|
| 1 | +# 让 LLM 既能“看”又能“推理”! |
| 2 | + |
| 3 | + |
| 4 | + |
| 5 | +DeepSeek-R1 会推理,GPT-4o 会看。能否让 |
| 6 | + |
| 7 | +## 1 LLM既能看又能推理? |
| 8 | + |
| 9 | +DeepSeek-R1取得很大成功,但它有个问题——**无法处理图像输入**。 |
| 10 | + |
| 11 | +### 1.1 DeepSeek模型发展 |
| 12 | + |
| 13 | +自2024.12,DeepSeek已发布: |
| 14 | + |
| 15 | +- **DeepSeek-V3**(2024.12):视觉语言模型(VLM),支持图像和文本输入,类似 GPT-4o |
| 16 | +- **DeepSeek-R1**(2025.1):大规模推理模型(LRM),仅支持文本输入,但具备更强的推理能力,类似 OpenAI-o1 |
| 17 | + |
| 18 | +我们已领略**视觉语言模型(VLM)**和**大规模推理模型(LRM)**,下一个是谁? |
| 19 | + |
| 20 | +我们需要**视觉推理模型(VRM)**——既能看又能推理。本文探讨如何实现它。 |
| 21 | + |
| 22 | +## 2 现有模型的问题 |
| 23 | + |
| 24 | +当前VLM 不能很好推理,而 LRM 只能处理文本,无法理解视觉信息。若想要一个既能**看懂图像**,又能**深度推理**的模型? |
| 25 | + |
| 26 | +### 物理问题示例 |
| 27 | + |
| 28 | +我是一个学生,向 LLM 提问物理问题,并附带一张图像。 |
| 29 | + |
| 30 | +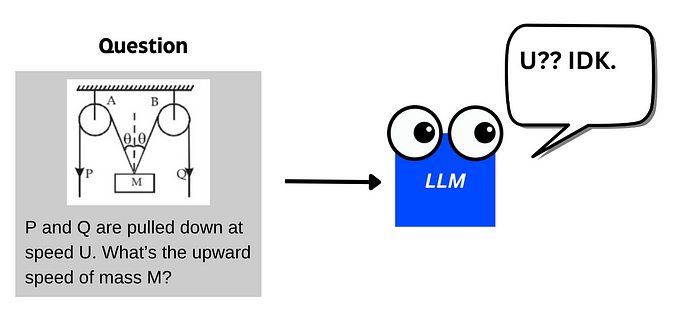 |
| 31 | + |
| 32 | +就需要一个模型能同时: |
| 33 | + |
| 34 | +1. **理解图像内容** |
| 35 | +2. **进行深度推理**(如分析问题、评估答案、考虑多种可能性) |
| 36 | + |
| 37 | +就需要👉 **一个大规模视觉推理模型(VRM)**,视觉推理模型示意图: |
| 38 | + |
| 39 | + |
| 40 | + |
| 41 | +讨论咋训练 VRM 之前,先了解VLM(视觉语言模型)架构。 |
| 42 | + |
| 43 | +## 3 VLM架构 |
| 44 | + |
| 45 | +如LLaVA,**L**arge **L**anguage **a**nd **V**ision **A**ssistant(大规模语言与视觉助手),2023年底发布的知名 VLM。 |
| 46 | + |
| 47 | +LLM 通常采用 Transformer 结构,输入文本后将其转化为 token,再通过数学计算预测下一个 token。 |
| 48 | + |
| 49 | +如若输入文本 **"Donald Trump is the"**,LLM可能预测下一 token 为 **"POTUS"(美国总统)**。LLM 预测过程示意图: |
| 50 | + |
| 51 | +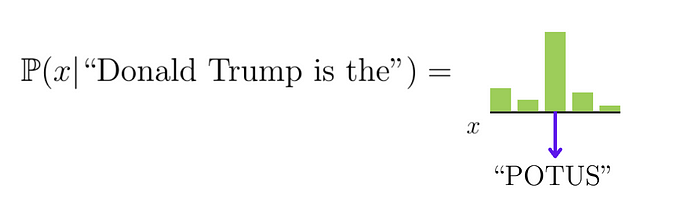 |
| 52 | + |
| 53 | +那VLM咋工作的?VLM不仅根据前面的文本预测输出,还会参考输入的**图像**。VLM 预测过程示意图: |
| 54 | + |
| 55 | + |
| 56 | + |
| 57 | +但**咋让 LLM 理解图像?** |
| 58 | + |
| 59 | +## 4 VLM咋处理图像输入? |
| 60 | + |
| 61 | +核心思路:**将图像数据转换成 LLM 能理解的格式**。 |
| 62 | + |
| 63 | +LLaVA论文用 **CLIP 视觉编码器**将图像转化为向量。然后,在编码器后添加一个**可训练的线性层**。图像编码示意图: |
| 64 | + |
| 65 | +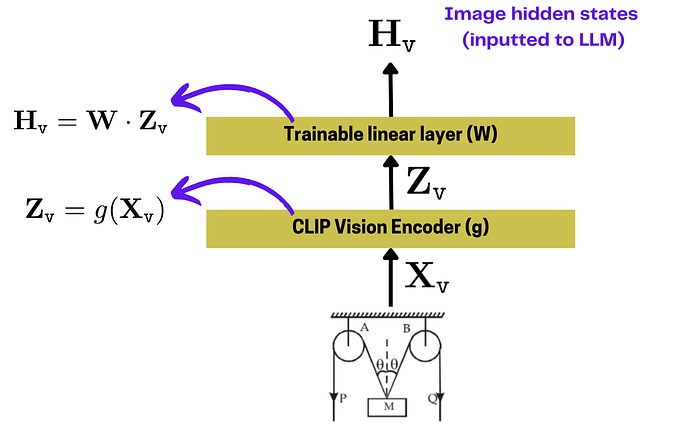 |
| 66 | + |
| 67 | +最终的视觉隐藏状态(**Hv**)会与文本 token 的隐藏状态拼接在一起,输入 Transformer 层,最后生成预测结果。 |
| 68 | + |
| 69 | +LLaVA 在这里使用的是 **Vicuna** 作为 LLM。 |
| 70 | + |
| 71 | +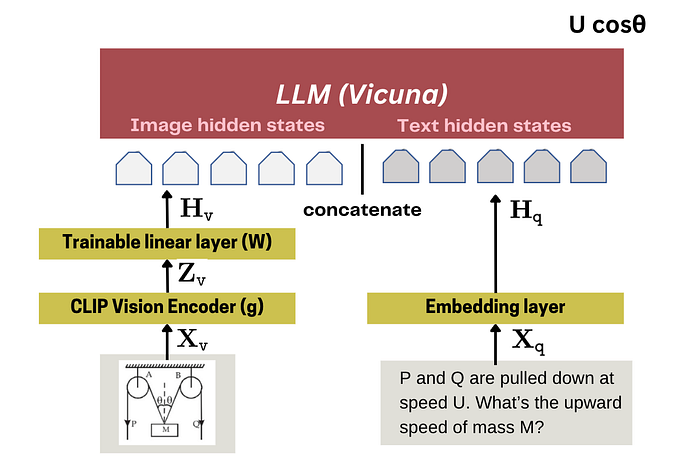 |
| 72 | + |
| 73 | +不过,仅仅有这个结构是不够的,模型还需要**训练**,才能真正理解图像内容。 |
| 74 | + |
| 75 | +## 5 VLM咋训练? |
| 76 | + |
| 77 | +LLaVA 采用了**端到端微调(End-to-End Fine-tuning)**的方式。 |
| 78 | + |
| 79 | +> **端到端微调**:将整个模型视作一个黑盒,并进行整体训练。 |
| 80 | +
|
| 81 | +LLaVA 端到端微调示意图: |
| 82 | + |
| 83 | +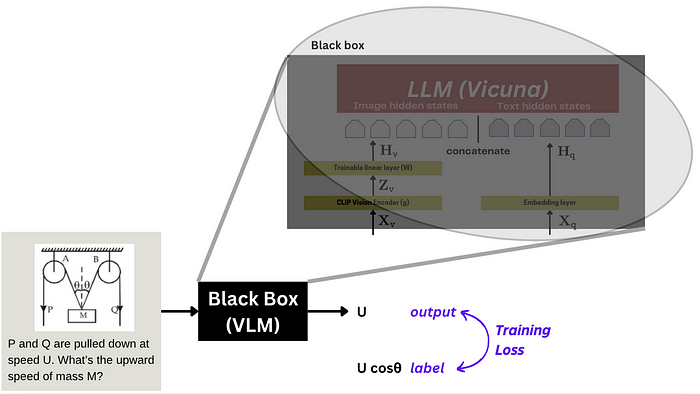 |
| 84 | + |
| 85 | +训练时,**CLIP编码器的参数通常是冻结的**,只更新线性层(**W**)和 LLM(**ϕ**)的参数。LLaVA 微调过程示意图: |
| 86 | + |
| 87 | +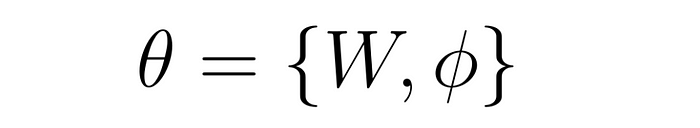 |
| 88 | + |
| 89 | +## 6 能否用强化学习(RL)训练 VLM? |
| 90 | + |
| 91 | +RL在 LLM 领域表现出色,提升了推理能力(如 RLHF 训练的 GPT-4)。**若用 RL 训练 VLM,是否能打造更强的视觉推理模型?** |
| 92 | + |
| 93 | +以**图像分类任务**为例。 |
| 94 | + |
| 95 | +### 6.1 任务定义:图像分类 |
| 96 | + |
| 97 | +训练时,希望模型能**根据图像内容,输出正确的类别标签**。 |
| 98 | + |
| 99 | +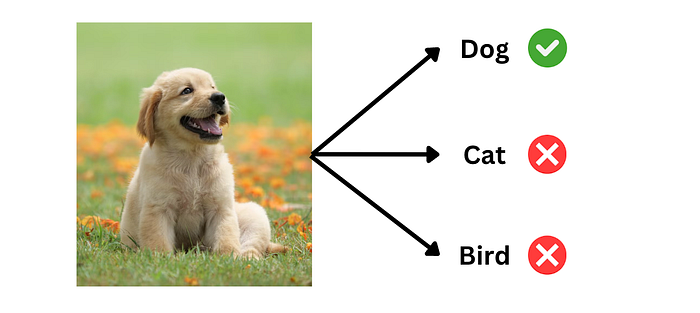 |
| 100 | + |
| 101 | +数据集中的每条数据包括:**图像、标题(正确答案)、问题**。 |
| 102 | + |
| 103 | + |
| 104 | + |
| 105 | +### 强化学习奖励设计 |
| 106 | + |
| 107 | +可设计两种奖励机制: |
| 108 | + |
| 109 | +1. **正确性奖励**:如果模型输出的答案正确(例如"dog"),则奖励 +1。 |
| 110 | + |
| 111 | + 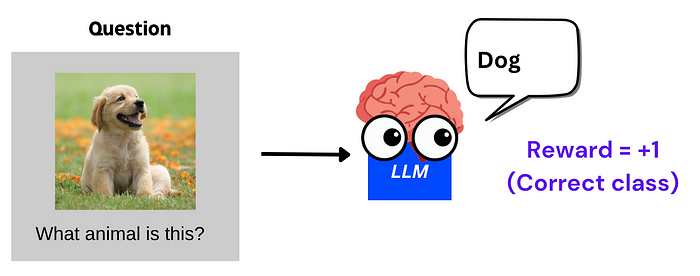 |
| 112 | + |
| 113 | +2. **格式奖励**:如果模型按照固定格式输出(先思考 `<think>`,再回答 `<answer>`),则额外奖励。 |
| 114 | + |
| 115 | + 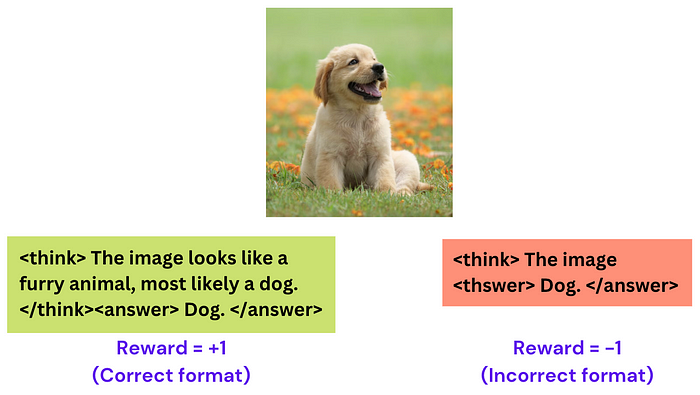 |
| 116 | + |
| 117 | +这可鼓励模型在回答前进行推理,而不是盲目给出答案。 |
| 118 | + |
| 119 | +## 7 实际应用 |
| 120 | + |
| 121 | +VLM目前在某些场景仍表现不佳,如**数学和科学类问题**。 |
| 122 | + |
| 123 | +如题目正确答案 **2 bpm**,但 GPT-4o 回答错误: |
| 124 | + |
| 125 | +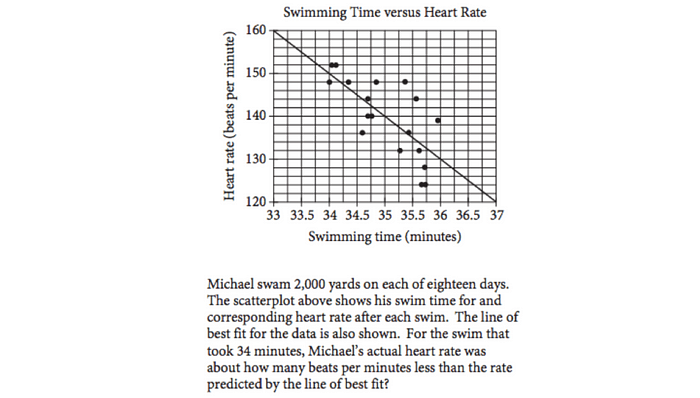 |
| 126 | + |
| 127 | +GPT-4o错误回答: |
| 128 | + |
| 129 | +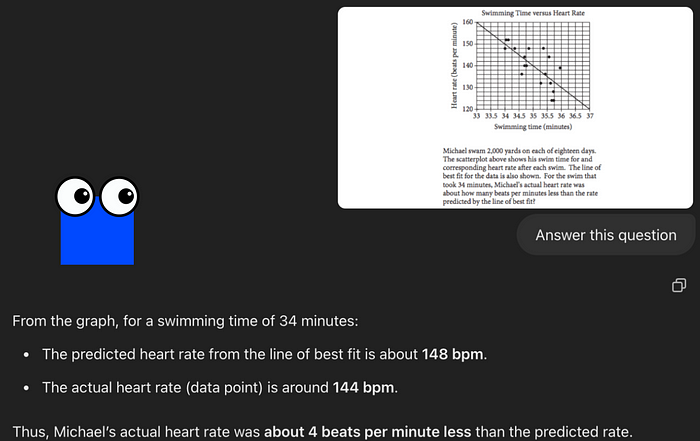 |
| 130 | + |
| 131 | +如能让 LLM 在视觉推理方面更强,或许能正确解答。期望的 VRM 结果: |
| 132 | + |
| 133 | +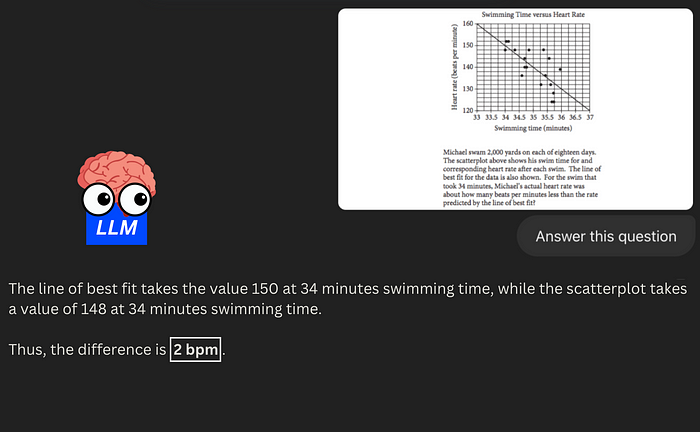 |
0 commit comments