unxz ubuntu-mate-16.04-desktop-armhf-raspberry-pi.img.xz
+```
+* Plug in your microSD card (you'll probably get an SD card adapter with any card you purchased) and run diskutil list
+```
+* Identify the disk for your microSD card. This should be something like `/dev/disk4`, **not** `/dev/disk4s1` (The "s" part denotes the partition and we want the whole disk). Triple-check that this is the correct device and size. You may want to eject it and put it back in and verify that the item is removed from `diskutil list` when you do this. You don't want to overwrite the wrong disk!
+* If this disk is not listed as being FAT32, you will need to format it as DOS FAT32. You can do this in OS X by opening up Disk Utility, selecting the microSD card, clicking Erase and then selecting MS-DOS (FAT).
+* Unmount the disk, with the "X" being the number you just identified: diskutil unmountDisk /dev/diskX
+```
+* Now we get to start the actual imaging process. Verify the name and location of the downloaded .img file you extracted, and enter in the correct disk location (the /dev/diskX part) and run this: sudo dd bs=1M if=~/Desktop/ubuntu-mate-16.04-desktop-armhf-raspberry-pi.img of=/dev/diskX
+```
+* Alternatively you can try an even faster method by using the raw disk location instead of the buffered disk identifier. Just add an "r" before the disk like so: /dev/rdisk4. This may not work for everyone:
+ sudo dd bs=1M if=~/Desktop/ubuntu-mate-16.04-desktop-armhf-raspberry-pi.img of=/dev/rdiskX
+```
+* **This will take a long time.** For my 64GB card it took 48 minutes using the first approach (not the rdisk method). You get no status from the dd command while it's working but you can press CTRL+T to get an update.
+* When completed you can pull out the card and put it in your Raspberry Pi! If you have any questions about this process or are not using a Mac, there are lots of more detailed guides online like [this one](http://elinux.org/RPi_Easy_SD_Card_Setup "RPi Easy SD Card Setup") and [this one](http://www.tweaking4all.com/hardware/raspberry-pi/install-img-to-sd-card/ "Raspberry Pi ¨C How to get an Operating System on a SD-Card").
+
+If you're dying to just get started immediately you can [buy a microSD card with NOOBS preinstalled](https://www.adafruit.com/products/1583) or [create your own](https://www.raspberrypi.org/documentation/installation/noobs.md) and install Raspbian Jessie or another OS instead of Ubuntu MATE.
+
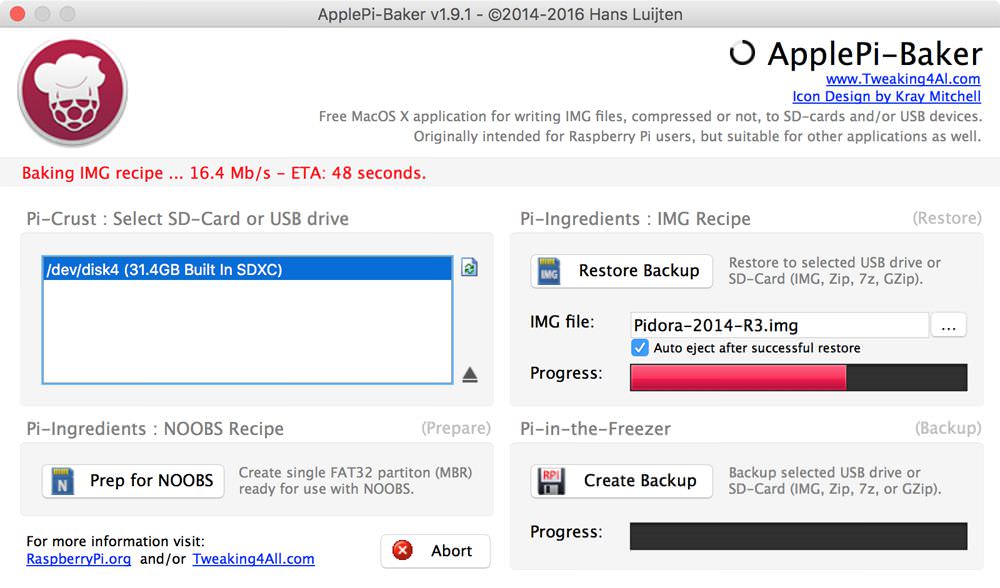
+**But there's an easier way for OS X users**: a new tool called [ApplePi-Baker](http://www.tweaking4all.com/software/macosx-software/macosx-apple-pi-baker/ "MacOS X - ApplePi Baker - Prep SD-Cards for IMG or NOOBS"). It's ridiculously easy to use. It automatically detected my microSD card and all I had to do was select the extracted img file. It did the rest and my card was ready to use after a few minutes.
+
+
+
+
+#### 开机!
+
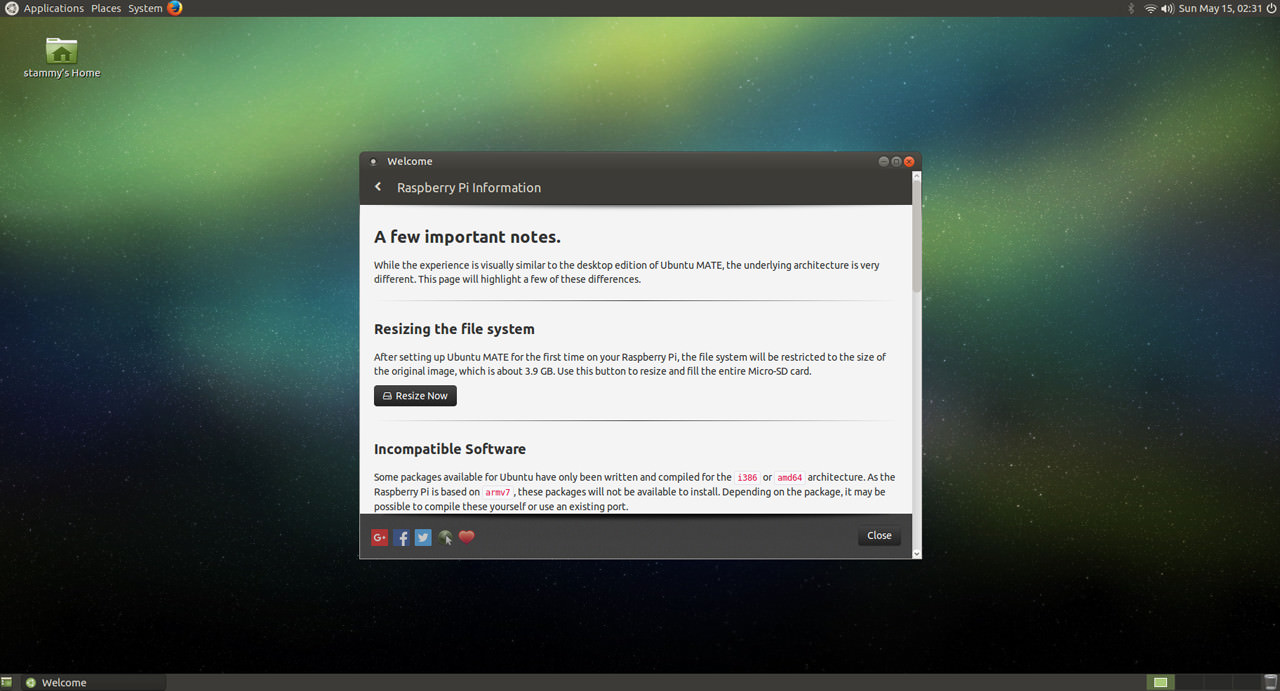
+With your new SD card ready to go, slide it in your Raspberry Pi 3 and power it up. It should boot into the setup wizard for whichever OS you chose. This part should be a breeze. After a short while you'll be greeted with your new OS! Take some time to browse around and get it setup to your liking. But you'll first want to resize the file system. You'll find it in the Ubuntu MATE welcome dialog here:
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-ubuntu-mate-first-boot.jpg)
+
+
+#### Set a DHCP reservation
+
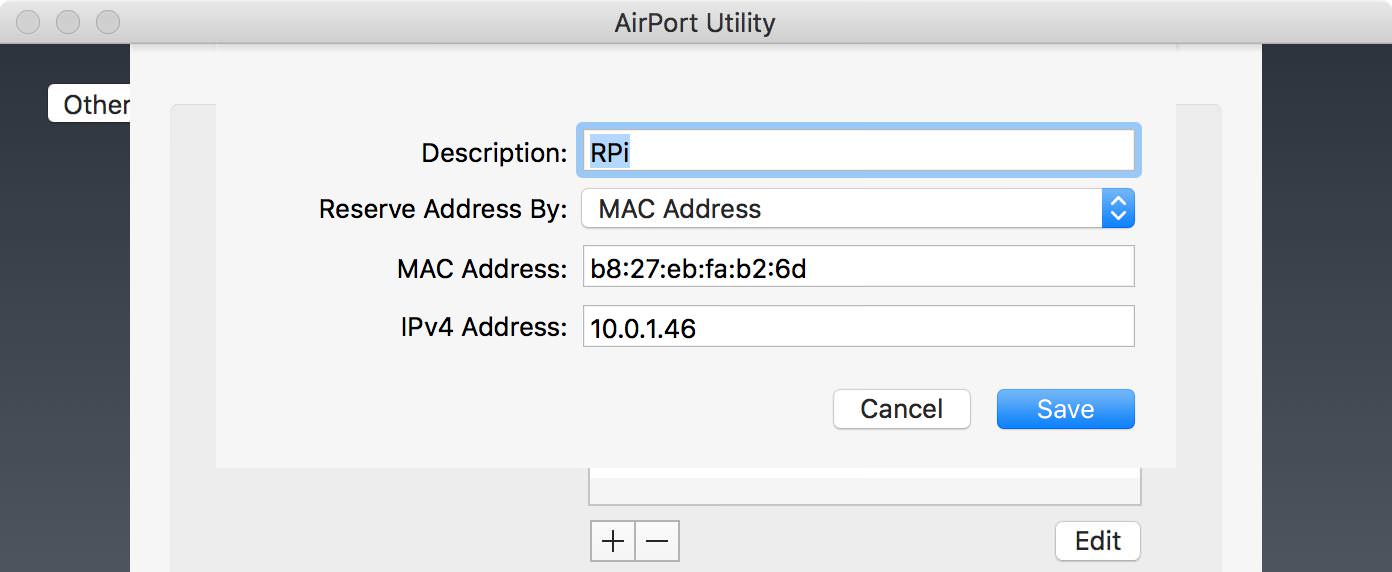
+The majority of how I work with my Pi is actually over SSH and VNC rather than directly using it on a display. As such it's important that I can always find the Pi on my network at the same IP address. To do this I added a DHCP reservation with the AirPort Utility (I have an AirPort Extreme).
+
+
+
+
+
+To do this you'll need to know the MAC address of your Raspberry Pi. You can do this by running `ifconfig eth0` if you're connected via Ethernet, or `ifconfig wlan` if connected via Wi-Fi.
+
+Now you can always ssh into your Pi from any computer on your network (or from any computer if you also setup port forwarding) with the same local IP. The default username for Raspbian is `pi` but you will have set your own username for Ubuntu MATE.
+
+```sh
+ssh pi@10.0.1.46
+```
+
+#### Setting up VNC
+
+Unless you have a dedicated display for your Pi, it will probably be annoying to constantly have it plugged into your TV. Installing a VNC server on the Pi and a VNC client on another computer will let you see and control the Pi with the window manager GUI instead of via SSH command line.
+
+While either SSH'd in or directly on your Pi, install the Tight VNC server:
+
+```sh
+sudo apt-get update
+sudo apt-get install tightvncserver
+tightvncserver
+```
+
+Now you need to enable the VNC server on the Pi. While it's sufficient to just type `tightvncserver` to run it, you'll want to customize a few things to get a higher resolution display, especially if you're accessing it on your LAN. Running the following command will setup a virtual screen with resolution of 1920x1080. You can use any screen resolution you like here within reason:
+
+```sh
+stammy@rpi:~$ vncserver :1 -geometry 1920x1200 -depth 24
+
+New 'X' desktop is rpi:1
+
+Starting applications specified in /home/stammy/.vnc/xstartup
+Log file is /home/stammy/.vnc/rpi:1.log
+```
+
+If you need to kill the server and change settings you can run `vncserver -kill :1`
+
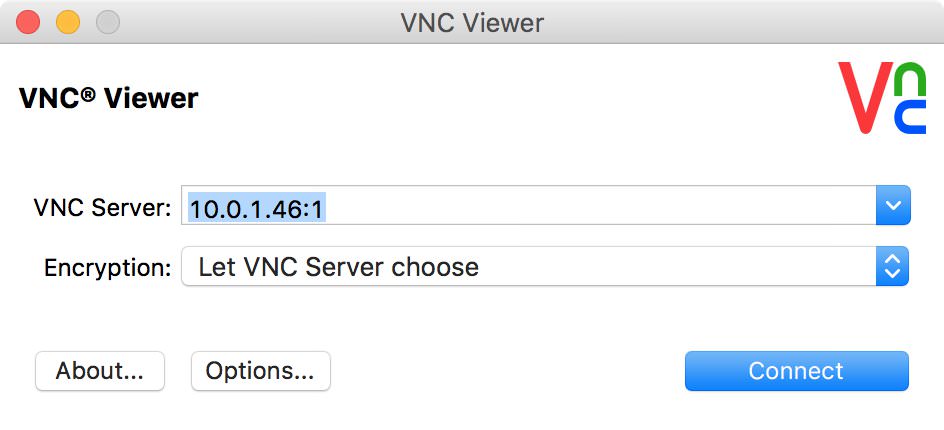
+The VNC server is now running on display **:1**. Download the [VNC Viewer client from realVNC](http://www.realvnc.com/download/) for your Mac and open it up. Type in the IP of your Pi on the network and append the :1 screen, like this:
+
+
+
+
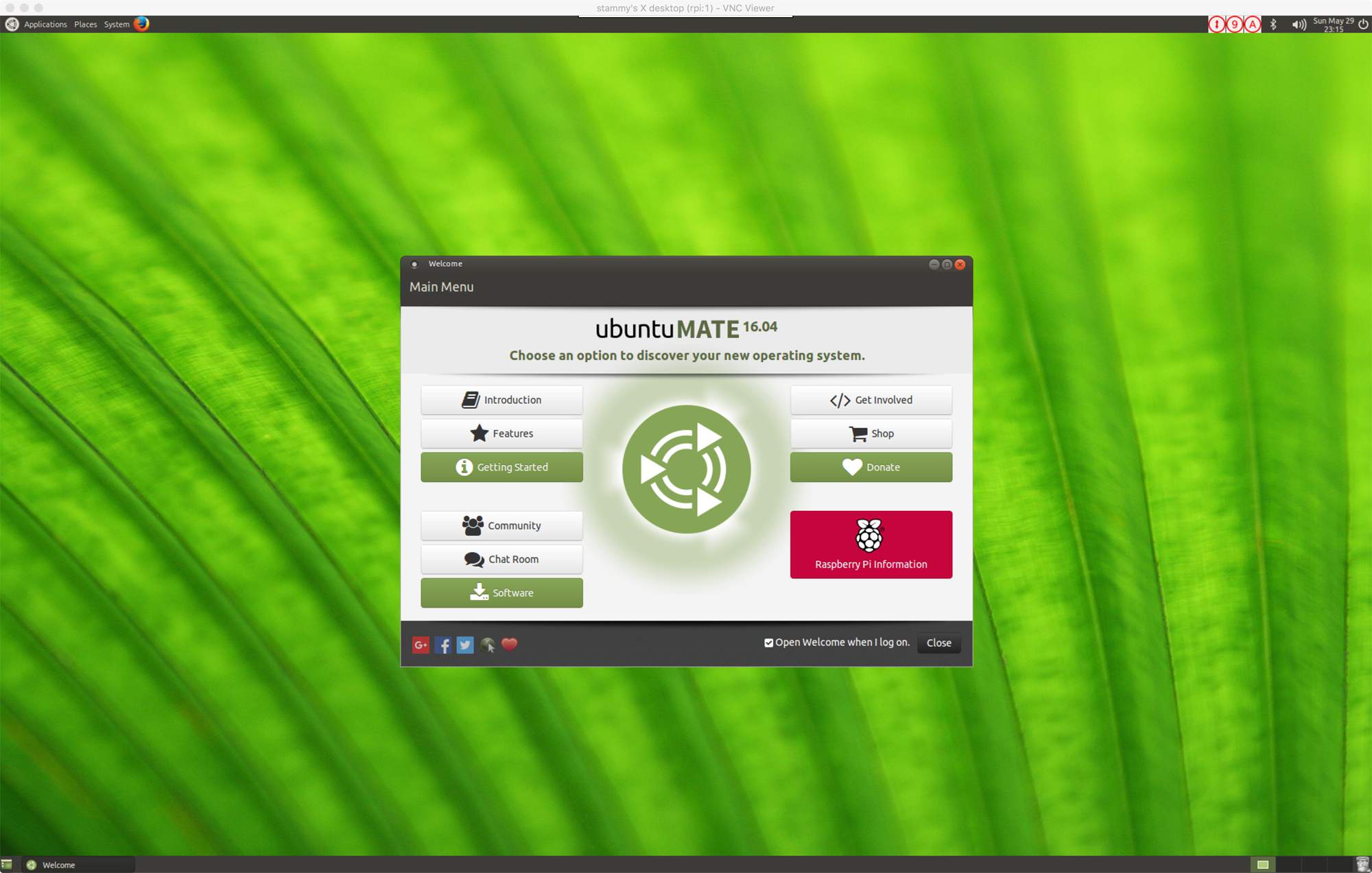
+Type in the password for your Pi and you're set! You'll quickly notice it's not quite as snappy as if you were using your Pi with a physical display but it can get the job done.
+
+
+
+Ubuntu MATE 16.04 running on a Raspberry Pi 3 over VNC
+
+
+Now you can fully control your Pi without the need for a hardware display. You will need to manually start the VNC server on the Pi whenever the Pi is rebooted. I'm usually logged in via SSH and rarely reboot so it's not a huge deal for me to run that line every now and then. But you can configure it to [automatically run at boot](http://elinux.org/RPi_VNC_Server).
+
+But you might be thinking.. **doesn't OS X have it's own screen sharing utility?** Why do I need to install another app for this?
+
+You're right! OS X is native VNC capable. To get this working we need to make the Pi discoverable via Bonjour and have it to broadcast it's new VNC support in a way that OS X can understand.
+
+```sh
+sudo apt-get install netatalk avahi-daemon
+```
+
+We're going to install `netatalk`[4](#footnote-4) which sets up the Apple Filing Protocol so we can also manipulate files on your Pi directly from the OS X Finder. If you're following this guide with Ubuntu MATE, you can leave off the `avahi-daemon` part as Ubuntu seems to come preinstalled with Avahi, the networking service discovery daemon.
+
+At this point your Raspberry Pi should be visible and accessible on the local network with your Mac! However, to be able to see the screen sharing capability advertised here you'll need to modify a file:
+
+```sh
+sudo nano /etc/avahi/services/rfb.service
+```
+
+Paste this configuration below and save. We're telling the avahi daemon about RFB (remote framebuffer.. VNC basically) and what port it works on.
+
+```xml
+
+
+
+ %h
+
+ _rfb._tcp
+ 5901
+
+
+```
+
+
+And then restart the daemon:
+
+```sh
+sudo /etc/init.d/avahi-daemon restart
+```
+
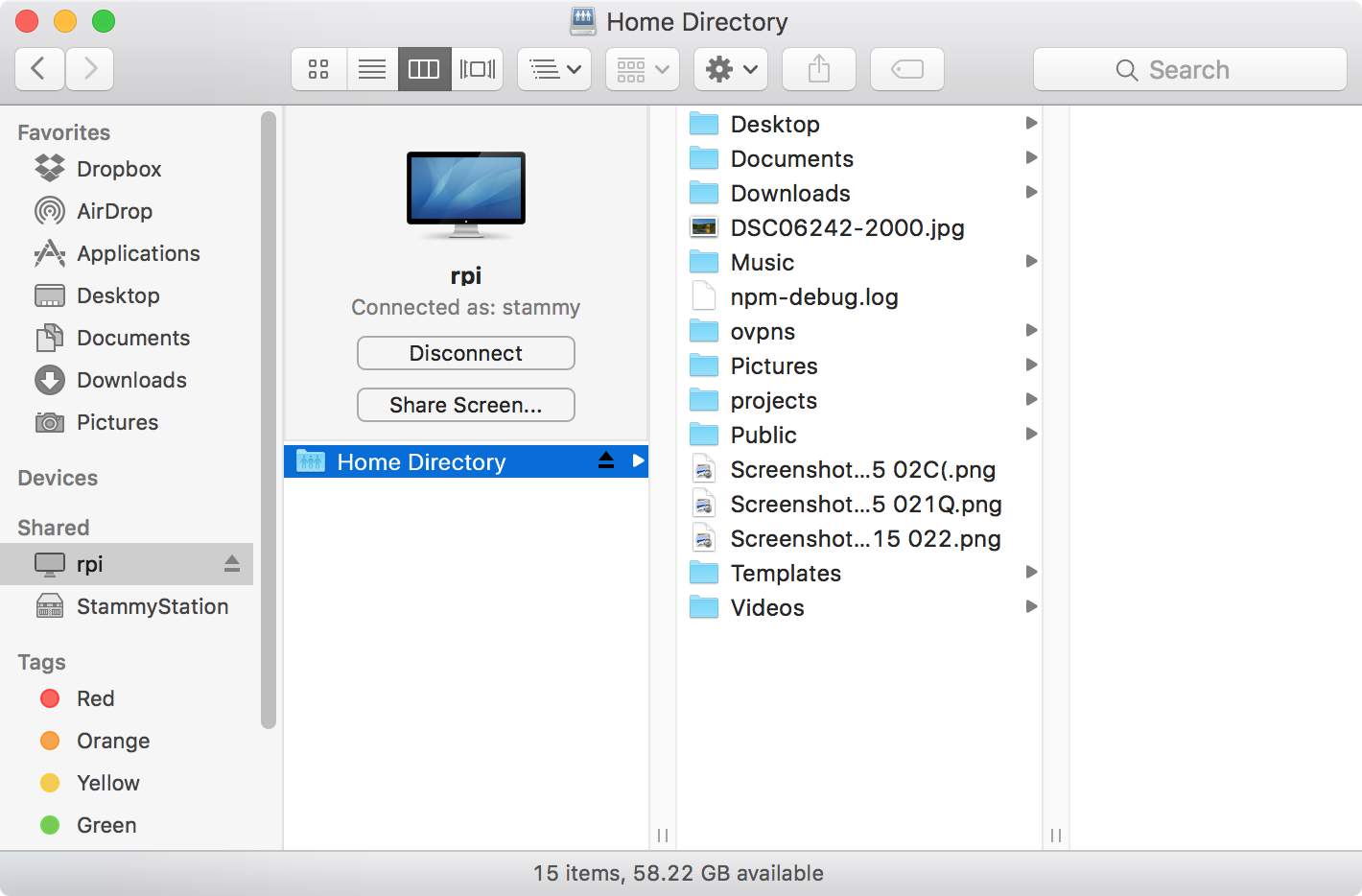
+You should now be see a new **Share Screen...** button. Click on that, type in your Pi password and you can now easily VNC into your Pi natively.
+
+
+
+
+Raspberry Pi visible in the OS X Finder
+
+This approach uses netatalk/AFP for sharing your Pi on the network so it will only work for Macs. If you'd like to share files for Windows machines, you'd want to setup Samba sharing. Also, AFP is technically deprecated, so a future-proof solution would be to setup SMB2... but I've always had a heck of a time getting it to work flawlessly and AFP works great for now.
+
+
+
+## 看看别人都用它做什么
+
+##### 一起做些什么
+
+
+#### Turning it into a NAS
+
+Now that you have your Pi and its files completely accessible via the OS X Finder, wouldn't it be neat to add more storage to your Pi, share that volume and backup to it? While I personally don't use my Pi for this ¡ª I [setup a larger Synology 4-disk NAS system](https://paulstamatiou.com/storage-for-photographers-part-2/ "Storage for Photographers (Part 2) - How a 12TB Synology NAS changed my digital life") for my terabytes of photos ¡ª it [can be done](http://www.howtogeek.com/139433/how-to-turn-a-raspberry-pi-into-a-low-power-network-storage-device/ "How to Turn a Raspberry Pi into a Low-Power Network Storage Device") with [a Raspberry Pi](http://www.techradar.com/how-to/computing/how-to-make-a-mac-time-capsule-with-the-raspberry-pi-1319989 "How to make a Mac Time Capsule with the Raspberry Pi"). Just don't expect it to be fast.
+
+
+
+#### Storage for Photographers (Part 2)
+
+How a 12TB Synology NAS changed my digital life
+
+
+](https://paulstamatiou.com/storage-for-photographers-part-2/ "Storage for Photographers (Part 2)")
+
+There are many small and energy efficient storage options from USB sticks to external laptop and desktop hard drives and SSDs. Keep in mind that **the Raspberry Pi 3 only has USB 2.0** so you won't get the entire speed benefit of an SSD. And for the smaller drives that don't require their own power source, you will still actually want to plug it into a powered USB hub before plugging into the Pi to make sure you don't cause stability problems by stealing too much juice from the Pi itself.
+
+The Raspberry Pi ended up getting so popular that Western Digital actually created a more efficient drive _just_ for the Pi. Called the [WD PiDrive](http://wdlabs.wd.com/products/wd-pidrive-314gb/) it's a 314GB hard drive (314GB as in ¦Ð, get it?) with a native 7mm USB connection. Unfortunately, it's pricey for how many gigabytes you get.
+
+As you might expect with a real NAS, **you can connect the Raspberry Pi to a UPS battery backup**: either a [real desktop-class UPS](https://melgrubb.com/2014/09/05/raspberry-pi-home-server-part-15power-failures/ "Raspberry Pi Home Server: Part 15¨CPower Failures") or a [tiny add-on board like this](http://www.modmypi.com/raspberry-pi/breakout-boards/pi-modules/ups-pico "UPS PIco - Uninterruptible Power Supply & I2C Control HAT") or [this](https://www.pi-supply.com/product/pi-ups-uninterrupted-power-supply-raspberry-pi/ "Pi UPS ¨C Uninterrupted Power Supply for Raspberry Pi") that sits on top of the Pi and has a cell-phone battery with enough battery to let your Pi run for a few hours and safely shut down.
+
+If you don't need the data portion of a real UPS system (being able to tell your Pi it's now running on battery and should shut off soon), you can just get a [good USB battery pack](https://www.amazon.com/Powerful-10000mAh-Anker-PowerCore-Technology/dp/B013HSQXZC/ref=as_li_ss_tl?srs=2528932011&ie=UTF8&qid=1464849921&sr=8-4&keywords=anker+powercore%2B&linkCode=ll1&tag=paulstamatiou-20&linkId=e2f04b6418a0bbb1e5b7890210d64b70 "Anker PowerCore+ 10050 Premium Aluminum Portable Battery Charger ") that you always keep plugged in. Make sure you get a reputable one with the appropriate circuitry to support pass-through charging or build your own with [this PowerBoost circuit](https://www.adafruit.com/products/2465 "PowerBoost 1000 Charger - Rechargeable 5V Lipo USB Boost @ 1A - 1000C") and a 3.7V LiPo battery.
+
+You can also setup your Pi to be a [Time Machine backup destination](https://pwntr.com/2012/03/03/easy-mac-os-x-lion-10-7-time-machine-backup-using-an-ubuntu-linux-server-11-10-12-04-lts-and-up/ "
+Easy Mac OS X (Mountain) Lion and Mavericks 10.7, 10.8 and 10.9 Time Machine backup using an Ubuntu Linux server [11.10, 12.04 LTS and up]") on the network and you can even [install CrashPlan](https://gist.github.com/n8henrie/37d96807e31d94ca0464 "Set up CrashPlan on Raspberry Pi (Raspbian Jessie)") to have all your Pi's files backed up to the cloud as well. But be warned it won't be particularly fast.
+
+###### Mounting and sharing a USB drive
+
+Regardless of what drive you get, you'll want to mount it and have netatalk share it so your Mac can access it. While Ubuntu MATE has some automounting stuff, I prefer to disable it and proceed the old-fashioned way. On Ubuntu MATE (not via SSH, you technically can with gsettings but it didn't work for me), type `dconf-editor` in the terminal to open the GUI dconf editor. Browse to `org.gnome.desktop.media-handling` in the left pane and uncheck `automount` and `automount-open`. Reboot.
+
+* Prepare your USB device by formatting it to ExFAT if it's not already. If you're not using Ubuntu MATE on your Pi, you will want to install this package to add support for ExFAT mounting: `sudo apt-get install exfat-fuse`
+* Plug in your USB device and type in `sudo blkid`:
+
+ stammy@rpi:~$ sudo blkid
+[sudo] password for stammy:
+/dev/mmcblk0: PTUUID="580a66ff" PTTYPE="dos"
+/dev/mmcblk0p1: SEC_TYPE="msdos" LABEL="PI_BOOT" UUID="4442-965D" TYPE="vfat" PARTUUID="580a66ff-01"
+/dev/mmcblk0p2: LABEL="PI_ROOT" UUID="e440adac-fcf9-4b68-9f94-6bfd030f60b3" TYPE="ext4" PARTUUID="580a66ff-02"
+/dev/sda1: UUID="9C33-6BBD" TYPE="exfat"
+```* We're looking for the UUID of the USB device so we can mount the drive based on it's unique id instead of it's location, so it will always mount flawlessly. In this case my drive is the last line with type `exfat`, since it is a large 128GB SDXC card that I plugged in (not the micro-SD card but a USB card reader and SD card just to test this out). You can verify that this is the correct line item by ejecting and running the `sudo blkid` command again to see that the line vanishes.
+* Create a new directory where we will mount the drive and then have your user account own it. If you are using the default pi username it will just be the following:
+
+ sudo mkdir /usb-drive
+sudo chown -R pi:pi /usb-drive
+```* Now for the real work, we need to add a line to our file systems table file. It is _very important_ that this is typed correctly with the correct UUID and filesystem type for your drive. If this is incorrect your Raspberry Pi will get stuck at boot and you won't even be able to SSH in, you'll have to enter emergency mode to fix the file.
+
+ sudo vim /etc/fstab
+```
+ 
+ * Now add this line to the bottom of your fstab file, making sure to replace XXXX-XXXX with the UUID from the blkid command earlier and using the correct file system type (vfat, exfat, etc):
+
+ UUID=XXXX-XXXX /usb-drive exfat auto,nofail,uid=1000,gid=100,umask=0002,rw 0 0
+```* Now we'll add this new drive as an item for netatalk to share. You'll need to edit this file:
+
+ sudo vim /etc/netatalk/AppleVolumes.default
+```
+ 
+ * Scroll to the very bottom and add this line representing the new persistent mount point for your USB storage device:
+
+ /usb-drive "USB Drive"
+```* Reboot. Your drive should now be shared and accessible on the network!
+
+#### Benchmarking, overclocking and cooling
+
+While I won't dwell on this too much, it's possible to overclock your Raspberry Pi to achieve higher CPU and RAM speeds. Why would you want to overclock your Pi? You might want to squeeze some extra performance from a CPU-limited process like video transcoding or the like. Or you might just want to see if you can overclock it for fun.
+
+There's a [simple Pi benchmark script](https://github.com/aikoncwd/rpi-benchmark) that includes overclocking documentation so you can run before and after your overclock to measure benefits. There are also quite a few guides on the topic if you're really curious: [Raspberry Pi 3 Overclocking](http://www.jackenhack.com/raspberry-pi-3-overclocking/ "Raspberry Pi 3 Overclocking") and [Pi 3 Overclocking, Stability Testing & Cooling](https://www.raspberrypi.org/forums/viewtopic.php?f=63&t=144391&p=960651 "Pi3 Configuration, Overclocking, Stability Testing & Cooling"). However, **do not attempt overclocking** without adding additional cooling to the Raspberry Pi CPU and RAM.
+
+###### Heatsinks
+
+Actually, even if you don't overclock your Pi but you put it through its paces or place it in a closed case you will still benefit from adding some heatsinks to your Pi. They're not absolutely required, but I sleep better at night knowing my Pi is nice and cool. Also, I used to overclock and watercool all my computers over a decade ago so I can't help but enhance my Pi's cooling situation.
+
+While you could go a bit extreme with a [massive heatsink and fan](https://www.youtube.com/watch?v=WfQMLInuwws "Raspberry Pi 3: More Extreme Cooling"), peltier setup or even a custom watercooling contraption, it's all bound to be overkill unless you are doing some crazy hardware voltage modifications to your Pi. I'm assuming that's not you and just a simple heatsink will do.
+
+There are 2 main chips to consider for cooling: The primary SoC that's on the top of the board and the RAM chip underneath the board. There is also a smaller chip that gets a bit warm near the USB ports and that's the USB and Ethernet controller. I did a bit of research and eventually ended up getting some high-quality (albeit pricey) copper [RAM heatsinks](https://www.amazon.com/gp/product/B002BWXW6E/ref=as_li_ss_tl?ie=UTF8&psc=1&linkCode=ll1&tag=paulstamatiou-20&linkId=2a12faeae15ac183f4fafcda6e879b2d "ENZOTECH Memory Ramsink BMR-C1") and [MOSFET heatsinks](https://www.amazon.com/gp/product/B004CLDIHK/ref=as_li_ss_tl?ie=UTF8&psc=1&linkCode=ll1&tag=paulstamatiou-20&linkId=9eec0bca23273108f9bfc933cc94d134 "Enzotech MOS-C1 MOSFET Heatsinks - 10 Pack") from ENZOTECH. The RAM heatsinks fit well over the SoC and the RAM, but you can also do the same by just placing 4 of the tiny MOSFET heatsinks on each chip.
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09376-1500.jpg)
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09390-1500.jpg)
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09392-1500.jpg)
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09397-1500.jpg)
+
+
+
+
+
+Unfortunately, they are a bit tall so having this on the underside of your Pi can limit your case mounting options. I also got a set of [low profile aluminum heatsinks](https://www.amazon.com/gp/product/B00A88DVTG/ref=as_li_ss_tl?ie=UTF8&psc=1&linkCode=ll1&tag=paulstamatiou-20&linkId=28ccdcc3c6502e804397c1590f214fc5 "LinuxFreak brand Aluminum Heatsink set for Raspberry Pi - Set of 2 Heat Sinks") that would work as well.
+
+With my Pi now heatsink'd up I can let it handle just about any task and not worry about it overheating. You can also get a 5V fan to blow over the heatsinks and [use a script to only spin it up when it gets hot](https://medium.com/@edoardo849/how-to-control-a-fan-to-cool-the-cpu-of-your-raspberrypi-3313b6e7f92c "How to control a fan to cool the CPU of your RaspBerryPi").
+
+
+
+## 使用I/O引脚
+
+##### Pi electronics 101
+
+
+
+Time for the fun part ¡ª tinkering with some electronics and the Pi's General Purpose I/O (GPIO) pins!
+
+The Pi 3 ¡ª and Pi Zero, just without the connector pins ¡ª has 40 pins, but 26 of them are GPIO pins accessible to program. The other pins are ground (8), 5V (2), 3.3V (2) and reserved EEPROM pins (2).
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09453-1500.jpg)
+
+
+
+
+There's a lot you can do with these pins. You can program any GPIO pin on or off (high or low) which provides 3.3V at a max current of around 50mA[5](#footnote-5). You can also have your program accept input on these pins, such as when connecting a sensor, switch or other device.
+
+However, 50mA off a 3.3V pin is really not a lot to power anything. If you need a bit more juice, there's the two 5V pins which come straight from the same power source powering the Pi, minus however much current the Pi consumes. So with a 2.5A power supply, subtract about 1A for general Pi use with some small devices plugged in and you can probably consume a max of 1.5A off those pins.
+
+Instead, the GPIO pin output should just be used as a signal to switch something on but not power it. If you're going to need to power anything more than an LED, you're going to want to use an external power source and something like a transistor, [FET](http://www.robertcudmore.org/blog/?p=181 "Switching 12vdc on and off with a Raspberry Pi") or relay. There are tons of [electronics and Raspberry Pi guides](http://elinux.org/RPi_GPIO_Interface_Circuits "Raspberry Pi GPIO interface circuits") that cover all of this in detail, but now that you have a primer let's build something simple!
+
+#### Parts
+
+To make things easier for tinkering I purchased a [breadboard](https://www.adafruit.com/products/239 "solderless breadboard") so I could prototype little circuits without soldering. I also purchased a [T-Cobbler](https://www.adafruit.com/products/2028 "Pi T-Cobbler Plus - GPIO Breakout") that directly connects the Raspberry Pi pins to the breadboard. And of course various LEDs, wires, transistors, resistors and buttons to play with.
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09490-1500.jpg)
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09486-1500.jpg)
+
+
+
+
+#### Setup & powering an LED
+
+First, attach the T-Cobbler board to the breadboard and then to the Pi with the ribbon cable. Make sure the ribbon cable's white wire connects to the corner side of the Pi. Aside from making it easy to physically connect things with the breadboard, the T-Cobbler board also provides you with the GPIO pin labels.
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09497-1500.jpg)
+
+
+
+
+It's important to note how the breadboard works so you don't short anything out by accident. On the breadboard, the outer rails (marked by blue and red lines) run the length of the board. These are the power rails where you can connect GND to the **-** blue line with a jumper cable and 5V to the **+** red line (or even an external power source instead of from the Pi) and be able to access those lines throughout the length of the board.
+
+The lines between those outer rails ¡ª the terminal strips ¡ª run perpendicular. So if you want to plug into GPIO pin #17 for example, you would put a jumper cable anywhere to the left of that pin, but not the blue or red outer rails. You can read more about [breadboards in this article](https://learn.sparkfun.com/tutorials/how-to-use-a-breadboard "How to Use a Breadboard").
+
+Now let's just try to power an LED. Nothing special for now, we'll just connect the LED to the 5V source that comes directly from the power adapter connected to the Pi.
+
+But first we should be cautious about how much voltage and current we supply to the LED; we don't want to burn it out. In my case I got a [25mA 3.4V UV purple LED](https://www.adafruit.com/product/1793 "UV LED"). I used [this LED resistor calculator](http://ledcalc.com/) to find out exactly what I needed. It said 68?, but I could only find a larger 220? resistor at the time. No biggie, it just won't be as bright.
+
+Resistors don't have polarity so it doesn't matter which way they are used. LEDs do however. There's the cathode (**-**) that is easy to identify as it's the shorter wire from the LED and there is a flat side of the LED identifying the cathode. The longer wire coming from the LED is the anode (**+**). This can be done various ways with the breadboard, but I started by placing a jumper from GND to the blue power rail and then plugging the LED into the power rail, making sure that the short end of the LED (cathode) stayed on the negative blue rail. Then I connected the resistor from the 5V terminal strip on the breadboard that comes from the Pi to the positive red power rail. Now our LED will light up!
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09516-1500.jpg)
+
+
+
+
+#### Control the LED
+
+Okay now that we've got the basics out of the way, let's actually control the LED instead of having it on continuously. To do this we need to power it from a GPIO pin instead of the 5V line. Since the GPIO pin is 3.3V and our LED has about the same forward voltage, we can ditch the resistor now. As a word of caution, we can get away with powering the LED from the GPIO pin since it won't draw much current. Don't try to power anything other than an LED off a GPIO pin or it might damage your Pi.
+
+This time we just need to connect the LED anode (the long wire) to GPIO pin 17 and the cathode to GND. You can see how I used jumpers to get this done in the photo below. As for why I used GPIO pin 17: no reason, you can pick any GPIO pin and program it below.
+
+Then we SSH into our Pi ¡ª or directly on it if you've got a display hooked up or are using VNC ¡ª and open up the python interpreter so we can use the python GPIO library. First we need import that library. It should be included in your OS automatically if you're using Ubuntu MATE or Raspbian Jessie.
+
+```
+stammy@rpi:~$ python
+Python 2.7.11+ (default, Apr 17 2016, 14:00:29)
+[GCC 5.3.1 20160413] on linux2
+Type "help", "copyright", "credits" or "license" for more information.
+>>> import RPi.GPIO as GPIO
+>>> GPIO.setmode(GPIO.BCM)
+>>> GPIO.setup(17, GPIO.OUT)
+>>> GPIO.output(17, True)
+>>> GPIO.output(17, False)
+```
+
+Then we need to set the pin mode. This determines what we mean when we provide a GPIO pin number: either by the physical pin position (`GPIO.BOARD`), or by the Broadcom pin number (`GPIO.BCM`). The latter is listed on the T-Cobbler for us so I provided the `GPIO.BCM` mode. Then we setup() each GPIO pin to be used and tell the Pi if it will be used for input or output (`GPIO.IN` or `GPIO.OUT`). We'll go with output since we just want to power the LED instead of listen for an input signal.
+
+And now we can finally **we can turn the LED on and off** with these commands: `GPIO.output(17, True)` and `GPIO.output(17, False)`. Go ahead and try it a few times! and think about how we're talking to a tiny computer over a network and having it control our electronics for us. Pretty neat. Despite everything being an app or connected device these days it's still fun to be able to control something simple like this.
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09519-1500.jpg)
+
+
+
+
+This [python GPIO library](https://sourceforge.net/p/raspberry-gpio-python/wiki/BasicUsage/) provides the essential foundation for interfacing with the i/o pins on your Pi. There is also a popular C library called [WiringPi](http://wiringpi.com/pins/) and one called [gpiozero](https://github.com/RPi-Distro/python-gpiozero), which provides higher-level functionality for quickly setting up common output and input components like LEDs, buttons, sensors and more. Definitely worth checking out for more advanced items.
+
+And while I just wanted to show the basics using the GPIO library in the python interpreter, you can of course write them as a .python file and run it as you please. There's a whole lot more you can do when actually writing your python programs.
+
+#### Using a transistor
+
+Remember how I mentioned that we don't really want to drive more than a simple LED directly off the GPIO pins? Since the GPIO pins can't provide much voltage or current [6](#footnote-6) you should find other means to trigger and power your connected components.
+
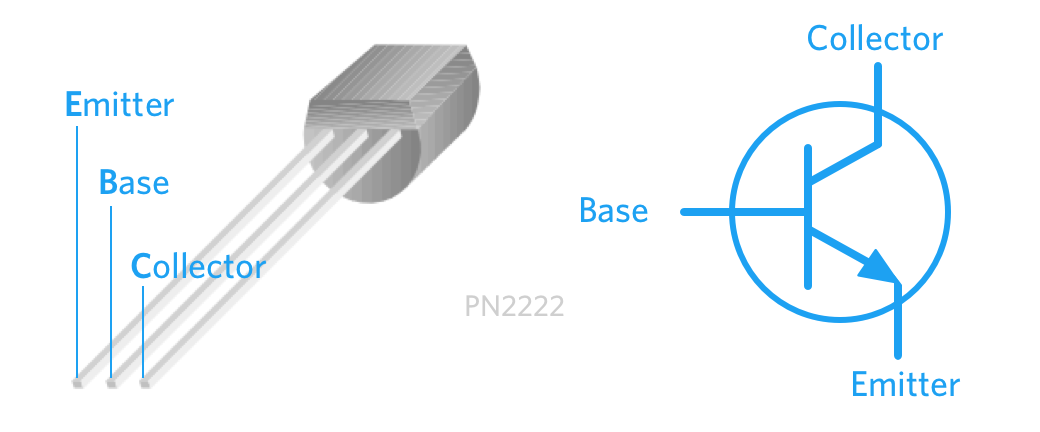
+One way to control your components is with a transistor. I'm using a basic BJT (bipolar junction transistor) NPN (negative-positive-negative) transistor, the PN2222. It can handle up to a peak of 40 Volts(!) at 1A, more than enough to drive something like a small motor, various lights, and so on. **They only need a tiny amount of current to flip on, thus saving your GPIO pins from doing the heavy lifting.**
+
+Typically you should also use a resistor between the transistor and the GPIO pin to reduce the current it draws. There is a bit more to it ¡ª like how the amount of current applied to the base can vary the collector current as the transistor acts as a simple amplifier, up to a "saturation" point ¡ª but that's best left for [some extra reading if you're curious](https://learn.sparkfun.com/tutorials/transistors/all "Transistors").
+
+
+
+
+Okay so we have 3 pins on our transistor: emitter, base, collector (EBC). It's important to note the exact pin layout as it varies by transistor. If you're looking at the flat side of the PN2222 NPN transistor, we have EBC from left to right. The middle base pin is what actually causes the transistor to trigger, making the normally open emitter and collector closed. This is the opposite behavior from a PNP transistor, with [some extra nuances](http://www.learningaboutelectronics.com/Articles/Difference-between-a-NPN-and-a-PNP-transistor "Difference Between an NPN and a PNP Transistor").
+
+
+
+While this circuit works for this very simple use, technically you would want to add a pull-down resistor from the base to ground to get it to switch off faster [and for other reasons](http://electronics.stackexchange.com/questions/56010/why-pull-base-of-bjt-switch).
+
+
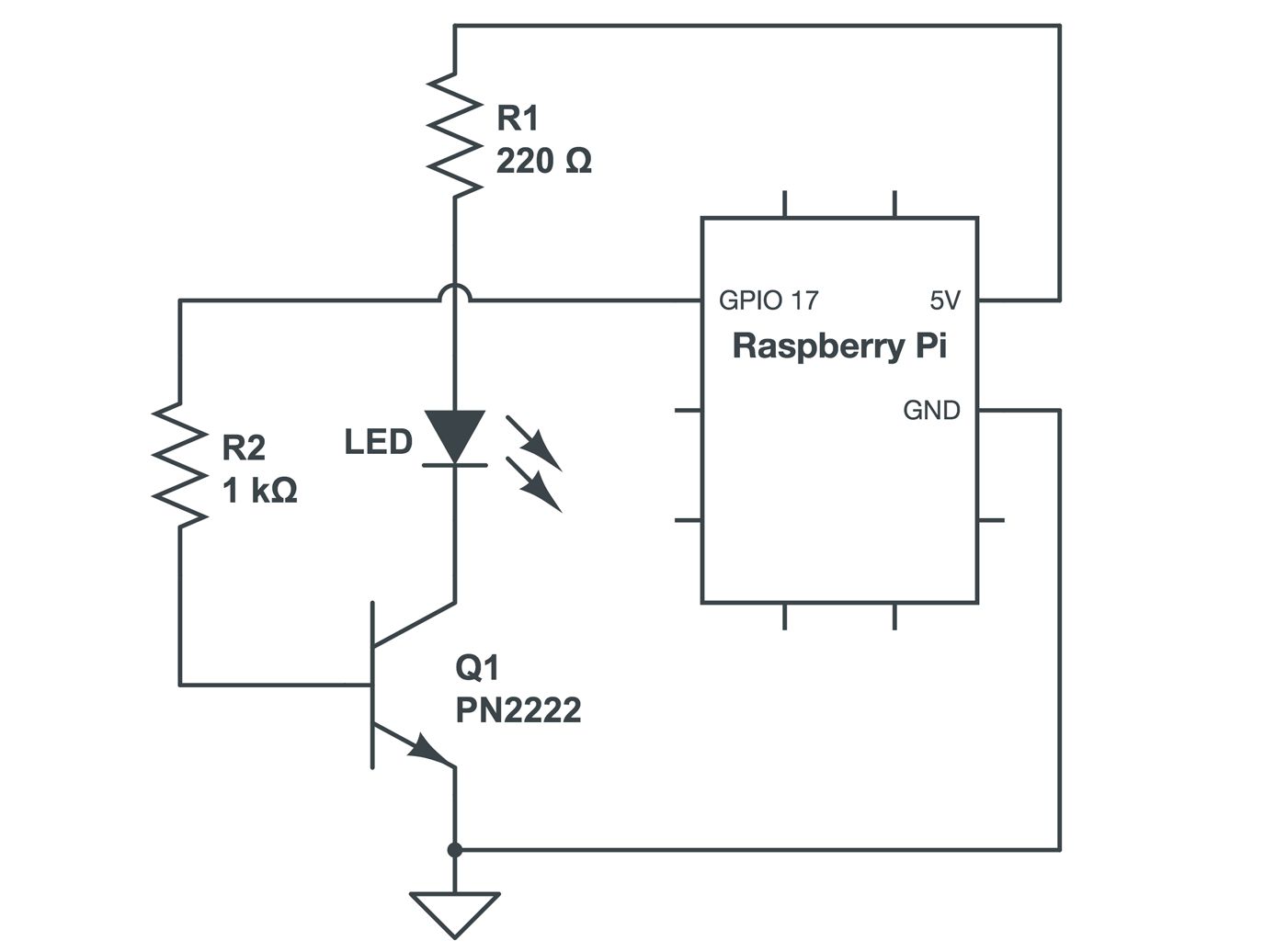
+We want to connect the base pin to our GPIO pin 17 along with a resistor. I wanted to use larger resistor but only had my same 220? resistors, so I put a few in series. This introduces enough resistance to lower the current used by the transistor on the GPIO pin but have enough juice to saturate the transistor into a fully on state.
+
+Current flows from the collector to the emitter, so I connected a jumper cable from GND to the emitter and then placed the LED[7](#footnote-7) between the Pi's 5V pin and the collector. Then connect the LED anode to the 5V line and the cathode (the flat side of the LED) to the transistor's collector with that same 220? resistor in between.
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09530-1500.jpg)
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09525-1500.jpg)
+
+I forgot to add a resistor from in front of the LED, so it was powered by 5V directly here. No issues but you don't want to be running it like this for more than a bit.
+
+Now you can run the same `GPIO.output()` commands from earlier to switch the LED on and off, via the NPN transistor! This is a safer way to control small devices off your GPIO pins.
+
+But what should you do if you need something even heavier duty for controlling a larger motor, high-wattage LED or anything demanding more than an amp of continuous current? You can use a beefier transistor like a heavy duty BJT, darlington or a MOSFET[8](#footnote-8). There are various differences between them that I'm not experienced enough to comment on. But I do know the about the next option: relays!
+
+#### Use a relay
+
+Lets get a relay working for our last experiment. There are several kinds from electromechanical to solid state and more, but the concept is the same: it will close or open any circuit you connect it to when triggered. The difference between our earlier BJT NPN transistor is that it's only on or off (no amplification characteristics) and the circuit you switch on is entirely separate to the switching logic (at least with electromechanical relays) so most relays can support much larger voltages while not interacting with your low voltage circuit. Okay I'm rambling a bit but basically this is what you want if you want to run an even larger device, like a 120V lamp for example (assuming your relay is rated for that).
+
+I ended up getting an electromechanical relay that was [preassembled to just need a control signal](https://www.amazon.com/gp/product/B00VRUAHLE/ref=as_li_ss_tl?ie=UTF8&psc=1&linkCode=ll1&tag=paulstamatiou-20&linkId=097665a19e82d17d0bcccfd7229da356) to make it easy to get started ¡ª it wires up just like our previous transistor. It bakes in the necessary transistor and some safeguards like a flyback spike protection diode for the relay coil. Again, there's [more to read about on the EE side](http://electronics.stackexchange.com/questions/100134/why-is-there-a-diode-connected-in-parallel-to-a-relay-coil "Why is there a diode connected in parallel to a relay coil?") here if you're interested.
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09540-1500.jpg)
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09544-1500.jpg)
+
+
+
+
+#### What's next?
+
+My intent with this section was to fall somewhere between informative overview and step-by-step. There's obviously a ton of detail I flew past and I only showed the most basic examples. But now you get to have fun trying out new circuits on your own! I love this stuff as you can probably tell.. I took a few EE classes in college long ago.
+
+While we only touched on using a single GPIO pin as output, there's lots to learn about using them for input as well. Here's some more reading about Raspberry Pi GPIO electronics to keep you busy:
+
+* Learn more about [circuits at Khan Academy](https://www.khanacademy.org/science/electrical-engineering/ee-circuit-analysis-topic)
+** [Connect a button](http://razzpisampler.oreilly.com/ch07.html "Connecting a Push Switch with Raspberry Pi") and use it as an input
+* [Control a servo motor](http://razzpisampler.oreilly.com/ch05.html#SEC7.12)
+* Hook up a [motion sensor as an input](https://www.raspberrypi.org/learning/parent-detector/worksheet/) and record a video when motion is detected.
+* Use an iOS app and Pi server like [Cayenne](http://www.cayenne-mydevices.com/ "Easy IoT for Raspberry Pi") or [MyPi](https://itunes.apple.com/us/app/mypi-control-your-raspberry/id1098156642?mt=8 "MyPi - Control your Raspberry Pi GPIO") to control your connected relays, sensors and other GPIO devices on your phone or the web. Or do it yourself with the self-hosted [Pi GPIO web interface](https://github.com/stuart-thackray/pi_gpio_web/ "Raspberry Pi GPIO Web Interface")
+
+
+
+## 做一个数码相框
+
+##### with a 10" 1920x1200 display
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC00194-1500.jpg)
+
+
+
+
+I wanted to do a real project with this Raspberry Pi. Something I would actually use around the house. I had narrowed it down to either a smart mirror or a digital photo frame.
+
+While there is definitely a strong cool factor with smart mirrors, I soon realized just would not get real value out of it. There's not much information I care about enough to be on an ambient display that I can't interact with.
+
+Weather, news headlines, email subject lines? The majority of those require me to pull out my phone to actually learn more. And I wouldn't put anything too personal on there that guests might see (like work emails). There might be something there in the future when it's easy to setup eye tracking and have the device detect when my eye is dwelling on and open a browser to learn more about that news headline, or read it out loud to me. But for now I already check my phone a million times per day and I already get my news read to me with the Amazon Echo every morning.
+
+A digital photo frame on the other hand has an aesthetic value for me and given that I'm a [photographer](https://paulstamatiou.com/photos) as well, it's right up my alley. It will fit in nicely with the other framed photos and travel books throughout my house.
+
+#### We're going to need a display
+
+Now the obvious question ¡ª where was I going to put this and what kind of display would I need? There's also the question of whether I wanted a touchscreen display. I decided to keep it simple, no touchscreen. Though I did initially think it would be neat to swipe between photos. Going with a regular display also makes mounting the display easier as I could put it behind glass.
+
+As I began searching for displays I quickly realized that it was hard to find a high-resolution display. The majority seemed to be somewhere between [800x480](https://www.adafruit.com/products/2718) (like the official Raspberry Pi 7-inch touchscreen display) and 1280x800. I even found some folks using iPad 2 displays (9.7-inch 1024x768). Not bad but not terribly appealing to me. A low resolution screen would not do my photos justice, especially as I have gotten used to seeing them on high PPI displays.
+
+I also knew I would be mounting this in a frame and put it on my bookshelf. While disassembling a regular desktop computer monitor is a popular route, I wanted something smaller and didn't want anything that required a bulky 120V cable and adapter. I needed a display that could be powered via a USB cable and accept an HDMI input.
+
+The maximum resolution the Pi can support is 1920x1200 so I wanted to get as close as possible in something around the 10" to 12" size. After lots of searching, I eventually stumbled across [this 10-inch beauty from Chalk Elec](http://www.chalk-elec.com/?page_id=1280#!/10-FullHD+-LCD-with-HDMI-interface/p/41737268/category=3094859 "10-inch FullHD+ LCD with HDMI interface"). Yes, it's expensive at $140 USD for just the panel, but it was just what I was looking for. It's 1920x1200 and at 10 inches this makes it a **ridiculous 226ppi panel**. That's a tad better than the 218ppi 5K iMac.
+
+I tested the display and everything was working great! I was just amazed at the resolution. It would have been overkill if I was going to use this for anything other than a photo frame. I would have had to use a lower resolution setting to make it comfortable to use for longer periods.
+
+
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09125-1500.jpg)
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09150-1500.jpg)
+
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09147-1500.jpg)
+
+
+
+
+The display's controller board can accept power from either a dedicated wall adapter or from USB. I wanted to go with USB so I followed their instructions and soldered a jumper (0¦¸ resistor) where it says R12 to be able to accept USB power. And while I was tinkering with it I also decided to put heatsinks on the two LVDS chips as they got very hot when in use.
+
+I was a bit nervous working with this board. The cable running to the display extremely short and delicate, whereas the huge HDMI cable is rather inflexible and heavy. I was quick to use some electrical tape to prevent the flat cable from getting plucked out and torn.
+
+
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-raspberry-pi3-DSC09379-1500.jpg)
+
+
+
+
+#### Mounting the display
+
+Now that I had my functioning display, I needed to figure out how to mount it. I decided I wanted to go with a real photo frame with matting. I planned on putting it on my bookshelf. The original thought of hanging it on my wall was intriguing but hiding the cables would be tricky and I didn't feel like drilling into my wall and installing an up-to-code flush electrical outlet behind the mounting location.
+
+I went to a local frame store and **picked up a 9" x 12" frame** with matting. I carefully measured the viewport of the display and cut the sides of the matting to add room. This worked but the matting had a beveled cut so my cuts don't look natural . Eventually I will have the frame store custom cut the matting in the size I need, but this will do for now.
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC09815-1500.jpg)
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC09821-1500.jpg)
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC09826-1500.jpg)
+
+
+
+
+I then placed the display behind the matting. Fortunately, the bezel of the display came with a sticky foam so I just peeled that back and placed it on the matting. After the display was in place, I ran a thin line of hot glue around the sides.
+
+I cut peices of cardboard and put them alongside the display to reduce pressure on the display when I put the back of the frame on. I then cut a space for the cables and the controller board to peek through as well. I'm surprised how easily this part all came together. It actually looks pretty decent! Well, everything except for the hacky way I cut the frame backboard.. in hindsight I could have probably just cut a hole for the display's cable only instead of having it be against the display. I was just a bit concerned with moving that cable as it's pretty short and very fragile.
+
+
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC09832-1500.jpg)
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC09840-1500.jpg)
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC09841-1500.jpg)
+
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC00010-1500.jpg)
+
+
+
+
+#### Mounting the Pi
+
+With the back of the frame in place, I still had a bit of room to tuck the Pi away out of sight. The HDMI cable was pretty thick so that pretty much held the Pi in place on its own. I hot glued the cables in place to be safe. Then I added some small 3M plastic hooks to keep the Pi in place ¡ª one hooks into the Ethernet port and the other I attached with a small wire to the corner mounting hole.
+
+
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC00040-1500.jpg)
+
+
+
+
+Now it was time to give it a test boot. I was powering the Pi and display off separate USB sources so that I had more than enough juice to spare for the Pi. Instead of having to find two USB power adapters, I opted for [this great Anker dual USB adapter](https://www.amazon.com/gp/product/B012WMWPJW/ref=as_li_ss_tl?ie=UTF8&psc=1&linkCode=ll1&tag=paulstamatiou-20&linkId=cdcfeeb2de9fca9e548e87beea54255e "Anker 24W Dual USB Wall Charger PowerPort 2") which provides 2.4 amps per USB port.
+
+
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC00051-1500.jpg)
+
+
+
+
+With the Pi Frame now up and running **I had two challenges**:
+
+* Figure out how to display my photos in fullscreen
+* Figure out how to turn the display and backlight off when needed.
+
+#### Displaying the photos
+
+The traditional route for a digital photo frame is to have a synced photos folder with something like Dropbox or rsync and then use a fullscreen image viewer like `feh` or `fbi`. Both are rather no-frills setups.
+
+I wanted to see if I could bypass the photo syncing portion of this and **just use the Google Photos website**. I've already [professed my love for Google Photos](https://paulstamatiou.com/storage-for-photographers-part-2/) so it would be great to use it here as well.
+
+I would only need to have a browser that could display in fullscreen or kiosk mode. I decided to give Firefox a try, only because there is currently an issue with the latest Chromium crashing on Ubuntu MATE. There are also dedicated kiosk browsers like [kweb](https://www.raspberrypi.org/forums/viewtopic.php?t=40860) and [FullPageOS](https://github.com/guysoft/FullPageOS).
+
+Fortunately, **Firefox's native fullscreen mode did the trick**. I just had to log into Google Photos, select an album and hide the mouse in the corner. To get photos to be the perfect aspect ratio to fill the 1920x1200 display and not have pillar or letterboxing, I created a new album and **uploaded some of my travel photos cropped to a 16:10 aspect ratio**. It worked perfectly!
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC00108-1500.jpg)
+
+
+
+
+I was able navigate between photos in the selected album using the left and right arrow keys. Google Photos also recently created a slideshow mode that I tested out. However, there were two issues with the slideshow mode to address. The first is that it puts a control box in the bottom left corner that does not hide. I ended up using the Stylish Firefox plugin to inject CSS to hide that box.
+
+The other issue with slideshow mode is that it's a bit too fast for this use case. It seems to progress to the next photo every ~5 seconds. I'd much prefer something every few minutes or hours. I ended up not using slideshow mode. I can just hit the right arrow on the keyboard to get the next photo or video.
+
+I decided to take a stab at automate this by writing and **injecting some JavaScript into the page to change the photos for me every 10 minutes**. I used the Firefox Greasemonkey add-on and wrote this script below. Unfortunately, when you get to the last photo in an album in Google Photos, the next arrow disappears and it does not loop you back to the beginning. So I had to have the script to detect when you got to the end and then go backwards until it hits the first photo and so on.
+
+You can adjust the time by changing the `600000` number (10 minutes in milliseconds) on the last line.
+
+```
+// ==UserScript==
+// @name google photos slower slideshow
+// @namespace piframe
+// @include https://photos.google.com/album/*
+// @version 1
+// @grant none
+// ==/UserScript==
+
+function next_or_prev() {
+ window.direction = window.direction || 'forward';
+ var next_el = document.getElementsByClassName("oJhm5 gMFQN")[0];
+ var prev_el = document.getElementsByClassName("oJhm5 KUdGif")[0];
+
+ if (direction == 'forward') {
+ var css_display = window.getComputedStyle(next_el).getPropertyValue('display');
+ if (css_display == 'block') {
+ next_el.click();
+ } else if (css_display == 'none') {
+ window.direction = 'backward';
+ next_or_prev();
+ }
+ } else if (direction == 'backward') {
+ var css_display = window.getComputedStyle(prev_el).getPropertyValue('display');
+ if (css_display == 'block') {
+ prev_el.click();
+ } else if (css_display == 'none') {
+ window.direction = 'forward';
+ next_or_prev();
+ }
+ }
+}
+window.setInterval(function(){next_or_prev()}, 600000);
+
+```
+
+**Update:** The issue with this approach is that it relies on the class names of the left and right arrows, which are bound to change with future Google Photos web deploys. **I rewrote this script (below)** to trigger a right arrow key event instead. It keeps trying to go to the next photo and if the URL doesn't change it figures it must be at the last photo so it goes to the first photo. This **requires you to provide the URL of the first photo** in the album you are using.
+
+```
+// ==UserScript==
+// @name google photos slower slideshow
+// @namespace piframe
+// @include https://photos.google.com/album/*
+// @version 1
+// @grant none
+// ==/UserScript==
+
+// CHANGE first_photo TO USE THE URL OF THE FIRST PHOTO IN YOUR ALBUM
+var first_photo = 'https://photos.google.com/album/XXXX/photo/XXXX';
+function pressKey() {
+ var key = 39; // right arrow keycode
+ var body = document.getElementsByTagName('body')[0];
+ if(document.createEventObject) {
+ var eventObj = document.createEventObject();
+ eventObj.keyCode = key;
+ body.fireEvent("onkeydown", eventObj);
+ } else if (document.createEvent) {
+ var eventObj = document.createEvent("Events");
+ eventObj.initEvent("keydown", true, true);
+ eventObj.which = key;
+ body.dispatchEvent(eventObj);
+ }
+}
+function next_or_prev() {
+ var current_url = window.location.href;
+ pressKey();
+ if (current_url == window.location.href) {
+ // page didnt change, must be at last photo
+ // load the first photo
+ window.location.href = first_photo;
+ }
+}
+window.setInterval(function(){next_or_prev()}, 600000);
+
+```
+
+Now we're in business! With the photo display stuff figured out, I put the Pi Frame in its new home on my bookshelf. I nestled it in between my travel book collection, hooked up an extension cord to the Anker power adapter and hid the cable.
+
+
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC00129-1500.jpg)
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC00138-1500.jpg)
+
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC00151-1500.jpg)
+
+
+
+
+#### Turning the display off
+
+With that out of the way, the next objective was to figure out how to turn off the display. There were two routes to explore. I could cut up the USB power cable going to the display and place a relay on it so the Pi's GPIO pin could programatically turn the power on and off. The other route would be to figure out how to programatically tell the display controller that there was no signal so it would turn off the backlight automatically. I explored the latter route.
+
+I was unable to get the display and backlight to completely shutoff by simply setting the OS setting for display inactivity. It would black out the screen but the display controller would still think there was a video signal and keep the backlight on. What I needed to do was turn off the HDMI port entirely.
+
+I wrote two bash scripts. The first, `display_off.sh`, simply ran this command: `tvservice -o`. I saved that file and made sure to `chmod +x` it to make it executable. I tested it out and it correctly turned off the display and backlight!
+
+The next script to turn the display back on was a bit trickier. This is what I put in my `display_on.sh` script:
+
+```
+tvservice -p
+chvt 9 && chvt 7
+xrefresh -d :0
+```
+
+I tried a lot of stuff before I landed on something that worked. The chvt commands require sudo, so this script must always be run with sudo. I added the bash script to the sudoers file so that it at least doesn't ask for a password. I ran `sudo visudo` and added this line to the end (replace stammy with your Pi's username):
+
+```
+stammy ALL=NOPASSWD: /home/stammy/display_on.sh
+```
+
+#### Wiring up a button and fan
+
+With these two scripts I could SSH into the Pi and turn the display on and off. But SSHing into the Pi each time I wanted to toggle the display was going to be annoying. I decided to wire up a physical button to run this script for me. I soldered up a push button, hot glued it to the top right corner of the frame for easy access and attached it to GPIO pin 17 and GND.
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC00163-1500.jpg)
+
+
+
+
+But... if I was going to be doing a bit of soldering I figured I would also **wire up a relay to control a fan to cool down the display controller board** when running. It's probably not entirely necessary, but even with the copper heatsinks the display controller still gets very hot.
+
+I rebuilt the relay circuit I talked about earlier in this article to control a small 5V 50mm fan powered off the Pi's 5V power source. Except this time I soldered everything (rather hackily at that) instead of using a breadboard. I wanted to use a transistor for this instead of a relay but I didn't have a 1N4001 flyback diode on hand to prevent inductive kickback when the fan shuts off.
+
+
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC00168-1500.jpg)
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC00172-1500.jpg)
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC00183-1500.jpg)
+
+
+
+
+With everything back in place, I put the Pi Frame back on the bookshelf. I just had to **write a python script to detect the button press** then appropriately trigger the display on or off bash script and trigger the fan relay.
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC00201-1500.jpg)
+
+
+
+
+With the button hooked up to GPIO pin 17 I setup that pin to listen for input. One thing to note is that it is configured with the Pi's internal pull up resistor so I didn't have to use a resistor along with the button when wiring it up. This resistor configuration makes it easier for the Pi to distinguish if the button is being pushed by making it so that the pin's input voltage doesn't float (as it would with stray capacitance) when not connected to anything.
+
+Since I just have the push button connected to GND and a GPIO pin, I use a pull-up resistor so the GPIO pin will read high normally and read low when the button is pushed. This is a bit opposite of what you may expect, thus why the script below only acts when the input is detected as false. The other way to do this is to wire the push button to a 3.3V line and a GPIO pin with a pull-down resistor. That will get the GPIO input to be pulled down to low by default and go high when the button is pressed and the circuit closes.
+
+```
+import RPi.GPIO as GPIO
+import time
+import subprocess
+
+GPIO.setmode(GPIO.BCM)
+GPIO.setup(17, GPIO.IN, pull_up_down=GPIO.PUD_UP)
+GPIO.setup(27, GPIO.OUT, initial=GPIO.LOW)
+display_on = True
+
+while True:
+ btn = GPIO.input(17)
+ if btn == False:
+ print('Button press registered')
+ if display_on == True:
+ display_on = False
+ GPIO.output(27, False)
+ subprocess.call("/home/stammy/display_off.sh", shell=True)
+ time.sleep(0.5)
+ elif display_on == False:
+ display_on = True
+ GPIO.output(27, True)
+ subprocess.call("/home/stammy/display_on.sh", shell=True)
+ time.sleep(0.5)
+```
+
+I connected the relay's signal line to GPIO pin 27 so I just needed to set that as output. Now I just listen for the button input and toggle between turning the display on and off. To actually run the aforementioned bash scripts I use the `subprocess.call()` lines. The `time.sleep()` lines are added in there so that holding the button a bit too long won't run the scripts multiple times.
+
+I saved the script as a python file and ran it in a terminal on the Pi. Again, I need sudo here for the chvt commands mentioned above:
+
+ sudo python display_button.python
+```
+
+To make it easier whenever you reboot the Pi, you can add this as a custom application launcher in the top panel. Set it to Type: "Application in Terminal."
+
+
+
+
+
+
+
+Time to actually enjoy the Pi Frame!
+
+#### What's next with the Pi Frame?
+
+I'm pretty impressed with the result of this little frame. Impressive, crisp image quality with a ridiculously easy Google Photos "integration"... love it. However, there are a few more things I'd like to explore with this project in the future:
+
+* Get another matting sheet professionally cut to my exact spec since I was unable to replicate the same beveled cut it came with.
+* Use a motion sensor to turn off the display after no movement has been detected in the room for a while.
+* Replace Firefox with Chromium when the issues are addressed and see if I can get hardware accelerated videos working so that my videos on Google Photos can play well (they play now but frames drop). Detect proximity and if someone is actively looking at the display while a video is playing, enable audio to play through a small speaker.
+* Setup an Amazon Echo Alexa skill so that I can tell the Pi to change to various Google Photos albums on command, or turn on/off the display.
+* Connect a Leap Motion to be able to gesture between photos without needing to touch anything.
+* Be able to use the display for various other tasks by hosting simple local webpages and changing the browser tab on command. For example one page could be a digital clock or analog clock with an interesting watch face.
+
+
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC00203-1500.jpg)
+
+
+
+[](https://turbo.paulstamatiou.com/uploads/2016/06/pstam-rpi-photo-frame-DSC00211-1500.jpg)
+
+
+
+
+Thanks for reading! If you've enjoyed this post I only ask that you please share it.
+
+
+[1](#r1) 只能运行较老的内核,并且软件支持更糟糕。
+
+[2](#r2) 例如,关闭不用的端口,板载LED,减少外设以及过度的软件消耗CPU周期。[这里是一篇文章](http://www.jeffgeerling.com/blogs/jeff-geerling/raspberry-pi-zero-conserve-energy "Raspberry Pi Zero - Conserve power and reduce draw to 80mA"),它谈到了对Pi Zero做这些操作,以减少空转,从而逼近仅仅80mA。
+
+[3](#r3) There is actually [a way to go through the initial setup via USB](http://blog.gbaman.info/?p=791 "Raspberry Pi Zero - Programming over USB") without a display at all, but it's a bit more complicated than I'd like to explain in this post. You can also preconfigure and build an image that has SSH ready to go so you can do the entire setup via SSH on boot, or if you use Raspbian it has SSH enabled by default. You'll need to connect via Ethernet instead of Wi-Fi at first and [then follow these steps](http://raspberrypi.stackexchange.com/a/27352 "How to set up Raspberry Pi without a monitor?").
+
+[4](#r4) This actually installs an older version of netatalk, which still works but if you must always have the latest version of everything, search for how to setup netatalk 3.0+. You'll have to build it yourself, but it lets Spotlight index and search your Pi as well.
+
+[5](#r5) Though I think that is just 50mA across _all_ GPIO pins combined. Not very much.
+
+[6](#r6) Especially if you will be using more than one GPIO pin since they seem to all share the 50mA maximum current available on the 3.3V line; though there is a chance this number is a bit higher for the Pi 3, it was very hard to actual find this listed anywhere official.
+
+What happens if you draw too much current off the GPIO pins when in output mode? Most likely it will just cause the Raspberry Pi to reboot. In more extreme scenarios of drawing lots of power (including various USB devices) you could blow the Raspberry Pi's built-in polyfuse which could take anywhere from a few minutes to hours to get back to normal.
+
+[7](#r7) Yeah, I'm still using the LED here to test it out but you can place a larger device here. Up to about ~500mA safely if you like, you just may want to power it from something other than the Pi's 5V line.
+
+[8](#r8) You'll have to do some searching for one that works at 3.3V, most require a bit more.. or just use a transistor to switch on that MOSFET with a larger power source.
\ No newline at end of file
diff --git a/raw/Page dewarping.md b/raw/Page dewarping.md
new file mode 100644
index 0000000..4874b4f
--- /dev/null
+++ b/raw/Page dewarping.md
@@ -0,0 +1,255 @@
+原文:[Page dewarping](https://mzucker.github.io/2016/08/15/page-dewarping.html)
+
+---
+
+
+扁平化卷曲页图像,作为一个优化问题。
+
+# 概述
+
+前阵子,我写了一个脚本来根据手写文本图片创建PDF。这没啥特别的 —— 只是[自适应阈值](http://docs.opencv.org/3.0-last-rst/modules/imgproc/doc/miscellaneous_transformations.html#cv2.adaptiveThreshold),然后将多个图像合并成一个PDF —— 但每当有学生给我发了一堆JPEG作为他们的作业的时候,这就派上了用场。在我向我的未婚妻演示了这个程序后,她最后让我偶尔在她用于语言学研究的归档文档上运行它。这个夏天,她从图书馆带回来了大量的图片,其中,由于卷曲页,文本明显的扭曲。
+
+因此,我决定写个程序_自动地_将诸如下面左边的图片转换成右边的图片:
+
+
+
+正如这个博客中的每个项目,代码[在github上](https://github.com/mzucker/page_dewarp)。如果你想要先看看更多之前之后的图片,那么随你跳到结果部分。
+
+# 背景
+
+我绝对不是第一个想出文档图像扭曲矫正办法的人 —— 甚至在Dan Bloomberg的开源图像处理库[Leptonica](http://www.leptonica.com/dewarping.html)中就有对其实现 —— 但当涉及到了解一个问题时,没有什么比自己实现更好的了。除了通过浏览Leptonica代码,我还扫了关于这个主题的几篇论文,包括一个扭曲矫正比赛结果的[综述](http://citeseer.ist.psu.edu/viewdoc/summary?doi=10.1.1.99.7439),以及关于竞赛获奖的坐标转换模型(CTM)方法的[文章](http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.552.8971)。
+
+Leptonica的扭曲矫正方法和CTM方法都有相似的分级问题分解:
+
+ 1. 拆分文本至行。
+
+ 2. 查找扭曲或者坐标转换,从而使行平行或水平。
+
+对我来说,较之CTM的3D “cylinder”模型,Leptonica对于第二个子问题的解决方法似乎有点特别。老实说,在破译CTM论文的过程中,我遇到了点麻烦,但我喜欢基于模型的方法这个想法。因此,我决定创造自己的参数模型,其中,页面的外观由多个参数确定:
+
+ * 一个旋转向量$r$,以及一个平移向量$t$,它们都在${\Bbb {R}}^3$中,其参数化页面的3D取向和位置。
+
+ * 两个斜率
+$\alpha$和$\beta$,指定页面表面的曲率(参见下面的曲线图)
+
+ * 页面上$n$水平跨度的垂直偏移$y_1,...,y_n$
+
+ * 对于每个跨度$i\in\{1,...,n\}$,$m_i$的水平偏移$x_i^{(1)},...,x_i^{(m_i)}$指向水平跨度(所有都位于垂直偏移$y_i$)
+
+该页面的3D形状来源于沿着局部$y$轴横扫曲线(从顶至底方向)。页面上的每个$x$ (从左到右)坐标映射到页面表面的位移$z$。我将页面表面的水平截面建模成一个三次样条,其端点固定在零点。样条曲线的形状可以完全由其在端点$\alpha$和$\beta$的斜率指定。
+
+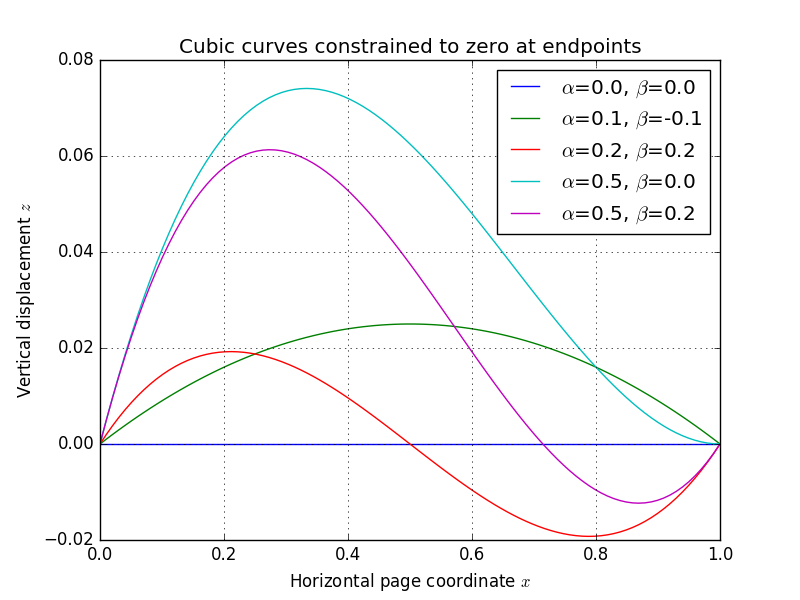
+
+如图所示,修改斜率参数,获得各种各样的“类页”曲线。下面,我已经生成了一个动画,它修复了页面尺寸和和所有的$(x,y)$坐标,同时改变位姿/形状参数$r$,$t$,$\alpha$和$\beta$ —— 你可以开始欣赏参数空间跨越有用的各种页面外观:
+
+
+
+重要的是,一定位姿/形状参数固定了,页面上的每个$(x,y)$坐标会被投影到图像平面上一个确定的位置。有了这个丰富的模型,现在,我们可以将整个扭曲矫正拼图框架为一个优化问题:
+
+ * identify a number of _keypoints_ along horizontal text spans in the original photograph
+
+ * starting from a naïve initial guess, find the parameters , , , , , , , , , which minimize the [reprojection error](https://en.wikipedia.org/wiki/Reprojection_error) of the keypoints
+
+Here is an illustration of reprojection before and after optimization:
+
+
+
+The red points in both image are detected keypoints on text spans, and the
+blue ones are reprojections through the model. Note that the left image
+(initial guess) assumes no curvature at all, so all blue points are collinear;
+whereas the right image (final optimization output) has established the page
+pose/shape well enough to place almost all of the blue points on top of each
+corresponding red point.
+
+Once we have a good model, we can isolate the pose/shape parameters, and
+invert the resulting page-to-image mapping to dewarp the entire image. Of
+course, the devil is in the details.
+
+<<<<<<< HEAD
+# 程序
+=======
+# 过程
+>>>>>>> 415706004c54800bb7338543c0b4b30b328dc2b2
+
+Here is a rough description of the steps I took.
+
+ 1. **Obtain page boundaries.** It’s a good idea not to consider the entire image, as borders beyond the page can contain lots of garbage. Instead of [intelligently identifying page borders](http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.81.1467), I opted for a simpler approach, just carving out the middle hunk of the image with fixed margins on the edges.
+
+ 2. **Detect text contours.** Next, I look for regions that look “text-like”. This is a multi-step process that involves an initial adaptive threshold:
+
+
+
+…[morphological dilation](https://en.wikipedia.org/wiki/Dilation_\(morphology\)) by a
+horizontal box to connect up horizontally adjacent mask pixels:
+
+
+
+…[erosion](https://en.wikipedia.org/wiki/Erosion_\(morphology\)) by a vertical box to eliminate single-pixel-high “blips”:
+
+
+
+and finally, [connected component analysis](https://en.wikipedia.org/wiki/Connected-component_labeling) with a filtering step to eliminate any blobs
+which are too tall (compared to their width) or too thick to be text. Each
+remaining text contour is then approximated by its best-fitting line segment
+using [PCA](https://en.wikipedia.org/wiki/Principal_component_analysis), as
+shown here:
+
+
+
+Since some of the images that my fiancée supplied were of tables full of
+vertical text, I also specialized my program to attempt to detect horizontal
+lines or rules if not enough horizontal text is found. Here’s an example image
+and detected contours:
+
+
+
+ 3. **Assemble text into spans.** Once the text contours have been identified, we need to combine all of the contours corresponding to a single horizontal span on the page. There is probably a linear-time method for accomplishing this, but I settled on a greedy quadratic method here (runtime doesn’t matter much here since nearly 100% of program time is spent in optimization anyways).
+
+Here is pseudocode illustrating the overall approach:
+
+```python
+edges = []
+
+for each contour a:
+ for each other contour b:
+ cost = get_edge_cost(a, b)
+ if cost < INFINITY:
+ edges.append( (cost, a, b) )
+
+sort edges by cost
+
+for each edge (cost, a, b) in edges:
+ if a and b are both unconnected:
+ connect a and b with edge e
+
+```
+
+Basically, we generate candidate edges for every pair of text contours, and
+score them. The resulting cost is infinite if the two contours overlap
+significantly along their lengths, if they are too far apart, or if they
+diverge too much in angle. Otherwise, the score is a linear combination of
+distance and change in angle.
+
+Once the connections are made, the contours can be easily grouped into spans;
+I also filter these to eliminate any that are too small to be useful in
+determining the page model.
+
+
+
+Above, you can see the span grouping has done a good job amalgamating the text
+contours because each line of text has its own color.
+
+ 4. **Sample spans.** Because the parametric model needs discrete keypoints, we need to generate a small number of representative points on each span. I do this by choosing one keypoint per 20 or so pixels of text contour:
+
+
+
+ 5. **Create naïve parameter estimate.** I use PCA to estimate the mean orientation of all spans; the resulting principal components are used to analytically establish the initial guess of the and coordinates, along with the pose of a flat, curvature-free page using [`cv2.solvePnP`](http://docs.opencv.org/3.0-last-rst/modules/calib3d/doc/camera_calibration_and_3d_reconstruction.html#cv2.solvePnP). The reprojection of the keypoints will be accomplished by sampling the cubic spline to obtain the -offsets of the object points and calling [`cv2.projectPoints`](http://docs.opencv.org/3.0-last-rst/modules/calib3d/doc/camera_calibration_and_3d_reconstruction.html#cv2.projectPoints). to project into the image plane.
+
+ 6. **Optimize!** To minimize the reprojection error, I use [`scipy.optimize.minimize`](http://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.minimize.html) with the `'Powell'` solver as a black-box, derivative-free optimizer. Here’s reprojection again, before and after optimization:
+
+
+
+Nearly 100% of the program runtime is spent doing this optimization. I haven’t
+really experimented much with other solvers, or with using a specialized
+solver for [nonlinear least squares](https://en.wikipedia.org/wiki/Non-
+linear_least_squares) problems (which is exactly what this is, by the way). It
+might be possible to speed up the optimization a lot!
+
+ 7. **Remap image and threshold.** Once the optimization completes, I isolate the pose/shape parameters , , , and to establish a coordinate transformation. The actual dewarp is obtained by projecting a dense mesh of 3D page points via [`cv2.projectPoints`](http://docs.opencv.org/3.0-last-rst/modules/calib3d/doc/camera_calibration_and_3d_reconstruction.html#cv2.projectPoints) and supplying the resulting image coordinates to [`cv2.remap`](http://docs.opencv.org/3.0-last-rst/modules/imgproc/doc/geometric_transformations.html#cv2.remap). I get the final output with [`cv2.adaptiveThreshold`](http://docs.opencv.org/3.0-last-rst/modules/imgproc/doc/miscellaneous_transformations.html#cv2.adaptiveThreshold) and save it as a bi-level PNG using [Pillow](http://python-pillow.org/). Again, before and after shots:
+
+
+
+# 结果
+
+I’ve included several [example images](https://github.com/mzucker/page_dewarp/tree/master/example_input) in
+the github repository to illustrate how the program works on a variety of
+inputs. Here are the images, along with the program output:
+
+**boston_cooking_a.jpg**:
+
+
+
+**boston_cooking_b.jpg**:
+
+
+
+**linguistics_thesis_a.jpg**:
+
+
+
+**linguistics_thesis_b.jpg**:
+
+
+
+I also compiled some statistics about each program run (take the runtimes with
+a grain of salt, this is for a single run on my 2012 MacBook Pro):
+
+Input | Spans | Keypoints | Parameters | Opt. time (s) | Total time (s)
+---|---|---|---|---|---
+boston_cooking_a.jpg | 38 | 554 | 600 | 23.3 | 24.8
+boston_cooking_b.jpg | 38 | 475 | 521 | 18.0 | 18.8
+linguistics_thesis_a.jpg | 20 | 161 | 189 | 5.1 | 6.1
+linguistics_thesis_b.jpg | 7 | 89 | 104 | 4.2 | 5.3
+
+You can see these are not exactly _small_ optimization problems. The smallest
+one has 89 parameters in the model, and the largest has 600. Still, I’m sure
+the optimization speed could be improved by trying out different methods
+and/or using a compiled language.
+
+# 总结
+
+The way this project unfolded represents a fairly typical workflow for me
+these days: do a bit of reading to collect background knowledge, and then
+figure out how to formulate the entire problem as the output of some
+optimization process. I find it’s a pretty effective way of tackling a large
+number of technical problems. Although I didn’t think of it at the time, the
+overall approach I took here is reminiscent of both [deformable part models](https://people.eecs.berkeley.edu/~rbg/latent/) and [active appearance models](https://www.cs.cmu.edu/~efros/courses/AP06/Papers/matthews_ijcv_2004.pdf), though not as sophisticated as either.
+
+Both Leptonica and the CTM method go one step further than I did, and try to
+model/repair horizontal distortion as well as vertical. That would be useful
+for my code, too – because the cubic spline is not an [arc-length](https://en.wikipedia.org/wiki/Arc_length) parameterization, the text
+is slightly compressed in areas where the cubic spline has a large slope.
+Since this project was mostly intended as a proof-of-concept, I decided not to
+pursue the issue further.
+
+Before putting up the final code on github, I tried out using the automated
+Python style checker [Pylint](https://www.pylint.org/) for the first time. For
+some reason, on its first run it informed me that all of the `cv2` module
+members were undefined, leading to an initial rating of -6.88/10 (yes,
+negative). Putting the line
+
+```python
+
+ # pylint: disable=E1101
+
+```
+
+near the top of the file made it shut up about that. After tweaking the
+program for a while to make Pylint happier, I got the score up to 9.09/10,
+which seems good enough for now. I’m not sure I agree 100% with all of its
+default settings, but it was interesting to try it out and learn a new tool.
+
+I do all of my coding these days in [GNU Emacs](https://www.gnu.org/software/emacs/), which usually suits my needs;
+however, messing around with Pylint led me to discover a feature I had never
+used. Pylint is not fond of short variable names like `h` (but has no problem
+with `i`, go figure). If I use the normal Emacs `query-replace` function bound
+to `M-%` and try to replace `h` with `height` everywhere, I have to pay close
+attention to make sure that it doesn’t also try to replace the h other
+identifiers (like `shape`) as well. A while back, I discovered I could
+sidestep this by using `query-replace-regexp` instead, and entering the
+regular expression `\bh\b` as the replacement text (the `\b` stands for a word
+_b_oundary, so it will only match the entire “word” `h`). On the other hand,
+it’s a bit more work, and I thought there must be a better place to do “whole-
+word” replacement. A bunch of Googling led me to [this Stack Exchange answer](http://emacs.stackexchange.com/a/12691/12975), which says that using
+the `universal-argument` command `C-u` in Emacs _before_ a `query-replace`
+will do exactly what I want. I never knew about `universal-argument` before –
+always good to learn new tricks!
+
+At this point, I don’t anticipate doing much more with the dewarping code. It
+could definitely use a thorough round of commenting, but the basics are pretty
+much spelled out in this document, so I’ll just slap a link here on the
+[github repo](https://github.com/mzucker/page_dewarp) and call it a day. Who
+knows – maybe I’ll refer back to this project again the next time I teach
+[computer vision](http://www.swarthmore.edu/NatSci/mzucker1/e27_s2016/)…
+
+
diff --git a/raw/Static types in Python, oh my(py)!.md b/raw/Static types in Python, oh my(py)!.md
new file mode 100644
index 0000000..53922d0
--- /dev/null
+++ b/raw/Static types in Python, oh my(py)!.md
@@ -0,0 +1,151 @@
+原文:[Static types in Python, oh my(py)!](http://blog.zulip.org/2016/10/13/static-types-in-python-oh-mypy/)
+
+---
+
+Over the last few years, static type checkers have become available for popular dynamic languages like PHP ([Hack](http://hacklang.org/)) and JavaScript ([Flow](https://flowtype.org/) and [TypeScript](https://www.typescriptlang.org/)), and have seen wide adoption. Two years ago, a [provisional syntax for static type annotations](https://www.python.org/dev/peps/pep-0484/) was added to Python 3\. However, static types in Python have yet to be widely adopted, because the tool for checking the type annotations, [mypy](http://mypy-lang.org/), was not ready for production use… until now!
+
+The exciting news is that over the last year, a team at Dropbox (including Python creator Guido van Rossum!) has led the development of mypy into a mature type checker that can enforce static type consistency in Python programs. For the many programmers who work in large Python 2 codebases, the even more exciting news is that mypy has full support for type-checking Python 2 programs, scales to large Python codebases, and can substantially simplify the upgrade to Python 3\.
+
+The Zulip development community has seen this in action during 2016\. [Zulip](https://zulip.org/) is a popular open source group chat application, complete with apps for all major platforms, a REST API, dozens of integrations, etc. To give you a sense of scale, Zulip is about 50,000 lines of Python 2, with dozens of developers contributing hundreds of commits every month. During 2016, we have annotated 100% (!) of our backend with static types using mypy, and thanks to mypy, we are on the verge of switching to Python 3\. Zulip is now the largest open source Python project that has fully adopted static types, though I doubt we’ll hold that title for long :).
+
+In this post, I’ll explain how mypy works, the benefits and pain points we’ve seen in using mypy, and share a detailed guide for adopting mypy in a large production codebase (including how to find and fix dozens of issues in a large project in the first few days of using mypy!).
+
+# A brief introduction to mypy
+
+Here is an example of the clean mypy/PEP-484 annotation syntax in Python 3:
+
+```
+def sum_and_stringify(nums: List[int]) -> str:
+ """Adds up the numbers in a list and returns the result as a string."""
+ return str(sum(nums))
+
+```
+
+And here’s how that same code looks using the comment syntax for both Python 2 and 3:
+
+```
+def sum_and_stringify(nums):
+ # type: (List[int]) -> str
+ """Adds up the numbers in a list and returns the result as a string."""
+ return str(sum(nums))
+
+```
+
+With this comment syntax, mypy supports type-checking normal Python 2 programs, and programs annotated using mypy will run normally with any Python runtime environment (mypy shares this excellent property with the Flow JavaScript type checker). This is awesome because it means projects can adopt mypy without changing anything about how they run Python.
+
+You run mypy on your codebase like a linter, and it reports errors in a nice compiler-style format. For example, here’s what the mypy output would be if I’d incorrectly annotated `sum_and_stringify` as returning a float:
+
+```
+$ mypy /tmp/test.py
+/tmp/test.py: note: In function "sum_and_stringify":
+/tmp/test.py:6: error: Incompatible return value type: expected builtins.float, got builtins.str
+
+```
+
+If you’re curious how to annotate something, check out the [mypy syntax cheat sheet](http://mypy.readthedocs.io/en/latest/cheat_sheet.html) (for simple things) and [PEP-484](https://www.python.org/dev/peps/pep-0484/) (for complex things); they’re great resources. If you want to play with mypy now, you can install it with `pip3 install mypy-lang`.
+
+When mypy has complete type annotations for a module as well as its dependencies, then it can provide a very strong consistency check, similar to what the compiler provides in statically typed languages. Mypy uses the [typeshed](https://github.com/python/typeshed) repository of type “stubs” (type definitions for a module in the style of a header file) to provide type data for both the Python standard library and dozens of popular libraries like requests, six, and sqlalchemy. Importantly, mypy is designed for gradually adding types; if type data for an import isn’t available, it just treats that import as being consistent with anything.
+
+# Benefits of using mypy
+
+Here are the benefits we’ve seen from adopting mypy, starting with the most important:
+
+* **Static type annotations improve readability**. Improved readability is probably the most important benefit of statically typed Python. With static types, every function clearly documents the types of its arguments and return value, which saves a ton of time reading the codebase to figure out the precise types a function expects so that you can call it. In many large codebases, developers write docstrings that contain little information other than the types of the arguments and often end up out of date. Type annotations are far better since they are automatically verified for correctness and consistency. It turned out that the code that we found most difficult to annotate was precisely the code where the type annotations improved readability the most: the cases where it was totally unclear from the code alone what all the objects being passed around are.
+* **We can refactor with confidence**. Refactoring a Python codebase without breaking things involves a lot of careful manual checking to confirm that you’ve updated all the code that used the old interface. With a statically typed Python codebase, the type checker can often verify this for you automatically. We’ve already found this to be [super useful when refactoring Zulip](https://github.com/zulip/zulip/commit/eb09dd217dbd5d9c214b14a5b28b3a12cf8b7854).
+* **We upgraded to Python 3**. Thanks to mypy, Zulip now supports Python 3\. For years, the 2to3 library has been able to do automatically most of the changes required to support Python 3\. The hard part of the migration is the unicode issue: Python 3 is much more strict about the distinction between arrays of bytes and strings than Python 2\. Mypy annotations made this project much easier, since we could explicitly declare which values were which across the entire codebase, and check those declarations for consistency. Even in Zulip, which has an unusually comprehensive automated test suite, mypy caught many Python 3 issues that the tests did not find.
+* **mypy frequently catches bugs**. When we started using mypy, Zulip was a mature web application with unusually high test coverage, so we didn’t find any super embarrassing bugs as part of annotating the codebase. However, mypy [flagged](https://github.com/zulip/zulip/commit/620411c0ea757c9f3f0ae08597e77de84f20ee97) [dozens](https://github.com/zulip/zulip/commit/d77c70220c91a47b06695409e178bb006fe996e8) [of](https://github.com/zulip/zulip/commit/fc02ea9f674e44d99eb12528fceaed64a950bbed) [latent](https://github.com/zulip/zulip/commit/e9f39922a09d2aad90de63a349abe408e93edd4d) [bugs](https://github.com/zulip/zulip/commit/7595e4b05fe69a786cf83cad9c8a77f6e47b2f0f), and dozens more [pieces](https://github.com/zulip/zulip/commit/eee36618fe297bf306c19a7deb11941b53680272) of [confusing](https://github.com/zulip/zulip/commit/c55ac01ae69ef1ca8ce8315ec4b179ec3ebb46a6) code. I’m glad that mypy helped us purge those categories of issues from the codebase. More important for us is that running mypy on code that hasn’t yet been reviewed or tested regularly saves time by catching bugs.
+* **Static types highlight bad interfaces**. Annotated functions with messy interfaces (e.g sometimes returning a `List` and sometimes a `Tuple` ) really stand out.
+
+# Pain points
+
+To provide a complete picture of the experience of adopting mypy, I think it’s important to also talk about the pain points with mypy today:
+
+* **Interactions with “unused import” linters**: Currently, linters like `pyflakes` don’t read the Python 2 type annotations style (since the annotations are comments, after all!), and thus will report that imports needed for mypy are unused. Since cleaning up unused imports is only marginally useful anyway, we just filtered out those warnings. This problem will go away when we move to the new Python 3 type syntax, since then type annotations are visible “users” of the imports to tools like pyflakes; I also expect that popular Python linters will add an option to check imports in type comments before long.
+* **Import cycles**: We needed to create a few import cycles in order to import types that were used as arguments (but not explicitly referenced) in a file. One can work around this (in the Python 2 comment syntax) using e.g. `if False: from x import y` (soon to be the cleaner `if typing.TYPE_CHECKING` ), but it won’t work when we move to the Python 3 syntax. I’m hopeful that someone will come up with a nice solution to the import cycle creation issue, which may just take the form of recommendations on how to organize one’s code to avoid this.
+
+## Non-pain points
+
+This section discusses the things that (before trying mypy) I was worried might be problems, but that after adopting mypy I don’t think are significant issues:
+
+* **Training**. Zulip has had well over 100 contributors at this point, so the thing I was most worried about when adopting mypy was that it could hurt the project by adding a new obscure technology that contributors need to learn. This has not turned out to be a material problem: new contributors usually annotate their code correctly on the first try. Python programmers know the Python type system, and the PEP-484 type syntax is a pretty intuitive way of writing it down. The [mypy cheat sheet](http://mypy.readthedocs.io/en/latest/cheat_sheet.html) helps a lot by providing a single place to look up all the common stuff.
+* **False positives**. Mypy is well-engineered and designed around the idea of only reporting things that are actual inconsistencies in a program’s types. It has a far lower false positive rate than the commercial static analyzers I’ve used! And, it has a really nice `type: ignore` system for silencing false positives to get clean output. Finally, we’ve had good luck with typing even some highly dynamic parts of our system (e.g. our [framework for parsing REST API requests](http://zulip.readthedocs.io/en/latest/writing-views.html#request-variables)).
+* **Mypy and typeshed bugs**. Zulip started using mypy in January 2016, when mypy itself was essentially the only open source project using mypy. Because we were the first webapp and the second large project using mypy seriously, we encountered a lot of small bugs at the beginning (in total, Zulip developers have reported ~50 issues in mypy and submitted 16 PRs for typeshed). Essentially all of those issues were fixed upstream (with tests!) months ago, and we rarely encounter regressions. So, I wouldn’t expect similar projects to encounter a similar scale of issues; exactly how many issues an individual project encounters will depend a lot on whether that project uses the same corners of Python as other projects that already use mypy and typeshed. Even as a super early adopter, I feel like we spent far more time annotating our code than investigating, working around with `type: ignore` , and reporting bugs.
+* **Performance.** Mypy today is really fast compared to other static analyzers I’ve used. With the mypy module cache, it takes about 3s to check the entire Zulip codebase and thus is about as fast as pyflakes (one of the faster Python linters). However, because mypy detects cross-file issues (unlike most linters), it doesn’t have a really fast (e.g. <100ms) way to fully check if a given diff/commit introduced a new issue.
+* **Community**. The mypy and typeshed communities are amazing and are impressively responsive to good bug reports (aka ones with a clean, simple reproducer, which I can almost always generate in under 5 minutes).
+
+# Finding bugs in your first few days with mypy
+
+This section details what you need to do in order to start benefiting from mypy in a large codebase. To give you a sense of the scale of work involved, I did everything described in this section in 4 days at a hackathon in January (and back then, mypy wasn’t mature, so I spent half the time filing good bug reports for all the issues I found). If you’re thinking about using mypy but want more data to help make a decision, I’d recommend completing the steps discussed in this section. It’s a pretty good effort/value tradeoff.
+
+**Read the mypy cheat sheet.** The [mypy cheat sheet](http://mypy.readthedocs.io/en/latest/cheat_sheet.html) provides a great overview of the PEP-484 syntax, and you’ll be referring to it often as you start writing annotations.
+
+**Standardize how you’ll run mypy**. Write tooling to [install](https://github.com/zulip/zulip/blob/master/tools/install-mypy) and [run](https://github.com/zulip/zulip/blob/master/tools/run-mypy) `mypy` against your codebase, so that everyone using the project can run the type checker the same way. Two features are important in how you run mypy:
+
+* Support for determining which files should be checked (a whitelist/exclude list is useful!).
+* Specifying the correct flags for your project at this time. For a Python 2 project, I recommend starting with `mypy --py2 --silent-imports --fast-parser -i `. You should be able to do this using a [mypy.ini file](http://mypy.readthedocs.io/en/latest/config_file.html).
+
+**Get mypy running** on your codebase with clean output. This usually requires just adding type annotations for empty global data structures. Back in January, this took a few hours of work (including reporting bugs with reproducers). It’s probably even less work now. By default, mypy will only check the interior of functions that are annotated, so with an unannotated codebase, this is just making sure mypy can analyze your entire codebase.
+
+**Check for basic consistency**. Add the `--check-untyped-defs` option to your mypy arguments, and get that running with no errors on the codebase. This option causes mypy to check every `def` in the codebase for internal consistency; mypy can detect many classes of bugs and mistakes in your codebase, without your having written a single type annotation!
+
+In most cases, you’ll want to fix bugs and bad code as you go, but you can also use `#type: ignore` annotations or exclude files to defer issues. For example, we excluded all of Zulip’s tests at first, since they’re both lower value to type-check and had most of the monkey-patching and other questionable Python in the project. For Zulip, getting clean `--check-untyped-defs` output took me about 2 days of hard work, including merging fixes for about 40 issues in the Zulip codebase.
+
+I spent another day or two generating nice reproducers for the mypy bugs I’d encountered and improving typeshed. Now that mypy is no longer in its infancy, mypy bugs are increasingly rare. But a large project should expect to encounter and fix typeshed issues (just submit a PR!).
+
+**Run mypy in continuous integration**. Once `mypy --check-untyped-defs` passes on your codebase, you should lock down your progress by running the `mypy` checker in your CI environment.
+
+Because mypy type annotations are optional, once you’ve done the setup above, you can start annotating your codebase at whatever pace you like. Over time, you’ll get the benefits of static types in the parts of the codebase that you’ve annotated, without needing to do anything special to the rest of the codebase (the wonders of gradual typing!). In the next section, I’ll discuss strategy for how to move the codebase towards being fully annotated.
+
+# Fully annotating a large codebase
+
+This section discusses what’s involved in going from having mypy set up to having a fully annotated codebase.
+
+The great thing about mypy is that you can do everything gradually. After the initial setup, we actually didn’t do anything with mypy for a couple months. That changed when we posted mypy annotations as one of our project ideas for Google Summer of Code (GSoC). We found an incredible student, Eklavya Sharma, for the project. Eklavya did the vast majority of the hard work of annotating Zulip, including upgrading our tooling, annotating the core library, contributing bug reports and PRs to mypy and typeshed upstream, and fixing all the mistakes we made early on. Amazingly, he also found the time during the summer to migrate Zulip to use virtualenvs and then upgrade Zulip to Python 3!
+
+One can divide the work of annotating a large project into a few phases.
+
+**Phase 1: Annotate the core library**. Strategically, you want to annotate the core library code that is used in lots of other files first. The annotations for these functions impose constraints on the types used in the rest of the codebase, so you’ll spend less time fixing incorrect annotations and catch more actual bugs faster if you do these files first. This is also a good time to [document how your project is using mypy](http://zulip.readthedocs.io/en/latest/mypy.html) (and link that doc from mypy failures in the CI system).
+
+**Phase 2: Annotate the bulk of the codebase**. Many projects will likely do this slowly over many months as developers touch the different parts of the codebase, which is a pretty reasonable strategy.
+
+It also works well to annotate a codebase as a focused effort; the story of how we did this for Zulip is instructive. About halfway through Eklavya’s summer of code, we went to the [PyCon sprints](https://us.pycon.org/2016/community/sprints/) with the goal of annotating as much of Zulip as possible. The PyCon sprints are my favorite part of PyCon. It’s an awesome 4-day party after the main PyCon conference where hundreds of developers work on open source projects together. It’s completely free to attend, and is a great opportunity to get involved in contributing to open source projects.
+
+We grabbed a few tables next to the mypy developers, and managed to attract a rotating cast of 5–10 developers to the Zulip mypy annotation project each day. During the PyCon sprints, Zulip went from 17% annotated to 85% (with 25–30 engineer-days of work, mostly by folks new to both Zulip and mypy). We used mypy’s coverage support and coveralls.io to track progress, but the more fun progress bar was our giant sheet of paper, pictured here at the start of the last day:
+
+
+
+Our PyCon experience is I think the best proof that mypy is accessible to new developers: aside from me, all of the contributors adding annotations were new to both Zulip and mypy. We found that with a good 5-minute demo and good documentation, new contributors were effective within their first hour of working with mypy. I would definitely recommend the mypy hackathon approach to other open source projects — it’s a great way for contributors to have meaningful impact on an unfamiliar project.
+
+**Phase 3: Get to 100%.** Annotating the last several files is relatively difficult work, because this is where you end up debugging all the mistakes you made in Phase 2\. While you do this, it’s important to lock down files/directories that reach 100% by adding the `--disallow-untyped-defs` option (which will report any functions missing type annotations) to the `mypy` flags to prevent regressions.
+
+Eklavya brought us from 85% to 96% before his college started up again, and then a few weeks ago we spent the couple hours needed to get to 100%. Now, all new Python code going into Zulip comes with mypy annotations (with the exception of a shrinking list of scripts, settings, and test files).
+
+**Phase 4: Celebrate and write a blog post**! At least, that was the next step for Zulip :)
+
+Overall, the focused time that went into fully annotating Zulip was a 1-week hackathon, a GSOC project, and a party at the PyCon sprints. In the scheme of things, this is a pretty modest level of effort.
+
+I should mention that even though Zulip is 100% annotated, Zulip’s mypy journey is not complete. We will eventually want to add stubs to typeshed for the most important libraries used by Zulip (e.g. Django).
+
+# Recommendations for annotating code
+
+We have a few recommendations for annotating that will likely save you a lot of time:
+
+* Make sure to handle `str` vs. `Text` correctly. Bytes vs. str and str vs. unicode errors are the majority of the problem for moving a codebase from Python 2 to Python 2+3\. If you do this right as you annotate your codebase, you’ll save yourself a lot of time when you upgrade to Python 3; we found the Python 3 upgrade went very quickly once we had the codebase mostly annotated. We ended up adding [a couple helper functions](https://github.com/zulip/zulip/blob/master/zerver/lib/str_utils.py) to do casts between `str` , `Text` , and `bytes` correctly (and readably!) in our codebase on both Python 2 and Python 3.
+* Remember to annotate class variables! We neglected to do this when we first annotated our Django models file, and ended up having to fix a number of incorrect annotations (primarily around Text vs. bytes) that got into the codebase because they weren’t being cross-checked against anything.
+* Avoid using a guess-and-check approach when adding annotations. In a partially annotated codebase, mypy will still detect many classes of errors in annotations, but it can’t detect every error (since the inconsistency might be with code you haven’t annotated yet). So you should make sure people writing annotations are actually understanding/tracing the code, and that you code review the annotations just like actual code. We found writing one commit per large file (or collection of related smaller files) to be a good commit discipline.
+* Use precise types where possible (e.g. avoid using `Any` ).
+* When using `type: ignore` to work around a potential mypy or typeshed bug, I recommend using the following style to record the original GitHub issue:
+
+ `bad_code # type: ignore # https://github.com/python/typeshed/issues/372`
+
+ That way, it’s easy for future you to verify whether the issue that required that use of `type: ignore` has since been fixed upstream. If a file would require a lot of `type: ignore` annotations, you can always add it to the exclude list (another feature of our `run-mypy` wrapper) and plan to come back to it later.
+
+# Conclusion
+
+Overall, the experience of using mypy (and the PEP-484 type system) has been awesome, and we feel that adopting mypy has been a big advance for the Zulip project. It improves readability, catches bugs in code without running it, has very few false positives, and hasn’t come with significant downsides. Deploying mypy in a large codebase required relatively little investment on our part, and annotating the codebase had the side benefit of making our Python 3 migration feel easy.
+
+If you have a large Python codebase and would like to make working in your codebase better, you should find a week to get started with mypy!
+
+Finally, if you’re excited to see what static types in Python look like in a large codebase, check out the [Zulip server project on GitHub](https://github.com/zulip/zulip/). We welcome new contributors!
+
+Huge thanks to Guido van Rossum, Alya Abbott, Steve Howell, Jason Chen, Eklavya Sharma, Anurag Goel, and Joshua Simmons for their feedback on this post.
diff --git "a/raw/Stupid Python Tricks\357\200\272 Abusing Explicit Self.md" "b/raw/Stupid Python Tricks\357\200\272 Abusing Explicit Self.md"
new file mode 100644
index 0000000..3193b1c
--- /dev/null
+++ "b/raw/Stupid Python Tricks\357\200\272 Abusing Explicit Self.md"
@@ -0,0 +1,142 @@
+原文:[Stupid Python Tricks: Abusing Explicit Self](https://medium.com/@hwayne/stupid-python-tricks-abusing-explicit-self-53d46b72e9e0)
+
+---
+
+在Ruby中,这样定义一个方法:
+
+```ruby
+class Foo
+ def bar(baz)
+ baz
+ end
+end
+```
+
+在Python中,这样定义一个方法:
+
+```python
+class Foo:
+ def bar(self, baz): # What's self doing there?
+ return baz # Not even using it
+```
+这个“显式self”是许多许多许多讨论的主题,而大量的人觉得它相当令人困惑。我想提供一个简短的解释,并且找到一些你永远不应该做的滥用显式self的方式。准备好了吗?那就开始吧。
+
+# 奇怪的实例方法
+
+让我们定义以下类:
+
+```python
+class Number:
+ def __init__(self, x: int) -> None:
+ self.x = x
+ self.minus = lambda y: self.x - y # we'll come back to this
+ def plus(self, y: int) -> int:
+ return self.x + y
+one = Number(1)
+```
+
+one.plus(2)是什么?那相当简单:
+
+```python
+>>> print(one.plus(2))
+3
+```
+
+但如果是Number.plus(one, 2)呢?
+
+```python
+>>> print(Number.plus(one, 2)) # ???
+3 # !!!
+```
+
+Here, plus is a “bound method”. The object doesn’t *furious air quotes* really have a method called ‘plus’. Instead, “one.plus(N)” is a shorthand for “Number.plus(one, N)”, the “unbound method”. With that in mind, it’s pretty obvious why self is needed: plus is a class method that takes two parameters: the object we’re using, and the number we’re adding.
+这里,plus是一个“绑定方法”。
+
+It’s a little more complicated than that (Python 3 simplifies things a bit), but that’s a pretty useful lie that makes it a lot easier to work out the logic here. Let’s provide a slightly more complex example:
+
+```python
+>>> Number.times = lambda self, y: self.x * y
+>>> print(one.times(2)) # automatically valid
+2
+```
+
+When we call “one.times(2)”, it automatically translates that to “Number.times(one, 2)”, which we just defined. This becomes a lot easier to reason about with the explicit self.
+
+Now let’s double back to that “self.minus” in the initializer. There, we’re not defining the method “properly”. It’s not part of the class definition. We’re just assigning a property to the object which also happens to be callable. Since this isn’t a proper method, it shouldn’t be translated to a bound method in the actual object, so we can drop the self. Similarly, there shouldn’t be an unbound version on the class, so trying to use that will be an error. Let’s give that a test:
+
+```python
+>>> print(one.minus(2))
+-1
+>>> print(Number.minus(one, 2))
+Traceback (most recent call last):
+ File "", line 1, in
+AttributeError: type object 'Number' has no attribute 'minus'
+```
+
+Boom.
+
+# 回调地狱
+
+Quick aside before the really stupid stuff. Recall that in Python, functions are first class objects. That means that you can pass functions to other functions like any other kind of object. This means you can do the following:
+
+```python
+>>> def subtract_two(minus):
+... return(minus(2))
+...
+>>> print(subtract_two(one.minus))
+-1
+```
+
+The function we pass in is the bound method of our object. This means that when we call it, it has access to the original object. We can use this for callbacks. Instead of giving a function complete access to our object, we give it only minimal access: just one method. Sometimes this is a good idea. Other times, it means you have to rethink your architecture. If you don’t see why, spend a few weeks writing Javascript front-ends and get back to me.
+
+(Aside on the aside: you should probably check out Javascript anyway, because object prototyping is really close to what we’re doing with unbound methods and JS uses prototyping much more openly and explicitly.)
+
+# 真正愚蠢的东西
+
+Okay, back on track. We’ve seen that if you create a new unbound method, it adds a bound method to all existing objects. It also works with modification: change the unbound method and you change all the bound methods. This means you can dynamically adjust a class based on the runtime. For example, if you’re getting a ton of calls to a particular method, you can start caching it.
+
+Here’s a toy example. We want to add a division method to Number. We want to start logging all divisions if and only if at some point we try to divide by zero. We can do it like this:
+
+```python
+def _divide(self, y):
+ try:
+ return self.x / y
+ except ZeroDivisionError:
+ print("Tried to divide {} by 0".format(self.x))
+ def __newdivide(self, y):
+ print("{} / {}".format(self.x, y))
+ return _divide(self, y)
+ self.__class__.divide = __newdivide
+Number.divide = _divide
+>>> six = Number(6)
+>>> eight = Number(8)
+>>>
+>>> print(six.divide(3))
+2.0
+>>> print(eight.divide(0))
+Tried to divide 8 by 0
+None
+>>> print(six.divide(3))
+6 / 3
+2.0
+```
+
+One object throwing an error triggered improved logging on a completely different one. There’s a few extremely specific cases where manipulating unbound methods might be a good idea. Practically, though, don’t do this in production code. Programming is hard enough as it is. You don’t need your method definitions changing underneath you.
+
+# 总结
+
+当你定义一个类上的实例方法时,它创建了该对象上的一个对应的“绑定”方法。这是类上的非绑定方法的别名。如果你直接在对象上定义实例方法,那么类上就没有对应的非绑定方法。
+
+修改非绑定方法也会改变所有现有的绑定方法。你可以用它来动态修改类。
+
+不要。
+
+真的,不要。
+
+# 进一步阅读
+
+* [Python method对象](https://docs.python.org/3/tutorial/classes.html#method-objects)
+* [Javascript中的原型](http://javascriptissexy.com/javascript-prototype-in-plain-detailed-language/)
+* [静态、类和抽象方法](https://julien.danjou.info/blog/2013/guide-python-static-class-abstract-methods) (还有一个关于Py2是如何有点复杂的重要注解)
+* [回调地狱](http://callbackhell.com/)
+* [回调地狱的一个反证](http://thecodebarbarian.com/2015/03/20/callback-hell-is-a-myth)
\ No newline at end of file
diff --git a/raw/The Python Packaging Ecosystem.md b/raw/The Python Packaging Ecosystem.md
new file mode 100644
index 0000000..fa72900
--- /dev/null
+++ b/raw/The Python Packaging Ecosystem.md
@@ -0,0 +1,391 @@
+原文:[The Python Packaging Ecosystem](http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html)
+
+---
+
+从开发到部署
+
+[TOC]
+
+最近已经有一些文章从最终用户的角度反映Python包生态圈的现状,因此,作为该生态圈的主架构师之一,对我来说,值得从我的角度写写我如何描述软件出版发行的整体问题空间,此刻我认为我们所处的境地,以及我所希望看到的未来的发展。
+
+作为背景,我回复的具体文章是:
+
+ * [Python Packaging is Good Now](https://glyph.twistedmatrix.com/2016/08/python-packaging.html) (Glyph Lefkowitz)
+ * [Conda:神话和误解](https://jakevdp.github.io/blog/2016/08/25/conda-myths-and-misconceptions/) (Jake VanderPlas)
+ * [PayPal的Python Packaging](https://www.paypal-engineering.com/2016/09/07/python-packaging-at-paypal/) (Mahmoud Hashemi)
+
+These are all excellent pieces considering the problem space from different
+perspectives, so if you'd like to learn more about the topics I cover here, I
+highly recommend reading them.
+
+## [我的核心软件生态设计理念](http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html#id1)
+
+Since it heavily influences the way I think about packaging system design in
+general, it's worth stating my core design philosophy explicitly:
+
+ * As a software consumer, I should be able to consume libraries, frameworks, and applications in the binary format of my choice, regardless of whether or not the relevant software publishers directly publish in that format
+ * As a software publisher working in the Python ecosystem, I should be able to publish my software once, in a single source-based format, and have it be automatically consumable in any binary format my users care to use
+
+This is emphatically _not_ the way many software packaging systems work - for
+a great many systems, the publication format and the consumption format are
+tightly coupled, and the folks managing the publication format or the
+consumption format actively seek to use it as a lever of control over a
+commercial market (think operating system vendor controlled application
+stores, especially for mobile devices).
+
+While we're unlikely to ever pursue the specific design documented in the rest
+of the PEP (hence the "Deferred" status), the "[Development, Distribution, and Deployment of Python Software](https://www.python.org/dev/peps/pep-0426/#development-distribution-and-deployment-of-python-software)" section of PEP
+426 provides additional details on how this philosophy applies in practice.
+
+I'll also note that while I now work on software supply chain management
+tooling at Red Hat, that _wasn't_ the case when I first started actively
+participating in the upstream Python packaging ecosystem [design process](https://lwn.net/Articles/580399/). Back then I was working on Red
+Hat's main [hardware integration testing system](https://beaker-project.org/),
+and growing increasingly frustrated with the level of effort involved in
+integrating new Python level dependencies into Beaker's RPM based development
+and deployment model. Getting actively involved in tackling these problems on
+the Python upstream side of things then led to also getting more actively
+involved in addressing them on the [Red Hat downstream side](http://www.slideshare.net/ncoghlan_dev/developing-in-python-on-red-hat-platforms-devnation-2016).
+
+## [关键难题](http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html#id2)
+
+When talking about the design of software packaging ecosystems, it's very easy
+to fall into the trap of only considering the "direct to peer developers" use
+case, where the software consumer we're attempting to reach is another
+developer working in the same problem domain that we are, using a similar set
+of development tools. Common examples of this include:
+
+ * Linux distro developers publishing software for use by other contributors to the same Linux distro ecosystem
+ * Web service developers publishing software for use by other web service developers
+ * Data scientists publishing software for use by other data scientists
+
+In these more constrained contexts, you can frequently get away with using a
+single toolchain for both publication and consumption:
+
+ * Linux: just use the system package manager for the relevant distro
+ * Web services: just use the Python Packaging Authority's twine for publication and pip for consumption
+ * Data science: just use conda for everything
+
+For newer languages that start in one particular domain with a preferred
+package manager and expand outwards from there, the apparent simplicity
+arising from this homogeneity of use cases may frequently be attributed as an
+essential property of the design of the package manager, but that perception
+of inherent simplicity will typically fade if the language is able to
+successfully expand beyond the original niche its default package manager was
+designed to handle.
+
+In the case of Python, for example, distutils was designed as a consistent
+build interface for Linux distro package management, setuptools for plugin
+management in the Open Source Application Foundation's Chandler project, pip
+for dependency management in web service development, and conda for local
+language-independent environment management in data science. distutils and
+setuptools haven't fared especially well from a usability perspective when
+pushed beyond their original design parameters (hence the current efforts to
+make it easier to use full-fledged build systems like Scons and Meson as an
+alternative when publishing Python packages), while pip and conda both seem to
+be doing a better job of accommodating increases in their scope of
+application.
+
+This history helps illustrate that where things really have the potential to
+get complicated (even beyond the inherent challenges of domain-specific
+software distribution) is when you start needing to _cross domain boundaries_.
+For example, as the lead maintainer of `contextlib` in the Python standard
+library, I'm also the maintainer of the `contextlib2` backport project on
+PyPI. That's not a domain specific utility - folks may need it regardless of
+whether they're using a self-built Python runtime, a pre-built Windows or Mac
+OS X binary they downloaded from python.org, a pre-built binary from a Linux
+distribution, a CPython runtime from some other redistributor (homebrew,
+pyenv, Enthought Canopy, ActiveState, Continuum Analytics, AWS Lambda, Azure
+Machine Learning, etc), or perhaps even a different Python runtime entirely
+(PyPy, PyPy.js, Jython, IronPython, MicroPython, VOC, Batavia, etc).
+
+Fortunately for me, I _don't_ need to worry about all that complexity in the
+wider ecosystem when I'm specifically wearing my `contextlib2` maintainer hat
+- I just publish an sdist and a universal wheel file to PyPI, and the rest of
+the ecosystem has everything it needs to take care of redistribution and end
+user consumption without any further input from me.
+
+However, `contextlib2` is a pure Python project that only depends on the
+standard library, so it's pretty much the simplest possible case from a
+tooling perspective (the only reason I needed to upgrade from distutils to
+setuptools was so I could publish my own wheel files, and the only reason I
+haven't switched to using the _much_ simpler pure-Python-only flit instead of
+either of them is that that doesn't yet easily support publishing backwards
+compatible setup.py based sdists).
+
+This means that things get significantly more complex once we start wanting to
+use and depend on components written in languages other than Python, so that's
+the broader context I'll consider next.
+
+## [平台管理或者插件管理?](http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html#id3)
+
+When it comes to handling the software distribution problem in general, there
+are two main ways of approaching it:
+
+ * design a plugin management system that doesn't concern itself with the management of the application framework that _runs_ the plugins
+ * design a platform component manager that not only manages the plugins themselves, but _also_ the application frameworks that run them
+
+This "plugin manager or platform component manager?" question shows up over
+and over again in software distribution architecture designs, but the case of
+most relevance to Python developers is in the contrasting approaches that pip
+and conda have adopted to handling the problem of external dependencies for
+Python projects:
+
+ * pip is a _plugin manager_ for Python runtimes. Once you have a Python runtime (any Python runtime), pip can help you add pieces to it. However, by design, it won't help you manage the underlying Python runtime (just as it wouldn't make any sense to try to install Mozilla Firefox as a Firefox Add-On, or Google Chrome as a Chrome Extension)
+ * conda, by contrast, is a _component manager_ for a cross-platform platform that provides its own Python runtimes (as well as runtimes for other languages). This means that you can get _pre-integrated_ components, rather than having to do your own integration between plugins obtained via pip and language runtimes obtained via other means
+
+What this means is that pip, _on its own_, is not in any way a direct
+alternative to conda. To get comparable capabilities to those offered by
+conda, you have to add in a mechanism for obtaining the underlying language
+runtimes, which means the alternatives are combinations like:
+
+ * apt-get + pip
+ * dnf + pip
+ * yum + pip
+ * pyenv + pip
+ * homebrew (Mac OS X) + pip
+ * python.org Windows installer + pip
+ * Enthought Canopy
+ * ActiveState's Python runtime + PyPM
+
+This is the main reason why "just use conda" is excellent advice to any
+prospective Pythonista that isn't already using one of the platform component
+managers mentioned above: giving that answer replaces an otherwise operating
+system dependent or Python specific answer to the runtime management problem
+with a cross-platform and (at least somewhat) language neutral one.
+
+It's an especially good answer for Windows users, as chocalatey/OneGet/Windows
+Package Management isn't remotely comparable to pyenv or homebrew at this
+point in time, other runtime managers don't work on Windows, and getting folks
+bootstrapped with MinGW, Cygwin or the new (still experimental) Windows
+Subsystem for Linux is just another hurdle to place between them and whatever
+goal they're learning Python for in the first place.
+
+However, conda's pre-integration based approach to tackling the external
+dependency problem is also why "just use conda for everything" isn't a
+sufficient answer for the Python software ecosystem as a whole.
+
+If you're working on an operating system component for Fedora, Debian, or any
+other distro, you actually _want_ to be using the system provided Python
+runtime, and hence need to be able to readily convert your upstream Python
+dependencies into policy compliant system dependencies.
+
+Similarly, if you're wanting to support folks that deploy to a preconfigured
+Python environment in services like AWS Lambda, Azure Cloud Functions, Heroku,
+OpenShift or Cloud Foundry, or that use alternative Python runtimes like PyPy
+or MicroPython, then you need a publication technology that doesn't tightly
+couple your releases to a specific version of the underlying language runtime.
+
+As a result, pip and conda end up existing at slightly different points in the
+system integration pipeline:
+
+ * Publishing and consuming Python software with pip is a matter of "bring your own Python runtime". This has the benefit that you _can_ readily bring your own runtime (and manage it using whichever tools make sense for your use case), but also has the downside that you _must_ supply your own runtime (which can sometimes prove to be a significant barrier to entry for new Python users, as well as being a pain for cross-platform environment management).
+ * Like Linux system package managers before it, conda takes away the requirement to supply your own Python runtime by providing one for you. This is great if you don't have any particular preference as to which runtime you want to use, but if you _do_ need to use a different runtime for some reason, you're likely to end up fighting against the tooling, rather than having it help you. (If you're tempted to answer "Just add another interpreter to the pre-integrated set!" here, keep in mind that doing so without the aid of a runtime independent plugin manager like pip acts as a _multiplier_ on the platform level integration testing needed, which can be a significant cost even when it's automated)
+
+## [接下来,要做什么?](http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html#id4)
+
+In case it isn't already clear from the above, I'm largely happy with the
+respective niches that pip and conda are carving out for themselves as a
+plugin manager for Python runtimes and as a cross-platform platform focused on
+(but not limited to) data analysis use cases.
+
+However, there's still plenty of scope to improve the effectiveness of the
+collaboration between the upstream Python Packaging Authority and downstream
+Python redistributors, as well as to reduce barriers to entry for
+participation in the ecosystem in general, so I'll go over some of the key
+areas I see for potential improvement.
+
+### [可持续发展与旁观者效应](http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html#id5)
+
+It's not a secret that the core PyPA infrastructure (PyPI, pip, twine,
+setuptools) is [nowhere near as well-funded](https://caremad.io/posts/2016/05
+/powering-pypi/) as you might expect given its criticality to the operations
+of some truly enormous organisations.
+
+The biggest impact of this is that even when volunteers show up ready and
+willing to work, there may not be anybody in a position to effectively
+_wrangle_ those volunteers, and help keep them collaborating effectively and
+moving in a productive direction.
+
+To secure long term sustainability for the core Python packaging
+infrastructure, we're only talking amounts on the order of a few hundred
+thousand dollars a year - enough to cover some dedicated operations and
+publisher support staff for PyPI (freeing up the volunteers currently handling
+those tasks to help work on ecosystem improvements), as well as to fund
+targeted development directed at some of the other problems described below.
+
+However, rather than being a true "[tragedy of the
+commons](https://en.wikipedia.org/wiki/Tragedy_of_the_commons)", I personally
+chalk this situation up to a different human cognitive bias: the [bystander
+effect](https://en.wikipedia.org/wiki/Bystander_effect).
+
+The reason I think that is that we have _so many_ potential sources of the
+necessary funding that even folks that agree there's a problem that needs to
+be solved are assuming that someone else will take care of it, without
+actually checking whether or not that assumption is entirely valid.
+
+The primary responsibility for correcting that oversight falls squarely on the
+Python Software Foundation, which is why the Packaging Working Group was
+formed in order to investigate possible sources of additional funding, as well
+as to determine how any such funding can be spent most effectively.
+
+However, a secondary responsibility also falls on customers and staff of
+commercial Python redistributors, as this is _exactly_ the kind of ecosystem
+level risk that commercial redistributors are being paid to manage on behalf
+of their customers, and they're currently not handling this particular
+situation very well. Accordingly, anyone that's actually _paying_ for CPython,
+pip, and related tools (either directly or as a component of a larger
+offering), and expecting them to be supported properly as a result, really
+needs to be asking some very pointed question of their suppliers right about
+now. (Here's a sample question: "We pay you X dollars a year, and the upstream
+Python ecosystem is one of the things we expect you to support with that
+revenue. How much of what we pay you goes towards maintenance of the upstream
+Python packaging infrastructure that we rely on every day?").
+
+One key point to note about the current situation is that as a 501(c)(3)
+public interest charity, any work the PSF funds will be directed towards
+better fulfilling that public interest mission, and that means focusing
+primarily on the needs of educators and non-profit organisations, rather than
+those of private for-profit entities.
+
+Commercial redistributors are thus _far_ better positioned to properly
+represent their customers interests in areas where their priorities may
+diverge from those of the wider community (closing the "insider threat"
+loophole in PyPI's current security model is a particular case that comes to
+mind - see [Making PyPI security independent of
+SSL/TLS](http://www.curiousefficiency.org/posts/2016/09/python-packaging-
+ecosystem.html#making-pypi-security-independent-of-ssl-tls)).
+
+### [将PyPI迁移到pypi.org](http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html#id6)
+
+An instance of the new PyPI implementation (Warehouse) is up and running at
+ and connected directly to the production PyPI database, so
+folks can already explicitly opt-in to using it over the legacy implementation
+if they prefer to do so.
+
+However, there's still a non-trivial amount of design, development and QA work
+needed on the new version before all existing traffic can be transparently
+switched over to using it.
+
+Getting at least this step appropriately funded and a clear project management
+plan in place is the main current focus of the PSF's Packaging Working Group.
+
+### [使得编译器的存在在终端用户系统上可选](http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html#id7)
+
+Between the `wheel` format and the `manylinux1` usefully-distro-independent
+ABI definition, this is largely handled now, with `conda` available as an
+option to handle the relatively small number of cases that are still a problem
+for `pip`.
+
+The main unsolved problem is to allow projects to properly express the
+constraints they place on target environments so that issues can be detected
+at install time or repackaging time, rather than only being detected as
+runtime failures. Such a feature will also greatly expand the ability to
+correctly generate platform level dependencies when converting Python projects
+to downstream package formats like those used by conda and Linux system
+package managers.
+
+### [在终端用户的系统上引导依赖管理工具](http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html#id8)
+
+With pip being bundled with recent versions of CPython (including CPython 2.7
+maintenance releases), and pip (or a variant like upip) also being bundled
+with most other Python runtimes, the ecosystem bootstrapping problem has
+largely been addressed for new Python users.
+
+There are still a few usability challenges to be addressed (like defaulting to
+per-user installations when outside a virtual environment, interoperating more
+effectively with platform component managers like conda, and providing an
+officially supported installation interface that works at the Python prompt
+rather than via the operating system command line), but those don't require
+the same level of political coordination across multiple groups that was
+needed to establish pip as the lowest common denominator approach to
+dependency management for Python applications.
+
+### [让distutils和setuptools的使用可选optional](http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html#id9)
+
+As mentioned above, distutils was designed ~18 years ago as a common interface
+for Linux distributions to build Python projects, while setuptools was
+designed ~12 years ago as a plugin management system for an open source
+Microsoft Exchange replacement. While both projects have given admirable
+service in their original target niches, and quite a few more besides, their
+age and original purpose means they're significantly more complex than what a
+user needs if all they want to do is to publish their pure Python library or
+framework to the Python Package index.
+
+Their underlying complexity also makes it incredibly difficult to improve the
+problematic state of their documentation, which is split between the legacy
+distutils documentation in the CPython standard library and the additional
+setuptools specific documentation in the setuptools project.
+
+Accordingly, what we want to do is to change the way build toolchains for
+Python projects are organised to have 3 clearly distinct tiers:
+
+ * toolchains for pure Python projects
+ * toolchains for Python projects with simple C extensions
+ * toolchains for C/C++/other projects with Python bindings
+
+This allows folks to be introduced to simpler tools like flit first, better
+enables the development of potential alternatives to setuptools at the second
+tier, and supports the use of full-fledged pip-installable build systems like
+Scons and Meson at the third tier.
+
+The first step in this project, defining the `pyproject.toml` format to allow
+declarative specification of the dependencies needed to launch `setup.py`, has
+been implemented, and Daniel Holth's `enscons` project demonstrates that that
+is already sufficient to bootstrap an external build system even without the
+later stages of the project.
+
+Future steps include providing native support for `pyproject.toml` in `pip`
+and `easy_install`, as well as defining a declarative approach to invoking the
+build system rather than having to run `setup.py` with the relevant distutils
+& setuptools flags.
+
+### [使得PyPI的安全独立于SSL/TLS](http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html#id10)
+
+PyPI currently relies entirely on SSL/TLS to protect the integrity of the link
+between software publishers and PyPI, and between PyPI and software consumers.
+The only protections against insider threats from within the PyPI
+administration team are ad hoc usage of GPG artifact signing by some projects,
+personal vetting of new team members by existing team members and 3rd party
+checks against previously published artifact hashes unexpectedly changing.
+
+A credible design for end-to-end package signing that adequately accounts for
+the significant usability issues that can arise around publisher and consumer
+key management has been available for almost 3 years at this point (see
+[Surviving a Compromise of PyPI](https://www.python.org/dev/peps/pep-0458/)
+and [Surviving a Compromise of PyPI: the Maximum Security
+Edition](https://www.python.org/dev/peps/pep-0480/)).
+
+However, implementing that solution has been gated not only on being able to
+first retire the legacy infrastructure, but also the PyPI administators being
+able to credibly commit to the key management obligations of operating the
+signing system, as well as to ensuring that the system-as-implemented actually
+provides the security guarantees of the system-as-designed.
+
+Accordingly, this isn't a project that can realistically be pursued until the
+underlying sustainability problems have been suitably addressed.
+
+### [自动化wheel创建](http://www.curiousefficiency.org/posts/2016/09/python-packaging-ecosystem.html#id11)
+
+While redistributors will generally take care of converting upstream Python
+packages into their own preferred formats, the Python-specific wheel format is
+currently a case where it is left up to publishers to decide whether or not to
+create them, and if they do decide to create them, how to automate that
+process.
+
+Having PyPI take care of this process automatically is an obviously desirable
+feature, but it's also an incredibly expensive one to build and operate.
+
+Thus, it currently makes sense to defer this cost to individual projects, as
+there are quite a few commercial continuous integration and continuous
+deployment service providers willing to offer free accounts to open source
+projects, and these can also be used for the task of producing release
+artifacts. Projects also remain free to only publish source artifacts, relying
+on pip's implicit wheel creation and caching and the appropriate use of
+private PyPI mirrors and caches to meet the needs of end users.
+
+For downstream platform communities already offering shared build
+infrastructure to their members (such as Linux distributions and conda-forge),
+it may make sense to offer Python wheel generation as a supported output
+option for cross-platform development use cases, in addition to the platform's
+native binary packaging format.
diff --git a/raw/Visualizing relationships between python packages.md b/raw/Visualizing relationships between python packages.md
new file mode 100644
index 0000000..63e5b8e
--- /dev/null
+++ b/raw/Visualizing relationships between python packages.md
@@ -0,0 +1,592 @@
+原文:[Visualizing relationships between python packages](https://kozikow.com/2016/07/10/visualizing-relationships-between-python-packages-2/)
+
+---
+
+## 简介
+
+我使用了[BigQuery上的github数据](https://github.com/blog/2201-making-open-source-data-more-available%20),提取github repo上的前3500个python包的共同出现关系。[通过速度verlet整合的d3中的力导向图](https://github.com/d3/d3-force)实现了可视化。我还使用[python-igraph](https://pypi.python.org/pypi/python-igraph)中的算法聚类了图,并且将其更新到。
+
+参见d3可视化中的集群的截图(点击图片以获得在线版本):
+
+[](http://clustering.kozikow.com?center=numpy)
+
+下面是刚刚从graphistry提取的numpy集群( 点击图片以获得在线版本):[](https://labs.graphistry.com/graph/graph.html?dataset=PyGraphistry/5R2115KURX&type=vgraph&splashAfter=1468271796&info=true&static=true&contentKey=numpycluster&play=0¢er=true&menu=false&goLive=false&left=-1.44e+3&right=973&top=-478&bottom=657&poi=true)
+
+图形属性:
+
+ * 每一个节点是在github上找到的一个python包。在[DataFrame with nodes](https://kozikow.com/2016/07/10/visualizing-relationships-between-python-packages-2/#DataFrame-with-nodes)部分计算得到半径。
+ * 对于两个包A和B,边的权重是,其中,是在相同文件中包A和包B出现的次数。很快,我会将其迁移到[标准化的逐点相互信息](https://en.wikipedia.org/wiki/Pointwise_mutual_information#Normalized_pointwise_mutual_information_.28npmi.29),因为有点难用BigQuery来计算它。
+ * 移除权重小于0.1的边。
+ * 根据[仿真参数](https://kozikow.com/2016/07/10/visualizing-relationships-between-python-packages-2/#Simulation-parameters),按照速度verlet集成来d3算法搜索最小能量状态。
+
+你可以访问看看我的应用。你可以:
+
+ * 在URL中传递不同的包名作为查询参数。
+ * 水平和垂直滚动页面。
+ * 点击一个节点可以打开pypi上对应的页面。注意,并不是所有的包在pypi上都有。
+
+有趣的graphistry视图在下一节,[具体集群分析](https://kozikow.com/2016/07/10/visualizing-relationships-between-python-packages-2/#Analysis-of-specific-clusters)。
+
+图形可视化除了看着酷以外,往往缺乏可操作的见解。
+Types
+of insights you can use this for:
+
+ * Find packages you have been not aware of in the close proximity of other packages that you use.
+ * Evaluate different web development frameworks based on size, adoption and library availability (e.g. [Flask](https://labs.graphistry.com/graph/graph.html?dataset=PyGraphistry/5R2115KURX&type=vgraph&splashAfter=1468271796&info=true&static=true&contentKey=flashcluster&play=0¢er=true&menu=false&goLive=false&left=-1.44e+3&right=973&top=-478&bottom=657&poi=true) vs [django](https://labs.graphistry.com/graph/graph.html?dataset=PyGraphistry/5R2115KURX&type=vgraph&splashAfter=1468271796&info=true&static=true&contentKey=djangocluster&play=0¢er=true&menu=false&goLive=false&left=-1.44e+3&right=973&top=-478&bottom=657&poi=true)).
+ * Find some interesting python use cases, like [robotics cluster](http://clustering.kozikow.com/?center=rospy).
+
+[Revision history of this post is on github](https://github.com/kozikow/kozikow-blog/blob/master/clustering/clustering.org) in the [orgmode](https://kozikow.com/2016/05/21/very-powerful-data-analysis-environment-org-mode-with-ob-ipython/).
+
+## 具体集群分析
+
+In addition to d3 visualization I also clustered the data using the [python-igraph](https://pypi.python.org/pypi/python-igraph)
+`community_infomap().membership` and uploaded it to graphistry. Ability to
+exclude and filter by clusters was very useful.
+
+### 科学计算集群
+
+Unsurprisingly, it is centered on numpy. It is interesting that it is possible
+to see the divide between statistics and machine learning.
+
+ * [d3 link](http://clustering.kozikow.com/?center=numpy)
+ * [graphistry link](https://labs.graphistry.com/graph/graph.html?dataset=PyGraphistry/5R2115KURX&type=vgraph&splashAfter=1468271796&info=true&static=true&contentKey=numpycluster&play=0¢er=true&menu=false&goLive=false&left=-1.44e+3&right=973&top=-478&bottom=657&poi=true)
+
+### Web框架集群
+
+Web框架很有意思:
+
+#### d3链接
+
+ * It could be said that [sqlalchemy](http://clustering.kozikow.com/?center=sqlalchemy) is a center of web frameworks land.
+ * Found nearby, there's a massive and monolithic cluster for [django](http://clustering.kozikow.com/?center=django).
+ * Smaller nearby clusters for [flask](http://clustering.kozikow.com/?center=flask) and [pyramid](http://clustering.kozikow.com/?center=pyramid).
+ * [pylons](http://clustering.kozikow.com/?center=pylons), lacking a cluster of its own, in between django and sqlalchemy.
+ * Small cluster for [zope](http://www.zope.org/), also nearby sqlalchemy
+ * [tornado](http://clustering.kozikow.com/?center=tornado) got swallowed by the big cluster of standard library in the middle, but is still close to other web frameworks.
+ * Some smaller web frameworks like [gluon (web2py)](http://clustering.kozikow.com/?center=gluon) or [turbo gears](http://clustering.kozikow.com/?center=tg) ended up close to django, but barely visible and without clusters of their own.
+
+#### 有趣的graphistry集群
+
+ * [Django cluster](https://labs.graphistry.com/graph/graph.html?dataset=PyGraphistry/5R2115KURX&type=vgraph&splashAfter=1468271796&info=true&static=true&contentKey=djangocluster&play=0¢er=true&menu=false&goLive=false&left=-1.44e+3&right=973&top=-478&bottom=657&poi=true)
+ * [Flask cluster](https://labs.graphistry.com/graph/graph.html?dataset=PyGraphistry/5R2115KURX&type=vgraph&splashAfter=1468271796&info=true&static=true&contentKey=flashcluster&play=0¢er=true&menu=false&goLive=false&left=-1.44e+3&right=973&top=-478&bottom=657&poi=true)
+ * [Twisted cluster](https://labs.graphistry.com/graph/graph.html?dataset=PyGraphistry/5R2115KURX&type=vgraph&splashAfter=1468271796&info=true&static=true&contentKey=twistedcluster&play=0¢er=true&menu=false&goLive=false&left=-1.44e+3&right=973&top=-478&bottom=657&poi=true)
+
+### 其他有趣的集群
+
+Looking at results of clustering algorithm, only "medium sized" clusters are
+interesting. A few first are obvious like clusters dominated by packages like
+os and sys. Very small clusters are not interesting either. [Here you can see clusters between positions 5 and 30 according to size](https://labs.graphistry.com/graph/graph.html?dataset=PyGraphistry/5R2115KURX&type=vgraph&splashAfter=1468271796&info=true&static=true&contentKey=topclusters&play=0¢er=true&menu=false&goLive=false&left=-1.44e+3&right=973&top=-478&bottom=657&poi=true).
+
+Some of the other clusters:
+
+ * Testing cluster, [d3 link](http://clustering.kozikow.com/?center=unittest), [graphistry cluster](https://labs.graphistry.com/graph/graph.html?dataset=PyGraphistry/5R2115KURX&type=vgraph&splashAfter=1468271796&info=true&static=true&contentKey=testclusters&play=0¢er=true&menu=false&goLive=false&left=-1.44e+3&right=973&top=-478&bottom=657&poi=true)
+ * Openstack cluster, [d3 link](http://clustering.kozikow.com/?center=nova), [graphistry link](https://labs.graphistry.com/graph/graph.html?dataset=PyGraphistry/5R2115KURX&type=vgraph&splashAfter=1468271796&info=true&static=true&contentKey=stackcluster&play=0¢er=true&menu=false&goLive=false&left=-1.44e+3&right=973&top=-478&bottom=657&poi=true)
+ * [String parsing and formatting cluster](https://labs.graphistry.com/graph/graph.html?dataset=PyGraphistry/5R2115KURX&type=vgraph&splashAfter=1468271796&info=true&static=true&contentKey=stringcluster&play=0¢er=true&menu=false&goLive=false&left=-1.44e+3&right=973&top=-478&bottom=657&poi=true)
+ * [Robotics land](http://clustering.kozikow.com/?center=rospy)
+ * [gaming cluster](http://clustering.kozikow.com/?center=pygame)
+ * [deep learning cluster](https://labs.graphistry.com/graph/graph.html?dataset=PyGraphistry/5R2115KURX&type=vgraph&splashAfter=1468271796&info=true&static=true&contentKey=deepcluster&play=0¢er=true&menu=false&goLive=false&left=-1.44e+3&right=973&top=-478&bottom=657&poi=true)
+
+## 进一步分析的潜力
+
+### 其他编程语言
+
+Majority of the code is not specific to python. Only the first step, create a
+table with packages, is specific to python.
+
+I had to do a lot of work on fitting the parameters in Simulation parameters
+to make the graph look good enough. I suspect that I would have to do similar
+fitting to each language, as each language graph would have different
+properties.
+
+I will be working on analyzing Java and Scala next.
+
+### 搜索"打包X的替代品",例如,seaborn vs bokeh
+
+For example, it would be interesting to cluster together all python data
+visualization packages.
+
+Intuitively, such packages would be used in similar context, but would be
+rarely used together. Assuming that our graph is represented as npmi
+coincidence matrix M, for packages x and y, correlation of vectors x and y
+would be high, but M[x][y] would be low.
+
+Alternatively, `M^2 /. M` could have some potential. M^2 would roughly
+represent "two hops" in the graph, while `/.` is a pointwise division.
+
+e high correlation of their neighbor weights, but low direct edge.
+
+This would work in many situations, but there are some others it wouldn't
+handle well. Example case it wouldn't handle well:
+
+ * sqlalchemy is an alternative to django built-in ORM.
+ * django ORM is only used in django.
+ * django ORM is not well usable in other web frameworks like flask.
+ * other web frameworks make heavy use of flask ORM, but not django built-in ORM.
+
+Therefore, django ORM and sqlalchemy wouldn't have their neighbor weights
+correlated. I might got some ORM details wrong, as I don't do much web dev.
+
+I also plan to experiment with [node2vec](http://arxiv.org/abs/1607.00653) or
+squaring the adjacency matrix.
+
+### 在repo关系中
+
+Currently, I am only looking at imports within the same file. It could be
+interesting to look at the same graph built using "within same repository"
+relationship, or systematically compare the "within same repository" and
+"within same file" relationships.
+
+### 加入pypi
+
+It could be interesting to compare usages on github with pypi downloads. [Pypi is also accessible on BigQuery.](https://mail.python.org/pipermail/distutils-
+sig/2016-May/028986.html)
+
+## 数据
+
+ * [Post-processed JSON data used by d3](http://clustering.kozikow.com/graph.js)
+ * [Publicly available BigQuery tables with all the data](https://bigquery.cloud.google.com/dataset/wide-silo-135723:github_clustering). See Reproduce section to see how each table was generated.
+
+## 重现步骤
+
+### 从BigQuery抽取数据
+
+#### 创建一个包表
+
+Save to wide-silo-135723:github_clustering.packages_in_file_py:
+
+```python
+
+ SELECT
+ id,
+ NEST(UNIQUE(COALESCE(
+ REGEXP_EXTRACT(line, r"^from ([a-zA-Z0-9_-]+).*import"),
+ REGEXP_EXTRACT(line, r"^import ([a-zA-Z0-9_-]+)")))) AS package
+ FROM (
+ SELECT
+ id AS id,
+ LTRIM(SPLIT(content, "\n")) AS line,
+ FROM
+ [fh-bigquery:github_extracts.contents_py]
+ HAVING
+ line CONTAINS "import")
+ GROUP BY id
+ HAVING LENGTH(package) > 0;
+
+```
+
+Table will have two fields - id representing the file and repeated field with
+packages in the single file. Repeated fields are like arrays - [the best description of repeated fields I found.](http://stackoverflow.com/questions/32020714/what-does-repeated-field-in-google-bigquery-mean)
+
+This is the only step that is specific for python.
+
+#### 验证packages_in_file_py表
+
+Check that imports have been correctly parsed out from some [random file](https://github.com/sunzhxjs/JobGIS/blob/master/lib/python2.7/site-packages/pandas/core/format.py).
+
+```python
+
+ SELECT
+ GROUP_CONCAT(package, ", ") AS packages,
+ COUNT(package) AS count
+ FROM [wide-silo-135723:github_clustering.packages_in_file_py]
+ WHERE id == "009e3877f01393ae7a4e495015c0e73b5aa48ea7"
+
+```
+
+packages | count
+---|---
+distutils, itertools, numpy, decimal, pandas, csv, warnings, future, IPython,
+math, locale, sys | 12
+
+#### 过滤掉不常用的包
+
+```python
+
+ SELECT
+ COUNT(DISTINCT(package))
+ FROM (SELECT
+ package,
+ count(id) AS count
+ FROM [wide-silo-135723:github_clustering.packages_in_file_py]
+ GROUP BY 1)
+ WHERE count > 200;
+
+```
+
+There are 3501 packages with at least 200 occurrences and it seems like a fine
+cut off point. Create a filtered table, wide-
+silo-135723:github_clustering.packages_in_file_top_py:
+
+```python
+
+ SELECT
+ id,
+ NEST(package) AS package
+ FROM (SELECT
+ package,
+ count(id) AS count,
+ NEST(id) AS id
+ FROM [wide-silo-135723:github_clustering.packages_in_file_py]
+ GROUP BY 1)
+ WHERE count > 200
+ GROUP BY id;
+
+```
+
+Results are in [wide-silo-135723:github_clustering.packages_in_file_top_py].
+
+```python
+
+ SELECT
+ COUNT(DISTINCT(package))
+ FROM [wide-silo-135723:github_clustering.packages_in_file_top_py];
+
+```
+
+```python
+
+ 3501
+
+```
+
+#### 生成图形的边
+
+I will generate edges and save it to table wide-
+silo-135723:github_clustering.packages_in_file_edges_py.
+
+```python
+
+ SELECT
+ p1.package AS package1,
+ p2.package AS package2,
+ COUNT(*) AS count
+ FROM (SELECT
+ id,
+ package
+ FROM FLATTEN([wide-silo-135723:github_clustering.packages_in_file_top_py], package)) AS p1
+ JOIN
+ (SELECT
+ id,
+ package
+ FROM [wide-silo-135723:github_clustering.packages_in_file_top_py]) AS p2
+ ON (p1.id == p2.id)
+ GROUP BY 1,2
+ ORDER BY count DESC;
+
+```
+
+Top 10 edges:
+
+```python
+
+ SELECT
+ package1,
+ package2,
+ count AS count
+ FROM [wide-silo-135723:github_clustering.packages_in_file_edges_py]
+ WHERE package1 < package2
+ ORDER BY count DESC
+ LIMIT 10;
+
+```
+
+package1 | package2 | count
+---|---|---
+os | sys | 393311
+os | re | 156765
+os | time | 156320
+logging | os | 134478
+sys | time | 133396
+re | sys | 122375
+__future__ | django | 119335
+__future__ | os | 109319
+os | subprocess | 106862
+datetime | django | 94111
+
+#### 过滤掉不相关的边
+
+Quantiles of the edge weight:
+
+```python
+
+ SELECT
+ GROUP_CONCAT(STRING(QUANTILES(count, 11)), ", ")
+ FROM [wide-silo-135723:github_clustering.packages_in_file_edges_py];
+
+```
+
+```python
+
+ 1, 1, 1, 2, 3, 4, 7, 12, 24, 70, 1005020
+
+```
+
+In my first implementation I filtered edges out based on the total count. It
+was not a good approach, as a small relationship between two big packages was
+more likely to stay than strong relationship between too small packages.
+
+Create wide-silo-135723:github_clustering.packages_in_file_nodes_py:
+
+```python
+
+ SELECT
+ package AS package,
+ COUNT(id) AS count
+ FROM [github_clustering.packages_in_file_top_py]
+ GROUP BY 1;
+
+```
+
+package | count
+---|---
+os | 1005020
+sys | 784379
+django | 618941
+__future__ | 445335
+time | 359073
+re | 349309
+
+Create the table packages_in_file_edges_top_py:
+
+```python
+
+ SELECT
+ edges.package1 AS package1,
+ edges.package2 AS package2,
+ # WordPress gets confused by less than sign after nodes1.count
+ edges.count / IF(nodes1.count nodes2.count,
+ nodes1.count,
+ nodes2.count) AS strength,
+ edges.count AS count
+ FROM [wide-silo-135723:github_clustering.packages_in_file_edges_py] AS edges
+ JOIN [wide-silo-135723:github_clustering.packages_in_file_nodes_py] AS nodes1
+ ON edges.package1 == nodes1.package
+ JOIN [wide-silo-135723:github_clustering.packages_in_file_nodes_py] AS nodes2
+ ON edges.package2 == nodes2.package
+ HAVING strength > 0.33
+ AND package1 <= package2;
+
+```
+
+[Full results in google docs.](https://docs.google.com/spreadsheets/d/1hbQAIyDUigIsEajcpNOXbmldgfLmEqsOE729SPTVpmA/edit?usp=sharing)
+
+### Process data with Pandas to json
+
+#### 加载csv,并用pandas验证边
+
+import pandas as pd
+import math
+
+df = pd.read_csv("edges.csv")
+pd_df = df[( df.package1 == "pandas" ) | ( df.package2 == "pandas" )]
+pd_df.loc[pd_df.package1 == "pandas","other_package"] = pd_df[pd_df.package1
+== "pandas"].package2
+pd_df.loc[pd_df.package2 == "pandas","other_package"] = pd_df[pd_df.package2
+== "pandas"].package1
+
+df_to_org(pd_df.loc[:,["other_package", "count"]])
+
+print "\n", len(pd_df), "total edges with pandas"
+
+other_package | count
+---|---
+pandas | 33846
+numpy | 21813
+statsmodels | 1355
+seaborn | 1164
+zipline | 684
+11 more rows |
+
+16 total edges with pandas
+
+#### DataFrame with nodes
+
+nodes_df = df[df.package1 == df.package2].reset_index().loc[:, ["package1",
+"count"]].copy()
+nodes_df["label"] = nodes_df.package1
+nodes_df["id"] = nodes_df.index
+nodes_df["r"] = (nodes_df["count"] / nodes_df["count"].min()).apply(math.sqrt)
++ 5
+nodes_df["count"].apply(lambda s: str(s) + " total usages\n")
+df_to_org(nodes_df)
+
+package1 | count | label | id | r
+---|---|---|---|---
+os | 1005020 | os | 0 | 75.711381704
+sys | 784379 | sys | 1 | 67.4690570169
+django | 618941 | django | 2 | 60.4915169887
+__future__ | 445335 | __future__ | 3 | 52.0701286903
+time | 359073 | time | 4 | 47.2662138808
+3460 more rows | | | |
+
+#### Create map of node name -> id
+
+id_map = nodes_df.reset_index().set_index("package1").to_dict()["index"]
+
+print pd.Series(id_map).sort_values()[:5]
+
+```python
+
+ os 0
+ sys 1
+ django 2
+ __future__ 3
+ time 4
+ dtype: int64
+
+```
+
+#### Create edges data frame
+
+edges_df = df.copy()
+edges_df["source"] = edges_df.package1.apply(lambda p: id_map[p])
+edges_df["target"] = edges_df.package2.apply(lambda p: id_map[p])
+edges_df = edges_df.merge(nodes_df[["id", "count"]], left_on="source",
+right_on="id", how="left")
+edges_df = edges_df.merge(nodes_df[["id", "count"]], left_on="target",
+right_on="id", how="left")
+df_to_org(edges_df)
+
+print "\ndf and edges_df should be the same length: ", len(df), len(edges_df)
+
+package1 | package2 | strength | count_x | source | target | id_x | count_y |id_y | count
+---|---|---|---|---|---|---|---|---|---
+os | os | 1.0 | 1005020 | 0 | 0 | 0 | 1005020 | 0 | 1005020
+sys | sys | 1.0 | 784379 | 1 | 1 | 1 | 784379 | 1 | 784379
+django | django | 1.0 | 618941 | 2 | 2 | 2 | 618941 | 2 | 618941
+__future__ | __future__ | 1.0 | 445335 | 3 | 3 | 3 | 445335 | 3 | 445335
+os | sys | 0.501429793505 | 393311 | 0 | 1 | 0 | 1005020 | 1 | 784379
+11117 more rows | | | | | | | | |
+
+df and edges_df should be the same length: 11122 11122
+
+#### Add reversed edge
+
+edges_rev_df = edges_df.copy()
+edges_rev_df.loc[:,["source", "target"]] = edges_rev_df.loc[:,["target",
+"source"]].values
+edges_df = edges_df.append(edges_rev_df)
+df_to_org(edges_df)
+
+package1 | package2 | strength | count_x | source | target | id_x | count_y |id_y | count
+---|---|---|---|---|---|---|---|---|---
+os | os | 1.0 | 1005020 | 0 | 0 | 0 | 1005020 | 0 | 1005020
+sys | sys | 1.0 | 784379 | 1 | 1 | 1 | 784379 | 1 | 784379
+django | django | 1.0 | 618941 | 2 | 2 | 2 | 618941 | 2 | 618941
+__future__ | __future__ | 1.0 | 445335 | 3 | 3 | 3 | 445335 | 3 | 445335
+os | sys | 0.501429793505 | 393311 | 0 | 1 | 0 | 1005020 | 1 | 784379
+22239 more rows | | | | | | | | |
+
+#### Truncate edges DataFrame
+
+edges_df = edges_df[["source", "target", "strength"]]
+df_to_org(edges_df)
+
+source | target | strength
+---|---|---
+0.0 | 0.0 | 1.0
+1.0 | 1.0 | 1.0
+2.0 | 2.0 | 1.0
+3.0 | 3.0 | 1.0
+0.0 | 1.0 | 0.501429793505
+22239 more rows | |
+
+#### After running simulation in the browser, get saved positions
+
+The whole simulation takes a minute to stabilize. I could just download an
+image, but there are extra features like pressing the node opens pypi.
+
+Download all positions after the simulation from the javascript console:
+
+```python
+
+ var positions = nodes.map(function bar (n) { return [n.id, n.x, n.y]; })
+ JSON.stringify()
+
+```
+
+Join the positions x and y with edges dataframe, so they will get picked up by
+the d3.
+
+pos_df = pd.read_json("fixed-positions.json")
+pos_df.columns = ["id", "x", "y"]
+nodes_df = nodes_df.merge(pos_df, on="id")
+
+#### Truncate nodes DataFrame
+
+# c will be collision strength. Prevent labels from overlaping.
+nodes_df["c"] = pd.DataFrame([nodes_df.label.str.len() * 1.8,
+nodes_df.r]).max() + 5
+nodes_df = nodes_df[["id", "r", "label", "c", "x", "y"]]
+df_to_org(nodes_df)
+
+id | r | label | c | x | y
+---|---|---|---|---|---
+0 | 75.711381704 | os | 80.711381704 | 158.70817237 | 396.074393369
+1 | 67.4690570169 | sys | 72.4690570169 | 362.371142521 | -292.138913114
+2 | 60.4915169887 | django | 65.4915169887 | 526.471326062 | 1607.83507287
+3 | 52.0701286903 | __future__ | 57.0701286903 | 1354.91212894 | 680.325432179
+4 | 47.2662138808 | time | 52.2662138808 | 419.407448663 | 439.872927665
+3460 more rows | | | | |
+
+#### 保存文件到json
+
+# Truncate columns
+with open("graph.js", "w") as f:
+f.write("var nodes = {}\n\n".format(nodes_df.to_dict(orient="records")))
+f.write("var nodeIds = {}\n".format(id_map))
+f.write("var links = {}\n\n".format(edges_df.to_dict(orient="records")))
+
+### 使用新的d3速度verlet集成算法绘制图
+
+The physical simulation Simulation uses the new [velocity verlet integration force graph in d3 v 4.0.](https://github.com/d3/d3/blob/master/API.md#forces-d3-force) Simulation
+takes about one minute to stabilize, so for viewing purposes I hard-coded the
+position of node after running simulation on my machine.
+
+The core component of the simulation is:
+
+```python
+
+ var simulation = d3.forceSimulation(nodes)
+ .force("charge", d3.forceManyBody().strength(-400))
+ .force("link", d3.forceLink(links).distance(30).strength(function (d) {
+ return d.strength * d.strength;
+ }))
+ .force("collide", d3.forceCollide().radius(function(d) {
+ return d.c;
+ }).strength(5))
+ .force("x", d3.forceX().strength(0.1))
+ .force("y", d3.forceY().strength(0.1))
+ .on("tick", ticked);
+
+```
+
+To re-run the simulation you can:
+
+ * Remove fixed positions added in one of pandas processing steps.
+ * Uncomment the "forces" in the [javascript file.](https://github.com/kozikow/kozikow-blog/blob/master/clustering/index2.js#L2)
+
+#### 仿真参数
+
+I have been tweaking simulation parameters for a while. Very dense "center" of
+the graph is in conflict with clusters on the edge of the graph.
+
+As you may see in the current graph, nodes in the center sometimes overlap,
+while distance between nodes on the edge of a graph is big.
+
+I got as much as I could from the collision parameter and increasing it
+further wasn't helpful. Potentially I could increase gravity towards the
+center, but then some of the valuable "clusters" from edges of the graph got
+lumped into the big "kernel" in the center.
+
+Plotting some big clusters separately worked well to solve this problem.
+
+ * 引力
+
+ * 包A和包B之间的边权重: ,距离为30
+ * 向心重力:0.1
+
+ * 斥力
+
+ * 节点间的斥力: -400
+ * 节点的碰撞强度:5
diff --git "a/\344\275\240\350\257\245\347\233\270\344\277\241\350\260\201\347\232\204\350\257\204\345\210\206\357\274\237IMDB\357\274\214\347\203\202\347\225\252\350\214\204\357\274\214Metacritic\357\274\214\350\277\230\346\230\257Fandango\357\274\237.md" "b/\344\275\240\350\257\245\347\233\270\344\277\241\350\260\201\347\232\204\350\257\204\345\210\206\357\274\237IMDB\357\274\214\347\203\202\347\225\252\350\214\204\357\274\214Metacritic\357\274\214\350\277\230\346\230\257Fandango\357\274\237.md"
new file mode 100644
index 0000000..d761113
--- /dev/null
+++ "b/\344\275\240\350\257\245\347\233\270\344\277\241\350\260\201\347\232\204\350\257\204\345\210\206\357\274\237IMDB\357\274\214\347\203\202\347\225\252\350\214\204\357\274\214Metacritic\357\274\214\350\277\230\346\230\257Fandango\357\274\237.md"
@@ -0,0 +1,3 @@
+原文:[Whose ratings should you trust? IMDB, Rotten Tomatoes, Metacritic, or Fandango?](https://medium.freecodecamp.com/whose-reviews-should-you-trust-imdb-rotten-tomatoes-metacritic-or-fandango-7d1010c6cf19)
+
+---
\ No newline at end of file
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/README.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/README.md"
new file mode 100644
index 0000000..beff5db
--- /dev/null
+++ "b/\350\257\273\344\271\246\347\254\224\350\256\260/README.md"
@@ -0,0 +1,2 @@
+* [官方 python 教程(python 3)](https://docs.python.org/zh-cn/3/tutorial/index.html) | [思维导图](http://naotu.baidu.com/file/a50273db8bba3a2c7f257f039d06e7c1?token=f389efed04f2e4b8)
+*
\ No newline at end of file
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/1. Python \346\225\260\346\215\256\346\250\241\345\236\213.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/1. Python \346\225\260\346\215\256\346\250\241\345\236\213.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/10.\345\272\217\345\210\227\347\232\204\344\277\256\346\224\271\343\200\201\346\225\243\345\210\227\345\222\214\345\210\207\347\211\207.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/10.\345\272\217\345\210\227\347\232\204\344\277\256\346\224\271\343\200\201\346\225\243\345\210\227\345\222\214\345\210\207\347\211\207.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/11.\346\216\245\345\217\243\357\274\232\344\273\216\345\215\217\350\256\256\345\210\260\346\212\275\350\261\241\345\237\272\347\261\273.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/11.\346\216\245\345\217\243\357\274\232\344\273\216\345\215\217\350\256\256\345\210\260\346\212\275\350\261\241\345\237\272\347\261\273.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/12.\347\273\247\346\211\277\347\232\204\344\274\230\347\274\272\347\202\271.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/12.\347\273\247\346\211\277\347\232\204\344\274\230\347\274\272\347\202\271.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/13.\346\255\243\347\241\256\351\207\215\350\275\275\350\277\220\347\256\227\347\254\246.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/13.\346\255\243\347\241\256\351\207\215\350\275\275\350\277\220\347\256\227\347\254\246.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/14. \345\217\257\345\217\240\346\210\264\347\232\204\345\257\271\350\261\241\343\200\201\350\277\255\344\273\243\345\231\250\345\222\214\347\224\237\346\210\220\345\231\250.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/14. \345\217\257\345\217\240\346\210\264\347\232\204\345\257\271\350\261\241\343\200\201\350\277\255\344\273\243\345\231\250\345\222\214\347\224\237\346\210\220\345\231\250.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/15. \344\270\212\344\270\213\346\226\207\347\256\241\347\220\206\345\231\250\345\222\214 else \345\235\227.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/15. \344\270\212\344\270\213\346\226\207\347\256\241\347\220\206\345\231\250\345\222\214 else \345\235\227.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/16. \345\215\217\347\250\213.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/16. \345\215\217\347\250\213.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/17. \344\275\277\347\224\250\346\234\237\347\211\251\345\244\204\347\220\206\345\271\266\345\217\221.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/17. \344\275\277\347\224\250\346\234\237\347\211\251\345\244\204\347\220\206\345\271\266\345\217\221.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/18. \344\275\277\347\224\250 asyncio \345\214\205\345\244\204\347\220\206\345\271\266\345\217\221.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/18. \344\275\277\347\224\250 asyncio \345\214\205\345\244\204\347\220\206\345\271\266\345\217\221.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/19. \345\212\250\346\200\201\345\261\236\346\200\247\345\222\214\347\211\271\346\200\247.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/19. \345\212\250\346\200\201\345\261\236\346\200\247\345\222\214\347\211\271\346\200\247.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/2. \345\272\217\345\210\227\346\236\204\346\210\220\347\232\204\346\225\260\347\273\204.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/2. \345\272\217\345\210\227\346\236\204\346\210\220\347\232\204\346\225\260\347\273\204.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/20. \345\261\236\346\200\247\346\217\217\350\277\260\347\254\246.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/20. \345\261\236\346\200\247\346\217\217\350\277\260\347\254\246.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/21. \347\261\273\345\205\203\347\274\226\347\250\213.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/21. \347\261\273\345\205\203\347\274\226\347\250\213.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/3. \345\255\227\345\205\270\345\222\214\351\233\206\345\220\210.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/3. \345\255\227\345\205\270\345\222\214\351\233\206\345\220\210.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/4. \346\226\207\346\234\254\345\222\214\345\255\227\350\212\202\345\272\217\345\210\227.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/4. \346\226\207\346\234\254\345\222\214\345\255\227\350\212\202\345\272\217\345\210\227.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/5.\344\270\200\347\255\211\345\207\275\346\225\260.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/5.\344\270\200\347\255\211\345\207\275\346\225\260.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/6.\344\275\277\347\224\250\344\270\200\347\255\211\345\207\275\346\225\260\345\256\236\347\216\260\350\256\276\350\256\241\346\250\241\345\274\217.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/6.\344\275\277\347\224\250\344\270\200\347\255\211\345\207\275\346\225\260\345\256\236\347\216\260\350\256\276\350\256\241\346\250\241\345\274\217.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/7.\345\207\275\346\225\260\350\243\205\351\245\260\345\231\250\345\222\214\351\227\255\345\214\205.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/7.\345\207\275\346\225\260\350\243\205\351\245\260\345\231\250\345\222\214\351\227\255\345\214\205.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/8.\345\257\271\350\261\241\345\274\225\347\224\250\343\200\201\345\217\257\345\217\230\346\200\247\345\222\214\345\236\203\345\234\276\345\233\236\346\224\266.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/8.\345\257\271\350\261\241\345\274\225\347\224\250\343\200\201\345\217\257\345\217\230\346\200\247\345\222\214\345\236\203\345\234\276\345\233\236\346\224\266.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/9.\347\254\246\345\220\210 python \351\243\216\346\240\274\347\232\204\345\257\271\350\261\241.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/9.\347\254\246\345\220\210 python \351\243\216\346\240\274\347\232\204\345\257\271\350\261\241.md"
new file mode 100644
index 0000000..e69de29
diff --git "a/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/README.md" "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/README.md"
new file mode 100644
index 0000000..80a56e4
--- /dev/null
+++ "b/\350\257\273\344\271\246\347\254\224\350\256\260/\346\265\201\347\225\205\347\232\204 python/README.md"
@@ -0,0 +1,9 @@
+# 流畅的 python
+
+### 本书源代码
+地址:[fluentpython/example-code](https://github.com/fluentpython/example-code)
+
+使用方式:
+```
+$ python3 -m doctest example_script.py
+```
\ No newline at end of file