|
| 1 | +# Memory Management |
| 2 | + |
| 3 | +- 메모리 주소는 물리적, 논리적 주소 있음. |
| 4 | +- `Logical Address` |
| 5 | + - 가상 주소 |
| 6 | + - 프로세스 마다 독립적으로 가지는 주소 공간 |
| 7 | + - 0번지 부터 시작되고, |
| 8 | + - **CPU가 보는 주소**임. |
| 9 | +- `Physical Address` |
| 10 | + - 물리 주소 |
| 11 | + - 논리 주소에 + 하나의 주소 값이 더해진 값 (유일) |
| 12 | + - 메모리에, 실제 올라가는 위치를 말함. |
| 13 | +- `Symbolic Address` |
| 14 | + - 코드 |
| 15 | + - 컴파일러는 이 주소를 읽고, 논리 주소로 바꿔준다. |
| 16 | + - 컴파일러가 심볼릭 주소를 논리 주소로 바꿔준 값은 중복 될 수 있음. |
| 17 | + |
| 18 | +> *Memory Management Unit* |
| 19 | +
|
| 20 | +- 위에서도 살펴봤듯이, 컴파일러가 심볼릭 주소를 논리주소로 바꾸는 값은 중복될 수 있음. |
| 21 | +- 그런데 CPU가 보는 값은 **논리 주소** |
| 22 | +- 그러면 컴파일러로 바꾼 값이, 중복 될 수 있는데 어떻게 컴파일러 마다 독립적인 값을 메모리에서 찾을 수 있는 걸까? |
| 23 | + - 하드웨어 적인 도움이 필요하다. |
| 24 | + - 주소 변환을 위한 하드웨어 |
| 25 | + - CPU 는 메모리에 접근할 떄, MMU의 도움을 받는다. |
| 26 | + - base register, limit register 를 통해 이게 **해당 프로세스의 요청**이 맞는지 확인 (해당 프로세스 요청 범위에 맞는 물리적 주소인지 확인) |
| 27 | + |
| 28 | +## Swapping |
| 29 | +- 프로세스를 일시적으로 메모리에서 backing store로 쫒아 내는 것. |
| 30 | +- 우선 순위가 낮은 프로그램을 쫒아 냈다가, 다시 불러냈다가 하는 방법 |
| 31 | +- 해당 방법을 실행하는 데 시간이 오래걸린다는 단점이 있음. |
| 32 | + |
| 33 | +## Dynamic Loading |
| 34 | +- 그때 그때 필요할 때마다 메모리에 올리는 방식. |
| 35 | + |
| 36 | +## Overlays |
| 37 | +- 프로세스 동작에 필요한 부분만 메모리에 올림. |
| 38 | + |
| 39 | +## Paging |
| 40 | +- Non contiguous allocation (현대 컴퓨터에서 가장 많이 사용되는 기법) |
| 41 | +- 물리 메모리를 동일한 크기의 frame으로 나누고, |
| 42 | +- 논리 메모리(swap memory)를 동일한 크기의 page로 나눔 (frame가 같은 크기) |
| 43 | + |
| 44 | +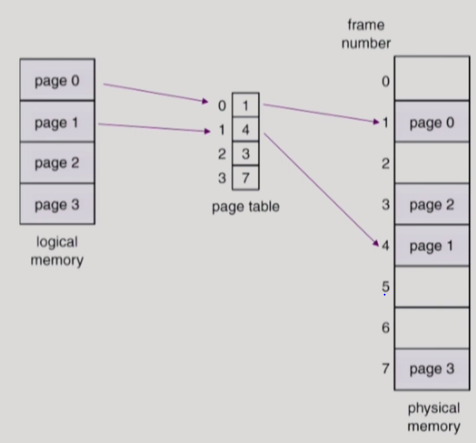 |
| 45 | +- 페이지 테이블을 이용하여, 논리 - 물리 메모리간의 중간 다리 역할로 사용 |
| 46 | +- 페이지 테이블을 프로세스 마다 존재, 그리고 이 페이지 테이블은 메모리에 저장됨. (Shared Page에 있음) |
| 47 | +- TLB를 통해 페이지 테이블로의 접근 시도를 줄임. (최적화) |
| 48 | + |
| 49 | +> *TLB Translation Look aside Buffer* |
| 50 | +
|
| 51 | +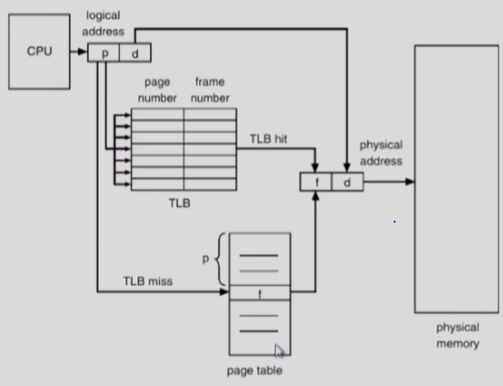 |
| 52 | +- 일종의 캐쉬 메모리 |
| 53 | +- 주소 변환을 해주는 계층 |
| 54 | +- CPU가 논리 주소를 요청하면, page table 에 접근하기 전에 우선적으로 살펴보는 공간. |
| 55 | +- 여기 CPU에서 요청하는 논리 주소가 있으면 바로 변환해서 물리 메모리에서 가져옴. |
| 56 | + - 없으면 page table을 참조해서 물리 주소를 가져옴. |
| 57 | + - 그리고 요청한 논리 주소를 TLB에 저장해 둠 |
| 58 | + |
| 59 | + |
| 60 | +# 리눅스가 메모리를 관리하는 방법 |
| 61 | +- swap 공간에서 메모리 주소를 가져오려면 운영체제의 도움이 필요하다. |
| 62 | + |
| 63 | + |
| 64 | +## 가상 메모리 사용 |
| 65 | +- Virtual Memory |
| 66 | + - Swap memory + physical memroy |
| 67 | + |
| 68 | +## I/O 장치 관리 |
| 69 | +- CPU가 논리 주소를 요청하면, TLB에 있는 지 확인 |
| 70 | +- 없으면, 해당 프로세스를 중단 |
| 71 | +- 여기서 리눅스(운영체제) 등장 |
| 72 | +- 운영체제는 해당 프로세스가 왜 멈췄는 지 다시 한번 확인 (악의적인 요청이 아닌지) |
| 73 | +- 논리주소를 기반으로, 하드 디스크의 Swap 공간에서 해당하는 메모리 주소를 가져오고, TLB에 그 주소(논리)를 등록 |
| 74 | +- Page table에 해당 주소 등록 |
| 75 | +- 운영체제는 다시 프로세스를 동작 |
| 76 | + |
| 77 | +> *Page fault* |
| 78 | +- CPU에서 요청한 논리 주소 값을 변환하여 메모리에서 찾았는 데, 해당 공간에 아무런 데이터가 없는 현상 |
| 79 | +- 이 현상이 발생하면, 리눅스는 해당 논리주소에 대한 값을 disk 에서 찾는다. |
| 80 | +- 그리고 physical memory에 올린다. |
| 81 | +- 그 주소를 page table에 저장한다. |
| 82 | + |
| 83 | +> *Page replacement* |
| 84 | +- page fault가 발생한다. |
| 85 | +- page의 위치를 disk에서 찾는다. |
| 86 | +- physical memory에 빈 공간이 있는 지 확인한다 (frame 확인) |
| 87 | + - 있으면 해당 프레임 사용 |
| 88 | + - 없으면? page replacement 진행 |
| 89 | +- 물리 공간에서 쫒아낼 frame을 선정한다. |
| 90 | +- 이 프레임을 disk에 저장한다. (page table도 업데이트) |
| 91 | +- 올리고자 하는 정보를 비어있는 frame 에 올린다 (page table 또 업데이트) |
| 92 | +- 이제 프로세스 다시 진행 |
| 93 | + |
| 94 | +> *Thrasing* |
| 95 | +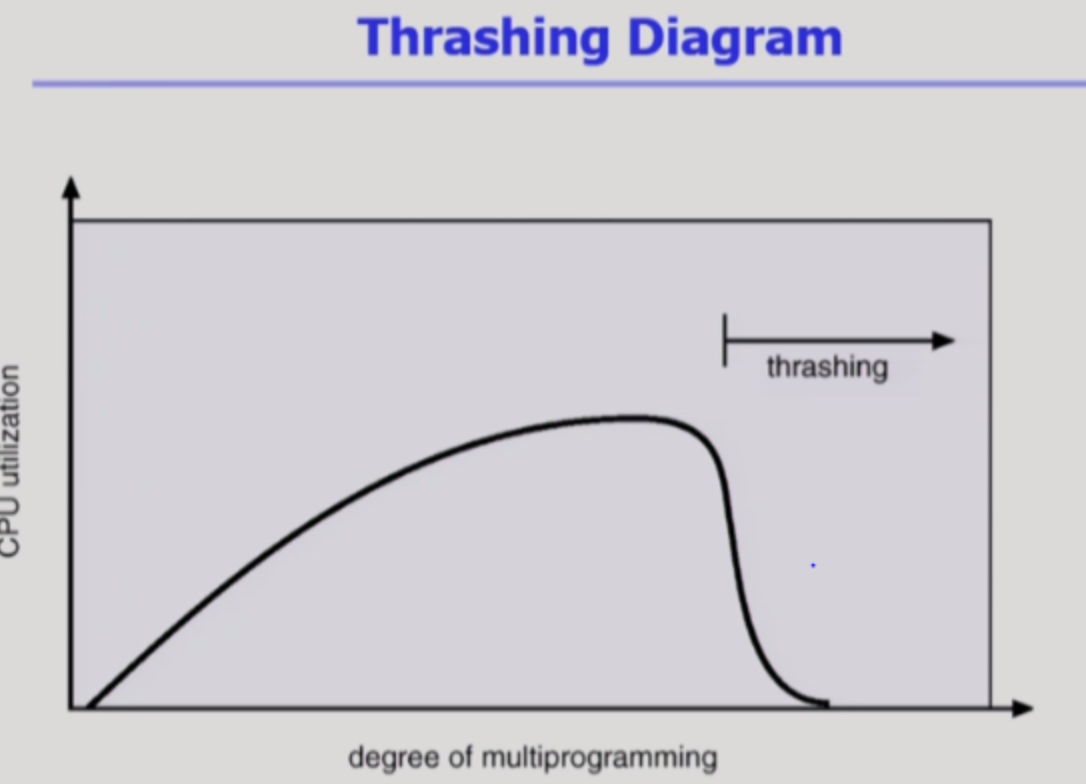 |
| 96 | + |
| 97 | +- Page fault rate가 높아져서, CPU는 할일이 없어지는 현상 |
| 98 | +- 프로세스 page는 swap in, out으로 매우 바쁘게 돌아가지만, 상대적으로 CPU는 한가해지는 현상을 의미한다. |
| 99 | +- 이를 방지하고자 working set model, page-fault frequency 를 사용하기도 함 |
| 100 | + |
| 101 | + |
| 102 | +# 메모리 고갈사항, CPU 사용률 확인 |
| 103 | +- [htop](https://happist.com/557995/%EC%84%9C%EB%B2%84-%EB%AA%A8%EB%8B%88%ED%84%B0%EB%A7%81-%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%A8-htop-%EC%82%AC%EC%9A%A9-%EB%B0%A9%EB%B2%95-ubuntu) 명령어를 통해, 모니터링 해보자 |
| 104 | + |
| 105 | +- 메모리 고갈되면 발생하는 사항 |
| 106 | + - 프로세스 Swap 활발, CPU 사용율 하락 |
| 107 | + - Thrashing 발생 |
| 108 | + - 해소되지 않을 경우, Out of Memory 판단 |
| 109 | + - 중요도가 낮은 프로세스를 찾아 강제 종료 |
| 110 | + |
| 111 | +- CPU 사용률 체크 |
| 112 | + - CPU 사용률이 급격하게 떨어지는 구간이 있으면, |
| 113 | + - 메모리 적재량 확인 (메모리가 고갈 되었다?) |
| 114 | + - 추가적인 서버 자원을 배치 |
| 115 | + |
| 116 | +# 정리 |
| 117 | + |
| 118 | +## 페이징 기법 내에서 리눅스가 메모리를 가져오는 순서 |
| 119 | + |
| 120 | + |
| 121 | + |
| 122 | +1. Symbolic address 가 컴파일러를 통해, Logical Address로 바꿔준다. |
| 123 | +2. Logical Address를 통해 리눅스에 있는 **MMU** 로 보낸다 |
| 124 | +3. Phsical Address로 변환 전에, 논리주소를 통해 TLB를 찾아본다. |
| 125 | + - TLB에 논리주소에 맵핑된 값(물리 주소)이 있으면, 바로 해당 물리 주소에 있는 데이터를 불러옴. |
| 126 | + - 없으면 다음 단계로. |
| 127 | +4. Page table을 참조하여, 해당 물리 주소를 가져옴. 그리고 이 주소를 TLB에 저장해둔다. |
| 128 | + - 이 과정에서 Page table에 논리 주소에 해당하는 값이 없으면 Page fault. |
| 129 | + - 해당 page에 대한 정보를 disk 에서 찾는다. 그리고 메모리에 올린다. |
| 130 | + - 만약에 메모리에 올릴 수 없으면? (Page replacement 진행) |
| 131 | + |
| 132 | + |
| 133 | +# 참고 |
| 134 | +- https://www.youtube.com/watch?v=qxmdX449z1U |
| 135 | +- http://www.kyobobook.co.kr/product/detailViewKor.laf?ejkGb=KOR&mallGb=KOR&barcode=9791158903589 |
| 136 | +- http://web.mit.edu/rhel-doc/4/RH-DOCS/rhel-isa-ko-4/s1-memory-virt-details.html |
| 137 | +- https://wogh8732.tistory.com/395 |
| 138 | +- https://m.blog.naver.com/4717010/220015472363 |
| 139 | + |
| 140 | + |
| 141 | + |
| 142 | +# QnA |
| 143 | + |
| 144 | +## Logical Address와 Physical Address가 별도로 존재하는 이유는 무엇일까요? |
| 145 | + |
| 146 | +- Multi-process 환경에서 발생할 수 있는 충돌을 최소화 하기 위해서 |
| 147 | +- 혹은 한정된 Physical Memory, Address 에도, 좀 더 확장성 있게 사용하기 위해서 (Logical Address를 통해) |
| 148 | + |
| 149 | +- 참고 |
| 150 | + - https://stackoverflow.com/questions/29771977/purpose-of-logical-address/47988290 |
| 151 | + |
| 152 | + |
| 153 | + |
| 154 | +## Address Binding에 대해 설명 |
| 155 | + |
| 156 | +- 데이터를 메모리에 올리는 걸 Address Binding이라 하는듯. |
| 157 | +- 언제 올리는 지에 따라서.. |
| 158 | + 1. Compile time에 메모리에 올릴 수 있고, |
| 159 | + 2. 혹은 Load time 프록그램을 실행 전에 |
| 160 | + 3. Execution time 실행 시에도 올릴 수 있음! (신기) |
| 161 | + |
| 162 | +- 참고 |
| 163 | + |
| 164 | +- https://jhnyang.tistory.com/133 |
| 165 | + |
| 166 | + |
| 167 | + |
| 168 | +## 컴파일러가 심볼릭 주소를 논리주소로 바꾸는 값은 중복될 수 있음 왜? |
| 169 | + |
| 170 | +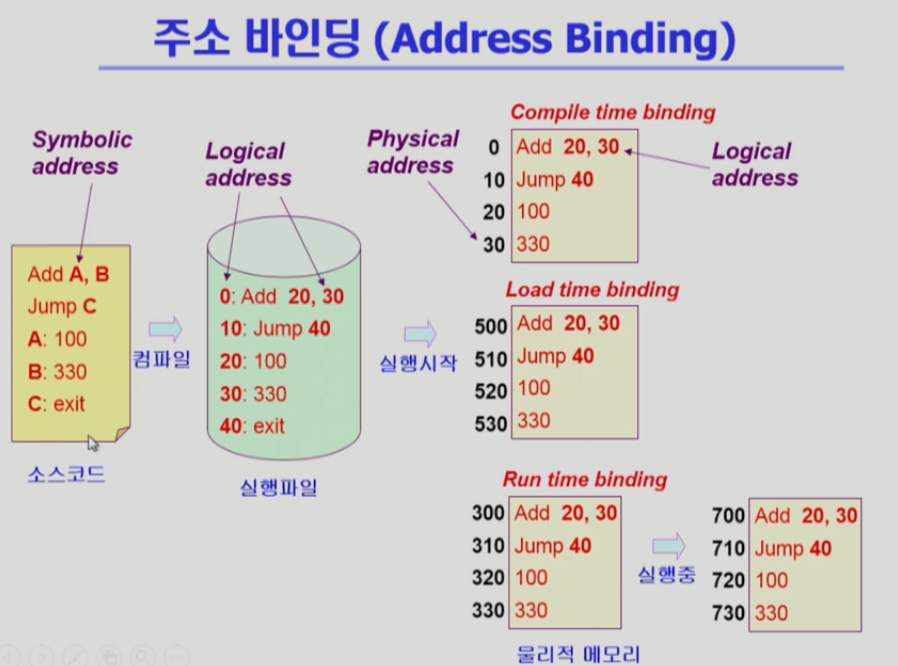 |
| 171 | + |
| 172 | +- Address binding 과 관련 있는듯. |
| 173 | + |
| 174 | +- symbolic address는 컴파일을 통해 Logcial Addess로 변환 되는데, 이 때 나온 값이 중복 될 수 있음. |
| 175 | +- 왜? |
| 176 | + - 프로세스 별로 컴파일이라는 과정을 유니크하게 보장할 수는 없을듯. |
| 177 | + |
| 178 | + |
| 179 | + |
| 180 | +## MMU가 base register, limit register를 사용하는 이유 |
| 181 | + |
| 182 | +- Address binding 과 관련 있는듯. |
| 183 | +- 프로세스 마다 접근할 수 있는 구역을 설정하기 위해서, 보장해주기 위해서 사용하는듯 |
| 184 | + |
| 185 | + |
| 186 | + |
| 187 | +## Dynamic Loading과 Virtual Memory는 어떤 관계 |
| 188 | + |
| 189 | +- CPU가 바라보는 주소가 있는 공간이 Virtual Memory |
| 190 | +- Dynamic Loading의 경우, 메모리 공간을 효율적으로 사용하기 위한 기법 |
| 191 | + |
| 192 | +- 둘 다 메모리 부족을 해결하기 위해서 등장한 기법, 방법으로 이해되어요. |
| 193 | + - 전자의 경우 Virtual Memory라는 가상공간을 통해서 Physical Memory의 부족을 해소 |
| 194 | + - 후자의 경우 프로그램에서 사용하는 부분만 Physical Memory에 올림으로써 해소 |
| 195 | + |
| 196 | + |
| 197 | + |
| 198 | +## Dynamic Loading vs Overlays vs Virtual Memory vs Paging 차이 |
| 199 | + |
| 200 | +> Dynamic Loading |
| 201 | +
|
| 202 | +- 프로그램을 Physical Memory에 동적(필요할 때 마다) 올림. |
| 203 | +- 프로그래머가 직접 컨드롤할 수 있는 부분도 있는듯 (코드 레벨에서 조절할 수 있다는 의미인듯) |
| 204 | + |
| 205 | + |
| 206 | + |
| 207 | +> Overlays |
| 208 | +
|
| 209 | +- Dynamic Loading과 비슷 |
| 210 | +- 다만, 메모리보다 프로세스가 더 클 경우 사용되는 기법(Dynamic Loading은 이와 같을 경우 해결이 불가능한듯) |
| 211 | + |
| 212 | + |
| 213 | + |
| 214 | +> Virtual Memory |
| 215 | +
|
| 216 | +- Physical Memory 부족을 위해 나온 개념 |
| 217 | +- CPU가 바라보로 있는 주소이고, 프로세스마다 독립적인 공간을 보장받을듯 싶음. |
| 218 | + |
| 219 | + |
| 220 | + |
| 221 | +> Paging |
| 222 | +
|
| 223 | +- Logical Address를 Page 라는 블록으로 분할하고 관리하는 기법 |
| 224 | +- 즉 프로세스를 일정 크기로 잘라서 메모리에 적재하는 방식 |
| 225 | +- 참고적으로 Page는 Logical Address를 나눈 크기를 의미하고, Frame은 Physical Memory를 나눈 크기를 의미 |
| 226 | + |
| 227 | + |
| 228 | + |
| 229 | +- 참고 |
| 230 | + - https://jhnyang.tistory.com/44 |
| 231 | + - https://jhnyang.tistory.com/290 |
| 232 | + |
| 233 | + |
| 234 | + |
| 235 | +## Page Fault 발생 과정 |
| 236 | + |
| 237 | +1. CPU 가 Logical Address를 가지고 page table에 들어감. |
| 238 | +2. 이 때 가져온 Logical Address 해당 프로세스에서는 사용되지 않는 주소이던지, Logical Address에 해당하는 Physical Address의 주소가 Page Table에 없을 경우 Invalid 판단이 내려집니다. 이 경우 page fault handler가 실행되어요. |
| 239 | +2.1 전자의 경우 해당 요청 명령이 abort되고, |
| 240 | +2.2 후자의 경우 physical memory에 올라갈 공간 (frame)을 확보합니다. |
| 241 | +3. 요청한 Logical Address에 대한 정보를 Disk에서 읽어서 Physical Memory에 가져옵니다. |
| 242 | +4. 그리고 그에 대한 정보를 Page table을 업데이트 합니다. |
| 243 | + |
| 244 | + |
| 245 | + |
| 246 | +- 즉 위 절차를 통해 생각해볼 때, 메모리 공간 데이터의 경우 아래 2가지 시나리오가 있지 않을까 싶네요 |
| 247 | + |
| 248 | +1. 요청한 Logical Address에 대한 정보가 page table, physical memory 에도 없을 경우 (위 절차를 밟아서..다시 가져올듯) |
| 249 | +2. 원하는 데이터가 physical memory(메모리)에 있는데, page table에는 없는 경우 아마도 MMU를 통해 메모리에서 찾은 후 page table을 업데이트하겠네요. |
| 250 | + |
| 251 | + |
| 252 | + |
| 253 | +- 참고 |
| 254 | + - https://data-engineer.tistory.com/53 |
0 commit comments