|
| 1 | +## 1. 字符串简介 |
| 2 | + |
| 3 | +> **字符串(String)**:简称为串,是由零个或多个字符组成的有限序列。一般记为 $s = a_1a_2…a_n (0 \le n ⪇ \infty)$。 |
| 4 | +
|
| 5 | +下面介绍一下字符串相关的一些重要概念。 |
| 6 | + |
| 7 | +- **字符串名称**:字符串定义中的 `s` 就是字符串的名称。 |
| 8 | +- **字符串的值**:$a_1a_2…a_n$ 组成的字符序列就是字符串的值,一般用双引号括起来。 |
| 9 | +- **字符变量**:字符串每一个位置上的元素都是一个字符变量。字符 $a_i$ 可以是字母、数字或者其他字符。`i` 是该字符在字符串中的位置。 |
| 10 | +- **字符串的长度**:字符串中字符的数目 `n` 称为字符串的长度。 |
| 11 | +- **空串**:零个字符构成的串也成为 **「空字符串(Null String)」**,它的长度为 `0`,可以表示为 `""`。 |
| 12 | +- **子串**:字符串中任意个连续的字符组成的子序列称为该字符串的 **「子串(Substring)」**。并且有两种特殊子串,起始于位置为 `0`、长度为 `k` 的子串称为 **「前缀(Prefix)」**。而终止于位置 `n - 1`、长度为 `k` 的子串称为 **「后缀(Suffix)」**。 |
| 13 | +- **主串**:包含子串的字符串相应的称为 **「主串」**。 |
| 14 | + |
| 15 | +举个例子来说明一下: |
| 16 | + |
| 17 | +```Python |
| 18 | +str = "Hello World" |
| 19 | +``` |
| 20 | + |
| 21 | +在示例代码中,`str` 是一个字符串的变量名称,`Hello World` 则是该字符串的值,字符串的长度为 `11`。该字符串的表示如下图所示: |
| 22 | + |
| 23 | + |
| 24 | + |
| 25 | +可以看出来,字符串和数组有很多相似之处。比如使用 `名称[下标]` 的方式来访问一个字符。之所以单独讨论字符串是因为: |
| 26 | + |
| 27 | +- 字符串中的数据元素都是字符,结构相对简单,但规模可能比较庞大。 |
| 28 | +- 经常需要把字符串作为一个整体来使用和处理。操作对象一般不是某个数据元素,而是一组数据元素(整个字符串或子串)。 |
| 29 | +- 经常需要考虑多个字符串之间的操作。比如:字符串之间的连接、比较操作。 |
| 30 | + |
| 31 | +根据字符串的特点,我们可以将字符串问题分为以下几种: |
| 32 | + |
| 33 | +- 字符串匹配问题; |
| 34 | +- 子串相关问题; |
| 35 | +- 前缀 / 后缀相关问题; |
| 36 | +- 回文串相关问题; |
| 37 | +- 子序列相关问题。 |
| 38 | + |
| 39 | +## 2. 字符串的比较 |
| 40 | + |
| 41 | +### 2.1 字符串的比较操作 |
| 42 | + |
| 43 | +两个数字之间很容易比较大小,例如 `1 < 2`。而字符串之间的比较相对来说复杂一点。字符串之间的大小取决于它们按顺序排列字符的前后顺序。比如字符串 `str1 = "abc"` 和 `str2 = "acc"`,它们的第一个字母都是 `a`,而第二个字母,由于字母 `b` 比字母 `c` 要靠前,所以 `b < c`,于是我们可以说 `"abc" < "acd" `,也可以说 `str1 < str2`。 |
| 44 | + |
| 45 | +字符串之间的比较是通过组成字符串的字符之间的「字符编码」来决定的。而字符编码指的是字符在对应字符集中的序号。 |
| 46 | + |
| 47 | +我们先来考虑一下如何判断两个字符串是否相等。 |
| 48 | + |
| 49 | +如果说两个字符串 `str1` 和 `str2` 相等,则必须满足两个条件: |
| 50 | + |
| 51 | +1. 字符串 `str1` 和字符串 `str2` 的长度相等。 |
| 52 | +2. 字符串 `str1` 和字符串 `str2` 对应位置上的各个字符都相同。 |
| 53 | + |
| 54 | +下面我们再来考虑一下如何判断两个字符串的大小。 |
| 55 | + |
| 56 | +而对于两个不相等的字符串,我们可以以下面的规则定义两个字符串的大小: |
| 57 | + |
| 58 | +- 从两个字符串的第 `0` 个位置开始,依次比较对应位置上的字符编码大小。 |
| 59 | + - 如果 `str1[i]` 对应的字符编码等于 `str2[i]` 对应的字符编码,则比较下一位字符。 |
| 60 | + - 如果 `str1[i]` 对应的字符编码小于 `str2[i]` 对应的字符编码,则说明 `str1 < str2`。比如:`"abc" < "acc"`。 |
| 61 | + - 如果 `str1[i]` 对应的字符编码大于 `str2[i]` 对应的字符编码,则说明 `str1 > str2`。比如:`"bcd" > "bad"`。 |
| 62 | +- 如果比较到某一个字符串末尾,另一个字符串仍有剩余: |
| 63 | + - 如果字符串 `str1` 的长度小于字符串 `str2`,即 `len(str1) < len(str2)`。则 `str1 < str2`。比如:`"abc" < "abcde"`。 |
| 64 | + - 如果字符串 `str1` 的长度大于字符串 `str2`,即 `len(str1) > len(str2)`。则 `str1 > str2`。比如:`"abcde" > "abc"`。 |
| 65 | +- 如果两个字符串每一个位置上的字符对应的字符编码都相等,且长度相同,则说明 `str1 == str2`,比如:`"abcd" == "abcd"`。 |
| 66 | + |
| 67 | +按照上面的规则,我们可以定义一个 `strcmp` 方法,并且规定: |
| 68 | + |
| 69 | +- 当 `str1 < str2` 时,`strcmp` 方法返回 `-1`。 |
| 70 | +- 当 `str1 == str2` 时,`strcmp` 方法返回 `0`。 |
| 71 | +- 当 `str1 > str2` 时,`strcmp` 方法返回 `1`。 |
| 72 | + |
| 73 | +`strcmp` 方法对应的具体代码如下: |
| 74 | + |
| 75 | +```Python |
| 76 | +def strcmp(str1, str2): |
| 77 | + index1, index2 = 0, 0 |
| 78 | + while index1 < len(str1) and index2 < len(str2): |
| 79 | + if ord(str1[index1]) == ord(str2[index2]): |
| 80 | + index1 += 1 |
| 81 | + index2 += 1 |
| 82 | + elif ord(str1[index1]) < ord(str2[index2]): |
| 83 | + return -1 |
| 84 | + else: |
| 85 | + return 1 |
| 86 | + |
| 87 | + if len(str1) < len(str2): |
| 88 | + return -1 |
| 89 | + elif len(str1) > len(str2): |
| 90 | + return 1 |
| 91 | + else: |
| 92 | + return 0 |
| 93 | +``` |
| 94 | + |
| 95 | +上面关于字符串大小的定义有点复杂,其实字符串比较大小最简单的例子就是「查英语词典」。在英语词典的目录中,前面的单词要比后面的单词小。我们将英语词典中的每个英语单词都当做是一个字符串,那么查找单词的过程,其实就是比较字符串大小的过程。 |
| 96 | + |
| 97 | +### 2.2 字符串的字符编码 |
| 98 | + |
| 99 | +刚才我们提到了字符编码,这里我们也稍微介绍一下字符串中常用的字符编码标准。 |
| 100 | + |
| 101 | +以计算机中常用字符使用的 `ASCII` 编码为例。最早的时候,人们制定了一个包含 `127` 个字符的编码表 `ASCII` 到计算机系统中。`ASCII` 编码表中的字符包含了大小写的英文字母、数字和一些符号。每个字符对应一个编码,比如大写字母 `A` 的编码是 `65`,小写字母 `a` 的编码是 `97`。 |
| 102 | + |
| 103 | +`ASCII` 编码可以解决以英语为主的语言,可是无法满足中文编码。为了解决中文编码,我国制定了 `GB2312`、`GBK`、`GB18030` 等中文编码标准,将中文编译进去。但是世界上有上百种语言和文字,各国有各国的标准,就会不可避免的产生冲突,于是就有了 `Unicode` 编码。`Unicode` 编码最常用的就是 `UTF-8` 编码,`UTF-8` 编码把一个 `Unicode` 字符根据不同的数字大小编码成 `1` ~ `6` 个字节,常用的英文字母被编码成 `1` 个字节,汉字通常是 `3` 个字节。 |
| 104 | + |
| 105 | +## 3. 字符串的存储结构 |
| 106 | + |
| 107 | +字符串的存储结构跟线性表相同,分为「顺序存储结构」和「链式存储结构」。 |
| 108 | + |
| 109 | +### 3.1 字符串的顺序存储结构 |
| 110 | + |
| 111 | +与线性表的顺序存储结构相似,字符串的顺序存储结构也是使用一组地址连续的存储单元依次存放串中的各个字符。按照预定义的大小,为每个定义的字符串变量分配一个固定长度的存储区域。一般是用定长数组来定义。 |
| 112 | + |
| 113 | +字符串的顺序存储结构如下图所示。 |
| 114 | + |
| 115 | + |
| 116 | + |
| 117 | +如上图所示,字符串的顺序存储中每一个字符元素都有自己的下标索引,下标所以从 `0` 开始,到 `字符串长度 - 1` 结束。字符串中每一个「下标索引」,都有一个与之对应的「字符元素」。 |
| 118 | + |
| 119 | +跟数组类似,字符串也支持随机访问。即字符串可以根据下标,直接定位到某一个字符元素存放的位置。 |
| 120 | + |
| 121 | +### 3.2 字符串的链式存储结构 |
| 122 | + |
| 123 | +字符串的存储也可以采用链式存储结构,即采用一个线性链表来存储一个字符串。字符串的链节点包含一个用于存放字符的 `data` 变量,和指向下一个链节点的指针变量 `next`。这样,一个字符串就可以用一个线性链表来表示。 |
| 124 | + |
| 125 | +在字符串的链式存储结构中,每个链节点可以仅存放一个字符,也可以存放多个字符。通常情况下,链节点的字符长度为 `1` 或者 `4`,这是为了避免浪费空间。当链节点的字符长度为 `4` 时,由于字符串的长度不一定是 `4` 的倍数,因此字符串所占用的链节点中最后那个链节点的 `data` 变量可能没有占满,我们可以用 `#` 或其他不属于字符集的特殊字符将其补全。 |
| 126 | + |
| 127 | +字符串的链式存储结构图下图所示。 |
| 128 | + |
| 129 | +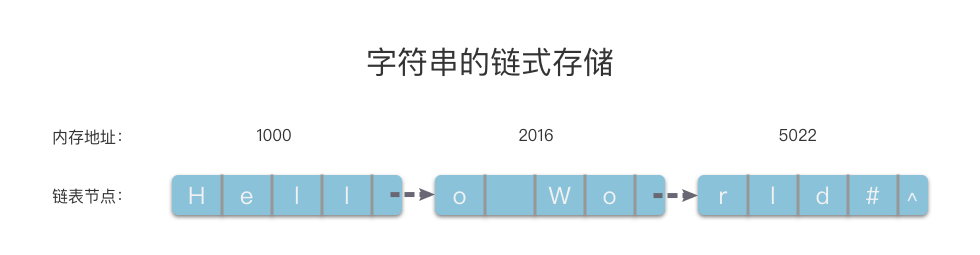 |
| 130 | + |
| 131 | +如上图所示,字符串的链式存储将一组任意的存储单元串联在一起。链节点之间的逻辑关系是通过指针来间接反映的。 |
| 132 | + |
| 133 | +### 3.3 不同语言中的字符串 |
| 134 | + |
| 135 | +- C 语言中的字符串是使用空字符 `\0` 结尾的字符数组。`\0` 符号用于标记字符串的结束。C 语言的标准库 `string.h` 头文件中提供了各种操作字符串的函数。 |
| 136 | +- C++ 语言中除了提供 C 风格的字符串,还引入了 `string` 类类型。`string` 类处理起字符串来会方便很多,完全可以代替 C 语言中的字符数组或字符串指针。 |
| 137 | +- Java 语言的标准库中也提供了 `String` 类作为字符串库。 |
| 138 | +- Python 语言中使用 `str` 对象来代表字符串。`str` 对象一种不可变类型对象。即 `str` 类型创建的字符串对象在定义之后,无法更改字符串的长度,也无法改变或删除字符串中的字符。 |
| 139 | + |
| 140 | +## 4. 字符串匹配问题 |
| 141 | + |
| 142 | +> **字符串匹配(String Matching)**:又称模式匹配(Pattern Matching)。可以简单理解为,给定字符串 `T` 和 `p`,在主串 `T` 中寻找子串 `p`。主串 `T` 又被称为文本串,子串 `p` 又被称为模式串(`Pattern`)。 |
| 143 | +
|
| 144 | +在字符串问题中,最重要的问题之一就是字符串匹配问题。而按照模式串的个数,我们可以将字符串匹配问题分为:「单模式串匹配问题」和「多模式串匹配问题」。 |
| 145 | + |
| 146 | +### 4.1 单模式串匹配问题 |
| 147 | + |
| 148 | +> 单模式匹配问题:给定一个文本串 $T = t_1t_2...t_n$,再给定一个特定模式串 $p = p_1p_2...p_n$。要求从文本串 $T$ 找出特定模式串 $p$ 的所有出现位置。 |
| 149 | +
|
| 150 | +有很多算法可以解决单模式匹配问题。而根据在文本中搜索模式串方式的不同,我们可以将单模式匹配算法分为以下几种: |
| 151 | + |
| 152 | +- **基于前缀搜索方法**:在搜索窗口内从前向后(沿着文本的正向)逐个读入文本字符,搜索窗口中文本和模式串的最长公共前缀。 |
| 153 | + - `Knuth-Morris-Pratt` 算法和更快的 `Shift-Or` 算法使用的就是这种方法。 |
| 154 | +- **基于后缀搜索方法**:在搜索窗口内从后向前(沿着文本的反向)逐个读入文本字符,搜索窗口中文本和模式串的最长公共后缀。使用这种搜索算法可以跳过一些文本字符,从而具有亚线性的平均时间复杂度。 |
| 155 | + - 最著名的算法是 `Boyer-Moore` 算法、`Horspool` 算法和 `Sunday (Boyer-Moore 算法的简化)` 算法使用了这种方法。 |
| 156 | +- **基于子串搜索方法**:在搜索窗口内从后向前(沿着文本的反向)逐个读入文本字符,搜索满足「既是窗口中文本的后缀,也是模式串的子串」的最长字符串。与后缀搜索方法一样,使用这种搜索方法也具有亚线性的平均时间复杂度。这种方法的主要缺点在于需要识别模式串的所有子串,这是一个非常复杂的问题。 |
| 157 | + - `Rabin-Karp` 算法、`Backward Dawg Matching (BDM)` 算法、`Backward Nondeterministtic Dawg Matching (BNDM)` 算法和 `Backward Oracle Matching (BOM)` 算法使用的就是这种思想。其中,`Rabin-Karp` 算法使用了基于散列的子串搜索算法。 |
| 158 | + |
| 159 | +### 4.2 多模式串匹配问题 |
| 160 | + |
| 161 | +> 多模式匹配问题:给定一个文本串 $T = t_1t_2...t_n$,再给定一组模式串 $P = {p^1, p^2, ... ,p^r}$,其中每个模式串 $p^i$ 是定义在有限字母表上的字符串 $p^i = p^i_1p^i_2...p^i_n$。要求从文本串 $T$ 中找到模式串集合 $P$ 中所有模式串 $p^i$ 的所有出现位置。 |
| 162 | +
|
| 163 | +模式串集合 $P$ 中的一些字符串可能是集合中其他字符串的子串、前缀、后缀,或者完全相等。解决多模式串匹配问题最简单的方法是利用「单模式串匹配算法」搜索 `r` 遍。这将导致预处理阶段的最坏时间复杂度为 $O(|P|)$,搜索阶段的最坏时间复杂度为 $O(r * n)$。 |
| 164 | + |
| 165 | +如果使用「单模式串匹配算法」解决多模式匹配问题,那么根据在文本中搜索模式串方式的不同,我们也可以将多模式串匹配算法分为以下三种: |
| 166 | + |
| 167 | +- 基于前缀搜索方法:搜索从前向后(沿着文本的正向)进行,逐个读入文本字符,使用在 $P$ 上构建的自动机进行识别。对于每个文本位置,计算既是已读入文本的后缀,同时也是 $P$ 中某个模式串的前缀的最长字符串。 |
| 168 | + - 著名的 `Aho-Corasick Automaton (AC 自动机)` 算法、`Multiple Shift-And` 算法使用的这种方法。 |
| 169 | +- 基于后缀搜索方法:搜索从后向前(沿着文本的反向)进行,搜索模式串的后缀。根据后缀的下一次出现位置来移动当前文本位置。这种方法可以避免读入所有的文本字符。 |
| 170 | + - `Commentz-Walter` 算法(`Boyer-Moore` 算法的扩展算法)、`Set Horspool` 算法(`Commentz-Walter` 算法的简化算法)、`Wu-Manber` 算法使用了这种方法。 |
| 171 | +- 基于子串搜索方法:搜索从后向前(沿着文本的反向)进行,在模式串的长度为 $min(len(p^i))$ 的前缀中搜索子串,以此决定当前文本位置的移动。这种方法也可以避免读入所有的文本字符。 |
| 172 | + - `Multiple BNDM` 算法、`Set Backward Dawg Matching (SBDM)`、`Set Backwrad Oracle Matching (SBOM)` 使用了这种方法。 |
| 173 | + |
| 174 | +需要注意的是,以上所介绍的多模式串匹配算法大多使用了一种基本的数据结构:**「字典树(Trie Tree)」**。著名的 **「Aho-Corasick Automaton (AC 自动机) 算法」** 就是在 `Knuth-Morris-Pratt` 算法的基础上,与「字典树(Trie Tree)」结构相结合而诞生的。而 AC 自动机算法也算是多模式串匹配算法中最有效的算法之一。 |
| 175 | + |
| 176 | +所以学习多模式匹配算法,重点是要掌握 **「字典树」** 和 **「AC 自动机算法」** 。 |
| 177 | + |
| 178 | +## 参考资料 |
| 179 | + |
| 180 | +- 【书籍】数据结构(C 语言版)- 严蔚敏 著 |
| 181 | +- 【书籍】大话数据结构 - 程杰 著 |
| 182 | +- 【书籍】数据结构教程(第 3 版)唐发根 著 |
| 183 | +- 【书籍】数据结构与算法 Python 语言描述 - 裘宗燕 著 |
| 184 | +- 【书籍】柔性字符串匹配 - 中科院计算所网络信息安全研究组 译 |
| 185 | +- 【博文】[字符串和编码 - 廖雪峰的官方网站 ](https://www.liaoxuefeng.com/wiki/1016959663602400/1017075323632896) |
| 186 | +- 【文章】[数组和字符串 - LeetBook - 力扣](https://leetcode-cn.com/leetbook/read/array-and-string/c9lnm/) |
| 187 | +- 【文章】[字符串部分简介 - OI Wiki](https://oi-wiki.org/string/) |
| 188 | +- 【文章】[解密 Python 中字符串的底层实现,以及相关操作 - 古明地盆 - 博客园](https://www.cnblogs.com/traditional/p/13455962.html) |
| 189 | + |
0 commit comments