|
1 | | -# 为啥要学习Spark? |
| 1 | +# 00-为啥要学习Spark? |
2 | 2 |
|
3 | 3 | ## 1 你将获得 |
4 | 4 |
|
@@ -30,20 +30,93 @@ Spark 还有那么火吗?会不会已经过时?若对此感到困惑,大 |
30 | 30 |
|
31 | 31 | 助你零基础上手 Spark 。这“三步走”方法论再配合 4 个不同场景的小项目,吴磊老师会从基本原理到项目落地,深入浅出玩转 Spark。 |
32 | 32 |
|
33 | | -### 2.1 专栏模块设计 |
| 33 | +## 3 专栏模块设计 |
34 | 34 |
|
35 | 35 | 结合 Spark 最常用的计算子框架,专栏设计为 4 个模块,它与“三步走”方法论的对应关系: |
36 | 36 |
|
37 | 37 | 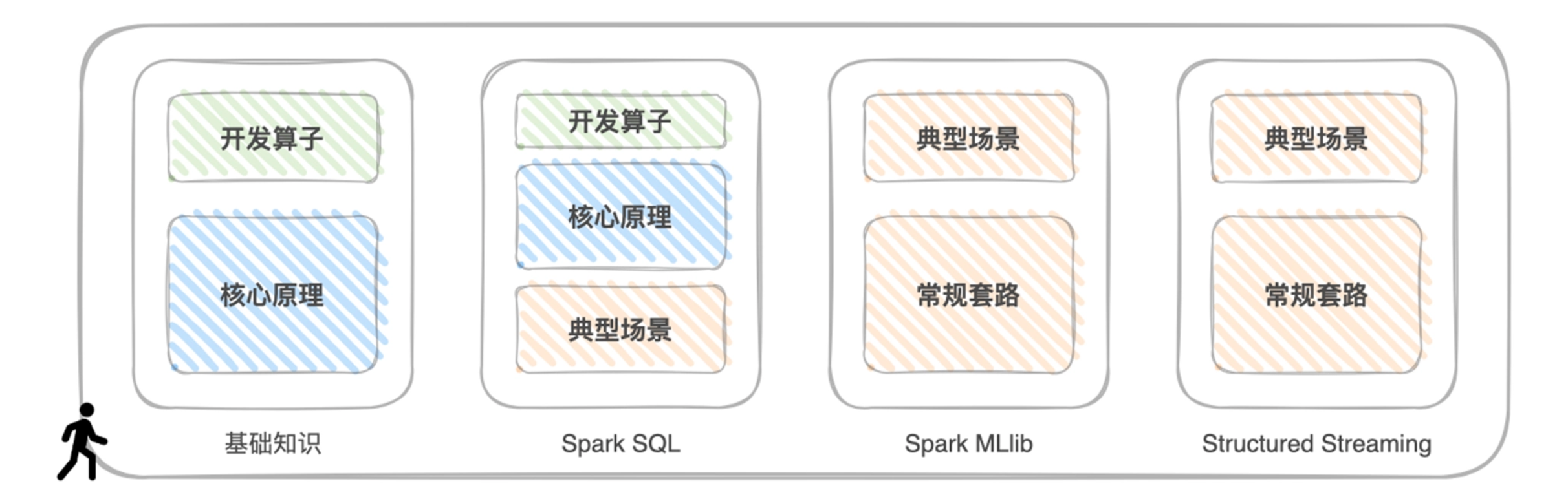 |
38 | 38 |
|
39 | | -**基础知识模块**:从“Word Count”开始,详解 RDD 常用算子的含义、用法与适用场景,以及 RDD 编程模型、调度系统、Shuffle 管理、内存管理等核心原理,帮你打下坚实的理论基础。 |
| 39 | +### 3.1 基础知识模块 |
40 | 40 |
|
41 | | -**Spark SQL 模块**:从“小汽车摇号”入手,熟悉 Spark SQL 开发 API,为你讲解 Spark SQL 的核心原理与优化过程,以及 Spark SQL 与数据分析有关的部分,如数据的转换、清洗、关联、分组、聚合、排序,等等。 |
| 41 | +从“Word Count”开始,详解 RDD 常用算子含义、用法与适用场景及 RDD 编程模型、调度系统、Shuffle 管理、内存管理等核心原理,打下坚实理论基础。 |
42 | 42 |
|
43 | | -**Spark MLlib 模块**:从“房价预测”入手,了解 Spark 在机器学习中的应用,深入学习 Spark MLlib 丰富的特征处理函数和它支持的模型与算法,并带你了解 Spark + XGBoost 集成是如何帮助开发者应对大多数的回归与分类问题。 |
| 43 | +### 3.2 Spark SQL 模块 |
44 | 44 |
|
45 | | -**Structured Streaming 模块**:重点讲解 Structured Streaming 是怎么同时保证语义一致性与数据一致性的,以及如何应对流处理中的数据关联,并通过 Kafka + Spark 这对“Couple”的系统集成,来演示流处理中的典型计算场景。 |
| 45 | +五大知识板块,掌握大数据处理技术Spark SQL,每个大数据工程师都不应错过的必备大数据开发技能! |
46 | 46 |
|
47 | | -## 3 大纲 |
| 47 | +熟悉 Spark SQL 开发 API,讲解 Spark SQL 的核心原理与优化过程,以及 Spark SQL 与数据分析有关的部分,如数据的转换、清洗、关联、分组、聚合、排序,等等。 |
48 | 48 |
|
49 | | - |
| 49 | +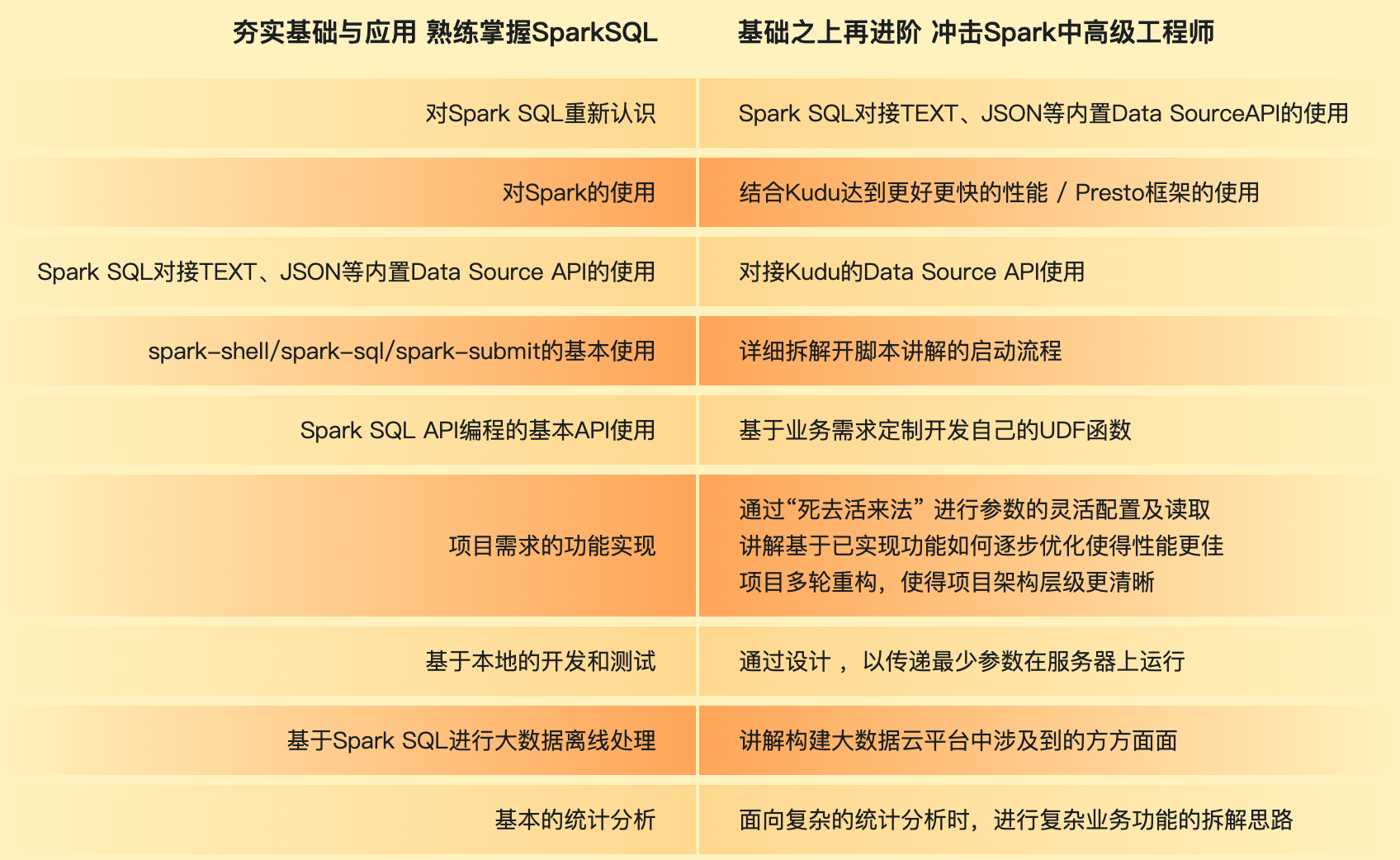 |
| 50 | + |
| 51 | +#### ① Spark SQL快速入门 |
| 52 | + |
| 53 | +- SQL on Hadoop |
| 54 | +- Spark SQL概述、架构、常见误区 |
| 55 | +- spark-shell/spark-sql启动流程分析 |
| 56 | + |
| 57 | +#### ② Spark SQL API编程 |
| 58 | + |
| 59 | +- SparkSession & SQLContext |
| 60 | +- DataSet & DataFrame API |
| 61 | +- DataFrame & DataSet |
| 62 | +- 与RDD的互操作 |
| 63 | + |
| 64 | +#### ③ Data Source API |
| 65 | + |
| 66 | +- Data Source API处理text/JSON/ |
| 67 | +- Parquet/JDBC数据 |
| 68 | +- SaveMode的正确选择 |
| 69 | +- 配置参数统一管理 |
| 70 | + |
| 71 | +#### ④ 整合Hive操作及函数 |
| 72 | + |
| 73 | +- Spark整合Hive的数据操作 |
| 74 | +- ThriftServer的使用 |
| 75 | +- Spark SQL内置函数&自定义函数实战 |
| 76 | + |
| 77 | +##### 学学大牛如何调优与思考 |
| 78 | + |
| 79 | +学习技术受用一时,领悟思想受用一生! |
| 80 | + |
| 81 | +Spark调优策略: |
| 82 | + |
| 83 | +- 合理设置资源 |
| 84 | +- 广播变量带来的好处 |
| 85 | +- Shuffle调优 |
| 86 | +- Spark与GC相关概念理解 |
| 87 | +- JVM GC引起的相关问题调优 |
| 88 | + |
| 89 | +Presto: |
| 90 | + |
| 91 | +- Presto概述、架构 |
| 92 | +- Presto部署 |
| 93 | +- Presto API操作 |
| 94 | +- 综合案例实战 |
| 95 | + |
| 96 | +关于大数据云平台建设: |
| 97 | + |
| 98 | +- 大数据云平台建设涉及哪些功能 |
| 99 | +- 产品化设计思路 |
| 100 | +- 元数据在大数据平台中的设计思路 |
| 101 | +- Spark V.S Flink |
| 102 | + |
| 103 | +另一个大纲: |
| 104 | + |
| 105 | +- Spark SQL:从“小汽车摇号分析”开始 |
| 106 | + |
| 107 | +- 台前幕后:DataFrame与 Spark SQL 的由来 |
| 108 | +- 数据源与数据格式:DataFrame 从何而来? |
| 109 | +- 数据转换:如何在 DataFrame 之上做数据处理? |
| 110 | +- 数据关联:不同的关联形式与实现机制该怎么选? |
| 111 | +- 数据关联优化:都有哪些 Join 策略,开发者该如何取舍? |
| 112 | +- 配置项详解:哪些参数会影响应用程序执行性能? |
| 113 | +- Hive + Spark 强强联合:分布式数仓的不二之选 |
| 114 | +- Spark Ul:如何高效地定位性能问题? |
| 115 | + |
| 116 | +### 3.3 Spark MLlib 模块 |
| 117 | + |
| 118 | +从“房价预测”入手,了解 Spark 在机器学习中的应用,深入学习 Spark MLlib 丰富的特征处理函数和它支持的模型与算法,并带你了解 Spark + XGBoost 集成是如何帮助开发者应对大多数的回归与分类问题。 |
| 119 | + |
| 120 | +### 3.4 Structured Streaming 模块 |
| 121 | + |
| 122 | +重点讲解 Structured Streaming 是怎么同时保证语义一致性与数据一致性的,以及如何应对流处理中的数据关联,并通过 Kafka + Spark 这对“Couple”的系统集成,来演示流处理中的典型计算场景。 |
0 commit comments