|
| 1 | +# 不止更快:Sonnet 4.6 以 Sonnet 价格,带来接近 Opus 级能力 |
| 2 | + |
| 3 | +## 0 前言 |
| 4 | + |
| 5 | +2026年2月17日 |
| 6 | + |
| 7 | +*Claude Sonnet 4.6 是目前功能最强大的 Sonnet 模型*。编程、计算机操作、长上下文推理、智能体规划、知识工作以及设计等方面实现了全面升级。测试阶段提供了 100 万 token 的上下文窗口。 |
| 8 | + |
| 9 | +[Free 和 Pro 套餐](https://claude.com/pricing) 的用户,Claude Sonnet 4.6 为 [claude.ai](https://claude.ai/redirect/website.v1.6e3b59f5-bfac-4640-a43b-b82b5d1ba4ff) 和 [Claude Cowork](https://claude.com/product/cowork) 的默认模型。API[价格](https://claude.com/pricing#api)与 Sonnet 4.5 一致,仍每百万 token 3 美元 / 15 美元起。 |
| 10 | + |
| 11 | +Sonnet 4.6 将显著提升的编程能力带给更多用户。在一致性、指令理解与执行等方面的改进,使得获得早期访问权限的开发者明显更偏好 Sonnet 4.6,而不是上一代模型。他们甚至常常更喜欢它,而不是 2025 年 11 月发布的最强模型 Claude Opus 4.5。 |
| 12 | + |
| 13 | +过去只有 Opus 级别模型才能胜任的性能表现——包括在真实、具备经济价值的[办公任务](https://artificialanalysis.ai/evaluations/gdpval-aa)中——现在通过 Sonnet 4.6 就可以实现。与以往的 Sonnet 模型相比,它在计算机操作方面也有了大幅提升。 |
| 14 | + |
| 15 | +和每一代新 Claude 模型一样,我们对 Sonnet 4.6 进行了[全面的安全评估](https://anthropic.com/claude-sonnet-4-6-system-card)。与近期其他 Claude 模型一样安全,甚至在某些方面更安全。我们的安全研究人员认为,Sonnet 4.6 “整体风格温和、诚实、具有亲社会倾向,偶尔还带点幽默感;安全行为表现非常强;在高风险场景下未发现明显的失控迹象。” |
| 16 | + |
| 17 | +## 1 计算机操作能力 |
| 18 | + |
| 19 | +每个组织都会用些难自动化的软件——如 API 等现代接口出现前开发的专用系统和工具。过去,想让 AI 用这些软件,通常需开发定制连接器。但如模型能像人类一样直接操作计算机,这问题迎刃而解。 |
| 20 | + |
| 21 | +2024 年 10 月就率先推出通用型计算机操作模型。当时提到,它“仍处实验阶段——在某些情况下操作繁琐且容易出错”,但预计会快速改进。作为 AI 计算机操作领域的标准基准,[OSWorld](https://os-world.github.io/) 展示了我们模型的进步。该基准包含数百项任务,覆盖在模拟计算机上运行的真实软件(如 Chrome、LibreOffice、VS Code 等)。它没有提供专门的 API 或定制接口;模型只能像人类一样,通过点击(虚拟)鼠标和输入(虚拟)键盘与系统交互。 |
| 22 | + |
| 23 | +在过去 16 个月中,Sonnet 系列模型在 OSWorld 上持续进步。这种提升不仅体现在基准测试中。Sonnet 4.6 的早期用户表示,它在浏览复杂电子表格、填写多步骤网页表单,甚至在多个浏览器标签页之间整合信息等任务上,已接近人类水平。 |
| 24 | + |
| 25 | +算机操作方面仍不及最熟练的人类。但进步速度令人瞩目。AI在更多实际工作场景中变得更有用,也预示更强大模型即将到来。 |
| 26 | + |
| 27 | +Chart comparing several Sonnet model scores on the OSWorld benchmark: |
| 28 | + |
| 29 | +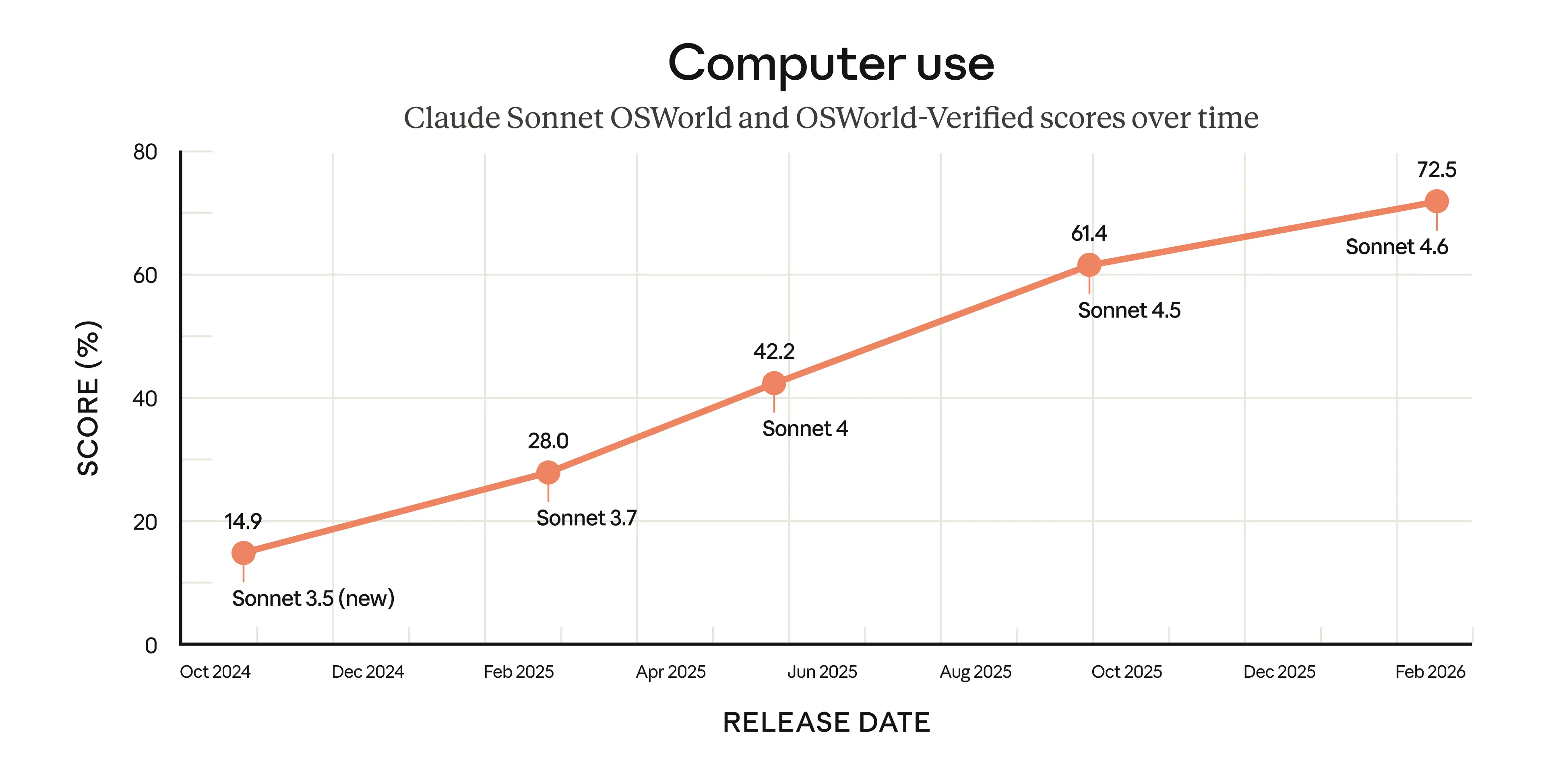 |
| 30 | + |
| 31 | +Claude Sonnet 4.5 之前的分数基于原始 OSWorld;从 Sonnet 4.5 开始使用 OSWorld-Verified。OSWorld-Verified(2025 年 7 月发布)是在原基准基础上的升级版本,改进任务质量、评分方式和基础设施。 |
| 32 | + |
| 33 | +计算机操作也带来新风险。如恶意攻击者可能通过在网页中隐藏指令发起“提示词注入攻击”,试图劫持模型。我们一直在提升模型对提示词注入的防御能力。[安全评估](https://anthropic.com/claude-sonnet-4-6-system-card)显示,与 Sonnet 4.5 相比,Sonnet 4.6 有明显改进,整体表现与 Opus 4.6 相当。关于如何防范提示词注入和其他安全问题,可参考我们的 [API 文档](https://platform.claude.com/docs/en/test-and-evaluate/strengthen-guardrails/mitigate-jailbreaks)。 |
| 34 | + |
| 35 | +## 2 评测 |
| 36 | + |
| 37 | +除了计算机操作能力外,Claude Sonnet 4.6 在各类基准测试中都有提升。在更具性价比的价格下,接近 Opus 级智能水平。完整的能力说明和安全行为分析可参见我们的系统说明文档;下方为简要总结及与其他模型的对比。 |
| 38 | + |
| 39 | +A table of popular benchmarks and Sonnet 4.6's relative performance compared to other frontier models: |
| 40 | + |
| 41 | +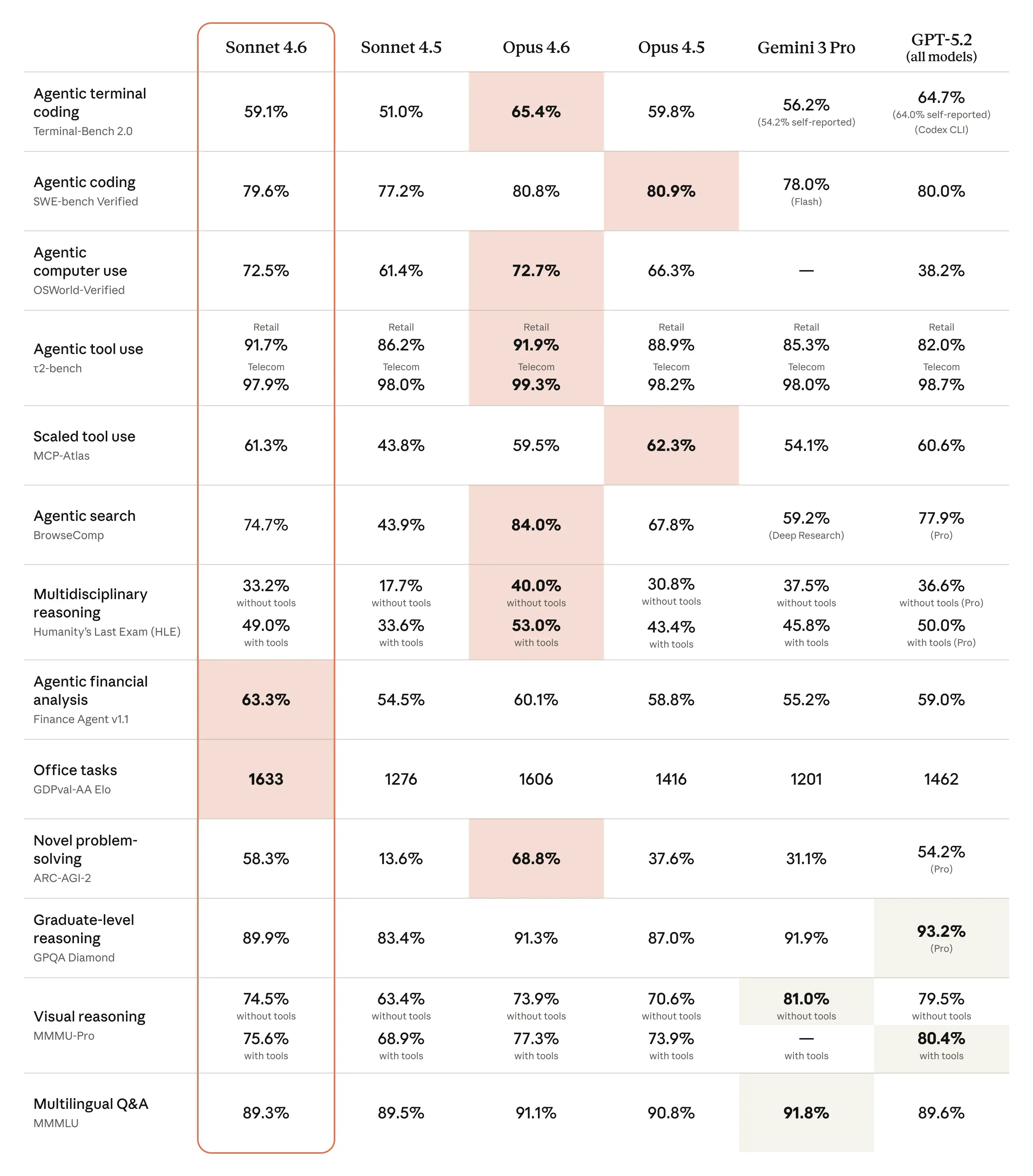 |
| 42 | + |
| 43 | +在 Claude Code 中的早期测试显示,用户约有 70% 的时间更偏好 Sonnet 4.6,而不是 Sonnet 4.5。用户反馈称,它在修改代码前更善于理解上下文,也更倾向于整合共用逻辑,而不是重复编写相同代码。因此,在长时间使用时,体验明显优于以往版本。 |
| 44 | + |
| 45 | +甚至在与 2025 年 11 月发布的前沿模型 Opus 4.5 对比时,用户也有 59% 的时间更偏好 Sonnet 4.6。他们认为 Sonnet 4.6 明显减少过度设计和“偷懒”现象,在执行指令方面更准确。虚假成功声明更少,幻觉现象更少,在多步骤任务中的执行更稳定。 |
| 46 | + |
| 47 | +Sonnet 4.6 提供 100 万 token 的上下文窗口,足以在一次请求中容纳完整代码库、冗长合同或数十篇研究论文。更重要的是,它能够在如此庞大的上下文中进行有效推理,这显著提升了其长期规划能力。在 [Vending-Bench Arena](https://andonlabs.com/evals/vending-bench-arena) 评测中,这一点尤为明显。该评测测试模型在一段时间内运营(模拟)企业的能力,并引入竞争机制,让不同 AI 模型比拼利润表现。 |
| 48 | + |
| 49 | +Sonnet 4.6有趣新策略:在前十个模拟月份中大幅投入产能建设,支出远高于竞争对手;随后在后期迅速转向利润优先策略。正是这种转型时机,使它最终明显领先于其他模型。 |
| 50 | + |
| 51 | +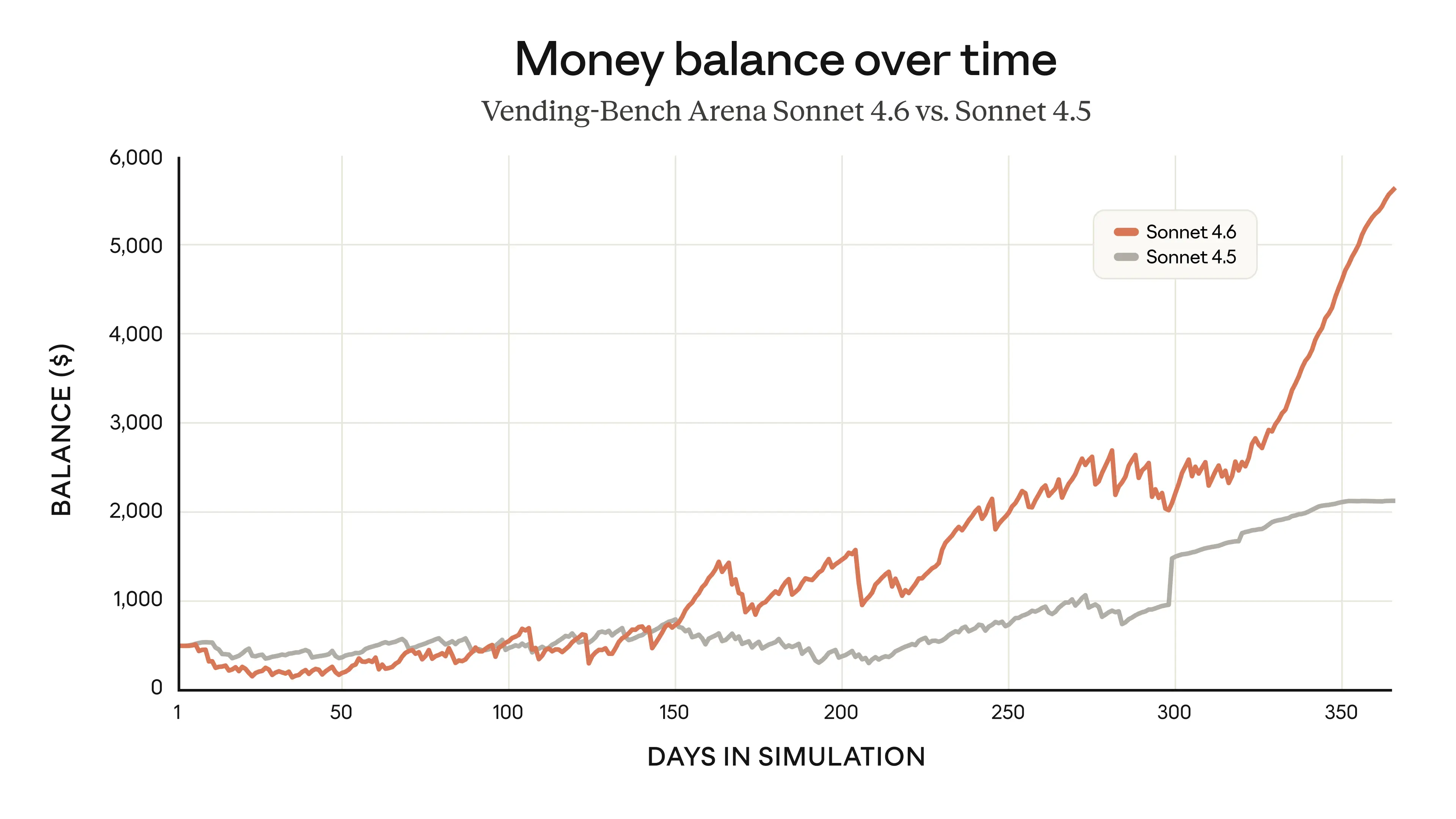 |
| 52 | + |
| 53 | +Sonnet 4.6 在 Vending-Bench Arena 中优于 Sonnet 4.5,得益于前期投入产能、后期转向盈利的策略。 |
| 54 | + |
| 55 | +早期客户也反馈了整体提升,尤其在前端代码生成和财务分析方面表现突出。多位客户独立表示,Sonnet 4.6 生成的视觉输出更加精致,布局、动画和设计感都优于以往模型。同时,为达到可投入生产环境的质量,所需的迭代次数更少。 |
| 56 | + |
| 57 | +## 3 产品更新 |
| 58 | + |
| 59 | +在 Claude 开发者平台上,Sonnet 4.6 支持: |
| 60 | + |
| 61 | +- 自适应思考(adaptive thinking) |
| 62 | +- 扩展思考(extended thinking) |
| 63 | +- 测试阶段提供上下文压缩(context compaction)功能。当对话接近上下文上限时,系统会自动总结较早内容,从而提升有效上下文长度。 |
| 64 | + |
| 65 | +在 API 中,Claude 的网页搜索(web search)和网页抓取(fetch)工具现在可自动编写并执行代码,对搜索结果进行筛选和处理,仅保留相关内容,从而提升回答质量并提高 token 使用效率。 |
| 66 | + |
| 67 | +代码执行(code execution)、记忆(memory)、程序化工具调用(programmatic tool calling)、工具搜索(tool search)以及工具使用示例功能现已全面开放。 |
| 68 | + |
| 69 | +Sonnet 4.6 在不同思考强度下都能保持强劲表现,即使关闭扩展思考功能也依然出色。我们建议在从 Sonnet 4.5 迁移时,根据具体应用场景,在速度与稳定性能之间找到最佳平衡。 |
| 70 | + |
| 71 | +对于需要最深层推理能力的任务,如大型代码库重构、多智能体工作流协调,以及对结果精确度要求极高的问题,Opus 4.6 仍是更强选择。 |
| 72 | + |
| 73 | +对于使用 [Claude in Excel](https://support.claude.com/en/articles/12650343-using-claude-in-excel) 的用户,插件现已支持 MCP 连接器,让 Claude 可与 S&P Global、LSEG、Daloopa、PitchBook、Moody’s 和 FactSet 等日常工具协同工作。你可以在不离开 Excel 的情况下调用外部数据。如果你已在 Claude.ai 中配置 MCP 连接器,这些连接会自动在 Excel 中生效。该功能适用于 Pro、Max、Team 和 Enterprise 套餐。 |
| 74 | + |
| 75 | +## 4 使用 |
| 76 | + |
| 77 | +现在所有 [Claude 套餐](https://claude.com/pricing)、[Claude Cowork](https://claude.com/product/cowork)、[Claude Code](https://claude.com/product/claude-code)、API 以及主流云平台上线。free套餐默认升级为 Sonnet 4.6,并支持文件创建、连接器、技能和上下文压缩功能。 |
| 78 | + |
| 79 | +开发者可通过 Claude API 使用 `claude-sonnet-4-6` 快速开始。 |
| 80 | + |
| 81 | +## 5 注释 |
| 82 | + |
| 83 | +- **OSWorld**:该基准在受控环境中测试特定计算机任务,是衡量模型能力的重要指标之一,但并不能完全代表真实世界场景。现实环境更复杂、更模糊,且错误成本更高,目前尚无基准能完全覆盖。 |
| 84 | +- **Humanity’s Last Exam**:Claude 模型以“带工具”模式运行,启用网页搜索、网页抓取、代码执行、程序化工具调用、在 5 万 token 时触发上下文压缩(最多 300 万 token)、最大推理强度和自适应思考,并使用域名黑名单去除评测污染。 |
| 85 | +- **BrowseComp**:Claude 模型启用网页搜索、网页抓取、程序化工具调用、在 5 万 token 时触发上下文压缩(最多 1000 万 token)、最大推理强度,但未启用思考模式。 |
| 86 | +- **ARC-AGI-2**:Claude Sonnet 4.6 在最大和高强度推理、120k 思考预算下运行。图中显示为最大强度结果;在高强度下成绩为 60.4%。 |
| 87 | +- **MMMU-Pro**:我们对实现做了两项小调整,影响了分数:1)移除了此前提示词中的 “Let’s think step-by-step”;2)此前通过选项的 on-policy token 概率评分,现在改为使用独立模型(Claude Sonnet 4)进行评分。 |
0 commit comments