzaZxjCiRf+ojmtzyctxZVBUz7lCaxYSUeRXHWWtYGFfjKifOr4p/Zxyrmaw0mrB0hYT3hwdws+/SaRPKLzhw2Xx2dxEU70b1R0r/aN5PoAHA+BLk4YxaF4D6NYLmcT0+90jAFurtoUgKxWRM00g+bOF1qKv4btsaLkjqJ5TZ5kWUVc/PFbZeEPAipbydI7bWUFBoS8pAZU6FxLesyhiPjJO4Z8J8fxvQArCe9xOd8zb1OoGgBJVWKEZcwH7EV4xUNJmwnzE2s+2kmTP0EarqK8e1SzPheC3azGdvBFtdvF4NC6OX2b1OfG6P/3RnkT8OsfuNq7hFSRY5plwX3jzZC9zL4/vmqS/0C2fRK08zM2nPgrdqtBiyfJVgxBgiMmHBixfNRnMT5NpULL3S09GqTsA+9vsLUYGF8YQXjxQDDJicc8eC9l8B3uMVV11NEv0xh+0+s2hV8n4vYY5nw5RUKnShc1zUSF/ytrXpVQnkNpdre7SKPBpmaXWHsXpgwYByZIlivSkab6OkYE183dujeaPXx7ogc8Y8aW5MNcil+/ECTuePZPOGLCXJGO6GFUEk5Y2V8bomN99xM/JynKs6sQTs23dX3W1HkPhTTMJZBM/1/6+Bu7rmxvDdNzmjGdT6E1yxjMRbI/JRFS0eJXXYTvZ5k/vFURfWTrTakL/jbyKkQxHbe/po8lgqkvhjGcVGtKf0H/Jpg4sMIExcVQnPz27+xR2Hs7/hJGRU8/w5VJbTVf5om9EkY90KGjZ/nG5axzM368CyaiaSmNnPqQGle+FHC+02OjVarsVY5YfIrLeeh18KjJAniFDIFXJuJjrNkf4Z4ulniv+a5EbKPwXy8ZuN+B0vq1gxvOazQbeorhlRWKM7qKf4Msp3QoI5WsY6Q9luwHLbglvsx7wW9qfemQCAQ/HnZHEorM3ZXUtcttUQ7iaO2KNbFbYbhgJvIj06Me2sW710yjmtLONq9VPFs1JcZ24xtPexl6YfGVp26SaXquPUCpQzYFLMs1/72to/YNfumZj71VS+O7+sn6tpk0NGGMFHUkIcM47gP1i/2ZJ4MtVnnVSNzP4f96xphvozRjv1EjmhO5xXTvzVmvx3f+SZv7UEB/40mx9dLLFdmbQbPwRYJeoyVCcW2085CSvqnj5spHzfb2HfzsiMhlkZa77cdC+PZSnfVRuRatr3R2NCM8tggjfiYfxzE3HHojRHHVZXsXnP9Ptcxmf+fvfsPbupME3z/ZYdp5Amh5SmSkatwLuqCHURgK3KcGaQMW+XDJdMWzXaQi0yQCjKJ8mM6BmaDDXsbC7aWyPRtkEgv2DANcdIdSiYTyoYZxqIrDOLW0pHYG2JlL7TFDFTEbVNX2kCtTyfuQUlc5fuHJFvWb8kG4+nnU5UKlnTOec/R0Tnv8/54Dr1KKwNZCcLSLHbjzhlgaTG+2EHfix3lb/aOH5fipWafkjdQqV7txpJrkqjWiONwH47DZWxvrok2//nc78030XK4zD64BVa6hoay5j+nRE86WPpqkXA/lQG/1GU1Rpr/PkLTpwEGWIq50LzhUgxHEvPAF5lQ9Nld61V6BUWfngAsV1I/J+ZZ2SFp4tnjCYWmDGXKnt6WwyIHHRdriC/LmBo1X8HlD7M5pklkCc8Z4WUOV88tWNLvOkbgTDcxoO3kAK60p7AojQAOFG01a4504r3gxLI+8zdUpCw5hoLHThTKgN+LvXZWdm9qoeHhqh/vTj8xmukb6shKCKqe2Uz1f+ik9R0/jnrLhMboWDhAEDDscPP2lowpEw0KNbe7ML/pw1/gMZa69V6i68jZhaKtb8ZbSj0q2att+KAtz2gAI8bV1Syd6me3FxSh+4Ab/UYb3mO9tK5OHH/1TBfuxTZsxz10vaTQnPOJKmZaDnbRlHOkU3LkUubL8w0oDaU9NSRTSb+5nBKPPWy+5cTnb87O4SKEEA+AsdtLesbuifJXCWpyDZ1Ne5xcbuOPYMn1nq7go+xKdZchVS2S3bxQOSqkrcP+w7acjQV5j+LDS7N6ss07CyfqKoe+cTMtk16XEWWTibrtTurebcWanpl+RCV00onrkAXH1gc4jUy+xHIAw2U/ROp3ivHFHno2lrfM+PQJPYac15US1rGwjGzcJZlkgrCKmbFvLzY0+kFV+DpZUm//nQj9oex1qIOF7xO6J4oMQS5Xg522DQWCgYcTnd2a5Ggyd5mrz904GqHvsIdovkYkCmfw1v9ZvkZELbr7drnVYXjKBMeDdO1uRb/dQp2hDr02MXUndLGbzlMAFpSys23mkcrNUI7MjoB02hr0TwCf9uM75aOmwTw2vH7oZgD/uX4ATIbsYf86gxkTvQT3OXHqmmkyJZaNx8L0B3vwHIOS9n1KGia1LDUpKPf9GpZDciqVW+Mh8I6J4EursO/W4jYFaN02hOecF0ukFUvDGtTuLloashvmqrTaPB0vydF8D4QhotdjxG5GGUpcIIQQ4oEzdslMz9hdKY1WQbnooem57GzA47IfaTOlZmtRVvvxPNdEoVJk9oxPiWQStsnqtdUwq8i07JwJnCpZV9GkNwnGN/wMLPTgebGOpkvpfbp6TC8244y4sZQ8N3oanLRTM6vQDDlrWfNJMxnWn+c8lfUcPPByTp+YifL07E1QfsKt4nL37k7kmsQc1gfcsc2sKjpHvTQarYKymvGkfFNZjrFrYWI0WWVPKMgUovtHoQKZ0K14i+bumH6GLT4C8WYcBzy8bMm+s+qW2XCf7Mw75LxclY9MysdIy6keoq+34nlpDZ1Z7+uxbO+jY0uOa/gTLfguguPFVtptvvG596myTvG+F1bCNWxPvmmPUylO8JiHwFNewtsTyRn1h/u4u3UNdVuNdJz0JnKlLHTjO9NF6+4OAk+5Mh7RV3xfrJlD7qeFgeaLd7GPaKYwX5IQQkytWaOjo6PTXYiyDauoaCdmOZ8GcVUlPqVJ8WaOuJrIklzud3DPjlnaowGn3bCKOruCfZzMPkziN/FAnMeV7ntcRY3fg9E25Zqu82+av/f4rRCB60NQU4eyJCMqLfi4uDQVXEcA1Gt++qNQs1wpPHWo1HJM8aituKqWlJW/4qR5YxuKJbK3P7wUc3150xNSx7B6sRljSaPj4qiqSvRa4kknifnL2skdt1T5S3p6yxQYVonc6CeSTGxRra/DsEBbJON9QlyNEUnuO1U1LF2iRzelv/lkpvbJnhPleJDunVOl0uvig3I/EUKIMs3MgF4IIYQQQgghhPgd92+muwBCCCGEEEIIIYQonwT0QgghhBBCCCHEDCQBvRBCCCGEEEIIMQNJQC+EEEIIIYQQQsxAEtALIYQQQgghhBAzkAT0QgghhBBCCCHEDCQBvRBCCCGEEEIIMQNJQC+EEEIIIYQQQsxAEtALIYQQQgghhBAzkAT0QgghhBBCCCHEDCQBvRBCCCGEEEIIMQNJQC+EEEIIIYQQQsxAEtALIYQQQgghhBAzkAT0QgghhBBCCCHEDCQBvRBCCCGEEEIIMQNJQC+EEEIIIYQQQsxAEtALIYQQQgghhBAzkAT0QgghhBBCCCHEDCQBvRBCCCGEEEIIMQNJQC+EEEIIIYQQQsxAEtALIYQQQgghhBAzkAT0QgghhBBCCCHEDCQBvRBCCCGEEEIIMQNJQC+EEEIIIYQQQsxAEtALIYQQQgghhBAzkAT0QgghhBBCCCHEDCQBvRBCCCGEEEIIMQNJQC+EEEIIIYQQQsxAEtALIYQQQgghhBAzkAT0QgghhBBCCCHEDCQBvRBCCCGEEEIIMQNJQC+EEEIIIYQQQsxAEtALIYQQQgghhBAzkAT0QgghhBBCCCHEDCQBvRBCCCGEEEIIMQNJQC+EEEIIIYQQQsxAEtALIYQQQgghhBAzkAT0QgghhBBCCCHEDCQBvRBCCCGEEEIIMQNJQC+EEEIIIYQQQsxAEtALIYQQQgghhBAzkAT0QgghhBBCCCHEDCQBvRBCCCGEEEIIMQNJQC+EEEIIIYQQQsxAEtALIYQQQgghhBAzkAT0QgghhBBCCCHEDDR7ugsghBD3wvBvfzvdRRAPsLkPPTTdRRBCCCGEmDTpoRdCCCGEEEIIIWYgCeiFEEIIIYQQQogZSAJ6IYQQQgghhBBiBpI59GJafPX114yMjDA6OjrdRRHTYNasWcyePZs53/rWdBdFCCGEEEKIGauCHvo4qqoSr2BjcVUlPlLBggAjcVS1kq0+CCo/ZgAMq6jDFWxVVXkQD9lXX3/NN998I8H877DR0VG++eYbvvr66wrXMMnflBAzSVydwfe/3Kbl/lRxPUKuN0IIIR5cWQG9esNP9yEPnv0ePO/6iKgZH7jVi6PaQe+t9Bdz3yQnBvBBPNXVeC5nfGgkcaPM99/Y8pc9VFd7CBbamwnrKuHWO5x/uxPKUHxNCZfamTWrPbuMOY/ZuPitEL3vJo555wkfodjE94NvVVP9VsE9zyFG76vVOE7Fin80V5lKrmxF8O3vIph5nhQwMlJpq47416bic6HIbyrdFx8fZev/XsdjtbU8/dL73Khsi+J3QDz92l/C9S9ewv1jKgLx2CkH1a/2kutqHjvRxKw3y70/lCKCb78HX6U/mLH7ca79L/X+FKP7uVk0najsPpallHpELmVcb4QQQoj7bcKQ+8gJO+ZtMdbsbMZWryH2yy5WGTw4TvXRtkKTfy23enHURmgdbcM09mKM3ldriGwbpW1FgRJ82kXTzt7Ev0eiDFwYorphKTXJkln3nqe5vsheqGG697bi3N+PJrVsdAB/vI6WPW6cGwxocywWfKsa8+4i68aKd7AH24Jin6tM5IQd8+44m/c4MNVrUG/6cBo3U3M4wNvrdKWv6HInq1LHMSl6BYbCdla9m/6qFfeHzRgLrizx3fWsi9KzoVgZYoR2+NBvcGDKdZBzkJ55kZLzXFCDdB0LkLuNyIB1uwV9qRv4ws/+1/4G2j7g6upH+c1XUFtxacV9dfssO/78pzx+4jQv/PG93VTsgoeWrW6643oUfRVwl8i5CJoNrXQcaEHJeRkM4qk24yy28vVeoh/YyHcljZ1pxX7Tzvktha/K91+MwI5W4k80Y1lU4P6fRSV0yEHT1l5YoaC56WfI0ILnsAvbknLWA8QHGLgIgYUDxDfoyL90iM5nWqGU+kKmmI/WTR5COd4ybvHiXlvGfVgIIYSYBuMB/Z1e2m0qruvncSxKvtZgwbSwie/8oBNLqKVIEFih+mbOf9ic+Petbppqe2h6r4wA+lYvLzc0E33JS+Cugi7tjh+/5cfzukLduU4C71izKlSmXaOM7iq07kR5ClEvddF1MRl6RAIAePd7SPxLi/kVR1ojR4a4n05bDGf4PM1LUi8qWBdrmLXFS/O6Mo75Ew56PrCnvRCma62ZHquLnhcNaa9rcjZuTBQleh0YuVvq1u+Jx2oTodevBwentRwPmsdqa+/rMbnf20Ojp67+LkOZr9/x0/5cCHM5Af2NX/Hz2xs41bSIecC8KS0ocPN9NvzdYk789ZNTveZpM9j9PKeXvM+Wuvu40VzHcV4ti/50GY9O+ZeWLk5o/xosvQY8x8N4n0i7Oo6ohE46aTauoulMHy31meGkibbRUdoKrD12oomaU0WKMBzB/wAOp4+f66EL4FwA12qlQDA9UeSYnbpuI33RUSw6gDiR4w7MDa1or3RgmV9qCVT8e5x0rWvDcdFJ6ykvHevy/fLjqOf8sKfUdacZUYmc02K70kVTZr1DU2IrtRBCCDGNxgP6G2G6MI8H80n6hiasm/xE7oCx4I24i5Zn/FSlvRK9AvZtZZTmTpQIASK3gAVAPEYoOJCo2F+LQFY1Po7/cDP9G3oJ/NCUVeHQLFBo6+7l7korXZeshUcKVEizoA5jfTL0mBsGwFBvJBFCV6PXAPnmv2uqqNYNEb0Th7TSx79UoUZfQuCdZrYGrXZ8HerZHrwxPep7PQQ2usuoRAGf+vF+CqETfiIbHaUHT1NoqoPI+x6UziAP3LHR6DA25OgVuxWjk0hZq7o9eAVYPjXlymEwcJqP2H7P1n//DfLRP3wES4p/ckq3mus4zlnGq0dc93bDN7w4d2jxRDqwLcx4b7YW44YOvCNNfGdfL/YCvezT7r0WVl2sKvABIy3vuZMBdgluduPYFGCzrw/22HEc89P1iqGEoD5E72EfLft60ralQb/Rhev4d/AFXVjWFruzxYld8uLe6aR3oYfAURv6W728vNrMqosuXNvsmBaU2dNfgiqtFq3E70IIIWag8YB+gR4rXgZugCktqI9fCdD7hAFn0YDQhvODVsxjf0fpeWlp1py/rjdW4X8411C2OMEzXtRFVXT0+mlZoaCJR+i/HEoMvY1EyQ7oVWI3Yli2ZgfzY+aaWLM2hjsSgxUTazOhQ6toPVNgl0aiDGCgqcBHNAuMKKlW/arEzLy6BiV/r/wEJprfs9C0filNG5sxPwJDET/d5zR0nHRXFEjHbwbxHnTiPKOn89xnGD9+mVXLV2Hd66J5vQn93CIrGA7S/gM3hu7zNB+34zyu4N1YrCQBXJtW0VXomQlr3Q/gkFJRigcm2L8VoRdoLenD/y/+9h9z6BdngbOsq90HNHLw/z7KszXAyG0Cb+9jv/d9Prn5CIu+/1e4/vOrmB8ZX8MX/T9n/7FT+P/hEwZ5hEWr17F15w6eXTQH+AJ/+7Ns/5vrwEc85mZ8/ZzmtT/x0ZjaVkr/IR77Ppwa3MKTANHTvPYn13k18hqa421sOXSaG396iE+OPMsjwBf/dJqDPz7IqXPXub1Q4dXWXWz9/qKCowwKLfPVxTcx2wbZFTzKs6lr1m8/YX/Ts9x4JcBPV1/HZW3l6D8BF2vZD/C9ZHn6D/HYkVo+OvIkV3/sxPU3fgZbT/Prv34S/tcn/Nz9U05fPMsnN+GRP1ZYt2UX27+/iDn5ykYtT37vNVw/Wcf/dBc6jltY9neDE0YL3A4cZf+Pf8b7/YOw8Emet29n+8tP80jq+hM9zWt/coUX/scGPj/yJgd7/Ny4XcuTz72Ga88LPP5QWqHuxPCta6IjM5hPo1/ZhHVThAhkBPSJYd69uRdLlmUADIXuIJOnXenk/NGs8SwZqllaSrAaj+E/1MzLO6JY/t5LW6MeDF1s3rCUpefcdOxxYFlSeEXxGFQ/nHlHrqJKC9HhQiMRVHw7mmg97idubKZlV4jPUg17C628HTbjP+LC1fAy/RqFpt1eOtY/sE0sQgghxH2TFtBbce7rwtLYhLqvGaMW1KvduLcO4Aq6Sxj6XUW1VpvWqxynKkeAZ9vdQ6uJrKFs8UseWg6b6Qg6CG2w4DgewLvRhGN7MjS+FKf1SPb6NBoID8bIrGqNixG5BjVPZYf8cdWPv76PoR3mHMulbaPEVvv4l4lK1d2JHe5j7qoq6lxgthZtMrDWrnZxPtJK+NN+oneB1VacB/VoynqgYBz/7jVsPuZnaL4N+7Y2QvsUdLOBhW/z2cog3cc6WLPYzNB8BceBPlyrcxQw5sNpc+B/qgvvBgW9yYPfZGbNLS9d25Pry2KiZShMc7Eizi696yM11D7XkPvUayn53sv1er71ZQas6a+l/l1uWUrZv3zL3Y/1pu9f+v9zbatQD/5UHpdsEXz7e2FdC5ZUI6Nu4k9r7Del0aKdcEr/bzy9ZReP6X+D8p8W87NfvUY9MGcewBf4d/8522MvcujEr1g27zdcfc/Jlj//Nfv/0YXyh8lVxGHRc262/vhR5vA5H/2fW3ht889Z/ItXeZx5KG1+js6tZR3JwDYlWs4+Xuf07le5oXkW1wc7eFTzbR4B+NVRXviuj2UdB/nFTx6DQT8HdzbwwudnOfXKstyrR4VpugAAIABJREFUKrLMnJU7OPRXJp5vP82TR56llq/45IiTQ/pDfNRUC9Ti/MdjfLv2WcgIogH4xUcc3X2Qzx/bztGgi3m/9+j4gVr8PPvfcPPoHPj8v+1jyw+28Oiis7z6eOITX/0/h3hhzQkebXPxtz+u59Gvfs1HV7+ids48Hi/jON7+hy18d/cX/KXnPT558lH4/DLv793Cd6+184ufNDLeHhNg/w8GUf5qF3+75RBzvrjMT5tfYNOPa7mwRxlvFJkNumCEGNnNxWNiEQJPaHJc0hPDvE2+ocQ9La9SpjmVQB0gcMGPlmqWmozohsP4r5R6sg0xEPQzUFOHkisgHwnisThwn4tT94MW3o42j+cNWGih42IU/xEXnrXVrEHBdbSPtoZczegGTC/qaPUFaVmR1tB+00/PSRPK7kIBuBZl69v07axBr82x7tk6lC0dKFvcqDejxHX3O5iP0HfYQ7QaWGKlZe10jF0TQgghsqWFaBqM288TXuuj54yP7o/j6FYqeKJvY5rC+2ZVdeawNpXwCScOWz9rgn4sCzVYTnQmhteFXLh2OApsX4dlYwvNm1roNnmzh0wCkeMttFxswftOnipVVTXaKRpnF/7UD0QJfupGyRreH8CztYnu2SR6qzfG8yT+CuE76CN0C/jSRNsFF4UGUiZoUHb2ENiZGdQk6UzYdpmw7fISV1UmfiiOei2A72Qnzt0hjAd9+LYYExXQhTa8V/S0v2SlxmDGtacZ62oFQ8ZoDY1WW/L8ylKkAuhCgXbma5nvpf+db32lKrcsk1nX/Vpv6u/JHJtC6y/WaFKaGKEdrbAyEdDHBgdg5RrGO717eXl5Ly8D1u7sBI5z5s3j2w8BaPj2vHnjQdyv3mf/8eVsv7gF8wKAeZg3b+e1f2jkvX98DeW5RIPEPPMLvDC2tnk02tfx+PHLXI++yuM1TJGz+B56n0Db02m92V/g977Jrze/z/vfX5Z4/fFn2f6Dj1i28yyBTcswz8lcTynLzMH8H4+xpelZXD1Psl9/Gtd/reVg8NkSEwW+z+CyAD+zZXz6D5/mhRfH/5z3vedZ1/FzPrlxGx5/JFG2n+/j13/1Pu//VWo/l9FYdqLRq5zqOM3y/yPAloZkGeYpbGnfzdU/aeP9TY1pjRBX0Xz/6ITPbW19lUO2X3F9j8JYs0G9DZfxO7S8qeDbZcoOvNUg7W84qXv9s7yN2tn3tHvkdmLEWjVaqoxGdGqE0OVw1seGrnhpv2KgzVZHdeabS/S5A/rZJhzv9eHQ6nPfQyYE0yoszHfF16C82oV5g5ml11pofqoGvgzjO9aH5oAPR562KIDIGQ+91/K/n4shvbFPCCGE+B2V1eeqXaLQpDPT9ErqFRU1PerUKLivm6jOCrKdmGdl5/t1FZlDHz5kZ+lBDR0f+2hOJR1aaOXtjw30HuoiMkzB4eua1W4Ch1t52fQdvOuasa81otNAPBbCd7yTnriVzqAbJd9Q88F+/BcKJ3+rXmzGWGzO3rAf7wE97n11uN/z0bzCklE5NONMT/YXD1EFYwG9ZgGEbD50H7RhWW3FubB6rNex2CN2gm/OKiFb/0SuYOrpA3ECRz0Eaux4oz1jjSdxVSWu0aKdb6Lt76M4LnXTdbQd73xzsnc/hm+bHc/VcraamMf57x8ur6yluJfDwu/1kPN7vf5cAfVkt5krgL/Xc/GHhkExpueWqOwJFLdvXOZXi+p57A+/4IsvUq/+EbV14I9+Tt48+H/4KI9VUvAinn/maSbG59f51XF4+ieP8dUXX/BV6uVHF/Pk7ct8/r+ArAaFEpd56Em2vrmVZ1/bzmu1H/HoTwLjw++LauTZf19K6P9HPDqh8/I6Vz+Add31ZLVDlOPWDT751dN8908yylDzJI3fvc3fXhtkS934e+YlEz8356FcUbceR3c/8VebMCw3Yd/WhGWhFlCJnO3BczyIYWc/3lfy98ZGQn78BW8hyR71ybZ6Ll7D5u1p8/i1Flq2W7I+FjsRoD2e8dkSaHWl9Dhr0C4sstZkj37oTB/+Gyo8otB20Y2yqHCrR/ViI8ZiU8Iy1NzXOe961rzecs+eeCOEEEJUKnsQ9a1eHLX2wvMCMyvSC2z0jNoqKoBhSx+jW3K8oTVg3eUe/3uRlfN+MOT4qH6dm/ONrYTO9uG/GkqO1NSi7A3gfiL/o250T7hxa+KELiceWJOvZ0NbVVckoI8TfMuJ90UXkS3VxBssNJ8I4N1QoIKkMWLbnt7nE6TdFkBvUlAWTOytiAQp2KphemOIoaxjmMhh4GscoGt9dneiZqzipMVyoI+J1cLsx9bpVthoW5H+HetQdvdQeLJCNo0WRn5b5kJpModzl/revVDJ9vIN35/seiez3ExheNHL+SlYz69vnoUbZ3n+8X3Zb35vkNs8ySPA7f7TvO99n8D/+Gc++qfbyQ800jgFZUin+b2MF6KDXAXO/kczp3N8XomSHdCXscycp9bx/MKD7Pr4BX7WXeY5k1lWgNufcLr7ff428An/HLjO2JH67njZbgDLHppUOA+fD3KWeTRmrUYDs+Gj2wUaYwrRGmn+4DPs1/z4zoUIXU6u1eigZ4c3a0TSOB3GfW40w6llhujvbie8vA378gl3kESP+tTncQNy5IKJDsCdMPZnutJeLPS40hjdz9VgP1nOVos0ps3WYVznSNtenNhlP1Fd/sZx7RIFZUmOaTYZImc89FLekPexBuqSlxBCCCFmjuyAvlhwXuBRbpXcaFOKJqgDwIq7wZC7UqLJrEAUp1/bQsva8b8r69mIEz7mwOpbQ+85BY0GWt7ajGKys1lT6DE7qcVjhIJRajICdn2DA8fKxL8DQ610FlrHXC1a4qilPPoobf7+ZGm0WjRj5S+9wpov6X8pCgXBheZx3wuV9kZnzl+fqt7zByZ53RS7OzQ+SigeCzMQ1VK3uPL1PbqgEVYqfNT9fN7wb2yudsd+frq3lnlzSCZb81W83dv/3z8D/7b4B2tqWQS82n0D58oSg+Aylhn8u//KwX95gReafBx6ex1P//WTlfecR8+ydU0bX7x0iH3HXNTOmwPc5vQP6jibUbbf/PYrmEwffU0tjXxE/KvMN+LEfwNPP/JorqVKpl2iYFuilLGEHsv2lrTG0BjdH7cTb9xMy4Yy56kFvXj2B5J/RAmfCxH5MoL/UgRXcBRHgUWNL/bQs7HQut1UW1Ty3x102D4YJfuuH6R9lhnGRnNNRpS+navwbfyMno16QIuy4zwGXWaIPXGaTS6xT1tpxZyznhF4z4PnIgxFAgRvqJA8hugsvH2hr8BxVBkI+vGNhAnfSh6p22F8n0a4u9pNYENley2EEELcD9kBvRrMM7c7aag/74OjCt1owYDVfx7y3KQnXymZDir+HXWsumih70QbpmSgrFnRhu9jLY4NrXQt78FRKNC948el9NA02EPLUBdjXQhzx3sTamoUij4FOObHtclDaMKLCpzcTFOy5+VuxE9wU4DRXaXl4C9JWvllKGJ5Cs2b/90VoeuZ7/DyubSXLNV0r1DQPwwsMGIxmKmZRHtN7ZJ6Hr94lo9uPs/zObOb3+byP57mtu00W8xpG4oOchmye+iH42SHqoMZQ+O/4vqvPqKkgJ7FLHsOnP/tMttXZg7Hn+Qyt06z/7/c4PmfnmZ7TT2vmd7k6Mq/ZUvdxCVKDb5vf+Lj9O0NnNr8dFrjyK8Z/O9Aqoeex1j8PXizWNlyHsc0NYt48vGP+EVgkOcXpn0vNz/iFxcfwdw6M0eoaPQW3A2JO652kRG91ohxpYOlS2rQJvOTxAo8rTFyoavw3PNICMoeSzXFbvjpPQc+bZDIRj16NOjqlbwN56mn4eRyNwJsynw1Ub8Yu7PVG1Gqali6pAZNesLMSzlWOFePZZ8F9WaIsYwE8/UY640YbXrqFulBzc5VIIQQQjwosgP64Qi+HT4MH7Sh5BxqaMS4upql5TzXHAAthoYCvR9ziwyHq85IDRfz0ZoVwBaxrAXvAQu6Gz48p3IlE4rA9T469kdzJBPKNfJAi7IjQHSvLisDvLa+mZ7rydzvt0orniZPZiXjlvPFhxrrLLg/zJ5PmS745qysal2+kRHRKzAUtrPq3ez3rHvP01xfrED3R75kcJNZ31SWpZLPTMUy6csVSxpYicx1Tl2jhB7Hh4V7JAG41V35Jh5/nu0b/4a//Gsn/OfXsCz6Nnz1Odc/+YjP9S/Q+MeP8Njjy6DHh//5xdTPg9/c8HH0JyfQMDGr12MLG+G/vM+pZ/8tllrg9x5hXs0yzHVXOXjsfZ5us1A75zdc/8VPOXrhj0os4DwaX9rF0e9u4bVvu3H+RT2PzoHfDF7mk1/N4ennnk7L5l7OMoOcbt/Cddtp9j81B3gW5098PL3zIOae7Tz5EMBj1H4PftZzinVLLNQCcx6ZlzfIfkS/nMc5xdlzz7P4T78NX1zHd/Qg7z9E2pF6hMZXdvDz76eV7atfc/mT37D4+4mGgJzHMWtry3i+5QV++p+2s/8PXfylOZXlfh9XmtrZn5mVv4jSRoVNlLr25U7gNkT/dYic7cBzK+sOkjeBm3aFg5ZJ9IDHPm2ldbCD8xtyTUgD6o2cX1+Tc7rafRHz4dzoRNsdwHvWin2nDt9epeD9fuxpODkE9lWzJuvVRP2ion3Upj1NJ5+cPRxxQj9SqHunjr5gB5ay60RCCCHE1MjzcDQtS5Nzuct2dwhVzdu/D2jQ5kyjWyadgvODsmdwJyoRWj3G+hxlqDeSt8mhJruCBsB8XVmJh/IZe/xWXlN03DLoV7fRljPzcFveZWpy9Grej/Knzz9Pfy3zvdS/c2W6T18m1zpzbaPcskxmufu13nzvlROUV7rc9JuHsvf/4tS7+zi04/vs+Kfb8Mhinm5Yx5bkQ+4ftx3i4Odvssv0OIPU8uRzf4nzJ0eptR2csKZHvr+Ln111suu7dexY+CRvdp7mhX+3iBc6f87gbheb6rZz+5HFPPuCkzf/pp45K0s8To+/yvsXajl65CAv1H3CIFBb14hi35p/Dn+RZQZ73mTrf3+V993jQ+xrm3ax7+/MOI8onG59kjk8wrNtP+fqTieNdduprXNx9O9e4PG823yBQx3/E9ceM8tuQm3d87zgPMTR2r8g/UjNqdvCz3vnsf+Ii7/4cfI59M/t4OD3CxzH7FYL5q12cUF7FJdrE0++knoO/SF+8XKuRo7Cio4KyyGVeyRfAjdjff5G63uawK22DqVhCkdeTYU7YXwnPHj2+tEfSOaUWevn7tY1GBQrrr3N2OtzP6K10JMDMtv2p0+caDQCN6qJqoAE9EIIIabJrNHR0dEJr9zqpqloUjxgT/bQ7ZLnwedNzlPApXZmmSAw2lYw6/0DKZl3IOew9JJHGlR43NIkeuineMh9qeVPjY4Ahn87iax44l+duQ89VP5ChX5TSXKeiUIqOu+mSexEEzWnmoh+kJ3fpdSnnOR6tGNhlc+hV0+9TPXrAWyvO9n8ii3r0bOxC5243uqk52OFrnAHlrHgPbHN7OflZMhR/yhJpfWIvNebOOqwZsry0gghhBCVyA7oH1QjcdRh7kkv9b2XSFg31c9rL9uwisrUJcWr1G//5V+YKaeduLdmzZrFQ3/wBxUsWfw3JQG9KGQmBfTEVdT4vRmlVXizKszV5uxFn5Eqrkc8IPdwIYQQIoeZE9CLfzW++vprvvnmm+kuhngA/P7v/z5zvvWte7JuCehFITMqoBdCCCGEyONfS7u7mEFSAdzIyIj01P+OmjVrFrNnz75nwbwQQgghhBC/CySgF9Nizre+JcGcEEIIIYQQQkyCDLkXQgghhBBCCCFmoH8z3QUQQgghhBBCCCFE+SSgF0IIIYQQQgghZiAJ6IUQQgghhBBCiBlIAnohhBBCCCGEEGIGkoBeCCGEEEIIIYSYgSSgF0IIIYQQQgghZiAJ6IUQQgghhBBCiBlIAnohhBBCCCGEEGIGkoBeCCGEEEIIIYSYgSSgF0IIIYQQQgghZiAJ6IUQQgghhBBCiBlIAnohhBBCCCGEEGIGkoBeCCGEEEIIIYSYgSSgF0IIIYQQQgghZiAJ6IUQQgghhBBCiBlodvofX339NSMjI4yOjk5XecQ0mTVrFrNnz2bOt7413UURQgghhBBCCFGCsR76r77+mm+++UaC+d9Ro6OjfPPNN3z19dfTXRQA4qpKfGS6SwEMq6jx6S5E5eLqFJV/JI5a6YqGVdThSjc8ie0+CCax71P13RX/LcVRVZVcm3owfof5y3cv1z2V+175d3kv971Ek/r9MoXX0Gm4BsUnue/3UsXHdRLn1CTuA1N2L5qUB+D3FFen6J42iX2ZbBkmUx/4V2X6fkvTf2+qfNn4dP8GE6WYxLWg0mXv7fVn1mgygv/tv/yLBPOCWbNm8dAf/EGBT8SJferHfzFMdOys1FCzzIzSYESnKbKBeIxQcIChHG/VLFcwzAcI0j7LDMFR2lZUsBOTEqLzmVbYe57megi+OQv3oig9G3QTPlXaBUmDVlv4gMTOtGI/FCqyHiMt77mxpBWh8PZT243R/VwNPeuyy1+2S+3MMkFgtA1TjrdjJ5qoOdVE9AMbmVsKvjkLMwFGd+VaMpcQnc940b/nxjLSTVNthNY82wVQL3XRdVEtYb1azK84MGkLfab8cy9+K0QgVoO5Xkfmt13+vqdM1XdXwv7c6qaptoemwR5sC8pcNvXJYvuZ5/wpeB7P1qKdW6h8E6WvSzNXi2Z2/s+OmYJ9L67Yd1lgW3nLF8G330910fN58io5h2NnWrHftHN+izHvNbS0Fflo3eRHKfFakE/hfcj//cRONFFzo7WC3++9ETq0ilbckzuuJf6ecipyHwCID8fRzM28EpZ6PUvcf3uLlWNt4hiUrdC+j8QInvTiPeUjfCfKwIUwLFNYWqPFsLoJ+0YbpoKHWiV8oZ9ovrdr6lCWaAveK6dsX4qopAyhQ6vwLvTiXqtLnAcH9FnLq5e66Lqt0LJWX16BMg2rqCUFrEXqWCNx1OF4aZ+tRLHvoND7JfyWcqvg3jSsopK8n06Q+3eZ876s0aLVpNePi/ym8+5fkPZZbvS5jskNH56L1TheNHGPb2uTuw5WuuxktlmCsSqPBPMCipwHN320vuSgV9OEbb2Csiz5k1Mj+M84cb4Ux3r0bdyFLuZ3/LgULzX7FMY/FcG/oxNzcJS2+eWUNoJvfy/hop8zYN1uGd9ezkaFapaajOg0cdRzfthTaH1BPNVmnMU2u95b/IY5HME/18bAO03UFPiYZsLVLUbvqzXYT05iu0lFg+El1snfnPNt+5cemn/gpjteR8seN64NhmRAHEc9Fynxhp5L4nzyNTbjbiiz7Lci9APVURVKvKWoF12sKreCpobofN2O60SYmM6AbVsXndvLvInd6qap1p6z8tv890N0rM23tjixywEGvkz+eWcAFZWBoB9/6vdXU4eypJzCAEEvnv2B3O9FAoA548UQXc+14o34CWJC0VcBd4mcC8IKBb2thEr7SAz/Wy1sPtBNfKGC/mGS64ig2dBKx4EWlAlfylTue7HrTykNSJWKEdrhQ79h8utXL3fS/KKL7qsxdMtsON/tpLm+hJUOh+ne04pzfz+aDa10HWzBlDqGwxH8JXXdFAiCaupQ5qpEClwL8l+/Mq75U+1yJ6t2Fg07YVkL3gOW0q8LeRq8U43dcdWPv0hTcub32Xqkk5Y/K/J9xny0bvKQq2nZuCUZxBUydi74iACgx7LdhXu3DUNWEFFI4v5r8g3RWijKmZ2xPwWuhUDxe+JwkPbVVvwmF659PRjmJ4OfkTjqcJTwqU6cxg6UU37aVuQLCiP4f9Q+VoboFT9D8xWWpm7sa90oS0pshIj5aN0Uwf5hM+U2W+TvJMjuGMikXvPTT6LhIVNc9RMpMlolHvHRemPppOsMoXebaD2T/krafeHhtJfz/b5ifjzbNuM+EUe/Wk8VwJcR/Dc12LZ14HlDQVeowfeGD8+pAjXL+eZ7E3QW+B1ak51MlQi+VV1Go2zu+q21O0rPhlLqx5NwJ0TrWT32FyfXgBp8cxbm3Tne2FPaMZiWa+gUKKUPY8xjtbUA/Hpw8J4UZqZ6rLb2vh6T+729BBXfvjX4/yzAwB5TVk+kss6B0+bEvNKDb6gDS8Fz34x9e0taq12Q+I7OCspUjb7emFWWCa51s+r1OOb0yt0dPy7FjeaHduqqUy9qqTKWMMIAABNto6O0FfhEogW8lHUBwxHCoQIt+w8vxTzhQq7D9sEotuRflfcCg2ZBHcb6CP4fNRFbdx7bEuCOn/bnYlj9Ngw11XmXjZzx0Hst8e+hKxG43kfH/iiJJYpUqG90YV/Zg9EXIFrjp6VRwTk/gnt1+S3o2hUOWtJaquO/dOLV6dBFtZh/0IKp5AplhO6dLUTXW4m+3ky30YttYfGl7mYEG+mt20N3IVGbmLidLlsd3if6CAyZqVYDuDeYsYz04/9hkfM53QIbPaO2ia/F/bRWtVJTW+gHGCdyJUToTurvaiz7LHAzROhm8qUl+vID+gUGjPWG3O/NzVU5MtL84Xnq3pyFGQ/nd5kY631463wJvQ8Rul8y06H14L3ixZjeGDiiEjrppNloZ3Mw/Xucyn1PXn+udbPqlI6eHypogfCJVfTqemhr0KPP92WqQbqOBVCT+xEAeM+D52Libe1KB44V97yPIvE7fMqL0RdgyFTNUNCN/Sk7mut9OBYVWjCOf69CS8yFL9pB9KAd8yYtn/kcZQbRQ0QuhxKNIkP9eH+kYk419i7RoxSJZhLXr4zwN9c1P1NGQB69AkNhO6veTb1ixf1hc/5G1oUKbT/Mc64nqRfaabpWysihNDnvTRCvTY1eKyLX97nSQvxjP231hXoyVSLntNiudNGU2XOkKXYexuh9XcE520XP7b7E7/BOiO49zSivawi9Zy27Jzp2s5/+AsWtWa5M7G2ccC2sYHTTVT/OS5sJBB0TexNna9Bq9ZhedOOKzMJ8LkTbinz32cT1rDmtDF2r3+b8KxUEtyMqkXMVDs0t0ElQ7KsMn1zFqgrrElPJuOU857ekvXCrm6baIGz1Fv9Ob3ZjN3VQfcBL+D0j2vQoJ3leGl/aTOA9W/7rg1aPsV6Tdi3XAmG6lV50H7Sh6PX579PpjQFD/USI0HfYQzT5ezasa8GS79o6ohI5Z6JlqDWt+TuAu3oN6r0KonOy4s3ZixwpsEwM3zY7nqvJP79MfLblGf9YFSgR2E5tSXMx7RpldFf6Kyq+16vx6Eq4HkzLNXRqlBzQT3UQOT1B6czwYB6bOOod0JuyhxWnaBYsRU9PYs7hFJy/TtMsnKRaBnP9ELUYGhQKVquqgqAjR5n1rHm95Z4Meynb7Qj9l0PkDZ3nV1GXYzh3gspQFLgTIYYJHclW9mjivYEi9UnNAiPKghpiR6DKqKCsAG7F6KSKugal4FCw6sVGjMlKlfqlD2J66uqNya++Jv/+AKEznUT3ddHXqAccdB4OUn3Ch3O1dRKnjkr4hIvN2wI0nQqhnLNi/Q+teA46sS0rvNb4LT+e1+10aD0EPrDBCTtm0xoi3V20NOQ/5xMBYi9crCMC6HKNnsi4EccvdOGMuvH5kgGH1oLr+NusWdyJ75W3sZY1SiVj3Rd9eJ+w43ti4uuRkB//XahebMa4QIvpxWSD2p0wwYsBAjfiOabNxMrb+Hw9dca6PAXzl7euEqhnPNhjTgbes2VfA2ZrMW7ooEtdxdJ9PiyHLcnzair3PXn9qQrCBT3mBgUdUPVL8C8yozQUqDxo9NTV3032xGoSAe1yI8ZkQ0L1gikeGppTHP87TqL7fMnfIWgbXXTuq8Pyjh/7XiX/ea/66f3RGjpvOzDOB+PeTtxGC2uUbmpmA9EBeK6UMuixbG/BAnCrm8CPIhMbe28FCy6duH5lFG24F9brCzcsPOGg5wN7oTWjpcBZMN+A0lA4oI/FOuFawY/kUem9Kff36T26hu8c9tH8TvFra5VWi7bcC/CnXlzHm+j40jF2P2C+Eds+F/1VrXi3WWl5ouAaskSvhAgV6A0u3MARJXodAjcSV+SSLDLSrHPQcUhB96IJfXpjwUicyOUuOo7paD5a+DsfM9xP4CT4h/1EXsnRyHXSTs0sO+CqYMh1CWZXUa3V3vthy/dFnOC7HQRWmKg52EVwbVuBRnoV3z47sd0DeDfk+K7mG7Ed7GLomaV4zljyj2JL/r4nXsurCOJHb1KyrjkTJBsDALgzhI8YeqNxrMG5puiXkvndVWf3CZQlRuQKsPAucUCTMa0legUM67KXuquqqGnHOX0aW6I+kVm/1KHs7skahzeBRkvhRoF7ZDiA74gRy8c1qGqy0OrdHB+cpmvoFCmrh148GKYn2NehbHDgfH0zztlOHI1G9Kn5SHGVyKc9dO50EtrSRdcUBcmuqZpDv1JfcDh7+UqY5xcdAENTaatbvIbN2yucT3fLR9cRHTqdl74bNhyLYOh6iNA1gCEitytZaWm0S5SxnsxE5XXpWFBTWIxwMIRl63j3m9aoYLX2E37HWmblRiVyzofvnB/vqS5ii1twXfBjW6KBFQEC9e20rqvGOd+B1aZgabSgLNKOLRt6103XqV56Pq7BfsBPeIMBjarCei/h5d24thrRb62jaZ0F6+vNGcO3gVu9dO63YGl04j5uo2ejPsfoiYlCv2ynZlP/xKGUixSsq18mEOrAWsEoBQCGg3h2e1F2hrKGaaYqyNqqOozJYDF+qR1lnZ+lr9iwNNQwdNaF+SUVx6m+CcNKJzYG5C6bRqugXPTQ9Jwnb/GU1dbSRx+UID4chRX2gg16huUmuJDd0zWV+14RjQ7jWMBfRRAg1aBWsgCuTavoKnQXLzjXOEzw3RrsZye+b1xtp6YxSHivkn+477UQnesVnGNBlRHz2hg9Ix7aVutQL7SLSLZIAAAgAElEQVRTdhPOCECUodJnu+QU/rQHo8lR+Do0OzWfNk7sUi89F6PE0WJY14Rl0RTWxhbq7mNQFSL4oxrsoYnfmr7BivJqgP7DVpR70U4UjxOihurMIEtTRTUh4hV0M5s3tUwYdVVWcS758MZ0cNiL7wcmLKU0kM630HHFR/eRTl5ebcd/KS3oWGRCWbkGx5kwtlKmohAn+JaLnu0duK86cR4z0/WKYeK1r4xpcTPOey2sulgoBC0+9H9MPELvDjtNH68hcK4F3lIwr47iPebK00if6HgyLS94V6BuBfiH71FqsvTGvlsxOgmztFgjQAW63liF/+EShnPfCeC/qEN30Udgt4Iy14jjgx4SzZlRel5aii9roQCerU10p91b0of8J+oT2fVLjVabOM/vhPGd8RG+A5oFZprWmwpPcUh30YX9ma6CHylv+kHy97jRSWjEQ3V1+mQCKxNr6dN0DZ0iJR3i1FD7XEPuU6+l5Hsv1+v51pcZsGa+lvq73PIUUup+TNU6M99PvVfo2KQvV6gMU3lc0unWvU3/ch/eA27su3sJ3ki9o8e03oJ9e4D+Rn0JFZgA3v0exmfbJoacFmzZq1As0g8VzKRMVeTDg0DW8KgS5/kle3mKGmutzy9340ZyiPgBH4EFbswb21l6tg3T2hZa1gLE6P64nZ5SyjBJd4dVUO+SaPOcOE85PAhMOP0iRE5aWbov7aWFegy46dhZTaA6cT6U9q1pqZo9BEYrnVs7kkFX+pDLNnqut6BeC+A7F84Y+qRFM1+PsqcP9zJ9svU5SHt1KuGMDbffhutmCN+FKDWZ98yR5PHf68PfqKAY7bTrfbQVnGuVaC3Xr8tsYqqiSguROyol9yqlu+PH+Zwdv6UX//rs5bMryBG8u53UvXOXjsbkHarBirK8ie8c9uFYMT5MNldjQKasIZKlGIkTuxGifxCgH/+Fu0CYCBB9z4Pn4hDaBieOPIdDqzOg29dHcIcpT49NnOCHPnSLlIzf4dTu+6TFkz31Xyb6T7gTxn8lOQHnzgC5B9mYaBkKJ4f3FpA51zidGiUa02PODHjm16CPBYiqYEwtPpj6fhK5Roj0w/KJjXe6xVaCN/UoDaZEA98NynNrgF7CWO5A7GwTNbZUk2lmpauAuJ++wzXYz+oJX/CPTWPKvgYBROh9aRXNNxVaX7Gij/vpajTQudVHz5a0qS93h8Z6dcYqrCWI3OiFh1sn3YgVOrRqbD7x3QiwKc8Hb0XoR09T5vepqUJLhNgdoGBQkaOBaFkLXlsEe2p6wpcRwDFxsSVGmnHS98sWTH82vrfxX/bRQzOucqfuMD46L698AfFwEM8bHZiPBnBctWPZ1oX/sKO0efzzjdh2vY1tV/GP5jUSw7fHjuPcGnrPNWO6o2fzhqUoV97Gs82OaeFUX0PG839MaHTMFRRlzjdXBwhc8KMlPSFxka2FA/gvaOFahFx3aN26LoYai6+n2Ajk2Kc+/Ge8uA77qdngYeBcMhfDLj8Di5xsXm3A1bAZ50YLympjWrCoRbdIh/vDIM4/y54aCsBwkL4zOgwN96GpLX4XFZW7ybaD+K0QgevJKUJ5jmGpbLt7EvXPggczTvCgi/5tvXiHrDjfasK/y5R2HYtTlTMKNON8L3/itkR9Inf9Mn6pnTXrutBubMPeUEXklBPjQQNdJzuwpK1vbATA7LRkffUtDIWL3tXQlDyNMk74mAPrYT2eoBXdQhgdTU6WTSaom2DS19BSpE3BmOIcVSUF9KnguVignf5aviC80PrKUW55Kl3XvVhnrvdTf0/22BTaRrGGk1JoF1loPmwpXpHMZ76C06/LSPpjxOi3UlNwzub9larIR27l/0xV9eSH1ug29DC6oYIF1TBd29bgxEPgDSN6uui9sQbrU/20HnTjKKlhZaqohIJ+OKfBf8OBY9HEecqRW+SoTGerojo5NE1DOH9GgSy6huYi56MG7RIF2xIl6x3DWkfhKRuAZqER64sTW2zVG724X22ma4GHwA+NaDDi+3CIpvUG/GtduA+kDT/NXN9U1ulGYgSPu3Hu9MIrXny78lRisqiot0H78MRP1+j0ZHapFewtu9TOLFPR9JATpRLTfNqVDBQUFHppP27EYqjBsM+NcYEBg64a/SIN5Bl6q2nYTKfRjNVWRde+ZpQl48FW/E4Y/7FWHCfq6DyXOXR8ivZ9qlwL4QeiFwK4Vito1Aihy6k5mJGcTwSB8oLL8mkmnqe3woQux0nlGslVBcldMSxdJBxEpxsgeEXFkbou5qp0FVrHcQ/txmY+e2KI8P7QWMLCXNeg+IUumkM2ei+6kg1CFqwNdTTpnXgb03IInHTRdLmKQj2Lk8ljUox+dRttyxL/Dp/wk3cSwmzNJM8HMy0HM+d/atCORMbzBVzrxn8pYzGthZa/92FfuZSm7S00maoZCvbg2R9C+eB8kXw6mYrnp8lHvdqN8xU7/ZYA/rV6NGu9dG21s9Tow533npho/M2bYDan3POL45920tS4mfDKDnxnmxPX/7kWOs59hu+Ik5ajevx7s+9BkzNEJBQiVJ3R6GhqoSNrDn1GB8OVXjp/lDibrHtLC+gHTnXSfolEw05tjn3RaJl8Ivk4kbO99C9owhvyYpzwe9Ng2ODm/PpWQmf68J70oW9ID+g1KK93UtdgpamqC/crCob5Y3cF1Gt+Onc46DZ2cr7h3ne1qleC+PGjuRjBsUhP/FY/ocvJJtpIlNwB/V2GVDWtIXeIXKl4itc/VUJv2bGea6L3nAkTvaxZbUa57aVrjw1Dkd/lXVUlNhxmIHoXUIlcHmLpK0uL7HEE7x4n2n2f0bMxuW+NVsy7zVgP+4mMTeNKGwGQPops9hQ+iSAWpGtvCy9/XEdfsANLCfmQJn8NnV73bMj9vR4WPpPXnyuYnort5Qrgp2Q+frGMn7nka3lKDjXN/bgqlURHiB7b9c+omoLxaNGbAVjeWnafZ6oiH4y34s7zmVQvfn6pzPk53pqQFKtEqcyqd3y8vNxBZIMH/55UYhcNph+eJ7SiE/fVGJp7l985240eukIuOvb20HkiiH2XaXyeMoljODHloQ79ul4iMSB1kb0VoR8TresVTMm5aqXIm80U4GQNs2zZLydGOxSpyOXsIUpV5CL4drYSbvQSemO8l1K72sX5K030XqRAj5AOvUFHJBZlYk98Yt6nobbUMzVO6Igd+55e4itduM+FsRbJEzCREesOG+btm9HvbWaNUUP0Qi+uHV5se8v4vaxoG2/xTlPSY5Hqmzn/YQlNg1orXUOWHB0ROqzv9KPZWs2ahg50sdjYnGedTkcs1kRfzgSdU7TvUyKOv9tN3cEO2NpJ7+sKtkUWWrZbEm/f6ibwo/SANiPxUEnyBKLaGmp0EaKZvQ6xCAFdNc7065bJTsv2tGC11gCnxvN2QKJH2nS3Cf+Fu6hhFX6/nDKG6D2swbV3M85jPUTWlZtcL9EzZH91CNfHdvRo0Kfm5pPrGgSRq35iVs/E0R0LTTStsxO5w/jIrE2phI3lSIzEsa6b/HU4fWpT1S8LfFCnZ2mu7/NOlAgG9CX0LOWe/5k2hLgqd3OCfm0HgWiI3rN+IjeiYLDTE+3JCMYKS0+yWqqxBGM3unAsb4eD/fjGRlfosRwMEL1Q6J44McHsZGiecOC94kA7P+OGP1ePZbt37FxM9GKXOHqvqDz5FkqZQ7/SibfMYf/mncmkdJfamXUg7Y1Sn/qQLu90IA2mH75deOrdbB3GdQ6MOeZ+s8DK2x9r2Fy9BuWgjlhs7K6AThcjtr6PoYOW+9DhEaHnWD+ugy56DnYT3NCGKT2B76U4rUcyFpmtRb86iOe5JiZMXlutYC0nWkuO2OvCTteJVM4BE23nBtBta2LNNg2Bd/Ilq9SgXa3Sva2JboAFiYZ2zQJz/iSvKcNhQmetNB1N/61pMD1jIXYwxvj4w4wRAAUyxOdV6AkHu9txH4tg3vc20QNFnmiQbgquocXdu/xdkw7oM4dyl/revVLJNvMN35/MOiez3AMnPclHqQpkR4cY/j2FKqWJR5Q4Jj2HPs7QUAxl8VRX0XUY97nRDIcIXQYYor+7nfDyNuzL0/e7QOb8CUmxSvRwMrPqfAtvRyLZXb0jcTRGO05jqpVRi7LjPAbdvbx1Reje+TKaHVGaVxsJL2/Bs7rQo30A9OiNOtwXQ7StSNzQ1Y/99K5XsirdxWRnMy2VDuvRIYaOlrdUIqjUY/vgs6xKYFxVic/WozRAfDgxLMyw/jznM8YAGFY4iG7zEfyBEVPqMH3qxxtrw13yvDANxvVuetZ7x3sg4iqRa/1EkidVtb4Ow0IDVv/5HNNGQL/BS0jfjfc9J/YfqeifsGI/VW7DAIBK8N0uAnfGX8l+6gHkffJBsUdOAfmz7mqpfgR4vZfoLhNxVQWtFk3yGbjVeXZl6vZ9cuK/dNF6bjOdwWY0I14sO7sxFcq+XErioRxyj8o0YHoxSuuZIM1PmMaGYAbP9sCL7sIjVxYuxXrST+COLZnEMUSgV4da3UX7ZcpIipcQOeHGbXQQftEIJ804Tyh4N5QeDMc/9dC0rgN9d6BwJuI01To9hKJMnLIfIxLUTUHNKNFAp59/P8+nXN8nhM55if7QXfbjz8qmyx7JVI70JKulGkswtshBzzeOrO8trqqJe6IpOZplrh7LPsvEpHdQcqdF4adPaNDOp7RRS5OdQ1/xI13vkaJJJnPIOR1oikZMaKupATafitK2Ik7itqBJjqSpvi+jFyPHW3l5bivRLRaMYQMt+5XEcPdCC+ksuD+0FPpEaeabcezz01pvmLivcw04jg7gKHj+pD+tIZOaVp/QoG90Y0mP8ufmbiSODYZBkydhLoBOwflB2Xe13N+jTo+50UXooGli3Tvmo3WTH6Vg/oZpvoZO0qRvW/l6f3MNKb8fKu2NzpzDnm+o+v0oywMnleRjWEVFO/FxMRXRYTlwnvyXreSjqyZNhYcdKIZcKfFSc89UIpcjqEQJn9PT/GGBi86YtMzMQGquerxxMy2lPiYnlRRrWC3peetZw2tTwfxIDP8RF56jPfji+sSzvEeiDFwYonrDZlw7m7HmnfubmuueyFYaSj02a6ifCCreHS/j/DSC6Y0eXLnaZ0Yi9G6z06LxEtigAyy4T4VQ1q3h7jteXI35j4Vpg4ualU48K7tw6Ppx7+ujead7Ur2j8VtBek8F6A/5CCWnSuifsGA0mmlaZ8pqWNFotWgmXZFTCb3rxLm3k37N+DOH70b8RDQ2Nu9x0rJu4nKaBgee5Wbsr2vx7raji/XgecON4UCgvIQr8/WJoGs4TPfuzbSciLK00YLFUANECb+5mb5BPfZ9HbjzDKfULbPg2GejZVK/aQ365Ubufpn2Ur2RCQMyCz1KLNfj99KVMexaU8YcmEnve2qu+7UIXB8Ya7yIBCFy3c3mUyHC2Oj4YE3OxdXLHuzr/TSd8icadt7w4tlkZtVLd+k74Mg7JFKj1aKJxwgFo9TkGwFUksTwVMNTdjZrvbRt1BE73o79sIHOjwtkuAdYYKV5ewvOAz6MO+pQT7pxa1rx+VswkhyhUeIc+vinHjZvi9B6NpFB2L5nM11P2XFqe3EtL7a0SvjdVta85Ed5x09HGY0AugY7zVsdNB/T41mvRxOP4NvbQsdqD4EKn/c8zkjz2QGisyv5csbnRUOc2NUw0cEalH3F+pE1KK96MJjSvs9THloOGPAEi3yfWdtNvnIzRCQSgWfctPxZCfsyEkdNSzY2dLOfyJBKVW3x+3liJEIcVS0hWdnsHPWQVG025sez00nnu0Eii0wo+iqiV/yE55pwbGrl/2fv/ULbuPKG/49fvPvK+6QgQxYkSF+ikkJkUqhMCpFoLjzBC1bIA5FJwBItpEoLqdxCI8XQWM1FKqeQSCl07RTaqAstciFBCjRYgTUeX2SRAg1WIMUKJOyEXw0SNKCB9bOeZ2vw70Kyrb8jyVaSZvd8ruzRzDlnZs45c75/j/+jOjH1uyW87+q1sZQ8bJcHbzMjQwOvpXVa39K2MtdQLpsks1Q0dijnU6yd0Lm0LD6++L9C5pFKQclief8q9WekEukYgXeCxW/oao7F+Syj6TV0gwVKrtJ6+9i3RiOPidKacEtGHkPboZHrOwVlfwbl4SSRpV6KuZ4UFi+PEv8pC8cmiTfIF6DcGMUzZiCWLiptnBcTZAZdHP41Suycs6nFWLkZIcF24qsNWEpbyNYtqxXJT9dqPrHxl+2DckWODeeYgf5TQazfB3AYoZCZYvR0jtCNOtb0svYajYZijoG8GUfDXZ1awYK9nmeUpqLMZsith/DVVe51Zg5NrmbJLpXmsV+yJO8prAyGSW0lvLYNRJb7KhrFnwsg/Xlvh+IEay16lXQqSZ4J6ZOrtR+i0kBWN/aeNmDe58Q22IcVpU7Gz6dH+vPexi7jGzSyTqokP7ThXQ6RnJ9kpkJo08jfCuF6zYmSSTXYNsjASq6YEb93MFx6TgbMB72EB4EeM31nzRgMRrhXdamWJjLgIvzHAMnpTYui4cA4yZtGvCM+orfijfey3uNl8qsso2+ZCSxbcZ9NEm20hUxTNDKXDuP8ysjoeS/DYx6CpmIG69yDBTKzYRwWFd/NGfztepqUvC+0Bgu5zOdO+q9JzNxeq9H6ao8SBN6SCHRnq7bHseC+IsP5AF77KIWdTjxnZaJtCCNltZD+3IP/SYDUz24s5TP6mXBpT95hIpaFun1Af0wXPVFoGltpKCap+Uez8xrQLPyksPBUNrrZ9r13qyh3M6hYCa+vQHdacJ2ZwwX0WoJYjAaMqDWLovz1kziOL+L8IVbmzWLB/U0Kw9hJvBctJC9UJ/Mr44lMSIozXHdeaINdLqLzGsExL44PC/Qe8RCan8TVtEwD0rkknvc8OHqzMOAn+r2/fQvGkySjQ1OYv5jb6J+G/eMkfzQQmFVQ9dwE1uegHg+R+wtNt6asYaeTyfsJImM+HO+lUUxWnG8Fka/oeUi0jsFkbb+cbiOWQUh/PUG65OoKRixDVsxaCxs+7XYTnafifQbno7ibxY+W1wsY99hxWHoBA2a7C2vD6zNMmPsJVu3vZ9pXUm7usuG0WnE0VcyUWErgbeqtw2YejjrXe94I03t5ioWvqvcgz5K47KXveIG/J6tCOlZVlMyijseciqKzjV4FTZTEhfstzGY7LDgvSsU5cacF224jtv0OvFYrZmMpTn2pQTk7LEiki/HxG30IDLusSPsl+vYC9+tfaj02x9ybxb+dFL28LEYDBiNkZps3+7eyj/22UZVirPurYdbFVeMeF37ZBfRiOWeht9sIavXMrpG+JOG63EvgVnxz3O2wM34rifG9YXzfzRE/oT8z5O8FCOBoINA39rprv6w6VvZ1jP14Ph7XMbypyJ8Nk60aF7aPZBZNQQJHrBz+KY/lgBff9SR+Xa/NUom3QxxqFqq3RZTZGAlkcjczeD+ygdGO90ydfrrVObRMrtgY/Tst2PbbsLkt9O+xgNpm6HKbdFygb5QMbjvldbo9WzlnO+dXX9csaeBWqS73t6uU0FBuBUjujTNeN9NoC0nytpOMq9FABpotmerH+RVYeAjKrXVNbiUbcX51aOoyrmudzJL5Ms9o2ruxx+kmBkxDo4wemyCezeN/vf70aNnIiN8mBju+Gxm8ptptmYz7fcQfNo+NthwJM3OkUYaCdsiQHJPx3l5j/M2qthxwYj3gxPJrF45bGfz7q957ebxyXfR2CsiTTadxfZio68Jl2OPC4xzGcS/L5JGqendYcV+cwX2x9rr2UFHuZ3AclSqF+XV2Sxw+6NHtA40peqK0Qvb6IQIPq0NOyrESvmit/5FeVkiOJbFeG0eqK0DbsA320rfxW2Uc+YoCULVV0j+K49j/J7mUTKiNrZKAlu5ddx7Rx3QsTCpnxFTdnm4LrstFhcCzwrDXTfgHd8NcIQ3ZYcM3vYhvehuV73RyVVmsCR8y7vdzdT+NhRbQnYNar9+O/5sU/m9av6Rx3g4HXQ2Usxu7lCwl8LwxTPrYDAv14nibuNy2otja0vvcsquvjfFcK0ns8q0p5Zp561B/K9CNWtJxpu2j/H3EVvtsd1pxvT+K6+U46SVvZTzsE5mQFMN8UWqohOkdbCD4VPMkQ2BMYVJ21w9b2W9DeqlPv89uZ245EmauyTc93+B4eb6GF44Ki/JKsb+VtnZbp+Zb0SAO21ge665HjRbagP1Ugsy7JmoiHY02fNf+vvWE0psFYR3oVHJFY0W+owoqtlatR578l1ArohYTF86MdGJt1xnU2SCec0ZiP8ZJHRnmpGmOqzoGlC3Noa2M2bpWC43MZxL935SS97WyzWYDtiXQl8eelx+r/m3973qZ7suvqVdmvTq20p5O3Eenyqz3e6Pf2hXIt3NtS5Rt4dOIVrMvG60OJN0JQ4cmbm1Pi0Zxfrb9jSdY81ML2LJiO2XCeyWKc0+1UK+Rn48Su25HOvt00nwZTNtxi+okJkxDEE0mye931rgga0tJZmbB+V7ncylY7XYSX0ySsAVwVbgZaqj3YkxeMeH7qlke/e21wT7kxFOvDasqmeshJm+7CVzWufemY7q1zLOWdkJOajC2sVevkX73OOMbHgH154HKo7301RuHHbr39qkjzG+Bja1/GvK02t9BtrHtw/OYg+wfFSi0uUVj+TZLPTtA+XOG7BdO/cRfgrYx2SScxyeJ3pIIDlX1jdU8ySuTJA4ME6w7zzjwnGkg3LSNhf4B6T/z/bayRtxhLG0T20GqLcof1zup6lvRTLGyFXaYOmNd7uS36bl957bAajHLv25rWtxNQX2QJHY5QmjeQmg+inuvAXcaRkde4ZUbYSbPeyt2x3k+aORyCjzqJafSgkdkY1oeUo2EQz2hsVkceqtltpMR/mnEuzcrcyvPZjt1bqXcTmTVNxglpNsRho9HdM5q3RKWcNfPQr7BdhPHbAl9d6bflgbbiPOLDLHPg/jsJ0ljr4yhP+IheD+Je9/zbme7WHHJQXp3Ag3DMsqx4J1epPfPISTLYbI7Ss+hlFyRA168Y4vEO5BxuhrbR0kWd08ROmZl+CewDvRhXlGQ7yhYhnz4pzP4nvJ+t5YTcRaNkco2/LKI/FMP9hNeAvPhhi7UrY1pF+G/+pq6Uzcdz4BrOlfMklx7NZ6Xu9BNq7ThZmvAtF/a9rzQyXt/5nQbsZRnIm5Eo0zATxnjwSBztg6Mt50SQdmKueW54Bmwo0n2cD12ubj64wyGgeyWFpH1kmwKytjjJXa/h9CYgx4n2ActRQ+d1RyL8xr9p/ykbjYaz0EcXc28/kKk1sZbENSblxXadtLfZ4v12BzBHfo9v7U5FVwX5vBtO09FdeXNLMovDp38NrVU1nP6TtSww4K0PM3ocX23L9sHMcJH9FqrIY9Z8NzqZ/i9cTJXyjLd73YxebtA5uYU4WNWvEMxlIutxMc/LYw4v1AoXDBsOz9Z19ra2hrA//zzn5T+FPwH09XVxX/94Q/Puxm/HZZV1O5O7K26VYpJglryeihLsNfxPapXNdRltqbF3VYyxc0MtW3V18HnoKkqWisa4bKEUM+03sqLKOaU+g1p3AVbe5fFK1sf/0+L7SZD7dgcuoW5oLwNW7kHTUVd7UQi2HVU0p86Ce9JNFBstcGWn+s2+tQ2vgNbHwNVtPouN+bCIs91DD0VtvEeNRVV28Y3YjvrgS2iqSo8Dcv+tng+Y+m3wlbH9MZuNE+nWc+Arb73p/s93xDo//df/+LXX399ClUIXiR+97vf8X9///vn3QyBQCAQCP6tUL7zEFADxDb2ShcIBAKBYPtsCPRQFOpXV1eFpf4/kK6uLrq7u4UwLxAIBAKBQCAQCAQvCBUCvUAgEAgEAoFAIBAIBIIXg//zvBsgEAgEAoFAIBAIBAKBoH2EQC8QCAQCgUAgEAgEAsELiBDoBQKBQCAQCAQCgUAgeAERAr1AIBAIBAKBQCAQCAQvIEKgFwgEAoFAIBAIBAKB4AVECPQCgUAgEAgEAoFAIBC8gAiBXiAQCAQCgUAgEAgEghcQIdALBAKBQCAQCAQCgUDwAiIEeoFAIBAIBAKBQCAQCF5AhEAvEAgEAoFAIBAIBALBC4gQ6AUCgUAgEAgEAoFAIHgBEQK9QCAQCAQCgUAgEAgELyBCoBcIBAKBQCAQCAQCgeAFRAj0AoFAIBAIBAKBQCAQvIAIgV4gEAgEAoFAIBAIBIIXECHQCwQCgUAgEAgEAoFA8ALSXf7P//7rX6yurrK2tva82iP4DdLV1UV3dzf/9/e/f95NEQgEAoFAIBAIBAJBiQ0L/f/+61/8+uuvQpgX1LC2tsavv/7K//7rX8+tDZqqomrPrfoiyyrq8tYu/U20f1VD7UQjtvEcQENVVbbUCk3tTPt/K2znfWzrHXQGTVXRVls4sVP9rgPlbXUctnyv1XTy3jv9HJ9HO7bab38D/V0gEAgEgt8qXWslCf5//vlPIcwLdOnq6uK//vCHyoNPsqRvp0g9UjeP7bTgsEvY9xo7VHOe6eNm4kdzxEdMG0e1pQyph4UWru+lz27DZNheK9KfduEgxdon9jZ/r99+gMyfDxG42axmF+G/+rBtueUl7kzQZYfU2jj176Ccxm3WfQ6rKtnbSeS7OTSMWA5KSAcsbPSEpWmGX44z/HMc964GVWsamsFA9evKfz+M+cYwuWtuTHUvBNQ00a9TqI1+L8N40Iv3gE4f1cqFPwNG4zY7UDVN3ofe/TZ8B8sqaguCp8ForHm+NWh5MulFCkCvxYFtd/kVaSa6HJBeY/xAk3La6nfA3SkOnaWyz9+d4tC0hdhlJ6Z2y9ugcZ/Wp417rWYLbW34bu9M0HXZUrc/qHeiRH+R8B+xtNnALbDl5998Du30dQKBQCAQ/Cew4XIvhHlBMyr7iEbmzx6GL2Sxv+Xj8IbaiOwAACAASURBVMC6wKyR/0lm8pgPjzVI/Bsfth2Ny1TvRIneri9+WY/5ce5ufK22tEDmbvm1CvLYFMkhH+GB8oWtkR5bI4FeJf2XKKknjeuxHvXj3NP49+1gOxEn/pbOCekwvU59i3b+ZgDPnzMNf3ddmMO3f8tNbJ3lNBODLuTXgvhGbBi1PJmvPFjPDpNM+rHpSpAa2e+DBM5FSD4qHrEM+QldDuHeuz1BWpkPMHXLie+iRCvijvrTNKGxIJGMAek1c/FgbhFZ68d/PkxwxIqeqkqvTwOw1/XUBK/05704zjU7y0VMT6ECKNdPcui4jOmEi+GdKvEbh8gfvMrMF16sOuMZ8iRPe4j8VHboHwoA/j/J9JQdtn0QI3ykjmC9qiLPUtnnV1XkpVbUNNsX/moVhVkUgIyMvFJ2+KU+HPtNZYqRosLAc722TEdXsOJ/13S7SoUmbVaSBB71bbNfNW5/S+1dVUicHSVwKYmCBeeZEOFz7ib9RU+p2SFFpkAgEAgE/+Z0Nz9lk//38ssA/H8///xUGiPoDP/v5Zef/ju6N4X3Qwgpi7irhe4BJ+4PfEwffwXv1w4WPmq8JDPs6se2v8rKrmWYcqYwj/h1m2A84MVfbjF7FEUeA7DhOuNtSXgDA5bXbKwoMhPH87hkN1ZAnZ9gOO9ibsSKuaH0VqkMUNIAMSKXUsUDOx14T9h1hT9lPkrigd4JGcChewdGm4fxj53Ff57ITBxPY782jrSzeMisoxSpqozkpQRZAAosPATl1iSRpd7iz00EUeX7IME3oqx84dwQcqQhO2bXK0RnvUweafwk8te9SOd6CF0vMPO6EVZVMteD+Aa8GH6M4dIRPisw2vGeKRPkltMEp02YTDmMdh/+N/WVA9qdCZxHUxyeTrEyYKqwYmtLMpH3JZyPEsif2BtauIt9WkH+bJj80Tnceym9l1L/Mvc2rF+5GdnoD4X7CjycYfJSjuIVVlxnnLr92v7JGmuf6JxQ8pDQ5VGU0eMFxpW/4y31Hf+FcabfceD5sp+FM3oilgnpXLyix2qzQczHIfBNCKlcuDOU9Yd8ksDbETJQRwHgInxev8mdpJ6iMAdwP0Om3O17Zw/9FQK9Cfe1NdzlV359mFfeg6sPZ/A2UgqW3zuwogD4OXR7Xf1hw/9tGOe27qoVatsPGSK2fnI7m3lbachnHfjyIZK5GBYU4mNOpPcNZL51NfaoATRVRt4/Q2Gsep4z6M6dAoFAIBAIirQs0HdaSHwmQucz4Fnfx2/muWkaGaxYGgqLFix7IbOsH2tp2GVDqhbWHilMYMG0s432qBkip4NwJc7kTR8nP+sj/rG+MF1qAab9EiZTnil66B+QsAP5/BT8rh9pQM/KV1IG/KP030MAK7b91uKBlyxN3Zrz9wIEVuotZtfx4r2gv7CteIZLeabI0meXap9rU3qx7LeV2qxSmIX87n5s+0u16wiiAD07jJBXyUGZ0KlRWDZh3KH3JDLELkwz/MUK3tdL53UbsY2ECWV6CFwP4NJRCjVC/Wma0Id+Uq4EmUEZ19HDBC5P6ljYM0ydCtL/zQrjA7XtNeySGJ+OknvJx9SRBfyv16+3+D7M5L+EHpuEdIDSe9nsX43ofdW24dGi/iMJeQv9+22l9prRfwOdIf9jkuQpL7Hysd1twfWWB8+lBZQzto33G/3oEPJLldb2Cnf+5SxT1+NY9kDspg/nKWv9MWHsx/Px+IbQOl7xoxkLiY7dXzMaKgrfcOE/0aIFfF0hdc5I6AIE3xql58sQ7tfr9DyTRPCavtLOYAQet3oHHeRBiuQ9Hz5rWdx8YQUqfC2ARzEilw4z9YsX204AG94rMbKvBojdczUcKxv09GI0CvFdIBAIBIKt0JaFXvBi8EwE/tedhAec+N8xExwbRtpjwlDqTVo+i/xdkNGvJSZvte/2qt5PIx+TiLXiab2skL4+RfBsDD5MED9lxzhiQXvbiVXyELrgw7PfstG2zlJSBpT+6/kbQDMlQB3uJYl+ndU95Wm6/W9ixDogUVRH5Ml/CVmrA2mgNddg05EQV2cP45BkvENWesmx8G2C/GCUq3UE5E00tHtg7q0+x0DPS82VQuWoj9LIt2eQr08z9dCK/7yMPGLFgB153kLw9GF6z1nxjbiQ/iQhvVkW34+Gds+Fw6rT1h1WHEczKE8pN5lxr4S0t/h3Pj8FD/pwDEi6Fs5ymuZkWM2xiJVhvUK6DfCkNsxDW1ZhR6Ug5z4XJ2Cn0toOoKlk56MEPwyjvpNg8RuI/LdE33yAyfNepL1VMfwGE7YBE6gKyRsJsk/AsMvB8DE7pm7gTpMbryZXQAWMlCdwK7DSbmK75SzR80EKx1xwNkjUHsXbKARkKc30jRQLmSTJW4swEGAyM4lkAt/BKQKnrfh/6ePwkBObrezeyvIzqA+SxG9mUTFgPjiM+0Abbvnfllv161Gy9LdcpML0hRArF5LYbnvpdZcrVUIVZ24ogcqVsDscON/KMPGjgv/1ZxDbLxAIBALBfygtiTnrrvb1XO7Xj63T6Ld6xxuVVy2QVh9b/7/d9ujR6Dq99ujdRzvtrNfGer83q6+6Xr373PYzM9jw/zWD43qU6PsS3vks+dJPpn0Sh497iWXc2NsOE1WIfx3FeWy8qRCT/vQVHOfAecqP/3YW5x6N5OlDyAMxwj9kcd2KETl/iJO3Vhi/nSP0ZrttaQetZKlfQQMMqGTnF4quuqgsNgj/tR6bY66FdjV2+6/i8SIJUvQvAbtKidV0FuKNWWFFBXV5pcHPBVS1eFMbFtkdVrzf/B3P4wwppQA4cJ4IYd3ZTDNjxXYKgsk0/gNlruzLaWYS4DtvbbHNYDSskHtiQbowR3hfpSLHsNdNOOkmtJQhOSuT+7WnylJvwjSUIH5bwb27gQDyOE38hhPnxZabtGVWllVQVyi+AY383RSLJW+Q7M/Ay7XXNHZfrqRa/i7HNODB96EX/3d2Ym+VnkM+SfjiDO7ToQqX/55eIxWG1QdRPCcmmL4DzlM+vDeyuPYVTxiXs7hvxYic7ufwLbCPjBOd9rLxdpfTTAy5SA1E8A0ayH7pwXYrROpbd7HO1RUKqoqhnoV4A6UYpaJkUXBiy8uEytzZc/fBekz30ZTQyM9P4XsvQG5ohtgXTrg5isfaR/LiVaY+kGpzchiAnVac7zkJXrFSnkPR+KaPq7IP7UmWzH0FZYkqJaNG+rPDuL4x4jnrQTIoJM7amNwXJfGFc3MuXH8GgGGHcaMM09EohaHmd6X33itRkc968DwcJXXFhmVHnLWR0k+lpHjlKI8SYA5UjaeiQk7O56HFAChd0uvhTEYc73qxC4O+QCAQCARAiwL9ulDaTNAuP9ZICNcrrx3abc9Wy6pua7v30Y6Cotn/231uje5j/V702lyXbhP2kXHsI+PNz20RbXaKYMZH9NvmC0D7mUVWPjFUJKVSl2SUZQAjliEfk0M+JjUNrcMJymvJkpkF8jKp8xKSoYByN7MRj678UnX6oySRG/pW+XIydzMkW0imlkknsezpYfIHGf8BqbjQL0SLP6bD9LYaiPskQ3oWZGOa/LuWWuXK9RDDd3tYt/pZf4zUzQWQmY8RvJMtWktHrhIfrFeZEefYDMkRB30P/PiPOuh9kiL+RYTMwThzOrH3lW3OIj8E634LFBRSt5WGpxp32zCyiPzAgLSxG4MFz/kw00c8jK5G8B+zY1mP+V7VUO7GiHwURL2QwPPUvSVUMmkZZg3Ij7x492go9zNk1vM1LFFXoAe2776800l4PkLwfQddb/dg3bdC9kkv3gsy0WNN1Gx7vURveYjV3RGgbEyuaqhaZShJ/maYyYMxlAsSBsA5YAGbk+m77qIL/o2T9N04WTq7gWLqkUws7cJli5G848N2wEn4r+udvpTlXvcG8iQ+9BC8LlPY6SbwVQ7/uofKkUlSOZmpcxPYejz0DgwTmp7EZaImDr4Vohl/MWs/wKMYobNGIkp8IyeJ84iD4EEXk/MKoXUPl3SE0ePTQFWyS4ORTm3CoD5KMnXayyQBFmb9uklN1zF0m2Ar2/oJBAKBQCDYNk/N5f5pu33/JuLIW6BeO9tVAHTiXusJ8FtTDjTPCl9LixaVx9N4344hfZHB2SR+Xn0gs5CrbduiCmo2hTxfW5n5NQlrO3H5baDNxgjbJplklKkbo0gjFpxn/KWY4DzTP040ESQ6wNI0obF+wvedJF+LEHtHwrunbKHfq+eOW4lyI8rMJ2FCNyeJ3XPXxsC+HWGuLIt4foeBzbzkRoz/mOZk3sXciAfn+1bMhpJb8VK6foW7nUzezpG5OYP8SCGHFc/1HPHX23DxUBUyd2uVJIX7MSbuWxl399fGoO+1lAn0YNjvZ27WwKHXXDjO5smvu51gwmTK03d2kbkPWvcY2DKP4kQzISYvxJn6Po3nEzv2E/6N+Pu0FmCq0bU/LyDPN/CsKNH7qgPbrsYSoGGvm7DsJqQWXe9rt7kzYbsYhvLxtDTN8Mue9qLdj8U2tmFTHiVw2KbK6rHhcOUJP8wXDbzr59axEBfRSH87Re50lOSeKcznY7iTrSbH3Lwv5+kw1nPW+p4lJgnfVxK+L1SyDwpYTJvH68bBl5RoM4VAndSWmwoN7WGG5LFhouV5C3bYOXwkTzivwrpK7WCQWPm2dXenOHS2zfwCR8LMfVAnJ8VPCQLnA0RuW/Bflsk22c2hHPMeCebXwxzWUSnkwNW+m1Z97B78Z8S2dQKBQCAQVLNtgb7aXbvV354WW61T77pGbvPb4Xk8m85QmQiuNXqxNLMePU4wOuJBeT+F3MwKCBQeZsjUsQj3DoZxopC5W/ub9vJTEuiX04TGZEa/TOEzaMSG/EzbY7XZ/8vZ48R/Rqpwo26Mmf6BZotrhemzfnIXkjj32bBcDtP/1gR9s+PYW7CwVfB4muA5CN32c/i1BWynJnA0Kcc04MM/sPl//vvkZlLB8r3hCws0tJt3m7Ad9W59m6o9Tvxnal0Q8t+nmNAOM3pGZ//6coy9GHEQ+TGO21SyJO8oWXd3Pou0dArTZ09iGMvhG7SRfc1PZFBm/EBzE6zp9TBhg0bmbtFW3EiZYezp1xXooRiPH9vdYGs5VJTZJAyU7USxy0W0UCBafWqLQq3JJJF6pLAhvKKwmAZrizkctDsR/F87CN23YdrpI3yxH8+nfbo7ElTf06ayUibZyiWz68rKosKqRtH4uKgRUjILZW3opc9euY2m4Y9mTA9z5KCsj+ZRHoDhNZ36X/cSv+ZppaWbdDeYSXZbkE7MEJy2YixfGdyd4tBZdLeQM9kknMejJM86N7dDfCKT+NKJ87SInxcIBAKB4GmybYG+1TjuZyXAblXgfp6Z6l8s4X49EVwx2VSt5a5dVLLfhxg9HYMPUyQ/bm3xbTnix38ENFWFsljSttHyZNKLFJ4sopIhdilCitKWYU9iBN4Jklmy478Wqp9hXM0QeduF7EogHzAAfmKXPTgGT7JyI4x3n54YXulGXZfCArHP+phaG9fJjl4Z72oAbB/FiGUcuP57heh0qPVEWE9kgiN+uJwqbrO1J0TkpgOX20DyWz+2JiY79YHMAv30lR802hh+t2TVXjKS+kxfVNLUsoRsqsKCUkDtsTTZvK+KfJrp63HkmxmU3CI8yeL5UxTL6y4kVxvJxroNGNtSiKzHuhe9RTLfRojcpqTIUImNnSR4T8H+UZxQvQ61qpA47cFviJEaMQFOwjcySEcPs/JNjNCQfrvXx8U6bSszyu9EXQ9fqX+f6qwMFdvJlbwwllXUFtyvq+cOy5AP6Q0/o3umCA4YWPhLgGAhTPJNmibFy98K4nLKHE7LJe8eG/7vYyzYHUi/xIheaL4femMU5LEpOBVGaiKb1ioarYQvgnY3U3THLywQ+0wj8HN8U/AF2O8kYOjHd9ZKbMxBLwUWvhzF/3OIhN477y5TJNBf4W3SNjtsOOvF4Ws55FmNQjE5COy0Eb5IZX/a4yF4Porr7SCGK6M4WCA65mPxfILJVsJTfl5Ans+h3FWKij8KKD+myf5swXfjKuat35VAIBAIBP/2iCz3LaAXe/4fy1IC78txhqsXpu2gZZhyORl96CA8ndmMVW2ZNJFeB6TXGD/Q/Oy6GFbI3c2QpRfnRal0zIzjRJg5oMfcR9BkwGCkNj52KcHJgWEWh2aIlVkBLSMxUoYAJ98NY7kVQmq4xjZiP+bFqif8LBlJfZbXOUEl+X4/3gdu5m6WW9EtuL9NYTw9SmJewTnS3EqmPYjiGQiijSWJb5xvwf1NCsPYSXwXbSQvSLplZK8f4hAp1s5EKayu3/hmFm80M5ZBS4UFMPOZmf6zVfdosiK9ZgYs2AatWA/2N23/xn3cmUCyz9D3RQDfV0EsG8+/gDKfZOojM5POVBuW23YwsJIrCnW9g2Gk0jHzQS/hQaDHTN9ZMwaDEe5VNzxNZMBF+I8BktPuDVdxw4FxkjeNeEd8RG/FG+9n/hRIuM10uRv/Xi+SPfOX4ZpM+9IgRI4PE4Fipv15K5HquWOXi1jawMT5AJ6/gPF1L/ItN00DHJbTRC+lcfwQq/Ri2O0mdt9C5NwCWkvCvLEirGGTNNrYFLztr9zOrg6WQS/egzonNFRo2fDPLmI+H+Cw9TDZvAX7CR+Jm/6WPGw2xt0nnXZJ15B/KPpcJGaDSEeMJU+Y6vMM2D9JkjAE8B8xk8aO970EyTPNx9imV8m6744B8z4J2/7DmK1WLKY6c69AIBAIBIINOi7QN0oCt53yOt2ep3ndVuopp1lCwa2il9zvuWGw4bmcZHiPrbR90/OgPNa9TXa5CM/nMO6qVURYjoaZO9q8iPTnvbiuSfTpmaAGXTqLYiPOiwtkDcZKN9liK3Benmn53gx7PUz9OIxpV5UGotuC6/IcrhbLKRZmrB8iYCpPUlbE9nGOtY+bF5lvnOOugsxskPT5FKkPqoUbI7ajPq7+MUfXQZnMJ/ZN4a08Fnk1xyIFsm8fIlr2THP3oZD1cOgvpQMNYpGrreQtY7Dju5HBazLVPDvjfh/xh77G1zZIsli4r8DDGSYv5erkD2ieZNE1nSM+Uk/Rlmaiq77PhO2DOeY+0Cl0aZrhlxtklNjtZPwbJ22l2dxhZ1yeq//bTjv+K88u7jp/w4v5OzPhgcbP1XHRuZlssZwdVtwXZ3A/gx0UWkMj+7UXz+1RUrcN+I8NM3E9zvibjTSURuxnrpI6c7WtWrY8XsiTeNuGbylIUm4cDiAQCAQCwb872xKjymPLy49V/7b+d70M8eXX1CuzXh1bac9Wr2uWTG4r8fXtPJvqcrcTz/80cgGsqCqqngWp26jrsmzcu/1l2EpBRW2wLVyRMgtxh6knzLeL42ysgdDUIjsaCM9tY8DUJK66Jcq2tGtcVeeycldj2uWEr2ZIvmXDubuqkmWFZFKGIW+ly/BuifGPy2zBn9QruUrMNHc+NthgMm3Na8Bowba/zpX7bTT0qTA/i3wA/4E8r+RtLYw7Q0vhSRr5Owmil4NMPnETuzmOfSckb4LniJVDIyFCH3qwV4+tZ06B3MM8+ce5zXAAgUAgEAj+A2lZoG8kAOoJho22RWu3zHayvnc6hr6Vdj/LZ9Pst61cu6Ws+t1GLIMq06eHmdY7r1FG5Y5gwDgoIX8+zPDnOqftK9se6jdIM7dm0LOU/rYwGCWk2xGGj0d0z7N90CjZ2vaxnIizaIwQGenj8B2wD1roAVYUuegK/HaAxWuuyuznO61IA88ge/3T4im1fysu90+FPS7mxno7pLh6ypxz0HWuyTnnO+se3+q4q9jqri4KUecrTBS8eMdmyB7dTMZp3O9nRvEgfx0iNHgSxv7OzLvPM+GdFd/tFTyrhqemHBQIBAKB4EWga21tbQ3gf/75T0p/CgR16erq4r/+8IfnUremqmhP0arbEssqKvoeB434TbR/VUNdZvveCtt4DttCU4sZ59tp/6qGulxKsfe8n38123kfz+sddIRtJtTcxnPb6jjcdvLNTtCp8fs82Wq/faH7u0AgEAgET5cNgf5///Uvfv311+fdHsFvmN/97nf839///nk3QyAQCAQCgUAgEAgElLncrwtqq6urwlIvqKCrq4vu7m4hzAsEAoFAIBAIBALBb4gNC71AIBAIBAKBQCAQCASCF4f/87wbIBAIBAKBQCAQCAQCgaB9hEAvEAgEAoFAIBAIBALBC4gQ6AUCgUAgEAgEAoFAIHgBEQK9QCAQCAQCgUAgEAgELyBCoBcIBAKBQCAQCAQCgeAFRAj0AoFAIBAIBAKBQCAQvIAIgV4gEAgEAoFAIBAIBIIXECHQCwQCgUAgEAgEAoFA8AIiBHqBQCAQCAQCgUAgEAheQIRALxAIBAKBQCAQCAQCwQuIEOgFAoFAIBAIBAKBQCB4ARECvUAgEAgEAoFAIBAIBC8gQqAXCAQCgUAgEAgEAoHgBUQI9AKBQCAQCAQCgUAgELyACIFeIBAIBAKBQCAQCASCFxAh0AsEAoFAIBAIBAKBQPACIgR6gUAgEAgEAoFAIBAIXkC2JtAvq6hah1vSApqqoq22fRHqFhurqR28z1Vty+34t2NZRV1+zm14Tu+jc31KQ1VVtlTUVu99G2OptqjWn8OWxn0jOvjet/4ut/HufiN0dG5svdIX+t11tB9vlW09w+302w71+Q72ge01YxvvsmPfv60+0xd//hEIBAJBJV1ra2trzU/LkzztQXHP4dsP6U+7CO/JER8xlZ2SJPB2hEyTkmwfxAgfMTU5q169eaaPm1FOrzF+oMXLgfz3w5hvDJO75qbVWtfrnj5uJn606j7roTVeHBp2GDF0A3cm6LJDam0ce6Ny1DTRr1OoLbTOeNCL94BRp0llH2yDEaOhhUJL5G8G8Py56ZvE/20YZ4NHoy1lSOXNOPabqK46/WkXDlKsfVLvSWjk78nIt7PkNm8A8z4H0oANUxv3oUvd96GSnV8g18r15n6kvTrPf1nDsKO6sW30qWYsTTP8cpzhn+O4d7X5eyt9sQ5tjaVVlezdBXIr0GPux7bXWNYP2nkOaSa6HJBuYdx3ahy2xDbeZbN3tyVaVFR0GzHu2G5d9e9dW8qQelho4fpe+uw6Y1nT0AyGmnlj63N5Nc3enU6fa/buNvqgAWPFpKvXjxWSl2R63/VibzyltIz2OEMqm0MzGOg192Mvm6e29Qxb6LcN5/YO9Xm99is3IyQeNCvBiuuME0vD33XG0cZ3tI05qQ76378SqxrqcpN2bPWZPpX5RyAQCATPk+56BzN/PkSAMHMf2DaOqUsyqp5G2iQRvObQOSFH/J0+ktWaaS1PJr1I9TLQ/JqEdWcL9VZQK5CpWRXURVLzMuVrpfXyN7gzQZc9WFvkdTNd7vIDoRphIH/Di/l0Fuk1c83lrgtFJchWUeYDTN1y4rso6SxC1lHJfh8icC7CgkGir9Sc3H0ZzeYndDGIe18LK8ZlBXmHm8Vvhqm9o00MOkWpt0Mcanfh+DhJ4B0vCcMw7mMS0npbVQX5ZpDgOxqur64SPqL3JBSSlxJk6/1kkvC9ZasRFDYpoNzNVFxbuB9j4jtwf+yhv7fsh72WWoF+Ocv0+QDBS0kUACw4z4QIn3NjbVWIepQkcqNu64vsdOA9YacD6/4W6zXiaFPQ0O5McPjoJLk3hnG9DpkbHhb+6CV2LYS0U//aWmXSSvFZfnQI+aWyw/v8xC47K/pWx8Zho7mgztivh3p3Ct+JENM/5THtcxP4cgr/my08wIb1VnG+nsCUwPuyh8RWri1DvRMleru+StF6zI9zd+OitaUFMnfLr1WQx6ZIDvkID5SPWSM9tmqBXiP7fZDAuQjJR8UjliE/ocsh3Htb1eLpjP1Sve325ZZZzjJ9bhT/54v0DvRBVqZg9RP9Jqz7zIrkyYwlsYxst20KyQ89eH/qwztkpZcC2VsePLunmPvG1fj7sTTNsE7fcU13QAHZAo0VyfrK43V6X7Vh05tnH0xz6H0Nh55An5cJ1RgmVlBm07hvrxF6U78NrCokzo4SuJRE2cr8v87dCL32KPZBCz1VP+kaRXQMK+0ZUwQCgUDwIlFXoNdUGbldhyw1Q1zXulxgQal33QKxz8o/QMWPpze9xniTxX+9OmoEsscF+EVh4W6GcnlMe7lKoD8wztra+Ob/yzKBVw8Re2sO5aKkIwSWOBgktl3LkdGO90zZYns5TXDahMmUw2j34X9TrxUa6U+duH48TGx+BWmXoeK3/HwE76AT5YbM+IEWFsjLCtmMjrX6pT4cOgLSSpUSptxjoLACNasUVJIXDyO/mWLxvL3meUtHvQTdQRwHIyQLkzgbLnx7seyvFdqVm6Oc1Bz4GzeZogDux7nZauSzYSYA84AP/6Dec8uTeF8i2B0i/ssMtp3AkwzT531I7xvIfOtqrW8YLdj2G8h+f4iEKc74gBHIMi0lMF0bR7JYGvfFcqG8sICCwsyVCLlSx7ce9ePco19vBU9kJo4vYHnL20rLi2gyoaNx7NNZQgOll3Q+RPpTJ46xBIVvXLrKCNNgkPjBsgPLMsGXh+F0jFDF8zfUL6cT47B6LgDUm6P0/tnUvNxHUTxvxLAlUxTsvRTSYTwHnWg/yoxXP9+6jDNTCNBINZq62Mvhej/schNfc9f7ZYOiZVAfw65+bPur1KtahilnCvOI/ugxHvDiL7dYPooijwHYcJ3x6iok89e9SOd6CF0vMPO6EVZVMteD+Aa8GH6M4WrJklga+w+mOXTDRPxjCSOUjSULlkavoMI7SiEF8G2EyO3Svel6RKkkxyT8yxFSK+5SHSrZr31IRydIpMexd8qzSAdtPor3gQdZ9mFdP3jGS9T5CpGbBSaPNGh/Rd9p0/p8d4pDZzdVASsKgJ9DtzcneNeFOXytDEgdRbKe8ngd414Jaa/OCT3p5oWYnIT/6qw89iTBamu3aQAAIABJREFUyT9GsTS9Bw35rANfPkQyF8OCQnzM2d78X4GXyF/b9CRaVVFmjbjvRxmuHjOtPESBQCAQvJDUFei3xLJCciyJ9dp4Qyucbb9E76tVH5WaD2iaYFe4hY9nPRoIZLNOpA/8SC0uqrQlmcj7HlInwnjnPQx/FiP6kdQ5d+8WUH+aJvShn5QrQWZQxnX0MIHLkwRHrPUFmXtT+M71E/3HOFKNNcCAaWCc+Dc5ek5N4cz4sdUro5w6SpAKdvbQX8edvoiGcj8Bt/tRABN5Eu+Z8VwvO+V87TXqE7DYG5UJhl19WIgX4w8brk2MWAekzQVtqWz5VhbJ1F6nUm4ECP7FQ/wa+N4fpX/2Ku5G1rZ7MULfDTP5D++mlWinDffFEAs9AWKnXfhfb6HSnVakASs9fwN5jwNpwAT0kEbGYpeQ9ASbcqH8SYEkeSw2W1G5AJj11nOleivvKUPA1NPeWLyXZsLkYWGgvDIj9hEv0qspFq64NsZh6oKHQ38BjpR5A1WEh2hkv48R32OB63F8Q772LV0dQSM1O4VtaAGzqpaEvkKN0go05G+C5C4mmRkqiq/GoRCxrw7zypUkvibKjCI99BqNDc/rrVGEdRbDLlttH3ukMIEFUzsKVjVD5HQQrsSZvOnj5Gd9xD9u5FmSIXZhmuEvVvC+Xnr53UZsI2FCmR4C1wO4Pmo6Y7Ex9nvSMG/BMSBhgqqx1ACDhf79KyVPMUNRKfyaDVtJQOzdpTP5qymSX/YReuguUxgYsb4bIHClH/neOPYtuGa3i5rPkj9wuGrus9C3H5KN3LfrsAJo/9CgNBNvKGPVldqTX/cSv+bRLc+wA8i3WHm3fv/XI/1pF45v7UiWxoNEGnQ1V85XodyIEj3mIVSlDI2WvIY2LN+PYkQuHWbqF29pzrXhvRIj+2qA2L0W5/8O0WM0YhTyu0AgEPzH0DmBHgAjFms//duJy7qXImnq53BTN8XmqLMhgn/px/VGlOB5ieQFqcFCQUW5GSfxY4bUbJLEEyv+8zLJESvGZSeJz4M4ek5iOuZEesOG4+gwzj1VJdVx6wfofdWBTW8xWF7EozTy7Rnk69NMPSy2QR6xYsCOPG8hePowvees+EZcSH+SkN60bNanaWSOOnQFHoPVgeue0prvxauHGT2zRUvnUoKpS06cQ0HC37mJv2XBfW2NDRtQXUuhCWnES/D9UYLdQbxDNizrkp2motyLM3U2SOaDKNG2+1eWzKwJydU8aAE01Acy0XOjBDISsfQkrt1g6x7FY3mF+MVJQickrDur3qmmkcFMb/XzN/TQSwbtWWQgKhfKl/JMkaWvmRJAByUjkznqayHUo4xuMOW12j62rFLAQE/ZY3N8OEn0mBm6q0fN5jsIP/GSyMTgz4eRbDKBL0J4B6yNc0J0YBxWo92JELruJvijRqS3l3KneNex8jMzpD8z48lUCp+WARfSe5XKjI7TQg6TFQV4u/2i1ftp5GMSsVbavqyQvj5F8GwMPkwQP2XHOGJBe9uJVfIQuuDDs99SzGewgYZ2D8y91RUY6HkJMm0Io1vGYMK2IfD3kAawSUitCOLLKjmMOGqejxHjHyH7j1banyL09iGiel/kI5VhcNWY3nDiPD1J9LgV73q40uNpJr+247hVNpOvrlBQVQw1cf6gzc8QBZhNERqUMJAhejxQdMdfzbGIleHyC7o3y8jfSzAzq6BixDJ4GNfrz8G9++0Ic3qx6W2i/m0Cz3tw9WHtt9B9Lk7AzoblO/9jkuQpL7FyxdcOB863Mkz8qOB/va2ZFFBYmJepUaM0yd8iEAgEgv886iwfVAo5YDlHHio+YkpGRl6B7M9AtetutxHLoMr06WGmgXXXeQ5IWJrEvpaTmY2RORrEoqqoda1gLfAkw/SFAP7vDQRuxfHvyRJxFxeUkctB3K9XfwyNaJQW3u+Eie8uW+TssOL6JI7rYw3lpxSKoqCtVl5vsDgJD6oodzPFmHc2Y0aNPf0tCxJGwwq5JxakC3OE91Uueg173YSTbkJLGZKzMrlfeyqFlp0mnDfipB+7sTRQhii34ySGnIRbacx1D+YufctLqJ5b5qrC9Fk/uQtJ5CEJyeZhwpJkvIUYYtPRqyy8liR2OYznXIL0o/VfLNiPOfGcSbEwZGnbeqPNxwnnvcSaWUhKsaSpfW5Gz8bITdsx3Zvi0HsQ/uskqVya6a8nGX7tMFl7jL8n3JvC7l4bPoLM/M2PvSw0QvvbDHF8hPRcQZ8G2goqKislWaIiYdkDBZqK6Qry9SS+U7HK570hMDdIbLbfSWB3P/5PJZKflCyyapbo5TCGC8lKz5AdvRgrzEhZom4vE9+nYciH790ZskdLHikfz5E9liR2OUC/MwkH3Iz/JYa37Ll2ahyWoz2I4j06ieVyCtcuC6ytUXTGLyVWKz95SWEBC8PVlmxDD0YU8k+Ap5WESs/Vtpwa5UkzFOJfR3EeG2+q3Et/+gqOc+A85cd/O4tzj0by9CHkgRjhH7K4bsWInD/EyVsrjN/OlcUjW7GdgmAyjf9AWbjNcpqZBPjOW+tX+LTQSpb6dSv1kyzy/VLw0ZPF2rCyXXacQx5iN7O4T222VbszTXTWS2B6s9+tFFRUlarkhHb8hSy+Zu1q9u72eIldV/GNWAnSR98OBfmJjfD1ZKV1OB1h9Ph0nW+xQuxSlOHpOOaLQSJ3ZMYP2PD9da7YtlIytVo00p9KuOb7CLzrwkqG6DEz4aEZEl80/tZvmYczTF7K0UudMKJ0jMillO7luqFH62h55D/7OHlZxZuewVvn/J7eSiu48igB5kDV96molJLzeZrPuWXstBG+aEC7m0G+H2PivpVxd3/RY65e/pa2KQvH2uvCr5uXRiAQCAS/dWoFem0B+UuAJKnLLlxli9Pc/QyZZVCW6pRUx3V+ossBn8+1ngl2WSZ2OYfVOoXn+FSpTtAXK8uafncKzwcREnfAeSaEnHVjNQLY8P+QxXljiuCxXjzYcX04ReyDYqx15s+HCNxssRIAplHKkmyVx46mtQBTePCfadNK8CSL/BCs+y1QUEjdrpdwoFTfbhtGFpEfGDY/7Hs8hC5O4xwZZeVzf6UVbFkhfT2C/6xK6Ian6bLCNBJnbaS95gOojxKE3/MR3RUh9bENAzaSfy0wfMyKfCRE+LJXP2kRYNzjxHfF2Xxx2zIKsUsTWMYWmltHd7mJ/cNddBFdZ1VFnqVocTbZcX9ix/1JDG2ZStdNoxP/D0k8B/sYPuNn2N5LIR0ncimDdG1OJ+b/6aDeTyMjY7it4N1jqUxYpuRotrhUb0YI5sIkq+Nu7yeY+ixNMVGVrU6iKhv+myl430Nv1wrWfT1kfwLn+RjJj/USEgJY8X6VxPOtscqCW2Sjb1wBTdVqQkI7Mg7XWc2T/i6E/50F+n9IMdnKgre7NjN7+xStp41ykdTPP7FJp11ttdkpghkf0W+b37/9zCIrnxgqdjNQl2SUZQAjliEfk0M+JjUNrXLw4BybITnioO+BH/9RB71PUsS/iJA5GGeuUez30+JBBhnIzZes1KpC5u56bgqlJoErWPBeiZMe7OOVmz7cAxZQZKa/LOD8IVbxDZ0+P0z6JWqs7QajsQN9B4xv+ond95M+V8qkfr5O/6+XZ2I5S/TDwwR3RkiNuDBbskh2idx0lFCjMK917kRwJSQSt0PYdwA4cR6RCB50MTmvEBp4NrFq1mNzzDVLWod+6JH6U4L4t3Ei38kwEOBqxo/UokbC0G2CTm1LuMeJ/0xxPZX/PsWEtg2POYFAIBD821OzbFZvTRM5FSNu9BO9oeB6d3Mh53jbj/9AcbG8aeUtbi0X+am6pAbZqYH6WWs15PMeYkejZK84SwuI0lZ1Ld6MYb+H0JdOYvuqXToBjFiPjhM/Oo72OIOyY1O4sJ2IE3+r+vxSVv6hxaJbcHVdJaEvf09msWyFl/0ZYAF5PodyV0EttcvXLPa1fNFYRqFaO19OhabegO3MHLLhEH1HHQTz+c2wRZMJU76P4P05fPv02tD6tnkbbGRdV0ieDZAdipH5SNpYeBgHQ8zdHyZxm8bhAM0yu9ejJauCRvpTDycLIRZONYnBbbDbQtGaTX3Xx5f6KrblsxyZJJXLkLglozzKgdVDPBfH9sxXYQrxrxcIfREi/sU06ZFx7OUJy+5oBL7UufzxNL734ni+VWpzLbSSdG6nHf+1v+NfVlFXy7aM28CAZSiMsyJDWXGsV+RZaIqLWGnrpY6NQ/LInweZuBhFORjmam6y5QU9Jgt9JoVctSX+SQ4FK5Zm1vluI9KgTOT4MJGGJ0lIRxrGG7CYlpF1Y93N9A80EdDWeTyN9+0Y0hcZnE3i59UHMgs1GTRVFlVQsynk+doaK3Ya2e1k8naOzM0Z5EcKOax4rueIP3O3bQ15Okz/F5Pw4RSJ9yXcZcIVS9OkPqtjpd7t4mq2QPZujIh9FK4skFqp9WDxVii4G3079WiQ8b3ciwDI5gFkopeK83lBSZG2BivdwUuos0E870+QPXgV+UrJ6+jAOHLWQvB9CedSktSZxvNnXlkgfyRQEuZL7LBz+EiecF6FTouh1eFg61u8mfrpb6kqFXW5wfaNPytkrcPEfozqePSYsF0MQ9WzNO+RYL6ASnmKl6LHo8ve+jNQH6VZ+Hnza7O5U08S7afidq6F3U5C24ossHD4fb/Ytk4gEAj+TagUe5dlQu8vELoxicuQIzwUZHow1jgRGAAmpHPxptmTq6m0rmmkPzuM5/YoiVnnlhLiVAiFs61cIJNcFwp3GDHWCHQqyjKoP2dZyJStVKvi1wo/TjFxfV0EtmAbDBNGI3M3h3mfDYuhlz67Ce41aU75orGMdrXzvTuNcDBC5pob07KKZjBiyBddJXubPdiKxFAt8tJ61nUL7mt/pzrPtqaqaN0WpAGKVu0dJUtKeeqmehnWm2FumK6vhErmcw+uKxZi6XFszYrXikkAa5UZVsIXQbubqY1PrpcY0GTDdaKVBF5PD+W7ACd3BMh94MSWteK/JCF/UrtzQF0eT3Ny0IPyfoqoblZ/ffI3A3geexrE/GoU7ifJ7iz3vTHh+qpA4avqc1OEew9DslCMV61ifR7p2DjEhOUNJ6EfJ7HvqlQ4JE97iu7jDbd+smI/kSNwM43v9c3nnZmNkfs43DwR5X4fc3/dom/KDgvOi07Uxxkyj2F9yzhOhZEq9F4allYE+scJRkeK/UA+1nzmKTzMkKmzB3jvYBgnCpm7tb/V7DTSbcJ21Nv8OT1FtL+FCMyOMpX2YViN4Tw7jf1bd2vO0t1GrAf6i+fWbMtXj058O9cbniXxXQqLtaR8fjVMGFB3WrDtNtJzxENglwmtjieacdBL6LtRbAcq37Nhr5uwrL9zAoBhhxnuLqJgL3tOCot3wfzGM7DO34syfLbpho2VNMhHYBzyE1bTRL+WMZa2t1PvRIn+IpUUyHmSp08W54EqN3yTTcJ5PEryrHNTUH4ik/jSifN0Gy7tD2eY+Hw9I78R6wEn4UFQ7mYx7rFhM/Zgfs0Kml7GDIFAIBD8J7Ep0KtpJlweUu8nkA8YAB9TZ4dx2g+Tuxlush+5EUMpvm64ZDGrpRRzerRqT9vlLNNnvXh+7Gfm+/FKLX8H0LVwl1NHoKtejCrzAabslfs4W9+NM/cuJSsBNUmGtkQ+zfT1OPLNDEpuEZ5k8fwpiuV1F5JrGPeBFrX9O9p041xPDFWyrDY9vaGbqErmL0GCF6ZYMEj0lTrPiiKjGNyMng/iP1q2Kl1P5rasotLActIOeZnIhydLSe10MtOXs75loKaiarXJotpi3WJUovB4AaWg0vNy86X7uqUz+zMoDyeJLPVS3EZLYfHyKPGfsnBskvhQ/euVG6N4xgzE0kUFkPNigsygi8O/Romdc2JqmHSruA/46OkYhrEF5I+aucc3YVlBVhsnA9t0xd7EYDRiqHp2DanIht/ZcWh5s96e3Suoj2Uy+XXLWT0vAwPSexGsdg+jxhjjb5nI34jgv2wlkm5h68vtUL3lJWm0sSkoeVW1jkr2+xCjp2PwYYrkx60pgixH/PiPFBV41HhktEf5FpeoCgtKAbXH0lzwXbdSP1Dg4eJGnLWSBuVhmNEbGbK4mbxWd+M/1LsRPMdkhm/IxW3mPooRedvBoXdWmLnsLYVvtcZGrDwFlIyKuYE11WA0YtDyZNI5zPVyUrTKLheT37ia9v/6yeYt2A4AKCQvJaCVGPMyjAMeQhdcjH5mYfJUP70UWPhylGAhRGKgTfV8lSUaIJdNknm8gvNiqn743XYUYfVYVkiOKfSVBHpNSRJ41LfhEVZv7gJgj4fg+Siut4MYroziYIHomI/F8wkm23meQyHmhgA0VFVr/J2tF/pYbCGLaZnkapbsUukh/pIleU9hZTBMagvhdAKBQCD4bbOx7FJuTSLvixLbsOQZsH0QR96ZQN3b26Lbe+W+15UUWHhY54obIULLXhZnvdvbkmq7Fm6jHc+7Vt0M8KlCgKlGP96N0GuH1FqDfWN32ghfbO58qN2ZQLLP0PdFAN9XQSwb66ECynySqY/MTDpTrVtct0D6814c55qdtenuXE3mcyf91yRmbq/VuIZqjxIE3pIIdGdr9kVOf95bjPvcRpZi9eYo/f8dx/JRhMWv3G0twgHyN7yYbwyTa2sv8wwT5n6CVatl076SMmOXDafViuO1FopSlWKs+6vhjcWrcY8Lv+wCerGcs9DbbQS12jqjkb4k4brcS+BWfFOJscPO+K0kxveG8X03R/xEPUtRnmm3Dc+PDsLXs/hbSGDYEuccdOn0I9fROgfrWdsGJfh8mOHPi//m7stYL1cpBtfp0Dis4ZFM7AbIuQSZd/3YMGI/4a+tY7eb6DwEx7w4PizQe8RDcD7amlLpeaNlmHI5GX3oIDydwa+3zVtd0kR629jDvETmMzP9Z6sHjxXpNTNFbwsr1oP9zQvqLiZEVLESXjcs77TgOjOHC+i1BLEYDRhRa7xt8tdP4ji+iPOHGOMHNoJocH+TwjB2Eu9FS4NdUjTksR4OXao67LSSGOjD3G3E+v+3d/+hTd3748ef/eIHInghhV44AQee0cEiG5jiwITrH57iBVO8YIoDExy4OMGlE1yiMJv1D5c6cMkGW7OBMxMcqTBpBleMsOLxD0ciTBphoxEmO4MJCUzIgQkNXCHfP5K2aZpf/eGP3vt6gGCTnHPe5/d5vc/7/XrvcuFW21RHPNKJaO0qw1eg0/G/RUXb2ur8LpI7HYLdLQL6Po2wbsfW2Gx/i5PRayniYxGG7Gny2HEfCJC6FlhRBf1iUsvF7lfWfgeOnQ586gD2rWA2eYaYVx09ZW33j0VhXD1141mcDdX+U6DwK2QeVAdkbVgDnB+mSVlCBPfbyOLEfyxF+tQq79UPU/jbvSSptcpRtyz/zPw9x8JW7FNx7HTg8KoM9KtgrrB7mxBCiBfeQkCvHkpyc1nNrQX7IS9Q7DKg710y7vVSJqVpaLyVqIeTzC7rv/48ZIn1Bpj9wMdAq1f5vVGir66yP2C/m+Cpzj/LTYfJns2Qea/xocSK40CAi38v0LNbJ/ehc+GBbUlSv7o3+gueFJilRL5uWCRPXVK/Rs4PK1Q+bFPIltmOAYrks1k8J1JNEqaBpd+Dzz2M616eif3rN7zQPOv+INd/jmB/7Vkm0nIwWpjPft5O5/OoPrFbW8v6BlhwHk+Re0dBWTaIg4PAd7+1STSo4DmnU9hqb/MGfxXOtnq4bpIhfl7Ht21tpu1Gl+fhEo90wofDWCdnmLrtZvhtGzcveFFbbCvLq16i//Z2N5oEsLa+1CbZSwkyjxq/N8gAXI4Ru934nRXXO36cjceJxYHv0zTD/Y71PQ46cHxQoPJB598VO548ja0UuqccjJIpWFEar1mbVDyfVisEmrOgna9QOd9pCdm2Qwo+K8r+KDf3r3LiJUP7NehzEvjyOoEvV1207q99z0RkoVKkeGUYW23ElfJ0kqjFifplkvRxZ5PcElacpy6SOXXx6Rex2fHezTnQIklO+e442hsJBtIzTOyTYfGEEGIjWfdx6FuPe12k+NXygP7FstZEMe0zVEOzBGFLKVvdcOE66cMO3Nsa6vUfG6TTOuzzL3k3oO4dZbQu2V3TwLIhQLc9tTeGCnank9TnE6QcITxLhtcpY95LMvGlQuBCi6Go5kqYZvu0fO0zQqvY2yX+68bCOM1tyrDGZsVPxRZl1emnLNvs/0UZlNd+HgLwKE/6SozYOR31nE7ikB3LwQy87+Nl+xTRzyP499hZey+btfSltqC+7mDur8ZvHTj0VmFoL2qLMltfXXsP9sXm5q2ssUvLU9EkmH/G5kwTs+0b7W6329qO/477r6G7ywulm/vHKq/d5i8JAm9lGPk+jTvrxv12jPTlII6nHPt2PC7WaX+U/yxgYNBbLMHqMhkJIYR4Trq8rVnRTt+k1DEITOF7qaftMHNNm9muebnrpXP5WzY17ypDdfs34wDqkSlmrTFih7YzdAece1U2U+1/nsWJ/60Qs98t7eNrfVVDe9bjnLfhOJlmdlucyEE7w7+Afc92bHMG+h0DdV+A4GSOQJO+lRarhnY7xvCb7bZgiyzP62WLivZ4sjpOcxud9qNgdU3u12qdzsPydAj1rTQDBwKM5i4uZrrfpOL5PEPpXor4+WHsb7tJ/hpFW2Peh9UPW2ZB2am9IJUxFqx7NfS67hFNLRv//H/cJivqXpPJ94dpe9XpZrut6fjvbv853muXGPL56e7+0e21u6HJ/akB4id0bBeSjO6ywq40ydIwoU9dTJ11Pp3wt8vjYr32h3XfBEYpiuWFra0RQgjRSk+lUqmseKrHJuamZ19Lv6qES+uR5Ox5qU8Q9kK9FemQrKde3Tqs11jL62I9kxiuQNmsjjyw9sWuYB80Wu26vyDn0vptw+dlDfvuBfFc9sE6Hn+rL//q9916JAzcuNbpmH9BrkFrsl7JX1dt419/hBBCLLW6gF4IIYQQQgghhBDP1f973gUQQgghhBBCCCHEyklAL4QQQgghhBBCbEAS0AshhBBCCCGEEBuQBPRCCCGEEEIIIcQGJAG9EEIIIYQQQgixAUlAL4QQQgghhBBCbEAS0AshhBBCCCGEEBuQBPRCCCGEEEIIIcQGJAG9EEIIIYQQQgixAUlAL4QQQgghhBBCbEAS0AshhBBCCCGEEBuQBPRCCCGEEEIIIcQGJAG9EEIIIYQQQgixAUlAL4QQQgghhBBCbEAS0AshhBBCCCGEEBuQBPRCCCGEEEIIIcQGJAG9EEIIIYQQQgixAUlAL4QQQgghhBBCbEAS0AshhBBCCCGEEBuQBPRCCCGEEEIIIcQGJAG9EEIIIYQQQgixAUlAL4QQQgghhBBCbEAS0AshhBBCCCGEEBuQBPRCCCGEEEIIIcQGJAG9EEIIIYQQQgixAUlAL4QQQgghhBBCbEAS0AshhBBCCCGEEBuQBPRCCCGEEEIIIcQGJAG9EEIIIYQQQgixAUlAL4QQQgghhBBCbEAS0AshhBBCCCGEEBuQBPRCCCGEEEIIIcQGJAG9EEIIIYQQQgixAUlAL4QQQgghhBBCbEAS0AshhBBCCCGEEBuQBPRCCCGEEEIIIcQGJAG9EEIIIYQQQgixAUlAL4QQQgghhBBCbEAS0AshhBBCCCGEEBuQBPRCCCGEEEIIIcQGJAG9EEIIIYQQQgixAUlAL4QQQgghhBBCbEAS0AshhBBCCCGEEBuQBPRCCCGEEEIIIcQGJAG9EEIIIYQQQgixAUlAL4QQQgghhBBCbEAS0AshhBBCCCGEEBuQBPRCCCGEEEIIIcQGJAG9EEIIIYQQQgixAUlAL4QQQgghhBBCbEAS0AshhBBCCCGEEBvQigP6smlSfvI0ivIUPTYxH69u0rJpYpbXtzgr9qSMudpCrHbdy6vfZutmLesNa9rvT8Xz2I/rXY4XiHlfR7+lk3u4xnUpF8nd0tFv5THXp2hCPBcvxDnxKI9+S0e/W+TZXmXKmKbZ5NpWpni3ul3yj1Y6T5P8el4bnte9/L/gei+EEKK1nkqlUun+51nGe1yQrTC6a+k3xrUYqfvdzMOO55Qbtf6jR3n0nwsdp+x9xYVjq6X5l2UTs2zBal3+ffajHlxkqHzobDqpeV9nhgG0V60N3xSZfNPG1IECU4eUxqkwbkwRvzpJ7uEcxnQWo9+Jpm5G3eHFc2wYd3/j/Fq4G2fwDER/COCo/2xSJfmpG+XOOD1OyFRGWViDcpFcdpbSspn1st3pQLF0s+6t1694ZRjbg1CT6UyylxKUdgdx93e3ek2VTcwnVqxblnyIabK4D5utN1B+mCNTtOHaqbCwtx/l0X+GgT125rd6p/0OYN5JkLjdzaOaFdc7fpxd7NKWy70zTs+nKoXvvDQeTaueZyttzodW2/VFVDYN8jmDEr2obzhQ646X7Ec9uMbAM9ns/Kxpc22xva5h7wMeTjL8ko8Ukebb5IlJfnqK5LU02Qfzx4oV+y43bu8w7mXXjaZrQu6LEQKfJ8g+ULAfiXH9G+/S66DYgMrkPhtm+LyB9vl1Lh58+nt0zedEN5qeE9Vrf+ZR/bXQIP1Jinz99fHOOD3OMBxMtr3W5b4YJHStu+J4zt0ksHM1ZYb5+5zvKkSaPLu0V33mCbe6NjR6lCf7c4E5gN7tuHbU3aNgTdfeFd8DaopXhrF9P7yq+44QQoiNYdPif3PE/xki1exX+6PcfM/R7JvWSjMkP56Ew6P4Xu9t/1vTIHc3325mzEyOUz7d+iGl+L1/1Tet/NVBBld0ozSYfMtFuBxi4mySsGKtBU7VNwSFbJLwPjvJsxmSh7p4wHtiok+z9G3GExP9YZtAs2wwcze39K1BaYbkx2VCf0zh3drlqqxYGeNGCMO+toC++L1/eYXBwxT+lwxCHR52zNtK7gf+AAAgAElEQVQRBhv39YMUg9p6BKkG+uk46X0BonueTbiV+2KQ5LYk0f3r8Lj1KEvshJ/olTxFgH43wbNRIofstKgKa1mmZQ/bVjvOfR5GDmsomxqnMMl+ESZyYYr0L0VAwX5ohMhYEM+rDUsuZxn/VxgdwOoh+l1dRdYCg/T7R/F/plfXAwAVz+dTJN5z0GVVWe24CDf9KpKtMNrXYfrf04wcGiJ+h+o67dmObRNQyBD/KEX8o6M437tO8nN32+DcvBbCfSJBEVB3qZS3qusezJcf5sj8Wmpf8bmBmfd1Zgp1FTEvxPLz6JfTGEVIXMsROag+xaBpfc6J4rUQvi9yTb9zvNfuOlS99oeuekgemg/oi+ROhwhT/1l3yqaOPt3db7WzLb54UsZ8XLtzmnO1D+comebCvdHSskzzwbqH5DrcM42rRxl8U8d+3Iumlpm57MP39xFS/x7FuaXNhM0q9LvUel86CF6O4pYIXggh/ifUPZaXMad1nOkSocaIaFPnu7S6P0hw/+LfxrfDhBQFpbwdz6kOb6L63QRPudv8oMjkT+NMdSzFKv0H+L/FP8umWQuuS8w1617wMMvUty4ifwRxL3kIsGC1Klj3BYmOZXj5+yyxQy0e8IppQm/FyAH8ZQAQ/KfOZgA8RFs9wMyzOvGfWrqjytMhQh/H8L3Ug6/+i/p53Y0zeGax2qbwM5TyPgYvzX/iIfpDAFuHxT93T6oPbQthS2kOaltvJay7/ATr3tiUfwyTVBSUghXX8WD7B7F59fsSmDMAggzeni9P7eGqxeRlU8dYj+b05Rzj+11c33Od3H/cKJvA/CVB6ICGf1OO5MHun+6aP2zr6FfjjF8IcvNaFG0+qHmcI+Z1E7pWrPttkfyVMMNXZpY9LJez15mYng9KSuj3Ajh2LFk6uY99DH2WRdnjZ+I9L2o5S2IsTOrEAPSt4O1jv4ebev15kmdSGyEBhJ09NA/155mkzlaDeff5DMmTTqz1FRmPdMb3DxL+YojxPSUuHmh1nTTJ3IhTBBznZ5g5tdLH9u7kv3UzeKa49rezL6Qi+rlBhr/tsiLmmS3fQeDKFJZrJQaOeJ5iML+O50QTc4ZO9gFYj3Tz6wyRtwZJbAKYw1jlMp0fVqh8WPvD1AnvGWT8XvVPx4c30c9qnSsp7sbodTaexeMM9Y7X/u8h+Ud8lSVcgQcJRt4sEMz/RuDV2menwuhjGp5zToxzWusK1WYV+t16bKBv8TL7zfCye3brigwhhBD/bZa9Z9vca8W6lhvBkyL6ZwGOfmohmc3AmIvBNwtc/DyI1u3zRovmwpZlpV1kPEiB6a42daNI+n0fsV+q380ZwFstp2T2DmA1KOJEIUus17XkQd9zsGGSrXZcu1JMfJnC8b4be199OcuY99MkvkzhfDPc+gHPOoDvg9GFIG90yZc21OZtJdowSH0dw/3Nb1w/slh9Um2mV2eHn6nvfMumXmTBChTb/GLdjLnoGWv8MEJoyd8Zkp/EyDQ2ec/GGHlzcvFnfxmAvfbbKiML3b+uN8lfiTDyfobh73No0x48/woR+zyM97UOJ4SiEf7O1fYnFivwe7dlWZ3y7SThcpSZc+6F4876mp+Jz3Ns/uw6kYP+lb8VPrvYcqX8e5rIoSHG78QIfetj5qQDKKOfrQXzipeLN+L4d1jhiUnuaoQkgWVvvnI/JiiiEf3UQej9GMlbOYI76oLccobkmSwQIPHvCdxbADTcDiuD9hFSl65jHPJ3V/4+O9oe++Lf93LV42uXn1GPnV5YaE20/D1XnvwlAA++Qw3BPECfhvddD+E7KRK/5Ll4oNXBVsas9d1Vt7aoKitXc3VYtljbXOfm+98270pRnlvvs7a6PIvV2hCM1MqxqbHLTOd5rWyaenOUu630emxisnw58xW1y9en2e8at3Hr5Vte9SwGcV3Pr+Wvq9vJYmXJz9fxnFD2R7m5f+ln80311b7V3vxTyyuSu1A2DXLfx4mci5F+oOC9nGRo2ofvo0HsPwaJnAswvEOl5abrcxA9H22zBCvqFlZd6dCtYk4nfdBHYslxYEVzD1N0Zsmd055e96ZNm+m1WrtvtSSEEOK/zvpkuX9SJHdjkvhpH9tfcjCSc5H8OYl3m4r3cp7kGzOMOGxs94aIX0mTe9h+dsXv/fQeS9UFlQbGVdj+UsveeGRSCsrPKfQHAAra2BRT31X/hRsD8jrlO5PE/3Tj/jXKxI9lwMlopUKlUqFSKZBsOq2D4PRvhG064TcHsPX00DP/zzbA8JiObew39JNt3sRZFBx7NDSHSvn3HLm7OfLFzWzfraHV9QPvyhOD1AkfQUuSif3lakKi2r+ZPxp+u8mC1VrtIlC+nyb5dYLE11NkHrHweTcSJwcZ/Gebf++nO1cKnM3UtnPt3x9JPN2u8+4wyR9ucnP+32d+wIZ9pwNH7Z+9YxNKE+PHFImxEYZe6WXoW/Df0hndpeD8UEd/B5IHennZPUL4Uqqu/3Sj+W1qhWKGqa8TJL5Okr5fXvj8WTSANh8Z8Ipt+ZuaXhtMF9dcSWPZ5sb/bnUP5bK1Jv0PksQ+qTaxD15OVIN5gE1WHIeiRJd1Ocmif1kERcN1YAAPkLusLw2mTZNqr3cbvfVBmaJih9Wvy+Ms48dD5FAInIkSORUkeCpI8N2hFhUddhzHFSDFxJfpZa0ozHuTxL5MAQqBnfZmMwByxJ0ufFerf6W8Nnp6hpmcvwY+zjP5/iC2zb309vay+f9eZviL3NK3dUWd+LtDvNyzmd7eXnp7N2PTQqTnK4iKaUZet+H6qH4ZPfR8lK1+fWW4+vebk3XbLct47Zo1fqf20cNJhnt66DmtY/4+ydFXqssLT8+Xpkz+SohBW60cf+vh5Tfj5NoG2p2myRFzVssx9PV82GWSfre6Dq7PcnA3juuVl/F9X/02XPv98JXq2mQ/6qGnZ5DEfZPsx4PY/tZLrydRDeKeFNG/GGHolR4299a2sW2Q0LXlIZ75Ywzf67ba7zZje91H7I7Z5fIXt3fb+f3YcA25M05PTw+DX+cxf4wxXNvmvZtf5ujVujI+rXMCAIPZ2wAadrWbK5WL8OX5a2+MajWCgn2PhrZXQ9vVTTezLGFbD5t7X8b1doz0Y43gpE7isIb3S53kSQ1uxTjqfJnezT30vJ1qnpSu3109h0/58SxUvFqw7fYtfL6SbgCrZbXawJxjruHz8l8l2GF5Jtd/IYQQ/7vavPNuLXM5Ruw20OfCf8SJdZMVzAI4/EydTjS8sbbiPJVk9qRJ/nYa/a4JK20uWVZxfnORzS3eghjfRgg54mR2J/CcnUS77EWtC6J6W7XENrPETk5gP5MjbolgP+hnezaJd1sXZdqi4n5vAvd7K1yXeo+zjO/zkNkTI7DXQv4rH44bETKXa10U5puVt2xOXqZ4K07gWIjc7ovoX3pRi2lSdfkIjIfAS43TGaTeHiTwu0boHQ9qWSexz078RJqp9xyLDx9zJUyz+hi1+FZLwXOh1LL5+CLLOr0xcOE7Fezy7YbKwJ7FNyGbf+z0eyub/1PAVDUi01Ec2+qPWwv2Q1GuH4pQvJfm+nSBubZtGMtkPx7C840V3xkfmsUgdcbBxGsJUp8vvjGv7yrQ/m1sE3/MoN+aA2xLkv/NU+wuHO/PMPvYi1L30G/8nIGDvvXps12uPVZbqtuqmNNJA+wI4dvbxWPrHZ2JInDKiWObinsvpKbTzDwI4pjPyaA40PbB5I0ppq75ce5XqLagSBAHOO7ADrTLurGs2A9ShI8FiN0B59kU0b/H6elp3+AerLjPJhm972P84yFe/rjZbxS0cymi+9ocG39TsSsG+SIor2lst6m1t/0Gk+9q+L4torzmJfiWDeNCjNQJN35lsYtE7kqYka+yqLs0tL/VmkffijH0rp3f0tVWFxbbduyPinXLgNavNTu4F8d/IEXqgYra72Dglep8jCt+NO8kRcWO95Qf2+9xYldHcFts5C43b27eeRoHgU9GSe4eJz0WI31gArc5RfyrIihBIu844H6GzaoT9UEWA1B3aah/Y0kyONBJj/k5elVH6VdRdm2vHu+/JAmfiJPtd6Lt3Qx/Geh3dGL/GsH+63X8/fPl9OHyTtZyHGiof5vDmC5jU6zwiC6Wv1T5zjju3WGy87/fXGD21iSh3QblrM7orqX7Rh/TsBeLbN6l4UQn+8Ag8eY47j8v4unjqZwTCx7opKaBHW4GusqLYjKb1dH7APK1t98uwpdrXWvmk+K1s8nJ8FiA8mM7Azs13Lvtiy1gttjxfnoT75k8+rROLpfH4vW0vp+Uc8TfdDOypMvPCOEjU9z8xrPkujf/7GI/sNIcMIlal7jmfdMtu31ExtyEvx4gfsSBdROUH6aJjMVwv/vbivvGr7tfrzPxSYFeVrPuQgghXnSrCuiXKlO8m6GkVB8oCj9naJ2vXsG+E0rZHEWnA8VSnXb2r6W/MvMmmLNkbumLN/FtKnM5Hb0hi7vx/Qi+0xaSWQ/ObQ5it1y4/mWQvDDatol/8U6c8OERZt/KoB9UsBBFPzfCkPoyU2cniH7gRm2ydeabJq5Eq8y6xWtRJnYnF/rXufeo4HAzeddbbYL//VG2f390fi71Wwh9zMfI12lKfV5CFwpM7amtbEM+gmw5RGMPwvKtBIGcl9TtSK2PuBvPngGG1TDJfYsPuVyNMHx3M40Jdjo1We3a5fp+5sCTArPdNtq86sPW0/jbSNOftmLe15nFjmMblIwMest2mVbUnVb4VSdvaZGQ60GSyBkrMWNqoULIvd9FeLeHiVsGkT3zww4sdhXoKnNzvYd5cnfLQBm1WSuOHT7Cex34vL0kzvtxKXPkv48RPFYi8tMa+/c+KWPcTRAe06vrtseBAmTv17o9NGkZ0Ezu9hRFILB7AAtWBvY5YFpn8paBv3/+0VvFNxZhMhcm9i8bsfoZKF6Sp91dVhaZGLfSTH4dYeJKniIK2oc3mfrQieXuDNperbZuBWZv5Zu/4ezTiOgGI/fSXJ/OkJ3OVQOYrQ7cu11oe90dEtA5CPyQpLeWZdt1JrnQ19m8ESP4bREOJsl8V6vEO+Li6N+HSZxLEjoYxAE4DifI7LfhnB8140GCoVeOkr6RJvu7H3Wbm+gPAww0WcaqTKfIHE7y20/exWugmSb2/iRFPCSz88e4H9fbvQxfipB830NwR8N8upzG8o8w0VMJBj+JE77ko7ccJ42C9/MQ2hZgZ4CbPwzUEpiB/7ObTa+nqasFIrdLjP6j7ujY4SeR9WDbpdaOGYOE+2WO3kiTztaOuYVygvvTGaZOVis1y6ZZ7SqzrbvlL8oRP14N5p3nZ8jUcibkPnExcDpL+Hgcdy64NMgrDhD6KUlwpxUeparHAAnyDy7WKsDX65xoVEa/ECYNuE94ugw8dcbf1Bnv/MMWatnyH6vYKFO4myZxN936539XKU/HSJT9+HctX0vjSpiRa0Ucp66TPutGeZwj8b6bo5cCxA5qTOxb/G36qxBpILLiUVoMstMGYMXfLK+OxcHotRSxEz7sx+oTks4y1U1iXCGEEGINVhXQu94K1iUSM8n+nCO3bHzXarZwjkfRlt3PrGx2VAN6o9m0f3MT3QvG3WbZW2vTkifx9hBHf3IwcWP+rXq1ib/ykY+jB2JM3Q7iaLaGj7NMnExhPTtLeiH7twX7kYvM7tVJ5dWmwTw0JPJZI+NBCpcjXhccO3B5ikR/LYLK4rA/taFu6reB6+0wyWNTOPrKmGUW3qQ3Ug//xm+WpaGW8YtO0RNbmvBtm5PhAz6MR8D8g85bMW7WZaFfyTBD81oFrdbdYW5eWD7oHh/aaNV4eZ5yIEGplGjyzdJWAcqOKNE2YWzp1xy5ZUMtVkdUyL/efHSG8kvNA/ryrznSB4dJ1Lfu2OJkaH+RaNGE+XLsDpNc7fBBTh/BU+3aKih4LudRL0WInPAQKmzG9oZGKK8vzzTfrSZ5DtQjU0wcWc1Dag59Mgd4cDmqe8rhHEYhh35Vx3hnsY+/ZdcoN3NOEp9OMnmvWtOi7g4QfM+DvevIpYT+iY/wDVAPRpgaCyw2y90Z4OYPger/F4a7qlOfPRuwbNMYfkdj+J3GZdSPK91tP+mqfLaaKE971YJxS6+96Syj/AP40aBggsMK9Nlx9oF5P4uezTDzk157E5vCKALdtChaEY3ImHfpNfCXDPEisNeOxdAXKr/KihPIYvxhwo6GHdP1NBa00wkC3w4RP+2q5vzYd5HICpI4AnAqQvAfjQeHFfsua3U4sdsZMrkc+q/Vb1K/FwF1sZwECR5fbKFkWW0ymd/zZO4BaPgPLIbIjoMjeE5nSd1raJECgAvXztry+mwL58GMUYRd1e2wPufEUsYVP75PirAjQrhj4FltnVW60PzbhQZMm6zVyrKtrQo1ny1/ZWX1TPrwL6tIKZK7lQY0Asfc1Yp+iwP/MT9Hvx0nfjfPxL7F9RqtJf21rDiPQxfD1vU5CU7OErxcxnxM82tBn4PoeZ5i8sQWXhli5JQMWyeEEP+t1uENvRXnkWZNorOUT8dhSfDf7bTdsDN0OknhNWfDEFpWtA+v89sHtF67LU4i2ZvLPi6bJuUtA7jfALMMVosV7fRN7ErDg4mZJfF1pnmfvnqvegjub/2QpCgamQcGi7d3g9ks2Pd0vu1atjlxAMVr4ZZDEEGtee5bS4fk61VUyBUwoS4ALmJklbZHhOPIFFOHOxZtaTlbPDhZtjrQGvu4PzYxn1BN92uhlqGc5QF+LWGUeSdBIr+92u1jZcUClo/MUFUdUaG8b4TgCt5yWv5uQ/m1QIH6h7Uixn2wvL6Kws17wgrPUiuOI1GmuspW3YV+J5pabUWh7vCgeYbx7FocW1nZ5gFSsGzdm7ink7wHkGPi7UESAE9q7XmmU+gP/IutQwAUDf95jS7T3zWh4rswi8tiX6iEMe/rpKdzFBZidQu2HS6ihRIJS12FUNPs2Z10OVY1MH9sAOgfDaN/1Ph9iXKtjOX7k4TfDRK7VQTFjvb60+4UbGVzQyxS/KPWmHt6nOHp5e9mS+XlObpXNE2fhvsgxL+o/hl4bxVdRP62eXnLocd5JsdGCH6mU6wNO9i49RbKSe+y9V6VolGrHGrYjgvnsU6xvuJ0JdZ8Tswrk780wtDbkxRxEvkqiLOLda+2zmoy9nw9q4p7rxv6elu05FLwflfB2/jxfMVah/HrGxaGVQGYXbJNzT+r7W0cW5aWoFPS32oCwxJGzsD4vYzjSIchdxt1GoLONEhPg3aqy/k9qSWmXHWyQiGEEP8LloUKRk5HLxjk5hOA/WWQuZOnsC1A6kKnRrUmxo0pEtfSZB8Uqm+cTg6iv2THuc+N/4AbteXITnlSX8SIf3cd/Ze6xq+KHfeBAIHTftzblt6clR3VR+emgV23QdATg/THYUJfTlLeVu0bCVD4WafsCBA8EyHQ2KTW6mD4nfbvkTPnexm652ob0Kv7AmhvBBnpjxPeY2HmUohwKUr6H8CdlpMt0Sxjcb1lWe4BZY+PwAk/ga9VYgdVLGWD9LkgE3tjZNo1Ad9ixYpJ/tYMrNdY0I+yxMcixL9Pky+qOPdYMG7lKfY78b8VIniydd/JspEmdGMzviPNQ6jivRAh2u+Dhd/emWQqpZO6Z9QN5afi2K8xfNCLs9PT5U43IcsAgTN2kqdd9FJi5qsRgn9ESO3r/Ghq3Jgg9rD28Fg758zCLPovLpJ/TK0suFnDuMbLNLTSaKS+7sJBity9JPq9YMPwc0vlbiVrye/mm6/WS5O6XW0CXTaLGPdnKTRmmMLEuGtgUsCw+rvqnGHZaq9WCD3OMv4vD+FbLVKH9XuYuJokMF/+ptmzq603Ju+Bu2nLI/sK3oBZUWpv1p2fZkgfabyeWGqBR474IR+xewreC7PE37FjXRg/+9mx9tVW9h9RMtf8yyrZLFuWn6UrmaZ8N0bkC1D6VXhgEL+UIrivw3CnXch95cP3WQ7l8EVmP/djty7vNrVQTkrMzVcmrkWfggboUK2Qm7fwfw1lhdfO9TwnKOrEThwldNUAnIz+kF7Wp7/DDGpjz2uMblOZa1yX+ylCpxNwMNny2ryk/DemiF+dJPfTbHWbXQ3j+WeC7Tu8eI4N4+5vF8xacO0NonwSI3xyBGXMg1rOEns3ATjx7XHQecyWVhn6PST3hpr8vo1OQ9C1/H5+NJcSxk9Z8ubiUILKvovo6TZVOOYsmVtpyr/kFyoqC/k0ud/ncJ/PrHjkASGEEBtPXdir4DgfxfI4R+5B7SNLLWu428b2V1WUJgM7LTKYfMtF0PQTOxlhxGFbeC4qF2fQL8dw2ZPEmiWde5RmxOnHeDvJxezFpcmGyib5G1H8qkbuJ53RnU2Ga+oQ2LVuem2SPuHC/ziCnk8ua7Zo3onhO+CmfCPT0D+0TCE30yZXANWm68uS0TXY6iGZtTB+NoTvElh3+NFveDs2OV9axgSJ263bCjQduq3PzcTPKWKnA7iOZTEUO+7D4WpSvY5LzJPSBmE9xoIu64Rf95E7kUQ3ri/kRQDgUY7JswG2v1laSPzV1O0Ivn82a37fabjChUKQ/UjDld7OxOkAF8+oLLyTMQ30a3GCtgmGmiSyWspBcHoW29kQQ/ahauXEkQCpa53Hsld2RPFZACzYXrOjWBw4PCoD22wLzTazbefQoNNDZauWD6uxw0NgX4ijN3KEjoexfx9ZyLVg/pIgcm07kQ+cWMihX84BCpFsYUkf5OKVYWzeFOkbWYpHVApfORg40+YhXLGjnVnJY2oZ/Vw1mHd+cJ3UmHvxWHtSxpiO4HOPM3Ikjmu+b3NDLopaSZn8qRrQu9q2POqGhQGnH0iQ/U4n/46z+XHycL759jC+Q7W8CWap7bXHfNwQ9W2qreztWWbLoFjAnL7O9ZWU1uHCT4zEj1Po9wM4uwgAu5/GIDkWJouT6NU4HB8gdDVI+Kq2kBiwXumvbqPuIvmfqves4UO+2vXdpPRni3ISI34lgDbfncQ0MZsMB9Zx+f0DuHeAfi9FctrA+051fsZ0svrmvuvkc4vy63VOPEpz1DFEogjsCpC8FMW72u44a+5LX31m8H1bhH4nnr1+om/1AgXy0xn0T46S+CSMdzJDsk13AMveCOnPDYZPxDnqrmWMUTSC/764PK/D0imx7tXQ5v/c6sBtt1HNmaKiqgPYt+aX5ivoShhX24SbDble+j3c1Bdv0o6dGptt27ErliX5aprdAyyqm+heE6MuEa61vzrKi08dwL4VzF9XvAJCCCE2mLqAXsV9KthF9vIWHmaZ+tZF7I/IsnGnsWp4z6lw/2WmsjG82xoe0h7kiD8YIfOBtjxws1ixH4gQ+aAH33Se0Z0rf+eo7g8SbPpNntxXRUay/qZ9EK27fPh2h5jKFwnuUJZMl9JCzH7gY6BVi7xXokRf7eJ93TY3o9+4G8ah717ZSBOatjP1gdb0TbZj5008tiahW5+T4DcZgt+scsHr4V6W8WJ1vy/bUn0OvKdHmHppiuxDP2qrIeicQSa+GW6akC1zvpehjoXIoY9liWQzBBoDNKsDz3sXsf3Zg2s6x+iuDm+bttjxnr+O93zHhS7RvOn/U9RnR9uzXjNT8X+ZRHf6mLwzzpAtgX3Pdmx/ztZa2qj07p5lVJkhXQtMHQ2jVShvuNFIoV+dQn/oxXM4zc1d9fkVelEd1YqW+pEBssuaqbdiUnxQDYY0t3tpxdEmC+q+ITTGyd6r67f+DFgPBIjuShC6E8blyBA4pKFioH+fxv7pLNG9FuhTsCtAMc7I2xYCr5qkv05U32QuoaC+rsDVIvrYUY7+4cT6io/oYTuKQ8PNJOniOL43smzfYqDfmUNR6Pzycl6fh8CnThLvZwk7t5M57kVTwbidIv3qBLPnteUhbpfTGN+GOHoDlONh/DscWM4Gif4zxuSJCL49E7hrSeHUg8BViL3rg2MqttfCBNuNLoAVpb+6kvETPizH7Jg3EiRuNZbTTeCck8SZLKm3X+blC/NZ7g3c/84zsd+6wuU7CHwVYcoZJn3MxfYr27FRTbwIKqOfrrzljH29zok+N9FvIliLGqHDjd3VVsrDxZ8TDDdem7NRet1dhPl3J6tJIfdOMPtDYGkF4yngXowBR4jJ8ylCh4JttpkFx3tT/HakSP6XWQrYGNhh72KQBweBH24S6FzSFWrT9WZZPhxq1+PVVa9ad/lXWbFYJPWWg8DDMGl9HVpyCSGEeK7WoQ99TZ+CXclw/UYO92FHw820jHlP53pWwf5ekwegfgcBxc/E127sTaYt3ooRu+Rk5Fqbm17dcGDNNUtYVR1n2v9lHG2rH2d90/onZYzpCSauOhk+0ywwVxl6N7i88uJ5sG7HtadJUPwUzZVMWuThq+kiQdgOJ6OKr7rfa0P9LCgXSX85QWqfn2i7bbxpM71N3qJBm+EKl1BQ9kHi32m8r7mXDUVV/j3N9WlwH9to6YSq50O7XbTiYfNa2eYl+bPKwAk/0St58reK1aRt/R6iF+IE/2HB+HqyGoQedDHQuLPq3mhO3S7iPdQkv8KaKGgHvShXJxk/Mszms36c81G9aZC+Mk4MUI67cT3Trqq1Vh1jIwQ/SxP/qJrpW3nNi7aplkjRouG/ECR7LIZ+NUZIseM/N8PUrwMMNwyj5zyZInLLQ/iWTuIjHQ5sJ3DYjtrvI3xukpkzOsVfdIr9HiZ+SmD/dy+DXVeKgOOkzqwSZuT9GOmvxqvDFSp2vLvBfELT4LDjNI9SxE6nACehY7VM7XvDJI4nGfoqjn/MTf5LN1YUvOen0HPDJB6kiJ0GPhwmuK9dJZsF7ViC4B0/sVspYqcV7O9EmHnPYMAzvuR3jg90ZpURhs8kyN+pJSjs96AuVNiubPmWXaOkb1vwHwmRqj8fLiUI/mPlb8Sb5hxZJeu+URo7k6yOiZGfYaahxQO/dxv/RQEAAAMASURBVFlLtM3OEJCYThK/pOLf46p1yStTuJ9BvzBFDlB227vrerFFwb5LWZ+WR//1ShR+LVL8vUBpPbqZCCGEeL4qK5KpRKASybb4+s9MZeK4u2JXqCivaRVtr1bR9tgrCkrFvj9Qmbhdaj3rws2Fael3VqfdpVZAqdgPRSpTP7eetvDvYPX3bf9NVGaaTfyfQuXm54GKu58KqBXnXq2ivaZ0WG51O9Dxn6eS/KPN5mznz9nKzZ8KlblKpVLJRioQqWSarfuk56mUozDpqXC22RJnKhMdt3Wb7b1sQTcr0SPOisriMePsp4Jir7hPJSuz7Q6Zbta96To0+Gu2MnXWX13u/LG3t1omdZe/EknNVvfDWmUjFQ4mK4VVTJo52+W6VCqVyk8TXewfrTLx0yoK0slcqVIqlSql0rpssbYyZ6v72DPZzRadq8xOBmvnecM/xV7xnr9ZKfyn0zwKleTB6jQtr4Gr1Wm7/WeuUiqVKnMdy1ipzJWq81o2p79afL5ic7WyrmReq5mm3XxWNpe5UqlS+ms95r/y5c89o/OhUlnpOdHGH8mKB1rcd7q8/3VxrSv9NFHxvqa0mIdS0U4mK7Nd7bd21nLezq9r8/vvMtlIF/fjLufVWJKV3APqFCY9zffFf+Yqz+iwFEII8ZT1VCqVykoqAMqmCV282atmi4WVDuW01mnXpGxSHYHqGS+3kydthsF5Wsom5hMr1hUP77OWRT6n/V5vPtM+LOm/uC7Wsh8fm5g82/3xojPv68wUoPcVV4ex4JdaPM6qut/PZYp3M8z+Bbb1SgopxDpa7TmxTLlILjtLCRsDe+zLWkA1nkPNdX8db0z6t9m2Hfs2pYtm813NfQ3nbTUJbKHFdnimVnsPKJuY5RfsmUYIIcS6WnFAL4QQQgghhBBCiOfv/z3vAgghhBBCCCGEEGLlJKAXQgghhBBCCCE2IAnohRBCCCGEEEKIDUgCeiGEEEIIIYQQYgOSgF4IIYQQQgghhNiAJKAXQgghhBBCCCE2oP8PXcxMoTibOYcAAAAASUVORK5CYII="
+ }
+ },
+ "cell_type": "markdown",
+ "id": "7b0458cd",
+ "metadata": {},
+ "source": [
+ "[](https://dacon.io/competitions/open/235698/talkboard/404068?page=1&dtype=recent)"
+ ]
+ },
+ {
+ "attachments": {
+ "image.png": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAABJcAAAKwCAYAAAAlcJ5cAAAgAElEQVR4nOzdf3wb9Z3v+9eMJFtOHJCX0No0bKMCPTgLXZyGnthbzhal4XEwJ+denAfdi33oHtbAXXDoveDAfZQY7uNBnfJYsGEPTcI+aEy6sA5LuXa6zcbpAxpl23Asdsmx6YbGFCgKJYu9bYKVxMSyLc3cP6SRJVuyFcVJHPp+gh+OJc0PjUYz3/nM5/v5GrZt24iIiIiIiIiIiBTAPNcrICIiIiIiIiIi5y8Fl0REREREREREpGAKLomIiIiIiIiISMEUXBIRERERERERkYIpuCQiIiIiIiIiIgVTcElERERERERERAqm4JKIiIiIiIiIiBRMwSURERERERERESnYWQguRYlEIkTP/ILSllfY0qKRCNHYHKxCrPB1OK1pT1Gu9xuNRDidVSh0O57ucufG2d5f59bp7cNz+d5P73tY2KRzuP5n8Xs4905zO4xEiIzks5jIvNhGc3bcPh35brOs5sEx5xx9lvPinHuaCj1ezYv9VkRERGQOnfng0uFuGssa6T585hYxtHM9q+7vYSi1vHZCM7w+mvUiIER7WRnt++dghfa3UzbTOhzezlpjLduzbZMc0w7tXM+qG1bN8rOenqF8VzLX+x2i+64yGnfkPSMY6mF9atmJ6WfajtGRbC3xPJcbjRCJ5PMzU2s/wsDeIANHsjyVa3/NeI/ZDNFz/yrW78zxgqEQ259Yx9obVrHq6goMo4JlgVWs+sY62l8MMTQnFxmnuQ+f7nc1fRvl8T3MMZNT3/8cp7T+WS7o09d/tu8wTNkX87i6HMlv3837OvX1jRjGxunrOMt2iB7up3tbO+1PtLP5xR76p2zq0FNllD01+yc3tKORsru6KeCTOvVgRs5j5kzHmzA9T3QQihSygqcm+zaLzvxZO29/tv02OkT/7u1sfiLxmbU/0U7797bT8+bQnAWkZv0sI2F6trWz/i/Szzd3sP6JDnreK3QD53m8muGYn3r/+XxfHbm+NwUp9Hg1h+0NERERkXnCfboziOzfTNPtrWx/a4jyq+pZ/8xmmr/qO7WZjAzQ/VQ7bc93EBqppPbmJloebaJ6cdpy3g7SNzh1wgqWX18JI2GCh2dp4B4J0f6tRtpeHEg0oMsrqb+/g80PVJPv2kZe76Bj3wzLubKO5jX+POd2aspXt9B13QwvONxF49U9RGYIUmRuwwHCAP1BgqPJhxYto2ZFjomPDBA8MO0DoOLqAJWxCOFXwzMum5EBtj+6npYnehLLxU/tA620PVJPZekM000x9GorDd/rz3hs8ECQ4cUBllWkP1pH2ytNVGWdywDdgVUQstmwOOsLpsvjPUYOBwlnCVxGX99I4OYgNd9tpe2HlVSU+vC6SQQbjgzQ9XQLVU8H6H51A9U5t0WE0LYOerMFxGbb7w5vZ+2lDXTnev6WTgZ/WE957jlMrkW27+GiZdSsKMebz34Q6WfzPQ20vjjAUN7fwX4237A++/qvaWPPvdk/5Rkd7qbx0i7WfthF/ZLkY/msP8BQkPb719H2YhT/aj8lwGg4SNhbz/qn22m+PvuWDD1VRs0js61YHZ3p6zTHwi82UPNIlHWPNlK9wkvkUA8tVeuo2NLL1ptn2gOyfAaDB+HIAA03dGS8su67e2jKdRxJGtrRSMWOtXnvd4UZov/BHvy3NlJ9iqekdOGd7XS/nf0533WNNK7MMfPD3TTO8L2r2z5I160zv/vwzvXccVc33pvrqVsdoDK5qMihID0PtdAYraPjuTZql+aex9DO9dOOmQlVND/fRu0sH0D09Y3cdHMHvntaafzWVlqWliVXIkxvqIeOGytp/4tudn27Gu/kmtPzRDcDWefoo+bO/D+TbMd8ToQJvl5N12Andae4A4UHegE4+B5UXz7Dcneup2FvgM4na09xHz0DxysRERGR88DpBZfe66Dh2k6qenoZri5jONRGw3W1RN8IsmGFd/bpIZEtcHMj/dWttO5sZRl9dDzYSM2aCH17N1CVnE341Y1s3Jk23Ykwwdcb6bU3MGs4J9rPxjV1BFd30D9aS7kXooeDtN9TR22sh+C3q8hnbb1LllO1IkzwsbUM3byH+iuBI0E2fmOIumA9lRVluSd+r4f2Hcmm9nAfYcLs2tLOYHKSypubqZ2hoRt5s2vmwNZwXzJoM8NL3u2nP+0iqfLxNhjpp9+5e7q4hOUrcmzNQ0E2PpbeXB4l/GqIxpDNhlkvhIfovidAi7uVrt/tomoxcKSf7Y82EbjHS//zdXk33svXtLFnTfojITZW1LDpG63sebg6z7nAKFDi/BGLEnGyqSKjOaYA6KX1m6voyPGtGTwAlTdPf7z/1RZC9/TSe/uU9Sv14SutpvHJVsJGDcG3NlC9MteyvfivrmL0ROajAy+uojUWoHlN9qkAWFJPl12f/GOI7d+ooOvm2S9ssxl4eRWrQk20XZ+2nywuYfmK8jy+Q2E66pfTec0ueodrKIv00nZrDbWxvlm+g1Eirwap7hlm/dSP2H0aUYMCRPe3c9OaLiqf7GTg+Sp8aftC5M3ttNxdxaq6HnY9MP39VD9sYz88w8wPb2ftpV0zLj8jwB1OXCR3PtFO4l/Ji/acKx9kc/0QLQN7aLrSeTBA3RVejHs7abq5OUcwFqCKxh920ZD2yMC2Wmq619L6w0Yq0x735hEsHhwKQyzxPcyl/3urWO8c82ODHGSYgfTv35o29txbkWvyOVN2RRVVWd7TwIur6FnSQGOu72zG9y7ERqMmEdDO+R2fItJD+38NUr3vIK1fnbo3Bai7vYWGR2qoebyH4S21uQO0I2GCpfUcfG4tU7eWd9avzxA9W1rgkYN03V2Z+ZSvitqlVdRW+VhVuYme26vTAj1l+Fdk+04PsD3QQ8UpBPymH/Mh+up6Sh6swH+Kh7Do2x20PAQbHvax8f52lj/fTFWu9cjnplX2pcyb45WIiIjI2XQawaUowedaGHy8h103Ji40fTe20vnsTXxhSw9Nz9XllxFUHqDxqSD+lZXJhmgtG57bTPjitXTua6ZqdeLRqnv3sOfetOlea8F42j97YAmIvNpBy6IWDj46eQfSuyTAhidbCV7RQfDuTdTmsbLeJVUEllQw9AyUVAUIrAQOD7GZEpZfH8h9UQfg81PlBNyODNPDEP6qqkSgBaiYZfnRcA/rQ7VZLxASGml8cOaLBf+a5kQQIjpE/94gvW8N4r28hprrqqlMZfDkSO9f0cSeV5rSHgjRYrThzyfD4s1OWl9Yy6YTjZMXaYurqH+8lb6S9XTeX0fzNXnMJ4vwi5vYtLQa/5ZNbL+tmvoZ7uCnvHeQEOALD8HK8kSXiuqWtBfUsTbrhDU0P93B2qzveZCuv1hGT5ZnKq9povyuTWxeXU7jCn8ia8kxEia0bRMd5U10zBBcBC/lKwJTgnARoi9D4PJTucAehRhERma6rJ9FdQPND+QfyHNE93bQMthGT09t4nvrq6X1ha3cdMVmeu7cSt0sWWQlZT58c3VtdmSQMBFGo8D+zax6qDsZwKjM8dkDhOl8ZD2+x99n063Tjzy+a+rZ9CKs9bfSfeuZyT5KBLiHE3+UJoLVlSuqksGdMvxeIFftH28JZeXDDB6JQtplf/REBCr8sx6vvT7f5FRHeuh6fgj/SCddoUbabjyVD6af4PP98GYnwffqacyx31fd3kXXbTPMxu0j5/FqDvmuDBC4cvrjJa9BMN+ZRIYZBAadYw4RBvb2MQhw5CBZQxgjEQbxU7MkV9jVS/kVfng7j66U7hLKfL68s3TTl+EtheHBxDKyrUlkcJBhyvBmPOmj8voAldNeXUIo/62WQ4SeF9upqu+bEgztoPmGICXZMrKODNCzrYV1T0ZofLmLDV/1ctNjN1F7bS/rn26lcXVlRqB4Lszp8UpERETkPHAazal+Qo9V0NCf2bzzX19H4K5e+rbUEcgreclL5copTdDFFfiBviMRyJHTEh4IwZU3Uc7slxfRkUHw1TAtr8hbgo/BRCHWM90IXFxJ4Prk+zw8xGYGWFYdIHAqF6DhIJ3fj0x/H2lm7KYBcGg7DdUtRG9rZu31lfBWB+vuacD/9B623jJ5wRwZ6CW41wcVywlcmWV+7x0kRCU3LQFmq3ETjdJPBWVT7/57Syijn2ghhUNiEULfa6DucR/toV6qQw3UVN9EeHsHG3J0S0quDKEXNzN8Yy3Dj28itKaV6pUbsO0NiadnyR4p8eW6YIhSkuPb5FuziYGd29m85Q4CtwUJvTf5nH9lgEBtIz0H6lOBxrxF++jdUcXyu07h9v2RfoI7IBgNEr6zMa/g7Fzpf20jFd+cckF4eYC61XfQ27+JutV5ZjuetiihnZ0Mlg/SvTdM4+2NdP2wIdW1NLchhnbXsXbLDFttaTVrb24gfBiY8t3OyMTJZtbglhPgTv5RkqgaM2tgO6WapudrWXvLMtbe1kTNxTAcDrL9VS+bXm7Lb18YCRN6eTMtD3Xjf3oP71/bzx2rK1m1ppXWbzVQvXS2zzBK6DtNtF3dyZ57Oml4dDuB5+rxZ/vulCaDIdEhQju66D0chcWV1N1ciz/v4/XM2YZAgV2VhggfAGYMCKe9encHm8vLKX9hF+FbG/EzTHh/f6Lb2HCY4WwTLQnQcHsLTd9qgYcaqb3Gjy+5eaORMP07NtPyUD9Nz3Wcwa6FPmof3EXwL+rwXx2g4Zs1LL+qknJvlKG3BugLddC5t4LGV7ryukHD4TB9cFrHnfALTTQNtNL99NTPrJ6WH66nhsmbLNE3N9N4dzvbD3mpv6eVXQN1qa6F1d/ew8CabjZ/dy2VtVH8a5po/2Ez1WfrMCQiIiLyKVN4cOlwmD78rJ16QewtwUeYoSNMu7jKW3SUYcC/OFdrNUxwR5Dm+9Ial5GD9O4N4jtykMhkhycAyitrqKrvInioPiOzJby3i+5ramg5Q/VNcoqOEnGyJkgU2O19N3l58XaYbE1v33Ut7CnPegmSoSznXW6AKMEtDQw9cpA9TheHG2upq26h5pbt9N+yIXXhP3yoj/79ZXClP2twKbyvm+AD6d1oIhwMBQkujnAwQuYncGUVTbSw67VmqtO6d0Rf20UXTbRmyQrIJfJeiODuTjqe3sxAVRvdB5oTtbmWdjJwaTuNt1fwhSuaaL6zgdrrq6ddhEZea6d5SyUtb2zG+91K6u5ZRm+ui9tpumm41MjoGjRVXZZucQC+FfVseK6eDfm9zbxE9/XQUd5Az5Ssr7BTR2taYDBK6OlW+h7eStv+FlpeDNCZJQPnlAz1sP6b7fTDLMGRxMW4/+apWVYllPggPEMg2dFx3yqCi9IfqaPteT+deS1/UvT1dpq31NCxu4aOqgY2Xh1kw0ofjJTMMqUXynsJDwE5M+SGCIeqpmRxJJcbCRJcsYvhB2tmXkqegZPoicTxYDRHSsloJEKkFHD78CUDu77VrewJr2fgzT4GR4HVdbQ8PSWbLtuyXm3hpvs7CB4po/62Zjb0v0+gHMDP1oEaQi93sGmNn5ojZQTu3MSuRwPTVyk2RM+jDTS+upyOF+sJLK2mfV8NNXVhOp/dkJzfFIe6uWN1E+Hr19N4s5/RvR2semgzzbu7aLpmcgmjwxEiEQAvPicCQzXNwwM0ZZlthjy7KkVe76BjYBmNt0/WCMvYbqPDRCKRKesAHNpO8/2DtO3uxf9kDQ3fWUbPw9XUPtBMLcDh7fQ+li2gXU7dc31U7e6k/ckGWl4OTXZ9vryautUNNO/ro/byOboz8u4uNj0xSBlTumkvraUtOEjroX56+/vof6ufQcC7pJLaB3fR+vxM+0+iVtzByvSbHt6M16c+u7T9NKsj/Wz/7nqaQ5V0vJitPt307CzvNQ20bltLx+XlWdfRd1UdG7bXseHZIQaOeKk8y4Gl3ufbad8HLK7J2K9EREREzkeFB5fc3rzqFBUiuq+HTprouDb7EqKvb2fzYCubr0t7/ndh+vb3UzYcZphlmRNc00THk0Fqq1cRvLOe2iro272djp3QuiNX0eczJ3IgRJAg3n1hGi/3Ez3cR/9+p47KIBnBpUiIju/3Zu82kc3+foI5G6pRoiPgK83crt5yP2VDmSMP+W9cR3OumjzRENufHqT1mZq0fWCYcH8//WXDhH9H5ifgq6X5xz00XLeMtQ80s7a6jOFQF+1P9BP44Z787ng7Swl1EozW0Ly7lcCUiyrfV5vpereR8N4eul/uJHR1WnApNkTomRYavnWQxlCQuiVeeDxI67du4guVXbQ+3caGG2cItGTUT8nTbIW0s8m7uHY/mx9p56ZHhqftv8HnNxJeBKxpI3Cl82yE/qcaqHt1Ld2vNlJ9pISG6lXcEe2i7baqwruE+JbT8O0NiYvkI0E27s1ewhfIGnA5FfWPdE2pYeLF541AnsuHKEO7W2n4i+0s29JL7TXlVP64l4bqAOFnN7PpxtnWoIr6R5fzhfs2Eti9IUvNmAih7zTTUtXE+7m6eZaU4ZujvjIDbwaBQUJvtiW66Gbopf1ba9nuJpGZc1s0x3Gkn56ne+g/DJyoZsPeVrKF2LyrW+ja15IZNHG4y6m+dQPVt26gMxohgi/j3BA9MkDvq91sfqSF/qpN9OxuSta58VP//AD+xxqoq/gCNY+20nRLbVpANErw2Sb6bu2m99Fksegb6whcvZYvPNRJbc9k5t32R9cSWgRc1ZxRgDmjK99pioZ7WL+7hIbbq4FBwvtg2f1p39THbqLsMYBWeu0NVAORtzpYf3MLPNlL8zV+2NLNwH+tY/mB9Wz6bmMegSEf/hub2HTjrCGyuZdeiw7A52f59X6WX5/5suhIWre8aQGiKOHd6+nxJmtTDYXpZRnr0zbbxtoyNgI82os9rW5ehIHdPXS/vImObUNUPdpG8NW6/AaBONVzJ9CjII+IiIhIwQoPLpX7WVYeZnBqhtKRQcJU5leLJ6vERbP/yb7sQYeREO33baLyof7M9PUrbmLdA/WUH95O72NTS1t7qbpvFwNrgvTs7if8HlRcv4HexwOn0L1iroTp+n4frU+30vX0dkK3bqB6ZSPNzsXh61HWP3Omlu0j8M1WWm9ex8bSVuqvryDav4uO77Qw+t2ePINsUUJPNLPp6hb6V6Z/AH5uuqeZ+iVDbH9j47Ti4v41m+gd7Kd7d5Dwe4NQ2UDXYBdVp9ifw3/bJjbN8h7919fTfH1mICj6+iaad/hoPdBD/VXJ9S6tpPG5g9y0t5uD/lyBpRlGaZthHWrubKS6kIBUXhJdi9aXbeX9m6fvwI1P7cksGvz2dtbd00wXDZN3/Evr6ez30VJfS9nLLRz8cVOW+ih58JZT5XRDTHb3zK4cf2U54aFBMjOUBhl8FyovnX1HyF7DJN/lJ4TfHKL25b7UiJb+NZvoOdBNMFaJd5ZpAfx3dtIXbWRt5TKqb2tm7Y2JWkWRQz10PdlJqLKFvu0zdDf8sI/g3pnrXZVdUUPVjBmIwEiQzif9tD2+nLbne2haObWgcw0tz6fVfYr2UwKpC23vEuiv76H8hxuoXV2XGAHM68PnZfoQ7a9vxMioSZaHtEBBNNRB+74KGl4YpGtl8rOKRohEvfh8Pqq/vYvB20Ns/34HG7eXU5PKegozsHeItU9VZwSI/Netpe6bYYaYDMNn7vND9NzfQPtbp7LC+Y2cljIyzOjVjSxLz9ydEhyJ7LyDyrvCNDwZnKzRVVrNhlf6qX6mjYEj3pzd6mYaoS6X2QaFmJVzDnX+3t/B2odOKTQ+axfD6PAoy25flnEEaJ2xyLmXyKE+fKvb6d1STXmur8XiKtoen5L76PWzfMVo9i6HuSzyn7GbZtnUfLN58twvIiIicp47jZpLlVTfPsj6nSGarpls/Pe/2sngt9sKzAZKXjTTSt/dWeYwMkDHPXVsumIz/becepUJ3+UB6u8NFLRmcyX8wnruKF3P4L21VA1U0vxEgODD1bkbtL5qGh+ozj4E/DRlLKuuyt0AB7wrN9Czr4euZzdzxzNhfJdXU/twP20z1ilyRBn4fiN1W/xsfiP/Ed5Syquou73wPLHQd4w8hnLP5Fy4eL/aSu/UOrLJO/PeqlqWEyGKD+/iAC3BSipSF43ZR2mDCMHH1hJa2cWG66dGPJKFlZPyu1DMd3juCKHH1lK3xU9nKM+aSVcGaHy4l9brpxRtLq+lNThIywizdouaC5UrGxm8v4fQ3VWTgeE3g3QObaBtlqHr54aX6m9vnVafyHdVHXUA1NExXJvolpazjpiPqnu7eP/WAYKvBunfnxwi3bucxpdb6MxWnyyp/Jo22rzR1DTDBzrZeKCSDfXLM+qo+UqWzxJcihJ6qoXO21sJ31tG9Ppaml7snbmLo7eK+gfSv3shNtb34k/WfUvfR8MhyNhIK5oZHp6eOTP4ciPLducYZCCtq5lvTRu7poz2NbSjkYodayez9MqrqX+4msxQbBkVV0D/YISMonhDYXrLsxeXTign8EgXM3c+nC7f7ogAlAZofWXmc4lvzVbC4SwZe1Evy29rYbk7+cS0Y07uEepmMtugEKds2iAOp8+7upU9q09pCqrvbqOafjbfsGqWLNA6Ag+kT5oIPGfrzpghEqLj+wdZltfxNykaYWjES/mp1skTERER+RQ7jUtKL4G72qmsbmCdr5MNt5UztKOd5icraQ9lqbeRh/ALjcmL5g1UTZ3BUA8t9Y1sX7qZ3ucKCGw4ohEiqRz+KINvH2RwGMqqZ6u3EmVofy8HTyRqCvU7tRKG+wgTofPBO2h5M0z1fV205qi4Hd6xjoYHvXSGEhdUtY9307+6jpsmOuh8pJbyGT6N4Xf76Z8xQBEm+OAgDR/OPkqVb0kNax8K0Jiti0suTr2UF/1sDm2lrtDMtCldLYYP9REejlBy6eyXgtmHch9i+zcq6Lp5kK5c3fimOtTDxofWs+nFKP7V/kQ3oNggB/dGWX53My2PNqUF6LKN0pZY7tAzMFBZQ2CWwJz/+kYar5vhBclC0rMOz30kRPs9Daz/sJZdoU3U5jMyHpDI7iHnRVQ+Q8dnSM++iYTpfy8MV62j+eqZJ/Ne30j71TU03OOj85EGyoe6aL+vjcone/Mq/p+qJZUUHRpg4HCYwfIm2m47vdpRQy+upeLltbzfXZ8I2GXLhEi3uJLArZWcSqg6NVpjapm9bIxOyRaZVTLA23MT3a8G8Hqh+al1BKobWOftZNPNs2yH6BD9oUEqpkTY0vfR3uH1bE5/0p2oIRSN5DEq2dR6Q6elnMAtTTTd1USHv521S71ED/XQet8mAk/2zngDw+vz4U2915kD7qckNspwJJI8vw0T7g/DFbmPXanA0lCQzY+2s3lHD9GlAfyLgMGDiRpW97TScm9dxjo6I9RFIxEo9Z1+8DdykN69PUTfGmAw+SEODvTQf2iU2sd7Z6wjN2shegDqaHtlhi7mI8NEIsk3GAnTF4ZlpzTgZJTIq0Gqe4andI1N580aPMrszpht3cL0PNhDSbbjb6oO1SADr/YTBgYPBBkYAv8Dezj4+LJscwSSx6vBMP3vJfMFT4TpfX2AwaVNdD97KiN8ioiIiJwfTq/JurSejr3Q8mAjNd8apmxNAy17O/IbDn6K8AsN1DwYYf3urunTx8Jsf3A9Q7cF6bu98tTqIQx101Cxlu1THvavTDTwfZdXU1NZQ931sxfzHR1MBHjKVrclLyq9VFzXSNtqoKSCZQ9V4PX64M2p00YJPRGg7smyzPdXWs2G3T347lpL0wt76Lo994Whf/UsAQp6GX6wY5b3kDAta2DK+/Tf2EatP/NqLPxiM+sP1xN8ozE12k5++tlYsZyWKUP6lV8VYFkFsKSK2spKamYJTMyZIz2sq25k+NEgA9un7EvOCHRrovSEmjMvlJKjyK3NI3g3VTQSpu/dGTpnHAnPWhck+vpGlldvouK+dg4+V59fzZGpZrqIgqwZFFN5fQEC+7rZ+JiPypU1+BeBd0kNlf58rt791G8JwqPraaxex/DiWhoeCtIxa1FxL77VAcI7NiZqsyyporYycXHmu7yWqsqZxk/MR5SD/b2wA0KH6vEvBS6vpfmBWSc8yyIEH1zOqn217EoraOxduYGeN3w03rqejqu7aJzpozgSpDWQ2I+bhzsmE4JKJwshV1QEmH57YIjgo9O7mgXYzrpvJI+uJ8IEX29M1RuaC741mxh4uZ31d9dwx+thyq/Kd58h472e6nfWEX11PSU3tKc90s2yUDuBqyuAxHegkmUsn3E9elhX1cjwoz30Pr0rs75ZdIieR+tYdmOYvqnHHEK0l9XAjN3GZuf119K2OkJ4/2S3T9/lVVStqKLBv5zKJRB5N/f00UgQsmZoOu8vyMZvpAceowQfLGHVE2mveXkZvU8nj/m+SqqvrYTKGbdaVkOH+ujLtX8vWkbNivLsN7b2tdJwQ47zY46BADIH0aiiakUtZf7l+H3pAdRsY9WWU/V4G96RfvqdkUG9FVSuqKKqtoJlV/oppz/3mxQRERE5T512ZxjvlfW0/bietoLnkLgTH7grTGNPJ41Lo0RSqUXJRpzbT/3zBymoek15HZ22TeesL5xWaWSaqZkH+fNSfXc3/XeWUz61fe6roumH7886otHQjkYqHhkk4J8hCLa6iprT/kR9VN/ePO3i0H9bJwdvK2R+VWwYtPMYJW1oWp2mM+K9fjYPraP3zixBSreP6lsaqLm/i4HDzVTNeEFaTt2zw9Tm0Zcmsq+VVS9U0HZ9rgviMmofr8U/Q8DIu7KJXe824Z+rkaGyLiStflEOVffuYc+9OZ7M2ZUsTWkl9Y/vov7xU1mxKppe2TP7qF8FSRx/Gvato/PZgzTf2kL5zlYCUwNs+zezqtD6M+/10L5jej2n4QPhjBG6MlxZR/OaqfuLj8CDvQx+t3xalqNvRRNd7ya3UD6fA4nsnmyq7t3DnmmPllP75J5E4fRcXt+IMfXAkWu7Dc7gA5kAACAASURBVB6EIwPZL/in1O3xfbWZraFmts607DPEu7oN25797BZ6bYYnU8ecqunHHG85tfeso+6xfI45hfGl1/QrdB4zZWgeHmJzxtHbS+BxG3vW73goj7NupsED/fSP5HhycQnLcwWXqpvZlK37JqQyR6fyLqkiUNDn4Z8cCfAURfdvJHBtB8t7+th0o8qKi4iIyPnlLFRamcX+dgJ3bWcI2Fj7hURmQkrrnN4FP6dKywvvyuf4Zjt7po2mU6CM7h3ZzeVIS/PG5VU0lTey6XsB/HdOKRA7EqZnyya6V66lJcdFRWp4d0dGN0tyD6dd3UDzA6fz2fnwn06x3jTT3sNUycLOn2qxKOH93Wx/soVNR+rp3LmBwOIoVe513HT1KgIPNdN8a4DKxckNcU0jXT+cqfNQFk7dIZ+fqhVZNuiKqtzd6ipyZGMtnoPjCHnsA3PVvW1pgA3fzl4qPmfAueL0ujhOddbeay7OMef7tVTeXjUtcym4rZPulYHcx5zhCJEZUxvP8PrPIwUXwHaXUObzZc96Hpkta/nsif5ukDBhyoaGQWPWiYiIyHnm3AeXVmxg0J49r2Umvuta2HNFxae/KfZIDcZsBa2zDuc8RamfwEhad5asTmH0pDy6U80bi2vZ1N/J5kdbqSnpIXx5NQF/SaKOBpXU39PKwd1100dOc/vwr46w/f7pXSwz5Botaa4+u9OR53uoureTtjUFhDDS94NTGl3vLDvSw7qrGwleu5amu/cwcKNT6NxL5e1bef/GxMhljdU3wT199N5Xlao7VJDFlQSuL2gsvrmX7348Ww2dfJ3L957ve72qmc4na+ckaJdV8pjT/lATy+8KwcrMmku1t7VwcHd9ltEaE91Bg0+tZe1T53D9ge76CowZU4dbWX8Gl+9oqTaYadzCnCPPvdxAhTFTcLhuWre4c8F34ybCw214f0+ChSIiIvLpYti2bZ/ZRSS6uZ29LJgokQgFXQjOWfHUWJTISGHrcFrTzhOFbsdoJEK0gKyZQqdLTQu5M47OM3O2D5/+mpzW97Cwz/NsH2vmq3O0Hc7RsWte7PMjESLkdwyZLIw+jzKOohEi0bO/PvPisztNp3PeOt/fu4iIiEi6sxBcEhERERERERGRTyvzXK+AiIiIiIiIiIicvxRcEhERERERERGRgim4JCIiIiIiIiIiBVNwSURERERERERECqbgkoiIiIiIiIiIFEzBJRERERERERERKZiCSyIiIiIiIiIiUjAFl0REREREREREpGAKLomIiIiIiIiISMEUXBIRERERERERkYIpuCQiIiIiIiIiIgVTcElERERERERERAqm4JKIiIiIiIiIiBRMwSURERERERERESmYgksiIiIiIiIiIlIwBZdERERERERERKRgCi6JiIiIiIiIiEjBFFwSEREREREREZGCKbgkIiIiIiIiIiIFU3BJREREREREREQKpuCSiIiIiIiIiIgUTMElEREREREREREpmIJLIiIiIiIiIiJSMAWXRERERERERESkYAouiYiIiIiIiIhIwRRcEhERERERERGRgim4JCIiIiIiIiIiBVNwSURERERERERECqbgkoiIiIiIiIiIFEzBJRERERERERERKZiCSyIiIiIiIiIiUjAFl0REREREREREpGAKLomIiIiIiIiISMEUXBIRERERERERkYIpuCQiIiIiIiIiIgVTcElERERERERERAqm4JKIiIiIiIiIiBRMwSURERERERERESmYgksiIiIiIiIiIlIwBZdERERERERERKRgCi6JiIiIiIiIiEjBFFwSEREREREREZGCKbgkIiIiIiIiIiIFU3BJREREREREREQKpuCSiIiIiIiIiIgUTMElEREREREREREpmPtcr4CIyFyzs/zb+W2k/YiIiJxV6ScoI/Fn5nnKxsDOPE/ZaRMYOnuJiMj8pOCSiHyqTW2GK7AkIiLnnJF508NOBpRI/TYyXpt4sc5eIiIyfxm2bduzv0xERERERE6HPS2fllRQaTJ4ZCSfNZjaSNcNEhERma+UuSQinz6zhczVMhcRkbPOBiymB5bSnnbylozJ56f0pBMREZmXFFwSkU+XqYGlXIEmtdBFROQcmh5Ycn7bYDthJSPxOiexSalLIiIyTym4JCIiIiJyxhkYmGS962EkA0pTq3inCjOlpTKJiIjMQ6q5JCLnp/RKqLmey/V6Nc5FRORcSB8eLnk+SjzkjBU3mcJkpL1skjntkemvEREROfuUuSQi5x97yr+ntKrtKX8bOf8QERE5S9IDS9MY0552RpCzU89OG0cuY9Y6vYmIyLlknusVEBGZK3baT9xOlE21gAkb4gbEjKmlVEXm3tSE4PS/nX9blpV6bGJi4uysmIicWwaJlrfzY2Q+7ALcGLgxIGbhwkyd1Axc2HaqAlNWljojiIjIOaRucSJy/rGB9EOX063ASPzhPDNhxXGbroxJ4/E4HtNMTW8YBoah+70yt+LxOLZt43a7Mx5zuVzE4/HUPmeak/d4LMvS/ijyKZZ+AySRkWRj2GCmB4zSX5DWL86yE2WX7GTHualHCWOGrCYREZGzQd3iROT8MyUmbtmJVrdTtyJmxXGb7lT907gVA8BluvC4XNiWNW0ezgW9bdu6uJfT5nIlgpqxWCwjwDQ+Po5pmrhcrozspamvE5FPHxubOHEsLEyMZEDIBkywzcQdkngckseP+Fji36Yb4lZi+kQ8OkuAyZg5q0lERORMU0tWRM4/hjEZHEo2qDNCRXayToVlYbpMTDPRjI+ORTENE4/bkwhGZUncVGBJTpeToQSJ/Sk9I8lI7nfOY04WU3oGk4h8OhnYqR9IhogMA8u2JhOVPC6s8RimaWK6E6PHxSbiGKaB220Ss+JpmU8kzndpGY+qvSQiIueKusWJyHnNtpNj6xiTo+yYGKnuBgY2tmVhmCbx8XFcRcWJi3snNpV20S8yVyYmJvB4PKm/x8fHKSoqSgWVYrFYRlDJ+Z0emBKRTxsbO1n5z8lbtNKeAzBxJZ61LEw7GYxyucCyiUajuIpLsKZ0gTOT5zDTmAxS64wmIiJnm26Vish5x57yk14U1cDGiscYHx3FjsUgHseIxyEex2WYib/TQuq2bad+ROaKaZoZ+1RRUREAb731VkbgyTTNVGDJtm0FlkQ+1QwM24Vhu3HhBtzYmFgYyZCTzURsFJc9gTs+gRmfwBj9BI4fg48+wjsygjuW6OZtGJMZuzp7iYjIfHDeB5ec7gWWZeniUOT3gA1Y2Jk/6QEiy8blMvEWFSUu2g0TLJvxyLHEv8cnQJlKcoa5XK5UtzenttJHH33Eli1b2LdvX9ZptE+KfMolTmCTPzZgm9h2YlQK07LwukyM0VH4ZASOHYdf/orBzpf5n4+1c/znIYyJWGp2hmFAWnc4ERGRc+m8rrmUK+NADXSReS6tXpKdVi8pWad0kpFZPyL9Kdu2MWwDw0601g0sTDueqHo6GgV3EZwYgX8b5O133uHfhiN8tfYmii/5HBiJjnNO/Rt1i5O55Nz0SM9E+uSTT3jrrbfYtm0bAF/+8pdZsGBBxjROMErZSyLzmHMiMtKyZ8kY2G3madPSjUzANMCwYmCNwcQ4nPgEjvwOfvlLfvnzn/PhWwcZOzlGFDd/suZ/A2tyIDkjrXagzmAiInKuzdvgUupkOcMFn3NBePz4cUpKSvB4PNPqXIjIPGPbGcElC4hhJBrZzt3c5HO4pgSUkr8t28aaiFHsKgLbwCaG4bJg5BhEx2DoKPS/xfAbfRzoe5PfHDvOpdf9KcVrbknM1LKxDDvVOBeZS/F4HLfbjW3bjI6OsmDBAmKxGH/913+NZVl0dXXxZ3/2Z9TU1KRGiXP2QxX2FpnHbMCynchORgKSmfwxLKZHmjLugcYTI8MZBkTBYBxiI3D4ffj1r4m+tp+P3vgXRj/8NfZIhEticY6VlGJe+1VYcgm4zIx6bUZygAtn7DkREZFzZd4Gl9Iv+JwuBekj7RiGwfj4OEePHuVf//VfWbVqFfF4HI/Hozu/IueFyZyk1Cg5pP3DcO7GGhlTALgMcJkWWOMQjWKcPAEnIvD+e/zb6//Cb/buwzP4W4qPDlNqw8UXlPLHSy+FEi8keslhG4nGuHM8yXuV09dRJAu3253KXFqwYAGWZREMBunt7cWyLI4cOcIPfvADrr32WoqLi1PnrImJiVR3OhGZ/9ITkWDKqcGYfA1G8pRmAC4LbAMmDAwbJg7/G2+/spOj+4JM/OsBLj46wkVjUcqskxjxGBS5+cBjcfFVy6DsAjCNjHOmMpdERGS+mLfBpammdluxLAu3281LL73Ejh07uPrqq1m8eDEul0uBJZH5LCOKZGBi4Eq2zi0zUU/JTnaWcyVvEFuGkSp4amBj2GO4XXE4FmH84DvQ28/w6/+Lj35xAM+J41SMjeEZPUnRxBjRskV88gdefH98GRTFiMcnsN1GIoEKZS7J3HNGhotGo7hcLo4dO8bWrVs5ceIELpcLy7LYtWsXt912G9ddd12q2Dcoc0lkXjNI9mMDJ0HJRVo3Nec1hp08l5Ec2c1w/seybYrMRDvWtOIc/+ADfvHjn/DZX7/P50fGuGAkyoJYlGI3xHEzNl6MdeEiLqmuhgtLE8uHU7sxIiIichbM21Zseh0l0zRTJ1CnxpJpmhw6dIjOzk5+/vOf09XVpaCSyHkhWYDUMLCdvCQnuIRNHDsVYMKwkwM3TwacTGwMKzFB3Iryys5uXtnawUev7OUzg//O544Oc/Gxj1k8PsoiK87E+BiLllSA/1IoMnB5XclVUJ0lOTOcYFFxcTGxWIyf/vSnhEKhVBaux+MhEonwgx/8gHg8ntoPnYwnEZmfbMAyIM5k7m2qO5xNosu3YWPbqbMYMHkei2NhGC4swCw2wYxx0dVf5L/9eQOXLFrEovEYf2AaLLBiuCyb8ZjNuMvLhUv84P8CuF1YUwLQOpeJiMh8MW+DS+lFCiERVJqYmGBiYgLbthkfH+cf//EfefPNNykqKqKzs5NDhw4BiXoXIjI/TZbfTu8zMPlsIuRkYZAIJFvYxLCxsHBZNq44uIwSrFELu6SU//Lf/5zP+j+Pe6EbOInH9Qlu1wTu4hh2SREni70sqfoKXFwOts1EPIZhGqmgtRrlciZYlkU8HicSifD8888TiUQAiMViqXopP/nJT/jFL36ROrc5Bb1FZP6aWhrQcEaAS7VZk79tG2wrEXjCStwYsS2w4sRi42Da4InDRcXwJ1fzR//5OsY9caKxTzBcNkaRi5OmzScLS/jM1VeDdyGW6cE2s3ed1blMRETOtXkbXILpASbTNHG5XJimydDQEFu3bk3Vqejr62P37t2MjIwog0lknptap8JpoZskuhi4bQPTSoaaDAPnPzN129jA9JRi2G64+LNce889XHLp57CNZBjKhmgcPp6YILpgEYsrvwTFpeAqSmRLGdPv/IrMlYmJCUzTxO1209vby89+9jNs28br9aayb+PxOMeOHWPz5s3EYomhxS3L0oAUIueBVDe41Mks2YebRH/r5CCmGBYYlo3LMjDiNoYFbtNNkdtDdOwT8JgwdhLeeZu3fr4XizjxEi9H4jYfxywmShdxbJGX0srLoXQhtsuDrepKIiIyT83b4FL6aHFOv3Kn0OnY2Bg/+tGPePfddxkbG8Pj8WBZFs888wxjY2PqViAyz2UEl4xEcW0A07JxWWDGDUw72dnAduG2TDxW4v4vTmAoZuJyLYBjUfjlrzhydBiXp5i4BUUewGXyidvLwqWXgf+LYBSDuwS3Gudyhnk8Hmzb5vjx4zz33HOpWkvRaBQglYHrdrvZvXs3//zP/4zb7SYejytzSWSeM9N+EtICS4ZBaigK28S0TUzLhWmZuGwT0zawLIPo+Dje4iKIfAz/3M8b33kCz6GPcI1bDLtLiC/x87FnERHvQiYuvRi+dDksLIF4IufXCVI7P5BZTkJERORcmLfBpfQAUfoJc3x8nGPHjrFt2zai0SgLFy5kfHwct9tNOByms7NTBVFF5rmM0eFI60pgG4kfTGxc2JhgG4m7vpaBZSSKftsWYFnwu2Hsn/6Mf/m7Fxk9GuGEZTBSWsqg6eJoyUJGynxc9EfL4HMV4HFjmUaiVoaNGuVyxr3yyiv89Kc/ZeHChViWhcvlwu124/F48Hg8RKNRPvnkE/7mb/6GiYmJVFBKROan9BpLkxlLydslqZOaiW0b2Lbz6gTn5S7A63LD8WPw7ru88Z2NFP06TIllccLtxr7qKi6591u4V9bw6wULsS5fClcsBdPGNhJ1nHKdu3T8EBGRc6ng0eIsy0oFcWKxWOquqzMSTj4Bnng8nrp7mz4fpxHunCRN00w1vIuLi3n++ef51a9+BcAnn3yCy+VibGwMgO9///vU1dVxySWXEIvFKCoqSo3cIyLnXpbmNoYTWEoOtWO5YDyeeJ0n+TI7FmOixMQkjicehePH4UfdHPib7/MHH/w7buD4hT4uWf7HlPoWsee1fUyULGT5iqtggYHlijNme3AZk+vhdIdTt7hPn6kjKdm2nbppEYvF2L9/Px999BGQKMA9OjpKSUlJKquouLiY8fFxDMPAsixKS0u54YYbUiOVOucpyDyXjY+Pp+otbdu2jbGxMeLxOKZpZmQlOd3fYrEYwWCQffv2UV1dneo6B9ovRealjNpKyX8bk+PFxS1wuQzGYhbFxQaxOExMxHAXuTAtK1Gf6fgJGDjIL9vacP3yAH9gmHxsu1i44louu+9+qPwjLvuTan7xwjYW/0kVXHgBuA2MZHvZsCcHuXF+G6iGoIiInFsFB5echrJTVwJINbTzCSw5gSRIBKrSg0ymaRKLxTBNE9M0sW07dUf3/fff56WXXmJ8fDw1r/QG+4cffsjf//3fc++991JcXMzY2BjFxcWpLAUV8BU59wynbW6QHAWOyTGcDYjGbVwuI1kIFYjHMYrcuKwx7JPH4eRJ7OAeDnZsxfvBbyh1FXPU4+HC6/6E0nvvAZeL/3DFFbwW+p/wpWWwwIthmkyMx8Djnnbg05DOnz5TP8/0O/pFRUV85zvfIRQK8bnPfS51A2JsbAyXy0VxcTHHjx+nqKgIj8fDhx9+yEUXXcQbb7zBxRdfDCTOd7FYLFUH0AlcFRUVMTExwa5du/jZz36WWmY8Hsfj8aQKd09MTKQeP3r0KNu2beMrX/nKmd4sInJa0gJLRlpwCXBSl1wuGJ8Ad7HJyXGb4iIDt+nGZViY4+Nw/CS88w4fbPkbPv75a1xqmkwUe3D7r+Dyu++Ca78MCxbBZy4m4FuH77M+KPWBu5i4beM2XGkn0Slrp3OZiIicQwUHl9KDQ07x0vQMo3TOiS79DoszrZPtlN7wj8fj0553fu/cuZNf/OIXqYBSek0m27Y5duwYnZ2d3HLLLVxyySWpjKX0eerkK3IOpbfHjcmeBDYQN5KD7iQfdYZ7Nj02TIzgnojCyDHYt5e+Z5+h+FcDXFhcyqDbYsF1X+bz/+8DsGQJuIpYsvRSVnz5GrjscohZWK44C4uKGI+Bkaz5r2PB7xfn847H40SjUfx+P93d3VRUVGAYBl6vl9HRUSzLoqioCMMwGB8f59Zbb+XNN9/E7XanMqCcoFL6/uPc9HBqLY2Pj2fchHEybJ2bM860lmXR09PD66+/zte//vWzv2FEJIscXcySQaVkBzUMp6N3MptoYgLcRTABmEUGY7FxStwurLFPMGMxePdXvP8/nubE3n9iiW3wSZGbic9/nmu+tQ6+9qdQcgETcQuP243vi1diu2zG4zZFthsjBrhJLltERGR+Kbg4UXpXNo/Hkyq27TTI038czt/pmU3pQSJnxJz0YJPzvMvl4je/+Q1/93d/l5qn07hPnz/AO++8wz/8wz+kpk3vvpD+OhE5u2zbzgwu2UZiRDiMZFApochFIsoUt3EbFtbEJ7hiUfhkFHr/hd5Nm4m/+x4e08UREy647j/yxf/nPqj4LCe8XkbMIqyLL+HywA2wqAyKF2LHwYyDBxsjS7cj1ar49JpaX8swDEpKSnC5XJSVleF2u1PnnaKiIhYuXIjH40kFhZwMWmd6R/qIpi6Xi6KiIoqKiti3bx8///nPicViqWCUE1jyeDypc5Nt25imSVFREcePH2fr1q2MjIyczU0jIknpx4mMDKVpP5PPWEwJQdnJASWSz7mBhW4Dc/Q47vEx+PWvef/ZZxna9xoLx8aw3UWM/eHnueb/vg/+09dg0YXYNngWLsTyuBg3YczwYLuKMGxwWWDFE8cUJ+sfyNrmFhEROdsKzlyCzOylWCzGiRMnOHHiBJFIhIULF04byQImT4ATExMUFxdzySWXpLKdnLvCzp1lt9udUTPppZde4sCBAxl3ex3OMjweD+Pj43R0dFBXV8fFF1+cKqIKZM2sEpGzzGmjmzZ2cnQd5yhhkmhAG8CENYHh1Fg6OgwH36fve1speucwReNw/MI/YNGXq/jC/7UO/qgSihbgsYvx4oExsFwlOPFntwdin4zhLimerBuueNLvJec8Mzo6yujoKBdccEHObnROl2ynC5xTcwkmg5PpGbhHjx5NBYnSb5Q43e6cbnHOMtJHiNuzZw/79+/na1/72lnZDiKSzWRgKdtNB9uYDCw5rzNtK1kHycA2wLLBsGOY8XGYGINYDN4L8+uObXz46h4qTJMRt5uJz36Wa791H3zt63DhYuK4cZlxiE8wxjiW4aLYcuOKgz0BpicxbwzdKBURkfmn4OBSetc2x0svvcTDDz+cqpk0U3DJCSDt3LmT6667LvV8+og66X9/8MEHdHZ2pu7UpNe4cBrwzt+WZfH222/zox/9iHXr1mXccU7PYBKRsycjc8RK9IeLAxYWJDsWmBaYtoFtWUxMjFFU4k40yo+dgPCH9G18HH79ASVRk3hpGe5lV3LlvU2w4stYpontKaYID3YUDA+YZqIhHrcm8LjduIuL0oepS1Ej/fdDelDH6c7t1D4aHh5OZd46QSSn69rY2FjG4855zcmcdX6Pjo7y29/+lgULFnDDDTdQUlLCsWPHMAyDUCiUep0z/ZVXXskXv/hFxsbGUjdRDhw4oOCSyFk2PTPRnvacw7IT3dLiptMlLjEohWFZgEnMsjHdBmZsHJdhwegofPAhQ9s6Cf/4J3xmLM6YASfLy6lZtw4CX4fSC4m5PNiGict0YcfGEucrXLgtEkPMuQADXIaBnezbbWQ7oYmIiJwjBQeXnEb6+Ph4Kuvo5MmTRKNRfvCDH3DttddOmyb9BP23f/u3PPHEE6lgj5MF5dRXckbocTKYuru7eeedd1JBJKeh79SzSA8sOaPVbdu2jRtvvJHLLrsstVyne4MuJkXOHWeE5nhyhB0XNmY8GXSybeKGRdGCYohH4d9/Cx8M8vZf/Q+87x5iYcwm4inFXvoFqu7+P+GaL4HhwvAUYWMQx8YsMSAGrngc04xhemxi9gRuz4LENYNBcmSdc7wh5KxwbmhMPfYPDAywatUqTp48idvtpri4mHg8nsouckYc/d3vfsfFF1+cyrh15ueci5x5LliwgEsvvZQtW7akRpsrKioiEolQVVVFLBZLdf8uKSmhvr6ev/zLv8Tr9U47l4nIuTc9c8nAsBMZtwAWia7eZqqAoI3bZTI2PorXZUM0CoP/zkdbn+fffrQbfzROPO7i5Gcu4j82/SX86X+ChReCdyH2RAyXJxmAdhUlzlHJpWBYxM040fEJSooWKqgkIiLz0ml1i4vH46mC2bFYjJKSEqLRKOXl5Xzuc5/LyFJKz2KybZuLLroo1Q0uGo1mDL/sBJycUeLef/99XnjhBSYmJlLLdBrtzhDQTiPfuZscjUZ566232LlzJ/fee69qLsk8k1bROsujUxnTXmM7MZK057Pt19NHspkTToPbmCy+nbEE22Zq5MbAwLaS9SFciQCTy3BiPckLdDtZINWOw9gYHPsYfnOYtx9/isj+/8XiuMXHcRvjS8u55t4m+OpKWOABlxvb8GBZNqbLIJ5chiu5LjFrAtMsSmy10/n+69BxXnOO/bFYjL/6q7/io48+AhJd1pyM1+9+97v8+Z//OatXrwYmB6wAWLhwYcbAFek1/2KxGIZhsGjRIhYuXJg6H1mWxejoKF6vl48//jg1mtzo6CilpaVcfPHFqZsrExMT0zKCRWRuWVjJwE0yk5HEecy2nUN8HAwrUabbTuTXQgyM8cRzJLKHPJjYmNiGG3CD6cHGxXhsAq/bDSeH4YND/O4Hnfxm90+46MRJ3G4vo+Wf5Y//259h1NbC58qxJuIQt3C5TGzbIoaB6U6sXaLLrYFtJYa3KC7yQMbZX0REZP6Y01asM9Ry+p0e505x+t1dp8tcLBZLNbrTuxk4mUcul4vR0VFeeeUV3n77bUzTZMGCBalsKadBnh6UcrrIORlKL774ImvWrOGyyy7Leuda5KyzreRoM5Ojy9gk/5x8UfL39H01UevBxibR+DWTI9Vku5Npp8ZeS6YKJZd3Wu1S24Z4shVuOvUnEjM0cUZINjLjWk4syk52h7NiuNxuiCVmZ7kTk5geA2IxXPEJiE/A+2EOPvXXjO9/gzIrynCxBVdWcu396+CPvwyLLgATLMMgboHhMrGsOEbyot8yDAzDgwtP8k3rfu/vC+c8ApmjAjrZsF/60pdS2UTOeeTCCy/kggsu4KqrruLrX/96qj5g+qijTn0lh/O3031uwYIF07piO4EjJ9sWyMh+crrbOfPVOUrkzEicOeOYuJI1khLnsDhgxaHIbWAYNpY1hm3HMYknMmiNE2AeBWskcdLyeGEcDBZgFF0MLGA07sLtviBxZ2MsCoOHGf3/XuLoj7opP3oMDC+/u2ABl9353zH+y43w2c+CBWZxMZYBhttFLB7DdLmTncXBbZpg28nzmBNU0vFBRETmp4KDS06Ad6fFdQAAIABJREFUyGksOyO3OXdqnefSG9lOQVS3251qWC9YsICxsbFUdwRnHk6D3+1284d/+Id873vfS3VdME2TV155hR07dqQKorpcLi688EIeeughFixYkOracMEFF7Bo0aKMYqyquyTnlGFCMpU+8XfiV2aOUfZcpPTg02QTM1dgKX0Oc9wYTZutU9jUSH/OTl9bI+2xxG+Xy83Y6BhFJcUAxJOFU2Pj4xS5TIiNw8GD/HrTFqJv9OM9NkK8pBj3F5dSdc/dsKIKPlOObcUZGx/HdLswTBPTTBSlsLETRVUxMJPhtzOwFWSecs4fzjnFCeL80z/9E2NjY6lzhmVZGV27f/nLX3L8+HHeeusturu7KSoqwuPxcPLkSTweT2q0U6/Xy1e+8hU8Hg9erzeVObtgwQJGR0dTXefSZRuxDjIDSQoqiZxZBuByzpjJkSSsZC0j0wQrNgHxo7iKxsAVhU/+Hfvoh0yMfsSoNcho9GPsWBy3y8OCBRfiKi6D4nK8iy+npOhzYI3BxAXw26OcfLmbNzq28YWTE1hApOxC/sP/cQuL/vc1sPQPEzeasMHtwrbi2LaFZTvjp6avtJk5UJ0OEyIiMk8VHFxKH30tvShqPB7n29/+NqWlpSxatIixsbFUQMdp6AOEw+FUY9u5k+t2u1Pd3dJH6lm1ahUlJSUAqeBVJBKhu7s7tT6GYeB2u7n99tspLS1NjQiXHugSmTdsI5VEZKcGMzYwnEBIquyKk+UEiRylRJ2gyXCJa7LROSXg40yTtlAw4mmP///svWmUZddV5/k7w733TTHlnJpHa7KFbQ2eZGPazKbpJRfG2NDQTIUx2AYKLz7hL7X6Q0GjVWUw4IKGYmiXS3IDi6EKiy5jDB6EJduSrMmap5RyisiM6b07nLP7w7nnxovIlGRnynam8vxyRcaLN9x374t49+z333v/9wlGqEohZnoM83GEMDUdCU/tnAG8ggkUWUGJZ8wEi6JQGnEllA4eeZAnfu/3qP7pn5k5vAzDBZZ27OT6n/gl+Pbvg2EfdKj8Knq9tmIpeLT5qWED0zneFI+fOcTf/3SL9b59+/jt3/5t7rzzzs6bLyY7vPedv1K/3+fmm2/ukhdbExLee2ZmZvjYxz7GFVdcscl3yTlHr9d7TmHpufyUjic0JRKJbwxhjW0TPBqCC5qQG4dmBewqrD6EO/IV1hbvwR15BC1HwEzIXUWuM2rvWFkVxPbR2Q7KpQsYzV2N6V0JK3tY/n/+O49/9BbOKxXL45rm7HPZ8bZ3MPN//Djs3hkqeMsKU4SqSETQypBbHXycjrfTabppIpFIJE5xTlhcWltb6yqEovfEtddey6//+q8jIpRlSa/XY3l5mZtvvpmZmRl++Id/GOccTdNw3XXXISLs3buXwWDQVUJprTuBKV7X7/e76qZo5D3d7gBB1PLeUxRF1zIX71eWZZe9TsF74lRAOgFoY6Cxiu1rUXXqxKBoBCF0b1mZvt8UL/jnvSFknajcIoBDbUqibt6adF+bYmEVKoq0UkFk0lDTkGEweGxdopoGHnqYpz7yEfb/z39kz+oY3+vxzOwMr/3Ar8Gb3gJ2JohX7Qf22O7qnAOtNrXKds+ZpKUzivh3EZMfWmvOOeccbrnlFqqq6ipkoz/fdDt3lmXdeuO970y8o+fftPl29Ascj8f0+/2uGupE1pm0NiUS3yREh9ZuM70ajtEsg+yHxXsZ7/8iq4tfwtRP0vOLWNZABU8/43UYOkEDFFAfptm/n/G+g4zkGZovVHzlz29l5+ISYBjv2st53/v97Pq5n4GduwjlUi4IS2bzxMlpF0PFlvNCOkUkEolE4hTnhMWl4XBI0zRdoF3XNddffz3XXXcdTdOQZRmTyYTV1VW+/OUvs23bNj74wQ92wXicmBPNTvv9fteqEG+LbQ0ARVHQNE33QSFOlJtuM7DWdp4X06aoRVF09wGO8cxIJL6ZSOv6EL2QVKwi6lrJPOgoAklnNhpudaHNy0cnbAHVVjepNg37nFVJ09VEJ0fceny2rc8h3X5vXLthvATaBtsK68AYcJMS1Xh4+HGe/dP/yuF/+BTb10uWJhPkwgt57S/9EnzHG2A4C9biadBKoVqRwDXB2N9og0bRSBTsODkD78RpSfQ/iuf+WJkUvfyUUlRVRb/fP64xdzTuLsuSmZmZbr2J61q/3+9Mvb33myp5Y9XsCxHXoyQqJRLfTNqmMxOWBgVYGgxrUD+MX7yDI0/9M37tIaw7yMiWZK5GnOB8AwgiYLwwzCzUDdTLQA+efYL12+/nif/xLLuWeqxXNStzC+z+3h9g13t+EbbNQd8SsivT73vpfAKbOvgRKpX8AROJRCJx+nFSnktKKfbt29dlh9fW1jDGdNPcsixjaWmJsixZXl7m4YcfJssy6rpGRLppb/1+nwMHDjA3N0e/3980DW468I7tC1FImjbujkxXNMXWhxjsp8qlxLeSTghVnjhxBrEhixq7ZbSaal0Llt0hs9pmN8NMGzofo4jakHGCcHU88bR14O4unzhxS5u63/DB50gF0SzOs4veT6GCKOxj7TzWGjJvMGVF5jQ8/CiH/+t/48G//Cu2Lx3BDAe4C3dx5bt+BL7nLbBjG9gMN/E48WSxHcloNAbfjvopq3LzxK3plsHkWXHGUBRFV8EUExJx6EPTNPzGb/wGd9xxR1clG6tdjTFdm7e1lizLGI/HbN++nQ9/+MPMzs5SVVVXpTS9xryQsDSdEEkkEt98hFAxa7RFC+2UtgmoRVi+k8Wn/idq/T56HMSaCb6pqRuw1mCMwolHWxs2VNVQAjKClQa+/DiHP73KzCFo3AS/fZZLvudN7P6Fd8PeswlzJTQCwSuwFaxRCmnXs+hJmkgkEonE6cgJi0vRx+i3fuu3+IM/+APyPO98lWJ1UmxVGY/HGGN4zWtes8noe9rAWynFb/7mb/ITP/ETeO+76TzxuaYzwtGcNd42bQIeRaWYod7qlTH9ISOR+GaxdYKiKAn+Sr4VlmKhkiFMmtEK0XpjCpuo4BGBI4xEjo1ooXZIRAcxR4WxyQrXPrLtP2sL/4UNL6ITRTElKkVRTHlohSXXtaEppsc9a8IxKASbabyEikeDgcefZOmjt/D4x/+C7UeO0usPedJkXPGjP0rx4z8K87PQ0+BrzIzFiEW0onGhkisOqNPoTcG5QoU2PEh+FWcQ0X8ry7LufB+NuQeDAcYY7rjjDu69917e/va30+v1utbpuq4ZDAasrq52iY7PfOYz3HXXXZ0wNb0+xSqo6Wml6cNhInFqIjicqgAPkmO8gF+Bta8y3v85/MqXGNklMtYAjcfjrUIyFfyZKo+rPVZnOO/I1QBW5vBfWOLAJ9fQT0Am0GzTzF1/Frt//C1w/nZEGVReUK9X2GGOzcHodjokdEL1psRIt8+bSWeXRCKRSJyqnLC4lGUZVVXxq7/6q7zvfe9jPB6jlOqqkYBNk+SATkyKo53ruu6qieK0tyj+RCFo2oMJ6ESl2HoXq6CALkMdxaYoPMXJQfHxSVhKfDOZbt0EpqbDCSIeJVONZW2VjVd6Q7eZvlFU6yMEXqnuIRt3CTVDunvQhmolqE33ffECVGmfyRMcohQiCi1qc0eagPYKlDCpSwqt6NU1HDjM5JaP88AtH2f70hLaGA4WBdf8xI/Tv/FG2LMHMkvlHXkmeFeiTY6i9Vdqj8V510780cdO20vC0hlFXAfi5fjeiz6BENaQq6++mg9+8IPdxLc4jTQmM2I73Ac+8AEeeeSR7rGwWcCKk+Sm15rj8XxVS6lNLpH4ZiBohFLG5LXCWA/lYeoD91IuPsCMOUqPMeJDq7mxBicO50sMitwYUJZ64inUAMoZuHuZJ/9ljeZRGGpYzqB/keXst5wLMwdAH0YNt+GqhmyY0yCIUngE8R6j9Oa49DkqbOXYqxKJRCKROKU4qba4PM/ZvXt3J+IopRiPx52nUrwuElsCYhAfK42i8Xa8LYpEkekscVyAp1sXtm4/Xo7PHYP96W0mEt8spidBiYSKJRGPUoKyFd6HhjGtMjwaNxVBCuClQYsnMwaNQUTRSJCNtAqZ2MZX5DpHY/HOh5nKAERD8NAq92J0hQVhq+3gayfYiJbW5DtUU2nAtLc5HzQx2xZb+bqhUY6e1rC0iPvL/5cH/vxP2Ll0GC3C4cGQy3/qx+n/wFvhrHNADDhQInit8UZ3DXfTrhQbWeDjTK9LnLFsFWtiwiKKR3Vd0+/3N60704+Ja5pzrkueRN+m6Wpa4BhhaXo7W4WlrW3aSVRKJL6xhKphABUmlGYC/gisP8ryoXvJm6NkyqHEoJyANsGbKdYQNwLiqHEUdggrOdxzhH3/sI57EApjWC4c2VVw9vecA7v3U678K4V6BTCHyxeou7pe8F3l/QsnQmTL93S2SCQSicSpyAmLS9Fvoqqqzmz7C1/4Ap/97GdZW1vbNJ1ta5tAbGErioIf+7Ef46yzzqIsy05kilVLicTpzPGqFIK4BFplIA5RYcKZoKioW5FJgTi0cmgaUA1KRTnF4CUDNUA8eNOg8GgNjgbEBGmne2rTCkuxj+3FCUljg55tp9j5bjJckHYMUE2EvKcQDUpDVTtMWWEKy8g5OHSI5pabueuP/4TtR49S1RVLszNc9vZ/w8zbboRLLwWdh6E+2mAJ1Vy1a8jN858fUuCdOB7xPVkUBevr68zOznbXT7drW2u7FrrBYNCtaWtra2zfvj35JiUSpykKjSELqRaZgDuErD8Efh+WNaySsLiZIiRH6hLVRsrBDtGQqR4cKeCrFQ/93Tr9R2HYwJGeo3dZxvnfuxcuqplkT7E6EfLlB1GDc9AUOCyKkCh63oUqLWKJRCKROA05YXGprmuMMZuqlO644w7+/b//91x33XVdZndrNRGEQH5paYm77rqLG264gXPPPbcL6AGqqnre1oJE4rSmNfAWsThtaZSnwaG0J6MkpwK1AjImuIW6NtA0QIbRQwzzZKagkSYYjGobTL9lo5poAz1lkvRiR6wbjt66vaQBaSAvFGV7Relr+pnGGAsrR2GyTH3Lx3n4//5jdjxzkMlkTLl3N9u+/3uY+ZmfgnMvAtunrhu8Ma0nhUYbyM3xzw0pFk88H1sFIe89i4uLfPrTn2Y0GuG9ZzKZdJWycU1aXV3lySef7Nq+k7CUSJy+KFEYLIgDtQ5ymOW1+xH2YfQYaMA3sSwYlIVM4RqPdqDdCKp5uGeNxb9bZOZBUEdB5mB4FZzzfQvw8gb6K4jUeFY5uvQ48zsWsXaEpofQ29gf2PAFjFccb7/ZWMHTWpdIJBKJU5UTVnDihB1gkwH3/Pw8N910Ey9/+cuPO50teiHdeuutvPOd7+w8k6y1nb9Fr9c75vkSidON4wmrQBchqvbL4Mh1jWYF5CCMn4HJfvz6QcrVRZp6glcanfcoRnPkg52gd8PM2Vg1i/U53g0Q8s7YulN6uudUW1Snk58Wp+KxhEY/fLzOB09yFNTOgxYKrcmoYW0dJmP473/HnX/0R2x7+lkyLEvbt7PjO76Ds9/9c/CyS8CFaTzaWkwWWgBrL+TPkex9waN58Q49cRoT349N03D++edz66238p73vKerXKqqitFoRFmWFEXReQkOBgPOPvtsyrJkOBymFrZE4nRGpPUDFJAxk8nT5HYJ5dahrsJ96gpMhrIa5x3Ka7T0YTIHd084eOsBmvuhKIE5qM6Cc94yB1cK2GdZE48peuRimKwsQj0GHaqMJezC13Qe+cb4JCYSiUQi8Y3hhMWlmNWdFpZEpJsa93wTc+Jt0fw0ejYBXVCfSLyU2DQtTrWTDn2Nlhpjx8BhWH+E6tBdTJbuo1l+FNscwfqSTAkoQwNMjGbNzqBGFzC742r0zLdBfjHaDsBBLRWSa5Rq2kjUgrQT4iRkSE+27iJqVxvi0pSeJaGSSUQFK3HtUOIolMCRRWgU/P3f8+Dv/2fmn9yHJmNfb4B907dz9q/8Mlx0AWJzVDvq2bQdfY0CMRpPjZeaTBWorYbhX8uOJ8544nvxQx/6EEVRdIMm4tS36QmmMfFR1zXOORYWFrokSCKROB3xoBuQuq0iFpr6CD21DExC7ke3cWoG6IambuiTwcTCoxVL/98z1PeDLqEaweRsuODGXXDZGIpDkEl4CrE0taIpx4RwewZpeqho3r3VMuJ59jqdcRKJRCJxOnBSnkuwEajHyW/RsyJOdTte5ZL3nqZpum3ECXHGmCQsJV4yxCo92NwSKuJQ2qHVGrAM4324pbs5+sztNKv3UfhnmTWrGLUG1OAFURqrQo2Qlz6Tlf0cXXuKbLCP0Y7XwjYP+V4yChwG37Wq+WAUIRsjj6e/f4OOHBHQRqG9Z6CAtaMwLuHT/8rtv/9HDO9/iKJ2LG/bzug1r+ey9/0SXHgxPtPUGoyv0B4UGSIKJyHgV4BVOgXaia+L+F6c/hoOh53HX0yUxDZva21n+h2nmRpjKMvymIETiUTi9EK1E02VM0jlwE1QlBt9Zxq8Ay2Cdpq+WJjMwIM1z/7TIeqHwE7AD8HvgQveuhuu6sH8Mtjgzp0Bziu8qxEZg5SgNIIJpbgISj9HArbbz83fE4lEIpE41TkpY6OqqrqqpSzL8N5TliX79+9nYWHhGGFp+gP24uIiRVGwsrICsGn8cyJxuvNcZt4ACo9SNZhVWH+I5tDtrD77WfzyvQzVIsOixpXrYeJbZvEYRCtEQSMN0qwwMhXr4xXWx0eo6kP03CKDXddB7xKQOYR+G6DWKJpQyYQBsbTDck782KBrgeti4zhWuZ2qY6zGe0eGg7VVOLIMd3yFT/+fv8XCM/uZocfKbIF6/eu47BffBy9/Ja6cINqTWUF0A1oHHykMGSDeo5xgdAYvQgVW4swjvgfzPKeu627qKYSq2SzLMMZsqmaKAybiEIrkuZRInM6Y8OWCiqScxqLBgTgDWuEQxIBvFMb3YL2ABxuOfmqV5S+EVjg3C/UuuPC7d8LVszA6ipMSo4FJSIKElvcSn1XAEVAV3gjaE2bGHccGUbZcTsJSIpFIJE4nTqotLgbldV1jrWU4HHLw4EHe+c53dpVL09UbMVifvn5ubg7vfTfW+fna6RKJU4fnD/s2/oblmOsUDtxRqB6jPngbR5/6J/T6fWzrraD1OlI2IUDVHifQSJBtlAltYEZ7fLnKMKvpmcMsrd7JYr2Oso7+rh5GKcTswAGhWW16Wtz07gvtXOYtOz99p63Hqrr/g0jVtsG16V5RoWpJmgZrIC9LWFuDu+/h9t/9Xeb3H2DkGpb7OfbqK7ni/e+Bl1+Jd2PUqMBkFcg6KI1DaERALLoVlJRoUAavPIJHo6f26Pl+V8kKNREQEcqyJM/zTe3Z/X6/W4uMMZ2nYKzIjR5MRVGkNSqR+IaxVbw9znutvYtMrVXTHoBRt5muAFLtNcEXsF1LjAVtyO0AmhwvDrSl8RWZztCNhfUhPKFZ/sxBlm6HQQnNAJZn4crvWoBrF2BmGdcrUSanqUqsMe1I1Ta27RUhWcRUFSXh5zAIduMYkz1gIpFIJE5nTqotLrayWWtRSvGOd7yD173udV27W+S4psbtz+edd17XYhC393ykrHHiW0+o0IEweSZeF9g89cVJg9GauvFkNqepazJbgyxRHvgSa09/iqK8n6FdRjMB3yBtXIqAEk2GwvsaEYcoBaLQRiFNjZEV5rWwVN7D0ScdxhXkezKUZAgjUIIyGZWrMcbiHWQG8J4gOpmNfZ4+FB2P0xEC8nA/EQleR40Hq0E7qromtwMMsDZx9Ho2iGO+Cgbed32FL910E+bu+1goHSsG1r/tMq79dz8HV1wIpkYPCxq1hpI1cDXK9jCS4X0QrjQKL4ITwDsaXWOUATzKg9a2OwDxU7G6mj4ORTzlpaD9pc3x1pzpdrYoGMWWuHj/6fUl3rdpGkSEuq43CVCJROLFZksS5Bha1ag9nYsBj6A70Wjqblq1CZa2PVw8Rknw8G5AiQPlIe9h8zmoRohaQbSgTIGWHqwJPA3Vpw5y8F9gtoTSwuo2eNn3zMI1szA6TF2MwYYOdI0G5XA1OJvjpEDpebA7wBdYsaA9SrVS1xZhacvRTr0ux78lkUgkEolTiZNqi4sBtvceEWFmZoYrrrji6/KjiI+dDvxjJjmROJU5bng3pTFtJCRjxlRQ2oGswvpjrC99BVU9yig7gnITKB2SE7rXfMi0Ku9RKFBNkLQkiDxKZ+FOfoI1nr5ZZ1znNMv3kA/2wMI8lh54DWiUCuLLRg2PtDv3XJVLcZ9jA1x4lFLte9sacI5Gg8mCT5r3UPQsmQI1nsD6MjzwIJ/6D/8X2x95lF41ZtGXzL3ySq58zzvgVXsgfxpowGlMvR6qurIMJgbyObSZA+njfQ8hx2QWlKIWhaBQKDZON3LsBJ7ul5BE6TOJ44k/UUyKxPXGe49zjizLNvn/RYwxncn36uoqo9HoG38AicQZzXSy5rmrhEOLtopphY21S28944fpcL7dpM41iKJaO0qu+8zMXsThw/eSqRqqCt8AEwWLMyx98lGOfBZmGxh7kB1w+Xdtw16Vw9wqPlvGGUFj0ALaaPAeU4CzPbzMMpo5F2QWKFDBQ3zqCI49tq/NiSmRSCQSiVOPE1ZwprO304H412t0qpTqfC26nUrCUuIU5znDuy0VM6oVcDQacBhVgT/M+pG7WF+9j75bRBUOGocX0Jg2RnZhE7ohBMshcFbiUWLZKG+qQFdY3UB9iPWVryLFHobzl6DMDN5nrcDUikXah2BcCWjdZXYVbQ1T7KCLMlQUk9rGAk9oRVBAow01Bg1kuDZpbFDrHuoG7nuAB3/zJmbvewi9vEQ5sqhrLueCd78Dvm0XlPfg993HpDpEQ8naeB1FhjI9ZuZ2YAY7yeYvQi9citbnIszQ1AqlC7TKWsEshuceER/EJW23fLKIs+wSZzLTZt55nrO8vMxwOEREqKqqS3RYaxmPx1hrcc51/ktra2ssLCwwHo/p9/vf6sNJJF7CqONcnqqwbUPOGDWGNIhC69Au7bqBFsHbSIngUNRKt2keR64MZjADeg/0X4by59IzAuUSvSqDpSHVJ/Zx5DMwV8JaA6s74WXfNcBeM4TtYyjWcNphbQ+8oFwFxgVDcA1jb5B8O72Fi8FsA52HNVdiquf5xbNEIpFIJE43TljFiSJSXddorbs2OeAFW9sik8mkmw6XqpYSpw/Hm+GyOTj0IiglXU41aE0OpUsoD7K6eC8Z+8ntBGkmiAdtAW3wrqF7Bym3YRWkQLVtO855jNYhAyqOzAiFW6eqnqJaeZhhfRDMrnY6zUbllG49kpQKQlHUknT7dUyIK23gq6bEJcJ/2mzsmsGhXY1WQ2hqeOBeHvrQh1j93BfYqT1rI8XabsU173krXKKonvkUlXsWP3kMq1ewlMwpjc1nqZxmfMAj2QyyuIdi/nL6O15NNryUTO8CZcBvCEthJ1RrXuHDkaitqeskLiU2WFtb41d+5Vf47Gc/i4hgjEFEusql6LsUTb4B9uzZw9/8zd90XoOJROIbwfGEls3XidoYKjFdf+vRTLsAmnBl8FhCIVa3zeCaUmqsshgZwMxlDLddTbO4ip00cEgY/8vj7Psnx1wJtYdyDi763gx77RBmjiC2xJs6TEUVhW88ykvnF15KxkS20599GQwvAjWHJyR0wjoMfF0CUxKgEolEInHqc8IqTvSmiH5LwDHTdV6IXq/XbadpGowxycsicZrw3H+nMtVWBgolMdHaAOs05bM0a4+zYFew0tDUBI8io/HOdYLUsduMzyx474IZqQrtaNZ7+qrG+EWqydPI2rOo3sUoNcArEPFdMG5UGIVsUGFgDhvi0pTZE6IE34buWtSGkCPt/gLaOzLlUfUE1bhQsfTwI+z/nf9I9bnPsLBWUfZq1i+0XPPT/wvseIrywGeo5CDGrNIvHEbVlNVq+EDPGtQlPSBXfeq1hxkf/Qoc+SrZWW+C+TdA0cfqHtBaR2k2fCtU9FfSrRgXXzOdGuPOYKbbrqM599NPP838/Dw/9VM/xcLCAs65rnUuCk6xauljH/sYn/vc57rkx9eaQEkkEl8PLxz/hZU1rkztv+lZFW21befB5MJ3DVgFzoQ1NFcZZePx3tIfXkC+49soV57Ajhuqf7mfQ//k6K9BpWFlBs57y4Dem3fA3BHE1ogVlG5VLtegPaGaVlkqr6jNHnT+Cmb3vB7sOXgZ4pTgKNGqraaVaWHp+QSmFBcnEolE4vTghMUlpdQmb4rJZLJpjPP0/aaJYtL6+jqj0Yi6rjtTcKDLICeRKXE6It2UmtZjieDVotCtkdKEav0Q1i1T6BLEh3a4LLSa1g0UeQaurRHa8jZQhOqlEJv64G3agKkhw6NlTFMtUq4eprdQtXvS7psIekubW2yYM7C50keB6wr3Q02TjhN6BHBB4OrlFrwDccEl9Z77eeJP/4yD//AJtk/GyKBHucPw6p/+briopJ58iYpnybMSkQmqPQVpVYXtiqPIBeUdlgmZhr5eYXLUsTIpyXc1FLtrGL4M9LZg5N295tF5Q7qXLbbwxSNOAtOZwfHWkCgwxQolEWHbtm380A/9EMPhkCzLjkmMxDa6L37xi9x2222UZcnMzMw3+3ASicQm4hlftWvrZlNsrbq7bOqKNoQO82oyIe/38Uaj9QB8jVq4nN6zD3D4C7ez8vkxo1UYC5QjOPctI/pv3g3DwzDjUO36LALiBJxDKYPXmsplrMoQ07+Y4bZrYO4VIDtw0kNosBsTM/jahKVEIpFIJE4fTqr/TES6FoJeL1QSxFa3F5rqNhqNqKpqU+XT9HaTuJQ4pTnen7eavrqbJxcmyilaAWZCNT5C5j2q8ihv0boOH2JV6PgK92sDzk4laZ+ivV4bjxeHbzvAlDMgFoPHSEUzGYN4lA4m3AqPimbX0TgJMF3R9OYUAAAgAElEQVTBj0xN2gm1P67df4PqvJj0lEKjjdnYlqvhq/ezevMt7P+Lv2TnZB3peQ6ebbj+PT8Iew6BewTRjzAzrBEMTQON1OBpp3cpqkZhbIbKhKaeYB0oanr1AZZXS2qpKLIyfEroXQZ6G2DazxEa3V7e+qtKZ5Mzi+daP6LHn3MO7z3ee/I876bHTZt8x21M+zTFNu5EIvGtZMNHMCwg7cVWaFK0iZ62wFBJaALX7SLXzwx+MgEsmVFQKVhU8LkDPPX3TzJ/ECY1lAuw54YZBm+agx1LYEoYN6DrsJ5iQFu8Aac1lVKs+wKGFzDY9SqK+VeD3wNqBqU0moZu1B3xW1qhEolEIvHS4aQMvWO1URSSPvGJT/DRj36Upmmed1xzvH9RFHzgAx/gqquu6toNtk7qSSROC6aEpWnPh1CNI+2UtTBD2VUTrG8dj7QNYo6v0RbyzOBK19pkq7CBaYFJgpeQMm1xk249zpwFF/rAjBJq12wSwBSqHZqm8F7ChLVj4tuuh6wNwXVI+k735MU4WCloGvzEoZsJHHyKp//yL3ny4x9nZ1Xh84Kjc47r/+33wVUF/ug+0IfIbIlvoGk/ELQWUGQmQ8QwbgTvFd43ZMYADmpQWcNcXlK5h1l60rMwOgvsDBQFqNm25U+3e705ad29ENNlTIkzhulEx/GqmaqqYjAYdGtQFJmmq5hEhPF4TK/Xo67rzocpkUh8c1HH/B+HTxASM+1irFQciyGI8ijxG6kH5dEaCgHWS1hcxt96G7f/579l9hA40awOPfPX7mX0xnPwew8yyWsGugdStx5/HnSO6IzaayrVozFz1Go32/a8gWL366G4HDfuYXoao8Bj8eLDytr18qVFKZFIJBIvHU7a0HvaM+n+++/nr//6r7nxxhvZvn17d3u8T8waK6V47LHH+Iu/+At++qd/OuyItVRVlcxSEy8pvPdYbcAJmDDhzRgTPJM0SNOgMoUXaBroGaaysKpTfoJnkAKxob3OO6yFSqBqHH2VBQ+mxoFRGG1BKUSgcY7MGkQcSgV9yquNTgIFQWxqBSbprhVsO+euM2zS0LSCl80seqxg/xL7/+xjPPzfbmFvWVMby8FtI9743h+EazXl6u1kvSWQMUpyXF3RZGFzOW31VONRoilUhnMelAtTfzRIASiD9zXIEtpnLD3+aRZevgfUAtBDkbd73Z6X2tdfOovX6NCRWuPOBKIwtHVARNM0m6acRq+/mCyZnloatzHtL1iWJcPhENhY29IwikTixeWFqteV92Ed1HrDb0+iyCThsrSNc8qgMNSNYGwOSqjMGC1NMO9eXoO/+wfu/sgfs+eIYjzRHBplXPzW1zD77Reyuuso9EtEKsaVp8j6lG4VMQ6MpiFjIjM4fTbDuWvYvfBK9I5Xg9oBzRBT9BBxQBhEobEo5RGa9mCkE8MSiUQikTjdOalIeDqza61Fa81ZZ53F+9//fq666qrO42K6vSCapf7t3/4tn/zkJ6mqqhOVorD0tRqCJxKnEsdzTpB2Nk2naKgMk/XxRYFzgriGDEWea+rGU9cOo9otCQRDpqj7tLbbShHnvFkbWtVc1WBQkOU4seS9PrSC1Ob3UltX1Zp1b7gUyUaM3h5DEJYUrq4x2oDRVD58GHdVCZMGFtd59uaP8+DHPs6OtQmVUqxtm+H17/5JeP1ZoP6R2hzAV4codAVkGAVWakA2puLhQGmUOKwK7X8iQQRzSiFaEBqMNFi/wrh8FJbvB3s22AW8160UFl6eznx80zy81H5wpqC1pizLro0tXo7ij3OOyWSCiHDbbbd1foFN05DnebcGVVUFwIEDByjLsrtPlmXd8IpIrHpKHxITiReXIOSGangVBaRYGiwKUabtJA8VSu1wUwyK9WqMzQqyLKOuQGiQ3GHdBCYCn/oU9/+XPyV/4lnGrsHtOJtzvvM1bP/Rt8J156EWv8KRA0OsW8SrmpXJGqYQxHiU1ehshkH/XHqjy7Bzr4LBpeBD0iNW+So8gkGrsKQDbTVzvJzOGYlEIpF4aXBS4tLW6iXnHKurq+R5vum247UlDIfDLuDfWq30Qn5NicS3nC1eSFG42BCYWp8jprOpGlSPfLDAqs2pAYMPRU1eoRVUNRiruyqjjaebavQSDVrhmhpwaA3ONG2WdkAtBaPhHEQjbj3dKOZRKogtG51x0v7bODCDQnwwWVK5Yb0u0crijSBSUrgKDi/i//RmDv35Rzl7cZlaOZ7ZtcAr3vVvMDd+NwyfZv3+Z8hlFVEVSnlQgvKKPNpOxC8DQo3yNcpbEIvyFmU9aE8jDUppRDLA4atnGC/eR3/mVWDPQpHjxXa/m40Kpfa40ynljCMKS3E63Hg8piiKrlpp9+7dfOITn+Bd73oXIkKWZZ1nYNM0XWIktshdcskljMdjFhYWmEwm9Ho9jDFMJhOMMalVLpF4kdgQW2QqhuyMB0Nrmhec03iVIZZ2LQkJGKkd1nhQnl5e0OApm5LMFGRaU1djmIzhE5/mKx/6XfqPP4Yxin35DNuufQNn/eIvw4V7IR9i97yMHXvfBOUhWD6Iqyc4BJNZTGYhG0FvJ2Q7QM2BLyBrW7o7N/EQD/iYOIoGh7JZZEokEolE4nTnpDyXtk7VsdZSFMUxXhXxewwYYlZZRKjrGmCTj0XyXEqcfnT23VPXtb4Kmtbvx4IaUgz2cMRsY9KMGOUg9Tp1LVhrQkyqNMr4zX5LTAfX0anU4eoGk4HKFGWj8QygvwtGO4AMQRNyvaFiMGZ7VZy0027fb9rrYEIuXqhcjco0KtMIDTmCnYxhaZmjt3yMp/78T+g/9QzaGFbnR7zsxv+N7f/7D8POAndoP+PxItt7NWJAKUHcBKX1lHl4qE6KL1XMOAchTrWZaGk9qsKOijT01CqTlafo+xWgRmmH9r7zpDp+gVLKDp8pTLe0RbPufr/fiUJN0/CHf/iHQKhqUkp17XHxcVVV0e/3uzVKRBiNRjjnum0YY+j1et16lkgkXhxE4kS2djKcjhW7BBHJKIw2iDddfaoQuuWKLLTCCQ6HQ6OxVqGqClXW5Gvr8PnbuPf3PkLx+OMwXudIv8/cG17L5b/4C3DOeUhvFlwPpeZAz4PdBQtrmCLDNAIm31iLpQAKIMNrDzTtGhsPRrVJj9AKp9p/GxmktDYlEolE4qXBSXkuxeB6egJPWZY456iqqsv6xgxwnM4jIt10uUiWZc9rvJpInFoc2wAXvkxbNaOmWs18K/JYYADFXnqzlzM+sJ/cPUtfC66eoMRircb7ZqOLqzX1Dm8Nj5MGxKCNxugMXB1usznjKsfrbcwuvAyKnTjpdfvjpzKkwcZpcw+cVmqj9koUONBGUzcNGo8BZDLGemBpBXfzx3ngj/8LZy3uRzLHgfkFzvpff4C973wXnLMHzAGWV56msAJ1Habg0VADufVQhz1xup2SJ6A94G0I1g145UA5ND5Mq/MC4jBU2MxwdLIE5QoMKpRyKO2C5xQGiU5LUa2SVuxWtDVaKoXzL2Gmp74ZYzqxqNfrdW3YWZahtWY0GnWPi1UScf2Jjwe6dS3LMqqq6lrkrLXdxLlY8ZTauhOJE0fEh68uC7HhSyRo6kahVTtQRvl2ImqLFsQLjXdgDaU4CqXIEGRlGXQGt93DHb/1+9g772VGKVZGQ3qvvprLP/DzcNUlMByhbAalx4tH5SFeVRhq1yB2gIglkzj2wiJe4U1YW2J0YDCE0abTSY/Ypr1VWHq+FWmrcJ1Wr0QikUicmpy0++i070SWZWRZxuLiIktLS93t00JRFJAOHDhAr9ejKAomk0nneTF9n0Ti1GSqimirwCS+9Vhoa4NUkJZC1tKA74Hexez2VzM5so/J2ipF1mCUQpommFiLQ+lWmHKqtZVovZJwALimIS9yjM5oRCgbQyUjst759BauAL0dcQM0dsocPJpd++cITVVUX0KCWEOe5YBHNSVW53BgCf72Vu784z+jv38/tXesjUZc8Y4fZvAjPwLnXQAyBlMxrg7Tyyua8RrWmvD84jeC7E1tf1OvofJI+0XcV4mvb43CY0WjmnXq8SrZXA2mBmwQ9IT2uThOZvi5fneJlxKxAmlaAPLe8+yzz+Kc6zyTokl30zT0ej2cc5sGT8TJp7E1rigKDh06RK/XY2FhoUucxJa7ZOidSJw8XVIgpmq6djJBUZObBlgDKUFVIBWhDU2DKkAM1hbUZPSVAVdCo1Emg8/fzt03/Se4937mc8ua0pgrX8Fl7/4FeMUVlIMC5R1qMsGSobOMGii9RklObkYIRfAD9ILWIW5VGkQcXglgu+okzfSUDj01WgK+NmEpktatRCKRSJz6nHAkPO2lFANvpRSPPvooN954Y9eKECuVYrAeK52qqmIymeC976qYnHMp45s4LTi280o2vqZG3isUXoKptyiFSIFmG2p4NfPbDjIuD9DUEwpxeF8jyiHah+FsAkpC5ZFWdXhOG57L1Q2u9hg06Iy66VEMz2V2x7fB6FJgG6hR53mqdAhzQ2ucxrX7Z6b2ftNhaPC14HJB+YqidLBSwf/4HF/+yEfpPbmPnrEcHG5j73d+F4O3/RBcfiVgQ1K2mVCrNSbZCs45hhZUo8lR0Gi88e14aNDTMbN20A6QNrKhdaFpJzcLSAOuxgCuqsi0IrQhuFbca72ZVPvATfggQJFab1/KRDPuPM+x1nZ+gG9/+9t58MEHqaqKpgktKtZalFLUdb3pclEUOOdwzpHneXd/Ywzz8/N89KMf5frrr6eua/r9PkDXdpdIJE6OKDBFM+/QIucxsgbmKFTPQHkA3GGkWUTqMdoZ0DMwcy4M9qJliLHboFIwyeDux7j7Qx9Gf+VLbG/GHOn18Jdewat++dfgjW+kZA1sH+UcmTEgGi+exmusHqAZ4Nt2N4vHOAWlC4tYZrDaEGpttxKuUdKuOxsZE5JYlEgkEomXEicsLsWWuLquuzaAt73tbbzxjW9kMplsqljaWr0EG+LUxRdf3AlQ0x4ZicSpzmaB6dhMpEZ3NtltTX/bjjYAczbFnuto1h5m7fAygsZoh9IlWjla7+uuCkcrg+hgsA2h3L6aOJwZUDHPRO9kNH8N2a7robgQ/ADdtpuJuDZ7CniFMjHU9e210jowTR1Y7dG5pqeAcQlHV+GTn+GeP/pD1FOPURhhtd9n4Ya3cO7P/iJcfQkUGVIalBmAFPSLEVIplIVGCThHRg7t67K1OWDTyyebf4RWJOteXmkrHTWojNAKBygPWlASj+l455JUGflSJwpCcZ2JgtCHP/xhmqbZ5MHkve8mxN1999382q/9Gu9///t561vf2lXmTidFsizDWsull17K2toaw+Gwa5Pr9Xpp2mki8XWxUU0qbV1P8E4SlHigRlGiWAe/Av4Q9VNfplx9lLXxk7jmMMofRVVjeuRkdoZaz1Pnu5g/55UYczboc+DOZ7n/P/4Zq3fcyZ7aMzaW6twLuO6974XXvQaMxs7M0+Cx2iBNE/Id1mAV1G1FrzWKqqno2QxtFGgTkhot3vvgK/hchwpTLfNfT6yb4uJEIpFInPqclOdSzO5Gw9Pdu3ezc+fOrmIpth3AZkPvuq4xxlCWJb1er8sUxw8E0xnkrcSKqETiW8eUaLFh9DD1s5q6nwnuPwokmlJrDYxgeAHDi74TKQyrh/+V3DcMrMP4GhUKeMJ/Krg3ePE47zAojIM8n2GFbaya88h2vI7RWd8Bw6vBbQOVt89boVUr5Uj4gOwFvGpdiVqzVKcEEUVOW/GTK2jKIIatrsMn/pF7P/L7mEfvB7fKwbkBO994Axf/7Pvh8peDWgXrUWTgDLBA5rYjkxmQDNM3eDsBXwEao0z4IKE25Dem/ctjFwGtwOYIr4MWxIO3mrHz7BzOAzmKHg5NZkGcD22GhMPbKgLq5Lf0kie2WMfERhSYrrrqqm4tMsZ0bXBaa5xzXXvbueeeyzXXXIOIdBVLWZbhnNuUVInXWWs7QSklRxKJ4xNit63nXwHqsEaGeiBEFFoZtAJfraCKdeApqqc/jTv6AOMDD2D0ETK7Qq7L0IQmNbr2GMkofc1svpfl++5iwV2IXr+UfX/0z/C5R9lbZyznC4zP3sNr3v/v4E1vBlPBaIAR8HUwPFRYUArnHd4ojBIyrdEC2sR283bR6iaygtXHef+rzfHC178CpXNKIpFIJE4PTlhcipN1on/FZDJhMpnQ7/e7CqQYhEe/i6Zpumyyc27TJJ4oRMWpcUlASpxeHD/4k+h3NDV+2KNxqsCqedTslYwygy76HH3mXyknTzCTrdMzNYoa7wRB47zC61BuLyqj9ob1ekA1upC5c17PYM+boXc5vlnA1ZYsB2gI4hSobpRzCGuVF4zW4KpQNZjZDU+mukblBnwNR1fgXz7L3b//EbLHH0XV64z7lh1veD0X/9y74eVXgwKfW7w0oAusMuB6jEZ7WFsakekhvhnjWx+nYEQVp/5MvYLHe8tHZUi3/htKQZ5TSg/b2wbZDHhLoxS+7Z1TWncxv0xtIsXnCWBTksNaS9M0XaIkTjuF0OIGdG1uUZRqmmZTNW5aqxKJr53nWCm7W4UwQdTiwa2iizVY/SrL+z4Dq7fjlx9gNh+DX2biV1F4cvLwSBOqDIu5gtUDD7GdC+Dh+3j67z7J+O51Fuqcxdqwcu75vOF9Pw/f/mbo95mwjq/XyM2ILAPvFHRDIUDhg4tiMEAMMS4bczGmq5Ce088wkUgkEokzgBMWl6qqwnvPTTfdxC233IK1FhHpxKE4Gc5ay2QyQWvdjWyenuQTA/R+v8973/tebrzxRsqyJM/zF+cIE4lvEdMfOqcvO6VotKFiSMYe8l6fwdm76Y9ezurBu1g58gDL1dNYVrCmxmhQytI0GucttQwwg7Mp5i5iYdcVqNlLwZ6P9wOUNmQ9QxjH5uhMulGAB+XawiSLOMAUKBVm2zk8XgSbm1C15Bu4/Qt85cO/TfHUY/j1ddZmtjNzzau45GffC694VXieQYayBbUfo3SJosQYIZubQ57JQsVUI2HSnLZ4N9U2IGrKfkJ1k6YxCrzD66B5eSPUThBlEdVn4uboDc+DYhtIhmDC9CABlInDhZjedPg25Y2VAv4zhq3VRN77bq3Ksqy7bjwed4mO2CoHdEmQaAQer59u/X6u50okEtNsnHulFWVU2yCtWsPr8NMY2A/jx1l96tMcfeZzDO0TGNkf2p/VJNQ5CWRShyGnFryxuFUYuV3woGf82acpv7hEMYajeoxcdg7X/9sfhO9/FQwU9DLybJb1uqJWHqd0Zx1ofFgbTVtxJX6zHXcikUgkEonNnLC4FIPsN7zhDczMzNDv97tKpthm0DQNZVnykY98hMFgwM/8zM9sGg0dDbxjpdMrX/nKTlRK2eDE6c50C+e0OSlAIx6rMhTbqF1OZkaonXuZGV3A4OhDuPJJqvEzjNcOUFdjNBm90Qwzg23Y/i6YORc1dz5ku8ANcW4Gkw0Bg3NBkGIqTIdpkSW4ZDsvWK1oSocyiswaJs2EDA9VCZ//PHfddBP6wQfxK6swO49c8jIu+/n3wquuBWOgl+EzqLzD6gKP0OAwykJ/G9nMOdRHnkH7CUaHKirnPda0o6XJwj5KO2kvelf4ONnOhf02oVLENZrG9WjUborRxVBsB91Dk4Vx1D46ObWHqYLzkkiSks50pkUfa21XURuTILHNzRjDeDzuBCQI611sj4v+gMfbbiKR+BoQDwqa9lydtQkQD6BA40COgHua8sl/ZvWZzzDiKQoO0uuXuKpEAT00YfpEExY4C1Iq8skA9vc4eOvDrN8FoxIqA+yFC7/3IrLvugS2NyCOWoUBGb2soIn7EKeUKlCiMCi8KFBmyrFvem1PJBKJRCIBL8K0uBtuuIEbbrgBYFPVUpwgd/DgQf7qr/6KhYUFfvInf/IYo9NYvaSUwjlHWZYURXFyR5VInCJsBJ6qa6uxwChWPACYEbgcmgL6I8zgQkyzRO5XGfkJoZzHABmoHEwf7BxQgM9A9zBmQ6QJlftZ+7ybzVKlDZ4bIM8UNGDFhBRy6TBNFbLC/3obX/oPv8Hwqw/hjxylHM7gLzyfa371l+C118BowKq15ASRynmH1lm7p30cDaa3i9HOV3NkeT/Gr2FNCarBZMHQVCvAG5C83UWH6AoIH/hNFiblee8wXpOh0Ri8DBjMXoaZvRz0PJCh25a+MI1HQSzWYkNUO27bXeKMYrqVLV6OvoCxGreua/I873yY4noWK5aSWXcicZKItC3e4UdP+MG3vcyaNfCLcOQe1g/eRlE/yNxgGXHLSBmGswVXtQyctIMqNBYDZQ8Oj1j6h8co74bBMqw3wDlw7ltm6b9aU5b3UXAWZHuhdhhRWDRlNSbPe3h8qKNSMVERLm+e75ZEpUQikUgktnJSht6RGHDH9oLpig0RwVpLr9frgvXpAD8ar0aj1OjllLJBiZcam/6mWwsmcR5lNegcJMP7HtrMgN0GVCBNe2cdInEJ09EcFi+GTLViigi4Bq8NxmZdd5nuVBZpxaUNsaX2gqo8OjOhg66uyAzw5S/y1d/9HdT99+OXVpH+EHfRRbz6l98Pb7geGeRMbE7TtgdYrbC6IHxcCJVSngFG74L5V5HN7qNujuCqNXLlyDLBNeAFlLRbUUH9UUqFPjjlQStEPM6Brz3iMpBZdLaX4c5XwswloIZ4bzpvDGmn4W3gkdbCOzXCJSIxmTG9FuV5zmAwwBjTTZSLfoJx/UrrUiJxckSvIkG1gn9Y1+LapFWNlnWYPMv603egx48xLI6g3SoQipRU9M8WAadAWbAjqDI4ZBj/4xMc+rxjfq0VsPbC2d8+wr52nvHMMyyv3M/8kQspFs4nMzOgcnzdUBiDbv2VdLezbFo4NgtMiUQikUgkpjlhcQk2BKHYAgd0U97ibQDj8ZiyLAG6CT3T7XBxck/cZgrgEy9pBGgcGBOEJYLQIkohKsNJg1EGj0WkQbel+UrC9DkwoYZHKWh8EKC0gFHoUIy06blieb8mZIgVIeurELQywZ7JV2AE7vwS9/7Ohxh/7jOM1mvq3ojy3Au55n3vD+OaC430DM5PyHWPrN2jsh6jtaYwfRrnQfVB7wQrDPeuMuYok8PrKPaj/TrQtG1rNULNxoCd0OagtQLt8E7wCkQymmaGfnYxw/lrYf4VkO8Fn3eTeKaKlVo87Zy8jc8H0X8qnWPOaKYTG9HYG8JaNTc3x2g0Yn19neFweMwUuLi2bW55TSQSXyuiQrLESFtR2loDigJFCSzD4kPURx6hYAmrJ2FhUwqtFF4EUaDjg1UPJgN4rKH+4hIHP1kzcwQqD9V22PnmHvb187BrHbFj7MojmINfhZlrwO7C1YITTZ5lIA6tpnYo7nMciCFp+UgkEolE4rk4YXEpeifFKqMYnMOxAtG0aeq06BR/np4SF7PDyXMp8ZJFCdjWYLsVOqbsgFFkOBoQjSJvy/Nb/yRpPZT+f/bePMqSqzrz/e1zTsQdcqjMVE2aSkiiJFkSQoDBYpQFNn7YXv2MMQ1twG7Ms3m2aS+/xrzl5YX9nxdr2d0MxljA6zbGINpNuz3x8DMGgYyEDRgEjQYEkqqkkko1qKpyzntvRJyz3x8nIvJmVkmAhKjp/LRSmXmnjLh1M8+53/72tzXEra5xoBYkToYLtT9JEUyzcQdinTi+ETZApT6OTM6BQS1OffNO7v3A+zn6+VvZNhgRbJfqaRfznDf/Grz4xbB1loIRqoG+6RGC4iuPsYZe1gEUDSW5zfAeNPQJfg677Zn0wkEGxTLVqI8vD5LbEtFVkFEUvbQ2KzUOKxMHyhUCwXXwYTtVdh79yWfDeddDvguYpgoW69aFpXhvoWkC3FB6FsbCzRNnM+MFkGbN8d7znOc8h1tuuQXnHJOTkwyHww05gOOiVCKR+N6JZqX4V9q065PUZYWApQA/z+qx++nIIl03jAUUC35Yr3mZEvDR5FpaKHpwJMP/rxUevHnI1CJkBuYnYNeL+mQvvQBm5inzVZzLmNJFiqP34nYegqnzsJ05yoo6m8+O26uaiEICAaOmFcMSiUQikUgcz5NuiztR/kSz+W4EoiY0FY6v8jai1HhL3YluN06qFJ8JbBYPz6Z/U60dO4pgUWwt/RB3twSchFgd1RDnMjeiUhPObXy8d6jb5SQj9oNVxJjUrB0WF3fGFTiDEYvXgPgS4zJCKDE6gm9/m/vf/z6OfebTbFsboqbHYMcFPPvX3gI/+ZMwNQkug+AxwWCCYFRwxsR2OFXAI+JBFUseN+r5JFDAtucx15lk9eEvsXjw6/TdIuijGF0gMwVZfZjex/PwBIKxlGaCIbOEfDdT25+H2/oSmLkKdIKgOdatZ0spIK5+HiXQhrJuYGPIeeLMpRGDmjWqKIoNE+Aa99H45xACMzMzeO+BjdPhmuDvxm2b1qFE4nujbUNtLbX1PkBBNGBMABlAeZTR2iN0qnnICzBCWSq2M0nhPeJKEMVag66ALPUovnSE/Z9aoT8PZQnlHFzwEkf2ojmYWUT7I5xxVKXHhAXKcJjh6sNkM1cwZIi6PgYha9v1moNuNCZpXcCJRCKRSCROzJNqi3s8GidSE47qnKMoCpxzVFWFtfYxN+fjYauJM5nx9IKzpxwYvTRNOGgzglnqFrbxz74WlWD9udF6sxulqY1PWfNYClR1GKmp++BsbWNSjAjWORisxkymB+/nwJ/9KYc+fTNb1wrKSih3nR+FpZe+FKanIXdUZQmZw5ks5lxs0Adrh5BoPfmtvlQMSh8x58N0xsT5k/SmLuLIwa+CfwT8o1S6QqklooqQYSTHi6HwOZWdobNlN1PbnoebeSbYi/HVJLgeisOuq2f102TWj4XHekWdHa+zs5lxAaiqKkRkQwHj8cK5q6pq16mm+NHcfjyLKZFIfO/EEkn8G61SFwA0uoWsKmgJg3EHq0IAACAASURBVKP4sIy1I6BAg+KJU1bVCk4glxxWHCxPEv51ngc/t0J2OC51xQyc+yM5nefPwYUVdJbxFFBaRCHoCM8ClV8gk1E9lXT9yGT8YFkfiRHXt7R+JBKJRCLxWDxl4lIzNW5ycpIQAsPhsB3n/J025klYOttotnNnh8AkGEQ3vakN49+YGPZNM/Y4gAmx9a315JvoehrXl5R6ok3dGmapnU9x7HMQg8cgqjg1UCnsvZejN93Ewb/5W+aOLCCugz9vJ1f/ypvhp38Stm6j6TtzWUZlYHk0pO/iEOim+ixSn4DmoM0bcrDi8QjKNM70YOYczMSlbO89nXLtQVZX9zAaHGRULCBSYCXD2j5Zd47J/nl0pi+FyUugdwG4GQKOKjcIBsO4kNRs/3U9W0nisxTGGuTO/FdXAja2bY8XMsbzlcYZd8w651p3E8BoNGqdTVmWpZbtROJJoRiNzlIvoW7VrosVvhZwQoGXkmA9Pigi4CwU4nE2J1eDHvXI8hzhq6vs/X+XyA5Bz8FqB855gdB5ySxcbsAeAylwAloGgkBlAqUpoFrF4ukQPb8WHnOqaCxh1FNO00qSSCQSicQJecrEpSbPwjnHu971Lnq9XlsJTuOcE8dzFr31102fYV1bG7+qqZqKjEUFhTqdIrqdjtdhTS2lxEfxGl2CcWKawQImCAwGcOhRjnzko3zzv3+cC9YKpDPB0ekZrn3dG7A/90qYnoKsFqmqOho7N5haZDKADXGz3fiElHxTsLaCGrxYAh0sE1g7Ddu2kYXLmCkPgZ8HvwzVqJ7804HOLLit4HaCnQP6BLUUjAgoTuJPW/dzyaanswljjXlVnvUYjbPkVXZW00wmbVq0h8MhnU6nLWw0a1CTD9h83bTRNSJTURR0Op32Pt57qqpqL0skEk+AerlvJFxpJoW2FxgqjX4iFbB1HUErjwsCwxxZ66P/uszeT6/gDsOWrmPJVmx9ljB9/U64uELdPGuhYMIBxiLeY8VQNFNJaxE5A6gUUxt9x0L8jjvsMHZ1IpFIJBKJjTxl4lKzqe/3+1x++eU459rpcM3nxyI5lxLfic2vnx/8a+ZJZEbJRvGo+VKbzjKgmYMsKCJK818Teyp1Qxj49VKrrgd++/oyb6Kbx6KEssIaFwO89x9ieNPH2Pc//padqyXDUlndNstFv/B67C+9AbbOMModDhP9U0aQAGXpyTJL9CNJnFinMRYqEH/nmxHOUu/SRSyWONzZIwRxuMoh2oFsDjrVejsdNrZImKw+eAch5jAZLDm9+rlThLCeRSVto0UrvY23L9SHuaERM3HmMu5UyrKMbrfbikfjLXHj4dzjwySadrqiKNp27vvvv58//dM/5VWvehUveMELTtapJRKnNwpxOEVdOCGuH1bqxU8sSo6S47H1ggJU0PEWU+Sw1IW7hhy4eYXOQchFWKSiexVM/9gOeFpJ6C9QuApbm3Rt8IgF1YDQg9ClY2qR2EPWtHq38YbNwA2aC9rWubR+JBKJRCJxYp5S5xJEkWl8A98Eoz6Wc6nZ3Cdn05mN6vhb/cfju9vGnZyx4N8vqULXA07He9yaTwoiNrbTtbvfhlB/WMaSR1shxde1VhlV2FCXYg8foPqff8Ed/+0mJo8uYvMuh6c7POM1r2b6378BdmylckLAMqQkx5AZB0bIjY0ToTExNapVySxKbJ9TBVMfTpOBZOuT80JUekwf6INWaDP5Tkw8DxGqsopv/l08ZlVFg8dI/TOo2nyq5g3AeFW5nfTTIKENZU3S0plP0w7XhHU360oTyG2txXtPWZZ0Op3W5VSWZVv8GAwGvOENb2Dnzp28973v5dixY7z//e/n/PPPT+JSIvGEqf8GS1zPAoEgATEhTkVVg2STZG4KrXICgveKVTB2Cwwn4esLPPjpo+jD0BdYFmX2SmHux7bB0wX6q5SmwlpBjKEq437UGUMoLZ4uavr0utNx0YgL0NjhxdUzXiZ1UQeSsJRIJBKJxOPzlDuXIL7xH68UhxBSbkXicdn4+ti8ndsoTI0LSidHZPoe0bEzqlvdYppDqK+OmUpgasGFjUJJrS9pK5dYouMnPmoAKqqYN6SQq2CxcWLcwX0Mb/4UX/+z9zFzZIHMTXN0Ypqnvf7nmH7TL8D2WYpyRG4nwHu8ixtrT4kGgxhX/zTBqcSSsICYrJW9jKFtb/D1+bha7HEmXhFCfcNaLBK0eZtBULCZIyiEaJqKU+gsBKooHEjzJNgNT4vWj7ThOWuf4+jhai48hV8hiSeJMaZ1LcH6pLiyLPnABz7Axz72seOctKrK9u3befvb3861117LcDjk0KFDzM3NUZZl+7iJROL7g9TrVyCgAkYCTi10Z5nsnkM16KLqUC0hdGHYobxzkYc/e5TyQehrzPSevRbmfvx82D2CqZWYERgcjGJoeFxSDfgu6jPETiNmCjs1R9N3F0QaEyyKR2p3Lq1LOJUmEolEIpH4Tjxl4hKwYSpcU0EeD0rdzHioauJMRseygqS+pJEG6u2bNgHRtdumbg3buLULUXRQQcRBKyyM5+80aUBPxWvqSTzmBu2s2bpujmGSjbdt8yjWH6S9Z9h4LLa+t1PBKlAWcPgwo5v/kZvf8y52zS+SGcfhzHH5z/w0c7/4Oth+DnR75GIg1O1wCJ5AZgzWWMpG7GmOS9YPKP7LNWXg2Fuw4V9MNf67Chhj29NSbbKQ6q18/Xw0WU7a/j9gcFhj6p+zMUBJ2o+xCvTYc5neGJw9hBBaYcl73wpLWZZx7bXXtvl/RVG00+NuueUW7rrrLqanp1u3U5MbGEKgLEtUlW63e5LPLpE42Yy7Vllv9d7EerljTOkX096+6UCLTc7NBFQH2Qy4rQSdxskMNgxhJYO9nnv/8Qj2IegBZQ8mLoW5l+yASxRmCwZhmY7pYIIFDaiFzAbUK1p4VKaosnMos23Q3wHSB8nbwaw6trit5xuOrXljp51IJBKJRGIjT1hc2uwQaZxJm8c3i0jbctDkWDRjnkMI/N3f/R1zc3Ncd911bS5Gnuff8ecmTnNCVVtcBK+BQIkRgyFDVEGremNnieJSzOUJGh09UYDwwLB+wAlQi5iYujM+PyxKHHZsCkwbCPQkeBL3l81fj2+xx6/YtGNvTBOq+KrEOlvnFBm0UsSt94ZZARHFBYXBKgyG6M3/wF033shFhxeZNLM8QmDXv/0Z5t78erhgO+pyJLi6y04IzuIJ9Vw2AypYiVe3k+LsurAUO+FqGSeO1GlrvrFyLCDHO4dipXj9cY5/bg3rf6qa+zVZS+sPb8eeyc1KktSz5Tb/7MSZyXh2UrMeNa1w1113Hc9//vPb7yEWQh544AEOHDhAv99v2+eaNQtoQ7yb+yQSZyVai0W68Y/seCfy2KWARyjr7x1gGOKxODI1aFGAA2sNBRWeHCszTOy8mnLhdvzSCrYq4cEBB/96P709MCFwtILpK2HHKy6AKxxMLFBRkXf6SAneF1gnGGOpCo+E6IBVMSyaWbZfch3IDvCzELrR2CRVLXMJ4AhtQ3dzzmPOxbSIJBKJRCJxHE/Y498IRxA35k27QLMph/UWgvHbfehDH+J1r3sdjz76KEVR8Fu/9Vu8853vJMuytkpcFMWTOqnEqU7cuKG23o02o+w9SnzjJpJTz3ABVVRLNJQxylosvgpoqB9HHCoQCPhQEXxFkw0aHS9+PdPou8p5+gFwnI1mvRUuBnM/RikYQATrMkCoKh81lmz9wYwFYxw6HEFRxMlwn/oUX/h//iu9fYfoD5WHhiVP+6mf4oJfeC3s2gGdDDo9KAMYIUh8S3D8FLaxPxpjhwxsrvEef5onUn023K6Vpk7wYeqP5pIxcWlcv9r8Y2T9gvHHT5z5bHbANmtW40hqJsWNRiOKouC+++5jZmaGnTt3MhwOmZycBKKY1Ol02nUpiUuJsxqR4/6+avs3ONDEXq/PNK3btutLQn1ZoSUheCTLY6agGhwdAl2qMI2ccxWz09eQVxfDN4X9f32Q8l7I1mB+CNuvhfN/dBYuBaYXKbtrlAwJIQ65UALeV0BArKECvLH47jS9rbuR3oUgs6DdtlVdpASimNwUqdY5RfYOiUQikUicwjxh59JwOCTLMqqq4r777uOjH/0oq6urGGPIsoyyLBERsizj5S9/OS9+8YsREfbs2cOdd95JWZZYa9u2hKbtIMuyx3UuJc4AFAhRkQgmGpjWG+ICSAZ13k6M5hGMqUWBSsDHTB4PlD5vw0CtCbEuWgszUhcao7hUEBCM5DzF3aBPnu9G/airxuIyPIpIhYilHAWyzFL4QMdYWF6Ez32Wr/zR+5jcs59u4VjtdTn35T/Kef/+1XD15dDJKaWDYshd/OGlNGHgjby0Hof93R5iInGyOFFr9ea266Z1rtvtcuedd3LXXXfxm7/5mwB0u1327t1Lr9fDOcfq6ipZluGca51QicTZSLsqjP2ORUGpWncoaVZ/ABgwnboAtN4OZ9RSWiEHZBRAwWQ5iMUPHRgPE8+GIwc4/Le3kd0LxQqYOch2wTkv2QbXTMDEUciWsR1QH/cQ3gtZrwPiKcqC0jhkcppC+iyHLezYfhW2dz7QjUdTi2Tra13TTt9goku4sT+n6IZEIpFIJE7IE94lN7kTo9GIEAKLi4usrq62wagAjzzyCLfffjtXXnll21IQQmgrxlVV0ev1ANr2hUaUShv4M5zYBTbW+eUIeIx6hAJfOhDF2FWMGQGrQACfg3eQd7FiEbp4DIFAk9oQ06Jt/WPirjEKTI3hfWMT1mlHPcgm9qFZPL6tCdsstv9lwxFUQ7j1C9z6n97JzAOPMK2WeWu56GUvY/ZX3wjXXEYQKOrKcigCeWbxfmPWkbQ/dKPAlEicbjTCkqqSZRmj0QhjDLfddhvz8/MMh0M++tGP0ul0OHr0KPv27eOiiy6i1+vhvWc0GrXh3onE2YlsWBlOXHDY5PIZj1wCJEDHCJ66C9vaOjsRrCe2fK86mO/x4Cfvwn9zwGwFq12o5uDpP34e/FAnhnfrclzyfXxcUMRAVY7ijsD1Kc0kK8UEduoiZnf+CHb6CrA7QHs0GVBoOLFm1J6KxKPdaMVNJBKJRCIxxhNWcMbDTXfv3s173vOeVhBqJvD8/d//Pb/+67/Oueee227iYX2Sj3MO730rNjXjo9NEnrMEAyo+VjM1x2hAGIKsYc0IzAqYI+DnoViGooSQQ9aJWlM2hcl2IDKFp4OSYyVvrFD1h0EkwxDFks2pRqc1nvo32NBMmjNGYW2E8R7+6Qt8813vY+e+g+RrA9a6E3Rf8MPMvvmNcPUVMNEDk2MwSGXpuviYVqDUmNnUdr3puri0OVY9kTgdCSHQ6XS45557+MhHPsJzn/tcvvGNb/Cxj30M7z2qyr59+/DeMxgMyLKsdeMmEmcrMd9u8wogKBng6pzv9Ty8tiMd4nAJAF8n9/n4SV2cIhy8JyvKOIDi3rs58scfZPSlb9KvHItZwcou2P3Tu5BnTcDkArgSJMNoCWV9cMZgnCWowXtDqTOM9HxC92L65zyP3rkvhHAu6Bxop84CDCC+PZex2tfGE2+nalgSiUQikUgczxMWl6yNmwERaVvhGldSIx7t2bOHoig4//zz20pxc/s8zxkMBqhqO42naYcbjUat0ylxhtJkNdSyiBFwosAq6DHQI7D8IGvL97C2eoDR2hJ+MMAUVUxsmJjA9bcyseXp9GYuxU1dBMyC9vBFhnVbYk9c/eBxmhwotm3BO91oQ/RVWudXk23hQ4X1ASMZrK7Cl7/CHR/4IP4bd7LFCEedZeKZV3LJ234TnvFDkGUE08WrQAWZIT5Xvm5VFMVIE6neTAbSpColTkvGB0GMZy8Nh0M+8YlPsGfPHt797nfzmte8pr3N/Pw8r3zlKwGYnJzcMIwikTjbWP8dGl8/N10mUhtrm3JHdCMZrROXmiKF1uJS8Ov38UNyNeBH8MBe9v35n3Psc7fSObbE2sQ0q+dMsvtnnkf3OVMM8j0Uukg/ODI3gVZrBFE0yymDMCog78zgZYJR2Epn+hlsO/86zOw1eD0XCdMY7YI1dfUkNuxJm9pXf9b1s9x4zqnEkkgkEonEiXjC4tJ4WHee5wyHQ/I8xxiDtZbV1VW+8IUvcOWVV7Jr1662jU5VW7dSnuftiOjm8cqyTMLSmY4E0FhmVLWIGAwBWILB/bByD4PDX6dcu5/hYC8iK/SNIRPFdkaIgq86jI5mLD/6L6x2L6A3czX9rc9AZq/Adi4AX5dE8XEjq1FgksfJyf7Bsvko5ISXrt96PQMi1Bt3MYIQcCg2GMQrjNbgK1/lnne9G3v33eTFiPmpPuZHnsMlv/LL8OwrIe+CyzHBUq2OyFwes9MrYs66Kg5FdKzxQQBdT6RYP+JE4vShadtuppvefvvtvPe97+W5z30ur3jFK9rLm9Y3YwwhBAaDASEEqqpKE0sTZx3jr3mtdZUoJpWgVcwADPVUTwNqKpToShYElXqWqAZEDWVQMpTgSoxRVD25FRiO4L77OPRf/oz9n/gkM2tLMN3h2Hnbue6XfxH+txdAuRdd/hIy2stwdITSL4OsgAt4m1OaLoVMsVbN0ssvYmb2CtzWK2HmUnBbUSZBemNTT0Odp1QHj6uCmHHj1YbPkNa+RCKRSCQeiycsLnnvY5880WnU7XZb4cgYwyOPPMI///M/8/KXv5z9+/fz0EMPURQFCwsL7f2stQwGg3Z6T+NiGn/sxJmIRgu6WKxagpZYOQblXkZH/4W1Q/8Ky/eS62G22AWcFAQfCKHACjgHvoSe9AiSMxocYTh6lHJwkAk/TzZ7LWSXA1uI4hIgjg3KyEntvBw/EPhOW9VGWGo2+E3kkjNCFQqcrzAeWFqDO+7h7j/5IMXXvs4WXzCYnUR+aDdX/vqb4fnPp0DJez20UMKgJO9FIVcrkDw+tjWChtBml8ZDlNhuyIYBbYnEacN4HqC1lvvuu4/f+73fwznH2972NqamptpMpsZl22QANkWTxqWbSJwttOvOmHOp+VLwtbhk10fGBRAJiHgMvm2js0ERjXJTludgAupHeB+QURXX6Pv2cPgv/juPfOqzTC4NYGKapdkJrnzNz8Mrfga2zYE7l76eC6sPEBYeplg9RPCLlGFEZSySTTM9cQG97oXI1NPB7YAwBWYL0EPpYGw8ziBanwOIxHPQAGLWXbp1XSU+B6S1L5FIJBKJx+NJtcVVVYW1tnUaNaJQURTcdNNNbVbFi170Iqy1lGVJWZZceOGFQNysNMJSVVV0Op02rylxJlPPLlYIleLyIfh7WHjkMwwPfZFs8AATukRHV5FqCHjs+EuiqrMbwgDjBzg7JLdDFpYe5Wg4wFS1wMR2B/mlEDpx+pwEUI/BUvmY4XnyeeytatCAqQ9S61YCDYGginEOI4ZRNSJzoMUaVAH2PcCe//xu+MrX2eqVowSqq3fznP/wq/CC51O5DnlvmrIMZNZFAbd2/we3niZhUKyRWMHVtkQNrA/LSTvsxKlO07YN0WHrvW+dsQcPHuR3f/d3uf3223nHO97BC1/4QlS1LXI09xn/OoTQPm4icbYwPnmxWYtMPSQjLmEZiEPVompiDSI4MlvbhH1JLIeUwKAO9Yv3c64PhUHcFOzdx+JH/hsPfPwvmToywPWmOTS9hWf8u9cw/XOvhdlZsI5Ku4ibxM5dhpkd0Q1DYBjXeBMbuaEP9MD3gS5IB4zDY9bzlEwtjhEQ49o9ibTrXftNPPf4bLSf0xKYSCQSicTxPGFxqXEZAaysrDA5OQlEgemee+7hr/7qr7jhhhv4/d//ff7wD/+wdTS94x3v4NZbb/3+HH3itCUAEiqcBdYeZLD4L4zmv0ju7yPXw+RUCFVsaducrqn1AzT7SEZkMqInS6wNKgaPZjgzReccoHMJPliMWAIBKzb+zFMcI4bKR/HWSL2RdZbgPajWDi6HsAq+gG9+m3vedSN6+9eYXB2wkoO/+GKe/X/8ErzohXiXEfpTDCvInMPXwi71eOj1EdHNG+e2NB3/JynIO3H6sNn9WpYlWZbhvedb3/oWb33rW/niF7/Ib//2b/O6170O5xyqymg0wjmXChyJxGMQB6spYg2IpfAFqobMZbFlvfRIWAYzguooDI6AXwUdQrlMVQyxnR6STyFmBjgHDsLhv/hr7vurjzO3tobLe6xMTPFDr3w1W171Wjh3J5UEsDni+ozCJAbFSImRCsHHKbBqCGoQkxHUohJHUogIFoMZG0oRPcHV40yObRzG438Lms1IIpFIJBKJE/GExaWmEmyMYWJiIj6YcywuLvIHf/AHLCws8PrXv57zzjsP5xzD4ZBOp0O326Uoiu/bCSROU4yNm00zj1/8BmuH/gVZuZu+WcHKEJHaNaMZUdxoFKUAogSltrY7lICYQE8KtDjMaOluVslwWYbdtg2vXQK9aIHXEUaE+NI/2W8gH1+qCSHgrIs14qpCBIL3GLGoeowfgYzg2/dz8IP/lcEtt3LOwhCZnGZw6UU8+z+8GV7+Y2gnw3anMTiWygI1rs4xjUJSIxo14d0C630AIoR2M55m5CRODxq3RSMyNcLSZz7zGd7+9rdz4MABfud3foc3velN5Hm+wYXrvf8Oj55InL1oIPp/PFTWozZKO56AU0PuCmABFu+gXLqdau1+fPEoo8EiZRHdhIWWTPe34gZbmKguYPCZA9z/l//E1HCREYbFqTmuefXP0vvFn4dd26nCEjLRRzUwGlU4ZzEqMSdJQDTD4MA7rMYpdCYeYu1QarYQtRPXBJSK9SrVY63FJwrvTiWWRCKRSCQei+9L5pL3HhFhNBrxoQ99iE9/+tO86U1v4vrrr2836k0m03gbXeLspLWVmwGM7mft2O2Y1fvp+Hny2qaudedcPdd444d41EbLemli91ZGbYbXClstsLZ0D2tHtzI1dw1ipgn0o5lf1o/g5DFuwTrxRlVVsaYe+KwapyVbg4QQrfxlESftPPQQ377xT1n65M1sXRshEz1Wd27lWb/8S/Cyl0F3kqGz9MQyHI7odLuE9vTjF+PzcTYmdguKtF6mtKVOnC6MD5xosNYyMzPDpZdeylvf+lZ+9md/ln6/T1mWbTvccDik1+ul0O5EYozxvDKtizsBT0AQDI4KWMFUq+AfpThyOyuPfonR8lfpyEGsrGD8iK50ybIOooo9coDO0jYWb/sC+z55gOljYDuwNNnnip95Gb03vgou2I6qR/sdilCSkZFbh6iJYpEIiqW1MY8Zi7Q+VpWACFhM2+Ym9VgM2bC3OO6sN3wXHzqtgolEIpFIPB5PWFwKIWwI9HbOccstt/COd7yDa6+9lt/4jd+g0+m0DiegDUgdDoffn6NPnJYISqAEWYXlOyiWv0G3mqerAQpFxaAuoKJAWW8ka5eReEARB16UkiruKwPYEmzh6BIQt8jKwrfoL99HNrODEX2EPkIWRRlzKmwSZdPnjThracY2i4kqWlUMyTSACfDQPva/+/0Ut3yVrUsVXhzHzt/KM974OnjFT8DkFHQmsKKsliOybh6FJKnjKaTJU9J1UakR8yRuuI+LHT8VnrZE4rtgvABSliXOOa677jpuvPFGpqen22DuLMsoioI8z+n1eq3LNpFIHE8QTyEjMpMhOFSH5LIGHIHVb7B86KsMj3wNVz3MFo7hZA2jFeIMagJaDMjKDI46uG0va59d4byjgqfDQr/gwhddxZaf/1G4ZBKKVehOgzjKakDfORATB8AGULGEWlRSYpxT2+otnkqKZrYqBoszrk1dEpqJcGN+3HZJbhrF15vm4nfN92khTCQSiUTiRDzhvqCmzWA0GiEifPjDH+Ytb3kLl156Ke985zvZsWPHhnHOTdUrz3P6/f735+gTpy3iPeiQ0epejH+EXAdYX6Ehtlo2ziUBjAaMeox6RLW+DLTWiJpMIqmtTsaUdGSNMDzE6vweYAHLiHbWmZ5KG8MTH4tpHBfjDoqywBkTd9AP7OWhD3yQA//4WcK+A5juJGs7dnDlG3+B7Of/LUxPwuQkIFSDEVmWI1jKMmCU2FKgtV9JG+9S41+KFd62M464/d4cbZpInMqMu5aafEDvPVu2bNmwfkFcl5qvk7CUSBxP+/tkBGMyfD23NNcRVIdh8Q5WD36O5QOfJvd30+Uh+tkqufWYskCHI8yoJBsIzHfhG8sc+NwK2UGQkbKqQ7Y/a4ZtPzwB7j4I98PECBjhFTrZBOrBF0VcrWR91VIdyw4URaUEqWIOE9RCkow1uVkER6yv1uJSa2IKxIa6sQt1fP07lfYPiUQikUicWjxh59JgMKDX67F//35uvPFGPvShD7Fr1y7e8573cMkllxBCaLMsjDEYY9opO4PB4Pt2AonTEcGohWLI2tIBnFmDMAI8NoNgAqpxj2dDY66pm+kM9QQacAJGspi74APGKnRKoCSEEZmZZbh8kOnhPDYfRbePBjaOnjtZnHiD2lwaQoitPbX1HxRchjgLD+zl2J99hGOf/AdmF9YocsfDc9M8+1d+ie5rXwkzM9DpQ1VCWdLvdlEMw7LEiYvtBG1LQfwsyIbgdM96lKndYF8an5SVNtmJU5P294eNDqY8zymKoi12jAtJnU6HEEKaWJpIPAYiguAQHD5UZGEAsgTL32Lw8OcZzH+ZLvvIzBrlaIQJ0HE5BhvXajpQTMLXB9z3iVX6R6FSWO3DBS+ZpfPSLlz2KAvH/oGJA6tkT+si7hJy30csjIqKbt+CX0aMIOSgTemjnmBHwEqdDaXRXTUuNMcT2XxiEAO+4/1rHxSsl6Q2D49LJBKJRCJxAp7wDrppH8jznC9/+ctcf/313HTTTVxzzTX0ej1EhMFg0E7eaTb7IpI27mc7WodzD1cYLh/BUaChbm/rGKpazDBah3A2Skdzd2itNMYLUga0qscd1wKSLyu6VgmDeRgtIlSxGS80ZwazZAAAIABJREFUIZ4nkyacfDwcYv3SQC2iESCEeMWogNEI9u3jwF//Dff99SfIDx+h1Aq98Fyuev1r6b7qlTC3nUFngtIrWAeZg3KEBk+eZVg7Zkdiw4+vMyo2HNn6zRQ2/CMkEqcwzZvJJqgbYG1tDVUlyzJEBOdcW/CoqgogrU2Jsw7d/M147h5a1yGkFpai3ydU0BEDtoLiMOHoXazO34Wp9rOlN6SXVUz0wOUWH4CQgZ+Egw6+Os/+m4/i98cO9dUuTD3T0fnR7bCrYGQfxLl9LB36Ehz7OoRDiF+LBaWOAzwqPhY6JMRUQNXa1azrQhAWoy46msOm8zrhUrYhcJBUPEkkEolE4nvnCTuXIIZ0z83N8fGPfxwRYWpqiizL2qpwt9ttb2uMwXu/oaLc5DaJSLvJ3zxCOnEGIgFMCVJiqhFQ4MSCiZPfggGrBkPj3PFRZTJQGkFFcRp1JLxHEKxTVDSKUcbSMYaVwRohWwRTxJwIAs4aPAFT2+RPDrFCGkLASidO3fEgORSiGAKGkgxDVQVckNj/9/B+yv/5P3j4w3/O1vlFKms5ODPFM1/9b9jyutfAOVsh62FLyLK6tTBrhi+HaEwSgxdpUyYeK/Vpw/XtjdLEnMTpQSMuNe1wwIZ27Ob6E92uWX/6/T5/8id/gqrS6XTIsozdu3ezdevWp/z4E4mnFA2tczWgcWgEBgmyHjUkippAQAiVwQlximsI9MQgOgR/DF24n0cO3sGkW4RyFfEFvoxtZbZjqQqwvgtLE/DVBfb90yrhAZhyMOzC1BXC9p++EJ42ouqOCDmYsIzTQxx76IvM9c9H+udSaZ8gBRVgpIto7SwSwbZr03iLm/C4VqPjrhJkwzxUeZzbJhKJRCKROBFPKtDbGEOe58zMzGxwJI2HfTc0k+JUlRACVVW1lePmsRrxaXyjnzgT0WhLMr4OT9J20+p9PSWtkjpDCWLAtNY5TPXn+uJ4dWijlOK+WJFQkjmDNQ6CQSTHkAPFppjqk4WiWjuoDLg4PZmyGmKckgPeB5ztQFnCvocZfepT3P3hjzB58CAlhuUtU1z12lex5dX/O5y3nSAZ6iHP12uw65Pe4ndyAjnphB0Cm5HHvTaROOPI85yrr766Xdeuu+46brvttg1Fk0Ti9KMOENLYfq5K60oaXx40BIIoIhbrqBfdEg0FQQUrixAOMFq9l645TEfmEVdC8FgrlJVCacjcbAzvvnOZfZ9boNoHPaDoQG83bH/pLjhvANMlQSqMCMoQG+ah3A8re6B7BWImMVK3q0mG6vETIdcjCo936H5nklspkUgkEoknyxPuARhvH7DWHvd9IxpBFJbG2w6ccxuyL5rWOWsteZ6390uc2agIPneURgk2oBoIBRhva5eNrmf8qCAa839cPSwNrR09IvixnCCVgDfgLaibQsMUopNYoppq0JMqMEXhRzA2TqtqFCCjgQ4V/TqTymgGRQVLy/C5L/Dl9/0XeoeOYI3h0a2zXPjqn+WcX3gt7DoPCEg3pzJKFWJbnRFwCg7BNP+piWHeiUTicSnLcoOzdjQaMTEx0U4/TSROW+rKg/EGpxar0SWsWjfCGQgCGgxBYVR6VssBA1ap3AiyAuwCVHtYPvpV3GAvZu0RMi3xHkZGMZ0+tpqARzN4MGffzUcp98IksOrAXgrn/sQuuMLCzAg/PEqeWRiNyPBYXYXiEKP5+6E6hmWEw+E0awtPm7OUmva9RCKRSCQSJ4cnZRFS1Q3hpyGEdnFvJsQ1rqRmOk8z/rlxLo0LUUVRYK1NbXFnPEJQAdvB9eaofB9lhIhiSoUg0Y4vIZrUx3ISbIj3p65aqgSCQFADhNgWJxAMFOqwnVkk2wJq4nWYdcv8SSOev5P6dR5ATUBMoIONxq5SofSwvIr/9Ge57T3vZfLRI3TznEPGs/uVr2TH6/8dXHwJQZXQ6eDVI1bWc5VYF+bi+ZqNWRNpD55IPCbN+tZ89Ho9yrJMztrEGUJTnIlfBg1UlIgoDgdaIqHCEnBZAQyAFQrWsDjwj8DoPmz5ED0WyCmRulMtiMMWHWRxCu6t2PM396P7IAuwaiG/GC64fidclsGWZapqHtOBcrSCFcGq4nREFRZYW36ITrUIeQH0ARuLQ0lESiQSiUTilOMJ75JV9bgqUSMyNZlLm68PIXDDDTewY8cOJiYmMMbQ7XYREbIsO2EuU+JMxGDIwEzT6V/IaOV+ijDAOcGGGNbpTYhtbiY6lVpbUojeo7gh9gQT6gqrwwSL0QoQKtuhCBPk/W3Qn0KlQEO3nixn4sS4k7Q3FQQr67966jxqlEBA1GBGHrDw6FG45Va+9gf/iR2HD2LxHLSWc1/+E+x4zc/DpZeDETTvErCMyoLJrIv6CrH16Lc2NKn+eKyQpUQisYE8z9viSVVVhBDaIkkicVojQDuNFLyUlDIkUNVphBnOerCrUByEtQfAP8qgWGQwWMGooSfL5MN76Ms8uS0RA6WAYjBlBzmWwZ6M/X/5APkDUVha6YC9CHb92A64qgv9BbwsI1MWtUq5Fug5hVLJKCnNkEGxANUK+FFdXdK0fiUSiUQicYrylJVgq6pqXUpN5dc5xw033MANN9wAwHA45JZbbiHPc6qqIs/zNE3urEBAHTBBt/80hnYng8EhulIgKpgmMKjOUGryrDd2sgUQpckfjS1f0bKkklPqFLjtdCfOAzOBhgplBHRPiYqn1NPh1NTTqkJFOSqYyLpx0z+/ALd+njvf9U6m9u+jK8pSN+O8G17Crv/z1+CSy1DXozQAjhJPljmEQOXLtuUu1KJSE46+nkuV9ueJxGNRFAV5nuO9b9u4q6pqswMTidOe2uZbhUBlClQqDAWWEscIigVY3Edx7B5Wl+6gqg4TTIEPnhAM3lZ0ikN0dQn1BSJx+lumPczaNOw3HPnbe5EHoDOCIgd3IVz0U0+DqxxMHIPeiOALnOswrEa4HlQlZApBPWI8GgqohoAHratMp8AankgkEolE4niesLi0MURRNziZGicS0LYRjAtG3ntEhG63y/bt29vNelmWZFnWfk6coaiAWmCCzvRuOpPfphzuodQ1shDlECeOUG8kZcN04GrDQzWtblZZt8pLTqmzTMxcRnfqYgh9ghIDxMVHO5QYTra8IgJVncAUCsVVFqzAwjG47fN84/1/xMT+++nZwH6E866/gfN//S1wyW6Y2ILW+VOiYMQRqKiqEVlei7r1jDgZa4cb0+0SicRj0IhJzjm893jvyfMcIDlrE6cRJ8oW1JirhKIiBKnqOWkCDDHhEIweYOWRO1jdfxdmsJ+uPcpkNsDYiiJ4KsmwlZCXI5xRlAzUkAeDLHfhIcexf3iIwd0wHWAlg7U52P2KHXBFgIkj0B9BNSDLM9YWRmRTPQodIPXyHCqHV4MYAz7ECpOJBSVR6kEgaSVLJBKJROJU4klnLo0LSuMik/ceay3OOURkw0a9EZM2T5DLsqz9nDiDEcBYYBImL6a35TKqlbuoilUcy4DHBG2Lk4KvR9rU8UHQxgnFYE9BNBDb5XJGMkXpzmV67gqYughCP77mxFERMGJPrnOnUXioM8kRcuMwHQOL8/C12/n6+/8Yf989SDVi3mWc88IXcv4b3wi7L4PJLWgAkxPzmryiUsWsDJdR+QpnMwSDHZsPB0lUSiS+GxqnbTP5tFmzmnUskTj10U2fx6/RemUwGASLIoygPAzDb3N03834xW+Rl8eY6gxxugjlMlSenoMiWASHMxlgEclgZJBBDvsd8//fQyzeDtMKKwHKC2H3vzkvOpZmV6FbEHSAMUBR0u9NUY0qTGYwNgaJV8GhOIzkqBrEOqiPlEZgSiQSiUQicUrxpHbJJ5rU0dBsxpvLmg35eEtBc52ItJenivDZgFB5j3M9YI7O1qso177J2iNHkODp2xGIR6oi3rx5SRhQa+IbvvqlZhG0djQV3lDKFFV+LhM7noWZ/SGw56Blv+4AiHPiPHGC2lPJeO7YY9wAEDJsdPcJsLwAX/g8X/nj92DuvoOeL5jv99Hdl3PVb/3fcPU1kHfA2qhP+VqcMkpGfAvhCagYmnE/0ghZtVFLVBFJjXGJxOPR/N5uXo+SsJQ4PdgoLDXrEdTmXqKzVQK44ECWoDqAHvkqx/Z/DlfdyaQexWWKqUqgiO3axoOAE6jKIopUrhPDlqoJeERY/MwjrHwZtgLzCv5CuOCnt8CzM5hcAjcgVFVck5o64qjEVUpQRTOD2gzIsdJDpIP0p0ENXgy+FcPWC5yJRCKRSCRODdJOOfEDRwHjHKMq4Owktvs0Jnc+D6lGlI9+k9ViP5kpsIDNTNzUVoFQBUqNbXOmihvkUsAjiOlQuS2E/BJk4kp6258FvYuAPio5EqKgomZdq3oqaTa845v69uugGGOp1oa4XpdcLCwcgTu+zh0fvBG9+y4mQ2Al72Ke8Uye9bbfhkt2E2yO6fcpfcC2JxHaEm7jURIx6+FKYfygGLsgbcgTiUTizGVcUJINlysaXb8eCCW4eTj2vxgd/Qp27R66Zj85q0jI4/qLJ+CRusNa1ZN3MiBDlyvEzMGRjIWbH2D+K7WwtAR6KVz40lnc1TlsWSDkQ1Q84g0ilgofN6EhgAqZh8ooPlRYN0lRdelMbQM7BZJDTBXEknLPEolEIpE4FUniUuIHTqw4gjV5vWHcCVPPZeLCSYbZDhYP/isdsxcXDpOxRhYq1FsUh5U62dsJuC7O5hSFYVR1Cdku+lteSP/c58HUpXi2ogiKx4htdRj5Ae1LmzbR9rzbPj/BFz7u0osSVpfgrm9w743vo/jXLzGncEwd+TXX8Mz/+Ntw7XNhaiZqbIA4EyfL1Wcn7bMqmMaRNNZ6V3c/4Ovbr986kUgkEmc67TokcU0KGnCmsTCtQdjLwtEvwPLtWP8QTod1W7pBRfGmrKeZ1o8nEEKJL6DLLOwzrNzyEGtfg+4SLBoIF8G2F0/gnj8D25eo3Goc1loFrORxNRJPFcCZaK8Vo2RecVYoKhhVfbZMXwTZVqrQieapUCKmXtQSiUQikUicUiRxKXFyULB1FdSHPtacD1NdumYa7c5w7OCtmKJPHo7RkQrrMgyK1yE+VKAO7zsU2sV2ttI752l0t1yN2XIdzFxOKV0qeqAmbqKbn/kDPMVGTAohbLpMEQ3YPIuOpT33s+fGGzn2+ds4D8tSFZDLLueZv/k2uPY5aLeHAJUPSGYoCDhigLkZm/2mbYYG68JS3SHnaTxL0nTIJRKJROKMY70Vbry4AfF7RevxqyEOt2Aelu5muPpNuv4wuRtitV4xpELxICEOaQM0gHNgQocsTMHRLou3PsIjt3pmlwELw61wwQ1b6b5wEuZWwC5jbEVcCg0BjS2nzeFZgaxZrAIiPaqyh+bnkm15OuRzBO0gVDiRlLeUSCQSicQpShKXEicFI+CLAGKwzhCYwXuL7fXoXXge589eynDhHlaPfZuV1UOE4RqZLcjzIWKgqDrgZnH5DnpTF9Obuxx6l4K9CJgh4LFkGMmwUqsrAiKxamueYvvS5rD7EEJ7mQkBY0J0LO3fx7fe90cU//Iltg09A8kwl+7mh/+v/wg/8iMwswVyy2hllc7EBINhQdbNAR+FJY0p52qi1LRBNBIINp56e0EtRyV5KZFIJM40GmEpbLy4tRw1olOIQyAYgh5k8cgdaHUYwSNiCVLUEtAwli8CZG2ItiGMAKZgfgvzt+xj6YsVs2txqNtwFra/bAvd6ybgghFrLNI3ilEHZYXLLKV6wGCDQVWprMGYWB4JIcOPukh2PpNbnwXTlxGYQCQHX2CsBdUTzsFLJBKJRCJxckniUuLkIIAErATAocEQmCZID8ckdnIL3e4uutueAcVRwtoS1WgRDUt475ma3I50t0N3J2TbwMyCn0GrGQgdjCkwYhBMHDRXh1qLUYR6stxTKLBsDhoVkTYcWIKHUMDe+3jwA+/n0X+6la1LK6jrUu26mCt/9dfgZT+O9jt4F3f0nckO6gt63ZwAtUupHp+HQdqGt/HnFwLaikkGjpsel0gkEokzCW2n945/T7sSSBz8oCUiQyiOMFzcS0cWyRiBrxCjqNb5iBJDwKPKJBByzLALSxMsf24fBz5fMnUUfAn+HNhxXZfJF8yhO9co8hVUK4IXDAZjM0BwGiAoaIaiBBSPomrw9BlWc2w550rczh+G/DxGXrAWRCyE5oASiUQikUicaiRxKfEDR4EKj8mII898hQmOTubwklMUnp49F2QaOjuhM8RMKfm6hx7UAjkhZATJsGRgM1QztAo4K4jROGEO8NLkNABjzWRPFeOB3uMuphACMhrAA/dy4KYPc/CT/8COYQXdSZZ37OTa33gL/MRPQO6QiS6hWMOIUAhghBzFBAhGUOy6gBVNYPEZqh1aENozDfXIaanqfwBLiqxIJBKJM5TYAheOm6amAiIOtITgYekIbnSUvlnGVgUZSl3BqEsRBoytJ616XNGFI7PwlWUevblk4ihkDpanYOZ5hsnr52DbEmTL5ChWDWWlOGOw1kCoEFXwiheHF5BQERQq16PMt5NPPQu383nQvxR0miCKMiQzGVoq4tLilUgkEonEqUgSlxJjjI8Xs2OXwboUM+6P2STPbPapb8qVbu4R5Q5D0CJmO9haJAkKVsizHiiEygEOsYGARTEYHOrrbCFr8Ra8Kh7P/8/em35Llp3lnb93733OiYg735uZVVlZWfMkqpBApREhg8Tghm5YprFh9XJ/wAYMDS03rMYf+j/obnu5jdsGw1oYWNjuFl64G2gMNhKyJDSLUkmoSiWVaq7K8c5DDOfsvd/+sM+JiHsrS2hCVarcv1pZNyPujYgTJ27GfuPZz/u8AlhjsJa2XSyFZoukEG8lIG1a0dfKybMybUdor+sKeh8hhogjgkbMcAjbW1z817/Jk//vH3JqWBPFsbu2zht/4ifge98Jp9bbO1acs0QNGOOSEyl4jHXTx1I5/mxOHtd8CT7NYtKTN+isXbN48Pkkp2s907xvnMlkMi8POj/IYS5ku/sumoY3aAxghIhFxKQ5cRrToqgB9JDJ/kVMHCNao8FD2bmDuvLQQHRINFhfwsEiPHTAE3+ySX8LKgs7FZx+c4/Vd56F8xMoDhFqtAErBikKQoToPYWTFNykSkMkSImhwEuP2qzj3e2snX87rL4O4ilgkcooE/UgJWpOtPxlMplMJpN5xZDFpeuVY5pBJxdEoGY6Xky70M8I4lpXTFvURk1WGWnvpBMtdO7uDETRNvMn7YHa9uFEFCNzrWmt8iGa7PgRg1gB6SXnz9wxibTiTRvQbaRrDTvhljeGFGIKRhzHS/KvXh45JsFNz6PS/QcG9YqxBo9gXYFthrC7BTt7bP2rX+PSu3+Pmyee2hTsbJzivp/5B5gf/ztw6hRRFKOagk2Nw1CA1/Q8LURie5oV30pu0mZIzabACaomhX5LO0VOgWOFedtWpzFdL0LEdfFU7euVptIlp5ikH5/dOpPJZDLfQLRtJAMQNVNVSQVi2yBtUVCPNRGMw6shRGkFJtCoGAIU+9T+SvqZ4OgXEXygKw1D9NjKoXWNhCVkf4A+fMTTf7TD4EorLAmsvFlY/eE7YOMQFjzUAaxBYiQSiW6CGrBFP2V2NzU4EGsJ9Nif9AnmRpbXXsfGDW+EldeD3gS6AVqiKIVYIj5Ne9XZtLiTLeiZTCaTyWRePrK4lGHepzL1q4SkHSUlZyYCKbHVkyxd0mdoC11r7Ex1mdtF1bn7l1bWUU2WIu2KQp2FkEordKWa2U57vaY7tVN5o00e6nrBpo/XXZxz2yiImK+rIDI/saYTezqMbQvfqJROoJnA/j5Xf+VXufBHf8Lq3hGuP+D5pQXe8jM/if2xvw0rK3iNWOcg1KT2vRTUbbrdaQ2IQIiaznd7wpsQiDG9BtZ27qnuNoqG9LpJsnURNGI7QVGBmFof5JgTal4pnMuPOnYpk8lkMt9IrinwTy2lrRNVYLpJFMGIYpkgegS2hvpZmHwODS9gTY1EQ4yKMaDeIwuLSD2ERpCwCJcNPB15/I93GOxAYWHLwE1vK1j4vptgbQcdeGp/RCGK8RGsTetK0UNMn7HvUdeRXs8wqj113UfKGxicvpNq+R566/fD4p1JVJJlEJcSEjWtg9ORdXkFymQymUzmFUkWl65TZsWpzl1hQCpAkp4ErbiRWs8ARFIYtrQiUkSJBFTSbqoV03ZYpeLPoBS0wksISSIyncD00gXitXciZe7rVz4r5uu1wyk671iCdDI6d5WgKq1bCvpG4WAPLl9k99+9m0v/8T0sXN7B9QY8WQh3/ux/j/3xH4L1NXC91D7nG7RQosSUpQRpYjTd6yUUOAigIogRCivEVodLTrFAN1HOiEWcS6+LQowCzuKBFF1huiAsMOnzQHKwadtGOJusd7xpLpPJZDLfWJJrZzr1szP/ymx9UDxiDFBClLbQG0PchMkzMPw8YfdR1D9PGD1Gj30sPt2rFaRw+GaMaoHRZbhSwec9T//BRdwLgMJ2DwZvgIV3DuCWIyhHCEJlBIoCH5RoHaO6IPh1yoVbGbs1alMRih5uYZm1wTmq5Vth8TZwp0AXiJMCU/ZQMSgT0saSwagBLVJH39RxnclkMplM5pVEFpeuQ7qsnkScNxkxLxpEwGsg6UHpV0VaoUEMRI2ElJpAKmhTq5tYA0Q0xiR+dDPKhJTzME0COuGI+SuFn69N1Pi6WuendW2YOrMESVkVaasVNCDjI9i6wsH/8/t86t/835y6eJnBwhKX+wUP/NjfYu3H/jbccCaJel7T7aIniiGQxB+JSVya35imPY2CSfOfY8CY1N5mJBAYzklCFu8tGguc9DFOaKZHH5MDKiR3lwYwEhAT6Rrjjmc0dflMkAWmTCaTeTmYtcJJl5vXtY+LQTGpoTkKEiNGjiBehf1HaLYeYrLzF9RHX8S6I8TvURQB0bSZEVGwEd8oPVmFzQqeNDz7ny8Rn4W+gWEPevfBzT90Fm6vQbagZ+HAgytRA7WCLSyRRcrefSze+l0sLt0NxTpMGnALICugS+2fAbgexnSt3wHwdJ6ladHSmpe6i7klLpPJZDKZVw5ZXLpOSfJARDqVogsSavWeaNJ4YJm6V1IRG4NBY40Rj5pU+DksQomqIfp2PpmFoJEYDWKSJGWmbXOpJU6OiUxfKS9jQdnFPcRAiB4A002wC+k8BUZYati9wt7v/S5P/c7vcmZzh7IseaESzv3YD7H2cz8NZ87SaEVhBBxEHzC9Ct8KdgKzKXAkt5egNDLCUGBjcjAZamAIcQ/kCKt1UqVEgBJnFsAugzpiKAgCWCVoQyRSmCJlWHWdcHEu+Pxk70U2LmUymczLxsyh1L7FdztGaRQcmAKvAQ2Ryo7APwW7D3N46UMcbf4Fi+Yyfbax4hHb4IJDfSS099k0gUG5CttL8PkJz/3+85iLUAKjAhYegBv/q5vhFqUpD3ClIsFD0R1QkdZ7gUYLpDgHg/vB3QOswKAbV5qGduj0D/ioGGPa+aZFKyxp98SnX7OolMlkMpnMK48sLl2XdEpSO2+4u6oVllRi60bqylcPXpCoFDRgx8A+MAT1bf5SD2IJ9MAU0BaHniK1zrXbjPM5QbSP8E2JKIFIFEU0ubOmRqyoWPWwtwn/8Y94+Ld/i6WnLlG4ivHpDW79vndw5md+EjbWobdErEG9IpVgiqLV+NInBp2+Vp0QZ9L0OAeGMYQA5gh0CyaX4PBZmqMraPA0oSEYsL1FysVTFP2z4M5hzDo9u4BSJaOVQhCHse0FOeFWgjnLVCaTyWReLmSahTdrWz851TMiqEaqQkE3iTufZPf59+L3H6bPJSozxJkaTCR40NAgYnFFCVgKW6WMpS96nvuTC/hnwUyg6cPivXDjO2+Ee0u8vcqEOjmeGqiqIrWuKYga6hpwa5Qr90D/TpCzNGGAxRHb+iO27um2AR9r7DWypGaZiscCBTOZTCaTybyiyOLSdYkidDlBbVh32+qkEpO4pLENd44pB8g2qbqMh8Au1M/D5BLNZIvga4z2KOwq0jsLvTNg+uBWcHYlpf9o1eWKghrMl10bvpSg8XIWl21xbyCKJNdS1w4H4MdJWPrT/8Rf/uqvcePVLWJlOVxZpPcdb+TMu34Obj7PxBRUwVBFhaoTdgSdBIrKtqlJnjRIOrXAhXZ3WkNA7BGYi+jBI4x3HqLe+wI6vILUI2KtiDXEIjK2hk1TItWNrG28jqWNB8DdhPTOYVkHqYg0qFicaVv7Tk4TnNb287lXmUwmk/lGI9ONB3vyGwB4HyhcBN0m7nyKg8vvwx98jAVzmYWyoakDMTpiXafprALGGcRazKRMgUpf8Dz/e8/Bs9CLMBpA73648bvX4R4BewVXwKLrE5oRtg0HjH6CsYKlJIQFqsXb6K3eB3IKHy1qTNoTMSaZrIDUXh5oZ60mt/Q1NzjIS08mk8lkMq9gsrh0HSLTvq7ZNV1Cdxo1b7DiEBokTsAMgW0YXkB3nmZ08AzDoyeJfpPg9zFEjJbAAOPWkXKD9Zvug8VboHcb1pxGWAfbnz5G1HbS25e1A/lSVeaXz9d9XHE72S6myGwcIFFhcgQHu/De9/DRX/k1lp96jr61XF7osfbWN3LXP3wXnD9PKCrE9gnDiHUW9WOkLEEFa1N7nTPgRWZT6LTd4dURYvZg9BTj/U+yd/WjNPufpvJXWJRIZQymsMQYUDzqLCMMR6ML7D//PAeXPsNNt34HLD8AvXuxnCIaQ8QRRNKHhA7x7elO8lYmk8lkXn6OTfWUOReyCIURDEMYPs7uhQ/htz/NSrFNZWqaUU1RlUS1RHVpsqlLeYoyEdh18JTl8nsuEJ4HGcGwn4xHZ9+6BN+6DIv70DfoeIQ2HusAa8AKsYn4GiiXwN3KYPV1mJU7QBbwCoU1qfqI3RRXQbqJtO0U2ZNL/izpel+lAAAgAElEQVQjMjl680qUyWQymcwrkywuXZcIovM7nqF1K0HUNnvHgDYeI4fARdh5iP0Lf0G9/xTSXKFgh4IJRgSDSTuWgK+Vpi7ZeuKjSO8O1s+9E5ZfiykAu9FOngODm4aEw1+D+HPyGZ+4b1V9ye99WShYDBqVUTPB9fq4OIThJnzogzz8f/4KK08/z7KtuGqFhe/6Tu76R78E5++EagGrAj5gnEFNBCek9sMibSMLEMEVdpqDoRoQaiRuwvhxhi+8n52dD2H0GRbNNs6MsL7CRAFfYyRA00BU+gYqMyJyRNNssfvUVezSMyzd1QfXB+0T2p3kIJ5Skm8qnaCUi5G74jKZTOblZrY51LWSQZO0Gbo/E4hXqHf/grj/aQZhk5IxqpGiKPC+QYyiYglicaXBNAb2DVwoufr7z3HwWSgjjHsQb4c7v3cdvmUAvSE4hdqnKaQxplZtIvgxtqgIYZGD5hTl+lsoTn8nyBqNbxBxCGFafyRjrJmNQ4XjmX5zz2n2LZndNpPJZDKZzCuKLC5dj8xXa13OEm3WTmyDuyc1rhrD+DmazY8x3PoI4fAxymaLvhlh4iFGuyIxFYYqipOGUgxBt5kc7rHz5IjFU5sU578LSk/wFdatHBN3/mq+caLTl4uGAGKoXIFDcM0YxkfwkQ/zgX/8v7Px9Av0vXK5dGy8/e3c+o/+Fzh7Fqo+uBI0YLvJPkbbnKWYJr6pnRbY0SviDKCINIgcQvMM/vn3E3c+TlU/TuG2Kc0EiyLREKNibIS2sY4ITgXiBGRIIUPGzZCI4+ipMyzctoArF4jSwwNODMoYwZMcS7MMpumEnq/xvGcymUzmqyTOvQOLTN+QUwN1wNJAc4Xh9sOU4RlKf4DEANYSQsT1HEdHDWXZp3B9xntDbNOHC8KV/+8Fmi/Amhg2JWJvgdu+fwO+dQCDQ5Bhmi4qbfuacYgzqDXUE8XHJYb+DL2NN7Bw+m1Q3AH0KFyZ3LHq27b4zq30Es9R4rGL3XgRyOtPJpPJZDKvVLK4dL3SZURLF+ydMn0sYBQwBxCew29/jK0X3oudPEpftyhDTTEVhgy0GU1d4ScUWIVY77NYKsPJkMOrWywUh5Q3vg238FpqHWCxfHljx155whIAhWNS1+g40heBvR346Ed49H/7p5x//jKFKptVgXv7d3LrL/7PsHEzrJ4BUTQ0qEvP3USb4q5EiChqFGsUGsAIMcp0j1qYQLwAW59kfOWDmPoL9M0upfWYmAQobCBKg9iQ7lddK1a5tpVvhJWGBY4YTZ5l5/KfUy5vUNywitUKpd8eS2yHWTtm4uHxzwG5wM9kMplvPMdWTrUgrk1SNFgMUMPoIpO9x1jjCiURok1LgYmE2BAFbKn4gxG98TJcqDj8w2fxnwa3D+MyUt4FN3z3OuW3L8PGCPwEwgTK1m0UBB8MY414LfGygpS30j/1ehZvfDusvxFYazMClYht4wkjIiG5kKRzYp0MVZK59SbtiB2Xl/IKlMlkMpnMK40sLl2vTF3ogUhAMQiShCUmUGzB5kPsXv4wOv48fbvFQI8w0o07TjkPsQ3hjG1WkyFNirGAMxOWew373nP1grLiShYXbkJCgbGONLf45Zlr/7UISwqM6wn9wkEQ2NyGv/xLPvsvfw37uS9SxcBVC4PXP8g9/+PPwd33wvIpgldsZUA9QWMbW5qK5thKc9NHsKRw7xS/lELV4wFsP8LhxU/g/POUsgfGY6KibSA7pn1NpDuz3Twhz7EpfeKpOKCIT7N98YOcWTiPW+pj7U3UahAxKC5NwZvL55rNKMqFfSaTybwcTFfNab+YBTGzhrmwz2TvWWzYorBDcAX4tDZYJ/gAS8t9JttjqnAaLvfY+5NnOHwYin2gAm6A29+xAW9aI/Y28XFIaRtwMPQRa5XSLhKkoikMtV1G3c2UC69h8dx3wcJ9YDbwocTaMB0jIph2vZvPf5Rja8osWWmaOJhXnEwmk8lkvgnI4tL1yGzLk4hPjhksdlqo7sDkUfY3/xw//CyLxRaFH4KPwCCFbroJXkJq3dJWb5JIjAEjBa7s4+uaKDW9yjEKlznY/DT95dsp1nqgC0CProz8eoR2/3XTtfIJkX5ZwOEBDMfw6KN84Z/8M8Yf/iTnXcG+NdgHH+Ce/+nn4f770bU1xIFFCOMxtpdcWyqGQHvuSEKQ1Zl454k0GBSlYAJhh3j109S7n2NQ1Ug0oI4YPErA2FY0i6Ca/mmLKGrqYxu9EoE6ImZCv7jK1v5DDHfuYmHxFMIyVpdBqule8cw7xXTK4PGd5kwmk8l8I1DmAq5b47FiUNOagHQEus9k73kqEwm+xjkHscFLoACcFrBrqMZrcLVg8qfPsfNxWJnAxEF9I5x/ZwlvXoKVPYIeIRJo2o0PV4H3JWO/QmPPEKoNqpU76K8+QHXqWyGcAlYIQREDIv103MFjLDDdVvlSq0i3AnXMFrG88mQymUwm88oki0vXM627JZLUIYNCbEB30O1HmBw8hgtXKN0QfJMqWgexqVHxqKQWOjtXJSoRNKBYxBo0BKyMWarGbB88zf6FT7O2fCeYM+1B6Imv7YG9jHQi0rVyoVQVqxFCA02Ezz7Ko//8XzD+xCe5sXTsEOGeu3ngF34RHnwDrK3RFJYYQZtAv1cRfY0rKiLSCkvtPm03E1oFLPjYEG2JMgJGMLnM5OBxemYTGBMJ7cS9VvyZ28qWLiBVfDru+YiO7qfEU9oxS6ZivPsIC6cfgPIczi4RKNrS/rhLaTYCO5PJZDLfeLRtRbfpnbntLBNp35llD8wOYbJJhRC84HpA0Q5iC2CaAoYLsL3A/nueYudj0BvD3gT6t8LZtzvkO87AyiFq9nAu1Qm2EMaN4huIpsfS+r30Nx6E5TuguhnsWTCnUR2gUiDi2xojURg3W3++AiS3wWUymUwm801BFpeuY9KeoAMaRCVl8sQR+D0Ot7+I8ZsUOsbGiJECYxTMEdEqdMKSr9rKsUmWGBNBGprgKXopf6nxHqtD+v4As/Ms7DwH63em1rpXGPPC0klxaXo5tJlIjz/D5/7xL1N/8uOsNyOOeo6j19zDgz/3c/Dmt0DZA+ewxGT0aU+VuGraOphyWWNqX1NmU3NUKEzKzpA4ATkgHr5APXmBQbFPNA2Kx2AwNrUWKGninjGKqp+6oVCQAEn9c6CCOCWKx0ikbwMHw8uw9yyceh3EBjGuba3rlEOT7icHemcymczLSEQZp3wlU7XTRT1QIxyBfw7GTyFhHw0WMYvE2LR5fgapDYxLGK0wee+zbH4EFg9h7CGch/6bHMXfOAc31DRxH1MIVgVtAFtR+AmlKRjLaWTlW+D0W6G4E1gDSqBEbNkea0j+6BgpjGnXOKaiGNOvgeNTRrqv3Xp44hTkBSiTyWQymVckWVy6TonaDZlJMd5pZ9BDHEM8YLT3HL24R2XBGQtWCM0Yg+JKiJG2LavtiaMNlNZUORaloa4nWNOWiHFCz9RI2IHd52C9ZrafKdcoFk86mb50mvRLDpx50TU69//jJvukHbXXtM8jtOPzjAquiy6qG3jicR7+57/M6GOf5FZrOXQWf8vNvP6n/h68429Ar4/2l6atZNIKNIE2Tiky3XFOj5dGM08H6MSANUKIAWcCcMRweIGm3kKKUXIQSUx3JCZldSOImvZ1nSvWu9dHzdTCFE1qu3MRaMY43WVycIHqJpNa5qZOtFn2e3fG5Cved85kMpnMca4xtrW7Wk7+3Oxdd7aCRYI0iNQYDoE9aC7B5GnY/jQuXIXWJds0Q4RI6fpJWDpY5eBPv8iVDyrlLkQLegpOv61k+XvOw/IuwdWIEaJ6rLG4wqHjBiMFTTR4BlCcheIWCBtEllLLW7vGhAjSbnwYM1tB8AGcnXt+Aabt1t25mPv5TCaTyWQy3zRkcek6xUwdKIIGgRiABiporr6Aq/coZQjG00QQHNYWiE6gAdP1WZl6rg4UommnwcSAKwy+jpSF4CNY04DZY3jwLIPmAKrATN5pJ5IByclzAu0EprnCc05velFzXZdvzXydPts27WQte0wca2+mYMQg4qmlwbTNYIwDMIDPP8Vzv/JPGP+XP+WUKkfS4+j2u/n2n/8Z+IHvh/6AUPaICi5ajICY2UeJ6XAc7cxbhrTjC0gDkibrBNJ5Kw0QtxmPLlIWBoNB1WOF5CbTgKig0RGx7WsbZ84w0eRKkwhGUYFawdg0ra5Ug4+HNMNNqkkD5QBpI95D+2okweqvTsnIZDKZTMeX2vZQFN9edqTNgRM3aa+IqqjIbH0KJeKEIBG1+5T6DBx8gaNnPk48eIJ49CRL5RjjamIzwhnBagmHBRyuou/f5NL7lMVdcAaulnDL20oWv/8GwtIl6KcWuOgV7wOhimkzRBVxBbUTRtawbJagrqAoiNFjiCAWYokzENKcuumZELR7qnPLyLXy++RLXsxkMplMJvPKJItL1yvT4ANLipf2wATiPuPJFoVMKPAETZPklIgQU77S1LUejxV9ihAlZfKISS4m6dxAGhAafNinrrcY6IS0Y3mysOx2aGfzYqYWHxVOVpkvld9wbBhcd8w6q9yPTTubc+HHzuzjG2wBaf5OSK4lIjz2eS799m+z+WfvY2M8ZmIqhqvLvOkf/DT84A/CyhK+7BFVsGpmd906xZSpuav938wilIQnbc9LuqU1ltpPKGVC8EdobFJ4t+js5p0LrbNDdQ947ITMLqtAUQghkNxMXnEuMmmGSXXszlWrhHWC3+xk5fyLTCaT+fK4dk+XMmtnnv9W9/Y7W8O6VTC9F4sarLX4yS6uGkJ8muGl91NffQiz/zRFc4VeMYQ4YjwZ0+v3CRMB34fhOuP/8iwX/izQ2wP14Ffh9u8o6b95A1YPkDVoRjV4g4mRwlnUKlEjRgwRy1gt0lsDtwraA+yco6pbRKeHPrt22hd3rJAgryeZTCaTybw6yOLSdYqShJTkWrcIE5AJ6B6TZpNKaoihLX0DSiCamKQgIQUudXekgFpEwGpoJ8cBsb3/GCGAGI/qiKY+gKm4BLTj7nU67mZWjs9LGl0NKp040xlzRDtv0VzzQPrhdLs5B097u6ns0yk9rZvJS/q5srRMxmOqogJfpyr86afY/je/w9O/9+85Na7xpmTnzAZv/4Wfhx/+AVhfxhcFE4RCBCNxTq1KbWmdwDRVxY4V2bQCmm2P0VCYgqZWKGwb2BQxxJlWFFpxTsLsD12Ln517oK7tIB2AxRIaDxIJKGocdVQwEY01IiXdcGhBZ+e1a9/LnwUymUzmq6Lb4tB2alq6JrUya2ttFWnffXX2dpvWPkH9GOeOYPgIzdZHGF14Lzp8koGZoPGQYAOmUNRFRn5I367A9gLxA1e58GcBc7UdxLEB66+F6rvOwB3KWI4wwWHEoSGiCMYIGmOb7eQIWuLjEoP+zVCtA0VqkxfbPrH5JurjX5OLNjtgM5lMJpN5tZLFpeuQTmro8n+mdZ6JgEdMIGp7ZdQUEG1SoHUwydwSW5HHTpWSlL80LSYldWJ14pMCxkZM6FryumJ6Voiqtpfm2t2Y3cWUJGKd+IFjbVsnOVHiSmdRUrqg6vSYnZCmhCiUpoBJhDrAlQs89+7f5Zn/8G7ONBOiLRhvrPP2n/1J+K//JqwuU4sBqYhEIpqm60xdSPKio5n9JaJi2g8RXegSiBhEhdIWQEVVLAAWsUU71Y/uFUzncu5hRAXVVlySmPKZ5h401D7pgyZinMNria2WwAhRQxIF6YSlFx1wJpPJZL5Kjm+OMCfft5sD4uimwcl0J0Ha9TqC7oO5SnP5I+y98F4q/wVK2cEZi5aBQIMChTO4uoKdBZq/2Of5PzvEXU2bPpMe3PhaqN5xFs43UB1RFIbaewpxqGqaSBrTYm4xiLEErRB7lv7iXa24VBLVkgKXps/u2HOd883mZSSTyWQymVcxWVy6LlG0nWCm0XYNWCRpx1EWPbxaYrQ4/NQVFE3r7mklB4MgEmcuIAyRVJSa6Ig0GBM73QkxigaLdX2Q7vFaRURlej/zLWTQFaexPe72mvkf6NSrYy1bxyvYLiKqk5SCSe4lFzunVEQIWDyooLVBok2uq8tXGf7Wv+XCu9/N2uE+WlVsLa3wlr//E/AjPwxLi2BKXNFHgR6Gut2FFtMKZtrt2MqxYvvFgpidXYyKxoAUfQglvd46R7EkuKrtEEwfSUQVIwaIM4OSdmOq0+Nq21WoklxPJrQvgShRLHXoMVi6AUwBCJGY3FZoe8SzMPC855zJZDJfLbEViEySi7oWOOlay7oBEE362VlCIGgBOgS3B1cfYufiByjqL7BUHBInNTEU2F5BdBFfB3ojA4er8OEhF/7TAYMraaXf6cHaa6H/jjNwnwN7iUYairKPDhuiCKoRKxFth52mlmnB+5Jq4S6KxXvArUPooViMSJsMPhOQpB0HkdeLTCaTyWSuD7K4dB3SOXQM7Si3AIiBYMFWlL01ajNAKRGtgSSJzMKnW3+NKjKXg6TSRXFbQrAYDGIawGMMRBWaYCnKJbAlx8SldGDHmO3axjlxadas9aXEpGs/71T3hulxcmxbNTUpgERFihJGDVy8wOG//12eePfvsnRlk1Aq2/0+9/93P4758b8DixWxPyCaAj/xlIXDCKnQnooy7QO1qtmLvVWtl0wk5W7Pi0vaijvao+qfYVhsMGy2KZ0iNJi2kFeNbRuFzh6rU5pkJsx1wlCX5xGBOli8rNJbOAfqWg2pDXBtX/ukTHGt2KtMJpPJfNkI85M7p++nCiJplEK3DdK9a6cfiaANcABHT7D1wseIoydZHoygnqABTOnwDYgU9H0P9gfwiV0uvmcEz6SHGfbh1LfD2jtuhLsslNvEMqS1YDiiEIsSsK5doduFIwaDp8K7Uyyu3Q/9O4AFMGVyOiud16p9Xt2xd+t292Sv5S7OZDKZTCbzaiCLS9chnf9Euh1SEZCC4CusLFH2b0SLFTT0wQ/bSXJg1KLiAMXoZCaCqEmtV4BKEkSMGgwWiBACiKIUIH0Wlk6D7fEicSkd1pw1pgv/7Pw+rbAkEFVbMQVgLp573u7UflXVaZneZRylezZJzAE6uUmigaDQDOHSFfy7/y8+9xu/wfrWJoOVRZ7sldz5oz/Kyt/9u7C6DCsLHIxGDEoorcG07YClMQgGE2eZTirgiWh7Zsz0QOdEoWMvUsQUkoQ/WUQWzlEu3sFo+wqFBiwNxPa5mPbJG9qWv9AZpY6dlvnopeAhFgWT2Kdcuh2zcDvEHpqCslpX1KxNb3o+T5ziTCaTycxQnS6OnBRTRE2yAQMpIy+5XNN7q51rkTN0tl8rtH3mE4g71Jc/Rdz/PIvFBCEy8YaiWkSKijhucEcGdiv4bODyn4zgC7BWFOwOGgavhbV3rsN9oHabsY7oFz3K4NEQMIUjxgZalysKUQvGYYCvzlGuvJZi/VuhPAexSjF8J4Wy9rnP8vrmW9PzDkUmk8lkMq9Wsrh0XTLL9JmKOCIELbEsINVpgl3D6zKOA6w0SbAQxah0usfxuxOmk+IQbbOTBCI0XvGuwMsS3p5Blm8F6QOuddB36ktsLTUnCnOl6xuYHnskhVGjgohNrV4vqlcjOmcF6u7ZtI4iiRGdZi+l9jJihLqB7S2O/vgPeOzf/g6r+3t4jVwA7v2RH+XUT/003Hwz2iupUQaD5VYmE0Ljsc7NZULNDqrbi+ZYq8B8oS0zk1PXwmYMhAhuEQbncEt347efxugEFydJR5KYHGSi7WXmztnsg40o6ecUMMrEg+2v4ONplpfvgf4tIH2knQ4InWupu7+/+jcrk8lkMi+NikyjBkUi0yEM864enS2w0q69UANHoFvU+4/TZ5NKJoR6QhDBGgN1Q+V7MFyCx0dcfc9lxk/CihUOpaG4B079wE1wV4DBIY2pcdbQTCYYBVuUhNEELVKuYgwgpkc0KxzJBnb5AZbPvw0W7wRZoYm2jVqK3aLVPcvpn3lZKQtLmUwmk8m8usni0nWIIDipZuYgAa8gRUXQGts/xcqNr2HvmachViyYMRoC4gJCaMfM2amjSUUJQhuFnXZZY2gwhYEY0KKksYvshxV6qw/A0r2gi0QxbVaQJFGn2yY187u97QEaBwghKEEDxqWcJBVaB5ZBSc4hmQo42mY+pIK2a6mzaqBJYlZ0ER88ztu29SvC/i7hD/8Dj/3Wb9K78ByYks21De76kR/h1N//CThzGpxDxeIEuhjwiOIKe3yzer5LgK5toMth6q41iGhqh5jmmyvYlI0ltkgCU3UjvY1vw15+EtccwGgXxGMqA+JQbVrtTUAcoiaFgqNo9Gjw6fwUNp3DhSX2x0u4xbvorz4A7iyYPtKete6ITz6PrDRlMpnMSzNz1SZmTiaIEvAirYDv26TDAlSJIab1TDxowNgirYd+DK4B3YXDZ/CjZ+jpDnF8SNUTolMmkwMWdABHDh4JPP/7FwhPQ7+AHaeUd8NN/80q3BOhGuOpEQISwAnJIRsabGFpMBjXJ0jJhEXG9jRm9QH6598BS98GegqNZXI5oe3GTnLlCszW8u58wGy969b8TCaTyWQyrzqyuHSdMiv2ElFAxSBaQlyit34/B1e/yHhvH0dDWR0k4aOpQQxatymfFrCpRc10mdWquKJAmwmRQLAlI+2j/ZuTnX5wJxr7zNri5lw9RlOXXps7oRhiW3QjgliDxRBbOWfqepKU7BDn2v1mYdmS7k9NEl46vSlGYhc2Hg0cHEAz5vAP/oBHf/NfY556in45YLi4xqm3fzc3/L2fhNtvo9aIcZKm1tFJWDN31Cz3qI3WYJZdYU986Jg5jGYX018i2jquFAHTw6CweBdnbn07e488z6I9xBZH4EZE9YhxGBwhaJoapJEYAkYMYquUcxXGTCYe+ksMwwp24W6WTz8IC3dAXELVoLb7kDAnlE0znAyZTCaT+epQFE+DIjhcan7TCGGEkRHYGvQA6iNoPDRjdLKPmDEpb+kxRC+i7CPSoFEQVRbsILXCPXbE3n++AM+ACzDug9wK5/7WObjjkFBuE50Fm0Sh6V5OTGtslIJGKzSuM45raO8ci6dfw+DG18Pg2xixgWMJI27ObRXblWF+Uwg6X/Kx7Yi0I5TJZDKZTOZVSBaXrkvmdxXNdJIYAFIAK9C7l8WNt+C1ph6D1xFF9DgBYyJibRqARiBGgNi6hgSDIU4miLHYqsKHkglLLJ6+j+UbHyTqaZQKido+buuUMWZOUGmPrd3p1HYIjcbU/hZD63oSwZj5WrV7XqEtaNvcilYo6QQwMTCJae924ErYPYDJBP7oj/nir/8G7sknWOr3uWL6nP/u7+XcP/xFuPVmqEpirFECTgFSS14hZibYxZhcR0L7ESKdk6mh6mRnwLUEJkm367KhogjEEmPOwOnXs3jzBUbbFZPmUUoZURjAe0zjcFjAI1axEiAGQgMYwZaGYrDMTjPAl7ewsv4g7swbobwJtI/YblJRGoU9/VUxbRsiBVlgymQyma8WJeKxFFgc1nswNcgujL8A46eZDJ9jdHSJyWiXZrxLrPfoFZ6FHqAH+HiRskrv8b5RSlPB0QA+O2H7T/c5+jT0VNgfKP4c3PvfnoHXAP0GKbV1Uumsc7rLVkLxFKg9hXe3USw/wPLZB2H9TpBTRG6gZHmu4W2Wq9T5g2f96bOvWUvKZDKZTOb6IItL1yUp8DnVhoZ5OUdwIItgb6G/8SCjeo/9yS6i+wyKbSR4oldELMYIRkLa+QRQQWNqXRNKfHDEZkAw6ywu38v66QegvIlJU1E4eyISqCtP099T00BqzuqkDJE2qzpC5WbJ0toKRipdqUty67RtevNuoq47IUrAVY5IRIeH6Vy89z08+uu/jnn8CdaXlrgclTNv/27O/eRPwR23w2LBsB5S9UoCPj2Spuct81lHpgs475rLuoP7q0vs7m5kmsnUTdoxBCnQsICVG7C3/g1MERltj5nEZ+jJHiUNPdNPQlY9BK3BRigrrJQ03lBHx7heIvRuZvnMm+ideTP0boO4RBKOPDYlWh3nRJtDJpPJZL5yuvZoS6CIE9AjaC7B4WNMNj/K4d4jaNxEwy5Wx5RMMIywvsGNIpGANYqKS8MjQpkylh6bsPPn++x/HhYFRqKYc3DvD5yBO4TY38FUnhiaNoAvzqZ/TtdQg0rFyC9y6vzr4fT3QO8uMMto7GHCAojBi3bm3PY5tQKSvFhYyjalTCaTyWSuH7K4dF3SikuQsnrmjOtJQ+ihvkCWvoW+jmm05nBPOWyeJuiQnm2IzQirDZZkaBEFMZ0LqgC3zGhU4uNplk5/C8XZB1ORqo6elVZ8afMXVFK4eHto0opEJoBowJow1TVs5/Lxoe05s0grkInp7q4VrgikvdiUY5F2VIWoSsBjFEofsHUD7/sgj/zWb+Iff4yNfp8X6sjqW9/GHe96F9x7FxQphHXQ6xFik9rwukJ6fvd3WkuncrtgNoS5a5ObNy+dbE+ciXypja9LdBKJ6RyZCtVVZOFuBrcZdH2JvasfZ3/vEXqyl17V8YS+GxCjtOfT0kjFmAXUnIXqPKs3vZbyhm+H8m4Iq2DKdPghgpNWmJvrYNCZPSx/XMhkMpmvDqOGKpZYqSFsQ/0s7HyCo0sfZrT/MKXdxugIiQ3OGgojKYMpeMRHvAimV9BMIoO4BJNFeDSw/cF99j8LroaDAtx5uPX7VuGBPrqwg6mAusYBtU3bB91alJZGm1zCUqFuHRZua9fscwRvMOLaBTZiiKikNS5NFJ0uey3HZ8TByQuZTCaTyWRejWRx6bpETvzp0o26oGmhiZaSFVi+j+VCKXcqdi4+xOjwIo3fZVDWxHiIxAnWKmAJWBpjCHaRo8kC1fLtrKzcj934Fli/C9iA2kFlW+lCEOx08Nw0dlsDGsepoLYeqCGMoR4DMYWJmwJMCfSAPoYeUEyfUuzUJlh+WX0AACAASURBVEAIyQWlnXAjiE+5RBwcwEc+ykP/4pfRz3+eRQPbCmtveDP3/OIvwV13wOoiCIRQY6XNbxJJbWPzFXP72J2DSrAzdxNJnDoRUz673fTaNkcqyvRYDRakae+mQGWBgMGVjoVTi5S9Mxz0zhEOnmUy3CWGA4IRopmgrgZT0MgCMriBldXXMlh/DSzcDOVZYBUfK0zRRo1PBKwB6bxLbu5rbHW0HOidyWQyXw1p5QggR1A/QX3pwww3P4QOH2Ugl6lkiLUCqmhQaNp1SwSMxbmCWCsLYRH8Bjw5ZucDF9n7DLAHIwvudjj/fSvwhjVitYVZMtTNmLJ96y5jWmIC7aojJm0OGSGIQe0iGgeI76Guj3EQg8fG0AYIthNP1aQJpLMnB1xrnZv2V//1n+BMJpPJZDIvG1lcui4RUgtUO1etdQOl5KMU6mnKghpBJj2K/j30+oucrc4zufIEh1tf5ChcQuI2hRxR2IhimUTLWPo0cpry1D30zrweu/o6cDeCDICKYAs0pJY6mDftKKINIjXoEDGH0OyknV2/C80uTPYgjpMzaek0uFVwa+BOgWwASxAHaCySkKOCiG2dWaFtU1NMFIqmgNrDn3+Cz/yzfwqf+wy9pmG/12f99W/iznf9AtxzN6wsgA0gSjMcYQeLGFI7Qtfplp5Jsm9FMYTWq5RCvAUV8O1Zd61jLGJPFN7tfcyHZreqmzFCoCESUzGPw9AjBsHYJYrFm1kvvw2GF9D6MsHvMhnvEWJNNIotl1jp30DZOwvFTWA3gAUIFY0q0dpp2W+laD8RTNrn5OYiurpMrO4Ys8CUyWQyXxkNyD40T1PvfpirV9+LGT3CanlAXzxMYlowjE2bFS4J/ooQomKD4sYWqZfgadh53ybDh6Hag1ABZ+GWv2nhDQUMtjGrFcPDbaxR6PXgaAzGYDRNpAgGMGkohYomv69YpL8IlSX4QxSPsQXB9hjXNZU1GCKi7rjzdtqenph5oueCnfK6kclkMpnMq5YsLl2XHG9smgoh0yuUEEIK7baLQAXRwPIi1dJ9VDddguGzTI5eYHx4iUkcI8bhykU2Vs5SLd8CgztAbwDOAkuo2iTEWAhxltcgbch2EiyGoNvAFkwuEHee5GDrCeqjSxD2IB4BNUEMo9jD9U+xvHKe5ZXbkYXboHcrmJsRWYVoMGLbYte00/AUiQHxAcYRPvEQT/3qv4JHPsdi9Bw4Q3n//dz5rnfBtz8IgwE4SxM9aE1v0AOgaWrUFNN8J5n2j3UpTxE6R5Ycj08H2jbAmaEJZm6gWQA5s54FwOIwhJSRoaRWwNhHAwh9YAmWzyFmH9fs4mQCrr2vaNE4ALsCsgyxR/SphdEWqfAPxGQKMwaiIq34J7kHLvM1MP8hM5N5taIn8uhmEdZzoUZTGpAddO8RDnY+idUn6Jc7SBgRPK1rScAKMUZCUIwoYixYg4klhCW4VHLwgctc+eiYUxPwBYzW4fx3Ouy3LcHSAVook9EBg8UBeJ+GVrgu/89iYpp3iglEUTwWT8XS2nmwixCVKLGdz9oAfaqyDzTH/01nzSjzTUFekTKZTOavmywuXecIYAVsJy+1E9hcTAmfYgo0GoR1sMuAh6VbYfm1VIypaEBbX4440rS5HjAA+qA9EDuXLaRYG/HUWEqMWuIEjK3B7cP4UTj4Szaf/Si2voCrd1jSEcZ4MDH5j4xhwVikfo5w6bNsXVykt3Qrize+Fda/B6oi7ajSgwlI4YguZQ9FP8KGMTz+WT73L/9X+NRnWByP2asc7r7X8Lqf/R/gTW+G3kr61yHgjEElRYxLjBROUEnHQhQKbNvKBmICRgKKJ2BQitnHixiJ2JRvEdOpDoBqTJPv2o8k2hqD1M7lNYWUjWVsm8OkYKbhqQaoknKnFRTr6QG6it+Y9MEEB+qSM821O8yq0yl/0qmMgKOcz1qffp3zZH1dfw8z31zMSvSTIe/HvXjX/u5LfPOaP5TJvPLQE5f02BaCEDVixKb38va9OoSIiCAyAb3M7pWHmOw/wsBsUuqYkjQLgqj4qLgy5RE6K5gQid5jyhImDi4XDN9/gcvvG3I6JrPT4Src8cMD7IMrsDwEq4h6elYIPolBxlggohoQY4jjNjepr4gqY63Qcp3Byp0g62B6QNVulxQYb9Jmii1QiWnDptsp6s6Aamrh4+QWVt6pyHy9uLZINBtOc/L37+Ttrv3dTCaTyXztZHEpc40CEGw3TlgsYIFy7haR5Nvv2ui61KROdDAoBsFOc4+A2SAZFIOliTUuVEhZQ7gAm59if/sDjHYfphcvUfgtyniEE58UF4VoLKrJ3xODEnEEevj9TfYm+5QToX/DuJ2ABqgFbzCAH+5T9Qx86iEe++X/g8lnHmZhNGFkCrjjTl738++Ct70VlhfSUXYZSkmCSzlKU5WsSUX53D+h1GIYQQIGwRAhBqwGsDWYCYQxsfaYcgEosFgQwXtPCBZjlnCFS24p0dSmFlN7nTGO+daC48PnTPsalV/eUDfp8qfS3XV3pdPr7TUyoV7yisx1T1vQz9X8X/LXMA8ezLxqOOlMYiqugCaXqqYhGmkTYQjbj8HoKUrdoWJIETU5eNs/rl1uY4xp+ieCiQ4O+7DV5+D9L/D8BxvWSSbc4Trc/YOL8IZlWDtC3QRMQNqpbqohbU60VlQ1aWk3hUJQCJGaiuBuwPXvRBbvhPIMkd50LTe4uTW8e96zNePF3/nS12QyX3/ywpLJZDIvN1lcynwVzFlc4MTf0/cEe+L62fcNLmX8xAnYAwjPE7c+yO7VDzE5ehjqi4iJiNZJkRLb9s4l55AgqW3Le9R6qkIp6wlHByMmjAj1BRZv+kEY3A8LK+DBjsGaJfjUR3jqt36How98nLUGxoNV9k+f4a2/+EvwHW+BU+uoNIg1REw3Uw+HxWBRSW1vhoBFMGpb0StNoIsmRaSaqBSiEEbgt4ErYLZANjFxBEcDMGvgNqBYwbkezi2B9vHBEY3FSMrBwAZMbHeD2w8fYrJ7KPNKYJaqcuyql/jJxDV6aPKvcuabiBf/uiZH6RQlCTvtxFJaR2va5dhlvPU5GD1PxQSHYrv9GSSNTWiU/5+9N3+27bju+z6ru/c+0x3fjPcwgwRJcJ5FyhIlcZAsy7YSVyWKY1mOnKQkJ1ZS+U+ScpUTpawoSblc5XLilG1JlihRFCFR4igSJAASIma86b535zPu3d0rP3Tvc8697wIQ8QgCIPa36r177zn77KFPD6u/a63v0tpjrUHEEbzFchq2Oowevs7ewzWnp7ALzM7BPZ8q4cdPwdouvpyANMRSckIEVUxTXEIUCaBao7bGdA2z2OWw3sB1H2Lj7Mehez/IJjEmnb1UzVUXjynLBFqLFq8PtD2yRYsWLV57tORSi1eIhtyQXIVNc5RSE/300lVhYox0XA3+OeqtP+Pg+h/ix9+ia67R7U3RKmCtmaeLNaEQ0kRJaSpqZpCko+QCq2bIePYEB9cqot1k7Z41YgRTS6pS9/jjPPsvfosX/uNnuU9K9uoZ9f2X+Ng//Q346Mfg3HnqOCMWBktNMsdduka+pubcMUcjZKpElEiFmJhjtmqsqWG6BQdPEfe+x3T8DLP6CtN4jRCnOB1QutO4znls9yy9zUuYzQegeADLBqqrqNis3xSxJlemC+S2kNaSavE6wXLkxsuJrzRzBcxD79p+3OKNhmPZNbck4TRdW5o3I0oNGsDv48eXKcIOxlQQIzGvZySXBWIEjQHViGiBrVZgq2D6xX0u//GQlW3wBurTcOdPdVn/2Bk4PUJ7gdp7SiM5dnZxZ5KrpaZ0d8AKQZRRsMzYJPbeRvfUR2Dzg8AZ0CZqSbBSpLVI65xi3aa4tXg9olmLTlqHll9r+26LFi1avFpoyaUWrwCytDE0OcVqOQc+E0svIrgiBAozBbYIe3/B7rU/xE2+xSpX0eoQ45OhLSYAgqpFYkNWhTnHYp1BfBeqiMqUKIEOBQPdZrr9Rdg4gyn6UHfhycs8/c//GQef/yx3TCsOxDK6eIEP/eN/CJ/6Kdg4w8yD9nqA4vFZMcliMrHVmCaiAlqAJFIpGA9GF7Fa9SGM/wq/8zXGN7+ETp7F6JhSZliZIRIJlcfYEq26TIYrTIYX6I0eYnD2w8jK+yhiSYh9apKuhRGLbTIQ22rOLV6X0Jz72ojTL42Z5WMatPZ9ix8FvGQmjs3HhFQ5FEWqMVrvUsghYmqiKjFnkIs3aX1BEDEEHzG+gJs9Jl/c4ebn9hncSKfcL+Huj5esffw8nBkTBhWqNaU1WClTGdiYqpimOFyYlzgtLJRdZh72qwHSeyenzn+C7umfAHc/mDVUkl6glURUCRE1ddZZy4KELVq8BtBb6Nwl4khlySaVpfeb/6XtuS1atGjxKqIll1rcHhphIlkml5gb3HrM8E6R9DOEHRh/h4ObXyWMHmdFtujEQ3wNrumVJkulqkdwyTiWxXsxRkwMoEIwEFUpNNA3U8L0KSbPfZHeve+GF6bc+D9+i+2H/5CN4QiPMLrrDj76T/4J/NynYdCBwmJKw2g2odcpAZN1k5hXbZvLLc2fPaXDqUQcEcMMJtswepLh1c/jD7+BTh+jZI/SGIgRRTFGMCWE7Jkupc9ouM3OcIvh4VVWTl9ncPZnscXdGBGqKEk+SpP4umktoxavKyyTy0c9xifJrbZo8cbHy1SdOjIMZP5SVEViTfAjijhDjZ/LEopY0IhqjjrygrOn4WbB7EtbbH9pjFxNRtv4FNz54Q6rP34JTo2JnQmIpxrX9Eqb5RANQU3WRPKICFYLIgWz2jGru1R2g97mgwzO/Djd0x+B7ttBNiFHJ0mMiwITmBxArO3mvMXrAll9koXBeZxgao5q6jm2nrkWLVq0eLXRkkstbh8y/+9ljmmMgDHEZxjd/ArV/hN0dZ8iTBAPHQDjiNEnJ2v+rGhYsCoKVpNjFpmBNYhzEC06c6iv6HWGxGuPwd7niJ+7zNP/z29zqrZ42+fg/AUe+K9/FX7xF2BjjWgsUWYU0mO900v6FNJpshnm1zz6iIqKEnBARKjAXyXsfIn65l/gt79IhysUdoKzgDrUBwQPxuFrRaOncFDaKaXrUoYbzMb7DMNNemIxpz6KdO+hYJVaIRpQKpxIFtxuDaUWP3wsU0nwMlpKLVr8SOLl1ztt9I1y4nQT5BtViSqpQEQ+j8FAlBThZAxYi6k7sDsgfGOPGw+Pic9CR2EygJUPC6s/cQruqKEzRUIFU0+/V8LMAxClIBpHLUqQGsTiZICYdWpdx3Oa/vpbWbvwAdh4H7iLIBtELEEDRgRVRWOOErGQ4nNbkrjF6wWayc4mpFuWliE5clSLFi1atPjhoCWXWryqaDSoU9WcJMoNU5hdZrb7HZhcoe9muOiTKWAcsVK0cNk4T6oRxiwEU+flnXMeWgiRuo44YzEGjFfc0MPBlMOH/w3f/Z3vcoHIRIXJufM89Ev/JSv/2X+Brg+IHYcYi4RUAc/PItaW6dxz6JLDa8kLLWmDYPAIuzB5Er/3ZUbXv8CpznUkDokBQgTEJ25MAV+DOIpOiYSKOKpQ9ul3ejgJjKZTbjzvOG8FbIHhToztoNnFrcQsmN6ixesFtxrvy7Edi0S5EwTAW7R4o+ElApYWv0cgZHIpFXoQMUmzyBRgSpQayenOormqnLGEA4+tNglfO+Tpz+1RXofCQLUGG++GjZ+8AA8WIHsoY6Tj0CrCtALXJcZVvNugsmvMxFERQAoKs4Fzp+gM7mRj/X7YfDCRSvE06CZRDFXIKXr5OY0RzHz9M3n9acdvi9cPXmpF0SOagC1atGjR4tVGSy61uD3MV/RjaQLHtE1jDNmLq6BTOLiKjK5TxhFO6pQa4BJxJEVBNCmFTNTm9HlDo7fUFK6hBkqwBaRCPBGkgpDKNY/+9Blu/NGE0weGUK5yY3WVh37pH7Dyy/8VrJ6ldhC1xhGxJhL9DDHlUTMkiSwRcghTKgttCE0ltxgpzRSqpzi88gXC9lfYKHaRukqGuYMgySkdY4q4SpLfER+UThCMsRh1RF9hZEZHAnV8jN0rJZvlaVhfw9FnFntYUxAISQeqRYvXKZo0TpPJ5RhIxK+A9xExkglj8N5TOJfSXI2Z/2zR4vUKveWv5PFIUX1prZActRRJlduUiI81ZbeHKVYg9hBmiPe4IGBdcsBMBTvdJD4y5unf2cdcS5fYdnDpo7DxM5fg4gSKQ6LM8HgKiZiOEGtFKRnpKdYu/Bjl5jtYLU6jpiBqF2s2waxCuQLaBRmA9sD0ichcWFzEJjHxrKGWa1cgOWq2JYdbvJaIMckLLBeTqEPEiSEEsA7qOlIUhhiVqB5n03anrgNl0TrnWrRo0eLVQksutXhlOJYidvT3HN3T6Ptmz62o5ryAGXq4hav3IY6ROM0kjiEah1iL4tEsgopaNJp0LuPTscFA6ZjMKrq9FFgUhzXGrcB+j8nnX+Dqw5HVfRiHLnsr53no7/6nnPrV/wZ6fShc2vhK2hSICCIpwa3JUMi8Ek3o9XJ+f1OFpySA3yNsP4aO/ooibmFllNvCAX6hf24AlVRxzkbQiKjNF4sYAacGxKPxJnH2NGHvUWz/TqTYxMR+9iC3w7bF6wOLMb4w8rNEGT4qMx9wztHY8iGCdfaIFptzLo2q/OJLEksvI3XTosUPEwuZ4GZdyMTSPMK1mfiTjpI1BtwqRf8c1bSP1X1WyhImCtMIbgCjDjxec/lz+7irYD2M+nDmPbD5sdNwt0J/hsqYUBiMtYQYIKRoXi8dYnERNt4Jmx8GexaRDlZL0AHQyc4ak1LzxKIYRKRZotKdC6jGeQiTiKGt8Nji9QCzJDyZXJaKtQW7O5GNDZNIUmfwAawVLA4fa5xxFC2x1KJFixavKlr3cIsfEI6K+qpqMkyJuVKOohqI0UOYMd6/jo1DnKmIsUqfMgVqHFGEiE/niRE0p8yJScKikpINkAJTGkK0hGAxxWm4sQ5f2OXgC5GNbZjNCnZWTnP+F/4ep37tn0KvB+sDkETRGHEIBWgJWiDGogY8qSJdKs9GVsdInrIFvVRjYg2TXcZb3yGMnkMYE0XTs0hByMRSQ1SpETARMYpYcsiVB1uDUVRLiF1sFOJsn4PdR2H2DMiMQhMnZbW17Vu8dphXf8v9MI11RTXrCGsiYn2IPPfCFf7N//vvGE2Uqk46adNZ2rBWdUXUiA8+Cd3b1uhv8cbBcZdKdlOgCN4rPlhiLIihm//10XoAfgXTv4gvThFsl0oj0Uoilm6W8D3HjX+3hzwOxRimBsq3w4VPnoOHVmGlhhIqFA9EUWIK6sVYYeItdXkGeveAuxfkbuAOkLMEs0JlutS2T227BFsSjKAmRVoZgUQ1eQSPEY/IgmBq0eL1AAG8D8xmMyC5L8ezms9+7gt889s3qCLUAXyEadVEEgqTyWyh892iRYsWLV4VtORSi9vEcXnfl/5dNZFF1WwfY6p5ZbjkOU0eJ9VFNRojYERphCmURPp4FSofESnwU7BxFcYb8OU9XvjCBL0GGoT91Q73/a2f4uI//odw7gysdFN16Kz9aMXkPyyIw8jC56x5uwBgc706yZuHCBA8MINqmzB8Hhd3KWxARakRvDEpSgkw2qTUaU4PTK8tmlAJ6NwxXBpHQc1s9DxMnoc4XZj2i9tq0eJ1ALnln49QlpYrV7f43d/7fX7v9z/LaBIyoZqWHVcUGDEYY+ZRS0pKk2vR4o2BJqY1QTAQDYXt4IzDYrFisGLTP0owK/QuvIMJm4jdJPge1cjAbAWeqLj8u1cZfxd6U4gdWH+74b6fPgVvLaBzyDQeEkwE59CcZkpM6WxB16jiKbrrb0vkEqeIYRViSn9THOCWlpAUWSXLYshEhFR8Io3mnAqni2du0eK1hK89hbN0Op30d4zYouCb33qc3/6//hXfeeI6kwpcAWVpGI6HWDEUzqExRdw2TpEWLVq0aPGDRZtf0+IHhqML9bLo0nEO0xNlgkqVStDEphsqhpArtBlMThUDwMwAIUQIWYNJQyKqyljAaIB++QYv/MEBxfV0ir2BYn/sLk79978I966nUjuFgs7AJVLJYBO3k7WcRBP3JBKJ2TNsESTk1IYcXGExWBXQIUyvoH4LZw4xNhB9JIoiqhhN9XUIFlQQ64mayaYIxPT80ZikzWQqwCChS8cYJnGf2egqnVPjFOFkQm6QgpYbbvF6goiguhj3CnR7A65vbfMv/9W/Bhyf+fTPsDKAyivWRMRYjJgjG/QXjWBq9wEtXjdIDoImDU41kTCqglFJKdcRgtf0i0aMaEprthaKs6yefifTy7vYsWegJTw54vKfHnDwKFwsYW8K7q1w7tMX4D0CnV18VGxhqCUghcWGiImRAsXPelTmDsqVd7N65v3g7gJdSetMhiuEgM93L5laMseiORRy5PDc8bJMLMlSZa4WLV4DOGPmCgxBNRVlASovfOVrj1DFCb/+67/K/fedhQiD/gq1n+HEIU0Gt2n7b4sWLVq8GmjJpRY/ACxX45ClVxtPaNI0Sqt6YnFMURJqQWIib2L0WANGF6lnQqPnkqAKSiJprAETBBPXoFpFv7rDU38wxF1OtvxsAzrvOs99v/TzcHETBo4apYg+GxUx6U3kcwdylFRIFzY2PZOf+21lHqQlSZYJYwLUB4ThFZRDRGaIeogR0/iFmxQ2bcTMMyUUc+RS1r4QMYh4kDrFRwWLw2OZMB5u0YnjlDqXWrM161u85khGeu7nywM1/zqpwJUdprOaRx/7Or5WEMdnPvWTrAzSqJpVM8qyxGTdDEGOnqtBSyy1eB1iMRNr1gfMpJP3qEaMBIwNmZDJzgGZAT3W7/wAs92bdIar8NwOz//B9xh9G9YF9oHu2+H8Z87D2y2UO9ALmBqwhjoGbDAUEYx0QAyjeoXYv5u1cx+ElfuBVTTKogBGVAgRaxvRcckRS/NHWFq+m9ePOTHmFV+Fllxq8ZrBGKL31DHiOiWKMPWAKdk7GPO5zz/MZDbif/off4P77z1DJFI4S6wyMWpyhPxJa02LFi1atLgttORSi9tEQywtRSxoCrRPZFCcE0RpITcgBWX3DPW4DwyxEpHYeHdLsnJLPln+EQwRB8ZijGKkxswE9vrw7Qk3PjvEPQkrFkYDKN5nOfPph+CBB2DjTg4DuNJRqEAIkAW8mzS7sPwETeSUTa8EBGOzXZ0jm1QUzBTsiOFsG0xENUAMFCJJA2NZ+9TGBTmFJClVJTFhTfqB1Ik0i4qJM2BG4YTJdB+YgPEE+qS4qda0b/HaQo9pfzURgDFPB50SRuMJruhw48Y2X//LR0D+JULkkz/zUdZXe/MopaMJtC192uL1jaZ/iqZUb8lxTKYhXwoFKmAKzIAJ6DhVMyWC7YKco7P+QfhW4Nr/9y0mX4XNAL4L1b1w98+fho+sgtmiZkYhDjEVMUKpAnXAiIBx1NJHV++mc+592DveC+VZFEe0KRLWpPhbwELMVeDmVSZYymjVHNVUpmNVFlFNjdBay/S2eK0RI8Y5OgK1KkEi1lmKssvhcMILl5/EFfA//y//jN/4736V++/dZNBxWOvQsAim15OcIy1atGjR4rbQkktvSixqn82ji44YjtnSvEVjQThy+NI7StJESvZp8/mmvtriaolc6iC9M3i7ivU3MTZm9WxA/C32q8YkzIiAqMGpTdXiJgP41oyn/sNNyudgzcKBBfsWuPOT76B+8DzccReYFUq7TiSn2yxZy7eYystBWDm9oaG6jCyeO6rHSpL9DsFjrSUHLeWS63EuPq6N1NLSNRaJBYlEi7kBJKfMiQmgFZYuoaob5WSinpBl2OINj5OLoB3fxL1eDWAl0ox1aO7TB+h1u1mUH6698AJfrmusRJyFn/zJH6PbdSCR4D3WGApXcOJzywkvt2jxWmFJL08UkADUQAUyAUYwu4mOb1DNdvD1AT6MoPA46TDQ0+A24Xrk2d9/jOkje5w1BYe+xpyDt/zcOXjvAOwNtB8obJfpaEhRSnaMFPggCH18XGNsz9I9/SF6Fz8OvbcCq3hcjr1VAjHpP2Hz4nOCe2K+5CddQVReJPH69ToPtfjBYNkqMsfeWVhyry1SuqnmSNdG3iDUHmcUxjs8/tgBhCkdF/gffuNXufeuS+AjnU7S9mQeuaQvEsX0w3vKRT3idN2mfEwT+Z8iH2UpnXVhhevSWZpP37qEnmxhHPvo0vG3nnd+7luOn0+CJ1zjJDJ6OepRWbYZjts/twptyJF3l3IcXvRx5MgLx9phOTPiJQyMl+/xL2WcnPTZo3uQIwvK/Hpyy9EnC4/Epd+Pj9eT7uD4tZvXGjVZQfPuZPnejvTJo7+cgLj0vjnhRpqogVsj3m89D3kTxfEv89YPzq/T5II37ZHvR4+te3JSW7zI7Rx5hmbDak94FD32IXNLuy2P9PT6yfcx798vM3xPxMmd5UUOuPXAF+vRf91baMmlNyHSMhYAg+iSnoKk11OHd0vC0REIIAVqlpY18SiWkN8XAoaYvKnaQXJymCKpChsKasGt0jtzL9tbA8TXrHaTfpIP4DpKnKWpDWOItUHKEo0zYvR0bQdmDiZr8MiQF/7DHsWz0FPYFeh/CC585gHqu9exd1yE3jqYLhYlatY7MoYmRU9Ig2D+TI2+N+mFJe3v/MzpraACHqwbIFpQV0rXdUAitY+IrdCU85e0nCKgJml0NBOJglWb2sTkxg6Lm/FhCnGTfmcDfAFRcd2GjmrxxkazbB83EJu3FxF/wXtsVr5vjj8+wccYkzD2y1x12Sh9xWSNkNM9k+i9ii6ZkIuIwNJCrGuMKmE2gxDZvn6dL//516hnlhC7fOrTP4YrQWzE2TQSva8pncvGYxqMIUSsXZqrXnbhPIo3Ck3X4oeD2+4PSRE4kTQCMc4wZgocgL9CuPkNqv3vMd1+ilLHaDWmu4sLkwAAIABJREFU8iNYMYTQozg8TXm1ZPcPHmf8509QjiK7BUzvhLf/3IPwILA2y5Xg6pSWLeC9IK4kFD0m2iXEs5SDB1k/+2HMqfdB+SD40wQ7QCUJdQua17Hs7RB76wPP91qy+HniMUdWwxZvWCw7AxavpW81EsIMawtQk4KrDdk+fCW7nFtxu71HiYhJWn0Gk/jSINhYY3UM9gCtAk99N+BioLSGX/lHv8K73nU/wyn0uxCD4oxQVRVl2UTM57vTxov3Ytvy28VRcigSiYT8qklOVEwOA84VhQGVEgWsLkiACKg0dSqXNqyN/W7IGgwxzQRLJNoRn/LSrXnSNKHLJ1Iw2LRVnjuDG+Kr8f6apbbLT6aJ4Ja5V9TQbD01q9ZpLpazaHFtrAuYP5eZ7+CjRJQkP5Fet80tJoeuLCwl1YXcxfw7jgZsaqfkC0/Xivn/Zh40+b5YbtdlTmVODOj8p4YARhCx8xF1KzW2ID906WklE0VRweDm9o9K4+ROCc1NHGoawZ6U9WEQCpbH9cnjW0EjqkKcrwWKUJO/eZQy7+3IYyzdqVVz9JmXyYj8SGJA5/W2DUoBwSC5e6TrNx3oGAXR8Cja7Lfycc11DUvE0eI5j/R5FEwNYtCYUmAl1VUlVQVfJhYjUSMqhrmgbn4WaziqRdj0IaMkJ5KkftckpTTBBPmcVsyCrIuSPpbn0aApetjO99/p5DG3uUhDy8VFv09f/OKblaNtsNSEt47p5bZtjmn+0qOvInJk+lh655afL4WWXHoTYsGKn9RFMmutzRqUu1mzOKlNfdEAarL+UKOXko9vBniilVhe9tLVu1DeSX/j7Yh/nmp2OdWwsen6ppA0mCYB0+0xmk7orRVIMPjdGuc34JFDtr6wx/QZGESY9WDtQTjz0+fhrRvUp+6iOPNWWDkH0aASKE2Ria/mAU4YLMea5KRWUsCIw9gO1I7+4CyjUScRaDUUzhCCoYmL0giiaaITiUdPNN/o52VEi9Te4nGdEpEerlgF1wPj5oO+Ne9/dHDczyEwr2RjjGDTwKCqKqJCp9OZp6QpmsZgI06qS+c7vmbQbA4W/f8VIS7ucWFkkBevZMBqSLrFRiPqKwqbNuJ1NeX61Rd45JEOv/mb/wJjAz/xEx9mdbUkEqlmE/qdHvGIN06x1hKjEkLSzrilAdvB0OKHiTzeYvAIY4wdQrxOffPbjLe/TRg+TrX3V5zpVpjqgDCbsNLtMh5HyskK7vKY7T96nu2Hd1mdgi+BSwUP/ScfRT50B76zxYRdRBxQpSoWhSUg4PoMa4vrXWRl/e0M1t8JK++Ezj3gzoDk+SEbn4tNSB6nL5tTfcIieOSPdrC9sXHrxnDxelpVrE3kgMYFx+JjsgOzAuViT/JDhyLWkkgwj7EFFouxYCViqNPmUgO+nvL449+lqiOYLv/53/8lPvC++xiOa1b7BcPRiJVBH4hoDHnNtc0OeYEfeJeXpa8gWXULCsOkKsZzx26za1+yo3Naq0COrp/TgiiCbYRBj9x/+mwIirVN9BOgisZM/uTPuXx7IRmviWRZbgPL0S4UdW6LLIilRMCb+aY9X98HrDveuCf1xRfvYOkKTSzNwh5ozhRjsp2OOI3nTe3BdY5cK2q6fyMNFb/Yrdxyd7fstAWNAVQRYxDrFgccG2aLr3yxkZf5ky4Km5jsGIg+z+N5DJqle2rOaBsPdvNKUMTKsUvr0vedrpV0Xpve1dB3zRUaVdqj7ZBSJ9K7xyiKeRvr/DBD6jlmcXsKGiqkyA8UYmJlmi6Tt2cyb7rFdZbOTkPK3dJ3jjArqT9GBZVEk801/Oe2scnf+eK+NSiFXSarmNe1SJ+NRyN/83Bc/GnydbK9rRGjyw6dmLNgJI07JRGdcrSb3tL/5/1tsYdc7LKPttB8uL/IENJ8nwuS6uh7J43O73flb8mlNyNUEF366kVRiblD5dfNYnCnAZ6YX5FOmoA8IGnSSJxQE+NTpNWuSY0jJl2KmFldAWIXU76Fwer7Odh/kvF0wrodgR9TjSNl0UnncoHgJwxWS4bTKSudDVzoweMT9v90j5tfhpVCOCwUuRMu/uzd8NAaeysrDC59BDbfB8Up1FtiCLgSQPA+lai9HSRPTAG+Q2flPAc3SwJQohAMtuqkjXccp2aJjYukPDpKY4r6MlFyG9rU6tETjaOWLkVvLVW3M4ZZZrLbzLgfbRiTJ35VQghY5yjLkoU/LmFBAKefSwH1R1eC+e9pVN/OvqCptpM8kQZpPHb5DoAULawg0WPxSJxR10lvRqi5cvkxfBzyv/3zgMHxyU99FArodvpEIgaXyatIDBFrDcZIGi4vsWi2aPHXwe3uFWMMiBGiVSxj8E+hO1/j4PLDVPtP0NE9zg48Ot3F+ynlwIFXeuMuctDj4I+eZudPD1kdJeennIO7PnUn8nc+CJfO46Il7m5h/A7VZJ/ZLOI6fbyzmHKdjbV76fYvYgcXoXse2IDQw9dKNB7jbB7lgSPbDIlLa3OLNzeOE0yLXXNV1zlyKfsVBYyxeQMWsXIbqXHyIpun7+O+g4bk3bcWxeA1mVkhxrRAhbxJLwqqWeDpp5/l937393FlF/Tv8OH3P8Bo7On3B8yqmk5p0fyML7WVWo6VeMVY3r2JIvhkQ6uBxi5vTm8UFQFcctqQNNA0RzWp5uAmo9kQt4mOWrp9JaAasJJIwUQsQYpeUcRI0gwloCi+9pRFF1FJEhTQLOYggQB4gSiSqQOLtXZhk6qidZ0IQLHZ8F9oMRrbMAkByZFQTU+UhlCTmGm2k5jwZBcJBvVylDwSoPYYZ5rTJNM7kwMBC9aSek2yWhpFOoDoYyLEzCJiaB5VlHVa0x3kiBTJ1aaNQzU2cV3zsI+GdEhON51b7wZzJHMsaefJ/EGEzGEsKXmYkE8oMC8BqmbBP0rqB5LKUC+3KkdS01RQr0ixaLIQFWKBtWXun5qqmzaNO++vTXGK9Lrq/OvN50o0p8kRdmjij2xDwGiNOKWqp9iixFq3zAUlPUCTI+wWVNuCvJFF7NYye6r5QRqHSvo//xSIGAIpQklkmSfKFrMJGOokZ+KEMFWs6ywF6tbzb13FYOjMyXVjUkp8OlMnNci8y+aoo3n/9IDH1wFnOxiTI/jEojEgojkAIiydQxZ7Z6lJUU7Hn/8o4aiyINcW3/Jib7DgzRrCet6KNFa8Wd5r6IIsTqd6edXfllx6s6LpRybPwHmabQIRms68mBJTN7SERE41zO58BskLXbJCUiSFRNDGuCWdQRqC5Tzd1YeYrb2T6XSHsb9KTxQxnpjLOaNgnSOOKlaKPty0cLXkuT+5yvSrcKEPV2ulc5/hLX/rHnjbJuONddyFd1FceDexvIihRzQupb6F5Iaz9ra3FtRhirWAHUD3LJSbVFVJKTYJhse8gM7HYLMqNZON5Inaz9smTUoh6zQ5pqEk2tN0B5cgOqJppoTjRmGLNyqOT+sNkgbE8t+ACHUIyeizaZFUFUKMGJu8IGgyHuPxmNa8OOicjNKlReX7vGc96mFRlbkjrjlnmKd3ah5vAaXGGgPGI4WwdfVpvqmW3/xf/3dmkwP+7i9+mmigmnl6HUtQxYklahL8bwg3jSkl4gdh57docRL0JcIyVEhVqozimEB9DX/j6xxc+Txx+AgDbtIxAeM9IjPoWagiVCWy3WP7809x82HPmQChA8M+3PeJPvKRTfDPgFmH8x9i/ez7QWZQz9JuzpWAoGaAlOdBVoEOUEAsiMYi4rBm4SU9qpp0Aunc4k2Kk2yIbAMi2cGXCBfvWdKezBG1zR7jRfrSS0U1ad6gvJTGzUsjaY41n45A7ZXSCa4sUpEIk4Trq9kMkS6z0SFPP/Mk//7f/1u8H1OYX+I973qAqGBdgY8+ry9CXXuKolxuFhqK4ejz/iAGUi4no8JciiKfWg0EkRzFm6glh2abcQo2ZAJmyYpQCOIIOKIaRIpE4IhLKWYxpogSzZtYE0gpTFMEj+ApiwChBlOQGAiXNpOaqAMVoSlK42hSd7J0RkyaqVIU+XkcSAekTJxf3nfbJTt2XlH5BIgefyd9LkaPsWXyx+ZoE2EKbgJFBX6WiZgCYx1IgWLx2HkyncOCBqKGVIhBQ9J/nbM1TbSPHu3o0WdN1JgjS4v0Txyqjhgt1pTzzGlRTZWgtU7VQwHU573BEvmvBkKBRpvaPsscSHN9MYk11IjaKqV7qUvvmQA6A52kqD1y4Yi5zkcmTRXAInl8SwhECqwMUgGjmHkNIyyTDXMDz+Sw9QCIIZrE40ZJsUQGj9GIRJMjACPYChime8vESJpfSjROicFhKBHjcgqbZKKzSVG0RwgsODn4dsHZppnFNPtZIIrJZ9PcGhWWOudL5vGkVXp4tdjOAOhAtGiUXNQ7UZKKSemC826RCGIAvMt9dgwuE3EmQszXkRoQyqIL1BC7hGhQIymSDFnMAaqLCGkaEi9kAs/NQwyO6KDNHb2aPxfnxyRZNMM8xXCJgGZ+1CLPaDGJ62Kf/33sPVty6c2Kpn8s5c7aJe4iRvKaYvPQyQtXSFnIapMnw6EphFcKNCad7WYiMEScpEElmrlVTcsR9GH9ftb9hwjjGxzsjpCO0u96tBonz4ezUNeY2IfDPlztcO3fPkv9OGxGmEXovgUuffo++MAdHKz2Mefey8r9P4m6u6joIzhc1lwiKHqU8H2FiDibc3hdH3rn6K7dz2jrKUqG9EyY5/w2gkvNpl5yrnEwqVWbFOQ0U3lUIIhBZUBVbVJ234JdewfEAVpHikKJVMjxEtEt3lg4Row0S/l8WIoQY+oryfgN1HWNdSUBoc7RdyIQrW3WeoTFQnR84Wg8IEIa9kfyyb8PNJ7RZe0vlYVHBEBcDtizjmCFKhtTpjTUs2kyQk3B1tYzfPWrM5xNUY+f+blP0Ot3mPqaUHsGvV56/rqiEItbJoa/D9u+3U+3eCU4TjKlJVJQVxAYYv012HmMyeUvIwffZWC3cYwo1EIdoOzCyEM1gMNNRn9yg63Pe85O0xi9uQ73faaH/NRZ2LjB/nhE9ZywEe+jOP9BMH0ommgKgBKhROnk7WaCsTZvM5OBmrhkmWf3HCex2/HQAhbrzvLWbb6BCsnmq2roFslhECIUhW0CgxbnOdahXnppaQiFV9YLG3NJWUToWJvWxBBhNB4h1qHUUM9yvAHU4ylPfGePsqP4quLXf+3XeOD+O+btEGJMThtr5o1zdAP5Axo9R2zvJhJhKYIjHxMVfCZyCgLCBOoD0D3QHQiH4KscteLyXLGGLdexZg2ki4+BoAWYAiMWYwIxelRcVsQJKfJS99N5/S6EA7A+ffHRgBlAcRrsJkbWMeRUXaaghxAPod4HP0npQrYHkxLcGhSnElnOAE9JoKTZLtv044S2yV/q0t52+b0oEW9BqRGxGK1wbgTsQrwOfgd0mtpV8p7D9FG7irOnEDlN0DXAQJximIBM0rPMdiEME9EQ63RdV4LtpH9RIM7ATNPPqCA9sOtgNhFzCmvXiarUaogRbFRK6xGZInGY2trv5LYbgtbp+zfr4M4j9hTIGmI61BqoY8SagsL2EGOoasVZgzJD4hgbpqCj9N3FHeAQzCwTJw2x1Ii/CokIWwW7jpgNXFxFQ5HWlKX0r1RRNBNtORUuSkPbJImOAFQSCWooRCijYLSGOAIdAwfpnvQmxEk6uemD70O5ibh1rFslxhUCXYg2RYgpOYpHM9HUSII0cV8LArDpJKLLK51BoyXGvJc1BdaAlSlWZhiZgO5CfQPiQcowiTWoTZVctQed0+DOIKwStEeMaT83j15r4ivUAi7xaNEk8teM0/nDHvhDCJM0XoxP/Sisgj0D7izWrAAlMRZEbOKT1OZIr7x/FkMT/UYTaze/gWMDSBpC8ijJP+eeWLL/T9pCNhPskTHZDMtbNhYvipZcejNiqbMssmpzXGUuT9zkpqbunNhSI9BxDvDMwmFavFXAlCAFgiFGQxAzF/BemLsw1xVqQup0AOvv4tRdM3bEcnj4GGG6TaEBZyus94hbhf0Sni/Y+/3nmTwKbghVF4br8ODPPoS85xLbXcfafe+n2PwQuLdQs0Gkj8ERiYk4s+aWVPpX2nwWQ4geSwfKs6yefg+jvaeYTEdYs0/hFCGANWk9kjQVm+wBmBNwS/OhSiLnajHUcRUt7qK/9hD07wezkvJ205Ht5uBHCMeJpZOQtIMtxgiPP/4k+4fT7HVt0sVCigpSCD7Mw22bs8+1lnJIsxyvmvF93vHyxhaU4w5GX3uMCE89+RQhWmzRI0xH1D570zRVJlGdsrN7nS996UvEHNH3C3/7E5RFgYhl5pWOk1RCWnPEUr5mu0Vu8WrhpMilmCMuYl7ZCiYwfZrZja9S7XybrmzRLWaoTylzrKzBuIZZFw7WmTx8hRc+P2Njkry90xU4/zeg98mLsH5A3ZlRuorJ8BlGu0+zsfkO6JxDQ9KEqUNEXB9skVfWJmpg4RWS7C6fb9ybfQGN83lZ5bcdP29u5MgRWKwP8//TRnQ2g7/8xuO4QhCjhFgTVTEmCQefBBF5yci/24WoEHxOXTLJYRKiErwwHB7S7/dShdIIUhi09hTdDnU1AR948nvfoZp6iqLDP/qVf8ADD9xNt+MIIRJVsSZH+ajO22YePXLb1mODFOkz17VpdnuGuSkuAmm7OQZ2YfI8YecJquHzTCZX8fUeoRpCjBS2R9nZpNO/gOtdwG7eC4NLOHcWU3epqg6uM0j1B0yKgDBMgG3wV4njZ5jtP8vs4AXC+Cb1ZC+tz8ZiilXKlTvpr99NuXYPdNegHsHwGof7zzGbXEf9HrGeoFHR6Oj2z1AOztNZu4hbvQu6d1K4c1g2iZTIfHdwrEnnG1iT2iMu1vkmeltVs0RNqsxp2IP6MkyeZbL/BNOD55kc3mxc4qjtYDubdAeXWFm7Hzu4B9O5CEUf7BhmN2G6RRhdYbL/PNX4BvXkANEaEaFwXcrOCtZ18dESY83h4XVEaqwRrBvgOqforNxJd/2tsH4fxpymY1dztGkNYRem1+HwWWaj5xkPnyeEXXx1SAwVzhT5+7sTU95BZ/1+GFyk6JzG2R5ehYBHxGGKSIz7FGaY7j/chMNnGG0/STW8DH6fanqYeq6xqFiiMaiVlGapBb3+OQaDS/TW7oXyLsTdhbizqAzmUT5Gc3Gm3PhRUsyM5AppjTtRCDiBkgone+C3oLoKw+cZHzzHcHSZmb9BjBMkJM3dsnOG7sol+qfuoVi5C9O5iDGnUQZEXyYCU1Lk09E9myANbaFN1s0SydR4VcXOs2PFZD1fmWRSdgfGlwnD55kMn2I2vEyc7oGvMVKmbJTOJp31S/RO3Y9duQfnLoFsotrHRws2nVhi2jM7MYitQXYzefgCjJ7hcP9JpsOr+OkBsR4hOiFSUPTvpOxdZG3tPuzKXdA5h3GnQdZR6TFfwXPGgVFFTJNDlOXcjxNLx5zJqpqEyrOukyyErBYmwHEz+sTpTebjciHL8fK2Q0suvQmhNDmZQDZRhcAiSdmksEwFEwIiMwwTDHWmgWd0XJWY6KCgBZgSkQ5d0yXQp6YESqCDxpKjpQQiSaQUMHfD2XU23Vn2rvw51d7X0fgcwdxkYAJsB7guHP7BZXa/Cqseqh5snYKH/t57kPfey/jcGTbueif23Lugex+EDcQMsNJJ40h9MhDEAXbJG/VKYYEuqi4x3WzA4L2snLrB+OaMkX+SXnGA1elcmK6hjJtwRcUlke+cNtgQS5WFij4VFxhsvAdz6t1gzgP9xGZjmsz723mAFq9zhBAwJpVZTtGsKZt/OJnxe//xs/zFVx5lb28EGikKR4gechRhXdcLcimHKi2TS3m54nbIJZO1FFQXrkfNi1Zah1LqHjFyY2uItSupqqT3iCvQUKW5RCPBD9neucIX//zhHAFl+eSn/gbrayks3MdIYQzBR4RAjBHryhe5txYtbh/NBjnN3UffMxqJOkPMDhx+g2r/yzi5QuFGaKgXemnDSao0Mdmg/rMbPPeHMwbbaZzsrMFdn+yx8pl1dPUqsYDCCdXhdU6vddne+Qp+4xLu3EXEnAYipRUijqApJcVIijFJuQy6MKyXvf5HoiR8cgghpAioY8L4Ld40OFoAnrzZX34/iexu3Tzgt//P/5tnn3sqyQCYSF0HjOmjL7F9eMm0UhbOtVcCg9IxSaknxJCqPaEURZe97RGz6TgL7YDWFWDwdYpkEQeT8SHf+95f8Tu/8ztU1Yxf/7X/lnvvu0RZJrJjPJ3S7ZRzLcEjaWdHxH1eORJdZVAs89pkJuZNYHYmAXAIs2cIw29Q7f4l9f43CZOrCJEiTumZCaUFUUscldTDNaZyGrl5iZUz78Sc+wCmdz/d4hzEKqXgaI2zFcSrMHmU0c7XGW59nXDwHN1YMTCCU4M1KeW+qqA6+CaTrVW0d4ZOtw9SMRvdJIy3KHVC6SJOBFVDUMF7w/SwYLi9QrF6P6tnPkxx6iMY8zaMX4Nudx4LdnLUW24TmYsJLaY0FcJsTNGZgF6Dg0cZ3fwy073vwPQKxh+w6QQ0pEq2wREmJXF7hRGnqd0Z1u57F+Wp02AqqpvPsnf9e9Tj63RkSM95OnGMRJ/kCWqHTAtqtYQoxKic7hXEUKG+Jk4DfiiM9tYYbd+D9h7g9KWPI6v3QDmAeoe4+xiT3e8w23uCavgCHTulwNOJjapUQMdQ7RtmukJ/8yE6a++kOPVhZOVtFOYMISjBTCjNDGQPRk/i9x5jtPsY1cF3iOMr9KjoF5YwS4l/TYXvaCNqI9HURAzVtuNwe4VxcYbu2tsYnPkobL4LMeepfBdTdolSYNRh1My/lwi4hS+DQiPGeIwZY+J1OPg2HD7G4eUvY6prxPqQgalYdSGn7sXkRBwVzEZ9bm6fQlbuYXD2PayeejdS3oflFMR1oJwPt0YnKWmTNSSJRUVYpIo1nUfmcRLRpWA62IPZ0zB8FMZPcvD8t1C/RYzbODtCGKd9aXBI6CF+QD3sM762hh3cw9rZD1Ccfj9SvAUXV/BigBKjOeNHAsQtmD4B4++xc/3b+MlzhOlzGH9IzwilUZzxRDFMJk8xO+iwdXVAb+VeVs68B3f63TB4EDVniZL2lzaTV6hFosE5aFZ9WVrum6p+yzNVk+Amoth5OkMisYNRNKc+mnySOa97ZFDKoj05Ome/3AzYkktvUujSFN4w0EmwT9No1BRpY2UCZgi6DbNtGO4QpruMxtepqyEalbLo0V3ZoOyfgv55bOcs1pwG1lBdIYXwmwXbLZIILLdCHQ3EDsXpD7HZX8dfXWey8w3C5Gl0eojsTLj5x8+x900oKxh3u+yuCvf+4kcoP/ZO9NIZ+ufvhQvvhbiZ0g/oUZR9vKbntAJiPKhPQ+n2mKXE1UeXoiliRLyDzp2snPsg0+kVxntDxColERt8IoOaTfd8t9JQxjkXWCK1OCp6TPUC0nsHg/Mfhs0HIQ7AlMmrNldKbsmlH2Wk6mipPGmIuVyvWMqyw3A05rFvP8pzz1+lmk3pdEp8PUM1UhQFoU7lZJt/C3IzWQVpbb6dlMqsuPAiu4MmvzsGjzMGI5FqfJg9JXEu2pmI31TZJIQxuzvXeOSRb/JbvxVwzvKJn/oYq6vQXMgYgxhNEVotWrzayAKuzUZ5vm5opCM1zG4y236EevQE64MZRgPTcaDXKcEWMBI46DP5i6s8/8dTunsw6MK+g7t+eoWVj5+CSzPEVEgQ/LRmsOqoqpu44lkmB4+yuvlRcGdSNFTZIa3JNot+Lq8jzc98j7csD7fEz7docQTLBFPjMnBlh8tXrvG1r3+D8fgAY5JuZQyNY+1WvFzUUlNV+5XyM6KKiR40YJzFWpO0oepI6fpMxgcQPCZrD1pjCaFOeyRNMiYhBp5+5ik+//nPUxQFv/zLv8w73nEPMUK32yVoyLRP8yxZu0ZfbHx9v2icjA3JlE8qESuaUovYg+mTTG9+jYNrf4o//BZ9rrJa5nLxUiFa4XLwRvRg9SbB7DA92GJnvEV3uMvKpTGsvwt0E9EO1nnwzxNufJWd6w8zO3yEPlfY7IwpvCJVJOklCc4GrIl0JJenHz9HPbLEUGFMzYabpVQfH9Bcnb0oCrx6OmXBRCyHu9cYHtxgc3+X1bMzWH8nsI5IP+8LFl4pFZknPFmy5Iwm52sK4ghYpphyAsOnmO18leH2Vwijb9HhOh1GODPDqUkV3IQcAZPSvoi71OE6o+dfYLa7AmFCNd7BhUNWC0+hE/CTVITEZGIrQtREBKqxaVPuFUKNlRrnAKPUus1sdkDlt9l64hpn7ngHduM0DLfYu/4I9fAperLNoDOGWGE0RQGJgjU+afNYxZse+zu7jPev0D08YO2OMWw+hHWbSWdH92H3G/gbX2f35jfR+ll6bptub4j1NeIjznbTdyhZMFo9GjwaU7RcX0qCFtTTy0wnl5kd3mAw3qJzxwfp9e7DE4isohRHgltkeThoRKTCyQHoDXT4GOPrDzO+9mXW5DqF38kpcgq1EkkaRMZACEq36DFhm8P9LXbGl5kdXOHMuR+D9fdCWOh9qeTIPiVrTjU30xAtKf5vucYfEZQKMWA4gNkz6O7XmVx9mNn2txi4KRr2iDJETIWxSeNJ1GIoibWhY7v42GG8/wI742sMDrdYOTNCNt8O9MCsIb5MAy/egPq71Dt/wsGNr8P0JmXYwbFDYWc4DPgazdF0HVPQtX1EOtSjm+zPrmDHl+lfOqTceC+BMyBrIGXO/W2wSJFvJC6axMGGXFoEHixmr3Ss5ilsUcBLjjmZNa8CL7ZHnqfV/TXmv5ZcelMiT2pz30GcC39FY6n8jK5ziA4hbMH4OTh4jMOtx5gcXMbpIU4nFDolaEUFTK6X4Dbo9u+mHNxH78L7ofcAoncg5QV8SJOEtaBeMKFLLlDA4SRwxg2gey/uzgGrZ98vneH9AAAgAElEQVQFV74Fj36bm3/4WW78Gdh9mKyc4cqm4b1//2+z8Td/Es6fQU6fg84piBukAU8irkIup9qUFm2Isx8Qkng5GKNpFEkH1u7i1MUPse9qZgdKrAPdMKKQVKsg0cuJSrdFTfRJDcA4h5qCKg6ouRMt386Fe/8mdB8CWUGdI2hEipQnjxyfElr8KKH5Xo2xKQTc2kVgQgSRiMQxs8NroJHpNIuCooTxsU3mMV/G0ZCG2+hBy7Vlj1wnb3pz3rwnpb9Z8UlvTEJ2AAuqixBrpAaNXLv+LJPJmN/8TZjNKn7+5z9Br2upQwD1FOJS5JJNoqS6XNlF06Lovce5dmlr8crR+ABO2ig7A4QpTG8yOXiOld6Mqj6gLA1F36UKRhOB/YLwlS2u/0nNys3kuD3cgNX3wsrP3gVr++APwEZMNCna0CumUIy9wfDwUVanz8HgAlKukcomZ/Hf2IybEwil5WG9cOdm87sxP1uC9s2Nl57/hbSiRBWKTpfxZEo1mZLEpGMSN1rGq5gGdyuU0PTravl1Sx2HQC7+EAIWi0ZNaTYKeCWIgqnxUXn88ceJ8f9n782fLDuuO7/Pycx773uvlq5eATQaG0FABAkSFAWS1nA4JDWUxE2bPQ6NxqIoUwtDnnFoNP+LbcVEaDyOGGs8ERrFMEIOWSJFSBQlUaS4DLhg39HotbrWV+/dJfP4h8y871Z1A2ywIdlk10EUuuqtefPmcvJ7vud7oJ57Pv1rv8o7H7qL6cyzNLa0XUPlbILcAoQINgcP5oa2l0U1pwWn2KYrCATdxMglqJ9g86U/Y/fC11hhnVW3g87BUgAJLDPkrT/pd3rUbzNyHXUI7F72eN9x5LSHo2/FuGNQX0Rf/GP85t9R7j7GWC4yctvY4GOmUVEQQpuYLt2CrBXmqJ+DVrhiHH1gaQAf8RsDUMQjrhhC6EAaJqXgOcvO5S+i8w1W5Qocey++PQbuCCEYCmsIwaPWJZ9BaELLKPlAKtD5DksNZgumT9Ke/Ss2Lv8t4p9lYi9gwyYSomC26sIniOxqj5gWMXMKtpg0F9ArMWOjwmPwmNojGlkwB88KfeXNzIgRxdguwoJpeBQ0WN2iDA0N52nOfRe5WOJ9S9ntMrZTCtlBpIvpdSKI7chi6EnWCLRmqXTUepbplb+g6c5xorgIRx9A/BJMX2H3uT/Czh+nai4hso3zU4JEjShTCCItIh6o072LKdMSiClWYQ9XWCrrmeiUWd2w/fJlRv4KK/f+BM68icAI3xVYZyPjVQKh8xhXpE2wofMbOLnCbOvLXHjmc4ybpxjJK5gwxdDQK/+TijQhEALWQGhmOJmxWs6p/R6zC1tszHZZu6VBTv4Tgq+omUS9cgQnHhM0naHoXc/MbfOAUZPIboKxLSZcBs7SrH+Z+sLfoJe/yqrdRFRR1xGkRU1I8ycK3xuN4vDW1Agdy25CZ1r2Lm0h9SZLkxq39ADTIDhZBjeFnceYnv889fafY+oXGCvYrsZojRGPiIngmoldF5qWcbUHYY7TGYZdNtYvsa2XOVXOGU3eR8MYT0WszxHAKCGpTbk8JjVEbaq0jkRJ4ehbI8LMp6wdawkEGgk4LBUGCRrXxiyKn26PiiGX+Mq7hGEQn15Mite0Qw/8JrWcv5xZSwZHR6BTT+FAuALhArr5bTZe/luazW9TcYklsw3tLmVCrdW2iBO8lnTdEmxfod09R9g5x9KJh+Dku6E0OHeSWefituEiyFTXSmuVpfEq03aLMcsYswRhBYxw5a//mo2vTRlNLfPiFNurJ3noUz/LsV/6GTiyCuMVcEuxwgIlIsWCO5mz8NJk6AGmfim6wcN1ygMOqlhxIBPgBGblbaxZx3oQdG+VunsZ8dtUMsfQ0gUIXUfoFHEG45ZoqJi3BZ29ldHKjzE6+jAsvZXgThNklOoQLI4Gh8eCH167ekTKvt9yJVq0A80VQTzSE2PzhpDhx4PMpfT8VVVYXp/lzWdxeI1el+TDa/97cso07IO58m6mMcSUnvB08202FR599Jv8p/9UYY3ykY98kKoSnHXMm4ZRNUrkPenTl0II/d+HwNKh3bC91vTQDnQP3btMaDbx7GJsiqJ6hzQTuFLC43u8+Gct9jyUCrMxLL8Djv307bC6CePdWPhBhzpIJmoEyi5GNvDtJazdAzPB45LSWY7rH2hrdg4PsJQk7xqad5HvcX2HdhPYwP8ZUBPyin3Vjyq9uK92McBBWICvr2M8vVZ1sOu1wEGdv3wyjzueJMXv4UsUFswj34AE1CtPP/UUzlZU1Qjv/xk/9q57mTUt47Jib77N0mhC23mccXEmXUur5HWZpEJQERlyWLw6QvDxQCy70D7D3vkv0W78Dcv6IhOZI74mGENQs1A8VLtojIngl5UWa3fj/QmBeiuwERqO2ims3gHrzzC/9GXs7HHKcAHrppiU3h6LwvmoLzc4XOYuFqOE4AlaR/aDdH0q31CSyhgL+JiOE/Zwbh0T5oTdOdOXOpZkGXv0YbwvMWYZEIy1tL1noYhJaT0m1pYrHBjmUJ9Fz/4lYfPrVO0zOHuZkZ3FAK7G9S5XYJM+CCbEal0NolD5XNlnX1mSQdZjYsiIRtmn3rNSVATfnyXStcdJgtE9SpmDD9iuhFBgfIj3llhlThWspHXcZL+N5D8ZTBCM7uG0Y7XsmO3NWH9mg+P3XoLydq48/yij+WMU3YtRoNq2IBEYjJWmlZCrl8VLSDtLvkkksddY2c/oHiNznrZrqTcM8qJh+XaHKUagBajFhxqxirUGkUATWkozx9kr1NvfZHrxrymaJyjbC0zMDNezxrLo3+DkknWEDIwENEwppMZ0c8K2Y7MzHC2OYY49jKGiUYtL/VU6u7hlpu+5yNwRwRiDUYnYl87BXoL1b7Dzyl8QNh/leLGOCTuocalod6puqAZRG7VJCFirfSBU2MPpBSqt0R3P3nMdk7eNGctpjO5CfQHd+gbzK1+D+klWyz1ckz5LAWPBeIxRQtJUH2cXNXic7mGoae2U6V5g8+WCY6fXKJeX8JS0ocS4jqABI6Nrnv8WPRz9cG08noAtbZzLqojEcaFAXc8Z2Qpji8XcTtPXh5xKmOZEv9i9vgXv0Au/SS0kenBIPoM1JSYEjJ/jygb0FZrLX2Hv/JfR7ccom7NMij1K04BtEx0wMvZMUBwdpZ+h3QaehtneJbbrCyyzgzm2CavvoiyO0uKIVEcLRcfYCIGOslhCmxp2A1xyTP/9Izz1B1/m1Jan82Nmt57hzb/w33HsF/8F3HYiTdgCghBEURsWVD0lRilypQiS468GI03aeF5dkPJ6LPedBJOApYSouwpZPcmJ8Z10lx9l9/zX2N1+mrmuU9g9zLiLC3SweC2Z64RWV5DxcVaOPMDo1Ptg7UGQ4yjjfrO12H3lfw/PBj/gdj03cF/1i8FbZQEc7QOfJDtV+b2Lrzoo2BpumMV3UFR+uAmZHua6yrlPv0TfPyyekCI1tMU3W5x/Zc4XvzhFvYcAH/vEBwClqsZ4DaiPYpPGxDRXa+OhuW1biqK4wWs7tEO72hYsphbMnJ2tVxBpKayj8S14R9WuwPYR+MoWL/7xNksX4sunE1h5p3Ds43fDXR7MNtg58cBDdPbVE3BoEIRA8HN25xscsU1KU/DYnEJikjC+7AcB8sEsz8Vcqlz2v+hQz/smtuEwkGs+OnitDHcNheB7YEl0/x5w3SLeElkGN2QZPJKMF6X29ehYDmYEBrtinBs6cKSwdLMpzz7zNLPZDGOVovxFHnzwHjyB8WiFuqup3AhN6SkaQG5Ursxb1ESAyYhJaeSCoQPdQS8/wd75b2KnL3Ck2kVCi1oPI/AdmM70RTliKplJOWQhAg3aIdSMbQvdLvXGJVi+DP52ds49g8yfxLKJcQGspZNeoQWLRPZGl7GI2E+oi2CDgDfzCNSgvd+dA9WxUpfijEW9j0wLaQh4umbKbEOp7SmOrZ2BYFEZgS3jtdCRy9BbLBCrUCMJWPIX4Mqj7Jz7C4rmSUrZwkmHdFGoGo3rn6qP4zNXbMagorGqroLFL0D9nrEBmJyRkDAMXbhSERMxKJIylSyR9BLZ2QkhAnwCYQTVnArmMUQAQzQypQajNqbdqQONpezL0iJ1TcEuhczZ2b5COLuDmZxGt57H+HOIznCSRLdFFnM1zYGgxM9DkMTeyoeIzC6j8/Ge20DFJl3zBLuXlXJ0nPLESgz2ywjjkgS7JLF7CcAUZk+ze/ZLhM2vcTRcwjVNDIGoIUhLsB6kS+lm0gOAdJLof5FBU9oWyxbz+hn25g3TYoWllSNUhQWOQoRKY5uDhyIGJvOYi7Lihs5EYMkFYmXF3e+y89JfwM6jjOU8phBCHUcYqljVuJXmEsgJgAtW8DIgCGtHJdtI9xTTizuY5WVGt78HZAXOPcrGuS/A/CkmsodrPHRF/FGJe3Uxi0y/kLbeUMbUvw6gxYSGVdtgmjnTC55ZOEH55hNY68CuAUoXPJUhFpBz6UZrZFJE4ChdQxCMs4iHLsQMHtM0qHaMnYJpKaqSnr2s0HVxvFibitOmJ3LQOvdLv+BeR9W4Q3DpJrWc927TBhtZd4ZSW2gv0qz/HRsv/znsfIu1YotytIf4vQUdugC8X2irqUfEI7bGECjsLpvTHTbPt7hmymq1hK3eQheWULNMoMPaGKctiCLfUgfYnnHx9/+QJ3//sxzfEeZ+xPzICe77uV9g5Vf/Rzh+BBVH12kUPIZUMURScl8MKxWGuKBKSBtCum6Afbn031fvIf2PjXM8KF1wBFYoTIWpVnAn1lhbPgN7L9DtnmVvepad+SV804AvKatjjFdv4/jaHcjqGRjdCXon1KvoaEKLogRc6m5J+5cYXUQgDu0H3l51JPZq8Ader8OHk+sf6Ui9wz08ag7hpTfmQKmD/w/bGx+VzA7UBQSl7B+yWTZMe4csOoIqyXExHZsb5/ny3/xVnKvS8bGPfzhiymJwzlzzUsyhHtOhXY9dfbq+ph2sfJX3D0xNU28wcmBx0EBl12BnifDNbc7/2SXKCxDm4E7A5H449rH74JYp6rYRVwPtohkZM9JUhlkj2NTMp2RmYiAQxGEkOtbxJx0wB/MsX9Qg1nKIIx3awGTx79AxetVB0h+BgRAPzHk/GX6qWXzAawNNesMDsmek56Zl4d+UXiTpSdkHtsK+XSsk1kIxZjbf4cUXn+Wzn/0s3jd8+td+hXvvvRNbWFQLmi5QOofv4gHstdqf07Nfs/35rJaQDdHEZgm7MDvL5rlvYmYvsix7iLbgA+IEcYoPUBgBH1PDAyQWR/TBkagzGhpwbpfVsmNvPqW7MsfNnyXsXGTs5ljTEETxKrHMOkmiXTWx5CUduE30oZW06ngwLQZdsJYgpuJoHCfeB0QcTorI2vEdlhZnFMw6m5uPweYT2JU1MGugsUCHlV71ZQGKA1YA5jB7mfn6t3DhZSp3hWDaBKoJYgfZCTmzTQ05iSg+OLh3A9bdIiVo8C8pYKeJaZYqKEYfPL7AYZGgoB1IOohLzGjQ0MXAd4hArBEb0QqvfWw7u225ElfEPBXaBkOHnzc451h1BbPL38XzLJUoxuyhIe0fPvtci8tTTQkcAURNJBMkEEINNCZJCmjEm5wPlNLR6jqhfoHdS/+VY8t3Q3UbhCUEi8fEIJ62lBJAt2g2nyBsPc6kOc/ETIkgpBDE401HMDEVzAT6yWqGcVEhobUe6zwjthEusnvl71i6fDucWqMqRrSUKEX0LJ0lojI+jZKFP+pJS4GpQTfpLj7KfP1brFWbFNLS1TF7xNjE7NoXdIljVyXgUbrelzb4rqUQxbmOsrvE9tkvM1qbgF2h2fg6fu8plkc7jI2B2if9FxP7I6WWxriQxPHozXBgR9xPYNU2uG6d7fN/x5HVO+HUCtYVeCoKU0TecQbQc5ORxZqX/N9m2lBOSgoB9hrmL71M0dWUtxyLN2NUQFWBKVFx2MLu8xcWEu7DnwX4to85/Sp2CC7dhJYPen0dBmMINRjnQTfg8rfZOfsl3Oy7jO0FCj/FNwEjFmNK2tBgijqCpomlGNfVFqMKOgcnTJgyrZ+g3oBtu8rqmSVKuQ8tHI3Gjd1RxhWw3oW9Kbv/8f/guT/4D5zcWae0jnNHTvCOf/5Jln/pl+D2E8A2YtOkIUK4HvAaCAJCl8pnunil0qFi4rapMa9WNKH236cJStA29Ud60EahOsXgGRFCgSvHUN4Ky+/EHZux6qesmlli41qQMdgVYAQUoBNgGYzFawvSYvEUlLF/uxQx2x8qOrQfYHs9EGfOTFCIO1GmI6R/c5raIl3gGg61XP3Q922vMv5UcnS49x6u+koBxKS8bwVCmw7IyUH0M6SouHThWb7y1QhSdd7w0Y9/gNVli08HB5PmcZcYS9ZavPc9k2l/w1673Yd2E9p1IC89wJTRUAnQ7eGsJ/iW4JWJOQbTNXh0i5f+9CKTl6EKcHEFRvfDmX92D5zcgsmMwBRjYuzaEz/Waaa0pwg3ggTBRR86+qoQo7NEbuACMl5cwFDMcxEASYd5GSwOh3PgJrdrDIBrzAVJrlIMaCUnJHIIrvH2a+wzf29mU+Q97XsKOV9mkRw+fCz97GtXZHNoaMA3tM2MF194js997vN47/nN3/h17r7rDgpXEEJg3rWMR5EVez0A0qubJk2ceCzW4JFgEDuD5jxh47s0W0+wLBu40MJcgQmq0MosBmIpiStGwKhHQxvvEflwDUUCmExZsyRCt3MWnV9hgsdLk1K7BJ/uu8UkUDAs0sPSodvn/6QFVQoMJpi+vHlfBTm935hUbVMBibpJPqVKGfYwzUvsnPs6K0v3gTlOTL9ySV/GpAPuIAVKGwhbsPU0s42nWCrqtBzHNGKVmPYjtltkYmkMmKOCisbXpY/L624/NnSBLIkYvE8jKIFLveYMgATEx+q8oiZqvPZAAnTikUoICeiSAE4tTnM+ZdhP3TMs9CgT3usDuHEFndJ5KKoC6Tx1t4UrHeo8bYg4gWr8/J5lsnAJsZLahQNK0I6gEYCMfS2It2goEAyVaUC3mW89CTtPg/0R4CiqJQGDGyXWlzRQX6bZeJqyu8hY92A2BTcGq4ibRx0uMoCW4AoTmWxYENPixeLzbPVgXEflZjThHJuXvsra6n1QHCUwIQqMG4wQMzlS97m8X6YVwVFDdwWmzzPbfJJS13FhRhRdN5TjAg11j2uptQnkiRXtgmgsAtAFSGPca0wV9daBFYruPJz/ajzDNS8xrnZQ3WPuO1xhY5qptKg2ID6mkGqGbx1iIYQaXLwXoQHbCMYaKjrGnGN25WuMj90L7gjaHsXZMaiPA7dLA9hHEfhgNN39gMFQLpdRdL6uYTrj7Oce4Zv/z5/w/nc9xKmfeB+8403puwNiSwIlDUJQKCWKpNthgCD58iF5FNdDfD4El25Ci/Up8kKbmDcEYBeal9i5/A1M/SwjucSI3aiXIoJYB8YhGvM/SefbHvg1CrTRSfZKWThUN9idP8d8/Rirx+9DJnegTRejMHl4NjVsbsEf/9987d/9Hke3tulCYL0w3PcLP8/yr34SbjsdF7TJCEK9CB9p3IxETJI6i99vsgLyMBFcIDKNbrwEs8l6VZLop4RIb8YSVAgUtIwwsoSxIX2lj20PXVzMpAAZE9TFrlPp0xXiAupTdEgXm9EQ8T+0H2jTA79f65ZmB3Tf+1K0Igok5ER7FjjO9wga37AdRIk48LcOX3jtL4wO3QL8WlTlSk6eUbSdY0cTzp99ji+rjVEZE/jExz/M8kQI3tOFjrIoKYqid/ivGTW/ns4+tJvTvsd4ODie4suFarRMUxusrMLsOPr1Dc7+2Tm654EaNi2Ub4MzP3sGTs9gZQ/VXWwhqXw6BwT0IoJkTDwUWTVMXAVewNioiyiJSZBSAg66efsvY4gkp0NN3rQO8+IOLdu+8X9wMsSx04scp3Szq1bYN2JfuV7Ta4xcjSdqHfikvaZOwoQzKwUFawTvFesE7+dgY3W0oC1PPfUUXadocPyrf/lb3HHmBJNxTOrpvMdIYtkq3yfAFEWmBcFrFL62SWeN5jw7G08zcrtUWiNtF32/ooxM/BZckQvUQNY5lMwaytfYgRiLDT4yWywUvoN2j6KwaOhSkNlgMYjY5IOGhWZGDlZB75MiEVBxwS38jrR/L7Tj4nrlu8gjsdYmUCleq29bluwOe1eeYmV+AZZvBx0Bsdx6jBdJUpQnnStq8Jt0Oy9g28sYV0PQGCzGJrHqABp1pqxYYqW0lHqlAUuBDU26rqS5lC8ur4cJjOoP1v24Tv2R/C2T11Qxi+8RCyI4EwhdE8ejxnvjNAFlQckgFHkt1xwIIN5XNBYKagKoxXqBWYczghND6Dyd16hrGbQPRsS2e3pqe77GDDApgMX6ENlWJiwKRHQx6F5aQFrq5jJh/UXM0iYUc4wpqXr/0seCFlfOU196kXG7jTWaxPUl3msT0/9QQUIB3Sh2pwWki9JtxoCxWLExK6PpYjpbaVh1LRvrZ+HUJVjao9IqpY6nNoT0S7peKxabD6RhCroJl57F7VxkLMCuQjlibMoIBjZdGq9VundxbOND/BxbMprXpPKHVPm++ZLgHRM6OPcCBEupM0obn1MtEVumexHDQYiDUKZ7UKRxotgwBxowDhsq8BYaj8WxKoH64kU4vg5rU1w3gaKFNpETTJnuW2IqFrHIDRkkzVOxq8HX3L67zXe++x2efvw7nHvkT7jn5z7M6vveC295AMoRppowLke0Yql90wvpyzAFTkwPLl3PEfQQXLoJTfBYaqyCyhIApmhALxL2HmN359tMwvmonxQCzoAUJaiifjdSZkNE7CNV1qMmbmDxSYvWIN5SmJaxbLJXP4u/8i1s+QBGVkFWgIDuXEC2NuGzf8Q3fvf3OLM5p/MFV06e4M6P/iQnP/XLcNtxKDxaVWntcuDjxFdje3fIYFP52BwTNqBFqjYQy7qjPX/6hnpQEjNKiah0XptEJa6BEhnFsSWSBPUKjClThCIyNRoiMu5IjMYsRI7FMsKQRJutxuu1gQFp+EYu4tD+P7SDWMfw332ufWJMSDp0Bkk6DcHEzSiLrGJTpZODWkj7U2ZyhPHGRk6q8gaD7184Y3rgtYu/9z8TBod2Y9JaEjxiYoWfycoKe7tTMI7LV17kr/6mQdMG/bOf+McsTxy1r8nqTk3TUFXVoaD3oX1vuwZgNLSQAiqLly94GV4NTsa48gSmOwbbAt+e8vIjr1B/B9Yc7FQwfhBu/ZlTcHcNawF0RqgVWwGdjcxX3yaplAJIlZGCYINQqKGqJikyPgIpE2Mp7g5XLRzXsqzH0b80z//D3eNmtteHBSVgUn30s/K5rk+eeL3I0huBROU9JwcO9+8/mlkoPRtnP1gQEjMl+FQuxbSoCqGbE7qW5559gS996W/R4PjMZz7NvffcQlWBszCvZ1TFmIwMHwSYvjfgJBgcIYAXARfwYY6VLegusLd3nhVp+6BuXCA6UE8RAsaDJ7GAQhGFiJPeUMqxQoNBqgpokv5QIJiAaEzhLW0ZWQ9Cfx1RgDXpE4Woy6ipnwWNQsmagrqSOzPdh14fMj9vMV0GnXIgzGK0wnqhKGpav067/TLF5H7QZdAyog8+fX6XGFS+Ad2F+WXmmy9SMcW0LRIESzq0JxYamnwiceTaWYvx4iCMYntt9lvSveqRxwVgthhXg5/M/tTFdfbAVO6TAMZUGC0GQzR/T/oxZvFdccCm+xfZJJQO2iaOYev6ioBIhQFKGbRxCCaFweca4aoq2RpZVqZxoB24vRjo7mKengCVVhxhhG5swckrIOtQ1PH+zIm53t02rK8z3psxIUAxipMjLMX750P8Wj9gdgmIWY1t8gExgjHpnBZKaOMwxziMcyx3Ac5tgtuGYhx1uXy9uFfigSb1X9I3Ug+yDfVZWD/HeLeG4KA+Fp+3GgWG7C30LOR8E4Y5kWKgLVOUP1WaTKc4E1FZkGYB6JmYYiaQiAAujkOTyln6NLax8TO1A6qUL5j6LZg01gWxy4yKERRbcOISFApuN4JF1ka9qgC0IWb+uAXYDJLEndL1be0w2r7AfX6KuXiJcvMVHnvyMdb++Avc+f73M/7QB+GtD0A1JzjHZHk1Vm5M59l83UPM6nroGYde+E1pCyQyMmMVbAvNBvXsaUL9PE62mbjkwIaAhibSTiGOrBZIAIcVCNKR02q7rqMwJU3TUlZCaTpm3UU2Ln6LE2vvg5XTaC1UYmFvG/3zP+Xr//Z/Y3T2EiITdkZLnHz/hzjzS5+E++4HJ4TCpa0gbnzOVkDaD2URsNlXYnnfHn/w0H3j/adJ02nxvWlRT2Bvdm+UWJLdKBRYRCwBTWSkRf0fVU3oe1r3JNFZJW+GUWsjoANS6KH9oFsOCF1lryroLSl9PT/fKzdwNc9pf4xhATPdaIuH/8+ff60Du/btWwBNijVCCAsdKN8LSS2YR3s724izEcANc66ce5mv/O1X6doOZ2f81E/9E5aXJ3Q+UFjBuiK6CSFcrb007OTDU/UPvC1uZfbOk1MIi/PBwK4e92k9zakpGcDNZwqv8TyUORAaXxvTKQpCGFPYk9Cegmc3OPeFl2megFWBxoB5E9z6kdNwvzKfbOB8g7MBOwJaJQdZ+0pDWDQYAh0eIeiIIEtQrRAFOlJad9IkiU7tq3TK/otedA/0UcdDO7TeDvhJw1mVmRf9S3WxlEr/dnmdANPrff21TK/jM3JgZQAuDd5TWEvrO1wRCQDxgNlC4ehmUx5//HH2pjWFc3zmM5/i7ntOsVdPWZmMCUFvzAMzErV4MFGLx0hktNcN42lgPC2wZg1kJTaui8xdK2PQmljkKbIl8G4BKkT4DzEOpgqhQawHbdM5dpKAii4dcMOiTUoEZWwUlY4gWTpOhpxyldfZnOLVLvpULUiRAKntvHIAACAASURBVJ40iqzSs6FwIA7nFaxw1AB6Fvy5+BmyQp9tIAJNGw/27EG4DLtnKZ/ZoDQO/DiCBqGIbQ4aD/nqe8JaZhItwAOSQnPMcMjVwPaBPMPxkkGZDDClbI34Xem1YuiZHaqLA0kYnMSHHwvpPSze41O7UKKKehfzGYt0Xb6NYJQkkCkMN7gQ701I4JopiYWO0nOkPumLp0SQD2OhacA28TynKfhuPASPs1O22ydYe+GvYfQ8mBIvFcFbCgnQblCf/xq6e4Gm26SkJobwFZWCpmljgKSLoueQtJ6iJBPGx72soyH4QCkjrDdoE/BBkXHFLHhm3/hLlo6vo+4IQUvEW7ou0Img4rHaJp3CCg2CSoeRLbR+jvnWdzCzp7HtNsvFhKZpaUnyC6FIAEwXb02PxUQ2GCFiZZJwms6nIZy2XQ/7iILeL6ZG51OWXR5GRBH+4OOtNyb+bYuYudZ2cYiZxCEAaFVoeJbGPoOMb0WrFeY+rnqmqJi2igRh1LSY4GnFoxJZbGj0U9p6htOO5b0Zy69cZG13k4m2sFuzZCpmjz7Otx9/lvZPH+Huj3+U0x/9aap774b5Hr5weLEskg0X/sr12iG4dFOaRRkP3MwOqKG+xM6V77Lithi3IQoGOiVYxWSucVqv4njr+gU368HESgzQtg1lVVB7RZzD2Bl1dwFmL8HymxjpMZgpfP7zfP1//V3Gr5zFBuHy2phbPvRh7vrt34FbToIdJfmkKEYXh7khb27mqsE+jCIMD8F2+NAbYouqXclljxQp8pcK7AOBRBY9biiuOu+KWWwai+vKpaPztdiF2OKh/cDa8P7td9QXr8j3PMfYIG5enhB9EUtyZpLKRF82d+hC5+jc8KR5o459IFd629/uOKL3+WnpOzU3ngSChSgamgNy8XotOdVPbKS3Gzq8B1GDupKLrzzH17QGM0WN8JGP/BRVaeJqYGKyr8mTZ3iZ+zG2Q/sBtuzcgWLxCWwRcmVQYFDlajhG80FJM3oP4nquqwFMlNKIWhUihK7GuBgl7OYtdqnCdw4XloBTsHcLLz/yecJ3Oo62htk44M/AXf/tKbhrii61mLImeI2sw3SWQAJBAy4t776O/FZbGFoK9nQJt3IGlm6BchlChzgHdITgsWbEVQP6WuNb9j919TpzaDezxcBcmj/XCESIOjS4dKCNP4qmpXwBTFxvobj+9Tfa7mEb0wMH95z+VXLgXemFIYA1jtB1i+IS2sb5X63STDd56cUX+JM//TxNV/Nrv/4/8I53xCpy2e/NLKUcELm+NDkF8SgdJkAIUZjfhRHsVFz44lnkyjbLsy2s82ANPhSRaBICqoHGdiiK9TNsJxhvEkBh8GLoDHgToqhy6BD12GAw3R6isUKziEeTqHnOmM2Aog+OgEOxcfcWTwSSfDzMty69vl0AkQEgp4gZQmgZFi3QABokVkZDmIfzhNF5XPUFxB8hUNK50LOyQuMpKcDXuGqOn1+iaDag3aAoYrtDWtJzYECgJ+sIiSRCwnt0MWJNzvIcDMThmNTBABvCkpkcZtN7M4YUJMN6MQ7sQuwyk94TiPhft/jYxY9ftDmP4ewX9XtdbkfSWarS9ebPJmNZA0wrn8lIrzW6yMZTs7HAqRSM1kgGNxQCO9ThGS65x9nzhiBQ2JLQKKKeqvKEbhPTQWli210RmNY7VCNo66gj6Dy9CLUXaFPmlst9kzpBtN5X5EUMtOESnrNcMp+PRQTUImFM5wNaKkhk8ZngQMuIwxkPZoYrppjgWbZRiWQ77GEcNAquUIJvFtggsZMj0yqJnB/IGg8Zm8v7qYlYsAOsSWQtIs6bFUwscRyYNBZs6u8gsYKbpvtRpP7JYxeFAqWwm1S6jZenqDWwWo3YaxqsG1P4ClGD1Q5Dh0rOWhBQg4jDt57KFRTBM+o6Ct8gXcuoLHBtQ7GzRWkrtpvnefL3/gPf/PO/5MzPf4x3/Pc/h5w8QW2EoEKhUccpX9PwvPJadggu3YQW95LEtREFnQN7+PoK0l3B6i4maHK8wSehubx4A2lWhn6kxYU8PmsgiguGgNWCZj6nHFlUpuxcfo6VlXdAa9n77Bd4+n//95inX6KioF5bZfnd7+Ku3/g0nDoJKytxFhJRWdDM+s2NuMYgv/Yp8u8PjDmQYHDg11f/XnPtll4TLHuNpw/tB9MGzssQZLxeCwy8qkT7D7qI0+4fKLr/9xv17FksBL3+UxrpevD7rrq4a7Grhg2O16LeMxkXzObtwFOKpXTXNy7z0tlX+IM//CwPvfOd3HvPLVEAMzkKwftYwvXQbhLTxc8+weq4WcT/5/SN9HjowKSy0kQtAVRi8F0gdB7feIqq6E8mrqrwAUqxMDdw0fPt//OL8FjNyU5oCMgZuPOnTsK9Bbo2I5ga6bQ/OISEoRprCG0gJLFu64Su66g7ZW6W8dUZVo8/CJPTIBPUuJ4tYU0uVvH6doPDvePQrrZhsOEaI0QHHkx2WK4KYLwBW8rrtuF+MXhkuL3JwRbuezKxZcPiU1I8R1F8vcfS6immO7u89NILfPvba/zZI49wz5tvZ2lcJKHkQWteTevvVS3gsuaOSZov8wLOT3npqy+w+9Ql1mb0sjxtijCV+fCfMnWsLg6vogsphpBS6ENqZgQXPDa08XpzxbshKNMPBUVpCbT7SDr5R1Rx2u7zNfrMQ+1Q7fYBMn2cTEFDhEtcAaodjbxArecxYYL3QksLNgaIDIZZq1gDbdHSNVPGxlAQqNPyl8GiPBpMAsoM7GPZ9QBT6g+n+4fHUOhd+/8tzORrHL4GeuapGTyhGgvC7ZMIkgWQQm7boJP0wIW4dH+CDkAYMhBEL62EpO/OfqRJQZJMbM1AW+qTDA50kq4pdZDVBJT04FIEPVrTMLYlXjtEWwo1hNAgjcd7mKTCbTa10fiYCTZOn1nkrLwEqnSZudQtuG8a8ZD9N1JhpI42NHidJz0hGzFdW9A2LRASeBOrXgQROg0EbSF4tIGqlJiKnpRUrI19l7fPfhrrYvzne9Pfbt2fBqak9yUwTttEgjJkXDWOGVKhjnR/wwDMMhn0O3D9+fIzEc8QKVXGRwC5oESCRX3AaCwflfXwelF9FO87jImtbjuPNjXGCqOypO08RTHCB4N1RVwzJDBennDs+BqUZe/RK6A96UEHvvu1z9lDO/TAb1ITIATFmhakBt3BN+tot5uQ0Cjy5yVGVWL52WRaxNkgGhmw/S6zWM0jsSlE9NoJjdQ03RZutg2bV+BLf8fTv/f72MdeYFmXuFJYjr/7H3HPv/lteODNMFmCwqCmwxMyJtsLNh7aof1wWxzkUazz6ueGjkm2YTRMdd9T+174/YBZV5v0H5IrdeTfF9ylQSN6DYxF5Ds6rnkBgRg+ioB14QzNPFWULEq82rieLI1ZXjnCbbfdxic+/jHuOHNL3KzN4trNtSrFHdoPlS1G21BTQ/tnDFEvRHu3MINL6bTmok6H0gKCw6LGMAO8elwZhWCDFywGV0YHsZ5vMQkdPPUSz/7u/8Xs6+e5pYFmrJjTcPpjx+DhIzCZEhRsbbB9xoqiEqIEhQYK56KuSKsgLa4sqBnh5QTFyoMUxx8GeyvajiJrKYBqEdkRh0jRob0h9j0GkoT0E9Uj+4qk/yBte9VG0TPUU6j06hbpNR5bvMUaG6uXoVG+pAfMEirjSqa7OyytHOGuu2/joXc+wMc++pNMxiVOFnvN920eUENoO8QIUiaGsZb43UDZwGQWD/gaIuNCbKwAl7OcDmyt+4JKPRiiJCav4vNXGGhSRphJB2ejC5BEGaQAHfjcfOjOiVa5DzI4lTTfMZlwnz5wAfLEBzRoBEASEGMl4DDYYHHiUvVXx6yboYXQeiUEgw+BypILqyHJfdjXTrMv2W//MEhAV53TmBZbxlVFmEVjPxoGyRrE4dEM/S4dvCcBXrkCX26bmEX7cgoUOgA3DjQ3hP1/54ZlMManz7Xp+2363CwJ5f2By9b9/+b7S/KbrC5ARiUycKYeZmLxdkLjY7WzcVki0mLLhnZ2hVULZg6VRAmvzkbgyhXx81y3YEwFA226Xy6BcJ0sAi7IIi0s9nPHXCDYZdQdpwklPgiuGBFSdbxCZykZzxKMobOC2Jqlao968wIUitRQOag70CqmrWVFrl6iaDCHRJI/eaDPMpAYJIFzNrU3ZR6K2T8WfWI0kUiFXqBL4J8bgMG9+5vuARJfXytIdRdUZ5j7VaRYpvUhavy6gNGO0kfARw14I7H6nghaREZmqZ4TgHnpZTafe47l+QzjYTdY9iZLXFobU77jLbznZz/Kyvt+HE7fBiurGCkodaEnlpl5uaHXQ9Y4BJduYguE5HpHByK0NUYD1grahX07aN58elGyA5YnoE+LpRUiX3Degjhk1rGkUHYtfOmveex/+UPsU+ssece8HLPyzrdzz//0r+Ctb4FxRSiULuVzZ+nqeDANKR3t0A7t5rR+WmYe9ADeudaSP4w1vGF2VZR24KVd8+gxRMM0brqQQjaC0ZDYJdFCF6tpVdUSjVdUDVQjVo+u8Z73vIdPffKf87GP/kSfIBsUgnqcMQTvMYfMpR9ay0fLaIPTy4FxJynSpsOIm0ShzeBbjIuVkgzQNS0Yj3EeJ4G9bpNVt4wYi1BBG5DgmZgGnnue5//tv+OVP/1LTsxLGlOwu9ryzo8/AA8bwuQyoWhQupQSkPX4YslsRem6QGE0bZjRq542hllxEh3/CCsn3gOT+yCM6IgE3gigSp8+cGiH9sbYaw2mDCMMco3+fxLck6t+0/6v79VEHzpIq0IIg+0sCU+DUFSO07ef5AMf+G/4zGd+lfvvuwMj4L1SGLlqDr6eynEKiHWYXK057MWqwKtLrNxxnGZznSYB2hqglbh0eQPaRYYIGrfPVFtnoQiRwAbSwV7sItyT2Uw+H4QTWLRgLaX2Se9a7ANb+urQjl72LReWy2CWatSSiX1Cv1jHfo6caylhLtBVp7HVLXS+JLSCCSaC8tZCaSnwmNJQWI/VHdh5FiczTGixov3Smvs0p4UZNzi0swCK4h9gipjqlVqWH15opcoAwlRBxPT/RnAnRBAi9bVB+rYE0agTm3L1lCjfIYQ0hQyqqYADICaANIk1F2+ks+XiwsSwoLbEm9+6gBrBqGARJCTULN9DZ9inGTK8+JAGk2ikGSlRuysA0kTUpDyCd6ext7wXlu+C1F7Ug2tA12H9Sdh9FurLxHRSD0UFEiJ6Qhdves4JNCZRxrJ2lQEZ04tjS0dOS6VYAV2Fow/AqYegugeYgPVJrKiIE4MpMV3TJgqwATODvRfh5a/B9Anwm/GagofSxgmUKgvGLglxQkmmH1lygY2FX5HJFbmynE/0sLy3y2KQk9Ayo4milbStTIj9ThHzAyWjaUIUs0/aaUagMiDH4NQH4dR7wd4OZiW22XooQ+zflMYfRb4NvQZYkUQnfAPrl9H//F/4xn/eoN5Q3NgxnxxnfP/9/NhHP4j98Pvh7tthVIEdEYLBiMOp6ed4/JEezLweB+TQA79JTUmoKg5HgWiBqMNo5PsF0/XioUa138z6nSIlh+YIQj7Z5vxjIyB5h2uhMBOYV/D0kzz/+UeQp19mRZdZNzB+4H5+5Hd+G97+IIxKulFJE2J2sotLZ1y8c8UeOagjc2iHdvNY9Fny+B+CS2YA0MS5MYR84qN61W+v3wahOu3/N/j3Wo0mlgsevkqAVJJZEsdkWAFYrKRiGI7R8lEmK6s89KPv4Fc+9S/48If+CVUBs1lDWZSobyMTRENMT3iVpvy9AG2H9g9u+9l8hl64QnMVwzxG/WAmxL1LxeCtQ1UwnUM0ahwgcwgXQK9Qyl7KMSmjI1sbcBN49mXO/95/ZOePPsfdtbIjho0jy7z70x+E+zzN5DnCxGBswBiNrNvOI51dnMREKRz4VrESwI1osUy7NbR4O6snP4Q7+mPAcYIETNHEGSK2ZxUccvMO7Ubs2utf3C0yKBv3E2Wg4rJghwx9wf69/1DWJ2zwanuPMASMrv0Z2frXGQemArFMlpa4//77eN/73sNv/dav86Y33YF6j3EWa29MZEEROmtj/6bza6uWyhm4/Qi3fvA+bns4MO42WBxcTcwxsnupithqPPD3YkNdPMhKlw7uNlXqqsBW8XCtqbpWqui8L0rV/5vudy6IkQW2s4i0Snze6eL2Dw+amtZZ69J35Pw7oRcAgihWbe+A0z8Lt/54BBKkgqKIascikQrjCggN+G1onoVn/gBm34nrtDQRBOiLG+Q130QAgnT+yMw7BSjoc5r23cQ8ljKgM3iY1AfDB7tm8N70vAHEY4d5ikAEZRJ9JaOAJqNYCbGTlgX1iMGwzn03yHMzHUXZpv1O6NNHNCGGkkTL+2pxgb5ymCT/MLSxHaKRptRVCZVTsCVelpClu+D+D8HkbXG82THM9mDcQHgezk7QFy8h3TqEGf064SwUsSI2oU6oZgGSxNfFgtZEpnpLLFZh0xjLyXuWrl3C3fl2ePNHwN4DjMHN4/vCKAFE83itUqT5KyBTmD8Pz9W0Lz9L4QJok/pBIgDVtixoa3mNS/eDnHPIYuzk+5PHuxC/0xcLQEg7aOf0pZ0z+pjvMwrECoCRwiRguzgeu1FCbKPYegiemV1j6e4TcPs9YM+ALkXwzYb4XUoS8bJJEyL3nUTEs5lF0OyWW9j9yjd4pqw4duIYp++9l7d8/Ocp3v++CCrREaoKM16KVWwHyLGkj++nRI86D6bDq9ghuHQTm5XEW1KLDQ5rJyAjus5QSNywLMTJm+efJF5fXqR6Zz4CPpLy1tQFaDukNBBWYG8FvrPL85/7GzYfa1nVJTZFKB56K2/51/8zvPNBWKrQcUmNx5h8XDYYbPzc4KOWE3B4PDy0m9H6+FM//BdVELPLq/3/D84RfZXfb6w91zUTr/l10VEVovD9Imku+oaNF0IbkGqZyfIaDz/8bn75V36Rn/zwBxkXcT9dXSrxnad0UYcmhIB1ln1890P74bKh853DzPmJ/uCbnCBZHGj61GpAxGFoETMFPwW/AXsv0+4+yWznOWgu0zUNTVsyMkdZW7oH1pWN//IXvPjZz3N6WtN6Q33Pnbz7N38RfvptYF9g/YUpo1Lw9Vmqoo1RbQGbijkYFBHBqyBFQdM4ZvOSxh2hOPI2Jqc+RHXqx8HdhoYqHlZQvA9Rf8NZ1ITE5z20Q3sjbTiiND2S95e80r+R/tf3uwdd3/sGW+RV7xBiNbRAiBowtiSElMfiCk6fuZ33vPdhfuMzn+bN992NESV0isHGFJgbQHczDyLQId7FmWwduBEcPcHt734Qc/E8+B1i/lsClyxxMfE5UStfTGJeEBZrYf4S9UC9aLDmJ5qBM8EAhMhpkJmRYRfsjKz+HGugD16ng4N33HfVB6QHEgb0IpQgBY1ZRierjO++G07eC34pCkk5gaaGnDJcjeJ36hS6gHKc3YsNVbmHDVNsrhrXs+tSApuWUUvPRAaNkTZiYSGmOyPEas+pTb3n9HqG9T4fI4NEsf80V5aTdCZSu6CMCajtIrMp3VISE2qxd+kAWDoAbIkn2DRuB12/7/U9ABIIiSnUA8MkLSfJaV0GuhkAXVFT2yWm5gjlsQlrJ1ZARngdYd2YuRFGy2OQE3TtCTa2hXG9x3JYB6t4b/GuoLURkLEsdMFA8FKigKMGSel9AaQrsWqwGsBUtMWIbR2xdstJ7JFj4JeZB0tZOOp2iitdxMFSZcKATUL2BkegcGvMjx3lyrrneLFL6bcRC01QjHVIGZJcafYKhv2cboQExHT7GXASU+JqKShGY3xb0cxrnExx1LiqwyXssp8+QEhzQPDxniXss8uYod3DqMMCnSnZ1opuyVGuLUfdR1uw13RY6bDOEGSExcYi4hhaE2d1hnIDoGaC0xbbtFxYPUL1Yw/z9gd/hFMf/qdw+50wHsHyhOAccx8QbxibcqEm/2pz4Tqd/kNw6SY0IU52k3KTRQ2ow1VHUbNGpxMKOgwJre2deUOQGM0STXUPQglY1ChBA9aDio/5pgojN4GdJfhOy/kvXMB/C46EkkvlGH3LW3nvv/mX8O63w9oIxiWtbyjsYjNyJETbEzcqiVoah471od28lhwpPCIa6fQpapT3hEj5vjqa+1p/vz4z/WcsosjDR7JztGjHsDB0/3j/QCbdxmuYtx6MpVhe5cjaLTz00I/yK5/8ZX7mEx/A2VihZD7rEDyTcQUEmnpOWVUxLc4MtrZ9F3oITv/Q2OBWZjFLkbCI4OYjg8QX5eQ4VWh9g3N7YF+GncfwFx9ltvU01OcodZOmuURlHGVYYTw/Dt95ksuPvMDFLzzBLTMhVIErK2Pe/plfhl/4GTi+BOYubl1a5txLX8RUIwivUHQbjLShIEWTfSCooVZLcMt4e5TaHEOW72Hp1vdSnvhHMaJPLHduXTyUSChigBNPrIkIso85cmiHdiO2H1jqVfSG+VEpNScyQ4drPteTJfGG2rW+Lu8yQj40Di21PT0a8l6UmBKqBXioVo5w51138pGP/CS//muf4i1veRO+mwNQuYqu8bjiRnmDeb8OlC4GT8GCn0CzjFu7g+leSWhbSp3FFvsqHfgSY8g1CzCjLzOfTrO5XnqhkSGS82ht1G0LvsHYlE/jF7oqmRXTlzkDEqK12Mt7QCZdh6TeTCmTQTQV3wGoU6pgyttTg8HRUTH1I1aOnoGV40mgxySd15BSfIRQOLLisdER6BJy7B7qzeOoXMbKDKuCU8VJl1ggUUMvihQXKYsi+yMpSK4WRQhpDEu6F8KgLxNmtt9yHwz6IzG94qkkaRkpsaBIEluKWI8SiBUCMb7X+DEa35PrskRMKAFRIj1+ldOpSQxcVXeAvTsE+KBnZxFT5mSIsKbvFiGyqdSCdAQJBKt4VzD3Fasrt0IxBimwUhIAWxrUBwKr2KU3UazcQ928RGU3KZhhbbxWDSBGsGg/ulDFaLsgKJlIsIlVxkMcygZaceyGCnf0DGb1NmBMjSRM0FDaCdqTDEZkV7PH2LAQRoxWTrO0ejt+dpGgW1jVKDAuRJFqk9Y5FTTElMd4bxVVj0gUpu8zChViRdolvDvC8sqbQVdp1s8xb5+lMiEOmyBIsPRphwISSkQFQ9PPr5DmrPYAWYdKoLOOJpRUy6coJifotCQgSGFjejyxH0zOAU2AbpppsQJlGygrQ9MJwRS86UP/lDe/731w8khkDVZL4Epa7+mawKicICQ2tR0A1Blnyw/lYX9walzDDsGlm9HynkRkCMYhWUG1BsUxumaZwF7/2rguGYJYggkY8RExTYfCoJHBKiJI6BAJEVgqlmB3CV5QLn7pAlf+KxzVgnUdw71v4b3/+nfgx98DR5YJRUmH4qyjoyMgWHIJXAZoadwChrGQQzu0H167RgghA0cmRhPzQVOTkxM32mulvek1Puf7bFI/IfNBt4/9JYH/4cE3x1IWfw0ZyYu5HJPjVAxFWdAGWDlyjHc9/C5+5ZOf5BMf/QCjcqFzsDR2qEbGkgZPWUWRCmPN4lIPF4kfbpMMqwpCiKM+DzfJcyI/r6AeS8vY7UH9DFz+EtPzX6HZeoIyXKGSGitzSjdHW8HWHrYK6r98msuPnOPYboxxbC7D237hRyk//i44VkK5BGaCnCw5feQ2Zhe/ynzrcdrtlyDsxio2XYNKwBQVlCtM2xHl8h2cuu1BOHofVHeDuQt0FRCiLn2AYKJAriHpEAKHwNKhvZEmB//QtMKndOustan50NrrJFzrA67DXidL5MBbr/6zL8Td8xQPtkr7PSsd4o1FfaQRGDvGlAX33vtm3v+Bf8xv/uavc/fdt8fDohFKUwDgnEU7RZKqd64Q93r0lgRJWm+KpaNrG4wdI+qgPI49dT/zy8cIMiH4PSpakG6QCh9ZIWrCfowDQC2iJlaWtBY10KmgboIUy3jGhG7GmA0kzNJJNIEueBAf93MTWxqI2lSxauBiXMT+XKyuA+5PvEKjfeU9DR4Vj6r5f9l78yfbruu+77P23uecO/Xc/Wa8EQ8zSBAEQJAYOFOmKMe25NiiOCgaqIGkJEsu/wn5JVUpu1KVOEm5yonKFafKSVmplBQrtjXRoS3SskhRpGgQJDEPD2/s4Q7n7L1Xftj73Hv74QEk8EACBO4X1Q/dt/uee4Y9rPVda30XooZaKnznKOXWzTDYIMQkUmwEokaMsYn4MZYmRowxWLFY14eDt1Fc/DrNlfNI9ImwaAk3m0uDVIk0mReVRMxoHh8aQCNiHG2mdEt8zLzoOSJmnx2Rx6wkAWlg2sVaM0mS5DsM+xgUgWgCIWcRqUyro6f+1XRkzrEkKko0QsRlgqEgStKndHGC1ZT91FbYTRWn2/PVTE6pmWXo5F/bVs1aDcSIqieIpdEedVxnsHIbna07wawk4lWE4CNFURCDIqaP9I/TX7uFC5e/xUR38c0zdEoQGkxUJM6d2/T2pWJbH1udK4NERaMnqEEpmciAkTnIxsatyPIxlAqsmXYAtGLT820fjzAdhVN72Q1g6Ti9ldvYHT2HmD0qvYKxaR5rm7qFpnsjMROQ2Zq1RSKFjJ/aqaiDsExkk+hugNX7wG5QjL7BZHcbT41TD42npJy93yQSOwWDcqdXjfnjO2mL1wlRlCglDcu47imWVm+D/glMHKAYrJisLxoQsTM9M1Fyv9tchSeUzmTbWij6S9AZpFLOMj3vaArAYKyhyi0EowJWpqb7vKzqq1mqF+TSWxKZ5fYxL8gOtIBqjaWtUzx7+S/odys07KUsU3FEsXgDuAYlJFLKw6hpsC4z9SFgbKptrkwfhsvweMn533+c4Vdg4B0vmAHD46e5/9d+C975LljZIJpIzC3nvCiSJ+B0G5sjl9KStKCWFnhzI4lSm5QdrUoMEWdc6lpiLD5qMhqAJAypGGOTEdUyN1cZvDqX4dQa3J+QwwAAIABJREFUjK8es4gdzGZj4ptbIy2/amRWRdvaPvn0ZgaCYIsSlYLJJEBTcOT0GW657WY+/bOf4K9/7AMUQmp7a2afJ9noE9Om5y/WhbcM8hCeL26Yi0Hk31vafD6NDZYGzDaMHiGc/xKXn/hXVPVjrMle2u9skbqtmF7SWbqwhH7xOZ7+V8+zMUzE0t4yHH1fRedu4NJ/gANlapNTboE9CWaN7uETdNfOwe6zhOELjCaX8M0EpEBsl6XuOoPuFiwfhs4GmB6RPqJLiOQshXa+TlU0I8WUSluYbgu8OlxFA+z73cw9Sx6GMy637nYQLFIUqM+6IXMsz4v6O7wsphHLV4n0fmtNCnrGRBQRAhhJ8ichhyqMoFHndiqme0UMAVP0iQ10OsucOn2G+99zH7/xG7/OiRMHSDEKxZki3Y9277Kze/ZKSKXpe1QotCD1ghvjHET1mTgYQOcoa4fvZe/cFSY7I6y9gisaYkjO4/Q4HtqOFpkjwJiASEzZOt4nZ1V6jOIaG5tvo1g5w4UnHiEOv0YRnseIR2xqd2WMIGKTIHfU3Dhnxq4keQpDiCGR3JLur6hJOi3RJIIMCHGCrQxITRNSKbCRDkgPNZv0D9wNg7NAj0CkbLWeKCBKboQAxkjuFg1qB2jYYuXwu7m8/QylCGW5C34HP6lxFFANoB5jHajW6dlnx15DCkAknaHcqt1YpqLTJotoN3Vuv5bTREhlbm12lhpJlFsmFzWm0q/CmqyhHJI/lDvhxuCJMYKT1BlQdVqBaEInkYYySeyUOBAhap0q6DoFTSyZ+AMsrZ3CVstceuG7GHmMQseZkIpoVCSlDRG8x5iZj6QImjdK2/pObfs7k/R7okAwFY0epfZnOHLggxBvBNlA6KBBKEwqRzEteWY7FCu3MVh/hr1zO/SKhmAvEeomSQApxJA+25C6jwsux0VtTh5wxOhRtwfOMNY+V/wq/a17qNbeCWxSq2AlYjBE32Ccncubb9crjyFiMnGLd+AOUWw+QLxyiZ3dXdREOowhNIit8E0qF7ROwcSp2LyRCu8NtugS2E3j14CREmSFcTxEf+M90L8P3CbdpS574yeRuIMrxqn7q0aS+HeZg1pK7WushCRHEx1iCow4hAZMJBhHwxp79RFWN96NW3oXxC1M7GMyuR0bwboSTy6DMzETpDGX3Of7ktKzKGyuyxNJYuuk526U6Ri4Wrx/usTM5XVM7/YrCNouLJS3KqQ1WsksewfcGm5wgs7qGXwzxjTbFLFJo8QISEAkYEiae9ZBYdPmrbFO3Z2twJ5CGMBTBed+53H2/hI6Y8Nescrw8DHu/82/B+++HzYPgqaeddZYDErAZ3Y7CUqqKNLmJU6J94UDucCbGyaFlojBY12BGJfcSoUQAq4oU/ip7Xkrlqi5v66Zy9yZh0AOozAXK7sOzMiq/R+Xzmfajzj4aVea1mYLcfazqiQViLpGgaq/ztbh49x48038/M9/mo9+9H2I1sQQ6FZd1DPbuabCzdMLZLa5Xut8ryfavsAbAnOPbfZEZf8wyJG4mHVVCgxCALMH9eNw6cs8/63foxsfZdDZg8kuYiJRAiIddGRxo2WGX3iaF/54l9UJ1A3oJmzdA72HN4hLj7N9xVI8Fekf/0ASz/VrIIfAbELvKHRuwsqQgeyRyk66IF0YKphezngqCWIIanGUcxFtSZF4SeUUkvN5ZdojcYEFXg2+9zoYYyBGS103FK5MZca2RJvsAM+XEL1i7CemXg2U1FK8FW821hFCjWokxNw1NPpkm+b3OGfwMZFD0UekqIhNpLu0walTN/LQQw/xq5/9RQ4fOpAzLtryQKGV0Jme/vVuHa1kkkmZYIm4MHgqHGsUB++lHF1kb2/MJD6NqXZBdsFr0q+xJifFCGSCI/mVkaCpVF7KPk3sM9YN3MqtsPluWLqJlXicy9/eofENwhVKO0Y0YFSxBKwpMwmh6LQdlaJR0GiIanDdkqA1wacMlUIz4R0N6j2u20GbIQ2KKR3qBoybLlHXCeVp1g68E6oTwAChIJVmJat/fmlrHdooAvQwxVEYjFk9+hBXnozsjh9huVdRdCI6GcEokUe+SeVX1oK1qataIlg0ETHOJcc5hukHafCJpKyqRDihiVTCgEnd5SKRGCOegLVmGujSAN5HjBaYokvTCM5VIIZoPCo1Qsh2jFIaAUqgSjZMzBpYqmANYiuiNYy9ZRRX6C3fjjv+brCrlP4rjM7votpQWsVJJPpxshXFYKsCmiRbompSRYmVJLs1zdByNKMRIorrpIDKXrOE6Z9lffMB6N0GxRGgQiXblJANNpM211BC9ySDA/fhm8vsXKqJ1Kz0J4x2RrnDaYGRlDmlmu4xEVxZEOqAxogpHMFWjLTEV0fort7F6qH7oXMjsIaVDolGzk072qiStBTTXOkdglGbxMfrCfRuYuP4w5x/+jw7O2NssU1ZTJL/WjhUQyIhQzIZrUCMDdY5gga8EaRyeK2YTJawHMEu3UF57EFwx0FWMVuGFXmaK89vo80eyz0LdZoHoa7TvTeOssoNdxQIJaFO88tWhiAw9A4tj9JbupvuxnugugVYTYkf+bGZOVotWd+Sr3+udqCVsmkNiZYA/x5rluR72WKWvCfTefhKzOcFufRWxL6OEGnDhS7ObWGWb2H5wNPsPv401m5T2B2gRmkwmhpWxJA1XXJXR2MV62JibD1g1uE7Fdv/+hns16F8Afz6OueX17j/738ePvAgbG4kRV4PjpSBEYJgKVIwIU+OKIpIZssXvuACbzEY02pFpDnRkjOqbTeStlV0u5HMhRb2zZc2WqzXP49agdHETM99fv5cTKrlz+1xjSuJzZiqcoR6jEaldIbGR1xh8UHxQTGuwhXLLK9uctPNt/CZX/4F3v/+++mUgFcql8mqOMcuXfNavr/NdIEfZSSj6UUGUEZO7EvzJoacrTABLsDlr3L5sd+nH75Ft5gQmnEKmvQdTRhjxkqxs4r/0rO88G+HdM7DOACHoLgbeh87Bkd20eoKJu6x8/w2Zb+kOOiAEqSbym1sH8oOwjIwTh5IdEAHeh3AEiUpcUQEI2amP57531QVntoKGywS8rhfJO8ucB2Yz16af6X9zprkODtrkqPeZne0Qim+vur9r+oEXh1UKF2P2mdyKxhCFKDAlpboJ8SYunkZMwtkaC750hAQV6JB6Swtc+bMjTzw4AP88i/9IrfcfIjGp1hqO8X2cUlTL+s6J19+e6DMpVUxSyYZYhxgylvpHRRcXGPn3JcZ7z1C1xZ0ZQQSYOzB5O5b5NIwlwLAjUaa6Ahhlb2wSWf1TlaOPgRLd4I9its8wWDvBSaXHePRI6i5QGWbVKXQQGhqXNGFEFLAyrRLUsSYAuccO/UOroSiTJ3RJWhyBsQiJkIcpgZeJYwp2W16TOIhVjfewdrx90L/VuAAIXaTbmuqAabO9ouSSnqS/LbJydAlRraga+CwIqFheLHG67fpsE0pnk60SITCOlCfHXBPEz1qwNhkj4yamEukFKORwlmIHl+PkQjO2rSHtE9fsk5T1oXsOohxQmw0N2wATEmkS5QeQ3WUnSWcKwjNkOivJE0ibXCQ3keAOMkTLkxNJ4xlHC27TUlt1+mu3s7ykffC6t3AOoOjh7lSbzPZ+zoTf5luMaYohVjvpgYodY1zpEwy8jFtK3aeGkM0vsYODNZ1aeiwV3fw1Un66++kc/Be6B0B0yUQ8Eww4vJ98FhCsksbC/YAbLyDVamJooy3QUfP0S0LNIxpCFjT0GYqFs6m7oV1nTqlVhCKDhOWmcgmRf8uBpsPYpfvAD0I2ks5EIa0f04FkHKHPDSbum62dwrpWosBxALW7mCFZ7j4zJCLO99g4BTRMZURnNH2tmRSM+lEEfeSZWtIxFJcIxQn6a+9h+7Rh6B3E541HH0oCip5iCp4xhcNF+vv0C2GOBdy+WsuyQ9za6YFSosYh5aOOvaoZYvO4A6Wtx6A5TtTkEorvCgGn7Lecjmmzb5AGp92bj1v0yvbf2Qap5rnhjSvY+3aZtvf6NXvb3/M3y8ylxZ4eQhRktSaQmJnMWmilCfort/N8PxjjPc8sXmMyqXsJaOJPDIx7WvBt2PREJuAiSa1VHzWsPNHz/DMFz0rO+BWDvB4f5n7P/ur8JEPwuoqIdZYyS2fJBHtbQdH8uaOAT+tIU5dM8x0Qi2wwJsVOa1WBDEmGfaStqgQIfiIqqHbXUZjymgwAiGkDShm02xed2naXnoqdPrq55BOzT5AYs6oiNPfKRZXVIzGdaoTF2XUKJOJJyUtKzEmYqrxgRABSqIUbG0c4K53vJOf/8Wf4/3vfzdLA4ghUlpHqCfYwrYBq5cnll7u3l7n9S/wRsHMyWszDJIFpSnaKhCYI2HjLoy+zc7zf4YZf5vlzg6+qbGFoGrw44ZCKsxul/Cftnn0d4dsXobYgF+H/m2w8d6DcAz2mst0O45O3RCD5dKzX+ZA/wboHwMUKarU1IIAlFiq5KxaCziamMs9JHdHxCJq9/uuMqNtDcxd3+z3CyzwWmGeKvK+RqRKXdKiZ3l5CbERH1KAwnbK6Zr/w4aoEBql1y2QIond1r4hBE9RWcb1hNYdkiTkA+RkFEPSKQyR7tI6Nxw7zgMPPcCvf/5znD6zQfBADBiVXBV11SR7LYIzMnP2ogAqOEkdToMoakr8ZBm3/DZKM6Abu+xc7jCsv0toXqCSPYoqkRpEIcZcNhYgSElNRW2WsZ0TdLo3s3LwHth4B+gBGr9MYXt0TnwY0+kyPtdlOHqEpn6WLmN6xmEd+HHqBpcIIoOPlklTEeMqJlSoXcbHCSJ1yr7QBvF1CgJbA65LI5bdxjJkFTo3srx6J8sb74Tl24FNNHaIwSVB89bMl5k8dqpdsNPki6gQ1WJYgs5p+kcnMFB2L3TY3v4reuykZxZrtB5hTK50s6CmwIeKGPtoHNAUXXpLy4RmyM7OBUw9oXIBVzUUVhnXI6wxU0HyGFIgPnUZBW1qNFgMAVeWIAWTUDGOS9SsYgdH6B08CctrsHOR7We/yXDnKbpmh17hMS6Vo2n0KAFVh4oQpcJrn1FcIhaHGKzdwsqRe2HtTohbEJdhdYmV0zuMntvg8vlvMm6eoTJCaZXK1RiNaDCATV3KAkDSvUJSc7jY6VBrl3pS0sRlysFJDhx+N7L2AFSnUBngcUTq6d6awohJWLwUQ6BAQoEpHKy/g3Uj7D5XsfvCVzG6i+gljNlDzAQjI2ITmfiAbWosfYIpmCiM6h6+OppI0AMPIGt3gx4iNhUqqUImcVMmzedpHRezOtGrJB6CBqxxhGiw7gDFwfvYsMqlZ7oMh4/j3DYwwuswZexpg/Ntxk9KeRNXEigZhw20Okt/5e10N++HlVupWSGwRFRDoQOkeysrhwzOleycX2KveYxCL+PiBBc9NgYkzGTBoinw0qWOFfW4QjvLDNZvp7/1Pli/D3QLQkHIzGVss7PmK1XbpUjal2ZGwbWXqJkqVSs60/KZLfm3/81Xh+xe8sDXxIJceguiZeAjKdEIoykdEIvhIHTvZOP4mEuPO66c32PJCJWpwTepa4UxEIdJB6asIDr8UCjtGjwHV/7f59n5Mqz4DueAvaVl7vrsr8JP/i0YLEFRYMWBUYIKQZMRXaUAbfpy7ZlOTxo01W4LM6digQXetAghRfRUMSaNeu8DGxtb3H7r3Rw/eis2C0xITuE21tL4JPinMuvPJpCJpfR1fQStTFOS27DPPLkElhAFa0usMTzz9JM8+sg3mIz3CGGIMYKPYzrdAaPJEIyl6q3R7a1yz73v4hOf/Dg/9pH3YEQpkKlAt7EVTT2h6FS8OHosc/9/6WtbrBpvPqRnavIYz5pEkkZkE2s6xkAYQ9wmXv4rhhe/wWYxgTBCTSSKo2kCVezDzjL+P+7w9P89ZPVcakCkG2BvhY0fPwUnGup4Bdft0UwCWk/oFRMme0+z89x/ZunkPeA8jSo+e3w2ggkFIhYKScKdpkEyFWtwGC1m5XBmlnU1H8efZiMuiKUFXhPMBtP+HKRI4QxBlaYZc+jwJm97+20gitgCwRE9Sbj4dTnriM0aKY0KXlNUstfrsn3lIk9891GeeuwRVAUfdKYyKBbEYaqSouxw8tQZHn74ffza536ZMzduTEucQpCUCTR1riRnF2VX6zXQ9VOTmS5NWQitJqGzDUEilAOQHvQMvZMdusPD7Jz7cyYXvk7QZ/FyDhhSFpbKlRi1NN5Saw9vtjC9MywdfCdu/S7onIS4hNcOxlXUUSjt2ykPbLDZP8344p8zvvAV/OhpxvUuJu7R7QiBCY1p8FIykmV8uYUrTtErN+kLDLefZW/4OM5eonRXkGKIwWBdj2FdEuw6tdmi6J5g5eDdVFt3QHkMdBmki4ihMJIFxdO9KIziJZBUkmIu+zeIGCxKVE8Qg7CJdG9nyXXplMcZFX9BfelRdofnsM0luuWEwA5e9whBaHRA0C2MnCSYIywdvIXO+iboDpz/NqPdJxlOnoNwgY6MQCxWkzC1TbLISU8qpo57znRAfOqMHQzjWDCWVaR7irJ/E0tbd8HqSaiWYbDDcvkIw4uPUO88ysXRk9h4AWt3EZeF17UkagevPZqwTrV0M6trd2E37oLeDcAApMRLClTIynvouoPE/o2Mtr/BaPfrjOunqWSHQmtK61J2UUj2YxIm8xjbgKnY1QGTsEJRHmZp+Ub6m7fB8s1QngG7TsAhOBwGQzFNio+S9rEaD2USoY/B4TgMywUDu06ve5bt57+J6lMQnyH6Czi5AjpKJXKyzOXxElquE6ou0j3G0uo99DfeCZ2zENbAlEkaok1QyjNfSSWqZrr05MYCkjVeRFKGnSi11ljXAdaAM7itFbZ6N7L97F9w5fmvMYnP48x5etUQ0RGTZkzql+GIVKisgztCt3uG/uY92PVboTyExj7GDNL8jU1aJeQodJfob6zT7Z7l8vkvEkaPUu89hfXbdAhUNmJsQI1luxaC3UDdDdjOcZY3zlJu3pGuX9fBVqnzYk7WV1rtSF5k+ursLqTejleVr6U426yqobUmDPN/J1OSaj4BzLRBO9JziC2nx/c2QRbk0lsUqdJ7Zl44CUkAEIexB2H1blaDMiwLJle+ymj0BBVj+pTY0EA0FKVL6Z2+oJQD8KRn/MUnOPenYF+AcrDG3tqAOz75KXo/+VNwIGksqQpiEwUbJDkCjlRuZ4W025p2Msh0gwdem8jRAgu83vg+xrC2ZJAIIaQOjGVpefjhh7j/3vcSvFAWlhh9EvDUiHWOum4Q6+ZiEyRiFnKuonLV/vOKT16nBnaYZi9Bm7lkcLZD4yPfeuQRfvt//aeMxiM0TACliR5rHUEFbAdMSW+wxrvf/SCf+vTP8OEPPoxRT7c0SAxJY8pVKevDlC9xMxfpHG85KHNyAkkodfb8syGlIb0SJ9BcYXT5W5jwHDHuYYgUHctk2FDpAEbrNP/+Is/80Q76OBBgsgrVzbD1N0/B8QaWJhA9ha2YjIeUADqk4y4x3P7PLMXzwEGcXUFw2BxqFE1WsqoSCNngIyfNM0vpz8Z0JKK5A0zbYWdKLi2wwHXhWqR8i+ReRJJe0eragJ//hZ/FxyG9QY+98QQjJSY6pp7PDxkiAWdCatutFjWWADRNw7/8P/4FTz35GKmMyaKqaW8Uk7KSsJiyy5kzN/PQQw/y67/2Oc6cPkLM3llhc86vkrNWMuuTM4x0qvNyPUhlbBGfCK+YUxSzdycIKhU1AcsStnsC6S2z3DuIrpzAjx9nt36S4fAcw9EIOxEKW1FWK/SWjtFZPgX909A5AdUNwAp1NKjY1CpHSiaxR+VuxK706fcP0e+fIO48ht95nmZ0gfOji0TTJPvcLmH6hxgMTrO0eiv0D8PukMGVZ7B73yGEZ6j9s0zGF4nBY7RHb/0Y3c4RVvonMf2T0D8BxRbIKkiJqmfaPF2ZBtJSi/X5LmOaUrIARDFWSb2xikQwOUe5skbZOQ4rj1FvP0UYPc/e9jNo3CbKLliLLTfo9U7SG9wG3dPQOQLdAdgRg+W3Mxg9zfjydxhuP0H0l4j1ZRo/QmKgsAXdaoCzFcEL0Xuu7O2krCMDUnUwnRX6g6N0N26D1ZvB3QBxGfUWMQEOHqG3dgu9S99i99K30Pppmvoco/o8TV1j7IBub4vB0iGWO0dx3Zugd3PS9QndHHB3YIU6eiwbuF6Hfv8g/dFJJldOUu8+jh89Tz25wt5wnEqyTKvYHBGjWKMEU2EGh1juHWV5+SZYOg1mA+ISkVWQPgBtfzOigazplXTCJWeVudyxzOHDEk4c9LuY4gCra7fA7mOMtx9lMnySUf0CUYcYEcQs4TaPYbpblKubFKunsr7QEYiriRDLQ6NtFt4mHRrmiaV2JubulcI0W18RnHRIs7mDxAMgS9BdZfn4UZYP34W//AhXLn2L3fHzxPoKxAllWVCVfYrOCkV1iF7vNCzdBMs3gawAJRGXM4ki1hokSrpHrEO3wlRrrC8dgOGj1Nvfod59Bj/cZqceEr0nYhisH8J0DlH0b8Qtn4buMbAbEJbQxiHOpWVB22UhBXGtFnli6HRNYrZKvRjt3+baOGOUtuR0nxOQF7R5Jb3W9pgns16Jz7Agl96CEE1ZDKUIPi/iNtYk2janU8pBzOZD9LuHKM+dZvvinxL9k0zCNtJcpBCHsw4ZTWBcwAsDrnzhSS5+EcrLMDbCuVK45VM/zfInPg5rW1B0crfThhAapHRpscmLWNCGYGMS/AXIrPkccZ3+WRBMC7wFIK3ekkZCAIzFCLz9zhuTmGlM9gZKLotLKcQ+VdHt2whSVge0WbVzHW9fMXISYXr/Vf6uzn2FALW/RJRd1O6B1AgNGiO4inoyoehvsLF5hLve8U5+5pM/zQc/+CCDPhTiEBLh7ZwDDTQhYIuSiW8oXVtnnoil75WJNTVUr4NSW+CNhNnTn1KKmvcGjRhn8DRZyqMBbWB0gcneE1TFHhohqCM2NRUl7C4TvnSZZ393B/dMigCOBmBvh0Mf3YIzNdGcR5uGsioJe3t0BKRb4f0IV5xDeRw//hauOgSxxNLPmVQQbduYQrEqaM5UEvU5oBhQsVM/U7OZbLNkZ9t9o00WWWx/C1wf9jsNM6Q1Mkm/CL2u4a67bgab9pZJUKyVaS+Y1w0xOV6NgnHZvYzwB/92ddo11UibDSiIpG5L3aU1Tp45w4MPP8SvfPYz3HDiCOO6pl+VGCJ1XdMpK9DWxQrTEq2UrTvzbK/r+mNExBNlhBqLiZ187AJECa1Ury2otYtoh6K3ifROU4wusKYT1nzWcTPt+lCkbKdyOX0Fx2QCrgxYJ4SsVWhJJX9J43QZOA1rBzBrI8o4oaz36IdJMhicTXa79BLpoH0QB0sBls7S5V5gBH4H9aNMNpRJ70b6QB/cMtCDWFI3BrEm2TZZw2vfXRXIqjcpYDW9yW1n3NQdy3qfGoboEqiD3jr0bqJc34HJDl1psp5RbiVvq9RAwayCW4XYT4RiqDH2ACzfSGdwD53JZfDDtF+EOu0nzkGnC65MYuq+porjrP0o6f7YLtABenh6RN9HTAqIWRSJBdgBbNzAYP1+qC+k+8Y4p4EUYKocPOtBsQmxB6GLujJraKdyb5FE6ioDhA50N6iKm6g2hhD2oNkDss7I1GfK41eSf0fRBbMEugqhA1RQdYiYJJuLTeo+bVsyAWMUKx4lZZQTA0YSEaSmyPyoIZYVrncEVm6ic+g9dMIQ/ChlD7SskRTpmVRLYPoELYlBKEyTVbXTrW/l5Nv5loKYc6uPupyEkP4yBTcLgrcUbTmdD4jpEJsCD5TVKrhjOHcLG2t7aYxonZ53TLphmAKqVXCbwBLQJQbw1BgrTPwOHddDyB0GNbcxpiTqJqZagvIs5eolyrgLYZK7WRZAmbvZ9aGzBKZDrRYfHZWtUtfkOJ0BecyPM21mEqlv2vbLuWhRrqrnyQZ/HqFYnb6Yxw7XTMBsVxKYO1Z+Q0pCeYlt4xpYkEuvM+bKJ6ePvTWb9aq/TC0Nr7Iu97GPs8XkasdyP7fZRgMMTlwayDpnwKojmArfOMrubRQ3rLGxcpCdc19hb/cxjLmA81ew23sMKGC3y/jfX+CFP71EcRm8dBkePsjxD32E9b/7t+HIQYItiUpqJy4OY0DEEFWJGrAiOCsESVoUaWud5Sxp68QufMMF3gpoUxuAGCPOFYgxjGtPUTpKC56QZoik6GygQSiwJm2y8/XSMv3nxSvLKz41ZKqlmJAKbduIkWLw2S6tOgalAQkQ62k73xAFyh6rq1u87W1v55Of/Dgf+/H30SlBoydowGjEFEXalMVQFAXjpqEsihed0fe/MCzc8jcE9kXDZs9ufszO59jNkrP3s6Ki+/547sUAIVDZCtEhUBMnF/H1ebpuQqwjpe3CxMB2B/3KNs/9yQ7VOZAa6mWwp+D4xw7CWYHyEpgG6wzUE6wtkhEaYsq21T2sbLN9+THWN+5BtEF1dlLtjtamottslE8jryJJi2F6H+Yih1fdE+b+ZoEFXjVecgClwmmNIQk4Z++/CZ7CuqlGx+s3/tJcaV1MJRFNTqCZeFK78+SIRzUp/y8aym6P02fO8vD73stnP/cZzpw5gPeBTmkRAo1vqMqSEALWGFrdwx/ITGsjNDbmIM1cboYqVoRGG4xYjPTwaglNTcdWUG4lg7jQ5AxrrkGQnNkrjlhHTFngpCHEkLqmmdnqagQihkgf4/qgG4lQsRFczISVEmJyaK0pEiEQhBA8WM3dxwIxeqSMmE66sBgjplXzxhKjARyKxRaSTRuDbwk8s/+2QCJSRAySUsimwTAhZWhPgwnkz/AdIgEx69hBDqFN703rF7U0VkUTCyR3e9MYifUEa9ahOgp2koyXeVojf340QOGxNkX3NDv7US2KA7GIFEmEHFK9pwKOAAAgAElEQVS3QiOJOIohZRBJSJlT2pDrsBJRZixtcD8EQ1SHsdVUEqG121QVMQUxGiSWGPrAWqr2MB5cnewtCanbtrS+nckaXfkjTRdiFzWpW68qxLY2e37ot7dN0riMeT9W1RQoJPlx2AJMQTQVo9jgzAqFS2Mc2zJUed/TdN21puuwRnCuzWJrwJZTv1WmAyTkjn7zFMjsuepcLU5h02GcBXE26fg6S2HXaPyEQgZgNvNhcm6UaM4QyvazKQmhQKNLp20S6QaerusSCQSf1wqX9vGoBtxKOmJYxeg64po0TJGkGRZdml+2AGOo0STabW169qoYsVhps7DmytimwnHzsyVd/XRFnssymv5F7p48bylPCaY5W+yasYarfv5+q4IX5NLrhfxAw/4fp2UrUZPIKKadLiHxmFqkN5mYJmqrUURIi4tVghiiWGTumDLlgPPIsLPKShGBWCW2GCWq4rWmLAvUdxF3FNaXWVp9G0vhIpPLT8LwAlUzgfPb7P3Bv+OFP/xLBhcLdunwTH+FrR/7CY585hfg8BGQiC00zXZTZJl7S4yKETPnL5hsgJvcCnW2Ge5jZBdm9QJvMsjVP+nMnLCuyAkZqWOaxogxQmnnySOldA5FaeNaPzgmNiVFqyqikjcukzZnifgYMCaX5YVIYavUtUOVVpgfX3L4xCnuvPNOfuEXPsWPf/R9OJv0/QGMSupQEnNompTe3SmKa0ZOXiQ8eE3MOwqLNeR1w9zQTE6Dzj1TmRpAydQLramXtC+ylxFNLvqMsn+Yt8SSKoUKEgtiLRCHjIbnsLZGqYkaoa5gZwBfucL5f7MD3wYdQdMHewsc+2tbcNqCuwIETBRo0r4bBaL3OJfamTsniFeG2xdZpyZKQxCfjUKHa9sJS5vBRHKAYWqtaYyICEZai35+jMrcv4vRu8Bri/1hCAuUyS6cTkalsq1Dt6/g+lXgevel9MlNo7hCUgmpRgRH1y6hvgAiaiJqBxAMZa/D8RMnePgDD/L5z32GMycPYCIUzuQGVEphS1Awxs551oowy5LVfWdwHedvUgmYo8g/m9n6QLLZS3HTTywExBUkhyDONC2M7j9u/jKFoApGKoyZZ/LzWqOaM6MTSZCyWgpU476LM1Zm162J5JGWeEkvYkzr1uZ13EC7X0/9i7l1PTmoBjdf33RVzNzKfn2r2bo39fKZjiOxqdNmu7FMP6Sciz7MjqKayIxEoOaPdyVttiiuvOYDTmtzezfi7IiSOn22916z/TYNDMR8X8Tmrngundvccfav7IIxQtt2PpECOv2tyeLvIm7uPNt76YCUeaetxs6MYaAlZluh8paTtDIjMdLnzx12Pq0s9z9LQ2aOrJwbAQ6bn227r+scF9SOgmTHOWOnj6v9P6YdM1DM+pileWivpfaTMv6kJb3yCVs35/Ha2fGdzcHJaYCHNO7bK8javqq5rHDK5bTP1GWxf/L5zN3bzNak+2OBPm2apWaCU0WQMl9HJsVtPkZ++tPrz70gEar0MbYVoTLzHzt9bldbDNMcL9n/+r47KNf89iVe+P6xIJdeT+iUUGR+iGpbYWrmU+RrJCpFdGBMKmfTJMGd3pSN6hwj1Twp0+DKzl+bZjodbflLTctC5eUuUhUdxvWQTtFFQ4GxAzDrBDlIdegmGF6CCxfwX/odHv03j7FyQai948raGjf9jb/BoU9/Cm46CyiNKMVUlyW1tNQ8EdtJpNmZFm2N6wUWeAvjKm0HkXaO5J9fgjyazZwfFLHUImaNm9km2Z6XQfG+wbiSsqioJwFX9AimTF1cyoqtgzdw59vu4tOf+jgf/tD7KAsIjccYizEmZVNKS1wJ8+GSV786LNaVNwSuZbhf489aF3afe5HHWSDFM207DVo73qQ9pDXSfJMDGC6iOqYZjehb6MgSXDDwhOXZP9zBPwJVA6MudG6Cgx9chbNA9wqqe4nEavuTW4gxt2MOSe8seo8pIqUxKbpoLBGHTnNw2/Oct+T2U0UC0/3wGibgS96nBRZ47dCOxeS4ata/Aeai1lOa4Dpwne/XREAYIlFrSlOk1vHBYqQDRZnKm6xQDZY4ceoGfuzHPsx/9XOf4vgNB1Ieh+SS00x2XNuzkhe98lpgurZpmwfGPiJkWoQw/TcTBaTsBrEvfybztsLVt3qetElH1qt+2X571We027F+76y1l3q68/Tc9+3g7ns9Ezhy9SfMntX3M7KMmf+UF3/ivvs3fXHf/14SiQB6+frlax7/JXGt+321pTejeWA/8XOtt00/f7ox5TvYvrx/a7rqh9n8n/+X6fv3z5trXWl7ft+LzNj/N9feE6/1V/NjenpK838xVxkApAY4+Z4ks/Na96+la/Y/v/33P8FMs6tmGVbzrvc+W16vfVX7r8ztf7F9x/7/vQgvkqd6mb99rbEgl15n2KuVuHLkQlvBP6BNRIzG0ORNMLSD1rTHUCKBaJLZrUwwFJg4x2jnhSSg2TgXXKvgJUk8zVvNnVuFqkysq3HCeLRNp9vFmgouX4F6Bf7oi3zjn/4u/ee3mYRIs7nM2gce4NDP/l04eQzVyMQIRdHJ1wZITKyumDlDmn3fL7DAAi/G/jlyrfydHyY0pVyz/zRUJMsUFOyNA1EFY1OrXg0BXMXWgUPce+89fPzjH+cnfuIDdCsYjRoG3RR9mkwmVFXVHnC/Q77AmwI6Z+i8VNZZMs/s7O/m0gb2UauiqJW2wCCpitQNFJZoBEQx0WOtwTWWTuzDqA9Pes7/X4/TfAM6NYQB1CfgxH+xAbc7WNoj6BCE1KkoatK+IIIFIwGCR6zFmKRWUbkO+BLjlhApcvBo3pDfP3NThFSn3y+wwBsJLz0mX9+xqtrqC/rsPBpCAO9B1WFdl+AbeoMVTp06wwMPvovP/OLPcfbs0VwJM2uz/XrMux/0Z76S439/Wb+v7tg/KLyR7t8b8fg/6M9/vc//e+HVnN8rmjNv8vv3WmBBLr0OUJhqCE3bD2v7Q3Km2gyiZHjG3BoVkIaAMtFR3hSqLBImBDU5bykRUtP47nwQY9qefN44z/83qYo4tg6iJLk9Hz2d7iCl8V8eIU0J//qP+MJ/97+w8vhFSue4tL7B8v33curXPw8nT0OnT20cpigIGGIIKZ1SaMMfvN4GygILvFHRpuZeG6/3vMlKOG27ZpmtJ4pM25WWlUWMSy2hfURcyaGDm9x99118+lOf4AMfSBlLo1Gg2ykIMeKMZGJJXhxyer0ve4HXBGlHm8tLmleXnwtC7iOU5omlfUHn9mhtBkAkiGJKBzEyCZ6qTG+uOsuI3YTdAN8e89TvPUXzTajGuSHPQTj7sXW4uSB2d6hlhFGltA40EmLMXRlT2ntSLUxlbs4JMQj9agDq0ld7vu3FsD+iOr2Et4ChucACM1zveG/LbSRnCCRdpaggxiHiCMOG7toGx47dwHsffpjPfu4XueGGQwQfsVb2R/QXWGCBtxRe3r5e4LXAglx6XTATDpO27IP5L4sguYCM1AaDCcgE7A4OTyWQUu6UqBEfHVEKVApS3WlI+hQv/uikJfYiYz1mwit3b5MkL1EYiFFwxsLeEIkG/uAP+er//E9YffY5usZwuXBU972LU5/9PJy5BaoeFB2sJsmUGCKlFBgDdYwYYzDyvVNrF1jgrYx9qbMv2ghfv9mj+b8oOlWG2c8BCI2POGcYTxqsK+l0+3S7He65934+8TN/hw998H30B1BPIt2OxQrUTUNR5u4b+ThTCPs+YcE0/ShDc+k3oLat/U6YZpGn4u40uPbrLLTFmAZN2oOqGI04idR4AooTQY1QGUuBJWiBNau4ZguevMLzv/8o/ptQ1iB9GG/BqY8dhVsMLKVymiKW2GjAC1FrVCNGTCqJEyGGVP6gKiA9fKioyiWQpPkyk63QXB43K4eBxQhe4K2M6xn9uYGEaspKnGsgYW2BYqiW1rnh2GE+8qGP8Ku/8sucPrmBGAg+7Uf7Aq4LR/NlscisXODNiJe3rxe4XizIpdcJ+5Td99WWKKqeZjKitErqIjGCcBniFTA7IE3SdbB9MCsYs0xplkD6BCoiFqJko3daKD/7uJmWNxglNSxMvxXc1GEssnVcuQKGe1A38Idf4D/84/8BvvrnHCgLLpcFK/few5nf+E24807UlTRFh9jMErEKa6Z1+01UiqlM1GJTX2CBa+GNPS/2O/ozYqnNYFIKZ2giqfOOtSwvL3P33e/gZ37m43z0ow/T7UDwSrcyhBBoYqAqk8hlDBFjrrU1Xa0z9Ua+Rwu8PObpSNn/skCij9qNqm1dY2j1u212MGdCGKnMW8QQCIx8Q9d1cVg0Ktb2oTyEfa7L03/wBKO/hOUGhg7iOpz+yWNwRwcGF1A3yZ1+bepUqIoYj7NZPSmAKzp4bVCB2oM3A0xxCKrN1BlIAiaXxLWZxOlM57vcLLDAAq8GYpLuWSrNnuUh1c0YVxjOnj3Lgw/dx6/8yi9z09kNQoDYNHSrAu8nODsfxHjr2aKv5HrfSvdlgbcGFmP6B48FufS6QJC5nk5idC7XPyCMKTu7EM/D7pOw9zjjvccYj55lNLmEr8dYNfT7m/SWjlL0j0LvOHSPYe1Boh8gJmk+KJqPn+W993mDEagxBCIWxWB0di5Rk8YE9QRGQ/jKV/mz/+a/Zu3pp+m7yIU4pnzPg5z5B/8A3n4XWpVQ9sArnUL2+QbpyqAo5gTOFhN8gQXelGirfHvdCiPKu+57J5/85Cf4az/2IFWZhQZNzMpvgaJInXFiCJi2zceLjjiv3rzAjzKmhZQSkqc4X6iSNQBVcg8aSS1RFT/XbJhcW27y+1N3FxGH0YiVSAzCxNeYZkyndPCdXS7/yTku/PE2ByN4A+MDcPNfX4c7DKxegGpImExw0YA1pB7GpMYyAkRNrYSD4IzD0+BNh7Hfon/gTugdA9NNLaGpMWqn+5zAtGh9MYIXeCPj5ciHNwoRY0ySgYhERFKCfwgTbrjhMGdvOcTnP/9LHD+2QeOhKkCsg+gpXG4qc9Ue80a5rgUWWGCBH3UsyKXXC7kjd0hWMkYEoUbYAS7A8DvUF/+KK89/jXr32zjO0SkmDEQhBiR4ZLvDzqUuY12mWD7J6sG7KLbeQdE5Bd6gujQ1vKfpSjoT9gbPrBVmRNRgYnIKvULphDDcgd1t+OrX+Oo/+kf0nnyCYmebYa+id+vtnP2tvw+33UFwFUNjKUJNYe3+cgdJPFbu9MqkGeOK6od+yxdYYIHXCi92ktsOdm0z2KDQ1GPW15b5qZ/6KT7y4QdxFiYTj6kEZyDEGmsNENAIxtprEEvt571EtssCP3KYjRx58aOc+zntTm1b47ShpC7UZk7sffaGtH8ZBIOGQM86CAU8+l0e/e3f4eL/8yVO2pIoNXEDzn54GblrCVavUFc7FDY3yIhx1sc3D73owZiALUpiM8ZUJSFaYrHCxB9mc+0OqI4AvfymgFDkYI3mS5VrD+8FFngD4eVIljcCAaNREWMwKEEjJtvSVRduufUUv/q5n+XIkU06nWTPagQhpHPPzZjnxfThjXFdPyy8kmtdlMUtsMACrxQLcukHhJeLgggpKOqDglU8HoeDuI0zzxMu/hkXn/oCDL+NmTzHqtmhtLvgJ+AdTgSRIRqVig4d02e0+xyX6qcYjJ6lt/kuWLoHkQK0l83xiPcTCtcqjPpsNNuULeAKwCahJWNxBTAcYUe78LWv8lf/8B/RfOk/sqawV/XwN9/Onb/xW3DbO2BplSgKYUJZCUKDikuqUTFnKpUQJGIIdAuD6EyEdbFpLbDAjw5amsdgplmO84VyTmaCzYN+xd/5L/8mH/7Q+6gqiEEZdB2qDaoRa2ZKNBjD9yaOFq75jzpmI8akJ381vySRqBHBEpEsnO0QLJaAqKa4iHGz2EjmmUyT4imNQAEwmcATT3Dpn/w253/n99gcjWgKz84a3PiBTey7V2FrB8oRxgSCz1m7FYiJiAGjYELOrVKAOmdQNXjTZxhXWDp4F6zeBuURvB8gJiQCra3jEzuXcsXLD/EFFljgZSBoFCTvF1agiRN8cNx49hj33Xc/J09tYExK2DfSSn4zU9fX/dL6Cxv0pbG4NwsssMArxYJc+gHh5RZk1WQyOys0CBoj1kwQs0dz/svsPv/vcMOv4ppnsGGXUie4OEEDSCjSbikeEXBmiDMeE3cZ1WNGL3iG27usHTHYjbuhOITQw2vAuhKNKXqjYqhDQ2ErxBUE7xHvMTmzKe4MMQ745jf5+v/4P6Ff+wabatgxgpw9y51/7zfhvvug1yciWCuUUqLUNKGmsOSyl0Raxaw/YYgpkvR93KcFFljgjYjsJWuW/28NdtHk+Aup/MA6br35DDccOcyglwx9lchkMqZT7de8eNHhXzJ7aYEffUybgM9Uk/IzN9LkDIPcLZUSk1VVop+ATlIbU6ugPpfMNRAmIAXG9MA7StdNxNKlC1z43/453/kX/5KtYU1jC8714c6ffBfujhLWn6eJe0hsUnZSUFxV4KUBA1YlZeFKkdMfJgQBNygYTUqGcZNy9Va6G7dDeRhYApdKzIW4vwy9JdEWw3iBBa4LxlpCExCrYMAZgxjhIx95mPX1JRAwEqd8rkyNzv3NARZYYIEFFnjtsSCXfoiYppeStI7AYrUCr4jbg+F3uPTEn6A7X2KgT9PRHSwuRT/FIRpTypOQo7YBjQUaoZAG1W0mk+8ymdRcloKN0sKGBQ4Qo0VsRRM9zqXH7hUUi6DYaLFtSUqIGDx8/Rs8+d//YyZ//EU2a2XPWIZnz3Lvr30W3v8ALC8nDQoCqKUSS6SLs0W+vgimyb2lbNZXsdkPbUsaFlhggR81GMyMBJpO4zSnBcUZg4+B0jnW13oEn4x9ZxVx+9+4r0Sq/X5BML25obPnHPNQSIRSIpdUwUpFyJp9lgZraghXIAyh2UHri0g4D2YI1oP0QA6DHgC/Aef2GP/2P+O7//x/59Bwj4kPXDh0hHd88sdxH72JyfCr1JMhnXILxyV8sz0dkc5YQgjERlM2b4yIEWJpidYxGfcY6Ra2/zbWDj6MbN0Oss5YTcqgotWLinP7nEyzJxZb3wILXB9EDMZAxBM1EEPDwc0lmhAxRtu8yPmi2dx5sj3AotxrgQUWWOAHgQW59ENCSyypKioRI0rwI6yzGBlC/ThXnvwCYfsvWTLP0Y2Xs+itQMwbok06DiqAUaIYNCjEiLWRjlUqs81YLds7/4krz3dYWVoHZyjtQRolieWS/DbnChoCRhUXBbzP9Xpj+M63+PI//G+xf/z/sV5HJkXF8OAB7v2VX4IPvZ/QMTTO02k1JTzJUYggxtEKsCadjJAFzIVpt5zFhr7AAm9iKNYI3kecMxQOWkljay1tM/mXLXN7EXnF1T8s8KOIuWyeVjIpvRQSJaNCDGCt4IKHMAK7A+E8bH+bZvdxzl95khgvEYbPI7pLWShCj0KOs9a5BUZH2Pm9L/PNf/Z/Mri4TXSW4foqt/ztj9P76b8Fh8b/P3vv/m7ZVdb5ft4xxpxz3fatdu26h4IkQMiFqwIBBEVRabqPYj/djQ/qQejWVlGffrrPT+c/OKeffvRgo6ht223rUY82gqit7Y2rAgJBEhOSQJJKJZW67L1rX9dac44x3vPDmGvttasqISmSFHTGJ1m1V63LXGPOWnuOMb/v+35fKl3GP9hh/ewdzLkOhevh4zbWCjE2GNoGFM5CLPABajXUocdYFxksv5T+odfD8m0ghwiUaCsgTS9qTWybaUgqjbuSx1Qmk3lKaARj0m+ZwaCiOOfwscFK2zmS5AM4LcOdVZrMpY6BmUwmk3m6yOLSs8h+gQlUPOgWuAuw9ml2Vj9OV07Tc9uYQLvi9unNkoIusfUjjCSLEjGKRNAYU6RGPaV4OqZmZ12Yu3gCc3AAHADfTQ3jJHXWsAZQpRSTSg7GqRSAB+/nvl96P+NPfZoju2N8WXH+2FFuf+9Pwve8BXolvoLImMmMHdoo0rRztCnTvrbuFG0cd3aqz2Qy36Roq/rI42QYpRbsBucMOpupMSmbu0xcehyRKZ8o/tdjan6SupgaUUJrnhTVYrTAYsEH0CFwAXa+TFj9PJurn6epT+HjOUrbMG8MJgbUB0zoIMMz6IUvM/p0w0N/fA8r60JDyQOdktv+xTtY/qH3wKElmBuCLtB/wRE6/Rex8djfsNs8QFGuMhyu4bTAogQbUGNoBLydA3MMdcdZOHgznZWXwdzNIAtoFIKAlYhJl7ukiTBOMyQSecmVyXzdzAhFCu2aM62DSzcpuVZSj+JL6lKzbV8mk8k8o+SVzrPItDuFCA2R0loYD4FVts9/gUIfouMuEv0YMzVn0L3offJARbQ1GZVUSx5ViTF10LAGnG3oF1sMx6fZuHAXS0s3g+7gzDy1BzuxbSJi22s9aw10HNx3Dw/811/nsT/5Uw6NG2oRhgcWed1P/2t461tgoc+4EIyFEBpqIoWxSOutKnGybSF9veJeLFeTsDUz1V+R3BI2k/lGZi/1RB8n/isIQTV18QltYy8ixpqU3mjM9JX7t/tEyOPcz3yzIgRMK0UqFlWbEn20ATeE+mFY+3uGq59md/0OtH6AwqyyvGgY7W7hvMV4UB8pqyOwtcnO5x7k0T/ZZH4VpIGtuT63vP0fs/wjb4OTh8EUjIJgraPoLGJPHOTAweMMz36e7Y176A3GNNvb+FATqYnGEMsuRfcw/f4LqXo3Ios3QXkCWEodWI3HiSFqalNhpgJqytab3HTSqiqTyVw10pp1a4wYM2lYEyldgQZF2qym1C05zrzxGg04k8lknkNkcekaoO2SGgqINWxeZLT5CJXZRGSYGuFYC1EQfBv1d0lUij7Nj7GAKETq9lqvSKlN0jZvjoFKasZbj8HmY7AwRrRuI8UOYUzwAdUqXeyFMTxwP9u/9/9y/r//Ptdt7OIRtq47ziv+1Y/CW94IBwcMY03h5jAqOOkT4zRGS+MVow2Vs21tu0V0Uga378cTCkuZTOYbl0ulJb1CpY8ixKiIBeuSIJ5KY5XQiuBP5jf98vNEvjr4X4NJ2oGkwhZNneGitua7dh3iKcLGp1g/8zHi5p10dZWuG2M00KyNMAGcEazrgqvgMRh/8jEe/vMRgwupc9zuPBy5fY6VtyzDoTUwqwSzgjO9NPcVfdAOmB7dG19EN67BxqPUu2uoeoxz2LIP5QDj+lDNgT1I8jEcEKJgrGAl5eSaSXc4OynKAcSieFLfO9/ak1vydzmTuTomc5BIEmqtKYgxgpq9xEhgGo2deV+uTG252qV2PniZTOZrkMWlZ4lJ1tIkI8dgiIww1hO2ziJhE8MuCFgLIabFqZ34XrfBz4BgxKSubjH1R7bOgBRoEGIM0DREG6hsjQ8XGW2cprMcoK5xxmCAoA1N09ARB3WEM49y7g/+gPv+629weHsXwbI7v8it7/hB7Pe/HVYWCVWF0dSBIzRK4dIVovcgReuRIYISkmG3XmkW2rssvewZfTJFc18r7ymTyVw79hxnnLWE1s9YmESaNXWtfNz3Zr45mF7etX97/H+7fc/MZuHOuhNpyoCzAlaGiKwS1u5g7dxf0+zeQd+s0jUjrG8gKEUUTG8BRgG2S9idg787z7mPj+hcgMrBdgVHbrcM3rTE2N6LrC5S9lawRYegcyAlQQNoH7FdjPEgh2DpJOVyA7FJQRJbQuunpESULlEXEGPaDIqYusPFVObHJFlixk+KaX5WJpP5epmWWre/crR+otGHFJjdR/6ty2QymWeTLC496yhCxBERhiAXGMez1M0Wg06BjqEoDF4FEcFEC0TQABiMqVBMcjS0ilghEFEaMGlSFZOMmazuIOE8Eteg2QZ7mOg9tijwUmKdQYLCI6fZ/C+/wUO/89sc3RqhKpw9cIBX/6sfh3/6z2HhEN5YoKSUgMaAsS518rFtkv+00sWmRfTkinLfnsMkmnvpxaWgMxccV3xByyTFObeUzWSuBbOFcHLJM5OSn8nj1sy8TkDaKSdnJH0zM+tlYlrRBaaZOjPsPSPMnvijQB09hbEoAWsDEkPbMnwVdu9lfO6zhJ27KMx5qsKBd4x8TbdjkDpCaCD2YbgEX/Q88EfbdM5AqbA+gIVXwuC7D8P1AbUPc/Fs5EDvCMVKhe3cQB1sckdShzFpfkUtSD8NEFImsCoqaV/BIDiszNR3I+l7bUiT4IyAtv83xc4ET/L3PZO5Wsw0BX52ggFT2P1rx9k15eOUcD9nyQcjk8k8Q2Rx6Rog7UWYhAhS09QXcXYMYYhTAa8pirrPgFBBAnvd1jyYkJwqBKJEIsKkI02M0Ol3GW6P2L34GNV1Y7BQVF1869lU1B4efoStD3+Ee37n/2NhdR0V2FqY59U/9h540xvh2DHolARpvyxe0RDBtaa+yp4/UtQ27VjQJ/BMukLOErOx78dfAlxJlspkMs82j/87ernc9ETPZ76ZmUglMyVglzz7eDKKQdsiSSFoMoY3EoAawhqs3c34wp2UnKNXNjBqiKoUVfJZkbKCbQsXS7h/xH1/cIrueZAaxj3o3wKH33IcnhdoOI0p+pRq2Tz3eZYP3QAcwZretCxv+n2WSSfDNM9GFDSgEpgIRGDaMk/dt0eXHJbLjlL+7mcyzwKX/Zrl37tMJpN5Nsni0rVAWy+i0AUpCOMRpRkjYYgTIKQAaBQlShKCputYUwNtt7f2IVFIjhWuLS0zGFsw3gxUYlOWUwxo0zDu9DAYysbDuTX4kz/jrg/8KkvrF3Gl49ygy4t+4Pvgn34/HD0OvZKxpgwEE0FUsLZAMVMBaeKTNNGT5ElEiOSy6BLsZSVNcp4vd3KZLcXIZDKZzLNNK7JMDEzYO5/vZRQ8ztug7SjqKWJExRGibSuoC2AHxhfYOXcndvwYvSLixgE/9rjCogbqMRSNxWzPwf3CQ//9FL3HksdSswz6PDj+3Q8ov68AACAASURBVMfghgqK8xhXE2JAguC37yeevwtz7HqMLELr82SMZa9kW6dBnRQ4MTPPTTqf5iBHJpPJZDKZzKXktiXXCpXUtk1tEmrU7y3MZ18GhJkQ8OTuvhweBaIk8QdQDMZ00GApXEk9qpPRYdnBaKQcDmFtg+GHPsJnf/EDLG9t4sOY1U7BjT/w/Sy/63+Hw4ehqqjVEydZRVFTGrJxiGnbkKPTn8DVdXmbXqRMSt1mr0Jm2YscZzKZTOYaMfHUm3Rz0FZgirM3TTdVYvtfkNhm4BqIbQaQTs76AdiF3ccY75ym58a4EKCOOCvgA34EVexj6hX4cs2jf3QaeRj6JF/u4gY4+faT8JIeXs5Sxy1sEUDHONmia1dZP3snNKuIjEF9yriNaZ/SLrU7IGmWnRT2MRWW9pM7m2YymUwmk8kkcubStUAi0QQsAbzgugs0O0Vav8ZimmkkBqKkzmuqESFMF+IaIRoBUSwGfIokxyKJUdo0FOWAIG23G+lBAyW7sLtL/J3f4+5f/XUObqwzHm+xtTzHwe94IyvveRecfAG4imAcVgxOUn8bFSGIYMyVk/ynmUtfc7GtUy+LiY9FenRiDvsElkvkAoNMJpO5ZihXiG6EdE6fZJZqWyon0mpPSVxSIlEsBWVbggaOiBEFdkAvsrv7KCI7eL9D9IGyKMF64thjfReag3C38PCfXSA8AANgR6B8Aax81xG4yYF9DDojSgOhVqwDp0NE1qnHj8J4FaoxQgGYNGe1mUpRfWsgmPZhWsY+ewyyoJTJZDKZTCZzGVlcugYoihLavzmquWWGq108neS51HoZJSPRVDJgiJNAarsNQXGpGbiCwYMEBAsiBAkogbFaFlZOgDpoAuyuU//pn3HHr/wKc4+dw8cx6x3Hsbe8mZM/+ZNw/ATBVtiiSstpSVHcqAaxrf7FTI7RzCL7qUVw90oPoO0kJdNnLvNknC2Gy/3iMplM5hoxeyJOKa3JA5BZcWniW5TmJ0WmbcMVoZGIcQYjtGbZEfAQdxnuXkD8NkKNKRwYJTZjjJ2D8RLcXXPqQ2fg4VQKt+NAjsHKP7oebqxBzuCLIe3EiJGUcNs0IGzh7BZNvU5BDRIx0/LudndMmuUUg2lnuulcM5mk8uSTyWQymUwmcxlZXLompPIuDzjXpZo/hHSWqeuzlKbGxABatW2PA2qa1Nk4ToLDjmhATYqqRuORMolPRiNOhVAoYyIj02ehOpDKE8Yj+Iu/5gs/9//QP/0wnaLgqzZy8m1v5eS73wOHjkH/QFrnB0XUow6iCFEEO7Vunayt9ySgp1waoJPStpkStxkFaW/76YLFTD91fzeqTCaTyTx7TEq11abzcypni0h7nhZAjab0WgRRi9GZrFSjRDNqi8/KNgvIpgzc2ODHW5RhTFkI0ULjI9JYTF3CVzxn/uoM9l5wI9hdhOEhuPntx+D6GuY2YOBxRggjRQWkSpm/BpAYUcY0462puDTVynQiI6Xwz/6gRp5xMplMJpPJZL4WWVy6BiSZxBKDBTtAqhW0PMq4fpTKrlNog7Rd39LiPJW/JSnHAi5FfEkeEYG02LeA9akTTwN4uhTd62DuJDQGPv5xPv8L76Pz8EO42LBVdTj6hjdw44//BNx0M74zwDeRyhWAB1HEpuhtjJGolsmomPFZurqFdysWtav3y0rsZtpdy+x7ctpSJpPJXGMmWUqp2G2vfGxiDpgylURNuj8x/J6+U9sM1ZQhRAQr6ZwfmxGlS68cj8Z0TRdhGR5sWP/EOdY/BytDCA7qA3Dz9x2EWwoYbEHV0PgaieA6BjzQKGqgrDr4kYBGgh8DvhXAEtomDEfVtkzvkuYR2cM7k8lkMplM5gnJ4tIzhKo+bjaPwaYWyL4CKcAeYn7xZWyPztHoDkWxi2ggeoVgMcZijW+NUUsEg0MITU1tQZ1DDIgGrIHGQxM7uOoI/f4tMDoEn7mTz/zfP0fvwa/i4oiL/YqDr/tWbvzJn4JbX0YsBlBZijGIxvTNEGnDuRFrzLSS7es8MnteS5PFegpwz3SbUzT6tmFc698Rzf6ShEldXiaTyWSeFSadQZ0Ygm9SYwfjUqG3BqKY1LWUVqRBENF0IxI1IJLmwIY0DxhjMMFDTLfSWaLAaDym16lgWMFXAo/92Rrjz8LhGoYW5Dp48Vt7SVha3GQY1+laR9FOW4jBR48qFGUFTdKSXFFgrYMQ9trbtRpTnBWb9gU2MplMJpPJZDJfiywuPUNcSVgSkeniHAVxZVpQmwP0Dr4Kv3uW7XOPgu7QsQFjIy4aCApN263GpGT9MB5hOyXS1NS1p9PvEoMHhKAFuKN07PXYudvgc4/yD//+P1He/yCd2LBblCx967dy44/9GLzsFTRSEJyFCJ0Cpq2XJf0UJZUPTNsytzuQ9uqK+696Jc/TNho8yXqadInbJxSlcgox7efoXiQ8r/QzmUzm2pISjALWpOWD+kDUSFGUKELtG5xzCBE0pLI5Tbm0RhShoGmgKnop6zY2aVZxBUgHWw0YrTlW5o/D2g48ULP58R12vwTzO0ArLB3/9jl45RwsbOLZwVVpfHUD1qZgi7iU+as+EINFpSCoo1v1wZapPFvMNHt2b47LbSMymUwmk8lknipZXHqWSV1pkkcFRmgiFGYOercwOLBBvfMI29s1kXW6MqSY1BPESWpPAKdICU3YpeMKOlUfPIzGjl1vUXcYLW6hXH4dfO4c9/7Ch+GL93IgBNbLguolL+HFP/6z8Mrboegh3S5F6vRMtJNiBZucoWIqVRAJrTQ06aAza3N6+SL8cnFpr8XQtCTC7AlUe02eZVomsdcCuo18z5TiSV78ZzKZzDVAU8ZPm4Eq4nBKqqRGKWJE6l3EeLAhmX1LDaFO76WkcAPQBvUeUYMUvVTbLRXV0glG55ZhXeBBZftja6x9DHpb0CiYI3D4O3tw+xwcqSHugCoOh68VZx1BUqZv0o2UECBIAbZLtD1cbwko97z/WnFJo7aBjYmD1AwzDSgymUwmk8lkMpeTxaVrwKQ9c9AA1tKoo2jmMYu3cZALnH/YUzf3ov4snbBDpSFFVzVCjBCVUBi8QtF4GEe2PVTzR9nZKumXL6LTexWcqrj/F3+X0d8/xKBp2HUWd9Nt3PSz/xZe/TpwFXS7IBCaQOkMilIHj9iyNQiXlHGVRs7lq+v9As8kMcuYfY+SRKWZbkLTW+p7J4S9ls9tJHlPjpK2aiESaQAoKGZ7+GQymUzm2UBI6UuhLSETIfkX1SBjjNkBswP1Guys4UebxHqIEClsAUUf3BL0VijMAKRHautmQAZ0qyOIeR7Ng5uMPrHO6t9Ab1twhWV94LnhuxbgtQM4PISwRpD2rWrQ6DFlhWokapx4iiPO4ZuKaBdxg2NQLYOWxACqESsWSGV/Zios7U1iU/elLDBlMplMJpPJPC5ZXHqWUVVUhCCubcHsCeIRKXDFUVh+PUvBcuFsFz+6h8jDuHKEBWgaYgCPYVgHqqJKZWPWEnsFa9LFHHwJnYXb4f4+Zz/wEcZ/cwfdOrI76FLccgu3vPffwqtvh26HsRUqAW0aTGiQoiSEQGErQruA9maSJWQRNI1j30r7a+4xs8LSREDS2DZ5Nq1xt4bkgSEWTAFqput4lZS4pe2i38wOIZPJZDLPGkGgJmCspJ6nfoRjBHYH/BnY/gq7a3cRxo9Q754hjDchBEw0ONNBTA/XO4DpHqdcuBl74BYongfjCEUFxXV0Ng/x2Cc3GH9qh95F8F4ZLnuOvK2EN3ZhcZNoxwTAGog1GDE464jeo4BzhtjEFKgwBWPtEuxRFg7cDO4AMVZoMhdM/lCm9ffDIJrEJpn2kIjtz70Sukwmk8lkMpnMfrK49AxxJUPvqd8SkqrijEEJiBpcUYFa0GO4w6/nyIElhhc+y/ZjX+DC1sO4egdLg6kMrlMhYtjaHeNjibgevrNA6Y6z9Py3wlcsZ371t1n95JeYi5adjmXneYd5zXt+GN7weujNEfsQglLXderMUxTJ60jMPgskFVKZGoLsC9leoRQuTvaTvWZwOslWSiUK6X6Dkdj6cIyBGhgBDannXQekAu1gqDA4vLaVge2Gdd/xvLLHVSaTyWSebgShJFBjGePcDsSzsP1VRqtfYmftTpqd+3F6gVK26ZtAUTiIggaL95awXbG9MU9cu5/uxleZO3gr0jsBchDONmx/9BTnPnWGhVVAYHwAVl7bof/th6nnziFdxWuDMwZjHKktXEQsBO/xqjhXYm2NRsO4cQQWML0bKZduAZZQrTC2RKNhYrVk1QCGmamlFZj2cnfzTJPJZDKZTCZzZbK49AzxRIbeouBUMApRS2Tyz6CC6gCxFdgOnUOHKaqXEbYfJWydZTw8y6a/QD3exdkO1nbpDI5QdlfoHzwO/RfA3Q33/9xvED73D9jhJhc6Pfz1z+MVP/0v4c1vgJ4l9qBWKK3gbGr5XAePiqUwJepjG8XVVG+gbc7RxFR74gN1SXnA5RZLrag0aescU0chq9ugF6A5B8066CYatwhxjDEFYvpIeQjsAXCHwCzitIvGEq+piI6ZBf/0uGaBKZPJZJ5RRIVCIHjB2W2QR2Dz86w9+reM1+/C1I8yV4yxYQcbfOvb156tVXEiVKagW24zDBe5ePpOwvb1LJ34Nti4gfr3P8upD36OhbUK4wLDJeXYm0uqb1vGV6v4UukWXcIIYkilb8YY8DU4ECOoFowboTJlykIKFf256yhWXgndFwLzqJRgbNsUNc70lJDpFDc7qeklP/Nsk8lkMplMJrOfLC49y0ibZz/x5k7eRAZCA9YhRUEIJcGsUJaLuJUbcAsbMF6nxwZLrBLDLtJYpLMMsgD0QUs4tc2D//G/sfrRL7G4uYkbdGlOXMcr3/2jlN/5XYT+HNLrUkvKDxIUggcUa8tJ0RvGmuTthE6duaeZTJP9mOhLkxKB6co7TvdTSelGIhFkBHEb6zcgnEfXvkS98xBb248wHq8SwhYiASMFzs1hZJFO/ziDxRcgC9dD5zhiDlKYRdAOMSZT2SgKRKxMhmpnFv+zItheLUOOPmcymczVIaTpqjQewlm4+HlWT/85w40v0jHnGfQajB9jxWNt24giClEDcZIHGz1+e0ins8mR7oCwHuDUGO6+gy/+t8+ycH6EmA7r/Ybr33iU6tsKOLxBLMF1CnZHO5TW4YzDj4YUtu0+GkFUseIY14pzPVTmqOUgg8WXYg6+HMxhoLsX1NnnoyT7fly639luKZPJZDKZTObxyeLSs87MqtVoUmmE5DOUOjejKhjbo6FGfIGjD+VRkDEUQwwBYgnBpG43TYRTj3DmA7/N2v/4HxyvA7sibC4u8vJ3/wjl9343LB1Bun12Rp5Ox+1lFpkCZNKrbWZhbWZMt+XS0ac/VSCQNlVMH047EZLRBcFHjAxx1SboQ7D6WXbO/z31xv04XaeUbSqGSGwwKlitkJFDKWg2CzZW5ykXb6B37LWw+HIwL0TDEjEWGOsIAlE9QsCKQ7FTlydDQHTio7E35hx5zmQyz22euDHD4zHJ8nEOCOdh4042Hvhzqvrv6dpHiOzQNFBai9fUd1SU1tuoQEwk+oA1JUUhKYgxVOx6RfjsQ9z/oU9wcH1AkIKL8wUrb30zg+9YgcW7YDDC1zWVEaLzqDQENViXsmKBFLBRg9FAZRfYDYvEzgsYHH0N5sjtUDwfWAAs1uzts0w6UMiVxaVZc+8nf7QymUwmk8lknltkcelaMCkTg3aVavbSacwkQmoRulhnIGirigRCHCezUulAM0odek6f5sEP/CZrf/4x5nd2CdawvbLMq971Lnjzm+HQYRpTMG4CVcelZbJq+zkGuVLftSdZYhanr5/skkGJWGOJoaHsALpD3LyLnQufIaz+DXHzy/TdCMsWyi5CKkmwShLN1IIoVVlRc5bt9XPs1hv0VzboLjdI/yZcXAJsMgoXmNh/T/yeJkc4XwRkMpnMlXiqMvukDLlBdQjj09Tnv0AxfgAzfgxndzBVcj/yPmBtmsxikzrLGQQ1ghhDjA2GCkIP1nvwd2s8+Cfn6VwAa4Zs9JUXfM+bWHj3O+BFFcP7Atu70KkOsLG7SlUIyjhl1TppxSWBaIh08NpnGBcJ3eczd+RV2OO3Q/dGVAc0USjsU+01OhtWyWQymUwmk8lciSwuXQMmHdBAMLpfCVHbEIlEBIMleA9BsdaiVvBSYRFoFMY1nD3Fw7/yy6x+5CO4M+egO8fFlYOc/KF3wL94Bxw5Cq6gcJamHuEoCMFjpWCazfOU/YoiSGi1MEPETPvARQyRkug9VkcgmzC8l42zH2d39TP0/H10ilWsRETHiKQuPDLV11q5yijoDkjEGs9498tceGTEUhgyOD6G8hbgIFYLVOy0C53o3rHdu9FmiO1dIOSLhEwmk3myzDgOaY3oGqPt+9hZvYO58BjqGywlEpUiNgAYcYQAhEClEUwEa6GwNLGGnRqzeRTubHjoQ49SrYIWsN5rWH7TbSy8+/vgRa+CMtK97Ufprt/F+tm7iZxmOH4EoxsYaqwNIDHNPdIn2GWiO8Hcyq10D94K/eeDO0xkQCOC3d/yNJPJZDKZTCbzNJHFpWuCtI2Nk7Bk0kMgiuARIgVlspAQkMIQTfueaNM/Wj2ErU1Wf+O3OPXBP+S6nSGh2+HC4oDbfvCf0fmhd8KRI2AcXgQrSqcq0vY1IGZPXLo6kifTbNaTSvuogjMBMWMYPcTumb9luPoZbH0vpZyja0dITJ5Myl6SlLZt6lJ1nSdERQrolTUmbrDTPMBoVSmIVMf6UDgKe4Cgrq3XMNPW0ek2W8rQRt0v6XmXyWQyz02eWsbSXrbtGPwZhuv/AOPTOLtFtIKIAx+RGCitoAGaAFYsGJveHwN4wTUg23340ph7PvgIixdTSfjWAOZf2uO6734hLAcoC+gsgy/g8GGWVm5l/OiXMOOzNLvnGA7XGYddVAK26lL1D9HpH6foX49buAHccWBAoAOUbdF0gEvK3DKZTCaTyWQyXz9ZXLoGCMkXYkI0SZQxBAzgAhNzC4I1BCDSIAEKLaCuYWudrd/9bR7+3Q9xcssTRjXr8z2u+8EfoPPD74CVQ9RYTFUQUBodU4rBYNoOcftdN55y9pKathzNojOCTRTA1IhuA+dh/YuM1/6Ojv8qHXMe14zSJY3onqg0HYtpy/TSeGwhGJR6VONknXkb0OYBts8oVf8kLM2DncNolUoHjVxyvTT7l9bttd1+jlpnMpnnLlcnLCUPpR0YfYXm4p3Mmd1Uml0IHrBeESzEiIjHWUFsAbEA3xC1wdQOWV+Eu4XTf/AI8+fTJoY9KG+Ck295PuPeGSpOQzFCxSHlUWCRKPNUJ0/C6CKFH9EjpFWMtL5LpgLbA3cApaTxJdZ0sKYEr8njybmcvprJZDKZTCbzDJDFpWvERFqaVMXJ7DOtsBSjEq3gifh6zLwpME0N584x/Mjv89n//GscPX+Ruglszc9x4w/8E+bf/SNw/DAjH3HdauqJZMURCKCCbQWhq0cAm1o2t53kUklcykUSGYFswcZX2Dl7B7p9P/1qnZJRspsyJJ2nfWPKeGq7CrVSlWkNViUqNoAzMXk3qcdTsbt2F73OMSiPIdqb6Eb7RnjZkNMRv9KzmUwmk7kil2QuUcP2KXT4MKUdo82Y6AqMsXiJFNYmIUcjzkAg4r3iqDBY2O3AnZ5Tf3SR8hGwYxj1YfBiOPTW43ADSLXO1tb9zIU1gj1G1A7GLlBj6KCYzkrqdKptUIFJubkFcTRRsabEOYuoSclKPpDmLZOngEwmk8lkMplngCwuXUO09SE1JDuKJCxpig5biKrYVsQx4jCq8OBX4C//ki+9/z9y6PxFRBwbKwc58v3fw/y/+UlYWWRUOopOB0NAQ8DYlBEUMTSqRAQrlxuaPunspWkHtoSQdKFkzO0xDIEt/PaDhJ1TdOI6rh6m/Ca1qcudwFRIajeShLYAShqHT9KYsw7EQR0hNnSrMVsb91It3YgdvARkEczeV3nW1Hs6wEwmk8k8KS6fC2byXLVhd/MMjl00jLFADB4MBBuwttX5I4ikUrhUBt6FiwHuaXj0jzcwXwEzAt+Fzgth5W0n4MQIeucoioph8wiENZAdfABrOzhxRAIxBoyUiHUops1LVaJGCGBFcJNoQ/BgSiiTsV/wii3zpJDJZDKZTCbzdJPFpWuEymQBDxIlRVYlddPxAmigDp7KVnSiJGFlawM+/lE+/Yu/wNzZ8xRq2Zjv8/x/8r0c/JfvgpVlfL9LciWKRN9Q2ApUGANGDKT/W23nKt2HLm3T3Io5E/8lg4fmArsbp5FmlY4ZI6EBZ6HsJyNyA0hsy+MUmdxvc6piAGvaKLNvP9NYrCgx7uDHj+JHp7HNJlSh9fRImPZwTo6z6BUGnclkMpmnwJ6bXT3aoXQQxjWuNNB4rAjBRDwRy15SkRGLi10Yz8H9Fzn91xfxD0A/QN2D3otg6TsOw/UGliNBthmNLRQjoh8iEqkKlwSkqDhTpPK3NjQRJt59CE4EY9tC7RjTRGIsCISQElxtJTl/NZPJZDKZTOYZIItLzzKqiooS8VgxCA71ETGpHK4OAVMYGjxl1UsqSSOwug1/+Rfc94EPMP/QQ1gt2JyfY+Etb+Lge94Jzz+B7/UAi2szgqxzbZaQULTd2KbCEuw5aT/1vWgzrFJdW1vNhmBShhUG1NMML9KnxqgHW0D0RG3ACUYCtG5SqhOz7XZs0iYihdCqQ61wpK0AZRsKu8Vw5xEqRiT1yYAYYlTEususl/asx7OddyaTyTwRs1lLkyDI9H4UhIIQheiEiMcY0OBxJmXjRic0ojhrKXwJWxU8FDj1ofOEr8Cig4sAL4bj33sQbq5gsA22JkTAdRh5y7ypMFLiiUCkNEUbmXFthisUl/onTduxzkRSBEhvwdPaND3jRzGTyWQymUzmuUUWl64BgmIBH2qcajI8bRfAzhakIgKDb0Z0aws7Y/jLj3LH+38Zd++9LJYl691Fuq94OS/8qR+HE0eI3S5BSixAbDDSiintCtpcqql8nStrbQsdJl+hSfaSmZTLNUP8eAvREeiYVn0i2IhKyq0ihulYZLKNyz5I2ycUJKJEgo4QdTT1BoQhqE/ldia2F0FXjkvnaHUmk8lcLTK9FUWf3eAorEk2Ru0pOjZtU4dScbaAoUVGc/BoxVd+76tUD0A5hIsCxY1w4m1L8BKDry7geoIyTl3ntMLZPkIBWEzb7CEJR2ZvOHCFeIHszRntXyeZTYb9b81kMplMJpPJPH1kcela0HoKOWMRSe7Wu+pBhIoC9ZHClZRhDLvb8LFPcvfP/TzV/ffhpOBRV7Dw7W/gxe99L5y8DhYXUS84YzBGUhZUCKnMTlrvjDjz+V+3sKRtIcIV9muy/WZM3ewiJhBDgxGIRlEbiSgh6r7mblNNaB8zqpNRIpGgkSgNYiLj0U7KZooebHXpO2eHtScs6TTNKpPJZDJPipmsT3FU3SV2pItqRYgjQgyUBdgIFhgOoV9W0ByA+yMX//ghug9AsQmhAPd8OPG9B+A2iy5u4V1krA2uiRhKCBXdYgnogBqMWMC2dW2pe2rKnXUIZn9gop1MlDAdc3qN2evSmrvFZTKZTCaTyTztmK/9kszTj+C9pggtycDbCu0yGSo1lE2E2sMnP8Fn/sP/RXnqQQZEtvsD+q+5nRf/6x+D226Gfh8NmkoJvCKRFDrWVA+g6YH0sU9bRdhkZW72m2bLTJaRkVRCUQhqYso6kvRzbyDJ+2LGymOmpCEZmSuktCvDNLUpKhgp0GhSyZwKiGl3ce+qQdrywAn77+XyuEwmk/na7IUAUrmcw3SXiW4JkR7qHRotxlQYk5pT9F0JF0t4pMtjf3aa9c8HOkMIDvxBuO47F+GVC9DbZleHSAlRNDVyM44QKrrdg1D0U1aq2pkAScqbbcMU7I+cpDN7KrqWGXkpto/69n4+/2cymUwmk8k83eTMpWuCQUyZ/B/CGGeFClKZWBAY1un+Jz7OP7zvffTuv4+OBtYqw/hlL+MVP/Mz8C2vwmvElV3i2FN2OvgGdKSIE7xLq3yLgoa2bsGiJi2t93kvPUWSd5GdbkEhGXJPF/oKpsCUneRvYVLXoJSAJK2Pt2kTiPSSrCUz9ctQkiA1c2mDQREt0Fhi7QBspzVoMu2WzNSLQ1oRSTBELu+Ol8lkMs9Nnmyd9CRjqf2pAqZCBseJ1WF0+2FKegRV8EoTxxTBAMvwcOTcH34Z7gd3EZoBjI/DiTfPwWsWoDgHHUs/WIbbgV63R9QdQhTUziGDI1AO8DhckHbSSnKRxaJYzHTckWmma2v0PZkPIpo6mYqm96uAFE+wz5lMJpPJZDKZqyFnLl0DJrYRgdTQRqKAFxgpBIW6hk9/mk/+h3+PvfceBn7IWcaUr7yV1/7MT8O3vBqvAt15xrXHdrppvexAnRClTV7CINpm8ghtadnTE7O9vKogZUjpRHgyPTrdA9TBEMVML09MEGw0GJ1sYzZlqT06bRbUJOtKCW3nHzDR4ugQfUm3ewBMB5WivZhIpt57VW/KZVHqaXZVJpPJPJd5chmcIqZtutCe8aWEwXVU888n6DwhVKAWbaDQPoRleNCy9ldnGd0D4zPQWYB6GU5+7wHs6w/Dwi46CBDGEBTnIY4jQUtGOqBceCEMXgB2QBSzl5skkzI3i8EyDZOITrNik7QEJrWYaF/n2tear6ORRSaTyWQymUzmicji0jUgCjQkcakwFWgBTQGmAyMPd9zBA+//BTpf+BxzuxuMnBK/5VZe/LM/Aa99DRQ9XDVAx0pVdUFgNB6BAV/CqEifYxWIDnBgTCvW7C8WuDr2X5Skv2kr5VjQDhQH6A+O4mMF0gEkZS55gwkGUZ0Zh+5dHEgA44lSoxLQSZmdRkQNEh1GK4Q+8/NHwfRABtpDewAAIABJREFUSmIrLglMu9c9/thzWUQmk8k8HpMOnnvMuuMVwCJLh2+mmD/JiC7BNIgE2C3hQcPuX5xn+w5wW2C6sLEMh79zDm7rwGCNqNtIv8t43ND4SFFY/ChQ6zy+PEn38O3QfwnoABGLmoAaZSxKw6R7aHubZKxOxpgs+pL/U0xleqKC4oiURMpWfspkMplMJpPJPJ3ksrinBZ21Edp7rH1g1vlHRVsj0rS4NYakNA1HYATu/BJ3/cqvMP7bT3PYFWwGpT55km/5qZ+BN7wRTAFVCQrOGBBofKBTVUSUnWZMt+hMEpWmxHYccok/xdN3BCYLfJvEsuIARe8oYxbp2HmMNthQg9eUXSQOxLcd4JhWXUy6vU2Si/Z1kYsCUqIyT2OOYfsvANdDSP5OZjYgPXUWv1RGuuRCJJPJZJ7jTGalKVe823ouaUn0FWbpJqqDt7Gxu4r1Co2HM5Hdz6xy+mNjersw9MBhWHl9l/L1h+HwOnR2YeyJW2Oqvkk9GdQSyzlGcphq7lZYuhWq4/hYIFYQo63LksyUws2Ovx3f7AOzc3KbeHXZNJ3JZDKZTCaTedrI4burZZJQA0BMXct0Yp4dUB0zyU8KGvAkK9GxegTFEiiBcV0nkcWN4e7P88gvvY/dj32U7nDMtuuy+oIX89L3/h/wuu+CaoFoi1agIpW5RcXZvVKwuaLCqmJUmVTEwURSEQTb3r6+5fUk/2ey7WRHXrRCkANf4ZZuoFp+CRfGPRpbJfOlEEAc2jhC7BDFEgwEA+ogYojBgBdMaC022sOqxhFMxa5ZIi68Eh3cAlQEv4OTVBgXdfrytK3kOjXTtXq/X1Qmk8k859iXfKqTWQvf3hoNrWm2EjXNM9G3E54vMOYguj2Hve6NVEffxLi5Ec4fZfRXW6z+zzEHdkE9hEOw8gbHwpsPw9ENdtwqoRhhCkVCxNcRLQt2XJd1WcQsvJy5w7dD9zrQEmMcQpiWYVe4Sd7Svtpsaf9LJXKyF0Mwe6+79KFMJpPJZDKZzNNLzly6SnSyqE0qz+RRaMvDRCy+abBGcLbAt88akdS2WQokeKrCwOp5ePgUX/1Pv8zqX/xPlprIuNdh59AKr//p98I/eht0uuAqjE3GppOyBSOzceV2JDIZhe6N82nsvTybiXWlLao6RPrgDtM/cBt+fI7ROFCK4qox+BFS9rGtB1SYNLMzYNSkyLQ24ASsogHqaFDTQd0itRxi7tBLkc4JoNhnoSEzu7kXzZ4Ye88YkD8tRyKTyWS+CZlkdrYnw8lpM50zFSsGVNGgWGfBCjHG9haIo0DZPwaNp7/yWjgfWf/w7zL83BZuDcYK9QIcub3L/LefgJUdQmdIrywYjxqIEdsbIMaxtlswlCMMDr6SpWPfAYuvAF0AKvZlI9HOb0/mBP44z+fzfiaTyWQymcwzRxaXroKI4gkYwEWXlCYLOjX7USIW44pkqB3BxhQJdsYSQ5tmpAoba7B6lrO/9p85/Yd/xHEPI5TN4yu89sffDW97CwwqKMpk1h3B1w1VWTypscozYF4qM3/O3tuz5LYQO4hZoXPgVRg/YvXUNut1zWK1TlE0hHorle0ZKAQQi0SLqAUilBbvAwGQCmoG1CxgqxN052+id/Bk8luiQMSBTroDXTrWibB0pZFnMpnMc4uUdZoKsyeWdkbSLbTKjY3tWbJtNKoOgniMCRhrMNUgmXHrcupu+qltzv35GdxpGPRgawCHbl9g/vYlWBpSx20YN5iRYIKh6VZshpLh+CC2upGVlVfTOfJq6L8I4hJIj4ibOVm3xXCaQwOZTCaTyWQy36hkcemqiChN253MgSY7oAhtwVkSgew+34pUjAYGqxGaBmINjzzKqV//NU5/8MOs1A2mN2B30OWVP/xO5H97G3RKYmGJztBExRnBFAVRWzenxxGPrvT4rEnr1y866WXy0lRaE8A6JPagej7lgZr+9iY7a8Im91HJOQadCLFBUGKEtEMzRkuqRAPRCd4ssFUv0chxDi68iv7Jbwd7EEIyKxdTAW7PV0P3KiP2RjcZc74wyWQymSkzpnR28ve4dxINAaKJKWsWJeAxlLDdwCgQP/hR7vjAh1lcd9jeAqu9hsG3nmDxO14Iz2tYjY/S7S1iiYy2aopejx0rNNUBBr2XMH/gFTB3K7hj4Oeh6KMiqLSlbipTL77UBmMy0nwuz2QymUwmk/lGIotLV0Fy7WnLzloDh0k8dfLTegUr1ICx4DDgIzEETGjA1/DwKTZ//Tc587sf4ujOCA+cW+zx8nf9CNXb3w5zS2BLxJR4jXhRRhG6xqXPuGYNz7Q1Bp8YdyQj74mwpAREIkEsNs5B90XMX1dQ9Za5eOETDLfuQuN5OrKNGI8xqVOcaiSGJh1DY8EOqGOX4egg0nkJBw++mv7B14DcAHEAVGBKwE0FpcvHOSOoQXZ0zWQyz2mS599kpppR4XXyR5vKJEITUtaSsabNeKqJdU3RONgawZ/+KV943y+xsjWk8XB+cYHrvuf1HH7P98Gih/AYbvcMu34LDZ5qsYfpLdKdm2dx/ijSvwGKIxDngRK1gtiU5as40GKvFA4BfBuEmHjnZTKZTCaTyWS+Ucji0lViWmvQCPtMs6ep+zOiUyT5CYXgcVZAIjzyMGu/9Vvc99u/x8qowauyfWCB2975g1TvfCcMDkDZB2PZ3t6inE9d0YyA14gT85Szjyavv7zN9NUya+u9t9BXaaPbYohiMWEB+jdRFQOWqgHD9aM0q3chuoqYHUSGwBgNAbEW1SqZfTNPLA4xmH8hg8PfAosvBfs8Yt3FFCXJfCoJS1HBzlxrXHpkspaUyWQyEyJJWLKXREYiqgExFh8j0TqshaAQg6fjLEIBWzvwqU/xxZ//eeYvnKNuAtuDAYPXv47DP/HT8OLrwIzADFmwNTTbEEMqZdYCyh7QBZ0D7YLrgBWUMY02iNipk+H+oEA+k2cymUwmk8l8o5LFpasguVUUXCpZyCR7RpSoo7YQrkAw1EBR2lQK9/BDxN//Pe77jd/kRBPZaRrWDy3zwn/+A/R+6IdhYQWKfmo252Cu36dBiaGmb7t477HF1Tf6e3p8mJ7IIFwJNKmkwRSE6LBhHsobKQ/OUfZfRN19KX50mu3dhxiNz+DDGkYilZ2jtAdx5jCd7gk6i9fD0vOhWgEGeHqYTjd16ougMbXQlrYcTmX2+kOnI81kMplMavYQCG2p9l4URAWCBFQillTqLcalBnFNpIiCeIHH1uGjn+Ke97+P3qn7KGg4NxjQvf3l3PR//ju47nngelA6lJoQh7iOT59DSQpEGDQKisO4kkjExwZMwIpti65NO96Zc7hW6ZEsMmUymUwmk8l8w5HFpatCWuPptMadFIftdWYDU6Tn3UTg0IiJHk6dYvPDH+aeX/svHNjaYctHhstLnPy+f8yB97wHFpah2wpLbVAZIyiBSgwuKiaCRG2FlGuxyJZLVZw9Uk0bjoJGxxRSpIsHbzCxAHsMyh7l805S+gv0/GMQ14jxIho9NvaARSiPg1kGuwjaAUq0qFAMNZFKbCviKdbItEtcjMz4c1wiLGm+IMlkMs9tJs5FwowvoCQnwTafKc1hAp4AKpQSKYyFc+vwmS9w9/t/Eb3nH6hiw2ixx+Ib3sCLfuZn4eTzaDp9jJR4LwRbUJgBUOO1ZiQGweJU0vYw7edGjEmCUhKTkrA07ZGxj3wez2QymUwmk/lGJItLV8NETQoRDIg1ePbch0QjEgLGWTQ2WBMxTQ3nzjP84B/ypV/+dQ6vbROahvXDB7jxn30/Kz/yQ3DsOLgB3qeFvQp4CxCxUXFRIAaMJGHnmgdvVZKhecvkgkSwBP5/9u48zrKqvvv9Z6219z5DVY/0wEwEVKAZBOeg0TxRSbioiKA0iiIiUQkao1HjvXmSV14vfZIYH1QSHKKocYoRjdwYE/VJHGO8iDMzMogC3TQNPVXVOWfvtdb9Yw+1q7q6gYKmu6u/b+hX1akznzq11zq/9Vu/X0ZiEiKRgMe4SIxVQe1sMUQP6SLIDgRGWFNUBZtSCBmEDpCCsWBdVcupfOFdWQYcY0y1FW56Jds2BTrqekvbl/UWEdl3mbIZBYZQZX16yiOmxWEjmCKSJAk5HrwnHY1g8wT819X87LIPYq+9lmWJYV3WY+XJz+bQP3wLHLMGOn0AYhyS4EhjpwkOOWPJ8EQCiUkxBGJ1z7Y5VteFuuvM3DIztT6po7iIiIjInkvBpfmKdf9mmA57VOEM47BJBz81ietkMBzAps1suuIL3PiJT7Pkvi3EAIOlyzjqzBex7Oyz4JCDKVxVqDst41bRlLWaDBYbqyXc3R5RmmWOztAGsNGV9Tyqwt/GRKIpP74QXfXhhnJvG6FqFGcguulWb9YAgWhC8+FixmZAE9onZnw1M5a7d7aFT0Rk4Wtq7RlISWdUzBsRiCGQREhsSgweEx1p9CTew3AKfnQ11/z9hxj+7GcsM3C/c4w/5SQOffXvwxFHM8wW4awj+hGJrfpyhvq428FYgzOhWoRxmOgw+FnH8fIB1g81mjIVte5NGpvju47oIiIiInsaBZfmJYAfQpIAZeHTcrZr8dW01wWHS/swsQW2boWv/Du3fuIzLL1rPXHkubPb4ZjTX8Cyc9bC446AtINJOwRf1Q5y05lQljJTqQw0QRlk2n3PHrbfYTY7P8jW2V3YqhhVuUI93aOobrFX1fyon1P1QSOaUJ5V32Y0TWCqPOmrrkFzP46Zj6i1X3GOYJiIyEI0V/MGG0yTTVS4MmsJDMaYclEA8NbiikBiLWzeAj/5CTd/9KOEH13FCmO5p5fh1hzNsW9+Mxx7HCxdQZLAtm0Dlox3IR9VCwX1AwHIqsxSiwnJ9PE/Aqaoxojywk0IKZpqrInVpr1y456p6jaJiIiIyJ5DwaX5MEBim+CGw+BMmdhfxIAJpkw9KnLYtBW+/nV++L7L6K/fQMdY7ukYjnjBaaw6Zy089nGQOnzaowBMU9C02kJWCVWMpAzFmN0cH6nXvOcqulpN/s30B5jpy1VPYkb2lW3FgcqIVCS0tsFVz9fUgSVT/W+qDxtVoGpmyyNaNzrzoSuwJCL7CGPM9gGm+vDtIcSITUy1gOHKLXKh3F5sRgVs2gLX3sQ177uMTf/f9znIBCZswB27hie96Q1wzNGw3woKIM9h0XgXn3ucdTNXIKrDvyHb/rGY6gKRagyYuTBQHutj9VVERERE9lQKLs1DBKK1ZVjFhzKjJgQIZW0kR4RQwKZN8M3v8uNLLmPJ3RuJReCXqeE3Tj2FQy48Hx7/WOj28M6RAx5PZiyQ42JdNNsRTFnfOzLda2f3ilW9DJgO5JRBIdMEnWa9teIcq8w2zijWWm4rLOuAlD+uV7LLDz+mVWeq7MRXXmumdiBr7sc+fTkRkYVtuwBTU7G76nkayz3YIURyYzExkoQc8gH8/Bp+8d73k1xzE0tHgQ2ZxzzuCJ588WvgicfBsuUUSUpR7Vy2EXCuzEIy05lGo3JUJAFcBGy5XboMQNXHbLvd4XxmJqpjTxj9RERERGRuCi7NS5WlFDyJAWIgFB6LKVdsixwmtsF/f4+fX3op/bvuxg5zNnczVv/OMzns9a+Bxx0OWQouJQ+Bkfd00xSDJ+QF1tW/Gk+5MW5PCoaUHwbK9eR6/1v1YaE5f+eaznrtbkDVorWh7hrUXsG2c9y6Ze7g0s4CS7NrMYmI7IMcGBOrhREw0ZAkVQe5qSm45lru/PuPsuX7V7Es99DrkR+8nJNfeyGc/BQYX4zP+gxGgX7H4gsPOCKeaMoFAoevlhzKgH/dVdXgKe/U0hTx3klaUr0Dujli69AtIiIissdRcGkeTAQXLTFagisnydFU2To+wv2b4SdX8+13v5v977iDfizYNNah84TjOOqNr4NjHgdZh0GIJD6SOEdiHRYoBoEs61U1KKbLhHerld2HFsLZVUxT+8iY2HT8Kc1VCyNWq9h1l6LpLW/VrTVfmzJKxj6IMNAOAklzxJvirDP3rGCdiMiu0c5aijESTKRwEWsMCQFCBGcxWJz3MDEB113HTZd9gOI732J1PmBbiIxWH8ITL7wQnvM8iiwh6Y/hh5aeMTDMSTuGYZjC2IRIgqvGLIuhA61liDqHKTb/DLHcSs2sUnqmWrgwVXcLrQ2IiIiI7LH26eBSnOP7um6QmfGTOYIY1Zw3OFvW/il8uVFr0xa4/gZ+9L8voferOwiT29jS7ZIcdzRHveXNZbvm/jjeGDKbkY8KHJYQwftIJ0vLyX5iKafhVf5ONQ+3drrDz55huiZGs71hh9Gvdq2mGTexfUBoRzXLTf2BRMVcRWTfU1emg6rZww4vBaEOzISyZpGJVUdTawgE8uCxMZI4C76AzZvgrru5/WOXs+m732H15DaGMZAfcgjHv/p8OOVUWLE/Lg0MI6SJKbfC2ZRQTOESS2htWI6Ysp9DlaQUTJ3tWm9dDs3jrasMlplNM5/t9PeKKImIiIjsqfbZ4FKc4x9QVf3xuKbeT52J44h1wKNO0XfgfSCxrgwsTUzBT37Gde95N+ZHP2J8NGByUZ/kmDUc/7a3wEknQWcJRIez4EMkTRxUq7bWVRPn+iuuCnLNmG3vdOPXo2bGA6i37Zk5zqt/YFtnbd/T7cE/oQdxwTkuMn2/dscXEhHZw0UiRTUIpdTNDUrT9bBjVQWvDOY7a8tGE9HgYt0gwjEqRqQGEhtgcivcfw+/vvxDbPzKv7ByYpKRMUwddABHv/YCeOnZkI2D6UIMpKba1RbL+7OuLNZtmv+qh9Iqg7d9M4qdnap/UtVZMmZnFxQRERGR3WyfDS5Nl6Fur51On0eMVZJNBFuWqQ4GkthaPQ2BLHGYqSkYDOC6G/jF317K4Mc/ZnmAwdgYE4ccxDPf+hY48QnQ6UKS4POAbRWnrrcF1DUpyu0Bc3Q721HsZrd7MOGuB/oQ8VDvb3dcV0Rkz9AcdWdneUYAizGhOhnxBKxx2NYFR3lOP+thfQH3bYQN61n/8Y/xy3/9MgflOd4aNu23nCe96pWYF5wGWQKL+4QIhrLwN8RWUzhbZikxMw7UPNjmi9n+jJ0+y4dwcRERERHZbfbN4FKkDB5VKfuuWlkt13gNJiZQ2DI/31owUJjqfAPORKoZNiYWUEzBzddz/WWXMvHf32VFgM3WMXXwoTzzf/7f8KQnwqIlYDvEosB1k+3bQ4uIiDwAiyGrT1QBnmqv26wVE0tiLd54RpT18bpVdCk3niS12GEBW7bA5k3c88lPc8tnPseKwZApHBuXLeHoC1+DWXs2LF8O3S7Bjsh9IDUZJirSIyIiIiLT9s3gUr0RLtatkMuTts7hj1Uq/hxz56K6nosBgi+3EvzqDn72vktY93/+gyNsytbCUxz5WJ72hj+A33wmjPUZ5QUuS3BZWt6Qmd4eEGOrmOl2S74iIiKVuuUatApeQ72pu/xu+rLGlHUBI+WaCBESZ0lCDpNTcP/9bPrkJ7n9yn9h8aatJFmHDUuX8KRXn0/3xS+GlSsojMFHj43gXL0XTmOViIiIiEzbN4NLzY6z6QykpjhErL5WpXkKIIaq6pIBbywheqwfYSa3wZ2/4oa/eTejb36TxxSBQWIYPOYxnPSGi+HU/6sszJT0iG5IdI68CKTOVtsGWrWHFFQSEZGHygCxrLAUoyvLZbsqgSlGYgjlQB8jsdoDHmOBLUawZSP5lVdw26c+zeqt2wgu495en8PPPJPuS14KB65mmFisSyiKIX3Tqaom2Tn2vomIiIjIvmzfDC7BdL9jO8cE2USw4Cn7xhEiaagzi8B6DyHAnb/mzg9+kHv/8xvsv20SXMbEypU85aKL4Hm/C2PjVesbS2ozhj6nm3Qo8kiSKrAkIiIP0YySRZZAJFR1+urafeXYVV7WGEsSpoc8E8FFA+vuIf/Xf+H7H7+cgzdvJkwN2bxsP457ydl0z30FLFkMnQ7GlPlQvaRL9GBsoqQlEREREdnOPhlcmi7ibbBmVjNnE6oCqLGaphusMc0qrS08TE3B7bew8fLLWff/fpn9Jwe4rMd9i5dx7PkXwHN/F8YWk0dD0nNEIvlgSDdJy4m9nf2IREREHpzWbm4CjqI65QiYZnQzBCwG2/TIjAB5ARvvZXTlV7j+U59g2YYNhKIg7H8AK59zCt1zXwmHHAxjXXw+IIkRm3YAhx9G6FY3pgCTiIiIiLTsk8GlWlV+Aphu4eyhauAcMBgcrsxSikU5KR8OYNP93P/xT3DjP13BqsGQEA1bli/liRf9AbzwDFi0GLopJoGp6AlFwXinD4UnFDk23adfdhEReZhmt4Qox7OAwVNWRbKEKpfJx4ArAibPYWISvvIVfvqxT5D96pckMbJ10WIOfuYzWfG618Lhh5Onhqk8Z3E3K8e/YQFphutQrsy4R/vZioiIiMiebp+NctSbCGwdYYoQbdkVLgI2RlKT4Ae+zDRKIwwmYWITd3/kQ9z9T1fwG6PI1sIyOGB/TrjwNfCCF8CqVQDkMWeEIRqLSTNyD4m1WBspQ1gOLf2KiMhDEzEEDGVHU2Oms3EDAUvE1k0posND1RI1wH0b4f/8Bzd+5EMsvu02rLHc3+my+Bm/xYo3XAyH/wZ0UrCRrnWMfMAZh02zcrSKlAUINXSJiIiIyCz7ZHBpRj+dOrhk2ivBFmccBINLHeSjsl3zYBubPv1JbrjiCg73gcHIs2nJUk548Zm4M15U1qgwAboZwXpMGb4qA1mWcvav+koiIjJvdSgpAklZIrAZVsoxpw4sOcAWECY3Qz4F3/8e3/27S9nvllsYi3D/2GL2e9pTOeLNf1QGlnod8tRCCJgI0aZ4DMGVt2qr+zeKLomIiIjILPtkcClWWwVsO6JUdYyzzfQZCg9mNMKNhjAxYMvlH+OmT32CgycGbMsj9y1ZzONf+TK6570CVuxX7q0bT5gspkhshxTbNIe2xDLApP0EIiLysLRTbk05vphyK7eJFp+X4R9jqgLeUyO46iqu/l9/xeLbb6NnAlvGeqRPfxJHvPUtcMhBsGgcUkf0HmscxtjyHgwEU4azkiozSulLIiIiIjLbPhlcgukAU5NIVBVdqkM/wUNSV0HdupUtH/8kv/jiv7Bow/1Ea9k4vow1a9ey3yteDgeuBh/wnZQi5uBsVUa1XO0l1K167MxgloiIyHzEqvWEsWVXuAgmWgjgEldGgwpg/Xq47hquvuRS4vU3sV+/y4YEsmOP4pg3XQyPPRyWLGZkLTYEUpcQgqnXW1oZvZFIJKDQkoiIiIhsbx8OLlV1SU25vaAMLVlMKLOZLJTFu++7B/9v/86tX7yS/p0bMAVsHOtw2JlnsN+rz4MDVzMMBdmiReXUuxiR2QRjXBlPCgFMWSAcwPoqfKWSSyIi8pBVubAmUlTZS6bqCWdCLAe3fAQhwuQkXPtTrrnkb+G6mziwP866qa2Ypz6JY97xJ2VgabyLd+VSSGIgFgHjXL1bHBfBUS6Q+DJHarc+exERERHZM+2zwaV6RTaYiMEDBlPn//sIFDC5Fb72Vb596ftZse4+nA9sW7KUw577PzjwVa+Ag/aHJCVNUwocBkMnScttBdFAjK3STtVar+blIiIyb2Wx7rKraZlNVFX2KxtU+AKMh833wTXXcMPHPsLUtT+nNxxwj/Usf8pTecyb3wxrjoflSxgYQx4KUpOQ4jAhYmwk1KlLhjJQFQ3Wmu261ImIiIiIwD4aXDKUdbcjUNiIJZJ4IAQ8BleMYLCVwZe+yO0f/jAHr19HGI7Yungxi5/3Pzjw918DR/4GOAcmwXqHDwaXlgvGWeqqvQQBbw2BFKoSqNGFVkFxRZpEROQhigaDIxpfbVMrt1wXQBI9jCbh1hu58X3vYesPfsRYHphILenxa3jMRa+FJz0Nej18NLgkw2EJhS/3iVsL5FgTCBg8DmddeZ/1eomGLhERERGZxT7wRfY8ZcbR9LJqPc+NJhJN2ZAZAsS6o05syp/WN1DthiMQCcQyyyj4snj31Db4P1/jJ5d/FG68id5wyOSiMZb91jM48nWvh6OOJloHaYdiMARjSJPyLrO0ulsAa4jVNoLp+hX1erOIiOx7yswjomuPXrTHqfa/GWYPZNUmNRPBBki8h8EAbriRm/72A0z+4IcsG42YwJMedSRPuPj18LSnQpZBv4dJuwzznBAjWV2nyWx3R4TpFNwdPDARERER2dftlZlL0Ri8cWAcJgYMsepo4wnWE/FlvaMIZW2KZuMbtqqtHQMYC7EosImliJEkBChy+O53uPa9lzB+zTUssykbOx3i03+Tx7zlbXD0GopOBniMj7huF6q1Y1OF6kzTEM7gqqLe0wu9tjpHS78iIvseC6RNZ7dy+7SvYjYzi/HFqvVEmTHUaggRc4yD4HMS1ylrJU1MlNm0N9/C3ZdcxtavfZOVo4JirM/osIN4wmvOh2c+C5YsBRI8sQoqJZiqG5xLqYazlLqWUzNWtYcsDV8iIiIiMsteGVwykbK2RDXRjtCstpaTcFP2T54xA45VrKlVsNtGTLAkuDKVafMm+K//4kcfuAx33Y0c0Olzb4xkJ57IMW99Kxx5BCHLGAKZcZjoCaZq92wixsyecU9nLLV/JiIi+7ZIxMTpVKB2DtP0KFGNIM1qSVUtsBrveq5D8AEGQ6yN8IsbuP7972XwzW+zMlhC1mNixUpOfu1r4dRToT9GbmyVresxGGKsUnmtJWAwdnrU2m600vAlIiIiIjuwVwaXbIxk3uPw+HqiHcFFgwsO4vTTimUsCUtRnqZs21yEKZxNsS6DIsD6e+Hn13DDZR/E/PTnLOsv4vbRCPuUJ3LM298KjzkE+h1sPmKskxFjJFbBJGPMHIElERGRWUwAM6pCRb4slm3LVYoymwmq5qIYA9GWoadAwJgCS4RoicOISR0uN8AIbrmejZ/8BBu++VVWTeZ2QfVgAAAgAElEQVRMug73r1rF0//gIvi9U2HJMsCW27ZtOV7FWK7Q1KOXRjERERERma+9MrgEYAlYInVVJaDaYlDuSQswa6YcWxPoSJo68sEkWboYtkzC9Tfy40suIf35z1kWIuuHnuwJJ/KEt7wFjlsDYz28H+GyMcgLTGJVdkJERB6iOvWWqvgfzNngoUpUmo41RcCXm9UCmCSDETA1Bevv4Nef+RQ3f/bTHBQto8QxuXwZJ73mfPjdU2B8URmlyrokAbwJ03cXy6zb6cypukqgiIiIiMiDt3cGl0zEW9/UHjXN9jhLbh25qRaCm6SmWFVFAhssEAl4Ugts2Qw/vZY7P/AB3E9/yqLRiE0B/DFrePIf/hE88YmwqENuPKnNwG8fUmpWf5W9JCIiO9OKIwVT7dE2ZfMHM+sy0daZt1VHuODKU9aBB4pJuPs21n/kQ/z6S//MY3KYHAzZctDBnPiq8+iceTosXw6dPrikyYiqR8Yq6XfOUJJGMxERERF5KPbK4FIkEs10wAgMAUMgIRozncnUzI7LMJSpl4GjwcYIwxyuvZGb3nsJk9/7DkvynE3B0z/+RE646A3wlKdAf4yRc8CIrVMTjHUWY1Onfm8iIvLQtconTXc9tU2gBzM9dsXmXKo6gun09QcDuOMX3PNPn+UXV36J8Xvvh2yMsHIlJ73sXLrnrIXFY8TxcQyWfBhwxpY3FsvsqXZgqc5WMspbEhEREZF52CuDS3UwqfyOaoOcwxuHC5AB5bJuKGsyYXDRYqKr9hgEGHq45kZ+9d73Uvzgv1k6NcE2axgdfQwnXPhqeMbTYPE4pBm2GJEkCUl3jJGJ0x3gwnTGkrKWRETkQanTbmOZk9Q0pzB1clG5XOKaRQxXXZbyssMhbLibic//Izd/6h9YtW0K2xvn1+k4T3n5q8jWvgwWLYHF42wdTNHPuiSJa4JWIVLVeJrOvBUREREReTj20uAS2FgVJKVe7a02DkTKVdk4BOsBR8BhosP4CKGA0RB+cTs3/v3Hmfj+91k8sY28m5EcdhhPvuDV8NznwLL98N0MQsSZBIqIdQ5DxBOwKKAkIiIPUTVoGWPKOoHQBJvKjNxAwOOIOKgylspcWRNsmXG7cQOT//xFrvn0Z1m5dYrRYMTW8T7HvexlZGevhZWrYazDgEDWHWvuushzjLU456YfjpkZXIpxrs6nIiIiIiI7Z3f3A5gPU3eGo+oGV02OTQgQPfgc/AAIeF8GmIZFIPgczBBuuZ47PvhB1v3b1+hODhh2u6w/cDW/8fK1cMopsHQZVAW7ozVEZ8GUK8flhN9XZTKMspZERORBM0CCxUaDja4MLFX/yp5wBZ6CctNaQiggGgt4KKZg8z0U//Rpbrr8chbfdR8ud2xavoLDzjqTJeeeAwfvD70OwZbX883NR0wKxoWqCmH9eGZuhLMaz0RERERkHvbSzCUD0Ux30TEBYrmNAAM4yl1xGCyOmAd6ZSgKrruGmy//OPf+29fYP8CEtQxX7seJr34V3bPOgt5iwOIxxBgJVQ2nqnMzCabqprOjMqgiIiI7U3ZkC7PWd0y1yduSAIbCGxKXQchhYits3crkl77EzZ/8JN271uFcxtbxxRz6e8/jgNdcAIccBL0OWChMq343VCNXtRCzg0elEU1ERERE5muvzFyKBry1dfyoZDzGBLyLFMbiky7DImJdRoqFwsOtt7H5M5/j/n/5V1Ztm6AYDtl2wEqe8PsXMPaSl8CSpTC2mMJHjI+YEJtF5WipG+xUWxk0DRcRkYcuVturCwuhKruEnV4bcThGo4B3tmxQOhjCli3w1X/jFx/+e3q3/JJutNw53mfR7z6XQy56HRy0P3Qz8Hk5bplqjaXJto04HJakyVWa/U9EREREZL72zuAS4JsWOvUPPRhPiIEAeBLSpIctfNlV58672PK5K7jus1ewbMskBsNg6SJOetlaeqe/ABYvZpR0IElIOl2MsRgirtWuuSnAGm1VB0NEROTBqxqWVoskAW8gOqrojsFhIQTGsg62ADcqYGoA3/421172AZLbbmdxd4z1EVY957c54vUXwoEHQL8PeQHWlgsikSoLqsyGKlN9HdV+ud35EoiIiIjIArRXbouLplrtraM+dVtnPM57jA8UNmKDxw6HcNd6wmf+mTv+8Qvst3VAMIaNi8d4wrnn0H3x6bByBSRdsqQLeQBnITqMjaQAVc+5iMGY6c4+IiIiD1U9hETjq+wicIaqBpPBhoAZDkmdhS33w3//F1f93QdZdPNtLEk63BIiK055Lo//ozfAYQeXgaW0UxYkrLqYWsDGgGsKdtvpfXLT9bxFRERERB4Re2VwqUzhj9OBpWrubH3AhIgpPKmzJHkBGzaw+YrPc/vnPkd293qMMQyXLuWEtS+l+/K1sHoFIetgbIfJySnGun0oCkjLts11baXYjihpD4GIiMyTieWY4mK5XS2WFQPLLqjRYYoCbIRNG+BHP+S///qvyW69jaTw3OtSVjz7WTz+rX8Mhx8GY31yHAZL4gw+FhgTsTFWP7VQF+nWuCUiIiIiu8jeGVyKkTTEso43CQ5IY0EvVFvZDJhhDhvvhy/9K9f/wz+wZOMGsm7CxqTPsae/iN55L4cDVsGiRQx9IOY5Y/1+ub3OeUzZWwdIqq8iIiIPj8FUtY88HR/IKPA4mn3eETAWJu6DH36PH7/7b1h00410BjkTi8dITjiex7/5D+HQQ6A3RrApYJmcGjHeyyBxGHxZWSm4sv9FtRMuVhlLqhooIiIiIo+0vTO4RJn9X06Oy647FouLliSCyXPYtIXBl7/MdR+9nEX3bsSayL3WcvSLX0T/FS+Dgw4gTyzeR1ySkSRld7joc2ziIAQMhlit+MYqccmY+oSm5iIiMh/lkoVtivmZ6dxYD0xug+99j59e+j7C9TfSzT2jfg973BqOvfgP4OjHlw0oLOQ+4Jyl38uYHIzodTMI5SLMzHusmlPgMdiqpLeIiIiIyCNjrwkuxWqiHGPZTrmIAWPBEYgBciyu04XJAfgCvvRFrvvoR+jccTuLOz3uzRax6rd+i8XnvxKOfAxkGc6VmwYIoclOMjYlhoixKbSm39a0wklGk3KRhSy2PpjX369bt46VK1eSpikxRkzrODDXaaD52Wg0Ik1TjDHbXVb2LZGIN76M9iQZkYRhKIeVxEQYboKf/4Sf/u/34356A4u85Z40pXfiiZzwljfCE54AvR4hBDCW1Lpma3i/kxFDKGsDtt5ixrSzlRRYElnovPc4V6YqhhAwxhBCwDlHCAFrbTMWxRjx3pMkMz8SzB7HNHaJiMgD2WuCSzMZXJqWdUtjtQJsDG44YGwwIPzHd/jJxy8nv+lGlnfHuN9Ylj/jGRz2R38Ejz2CoTN00qzanlDd4gMMmBpORfYd7eNBCIHNmzfzZ3/2Z+y///6ce+65HHrooaRp2lzGWstwOCTGSLfbba6f5zlpmpJl2YzTsu+ZGXwEZ8utcFMTA7KxLkkMcN96uP56bnn/+zA33Eh3kFOML6Z7zOM54XWvhxNPguXLiMESTRkkMpTBozgjU6nOhJr+MDhdKrDK0n10nraI7AbOOWKMFEVBkiQYY3DOsWnTJpYsWUKe5yRJwnA4pNPpkCRJswhSj1Oz58V1gMravbLRtIiIPAr20uBSWRrJkuCsIzWGlIJF2zYx+MpXuO6znyH95a9YNr6Y+2zK4qc9jcMufi0ccTD0O6SmLHCq1VsRmUsIAe99s6oLcPXVV3PrrbdyxRVX8MpXvpIzzjiDxz3ucYxGI6y1dDqd5nrWWowxpGmK975ZMVZgSSwWZ1J8CJho6WcJ+AFs2wy33MyvL/8o933jmyyPlq39LpMHrOI33/iH8OSToD8OGIxzZf5R68Pfjr6fi7IPRBaudsZRmqYURYG1lnvvvZdLLrmEo446ilNOOYXVq1c3mUwhhGa8yrKMPM+x1jbZTzUdO0REZGf2yuUHgwEfMdEQsESfs5/3PBbL9f90BebmW+j7wPqpAdmJT+DIN14MJ50IS5YwGuWEwpcrt7P+iYgAzaTaWttMzvM8Z9u2bdxwww386Z/+KS984Qv5i7/4C26//Xa893jv57ytOqhkrSWEoGPNPqz8YGYIERyOkBdAhIktcOvN/PJv38+9//mfrDSGwjn84Yfxm2+6GJ74BFi5EpIO3iRl1i6zs5Xa9yEi+ypjDHmeUxRFs+Wtzlz6wQ9+wMUXX8zZZ5/Npz/9aTZv3txsmwNIkoRt27aRpinOOUajUXO7RVHo+CIiIju1V2YumQgZFouhsIZOgOPtOM9etBR/3Y2sTixbnePAk0/m0D/+Izj+eLApRWHJ0h6EABjVThKROdX1Krz3FEVBmqaMjY0RY2wCT7fddhvvfOc7+dznPsfatWs566yzOOKIIzDGNJP7OlNpOBw2ASYFl/ZxFmIIRCLdNIEtm+GeX3PL+9/H1H/+B/2Nmxn0FjM85CCe+NoL4Hd/BxYtpjABm2aM8khiItYE1fASke3UGUu1TqfTLJAYY5iamuJb3/oWV111FU9+8pM577zzeMELXsCyZcsYjUaMj483x5V6SzfQBJvm2jInIiICe2lwCcBaR1k1ItLFsmrRGPuNj5EN4b58SP+oozn0wt+Ho48mLFnKKDpSA0wNId1rn7aIPArqwJK1tgkw1VlHzjmGwyFQTuJvuOGGJsh05plncuaZZ7JmzZoZ9SnqyT0wI8CkCfrCNzuYaGOkYyMuFPQntsL6e/jl317GnV//T44sIqNeny0HHMgJF74Gnvs7sGScIjF45xiOynLcLjEYFFQSke3VmUh15pJzjiRJZtRh6nQ6TE1N8e1vf5sf/OAHfOhDH+J1r3sdL3rRi5q6S51OB4DBYECn08EYs90CiY5BIiLStldGWaKB3EQCAVMMGBK5ZWIDK7Ict3Q5G+8fcs2117L5Hf8Pv+r32JSl2CzFeE8394Q8JzpH0KAoIjsQYyRNU4bDIb1ejxtuuIEkSZqtAVmWNUW8vfdcc8013HzzzXz+85/njDPO4Oyzz+aoo45icnKSXq/XFE/NskyT833E7MCSMQYXAr0YWAQsvevX3PX3H2Xdl7/GAUPD5iIysd8qjjvvfPi9U2HpUmInoyhyHAW9zOFziAEiobnN2fc513tKGXMi+4Y6o7HOXqq3bA+Hw6Yj3HA4bAJFIQR+9KMfcdFFF/HhD3+Yiy66iGc/+9kceOCBTE1NNR1SR6MRWZY1Cy1NswCNYSIiUjFxL5lx1g+z/Gr4q7/6a/7sT/8nCYGxWDAe4BDguOVL2Lh5gmt8wX1k3IMn9LvEfAIi2GiwAQKoW46IzKmeOLe74rQn1O3Mo7qWEtAUR40xcuSRR3Luueeydu1aDj744Gb1OM9znHPN9jlNzBeu+n2yceNGjjrqKO6//356IbAEWAO85PFHceQwZ/WmLZgQWD/e56ZOhvnNp3PXeJ+tHUuRJeTFCGtSnO9iTUIgBxO2u58HyohTxpzIwldnK9VBJWNM01jiyiuv5M4772wu2x6/er1eU/z7qU99Kueddx6nnXYaK1asaC5TZ0XN/iciIgJ7YXCpZHj3u/+Gd7zjTzAEbAj0HGQBbIAuUJAxJGUbkYErwFVFCQOYaGkqooqIzFJPzturs/X39YQ9y7Km2Gmd0QQ0ASljDJ1Oh4MOOohXvepVnH/++axYsWJGnRy1dF642i27169fz5o1a9i0aROLvOcQ4JSlSzllbJwVWyfo24wNWZd/vu9evltMcAewlXIRpDAwqho2pd5ChGDKDN4dBZX2kmFdRHaROmiUZVmzrbvuAlcfH9rjVpIkTde4uvh3mqaccMIJvP71r+f5z38+/X6/uQ0FmEREZC575bY4iE2bu8JHjCsn29sMJCm4wpJFV2UnRYwPVAlPEMufocm3iOxAnVlU11yqee+bCXm9wgvTgYR6Ql93mrPWsmTJkiaolOc53W53h53lZOGw1jZF3ev3k/ceC+w/PsYB++1HNhqS9HvcXcC37rmT71FwG5YJEylMxAWwESyWiIGyPyqx6jgHMwNJCiqJCDCjA1wdWKpP1zWV6sBSfWxqb6XL8xyAq6++mgsuuICnP/3pnHfeebzwhS9k0aJFCiqJiMic9srgkgGe9VvP5G/+6t3kHm6/45d86pMfZ+uWTeQeXOIYFZ6IJ0IZiAoWiJiqS1wwQdviRGRO7dbNIQQ6nU4z2Y4x0u12GQwGwPREvT2R73a7PPaxj+WVr3wlL3nJSzjggAOaQFR925qUL1x1sDFNU0ajUVNc11pLEQK/3jbBLzr3sF9/MRs6KddNbeE7FNwGbEkduc/rtRAAYmGgylTyQDl66f0jIttrb92ux606e6neml2Pb+2i39578jwny7LyWFUUzXbuG264gauuuopTTjmFJUuWNPejcUxERNr2muBSe7AEePJTn8KTn/pUCHD9jbdhcExMbiUfTeB9TuIcMYKJjnJWXk7FTfWNJxA1JorIHOoMpLoIt7WWr371q9x3331YaxkOh4yNjeG9ZzAYzAhCnXTSSZx77rm86EUvagqitjOcZm+3a1NNnIWhfo/UGUt5nrNixQq89/TxTG2d5AcbtxKKSOIyfr75fn4J3A8Mfd5k2drqqylTbqv+qDO13yt6/4jI7JpLzrkZ59Vf68wlYMZWuMFgQLfbBWDFihWcccYZnHvuuaxZs2ZGBpSIiMhse03NpZkiIRbNxDwG2DaIpH2Ds5DHAYkBg8GSYKIr13ljlcVEAGOUuSQic6q3CdST8nXr1vGCF7yAH/7wh812g3oLQZ2pdPzxx3PmmWfy4he/mNWrV9PtdpuaTHW3nTpotbNaSzsKPMnep175HwwGXHvttWUWQT7FZz9yKTf99Gf4iYhLumyLHnoZhYPJYkSBIRpLxOKCIQ3l+NXUWprjvtSBUERqMUbyPGfRokUURcFgMCBNU26//Xa2bduGtXbGOFdv43XO0ev1WLp0Kaeeeirnn38+J554YtNZrt7uDTrOiIjI9vbS4FIg4jEYwhAiCSSQR8ABJsdQbiuwZBiSMosJKMNMgXItWAOjiGwvhNDUoLDWsm3bNp71rGdx/fXXN4GlGCOdToejjz6al770pZx11lkcdthhzXWKosB7T6fTaS5fT9B3NilXcGlhyPOcPM/p9/vldjbv8d6TuogpJjFJivcdXJbhi8jk5Fa6HbDOEJO0rK5kEmw0uBAwMRLnWBRREW8RafPek2UZIYRmHOr1eqxbt461a9fyzW9+c8bl60WPTqfD/vvvz/Of/3xe8pKX8LSnPY0kScpaca2gkjIkRURkR/aabXGz5fmALE0xiSlbM4+gm0LwYJOUMgAVqJs1W1MWRm02Fhhb1l8SEZnFWttsX6szjer6FNZaOp0OJ5xwAmvXruWMM87goIMOAmhq67RXg2vtmkx1RtRcgSRN2BeGNE2belz1tsksywg+J8SUxI0xHAZMAb2OYdHY4rLdaRiBB0xZHzAaQ2Et0URsjBgiFsvsmkt634gI0IxVSZKQZRnee0ajEWma0uv1mmBSLYTAgQceyOmnn855553HmjVrmm1xQNPYov1VRERkLnttcClLO0DAWAPBY1MHHmwC+AiuDB4ZtP1NRB6a+oN6PUGvC6AuWrSIxz/+8Zx//vk897nP5cgjjwRoMlOSJGm2yrVXedvZJe36F7PPl4Wh/b6pg4xZllUr/haX9picGNDp9bEWYl5ue8tHI9JeCjGAsRBNGWOqKgYaE6hHNhX0FpG5xBhJknJ6PxqNyLIM5xx5njMcDpt6gtZaDjjgAE4//XTOOeccjjnmGMbGxprxqx6b2uNTvegiIiIyl700uGRoHroBnGW6LRxVFVRXnd3KTzLNFdDEXER2pq6pVBc+ffKTn8y5557LWWedxerVq6dby1e1K+rJPDBnxtLs7+c6LQtDHUCs23oDzdZIYy0R6Pa7hBjxwWAcQMSlGSFGrJ0e3+qhrewPV79f9L4Rkbm1aynV2+MAkiTBGEO/32fp0qWcfvrpvOpVr+LYY49tOsTNDizVdjSmiYiItO2lNZdERHYt7/2MLXH33nsvS5cuJUkSiqJoVnTVjlkejHaXprKhRJzx8/o9ZIx5wC3bereJyI60m1GMRiOcczjnuPvuu3n7299Ot9vlwgsv5KSTTmI4HDZb4IbDYVMjEBREEhGRh07BJRGROQyHQ5IkwTnH1NQUnU4HYwyj0ahZAW4HBER2ph1cqovCz0XBShF5uOoAU521VB9v7r77blauXIkxptmyWzebAJpuqKBxTUREHjoFl0REZqmzltoFmY0xTTFutX2X+ZhruJ0rS0DvKRGZrzpA1D6OFEVBURQ455oOcO26THUNpvoyoOOQiIg8dAouiYjsRL1VIISA9367+koiD1Y7kLSzzCURkYerXiSZ3bm0VndDbXdGbS+e6FgkIiIPlYJLIiI70K5dUXcAExER2VO1t97WAaI6O6luLFCPa+0tcYAyl0RE5GHZfilDRGQfV9epqNUTcygn3yIiInuidmZkPZbV3eDqbXFzZU+2xzkREZH5UOaSiMiDpOwlERHZ09VZt+3s27r76extb+0MJ9UTFBGRh0OZSyKy4NS1JmDmZLmdkeS9B2ZmIrW/r89vXydJku2ymkRERB5JIYRm7JprrHogde2kuQJEs4t9z/5eHStFRGS+lLkkIgtaXYS7vWrbrjdRbw9od8+BcnKf5zlpmuK9x3tPp9MBtKIrIiK7Rj0u1cGkulvpg1WPW+3bqYNNcxX2FhEReaRolBGRBcl730yqrbUYY7DWNqvAML0S3O4A570nz/MZ10nTtDmtwJKIiOwqdXZsPS7ViyMhhAeVvZSmaXN9oLkNa61qBoqIyC6lzCURWXDa2wHyPG+2s+V5TrfbxXvfBIva2jWVQgiMRqMmsFQfKrXyKyIiu1KdaQvscLzamfo6MUZCCBhjmoxdERGRXUWfkkRkwWlvdUvTtJlYd7vdZltcHSwqiqJZzU2SpMlsqjOWrr76av7yL/+Sm266qVlBFhER2VXqQFK9rbsee9qZtztTB5astSRJgnNOWUsiIrLLKbgkIgtSe5U3z3OgDCTN7opTbxloX280GgFlrYvrr7+ed77znU1wSZlLIiKyq9QBpVq9nW0wGOCca7bI7exfPVZNTk4SQuDrX/8611xzzW58ViIisi9QT20RWXDqrQDOOSYnJ+n3+6xfv54LLrgA7/12hU2LoiDLMrz3nH322bziFa9gMBgAND/fWfcdkYdsvhvS9fYTWdDq7Wv1lm4ot8n1+/1mq/bO1AskSZLQ7/fZunUrL3vZyzj55JP5whe+oAUSERHZZRRcEpEFp161jTHS6/UYjUZkWcbJJ5/MaDRidqk55xy33norn/3sZzn11FMZjUZ0u10Atm3bRpZlzbYE1a0QEZFdpV7EqLNq6/pJRVFw5ZVXPmAG0n777cd5551Hv9/HWstoNKLT6WjsEhGRXU7BJRFZkOpA0HA4pNPpAPDWt76VEMKMznD1pP3zn/88X/rSlzj88MOb68cYybKMoigUWJJHljKQRGQO9UJGu6B3nUH7i1/8gquuuoo0TZsaTHXDiqIo+PGPf8zq1au58MILm/qAnU6H0WiEtXbG7YqIiDzSFFwSkQWnLtoN5cR68+bN9Hq9phtce9sclJlLP/zhD0nTlOOOO64poFpnOGkrnIiIPBrqAFCe5xhjyLKMwWBAlmX88R//MX/yJ3/SXDbPc9I0JcbIli1bOPnkkzn00ENn1Ads12ASERHZlRRcEpEFp73tzXvPkiVLGA6HbN68mU2bNjEYDJicnGQwGLBu3To2btzIF7/4RZ73vOexdOnSpu1z/U9EROTRUAeB2rWV0jRtagNOTEwwNjZGURSkacpgMMAYw69+9Ss2bNjAWWedhXOuqRNY/1NwSUREdjUFl0Rkwam75PT7fZIkYd26dbztbW/jO9/5DosWLaLb7eK9p9/vk6Yp119/PVu3buW0005rttDVZtdnEhER2VXqBhJAs/WtDiINh0NijNxzzz1MTExQFAWTk5NMTU3x1a9+lampKZ7xjGfM2MJdL5DU2+RERER2FQWXRGRB6vf7FEWB955Vq1bxpje9iZe//OWsWLECgOXLl+O9Z8uWLZx99tkcffTRPPOZz2y2zYECSyIi8uhyzjVdTZMkabbI/fu//zsf+9jHyPOcPM8ZDodN0GnTpk3cfffdPOlJT+LYY49ttn7X169Pi4iI7EoKLonIglMUBc65ZlJdFAVr1qwBZhZLHQwGXHbZZWzZsoX3vOc9rFq1Cmst3vvmthRgEhGRR1M782hqaoper8cJJ5zAb//2b7No0SL6/T6rVq2i0+kwPj7O5z//ed773vdy1llnsXz58iaY1K4bWHehExER2VUUXBKRBafunlN3x6kn1mmaMhqNgHKyfcUVV/CFL3yBc845h+c85znNZLxdm0KTcRERebSMRiOyLGvGsF6vh/eeAw88kDe+8Y2EEEjTlKmpKfr9PjfeeCNf/vKXefazn83atWux1jYLKzBd0FtjmYiI7Gqq7iciC1IdIKozmOqtBlmWYa3lG9/4Bu9617t4+tOfztvf/naSJCFN0xmT8Lkm48pkEhGRXSXLshmLHHUmbr/fJ8ZIlmWMRiP6/T4bNmzgz//8zwkh8I53vIOxsTG89xhjSJJkRqYuaPwSEZFdS8ElEVlw2vUlYox475sJ+sTEBFdeeSUXX3wxxx13HO9+97tZtmxZ0yGuXZeizniqtxNoW4GIiOxqdSFvKDNxJycnAZpt21mWsW3bNi699FK+9a1v8ba3vY2nPOUpJElClmXN7dRBqvY4JiIisqtoW5yILDh19tHU1BTOuWayfc899/CP//iP/N3f/R3HH388l1xyCfvtt19z+fYKr4iIyKOtKAqSpJyeD4dDkiRpOpzWtbmQZpQAACAASURBVJjuu+8+Lr30Uj7wgQ/wtre9jRe/+MV0Oh0Fj0REZLdScElEFpx6cl5PyEejEd/61rd4z3vew09+8hPOOecc3v72t7N06VKcc82qbr3Cqwm6iIjsDnXHUmMMnU4HgMFggLWW4XDIHXfcwbve9S6+8Y1v8Na3vpULLriA8fFxYGZgSkRE5NGmEUhEFpx6cm2MIc9znHPcfffdjEYjLrnkEs444ww6nQ7D4bApjgrMWBkWERF5tM0OEHnvsdYyGo347Gc/y+WXX86GDRt4z3vew2mnnUa/3yfPc6y1CiyJiMhupVFIRBakPM9J05Rer0ee56xdu5bnP//5jI+P45xjNBrR6XQoigIoO/QYYxRcEhGR3aYOENUZtfWYdOutt/KZz3yGTqfDF77wBY477rimRmCaps1CioiIyO6i4JKILEhpmjaZSEmSEEJg2bJlTV2legKfJAnbtm1rthWo7pKIiOwu9VbuXq83o8nEMcccwwc/+EFWrlzJ8uXLZ2Q41Yspw+Gw2UonIiLyaNMnKBFZcOp2y8YYiqJoMpLqukp1ACnPc0IITWCp3f5ZRETk0eaco9frAcyoARhj5LGPfWyzpTtJkqajXJqmxBgVWBIRkd1Kn6JEZMGpJ+PW2hkTc2NME3iCckLePl9ERGR3qjOV8jwHmNHJ1HtPv9+n0+k02+Dqy88e30RERB5tCi6JyIJW16Cog0jGmBnZSe2f19+3J+tjY2OsWrWqCUTV54mIiDzS6vGpPebUGbftTKa6EcXs8awOMHnvm38hhGZ7uIiIyK6imksiIrNYa5sJ+umnn85pp53WbDfQtjkREXm01GPOQxl7QgjNwkqapoyNjTE5OdkEpERERHYFE5VDKyKynbpTTz2hHwwGdLvdpnCqiIjII62dnfRwb8N7z8TEBHfddRedToeDDz5Y45eIiOwyCi6JiMzS7sIDKKAkIiJ7jXrMCiFQFEWzSOKce9iBKxERkR3R/g4RkVnaXXjagaW6wKqIiMijoc6irf89EO99E1gaDoekadqMaaq5JCIiu5KCSyIiO5GmKd57iqIgTVOKotjdD0lERPYRdbOJdtOJnalrLcUY6fV6DIdDYox0Op1m0URERGRX0LY4EZFZvPc45xgOh00hb3hkamGIiIjsKvW0vq65NNdYJiIisisouCQiMks7iDQajciyrNmS8GBXj0VERB6O9hT9wY479Tg113VDCOp4KiIiu4yCSyIiIiIiIiIiMm9avhARERERERERkXlTcElEREREREREROZNwSUREREREREREZk3BZdERERERERERGTeFFwSEREREREREZF5U3BJRERERERERETmTcElERERERERERGZNwWXRERERERERERk3hRcEhERERERERGReVNwSURERERERERE5k3BJRERERERERERmTcFl0REREREREREZN4UXBIRERERERERkXlTcElEREREREREROZNwSUREREREREREZk3BZdERERERERERGTeFFwSEREREREREZF5U3BJRERERERERETmTcElERERERERERGZNwWXRERERERERERk3hRcEhERERERERGReVNwSURERERERERE5k3BJRERERERERERmTcFl0RERERERGRBizHO6zwReXAUXJJ50cFZRERERET2FsaYeZ0ne58Yoz6T7gYm6lWXSvutoAPs3m1X/y71XhERkUeKxhQR2VV0fJFHi95rkOzuByB7DmOMIrwLzK46sO2rB0wREXnkaf4hIruKji97rtm/l4Xw+WIhPIeHQ5lLIiIiIiIiIrJbxBgXdGBmoT+/mmouiYiIiIiIyD5DNXn2LPtC4GVfoG1xu8kDHcwe6A9sV1x/Pn/U801nfLgH84d7AHq4r9/e5NEYOBfS6yWy0O3u4+8D2dXH5739+P9wx++9ff7xaP7+HuixPlJzKZFHyt5+fHu4Hszf5OzL1Kcfiddmb3/9H81g266sCftAv/MH+zja14sxYu3O83JCCM1t7um/611FwaU9VP3m3JEHesM+0PXnuq2Hkq43+4+tvp1H8gAtD99cvyd4+L+f9sHzkbpNERF5YLt6nN3T5x+7ywO97vX5D/Th7IE+nIjI/M01190bji+Plod7fH8k7n9nv5dHYnzZUY2th/o5aPYx/cEE3trPb/b97CvvQY1wO1EUBQDe++b7Bztpqt+A3vvmZ3meN7cbQiCEgPeeEEKTmum9byKjeZ43k5AQQvOz+rbr6xljGA6HM26nfnPXt1U/Dmtt8xy891hrm8cz+4+nfs55nm/3POr7qG/De48xhjzPZ/zxtF+v+vnVPyuKAmMMRVE037dv1xhDCKE5z3vf/Lz9+Orv26/L7N9Tfb95njfnt1+/doS5fkyzf/dzHVRGo1Hz89FotN359e+z/f5pp+HWz682HA5nXG8u7Z/X76n272f26fq5tZ93fX59Xv06tCfP7dto/47qx9a+bv16149HRHaufcytj21t7ePCXKcfjvpYXI8d9fFhMBjM+fjqY1b7OFw/7vpvf/axbPZY1T5WxRgZDAYzbqf92NpjgPe+GVfqx1kfx9uPdfb3s4/L7eNwe6wyxjSXqcdRmPl616/X7Ptojw9FUTTH7/b1Zx8T69tp33577BiNRs3r2h4v2v+stTOu0x4T2r+39n3PNaa1j/MhBEajUTN3aI977XlEjLG57/p3VL+27TlHPWdpj7Ozx/B6/Gy/tvV9tH+n7d/h7PlB+33Sfu4PZK7f81zjbn2b7ddt9vjanv/Uz7V+PYEZf2PteU19+zt6L8vea66Fvfb8HGa+92Yftx7I7PdNfUyc6++hfv/VX9t/R3Pdbv1eL4pixnG8nmfXx+T2cbD9tdYeK+q/hfpr+2+g/dmnvs7s+edcr2X7fmY/vvqzTf33Nvt1ro1Go+2O0XPNsWOMTE5OzrjM7ONN/VkKZh4X5jqu/P/sfXeYzff27rt7m16Ywswwg9F7jWBwMBE1EVFSJIgSKYKjhkQJIiTqwUSNCNKQRIQkCImWGC2IzhjMKFN2r/cPd61Z341wzr33ub/kzHoeDzP2/pZPWeVd71qfYB1Hv6PPuVwuBAIB2Gy2u3QP6Vs57vfSTcESbEOC3yE4BpBxpBxL0nVSD9N3aBxo7Oj70gbI96d5crvd94ztSKSfQbaI7AvFymRP5DjK2I5+L3VvsK2TY0j/r1KpYLfbFUkB6SvJ5yMfQMbFwdcMxhP+jnFTKbh0H5FOgEajgVarvQuNfBjRaDT872BlQ4pIrVbzZtVoNOy8GQwGxUby+XzQ6XSKwAC4s8iNRqOCrkfPKw0AKSO56VwuF9RqNTQaDX+XlAFdQ6fTQaPRwO1237UpVSoVHA4HNBoNXC4X9Hq9QlnRNen56T6kWOidtVotGzKVSgW1Wg2r1QqVSgWdTgeHwwGtVsvf9fl80GrvEO/o/2g81Go11Go1nE4nPwfNg7y/VED3mzc5pjRHQImB1Ov1/Ax6vf4uR1Wj0fCzkrGWY0xjTwrPYDCwUbmf0HdpPXi9XsU4BwIBaDSauxSYnFOtVsvvIsFDGQxotVoF6ETjRj+ToyKVd2lGtlRK5cEi96zX64VGo+E96/F44PV6Wb+Rwyx//j8V6RwajUa43W5oNBrodDrW1eSwkb1Sq9VwuVzQarXw+XzsDFIQo1KpoNVq2VnX6XQK3SL1Cd2XdB/pSeCOPSM9Tbpdo9EoHHsACh0vbUqwU0c6mp6BxpNslXw2o9EIAKwj6d8qlYptgnS46Xc0h3q9XuG8AndsibTD9B3SxfL+ZEOlnyFtlUwQSCc/WO/SdXU63V33kOAUAXz0/DLRIK9JiS2yaQaDge2avJfT6eRnIhtDc0vfpd+r1WqFPSJ/i9acTHzRHNK8arVaOBwO/pxMyjyMDXK73Wzr5NjTGMhgjT6r1WrZxst5p/H0er3Q6/XQaDRwOp3w+/28nkwm012JN9pHEoyj9y+Vv7bIWEGCrgB4zdpsNsX+kSDsg4T2D+k96YvJe7pcLvYTKU4g31XuTaAEfKfrEsgUDIwBYFtBQDjZAOk3y71Me5h0O/metAfkZ+n60h6SLpZ7SAIzwTpVq9XCbrdzvCT3NdkHij/0er1C55KOkfEO2Rmz2azwzemZZVJBjp1Wq2VdQDqUri33Os2JBHJIJ5pMJkVMQ3NG70/2lmICGXPeT+hapEvlOrgX2E1jY7PZANwBUHQ6Hc+fHF96b7q2fD85tzLG1ul00Ov1/DkZD8rYhNan1+uFTqdjwIdiZZ1O91D7h2JJn88Hh8PBvgolBKTNooRTSEgIPzP5L3Ks6HoGg4Gfga5La1DaEtqj9Lk/IxT8FUUzadKkSf+/H+L/t0ilT0IGIDjbFPy5+4lEQ4MDb+mEyMwuKZSLFy9i3rx5CA8PR2hoKD777DP8/PPPqFevHj8vbWZS2g6HAwaDAVarlRUqOdCkyDUaDZYsWYKTJ0+iSpUqMBgMfB0CnmTGUTpNBIKQUXO5XPjqq6/w008/oVatWmzYgh1Uel6prKxWK+x2O0JDQxWKgwIoUmDkhB46dAhr165FSkoKO2sy0DIYDLDZbHC5XIzyOxwOhQPt8XjgcDhgtVr5GelPsDNHyp8MJ40d/U3PabfbkZWVhVOnTqFatWoIBAKKsSdlQsqXfi+BJlLOHo8H27dvx1dffYXq1auzggp2SqSQsZIKVa5Z+Z50vx9++AFffvklqlWrBpPJxN/TarVwuVwoLCxkY+n1elFcXMzG0ev1wmazQa/XQ6fTobi4GNOnT4fRaET58uV5LB/WwS+VUvlvFalnJTBCjl7w76ROlUHEfyrkBAUHBcAdx9Hj8cBiseDMmTN49913kZCQgNjYWNZl0vkyGAxwu92sk6UuoutKh14CVsEsFwlQUYAvQSWn08kADiUeSL+Rw0pjGmx/A4EA60v5e5VKhVu3bmHJkiW4ceMGEhMT7xqb4GCJnpueh35PYIi8BwV3KpUKTqeTx4meSc5p8DNLG0V/07+lQ0+2WX6GRAZjMtFAYBi9nwRu9uzZg48++gjJycnwer1YsWIF8vLyUKNGDQY/ybcg2wGUOMnkVNOckO0rKCjAe++9h0AggPLlyyvWh3TS5bNL5jWtXZVKBavVihUrViA/Px8pKSmKAFSO8b2EAtfCwkJeYxqNBkVFRbzuKGgjf0IGUjSedB+yxQ6Hg8eH5lMG636/H0eOHMHKlSsRExODsLAw3t/05z9JYpbK/yyRfpvUrXL/GQwGACXA9L/jO0l/ku5DQLJkYRiNRk7UUmLA7XZj7dq1OH78ONLT0xX6QuoCtVrN/iwAhe6RMQX9H61f+q70QwEodLrD4QAABoAky48AItJRcvwkKEE6QfrJ9H9qtRpHjhzB8uXLUblyZYSEhPCY0HWtVis8Hg/cbjccDgccDgfrMQKTyK7Z7XYGH0iXS3YUASM6nY6Bl2CbTu9GgJbUCWQvaC0QQGO32/n69F5yXKQdlD8/SH9QHCdjOjmPpPf27t2Lzz77DElJSTAYDJgzZw78fj8qVqyoiBOl/aV3JT3sdrv5fSnOzMvLw4oVK1BYWIjy5cvz3JJNo2ehfSFjcLoOAZw3b97Ehx9+CJfLhfj4eB77e8V2JDJhJ+Nn6bPQPJGOp6Q/6Xqpt4PX4unTp9lviouLU4Cm5FdkZ2dj6dKlSE5ORnh4OL/zwwLM/9OltOeSkOBJpeCfFrMENB7kvEg0FyhB3AsLC7Fr1y7O+koQJyUlBXXr1sW1a9ewYMECpKeno2bNmti4cSMuXLiAoUOH3kXHJqWcm5uLc+fOwel0IiIiAunp6YiNjVWATyqVCps2bYJer0enTp2g0+l4I5JyA0oMBqHDMhtBhkCv12Pnzp3Izs7GwIEDWalIRSLHVW7Y69ev4/HHH8fSpUvRtGlTBXi1e/duDB8+HJMmTUKHDh2gVquRnZ2NhQsXonXr1khMTLwro3r9+nU88cQTOH/+PD8jGTEyJvTcWq0W8+fPR8eOHe+rhEnpDB06FOHh4Zg8eTIrcHo/ACguLsaGDRsQERGBXr16KcBCAPzZ/Px8/PTTT7h9+zYiIiJQu3ZtlC1blkEmADAYDNi3bx9WrVqF7t27Iyws7E8VTDBgSfcDoBh/Gltar7t378aGDRvQt29fREVFKdbmzz//jOeff56BObVazYEcGcqIiAj861//QsOGDWG1WjFr1izExcWhcePGvJ7lOPwdlGSplMr/C5HOmWRiUuZMOjqSkfMwmckHic1mw969exEfH48aNWpApVIx+3LUqFEAgBkzZsDpdGLOnDlo2LAhg97EdjUYDDh9+jSys7MBlADU0iGUDqVOp0ODBg1QoUIFOBwOmEwmBnykrbxw4QJ27dqFr7/+GqdOncL169ehUqlQpUoVNG7cGG3btkWLFi1Yp8uMtxwfCTKRHZfAlBx/lUqF9evXo06dOujQoYMi60qfk3NBfxuNRn4/jUaDnJwcnD9/Hjdu3GA9nJKSgpSUFISFhXG2Uz4fAAa9cnNz8euvv96VyArWoz6fDyaTCTVq1GDnnGw4PYtkF5P4/X6cOXMGv//+u6JchWxa06ZNkZCQgBMnTmDu3Lno3r07J6Xatm2LLl26cNaW7CqN79GjR3H9+nXY7XakpKQgPT0dOp0OarWag0idToeFCxfC5XKhZcuWiuBEsjikLyYDFgoqCNRbv349mjZtinbt2nGi6UG+GcnIkSOxfv16ngvJHHK5XPyOXq8XtWrVwrfffqtgX8uxttls+Prrr7F582bs2rULarUa6enp6NOnD7p27cpBjM/nw7Fjx5CVlYUmTZqgSpUqd71vaWLm7yESKHS5XJzMDRbyK4nV9+/oeFortE5PnDiBS5cuoX379pyo1el0OHHiBF544QUsX74c1atXx6ZNm+Dz+dClSxdEREQorllUVIRffvkFDodDwV6SOh0oCb4jIiJYHwMlAJBkyLtcLvz222/49ttvsXPnTuTm5sLv9yMyMhLJycl47LHH0LlzZ8THxyuSrhJkCraTdD/6vWT3ut1uXL58GYsWLULfvn35mjSuVqsVAwYMwK+//soMJbJBTqeT9b3UpQaDAePHj8cLL7wAoCTBTWADge0GgwFnzpzB+fPnUVBQwAB+SkoK0tLSeL5lJQYJ6cA//vgDx48f5zXh9/vhcDhgNpsZvKbrGAwGNGjQAGXLllWwZh60Ns+fP48jR44wW5bGUqfToVGjRkhMTMT+/fsxb948tGnTBhaLBYsWLYLb7UbLli0ZVFGpVAyuaTQa/Prrr7h06RLUajXKlSuHOnXqKBJAxEL+8MMP0alTJ7Rv315hQ4OT8dJO0noi1pJOp4PJZMKaNWtgtVrRpEkTfr8/GweDwYCCggJcunQJ586d4/Uq2cEELJGvUlRUBJPJhIiICLRt21axZqQP4na7cfXqVaxcuRKtW7dGamoqjEajIjEHAGfPnsW8efPQqVMnlC9f/q7k3F9dSsElKLMM9DcpMdp4V69eRVhYGMLDwx/KeaEFJDMAAHD48GE888wzSExM5P+jDMNTTz3FjBLKpJEQCEEKnoyJSqXCqlWrsGjRIlitVrjdboSEhKB27doYOXIkqlWrBqCElk0bQipa4M6GWLNmDdatW8fXldlfj8eD0NBQjBkzBs2bN+dMHlCSwZOKnyQYZFCpVCguLkZ+fj6Pj2RPBQIB5Ofn49atW/y+wZtOgnsqlYqZS71790b79u35e2R0QkNDUVhYyM5+pUqV7staomemDOSNGzcYYCMDQo6g2WzmIMvhcMBisfB7EKr97bffYsaMGcjJyYHZbIbNZkN8fDzeeustZGRkwOPxwGQycTbHYrEoMj/B6zN4XPPz8zF+/HicO3eOgzVSul6vFyEhIXj66afRq1cvNpB2u50dH1kWU6NGDaxYsYLn8aeffkJWVhZGjx6NChUqQKvVQqvVolq1aozy07qW400/l0qplMr9JZgBIR01n8+H/Px83L59GwAQEhKCiIgImEwmzpAC/7kj4nK50K9fPwwZMgSVK1eGwWCA2WyGz+eD1WqFVqtldiLZC7I5xOoBgEOHDoHIzwQSkT6UNHGv14vc3FzMnTsXSUlJDMpIO0TAx+uvv47z588jIyMDTz75JKKjo+H1enHmzBls27YNGzZswODBg/Haa68pADdZPkVOqUzG0DPOnj0b27ZtY/YKZWqPHj2KK1eu4Pz585z8CQQCsFgsGDZsGDIyMhgsISFg5uzZs1i8eDH279+PvLw8mEwmDihNJhMqV66MgQMHokGDBsxYkCATMX22b9+OuXPnKpi+JNIG2O12FBYWYunSpUhKSuKxD2aLUXBL46FSqbBr1y688sorSE1NBVAS3BqNRkycOBHly5dngIXGVT4DrT36/+LiYrzzzjvYuXMnM4fNZjNat26NESNGICoqihkUQInNJ/9K2tdx48bh4MGDijIFYgrYbDZUqVIFb775JhITE2G1WhUOO733w+6JoqIiREVF4a233oJer4fBYGD2d2hoKIqLi2GxWOB0OhEXF6dgxVFwqFKpUFRUhMWLF2Px4sVo3bo1Fi5ciEAggF27dmHixIk4evQonnvuOV6f+fn5XIohg6CHSVqWyl9DKACmNW8wGHDr1i3Y7XY4HA7WowkJCQwySHb8wwrtbwq6v/zySyxcuBDHjh1DZGQkLBYLr9Xc3FwFo7CwsFChe2Ui/IMPPkBubi4nHMivpSQBPWdOTg5q1KiBL774gtkX9D6kfzQaDbKysvD+++8jPT0dTz/9NCpVqsRs+gMHDmDevHn49NNP8d5776F69eo8fvR9u92ODRs2YO3atey/EuhCPnn16tUxYcIEREZGKnS7ZDaRb6vT6fDPf/5Toau1Wi3Onz+Pt99+G5UqVcLQoUNRtmxZ1mk6nQ5paWkKvQooS+NOnz6NhQsXYv/+/TzPpDNDQkKQmpqK0aNHIz09XQGqAyX73+v14ueff8b777/P+o3Kqeg96N1dLhfy8/PxxRdfcPWAZOfeT3Q6HT755BPMmTOH7Qex0aKjo/H222+jbNmyXK5GNlxWREig3ePxoLi4GLNmzcLWrVtZdxuNRrRq1QpjxoyByWSCVqtlAMxut3MsJWNAj8eD6dOn48CBA1zVQeNN94uKisLixYthNBpht9vZd5JMuz+TQCCAiIgILFq0CMuXL4fRaITNZuPkT3BMSrGT0+lEq1at0LZtWwXQlZubi9u3b3PS5/Lly7BarTh79izS0tJ475hMJiQmJjKjSzKSAWVy7K8upZZMiKSYUrbN4XBg+fLl2LBhA2bNmoUmTZo8cONKCaaKEj1z1apVaNSoEfz+O01UDQYDL1RySn0+H+x2O29IieRSpvmrr77C1KlT0atXL7z00kuIjo7G/v37MXr0aIwcORLLly9HQkICbDYbzGYzg0yyHI8yupcuXcKhQ4fQt29fxMbGMrBExkKr1SIxMZE3Cm1CQpslQ4nGUzp6pGRlmYHsA0Gb2el0YuPGjfj999/h8Xhw9uxZ3nx0TwlKUYalQoUKaN26tcIASsqmpFPSON5PPB4P7HY7GxZSJA6Hg38uLi6Gw+GA3W7nelw5hydPnsTLL7+M5s2bY/78+UhOTuYyk3/+859YuXIlqlWrxgEKvZfZbL7LQb7Xz36/HxaLBY0bN0aFChV4roA7hv/q1atYvnw52rZtqzCEkn1AhlKv1yM2NhbNmzdXZNwWLFiAihUrMmhHKD6tAckYUKnulBOaTCZFUPN3QeJLpVT+bwrpMqnbVCoVrly5guXLl2PLli24ePEi/H4/KlWqhF69eqFnz56IiIhQOFD/yf5yOp0wm83sNJHuVavVnLklB5acR0mZ93g8MJvNeOqpp9CxY0cFYCIz3ZRhvHjxIpo1a6agj2s0Gnbqif0xb948HDt2DKtWrULLli1ht9u5z0Xbtm3Rv39/zJkzBwsWLMCjjz6Kxo0bc6ZRMl0kDV2WOFksFtSqVQvAHXCE7OGlS5dw9OhRBAIB1KxZE+Hh4YpSj6SkJL6WHBeVSoXs7GwMGTIEXq8Xzz33HNq1a4fy5cvD5/OhsLAQ+/btw4cffoi+ffsyACGz1hQE6XQ6PPvss3j22WfvWQIp53nnzp14/vnn+Rqyr1SwnwAoWdhUivDLL7/AZDLB4XAgLCyMWQ4SRCSGkNFoVCRkCIxyOp2YN28ePv/8c4wfPx7t2rWDwWDAN998g7Fjx8Lv92PKlCnQ6/VcVkCAFWX56Zl1Oh0OHTqEvLw8dOvWDSEhIbwuKIkUExOD0NBQTp7QuMhxelgHXaPRwGw2o0aNGoiLi+MAIywsjLPUknFFAS2VqVCw+tNPP2H27NmYMmUK+vbty8yqDh06oH79+hg6dCiWLFnCvSN9Ph8iIyN5XshXIV8oeK5L5a8nNKekDz0eDxYuXIhNmzbh0qVL8Hq9KFeuHDIzMzFy5EhERUUpGCQPyz4hX00yWyVoTWuV+sZIlijt6WBQMzw8HN988w1sNpvCPkmWDTF8hg4dilOnTt3VrkLKzp07MX/+fHTr1g1vv/02t8MgHdWuXTv07dsXTz31FLKysjBjxgzWC/Q5nU6HlJQUtGjRgv1W+S6ffPIJdu3axT4n+fiUtCEhQEatVqNevXocexF4fejQIdjtdly6dAnlypVDjRo1GIwili0l9+l6pMdOnz6N/v37w2g0YtCgQcjIyEC5cuUYeDl48CCWLl2KzMxMLF++HO3atWNbSnGRz+eDXq9Hv3798NRTTzETU5ZLUizi8Xiwd+9edOnS5a7yyAcJvUv9+vWxZMkSxMfHc1JL2jmKxygJQLEN2Svq4+X3+zFv3jysWrUKU6ZMQZcuXeDxeLB161a89dZb0Gq1mDJlCicyyO8gnSdLx71eL7Kzs3HmzBm2cfTeUh9LJh3NTzDwd799Q+vqjTfewCuvvALgBEnAFAAAIABJREFUTmxDfSDV6pJ+j0ajEUVFRQgEAoiOjobNZuMYWq/Xo6CgAKNGjcL333+vSFap1WpMmjQJkyZN4jGrVasWNmzYgNjYWLYhtI5kCf7fQf+Xgkv/W0gp0Z+cnBx8/fXXWLVqFRsD2gwPm2GSCoHQZ8rohoWF8YIzmUy8uei6tOgow0vN1yT1zufzYe7cuWjQoAFGjBiBiIgIeL1etGjRAtOnT8cLL7yAzz//HAMHDuTsw40bNxATE8MKmhxJes6oqCgMHjwYFStWZCVNTpx8L3LKJQsmGIGXm4TAJHL6dDod9uzZg4KCAu7wr9Vq8fvvv8Pv9+PixYs8J1evXuWm4cGMIxonUoxkiAigo3sBJcrjXtT74HVAqPOtW7dw/Phx1K9fH/n5+ejRowdu374Nm80GtVqNW7duoWPHjjzXpDA0Gg0WLlyIMmXKYMKECVyjXL16dYwbNw69evXCggULMGfOHKaU0rtZrdZ7AnPyZxpji8WC/v37s8GTiPiePXuwZs0aVK5cmefH6XQq5lsKGTn6/r59+5Cfn49du3YxQEXzTmuVsk80buSQk7NRKqVSKneLBLel3vJ4PNi5cye2bt2K119/HbVq1YLH40FWVhamTJmCkJAQ9OnT554lT//p/ekZZLkBOXkAmF0py2PlwQMWi4WdT9KBMpBRq9Uwm83MHJWsXgks2Ww2nDp1Ck2bNsUjjzyCQCDAAJhMKvTs2RMrV67EuXPnULduXW7mSXZIlm0A4GciJ71du3Zo164ds27y8/MxZswYWCwWGAwGxMXFoV+/fggLC2MATOp1uibp23nz5sFut3NfQMqEWywW6PV6dOnSBc2bN0e/fv0wbdo0pKenIy4ujm2y9CUIRAnOugfPM4F/5KiTBJcJys/TfIaHh3NGlrLSTqeTM8tUJk2BhuxpSKLX62Gz2XDu3Dl8+OGHGDJkCPr27ctro3fv3rBarZg9eza6d++Ohg0bKoJUur4M2mh9pKWlYeTIkTAajbwWJchJJe8E8tG70DUeBliitXzs2DG0bNmSwSr6PTF8KdEzcOBAjBkzhteVLM3bsmULKlSogLZt27ItJxZzu3btULNmTURHR2P69OnQ6XT45ptvMG3aNE7Myb38dwgqSqVkH1Kw63a7kZ6ejrp16yI9PR1utxs//PADpk6dCrvdjpkzZ3IC+WHXAPmc0heWDbyBkh5K0m+ToD5wNyBEwbFGo+HSUHlNWTYUEhICvV7PSfDghIROp8Pp06cRCATw9NNPIzQ0lH1d8jXNZjMqVaqEzMxM7Nu3T8Faksz4Fi1aoHnz5nclmq1WK37++WdFQoRE9n0je0MgHO1vp9OJwsJCrFq1CitWrMDkyZNx/PhxvPrqq5g4cSLatGnD400tN2QcqNFo4HA4MGvWLDidTixZsgTVq1dnvWUwGKDX69GxY0fUqVMHQ4YMwdtvv40GDRogKioKTqeT9Zz0CcLDw+HzlfQ1lO9E9ozYlgQqBsdi9xOyMwAUfd/IRsoYSqPRKMqb6VADnU7H8dSxY8fw0UcfYcSIEejduzfblm7duuH69euYM2cOOnXqhIYNG7KOJt0t9Z5knCUlJWHkyJE81rIMXpbOyR5Y9MwP2kfS3zKbzcjNzcUzzzyD3r17o3///vwsGo0GO3bswMSJEzF//nwYjUaYTCZek9SG5t1332UQUzLLnE4nQkND4XA4EBISArfbzQw/AMwMl20B/i7yXwsu3WvxSXBp7ty5+Oqrr9CsWTN07NgRWVlZfLLKw1KXZZ8AqrmXFHij0aigfhOqLnvx0EKVypoU+4EDB3Dr1i288sor7MzQtWrXro369evjxx9/xMCBA1lpREZGshMl6elECaT7koKSdaUAGKW3Wq0cMMjsGz0vcP/sCzXRW7JkCUwmk0L5u91uuFwuvPHGG3jyySehVquRlZWFqVOnKhhLcs7IMbxx4wZOnz7N2RqaKzphwWw2o7i4GHFxcZw5vJ/s2LEDN2/ehNPpxIYNG5CSkoLo6GjMmjWLDWlRURGmTp2qyP5Q0HHt2jUcOnQInTt35iw2Kf+UlBRkZmbihx9+wPXr15GQkMDjSI5AMDAXLDQ3suwy+ASO33//HQBQs2ZNfkY6eUL2yiDR6XSw2WywWCwMKjVp0gTr1q1D9+7dUbNmTUWmgRhXixYtwpdffgmz2YzZs2dzucX9FPzfBZkvlVL5T4V0tdSXpPvT0tKwbNkypKamciA+evRonDhxAqtXr0anTp0UDUr/TwAm0qnyGYCSkioKRogdSo4QJVu+/fZbvPfee6y/yMkDShxFAo/okABy/kmHERDj8XgQEhKCnJwc5OXlIT4+nnUM6U6DwYCjR4/CZrMhJCSEgSUZzMkMrjyAghxot9sNm82G69ev4+uvv8b69esRHh6OtWvX4saNG3jnnXewY8cOPPPMM2jQoAESEhIUTFk55na7HQcPHkRmZiYqVarEgA85uCTh4eHo27cvBg0ahMLCQiQnJzNQJ9k8mzdvxocffqj4rvRL6OeioiJOcEhnO5hdIOeZyksouUDgFgUrQEnASs9FdkOn08FsNisazppMJmRnZ8NkMqFr1648P9R7o127dli4cCF27dqF5s2b35X1l0EAgVo0JgB4TdHapKBHNgCmhJ8s0X6Y5B8FcikpKRg3bhxiYmI44CVwjda7x+NBamoqszUoGWgymVBQUACr1Yr4+HjEx8fzuqdrhISEIDQ0FHa7HdHR0QgNDUVISIiiZJPmTDLOSuWvLTSHtBbDwsLw+OOPs49NIOrx48fx008/oaioCJGRkQpw5kFCfrAEVukP+YKkN4lhQslA6sNKfTppX6rVahQXF2Ps2LG4ePEiM3vI55MAu8/nw4kTJ1C5cmVmxAMleof2I+nxI0eOoF69egqGHoE1DocDJ06c4DGQPj6x4knXkc4iH/bq1au4cOECnnjiCbZXZIcIVKNxDQQCHA/4/X5cv34dv/76K1auXIlLly5h6tSp6NChA4qLi7Fw4UKMHz8eu3fvRteuXZGWlgaTycSAuATncnNzcfr0aXTr1g3p6ekKgIfYSB6PB+XLl0e3bt0wffp05OTkwGKxMIBH+sblcmHz5s1YtGgRM3xl6TeNgdfrRVFRETONad09zNqhnnIUi9E7kS9AMSYlL2TSmX6mOfR6vTh8+DA0Gg3at2/P+hkAzGYzOnXqhJUrV2Lfvn1o3rw5626po2VbAAIJpc0OZg3TvclmUIm2BOEetHdk3yoaywsXLvA7U7uQvLw8XLt2DVarVcG0lW1S4uPj4fF4cPXqVWzevBk//PADrFYroqKiUKdOHXTv3h0WiwWBQADnz5+HWq3GpUuXYLFYOO6T6/rvIP+14NK9gCVa2IFAAJ06dcKAAQOQkpKCLVu2sFP8MBuXrkUbQAbkpBTkdcjB1uv1sFqtdx2vTM8bzAY6f/48fD4fn/hAzBwAiIyMRMWKFbFz505cu3aNaf2yeadUVBaLhU/lsdlsrLCI2UQNpmVgIEslpJN8P8aSpPd7vV6sWbMG9evXV4Aze/bsUTTMI+VBSPr9WEdmsxlz5szBBx98wE4pAWD0fGazGVarFZMnT8bLL7/Mhpfekz7366+/4t1338Xzzz+PpKQkvPPOO0hMTMSLL76IJk2a8OetVivmzp0LoMQRJsV7/fp1WK1W1KxZk40gKc1AIIAKFSrg9u3byMvLQ7ly5Xg+aCzku/3ZWqVghowPORGFhYXYsGED2rZti8jISGYM0JxJ4yh7f9F7bNq0CdevX8fixYsxffp0jBo1ikvkZFbJ7/cjLS0NDRs2hFarRURExAMzsKXAUqn8t4sMImWPO41Gg7p16wIo0X8ajQaxsbFIT0/Hd999xzpRlizI65J+kHpVOm4EdFN/A5npJf0ty9fIuZP2jK6Zl5eHX3/9FX369EF0dDQ7rJS0oEynWq1G586d0ahRIy6pIptHDqvZbEb//v0xZMgQDBkyBP3790fVqlVRtmxZeL1eXL58Gfv27cP777+PRx55hJt3ymSCfE56X7KdLpcL2dnZWLduHS5fvoyTJ08iISEBAwcORKdOnRAbGwu1Wo369etjw4YNWLBgAYqLi1GtWjWkpqbihRdeYFBIjovX62U2EAVGwXZSr9cjLCyMx5XmQ2arVSoVzpw5g+zsbPTq1UvBMKZSDjlHBoMBNWrUUNDrg30PaZsB8GeDy5aJHU22Nri0QAJ4cl0cPnwYycnJrPfpXoFAACkpKQgJCcG5c+eYeUzrRgazEhikpAUdMU3ZYbVareg3RvaLAl7ya+5XEidLheQ4hYeHo1WrVihTpowisJf+Be0VYiHI/aPX62E2m3HmzBkGPOV9/H4/7HY7ypQpw3NIpXFy79L8BN+7VP6aQutIlmWRzpNMyypVqmD//v3/8X2Cg1zqq0qgkQRvg0FX6rcZzEyy2+04cOAA9Ho9H6oj/XrSFxqNhg/ZITbHvZ6vadOmePTRRzFt2jRYrVa0atUKycnJMBgMKCwsxO+//47Vq1fjt99+4/JRmXghHSntlExmHzx4EEVFRcjMzOTfS39Ygk3UQ+jHH3/E2rVrcfToUfh8Pjz++OOYNm0akpKSoFbf6ekzatQotGnTBsuWLUPfvn1Ro0YN1K5dGz179kRKSgrrIbIDOp2OAQQCl6QvrFaruScugVyynFnarnPnziE7OxsvvfQSA1rBySjSfZ06dUJaWppiboMTDCT0M/n5EuQme0xxIIEdxFiKi4tj/SRPSwPu9BJOSkpCuXLlmG1FzxMREYHExEQcPnyY45PgUj/yZ+iZaP8UFxczEEpNsSmZIL8nx07GM/Kdyd5RTCvZqSaTCbGxsfw5mdCiZ7BYLMwAlgl9sje//fYbXnnlFfh8Pjz66KMoW7YsCgsL8fXXX2PdunV45513cPPmTbz22muKRILEA/5OiYX/WnApWIIXYEZGhmLySVk8zORLp55EOgy0+Okzt2/fxrPPPovs7GyEhYWhuLiYNyj9kUEDGQMyJOSEkoInher1lhz5CZRQRIMzC4QkUyOyjh07cuBCz5qVlYUWLVowcksNnWU2g5R/sHNLykLWx1KjTHkt6Ujv378fYWFhcLvdOHnyJDubRMOU2Vqj0YjPP/+cj3n2er04duwYBg8ejEGDBqFHjx5MfzWbzXwNqaQJeMvOzsZrr72GihUr4rXXXkNYWBhu3bqF+fPn4+bNmxgwYAASExN5/IhxBZSg4U6nE1arFRqNBlFRUYqyMRJqnktsOI1GeSz0gyS49JAUHK297777DhcuXMDrr7+uyEqrVHdOLPzmm28QGxvLLDdyrlUqFXbu3ImFCxfi5ZdfRs2aNfHmm2/i1VdfxSuvvIIpU6agWrVqipN02rdvj6FDh/L8y/LHUimVUrlbpIMu+6QBYAo6lZoBJf0G6DSde5U+0XXpb9JxEvSn4ObMmTMoLi7GsWPH+HrSRtH3HA4HO5Ok32QPOp/PB4vFgl69eqFZs2YAlI6ttF0EXhNdXAJR9N7t2rXDggULsHLlSowZM4aDc4fDgdjYWISGhqJDhw549dVXUaZMGQ6spL0lh15mgg0GAzdV1Wq1aNmyJUaOHImqVasiIiKC7WkgEEC5cuXw8ssv47nnnsOBAwewb98+fl6ZrSUbXq5cOezfvx92u50BCAIf6N8ejwfbtm1DUlISQkND79KPcnxCQkLw0ksvoUqVKjzedB3S4fRexEYg+0tzTe8vwSt5L6AENAGAI0eO4MUXX4TVauU+gjJDTiwnCYJ4vV7k5eXBbDYjMjKS147sv+X3+1FYWMiBtmRXBbOxKYO7d+9eTlZQRjoxMREfffQRM4ikv0DrnIIjWneS2SHLTWQmvqCgAN9//z0fzhG8dgjMslgsqF27NgOQtJ88Hg9atmyJzZs3Y/v27ejSpQvPhU6nw9atW3HkyBG43W7s2bMHKpWKM+AysJDtEEqBpb++BAe35K/KwxCKi4vxyy+/oEqVKor+Mw8TYxCYKvek0+nEwYMH4XK5cObMGcTExPCzUMBM7FEA3A/PbDYzUEI6yOVyoVWrVhg3bpzi+aVdIeCBkpayNJr2jdfrRVRUFGbNmoV//etfWLduHRYvXgyv1wu73Q6DwYDo6GgkJCRg7dq1XD4rE9vBe1uyqIqKirBs2TI0atQINWrUYJ1IgJosmZJHzpctWxYWiwUjRoxA06ZNERYWhrCwMAAlyR6TyYRGjRqhWrVqyMvLw7Zt25Cbm4uoqCi2yzQGoaGh0Ov12L17NwYMGMClT9IXJn2xY8cOmEwmJCcn31XGLMH9sLAw9O/fHykpKTwepFMJGCSRSSIZC9xPyN4R2zQQuHOo1IEDB9CzZ09mKdEhQxSvkb2WsaPT6YTf74fJZIJer+c1IBnOVFkiq2P+TAKBALKzs1GnTh1eb3a7HampqVi1ahWPnWQ4EePoz2IoWj/0THT6HsmtW7cUJdLE2AXulA/S/qD9RrGkzWbDnDlzoFarsWbNGlSoUIHtcE5ODgYMGIAFCxZg2bJl2LdvH3Q6HTZu3IixY8cqkhr3qs75q8p/Lbh0LyMuHfPgvyXd8GEmn5wFmaEjYIWUB22I0NBQjB07loGGEydOYMKECQqFAyhRTaq3JZZKXFwcgyukdKgMiq4hHRjK9pEiIBQ3Li4OY8eORXJyMvcOcLlcSE9Px9mzZzF27FhYrVb4/XeOy0xKSlJkxum+cnxkkCHL3ywWC49BMO31008/xaZNmxQKg4wyXf/69etwuVz8GbPZrDg+VdYRExpfVFSEwsJCNvLJyclcf/3ll19izpw5KFeuHGbPns3ZoFdffRXx8fGYNWsWDh06hMWLFyMqKooz8NLRJ8Uje2XJPh10Ao3H44HT6YTFYmFnlIK1hym7lKwHahRKQUdOTg7ee+89NGzYEC1btuT5Icfa4/Fg5syZ0Gq1MJvNmDx5MjIzM2G1WvHLL79gzJgxaNmyJXr27Am/34/KlSvjk08+wciRIzFgwABMnjwZjz32GDssEigtBZZKpVQeTmRWU7JASWT5wJEjR3Dw4EE0bdoUUVFRD8UMpH0pGauUzPjuu++g1+vxxx9/IDc3F8nJyYoAY9u2bejWrRtsNhsAsGNuNps5sDAYDHy6Jel2ug+BY8HJDCq7lUkCuicFX5mZmXj00UeRk5ODa9euse4qU6YMoqKikJiYyA4gZQ8pSKcxlDaabExRURFCQkLwwgsvcOBx/fp13Lx5U9GrgXwDj8eDihUrIjU1FYFAAAUFBQgJCeHSYrX6zgEdgwcPxrBhw/Dmm29i+PDhnOGlhtcFBQVYsWIF1qxZg5EjRyIhIeGu5BOtBbLLlHgh55+CQAJkqKye/AsaCxmQBfs4EuQjQIMYwWlpaXj33Xf5O1u2bMH69es5208nH0ndTuU+TqcTdrude0xRLy7ZF4TKa8g+SxYWPZter4fJZELVqlUxYsQIRZNgr9eLhIQEbNq0CfPnz+deGYcOHWI2sSyJkC0JyC7KJqxerxfly5fHjh07MG3aNEVihNak7DkVGhqKJUuW8PzTWvf7/ejYsSO2bt2KsWPHIjc3Fy1btgRwp5Hxxx9/jF69eiEzM5ODqp07d2LNmjU8nsEMpocFGErlf7ZIZh5wBxC6cOECAODSpUv4+uuvUVRUhLfffpvLY+7n+wXvZSpZop5pHo8Hv//+O65du4aIiAjs3r0b9erV48MQKOE5btw4aDQaHDlyBA0aNIDFYlGwFMlmEPAf3D+T3kmyc0j/k/4kAIR0qE6nQ1xcHP75z39iwIABuHHjBm7evMk6NCoqCuXLl2dfmHx9CdBJxiXFGoFAAIsXL8apU6fw8ccf38X+oP6iklFJ8VC1atUwZ84cjimoPI/GWa1Ww2q1IiQkBFFRUQgPD0d6ejp8Ph+TDegZqeXJ66+/jqFDh2Ly5MkYOHAg4uPjFQl/6uu0adMmvPbaa4iOjlbYKdI9MhkdzDwlPUanpNG9KQHwMMASCa05AlfsdjsqV66M+fPns339+uuv8c0336CgoAAJCQl8+iABUwSIyMQGzbkkM1DShGLU4OeT65t0YEpKCjeALyoqYuZQdHQ01q5di48//phByhMnTuDxxx+/ixF6L6GEic/nw7Vr11BYWAiXy4Xi4mL88ccfOHv2LAAwwHTkyBFmFZNPQ/4SHXBkNBpx5swZ1K5dGykpKfw+xFqtUqUKDh8+DJfLxeznqKgoXj/S7/i7xE//teDSgzafLCMAwLXKwL93VKj8PCl52YSTMrktWrTgACMuLo4bJkuHOVjKlSvHNaF0nDRwR5E5HA64XC6EhYVxZja4PIKAEDJSRqMRBoMBbdu2RcWKFRXoLQBcvHgRzZs35yZkMqiQSLEE1oKBOqmYFy1ahKSkJFY+drsdFy5cQCAQwPjx4/Hiiy/C4/FgxYoVeOedd1jh6fV63LhxAy+//DK2b9+uqFmWtdg+nw8zZszAzJkzFZRLevZy5crhk08+QaVKlWCz2fDtt9+iadOmGD9+PGJiYjgo0el0TIu1Wq0IDw9XnJxASoEak+v1ekRFRcFgMODcuXN45JFHOEggY15QUIDIyEiEh4dz7wjJ8HpY0el0sFqtMJlMUKnuNGwfO3Ys3G43hg8fjrCwMAVjTK1WIzIyElu2bEF8fDw35nW73Vi/fj0mT56MJ598EqNGjeJTNKhX19y5c7Fz507OKlO9tixHoayVpPuWSqmUilKCQVhyKmivktPi8XiQl5eHuXPnwm63MzDyIJGOr9/vV5RCFxcXY8uWLRg0aBC2bduGzz77DMOHD1c0MC5XrhwaNmyIvLw8HD9+XJG9Bkr6GdntdhQVFWHVqlX48ccfWQcGByzkEJcvXx49evRgna1Wq/Hll19yzwYCIegdAPC43IsZS9fp1asXKlWqBKCEKi//rdFoMHPmTD6+mPoCkVOn1Wpx8+ZNPhSDmMCUlaVn+PTTT9G8eXMF67Vr166w2+2YO3cuOnbsiGbNmiEhIQEulws2m41ZTcOHD8ezzz7LwQA9H9lmsrc+nw9LlixBTEwMZ6TJMaeyCiqxqlSpEvr06aMIUIIZXHIsaR7pHSWrq02bNvz7K1euYOnSpYoSAgpoCRBRqVSoUaMGlixZwsAbrTWVSoXr16/D4XCgfPnyzEImO0g+AI0rBVE2mw2xsbFo3749B8Z0L5fLhcTERLRu3RpqtZp7LALKPkvSUZe+iOwrptPpMHbsWIwePVrBFpDBscViYTCMmAQE7FFQp1bfKdv74IMPsGzZMqxfvx5vvvkmLBYL0tLS8NRTT6Ffv34wGo0wGo383FQiSc8pe2aVyl9fggFUl8uF3NxcdOzYEXa7HU6nE2FhYRgxYgQqVaqk2L/Aw5XHUBkole5s3LgRYWFheOKJJ7Bx40b06tULycnJAMAAVFpaGmJiYpCbm6vw1YLv5/F4sH//fkydOpWBHdIbBDiTH+33+9GnTx8GXzQaDXJzc/Hxxx8DAJ86RzbD5XLBbDYzcBXcNoR0TOPGjdG+fXtF4oV0td/vx+eff45ly5bhhRdeQKNGjRQJdADMlKQSQfr+hg0bcPjwYcXBCcSMIiaMrLiQcQ4B4D179kRaWhoAMBuqefPmmDVrFmbNmoUff/wRNWrUYKDhypUrOH36NHJycjBy5Eg8//zzilLEYHYljdu8efPYJkugnIgD9NmkpCS8+OKLDw1Oa7VaReWIZHp16NCBddIff/zB1SEEUFJCnXS22WxGamoqfvzxR1itVkRGRrKOJPZzTk4O2305H/cTqvro0qWLwuZQEj8xMZFPk1Wp7pywK3U8yf3uEQgEYLPZMHToUOzZswcej4dPS61Xrx4AcLKG9utTTz0FnU6HihUrYtWqVRxz07rt1KkTVq9ejffffx89evRATEwMnE4nNm/ejB07dqBNmza4dOkSFi1aBAA4efKkgp0r5/7vADD914JLDxI5uZJ59LAi+wgEX4dQXMrIEkWblKZkAdH35N907aSkJISFhWHr1q2oX78+K0e9Xo/z58/j+++/R8+ePREaGgqgJOAgpUAoPClZ2UycFDU1ADWZTChbtizeeOMNAHcctNu3b2Pv3r2KI4X/zDjSvcPCwtC5c2dcv34ddrudAQrKCLZp0wZpaWm80cippSBFq9UiKioKS5cuhdfrhc1m4yDC5XLxiRRkWMxms0Kh0TgYDAZuUhoWFoaFCxdyJp7Gi5SV2+1GzZo1WYFRvXTz5s0RExPDhpbGMioqChUqVMDWrVvxzDPPcEZXo9GgoKAAn3/+OerWrYuIiIi71tz9KJ33EipLIdrp6NGjsW/fPkyZMgUNGjTguaKxpbk0Go38PXJ669ati8mTJ3PDYHLYdTodiouLERYWhlatWnHQZTAY0LFjR1StWlVRhlEKLJVKqfy5BOvy4P5ndOJYdnY2pk2bhj/++AOTJk1CzZo1WS/di5lCIu2XBP+dTifef/99hIaG4sUXX0RYWBiysrLQoUMH1K5dm7ONaWlpmDBhAn777TesXr1a0TtJ6vikpCR06NABly9fxqVLl6DT6XDz5k0cPnwYDRo04DJkSqi4XC7W0X6/H1arFVeuXOHeFzIjTI73gQMHYDKZULlyZQVTij4XGRnJDcPJUaaxob9tNhtGjRqFgQMHMuNHZjnz8/Px4osvom7duhg/fjz0ej0zS8n2AEDZsmUVQQt9rkePHmjRogX27t2LnTt34ujRo/D7/UhJScGgQYPwyCOPID4+HiEhIQrQQ7KBtFotkpKS0KxZM+Tk5HAAmJOTg0OHDqFZs2awWCxc6iFZTZTVlfZNrg35MwVOsjyAAid6FrfbjaioKAUL2uFwcKBJ16pSpQquXr2KkydPIikpSQEa7d69G/n5+ahbty6/MwWoNE+yv6BGo+HejlTCLhMuBoMBtWvXRt26daHRaHDjxg3s37+fry0hf86fAAAgAElEQVQZW5JNS3uDQLMDBw4wq4LsomwIS8EiBWoUSFEz7+TkZFStWpWZUGQjX3rpJfTo0YPtZXR0NANtsnluUlISGjRogMTERAVLo1T+PiLXH+2zuLg47NmzB3a7HTdv3sT333+P1atX4/fff8fbb7+N6OhoRXsJKcFBsiyjAYCrV69i2bJlePPNN/HYY4/hs88+w+rVqxk8ValUiIqKwpAhQ1ChQgWcP38eNpvtrioM8sNbt26NCxcu4Pjx4wy8/vTTT9DpdGjWrBk/I72j9MEJtDp16hRu3brFeoqSqMCdfrGnTp1CkyZNGCSRoDiVmj322GOcyKQ4SaVSYf369Rg3bhxatWqFN954Q/EOVK5E8yD74FE/t+PHj3PMRXueQJvdu3cjJiYGtWrVYkaoZOYYDAa0bt2agTvSIdSjqnHjxti1axd++eUXHD58GB6PB8nJyejXrx8eeeQRJCUlsT6QJYQ0njqdDpUqVUKDBg1w6tQpTgpfvnwZx48fR+PGjRESEsJljRTLSPv3IKHkBiVnKLFEa0Cyxsivp9JCSiDR+nM4HGjUqBHmzJmD77//Ht26dYNOp2OW0v79+5GXl4fmzZvz+z1IaH1RLEZCFSHNmzdHs2bNeO1t3ryZbUkww/ZeQuSAxYsXo6ioCG63G8OGDYPBYMCKFSu4fFSj0WDOnDnYvn07srKyEBsbC5PJxAdCkX3SaDQYNGgQAoEAPvvsM8yfPx9+v5/LJVu1aoXXX38dp06dwokTJ+Dz+ZCfn8/3oPkoZS79DSU4oA92LCRyfr+yOLmpJcVPNiGjTVpUVMQZVcqc0X2CT1UJvi5dJzk5Gd27d8eqVavQokULtGrVilFWOsGnR48eiswrfZfuTU4NXZeaZxLARQpH0u6pfIuUGr0DjQuNU7DDRPdISEjAihUroNFocPr0acTHx9/lxBNNVVI+ZVM3YtP4/X5ER0dzpnTfvn04dOgQjh07xvctX7486tSpg5YtW7JiJ4eVxp2OiKRMrUajYSO0fft2/PHHH7h58yYCgQBCQ0NRr149NG3aFCNGjGDHnsaJwK9+/fph8ODBWLZsGZ599lmEhYWhoKAAq1atwoULFzB8+HCuzabMCPBwWSuaIwLUzpw5g7Fjx+Lo0aOYMWMGunTpwteUpSeSzg8om7rXq1ePA0yfz4eCggIcPXoU27Ztw7lz51BYWAiLxYKYmBg0adIEjRs3xqpVqxSMsVLWUqmUyoMlOOkAQBFk2u12fPHFF5g6dSoqVaqEjz76CNWrV+cMMO3fYIAJKLEXpMMlY2Pr1q3YtGkT3n77bURGRuKJJ57AmjVrMG3aNCxdupR7wVGwTjqbkiEktM9btmyJVq1asa0MBALYvn07OnfujHHjxqFNmzb8XsRMIsdap9PBZDJxA+/gUili4Hbu3BnlypVDVlYWPx/ZUbI1kg1EY0A2iAB4k8mEmJgYRQkvSWhoKB8znJSUpGB60bOQrSM2EznaFMjExMSge/fu6NatGyeNpINOdtjhcDAgQY42jWf37t3Ro0cP/p7b7cY333yDfv36YerUqXjkkUcUDUAp2UGfp6BWjoFcE1RCKPthEKOZnoHsg91u5z5fcp1RsKFSqdCkSRM0bdoU06dPR2JiIh/BfebMGbz33nuoXr06/vGPf/C1Keige8hMs8fjwa1bt2CxWJjJK0sryF7Td2mOyGbLMZDBqjx2/cCBA5g0aRIHD7KPjNlsxpUrVzg5JP0jup/P58PQoUORmprKwBGVlhiNRsTHx+PChQs4dOgQ9u7diwsXLuDWrVswGo1IT09HxYoV0b59e3z44Yd86i41AZfrshRs+uuLTACQvitTpgw0Gg1SU1NRrVo1VKhQAYMHD8aTTz6JjIwMBQscuD/zQrJqKKnYoEEDdOnSBdHR0ejTpw9WrlyJFi1aoGXLllzKRKeBOp1OZhAB4OfTaDSwWCx49913GXzR6XS4desWevTogcjISKxYsYJBIlnqLBk+qampWL16NSeDZULAYDBg7dq1GDBgAGbPns12jd6HKg8oiUtJep/PB5vNhk8//RRTp05F165dMWHCBLYJ9F3ZD1TGLSrVndMg+/Tpg969eyuYX8CdPZ6Xl4fMzEy0bdsWkydPZuCIPkOsR8k0llUoKtWdXk29evVCr1692PaRjyxBZtJfcp2QzerUqRO6d+/OvrjRaMSyZcvw1ltvYfr06WjUqJGiGuVe/sSfrR+NRsPj63K5EBsbi0Cg5GAEYnJJprL8HsWKBoOBS5mbN2+O+fPnIz09HZUqVYLRaMTRo0cxe/ZsNGrUCFWrVr2r/O1+QnuAktUUd8pEnGTf0jqVgC7d415j4PV6ERoaitDQUJQtW5YTOUajkXU/JZCo8icmJgbly5fntU9gHo1RZGQkJkyYgN69e+PatWsoLi6GTqdDUlISkpOTYTabERcXh1atWgEAPvnkEwwePBharVZhB+/3zH81KQWXhNwLHAJKnBdJWQtmE8ksqfw3UFImRpRqvV6PZcuWISIigp0lcs5ffPFFBWosqe3y2QhtHjRoEK5cuYLXXnsNGRkZMJvNyM7OxsWLFzFz5kxUq1aNs2MUMEgHUlJjiR5vtVq5ppYoraRIvV4vBxqkmOgZ7/WsJHLMyKCdOnUKffr0wfDhw9G7d29G6IGSshFSFhqNRuHw09Ge9FwbN27EjBkz4Ha7Ua9ePT6FTqPR4OrVq1i1ahVmzpyJYcOGoX///tzvieZW1rAbjUbk5ORg4sSJ+PHHH1GtWjVUqVIFKSkpUKnuNOTcvXs3ZsyYgU6dOmH8+PFcRysNVkZGBkaNGoV58+Zhz549qFixIk6fPo09e/Zg9OjRyMzMBKDsC/GwSoWckEuXLmHt2rVYuXIlTCYTPv74Y9SuXZvLLQkABO4YCMrI0hqTzb5pfgwGAw4ePIgJEybgzJkzaNy4MSpWrAiTyQSv987RrytWrMCECRMwbNgwDBs2jEG/UmCpVErlwSJtBQW3tP+vXbuGxYsXY8mSJXjmmWcwcuRIREREKIJrmU0leyBLiADlYQoELI0fPx4ZGRno1q0bDAYDEhISMGjQILzzzjv44IMPMHz4cAUQQsEzUBLQACV9cCRbk/SNz+fjJrESwCEnWAIBsoStoKAA69evR0JCAtq1a8cZZTrhh96Vgo1gdlZw7wrJiJHO/I0bN7BgwQIA4EChuLgYly9fhkqlwsSJExXv1L59e7Ro0YL1NH3HZrPxNYkBSveXJecElNAYUB8OYg4T6EIigwzSq/S+NDc0BhKAIWbR/TKf9D5UkjJu3DhEREQw+4n6Nb7++us8bsTMItsRfNqsz+fDu+++i6FDh2LgwIFo3LgxNBoNvv/+e0RERGDatGkwm81sF6lXEr0njQOBpkajEWazGcXFxYqAkHqFURBrNBq5jEH2VpTXo7+pDC8QCKBr165o3749jwMF0CqVCkVFRXj11VeRnZ2NH374ASaTia9D8yCZhtK/U6lUcDgc+OWXXzBx4kRcu3aNT8WqWbMmVCoVcnNzsWLFCsybNw/9+/fHSy+9hNDQUA5SJEOjVP76IhPLpC/VajVsNhsMBgNCQkLQrFkzlClTBjt37kSbNm3Y75bxw/2qGLzeOyciT5o0CSdOnMC6deu4zcIzzzyD7777DqNGjcK//vUvBljoWQwGw11sTwJR6LOkpzweD0JCQlh3E6OQmCl0QhrpZtIRVNq9bds2/PHHH+jVqxciIyMVYIhkapA+I5+f9h3FKgcPHsSSJUvw3Xff4bXXXsOzzz7Le1TqPPo+tYogQI30J+2vW7du4eOPP0ZSUhIzpGhvSyYPjblGo1Gcikf6j56TxkqyJSVLk0rLpJ2g9ybdSGNPLTfINkiwXCaWaaztdruiTO5+CSf5s9vtRm5uLubOncvxAq2P+Ph49O7dm2MwSkjIxuHSxkVERGDcuHEYPHgwnn/+ebRq1Qo2mw379u2D2WzGrFmzEB8fz2MUDCwFx97EULNarYr+igQyURxN/se/A8bIvUV9ccPCwvh6EsySa4LmhewAlZqSn0P2MS8vDydPnkSfPn247JPGScZltJ7ID5Al3H8H9lIpuPS/5V6LUypB2nSUMSW5H0JKwTstFFI0CQkJaNGiBc6fP88KXrKaaDPdj0lFQj0BDAYDpkyZgu3bt2Pz5s24evUqGjZsiJkzZyI9PV3hCEomljz5hoAVqo3NzMzkRU8bm5SyRqPBF198gYoVK3IJnjRMNG6yhpTejQIV2qgmkwlWqxUAFAaFMoYUhMTHx6N58+Zc7kaOP93j4sWLGDNmDJo0aYJJkyYhKiqKSwHJAFy7dg2ffPIJFi1ahLS0NPzjH/9g0IU2NSH2KpUK06dPx5YtWzBnzhy0a9eOj6IkI2C1WnH48GEMGzYMM2bMwPvvv68Y00AgAIvFgv79+6NatWrYuHEjjh07hri4OKxatQqPPPIIKyO5rh6WIq/RaGCz2XDo0CGsWLECrVq1wqhRo5CQkKDoWXI/eqv8Nxl4WmNXr17F6NGjYbFYsHHjRiQnJ3Njd2okePv2bWzZsgXjx49HUlISevbseZdzXyqlUir3FskmlEGE2+3Gjh07sHr1aowcORKDBg3iz5JTLL8bbBfo/4NLgnw+H/bs2YPU1FRMnDiRgXy/349evXrhypUr+OWXX3DlyhVFFpAyh9RbjoIkCeBIp4n0isvlgtPp5ICDRDpwNpuNT2uhDOSSJUuQkZGBjh07AlDS4lUqFTvn8v2kg3evrJ90GFWqO6dlHjlyhB1I0n3169eHRqPB8ePHAdzRlzt37oTT6USTJk0Y2KPggBx/yR6iIECWckmmj0yYUDB1r2eWYBSNOc2lBPBlKYoEUeiZ5HXJnsfGxqJ+/fq4cuUKzp49y7bU7/cjLi5OcTIgsS6CyzcAcKLJYrEgKysLGzduxJ49e+BwOPDcc8/hscceQ3p6Oo8lPSsF0DI4kv0sv/vuOzRp0gQAGGAkX8PhcKBixYr45ptvuFE4Pa9kXxA4R2Mvk1YS7KPElc/nQ0REBFQqFSfZCFwjO0kAGF1H+jMq1Z1+h6+++ipq166NFStWICIigrPeer0eVqsVNpsNWVlZmD17NtLS0tChQwcGrogVUMpc+utLMMAtWSYEepAf6fF4ULZsWd4LslkycHdsQnomEAjgwIEDyM7OxoQJE1C1alX2jcuUKYPJkydj7NixOHLkCNLS0tj3d7vdij4vtJYJNAjW2eRr0j4hfSFBEgK5ZSKAwNLffvsNH374ITIyMrjslXzdYMaSLPkmnaHT6XD+/HlMnz4dVqsVy5cvR9OmTRUtJYKfgZhCdA9ZuUG62WKx4L333kPnzp3RsWNH1nOShXsv0JrGSx7oI1tISLtMvjjZaLnXKbEgTx2jdwnWPfKwH6kfyBbQmqI4TbJ67xXbut1uVKxYEbVq1cLp06cVjCWdTocKFSrA5XIpmHQy1gsmK9hsNlSuXBnr1q3D2rVr8euvv8LpdKJv3754+umnERsby2P4MOC5VqvFb7/9hgYNGrD+pz1D67hevXrIyspiO0LPFGyngvcO/U3vHBISgvz8fGaWySRScKwfDH7SZ+R8/vzzz/jkk0/QvXt3BUub7Byt78jISNb/8h5/l9ipFFz6EyFlSk6EzBKS3L59Gw6HA2XKlLnL8ZCoPDktqampWLduHTvvktFDC2///v0KdFouSFp8pOQAICQkBF26dEHXrl0VzCnqMxSslIiBJE9XoSCjadOmCgdeKlui0SYmJiqcNcpi0CaR4xO8USQ6S0qPkOFgUIIywJmZmWjTpg0baxoPytTm5eXh2rVrGDJkCFJSUhiUonf0+/1ITExEz549sXTpUpw4cQLt27dX3EeWZNy8eRPHjx9HmzZt0KNHDwa0yODp9XpERESgSZMm6NixI7766isUFBSgTJkyCvaO3++H0WhERkYGWrduzb+Tjj85tzT/cl5JgoNQ+p3FYkHbtm3x5ZdfIiEhgbO0EtSktUdzSYpX9qggIeWdk5ODM2fOYOrUqUhPT+csAhlts9kMg8GAzp07Y+XKldi3bx/69Olz11iWSqmUyv1FJh5IvF4vli1bhurVq+P555+/y6kCoAB1qLw6OjpaQREnfU82SKPRYOTIkdBqtQy8U0BvNpsxePBgPPfcc0hMTFSUcZPOkCVCRUVFfDIW6WCghM108+ZN+Hw+vPnmm1iwYIECMCf9GR8fj2nTpnFALR14CpzIlpUvX56bmsoyANI1shwqmPlBDiEAdoxTU1Px2Wef/encEJOlVq1aXA5HWVKfz4dDhw5h0qRJrGtl1p2+/2eiVqvRsWNHDBw4EAUFBRg8eDBsNpuCKUaAye3bt+Hz+TBs2DCUK1eOG7GSXdDpdChXrhzmzZunGINgm0EAYKdOndCpUyeFr3CvUgqyVdT/S5anqdVqBgoDgQDKli2LgQMH4qWXXuL3k8GJdMRl1lg2C/b5fJg2bRquXr3Kz0GfpXehtUxrgX4XbHfuxfqg5woWyZKWwG0wW06OC31O2s+TJ0/i0qVLmDlzJlJTU9n/ovVoMplgMpkwcOBArFixAnv27EGHDh0UeoDmo1T+2iLZLn6/H4WFhbxmqbl9fn4+srKyoFar0b59e9a1dHpVYmIiX0cCG5LRl5GRgY8//hjly5dXlAWr1WrUr18fy5YtQ9myZXHs2DFmnch9Q3bEZDLho48+wrp16xT6QLIEjx07Bp/Px3EGvadMPA8cOBCZmZmKsuB7gVbh4eF8nLzs2SrthAR2YmNjsXjxYmi1WoSHhzNwRe8hwWLSJ3R/CTaTECChUqmYkU8xTlJSEuLj4xnQkWA0vTMBET/88APmzp3LCZfgRPv9RDKDe/bsiaeffhq5ubmYPHkyrl+/rmCokp68ePEi8vPz8cYbb3DPQgIj6fnq1KmDMWPG8GEI9wImaS569OiBp556in+WOpOYQbTeyO7Sc0uQTerxmJgYDBs27J7VN7JiguZA2kuy6waDASNGjMBLL73EvocEP0kiIiKYoECgKgCF3r7fu//888+YMmUK+zkulwtHjx5ldivFcX6/H8eOHYPX68XLL7/Mvo5arUaPHj3wzDPPKNbevZIZ0h+RCb+MjAxm0Qa/299BSsGlPxFy0mjRSFq/Wn3nqMoJEyZg27Zt+Pzzz7nfwJ8pFpnJoM/KxUUKlSh5wXX40sEJzlxLp4RKE4CSkjTqtxCcNQ0EAtwTIC0tjYEbUqqSCk90UWokJ0sj7oeS30tIkVMwQb8LRuXJeaVSBBJZbhAaGoqIiAh8+umnqFq1KtP71Wo1P6/D4eDTjOLi4hTjJxF+oiqWLVsWR44cwd69e1G/fn2+HznIarUaZ8+eZTZAaGjoXcb0XswCOVdkFMiwScZaMKMhWCgAtFgsSExMREhICN9LUmjleJPSozmTik4CfWXKlEFsbCy+//57ZGRksJNDitLhcCAQCGD//v24ePEinn/+eQC4K7ArlVIplXuLBH9l4HD58mVcvnwZYWFheP/99xUgCunCrl27okaNGti/fz+ee+45PP3003jrrbfuAvKlQ6zT6bi0QWaGyTmMiIhAdHQ0O6xSL0vHjexWlSpVEB8fz8GKZKi6XC784x//4ASFzCaTrYiIiOASZNKFxAQi+6pSqRASEoL58+dzuZcEvgKBAJd1SFsdLMH689+xUWSfZTKGnO2mTZsCgOKEPKK7P+gegUAASUlJ7HA3atQIxcXFiutTgkSn0yEzM1NRWkN2iH6Ojo6G2+3m47zvB1DIoDD498F2Spb8WSwWLkeQJxzdb0xpPiUABpSsyWBmHY13tWrVULt2bf6sXMNks+l+N2/eVNxXvvfDBHc0V/JnOpY7mAUXbCOlUPkP2eEdO3agUaNGfLqc0WhUgHNffvklbty4gTp16jCD8N/xnUrlf75Q4CznfNOmTahUqRIzPU6cOIGcnBxMnToVCQkJ3JJi+PD/xd7bx0Vdpf//L25nuAdFxZvUQdtEy8RqFVrbxLTEbBOyNkkrMbPV2gxrtyR3NbRSqLa0ditsM7GtTawsrNzQchc0Teqrq5YmVhZ4yyA3M8AAvz/gOp55MzOMo+7v0+7r+XjwAGbeN+fufd7nvM51XecBbN++HW+88QaGDRumrie/RZCRfqB79+6qf9QnqSLi65YR+oKjuJtJXKELL7wQI0eOVBanxgUKCeQdGhoKu92u8qZbWnXr1s2pHevCu/wPAGPHjsXnn3+udr7Uj5U+RreSioiIQEhISAeRyN18Sy8jWWzWBQ4pCz+/NvdmmW/16tUL+fn56l2kW4nqwoi8I7t06aLKTMbH3ohL+oJv7969Vblecsklqj5lDici2MiRI1FXVwez2azEGLHUkT524MCBTvMGY/m4smZy9U4QK6aQkBCVb+nn9LmTMU/GetEXiYz1I1akwOlxheQpOTlZjTlcvdP1uIEitIoVtKvjjekMDQ3F1VdfreKQyW5/uiGHlP9ll12m3oeykZPD4UCfPn06LMSIsYBuiGD05AHgtDijtxt9vPdTh+KSG3TzvS5dumDChAnKDFPU4sjISPz85z9HYGCgCtQHwO0AR3/ojYKQCAtiAimqqT6Y0wUouZargaSunEoHK2as8qLQVxClwcv9W1tbnXyL9UmLdNb6KqLc60wHSJKmHTt2ICIiwsmsX38xS3569+6tXs4iNrW0tGDgwIH47W9/i5dffhk7d+7Eddddh/j4eERERKC2thbffvst/vWvf2HPnj345S9/iV/96lcdOj69zsxmMxYtWoTMzEzMmDED1157LYYMGYK4uDgEBQWhsrISO3bswObNmxEZGYns7Gw1kDT6B7taUTWueIprnAzGjcKXsS3pkw95qcgETawA9A5Nv5686HVzT33lNCAgAD169MCjjz6KBQsW4LbbbsMvfvELDB48GNHR0airq8Px48exdetWfPrpp5g0aRKuvfZaJUCeK5c4TxMXQn7qyIBNnhe9P7/66qvxww8/4LPPPnNawZWJ6tVXXw0/Pz/07dsXKSkpaqdQvV8xToz9/f2V6TxwejAkbhoiOEs/EBYWhpaWFqfg1TLwiYqKwv33368Gx3p/ovdrep8j99Tfqy0tLTh16pQS5hsbG+FwOFBZWYn33ntP9d/S/8t7UQSAHj16KPcpGZjqlr6u8CTY68hgUo7Ty9Xf3x/Dhg1TbiiCLrB1Zn0ikwuxZJg9e7aaBOrlJvEu9CC1ugAndaKXq2x84SqPxvwbJwGCvDOkXiW+in5v4/nGe8g4Q2hoaOhgkSDjEMmHjDt0Kwy9TmQwLvnT45Dogmln9Sv3058R3e3NWH/G97H8LZYdTU1NiI+Px+LFi5GXl4ctW7YgLS0NFotFPXdfffUVPvnkE/z73//GlClTMHr0aDWGcSW6kZ8uuugeEBCAG2+8ETabDdu3b0d1dTVCQ0Mxfvx4TJgwAQMHDlRWRWFhYUhKSkJUVBR69uzp1Kfo/Zu8M1pbW5UlqvTDMh7U4/3IRF4EYuMz0tzcjBEjRmD48OEdPDCk7cu4TneD1q8jLlW6pwRw2gXpk08+wcGDBxEQEKB24hTLV32ecvnll6vduPTnQ18U8UaQlbmJq/5Y5lktLS2orKzE5s2bVZ8rz59YiEq/EBUVhSuuuEIJaoGBgRg2bBiGDh3qlB49ZIc79HKVeouNjcXMmTNVH6gv6uvzQN1tWV90b2lpcTrHU9l4I17ImEPSEh4eDpvN5pQHd/cxvlOMx+iin7QTfSwh3xnn1PK33kcGBwejqqrK7VzZmC4AuOyyyzB06FAl6uju7iI26Rbbkh8pc6OlkZ72hoYG2Gw2fPDBB0pslTYjgrAId42NjejTpw+GDh3qdK3/BvgWc4PekV599dUYNWqU02BJOtE77rgDd9xxh1Njc/dQGzt03VpGvhdLnF69eiEiIgKBgYFqUCbpkoeoswGUDFTkQTW+eIxWTHq+Je96DAN96115iOSlB0BZOXmTNrlet27dsH79erz99ttOLzNRzuUhb21txT333IOHHnrIaaVfHtY777wTV111FT744AN8+umneOWVV5R1lcViwdChQ3HbbbdhzJgxymTUWDf6KkufPn3wt7/9DR988AG2bNmClStXqh0FYmNjcfHFF+Oee+7B9ddfj7i4OKcAgNLB6XVrzLte/6KES4BSfYWkM8SMVDpio+ioT+7q6+tVuvTO2SgOms1mXHPNNYiPj8emTZuwZcsWvPvuu6ipqUFLSwv69u2LSy+9FI8//jh+9atfqZevPuk4V1BYIv+NyLMmz6EI9gMHDsTy5cud+g19kKZbAcXHx+OVV14B4H4gqg/G9UGo9LHSR4hI3dDQgMjISKd4OtLXC/KM665XRlFLBtjGFWvdslHeddL3BgQEoHv37ti2bRu2b9+u+i55b8qEQISWK664AitXrlSbUQCnB4aCpwUeT/j5+aG+vl71a9IfS9+sb6utvzfORLySMpM+V1+plfvp5SornMbBtdxbJjz6wpC3eTeOS6Kjo9GjRw8EBgaqRR95F+v17i6fUu+6xZ3JZEJ1dbV6V9XX1yuRSG+nMjE3ok+oxerCz6/NUk5W9/VJbWfo70Zpg3qd6AtOnupT7uvv74+MjAxccsklKC4uxieffIJXXnkFtbW1CA4ORnx8PAYNGoSZM2di+PDh6NGjhxqX6e9g8tNHt8BxOByIiorCnDlznARN3R1T77Nmz57tZL0jbVPO03dJFOQ4Vwvc0ifGxMSo/qGhoUFZsgJwiiFjtPKR+xvjjhmFVj0Pev6kP1q6dKl694jngsypZExuMpnw1FNPYcyYMU59gC4W6PMlV0h6ZN6gixSyQCHvpt69e2Pbtm3YvXu3iv8qfYhuLdbQ0ICrrroKTz31FGJjYzvExtK9L7wVh0WoEPT3gCw263McEXqkjvR2IOnVrdTc4YoKRicAACAASURBVI34DrSVeXh4OLp3765irsqmC3r/72m+axSFdHSLaBkzAK4tleQY+S11azKZUFNTo1zXdXdCT9cATo9FxIpIzpP3nYyPpH+WetDFMABOde9wtO00WldXhyeeeEK5uksdmUwmp13mWltbcdttt6kdE/XwMj91/Fr5NnOJcZAKOIs1ouoaYxvonfqZoHe6IgLIw/f222+jvr4eU6dORWNjo5M44uk++kqHTF5Wr14Ns9mM9PR0p85JnwToSq3x+vLwNjU14cMPP8TRo0dx5513qnQZV+I748SJEwgKCuoQCE98XsWfV1wTZJXGFa2tbaabInLprmCSx6CgICchCOgorhjrV7Yt9vf3V4qz7soGwG3H4KoMjaKP1NWHH36Ir7/+GtOmTUNkZKTbctRf/q6+d7d629jYiC1btuDLL7/E9OnTERkZ2SENui+1PsGS33rsERl0yMTUXX4JIc7Ic6IL6kaLQsDZClW2fBZ0QUm/prfWg8YVYBncSV8bHByMH374AWvWrMHEiRMxcOBAp4Ckck9Jp5xr7Ht0k3Hg9M6U+nFyzerqakRGRqognjKp0cUb/TPZZcu4+nguqKmpwQsvvIAhQ4YgNTXVKZ9GjKKaN+KS/q7RPxOMbsa6+CLHGlfwz5XliywkBQUF4ciRI3j77bfRu3dvTJw4Ue0ep4tprtAH4RILrK6uDs8//zxGjBiBK6+8Uk2g9XeI8RpG4Utf6Fq1ahV69uyJ66+/Xq3oG93pXOFubLNu3TocOXIE06ZNQ2hoqGq3ro7X60ePLaWnUXddkbYpC0ry/Bqvfa6sf8n/f3iqU1cWcLorsKdnSn++3U2i9X5d/hfLQ5lfrF+/Hv7+/rjxxhudLBJ1cdY4JzCmQ+/ndO8H3a1IFseNnhLyXEl+JT6ZLJR6WiDwhDx7LS0t2LdvH9avX4+7774bXbp0cSp3eU7FyrO6uhrh4eEA2uZ+ulWoEBAQoFyvjH2VPib3Js36fE8/XzDuKmecoxg/kzzpov7ZIm3WZrOpeeSf/vQnDB8+HCkpKer9Y2yzxrzoi+nyu6qqCmvWrEFCQgKuueYap/eNMa+6eGa8pp+fH6qqqvDGG2/g0ksvxfDhw53GCt6UgzfPlCtEHJVz9fmiiF8SnkUswMPCwpTRg8xxJd8yr/pvsV6luOQBWbHU/SH1B1k30+zMJa4zjJ0NACfLID+/0wGV9U7dnfgg3+kmsLoAImITAKdBoqtBlK7MSn5ltaW19bQVlAgO3uZd3yVBL0fJswzKxFxWJmBGUU86Jn0lXi8LPU6HviIkGAdyuiinC0p6WegvUd1U0t/fX/km6+nw1PnqEzJXkylX9atP5iTPeodknLRIGvWVMH0FSB9Q6D7q8uKX/Mu9ZPIp99EnuhwcE+IZ4yDG0zNjFK31wa1sV6z3B8ZBp6uFD90dSX927Xa7WsmTBRb9/sbtdF3dQx8QuurDjIN8SYc+OBMXDrEKkbwZ+y3dHVcmA52JHt6iu2oY60esZ1yt1vs6sNcH35IX/Z1onPTp95Sxw7noe/UJmvG9oI8djIN3V5MKXfB0FRdLJnm6W4FYaLlCX5nW31Wysi/nelsHxjIVyyx95y5dwDWiP4syVpGFKRl76HFK9MU+yYNxc42zaUPk/wbSfmQsCHQUleTZdmV1ahzj6UKPCDPu3MN08UYWgvXxof5+cCec6vc0xqHRxVt3C5mCzGFk0VLG6XKujK2bm5tRV1eHyMjIDiK6cX5iXJg1lqs+PpXyctVf6YvIki4937pYLWKazCV0IU7vj84U47zPWJ7STuQz4+KRUeDwFm/mqbKIIHM7Ed3kM1dl6ul++vtAylQX5Iz9n6fFcwmgLmJMU1OTk3GDPq5whdGF3d0YRX8nG+fn+rX0+pNnT9LY0tLSYUc44LTrt7hWG+/9U4fikhuMgzTdHUEfxMpx+kDUFcZilobrqqMUFV8eDl1w8dZ0ThqobsEjsX1083p9cOVqJdlYJvKA6YNGGXSK64RxwO0OKVO9E9fTLvc0dkZGly89rRJwTa4jHY24UzQ3N6sXhGC8r+RTf/Hqkwm5h5Sn/iI8k4DWer71F5zkW+/8gI4TOG9wtQol+XfXsRrbmbzcdGFN6k2fGLjrfM8WV13Uuex8z/f1CXGFLtrrn0nfY3zHAKctao0TUN0KAnDfR7h71ltb24Jjm81mNcHW3a91d2fpk89kIcE4MdHdHORv3eVNX53VB+CuBAyxipF3w7lCtxTT/zaWvfSPxtXVznC3MAB0tEoT9HeUbpFrnGCdSb24EoSkjvWFA108MQ7ejQspeputq6tTu/2JYChjD2MepQzdDfilzAIDA5UFsh7QVl+Y8gZjO9Tvq4cg8FRu+jtWxgkyCQOc40fp4xcpD32TEDmG/Peg9xdGCya9vRuFTF2ANJ4r5+vPmqt+SR+/ujsG6Gil5E5w0gUOd+KycWwu19fTqo9pjQKxPhfQcdfHuVqslfLUt4LX3636pja6O5UeZ0hEZr3Pc9VXG9NonNO5wjifdJVHTwKJPj/QP5N67qwP6UxcknTpbmuSFlnQ8nS+q/sZx9lyLekrRYjU52/Gd5OkTe+b9fGCbunamfAlcyF93iV4WqTRrdn0ewGn+3q9bvTvpP/XLf/0XQ//m/p+ikseMD6Auipq/C2Nyd2qk7GY9Q7I3X2MMYdkhdrT4FG/ljxoevwL6RjkxWV8gGRgqcc3cPVSE8RPW1Rao/rfGeLHKwKL8aGUfMh95J7SyeuDcFfWAHoHo3eYev6Mq8J6ByXXkcme8SUtKrpepsZOxVhmgvG+evnrgwp3LwLj4EIXOPWBgL6aowuVntwQ9EmLMRaInj+j5YQ3KyJngl5u+t/ncmXX1T24ckzON/qz5CpWnSu3Gx13/ayr1U/AvQWTcZCqrzDK+8O4I5ynvBgn257u7Wqiofcz7iZmQEeLLlfn6N/p6egMoxWqMV962o0Cj7fvP+PxRrFRf1+5s1RwJcCdLbq4pFvw+vufjqmotw85B3AuX6MQaozJp1sLnanVq36c/O3OzexM866PC87ERUGPsaNbtRsXqozhFYzv6v+mCcb/MtL+jW3K+NvY5o1ikfF5Nz53RmHF+Fx56s9dCU6u0qkL58b0GvspV58DHXeDNrZz3WNAXyhwZbHpSVzS+yJPC/H6/YyufK6OlbmEfp7uUeGL1ai7hQrj/FDyp48J9PL25F7tK8Z2Azi3aSPGOvA0/9HFPGmTANy++43XNIpV8p3+HvUkLrmqK1fPpbGtenq3G+tAn8fpbVJ/D4io6mps8VOH4tJ5wt0LQoQSV65tUhWulH89XoVx8Kn/bmpqUqaC8nCJ+akM9IKCglSnKyttugWO/nKSwGOSFhkUSZpFsBILFxGJ9DTKA2ScTOm7i+nCklxH/jauIIq4pKvpxsGtu3LXd1mT9LsSbVytoLa2tjqVo6RFXuD6bka66GgUIPXdJORe+stUr39dWHM10NUnJDJ4l9/6CrNxUCudnrsXtFxb2ovUmR7g1lXAO301wTg40fMoGDtr40qxiFuyiqQr/Ho5SR3rEyy97uUaNptNxdsyTmRlxUrq/b+hgyeEEEIIIYSQ/wQUl/4D6Kq33W6Hn5+fV+5TYjIok3h3qqYu6oh5oVGokFVxXS2VIM0nT55EUFAQYmJinEz09GuKiHHkyBEEBQWhW7duTu5m4iJltVoREBCAyMhIAOggFBhX56T56QKZbrHkaoKv+0qLgCR50q9lXAGRMtXN8d2JS7q4I2m22+0IDQ1VZSjCkQRLFLVbdn4LDg5GVFRUhy0yRbSR840rUZJvvXz1fLsqP9kpSFYDdNNNXTwUwVAX8PS6MZYxAJw6dQpms9kphkBzczPsdjuqq6sRHByM6Ohop1UU46qL/r9+b6MVoKRXX8GSdMnqtAiZEiSvpqYGMTExCAgI6CBi6u1d6tW4yiEi8KlTp2Cz2dC1a1fV/rmKTAghhBBCCCGd89MPSf5/GKO44XA4cOzYMfztb39TVhKeaGlpwXXXXYfLLrusg2WO0XcbaBNKamtr8dJLLyElJQWDBg1yEqeOHDmCoqIiDB06FAkJCTCZTCgpKUFGRgZeeOEFjBs3Th0rE3yZeAPA8ePHcdNNN+HKK6/EY489poJ7ygT+5MmTmDx5MoYPH44//elPKnYUcFr80PNQX1+vLH10qyJ9i0jjLhpicSXCki6CyE5xIrCIqNfS0qK2Lg4PD4fdbu+07EUMEfHK398foaGhqK+vdxIHRYz75JNPcOLECYwfPx5HjhzB6NGjMX/+fNx9991OAoWIdPK3pNFoTSVtR9Iu4ohefrp5ZXBwMI4fP44vv/wSu3btQm1tLcLCwmAymfDzn/8c/fv3R0REhFPZeUIXiiIjI9Hc3KwCe4s4VFdXh6ysLNTX12PdunUd3BuM7hq6IGcsZ110CggIwOeff47t27fjjjvucNoh68SJE1i1ahVuuOEGDBkyBI888gh27dqF1atXIzIyUrnp6ZZr/v7++PLLL1FcXIw777wTJpMJISEhqk1KG3r33XeRnZ2N999/HwkJCeqeZ+pSQwghhBBCCCH/a1BcOk+IwAGctuRobm5GTU0NiouLncQloxUK0GYtsmvXLsTGxuLSSy91Ejvktz4Z14MwP/3004iJicGQIUPU9RoaGmC1WvH888/j3nvvxWWXXaYEl7q6OuVqJm5OJpMJe/fuxXfffafc6Orq6mC1WrFv3z7885//RENDAyIiItDY2IgRI0bAbrerQHm6X7IuGAnV1dXYtWsX/vGPf2DTpk04efIkmpub0a1bN1xzzTUYNWoUrrjiCpjNZqd4BBKUW/xUly5ditdee80pLoeUtb6rQXNzMyIiIrBq1SoMHTrUSeRxhdFCrKmpCUeOHMGjjz6KyMhIPP744zCbzcpiacOGDdixYwfGjh2LxsZGp+DXYmUVFBSEoKAglJSUYNasWSpOlRynW9RI0HCTyYRZs2bhrrvucvKTN8b7KigowMsvv6xEJQnM29LSguXLlyM+Ph6/+93vkJSU5BTnxB0i9gQGBsJut2P//v2oqKhQMbKkrZWXlwMAPvroI+UaJ+V/0UUXoWfPnspqSp4LV37lRgulDRs24MMPP8Stt96KwMBAFXvs+PHjWLJkCfr164chQ4agoaFBtd/6+nolREmdS7v75ptvkJubi9TUVFx00UXKTQ447edts9mcBFHGvyCEEEIIIYQQ76C4dJ7QXcp0i52EhASsX7/eyRpHR0SG7du3Y8qUKSp2jn6cWIjobkMymQ4JCUFtba0SLmQCLcKGzWYDAPWdvt2zHqW/oaEBb731Fl566SUVS0gm5Nu3b8ftt9+OwMBANDQ0oEuXLnjrrbcQFRWl8mrcEUXEipaWFhw7dgxPPfUU3nnnHfTv3x+TJ09G165d4e/vj2+//Raffvop/vrXv+LGG2/EwoULVdpEtBAXNT8/P0yYMAFDhw5V21GaTCanQN8ibm3evBkvvvgi/Pz81O5CndWflIWILGFhYfjqq6+QkJCg3OOkHHXBRMpPytdkMjm5a/Xr1w8LFy50ipckVjYiNgUHB+Pw4cPIyclBdXW1EkAkXXpwxY8//hiPPvookpOT8eCDD6JPnz7o2rWrEl12796NZcuWYdasWXj99dedREd36LGSgoKCsHHjRjz99NNObTQ4OBiHDh2CyWTCjBkznOJUAcCCBQtw++23IyAgANXV1QgLC3O53bK47fn5+am4SrorqJSJuL2Ja6E8X1J24j6oB6MFnHd6ampqUjGvxGJJLMP0Lc0JIYQQQgghhHgPxaXziAgKMgkWa4+QkJAOwhBwetIu1i51dXVOO5fZ7XaYTCYlAumuUiJmtba2IiIiAh9++CEqKiqU21lwcDCOHTuG+vp6mEwm5XIVGhqKhoYGtLa2qkm4CAT3338/7r77bhUA+dSpU8qKRA+y7XA4YDablWXL9u3b8fjjjyMoKAgTJkxAQkKCEoNaWlrw2muv4a233sLChQsxceJEREdHKyGhvr4eM2fOxOrVq5GTk4OoqCgsWLDAaVcycdfz8/PD8OHDMWTIEAQEBCjhQg+o3dzcrFzB/vznP3vcQUBHD7aubwMu9WkMri3uh2JJJrv9SV3pLpK9evXCDTfc4BTbSRez5Pjjx4/jySefVGKa1Jsew8nf3x+vvvoqunbtiieffBLdu3dX6QoLC0NzczNGjBiBJ554AjfffDP++c9/YvDgwZ1a5Og7irS2tmLOnDnIzMx02jViw4YNuP/++xEWFoa8vDyMGzcOZrMZDQ0NAKBiPzkcDkRERCirOONWs7qwJO1aLOROnjyJ+Ph4Zf2nB4sHTsewki1l5RmQehaR8fvvv0d1dTX27duHiy++GDabDZ9++inKysqUgFZSUqLEJr0NEEIIIYQQQgjxDMWl84RMasUKA2gTPfbs2YNjx46pz9zx9ddfIzw8HKGhoWpCLoGMdWsaPSiyCBp2ux27d+9GfX29CnxsNptRX1+PY8eOKZc8ffJdVlaGkJAQBAcHY/jw4QgODkZERASCg4Px1VdfYcOGDfjnP/+Jb775BoGBgRg4cCBuuukmpKSkIC4uTk3+TSYTDh06hI0bNyI6OhqJiYkYNGiQsio5evQoXn/9dUybNg3p6ekIDw9XgoEILREREZg+fToOHDiA1atXY9asWejevbvTbmcBAQGw2Wz47rvvcOTIETQ2NnbY4UsPGv3FF1+oIObeiAbGGEgijEg+dDFI6qOxsVG5tAFQxxq3Qz1x4gR27typ0qfH9NF34fvxxx9VPCXdrVAPDi4ipNlsRnR0tLJEEyFGBJ7w8HCEhISgrq6u07wDcLK2k3qJjIxEU1MTvvvuOxQWFiI/Px+TJ09GQEAAlixZglOnTmH06NGwWCxK0BQxTKzeRGCUetFdJltbW2EymXD8+HFs3boVDocDmzdvhsVicdod0OFw4N///jc++eQTHDp0SJW/BMDXRV0RdD/66CO0trbizTffxDXXXKPadVFREfz8/BAWFoby8nIVtF1vIxSZCCGEEEIIIcQzFJfOE+LWA0C5C1VXV+OJJ57Av/71LyWm6Lt6AacFkYaGBmXxobuYyY8x5pIIAIGBgQgKCsLvfvc7TJ48GSEhIUoAOXDgAKZNm6bchhwOB4A2d6NnnnkGf/7znxEfH49XXnkFffv2hcPhwMGDBzF79mzU1dXhpptuwtSpU9HU1ISdO3di4cKF+Mc//oHc3FxERkYq8WLSpEl45plnnMSPsLAwOBwOVFVVwW63Y8CAAQgPD3cKVu3v74+QkBDlJjVkyBC88847qK+vV2kFoASLkJAQPPvss3j55ZfRtWtXJ+FCDyItZdetWzeYTCav61BEJQDKDUwEEX3XO13oa2hoUC5YYukkwpJYHO3atQuTJk2C2WxWMaX0+0gejJZpgPOOcdIGrr32WixatAj5+fm46aabEBsbq1wdm5ubcfz4cbz88ss4dOgQRowYoT7vDBEea2tr8d133+Hbb79FcXExtm3bhubmZvz+97/HxIkTERgYiA8++AB/+ctfsHbtWiQkJODaa69F79690a9fP0RERCgrMom/pAddF8FUdjr86KOPUFdXh1tuuQUrV65EUlISLrzwQiVINTY2YuXKlfjrX/+KxsZGJCYmKiFN32VOLJnef/99bN++HbNnz8Ybb7yBt956C1OnTsWMGTNw3333AWgTAN988008+OCDqK+vV+2MEEIIIYQQQkjnUFw6j+hWRS0tLYiNjcVf//pX5boj7m8igojoI3FyZs+e7WStJK5gAJS4IOfI/YxBufXYT0aXKj2Gz7PPPouJEycCgBI8AgIC8Oqrr8Jut6OgoACDBg1Srl433ngjRo4ciYcffhiff/45fvnLX6q0NDU1qWDSuuWWCCaBgYGoqKhQ5SSCih6AOTAwEIcOHUJAQIASyCSGkYguYg3TvXt37NixA0FBQQgNDVX31q2Y5D5ms1mJG7p4oO9WpotUuuXOqVOncPToUURGRsJmsyn3QKlfPz8/mEwmFedJd/+SvIlYFBwcjFWrVmHUqFFO9StpE2HE4XCoHe5CQ0OdAmBLPU+dOhUVFRXIy8vDO++8g6FDh6J79+7w9/fHkSNHUFJSghMnTuDxxx/HiBEjnKyt9DIyimbSLnft2oXf/OY3CAsLQ0JCAmbNmoWrr74avXr1UuLojTfeiGuuuQabN2/Ghx9+iD/84Q+ora3Fc889hyuvvFJZJelxkgCoshNR6LPPPsMzzzyDtLQ0zJgxAzNmzMCCBQvw2GOPYcCAAcotdOHChbjjjjvw8MMPY+fOnWrnQr1OW1pasGXLFmRnZ2Pq1Kn47W9/i5iYGCxZsgR2ux3Tpk1TFm8SAF0srvTyMP5NCCGEEEIIIcQZikvnidbWVjQ2NsJkMilxQqxtzGazkzWSWMPou8uFh4crsUPf2Upc2kRoMu5oJuLAvn37sHnzZvV9U1MTqqurVRwnm82mrIQcDge6dOniJLyIVcmxY8fQo0cPdO3aFY2NjWq3Nn9/f/Tv3x8tLS2oqqpCcHCwEnXeeecdfPLJJ4iOjsbChQsxduxYZVnSpUsX/PKXv0RhYSGuuuoqXHHFFU7CWXNzMxwOB7Zs2YJ3330XEyZMQFRUlBKWJIg4ACXuBAYGIioqCiaTCfX19QgPD4e/v78K3K3v2KbXj/wWEUnKyhhsWkSFr7/+GkeOHEFQUBB+/PFHFQtI0l1fX4+PP/5YBdKWnfNEsBI3LblPSEgIQkNDnURDSX9jY6OKmaTvtCZtStpJUFAQzGYzfve73+G6667DZ599hs8++wy7d+9GS0sL+vbti2nTpuHKK6/ERRddpAQefZdBaU9yTdkhToTNESNG4L333oOfnx/i4uLQ0tKC4OBgJ4FOrLCuv/563HDDDTh69Ciam5sRFxenXPMktpFu8SUxmRwOB7744gs89NBDsFgsmD59OiIiIpCTk4O5c+fi9ttvx+OPP46YmBgAQExMDPz9/REWFqYCt0dGRqr6tdlsePfdd7FkyRKMGzcO9957LyIiIpCVlQWTyYRnnnkG27dvxx/+8Af06dNHudTpAcQJIYQQQgghhHgHxaXzhLiuNTc3o7q6Gr/97W+drG4kaLCIOBJbB2gTEU6dOoXy8nIsXrwYr7/+Onr27InFixcr9ywAyioKOO3C1NzcjO7du+O1117DG2+8oVy7/P39YbPZEB4erra414Nky8S/vr5eBfkOCAjApEmTMGvWLCxcuBCTJ0/GgAED4HA48OWXX+LFF19E3759MWLECHWtwMBADBo0CDNnzgQADB48WAkkYiEyd+5c3HPPPbjvvvswfvx4TJw4EXFxcWhtbcXhw4fxj3/8A6+//jp69eqFWbNmKasUffc1CXItO7N9++23iIyMRHNzs9otTyylampqlDVWaGioClruySqlsbERAQEBSrhobm7G2rVrMXLkSOzfvx+ffvopLBaLEiTCw8OxdetW3H///aitrUV9fb0qd92VEWgTPmw2G2pqanDy5ElloSRujVVVVUpEkxhTffv2VTGfWltbUVNTowKsixXS4MGDYbFY8Otf/9opb5KHuro61NbWKlfEkJAQhISEOAXTljZrMplgt9uxefNmrF69Wu1+19DQALPZDLvdjvDwcNTV1amg7rorngh0ZrMZv/71rzFmzBgnqyhJW2BgIAIDA/HZZ59hzpw56Nu3LxYtWqQsr4YOHYpnn30WS5cuRW1tLbp3765EMSkjEWDlmWhoaMBLL72EZ599FqmpqfjjH/+oBEq73Y45c+Zg0KBBeO2111BTU6N2WTRazxFCCCGEEEII8Q6KS+cJEWtEOBowYADq6uqcRAvdHUoEGBGMmpqa8POf/xz19fVobm5Gr169AMAp1hJwWhgRy6GwsDB88sknToKBfCfxbmS3OhEQQkJCUFNTg5aWFoSEhMBmsynLlpSUFLz88st48cUXkZmZiVOnTqG1tRUXXHABhg4digceeAD9+vWDzWZTE/2LL74Yv/71r1WcHd0qy2w2w2Kx4JVXXsHq1auxZcsWrF69WuWza9eu6NevH37zm98gIyMDkZGRSriQgNmAc6Bpq9Wq3MsCAgJQV1enRDOHw4GwsDA0NTWhoaEBd911F/Ly8pQLn3GnPhGBRJCRst68eTM2btyIvLw8/L//9/+wevVqXHfddejatSsCAgJQW1uLcePGIT8/H0ePHsU111yDoKAgVcdSd1IGYWFhuPnmmxEeHq6spurq6tClSxfU1NQ4tYnY2Fhs3boVUVFRqkxfeukl5OTkKCFI6lfKRLd2k3w0NDQoEcVkMuHpp59GRkaGyrsxHpWIgV26dFHWVLpAVF9fj23btqGxsRE33nijyq+499lsNoSFhal4WJInPSaWzWZDYGAghg0bhiVLlmDo0KHo06ePEtBCQ0ORkJCAF154Af7+/vjiiy/U9cVqTUQ3EehCQ0MxadIk9O/fH6NGjUKXLl2UCCnC7NixY5GSkqIEX2nz4lZJCCGEEEIIIcR7/Fpl5kvOKQ0NDWqyLpNymdTr34vYJKKGWGDo8X7kt+6uJkKCHntH3I9kYi9CgtVqxbfffouGhgbYbDY0NzcjKioKPXr0QFRUFL7//nvExcUpNy25v1gvBQYG4ocffoDNZkNdXR0CAgIQERGBuLg4FTOntbUVJ06cwJNPPokBAwZg9uzZCAgIUBZVutAlebfb7aivr8fRo0eVS19wcDC6du2KyMhIp2vrO6TpaTtx4gQqKirU9UwmE15++WW89957eOqppxAfH68sUgICAtC1a1fl2gVAWR4BzsG0m5ublfBw4sQJZGZmIiIiAqtWrcLevXsxdepUpKen4/e//z0CAgLwyCOPYOvWrSgsLERFRQXGjh2LBQsWYObMmarOxMqspqYGBw8eVGXh5+eHsJrLWgAAIABJREFUAwcO4N5770VmZiYmT57s5MoXHByMn/3sZ+r/oKAgHDx4EE1NTSq+lQQN9/Pzw6lTp7Bs2TLs2bMHf/vb35R1kFh7ibjYo0cP5WYmwoy0J7GYkrI3xmgS67rMzExUVVWhuLhY1aGUq5wvVnIAXAZUF9c83ZVU0nL8+HH14+fnh9raWhw5ckRZaf3973/Hvn378Nhjj8FkMiEoKEhZZhmDoDscDhw7dgzfffedErVaW1sRFhaG7t27IygoCJWVlRg4cKByEWXMJUIIIYQQQgjpHFounScktg0AFaw4KCgIu3fvxrJlyzB37lwMGzbMaXt2/VgRJGSCW1tbq1yYdLFCtlzXBRygzTrm22+/xWuvvYZt27bh8OHDOHLkiLpH165dER4ejl/84hfIyMhAbGwsACjLGHEVamxsRF1dHXr06IGGhgbs3LkT27Ztw549e1BXV4fW1lb069cPvXv3xqhRo/Doo48iNjZWWcsAcIrxI+KBCGWRkZGIiopyit8jFlziAge0CQQSs8rhcCgxpVu3boiLi1PiiL+/P2JiYpSbWHx8vCpfua4uxujxdXRBT2Ij2e12LFu2DIcOHcKrr74Kh8OBiy66CLfccgtefPFFXHbZZRg3bhyCgoIQFBTkZJ2j7wIneWtubkZERAQuueQSp53tJB7ThRdeiCFDhijrNaljKUdxQYuPjwfQJlzK7mZhYWFK1AkJCUFUVBQuuugi+Pv7OwlE+g53ElxeXCobGhqUW6TUE9Amhp46dUq5vLW0tKCurg6nTp2Cw+HADz/84BS4HQBiY2PR0NDgFCfK2B50y73m5mZlOXTq1Cls2LABb775Jr755hs4HA5YrVaYTCYEBgYiJiYGffv2xcyZM5GRkYGgoCBlbSairYhhAQEBOHjwIJ555hns3r0bJ06cwPHjx5VAKSLrjTfeiNtuu03FuiKEEEIIIYQQ4h0Ul84juluSTK6tVivefvtt/OpXv8Ill1yiLEHEWkasLQQJBB0SEqIseQAooUYm1UCbUGI2m9HU1ISamhpkZ2fjiy++wG233YaUlBTEx8crC4wff/wR27ZtQ35+Pj799FO8+uqr6N+/v3JfErEhODgY/v7+2Lt3L+677z4cO3YMQ4cORUxMDLp37w4/Pz8cOXIEBw8exLPPPosrr7wSjz76KH72s5/Bbrer80VsknxKeiXtAJwsZ/QA5uK2JcKSHCPxfyROlM1mQ3BwsBJ5RNiQchO3QAlYLWkzWjGJK2NrayuWLl2KgoICPPbYY7j00ktV/UyfPh3btm1DdnY2BgwYoCyQgDaRRwRCEWJ06ygRk0wmk7I4E6FFAlxLevUd/cTNT2INibVbeno6EhIS8PTTT8Pf319ZyunWc/X19U7WOCJYGa2SQkNDndqrBKI/fPgw0tLSUFFRofIEQJXx0KFDVUB1Pz8/3HLLLU4BuPXd/SR2li66iqubiE0vvPACXnzxRdx6662YO3cu+vXrh65du8Jms+HUqVPYv38/Vq1ahTvvvBNPPfUU0tPTVTsQsVXa+sGDBzFz5kzU19djypQpSE5ORp8+fRAWFoba2lr8+OOPKCoqwnPPPYcdO3YgLy8PPXr0OKtnnxBCCCGEEEL+l6C4dJ7Q3WhEJJAJvQgHYhkjIoecJ+KDILFs5HsRpHRhRmLviED11Vdf4cMPP0ReXh5uvfVW5RYksaAiIyNx8cUX49JLL8X111+Pzz//HL169VLxiWSiDwB2ux0PP/wwgoKC8Oqrr2LAgAGIiopSwk1raytOnjyJL7/8Eg888ABeeuklLFy4ECEhIQDarGuOHDmCw4cPw2azKSEBgCoDsZLRdxILDAxUsYQAID4+HjExMXA4HNi9e7dKp8R1EqHk4MGDaGxsxK5du3D8+HGnHfOANpGmV69e6NGjByIjIzvsECZl3NraitGjR6Nnz56YMmWKCvbc1NSEbt26YenSpfj444/Rs2dPJdgEBwcr10M9mLfdbsdXX32lYlZJ8HQRQfbv34/W1lbs2rULFosFwcHBqm2IoBYeHg6LxYKIiAgV1Ly5uRk1NTWwWq0qf1JegrhIilApdavvlCdlLpZxwGl3soCAAPTp0wcFBQVOLphyLf16NpsNDz/8sIpvJBZ20u6k/Uublrhk4hra0tKCgwcPYvXq1bj99tvx0EMPKaFLArJ3794dFosFV1xxBe677z4sX74cY8eORZcuXZRYJWkHgKKiIuzfvx8rVqzAtdde6/Q8hoaGokuXLrjkkkvQv39/zJkzB1OnTsW111575g89IYQQQgghhPyPQnHpP4BMdEVkkHgwIggBUGKEWLmI5Y1Mwl25zenoYpBYiTgcDkRERKjPdcFD4hBFRkbCZDKhqqoKoaGhTq5aYnlTX1+P3bt34+6770ZCQoKKyyQCUVBQELp27Yrk5GT87Gc/w7fffquELBGS1q9fj6VLl6pg2964HYl7l1gSLVu2DJMnT8Y333yDO+64A/X19coCRspOLH1aW1sxd+5clXcjEyZMwHPPPQfA2TVOx8/PD1deeSWuvPJK9b8e92rQoEEYMGCA0254YpGkxxyS4NdPPvkkNm7c6NI6TX6vWbMGa9asUfcS97jW1lYMHDgQf/nLX3DJJZeo43WXOj24+6xZs3Dy5EkVxFtiX0lZuSp/Y7qMMa8GDx7c4Ts9LpgIXXpcMDlOF/iMu7G5cgX19/dHRESEEopEOJSyknyEh4er9qHfRxeQxE2xa9euqrz0mGVSxlFRUTCbzaitrXXZFhh3iRBCCCGEEEJcQ3HpPKFPRsVqSNyOJNaL7n4k54hIose8cWVN0tm9L7roIowbNw5PPPEE6uvrMWTIEFx44YUqHs3x48exZ88ePPHEE4iIiMBVV13ltLObuJ35+fmhe/fuuOaaa/D888/jggsuwMiRI9G7d28VKPrkyZM4cuQI3njjDZSUlOChhx5CZGSkU1Ds6dOnY/Lkycp1SmIeuUPKoampSbm+denSBQAwaNAg7Ny5U8XV0QUz3erIU6x6EfuknHVhTnc/dIUIWE1NTcoVUepGgnSL0CHXjoqKwvLlyxEWFoa6ujqvRAq5nr4jXEREhAr6LrGURCCRnfHsdjuGDx8Os9ms3Nb0dLkKqu0KT2nUY36J5ZMeAFvc+3QhNSAgQImluhgqeQHahMru3bsjNTUVzz33HBwOB8aPHw+LxYLIyEg0Njaiuroau3fvxgcffID169fj4YcfRmRkpCpzacdSLikpKXjzzTeRlZWFuXPnYuTIkcrtrbq6GocPH8b27dvxpz/9CYMGDcKYMWO8Kh9CCCGEEEIIIW1QXDrPyKRarCMkUPY999yD7t27q120ZGLc0tKiLE38/f1xyy23YM6cOQgNDVXCjyuMQkBUVBSWLl2K3Nxc5Obmwmw2o66uTl2/oaEB4eHhiIuLw9KlSzF48GAlgMnEXESIpqYm5OTkoF+/fvjLX/6C3NxcdU/Z4Ss0NBQRERHIysrCXXfdpYQfcXsKCgpCt27dALTFJBILE3fo1jD+/v4ICQlRli0hISHKpUnfzUvECqNw4aqcjDGJpPxFOHIlrIiIIoi4I5YzIoKZTCYl9tjtdhXrKDo6GgAQExPjUbgxWsiIoBgWFqbiCukCTWBgINatW4fdu3crFzqxkhPXSbE+GjBgAHJzcxEXF+ex/I3lZfxMxDexUJK/pd3qgefFEk+Okb8l/cZ7RERE4MEHH0RsbCwKCwuxdu1a2O129XyIxZJYs02cOFGJbLr42tLSApvNhkGDBuG5555Dbm4uli1bBrvdrizLwsLCVMypUaNGYdasWYiIiKCFEiGEEEIIIYScAX6tnsw7iM+4cv9pamrCiRMn8N5778FsNqvJuB47SYQah8OB5uZmDB06FJdffjmA0xNzfYJuRN+dTI774Ycf8PXXX6OiogINDQ0IDAxEbGws+vfvj4EDBwKAU1r12FAiFMi19u/fj8OHD6OqqgrV1dUICAiA2WxGnz59MHDgQHTp0kW5NemBrOV64jbWWbPT3QAl77qFkuRRBK7OXJaM34noI/UiIpFx+3l31xDLLomZ9Pnnn6O6uhpJSUkq+PUf//hHpKWlqXz4+fl1qG9X99HzI+Unrl16ecoOax999JGKLSUijB7DSCx5wsLCEBoailGjRiEqKsqtiOYtuvWSBFevqqrC9OnTERcXh2eeecZJvHMnJgl6YHWpi4qKCnzzzTc4evQoqqurERQUhJiYGPTo0QMWiwWxsbFOz4Or9i/labfbcfToUezZswdVVVXK3bR3797o168fBgwYoO4vFoPGOqfoRAghhBBCCCEdobh0ntAnvEYXIgAq9pLxGBERxCVKJu4mk8mnia1uYaIH0paJtVi06Nvc69ZRepolgLMIOmKRpLtGSTwb3T1KrFt8nZjrZePJessXxFpLFyM8iXeCLmKIlZbEGGpubsapU6cQEBCAiIgIAHASiTq7tiB1JG6Kcj89zpQgVkr68UbrLP1vo5B2pujCofwtFkH19fUIDAxEeHi4k5imn+OuHPSA7nV1dYiIiFAudnocJQkorrud6hZUkjdjTC5Jj1io6XGaJMaZlDOFJEIIIYQQQgjxDopL5xF9pyyZMMs28foktrm5WYkCeowlfft44LR7lNEiqLN7i1Clb9UuohBwOoaQTOwbGxudAikbrbDk/roFEQC1BbwuirhKkzcWILoooQsRRosS465n8pmO0fpEylJ319Lz6E36RJgTwU3OFcsh2TVOdswzCivyt7v76JZKkh7dbVG37pGA3yaTSVmmyeey25xYk0n7k//PRkDR26O+i6HEhJKYR8Z2ZixjY3sWV0uJz6W7GeqCloiCUne6eOauLF1ZvekB941pI4QQQgghhBDSORSXzhNGyxDd5Uf+l93E9Amx7OIlE3FXItKZTH5FuNLFIZls6wKQvoOWcaKvu56JQBEcHKwm9bowo7ub6dvWn2m65XgREUSwEEHhXCBCFeAskBndGd2lTY4XQU0PXK1zthZXRrcvSavRoksEKN3tUKx7pJ5EUPPVcsmV25mkRT4TwUl3SRORTLcU0q+p50uOFzFNythYN8ay0N3ZxIJKdjaU7yWdcr5u7SRuhb5aCRJCCCGEEELI/yoUl84zutWIOxc13RVIJtV6UGKxQvFG9NDRBQSZVBstfFzFAdKFMBEEjLGX5FxJl2694sqy6kzcwaTcdDFGv6YueAFwyo/+vztcnaeXvzdp1WMI6S6CIg7Kd0bXwTMV2HQrMVfxl3TrIcmTpEkXd+RzEQel/fkqLhlFSFflopepK5e4zizw9Hpw59LnysJLT4f8rYuIrp6p8+FySQghhBBCCCH/K1BcIoQQQgghhBBCCCE+4zlwDyGEEEIIIYQQQgghHqC4RAghhBBCCCGEEEJ8huISIYQQQgghhBBCCPEZikuEEEIIIYQQQgghxGcoLhFCCCGEEEIIIYQQn6G4RAghhBBCCCGEEEJ8huISIYQQQgghhBBCCPEZikuEEEIIIYQQQgghxGcoLhFCCCGEEEIIIYQQn6G4RAghhBBCCCGEEEJ8huISIYQQQgghhBBCCPEZikuEEEIIIYQQQgghxGcoLhFCCCGEEEIIIYQQn6G4RAghhBBCCCGEEEJ8huISIYQQQgghhBBCCPEZikuEEEIIIYQQQgghxGcoLhFCCCGEEEIIIYQQn6G4RAghhBBCCCGEEEJ8huISIYQQQgghhBBCCPEZikuEEEIIIYQQQgghxGcoLhFCCCGEEEIIIYQQn6G4RAghhBBCCCGEEEJ8huISIYQQQgghhBBCCPEZikuEEEIIIYQQQgghxGcoLhFCCCGEEEIIIYQQn6G4RAghhBBCCCGEEEJ8huISIYQQQgghhBBCCPEZikuEEEIIIYQQQgghxGcoLhFCCCGEEEIIIYQQn6G4RAghhBBCCCGEEEJ8huISIYQQQgghhBBCCPEZikuEEEIIIYQQQgghxGcoLhFCCCGEEEIIIYQQn6G4RAghhBBCCCGEEEJ8huISIYQQQgghhBBCCPEZikuEEEIIIYQQQgghxGcoLhFCCCGEEEIIIYQQn6G4RAghhBBCCCGEEEJ8huISIYQQQgghhBBCCPEZikuEEEIIIYQQQgghxGcoLhFCCCGEEEIIIYQQn6G4RAghhBBCCCGEEEJ8huISIYQQQgghhBBCCPEZikuEEEIIIYQQQgghxGcoLhFCCCGEEEIIIYQQn6G4RAghhBBCCCGEEEJ8huISIYQQQgghhBBCCPEZikuEEEIIIYQQQgghxGcoLhFCCCGEEEIIIYQQn6G4RAghhBBCCCGEEEJ8huISIYQQQgghhBBCCPEZikuEEEIIIYQQQgghxGcoLhFCCCGEEEIIIYQQn6G4RAghhBBCCCGEEEJ8huISIYQQQgghhBBCCPEZikuEEEIIIYQQQgghxGcoLhFCCCGEEEIIIYQQn6G4RAghhBBCCCGEEEJ8huKSl9itVtgdPpzosMNqtZ+zNPh2KTusVivOOhV2q+95OZtzzyc+18/ZlOk5qg8AqLXCWnsuLnQmnMP0nw2+5v3/als04iF/vvcFBs62f6o9R+nwuU58bIvnsF8+1/zH3zX/h8uCEEIIIYT8dPjJikvWrfnIW19+Hu9QiaIHxmDe+koAlSicGYO8HS6O+qIQ+cvykLcsDyteL0WlcVKwIw8xMXkoPQfpKZwZg8x1lWd+6uFCZMZkovDwWaZgXSZiZhbChxR4f669EmWbilHcyU/Z4bOYDO1YgTHjVqAMaKsfX/J0NmXqzbmuJtsuJoGlT8cg5umOrat8fVub9PxTBPdPkBV7NxVj7/EzTb8V5RvyMW/6GIwZl4x4Pz/4XZiMMePGYMZD+Sg6YPWQ6TPDZd5diR2GcvO2LdqtVljlp9PmZj99rKefMxDD3NWtd32Ba9Glg3DhQ/9UuX4exjxQhMr2NHpMh7E+9LrQnkOf+xZfn8MzzLf1QBHyH5qBMePGIPlCP/j5xSN53BiMmT4P+RvKcSatuqMwWIYV4+ahqBIASpEX4/pd03ZyJco2laHSVXvsJE+lj/nB7zEX3/raBxJCCCGEEKIR6PuppVjsl4xs7ZO4i1Mw4ebZyJqbhoRww+GOShS/kIMVa4pQuLUcQBwSRk9Axj1ZmD05AdH6sQfyMeHCGehZWIWXJ0XDFfbyIsw7MBhZEy0+58C6rxg7K1x90xPDR8fAergY5W4ng3aUPpaC5FU9kbMoE0lxdux9PRuJCyxYsfFlpPX3Ph2lj/kheYGLLyYXoOLNKYhzd+KOFRjzSKHb6ybeW4DciW7PduZAEfLW7XXxRTSS78pEkutqgKt24MSiErQ+muRdGgDAXo6dO8o8TNaqsHPNYtgfqsDaW93lzY7KHSXYU2P4uOdwpAyKBhxWFG+ER2sH644VmH1nDtbsrkTcxVMw74UVyPqF20Jop22S6LJGJubi43sTOzn/NJXrMtFzXbpz/e/IQ0wSUNI6H52VaOUX8zCvdDZyR/v6fOxFYcoYoLQV82O9Pacca6YlI9s+D8sXFSA7LhrR0WaI0FFRWoDs8QkoWFSCgls9pMttWwR6jp6NKZeb3Z5a+nQMcgca2saOPMQ8ZfH8LGlUbspD1n25WGO3IMUSAsCG8o3lMN86D8ufykKKq4scLkTmBRmu617H4/Ngxd5NOyFd0t7vAWAnijfZ2j6Q9usNhwuRecFapH+/FlP6yIelyItJbqvTke5PdeoXIwZjcPge7JH/ew7H4NpyFB/2Tk7pUB96XXh8Ds/ds9S2UJCBvN3aRzVtsmrWuGKEaB+76jPLX89A8gI75j2bg4JHeiI6OhpmtItElSUoWDAGCa/noGTVFHT+tFWicGZPrJ2kt1E7rBvLYfXGWul4MXJSjPV6vvBQB04kImtVLlK9fNUQQgghhJD/Ts5CXGoj7cU9yJ/cE0AVyjcVIuehdAwufRkHizJPD7QPFWHOrROwNiQT2Q8VICcpAebKnSgrK0KJ3QzjdKls/QpUDEtE0fpi5E5K6/D9uaJqfxnK9gEiWFiTcpFiAQA7LKNjPJ/8xQrMfj4ZH+/PRUq7kJYyOhXDFyQjeWkRqp5PPbN0P/w+qh5KPv1/aS5iXunknP4pmP9wQvs/e7EmZQ7w/MeYMqjtk5gLzyAF0RYkGiftx4ux+OadsEzN9HBiEua3tmI+AKASa242TpzOkOgkZD7oSTqpxJrti7HW40WsKF46Brnm+ci4RKvHQRbvJucH8pFxRQESi0pQlRSDqtJcZIxKhX17MeZ7EDbaJonFSCqqwjxjFgLPVSsuQcGyPJS0/1deCrhVmpIykOWxLD1jA05PvB12WGvbZQCrzfUJh0ux9rVk5HyfhVSnia8Z0dFxiB6fhdwFJYhfV4q8Wy3uhR5XbRHlKPrNDNhHZfmWGa+wo2zZBKQWJiDvtb0oGKbVmcOKsr9nY3biGKSvfx9ZxvT1mYK1rVM8Xr30MT8kezyiCuU7yiCyWvlhANiLsh3t5e5t+z1LqvaXoax0JwoetyJ5ZTZCYouRv6C9fxxvweDzngLg3D5LcUhZsNap7O0bs9HzZmDeyhzVfwMAzMZrV6J03RokL6pA1njnFmuOjkZcdCqyluagxLIWpUumwHK+BR+jAGXXrKCqnJ5YoLII86bltVloArCVA0AWxmyRY9pFIbc3syDl4flIcPs92t8Re70TxgghhBBCyH81Zy0uITwG0dHRAKKROCkLay3A8MQVKPwiE1nDAKASax6agBUxudj5ZhYSZSAflwLLsBSkdbhgGYpXVSB90Qok35CPtY+kIXPgWafSJZaJWcia2J7G7YtRPi0LWWpFv9Kjy0Tl3hKUjUrHYCcLLTOSUtOBqXtRjlScydo6QqQc24kJARw2VFmtaJvGVsFmHMDHJiBltAz9Q9rSm5iCFA9WCW5xulY7X5RhXlwILF7rRDbYrEDJgTbLtA7sfx/Ll1UgBglIezDV9Sq/3QqrvQrlZeWo6vglKneX4P393qXGMn4Oss5Y5LKjeGU2KpYW4f3xbSmMHp+DghcnIP75Isxe2bnYGRITjehzoQGo8mqnvMTT0eeWA3tQCiC6vBIYGdduNaXbp6Uh3XhOnwQkjyzE8ucLkfhAKhJidQHGDuu+IuQ/X4ikm7M9WxC5aov2YhTtS0GcF1ZUJUsyMEYXZmvKgQtyOj/xQAGyH4pGXvlyTDFaHgZGI/HW5ShwpCN+aSEyvLSCOjMsSH0wq32yb0VR+Tys6KkJhLVtrnUu+wKXlOP95/NQcboBoQRAYpUVVjE8MgoSaO8XE9eg5PFyZNyZhCRYUP7a6f6x8vUzy1XhlJ7w03W3sfNRsqkY0fvKgU5sfc7Vs2RutzYCANTuxYq/r4VlIFCwfjZS70mAe8k4DglJSSh8djkKE+chdVC007H243tR9OJyFI5MR7ZXwlJbH2mtNQq0VuwpLUZx7F54KhX7/p0oRAmGHwbQp93CcYpuW6S187gUZL/pWc40RwM45O7baCSMTvEsLh2uxAq4tjIkhBBCCCH/W5y9uGQkticsKINdVlO/KEDu3xORW6YJS57YWoTcykwUjE2B9c50rNhUjsyBbobaq/RVWFd4a65vAxxAxTEr4KW9UZxlOOK27MSe2imI0/K1t6wYGJvlhXuEF6ybgcHrZjh9lDb5XFzYO8rLilE2abb3eTlQjMJdccCutSiem+RsEeAl9h0rkL6oGAAQPTAJyRbN8sjcEwkXD4elG2AN92RBdDaUofTxnsgoc5YGLaPTkDKzBDufT0PK+bq1kW4WDL888XSLDN8LwIKMB7OUsVKpfR5WuDvf5+fDjtLXV6BqfCqqli5H6cQcJI2cj9bWNvs0HF6D9Atc2Y4lImvjQSS8kofsm7NRsmnv6TgucQlIGZWCtAUHUTzeh6djXxmK41KQ7oXQnHzf8nZrynZcWQFuyUHGuHwAacj9aHabEHy8EkWT0rHcg0urZVQ60qaVo4N8arAScYWtHMC0ztMPALDvRMk6AHHFKH0wCUnmNhcz3X22874gBpbERCQqQc6MvQAWp8ZgsdNxXghvZ8Fp61a01cX0Qqx4vLTdNc2TVeQ5xm7F3k35yL4vF9bphdizEsi7IQWDN83D8kWZSDEIR0Li3GIcHJSPvAXpyN5SjL2nGzUSRicjZVI2Dm50I5Yb+aIQKzYCZccKUXZXlrYAsQeFLyxGaaAN7kulEoUv5SF1fCqyn1qDKW9OgeXWtWi9tf3rrYvh52TlZW53SwWs+4qwdv1eWGFGz1HpmDLyXEqjFq9EX0IIIYQQ8t/NOReX7IfLUY4UpLYPNsu3F6EsLh35w7w6G8XvLgfuLECyORr2iZlIX2QchLcRNykfVeM7v2IHLweXVGLPOmDv+CrgcBHStdgpaZPcnDIyEyvGJyPjBiDnwVRYzHZUblyBrFfiUFB6hi5x7nCKudTucubu2EPl2AkAYmmydTH8OrM08Ug5iv9ehNn3FDjnxbqnzeoAMRiclIg4mY05ypH/yAxgyR4UVWYi9TdrULJyCix6C7twAuY86Nniw/yL+fj4o/kejihFWQoQsugMS1iPT+VpUnu4HDthQbpxsmQOQTTKUXkcQCcWCvlzx6A4Qv8kDbmrLCgQ8cFRgT1I6Lw+ogcjeXTK6fIKKQVQjp2biiF2D3u/B3BBx1OT5lah6t7T/1f8PRODN6Riz8p0aLKLy+fD+s88ZD2fgOztK2BekoC03wzuWJfuCLcg9d7lSL2380O9x47iN3NRcWeBd9aA4S6sAI0kZWH5ynT0hOaWGwjElZajEh7saSrLUTLM3FGEcFhRvjEaU3blI91T+/DKpcuO0mXZyJ9agILaLGQtS0HRo0lIerQVrY8CnfYFimgMTkpBikpPm3Vjjh5zqYMgoVOBKk1vr6qxA5Lz9n6g4nsAnQl+en3EhACjslHw5hTEebx3G+fZG7gMAAAgAElEQVTkWdqXj4w7F2PNViD1ntnIXLcXaRe3pWd+8V5M2VCAvAeGY8IGIOnW+chfk2mw1jHDMn42lo+f3UlGO8GxFysemQfLmhJkb0jD7MeSUfRoUnvxJiN71VpM6dMWw84V5a9lIev7HBRtTEXK2OHIeMyine8OO0ofn4C0ldHIeCQDKeZyFD6SiOUX56Pw2dTTfYtmJWsOj4bZ25HB4XIUIgbz/lOCOyGEEEII+T/L2YtLtVWwWs2AtRwlpWux4oHFMC8qQUb7hKOyshgYlek0oXWLvQRFjwNzSlPaBrmj0zA7LRvFX2Qh0ShOmaMRfa4GtAf2oDQuDntKy2C9S2KndDaBi0Payj1I3lqItUWFWHHYjORRs1GyNxUWX5QlW1W7y0s7VW7i2rjBWlaMkoEW4LX3UX5rJiyXZ6Gqqn0ydHgtMi8pOrPrrc9DdkUuiiYaMrOr3eoAichaldhm9VJZjMUzM7A8ugAldybAggKsmD4G8aOKsXzBfGT6YqnijsoK7EEaJpzpwrsen2rfGhRvdXNcoAvh4AyZsmCtIU6MGdFmK/Dw/DaXp+PFWLzJV1eSCuzdUaaCIJcfhktxCeHRTpNOeziAwBDEREe7n4w6KlH6QjYy7tuDzNJipPUxA0uLkXPfBMQnrEXOs7mY76Yu3Qal90BOJ4GlFQcKkPe4BfPKUs66bhSuyuLyKchJjEfWYymuJ+3WUiyem43hvznoVuQKiT5LNy5HJYqXZSKjaAIKN05pc0m7IQ3Dd83Dy0/NRkqf/9As/nA5ClGBdCuA6AqUbwHKxlZAyW7t/YCtHOg52vOlrHtLULypvVC8cIXTOSfP0qBM5G/IQIHLF0a0Eo6WO+yw6jEAOwj0XuAuYLv0kbEFKLk1CZaJhdh7QxoSNmUgf00nMrO1HIVPzcDsl+KQVzofieFA4vqPUXVzGhI2TUDO0uXIdBcL7kABch6JRl75WuXqmToxGdmj0rB8UzlyRrefV5qHOTevAQCkLfkYsy93ca12MdCbDQUIIYQQQsj/HmctLhXOHIzCmYDa/e35PZg9yVMMC/dYN6xB3rB52CkTzugUpD1Yhow3izF7WPvEspMd0lzSye5CZetWwLwoB3MW5GPtgTOJ8WRG3OVpyBiUiozTuYCuEaH/FBzcH+JRXDNHpyBlSx7Sb85z+jzlYs/xMhT2UqxYtBPzXl8L3JWKFRszkDv2tEsEaj25Rrng0BrMnrkWGavKO06ixepA/q8sREbPebAuKsDeR1PaJ2YWpK3ciYMbCrCmFl62hTYxL+Pv3iVxjcUPGUhDgbe7JulxfEI8RNOKs2BwXDkqjBZKxytQjgSvAva6jhMTh8TR7aXmbZySv2egp1+G4cMcz25xHifEhS6uBzUhtm9djqx10cjZVYQpF7fXWngCMlfuwYRNhdhjcS8KnLaqOcfUlmLx1BmoWrITs72yfnQR4wcAJhd4caYFmWt2wj4zHQmXJCHjgXSk9o8GYEX5hrXIe60UCY/sRMFd7spB4uZ4ukdPDB+d4FrgO16EOUkTUJSYi8L1WUgKB4AkzP+oDElPZyH7+WIULTkTq8hCZFzgh44tqHPKdxUjcVgVdu63Y0rgXuyEiO/teW/vB8of80Ouh+vEDctF6r5ylO2QTxKQO97i9fvhrJ+lw2ucLFG9QixGdVfQs6SytAglV+Sj7OF2a6HwtnpN2VKFxDirR3fK8vXzMG9fKgrKtJ0KY1OQ89FepK8vBga5L037/jIUTU5Hvu7qGZ6ECRMrkVtphXLuNPbr3uarfCcwOf3cuIETQgghhJCfNGe/W9wazzuDxcWlAM+XowIuQzxrWFG8Ph/4AhjuN89wkWKULEhpi3UzLBNr33QxQfaEJ1eUQ2uQ+9RwZO7KRCIKkbxoDVK82lK6nQ6Bjl2R43G1N/Hej/Gxz25EdpQuy8LyS7JRdnkizIvSkTAtE8NLCzoGJfaGQ2swY2wGyn9TgvyxXkwB49KQb0uD2XioHYhJysT8doHLbEntZFIZhylvtsLzflv/CRKQdGcF5q0vxexhSSq9ZRsLUPFw7pkFaT8L4vRYKmfCWUyIzb/IQUmx4cP2XeLMiakYDivsiIY5NgXZxQnoaRRRrKXIf6kEnW5SPygNWRO9eMKsZcibloblFxag5OFErwSJsxa5ohMx+82DyNhXjKKNZUoUMSdmYu1DBUhwJxyFW5C6NBXWQ2UoOwQA5Sh+aAVwj+xAKdhhcScuxaYip7QKy2MN3wbG/X/s3X9oU2f/+P+nH3xDBG9IwTek4MAzHJiygSneYMLtH57SgRHfYIoDExy4bIOZOpjJhNnMP7yrA5c4cK2DzUxwpMKkKbylESY9/WM3iTBpBEcjTHYGKyTwFnpgBQ98C37/SNrmx8nP1l/3/XqAbD05P65zznVOe73yuq4LzwfjpG1Nss5qtTF7XUNmlokrCtGzKqEbaYb2JTHOxYlcKQXfD3awq7VJEyzs9DGjUeqC1vL90KXtPhKLiyRql2dj9HhhejFiMYNf5QymBtlrCTKPWx2oySQFgONwjOnaLtabHbjLQbLwYqLc/dCGfVCt+s2sHJvk92M125ZniVP2q7Bc7q5YeT1XzuS/e3H8Vqj5/VtEfwi2t1qdU2uFog47HM9sRlchhBBCCPHq2PgBvWsob6k4ipNo90fqu7ZVejRJ4pqXsVySQGVQxMww6jpI6k4E9ZAdNpcycoyHGnP0r29q7qUc8Y/D6KfT+LYBx0YZ/r6fwBk7qXP97e2jVWO+jXFFVui34qRos+ENgEn+uyC+KwrxrK/UeDgUI3VCxTP4Pk+mYgTfbPf6mORvRBk+lcR2eg7tk/Ya88BqYMn8I834uVHGr2XRKz53vOklcGqU6HFX60aIkSXx3Tx9HwRxr7PFUtkdxyzmyS/o9O6PtQhg2VA/jON0Bxi2Jxk55qA4FSd8yUk82163LD2noVX0alw5dsERInass+/4jbsJEvk+gsdbja1ise2jNMlLCVI/Z9B+LY9CvDKw9vEwgQNK433+keb8mQhjN0yUQaU0n9hygflZk/6PwkTPhdbG21phdzH0QdO5pchc7OHgfU/LOl6cjRP6MEJuX5LMtx0Ee2FD6pB9l4p/l9rBBm6Cn1Y+6FnM0+NQNQNlG7upDSwBUCT1YS+Jwd+ZKWcO2berKO0MmN/xtTDQzoWZ9MXJHLYRuejFd9tD/Bc/XkcG57HzbGl3UPKK8qdPBYj/2uDjL8r/fTNcl2W1/mepnMG5ZGC0McNe1axyQGkW1NoxmGpkY/R4c3iaBJeqLBfJ3kyQuDaNdmflXangHlTxHPUR+nGmYddq416C6NnzjOdsqG+V82H/0tH+sOE/MUr0k5rZLPd4idj6CZ1xkjztoYdF5r4ZJvznKKkD6x/U2/VBmvnH6+9KLIQQQgghXn3PPLjEXi+RvVFilybwNckI0mcnSB/wM7a79tt5Fe9xBwNTGqOH1v5wzt8cYIAG41u0xSB9ysv4tnFmPinno9hcjNyew3Y6jb7UvJG86lGa+FSTbhl6Biy+G7dSvB8hQqOGtx319AxOx8oVMMl/PUTf5V6uzlZOnW7D/bnGnD1AdCpP4E13G3/4F5nwuwj84iF2M0/4H120yB8lGHojgTIxzty3LuwVNctc0Iif8NKvp5g/16I8Szrp02m2HF1fcMm+XYW745y/q+AadNIL2Hd6cTpMWGix8Q4/iVmIng7i+XiRnkMBorOJNjLBSlkH+tT50mxc2114naUGoH2nF5ezp+nWVkw9TeT2FgLHreu588gMMxZNX+P2MP3v6QS/j5G8oOBY6SJpGhT/yJA47aH/5yTzFywCZo/TDLuDLJ7TyE/UZNksG2S/DuA7ZJLO1g60b1LIzVFocj76Y6zHiForOekT/RycUghfmidxtEGWTzMt6pB9X5SZN3pfnWyLPzQmb4L258rkBg68l2ZKYw610up5qst2saO4h0nsLz2noa8iFP70lbqebo+RWtJgea7DE7DT7x9h5K/Gaxiz5xl6WJnztrHPUu7aEJFb1cvUQYi/M0QcyoFTJ3GLbrZmcY65ZpX6j6ZDwNfQmXjPw5h9lNHLKWI7HKWxA5dNjIUck5ejeL7NkZ4dwVX7YN6P4/37JGo6w9PawJCpkzodQD1tI3+lsuuki/CdeXrPRTjoPEi+qOA+HqrodrlOWx04N2I/QgghhBDilffsg0u4CH0zhnYggEfViJ4Morqd9Bh55vPz6L1DBPfqpK5o+E4nLf5Et6G+E8HlSjB5ppPxkFqx472iM187gLPdRfhbF1Csyr5p6HGOyGmdMc1v/e32HhczR3qbf/PdFhuOPRUzh2HDeTLJ4jGrMUlsuE5OMt32vh34LmgUtjtxdFkjir+kSR8ZpnC0PjvJtl1l5HSQ6D6N3Dn3cxgMtkXju1VwCbDt8hP7X3/T8WTquQj9NMM655TqiH2XilV+Tf7eOPqJDCMHamqezY5jl5eRM8NE3VlyF9T6+/Eox3hxmMwHFoGdzXbcRwJ4Tk2SXwjjqmqI50mpEeY/C9DfqO3/RozYrmYZE3a8p6eZv+DE+YyiP7btrooZ1EpyXw/UBR9aKQ183KjblE4G4Hqc+M+1n9nxtJtJ9FgjejSMbSJD8raP0McKyUu+9mbua8c2J2rNgNzKobXcPtveMLHVzCsb7qNeijfqOpm1UPvuqlcsjsPDyiUb+yy17Hq8MMHQa9bTN+RvDhD5bYTAW40qtZPYRWd74xUtZJn8YYjoX0HUyqDMZhv2HW6Cl0YpbvKQvj+CqybjrZjPkD0ybJ1xZFPw+Q8y5M6Rv+Ktfqa3OvFfnMZ/sZ0CljUZu82zqUE38JXBzBdSBP4+RPbINHOXN2jmVCGEEEII8dJ7DsElsO0OMf3Aw8Q344yd9jD8CFYGAA9eGIL7Gsn7QaKDDf48360S2B0h9bNOcGdF+Kl2hjWrYzebVnkDZgYrUejfb9FI70bLc6oYqJt1zkxVudcdbTaOGnD83YvXP8bYbTfRQaXqmpuPcyS/TeD4rM2p5IEnhoHR9Bvxyuvwb65imnBr9ddC2emDy9Okj7nw7qjZckkn/b/TOI5FrPMtdroIOYKMfa2ifOCu7v62pJO+MkZq7xBRy8HNFQ6eCLc3yHojO5wbEIxtow5VzDjpOj7JZO24Ni3YtgLYUN5y8aQuK8eFS/M12LIHpVXVfZwnfSNO/IKG/Uya5FEXtkMaTz4+yOvOJLHLowT3O9ueMbPVteho+vn/QMqBYcJNxhZs2zYn/XvDJK8F6K99tpYNcjeTTDtCRC2+RHE4Pbj9Y4xNuYgcclZnhz7OkbwyhuOjxIY8O1TONtquirENt2wF/esc+ctemVlOCCGEEOI/xDqaE25Gnj5tf/VtLvyfX8X/+VWLD8PMNd2Vi3DuKeGKJY1mWKvVcFrlliq7obUaojja+NvclXK0GPgc2jynN8MkL3nXFQh6JnYGST7oYfzCQRRvHt5U6et9gn4ni77TS+jjFPmTbXTR22xHGTSYODXERLP11nMdLAa+fWltVVCXJlanCbfmI/ZTqCpw5ziaZN4WJ360j4N3wV0eN+mJrpHFTfDdCNoVn/X121Ya+2z83CieLWn0nW5UZQuFBxp5nPhPjDJ/29fg+lnPUFZb3rZn+etGm3XIdTJJ7FD5CmztYLDsKq2zcjpl3omgvJum/3CIkdzVtRnCtjoJfv87B+9OkLg8hNNr3Y2rSpvXopP35CvXrXADWM5AWKOddzw2FyO3UoyfHUVV0ixuU+nrpTRu0l1wHw8xmgujWg0cvztM+oHC+IUhnD6rd2yS3EfqxtyXzesI3m/3cfWXaWz78zIWkxBCCCHEf5BNT592EiH6z2UaBryy3+6bGIZpMVhtp7sxMMx2Gh2l4wFV2SEvpWUTY4kuGlLruaYbdD/aVZ7xDYDNduwdjpFiGgZml9s+U0sGBi9Zmf7TLBkYmzfgGW/73VK34QY9S8/5mVw56sqz1UUm5uq2633Hdv0ObMQg+08vsZ2p1sE2IYQQQgjxb0OCS0IIIYTYEPoPASJGhOTJ9mccFUIIIYQQrz4JLgkhhBBCCCGEEEKIrv2/F10AIYQQQgghhBBCCPHqkuCSEEIIIYQQQgghhOiaBJeEEEIIIYQQQgghRNckuCSEEEIIIYQQQgghuibBJSGEEEIIIYQQQgjRNQkuCSGEEEIIIYQQQoiuSXBJCCGEEEIIIYQQQnRNgktCCCGEEEIIIYQQomsSXBJCCCGEEEIIIYQQXZPgkhBCCCGEEEIIIYTomgSXhBBCCCGEEEIIIUTXJLgkhBBCCCGEEEIIIbomwSUhhBBCCCGEEEII0TUJLgkhhBBCCCGEEEKIrklwSQghhBBCCCGEEEJ0TYJLQgghhBBCCCGEEKJrr1ZwacnAWOp2YxPDMDvfyjAwl7s95rNjGgZdnE7DfXV1jl3ej40s+8r+NuIedVuu9Z2PiWEYbMTl2Ojrup5yPM/61KQkG3Zt11cMo6t3z0tTfl6eutUZg/ysRv5x/SfrOp/l7n6XvEz3UwghhBBCiI22zuCSSfGehjbb/F9uocWf01aNL4s/4LNf9dDzVbaD8uUYf3uA8XvAQopgT5xOtoYs8Z4e4vc62ORxnuxUgviX8bV/11JkHxodHbm5IqkPewhOFZusU3/91hr9RdKnBojcKtLVOZZ1fj9Kx25d9tZyX6+Uv7S/ZuU3DQOjyT+zSbkabrt6add5Pgspgj1BUgvdbb6mcTmMuwnit/R17v/F1qfijQAHr62cg9n0fq6Wc8OubQNLNQGKynfWvXEG3h4nBxSngvR8mKLjGmJR/uwXHoZvWb9LirciDLw90OJfhHTHBem+jlc+Py0Djmbz57Tt/azKk1IHSD3auPMB4F6cno5/l/Ds66MQQgghhBAv0Ob1bW6gXRwgnFfp6228lutkEtd2R8PPi1NBeqeGKPzoZ3Wte3F63JB5OoK70YZmkVx2nsXyj71v9GH+tvJzD31uE+OOBufaO5virQiBr3MVS56gA3wygPa3isVvhkle8lJ9Ria5rwMMXcjjPhbi4H4XDltpefFXjbEjIQLOKJPfh3BtbVEQI8f4iQCjN/IUHU78pxKMf+rG3t5plCykCL6mE1m9fkVSH/ain3rKyF4wFjT0Blki9ddhhYvw9Rjexrey3r1xBs6kqhYVHsBiPsDAtcqlPmI/hXBVLnqcJf5xkNgNk/5PR4md9eMsXzvTaFz+mrNBOxcg/uvKwefRHvegvrVSYZudU47EOxFSNUsLDzSclwpMHm19IYx744SOjzLxaxHHm34i34wT/kdHd5JSkLS+HCt8F2YI7Wm8tamniTzqI3xI6fC4FV5kfTI1xs72EMqWy1/UGH03zsoeCw80FrdVvIMsn892ylPjUIyZk66GH2e/6iG2s6Ie3IvTc0kpvceWDbQ7NMhSaXI/WxzTfSTI6JEEuUNhatdyDEaZ3NfkfBYmCb6VxmgVnFnPMwuAQf7GKJGzceZs5fuyXGB+tvwcn/HjtHgEilNBev2Navma0WypzlkpBZ1XfrJ4f78ZJnmpv8GeS/eFFs+TpWKaSEWdrOQ6mSR2qJOXphBCCCGEEK+edQaXSjxnkm01tDecqTN3L0duNkJm2wijJ7ZQuBnn/aydEb/KFldfR7ura5wtaURfG4JTSUYHbRUf2OoDPffHCX4Mo/o8/h01n+334j8ZYuKd1wl+52Huk8aNR9BJ+PtJ7p4ms+ihx8gQO+rBuzyH9pkLW5MtN8ySjrbVz/z3Q9TGDG2dxkV2B5n8MVCxIE/ikIdJ3yiTx52Ve665pjqJdz1M7p4mU+hFO+1FPedAv6h2eA0ceC/N4C3/VLwxRO/UEMnKQGZDLkI/zRCqWpYj7uqnsK2NC/EoQeDvSVzpDIvuHhazMQL7vJi/aIzs6eQsSkFSd3qRiEWk1dYqWPmirbM+GbcnSLwbZHRbeYHDS+yn1TvKxDu9TB5u/x1kdwUY+czbdJ38jQGGn1k/sCb3c3OLC7IzQHhQYXI2hGt/dR0y7k+S+LlJhuTiHG3lr3X9zAIUSb3nIfQ4SHL2Cer2ijKaRbSvgqh/1xifvYpve/WWjqOTPD3arGBZzm/yNC26MjjCyJsVCz6rWeFvfU2C9J19GVFl2UC/Y8f/IMFQzXl1/tIUQgghhBDi1bMhwaUN8ds0Y18W6Fn5Wc8ALhYNg5Xm0uITYEvFNnY3wU/dZM0IhZ3DePc6AA/vP1YY/tSPgyxaJ2Ww2bGvtoVM8jeSTO5U4OYkoQOh1awZS6ZJDidKbWBplYKyC3JLzRus5myCaCFGOu1FAbB7Gf3hKgffGCf9wVV825puXiOKZ1O0aklwv4b2xGC+VS+9zVvosds7y5ay3I8N+9pFxbg9SbKoYFyfJHMshrfR+dxPMV6IkShfh+ClcbL/PUH6tNrhNahWKOrws44ObQSX6pl30ySLI8T2VTfs9dtjxBd6YJevnCFkon0fpXAxzfSBUsaN/cAoyW8P8vqVNKHvfR1f2y09duwvtJ36IupTkfSNaYZPXW3weYHCb5B51P4dtW13odYGAGps+Vd7pUv5e9nkr1gwOEJmVsP+UAeaZ4p1dz9teAYDDNzUiOz3Vl1PU08TyXotg3glQYKn24h1dPvMAubsGKGcn9TPI7hr35c2B+pnk6SeePBdy+L7vGFOatfsu1TUXSb5qTjxr5NMz+bhTZWD74QZ+cyLshkod1Csf2bXb4v9RT+jQgghhBBCvBgvT3DpvxX697jWGktb88B5Dvacr16vm2+VO2JiPNRInB0m9jhIKpeErw+iujQil0cJ7ndWBKAq7PYS2+8l/F4v0dNDqDsd2MpX1yzm0X6IMvydytjt5g2q3L/O0/vuXHVXk50qvsH3yeTG8A12kvEywvRihNJ3/QUm3+vj/PXz6H8rdXNxtth6I5l/ZElejhK9pTB+53dcv7zPwFsD+C6MEjriRqlpiBbzGXKHImvXYZsL9fAQcw+v4vtHt4XIkr5uoGwdI3krhPtQh61AI0v8kzGcl3OoLW9DjuwXvQRy1Vlqyn4f6ocZ5q742tjHBroeZuDnLU1WaKeL2guoT8YcmZsBfNetPzbvpkkuKWy5kiT9kbtp4ONZ8H07T+JIOZSTjdHzXorxL7Lwlw4En8kxbW958L+dIX/FW99lWNdIfmesBekt2PcFCe5tXfc7fWYBjGKe4qFIfWBprfS43/ZSvKxTxF0VDmzdXbHUza3VVdWvDdF308PM9TmubrfBkk76QgDPx5C/4l1/wFwIIYQQQghRZ0OCS5kLtWNx1GgxjggA9j48+9W1xsaWLDBaNeZS9p+baNQpQi8WWM1cMJ7wpPKznIb25zwGzRrXeRL+IOdvZOFAiNAH0+QPO0sNkc9myB9Jk7wUod+bhr1+Rq4lCe6q2NzmIvxTDs/NBIkTKsHZ/OoAvo43VQ6+EySZ8+Nu2ngvoj8A5XBt3sEWtthBf2zQWb5NZbaIyZbNEPxqhpG95a5EzTb9eZTA24mqRa6TSQJ/BFbHNHmiA+8224mJdvYgw99pLG7zEzg1Qu6iimMzsOMqv+/LMvHdGAff8LC4TSV4aXq1+6H+KIXvjVjFvhSUNyH2bZSebA96FtjZwaXAJPtlmDH3GJn3cgQOhUjMJgjuai/CY/w6QfSDMPn/STF9pP4eKAeGCVd2y1rQmUNhqDbYYduCHZ3iY6BF9sxGcRxOsHig9Xqte++8gPr0KMfk4X7CVrdpqRTs81zKEPw1gPdUAu1KsHmGYVsMFgvg29dGNsvWHuwrqSo9W2BftNTl8u55NrVIzEnUjuWGj9h1heTK2D3LBeZxMlS7oUOhzzHO/CNwVzwD9n1RZhyLtWvX6dnerM53/8wCsNkGD+sDR5WKf+Zhm6e+e2uT7pOVmncDLZK9ncZ3LLHWJW+rgvfDYTxKriogV/fMPhc601fiFHrY0IwpIYQQQgghXrR1Bpcc+L5dpPnoJbQeR2RdSgGZ3K7ynF9/zsOdRXQTlHLbQrt+Hn1LgXkCTfbjJPhtmsB1+2rGUSX7Ti+hK15CV8A0TOuG+GYH7qMjuI+OdH02tg3NZtGZm9XKgbZS16Vm4bUq7jBjtY08mx3+WBvTJH9DazFjkg31zCSZM3brbC+HG//nbvyfJzENA+uVKvwX9Ozox7XHju03KLR7LkaeibNBAr8cJHPHi7LVS/LbYQJOlezlUUY/UMuDr9cqZbElL8UZvQWBKxlmDrfZGNxs2/DxsaLuTUQtljcb4Bio6e65Hs+/PhX1eYoOV10mTinYF2DOm0E7pGA7lCTxcYC+wSxjF0YJ7ne0vP76rTgpyg18I0viu3n6PgjitpsYFtPXWzHyGbTZ8sugja5wlfxnJ2vGXLJhtxnw2UjpnfpY4/xs3mLLXpR9GvpjSgFWI0viuwxtz0d5L4e2zUPwuNUkAet7Zh0HgoQ/DhD+wU3ymMW1+GOC8KkM4etJ6wyidXfHdeDa5yZ8e5r8gWBp4PBlg+zNJKkDPmIttxdCCCGEEEJ0Y92ZSza7fWMa0TcD9G6qDf6Mtt7OnGfuNxcuYx4dN8WHWRwOO7mHoO4urRL8aoaR7RMMvdZoONtS5kXgZicF9pH8cxL/doPstQSZNhujJXY8HwRx17WgHChOR3UWFrAyrozztQ6+Zd+q4L3oxLiXW53BqGcwhrPdbkONGnm7VNRyxlarcWmy/9yE52z7RYa1QIljh4/UH0XWGuulIKL7Yx/qP0rHbms8rWWdxIcqE9vjzN9Zm21OOTSGpqcZv5hDX1YtsyyMqWGcZwsMfThC7nKjAFQDDoU+h06hNkPpcQEdJ0pHWUtuRp4+pRSyzHJ+Uwzlz0n8rfZhMetXS42yDF9UfVo2obenertHCYKDEyiX5tGOOsvvHwXvZY3fb48Tv6fD/tbPSvF+hAieUnBpSSd9Os2Wo0Hc9vgtQhAAACAASURBVPaeN8fuGN6HOrl7K0ucxA4obb8PrcdccuBaKftCkXGsgkslc3oR9m5s5s16nlkAtqrEsuNE3vPw+o0hQse8uBy20syet5KMT5n4rmSINerea8yXxqxqdsDeftRdjddwnkyT+jLEkPN98kUABe9HI8xNBDsI/T0rCgdPhFs/u0IIIYQQQrxiug4uVU/53J5GU6a3niWoseLUOJo/SuSXUVL/Uli84iN+ySQ8oRHa3W5eRSkDa/Hb2uUZYj0HodEsXXYAG8pbLp781Umpe1azqmo59wYpnEqT/ciFe2Wd+1ppEOlOpscuD3be4EPU0zM4HXbAgetiDJ7BWDXuTxZZPFm7tDRWT/pAxVg1FVa6vChv9OO4lCH3ubs07tLjDNpNH+qlDguxWSH4Y8FynBbbDi/hKyt5dzaUAzG8FTfGfvgqhcOtDlDO3qtLZXPiPl4gcitLaLd7NeCQu5Ok8FnMYvr2Z6Bu1q82NMoyfAnq06qdQSYLlncU5UCYsZUugFsVvBe9lmMDNWUuUrjvorfFdsqhMOFDjcroY0Yrj0OleDsKOnWsfG+MhxpzLdP5euhzuxoGStfzzK7a4SOmeYncTzN9J09uoVzMwVEylxof26Z4iQ0a6PfK4UtdI/INhC6q1UGhXUrT4BLYcZ8cJ/NBompg8jUOvBd/x23vLDBnGgambQMmORBCCCGEEOLfUNfBJdfxSSaP1S7tsBFSw7ibIJHva9Bdo575MEH4FER+8eHdpdF/JID9RIroURuFy16CN+IotNd1x2a3Y1s2MVrM5lZeuaI3iA3HHhUHJoZhrjuTy7Y/SPwtD4ETdpJnAziKk8Q/ieG8lOluAOg2s1d8+8PVC+oyCAz0ezq6DgcvhdcCX81stWMvX5eWNtuxV9aPvX5Gez1Ev/KQOO5g7lKM6Y+ixLr9xr+YJrIylk0TrpO1wZj2stp8EwUmq8ZvsaF+GMfpDjBsTzJyzEFxKk74kpN4Vl13oOGJYWCUr9fiH3OY2/vqVyrP+mU81JijebZH2553fdpsg7+eYELdNWs9ADSAi3Dde6oFm8rookZ7UYQi6VMB4r82+PiL8n/fDNd1ytVzGlrF4HBmMU9+QafgCBGz6lJWozazavG3HLmHzbbQ0U4XCDTLelvPM1vFhmO3j+Du1rtZYd8bJFzZvfOuSeQbCHwarh+4vIXiVJDeqSEKP/otshKLpE+/zuTh2me2JHM9TvxnWNQzZB8Z8JeOdlcHh5ers9NNBhQ3mM9qpJfz5BfK1+//8qTv6zwZjJHp8gsUIYQQQgghXgXdd4vbavUNbmmQ36pBbjtg6mkit7cQOG7dlHAemWGmYk4q2/Y+Dn6rlhpK28PEjin0flLKEgnfSDBRhEYd4SzdTzBU23AeVOGrIYa+Kv1YeKDhvGTRKFlIEXxtkqF2uis1peC/osG5CEH3MIvbvATOaCSOdtmhY4fKyGfN5vHKM6EOY1TOwrdVQSVbmvUKO869HpS/AbZePEecnXUtKWqM1gV1VLg5zFA5YPNE18i+m+Fp1dTkCsErCfInAvSeeoLzaJT0t+uY6cneT2BlLBtLBtoXQ+SXapc78P/4FL/VJsBK8MlyMOsdfhKzED0dxPPxIj2HAkRnE/h3dFLwLOc3eerHWnorQ3x/H72bQdntxfehRXCpLH9zgAFqr2+XnnN9crzWBzeKFKgfzcjuCjDyWZMR3x5rnH8nj7Hc4pws2Np+f9np948w0iRz0Zg9z9DDyhGRbNgHVfSp85wH2O7C6ywF4+07vbiczeZ6g1I3WRc9NYEdZTBIcF+z7TIsnk40W6Gk62f2JfPbNGNfFixmzltk7jerDZz4tJm1QNYeF+qWXvp29WKr/ELhrsWm5Sw544/cWkfGbQquPS5cfoX+nQoYjbs4CiGEEEII8arbkNninhf7LhW1csFWN/7VbikKvosV2RI7vPh3ZEuNt3btCTHzU6jJCm3MirURtjrxX5zGf3ED9rXNibq/WTBgS90gyo5DMWYadffplMNL7KfmQ743nAVwh5dY+veNGYTXVjGWjaUixW9oMsJNl4fd5Sf2v/51nEPleEvNFJno+hgdeN71aZeL0JSGbvrrupLatrtQmwVy68YssspC87CpYoyh1GubajKMVsZWa3SQlczFxorFcajKKHIR+mmGZm+apowC+n0V367qxcWpIL1nC6hKk1zNQReeVm/9rp7ZFhlcllyEr8fw2hoMSK5nAEh+GSdT+1nDAckr/LdC/x6XxToGi3esnnU7zv0qzWp3Q027ja4e1oJJ7guV/u/7mc6O4X2W3UmFEEIIIYR4hl6+4NLyExYNo0m3IVuDcTReDpXdlSw17UoixDPyZBHDaD6fmG2r9UyJL5S9H8+RaNUA/d1rNLZac5YzQ75A5i8a4x+pjFq9Bt+NM/NCsokcqGcnrYPETdjsgKnQv+cJi7Uf7nExc6TBhn9rYwwrex+e/VaBv2cTSO6OSaGgw6MeCgbPdqwyIYQQQgghnqGXqym5VUFdmmD4nWY5GD5iP4XaHBC51M2BnUAbQ4isy2Y7yqDBxKmh5hkkjWbjEh1xHpkhutVOg3QAUcFmV1F/jjP0Trzpeo0G3H+xHKiHFbx3coR3r/+52bDZLV8Yk8xsktCBqHXWztnqTCxL555Nd7aur23LrMIuWc5AusbXcrD+58GO97LO4gWbfOkghBBCCCFeaZuePn36dCN3uDqjzkvXgjMxDNad9fSynN9GlsM0DOgma2XJwGADMrHWuZ+uy2+xn26u6fruxcYMBL/+cmycDa9PSxoRVxpvLobaUR3ZuGu7LqaBYXaTcWlR/scp3h/UCeXCz2fGwUY26tl/FS2bGEvd/C55SeqjEEIIIYQQz8CGB5eEEGKj6d8dZJgxpj/ocmD7fxO5LwdI7Jpk7NBL1ldPCCGEEEII8R9NgktCCCGEEEIIIYQQomv/70UXQAghhBBCCCGEEEK8uiS4JIQQQgghhBBCCCG6JsElIYQQQgghhBBCCNE1CS4JIYQQQgghhBBCiK5JcEkIIYQQQgghhBBCdE2CS0IIIYQQQgghhBCiaxJcEkIIIYQQQgghhBBdk+CSEEIIIYQQQgghhOiaBJeEEEIIIYQQQgghRNckuCSEEEIIIYQQQgghuibBJSGEEEIIIYQQQgjRNQkuCSGEEEIIIYQQQoiuSXBJCCGEEEIIIYQQQnRNgktCCCGEEEIIIYQQomsSXBJCCCGEEEIIIYQQXZPgkhBCCCGEEEIIIYTo2vMJLi0ZGOYG7Wep241NjC4KYRoG5nK3x3xG1n0dDDbidmycdZapm/plGl3VB+tdbWAdWe6unna9XZlpbNAzuoHXdX3F6PZ8Xo7n40WU/6V4162r/rwc965tL8mzUmcd75JW9dZ4qKE9NKw2fAH3/RWrL0IIIYQQL7lnFlzKfT3AwNc5ALJf9RCcKjZe2eoPS4s/cLNf9dDzVbaTUjD+9gDj94CFFMGeOJ1sDVniPT3E73WwyeM82akE8S/ja/+upcha/UHdpc6vQ4WFFMGeIKmFFus9zqPNai3+5Wl1VlYN1roGSLtlqlC8FWHgVJoibdQvq+2ngvR8mKKzray0WUeWSw2Zhv9WgoX34vTU1lOz0XYVF9Fqu7YVSX3Y+TW03FOj6/ooTfxatmV9acWsbQxWBBbX3jnrOJ9GdbGYJvL2AAMt/kVutX/M3NeN1rcqf4v6s3JRWj1LCxMMbRpiou7z0jGt67FO+ssE2fXePKsgcM17vvVzaZC9Fif9yOKjNt8jZsV1ax1Ma3Hda5/fDnT2DjLQbyeIvDfAwNseXt+0iU1veBh4e4D3TydIP+rk5lgEVe6Nr75PW71LGgaI2nju8jcHGLiZr99yPe/jLn5/rGs7IYQQQghhafNG7CT39QARYsycdK0uMw0Nrc3vBItTQXqnhij86MexsvBenB43ZJ6O4G60oVkkl51nsfxj7xt9mL+t/NxDn9vEuKPBufbOo3grQqAcECt5gg7wyQDa3yoWvxkmecm7VtZSYch9HWDoQh73sRAH97tw2ErLi79qjB0JEXBGmfw+hGtr4zKUGpxWn/iI/RTCZfVR/Zkw8U4vk4cLTB51tF7dyqMUA2oC96DCloYr+YjtdzYpU5Z4jweyTxnZu1a21Iety2Y81JgrlH/4Wx99W+eZX/m5t5++JR1tod0GVY7xtyOkKhcV5uFxnsDbieozujBDaM/KTzrpL1PUN4UA7Hg+COK2t1mE+wmGzqyU4An6nSzsVVFW6tWh6uenUvHOaE29BP7S0e4Gmz8fK4wc4ycCjN7IU3Q48Z9KMP6pm3aLvqJx3WxefgAe54jcVggcb1naJrLEe2Iof07i315e8lUPsZ2lutT8nWNRB9otO4BDJfqjp8kKBSbf6yPdQZDB/D8NfVubKy+kCL4WsC4/4JtYx7PeUpHc6TTK0Q7qu4XKe7XqXpyeS0r1u78pE/12BN0Zxruzk6Mb5G+MEjkbZ86m0tcLLBeYnzXp/3SU2Bk/Tqtza3HdV53L8PTzZnW723cQgM7Eux6iZoSxc0miDjt2u42VIFEhmyR6wEnyXIbkUaVVScvnNMlQxXPEstH2+zR/c4ABWp1v2b1xBs6snfUTHSDMwM8rv1VchK/H6LfcuEj6VABtf5LYoQ7rdjFN5N04OYuPXCe72J8QQgghhGhpQ4JLnQSSNpSpM3cvR242QmbbCKMntlC4Gef9rJ0Rv8oWV19Hu3MMRpncV7FgSSP62hCcSjI6aKv4wFbfML8/TvBjGNXn8e+o+Wy/F//JEBPvvE7wOw9znzRuyJqGhrZnmsXTtQ1Zi2M+c0HiP7URvHgGFn/LkcvOkfzCwPN9lC3bNBJnz2O4Y6gHFDq7sy6CP04SqFiSv+bFkxpi9McgzorltqrAXw/KHheVd768NRNqmt5OGtt7Qsz8FCr/kOX8Jg98NVMRdGvMcSjGzKHqZcatYXq+drTRINdJ+PtJ7p4ms+ihx8gQO+rBuzyH9pnVuTXWuG4Cm59/7exMKdDsTi8Sqa3Q7ZTdyDH5XaZJ5tUic3on5dHRf4XMf+mAg+pA5iJzv9Wsvt3P5FN/+Ydy/akK2jZWFRRcLjDPIvl3B0isvP0PxZg52dtJ4V+gAvrPMH+kCHvbDRAUSb3nIfQ4SHL2Cer2ilpvFtG+CqL+XWN89iq+7TWbVl13a9l/bqJZ2LGk23cQsJBl8gcPo3+G8VaVz4bd7sB+IEzsbIbXp7LEjyptBunW4f8D/mvtx7VswkWe1GaC7VAZ+azy7EZqVuihr8njZyxo6N10AV820O/Y8T9IMFR7T20v+7tKCCGEEOLVtCHBpQ3x2zRjXxboWflZzwAuFg1jtUG3+ASq0mjsboKfusmaEQo7h/HudQAe3n+sMPypHwdZtE7KYLNjX213mORvJJncqcDNSUIHQjibZBxhmuRwotQGllYpKLsgt9RGEG5LD3b7v88fwJnrceI/r/xUbjgvLWIY5YttPKnbRjkUJuyaIPOFTuC4GzcK+g/n0d8NE94LxRudlcFmt68FUh6nmbxeRFlKMpkNEjvQ6Frbce5Xqxp+JVs6rVnVjEUKQEHvpIFcqUj6h3G8R3+nOk8hQ/LLOJmKrCpzNkG0ECOd9pbWtXsZ/eEqB98YJ/3BVXztZs6seOF1M0XgtU1VjXT18wzarJ38n8Brzbfe0mOnq+Iv6aRPZ/BaNVbLgh9E2m+4LmSZzDogO4n2iRu12bulVl39McjPzlEAeDxfFwBzHZ9k8liT/W22wwZ0EG1Hyt/LptpYzZFk9c+rvwuc+D71VtfxhTxzRcjk5jGPONoKjpqzY4RyflI/j+Cuvc42B+pnk6SeePBdy+JrJxunS929g4DtTjx7U4xdSeE65cW5rfKsTYyHaRJXUrjfibYXWDKfYGDwpPZXkTFPZlbD/lAHGmVA6czfBew6Rdw4ytmp0Yo1fEcqftjmRN3vxHyYIn5xnORtjTxO1AMBwmdH8JZ/Xxah+X3v0hZ7l8+7EEIIIYTo2MsTXPpvhf49rrXsnK154DwHe85Xr9dmF7fumRgPNRJnh4k9DpLKJeHrg6gujcjlUYL7nRUBqAq7vcT2ewm/10v09BDqTge28tU1i3m0H6IMf6cydvt55AE94cnGDfG0br1vuXDtWvnJYPEOnP+wj9SHlWv5GHrWBVnSyd4cJ3omhXJ5ht//nuP9QScDh0YZ/TiAe0ebeTwLOnM0bn61UrydKAUtLyfJHQ232dVxjf5DmPCfo6Tb6AKT+9d5et+dqz7GThXf4PtkcmP4BjvJXVqnn0frugDVqu8SVLcGVysCPJmLPQSnxjl/t9zl5t2NKqwVHW0igdHTZJVtHoLHW3U51Jk4E6ZwOkVyMUTgxASZ6368n4bxAlBk4pfzTDbYung7wbjDgeOHafSjQRQW0e/lSllPi/pqN+FVW+2l8phFslOTZBZM2ObEd9iL0nbDO8NoZbaTlTa6F9Z137t7nk2X2i2DSfZaDP2TMEPX4iTfUwm20TXOKOYpHorUB5ZW2XC/7aV4eSVgUqFJ96oVHdW7rt5BLsJ3fsd5LU70nSiZ2fxaKNDhRN2n4jv7O9qB9t5IualxNHIsTuUIflpxvx6kGP8iC3/pQNByW/PuBOP/58X7fzHG/uVj9B9uRp4+Lecjlbtj1270KMGQM4VHSzL3vQPbsol+Z5SAexgejOHtNMAthBBCCCFeShsQXCpS+A3YuohBlvFNFd9idhIIsvfh2a+u/WG/JQuMVo0p06z7gV4swMrWxhMqc2H0nIb25zxGk9GDIE/CH+T8jSwcCBH6YJr8YWepUfbZDPkjaZKXIvR707DXz8i1JMFdFZvbXIR/yuG5mSBxQiVY0QBwvKly8J0gyZwf90b1WcgmiX+ZwXLsHyNP7g6kds9jHm3v231rCcJva02uWmm8DG+Lc1JcKmrFmEvFb2oamQsTDL3WqCldYNGAldb64l8mrJxR+Zv2wp9Ak0ameSfKwVMJtMc9+I+FGcn9juoAULia95C9mWDskILncQ/qB2NMn1NrrplB9lqCeWeQ4N6VC21bDR4CPFk0MAxgsx17syyUPyYInyoQuT2DcslD6IyL9AW1vS6Py0W0L4MEvu9l/M4Irrob6yHwabiiG2MR/QEoh2u7PG1hix30xwY8+040JXvCLOZDLVer6xJkoTIboWcLeM4kmTzqaKt7UqJ2/DR8xK4rJFcCCMsF5nHWBzq3qUQ1R33gptbflObPm5Fn4myQ8MIwqStu3CSI+L14/kcncTGEd1eLmlCuP7HbGZRLHgL/7CP9uXstMLUwQeYLi2fpjxTvD4bQ90cIHlZ4Mptg4Mw44duThHavlXi1HmMrj+sD4Ca8mKfl3duorpFvHCxnnlbTb0UIX/Ew+iCG8+8BPMeG6bkxhq9htuhKuWzw0CJwVKH4Zx62eervXbPuVVXHaH7u634HbVXwnhzDe7LFubbycJzoaYVkNsr04RDn3WlG/lEu+74oyR/9OO6eZ5PVdyBGlvgnYzjP5Bi3jeI8EqQvm6zvBl6j+Eua9JEAif3l30WbbSgHggy7Xyf3qCK41OC+P1s601fiFHqAXT7ChzYiX0oIIYQQ4j/T+oNL5jyZHwA05i7FVr/FbG8cio1QakDndpVy/It/zsOdRXQTlPJf59r18+hbCsxXdaap5ST4bZrAdXtV0GCFfaeX0BUvoStgGqZ175fNDtxHR3AfrR1X4vkyZlOM73Xj/iFN5qzaWZebFXvCLC62EQx4ll0OFnRSFBgyAHtprJXcYIHVnKHyN+1PdOjd36SMg1Emf45WNJYrVNyzpGlgYLcIDpQGEU7bAgT3AkWdDH1EKlpB5709nIemA/sWZ88T9I9hv5QhvFuBK2l0vxfn/wQZPxfBt7vBxVzSyd6aIHY2Ss41RvqXEK42r7ttoxOTznrYdNZieasBjTfbrK9/xwzmsxpauUGabxFYrOU/O1kz5pINu82Az0ZKwZnHGudnK4dwLwUWM4/bPUKO3GyDwd4fp3n/rSD60Tja//rL3WxdhP83j+frKGNTedTP3A2DU8avCSKHo7Baf1Lk/8dH/4MIYxeCeHc2qhQm2rch5o6myJwr7/+AD/WtIV4/k8SbDq5m4U2cGyL7N+omLajq0rUOmQsBBq5VLPhLh9dGm29k5EldjBC6ZjI8NV0KRhxNkH4cYEh5neS5q4x/rjYMSjgOBAl/HCD8g5vkMYvgwR8ThE9lCF9PNgzyrrd7VbfvoOw/N+Gxet6aGG0wFtfq+2cig3+vgm8qz8HDTrRjCZK+5vss3h0nemyY+XczaEcc2IihXRjmoPI6k+fGiH3mRWnw14TjLRX3qWmmf/USfLN0EY27KZJTXnwXOzs3IYQQQgjx8lp3cKk4NU7ys2kmlw8yPhVB7XbGopsBejfVBn9aNDoAzHnmfnPhMubRcVN8mMXhsJN7COru0irBr2YY2T7B0GuNRtwtpfMHbnZSYB/JPyfxb++08QkdzzRmxR0g/KlVYz5H4uI0IxfyqLedRL8OdDxwM7CBwQCIujdVjckB4Dvcejv9gYZr9yJzv5n4N+eZw8F8NofxQbmBWP6mXf/nJmKNdnL3PJvctUdvoUWgxFx8Qt/xvqrGbKMG3QpjNor3wzyBm3nCK5kCW0uBBfXaKMnfFhsEl3LE9w0x6QoSubnIZKMAlCUHitNRndUHQIHCb+B8rbNn1f35U55+Xvr/7D831c/8ZaWNbkV1LGdjBHDguugl/0eO3B/lRW/E8Crt11PrMZccuPavZNEVGW8wP+C6bfMy9puObWttee24T45VZJw58H27iLcicmvceh/nhzqBSxpjK90ht7oZ+SmH+5sY+ce2JkE2nfxskaGvqgNXyr4hfO/qFFnr4hmsGmS+NFtX/NdOTrJxNqPzyAzJf9QvH/lbX/PMvWWdvOElmQuVs30AbLhOTjJ/WCO90N8822WrSiw7TuQ9D6/fGCJ0zIvLYSvNNnoryfiUie9KhljDLqLVAU1rvfTvd1qfxzreQZXP3PoUydzK4Pk+x8iB0tWy7R1hJqeiGS4cRpMndCnL2Ccp7OfmSR91luuQDefxq8wPaqTySsPAEgBvhkjfNAkddfL+r6V8XuVAiJFfkm11a3y2FA6eCK/NmieEEEIIIbq2vuDS4zSjp3Qit734iBE7EGbC3TpNvpbj6CRPj3ZXhOLUOJo/SuSXUVL/Uli84iN+ySQ8oRHa3awbXFUJ8H27yOK3tcszxHoOgtUMU6xk7dhQ3nLx5K9OSt1DB+3hDphk/xki8lqc3/fbUZQ4ijvE6J40o4NtBiU2NBhQOR5Hh8wsE1cUomdVQjfSDO1LYpyLE7mSYPKRj4Pt7qdBBlbhZpC+217mvx+ibp6sFl1cbIOjzAy2W4AS+/7R+hnASp/gOh5bGxNpm4vYxcpQkItw7nfCrQ6wJ8ziInWNW+feIIVTabIfuXCv1Ln7GsniCLGmYxttEIdK9MdOcxgbzYyoVIxLVM95ZIaZ8vDryoHOgk6N2XEfD+N+nEd7UGi5ds8bHlzbGx93JbDUTkZKZddR+6Gr6LpFJpppo/9YlP7N5Q+2qUQ1J71VgZAeet+AXKGifymUMvAcNAk8O1DPTnacgdoom9G+S0XdVb1sdaaxZWAz2PdFmXmjt/r+b/MycqXBsbarazO8WZ572Q4fMc1L5H6a6Tt5cgvlMg2OkrnkwtHoImxV8F70YqwGNHW00+PwUQy1KgnKRGkUXFrvO8jIkmg6U2FZ025dDnyXpi0Wu0sBu+Uwi9+Wa8dmO+pgRb3Y6mY0O1O3qWkYmFv78f4dDBPsNjvq6RmcjvqrYP9HiPGfgyQaZMA5DsT43d3TUZc40yhibna8gFlUhRBCCCGEle6DS0aW8+8EmTuRIrYbIET8hIpn8H24PdbVYMfG3QSJfF8bA+KWmA8ThE9B5Bcf3l0a/UcC2E+kiB61UbjsJXgjjgJNR1paYbPbsS2bGO3M5lY1q5wNxx4VByaGYW5M95E/59BmC+j39HKDYhH9lyz5PxVCU1frGyIAy0XS5wIEv1NIZv2l67/DT2JKR3X3M3TxKuOfNO46sqpRMCAbo8cL04sRi8Zmo2DAitI06xwO423rm2oD7VyYSV+czGEbkYtefLc9xH/x43VkcB47z5Z2B9AtZ2CtTZfdTItsraoZ7nTmdOjrcHz2qmnhG/KhflqzqK3sh+oxygBs+4PE3/IQOGEneTaAozhJ/JMYzksZ1PVW1NrrYSr01a1Uvv4LOTLFXjx71jMGWFmLAOjKFACuk/XdYPWchlYxIJtZzJNf0Ck4QsSsukytMHRy95pnNOmzEQrH2sjmghYZKdYDI68Glooa4+fijE+lMXeoKH8DCvOl8XxOjBI96asJljhQj4QIfRgiocQZ2mHD/CPN6CdjqJcyTQeUt9nt2MwiuWyBXneTIEwHSjOHxUhcy6I7nKg7TLS7Oo43vQx9GGX0pHUdKd6KEPi6VdjbRfi6q8E4cDYcu30Ed3dQ2PKMpGuymKfHoTxrZVvW+w6yuxj6oH7OykqZiz0cvO9pf8ygYpaJ7xIk0hra3XJG70436j4P/iMhJn9SrN/pyzrpL6JErkys1T2g8EDDdIUInxklZBVcXUgRfG2SoT8nLbOEircjvD41ROFHi7G2bo8RX+iB/8uTvq+XxkWbzVNEIfzTPLGGl6aUcZZezpNfKF/58j6eDMbIdPmFlhBCCCGEsNZ1cEm/PYb2ZoLk5+7VNHn352nmtk9idtkCMfU0kdtbCBy3brFXZiYA2Lb3cfBbtfTH6vYwsWMKvZ+UyhO+kWCiCI06wlm6n2DoTKp62aAKXw0x9FXpx8IDDecliwZkiz+e2+XYHSNmM8ndWym5jd43VVx7DtLrdKI4sGxUF6fCBO84Gc9WD3Br2ztC+hc7oW+LPGnrbjcIaZCZhgAAIABJREFUsPSUQnQ9dnsX3xQXyZ2OwL4GwaW6jAM7inuYxP7SvQx9FaHwp698n2OkljRYnuvo+Nq5+u49KhMMvzNR+uEvHe1usCI4Y6Kd3sLAlxUb3Owjc1mlrxewO3H/3QnO/g7KAcrgCCNvNlnh4QQDJywaoXtHePq0SQ5Yo0F4UfBf0eBchKB7mMVtXgJnNBJtzDRXyTrTpuJ6bHfhPRyyCC6VGD+PMtCg8dgxez+BlTGSrI+G9sUQ+aXKZTbsgyr61PlS8Gm7C6+zFKa17/TicjabAg7YqRL8oHkOT2YxQvO58Nbot+KkHjb6dLFBlhvwOM2wK8jiuTSZy9PYK59ps0j6nI++Azpz2epZCO2HxsjfjBP5yMP75UBO2/Xgscaouv53G1CeOSyBMjHO3LeuqvKbCxrxEz6chST6hdpB9cExGGVyX5N9L0wSfCuNsbzOMj4T3byDVpgUcnM0y5vTHwOvtVmUPyYIuMfouTDK2FQMxVH+QmTJQP91kvEzHrz30xbdqQ3SH3sILo2i5ZM4a34RGHfjBA57MW9nCFsG8CoGz66x+MDqN3UpE8qxmhXswnWgB8Wl0FM5ccKCxaYVGWerIeFtCq49Llx+hf6dChjPqPurEEIIIcR/qK6DS8rRJDN13/zZcR0vTWGcXUehGrHvUlErF2x14z+0WiJ8Fys6D+3w4t+RXc1iaMueEDM/NRvEusFUyxtIORQmfKj1erUcR5IUDmN5R+17QiSfRxeobtkqxrwpUw751z7eGya2miVgw33US/FGu814AAfeSzNNghFYBGdsqBef8rTlgLPZjuq6VdegKluewZOz1Yn/4jT+dQye2+7YL8Ub3R+jbRb1paYUFL+hZuQkF6GfZlrPeNbIQorga1EKg0qTTEgVV5uZbMX7ESJ/jjFz1DrtwrVHpecNizDuoxzjxWEyH7jqg7w2B94Tw/i+mCS/EMZVEwiy/yPM1WyYq+0V8ZkozRw2TOFofflt21VGzgwTdWfJXVCpu5RVGaMWlmrvzHrGjGo0lp5OBuB6nPjPtZ81G0uvm3fQijwpNcL8ZwH6G8VA34gR29Ve2LaYnWTiSJQnx2tnpLOj7A0Su1BkkztN7jNXzT3Ik/umyHA2WBdYArDvDRDYF2EyXyS826osPSguFy6LbovGX2moC7auZAV3oS7jzIJlP0OT3Bcq/d/3M52tmMlOCCGEEEK0tP7Z4jba8hMWDaNJ15mNG2j6WXhiGBjNZmdrNVX9erx8d7PK2jTnDbRqPIpXW8tnm5e8DgSJ/1SbVbIOr/Wj7u9wbztdhBxBxr7z4jzuqstc0q4lSe1ViT6DAYpbvtvaeDc7/u7F6x9j7LZK9EBN97fHORJXxnB8lmzaVa996xkzqtFYei5cWqOp1Z7VWHqwkQNP29/ox30qScLfT3Bv/T2YmJjG8VGU+rCnE9dHDoJXxlG3B3FXdn9bNtHvjDF2083QmUbhIDt9bhXVqltccdwiuPQimBQKOjzqoWAAElwSQgghhGjbMwtH1HZha8tWBXWpopuAJR+xn0JtNj6c+LSZ0ixKbQyltC6b7SiDBhOnhmhWeg7FmDm5MU2nV0epS5JW0b3Qiutkktih9r6nthz4V7y82nq2O6sDz18Uz6bOx71q6KyHTU0H9bbY1zYvY7kk8TMh+j/Mwt7qMZe8x6LM3/Z3+uZtrt13W8OB/SvsDJJ8sIXRMyqKN8+WcvkLDzTyW90EP0yS+6S+S1y3uh8Dbx1ZM89EisBrm6gfRazSygymzfdk2zNC+uY40Qsqyq1Fevb30bsZnugaWdwEPxwl94lq8W61472cI/nNKKP7t5B+pOAeVNhSmEf7FZxHhxl9kMbXsNtvi3M4MtS84M+FHe9lncULtmf3JZAQQgghxL+pTU+fPn36zI+yZGBsftEZCSaGwbqznkzDwHzR2RVLBgbdZkB1OfD4somxtP7r90xsRP1ax/mZhgFb7dg2IlTbbTnWeX82rF6bBob54rMLuz+fDRyY/zlYGyR6/dd8Q+txe0fEMMpR/w3J6Hy17l2dF/KOrbgHnT4vpkFp0xf9vHd731/x+iKEEEII8ZJ5PsElIYQQQgghhBBCCPFv6f+96AIIIYQQQgghhBBCiFeXBJeEEEIIIYQQQgghRNckuCSEEEIIIYQQQgghuibBJSGEEEIIIYQQQgjRNQkuCSGEEEIIIYQQQoiuSXBJCCGEEEIIIYQQQnRNgktCCCGEEEIIIYQQomsSXBJCCCGEEEIIIYQQXZPgkhBCCCGEEEIIIYTomgSXhBBCCCGEEEIIIUTXJLgkhBBCCCGEEEIIIbomwSUhhBBCCCGEEEII0TUJLgkhhBBCCCGEEEKIrklwSQghhBBCCCGEEEJ0TYJLQgghhBBCCCGEEKJrElwSQgghhBBCCCGEEF2T4JIQQgghhBBCCCGE6NpzCC6ZGIaB2c2myyaG0dWWpSMbBuZy15tX7qjLcry4c68uxnMu/0aWfbUcG7G/ddyPjdT19VlP+V+Sc+9a9+U313Pe8hyulWKj3qcbvK8uC7DB76jnfNwlA2Op60K84u+CUv15EbevphTd38t13L9uz/3F/z1U1uW5vxz3vF735er2OXz1n18hhBD/vjY9ffr06TM9wsIEQ69NMvTnJP7t5WWP0sSn8hYr2/F8EMRtL/949zyb3JB5OoK7rYMVSZ8KoPtnCO0pMvFOL/qpp4zsbbHZsomxBHa7bW1PtyIE/ggwc9JF8cYQvVNDFH7046jb2CA/OwdvqTi3tXHuUPrjrMFfBratdmybae/clwyMzXZWi115HvfGGTgDsZ9C9DYtfxONyt9Kx/fNSo7xt5Mo12N4lycYek0n0mp/ywb5n9No9wqY2FH2qah7FVaqU8PzMbIkvpunr7LuVTHIXksw7wwS3Gu5QmsV98N19zybLinP734027aYJvJunFyLzV0nk8QONS+tfitO6mGrgjjxfepFsfhkNQi02Y59a5vlX9GwzmU5vymG0s01a7rfCv9mz6G5BLba60+W85s8kG3jfWqlmCbyroZ6PYbX0e67WSf9ZQoOh/Hu7OKYzYrT8F6Ujmn126nKLh/hQ1a1uMw0MW02bDWLm/8uqSslE+/0Mnm4wOTR6rWz/9yEhwxPP7e4s92+B2tPobIBa6uo39ZrtxdwsHq2LRgPNdJ3chRMsO/0oO53o6yeQKPr0rq+6LfipGhx75qprMft/l6y0PT+NS9AwzrR4ogdP7+NytiqDpsL/3975x/a1L3//4df/MIpODgFv5CAF8xwYMoET/GCCdc/eqSDpvgBUxyY4GA318GMDrZEYTbzD2+q4BIveFsHm/GCl1SYtMKVRljp6R/7kAyUZuBohCseYYUEJuTACj1/CH7/SNrmd06SOue978c/2pPz431+vH89368fWVLzGvpzkHY5cQ95UCp27O7eu73vcpkMA9bHVpYpje3yjX56awD3ARtSL+Xqtl3vZRwgEAgEAsErpqOuthHGwymCH0aZ/qmA7V0f4a+mCP2piwl4cYnkZRP78WYT/DJmgWxmmWLNZntZ3DFWNIxOV+cexumvnYSt6miWlqNyzKqHS4O2WnGpCYW7Aeyf5VD32et+815aIHjA2nkyf+sntqdiUPMwTv+6aPHCQJunyepWlqn3wsw2+ulIjIUzirUCAOuCXvynik2/6gCE3tPoq9jcSKAw/jdO8OMY0+YgoYsxosed5QmZiTGvW3+Xqxkmhr1o+yIEjyvIZoHs136c58dIpUIorSZGqzqpcyn6mn57Jvr9MCnJT6DpwNyk8DDN8q81m+2DqHtlaPk+SnRXl3p8lzaVyLfuFjvkmfnzACkLK82FH8OEM0FiQ51N3MzHCU4fizDHAAP2NfR5HcenU0xeUNmoIcZaR+dsy8o0Y3/wN3xu0Q4FlP+EesjzDPFPAsRu5ygA2Jz4PkswddaF5db8eQ7tUf1UzL5PxfnCQO+kPgNQIH0ujLk/iGdPS2WjiuzfDxO+1+CHd0Mkr3o6E/YaoC+GmTLdDQQKk9ztCOELcVJPSlscIyGiV6P49lovf0/00g6WKSzGCX0SY9p0oDr6gFKdlI6HmbwaQm30AFdmCTSpT1VcbCcqmGT+quJdHCByxocimxQeJvCfijB2b47QgVY3UCB7LgyHmotLhR/DhGn07jYxHmss1X7G62KCle/4hc7s+dOEv0yh48BzNkrsgg9nG1Gt6XeLt7Qo0bzEZP6RIP28wU/tRNAtRr/tx33B5PTFAK4DEsazFBHlNPbraW4c7aDmPZzi8Pnqryn/CIo5P4f/Ubm13bMByBDv70YYL43t0h/HUGsf4c4+Bg/Y6sTjEqW2WBtqvyBTf2jzxR4rCzwCgUAgELxuehOXniTw/zGJkkpTdPVTzMTwH/JgPtAYbzUI3OMhdNZTvW1lmvTlGapWix7rUGvjYCyRvFzZ+a6hz2cIdCDubDVrsDl5e2FirJankq0mxIciJDu1YNgyTIx5DVeqSLh2nL+9U2HQhnphhkp5wpyPYH8fwjejqJUDaqnm3E8S+A/NoKTS5O0aoRGVyE6d2HDnEzH9doTIHxOsXfNsDPjUERd279sk5gNMHml3X2miHxwm0aRG5B+B82ir4w20K4eJSeP49/Vvbt7rKIlL7ei2LvX6Lo0sM9+kMZruUGRJb3+aDVx+Qmc7WJE2NaJDEdaupMmfKNd1I8PEiJuB/tqdvYxt/L9GTGkgpJQG460u7uXGowRjG6u/JSFt9lac+PflTXoaaCW+9cLvpB6aWSaOeNGGE2TXPNgkMFc04qe8eF6k0D5XmkyianimMXG5ckJY0TZ3scJuzs+QAJhPEx1WrZUBMA0N+dgyiWOb4n3+ToCB+eZf+SYOPGdDeFrskTHDTDXYXrgTQL3QR/ROkbn9JUE5eydCcCiA9CCJ19IzqLScKrL0b9DvTxJfKVeGNmJBb+2gSfbLUTyzTuL/zJHcX7Hv+r0ohxuLPLt8zLz0tbyzksVKG54kiVwYJPHrJJ71b3bIg8s2xts3NQIHPG3FzsSnh9Heavzbmg580Pr43J3DHK4VyVuKCZWYaOfdBAtRUvkkDnRmznlQT0lkb3lb9vemoaEdmKN4rvYpSW3uWcKxT2GtZmEjd/sw0RcqoZZtYCXVIpWeAUgS/zJd2rDTTeDDFm27qTHlKxDJLRDcu75RxfuOxLYzSYJHQ21EoAr2B5j51l95NySOuJnxRpn50Fmxvd2zAYwieUDu0iXQ/UGIUIfWmsaKht6N2+MLA31exlfVL5WpbbcFAoFAIPgd0oO4ZKLdjJC/kmJupDQIk0eiJL8e5e3rKYI3vc07/aZWA17G0NEuT5R++1UHAtW72DzEvqsc+meIbIvh6EGlMX8t2UGtmVA1evx5CW1xDSPXYlLyZJkMIOsFOGgrW0FFau7p1THrs7Otckw/PE56UUNuJMzV0NcvI2/BeEWS5c3Htppj6s4Mjj2QvBfE87Gz6YA8e2+K/JVE+fsJMHU9Q//tFJHhFt9OE/p2yFAwyFN51ybFVRvyDivTUjehaw0GdMCG9Y6FszhGThPq2Gy/h7pUput3uaqTOpfG02gwWyZwMmx9YHsrxOHv+5r/XmuR81BjYl+UpycqvlXZRehiiMiXTp5+Fyi9z7IrwCb1Ykodkgy0Vsb65MrnZtK3Hez7FJT1ydGOtg5SwJtdD435BJG3Iixf3LTqkXapjF+Nor2TQPt4Eo+V8h0IsvBdsGJDuW3uxnXj2TSBD9KcTs3BRT+BbzQSJ5vfQx07+pErHqppwRULaOqyXdTTZJ6U+oHGAkWW5KVpxq6tEdhfLuV2GeV4jGi2j/CdMN5PrUyt+3EcWBfzDIrzUNg9iHKgfC/2OsW1ip7awSdJIudk4vokvt01v22XUY5PknwxxttXZvG/qoURqQ+ZPMZzoOKdmasGNrnezbARvgsz9WJtmfSVfkatlKNTkXydJ0niX44y9UsAZSeAQuB6ktw7YZI/egntb3N8X/V3aw0J2wG15n0YmHdA3VNvHd3qPJUilfRvACfKgbKY85YDiRbWt1If/bYi+efVAynzVwPsjs769O1SVZgC4/4MyYID49YM6RMxPB0sJBqLs0wBtn9pRP5kXaR+nVT3SwKBQCAQvDn0IC5lyVy2489WD5gdQ17Uj9IsXfeituzFo81jgXy3QBA2Yoa05Mc0Kdsgo7WDYcsYpG7HAZi+H0E9WtGjLyaZeNYH+WVwNjrWJHN7iuKIh+KVSTJHorgOjvPy5Xjp57oJceVll0uTz5rN/e+4UXZZH/54v65Yoc/E6P/zLFOXM42FuVeJaZBbTBD5JIbx51mWb0L8f1QGFsNMXgyg7pVrBnUFcpksnk82vx9ZUfF6l8jd9HYcw8J2JMqN+VHcqkZgxEk/eZZuzVIYTnBjyNrzbD6gK4kOr45e61Kv6GjTCYxW89byqnXb8e6xCDN1K+8V1FjkmGsm7KgXo6Q+CX4xWlhUVYgpz3Ok7qXIPQdpl5uxYy5sPbwvh6Kirq9U92UsHfPm1kMwV/Mgu6l7/esT/VXoWO2FsvDuZHQXsGK1/AW0vwf5y7k8nn8lGR9xgDPB6eMDDMzHmLwYwGPFEtAK30fxv5egyrVG7kdGou9dJ7bKB3XIw+m9diRMtPN2krtrpRUT80ew99c+XYm+tyC7ajX8roxzSC13NwUKX0HO6UYdsibl9NQOPi+QOjrGZIu+1HFoDO8HOjpUixkWYrdZsRpil5foTY1R12G0kx6cb0E+m2C24CFx05ow0Eqs7W+he28FhQcpUh8HSFaKHzvceE5kmXigE9r/G7momUuk7yoMftSJBFgtUvX9L8Ag6pDV3thF8JaHsWMDjJ0I4v5/UNQ1puclJu/E2kjsjTGfZUheixC552Bq/inKg79weN9hvJeiBI+5cLQTjZ9NEzy1TPS7GYofRIj/T4rxDsM2RFzbiNRtbTF+FQgEAoHgv5jup2ArOks4GKtdQZL6kNEpPAdarlivUTTKk0dDZ0kvAgb6Qx17BwFcs/NJskcjOAwDgyJrHZo+G/ejBLNRFjSI+IJMK8nNVdsP4ix84SoHsGxw7P/GCV13EnkwhXTJiffUAOmbPhxtnqrk8BAbNtAfZkvxO9g0wZf7BjsSl6pW6Pv7Nt3tLAhz9e4DXmK3HCTXJwkv8izjbG159TiB/8MJpn8Az8dBAndzeN8tlWdcy+G7nyT+2SCj98F1fJzEdKA8cdLR73gZuFJxrt0OnMSYPN9Pul8nTTubj8rn4CRw8yn+Z1nSehFw4/kwinOn1Wc5i/8P2/C32MPb0i2uAZVxI1qJDD3XpR7e5U6ViGari2FWR3nVui0drrxLipvA3RjTP3gZP7h+BZ3prxNQ6Cf8XtlerEn5zR8mGD2aQD4xjn+oD/1uBOWak8SdSTwVz2zNMDB2YCmgcLobt7g3th6CzelG8c2gPfNVWazoizPM7ncT6TJorP79LNrZSlcYg+WMhrbTYNmgKg4ULzLEPQFi8yaDH4e4kQ9uxvbZ7WHy+zzaV1HiR/oZRSX69RzjFkXjprhCTN4cw17pWrPTRaClxYqOWQBJqlUpnCgfQySVIXTQVWFBlmFuFoIXG65OtGGNNQOM1Sbu1WtFDKMkv24Irb20g9vBltEp0KLdLeik9zewIGrlzlN1jXZtg4Tzwxs8PaaTfaBTBNxH0kQbiKLNaCwGVHDR4onWqRTO2tRF/cks2MM1WmxJYNQKLZ9siQaWn95LSRzTmy7A7V20wfw+RcLmJ1VjKaVnNbQ1NmMBNj9D2YJpjVqDbgBelMZvEhVJSAB5OMqCHib34xL5NWDYS+Sao8NA2ibahVFOf6NR3OnD/9k42StqacFg9w2eHsow/c0ko++4Ke5UCVydI9rAld74KUH4aATjXIrQsAJ3c6guD/npBNHjTgt6uYvxly8Zh99hEG2duetx8v385nG1BAKBQCBoRffi0nZrJuqNj5VxDGeIvz9GyWZIxnnQjeMtkPcoFVlh2rCqkbyax+mcwv9+KQpG/hEtBYJNDHK3IwR8S5zOaKgHJZLX/sJhx9vMfD1HrNUE9EWBzFcR/J8sE8hoeHdJcEUj+skobztniF6LlVbcmyAfDGz48Jfid3Rpgg8YuTTaYvmBWXDBqaTefUBClgz4fLwUc+S5xsRiG7egvQES9/0kG6YSknGMBJkcCTL5wsQw28dH6KMfh6Kg7JTINc7TUkezLGXZxSSRH3IYgHz8BjPDTU6wy0uiWCzFdwEgTax/FGpj4XQa82C3yvjn5Unl42m0H5rs10tdKtP5u2wRBLYhWbKLNdkcG3HBzbYLrc9UFTB7p5fxf2n4XQOkP/ahOkyWbiXRHGHS2QDO9QezMkNgX61jok7yYgT5ylNm1t3qRry4L7jxXtfQL61bOqSJfzLG9Hbq3PI2RCeALsTpdd7oerg/SOKqhsd1GO2kD48CS/enSdyD6N12wXKbYGaYvpYn+pW74tsuomezZPuL6L/AQOX+210Ebs0RkB2Ns5Jtt6GemUQ9E8N4ZsDuNjVmtYhhVFy5UfyT7X30y/LGs7CW7VBHuwvYksSfgXNjIUTGc26O1HE3A49DhI666X+eZuZanOyhGRbaxnxrwPMsmXnQ5AyFk456N7Q7UcYe9gEKoVsxnA96bAcP+IgqbxP6q0rqiwZWikaGiU8jDJ562vSb6Mmdp2kWWY3khQw5A5B93Pi2mWObi1CxyKZjZtmdeaQ6/lbH8czkQfwW66K03QZdtiFAQ8tPaYeEwTjjvwIYaJe1NtkMs0xdiDN6oVj3nrRbE+hvAUdiqHtb1ewc2XmgkCF7Ra230MnEOf3+NFBOQrInQ6Jh7L4sqWspsivAry7GF6O0Nx6TUM/PkD7fJEOhzYXvCxe+L5KlLHCVO70w0X9Kkbo+RfQe+K+nuXG03BYfHEfLOQh/OIDzmwCRM0HGRpRqC8WK8xgrufKiJ/B8GaMsjs+uZtGfQz4n4b/5KoMeCAQCgUDw5tG9uGRzMGDTyddaVTzPo+NsHWejLm5SmYdTHD6fY/CoWi6djDrcYNUMABPtop/k0QS56+tBPssprq2U/4VO6rZJ4FGKwLulKziO3WDp3xr6dmdLbxjzh0lCd2Wij1L4yseWVoyXGV2cZdnRfGJZ+FFjucJMJPczwBLaYh79oY4BSAf8BC2Y79v2x/A81sk+XN/iJDZi0cKEZu4DNpR1F4yVAlOthrEtMm415ViynMLYhuPoLHoBWLeWWNFZwkX4mIqLPjJo1u5jR2UkCBn512n+UvCycNyP55QTu1SO37BS+1KbZHijtHrPsyWW6h5mPwOuJgPSWnY6UYfK4lKrD6qXulSm53e5Bbi+eMnLLzo/znFkkvQvOTIPsiwVJAL/DJPYXxM8d7VBhVjNkb3vZezryvom4XrPQ+FaAYN11x03kVs1K87bZRzDBtOfjTFddVIV759DmxkbfzAJf9W6/G92PQSQUD6dI3dEI3U/i/4E7EPjpK+o1oX+KkwyX4aY3Bche7DyKTgYPRXCt6vA9IOJunZatlkR5CTkOpe0mj1kFePOacbuVG9X3219M/3vKChtYzMpKJp34y975SnLFlbZe3NoT3TyOPHfyTOzv7voRPrdBHNfxIjemyT5o68+Xk/ZsnadQtft4DoOAtNLmB+N4dznwv/ZGJ7dMmCg358h/s8MzvNLJE82e0/rlmmt7srO4FATqxFJqorpI8tFpj8q4NV8+I+cxmmTSlYyFKi9g4YZ3jDQV8H4OcdStkkWQyuxeyTrddG+R4XFYknIqyhHMQ9el4XvoInl56a7WtlVsukJTDJ/DRLuv8HTo/XnCfxtwVLGNHM+SeydGDElRvJeEFetOFqbkMSU6IMNcUnaBVlfCtu343iGvUR294NUEovaORpn/roNd5sFilo2Fiy250hdSKEfDZG+4tlov0zDgB0y0l4fkxkPoftJ4l/FmNuXJNDISn5VI/ZRvFTWXQoepx3PFQ88y1Lco6Ds7sNzQsGJ8Yp71Wast6Wv5eICgUAgEDSlh8gkTlwf5gnfyxDcv+kGkJ1Pkv88Zmm1u25A+DiLNg/pRa3spuNk/HOQngNVg0CTzOVR/N+fZna+ffaYhmxXCP3rRt1meY9aKrstQfFF+cw7HKi7Nq8i/SlKulb3KGeJkxQPgxiYyEg7VSKaE3tF2YsPppi4sz4Ec6AMx4hhkn2Yx/6ugkPqZ8Blgx/b34LjSKh5Jpg9Xha0cqgoh6ejya5l6ix+ymRi9Htgrhhu4FC0bjXhwKHYiH2fZfxg6WsxHmjMHlMbZmJqhW0oSGho8+/C7RT833KsCKNiRbW4VDOhNVianqhO377OsAp3J5io+0EhdEvBs6XRbHuvS50j4/owhKtJ+vhaWsYCs3iOKmrdMnY6cY04cVGaCOR/1NCL0GcfwLnLhtygLrHDjr2BKFf4OQfSYOvrNxO4u+DNroebyHtUfGfUHgtjkvsmgPe6g6kHrbNjbVJaFPDfab/nJl6STVxUlDMLLJzp5Fwl5L0q6t72+7Vkuw3laKD3OvtsmsgFiH4fYnTfEsrHE7jnx3G1EL+6bwcrkBWC3z7F/1gjNZ/dEEwlJcDMuWRzMWaHA88VD8azLNlnADrauSmoS+Nu4mgmLu1SCZ6t+P5WpknRx+CQiqvK0rKURa8SfX6CiXuNTqrCD1NMNLAa9V6yKC51gE1R8byfIHXes/ltPteY/cqD57NX7bpkkLk8hve6g2Qm0FWMIwBWM8QvJAlc0gm+ZaIeCTKdSdYHea9EUvCdrfzqM0z40jhcKuquaqtAPQOtghW5Pi1SrKu/TazQ1i+/US8UgnXjugzxfjdsWMxuWnI2RfYQLfcPG8JUw9GyDc+Vp7hk6wMC0yhgbrd1N24VCAQCgeB3Tg/ikoT6URyny89pOcn4CRuFu3FCV53EM9YCbxb/nSVD0KDKAAALN0lEQVRbZcbvJHYFzIfZqsCg5h8qBoGrOabPB/A/GGTuduvBdicYT1IkryaY/T6N9lMBANu7Ku5DHsY+CLNwtcng4VmKifNhJm+bOIYdJZPvF3mWF0uxQyIXg1VWLs6TMyycpCxGUZURpTtqUrLXcrn877uhOnfBjfgLZcxCjtyKTt4WJHbCohWBLMGqgWHBFaAqmxXgOh7FfihC/FCCgG2J2JU5gudjXWchMh5rLDFY7W4jK4ydLFsPrcikL1e6VtnwXF3Ag4lhmHXl66oMFe5R68/TPhSjdZLu3utS1+/S0Mk+bL32qi+GyZ/IM9MsC16TcxQfJZl45GTcN1gfLHqvoy7mh/l4msipEMlfBhhwOnH9UaIwP8GyrlF4J0Tsegyl6mEoeM5JDH4cwXk7jFuGYnaK05/lid71WPuOjAyJb5YZaOfu15Y3tx5WYRoYG7GnTfKPl8kXod9lwZTyRYHURT+B2w6mMjfwWl5Vt+H79mWDOpJhYlvlpLADun6vWabeC7e3AqvNeliDaRibWbXKMQWNPoeV6F3wXCNyPARX0yWrij1R4vfceH0SqVshlDb303k7WI+8V8W3twOhUa6NVZXBPDcFXaRxL4nVMPhO1QVQjq7HCcsjZyaqsneuC4qthYAOKGeKBUrt2xMd3j1NaF+b4/b4iVxM4P0ggnT9NG6WSJwLsnxxlkkrcSQrrwtgFsj9lEf/xU7wiq+5YPQ8Q/yUn/DPHuYyk3i6TXCymiNxysucZxZtSEIiRPyUivv4aaTbk3jbndcskM3ksdeIR46hAIFDpf+ni+HWC0g7ZORyn9wWCzH0eqNWmKqlQOrc28wcre8f9fuTxFf64ZccqR/18rgwRwEHoe+WiTUNw1ayAEy9yJFbKT+D8jnWhmOkj2/h7QkEAoFAsMX0NgTb7SOxCJFzAdyfFOk/4ieymGi9wlXB+op/YTHB5J3URqpnkHEOj+E/4aPWkly/GyW6GmB5PoBziwYV5g8TeI6mGb0e5cYlJ46y4GMaBfRMksgJhblLWZLHagrzPMVpV4DiRY3cdM1q7AuDzN/9eI+YpDKh+pXsh3H6XTTPOLJTIXYFCxNkmUHfejyGxhiLE4w9royGICEPq+jrljlls28AeY8Hxdk63XUt2X+MEa5ZNVaH2Yyp9SLP8qKTeK2lwZ4Ak1/nOH3CTnjVie98ikQ3sUnK5O4c5jBpXp6tsDqjIqWxaccx7ECu/epXZglsQbBOedf6KrkDZdiJndLzdNrM9tmyuq5LPb7LPSqBk62nvOliuN4qpuocHkJn662ACrfTTJijnD5rIW358xThoUnkm1nyIxV7nwUw0f8ZwO2KIOvRqsx5yqcay7YI4SNORn8q4DgYIHgnReigRZlwVSd1LkXf8SYiRKXlUUve0HpYmMVvr3UNBMdBtRwDz4Xb6cY71F5c0m+HCK/40B4EcL7uZfk271U+FGHhHXsD6wETo01g6vydAAOF6olv9rKdwfOF6h1tTtR9dkoWqk6ch9pY0wHm4wT+oQjmuRQzx9elBAe+m2mkc38heEUhdam16NN1O/h74cksh1VIvwyRKG66l22Koib23WqDTGHthABrSLKK+v0sE5c3Y0FKu9w4HVbaFAnXFylmpTChI3YyuAh8NEvqrKvtIsHmdWH9m7ED7HTgOeCsF+jLmD9MMOiaxP5pnOWbvu7HRYZG+I+HSY/Mkfxivbyl+1mSA4ydS6BMB1rHTHquEVVLfWmomNh8eTs2Y5vZ7Sptl0wKGtG67IMqVLi7rukamQ/SvPzi1edsq0+6sEl9gHUZ9dwCto2+QEEZ6cehOOivFMMajQkqLAA3lmt2OlAOKCg+B4N7HGC8Hkc8gUAgEAis0PPwUtrrI/YvH7Euj9f/Mcrbd9wsXE8QtpV88k2jgL44SUDxE36QrFoBd5xIsnyi11JXk52PwIVlxo9WTyEl2YZzJMTUxTT2OxrxYzWT5CdZpgqnSZ9sYOa/XcZ1zI/7sxlyKyGUTkWLPR5CZ63sWJ0+uBGFwhRUWYgpBL9boIVReEe0dUMpZ1pphONIjLkj3X49TZDkxibnW+gK1eDkZSuoJlhIxd5dXerxXa7MEvhDhPy61V1DVJRXPX5/kmWqMEp6pNGXLOEYGWP0g2SDzHkSzuMx5o5v8Te0zk4n6lD73d7Yemjzknz5kmTbs7eLlPJq2uZXhbRLQW3RJrcKTG02mLwrn+d5+Xn76xbaBASU9vqZejCGbVfNxbc78F5dwNv4sCYns94OZv9+uE6YbIf30gLBA80SA5SyfVKZeXEDC4kBgJIg1mh7m7a2R1rWIwvtOMi4zt4gfbbe7b7r67ZAOhhk7t9BHHt6VHRllchiHnlXbSsmo5yZ4Wm5bIW6A5uUq0kFUs4ssNDuYAt9deav22osAZtZj66V3EAbCkSlYPjt3Nzrky6sU3bXq9rWvi9oSp0FYAPqo6YDYD6cQP1jgsHUEpMjr1vdFwgEAsF/K6997dIoLMGeIIO75YoVShvOITeDhRS6hTTsveLY60O/mmR2KIy31lVnRSNxO41rKFI/WNijELQFmPy7iuOkqzrI86pO6vokswfHWqTyLqXzbTJWAKrT/AosUJGeuylS4yw01ZnDGvDKTfBfFwHi3zWxoPut2O9i3OZvXpeuxkgcHCP4itqCdu9e1MM3k7Z1uklb8PqQsDWLbdYJHbaDyoczzHQoDJbi3Eg49inltPWVVAc+r6af9kZA7fvGKmusyiOLBq1vvfFxby4yDisud1bOVCcsdUfbevdK3kEL69Gmwm8/AxZ0mMZJFwBM+n4n/YL5Sx4dnf5CEUREJ4FAIBC8Jl57t6ic0UheDDNoD+PYVw7U+CLP8s8O/NNJgrUZclpSMkcudhhvwHYsgbY9TvzDQcZ+AFfZiiP/SKO404P/vEbqeAPHmJ0eJrNJpi5Gcfel0Pe4UB195B9p5HDiOxVl+b63sUvNdhl1WNt0WWlCaXW4s/v5z8CJV4vQvxOoWxVvTMmtIM7Y+62eKChnksSOVAyim2YOq6FNnJWWWHaveh1EcG+LtNkn2tyFcyuQVKKPZpm60EVd6gWL7/6/tx5uEY0Csr9KLL7XurYAgFn8f9hWFxuriovh3sv4iuiqHdzRxMqp/dW6t9JohsW+kXdDJK9WxlYruZlqfxtj7G+dHNcBld+xxX7pvwqrfSleYt8FtzhZxSv4FstEXNto1UN6j7b48TdCHplEL8aQ/qOEU4FAIBC8aWx7+fLly1d7CevBkjeCoG6RhUhXwT3LWd+gc2uFrS7/lmEaGGY3K4VbFei61/OYGMZWBD//ndB1MPdenuPWBS23fsluv7vKgMi9r3CbpY/nt7vv5gV5o+vhlgVL7uBcW3nN3wU91IkqVg0Mfmf9zH8dPfRLPbw/0zAwu7C427K6tFXfcK+88XWg2/b4NfTlAoFAIBBY5DcQlwQCgUAgEAgEAoFAIBAIBP+p/J/XXQCBQCAQCAQCgUAgEAgEAsGbixCXBAKBQCAQCAQCgUAgEAgEXSPEJYFAIBAIBAKBQCAQCAQCQdcIcUkgEAgEAoFAIBAIBAKBQNA1QlwSCAQCgUAgEAgEAoFAIBB0jRCXBAKBQCAQCAQCgUAgEAgEXSPEJYFAIBAIBAKBQCAQCAQCQdcIcUkgEAgEAoFAIBAIBAKBQNA1QlwSCAQCgUAgEAgEAoFAIBB0jRCXBAKBQCAQCAQCgUAgEAgEXSPEJYFAIBAIBAKBQCAQCAQCQdcIcUkgEAgEAoFAIBAIBAKBQNA1QlwSCAQCgUAgEAgEAoFAIBB0jRCXBAKBQCAQCAQCgUAgEAgEXfP/AV/XM0K59vpqAAAAAElFTkSuQmCC"
+ }
+ },
+ "cell_type": "markdown",
+ "id": "c3edb0a0",
+ "metadata": {},
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 58,
+ "id": "88b114de",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 라이브러리 불러오기\n",
+ "from sklearn.datasets import load_iris\n",
+ "import pandas as pd \n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline\n",
+ "\n",
+ "# 정규화 라이브러리 호출\n",
+ "from sklearn.preprocessing import MinMaxScaler\n",
+ "\n",
+ "# PCA 라이브러리 호출\n",
+ "from sklearn.decomposition import PCA"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 57,
+ "id": "17f2d9d1",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "| \n", + " | 컬럼 | \n", + "VIF | \n", + "
|---|---|---|
| 0 | \n", + "x1 | \n", + "2.325643 | \n", + "
| 1 | \n", + "x2 | \n", + "25.897343 | \n", + "
| 2 | \n", + "x3 | \n", + "24.825742 | \n", + "
\n",
+ "\n",
+ "\n",
+ " \n",
+ "
\n",
+ "
"
+ ],
+ "text/plain": [
+ " sepal_length sepal_width petal_length petal_width target\n",
+ "145 6.7 3.0 5.2 2.3 2\n",
+ "146 6.3 2.5 5.0 1.9 2\n",
+ "147 6.5 3.0 5.2 2.0 2\n",
+ "148 6.2 3.4 5.4 2.3 2\n",
+ "149 5.9 3.0 5.1 1.8 2"
+ ]
+ },
+ "execution_count": 57,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "# 사이킷런 내장 데이터 셋 API 호출\n",
+ "\n",
+ "iris = load_iris()\n",
+ "\n",
+ "# DataFrame으로 변환\n",
+ "df = pd.DataFrame(iris.data)\n",
+ "df.columns = ['sepal_length','sepal_width','petal_length','petal_width']\n",
+ "df['target']=iris.target\n",
+ "df.tail()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 62,
+ "id": "4ed91019",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAYQAAAEKCAYAAAASByJ7AAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjQuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8rg+JYAAAACXBIWXMAAAsTAAALEwEAmpwYAABT8UlEQVR4nO2deXijVb34Pydbk7bpvk47086+MzvDwDDK4mUHZVEUFBTlyiIoInLVn4pecQG9CF4FFDcEVLgKiICggKwDM8Ps+7TTTvd9y5687/n9kUzaNOk0mUmbtD2f58nTvOc973m/OW3fb875bkJKiUKhUCgUhlQLoFAoFIr0QCkEhUKhUABKISgUCoUihFIICoVCoQCUQlAoFApFCKUQFAqFQgGMk0IQQhiFEFuFEM/FOPdBIUSfEGJb6PXN8ZBJoVAoFJGYxuk+twJ7gZwRzr8hpbxwnGRRKBQKRQzGXCEIISqBC4DvAbclY8yioiJZXV2djKEUCoViyrBly5ZOKWXxSOfHY4VwH3AHYD9Gn3VCiO1AM3C7lHL3sQasrq5m8+bNyZNQoVAopgBCiPpjnR9TG4IQ4kKgXUq55Rjd3geqpJTLgAeAp0cY63ohxGYhxOaOjo7kC6tQKBRTnLE2Kp8GXCyEqAP+CJwphPjD0A5Syn4ppSP0/nnALIQoGj6QlPJhKeVqKeXq4uIRVzwKhUKhOE7GVCFIKf9LSlkppawGrgRekVJePbSPEKJMCCFC708OydQ1lnIpFAqFIprx8jKKQAjxeQAp5YPA5cANQogA4AaulMeRgtXv99PY2IjH40musEnEarVSWVmJ2WxOtSgKhUIRhZiI6a9Xr14thxuVDx8+jN1up7CwkNCCI62QUtLV1cXAwAAzZ85MtTgKhWIKIoTYIqVcPdL5SROp7PF40lYZAAghKCwsTOsVzERESknA7cLb243f0Y8e8KdaJIViwpKSLaOxIl2VwVHSXb6JiH+gD0fdofCxJa+AzPLpGNS2nEKRMJNmhaCYeuh+H86mSLdqX283msedIokUionNpFcIvb29/PznPx/z+zz99NPs2bNnzO+jGETXNKQ/eotI19S2kUJxPCiFMAwpJbquJ3wfpRDGH4PZgikrO6rdaLGmQBqFYuIz6RXCnXfeSU1NDcuXL+dLX/oSZ511FitXrmTp0qU888wzANTV1bFw4UJuvPFGVq5cSUNDA9/97ndZsGABH/rQh/j4xz/OvffeC0BNTQ3nnnsuq1at4vTTT2ffvn28/fbbPPvss3zlK19h+fLl1NTUpPIjTxkMRiOZ02ZgzMwCQBhNZM2YjdFqS7FkCsUERUo54V6rVq2Sw9mzZ09Um5RSHj58WC5evFhKKaXf75d9fX1SSik7Ojrk7Nmzpa7r8vDhw1IIId955x0ppZSbNm2Sy5Ytky6XS/b398s5c+bIe+65R0op5ZlnnikPHDggpZRy48aN8owzzpBSSnnNNdfIJ598MqYM8cipOH60gF/63S4Z8HpTLYpCkdYAm+Uxnq2TystoNKSUfO1rX+P111/HYDDQ1NREW1sbAFVVVZxyyikAvPnmm1xyySXYbMFvmhdddBEADoeDt99+myuuuCI8ptfrHedPoRiOwWjCYJxSf8oKxZgwpf6LHnvsMTo6OtiyZQtms5nq6upwXEBWVla4nxwhWE/XdfLy8ti2bdt4iKtQKBTjyqS3IdjtdgYGBgDo6+ujpKQEs9nMq6++Sn197Eyw69ev529/+xsejweHw8Hf//53AHJycpg5cyZPPvkkEFQc27dvj7qPQqFQTEQmvUIoLCzktNNOY8mSJWzbto3NmzezevVqHnvsMRYsWBDzmjVr1nDxxRezbNkyLr30UlavXk1ubi4QXGU88sgjLFu2jMWLF4cN01deeSX33HMPK1asUEZlhUIxIZk0uYz27t3LwoULk3YPh8NBdnY2LpeLDRs28PDDD7Ny5coTHjfZcioUCkW8jJbLaErZEBLh+uuvZ8+ePXg8Hq655pqkKAOFQqFIZ5RCGIHHH3881SIoFArFuDLpbQgKhUKhiA+lEBQKhUIBKIWgSDFSSnS/D10LpFoUhWLKo2wIipSh+bx4uzrwdndiMJvJLK/ElJ2j6kYoFClCrRCSzIsvvsj8+fOZM2cOP/jBD1ItTtoipcTb1YGnoxWpBdA8bgYOH0Rzu1ItmkIxZVEKIYlomsZNN93ECy+8wJ49e3jiiSdUSuwR0P1+vF0dUe0BpRAUipQxZbeMvD1duFub0P0+DGYLtrIKMvILT2jM9957jzlz5jBr1iwgGL38zDPPsGjRomSIPKkQBoEwmZA+LbLdaEyRRAqFYkquELw9XTgb69H9PiBUirGxHm9P1wmN29TUxPTp08PHlZWVNDU1ndCYkxWDKWgziGizWDHZMlMkkUKhmJIrBHdrE8hhVdGkjru16YRWCbHSgCgD6ciY7bnYZ88n4HZhMJowZWZhzFDVzhSKVDElFcLRlUG87fFSWVlJQ0ND+LixsZFp06ad0JiTGWEwYM6yY86yp1oUhULBFN0yMpgtCbXHy5o1azh48CCHDx/G5/Pxxz/+kYsvvviExlQoFIrxYkquEGxlFTgb6yO3jYQBW1nFCY1rMpn42c9+xjnnnIOmaXzmM59h8eLFJyhtatC8HvwDfQRcDsz2XMzZOSesMBUKRXozJRXCUTtBsr2MAM4//3zOP//8Ex4nleh+P44jteGYAF9vD5aCIrKmTUcYlBeQQjFZmZIKAYJKIRkKYDKied1RAWK+7k6shSXKC0ihmMRMSRuC4thMxKJJCoXixFEKQRGFMcOGwRJpLzDn5GGwZKRIIoVCMR5M2S0jxcgYLRbs1XPx9nThdwxgycvHkpOPQUURKxSTGqUQFDExWm1kllcidR1hUAtJhWIqMC7/6UIIoxBiqxDiuRjnhBDifiHEISHEDiGEKl6cRihloFBMHcbrv/1WYO8I584D5oZe1wO/GCeZks5nPvMZSkpKWLJkSapFUQxB83nx9fXg7elS2VQVimMw5gpBCFEJXAD8aoQulwC/l0E2AnlCiPKxlmssuPbaa3nxxRdTLYZiCJrXw0DtQRz1NTgbDtN/aB9+50CqxVIo0pLxsCHcB9wBjJSwpgJoGHLcGGprGUuh6t/dx85n3sLVPUBmgZ2ll5xG1doFJzTmhg0bqKurS46AiqTgdzrQfZ7BBqnjbmvBVJWpUm0rFMMY0xWCEOJCoF1KueVY3WK0RTnCCyGuF0JsFkJs7uiILqySCPXv7mPzY//E1R38pujqHmDzY/+k/t19JzSuIv2QMRIW6l4Pcni2W4VCMeZbRqcBFwsh6oA/AmcKIf4wrE8jMH3IcSXQPHwgKeXDUsrVUsrVxcXFJyTUzmfeQvNFFnXXfAF2PvPWCY2rSD+MmVlRbZaCIgwmcwqkUSjSmzFVCFLK/5JSVkopq4ErgVeklFcP6/Ys8KmQt9EpQJ+Ucky3i46uDOJtV0xcTJlZZFZWBbeHhCCjoFilLFEoRiAlcQhCiM8DSCkfBJ4HzgcOAS7g02N9/8wCe8yHf2aByss/2TAYTVgLijFn54KUGCxmhFCutApFLMbtP0NK+ZqU8sLQ+wdDyoCQd9FNUsrZUsqlUsrNYy3L0ktOw2iJ1IVGi4mll5x2QuN+/OMfZ926dezfv5/KykoeeeSRExpPkTyMFgvGjAylDBSKYzAlI5WPehMl28voiSeeSIZ4kwY9EEDzuNG1AMYMKyarLdUiKRSKYzAlFQIElcKJKgDFyOh+P57uDjxtLYBEmExkTZ+JxZ6batEUCsUIqPWzYkwIuF142po56kEsAwFczQ1oPm9qBVMoFCOiFIJiTND90Q9+3etB9/tTII1CoYgHpRAUY4LBHF07wWDJQJim7C6lQpH2KIWgGBMMNivW4rLwsTAayZw2HVOGNYVSKRSKY6G+rinGBJM5A0NxGWZ7btDLyGLBZIuOGlYoFOmDWiEkkYaGBs444wwWLlzI4sWL+elPf5pqkVKKwWTCnG0nIzdfKQOFYgKgVghJxGQy8eMf/5iVK1cyMDDAqlWr+NCHPsSiRYtSLVpMAm4nEoHZlplqUU4IqevoAT/CYMSgbBSKNMTvD9DZ3kWGNYOCwrzjGsPn9dHV0Y0ty0Ze/ti4b0/ZFcLfn36Zc079KMuqP8g5p36Uvz/98gmPWV5ezsqVwYJvdrudhQsX0tTUdMLjJpuAx4WrpYmBmgM4ag/gbm8h4HGnWqzjQvN6cDbW0bdvF/01+/AP9CFlVLJchSJlNDY086O7HuCiM67mExf/J6++/CZ+X2LednW1DXz7q/dwwQc+wbWXf4GNb25G15OfsXdKKoS/P/0yd915Dy1NbUgpaWlq464770mKUjhKXV0dW7duZe3atUkbM1n4HQN4OlqQuobUArhbmwi4nKkWK2GkpuFsacDX2w1IdK+HgbpDaBNUuSkmH4FAgMceeYo/Pfo0Pq+P5sZWvvi5b7Bn14G4x3C7PfzP9x/kub++RCCgUXuonhuv/SoH99cmXd4pqRDu/9Ev8bgj/eQ9bi/3/+iXSRnf4XBw2WWXcd9995GTk5OUMZOFpmn4e3ui2v39veMvzAmi+f0E+vsiG6VE83piX6BQjDOd7d389c/PR7RJKak5WBf3GG0tHbz60psRbQF/gLpDR5IhYgRTUiG0Nrcn1J4Ifr+fyy67jKuuuopLL730hMcbCwwWS4y26LiBdEcYDAhjtM1AVUJTpAu2TCtl5SVR7Tk52fGPYcsgvyDaZmDPjX+MeJmSCqFsWvQv6Fjt8SKl5LrrrmPhwoXcdtttJzTWWGE0GsnILwLD4K9eGE1YciZejiGjxUJmxfSINlO2XSXRU6QNuXk5fOWbN2MY8v+2cMk8Fi2dH/cYpeUl3PntWyLa1p2+mnkL5yRNzqNMSZeMW+74HHfdeU/EtpHVlsEtd3zuhMZ96623ePTRR1m6dCnLly8H4O677+b8888/oXGTjdmeg716LgGPCyEExgwb5uyJWQvCkpOPYXYGmteDwWjClJmJwRy9AlIoUsXa01by2NO/oOZgHdn2LBYumUd5RWlCY5x57gZ+/5f/pb62gbz8XBYumUdRcUHSZZ2SCuGCD38ICNoSWpvbKZtWwi13fC7cfrysX79+wni4mLPtE1YJDEUYDJizsjFnJX/5rFAkA5PJxOJlC1i87PizK2dkWFi+agnLVy1JomTRTEmFAEGlcKIKQKFQKCYTU1YhTGWkrhFwOvB0dyAwkFFYjCkrK6FqYnogQMA5gLe7E2EyYy0owpiZhRAi3CfgduHr7SbgcmLJL8Riz1HbOQpFGjOpFIKUMuKBlG6ky3ZSwOlg4PDB8LGvrxv7rPkJbSH5Hf04jwz6Qft6u8iZvQBTZjBFheb1MnD4IDLgD91zAL24FFtZZVr/jhSKqcyk8TKyWq10dXWlzUN3OFJKurq6sFpTm+1TSom7sy2q3dvbHfcYuqbhaW8ZPjB+R3/4UPO4w8rgKJ7OdnRVIEehSFsmzQqhsrKSxsZGOjo6Ui3KiFitViorK1MtBoLob+jJ+c6uvvkrFBOZSaMQzGYzM2fOTLUYaY8QAmtRKf6ByAhfS378LmwGoxFrSXnElhFCRGw5GW1WhMkcsUqwFpVOyAA4hWKqMGkUgiJ+TFnZ2GfOw9vTCUKQkV+EKTMxt02zPYfs6jl4ezoxGM1YCgoxDsmaarRYsc+aFzQqu51k5BVgzs5R9gOFIo1RCmEKIgwGzPYczPbjz7NkMJqw5ORhyckbsY/JasNUVnHc91AoFOPLpDEqKxQKheLEUCuEJCJ1jYDbhebxYDCZMNoyMY7BnnnA40Zzu0BKjLZMTMMK3OgBPwG3C93nw2CxYLJlYjCZky6HQpFK+nr62b1rPy2NbZRXlLLopPnk5aVXduGJhlIIScTX14OzoS58bMzKxj5jNgZz8h7GAbeLgdoDSC0QbDAYyJk1L2wDkLqGp6MVT8ega2lGUSmZpdNUFlDFpMHj8fDrBx/nNw8+EW771Oc+ys1fvg6rLbWu3RMZtWWUJDSfD1dzY2Sb00HA7Urqffz9vYPKAEDX8XR2hOMvNK83QhkAeDvb0JT/v2ISUVfbyG8f+mNE26O/epLDNcmvETCVUAohSUhdj3xQh9u1pN5H80Y/2HWfB0IKQWqx7zdSu0IxEXE6XFFBqFJKnI7kfgGbaiiFkCSMZjPm4R43QmDMSO7y1ZKXH91WUIwI5Vs3WDKi8gUJs1n5/ysmFZUzyqPql5SWFTO9Snm1nQhKISQJYTRiK6vEklcIwoAxw4p95lyMSS7WYsrKJrOiCmEyD95zSHEbo8VCdvVsTNk5IASmLDv2qjkYY1RJUygmKqVlxdz/q7tZt2ENlgwLp6xfzf2P3E1peXGqRZvQiHTN/XMsVq9eLTdv3pxqMWIidR094EcYjBhMY2ez1/1+JBLjCNlDdU1DagGE0YRBGZMVkxSX001fXz+5uTlkZqlKeaMhhNgipVw90nnlZZRkhMEwJq6mwxnNc8lgNIJSBIpJTmaWTSmCJDKmCkEIYQVeBzJC93pKSvmtYX0+CDwDHA41/UVK+Z2xlGuyo+s6mtuF7vdiNGdgsGVG1HQFCHg9aB53sISm1RalxKSuo3k96IEABrMZY4Z1TNJOaD4vmteLwWjEkGFVqxmFIoUkpBCEEKcC1UOvk1L+/hiXeIEzpZQOIYQZeFMI8YKUcuOwfm9IKS9MRBZFbHRdx9fThav5SNDzSAgyp83Akl8YVgp+pwNXYx2a1wOAMTOLrGkzwrUMpK7j7e4MjgEgDGRXzTpmmorjIeByMlB3EBkIemdZCoqxlU7DmMS4DYVCET9xG5WFEI8C9wLrgTWh14h7UQAyiCN0aA69Jp7RYgKhuV2DygBASlzNR4KRzSF8fd1hZQCguZxRtQzCygBA6jgbDsd0eT1edE3D1dIYVgYAvu6OCDkVCsX4ksgKYTWwSCZohRZCGIEtwBzgf6WU78botk4IsR1oBm6XUu6OMc71wPUAM2bMSESEKYUe8A8qg6NIGWwHdF1Dczmjrgs4HeH3+rDCNhCMY9C1AEaSYx+RWoBADDl0vy8p4ysUisRJxO10F1CW6A2klJqUcjlQCZwshFgyrMv7QJWUchnwAPD0COM8LKVcLaVcXVysXMtGwmC2wDB7AcIQjk0wGIyYsqLzvZiG1DKIVfdYmExJzYdkMJoi7nkU5R6rUKSOURWCEOJvQohngSJgjxDiH0KIZ4++4r2RlLIXeA04d1h7/9FtJSnl84BZCFGUwGdQDMFotZFVUYUwhIyzBgNZlVUR8RCW3LyI+gfmnFzM2TlDxrCSNb0aRPDPQxiNZM+YldSHtTAaySyriAiYs5aUY7RlJe0eCoUiMeLZMrr3eAcXQhQDfillrxDCBpwN/HBYnzKgTUophRAnE1RSXcd7z6mOwWAgI78QY4YVPeDHYDKHjcVHMWVmkTVjJprXg0BgsFoj4hmEMGDJK8SYmY0M+DGYLBgzku9Ka7JlkjN7AZrPG3TXzbCGI64VCsX4M6pCkFL+G0AI8UMp5VeHnhNC/BD49zEuLwd+F7IjGIA/SymfE0J8PjT2g8DlwA1CiADgBq5M1E6hiGa4EhiO0ZJxzHgJIQSmDCskOfXGcAxmc1KzwSoUiuMn7khlIcT7UsqVw9p2SClPGhPJjkE6Ryrrmhb8Zm4wxNyLjwfN70P3+xFGY/ChfDxj+HyhFYIp5oNfSonu84EI2gxixRjoAT+6pmEwmTAYjy9kJeDxIHUNg9kyod1JpZS4uvuROmQW2qPiOuJB0zRamtoRQjCtsjTmnPd09dLfP0BBUQF2u9o+UySXE45UFkLcANwIzBJC7Bhyyg68deIiTh4CHjeulgYCA/0Is5msaVWYc3ITCujyOwZwtTSiuZ0YLBlkTqvElJ2b0APIP9AfdDX1ejBmWLFNm47FPpjvSPf58HS14+lsAwS2kjIsBcURD2y/ox9nYz26zxuMU6iYgSmB/X1d1/H39+BuaUT3+zFlZWMrq8SclVjt5nTA63Bz+K1d7P77u0hdMu/M5cw9cwW2vPg/S0dbJ4/95v949JEnMRmNfO4Ln+Syj19EfsHg72XTO1u56857OVLXyLJVS/j6d7/IgsVzx+IjKRQxiecp8zhwEfBs6OfR1yop5dVjKNuEQtc0XM1BZQAg/X4c9YcS8qvXvF6cTfVo7qA7pu7z4qg/nNAYAbcLR0NtOM5A83pwHjkcUZfBN9CHp6M16J4qddxtzWjOgcExPG4GDh9CD9VQ0FxOHPW1Md1RR/wsLifOI4fR/cFrAk4H7pZGNH/8Y6QLHQcb2fHXt9B8AfSAxr6XttC8ozahMV5/5R1+/YvH8fv8uN0e7v/RL9m8cWv4fF3NEW7+9J0cqQvW1Ni+ZRd3fOE7dHf1JvOjKBTHJB6FYAT6gZuAgSEvhBAFYyfaxEL3+wgMCe46iubzxOgdG83nRfcO6y/18IM53jGGBntB0Of/aIEcKYORzMPx9fWG3+s+L0g94rzu86L54o8R0IZ/DiDgciT0WdKFpu3RD//Db+9BC8RXYyIQ0HjmqRej2v/54hvh9w1HmnG7I+esruYILU1twy9TKMaMeBTCFmBz6GcHcAA4GHq/ZexEm1gIoxERw08/kb13g9EYdvUcPnb8Y8S+39F2IQwxU3IbbYNtItYYwpBQnqFYfYXJNOgOO4HILS+MasufUYzBGN82nslkZMGi6K2fufNnDt4jNzomw2rNIFvZERTjyKh/0VLKmVLKWcA/gIuklEVSykLgQuAvYy3gRMFotpBZERlBbc7Jw2jLjHsMg9WGrSyywIclvxCjNf4xjFYb1uLI+EFrcVmEEsgoLIpQMsJkjshTZLTayCiMLD6SOa0yoSI7Blsm5iF2CwBbWSUm28TLTDntpFnY8gftBZbMDGatX5qQbejSKy8gd0gB+NKyYs74j/Xh41nzqvnEtZdGXPOVb97M9KppJyC5QpEYiXgZbZFSrhrWtvlYFuuxIl29jKTU0dzuoH+/yYTJlplwdK8e8BNwu9C9XgwmM0abLeGqawGfF93tRvf7gt49tsyooLKA14PmdoWynWZGxRnogQCax4Xu92OwZGCy2hJaqQy9hwwEMGZkYLRljWmNiLHE0dFHX1MHui7Jm1aIvSzx3dK62gYO7qvFYDQwf8FsKoc97Pt6+9m/p4bO9i4qZpQzf+FsVTBekVRG8zJKRCH8A3gD+APBBHVXAxuklOckQ9BESFeFoFAoFOnMaAohEWfqjwPFwF8J5hsqCbUp0hSpHdvoKXUdqevH7KMYX3Rdx+1MfcZXv9+P0xGdfFAxuYl7/S6l7AZuHUNZFEki4PHg6+nE7+jHnJ2DJb8Q0xAbgtQ0/M4BPB1tIAS24lJMWXaVNiLF7NtxgKeffJ6t7+/mjDNP5ZyLzmDmvOpxl2Pjm5t58g/P0tLcxnmXnM0HzlrHjOrKcZdDMf7EE5h2n5Tyi0KIvxGjloGU8uIxkUxxXOgBP86G2nDsguZ24Xf0Y585N2zP8DsHcNQdCl8z4OjHPms+5hjZRxXjQ2NtI1+68Zs0NbQAsHfXAXbt3Mf37/sG9rzx+71s3bSTWz/79bAL7K7t++jr7efmL183bjIoUkc8K4RHQz+PO8mdYvzQQobciDa3C83rwWAyI6XE09kedZ23t0sphBRSc7AurAyO8vqrG6mrOcLSVYvHTY4De2ui4iGe+O1fOP+Ss5k1p2rc5FCkhniS2x2NNTACG6WUqd/gVIyIiBHHEGwfdJGMtTWktotSi8kUI25DCIxxxjokC2MMOSwZFkyq1vWUIJG/tmuBbUKId4QQPxJCXCSEyB8juRTHiSEjA/Ow2sdmey6GkOuqEAJrUWSMAUJgyVVB56lk9vxZLF46P6LtI1ecR9Xc8f1WvmDxHAoK8yLarrvhE8yYqWwIU4G43U7DFwgxjWDK6tuBaVLKcXcsV26nx0bzefE7Bgg4BjBl2zFn2yMynkqpE3A58fX1IIQBc04epsyshAKtFMmndv9h3nl9M7t37mftqStZs24501IQmLZt807eePVdmhtb2HDWqaw5ZRlFJapm1WQgmXEIVwOnA0uBTuBN4A0p5TvJEDQRlEJQKBSKxDnh9NdDuA+oAR4EXpVS1p2YaAqFQqFIJxKJQygSQiwGNgDfE0LMBfZLKT85ZtKNI1IPbqME3M5w2clEU0boWgDN7SLgcmEwmzFlZUcVp/E7HQRcTqSuYbJlYco+vmIrx0Lz+9FcTjSvG2OGFVNmtqpKdgy8Tg/dh1vpa+4kqyiXwpllZOann8eVz+tn5/u72bVtL5lZNk5asZj5SyOT5jU3trJj6x5am9tZsGQuS5ctJCs7/lxY8eByuti5bR97dx2grLyYpSsXU1EZmT+r9lA9O97fjdPhYumKhSxaOh/TkLQlyZjzro4edm3fS+3BOmbOqWLpioUUFilb2IkQt0IQQuQAM4AqoBrIBSZNmKtvoA9nfU342GCxYJ85LyGl4OvtwdVUHz422jLJrp4Trlfsdzpw1B+KSE+dXTUbS27ybPNS03C3N+Pr6gi3WQqKyCyfnlC20qmCrunU/Hs7u54d3PksX1rNydecQ0Z2eiXi2/TWFm7+7NfQQhHoBUX5PPSbHzH/pHkAtLd1csfNd7Fj657wNd/43m189OpLkirHC8/8i7v+a9ALfcmyBdz38H9TUlYMQO3BOq77+Jfo6ugGgnW+H3z0Hk5ZH9ypSMacu1xufvHT3/LnR58Ot13+iYu4/Rs3kZmVXr+3iUQiX03fJFgYZwfwMSnlfCnlNWMj1viiB/y4Wxoj23y+iKIyo6H5vFFjaG5XRExAwOmIqlXgbm9NatEYzeeJUAYAvu7O6DoLCgAcHb3s+fu7EW0tO+voa4muGZFKnANOfvm/fwgrA4Duzh42bdwWPj64tyZCGQDc94OHaG5sTZocLU1t/OT7D0a07dq+j/17B79Mvb9pZ1gZQDAdxy/u+y0ulxtIzpzX1zZEKAOApx7/G3W1R+IeQxFNIltGx6ydLIR4QEr5hRMXafyRuox6UMPouYAi+kqJ1KP7D80VJLVY9whEFaM5EaQWeyyVsyg2mj+AHmPONG96VXbzerx0dfVEtff29IXfu1zRSt/pcOHzJe+z+Hx+nI7oL0ru0MN+uExH6Wjrwu/zQ6YtKXM+PHhutHZFfCRz8/q0JI41rhjMZjIKi6PaTQnUMjCaLVjyhu1fDitGY4pRT9iSXxhlZzgRjBnWqLoFBoslKr21IkhWYS7Fc4fVoMiyYi9Nr73oguICrvj4RVHtq09ZHn4/a04VtmHpss+96EzKK4bFnZwAZdNKOP+SsyParNYMZs2tDh+vXBP93fETn740XA8iGXM+o7qSqmGxEZUzpjGjSsVLnAgJxyGMOJAQ70spVyZlsFEYC7dTzefD29OJt6sDg9lCZlkFpmx7Qr75mteLt6sdb29XsLh9WQXmrEFDmR4I4Hf04WlvRWoBLPlFWPIKIhLPJYOA24WnvQV/KA7BVlKekHKbavS3dnPgn+/TtL2GgqpSFl+0joKq0lSLFUVrYysvPPMvHn/0r+Tk2Lnh1ms49YNrI/bMt23exQP3/oqag3VccMnZXHnNR5heVXGMUROn8Ugzf3r0aZ7768vMmj2Dm7/yWVasXho+7/P6eOeNzTxw76/o6+3n6s9cwQUf/hBFJYMP/GTM+cF9Nfzqfx/j3be2cPKpK/nsTVczb+HspH3OyUjS4hDiuNGEVghH0f1+MCRWLnIoUoa2n44xhub3InWJKUEvpoTk0HWkpgVLe6q0FKOiaxpehwezzYLJkt4eWe3NHZgtJvKLYjsjuJxuXC43BYV5SfdgO4qu63R39ZKZZSMzM/YXmoF+B36/n4LC2HImY859Xh/9fQPk5NqxZFhGv2CKk8w4hFHvlcSxUsaJumcKIRCjjGE0j/32jTAYlCJIAIPRiC13YtQvLpkWvb05lMws25h72hgMBoqKj73FY8+J3iKNGCMJc27JsFBUEl3zWnF8JFMh/DSJY01IpJRoXg+6z4swmjBabQmvNIaOYTCZMWZYo0pXBjwedK8bKSVGqy3pW06K9KW5sYXDNQ1kZFiYPbea/GF5h5JBR3M7NQfqcPQ7qZo9nbmL5yQ8RkNdIwf31eLxeJk1t5oFi+eOfpEi5cRTDyFmHYSjHK2HIKX8bfLEmpgEHAMM1B0Kew1lFJZgK52WUB1hX38vziO1ENrKs5VVYC0sCSuFgMuJs7EOzRP06jCYLWTNmIU5hsFaMbnYt/sgN1xzR9ilc93pq/n2D++gvCJ59o7mumbu++HDvPj8qwBk27O4/6H/ZvVp8e8G7999kB9+5wE2b9wOBOMl7v3Zt1m9bnnS5FSMDfE8qVQdhDjQ/X6cjXURLqTernYsuXkYsnPiGkPzenE11oWVAYC7tQlzdg6mzODS2j/QF1YGwfv68PV0KoUwyfH7/PzmoSci/PvfeWMzWzftTKpC2LvrQFgZADgGnPzPDx/igV9+n4I4vYC2b90TVgYQjJf4/a/+zIIlc8m2T4xtualKPPUQ/j0egkx0dC2A7vdFtycQdCa1QMzYBz0wOEbAE+0DHnC70DVNRSJPYpxOFzve3x3VXnPwcFLv09nZHdW2b28N/X39cSuE+sONUW379hykp7NHKYQ0J26roxBirhDiKSHEHiFE7dHXWAo3kTCYzBhjuHYmEmNgMJsxmId7SoiItqFurOE2e65SBpOcnFw7Z527Iap9yfJFSb1PZWV5VNup61dTmIDhdkEMm8Opp68Z1RiuSD2JuKH8BvgFEADOAH7PYHnNKY/BZCKrsmowKMxgILOyCqMtfoPvUXvAUQUgDEayZswaFtyWgyVv8J/TbM/FkpuXlM+gSF8MBgNXXHVxOB+QyWTkuhuvYvnK5JbXXHjSfG758mfDLpwLFs3hxluvSaiu8/IVi7nqM5eHq8CtPPkkLrvyQjJUcGTak0g9hC1SylVCiJ1SyqWhtjeklKePqYQxSOd6CHrAj+7zIYxGDJaM4yo6o/t9aH4/BqMxZnI9PRAYNCpnWDGqTKZTBseAg8aGFixmM9OrKzCPwe/e5/NxeN9hXE4PFVXllExLPNLZNeDiwL4avF4fM2fPoKRcrQ7SgWTGIXhEsGDvQSHEzUATkLyY+EmCwWTGYDqxf1KD2RJj62joPUwYstMvPbNi7Mm2Z7Ng0di6cFosFuafNH/0jscg057J8jVLR++oSCsSUQhfBDKBW4DvAmcCx8x2KoSwAq8DGaF7PSWl/NawPoJgDMP5gAu4Vkr5fgJyxY3m8yI1LfjAjeEKqmsaut+HMAiMlrGLIh4NzedB9/kRRhOmGFtOUko0nxekxGjJiBmApvv96AF/UEGlcAXh7O4n4PZhzcsmI+v45rS3sYOA1092cR7WnGg7jc/lwd3jwGSzkFUQn0fXcDpaOulo7SC3IJeKGGUrA4EATQ0t6LpORWV5zKjY1sZWujt6KCjOp2xYfYDxZO+uAwwMOJlWWUrl9OjP4vf4cHUPYLSYyC7KjTlG3YE63G4v02aUkZsf3Wegb4C21g6ysjMprxibzxrPnHd1dNPd1Ut+Yd6ogXJjSUtTGw6Hk9KyYnJyo7+suZwumpvasNqsVE6PttOkC4lkO90EEFol3CKlHIjjMi9wppTSIYQwA28KIV6QUm4c0uc8YG7otZagnWJtvHLFJbuu4+vvxdVUj9Q0jLZMsiqrI/L7aB43zqYGAs7+4P5/eSUZeYVRQWFjjd/Rj7PpCLrXgzCZyZw2HXPOYAoC3e/H09mGp7MNpMRSUIStZBpGi2XIGAM4Gw6j+31Bu8T0asxxur4mCy2g0bS9hvcffwWf00NBVSmrP3k2eZXxbx14HG7qN+5l93MbCXh8FM2pYNnlp1NYPfgA6m3qZPOjL9Nd14Yly8rKK8+gYvlsjOb4v+ts37STb995DzWH6ikqKeD/fedLbPjQaRhDe+Bdnd384ZGn+N0v/4Su6XzkY+dz/S2fonzaoLvnu29s5tt33kNTYysVlWV86+7bOeUDa+KWIRk4+hy89MJr/M/3H6Kvt58FS+by1W9+gVVrl4X79Ld2s/VPr9G29wimDDPLLjudqrULMIUeto4+B3//y0vcd+8vcTpcrFm7nDu/9YWI4LQD+2q566s/Yue2veTm5fD1736RM889HYsleakj4pnzLe/t4Bu33U1TQwsV08v57r13RiT7Gw/8Pj+vvPQm//31n9DX28/iZQu460d3MG/BYE6lwzVH+MG3fso7b2wmM8vGl79+Ixd8+ENpWbchES+j1UKInQTrIewUQmwXQqw61jUyiCN0aA69hhstLgF+H+q7EcgTQiRVhWoeN84jtWGXTs3twtlUjx5KRy11HXd7S1AZAOg6rqYjCdVDSAYBrwdnY324doEM+IMP9iFy+J0DeDpaw7EKvu5OfP2DaZE1rxdH/aGwC6zu9+Gor0HzjW9a4L7mTjb+6nl8zuB9u+vb2PLEq/jc3rjH6K5tYftTrxPwBD9L56Em9r2wKTyG3+1l6x9fobuuDQCf08PGX79AX3P8efXbmtr42m13U3MoWNios72b22/5Dof2DOb33/TONh75+WME/AF0Xef/nniOV/7xRvh83cF6br/5LppCdQeaGlv58s3fpu5APePJzh37uOvOe+nrDf4d79t1kJ/c/Quam4LzowUC7Hn+Pdr2BmsGBLx+tjz+Cj317eExdm/by/e+/dNwiutN727j4Z/9HpczVMvA4eT7/+8+dm7bC0Bfbz9fveW7HNyXXPfX0ea8qaGFL37u6zQ1tISPb/3c12kMHY8XB/cf5o6b7wrP+e7t+/jeN/6HgQEnEMy19MsHHuWdN4I2T5fTzXe/9mP27to/rnLGSyJeRr8GbpRSVkspq4GbCHoeHRMhhFEIsQ1oB16WUr47rEsF0DDkuDHUljRiPQw1lzMcI6AH/Pj6eqP7jHNRGd3nQ/cNe2BKGSG/v7836jpfT3e43oHu90XFMkhNQ/dFx0iMJY723ijV31XTjKfXEbN/zDE6ovPqt+yuw9UTXJy6+1x0HGyO7CBD946TlsY2Go5EjuH3+TlSN+hL/+9/vh113d//+jK+0Jw2N7SEHwhHGeh30NTQHHXdWNJQ18hwJ5Gd2/bSGlII3n43TVsPRV3X3zb4haK+LjqG4NV/vUNnaycAnW1dbHlve8R5KWXEfCWD0ea8pakt5py3JLEYUDwciTHnWzftpKMtOF/d3b3884XoUK662oaotnQgEYUwIKUMq2gp5ZvAqNtGUkpNSrkcqAROFkIsGdYllhtOlOuTEOJ6IcRmIcTmjo6OGJeMTCwjrzCZw777wmjEaI3e304k5UQyMBiNEMMeIIyD8seKdTBlZkHImym4xRU9pcI4vp/Fao+W05aXhdkWv+thrHKK9tL88BhmmwVbfnSEdoY9/qV4bp49Zs3hobV5Fy6dF3V+2crFYQ+f/IK8sIvlUYxGI/kFeXHLkQzyY2QVLSktwh7a0zbZLOROi44nsOYOfv6CGDLPml1FViigLNueRWkMj6HCETKvHi+jzXlefk7MOc+LYe8YS2Jlci0pLcJuD/5dZmVnMXv+zKg+6Vr7ORGF8J4Q4iEhxAeFEB8QQvwceE0IsVIIMWqiEyllL/AacO6wU43A9CHHlUDUVysp5cNSytVSytXFxYm5sBmtNiz5RUNaRDBmIOTJYzCayCyfDmJwOszZueF0EeOFKTMrKMcQMgqLMQwpemK252IYYvAWJhMZBUVh91ZjhhXbtMgiIbby6QnVhk4GuRVFzDx10EdeGAysuuosbHnxp9jIryqhZMGM8LHRbGTph08jK1SM3ZabxeqrzoowqlevW5iQnWLm/Jnc+c0vRLgHf+ozVzBn4eA/8YYz1zFz9uDvpbC4gI987ILwNbPmz+TWr3wuYtxbbr+O2QtmxS1HMpi7YBbnXnRm+NhkMnLb129gbuiBZLFlsOzyDRH2lbIl1RTMGNyXX3TSfNZvODl8nJFh4bb/+k8KQ7UMikoK+eb3b494GF9y+blJr0Mw2pxXzZzO7d+4KeKa275+A9WzI/9/xpp5i2bzkY+dHz42mYx88/u3U1waVLx2exZf+cZNWK2DX4ROP/MUFp2gF9dYkUgcwqvHOC2llGcObxRCFAN+KWWvEMIGvAT8UEr53JA+FwA3E/QyWgvcL6U8efhYQzmeOISjvvu6FsBoycBotUXFCAQ8bjSvB4PBiNFmO2H30eNBDwSCtZh9XgxmM0ZrZoTBGILFfDSPO+hlZLNGeURJTUPzutH8foxmM8YM27gbxwG8Tg99TZ34nG6yi/PImVaYcH5+R0cvPQ0dBDw+7GX5FM2K9JrRdZ3+5i4cHX1YsqzkVhQl7M3kcbo5sKeGxiPNFJUUMm/RHPIKI79ptja3c2h/LZquM3tuNZUzIuVw9Dk4sKeG1uY2yqaVMG/RHLJzxz+/1JG6Rg7sraG3p58Z1RWctHIR1mGr376WLgZaezDbLORWFEWt5tqa2jmw5xAOh5OZs2ewYNjDS9M0ag7U0VDfRG5eDnMXzApXQ0smo825x+3h0IHDtDa3U1pewtz5M7Haxt87sK+3n4P7aunt6WNGdSWz51VjHPb/VnuwjrraBrKyM5m7YNaINSLGmnErkDPCzU8CfgcYCa5G/iyl/I4Q4vMAUsoHQ26nPyO4cnABn5ZSHvNpn86BaQqFQpGuJC0wTQhRCtwNTJNSnieEWASsk1I+MtI1UsodwIoY7Q8OeS8JGqjTAj0QQBgEwqByA6ULmj+A5g9gyRz525/P5cFoMWEcQ7uP3+sHKTFbY7tX6rpOwO3DZLOMuBLye3wgBOaM2KtPvz+A2+kmOydr5DHcXoTRcEKV3XwuD0azKSH33ImKy+kGwYiV3RSDJPLX8FuCXkVfDx0fAP4EjKgQJhK6z4e3rwdvd7Cmsq20HFNm9nGlnlAkByklnTXN7H3hPZyd/cw6fSnTV80jc4gh2dnVT/17+6h7Zw95FUXMP2d1RJxCMgj4/LTva2DPC++h+QMsPGcNZUuqsQwxkPe1dFPz2nZa99RRurCKuWcsI6d80IDrc3tp3VXHvpc2YzAaWHjeyZQumIFpiGLYv/cQjz7yJNs27eSsczdw6ZUXRhSS9zrcNG2v4cC/tpKRbWPheWsomVeZUGJDd6+Dhi0HqXl9B1lFOSw892SK5kyblH/njgEHb7z2Lr/5xROYzSY+e/MnWbd+VUq2lSYKidgQNkkp1wghtkopV4TatoU8iMaVZG8ZSSlxt7fgaRtiyxaCnNkLxt2wrBikp6Gdf/3wT+iBQTfaxReewqIL1iKEQAsE2Pqn16h9Y1f4vMlq4eyvXklOefK8ONr2HeHf9/0lom3d9RcwfWUwhYSn38Vr9/2F/ubO8Pmc8gI++KXLw5HVjVsP8fZDz0WMseHWj1C2sAoIulFe/eEb6GgfjKE4Zf1qfvLgXWSHPFZq39zJ5j/8K3xeCMEZt19B0ezoaORYSCnZ8/y77P7bYFyowWTkrDs+Sv6M5NVUSBf+9Y83+NL134hoe+gPP2bd6SPumEx6RtsySsTC5xRCFBJyCRVCnAJEO4pPQHS/H29nW2SjlASGFKJRjD99TZ0RygBg/z/fxx2KZXB1D3D4rcgaAQGPL6HAtHho2HIgqu3Qq9vQQvEejo7eCGUA0N/SzUB70L9f13QOvbY9aowjmwaDk2oP1UcoA4CNb26m4Ugw0Mrn8rL/5ciMLlJK2vfH78/u7nNy4F9bI9r0gEZvY+cIV0xcAoEAf/zdX6LaX3j2nymQZuKQyJbRbcCzwGwhxFtAMXD5mEg1zggRtBkMD+hSRepTiyHG/rbZasFgDP5eDEYDRrOJgDeyCJHRnFz7jyWG11KGPTO8zWIwxb7f0dQXQggysmOMMSR1QUaMPD1GoxFzaA6E0YA5MzqGw2SLP12EwWjAnGHB74oMfpyMdgSDwRAzJiE3b3zjFCYaiTzxZhPMO3Qq8A/gIIkplLTFYDZjK48MjhYmc0SuI8X4kz+9JCrw7KRL12PNCW7jZRbksOTiUyPO55QXJBSHEA+VK+ZGPDSFQTD3jGVho6+9JJ+qtQsirpmxZj7Zpfnh/nPOWB7xBcNoNjF91WDW0llzqzj51Mhwnquvu5yq6qANwZxhZvGFp0TEHJozMyiZF7/fvdWeyUmXro9sy8sif8bkS1psMBj4xLWXRcRLWK0ZnHPhGSmUKv1JxIawQ0p5khBiPUFvox8DX5NSJjURXTyMhdup1DT8LicBRz8GswVTth2TVXklpJr+1m7a9zfi6hmgdMF0CmeWhROxQdBbpqu2lY6DjWSX5FE8txJ7SV7S5eg50kbbvgb0gEbpghnkV5dGeAG5ex101jTTXd9G/owSimZXRBi/pS7prm+jbW89BpORkgUzKBj2IG5pamXLezs4uK+WZSsXs2zVkogIYM0fCI6x7wiWTCsl86aTV1lEIgS8froOt9C+vwFbXjYl86Yn1d6STui6zq4d+9j4xhbMZhNrT1vFohgR0FOJpMUhHDUmCyG+D+yUUj4+1MA8nqg4BIVCoUicZBqVm4QQDwEfBZ4XQmQkeL1CoVAo0phEbAAfJRhNfG8oFUU58JWxEUuhCHK4pp733t5Ke2sHa9at5KQViyLyyLt6B+g82ExnTTNZRbkUz62goCrShfLgvlree+d9+nr6Wbt+NUuXLYhZbOVE6G/touNQM71H2smbXkLRnApyh2zFaJrG7h372fjmFswmI2vXr47avhjcMjrMspWLoraMXE4Xm9/dzntvb8Vuz+LkU1eyYlhVMkd7L+0HG3G091I0p4KiWeUxjeInQnCbroWOg01juk03How258nA7fKwY+tu3nv7fYpLi1h76kpmzqlK6j2SxZimrhgr1JbR1OBIXSPXXfkl2loG8/V///7/xwWXnB0+3vPCe+x6ZjBVsr00n1P/88JwVs+D+2v59BW30N8XTMwrhOBnv/kBp59xStLkdPc7ef+JVyNSS1csn83KT5yJLWQA37ppJ9ddeSuBkBut1ZrBb/58P4uXBY3RPV293PGFu3j3rUHX0muuv5JbvvJZzKGI5Jef/ze33/itcLple042P/vND1ixOqgUXD0DvPHA0xFut8suP515Z61MauDZgVe2su3Pgymdc8oL2PCFj5BZMLHKusYz58nghWf/xVe/8J3wcWlZMb/6430RQYfjRTK3jBSKcWXvroMRygDgvrsfpKsz6N/f29TBvhc3RZwfaOuht2Hwmvff3RFWBhD03X/wvt/gciav+FF/c1dUnYGmbTX0NXWG7/nE7/4SVgYAHo+Xl55/LXxcc7Au4sEE8IdHnuRIXRMAvT19/PahJyJy7w/0O9i8cVv4uLexMyoGY/ffNuLqiqwbcCI4u/oiFDAEYy56GxNLSZ8OjDbnyaC7q5f7fvBQRFtba8ekKJCjUIwrXm90UR+n04U/XNhIR/MHovpofi2i/3D6+xz4A9HXHS9D7xerXdM0erp7o873dg/Gdcb6rJqmhT9rwB8IV+EaytHKZkBUEB+A5guga/qxP0AC6Nrocz5RGG3Ok0HAH8AR4/fm8Yxvwap4UQpBkbbMWzA7aq//k5/9KKVlwTgDe2k+M9ZEpmY2WS3kVgzmEFp58klRSeI+9dmPkZubvHTNOeUFUa6b9tL8cJvJZOLKay6Nuu7ci88Kv581p4qS0kgX0lPWr6ZyRrCabFFJIVd84qKI8waDgTVDagjnlBdEJd6rPnURmYXJ28rJLLAz87TFEW0ma+zCO+nOaHOeDIpLC/nU5z4a0Wa2mJmf5PoRyULZEBRpi5SSbZt38fDPHqXpSDOXX3Ux5154JiVlg//EvY2dHNm0j8ath8guyWf+2SsoHVJUx+8PsOXd7Tz8wO/p6erlk5+9gjM+tJ78wrykytp1uIWa13fSeaiJwtkVzN6wlKJZgw+Wo4nWfv3zx7FYzDETre3fc4hHf/0kW9/bydnnRSe3a2po5tWX3uL/nngOe04211x/Jad+4GRsQ5LsddW1sv8fm+lt6qRq7QKq1y4kqyi50bnOrn7q391L3ca95E4rZMG5a5KeUHC8GG3Ok0FHWyf/+Pur/PkPz1IxvZzP3XQ1K9YsTUlCwZTWQxgrlEKYWni9PnxeH/ackQvOuHoHMNssmDNil+j0eDz4/Rp2+9glK9QCAbz9bjJybCOm4XY6XQghRkzF7PcHcDld2HOyR0x/3dXRjSXDjD0n9jd/LRBA8x07XXgyGI+U4+NBPHOeDAb6HVgyLDHTlIwXSiEoFAqFAkhigRzF1MLv9tHX3Imnz0lWUS455QUpSYLmGXDR19SF3+0lpyw/osZAvNTuP8yB/bV4PD5mz61i6YpFCY/h6h6gr7kLqevkTCskO8nbMBA0EB/cX0tnexcV08uZPa8ay7DyqfWHG6k9VIc1I4M582dSXJpY6gqF4lgohaCIwu/1se/lzex9/r1gg4C115zDjLULxnXf093rYPPjr9CyoxYIJoTbcMuHKZ4b/x7vnu37uOtrP2bvrmAKa3tONj/5xV2sXR9/TvyB1h7e/MWzDLQF3V2tuZls+MJHkppEz+V08esHH+eXDzwKBOMlvveTr3HBRz4UnvPdO/Zz/VW3MdAfTP+9dPlCfvTAt6hIohFUMbVRXkaKKPqbuweVAYCELU+8grNzfMtf9BxpDysDCCZ32/rn1/E6PXGPsWPbnrAygOA+7m8f/jN9vfH75jfvOhxWBgCePheH395NMrdbaw7Wh5UBBA3q//2Nn9BQHyza5PP6eOTnj4WVAcDObXvZsim6zoJCcbwohaCIwuuILgwU8PoTehAnA89AjBiCli4CMfzHR6IxVGBmKLWH6ujrjl8h9B5pi2rrqm1Jqn9/rDgFl9NNf38wqM7lcscMZqqvbUyaDAqFUgiKKLKKcqKKvmQW5pA1zqkJYuXHqVwxhwx7/HUqFi2dH9W24ax1TJsRv5tk+dJZUW0zTl4QLoCTDCqml0fFXFRML6esPJgiOzcvh/OGxC0cZdmqxVFtCsXxohSCIoqc0gJO+/xFWHODLpo5ZQWs+9z54cI040X+jFJWX3UWplCwVcmC6Sy6YC2mBIzbS5ct4D9v+RRWa9Ad9QNnn8qHLzsXUwKukiXzp7PgnNUYjAaEEMxav4SK5XMS+zCjMHP2DO57+L8pLgkazWfNqeJHP/sWRcXB4DYhBJdeeSH/ccEZwQpsGRZu/er1LFupFIIieSi3U8WIuHod+J0erLlZZGSnrliQo7MPzRsgs9AeFYkbDz6vj4N7avD6/cycVUl+UeIFYXRNx9nZh5SSrKKcMfO9b2vtoL93gKKSAvIL8qLOe9wemhtbMZvNVMwoH1O/ecXkQ8UhKBQKhQJQcQiKNMfn9ODs6sdkMZFVkndc33g9Ay5c3Q7MNgvZxblRrrFaQMPZ0YsW0MguysVsix3NfKK0NrfT1dlNYVE+ZdNKR79AMWXo6+unuaEVm83K9OoKjMbk2Z+SiVIIipTR19zFpt+9RHd9GwaTkSUXr2PW6UuxJPDA7jnSzsZHXmCgrQejxcSKj32QGSfPx2QO5rP3Otwc+Nf77PvHFqSuUzKvkpVXnUVOaXKLoGx8czN33vrfdHf2UFCYx933fYNTN6xJ6j0UE5OaA4f5xu0/YPf2fZgtZr5w+3Vc/omLyLaPnIolVagNSEVKCPgD7H5uI931QZdOPaCx4y9v0nOkfZQrB/G5PGx5/JVwjIDmC7D50X/S1zhYE6CrtoW9L2xC6kEX0fYDjdT8ewe6njyX0cb6Zm77/DfpDtVp6O7q5cs3fDOpefUVExOv18vP/+c37N6+DwC/z89P7n6QPTsPjHJlalAKQZESfANuWnYejmp3tPfGPYan3013XWv0GEMC6Hrqo2MImrYewp/EmIrWlvaonPdOh4vW5viVm2Jy0tPVxxuvbIxqT9cvC0ohKFKCOTODvBklUe22/PiX0ZbMDLKKousa2HIH3WPtZdEeRYWzyjDZkpdxMr8wL6rkoslsSnptXsXEw56TzcJhtbMBSsvSMweVUgiKlGC2Wlh+2ekRBt7pq+dREENJjIQ1J5PVV58dkXRv7hnLyasc/GcrnF1O6cLB+ggZ9kwWnLsmqW6jVTMr+fp3vxg2iBsMBr7+nS9SNWv8a+Yq0ous7Ey+/PUbI1K3n3vxmTEDJtMB5XaqSCkD7b0MtPdgtlrIKS8kIyuxHP5SSgZae3B09mHJspJTXohl2Ld/j8NFf3M3mj9ATml+0gvGQHBvuPZQPa0t7ZSWFTNrTlVU5LFi6nKkron6ww1kZWcyZ241OXnJq9iXCCoOQaFQKBTA6AphTLeMhBDThRCvCiH2CiF2CyFujdHng0KIPiHEttDrm2Mp02Shr28gokj78eB1uPE6xjdhXSw8/U78bu+I5/0eH55+54jZRXVdp7OjG5crOinfRMPtcNHS0IovgQR+Y4HT4aKrozupGV0V6c9YxyEEgC9LKd8XQtiBLUKIl6WUe4b1e0NKeeEYyzIpcDldvPHqRv73x7/G7/fz2Zuu5uxzP0BufvxLUK/TQ9PWQ+x98T2EwcCSi9ZRvrQas3VsArZGwtndT907e6h5fSeZ+dks/fBpFM+rDO/F67pOx8Emdj39Fs7uAWafvpSZpy4mc0iSvcb6Zv70h6d57q8vM2tOFTfffh0rVi8d18+RLHZs3sVDD/ye3bsOcPqGk/nkZ69g3uK54yqDpmlseXc7P/3RL2ltauPyqy7mw1ecR3mFCrSbCozrlpEQ4hngZ1LKl4e0fRC4PRGFMJW3jN567V1uuOaOiLYf3P//OP+Ss+Me48jm/Wz81QsRbafffAnlS2YmRcZ4kLpk57Nvs+/FTeE2YRCcecfHwgXbu+vb+NcP/xSOIQBY8B+rWPrh9QiDwOv1cddX7+G5v74UPm+1ZvD43x5izrzx+yzJ4PCBOq792C30DFn1LV2+kPt/eTeFJYnnXjpedu/Yzyc/cgOBgBZu+/TnP86tX71e5U2aBKR0y2iYINXACuDdGKfXCSG2CyFeEEKo9I3H4KXnX4tq+/OjzxDwB+K6Xtd0av69I6r9yObxDZRx9zmoeS2yuIvUJf1NneHj/lDJyqEc+vcO3L3BIjGtze08/8w/I857PF5qD9aNjdBjSF3NkQhlAMECOI3j7K9+6MDhCGUA8MffP017W+cIVygmE+OiEIQQ2cD/AV+UUg6vTPI+UCWlXAY8ADw9whjXCyE2CyE2d3R0jKm86UxJWXTZxtJpJRiM8f0qhUFEbLkcJTNvfMPojWYTluxojyLTkGymxmG+/QCWbBsGczAPjMViJis7ujaCLTN1mVmPF5stxlyYjFjHKO/SSGRmRsuRX5CLJcbvQjH5GHOFIIQwE1QGj0kp/zL8vJSyX0rpCL1/HjALIaKiNqSUD0spV0spVxcXJ6+W7UTjrHNOJ9s+GHhltpj5+DUfiXs5L4RgzgeWRRTAMVktVK4c373qjGwbyy7fENGWVZxL/pA4hPyqErKHFclZdtnpWEMFcsorSrntvz4fcX7JsgXMXzh7bIQeQ+YsmMXpH1wb0fbpz13JzHnV4yrHwqXzqJo5PaLt9m/cSEGhCrKbCoypDUEE007+DuiWUn5xhD5lQJuUUgohTgaeIrhiGFGwqWxDADi4r5btW3cT8Ac4acUiFi6ZF5Xh81hIKelp6KC7tgVhNFA4szwimGu8CPgD9NS30V3XRka2jcJZ5VFV0hwdvXTVtuAZcFNQVUp+dWlEgRyX08Wu7fvYu+sgpeXFLF2xiIrK+KuhpRONh5vYtW0vDUeamDt/FktWLKSodPx/L0fqmtixdQ/dnT0sXraAJcsWkKFiKiYFKY1DEEKsB94AdgJHN4O/BswAkFI+KIS4GbiBoEeSG7hNSvn2scad6gpBoVAojoeU1kOQUr4JHPOrq5TyZ8DPxlIOhUKhUIyOqocwwZC6pLu+laZtNWh+jcoVcyiYWZbUgu/jhbvPSceBRpp3HiazwM60JTMpmjMt1WIpFFMWpRAmGN31rbz646fQQ66BB1/dyge+eBml86ePcmX60fj+Qbb+6bXw8eE3d7H+pospnFmeOqEUiimMijSZYDS+fyisDACQcPBfW5Na8GU8GGjvZd8/NkW0eR1uehumrkuxQpFqlEKYYAR8/qg2zeeHiZZzRko0vxbVrGsTS7EpFJMJpRAmGNNXzYsy0885YzmGNC3aPRL20nzmnLE8os1oNpFXOXVjTBSKVKNsCBOMwpllbLjlIxz45/toPo15Z6+gZMHEsx8AVJ28AEtmBkfe24ct386cDSdRPLci1WIpFFMWVQ9hgqKF7AgT0btoOD6PF6PJmNQqZgqFIpqUxiEoxo7JoAiOYhnntNsKhSI2SiEkgO73EXC7kLqOMcOK0WpLKGXEeOF3e+lt6sTVNUBmoZ3ciuKospLpgNQlfc2d9Ld0Y7JZyKssHvcke+mE1+mhr7EDd5+TrKJc8iqLMVnUv6hi/FB/bXGi+bw4Gg6jOYOplxECe/UczPbk1+c9ETR/gIOvbWfXM4PZP5ZctI55/7EqIgdQOtB+oJE3Hvhr2LOoaM40TrnuPDLzo7OxTnZ8bh97ntvIwVe3hdtWfeJMZq1fijCk35cOxeREeRnFieZ2DSoDAClxNjegB+KrQzBeDLT1sPvZdyLadj+3EUdbT4okio3P5WHbU/+OcDPtPNRMd31bCqVKHf0tXRHKAGDbk6/j6OhNiTyKqYlSCHES68Gv+7xIPdqXPpX43d6oOrhSSnyu1NdOHkrA48fR3hvV7nNM/LrIx0Os34/mD+D3pLa2smJqoRRCnBit0UVXLLkFGEzpVTgkszCXDHtk0ZgMu42swvTa2rLmZlJ18oKo9pyy8SsXmU5kF+VhHGYvsJfmxyxmpFCMFUohxInJlknWjJkIY/Cf1pybj7W0HJFmdWazCuysv/EickMBXrkVRZx2w8VkFeakWLJIDEYj8/9jNTNWBwPtMuw21n7mXPKqSka/eBKSU5bP6Tddgr0kWIimcFY5p3z2vHAxIIViPFBxCAmi+XwgdQxmM8KQvq6fXocHn9ONJctGRoxSlelCwB/A3ePAaDZOSWPycDwDLvwuLxk5mVjGuXymYvKj4hCSjNGSfu6bscjItqa1IjiKyWyKqpI2lbHaM9WqQJEylEJQKOKgv7efuoP1aJpO9ewZ5BcnXmPY5/Iw0N6LwWAguyQPs3VifLlQTB2UQlAoRuFITQM//dHDvPzi6wCsWbuMr3/3S8yaPzPuMRwdvWx+7F+072sAoHLlXJZdvoEsZTRWpBHpZRFVKNKQd99+P6wMADa9u50X//ZKQmM0bDkYVgYQLA7Utrc+aTIqFMlAKQSFYhQ2vbM1qu2Nf7+Hx+ON63pd02jeXhvV3rZHKQRFeqEUgkIxCstXLolqO3ntMqxxJuUzGI2ULp4R1V48r/KEZVMokolSCArFKJy6YTWrTj4pfDx33kwu+PCHEhpjxpoF5FUWhY+L5lZQtrg6WSIqFElBxSEoFHHQ2dpJ7YE6AprGrLlVlFWWJTyGu9/FQGs3wiDIKSsgIzs6+l2hGEtUHIJCkQSKyoooKisaveMxsOVkYstRMQaK9EVtGSkUCoUCUApBoVAoFCGUQlAoFAoFoBSCQqFQKEIohaBQKBQKQCkEhUKhUIRQCkGhUCgUgFIICoVCoQgxpgpBCDFdCPGqEGKvEGK3EOLWGH2EEOJ+IcQhIcQOIcTKsZRJoVAoFLEZ60jlAPBlKeX7Qgg7sEUI8bKUcs+QPucBc0OvtcAvQj8Vx4mjs4/mHbW07q6nbNEMpp00m+zi3FSLpVAo0pwxVQhSyhagJfR+QAixF6gAhiqES4Dfy2BSpY1CiDwhRHnoWkWCeJ0etjz2L9r2HgGgdXcdzTsOc+r1F2DJSv+SmgqFInWMmw1BCFENrADeHXaqAmgYctwYalMcB4723rAyOEr7/gYG2npSJJFCoZgojItCEEJkA/8HfFFK2T/8dIxLolKwCiGuF0JsFkJs7ujoGAsxJwUjZa+deDltFQrFeDPmCkEIYSaoDB6TUv4lRpdGYPqQ40qgeXgnKeXDUsrVUsrVxcXFYyPsJCCnNJ/i+ZGFV4rmVGAvyUuNQAqFYsIwpjYEIYQAHgH2Sil/MkK3Z4GbhRB/JGhM7lP2g+PHkmVlzdVn07S9lpYdtZQtnUnl8tkq975CoRiVsfYyOg34JLBTCLEt1PY1YAaAlPJB4HngfOAQ4AI+PcYyTXqyi/OYf/ZK5p+tPHgVCkX8jLWX0ZvEthEM7SOBm8ZSDoVCoVCMjopUVigUCgWgFIJCoVAoQiiFoFAoFApAKQSFQqFQhFAKQaFQKBQAiJEiW9MZIUQHUJ9CEYqAzhTePxEmiqxKzuQyUeSEiSPrZJCzSko5YmTvhFQIqUYIsVlKuTrVcsTDRJFVyZlcJoqcMHFknQpyqi0jhUKhUABKISgUCoUihFIIx8fDqRYgASaKrErO5DJR5ISJI+ukl1PZEBQKhUIBqBWCQqFQKEIohTAKQgijEGKrEOK5GOc+KIToE0JsC72+mSIZ64QQO0MybI5xXggh7hdCHBJC7BBCpCwNahyypsuc5gkhnhJC7BNC7BVCrBt2Pi3mNA45Uz6fQoj5Q+6/TQjRL4T44rA+6TKf8cia8jkNyfElIcRuIcQuIcQTQgjrsPOJz6mUUr2O8QJuAx4Hnotx7oOx2lMgYx1QdIzz5wMvEMw8ewrwbhrLmi5z+jvgs6H3FiAvHec0DjnTYj6HyGMEWgn6w6fdfMYpa8rnlGCZ4cOALXT8Z+DaE51TtUI4BkKISuAC4FepluUEuQT4vQyyEcgTQpSnWqh0RQiRA2wgWNwJKaVPStk7rFvK5zROOdONs4AaKeXwwNKUz2cMRpI1XTABNiGECcgkutJkwnOqFMKxuQ+4A9CP0WedEGK7EOIFIcTi8RErCgm8JITYIoS4Psb5CqBhyHFjqC0VjCYrpH5OZwEdwG9C24W/EkJkDeuTDnMaj5yQ+vkcypXAEzHa02E+hzOSrJDiOZVSNgH3AkeAFoKVJl8a1i3hOVUKYQSEEBcC7VLKLcfo9j7B5eQy4AHg6fGQLQanSSlXAucBNwkhNgw7H6tIUarcy0aTNR3m1ASsBH4hpVwBOIE7h/VJhzmNR850mE8AhBAW4GLgyVinY7SlzAVyFFlTPqdCiHyCK4CZwDQgSwhx9fBuMS495pwqhTAypwEXCyHqgD8CZwoh/jC0g5SyX0rpCL1/HjALIYrGW1ApZXPoZzvwV+DkYV0agelDjiuJXl6OC6PJmiZz2gg0SinfDR0/RfDBO7xPqud0VDnTZD6Pch7wvpSyLca5dJjPoYwoa5rM6dnAYSllh5TSD/wFOHVYn4TnVCmEEZBS/peUslJKWU1w6fiKlDJCAwshyoQQIvT+ZILz2TWecgohsoQQ9qPvgf8Adg3r9izwqZDXwSkEl5ct4ynnUflGkzUd5lRK2Qo0CCHmh5rOAvYM65byOY1HznSYzyF8nJG3YFI+n8MYUdY0mdMjwClCiMyQLGcBe4f1SXhOx7Sm8mRECPF5ACnlg8DlwA1CiADgBq6UIfP+OFIK/DX092kCHpdSvjhMzucJehwcAlzAp8dZxkRkTYc5BfgC8Fho66AW+HSazulocqbFfAohMoEPAf85pC0d5zMeWVM+p1LKd4UQTxHcvgoAW4GHT3ROVaSyQqFQKAC1ZaRQKBSKEEohKBQKhQJQCkGhUCgUIZRCUCgUCgWgFIJCoVAoQiiFoFAoFApAKQSFIiFEMPVxVCr0IeevFUL8bAzue60QYtqQ47oURhwrJilKISgUE4NrCeasUSjGDBWprJh0hNJi/Jlg7hYj8F2C0Zo/AbKBToK541uEEK8B2wjmVMoBPiOlfC+UkuA+wEYwGvXTUsr9CcpRDDwIzAg1fVFK+ZYQ4tuhtlmhn/dJKe8PXfP/gKsIZqnsBLYQrCGxmmBEshs4WgTnC0KIiwAzcIWUcl8i8ikUw1ErBMVk5FygWUq5TEq5BHiRYFbKy6WUq4BfA98b0j9LSnkqcGPoHMA+YEMoi+g3gbuPQ46fAv8jpVwDXEZkXY0FwDkEFdG3hBBmIcTqUL8VwKUElQBSyqeAzcBVUsrlUkp3aIzOUObYXwC3H4d8CkUEaoWgmIzsBO4VQvwQeA7oAZYAL4fyKBkJ5pA/yhMAUsrXhRA5Qog8wA78Tggxl2DKYPNxyHE2sCh0T4Cco8n9gL9LKb2AVwjRTjDP03rgmaMPfCHE30YZ/y+hn1sIKhCF4oRQCkEx6ZBSHhBCrCKY2Ov7wMvAbinlupEuiXH8XeBVKeVHhBDVwGvHIYoBWDfkGz0AIQXhHdKkEfxfjJW//lgcHePo9QrFCaG2jBSTjpA3jktK+QeCVaXWAsUiVIA+tD0ztMrVx0Lt6wmmCO4DcoGm0Plrj1OUl4Cbh8i1fJT+bwIXCSGsQohsguVbjzJAcNWiUIwZ6luFYjKyFLhHCKEDfuAGgimC7xdC5BL8u78P2B3q3yOEeJuQUTnU9iOCW0a3Aa8cpxy3AP8rhNgRuufrwOdH6iyl3CSEeBbYDtQTtBv0hU7/FnhwmFFZoUgqKv21YkoT8jK6XUq5OdWyAAghsqWUjlBO/teB66WU76daLsXUQK0QFIr04mEhxCLACvxOKQPFeKJWCArFcSCE+DRw67Dmt6SUN6VCHoUiGSiFoFAoFApAeRkpFAqFIoRSCAqFQqEAlEJQKBQKRQilEBQKhUIBKIWgUCgUihD/H44zLm4W/l/1AAAAAElFTkSuQmCC\n",
+ "text/plain": [
+ "| \n", + " | sepal_length | \n", + "sepal_width | \n", + "petal_length | \n", + "petal_width | \n", + "target | \n", + "
|---|---|---|---|---|---|
| 145 | \n", + "6.7 | \n", + "3.0 | \n", + "5.2 | \n", + "2.3 | \n", + "2 | \n", + "
| 146 | \n", + "6.3 | \n", + "2.5 | \n", + "5.0 | \n", + "1.9 | \n", + "2 | \n", + "
| 147 | \n", + "6.5 | \n", + "3.0 | \n", + "5.2 | \n", + "2.0 | \n", + "2 | \n", + "
| 148 | \n", + "6.2 | \n", + "3.4 | \n", + "5.4 | \n", + "2.3 | \n", + "2 | \n", + "
| 149 | \n", + "5.9 | \n", + "3.0 | \n", + "5.1 | \n", + "1.8 | \n", + "2 | \n", + "
"
+ ]
+ },
+ "metadata": {
+ "needs_background": "light"
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "import seaborn as sns\n",
+ "sns.scatterplot(x='sepal_length', y='sepal_width', hue='target', data=df);"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 64,
+ "id": "443c3ab5",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "(150, 2)\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Target 값을 제외한 모든 속성 값을 MinMaxScaler를 이용하여 변환\n",
+ "df_features = df[['sepal_length','sepal_width','petal_length','petal_width']]\n",
+ "df_scaler = MinMaxScaler().fit_transform(df_features)\n",
+ "\n",
+ "# PCA를 이용하여 4차원 변수를 2차원으로 변환\n",
+ "pca = PCA(n_components=2)\n",
+ "\n",
+ "#fit( )과 transform( ) 을 호출하여 PCA 변환 / 데이터 반환\n",
+ "df_pca = pca.fit_transform(df_scaler)\n",
+ "print(df_pca.shape)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 65,
+ "id": "08992c12",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "
\n",
+ "\n",
+ "\n",
+ " \n",
+ "
\n",
+ "
"
+ ],
+ "text/plain": [
+ " PCA_1 PCA_2 target\n",
+ "0 -0.630703 0.107578 0\n",
+ "1 -0.622905 -0.104260 0\n",
+ "2 -0.669520 -0.051417 0"
+ ]
+ },
+ "execution_count": 65,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "df_pca = pd.DataFrame(df_pca)\n",
+ "df_pca.columns = ['PCA_1','PCA_2']\n",
+ "df_pca['target']=df.target\n",
+ "df_pca.head(3)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 66,
+ "id": "2d386873",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAYsAAAEHCAYAAABfkmooAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjQuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8rg+JYAAAACXBIWXMAAAsTAAALEwEAmpwYAABbVElEQVR4nO3dd5yU1bnA8d+ZXrf3vrCURZp0FAQUe8cSNc3EqzGapjGJ0fRyY2KK5ibGaIzRxGhiDZbYG4JIEaT37b2X6eXcP2YZGGZg2+zOAuf7+fBh58w77zwLu/O87ynPEVJKFEVRFOVYNIkOQFEURRn7VLJQFEVR+qWShaIoitIvlSwURVGUfqlkoSiKovRLl+gARkJGRoYsKSlJdBiKoijHlY0bN7ZKKTNjPXdCJouSkhI2bNiQ6DAURVGOK0KIqqM9p7qhFEVRlH6pZKEoiqL0SyULRVEUpV8qWSiKoij9UslCURRF6dcJORvqRBLweQm4XEgZRGs0oTOZEx2SoignIZUsxrCAx0Nv9X4CLmeoQaMhadxEdBZbYgNTFOWko7qhxjC/s/dQogAIBnE2NSCDgcQFpSjKSUklizEs4HFHtQXdLmQwmIBoFEU5malkMYbprNHdTYaUNIRW9R4qijK61KfOGKazWDHnFuJqqoNgEENKKsa0TIQQiQ5NURSgtrqe1e+t45ON25l3+iwWLppNdm5WosMaESpZjGEarQ5TRhaG5BRkMIjWYEBotIkOS1EUoKOtk+/fcQ8bP/oEgJeef52LVpzD939+O2bLiTdrUXVDjXFCCLQGIzqTWSUKRRlDDuyvCieKg1567nWqKmoTFNHIUslCURRlCIKB2BNNAifoBBSVLBRFUYagdHwRZRNLItoWnjGXouKCxAQ0wtSYhaIoyhBkZKXz6z/9hJeee40PV23kzHMXcd7FZ2JPsh71Nc1NrRzYW4VGIxhXVkxGVvooRjw8QkqZ6Bjibs6cOVJtfqQoymjxer0YDIZjHlOxv5rbv/R99u+tBGDSlDJ+/cCPKS4dO3ciQoiNUso5sZ5T3VCKoijD1F+iAHh15VvhRAGwe8c+3n3jgxGMKr5UslAURRlhUkrWrfk4qv3I2VRjmUoWiqIoI0wIwfILlkS1L1l+egKiGRqVLBRFUUbBsrMXce5Fy8KPL7niXE5fMi+BEQ2OGuBWFEUZJS6ni+rKOoQQFJXkYzKbEh1ShGMNcKups4qiKKPEbDEzaUpZosMYEtUNpSiKovRL3VmMkoDXQ8DtAinRmixojcZEh6QoijJgKlmMgoDbRU/FXoI+LwBCp8NeOhGd2ZLgyBRFUQZGdUONAm93ZzhRAEi/H09HWwIjUhRFGRyVLEaB3+WIags4HZyIM9EURTkxJTxZCCHOE0LsFkLsE0LceYzj5gohAkKIK0czvngwJKVGt6WmqR3vFEU5biQ0WQghtMAfgfOBKcC1QogpRznul8BroxthfOhtSZgyc0AIQGBMz0KflJLosBRFUQYs0QPc84B9UsoDAEKIp4BLgR1HHPdV4Flg7uiGFx8avR5zTj7GtAwkoNUbEJqE39QpiqIMWKI/sfKBmsMe1/a1hQkh8oHLgQePdSIhxE1CiA1CiA0tLS1xD3S4hBBojSZ0RlNEogj6fQQOG/xWFEUZixKdLGJ12h856nsf8B0pZeBYJ5JSPiSlnCOlnJOZmRmv+EaMDATwdLbRvXcn3Xu242qqj5gxpSiKMpYkuhuqFig87HEBUH/EMXOAp/oGgzOAC4QQfinlC6MS4QjxOXtxVFeEH7ua6kGrxZyRncCoFEVRYkt0slgPTBBClAJ1wDXAdYcfIKUsPfi1EOJvwEvHe6IA8Pf2RLV521owpqaj0Sb6v0VRFCVSQj+VpJR+IcRXCM1y0gJ/lVJuF0Lc3Pf8MccpjmcavT6qTRiMCJHonkFFUZRoCb+ElVK+ArxyRFvMJCGlvH40YhoNelsSQqdH+n2hBiEwZ+WoWVKKooxJCU8WJyutyYx9/CQCLicyGERnMqNVtaIURRmjVLKIk2DAj/QHEDodGq12QK/R9U2lVRRFGetUsogDv9OBo76agNOB1mLDmleIzmJNdFiKoihxozrIhyng9dBTuZeAM1QsMODspadqHwGvWjOhKCczl8tNTVU9HW2diQ4lLlSyGKag14P0+yPapM9H0OtJUESKoiTa/r2VfPsrP+bCM67lsytu5cNVGwgGg4kOa1hUshgmcZQ1EWKA4xaKopxYensd/O/3fsd7b64BoLqyllu/8B3276lMbGDDpJLFMGmNxlBF2cOYsnLRqoFrRTkpNdW3sH7t5og2v89P5YGa2C84TqgB7mESGi2mzBz09iQCXi9agwGt2aLWSyjKScpsNZOUbKe7K7JKQ1KKPUERxYf6RIsDjU4X2rMiLQO9LUmV61CUk1hefjZ3/vhrEW1nX7CEiZPHJyii+FCfaoqiKHF29gVLKSopoOpADWkZKUw+ZSKpacmJDmtYVLJQFEWJM6PRwPRTpzD91KiNP49bqhtqjAkG/AQ8boIBf/8HK4qijBJ1ZzGG+J29OOqqCbicaC1WrHlFESvBpQwS8HiQAT8avRGNTgdIhEZN01UUZWSpZDFGBDweeir2IfvuKAJOB71V+7CXlaPVG5CBAO72VlyNtWgMRozpmfi6O5HBIKaMbPT25AHXpFIURRks1Q01RgS8nnCiOCh42Epwv9uJq6EGpMSYloGrvgZ/bw8BpwNH9QF8PV2JCFtRlJOEShZjxNHuCg52MQX7ak1p9AYCblfUce7WJmTwmNuUK4qiDJlKFmOE1miKXgmenRdeCa7RGwCQUsbcTS+0CFCMeJyKopyc1JjFGCG0fSvBbUkE/V40egNaszW8ElxrtmDKzMHd0ojGYAQhQMrw682ZuWrVuKIoI0YlizFEo9OhsSfFfk6rxZydiyE5lWAwiL10Ir7ebmQwiCEpRe2foSjKiFLJ4jgiNNqIpKC3Hd+1ZhRFOX6ofgtFURSlXypZKIqiKP1SyUJRFEXpl0oWiqIoSr9UslAURVH6pZKFoiiK0i81dXaUBLweAh4PGq0GqdES9LgRQoPWaARCi/I0On2Co1QURYlNJYtR4Hc5QhVl/T4A9EkpCI0Gb2c7GqMJQ1Iy3q5OrPlF6GxJCBFZtkMGg/hdTgJuFxqtFq3FitZgTMS3oijKSUp1Q40wGQjgbKwPJwoAX3cnWpMZrdlC0OcFBEGfj57KfTGLBPp6uunZvwtnXRW91QfordxHoK8araIoymhQyWKEBYMBAs7eiDZTZjYyKNHo9JjSsxB6Q2gjIykJeNyRr/f7cDZUR7QF3C4CLueIx64oinJQwpOFEOI8IcRuIcQ+IcSdMZ7/tBBiS9+fNUKIGYmIc6g0Wh0626F6T4aUNHy9Pbib6/H1dOFuacTf24XmYHVZbWTPoAwGCfp8HCkYUOXIFUUZPQlNFkIILfBH4HxgCnCtEOLIHc4rgCVSyunAT4GHRjfK4REaDebs3HAy0BpNUXcFvu4udBYr+qQUtGZzxHMavQFjWkbUeXUmc1SboijKSEn0APc8YJ+U8gCAEOIp4FJgx8EDpJRrDjt+LVAwqhHGgc5kIWn8pND+2X5/7GMsVkzpmVEzooQQmDKyQQg87a1o9AYseYVozZbRCF1Rjkvd3b1U7q/G6/FSXFpAZnb0BZcyOIlOFvlAzWGPa4H5xzj+BuC/sZ4QQtwE3ARQVFQUr/jiRqPTo9HpCfp8aE3miIFsnT0JndWGRqsj6PeBlOHNjiB0N2LJLcSUkYPQaELjG4qixNTY0MyvfvwH3vzvewCUji/iNw/+hLKJpQmO7PiW6DGLWFu7yRhtCCGWEUoW34n1vJTyISnlHCnlnMzMzDiGGF8avR5r0ThM2XnoLDbMuQVY84oQCDyd7XTv20XXnh24mhv6ZkqFCCHQGgwqUSgjqrO2lX3vbWH3mx/TVtGIDMb8dRzTNq3bEk4UABX7q3nqsefxH+WuXhmYRH/y1AKFhz0uAOqPPEgIMR34C3C+lLJtlGIbMTqTGZ3JjMzKDa+p8PZ046g+ED7G1ViH0GhCXVCKMgo6alt499dP43OHLlKERsPS264gc0J+giMbnB1b90S1rf1gA85eF0kpag+YoUp0slgPTBBClAJ1wDXAdYcfIIQoAp4DPiuljP4pOI4dvvjO39sd9by7rQVDanrUDClFGQmNWyvCiQJCM/F2v7mRtNIctDptAiMbmJrqevbs2EfxuMKo5844ayG2pMHtJhkMBqmuqKW310FufjbpGWnxChW/38/eXQeorqwjOcXOpCllpKalxO38IyGhn0JSSr8Q4ivAa4AW+KuUcrsQ4ua+5x8EfgCkAw/0fbj6pZRzEhXzSBH66FIfGr0BIRLdU6icLNw90Wt3XF0OZDBI6Ndz7Ko8UMMtn/sWtTUNXHT5OSw//wxWv7sOq91CZnYGV113CZpB7FHvcrr5zzP/5Tc/ewCPx0tRSQH3PvAjyk+ZEJd4V7+7jq/feDfBYBCAcy5cyl0/vY209JS4nH8kJPyTSEr5ipRyopRyvJTy531tD/YlCqSU/yOlTJVSzuz7c8IliqDfj95qR2u1HWoUAnNWLmIQP+CKMhx508dFtU1YOhOdYezXLNuwdjO1NQ0AvPriW8yeP4Nbbv8iF11+Dl+5/Ytk5QxuHHPPzn387/fvw+MJ3WlVV9byv9+/j54ex7BjbWlu46d3/SacKABef/lddu/YN+xzjyTVv5FAUkr8jh6c9bUEPG4MKamYM3MJ+rzozBY1PVYZVenj8jj95ovZ/tJa/F4fk8+ZQ+7UkkSHFcHv94MEnT7yo6u5sSX89XVfuIJ/PPIMdX3J429/foof/fJbrLjmoqOe1+f1sWPrbrZv3UNSkg1/jEWvn2zcRntrB3b74LqzDtfb46CupoHmptao5zo7uoZ83tGgkkUCBdwueir2ggzNOPF2tCEDQWxFJQjN2L7tV048OoOO/JnjyZpUQDAgMdpMiQ4pzO/3s3nDNv7x12fo7urh2utXsHDRbGz20N34rHmHCjvYbNZwojjovnseYtHSBWTlxF5vsXb1Rr7yhTuRfb+Lt9/15ahjSsYXkZRsi2ofqLaWdn53z59pb+1g9vwZbPzok/BzGo2G4tKxvYRM9XEkUMDjDieKg3zdHQS80eU9FGW06M3GMZUoALZ/spsbr7udt19bxYa1m/nmzT9g9Xvrw89PP3UK//u7u8nISgt/4B/O4XDi98WeOtvT1cP9v3wo/LrSsmJcLjef+tzl4WMsVjM/+N9vDmsQetsnO1n5zKusfm8di5ctYNbc6QCkZ6bxmz/9mAmTxw/53KNB3VkkUKy7B6HVIjSxlp8oSmwBn5/2qiY6q5sx2Mykl+Zgy0xJdFhxtfr9dQSO6Br625+fYvGZC7BYzFisZi5acQ4LFs2msb6ZRx98Erf7UGXm665fQXZe7HELj9dHW2sHGo2Gm79xPdUVtbz8/OtccuX5PPzk7/B5fRQW5w/7yr+6sg4IdT/f/8uHOH3pPG795g2cc+FSSsePvYXER1LJYoT4nQ58vd0gJTpbEjqLNWqfCp3ZgtZqI+A4VJXWkleo9qpQBqVxeyWrH3wp/NiWncIZX70cW0ZyzOMdbd007aqmZXcNmZMKyZ5chDU9KeaxY4UhxiC70WRAc8SFVUZWOhlZ6Tz8z9/ylweeoGJfFZd/6kIuvOxstNrYXbsZmWlc87nLqK6o442X32Xv7tB6pz/8+i+UlhXzyJO/IyMrfdjfQ2lZcfhrKSUfvPMR9iQb+QU5wz73aFDJYgT4nA569u861MXU1IB93ET0tsgFQRq9HlthKQGXk6Dfj9ZkQqcGtZVB8PQ42fzM+xFtvU2ddFQ1xUwWXqeHTU+9Q/3WCgCq1u0mb3op864/D4Ol/4uU3pZOOutCg7Mp+Rmjdgdz2hlzeej3j0fcLdxwy6cxmWJ3l82YPZVfP/BjPC7PgBbiXXb1Baxbs4kXn3stor1iXxWVFTVxSRZTZ0zm8zddw9//8m+CwSBlE0u58dbPYDAa+n/xGKCSxRDJvr0nAm43Gq0Grckcrufk62w/YixC4mlrQWe1Rd1daA1GdSehDFnAH8DTE71hlt8Te9yrp6kjnCgOqt9SQU9TB+mlx77C7apr5b37n8PdHVqPYUq2sORrK0jOH/kifVOmTeLRp3/PW6++T3dXD+dcuIwZs6fGPLa9rRMpJekZqTgdTtat+ZjeHgdFpQWMn1AS9TsIkJ2TyfgJJTHPZzDE58M8JTWZr9xxAxevOAeXy01hcR5p6alxOfdoUMliiPyOXnoq9oSTgs5mx1pYilZvIBijBk0wcKgt6PPid/TidfSgM1nQ2+xojWNrQFE5PpiTbYxfMp3dr28MtwmNOOoHuDxsbv9A2g9XvX53OFEAuLucVG/Yw7RhJItAIIAMyqipsLHk5mVzyZXnk5qWTHJKdLdZb08vb726ij/+9q8E/AG++5Ov89Lzb/D2a6sAMBoN/Onxe5mzYGbM85eMK+SSK85j5bOvhtvOuXBZXMcTjEYDE8vH9kD20ahkMQTBgB9nQ03E3YO/t4eA04k22YAhNQ1vZ2QJK1N6JkIIZDCIq6URT2szAF5Aa7ZiLylDE2MVt6Ici9AIypbMQKPTcmDVNiypdqZffjophaHBXL/Pj7OjBxkIYE62Y89OJa0kh/bKxvA50kpysGX3f4XbUd0c3VbVNKS4D58K29vdy7XXr2D+otnYbLHXMGxYu5kffvtX1FTVMa6smB/f+x1mzDol8piPPuH7d9wTfrx/b2U4UQB4PF5+8cPf89d/3Rcz2fh8PqafWk5BUS61NQ3kFeQwd+Gp2JOGPl32RKKSxRDIQCBq+1MIbYEKoLfYsBWPx9XcAFJiyswBocHV0ojWZA4nioMCLgd+twuDShbKEFjTk5h68ULKlsxAZ9ChN4e6NR1t3TRsr6SrtpX6LQewpNmZevFC5n/xXKrW7aJhayW500oonjsZky20mZajvQdnWzcGqwl7dgqawwaFi+ZNonFHVcR7F82bPKSYt3+yixuvuz08w2ndh5v49Z9+zDkXLI06tqaqjq/feDc93aGJIAf2VXHbl77HP//zZ3LyssLHvfri2xGv88aYgn5gbyWOXmfMZLFn535+9r3fodPrSE9Ppa2tg+f/9TJPrvxzXMYsjncqWQyBRqfHkJQadfdwsCtJaLUYklPR2ZKQwQDOhtrQOAZgysqNec6g14MMBiPKewQ8bgIuF1IG0ZrM4cFvv8uJt6uDgNuFISUNndWOViWak5oQAnNy5FV5065q2g40ULV2JwCuzl5W/eEFzrrzGqZetJDyc+eh1R9KBq3761n94It4elwIjYYZVy5m3OlT0RlDP1vZ5cWUnz+X3W98DMCks2eRXT60LppV734UPRX2wSdZvHQBZktkl2xdTWM4UYRjbW6noa6JnLwsnA4nGq2G/ILI3y1zjMHvM89dRHpm7Luo3h4H13/pGvQGPY4eJyuffZWmhhZ6enpVskAliyE5uFVqMODH39OF0Ggx5xZEzWTSaLX43E58ne3o7cnoLFbQCCx5RbiaG5B9dyJCrw8lBo/7UEJwu+it2HtoTwuhwT5uIhqdjp6KPeEd93zdnZhzCjBlZsccuFNOTn6vD6/DTc2GyELNwUCQrro2UguzIhKFu8fJ+sfeCA+Wy2CQzf9+j/TS3PDAtznZyikXL6T0tFD3jyU9aVDF+Q4Xa9DYYDTEXGOUkpoU6sI9rNtXp9dhtpp45T9v8thDT2G2mPnS1z7PU48/H04sH7z7EXf/7Dbu/+VD9PY4mLtgJrd+84sYjdETSgKBAG6Xm00btlJ1oBadXsstt32Bd99aQ0amShSgkkVMB2c6Sb8fjcEQc7aS1mjCXjSOgM+LEBq0MX4AAWQgiD4pBQBXU99WHUJgyS/G09qM1mhEa7bgaqrHkHzoisff2xOx+REyiLulAUNKejhRGPu2YZUBP77ebvRWmyoTogCg1ekwWEwYrCbcXZHF73SG6F97T4+TnuaOqHZne3fELCmNRhOX6bKnL5nHw//3eLhQH8D/3PoZTKbo36OS8UXcescN/OHev4Tb7rj7FhrrW7jzaz8Nt33zyz/g/r/8nPraRoJByZSpE5k0pYxFS+fjcrrIyc8+6pjI3t0HqDhQQ2paClOnT8Zqt/K3h5/i9w//Qo1Z9FHJ4ggyGMDT0YazPjSALbQ6bCXj0Vuj52oLrRad1nzM82lNRnQWK67GusPeROJuqseYkYm3vQ1vVwcavQHtYVdbEYmiT8DjCQ+qG9My8DsdBFx9s1NaGrEWlWJMUVdBSmjgO600h7KlM9j2n0Pb2NuzU0kpzoo63mizYM1IwtEaua+KOXVkNguaMm0ijz79f7z53/fo6e7l3IuOPhXWZDLy6euvYP7CU2mobyavIIeScUXcev23I47r7XHwzusf8O0ffDWiPb8wdtfvQX6/n5eff4PHHvpXuK2gKI+zz1sS1VUWD22tHaxb8zFvv7aKyVMnsOzsRYw7bMHeWKWSxRECbjfOuurwYxnw46ipIGl8+ZBmK2kNJkSMzYuCPi8agwmdLQm0Wqx5RRH7butsdmhpjHiNMS0DrdmC0GrR6A0E2iMrVzrratBZ7BFJRzl5peRnoNXrSMpJo6u+DUuqjcwJ+djSoxfrmZIszPvcOXzw4Iv4nB6EEEy97DRS8kfm4kMIwdQZk5k6Y2AD5FabhRmzpzJjduix3+cnKTk6kSUlDT657dtTwROPPhvRVltdT0paCqlpsVfBD1UgEOCpx57jz79/HIDXXnqHZ554kUeeuo+8Mb6SWyWLIwRiXNEHvV6Cft+Qp7bqzNF3HzqLDW97KwGfF1vROHQmc9TzloJiXA11yGAAU0Y2hpQ0tHoD9nGT8PX2RJ1TBvwg+58vr5w87Fkp2LNSKDi1rN9jMycWcPZd1+Jo7cZoM2PPTkU7gPUPiaDT67j+S9ew+r114X0hzGYTZ5y1cFDnCQQCVOyrjrnXeG5+NgVFeXGJ96C6mkYe/fNTR7Q1sHf3AZUsjjdaXewd6zS6of9TaU0WrIUlOOtqkMEAWpMZY0YW3o42gm4XAbcrKllotFpMaZno7ckgZd+ueaHBv4OD4C4hItZ6GFLSIu5OFGWwbBkp2DJSEh3GgMycM42/PfN/rH5vHWaziQWL5zBl6kR8Pj8NdY0IoSG/MOeYg/BNDS089dhznHPhUv678q1we3pmGqfOid0tNhxSBgnG6NoKBsb+RZ5KFkfQmsyYcwpwNdYCocqw1sKSYX0IC40GY2oGWpOlr0SIE0dNBVqTBUteYcwV3+F4jvK+WpMZe+mE0MZJXjeGlHTMmdlqZz0l4fweL872XrR6LdajFDOMB71ex8zZU5l52FhHU2MLf//Lv/nn355Dq9HwxVs+zac+e+lRy2potVr2761i/MRSPn/Tp9i0fitFJQVctOIcCovz4x5zXkEOn/rc5Tzx12fCbWkZqZRNKo37e8XbgJOFEEIvpfQd0ZYhpYze8uk4JrRaTBlZ6O1JoeJ+BkPcSnEInR5X9QGCfQv6Ai4HLq8HW8ngl/8LIdDbkrCPm4gMBtHo9WrqrBLF2dGDo60bvdmIPStlxLuVepo62PzM+zRsrUBnMjBjxSKK509GZzQQDAbZs3M/+/dWYrGYmTx1Arl52XF9/3ffWM3jD/8bgDPOXYwMBtm6aSdzFs7Eao0u0pmdm8nXvn0jP7v7tyQl25kybRKNDc2UjC+kvrYRt8tNTl4WlhivHQq9Xs/1X7qGcWXFrHz2VabNLOeyqy4YkcQUbyLWRiERBwixDPg7YAQ2ATdJKSv7nvtYSjlrpIMcrDlz5sgNGzYkOowIfo+bgMuBo7oi6jlbSRmGvum1B8lggIDbTfDg9F2jSSUDZVDaKxv54E8v4u5yIDSCUy5eyISlM8IrvOMt4A/w8ZNvU7F6e0T70tuvJGtiAevWbOLmz90R3oRo0pQy7nvoZ/3OVhoovz/A9Vd9lS0fb+cLX7qWTz7ezsfrtwBw7kXLuP2uL5ObH52cent62bxhG2tWraewKJ8Fi2azdfNOfvnj/6Onu5eFZ8zlzh9+jdKy+O45EQgEjlo2PVGEEBullHNiPTeQPotfAedKKTOBh4A3hBALDp47TjGe0AJeL70V+wi43cT6J9McMVtKBgK4W5vp3reT3sq9dO/dga9nbO/Pq4wtHoebjU++HV5jIYOSbf9ZEy4vPiLv2eOkduPeqPbuhjZ6exzc98s/R+xWt3vHPrZ9situ76/TaTll+iQystJwud3hRAGhWUcffhD7AtJmt7Fo2QK+/YOvcu31K+js7OZ73/xFeHHfh++v50/3PRqxJiQexlqi6M9AkoVBSrkdQEr5DHAZ8JgQ4nLg2LclChDaazvodePr7sSYHlmh05CageaIwe2AxxW1LsNRU0nA60FRBsLrcNNRFV34z9nWHdXmc3uo33qA1Q++yMZ/vkVbRUPMrUn7ozcZSMqLnmprTrbidLqoraqPeq69LXoh4HCs+NSFzJw9lR1bdkc9t3bVwHobqg7URLW9+d/3aGtpH3Z8x7OBJAufECI8p6svcZwF/BCYMFKBnVD6prMG3C4CHjfm7HxMWblYi8djzsmPKNYGEIyxV7AM+ENTYxVlAIxWE8kF0duIxlpk17i9ig/+uJK6zfvZ//5W3vnNMzErzPZHbzYyfcWiiHGRrEmFpBZnk5GZxqVXnR/1mklTIqf0BgIBenscUccN1KQpZXzz7luZPW9G1HOz5k0f0DnS0lOi2krLSrDaTu6NyQYy2nUnkA2EV4hJKWuFEEuAr4xUYCcSjdGEPikVX3cn/t4e/L09GNIyMNuTY85e0sRYVBeavqumxSoDY7CamH3dmax+YCWeXhcImHLB/HDp8oN8Lg87/rsuoi3oD9C8u4a04sEPPmeW5bP8rmvpaexAZ9STXJCBOSlUYuOaz16Go9fBC/9+heTUZO64+8vIoOSt195n3PhifH4/Tz32PB+v38LZ5y/lkivPHdLAb35hDpd96gJWr1rHnh37AZg9fwaLls4f0OvLp05iyVmn8d5boZXveoOe7/zwqzEr1Z5M+h3gHvCJhHhWSnlFXE42TGNlgDvo8+Ht7sTd2oTQajGmZeLt6kBvS0JvsyMDfoRGGxq8PuzuQgaDeLs6cNRVQTCI0OmxFY+LWXIEQrWsgj4fQqMZ1noQ5cTjaOvG0dqF3mLEnpMWtcmQz+Xh7d88TVdt5FjG9BWLmHxOzHHOYfH5fDQ3tuLz+fjdL/7MO69/AMD1X7qG/658m6aGQ3c0i89cwL1/+OGQZyK1tbRTsb8avz+ARquluaGZcROKmTSlrN/xgva2Dvbs3E9Pt4OS8YWUTSw9KSaYHGuAO56fLOPieK4TgrenC2fdofr/TqcD+7hJCI0monKsMSMbc1YOmr4FgUKjCZUet1hDs6GOqBt1uIDXg6e1GU97K0Kvx5JXiN5mRwi13kIJ7XVhTT/6FbHebGTK+fP48OFXwm0anZasSYUjEo9erye/MJe3Xl0VThQARqMxIlEArHp7LdVV9Uye0v/q81jSM9Pw+fx869Yf8cnHoRlaWq2WPzx6D6cvmXfM16alp7JgUfyT5fEsnslCDXYfJhjw4+mr7aSz2kN3ElIS9Hrwu53hRAHgaW3CYE9CYz+0gEkIgdZoQnuMWY5SStytzXhaQ7uVSU+A3oq9JJVNRmdRlTJPdgGfn46aFrrqWjFYjKQVZ8dcJJdzSjGLbr2EAx9sw5RkpXThFFKLoosNxlNzU0vEY602+uJGq9Wi0w1vxtCOrbvDiQJCYyK//PH/8fizfyAldeQWDJ6IVJ/FCBEIhE6HBhNas/lQeXIIb4zk7z00MyXg8zLYylNBnw9Pe0tUu9/lUslCoXFHFasffDF8GZdckMGiL18SdaehNxnJmzaOvGmj1zlQNjFyxXJtdT3TTp3C1k07wm3XfeEKiksKhvU+3V3RNdTqaxtxOd0qWQxSPJPFid+hNwBBvw+/00nA7cSYnkXA7cJ9RPVYb1cH5uy8iGQRa8+M/oTGKPQEj5hSe+TsKuXk4+lxsvmZ9yLu97tqW+mobj5mt9RoOWX6JO7+2W387hcP4nS46Orq4fs/u41dO/axc/te5syfyax509AbhrcDZGlZcdTGSRevOIeMrLThfgtjTntbJxX7KvH7A5SWFZOVndH/iwZhyMlCCFEIXCOlvLev6TvxCen4JYNB3K3NuJsbgNAsKHN2XkSxv/Cxh31tyspFax78IJ5Gp8OSW0hv1b5DbSYTWnPsDV6Uk0fA58fd6Yxq97kGtrDM7/PT09iO1+HGmp6MLTO+V+EWq4VPffYyTl86D4/bS15+DmaLiclTJ3JZHN9nytSJ/PbBn3DPD39Pa0s7F15+Nl+4+Tr0J9g2xLXV9dx9+/+yaf1WAIpLC7nv4Z8xfkJJ3N5jUMlCCJEBXAVcC+QDzx98Tkr5+lACEEKcB9wPaIG/SCnvOeJ50ff8BYATuF5K+fFQ3mukBbwe3M2H7iKCHje+ni40RlO4HhT07dGdlBIaiD44G2qIBQD19iTs4ycTcLtCmzGZrUfdtU85Mbh7nHRUNePs6MGenYrOZMDT7cSUbAnPeDIl2xi3aCp739kcfp0QgqS8/q+ofS4Pe97axPaX14IMDYIvuuUSMifEv35RQWF8S4AfSW/Qc9Z5ZzBj9lTcbg/Z2RnDvlsZiz5ctSGcKACqKmp44d//5fa7bo7bLK5+k4UQwg5cDlwHTCSUIMZJKYfXmRg6txb4I3A2UAusF0KslFLuOOyw8wkt/psAzAf+1Pf32BMMcuQ4v7ezHXvJBFytjfh7utGaLVjyiqL26x4qodGgt9rQW9UYxcnA5/ay/cW17H9/C6ZkKxOWzWT7ix+GSlwLOPWqpYxbPBWtXseEs05FaAQVq7djTrUz88rFpBb2P3DdWdfG9pfWHnpPl4dtL68la9kUGuqbSc9IY8LkUmz24+dnLiPzxOt2OtyWTduj2tat+RiPxxtzq9qhGMidRTOwDvge8IGUUvaV+oiHecA+KeUBACHEU8ClwOHJ4lLgcRnqdFwrhEgRQuRKKRviFEPcaAxGtBYrAeehFahCo0VjNGIrGh9aV6HVRtWCUpSB6m5sZ//7oZpHxfMns/PV9Yf2QpCw+en3yJiQR2phFraMZKZfsZiJy2ehM+gxWAdWPdnVETkobEq20mYXfOPSL4f7/r/wpWu56WufO+lXNY8V80+fzX+efjWibfn5Z8QtUcDAyn3cBZgIXdF/Vwgx+HraR5cPHF6IpbavbbDHIIS4SQixQQixoaUleobQaNDodNgKSjCkZaIxWbDkF4cGsp0OpN+H1mBUiUIZFr/70JiDRquNeAx906m7Dl2saDQaLKn2AScKAEt6EtbsFDLOKMc4t4Ss5dP4x5MvRAwSP/rnJ9m/N7qCspIY8xbOYsU1F4W7nBYtm8/5F58V1/fo95NLSvk74HdCiHGExipeAPKEEN8BnpdS7hnG+8fqTDtyNHggxyClfIhQVVzmzJmTsDUfWpMZa34Rvp5ueisPVeDUGAzYSyfGbW8M5eTh6XXR09yB3+3DYDNhSrLg7nbi93gx2i14eg4NZGt0Wixpw5vtZM1OpqvIxve+90sCgQAGo4FbbvsCf3/k6Yhieu2tncN6HyV+snIyuPNHX+W661cQCAQoLMnHZovvRJcBj6pKKQ9IKX8upZwGzAWSgf8O8/1rgcOXihYAR5amHMgxY4oMBiPWVUBoH2+/c+gF0pSTk7Ozl6qPdrHub6+z8Ym3qNu8nwU3nE/W5EJqNuxh+mWnY7SHuoL0JgPzv3ge9pzYu8INVHVVPb/62R8J9G3/6fV4eeSBJ7h4xTnhY/QGPYXFQx+c7uzoYuumHezctgenwzWseJUQk9nExPLxlE+dGPdEAQMb4C4DsqWUqw+2SSm3CiFSgb8O8/3XAxOEEKVAHXANoYH0w60EvtI3njEf6BqL4xURgkGCvugpikG/L8bBinJ0rfvr2fz0e+HHO19Zh1anZc5nlyOEBqPNRHZ5Ea6uXow2M7bMlEGd3+f20LqvgdpN+7Ck2sibOZ6W5jaCwUN7QgshOO/iMyktK+bmr38ejUbD1BnllJYVD+l7qjxQw/e++Qu29K2svviKc/n6t28iKye+6wKU+BpIB/p9hMYtjuQEfgdcPNQ3l1L6hRBfAV4jNHX2r1LK7UKIm/uefxB4hdC02X197/mFob7faBE6Hcb0TNxH3F3o1PoHZZDqP9kf1da4o4rC2ROxZYfWPujS9FjSYheZ7Pf8Wyr46K+HBkb3vL2JyZ8/E51Oi98furP4/E2f4oN3PuLpJ1YCkJqWzJ//8Rs0Q5juLaXk+X+9Ek4UAC8++xqnL5nHBZcuH9L3oIyOgfxvl0gptxzZKKXcAJQMNwAp5StSyolSyvFSyp/3tT3YlyiQIbf2PT+t733HNCEExtQMTJk5oNGgMRiwFo9HZ1HJ4mQR8PrpaezAEWOzocGwpEQnAaPdgjHJHNXu7nZS9dFOVv3hBbauXENXP7vieXpdbFv5YUSbz+nB7JX84r7vYbaYMVvM6HQ69u05NJjd0d7FE48+g98/+P1VnA4n7721Oqp984Ztgz6XMroGcmdxrBHZ6J9YBQCtwYA5Jx9jehZCI8IVZZUTX09zB1v/s4baj/eiNxuZsWIxRXMnojMOfj+SgjkT2Pf+lvCsJ41OS9mS6RjMkb+WMiip+HA7DVsqcLR107CtkooPtrHsjquxZ6XEPLeUkmDf3cPhAi4f51y0jMlTJ+DodfLCv6OHJrdt3oXb5cFmH9zsPrPFzMLFczmwtyqifdrM8kGdRxl9A7mzWC+EuPHIRiHEDcDG+Id0fAr4vHi7u/B0deB3hwbshBBoDQaERos8rA9YOXEFA0H2vrUptBe1DF2pb/jHm7RXNg3pfGlF2Zz5rauZdd2ZzLx6CcvuuCpm+fCuhjZ8Tg9CqyFvWimnXLQAT6/7mHcXJruF8vPmRrRpdFrSSrIRQlBcWsiUaZNYsGh21GvPv3Q5Nvvg75Q1Gg1XXXcx48pKwm1Llp/GnAUzB32ugzweL+2tHRF3OlJKXE73MV6lDNZALgu+ATwvhPg0h5LDHMBAaGX3SS/g8dBbvZ+Aq28Ko0ZD0riJaE0WfL09uFsbQYIpMxu91R6x0ZFyYvH0OKleH73/c3t185D3iEjKScVoM6M3G9DFKFXh9/nZ89YmKteExgFa9tRizUiibEn/24gWzpmIzmxg/3tbsKQnMWHZDFIKM5FSUl/biNfrZerMcr582xd45IEn8Hl9XHDpci68bOjjC+MmlPCXJ39LZUUtep2W0rJikpKHNuaya9teHv7j3/lk43aWnn06n/nilQSl5Pl/vczaDzaydPnpXLTiHIpLh11w4qQ3kHUWTcBpQohlwNS+5pellG+PaGTHEb+zl6DXiyElHSmD+Lq7cDbVY87Ijlhr0evowVZShiEpJXHBKiNKZ9Rjz02jbX/khL2gz093QztJuYMrO9Hd2M7uNzZSv+UAacXZnHLxwqjtTh2tXVR+uP2Itm6MdjPJ+ceeYWS0mSmZX07h7IloNBqERtDb6+DF517n/nv+jMvp5uwLlvCNO7/EBZcuJ+D3k1+Ui3GY9ccystLJyEof1jnqaxv48vXfDq/9+Pc//kNWTgb/XfkW+/dUArB7xz42rN3M/Q//nKQY4z/KwPXbDSWEMAkhvgFcAXiBP6lEEUnKIMa0DPyOHoIeN+bsPITBhLujLeI4odES8Hrw9nbjd7tU19QJSG82MvWihWj1h+4eU4uycHU56G5oO8YrIeAL4PMcmnLtdbpZ//c3qVi9HU+Pi4Ztlbz/++fpbe2Keq2IsXY1KTf9qOMVR9LqtAhN6BzbNu/iF9+/D6fDhZSS119+lycefZaColzGTShBp9NReaCGXTv20RNjv4jRUrG/JmKRIITusg4mioM2rvuEqsraUYzsxDSQbqjHAB+wilBRv3JCXVNKHxkMHtqzwgeuxlpsRePxdnccOkgIzDl5uJoakAE/IDDn5mNKy1TdUicYW1YK5efPJ+gPILQCZ1sP+9/bQt7U0pjHBwNBWvbVsevV9Xh6XUw881Ryp5XibO+hbX/k9Guvw01PYwe2w3a8s2YkU7roFA6sOjSjyJadSlpJ5B3IQO3avjeq7b8r3+KGL1+HyWLiuSdf4v/u/Qsej5cZs6fy4199K2IMYrSYzNF3N5oYO+4Bw95xTxlYspjSt2obIcQjhIoKKn2CgQDe9uhBRG9PF1qrDTo7AIkhJQ13a3NfogCQuBpq0VlUxdgTjSXNjs5kYPO/3w23pRRmklwQu0uovaqR9+97Llx7ad1jrzPns2eTMT4XjVZDMBDElpVC6WmnEPD68PQ66W3rwpbet85Cr2PKBfNJK8mhdtM+MsbnUXBqGZbUoXW75ORFV6adMKkUq83K1s07+PXPHgi3f7JxG3/+/eP89N47MQxhttdwjJ9QwpLlp/Hem2vCbdk5mZx2xlzWvL8+3BYasxiZPcVPJgNJFuFlx32L6EYwnOOPEKFFeEfSaLV4W5sx5+YTcIe2OfV2RHdDxFrprRzfhBCULCwnKSeV1v312DKSyZiQjyXVTkd1M817apHBIFkTC0gtzqZlT104UeTPHE9KQSaenlBpmCkXLWDnKx8xfvE0tjz3Qfg4e04ai79yafgOw5JqZ9zpUxl3+tTYQQ3CjFlTOHXOVDb1rX0wW8x85Zv/g9lioqoiujvn3TfW0N7WGTPJjKSU1GTu/tltXLziXCoPVDN5ShnTZ53C/NNns27Nx3zy8XZmz5/B3IWnYrGqWf7DNZBkMUMIcXBlkQDMfY8FoTVzid+jcZQE/X4CLicBrwetwYjWbEaj02POyqWn91DfrdBqEXo9AY8bV0MtGr0BndWOxmCM3gJVrb84LvU0tdNR3UIwGCQlP4OUgsyI5w1mIzlTismZcqgkRltlI+/+5hkCvtDdpUanZeltV6Azhn4NSxZOwdXZG95LYs9bm1l06yVkTixg4z/ejKj62tPYTkdVU0R3VLzk5ufw6wd+wt7d+3E63YwrK2ZcX2mPWFt1Tj5lAvak4d0dV1XUUl/bSGpaMiXjiwZcWjsnN4ucCyOTVEpqMpddfQGXXX3BsGJSIg1kNpTq7OPQuMTh+2kbM7KxZOehs9qxl03G7+hFaLTorTaCgQBCr0f6fAQDfoQQmDKycDXVI/sKtBkzssI75AV9PkCi0Y/urbwyeF31rbz7u+fC1V61Bh1Lb7uS9NKcY76uZv3ucKIACPoDHFi1lcnnz0VvNmJNT6Lyw0NbuXh6nOx6dT2nfmoprq7oIpRex8itI8jMTiczO3q20pTpk1h+/hLe/G+oXpXNbuX2u27GarMQDAbp7XFgtpjR6we+WG/t6o1848a7cTpcCCH42rdv5NrPr1B3A2OM2lxhgAIed0SiAPC0NmFMTUNntqK32NBbDl1daYHksnICPi8arY6A14OzvhpjagZoNAgh8HZ1YEhJx93WjKupAZCYsvIwpqSqO44xrGFrZURZ8IDXz963N5H6hXOPWS/J3R39ge/udmDPSmXZHVdRsyG62n/bgQaE0DBu0VR2v37YGlhBv9NiR0JmVjo/vOcOPv2FK3D0OigeV0RxaQGVB2p45p8reef11cyeP4PP3HAlEyf3v/VNS3Mb3//mL8KVZ6WU3P/Lh5i7cCbTTz1lpL8dZRBUshigg3cDA2kP+nwEPKFph1qjGa3BEEoQWh3u1kMreQ0paciAH2dddbjNVV+NRqfDmHJibwN5POuNsY9DT1MHMhCEYySL4vnlVK+PTAjjzpiOEIKU/Ayc7dHTUHOnlWK0myhbMgMZlBxYtRVTsoWZVy4htWh0xwgOSk5JYvb8GeHH3V09/PDbv2LT+lAJuZqqOj5avZHHnvlDv+MYne1dNDVEb1bW3HjsulbK6FPJYoA0RiMavSFiQFro9GgMkX2rAY+b3qr9BPpKfmgMRuwlZaDRYMrKJeB0EPC40duS0Cen4Gqsi3ovT3urShZjWP6M8RHTVAHGLZ6Gtp+ul8wJ+Zx204XseGUdQRlkynnzIlZ1p5fmUH7eXHa9vgEZlKSV5jBp+Ww0Wi3W9CSmr1jExLNORavXYbSNnS6amqq6cKI4qKGuicoD1f0mi/TMVAqL86mpivw9yM0/dpeeMvpUshggrd6ArWQ8zvpa/I5edFYrltxCtEckC29vdziBBNwugl4Pno42NDo9zoYahE6P1mDE3dqI1mZHazTjozPyvYa5OlYZWenj85jzmeVsW7mGgC/A5HPnkD9jXL+v0xkNFMyaQHZ5EZLQIPjhjDYzUy6cT9G8yQR8fmyZyRgshwoGHtwidazRG/QIISIG4IEBTaVNS0/l57+9i9tu/j5tLe0YjAa+88OvUjYp9poUJXFUshgEndmKraQMGfAjtDo0RyymC3g8BD1ugh43GqMJQ2o6rsb60MC3PjQGIf0+hNmCKSMbb1szWpMZc3Y+ruZ6kBI0mtC4hjJmGcxGxi2aSu60UmQwOOAPcFeXg87aFnwuD0k5aejzMsKrpg/S6nUk5w2vDMZoKy4t4NrrL+efjz4Xblt85oLwDKr+zJwzlSdX/pnG+iaSU5MoKilAe9jvViAQwOlwYbVZhrSHhhIf4sirgRPBnDlz5IYNo7vthQwEcNRW4u06tGpbaHUY0zIQOh0BlwtvZxsavQFDSirulkNjFxq9Hkt+MdLvR2u2oDNbRjV2ZeQ5O3pZ//jrNO0MjU9ptBoWf/UysicXhY/pqGmmaWc1AV+A7MmFpJXkHHVF8ljT1trOpvXb2Lp5BxPLxzNr7nRy84e2gvxw+/dW8swTK1n9/noWL1vAlddeNOQd+pT+CSE2SinnxHxOJYv48LtddO/ZHtVuzi3EkJyC9PvoPrAHU1om7vYWOKIulK14PIbk4e2drIxd9VsO8MEDKyPaknLSWPatqzFaTXRUN/POb57G7wmtgRVCsOS2FWRNPHlXHre1tnPTp7/J3l0Hwm3l0yby4OP3kpqWkrjATmDHShaqGypuRGg59xHJV2s0hcY1DEaSyspD6ynamqNefSImbeUQT68rqq2nuRO/24vRaqJ+y4FwooDQz8PuNz4mfVwe2lGua+RxuGnZU0PNhj3Ys1MpmDUhatHhaKiqqI1IFAA7t+6huqKW1LQUWpvb2bFtN60t7RQV5zNl2kQsVnVXPlJUsogTrdGIKTMHd/Oh0tRakxmd+dCsFZ3JjDSaMGVkR6zZEBotWtPYmd2ixIfP7UWr16HRarBnR981Fs6ZiCk59OHmdXqinvc63FEXH6Ohet0uNv3r3fDjfe9t4cxvXU1STmiGXmtzGwhBRubIztjTxyijA6DT6+no6OJ/f3BfeHEgwHd/+g2u+exlqJJEI+P46BA9DgghMKZnYSsejzE9E0t+Mbbi8VErsg+u5LbkFaE1WzCkpmMfNxGdShbHHVeXg9rN+9j+0lpqN+0Lr7J2tHWz67UNvPWrf7H+8ddpr2oipSiL+V88D4M1NLspb8Z4TrlwPtq+D8RYs6kmnDmz3+m48XZ4uZGDvA43nTUtdHZ28+Rjz3Hl+Tdw9QU38Mw/X6R7BEuUl4wv4uwLlkS0XXj52ZSML2Tf7oqIRAFw3/8+SE1VZJVeJX7UnUUcafV6tMmp/Y49aPQGTBlZGNPSQWjUldBxyOfxsm3lGipWHxqnKlk4hRlXnsHOV9dzYNVWALrr26jfWsHy71xD8bzJZE7IJ+D1Y061Rex6lzYul8VfuZQdr6zD7/Ux+ZzZ5JQnZiBXBqPvZiSwdtUGfvGD+8NtP/nur0lNT+GscxePSBz2JBvf/sFXOPPcxWz7ZBfTZ5Yza/4MrFYLjp7o1fAulxuXK7q7T4kPlSwSSGhU2a3jVU9jR0SiAKj8cAfjFk2lYnXkgj2f00NXfRv27NSjTrPV6XXkTi0lc0IBUkr0psTUCDOn2Cg/fy5bnvsg3KY3GUgryeb5+x+KOv7l59/gtDPm0dXRRVpGCgZDfOPOzs3iwsvO5sLLzo5oLx5XiNlixuU8lBxOnTuNvILcuL6/cohKFooyBAFf7PIvEKomG/D6j2gbWI+vzpj4mmAlC6dgSrJSsXobSblplC6aiinZytyFs/hw1aFZhjq9jnMvWsaP7/wVWz7ewbzTTuXK6y5m6ozyEY+xdHwRD/79Xu796R/Zs3M/y84+nS/fdj12u3XE3/tkpabODkHQ78fv6MXT3oLQ6zGmZqCzWFV30knE3e3gnd8+Q0/joXU19qxUlt5xJVUf7mTL84euzO3ZqSz5+gosaWNv9fWxBINBerp7+XDVBp567HnSMlOZPW86f3vwKZoaW/jcjVfz9qurqK05NKmjfOpE7n/456O2t0VPdy+9PQ7SMlIxjvLmSyciNXV2gKSUSL8PNNqo1dmH8/V246g+NKXP29FG0vjJ6CzqquZkYUqyctpNF7H7zY9p2llF9uQiJi2fhTnJSumiqdhz02jeWY09J43syYXhRNHT1EF7VRM+l5fUoixSi7LG5MK7nuYOelu6+PCTrfzou78Ot7/7xmp++6ef9JUiN/H4w/+OeN3ObXs4sK/ymMnC7fag0Yi4dFnZk2zD3ktDGRiVLPoEPB7cbc14O9rQGI1YcgrQWW1RdwvBgD9ieiwAUuLr7VHJ4iSTnJfO7OvOxOfyoDcbw+shjFYT+dPHkT89coZTd1MH793/LK72XiA0M27x1y4np7wo6tyJ1Haggfd//zwpk/J59F+RycDv81NTVcdn/+dqVr2zNuq1QgiMR6lt1tPdy5pV6/n7X57GajXzhZuvZfa8GegNie96U/o39i5pEkAGg7ia6vG0NiEDfgJOBz0Ve8KVYyMdpatJ9UCdlLQ6LSa75ZgL55ydvTTvqaV5d004UUDoTnbrC6vxuaLXWCSKz+3lk+dW4XN7kUGJXh/9Qa7rm847cfI4TjtjbsRzl1xxLhPKYxdVXPP+er51y4/Y8vF2Ply1gS995g62frIz/t+EMiLUnQWhfbC9nUfsjy0lAY87qk6TRqvFlJUb0Q2FEOitx1d/tBLN63TjbO9BZ9Rjy0yJyzk7altY/cBKvA434xZF74/t7nYQ8AcYK9fWPpeHzprQ/hIdu2v57Kcv44c//F34eYvVzKy504HQTKVvff9WNq3fxt7d+ymfOpFZ86aRlBT9u+B2u/n7XyLvUqSUvPfmmvD5lLFNJQsAIRBabdRGRuIoFS719iRsJWV42lsROj3GtHS0qvjfca2rvpX1j79Be2UTOpOBmVedQdHcyegMQ/8V8fv87HhpbXhTI6Pd0rdz/aFjypbMwGQfOz87RruZvBnjqF63m4DXj6W+l3t+8R3Wbd5KZnYmZ567iElTysLHj59YyviJ/ZcT12g0MUtxqK1Tjx8qWQBagxFzbgHO2qpDbWYLWlPsX2KNVochKQVDUsooRaiMJL/HyyfPrqK9MlQJ2O/2suHvb5KUk0bG+Lwhn9fncNO8pzb8uGrdLqZfvoiKNdvxOjxMWDaD4gUjP810MLQ6HVPOn4ejtZu2Aw046juYNrec5T9ZjmEYaz8MBgNf/PK1fLR6Y7gOmslkZPGyBfEKXRlhCUsWQog04F9ACVAJXC2l7DjimELgcSAHCAIPSSnvZwQYk9PQGoz4XU40egM6izW0HeoAyECAgDfU76w1GBHHmEmljD3ubheN26ui2ntbOoeVLPRWE9mTi6j9eC8QWs29/cW1LP7aZdizUjEnj80JEUm56Sz+yqU42nrQGXRYM5Pjso/ErHnT+eu/7+fdN9Zgs1tYvGwBU6ZNikPEymhI5J3FncBbUsp7hBB39j3+zhHH+IFvSik/FkLYgY1CiDeklDviHYzQakNbndqSBvW6gNeDq6E2vI+FITkVc25B1A56ytilNxuwZ6fS0xRxrYIpaXjdQzq9jikXzqeztoXe5k4Qoe1Xk3LSxlTXUywGiylil764nNNgYPa8GcyeN6P/g5UxJ5HJ4lJgad/XjwHvckSykFI2AA19X/cIIXYC+UDck8VQ+Xq6IjY88nZ1oLPa0WaMzqIkZfiMNjOzrzuTVX94Ibwyu2jeZFIKB/d/GAwG8bu96EyG8JV4Sn4GZ95xFb0tXWgNOuxZqWNilbaiDFbCVnALITqllCmHPe6QUh61Ap8QogR4H5gqpeyO8fxNwE0ARUVFs6uqorsVRkL3gT34eyPD0VntJI1Xt9fHEykl3Y3t9DZ3orcYSc7LwGgd+JV1V0Mb+975hKadVeRMLaHsjOkk5R5f26Mq8eHz+aitrcXtdic6lKMymUwUFBRETY1O2ApuIcSbhMYbjnT3IM9jA54FvhErUQBIKR8CHoJQuY9Bhjpkeps9Klno7YPrylISTwhBcm46yUP4gHd3O1jz55fCpT/2vfMJLXvrWfr1y0MzoIDOulY6KpsASWpxdkI2E1JGR21tLXa7nZKSkjFZAkhKSVtbG7W1tZSW9j+T7aARTRZSyuVHe04I0SSEyJVSNgghcoHo7eNCx+kJJYonpJTPxTomkfRJqXg62wn2LeDTmMzo1Sypk0pPU2dEjSiArtoWepo7MdottFc18e5vnwnvhKcz6ll625WklQx/j2pl7HG73WM2UUDowig9PZ2WlpZBvS6RYxYrgc8D9/T9/Z8jDxChf+1HgJ1Syt+ObngDozOZSCqdSMATShZaoxlNjFWvyolLc5TV2wfbqz7aGbFlqt/jo3LtTpUsTmBjNVEcNJT4Elnu4x7gbCHEXuDsvscIIfKEEK/0HXM68FngTCHE5r4/FyQm3KPT6PXhmVQqUZx8knJSKZw9MaKteEF5eCtVR2tX1GscrZ2jEZqixE3C7iyklG3AWTHa64EL+r7+AFV1SRmDPA43HZWNdDd2YM1IYspFC8ifOZ6O6mZSi7PJLMsLb2BUsvAU6rdURLy+5LRTRiSujpoWqj7aSWdtC6ULp5BdXjzsKcCDEQgEaG/txGozx1yxfTLr7Ozkn//8J7fccsuIvs8LL7zAxIkTmTJlSlzPq1ZwK8ogBfwB9rz1MTtfWRduK5o7iVnXnknR3OhZcFkTC5jz2eXsePkjkDDlwvlkTy6Me1zdTR28d9+zeB2hWTjNu2qYeulplJ83d1S6RWoq63jib8/wygtvUVpWxNe/c5Oq+3SYzs5OHnjggQEnCyklUspBL4h84YUXuOiii+KeLFTVWUUZpN7mTna9uj6irXr9brob2mIerzHoyJs+jrPuvIbld13LuEVT477gDUKD6gcTxUG7Xl0frk01kjweD3/4zSP889Hn6OzoYtP6rXzp099k356K/l98krjzzjvZv38/M2fO5LbbbuOss85i1qxZTJs2jf/8JzRkW1lZSXl5ObfccguzZs2ipqaGn/70p0yePJmzzz6ba6+9ll//OrS/yP79+znvvPOYPXs2ixcvZteuXaxZs4aVK1fyrW99i5kzZ7J///64xa/uLBRlkAJeHzIYPTv78EHsgzqqm9jx33W0VzZRcOoEypZMH/XV26Mx1tpY38yrL74d0ebxeDmwt4qyARQaPBncc889bNu2jc2bN+P3+3E6nSQlJdHa2sqCBQu45JJLANi9ezePPvooDzzwABs2bODZZ59l06ZN+P1+Zs2axezZswG46aabePDBB5kwYQIfffQRt9xyC2+//TaXXHIJF110EVdeeWVc41fJQlEGyZqZTEphZriUN4SqtdqzUyKO623t4r37nw9f7e99exPdjW2cdtNF4fGMeEopyMRoM+PpPbQPy5QL5mNOHfny+QaDAZvdSk93b0S7ZRALG08mUkruuusu3n//fTQaDXV1dTQ1hQpZFhcXs2BBqMDiBx98wKWXXorZHKrOe/HFFwPQ29vLmjVruOqqq8Ln9HhGdl8UlSwUZZCMVjPzv3geu15dT8PWCtLH5XLKJadhTU+OOK6noT2qW6hpRzWO1q4RWZRnz05lyTeuoGbjbrrqWimaO5nsyUWjMl6Rm5/NN+/+Mj/6zr3hthmzTmFiedkxXnXyeuKJJ2hpaWHjxo3o9XpKSkrCK76t1kMFJo9WYSMYDJKSksLmzZtHI1xAJQtFGZLk3HTmfHY53l43eosRXYytQbUx9sLQaDVHXZcRDykFGaQUZIzY+Y/lvEvOorA4n90795GVncG0U6eQlZ2YWMYiu91OT09o/Kirq4usrCz0ej3vvPMORytPtGjRIr70pS/x3e9+F7/fz8svv8yNN95IUlISpaWlPP3001x11VVIKdmyZQszZsyIeJ94UgPcijJEWp0Oc4otZqIASMpLJ2tS5Kyn8vPnxW0XvrHGYjEzd+GpfOaLV3HOhcvIzVOLDg+Xnp7O6aefztSpU9m8eTMbNmxgzpw5PPHEE0yePDnma+bOncsll1zCjBkzWLFiBXPmzCE5OXQH+8QTT/DII48wY8YMTjnllPAg+TXXXMO9997LqaeeGtcB7oQVEhxJc+bMkRs2bEh0GIqCo72HtgP19DR1kFacTVpp7qAKFCrHn507d1JeHr9NrXp7e7HZbDidTs444wweeughZs2aNezzxoozYYUEFWU0+TxeNEITs/tnoAL+AN0NbTjbezAlW0nOTY8oKe5xuPF0OzBYTZiS+t+8yJpmx5qmKhArQ3fTTTexY8cO3G43n//85+OSKIZCJQvluOdxuGnYWsGetz5GbzZSfv48Mifkox3k2ICUkrqP9/LRo6+FBxanXXoaE86ahc6go72qifWPv0FXXSuWNDtzP3s2WZMLx3wdoKPpqmuldtM+uurbKJw9gaxJhRhtak/sseaf//xnokMA1JiFcgJo2HqAdX97jc6aFlr21PL+75+jvbJx0OfpbeliwxNvRcxA2bpyDd0Nbbi6HKx56GW66loBcLb38MEDK+lp6ozXtzGqepo7ee/+59j+0lpqP97Lhw+/QsWa7UedfaMoKlkoxzWf28vuNz6ObJTQtLN60OfyOtzRC+skeHqcODt6cLZF7lsS8PljFgk8HnTVtuDudka07Xj5o1FZ7a0cn1Q3lHJcExqBwRy9wG0oi94sqTbMKTZcnYcWlml0WizpSWg0GrR6HQGfP+I1BtvRB6tlUNJZ20JXXStag47UoqwxMxMq1h1ErFXpinKQurNQjms6g57yC+ZH1CbWmQxkTS4a9LnMKTYW3ngBlvTQTodGu5nTbrqQpOw0bJkpnPqppRHHTz53Lsm5aUc9X+u+Ot765VOse+x1Pnz4Fd677zm6mzqOevxoSs7PwGAxRrRNPncOllFY7a0cn9SdhXLcy5yQz7Lbr6JxeyV6s5HsKcWkFg5thXTG+DzO+vancHc5MNjMWNMOfXgWzZ9MSkEGjrZuTMk2kvPT0Rlj38H4vT62vbSWYCAYbnO0ddO6t46k7KNuNT9qknLSWHLbFVSs3kFnXTOlC08h55QShEbQ2dlFc0Mr9mSbWitxHHv11Vf5+te/TiAQ4H/+53+48847h3U+lSyU455WryNzQj6ZE/Ljcj5zshVzcvS0WJ1eR1pJDmklsbaVjxTw+nG2R28X7+rqjXF0YqQWZpF6TRbBYDBcBnvntr18/45fsGfnflJSk/nBL77JkuWno9erj4qR4ulow9VYR9DnRaM3YM7Jx5g6+L3gDxcIBLj11lt54403KCgoCC/uG07ZctUNpSgjwGgzM27xtKj21KIsepo7x9T4wMFE0dnRFU4UBx/fccuPOLC3MoHRndg8HW04aqsI+rwABH1eHLVVeDpil7sfqHXr1lFWVsa4ceMwGAxcc8014RXeQ6UuFxRlhBTPm0zA42fP25swmI1MOHMmO17+iK66NmZcsZiSheVH7cY6KBAI8MnH23nuyZfp7XVw5XUXM2f+DEzm+K8Cb2lqCyeKg4LBIDVVdUyaogoCjgRXYx3IYGSjDOJqrBvW3UVdXR2FhYdKzRQUFPDRRx8N+XygkoWijBhLqp1TLl5AyWlTqP14LzteWYfPFSoj/fFT75BckEFm2bG7zrZt3skNn/oGgUAAgLdfW8X/PfILliw/Le7x2pNspKYl09EeOR04LSPxYywnqoN3FANtH6hYs92Gu3hUdUMpyggSQiCEYOvzq8OJ4qDe5s5+X//OG6vDieKgxx7+F17v8D5MYsnJy+IH93wLrfbQyvdPf/FKyiaNi/t7KSEafew7y6O1D1RBQQE1NTXhx7W1teTl5Q3rnOrOQlFGmN5sICk/g67aloh2U4xB9CPFuhoUmpErL7LkrIU89fJD1FbWk5aZStnEUuxJthF7v5OdOScfR21VZFeU0GDOGd5kjblz57J3714qKirIz8/nqaeeGnbZEHVnoRy3/D4/7dVN1H2yn46aZgL+QP8vSgCDxcSsTy2NKEhYNG8yqYVZ/b526dmnozuixtXnb/wUBkP8d9oD0Ol0TCov46zzz+DUOdNUohhhxtR0rAXF4TsJjd6AtaB42LOhdDodf/jDHzj33HMpLy/n6quv5pRTThnWOVWJcuW4FPD5OfDBNjb9+12QoSvwuZ87m+L55SN65T0c3Y0d9DZ3oLcYScpNH1Cp8kAgwNbNO1n5zKs4ep1cdvUFzJwzFfMIDHAr8RHvEuUjRZUoV04KPU2dbH76Pei71pFSsvGfb5FWmkNSztFXVSdSUk4qSTmDGyzWarXMnD2VmbOnjlBUijIwqhtKOS55epxRaxUCvgCeHleCIlKUE5tKFspxyZJmjxgDADBYTVjSVG0jRRkJKlkoxyVbVgoLb7wQoz20WY85zc6iWy/B0dZNW0Vj1DRVRVGGR41ZKMclIQS5U0tY/t1r8fS4kFLy0SOv0tvSCUDR3EnMuGIx5hQ1m0dR4kHdWSjHNWtaEsn5Gex/b0s4UQBUr99N64GGxAWmKCcYlSyU457f5aV5V01Ue1ddS4yjFeXE98UvfpGsrCymTo3fLLqEJQshRJoQ4g0hxN6+v486p1AIoRVCbBJCvDSaMSrHB73FSM7U4qj2lIL+F70pSqJVfbSLl+56hH/ffB8v3fUIVR/tGvY5r7/+el599dU4RHdIIu8s7gTeklJOAN7qe3w0Xwd2jkpUynFHo9Uw8cxTSc7PCLeNWzyN9HG5CYxKUfpX9dEuNjzxZnjvc2d7DxueeHPYCeOMM84gLS2+640SOcB9KbC07+vHgHeB7xx5kBCiALgQ+Dlw+yjFphxnknLTWfqNFfS0dKLV67BnpUZNrVWUsWbrf1YT8Ebu6x7w+tn6n9UUz5+coKhiS2SyyJZSNgBIKRuEEEfrM7gP+DZwwkygl4EAAY+boN+HxmBEazQNu3ywAka7BaPdkugwFGXADt5RDLQ9kUY0WQgh3gRi7UF59wBffxHQLKXcKIRY2s+xNwE3ARQVFQ0u0FEU9Ptxtzbhbu6bqSMEtuIyDEnJiQ1MUZRRZ0mzx0wMY3Fx6YiOWUgpl0spp8b48x+gSQiRC9D3d3OMU5wOXCKEqASeAs4UQvzjKO/1kJRyjpRyTmZm5gh9R8MX8LgPJQoAKXHUVhIYgf0JFEUZ26ZdejpaQ+Q1u9agY9qlpycooqNL5AD3SuDzfV9/HojaIFZK+V0pZYGUsgS4BnhbSvmZ0Qsx/oJ+X1Sb9PuQAX+MoxVFOZEVz5/MnE8vD99JWNLszPn08mGPV1x77bUsXLiQ3bt3U1BQwCOPPDLsWBM5ZnEP8G8hxA1ANXAVgBAiD/iLlPKCBMY2YrQxdsDSGIxo9GowVlFORsXzJ8d9MPvJJ5+M6/kggclCStkGnBWjvR6IShRSyncJzZg6rmlNZqyFJTjqqiEYRKM3YCsqRaNTyUJRlLFL1YYaZUKjwZCSjs5iIxgIoNUb1F2FoihjnkoWCSCEQGs0oe3/UEVRlDFB1YZSFEVR+qWShaIoitIvlSwURVGUfqlkoSiKcoKpqalh2bJllJeXc8opp3D//fcP+5wqWSiKoiTQyy+8wbmnXc2MkqWce9rVvPzCG8M+p06n4ze/+Q07d+5k7dq1/PGPf2THjh3DO+ewo1IURVGG5OUX3uDHd96Lu2/P+Ia6Jn58570AXHjZ2UM+b25uLrm5oRL9drud8vJy6urqmDJlypDPqe4sFEVREuT3v3o4nCgOcrs8/P5XD8ftPSorK9m0aRPz588f1nlUslAURUmQxvpY9VOP3j5Yvb29XHHFFdx3330kJSUN61yqG0o5KXTVtVKzcQ8dNc0UzplETnkxpiS194WSWDl5WTTUNcVsHy6fz8cVV1zBpz/9aVasWDHs86k7C+WE19vSyXu/f44dr6yjYWsl6x59jf3vb0EGZaJDU05yX/v2jZjMxog2k9nI175947DOK6XkhhtuoLy8nNtvj88GoypZKCe8rrpW3F3OiLZdr63H0d6doIgUJeTCy87mh/d8i9z8bIQQ5OZn88N7vjWswW2A1atX8/e//523336bmTNnMnPmTF555ZVhnVN1QyknPBnjBkJKQN1YKGPAhZedPezkcKRFixYhY/3gD4O6s1BOeMn5GVF7c086ezaW9LG3daWijFXqzkI54dmzUljyjRVUfbSLjuomSuaXkz2lGI1GXSspykCpZKGcFFLyM0hZsSjRYSgnCSklQohEh3FUQ+miUpdWiqIocWQymWhra4v7mEG8SClpa2vDZDIN6nXqzkJRFCWOCgoKqK2tpaWlJdGhHJXJZKKgoGBQr1HJQlEUJY70ej2lpaWJDiPuVDeUoiiK0i+VLBRFUZR+qWShKIqi9EuM1RH74RBCtABVR3k6A2gdxXAGYizGBGMzrrEYE4zNuMZiTDA24xqLMcHox1UspcyM9cQJmSyORQixQUo5J9FxHG4sxgRjM66xGBOMzbjGYkwwNuMaizHB2IpLdUMpiqIo/VLJQlEURenXyZgsHkp0ADGMxZhgbMY1FmOCsRnXWIwJxmZcYzEmGENxnXRjFoqiKMrgnYx3FoqiKMogqWShKIqi9OuETxZCiDQhxBtCiL19f6ce5bjbhBDbhRDbhBBPCiEGV5JxZGJKEUI8I4TYJYTYKYRYOFIxDSauvmO1QohNQoiXEh2TEKJQCPFO37/RdiHE10colvOEELuFEPuEEHfGeF4IIX7f9/wWIcSskYhjCHF9ui+eLUKINUKIGYmO6bDj5gohAkKIK0c6poHGJYRYKoTY3Pez9F6iYxJCJAshXhRCfNIX0xdGOqaYpJQn9B/gV8CdfV/fCfwyxjH5QAVg7nv8b+D6RMbU99xjwP/0fW0AUhL9b3XYsbcD/wReSnRMQC4wq+9rO7AHmBLnOLTAfmBc3//FJ0e+B3AB8F9AAAuAj0by32YQcZ0GpPZ9ff5IxzWQmA477m3gFeDKMfJvlQLsAIr6HmeNgZjuOvhzD2QC7YBhpP+9jvxzwt9ZAJcS+tCl7+/LjnKcDjALIXSABahPZExCiCTgDOARACmlV0rZOYIxDSiuvtgKgAuBv4xwPAOKSUrZIKX8uO/rHmAnoQuAeJoH7JNSHpBSeoGn+mI7MtbHZchaIEUIkRvnOAYdl5RyjZSyo+/hWmBwtalHIKY+XwWeBZpHOJ7BxHUd8JyUshpASjnSsQ0kJgnYRWg3JRuhZOEf4biinAzJIltK2QChDxUg68gDpJR1wK+BaqAB6JJSvp7ImAhdabQAj/Z19/xFCGEdwZgGGhfAfcC3geAIxzOYmAAQQpQApwIfxTmOfKDmsMe1RCekgRwTb4N9zxsI3f2MpH5jEkLkA5cDD45wLIOKC5gIpAoh3hVCbBRCfG4MxPQHoJzQBexW4OtSytH43YtwQuxnIYR4E8iJ8dTdA3x9KqFsXgp0Ak8LIT4jpfxHomIi9H8zC/iqlPIjIcT9hLphvj/UmOIRlxDiIqBZSrlRCLF0OLHEK6bDzmMjdKX6DSlldzxiO/z0MdqOnHc+kGPibcDvKYRYRihZjPT+sgOJ6T7gO1LKwChuPzqQuHTAbOAswAx8KIRYK6Xck8CYzgU2A2cC44E3hBCrRuBn/JhOiGQhpVx+tOeEEE1CiFwpZUNfl0Cs28rlQIWUsqXvNc8R6ucdcrKIQ0y1QK2U8uAV8jOEksWwxCGu04FLhBAXACYgSQjxDynlZxIYE0IIPaFE8YSU8rmhxnIMtUDhYY8LiO6qHMgxiYgLIcR0Qt2G50sp28ZATHOAp/oSRQZwgRDCL6V8IcFx1QKtUkoH4BBCvA/MIDQOlqiYvgDcI0ODFvuEEBXAZGDdCMUU08nQDbUS+Hzf158H/hPjmGpggRDC0tcveBahfu+ExSSlbARqhBCT+prOIjTwNpIGEtd3pZQFUsoS4Brg7eEkinjE1Pd/9giwU0r52xGKYz0wQQhRKoQwEPreV8aI9XN9s6IWEOrObBiheAYclxCiCHgO+OwIXiEPKiYpZamUsqTv5+gZ4JYRThQDiovQz9diIYROCGEB5jOynwUDiama0O8/QohsYBJwYARjim20R9RH+w+QDrwF7O37O62vPQ945bDjfgzsArYBfweMYyCmmcAGYAvwAn0zWhId12HHL2XkZ0P1GxOhbhXZ9++0ue/PBSMQywWErjD3A3f3td0M3Nz3tQD+2Pf8VmDOKP2M9xfXX4COw/5tNiQ6piOO/RujMBtqoHEB3yJ0YbaNUJdmov//8oDX+36mtgGfGY1/qyP/qHIfiqIoSr9Ohm4oRVEUZZhUslAURVH6pZKFoiiK0i+VLBRFUZR+qWShKIqi9EslC0VRFKVfKlkoyhD0ldXeLEIl7Z/uW8CFECJHCPGUEGK/EGKHEOIVIcTEw153mxDCLYRI7uf86SJUdr1XCPGHkf5+FKU/KlkoytC4pJQzpZRTAS9wc99K8ueBd6WU46WUUwiVl84+7HXXElq1e3k/53cTqgN2R/xDV5TBU8lCUYZvFVAGLAN8UspwJVUp5WYp5SoAIcR4QiWmv0coaRyVlNIhpfyAUNJQlIRTyUJRhqFv/5PzCZVimApsPMbh1wJPEkouk4QQxyy3rihjiUoWijI0ZiHEZkK1u6rp26SqH9cAT8nQXgTPAVeNXHiKEl8nRIlyRUkAl5Ry5uENQojtQMy9pPtKhE8gtBcBhLbQPECo8KCijHnqzkJR4udtwCiEuPFggxBirhBiCaEuqB/JvrLcUso8IF8IUZyoYBVlMFTVWUUZAiFEr5TSFqM9j9AucLMJDU5XAt8gVGL6fCnlrsOO/S3QJKX85VHeoxJIInQX0gmcI6Uc6T1NFCUmlSwURVGUfqluKEVRFKVfaoBbURJICHEucGQ3VIWUsr9Fe4oyqlQ3lKIoitIv1Q2lKIqi9EslC0VRFKVfKlkoiqIo/VLJQlEURenX/wM0P724xcoN3wAAAABJRU5ErkJggg==\n",
+ "text/plain": [
+ "| \n", + " | PCA_1 | \n", + "PCA_2 | \n", + "target | \n", + "
|---|---|---|---|
| 0 | \n", + "-0.630703 | \n", + "0.107578 | \n", + "0 | \n", + "
| 1 | \n", + "-0.622905 | \n", + "-0.104260 | \n", + "0 | \n", + "
| 2 | \n", + "-0.669520 | \n", + "-0.051417 | \n", + "0 | \n", + "
"
+ ]
+ },
+ "metadata": {
+ "needs_background": "light"
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "sns.scatterplot(x='PCA_1', y='PCA_2', hue='target', data=df_pca);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e4ed57f3",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "988d7ff8",
+ "metadata": {},
+ "source": [
+ "### 연속형 변수 변환"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "56c49ee0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def func(x):\n",
+ " if x < 3:\n",
+ " return 'lowest'\n",
+ " elif x < 3.3:\n",
+ " return 'low'\n",
+ " elif x < 3.5:\n",
+ " return 'normal'\n",
+ " else :\n",
+ " return'high' \n",
+ "\n",
+ "train['pH'] = train['pH'].apply(lambda x : func(x))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "653e4559",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# train 데이터의 alcohol 변수를 구간이 5개인 범주형 변수로 변환\n",
+ " train['alcohol'] = pd.cut(train.alcohol, 5,labels=False)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 70,
+ "id": "a71073ea",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ " sat weight width\n",
+ "147 4 3.025 29.5\n",
+ "5 0 2.100 23.8\n",
+ "95 1 2.800 29.0\n"
+ ]
+ },
+ {
+ "data": {
+ "text/html": [
+ "
\n", + "빈도에 기반하여 텍스트 -> 숫자 변환 / 단어의 특징을 나타낼 수 있어 활용도 높음
\n", + "##### 단점\n", + "- 문맥 의미를 완벽하게 반영할 수 없다 : 순서 고려하지 않기 때문. 보완위해 n_gram 기법 활용 가능하나 제한적.\n", + "- 희소 행렬 문제 : 단어가 굉장히 많은 데이터에서 BOW로 텍스트 데이터를 벡터화하면 행렬 대부분의 값이 0으로 채워진 희소 행렬 형태로 변환. 일반적으로 머신러닝의 성능 저하" + ] + }, + { + "cell_type": "markdown", + "id": "222e5f40", + "metadata": {}, + "source": [ + "#### BOW의 피처 벡터화\n", + "1. 카운트 기반 벡터화 ( CountVectorizer )\n", + "2. TF-IDF ( Term Frequency - Inverse Document Frequency )" + ] + }, + { + "cell_type": "markdown", + "id": "d1fd4a73", + "metadata": {}, + "source": [ + "### 1. CountVectorizer" + ] + }, + { + "cell_type": "markdown", + "id": "72494539", + "metadata": {}, + "source": [ + "**단어에 값을 부여할 때 각 문장에서 해당 단어가 나타나는 횟수**
\n", + "Count를 부여하는 경우 -> `카운트 벡터화` / 높을수록 중요한 단어" + ] + }, + { + "cell_type": "code", + "execution_count": 2, + "id": "342ef467", + "metadata": {}, + "outputs": [], + "source": [ + "from sklearn.feature_extraction.text import CountVectorizer" + ] + }, + { + "cell_type": "code", + "execution_count": 3, + "id": "efa00628", + "metadata": {}, + "outputs": [], + "source": [ + "corpus = [\n", + " 'This is the first document.',\n", + " 'This is the second second document.',\n", + " 'And the third one.',\n", + " 'Is this the first document?',\n", + " 'The last document?',\n", + "]\n", + "vect = CountVectorizer()" + ] + }, + { + "cell_type": "code", + "execution_count": 4, + "id": "864f30a7", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "[[0 1 1 1 0 0 0 1 0 1]\n", + " [0 1 0 1 0 0 2 1 0 1]\n", + " [1 0 0 0 0 1 0 1 1 0]\n", + " [0 1 1 1 0 0 0 1 0 1]\n", + " [0 1 0 0 1 0 0 1 0 0]]\n" + ] + } + ], + "source": [ + "print(vect.fit_transform(corpus).toarray())" + ] + }, + { + "cell_type": "code", + "execution_count": 5, + "id": "173b6413", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "{'this': 9,\n", + " 'is': 3,\n", + " 'the': 7,\n", + " 'first': 2,\n", + " 'document': 1,\n", + " 'second': 6,\n", + " 'and': 0,\n", + " 'third': 8,\n", + " 'one': 5,\n", + " 'last': 4}" + ] + }, + "execution_count": 5, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "vect.vocabulary_" + ] + }, + { + "cell_type": "code", + "execution_count": 8, + "id": "c3960450", + "metadata": {}, + "outputs": [], + "source": [ + "import pandas as pd\n", + "\n", + "train = pd.read_csv('train.csv',usecols = ['category','data'])\n", + "test = pd.read_csv('test.csv',usecols = ['data'])" + ] + }, + { + "cell_type": "code", + "execution_count": 12, + "id": "63915667", + "metadata": {}, + "outputs": [], + "source": [ + "# 결측치는 없어야 함\n", + "train.fillna(' ',inplace= True)" + ] + }, + { + "cell_type": "code", + "execution_count": 13, + "id": "948139b8", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "
\n", + "> 개별 문서에서는 높은 가중치, 모든 문서에서는 패널티\n", + "\n", + "모든 문서에서 등장하는 단어보다 특정 문서에서 빈번히 등장하는 단어를 높게 부여" + ] + }, + { + "cell_type": "code", + "execution_count": 19, + "id": "ff267958", + "metadata": {}, + "outputs": [], + "source": [ + "from sklearn.feature_extraction.text import TfidfVectorizer" + ] + }, + { + "cell_type": "code", + "execution_count": 20, + "id": "3d4436c5", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "array([[0. , 0.38947624, 0.55775063, 0.4629834 , 0. ,\n", + " 0. , 0. , 0.32941651, 0. , 0.4629834 ],\n", + " [0. , 0.24151532, 0. , 0.28709733, 0. ,\n", + " 0. , 0.85737594, 0.20427211, 0. , 0.28709733],\n", + " [0.55666851, 0. , 0. , 0. , 0. ,\n", + " 0.55666851, 0. , 0.26525553, 0.55666851, 0. ],\n", + " [0. , 0.38947624, 0.55775063, 0.4629834 , 0. ,\n", + " 0. , 0. , 0.32941651, 0. , 0.4629834 ],\n", + " [0. , 0.45333103, 0. , 0. , 0.80465933,\n", + " 0. , 0. , 0.38342448, 0. , 0. ]])" + ] + }, + "execution_count": 20, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "tfidf = TfidfVectorizer()\n", + "tfidf.fit_transform(corpus).toarray()" + ] + }, + { + "cell_type": "code", + "execution_count": 21, + "id": "db0be9c3", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "{'this': 9,\n", + " 'is': 3,\n", + " 'the': 7,\n", + " 'first': 2,\n", + " 'document': 1,\n", + " 'second': 6,\n", + " 'and': 0,\n", + " 'third': 8,\n", + " 'one': 5,\n", + " 'last': 4}" + ] + }, + "execution_count": 21, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "tfidf.vocabulary_" + ] + }, + { + "cell_type": "code", + "execution_count": 24, + "id": "6c2e4367", + "metadata": {}, + "outputs": [], + "source": [ + "vect = TfidfVectorizer()\n", + "train_x_2 = vect.fit_transform(train['data'])\n", + "test_x_2 = vect.transform(test['data'])" + ] + }, + { + "cell_type": "code", + "execution_count": 25, + "id": "f84f8d93", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "(40000, 742720)" + ] + }, + "execution_count": 25, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "train_x_2.shape" + ] + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 3 (ipykernel)", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.8" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git "a/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523-16508874838011.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523-16508874838011.png" new file mode 100644 index 0000000..535fbae Binary files /dev/null and "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523-16508874838011.png" differ diff --git "a/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523-16508986033022.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523-16508986033022.png" new file mode 100644 index 0000000..535fbae Binary files /dev/null and "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523-16508986033022.png" differ diff --git "a/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523.png" new file mode 100644 index 0000000..535fbae Binary files /dev/null and "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523.png" differ diff --git "a/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img-16507279048902.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img-16507279048902.png" new file mode 100644 index 0000000..aa08590 Binary files /dev/null and "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img-16507279048902.png" differ diff --git "a/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img-16508985826691.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img-16508985826691.png" new file mode 100644 index 0000000..aa08590 Binary files /dev/null and "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img-16508985826691.png" differ diff --git "a/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img.png" new file mode 100644 index 0000000..aa08590 Binary files /dev/null and "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img.png" differ diff --git "a/\354\240\204\354\262\230\353\246\254.assets/image-20220418203259483.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418203259483.png" similarity index 100% rename from "\354\240\204\354\262\230\353\246\254.assets/image-20220418203259483.png" rename to "\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418203259483.png" diff --git "a/\354\240\204\354\262\230\353\246\254.assets/image-20220418203418612.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418203418612.png" similarity index 100% rename from "\354\240\204\354\262\230\353\246\254.assets/image-20220418203418612.png" rename to "\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418203418612.png" diff --git "a/\354\240\204\354\262\230\353\246\254.assets/image-20220418204854106.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418204854106.png" similarity index 100% rename from "\354\240\204\354\262\230\353\246\254.assets/image-20220418204854106.png" rename to "\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418204854106.png" diff --git "a/\354\240\204\354\262\230\353\246\254.assets/image-20220418205336654.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418205336654.png" similarity index 100% rename from "\354\240\204\354\262\230\353\246\254.assets/image-20220418205336654.png" rename to "\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418205336654.png" diff --git "a/\354\240\204\354\262\230\353\246\254.assets/image-20220421005436684.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220421005436684.png" similarity index 100% rename from "\354\240\204\354\262\230\353\246\254.assets/image-20220421005436684.png" rename to "\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220421005436684.png" diff --git "a/\354\240\204\354\262\230\353\246\254.md" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.md" similarity index 97% rename from "\354\240\204\354\262\230\353\246\254.md" rename to "\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.md" index 4cfd7f9..099c9b4 100644 --- "a/\354\240\204\354\262\230\353\246\254.md" +++ "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.md" @@ -1,149 +1,149 @@ -# 전처리 - -## 결측치란 - -- 분석 결과/인사이트와 모델 성능에 직접적인 영향을 미치는 과정이기 때문에 중요하게 다루어지는 과정 - -- 한 설문조사에 의하면, 분석가의 80% 시간을 데이터 수집 및 전처리에 사용한다고 하니, 얼마나 중요한 과정인지 짐작할 수 있다. 물론 지루하고 반복 작업의 연속이기 때문에 시간이 많이 들어가는 측면도 있을 것이다. - -패턴이 있는 것과 패턴이 없는 것이 있음 - -## 결측치 처리 - -1) 결측치 사례 제거 -2) 수치형의 경우 평균이나 중앙치로 대체(imputation)하거나 범주형인 경우 mode 값으로 대체 -3) 간단한 예측 모델로 대체하는 방식이 일반적으로 이용된다. - -가장 쉬운 방법은 Null이 포함 행 혹은 일부 행을 제거하는 것이다 - -### Missing Value 파악 - -데이터셋을 읽었다면, Missing Value 파악을 위해 `df.info()` 가장 처음에 이용하는 것을 추천 - -**DataFrame.info()** - - - -**DataFrame.isnull().sum()** - - - -### 제거 - -#### dropna - -- 결측치의 특성이 '무작위로 손실' 되지 않았다면, 대부분의 경우 가장 좋은 방법은 **제거**하는 것이다. - -https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.dropna.html - -- pandas에서 제공하는 Na/NaN과 같은 누락 데이터를 제거하는 함수입니다. -- axis: 파라미터 값으로 0을 주면 행 제거, 1을 주면 열 제거입니다. default값은 0입니다. -- subset: array, 특정 feature를 지정하여 해당 Feature의 누락 데이터 제거가 가능합니다. - -```python -# 목록삭제(Listwise) - -df = df.dropna() # 결측치가 있는 행은 전부 삭제 - -df = df.dropna(axis = 1) # 결측치가 있는 열은 전부 삭제 - -# 단일값 삭제(Pairwise) - -df = df.dropna(how = 'all') # 행 전체가 결측치인 행만 삭제 - -df = df.dropna(thresh = 2) # 행의 결측치가 2개 초과인 행만 삭제 - -# 특정 열들중에 결측치가 있을 경우에 해당 행을 삭제 -df = df.dropna(subset=['col1', 'col2', 'col3']) - -# 특정열 모두가 결측치일 경우 해당 행 삭제 -df = df.dropna(subset=['col1', 'col2', 'col3'], how = 'all') - -# 특정열에 1개 초과의 결측치가 있을 경우 해당 행 삭제 -df = df.dropna(subset=['col1', 'col2', 'col3'], thresh = 1 ) -``` - - - -### 대체 - -대체값 종류 - -- 최빈값(mode) - - 범주형에서 결측값이 발생시, 범주별 빈도가 가장 높은 값으로 대치한다. -- 중앙값(median) - - 숫자형(연속형)에서 결측값을 제외한 중앙값으로 대치방법 -- 평균(mean) - - 숫자형(연속형)에서 결측값제외한 평균으로 대치방법 -- Similar case Imputation - - 조건부 대치 -- Generalized Imputation - - 회귀분석을 이용한 대치 - -#### fillna - -https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.fillna.html - -```python -df.fillna(0) # 전체 결측치를 특정 단일값으로 대체하기 - -# 특정열에 결측치가 있을 경우 다른 값으로 대체하기 - -# 0으로 대체하기 -df['col'] = df['col'].fillna(0) - -# 컬럼의 평균으로 대체하기 -df['col'] = df['col'].fillna(df['col'].mean()) - -# 결측치 바로 이전 값으로 채우기 -df.fillna(method = 'pad') - -# 결측치 바로 이후 값으로 채우기 -df.fillna(method = 'bfill') -``` - -#### replace - -https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.replace.html - -```python -# 결측치 값을 -50으로 채운다. -df.replace(to_replace = np.nan, value = -50) -``` - - - -#### interpolate(보간법) - -https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.interpolate.html - -```python -# interpolate는 인덱스를 무시하고 값들을 선형적으로 같은 간격으로 처리하게 된다. -df.interpolate(method = 'linear') -# ‘linear’: Ignore the index and treat the values as equally spaced - Default -``` - -inplace의 의미 - - - -## 이상치 - -### 방법 - -IQR 방식은 75% percentile + 1.5 * IQR 이상이거나 25 percentile - 1.5 * IQR 이하인 경우 극단치로 처리하는 방식이다. 이해하기 쉽고 적용하기 쉬운 편이지만, 경우에 따라 너무 많은 사례들이 극단치로 고려되는 경우가 있다. - - - - - -```python -# IQR 기반 예제 코드 -def outliers_iqr(ys): - quartile_1, quartile_3 = np.percentile(ys, [25, 75]) - iqr = quartile_3 - quartile_1 - lower_bound = quartile_1 - (iqr * 1.5) - upper_bound = quartile_3 + (iqr * 1.5) - return np.where((ys > upper_bound) | (ys < lower_bound)) -``` - +# 전처리 + +## 결측치란 + +- 분석 결과/인사이트와 모델 성능에 직접적인 영향을 미치는 과정이기 때문에 중요하게 다루어지는 과정 + +- 한 설문조사에 의하면, 분석가의 80% 시간을 데이터 수집 및 전처리에 사용한다고 하니, 얼마나 중요한 과정인지 짐작할 수 있다. 물론 지루하고 반복 작업의 연속이기 때문에 시간이 많이 들어가는 측면도 있을 것이다. + +패턴이 있는 것과 패턴이 없는 것이 있음 + +## 결측치 처리 + +1) 결측치 사례 제거 +2) 수치형의 경우 평균이나 중앙치로 대체(imputation)하거나 범주형인 경우 mode 값으로 대체 +3) 간단한 예측 모델로 대체하는 방식이 일반적으로 이용된다. + +가장 쉬운 방법은 Null이 포함 행 혹은 일부 행을 제거하는 것이다 + +### Missing Value 파악 + +데이터셋을 읽었다면, Missing Value 파악을 위해 `df.info()` 가장 처음에 이용하는 것을 추천 + +**DataFrame.info()** + + + +**DataFrame.isnull().sum()** + + + +### 제거 + +#### dropna + +- 결측치의 특성이 '무작위로 손실' 되지 않았다면, 대부분의 경우 가장 좋은 방법은 **제거**하는 것이다. + +https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.dropna.html + +- pandas에서 제공하는 Na/NaN과 같은 누락 데이터를 제거하는 함수입니다. +- axis: 파라미터 값으로 0을 주면 행 제거, 1을 주면 열 제거입니다. default값은 0입니다. +- subset: array, 특정 feature를 지정하여 해당 Feature의 누락 데이터 제거가 가능합니다. + +```python +# 목록삭제(Listwise) + +df = df.dropna() # 결측치가 있는 행은 전부 삭제 + +df = df.dropna(axis = 1) # 결측치가 있는 열은 전부 삭제 + +# 단일값 삭제(Pairwise) + +df = df.dropna(how = 'all') # 행 전체가 결측치인 행만 삭제 + +df = df.dropna(thresh = 2) # 행의 결측치가 2개 초과인 행만 삭제 + +# 특정 열들중에 결측치가 있을 경우에 해당 행을 삭제 +df = df.dropna(subset=['col1', 'col2', 'col3']) + +# 특정열 모두가 결측치일 경우 해당 행 삭제 +df = df.dropna(subset=['col1', 'col2', 'col3'], how = 'all') + +# 특정열에 1개 초과의 결측치가 있을 경우 해당 행 삭제 +df = df.dropna(subset=['col1', 'col2', 'col3'], thresh = 1 ) +``` + + + +### 대체 + +대체값 종류 + +- 최빈값(mode) + - 범주형에서 결측값이 발생시, 범주별 빈도가 가장 높은 값으로 대치한다. +- 중앙값(median) + - 숫자형(연속형)에서 결측값을 제외한 중앙값으로 대치방법 +- 평균(mean) + - 숫자형(연속형)에서 결측값제외한 평균으로 대치방법 +- Similar case Imputation + - 조건부 대치 +- Generalized Imputation + - 회귀분석을 이용한 대치 + +#### fillna + +https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.fillna.html + +```python +df.fillna(0) # 전체 결측치를 특정 단일값으로 대체하기 + +# 특정열에 결측치가 있을 경우 다른 값으로 대체하기 + +# 0으로 대체하기 +df['col'] = df['col'].fillna(0) + +# 컬럼의 평균으로 대체하기 +df['col'] = df['col'].fillna(df['col'].mean()) + +# 결측치 바로 이전 값으로 채우기 +df.fillna(method = 'pad') + +# 결측치 바로 이후 값으로 채우기 +df.fillna(method = 'bfill') +``` + +#### replace + +https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.replace.html + +```python +# 결측치 값을 -50으로 채운다. +df.replace(to_replace = np.nan, value = -50) +``` + + + +#### interpolate(보간법) + +https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.interpolate.html + +```python +# interpolate는 인덱스를 무시하고 값들을 선형적으로 같은 간격으로 처리하게 된다. +df.interpolate(method = 'linear') +# ‘linear’: Ignore the index and treat the values as equally spaced - Default +``` + +inplace의 의미 + + + +## 이상치 + +### 방법 + +IQR 방식은 75% percentile + 1.5 * IQR 이상이거나 25 percentile - 1.5 * IQR 이하인 경우 극단치로 처리하는 방식이다. 이해하기 쉽고 적용하기 쉬운 편이지만, 경우에 따라 너무 많은 사례들이 극단치로 고려되는 경우가 있다. + + + + + +```python +# IQR 기반 예제 코드 +def outliers_iqr(ys): + quartile_1, quartile_3 = np.percentile(ys, [25, 75]) + iqr = quartile_3 - quartile_1 + lower_bound = quartile_1 - (iqr * 1.5) + upper_bound = quartile_3 + (iqr * 1.5) + return np.where((ys > upper_bound) | (ys < lower_bound)) +``` + diff --git "a/\355\212\234\353\213\235/Lv3_\355\212\234\353\213\235_Bayesian Optimization.md" "b/\355\212\234\353\213\235/Lv3_\355\212\234\353\213\235_Bayesian Optimization.md" new file mode 100644 index 0000000..3166163 --- /dev/null +++ "b/\355\212\234\353\213\235/Lv3_\355\212\234\353\213\235_Bayesian Optimization.md" @@ -0,0 +1,159 @@ +# Bayesian Optimization + +## Optimization + +어떤 임의의 함수 f(x)-모델-의 값-모델의 점수-을 가장 크게(또는 작게)하는 해를 구하는 것이다. 이 모델은 수많은 변수를 가질 수 있다. 이 변수들을 조정하여 주어진 데이터 셋에 대해서 가장 좋은 결과를 내어놓는 x를 찾는 것이 hyperparameter 튜닝이다. + + + + + +## 대표적인 hyperparameter 튜닝 기법들의 단점 + +### 1. GridSearch + +- 모든 hyperparameter 후보들에 대한 일반화 성능을 확인하기 때문에, 시간이 너무 오래 걸린다. + +### 2. RandomSearch + +- 위에 비해 시간은 적게 걸리지만, 말 그대로 랜덤하게 뽑는 방식이기 때문에 정확도가 다소 떨어진다. + + + +-> Bayesian Optimization은 이 둘에 비해 효율적으로 최적값을 찾아낸다는 장점이 있다. + + + + + +## Bayesian Optimization + +**이전의 정보를 최적 값 탐색에 반영하여 탐색을 반복해 최적의 값을 찾아 나가는 방식** + + + +#### 1. Surrogate model + +- 지금까지의 데이터를 통해 예상하는 모델을 만듦 +- '최종 목적함수(우리가 찾으려고 하는)에 대해 확률적으로 추정한 결과' +- 이 모델을 기반으로 다음 탐색 지점을 결정 +- (Gaussian Process를 주로 사용) + +#### 2. Acquisition function + +- 위 모델을 검증하고, 다음 모델을 만드는 데 있어서 최적의 하이퍼파라미터를 추천하는 단계 +- (Expected Improvement 사용) + + + +#### Bayesian Optimization 수행 과정 + + + +위의 파란색 선은 우리가 찾으려고 하는 목적함수를 나타내고, 검은색 점선은 지금까지 관측한 데이터를 바탕으로 우리가 예측한 estimated function을 의미한다. 검은색 점선 주변에 있는 파란 영역은, 목적함수 f(x)가 존재할만한 영역을 의미한다. 밑에 있는 EI(x)는 위에서 언급한 Acquisition function을 의미하며 다음 입력값 후보를 추천해준다. Acquisition function 값이 컸던 지점의 function 값을 관측하고 estimation을 update 한다.한다. 계속 update를 진행하면 estimation과 실제 function이 흡사해진다. + +1 입력값, 목적 함수 및 그 외 설정값들을 정의합니다. + +- 입력값 x : 여러가지 hyperparameter +- 목적 함수 f(x) : 설정한 입력값을 적용해 학습한, 딥러닝 모델의 성능 결과 수치(e.g. 정확도) +- 입력값 x 의 탐색 대상 구간 : (a,b) +- 입력값-함숫결과값 점들의 갯수 : n +- 조사할 입력값-함숫결과값 점들의 갯수 : N + +2 설정한 탐색 대상 구간 (a,b) 내에서 처음 n 개의 입력값들을 랜덤하게 샘플링하여 선택합니다. + +3 선택한 n 개의 입력값 x1, x2, ..., xn 을 각각 모델의 hyperparameter 로 설정하여 딥러닝 모델을 학습한 뒤, 학습이 완료된 모델의 성능 결과 수치를 계산합니다. + +- 이들을 각각 함숫결과값 f(x1), f(x2), ..., f(xn) 으로 간주합니다. + +4 입력값-함숫결과값 점들의 모음 (x1, f(x1)), (x2, f(x2)), ..., (xn, f(xn)) 에 대하여 Surrogate Model 로 확률적 추정을 수행합니다. + +5 조사된 입력값-함숫결과값 점들이 총 N 개에 도달할 때까지, 아래의 과정을 반복적으로 수행합니다. + +- 기존 입력값-함숫결과값 점들의 모음 (x1, f(x1)),(x2, f(x2)), ..., (xt, f(xt)) 에 대한 Surrogate Model 의 확률적 추정 결과를 바탕으로, 입력값 구간 (a,b) 내에서의 EI 의 값을 계산하고, 그 값이 가장 큰 점을 다음 입력값 후보 x1 로 선정합니다. +- 다음 입력값 후보 x1 를 hyperparameter 로 설정하여 딥러닝 모델을 학습한 뒤, 학습이 완료된 모델의 성능 결과 수치를 계산하고, 이를 f(x1) 값으로 간주합니다. +- 새로운 점 (x2, f(x2)) 을 기존 입력값-함숫결과값 점들의 모음에 추가하고, 갱신된 점들의 모음에 대하여 Surrogate Model 로 확률적 추정을 다시 수행합니다. + +6 총 N 개의 입력값-함숫결과값 점들에 대하여 확률적으로 추정된 목적 함수 결과물을 바탕으로, 평균 함수 μ(x) 을 최대로 만드는 최적해를 최종 선택합니다. 추후 해당값을 hyperparameter 로 사용하여 딥러닝 모델을 학습하면, 일반화 성능이 극대화된 모델을 얻을 수 있습니다. + + + +#### 실험 결과를 반영해가면서 효율적으로 hyperparameter을 찾아나가는 것이 가능해짐 + + + + + +#### 예제 코드 + +```python +# X에 학습할 데이터를, y에 목표 변수를 저장해주세요 +X = train.drop(columns = ['index', 'quality']) +y = train['quality'] +``` + +```python +# 랜덤포레스트의 하이퍼 파라미터의 범위를 dictionary 형태로 지정해주세요 +## Key는 랜덤포레스트의 hyperparameter이름이고, value는 탐색할 범위 입니다. +rf_parameter_bounds = { + 'max_depth' : (1,3), # 나무의 깊이 + 'n_estimators' : (30,100), + } +``` + +```python +# 함수를 만들어주겠습니다. +# 함수의 구성은 다음과 같습니다. +# 1. 함수에 들어가는 인자 = 위에서 만든 함수의 key값들 +# 2. 함수 속 인자를 통해 받아와 새롭게 하이퍼파라미터 딕셔너리 생성 +# 3. 그 딕셔너리를 바탕으로 모델 생성 +# 4. train_test_split을 통해 데이터 train-valid 나누기 +# 5 .모델 학습 +# 6. 모델 성능 측정 +# 7. 모델의 점수 반환 + +def rf_bo(max_depth, n_estimators): + rf_params = { + 'max_depth' : int(round(max_depth)), + 'n_estimators' : int(round(n_estimators)), + } + rf = RandomForestClassifier(**rf_params) + + X_train, X_valid, y_train, y_valid = train_test_split(X,y,test_size = 0.2, ) + + rf.fit(X_train,y_train) + score = accuracy_score(y_valid, rf.predict(X_valid)) + return score +``` + +```python +# 이제 Bayesian Optimization을 사용할 준비가 끝났습니다. +# "BO_rf"라는 변수에 Bayesian Optmization을 저장해보세요 +BO_rf = BayesianOptimization(f = rf_bo, pbounds = rf_parameter_bounds,random_state = 0) + +# pbounds: 테스트하고자 하는 hyperparameter의 집합 +``` + +```python +# Bayesian Optimization을 실행해보세요 +BO_rf.maximize(init_points = 5, n_iter = 5) + +# init_points: random search로 탐색할 횟수 +# n_iter: 최적값을 찾을 횟수(몇 개의 입력값 - 함숫값 점들을 확인할지) +# maximize: 목적함수를 최대로 만드는 최적해를 찾는다 +``` + +```python +# 하이퍼파라미터의 결과값을 불러와 "max_params"라는 변수에 저장해보세요 +max_params = BO_rf.max['params'] + +max_params['max_depth'] = int(max_params['max_depth']) +max_params['n_estimators'] = int(max_params['n_estimators']) +print(max_params) +``` + +```python +# Bayesian Optimization의 결과를 "BO_tuend_rf"라는 변수에 저장해보세요 +BO_tuend_rf = RandomForestClassifier(**max_params) +``` + diff --git "a/\355\212\234\353\213\235(Lv4).assets/image-20220502193613401.png" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502193613401.png" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/image-20220502193613401.png" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502193613401.png" diff --git "a/\355\212\234\353\213\235(Lv4).assets/image-20220502230520657.png" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230520657.png" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/image-20220502230520657.png" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230520657.png" diff --git "a/\355\212\234\353\213\235(Lv4).assets/image-20220502230748658.png" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230748658.png" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/image-20220502230748658.png" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230748658.png" diff --git "a/\355\212\234\353\213\235(Lv4).assets/image-20220502230822164.png" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230822164.png" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/image-20220502230822164.png" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230822164.png" diff --git "a/\355\212\234\353\213\235(Lv4).assets/image-20220502230848119.png" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230848119.png" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/image-20220502230848119.png" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230848119.png" diff --git "a/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234 (1).jpg" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234 (1).jpg" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234 (1).jpg" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234 (1).jpg" diff --git "a/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.jpg" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.jpg" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.jpg" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.jpg" diff --git "a/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.png" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.png" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.png" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.png" diff --git "a/\355\212\234\353\213\235(Lv4).md" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).md" similarity index 96% rename from "\355\212\234\353\213\235(Lv4).md" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).md" index 020c0e7..c5e956d 100644 --- "a/\355\212\234\353\213\235(Lv4).md" +++ "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).md" @@ -1,194 +1,194 @@ -Bayesian Optimization 을 이용해 모델을 튜닝 - -현재까지 얻어진 모델의 파라미터와 추가적인 실험 정보를 통해 **데이터가 주어 졌을 때 모델의 성능이 가장 좋을 확률이 높은 파라미터를 찾아냅니다.** - - - -# 모델 튜닝 - -## XGBoost 모델 튜닝 - -.assets/다운로드.jpg) -
-### learning rate(학습률)
-
-[경사하강법](https://velog.io/@sasganamabeer/AI-Gradient-Descent%EA%B2%BD%EC%82%AC%ED%95%98%EA%B0%95%EB%B2%95)
-
-> 경사하강법(Gradient Descent)은 1차 근삿값 발견용 **최적화 알고리즘**이다. 기본 개념은 함수의 기울기(경사)를 구하고 경사의 절댓값이 낮은 쪽으로 계속 이동시켜 극값에 이를 때까지 반복시키는 것이다.
-
-- 취솟값을 구하기 위해 미분계수 계산 과정을 컴퓨터로 구현하는 것보다, **경사하강법을 구현하는 것이 훨씬 쉬움**
-
-- 데이터의 양이 매우 큰 경우 경사하강법과 같은 순차적인 방법이 **계산량 측면에서 훨씬 효율적**
-
-- **공식**
-
- - 경사하강법은 **함수의 기울기(=gradient)를 이용해서 함수의 최소값 일 때의 x값을 찾기 위한 방법**이다. 기울기가 양수인 경우는 *x* 값이 증가할수록 함수 값도 증가하고, 반대로 음수인 경우에는 *x* 값이 증가할수록 함수 값이 감소한다. 그리고 기울기 값이 크다, 기울기가 가파르다는 것은 최소값으로부터 거리가 멀다는 뜻이다.
-
- .assets/image-20220502230520657.png)
-
- 기울기가 양수면 x를 음의 방향으로, 기울기가 음수면 x를 양의 방향으로 x를 이동시킨다.
-
- .assets/image-20220502230748658.png)
-
- 미분 계수(=기울기=gradient)는 극소값에 가까워질수록 값이 작아진다. 따라서, **이동거리에는 미분 계수와 비례하는 값을 이용**한다. 그럼 극소값에서 멀 때는 많이 이동하고, 극소값에 가까울 때는 조금씩 이동할 수 있다.
-
- .assets/image-20220502230822164.png)
-
- > .assets/image-20220502230848119.png)
-
-
-
-- 경사하강법 알고리즘은 기울기에 learning rate 또는 step size라고 불리는 스칼라를 곱해서 다음지점을 결정한다.
-
- .assets/image-20220502193613401.png)
-
-learning rate(step size)이 크면 데이터가 무질서하게 이탈해서 최저점에 수렴하지 못하고 learning rate(step size)가 작으면 학습시간이 오래걸려서 최저점에 도달하지 못한다. 적절할 값을 설정해줘야한다. [최종 학습시에는 0.05 이하의 값을 사용하여 모형 성능 향상에 초점을 맞추고, 하이퍼파라미터 튜닝시에는 0.1이상의 값을 사용하여 학습속도를 높이는 것이 좋다.](https://psystat.tistory.com/131)
-
-**gamma**
-
-- gain - gamma < 0 이면 해당 분기점은 없어진다.
-
-- gamma 값에 따라 분할할지 말지 정할 수도 있음
-- https://gwoolab.tistory.com/31
-
-**[lambda, alpha](https://wooono.tistory.com/221)**
-
-- **L1 Regularization** 과 **L2 Regularization** 모두 **Overfitting(과적합)** 을 막기 위해 사용
-- L1 Regularization은 가중치 업데이트 시, 가중치의 크기에 상관 없이 상수값을 빼면서 진행
-- L2 Regularization은 가중치 업데이트 시, 가중치의 크기가 직접적인 영향을 미침
-- 다만, L1 Regularization은 아래 그림처럼 미분 불가능한 점이 있기 때문에 Gradient-base learning 에는 주의가 필요
-
-- 따라서, L2는 L1 보다 가중치 규제에 좀 더 효과적
-
-
-
-### learning rate(학습률)
-
-[경사하강법](https://velog.io/@sasganamabeer/AI-Gradient-Descent%EA%B2%BD%EC%82%AC%ED%95%98%EA%B0%95%EB%B2%95)
-
-> 경사하강법(Gradient Descent)은 1차 근삿값 발견용 **최적화 알고리즘**이다. 기본 개념은 함수의 기울기(경사)를 구하고 경사의 절댓값이 낮은 쪽으로 계속 이동시켜 극값에 이를 때까지 반복시키는 것이다.
-
-- 취솟값을 구하기 위해 미분계수 계산 과정을 컴퓨터로 구현하는 것보다, **경사하강법을 구현하는 것이 훨씬 쉬움**
-
-- 데이터의 양이 매우 큰 경우 경사하강법과 같은 순차적인 방법이 **계산량 측면에서 훨씬 효율적**
-
-- **공식**
-
- - 경사하강법은 **함수의 기울기(=gradient)를 이용해서 함수의 최소값 일 때의 x값을 찾기 위한 방법**이다. 기울기가 양수인 경우는 *x* 값이 증가할수록 함수 값도 증가하고, 반대로 음수인 경우에는 *x* 값이 증가할수록 함수 값이 감소한다. 그리고 기울기 값이 크다, 기울기가 가파르다는 것은 최소값으로부터 거리가 멀다는 뜻이다.
-
- .assets/image-20220502230520657.png)
-
- 기울기가 양수면 x를 음의 방향으로, 기울기가 음수면 x를 양의 방향으로 x를 이동시킨다.
-
- .assets/image-20220502230748658.png)
-
- 미분 계수(=기울기=gradient)는 극소값에 가까워질수록 값이 작아진다. 따라서, **이동거리에는 미분 계수와 비례하는 값을 이용**한다. 그럼 극소값에서 멀 때는 많이 이동하고, 극소값에 가까울 때는 조금씩 이동할 수 있다.
-
- .assets/image-20220502230822164.png)
-
- > .assets/image-20220502230848119.png)
-
-
-
-- 경사하강법 알고리즘은 기울기에 learning rate 또는 step size라고 불리는 스칼라를 곱해서 다음지점을 결정한다.
-
- .assets/image-20220502193613401.png)
-
-learning rate(step size)이 크면 데이터가 무질서하게 이탈해서 최저점에 수렴하지 못하고 learning rate(step size)가 작으면 학습시간이 오래걸려서 최저점에 도달하지 못한다. 적절할 값을 설정해줘야한다. [최종 학습시에는 0.05 이하의 값을 사용하여 모형 성능 향상에 초점을 맞추고, 하이퍼파라미터 튜닝시에는 0.1이상의 값을 사용하여 학습속도를 높이는 것이 좋다.](https://psystat.tistory.com/131)
-
-**gamma**
-
-- gain - gamma < 0 이면 해당 분기점은 없어진다.
-
-- gamma 값에 따라 분할할지 말지 정할 수도 있음
-- https://gwoolab.tistory.com/31
-
-**[lambda, alpha](https://wooono.tistory.com/221)**
-
-- **L1 Regularization** 과 **L2 Regularization** 모두 **Overfitting(과적합)** 을 막기 위해 사용
-- L1 Regularization은 가중치 업데이트 시, 가중치의 크기에 상관 없이 상수값을 빼면서 진행
-- L2 Regularization은 가중치 업데이트 시, 가중치의 크기가 직접적인 영향을 미침
-- 다만, L1 Regularization은 아래 그림처럼 미분 불가능한 점이 있기 때문에 Gradient-base learning 에는 주의가 필요
-
-- 따라서, L2는 L1 보다 가중치 규제에 좀 더 효과적
-
-.assets/다운로드.png) -
-## Light GBM 모델 튜닝
-
-.assets/다운로드 (1).jpg)
-
-**min_child_samples**
-
-- **min_child_samples** 파라미터는 최종 결정 클래스인 Leaf Node가 되기 위해서 최소한으로 필요한 **데이터 개체의 수**를 의미하며, 과적합을 제어하는 파라미터이다. 이 파라미터의 최적값은 훈련 데이터의 개수와 **num_leaves**에 의해 결정된다. 너무 큰 숫자로 설정하면 under-fitting이 일어날 수 있으며, 아주 큰 데이터셋이라면 적어도 수백~수천 정도로 가정하는 것이 편리하다.
- - **num_leaves** 파라미터는 하나의 트리가 가질 수 있는 최대 리프의 개수인데, 이 개수를 높이면 정확도는 높아지지만 트리의 깊이가 커져 모델의 복잡도가 증가한다는 점에 유의해야 한다.
-
-
-
-## 코드
-
-### XGBoost
-
-```python
-# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(실습)
-
-#학습
-xgb_tune =XGBClassifier(gamma = 4.376,max_depth = 3, subsample = 0.9818)
-xgb_tune.fit(X,y)
-
-
-#예측
-pred = xgb_tune.predict(test.drop(columns = ['index'] ))
-
-#정답파일 내보내기
-sub = pd.read_csv('data/sample_submission.csv')
-sub['quality'] = pred
-sub.to_csv('tune_xgb.csv',index = False)
-
-#0.573
-
-# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(max_params)
-
-#학습
-xgb_tune =XGBClassifier(gamma = 3.852,max_depth = 2, subsample = 0.8105)
-xgb_tune.fit(X,y)
-
-
-#예측
-pred = xgb_tune.predict(test.drop(columns = ['index'] ))
-
-#정답파일 내보내기
-sub = pd.read_csv('data/sample_submission.csv')
-sub['quality'] = pred
-sub.to_csv('tune_xgb_lwt.csv',index = False)
-
-#0.567
-```
-
-
-
-### light gbm
-
-```python
-max_params = BO_lgbm.max['params']
-
-max_params['max_depth'] = float(max_params['max_depth'])
-max_params['n_estimators'] = float(max_params['n_estimators'])
-max_params['subsample'] = float(max_params['subsample'])
-print(max_params)
-# {'max_depth': 2.5563135018997007, 'n_estimators': 90.90085037727735, 'subsample': 0.989309171116382}
-
-
-# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(실습내용)
-
-#학습
-lgbm_tune =LGBMClassifier(n_estimators = 43 ,max_depth = 3, subsample = 1)
-lgbm_tune.fit(X,y)
-
-
-#예측
-pred = lgbm_tune.predict(test.drop(columns = ['index'] ))
-
-#정답파일 내보내기
-sub = pd.read_csv('data/sample_submission.csv')
-sub['quality'] = pred
-sub.to_csv('tune_lgbm.csv',index = False)
-# 0.57199
-
-# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(max_params적용)
-
-#학습
-lgbm_tune =LGBMClassifier(n_estimators = 91 ,max_depth = 3, subsample = 1)
-lgbm_tune.fit(X,y)
-
-
-#예측
-pred = lgbm_tune.predict(test.drop(columns = ['index'] ))
-
-#정답파일 내보내기
-sub = pd.read_csv('data/sample_submission.csv')
-sub['quality'] = pred
-sub.to_csv('tune_lgbm_lwt.csv',index = False)
-# 0.57699
-```
-
-
-
-# voting classifier
-
-```python
-# 모델 정의 (튜닝된 파라미터로)(실습)
-LGBM = LGBMClassifier(max_depth = 3,n_estimators=60, subsample = 0.8229)
-XGB = XGBClassifier(gamma = 4.376, max_depth = 3, subsample = 0.9818)
-RF = RandomForestClassifier(max_depth = 3, n_estimators = 35) # float값이 안들어가서 몇개는 반올림 해줌
-
-# VotingClassifier 정의
-VC = VotingClassifier(estimators=[('rf',RF),('xgb',XGB),('lgbm',LGBM)],voting = 'soft')
-# 0.555
-
-# 모델 정의 (튜닝된 파라미터로)(max_params적용))
-LGBM = LGBMClassifier(max_depth = 3,n_estimators=100, subsample = 1)
-XGB = XGBClassifier(gamma = 4, max_depth = 1, subsample = 1)
-RF = RandomForestClassifier(max_depth = 3, n_estimators = 100)
-
-# VotingClassifier 정의
-VC = VotingClassifier(estimators=[('rf',RF),('xgb',XGB),('lgbm',LGBM)],voting = 'soft')
-# 0.556
-
-# 0.001차이로 max_params가 높음
-```
-
-
-
-
-
-
-
+Bayesian Optimization 을 이용해 모델을 튜닝
+
+현재까지 얻어진 모델의 파라미터와 추가적인 실험 정보를 통해 **데이터가 주어 졌을 때 모델의 성능이 가장 좋을 확률이 높은 파라미터를 찾아냅니다.**
+
+
+
+# 모델 튜닝
+
+## XGBoost 모델 튜닝
+
+
+
+### learning rate(학습률)
+
+[경사하강법](https://velog.io/@sasganamabeer/AI-Gradient-Descent%EA%B2%BD%EC%82%AC%ED%95%98%EA%B0%95%EB%B2%95)
+
+> 경사하강법(Gradient Descent)은 1차 근삿값 발견용 **최적화 알고리즘**이다. 기본 개념은 함수의 기울기(경사)를 구하고 경사의 절댓값이 낮은 쪽으로 계속 이동시켜 극값에 이를 때까지 반복시키는 것이다.
+
+- 취솟값을 구하기 위해 미분계수 계산 과정을 컴퓨터로 구현하는 것보다, **경사하강법을 구현하는 것이 훨씬 쉬움**
+
+- 데이터의 양이 매우 큰 경우 경사하강법과 같은 순차적인 방법이 **계산량 측면에서 훨씬 효율적**
+
+- **공식**
+
+ - 경사하강법은 **함수의 기울기(=gradient)를 이용해서 함수의 최소값 일 때의 x값을 찾기 위한 방법**이다. 기울기가 양수인 경우는 *x* 값이 증가할수록 함수 값도 증가하고, 반대로 음수인 경우에는 *x* 값이 증가할수록 함수 값이 감소한다. 그리고 기울기 값이 크다, 기울기가 가파르다는 것은 최소값으로부터 거리가 멀다는 뜻이다.
+
+ .assets/image-20220502230520657.png)
+
+ 기울기가 양수면 x를 음의 방향으로, 기울기가 음수면 x를 양의 방향으로 x를 이동시킨다.
+
+ .assets/image-20220502230748658.png)
+
+ 미분 계수(=기울기=gradient)는 극소값에 가까워질수록 값이 작아진다. 따라서, **이동거리에는 미분 계수와 비례하는 값을 이용**한다. 그럼 극소값에서 멀 때는 많이 이동하고, 극소값에 가까울 때는 조금씩 이동할 수 있다.
+
+ .assets/image-20220502230822164.png)
+
+ > .assets/image-20220502230848119.png)
+
+
+
+- 경사하강법 알고리즘은 기울기에 learning rate 또는 step size라고 불리는 스칼라를 곱해서 다음지점을 결정한다.
+
+ .assets/image-20220502193613401.png)
+
+learning rate(step size)이 크면 데이터가 무질서하게 이탈해서 최저점에 수렴하지 못하고 learning rate(step size)가 작으면 학습시간이 오래걸려서 최저점에 도달하지 못한다. 적절할 값을 설정해줘야한다. [최종 학습시에는 0.05 이하의 값을 사용하여 모형 성능 향상에 초점을 맞추고, 하이퍼파라미터 튜닝시에는 0.1이상의 값을 사용하여 학습속도를 높이는 것이 좋다.](https://psystat.tistory.com/131)
+
+**gamma**
+
+- gain - gamma < 0 이면 해당 분기점은 없어진다.
+
+- gamma 값에 따라 분할할지 말지 정할 수도 있음
+- https://gwoolab.tistory.com/31
+
+**[lambda, alpha](https://wooono.tistory.com/221)**
+
+- **L1 Regularization** 과 **L2 Regularization** 모두 **Overfitting(과적합)** 을 막기 위해 사용
+- L1 Regularization은 가중치 업데이트 시, 가중치의 크기에 상관 없이 상수값을 빼면서 진행
+- L2 Regularization은 가중치 업데이트 시, 가중치의 크기가 직접적인 영향을 미침
+- 다만, L1 Regularization은 아래 그림처럼 미분 불가능한 점이 있기 때문에 Gradient-base learning 에는 주의가 필요
+
+- 따라서, L2는 L1 보다 가중치 규제에 좀 더 효과적
+
+
+
+## Light GBM 모델 튜닝
+
+
-
-## Light GBM 모델 튜닝
-
-.assets/다운로드 (1).jpg)
-
-**min_child_samples**
-
-- **min_child_samples** 파라미터는 최종 결정 클래스인 Leaf Node가 되기 위해서 최소한으로 필요한 **데이터 개체의 수**를 의미하며, 과적합을 제어하는 파라미터이다. 이 파라미터의 최적값은 훈련 데이터의 개수와 **num_leaves**에 의해 결정된다. 너무 큰 숫자로 설정하면 under-fitting이 일어날 수 있으며, 아주 큰 데이터셋이라면 적어도 수백~수천 정도로 가정하는 것이 편리하다.
- - **num_leaves** 파라미터는 하나의 트리가 가질 수 있는 최대 리프의 개수인데, 이 개수를 높이면 정확도는 높아지지만 트리의 깊이가 커져 모델의 복잡도가 증가한다는 점에 유의해야 한다.
-
-
-
-## 코드
-
-### XGBoost
-
-```python
-# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(실습)
-
-#학습
-xgb_tune =XGBClassifier(gamma = 4.376,max_depth = 3, subsample = 0.9818)
-xgb_tune.fit(X,y)
-
-
-#예측
-pred = xgb_tune.predict(test.drop(columns = ['index'] ))
-
-#정답파일 내보내기
-sub = pd.read_csv('data/sample_submission.csv')
-sub['quality'] = pred
-sub.to_csv('tune_xgb.csv',index = False)
-
-#0.573
-
-# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(max_params)
-
-#학습
-xgb_tune =XGBClassifier(gamma = 3.852,max_depth = 2, subsample = 0.8105)
-xgb_tune.fit(X,y)
-
-
-#예측
-pred = xgb_tune.predict(test.drop(columns = ['index'] ))
-
-#정답파일 내보내기
-sub = pd.read_csv('data/sample_submission.csv')
-sub['quality'] = pred
-sub.to_csv('tune_xgb_lwt.csv',index = False)
-
-#0.567
-```
-
-
-
-### light gbm
-
-```python
-max_params = BO_lgbm.max['params']
-
-max_params['max_depth'] = float(max_params['max_depth'])
-max_params['n_estimators'] = float(max_params['n_estimators'])
-max_params['subsample'] = float(max_params['subsample'])
-print(max_params)
-# {'max_depth': 2.5563135018997007, 'n_estimators': 90.90085037727735, 'subsample': 0.989309171116382}
-
-
-# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(실습내용)
-
-#학습
-lgbm_tune =LGBMClassifier(n_estimators = 43 ,max_depth = 3, subsample = 1)
-lgbm_tune.fit(X,y)
-
-
-#예측
-pred = lgbm_tune.predict(test.drop(columns = ['index'] ))
-
-#정답파일 내보내기
-sub = pd.read_csv('data/sample_submission.csv')
-sub['quality'] = pred
-sub.to_csv('tune_lgbm.csv',index = False)
-# 0.57199
-
-# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(max_params적용)
-
-#학습
-lgbm_tune =LGBMClassifier(n_estimators = 91 ,max_depth = 3, subsample = 1)
-lgbm_tune.fit(X,y)
-
-
-#예측
-pred = lgbm_tune.predict(test.drop(columns = ['index'] ))
-
-#정답파일 내보내기
-sub = pd.read_csv('data/sample_submission.csv')
-sub['quality'] = pred
-sub.to_csv('tune_lgbm_lwt.csv',index = False)
-# 0.57699
-```
-
-
-
-# voting classifier
-
-```python
-# 모델 정의 (튜닝된 파라미터로)(실습)
-LGBM = LGBMClassifier(max_depth = 3,n_estimators=60, subsample = 0.8229)
-XGB = XGBClassifier(gamma = 4.376, max_depth = 3, subsample = 0.9818)
-RF = RandomForestClassifier(max_depth = 3, n_estimators = 35) # float값이 안들어가서 몇개는 반올림 해줌
-
-# VotingClassifier 정의
-VC = VotingClassifier(estimators=[('rf',RF),('xgb',XGB),('lgbm',LGBM)],voting = 'soft')
-# 0.555
-
-# 모델 정의 (튜닝된 파라미터로)(max_params적용))
-LGBM = LGBMClassifier(max_depth = 3,n_estimators=100, subsample = 1)
-XGB = XGBClassifier(gamma = 4, max_depth = 1, subsample = 1)
-RF = RandomForestClassifier(max_depth = 3, n_estimators = 100)
-
-# VotingClassifier 정의
-VC = VotingClassifier(estimators=[('rf',RF),('xgb',XGB),('lgbm',LGBM)],voting = 'soft')
-# 0.556
-
-# 0.001차이로 max_params가 높음
-```
-
-
-
-
-
-
-
+Bayesian Optimization 을 이용해 모델을 튜닝
+
+현재까지 얻어진 모델의 파라미터와 추가적인 실험 정보를 통해 **데이터가 주어 졌을 때 모델의 성능이 가장 좋을 확률이 높은 파라미터를 찾아냅니다.**
+
+
+
+# 모델 튜닝
+
+## XGBoost 모델 튜닝
+
+
+
+### learning rate(학습률)
+
+[경사하강법](https://velog.io/@sasganamabeer/AI-Gradient-Descent%EA%B2%BD%EC%82%AC%ED%95%98%EA%B0%95%EB%B2%95)
+
+> 경사하강법(Gradient Descent)은 1차 근삿값 발견용 **최적화 알고리즘**이다. 기본 개념은 함수의 기울기(경사)를 구하고 경사의 절댓값이 낮은 쪽으로 계속 이동시켜 극값에 이를 때까지 반복시키는 것이다.
+
+- 취솟값을 구하기 위해 미분계수 계산 과정을 컴퓨터로 구현하는 것보다, **경사하강법을 구현하는 것이 훨씬 쉬움**
+
+- 데이터의 양이 매우 큰 경우 경사하강법과 같은 순차적인 방법이 **계산량 측면에서 훨씬 효율적**
+
+- **공식**
+
+ - 경사하강법은 **함수의 기울기(=gradient)를 이용해서 함수의 최소값 일 때의 x값을 찾기 위한 방법**이다. 기울기가 양수인 경우는 *x* 값이 증가할수록 함수 값도 증가하고, 반대로 음수인 경우에는 *x* 값이 증가할수록 함수 값이 감소한다. 그리고 기울기 값이 크다, 기울기가 가파르다는 것은 최소값으로부터 거리가 멀다는 뜻이다.
+
+ .assets/image-20220502230520657.png)
+
+ 기울기가 양수면 x를 음의 방향으로, 기울기가 음수면 x를 양의 방향으로 x를 이동시킨다.
+
+ .assets/image-20220502230748658.png)
+
+ 미분 계수(=기울기=gradient)는 극소값에 가까워질수록 값이 작아진다. 따라서, **이동거리에는 미분 계수와 비례하는 값을 이용**한다. 그럼 극소값에서 멀 때는 많이 이동하고, 극소값에 가까울 때는 조금씩 이동할 수 있다.
+
+ .assets/image-20220502230822164.png)
+
+ > .assets/image-20220502230848119.png)
+
+
+
+- 경사하강법 알고리즘은 기울기에 learning rate 또는 step size라고 불리는 스칼라를 곱해서 다음지점을 결정한다.
+
+ .assets/image-20220502193613401.png)
+
+learning rate(step size)이 크면 데이터가 무질서하게 이탈해서 최저점에 수렴하지 못하고 learning rate(step size)가 작으면 학습시간이 오래걸려서 최저점에 도달하지 못한다. 적절할 값을 설정해줘야한다. [최종 학습시에는 0.05 이하의 값을 사용하여 모형 성능 향상에 초점을 맞추고, 하이퍼파라미터 튜닝시에는 0.1이상의 값을 사용하여 학습속도를 높이는 것이 좋다.](https://psystat.tistory.com/131)
+
+**gamma**
+
+- gain - gamma < 0 이면 해당 분기점은 없어진다.
+
+- gamma 값에 따라 분할할지 말지 정할 수도 있음
+- https://gwoolab.tistory.com/31
+
+**[lambda, alpha](https://wooono.tistory.com/221)**
+
+- **L1 Regularization** 과 **L2 Regularization** 모두 **Overfitting(과적합)** 을 막기 위해 사용
+- L1 Regularization은 가중치 업데이트 시, 가중치의 크기에 상관 없이 상수값을 빼면서 진행
+- L2 Regularization은 가중치 업데이트 시, 가중치의 크기가 직접적인 영향을 미침
+- 다만, L1 Regularization은 아래 그림처럼 미분 불가능한 점이 있기 때문에 Gradient-base learning 에는 주의가 필요
+
+- 따라서, L2는 L1 보다 가중치 규제에 좀 더 효과적
+
+
+
+## Light GBM 모델 튜닝
+
+.assets/다운로드 (1).jpg) +
+**min_child_samples**
+
+- **min_child_samples** 파라미터는 최종 결정 클래스인 Leaf Node가 되기 위해서 최소한으로 필요한 **데이터 개체의 수**를 의미하며, 과적합을 제어하는 파라미터이다. 이 파라미터의 최적값은 훈련 데이터의 개수와 **num_leaves**에 의해 결정된다. 너무 큰 숫자로 설정하면 under-fitting이 일어날 수 있으며, 아주 큰 데이터셋이라면 적어도 수백~수천 정도로 가정하는 것이 편리하다.
+ - **num_leaves** 파라미터는 하나의 트리가 가질 수 있는 최대 리프의 개수인데, 이 개수를 높이면 정확도는 높아지지만 트리의 깊이가 커져 모델의 복잡도가 증가한다는 점에 유의해야 한다.
+
+
+
+## 코드
+
+### XGBoost
+
+```python
+# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(실습)
+
+#학습
+xgb_tune =XGBClassifier(gamma = 4.376,max_depth = 3, subsample = 0.9818)
+xgb_tune.fit(X,y)
+
+
+#예측
+pred = xgb_tune.predict(test.drop(columns = ['index'] ))
+
+#정답파일 내보내기
+sub = pd.read_csv('data/sample_submission.csv')
+sub['quality'] = pred
+sub.to_csv('tune_xgb.csv',index = False)
+
+#0.573
+
+# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(max_params)
+
+#학습
+xgb_tune =XGBClassifier(gamma = 3.852,max_depth = 2, subsample = 0.8105)
+xgb_tune.fit(X,y)
+
+
+#예측
+pred = xgb_tune.predict(test.drop(columns = ['index'] ))
+
+#정답파일 내보내기
+sub = pd.read_csv('data/sample_submission.csv')
+sub['quality'] = pred
+sub.to_csv('tune_xgb_lwt.csv',index = False)
+
+#0.567
+```
+
+
+
+### light gbm
+
+```python
+max_params = BO_lgbm.max['params']
+
+max_params['max_depth'] = float(max_params['max_depth'])
+max_params['n_estimators'] = float(max_params['n_estimators'])
+max_params['subsample'] = float(max_params['subsample'])
+print(max_params)
+# {'max_depth': 2.5563135018997007, 'n_estimators': 90.90085037727735, 'subsample': 0.989309171116382}
+
+
+# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(실습내용)
+
+#학습
+lgbm_tune =LGBMClassifier(n_estimators = 43 ,max_depth = 3, subsample = 1)
+lgbm_tune.fit(X,y)
+
+
+#예측
+pred = lgbm_tune.predict(test.drop(columns = ['index'] ))
+
+#정답파일 내보내기
+sub = pd.read_csv('data/sample_submission.csv')
+sub['quality'] = pred
+sub.to_csv('tune_lgbm.csv',index = False)
+# 0.57199
+
+# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(max_params적용)
+
+#학습
+lgbm_tune =LGBMClassifier(n_estimators = 91 ,max_depth = 3, subsample = 1)
+lgbm_tune.fit(X,y)
+
+
+#예측
+pred = lgbm_tune.predict(test.drop(columns = ['index'] ))
+
+#정답파일 내보내기
+sub = pd.read_csv('data/sample_submission.csv')
+sub['quality'] = pred
+sub.to_csv('tune_lgbm_lwt.csv',index = False)
+# 0.57699
+```
+
+
+
+# voting classifier
+
+```python
+# 모델 정의 (튜닝된 파라미터로)(실습)
+LGBM = LGBMClassifier(max_depth = 3,n_estimators=60, subsample = 0.8229)
+XGB = XGBClassifier(gamma = 4.376, max_depth = 3, subsample = 0.9818)
+RF = RandomForestClassifier(max_depth = 3, n_estimators = 35) # float값이 안들어가서 몇개는 반올림 해줌
+
+# VotingClassifier 정의
+VC = VotingClassifier(estimators=[('rf',RF),('xgb',XGB),('lgbm',LGBM)],voting = 'soft')
+# 0.555
+
+# 모델 정의 (튜닝된 파라미터로)(max_params적용))
+LGBM = LGBMClassifier(max_depth = 3,n_estimators=100, subsample = 1)
+XGB = XGBClassifier(gamma = 4, max_depth = 1, subsample = 1)
+RF = RandomForestClassifier(max_depth = 3, n_estimators = 100)
+
+# VotingClassifier 정의
+VC = VotingClassifier(estimators=[('rf',RF),('xgb',XGB),('lgbm',LGBM)],voting = 'soft')
+# 0.556
+
+# 0.001차이로 max_params가 높음
+```
+
+
+
+
+
+
+
+
+**min_child_samples**
+
+- **min_child_samples** 파라미터는 최종 결정 클래스인 Leaf Node가 되기 위해서 최소한으로 필요한 **데이터 개체의 수**를 의미하며, 과적합을 제어하는 파라미터이다. 이 파라미터의 최적값은 훈련 데이터의 개수와 **num_leaves**에 의해 결정된다. 너무 큰 숫자로 설정하면 under-fitting이 일어날 수 있으며, 아주 큰 데이터셋이라면 적어도 수백~수천 정도로 가정하는 것이 편리하다.
+ - **num_leaves** 파라미터는 하나의 트리가 가질 수 있는 최대 리프의 개수인데, 이 개수를 높이면 정확도는 높아지지만 트리의 깊이가 커져 모델의 복잡도가 증가한다는 점에 유의해야 한다.
+
+
+
+## 코드
+
+### XGBoost
+
+```python
+# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(실습)
+
+#학습
+xgb_tune =XGBClassifier(gamma = 4.376,max_depth = 3, subsample = 0.9818)
+xgb_tune.fit(X,y)
+
+
+#예측
+pred = xgb_tune.predict(test.drop(columns = ['index'] ))
+
+#정답파일 내보내기
+sub = pd.read_csv('data/sample_submission.csv')
+sub['quality'] = pred
+sub.to_csv('tune_xgb.csv',index = False)
+
+#0.573
+
+# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(max_params)
+
+#학습
+xgb_tune =XGBClassifier(gamma = 3.852,max_depth = 2, subsample = 0.8105)
+xgb_tune.fit(X,y)
+
+
+#예측
+pred = xgb_tune.predict(test.drop(columns = ['index'] ))
+
+#정답파일 내보내기
+sub = pd.read_csv('data/sample_submission.csv')
+sub['quality'] = pred
+sub.to_csv('tune_xgb_lwt.csv',index = False)
+
+#0.567
+```
+
+
+
+### light gbm
+
+```python
+max_params = BO_lgbm.max['params']
+
+max_params['max_depth'] = float(max_params['max_depth'])
+max_params['n_estimators'] = float(max_params['n_estimators'])
+max_params['subsample'] = float(max_params['subsample'])
+print(max_params)
+# {'max_depth': 2.5563135018997007, 'n_estimators': 90.90085037727735, 'subsample': 0.989309171116382}
+
+
+# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(실습내용)
+
+#학습
+lgbm_tune =LGBMClassifier(n_estimators = 43 ,max_depth = 3, subsample = 1)
+lgbm_tune.fit(X,y)
+
+
+#예측
+pred = lgbm_tune.predict(test.drop(columns = ['index'] ))
+
+#정답파일 내보내기
+sub = pd.read_csv('data/sample_submission.csv')
+sub['quality'] = pred
+sub.to_csv('tune_lgbm.csv',index = False)
+# 0.57199
+
+# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(max_params적용)
+
+#학습
+lgbm_tune =LGBMClassifier(n_estimators = 91 ,max_depth = 3, subsample = 1)
+lgbm_tune.fit(X,y)
+
+
+#예측
+pred = lgbm_tune.predict(test.drop(columns = ['index'] ))
+
+#정답파일 내보내기
+sub = pd.read_csv('data/sample_submission.csv')
+sub['quality'] = pred
+sub.to_csv('tune_lgbm_lwt.csv',index = False)
+# 0.57699
+```
+
+
+
+# voting classifier
+
+```python
+# 모델 정의 (튜닝된 파라미터로)(실습)
+LGBM = LGBMClassifier(max_depth = 3,n_estimators=60, subsample = 0.8229)
+XGB = XGBClassifier(gamma = 4.376, max_depth = 3, subsample = 0.9818)
+RF = RandomForestClassifier(max_depth = 3, n_estimators = 35) # float값이 안들어가서 몇개는 반올림 해줌
+
+# VotingClassifier 정의
+VC = VotingClassifier(estimators=[('rf',RF),('xgb',XGB),('lgbm',LGBM)],voting = 'soft')
+# 0.555
+
+# 모델 정의 (튜닝된 파라미터로)(max_params적용))
+LGBM = LGBMClassifier(max_depth = 3,n_estimators=100, subsample = 1)
+XGB = XGBClassifier(gamma = 4, max_depth = 1, subsample = 1)
+RF = RandomForestClassifier(max_depth = 3, n_estimators = 100)
+
+# VotingClassifier 정의
+VC = VotingClassifier(estimators=[('rf',RF),('xgb',XGB),('lgbm',LGBM)],voting = 'soft')
+# 0.556
+
+# 0.001차이로 max_params가 높음
+```
+
+
+
+
+
+
+
\n",
+ "\n",
+ "\n",
+ " \n",
+ "
\n",
+ "
"
+ ],
+ "text/plain": [
+ " 0 1 2 3 4 5 6 7 8 9\n",
+ "30 1.0 0.0 2.000 23.1 0.0 0.0 0.0 4.000000 46.2000 533.61\n",
+ "31 1.0 4.0 1.950 24.7 16.0 7.8 98.8 3.802500 48.1650 610.09\n",
+ "32 1.0 4.0 3.025 29.5 16.0 12.1 118.0 9.150625 89.2375 870.25\n",
+ "33 1.0 0.0 2.100 23.8 0.0 0.0 0.0 4.410000 49.9800 566.44\n",
+ "34 1.0 1.0 2.800 29.0 1.0 2.8 29.0 7.840000 81.2000 841.00"
+ ]
+ },
+ "execution_count": 70,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "from sklearn.preprocessing import PolynomialFeatures\n",
+ "poly_features = PolynomialFeatures(degree=2) # 차원은 2로 설정\n",
+ "\n",
+ "test_poly = poly_features.fit_transform(X_test) # fit_transform 메소드를 통해 데이터 변환\n",
+ "test_poly = pd.DataFrame(test_poly)\n",
+ "print(X_test.tail(3))\n",
+ "test_poly.tail()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "da245f0a",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git "a/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv.5)(10~14).ipynb" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv.5)(10~14).ipynb"
new file mode 100644
index 0000000..8e187cf
--- /dev/null
+++ "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv.5)(10~14).ipynb"
@@ -0,0 +1,418 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "1c28cc7e",
+ "metadata": {},
+ "source": [
+ "## BOW (Bag of Words)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5b699de3",
+ "metadata": {},
+ "source": [
+ "**단어들의 문맥이나 순서를 무시하고, 단어들에 대한 빈도 값을 부여해 변수를 만드는 방법**| \n", + " | 0 | \n", + "1 | \n", + "2 | \n", + "3 | \n", + "4 | \n", + "5 | \n", + "6 | \n", + "7 | \n", + "8 | \n", + "9 | \n", + "
|---|---|---|---|---|---|---|---|---|---|---|
| 30 | \n", + "1.0 | \n", + "0.0 | \n", + "2.000 | \n", + "23.1 | \n", + "0.0 | \n", + "0.0 | \n", + "0.0 | \n", + "4.000000 | \n", + "46.2000 | \n", + "533.61 | \n", + "
| 31 | \n", + "1.0 | \n", + "4.0 | \n", + "1.950 | \n", + "24.7 | \n", + "16.0 | \n", + "7.8 | \n", + "98.8 | \n", + "3.802500 | \n", + "48.1650 | \n", + "610.09 | \n", + "
| 32 | \n", + "1.0 | \n", + "4.0 | \n", + "3.025 | \n", + "29.5 | \n", + "16.0 | \n", + "12.1 | \n", + "118.0 | \n", + "9.150625 | \n", + "89.2375 | \n", + "870.25 | \n", + "
| 33 | \n", + "1.0 | \n", + "0.0 | \n", + "2.100 | \n", + "23.8 | \n", + "0.0 | \n", + "0.0 | \n", + "0.0 | \n", + "4.410000 | \n", + "49.9800 | \n", + "566.44 | \n", + "
| 34 | \n", + "1.0 | \n", + "1.0 | \n", + "2.800 | \n", + "29.0 | \n", + "1.0 | \n", + "2.8 | \n", + "29.0 | \n", + "7.840000 | \n", + "81.2000 | \n", + "841.00 | \n", + "
\n", + "빈도에 기반하여 텍스트 -> 숫자 변환 / 단어의 특징을 나타낼 수 있어 활용도 높음
\n", + "##### 단점\n", + "- 문맥 의미를 완벽하게 반영할 수 없다 : 순서 고려하지 않기 때문. 보완위해 n_gram 기법 활용 가능하나 제한적.\n", + "- 희소 행렬 문제 : 단어가 굉장히 많은 데이터에서 BOW로 텍스트 데이터를 벡터화하면 행렬 대부분의 값이 0으로 채워진 희소 행렬 형태로 변환. 일반적으로 머신러닝의 성능 저하" + ] + }, + { + "cell_type": "markdown", + "id": "222e5f40", + "metadata": {}, + "source": [ + "#### BOW의 피처 벡터화\n", + "1. 카운트 기반 벡터화 ( CountVectorizer )\n", + "2. TF-IDF ( Term Frequency - Inverse Document Frequency )" + ] + }, + { + "cell_type": "markdown", + "id": "d1fd4a73", + "metadata": {}, + "source": [ + "### 1. CountVectorizer" + ] + }, + { + "cell_type": "markdown", + "id": "72494539", + "metadata": {}, + "source": [ + "**단어에 값을 부여할 때 각 문장에서 해당 단어가 나타나는 횟수**
\n", + "Count를 부여하는 경우 -> `카운트 벡터화` / 높을수록 중요한 단어" + ] + }, + { + "cell_type": "code", + "execution_count": 2, + "id": "342ef467", + "metadata": {}, + "outputs": [], + "source": [ + "from sklearn.feature_extraction.text import CountVectorizer" + ] + }, + { + "cell_type": "code", + "execution_count": 3, + "id": "efa00628", + "metadata": {}, + "outputs": [], + "source": [ + "corpus = [\n", + " 'This is the first document.',\n", + " 'This is the second second document.',\n", + " 'And the third one.',\n", + " 'Is this the first document?',\n", + " 'The last document?',\n", + "]\n", + "vect = CountVectorizer()" + ] + }, + { + "cell_type": "code", + "execution_count": 4, + "id": "864f30a7", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "[[0 1 1 1 0 0 0 1 0 1]\n", + " [0 1 0 1 0 0 2 1 0 1]\n", + " [1 0 0 0 0 1 0 1 1 0]\n", + " [0 1 1 1 0 0 0 1 0 1]\n", + " [0 1 0 0 1 0 0 1 0 0]]\n" + ] + } + ], + "source": [ + "print(vect.fit_transform(corpus).toarray())" + ] + }, + { + "cell_type": "code", + "execution_count": 5, + "id": "173b6413", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "{'this': 9,\n", + " 'is': 3,\n", + " 'the': 7,\n", + " 'first': 2,\n", + " 'document': 1,\n", + " 'second': 6,\n", + " 'and': 0,\n", + " 'third': 8,\n", + " 'one': 5,\n", + " 'last': 4}" + ] + }, + "execution_count": 5, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "vect.vocabulary_" + ] + }, + { + "cell_type": "code", + "execution_count": 8, + "id": "c3960450", + "metadata": {}, + "outputs": [], + "source": [ + "import pandas as pd\n", + "\n", + "train = pd.read_csv('train.csv',usecols = ['category','data'])\n", + "test = pd.read_csv('test.csv',usecols = ['data'])" + ] + }, + { + "cell_type": "code", + "execution_count": 12, + "id": "63915667", + "metadata": {}, + "outputs": [], + "source": [ + "# 결측치는 없어야 함\n", + "train.fillna(' ',inplace= True)" + ] + }, + { + "cell_type": "code", + "execution_count": 13, + "id": "948139b8", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "
\n",
+ "\n",
+ "\n",
+ " \n",
+ "
\n",
+ "
"
+ ],
+ "text/plain": [
+ " category data\n",
+ "39997 2 무서운데 지켜야 할게 있어요 도와주세요. 안녕하세요 . 한부모엄마 입니다.\\n양육비...\n",
+ "39998 2 교복에 고정식 이름표를 달게 하는 것을 금지해 주세요.. 교복에 이름표를 박아놓아...\n",
+ "39999 0 합의성관계 가능 나이연령을 올리십시오. 제가 형법공부를하다가 문제를풀고있는데\\n금지..."
+ ]
+ },
+ "execution_count": 13,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "train.tail(3)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 18,
+ "id": "dd6edb40",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(40000, 742720)"
+ ]
+ },
+ "execution_count": 18,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "vect = CountVectorizer()\n",
+ "train_x = vect.fit_transform(train['data'])\n",
+ "train_x.shape"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 17,
+ "id": "c2d5e8c1",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(5000, 742720)"
+ ]
+ },
+ "execution_count": 17,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "test_x = vect.transform(test['data'])\n",
+ "test_x.shape"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b2b28784",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1deda039",
+ "metadata": {},
+ "source": [
+ "### 2. TF-IDF"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d5535d97",
+ "metadata": {},
+ "source": [
+ "단어의 빈도만 고려한다면 모든 문서에서 자주 쓰일 수 밖에 없는 단어들이 자칫 중요하다고 인식될 수 있음.| \n", + " | category | \n", + "data | \n", + "
|---|---|---|
| 39997 | \n", + "2 | \n", + "무서운데 지켜야 할게 있어요 도와주세요. 안녕하세요 . 한부모엄마 입니다.\\n양육비... | \n", + "
| 39998 | \n", + "2 | \n", + "교복에 고정식 이름표를 달게 하는 것을 금지해 주세요.. 교복에 이름표를 박아놓아... | \n", + "
| 39999 | \n", + "0 | \n", + "합의성관계 가능 나이연령을 올리십시오. 제가 형법공부를하다가 문제를풀고있는데\\n금지... | \n", + "
\n", + "> 개별 문서에서는 높은 가중치, 모든 문서에서는 패널티\n", + "\n", + "모든 문서에서 등장하는 단어보다 특정 문서에서 빈번히 등장하는 단어를 높게 부여" + ] + }, + { + "cell_type": "code", + "execution_count": 19, + "id": "ff267958", + "metadata": {}, + "outputs": [], + "source": [ + "from sklearn.feature_extraction.text import TfidfVectorizer" + ] + }, + { + "cell_type": "code", + "execution_count": 20, + "id": "3d4436c5", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "array([[0. , 0.38947624, 0.55775063, 0.4629834 , 0. ,\n", + " 0. , 0. , 0.32941651, 0. , 0.4629834 ],\n", + " [0. , 0.24151532, 0. , 0.28709733, 0. ,\n", + " 0. , 0.85737594, 0.20427211, 0. , 0.28709733],\n", + " [0.55666851, 0. , 0. , 0. , 0. ,\n", + " 0.55666851, 0. , 0.26525553, 0.55666851, 0. ],\n", + " [0. , 0.38947624, 0.55775063, 0.4629834 , 0. ,\n", + " 0. , 0. , 0.32941651, 0. , 0.4629834 ],\n", + " [0. , 0.45333103, 0. , 0. , 0.80465933,\n", + " 0. , 0. , 0.38342448, 0. , 0. ]])" + ] + }, + "execution_count": 20, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "tfidf = TfidfVectorizer()\n", + "tfidf.fit_transform(corpus).toarray()" + ] + }, + { + "cell_type": "code", + "execution_count": 21, + "id": "db0be9c3", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "{'this': 9,\n", + " 'is': 3,\n", + " 'the': 7,\n", + " 'first': 2,\n", + " 'document': 1,\n", + " 'second': 6,\n", + " 'and': 0,\n", + " 'third': 8,\n", + " 'one': 5,\n", + " 'last': 4}" + ] + }, + "execution_count": 21, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "tfidf.vocabulary_" + ] + }, + { + "cell_type": "code", + "execution_count": 24, + "id": "6c2e4367", + "metadata": {}, + "outputs": [], + "source": [ + "vect = TfidfVectorizer()\n", + "train_x_2 = vect.fit_transform(train['data'])\n", + "test_x_2 = vect.transform(test['data'])" + ] + }, + { + "cell_type": "code", + "execution_count": 25, + "id": "f84f8d93", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "(40000, 742720)" + ] + }, + "execution_count": 25, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "train_x_2.shape" + ] + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 3 (ipykernel)", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.8.8" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git "a/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523-16508874838011.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523-16508874838011.png" new file mode 100644 index 0000000..535fbae Binary files /dev/null and "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523-16508874838011.png" differ diff --git "a/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523-16508986033022.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523-16508986033022.png" new file mode 100644 index 0000000..535fbae Binary files /dev/null and "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523-16508986033022.png" differ diff --git "a/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523.png" new file mode 100644 index 0000000..535fbae Binary files /dev/null and "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/image-20220425205122523.png" differ diff --git "a/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img-16507279048902.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img-16507279048902.png" new file mode 100644 index 0000000..aa08590 Binary files /dev/null and "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img-16507279048902.png" differ diff --git "a/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img-16508985826691.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img-16508985826691.png" new file mode 100644 index 0000000..aa08590 Binary files /dev/null and "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img-16508985826691.png" differ diff --git "a/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img.png" new file mode 100644 index 0000000..aa08590 Binary files /dev/null and "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254(Lv3).assets/img.png" differ diff --git "a/\354\240\204\354\262\230\353\246\254.assets/image-20220418203259483.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418203259483.png" similarity index 100% rename from "\354\240\204\354\262\230\353\246\254.assets/image-20220418203259483.png" rename to "\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418203259483.png" diff --git "a/\354\240\204\354\262\230\353\246\254.assets/image-20220418203418612.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418203418612.png" similarity index 100% rename from "\354\240\204\354\262\230\353\246\254.assets/image-20220418203418612.png" rename to "\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418203418612.png" diff --git "a/\354\240\204\354\262\230\353\246\254.assets/image-20220418204854106.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418204854106.png" similarity index 100% rename from "\354\240\204\354\262\230\353\246\254.assets/image-20220418204854106.png" rename to "\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418204854106.png" diff --git "a/\354\240\204\354\262\230\353\246\254.assets/image-20220418205336654.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418205336654.png" similarity index 100% rename from "\354\240\204\354\262\230\353\246\254.assets/image-20220418205336654.png" rename to "\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220418205336654.png" diff --git "a/\354\240\204\354\262\230\353\246\254.assets/image-20220421005436684.png" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220421005436684.png" similarity index 100% rename from "\354\240\204\354\262\230\353\246\254.assets/image-20220421005436684.png" rename to "\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.assets/image-20220421005436684.png" diff --git "a/\354\240\204\354\262\230\353\246\254.md" "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.md" similarity index 97% rename from "\354\240\204\354\262\230\353\246\254.md" rename to "\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.md" index 4cfd7f9..099c9b4 100644 --- "a/\354\240\204\354\262\230\353\246\254.md" +++ "b/\354\240\204\354\262\230\353\246\254/\354\240\204\354\262\230\353\246\254.md" @@ -1,149 +1,149 @@ -# 전처리 - -## 결측치란 - -- 분석 결과/인사이트와 모델 성능에 직접적인 영향을 미치는 과정이기 때문에 중요하게 다루어지는 과정 - -- 한 설문조사에 의하면, 분석가의 80% 시간을 데이터 수집 및 전처리에 사용한다고 하니, 얼마나 중요한 과정인지 짐작할 수 있다. 물론 지루하고 반복 작업의 연속이기 때문에 시간이 많이 들어가는 측면도 있을 것이다. - -패턴이 있는 것과 패턴이 없는 것이 있음 - -## 결측치 처리 - -1) 결측치 사례 제거 -2) 수치형의 경우 평균이나 중앙치로 대체(imputation)하거나 범주형인 경우 mode 값으로 대체 -3) 간단한 예측 모델로 대체하는 방식이 일반적으로 이용된다. - -가장 쉬운 방법은 Null이 포함 행 혹은 일부 행을 제거하는 것이다 - -### Missing Value 파악 - -데이터셋을 읽었다면, Missing Value 파악을 위해 `df.info()` 가장 처음에 이용하는 것을 추천 - -**DataFrame.info()** - - - -**DataFrame.isnull().sum()** - - - -### 제거 - -#### dropna - -- 결측치의 특성이 '무작위로 손실' 되지 않았다면, 대부분의 경우 가장 좋은 방법은 **제거**하는 것이다. - -https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.dropna.html - -- pandas에서 제공하는 Na/NaN과 같은 누락 데이터를 제거하는 함수입니다. -- axis: 파라미터 값으로 0을 주면 행 제거, 1을 주면 열 제거입니다. default값은 0입니다. -- subset: array, 특정 feature를 지정하여 해당 Feature의 누락 데이터 제거가 가능합니다. - -```python -# 목록삭제(Listwise) - -df = df.dropna() # 결측치가 있는 행은 전부 삭제 - -df = df.dropna(axis = 1) # 결측치가 있는 열은 전부 삭제 - -# 단일값 삭제(Pairwise) - -df = df.dropna(how = 'all') # 행 전체가 결측치인 행만 삭제 - -df = df.dropna(thresh = 2) # 행의 결측치가 2개 초과인 행만 삭제 - -# 특정 열들중에 결측치가 있을 경우에 해당 행을 삭제 -df = df.dropna(subset=['col1', 'col2', 'col3']) - -# 특정열 모두가 결측치일 경우 해당 행 삭제 -df = df.dropna(subset=['col1', 'col2', 'col3'], how = 'all') - -# 특정열에 1개 초과의 결측치가 있을 경우 해당 행 삭제 -df = df.dropna(subset=['col1', 'col2', 'col3'], thresh = 1 ) -``` - - - -### 대체 - -대체값 종류 - -- 최빈값(mode) - - 범주형에서 결측값이 발생시, 범주별 빈도가 가장 높은 값으로 대치한다. -- 중앙값(median) - - 숫자형(연속형)에서 결측값을 제외한 중앙값으로 대치방법 -- 평균(mean) - - 숫자형(연속형)에서 결측값제외한 평균으로 대치방법 -- Similar case Imputation - - 조건부 대치 -- Generalized Imputation - - 회귀분석을 이용한 대치 - -#### fillna - -https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.fillna.html - -```python -df.fillna(0) # 전체 결측치를 특정 단일값으로 대체하기 - -# 특정열에 결측치가 있을 경우 다른 값으로 대체하기 - -# 0으로 대체하기 -df['col'] = df['col'].fillna(0) - -# 컬럼의 평균으로 대체하기 -df['col'] = df['col'].fillna(df['col'].mean()) - -# 결측치 바로 이전 값으로 채우기 -df.fillna(method = 'pad') - -# 결측치 바로 이후 값으로 채우기 -df.fillna(method = 'bfill') -``` - -#### replace - -https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.replace.html - -```python -# 결측치 값을 -50으로 채운다. -df.replace(to_replace = np.nan, value = -50) -``` - - - -#### interpolate(보간법) - -https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.interpolate.html - -```python -# interpolate는 인덱스를 무시하고 값들을 선형적으로 같은 간격으로 처리하게 된다. -df.interpolate(method = 'linear') -# ‘linear’: Ignore the index and treat the values as equally spaced - Default -``` - -inplace의 의미 - - - -## 이상치 - -### 방법 - -IQR 방식은 75% percentile + 1.5 * IQR 이상이거나 25 percentile - 1.5 * IQR 이하인 경우 극단치로 처리하는 방식이다. 이해하기 쉽고 적용하기 쉬운 편이지만, 경우에 따라 너무 많은 사례들이 극단치로 고려되는 경우가 있다. - - - - - -```python -# IQR 기반 예제 코드 -def outliers_iqr(ys): - quartile_1, quartile_3 = np.percentile(ys, [25, 75]) - iqr = quartile_3 - quartile_1 - lower_bound = quartile_1 - (iqr * 1.5) - upper_bound = quartile_3 + (iqr * 1.5) - return np.where((ys > upper_bound) | (ys < lower_bound)) -``` - +# 전처리 + +## 결측치란 + +- 분석 결과/인사이트와 모델 성능에 직접적인 영향을 미치는 과정이기 때문에 중요하게 다루어지는 과정 + +- 한 설문조사에 의하면, 분석가의 80% 시간을 데이터 수집 및 전처리에 사용한다고 하니, 얼마나 중요한 과정인지 짐작할 수 있다. 물론 지루하고 반복 작업의 연속이기 때문에 시간이 많이 들어가는 측면도 있을 것이다. + +패턴이 있는 것과 패턴이 없는 것이 있음 + +## 결측치 처리 + +1) 결측치 사례 제거 +2) 수치형의 경우 평균이나 중앙치로 대체(imputation)하거나 범주형인 경우 mode 값으로 대체 +3) 간단한 예측 모델로 대체하는 방식이 일반적으로 이용된다. + +가장 쉬운 방법은 Null이 포함 행 혹은 일부 행을 제거하는 것이다 + +### Missing Value 파악 + +데이터셋을 읽었다면, Missing Value 파악을 위해 `df.info()` 가장 처음에 이용하는 것을 추천 + +**DataFrame.info()** + + + +**DataFrame.isnull().sum()** + + + +### 제거 + +#### dropna + +- 결측치의 특성이 '무작위로 손실' 되지 않았다면, 대부분의 경우 가장 좋은 방법은 **제거**하는 것이다. + +https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.dropna.html + +- pandas에서 제공하는 Na/NaN과 같은 누락 데이터를 제거하는 함수입니다. +- axis: 파라미터 값으로 0을 주면 행 제거, 1을 주면 열 제거입니다. default값은 0입니다. +- subset: array, 특정 feature를 지정하여 해당 Feature의 누락 데이터 제거가 가능합니다. + +```python +# 목록삭제(Listwise) + +df = df.dropna() # 결측치가 있는 행은 전부 삭제 + +df = df.dropna(axis = 1) # 결측치가 있는 열은 전부 삭제 + +# 단일값 삭제(Pairwise) + +df = df.dropna(how = 'all') # 행 전체가 결측치인 행만 삭제 + +df = df.dropna(thresh = 2) # 행의 결측치가 2개 초과인 행만 삭제 + +# 특정 열들중에 결측치가 있을 경우에 해당 행을 삭제 +df = df.dropna(subset=['col1', 'col2', 'col3']) + +# 특정열 모두가 결측치일 경우 해당 행 삭제 +df = df.dropna(subset=['col1', 'col2', 'col3'], how = 'all') + +# 특정열에 1개 초과의 결측치가 있을 경우 해당 행 삭제 +df = df.dropna(subset=['col1', 'col2', 'col3'], thresh = 1 ) +``` + + + +### 대체 + +대체값 종류 + +- 최빈값(mode) + - 범주형에서 결측값이 발생시, 범주별 빈도가 가장 높은 값으로 대치한다. +- 중앙값(median) + - 숫자형(연속형)에서 결측값을 제외한 중앙값으로 대치방법 +- 평균(mean) + - 숫자형(연속형)에서 결측값제외한 평균으로 대치방법 +- Similar case Imputation + - 조건부 대치 +- Generalized Imputation + - 회귀분석을 이용한 대치 + +#### fillna + +https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.fillna.html + +```python +df.fillna(0) # 전체 결측치를 특정 단일값으로 대체하기 + +# 특정열에 결측치가 있을 경우 다른 값으로 대체하기 + +# 0으로 대체하기 +df['col'] = df['col'].fillna(0) + +# 컬럼의 평균으로 대체하기 +df['col'] = df['col'].fillna(df['col'].mean()) + +# 결측치 바로 이전 값으로 채우기 +df.fillna(method = 'pad') + +# 결측치 바로 이후 값으로 채우기 +df.fillna(method = 'bfill') +``` + +#### replace + +https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.replace.html + +```python +# 결측치 값을 -50으로 채운다. +df.replace(to_replace = np.nan, value = -50) +``` + + + +#### interpolate(보간법) + +https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.interpolate.html + +```python +# interpolate는 인덱스를 무시하고 값들을 선형적으로 같은 간격으로 처리하게 된다. +df.interpolate(method = 'linear') +# ‘linear’: Ignore the index and treat the values as equally spaced - Default +``` + +inplace의 의미 + + + +## 이상치 + +### 방법 + +IQR 방식은 75% percentile + 1.5 * IQR 이상이거나 25 percentile - 1.5 * IQR 이하인 경우 극단치로 처리하는 방식이다. 이해하기 쉽고 적용하기 쉬운 편이지만, 경우에 따라 너무 많은 사례들이 극단치로 고려되는 경우가 있다. + + + + + +```python +# IQR 기반 예제 코드 +def outliers_iqr(ys): + quartile_1, quartile_3 = np.percentile(ys, [25, 75]) + iqr = quartile_3 - quartile_1 + lower_bound = quartile_1 - (iqr * 1.5) + upper_bound = quartile_3 + (iqr * 1.5) + return np.where((ys > upper_bound) | (ys < lower_bound)) +``` + diff --git "a/\355\212\234\353\213\235/Lv3_\355\212\234\353\213\235_Bayesian Optimization.md" "b/\355\212\234\353\213\235/Lv3_\355\212\234\353\213\235_Bayesian Optimization.md" new file mode 100644 index 0000000..3166163 --- /dev/null +++ "b/\355\212\234\353\213\235/Lv3_\355\212\234\353\213\235_Bayesian Optimization.md" @@ -0,0 +1,159 @@ +# Bayesian Optimization + +## Optimization + +어떤 임의의 함수 f(x)-모델-의 값-모델의 점수-을 가장 크게(또는 작게)하는 해를 구하는 것이다. 이 모델은 수많은 변수를 가질 수 있다. 이 변수들을 조정하여 주어진 데이터 셋에 대해서 가장 좋은 결과를 내어놓는 x를 찾는 것이 hyperparameter 튜닝이다. + + + + + +## 대표적인 hyperparameter 튜닝 기법들의 단점 + +### 1. GridSearch + +- 모든 hyperparameter 후보들에 대한 일반화 성능을 확인하기 때문에, 시간이 너무 오래 걸린다. + +### 2. RandomSearch + +- 위에 비해 시간은 적게 걸리지만, 말 그대로 랜덤하게 뽑는 방식이기 때문에 정확도가 다소 떨어진다. + + + +-> Bayesian Optimization은 이 둘에 비해 효율적으로 최적값을 찾아낸다는 장점이 있다. + + + + + +## Bayesian Optimization + +**이전의 정보를 최적 값 탐색에 반영하여 탐색을 반복해 최적의 값을 찾아 나가는 방식** + + + +#### 1. Surrogate model + +- 지금까지의 데이터를 통해 예상하는 모델을 만듦 +- '최종 목적함수(우리가 찾으려고 하는)에 대해 확률적으로 추정한 결과' +- 이 모델을 기반으로 다음 탐색 지점을 결정 +- (Gaussian Process를 주로 사용) + +#### 2. Acquisition function + +- 위 모델을 검증하고, 다음 모델을 만드는 데 있어서 최적의 하이퍼파라미터를 추천하는 단계 +- (Expected Improvement 사용) + + + +#### Bayesian Optimization 수행 과정 + + + +위의 파란색 선은 우리가 찾으려고 하는 목적함수를 나타내고, 검은색 점선은 지금까지 관측한 데이터를 바탕으로 우리가 예측한 estimated function을 의미한다. 검은색 점선 주변에 있는 파란 영역은, 목적함수 f(x)가 존재할만한 영역을 의미한다. 밑에 있는 EI(x)는 위에서 언급한 Acquisition function을 의미하며 다음 입력값 후보를 추천해준다. Acquisition function 값이 컸던 지점의 function 값을 관측하고 estimation을 update 한다.한다. 계속 update를 진행하면 estimation과 실제 function이 흡사해진다. + +1 입력값, 목적 함수 및 그 외 설정값들을 정의합니다. + +- 입력값 x : 여러가지 hyperparameter +- 목적 함수 f(x) : 설정한 입력값을 적용해 학습한, 딥러닝 모델의 성능 결과 수치(e.g. 정확도) +- 입력값 x 의 탐색 대상 구간 : (a,b) +- 입력값-함숫결과값 점들의 갯수 : n +- 조사할 입력값-함숫결과값 점들의 갯수 : N + +2 설정한 탐색 대상 구간 (a,b) 내에서 처음 n 개의 입력값들을 랜덤하게 샘플링하여 선택합니다. + +3 선택한 n 개의 입력값 x1, x2, ..., xn 을 각각 모델의 hyperparameter 로 설정하여 딥러닝 모델을 학습한 뒤, 학습이 완료된 모델의 성능 결과 수치를 계산합니다. + +- 이들을 각각 함숫결과값 f(x1), f(x2), ..., f(xn) 으로 간주합니다. + +4 입력값-함숫결과값 점들의 모음 (x1, f(x1)), (x2, f(x2)), ..., (xn, f(xn)) 에 대하여 Surrogate Model 로 확률적 추정을 수행합니다. + +5 조사된 입력값-함숫결과값 점들이 총 N 개에 도달할 때까지, 아래의 과정을 반복적으로 수행합니다. + +- 기존 입력값-함숫결과값 점들의 모음 (x1, f(x1)),(x2, f(x2)), ..., (xt, f(xt)) 에 대한 Surrogate Model 의 확률적 추정 결과를 바탕으로, 입력값 구간 (a,b) 내에서의 EI 의 값을 계산하고, 그 값이 가장 큰 점을 다음 입력값 후보 x1 로 선정합니다. +- 다음 입력값 후보 x1 를 hyperparameter 로 설정하여 딥러닝 모델을 학습한 뒤, 학습이 완료된 모델의 성능 결과 수치를 계산하고, 이를 f(x1) 값으로 간주합니다. +- 새로운 점 (x2, f(x2)) 을 기존 입력값-함숫결과값 점들의 모음에 추가하고, 갱신된 점들의 모음에 대하여 Surrogate Model 로 확률적 추정을 다시 수행합니다. + +6 총 N 개의 입력값-함숫결과값 점들에 대하여 확률적으로 추정된 목적 함수 결과물을 바탕으로, 평균 함수 μ(x) 을 최대로 만드는 최적해를 최종 선택합니다. 추후 해당값을 hyperparameter 로 사용하여 딥러닝 모델을 학습하면, 일반화 성능이 극대화된 모델을 얻을 수 있습니다. + + + +#### 실험 결과를 반영해가면서 효율적으로 hyperparameter을 찾아나가는 것이 가능해짐 + + + + + +#### 예제 코드 + +```python +# X에 학습할 데이터를, y에 목표 변수를 저장해주세요 +X = train.drop(columns = ['index', 'quality']) +y = train['quality'] +``` + +```python +# 랜덤포레스트의 하이퍼 파라미터의 범위를 dictionary 형태로 지정해주세요 +## Key는 랜덤포레스트의 hyperparameter이름이고, value는 탐색할 범위 입니다. +rf_parameter_bounds = { + 'max_depth' : (1,3), # 나무의 깊이 + 'n_estimators' : (30,100), + } +``` + +```python +# 함수를 만들어주겠습니다. +# 함수의 구성은 다음과 같습니다. +# 1. 함수에 들어가는 인자 = 위에서 만든 함수의 key값들 +# 2. 함수 속 인자를 통해 받아와 새롭게 하이퍼파라미터 딕셔너리 생성 +# 3. 그 딕셔너리를 바탕으로 모델 생성 +# 4. train_test_split을 통해 데이터 train-valid 나누기 +# 5 .모델 학습 +# 6. 모델 성능 측정 +# 7. 모델의 점수 반환 + +def rf_bo(max_depth, n_estimators): + rf_params = { + 'max_depth' : int(round(max_depth)), + 'n_estimators' : int(round(n_estimators)), + } + rf = RandomForestClassifier(**rf_params) + + X_train, X_valid, y_train, y_valid = train_test_split(X,y,test_size = 0.2, ) + + rf.fit(X_train,y_train) + score = accuracy_score(y_valid, rf.predict(X_valid)) + return score +``` + +```python +# 이제 Bayesian Optimization을 사용할 준비가 끝났습니다. +# "BO_rf"라는 변수에 Bayesian Optmization을 저장해보세요 +BO_rf = BayesianOptimization(f = rf_bo, pbounds = rf_parameter_bounds,random_state = 0) + +# pbounds: 테스트하고자 하는 hyperparameter의 집합 +``` + +```python +# Bayesian Optimization을 실행해보세요 +BO_rf.maximize(init_points = 5, n_iter = 5) + +# init_points: random search로 탐색할 횟수 +# n_iter: 최적값을 찾을 횟수(몇 개의 입력값 - 함숫값 점들을 확인할지) +# maximize: 목적함수를 최대로 만드는 최적해를 찾는다 +``` + +```python +# 하이퍼파라미터의 결과값을 불러와 "max_params"라는 변수에 저장해보세요 +max_params = BO_rf.max['params'] + +max_params['max_depth'] = int(max_params['max_depth']) +max_params['n_estimators'] = int(max_params['n_estimators']) +print(max_params) +``` + +```python +# Bayesian Optimization의 결과를 "BO_tuend_rf"라는 변수에 저장해보세요 +BO_tuend_rf = RandomForestClassifier(**max_params) +``` + diff --git "a/\355\212\234\353\213\235(Lv4).assets/image-20220502193613401.png" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502193613401.png" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/image-20220502193613401.png" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502193613401.png" diff --git "a/\355\212\234\353\213\235(Lv4).assets/image-20220502230520657.png" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230520657.png" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/image-20220502230520657.png" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230520657.png" diff --git "a/\355\212\234\353\213\235(Lv4).assets/image-20220502230748658.png" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230748658.png" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/image-20220502230748658.png" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230748658.png" diff --git "a/\355\212\234\353\213\235(Lv4).assets/image-20220502230822164.png" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230822164.png" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/image-20220502230822164.png" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230822164.png" diff --git "a/\355\212\234\353\213\235(Lv4).assets/image-20220502230848119.png" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230848119.png" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/image-20220502230848119.png" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/image-20220502230848119.png" diff --git "a/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234 (1).jpg" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234 (1).jpg" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234 (1).jpg" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234 (1).jpg" diff --git "a/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.jpg" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.jpg" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.jpg" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.jpg" diff --git "a/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.png" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.png" similarity index 100% rename from "\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.png" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).assets/\353\213\244\354\232\264\353\241\234\353\223\234.png" diff --git "a/\355\212\234\353\213\235(Lv4).md" "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).md" similarity index 96% rename from "\355\212\234\353\213\235(Lv4).md" rename to "\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).md" index 020c0e7..c5e956d 100644 --- "a/\355\212\234\353\213\235(Lv4).md" +++ "b/\355\212\234\353\213\235/\355\212\234\353\213\235(Lv4).md" @@ -1,194 +1,194 @@ -Bayesian Optimization 을 이용해 모델을 튜닝 - -현재까지 얻어진 모델의 파라미터와 추가적인 실험 정보를 통해 **데이터가 주어 졌을 때 모델의 성능이 가장 좋을 확률이 높은 파라미터를 찾아냅니다.** - - - -# 모델 튜닝 - -## XGBoost 모델 튜닝 - -
-
-### learning rate(학습률)
-
-[경사하강법](https://velog.io/@sasganamabeer/AI-Gradient-Descent%EA%B2%BD%EC%82%AC%ED%95%98%EA%B0%95%EB%B2%95)
-
-> 경사하강법(Gradient Descent)은 1차 근삿값 발견용 **최적화 알고리즘**이다. 기본 개념은 함수의 기울기(경사)를 구하고 경사의 절댓값이 낮은 쪽으로 계속 이동시켜 극값에 이를 때까지 반복시키는 것이다.
-
-- 취솟값을 구하기 위해 미분계수 계산 과정을 컴퓨터로 구현하는 것보다, **경사하강법을 구현하는 것이 훨씬 쉬움**
-
-- 데이터의 양이 매우 큰 경우 경사하강법과 같은 순차적인 방법이 **계산량 측면에서 훨씬 효율적**
-
-- **공식**
-
- - 경사하강법은 **함수의 기울기(=gradient)를 이용해서 함수의 최소값 일 때의 x값을 찾기 위한 방법**이다. 기울기가 양수인 경우는 *x* 값이 증가할수록 함수 값도 증가하고, 반대로 음수인 경우에는 *x* 값이 증가할수록 함수 값이 감소한다. 그리고 기울기 값이 크다, 기울기가 가파르다는 것은 최소값으로부터 거리가 멀다는 뜻이다.
-
- .assets/image-20220502230520657.png)
-
- 기울기가 양수면 x를 음의 방향으로, 기울기가 음수면 x를 양의 방향으로 x를 이동시킨다.
-
- .assets/image-20220502230748658.png)
-
- 미분 계수(=기울기=gradient)는 극소값에 가까워질수록 값이 작아진다. 따라서, **이동거리에는 미분 계수와 비례하는 값을 이용**한다. 그럼 극소값에서 멀 때는 많이 이동하고, 극소값에 가까울 때는 조금씩 이동할 수 있다.
-
- .assets/image-20220502230822164.png)
-
- > .assets/image-20220502230848119.png)
-
-
-
-- 경사하강법 알고리즘은 기울기에 learning rate 또는 step size라고 불리는 스칼라를 곱해서 다음지점을 결정한다.
-
- .assets/image-20220502193613401.png)
-
-learning rate(step size)이 크면 데이터가 무질서하게 이탈해서 최저점에 수렴하지 못하고 learning rate(step size)가 작으면 학습시간이 오래걸려서 최저점에 도달하지 못한다. 적절할 값을 설정해줘야한다. [최종 학습시에는 0.05 이하의 값을 사용하여 모형 성능 향상에 초점을 맞추고, 하이퍼파라미터 튜닝시에는 0.1이상의 값을 사용하여 학습속도를 높이는 것이 좋다.](https://psystat.tistory.com/131)
-
-**gamma**
-
-- gain - gamma < 0 이면 해당 분기점은 없어진다.
-
-- gamma 값에 따라 분할할지 말지 정할 수도 있음
-- https://gwoolab.tistory.com/31
-
-**[lambda, alpha](https://wooono.tistory.com/221)**
-
-- **L1 Regularization** 과 **L2 Regularization** 모두 **Overfitting(과적합)** 을 막기 위해 사용
-- L1 Regularization은 가중치 업데이트 시, 가중치의 크기에 상관 없이 상수값을 빼면서 진행
-- L2 Regularization은 가중치 업데이트 시, 가중치의 크기가 직접적인 영향을 미침
-- 다만, L1 Regularization은 아래 그림처럼 미분 불가능한 점이 있기 때문에 Gradient-base learning 에는 주의가 필요
-
-- 따라서, L2는 L1 보다 가중치 규제에 좀 더 효과적
-
-
-
-## Light GBM 모델 튜닝
-
-.assets/다운로드 (1).jpg)
-
-**min_child_samples**
-
-- **min_child_samples** 파라미터는 최종 결정 클래스인 Leaf Node가 되기 위해서 최소한으로 필요한 **데이터 개체의 수**를 의미하며, 과적합을 제어하는 파라미터이다. 이 파라미터의 최적값은 훈련 데이터의 개수와 **num_leaves**에 의해 결정된다. 너무 큰 숫자로 설정하면 under-fitting이 일어날 수 있으며, 아주 큰 데이터셋이라면 적어도 수백~수천 정도로 가정하는 것이 편리하다.
- - **num_leaves** 파라미터는 하나의 트리가 가질 수 있는 최대 리프의 개수인데, 이 개수를 높이면 정확도는 높아지지만 트리의 깊이가 커져 모델의 복잡도가 증가한다는 점에 유의해야 한다.
-
-
-
-## 코드
-
-### XGBoost
-
-```python
-# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(실습)
-
-#학습
-xgb_tune =XGBClassifier(gamma = 4.376,max_depth = 3, subsample = 0.9818)
-xgb_tune.fit(X,y)
-
-
-#예측
-pred = xgb_tune.predict(test.drop(columns = ['index'] ))
-
-#정답파일 내보내기
-sub = pd.read_csv('data/sample_submission.csv')
-sub['quality'] = pred
-sub.to_csv('tune_xgb.csv',index = False)
-
-#0.573
-
-# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(max_params)
-
-#학습
-xgb_tune =XGBClassifier(gamma = 3.852,max_depth = 2, subsample = 0.8105)
-xgb_tune.fit(X,y)
-
-
-#예측
-pred = xgb_tune.predict(test.drop(columns = ['index'] ))
-
-#정답파일 내보내기
-sub = pd.read_csv('data/sample_submission.csv')
-sub['quality'] = pred
-sub.to_csv('tune_xgb_lwt.csv',index = False)
-
-#0.567
-```
-
-
-
-### light gbm
-
-```python
-max_params = BO_lgbm.max['params']
-
-max_params['max_depth'] = float(max_params['max_depth'])
-max_params['n_estimators'] = float(max_params['n_estimators'])
-max_params['subsample'] = float(max_params['subsample'])
-print(max_params)
-# {'max_depth': 2.5563135018997007, 'n_estimators': 90.90085037727735, 'subsample': 0.989309171116382}
-
-
-# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(실습내용)
-
-#학습
-lgbm_tune =LGBMClassifier(n_estimators = 43 ,max_depth = 3, subsample = 1)
-lgbm_tune.fit(X,y)
-
-
-#예측
-pred = lgbm_tune.predict(test.drop(columns = ['index'] ))
-
-#정답파일 내보내기
-sub = pd.read_csv('data/sample_submission.csv')
-sub['quality'] = pred
-sub.to_csv('tune_lgbm.csv',index = False)
-# 0.57199
-
-# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(max_params적용)
-
-#학습
-lgbm_tune =LGBMClassifier(n_estimators = 91 ,max_depth = 3, subsample = 1)
-lgbm_tune.fit(X,y)
-
-
-#예측
-pred = lgbm_tune.predict(test.drop(columns = ['index'] ))
-
-#정답파일 내보내기
-sub = pd.read_csv('data/sample_submission.csv')
-sub['quality'] = pred
-sub.to_csv('tune_lgbm_lwt.csv',index = False)
-# 0.57699
-```
-
-
-
-# voting classifier
-
-```python
-# 모델 정의 (튜닝된 파라미터로)(실습)
-LGBM = LGBMClassifier(max_depth = 3,n_estimators=60, subsample = 0.8229)
-XGB = XGBClassifier(gamma = 4.376, max_depth = 3, subsample = 0.9818)
-RF = RandomForestClassifier(max_depth = 3, n_estimators = 35) # float값이 안들어가서 몇개는 반올림 해줌
-
-# VotingClassifier 정의
-VC = VotingClassifier(estimators=[('rf',RF),('xgb',XGB),('lgbm',LGBM)],voting = 'soft')
-# 0.555
-
-# 모델 정의 (튜닝된 파라미터로)(max_params적용))
-LGBM = LGBMClassifier(max_depth = 3,n_estimators=100, subsample = 1)
-XGB = XGBClassifier(gamma = 4, max_depth = 1, subsample = 1)
-RF = RandomForestClassifier(max_depth = 3, n_estimators = 100)
-
-# VotingClassifier 정의
-VC = VotingClassifier(estimators=[('rf',RF),('xgb',XGB),('lgbm',LGBM)],voting = 'soft')
-# 0.556
-
-# 0.001차이로 max_params가 높음
-```
-
-
-
-
-
-
-
+Bayesian Optimization 을 이용해 모델을 튜닝
+
+현재까지 얻어진 모델의 파라미터와 추가적인 실험 정보를 통해 **데이터가 주어 졌을 때 모델의 성능이 가장 좋을 확률이 높은 파라미터를 찾아냅니다.**
+
+
+
+# 모델 튜닝
+
+## XGBoost 모델 튜닝
+
+
+
+### learning rate(학습률)
+
+[경사하강법](https://velog.io/@sasganamabeer/AI-Gradient-Descent%EA%B2%BD%EC%82%AC%ED%95%98%EA%B0%95%EB%B2%95)
+
+> 경사하강법(Gradient Descent)은 1차 근삿값 발견용 **최적화 알고리즘**이다. 기본 개념은 함수의 기울기(경사)를 구하고 경사의 절댓값이 낮은 쪽으로 계속 이동시켜 극값에 이를 때까지 반복시키는 것이다.
+
+- 취솟값을 구하기 위해 미분계수 계산 과정을 컴퓨터로 구현하는 것보다, **경사하강법을 구현하는 것이 훨씬 쉬움**
+
+- 데이터의 양이 매우 큰 경우 경사하강법과 같은 순차적인 방법이 **계산량 측면에서 훨씬 효율적**
+
+- **공식**
+
+ - 경사하강법은 **함수의 기울기(=gradient)를 이용해서 함수의 최소값 일 때의 x값을 찾기 위한 방법**이다. 기울기가 양수인 경우는 *x* 값이 증가할수록 함수 값도 증가하고, 반대로 음수인 경우에는 *x* 값이 증가할수록 함수 값이 감소한다. 그리고 기울기 값이 크다, 기울기가 가파르다는 것은 최소값으로부터 거리가 멀다는 뜻이다.
+
+ .assets/image-20220502230520657.png)
+
+ 기울기가 양수면 x를 음의 방향으로, 기울기가 음수면 x를 양의 방향으로 x를 이동시킨다.
+
+ .assets/image-20220502230748658.png)
+
+ 미분 계수(=기울기=gradient)는 극소값에 가까워질수록 값이 작아진다. 따라서, **이동거리에는 미분 계수와 비례하는 값을 이용**한다. 그럼 극소값에서 멀 때는 많이 이동하고, 극소값에 가까울 때는 조금씩 이동할 수 있다.
+
+ .assets/image-20220502230822164.png)
+
+ > .assets/image-20220502230848119.png)
+
+
+
+- 경사하강법 알고리즘은 기울기에 learning rate 또는 step size라고 불리는 스칼라를 곱해서 다음지점을 결정한다.
+
+ .assets/image-20220502193613401.png)
+
+learning rate(step size)이 크면 데이터가 무질서하게 이탈해서 최저점에 수렴하지 못하고 learning rate(step size)가 작으면 학습시간이 오래걸려서 최저점에 도달하지 못한다. 적절할 값을 설정해줘야한다. [최종 학습시에는 0.05 이하의 값을 사용하여 모형 성능 향상에 초점을 맞추고, 하이퍼파라미터 튜닝시에는 0.1이상의 값을 사용하여 학습속도를 높이는 것이 좋다.](https://psystat.tistory.com/131)
+
+**gamma**
+
+- gain - gamma < 0 이면 해당 분기점은 없어진다.
+
+- gamma 값에 따라 분할할지 말지 정할 수도 있음
+- https://gwoolab.tistory.com/31
+
+**[lambda, alpha](https://wooono.tistory.com/221)**
+
+- **L1 Regularization** 과 **L2 Regularization** 모두 **Overfitting(과적합)** 을 막기 위해 사용
+- L1 Regularization은 가중치 업데이트 시, 가중치의 크기에 상관 없이 상수값을 빼면서 진행
+- L2 Regularization은 가중치 업데이트 시, 가중치의 크기가 직접적인 영향을 미침
+- 다만, L1 Regularization은 아래 그림처럼 미분 불가능한 점이 있기 때문에 Gradient-base learning 에는 주의가 필요
+
+- 따라서, L2는 L1 보다 가중치 규제에 좀 더 효과적
+
+
+
+## Light GBM 모델 튜닝
+
+
+
+**min_child_samples**
+
+- **min_child_samples** 파라미터는 최종 결정 클래스인 Leaf Node가 되기 위해서 최소한으로 필요한 **데이터 개체의 수**를 의미하며, 과적합을 제어하는 파라미터이다. 이 파라미터의 최적값은 훈련 데이터의 개수와 **num_leaves**에 의해 결정된다. 너무 큰 숫자로 설정하면 under-fitting이 일어날 수 있으며, 아주 큰 데이터셋이라면 적어도 수백~수천 정도로 가정하는 것이 편리하다.
+ - **num_leaves** 파라미터는 하나의 트리가 가질 수 있는 최대 리프의 개수인데, 이 개수를 높이면 정확도는 높아지지만 트리의 깊이가 커져 모델의 복잡도가 증가한다는 점에 유의해야 한다.
+
+
+
+## 코드
+
+### XGBoost
+
+```python
+# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(실습)
+
+#학습
+xgb_tune =XGBClassifier(gamma = 4.376,max_depth = 3, subsample = 0.9818)
+xgb_tune.fit(X,y)
+
+
+#예측
+pred = xgb_tune.predict(test.drop(columns = ['index'] ))
+
+#정답파일 내보내기
+sub = pd.read_csv('data/sample_submission.csv')
+sub['quality'] = pred
+sub.to_csv('tune_xgb.csv',index = False)
+
+#0.573
+
+# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(max_params)
+
+#학습
+xgb_tune =XGBClassifier(gamma = 3.852,max_depth = 2, subsample = 0.8105)
+xgb_tune.fit(X,y)
+
+
+#예측
+pred = xgb_tune.predict(test.drop(columns = ['index'] ))
+
+#정답파일 내보내기
+sub = pd.read_csv('data/sample_submission.csv')
+sub['quality'] = pred
+sub.to_csv('tune_xgb_lwt.csv',index = False)
+
+#0.567
+```
+
+
+
+### light gbm
+
+```python
+max_params = BO_lgbm.max['params']
+
+max_params['max_depth'] = float(max_params['max_depth'])
+max_params['n_estimators'] = float(max_params['n_estimators'])
+max_params['subsample'] = float(max_params['subsample'])
+print(max_params)
+# {'max_depth': 2.5563135018997007, 'n_estimators': 90.90085037727735, 'subsample': 0.989309171116382}
+
+
+# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(실습내용)
+
+#학습
+lgbm_tune =LGBMClassifier(n_estimators = 43 ,max_depth = 3, subsample = 1)
+lgbm_tune.fit(X,y)
+
+
+#예측
+pred = lgbm_tune.predict(test.drop(columns = ['index'] ))
+
+#정답파일 내보내기
+sub = pd.read_csv('data/sample_submission.csv')
+sub['quality'] = pred
+sub.to_csv('tune_lgbm.csv',index = False)
+# 0.57199
+
+# 튜닝된 파라미터를 바탕으로 test 데이터 셋 예측(max_params적용)
+
+#학습
+lgbm_tune =LGBMClassifier(n_estimators = 91 ,max_depth = 3, subsample = 1)
+lgbm_tune.fit(X,y)
+
+
+#예측
+pred = lgbm_tune.predict(test.drop(columns = ['index'] ))
+
+#정답파일 내보내기
+sub = pd.read_csv('data/sample_submission.csv')
+sub['quality'] = pred
+sub.to_csv('tune_lgbm_lwt.csv',index = False)
+# 0.57699
+```
+
+
+
+# voting classifier
+
+```python
+# 모델 정의 (튜닝된 파라미터로)(실습)
+LGBM = LGBMClassifier(max_depth = 3,n_estimators=60, subsample = 0.8229)
+XGB = XGBClassifier(gamma = 4.376, max_depth = 3, subsample = 0.9818)
+RF = RandomForestClassifier(max_depth = 3, n_estimators = 35) # float값이 안들어가서 몇개는 반올림 해줌
+
+# VotingClassifier 정의
+VC = VotingClassifier(estimators=[('rf',RF),('xgb',XGB),('lgbm',LGBM)],voting = 'soft')
+# 0.555
+
+# 모델 정의 (튜닝된 파라미터로)(max_params적용))
+LGBM = LGBMClassifier(max_depth = 3,n_estimators=100, subsample = 1)
+XGB = XGBClassifier(gamma = 4, max_depth = 1, subsample = 1)
+RF = RandomForestClassifier(max_depth = 3, n_estimators = 100)
+
+# VotingClassifier 정의
+VC = VotingClassifier(estimators=[('rf',RF),('xgb',XGB),('lgbm',LGBM)],voting = 'soft')
+# 0.556
+
+# 0.001차이로 max_params가 높음
+```
+
+
+
+
+
+
+