|
| 1 | +# 06-文档转换实战 |
| 2 | + |
| 3 | +## 1 文档切割器和按字符分割 |
| 4 | + |
| 5 | +### 1.1 原理 |
| 6 | + |
| 7 | +1. 将文档分成小的、有意义的块(句子). |
| 8 | +2. 将小的块组合成为一个更大的块,直到达到一定的大小. |
| 9 | +3. 一旦达到一定的大小,接着开始创建与下一个块重叠的部分. |
| 10 | + |
| 11 | +### 1.2 示例 |
| 12 | + |
| 13 | +#### 第一个文档分割 |
| 14 | + |
| 15 | +```python |
| 16 | +from langchain.text_splitter import RecursiveCharacterTextSplitter |
| 17 | + |
| 18 | +#加载要切割的文档 |
| 19 | +with open("test.txt") as f: |
| 20 | + zuizhonghuanxiang = f.read() |
| 21 | + |
| 22 | +#初始化切割器 |
| 23 | +text_splitter = RecursiveCharacterTextSplitter( |
| 24 | + chunk_size=50,#切分的文本块大小,一般通过长度函数计算 |
| 25 | + chunk_overlap=20,#切分的文本块重叠大小,一般通过长度函数计算 |
| 26 | + length_function=len,#长度函数,也可以传递tokenize函数 |
| 27 | + add_start_index=True,#是否添加起始索引 |
| 28 | +) |
| 29 | + |
| 30 | +text = text_splitter.create_documents([zuizhonghuanxiang]) |
| 31 | +text[0] |
| 32 | +text[1] |
| 33 | +``` |
| 34 | + |
| 35 | +#### 按字符切割 |
| 36 | + |
| 37 | +```python |
| 38 | +from langchain.text_splitter import CharacterTextSplitter |
| 39 | + |
| 40 | +#加载要切分的文档 |
| 41 | +with open("test.txt") as f: |
| 42 | + zuizhonghuanxiang = f.read() |
| 43 | + |
| 44 | +#初始化切分器 |
| 45 | +text_splitter = CharacterTextSplitter( |
| 46 | + separator="。",#切割的标志字符,默认是\n\n |
| 47 | + chunk_size=50,#切分的文本块大小,一般通过长度函数计算 |
| 48 | + chunk_overlap=20,#切分的文本块重叠大小,一般通过长度函数计算 |
| 49 | + length_function=len,#长度函数,也可以传递tokenize函数 |
| 50 | + add_start_index=True,#是否添加起始索引 |
| 51 | + is_separator_regex=False,#是否是正则表达式 |
| 52 | +) |
| 53 | +text = text_splitter.create_documents([zuizhonghuanxiang]) |
| 54 | +print(text[0]) |
| 55 | +``` |
| 56 | + |
| 57 | + |
| 58 | + |
| 59 | +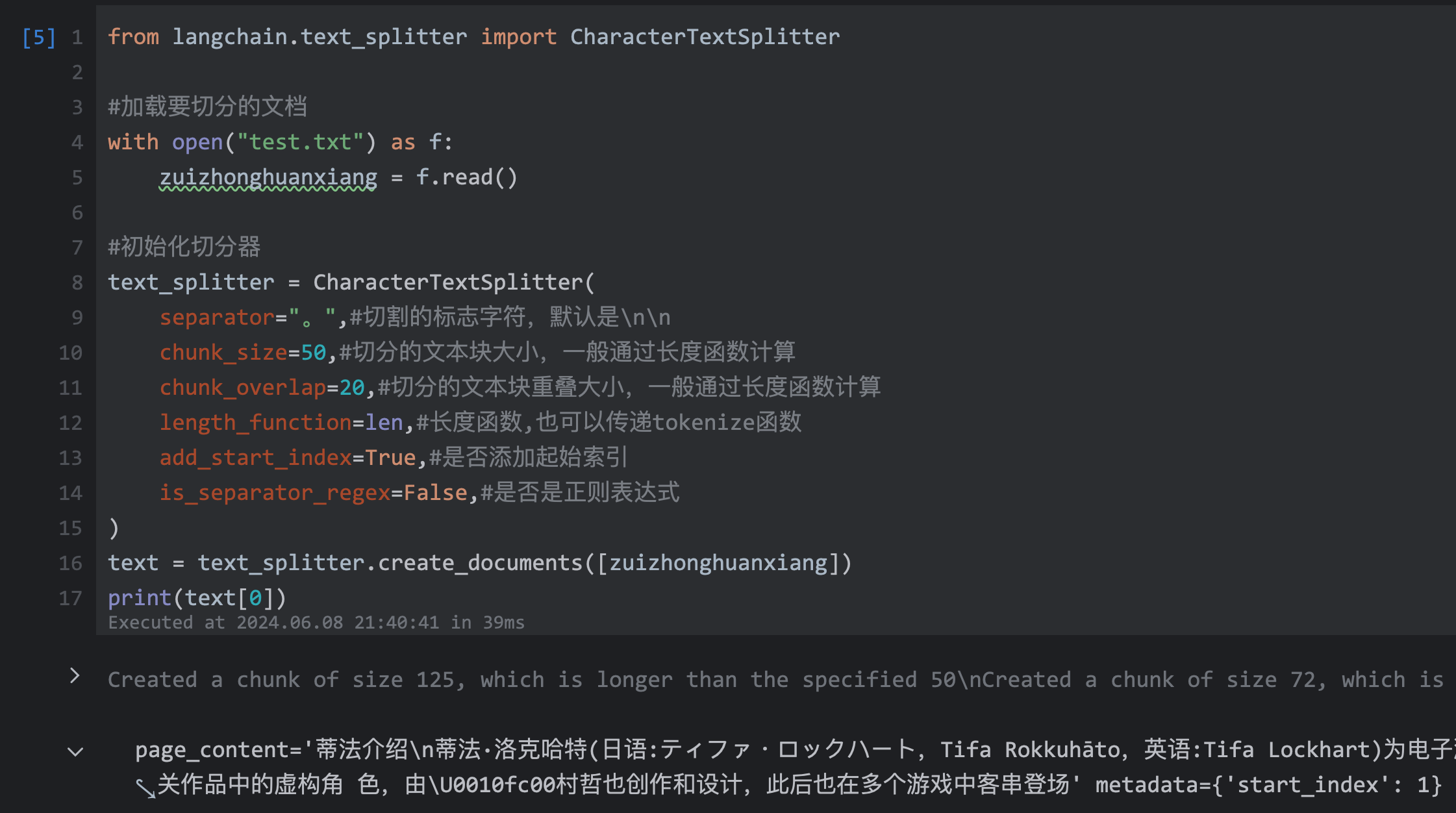 |
| 60 | + |
| 61 | +## 2 代码文档分割器 |
| 62 | + |
| 63 | +```python |
| 64 | +from langchain.text_splitter import ( |
| 65 | + RecursiveCharacterTextSplitter, |
| 66 | + Language, |
| 67 | +) |
| 68 | + |
| 69 | +#支持解析的编程语言 |
| 70 | +#[e.value for e in Language] |
| 71 | + |
| 72 | +#要切割的代码文档 |
| 73 | +PYTHON_CODE = """ |
| 74 | +def hello_world(): |
| 75 | + print("Hello, World!") |
| 76 | +#调用函数 |
| 77 | +hello_world() |
| 78 | +""" |
| 79 | +py_spliter = RecursiveCharacterTextSplitter.from_language( |
| 80 | + language=Language.PYTHON, |
| 81 | + chunk_size=50, |
| 82 | + chunk_overlap=10, |
| 83 | +) |
| 84 | +python_docs = py_spliter.create_documents([PYTHON_CODE]) |
| 85 | +python_docs |
| 86 | +``` |
| 87 | + |
| 88 | +## 3 按token分割文档 |
| 89 | + |
| 90 | +```python |
| 91 | +from langchain.text_splitter import CharacterTextSplitter |
| 92 | + |
| 93 | +#要切割的文档 |
| 94 | +with open("test.txt") as f: |
| 95 | + zuizhonghuanxiang = f.read() |
| 96 | + |
| 97 | +#初始化切分器 |
| 98 | +text_splitter = CharacterTextSplitter.from_tiktoken_encoder( |
| 99 | + chunk_size=4000,#切分的文本块大小,一般通过长度函数计算 |
| 100 | + chunk_overlap=30,#切分的文本块重叠大小,一般通过长度函数计算 |
| 101 | +) |
| 102 | + |
| 103 | +text = text_splitter.create_documents([zuizhonghuanxiang]) |
| 104 | +print(text[0]) |
| 105 | +``` |
| 106 | + |
| 107 | + |
| 108 | + |
| 109 | +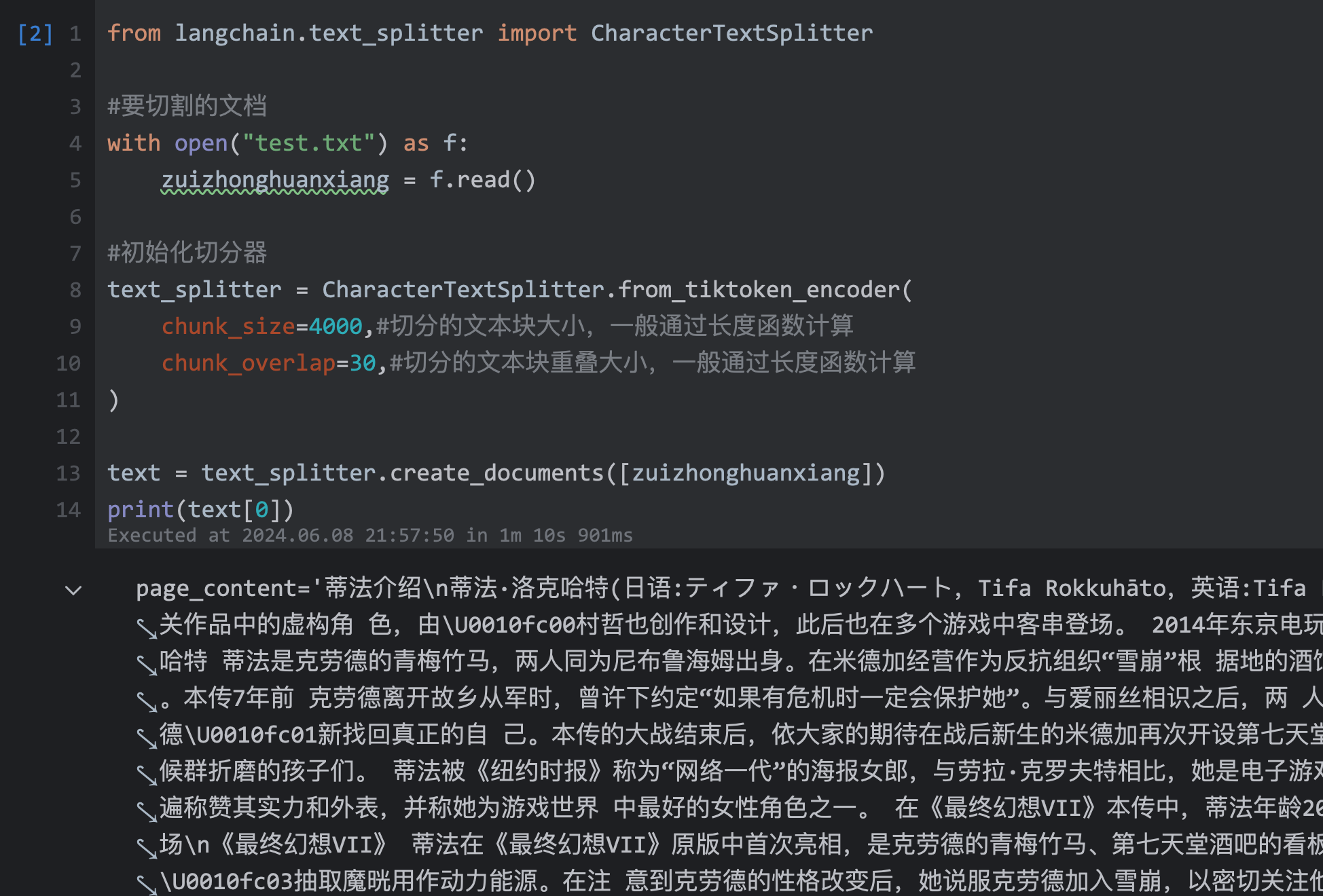 |
| 110 | + |
| 111 | + |
| 112 | + |
| 113 | +## 4 文档总结、精炼、翻译 |
| 114 | + |
| 115 | +先装包: |
| 116 | + |
| 117 | +```python |
| 118 | +! pip install doctran==0.0.14 |
| 119 | +``` |
| 120 | + |
| 121 | + |
| 122 | + |
| 123 | +先加载文档: |
| 124 | + |
| 125 | +```python |
| 126 | +with open("letter.txt") as f: |
| 127 | + content = f.read() |
| 128 | +``` |
| 129 | + |
| 130 | +```python |
| 131 | +from dotenv import load_dotenv |
| 132 | +import os |
| 133 | +load_dotenv("openai.env") |
| 134 | +OPENAI_API_KEY = os.environ.get("OPEN_API_KEY") |
| 135 | +OPENAI_API_BASE = os.environ.get("OPENAI_API_BASE") |
| 136 | +OPENAI_MODEL = "gpt-3.5-turbo-16k" |
| 137 | +OPENAI_TOKEN_LIMIT = 8000 |
| 138 | + |
| 139 | +from doctran import Doctran |
| 140 | +doctrans = Doctran( |
| 141 | + openai_api_key=OPENAI_API_KEY, |
| 142 | + openai_model=OPENAI_MODEL, |
| 143 | + openai_token_limit=OPENAI_TOKEN_LIMIT, |
| 144 | +) |
| 145 | +documents = doctrans.parse(content=content) |
| 146 | +``` |
| 147 | + |
| 148 | +### 4.1 总结 |
| 149 | + |
| 150 | +```python |
| 151 | +summary = documents.summarize(token_limit=100).execute() |
| 152 | +print(summary.transformed_content) |
| 153 | +``` |
| 154 | + |
| 155 | +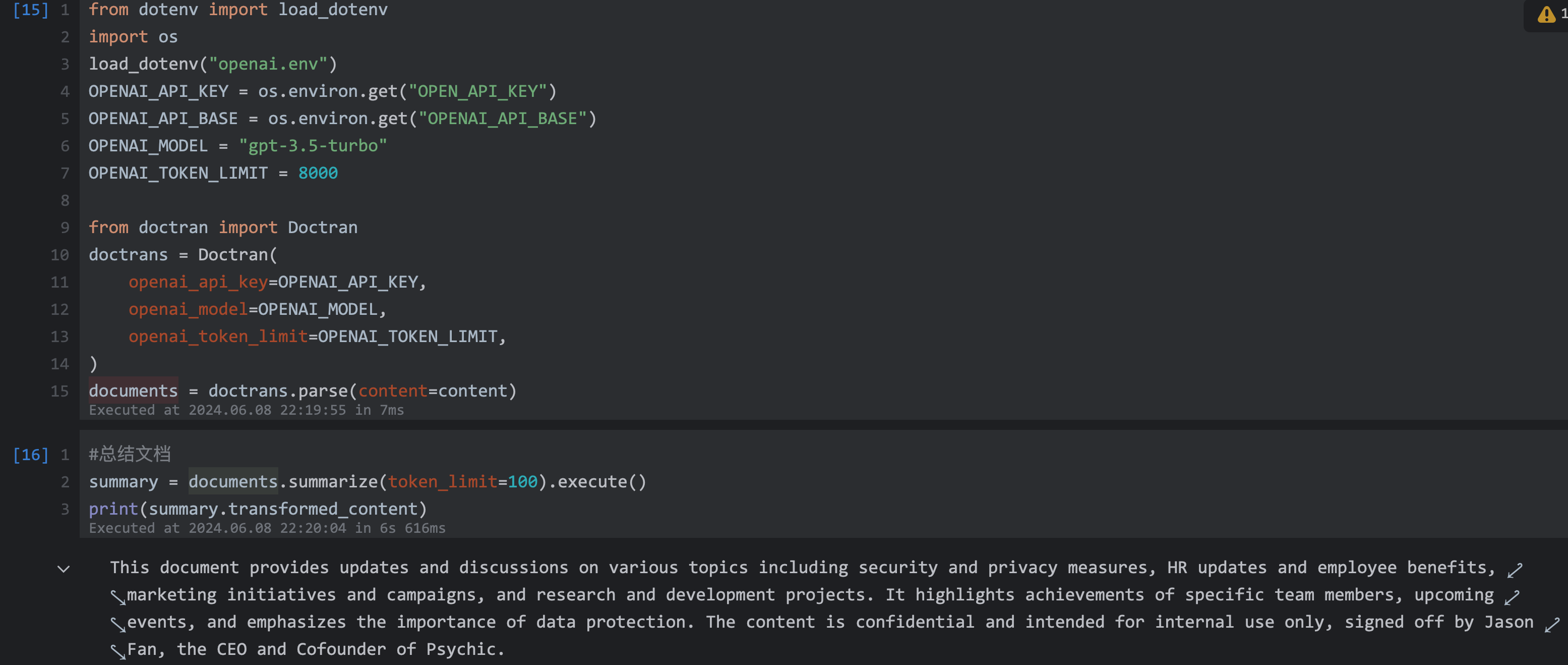 |
| 156 | + |
| 157 | +### 4.2 翻译 |
| 158 | + |
| 159 | +```python |
| 160 | +translation = documents.translate(language="chinese").execute() |
| 161 | +print(translation.transformed_content) |
| 162 | +``` |
| 163 | + |
| 164 | +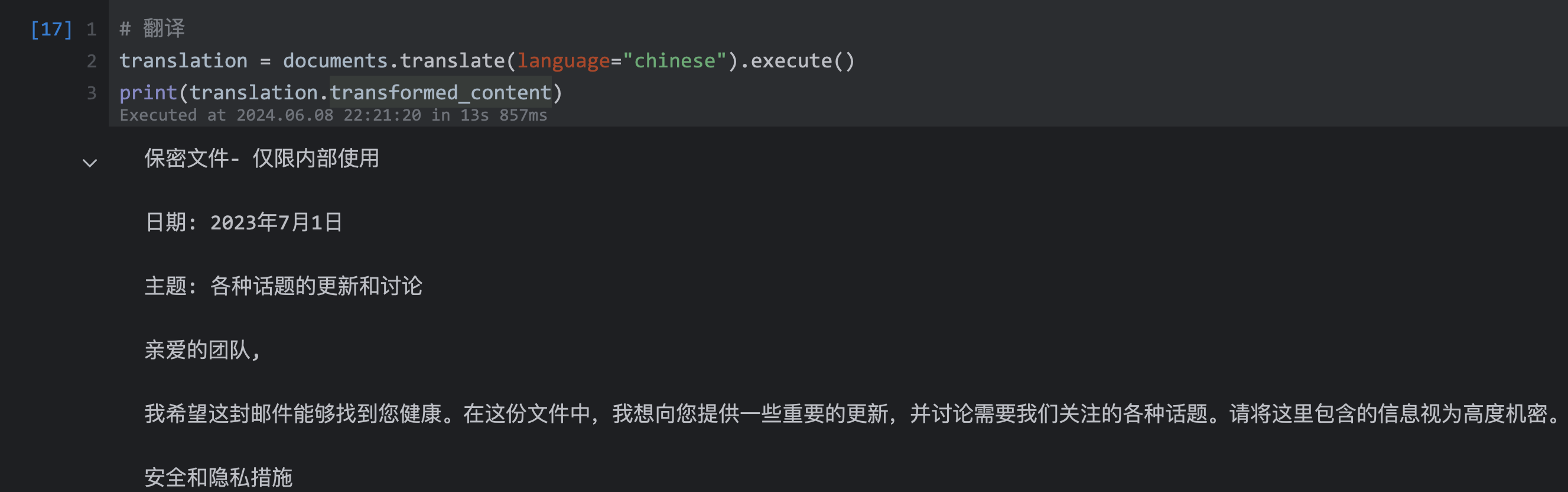 |
| 165 | + |
| 166 | +### 4.3 精炼 |
| 167 | + |
| 168 | +删除除了某个主题或关键词之外的内容,仅保留与主题相关的内容 |
| 169 | + |
| 170 | +```python |
| 171 | +refined = documents.refine(topics=["marketing","Development"]).execute() |
| 172 | +print(refined.transformed_content) |
| 173 | +``` |
| 174 | + |
| 175 | +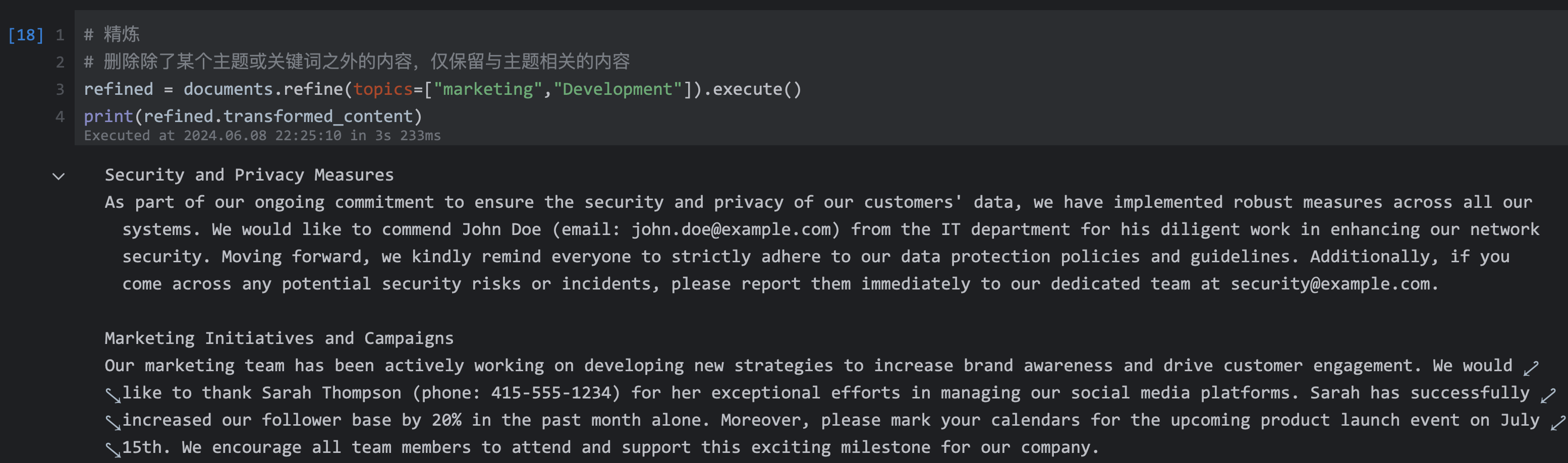 |
0 commit comments