|
| 1 | +# Hive执行原理 |
| 2 | + |
| 3 | +MapReduce简化大数据编程难度,但对经常需大数据计算的人,如从事研究BI的数据分析师通常使用SQL进行大数据分析和统计,MapReduce编程有门槛。且若每次统计和分析都开发相应MapReduce程序,成本确实太高。 |
| 4 | + |
| 5 | +是否可直接将SQL运行在大数据平台?如何用MapReduce实现SQL数据分析。 |
| 6 | + |
| 7 | +## 1 MapReduce实现SQL的原理 |
| 8 | + |
| 9 | +常见的一条SQL分析语句,MapReduce如何编程实现? |
| 10 | + |
| 11 | +```sql |
| 12 | +# 统计分析语句 |
| 13 | +SELECT pageid, age, count(1) |
| 14 | +FROM pv_users |
| 15 | +GROUP BY pageid, age; |
| 16 | +``` |
| 17 | + |
| 18 | +统计不同年龄用户访问不同网页的兴趣偏好: |
| 19 | + |
| 20 | + |
| 21 | + |
| 22 | +- 左边,要分析的数据表 |
| 23 | +- 右边,分析结果 |
| 24 | + |
| 25 | +把左表相同的行求和,即得右表,类似WordCount。该SQL的MapReduce的计算过程,按MapReduce编程模型 |
| 26 | + |
| 27 | +- map函数的输入K和V,主要看V |
| 28 | + |
| 29 | + V就是左表中每行的数据,如<1, 25> |
| 30 | + |
| 31 | +- map函数的输出就是以输入的V作为K,V统一设为1 |
| 32 | + |
| 33 | + 比如<<1, 25>, 1> |
| 34 | + |
| 35 | +map函数的输出shuffle后,相同K及对应V放在一起,组成一个<K, V集合>,作为输入交给reduce函数处理。如<<2, 25>, 1>被map函数输出两次,到reduce就变成输入<<2, 25>, <1, 1>>: |
| 36 | + |
| 37 | +- K=<2, 25> |
| 38 | +- V集合=<1, 1> |
| 39 | + |
| 40 | +在reduce函数内部,V集合里所有的数字被相加,然后输出。所以reduce输出就是<<2, 25>, 2> |
| 41 | + |
| 42 | +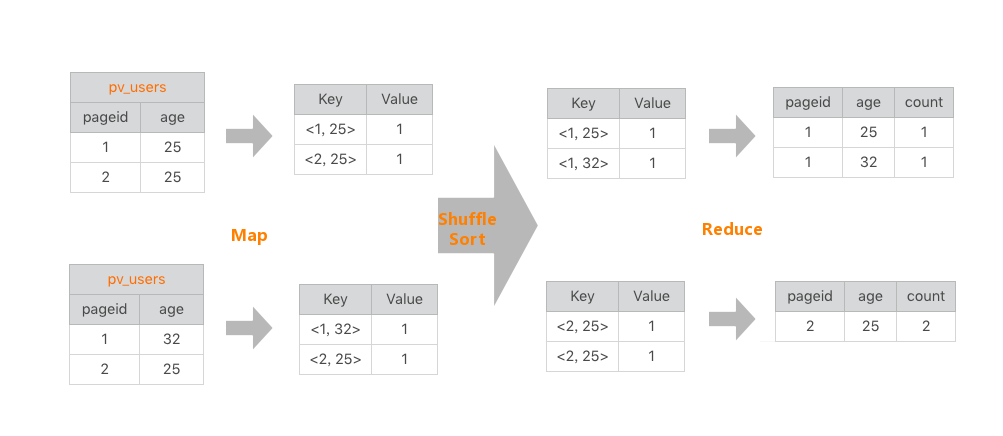 |
| 43 | + |
| 44 | +如此,一条SQL就被MapReduce计算完成。 |
| 45 | + |
| 46 | +数仓中,SQL是最常用的分析工具,既然一条SQL可通过MapReduce程序实现,那有无工具能自动将SQL生成MapReduce代码?这样数据分析师只要输入SQL,即可自动生成MapReduce可执行的代码,然后提交Hadoop执行。这就是Hadoop大数据仓库Hive。 |
| 47 | + |
| 48 | +## 2 Hive架构 |
| 49 | + |
| 50 | +Hive能直接处理我们输的SQL,调用MapReduce计算框架完成数据分析操作。 |
| 51 | + |
| 52 | +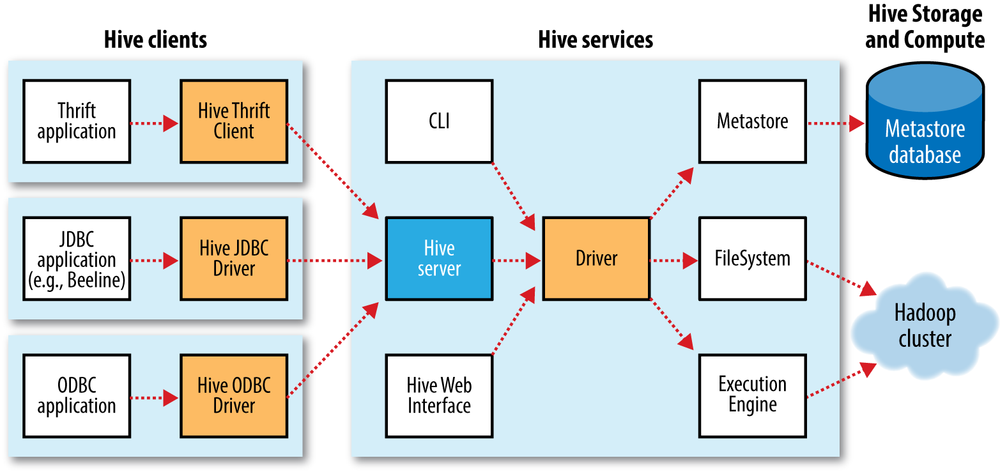 |
| 53 | + |
| 54 | +通过Hive Client向Hive Server提交SQL命令: |
| 55 | + |
| 56 | +- DDL,Hive会通过执行引擎Driver将数据表的信息记录在Metastore元数据组件,该组件通常用一个关系DB实现,记录表名、字段名、字段类型、关联HDFS文件路径等这些数据库的元信息 |
| 57 | +- DQL,Driver会将该语句提交给自己的编译器Compiler进行语法分析、语法解析、语法优化,最后生成一个MapReduce执行计划。然后根据执行计划生成一个MapReduce的作业,提交给Hadoop MapReduce计算框架处理 |
| 58 | + |
| 59 | +对简单SQL: |
| 60 | + |
| 61 | +```sql |
| 62 | +SELECT * FROM status_updates WHERE status LIKE 'michael jackson'; |
| 63 | +``` |
| 64 | + |
| 65 | +对应的Hive执行计划: |
| 66 | + |
| 67 | +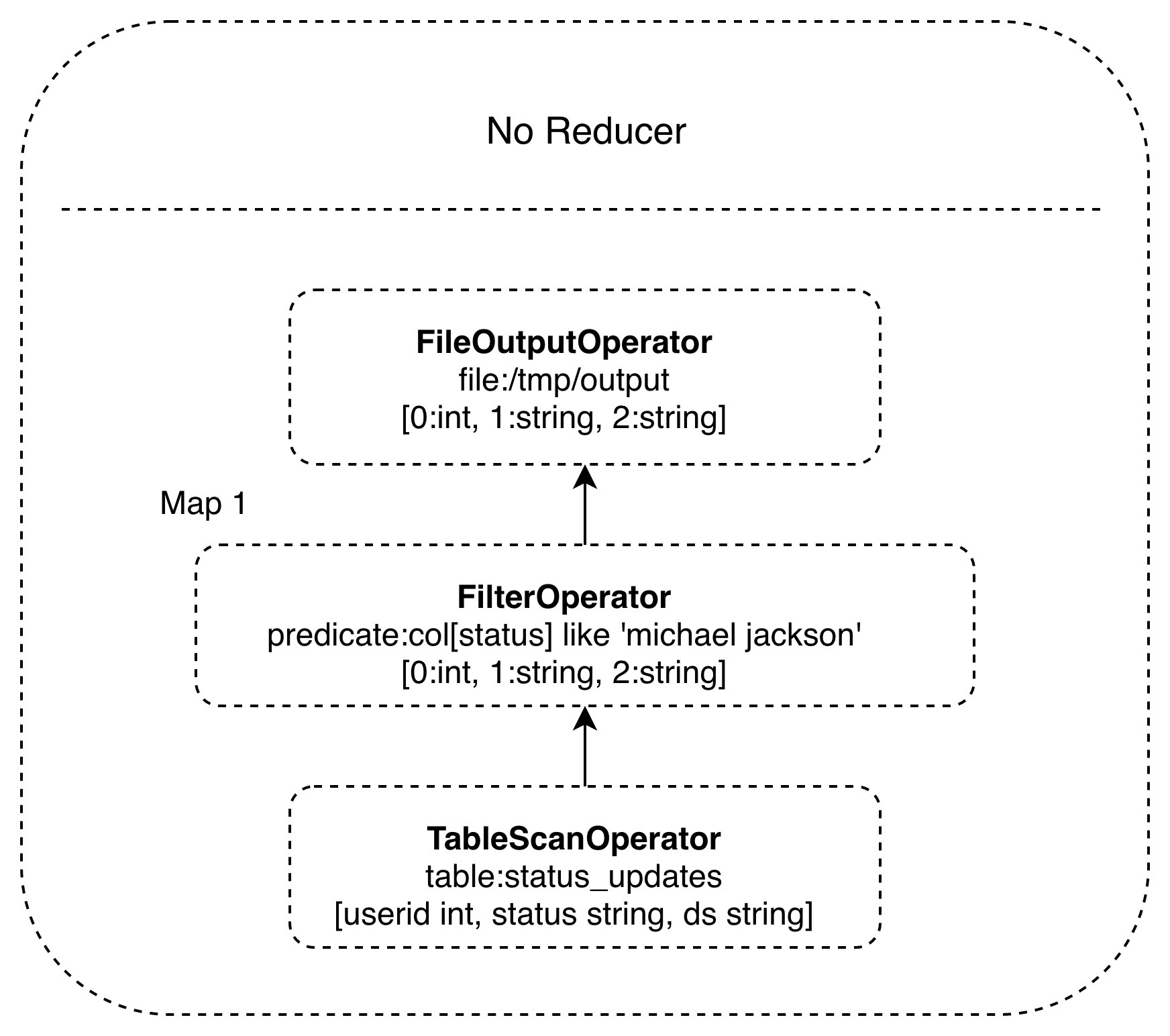 |
| 68 | + |
| 69 | +Hive内部预置很多函数,Hive执行计划就是根据SQL语句生成这些函数的DAG,然后封装进MapReduce的map、reduce函数。该案例中的map函数调用三个Hive内置函数就完成map计算,且无需reduce。 |
| 70 | + |
| 71 | +## Hive join操作 |
| 72 | + |
| 73 | +除简单的聚合(group by)、过滤(where),Hive还能执行连接(join on)。 |
| 74 | + |
| 75 | +pv_users表的数据无法直接得到,因为pageid来自用户访问日志,每个用户进行一次页面浏览,就会生成一条访问记录,保存在page_view表。而age年龄信息记录在表user。 |
| 76 | + |
| 77 | +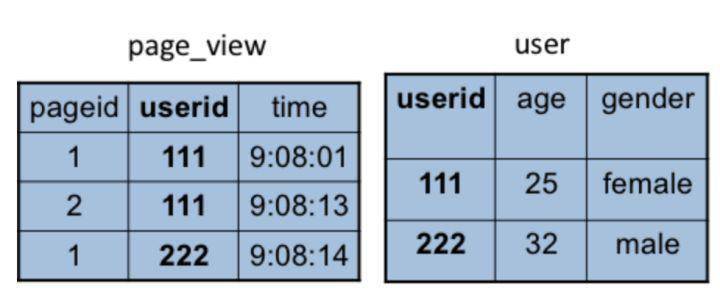 |
| 78 | + |
| 79 | +这两张表有相同字段userid,可连接两张表,生成pv_users表: |
| 80 | + |
| 81 | +```sql |
| 82 | +SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON (pv.userid = u.userid); |
| 83 | +``` |
| 84 | + |
| 85 | +该SQL命令也能转化为MapReduce计算,连接过程: |
| 86 | + |
| 87 | +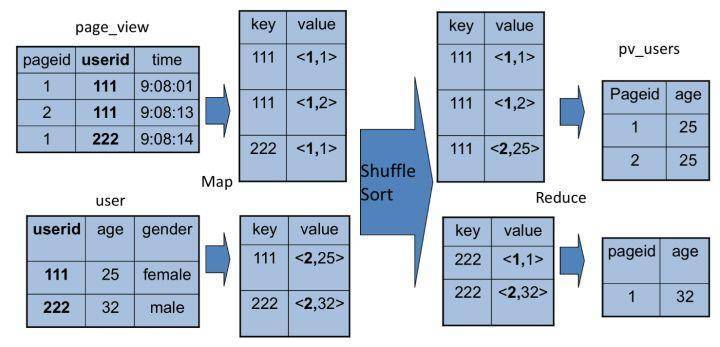 |
| 88 | + |
| 89 | +join的MapReduce计算过程和group by稍不同,因为join涉及两张表,来自两个文件(夹),所以要在map输出时进行标记,如来自第一张表的输出Value就记为<1, X>,这1表示数据来自第一张表。shuffle后,相同Key被输入到同一reduce函数,就可根据表的标记对Value数据求笛卡尔积,用第一张表的每条记录和第二张表的每条记录连接,输出即join结果。 |
| 90 | + |
| 91 | +所以打开Hive源码,看join代码,会看到一个两层for循环,对来自两张表的记录进行连接操作。 |
| 92 | + |
| 93 | +## 功能 |
| 94 | + |
| 95 | +SQL:命令行、代码 |
| 96 | + |
| 97 | +多语言Apache Thrift驱动 |
| 98 | + |
| 99 | +自定义的UDF函数:按照标准接口实现,打包,加载到Hive |
| 100 | + |
| 101 | +## 小结 |
| 102 | + |
| 103 | +SQL转换成一系列可以在Hadoop上运行的MapReduce/Tez/Spark作业。 |
| 104 | + |
| 105 | +SOL到底底层是运行在哪种分布式引擎之上的,是可以通过一个参数来设置。 |
| 106 | + |
| 107 | +## 总结 |
| 108 | + |
| 109 | +开发无需经常编写MapReduce程序,因为网站最主要的大数据处理就是SQL分析,因此Hive很重要。 |
| 110 | + |
| 111 | +随Hive普及,我们对在Hadoop执行SQL的需求越强,对大数据SQL的应用场景也多样化起来,于是又开发各种大数据SQL引擎。 |
| 112 | + |
| 113 | +Cloudera开发Impala,运行在HDFS上的MPP架构的SQL引擎。和MapReduce启动Map、Reduce两种执行进程,将计算过程分成两个阶段进行计算不同,Impala在所有DataNode服务器上部署相同的Impalad进程,多个Impalad进程相互协作,共同完成SQL计算。 |
| 114 | + |
| 115 | +Spark也推出自己的SQL引擎Spark SQL,将SQL语句解析成Spark执行计划,在Spark执行。由于Spark比MapReduce快很多,Spark SQL也比Hive快很多,随Spark普及,Spark SQL也逐渐被接受。后来Hive推出Hive on Spark,将Hive的执行计划直接转换成Spark的计算模型。 |
| 116 | + |
| 117 | +还希望在NoSQL执行SQL,毕竟SQL发展几十年,积累庞大用户,很多人习惯用SQL解决问题。于是Saleforce推出Phoenix,一个执行在HBase上的SQL引擎。 |
| 118 | + |
| 119 | +这些SQL引擎只支持类SQL语法,不像DB支持标准SQL,特别是数仓几乎必用嵌套查询SQL:在where条件里嵌套select子查询,但几乎所有大数据SQL引擎都不支持。 |
| 120 | + |
| 121 | +Hive技术架构没啥创新,数据库相关技术架构已很成熟,只要将这些技术架构应用到MapReduce就得到Hadoop大数据仓库Hive。**但想到将两种技术嫁接,却极具创新性**,通过嫁接产生出的Hive极大降低大数据应用门槛,也使Hadoop普及。 |
| 122 | + |
| 123 | +> 参考 |
| 124 | +> |
| 125 | +> - https://learning.oreilly.com/library/view/hadoop-the-definitive/9781491901687/ch17.html#TheMetastore |
0 commit comments