|
| 1 | +# 1,2,3차 정규화란 무엇인가? |
| 2 | +그리고 정규화는 어떻게 이용 될 수 있을까? |
| 3 | + |
| 4 | +### 데이터베이스 정규화란? |
| 5 | + |
| 6 | +데이터베이스 정규화는 **데이터 중복을 줄이고 데이터 무결성을 개선하기 위해** 이른바 정규 형식(normal forms)에 따라 **데이터베이스(일반적으로 관계형 데이터베이스)를 구조화하는 프로세스**입니다. |
| 7 | + |
| 8 | +정규화에는 데이터베이스 무결성 제약 조건에 따라 종속성이 적절하게 적용되도록 데이터베이스의 열(어트리뷰트) 및 테이블(릴레이션)을 구성하는 작업이 수반됩니다. 이는 합성(새 데이터베이스 디자인 생성) 또는 분해(기존 데이터베이스 디자인 개선) 프로세스를 통해 일부 공식 규칙을 적용하여 수행됩니다. -Wikipedia- |
| 9 | + |
| 10 | +### 정규화를 하는 이유 |
| 11 | + |
| 12 | +테이블(릴레이션)을 수정(삽입, 삭제, 수정)하려고 할 때 충분히 정규화되지 않은 테이블(릴레이션)에서 다음과 같은 부작용(side-effects)이 발생 할 수 있습니다. |
| 13 | + |
| 14 | +- 삽입 이상(Insertion anomaly) : 새 데이터를 삽입하기 위해 불필요한 데이터도 함께 삽입해야 하는 문제 |
| 15 | +- 삭제 이상(Deletion anomaly) : 중복 튜플 중 일부만 변경되어 데이터가 불일치하게 되는 문제 |
| 16 | +- 갱신 이상(Update anomaly) : 튜플을 삭제하면 꼭 필요한 데이터까지 함께 삭제해야되는 데이터 손실 문제 |
| 17 | + |
| 18 | +### 제 1 정규화 만족(Satisfying 1NF) |
| 19 | + |
| 20 | +제 1 정규화란 테이블의 컬럼이 원자값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해하는 것입니다. 예를 들어 아래와 같은 고객 취미 테이블이 존재한다고 하면, |
| 21 | + |
| 22 | + |
| 23 | + |
| 24 | +위의 테이블에서 추신수와 박세리는 여러 개의 취미를 가지고 있기 때문에 제 1 정규형을 만족하지 못하고 있다고 할 수 있다. 그렇기 때문에 이를 제 1 정규화하여 분해 할 수 있다. 이를 변경하면 다음과 같다. |
| 25 | + |
| 26 | + |
| 27 | + |
| 28 | +### 제 2 정규화 만족(Satisfying 2NF) |
| 29 | + |
| 30 | +제 2 정규화란 **제 1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해**하는 것이다. 여기서 **완전 함수 종속이라는 것은 기본키의 부분집합이 결정자가 되어선 안된다는 것을 의미**한다. |
| 31 | + |
| 32 | +예를 들어 아래와 같은 수강 강좌 테이블을 살펴보면, |
| 33 | + |
| 34 | + |
| 35 | + |
| 36 | +이 테이블에서 기본키는 { 학생번호, 강좌이름 }으로 복합키다. 그리고 { 학생번호, 강좌이름 }인 기본키는 강의실을 결정하고 있다. { 학생번호, 강좌이름 } → { 강의실 } 그런데 여기서 강의실이라는 컬럼은 기본키의 부분집합인 강좌이름에 의해 결정 될 수 있다. { 강좌이름 } → { 강의실 } |
| 37 | + |
| 38 | +그렇기 때문에 위의 테이블의 경우 다음과 같이 기존의 테이블에서 강의실을 분해하여 별도의 테이블로 관리한다면 제 2 정규형을 만족시킬 수 있다. |
| 39 | + |
| 40 | + |
| 41 | + |
| 42 | +### 제 3 정규화 만족(Satisfying 3NF) |
| 43 | + |
| 44 | +제 3 정규화란 **제 2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해**하는 것이다. 여기서 이행적 종속이라는 것은 A → B, B → C가 성립할 때 A → C가 성립되는 것을 의미한다. |
| 45 | + |
| 46 | +예를 들어 아래와 같은 계절 학기 테이블을 살펴보면, |
| 47 | + |
| 48 | + |
| 49 | + |
| 50 | +기존 테이블에서 학생 번호는 강좌 이름을 결정하고 있고, 강좌 이름은 수강료를 결정하고 있다. 그렇기 때문에 이를 { 학생 번호, 강좌 이름 } 테이블과 { 강좌 이름, 수강료 } 테이블로 분해해야 한다. |
| 51 | + |
| 52 | +이행적 종속을 제거하는 이유는 비교적 간단하다. 예를 들어 501번 학생이 수강하는 강좌가 스포츠경영학으로 변경되었다고 할 때, 이행적 종속이 존재한다면 501번 학생은 스포츠경영학이라는 수업을 2만원의 수강료로 듣게 된다. 물론 강좌 이름에 맞게 수강료를 다시 변경 할 수 있지만, 이러한 번거러움을 해결하기 위해 제 3 정규화를 하는 것이다. 즉, 학생 번호를 통해 강좌 이름을 참조하고, 강좌 이름으로 수강료를 참조하도록 테이블을 분해해야 하며 그 결과는 다음과 같다. |
| 53 | + |
| 54 | +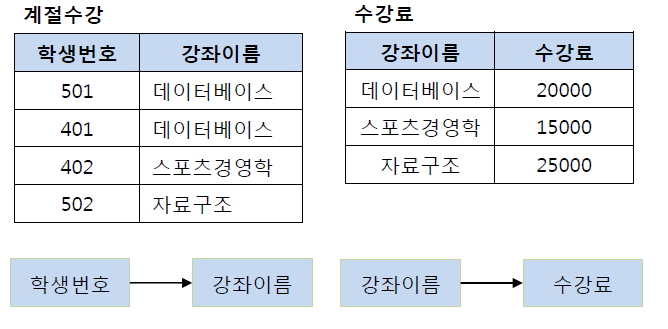 |
| 55 | + |
| 56 | +### 출처 |
| 57 | + |
| 58 | +- [https://en.wikipedia.org/wiki/Database_normalization](https://en.wikipedia.org/wiki/Database_normalization) |
| 59 | +- [https://yaboong.github.io/database/2018/03/09/database-anomaly-and-functional-dependency/](https://yaboong.github.io/database/2018/03/09/database-anomaly-and-functional-dependency/) |
| 60 | +- https://mangkyu.tistory.com/110 |
0 commit comments