 +
+ +
++Delivering Hydrogen Fuel Gas +
+
+
+
+julia
+
+hydrogen
+
+
+
+Thinking about hydrogen as a utility fuel gas by way of the relative compression costs.
+
+
+
+
+May 7, 2026
+
+This blog is a collection of (mostly) jupyter notebooks, in either python or julia, solving various engineering and math problems. These are my weekend projects and are often inspired by things happening in the world, interesting problems I may have encountered at work, or just passing interests of mine. There isn’t really a theme other than mostly chemical engineering, since that’s my profession, and mostly process safety and consequence modelling, as that’s something I’m personally interested in.
+I think the best way to learn something new is to try it out yourself, play around with solving problems, see what works and what doesn’t. That’s what these notebooks are. I am also a big believer in putting one’s random projects and terrible code online for other people to look at. The source code for each post is available for you to download and modify to your hearts content. I also try to provide references for everything I’m doing, and those are a good resource for more context. This is a great opportunity for you to tell me all the ways my code is terrible and what I should be doing instead, or tell me all the interesting things you did with it, and the new directions you went in. The internet is a better place when we share.
+These blog posts do not contain my professional advice or opinion, nor do they represent the opinions of my employer. These are weekend projects, with no guarantees of correctness. You have to think for yourself.
+The blog itself is rendered directly from the jupyter notebooks by quarto. However, a lot of the boiler plate and set-up is hidden in the final blog post for readability. If you want more details (especially how the plots are generated), please see the source noteboook.
+Posts which use julia take advantage of the built in environment manager and there is an associated Project.toml for each notebook with compat entries frozen at the last known working versions. Many packages under active development will change significantly over time, so it is worth checking to see which version I was using as the package may have changed in the meantime.
Posts which use python use the poetry-kernel to track the associated virtual environments, which are maintained in the pyproject.toml for each notebook. This shows the state of the virtual environment at the last time I ran the notebook.
From my previous analysis, I showed that the same piping operating at the same pressures delivers approximately the same energy, in terms of higher heating value, in systems in full hydrogen service as those in natural gas service. So, for an end user of natural gas (such as me, it’s how I heat my home) making some modifications to the fired equipment and getting a stream of hydrogen versus natural gas is a plausible pathway to low-carbon heating. That doesn’t entirely hold up for utility providing the gas, however, as there is an additional cost associated with compressing hydrogen over natural gas, which might make such systems impractically expensive to operate. At least that is the question I’m looking to answer here: is distributing hydrogen fuel gas to residential or industrial customers through a distribution network like natural gas feasible or not?
+The full economic analysis of hydrogen as a fuel gas versus some other low carbon source of energy would so strongly depend on local factors – the local cost of electricity versus hydrogen, whether that region is subject to a carbon tax and how that tax works, etc. – that I don’t think much can be generalized. The economics of hydrogen, where I live, where natural gas is abundant and widely used, export infrastructure is limited, and the carbon tax largely excludes all but the largest industrial emitters, is pretty different from a place where all natural gas is imported at large expense, or with a very different approach to carbon pricing.
+We already know that natural gas distribution systems are feasible, there is one delivering natural gas to my house right now and it is also delivering natural gas to the chemical plant I work at, the gas fired power plant that is powering my laptop right now, etc. To some extent we also already know that hydrogen distribution systems are feasible as they already exist, the longest hydrogen transmission pipeline in Europe is >1000km long and there are >700km of hydrogen pipelines in the United States.1 However those are primarily for supplying hydrogen as a feedstock to chemical and petrochemical facilities, not quite the same use case as hydrogen as a fuel gas.
+1 Sendehboudi and Gharbani, Hydrogen Production, Transportation, Storage, and Utilization.
A reasonable approach to answering this question is to compare a hypothetical hydrogen transmission system to a natural gas system. This is basically what I’ve already done for pipe-flow when looking at hydrogen blending: once the hydrogen is in the pipe and at pressure, everything works from that point down. What remains to be seen is whether it is feasible to get it into the pipe and at pressure. Specifically how much more work does it take to compress hydrogen to line pressure than natural gas?
+The standard equation for determining the work, , to compress a mass flowrate
of gas from a pressure of
to
is234
2 GPSA, Engineering Data Book.
3 Boyce et al., “Transport and Storage of Fluids.” 10–42.
4 Strictly speaking this is an approximation as it neglects the change in kinetic energy of the fluid, but for small compression ratios, less than ~5, it is appropriate
This is related to the isentropic work through the isentropic efficiency,
Where the integral of the specific volume is taken along an isentropic path. Real compressors are not isentropic, but compressor manufacturers provide tables or figures giving the isentropic efficiency, with values of 70% - 80% being fairly typical.
I am going to assume that whatever efficiency can be achieved for a standard natural gas compressor can also be achieved with a hydrogen compressor. They may be different compressors, but the isentropic efficiency is something of a design choice. The ratio of work for a hydrogen system to a natural gas system, , is then
The integrals, though, do not have to be tackled directly, recalling the differential for (specific) enthalpy
+Integrating from state 1 to state 2 along an isentropic path (i.e. ) gives:
Thus the ratio we’re looking for is given by:
+It is important to note that state 2 is not the same for hydrogen and natural gas. Since the integration is along an isentropic path, state 2 is at a pressure of and a temperature
defined by
and the entropy of hydrogen and natural gas are, in principle, different.
Compressors typically don’t raise pressures all the way from, say, atmospheric pressure to the 200-1500psi working pressures of natural gas transmission lines in a single stage. For one, as gases are compressed they heat up and that large temperature rise can damage a compressor. Usually compression is accomplished with a series of stages with interstage cooling. This work ratio is really only valid for a single stage.
+Suppose we are evaluating a system that uses a multi-stage compressor to take gas at ambient conditions, in this case suppose 1bar and 15C, to a relatively high transmission line pressure of 100bar using 4 stages, Figure 1. The overall compression ratio is 100, with 3 stages this gives a per stage ratio of
+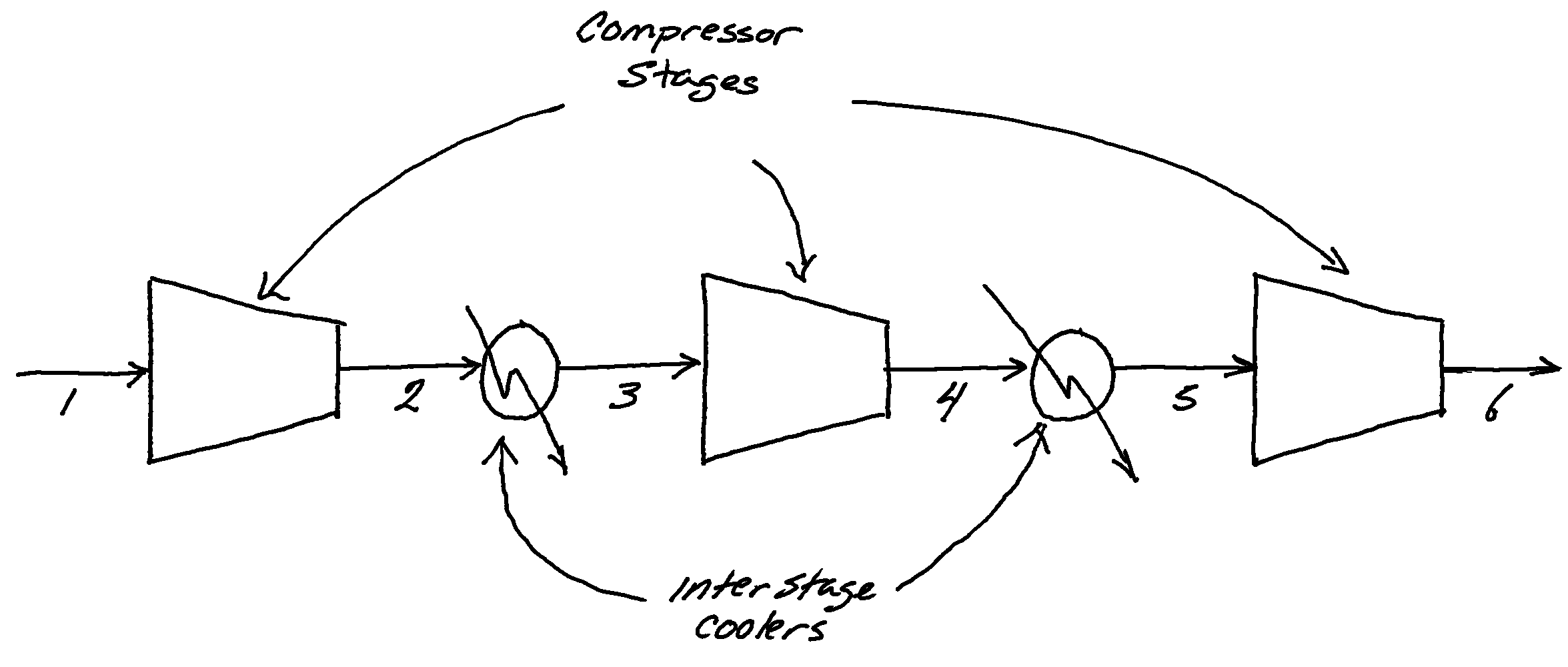 +
+Suppose, for simplicity, the interstage coolers bring the gas temperature down to 15C:
+With the inlet gas to each stage being at 15C and exiting at some temperature which is determined from the energy balance and isentropic efficiency.
+The total work required to compress the gas is then
+A useful first approach to most problems in life5 is to assume an ideal gas. It allows one to build some intuition about the problem and how fluid non-ideality may change the results. Starting with an ideal gas in stream 1 being isentropically compressed to stream 2,6 and equating the specific enthalpies
+5 for chemical engineers at least
6 Gmehling et al., Chemical Thermodynamics for Process Simulation, 596.
Assuming is a constant this simplifies to
For an ideal gas , giving
A well known result. The enthalpy of an ideal gas with constant is just
, so we have:
From the ideal gas law,
Which allows us to write the work ratio, for a single stage, compressing an ideal gas with constant heat capacity, as:
+where . From the ideal gas law the ratio of specific volumes is just the ratio of molar weights
and, since the inlet streams are all at the same temperature
+Furthermore, if we assume then
This is where I’ve encountered what I consider a serious error: assuming an equal mass flowrate of the two fuels. Making this assumption gives
+using Unitful, Clapeyronideal_hydrogen = ReidIdeal(["hydrogen"])
+ideal_natural_gas = ReidIdeal(["methane"])This gives a work ratio of 7.9, leading us to conclude that it will take 7.9× the power to run a hydrogen transmission system than a similar natural gas system.
+I think this is a mistake because the goal is not to deliver the same mass flowrate but the same thermal energy (combustion energy). Supposing we are seeking to deliver the same energy in terms of higher heating value
+and so
+where is the specific higher heating value (or gross heating value)
This gives a work ratio of 3.1, quite a bit smaller of an estimate.
+But the assumption that is perhaps not a good one, so we should explore how compression effects differ even as ideal gases.
k(gas) = isobaric_heat_capacity(gas, 1u"bar", 288.15u"K") /
+ isochoric_heat_capacity(gas, 1u"bar", 288.15u"K")This gives a work ratio of 3.25, which shows that our original approximation was reasonable: accounting for differences in isentropic expansion factor, , changes our estimate by only 5.0%.
To account for non-ideality we need to lose some generality. The ideal gas case ultimately doesn’t depend on what the initial and final conditions are (since all of that cancels out) but for real gases how non-ideal they are depends strongly on the actual pressures and temperatures of the system.
+I am going to use a volume translated Peng Robinson cubic equation of state for both hydrogen and methane.
+real_hydrogen = PR(["hydrogen"];
+ idealmodel=ReidIdeal,
+ alpha=TwuAlpha,
+ translation=PenelouxTranslation)real_natural_gas = PR(["methane"];
+ idealmodel=ReidIdeal,
+ alpha=TwuAlpha,
+ translation=PenelouxTranslation)Clapeyron.jl does not define functions for finding the enthalpy as a function of pressure and entropy, so we will need to first find the isentropic temperature, and then calculate the enthalpy.
using Roots: find_zero
+
+function isentropic_temperature(gas, p1, T1, p2)
+ s1 = entropy(gas, p1, T1)
+ k_ig = k(gas)
+ T2_guess = T1*(p2/p1)^(1-1/k_ig)
+ T2 = find_zero( T -> entropy(gas, p2, T) - s1, T2_guess)
+ return T2
+endFirst, the specific enthalpy difference for hydrogen
+Then the specific enthalpy difference for natural gas
+Finally, the work ratio of compressing hydrogen versus natural gas
+In this case the ideal gas law estimate and the estimate using a cubic equation of state differ by only 1.0%.
+The difference does become more pronounced at higher pressures, see Figure 2, but even at stage three the work ratio for the real gases differs from the ideal gas case by only 6.0%.
+In online discussions I have seen it claimed that the difference in work – why so much more energy is required to compress hydrogen over natural gas – is due to some obscure feature of hydrogen’s phase diagram. I would say that is false. The main reason why hydrogen requires more energy to compress is simply due to its low molecular weight. That hydrogen has a high energy density, on a mass basis, offsets this greatly when hydrogen and natural gas are compared on an equivalent energy basis, though.
+There are additional effects that make hydrogen even more difficult to compress than you would expect, from a pure ideal gas analysis, but they are pretty small unless the working pressures are either huge or the compression ratio is tremendous. Neither of which are particularly relevant for a gas transmission system using normal compressors and typical pipeline pressures.
+I wrote this post to address some misconceptions that I’ve encountered regarding hydrogen7 and in particular the rhetorical device of finding one single fact about hydrogen and taking that to mean some project or another has been “debunked”. Real engineering projects are just too complex for that to be a useful exercise. Reality always depends on a great many factors.
+7 is this all just an extended response to a thread on mastodon? I mean… sort of
Is the fact that a hydrogen fuel distribution system would require >3× the energy to operate mean that such a system is impractical? That really depends. It could be that a large, continent spanning, transmission system for hydrogen such as natural gas distribution employs in North America is rendered totally infeasible by the increased power demands. But then again, why should hydrogen be so geographically constrained? Natural gas is constrained by geology but presumably one could make green hydrogen wherever there is water and renewable power. Perhaps blue hydrogen is best built on top of the existing natural gas infrastructure – send natural gas across the continent and convert it to hydrogen closer to the end use. I am doubtful that one could come up with a sweeping conclusion from all of this that would say anything beyond one’s ignorance of the specific conditions of niche industries and use cases for hydrogen versus the panoply of alternative low carbon energy sources.
+I think the dreams of existing gas fired power plants simply retrofitting to hydrogen and continuing on as before are looking increasingly like a relic from a bygone era. The price of renewables and storage continues to plumet and the economics of these schemes seem increasingly out of touch with that reality. But for other industries, with other heating demands, perhaps there is a compelling case to be made.
+I say all of this as someone who is broadly skeptical of the hype around hydrogen. I think it is being pursued mostly as a saviour of fossil fuels and not as a technology that actually best solves the problems which face us as we transition to a low carbon future. But there are also a lot of really smart engineers working on projects centered around low-carbon hydrogen, and I imagine they know what they are doing.
+The standard references I looked at either provided an equation without giving any sense where it came from or, in one notable exception, gave an equation that (as far as I can tell) can’t possibly be right. So I thought this might be fertile ground for investigation.
+Gaussian plumes are a common first dispersion model for chemical release screening tools. They are easy to implement, especially in spreadsheets, and have convenient mathematical properties that makes calculating the parameters relevant to a hazard screening simple. The cases where either the plume is grounded1 or is free2 are particularly convenient as the plume extents can be calculated directly.
+1 emitted at ground level and perfectly reflecting off the ground plane
2 emitted high enough above the ground that the ground plane can be neglected entirely
For what follows I am going to examine a free plume – the results are very similar for a grounded plume – which is given by
+Where the origin has been chosen to coincide with the release point. The standard assumptions for a Gaussian plume are:
+For a free plume it is further assumed that there is no ground plane, the z-axis extends infinitely up and down.
+To actually use this model, we need a parametrization of and
for which I am going to use the simple power law
and
# System parameters
+w = 1 # kg/s
+u = 1 # m/s# Class D - Neutral atmospheric stability
+a = 0.128
+b = 0.905
+c = 0.20
+d = 0.76σy(x) = a*x^b
+σz(x) = c*x^dχ(x,y,z; w=w, u=u) = w*exp(-0.5*((y/σy(x))^2 + (z/σz(x))^2))/(2π*u*σy(x)*σz(x))Suppose I am interested in the region of the plume between two concentrations and
, these might be the upper flammability limit (UFL) and the lower flammability limit (LFL) (respectively). It doesn’t really matter. But further suppose that I have both the concentrations and the point along the
axis where the centerline concentration equals that concentration. This is the point where the isosurface crosses the
axis.
This is typically the step along a hazard analysis or consequence analysis where calculating the potential explosive energy takes place.
+x₁ = 10 # m
+x₂ = 100 # mχ₁ = χ(x₁,0,0)
+χ₂ = χ(x₂,0,0)At the level of screening tools, estimating the potential explosive energy in a vapour cloud typically involves estimating the mass of explosive material in the cloud3, then calculating the energy from the specific enthalpy of combustion.
+3 How one defines the flammable mass of a vapour cloud varies significantly from author to author, depending on whether one takes it to be the entire region with a concentration greater than the LFL, some fraction of the LFL (1/2 is common), or only the region between the LFL and UFL.
4 Bakkum and Duijm., “Vapour Cloud Dispersion,” 4.78.
5 “Calculation of the Amount of Gas in the Explosive Region of a Vapour Cloud Released in the Atmosphere”.
The CCPS tools CHEF and RAST, the TNO Yellow Book,4 and Van Buijtenen5 give the mass of a vapour cloud as
+Where is the mass of the region defined by the concentration
and
is a constant, which generally depends upon atmospheric stability. If the explosive mass is taken to be the region between two concentrations
and
with
then
| + | C | +
|---|---|
| CHEF & RAST | +1 | +
| TNO Yellow Book | +|
| Van Buijtenen | +
Woodward6 gives the following as the rigorous method for plumes, specifically for a free plume it is
+6 Estimating the Flammable Mass of a Vapour Cloud.
where is the complete elliptic integral of the second kind and
is a function of
and atmospheric stability.
The mass in the region of a Gaussian plume with a concentration greater than is given by the volume integral
where
+The mass in a free plume is given by
+By symmetry this is equal to
+Recalling that the concentration in a grounded plume is twice that of a free plume
+The total mass in the plume contained between the planes and
is simply the integral
Which follows directly from properties of Gaussian functions
+Which is the result used in CHEF v4.5 – the total mass in the plume. This also presents a useful upper bound: the mass in the flammable region of the plume must be less than the total mass of the plume.
+The isopleths for a free Gaussian plume are given by
+where
The whole isosurface is defined by
+These can be used directly, but a more general approach is to use marching squares to find the isopleth.
+For a general plume one can find the surface using marching tetrahedra. In the following the surface for is calculated by marching tetrahedra, as shown in Figure 3.
using Meshing: MarchingTetrahedra, isosurface
+using GeometryBasics: Mesh, Point, Vec, Triangle, TriangleFace, volumeχ_safe(x,y,z) = isnan(χ(x,y,z)) ? 0.0 : χ(x,y,z);xs = LinRange(0.0, x₂, 100)
+ys = LinRange(-7.5, 7.5, 25)
+zs = LinRange(-7.5, 7.5, 25)
+
+χfield = [ χ_safe(x,y,z) - χ₂ for x in xs, y in ys, z in zs ]
+pts,fcs = isosurface(χfield, MarchingTetrahedra(), xs, ys, zs);msh = Mesh(Point.(pts), TriangleFace.(fcs))Mesh{3, Float64, TriangleFace{Int64}}
+ faces: 43472
+ vertex position: 21740If the potential explosive energy was being determined using the volume of the cloud, well we would be done. The volume of a meshed surface can be calculated directly
+abs(volume(msh))8085.175640305937Presumably one could tetragonalize this mesh and calculate the volume integral of the mass through that. I will leave that as an exercise for the reader. For the particular case of a free plume that will be more work than is required.
+The most direct approach to calculating the explosive mass is to numerically integrate over a rectangular region containing the plume7
+7 Woodward, Estimating the Flammable Mass of a Vapour Cloud, 241.
This can be done directly using the trapezoidal rule in three dimensions.
+@inline χ_inbounds(x,y,z; χₗ,w,u) = χ(x,y,z; w=w,u=u)≥χₗ ? χ(x,y,z; w=w,u=u) : 0.0function mass🪤(xₗ; lower, upper, N=100, w=w, u=u)
+ y_a, z_a = lower
+ y_b, z_b = upper
+ x_a, x_b = 0.0, xₗ
+
+ Δx = (x_b - x_a)/N
+ Δy = (y_b - y_a)/N
+ Δz = (z_b - z_a)/N
+
+ χₗ, Σχ = χ(xₗ,0,0; w=w, u=u), 0.0
+ for i in 1:N, j in 1:N, k in 1:N
+ xᵢ₋₁, xᵢ = x_a + (i-1)*Δx, x_a + i*Δx
+ yⱼ₋₁, yⱼ = y_a + (j-1)*Δy, y_a + j*Δy
+ zₖ₋₁, zₖ = z_a + (k-1)*Δz, z_a + k*Δz
+
+ Σχ += ( χ_inbounds(xᵢ₋₁, yⱼ₋₁, zₖ₋₁; χₗ=χₗ, w=w, u=u)
+ + χ_inbounds(xᵢ₋₁, yⱼ₋₁, zₖ; χₗ=χₗ, w=w, u=u)
+ + χ_inbounds(xᵢ₋₁, yⱼ, zₖ₋₁; χₗ=χₗ, w=w, u=u)
+ + χ_inbounds(xᵢ₋₁, yⱼ, zₖ; χₗ=χₗ, w=w, u=u)
+ + χ_inbounds(xᵢ, yⱼ₋₁, zₖ₋₁; χₗ=χₗ, w=w, u=u)
+ + χ_inbounds(xᵢ₋₁, yⱼ₋₁, zₖ; χₗ=χₗ, w=w, u=u)
+ + χ_inbounds(xᵢ, yⱼ, zₖ₋₁; χₗ=χₗ, w=w, u=u)
+ + χ_inbounds(xᵢ₋₁, yⱼ, zₖ; χₗ=χₗ, w=w, u=u) )
+
+ end
+
+ return Σχ*Δx*Δy*Δz/8
+endm🪤 = mass🪤(x₂; lower=[-7.5,-7.5], upper=[7.5,7.5]) -
+ mass🪤(x₁; lower=[-1.5,-1.5], upper=[1.5,1.5]);The mass by trapezoidal rule is 55.77kg
+The obvious downside of this approach is that it integrates over regions that are outside the plume isosurface with the same resolution as regions within the plume. Getting a good result requires a very fine grid and calculating a great many points which are ultimately discarded.
+We can reduce the number of discards by taking advantage of what we know about the Gaussian plume: we know the vertical and crosswind isopleths. Introducing a change of variables ,
such that
and
and
where
This changes the domain of integration from a rectangular prism to one with a rectangular cross-section whose size is a function of . It is somewhat more efficient, and doesn’t require the user to pick a good bounding box.
function mass🪤2(xₗ; N=100, w=w, u=u)
+ χₗ = χ(xₗ,0,0; w=w, u=u)
+ function integrand(x,ξ,ζ)
+ K = 2*log(w/(2π*u*σy(x)*σz(x)*χₗ))
+ y_lim = σy(x)*√(K)
+ z_lim = σz(x)*√(K)
+ y, z = y_lim*ξ, z_lim*ζ
+ I = y_lim*z_lim*χ_inbounds(x,y,z; χₗ=χₗ, w=w, u=u)
+ return isnan(I) ? 0.0 : I
+ end
+
+ x_a, x_b = 0.0, xₗ
+ ξ_a, ξ_b = -1.0, 1.0
+ ζ_a, ζ_b = -1.0, 1.0
+ Δx = (x_b - x_a)/N
+ Δξ = (ξ_b - ξ_a)/N
+ Δζ = (ζ_b - ζ_a)/N
+
+ Σχ = 0.0
+ for i in 1:N, j in 1:N, k in 1:N
+ xᵢ₋₁, xᵢ = x_a + (i-1)*Δx, x_a + i*Δx
+ ξⱼ₋₁, ξⱼ = ξ_a + (j-1)*Δξ, ξ_a + j*Δξ
+ ζₖ₋₁, ζₖ = ζ_a + (k-1)*Δζ, ζ_a + k*Δζ
+
+ Σχ += ( integrand(xᵢ₋₁, ξⱼ₋₁, ζₖ₋₁)
+ + integrand(xᵢ₋₁, ξⱼ₋₁, ζₖ)
+ + integrand(xᵢ₋₁, ξⱼ, ζₖ₋₁)
+ + integrand(xᵢ₋₁, ξⱼ, ζₖ)
+ + integrand(xᵢ, ξⱼ₋₁, ζₖ₋₁)
+ + integrand(xᵢ₋₁, ξⱼ₋₁, ζₖ)
+ + integrand(xᵢ, ξⱼ, ζₖ₋₁)
+ + integrand(xᵢ₋₁, ξⱼ, ζₖ) )
+
+ end
+
+ return Σχ*Δx*Δξ*Δζ/8
+endm🪤2 = mass🪤2(x₂) - mass🪤2(x₁);The mass by trapezoidal rule, with a change of variables, is 55.73kg
+This is still a very wasteful integration since it suffers from the curse of dimensionality. To come up with a somewhat reasonable answer requires evaluating the integrand times. A large proportion of those evaluations are still being thrown out, as they are outside the region of interest.
This could be sped up by parallelizing the calculations, which would allow for larger values of N to get more accurate results, but a more efficient approach is to use Monte Carlo integration.
+using MCIntegrationfunction mass🎲(xₗ; w=w, u=u)
+ χₗ = χ(xₗ,0,0; w=w, u=u)
+ function integrand(x,ξ,ζ)
+ K = 2*log(w/(2π*u*σy(x)*σz(x)*χₗ))
+ y_lim = σy(x)*√(K)
+ z_lim = σz(x)*√(K)
+ y, z = y_lim*ξ, z_lim*ζ
+ I = y_lim*z_lim*χ_inbounds(x,y,z; χₗ=χₗ, w=w, u=u)
+ return isnan(I) ? 0.0 : I
+ end
+
+ xξζ = CompositeVar(Continuous(0.0,xₗ),
+ Continuous(-1.0,1.0),
+ Continuous(-1.0,1.0))
+ res = integrate(((x, ξ, ζ), c)-> integrand(x[1],ξ[1],ζ[1]); var = xξζ)
+ return res.mean[1]
+endmass🎲 (generic function with 1 method)m🎲 = mass🎲(x₂) - mass🎲(x₁);Total iterations * blocks 160: 100%|██████| Time: 0:00:02 (17.37 ms/it)
+
+The mass by Monte Carlo, with a change of variables, is 56.36kg
+Both of these approaches have a similar relative error (spoilers!) but the Monte Carlo integration is much more efficient – in time and memory.
+using BenchmarkTools🪤res = @benchmark mass🪤2(x₂)BenchmarkTools.Trial: 1 sample with 1 evaluation per sample. + Single result which took 9.444 s (11.24% GC) to evaluate, + with a memory estimate of 9.10 GiB, over 607442648 allocations.+
🎲res = @benchmark mass🎲(x₂)BenchmarkTools.Trial: 30 samples with 1 evaluation per sample. + Range (min … max): 161.499 ms … 184.335 ms ┊ GC (min … max): 8.80% … 6.33% + Time (median): 165.566 ms ┊ GC (median): 10.62% + Time (mean ± σ): 167.251 ms ± 5.510 ms ┊ GC (mean ± σ): 10.25% ± 2.34% + ▃ ▃▃█ ▃▃▃▃ ▃ + █▁▁▇▇███▁████▇▇▇▁▁▁▇▇▁▁▇▁▁▁▇▇▁▁▁▁▇▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁█ ▁ + 161 ms Histogram: frequency by time 184 ms < + Memory estimate: 164.92 MiB, allocs estimate: 10748898.+
The only reason I included the trapezoidal rule is that I saw it suggested in an online resource that, on reflection, I think may have been AI slop and so I’m not linking to it (I was going to have a much longer diatribe here about it too, so consider yourself saved). The moral of the story is don’t use the trapezoidal rule for multidimensional integration unless you have some really compelling reason to do so.
+The advantage to the Monte Carlo approach given above is that it will work pretty much out of the box for any plume. The error will be smaller the more tightly the domain of integration can be bound around the region where , but it is in general pretty forgiving.
The other standard approach for multi-dimensional integration is adaptive cubature, for example h cubature. This approach really only works well when the bounds of integration are constants (e.g. the limits and
do not depend on
) and when the function being integrated does not have abrupt step changes. Taking the integrand from above and just running h cubature over it will be terribly inefficient.
A better approach is to re-write the integral such that the integration is only over the region with , and with an integrand that is smooth and continuous throughout. Firstly we re-write the integral.
Note that defines an ellipse, Figure 4, which suggests the change of variables
,
such that
and ,
This can be integrated directly with h cubature without involving any discontinuous functions.
+using HCubature: hcubaturefunction mass📦(xₗ; w=w, u=u)
+ lower = [0.0, 0.0, 0.0]
+ upper = [1.0, 2π, xₗ]
+ χₗ = χ(xₗ,0,0; w=w, u=u)
+
+ function integrand(r)
+ (ρ,θ,x) = r
+ K = 2*(log(w) - log(2π*χₗ*σy(x)*σz(x)*u))
+ y = σy(x)*√(K)*ρ*cos(θ)
+ z = σz(x)*√(K)*ρ*sin(θ)
+ return σy(x)*σz(x)*K*χ(x,y,z; w=w, u=u)*ρ
+ end
+
+ I, err = hcubature(integrand, lower, upper)
+ return I
+endm📦 = mass📦(x₂) - mass📦(x₁);The mass by H cubature is 56.23kg
+📦res = @benchmark mass📦(x₂)BenchmarkTools.Trial: 208 samples with 1 evaluation per sample. + Range (min … max): 19.541 ms … 35.658 ms ┊ GC (min … max): 0.00% … 37.93% + Time (median): 25.003 ms ┊ GC (median): 19.48% + Time (mean ± σ): 24.127 ms ± 2.908 ms ┊ GC (mean ± σ): 13.37% ± 10.14% + ▁ ▄▂█▂ + ▄▆▇█▇▄▄▃▃▁▃▁▁▂▁▁▁▂▃▂█████▆▆▃▂▃▃▂▁▂▁▂▁▂▁▁▁▂▁▁▂▁▁▂▁▁▁▁▁▁▁▁▂▁▂ ▃ + 19.5 ms Histogram: frequency by time 34.2 ms < + Memory estimate: 23.05 MiB, allocs estimate: 1459221.+
This is both significantly more accurate (spoilers!) and a dramatic improvement in both compute time and memory useage. Though at a cost that this is not as easily adapted to other plume types. For example, a Gaussian plume at some height above the ground with ground-reflection does not have a nice clean expression for the lower plume extent and the change of variables to polar coordinates doesn’t work as nicely.
+You might get the sense now that I am leading you somewhere very specific. By choosing polar coordinates for the integration, and noting that for the Gaussian free plume the isopleths form an ellipse, it should immediately suggest that we could just…integrate this analytically. Substituting ,
directly into the definition of
gives
The last integral is a simple one dimensional integral which can be done with QuadGK.
+using QuadGK: quadgkfunction mass🔴(xₗ; w=w, u=u)
+ I, err = quadgk( t -> σy(t)*σz(t), 0, xₗ)
+ return (w/u)*xₗ - 2π*χ(xₗ,0,0; w=w, u=u)*I
+endmass🔴 (generic function with 1 method)m🔴 = mass🔴(x₂) - mass🔴(x₁);For the special case where and
the integral can be done analytically to arrive at
Which is the result from Van Buijtenen8 given above. Similarly if we take and
then
8 “Calculation of the Amount of Gas in the Explosive Region of a Vapour Cloud Released in the Atmosphere”.
Which is the result from the TNO Yellow Book.9
+9 Bakkum and Duijm., “Vapour Cloud Dispersion”.
mₑ = (w/u)*((b+d)/(b+d+1))*(x₂ - x₁);The mass by QuadGK is 56.23kg, and the exact analytic solution is 56.23kg
+🔴res = @benchmark mass🔴(x₂)BenchmarkTools.Trial: 10000 samples with 1 evaluation per sample. + Range (min … max): 21.956 μs … 13.849 ms ┊ GC (min … max): 0.00% … 99.31% + Time (median): 29.064 μs ┊ GC (median): 0.00% + Time (mean ± σ): 29.891 μs ± 138.294 μs ┊ GC (mean ± σ): 4.60% ± 0.99% + ▁█▅▂ ▅█▇▅▂ + ▂▄▂▂▂▂▁████▆▄▃▂▂▃▃▇█████▇▅▄▃▂▂▂▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁ ▃ + 22 μs Histogram: frequency by time 43.7 μs < + Memory estimate: 24.86 KiB, allocs estimate: 1519.+
It is definitely a little bit of cheating to point out that the simple one-dimensional integral is much more performant than any of the three integrations of the whole volume, see Table 1.
+| + | Mass (kg) | +Error (%) | +Median Time (ms) | +
|---|---|---|---|
| Trapezoidal Rule | +55.73 | +0.9% | +9443.63 | +
| Monte Carlo | +56.36 | +0.23% | +165.57 | +
| H Cubature | +56.23 | +1.0e-8% | +25.0 | +
| QuadGK | +56.23 | +5.0e-10% | +0.03 | +
With a slight change, the integration over the cross-sectional area of a free plume can be modified to give us the mass in a grounded plume
+where
The masses within the free iso-surface and grounded iso-surface which intersect the x-axis at are the same, as we expect, but the concentration which defines that iso-surface is not the same. An important distinction.
You may have noticed the absence of the rigorous method given by Woodward in the analysis above. The rigorous method looks quite different from the previous integrations, but is similarly easy to calculate using QuadGK.
As a reminder the “rigorous” method given by Woodward for a free plume is
+with and
the complete elliptic integral of the second kind.
using SpecialFunctions: ellipek²(x) = 1 - (σz(x)/σy(x))^2k² (generic function with 1 method)I, err = quadgk( t -> σy(t)^2 * ellipe(k²(t)), x₁, x₂)(3522.359412198113, 4.6837135414534714e-7)m_rigorous = 4*(χ₁ - χ₂)*I;m_rigorous1853.438596397458That is far too high, it is 33.0× the exact solution and 18.5× the entire mass in the plume at x₂.
+Clearly this doesn’t work. So what’s gone wrong? Referring to the original paper by Hesse10 the mass is given as
+10 “A Computational Procedure for Calculating the Mass of Flammable Vapor in a Neutrally Buoyant Cloud”.
where is the area between the ellipses defined by
and
.
Hesse proposes that11
11 Hesse equation 20.
where is the perimeter of the elliptical isopleth in the y-z plane defined by the concentration
. That is to say, Hesse is integrating the cross-sectional area by treating it like a series of concentric, elliptical, rings with perimeter
and width
. For the free plume the perimeter is
Where is the complete elliptic integral of the second kind with the elliptic modulus given by
, a constant with respect to
and
.
Substituting in and making the change of variables to
From here the remainder of the derivation follows rather obviously….Unfortunately, this doesn’t actually work as a method of integration. The problem is right at the very first step
+To demonstrate this, consider the integration simply over the cross-sectional area. Hesse proposes that this relation holds
+That is, we should be able to use Hesse’s technique to recover the area of an ellipse, since he is integrating over an elliptical cross-section. However, since is a constant, that’s not what we get:
But we know that the area of an ellipse is . The only case in which Hesse’s technique works is when
, since
(i.e. a circular cross-section).
There is another glaring flaw with how this integration is being done. Even were it the case that the integration over the cross-section was correct, the axial integration is being done over the region where the cross-section is no longer well defined. The ellipse that defines the inner boundary of our cross-sectional domain of integration is not defined for . This is, in fact, the definition of
12. The only region over which the integration even makes sense is from
, and yet the actual integration is being done over
.
12 is the point where
, i.e. where the inner ellipse vanishes. At any point
there is no point in the plume where
and so the isopleth does not exist
Even if the cross-sectional integration was adjusted such that the innner ellipse is ignored, and so the problem of being undefined in the region is solved, it still doesn’t work because it excludes the mass in the plume between
for which
. Clearly from Figure 1 and Figure 2, this is not a negligible region.
One might be tempted by the logic
+But that only works if , which is not the case in general.
It is possible this was fixed in errata that did not make it into the final publication. Spicer and Havens13 also reference Hesse but note the inclusion of “important author errata distributed at the meeting where the paper was presented”. Regardless, what is published in Hesse and Woodward is wrong.
+13 “Application of Dispersion Models to Flammable Cloud Analyses”.
For a screening level analysis I would use the relation
+to calculate the mass within an isosurface defined by . This gives some freedom in choice of dispersion parameters
and
. The free plume choice is a useful simplification even when considering release points at some elevation where ground reflection is important. The free plume model, while ignoring the ground plane entirely, does capture much of the mass that would accumulate along the ground (by integrating over the region that “passes through” the ground in the free model).
Something that may be worthwhile to explore is whether the mass within the isosurface that intersects the x-axis at for a plume at some height
with ground reflection is also the same as the mass in the grounded and free plumes. One would expect the concentration along the centerline to be somwhere between that of the grounded and free plumes, so it is certainly suggestive when the mass within the two plumes is identical. I don’t seen an obvious way of doing this analytically, but it would be nice to have an answer to the question of “how wrong would I be if I just used the same
equation for everything?”
The standard approach for assessing the consequences of a release from a pressure vessel is to:1
+1 Center for Chemical Process Safety, Guidelines for Consequence Analysis of Chemical Releases, 11.
The mass release rate from a vessel blowdown is taken as the max release rate (at the start of the blowdown) and generally assumed to be constant.2 While the standard references do acknowledge that the flow will decrease over time, this is typically not taken into account in the dispersion models. The one exception that I’m aware of is when modelling flaring due to vessel and pipeline blowdowns: sometimes an average flowrate is taken instead of the max, in which case the blowdown curve is used to derive that average. It is still a constant, though, for the purposes of dispersion modelling.
+2 Center for Chemical Process Safety, 29–35.
3 Palazzi et al., “Diffusion from a Steady Source of Short Duration.”
However, if we think back to the development of the Palazzi model3 for short duration releases, a rather obvious path presents itself for the special case of a release of an ideal gas from an isothermal blowdown: integrate the Gaussian puff model over time with an exponentially decaying mass release rate.
+Recalling the isothermal blowdown of an ideal gas, the mass release rate, , is given by
Where4
+4 This follows from the definition of :
For a blowdown through an isentropic nozzle the time constant is given by
With:
+For a release centred at the origin with an elevation h, the concentration profile for a single Gaussian puff is given by:5
+5 Center for Chemical Process Safety, Guidelines for Consequence Analysis of Chemical Releases, 90–91.
Where the gs are Gaussian functions in the x, y, and z directions
+gx(x,t,u,σx) = exp(-0.5*((x-u*t)/σx)^2)/(√(2π)*σx)gy(y,σy) = exp(-0.5*(y/σy)^2)/(√(2π)*σy)gz(z,h,σz) = ( exp(-0.5*((z-h)/σz)^2)
+ + exp(-0.5*((z+h)/σz)^2))/(√(2π)*σz)With:
+For puff releases, the dispersion parameters are typically given in reference to the centre of the cloud,6 here I have taken some puff dispersion parameters for a class D atmospheric stability.
+6 Center for Chemical Process Safety, 90.
# Puff dispersion parameters for Class D atmospheres
+σx(xc) = 0.06*xc^0.92
+σy(xc) = 0.06*xc^0.92
+σz(xc) = 0.15*xc^0.70I like to use Unitful to manage units. This can be a little tricky with correlations, so to make that easier I use a simple macro to add a method to each correlation function mapping the correct input units and output units.
+import Pkg
+Pkg.add(url="https://github.com/aefarrell/UnitfulCorrelations.jl")using Unitful
+using UnitfulCorrelations@ucorrel σx u"m" u"m"
+@ucorrel σy u"m" u"m"
+@ucorrel σz u"m" u"m"A good habit to get into, when developing code in julia, is to collect model parameters into structs. This is what I do here, collecting the parameters for a single Puff into a Puff struct.
struct Puff
+ m # mass
+ h # release height
+ u # velocity
+ t # release time
+endNow I create the concentration function which takes a single puff, and a location in space and time, and returns the concentration. I also check for the special case where the puff hasn’t actually been released yet, and so does not contribute to the concentration.
+Since I want this to be unit aware, both return values have to have the same units. I don’t want to hard-code this as I may also want to use this function with simple numeric types, like Float64. By using the unit function I can ensure the zero result has the same dimensions as the correct result, falling back to no units in the case where all inputs are simple numbers.
function c(p::Puff,x,y,z,t)
+ λ = t - p.t # time since release
+ xc = p.u*λ # location of cloud center
+ if λ > 0t
+ return p.m*gx(x,λ,p.u,σx(xc))*gy(y,σy(xc))*gz(z,p.h,σz(xc))
+ else # the puff hasn't been released yet
+ return 0*unit(p.m)/unit(xc)^3
+ end
+endThe single puff model assumes all of the mass is released in a single instant. This significantly over-estimates the concentration for longer duration releases, and so an alternative approach is to break up the release into several puffs and sum the result.
+Where is the duration of each puff and
is the time when puff i was released.
c(ps::Vector{Puff},x,y,z,t) = sum( c.(ps, x, y, z, t) );Taking the limit takes this from a discrete sum to the corresponding integral
For the Palazzi7 model 8 and, assuming the
s are independent of time, this can be integrated to give:
7 Palazzi et al., “Diffusion from a Steady Source of Short Duration.”
8 being the Heaviside function
using SpecialFunctions: erf, erfcstruct Palazzi
+ w # mass release rate
+ h # release height
+ u # velocity
+ t_f # end of release
+endfunction c(p::Palazzi,x,y,z,t)
+ Δt = min(t, p.t_f)
+ w, u = p.w, p.u
+ xa = u*(t-Δt)
+ xb = u*t
+ # n.b. erf(b,a) = erf(a) - erf(b)
+ return (w/(2u))*erf((x-xb)/(√2*σx(xb)), (x-xa)/(√2*σx(xa))) *
+ gy(y,σy(x))*gz(z,h,σz(x))
+endIt should be pretty obvious where I am going next: instead of assuming is a constant, let it be the exponential decay from an isothermal vessel blowdown. The integration is a little more tedious but it is not really any more difficult than the Palazzi case.
Splitting this into elements that depend on time and those that don’t
Letting everything within the integral equal
It makes the integration a little easier to introduce
By expanding everything within the , collecting terms and completing the square we arrive at:
If we evaluate the s at the end points then, given that
as
, this simplifies to:
Giving a final concentration of:
+struct IsothermalBlowdown
+ w_0 # mass release rate
+ τ # time constant
+ h # release height
+ u # velocity
+ t_f # end of release
+endfunction c(p::IsothermalBlowdown,x,y,z,t)
+ w₀, u, τ = p.w_0, p.u, p.τ
+ xb = u*t
+ xa = t < p.t_f ? 0*xb : u*(t-p.t_f)
+ return (w₀/(2u))*
+ exp( (σx(xb)^2 + 2u*τ*(x - xb))/(2*(u*τ)^2) ) *
+ erf( (σx(xb)^2 + u*τ*(x - xb))/(√(2)*σx(xb)*u*τ),
+ (σx(xa)^2 + u*τ*(x - xa))/(√(2)*σx(xa)*u*τ) )*
+ gy(y,σy(x))*gz(z,h,σz(x))
+endNote that I have implemented a slightly different version of the model. In the case where , with
being the time at which the blowdown ceases, this simplifies to the model given above, where I implicitly assumed
.
In the case where is some finite number and
, an extra term is added to, essentially, “turn off” the blowdown.
Just to have something to look at, suppose an isothermal blowdown from a vessel which starts at an initial release rate of 1kg/s and the vessel contains 1000kg of an ideal gas. The vent stack is 2m above the ground and ambient windspeed is 2m/s.
+# The example case
+u = 2.0u"m/s"
+h = 2.0u"m"
+w₀ = 1.0u"kg/s"
+m₀ = 1000.0u"kg"
+τ = m₀/w₀The mass release rate, per above, is simply the exponential decay.
+w(t) = w₀*exp(-t/τ)The total mass released by time t is simply the time-integral:
+m(t) = w₀*τ*(1 - exp(-t/τ))Suppose that after time has elapsed a block-valve shuts and the release abruptly ends. This release can be modelled as a series of discrete puffs by dividing the interval
into
sub-intervals and releasing a single puff at the start of each interval i with a mass
.
function discrete_puffs(;n=100, t_0=0τ, t_f=τ)
+ δt = (t_f - t_0)/(n-1)
+ pfs = Vector{Puff}()
+ for t_i ∈ range(t_0;stop=t_f,length=n)
+ m_i = w(t_i)*δt
+ pf = Puff(m_i,h,u,t_i)
+ push!(pfs,pf)
+ end
+ return pfs
+endpfs = discrete_puffs(n=25);For the purposes of illustration I chose a rather small number of puffs, as shown in Figure 1. However, if we calculate the total mass released we find that it isn’t too far off.
+m(pfs::Vector{Puff},t) = sum( pf.m for pf in pfs if pf.t < t );After time τ has elapsed, the total released mass is 632 kg, the total mass of the discrete puffs is 645 kg, an excess of only 2.1%.
+With the discrete puff case implemented, we can now compare with the approximate integral. Recall that I didn’t actually integrate the full expression, I approximated the integral as one where the s are constant (they aren’t) and integrated that. I then took that result and substituted back in the correlations for the
s. The hope is that this will be close enough to the full expression that we can use it.
For a less than rigorous approach, let us consider a point 1000m downwind of the vent stack, at the same release height as the stack. We will look at the concentration profile over time at that point.
+Another useful comparison is to the Palazzi model, we expect the concentration profile for the blowdown to be bounded between the Palazzi case with a constant mass rate and the case with a constant mass rate
. Furthermore, we expect the blowdown case should connect the two curves with something resembling an exponential decay.
bd = IsothermalBlowdown(w₀,τ,h,u,τ)The results are showin in Figure 2 above, which matches our expectations. The approximate integral model developed here is virtually identical to the discrete puffs model with 100 puffs. For comparison I also included the case where the Palazzi model is used but with a time-averaged constant release rate. This will have the correct total mass in the release, but clearly underestimates the peak concentration.
+The ground level concentration also conforms to our expectations, as shown in Figure 3. The region around the vent itself, besides having some artifacts of the discretization and marching squares, is likely quite unreliable. This is the region where the fundamental assumptions, that the release has zero momentum and no buoyancy, are most egregiously violated. I think this model is still reasonable for concentrations far enough from the vent that the windspeed dominates the advection, though an effective release point would need to be used.
+It is the nature of the universe that the instant I post this I will find where this model was published in the literature. I haven’t found it yet, but I can’t imagine I am first person to come up with this. Knowing me, it is probably in one of the references I look at all the time and, somehow, failed to notice.
+If this paragraph is still here when you see this, and you know of a published reference for this model, please leave a comment.
+1 Ooms, “A New Method for the Calculation of the Plume Path of Gases Emitted by a Stack”.
The Ooms plume model is a model of a continuous jet of fluid exiting into a crossflow. Unlike, for example, a simple Gaussian model which assumes the source has no momentum, or a free jet model which assumes there is no crossflow, the Ooms model accounts for the buoyancy and momentum of the jet as well as the crossflow without resorting empirical correlations (such as the Briggs’ model).
+However, unlike those simpler models, the Ooms model is not in the form of simple closed form expressions. It is an integral plume model which results in a system of differential algebraic equations which must be solved numerically for each particular plume. Unlike earlier integral plume models, which assumed a top hat velocity and density profile, the Ooms model assumes the plume parameters follow Gaussian profiles.
+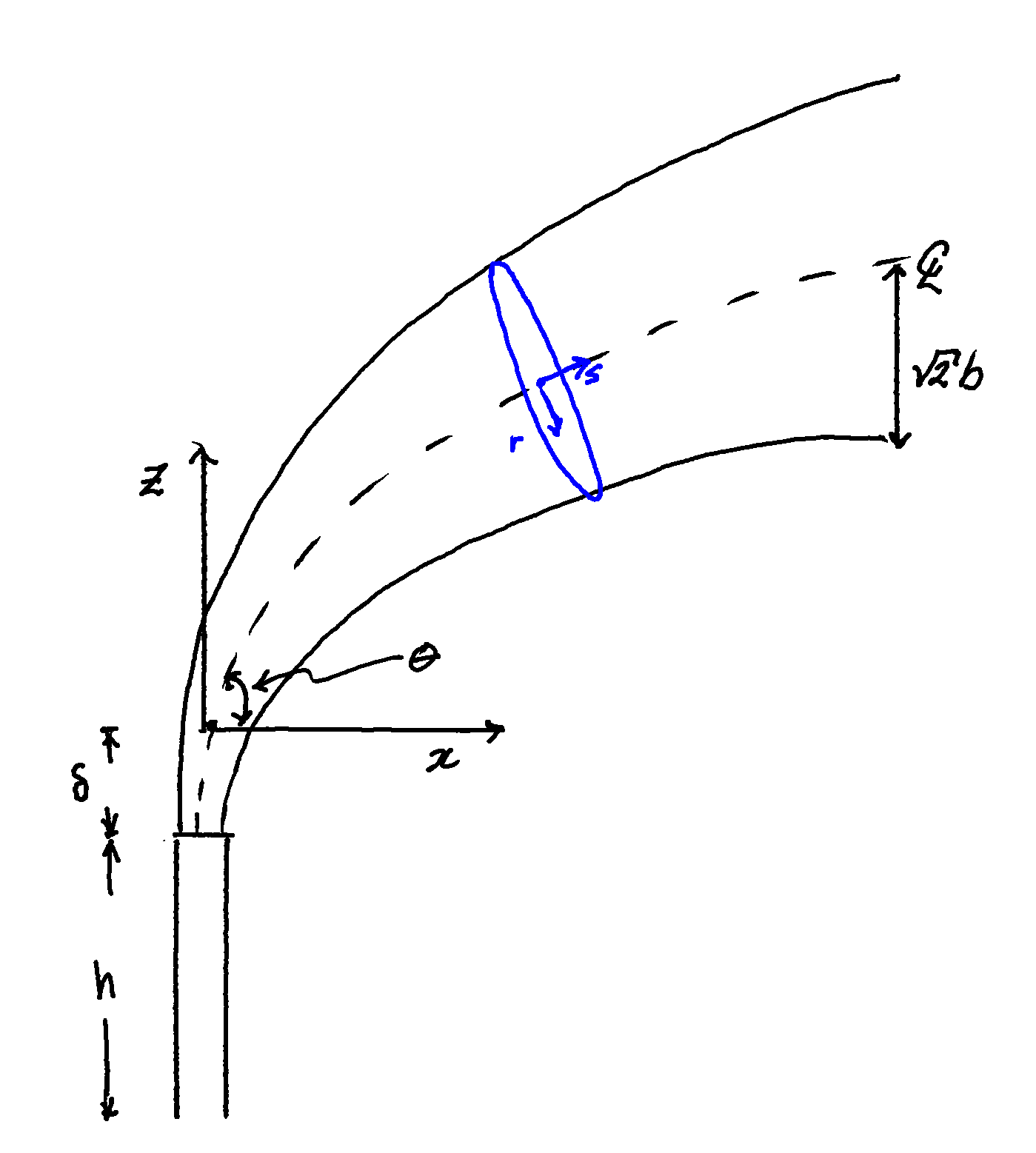 +
+Consider the sketch of a vertical vent shown in Figure 1. The plume starts at some point down stream of the actual vent, after the zone of flow establishment characterized by an elevation δ. The plume rises due to the buoyancy and momentum in the vent gases and bends over as it is carried along by the wind. The coordinate system is arranged such that the wind is in the positive x-direction and the center-line of the plume is within the x-z plane.
+Taking a slice through the plume, we assume it has a circular cross-section and use a local cylindrical coordinate system with s the direction along the plume axis, r the radial direction, and φ the radial angle. The overall plume radius at any point is , with b a characteristic length which is a function of distance along the center-line.
Zooming in on a differential element of the plume, Figure 2, we take it be approximately a cylinder where flow within the plume enters and exits through the circular ends and air is entrained through the outer surface with some entrainment velocity E.
+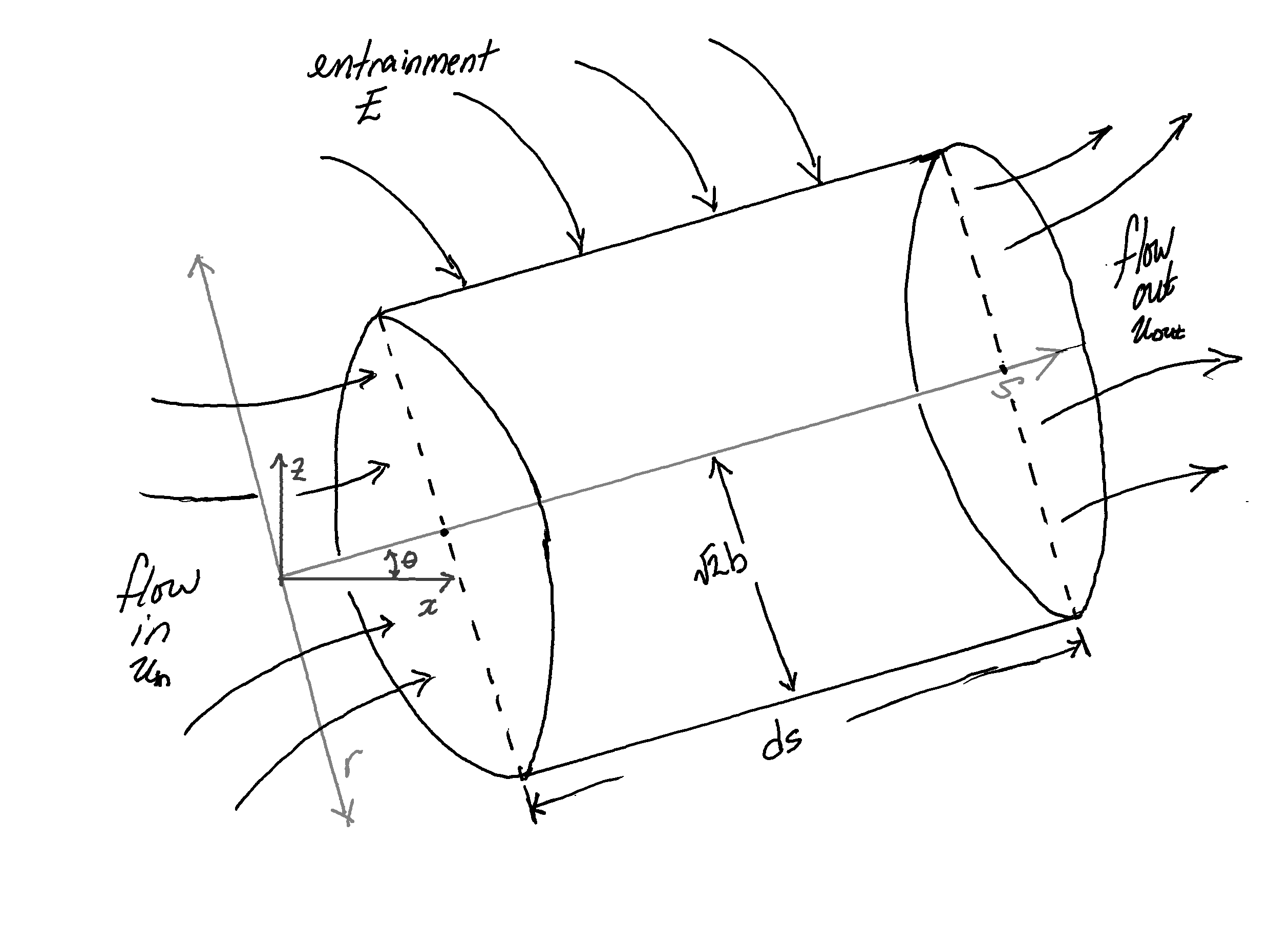 +
+The Ooms model comes from the conservation relations for this differential element.
+The mass exiting the differential element is equal to the mass entering through the plume plus the entrained air.
+The mass of entrained air is simply the product of the mass flux (ρE) and the area:
+Giving a mass balance equation:
+The mass passing through a surface is simply the mass flux G = ρ u integrated over the surface area:
+
Finally giving
+
An errant has disappeared from the right hand side of the equation. It has been absorbed into the constants in E. The right hand side of the balance equations in Ooms2 appear at first blush like they were done for a top hat model of a plume with radius b, which would be a mistake. However, as the overall radius of a plume in a top hat model btop-hat =
, when the constants are scaled by a factor of
the two look the same.
2 “A New Method for the Calculation of the Plume Path of Gases Emitted by a Stack”.
The total mass of the vented substance is conserved as the plume expands. Assuming the vent is some species i with mass concentration c:
+
There are two equations for conservation of momentum: in the x-direction and z-direction. This is a consequence of the choice of coordinates – that the plume centerline is confined to the x-z plane and neither the jet nor the crossflow have velocity in the y-direction. In particular the coordinates were chosen such that the crossflow is entirely in the x-direction with velocity .
In the x-direction the total momentum into the differential element is the mass in times the velocity component in the x direction:
+And similarly for the total momentum leaving the element
+The change in momentum is equal to the momentum added to the plume from entrainment and drag from the wind. In this case the drag force acts in the positive direction, pushing the plume along.
+Ooms notes that the drag force on the plume is only due to the component of the wind velocity which is perpendicular to the plume direction, . Drag then follows the standard relationship, with the area being the outside surface area of the cylinder.
The drag force in the x-direction is acting on the area perpendicular to the x-direction
+Where the absolute value comes from the drag force being always positive.
+Giving
+In the z-direction the change in momentum is due to buoyant forces and drag in the z-direction. The buoyant force can be written as:
+Assuming the density within the differential element is approximately constant with s. Combining with the drag force in the z-direction gives the final momentum balance:
+Where ensures the drag force is acting in the right direction.
Starting from an energy balance, using the ambient temperature as the reference temperature, the enthalpy entering the differential element is:
+Similarly for the enthalpy out, giving an enthalpy change over the element of:
+To be very abusive of notation. Where T is the temperature of the plume and Ta,0 is the reference temperature – the ambient temperature at the vent exit. The enthalpy change is assumed to come only from entrainment. The enthalpy added to the differential element from entrainment of air is:
+Putting it all together we get the energy balance:
+Assuming the ideal gas law, we can make the substitution:
+Furthermore, if we assume and
then we can cancel all those constants giving:
These seem like radical assumptions if you are coming to the Ooms plume model as a dense gas dispersion model, but the original paper is concerned with the release of stack gases from combustion equipment. For stack gases this is not unreasonable and other models such as the Briggs’ model for plume rise make similar simplifications (any model that calculates buoyant flux from plume temperature alone is making that assumption implicitly).
+Up until this point all of the plume parameters have been calculated along the plume axis. This needs to be translated into the original coordinate system to be useful, in particular the curve the plume axis takes through space is given by:
+
One of the most important parts of the model is how it accounts for entrainment. Ooms considers entrainment to be the sum of three processes.
+In the immediate vicinity of the jet exit, when the jet velocity dominates, the entrainment is taken to be the same as a free jet, namely that it is proportional to the jet center line velocity. In this case we take the excess velocity:
+Where is the component of the wind velocity parallel to the jet. The parameter
is called the entrainment coefficient for a free jet and is independent of Reynolds’ number when
. Ooms gives this as
.
At distances further down the plume axis, when , the entrainment is taken to be the same as a cylindrical thermal in a stagnant atmosphere, given as:
Where is called the entrainment coefficient for a line thermal, it is similarly a constant at large Reynolds’ numbers. Ooms gives this as
To connect these two regimes, Ooms multiplies the line thermal term by . This doesn’t seem to have any theoretical justification, it just works to make the second term disappear when the vent is still mostly vertical. This is an important feature to note. The model is often presented such that the initial angle of the jet can be anything, but a key assumption of the entrainment model is that the jet is initially vertical.
Finally, Ooms adds a term to entrainment due to atmospheric turbulence. Presumably if you were only interested in jets entering a crossflow where that flow was nice and laminar you would leave this out. But Ooms is specifically developing his model for vent stacks releasing plumes into the atmosphere, and the actual structure of the atmosphere and its turbulence must be accounted for. He does this by including an entrainment velocity due to turbulence
Where is the entrainment coefficient due to turbulence, which is taken to be
. The entrainment velocity due to turbulence can be accounted for in one of two ways:
The total entrainment is then:
+or
+Where is defined in the next section.
Earlier I mentioned that the velocity, density, and concentration in the plume are assumed to have Gaussian profiles. Though it doesn’t really have a theoretical basis, Gaussian profiles are mathematically convenient and fit observed profiles quite well. This has been experimentally validated for both free jets and bent over plumes.3
+3 Keffer and Baines, “The Round Turbulent Jet in a Cross-Wind”.
The velocity is taken to be the component of the wind velocity parallel to the plume axis plus an excess velocity:
+The plume density, similarly, is the air density plus an excess density:
+Finally, the concentration simply follows a Gaussian profile:
+Where is the turbulent Schmidt number. This is entirely analogous to a free jet. I’m not sure entirely why Ooms gives the Schmidt number as what I would call the inverse of the Schmidt number, but that is just a quibble of notation.
Ooms uses a value of or
, which is consistent with observations of free jets.
The original paper does not provide the final differential algebraic equations, nor does it provide the worked out integrals, that is left as an exercise for the reader. I looked around and could not find a detailed description of the final model equations other than in the model documentation for DEGADIS.4 An earlier version of DEGADIS used the Ooms plume model for dense gas plumes with modifications to the model assumptions and, especially, the energy balance. This is a good start, but it is presented in its final matrix form with 17 model constants that are pre-calculated. It is not immediately clear where the model constants come from and how they are related to the constant λ.
+4 Havens and Spicer, “A Dispersion Model for Elevated Dense Gas Jet Chemical Releases,” 7–13.
 +
+5 Havens and Spicer, 12.
The version in DEGADIS is intended for dense gas dispersion and makes additional assumptions such as that there is no vertical change in air density. This is a reasonable assumption for dense plumes that fall back to earth and roll along the ground, but is something that would have to be corrected for large buoyant plumes rising high into the air.
+I did my own working out here because I wanted two things:
+The integrals are not difficult to work out, though they can turn into a sort of alphabet soup of variables. The integrals involving Gaussians all involve something of the form which has a nice closed form solution.
I worked out five different constants that are integrals of the Gaussian profiles and the products of them:
+
These are basically in the order that I encountered them when working out the integrals and could probably be cleaned up for some consistency. Throughout I made the substitution such that every integral of a Gaussian in the model becomes
where the C corresponds to one of the above. Each of the 17 constants in the DEGADIS model correspond to one of these constants times a scaling factor. For all but
and
they are integer scaling factors, for the first two they
times
and
respectively. Below is a table showing the concordance.
| DEGADIS6 | +Me | +
|---|---|
6 Havens and Spicer, 12.
It is decidedly easier to put everything in dimensionless form first, using the following (where a bar over the variable indicates that it is dimensionless):
+
Where D is the initial jet diameter. This is the main point where what follows diverges from DEGADIS, where the model is given in dimensional form, which makes each of the expressions much larger and makes direct comparison between the two something of a chore.
+Thusly equipped, we can work out the integrals and subsequently all the derivatives. Starting with the conservation of mass:
+
So the balance equation is:
+
Where is the dimensionless entrainment velocity.
Expanding out the derivatives and dividing through by b, we get:
+
In the interests of not having this go on forever, I’m going to skip the details on the integral (they should be fairly obvious) and just give the balance equation and the final form with expanded out derivatives.
+The balance equation is:
+The final form is:
+
The balance equation in the x-direction is:
+The final form is:
+
The balance equation in the z-direction is:
+Where is the dimensionless gravity.
The final form is:
+
The balance equation is:
+Where is the dimensionless air density.
The final form is:
+
Implementing this in julia is very straightforward, starting with the model constants
+# constants from Ooms 1972
+const λ² = 1.35
+const α₁ = 0.057
+const α₂ = 0.5
+const α₃ = 1.0
+const ϵ = 0.0
+const Cd = 0.3# integration constants
+const C₁ = 1-exp(-2)
+const C₂ = λ²*(1-exp(-2/λ²))
+const C₃ = (λ²/(λ²+1))*(1-exp(-2*(λ²+1)/λ²))
+const C₄ = (1-exp(-4))/4
+const C₅ = (λ²/(4λ²+2))*(1-exp(-(4λ²+2)/λ²))# physical constants
+const g = 9.80665 # standard gravity, m/s²
+const MWₐ = 0.0289652 # molar weight dry air, kg/mol
+const cpₐ = 1.006 # specific heat dry air, kJ/kg/K
+const ρₐ₀ = 1.2250 # standard density dry air, kg/m³The standard way of writing a differential algebraic equation is in the form of a mass matrix, M:
+Where state is the state vector for this system. In this case M is not a constant, it is a function of the state of the system as well. Below is a function that calculates the mass matrix for a given state of the system, this is done in place to reduce the number of allocations required. The state variables are all in dimensionless form – the overbars are implied.
function ooms_matrix!(M,state,p,s)
+ # unpack variables for readability
+ c, b, u, θ, ρ, x, z = state
+
+ # calculate atmospheric conditons at centerline elevation
+ ρₐ_bar = p.rhoa_bar(z)
+
+ # species balance
+ M[1,1] = b*( C₃*u + C₂*cos(θ) )
+ M[1,2] = 2*c*( C₃*u + C₂*cos(θ) )
+ M[1,3] = C₃*c*b
+ M[1,4] = -C₂*c*b*sin(θ)
+ M[1,5] = 0
+ M[1,6] = 0
+ M[1,7] = 0
+
+ # overall mass balance
+ M[2,1] = 0
+ M[2,2] = 2cos(θ)*(2 + C₂*ρ) + 2u*(C₁ + C₃*ρ)
+ M[2,3] = b*(C₁ + C₃*ρ)
+ M[2,4] = -b*sin(θ)*(2 + C₂*ρ)
+ M[2,5] = b*(C₂*cos(θ) + C₃*u)
+ M[2,6] = 0
+ M[2,7] = 0
+
+ # x momentum balance
+ M[3,1] = 0
+ M[3,2] = 2cos(θ)*( 2u^2*(C₄ + C₅*ρ) + 2u*cos(θ)*(C₁ + C₃*ρ)
+ + cos(θ)^2*(2 + C₂*ρ))
+ M[3,3] = 2b*cos(θ)*( cos(θ)*(C₁ + C₃*ρ) + 2u*(C₄ + C₅*ρ) )
+ M[3,4] = -b*sin(θ)*( cos(θ)*( 4u*(C₁ + C₃*ρ) + 3cos(θ)*(2 + C₂*ρ) )
+ + 2u^2*(C₄ + C₅*ρ) )
+ M[3,5] = b*cos(θ)*( C₂*cos(θ)^2 + 2C₃*u*cos(θ) + 2C₅*u^2 )
+ M[3,6] = 0
+ M[3,7] = 0
+
+ # z momentum balance
+ M[4,1] = 0
+ M[4,2] = 2sin(θ)*( 2u*cos(θ)*(C₁ + C₃*ρ) + cos(θ)^2*(2 + C₂*ρ)
+ + 2u^2*(C₄ + C₅*ρ))
+ M[4,3] = 2b*sin(θ)*(cos(θ)*(C₁ + C₃*ρ) +2u*(C₄ + C₅*ρ))
+ M[4,4] = b*(2u*(cos(θ)^2 - sin(θ)^2)*(C₁ + C₃*ρ)
+ + (1-3sin(θ)^2)*cos(θ)*(2 + C₂*ρ)
+ + 2u^2*cos(θ)*(C₄ + C₅*ρ))
+ M[4,5] = b*sin(θ)*(C₂*cos(θ)^2 + 2C₃*u*cos(θ) + 2C₅*u^2)
+ M[4,6] = 0
+ M[4,7] = 0
+
+ # energy balance
+ M[5,1] = 0
+ M[5,2] = 2(2cos(θ) + C₁*u - ρₐ_bar*(u*(C₁ + C₃*ρ) + cos(θ)*(2 + C₂*ρ)) )
+ M[5,3] = b*( C₁ - ρₐ_bar*(C₁ + C₃*ρ) )
+ M[5,4] = -b*sin(θ)*( 2 - ρₐ_bar*(2 + C₂*ρ) )
+ M[5,5] = -b*ρₐ_bar*( C₂*cos(θ) + C₃*u )
+ M[5,6] = 0
+ M[5,7] = 0
+
+ # x coordinate
+ M[6,1:5] .= 0
+ M[6,6] = 1
+ M[6,7] = 0
+
+ # z coordinate
+ M[7,1:6] .= 0
+ M[7,7] = 1
+endIn dimensionless form, the only parameter of the system that is relevant to the mass matrix is which is a function of the (dimensionless) elevation.
The right-hand-side of the system of equations is below, and is also in place. In this case there are three parameters: ,
and
. These are all functions of elevation, the latter two because
is a function of elevation.
function ooms_rhs!(f,state,p,s)
+ # unpack variables for readability
+ c, b, u, θ, ρ, x, z = state
+
+ # calculate atmospheric conditons at centerline elevation
+ ρₐ_bar = p.rhoa_bar(z)
+ g_bar = p.g_bar(z)
+
+ # entrainment
+ u′ = p.uprime_bar(b, z)
+ E = α₁*abs(u) + α₂*abs(sin(θ))*cos(θ) + α₃*u′
+ sgn = θ<0 ? -1 : +1
+
+ f .= [ 0 # species balance
+ 2E # overall mass balance
+ 2E + Cd*abs(sin(θ)^3) # x momentum balance
+ -C₂*b*ρ*g_bar + sign(θ)*Cd*sin(θ)^2*cos(θ) # z momentum balance
+ 2*(1-ρₐ_bar)*E # energy balance
+ cos(θ) # x coordinate
+ sin(θ)] # z coordinate
+endThe most direct way of implementing the model is as an ODE where
+Though instead of taking the matrix inverse a linear solve is done. This is what you might call the conventional approach, or traditional approach perhaps. People who spend a lot of time with DAEs and numerical computation will tell you not to do this – it can be unstable and fail if M is singular or near-singular – but it is also throughout the literature, especially in older code. For example, this is how DEGADIS implements the right-hand-side of the ODE.
+using OrdinaryDiffEqfunction ode_rhs!(dstate,state,p,s)
+ ooms_matrix!(p.M,state,p,s)
+ ooms_rhs!(p.f,state,p,s)
+ dstate[:] = p.M\p.f
+endInstead of allocating (and garbage collecting) a matrix M and vector f every time the right-and-side is called, I pre-allocate them and store them with the model parameters as a kind of scratch space.
+For a working example, suppose the vent is releasing into a neutral atmosphere with no density gradient and a windspeed at the stack height of 2m/s
+const dρₐdz = 0.0
+const uₐ₀ = 2.0 # m/sThe vent itself is basically air but hotter and thus at a lower density. The vent stack is 2m from the ground and 20cm in diameter, the vent is being ejected at 10m/s vertically. I am also ignoring the zone of flow establishment and having the plume start exactly at the vent exit.
+const MWⱼ = MWₐ # kg/m³
+const cpⱼ = cpₐ # kJ/kg/K
+const ρⱼ = ρₐ₀/2 # kg/m³
+const D = 0.2 # m
+const u₀ = 10.0 # m/s
+const h = 2.0 # m
+const θ₀ = π/2
+const c₀ = ρⱼThe system parameters are simply the scratch space for M and f, and the three dimensionless groups which are each functions of elevation. In this case I am further assuming that windspeed is uniform.
+params = (M = zeros(7,7),
+ f = zeros(7),
+ rhoa_bar = (z) -> 1.0 + (dρₐdz/ρₐ₀)*D*z,
+ g_bar = (z) -> (g*D)/uₐ₀^2,
+ uprime_bar = (b, z) -> ∛(ϵ*b*D)/uₐ₀)The initial state, in dimensionless form, is then
+state0 = [ 1.0 ,# c
+ 1/(2√(2)) ,# b
+ u₀/uₐ₀ ,# u
+ θ₀ ,# θ
+ (ρⱼ - ρₐ₀)/ρₐ₀ ,# ρ
+ 0.0 ,# x
+ h/D ]# zThe initial value for might seem strange and arbitrary, but this comes from matching the initial dimensions of the plume to the exit of the vent stack. Recall the plume radius is
so, if the plume initially has a radius equal to the vent
and
Integrating out 100 stack diameters along the plume
+span = (0.0, 100)
+prob = ODEProblem(ode_rhs!, state0, span, params)sol = solve(prob, Tsit5())
+
+sol.retcodeReturnCode.Success = 1Nesting the linear solve step within the right-hand-side of the ODE can be dangerous if M ever becomes singular, or close to it. It is probably safer to use a DAE solver instead.
+DAE solvers expect to be solving a differential algebraic equation of the form:
+Using the matrix and rhs functions defined earlier this easy enough to do, in this case the function is in-place.
+function dae_lhs!(resid,dstate,state,p,s)
+ ooms_matrix!(p.M,state,p,s)
+ ooms_rhs!(p.f,state,p,s)
+ resid[:] = p.M*dstate - p.f
+endThe DAE solver also needs an initial state for all of the derivatives, which can be calculated by solving the linear system for the derivatives given the initial conditions.
+M0 = zeros(7,7)
+ooms_matrix!(M0,state0,params,0)
+
+f0 = zeros(7)
+ooms_rhs!(f0,state0,params,0)
+
+dstate0 = M0\f0diff_vars = fill(true, 7)
+daeprob = DAEProblem(dae_lhs!, dstate0, state0, span, params;
+ differential_vars = diff_vars)The DAEProblem also needs a hint as to which are differential equations, this is what is being passed by the differential_vars keyword argument. In this case they are all differential equations so I pass a vector of seven trues.
The DAE solver I am going to use is IDA from Sundials.
using Sundialsdaesol = solve(daeprob, IDA())
+
+daesol.retcodeReturnCode.Success = 1This works as well as the lazy method, slightly slower but it has not been implemented in a particularly optimal way.
+If you know anything about the universe of tools in julia for modelling differential algebraic equations you are probably yelling at your screen “use ModelingToolkit!”. In terms of getting a DAE from nothing to a working model it is by far the easiest way to do it. I deliberately put all of the working out in this blog post because it annoys me that it is so hard to find online and I want it to be somewhere. But if I didn’t care about that, ModelingToolkit is the obvious choice.
+using ModelingToolkit, Symbolics
+using ModelingToolkit: t_nounits as s, D_nounits as ∂
+
+# I would use D for derivative but I'm already using
+# that for jet diameter so I'm using ∂ insteadFirst I define the system variables, again these are in dimensionless form.
+vars = @variables c(s) b(s) u(s) θ(s) ρ(s) x(s) z(s)If this wasn’t in a notebook that includes other methods of solving the DAE, I would have declared the model constants using the @constants macro. It makes the formulas look nicer for one, e.g. instead of numbers like 0.86466 there would be the appropriate constant .
# conservation of mass
+∫ρurdr = b^2*( (C₁ + C₃*ρ)*u + (2 + C₂*ρ)*cos(θ) )
+
+E = α₁*abs(u) + α₂*abs(sin(θ))*cos(θ) + α₃*∛(ϵ*b*D)/uₐ₀
+
+eqn1 = expand_derivatives( ∂( ∫ρurdr ) ) ~ 2*b*E# conservation of species
+∫curdr = c*b^2*(C₂*cos(θ) + C₃*u)
+
+eqn2 = expand_derivatives( ∂( ∫curdr ) ) ~ 0# conservation of momentum
+# x-direction
+∫ρu²cosθrdr = b^2*cos(θ)*(2u*cos(θ)*(C₁ + C₃*ρ) + 2u^2*(C₄ + C₅*ρ)
+ + cos(θ)^2*(2 + C₂*ρ))
+
+eqn3 = expand_derivatives( ∂( ∫ρu²cosθrdr ) ) ~
+ b*( 2E + Cd*abs(sin(θ)^3) )# z-direction
+∫ρu²sinθrdr = b^2*sin(θ)*(2u*cos(θ)*(C₁ + C₃*ρ) + 2u^2*(C₄ + C₅*ρ)
+ + cos(θ)^2*(2 + C₂*ρ))
+
+eqn4 = expand_derivatives( ∂( ∫ρu²sinθrdr ) ) ~
+ -C₂*b^2*ρ*(g*D/uₐ₀^2) + sign(θ)*Cd*b*sin(θ)^2*cos(θ)# energy balance
+ρₐ_bar = 1 + dρₐdz*D*z/ρₐ₀
+
+∫ρucₚΔTrdr = b^2*(2cos(θ) + C₁*u - ρₐ_bar*( u*(C₁ + C₃*ρ)
+ + cos(θ)*(2 + C₂*ρ) ))
+
+eqn5 = expand_derivatives( ∂( ∫ρucₚΔTrdr ) ) ~ 2*b*(1 - ρₐ_bar)*E# The full system of equations
+
+eqns = [ eqn1
+ eqn2
+ eqn3
+ eqn4
+ eqn5
+ ∂(x) ~ cos(θ)
+ ∂(z) ~ sin(θ) ]Symbolics.jl has done all the derivatives and set up all the equations, what remains is to build ODESystem and solve.
@named sys = ODESystem(eqns, s)
+sys = structural_simplify(sys)In this case there are no model parameters as I inserted the equations for the dimensionless groups directly into the model.
+mtk_params = ()The initial values simply map over the initial state I worked out previously. Because ModelingToolkit generates its own internal structure and shuffles things around, a mapping needs to be provided for the initial conditions.
+initial_vals = [ c => state0[1],
+ b => state0[2],
+ u => state0[3],
+ θ => state0[4],
+ ρ => state0[5],
+ x => state0[6],
+ z => state0[7] ]mtk_prob = ODEProblem(sys, initial_vals, span)mtk_sol = solve(mtk_prob, Rodas5P())
+
+mtk_sol.retcodeReturnCode.Success = 1In terms of julia code that needed to be written, and calculus that needed to be done, this the simplest by far. Simply compare to the enormous mass matrix expression above to convince yourself of that. There are also code generation tools that can be used if you want to extract the model either as a julia script or even C code. Furthermore, if you want to go through term by term and look at the coefficients for each derivative, Symbolics.jl can do that too. I actually used Symbolics to check all of my work in the mass matrix.
+Another approach to the ODE problem is to use a matrix operator. This is a mass matrix problem with a state dependent mass matrix, which is one of the use cases for SciMLOperators.jl
+using SciMLOperatorsM = MatrixOperator(zeros(7,7); update_func! = ooms_matrix!)massprob = ODEProblem(ODEFunction(ooms_rhs!, mass_matrix=M), state0, span, params)mass_sol = solve(massprob,Rodas5P(); initializealg=BrownFullBasicInit())
+
+mass_sol.retcode┌ Warning: At t=0.0, dt was forced below floating point epsilon 5.0e-324, and step error estimate = NaN. Aborting. There is either an error in your model specification or the true solution is unstable (or the true solution can not be represented in the precision of Float64). + +└ @ SciMLBase ~/.julia/packages/SciMLBase/rvXrA/src/integrator_interface.jl:623 ++
ReturnCode.Unstable = 7I tried a bunch of different solvers and initialization algorithms, nothing could get past the first timestep. That there are two working versions of this system, in this post, using the same exact mass matrix function leads me to suspect it is not a model error, or that the solution is unstable. There is probably some aspect to how I’m supposed to be initializing this problem, or some other feature of using matrix operators, that I’m doing wrong, but I find the documentation on that to be mostly absent. I know these can work because I have used this exact method on simpler systems in the past.
+If I ever figure out what I need to do to make this work, or more definitively why it doesn’t, I’ll come back and update this. Consider this an invitation to tell me all the ways I’m doing this wrong in the comments.
+The plume solution is fundamentally in terms of the plume axis. It is not immediately obvious how to calculate the concentrations at particular points in space relative to the problem coordinate system. The way I see it, there are three related problems that involve calculating concentrations from the Ooms model.
+These all stem from the problem that for some arbitrary point not on the plume axis, it is not immediately clear which part of the plume axis is governing the concentration there. This is because the concentration profiles are not perpendicular to the x-axis, they are perpendicular to the s-axis and that curves through space.
+The easiest problem to solve is the isopleths in the plane . Suppose we want to calculate the isopleth for some concentration
. Recalling the concentration profile:
Where is the center line concentration at that point along the plume axis. We first solve for
, the distance from the plume axis:
Converting from cylindrical coordinates to Cartesian coordinates, , aligned such that
is aligned with the plume axis, the radius is
Since we are confined to the plane , we find
. Then we rotate the axis to align with the problem coordinate system and translate the origin to the problem origin.
Where and
is the location of the particular point on the plume axis we were looking at. The origin relative to the point on the plume axis, hence the subscript o. The positive r gives the upper isopleth and the negative r gives the lower isopleth.
Casal7 provides an alternative form of these isopleths:
+and
+These are actually equivalent, using the identity and the definition
, the first equation can be written as:
The second equation can be re-written to solve for x:
+
7 Casal, “Atmospheric Dispersion of Toxic or Flammable Clouds,” 306.
function upper_isopleth(solution, s, c)
+ cₒ, bₒ, uₒ, θₒ, ρₒ, xₒ, zₒ = solution(s)
+
+ if c ≈ cₒ
+ return Point(xₒ,zₒ)
+ elseif c > cₒ
+ return nothing
+ else
+ r = bₒ * √(λ²*log(cₒ/c))
+ x = xₒ - r*sin(θₒ)
+ z = zₒ + r*cos(θₒ)
+ return Point(x,z)
+ end
+endfunction lower_isopleth(solution, s, c)
+ cₒ, bₒ, uₒ, θₒ, ρₒ, xₒ, zₒ = solution(s)
+
+ if c ≈ cₒ
+ return Point(xₒ,zₒ)
+ elseif c > cₒ
+ return nothing
+ else
+ r = bₒ * √(λ²*log(cₒ/c))
+ x = xₒ + r*sin(θₒ)
+ z = zₒ - r*cos(θₒ)
+ return Point(x,z)
+ end
+endFor an example, suppose we want the isopleth for
cₗ = 0.02 # c/c₀ = 2%First, I find the point along the plume axis where the concentration drops below 2%, there is no point in looking for an isopleth past this point since it doesn’t exist.
+using Roots: find_zeroi_end = findfirst(sol[1,:] .< cₗ )20s_end = find_zero( (s) -> sol(s, idxs = 1) - cₗ, sol.t[i_end])46.23790952011145Then I can calculate a series of points for the upper isopleth and the lower isopleth from the origin out to where the plume concentration has dropped below 2%.
+upper_points = [ upper_isopleth(sol, s, cₗ) for s in LinRange(0.0, s_end, 100)
+ if !isnothing(upper_isopleth(sol, s, cₗ))];
+lower_points = [ lower_isopleth(sol, s, cₗ) for s in LinRange(0.0, s_end, 100)
+ if !isnothing(lower_isopleth(sol, s, cₗ))];A somewhat more difficult problem is finding the isopleths on the plane z=a. The logic is the same: for each point along the plume axis, work out the distance r to the given concentration, then solve for y given z=a.
+function cross_isopleth(solution, s, c, a)
+ cₒ, bₒ, uₒ, θₒ, ρₒ, xₒ, zₒ = solution(s)
+
+ if c ≈ cₒ
+ return Point(xₒ,0.0)
+ elseif c > cₒ
+ # isopleth doesn't exist here
+ return nothing
+ else
+ # find the x coordinate
+ xₒ′ = xₒ*cos(θₒ) + zₒ*sin(θₒ)
+ x = (xₒ′ - a*sin(θₒ))*sec(θₒ)
+
+ # find the y coordinate
+ r² = bₒ^2 * λ²*log(cₒ/c)
+ z′² = ((a - zₒ)*cos(θₒ) - (x - xₒ)*sin(θₒ))^2
+
+ if z′² > r²
+ # the isosurface doesn't intersect z=a
+ return nothing
+ else
+ y′ = √( r² - z′²)
+ y = y′
+ return Point(x,y)
+ end
+ end
+endPicking an arbitraty height of 20 stack diameters in elevation.
+a = 20 # 20 stack diametersWe need to find the start and end of the isopleth, which not immediately obvious like it was of the isopleths in the plane y=0. But we can re-use the vertical isopleths – the start of the isopleth is the point where the upper isopleth intersects z=a and the end is where the lower isopleth intersects it. I have used the word isopleth a lot, hopefully it makes sense and has not lost all meaning.
+# the start of the isopleth
+s_start = find_zero( (s) -> upper_isopleth(sol, s, cₗ)[2] - a, 14)14.87383455152286# the end of the isopleth
+s_end = find_zero( (s) -> lower_isopleth(sol, s, cₗ)[2] - a, 33)33.55677883331305cross_points = [ cross_isopleth(sol, s, cₗ, a) for s in LinRange(s_start+1e-3, s_end, 100)
+ if !isnothing(cross_isopleth(sol, s, cₗ, a))]flipped_points = [ Point( pt[1], -1*pt[2] ) for pt in cross_points ]Calculating the concentration at some arbitrary point involves first backing out where along the plume axis the concentration is coming from, then calculating the concentration using the Gaussian profile.
+To find the location on the axis that governs the concentration at the point, i.e. the location on the axis where a vector connecting it to the arbitrary point is perpendicular to the plume axis, I basically just rotate the problem coordinate system to align with the plume axis and check. Since the ODE solution includes a set of pre-calculated points, I use it to generate an initial guess of where to look and then use Newton’s method to find the exact location s.
+function find_centerline(solution,x,y,z)
+ function perp_test(s)
+ θₒ, _, xₒ, zₒ = solution(s, idxs=4:7)
+ x′ = x*cos(θₒ) + z*sin(θₒ)
+ xₒ′ = xₒ*cos(θₒ) + zₒ*sin(θₒ)
+ return x′ - xₒ′
+ end
+
+ # find initial guess
+ i0 = argmin( [ abs(perp_test(s)) for s in sol.t ] )
+ s0 = sol.t[i0]
+
+ # find the zero point
+ return find_zero(perp_test, s0)
+endThe concentration then builds on this by first finding the location along the plume axis that connects to the arbitrary point, calculating the distance r from the plume axis to the point, and finally returning the concentration.
+function concentration(solution,x,y,z)
+ # get the point on the centerline that governs this point
+ sₒ = find_centerline(solution,x,y,z)
+ cₒ, bₒ, uₒ, θₒ, ρₒ, xₒ, zₒ = sol(sₒ)
+
+ # rotate the coordinate system to the plume axis
+ y′ = y
+ z′ = (z - zₒ)*cos(θₒ) - (x - xₒ)*sin(θₒ)
+ r² = (y′)^2 + (z′)^2
+
+ # calculate concentration
+ c = cₒ*exp(-r²/(bₒ^2*λ²))
+
+ return c
+endHow do I know this is actually working? I don’t really have test data to compare against. But I do have some isopleths that I calculated independently (though using the same trig), I can check that the concentration at those points is indeed what it is supposed to be (2%).
+upper_concentrations = [ concentration(sol, pt[1], 0, pt[2]) for pt in upper_points ]
+lower_concentrations = [ concentration(sol, pt[1], 0, pt[2]) for pt in lower_points ]
+cross_concentrations = [ concentration(sol, pt[1], pt[2], a) for pt in cross_points ]Indeed it does recover the concentrations as expected. There is one massive caveat though, it is assuming that there is only one location on the plume axis where a line connecting the point to the plume is perpendicular to the plume axis. If the plume is strongly curving, such as when a dense plume is emitted and bends back down to earth, this is no longer true. I think the basic assumptions of the plume itself start to break down once the plume bends back and intersects itself. I don’t think there really is a “correct” answer for how to calculate the concentration there.
+The plume model only assumes that the vent gas has a similar molar weight and heat capacity to air. It is still possible to have a negatively buoyant plume, this would be equivalent to a vent of cryogenic gas. In this case the plume will crash to the ground and…continue going. There is nothing in the Ooms model that requires z to be positive. If we assume the initial condition is where h is the height of the vent stack, we can use a simple callback function to trigger once the integrator has crossed the ground plane and reflect the plume back.
ground_check(state, s, i) = state[7] # zfunction reflect_plume!(integrator)
+ # bounce off the ground
+ integrator.u[4] = abs(integrator.u[4]) # θ
+ integrator.u[7] = 0 # z
+endground_cb = ContinuousCallback(ground_check, reflect_plume!)This makes the plume bounce along the ground. An alternative, and what DEGADIS does, is to terminate the integration once the plume contacts the ground and transition to another model.
+dense_state0 = [ 1.0 ,# c
+ 1/(2√(2)) ,# b
+ u₀/uₐ₀ ,# u
+ θ₀ ,# θ
+ 10.0 ,# ρ
+ 0.0 ,# x
+ h/D ]# zdense_prob = ODEProblem(ode_rhs!, dense_state0, span.*2, params)dense_sol = solve(dense_prob, Tsit5(); callback=ground_cb)
+
+dense_sol.retcodeReturnCode.Success = 1ModelingToolkit implements callbacks a little bit differently, as symbolic equations.
+ground = [ z ~ 0 ]
+reflect = [ θ ~ -Pre(θ) ]Which are then added to the ODESystem
@named dense_sys = ODESystem(eqns, s; continuous_events= ground => reflect)
+dense_sys = structural_simplify(dense_sys)dense_vals = [ c => dense_state0[1],
+ b => dense_state0[2],
+ u => dense_state0[3],
+ θ => dense_state0[4],
+ ρ => dense_state0[5],
+ x => dense_state0[6],
+ z => dense_state0[7] ]dense_prob_mtk = ODEProblem(dense_sys, dense_vals, span.*2)dense_sol_mtk = solve(dense_prob_mtk, Rodas5P())
+
+dense_sol_mtk.retcodeReturnCode.Success = 1I make no claims that this is a reasonable thing for the plume to do. It is mostly just for fun. If the reflect callback was changed to terminate!, then the plume would halt when the center line impacted the ground. There is also a case to be made that once the plume boundary impacts the ground, , then the integration should terminate and another model used. This is basically what DEGADIS does, once the plume is at ground level it transitions to another model for grounded plumes.
It is all fine and good to say “well, those look like plausible curves,” I would like to have some validation that this is actually working as intended. For some confirmation I pulled data points from figure 3 in Ooms8 using a graph digitizer. I chose that figure since covers most of the range of the z-axis. The other two figures are squashed down, making it difficult to get good resolution on the data points.
+8 Ooms, “A New Method for the Calculation of the Plume Path of Gases Emitted by a Stack,” 907.
Unfortunately while Ooms provides most of the dimensionless groups needed to generate the plots, it is missing two important ones:
+The actual dimensions and starting location of the plume will depend on how the zone of flow establishment is calculated, and those details are missing from the paper. I assumed the initial plume dimension , which corresponds to the plume starting with an identical width to the jet. Further I just picked a flow establishment of ~6.5 diameters, which is reasonable for a free jet. This recreates the curve really well.
Putting aside basically guessing the length of the zone of flow establishment, which feels pretty sketchy, that the curve has the correct shape and reproduces figure 3 in the paper is decent validation. Adjusting the initial height simply translates the curve up and down, it doesn’t impact the result otherwise.
+I tracked down the original reference9 for the figure 3 data, and the zone of flow establishment is 6.2 diameters. Which, at the resolution of this plot, is indistinguishable from my guess of ~6.5. I think that safely puts this in the “validated” camp.
+9 Fan, “Turbulent Buoyant Jets into Stratified or Flowing Ambient Fluids”.
# x/D z/D
+lfn_data = [ 16.628 19.953;
+ 43.054 29.86;
+ 46.366 32.233;
+ 61.684 36.698;
+ 84.591 42.558;
+ 109.085 48.977]lfn_prms = (M = zeros(7,7),
+ f = zeros(7),
+ rhoa_bar = (z) -> 1.0,
+ g_bar = (z) -> 4.278,
+ uprime_bar = (b,z) -> 0.0)# initial values
+lfn_state0 = [ 1.0 ,# c
+ 1/(2√(2)) ,# b
+ 8.0 ,# u
+ π/2 ,# θ
+ -0.148 ,# ρ
+ 0.0 ,# x
+ 6.5 ]# zlfn_prob = ODEProblem(ode_rhs!, lfn_state0, (0.0,150.0), lfn_prms)lfn_sol = solve(lfn_prob, Tsit5())This actually relates to one of the main difficulties in finding test data to compare against, to validate that my code is working. Results from the first version of DEGADIS are not directly applicable as DEGADIS initializes a jet using a different algorithm and the inputs into the Ooms model are not the jet parameters passed to DEGADIS. That’s assuming that I could even find DEGADIS results where the plume had the same molar weight and heat capacity as air, at which point the DEGADIS model reduces down to the original Ooms model. It has a different energy balance and for all other situations would be expected to generate different results.
+That I can recreate the figures from the original paper and that the first 4 balance equations given here are equivalent to what is given in the DEGADIS documentation (once rendered dimensionless and with the corresponding constants substituted), and the 5th equation matches in the special case of the vent gas being air and the atmosphere having no density gradient (the right hand side of the equation is zero) leaves me pretty confident that my result is correct. I also have the advantage of being able to cross-check my integrals and all those derivatives using a CAS. But it would be more satisfying if I had some unambiguous test cases to reproduce.
+I only implemented the first version of the Ooms model. There are two subsequent papers that make modifications which may be worth implementing. The first significant modification is a more complex energy balance, which is the basis for the DEGADIS implementation of Ooms, in this case the molar weight and heat capacity of the plume are calculated from the concentration in the plume. This makes the integral vastly more complex and it might make sense to try this model out while numerically integrating the balance at each step. The second significant modification is a change to the plume shape. The Ooms model assumes the plume has a circular cross-section, which is known to be incorrect for plumes dispersing in the atmosphere. The plume can be modified to an elliptical cross section in such a way as to preserve the cross-sectional area while better matching the observed shapes of real plumes. I did not implement either of these mostly because I wanted the “minimal viable plume model” first. This can be a known-working starting point on top of which these modifications can be made.
+Another obvious modification is to add ground-reflection. Once the plume has been solved, and there is a way to calculate concentrations at arbitrary points, it is not a huge challenge to add in ground-reflection. That is, managing the situation once the plume disperses into the ground. For conventional Gaussian plumes the typical assumption is that the plume simply reflects off and the concentration in this zone is the sum of the normal plume concentration and the concentration of reflected plume. Something similar could be done for Ooms as well.
+Thus my project for the Victoria Day long weekend was to figure out how to collect data from my atmotube using python. This works on my laptop but could, presumably, be ported to something like a raspberry pi easily enough.
+The Atmotube documentation gives two main ways of getting data from the device: using GATT or just passively from the advertising data the Atmotube broadcasts when it isn’t connected to anything (the BLE advertising packet). The most straightforward, to retrieve something specific, is via GATT.
+I am going to be using Bleak to scan and connect to BLE devices. To start I need a BleakScanner to scan for devices and, once I have found the one I want, connect to it as a BleakClient. Then, to make the various requests, I need the corresponding UUIDs – these correspond to specific packets of data as described in the docs
import timefrom bleak import BleakScanner, BleakClient# some constants
+ATMOTUBE = "C2:2B:42:15:30:89" # the mac address of my Atmotube
+SGPC3_UUID = "DB450002-8E9A-4818-ADD7-6ED94A328AB4"
+BME280_UUID = "DB450003-8E9A-4818-ADD7-6ED94A328AB4"
+SPS30_UUID = "DB450005-8E9A-4818-ADD7-6ED94A328AB4"
+STATUS_UUID = "DB450004-8E9A-4818-ADD7-6ED94A328AB4"The function scan_and_connect scans for the device which matches the mac address of my Atmotube, then proceeds to request each of the four packets of data. This simply returns a tuple with the data and the timestamp.
async def scan_and_connect(address):
+ device = await BleakScanner.find_device_by_address(address)
+ if not device:
+ print("Device not found")
+ return None
+
+ async with BleakClient(device) as client:
+ stat = await client.read_gatt_char(STATUS_UUID)
+ bme = await client.read_gatt_char(BME280_UUID)
+ sgp = await client.read_gatt_char(SGPC3_UUID)
+ sps = await client.read_gatt_char(SPS30_UUID)
+ ts = time.time()
+ return (ts, stat, bme, sgp, sps)I can connect and get a single data point, but what I have is a timestamp and a collection of bytes. It is not cleaned up and readable in any way.
+res = await scan_and_connect(ATMOTUBE)The easiest way to unpack a sequence of bytes is to use the struct standard library. But there are two exceptions:
+import structfrom ctypes import LittleEndianStructure, c_uint8, c_int8
+
+class InfoBytes(LittleEndianStructure):
+ _fields_ = [
+ ("pm_sensor", c_uint8, 1),
+ ("error", c_uint8, 1),
+ ("bonding", c_uint8, 1),
+ ("charging", c_uint8, 1),
+ ("charge_timer", c_uint8, 1),
+ ("bit_6", c_uint8, 1),
+ ("pre_heating", c_uint8, 1),
+ ("bit_8", c_uint8, 1),
+ ("batt_level", c_uint8, 8),
+ ]int.from_bytes() directly, but I think this is a little neater and easier to read.class PMBytes(LittleEndianStructure):
+ _fields_ = [
+ ('_pm1', c_int8*3),
+ ('_pm2_5', c_int8*3),
+ ('_pm10', c_int8*3),
+ ('_pm4', c_int8*3),
+ ]
+ _pack_ = 1
+
+ @property
+ def pm1(self):
+ return int.from_bytes(self._pm1, 'little', signed=True)
+
+ @property
+ def pm2_5(self):
+ return int.from_bytes(self._pm2_5, 'little', signed=True)
+
+ @property
+ def pm10(self):
+ return int.from_bytes(self._pm10, 'little', signed=True)With those two pieces out of the way, I define the actual variables I want – these are the column names I want to have in the final dataframe – and process the bytes. The first step is to use the InfoByte struct I defined above to pull out the flags and battery status, I add this to the results more for my own interest. Then I use struct.unpack() to unpack the integers from each byte-string and store the results.
Finally I use the PMBytes class to process the PM data. If the sensor isn’t on the results are -1 and so I clean those out. The idea is to leave any blank readings as None, since that is easy to filter out with pandas later on.
HEADERS = ["Timestamp", "VOC", "RH", "T", "P", "PM1", "PM2.5", "PM10"]def process_gatt_data(data):
+ result = dict.fromkeys(HEADERS)
+ if res is not None:
+ ts, stat, bme, sgp, sps = data
+ result["Timestamp"] = ts
+
+ # Info and Battery data
+ inf_bits = InfoBytes.from_buffer_copy(stat)
+ for (fld, _, _) in inf_bits._fields_:
+ result[f"INFO.{fld}"] = getattr(inf_bits, fld)
+
+ # SGPC3 data format
+ tvoc, _ = struct.unpack('<hh', sgp)
+ result["VOC"] = tvoc/1000
+
+ # BME280 data format
+ rh, T, P, T_plus = struct.unpack('<bblh', bme)
+ result["RH"] = rh
+ result["T"] = T_plus/100
+ result["P"] = P/1000
+
+ # SPS30 data format
+ pms = PMBytes.from_buffer_copy(sps)
+ result["PM1"] = pms.pm1/100 if pms.pm1 > 0 else None
+ result["PM2.5"] = pms.pm2_5/100 if pms.pm2_5 > 0 else None
+ result["PM10"] = pms.pm10/100 if pms.pm10 > 0 else None
+
+ return resultNow I can process the result I collected earlier.
+process_gatt_data(res){'Timestamp': 1747673644.60206,
+ 'VOC': 0.223,
+ 'RH': 32,
+ 'T': 21.3,
+ 'P': 93.37,
+ 'PM1': 1.0,
+ 'PM2.5': 2.18,
+ 'PM10': 3.27,
+ 'INFO.pm_sensor': 1,
+ 'INFO.error': 0,
+ 'INFO.bonding': 0,
+ 'INFO.charging': 0,
+ 'INFO.charge_timer': 1,
+ 'INFO.bit_6': 0,
+ 'INFO.pre_heating': 1,
+ 'INFO.bit_8': 0,
+ 'INFO.batt_level': 63}The results are what I expect for my apartment. In addition to the air quality data, we can see that the PM sensor was on and that the Atmotube had been charging recently.1 The pre-heat flag indicates that the device has completed any pre-heating and is ready. So everything looks good.
+1 I unplugged it before charging was done so it wouldn’t interfere with any temperature readings when I tested this code, that’s why the battery was only at 63%
I could, at this point, just start a service or cron job to poll the device every so often and log the results. It will only return PM results when the atmotube is actively sampling, which could present some issues with timing. If the device is set to sample, for example, every 15 minutes and the script doesn’t make a request during that window, it will never return results. For everything that follows I set my atmotube to sample continuously.
+The other way of logging data from the atmotube is to pull it out of the advertising packet the atmotube broadcasts as a bluetooth device. In this case I don’t actually connect to the device, the scanner runs continuously and sends back any advertising data it finds using the adv_cb() callback function. This checks if the data came from my atmotube and, if it did, adds it to the results.
The scanner runs inside an event loop which starts the scanner, waits until the collection_time has elapsed, then shuts down and returns the results.
import asyncioasync def collect_data(device_mac, collection_time=600):
+ def adv_cb(device, advertising_data):
+ if device.address == device_mac:
+ results.append((time.time(), device, advertising_data))
+ else:
+ pass
+ return None
+
+ async def receiver(event):
+ async with BleakScanner(adv_cb, scanning_mode='active') as scanner:
+ await event.wait()
+
+ results = []
+ loop = asyncio.Event()
+ task = asyncio.create_task(receiver(loop))
+ await asyncio.sleep(collection_time)
+ loop.set()
+ _ = await asyncio.wait([task])
+ return resultsRunning this for 10 seconds lets me collect some example data to play with.
+broadcasts = await collect_data(ATMOTUBE, 10)Processing the advertising packet is similar to what was done with the GATT data, except that it comes in two flavours: the broadcast packet has the basic temperature, pressure, VOC, device status and the scan response packet contains the PM data and is shorter. Here the PM data is at a lower resolution – 16-bit integers – and so they can be unpacked using struct.unpack(). The GATT data returns the PM data to 2 decimal places (and the temperature to 1 decimal place), whereas the advertising packet data is rounded to the nearest whole number.
def process_adv_data(full_data, company_id=int(0xFFFF)):
+ result = dict.fromkeys(HEADERS)
+ if full_data is None:
+ return result
+ else:
+ timestamp, device, advertising_data = full_data
+ result["Timestamp"] = timestamp
+
+ # process advertising data
+ data = advertising_data.manufacturer_data.get(company_id)
+ if len(data) == 12:
+ tvoc, devid, rh, T, P, inf, batt = struct.unpack(">hhbblbb", data)
+ result["VOC"] = tvoc/1000
+ result["RH"] = rh
+ result["T"] = T
+ result["P"] = P/1000
+ elif len(data) == 9:
+ pm1, pm2_5, pm10, fw_maj, fw_min, fw_bld = struct.unpack(">hhhbbb", data)
+ result["PM1"] = pm1 if pm1 > 0 else None
+ result["PM2.5"] = pm2_5 if pm2_5 > 0 else None
+ result["PM10"] = pm10 if pm10 > 0 else None
+ else:
+ pass
+ return resultI can process this and look at examples of the two types of advertising packet
+process_adv_data(broadcasts[0]){'Timestamp': 1747673646.9507601,
+ 'VOC': None,
+ 'RH': None,
+ 'T': None,
+ 'P': None,
+ 'PM1': 1,
+ 'PM2.5': 2,
+ 'PM10': 3}process_adv_data(broadcasts[5]){'Timestamp': 1747673647.2869163,
+ 'VOC': 0.208,
+ 'RH': 36,
+ 'T': 21,
+ 'P': 93.357,
+ 'PM1': None,
+ 'PM2.5': None,
+ 'PM10': None}The way I have this set up is very wasteful of memory if the atmotube is set-up to only sample periodically. In those cases there will be a lot of packets with no PM data that are being dutifully logged in results. By processing the data as it is retrieved, I can collect only the packets that had measurements in them.
async def better_collect_data(device_mac, collection_time=600):
+ def adv_cb(device, advertising_data):
+ if device.address == device_mac:
+ row = process_adv_data((time.time(), device, advertising_data))
+ if len( [ val for key, val in row.items() if val is not None ]) >1:
+ # only collect results when we actually have a measurement
+ results.append(row)
+ else:
+ pass
+ return None
+
+ async def receiver(event):
+ async with BleakScanner(adv_cb) as scanner:
+ await event.wait()
+
+ results = []
+ loop = asyncio.Event()
+ task = asyncio.create_task(receiver(loop))
+ await asyncio.sleep(collection_time)
+ loop.set()
+ _ = await asyncio.wait([task])
+ return resultsWhich I let collect for 5 minutes
+new_broadcasts = await better_collect_data(ATMOTUBE, 300)At this point we want to actually look at the results and maybe do some stats. By logging the data as a list of dicts, transforming this into a dataframe is very straightforward.
+import pandas as pddf = pd.DataFrame(new_broadcasts)df.describe()| + | Timestamp | +VOC | +RH | +T | +P | +PM1 | +PM2.5 | +PM10 | +
|---|---|---|---|---|---|---|---|---|
| count | +4.100000e+02 | +57.000000 | +57.000000 | +57.0 | +57.000000 | +353.0 | +353.000000 | +353.000000 | +
| mean | +1.747674e+09 | +0.203228 | +35.105263 | +21.0 | +93.351193 | +1.0 | +2.005666 | +3.039660 | +
| std | +8.914660e+01 | +0.002797 | +0.450564 | +0.0 | +0.004576 | +0.0 | +0.184550 | +0.246825 | +
| min | +1.747674e+09 | +0.199000 | +34.000000 | +21.0 | +93.343000 | +1.0 | +1.000000 | +2.000000 | +
| 25% | +1.747674e+09 | +0.201000 | +35.000000 | +21.0 | +93.348000 | +1.0 | +2.000000 | +3.000000 | +
| 50% | +1.747674e+09 | +0.203000 | +35.000000 | +21.0 | +93.351000 | +1.0 | +2.000000 | +3.000000 | +
| 75% | +1.747674e+09 | +0.204000 | +35.000000 | +21.0 | +93.355000 | +1.0 | +2.000000 | +3.000000 | +
| max | +1.747674e+09 | +0.210000 | +36.000000 | +21.0 | +93.361000 | +1.0 | +3.000000 | +4.000000 | +
This shows a real asymmetry in quantity of data found and what was in it – of 410 packets received 353 were PM data and 57 contained the VOC, temperature, etc. data.
+df['Time'] = df['Timestamp'] - df.iloc[0]['Timestamp'] +
+Plotting the timeseries data shows the PM data is very noisy – largely because it is rounding to the nearest whole integer. I also suspect that I should be cleaning up the scan responses better. Probably a lot of those are duplicates – it is not actually a fresh reading just rebroadcast of what had been read last. I’m not really sure.
+If you are only collecting 5 minutes of data, reading directly into memory like this is reasonable. But probably you want to log the data over a longer stretch of time, and it makes more sense to log the data to a csv – saving it more permanently. The following creates a new csv with the given filename then, for every valid packet processed, appends the results to the csv.
+import csvasync def log_to_csv(device_mac, collection_time=600, file="atmotube.csv"):
+ def adv_cb(device, advertising_data):
+ if device.address == device_mac:
+ row = process_adv_data((time.time(), device, advertising_data))
+ if len( [ val for key, val in row.items() if val is not None ]) >1:
+ # only collect results when we actually have a measurement
+ with open(file, 'a', newline='') as csvfile:
+ writer = csv.DictWriter(csvfile, fieldnames=HEADERS)
+ writer.writerow(row)
+ else:
+ pass
+ return None
+
+ async def receiver(event):
+ async with BleakScanner(adv_cb) as scanner:
+ await event.wait()
+
+ # prepare csv file
+ with open(file, 'w', newline='') as csvfile:
+ writer = csv.DictWriter(csvfile, fieldnames=HEADERS)
+ writer.writeheader()
+
+ # start scanning
+ loop = asyncio.Event()
+ task = asyncio.create_task(receiver(loop))
+
+ # wait until the collection time is up
+ await asyncio.sleep(collection_time)
+ loop.set()
+ _ = await asyncio.wait([task])
+
+ return TrueThe callback function is doing a lot of work and blocking to write to a csv. This is, in general, not a good idea. When I put this together, I figured that the rate of new data from the Atmotube is significantly slower than the time required to process data and write it to a csv. Which is true, but it isn’t really robust. A better solution might be to have the callback put the data into a queue and have a seperate worker process results into the csv.
+To get this going, I just created a csv with the current timestep in the filename – so if I stop and start I don’t clobber previous data – and leave it to run for an hour. I just left this running in jupyter while I switched to a different desktop and went about my life, but a longer-term solution would be in a script that runs in the background.
+import mathnow = math.floor(time.time())
+timestamped_file = f"atmotube-{now}.csv"
+result = await log_to_csv(ATMOTUBE, 3600, timestamped_file)
+
+print("Success!") if result else print("Boo")Success!While it is running, you can check on the progress with tail -f %filename, and watch the results come in live on the terminal. Once it is done, the csv can be read into pandas and plotted like before
logged_data = pd.read_csv(timestamped_file)logged_data.describe()| + | Timestamp | +VOC | +RH | +T | +P | +PM1 | +PM2.5 | +PM10 | +
|---|---|---|---|---|---|---|---|---|
| count | +4.823000e+03 | +835.000000 | +835.000000 | +835.0 | +835.000000 | +3988.0 | +3988.000000 | +3988.000000 | +
| mean | +1.747676e+09 | +0.226522 | +34.810778 | +21.0 | +93.320590 | +1.0 | +1.919007 | +2.945587 | +
| std | +1.037307e+03 | +0.012884 | +0.711420 | +0.0 | +0.018019 | +0.0 | +0.328726 | +0.325025 | +
| min | +1.747674e+09 | +0.195000 | +34.000000 | +21.0 | +93.283000 | +1.0 | +1.000000 | +2.000000 | +
| 25% | +1.747675e+09 | +0.217000 | +34.000000 | +21.0 | +93.303000 | +1.0 | +2.000000 | +3.000000 | +
| 50% | +1.747676e+09 | +0.230000 | +35.000000 | +21.0 | +93.325000 | +1.0 | +2.000000 | +3.000000 | +
| 75% | +1.747677e+09 | +0.237000 | +35.000000 | +21.0 | +93.337000 | +1.0 | +2.000000 | +3.000000 | +
| max | +1.747678e+09 | +0.249000 | +37.000000 | +21.0 | +93.355000 | +1.0 | +3.000000 | +4.000000 | +
logged_data['Time'] = logged_data['Timestamp'] - logged_data.iloc[0]['Timestamp']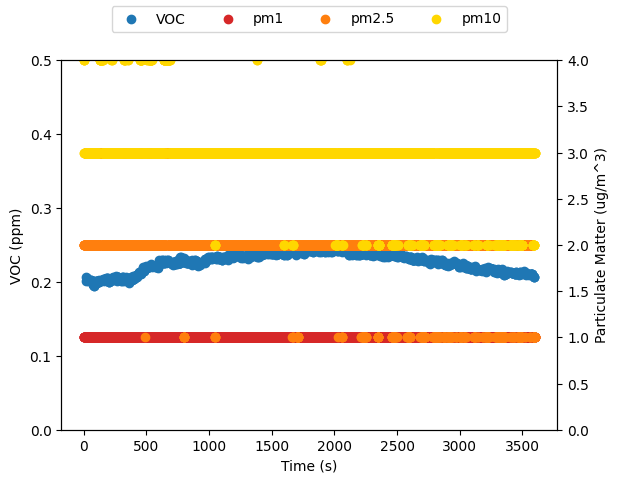 +
+The atmotube is also logging data to its internal memory, so I exported that and plotted it against what was broadcast.
+export_data = pd.read_csv('atmotube-export-data.csv')
+export_data.describe()| + | VOC, ppm | +AQS | +Air quality health index (AQHI) - Canada | +Temperature, °C | +Humidity, % | +Pressure, kPa | +PM1, ug/m3 | +PM2.5, ug/m3 | +PM2.5 (avg 3h), ug/m3 | +PM10, ug/m3 | +PM10 (avg 3h), ug/m3 | +Latitude | +Longitude | +
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | +66.000000 | +66.000000 | +66.0 | +66.0 | +66.000000 | +66.000000 | +66.0 | +66.000000 | +66.000000 | +66.000000 | +66.000000 | +0.0 | +0.0 | +
| mean | +0.239985 | +85.045455 | +1.0 | +21.0 | +34.484848 | +93.316364 | +1.0 | +1.530303 | +1.559175 | +2.545455 | +2.861027 | +NaN | +NaN | +
| std | +0.018563 | +1.156012 | +0.0 | +0.0 | +0.769464 | +0.019817 | +0.0 | +0.502905 | +0.036129 | +0.501745 | +0.041909 | +NaN | +NaN | +
| min | +0.212000 | +82.000000 | +1.0 | +21.0 | +33.000000 | +93.280000 | +1.0 | +1.000000 | +1.466667 | +2.000000 | +2.722222 | +NaN | +NaN | +
| 25% | +0.228250 | +85.000000 | +1.0 | +21.0 | +34.000000 | +93.300000 | +1.0 | +1.000000 | +1.550000 | +2.000000 | +2.866667 | +NaN | +NaN | +
| 50% | +0.238000 | +85.000000 | +1.0 | +21.0 | +34.500000 | +93.320000 | +1.0 | +2.000000 | +1.561111 | +3.000000 | +2.877778 | +NaN | +NaN | +
| 75% | +0.244750 | +86.000000 | +1.0 | +21.0 | +35.000000 | +93.337500 | +1.0 | +2.000000 | +1.583333 | +3.000000 | +2.888889 | +NaN | +NaN | +
| max | +0.295000 | +87.000000 | +1.0 | +21.0 | +36.000000 | +93.350000 | +1.0 | +2.000000 | +1.616667 | +3.000000 | +2.888889 | +NaN | +NaN | +
from datetime import datetimeexport_data['Timestamp'] = export_data[['Date']].apply(
+ lambda str: datetime.strptime(str.iloc[0], "%Y/%m/%d %H:%M:%S").timestamp(), axis=1)export_data['Time'] = export_data['Timestamp'] - logged_data.iloc[0]['Timestamp'] +
+The basic atmospheric data like temperature, pressure, and relative humidity appear to be the same. But there is something weird going on with the VOC measurements.
+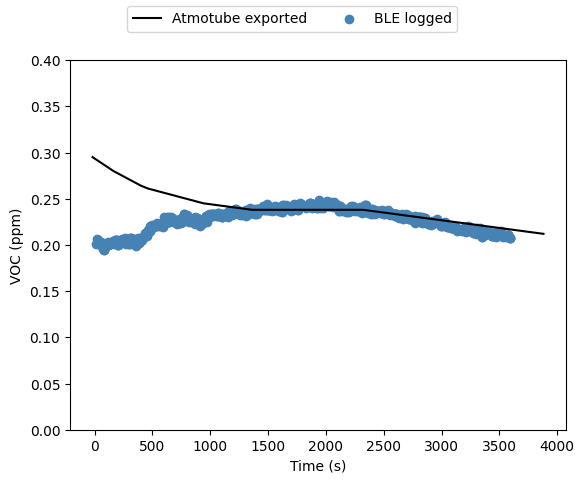 +
+I think the atmotube is actually exporting the rolling average of the VOC results over a fairly broad window, whereas the broadcast reading is more direct from the sensor. I would have to run this for much longer to see if that’s the case.
+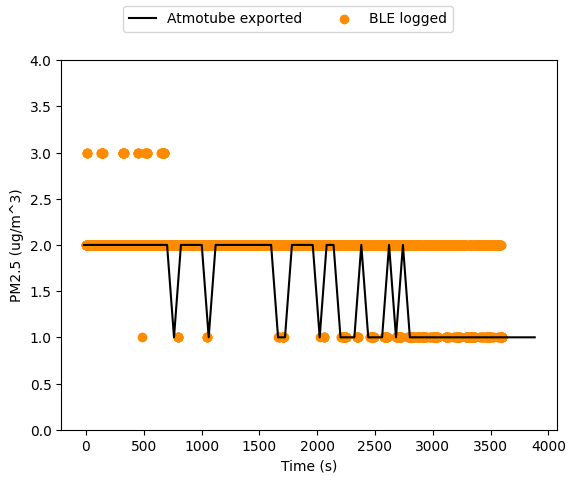 +
+The PM data shows the results are closer, but still have issues. The exported data is (I believe) a by-the-minute average, rounded to the nearest integer. There is a single data point for each minute in the dataset, giving 66 overall. Whereas the raw PM broadcast data has 3988 data points, and I think most of those are just rebroadcasts and are not “real”.
+One thing I was thinking of doing was to capture only the first scan response packet after an advertising packet then ignore all the rest until the next advertising packet. I have also been ignoring the info flags since, when I was just noodling around, they didn’t seem to change at all (with the device always sampling), they might actually be telling me things that I’ve been ignoring.
+Hopefully this helps you get set-up collecting data from your atmotube (I don’t know why else you would read this far). From here to building a simple dashboard or datalogger should be an easy weekend project. I think for applications where you want higher fidelity data over a long stretch of time, periodically requesting data using GATT makes the most sense. The PM data comes with more decimal places of precision, and you don’t need it more frequently than every minute or so.
+The BLE advertising data could be an easy way of building a passive dashboard, continuously listening and updating the air quality statistics. Though some effort would need to be put in cleaning up the data, or perhaps just presenting a rolling average of some kind to smooth out the noise.
+There is also a whole section of the documentation on connecting to an atmotube and downloading data from it, which I didn’t bother to investigate. It looked overly complicated for what I wanted to do. If you figure that out, please let me know!
+I have taken what I figured out in the following section and put it into a minimal python module with a few helper functions. See this example showing how to collect data from an AtmoTube and process the results.
+I was thinking about this more and there was one avenue I neglected to explore: subscribing to GATT notifications from the atmotube. Instead of requesting a single data point, like I did above, one can subscribe to the feed and the atmotube will just send packets whenever an update occurs. That is what I do below.
+To get started I decided to make cytpe structs for each of the bytestrings that can be returned. I don’t think this is necessary, but I like how it seperates the logic of decoding the response on an aesthetic level. It also makes it very clear how the bytestrings are structured.
+from ctypes import LittleEndianStructure, c_ubyte, c_byte, c_short, c_int
+
+class StatusData(LittleEndianStructure):
+ _fields_ = [
+ ("pm_sensor", c_ubyte, 1),
+ ("error", c_ubyte, 1),
+ ("bonding", c_ubyte, 1),
+ ("charging", c_ubyte, 1),
+ ("charging_timer", c_ubyte, 1),
+ ("_bit_6", c_ubyte, 1),
+ ("sgpc3_pre_heating", c_ubyte, 1),
+ ("_bit_8", c_ubyte, 1),
+ ("battery_level", c_ubyte, 8),
+ ]
+
+ def __new__(cls, ts, data):
+ return cls.from_buffer_copy(data)
+
+ def __init__(self, ts, data):
+ self.timestamp = tsclass SPS30Data(LittleEndianStructure):
+ _fields_ = [
+ ('_pm1', c_byte*3),
+ ('_pm2_5', c_byte*3),
+ ('_pm10', c_byte*3),
+ ('_pm4', c_byte*3),
+ ]
+ _pack_ = 1
+
+ def __new__(cls, ts, data):
+ return cls.from_buffer_copy(data)
+
+ def __init__(self, ts, data):
+ self.timestamp = ts
+
+ @property
+ def pm1(self):
+ res = int.from_bytes(self._pm1, 'little', signed=True)
+ return res/100 if res > 0 else None
+
+ @property
+ def pm2_5(self):
+ res = int.from_bytes(self._pm2_5, 'little', signed=True)
+ return res/100 if res > 0 else None
+
+ @property
+ def pm10(self):
+ res = int.from_bytes(self._pm10, 'little', signed=True)
+ return res/100 if res > 0 else Noneclass BME280Data(LittleEndianStructure):
+ _fields_ = [
+ ('_rh', c_byte),
+ ('_T', c_byte),
+ ('_P', c_int),
+ ('_T_dec', c_short),
+ ]
+ _pack_ = 1
+
+ def __new__(cls, ts, data):
+ return cls.from_buffer_copy(data)
+
+ def __init__(self, ts, data):
+ self.timestamp = ts
+
+ @property
+ def RH(self):
+ return self._rh
+
+ @property
+ def T(self):
+ return self._T_dec/100
+
+ @property
+ def P(self):
+ return self._P/1000class SGPC3Data(LittleEndianStructure):
+ _fields_ = [
+ ('_TVOC', c_short),
+ ]
+ _pack_ = 1
+
+ def __new__(cls, ts, data):
+ return cls.from_buffer_copy(data)
+
+ def __init__(self, ts, data):
+ self.timestamp = ts
+
+ @property
+ def TVOC(self):
+ return self._TVOC/1000With that out of the way, there are two other components I need for this to work: a collector which will collect all of the data sent back from the atmotube and a worker which will log it to a csv. Unlike above, where I logged each advertising packet as it came in, I am going to make these run asynchronously using asyncio. I think this is what really should be done, instead of blocking for file i/o every time a callback function is triggered.
To make this happen I largely copied what was done in this example which uses an async queue to pass data between the two workers. The basic idea is:
+collection_time and every time it gets a new set of data uses the callbacks status_cb and sps30_cb to process the bytestring and put the result on the queueasync def collect_data(mac, queue, collection_time):
+ async def status_cb(char, data):
+ ts = time.time()
+ res = StatusData(ts, data)
+ await queue.put(res)
+
+ async def sps30_cb(char, data):
+ ts = time.time()
+ res = SPS30Data(ts, data)
+ await queue.put(res)
+
+ device = await BleakScanner.find_device_by_address(mac)
+ if not device:
+ raise Exception("Device not found")
+
+ async with BleakClient(device) as client:
+ # start notifications
+ await client.start_notify(STATUS_UUID, status_cb)
+ await client.start_notify(SPS30_UUID, sps30_cb)
+
+ # wait for collection period to end
+ await asyncio.sleep(collection_time)
+
+ # signals end of queue
+ await queue.put(None)Concurrently with that, a logger needs to write things to a csv. The basic idea is this:
+filename, and writes the column headers.battery_level as a lazy check of which type of result it is.None, that is a signal that the collector has finished and the loop exits.task_done() to notify the queue of this and the loop begins again.import aiofiles, aiocsvHEADERS = ["Timestamp", "PM Sensor", "PM1", "PM2.5", "PM10"]async def write_row(filename,row):
+ async with aiofiles.open(filename, 'a', newline='') as csvfile:
+ writer = aiocsv.AsyncDictWriter(csvfile, fieldnames=HEADERS)
+ await writer.writerow(row)async def log_to_csv(filename, queue):
+ # prepare csv file
+ async with aiofiles.open(filename, 'w', newline='') as csvfile:
+ writer = aiocsv.AsyncDictWriter(csvfile, fieldnames=HEADERS)
+ await writer.writeheader()
+
+ # log data from queue
+ flag = True
+ while flag:
+ result = await queue.get()
+ if result is not None:
+ # we have some data to write
+ row = dict.fromkeys(HEADERS)
+ row["Timestamp"] = result.timestamp
+ if hasattr(result, "battery_level"):
+ # we have a status type
+ row["PM Sensor"] = result.pm_sensor
+ else:
+ # we have pm data
+ row["PM1"] = result.pm1
+ row["PM2.5"] = result.pm2_5
+ row["PM10"] = result.pm10
+
+ await write_row(filename,row)
+ else:
+ # the end of the queue
+ flag = False
+ queue.task_done()My first attempt at this I put the while loop inside the with block, so the whole thing ran inside the file context manager. This had the effect of nothing actually being written to the csv until the with block exited and the file closed. It took me a long time to realize that is what was happening, since it looked exactly the same as the two processes running sequentially: collect all the data and then write it all to csv.
In this version, every time a row is added to the csv the file is opened, a line is written, and then it is closed. There is probably a way of holding it open while logging, but that might make things more complicated since a whole bunch of new logic would be needed to catch any exceptions and ensure that the file is closed properly – something that happens behind the scenes with a simple with block.
Finally, I put it all together with a simple sequence of tasks:
+Queueasync def save_data(mac, csv, collection_time):
+ q = asyncio.Queue()
+
+ logger = asyncio.create_task(log_to_csv(csv, q))
+ collector = asyncio.ensure_future(collect_data(mac, q, collection_time))
+
+ await collectorI ran this for an hour in the background as a test and it seems to work fine.
+await save_data(ATMOTUBE, f"atmotube-{math.floor(time.time())}.csv", 3600)df = pd.read_csv("atmotube-1748482080.csv")df['Time'] = df['Timestamp'] - df.iloc[0]['Timestamp']df.head()| + | Timestamp | +PM Sensor | +PM1 | +PM2.5 | +PM10 | +Time | +
|---|---|---|---|---|---|---|
| 0 | +1.748482e+09 | +NaN | +10.92 | +13.43 | +14.97 | +0.000000 | +
| 1 | +1.748482e+09 | +NaN | +10.93 | +13.03 | +14.66 | +2.610108 | +
| 2 | +1.748482e+09 | +NaN | +11.05 | +13.42 | +15.19 | +5.220881 | +
| 3 | +1.748482e+09 | +NaN | +11.35 | +13.75 | +15.34 | +7.784888 | +
| 4 | +1.748482e+09 | +NaN | +11.59 | +14.13 | +15.50 | +10.395001 | +
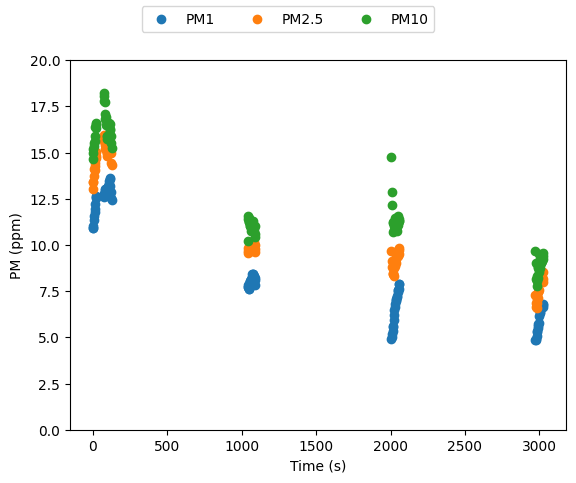 +
+With no context it looks like something is horribly wrong, what are all those gaps in the data? My atmotube is set to only sample every 15 minutes, this is usually how I leave it to save on battery. This also explains some of the weirdness with the data, why does each sample start with a rapidly increasing concentration before levelling out? The atmotube is returning data right when the sampling fan has just turned on; this is not yet an accurate sample of the ambient air, it is the stagnant air inside the atmotube. This is a much more obvious problem with VOC data, it is clearly visible on the app as a funky saw-tooth wave where the VOC concentration plunges whenever the fan starts and, once it stops, slowly creeps up. It is an artifact of how the atmotube is sampling the air, not of how the data is being collected.
+If the atmotube is set to always on mode, these artifacts go away, but if you want to monitor it in other configurations it is worth considering how the data should be cleaned up. For example watching for the pm_sensor flag to turn on then throwing out the first ~30s of pm data before looking at the rest. The GATT notifications make it very clear when the atmotube is sampling and when it isn’t. There will be a notification that pm_sensor has turned from 0 to 1, then data will start arriving with pm data, then a notification that the pm_sensor has turned from 1 to 0, followed by an empty row of pm data. See a snippet of the csv below. Note that pm_sensor values and actual pm values are always on seperate rows.
df[36:42]| + | Timestamp | +PM Sensor | +PM1 | +PM2.5 | +PM10 | +Time | +
|---|---|---|---|---|---|---|
| 36 | +1.748482e+09 | +NaN | +12.42 | +14.34 | +15.23 | +127.802146 | +
| 37 | +1.748482e+09 | +0.0 | +NaN | +NaN | +NaN | +130.322095 | +
| 38 | +1.748482e+09 | +NaN | +NaN | +NaN | +NaN | +130.322191 | +
| 39 | +1.748483e+09 | +1.0 | +NaN | +NaN | +NaN | +1035.107224 | +
| 40 | +1.748483e+09 | +NaN | +7.74 | +9.55 | +10.21 | +1040.146906 | +
| 41 | +1.748483e+09 | +NaN | +7.81 | +9.82 | +11.40 | +1042.621936 | +
In addition to some data-wrangling, there are some other obvious upgrades to my code before it would be ready to deploy in an app. For one, there is minimal error handling. Any malformed bytestrings returned by the atmotube will throw an exception and kill everything. Additionally there are no checks to maintain a connection to the atmotube. It would simply timeout, having collected nothing. If you were planning on running this passively for a long period of time, unattended, that could be a big deal.
+ + +I live in an older core neighbourhood in Edmonton, which has a beautiful canopy of boulevard trees. Primarily elm, but also ash, maple, and oak. The legacy of people like Gladys Reeves and the Edmonton Tree Planting Committee who, starting in 1923, defended our city green spaces and built up our urban forest. A legacy we still fight for over a century later.
+In particular I’m going to be looking at American Elm, the most common boulevard tree in my neighbourhood, and I’ll restrict myself to just here (not the whole city).
+For a lot of problems, I find it easier to work with Unitful.jl. It enforces unit consistency and inconsistent units in an answer is a good indication that I have made a math mistake somewhere. However there are two questions that I need to answer before getting too deep into things:
I could calculate the pollen concentration on a mass basis, but that seems kind of weird to me. I think the logical unit is in terms of individual pollen grains. That is not a unit that Unitful.jl is aware of and so I need to define first what a pollen grain is. It is a unit of “number”, like a mole, and in fact there are 6.022×10²³ grains in a mole of pollen.
using Unitfulbegin
+
+@unit grains "grains" Grains (1/6.02214076e23)*u"mol" true;
+Unitful.register(@__MODULE__);
+
+endCorrelations can be annoying with Unitful.jl since the various constants in a correlation are not usually given with units and figuring them all out so that units remain consistent is kind of tedious. The easiest workaround is to use a macro to strip the units off the input to a correlation function and then stick the correct units back on the output.
macro ucorrel(f::Symbol, in_unit::Expr, out_unit::Expr)
+ quote
+ function $(esc(f))(x::Quantity)::Quantity
+ x = ustrip($in_unit, x)
+ res = $(esc(f))(x)
+ return res*$out_unit
+ end
+ end
+end;For an initial sketch I’m going to consider a single tree as an elevated point source producing pollen at a constant rate P and with the wind carrying the pollen away with a constant wind speed u. Individual pollen grains settle out of the plume as they are carried downwind with velocity . The coordinate system is centred at the base of the tree with an x-axis parallel to the wind.
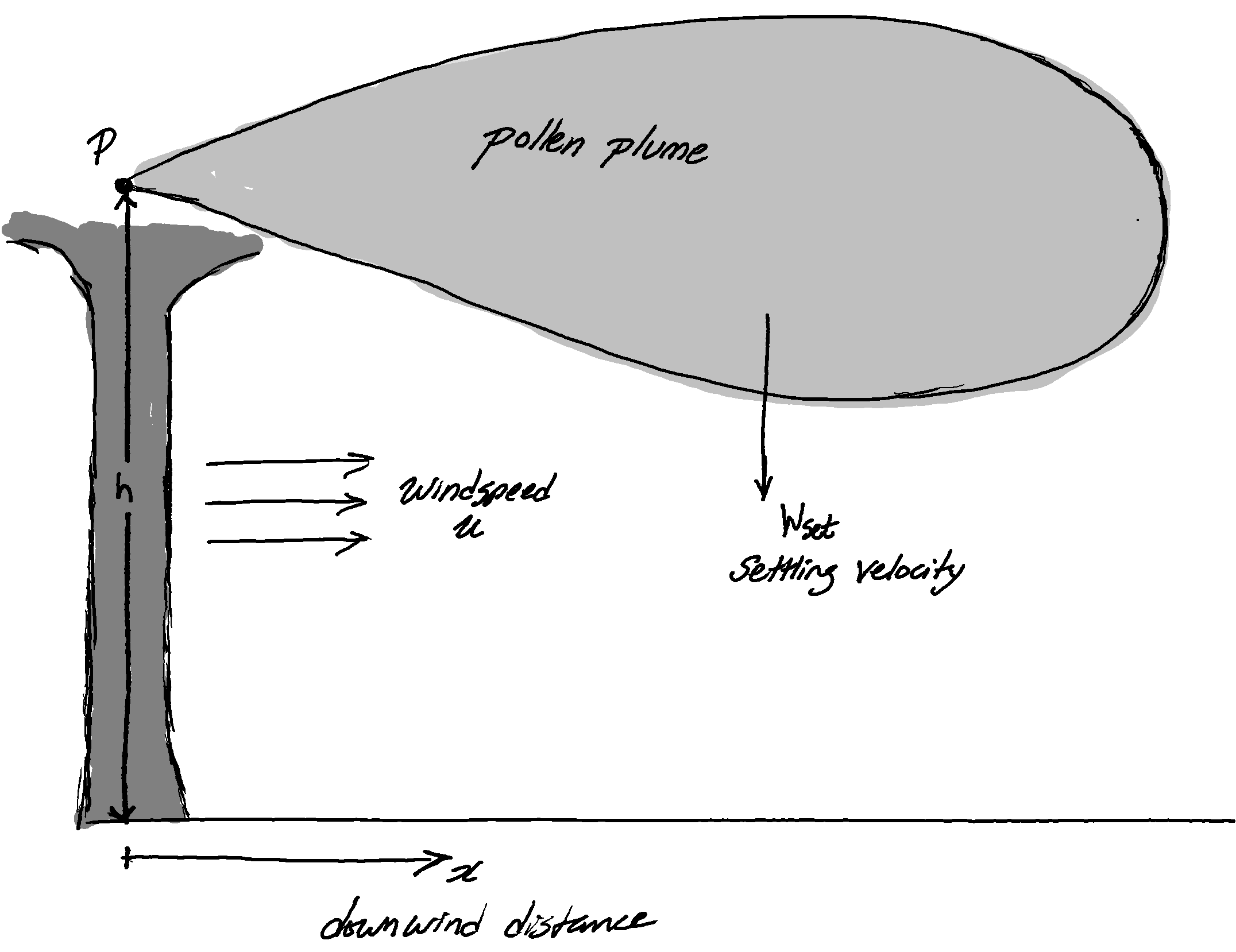 +
+There are a few things I will need to know about each elm tree in the neighbourhood:
+Neither of these are typically measured and available in data sets for urban forests. I will need to use correlations – what foresters call allometric equations. These correlate physical parameters of trees to something easier to measure, such as the diameter at breast height or DBH.
+To build an example elm tree, suppose it has a DBH of 88 cm
+# Model Elm tree
+DBH = 88u"cm" |> u"m"The crown height for an American Elm is correlated to DBH by the following equation1 for urban trees in the North climate zone
+1 McPherson, Doorn, and Peper, “Urban Tree Database and Allometric Equations”.
# McPherson, van Doorn, and Peper, *Urban Tree Database*
+# Ulmus Americana, North climate zone
+crown_height(DBH) = 0.44998 + 0.55096*DBH - 0.00666*DBH^2 + 3e-5*DBH^3@ucorrel crown_height u"cm" u"m"I am going to assume this is the height at which pollen is released, that’s not particularly accurate but it is a start. A better value would be the “centre of mass” for pollen in the crown of an Elm tree, but that isn’t readily available.
+For the example tree, this predicts a height of 17.8 m which, just standing around and looking at the trees on my street seems plausible. The example elm tree should be taller than a 5 story building, and there is an elm tree at the end of my block that is about that in both diameter and height.
+The total amount of pollen in a given elm tree is given by the following equation2 where B is the tree basal area. The total pollen is based on counts of pollen per anther and an estimate of the total number of anthers per tree for urban elm trees in Ann Arbor, Michigan. Maybe not perfectly comparable to Edmonton, but it’s good enough for this exploratory work.
+2 Katz, Morris, and Batterman, “Pollen Production for 13 Urban North American Tree Species”.
# Ulmus Americana total pollen per tree
+# Katz, Morris, and Batterman, "Pollen Production," Table 2
+function total_pollen(DBH)
+ B = π/4*DBH^2
+ return exp(5.86*B + 23.11)
+end@ucorrel total_pollen u"m" u"grains"This gives a total pollen content of 384,082,918,235 grains for the model elm tree, which sounds like a lot.
+Elm trees release their pollen, in Edmonton, somewhere from the end of April to mid May and it usually lasts 1-2 weeks. As a very rough model I’m going to assume each tree releases its pollen at a constant rate over a 2 week period, and that the periods over which each of the trees are releasing overlap.
+Δt = 14u"d" |> u"s"pollen_rate(DBH) = total_pollen(DBH)/ΔtFor the example tree, this gives a pollen release rate of 317,529 grains s^-1.
+Elm pollen is relatively large and will settle out of the air. To account for this I am going to assume the pollen settles with a velocity equal to the terminal velocity given by Stokes’ Law, where each individual pollen grain is a solid sphere.
+ +
+begin
+
+# Ulmus Americana pollen
+# Brush and Brush, "Transport of Pollen," Tables 3 and 12.
+d = 31u"μm" |> u"m"
+SG = 1.1
+ρ = SG*1000u"kg/m^3"
+
+end;begin
+
+g = 9.80665u"m/s^2" # standard gravity
+ρₐ = 1.225u"kg/m^3" # density of dry air (15°C, 1atm)
+μₐ = 17.89e-6u"Pa*s" |> u"kg/m/s" # viscosity of dry air (15°C, 1atm)
+
+end;# Stokes Law
+vₜ = ((ρ - ρₐ)*g*d^2)/(18*μₐ)This gives a settling velocity for a grain of American Elm pollen in air of 3.22 cm s^-1
+We might naively consider the pollen being launched out of the tree like little cannon balls, with a velocity in the x-direction equal to the wind speed and the velocity in the z-direction equal to the terminal velocity of pollen. Assuming a wind speed of 2 m s^-1, then a pollen grain from our example tree would travel 1107 m before hitting the ground. That’s pretty far and also kind of unrealistic. It ignores all the turbulent mixing in the air column which will both loft it to much greater heights and, at times, push it towards the ground.
+The turbulent mixing in the air is captured using the dispersion parameters and
which are functions of the downwind distance. This gives an average view, averaged over all of the pollen grains. In this case I will be using the Briggs’ correlations for Urban terrain.3 I am also assuming class D atmospheric stability.
3 Briggs, “Diffusion Estimation for Small Emissions. Preliminary Report,” 38; Griffiths, “Errors in the Use of the Briggs Parameterization for Atmospheric Dispersion Coefficients”.
# wind speed, assumed
+u = 2u"m/s"σ_y(x) = 0.16x/√(1+0.0004x)@ucorrel σ_y u"m" u"m"σ_z(x) = 0.14x/√(1+0.0003x)@ucorrel σ_z u"m" u"m"I will be using the Ermak equation4 to model the dispersion of pollen, which results in a Gaussian-like dispersion but with the pollutant falling out and collecting on the ground. The Ermak equation is the solution to the advection diffusion equation with a constant settling velocity and deposition velocity
4 Ermak, “An Analytical Model for Air Pollutant Transport and Deposition from a Point Source”.
with boundary condition at the ground
+where K is the eddy diffusivity and r is defined as
+and the other boundary conditions are as for the conventional Gaussian dispersion (e.g. constant mass emissions, m, at a point h above the origin, etc.). This can be solved and put in terms of and
as, by definition,
where . In practice, relationships for
s are much easier to find than Ks and the following is used to recover
This follows from the definition of (and r). In this case I am going to generate the
using automatic differentiation with
ForwardDiff.jl.
using ForwardDiff: derivative∂ₓσ_z²(x) = 2*σ_z(x)*derivative(σ_z, x)@ucorrel ∂ₓσ_z² u"m" u"m"K_z(x; u) = (1/2)*u*∂ₓσ_z²(x)Models like this, with a point source emitting mass, have nonphysical results in the vicinity of the emission source. The concentration rises sharply and there is a singularity at the source itself. There are many ways of dealing with this, but the easiest is to define a maximum concentration, usually given from a mass balance, and cut off the dispersion model at that. I don’t have any specific upper bound, so I picked a large number simply to prevent the propagation of Inf or other errors.
This is only a problem very close to the source, and I am more interested in concentrations far from the tree, so this is not a concern. A better model would calculate a “virtual origin” for the tree such that the pollen concentration in the crown of the tree was more realistic.
+max_pollen = 1e6grains/1u"m^3"using SpecialFunctions: erfcfunction ermak(x, y, z; u=u, h=crown_height(DBH), P=pollen_rate(DBH),
+ W_set=vₜ, W_dep=vₜ, p_max=max_pollen)
+
+ if x<zero(x) || z<zero(z)
+ return zero(p_max)
+ end
+
+ s_y = σ_y(x)
+ s_z = σ_z(x)
+ K = K_z(x; u)
+
+ Wₒ = W_dep - 0.5*W_set
+
+ p = (P/(2π*u*s_y*s_z))*exp(-0.5*(y/s_y)^2)*
+ exp(-0.5*W_set*(z-h)/K - 0.125*(W_set*s_z/K)^2)*(
+ exp(-0.5*((z-h)/s_z)^2) + exp(-0.5*((z+h)/s_z)^2)
+ - (√(2π)*Wₒ*s_z/K)*exp(Wₒ*(z+h)/K + 0.5*(Wₒ*s_z/K)^2)*
+ erfc((Wₒ*s_z/K + (z+h)/s_z)/√(2)) )
+
+ return isnan(p) ? zero(p_max) : min(p, p_max)
+end;Using this model, the ground level pollen concentration 100 m downwind of the example tree is 105.82 grains m^-3. As shown in the figures below, the pollen is most concentrated in an area from about 75 m to 300 m downwind of the tree. Which is about 2.5 blocks going east-west (city blocks in Edmonton are longer in the north-south direction)
+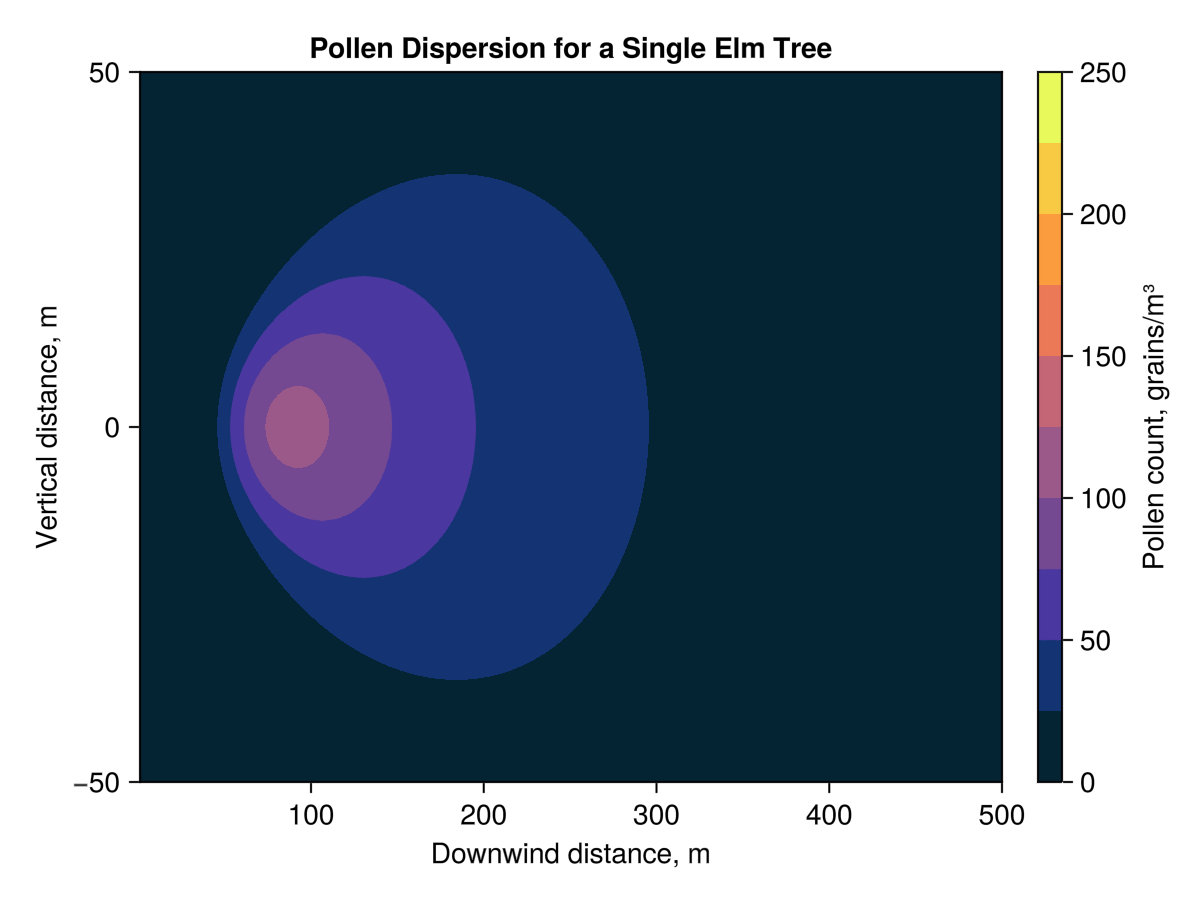 +
+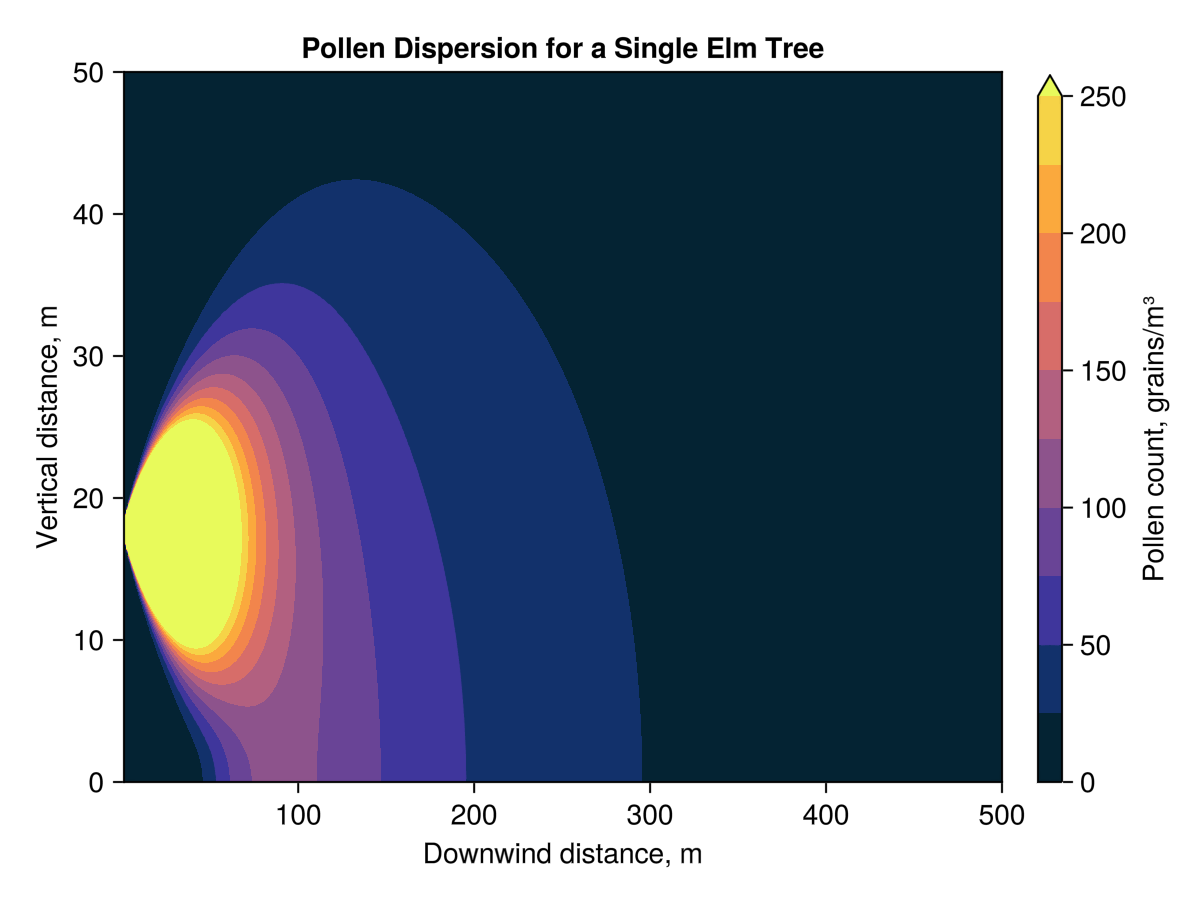 +
+I am left with some questions about how much pollen is actually needed, in the air, for pollination to have a chance. The pollen has to end up on a corresponding flower, so there must be a point where the concentration is just too low to make this likely. Trees do put some effort into improving the odds, they typically flower and disperse pollen before their leaves have meaningfully come back, helping to remove obstructions. The branching structures of trees are both useful for light gathering and provide a large effective area over which their flowers sieve the air for pollen.
+On the other side, pollen grains are somewhat fragile too, they can dry out or be damaged by excessive UV exposure. While a single pollen grain may have the potential to make it thousands of meters away from the tree, it may not be viable by the time it gets there.
+I would guess, from these calculations, that Elm trees are getting most of their action within 300 m or less. Anything beyond that and the pollen is so dispersed that the odds of it finding a pistil are too low.
+To move from modelling a single tree to an urban forest, I will need a data structure to contain the relevant parameters of a tree. In this case I need both the map location and the location of the tree relative to the origin of the local coordinate system, . Each tree also has a diameter, height, pollen release rate, and terminal velocity. In this case all the trees are Elm trees, and have the same pollen, but I’m leaving it general in case I want to model something else in the future.
begin
+
+struct Tree{G,L,P,V}
+ geopt::G
+ xₒ::L
+ yₒ::L
+ zₒ::L
+ DBH::L
+ h::L
+ P::P
+ vₜ::V
+end
+
+function Tree(geopt, xₒ, yₒ, DBH; v=vₜ)
+ h = crown_height(DBH)
+ P = pollen_rate(DBH)
+ xₒ, yₒ, zₒ, DBH, h = promote(xₒ, yₒ, zero(yₒ), DBH, h)
+ return Tree(geopt, xₒ, yₒ, zₒ, DBH, h, P, v)
+end
+
+end;elm = Tree(nothing, 0u"m",0u"m",DBH)Tree{Nothing, Quantity{Float64, 𝐋, Unitful.FreeUnits{(m,), 𝐋, nothing}}, Quantity{Float64, 𝐍 𝐓^-1, Unitful.FreeUnits{(grains, s^-1), 𝐍 𝐓^-1, nothing}}, Quantity{Float64, 𝐋 𝐓^-1, Unitful.FreeUnits{(m, s^-1), 𝐋 𝐓^-1, nothing}}}(
+ geopt = nothing
+ xₒ = 0.0 m
+ yₒ = 0.0 m
+ zₒ = 0.0 m
+ DBH = 0.88 m
+ h = 17.803579999999993 m
+ P = 317528.8675882605 grains s^-1
+ vₜ = 0.032156589905762846 m s^-1
+)I then added a method to ermak that takes a Tree object and returns the concentration of its pollen at a point x, y, and z on the local coordinate system.
function ermak(t::Tree, x, y, z; u=u)
+ x′ = x - t.xₒ
+ y′ = y - t.yₒ
+ z′ = z - t.zₒ
+ return ermak(x′, y′, z′; h=t.h, P=t.P, W_set=t.vₜ, W_dep=t.vₜ)
+end;The Ermak equation assumes the local area is a flat Euclidean plane. The earth is not that, and so a central task is going to be defining a local coordinate system that approximates my neighbourhood, Wîhkwêntôwin, as a flat plane. Then I will need to find all of the local trees and place them in this local coordinate system before adding in their individual contributions to the local Elm pollen situation.
+I arbitrarily picked a point more-or-less in the middle of the neighbourhood to act as the origin. My neighbourhood is pretty flat and so I’m going to assume everything is at the same altitude.
+using Geodesybegin
+
+latₒ, lonₒ, altₒ = 53.54100, -113.52141, 671
+Δlat, Δlon = 0.015, 0.035
+
+end;I oriented the grid such that the wind goes from west to east – which is usually the case. Another approach would be to look up the local windrose and orient the grid to the most frequent wind direction with the wind speed as the median wind speed.
+I am assuming that the area is locally flat relative to the curvature of the earth. Namely that the distance, in meters, per degree longitude is a constant across the whole neighbourhood – which I calculate from a straight line running through the origin going from the furthest west to the furthest east. Similarly for degrees latitude. This isn’t strictly true but the difference between the distance along the ellipsoid and the locally-flat distance is going to be trivially small, so I can safely ignore it.
+begin
+
+Δx = euclidean_distance(LLA(latₒ, lonₒ - Δlon/2, altₒ),
+ LLA(latₒ, lonₒ + Δlon/2, altₒ), wgs84)/Δlon
+Δy = euclidean_distance(LLA(latₒ + Δlat/2, lonₒ, altₒ),
+ LLA(latₒ - Δlat/2, lonₒ, altₒ), wgs84)/Δlat
+endfunction local_coords(lat,lon)
+ x = (lon - lonₒ)*Δx
+ y = (lat - latₒ)*Δy
+ return x, y
+endAt first glance it looks like I’m doing a lot of additional work for no reason. I ultimately want to overlay my maps on top of satellite imagery, which will require me to convert everything into Web Mercator. Why not use that as the local coordinate system? Points in Web Mercator are northing and easting in meters on a flat plane.
+Unlike UTM, where that kind of thing works out well enough for a lot of situations, there is a lot more distortion with Web Mercator. Especially closer to the poles. I’m not particularly close to the north pole, but more than close enough that the map distortion leads to significant errors when using Web Mercator naively like that.
+To demonstrate this I’m going to calculate the distance between my favourite coffee shop, stopgap, and a local park on the other side of the neighbourhood, Oliver park.
+begin
+
+stopgap = LLA(53.535618490862944, -113.5118491580413)
+oliver_park = LLA(53.54542679826651, -113.52603529325418)
+
+enddist = euclidean_distance(stopgap, oliver_park, wgs84)First I calculate the distance along the ellipsoid, which is 1441 m (the same as what Google maps tells me).
+Then I convert the coordinates to Web Mercator, which are northing and easting relative to the equator and the prime meridian.
+WM = WebMercatorfromLLA(wgs84)begin
+
+stopgap_wm = WM(stopgap)
+oliver_park_wm = WM(oliver_park)
+
+endwm_dist = √( (stopgap_wm[1] - oliver_park_wm[1])^2
+ + (stopgap_wm[2] - oliver_park_wm[2])^2 )The naive Euclidean distance using Web Mercator is 2423 m, about 68% greater than the true distance. If I set my local grid naively using the northing and easting of Web Mercator, everything would be distorted.
+Thankfully, I don’t need to wander the neighbourhood with a GPS unit and a tape measure to find all the local Elm trees and map them. The City of Edmonton has already done that. I filtered the data set to just my neighbourhood and just Ulmus Americana and downloaded it as a csv.
+using CSV, DataFramestrees_df = CSV.read("data/Ulmus_americana_wihkwentowin.csv",
+ DataFrame);describe(trees_df, :min, :max)19×3 DataFrame
+ Row │ variable min max
+ │ Symbol Any Any
+─────┼──────────────────────────────────────────────────────────────────────────────────────────────
+ 1 │ ID 155206 619701
+ 2 │ NEIGHBOURHOOD_NAME WÎHKWÊNTÔWIN WÎHKWÊNTÔWIN
+ 3 │ LOCATION_TYPE Alley Park
+ 4 │ SPECIES_BOTANICAL Ulmus americana Ulmus americana Patmore
+ 5 │ SPECIES_COMMON Elm, American Elm, American
+ 6 │ GENUS Ulmus Ulmus
+ 7 │ SPECIES americana americana
+ 8 │ CULTIVAR Brandon Patmore
+ 9 │ DIAMETER_BREAST_HEIGHT 5 110
+ 10 │ CONDITION_PERCENT 0 65
+ 11 │ PLANTED_DATE 1990/01/01 2024/09/25
+ 12 │ OWNER Parks Parks
+ 13 │ Bears Edible Fruit false false
+ 14 │ Type of Edible Fruit
+ 15 │ COUNT 1 1
+ 16 │ LATITUDE 53.5346 53.5496
+ 17 │ LONGITUDE -113.536 -113.51
+ 18 │ LOCATION (53.534594143551985, -113.510361… (53.549586375568154, -113.530880…
+ 19 │ Point Location POINT (-113.50950085882668 53.53… POINT (-113.53589639202552 53.54…What I would like is a vector of Trees. I could have added a column to the dataframe with Tree objects when it was created, but I’m not using the dataframe for anything else so I didn’t really see the point.
begin
+trees = Vector{Tree}()
+
+for row in eachrow(trees_df)
+ lat, lon = row.LATITUDE, row.LONGITUDE
+ DBH = row.DIAMETER_BREAST_HEIGHT*1u"cm" |> u"m"
+ pt = LLA(lat,lon,altₒ)
+ x, y = local_coords(lat, lon).*1u"m"
+ tree = Tree(pt,x,y,DBH)
+ push!(trees, tree)
+end
+
+endThere are 996 Elm trees in Wîhkwêntôwin alone. That’s impressive, we have a pretty great urban forest.
+trees[1]Tree{LLA{Float64}, Quantity{Float64, 𝐋, Unitful.FreeUnits{(m,), 𝐋, nothing}}, Quantity{Float64, 𝐍 𝐓^-1, Unitful.FreeUnits{(grains, s^-1), 𝐍 𝐓^-1, nothing}}, Quantity{Float64, 𝐋 𝐓^-1, Unitful.FreeUnits{(m, s^-1), 𝐋 𝐓^-1, nothing}}}(
+ geopt = LLA(lat=53.53695945675063°, lon=-113.51201340003675°, alt=671.0)
+ xₒ = 623.0131311454173 m
+ yₒ = -449.74535157065054 m
+ zₒ = 0.0 m
+ DBH = 0.2 m
+ h = 9.04518 m
+ P = 10810.758180096327 grains s^-1
+ vₜ = 0.032156589905762846 m s^-1
+)I am assuming that pollen is additive and doesn’t alter the properties of air at all. The concentration of pollen from multiple trees is just the concentration of pollen from each tree added together.
+ermak(trees::Vector{Tree}, x, y, z; u=u) =
+ sum( ermak.(trees, x, y, z; u=u) );Now that I have a set of trees and a bounding box, I need to generate some actual maps. I am going to use Tyler.jl to download the map tiles and make them plot-able in Makie. For which I need to give it a bounding box for the neighbourhood and identify a map provider. I am using the imagery from ESRI.
+using Tylerwihkwentowin = Rect2f(lonₒ - Δlon/2, latₒ - Δlat/2, Δlon, Δlat);provider = Tyler.TileProviders.Esri(:WorldImagery);I have defined a helper function to take a tree and return the appropriate Web Mercator coordinates to map on top of the ESRI imagery.
+function map_tree(tree::Tree)
+ x, y, _ = WM(tree.geopt)
+ return Point2f(x,y)
+endMapping all of the trees in the data set matches what I expected: they are mostly boulevard trees and the northwest corner of the neighbourhood is much more densely forested with Elm.
+ +
+Now I have all the tools in place to generate concentration contours for Elm pollen and plot them on top of the ESRI imagery for my neighbourhood. First, I create a helper function to convert grid points in Web Mercator to local grid coordinates, then return the concentration at that point with contributions from all 996 Elm trees.
+If I was doing this for the whole city I might want to first filter out all the Elm trees that are too distant from or downwind of the point of interest – since they won’t contribute anything.
+LLA_WM = LLAfromWebMercator(wgs84)function map_ermak(x, y)
+ lla = LLA_WM([x,y,altₒ])
+ local_x, local_y = local_coords(lla.lat, lla.lon).*1u"m"
+ return ustrip(ermak(trees, local_x, local_y, 0u"m"))
+endI then divide the neighbourhood into a grid of 10,000 points and calculate the concentration at each point.
+# defining the bounds of the grid
+
+begin
+
+xₗ, yₗ, _ = WM(LLA(latₒ - Δlat/2, lonₒ - Δlon/2, altₒ))
+xᵤ, yᵤ, _ = WM(LLA(latₒ + Δlat/2, lonₒ + Δlon/2, altₒ))
+
+end;begin
+
+xs = range(xₗ, xᵤ; length=100)
+ys = range(yₗ, yᵤ; length=100)
+
+zs = map_ermak.(xs, ys')
+
+end;Finally I overlay a contour plot on top of the ESRI imagery, showing everywhere with a pollen concentration >10 grains m^-3
+ +
+A major limitation to this style of dispersion modelling, especially in a neighbourhood like mine dominated by large apartment buildings, is that building downwash effects are not being accounted for. The Elm trees are at a similar height or shorter than the buildings around them. This model essentially ignores the buildings other than their contribution to surface roughness – reflected in the dispersion parameters and
. Short of doing a CFD model of the neighbourhood, I don’t think there is an easy way around that. Probably this would work better in neighbourhoods like Highlands or Ritchie which have mature Elm trees but where housing is mostly older homes, less than 2 stories, with yards spacing them out from each other.
A limitation to this specific example is that I haven’t included all the Elm trees in adjacent neighbourhoods – Westmount in particular. This under counts the Elm pollen on the west side of Wîhkwêntôwin. I can imagine one producing maps like this, for the whole city, based on which trees are producing pollen in any given week showing where the peak pollen action is. A where not to park your car map, if you want to avoid washing your windshield every morning, or where to avoid if you are allergic to tree pollen.
+The properties of the vessel form a natural data structure containing the valve properties, the vessel volume, and the initial conditions. It can also be divided into two distinct sub-problems: the gas expansion within the vessel and the gas expansion across the valve. The gas expansion within the vessel will be governed by the ODE or DAE for the particular expansion type – isothermal, adiabatic, &c. – whereas the expansion across the valve will always be isentropic. These sub-problems can then be solved in a way that is agnostic to the equation of state.
+An important decision must be made regarding which subset of the state variables, , will be used to define the system. The remaining variable will be defined by the equation of state. Equations of state are typically given in relation to the Helmholtz free energy,
, a function of molar volume and temperature, which makes those a natural choice. The pressure vessel can then be instantiated with the total volume, total mass of material contained, and the vessel temperature. The pressure then varies with the equation of state. Alternatively, the pressure and temperature of the vessel could be chosen as the state variables. But then the total mass in the vessel depends on the particular equation of state, which strikes me as weird.
begin
+
+struct PressureVessel{F <: Number}
+ c::F # valve discharge coefficient
+ A::F # valve flow area
+ V::F # vessel volume
+ T::F # vessel temperature
+ m::F # total mass of material
+end
+
+PressureVessel(c, A, V, T, m) =
+ PressureVessel(promote(c, A, V, T, m)...)
+
+endAbstracting the fluid properties – the P-v-T relationship, entropy, enthalpy, and the like – allows the vessel blowdown model to be re-used easily. Using Julia’s multiple dispatch no code even needs to change, just add new methods for a new fluid model and everything works. This leads naturally to a way of checking that the vessel model is working by comparing an ideal gas model to the known analytic solution. Verifying that it works with an ideal gas then gives confidence that the model is working with a real gas, for which the analytic solution is unknown.
+Collecting the ambient conditions into a data structure does not lead to any spectacular improvements or insights, it is just neat and tidy.
+begin
+
+struct Environment{F <: Number}
+ P::F
+ T::F
+end
+
+Environment(P, T) = Environment(promote(P,T)...)
+
+endFinally, a data structure for blowdown solutions is useful for dispatch.
+struct Blowdown{S}
+ pv::PressureVessel
+ env::Environment
+ sol::S
+endBase.length(::Blowdown) = 1Base.iterate(b::Blowdown, state=1) = state > length(b) ? nothing : (b,state+1)The first fluid model worth creating is the ideal gas model that corresponds to the known, analytic, solution. Specifically an ideal gas with constant heat capacities such that . Starting with the following data structure.
begin
+
+const R = 8.31446261815324 # m³⋅Pa/K/mol
+
+struct IdealGas{F <: Number}
+ cᵥ::F # J/kg/K
+ cₚ::F # J/kg/K
+ k::F
+ R::F # J/kg/K
+ MW::F # kg/mol
+end
+
+function IdealGas(cᵥ,MW; R=R)
+ cᵥ, MW = promote(cᵥ,MW)
+ cₚ = cᵥ + R
+ k = cₚ/cᵥ
+ return IdealGas(cᵥ,cₚ,k,R,MW)
+end
+
+function IdealGas(model::Clapeyron.EoSModel;
+ P=101325, T=288.15, z=[1.])
+ MW = Clapeyron.molecular_weight(model, z) # kg/mol
+ cᵥ = Clapeyron.isochoric_heat_capacity(model, P, T, z) # J/mol/K
+ return IdealGas(cᵥ, MW)
+end
+
+endA good practice, when solving ODEs, is to use NaNMath.jl for roots, logarithms, and the like. These versions return NaN when results are outside of the function domain – for example – instead of throwing a
DomainError. Returning NaNs makes it easier for the ODE solver to detect when it has left the domain of a valid solution.
begin
+
+using NaNMath
+
+√ = NaNMath.sqrt
+log = NaNMath.log
+
+endThe equation of state is implemented as a series of high-level functions, dispatching on the fluid model and returning the relevant fluid properties. Extending the blowdown model to use a different equation of state involves merely overloading these to dispatch on a different fluid type.
+pressure(model::IdealGas, v, T) = model.R*T/vvolume(model::IdealGas, P, T) = model.R*T/Pmolecular_weight(model::IdealGas) = model.MWmolar_enthalpy(model::IdealGas, v, T) = model.cₚ*Tmolar_entropy(model::IdealGas, v, T) =
+ model.cᵥ*log(T) + model.R*log(v)molar_internal_energy(model::IdealGas, v, T) = model.cᵥ*Tspeed_of_sound(model::IdealGas, v, T) =
+ √(model.k*model.R*T/model.MW)Clapeyron.jlThe high-level functions defined above are mapped to the corresponding Clapeyron.jl functions. And that’s it. Everything is ready to use for whichever equation of state your heart desires.
+import Clapeyronpressure(model::Clapeyron.EoSModel, v, T) =
+ Clapeyron.pressure(model, v, T)volume(model::Clapeyron.EoSModel, P, T; v0=nothing) =
+ Clapeyron.volume(model, P, T; phase=:vapor, vol0=v0)molecular_weight(model::Clapeyron.EoSModel) =
+ Clapeyron.molecular_weight(model)molar_enthalpy(model::Clapeyron.EoSModel, v, T) =
+ Clapeyron.VT_enthalpy(model, v, T)molar_entropy(model::Clapeyron.EoSModel, v, T) =
+ Clapeyron.VT_entropy(model, v, T)molar_internal_energy(model::Clapeyron.EoSModel, v, T) =
+ Clapeyron.VT_internal_energy(model, v, T)speed_of_sound(model::Clapeyron.EoSModel, v, T) =
+ Clapeyron.VT_speed_of_sound(model, v, T)The vessel blowdown relies on a good model of isentropic nozzle flow. This involves finding the pressure and temperature in the throat of the nozzle which maximizes the mass flux, G, while satisfying the constraints that the path from a stagnation point in the vessel through the nozzle is isentropic and that the enthalpy is conserved. The flow is further constrained to be either sonic or subsonic, i.e. the Mach number is less than or equal to one.
+For almost all of the blowdown the flow will be sonic and the pressure in the throat of the nozzle will be greater than atmospheric, this is called choked flow. The entropy and enthalpy balances can be solved for the throat conditions, , assuming the velocity is the local speed of sound. I do this here using NonlinearSolve.jl, where the objective function,
choked_nozzle_balance!, is in-place.
using NonlinearSolvefunction choked_nozzle_balance!(obj, y, prms)
+ # y = [v; T]
+ obj .= [ prms.entropy - molar_entropy(prms.model, y[1], y[2])
+ prms.enthalpy - molar_enthalpy(prms.model, y[1], y[2]) - 0.5*molecular_weight(prms.model)*speed_of_sound(prms.model, y[1], y[2])^2 ]
+ return nothing
+endchoked_nozzle_prob = NonlinearProblem(choked_nozzle_balance!, [0.0; 0.0],
+ (model=nothing, env=nothing,
+ entropy=0.0, enthalpy=0.0))In the case where the flow is subsonic, the pressure in the throat of the nozzle is atmospheric and the entropy and enthalpy balances are solved for gas velocity and temperature, .
function non_choked_nozzle_balance!(obj, y, prms)
+ # y = [u; T]
+ v = volume(prms.model, prms.env.P, y[2])
+ obj .= [ prms.entropy - molar_entropy(prms.model, v, y[2])
+ prms.enthalpy - molar_enthalpy(prms.model, v, y[2]) - 0.5*molecular_weight(prms.model)*y[1]^2 ]
+ return nothing
+endnon_choked_nozzle_prob = NonlinearProblem(non_choked_nozzle_balance!,
+ [0.0; 0.0],
+ (model=nothing, env=nothing,
+ entropy=0.0, enthalpy=0.0))The most obvious and direct way of solving the entropy and energy balances is to solve the optimization problem. However, I could not get that to work reliably. Using the same constraints on entropy and enthalpy as well as constraining the Mach number to be less than or equal to one, I could get it to work but only with very good guesses of the initial conditions. Using Optimization.jl, it would either get stuck in a local maximum or, depending on the solver, sometimes return results that simply did not satisfy the constraints (but came with return code “Success”). Given that this is going to be wrapped in an ODE and executed, potentially, hundreds of times, that is not good.
My completely stupid but it works approach is to solve the choked flow nonlinear system first and, if the nozzle pressure is below atmospheric, solve the non-choked flow system instead. This works perfectly though, presumably, is not nearly as efficient as solving the optimization problem directly would be if I could get it to work properly.
+function mass_flow(model, pv, env, v, T)
+ # calculate the molar entropy and molar enthalpy
+ # at vessel conditions
+ s₁ = molar_entropy(model, v, T)
+ h₁ = molar_enthalpy(model, v, T)
+
+ # solve the choked flow energy balance for
+ # an isentropic nozzle
+ params = (model=model, env=env, entropy=s₁, enthalpy=h₁)
+ y₀ = [v; T]
+ prob = remake(choked_nozzle_prob, u0=y₀, p=params)
+ sol = solve(prob, NewtonRaphson())
+ vₜ, Tₜ = sol.u
+ Pₜ = pressure(model, vₜ, Tₜ)
+ if Pₜ > env.P
+ # flow is choked, we're done
+ uₜ = speed_of_sound(model, vₜ, Tₜ)
+ else
+ # flow is not choked, solve the non-choked problem
+ v₀ = volume(model, env.P, T)
+ y₀ = [ speed_of_sound(model, v₀, T); T ]
+ prob = remake(non_choked_nozzle_prob, u0=y₀, p=params)
+ sol = solve(prob, NewtonRaphson())
+ uₜ, Tₜ = sol.u
+ vₜ = volume(model, env.P, Tₜ)
+ end
+
+ ρₜ = molecular_weight(model)/vₜ
+ return pv.c*pv.A*ρₜ*uₜ
+endThe general adiabatic blowdown solution proceeds in the same way as the ideal gas case (solved previously). Here the isentropic path is not directly available, so the problem is rewritten as a Differential Algebraic Equation (DAE), where the vessel state is constrained to be isentropic.
+The first step is to define a basic type, PressureODE; which will allow functions like blowdown_pressure to dispatch on solution type.
struct PressureODE{S}
+ ode_sol::S
+endThe governing equations are the ODE as defined before, plus the constraints that the P-v-T behaviour follows the equation of state and the entropy is constant.
+The equation of state does not need to be pulled into the DAE like this. It could be incorporated into the right hand side of the ODE. However, it is often convenient to have all of the state variables directly accessible in the solution.
+using OrdinaryDiffEq, DiffEqCallbacksfunction adiabatic_vessel!(dy, y, prms, t)
+ P, v, T = y
+
+ a² = speed_of_sound(prms.model, v, T)^2
+ w = mass_flow(prms.model, prms.pv, prms.env, v, T)
+
+ dy .= [-w*a²/prms.pv.V
+ v - volume(prms.model, P, T)
+ prms.init - molar_entropy(prms.model, v, T) ]
+ return nothing
+endabd_rhs = ODEFunction(adiabatic_vessel!, mass_matrix = [1 0 0
+ 0 0 0
+ 0 0 0])A callback function is used to terminate the integration once the vessel is within a given tolerance of atmospheric pressure. Without this the blowdown would continue forever, or until the limits of machine precision (whichever came first). Technically, this blowdown model predicts the pressure in the vessel will get arbitrarily close to atmospheric pressure but never actually achieve it.
+depressured_callback(y, t, I; reltol=0.001) =
+ y[1] - (1+reltol)*I.p.env.PThe entire model is packaged into a function which takes a fluid, pressure vessel, and environment and returns a Blowdown solution. By splitting the problem up like this, different fluid models, vessels or ambient conditions can be swapped around while reusing what has already been defined.
function adiabatic_blowdown(model, pv::PressureVessel,
+ env::Environment;
+ solver=Rodas5(),
+ tspan=(0.0, 600.0))
+
+ # vessel initial conditions
+ V, T₀, m = pv.V, pv.T, pv.m
+ n₀ = m/molecular_weight(model)
+ v₀ = V/n₀
+ P₀ = pressure(model, v₀, T₀)
+
+ # defining the parameters
+ s₀ = molar_entropy(model, v₀, T₀)
+ params = (model=model, pv=pv, env=env, init=s₀)
+
+ # callbacks
+ dpcb = ContinuousCallback(depressured_callback, terminate!)
+
+ # set up the ODEProblem and solve
+ y₀ = [P₀; v₀; T₀]
+ prob = ODEProblem(abd_rhs, y₀, tspan, params)
+ sol = solve(prob, solver; callback=dpcb)
+
+ return Blowdown(pv,env,PressureODE(sol))
+endFrom the ODE solution the blowdown time, pressure curve, and temperature can be recovered.
+blowdown_time(bd::Blowdown{<:PressureODE}) =
+ bd.sol.ode_sol.t[end]function blowdown_pressure(bd::Blowdown{<:PressureODE}, t)
+ bdt = blowdown_time(bd)
+ t = min(t, bdt)
+ return bd.sol.ode_sol(t; idxs=1)
+endfunction blowdown_temperature(bd::Blowdown{<:PressureODE}, t)
+ bdt = blowdown_time(bd)
+ t = min(t, bdt)
+ return bd.sol.ode_sol(t; idxs=3)
+endThe entire model, including all of the sub-models, is complicated and could easily have typos and hard to notice errors in it. An easy way to check this is to compare the results against the known analytic solution for the case where the gas is an ideal gas and the flow through the nozzle is always choked.
+struct IdealGasChoked{F <: Number}
+ P₀::F
+ k::F
+ τ::F
+endfunction adiabatic_choked_blowdown(model::IdealGas, pv::PressureVessel,
+ env::Environment)
+ # vessel parameters
+ c, A = pv.c, pv.A
+
+ # vessel initial conditions
+ V, T₀, m = pv.V, pv.T, pv.m
+ n₀ = m/molecular_weight(model)
+ v₀ = V/n₀
+ P₀ = pressure(model, v₀, T₀)
+
+ k, R, MW = model.k, model.R, model.MW
+ τ = 1/( (c*A/V)*√(k*R*T₀/MW)*(2/(k+1))^((k+1)/(2*(k-1))) )
+ return Blowdown(pv,env,IdealGasChoked(P₀,k,τ))
+endfunction blowdown_time(bd::Blowdown{<:IdealGasChoked})
+ P₀, Pₐ, k, τ = bd.sol.P₀, bd.env.P, bd.sol.k, bd.sol.τ
+ return (2τ/(1-k))*(1 - (Pₐ/P₀)^((1-k)/2k))
+endfunction blowdown_pressure(bd::Blowdown{<:IdealGasChoked}, t)
+ P₀, k, τ = bd.sol.P₀, bd.sol.k, bd.sol.τ
+ t = min(t, blowdown_time(bd))
+ return P₀*( 1 + 0.5*(k-1)*(t/τ))^((2*k)/(1-k))
+endfunction blowdown_temperature(bd::Blowdown{<:IdealGasChoked}, t)
+ T₀, P₀, k = bd.pv.T, bd.sol.P₀, bd.sol.k
+ t = min(t, blowdown_time(bd))
+ P = blowdown_pressure(bd, t)
+ return T₀*(P/P₀)^((k-1)/k)
+endThe same situation as the previous post on ideal gas blowdown is used here, a gas cylinder at 3000psia blowing down through a valve into the air. In this case the gas is nitrogen, instead of air, as having a single species is simpler than a mixture (though not by much).
+atm = Environment(101325,288.15)vessel = let
+ c = 0.85
+ D = 0.005 # m
+ A = 0.25*π*D^2 # m²
+ V = 0.01111 # m³
+ m = 2.743 # kg
+ T = 288.15 # K
+ PressureVessel(c, A, V, T, m)
+endThe real gas is modelled using a volume translated Peng-Robinson equation of state.
+using Clapeyron:PR, ReidIdeal, RackettTranslationnitrogen = PR(["nitrogen"]; idealmodel=ReidIdeal,
+ translation=RackettTranslation);ig_nitrogen = IdealGas(nitrogen);choked_model = adiabatic_choked_blowdown(ig_nitrogen, vessel, atm);ideal_gas = adiabatic_blowdown(ig_nitrogen, vessel, atm);real_gas = adiabatic_blowdown(nitrogen, vessel, atm); +
+The blowdown using an ideal gas equation of state matches the known solution for the entire domain where flow is actually choked. This gives some assurance that the general model is working properly. The real gas model, VTPR, appears to work well and is not too far from the ideal case, as expected.
+When I first played around with this I assumed flow through the nozzle was always choked (as a test) and this led to numerical difficulties near the end of the integration. I had to manually stop the integration at around 20s. Each subsequent time step would end up venting a physically unrealistic amount of material and the thermodynamic models would start to suffer from domain errors. Pleasingly, once a better model for the valve was swapped in, these problems went away.
+ +
+Another problem that can happen, depending upon the equation of state, is that the vessel may be outside the range where the equation of state can return a physically real gas. The temperature in the vessel, and especially within the nozzle, drops dramatically and in this case it drops below the boiling point of nitrogen by the time the vessel is fully depressured. This is a real result. It is not a consequence of some numerical error. It is a consequence of assuming a perfectly adiabatic vessel.
+Another way of approaching this problem is to perform a mass and energy balance. This is a more general approach and is what underlies more complex blowdown simulators (such as BLOWDOWN). Starting with a mass balance:
+The energy balance is that the change in the internal energy within the vessel is equal to the rate of heat in, through the walls of the vessel, minus the rate of heat lost due to flow out of the vessel.
+Where is the specific enthalpy, note this is at vessel conditions. The boundary for the energy balance is around the vessel, not including the valve.
The total internal energy is the product of the mass remaining in the vessel and the specific internal energy, . Applying the chain rule:
Combining these two expressions:
+The specific internal energy, , is related to the molar internal energy,
, by the molar weight,
, similarly for the specific and molar enthalpy. Substituting and multiplying through by the molar weight gives:
The remaining mass, , can be written in terms of the molar volume,
:
The mass balance can also be written in terms of the molar volume:
+The full system of equations, in terms of is then:
The adiabatic case is the special case where .
It is not immediately clear that this is the same model as the adiabatic pressure equation. The adiabatic pressure equation assumes the expansion within the vessel is isentropic, but that condition is not explicitly applied in the energy equation. One hint this is the same model is that the ideal gas solution can be derived from the energy balance.
+Consider an ideal gas with constant heat capacities such that and
. For the adiabatic case the energy balance becomes:
Isentropic choked flow of an ideal gas occurs with:
+With nozzle density and temperature related to the vessel conditions by:
+Substituting all of this into the energy equation and dividing by gives:
Where . The time constant
is defined such that:
Which simplifies the ODE to:
+This is a separable equation and can be integrated to give:
+For an adiabatic expansion of an ideal gas:
+Which recovers the original solution:
+The governing equations for the vessel blowdown can be implemented as a DAE though, as the state variables, , no longer include pressure, determining when the vessel has fully depressured is slightly more complicated. The callback function must first calculate the pressure in the system. Previously, the callback function was a
ContinuousCallback, which adjusts the final time step to exactly depressurize the vessel. Here the callback is a DiscreteCallback which terminates once a time step has crossed the threshold.
function energy_eqn!(dy, y, prms, t)
+ u, v, T = y
+
+ h = molar_enthalpy(prms.model, v, T)
+ w = mass_flow(prms.model, prms.pv, prms.env, v, T)
+ M = molecular_weight(prms.model)
+ V = prms.pv.V
+
+ dy .= [ (M*prms.Qᵢ(T) + (u-h)*w)*v/(M*V)
+ (w*v^2)/(M*V)
+ u - molar_internal_energy(prms.model, v, T) ]
+ return nothing
+endueqn_rhs = ODEFunction(energy_eqn!, mass_matrix = [ 1 0 0
+ 0 1 0
+ 0 0 0 ])depressured_callback_2(y, t, I; reltol=0.001) =
+ pressure(I.p.model, y[2], y[3]) < (1+reltol)*I.p.env.PTo generate the blowdown curve the pressure must be calculated, as it is no longer an output of the ODE. This could be done on demand, retrieving the molar volume and temperature for a given time and calculating the pressure. Another approach is to calculate the pressure at each time step and interpolate. This is implemented here as a SavingCallback, which calculates and saves the pressure after each time step. A cubic interpolation of the pressure is created from the results and used to generate the blowdown curve. The solution type contains two pieces: the ode solution and the pressure-time interpolation.
using DataInterpolationsstruct EnergyODE{S,I}
+ ode_sol::S
+ p_interp::I
+endfunction energy_eqn_blowdown(model, pv::PressureVessel,
+ env::Environment;
+ Qi=(T)->0.0,
+ solver=Rodas5(),
+ tspan=(0.0, 600.0))
+
+ # vessel initial conditions
+ V, T₀, m = pv.V, pv.T, pv.m
+ Mw = molecular_weight(model)
+ v₀ = Mw*V/m
+ u₀ = molar_internal_energy(model, v₀, T₀)
+
+ # defining the parameters
+ params = (model=model, pv=pv, env=env, Qᵢ=Qi)
+
+ # callbacks
+ svs = SavedValues(Float64, Float64)
+ svcb = SavingCallback((y, t, I) -> pressure(I.p.model,y[2],y[3]), svs)
+ dpcb = DiscreteCallback(depressured_callback_2, terminate!)
+ cbs = CallbackSet(svcb,dpcb)
+
+ # set up the ODEProblem and solve
+ y₀ = [u₀; v₀; T₀]
+ prob = ODEProblem(ueqn_rhs, y₀, tspan, params)
+ sol = solve(prob, solver; callback=cbs)
+
+ # set up pressure interpolation
+ pi = AkimaInterpolation(svs.saveval, svs.t)
+
+ return Blowdown(pv,env,EnergyODE(sol,pi))
+endThe methods for blowdown time, pressure, and temperature are easily implemented.
+blowdown_time(bd::Blowdown{<:EnergyODE}) =
+ bd.sol.ode_sol.t[end]function blowdown_pressure(bd::Blowdown{<:EnergyODE}, t)
+ bdt = blowdown_time(bd)
+ t = min(t, bdt)
+ return bd.sol.p_interp(t)
+endfunction blowdown_temperature(bd::Blowdown{<:EnergyODE}, t)
+ bdt = blowdown_time(bd)
+ t = min(t, bdt)
+ return bd.sol.ode_sol(t; idxs=3)
+endThe results from the energy model can be compared to the pressure model, they are functionally identical.
+ideal_gas_energybd = energy_eqn_blowdown(ig_nitrogen, vessel, atm);real_gas_energybd = energy_eqn_blowdown(nitrogen, vessel, atm); +
+ +
+I did not put a lot of effort into making exceptionally performant code. Firstly, the model for isentropic flow through the valve could be improved. Presumably this could also be incorporated into the governing equations of the ODEs, at a cost to model simplicity and reusability, which might unlock some performance opportunities.
+Given those limitations, the performance of the two models can be compared using BenchmarkTools.jl.
@benchmark adiabatic_blowdown(nitrogen, vessel, atm)BenchmarkTools.Trial: 42 samples with 1 evaluation.
+ Range (min … max): 111.588 ms … 149.424 ms ┊ GC (min … max): 0.00% … 20.45%
+ Time (median): 120.515 ms ┊ GC (median): 6.11%
+ Time (mean ± σ): 120.226 ms ± 5.882 ms ┊ GC (mean ± σ): 4.39% ± 4.00%
+
+ ▂ ██ ▅█ █
+ ▅██▁▅█▅▁▁▁▅▅███▅████▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▅ ▁
+ 112 ms Histogram: frequency by time 149 ms <
+
+ Memory estimate: 59.87 MiB, allocs estimate: 948090.The adiabatic blowdown using the energy model is about 35% faster than the pressure model. Partly this is due to the choice of terminating callbacks. Whether or not integration is terminated with a DiscreteCallback or a ContinuousCallback does not meaningfully change the performance for the pressure model. However, this choice dramatically changes the performance of the energy model. Changing to a ContinuousCallback erases the difference between the two models.
@benchmark energy_eqn_blowdown(nitrogen, vessel, atm)BenchmarkTools.Trial: 56 samples with 1 evaluation.
+ Range (min … max): 82.811 ms … 122.534 ms ┊ GC (min … max): 0.00% … 28.08%
+ Time (median): 89.420 ms ┊ GC (median): 0.00%
+ Time (mean ± σ): 89.381 ms ± 6.032 ms ┊ GC (mean ± σ): 4.05% ± 5.62%
+
+ ▂ ▂ ▂ ▂ █▂
+ █▅▅▅▁▅█▅█▅▅█▅▁▅▅██▅▁▁▁▁▁▁▁▁▁▅▁▁▁▁▅▁▁▁▁▅▅█▅██▁██▅█▁▁▅▅▁▅▁█▁▁▅ ▁
+ 82.8 ms Histogram: frequency by time 95.7 ms <
+
+ Memory estimate: 44.30 MiB, allocs estimate: 727470.The pressure model performance at the end of the blowdown is strongly dependent on whether molar volume is used as a state variable. When used as a state variable there is a major performance hit compared to moving the volume into the RHS, nearly double the compute time. Removing it as a state variable comes with a cost to the accuracy near the termination of the blowdown. It is not obvious to me why this is the case (maybe using volume as a system variable forces the solver to take smaller time steps?), but it hints that there are opportunities to improve the pressure model by tweaking how molar volume is incorporated.
+ +
+A big caveat to the kind of loose performance comparison I did here is that I did not define a metric for performance. If you wanted to more rigorously benchmark these two approaches defining what constitutes “good enough” in terms of the blowdown curve is necessary. You can always make a model faster by making it less precise.
+Extending the ideal gas blowdown to real gases using Clapeyron.jl is straightforward. Though the adiabatic case immediately calls into question the point in doing so. Even for a system as simple as a cylinder of nitrogen, the adiabatic assumption is too extreme to be plausible: it predicts the blowdown of a room temperature cylinder will result in a spray of liquid nitrogen. Really, though, the model breaks down once it results in the gas inside the vessel dropping below the boiling point while remaining a gas.
Rapid blowdowns often lead to cryogenic conditions where the assumption that the fluid in the vessel remains a gas becomes increasingly unlikely. The energy model given here can already accommodate variable heat transfer, for example , and it could be extended to include phase change by performing an isothermal flash calculation at each time step (and adjusting the enthalpy and internal energy calculations to account for the multiple phases). For a more realistic SCUBA tank model, this level of complexity isn’t needed, once a realistic heat transfer model is added the liquefaction problem would go away.
Slower blowdowns, relative to the volume of the vessel, make more sense to model as always a gas. In these cases however, modelling the vessel as having no internal flow may be a serious limitation. Modelling the blowdown of pipeline segments, for example, without accounting for the frictional losses from internal flows leads to a significant error. I didn’t include an example of isothermal blowdowns here, but it is even easier to implement than the adiabatic case (for the pressure equation).
+I think there is a limited space between the pure ideal gas blowdown model and a full real fluid model with heat transfer &c. Most real situations either don’t require meticulously accounting for fluid non-ideality, and the ideal gas model works well enough, or are complex enough that a realistic model that includes phase change and heat transfer is required. However, building up from the ideal gas case step by step offers multiple points where the intermediate steps can be checked against known solutions. This is a useful exercise when building complex models, which can otherwise be difficult to test and troubleshoot.
+ + +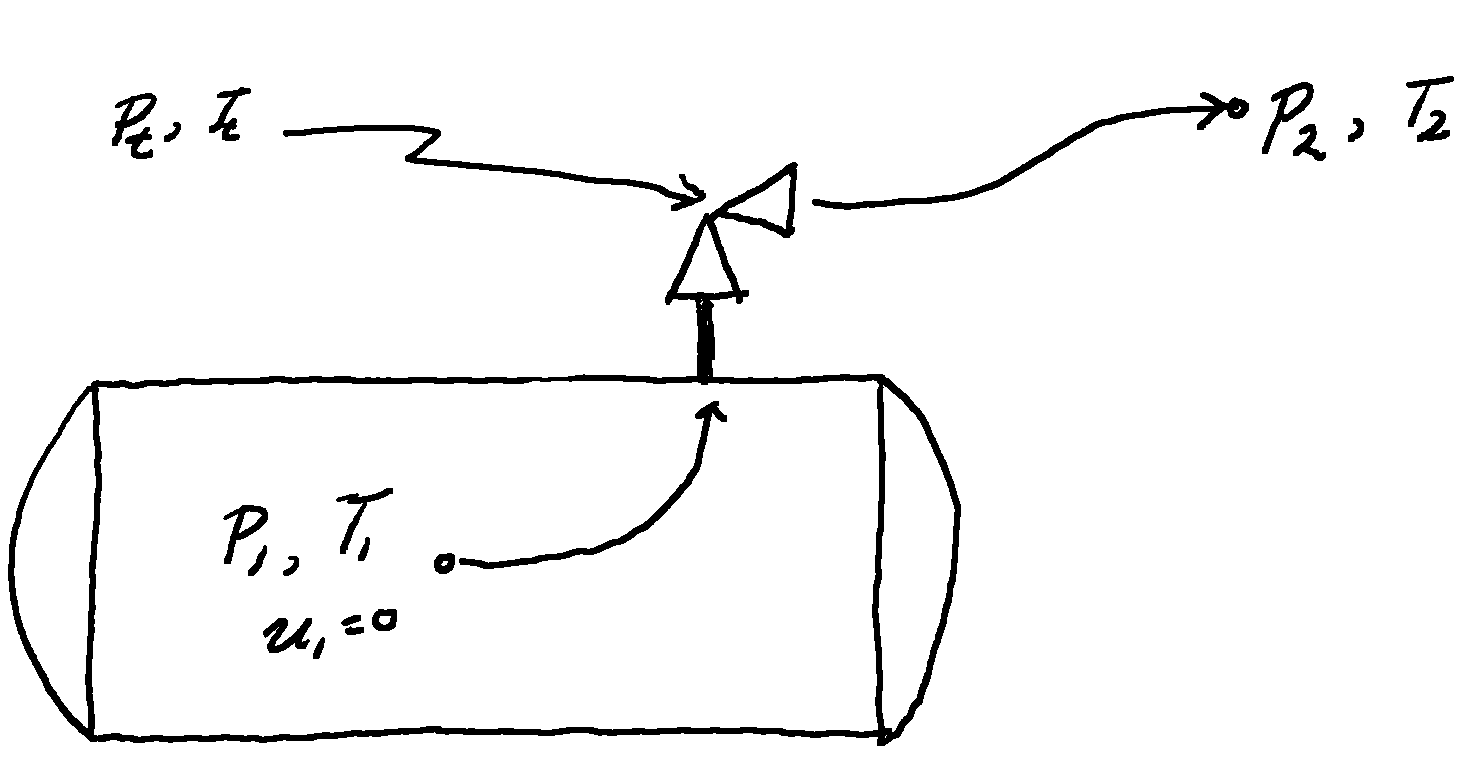 +
+Consider the blowdown of a pressure vessel to a vent stack, where the vessel contains a gas. What we want is the time to fully depressure and the pressure curve (the blowdown curve). As a first approximation we can consider the ideal gas case and examine two limiting behaviours for the vessel: when the walls are perfect insulators (the adiabatic case) and when the walls are perfect conductors of heat (the isothermal case). Furthermore we assume the blowdown is through an isentropic nozzle.
+The adiabatic case is often a good approximation for small vessels and early in the blowdown, when the rate of energy lost from the vessel through the bulk transport of the gas is much higher than any heat gained from the environment.
+Starting with a mass balance on the vessel:
+where m is the mass inside the vessel and w is the mass flow through the valve. Since the volume of the vessel is a constant, V, we can write the mass balance as
+We can perform a change of variables from ρ to P
+The partial derivative is taken along an isentropic path as the adiabatic expansion within the vessel is isentropic (not because the valve is isentropic).
+We can write the mass flow through the nozzle in terms of the theoretical, friction less, mass velocity G, the discharge coefficient , and the flow area A.
giving1
+1 Botros, Jungowski, and Weiss, “Models and Methods of Simulating Gas Pipeline Blowdown”.
Assuming the flow through the valve is choked, the velocity in the throat is the sonic velocity which, for an ideal gas, is given by
An ideal gas undergoing an adiabatic expansion from vessel pressure to the pressure in the throat of the valve has the following relationship between density and pressure2
+2 Any physical chemistry textbook, such as Laidler, Meiser, and Sanctuary, Physical Chemistry, 79–81.
and, for choked flow, the pressure ratio is at maximum at3
+3 Tilton, “Fluid and Particle Dynamics,” 6-22-6-23.
putting this all together we can write G in terms of vessel conditions and
From thermodynamics we know
+and we can put this all together to get
+At this point, it is standard to introduce a time constant
or, more clearly,
+Where the subscript 0 indicates the initial conditions in the vessel. This simplifies the expression to
+Which is separable and can be integrated to give (after some rearrangement)
+and the depressure time is
+Another useful thing to determine is the mass flow rate over time, which can be recovered rather easily recalling
+and
+we get
+By recalling the definition of this simplifies to
This final model, for mass flow, is the model most often given in process safety references for blowdown rates. This makes some sense as early in a blowdown the observed pressure curve tend to approximate the adiabatic curve. However (foreshadowing) the isothermal curve leads to higher predicted vessel pressures, and generally higher mass flow rates, which might be more conservative depending on the context.
+The adiabatic model is the only simple model given in Lees,4 with the recommendation to use software such as BLOWDOWN to handle more complex, multi phase, mixtures and heat transfer problems. This is also what my older copy of Perry’s gives,5 albeit with a typo.
+4 Lees, Loss Prevention in the Process Industries, 15/44.
5 Crowl et al., “Process Safety.” 23–57.
Perry’s gives the following
+Note the sign change, it should be k-1 not k+1, given typical values of k~1.4 this actually a huge difference.
+Perry’s only gives the mass flow, so if you wanted the pressure (and the gas density and temperature) you would need to find some other reference. Or do it yourself, it does sketch out how the equation is derived, if you have the spare time to sit down and integrate.
+There are two obvious limitations to this model: it relies on the gas being well approximated by an ideal gas and that the flow out of the vessel is always choked. The first issue I am not going to deal with right now, the second one I think can be easily dealt with by slightly modifying the governing equations.
+We can solve this numerically given
+function isentropic_mass_flow(P, ρ; k=1.4, Pₐ=101325)
+ η = max( Pₐ/P, (2/(k+1))^(k/(k-1)))
+ G² = ρ*P*(2k/(k-1))*( η^(2/k) - η^((k+1)/k) )
+ G = G² > 0 ? √(G²) : 0
+ return G
+endfunction speed_of_sound(P, ρ; k=1.4)
+ a = √(k*P/ρ)
+ return a
+endfunction adiabatic_vessel(P, params, t)
+ c, A, V, k, ρ₀, P₀, Pₐ = params
+ ρ = ρ₀*(P/P₀)^(1/k)
+ a² = speed_of_sound(P, ρ; k=k)^2
+ G = isentropic_mass_flow(P, ρ; k=k, Pₐ=Pₐ)
+ return-c*A*a²*G/V
+endwith a callback function to terminate the integration once the vessel is fully depressured
+function depressured_callback(P, t, integrator; tol=0.001)
+ c, A, V, k, ρ₀, P₀, Pₐ = integrator.p
+ return P - (1+tol)*Pₐ
+endJust to have a real system to think about, I used to SCUBA dive when I was a teenager and had a few mishaps early on, when I was still figuring things out, accidentally opening the tank valve when the regulator yoke was not fully attached. Blasting air all over the place while I scrambled to shut it off. Typical tanks have capacities ranging from 80 cu. ft. to 100 cu. ft., with working pressures of >3000 psi. That’s a pretty high pressure for a relatively small tank. How fast could the tank blowdown if I opened the valve fully and just sat back and watched?
+# Ambient conditions
+begin
+ Pₐ = 101.325e3 # Pa
+ Tₐ = 288.15 # K
+ ρₐ = 1.21 # kg/m³
+end;I looked around online and a typical tank with a 80 cu. ft. capacity might have a “water volume” (actual internal volume) of 678 cu. in. (11.11L) and a working pressure of 3000 psi (20.68 MPa). I don’t actually know the flow area of a tank valve, I couldn’t find it easily, so I’m going to guess it’s basically a 1 mm diameter tube when fully open, with a discharge coefficient of 0.85 – all of this could be firmed up better with some real details of the valve. But this is a start.
+#Vessel conditions
+begin
+ c = 0.85
+ D = 0.001 # m
+ A = 0.25*π*D^2 # m²
+ V = 0.01111 # m³
+ P₀ = 20.68e6 # Pa
+ T₀ = Tₐ
+ ρ₀ = ρₐ*(P₀/Pₐ) # ideal gas law
+ k = 1.4
+end;I then set up the differential equation and integrate to get the blowdown curve.
+using OrdinaryDiffEq, Plotsbegin
+ params = (c, A, V, k, ρ₀, P₀, Pₐ)
+ t_span = (0.0, 12.0)
+ prob = ODEProblem(adiabatic_vessel, P₀, t_span, params)
+ sol = solve(prob, Tsit5(),
+ callback=ContinuousCallback(depressured_callback, terminate!))
+end; +
+This model has the tank blowing down pretty fast, in less than 30s. Probably my guess for the valve area is too large. I did just make it up.
+Regarding the models themselves, the adiabatic choked model is a very good approximation to the full ODE until the last few fractions of a second, at which point the models diverge. This likely to be true for any high pressure blowdowns, where the vessel pressure starts well above ~2atm, as in that case the majority of the blowdown will be entirely in the choked flow regime.
+To play around with this more, I am first going to detour into creating some helper functions and I think this is a natural point to create a struct to contain the vessel parameters.
begin
+
+struct PressureVessel{F <: Number}
+ c::F
+ A::F
+ V::F
+ k::F
+ ρ₀::F
+ P₀::F
+ Pₐ::F
+ τ::F
+end
+
+PressureVessel(c, A, V, k, ρ₀, P₀, Pₐ, τ) =
+ PressureVessel(promote(c, A, V, k, ρ₀, P₀, Pₐ, τ)...)
+
+function PressureVessel(c, A, V, k, ρ₀, P₀, Pₐ)
+ τ = 1/( (c*A/V)*√(k*P₀/ρ₀)*(2/(k+1))^((k+1)/(2*(k-1))) )
+ return PressureVessel(c, A, V, k, ρ₀, P₀, Pₐ, τ)
+end
+
+end;Where I have added a helper function to ensure all numbers are of the same type, and calculate the value of τ when the PressureVessel type is constructed.
Recreating the results from above, I start with a definition of the vessel
+vessel = PressureVessel(c, A, V, k, ρ₀, P₀, Pₐ);I would like to create some generic functions for the blowdown properties I am interested in: pressure and mass flow rate as functions of time and total blowdown time. To accommodate this I define another type to contain the VesselBlowdown solution.
abstract type Blowdown endstruct AdiabaticBlowdown{S} <: Blowdown
+ pv::PressureVessel
+ sol::S
+endHere I add some functions to make a Blowdown object act like an iterator with only a single element. This is absolutely pointless except that I just happen to like being able to generate a vector of results by using the “dot” notation, like so
my_function.(blowdown, time_vector)where I want it to broadcast over the time_vector.
Base.length(::Blowdown) = 1Base.iterate(b::Blowdown, state=1) = state > length(b) ? nothing : (b,state+1)For the simple choked model this is fairly straight forward.
+adiabatic_blowdown_choked(vessel::PressureVessel) =
+ AdiabaticBlowdown(vessel,nothing)function blowdown_pressure(bd::AdiabaticBlowdown, t)
+ P₀, k, τ = bd.pv.P₀, bd.pv.k, bd.pv.τ
+ return P₀*( 1 + 0.5*(k-1)*(t/τ))^((2*k)/(1-k))
+endfunction blowdown_mass_rate(bd::AdiabaticBlowdown, t)
+ ρ₀, V, P₀, k, τ = bd.pv.ρ₀, bd.pv.V, bd.pv.P₀, bd.pv.k,
+ bd.pv.τ
+ m₀ = ρ₀*V
+ w₀ = m₀/τ
+ P = blowdown_pressure(bd, t)
+ return w₀*(P/P₀)^((k+1)/(2k))
+endfunction blowdown_time(bd::AdiabaticBlowdown)
+ P₀, Pₐ, k, τ = bd.pv.P₀, bd.pv.Pₐ, bd.pv.k, bd.pv.τ
+ return (2τ/(1-k))*(1 - (Pₐ/P₀)^((1-k)/2k))
+endFor the full model the initial step is to integrate the differential equation. As a first guess, I calculate the blowdown time for a fully choked blowdown and set the outer-bound for the integration to 10× this. The integrator will terminate when the pressure reaches ambient and thus the last time stored will be the actual blowdown time.
+function adiabatic_blowdown_full(vessel::PressureVessel; solver=Tsit5())
+ # unpack the parameters
+ c, A, V, k, ρ₀, P₀, Pₐ = vessel.c, vessel.A, vessel.V,
+ vessel.k, vessel.ρ₀, vessel.P₀,
+ vessel.Pₐ
+ params = (c, A, V, k, ρ₀, P₀, Pₐ)
+
+ # estimate the time span needed to fully blowdown
+ τ = vessel.τ
+ t_bd = (2τ/(1-k))*(1 - (Pₐ/P₀)^((1-k)/2k))
+ t_span = (0.0, 10t_bd)
+
+ # set up the ODEProblem and solve
+ prob = ODEProblem(adiabatic_vessel, P₀, t_span, params)
+ sol = solve(prob, solver,
+ callback=ContinuousCallback(depressured_callback, terminate!))
+
+ return AdiabaticBlowdown(vessel,sol)
+endfunction blowdown_pressure(bd::AdiabaticBlowdown{<:ODESolution}, t)
+ if t < blowdown_time(bd)
+ return bd.sol(t)
+ else
+ return bd.sol.u[end]
+ end
+endfunction blowdown_mass_rate(bd::AdiabaticBlowdown{<:ODESolution}, t)
+ if t < blowdown_time(bd)
+ # unpack the parameters
+ c, A, k, ρ₀, P₀, Pₐ = bd.pv.c, bd.pv.A, bd.pv.k,
+ bd.pv.ρ₀, bd.pv.P₀, bd.pv.Pₐ
+
+ # calculate w = c*A*G
+ P = blowdown_pressure(bd, t)
+ ρ = ρ₀*(P/P₀)^(1/k)
+ G = isentropic_mass_flow(P, ρ; k=k, Pₐ=Pₐ)
+
+ return c*A*G
+ else
+ return 0.0
+ end
+endblowdown_time(bd::AdiabaticBlowdown{<:ODESolution}) =
+ bd.sol.t[end] +
+At this point I’ve built up enough machinery that playing around with all sorts of variations to the original case become quite simple. As an example, I look at the same air tank but pressured to 1.5 atm instead.
+test_vessel = PressureVessel(c, A, V, k, ρ₀, 1.5Pₐ, Pₐ); +
+Now it is clear that the fully choked model model isn’t working well, it predicts a blowdown time of 11.68s whereas numerically solving the ODE gives an answer of 20.49s, a 75.0% greater predicted blowdown.
+That said…I’m being a little coy about something: the full ODE predicts that the vessel will never blowdown. The pressure will get closer and closer to ambient but never get there. This is because G, for non-choked flow, asymptotically approaches zero as the vessel pressure approaches ambient pressure. How you define blowdown time is really a function of how close to ambient is close enough. Even if I set the tolerance in the depressured_callback function, which terminates the integration once the integrator is within tolerance of the ambient pressure, to zero it would, in reality, simply terminate at the default numerical precision of DifferentialEquations.jl. In this case I’ve said “within 0.1% of ambient is close enough,” but that’s totally arbitrary.
The other limiting case worth exploring is the isothermal case, which is equivalent to the vessel having perfectly conductive walls and remaining always at thermal equilibrium with the environment. This is often a good approximation for large vessels where the blowdown rate is small relative to the thermal mass of the gas in the vessel.
+Recalling, for the adiabatic case, we had the following
+For the isothermal case the vessel is being depressured along an isothermal path (not an isentropic path) and so we substitute the appropriate partial derivative6
+6 Botros, Jungowski, and Weiss, “Models and Methods of Simulating Gas Pipeline Blowdown”.
As before, the blowdown is through an isentropic nozzle and we assume that flow is choked
+From thermodynamics we can write the partial derivative as
+Thus
+where the densities, , can be cancelled and, since the vessel is isothermal (i.e.
is a constant), the various constants can be collected to give
Where is as defined for the adiabatic case. This can easily be integrated to give
it also follows, from the ideal gas law, that
+and
+This can also be rearranged to give the blowdown time7
+7 N.B. the is the natural log, this matches the convention used in julia
This is the equation seen most often in references for estimating blowdown time for pipelines and compressor systems. It is also what is going on under the hood with many online calculators for vessel blowdown times. Though, in my experience, this is not always well documented and a modified form is often presented.
+The time constant, , can be broken up to look like this
Where we have made the substitution for
to account for non-ideal behaviour. If the gas has a value of k ~ 1.4, we can write
Where the constant is calculated entirely from the properties of air. Generally, I have found, few references describe where this constant comes from and in particular that it depends implicitly on a particular value for k. It also often has unit conversions absorbed into it, for example8
+8 Campbell, Gas Conditioning and Processing, 2:29; VANEC, “Pressure Volume-Blowdown Time Calculation”.
with the units
+I have also found a few sources that leave the value of the constant as a mystery for the user to puzzle out.9 I was honestly surprised at the quality of the results when I first googled this and looked it up in Knovel. The highest ranked results, at the time, were cryptic to the point of uselessness or included obvious mistakes (several referred to t as the “interstitial velocity” with units of cm/s, an obvious misprint being blindly recopied in several places, including some e-books on Knovel where one would hope the quality control would be better). There are a few places with useful derivations10 but I think a good starting point is the Tank Blowdown Math set of notes. It is pretty straight forward and does not require a lot of prior knowledge of the partial derivatives of various thermodynamic state variables.
+9 Temizel et al., Formulas and Calculations for Petroleum Engineering, 262; Engineers Edge, “Blowdown Time in Unsteady Gas Flow Calculator and Equation”.
10 Wheeler, “Tank Blowdown Math”; Botros, Jungowski, and Weiss, “Models and Methods of Simulating Gas Pipeline Blowdown”; Botros and Hardeveld, Pipeline Pumping and Compression Systems - a Practical Approach, 447; Saad, Compressible Fluid Flow, 98–103, to list but a few.
I personally would not bother with the models that pre-calculate the constant for you. We no longer live in the age of slide-rules. The blowdown time equation for fully choked flow is well within the capabilities of excel or any competent person with a scientific calculator. I think it is easier to justify and explain, will be a better model for gases where k is not 1.4, and allows one to incorporate small levels of non-ideality through the isentropic expansion factor n.
+The isothermal fully-choked model can be implemented building on the types already created, by first creating an IsothermalBlowdown type and associated blowdown functions
struct IsothermalBlowdown{S} <: Blowdown
+ pv::PressureVessel
+ sol::S
+endisothermal_blowdown_choked(vessel::PressureVessel) =
+ IsothermalBlowdown(vessel,nothing)function blowdown_pressure(bd::IsothermalBlowdown, t)
+ P₀, τ = bd.pv.P₀, bd.pv.τ
+ return P₀*exp(-t/τ)
+endfunction blowdown_mass_rate(bd::IsothermalBlowdown, t)
+ ρ₀, V, τ = bd.pv.ρ₀, bd.pv.V, bd.pv.τ
+ m₀ = ρ₀*V
+ w₀ = m₀/τ
+ return w₀*exp(-t/τ)
+endblowdown_time(bd::IsothermalBlowdown) =
+ bd.pv.τ*log(bd.pv.P₀/bd.pv.Pₐ)In a similar vein as the adiabatic case, the requirement for fully choked flow can be relaxed and the ODE integrated numerically instead, starting with the system
+We can solve this numerically given that, for an isothermal system, the density is given by
+and using the definition of G given in the adiabatic case.
+function isothermal_vessel(P, params, t)
+ c, A, V, k, ρ₀, P₀, Pₐ = params
+ ρ = ρ₀*(P/P₀)
+ a² = speed_of_sound(P, ρ; k=k)^2
+ G = isentropic_mass_flow(P, ρ; k=k, Pₐ=Pₐ)
+ return-c*A*a²*G/(k*V)
+endfunction isothermal_blowdown_full(vessel::PressureVessel; solver=Tsit5())
+ # unpack the parameters
+ c, A, V, k, ρ₀, P₀, Pₐ = vessel.c, vessel.A, vessel.V,
+ vessel.k, vessel.ρ₀, vessel.P₀,
+ vessel.Pₐ
+ params = (c, A, V, k, ρ₀, P₀, Pₐ)
+
+ # estimate the time span needed to fully blowdown
+ τ = vessel.τ
+ t_bd = τ*log(P₀/Pₐ)
+ t_span = (0.0, 10t_bd)
+
+ # set up the ODEProblem and solve
+ prob = ODEProblem(isothermal_vessel, P₀, t_span, params)
+ sol = solve(prob, solver,
+ callback=ContinuousCallback(depressured_callback, terminate!))
+
+ return IsothermalBlowdown(vessel,sol)
+endfunction blowdown_pressure(bd::IsothermalBlowdown{<:ODESolution}, t)
+ if t < blowdown_time(bd)
+ return bd.sol(t)
+ else
+ return bd.sol.u[end]
+ end
+endfunction blowdown_mass_rate(bd::IsothermalBlowdown{<:ODESolution}, t)
+ if t < blowdown_time(bd)
+ # unpack the parameters
+ c, A, k, ρ₀, P₀, Pₐ = bd.pv.c, bd.pv.A, bd.pv.k,
+ bd.pv.ρ₀, bd.pv.P₀, bd.pv.Pₐ
+
+ # calculate w = c*A*G
+ P = blowdown_pressure(bd, t)
+ ρ = ρ₀*(P/P₀)
+ G = isentropic_mass_flow(P, ρ; k=k, Pₐ=Pₐ)
+
+ return c*A*G
+ else
+ return 0.0
+ end
+endblowdown_time(bd::IsothermalBlowdown{<:ODESolution}) =
+ bd.sol.t[end] +
+It is a similar story to the adiabatic case: for systems with a high initial pressure, the flow out of the valve is fully choked for almost the entire blowdown. It is only in the final fraction of a second that the full ODE system deviates from the model that assumes flow is choked all the time.
+In most practical situations, the difference would likely be swamped by two much greater problems with these models:
+Both of these assumptions will have a much greater impact on how well the model fits observed blowdowns than the slight deviation at the end of the blowdown due to non-choked flow.
+I think it might be simpler to visualize when the choked flow blowdown models will fall down by looking at the high pressure blowdown, the original example, versus the low pressure blowdown in dimensionless form. In this form, the choked flow blowdown curves (both adiabatic and isothermal) only depend on k. They are in fact the exact same curve. All that has changed is where along the curve the blowdown terminates.
+ +
+In the high pressure case the blowdown terminates much closer to and most of the curve is fully choked.
 +
+In the low pressure case the blowdown terminates at a much steeper part of the blowdown curve and the departure for non-choking flow is much more apparent.
+It is not immediately clear to me why the adiabatic case is all over the standard references for process safety, and the isothermal model is not. If what you care about is the pressure sustained within a vessel, the mass flow rate emitted through a blowdown stack or vent, and the duration of the blowdown, it is almost always more conservative to use the isothermal case. The isothermal (fully choked) model is also just easier to calculate, being just .
The adiabatic case will give a better sense of how temperature changes within the vessel. I’ve largely left it out, but adiabatic blowdown does lead to a significant temperature drop and this cryogenic cooling can be a process hazard on its own. The gas exiting, and the vessel walls themselves, will get quite cold. Anyone who has gone camping in more marginal weather and watched a one-pound propane cylinder develop frost on the outside while cooking has seen this effect in action.11 But actually calculating the vessel temperature is almost entirely ignored in blowdown calculations for ideal gases, in my experience.
+11 This is also why butane cylinders are often not a good idea for early spring camping (in Canada), the cooling effect is strong enough to cause the butane inside to liquefy and the stove won’t work very well.
The isothermal model, in my review of the literature, appeared to be more commonly used in operational contexts, such as estimating the time required to blowdown a system through a blowdown vent. In this case it is likely to be the conservative answer. The two curves do cross at high and so it is not always the case that the isothermal model is more conservative. Something worth noting.
I deliberately set up the ODEs such that there is a clear path to implementing a real gas model through an equation of state. All that really needs to be done is to create functions for these three steps:
+Plugging those into the relevant steps in the adiabatic_vessel and isothermal_vessel functions changes from the ideal gas case to the real gas case. The rest of the code remains the same and operates unchanged.
In this case I think solving the full ODE for the ideal gas case alone is probably not worth the effort for most cases. The error in assuming an ideal gas, or in assuming one of the limiting heat transfer cases, is probably far larger than the error in assuming fully choked flow for all but the few cases that are near atmospheric pressure. If you are going to be estimating the blowdown for a real gas, then that’s different. If you are going to the hassle of setting up and solving the ODE, might as well have as few unnecessary assumptions as you can get away with. It really isn’t any more person effort, at that point, just more computer effort, and when the calculations happen in less than a second, how much less than a second is of little practical importance.
+1 API, Standard 520, Sizing, Selection, and Installation of Pressure-Relieving Devices, Part i - Sizing and Selection, 10th Ed, 68.
Clapeyron.jl comes to the rescue here with a wide array of equations of state for real fluids. Combined with julia’s robust ecosystem of libraries for integration and optimization, solving real fluid problems becomes simple. This post walks through how to size a relief device, in gas service, starting from an ideal gas and working through various methods for real gases using equations of state.
+The general idea for sizing a relief valve is to determine the minimum area required such that the mass flow through the valve equals the mass flow required for the governing release case via the relation2
+2 API, Standard 520, Sizing, Selection, and Installation of Pressure-Relieving Devices, Part i - Sizing and Selection, 10th Ed equation B.5.
where is the required mass flow-rate,
is a capacity correction,
is the theoretical flow area, and
the frictionless) mass flux through the valve. Valves are sized based on the theoretical flow area.
The general process is as follows:
+Standards, such as API-2020, give equations that combine steps 3 and 4 and absorb unit-conversions into the constants, so that the equation is in a more convenient form, but this is what is happening under the hood.
+The complications creep in through calculating , it is path-dependent and is a function of the equation of state for the fluid. For gas releases the relief device is typically treated as an isentropic nozzle, the assumption being that the flow-rate through the valve is typically large enough that any heat transfer can be neglected.
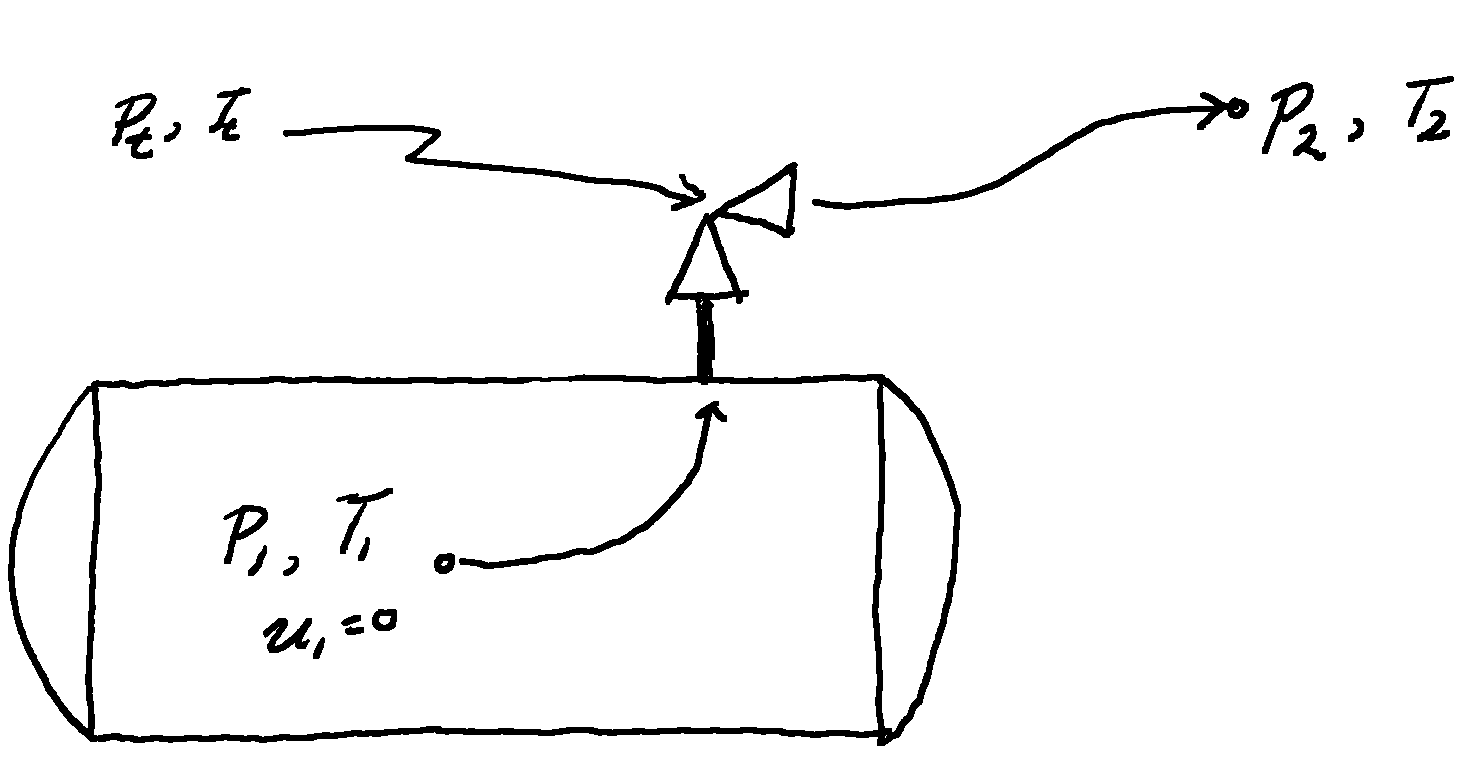 +
+Consider the differential form of the mechanical energy balance, along a streamline from the stagnation point, in the vessel, through the valve and out into the atmosphere, assuming no elevation change and no friction
+Integrating from the stagnation point to the throat of the nozzle gives
+Where the velocity at the stagnation point, . Putting this in terms of the mass flux
This integral cannot be solved directly at this point as the conditions at the throat of the nozzle are not known. Solving this requires simultaneously solving for the nozzle conditions, .
If we specify that the streamline follows an isentropic path, then we can construct a constrained maximization problem: the nozzle conditions are the and
which maximizes
where the integration is taken along an isentropic path.
In the case where flow is choked, i.e. the flow in the nozzle reaches sonic velocity, the maximum occurs at the sonic velocity with a pressure
. This can allow for the direct calculation of the mass flux as
, where
is the sonic velocity at the throat. No integration required.
Consider the release of ethane from a vessel at 200 bar and 400 K, for the sake of simplicity assume the release is directly into the atmosphere at 1 bar and 288.15 K (15°C) (the flow is going to be choked, so this doesn’t actually matter).
+using Unitfulbegin
+# the vessel properties
+ P₁ = 200u"bar"
+ T₁ = 400u"K"
+
+# the ambient properties
+ P₂ = 1u"bar"
+ T₂ = 288.15u"K"
+endWe can use Clapeyron.jl to initialize a few example equations of state for ethane. In this case I’m going to use an ideal gas model (ReidIdeal is an ideal gas model that also includes correlations for the ideal gas heat capacity), a cubic equation of state (volume translated Peng Robinson), and an empirical Helmholtz model (GERG-2008).
using Clapeyronbegin
+# assorted equations of state for ethane
+ ig_ethane = ReidIdeal(["ethane"])
+ vtpr_ethane = VTPR(["ethane"]; idealmodel = ReidIdeal)
+ gerg_ethane = GERG2008(["ethane"])
+end# this is a hack, ideal models in Clapeyron do not return a
+# molar weight and so cannot return a mass density
+Clapeyron.mw(model::IdealModel) = Clapeyron.mw(vtpr_ethane)At system conditions ethane is a super critical fluid, with the temperature and pressure above the critical point, which can be modelled as a dense gas.
+Considering the choked flow case, we know that and, for an ideal gas, the sonic velocity is given by3
3 Tilton, “Fluid and Particle Dynamics” equation 6-113.
Combining these we have
+It can be shown that, along an isentropic path defined by , the critical pressure ratio is4
4 Tilton equation 6-119.
Which allows us to write
+and (using )
Substituting back into the equation for 5
5 API, Standard 520, Sizing, Selection, and Installation of Pressure-Relieving Devices, Part i - Sizing and Selection, 10th Ed equation B.21.
or, to put it in terms of density
+where , the isentropic expansion factor for an ideal gas, is the ratio of heat capacities
This is the basis of API 520 Part 1 equation 9 where the following substitutions is made:
+and the constant and some unit conversions are rolled up into the constant 0.03948 in the expression for
We can use Clapeyron.jl to calculate at any given temperature, using correlations for the ideal gas heat capacity.
function isentropic_expansion_factor(model::IdealModel, P, T; z=[1.0])
+ cₚ_ig = isobaric_heat_capacity(model, P, T; phase=:vapor)
+ cᵥ_ig = isochoric_heat_capacity(model, P, T; phase=:vapor)
+ return cₚ_ig/cᵥ_ig
+endFrom which we calculate k= 1.146.
+We can check our work by comparing with the tabulated values. At 15°C and 1 atm we calculate k= 1.193 which is the same as the tabulated value of 1.19 (given at 15°C and 1 atm).6
+6 API, 70.
function mass_flux_choked(model, P, T; z=[1.0])
+ k = isentropic_expansion_factor(model, P, T; z=z)
+ ρ = mass_density(model, P, T, z; phase=:vapor)
+ Gₜ² = k*P*ρ*(2/(k+1))^((k+1)/(k-1))
+ return √(Gₜ²)
+endThe theoretical mass flux for the ideal gas is then 38359 kg m^-2 s^-1
+The ideal gas model, when the flow is choked, calculates the mass flux directly without needing to calculate the actual conditions at the nozzle. These can be calculated easily as well.7
+7 Tilton, “Fluid and Particle Dynamics” equations 6-119 and 6-120.
nozzle_pressure_ideal(P, T, k) = P*(2/(k+1))^(k/(k-1))nozzle_temperature_ideal(P, T, k) = T*(2/(k+1))The pressure at the nozzle is 115 bar the temperature at the nozzle is 373 K, which is above the critical point. The fluid supercritical and choked when leaving the PSV.
+At the vessel conditions, the VTPR model of ethane gives a compressibility factor of 0.672 (GERG-2008 model gives a similar value of 0.69), well below 0.8 and therefore outside the range where the ideal gas model is expected to work well.
+An alternative method is to calculate what the effective isentropic expansion factor would be, for the real gas, assuming that the real fluid obeys
+where is a constant.
The derivation of follows from the definition of the speed of sound in a gas8
8 Tilton, 6–22; Gmehling et al., Chemical Thermodynamics for Process Simulation, 113.
The constant entropy partial derivative can be re-written to eliminate entropy9
+9 Gmehling et al., Chemical Thermodynamics for Process Simulation, 660.
Using the relations10
+10 Gmehling et al., Chemical Thermodynamics for Process Simulation equations C.21 and C.8 (respectively).
and
+we get
+and the sonic velocity is then
+equating this to the ideal gas case, , and solving for
gives11
11 API, Standard 520, Sizing, Selection, and Installation of Pressure-Relieving Devices, Part i - Sizing and Selection, 10th Ed equation B.13.
where has been used to distinguish it from
(the ideal gas case). This is the version of
presented in most references, such as API 520. The derivation, however, hints at a useful shortcut to calculating
that does not require digging into the internals of
Clapeyron.jl to retrieve partial derivatives:
The remainder of the calculations are identical as the ideal gas case, simply substituting wherever
appears. Unfortunately
is not actually constant and depends on the temperature and pressure, which are not actually known in the nozzle, so the temperature and pressure at the stagnation point are often used instead.
function isentropic_expansion_factor(model, P, T; z=[1.0])
+ ρ = mass_density(model, P, T, z)
+ c = speed_of_sound(model, P, T, z)
+ n = ρ*c^2/P
+ return n
+endUsing effective isentropic expansion factors from the VTPR equation of state, the theoretical mass flux is 57811 kg m^-2 s^-1 ( 59321 kg m^-2 s^-1 from GERG-2008 ). This is quite a bit larger than the ideal case, indicating that the ideal gas law leads to a significantly over-sized PRV, 51.0% larger.
+ +
+The isentropic expansion factor method works best when is approximately constant over the isentropic path. As the above figure shows, this breaks down in ethane for pressures greater than ~100 bar. It also shows that the different equations of state start to diverge greatly further into the supercritical regime.
Another approach, and one I have seen more often in older references, is to perform an energy balance over the isentropic path and, assuming the flow is choked, solve for sonic velocity in the nozzle.12 Consider an energy balance starting at the stagnation point, (1), and following an isentropic path to immediately after the throat of the nozzle (t).
+12 Crowl et al., “Process Safety.” 23–55; Gmehling et al., Chemical Thermodynamics for Process Simulation, 603.
Where is the speed of sound at the nozzle, a function of
and
. The procedure is then to solve the system of equations given by the energy balance and the entropy balance,
, for
and
, then the theoretical mass flux is given by
There are a few ways this could be done, a straight-forward way is to divide the problem into two: 1. Define the isentropic path, i.e. find the isentropic temperature for a given pressure P 2. Use the energy balance to solve for the pressure, following the isentropic path.
+A more direct way is to solve for and
simultaneously. This is what I do next, using NonlinearSolve.jl
# Clapeyron does not expose this by default
+molecular_weight(model,z) = Clapeyron.molecular_weight(model,z)function nozzle_balance(y, prms)
+ P, T = y
+
+ # stagnation point
+ s₁ = prms.entropy
+ h₁ = prms.enthalpy
+
+ # at throat conditions
+ s₂ = entropy(prms.model, P, T, prms.z)
+ h₂ = enthalpy(prms.model, P, T, prms.z)/prms.Mw
+ c² = speed_of_sound(prms.model, P, T, prms.z)^2
+
+ return [ s₁ - s₂
+ h₁ - h₂ - 0.5*c² ]
+endusing NonlinearSolvefunction mass_flux_choked_energy_balance(model, P, T; z=[1.0])
+ # calculate the entropy and specific enthalpy at
+ # initial conditions
+ Mw = molecular_weight(model, z)
+ s₁ = entropy(model, P, T)
+ h₁ = enthalpy(model, P, T)/Mw
+
+ # solve the choked flow energy balance for
+ # an isentropic nozzle
+ params = (model=model, entropy=s₁, enthalpy=h₁, z=z, Mw=Mw)
+ y₀ = [P; T]
+ prob = NonlinearProblem(nozzle_balance, y₀, params)
+ sol = solve(prob, NewtonRaphson())
+ Pₜ, Tₜ = sol.u
+
+ # velocity is the sonic velocity at nozzle conditions
+ ρₜ = mass_density(model, Pₜ, Tₜ, z)
+ cₜ = speed_of_sound(model, Pₜ, Tₜ, z)
+
+ return ρₜ*cₜ
+endfunction mass_flux_choked_energy_balance(model, P::Quantity, T::Quantity; z=[1.0])
+ P = ustrip(u"Pa", P)
+ T = ustrip(u"K", T)
+ return mass_flux_choked_energy_balance(model, P, T; z=z)*1u"kg*m^-2*s^-1"
+endSolving the choked flow energy balance, using VTPR equation of state, the theoretical mass flux is 54629 kg m^-2 s^-1 ( 54353 kg m^-2 s^-1 from GERG-2008 ). This is also quite a bit larger than the ideal case, 42.0% larger. Though the values for the two equations of state are closer, indicating that this method is less sensitive to model choice.
+ +
+In this case the ideal gas method and the isentropic expansion factor method bracket the more exact method of solving the energy balance directly.
+As it is written, this method would need to be modified to allow for non-choked flow. This is done by eliminating the assumption and instead finding the conditions which maximize
(subject to the constraints of the entropy balance and the enthalpy balance). This will arrive at the same solution, in the case of choked flow, but with a little more effort.
Direct integration is the method most commonly recommended today, as it is entirely general. It can be used to solve all flow conditions from liquids to gases as well as two-phase mixtures. As a reminder, this method constitutes finding the and
that maximize the mass flux given by
First introduce the change of variables such that the integration is from
to
.
This allows us to write the corresponding differential equation
+subject to the constraint
+Which can be implemented as a differential algebraic equation using DifferentialEquations.jl
+using DifferentialEquationsfunction rhs(u, params, ΔP)
+ ∫vdP, T = u
+ model, P₁, s₁, z, Mw = params
+ P = P₁ - ΔP
+ return [ volume(model, P, T, z)/Mw
+ s₁ - entropy(model, P, T) ]
+endBut we want to stop the integration when or, equivalently, when the velocity is sonic. We can show that these are the same by finding the stationary points of
by applying the chain rule and cancelling we get
recalling the definition of the speed of sound (above)
+we have
+which is simply restating .
function ∂G²_callback(u, ΔP, integrator)
+ ∫vdP, Tₜ = u
+ model, P₁, s₁, z, Mw = integrator.p
+ Pₜ = P₁ - ΔP
+ c = speed_of_sound(model, Pₜ, Tₜ, z)
+ return 2∫vdP - c^2
+endfunction mass_flux_direct_integration(model, P₁, T₁, P₂;
+ z=[1.0], solver=Rodas5P())
+ s₁ = entropy(model, P₁, T₁, z)
+ Mw = molecular_weight(model, z)
+
+ # defining the ODEFunction
+ M = [ 1 0
+ 0 0 ]
+ f = ODEFunction(rhs, mass_matrix = M)
+
+ # defining the ODEProblem
+ u0 = [0.0; T₁]
+ params = (model, P₁, s₁, z, Mw)
+ ΔP_span = (0.0, P₁ - P₂)
+ prob = ODEProblem(f, u0, ΔP_span, params)
+ cb = ContinuousCallback(∂G²_callback, terminate!)
+
+ # solving the DAE
+ sol = solve(prob, solver, callback=cb)
+
+ # unpacking the solution
+ ΔPₜ = sol.t[end]
+ ∫vdP, Tₜ = sol.u[end]
+ ρₜ = mass_density(model, P₁-ΔPₜ, Tₜ, z)
+ G = ρₜ*√(2*∫vdP)
+endfunction mass_flux_direct_integration(model, P₁::Quantity, T₁::Quantity,
+ P₂::Quantity; z=[1.0])
+ P_1 = ustrip(u"Pa", P₁)
+ P_2 = ustrip(u"Pa", P₂)
+ T_1 = ustrip(u"K", T₁)
+ return mass_flux_direct_integration(model, P_1, T_1, P_2; z=z)*1u"kg*m^-2*s^-1"
+endDirect integration of the VTPR equation of state gives a theoretical mass flux of 54629 kg m^-2 s^-1 ( 54353 kg m^-2 s^-1 from GERG-2008 ). Which is exactly the same as from solving the choked flow energy balance, as expected.
+ +
+Writing this as a differential algebraic equation was largely necessary because Clapeyron.jl does not expose any routines to calculate the volume as a function of pressure and entropy. Some libraries like CoolProps do, in which case the code could be simplified to be a one dimensional ode.
This method could be extended to include liquid and two-phase flows however, as it is currently implemented, it only handles gases. Unlike the energy balance method, though, the flow does not have to be choked. If the flow is not choked, the maximum will occur once the nozzle pressure reaches . This result will simply pop out without any extra effort.
For the sake of completeness, there are two other methods that should be looked at, which are really special cases: 1. the ideal gas case, but using the real compressibility, , at stagnation conditions, this is the API 520 standard approach for gases 2. using the isentropic expansion factor, n factor, method but calculating n at the average of the stagnation and nozzle conditions
These two approaches do better than the basic methods I presented, but I don’t think they add enough value on their own. Given a model of the gas which can generate the compressibility, using either the energy balance method or the direct integration method produces superior results than correcting the ideal gas case. Once a viable equation of state is in hand, the simplifications are not saving any actual engineer doing their job time, they are saving fractions of a second of compute time.
+I think the choice between the first law energy balance and the direct integration technique is more a matter of taste, at least in the case of choked flow. The direct integration method is in the relevant engineering codes/standards, and that is a strong justification for using it.
+ +
+In this case the choice of equation of state did not matter strongly, just for fun I have included a few other common cubic equations of state, they all perform reasonably. However this example is for a single compound that is not strongly associating, it is the type of example where cubic equations of state should work well. The choice of equation of state will be far more important with mixtures and strongly associating substances.
+I have long been an advocate for engineering to move out of using spreadsheets for everything and to use scripting languages and notebooks like Jupyter and Pluto far more. There are large classes of problems that are easy to solve with code and hard to solve with a spreadsheet. I think almost any calculation using equations of state fit into that category. We end up beholden to commercial software suppliers for calculations that, in my view, engineers should be doing themselves.
+Presumably you could do the calculations I laid out above in Excel, at enormous effort, and making liberal use of the solver. Julia, however, has a robust ecosystem for doing all the complicated math, it only needed to be connected up. What remains, for the engineer, is assessing the physical system and picking the appropriate methods and thermodynamic models.
+Hydrogen presents an interesting challenge for hazard analysis as it is lighter than air, rising and accumulating in places a more standard analysis would neglect. In my experience, the typical release modelling tools are for neutrally buoyant or negatively buoyant (heavier than air) gas releases, such as Gaussian plume models or dense gas models like SLAB, DEGADIS, and PHAST. They are not designed for, and may not accurately capture, the dispersion of hydrogen.
+Dense gas models typically assume cloud dynamics that are particular to denser than air clouds, with limiting behavior that brings the results in line with a neutrally buoyant release. Denser than air clouds pile up around the source, leading to dispersion upwind of the source, and have sharper cloud fronts than a more neutral cloud. These features are often written into the governing equations for plume dispersion from the outset.
+Neutral and positive buoyancy plume models typically account for buoyancy differences only through temperature as they are generally intended for hot stack gases and not low molecular weight gases. For example, the standard implementation of Brigg’s plume-rise in tools like ISC3 use only the temperature of the source to calculate the buoyant flux – implicitly assuming the molar weight of the gas is similar to that of air. The original Ooms model1 for positively buoyant plumes also only accounts for buoyancy differences due to temperature. These models would erroneously conclude that a stream of cold hydrogen gas would be heavier than air and would thus sink.
+1 Ooms, “A New Method for the Calculation of the Plume Path of Gases Emitted by a Stack”.
2 Ehrhart et al., “HyRAM+ (Hydrogen Plus Other Alternative Fuels Risk Assessment Models)”.
This leaves a lot of room for integral plume models that better handle the behaviour of low molecular weight gases. One such model is incorporated into HyRAM+, from Sandia National Laboratories in the United States.2 It includes an integral plume model for positively buoyant plumes that accounts for differences in buoyancy by molar weight in addition to temperature, and was designed with hydrogen dispersion in mind.
+HyRAM+ is implemented in python, with a Windows GUI, though I will be using it directly in a jupyter notebook. Partly because I use linux at home, but also I am interested in how one would use the plume dispersion and other tools independently. I’m interested in the use case where this is integrated into an existing process safety management system and what is needed are specific values from a consequence analysis such as the explosive mass.
+Just for something to play around with, consider the case of a leak from a hydrogen cylinder into the ambient air. Suppose a cylinder containing 50kg of hydrogen at 35MPa has fallen over and the valve has broken, creating a leak from a 1/4 in. hole at essentially ground level and is oriented at 45° upwards. The hydrogen is initially at ambient temperature and the ambient air is at standard conditions and is otherwise quiescent.
+ +
+Using the HyRAM+ API we can create the ambient air, air, and hydrogen, h2, fluid models at initial conditions.
import numpy as np
+import hyram.phys.api as api
+import hyram.phys as hpTa, Pa = 288.15, 101325
+air = api.create_fluid("Air", Ta, Pa)
+
+Th2, Ph2 = Ta, 35e6
+h2 = api.create_fluid("Hydrogen", Th2, Ph2)The broken valve is initialized as an Orifice object, which has a diameter and a discharge coefficient. In this case I assume the discharge coefficient is 0.6.
d_H = 25.4e-3/4 # mm
+c_d = 0.6 # assumed
+theta = np.pi/4
+orifice = hp.Orifice(d_H, c_d)The jet is modeled, by HyRAM+, as as a steady-state jet consisting of 3 distinct zones:3
+3 Ehrhart, Hecht, and Schroeder, Hydrogen Plus Other Alternative Fuels Risk Assessment Models (HyRAM+) Version 5.1 Technical Reference Manual.
4 Ooms, “A New Method for the Calculation of the Plume Path of Gases Emitted by a Stack”.
The jet is created by initializing a Jet object, which solves the zones and integrates the governing equations to determine the plume center-line.
HyRAM+ has several internal models for solving the notional nozzle, the default is the model by Yüceil and Ötügen and is selected with the keyword parameters nn_conserve_momentum=True and nn_T='solve_energy'
jet = hp.Jet(h2, orifice, air, theta0=theta,
+ nn_conserve_momentum=True,
+ nn_T='solve_energy',
+ verbose=True)solving for orifice flow... done
+solving for notional nozzle... done.
+integrating... done.With this done, we can retrieve the mass flow-rate (in kg/s)
+jet.mass_flow_rate0.4024272255826383We can compare this to a simple ideal gas model of an adiabatic orifice5
+5 AIChE/CCPS, Guidelines for Consequence Analysis of Chemical Releases.
A_h = (np.pi/4)*d_H**2
+k = 1.41
+
+ideal_gas_jet = c_d*A_h*np.sqrt( h2.rho*h2.P*k*pow(2/(k+1),(k+1)/(k-1)) )
+
+ideal_gas_jet0.37797876222402915jet.mass_flow_rate/ideal_gas_jet1.0646821086315916The HyRAM+ model is estimating a ~6% greater mass flow rate through the orifice than a simple ideal gas jet model. From an end user perspective, this adds a dimension of realism to the model without requiring really anything more from the user. There are probably several opportunities to use more realistic fluid models, elsewhere in the standard literature of hazard analysis, that haven’t been realized more for reasons of tradition and laziness than anything else.
+In the past, modelling an isentropic nozzle with a real gas from scratch was a pain as there is a lot of overhead in implementing a more realistic equation of state. Especially gathering all of the relevant model parameters. With libraries like CoolProp, it really drops the barrier for incorporating more realistic fluid models into ones calculations.
For hydrogen, the hazard we are most concerned with is fires and explosions. Conveniently, we can retrieve the lower flammability limit (LFL) for hydrogen without needing to look it up ourselves.
+lfl = hp.FuelProperties(h2.species).LFLand calculate the distance, along the plume center-line, to the LFL
+streamline_dists = jet.get_streamline_distances_to_mole_fractions([lfl])
+
+streamline_dists[0]19.655324152591245similarly we can retrieve the x-y coordinates of the plume extent, out to the LFL
+mole_frac_dists = jet.get_xy_distances_to_mole_fractions([lfl])
+
+mole_frac_dists{0.04: [(0, 13.734800620965242), (0, 14.201255169630102)]}
and, finally, calculate the flammable mass in the steady-state jet.
+jet.m_flammable()0.2789535809847125The next obvious thing we want to do is plot the actual plume dispersion, to do this we retrieve the x-y coordinates and corresponding mass fraction (X), mole fraction (Y), velocity (v) and temperature (T) fields.
+x, y, X, Y, v, T = jet._contourdatawe can use matplotlib to plot the concentrations and highlight the contour corresponding to the LFL
+
Above I walked through the steps using the physics models included in HyRAM+, but if what you want is just the final plot and some basic parameters for QRA there is a much easier way: use the analyze_plume_jet model in the HyRAM+ API.
plume = api.analyze_jet_plume(air, h2,
+ orif_diam=d_H,
+ rel_angle=theta,
+ dis_coeff=c_d,
+ nozzle_model='yuce',
+ contours=lfl,
+ xmin=0.0,
+ xmax=60,
+ ymin=0.0,
+ ymax=75,
+ vmin=0,
+ vmax=2*lfl,
+ output_dir='figures',
+ filename='h2_plume_fig.png')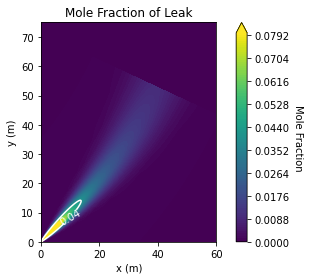
By default this outputs a file, instead of plotting directly into the notebook, and does not allow for as much control of the final figure. But it returns the necessary arrays if you wanted to do your own thing.
+The mass flow-rate, distance along the streamline to the LFL, and contour of the LFL are also retrievable.
+plume['mass_flow_rate']0.4024272255826383plume['streamline_dists'][0]19.655324152591245plume['mole_frac_dists']{0.04: [(0, 13.734800620965242), (0, 14.201255169630102)]}This does not return a Jet object, it returns a Dict with just the contours of the plume and some distances, so I am not entirely sure how one would get the explosive mass. This isn’t obviously exposed through the API either.
An important limitation, from a usability standpoint, is that there is no obvious way to retrieve the concentration for a given point. Suppose you have some coordinates x, y, z and you really need to know what the hydrogen concentration will be at that location specifically. HyRAM+ is not really set up to answer that question, or at least that functionality is not obviously exposed to the user. You could take the arrays of x and y points used for generating the plots, do a 2D-interpolation, and work it out from there, but that is kind of clunky.
+Another limitation of this model, if it is being used for process equipment outdoors, is that there is no accounting for wind. Ambient conditions are always assumed to be quiescent. This leads to less dispersion than you would expect were wind included, and may over-estimate the degree to which the plume will rise and disperse vertically.
+Another, more major limitation, is that there is no accounting for the ground. For large releases, near ground level, it may not be obvious that mass is being lost through the ground, and not accumulating as you would actually expect. For example, taking the above scenario and setting the release angle to 45° downward, the jet simply disappears into the earth. In reality the hydrogen should accumulate along the ground, or reflect off with some momentum. Releases near ground-level, with shallow release angles relative to horizontal, may have hazardous build-ups in areas, and that is being neglected by this model.
+plume = api.analyze_jet_plume(air, h2,
+ orif_diam=d_H,
+ rel_angle=-theta,
+ dis_coeff=c_d,
+ nozzle_model='yuce',
+ contours=lfl,
+ xmin=0,
+ xmax=60,
+ ymin=-65,
+ ymax=10,
+ vmin=0,
+ vmax=2*lfl,
+ output_dir='figures',
+ filename='h2_downward_plume_fig.png')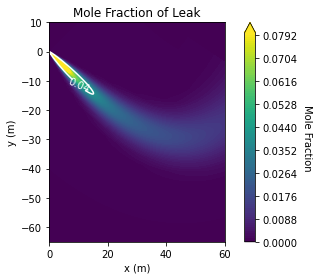
For integral plume dispersion models, like this one, it is typical to restrict the plume center-line such that it cannot extend below the ground, i.e. any integration step that would have a center-line with y<0 is rejected and replaced with one with y≥0. It is also common to implement ground reflection where the plume dispersion “bounces off” the ground, perfectly elastically.
+Preventing the plume from passing through the ground is strictly necessary for denser than air models, for example DEGADIS, as the plume naturally falls to ground level and rolls along it. That perhaps explains why HyRAM+ doesn’t implement this, the plume will naturally rise away from the ground due to the relative density of hydrogen. However, since HyRAM+ assumes the plume is on the ground by default, this strikes me as a significant trap for users. Shallow release angles will have non-physical results in the immediate vicinity of the jet.
+An important feature of this tool is that it allows one to easily model the accumulation of a buoyant layer along the ceiling in an enclosed space. Suppose, to continue the example, this happened in my workroom, which for the sake of simplicity is just a 4m × 4m room with 2.7m (9ft) ceiling. While the explosive mass in the steady state plume is pretty small, the lfl extent of the unconfined plume extends much further than the walls of my room. The hydrogen will hit the far wall and accumulate quite significantly.
+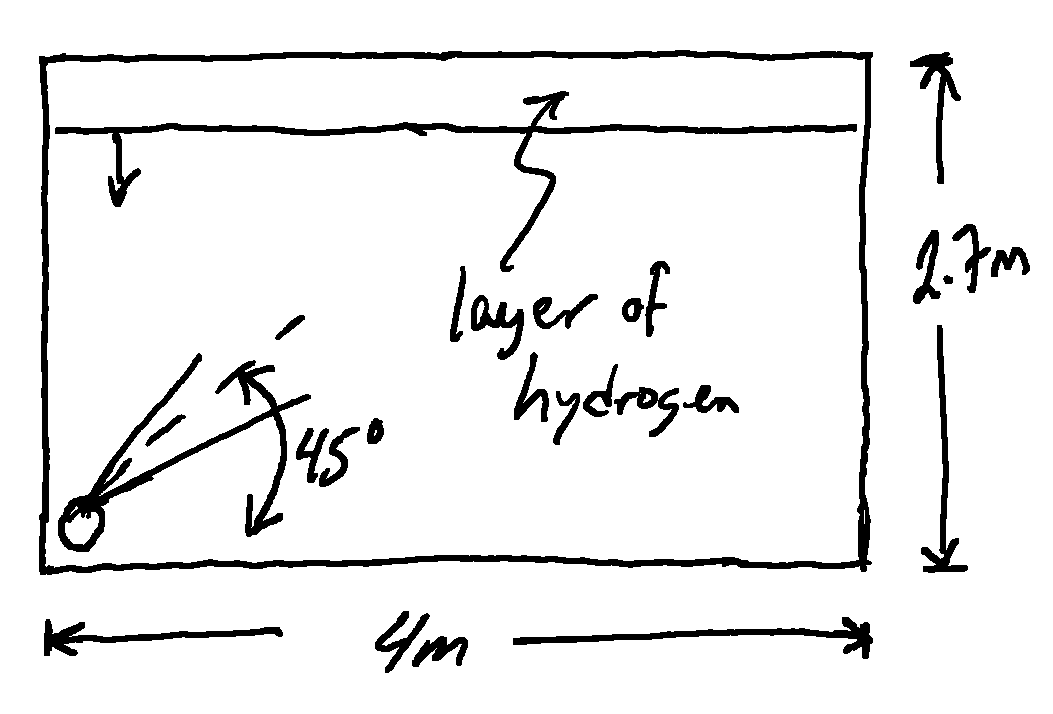 +
+The blowdown of the hydrogen cylinder will take some time and the exact blowdown curve is necessary for determining how rapidly the hydrogen will accumulate in the room. Assuming the jet it at the initial steady state mass-rate throughout will be very conservative and the entire contents of the cylinder will be gone within a few seconds.
+HyRAM+ uses the governing equations for adiabatic blow-down.
+where m is the mass remaining in the tank, u is the specific internal energy, h the specific enthalpy, and v the velocity through an isentropic nozzle. The thermodynamic state variables (P, T) are recovered from the fluid model and the internal energy, u, and the density ρ = m/V.
+First the cylinder is defined as a Source with an initial mass of hydrogen.
m_h2 = 50 #kg
+cylinder = hp.Source.fromMass(m_h2,h2)Then the cylinder can be blown down through the orifice previously defined. This numerically integrates the governing equations and returns the mass, pressure, temperature, and flowrate as functions of time.
A convenience function can also plot them for us.
+cylinder.empty(orifice)
+
+cylinder.plot_time_to_empty()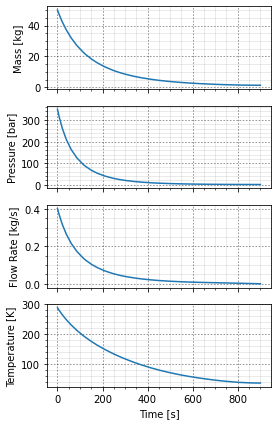
At this point the release is still unconfined. We need to define the room. This also includes defining the location of vents. Since no room is perfectly leak free, and for the sake of an example, I assume a similar leak area for a vent near the ceiling and one near the floor. I also define the cylinder as leaking from ground level essentially at one wall and aimed 45° upwards towards the opposite wall.
+ceiling_height = 2.7 #m
+floor_area = 16 #m^2
+release_height = 0 #m
+
+ceiling_vent = hp.Vent(A_h,2.6)
+floor_vent = hp.Vent(A_h,0.01)
+
+room = hp.Enclosure(ceiling_height, floor_area, release_height, ceiling_vent, floor_vent, Xwall=4)The release model then estimates the accumulation of a flammable layer starting at the roof and extending downwards.
+release = hp.IndoorRelease(source=cylinder,
+ orifice=orifice,
+ ambient=air,
+ enclosure=room,
+ theta0=theta,
+ nn_conserve_momentum=True,
+ nn_T='solve_energy',
+ tmax=30,
+ verbose=False)
+
+release.plot_mass()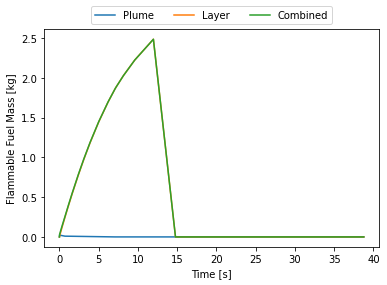
At this point I thought, initially, that there was something wrong with the code. Why does the flammable mass suddenly disappear? Where does it go? Nowhere. HyRAM+ by default assumes the flammable mass is between the LFL and UFL. At around 15 seconds the room is essentially saturated with hydrogen and above the UFL, hence why it suddenly disappears. This can be seen by plotting the flammable layer at the ceiling.
+release.plot_layer()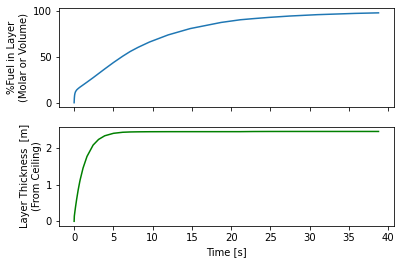
By 15 seconds the layer reaches the floor and the entire room is above the UFL. Some recommend not cutting off at the UFL, this room is still quite hazardous, say if someone opened a door there would be an explosive mixture right in the door-frame that could explode and that explosion would mix with the rest of the gas and the whole mass of released hydrogen could explode.
+To consider the flammable mass to be the mixed area above the LFL and include areas that exceed the UFL, the X_lean and X_rich keyword arguments must be used.
full_release = hp.IndoorRelease(source=cylinder,
+ orifice=orifice,
+ ambient=air,
+ enclosure=room,
+ theta0=theta,
+ X_lean=lfl,
+ X_rich=1.0,
+ nn_conserve_momentum=True,
+ nn_T='solve_energy',
+ tmax=30,
+ verbose=False)
+
+full_release.plot_mass()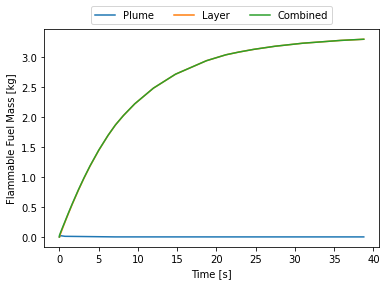
This whole analysis can also be accomplished using the API and the analyze_accumulation function. It outputs a series of plots into a given folder, including calculating the jet trajectories for a series of user selected times.
api.analyze_accumulation(amb_fluid=air,
+ rel_fluid=h2,
+ tank_volume=cylinder.V,
+ orif_diam=d_H,
+ rel_height=release_height,
+ enclos_height=ceiling_height,
+ floor_ceil_area=floor_area,
+ ceil_vent_xarea=A_h,
+ ceil_vent_height=2.6,
+ floor_vent_xarea=A_h,
+ floor_vent_height=0.01,
+ dist_rel_to_wall=4.0,
+ tmax=30,
+ times=[1,5,15,20,25,30],
+ orif_dis_coeff=c_d,
+ rel_angle=theta,
+ nozzle_key='yuce',
+ output_dir="figures/accumulation"){'status': 1,
+ 'pressures_per_time': array([ 388375.73527918, 3092893.44785494, 0. ,
+ 0. , 0. , 0. ]),
+ 'depths': array([1.34306015, 2.41226448, 2.45803334, 2.45809352, 2.4631503 ,
+ 2.46359848]),
+ 'concentrations': array([18.58049761, 43.85233797, 81.37521187, 89.24254417, 93.32644083,
+ 95.79735125]),
+ 'overpressure': 8136855.548411997,
+ 'time_of_overp': 11.970055170861283,
+ 'mass_flow_rates': array([0.3978773 , 0.38039983, 0.3417355 , 0.32307435, 0.30734882,
+ 0.29251744]),
+ 'pres_plot_filepath': 'figures/accumulation/pressure_plot_20240921-132132.png',
+ 'mass_plot_filepath': 'figures/accumulation/flam_mass_plot_20240921-132132.png',
+ 'layer_plot_filepath': 'figures/accumulation/layer_plot_20240921-132132.png',
+ 'trajectory_plot_filepath': 'figures/accumulation/trajectory_plot_20240921-132132.png',
+ 'mass_flow_plot_filepath': 'figures/accumulation/time-to-empty_20240921-132132.png'}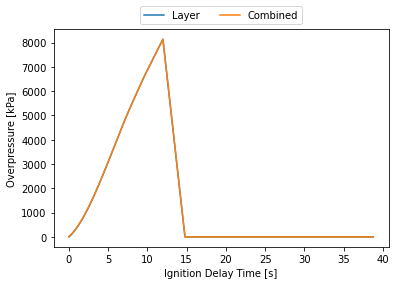
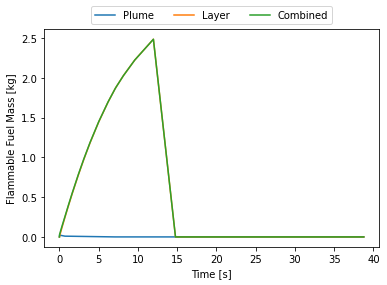
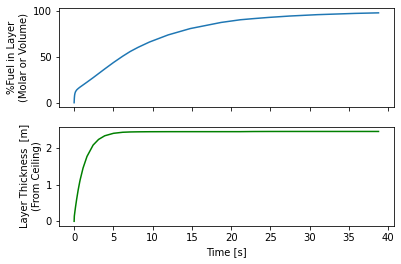
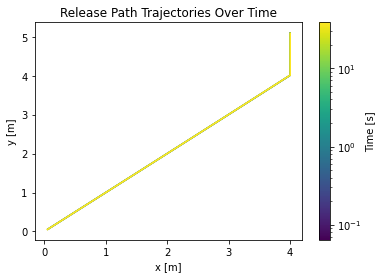
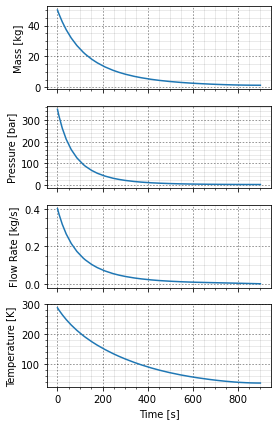
One limitation that stuck out to me, in the blowdown model, is that the blowdown is either at a constant heat flux or adiabatic (which is constant at zero). Blowdown models where the vessel is isothermal are fairly typical, especially for large (un-insulated) vessels blowing down through a small valve. For small vessels, assuming an adiabatic blowdown is reasonable, but this limits the model as the vessels get larger.
+If you are looking for a quick and easy-to-use tool for performing hazard analysis of hydrogen releases, HyRAM+ is worth checking out. I haven’t gone into it here, but the tool allows you to continue the analysis into blast over-pressure and a much more fully featured QRA. They python library allows you to split out each piece of the model, allowing you to really explore what it is doing, but also making it easier to pull out relevant pieces for comparison to other hazard analysis tools one might be using in a plant setting.
+The indoor accumulation model is worth exploring, for sites that are transitioning to hydrogen, as most “screening level” indoor accumulation models I have seen consider either a heavier-than-air layer along the ground or the entire indoor space (or zone, if it divides the area into zones) having one, fully-mixed, concentration. So it is possible that the standard plant tools for, e.g., LOPA may have blind spots for the unique hazards that hydrogen can present (e.g. accumulating as a flammable layer along the ceiling).
+For chemical plants that also operate a cogen, they may already have hydrogen venting into the air in an indoor space: large turbines (>60MW) typically use hydrogen coolant. It might be worthwhile running a HyRAM+ model for that venting just to confirm that the small quantities vented into the turbine hall are not an issue. While this may be a well known and well understood aspect of turbine operations, for people in the power business, process safety engineers tend to gasp and clutch their chests when told of routine venting of flammable and explosive gases into enclosed spaces.
+1 Celia, “Recycling Plastic Is a Dangerous Waste of Time”.
I won’t be commenting on the broader life-cycle of plastic as I’m hardly an impartial participant: My current employer is one of the world’s largest plastic manufacturers and my day job is working on a major expansion of one of its plastics manufacturing facilities. My employer has a whole suite of messaging about the importance of recycling and goals for advancing a circular economy which I don’t feel particularly compelled to try and advance, nor contradict, on my little side project blog about doing math in my spare time.
+Celia estimates that up to 2/3rds of the microplastics discharged directly into the environment2 come from the recycling industry. This is a huge number. One that should immediately raise eye-brows. So lets break that down, it comes from two numbers:
+2 These are so called “primary” microplastics, as opposed to “secondary” microplastics which are generated from plastic waste already in the environment
Celia takes the value of about 2Mt/y of microplastics emissions from the recycling industry from an interview given by an author of a recent study,3 and leaves it rather mysterious as to where exactly it comes from. However, this is a really easy number to calculate yourself: Approximately 9% of total plastic waste, globally, is recycled, that study estimated that up to 6 - 13% of recycled plastic could be lost to the environment as primary microplastics, which equates to about 2 - 4Mt/y.
+3 Brown et al., “The Potential for a Plastic Recycling Facility to Release Microplastic Pollution and Possible Filtration Remediation Effectiveness”.
4 OECD, “Global Plastics Outlook,” 20.
For example, the OECD estimated that, in 2019, global plastic waste generation was 353Mt of which 33Mt were recycled (~9%)4 6 - 13% of that is 1.98 - 4.29 Mt. So in some sense, taking the high end of that, makes the argument more dramatic.
+The main reference around which the entire essay revolves is that one study of a single plastics recycling plant in the UK. In that study, the authors looked at a relatively new plastics recycling facility that underwent an upgrade to its wastewater treatment process, adding additional filtration. The study looked at the microplastics emissions prior to and after the upgrade. Based on the concentrations measured in the wastewater they estimated that up to 13% of the mass of plastic brought into the facility may have been discharged in the wastewater as microplastics prior to the filtration upgrade and, after the upgrade, this dropped to 6%. These two numbers 6% and 13% form the basis for the estimate of how much primary microplastics are being discharged from the recycling industry as a whole.
+At this point we should pause consider the error bars on those numbers. The study gives a range for the total annual mass discharge in the wastewater, based on measured mass concentrations in the facility wastewater. The ratio of this mass out to the plastic taken in is the origin of the 6 - 13% range. However, I think it is deeply disingenuous to present these numbers without context as the study’s estimates span three orders of magnitude.
+| estimate | +low end (t/y) | +high end (t/y) | +
|---|---|---|
| before filter upgrade | +96 | +2933 | +
| after filter upgrade | +4 | +1366 | +
I think the take away from this is that far more data is needed to narrow these error bars. The low end estimates are still much larger than other studies for the whole life-cycle of plastic5 and the high end estimates are many orders of magnitude larger still. This study is only a single data point, but it is showing that the estimates used in other life cycle analysis may be far too small and that recycling is a much larger contributor to primary microplastics than has been accounted for.
+5 Ryberg, Laurent, and Hauschild, “Mapping of Global Plastics Value Chain and Plastics Losses to the Environment” page 56, estimates 0.005% loss;
+Boucher and Friot, “Primary Microplastics in the Oceans” page 37, estimates 0.00033 - 0.001% loss;
+The low end post-upgrade estimate from Brown et al., “The Potential for a Plastic Recycling Facility to Release Microplastic Pollution and Possible Filtration Remediation Effectiveness” is 0.018%
I think the ~3Mt/y is a relatively robust estimate, for the type of study Celia references, because it has been replicated6. However, this is the source of the most egregious and obvious mistake, and the one that prompted me to write this blog post in the first place. The studies referenced as the sources for the 3Mt/y number include recycling as a source in the estimate but do not estimate the losses from recycling to be anywhere near as high. Dividing these two numbers is simply a mathematically invalid operation.
+6 Ryberg, Laurent, and Hauschild, “Mapping of Global Plastics Value Chain and Plastics Losses to the Environment” estimates 3.1Mt/y;
+OECD, “Global Plastics Outlook” estimates 2.7Mt/y;
+Boucher and Friot, “Primary Microplastics in the Oceans” estimates 1.8 - 5Mt/y
Before I go any further, where do numbers like 3Mt/y come from? They are not from direct measurements of microplastics in the environment. They come from a life-cycle analysis that looks at the entire life of plastics and estimates rates of losses at the various steps along the path from the creation of virgin plastic to its ultimate fate. Adding all of these losses up gives the total estimated primary microplastics loss. This is why it is incorrect to simply ratio 2Mt/y over 3Mt/y: that would only work if the 2Mt/y was included in the total, and it isn’t.
+Supposing that we are going with 2Mt/y of primary microplastics from recycling, most studies (importantly the ones referenced by Celia) do not use a number anywhere near this high. In fact most assume it quite small and some take it to be negligible.7 The correct procedure would be to subtract the previous estimate for losses due to recycling from the total losses, and then add the new estimate of 2Mt/y, giving a corrected total. This would then be the denominator.
+7 Ryberg, Laurent, and Hauschild, “Mapping of Global Plastics Value Chain and Plastics Losses to the Environment,” 56.
8 Ryberg, Laurent, and Hauschild, 54.
Consider a UNEP study that estimates the total primary microplastics losses from the entire plastics value chain as 3.1Mt/y.8 Conveniently, this study assumed the losses due to recycling were negligible (i.e. zero). So based on this study’s estimates for all other sources of primary microplastics, and our estimate of 2Mt/y from the recycling industry alone, we would estimate a new total of 5.1Mt/y, of which 2/5.1 = 39% came from the recycling industry. So.. not 2/3rds.
+But considering how wide the error bars are for the estimate of primary microplastics emissions, from that one plastics recycling facility, all we can really say is that recycling is somewhere between a small, but important, source of primary microplastics and the single largest source of primary microplastics. Which is important in the sense that it identifies that we may be missing a major source of primary microplastics, but it really does not live up to the hype in Celia’s article.
+Celia makes reference to the landfilling of municipal solid waste being a source of methane emissions as part of the argument for why recycling should be abandoned and plastic incinerated instead. Independent of the merits of recycling or incinerating, this is at best irrelevant. Plastic has a negligible methane generating potential when landfilled, a fact that is related to the primary concern with plastic waste in the environment: its environmental persistence. The methane emissions coming from the landfilling of municipal waste is from decomposing organic matter, not the plastic. In fact a recent meta-analysis9 shows that, if anything, the presence of non-biodegradable plastic reduces the methane emissions from anaerobic digestion as non-biodegradable plastics may leach toxins that prevent bacteria from decomposing organic matter. I wouldn’t take that to mean we should be landfilling plastic waste, as some climate mitigation strategy, merely that the methane emissions from doing so are irrelevant to the argument around what to do with plastic waste.
+9 Gao et al., “Comprehensive Meta-Analysis Reveals the Impact of Non-Biodegradable Plastic Pollution on Methane Production in Anaerobic Digestion”.
There is certainly a growing chorus of concern over the fate of plastics in the environment, and the environmental and health consequences of microplastics given their ubiquity. That alone should warrant a lot more study into the sources of microplastics. That the estimate that recycling accounts for 2/3rds of primary microplastics doesn’t hold up, due to rudimentary math mistakes, doesn’t invalidate the broader concern that recycling simply has not lived up to the promise and may in fact be worsening the microplastics problem. We don’t know that is the case, given the data cited, but I think the onus is on the recycling industry to show that they are, in fact, part of the solution and not making the problem worse.
+I am not going to comment on the relative merits of incineration, recycling, or advanced recycling other than to say few of the technical problems in this field are truly insurmountable. The real question always comes down to cost and how much we are willing to pay to achieve the environmental performance we want.
+The same basic principles of extraction and diffusion apply to an espresso maker as apply to a French press, and we expect the same basic parameters to be relevant: the particle size, solid phase diffusivity, etc. The major difference is that the liquid phase, water, is moving through a fixed bed of coffee particles and this significantly changes the mass transfer problem.
+In the case of the French press I made the simplifying assumption that the system was well mixed, and so I could generally ignore the flow of the fluid. In the case of the espresso maker, it is more complicated than that.
+Making espresso involves packing coffee grounds into a cylindrical puck within a portafilter then passing hot water through the grounds under pressure, up to 10 bar.1 The specific unit operation that corresponds to making espresso is packed bed leaching, in which the coffee solubles are being leached from the coffee grounds. In a lot of standard undergraduate texts on unit operations and separations, I find, this is not well explored. Especially the non-equilibrium case, which is exactly the situation when pulling a shot of espresso: one doesn’t typically fully extract the beans and stops at some point in the transient regime. That said, the basic system is the same as desorption and so a good reference for what follows is often a text on chromatography and adsorption/desorption processes.
+1 Cameron et al., “Systematically Improving Espresso,” 631.
The espresso puck can be modelled as a perfectly cylindrical packed bed of ground coffee. Meaning both that the bed is a perfect cylinder and that the grounds are perfectly evenly distributed, i.e. has a constant porosity . A lot of technique goes into preparing the puck, to ensure the grounds are evenly distributed in the packed bed and the distribution of water through the bed is even, so this is a reasonable assumption.
 +
+In practice the pressure can vary over the course of the shot, but for simplicity I am only considering the case where the pressure is constant and, consequently, the flow rate of water is constant. We can simplify the flow condition more by assuming plug-flow, i.e. the velocity is a constant throughout. One final simplifying assumption is that the espresso is pulled at a constant temperature, this ensures the physical properties of water are also constant, e.g. constant density and viscosity.
+All of these assumptions, at their core, are to eliminate various partial derivatives and narrow down the governing equations to only core variables.
+Zooming in on a thin slice of the packed bed with depth, Δz, we can take a mass balance of the liquid phase.
+ +
+The mass flow into the liquid phase can be due to:
+Similarly the mass flow out of the liquid phase can be due to advection or axial diffusion out the bottom of the slice. Putting that together into a mass balance we have
+where as is the specific area of the coffee grounds, the surface area per unit volume. By writing the volume of the liquid phase and solid phase in terms of porosity and cross sectional area, A, we can cancel out some terms.
+In the limit Δz → 0 this becomes
+Assuming axial diffusion is Fickian
+For the solid phase, I am assuming a uniform bed of spherical particles, all with the same radius b. Actual coffee grounds, beyond being non-spherical, are also composed of multiple phases: the solid phase, the coffee oils, and the liquid water phase within the micro-porous structure of the bean. To simplify things greatly, I am assuming an effective solid phase diffusion, wherein diffusion within the particle of coffee follows Fick’s law with an effective diffusion coefficient that combines all of that complexity into a single parameter.
+In spherical coordinates, this becomes
+Where the solid phase concentration, q, is in units of mass per unit volume.
+Connecting the two phases, the liquid coffee and the solid coffee grounds, is a thin film. This is where the inter-phase mass transfer occurs, and I assume it follows a linear mass transfer relation.
+Where h is the mass transfer coefficient and cs is the liquid concentration immediately at the solid surface. I am making the additional assumption that this concentration is in equilibrium with the solid phase concentration at the surface, and that equilibrium is linear, i.e.
+The initial conditions for espresso are complicated. The bed is initially full of air and the first phase of making espresso, the pre-infusion, is to saturate the bed with hot water at a lower pressure than is used during the main extraction phase. This initial step has a very complicated multi-phase flow and mass transfer which dramatically complicates the model and most papers I’ve read avoid this by making one of two simplifying assumptions:
+Basically everyone ignores pre-infusion and focuses on the main extraction phase, after the bed has been filled with water. I am going to make the second assumption, that after pre-infusion the bed is full of water that is in equilibrium with the solids. This is in part because it is a convenient initial condition for solving the partial differential equations2 and in part because the actual volume of water in the bed is small and the pre-infusion step, which can take between 5-10s, is sufficiently long enough that the water will have extracted some coffee.
+2 Schwartzberg, “Leaching – Organic Materials,” 559.
For my model, the initial conditions are:
+Several recent papers that numerically integrate the pde use some variation on the first assumption3 and this will be the major difference between my approach and some of the published literature.
+3 Cameron et al., “Systematically Improving Espresso” page 635; Moroney et al., “Modelling of Coffee Extraction During Brewing Using Multiscale Methods” page 225; Vaca Guerra et al., “Modeling the Extraction of Espresso Components as Dispersed Flow Through a Packed Bed” page 5
I am assuming the water and portafilter are isothermal and the liquid phase has the same physical properties of pure water throughout. This is not entirely true in that the system is not perfectly isothermal but also the process of extracting coffee changes the density and viscosity of the coffee. I am assuming this effect is small and can be ignored.
+using Unitful
+
+# physical properties coffee
+# assumed to be water at 90C and 10bar
+ρ = 965.34u"kg/m^3"
+μ = 0.282*0.001u"Pa*s"
+ν = μ/ρ
+ν = upreferred(ν)The most significant factors for both modelling the flow and also determining the mass transfer parameters are the features of the espresso bed itself. Primarily the porosity and the particle size. For simplicity I am taking both of these from the literature for actual espresso shots,4 but in practice these are probably the most difficult to derive for someone making espresso at home, with the sorts of tools available in a kitchen.
+4 Cameron et al., “Systematically Improving Espresso” supplemental materials.
The porosity will vary from espresso shot to espresso shot, as it is a function of the particle size distribution, the distribution within the portafilter, and also the degree of tamping. Furthermore the porosity of the dry bed will not be the same as the porosity of the bed once fully saturated with water. The coffee grounds will swell somewhat and any liquid within a particle is already accounted for in the effective solid phase mass transfer, including it in an estimate of the porosity would be double counting. One could try measuring the mass and volume of the spent puck and calculate it directly, but I’m not sure how one would account for the volume of water absorbed into the grounds while discarding the water that is only in the void space between coffee particles.
+The particle size distribution for a given coffee, grinder, and grind setting can be measured in a variety of ways, including with an app on one’s phone5 where in this case we are interested in the Sauter mean radius as we are assuming a bed of uniform spherical particles. Camera based approaches have one main weakness in that particles of coffee have microscopic pores that increase the apparent surface area but are too small to be resolved by a typical camera. Laboratory methods tend to measure the adsorption of a neutral substance, like nitrogen, to measure this. Not something one is going to be doing in the kitchen.
+5 Gagné, The Physics of Filter Coffee, 199.
The flow rate through the bed is also an important factor, I am simply taking the total volume of the shot divided by the time taken to pull a shot as the flow rate, but this is only a rough estimate. The pre-infusion phase adds water at a lower flow rate and it is only the flow after the pre-infusion has ended that is relevant to the problem. This can be measured with some higher end coffee scales that can output the time series of mass measurements during a shot. I don’t have one of these, but it’s not out of the question that I could just write down the mass and time at several points. Or take a video of my coffee scale’s screen during the actual shot and extract the data very tediously that way.
+# Cameron et al, "Systematically Improving Espresso," supplemental materials.
+
+# porosity and particle size
+ε = 1 - 0.8272
+b = 12e-6u"m"
+
+# bed size
+R_pb = 29.2e-3u"m"
+L_pb = 18.7e-3u"m"
+A_pb = π*R_pb^2
+
+# shot size
+M_shot = 0.04u"kg" # the mass of the espresso shot
+t_shot = 20u"s"
+Q_shot = (M_shot/ρ)/t_shot
+
+v_s = Q_shot/A_pb # superficial velocity, m/s
+v = v_s/εFrom the dimensions of the packed bed, assumed porosity, and assumed flow rate, I can calculate the time for the water to traverse the bed.
+(ε*A_pb*L_pb)/Q_shot4.177834449522944 sIn practice, for a lot of chemical engineering mass transfer problems, accurate mass transfer coefficients and diffusivities are hard to come by. This is equally true for the espresso system. I am going to be using a literature value for the effective solid phase diffusion, but then estimating the remainder from correlations.
+# effective solid phase diffusivity
+# Cameron et al, "Systematically Improving Espresso," 11.
+𝒟ₛ = 6.25e-10u"m^2/s"
+
+# (stagnant) liquid diffusivity
+# Schwartzberg, “Leaching – Organic Materials,” 557.
+D = 5*𝒟ₛThe thin film mass transfer coefficient is typically estimated from the Sherwood number which is a function of the Reynolds number and Schmidt number
+# Reynolds number
+Re = v_s*(2b)/ν# Schmidt number
+Sc = ν/DThe Sherwood number can be estimated using the Wilson-Geankopolis correlation for packed bed flow
+# Wilson-Geankopolis correlation
+# Hottel et al, "Heat and Mass Transfer," 5-77.
+Sh = (1.09/ε)*∛(Re*Sc)Giving the thin film mass transfer coefficient
+h = Sh*D/(2b)0.0014874874803418145 m s^-1The axial diffusion can be calculated using the Edwards-Richardson correlation
+# Edwards-Richardson correlation
+# LeVan and Carta, "Adsoprtion and Ion Exchange," 16-22.
+γ₁ = 0.45 + 0.55*ε
+γ₂ = 0.5*(1 + 13γ₁*ε/(Re*Sc))^-1
+Pe = ( γ₁*ε/(Re*Sc) + γ₂ )^-1𝒟ₗ = v*(2b)/Pe4.623616336378663e-8 m^2 s^-1I am using literature values for the saturated concentration of solubles both in the bean and in the coffee, and calculating an equilibrium constant from that.
+# saturation concentrations
+# Cameron et al, "Systematically Improving Espresso," 11.
+q_sat = 118.0u"kg/m^3"
+c_sat = 212.4u"kg/m^3"
+K = q_sat/c_sat0.5555555555555556Looking forward a little bit, I know that I will be using multiple approaches to the packed bed model and keeping track of all of the model parameters can be tricky. Especially in a notebook where everything is in the global name space. Which is why I think it is prudent to define a PackedBed data structure to contain all of the model parameters.
struct PackedBed
+ q₀
+ K
+ 𝒟ₛ
+ 𝒟ₗ
+ h
+ ε
+ b
+ c₀
+ v
+end# initial concentration
+c₀ = 0.0u"kg/m^3"pb = PackedBed(q_sat, K, 𝒟ₛ, 𝒟ₗ, h, ε, b, c₀, v);A good first approach to solving the pde is to try simplifying the mass transfer problem by eliminating some of the diffusion terms. Making the following simplifications:
+The governing equations can be reduced to
+with
+This is a dramatically simpler model, eliminating much of the real complexity of the mass transfer. However an effective mass transfer coefficient, h, can be fit from measured data that combines the solid diffusion and thin film mass transfer.6 Similarly an effective mass transfer coefficient can be calculated by addition of linear mass transfer resistances. Essentially this is shifting some of the complexity out of the governing equations and into the parameters. This is a fairly common model for packed beds and was first solved, for the equivalent heat transfer case, by Anzelius and independently by Schumann.7 What follows is a general sketch of a solution.
+6 See Moroney, “Analysing Extraction Uniformity from Porous Coffee Beds Using Mathematical Modelling and Computational Fluid Dynamics Approaches” for an example of this model being used for espresso extraction.
7 Anzelius, “Über Erwärmung Vermittels Durchströmender Medien”; Schumann, “Heat Transfer”.
8 Setting the pde in dimensionless form follows Bird, Stewart, and Lightfoot, Transport Phenomena pages 753-755
The first step is to transform this pde into dimensionless form8, first by introducing a dimensionless time . Which, when substituted into the equation for the solid phase, becomes
Further introducing a dimensionless space where
transforms the equation for the liquid phase into
By defining a dimensionless liquid phase concentration
+where q0 is the initial concentration of the solid phase and c0 is the concentration in the water at z=0. We can re-write the equation for the liquid phase as
+Letting
+the final system of equations is then
+Which, at this point, is just something that you can look up in Carslaw and Jaeger.9 The solution follows directly from taking the Laplace transform of , with respect to τ, which gives
9 Carslaw and Jaeger, Conduction of Heat in Solids, 393.
then taking the Laplace transform of , with respect to τ gives
which is a differential equation that can be easily solved using the initial condition u(0) = 1 or, in the Laplace domain, U(0) = 1/s
+Inverting this requires a little work, though not as much as it may seem. I am departing from Bird10 since I find their approach mystifying. It is clearly designed to reverse engineer a particular form of the answer as opposed to arriving at it naturally. The approach in Carslaw and Jaeger is more intuitive11 and is what I am following here.
+10 Bird, Stewart, and Lightfoot, Transport Phenomena, 762–63.
11 Carslaw and Jaeger, Conduction of Heat in Solids pages 393-394; and also Goldstein, “On the Mathematics of Exchange Processes in Fixed Columns i. Mathematical Solutions and Asymptotic Expansions” pages 153-158.
First, recognize that
+Then, looking at a table of Laplace transforms we find12
+12 With the caveat that you need a good table of Laplace transforms, most undergraduate textbooks have a very brief one. The tables in Carslaw and Jaeger are extensive and Perry’s is also a good reference.
where I0 is the modified Bessel function of the first kind. A basic property of Laplace transforms is that
+from which it follows that
+Another property of Laplace transforms is that
+which gives
+Which is laying the groundwork for the observation that since
+then
+and U can be rewritten as
+then by taking the inverse Laplace transform
+This is the solution that Schumann13 arrives at via a different means, though it is not in the form one generally sees in the standard references. To get there, we must take advantage of some properties of the Anzelius J Function (named because it is the solution to this differential equation).14
+13 This is equation 27 in Schumann, “Heat Transfer” page 409.
14 Goldstein, “On the Mathematics of Exchange Processes in Fixed Columns i. Mathematical Solutions and Asymptotic Expansions,” 160.
from which we can see that
+and finally
+Which is the form typically given in references. I think it is important to pause here and comment that this answer is not the answer, it is an answer. Both the solution above from taking the inverse Laplace transform and this solution are valid and, in fact, both are used when evaluating the Anzelius J function. It just happens to be the case that the latter result is what one tends to see in the literature.
+At this point we can calculate the dimensionless space and time for a point at the exit of the espresso bed, and at a similar point in (dimensionless) time.
+z = L_pb
+
+m = ε/(1-ε)
+aᵥ = 3/b
+ξ = (h*aᵥ*z)/(m*v)
+
+# τ = ξ
+t = (K/(h*aᵥ))*ξ + z/v
+τ = (h*aᵥ/K)*(t - z/v)
+
+@show ξ; @show τ;ξ = 7437.232219350375
+τ = 7437.232219350374It is convenient to create an AnzeliusSolution struct that takes a PackedBed and a particular point in space and generates a datatype that allows us to go back and forth between the problem in dimensionless form and the problem in actual units.
struct AnzeliusSolution{F,Q1,Q2}
+ ξ::F
+ τ₁::Q1
+ τ₂::Q2
+ pb::PackedBed
+end
+
+function AnzeliusSolution(z, pb::PackedBed)
+ m = ε/(1-ε)
+ aᵥ = 3/pb.b
+ ξ = (pb.h*aᵥ*z)/(m*pb.v)
+ τ₁ = (pb.h*aᵥ/pb.K)
+ τ₂ = τ₁*(z/pb.v)
+
+ return AnzeliusSolution(ξ, τ₁, τ₂, pb)
+endanzelius = AnzeliusSolution(z, pb);Generally the Anzelius solution is given in terms of an integral of a Bessel function that is wildly impractical to numerically integrate directly as written. For an example, Bird15 gives this as the the solution:
+15 Bird, Stewart, and Lightfoot, Transport Phenomena, 755.
where J0 in this case is the Bessel function of the first kind (not the Anzelius J function). This is correct, however, attempting to use it as written will run aground on numerical difficulties at even moderately large values of τ. The first issue with this form of the answer is that it requires one to cast everything into complex values only to cast back into floats (the answer is a real number), but the most important issue is that the integrand is the product of an exponential that decays rapidly to zero and a Bessel function that blows up rapidly to infinity. For even moderate values of τ this leads to NaN errors of the type 0*Inf.
When I was first playing around with this I attempted to integrate it as is. After that clearly didn’t work, I looked into whether or not there are scaled versions of the Bessel function. I think this is a good practice that maybe isn’t taught well in school: often functions like Bessel functions or the Gamma function explode to large numbers that would overflow, thus leading to NaN errors, consequently libraries of special functions tend to have scaled or log versions. Bessels.jl has an exponentially scaled version of I0 that works perfectly for what I need, with the exponentially scaled version being
By completing the square we can rewrite
+as
+Below is a figure showing a plot of the integrand for a value of τ much smaller than our particular example, just for illustration. The first curve is the original version of the solution (shifted up for visibility), which begins to fail due to NaN errors part-way up the curve (where the red X is). The second curve uses the exponentially scaled modified Bessel function and does not have this issue. The larger the τ the earlier problems arrive and by the time we get to the value of τ being used for this example the integrand doesn’t evaluate to any positive value prior to turning into NaNs.
using Bessels:besselj0, besseli0x
+
+f_orig(λ, τ) = exp(-(τ+λ))*real(besselj0(im*√(complex(4τ*λ))))
+
+fₐ(λ, τ) = exp(-(√(τ)-√(λ))^2)*besseli0x(√(4τ*λ))Now that we have a version of the integrand that we can actually calculate, the obvious approach is to integrate using a standard package for numerical integration, such as QuadGK.jl. To make things a little easier, I have made the change of variables , thus changing the bounds of integration to
using QuadGK: quadgk_count
+
+integrand(x) = exp(-(√(τ)-√(ξ*x))^2)*besseli0x(√(4τ*ξ*x))
+
+∫, e, N = quadgk_count(integrand,0,1)
+
+u = 1 - ξ*∫
+
+@show u; @show e; @show N;u = 0.5016355470840097
+e = 1.0518776639256381e-13
+N = 165Because of my particular choice of τ the integral stops somewhere on the curve where it is appreciably positive. There is a potential trap here when using an integration routine with automatic step-sizes like Gauss-Kronold: if the bounds of integration extend well past the peak of this curve, it is possible for the algorithm to step over it entirely and return a value of 0, when the actual integral should be ~1.
+One way of dealing with this issue is to take advantage of the symmetry of the J function and use the following rule:16
+16 Lassey, “On the Computation of Certain Integrals Containing the Modified Bessel Function ,” 631.
This ensures that the numerical integration is always being taken to the left of the peak of the integrand (where ξ = τ) and thus avoids the stepping over problem.
+using QuadGK: quadgk
+
+function J_quad(x,y)
+ if x ≈ 0
+ return 1.0, 0.0
+ elseif y ≈ 0
+ return exp(-x), 0.0
+ else
+ integrand(λ) = exp(-(√(y)-√(x*λ))^2)*besseli0x(√(4y*x*λ))
+ ∫, e = quadgk(integrand,0,1)
+ J = 1.0 - x*∫
+ return J, e
+ end
+end
+
+function c_quad(t, model::AnzeliusSolution)
+ # unpack some things, calculate model parameters
+ cₛ = model.pb.q₀/model.pb.K
+ c₀ = model.pb.c₀
+ τ = model.τ₁*t - model.τ₂
+ ξ = model.ξ
+
+ # use Gause-Kronold to integrate
+ # modified integral for τ < ξ from Lassey p. 631
+ if τ < 0 || ξ < 0
+ # outside the domain of the problem
+ J = 0.0
+ elseif ξ ≤ τ
+ J, e = J_quad(ξ,τ)
+ else # τ < ξ
+ J, e = J_quad(τ,ξ)
+ J = 1 + exp(-(√(τ)-√(ξ))^2)*besseli0x(√(4τ*ξ)) - J
+ end
+
+ # return back the concentration
+ c = cₛ + (c₀ - cₛ)*J
+ return c
+endA brief review of the literature around the Anzelius J function will reveal a multitude of series representations. For example, Goldstein17 gives the following
+17 Goldstein, “On the Mathematics of Exchange Processes in Fixed Columns i. Mathematical Solutions and Asymptotic Expansions,” 159.
Naïvely implementing this, without the use of any techniques like Richardson acceleration, ends up requiring a large number of iterations to approach the performance of direct integration by Gauss-Kronold. Since each iteration involves calculating exponentially scaled Bessel functions of higher and higher order, this doesn’t obviously lead to any improvement over direct numerical integration.
+# Naively, just adding them up
+using Bessels:besselix
+
+function J_series(x,y,N)
+ if x ≈ 0
+ return 1.0
+ elseif y ≈ 0
+ return exp(-x)
+ else
+ α = 2√(x*y)
+ η = √(x/y)
+ partial_sum = 0.0
+ for k in 1:N
+ partial_sum += besselix(k,α)*η^k
+ end
+ J = 1 - exp(-(√(x)-√(y))^2)*partial_sum
+ return J
+ end
+end
+
+N = 900
+u = J_series(ξ,τ,N)
+
+@show u; @show N;u = 0.5016355470840961
+N = 900An alternative approach from Bac̆lić et al.18 removes the need to calculate higher order Bessel functions and, though it also requires a large number of iterations, each iteration is a simpler calculation and thus the algorithm could be faster overall. If you were going to roll out the J function in production code it would be worthwhile bench marking this against numerical integration with QuadGK.jl.
+18 Bac̆lić, Gvozdenac, and Gragutinović, “Easy Way to Calculate the Anzelius-Schumann j Function,” 114.
function bac̆lić_sub_A(α₋₁,β₋₁,α₀,β₀,d₁,z,ε,max_iter)
+ αₙ₋₂, βₙ₋₂ = α₋₁, β₋₁
+ αₙ₋₁, βₙ₋₁ = α₀, β₀
+ αₙ, βₙ = 0.0, 0.0
+ dₙ = d₁
+ for n in 1:max_iter
+ αₙ = dₙ + (n/z)*αₙ₋₁ + αₙ₋₂
+ βₙ = 1 + (n/z)*βₙ₋₁ + βₙ₋₂
+
+ if βₙ > 1/ε
+ return αₙ, βₙ, n
+ else
+ dₙ = dₙ*d₁
+ αₙ₋₂, βₙ₋₂ = αₙ₋₁, βₙ₋₁
+ αₙ₋₁, βₙ₋₁ = αₙ, βₙ
+ end
+ end
+ return αₙ, βₙ, max_iter
+endfunction J_bac̆lić(x,y,ε=1e-9,max_iter=10^6)
+ if x ≈ 0
+ return 1.0
+ elseif y ≈ 0
+ return exp(-x)
+ else
+ z = √(x*y)
+ α₋₁ = 0.0
+ β₋₁ = 0.0
+ β₀ = 0.5
+ if y < x
+ α₀ = 1.0
+ d₁ = √(y/x)
+ αₙ, βₙ, N = bac̆lić_sub_A(α₋₁,β₋₁,α₀,β₀,d₁,z,ε,max_iter)
+ J = (αₙ/(2*βₙ))*exp(-(√(y)-√(x))^2)
+ else
+ α₀ = 0.0
+ d₁ = √(x/y)
+ αₙ, βₙ, N = bac̆lić_sub_A(α₋₁,β₋₁,α₀,β₀,d₁,z,ε,max_iter)
+ J = 1.0 - (αₙ/(2*βₙ))*exp(-(√(y)-√(x))^2)
+ end
+ return J, ε, N
+ end
+endu, e, N = J_bac̆lić(τ,ξ)
+
+@show u; @show e; @show N;u = 0.5016355471003766
+e = 1.0e-9
+N = 698function c_bac̆lić(t, model::AnzeliusSolution)
+ # unpack some things, calculate model parameters
+ cₛ = model.pb.q₀/model.pb.K
+ c₀ = model.pb.c₀
+ τ = model.τ₁*t - model.τ₂
+ ξ = model.ξ
+
+ if τ < 0 || ξ < 0
+ u = 0.0
+ else
+ u, err, N = J_bac̆lić(ξ,τ)
+ end
+
+ c = cₛ + (c₀ - cₛ)*u
+ return c
+endThomas19 provides an asymptotic expansion of J which forms the basis for several approximations to the J function
+19 Thomas, “CHROMATOGRAPHY” page 171. Note: Thomas gives this in terms of φ where
Taking the first terms of the asymptotic expansion and the limit as z → ∞20
using SpecialFunctions: erf, erfcfunction J_approx(x,y)
+ if x ≈ 0
+ return 1.0
+ elseif y ≈ 0
+ return exp(-x)
+ else
+ return 0.5*(erfc(√(x)-√(y)) + exp(-(√(x)-√(y))^2)/(√(π)*(√(y)+(x*y)^0.25)))
+ end
+end
+
+u = J_approx(ξ,τ)
+
+@show u;u = 0.5016355333390161function c_approx(t, model::AnzeliusSolution)
+ # unpack some things, calculate model parameters
+ cₛ = model.pb.q₀/model.pb.K
+ c₀ = model.pb.c₀
+ τ = model.τ₁*t - model.τ₂
+ ξ = model.ξ
+
+ # approximate integral
+ if τ < 0 || ξ < 0
+ u = 0.0
+ else
+ u = J_approx(ξ,τ)
+ end
+
+ # return back the concentration
+ c = cₛ + (c₀ - cₛ)*u
+ return c
+endRice21 goes even further and suggests that, for
21 Rice, “Letters to the Editor,” 334.
function J_rice(x,y)
+ if x ≈ 0
+ return 1.0
+ elseif y ≈ 0
+ return exp(-x)
+ else
+ return 0.5*erfc(√(x)-√(y))
+ end
+end
+
+u = J_rice(ξ,τ)
+
+@show u;u = 0.499999999999992function c_rice(t, model::AnzeliusSolution)
+ # unpack some things, calculate model parameters
+ cₛ = model.pb.q₀/model.pb.K
+ c₀ = model.pb.c₀
+ τ = model.τ₁*t - model.τ₂
+ ξ = model.ξ
+
+ # approximate integral
+ if τ < 0 || ξ < 0
+ u = 0.0
+ else
+ u = 0.5*erfc(√(ξ)-√(τ))
+ end
+
+ # return back the concentration
+ c = cₛ + (c₀ - cₛ)*u
+ return c
+endI don’t see any great reason to use anything other than direct numerical integration, so that is the default method I am going to set going forward.
+c(t,m::AnzeliusSolution) = c_quad(t,m)That said, for this particular case, the mass transfer across the thin film is so rapid that all of the approximations are close enough as to be indistinguishable. Indistinguishable to the naked eye when staring at a plot but, more importantly, experimentally indistinguishable.
+I wouldn’t take this to mean that the simple, single term, approximation will work for modelling an actual espresso shot, though it is certainly suggestive. This approach, neglecting the solid phase diffusion entirely and neglecting axial diffusion, has lead to a very sharp moving front that is physically unrealistic. What this model is telling us is that we should expect an espresso shot to start as fully and overly extracted coffee and, after some time, transition into essentially tap water in a fraction of a second. That is not my experience, qualitatively. What this shows is that we need to increase the complexity of the model.
Rosen22 solved the problem for the case where solid diffusion is included, but axial diffusion is still neglected, in a similar manner as above with Laplace transforms. In this case actually solving the pde is more tedious and what follows is just a loose sketch. Starting with the pde
+22 Rosen, “Kinetics of a Fixed Bed System for Solid Diffusion into Spherical Particles,” 387–94.
were
+Rosen introduced
where
+is the volumetric average concentration in a particle. This follows directly from a mass balance.
+We can put the liquid phase equation in dimensionless form by introducing a dimensionless time, , and a dimensionless z-coordinate,
, where
and, with the same dimensionless concentrations u and y as defined above for the Anzelius solution, we have
where and ys is the dimensionless solid phase concentration at the surface of a solid particle, i.e. at r = b.
If we further introduce a dimensionless particle radius we can rewrite the solid phase diffusion equation in dimensionless form
where 1/3 is 1/(asb). The solution to the solid phase diffusion problem is available in Carslaw and Jaeger23 and, with initial condition y=0 when τ=0, gives
+23 Carslaw and Jaeger, Conduction of Heat in Solids, 233.
This can be integrated over to get the volume average (dimensionless) concentration
since
+Taking the derivative with respect to τ gives (by integration by parts)
+At this point we can eliminate y and ys and have an expression entirely in terms of u. First we use the expression for the liquid phase concentration to obtain an expression for ys
+Thus
+and since
Rosen solves this by taking the Laplace transform, with respect to τ, with the following relations:
+arriving at
+Letting
+then
+and, solving this ode with initial condition u=1, U=1/s, gives
+The final solution follows from taking the inverse Laplace transform, by way of the contour integral
+A major component of the integration involves first defining YD in terms of trigonometric functions. The details are tedious, but the main result is
+with and
and
+Which allows Rosen to write the integral in terms of these harmonic functions24
+24 For details of the integration see Rosen, “Kinetics of a Fixed Bed System for Solid Diffusion into Spherical Particles” pages 390-391
At this point we can calculate the dimensionless space and time for a point at the exit of the espresso bed, and say at a similar point in (dimensionless) time, and proceed with calculating the integral to find the concentration.
+m = ε/(1-ε)
+aᵥ = 3/b
+
+ξ = (K*𝒟ₛ*aᵥ)/(b*m*v)*z
+
+τ = (𝒟ₛ*aᵥ/b)*(t-z/v)
+ν = (𝒟ₛ*K)/(b*h)
+
+@show ξ; @show τ; @show ν;ξ = 144.6719346388569
+τ = 144.6719346388569
+ν = 0.019452389057107278Unlike with the Anzelius case, I am not going to define a struct for the Rosen solution yet, first I am going to work through some details on how to perform the integral.
+The integral extends to infinity and so the performance of the harmonic functions at very large λ is important. The hyperbolic trig functions will blow up to infinity and, in the naïve implementation, lead to NaN errors as the numerator and denominator overflow. Rosen provides limiting behaviour, and a pre-calculated table of values, which can be used with the integrand switching from the default definition of the harmonic functions to the limiting behaviour after some λ threshold. An alternative, which I employ below, is to rewrite the hyperbolic trig functions in terms of exponentials, cancelling a exp(+4λ) from the numerator and denominator, to generate a form that handles large values of λ more gracefully.
function HD1(λ)
+ if λ ≤ eps(0.0)
+ return 0.0
+ else
+ # λ*((sinh(2λ) + sin(2λ))/(cosh(2λ) - cos(2λ))) - 1
+ return λ*( (1 - exp(-4λ) + 2*exp(-2λ)*sin(2λ)) / (1 + exp(-4λ) - 2*exp(-2λ)*cos(2λ))) -1
+ end
+end
+
+function HD2(λ)
+ if λ ≤ eps(0.0)
+ return 0.0
+ else
+ # λ*(sinh(2λ) - sin(2λ))/(cosh(2λ) - cos(2λ))
+ return λ*( (1 - exp(-4λ) - 2*exp(-2λ)*sin(2λ)) / (1 + exp(-4λ) - 2*exp(-2λ)*cos(2λ)))
+ end
+endThe integrand can be divided into a decay component, f, that is independent of τ, and an oscillatory component, K, that is a function of τ.
+This clean division also presents an opportunity to pre-calculate the integral to an extent. With a predefined set of points { λi } then f can be entirely pre-calculated. Using prosthaphaeresis you could go further and pre-calculate parts of , for some incremental improvements, though I leave that as an exercise for a more motivated individual.
It is worth looking at the case where τ gets large as this becomes a highly oscillating integral and can be tricky to evaluate – requiring a very large number of steps for conventional numerical integration techniques like Gauss-Kronold. In this example that starts to happen near the end of the extraction, but if the bed were, say, twice as deep then much of the extraction curve would be in this regime.
+function fᵣ(λ; ξ, ν)
+ hd1, hd2 = HD1(λ), HD2(λ)
+ H1 = (hd1 + ν*(hd1^2 + hd2^2))/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ return exp(-ξ*H1)/λ
+end
+
+function 𝒦ᵣ(λ, τ; ξ, ν)
+ hd1, hd2 = HD1(λ), HD2(λ)
+ H2 = hd2/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ return sin((2/3)*τ*λ^2 - ξ*H2)
+endBy introducing the change of variables25 β = λ2, the integrand is “compressed” along β and we can take advantage of the exponential decay to truncate the integration.
+25 Rosen, “General Numerical Solution for Solid Diffusion in Fixed Beds,” 1590–94.
function fᵣ₂(β; ξ, ν)
+ λ = √(β)
+ hd1, hd2 = HD1(λ), HD2(λ)
+ H1 = (hd1 + ν*(hd1^2 + hd2^2))/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ return exp(-ξ*H1)/β
+end
+
+function 𝒦ᵣ₂(β, τ; ξ, ν)
+ λ = √(β)
+ hd1, hd2 = HD1(λ), HD2(λ)
+ H2 = hd2/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ return sin((2/3)*τ*β - ξ*H2)
+endQuadGK.jl can compute the improper integral directly, by making the substitution λ = t/(1-t).
+using QuadGK: quadgk_count
+
+I₁, err₁, N₁ = quadgk_count(λ -> fᵣ(λ; ξ=ξ, ν=ν)*𝒦ᵣ(λ, τ; ξ=ξ, ν=ν), 0, Inf)
+
+@show I₁; @show err₁; @show N₁;I₁ = 0.011703238397164204
+err₁ = 1.0292584595556625e-10
+N₁ = 195By making the substitution β = λ2 and truncating the integral to the range [0,2] we can achieve similar precision, with almost half as many steps.
+I_2, err_2, N_2 = quadgk_count( β -> fᵣ₂(β; ξ=ξ, ν=ν)*𝒦ᵣ₂(β, τ; ξ=ξ, ν=ν), 0, 2)
+
+@show I_2/2; @show err_2; @show N_2;I_2 / 2 = 0.01170323839564812
+err_2 = 2.183245425172356e-10
+N_2 = 105I have mentioned a few times that highly oscillating integrals can be tricky to evaluate. Gaussian quadrature will, in general, work but it will require a large number of steps. An alternative is to use Levin colocation, an example implementation is given below using ApproxFun.jl.
+Given the integral
+if we suppose there is a function such that
Then we can eliminate the integral, using the fundamental theorem of calculus
+The problem is then one of finding the function .
If we choose such that
, then
Eliminating K(x) gives
+Solving this ode then gives the final solution.
+In this case I set K(x) to
+where h(x) = (2/3)τx2 - ξH2(λ), and f(x) is
+and the ode is solved for F in terms of Chebyshev polynomials.
+using ApproxFun:Interval, Fun, Derivative, Evaluation, \, I
+using LinearAlgebra: ⋅
+
+function levin(ξ, τ, ν, a, b)
+ d = Interval(a,b)
+ λ = Fun(d)
+ D = Derivative(d)
+ E = Evaluation(a)
+
+ HD1 = λ*(sinh(2λ) + sin(2λ))/(cosh(2λ) - cos(2λ)) - 1
+ HD2 = λ*(sinh(2λ) - sin(2λ))/(cosh(2λ) - cos(2λ))
+
+ H1 = (HD1 + ν*(HD1^2 + HD2^2))/((1 + ν*HD1)^2 + (ν*HD2)^2)
+ H2 = HD2/((1 + ν*HD1)^2 + (ν*HD2)^2)
+
+ h = (2/3)*τ*λ^2 - ξ*H2
+ h′ = D*h
+ w⃗ = [ sin(h); cos(h) ]
+
+ f = exp(-ξ*H1)/λ
+ f⃗ = [ 0; 0; f; 0 ]
+
+ L = [ E 0;
+ 0 E;
+ D -h′*I;
+ h′*I D ]
+
+ F = L\f⃗
+
+ return F(b)⋅w⃗(b) - F(a)⋅w⃗(a)
+endlevin(ξ, τ, ν, 0.0001, 2)0.011703248012960965This works well enough, though there is a complication in that there is a singularity at x=0, it is also rather slow.
+If the system of interest was consistently at large values of τ, where it is a highly oscillating integral throughout the main part of the problem domain, it would be worth looking at techniques to eliminate the singularity and speed it up. I include it here mostly for completeness. It is by delightful coincidence alone that I can get by solving this particular problem using more conventional numerical integration techniques.
+As I mentioned above, by splitting the integral into a function f that depends only on space and a function K that is a function of time and space, we can pre-calculate all of the space dependent components and write the integral as a weighted sum.
+The obvious way to do this is to use QuadGK.jl to take the weight function f and generate points that way. For example:
+pts, wts = gauss( x -> fᵣ₂(x; ξ=ξ, ν=ν), 20, 0, 2);I could not get this to work reliably, it would routinely run aground on DomainErrors close to the singularity at x=0. When I did get it to work it took a very long time to generate points, like leave my desk and go make coffee and maybe it will be done when I get back long time. I think if you really wanted to invest the time, and evaluating this integral was going to be in production code, it would be worth investigating a better quadrature rule since, when it does work, it allows you to use significantly fewer points in each integration.
The alternative, which works well enough for my purposes, is to use the gauss function to generate a set of points and weights in the truncated range and then pre-calculate the values of f over those points. The final integral is then the weighted sum. This involves calculating far more points for any given integral, but it is much faster than either Levin colocation or trying to have QuadGK generate the weights.
using QuadGK: gauss
+
+pts, wts = gauss(N₁, 0, 2);
+
+wts = wts .* fᵣ₂.(pts; ξ=ξ, ν=ν);
+
+I_gauss = sum( wts .* 𝒦ᵣ₂.(pts, τ; ξ=ξ, ν=ν) )/20.011703238395545075This can be packaged neatly into an IntegralTransform struct that, when constructed, generates the set of points and appropriate weights such that it only the kernel function actually needs to be evaluated for any given time.
struct IntegralTransform{T}
+ a::T
+ b::T
+ params::NamedTuple
+ numpts::Integer
+ pts::Vector{T}
+ wts::Vector{T}
+ kern::Function
+end
+
+function IntegralTransform(params, fun, kern; a=0.0, b=2.0, numpts=350)
+ pts, wts = gauss(numpts, a, b)
+ wts = wts .* fun.(pts; params...)
+ return IntegralTransform(a, b, params, numpts, pts, wts, kern)
+end
+
+function integrate(t, it::IntegralTransform)
+ return sum( it.wts .* it.kern.(it.pts, t; it.params...) )
+endOne could go further here: pre-calculating H1 and H2 as they only depend on ν and λ, splitting K into parts by prosthaphaeresis26 and pre-calculating the parts that only depend on ξ and λ. The current performance is more than good enough for me, but I think it worth highlighting that there are many opportunities for improvement.
+26 I love this word.
At this point I am finally ready to circle back and create my RosenSolution struct, one that includes the pre-calculated IntegralTransform for the particular location in the bed.
struct RosenSolution{Q1,Q2,T}
+ τ₁::Q1
+ τ₂::Q2
+ pb::PackedBed
+ it::IntegralTransform{T}
+end
+
+function RosenSolution(z, pb::PackedBed; fun=fᵣ₂, kern=𝒦ᵣ₂, a=0.0, b=2.0, numpts=200)
+ m = pb.ε/(1-pb.ε)
+ aᵥ = 3/pb.b
+ ξ = (pb.K*pb.𝒟ₛ*aᵥ*z)/(m*pb.v*pb.b)
+ ν = (pb.𝒟ₛ*pb.K)/(pb.b*pb.h)
+ τ₁ = pb.𝒟ₛ*aᵥ/pb.b
+ τ₂ = τ₁*(z/pb.v)
+
+ p = (ξ=ξ, ν=ν)
+ it = IntegralTransform(p, fun, kern; a=a, b=b, numpts=numpts)
+
+ return RosenSolution(τ₁, τ₂, pb, it)
+endThe concentration can then be obtained by calling the integrate function with the integral transform.
function c(t, model::RosenSolution)
+ # unpack some things
+ cₛ = model.pb.q₀/model.pb.K
+ c₀ = model.pb.c₀
+
+ # compute the integral
+ τ = model.τ₁*t - model.τ₂
+ I = integrate(τ, model.it)
+
+ # return back the concentration
+ u = 0.5 + I/π
+ c = cₛ + (c₀ - cₛ)*u
+ return c
+endrosen = RosenSolution(z, pb; a=0.0, b=2.0, numpts=200);Rosen27 provides an asymptotic approximation for cases where ξ is large
+27 Rosen, “General Numerical Solution for Solid Diffusion in Fixed Beds,” 1591.
Which is decidedly simpler to calculate.
+function c_approx(t, model::RosenSolution)
+ # unpack some things
+ cₛ = model.pb.q₀/model.pb.K
+ c₀ = model.pb.c₀
+
+ # compute the integral
+ τ = model.τ₁*t - model.τ₂
+ u = 0.5*(1 + erf( ( (τ/ξ) - 1 ) / ( 2*√((1+5ν)/(5ξ)) ) ) )
+
+ # return back the concentration
+ c = cₛ + (c₀ - cₛ)*u
+ return c
+endI briefly mentioned, above, an effective mass transfer coefficient can be derived for the Anzelius solution, one that accounts for the solid phase diffusion. This can be calculated rather simply from the linear resistance model28
+28 LeVan and Carta, “Adsorption and Ion Exchange,” 16–24.
Adapting the AnzeliusSolution to use a generic function to calculate the effective mass transfer coefficient allows us to reuse everything from the Anzelius case.
function AnzeliusSolution(z, h_fun, pb::PackedBed)
+ m = pb.ε/(1-pb.ε)
+ aᵥ = 3/pb.b
+ h = h_fun(pb)
+ ξ = (h*aᵥ*z)/(m*pb.v)
+ τ₁ = (h*aᵥ/pb.K)
+ τ₂ = τ₁*(z/pb.v)
+
+ return AnzeliusSolution(ξ, τ₁, τ₂, pb)
+end
+
+h_eff(pb) = 1/( 1/((1-pb.ε)*pb.h) + pb.b/(5*pb.K*pb.𝒟ₛ) )The Rosen solution is a significant departure from the pure Anzelius solution, i.e. neglecting solid diffusion, showing that for this problem the rate of solid phase diffusion is quite important. In this case ξ is large enough that the asymptotic approximation to Rosen’s integral is also a very good model and, with an appropriate effective mass transfer coefficient, the Anzelius solution also works well.
+Rasmuson and Neretnieks29 provide an exact solution for the case where axial diffusion is included. This is the original pde derived at the beginning. Their solution follows essentially the same steps as Rosen, with the main difference that the ode in the Laplace domain is second order, due to the inclusion of the term. The original paper has an detailed derivation in the appendix, if you are interested. In practice, this amounts to a relatively minor modification on what we have already put together for the Rosen solution.
29 Rasmuson and Neretnieks, “Exact Solution of a Model for Diffusion in Particles and Longitudinal Dispersion in Packed Beds,” 686–90.
First we define the decay function, f, and kernel, K, using the same harmonic functions as Rosen.
+function f_rasmuson(λ; ν, δ, R, Pe)
+ hd1, hd2 = HD1(λ), HD2(λ)
+ H1 = (hd1 + ν*(hd1^2 + hd2^2))/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ H2 = hd2/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ a = Pe*(0.25*Pe + δ*H1)
+ b = δ*Pe*((2/3)*λ^2/R + H2)
+ return exp(0.5*Pe - √(0.5*(√(a^2 + b^2) + a)))/λ
+end
+
+function 𝒦_rasmuson(λ, y; ν, δ, R, Pe)
+ hd1, hd2 = HD1(λ), HD2(λ)
+ H1 = (hd1 + ν*(hd1^2 + hd2^2))/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ H2 = hd2/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ a = Pe*(0.25*Pe + δ*H1)
+ b = δ*Pe*((2/3)*λ^2/R + H2)
+ return sin(y*λ^2 - √(0.5*(√(a^2 + b^2) - a)))
+endRasmuson and Neretnieks parameterize things slightly differently, and add some extra dimensionless groups due to the , but the result a similar sort of integral problem as Rosen, namely integrating a highly oscillating integral that decays rapidly.
γ = 3*𝒟ₛ*K/b^2
+δ = γ*z/(m*v)
+ν = γ*b/(3h)
+σ = 2*𝒟ₛ/b^2
+
+R = K/m
+Pe = (z*v)/𝒟ₗ
+y = σ*tThus it can be represented using the IntegralTransform type previously created.
p = (ν=ν, δ=δ, R=R, Pe=Pe)
+
+it = IntegralTransform(p, f_rasmuson, 𝒦_rasmuson; a=0.0, b=2.0, numpts=200);integrate(y, it)0.011984085774006418struct RasmusonSolution{Q,T}
+ σ::Q
+ pb::PackedBed
+ it::IntegralTransform{T}
+end
+
+function RasmusonSolution(z, pb::PackedBed; fun=f_rasmuson, kern=𝒦_rasmuson, a=0.0, b=2.0, numpts=350)
+ m = pb.ε/(1-pb.ε)
+ γ = 3*pb.𝒟ₛ*pb.K/pb.b^2
+ δ = γ*z/(m*pb.v)
+ ν = γ*pb.b/(3*pb.h)
+ σ = 2*pb.𝒟ₛ/pb.b^2
+
+ R = pb.K/m
+ Pe = (z*pb.v)/pb.𝒟ₗ
+
+ p = (ν=ν, δ=δ, R=R, Pe=Pe)
+ it = IntegralTransform(p, fun, kern; a=a, b=b, numpts=numpts)
+
+ return RasmusonSolution(σ, pb, it)
+endrasmuson = RasmusonSolution(z,pb);function c(t, model::RasmusonSolution)
+ # unpack some things
+ cₛ = model.pb.q₀/model.pb.K
+ c₀ = model.pb.c₀
+
+ # compute the integral
+ y = model.σ*t
+ I = integrate(y, model.it)
+
+ # return back the concentration
+ u = 0.5 + 2I/π
+ c = cₛ + (c₀ - cₛ)*u
+ return c
+endGoing from Rosen’s solution to Rasmuson’s solution is a less dramatic change than from Anzelius, but it is clear that axial dispersion is an important effect in this case. I haven’t shown it, since I think it should be obvious at this point, but one could generate asymptotic relations for Rasmuson, and also find effective mass transfer coefficients, h, that would bring both the Rosen and Anzelius solutions in line with the Rasmuson solution. I leave that as an exercise for the reader (hint: it is just linear mass transfer resistances).
+The more direct approach, when faced with a pde, is to integrate it by finite differences or Method of Lines. This allows one to use whatever kinetics and initial conditions one wants. The above cases are all limited by linear extraction and the initial conditions that the bed is at equilibrium. The major downside is that, for problems like this with a rather sharp moving front, the discretization needs to be very tight or another method, like moving finite element, needs to be used. Thus making the actual run time rather slow.
+The first step is to put the pde in dimensionless form, by introducing the following variables
+we can write the pde for the liquid phase concentration as
+and the pde for the solid phase concentration as
+with
+These equations can be discretized in both spatial dimensions ξ and , turning them into an ode in τ.
 +
+In general the bed can be divided into n cells with each cell transferring fluid to the cell below by advection and exchanging mass with the solid phase through the thin film approximation. The solid phase would then be divided into m cells per cell of the column making the overall ode an n×(m+1) vector of cells.
+As an example of the how tight the discretization needs to be, I have implemented the simple Anzelius case using an effective mass transfer coefficient. This is equivalent to the pde for the Rosen model, but with the solid phase mass transfer incorporated into the mass transfer coefficient, making the problem simpler to simulate: in this case m=1.
+I divide the bed into n cells with the first n elements in the vector u the liquid phase concentrations and the next n elements the average solid phase concentrations. The spatial derivatives are replaced with their discrete equivalents.
+using SparseArrays
+
+h_e = h_eff(pb)
+
+function parameters(n)
+ v_dm = v*t_shot/L_pb
+ h_dm = h_e*(3/b)*t_shot
+ dξ=1/(n-1)
+
+ # initial conditions
+ u0 = ones(Float64,2n)
+
+ M = spzeros(Float64,2n,2n)
+ # Liquid phase
+ # start of column, with the boundary condition that u[0]=0
+ # du[1] = -v/2dξ*(u[2] - u[0]) - h/m*(u[1] - u[n+1])
+ M[1,1] = -h_dm/m
+ M[1,2] = -v_dm/2dξ
+ M[1,1+n] = h_dm/m
+
+ # middle column
+ for i in 2:n-1
+ # du[i] = -v/2dξ*(u[i+1] - u[i-1]) - h/m*(u[i] - u[n+i])
+ M[i,i-1] = v_dm/2dξ
+ M[i,i] = -h_dm/m
+ M[i,i+1] = -v_dm/2dξ
+ M[i,i+n] = h_dm/m
+ end
+
+ # end of column
+ # du[n] = -v*(u[n]-u[n-1])/dξ - h/m*(u[n] - u[2n])
+ M[n,n-1] = v_dm/dξ
+ M[n,n] = -v_dm/dξ - h_dm/m
+ M[n,2n] = h_dm/m
+
+ # Solid phase
+ for i in n+1:2n
+ # du[i] = h/K*(u[i-n] - u[i]
+ M[i,i-n] = h_dm/K
+ M[i,i] = -h_dm/K
+ end
+
+ return u0, (0.0, 1.0), M
+endThe ode for this system is linear and is simply
+function rhs!(du,u,M,t)
+ du .= M*u
+endWhich could presumably be solved by eigendecomposition, but more generally this would be solved using a standard ode solver.
+using OrdinaryDiffEq
+import Static
+
+sol = solve(ODEProblem(rhs!,parameters(10)...), Tsit5(thread=Static.True()))
+
+sol.retcodeReturnCode.Success = 1The liquid concentration at the exit is then extracted from the vector solution.
+# Pull out the concentration at the exit
+function c(t,sol::ODESolution)
+ n = length(sol.u[1])÷2
+ τ = t/t_shot
+ u = sol(τ)
+ return u[n]*c_sat
+endBelow is a figure showing a series of runs for increasing n. At low values of n the solution looks reasonable, but with much more diffusion than is actually warranted given the mass transfer coefficient. This is a common feature of Method of Lines when applied to pdes of this type and can, if one is not careful, lead to under-estimates of the actual effective diffusion (since much of the diffusion seen in the results is coming from the numerical method). As n increases, a spurious oscillatory behaviour appears at the end of the extraction and damping this requires increasing n > 250.
+Since I am ultimately modeling the same pde as was solved, exactly, by Anzelius I can plot the exact solution, showing that n must be quite large, >500, to start to align with the correct answer. Were we to have used the full pde, with n=m=500, this would have required a 250,500 element state vector. This approach becomes severely computationally intensive rather quickly. That said, this is mostly an issue when the moving front is very sharp.
+This can be alleviated by using a different discretization technique, such as moving finite element but, personally, there is a point where solving the pde gets complicated enough that it’s easier to just use a multiphysics program like comsol than to try implementing it yourself.
+So far I have reviewed the “conventional” approach to packed bed mass transfer, examining the solutions that are recommended in the standard texts on unit operations and leaching.30 All of these approaches over-estimate the initial concentration in the espresso because they assume the bed starts in equilibrium, though if the extraction runs for long enough these models fit the observed results better and better. An alternative approach is to assume the bed is filled with water that is not at equilibrium and the extraction only begins at t=0. This is the approach taken by much of the recent literature on modeling espresso31. The downside to this approach is that it generally underestimates the initial concentration of the espresso.
+30 Schwartzberg, “Leaching – Organic Materials,” 558–63.
31 Cameron et al., “Systematically Improving Espresso” page 635; Moroney et al., “Modelling of Coffee Extraction During Brewing Using Multiscale Methods” page 225; Vaca Guerra et al., “Modeling the Extraction of Espresso Components as Dispersed Flow Through a Packed Bed” page 5
Since the initial conditions are different, none of the models above are directly comparable to the approaches taken in the literature. Though it should not be a huge undertaking to change the initial conditions after taking the Laplace transform and completing the result from there. Since the Laplace transform and its inverse are linear this should equate to adding an term to the solution somewhere.
I think it is also reasonable to be skeptical of the mass transfer coefficients that I estimated. These are based on correlations for packed beds with spherical packing and, while I am modeling the particles as spheres, something may have been lost in the accounting. Most of the mass transfer coefficients ultimately depend upon a good estimate for the solid phase diffusion, which in this case I obtained from literature and is comparable to what one would expect for plant matter like coffee beans.32 But an obvious next step is to compare with actual measured data.
+32 Schwartzberg, “Leaching – Organic Materials,” 557.
The model is also highly sensitive to particle size, which the figure below illustrates by successively doubling the effective diameter of the particles, while using the Rasmuson solution (all other parameters remaining equal). This diameter is also an effective parameter and not a directly measured one. It is the diameter of the sphere with an equivalent surface area to a coffee ground or, more accurately, the average of such diameters over the actual particle size distribution of the coffee grounds. This makes it somewhat difficult to determine exactly, especially if one is trying to incorporate the effects of microscopic pores on the effective surface area of coffee grounds. Rough estimates can be made using images taken of the grounds, using an app, but that will always be limited by the resolution of a camera.
+Another note of caution is in using the direct numerical integration of the Rosen and Rasmussen solutions. In this notebook I specified the (finite) bounds of integration and the number of points to sample within the interval, which were tuned more or less by eye. That does mean the code is brittle to major changes in some of the packed bed parameters, without going back and re-tuning the parameters of the numerical integration. A more robust approach would determine some of these algorithmically, especially the bounds of integration. I could just leave the upper bound of the integral as Inf, but in my experience there can be domain issues if one isn’t careful and the integrand isn’t capturing all edge cases properly.
While I focused mostly on calculating the various integrals numerically, the asymptotic and approximate forms are probably more useful if you just want to play around and explore how changing different coffee parameters changes overall extraction. They are certainly easier to calculate.
+Hydrogen is not, itself, a greenhouse gas, in the sense that hydrogen does not significantly absorb infrared radiation. However hydrogen does have a significant global warming potential. Hydrogen influences chemical processes in the atmosphere that impact other greenhouse gases. In particular hydrogen preferentially reacts with oxidants in the air, oxidants that would otherwise be available to oxidize methane, leading to methane having a longer lifetime in the atmosphere. It also increases tropospheric ozone, both an important actor in ground-level pollution and a greenhouse gas.1 There has been increased recognition of this in the literature,2 as there are growing plans to transition many sectors of the economy to hydrogen. But this concern has not, as of yet, lead to hydrogen being listed on the standard tables of greenhouse gases used for emissions reporting, national inventories, and, importantly, “carbon tax” programs.3 As a consequence I haven’t seen a lot of effort, from industry, to quantify the climate impact of switching to hydrogen due to those fugitive emissions. Typical modeling of a hydrogen transition project (i.e. transitioning from natural gas to hydrogen as a fuel source for combustion) focuses on the combustion products and, if there is any attention paid to fugitive emissions, it is to claim that fugitive emissions will “disappear” as hydrogen “is not a greenhouse gas”.
+1 Sand et al., “A Multi-Model Assessment of the Global Warming Potential of Hydrogen,” 2.
2 Dutta et al., “The Role of Fugitive Hydrogen Emissions in Selecting Hydrogen Carriers”; Bertagni et al., “Risk of the Hydrogen Economy for Atmospheric Methane”; Ocko and Hamburg, “Climate Consequences of Hydrogen Emissions”.
3 Hydrogen is not listed on the most recent IPCC table of greenhouse gases, Smith et al., “The Earth’s Energy Budget, Climate Feedbacks, and Climate Sensitivity Supplementary Material”, Table 7.SM.7.
+Hydrogen is also not listed in Schedule 1 of the Technology Innovation and Emissions Reduction Regulation, AR 133/2019, which is the industrial “carbon tax” in Alberta.
4 Hydrogen GWP100 from Sand et al., “A Multi-Model Assessment of the Global Warming Potential of Hydrogen” page 5. Methane GWP100 is that for fossil fuel derived methane from Forster et al., “The Earth’s Energy Budget, Climate Feedbacks, and Climate Sensitivity” page 1017.
Taking the broader view of hydrogen’s impact on atmospheric chemistry, it has a GWP100 of 11.6 as compared to the methane’s GWP100 of 29.84 and so, assuming similar leak rates, one would expect that a transition from natural gas (primarily methane) to hydrogen would lead to a reduction in overall climate impact. Though this is also another point towards hydrogen not actually being a zero emissions fuel.
+The first time this question landed on my desk it was related to a project to transition a large petrochemical facility from natural gas to hydrogen fuel gas. I did some back of the envelope calculations to estimate the climate impact, in CO2-e, of hydrogen fugitive emissions from this system with a few basic assumptions:
+The first assumption is not as close as you might think, at least in this part of Alberta, the utility natural gas to the site is ~90% (mol) methane (that the hydrogen is essentially pure was a much closer approximation in this case). The second assumption is probably closer, though it will depend on the actual line pressure, it is something of a joke among chemical engineers that all gases are ideal gases unless we’re absolutely forced to do it otherwise.
+The third assumption is at least superficially reasonable, here I am imagining leaks at flanges to be basically holes in the gaskets, gaps due to misaligned fittings, or possibly pinhole leaks in the metal itself (hopefully less likely, though that depends on how seriously you take mechanical integrity). The standard way of estimating flow from a hole or orifice uses a discharge coefficient cD which is a function of geometry and not the gas moving through it.
+The other main component of fugitive emissions from this system would be low level venting, typically seen when burners start and stop. During start-up some volume of fuel gas is purged before the burner actually lights and similarly a small volume leaks out after the burner is turned off. For some systems, where the burners are starting and stopping frequently, this can be a major component of fugitive emissions. I’m choosing to neglect those, or consider those part of stack emissions.
+The fourth assumption is pretty reasonable for the fuel gas distribution system at an industrial facility, where the line pressures are relatively high. This means that the leak rate for any given hole is independent of the system pressure and the flow will be turbulent.
+Pulling these together and assuming that for any given leak in the distribution network the mass flow is given by the equation for an ideal gas through an isentropic nozzle:
+The ratio of mass flow of hydrogen to that of methane is then:
+Assuming the system pressure, P1, after having switched to hydrogen, is the same as the system pressure when operating natural gas.
+For a system delivering fuel gas there is a good reason to assume this as the system will deliver approximately the same energy (in terms of HHV) when operated at the same pressure (pure methane versus pure hydrogen). Though this is worth keeping in mind as the hydrogen line can operate at slightly lower pressures while delivering the same heating value, which also reduces the leak rate. This effect is small at low and moderate pressures but could be important at high pressures.
+Because everything related to the particular hole and the conditions around it canceled out, we have gone from a relation for a single leak in a network to a relation that holds for the whole system. Since this was a back of the envelope calculation, I further assumed that as is within 10% of
then
and thus
+putting this in terms of emissions in CO2-e, with
and so we expect a ~87% reduction in fugitive emissions (in CO2-e) after having transitioned the system from natural gas to hydrogen.
+Since I’m now sitting in front of a computer, I can loosen off some of the aggressive approximations, using gas properties from Crane’s.5
+5 Crane, “TP410M”.
using Unitful
+
+# GWPs: Forster et al. "The Earth's Energy Budget," 1017.
+# Sand et al. "Multi Model Assessment," 5.
+#
+# Fluid properties: Crane's *Flow of Fluids*, A-6 and A-9
+
+# Methane
+GWP_CH4 = 29.8 # t-CO2e/t
+MW_CH4 = 16.043u"g/mol"
+μ_CH4 = 0.01103u"cP" # at 20°C
+k_CH4 = 1.31
+
+# Hydrogen
+GWP_H2 = 11.6 # t-CO2e/t
+MW_H2 = 2.016u"g/mol"
+μ_H2 = 0.008804u"cP" # at 20°C
+k_H2 = 1.41g(k) = k*(2/(k+1))^((k+1)/(k-1))
+
+E_H2 = GWP_H2*√(MW_H2*g(k_H2))
+E_CH4 = GWP_CH4*√(MW_CH4*g(k_CH4))
+
+E_H2/E_CH40.1415674991761294I assumed, above, that the fuel gas distribution system was at a high enough pressure for flow to be choked, but how high would that have to be? Choking flow for an isentropic nozzle is when
+where (1) is upstream of the nozzle and (2) is downstream of the jet, in this case atmospheric pressure since the leaks are all to atmosphere. From this we can back calculate the critical system pressure above which all jets are choked.
+# choking condition
+η_c(k) = (2/(k+1))^(-k/(k-1))
+
+P₂ = 101.325u"kPa" # atmospheric pressure
+
+P₁(k) = η_c(k)*P₂
+
+Pₘᵢₙ = min(P₁(k_H2),P₁(k_CH4))186.28417600555758 kPaor in terms of psi (absolute)
+uconvert(u"psi",Pₘᵢₙ)27.018235462782194 psiSystem pressures for the fuel gas distribution networks within chemical plants within them are often above 100psia, though by the time this has been stepped down to a burner it can be around 25psia. This is quite different from the operating pressures of the distribution network to residential customers, where typical pressures are in the range of 0.1-0.4psig.6
+6 For plant piping I have no references that are not confidential to the companies I have worked for, so I guess you’ll just have to trust me. For the residential distribution network see Mejia, Brouwer, and Kinnon, “Hydrogen Leaks at the Same Rate as Natural Gas in Typical Low-Pressure Gas Infrastructure” page 8815.
After getting a general sense of how I would expect fugitive emissions to change, I spent some time looking for more specific data, in particular measured performance of actual systems. In industrial settings, actual leak data from systems in hydrogen service is available. Hydrogen has been a common industrial gas for over a century. However the relevant question is not “what are the fugitive emissions from a system designed for hydrogen service?” it is the subtly different question “what are the fugitive emissions from a system designed for natural gas service, but operating in hydrogen service?”. Maybe switching from natural gas to hydrogen will lead to a system that leaks like a sieve with hydrogen leaking from fittings that would otherwise be gas-tight.
+The literature is pretty consistent that this is not the case. Hydrogen leaks from fuel gas systems switched over from natural gas at rates that are entirely consistent with what you would expect, given the differences in density and viscosity.7 What is different, from my analysis, is the model of fluid flow primarily used in the literature.
+7 Mejia, Brouwer, and Kinnon; Swain and Swain, “A Comparison of ,
and
Fuel Leakage in Residential Settings”; Schefer et al., “Characterization of Leaks from Compressed Hydrogen Dispensing Systems and Related Components”.
I assumed all leaks would be essentially turbulent flow, through a nozzle, using a modified Bernoulli equation. That model works well for large, macroscopic, jets of gases much like what one typically encounters when modeling leaks of process safety relevance. However most fugitive emissions are not big jets of gas like that, somebody would notice that and get it fixed. Fugitive emissions from flanges and fittings come through minuscule gaps in the pressure envelope that involve flow paths that are longer than they are wide, more analogous to pipe flow. Thus the model of fluid flow more commonly seen in the literature treats leaks like a series of tiny, tortuous, tubes.
+Starting from the Darcy-Weisbach equation, in terms of the Fanning friction factor, f, for incompressible flow
+The volumetric flow, Q, would be
+where ΔP is the pressure drop, D the hydraulic diameter, L the effective length and ρ the density. The relative leak rate is then the volumetric flow for hydrogen over that for methane
+This is the typical starting point in the literature. If we assume fully developed turbulent flow, f is a constant and independent of the Reynolds number, then (for ideal gases)
+If we assume laminar flow and
For pipe-flow , which after substitution gives
and, after squaring both sides and canceling
+These two equations are the ultimate source for most of the bounds given on the relative leak-rate of hydrogen fugitives versus natural gas fugitives.
+turbulent_leak_ratio = √(MW_CH4/MW_H2)2.8209638958319374laminar_leak_ratio = μ_CH4/μ_H21.2528396183552932I think it is important to show where these numbers come from, in particular the assumptions that go into them, as I have seen these values – 1.2× to 2.8× the leak rate of methane/natural gas – used directly in relation to GWP100s and other measures that are on a mass basis. This is incorrect. These are the ratios for volumetric flow. Hydrogen has a density ~1/8th that of methane, the mass flow rate is much less for both the turbulent and laminar regimes.
+For turbulent flow:
+and for laminar flow:
+turbulent_mass_ratio = √(MW_H2/MW_CH4)0.3544887623260728laminar_mass_ratio = (MW_H2/MW_CH4)*(μ_CH4/μ_H2)0.1574346861936216The mass emission ratio for the turbulent case is entirely what I came up with in my back of the envelope calculations, and I think you could extend this to include compressibility.8
+8 Schefer does this, replicating the same result as my model above, and goes further to provide a model for non-ideal gases that accounts for differences in compressibility factor, Schefer et al., “Characterization of Leaks from Compressed Hydrogen Dispensing Systems and Related Components” page 1251.
9 Frazer-Nash Consultancy, “Fugitive Hydrogen Emissions in a Future Hydrogen Economy,” 25; Mejia, Brouwer, and Kinnon, “Hydrogen Leaks at the Same Rate as Natural Gas in Typical Low-Pressure Gas Infrastructure,” 8813–14; Swain and Swain, “A Comparison of ,
and
Fuel Leakage in Residential Settings,” 808.
At this point we are drifting away from the original problem, the laminar regime is unlikely to occur at the high system pressures of typical transmission lines and plant fuel gas systems. We’ve basically just circled around to the answer I arrived at originally, but with more footnotes.9
+It is worth noting that for very low system pressures, like what is seen with residential distribution lines, an entirely different flow regime is encountered. In these mechanically assembled piping systems, e.g. NPS piping, leaks are primarily through the gaps in the threads or mechanical joints. These gaps, due to manufacturing defects or damage, form micro channels that are small enough for the continuum hypothesis to breakdown and flow is in a molecular flow regime.10 In this case the volumetric leak rate is identical for both hydrogen and natural gas.
+10 Mejia, Brouwer, and Kinnon, “Hydrogen Leaks at the Same Rate as Natural Gas in Typical Low-Pressure Gas Infrastructure,” 8814–15.
molecular_flow_mass_ratio = MW_H2/MW_CH40.12566228261547094Fugitive emissions are generally small compared to combustion emissions for fossil fuels. The large majority of the emissions, in CO2 equivalents, is what is coming out of the stack. In the case of hydrogen, very little is coming out of the stack other than water and nitrous oxide. So it is worth checking to see how important, relatively, fugitive emissions have become.
+As a first pass I am going to divide emissions into combustion and fugitive wherein the combustion emissions are the direct emissions of combustion products and the fugitive emissions are all the leaks in the entire system (burners included).
+My model for fugitive emissions will be quite simple: some fraction η of flow is lost from the system and the emissions, in CO2 equivalents is
+When hydrogen undergoes combustion it produces water
+Since there is no carbon in the fuel, no carbon dioxide is generated. Similarly, there is no possibility of generating methane through incomplete combustion. However nitrous oxide can be generated from any gaseous flame that uses air as a source of oxygen, though the chemistry of this process is complex.11 Thus the combustion emissions for hydrogen are
+11 Colorado, McDonell, and Samuelsen, “Direct Emissions of Nitrous Oxide from Combustion of Gaseous Fuels” lists 23 different reactions involved in the formation of N2O in gaseous flames..
Where EF is the emission factor for nitrous oxide and HHV is the higher heating value of hydrogen.
+The ratio of fugitive to combustion emissions is then12
+12 I am using the nitrous oxide emission factor for natural gas combustion, for lack of any more appropriate emission factor. This factor is highly dependent upon the actual burner design/operation, fuel gas, and host of other parameters relating to the actual stationary combustion device. I am implicitly assuming that whatever the nitrous oxide emission factor would be for hydrogen, it would be of the same order of magnitude as that for natural gas.
SG_H2 = 0.0696 # GPSA
+ρ_air = 1.225u"kg/m^3" # GPSA, at 15°C and 1atm
+ρ_H2 = SG_H2*ρ_air
+
+GWP_N2O = 273 # Forster et al., 1017.
+EF_N2O = 8.7e-7u"kg/MJ" # AEPA, 1-9 Industrial
+HHV_H2 = 12.102u"MJ/m^3" # GPSA, at 15°C and 1atm
+
+fugitives_to_combustion(η) = ((GWP_H2*ρ_H2)/(GWP_N2O*EF_N2O*HHV_H2))*(η/(1-η));Assuming that the leak rate is 1% we then have
+fugitives_to_combustion(0.01)3.4755942870304137At any appreciable leak percentage the amount of hydrogen lost to fugitive emissions rivals the stack emissions for climate impact.
+More relevant to a fuel switching program is to re-assess how much of a reduction switching to hydrogen achieves. Instead of comparing hydrogen to itself, we should compare hydrogen to the natural gas system that preceded it.
+For the natural gas system the fugitive emissions are similar, except that I am assuming the only climate relevant component of natural gas is methane
+and the combustion emissions now include carbon dioxide and methane along with nitrous oxide
+Total emissions are just .
What we are interested in is the ratio
+There are a few assumptions we need to make to proceed. The first is to assume that the system with natural gas and the system with hydrogen are operating under the same pressure. At the same pressure the hydrogen system will deliver about the same energy in HHV as the natural gas system, slightly more (depending on the exact natural gas, etc.). Which makes this a plausible assumption. The whole point of the fuel delivery system is to deliver sufficient energy to a combustion device, in the form of fuel heating value. This is not exact, so a more detailed analysis would work out the actual pressure of the hydrogen system and that would add a whole layer of complication.
+The second assumption is that the fraction of gas lost between the two systems is the same. At first blush this seems like a crazy assumption. I spent two sections talking about how significantly different the leak rates were, so what is going on here? Well the volumetric leak rate is higher with hydrogen but the line flow rate is also higher, and they are both higher by the same amount. It cancels out.
+Suppose the leaks are all in the turbulent regime, so
+For fully developed turbulent pipe flow we know the ratio of line flow rates is also
+By the definition of η
+To make the math a little less tedious to type out, I am going to define two emission factors, the fugitive emission factor13
+13 Note that the flowrates here are at standard state. The volumetric emission factors, heating values, and densities are also at standard state thus this is equivalent to the relation at actual conditions.
and the combustion emission factor
+Finally we can answer the question of “how much do the total emissions go down after switching to hydrogen?”
+# hydrogen
+EF_f_H2 = GWP_H2*ρ_H2
+EF_c_H2 = GWP_N2O*EF_N2O*HHV_H2
+
+# methane
+SG_CH4 = 0.5539 # GPSA
+ρ_CH4 = SG_CH4*ρ_air
+
+# natural gas
+x_CH4 = 0.90 # Alberta typical
+SG_NG = 0.61 # Alberta typical
+EF_CO2_NG = 1.962u"kg/m^3" # ECCC, 3.
+EF_CH4_NG = 3.7e-5u"kg/m^3" # ECCC, 3.
+EF_N2O_NG = 3.3e-5u"kg/m^3" # ECCC, 3.
+
+EF_f_NG = GWP_CH4*ρ_CH4*x_CH4
+EF_c_NG = EF_CO2_NG + GWP_CH4*EF_CH4_NG + GWP_N2O*EF_N2O_NG
+
+# Final answer
+emissions_ratio(η) = ((EF_c_H2*(1-η)+EF_f_H2*η)/(EF_c_NG*(1-η)+EF_f_NG*η))*√(SG_NG/SG_H2);emissions_ratio(0.01)0.017665064441514864So switching to hydrogen has reduced the overall emissions from this system by ~98.2%. Which is pretty significant, though it is not zero even though this analysis is assuming pure hydrogen.
+Even at relatively high leak rates, the total greenhouse gas emissions from a hydrogen system are a small fraction of that of a natural gas system. Transitioning to hydrogen does what you would expect: it radically reduces the climate impact of stationary combustion equipment. That said, it is not zero emissions. Which shifts the perspective on where hydrogen fits in the energy transition. If the goal is zero then hydrogen will not get us there by the simple fact that hydrogen has a significant global warming potential and fugitive emissions are unavoidable. If the goal is to radically decarbonize existing systems and run out the remaining life of a vast global fleet of process equipment, then transitioning to hydrogen may be a major player.
+Hydrogen may also be limited by the fact that it is not a zero impact fuel with regards to all of the other air emissions that are more locally important, such as nitrogen oxides (NOx), VOCs, and ground level ozone. Hydrogen combustion does directly produce nitrogen oxides and direct hydrogen emissions impact atmospheric chemistry increasing VOC and ground level ozone concentrations. If the choice is between hydrogen combustion and electrification, well electrification actually is zero emissions – both greenhouse gas emissions as well as other air pollutants – and while electrification projects are more complex than hydrogen as a “drop-in” solution, that can be a pretty strong advantage. For example in airsheds that are already stressed for NOx, switching to hydrogen fuel gas may also require the installation post-combustion NOx reduction technology such as SCR, as hydrogen combustion generally produces more NOx than natural gas. Replacing stationary combustion equipment with their electric equivalents has the advantage that it reduces all air emissions.
+Five pin bowling uses five pins but, unlike ten pin bowling, the pins are worth different amounts. Notably no pin is worth 1, and so a score of 1 is the first impossible score.
+ +
+Like ten pin bowling, if a strike or a spare is recorded in a given frame then the scores of subsequent ball(s) are counted in that frame, as well as the frame in which they were thrown. So, for example, if I throw a strike in the first frame I don’t actually know what to write on the score sheet for the first frame until the second, and possibly third, frames have been thrown. I know it is at least 15, but until I throw the next ball it could be anything up to 45. This was what initially gave me pause. It adds a layer of complexity since the possible scores for a given frame depend on what happens next.
+By symmetry, though, this way of scoring is equivalent to every strike and spare adding a multiplier to the next frame, and each frame is just scored counting whatever the pinfall is and applying the multiplier (no looking backwards). So, if I throw a strike in the first frame, then I record a 15 for the first frame and double count the next two balls. If I have thrown two strikes in a row then I triple count the first subsequent ball and double count the next one. This is a weird way of managing a score sheet, for bowlers, but makes it a lot easier to reason about the possible scores, since you don’t have to constantly be looking back two or three frames. This passing forward score sheet looks different to a regular one: The maximum score for the first frame is now 15, and for the second frame 30, and in the tenth frame it is possible to score 90 points. On a conventional score sheet the max score in any frame is 45.
+While hanging out at the lanes a few obvious impossible scores got thrown out: a 1, obviously, but also a 449 – there’s no way to throw a 14 with the last ball in the tenth frame. But the question still lingered: are there any other gaps? It was not immediately obvious, to my bowling team, how you would figure that out without checking.
+Maybe we can brute-force this and try every conceivable bowling game? However there are a lot of possible bowling games. As a first pass, there are thirty balls thrown in a game and each ball has up to fourteen possible pinfall scores (0 through 15 excluding 1 and 14). This would give 1430 possible bowling games. Even if it took a single nanosecond to evaluate each game that would take longer than the current age of the universe to work through.
+But that’s not a great upper bound, it doesn’t take into account the rules of bowling: you can only knock down up to five pins in any given frame, for example if the first ball scores a 13 then the second ball doesn’t get to choose from fourteen possibilities, it gets to chose from two: 0 and 2. Still, it is going to be a large number. The vast majority of those games are going to be completely redundant, since we are only looking for scores from 2 to 450.
+I was thinking about this some more and there is a different way of looking at this that gives a better estimate for the number of possible games.
+First let’s consider a single frame (within the first 9 frames). The order that pins are knocked down – the score per ball – matters because of the way strikes and spares are counted. So we are trying to answer the question “how many ways can 5 pins be divided into 4 categories (hit by ball 1, 2, or 3, or left standing)?” This is the sum of a multinomial and is well known, for n objects divided into m categories, the number of ways is :
The tenth frame has some extra rules, so lets go through it:
+| Frame | +Number of Possibilities | +description | +
|---|---|---|
| ? ? ? | +1024 | +Any combination of the first set of 5 pins | +
| X ? ? | +35 -1 = 242 | +Every follow up to a strike except X–, which has already been counted in ??? | +
| X X ? | +25 -1 = 31 | +Every follow up to 2 strikes except XX-, which has already been counted in X?? | +
| ? \ ? | +25 × (25-1) = 992 | +Every follow up to every spare except ?\- which were counted in ??? | +
Which gives 2289 possible ways of bowling the 10th frame.
+So this gives a total count of possible 5 pin bowling games of which is about
The easiest case to look at is when one never throws a strike or spare. In this case the possible scores for each frame are the same: just what you can get from knocking down any subset of the pins. This happens to be anything from 0 to 15 except 1 and 14. That’s easy enough to see just by inspection.
+This also leads to a (kinda loose) argument for why you should be able to get anything from 0 to 150 except 1 and 149:
+Suppose you are playing game with n frames and your goal is a score .
If and
then you can always get from a multiple of 15 to the final score in one frame.
If or
then you can’t get from a multiple of 15 to the final score in one frame, this is because you cannot score 1 or 14 in one frame. You can score 1 more than a multiple of 15 if you have two frames remaining: score a 13 in the first and a 2 in the next. Similarly you can score 1 less than a multiple of 15 if you have two frames remaining: score a 7 in the first frame and a 7 in the second.
Since for any x such that there are
frames remaining, all of those scores can thus be achieved.
What remains is the x such that and
, this single score is not achievable in a game with no strikes and spares.
Which is all to say there are only two impossible scores: 1 and 15n -1 or 149 in a standard ten frame game.
+I suspect that, if you wanted to put the work in, you could extend this argument to include spares and strikes, with all of the complications around how the 10th frame is scored. But an alternative is to just look through all possible scores and try and find a game that achieves it, using this general approach as a guide.
+This is pretty easy to do when only looking at the case where there are no strikes or spares: I generate a list of possible scores for a single frame (a possible move I can take towards my goal), sorted largest to smallest.
+basic_moves = [ n for n in range(16) if n not in [1,14] ]
+basic_moves.reverse()Then I define a function that recursively walks through the tree of possible games, always picking the largest viable move at each frame. If it finds an answer it returns it (in reverse order), if it exhausts the possible moves then it returns an empty list.1
+1 This code stops once it has found a single valid solution, it could be extended very easily to find every valid solution, however the space of possible games is huge.
def make_moves(cur_frame, cur_score, max_frame, target, moves=basic_moves):
+ if cur_frame == max_frame:
+ return [0] if cur_score == target else []
+ else:
+ next_frame = cur_frame + 1
+ mn, mx = min(moves), max(moves)
+ n = max_frame - next_frame
+ r = target - cur_score
+ for move in filter(lambda x: n*mn <= (r-x) <= n*mx, moves):
+ new_score = cur_score + move
+ advance = make_moves(next_frame, new_score, max_frame, target, moves)
+ if len(advance) > 0:
+ advance.append(move)
+ return advance
+ else:
+ return []Looping through all the scores: yields the impossible to bowl scores.
for score in range(151):
+ game = make_moves(0,0,10,score)
+ if len(game) == 0:
+ print("Score {0} is not possible".format(score))Score 1 is not possible
+Score 149 is not possibleWhich is what I expected, good news as I will be building off this general strategy for the cases where strikes and spares are included.
+Another question that comes to mind is: what if you were restricted to always hitting a pin, no gutter balls? Now you can’t get a score less than 7 (equivalent to hitting 2-2-3, the lowest pins). Does this change anything?2
+2 In five pin it is actually possible to bowl between the pins and hit nothing without it technically being a gutter ball, and you can bowl into the blank spots left by pins that were already knocked down to score zeros without putting it in the gutter. I am using the term gutter ball loosely.
Probably I could go back and look at the math again, but the nice thing about having written code is that I can just change the space of possible moves and run it again.
+no_gutters = [ n for n in range(7,16) if n != 14 ]
+no_gutters.reverse()for score in range(70,151):
+ game = make_moves(0,0,10,score,no_gutters)
+ if len(game)==0:
+ print("Score {0} is not possible, with no gutters".format(score))Score 149 is not possible, with no guttersSo nothing really changes. I mean you can’t get a score <70, obviously, but this doesn’t open up any gaps in possible scores either.
+It does mean the strategy changes, now the code takes the biggest strides it can until the remainder is a multiple of 7 then runs out the game with a string of 7s.3
+3 You may have noticed an extra “frame” at the end with a score of 0. This is because, in five pin bowling, the last frame has special rules. You always get 3 balls in the last frame, even if your first two are a strike or spare. In this case, with no strikes or spares allowed by design, that extra scoring doesn’t enter into it.
[ frame for frame in reversed(make_moves(0,0,10,100,no_gutters)) ][15, 15, 15, 13, 7, 7, 7, 7, 7, 7, 0]Adding in spares means I can’t easily track the state of each frame with an integer, like I did for the case with deadwood every frame. Now I need to track three different properties for a given frame:
+Instead of diving into the full set of scoring rules for everything, I’m going to take one baby step forward and add in a data structure to track the state of the frame and select from two sets of possibilities for the subsequent frame: was there a spare or not?
+The data structure I’m using is just a struct, tracking the score, whether it is a “special” frame and whether or not it is the end of the game.
+class SingleFrame:
+ def __init__(self, score, special=None, end=False):
+ self.score = score
+ self.special = special
+ self.end = endInstead of a list of integers for possible moves, I now need a list of possible SingleFrame objects that represent a possible frame, now including the possibility of a spare. Note the pass forward approach to scoring: a spare in a regular frame is only worth 15.
single_frame_moves = [ SingleFrame(score) for score in basic_moves ]
+single_frame_moves.insert(0, SingleFrame(15,"spare"))Now I iterate through the possible first, second, and third balls for a frame following a spare. There are more possible scores here since the first ball will be double counted. First I exhaustively generate every combination then use set() to extract only the unique elements. For this purpose it doesn’t matter how many ways you can get a given score.
spares = [ 2*f+s for f in basic_moves
+ for s in filter(lambda x: f+x==15,basic_moves)]
+
+spares = list(set(spares))
+spares.sort(reverse=True)
+
+non_spares = [ 2*f+s+t for f in basic_moves
+ for s in filter(lambda x: f+x<15, basic_moves)
+ for t in filter(lambda x: f+s+x<=15, basic_moves) ]
+
+non_spares = list(set(non_spares))
+non_spares.sort(reverse=True)Now I generate a list of moves by combining the spares and non-spares. They are arranged such that the code tries the spares first before the non-spares, going from largest to smallest. There are now 42 possible ways of scoring a frame when spares are included (versus only 14 when they aren’t).
+spare_frame_moves = [ SingleFrame(score,"spare") for score in spares ]
+spare_frame_moves += [ SingleFrame(score) for score in non_spares ]
+
+len(spare_frame_moves)42There are only two scores that are not achievable in the frame following a spare: 1 and 29
+[ s for s in range(31) if s not in [x.score for x in spare_frame_moves] ][1, 29]Adding spares has also complicated determining if a move is valid or not. Since scoring now depends on the state of a given move – is it a spare or not – this impacts the bounds of possible scores that can follow any given move. Instead of putting this all into the same function, as I did before, I have broken it out into its own function that decides, given a move, a remaining number of frames, and a remaining number of points to pick up, is the move valid.4
+4 There is an extra move at the end because of the last frame rule: A spare at the start of the last frame leads to an extra ball, but one that can only count for up to 15.
def valid_spare_moves(move, n, r, mn=0, mx=15):
+ if move.special=="spare":
+ up = (2*n + 1)*mx
+ else:
+ up = (1 + 2*max(n-1,0) + 1)*mx
+
+ return n*mn <= (r - move.score) <= upThe bulk of the main function is the same. The one exception is that it now tracks whether the previous frame was a spare (with was_spare) and uses this to determine how to finish the last frame: if the last frame was a spare, then an extra ball is thrown but with no multiplier.
def make_spare_moves(cur_frame, cur_score, max_frame, target,
+ moves=single_frame_moves, was_spare=False):
+ if cur_frame == max_frame:
+ if cur_score == target:
+ return [SingleFrame(0,False,True)]
+ elif was_spare and (target - cur_score) in basic_moves:
+ # extra ball in the last frame
+ return [SingleFrame(target-cur_score,False,True)]
+ else:
+ return []
+ else:
+ next_frame = cur_frame + 1
+ n = max_frame - next_frame
+ r = target - cur_score
+ for move in filter(lambda x: valid_spare_moves(x,n,r), moves):
+ new_score = cur_score + move.score
+ if move.special == "spare":
+ next_moves = spare_frame_moves
+ else:
+ next_moves = single_frame_moves
+
+ advance = make_spare_moves(next_frame, new_score, max_frame, target, next_moves, move.special=="spare")
+ if len(advance) > 0:
+ advance.append(move)
+ return advance
+ else:
+ return []Looping through all the scores: yields the impossible to bowl scores, when spares are allowed.
for score in range(301):
+ game = make_spare_moves(0,0,10,score)
+ if len(game)==0:
+ print("Score {0} is not possible, with only spares allowed".format(score))Score 1 is not possible, with only spares allowed
+Score 299 is not possible, with only spares allowedWhich is perhaps not surprising, we still can’t get 1 less than the largest multiple of 15 because we cannot bowl a 14 with the extra ball at the end of the 10th frame.
+This puts me in a good position to try a full game, I need to add the possibility of a strike. For single frame scores with nothing special before them, this just means adding a third way to score a 15. There are now 16 possible moves.
+# all the different scores for a frame following a regular frame
+
+single_frame_moves = [ SingleFrame(score) for score in basic_moves ]
+single_frame_moves.insert(0, SingleFrame(15,"spare"))
+single_frame_moves.insert(0, SingleFrame(15,"strike"))
+
+len(single_frame_moves)16Similarly the possible ways to follow a spare are the same as before, except that there is no way to “spare” with 30. Scoring a 30 after a spare requires that one throw a strike.
+# all the different scores for a frame following a spare
+
+spare_frame_moves = [ move for move in spare_frame_moves if move.score !=30 ]
+spare_frame_moves.insert(0, SingleFrame(30,"strike"))
+
+len(spare_frame_moves)42Following a single strike the rules are different: the first two balls count twice and the third counts once. Here I exhaustively generate all strikes, spares, and remaining that could follow a single strike and then trim only to the unique scores. This is a much smaller set as all spares that follow a strike must, by definition, have a score of 30.
+# all the different scores for a frame following a single strike
+
+non_spares = [ 2*f+2*s+t for f in filter(lambda x: x!=15,basic_moves)
+ for s in filter(lambda x: f+x<15, basic_moves)
+ for t in filter(lambda x: f+s+x<=15, basic_moves) ]
+
+non_spares = list(set(non_spares))
+non_spares.sort(reverse=True)
+
+single_strike_moves = [ SingleFrame(30,"strike") ]
+single_strike_moves += [ SingleFrame(30,"spare") ]
+single_strike_moves += [ SingleFrame(score) for score in non_spares ]
+
+len(single_strike_moves)30Following a double strike the rules are different again: the first ball is triple counted, the second double counted, and the third single counted.
+# all the different scores for a frame following 2 strikes
+
+spares = [ 3*f+2*s for f in filter(lambda x: x!=15,basic_moves)
+ for s in filter(lambda x: f+x==15,basic_moves)]
+
+spares = list(set(spares))
+spares.sort(reverse=True)
+
+non_spares = [ 3*f+2*s+t for f in filter(lambda x: x!=15,basic_moves)
+ for s in filter(lambda x: f+x<15, basic_moves)
+ for t in filter(lambda x: f+s+x<=15, basic_moves) ]
+
+non_spares = list(set(non_spares))
+non_spares.sort(reverse=True)
+
+double_strike_moves = [ SingleFrame(45,"strike") ]
+double_strike_moves += [ SingleFrame(score,"spare") for score in spares ]
+double_strike_moves += [ SingleFrame(score) for score in non_spares ]
+
+len(double_strike_moves)55This change in scoring, allowing for triple scoring, changes the bounds of possible scores following a given move. Now, after a strike, the next frame could count triple. But there are also potentially two more balls in the 10th frame that don’t count equally towards the upper bound on the score. The function to check for valid moves needs to be updated to reflect this.
+def valid_full_moves(move, n, r, mn=0, mx=15):
+ if move.special=="strike":
+ # max score is 3 times the max score for the remaining frames
+ # plus the multiplier for the remaining balls in the last frame
+ up = (3*n + 2 + 1)*mx
+ elif move.special=="spare":
+ # max score is 2 times the max score for the next frame
+ # 3 times the max score for the remaining frames
+ # plus the multiplier for the remaining balls in the last frame
+ up = (2 + 3*max(n-1,0) + 2 + 1)*mx
+ else:
+ up = (1 + 2*max(n-1,0) + 2 + 1)*mx
+ return n*mn <= r - move.score <= upAt this point all of the sets of moves for a regular frame contain every score except 1 and 1 less than the max score (i.e. a frame following a spare or single strike cannot score a 29 and a frame following a double-strike cannot score a 44). At this point you may expect that the only impossible scores will be 1 and 449 – this was true with the cases above. However there are two more sets of scoring possibilities just for the last frame.
+If the last frame starts with a spare, then it is the same as before: single ball, no multiplier.
+If the last frame starts with a strike, and is not preceded by one, then there are potentially two more balls left with no multipliers attached. And these do leave gaps.
+# all the different scores for the last 2 balls of the last frame
+# assuming the first ball in the last frame was a strike
+last_frame_moves = [ f+s for f in basic_moves
+ for s in filter(lambda x: f+x<=15,basic_moves) ]
+last_frame_moves += [ 15 + s for s in basic_moves ]
+last_frame_moves = set(last_frame_moves)
+
+[ s for s in range(31) if s not in last_frame_moves ][1, 16, 29]If the last frame starts with a strike and is preceded by one, then there are potentially two more balls but the first one is double counted. Again, this leaves gaps.
+# all the different scores for the last 2 balls of the last frame
+# assuming the second to last frame was a strike and the first ball
+# in the last frame was a strike
+last_frame_double_moves = [ 2*f+s for f in basic_moves
+ for s in filter(lambda x: f+x<=15,basic_moves) ]
+last_frame_double_moves += [ 30 + s for s in basic_moves ]
+last_frame_double_moves = set(last_frame_double_moves)
+
+[ s for s in range(46) if s not in last_frame_double_moves ][1, 29, 31, 44]It certainly looks now like there will be at least 4 scores that can’t be achieved because there no way to make the last step with the extra balls in the 10th frame, because the 10th frame is scored differently. This additional scoring complexity now makes it unwieldy to put all of that into the main function. I have broken it out into a separate function that just checks the last frame and either returns the last move with the remaining balls or returns an empty list if there is no possible move.
+def last_frame_rule(remaining, last_frame, max_move, mx=45):
+ if remaining == 0:
+ # hit the target, don't need any additional balls
+ return [SingleFrame(0,None,True)]
+ elif last_frame == "strike" and max_move == mx and remaining in last_frame_double_moves:
+ # two extra balls following a double strike
+ return [SingleFrame(remaining,None,True)]
+ elif last_frame == "strike" and remaining in last_frame_moves:
+ # two extra balls following a single strike
+ return [SingleFrame(remaining,None,True)]
+ elif last_frame == "spare" and remaining in basic_moves:
+ # only one extra ball
+ return [SingleFrame(remaining,None,True)]
+ else:
+ # not possible
+ return []The main function now has to track whether the last frame was a strike, to trigger the double strike rules, versus single strikes, spares, and regular frames. The logic is the same, though.
+def make_full_moves(cur_frame, cur_score, max_frame, target,
+ moves=single_frame_moves, last_frame=None):
+ if cur_frame == max_frame:
+ # max_move is used to check if the second-to-last frame was a strike
+ max_move = max( s.score for s in moves )
+ return last_frame_rule(target-cur_score, last_frame, max_move)
+ else:
+ next_frame = cur_frame + 1
+ n = max_frame - next_frame
+ r = target - cur_score
+ for move in filter(lambda x: valid_full_moves(x,n,r), moves):
+ new_score = cur_score + move.score
+ if last_frame == "strike" and move.special == "strike":
+ next_moves = double_strike_moves
+ next_last_frame = "strike"
+ elif move.special == "strike":
+ next_moves = single_strike_moves
+ next_last_frame = "strike"
+ elif move.special == "spare":
+ next_moves = spare_frame_moves
+ next_last_frame = "spare"
+ else:
+ next_moves = single_frame_moves
+ next_last_frame = None
+
+ advance = make_full_moves(next_frame, new_score, max_frame, target, next_moves, next_last_frame)
+ if len(advance) > 0:
+ advance.append(move)
+ return advance
+ else:
+ return []Looping through all the scores: yields the impossible to bowl scores, when spares and strikes are allowed.
for score in range(451):
+ game = make_full_moves(0,0,10,score)
+ if len(game)==0:
+ print("Score {} is not possible, full game".format(score))Score 1 is not possible, full game
+Score 434 is not possible, full game
+Score 436 is not possible, full game
+Score 449 is not possible, full gameThis conforms with our intuition, after looking at the possible last-frame moves. Of course this is entirely academic as, the way I bowl, I am in no danger of coming close to these impossible scores.
+ + +Typically, when evaluating various release scenarios, key pieces of the model are specified in advance and each scenario uses the same set of assumptions: comparing apples to apples. For a Gaussian plume dispersion model there are really three key correlations used for the model parameters: the wind-speed profile, crosswind dispersion, and vertical dispersion. Correlations for each of these are given in the standard references and there is not, to my mind, any deep reason to prefer one reference over the another. Besides maintaining consistency with other modeling or perhaps with industry practice in a particular area.
+This raises the obvious question: how much does it matter which reference you use? Usually one takes the results of a Gaussian plume model with a fair grain of salt, these are “order of magnitude” estimates really. That’s what I’m going to look at here.
+The windspeed correlations I am looking at here are the basic power law
+where uR is the known windspeed at a reference height zR and p is a parameter that depends upon the Pasquill stability class. There are more complex models that incorporate the surface roughness, Monin-Obukhov mixing length, and other measures of stability, they are beyond this analysis.
+There are three different standard references used in GasDispersion.jl for windspeed: the default which comes from Spicer and Havens,1 the correlations used by the EPA Industrial Source Complex (ISC3)2 dispersion models, and the correlations given in the various CCPS guidance documents3
1 EPA-450/4-89-019.
2 EPA-454/b-95-003b.
3 AIChE/CCPS, Guidelines for Consequence Analysis of Chemical Releases.
4 Handbook on Atmospheric Diffusion.
The ISC3 and CCPS correlations are divided into urban and rural terrain and are exactly the same correlations for the unstable classes. They appear to be the correlations given in Hanna, Briggs, and Hosker.4 They also bracket the default correlation. Clearly whether or not the terrain is urban is significant, it can lead to a 20-30% difference in estimated windspeed (depending upon elevation).
+For the stable atmospheres the ISC3 and CCPS rural correlations are the same. However they are very different for urban terrain and they no longer bracket the default correlation. The CCPS urban correlations are the same as Hanna, Briggs, and Hosker,5 the ISC3 correlations use the parameter p = 0.30 and no reference is given in the model specification so I don’t know why.
+5 Hanna, Briggs, and Hosker.
For an urban release scenario, whether or not one choses the default, the ISC3 urban, or the CCPS urban correlation can lead to a 300% difference in windspeed (for class F stability, depending on elevation). Which is a pretty large difference.
+The more diverse sets of correlations are for the plume dispersion parameters, the crosswind and vertical dispersion. To some extent this is because the early Turner6 presented the dispersion parameters graphically and many subsequent authors generated their own curves to fit these plots.
+6 Workbook of Atmospheric Dispersion Estimates.
Crosswind dispersion can be divided into the various attempts at fitting the curves presented graphically by Turner and those based on Briggs’ urban and rural correlations7
+7 Briggs, “Diffusion Estimation for Small Emissions. Preliminary Report” page 38; Note that the correlations are given with respect to half-width/half-depth
The default correlation is a simple set of correlations of the form
+which attempts to fit the Turner curves.
+The CCPS correlations are from Briggs8 and the ISC3 urban correlations are from Briggs as well, the ISC3 rural correlations are something else entirely but I suspect are intended to fit the Turner9 curves. The correlations from the TNO yellow book10 are also a different attempt at fitting the Turner curves. What GasDispersion,jl gives as “Turner” is the fit to the Turner curves given in Lees.11
8 Briggs.
9 Turner, Workbook of Atmospheric Dispersion Estimates.
10 Bakkum and Duijm., “Vapour Cloud Dispersion”.
11 Lees, Loss Prevention in the Process Industries.
Zooming in on the class F curves is illustrative of the lot: most of the lines overlap and hew pretty close to the curve-fit for Turner12 with the exception of the Briggs’ urban/rural correlations. The biggest impact on these model parameters is whether or not a rural/urban terrain is used or not. Note these are log-log plots.
+12 Turner, Workbook of Atmospheric Dispersion Estimates.
The vertical dispersion correlations are decidedly more varied. Varied enough that I’m just going to show them all at full scale13
+13 The correlations given in AIChE/CCPS, Guidelines for Consequence Analysis of Chemical Releases for urban conditions has typos in the class A, B and D correlations, I have corrected them here to match the Briggs correlations on which they are supposed to be based.
For some of these there is an order of magnitude spread in vertical dispersion, depending on which model happens to be used. Even when looking only at the correlations that are “universal”, i.e. are not for either urban or rural terrains. From this alone one would expect that the concentration profiles would vary by a large amount, depending on which set of correlations one used to model a given scenario.
+Just to give an example of how this works out, lets look at the emissions from a large stack. I happened to have picked the stack for a large power plant in the Edmonton area: TransAlta’s Sundance station. This power plant is on the shores of Lake Wabamun and is pretty rural, it has several stacks but let’s consider only Stack 2 and examine the dispersion of SO2 emissions.
+From Alberta’s AEIR Air Emission Rates dataset we can pull the mass emission rates for SO2 as well as the relevant stack dimensions. Note this dataset is from 2018 and thus may not represent the current operations at Sundance.
+# TransAlta Sundance - Stack 2
+m = 3200/3600 # mass emission rate: 3200kg/h in kg/s
+h = 155.5 # stack height, m
+d = 7.3 # stack diameter, m
+v = 35.6 # stack exit velocity, m/s
+T = 439.7 # stack exit temperature, KFor the sake of modeling let’s assume a class D atmospheric stability with a windspeed at 10m of 2m/s. The atmosphere is otherwise at standard state.
+# assumed weather conditions
+uᵣ = 2 # windspeed, m/s
+zᵣ = 10 # windspeed elevation, m
+stability = ClassD
+
+# standard state
+Pₛ = 101325 # Pa
+Tₛ = 273.15 # KWe can construct the relevant scenario for GasDispersion.jl directly.
r = VerticalJet(m, Inf, d, v, h, Pₛ, T, 0.0)
+
+a = SimpleAtmosphere(pressure=Pₛ, temperature=Tₛ, windspeed=uᵣ, windspeed_height=zᵣ, stability=stability)
+
+# a dummy substance, since I know a gaussian plume doesn't require any material
+# properties I have just left them as NaNs
+SO2 = Substance(name=:SulfurDioxide,molar_weight=0.064066,liquid_density=1,boiling_temp=1,
+ latent_heat=1,gas_heat_capacity=1,liquid_heat_capacity=1)
+
+scn = Scenario(SO2,r,a)Substance: SulfurDioxide
+ MW: 0.064066 kg/mol
+ P_v: GasDispersion.Antoine{Float64}(0.007705368698167287, 0.007705368698167287, 0.0) Pa
+ ρ_g: 2.7095140841291006 kg/m^3
+ ρ_l: 1 kg/m^3
+ T_ref: 288.15 K
+ P_ref: 101325.0 Pa
+ k: 1.4
+ T_b: 1.0 K
+ Δh_v: 1 J/kg
+ Cp_g: 1 J/kg/K
+ Cp_l: 1 J/kg/K
+VerticalJet release:
+ ṁ: 0.8888888888888888 kg/s
+ Δt: Inf s
+ d: 7.3 m
+ u: 35.6 m/s
+ h: 155.5 m
+ P: 101325.0 Pa
+ T: 439.7 K
+ f_l: 0.0
+SimpleAtmosphere atmosphere:
+ P: 101325.0 Pa
+ T: 273.15 K
+ u: 2.0 m/s
+ h: 10.0 m
+ rh: 0.0 %
+ stability: ClassD The Gaussian plume model is then given by the following, neglecting the effect of plume rise.
+conc = plume(scn, GaussianPlume; plumerise=false);Plotted below are the results for every equation set, at near ground level (at basically “my head” level). Clearly the urban/rural choice is quite important, leading to a ~4× greater maximum concentration. The TNO correlations, which uses the default correlation for windspeed and the TNO correlations for the crosswind and vertical dispersion, leads to less dispersion and thus a greater maximum concentration relative to the rest.
+Plotted below is the 172ppbv isopleth, the 1-hr Ambient Air Quality Objective (AAQO) for SO2 in Alberta. As we would expect, the correlations that lead to a higher maximum concentration correspond to less overall dispersion and the isopleth is quite a bit smaller for the urban versus rural case and the TNO versus the remaining cases. The scale is in kilometers so this is quite a large difference in area.
+The above was assuming no plume rise, however the relative differences are much more pronounced when plume rise is included.
+conc = plume(scn, GaussianPlume; plumerise=true);Plotted below is the same downwind concentration plot as above, but incorporating the Briggs’ plume rise model. Since this leads to a greater overall dispersion, the concentration is much smaller (everything is well below the AAQO at ground level, which is good news). However this adds another dimension along which the models can vary: plume rise is a function of windspeed, and overall dispersion is a function of plume rise. These different sets of correlations lead to the plume rising to a different elevation, and also dispersing to a differing degree, magnifying the differences between them. In this case there is up to a ~30× difference between the max concentrations predicted between the urban and rural case.
+I think the above illustrates the necessity of picking a standard set of correlations for use when screening scenarios at a particular plant (e.g. using either the CCPS urban or rural correlations as appropriate for the area around the plant) and being careful to keep these consistent. It also shows how seriously one should take the exact values generated by the models: not very. The dispersion model results are highly sensitive to the choice of correlations, and they are also quite sensitive to the other assumptions that go into a release scenario (e.g. atmospheric stability, wind-speed, mass emission rate). The results are really order of magnitude at best.
+It is often the case that chemical plants are situated at the periphery of cities, in areas that blur the line between “urban” and “rural”. Also, cities grow and industrial areas fill in. A plant that was essentially rural may, overtime, fill in such that the urban correlations better represent the area. I think it is worth comparing the urban/rural models for a range of plausible results and considering whether assumptions made in the past about the area around the plant are still valid given changes in the area.
+There are other correlations, for wind-speed and for dispersion, that take into account the local surface roughness which could be used instead and the sensitivity to the models to assumptions about surface roughness could be evaluated. This would likely lead to a smaller range of values, and give a path for updating the screening model as the area around the plant changes (update the assumed surface roughness and re-run).
+Making coffee involves heat, mass, and momentum transfer across multiple phases – pretty standard stuff for undergraduate chemical engineering curricula. On the other hand, while industrial scale leaching operations are generally designed for maximum efficiency – removing the most amount of a substance with the least amount of solvent, energy, etc. – coffee makers are specifically designed to avoid that outcome. A saturated cup of coffee would be strong, harsh, and undrinkable. Coffee making, as a unit op, aims at a managed inefficiency, which makes for an interesting design case1
+1 I am not the first person to think of this: using coffee as a basis for exploring engineering concepts is the entire premise of this book. From the reviews it sounds like it is, essentially, a lab manual for exploring chemical engineering concepts using coffee.
I claimed that making coffee is, in a sense, a deliberately inefficient process. By this I mean the goal is not to maximize extraction – defined as the mass of solids dissolved in the final cup of coffee relative to the starting mass of coffee grounds – but instead to target some middle ground. This is largely because extraction is an imperfect measure of what we actually want. Coffee releases a whole slew of flavour compounds and a good cup of coffee is a balance of all of these. However we have both limited variables to control and limited knowledge of that final composition. Even simply measuring the total dissolved solids (TDS) with a refractometer puts one well into the stratospheric heights of coffee nerd-dom. Trying to monitor all of the relevant flavour compounds would require something like a quarter-million dollar GC-MS, well out of the reach of most coffee obsessives.
+So extraction is really the best we have, as far as quantitative measures go, with the giant caveat that coffee with the same extraction, from the same beans, can taste quite different depending on the brew method. Using an indirect measurement for the actual process variable of interest is not too different from how a lot of unit operations are controlled, distillation, for example, often uses temperature as a proxy for the composition.
+ +
+2 Batali, Ristenpart, and Guinard, “Brew Temperature, at Fixed Brew Strength and Extraction, Has Little Impact on the Sensory Profile of Drip Brew Coffee,” fig. 1.
The standard way of thinking about coffee extraction starts with Lockhart’s coffee control chart, this plots the concentration of solids (TDS) against total extraction. The diagonal lines represent a given dose of coffee (I typically brew 55g/L with my V60, which puts me pretty near the sweet spot). A given brew moves along the diagonal line for the given dose, moving from the bottom left to the upper right as the brew proceeds. The goal is to stop the brew once the extraction and strength (concentration) have reached the optimal level3:
+3 For a given dose of coffee, the concentration and extraction are directly proportional to one another.
+where the subscript cup means the mass/volume that ends up in the final cup of coffee. This is only approximately the case as some water is absorbed into the coffee grounds. The amount of water retained in the coffee grounds can be accounted for, giving a more accurate measure of final extraction.
For industrial scale distillation, absorption, extraction, leaching, etc. the process is usually modeled as a series of equilibrium stages, and the whole point is to maximize extraction and concentration. This leads to designs for counter-current solids extractors such as a Rotocel extractor or a Bollman extractor
+ +
+Extractors like this are, in fact, how one might decaffeinate coffee. In that case one does want to maximize the extraction of caffeine, and is free to adjust several parameters such as the solvent (with options such as supercritical CO2, dichloromethane, or ethyl acetate) that are otherwise pretty fixed for normal coffee making. At the end of the day a cup of coffee has to be made with water, a steaming cup of dichloromethane just won’t cut it.
+Coffee makers inhabit a space where the design parameters are highly restricted. Outside of espresso, the machine has to operate at atmospheric pressure and temperatures achievable with a normal kettle. The solvent must be water. The process is likely batch or semi-batch.4 The extraction happens fully within the mass-transfer dominated regime, specifically avoiding reaching equilibrium (the fundamental design assumption in most industrial extractors) as that leads to over-extracted coffee.
+4 I would love to see a fully continuous coffee maker, like the fully continuous industrial operations, and there is no reason why you couldn’t make one. Imagine going into your local coffee shop and seeing a glass fluidized bed continuously circulating grounds and hot water, that would be pretty groovy.
Perhaps the simplest method for making coffee is to put coffee grounds and water in a vessel, add heat, and let it steep for a while. This is, for example, how Turkish coffee is made as well as qahwa, bunna, and many others. A French press and other infusion brewers are a very similar idea except that the water is also the source of heat, and the pot is left to steep without any additional heat input. That’s not the only difference, of course, they differ quite substantially in grind size, whether or not the grounds are strained out at the end, and in the addition of spices or sugar during the brew. But for the purposes of building a simple model all of these methods are vessels in which coffee steeps in hot water. There are three main process variables that impact coffee extraction, and taste, for a given set of beans: brew temperature, grind size, and brew time.
+In some ways this makes these methods some of the easier ways to make good coffee. Dialing in grind size and temperature is reasonably straight forward and once set remain constant. The remaining variable, time, is relatively easy to adjust: simply wait longer.
+Modeling extraction is fairly straight forward, after some basic assumptions are made: that the brew is isothermal, that the ground coffee is uniform and with constant dimensions, and that the liquid phase is well mixed. All of these assumptions are wrong to some degree, and how wrong they are will ultimately govern how useful this model is.
+Brew temperature is an obvious variable to change, though it has wide ranging impacts and parsing out what exactly changing the temperature does is not obvious. Firstly, the solubility of the various compounds extracted from the beans is a function of temperature and in general solubility is difficult to predict, but broadly speaking solutes are more soluble at higher temperatures. Coffee is more extractable at higher temperatures. However the coffee matrix is complex and there are more than just two phases involved: flavour compounds in the coffee will partition between the solid matrix, coffee oils, and the water at different proportions depending upon the temperature. This is perhaps what is behind the notable difference in taste between cold brew versus a hot immersion brew. Even when made with the same beans, and to the same concentration, the flavour profile of cold brew is quite different.5 That said, over the range of temperatures used to brew a French press, this may not be very important.6
+5 Batali et al., “Sensory Analysis of Full Immersion Coffee”.
6 Batali, Ristenpart, and Guinard, “Brew Temperature, at Fixed Brew Strength and Extraction, Has Little Impact on the Sensory Profile of Drip Brew Coffee”.
7 Schwartzberg, “Leaching – Organic Materials,” 558; Poling, Prausnitz, and O’Connell, The Properties of Gases and Liquids, 11.21–33.
Secondly, brew temperature impacts the rate of extraction. Generally speaking, diffusion coefficients are proportional to (absolute) temperature, .7 At higher temperatures the various flavour compounds will diffuse more quickly through the grounds and also through the coffee, thus making the brew faster.
To make modeling extraction simpler, we assume the brew temperature is constant. This means that, whatever the relative solubilities or rate constants turn out to be, they are constant with respect to time. The only thing varying over time is the concentration of coffee solubles in water and remaining in the grounds. For something like Turkish coffee, the system is probably close to isothermal as it is continuously heated and will remain at or near the boiling point of water the entire time. For a French press this is less true, as the press will lose heat to the environment. How much heat is lost over the course of the brew is going to depend strongly upon the press and the environment it is in. My French press is a double walled stainless steel carafe like this one and likely loses much less heat than a more typical glass carafe. It is also important to consider whether or not the French press is pre-heated. If not, the brew temperature is not going to be the temperature of the kettle. The carafe has significant thermal mass, especially if it is glass, and it will absorb a lot of heat out of the water over the course of the brew (in addition to losing heat to the environment).
+Suppose my French press starts off at 95°C and cools to 75°C – a sizable loss of heat – how much impact would that have on extraction rate? Since , the percent change in the rate constant is equal to the percent change in (absolute) temperature
ΔT = 20
+T = 368.15
+ΔT / T = 0.054325682466385986Even over this significant loss of heat, that translates to only a 5.4% change in the rate constants. To the exacting standards of a coffee nerd that may seem like a lot, but to chemical engineer that is really not much, it justifies the isothermal assumption (at least as a first approximation).
+Grind size is important if only for being where most of your money can get sunk when building out your home coffee set-up. A good grinder is not cheap, and a bad grinder leads to truly bad coffee. In this case what you are chasing is the ability to tune the average grind size as well as the uniformity of the size of particles produced by the grinder. A good grinder can reliably produce a consistent and suitably narrow particle size distribution.
+Why does grind size matter at all? The grind size determines the available surface area of the coffee. Mass transfer from the coffee beans (grounds) to the water is proportional to the surface area of coffee exposed to water, and so changing the grind size directly impacts the rate of extraction. The direct impact of grind-size is typically quantified through the specific area, av, which is the surface area of the particle per unit volume. For a sphere this is
+where b is the radius of the particle. This leads immediately to the observation that, for the same dose of coffee, a finer grind leads to larger overall surface area and thus a faster rate of extraction. It also hints at why a uniform particle size distribution is important: a smaller particle has proportionately more surface area and will experience faster extraction than a larger particle, leading to the smallest particles (the fines) being over extracted while the largest particles (the boulders) are under extracted.
+Of course coffee grounds are not perfect spheres, they have a complex shape arising from the combination of cutting and brittle fracture that characterize the grinding process. The standard engineering approach is to assume that they are spheres anyways, since that is a simpler geometry to work with, and adjust for the non-sphericity with some sort of shape factor or other parameter. In the case of mass and heat transfer, typically that is the Sauter mean diameter (or Sauter mean radius), which is essentially the average diameter of the distribution of spheres that would have the same specific area as the actual particles. For an individual particle the Sauter radius is
+It is important to note, though, that the following model is developed for spheres and only works as well as the grounds can be approximated as spheres.
+Mass transfer problems, like this one, ultimately come down to finding good rate constants. They can be measured, estimated from a correlation, or simply tabulated in a reference, but regardless the model is only as good as the rate constants. The rate constants define, to some extent, the model itself and govern one of the key brew variables: brew time.
+In the case of coffee, and organic materials in general, there is a complex micro-scale geometry involving multiple phases: the solid ground itself, coffee oils, and water. The coffee will diffuse from the solid into the oils, into water in the interstitial spaces, and also out into the bulk liquid. All of these processes have potentially different rate constants. Additionally the solid phase is not structurally homogeneous, it is a complex arrangement of coffee bean cells, voids, pores and such. Building a model to incorporate all of this complexity is certainly possible8 but the standard approach is to treat this as a two-phase problem where all of the complexity of the solid phase, the marc, and any secondary phases (e.g. coffee oils) are all averaged together into one pseudo-homogeneous solid phase and the solvent (water) forms the liquid phase. This approximation leaves us with two mass transfer rates: the diffusion through the (pseudo-homogeneous) solid phase, within the coffee particles, and the diffusion through the solvent phase, the water outside of the coffee particles. At the interface, the solute leaves the solid phase and enters the liquid phase.
+8 Moroney et al., “Modelling of Coffee Extraction During Brewing Using Multiscale Methods”.
9 Schwartzberg, “Leaching – Organic Materials,” 557.
For organic material with hard cell walls the relative diffusivity of the solid phase to the liquid phase generally falls along the range ,9 this allows us to estimate the (effective) diffusivity within the solid based on measured diffusivities in liquid water. It also tells us that diffusion through the solid is 5-10× slower than in the liquid phase and so, depending upon the geometry of the problem, diffusion through the solid phase may be the governing rate.
Diffusion through the liquid phase is complicated by mixing. The diffusivity used above is the diffusivity in quiescent liquid water. In practice, in the brew vessel, the liquid will be moving and convective mass transfer will be very significant. Usually for mass transfer problems this is all rolled up into a mass transfer coefficient h which combines all of the flow complexity and geometry of the problem into a single coefficient. This is then typically estimated using correlations for the Sherwood number.
+The interface between the solid and liquid phase introduces a complication as there is some partitioning between the phases happening at the interface. If there wasn’t coffee couldn’t be made. A critical piece of the model is assuming a relationship between the concentration immediately on the solid side of the interface and the concentration immediately on the liquid side of the interface. For organic leaching it is typical to assume linear equilibrium with an equilibrium distribution coefficient
+Where q is the concentration of solute in the solid phase and c is the concentration of solute in the liquid phase. This is equivalent to assuming that there are two first order processes happening
+At equilibrium the rates of these two processes are equal
+Typically one assumes that at the interface, in the infintesimally thin slice of liquid on one side and the infintesimally thin slice of solid on the other, the solute is always at equilibrium (this is not the same as assuming the system is at equilibrium)
+At this point we can start defining what our specific brew is going to be: roast, grind size, dose, and water temperature. From this we can work to estimate the necessary parameters, such as the equilibrium constant, solid and liquid phase diffusivities. To an extent, these parameters then govern what specific model is used to model the brew.
+# properties of the coffee grounds
+# equilibrium parameters
+# Moroney et al. 2015
+q_sat = 118.95 # kg/m³
+c_sat = 212.4 # kg/m³
+K = q_sat/c_sat
+
+# effective diffusivity
+# Moroney et al. 2015; Schwartzberg 1987, 557
+𝒟ₗ = 2.2e-9 # m²/s
+𝒟ₛ = 0.1*𝒟ₗ
+
+# particle size
+# Moroney et al. 2015
+b = 569.45e-6 # m
+
+# density, medium roast
+# Rodrigues et al. 2002, 8
+ρₛ = 314.0 # kg/m³
+
+# dose
+# assumed, 22.5g in 500mL
+mₛ = 0.0225 # kg
+Vₛ = mₛ/ρₛ # m³
+Vₗ = 500e-6 # m³# properties of the water
+# density
+# Poling et al. 2007, 2-103
+MW = 18.015 #kg/kmol
+function ρₗ(T)
+ τ = 1 - T/647.096
+ mol_dens = 17.863 + 58.606*τ^0.35 - 95.396*τ^(2/3) + 213.89*τ - 141.26*τ^(4/3)
+ return mol_dens*MW
+end
+
+# viscosity
+# Poling et al. 2007, 2-432
+μₗ(T) = exp(-52.843 + 3703.6/T + 5.866*log(T) - 5.879e-29*T^10)
+νₗ(T) = μₗ(T)/ρₗ(T)
+
+# brew temperature
+# assumed, 95°C
+Tₗ = 95+273.15 #K
+
+# initial concentration
+c₀ = 0.0 # kg/m³
+
+# final (max) concentration
+c_max = min(q_sat*Vₛ/Vₗ + c₀, c_sat) # kg/m³These are a lot of parameters and I think it is good practice to think about how to organize them into a struct. In this case I define an InfusionBrew struct to store all of the parameters necessary for defining the brew recipe for an infusion brewer.
struct InfusionBrew{T}
+ K::T
+ q_max::T
+ c_max::T
+ Vₗ::T
+ Vₛ::T
+ mₛ::T
+ 𝒟ₛ::T
+ 𝒟ₗ::T
+ b::T
+end brew = InfusionBrew(K,q_sat,c_max,Vₗ,Vₛ,mₛ,𝒟ₛ,𝒟ₗ,b);Pulling together all of the information we have collected about coffee we can build a partial differential equation to describe the brewing process, making the following assumptions:
+We can visualize this set-up with three “phases”, the bulk liquid, a thin film around the coffee particle, and the pseudo-homogeneous solid coffee particle itself. Coffee is extracted from the particles into the thin film and from the thin film into the bulk liquid.
+ +
+There are two rates important processes governing the extraction of coffee:
+Starting with (1) the mass flux into the thin film is given by Fick’s first law (in spherical coordinates)
+Of course the concentration in the solid, q, is a function of time (as more is extracted, there less left behind), which is given by Fick’s second law (in spherical coordinates)
+Turning to (2) the mass flux from the thin film into the bulk liquid is given by
+Where c is the concentration in the bulk liquid and cs is the concentration at the surface.
+The change in concentration in the bulk liquid with respect to time can also be written in terms of a mass balance on the liquid phase:
+The solution to this partial differential equation depends upon which of these mass transfer processes, (1) or (2), is dominant.
+The standard approach to solving this problem is to look at the limiting cases, where the Biot number is either very large or very small10
+10 Seader, Henley, and Roper, Separation Process Principles, 663.
11 The intermediate solution is not given in Seader, Henley, and Roper, Separation Process Principles, only a reference: Schwartzberg, Henry G. and R. Y. Chao. 1982. “Solute Diffusivities in Leaching Processes.” Food Technology. 36, no. 2: 73-86, which has not been digitized and is not available from my local library, so I have no idea what it says ¯\_(ツ)_/¯
12 Conduction of Heat in Solids, 240–41.
13 Seader, Henley, and Roper, Separation Process Principles, 663.
I will argue in a very hand-wavy way that the Biot number for mass transfer is likely to be large, and so the model from Carslaw and Jaeger12 is the probably the best model. First let’s start with Biot number for mass transfer, which for this situation is13
+Where Sh is the Sherwood number, defined as
+Defining the Biot number in terms of the Sherwood number might, at first glance, not seem tremendously useful. However, if we suppose the Froessling equation14 for flow past a single sphere applies
+14 Hottel et al., “Heat and Mass Transfer,” 5–69.
with Re the Reynold’s number and Sc the Schmidt number, then we have a correlation for the Biot number as a function of the Reynold’s number.
+Where = 0.1 is assumed from Schwartzberg15 The Schmidt number, Sc, and equilibrium constant, K, can be calculated
15 “Leaching – Organic Materials,” 557.
Sc = νₗ(Tₗ) / 𝒟ₗ = 139.98370415887905
+K = q_sat / c_sat = 0.5600282485875706
+
+Bi = 35.7124842370744 + 51.178588534736114 √ReUnder this model, any flow with Re > 10.3 corresponds to Bi > 200, which occurs when the velocity is
+Re = 10.3
+
+v = Re*νₗ(Tₗ)/b0.005570341094459917that is 5.6mm/s, a velocity so small that it may be achieved through the natural convection occurring within a French press (and especially so in the case of something heated from below like Turkish coffee), but is certainly the case when the French press is stirred.
+Regardless it is unlikely that and thus the simple exponential model is probably not a good fit, we turn instead to the model from Carslaw and Jaeger.16
16 Conduction of Heat in Solids.
In the above I casually disregarded boundary conditions, focusing instead on refining the model. Before we move forward we should take a moment to clarify what the boundary conditions are.
+First off the coffee starts with a set of initial concentrations q0 and c0, usually these would be the max concentration in the solid phase and zero respectively but they don’t have to be. By disregarding the transfer through the thin film we impose another boundary condition: that at r = b the solid-phase concentration is at equilibrium with the concentration in the bulk liquid qr=b = K c
+It might, at first glance, appear that I have lost the thread, Carslaw and Jaeger17 is a book on heat transfer, this is a mass transfer problem. This is an example of the unreasonable effectiveness of treating transport phenomena as a unified subject. By putting the PDE into dimensionless form we find that the PDE for the equivalent heat transfer problem (a solid sphere cooling in a liquid) has already been solved and we can just use that answer.
+17 Carslaw and Jaeger.
First step, to put the PDE in dimensionless form we make the substitutions:
+After which the PDE becomes
+With boundary conditions
+And the mass transfer into the liquid bulk becomes
+With and boundary condition
This is the equivalent PDE (in dimensionless form) to the heat transfer case for a hot solid sphere cooling in a well mixed fluid,18 with the solution
+18 Carslaw and Jaeger, 240–41; Bird, Stewart, and Lightfoot, Transport Phenomena, 379–81.
Where the xk s are the roots of the equation
+(the particular form shown here comes from Schwartzberg19)
+19 “Leaching – Organic Materials”.
The first problem, when actually using this solution, is generating the roots of the equation. The original equation has a repeated singularity and, in my experience, off-the-shelf root finding algorithms have trouble with that and will find spurious zeros in the vicinity of the singularities.
+A better approach is to re-write it in a different way
+This latter form is nice and continuous, with no singularities.
+using IntervalRootFinding
+using Roots
+
+α = Vₗ/(K*Vₛ)
+
+f(x) = tan(x) - 3x/(3+α*x^2)
+g(x) = (3 + α*x^2)*sin(x) - 3x*cos(x)
+
+# find the first 5 roots
+k=5
+xk = find_zeros(g, 0, (k+1/2)*π)6-element Vector{Float64}:
+ 0.0
+ 3.214656575481129
+ 6.321030394109289
+ 9.45018248676156
+ 12.585470558898335
+ 15.723260568418107Since α is fixed for a given problem we will end up using the same roots over and over again, so it would be nice to pre-calculate those roots. However, at this point, we don’t know how many we will need to get a reasonable answer. So my approach is to calculate as many as we need dynamically: if we need more roots than have already been calculated, calculate those ones and append them to the list of already calculated roots.
+function getroots(n)
+ if n ≤ length(xk)
+ return xk[2:n]
+ else
+ new_roots = find_zeros(x -> g(x), xk[end], (n+1/2)*π)
+ append!(xk, new_roots)
+ return xk[2:end]
+ end
+endThe standard approach to calculating an infinite series is to use Richardson extrapolation as this accelerates convergence and allows for an error estimate.
+using Richardson:extrapolate
+
+function u_f(τ)
+ val, err = extrapolate(1, x0=Inf) do N
+ xk = getroots(Int(N))
+ 6α*(α+1)*sum( exp.(-τ.*(xk.^2))./((9*(α+1)).+(α.*xk).^2) )
+ end
+ return val
+endNow we can put together a bulk concentration function
+function c(t)
+ τ = (𝒟ₛ*t)/b^2
+ c = (c₀ - c_max)*u_f(τ) + c_max
+ return c
+endExtraction is simply concentration over dose
+extraction(t) = c(t)*Vₗ/mₛAt this point we have enough to put together a struct to contain the parameters needed for the Carslaw and Jaeger model
struct CarslawSolution{T}
+ α::T
+ τ₁::T
+ xk::Vector{T}
+ ib::InfusionBrew{T}
+end
+
+function CarslawSolution(ib::InfusionBrew)
+ α = ib.Vₗ/(ib.K*ib.Vₛ)
+ τ₁ = ib.𝒟ₛ/ib.b^2
+ xk = find_zeros( x -> (3 + α*x^2)*sin(x) - 3x*cos(x) , 0, (10.5)*π)
+ return CarslawSolution(α, τ₁, xk, ib)
+endand update our code to add some methods for calculating the concentration and extraction based on a Carslaw and Jaeger model for the infusion brew.
+function getroots(n, model::CarslawSolution)
+ if n ≤ length(model.xk)
+ return model.xk[2:n]
+ else
+ new_roots = find_zeros(x -> (3 + model.α*x^2)*sin(x) - 3x*cos(x),
+ model.xk[end], (n+1/2)*π)
+ append!(model.xk, new_roots)
+ return model.xk[2:end]
+ end
+end
+
+function c(t, model::CarslawSolution)
+ τ = model.τ₁*t
+ α = model.α
+ u_f, err = extrapolate(1, x0=Inf) do N
+ xk = getroots(Int(N), model)
+ 6α*(α+1)*sum( exp.(-τ.*(xk.^2))./((9*(α+1)).+(α.*xk).^2) )
+ end
+ c = (c₀ - c_max)*u_f + c_max
+ return c
+end
+
+extraction(t, model::CarslawSolution) = c(t, model)*model.ib.Vₗ/model.ib.mₛsol = CarslawSolution(brew);The advantage of packaging code like this is that is now easy to explore the impact of changes to individual parameters, for example below is the impact that changing grind size has on the extraction curve. It follows our general intuition that smaller grind sizes extract faster. It also shows a major weakness of this model: there is only one particle size in the model, which is average over the range of actual particle sizes. This model works well if the grind is quite uniform, however if there is a wide range of particle sizes the actual coffee will be a mix of over extracted coffee (from the small particles) and under extracted coffee (from the large particles).
+I think this shows that making coffee can be an interesting exploration of how one would go about building a mass-transfer model for an extraction operation, and going through the stages of simplifying the model by, for example, assuming simpler geometries, limiting cases and such. I think you could also take this as an example of how very often chasing down appropriate model parameters is the limiting step when building an engineering model (at least in chemical engineering). Often the exact chemical process that you want to model has not been explored, experimentally, over the entire range of your process variables (if at all).
+The next obvious step with this model is to build some datasets and fit some of these models to actual observed extractions. This could be a jumping off point for exploring how changes in different parameters impact the overall extraction or required brew time.
+In anticipation I had ordered an Atmotube PRO as a relatively cheap and portable solution – something I can also hang from my backpack for when I travel. Just due to poor timing on my part, it did not arrive until part-way through the day on Saturday, May 20th, and I couldn’t use it to capture the impact of the smoke arriving as it was well and truly already here. That did not stop me from setting up two experiments, one to measure the rate of infiltration and another to demonstrate (to myself really) the effectiveness of a remedy.
+On Sunday, May 21st, I ran a very simple experiment to measure the ventilation rate in my bedroom (i.e. the rate of air infiltration). I live in an older apartment building with radiant heat, which makes my bedroom somewhat perfect: It has no vents or other connections to adjacent rooms, heat comes only from the radiators which are turned off (it’s summer). My bedroom has an older aluminum frame window, of the sort common with other apartments of the same vintage in my neighbourhood.
+The set-up was quite simple: I ran a portable HEPA filter in my bedroom, with the door closed, to maintain the particulate concentrations at a low level (more on that later) until 2:15pm. At that point I turned off the filter, left the room, and blocked off the gaps beneath the door with a wet towel. I left the atmotube sitting in the middle of the room, passively collecting at 15 minute intervals. A little over 10 hours later I returned and turned the HEPA filter back on, ending the experiment. I waited until Sunday to run the experiment as I had plans that day and knew I would be out of the apartment and thus not be tempted to go in the room for several hours.
+A house on the same block as my apartment building has a purple air outdoor air quality monitor mounted in their yard and the data is available at a 10-minute frequency through the purple air real-time air quality map. Using this and the data from the atmotube, I should be able to fit a simple building infiltration model.
+The purple air monitor can output the raw pm2.5 concentrations as a csv, which is easily imported into julia. As a first step I define when the experiment started such that I can also calculate how much time has elapsed – it is going to be easier to work with a time variable that is just a number starting at 0 when the experiment started than datetime objects. The default units of time, in julia, are milliseconds however the more convenient units for building ventilation are hours and so the time variable here is in hours.
+using CSV, DataFrames, Dates, Pipestart = DateTime(2023,5,21,14,15)2023-05-21T14:15:00The purple air monitor has dual particle count sensors, labeled in this dataset as “Purple Air A” and “Purple Air B”, for convenience I take the average of the two as the outdoor concentration.
+using Statistics: mean
+
+outdoor = @pipe "data/22_May_2023_raw-pm25-gm.csv" |>
+ CSV.read( _ , DataFrame, dateformat="yyyy-mm-dd HH:MM:SS") |>
+ transform( _ , AsTable(["Purple Air A", "Purple Air B"]) => ByRow(mean) => :pm25) |>
+ transform( _ , :DateTime => ByRow((x) -> Dates.value(x - start)/(3600*1000)) => :time);The atmotube outputs a whole bunch of stuff in one csv, including temperature, barometric pressure, VOCs, pm1, pm2.5 and pm10, I am only interested in the pm2.5s. That said, the csv has one serious issue: it implements a zero-order hold on data. There are pm2.5 values for every minute however the pm2.5 values are not sampled every minute, the atmotube holds the last value for all the minutes in between measurements. This is a problem as I am fitting a model to this data and I need the actual data at the times it was taken.
+raw_indoor = @pipe "data/C22B42153089_22_May_2023_00_43_32.csv" |>
+ CSV.read( _ , DataFrame; dateformat="yyyy-mm-dd HH:MM:SS") |>
+ sort!( _ , :Date);To retrieve only the actual measured data, and not the filled in rows, I create a new dataframe and walk through the raw data keeping a data point if it differs from the previous one or if more than 15 minutes have elapsed. Rows where the concentration value has not changed, and it has been less than 15 minutes from the last update, are assumed to be filled in rows and not “real”.
+last_good_data = raw_indoor[!, "PM2.5, ug/m3"][1]
+last_good_datetime = raw_indoor[!, :Date][1]
+
+indoor = DataFrame(datetime = DateTime[], meas = Float64[], time = Float64[])
+
+for r in eachrow(raw_indoor)
+ dt = r[:Date]
+ meas = r["PM2.5, ug/m3"]
+ time = Dates.value(dt - start)/(3600*1000)
+
+ if meas != last_good_data
+ last_good_data = meas
+ last_good_datetime = dt
+ push!(indoor, [dt, meas, time])
+ elseif Dates.value(dt - last_good_datetime) > 15*60*1000 # more than 15 minutes
+ last_good_data = meas
+ last_good_datetime = dt
+ push!(indoor, [dt, meas, time])
+ else
+ continue
+ end
+endPlotting the data looks encouraging (as far as fitting a model goes, not encouraging if one wanted to spend time in there breathing) as the particulates appear to be infiltrating with a rate proportional to the difference between the concentrations – the standard building infiltration model.
+ +
+The type of fit I am doing is quite simple: I am fitting a differential equation to the indoor concentration while taking the outdoor concentration as a parameter of the model. Thus I need the outdoor concentration as a continuous function of time and, for simplicity, I am using a linear interpolation of the measured outdoor concentration.
+using Interpolations: linear_interpolation, Flat
+
+cₒ = linear_interpolation(outdoor.time, outdoor.pm25, extrapolation_bc=Flat());To start, I define the differential equation that I am going to be fitting to the measured indoor concentration. This is the simple linear model for building infiltration
+Where c is the indoor concentration, co the outdoor concentration, and λ is the ventilation rate in units of h-1.
+using OrdinaryDiffEq
+
+# the model
+f(c, λ, t) = λ*(cₒ(t) - c)
+
+# initial condition
+c0 = indoor.meas[1]
+
+# timespan
+tspan = (0, indoor.time[end])
+
+# parameters
+p= [0.5] #initial guess of λ=0.5
+
+prb = ODEProblem(f, c0, tspan, p)Now I define the fit itself: with the cost function as the L2 loss between the measured indoor concentration and the predicted indoor concentration.
+using DiffEqParamEstim: build_loss_objective, L2Loss
+
+lossfn = L2Loss(indoor.time, indoor.meas)
+
+cost_function = build_loss_objective(prb,Tsit5(),lossfn,
+ maxiters=10000,verbose=false);Then using the Optim package to find the parameter λ which minimizes the cost function.
using Optim: optimize
+
+result = optimize(cost_function, 0.0, 1.0)Results of Optimization Algorithm
+ * Algorithm: Brent's Method
+ * Search Interval: [0.000000, 1.000000]
+ * Minimizer: 7.848374e-02
+ * Minimum: 1.517807e+03
+ * Iterations: 35
+ * Convergence: max(|x - x_upper|, |x - x_lower|) <= 2*(1.5e-08*|x|+2.2e-16): true
+ * Objective Function Calls: 36I can then retrieve the ventilation rate for my bedroom
+λfit = result.minimizer[1]0.07848373551388874prb = ODEProblem(f, c0, tspan, λfit)
+fit = solve(prb, Tsit5()); +
+I think this simple linear model works relatively well, all things considered. A more fulsome model would have treated the ventilation rate as a function of air pressure, windspeed, and the difference between indoor and outdoor temperatures.
+There are also a few weaknesses in the experimental design, beyond the quality of the sensors. For one I didn’t seal my door perfectly, and so there was some exchange with the rest of my apartment which had a much lower particulate concentration. I am also assuming that there is no deposition or adhesion of particulates when passing through the small leaks around my window. It’s possible that some particulates are being lost along the way, which would impact this. The placement of sensors could also be an issue, especially the outdoor ones: I live in a neighbourhood full of large apartment buildings and that creates complex wind patterns, I also live several stories up whereas the purple air monitor is at ground level. A better location would have been on my balcony, adjacent to the bedroom window.
+But I think as a first pass, and especially for screening potential shelter in place locations, something as simple as this could work and the time investment is very minimal. It’s major weakness is that the key variable, the outdoor concentration, is not controlled and this whole exercise is dependent upon the whims of wildfire smoke and on the individuals responsiveness to smoke forecasts.
+After all that time measuring how rapidly the particulates infiltrated a room, what is to be done? The air quality in Edmonton has been poor for several days on end. Without any sort of mitigation my bedroom would be well above the limits and would be unhealthly to be in and yet that’s where I sleep. The solution is either installing furnace air filters with a high MERV rating or, in places like mine that lack central air, using a portable fan with a HEPA filter. I picked up a portable air filter from IKEA and similar ones are available from many places, and can be made by hand. Unfortunately, dangerously high levels of pm2.5s are invisible and generally undetectable to one’s senses, so without some sort of monitoring one is left merely trusting that the system is doing what it is supposed to be doing.
+I tested my IKEA unit on Saturday night in a similar manner to the building infiltration test: I turned off the unit, closed my bedroom door, and left the space to accumulate particulates for several hours. Then, before I went to bed, I went in and turned it on. Throughout this the atmotube was located in the middle of the room collecting data. From the plot below it is clear that the air filter works: the indoor particulate concentration drops rapidly and stays at a low level throughout the night, even as the outdoor concentration rises to very high levels.
+indoor_hepa = @pipe "data/C22B42153089_21_May_2023_10_05_00.csv" |>
+ CSV.read( _ , DataFrame; dateformat="yyyy-mm-dd HH:MM:SS");
+
+outdoor_hepa = @pipe "data/21_May_2023_raw-pm25-gm.csv" |>
+ CSV.read( _ , DataFrame, dateformat="yyyy-mm-dd HH:MM:SS") |>
+ transform( _ , AsTable(["Purple Air A", "Purple Air B"]) => ByRow(mean) => :pm25); +
+Using wildfire smoke to measure the ventilation rates of different buildings, or rooms in buildings, is certainly a niche activity. I don’t imagine there are many places where it is important to screen for safe shelter-in-place locations that also experience significant wildfire smoke events regularly. That does describe the petrochemical industry in Alberta, wildfire smoke is a regular occurrence now, and perhaps locations along the west coast, but it’s not universal.
+That said I wonder if this might be a more broadly useful activity when planning for how to manage indoor air quality beyond industry. The office building I work in struggles with indoor air quality during smoke events like this one whereas my home office does not because I have invested in HEPA filters and simple air monitoring. Perhaps schools, offices, and other places could use similar techniques to screen spaces for interventions. Rooms with high ventilation rates could benefit from interventions such as better sealing around windows. Perhaps the plastic sheeting used to seal drafty windows in the wintertime could find a second use during wildfire season. In this way the air filters themselves are being used more effectively: an air filter can manage a larger space if that space has a low ventilation rate.
+Currently a lot of the advice is merely to stay indoors, with little acknowledgment that indoors is often severely polluted as well.
+ + +As a re-cap the Britter-McQuaid model1 is a series of correlations for the dispersion of denser than air gases. These are given as a series of correlation curves and the typical procedure is to interpolate the downwind distance to the concentration of interest, for example to the Lower Flammability Limit (LFL). The model also gives some equations for estimating the plume horizontal and vertical dimensions, where conventional practice is to assume the plume has a rectangular cross-section and a uniform concentration.
+1 Britter and McQuaid, “Workbook on the Dispersion of Dense Gases”.
Just to have some numbers to look at, I am going to use a scenario adapted from the Burro series of trials of LNG dispersion.2 The release conditions are:
+2 AIChE/CCPS, Guidelines for Consequence Analysis of Chemical Releases., 122.
The goal is to find the distance to the lower flammability limit (LFL) which is 5%(v/v) and ultimately work out the extent of the plume and total explosive mass.
+using Unitful
+
+Tₐ = 288.15u"K" # ambient air temperature
+ρₐ = 1.225u"kg/m^3" # density of air at 15°C and 1atm
+u₁₀ = 10.9u"m/s" # windspeed at 10m
+
+ρₗ = 425.6u"kg/m^3" # liquid density of LNG, given
+ρᵥ = 1.76u"kg/m^3" # vapour density of LNG, given
+ṁ = ρₗ*0.23u"m^3/s" # mass release rate
+Tᵣ = (273.15 - 162)u"K" # boiling point of LNG, given
+LFL = 0.05 # lower flammability limit, volume fraction
+
+Qₒ = ṁ/ρᵥ # gas volumetric flowrate: mass flowrate divided by gas densityFirst calculate the critical length, D, and the dimensionless parameter α for the model
+D = √(Qₒ/u₁₀)
+
+g = 9.806u"m/s^2"
+gₒ = g * (ρᵥ - ρₐ )/ ρₐ
+α = 0.2*log10(gₒ^2 * Qₒ / u₁₀^5)Then, using digitized curves,3 work out the points for the linear interpolation in terms of
3 AIChE/CCPS, 118.
Cs = [ 0.1, 0.05, 0.02, 0.01, 0.005, 0.002]
+βs = [ 0.24*α+1.88, 0.36*α+2.16, 0.45*α+2.39, 0.49*α+2.59, 0.59*α+2.80, 0.39*α+2.87]These points only cover the middle region of the concentration curve, where the concentration ratio, , is between 0.1 and 0.002, there is a near-field correlation that needs to be connected for concentration ratios >0.1
function Cm_nf(x′)
+ if x′ > 0
+ return 306/(306 + x′^2)
+ else
+ return 1.0
+ end
+end
+
+xnf = 30
+βnf = log10(xnf)
+Cnf = Cm_nf(xnf)And a far field correlation for when the concentration ratio is <0.002 which is basically just continuing the curve from the last point but such that the concentration decays with 1/x2
+xff = 10^(maximum(βs))
+A = minimum(Cs)*xff^2
+
+function Cm_ff(x′; A=A)
+ return A/x′^2
+endFinally, putting together the pieces: near field correlation, a linear interpolation for the middle of the concentration curve, and a far field correlation, to form the complete concentration function, along with a correction for non-isothermal releases (of which this is an example)
+using Interpolations
+
+itp = interpolate( ([βnf; βs],), [Cnf; Cs], Gridded(Linear()) )function Cm(x::Quantity; xnf=xnf, xff=xff, D=D, T′=Tᵣ/Tₐ)
+ x′ = x/D
+ c′ = if x′ < xnf
+ Cm_nf(x′)
+ elseif xnf ≤ x′ < xff
+ itp(log10(x′))
+ else
+ Cm_ff(x′)
+ end
+
+ c = c′ / (c′ + (1 - c′)*T′)
+
+ return c
+end +
+If all one needs is the distance to the LFL there is an easier way of doing this: interpolate the concentrations to find the β corresponding to the LFL (after applying the non-isothermal correction). However, if one also requires the plume dimensions the concentration profile is required.
+From the concentration profile calculating the downwind distance to the LFL is very straight-forward.
+using Roots
+
+xn = find_zero((x) -> Cm(x) - LFL, (300,400).*1u"m", Roots.Brent())354.5630187009715 mAt first glance the workbook seems to be giving the user everything they need to workout the size of the plume, giving the following diagram
+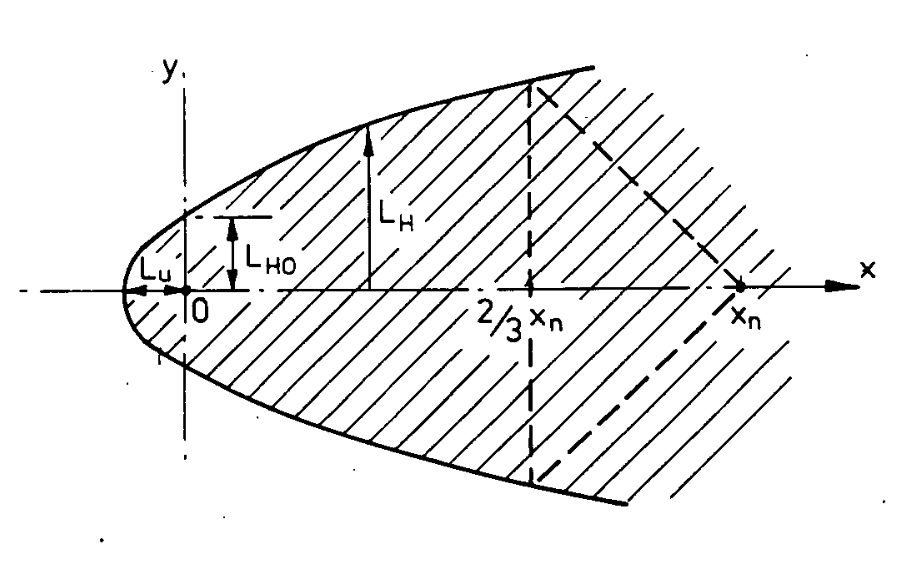 +
+4 Britter and McQuaid, “Workbook on the Dispersion of Dense Gases,” fig. 10.
and the following relations for the labeled distances
+with the buoyancy scale lb defined as
lb = (gₒ*Qₒ)/u₁₀^30.18392758812310803 mLᵤ = D/2 + 2lb1.4973003373658906 mLₕₒ = D + 8lb3.7303110272242135 mLₕ(x) = Lₕₒ + 2.5∛(lb*x^2)The curve given for LH for x > 0 is not the curve for x < 0, the upwind extent of the plume. This is the blue curve in the figure below. The orange curve is slightly adjusting LH such that for x < 0 the second term is subtracted (so the curve actually converges to zero instead of blowing up to +∞ as x → -∞). The black dots are points taken from the diagram given by Britter and McQuaid, using a graph digitizer and scaling to the actual LHo and LU. Clearly the given curve for LH is not at all what is shown in the diagram for the upwind region.
+A conservative approach to estimating the size of the upwind extent is to assume LH = LHo for LU < x < 0, i.e. making the upwind region a rectangle of width LHo and length LU.5 This is the green curve in the figure below.
+5 Bakkum and Duijm., “Vapour Cloud Dispersion”.
Alternatively one could “fit” a curve to hit the end points while also having the same power of x: where LU < x < 0, this at least retains the same general shape and is the red curve in the figure below. I think this should be taken with the giant caveat that I don’t know if insisting on the same power law is truly justified.
 +
+For most typical cases I would think the upwind region would be a small component of the overall plume and taking the conservative, rectangle, approach would be a small error.
+The vertical extent is not given on the diagram, but an equation is given in the text, with the note that this comes from continuity, however I think this is incorrect.
+Suppose a steady state plume with a system boundary such that the plume is sliced along the y-z plane at some downwind distance x. All of the mass entering the plume, from the source, exits the plume through this plane
+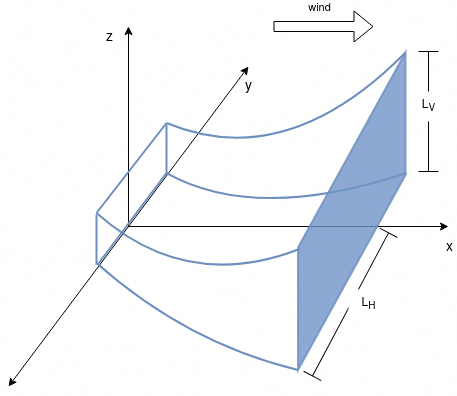
Consider the steady state mass balance
+By the nature of a top-hat model the plume cross section is a rectangle with half-width LH and height LV and the concentration everywhere inside the rectangle is cm. Assuming a constant advection velocity, u, the integral can be simplified to
+The steady state mass balance is then
+and the vertical extent can be solved for with some simple re-arrangement
+Setting the advection velocity of the plume to the reference windspeed gives
+Lᵥ(x) = D^2/(2*Cm(x)*Lₕ(x))This is definitely similar to what is given by Britter and McQuaid but with two big differences:
+The last point could equally be a mistake in the diagram (I have no real way of checking) as while the diagram shows LH as the plume half-width, the text simply refers to it as the “lateral plume extent”, which is ambiguous – do they mean the entire lateral extent or from the center-line of the plume?
+The TNO Yellow Book gives a different equation6 for the vertical extent:
+6 Bakkum and Duijm. equation 4.104.
Which clearly follows from assuming LH is the half-width, and the corresponding figure is labeled as such (using the same equation for LH as Britter and McQuaid). But it doesn’t depend upon concentration.
+I think the vertical extent has to depend upon the concentration as otherwise mass will simply disappear from the plume as it extends downwind. There is also the obvious problem that since the plume lateral extent monotonically increases, and the vertical extent is inversely related to it, the vertical extent is monotonically decreasing. In fact it becomes vanishingly small quite quickly. This entirely the opposite of what is observed with actual dense plume dispersion.
+This can be seen most clearly in the following figure in which the vertical extent is shown as a function of downwind distance along with the mass flowrate in the plume (i.e. )
 +
+I think it is fairly obvious that both the Britter-McQuaid and TNO models give silly answers for the vertical extent. Though the corrected curve, the green curve, clearly has problems too: it has an odd bumpiness, as a result of the linear interpolation, and it is also too small due to both assuming the concentration everywhere is equal to the ground level concentration and due to an overly large advection velocity (the windspeed at 10m is quite a bit higher than the windspeed at ~1m).
+An alternative approach to using the reference windspeed as the advection velocity is to assume the advection velocity is some constant fraction of the reference velocity, e.g. , which is what Britter and McQuaid use for the instantaneous model.
Another alternative might be to use an average windspeed, ū over cross-section of the plume as the advection velocity, assuming windspeed is only a function of height.
+Assuming the windspeed follows a powerlaw distribution gives
plugging it into the simple mass balance
+re-arranging to solve for LV
+The red curve in the figure above is this model, using p = 0.15.7
+7 AIChE/CCPS, Guidelines for Consequence Analysis of Chemical Releases., 83.
This could also be done using the logarithmic windspeed curve where
is the friction velocity and z0 is the roughness length. Though I don’t imagine the expression would work out as nicely.
For the upwind region, assuming a simple rectangular prism with length LU, width 2LHo, height LVo and uniform concentration co is a conservative approach. Likely the plume downwind of the source will be much larger than the upwind area and so this will be a small overestimate.
+The simple mass balance approach to calculating the plume height is a reasonable approach if one simply wants to reference Britter and McQuaid and not have to justify additional assumptions. It is not what is given in the text, but it is what is described in the text. The other models for plume height may be more realistic, in the sense that they represent more realistic advection velocities, and will give larger explosive masses for the plume, however they have not been validated against any actual data. That validation may be a worthwhile exercise but is well beyond the scope of this blog post.
+The explosive mass in the cloud is the given by the volume integral
+where V is defined as the region where c ≥ LFL.8
+8 Some sources recommend 1/2 LFL.
Using the concentration profile and the plume extents, we could work out the function c(x,y,z) such that the concentration is returned if we are:
To determine the explosive mass in the downwind region this might be done by the following
+
+cₒ = ustrip(u"kg/m^3", ṁ/Qₒ)
+
+Lₕ(x::Number) = ustrip(u"m", Lₕ(x*1u"m"))
+Lᵥ(x::Number) = ustrip(u"m", D)^2/(2*Cm(x)*Lₕ(x))
+
+function c(x,y,z; lim=LFL)
+ c_ = Cm(x)
+
+ if c_ ≥ lim
+ if (abs(y) ≤ Lₕ(x)) && (z ≤ Lᵥ(x))
+ return cₒ*c_
+ else
+ return 0.0
+ end
+ else
+ return 0.0
+ end
+end
+using HCubature: hcubature
+
+x_min, x_max = 0, xn
+y_min, y_max = -Lₕ(xn), Lₕ(xn)
+z_min, z_max = 0, Lᵥ(xn)
+
+m_e, err = hcubature( c, [x_min, y_min, z_min], [x_max, y_max, z_max])This is a pretty tedious integration, is very inefficient, and doesn’t take into account any of the structure of the model and it turns out that a top-hat model has some pretty convenient structure.
+Returning to the integral for the explosive mass, the plume can be divided into an upwind region (x < 0) and a downwind region (x ≥ 0)
+with the explosive mass of the downwind region being
+For a top-hat model, since the concentration at a given downwind distance is constant everywhere within the plume cross-section , and, from a mass balance on the plume
which is a constant, thus
+For the explosive mass of the upwind region a simple box model gives . Putting everything together9
9 This is not specific to the Britter-McQuaid model, it works for any top hat model.
This can be simplified greatly by setting the advection velocity to uref
+cₒ = ṁ/Qₒ
+
+mₑ = cₒ*D^2*(Lᵤ+xn)3197.617661470163 kgThis very simple expression is the obvious strength of a top-hat model: it makes calculating the explosive mass incredibly easy.10 It also retroactively justifies why the Britter McQuaid model is oriented around calculating xn: that’s all you actually need.11
+10 Woodward, Estimating the Flammable Mass of a Vapour Cloud.
11 Some sources recommend calculating the explosive mass as the region of the plume with the concentration LFL ≤ c ≤ UFL, in which case
If this seems too good to be true, the integration can be performed numerically by taking
+using QuadGK: quadgk
+
+function ∫∫cdA(x)
+ if Cm(x) ≥ LFL
+ return cₒ*Cm(x)*(2Lₕ(x))*Lᵥ(x)
+ else
+ return 0.0u"kg/m"
+ end
+end
+
+m_ed, err = quadgk(∫∫cdA, 0u"m", xn)
+
+m_eu = 2*cₒ*Lᵤ*Lₕₒ*Lᵥ(0u"m")
+
+m_eu + m_ed3197.617661470163 kgWhich is exactly the same.
+Above I claimed the upwind region was “small” relative to the downwind region, this can be shown easily as the mass in each region is directly proportional to the length.
+Lᵤ/(Lᵤ+xn)0.004205187316042018Since the mass in the upwind region is <0.5% of the total mass in the cloud, I think the simple box model is justified.
+According to Britter and McQuaid the top-hat model generates an overly conservative plume extent and they recommend using given the lateral extent curve up to 2/3 xn and after which connecting to xn using straight lines, as shown in the plume diagram. This makes the integration for explosive mass a little more complicated.
+For simplicity the plume can be divided into three regions, the upwind region (x < 0), the downwind region up to the cutoff (0 ≤ x < 2/3 xn), and the downwind cutoff region (2/3 xn ≤ x < xn )
+The upwind region, me,u, and the first downwind region me,d1 are already known, they are the same as above up to 2/3 xn. What is left to determine is the explosive mass in the cutoff region.
+The integral can be re-written to take advantage of cmA being an invariant for a top-hat model,
+Assuming the vertical extent remains unchanged in this operation, the ratio of areas is the same as the ratio of horizontal extents
+From some simple geometry, the horizontal extent is
+Which then leads to
+There is probably a closed form for this integral but it is just as easy to integrate that numerically.
+mₑ_cutoff = cₒ*D^2*(Lᵤ + (2/3)*xn
+ + 3*Lₕ((2/3)*xn)*quadgk( (x) -> (xn - x)/(xn*Lₕ(x)), (2/3)*xn, xn)[1] )2620.489605856347 kgThis works out to be about 20% less than the original explosive mass.
+mₑ_cutoff/mₑ0.8195131136008078I think the error in the vertical extent may have limited the apparent utility of the Britter-McQuaid model. Most references I have do use the Britter-McQuaid model, noting that it is “reasonably simple to apply, and produces results which appear to be as good as more sophisticated models”,12 however they either claim that it is only good for calculating xn or gloss over how it could be used for anything else. The CCPS references seem consistent in neglecting to mention at all that the model can also estimate the plume extent. So, while I can’t imagine I’m the first person to have noticed that the given equation for LV doesn’t work, I have yet to encounter anyone actually admitting it.
+12 AIChE/CCPS, Guidelines for Consequence Analysis of Chemical Releases., 122.
13 Lees, Loss Prevention in the Process Industries; Casal, Evaluation of the Effects of Consequences of Major Accidents in Industrial Plants.
14 Bakkum and Duijm., “Vapour Cloud Dispersion”.
That said, the correction also seems obvious to me: one simply follows what is described in the text which is exactly how Britter and McQuaid calculated the cloud height for the instantaneous model (which is correct) in the same workbook. That the incorrect equation for LV is repeated in other references,13 with only the TNO Yellow Book14 making a correction, while still repeating a critical mistake, strikes me as very odd.
+The Britter-McQuaid model would seem to be the perfect fit for screening models, which are often only order of magnitude estimates at best anyways. It gives reasonable concentrations, plausible plume extents, and the explosive mass is ridiculously easy to calculate (slightly more tedious if you are using the 2/3 cut-off region but nothing that couldn’t be worked out in advance if this was going to be incorporated into a routine calculation tool).
+To re-cap on what a Gaussian puff model even is: for a short duration release (strictly an instantaneous release) of a neutrally buoyant substance at ground-level, the concentration can be modeled as the product of three Gaussian distributions:
+where
+Where is the mass emission rate, Δt the duration of the release, and u the ambient windspeed. The coordinates are such that the release point is at the origin, the puff moves in the downwind, x, direction while spreading into the crosswind, y, and vertical, z, directions.
The dispersion parameters, σx, σy, σz are all functions of the downwind distance and the atmospheric stability.
+# class F puff dispersion
+# x is in meters
+σx(x) = 0.024*x^0.89
+σy(x) = σx(x)
+σz(x) = 0.05*x^0.61What this generates is an instantaneous release of all of the mass in an infinitesimal point that grows as it moves downwind. This isn’t terribly realistic for releases of any appreciable duration (all of the mass is released instantly in this model), so a common approach is to break up the release into a sequence of n smaller puffs that each capture the mass released over the sub-interval . Taking the limit as
equates to integrating the puff model from t - Δt to t giving a nice solution in terms of the error function erf and … this is where I made the critical mistake.
The dispersion parameters are functions of the downwind distance, but critically..to what? Taken as the downwind distance to the point being calculated, the dispersion parameters are constants (with respect to time) and the problem simplifies to integrating the Gaussian with respect to t, which is what I had assumed. However if the dispersion parameters are actually correlated to the downwind distance of the cloud center, which is
, they are in fact functions of time and this does not work.
This distinction is by no means made obvious in many of the references for chemical hazard analysis. Most are either vague about it or take the dispersion parameters at the downwind distance of the point being calculated. My main reference is the CCPS Guidelines for Consequence Analysis of Chemical Releases and it does this.1 As do several workbooks I have seen. However Lees2 notes that the dispersion parameters for the Pasquill-Gifford puff model (which this is) are given by3
+1 AIChE/CCPS, Guidelines for Consequence Analysis of Chemical Releases., 107–8.
2 Lees, Loss Prevention in the Process Industries.
3 Lees, 15/112.
where C and n are some constants from Sutton, and in general the dispersion correlations are functions of travel time with a lot of discussion in the literature of to what power. The standard correlations for the dispersion parameters come from Slade4 which gives some details on how the measurements were actually taken. It certainly seems to me that the downwind distance was to the cloud center, i.e. the experimenters measured the cloud dimensions at the downwind point to which it had traveled. Which makes the travel time and windspeed implicit.
+4 Slade, Meteorology and Atomic Energy, 117–89.
I think it is a reasonable confusion as the dispersion parameters for a continuous release, a Gaussian plume model, are indeed functions of the downwind distance to the point being calculated. It is also frequently the case that examples are given for the concentration at the cloud center, in which case the downwind distance at the point being calculated is the downwind distance to the cloud center.
+How critical of a mistake is this? For regions far enough from the origin the dispersion parameters do not vary much in the neighborhood of the plume center. This is shown in the plot below where the difference is taken over the interval . At distances further than a few hundred meters the difference is only a few percent. Suggesting that it might not be an unreasonable approximation to assume the dispersion parameters are constants for the purpose of the integral.
 +
+Another way of approaching this is simply to view it as an approximation instead of an error. On the one hand this is a pretty great rhetorical trick: my answer isn’t wrong, it’s just differently true. But it could be the case that this is a useful simplification, just by eye-balling isopleths and looking at limiting behavior in the previous notebook it certainly looked reasonable.
+To make life easier, going forward, I am going to define a unit-less time
and unit-less distances
+where I am abusing notation with the indicates the variable with units, and no
indicates it is unitless. A characteristic length,
, is introduced to make everything unitless and, due to the dispersion correlations
is the most convenient.
We can then explore the performance of different approximations to the integrated puff model by only examining the Gaussian distributions – with no dependence upon or u.
g(ξ,σ) = exp(-0.5*(ξ/σ)^2)/(√(2π)*σ)
+
+gx(x, t) = g((x-t),σx(t))
+gy(y, t) = g(y,σy(t))
+gz(z, t) = 2*g(z,σz(t))
+
+pf(x,y,z,t; Δt) = gx(x,t)*gy(y,t)*gz(z,t)*ΔtThe first type of approximation is to divide the release interval into n sub-intervals and n Gaussian puffs
+function Σpf(x,y,z,t; Δt, n)
+ Δt = min(t,Δt)
+ δt = Δt/(n-1)
+ _sum = 0
+ for i in 0:(n-1)
+ t′ = t-i*δt
+ pf_i = t′>0 ? gx(x,t′)*gy(y,t′)*gz(z,t′)*δt : 0
+ _sum += pf_i
+ end
+ return _sum
+endThe next type of approximation is the one I made in the previous post wherein is integrated with respect to time, treating the σs as constants.
There is a little sleight of hand as I include the downwind distance dependence of the σs after the integration (they aren’t actually constants)
+using SpecialFunctions: erf
+
+function ∫gx(x,t,Δt)
+ Δt = min(t,Δt)
+ a = (x-(t-Δt))/(√2*σx(t-Δt))
+ b = (x-t)/(√2*σx(t))
+ return erf(b,a)/2
+end
+
+∫pf_approx(x,y,z,t; Δt) = ∫gx(x,t,Δt)*gy(y,x)*gz(z,x)Finally, I take advantage of the QuadGK package to numerically integrate the Gaussian puff model, including the time dependence of the dispersion parameters.
using QuadGK: quadgk
+
+function ∫pf(x,y,z,t; Δt)
+ Δt = min(t,Δt)
+ integral, err = quadgk(τ -> gx(x,τ)*gy(y,τ)*gz(z,τ), t-Δt, t)
+ return integral
+endTo give a sense of how these successive approximations work, lets examine a series of slices through the cloud. The first is at a constant x on the center-line of the release, looking at how the concentration changes with time.
+Just by eye-ball the the approximate integral is very close to the numerical exact(ish) integral, as is a large enough number of puffs. Importantly, I think, the approximate integral error is of the same order of magnitude as a large number of puffs – so this is at least as good in a sense as the discrete sum of puffs method, given that we can vary the number of puffs to always make it a better/worse approximation
+ +
+In the crosswind and vertical directions the sum of discrete puffs approximation works decidedly less well, at least at this slice in the cloud, while the approximate integral still works relatively well. I would say it is still at least as good as a sum of discrete puffs for a suitably large number of puffs.
+ +
+ +
+This is, of course, very particular to that point downwind of the release. As we move closer to the origin the integral approximation gets worse, but then so does the sum of discrete puffs model. Especially for a low number of puffs: they become visibly discrete. I think this reinforces that, at least for class F stability, this approximation is in the same ball park as summing over a set discrete Gaussian puffs.
+ +
+Model error is not the only factor in deciding upon an approximation. Since QuadGK exists we have to ask ourselves, why would we not always use it? We can answer that by benchmarking the three approaches at a particular point of interest (I don’t think the choice of point impacts the calculations at all)
using BenchmarkTools: @benchmark
+
+# point of interest
+x₁ = 100
+y₁ = σy(x₁)
+z₁ = σz(x₁)
+t₁ = x₁Starting with the full numerical integration of the model, this is the time to beat. Any approximation that takes longer than ~30μs is literally pointless: it generates worse results and takes longer.
+@benchmark ∫pf(x₁,y₁,z₁,t₁; Δt=10)BenchmarkTools.Trial: 10000 samples with 1 evaluation. + Range (min … max): 28.056 μs … 57.603 μs ┊ GC (min … max): 0.00% … 0.00% + Time (median): 28.200 μs ┊ GC (median): 0.00% + Time (mean ± σ): 28.570 μs ± 1.565 μs ┊ GC (mean ± σ): 0.00% ± 0.00% + █▆▁ ▃▃ ▁▂▁▁ ▁ + ███▇▅██▇▅▄█████▆▆▆▇▆█▇▆▄▃▁▄▄▄▃▆▅▄▄▃▁▃▁▃▁▁▁▁▁▁▁▁▁▃▁▁▁▁▁▄▅▆▇▆ █ + 28.1 μs Histogram: log(frequency) by time 37.7 μs < + Memory estimate: 384 bytes, allocs estimate: 3.+
As we expect, the sequence of discrete puffs is much faster for fewer puffs, and adding an order of magnitude more puffs increases the time by an order of magnitude. At around n=100 we are no longer gaining anything over the full numerical integration. So, if the near-field matters a lot to you, then this is probably not a great approximation as the number of puffs required to approximate the full numerical integration well takes longer than just doing the integration.
+@benchmark Σpf(x₁,y₁,z₁,t₁; Δt=10, n=10)BenchmarkTools.Trial: 10000 samples with 8 evaluations. + Range (min … max): 3.746 μs … 11.498 μs ┊ GC (min … max): 0.00% … 0.00% + Time (median): 3.768 μs ┊ GC (median): 0.00% + Time (mean ± σ): 3.920 μs ± 450.991 ns ┊ GC (mean ± σ): 0.00% ± 0.00% + █ ▅ ▅▂▁▁▂ ▁ + ██▄█▇▅██████▇▆▄▄▄▃▅▄▄▂▄▄▅▃▄▅▅▆▇▇▆▆▇▇▆▆▅▅▅▅▆▅▅▅▅▄▃▅▅▄▅▅▄▄▄▂▃ █ + 3.75 μs Histogram: log(frequency) by time 5.97 μs < + Memory estimate: 16 bytes, allocs estimate: 1.+
@benchmark Σpf(x₁,y₁,z₁,t₁; Δt=10, n=100)BenchmarkTools.Trial: 10000 samples with 1 evaluation. + Range (min … max): 37.090 μs … 77.023 μs ┊ GC (min … max): 0.00% … 0.00% + Time (median): 37.199 μs ┊ GC (median): 0.00% + Time (mean ± σ): 37.760 μs ± 2.411 μs ┊ GC (mean ± σ): 0.00% ± 0.00% + █ ▂▁ ▃ ▁ + █▇▁▁▁██▃▃▁▃█▇▇▆▄▄▇█▅▄▄▄▄▄▄▃▄▄▃▁▅▁▄▃▁▁▃▃▃▃▄▇▇█▇▇▆▄▅▅▅▆▄▄▆▄▄▄ █ + 37.1 μs Histogram: log(frequency) by time 49.3 μs < + Memory estimate: 16 bytes, allocs estimate: 1.+
Finally we have the integral approximation. This takes ~1/50th the time as the full numerical integration and, by the results above, it potentially performs just as well as the discrete puff approximation. In the examples above it was doing as well as discrete puff approximations that are too large to be worthwhile.
+@benchmark ∫pf_approx(x₁,y₁,z₁,t₁; Δt=10)BenchmarkTools.Trial: 10000 samples with 189 evaluations. + Range (min … max): 534.974 ns … 988.852 ns ┊ GC (min … max): 0.00% … 0.00% + Time (median): 547.606 ns ┊ GC (median): 0.00% + Time (mean ± σ): 560.844 ns ± 40.302 ns ┊ GC (mean ± σ): 0.00% ± 0.00% + ▇▃▅█▅▅ ▅▃▄ ▃▄▁▁▁▁▁ ▂ + ██████▇█████████████▇█▇▇▆▆▆▆▅▇▇▆▅▆▇▆▆▅▅▅▅▄▄▆▅▅▅▆▆▄▅▅▂▅▄▅▄▃▅▅▅ █ + 535 ns Histogram: log(frequency) by time 770 ns < + Memory estimate: 16 bytes, allocs estimate: 1.+
I also have put no effort into optimizing any of this code, so take this with a grain of salt. Like the examination of the model error this is hardly rigorous, it is more suggestive than anything. It is possible that one could dramatically improve the discrete puff model, or re-write how the models are calculated to be more performant than I have. I prefer to write code that is easy for me to read, and re-uses things, but that does not necessarily translate into fast.
+I think it’s worth noting that calculations that take on the order of tens of microseconds, on my crappy old laptop, are fast. To make the various plots required calculating the concentration at hundreds of points and my laptop did it all in the blink of an eye. I would say the first choice, all things being equal, would be simply to use the QuadGK model and call it a day. In terms of lines of code it is certainly short, all the heavy lifting is being done by the library. It also best captures what you are trying to achieve.
If you are doing a huge number of calculations, and can tolerate some model error, then the integral approximation is a good choice. It is the fastest and can perform as well as the discrete puff model. That said, there is an elephant in the room: The two integral approaches strictly require that all of the puffs are moving along the same line, at the same speed. For a great many chemical release scenarios that is entirely the set of assumptions being made, so it works great. However, for more complex atmospheric conditions – with variable windspeed and direction – then they don’t work at all. Or, at least, it is not obvious to me how to adapt them to work. A slightly tweaked discrete puff model, tracking each puff’s individual center location and windspeed, would be quite easy to implement, giving a more flexible model overall. This is in fact the how several more complicated atmospheric dispersion modeling tools work.
+Very generally DMD is an approach to system identification problems that is well suited for high dimensional data and systems with coherent spatio-temporal structures. In particular DMD finds the “best fit” linear approximation to the dynamical system, i.e. it finds the matrix A such that
+Where x is the high dimensional state vector for the system. One key strength of DMD is that it allows one to calculate x(t) without explicitly calculating A. This may not seem like a particularly useful property on its face unless one notes that the matrix A is n×n and, for systems with a very large n (i.e. very high dimensionality) that can be huge. Context for huge is also important: a matrix that fits easily in memory on my laptop may be infeasibly huge for an embedded system. For control applications, such as MPC, DMD may be a good method for generating approximations that are both good and space efficient.
+As a motivating example, I am going to use the flow past a cylinder dataset from Data-Driven Science and Engineering, specifically the matlab dataset. This dataset is the simulated vorticity for fluid flow past a cylinder. The vector x in this case is the vorticity at every point in the discretized flow field at a particular time; a two dimensional array of 89,351 pixels reshaped into a column vector. The data is a sequence of equally spaced snapshots of the flow field, and ultimately we wish to generate a linear system that best approximates this.
+The MAT package allows us to import data from matlab data files directly into julia
using MAT
+
+file = matopen("data/CYLINDER_ALL.mat")
+
+# import the data set
+data = read(file, "VORTALL");
+
+# the orinal dimensions of each snapshot
+nx = Int(read(file, "nx"))
+ny = Int(read(file, "ny"))
+
+# the final dimensions of the data matrix
+n, m = size(data)(89351, 151)The data set, data, has already been processed into the form we need: each column represents a “frame” of the animation. We can walk through the matrix, taking each column and re-shaping it back into a 2D array, and recover the original flow as a movie.
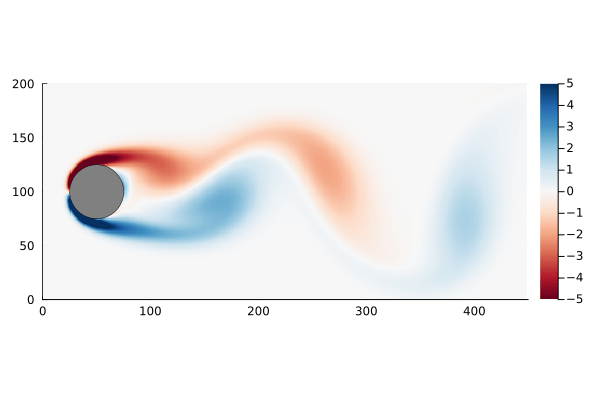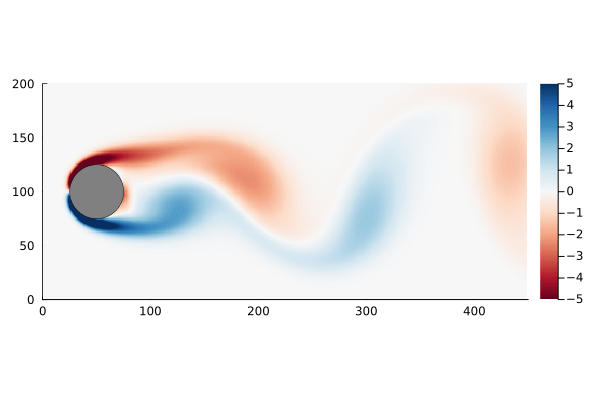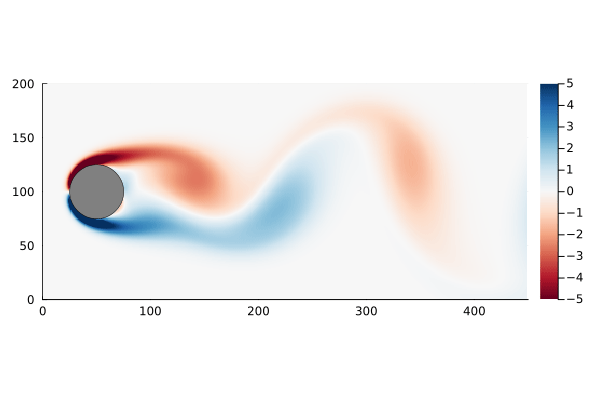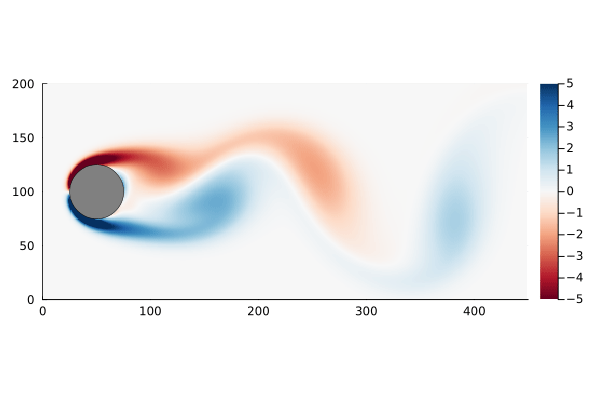 +
+The data set has the property that the number of data points at each time step, n, is much greater than the number of time steps, m. In fact n is large enough that the n×n matrix A might be unwieldy to store: If we assume it is a dense matrix of 64-bit floats, 8 bytes each, we would need ~64GB of memory just to store it.
+size_A_naive = n*n*863868809608DMD provides us a method to both find a best fit approximation for A while also being more space (and computation) efficient. To get there we first need to define what a best fit means.
+Consider the general linear system Y = AX, where Y is a n × m matrix of outputs, X is a n × m matrix of inputs and A is an n × n linear transformation matrix. We say that the best fit matrix A is the matrix that minimizes
+where is the Frobenius norm.
The solution to which is
+where X† is the Moore-Penrose pseudoinverse of X.1
+1 I think this can be shown fairly easily by starting with the definition of the Frobenius norm and finding the matrix A that minimizes that using standard matrix calculus, and some properties of the pseudoinverse.
The conventional way of calculating the Moore-Penrose pseudoinverse is to use the Singular Value Decomposition: for a matrix X with SVD , the pseudoinverse is
. Returning to the best fit matrix A we find
We can calculate a projection of A onto the space of the upper singular vectors U
+Which then allows us to reconstruct the matrix A on demand while only needing to store the matrices à and U, by the following
This is useful when n > > m as U is n×m and à is m×m. For this example this has reduced the memory requirement to ~108MB, a >99.8% reduction
+size_A_exact = (n*m + m*m)*8108118416size_A_exact/size_A_naive0.0016928202774340957Returning to the original problem, we have a sequence of discrete snapshots arranged in a matrix such that each column, k, is the vector xk. Our aim, then, is to find the best fit matrix A for the linear system
+for all xk in our data set. Or in other words, to find the best fit matrix A for the system
+where X1 is the matrix of all of the vectors xk and X2 is the matrix of the corresponding xk+1’s.
+Though, using DMD, we will instead calculate à and U, leaving us with
+To start, we divide the data set into X1 and X2
+using LinearAlgebra# dividing into past and future states
+X₁ = data[:, 1:end-1];
+X₂ = data[:, 2:end];Then compute the SVD of X1.2
+2 The svd function in julia returns the singular values in a Vector, but for later on it will be more convenient have this as a Diagonal matrix.
# SVD
+U, Σ, V = svd(X₁)
+Σ = Diagonal(Σ);Then calculate the projection à (I am pre-computing YVΣ-1 as that will come in handy later)
+# projection
+YVΣ⁻¹ = X₂*V*Σ^-1
+Ã = U'*YVΣ⁻¹
+
+size(Ã)(150, 150)We can then calculate the predicted xk+1’s, without ever having to actually compute (or store) A
+X̂₂_exact = (U*(Ã*(U'*X₁)));As before, we can step through the matrix, extract each frame of the 2D flow field, and animate them, giving us a general sense of how well this worked
+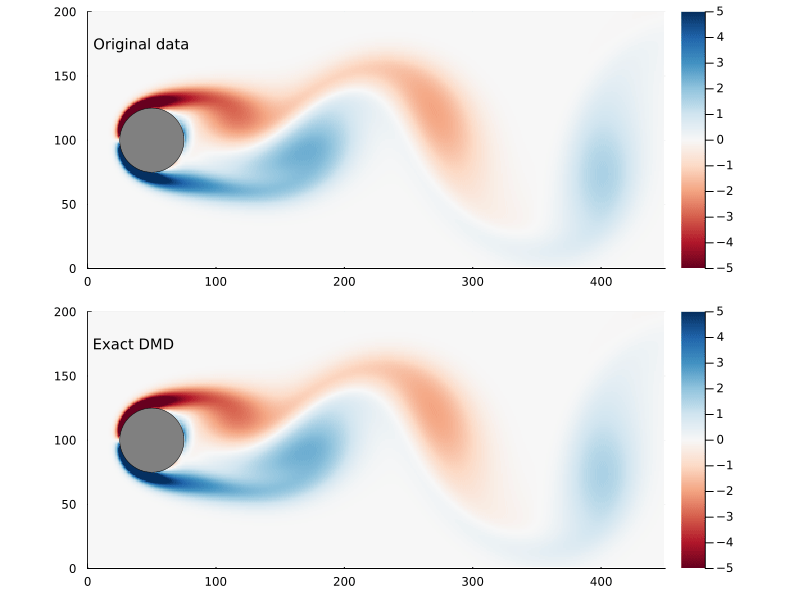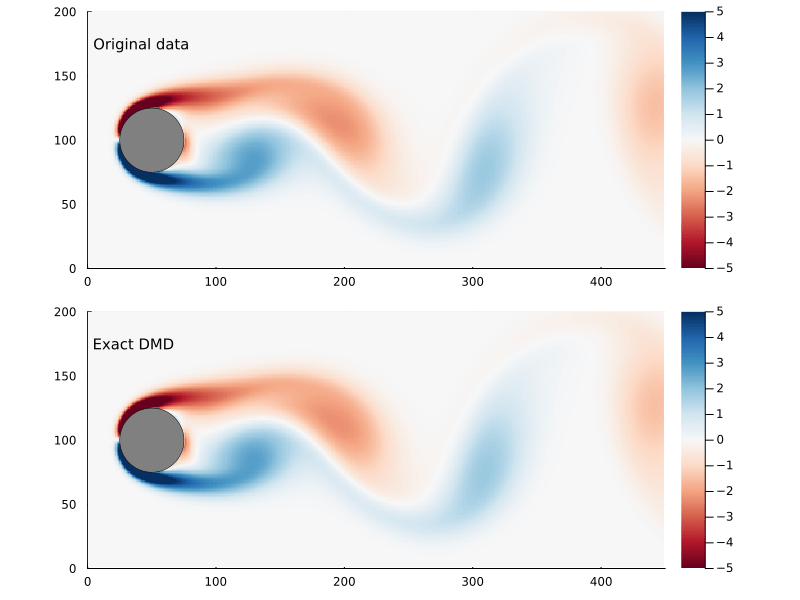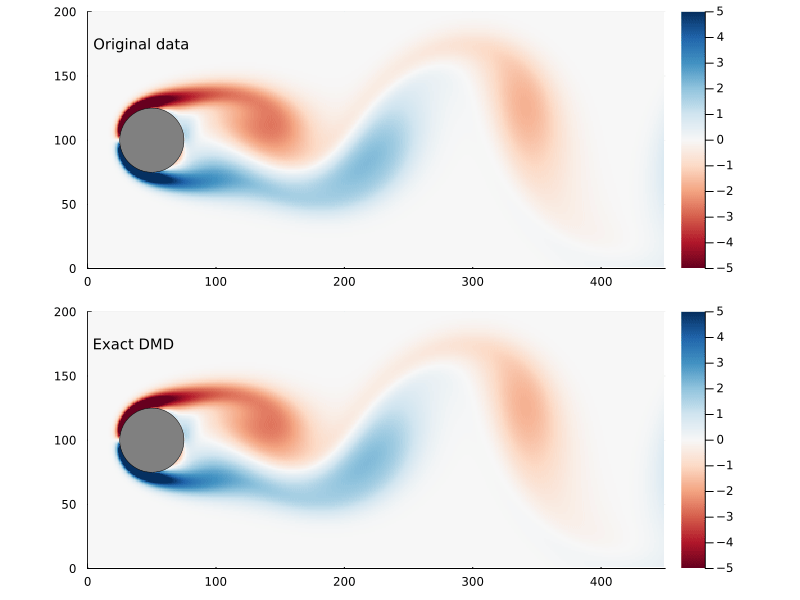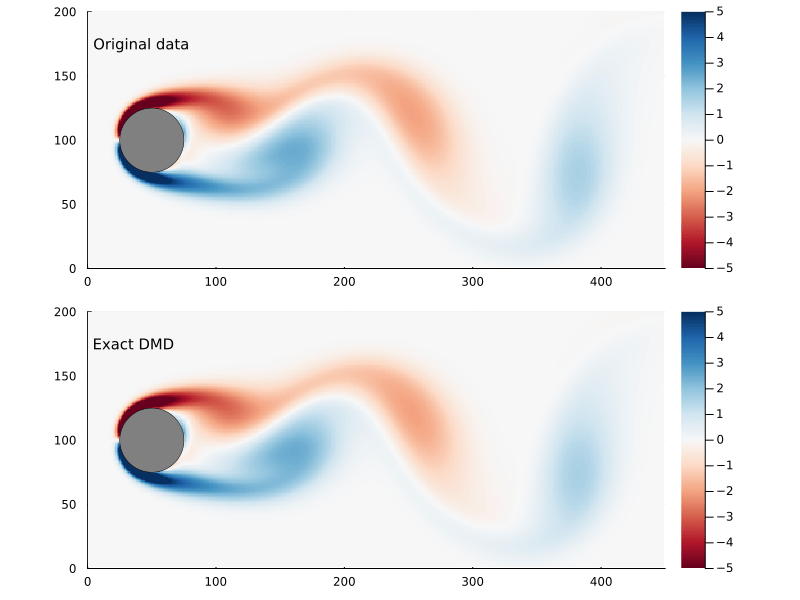 +
+Of course this only solves the problem in the discrete case (for control applications that may be all you need). Consider again the system , the solution to this differential equation is
where x0 is the initial conditions. If the matrix A has eigendecomposition ΦΛΦ-1 then this can be written as
+So it would be very convenient if we could get those eigenvalues and eigenvectors, preferably without having to actually compute A.
+Recall, by definition, the projection matrix à is unitarily similar to A, which means the eigenvalues are identical. The eigenvectors of A can also be recovered from properties of Ã: Suppose à has the eigendecomposition WΛW-1
+where
+This is what is given in the original DMD, however more recent work recommends using
+# calculate eigenvectors and eigenvalues
+# of projection Ã
+Λ, W = eigen(Ã)
+
+# reconstruct eigenvectors of A
+Φ = YVΣ⁻¹*W;Whether or not the ultimate goal is to generate the continuous system, the eigenvectors and eigenvalues are useful to examine as they represent the dynamic modes of the system.
+ +
+I’ve played somewhat fast and loose with variables: the A for the discrete system is not the same A as the continuous system. Specifically the eigenvalues of the continuous system, ω are related to the eigenvalues of the discrete system, λ by the following
+where Δt is the time step. The eigenvectors are the same, though. So we can generate a function x(t) pretty easily:
+# calculate the eigenvalues for
+# the continuous system
+Δt = 1
+Ω = Diagonal(log.(Λ)./Δt)
+
+# precomputing this
+Φ⁻¹x₀ = Φ\X₁[:,1]
+
+# continuous system
+x̂(t) = real( Φ*exp(Ω .* t)*Φ⁻¹x₀ )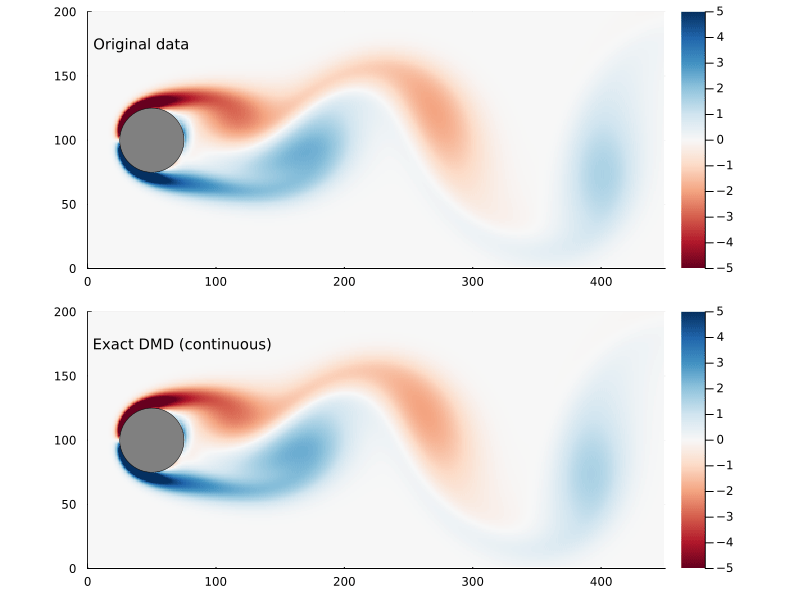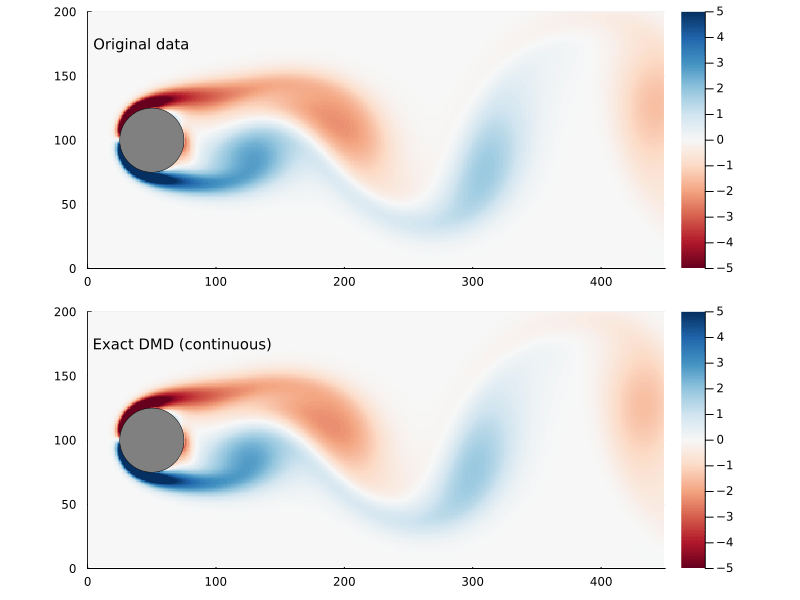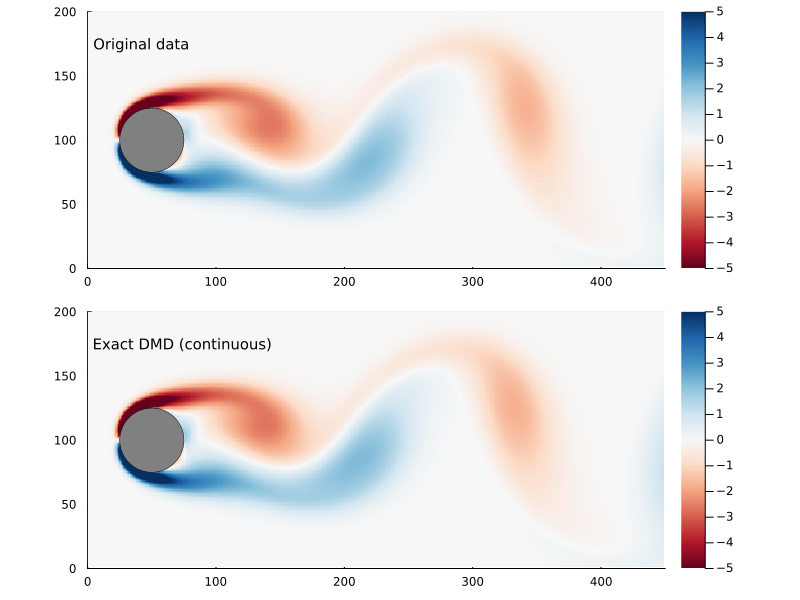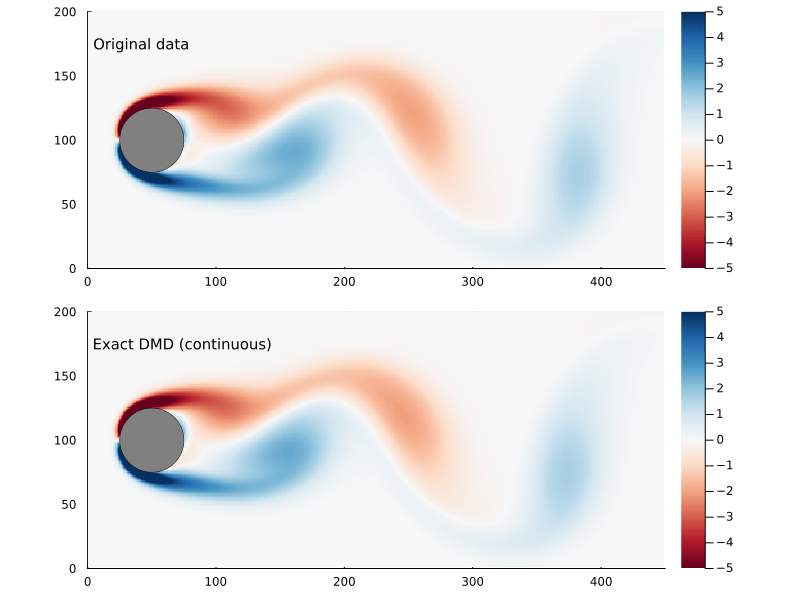 +
+Through taking the SVD, the eigenvalue decomposition, and projections, DMD involves generating a whole bunch of matrices, which can be really unwieldy to manage without some structure. The low hanging fruit for refactoring is to introduce a struct to store those matrices.
struct DMD
+ r::Integer # Dimension
+ U::Matrix # Upper Singular Vectors
+ Ã::Matrix # Projection of A
+ Λ::Diagonal # Eigenvalues of A
+ Φ::Matrix # Eigenvectors of A
+endThen we can introduce a method that takes an input matrix X and output matrix Y and returns the corresponding DMD object. We can take advantage of multiple dispatch to to add further methods, such as for the case where we have a single data matrix X and wish to calculate the DMD on the “future” and “past” matrices.
function DMD(Y::Matrix, X::Matrix)
+ # dimension
+ r = rank(X)
+
+ # Full SVD
+ U, Σ, V = svd(X)
+ Σ = Diagonal(Σ)
+
+ # projection
+ YVΣ⁻¹ = Y*V*Σ^-1
+ Ã = U'*YVΣ⁻¹
+
+ # calculate eigenvectors and eigenvalues
+ # of projection Ã
+ Λ, W = eigen(Ã)
+ Λ = Diagonal(Λ)
+
+ # reconstruct eigenvectors of A
+ Φ = YVΣ⁻¹*W
+
+ return DMD(r,U,Ã,Λ,Φ)
+end
+
+function DMD(X::Matrix)
+ X₁ = X[:, 1:end-1]
+ X₂ = X[:, 2:end]
+ return DMD(X₂, X₁)
+endWe can check that this is doing what it is supposed to be doing by comparing with what we have already done
+d = DMD(data)
+
+# This produces the same result as before
+d.Φ == Φ && d.Λ == Diagonal(Λ)trueIf you were to build this into a larger project, it would be worthwhile to define some actual unit tests to validate that the DMD is working properly.
+Since we have a DMD type to work with, we can also refactor how discrete systems are generated. In this case I have defined a struct for the discrete system, and then added a method such that any discrete system acts as a callable xk+1=f(xk)
struct DiscreteSys
+ Ã::Matrix
+ U::Matrix
+end
+
+function DiscreteSys(d::DMD)
+ return DiscreteSys(d.Ã,d.U)
+end
+
+function (ds::DiscreteSys)(xₖ)
+ return (ds.U*(ds.Ã*(ds.U'*xₖ)))
+endds = DiscreteSys(d)
+
+# This produces the same result as before
+X̂₂_exact == ds(X₁)trueSimilarly we can refactor the generation of continuous systems, first by defining a struct for the continuous system, then by adding a method xt=f(t). This requires a little more information: we need to keep track of the initial state of the system x0 as well as the step size Δt
struct ContinuousSys
+ Φ⁻¹x₀::Vector
+ Ω::Diagonal
+ Φ::Matrix
+end
+
+function ContinuousSys(d::DMD, x₀, Δt=1)
+ Φ⁻¹x₀ = d.Φ\x₀
+ Ω = Diagonal(log.(d.Λ.diag)./Δt)
+ return ContinuousSys(Φ⁻¹x₀, Ω, d.Φ)
+end
+
+function (cs::ContinuousSys)(t)
+ return real( cs.Φ*exp(cs.Ω .* t)*cs.Φ⁻¹x₀ )
+endcs = ContinuousSys(d, X₁[:,1]);
+
+# This produces the same result as before
+x̂(150) == cs(150)trueI have been using the default tools in julia, which work well for small matrices. If you are planning on doing DMD on enormous matrices then it is worth investigating packages such as IterativeSolvers.jl, Arpack.jl, KrylovKit.jl and others to find better ways than vanilla svd and eigen. It also may be worth thinking about refactoring the problem to be matrix-free, though that is way beyond the scope of these notes.
Whenever a problem involves computing the SVD of a matrix, dimensionality reduction lurks about in the shadows, winking suggestively. By the Eckart-Young theorem we know that the best rank r approximation to a matrix X=UΣVT is the truncated SVD Xr=UrΣrVrT, i.e. the SVD truncated to the r largest singular values (and corresponding singular vectors). So an obvious step for dimensionality reduction in DMD is substitute a truncated SVD for the full SVD.
+function DMD(Y::Matrix, X::Matrix, r::Integer)
+ # full SVD
+ U, Σ, V = svd(X)
+
+ # truncating to rank r
+ @assert r ≤ rank(X)
+ U = U[:, 1:r]
+ Σ = Diagonal(Σ[1:r])
+ V = V[:, 1:r]
+
+ # projection
+ YVΣ⁻¹ = Y*V*Σ^-1
+ Ã = U'*YVΣ⁻¹
+
+ # calculate eigenvectors and eigenvalues
+ # of projection Ã
+ Λ, W = eigen(Ã)
+ Λ = Diagonal(Λ)
+
+ # reconstruct eigenvectors of A
+ Φ = YVΣ⁻¹*W
+
+ return DMD(r,U,Ã,Λ,Φ)
+end
+
+function DMD(X::Matrix, r::Integer)
+ X₁ = X[:, 1:end-1]
+ X₂ = X[:, 2:end]
+ return DMD(X₂, X₁, r)
+endOne consequence of truncation, however, is that the resulting matrix Ur is only semi-unitary, in particular
+but
+This leads to a complication as the matrix U is required to be unitary, in particular when recovering A from the projection matrix Ã, and also when recovering the eigenvalues and eigenvectors of A from Ã.
+But, supposing that this at least approximately works, we are still left with the problem of picking an appropriate value for r. One could look at the singular values and pick one based on structure. For this problem it looks like an elbow happens at r=45.
+
We can then generate a set of predictions for the reduced DMD, with r=45, and compare with the exact DMD
+ds_45 = DiscreteSys(DMD(data, 45))
+X̂₂_45 = ds_45(X₁)
+
+norm(X₂ - X̂₂_45) # Frobenius norm0.005459307491383062norm(X₂ - X̂₂_exact)0.0005597047465277092An alternative is to specify how much of the variance in the original data set needs to be captured. The singular values are a measure of the variance in the data, and so keeping the top p percent of the total variance equates to keeping the top p percent of the sum of all of the singular values.
+That is to say we calculate the r such that
+where σi is the ith singular value (in order of largest to smallest).
+function DMD(Y::Matrix, X::Matrix, p::AbstractFloat)
+ @assert p>0 && p≤1
+
+ # full SVD
+ U, Σ, V = svd(X)
+
+ # determine required rank
+ r = minimum( findall( >(p), cumsum(Σ)./sum(Σ)) )
+
+ # truncate
+ @assert r ≤ rank(X)
+ U = U[:, 1:r]
+ Σ = Diagonal(Σ[1:r])
+ V = V[:, 1:r]
+
+ # projection
+ YVΣ⁻¹ = Y*V*Σ^-1
+ Ã = U'*YVΣ⁻¹
+
+ # calculate eigenvectors and eigenvalues
+ # of projection Ã
+ Λ, W = eigen(Ã)
+ Λ = Diagonal(Λ)
+
+ # reconstruct eigenvectors of A
+ Φ = YVΣ⁻¹*W
+
+ return DMD(r,U,Ã,Λ,Φ)
+end
+
+function DMD(X::Matrix, p::AbstractFloat)
+ X₁ = X[:, 1:end-1]
+ X₂ = X[:, 2:end]
+ return DMD(X₂, X₁, p)
+endCapturing 99% of the variance, in this case, requires only keeping the first 14 singular values.
+ +
+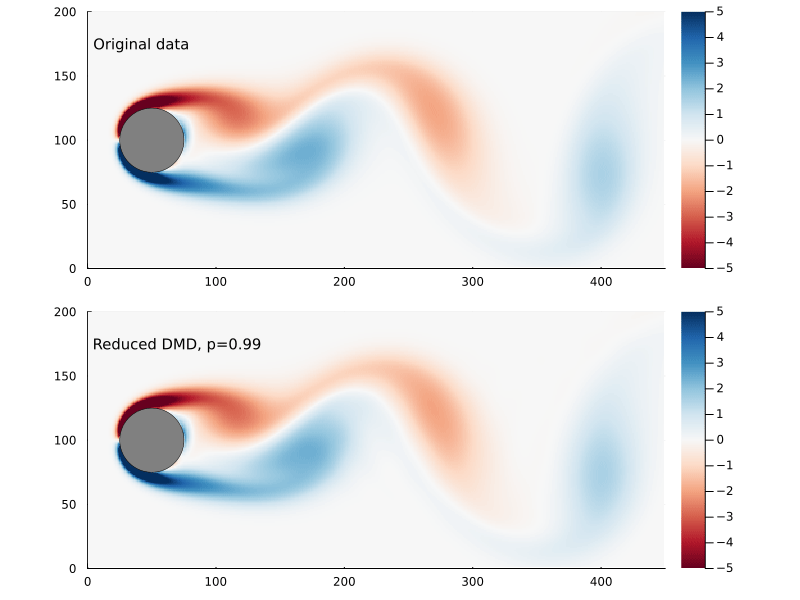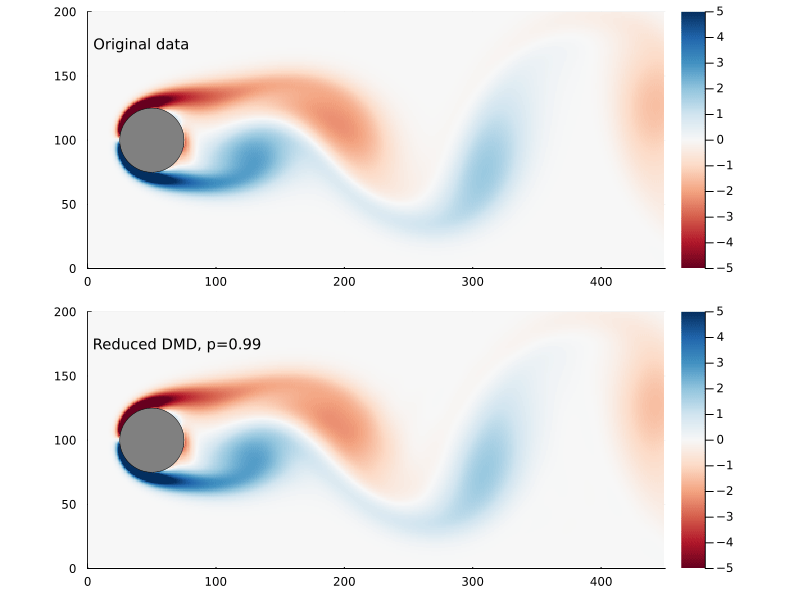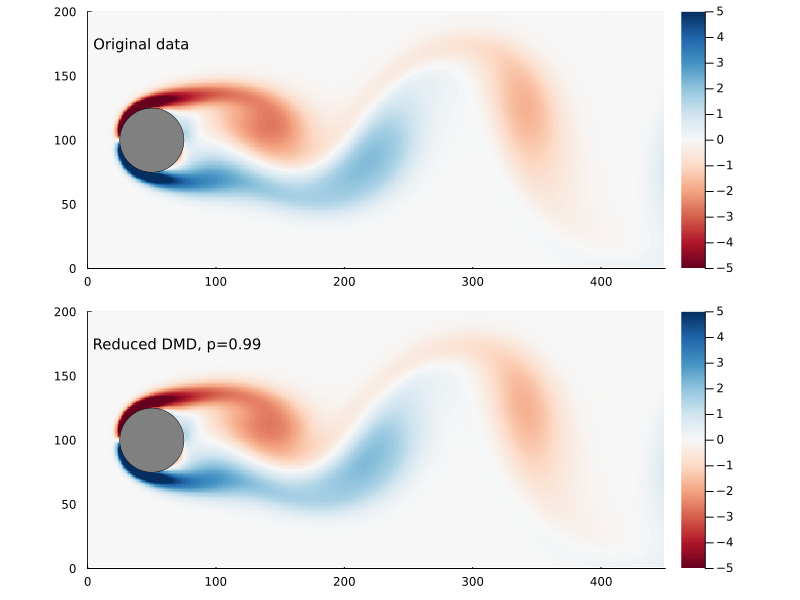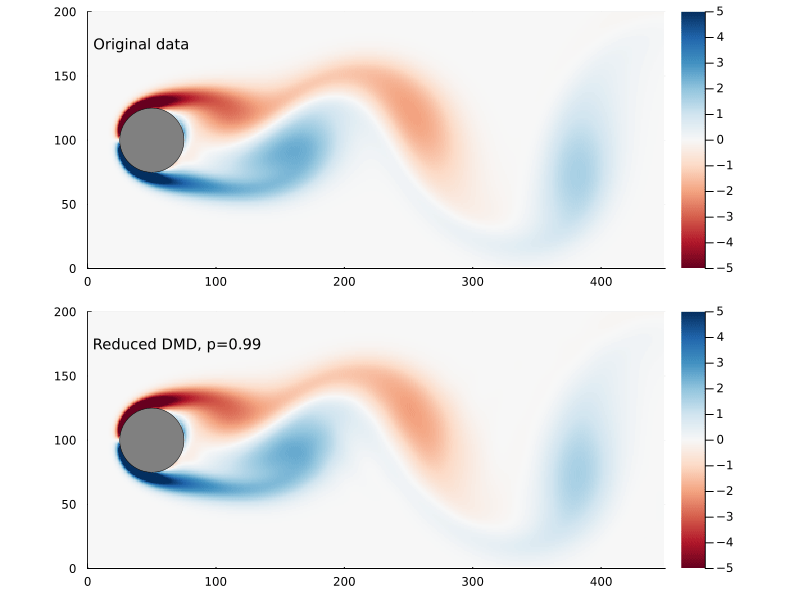 +
+There are also methods for finding the optimal rank for truncated SVD for a data set that involves gaussian noise which I am not going to go into here.
+So, supposing that p=0.99 works for us, how much further have we reduced the size of our matrices?
+# for p=0.99, r=14
+r = 14
+size_A_reduced = (n*r + r*r)*810008880To recover the (approximate) A matrix we only need to store 10MB, a ~91% reduction over the exact DMD
+size_A_reduced/size_A_exact0.09257331331972159and a >99.98% reduction of the naive case (recall the naive approach of storing the entire A matrix would take ~64GB)
+size_A_reduced/size_A_naive0.00015670998193688458In the above code I simply calculated the full SVD and then truncated it after the fact. If m (the rank of X) is particularly large, then this can be hilariously inefficient. In those cases it may be worth writing a method that uses TSVD.jl to efficiently calculate only the first r singular values – as opposed to calculating all m singular values and then chucking out most of them.
+Compressed DMD attempts to tackle the slowest step in the DMD algorithm: calculating the SVD. An SVD on full data is if we instead compress the data from n dimensions to k dimensions then the cost of the SVD is reduced to either
(when k>m) or
(when k < m), which for large n can be a dramatic speed-up.
Suppose we have some k×n unitary matrix C which compresses our input matrix X into the compressed input matrix Xc and our output matrix Y into the compressed output matrix Yc
+We suppose again that X has the SVD X=**UΣV***, then
+and, since C is unitary, the SVD of Xc is
+where Uc=CU is the upper singular values of the compressed input matrix.
+The projection matrix Ãc of the compressed input matrix is
+and so we should recover the same eigenvalues and eigenvectors as from the uncompressed data.
+using SparseArrays
+
+function cDMD(Y::Matrix, X::Matrix, C::AbstractSparseMatrix)
+ # determining dimensionality
+ r = rank(X)
+
+ # compress the X and Y
+ Xc = C*X
+ Yc = C*Y
+
+ # singular value decomposition
+ Uc, Σc, Vc = svd(Xc)
+ Σc = Diagonal(Σc)
+
+ # projection
+ Ã = Uc'*Yc*Vc*inv(Σc)
+ U = C'*Uc
+
+ # calculate eigenvectors and eigenvalues
+ # of projection Ã
+ Λ, W = eigen(Ã)
+ Λ = Diagonal(Λ)
+
+ # reconstruct eigenvectors of A
+ Φ = Y*Vc*inv(Σc)*W
+
+ return DMD(r,U,Ã,Λ,Φ)
+end
+
+function cDMD(X::Matrix, C::AbstractSparseMatrix)
+ X₁ = X[:, 1:end-1]
+ X₂ = X[:, 2:end]
+ return cDMD(X₂, X₁, C)
+endThe giant caveat is: how do we generate a unitary compression matrix? In fact we can relax this condition if we simply want to recover the eigenvalues and eigenvectors of A. It is enough that the data is sparse in some basis and that the compression matrix is incoherent with respect to that basis.
+We can think of C as a set of k (1×n)-row vectors that project an n dimensional vector x onto a k dimensional space. There are several ways of finding the basis for this projection – e.g. a uniform random projection or a gaussian projection – but by far the simplest is to pick a random subset of k single pixels and only take the measurements from those pixels.
+function cDMD(Y::Matrix, X::Matrix, k::Integer)
+ n, m = size(X)
+ @assert k≤n
+
+ # build (sparse) compression matrix
+ C = spzeros(k, n)
+ for i in 1:k
+ C[i,rand(1:n)] = 1
+ end
+
+ return cDMD(Y, X, C)
+end
+
+function cDMD(X::Matrix, k::Integer)
+ X₁ = X[:, 1:end-1]
+ X₂ = X[:, 2:end]
+ return cDMD(X₂, X₁, k)
+endSuppose we sample at 300 randomly chosen points in the flow field to form the compression matrix
+k = 300
+
+C = spzeros(k, n)
+for i in 1:k
+ C[i,rand(1:n)] = 1
+endThat is to say we are only sampling the vorticity at the green dots. This reduces the dimensionality of the data going in to the DMD algorithm from 89351 to 300.
+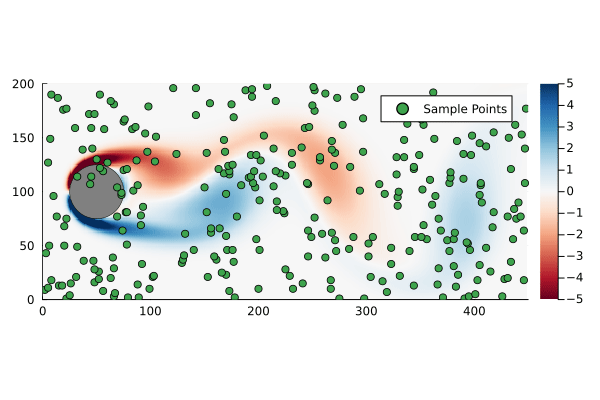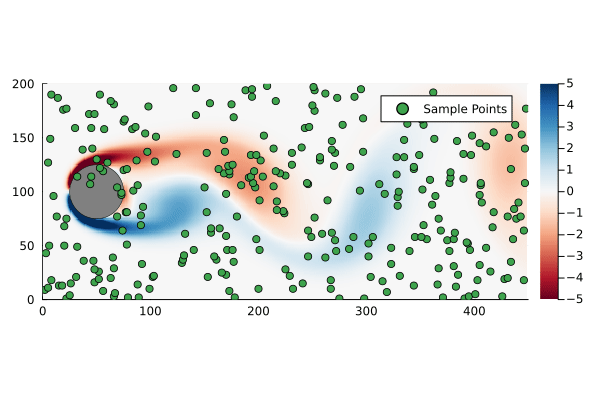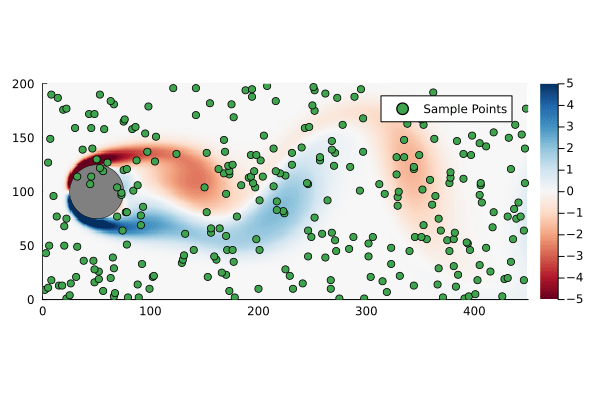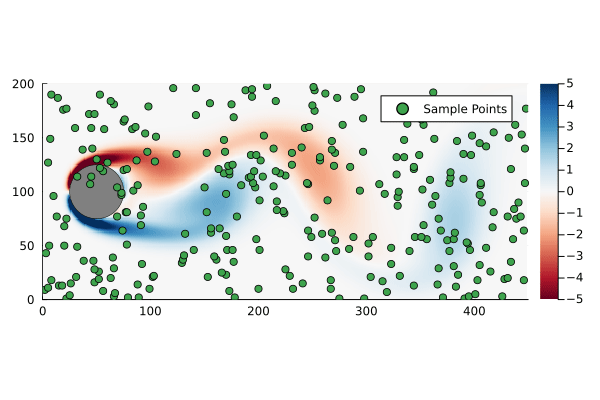
Original flow field with randomly generated sample points for compressed DMD.
+We can generate a few different compressed DMDs to get a sense of how this impacts the overall performance (in terms of the Frobenius norm) and, much like we saw with reduced DMD, there are diminishing returns.
+ +
+Using the compression matrix from above, we can generate a compressed DMD3
+3 While we can reconstruct the eigenvalues and eigenvectors quite successfully, I don’t believe we adequately reconstruct U, and so this really only works for the continuous system. The reconstruction of U strongly depends on C being unitary and I don’t think that condition can be relaxed.
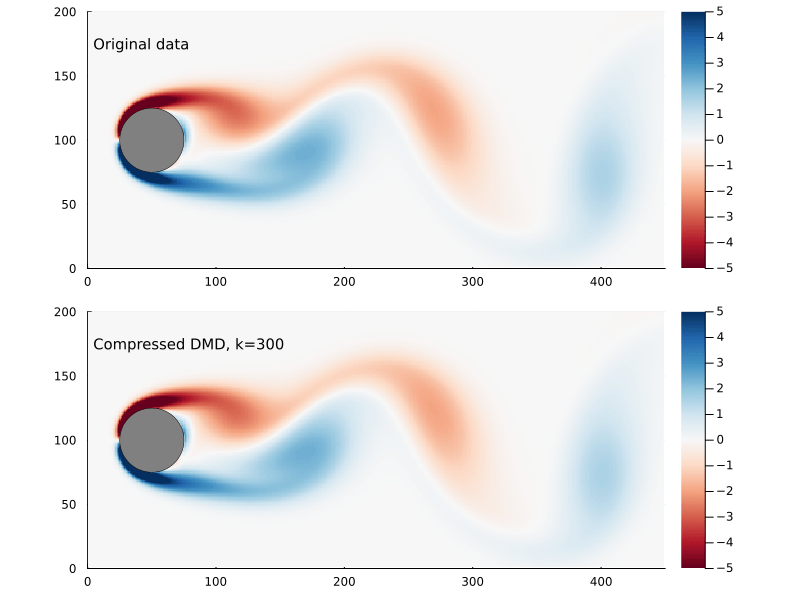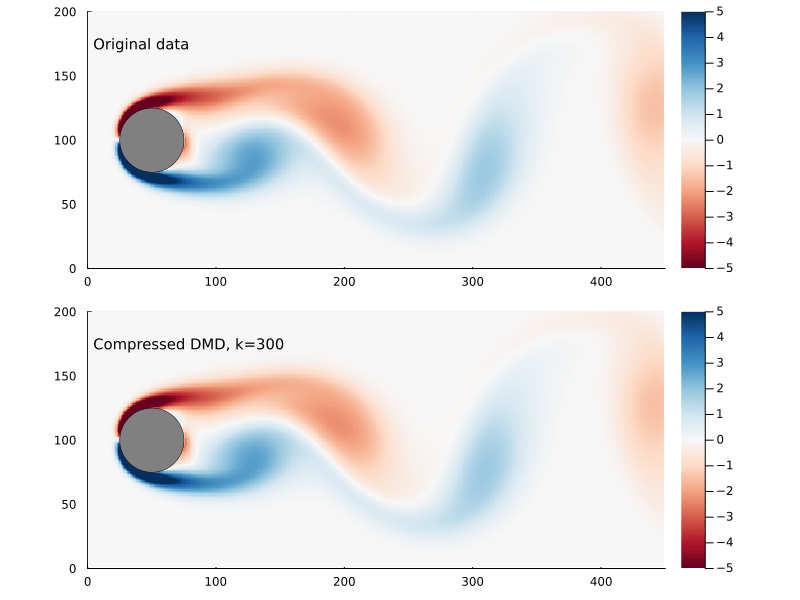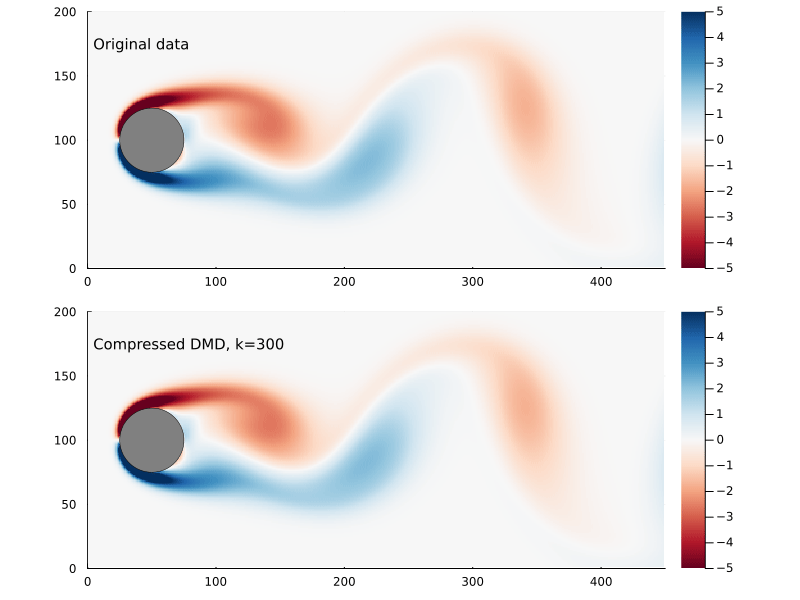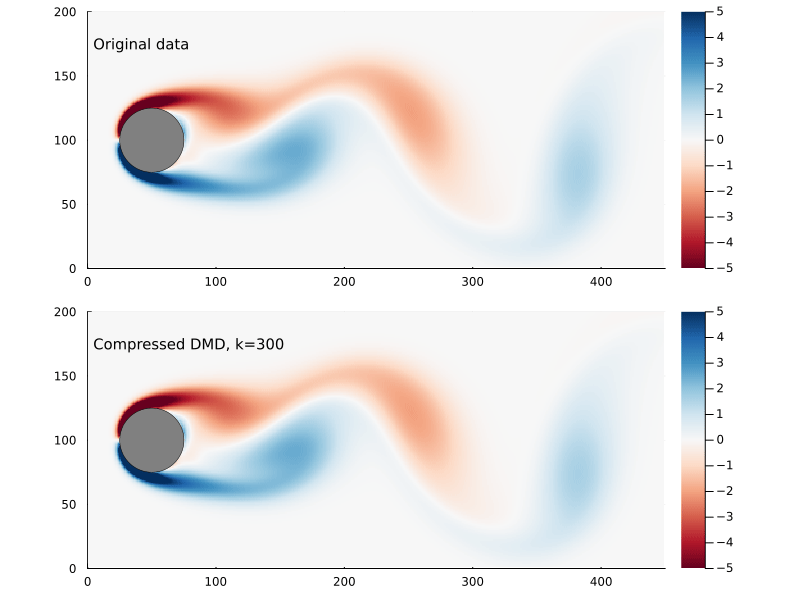 +
+The compressed DMD does not actually reduce the storage size of any of the matrices, it is more a technique to speed up the calculation of the SVD. Compressed DMD and reduced DMD can be combined: first by compressing the n×m matrix X to a k×m matrix Xc and then finding the best rank r approximation to the compressed matrix by truncating the SVD to the r largest singular values. The reduction step reduces the memory requirements and, if truncated SVD is used as well, this could significantly improve performance for enormous systems.
+There is a related approach called compressed sensing DMD, in which the full state vector is not available in the first place. A much smaller dimension set of measurements is sampled and the full state DMD generated using the same general idea as compressed DMD. It isn’t that much of a leap from what is above, just with a convex optimization step added to reconstruct the actual state matrix for a given set of measurements.
+The idea behind physics informed DMD is that the physics of the system imposes structure upon the solution, which we can build into the DMD algorithm. This way we generate results that are consistent with physical reality. Which is to say that we are not merely finding the best fit matrix A, we are finding the best fit matrix A subject to some constraints on its structure. The paper I am using as a reference gives a nice table of different types of flow problems and the sort of structure one might want to impose upon the solution,4
+4 Baddoo et al., “Physics-Informed Dynamic Mode Decomposition (piDMD)” fig 3.
 +
+5 Baddoo et al., fig. 3.
Conveniently the flow past a cylinder example is on that table (that definitely wasn’t a motivating factor for choosing it as the example in the first place, nope, not at all) and what we want to impose on the solution is conservation of energy. Conservation of energy in this case equates to requiring that A be unitary, which is the standard procrustes problem
+We modify the best fit such that we are looking for the A matrix that minimizes
+For which the standard solution is to define a matrix M
+supposing M has SVD
+then the solution is
+Of course we can’t directly compute M in many cases for the same reason that we can’t directly compute A : it would be a n×n matrix and for large n that would be enormous. So instead we project X and Y onto the upper singular values of X and solve the procrustes problem in that smaller space:
+since SVD is invariant to left and right unitary transformations, the SVD of the projected is
where
+and the A matrix which solves the projected procrustes problem is
+which is exactly the projected A matrix we need to proceed with reconstructing the eigenvalues and eigenvectors as per the standard DMD algorithm.
+# this is piDMD *only* for the case where A must be unitary
+# see arXiv:2112.04307 for details on the alternative cases
+function piDMD(Y::Matrix, X::Matrix)
+ # dimension
+ r = rank(X)
+
+ # Full SVD
+ U, _, _ = svd(X)
+
+ # projection
+ Ỹ = U'*Y
+ X̃ = U'*X
+ M̃ = Ỹ*X̃'
+
+ # solve procrustes problem
+ Uₘ, _, Vₘ = svd(M̃)
+ Ã = Uₘ*Vₘ'
+
+ # calculate eigenvectors and eigenvalues
+ # of projection Ã
+ Λ, W = eigen(Ã)
+ Λ = Diagonal(Λ)
+
+ # reconstruct eigenvectors of A
+ Φ = U*W
+
+ return DMD(r,U,Ã,Λ,Φ)
+end
+
+function piDMD(X::Matrix)
+ X₁ = X[:, 1:end-1]
+ X₂ = X[:, 2:end]
+ return piDMD(X₂, X₁)
+end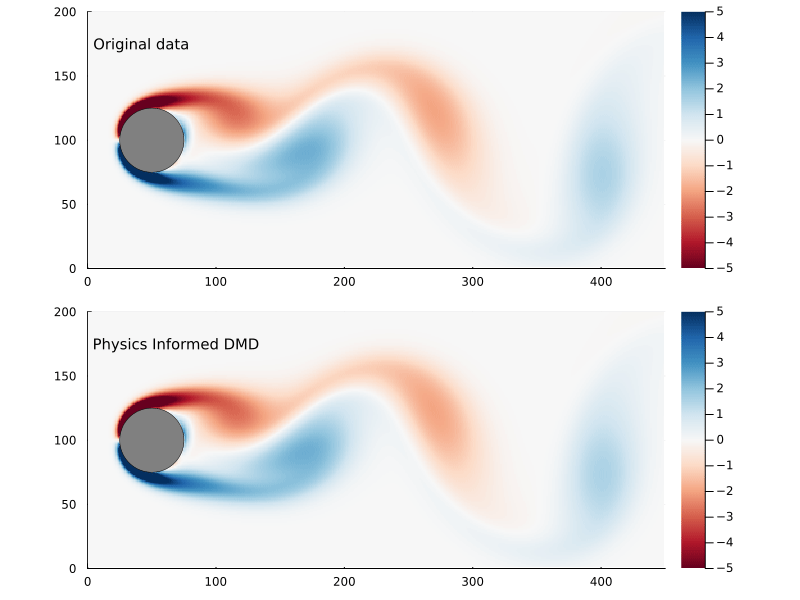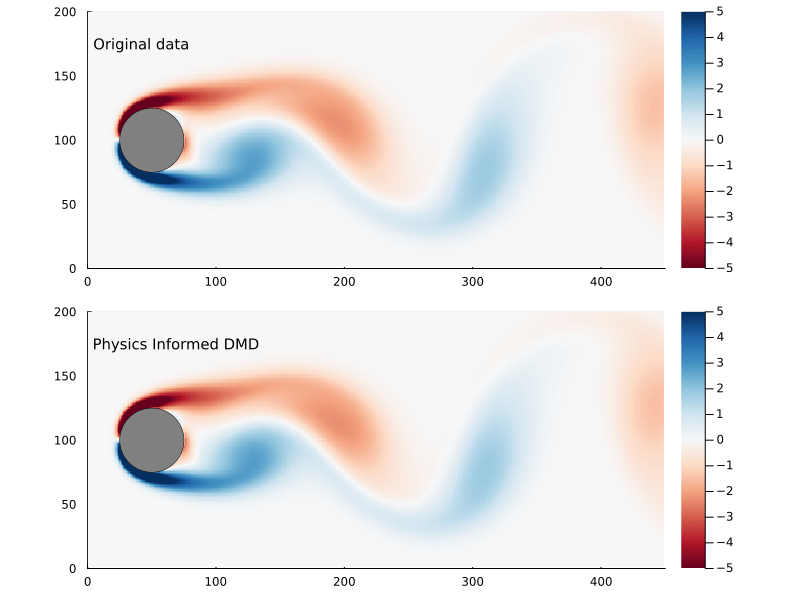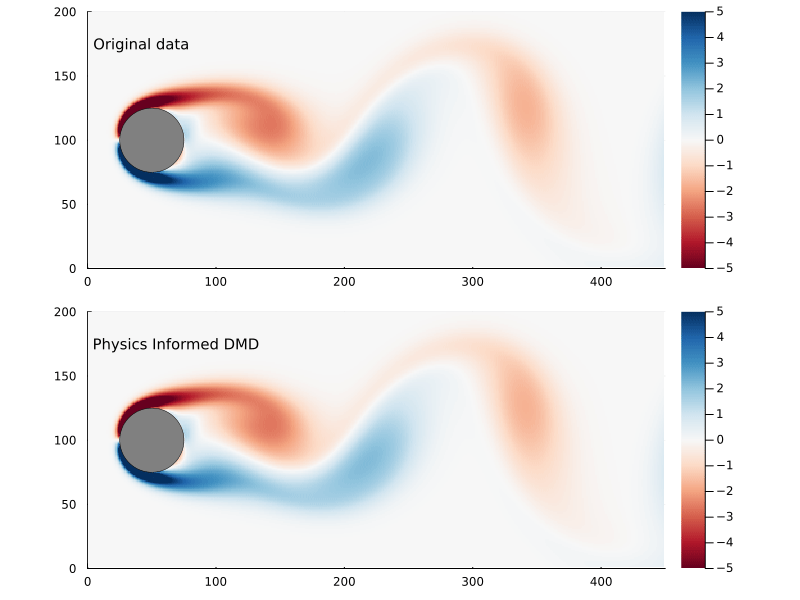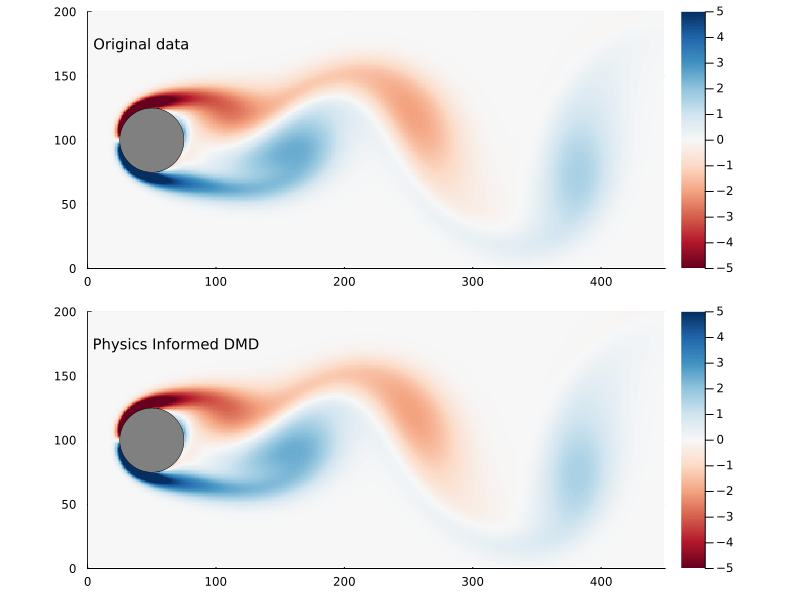 +
+We can compare the Frobenius norm of the actual data versus the predicted, and it’s clear the physics informed DMD does not generate as good of a fit as exact DMD. Though it could equally be the case that the exact DMD is over-fitting.
+norm(X₂ - X̂₂_pi, 2)18.35684111920036norm(X₂ - X̂₂_exact, 2)0.0005597047465277092The main reason why you would pursue physics informed DMD, though, is not necessarily to generate a better fit as much as to generate better (or more physically realistic) dynamic modes.
+Similarly to compressed DMD, physics informed DMD can also be combined with reduced DMD. In this case there are two SVD steps but only the upper singular values of X, the U matrix, needs to be truncated. The second SVD proceeds without truncation.
+I recently spent some time looking in detail at the Britter-McQuaid workbook model for dense gas dispersion and I thought the plume model deserved some extra attention. Firstly because I believe there is an error in the plume dimensions, and secondly because I think an important feature of top-hat models is often neglected and the Britter-McQuaid workbook model should be used more.
+As a re-cap the Britter-McQuaid model1 is a series of correlations for the dispersion of denser than air gases. These are given as a series of correlation curves and the typical procedure is to interpolate the downwind distance to the concentration of interest, for example to the Lower Flammability Limit (LFL). The model also gives some equations for estimating the plume horizontal and vertical dimensions, where conventional practice is to assume the plume has a rectangular cross-section and a uniform concentration.
+Just to have some numbers to look at, I am going to use a scenario adapted from the Burro series of trials of LNG dispersion.2 The release conditions are:
+The goal is to find the distance to the lower flammability limit (LFL) which is 5%(v/v) and ultimately work out the extent of the plume and total explosive mass.
+using Unitful
+
+Tₐ = 288.15u"K" # ambient air temperature
+ρₐ = 1.225u"kg/m^3" # density of air at 15°C and 1atm
+u₁₀ = 10.9u"m/s" # windspeed at 10m
+
+ρₗ = 425.6u"kg/m^3" # liquid density of LNG, given
+ρᵥ = 1.76u"kg/m^3" # vapour density of LNG, given
+ṁ = ρₗ*0.23u"m^3/s" # mass release rate
+Tᵣ = (273.15 - 162)u"K" # boiling point of LNG, given
+LFL = 0.05 # lower flammability limit, volume fraction
+
+Qₒ = ṁ/ρᵥ # gas volumetric flowrate: mass flowrate divided by gas densityFirst calculate the critical length, D, and the dimensionless parameter α for the model
+D = √(Qₒ/u₁₀)
+
+g = 9.806u"m/s^2"
+gₒ = g * (ρᵥ - ρₐ )/ ρₐ
+α = 0.2*log10(gₒ^2 * Qₒ / u₁₀^5)Then, using digitized curves,3 work out the points for the linear interpolation in terms of \(\beta = \log_{10}(x/D)\)
+Cs = [ 0.1, 0.05, 0.02, 0.01, 0.005, 0.002]
+βs = [ 0.24*α+1.88, 0.36*α+2.16, 0.45*α+2.39, 0.49*α+2.59, 0.59*α+2.80, 0.39*α+2.87]These points only cover the middle region of the concentration curve, where the concentration ratio, \({ c_m \over c_0 }\), is between 0.1 and 0.002, there is a near-field correlation that needs to be connected for concentration ratios >0.1
+function Cm_nf(x′)
+ if x′ > 0
+ return 306/(306 + x′^2)
+ else
+ return 1.0
+ end
+end
+
+xnf = 30
+βnf = log10(xnf)
+Cnf = Cm_nf(xnf)And a far field correlation for when the concentration ratio is <0.002 which is basically just continuing the curve from the last point but such that the concentration decays with 1/x2
+xff = 10^(maximum(βs))
+A = minimum(Cs)*xff^2
+
+function Cm_ff(x′; A=A)
+ return A/x′^2
+endFinally, putting together the pieces: near field correlation, a linear interpolation for the middle of the concentration curve, and a far field correlation, to form the complete concentration function, along with a correction for non-isothermal releases (of which this is an example)
+using Interpolations
+
+itp = interpolate( ([βnf; βs],), [Cnf; Cs], Gridded(Linear()) )function Cm(x::Quantity; xnf=xnf, xff=xff, D=D, T′=Tᵣ/Tₐ)
+ x′ = x/D
+ c′ = if x′ < xnf
+ Cm_nf(x′)
+ elseif xnf ≤ x′ < xff
+ itp(log10(x′))
+ else
+ Cm_ff(x′)
+ end
+
+ c = c′ / (c′ + (1 - c′)*T′)
+
+ return c
+end +
+If all one needs is the distance to the LFL there is an easier way of doing this: interpolate the concentrations to find the β corresponding to the LFL (after applying the non-isothermal correction). However, if one also requires the plume dimensions the concentration profile is required.
+From the concentration profile calculating the downwind distance to the LFL is very straight-forward.
+using Roots
+
+xn = find_zero((x) -> Cm(x) - LFL, (300,400).*1u"m", Roots.Brent())354.5630187009715 mAt first glance the workbook seems to be giving the user everything they need to workout the size of the plume, giving the following diagram
+ +
+and the following relations for the labeled distances
+\[ L_U = {D \over 2} + 2 l_b \]
+\[ L_{Ho} = D + 8 l_b \]
+\[ L_H = L_{Ho} + 2.5 \sqrt[3]{ l_b x^2 } \]
+with the buoyancy scale lb defined as \[ l_b = { { g_o Q_o } \over u_{ref}^{3} } \]
+lb = (gₒ*Qₒ)/u₁₀^30.18392758812310803 mLᵤ = D/2 + 2lb1.4973003373658906 mLₕₒ = D + 8lb3.7303110272242135 mLₕ(x) = Lₕₒ + 2.5∛(lb*x^2)The curve given for LH for x > 0 is not the curve for x < 0, the upwind extent of the plume. This is the blue curve in the figure below. The orange curve is slightly adjusting LH such that for x < 0 the second term is subtracted (so the curve actually converges to zero instead of blowing up to +∞ as x → -∞). The black dots are points taken from the diagram given by Britter and McQuaid, using a graph digitizer and scaling to the actual LHo and LU. Clearly the given curve for LH is not at all what is shown in the diagram for the upwind region.
+A conservative approach to estimating the size of the upwind extent is to assume LH = LHo for LU < x < 0, i.e. making the upwind region a rectangle of width LHo and length LU.5 This is the green curve in the figure below.
+Alternatively one could “fit” a curve to hit the end points while also having the same power of x: \(L_H = L_{Ho} \left( {x + L_U} \over L_U \right)^{2/3}\) where LU < x < 0, this at least retains the same general shape and is the red curve in the figure below. I think this should be taken with the giant caveat that I don’t know if insisting on the same power law is truly justified.
+ +
+For most typical cases I would think the upwind region would be a small component of the overall plume and taking the conservative, rectangle, approach would be a small error.
+The vertical extent is not given on the diagram, but an equation is given in the text, with the note that this comes from continuity, however I think this is incorrect.
+\[ L_V = {Q_o \over {u_{ref} L_H} } = { D^2 \over L_H } \]
+Suppose a steady state plume with a system boundary such that the plume is sliced along the y-z plane at some downwind distance x. All of the mass entering the plume, from the source, exits the plume through this plane
+
Consider the steady state mass balance
+\[ \textrm{mass in} = \textrm{mass out} \]
+\[ c_o Q_o = \iint_A c u \,dA = \int_{0}^{\infty} \int_{-\infty}^{\infty} c(x,y,z) u(x,y,z) \,dy \,dz \]
+By the nature of a top-hat model the plume cross section is a rectangle with half-width LH and height LV and the concentration everywhere inside the rectangle is cm. Assuming a constant advection velocity, u, the integral can be simplified to
+\[ \iint_A c u \,dA = c_m u \int_{0}^{L_V} \int_{-L_H}^{L_H} \,dy \,dz = 2 c_m u L_H L_V \]
+The steady state mass balance is then
+\[ c_o Q_o = 2 c_m u L_H L_V \]
+and the vertical extent can be solved for with some simple re-arrangement
+\[ L_V = { { c_o Q_o } \over { 2 c_m u L_H } } = {1 \over 2}{ c_o \over c_m } { Q_o \over {u L_H} } \]
+Setting the advection velocity of the plume to the reference windspeed gives
+\[ L_V = {1 \over 2}{ c_o \over c_m } { Q_o \over {u_{ref} L_H} } = {1 \over 2} { c_o \over c_m } { D^2 \over L_H }\]
+Lᵥ(x) = D^2/(2*Cm(x)*Lₕ(x))This is definitely similar to what is given by Britter and McQuaid but with two big differences:
+The last point could equally be a mistake in the diagram (I have no real way of checking) as while the diagram shows LH as the plume half-width, the text simply refers to it as the “lateral plume extent”, which is ambiguous – do they mean the entire lateral extent or from the center-line of the plume?
+The TNO Yellow Book gives a different equation6 for the vertical extent:
+6 Bakkum and Duijm. equation 4.104.
\[ L_V = {1 \over 2} { Q_o \over {u_{ref} L_H} } = {1 \over 2} { D^2 \over L_H }\]
+Which clearly follows from assuming LH is the half-width, and the corresponding figure is labeled as such (using the same equation for LH as Britter and McQuaid). But it doesn’t depend upon concentration.
+I think the vertical extent has to depend upon the concentration as otherwise mass will simply disappear from the plume as it extends downwind. There is also the obvious problem that since the plume lateral extent monotonically increases, and the vertical extent is inversely related to it, the vertical extent is monotonically decreasing. In fact it becomes vanishingly small quite quickly. This entirely the opposite of what is observed with actual dense plume dispersion.
+This can be seen most clearly in the following figure in which the vertical extent is shown as a function of downwind distance along with the mass flowrate in the plume (i.e. \(c_m u A\) )
+ +
+I think it is fairly obvious that both the Britter-McQuaid and TNO models give silly answers for the vertical extent. Though the corrected curve, the green curve, clearly has problems too: it has an odd bumpiness, as a result of the linear interpolation, and it is also too small due to both assuming the concentration everywhere is equal to the ground level concentration and due to an overly large advection velocity (the windspeed at 10m is quite a bit higher than the windspeed at ~1m).
+An alternative approach to using the reference windspeed as the advection velocity is to assume the advection velocity is some constant fraction of the reference velocity, e.g. \(u = 0.4 u_{ref}\), which is what Britter and McQuaid use for the instantaneous model.
+Another alternative might be to use an average windspeed, ū over cross-section of the plume as the advection velocity, assuming windspeed is only a function of height.
+\[ \bar{u} = { { \iint_A u \,dA } \over A } = { { \int_{0}^{L_V} u(z) \,dz } \over L_V } \]
+Assuming the windspeed follows a powerlaw distribution \(u = u_{ref} \left( z \over z_{ref} \right)^p\) gives
+\[ \bar{u} = { { \int_{0}^{L_V} u(z) \,dz } \over L_V } \]
+\[ = {1 \over L_V} \int_{0}^{L_V} u_{ref} \left( z \over z_{ref} \right)^p \,dz \]
+\[ = { u_{ref} \over {p+1} } \left( L_V \over z_{ref} \right)^p \]
+plugging it into the simple mass balance
+\[ c_o Q_o = c_m \bar{u} A \]
+\[ = c_m {u_{ref} \over {p+1} } \left( L_V \over z_{ref} \right)^p { 2 L_H L_V } \]
+re-arranging to solve for LV
+\[ L_V = \left( { {p+1} \over 2 } { c_o \over c_m } z_{ref}^p {Q_o \over {u_{ref} L_H} } \right)^{1 \over {p+1} } \]
+\[ = \left( { {p+1} \over 2 } { c_o \over c_m } z_{ref}^p {D^2 \over L_H } \right)^{1 \over {p+1} }\]
+The red curve in the figure above is this model, using p = 0.15.7
+This could also be done using the logarithmic windspeed curve \(u = {u_{\star} \over \kappa} \log \left( z \over z_) \right)\) where \(u_{\star}\) is the friction velocity and z0 is the roughness length. Though I don’t imagine the expression would work out as nicely.
+For the upwind region, assuming a simple rectangular prism with length LU, width 2LHo, height LVo and uniform concentration co is a conservative approach. Likely the plume downwind of the source will be much larger than the upwind area and so this will be a small overestimate.
+The simple mass balance approach to calculating the plume height is a reasonable approach if one simply wants to reference Britter and McQuaid and not have to justify additional assumptions. It is not what is given in the text, but it is what is described in the text. The other models for plume height may be more realistic, in the sense that they represent more realistic advection velocities, and will give larger explosive masses for the plume, however they have not been validated against any actual data. That validation may be a worthwhile exercise but is well beyond the scope of this blog post.
+The explosive mass in the cloud is the given by the volume integral
+\[ m_e = \iiint_V c dV \]
+where V is defined as the region where c ≥ LFL.8
+8 Some sources recommend 1/2 LFL.
Using the concentration profile and the plume extents, we could work out the function c(x,y,z) such that the concentration is returned if we are:
To determine the explosive mass in the downwind region this might be done by the following
+
+cₒ = ustrip(u"kg/m^3", ṁ/Qₒ)
+
+Lₕ(x::Number) = ustrip(u"m", Lₕ(x*1u"m"))
+Lᵥ(x::Number) = ustrip(u"m", D)^2/(2*Cm(x)*Lₕ(x))
+
+function c(x,y,z; lim=LFL)
+ c_ = Cm(x)
+
+ if c_ ≥ lim
+ if (abs(y) ≤ Lₕ(x)) && (z ≤ Lᵥ(x))
+ return cₒ*c_
+ else
+ return 0.0
+ end
+ else
+ return 0.0
+ end
+end
+using HCubature: hcubature
+
+x_min, x_max = 0, xn
+y_min, y_max = -Lₕ(xn), Lₕ(xn)
+z_min, z_max = 0, Lᵥ(xn)
+
+m_e, err = hcubature( c, [x_min, y_min, z_min], [x_max, y_max, z_max])This is a pretty tedious integration, is very inefficient, and doesn’t take into account any of the structure of the model and it turns out that a top-hat model has some pretty convenient structure.
+Returning to the integral for the explosive mass, the plume can be divided into an upwind region (x < 0) and a downwind region (x ≥ 0)
+\[ m_e = \iiint_V c \,dV = m_{e,u} + m_{e,d} \]
+with the explosive mass of the downwind region being
+\[ m_{e,d} = \int_0^{x_n} \iint_A c \,dA \,dx \]
+For a top-hat model, since the concentration at a given downwind distance is constant everywhere within the plume cross-section \(\iint_A c dA = c_m A\), and, from a mass balance on the plume
+\[ c_m A u = c_o Q_o \]
+\[ c_m A = { {c_o Q_o} \over u} \]
+which is a constant, thus
+\[ m_{e,d} = \int_0^{x_n} c_m A \,dx \]
+\[ = \int_0^{x_n} { {c_o Q_o} \over u} \,dx \]
+\[ = { {c_o Q_o} \over u} x_n \]
+For the explosive mass of the upwind region a simple box model gives \(m_{e,u} = 2 c_o L_U L_{Ho} L_{Vo}\). Putting everything together9
+9 This is not specific to the Britter-McQuaid model, it works for any top hat model.
\[ m_e = 2 c_o L_U L_{Ho} L_{Vo} + { {c_o Q_o} \over u} x_n \]
+This can be simplified greatly by setting the advection velocity to uref
+\[ m_e = 2 c_o L_U L_{Ho} L_{Vo} + { {c_o Q_o} \over u_{ref} } x_n \]
+\[ = 2 c_o L_U L_{Ho} {1 \over 2}{D^2 \over L_{Ho} } + c_o D^2 x_n \]
+\[ = c_o D^2 \left( L_U + x_n \right)\]
+cₒ = ṁ/Qₒ
+
+mₑ = cₒ*D^2*(Lᵤ+xn)3197.617661470163 kgThis very simple expression is the obvious strength of a top-hat model: it makes calculating the explosive mass incredibly easy.10 It also retroactively justifies why the Britter McQuaid model is oriented around calculating xn: that’s all you actually need.11
+11 Some sources recommend calculating the explosive mass as the region of the plume with the concentration LFL ≤ c ≤ UFL, in which case \(m_e = c_o D^2 \left( x_{n,LFL} - x_{n,UFL} \right)\)
If this seems too good to be true, the integration can be performed numerically by taking
+\[ \iint_A c \,dA = c_m \cdot 2L_H \cdot L_V \]
+using QuadGK: quadgk
+
+function ∫∫cdA(x)
+ if Cm(x) ≥ LFL
+ return cₒ*Cm(x)*(2Lₕ(x))*Lᵥ(x)
+ else
+ return 0.0u"kg/m"
+ end
+end
+
+m_ed, err = quadgk(∫∫cdA, 0u"m", xn)
+
+m_eu = 2*cₒ*Lᵤ*Lₕₒ*Lᵥ(0u"m")
+
+m_eu + m_ed3197.617661470163 kgWhich is exactly the same.
+Above I claimed the upwind region was “small” relative to the downwind region, this can be shown easily as the mass in each region is directly proportional to the length.
+Lᵤ/(Lᵤ+xn)0.004205187316042018Since the mass in the upwind region is <0.5% of the total mass in the cloud, I think the simple box model is justified.
+According to Britter and McQuaid the top-hat model generates an overly conservative plume extent and they recommend using given the lateral extent curve up to 2/3 xn and after which connecting to xn using straight lines, as shown in the plume diagram. This makes the integration for explosive mass a little more complicated.
+For simplicity the plume can be divided into three regions, the upwind region (x < 0), the downwind region up to the cutoff (0 ≤ x < 2/3 xn), and the downwind cutoff region (2/3 xn ≤ x < xn )
+\[ m_{e, \textrm{cut off} } = m_{e,u} + m_{e,d1} + m_{e,d2} \]
+The upwind region, me,u, and the first downwind region me,d1 are already known, they are the same as above up to 2/3 xn. What is left to determine is the explosive mass in the cutoff region.
+\[ m_{e,d2} = \int_{2/3 x_n}^{x_n} \iint_A c \,dA \,dx \]
+The integral can be re-written to take advantage of cmA being an invariant for a top-hat model,
+\[ m_{e,d2} = \int_{2/3 x_n}^{x_n} \iint_A c \,dA \,dx \]
+\[ = c_m A_{\textrm{original} } \int_{2/3 x_n}^{x_n} { A_{\textrm{cut off} } \over A_{\textrm{original} } } \,dx \]
+Assuming the vertical extent remains unchanged in this operation, the ratio of areas is the same as the ratio of horizontal extents
+\[ { A_{\textrm{cut off} } \over A_{\textrm{original} } } = { L_{H, \textrm{cut off} } \over L_{H, \textrm{original} } } \]
+From some simple geometry, the horizontal extent is
+\[ L_{H, \textrm{cut off} } = 3 L_{H, 2/3 x_n} { {x_n - x} \over x_n }\]
+Which then leads to
+\[ m_{e,d2} = 3 c_o D^2 \int_{2/3 x_n}^{x_n} { L_{H, 2/3 x_n} \over L_H } { {x_n - x} \over x_n } \,dx \]
+There is probably a closed form for this integral but it is just as easy to integrate that numerically.
+\[ m_{e, \textrm{cut off} } = c_o D^2 \left( L_U + \frac{2}{3}x_n + 3 L_{H, 2/3 x_n} \int_{2/3 x_n}^{x_n} { 1 \over L_H(x) } { {x_n - x} \over x_n } \,dx \right)\]
+mₑ_cutoff = cₒ*D^2*(Lᵤ + (2/3)*xn
+ + 3*Lₕ((2/3)*xn)*quadgk( (x) -> (xn - x)/(xn*Lₕ(x)), (2/3)*xn, xn)[1] )2620.489605856347 kgThis works out to be about 20% less than the original explosive mass.
+mₑ_cutoff/mₑ0.8195131136008078I think the error in the vertical extent may have limited the apparent utility of the Britter-McQuaid model. Most references I have do use the Britter-McQuaid model, noting that it is “reasonably simple to apply, and produces results which appear to be as good as more sophisticated models”,12 however they either claim that it is only good for calculating xn or gloss over how it could be used for anything else. The CCPS references seem consistent in neglecting to mention at all that the model can also estimate the plume extent. So, while I can’t imagine I’m the first person to have noticed that the given equation for LV doesn’t work, I have yet to encounter anyone actually admitting it.
+That said, the correction also seems obvious to me: one simply follows what is described in the text which is exactly how Britter and McQuaid calculated the cloud height for the instantaneous model (which is correct) in the same workbook. That the incorrect equation for LV is repeated in other references,13 with only the TNO Yellow Book14 making a correction, while still repeating a critical mistake, strikes me as very odd.
+The Britter-McQuaid model would seem to be the perfect fit for screening models, which are often only order of magnitude estimates at best anyways. It gives reasonable concentrations, plausible plume extents, and the explosive mass is ridiculously easy to calculate (slightly more tedious if you are using the 2/3 cut-off region but nothing that couldn’t be worked out in advance if this was going to be incorporated into a routine calculation tool).
+I was looking through some books and it struck me how strangely inconsistent many standard references are when it comes to adiabatic compressible pipe flow. There are standard methods for incompressible flow and isothermal compressible flow of an ideal gas, but when it comes to adiabatic pipe flow the guidance is very scattershot.
+For brevity, from this point on whenever I refer to a flow I am referring to the ideal gas case in a constant area duct, unless otherwise specified
+As a brief review of some common references: Crane’s1 gives a graphical method for adiabatic flow, which is the easiest to use with a pencil and paper, but doesn’t give a lot of details on how that model was developed. Albright’s2 recommends assuming flow is locally isentropic and gives a model of isentropic flow – that is flow which is both adiabatic and reversible – but with frictional losses also included, which allows for direct calculation if one assumes the friction factor is constant (with respect to the Reynold’s number). Perry’s3 gives the adiabatic irreversible flow model (i.e. Fanno flow), though with only a sketch of how to perform the iterative solution. Hall4 gives the Fanno flow model and, helpfully, a procedure for how to actually do the calculations and example VBA code. Ludwig’s5 gives both the isentropic and Fanno flow models but in a very confused manner: the section labeled “Adiabatic Flow” gives a model of isentropic flow (albeit with a typo in the equation) and suggests that all adiabatic flow is isentropic (which is false) and much later in a section labeled “Other Simplified Compressible Flow Methods” gives the Fanno flow model, though it doesn’t explain what it is, misattributes the derivation, and gives no clues on how to use it. Probably the best reference to sort all of this out is Coulson and Richardson’s6 as it provides easy to follow derivations of both the reversible and irreversible adiabatic flow models (the isentropic and Fanno flow models) and highlights their differences.
+Another part of this confusion is differences in how the problem is being approached – or what problem, exactly, one is trying to solve. Typically the isothermal and isentropic flow models are presented as ways to solve for the flowrate given the pressure drop between two points, whereas the Fanno flow model is often given in terms of the Mach number and one is solving for the pressure drop. If you have the Mach number, rather obviously, you already know the flow, and it is often left as an exercise for the reader to figure out how to use the Fanno flow model to solve for flow.
+Given all of that, I thought it may be worthwhile to unpack these various approaches to adiabatic flow, and see how they perform relative to one another.
+To give us something to work towards, suppose we wish calculate the flowrate of air in a horizontal section of piping – a 20m length of 2in schedule 40 steel pipe. In this case the pipe starts a 100kPag vessel which is at ambient temperature and exits into the air at ambient pressure.
+ +
+# Pipe dimensions
+L = 20 # m
+D = 0.0525 # m
+ϵ = 0.0457*1e-3 # m
+
+A = 0.25*π*D^2For “ambient” conditions I am assuming standard conditions: 1 atmosphere and 15°C
+P₂ = 101325 #Pa
+P₁ = P₂ + 100e3
+T₁ = 288.15 #K# Universal gas constant
+# to more digits than are at all necessary
+R = 8.31446261815324 # Pa⋅m³/mol/K
+
+# Some useful physical properties of air
+Mw = 0.02896 # kg/mol
+γ = 1.4 # Cp/Cv, ideal gas
+
+# density of air, ideal gas law
+ρ(P,T) = (P*Mw)/(R*T); # kg/m³
+
+# viscosity of air, from Perry's
+μ(T) = (1.425e-6*T^0.5039)/(1+108.3/T); # Pa⋅sThe mass velocity, G = ρu, in a pipe with constant cross-sectional area at steady state is constant7, and the Reynold’s number can be written in terms of G as:
+7 This is a consequence of the steady state assumption, \[\dot{m}_{in} = G_{in} A = G_{out} A = \dot{m}_{out}\]
\[ \mathrm{Re} = { {G D} \over \mu } \]
+Where only the viscosity is a function of temperature, and for most gases only weakly so.
+# Reynold's number
+Re(G,T) = G*D/μ(T);The Darcy friction factor, f, is a function of the Reynolds number and, for ease of calculation, I am assuming the Churchill correlation applies,8 and that it can be taken as a constant at the average temperature (the arithmetic average of T1 and T2)
+function churchill(Re; κ=ϵ/D)
+ A = (2.457 * log(1/((7/Re)^0.9 + 0.27*κ)))^16
+ B = (37530/Re)^16
+ return 8*((8/Re)^12 + 1/(A+B)^(3/2))^(1/12)
+end;
+
+K_entrance = 0.5
+K_exit = 1.0
+
+Kf(Re) = K_entrance + churchill(Re)*L/D + K_exit;For a large Reynolds number approximation I am using the Nikuradse rough pipe law.9
+fₙ = (2*log10(3.7*D/ϵ))^-2
+
+Kf() = K_entrance + fₙ*L/D + K_exit;A pitfall of compressible flow calculations is that flow at the exit of the pipe cannot exceed Ma=1, once the exit velocity achieves sonic velocity then the exit pressure will rise and the overall flowrate will remain at a constant, no matter the upstream pressure.
+The easiest way to check for this is to use the limiting factors in Crane’s.10 Using the estimated Kf > 8 and γ=1.4, we can check:
+10 Crane, A–23.
\[ {\Delta P \over P_1} \lt 0.762 \]
+(P₁ - P₂)/P₁0.496709300881659(P₁ - P₂)/P₁ < 0.762trueThere is a fit to the critical pressure ratios, as a function of Kf
+\[\log \left( {\Delta P} \over P_1 \right) = A \left( \log K_f \right)^3 + B \left( \log K_f \right)^2 + C \left( \log K_f \right) + D\]
+With the constants for γ=1.4:
+| A | +0.0011 | +
| B | +-0.0302 | +
| C | +0.238 | +
| D | +-0.6455 | +
function critical_pressure(Kf)
+ @assert Kf > 0
+ x = log(Kf)
+ y = 0.0011*x^3 - 0.0302*x^2 + 0.238*x - 0.6455
+ return exp(y)
+end
+
+critical_pressure(Kf())0.7707810480736812(P₁ - P₂)/P₁ < critical_pressure(Kf())trueFor this problem we are well within the sub-sonic region.
+Consider the differential form of the mechanical energy balance:
+\[ {u \over \alpha} du + g dz + v dP + \delta W_s + \delta F = 0 \]
+From the assumptions listed above, and noting that in this system there is no shaft work Ws, this can be simplified to:
+\[ u du + v dP + {u^2 \over 2} {f \over D} dl = 0 \]
+where f is the Darcy friction factor.
+For compressible flow the velocity, u, varies along the length of the pipe while the mass velocity does not, so it is convenient to make the substitution u=G/ρ=Gv
+\[ G^2 v dv + v dP + G^2 {v^2 \over 2} {f \over D} dl = 0 \]
+Dividing through by v2 and integrating gives:
+\[ G^2 \log \left( {v_2 \over v_1} \right) + \int_{P_1}^{P_2} {dP \over v} + {K_f \over 2} G^2 = 0 \]
+where Kf is the pipe friction fL/D
+The integral \(\int {dP \over v}\) is where the reversible and irreversible models differ, but they both amount to the same thing: integrate over an adiabatic path, and solve the mechanical energy balance for G.
+Typically the isentropic flow model comes as a consequence of examining non-isothermal flow more generally, where one assumes Pvk is constant with k being a function of heat transfer (for the isothermal case k=1). The adiabatic case is then taken to be when k=γ. I think this is the greatest source of vaguery and confusion in the various sources I’ve looked at. Coulson and Richardson’s11 emphasizes that this is only an approximation as this equates to assuming an isentropic path, but many other sources either don’t make the distinction or only hint at it.
+\[ Pv^\gamma = P_1 v_1^\gamma \]
+\[ \int_{P_1}^{P_2} {dP \over v} = \int_{P_1}^{P_2} {1 \over v_1} \left( P \over P_1 \right)^{1 \over \gamma} dP \\ += {\gamma \over {\gamma + 1} } {P_1 \over v_1} \left( \left( P_2 \over P_1 \right)^{ {\gamma+1}\over\gamma} - 1 \right)\]
+Substituting this into the mechanical energy balance gives
+\[ G^2 \log \left( {v_2 \over v_1} \right) + {\gamma \over {\gamma + 1} } {P_1 \over v_1} \left( \left( P_2 \over P_1 \right)^{ {\gamma+1}\over\gamma} - 1 \right) + {K_f \over 2} G^2 = 0 \]
+Making the substitution \[ {v_2 \over v_1} = \left( P_1 \over P_2 \right)^{1\over\gamma} \]
+\[ \left( {K_f \over 2} - {1 \over \gamma} \log \left( {P_2 \over P_1} \right) \right) G^2 + {\gamma \over {\gamma + 1} } P_1 \rho_1 \left( \left( P_2 \over P_1 \right)^{ {\gamma+1}\over\gamma} - 1 \right) = 0 \]
+This form is a convenient objective function for numerical solution, however it can be re-arranged to solve for G, giving:
+\[ G = \sqrt{ { {2 \gamma \over {\gamma + 1} } P_1 \rho_1 \left( 1 - \left( P_2 \over P_1 \right)^{ {\gamma+1}\over\gamma} \right) } \over { K_f - {2 \over \gamma} \log \left( {P_2 \over P_1} \right) } } \]
+Which is the form typically given in texts. If one assumes Kf is a constant then the mass velocity can be calculated directly. In practice, however, Kf is a function of the Reynolds number and so this must be solved numerically.
+function isentropic_flow(P₁, K::Number; T₁=T₁, P₂=P₂, γ=γ)
+ q = P₂/P₁
+ ρ₁ = ρ(P₁,T₁)
+ G = √( ((2γ/(γ+1))*P₁*ρ₁*(1-q^((γ+1)/γ)))/(K - (2/γ)*log(q)) )
+ return G
+end;using Roots: find_zero
+
+function isentropic_flow(P₁, K::Function; T₁=T₁, P₂=P₂, γ=γ)
+ # Initialize Parameters
+ q = P₂/P₁
+ ρ₁ = ρ(P₁,T₁)
+ T₂ = T₁*(q^((γ-1)/γ))
+ Tₐᵥ = (T₁+T₂)/2
+
+ # Initial guess
+ G_est = isentropic_flow(P₁, K(); T₁=T₁, P₂=P₂, γ=γ)
+
+ # Numerically solve for G
+ obj(G) = (K(Re(G,Tₐᵥ)) - (2/γ)*log(q))*(G^2) - (2γ/(γ+1))*P₁*ρ₁*(1-q^((γ+1)/γ))
+ G = find_zero(obj, G_est)
+
+ return G
+end;ṁ_i = isentropic_flow(P₁, Kf)*A0.43138829795543004 +
+The integration for Fanno flow is decidedly more tedious. As a sketch, start with the invariant (which comes from taking an energy balance for an ideal gas):
+\[ {1 \over 2} \left( Gv \right)^2 + {\gamma \over {\gamma -1} } Pv = \textrm{a constant}\]
+Solve for P, take the derivative to determine dP, substitute and integrate. The result is:
+\[ \int_{P_1}^{P_2} {dP \over v} = { {\gamma -1} \over {\gamma} } G^2 \left( \left(v_1 \over v_2\right) -1 -2 \log \left(v_1 \over v_2\right) \right) - \frac{1}{2} {P_1 \over v_1} \left( 1 - \left(v_1 \over v_2\right)^2 \right)\]
+Which, when substituted into the mechanical energy balance and simplified, becomes:
+\[ \left( K - { {\gamma -1} \over {2 \gamma} } \left( 1 - \left( { \rho_2 \over \rho_1 } \right)^2 \right) - { {\gamma +1} \over \gamma} \log \left( { \rho_2 \over \rho_1 } \right) \right) G^2 - \left( 1 - \left( { \rho_2 \over \rho_1 } \right)^2 \right) P_1 \rho_1 = 0 \]
+and can be further re-arranged to solve for G
+\[ G = \sqrt{ { P_1 \rho_1 \left( 1 - \left( { \rho_2 \over \rho_1 } \right)^2 \right) } \over { K - { {\gamma -1} \over {2 \gamma} } \left( 1 - \left( { \rho_2 \over \rho_1 } \right)^2 \right) - { {\gamma +1} \over \gamma} \log \left( { \rho_2 \over \rho_1 } \right) } } \]
+The obvious complication here is that ρ2 is unknown, so solving this requires simultaneously solving for either ρ2 or T2.
+Most often the Fanno flow model is given in terms of the Mach number, however the equation above is equivalent. This can be shown most easily by starting with the definition of the Fanno parameter, Fa, and the relation K = Fa1 - Fa2,
+\[ Fa = \left(\frac{1 - Ma^2}{\gamma Ma^2}\right) + \left(\frac{\gamma + 1}{2\gamma}\right)\log\left[\frac{Ma^2}{\left(\frac{2}{\gamma + 1}\right)\left(1 + \frac{\gamma - 1}{2}Ma^2\right)}\right] \]
+\[ K = \left(\frac{1 - Ma_1^2}{\gamma Ma_1^2}\right) - \left(\frac{1 - Ma_2^2}{\gamma Ma_2^2}\right) + \left(\frac{\gamma + 1}{2\gamma}\right)\log\left[\frac{Ma_1^2}{Ma_2^2}\frac{\left(1 + \frac{\gamma - 1}{2}Ma_2^2\right)}{\left(1 + \frac{\gamma - 1}{2}Ma_1^2\right)}\right] \]
+Then, making the substitution:
+\[\left(v_1 \over v_2\right)^2 = { {Ma_1^2 \left( 1 + { {\gamma-1}\over 2} Ma_2^2 \right)} \over {Ma_2^2 \left( 1 + { {\gamma-1}\over 2} Ma_1^2 \right)} }\]
+we get:
+\[ K = \left( \frac{1}{\gamma Ma_1^2} + \frac{\gamma-1}{2\gamma} \right) \left( 1 - \left(v_1 \over v_2\right)^2 \right) + \frac{\gamma + 1}{\gamma} \log\left(v_1 \over v_2\right) \]
+Then, using the definition of the Mach number, in terms of G, \(Ma=\frac{G}{\sqrt{\gamma P \rho} }\)
+\[ K = \left( \frac{P_1 \rho_1}{G^2} + \frac{\gamma-1}{2\gamma} \right) \left( 1 - \left(v_1 \over v_2\right)^2 \right) + \frac{\gamma + 1}{\gamma} \log\left(v_1 \over v_2\right) \]
+Solving for G, and making the substitution ρ = 1/v
+\[ G = \sqrt{ { P_1 \rho_1 \left( 1 - \left( { \rho_2 \over \rho_1 } \right)^2 \right) } \over { K - { {\gamma -1} \over {2 \gamma} } \left( 1 - \left( { \rho_2 \over \rho_1 } \right)^2 \right) - { {\gamma +1} \over \gamma} \log \left( { \rho_2 \over \rho_1 } \right) } } \]
+Which puts us back where we started.
+When it comes to actually using the Fanno flow model, if the goal is to calculate the flowrate for a given pressure drop, working in terms of the specific volume or density is far easier than using the model given in terms of the Mach number.
+An obvious simplifying assumption is to estimate the exit temperature using the relationship for isentropic flow.
+\[ {T_2 \over T_1} = \left( P_2 \over P_1 \right)^{ {\gamma-1} \over \gamma} \]
+If we were assuming Kf is constant, then using this assumption to estimate the density at the exit allows for a direct calculation of the mass velocity, no numerical methods required. In the more general case, the flow still needs to be calculated iteratively as the friction factor is a function of the flow (Reynolds number).
+function approx_fanno_flow(P₁, K::Number; T₁=T₁, P₂=P₂, γ=γ)
+ ρ₁ = ρ(P₁, T₁)
+ ρ₂ = ρ₁*(P₂/P₁)^(1/γ)
+ q = ρ₂/ρ₁
+ G = √( (P₁*ρ₁*(1-q^2))/(K - ((γ-1)/(2γ))*(1-q^2) - ((γ+1)/γ)*log(q)) )
+ return G
+end;using Roots: find_zero
+
+function approx_fanno_flow(P₁, K::Function; T₁=T₁, P₂=P₂, γ=γ)
+ # Initializing some parameters
+ T₂ = T₁*(P₂/P₁)^((γ-1)/γ)
+ ρ₁ = ρ(P₁, T₁)
+ ρ₂ = ρ(P₂, T₂)
+ q = ρ₂/ρ₁
+ Tₐᵥ = (T₁+T₂)/2
+
+ # Initial guess
+ G_est = approx_fanno_flow(P₁, K(); T₁=T₁, P₂=P₂, γ=γ)
+
+ # Numerically solve for G
+ obj(G) = (K(Re(G,Tₐᵥ)) - ((γ-1)/(2γ))*(1-q^2) - ((γ+1)/γ)*log(q))*(G^2) - (1-q^2)*P₁*ρ₁
+ G = find_zero(obj, G_est)
+
+ return G
+end;ṁ_fa = approx_fanno_flow(P₁, Kf)*A0.38355173684967075Actually calculating the exit conditions requires a little more work. I am going to simultaneously calculate the density at exit since it is somewhat simpler to work with than the temperature, though either could be done.
+To start we note that:
+\[ {1 \over 2} \left( Gv \right)^2 + {\gamma \over {\gamma -1} } Pv = C = \textrm{a constant}\]
+Which is a quadratic in v, and solving for v:
+\[ v = {1 \over G^2} \left( \sqrt{ \left( {\gamma \over {\gamma -1} } P \right)^2 + 2 G^2 C} - {\gamma \over {\gamma-1} } P \right) \]
+Where C is calculated at the entrance conditions and ρ = 1/v.
+From this the temperature at the exit can be backed out using the ideal gas law, and used to update the Reynolds number.
+This makes the whole calculation somewhat more complicated, and I think that added complication makes the simplification that Kf is constant pointless – that assumption does not make the math easier in any case.
+using Roots: find_zero
+
+function fanno_flow(P₁, K::Function; T₁=T₁, P₂=P₂, γ=γ)
+ # Initialize some parameters
+ ρ₁ = ρ(P₁,T₁)
+
+ # Initial guesses
+ q = (P₂/P₁)^(1/γ) # isentropic
+ G_est = √( (P₁*ρ₁*(1-q^2))/(K() - ((γ-1)/(2γ))*(1-q^2) - ((γ+1)/γ)*log(q)) )
+
+ function obj(G)
+ # Calculate the downstream density
+ C = 0.5*(G/ρ₁)^2 + (γ/(γ-1))*(P₁/ρ₁)
+ G²v = √(((γ/(γ-1))*P₂)^2 + 2*(G^2)*C) - (γ/(γ-1))*P₂
+ ρ₂ = (G^2)/G²v
+ @assert ρ₂ > 0
+
+ # Update Temperature dependent parameters
+ T₂ = (P₂*Mw)/(R*ρ₂)
+ Tₐᵥ = (T₁+T₂)/2
+
+ # Calculate the objective value
+ q = ρ₂/ρ₁
+ return (K(Re(G,Tₐᵥ)) - ((γ-1)/(2γ))*(1-q^2) - ((γ+1)/γ)*log(q))*G^2 - P₁*ρ₁*(1-q^2)
+ end
+
+ G = find_zero(obj, G_est)
+
+ return G
+end;function fanno_flow(P₁, K::Number; T₁=T₁, P₂=P₂, γ=γ)
+ fn() = K
+ fn(Re) = K
+ return fanno_flow(P₁, fn; T₁=T₁, P₂=P₂, γ=γ)
+end;ṁ_f = fanno_flow(P₁, Kf)*A0.40934309494917254 +
+The approximation produces reasonable results in this case, especially at higher pressure drops, but one should always be cautious when mixing results from different models.12
+12 This is something worth keeping mind more generally, as I have seen the assumption that Fanno flow is approximately isentropic (implicitly) taken for calculating different flow parameters, and it is often a bad assumption. For example, some references use the isentropic choking condition for a nozzle as an estimate for the choking condition in Fanno flow. Unless the pipe is incredibly short this is a terrible approximation – in the current example the pressure drop exceeds the choking flow condition for a nozzle and yet the pipe flow is far from choked.
By far the simplest method is to use a modified Darcy equation with expansion factors (Y factors). This takes the well known Darcy equation for incompressible pipe flow and, in a classic engineering move, tacks on a Y factor to account for all the complexity in adiabatic flow.
+\[ G = Y \sqrt{ { 2 \rho_1 \Delta P } \over K } \]
+Where the expansion factor, Y, is read off of a chart. This is great if you are working things out by hand, but can present some challenges when calculating things on a computer. Ludwig’s13 provides a complicated series of equations to iteratively calculate the Y curves yourself, but I think if you are expending that level of effort then you really are not saving anything over using the Fanno model above. A much simpler approach is to either interpolate the critical expansion factor, Ycr, and critical pressure ratio, qcr, from the values given in Crane’s or use a correlation for them (that’s what I will use). Though this adds the wrinkle of only being able to use Y factors for gases with the same γ as what is either tabulated or available in a correlation.
+The actual Y value then comes from a simple linear relationship (where \(q={ {\Delta P} \over P_1}\) )
+\[ Y = \left( Y_{cr} -1 \right) \left( q \over q_{cr} \right) +1 \]
+This has the added convenience of telling you when you have crossed into choked flow, it happens when q>qcr.
+One downside is that this method does not directly produce the exit conditions, so the Reynolds number is typically taken at the entrance conditions only. Since the Reynolds number is only a function of Temperature through the viscosity, this works out fine over ranges where the viscosity is approximately constant.14
+14 The temperature can be worked out by using the method given in the section for Fanno flow, calculating the invariant at entrance conditions (once G is known) and then solving for the exit density.
# Correlations for γ=1.4
+
+function Ycr(K)
+ x = log(K)
+ y = 0.0006*x^3 - 0.0185*x^2 + 0.1141*x - 0.5304
+ return exp(y)
+end;
+
+function qcr(K)
+ x = log(K)
+ y = 0.0011*x^3 - 0.0302*x^2 + 0.238*x - 0.6455
+ return exp(y)
+end; +
+The correlation curves I am using fit the tabulated values from Crane’s reasonably well, but clearly the fit is not perfect.
+function Y(K,q)
+ Yc, qc = Ycr(K), qcr(K)
+ if q < qc
+ return (Yc-1)*(q/qc)+1
+ else
+ return Yc
+ end
+end; +
+16 Crane, A–23.
The calculated curve is between the bracketing curves in Crane’s and looks plausible.
+If you are assuming that Kf is constant then the mass velocity can be calculated directly, however if you wish to be more exact you can also iterate.
+function modified_darcy(P₁, K::Number; T₁=T₁, P₂=P₂, γ=γ)
+ ρ₁ = ρ(P₁,T₁)
+ q = (P₁-P₂)/P₁
+ G = Y(K,q)*√(2*ρ₁*(P₁-P₂)/K)
+ return G
+end;using Roots: find_zero
+
+function modified_darcy(P₁, K::Function; T₁=T₁, P₂=P₂, γ=γ)
+ # Intialize Parameters
+ ρ₁ = ρ(P₁,T₁)
+ q = (P₁-P₂)/P₁
+
+ # Initial Guess
+ G_est = modified_darcy(P₁, K(); T₁=T₁, P₂=P₂, γ=γ)
+
+ # Numerically solve for G
+ obj(G) = G - modified_darcy(P₁, K(Re(G,T₁)); T₁=T₁, P₂=P₂, γ=γ)
+ G = find_zero(obj, G_est)
+
+ return G
+end;ṁ_y = modified_darcy(P₁, Kf)*A0.4049511071122898 +
+Below is a plot showing all of the methods examined so far, including assuming the isothermal case (this a common recommendation for a simplifying assumption). The expansion factor method approximates the Fanno flow method, from which it was derived, quite well, to the point where they are essentially indistinguishable. The isothermal model is practically just as good for this particular example, while the isentropic model works well only for low pressure drops, the version of the Fanno flow that approximates the temperature as isentropic is the opposite, being the worst model at low pressure drops and converging towards the Fanno model at higher pressure drops.
+ +
+But this is just one example, perhaps we can look at a wider range of Kf and pressure drops. Conveniently, Crane’s has a table with Kf ranging from 1 to 100 and calculated pressure drops and expansion factors: the limiting factors. Using the models examined above, the effective expansion factors can be calculated quite easily for each K in Crane’s table (taking the pressure ratios as givens).
+ +
+17 Crane, A–23.
Note that this represents the greatest pressure drop for a given Kf, which should correspond to the “worst case” for most models (except the approximated Fanno model). The Fanno model and the correlation I was using to generate Y factors line up quite nicely, though there is a fair amount of scatter with the tabulated Y factors which is interesting. The isentropic model is close, but not in great agreement, over the entire range. What I find more interesting is how rapidly the isothermal model comes into agreement. We would expect, then, at Kf=100 that the isothermal model would basically fall on top of the Fanno model over the entire range of pressure.
+ +
+They are basically indistinguishable. However, this is not at all implying that the temperature in the Fanno flow model is remaining constant over these large pressure drops. As one would expect, the adiabatic flow moves further from isothermal as the pressure drop increases. The mass flows just happen to be the same.
+ +
+I think the big take-away is that the isentropic flow model is not a very good approximation of Fanno flow and references that suggest that it is are in error. The other big take-away may be that, at least when calculating mass flow rates, the isothermal model is often better than one would expect: it does well at low pressure drops and also for long lines where Kf is large. In practice, when the flow conditions are within the range of available Y factors, the modified Darcy equation is the easiest to use and gives excellent agreement with the full Fanno model, however when the situation is outside of that range and Y factors have to be calculated it is not a time-saver.
+The big elephant in the room is that, in practice, no actual gas flow is perfectly ideal or perfectly adiabatic, nor is the friction factor truly a constant. These assumptions play a big role in the overall model error, and being fussy about some of the details of different adiabatic ideal gas models may amount to nothing in practice.
+I have had an Atmotube Pro for a few years, mostly using it during the summer to keep an eye on poor air quality during wildfire smoke events. I often export data from it, as a csv, to noodle around, but I haven’t really looked at how to log data directly from it with my laptop. Atmotube provides documentation on the bluetooth API and a guide for how to set up an MQTT router. But I couldn’t really find anything on just logging data from it directly, using python.
+Thus my project for the Victoria Day long weekend was to figure out how to collect data from my atmotube using python. This works on my laptop but could, presumably, be ported to something like a raspberry pi easily enough.
+The Atmotube documentation gives two main ways of getting data from the device: using GATT or just passively from the advertising data the Atmotube broadcasts when it isn’t connected to anything (the BLE advertising packet). The most straightforward, to retrieve something specific, is via GATT.
+I am going to be using Bleak to scan and connect to BLE devices. To start I need a BleakScanner to scan for devices and, once I have found the one I want, connect to it as a BleakClient. Then, to make the various requests, I need the corresponding UUIDs – these correspond to specific packets of data as described in the docs
import timefrom bleak import BleakScanner, BleakClient# some constants
+ATMOTUBE = "C2:2B:42:15:30:89" # the mac address of my Atmotube
+SGPC3_UUID = "DB450002-8E9A-4818-ADD7-6ED94A328AB4"
+BME280_UUID = "DB450003-8E9A-4818-ADD7-6ED94A328AB4"
+SPS30_UUID = "DB450005-8E9A-4818-ADD7-6ED94A328AB4"
+STATUS_UUID = "DB450004-8E9A-4818-ADD7-6ED94A328AB4"The function scan_and_connect scans for the device which matches the mac address of my Atmotube, then proceeds to request each of the four packets of data. This simply returns a tuple with the data and the timestamp.
async def scan_and_connect(address):
+ device = await BleakScanner.find_device_by_address(address)
+ if not device:
+ print("Device not found")
+ return None
+
+ async with BleakClient(device) as client:
+ stat = await client.read_gatt_char(STATUS_UUID)
+ bme = await client.read_gatt_char(BME280_UUID)
+ sgp = await client.read_gatt_char(SGPC3_UUID)
+ sps = await client.read_gatt_char(SPS30_UUID)
+ ts = time.time()
+ return (ts, stat, bme, sgp, sps)I can connect and get a single data point, but what I have is a timestamp and a collection of bytes. It is not cleaned up and readable in any way.
+res = await scan_and_connect(ATMOTUBE)The easiest way to unpack a sequence of bytes is to use the struct standard library. But there are two exceptions:
+import structfrom ctypes import LittleEndianStructure, c_uint8, c_int8
+
+class InfoBytes(LittleEndianStructure):
+ _fields_ = [
+ ("pm_sensor", c_uint8, 1),
+ ("error", c_uint8, 1),
+ ("bonding", c_uint8, 1),
+ ("charging", c_uint8, 1),
+ ("charge_timer", c_uint8, 1),
+ ("bit_6", c_uint8, 1),
+ ("pre_heating", c_uint8, 1),
+ ("bit_8", c_uint8, 1),
+ ("batt_level", c_uint8, 8),
+ ]int.from_bytes() directly, but I think this is a little neater and easier to read.class PMBytes(LittleEndianStructure):
+ _fields_ = [
+ ('_pm1', c_int8*3),
+ ('_pm2_5', c_int8*3),
+ ('_pm10', c_int8*3),
+ ('_pm4', c_int8*3),
+ ]
+ _pack_ = 1
+
+ @property
+ def pm1(self):
+ return int.from_bytes(self._pm1, 'little', signed=True)
+
+ @property
+ def pm2_5(self):
+ return int.from_bytes(self._pm2_5, 'little', signed=True)
+
+ @property
+ def pm10(self):
+ return int.from_bytes(self._pm10, 'little', signed=True)With those two pieces out of the way, I define the actual variables I want – these are the column names I want to have in the final dataframe – and process the bytes. The first step is to use the InfoByte struct I defined above to pull out the flags and battery status, I add this to the results more for my own interest. Then I use struct.unpack() to unpack the integers from each byte-string and store the results.
Finally I use the PMBytes class to process the PM data. If the sensor isn’t on the results are -1 and so I clean those out. The idea is to leave any blank readings as None, since that is easy to filter out with pandas later on.
HEADERS = ["Timestamp", "VOC", "RH", "T", "P", "PM1", "PM2.5", "PM10"]def process_gatt_data(data):
+ result = dict.fromkeys(HEADERS)
+ if res is not None:
+ ts, stat, bme, sgp, sps = data
+ result["Timestamp"] = ts
+
+ # Info and Battery data
+ inf_bits = InfoBytes.from_buffer_copy(stat)
+ for (fld, _, _) in inf_bits._fields_:
+ result[f"INFO.{fld}"] = getattr(inf_bits, fld)
+
+ # SGPC3 data format
+ tvoc, _ = struct.unpack('<hh', sgp)
+ result["VOC"] = tvoc/1000
+
+ # BME280 data format
+ rh, T, P, T_plus = struct.unpack('<bblh', bme)
+ result["RH"] = rh
+ result["T"] = T_plus/100
+ result["P"] = P/1000
+
+ # SPS30 data format
+ pms = PMBytes.from_buffer_copy(sps)
+ result["PM1"] = pms.pm1/100 if pms.pm1 > 0 else None
+ result["PM2.5"] = pms.pm2_5/100 if pms.pm2_5 > 0 else None
+ result["PM10"] = pms.pm10/100 if pms.pm10 > 0 else None
+
+ return resultNow I can process the result I collected earlier.
+process_gatt_data(res){'Timestamp': 1747673644.60206,
+ 'VOC': 0.223,
+ 'RH': 32,
+ 'T': 21.3,
+ 'P': 93.37,
+ 'PM1': 1.0,
+ 'PM2.5': 2.18,
+ 'PM10': 3.27,
+ 'INFO.pm_sensor': 1,
+ 'INFO.error': 0,
+ 'INFO.bonding': 0,
+ 'INFO.charging': 0,
+ 'INFO.charge_timer': 1,
+ 'INFO.bit_6': 0,
+ 'INFO.pre_heating': 1,
+ 'INFO.bit_8': 0,
+ 'INFO.batt_level': 63}The results are what I expect for my apartment. In addition to the air quality data, we can see that the PM sensor was on and that the Atmotube had been charging recently.1 The pre-heat flag indicates that the device has completed any pre-heating and is ready. So everything looks good.
+1 I unplugged it before charging was done so it wouldn’t interfere with any temperature readings when I tested this code, that’s why the battery was only at 63%
I could, at this point, just start a service or cron job to poll the device every so often and log the results. It will only return PM results when the atmotube is actively sampling, which could present some issues with timing. If the device is set to sample, for example, every 15 minutes and the script doesn’t make a request during that window, it will never return results. For everything that follows I set my atmotube to sample continuously.
+The other way of logging data from the atmotube is to pull it out of the advertising packet the atmotube broadcasts as a bluetooth device. In this case I don’t actually connect to the device, the scanner runs continuously and sends back any advertising data it finds using the adv_cb() callback function. This checks if the data came from my atmotube and, if it did, adds it to the results.
The scanner runs inside an event loop which starts the scanner, waits until the collection_time has elapsed, then shuts down and returns the results.
import asyncioasync def collect_data(device_mac, collection_time=600):
+ def adv_cb(device, advertising_data):
+ if device.address == device_mac:
+ results.append((time.time(), device, advertising_data))
+ else:
+ pass
+ return None
+
+ async def receiver(event):
+ async with BleakScanner(adv_cb, scanning_mode='active') as scanner:
+ await event.wait()
+
+ results = []
+ loop = asyncio.Event()
+ task = asyncio.create_task(receiver(loop))
+ await asyncio.sleep(collection_time)
+ loop.set()
+ _ = await asyncio.wait([task])
+ return resultsRunning this for 10 seconds lets me collect some example data to play with.
+broadcasts = await collect_data(ATMOTUBE, 10)Processing the advertising packet is similar to what was done with the GATT data, except that it comes in two flavours: the broadcast packet has the basic temperature, pressure, VOC, device status and the scan response packet contains the PM data and is shorter. Here the PM data is at a lower resolution – 16-bit integers – and so they can be unpacked using struct.unpack(). The GATT data returns the PM data to 2 decimal places (and the temperature to 1 decimal place), whereas the advertising packet data is rounded to the nearest whole number.
def process_adv_data(full_data, company_id=int(0xFFFF)):
+ result = dict.fromkeys(HEADERS)
+ if full_data is None:
+ return result
+ else:
+ timestamp, device, advertising_data = full_data
+ result["Timestamp"] = timestamp
+
+ # process advertising data
+ data = advertising_data.manufacturer_data.get(company_id)
+ if len(data) == 12:
+ tvoc, devid, rh, T, P, inf, batt = struct.unpack(">hhbblbb", data)
+ result["VOC"] = tvoc/1000
+ result["RH"] = rh
+ result["T"] = T
+ result["P"] = P/1000
+ elif len(data) == 9:
+ pm1, pm2_5, pm10, fw_maj, fw_min, fw_bld = struct.unpack(">hhhbbb", data)
+ result["PM1"] = pm1 if pm1 > 0 else None
+ result["PM2.5"] = pm2_5 if pm2_5 > 0 else None
+ result["PM10"] = pm10 if pm10 > 0 else None
+ else:
+ pass
+ return resultI can process this and look at examples of the two types of advertising packet
+process_adv_data(broadcasts[0]){'Timestamp': 1747673646.9507601,
+ 'VOC': None,
+ 'RH': None,
+ 'T': None,
+ 'P': None,
+ 'PM1': 1,
+ 'PM2.5': 2,
+ 'PM10': 3}process_adv_data(broadcasts[5]){'Timestamp': 1747673647.2869163,
+ 'VOC': 0.208,
+ 'RH': 36,
+ 'T': 21,
+ 'P': 93.357,
+ 'PM1': None,
+ 'PM2.5': None,
+ 'PM10': None}The way I have this set up is very wasteful of memory if the atmotube is set-up to only sample periodically. In those cases there will be a lot of packets with no PM data that are being dutifully logged in results. By processing the data as it is retrieved, I can collect only the packets that had measurements in them.
async def better_collect_data(device_mac, collection_time=600):
+ def adv_cb(device, advertising_data):
+ if device.address == device_mac:
+ row = process_adv_data((time.time(), device, advertising_data))
+ if len( [ val for key, val in row.items() if val is not None ]) >1:
+ # only collect results when we actually have a measurement
+ results.append(row)
+ else:
+ pass
+ return None
+
+ async def receiver(event):
+ async with BleakScanner(adv_cb) as scanner:
+ await event.wait()
+
+ results = []
+ loop = asyncio.Event()
+ task = asyncio.create_task(receiver(loop))
+ await asyncio.sleep(collection_time)
+ loop.set()
+ _ = await asyncio.wait([task])
+ return resultsWhich I let collect for 5 minutes
+new_broadcasts = await better_collect_data(ATMOTUBE, 300)At this point we want to actually look at the results and maybe do some stats. By logging the data as a list of dicts, transforming this into a dataframe is very straightforward.
+import pandas as pddf = pd.DataFrame(new_broadcasts)df.describe()| + | Timestamp | +VOC | +RH | +T | +P | +PM1 | +PM2.5 | +PM10 | +
|---|---|---|---|---|---|---|---|---|
| count | +4.100000e+02 | +57.000000 | +57.000000 | +57.0 | +57.000000 | +353.0 | +353.000000 | +353.000000 | +
| mean | +1.747674e+09 | +0.203228 | +35.105263 | +21.0 | +93.351193 | +1.0 | +2.005666 | +3.039660 | +
| std | +8.914660e+01 | +0.002797 | +0.450564 | +0.0 | +0.004576 | +0.0 | +0.184550 | +0.246825 | +
| min | +1.747674e+09 | +0.199000 | +34.000000 | +21.0 | +93.343000 | +1.0 | +1.000000 | +2.000000 | +
| 25% | +1.747674e+09 | +0.201000 | +35.000000 | +21.0 | +93.348000 | +1.0 | +2.000000 | +3.000000 | +
| 50% | +1.747674e+09 | +0.203000 | +35.000000 | +21.0 | +93.351000 | +1.0 | +2.000000 | +3.000000 | +
| 75% | +1.747674e+09 | +0.204000 | +35.000000 | +21.0 | +93.355000 | +1.0 | +2.000000 | +3.000000 | +
| max | +1.747674e+09 | +0.210000 | +36.000000 | +21.0 | +93.361000 | +1.0 | +3.000000 | +4.000000 | +
This shows a real asymmetry in quantity of data found and what was in it – of 410 packets received 353 were PM data and 57 contained the VOC, temperature, etc. data.
+df['Time'] = df['Timestamp'] - df.iloc[0]['Timestamp'] +
+Plotting the timeseries data shows the PM data is very noisy – largely because it is rounding to the nearest whole integer. I also suspect that I should be cleaning up the scan responses better. Probably a lot of those are duplicates – it is not actually a fresh reading just rebroadcast of what had been read last. I’m not really sure.
+If you are only collecting 5 minutes of data, reading directly into memory like this is reasonable. But probably you want to log the data over a longer stretch of time, and it makes more sense to log the data to a csv – saving it more permanently. The following creates a new csv with the given filename then, for every valid packet processed, appends the results to the csv.
+import csvasync def log_to_csv(device_mac, collection_time=600, file="atmotube.csv"):
+ def adv_cb(device, advertising_data):
+ if device.address == device_mac:
+ row = process_adv_data((time.time(), device, advertising_data))
+ if len( [ val for key, val in row.items() if val is not None ]) >1:
+ # only collect results when we actually have a measurement
+ with open(file, 'a', newline='') as csvfile:
+ writer = csv.DictWriter(csvfile, fieldnames=HEADERS)
+ writer.writerow(row)
+ else:
+ pass
+ return None
+
+ async def receiver(event):
+ async with BleakScanner(adv_cb) as scanner:
+ await event.wait()
+
+ # prepare csv file
+ with open(file, 'w', newline='') as csvfile:
+ writer = csv.DictWriter(csvfile, fieldnames=HEADERS)
+ writer.writeheader()
+
+ # start scanning
+ loop = asyncio.Event()
+ task = asyncio.create_task(receiver(loop))
+
+ # wait until the collection time is up
+ await asyncio.sleep(collection_time)
+ loop.set()
+ _ = await asyncio.wait([task])
+
+ return TrueThe callback function is doing a lot of work and blocking to write to a csv. This is, in general, not a good idea. When I put this together, I figured that the rate of new data from the Atmotube is significantly slower than the time required to process data and write it to a csv. Which is true, but it isn’t really robust. A better solution might be to have the callback put the data into a queue and have a seperate worker process results into the csv.
+To get this going, I just created a csv with the current timestep in the filename – so if I stop and start I don’t clobber previous data – and leave it to run for an hour. I just left this running in jupyter while I switched to a different desktop and went about my life, but a longer-term solution would be in a script that runs in the background.
+import mathnow = math.floor(time.time())
+timestamped_file = f"atmotube-{now}.csv"
+result = await log_to_csv(ATMOTUBE, 3600, timestamped_file)
+
+print("Success!") if result else print("Boo")Success!While it is running, you can check on the progress with tail -f %filename, and watch the results come in live on the terminal. Once it is done, the csv can be read into pandas and plotted like before
logged_data = pd.read_csv(timestamped_file)logged_data.describe()| + | Timestamp | +VOC | +RH | +T | +P | +PM1 | +PM2.5 | +PM10 | +
|---|---|---|---|---|---|---|---|---|
| count | +4.823000e+03 | +835.000000 | +835.000000 | +835.0 | +835.000000 | +3988.0 | +3988.000000 | +3988.000000 | +
| mean | +1.747676e+09 | +0.226522 | +34.810778 | +21.0 | +93.320590 | +1.0 | +1.919007 | +2.945587 | +
| std | +1.037307e+03 | +0.012884 | +0.711420 | +0.0 | +0.018019 | +0.0 | +0.328726 | +0.325025 | +
| min | +1.747674e+09 | +0.195000 | +34.000000 | +21.0 | +93.283000 | +1.0 | +1.000000 | +2.000000 | +
| 25% | +1.747675e+09 | +0.217000 | +34.000000 | +21.0 | +93.303000 | +1.0 | +2.000000 | +3.000000 | +
| 50% | +1.747676e+09 | +0.230000 | +35.000000 | +21.0 | +93.325000 | +1.0 | +2.000000 | +3.000000 | +
| 75% | +1.747677e+09 | +0.237000 | +35.000000 | +21.0 | +93.337000 | +1.0 | +2.000000 | +3.000000 | +
| max | +1.747678e+09 | +0.249000 | +37.000000 | +21.0 | +93.355000 | +1.0 | +3.000000 | +4.000000 | +
logged_data['Time'] = logged_data['Timestamp'] - logged_data.iloc[0]['Timestamp'] +
+The atmotube is also logging data to its internal memory, so I exported that and plotted it against what was broadcast.
+export_data = pd.read_csv('atmotube-export-data.csv')
+export_data.describe()| + | VOC, ppm | +AQS | +Air quality health index (AQHI) - Canada | +Temperature, °C | +Humidity, % | +Pressure, kPa | +PM1, ug/m3 | +PM2.5, ug/m3 | +PM2.5 (avg 3h), ug/m3 | +PM10, ug/m3 | +PM10 (avg 3h), ug/m3 | +Latitude | +Longitude | +
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | +66.000000 | +66.000000 | +66.0 | +66.0 | +66.000000 | +66.000000 | +66.0 | +66.000000 | +66.000000 | +66.000000 | +66.000000 | +0.0 | +0.0 | +
| mean | +0.239985 | +85.045455 | +1.0 | +21.0 | +34.484848 | +93.316364 | +1.0 | +1.530303 | +1.559175 | +2.545455 | +2.861027 | +NaN | +NaN | +
| std | +0.018563 | +1.156012 | +0.0 | +0.0 | +0.769464 | +0.019817 | +0.0 | +0.502905 | +0.036129 | +0.501745 | +0.041909 | +NaN | +NaN | +
| min | +0.212000 | +82.000000 | +1.0 | +21.0 | +33.000000 | +93.280000 | +1.0 | +1.000000 | +1.466667 | +2.000000 | +2.722222 | +NaN | +NaN | +
| 25% | +0.228250 | +85.000000 | +1.0 | +21.0 | +34.000000 | +93.300000 | +1.0 | +1.000000 | +1.550000 | +2.000000 | +2.866667 | +NaN | +NaN | +
| 50% | +0.238000 | +85.000000 | +1.0 | +21.0 | +34.500000 | +93.320000 | +1.0 | +2.000000 | +1.561111 | +3.000000 | +2.877778 | +NaN | +NaN | +
| 75% | +0.244750 | +86.000000 | +1.0 | +21.0 | +35.000000 | +93.337500 | +1.0 | +2.000000 | +1.583333 | +3.000000 | +2.888889 | +NaN | +NaN | +
| max | +0.295000 | +87.000000 | +1.0 | +21.0 | +36.000000 | +93.350000 | +1.0 | +2.000000 | +1.616667 | +3.000000 | +2.888889 | +NaN | +NaN | +
from datetime import datetimeexport_data['Timestamp'] = export_data[['Date']].apply(
+ lambda str: datetime.strptime(str.iloc[0], "%Y/%m/%d %H:%M:%S").timestamp(), axis=1)export_data['Time'] = export_data['Timestamp'] - logged_data.iloc[0]['Timestamp'] +
+The basic atmospheric data like temperature, pressure, and relative humidity appear to be the same. But there is something weird going on with the VOC measurements.
+ +
+I think the atmotube is actually exporting the rolling average of the VOC results over a fairly broad window, whereas the broadcast reading is more direct from the sensor. I would have to run this for much longer to see if that’s the case.
+ +
+The PM data shows the results are closer, but still have issues. The exported data is (I believe) a by-the-minute average, rounded to the nearest integer. There is a single data point for each minute in the dataset, giving 66 overall. Whereas the raw PM broadcast data has 3988 data points, and I think most of those are just rebroadcasts and are not “real”.
+One thing I was thinking of doing was to capture only the first scan response packet after an advertising packet then ignore all the rest until the next advertising packet. I have also been ignoring the info flags since, when I was just noodling around, they didn’t seem to change at all (with the device always sampling), they might actually be telling me things that I’ve been ignoring.
+Hopefully this helps you get set-up collecting data from your atmotube (I don’t know why else you would read this far). From here to building a simple dashboard or datalogger should be an easy weekend project. I think for applications where you want higher fidelity data over a long stretch of time, periodically requesting data using GATT makes the most sense. The PM data comes with more decimal places of precision, and you don’t need it more frequently than every minute or so.
+The BLE advertising data could be an easy way of building a passive dashboard, continuously listening and updating the air quality statistics. Though some effort would need to be put in cleaning up the data, or perhaps just presenting a rolling average of some kind to smooth out the noise.
+There is also a whole section of the documentation on connecting to an atmotube and downloading data from it, which I didn’t bother to investigate. It looked overly complicated for what I wanted to do. If you figure that out, please let me know!
+I have taken what I figured out in the following section and put it into a minimal python module with a few helper functions. See this example showing how to collect data from an AtmoTube and process the results.
+I was thinking about this more and there was one avenue I neglected to explore: subscribing to GATT notifications from the atmotube. Instead of requesting a single data point, like I did above, one can subscribe to the feed and the atmotube will just send packets whenever an update occurs. That is what I do below.
+To get started I decided to make cytpe structs for each of the bytestrings that can be returned. I don’t think this is necessary, but I like how it seperates the logic of decoding the response on an aesthetic level. It also makes it very clear how the bytestrings are structured.
+from ctypes import LittleEndianStructure, c_ubyte, c_byte, c_short, c_int
+
+class StatusData(LittleEndianStructure):
+ _fields_ = [
+ ("pm_sensor", c_ubyte, 1),
+ ("error", c_ubyte, 1),
+ ("bonding", c_ubyte, 1),
+ ("charging", c_ubyte, 1),
+ ("charging_timer", c_ubyte, 1),
+ ("_bit_6", c_ubyte, 1),
+ ("sgpc3_pre_heating", c_ubyte, 1),
+ ("_bit_8", c_ubyte, 1),
+ ("battery_level", c_ubyte, 8),
+ ]
+
+ def __new__(cls, ts, data):
+ return cls.from_buffer_copy(data)
+
+ def __init__(self, ts, data):
+ self.timestamp = tsclass SPS30Data(LittleEndianStructure):
+ _fields_ = [
+ ('_pm1', c_byte*3),
+ ('_pm2_5', c_byte*3),
+ ('_pm10', c_byte*3),
+ ('_pm4', c_byte*3),
+ ]
+ _pack_ = 1
+
+ def __new__(cls, ts, data):
+ return cls.from_buffer_copy(data)
+
+ def __init__(self, ts, data):
+ self.timestamp = ts
+
+ @property
+ def pm1(self):
+ res = int.from_bytes(self._pm1, 'little', signed=True)
+ return res/100 if res > 0 else None
+
+ @property
+ def pm2_5(self):
+ res = int.from_bytes(self._pm2_5, 'little', signed=True)
+ return res/100 if res > 0 else None
+
+ @property
+ def pm10(self):
+ res = int.from_bytes(self._pm10, 'little', signed=True)
+ return res/100 if res > 0 else Noneclass BME280Data(LittleEndianStructure):
+ _fields_ = [
+ ('_rh', c_byte),
+ ('_T', c_byte),
+ ('_P', c_int),
+ ('_T_dec', c_short),
+ ]
+ _pack_ = 1
+
+ def __new__(cls, ts, data):
+ return cls.from_buffer_copy(data)
+
+ def __init__(self, ts, data):
+ self.timestamp = ts
+
+ @property
+ def RH(self):
+ return self._rh
+
+ @property
+ def T(self):
+ return self._T_dec/100
+
+ @property
+ def P(self):
+ return self._P/1000class SGPC3Data(LittleEndianStructure):
+ _fields_ = [
+ ('_TVOC', c_short),
+ ]
+ _pack_ = 1
+
+ def __new__(cls, ts, data):
+ return cls.from_buffer_copy(data)
+
+ def __init__(self, ts, data):
+ self.timestamp = ts
+
+ @property
+ def TVOC(self):
+ return self._TVOC/1000With that out of the way, there are two other components I need for this to work: a collector which will collect all of the data sent back from the atmotube and a worker which will log it to a csv. Unlike above, where I logged each advertising packet as it came in, I am going to make these run asynchronously using asyncio. I think this is what really should be done, instead of blocking for file i/o every time a callback function is triggered.
To make this happen I largely copied what was done in this example which uses an async queue to pass data between the two workers. The basic idea is:
+collection_time and every time it gets a new set of data uses the callbacks status_cb and sps30_cb to process the bytestring and put the result on the queueasync def collect_data(mac, queue, collection_time):
+ async def status_cb(char, data):
+ ts = time.time()
+ res = StatusData(ts, data)
+ await queue.put(res)
+
+ async def sps30_cb(char, data):
+ ts = time.time()
+ res = SPS30Data(ts, data)
+ await queue.put(res)
+
+ device = await BleakScanner.find_device_by_address(mac)
+ if not device:
+ raise Exception("Device not found")
+
+ async with BleakClient(device) as client:
+ # start notifications
+ await client.start_notify(STATUS_UUID, status_cb)
+ await client.start_notify(SPS30_UUID, sps30_cb)
+
+ # wait for collection period to end
+ await asyncio.sleep(collection_time)
+
+ # signals end of queue
+ await queue.put(None)Concurrently with that, a logger needs to write things to a csv. The basic idea is this:
+filename, and writes the column headers.battery_level as a lazy check of which type of result it is.None, that is a signal that the collector has finished and the loop exits.task_done() to notify the queue of this and the loop begins again.import aiofiles, aiocsvHEADERS = ["Timestamp", "PM Sensor", "PM1", "PM2.5", "PM10"]async def write_row(filename,row):
+ async with aiofiles.open(filename, 'a', newline='') as csvfile:
+ writer = aiocsv.AsyncDictWriter(csvfile, fieldnames=HEADERS)
+ await writer.writerow(row)async def log_to_csv(filename, queue):
+ # prepare csv file
+ async with aiofiles.open(filename, 'w', newline='') as csvfile:
+ writer = aiocsv.AsyncDictWriter(csvfile, fieldnames=HEADERS)
+ await writer.writeheader()
+
+ # log data from queue
+ flag = True
+ while flag:
+ result = await queue.get()
+ if result is not None:
+ # we have some data to write
+ row = dict.fromkeys(HEADERS)
+ row["Timestamp"] = result.timestamp
+ if hasattr(result, "battery_level"):
+ # we have a status type
+ row["PM Sensor"] = result.pm_sensor
+ else:
+ # we have pm data
+ row["PM1"] = result.pm1
+ row["PM2.5"] = result.pm2_5
+ row["PM10"] = result.pm10
+
+ await write_row(filename,row)
+ else:
+ # the end of the queue
+ flag = False
+ queue.task_done()My first attempt at this I put the while loop inside the with block, so the whole thing ran inside the file context manager. This had the effect of nothing actually being written to the csv until the with block exited and the file closed. It took me a long time to realize that is what was happening, since it looked exactly the same as the two processes running sequentially: collect all the data and then write it all to csv.
In this version, every time a row is added to the csv the file is opened, a line is written, and then it is closed. There is probably a way of holding it open while logging, but that might make things more complicated since a whole bunch of new logic would be needed to catch any exceptions and ensure that the file is closed properly – something that happens behind the scenes with a simple with block.
Finally, I put it all together with a simple sequence of tasks:
+Queueasync def save_data(mac, csv, collection_time):
+ q = asyncio.Queue()
+
+ logger = asyncio.create_task(log_to_csv(csv, q))
+ collector = asyncio.ensure_future(collect_data(mac, q, collection_time))
+
+ await collectorI ran this for an hour in the background as a test and it seems to work fine.
+await save_data(ATMOTUBE, f"atmotube-{math.floor(time.time())}.csv", 3600)df = pd.read_csv("atmotube-1748482080.csv")df['Time'] = df['Timestamp'] - df.iloc[0]['Timestamp']df.head()| + | Timestamp | +PM Sensor | +PM1 | +PM2.5 | +PM10 | +Time | +
|---|---|---|---|---|---|---|
| 0 | +1.748482e+09 | +NaN | +10.92 | +13.43 | +14.97 | +0.000000 | +
| 1 | +1.748482e+09 | +NaN | +10.93 | +13.03 | +14.66 | +2.610108 | +
| 2 | +1.748482e+09 | +NaN | +11.05 | +13.42 | +15.19 | +5.220881 | +
| 3 | +1.748482e+09 | +NaN | +11.35 | +13.75 | +15.34 | +7.784888 | +
| 4 | +1.748482e+09 | +NaN | +11.59 | +14.13 | +15.50 | +10.395001 | +
 +
+With no context it looks like something is horribly wrong, what are all those gaps in the data? My atmotube is set to only sample every 15 minutes, this is usually how I leave it to save on battery. This also explains some of the weirdness with the data, why does each sample start with a rapidly increasing concentration before levelling out? The atmotube is returning data right when the sampling fan has just turned on; this is not yet an accurate sample of the ambient air, it is the stagnant air inside the atmotube. This is a much more obvious problem with VOC data, it is clearly visible on the app as a funky saw-tooth wave where the VOC concentration plunges whenever the fan starts and, once it stops, slowly creeps up. It is an artifact of how the atmotube is sampling the air, not of how the data is being collected.
+If the atmotube is set to always on mode, these artifacts go away, but if you want to monitor it in other configurations it is worth considering how the data should be cleaned up. For example watching for the pm_sensor flag to turn on then throwing out the first ~30s of pm data before looking at the rest. The GATT notifications make it very clear when the atmotube is sampling and when it isn’t. There will be a notification that pm_sensor has turned from 0 to 1, then data will start arriving with pm data, then a notification that the pm_sensor has turned from 1 to 0, followed by an empty row of pm data. See a snippet of the csv below. Note that pm_sensor values and actual pm values are always on seperate rows.
df[36:42]| + | Timestamp | +PM Sensor | +PM1 | +PM2.5 | +PM10 | +Time | +
|---|---|---|---|---|---|---|
| 36 | +1.748482e+09 | +NaN | +12.42 | +14.34 | +15.23 | +127.802146 | +
| 37 | +1.748482e+09 | +0.0 | +NaN | +NaN | +NaN | +130.322095 | +
| 38 | +1.748482e+09 | +NaN | +NaN | +NaN | +NaN | +130.322191 | +
| 39 | +1.748483e+09 | +1.0 | +NaN | +NaN | +NaN | +1035.107224 | +
| 40 | +1.748483e+09 | +NaN | +7.74 | +9.55 | +10.21 | +1040.146906 | +
| 41 | +1.748483e+09 | +NaN | +7.81 | +9.82 | +11.40 | +1042.621936 | +
In addition to some data-wrangling, there are some other obvious upgrades to my code before it would be ready to deploy in an app. For one, there is minimal error handling. Any malformed bytestrings returned by the atmotube will throw an exception and kill everything. Additionally there are no checks to maintain a connection to the atmotube. It would simply timeout, having collected nothing. If you were planning on running this passively for a long period of time, unattended, that could be a big deal.
+ + +In a previous notebook, I explored building infiltration due to forest fire smoke and noted that ambient conditions would impact the scenario, in this scenario I continue exploring building infiltration and examine the sensitivity of infiltration to changes in ambient conditions. In this case the scenario is a release of chlorine from a storage cylinder creating a cloud that moves downwind to a building. We would like to know what impact this has on the interior conditions of the building while also taking the opportunity to evaluate the impact of changes in ambient weather conditions.
+The scenario is the catastrophic failure of a liquid chlorine cylinder, perhaps one being used as part of a water treatment facility. The release is outdoors and a small building is downwind of the release, which can be occupied and so the infiltration of chlorine is important.
+For simplicity suppose the entire contents of the cylinder are released essentially immediately and form a neutrally buoyant cloud. The mass of the release is the mass of chlorine in the cylinder which we can assume to be 68kg. CAMEO Chemicals lists the three emergency response planning guideline (ERPG) levels for chlorine as 1ppm, 3ppm, and 20ppm respectively.
+Suppose the release is 1m off the ground and is otherwise the center of the coordinate system.
+The building is a small one story structure 100m downwind of the release point. For the scenario it will be taken as a given that the building volume is 255 m³ and the equivalent leak area is 690 cm². For simplicity any obstructions around the building are ignored.
+For neutrally buoyant gaussian dispersion a class F Pasquill stability is the worst case scenario, this leads to the least dispersion and thus greatest concentrations downwind. The windspeed is initially assumed to be 1.5 m/s.
+| m | +68 kg | +
| erpg-1 | +1 ppm | +
| erpg-2 | +3 ppm | +
| erpg-3 | +20 ppm | +
| h | +1 m | +
| d | +100 m | +
| \(A_l\) | +6.90×10⁻² m² | +
| V | +255 m³ | +
| stability | +F | +
| u | +1.5 m/s | +
using Contour, Plots, OrdinaryDiffEq, Statistics, SpecialFunctions, ForwardDiff, Rootsm = 68.0 # mass of chlorine released, kg
+MW = 70.9 # molar mass chlorine, kg/kmol
+MVC = 24.465 # molar volume at 25C and 1atm, m3/kmol
+
+ppm_to_kg(ppm) = (ppm*1e-6)*(MW/MVC)
+erpg1 = ppm_to_kg(1) # erpgs for chlorine, kg/m3
+erpg2 = ppm_to_kg(3)
+erpg3 = ppm_to_kg(20)
+
+h = 1.0 # height of release point, m
+
+d = 100.0 # downwind distance to building, m
+Aₗ = 6.90e-2 # equivalent leak area of building, m2
+V = 255.0 # volume of building, m3
+
+u = 1.5 # windspeed m/sThe simplest model for a neutrally buoyant cloud is a gaussian disperison model, in this case because the cylinder is assumed to fail catastrophically the release can be treated as instantaneous and so we use a gaussian puff model.
+It is often worth-while to estimate the initial dimensions of the cloud and then calculate a virtual emission point from which the release is assumed to take place. This is especially useful if the area immediately around the release point is of interest as the gaussian model assumes all of the mass is initially concentrated in a single point. However for a simple screening just using the default dispersion model is likely fine, and more conservative. The model gives the concentration as a gaussian distribution in the x, y, and z directions, while also adding in a term to account for ground reflection (mass cannot disperse below groundlevel)1
+\[ c_{puff}(x,y,z,t) = { m \over { (2 \pi)^{3/2} \sigma_x \sigma_y \sigma_z } } +\exp \left( -\frac{1}{2} \left( {x - ut} \over \sigma_x \right)^2 \right) +\exp \left( -\frac{1}{2} \left( {y} \over \sigma_y \right)^2 \right) \]
+\[ \times \left[ \exp \left( -\frac{1}{2} \left( {z - h} \over \sigma_z \right)^2 \right) + \exp \left( -\frac{1}{2} \left( {z + h} \over \sigma_z \right)^2 \right)\right]\]
+The parameters σx, σy, and σz are generally found using empirically derived correlations that are functions of the downwind distance to the center of the puff xc and atmospheric stability.
+function c_puff(x,y,z,t; # point in space
+ m, u, h, # parameters of the problem
+ σx::Function, σy::Function, σz::Function)
+ xc = u*t # center of the cloud
+ sx = σx(xc)
+ sy = σy(xc)
+ sz = σz(xc)
+
+ C1 = m / ( (2*π)^(1.5) * sx * sy * sz )
+ C2 = exp(-0.5*((x-xc)/sx)^2)
+ C3 = exp(-0.5*(y/sy)^2)
+ C4 = ( exp(-0.5*((z-h)/sz)^2) + exp(-0.5*((z+h)/sz)^2) )
+
+ c = C1*C2*C3*C4
+
+ return isnan(c) ? 0.0 : c
+endThe dispersion parameters for puff models are not, in general, as well developed as for plume models, the following values were interpolated from a sparser set of correlations and it is worth keeping in mind. It is also worth noting that the dispersion parameters are where the impact of different windspeeds will be made most apparent as stability is a function of windspeed.
+| Stability | +\(\sigma_x = \sigma_y\) | +\(\sigma_z\) | +Max Windspeed | +
|---|---|---|---|
| A | +$ 0.18 x^{0.92} $ | +$ 0.60 x^{0.75} $ | +3 m/s | +
| B | +$ 0.14 x^{0.92} $ | +$ 0.53 x^{0.73} $ | +5 m/s | +
| C | +$ 0.10 x^{0.92} $ | +$ 0.34 x^{0.71} $ | +6 m/s | +
| D | +$ 0.06 x^{0.92} $ | +$ 0.15 x^{0.70} $ | ++ |
| E | +$ 0.04 x^{0.92} $ | +$ 0.10 x^{0.65} $ | +5 m/s | +
| F | +$ 0.02 x^{0.89} $ | +$ 0.05 x^{0.61} $ | +3 m/s | +
# Class F
+
+σx(x) = 0.02*x^0.89
+σy(x) = 0.02*x^0.89
+σz(x) = 0.05*x^0.61The outdoor concentration can be calculated at any point using the above equations and below is an animation showing the cloud moving from the release point down to the location of the center of the building. The horizontal slice is at 1m elevation, and the vertical slice is at 0m crosswind distance, the center planes of the cloud.
+As is clear, for a very stable cloud the dispersion is small relative to the distance traveled (the cross wind distance is exaggerated for visibility) and the bulk of the mass of chlorine is contained in a 10m diameter ball by the time it reaches the building.
+[ Info: Saved animation to /home/allan/Code/notes/notebooks/tmp.gif ++
 +
+The concentration as a function of time also shows how brief the exposure is at this point. A rapid pulse of chlorine passes over the area and is gone within a few seconds. However the concentration at that time is millions of times larger than the ERPG-1 limit (note the units, the scale is in kg/m³ whereas the ERPG limits are on the order of mg/m³)
+ +
+The concentration along the centerline of the cloud is also worth looking at, as this provides some context for the extent of the downwind impacts of the release.
+ +
+Downwind distance to ERPG-3 (outdoors) 13.5km
+Downwind distance to ERPG-2 (outdoors) 29.9km
+Downwind distance to ERPG-1 (outdoors) 47.3kmClearly this release presents a serious hazard, one would have to travel downwind over 10km to be below the ERPG-3 line and nearly 50km to be below the ERPG-1 line. Though, keep in mind, this is for instantaneous exposure and not overall dose.
+The single zone model assumes the air within the building is generally well mixed and well described by a single concentration. This is approximately true over long timescales, however in the situation of the brief pulse of chlorine passing over the building this assumption may breakdown and is a critical weakness of the discussion that follows.
+Very likely in the ~10s it takes for the cloud to pass very little of it will have had time to diffuse into the interior space of the building and the interior mixing (or lack thereof) will be a significant slow step in the overall mass transfer.
+The single zone model, however, will work as a first pass at least, and in this model the interior concentration is related to the outside concentration by the following ODE3
+\[\frac{d}{dt} c_i(t) = f \left( c_i, \lambda, t \right) = \lambda \cdot \left( c_o(t) - c_i(t) \right) \]
+Where cᵢ is the inside concentration, cₒ the outside concentration, and λ the natural ventilation rate of the building.
+The natural ventilation rate itself is a function of windspeed, the temperature difference between inside and outside, and how leaky the building is.
+The model is defined in a more generic way for now as this will be more useful later.
+f(cᵢ, λ, t; cₒ=zero) = λ*(cₒ(t) - cᵢ)
+
+f(g) = (cᵢ, λ, t) -> f(cᵢ, λ, t; cₒ=g)The last parameter we need to estimate before solving the problem is the ventilation rate, λ, which can be estimated using the simplified ASHRAE model4
+\[\lambda = \frac{Q}{V} \\ +Q = A_L \sqrt{ C_s \vert \Delta T \vert + C_w u^2 } \\ +\lambda = \frac{A_L}{V} \sqrt{ C_s \vert \Delta T \vert + C_w u^2 } \]
+Where \(A_L\) and \(V\) were given earlier, \(C_s\) and \(C_w\) are tabulated constants, \(\Delta T\) is the difference between indoor and outdoor temperatures, in K, and u the windspeed, in m/s, and the ventilation rate is in s⁻¹.
+In this case the indoor and outdoor temperature are assumed to be the same for simplicity5
+5 Note that the constants have been adjusted such that the leak area is in m², in the ASHRAE handbook the leak area is in cm²
| + | Shelter Class | +1 Story | +2 Story | +3 Story | +
|---|---|---|---|---|
| \(C_s\) | +all | +14.5×10⁻³ | +29.0×10⁻³ | +43.5×10⁻³ | +
| \(C_w\) | +1 | +31.9×10⁻³ | +42.0×10⁻³ | +49.4×10⁻³ | +
| + | 2 | +24.6×10⁻³ | +32.5×10⁻³ | +38.2×10⁻³ | +
| + | 3 | +17.4×10⁻³ | +23.1×10⁻³ | +27.1×10⁻³ | +
| + | 4 | +10.4×10⁻³ | +13.7×10⁻³ | +16.1×10⁻³ | +
| + | 5 | +3.20×10⁻³ | +4.20×10⁻³ | +4.90×10⁻³ | +
With the shelter class defined as 1. No obstructions or local shielding 2. Isolated rural home 3. Another building across the street 4. Urban buildings on larger lots, with the nearest building >1 building height away 5. Immediately adjacent buildings (closer than 1 building height)
+For this scenario we are assuming the (one-story) building is isolated and there are no obstructions or local shielding, so the class is 1.
+# 1 Story building, shelter class 1
+
+λ(ΔT, u; Aₗ, V, Cs, Cw) = (Aₗ/V)*√(Cs*abs(ΔT)+Cw*u^2)
+
+λ₀ = λ(0.0, u, Aₗ=Aₗ, V=V, Cs=14.5e-3, Cw=31.9e-3)7.249290622734888e-5The indoor concentration is calculated simply by solving the ODE with the initial condition that the indoor concentration is zero. Since the pulse of chlorine is so brief it is important to be careful with the integrator, typical variable step integrators can step right over brief pulses and miss them entirely. To counteract that the first phase of the response, up until twice the time it takes for the wind to travel the distance, is solved using a maximum timestep of 1s, the remainder is left free to the solver to adjust as necessary to meet the tolerances.
+# puff model, note the units have changed to mg/m³
+
+cₒ(t) = c_puff(d, 0, h, t; m=m, u=u, h=h, σx=σx, σy=σy, σz=σz)*1e6
+
+c0 = 0.0 # initial condition
+sys = f(cₒ)
+
+tsp1 = (0.0, 2*d/u)
+prb1 = ODEProblem(sys, c0, tsp1, λ₀)
+sln1 = solve(prb1, Tsit5(), dtmax=1);c0_2 = sln1[end]
+tsp2 = (tsp1[end], 2.5*(1/λ₀))
+prb2 = ODEProblem(sys, c0_2, tsp2, λ₀)
+sln2 = solve(prb2, Tsit5());This is a very conservative model. It assumes all of the mass transfer occurs at a point, which happens to be where the maximum outdoor concentration will be, and that interior mixing is essentially instantaneous. It also has a significant weakness in that it assumes the building does not impede the movement of the cloud. If the building is very small relative to the cloud this might be reasonable, but in this case the cloud is quite concentrated and the deflection around the building is important.
+The first assumption can be moderated by taking an average outdoor concentration over the building footprint. In this case I assume the building is a 10m×10m square just for demonstration. This tries to capture the reality that not all of the building is being exposed to an equally high concentration and that an effective outdoor concentration might be better estimated as a spatial average. These points are hanging in space at the centerline of the cloud and as such are exposed to the highest concentrations. Instead of a slice like this, a more fully featured box could be used, but at that point it would probably be more useful to look into the ways the building itself is deflecting and shaping the cloud. Recall that the cloud is essentially passing through the building in this model.
+box_x = (d-5):1:(d+5)
+box_y = -5:1:5
+
+function box_average(t)
+ cs = [ c_puff(x, y, h, t; m=m, u=u, h=h, σx=σx, σy=σy, σz=σz)*1e6
+ for x in box_x, y in box_y ]
+ return mean(cs)
+endsys_avg = f(box_average)
+
+tsp_box = (0.0, 2*d/u)
+prb_box = ODEProblem(sys_avg, c0, tsp_box, λ₀)
+sln_box = solve(prb_box, Tsit5(), dtmax=1);c0_box2 = sln_box[end]
+tsp_box2 = (tsp_box[end], 2.5*(1/λ₀))
+prb_box2 = ODEProblem(sys_avg, c0_box2, tsp_box2, λ₀)
+sln_box2 = solve(prb_box2, Tsit5()); +
+In either the single point or averaged outdoor concentration models the indoor concentration rapidly rises above the ERPG-3 limit, which is very bad, and then slowly decays over time6. In this case almost immediately after the cloud has passed the indoor space is more concentrated in Chlorine than the outside air. At the very least this suggests that the building is not a good shelter in place location, or at least a much more detailed analysis of building infiltration would be needed to show that it was a good shelter in place location.
+6 Note that the indoor concentrations are in mg/m³ whereas the outdoor concentration peaks in the kg/m³, so the building is doing something, it is reducing the indoor concentration by several orders of magnitude, it just isn’t enough
For the scenario modeling I approached the problem in a very general way such that the methods for solving the indoor concentration didn’t depend explicitly upon the model of the outdoor concentration. Which is why it was solved numerically. This is a very useful way of approaching things, especially from a code re-use point of view.
+However, in this particular case, if we take the outdoor concentration to be simply the gaussian puff model at a single point then this ODE can be solved analytically and that is useful for exploring the system’s sensitivity to windspeed, atmospheric stability, etc.
+Starting with the original puff model for the outside concentration
+\[ c_{o}(x,y,z,t) = { m \over { (2 \pi)^{3/2} \sigma_x \sigma_y \sigma_z } } +\exp \left( -\frac{1}{2} \left( {x - ut} \over \sigma_x \right)^2 \right) +\exp \left( -\frac{1}{2} \left( {y} \over \sigma_y \right)^2 \right) \]
+\[ \times \left[ \exp \left( -\frac{1}{2} \left( {z - h} \over \sigma_z \right)^2 \right) + \exp \left( -\frac{1}{2} \left( {z + h} \over \sigma_z \right)^2 \right)\right] \]
+We can split this into the product of three gaussians:
+\[ c_{o}(x,y,z,t) = m \left[{ \exp \left( -\frac{1}{2} \left( {x - ut} \over \sigma_x \right)^2 \right) \over { \sqrt{2 \pi} \sigma_x } } \right] +\left[{ \exp \left( -\frac{1}{2} \left( {y} \over \sigma_y \right)^2 \right) \over { \sqrt{2 \pi} \sigma_y } } \right] \]
+\[ \times { 1 \over { \sqrt{2 \pi} \sigma_z } } \left[ \exp \left( -\frac{1}{2} \left( {z - h} \over \sigma_z \right)^2 \right) + \exp \left( -\frac{1}{2} \left( {z + h} \over \sigma_z \right)^2 \right)\right]\]
+\[ c_{o}(x,y,z,t) = m C_x(x, t) C_y(x, y) C_z(x, z)\]
+and noting that only \(C_x\) depends on time we can collect the other stuff into a big constant called \(C_1\), giving usI am assuming the dispersion parameters are all constant, this is not strictly true as they all depend upon the downwind location of the center of the puff, which is a function of time
+\[ c_{o}(t) = C_1 { 1 \over { \sqrt{2 \pi} \sigma_x } }\exp \left( -\frac{1}{2} \left( {x - ut} \over \sigma_x \right)^2 \right) \]
+this is a gaussian in time, let \(\mu = \frac{x}{u}\) and \(\sigma_t = \frac{\sigma_x}{u}\)
+\[ c_{o}(t) = { C_1 \over u } { 1 \over { \sqrt{2 \pi} \sigma_t } }\exp \left( -\frac{1}{2} \left( {t - \mu} \over \sigma_t \right)^2 \right) \]
+suppose the Laplace transform of this is \(C_{o}(s)\), and taking the Laplace transform of the ODE we arrive at
+\[ C_{i}(s) = { \lambda \over {s + \lambda} } C_{o}(s) \]
+where \(C_{i}(s)\) is the Laplace transform of \(c_{i}(t)\), inverting the Laplace transform leads us to conclude
+\[ c_{i}(t) = { C_1 \over u } \int_{0}^{\infty} \lambda \exp \left( -\lambda \left(t - \tau \right) \right) +{ 1 \over { \sqrt{2 \pi} \sigma_t } }\exp \left( -\frac{1}{2} \left( {\tau - \mu} \over \sigma_t \right)^2 \right) d\tau\]
+that is, the solution is the convolution of the exponential and gaussian times some constants. Conveniently for us this is a well known integral and we can just look up the answer in a book
+\[ c_{i}(t) = { C_1 \over u } \frac{\lambda}{2} \exp \left( \frac{\lambda}{2} \left( 2\mu + \lambda \sigma_t^2 - 2t \right) \right) \mathrm{erfc} \left( { \mu + \lambda \sigma_t^2 -t } \over { \sqrt{2} \sigma_t } \right) \]
+where \(\mathrm{erfc(x)}\) is the complementary error function \(1 - \mathrm{erf}(x)\)
+You could expand all this back out, but it is far more compact and readable in this form, especially when written out as code
+function cᵢ(x,y,z,t; # point in space
+ m, u, h, λ, # parameters of the problem
+ σx::Function, σy::Function, σz::Function)
+
+ sx = σx(x)
+ sy = σy(x)
+ sz = σz(x)
+
+ # time independent part
+ C1 = m / (2*π*sy*sz)
+ C1 *= exp(-0.5*(y/sy)^2)
+ C1 *= ( exp(-0.5*((z-h)/sz)^2) + exp(-0.5*((z+h)/sz)^2) )
+
+ # the convolution
+ μ = x/u
+ σₜ = sx/u
+
+ c = (C1*λ)/(2*u)
+ c *= exp(0.5*λ*(2*μ+λ*σₜ^2-2*t))
+ c *= erfc((μ+λ*σₜ^2-t)/(√(2)*σₜ))
+
+ return isnan(c) ? 0.0 : c
+endFrom here we can use automatic differentiation to find the max concentration, for the original case
+# at the point x=d, y=0, z=h, note the units in mg/m³
+
+c(t) = cᵢ(d, 0, h, t, m=m, u=u, h=h, λ=λ₀, σx=σx, σy=σy, σz=σz)*1e6
+
+∂c∂t(t) = ForwardDiff.derivative(t -> c(t), float(t))
+
+tₘₐₓ = find_zero(∂c∂t, d/u)
+
+cₘₐₓ = c(tₘₐₓ)
+
+tₘₐₓ, cₘₐₓ(70.04333860265841, 551.5422273514416)An alternative is to make the approximation \(\mathrm{erfc}(-x) \approx 2 H(x)\), where \(H(x)\) is the Heaviside step function ( \(\mathrm{erfc}(-x)\) runs from 0 to 2 and \(H(x)\) runs from 0 to 1 hence the factor of 2)
+\[ c_{i}(t) = { C_1 \over u } \frac{\lambda}{2} \exp \left( \frac{\lambda}{2} \left( 2\mu + \lambda \sigma_t^2 - 2t \right) \right) \mathrm{erfc} \left( { \mu + \lambda \sigma_t^2 -t } \over { \sqrt{2} \sigma_t } \right) \]
+\[ = { C_1 \over u } \frac{\lambda}{2} \exp \left( { \left( \lambda \sigma_t \right)^2 \over 2 } \right) \exp \left( -\lambda \left( t - \mu \right) \right) \mathrm{erfc} \left( { \mu + \lambda \sigma_t^2 -t } \over { \sqrt{2} \sigma_t } \right) \]
+\[ \approx { \lambda C_1 \over u } \exp \left( { \left( \lambda \sigma_t \right)^2 \over 2 } \right) \exp \left( -\lambda \left( t - \mu \right) \right) H( t - \mu - \lambda \sigma_t^2 ) \]
+\[ \approx { \lambda C_1 \over u } \exp \left( { \left( \lambda \sigma_t \right)^2 \over 2 } \right) \exp \left( -\lambda \left( t - \mu \right) \right) H( t - \mu ) +\]
+the maximum of this is clearly
+\[ c_{max} = { \lambda C_1 \over u } \exp \left( { \left( \lambda \sigma_t \right)^2 \over 2 } \right) \]
+and occurs when \(t = \mu\)
+let x=d, y=0, z=h, λ=λ₀
+ sx = σx(x)
+ sy = σy(x)
+ sz = σz(x)
+ μ = x/u
+ σₜ = sx/u
+
+ C1 = m / (2*π*sy*sz)
+ C1 *= exp(-0.5*(y/sy)^2)
+ C1 *= ( exp(-0.5*((z-h)/sz)^2) + exp(-0.5*((z+h)/sz)^2) )
+
+ c = (λ*C1)/u
+ c *= exp(0.5*(λ*σₜ)^2)
+
+ return (μ, c*1e6)
+end(66.66666666666667, 551.6845234598728)We can compare the solution from the ODE solver with the two approximations – the convolution and the step-function approximation – to convince ourselves that we are capturing the dynamics well.
+ +
+The sensitivity to atmospheric stability, at the max windspeed given in the table of dispersion parameters above, is shown below. Clearly the indoor concentration depends strongly on the atmospheric stability, and that makes sense as more unstable conditions lead to far greater mixing and thus lower outdoor concentrations. This effect is far greater than any increase in ventilation rate due to the greater windspeeds.
+ +
+Returning to the original scenario parameters we explore the impact of changing the windspeed, while assuming the atmospheric stability remains constant, in the figure below. In this case windspeed impacts both the parameters of the gaussian puff model and the natural ventilation rate in the single zone building infiltration model.
+ +
+This was, to me, a surprising result. I expected the max indoor concentration to depend strongly on the windspeed whereas it appears to have far more to do with how quickly the indoor build up of Chlorine dissipates. This is due to the difference in timescales between the puff passing over the building and the single zone building infiltration model.
+The time-scale of interest for the puff model is the width of the gaussian \(\sigma_t\), whereas the time-scale of interest for the building infiltration model is the time constant of the exponential decay \(\tau = \frac{1}{\lambda}\), for this situation with a class F atmospheric stability they are
+σₜ = σx(d)/u0.8034127814324771τ = 1/λ₀13794.453168477568σₜ/τ5.82417274262381e-5The time it takes the cloud to pass is simply orders of magnitude faster than the response of the infiltration model. So, in effect, the puff is acting like a impulse – causing a step change – and changing the windspeed merely moves the time at which that step change takes place. The faster the windspeed the better the approximation $ (-x) H(x) $ gets and if we take another look at the approximation for max concentration, we see it is independent of windspeed.
+Note that for the simplified ASHRAE model with \(\Delta T = 0\) the natural ventilation rate is directly proportional to windspeed, i.e. $ = k u $ where k is all the vaious constants of that model collected for convenience, plugging this into the approximation we find the windspeed cancels out entirely.
+\[ { \lambda C_1 \over u } \exp \left( { \left( \lambda \sigma_t \right)^2 \over 2 } \right) \]
+\[ = { { k u C_1 } \over u } \exp \left( { \left( k u \frac{\sigma_x}{u} \right)^2 \over 2 } \right) \]
+\[ = k C_1 \exp \left( { \left( k \sigma_x \right)^2 \over 2 } \right) \]
+Which is independent of windspeed.
+We can perhaps see how small the effect is more clearly by directly varying the ratio \({ \sigma_t \over \tau}\) while keeping \(\mu\) constant and looking at the response. The maximum indoor concentration does change, but only slightly.
+ +
+Which is not to say the model is insensitive to the natural ventilation rate, merely that for a given building the impact of changing windspeed on the ventilation rate is canceled out by the change in the outdoor concentration profile.
+Below the equivalent leak area \(A_L\) is varied while keeping all other parameters constant. Unsurprisingly building tightness matters, and the impact is approximately linear. This is intuitive, of course, because the outside concentration does not depend in any way on the leakage area and so there is no canceling of effects like was seen with windspeed, and of course having more leaks leads to more of the outside air getting inside.
+ +
+A similar effect as was seen with equivalent leak area is present with changes in the temperature difference between indoors and outdoors. Though in this case the change goes with the square-root of the temperature difference.
+ +
+On a summer day like today large temperature differences like this might seem extreme, but in the depths of winter when days around here routinely get to -30°C a standard heated building with a normal indoor temperature around 20°C would have a 50°C temperature difference with the outdoors.
+The most obvious case of interest, however, is how far downwind would the building have to be such that it did not exceed the ERPG limits. With all other parameters equal to the scenario, the max indoor concentration as a function of building distance is shown in the figure below.
+ +
+Downwind distance to ERPG-3 (indoors) 625.0m
+Downwind distance to ERPG-2 (indoors) 2383.0m
+Downwind distance to ERPG-1 (indoors) 5006.0mAs was seen above when examining the outdoor concentrations, this is a significant release and the downwind distance is large. This also shows the value of sheltering in place as an unprotected individual would have to travel downwind for many tens of kilometers to reach a safe distance, whereas indoors that is greatly reduced.
+Again, this is all considering the instantaneous concentration and not considering dose.
+The results of the scenario speak to something the previous discussion noted, namely that after the cloud has passed the indoor concentration exceeds the outdoor concentration and so an important response, post release, is not just when to shelter in place but when to stop.
+The worst case indoor concentration far exceeded the ERPG-3 limit, however it was still significantly lower exposure than had one been standing outside. But once the chlorine had leaked into the building it would take hours to fully clear purely by natural ventilation. At that point it would be far more prudent to leave the building and to turn the ventilation system back on. Identifying when this is the case is an interesting problem, because there are no guarantees that the emergency outside the building is fully resolved merely because the toxic release has passed. So one must balance the risks of sheltering in a place that is no longer safe versus evacuating into a potentially dangerous environment. In such a scenario it may be prudent to have indoor and outdoor air monitoring in the shelter in place location and a store of emergency escape respirators, though a better solution would be to move the shelter in place to a safer location.
+These two examples cover two extremes of building infiltration, the forest fire smoke looked at enormous clouds that take hours to pass and this chlorine example covers very concentrated clouds which pass in under a minute. Most real scenarios at a chemical plant or other facility are likely to be between these extremes, but the same tools would apply.
+A common part of emergency planning is the shelter in place. More often than not trying to outrun whatever calamity is happening at a chemical plant is more dangerous than finding a safe place to ride it out, which is usually the lunch room or somewhere like that. Sometimes facilities have different shelter in place locations depending on what the hazard is – for example a severe weather shelter location may not be where you go for a toxic gas release.
+Naturally, when evaluating the consequences of a release, one wants to evaluate the effectiveness of a shelter in place location. This usually involves looking at some building infiltration model.
+Another situation in which building infiltration has come up in recent years is forest fires, and I think this presents a unique opportunity to validate the models and the selection of shelter in place locations. I’m not talking about sheltering in place because the forest fire is at the plant boundary, I’m talking about smoke days where forest fire smoke blows in and blankets the whole area in higher than usual airborne particulates.
+At least where I live, in Alberta, this is not an uncommon event. Every other year, it seems, there is a large forest fire either in the northern boreal forest or in the Rocky Mountains and the smoke from these enormous fires will blanket the entire province.
+This is the view from my apartment of one of the last big smoke days, on May 30th of 2019
+ +
+This haze is unsurprisingly bad for outdoor air quality, but what does it do for indoor air quality? Typically people shut-down air handling systems to minimize the smoke infiltration and wait it out (which is why I think it is a good proxy for a release scenario), so a model of how quickly smoke, or airborne particulates, can work its way into the building is useful to have.
+The outdoor concentration of airborne particulates, PM2.5, is needed. There are several air monitoring stations throughout Alberta, with the closest one to me being the Edmonton Central station. Hourly air quality data can be downloaded as a csv from Alberta’s Air Data Warehouse and imported into julia as a dataframe.
+using CSV, DataFrames, Dates, PipeI am using the Pipe.jl package to streamline the data manipulation process. It takes the output from what is on the left of |> and puts it in where the _ is on the right, which is very convenient when chaining together several single-input-single-output functions.
data_file = "data/Edmonton Central pm2.5.csv"
+
+# import the csv file, remove missing data
+# insert a column for the time since the start of the dataset in hours
+
+ambient_data = @pipe data_file |>
+ CSV.File( _ ;
+ dateformat="mm/dd/yyyy HH:MM:SS",
+ types=[DateTime, DateTime, Float64],
+ header=16) |>
+ DataFrame(_) |>
+ rename(_, "MeasurementValue" => "conc") |>
+ rename(_, "IntervalStart" => "date") |>
+ select(_, Not([2])) |>
+ hcat(_, Dates.value.( _.date - _.date[1])/3.6e6) |>
+ rename(_, "x1" => "time") |>
+ dropmissing(_)
+
+first(ambient_data, 6)6 rows × 3 columns
| date | conc | time | |
|---|---|---|---|
| DateTime | Float64 | Float64 | |
| 1 | 2019-05-24T00:00:00 | 16.0 | 0.0 |
| 2 | 2019-05-24T01:00:00 | 7.0 | 1.0 |
| 3 | 2019-05-24T02:00:00 | 9.0 | 2.0 |
| 4 | 2019-05-24T03:00:00 | 13.0 | 3.0 |
| 5 | 2019-05-24T04:00:00 | 9.0 | 4.0 |
| 6 | 2019-05-24T05:00:00 | 10.0 | 5.0 |
 +
+In this case I restricted the dataset to just the PM2.5 concentration, since that is all I am interested in, and to a window of time around May 30th. The data clearly shows that May 30th had a big spike in airborne particulates, well in excess of the ambient air quality objectives. Though it was somewhat hazy in the days before and after too.
+Building infiltration models can range from highly detailed CFD simulations of indoor airflow to simple “fully mixed” models that assume a single average indoor concentration. This second type is the easiest to use and a good start for screening scenarios. It is a simple differential equation that assumes the rate of infiltration is proportional to a ventilation rate, λ, and the concentration difference between the outside and inside air1
+\[ \frac{d}{dt} c = f \left( c, \lambda, t \right) = \lambda \cdot \left( c_o(t) - c \right)\]
+The outside concentration, \(c_o\), can be a constant, but it is more usefully thought of as a function of time. In practice the ventilation rate, λ, is usually taken to be a constant, but it is a function of ambient conditions and could be implicitly made a function of time as well.
+This model is for for a single zone or single cell building, where the interior air is assumed to be well mixed and at a single uniform pressure and concentration. This works well for houses, non-segmented industrial buildings, and small open plan commercial buildings. For much larger buildings, with many zones, there are multiple zone models of various scales of complexity.
+using Interpolations, OrdinaryDiffEqThe function below represents the right-hand-side of the differential equation in standard form, with the outside concentration as a generic function of time that is passed as a parameter. For convenience later on, I also created a function that takes the outside concentration and returns a callable with that pre-set.
+The order of arguments is important here, OrdinaryDiffEq expects the arguments to be in the order unknowns, parameters, time, where both the unknowns and parameters can be vectors (if there’s more than one)
f(c, λ, t; cₒ=zero) = λ*(cₒ(t) - c)
+
+f(g) = (c, λ, t) -> f(c, λ, t; cₒ=g)Any structure, unless it is hermetically sealed, has some natural ventilation rate. This comes from leaks around doorframes, through ventilation systems (even when turned off), and other breaks in the building envelope. This natural ventilation rate, λ, is reported in air changes per hour (ACH) and is, in general, a function of ambient conditions inside and outside the structure.
+ +
+The following plot is for a building infiltration model showing a building with windows open versus closed, showing the functional relationship between temperature differences and windspeed and the ventillation rate. Note the first plot is against the square root of the temperature difference.
+ +
+ASHRAE2 gives guidance on how to estimate the natural ventilation rate for single zone buildings, and a basic model of air leakage is
+\[ Q = A_L \sqrt{ C_s \vert \Delta T \vert + C_w u^2 }\]
+Where Q is the air leakage rate, in m³/s, \(A_L\) is the effective air leakage area, in m², \(\Delta T\) is the temperature difference between indoors and outdoors, u the windspeed, and \(C_s\) and \(C_w\) constants tabulated based on building height and extent of shelter from the wind (due to other buildings in the vicinity).
+The ventilation rate is then simply the leakage rate divided by the building volume
+\[ \lambda = {Q \over V } \]
+This model effectively treats the leakage from the building like a leakage through a hole using Toricelli’s law, and the one big unknown that needs to be determined is the effective air leakage area. This can be determined by working through the different parts of the building and counting the elements such as windows and vents, or it can be determined experimentally for a given building, either by using a tracer (SF₆ is common) or by using the a blower system to pressurize the building and measuring how much flow is required to raise the internal pressure by a fixed amount (such as by 50Pa).
+This is a lot of work for a simple building infiltration screening. However this may have already been done for the design of the building, as the air leakage is a critical component in a building’s overall thermal efficiency. If the data already exists for a given building, for other purposes, then why not use it, but if it isn’t readily available then it is more practical to use tabulated values for representative buildings.
+This can be tricky, though, as most tabulated values are for houses and how “leaky” a house is depends very strongly on where that house was constructed (and when). Many references, such as Lees’ give values for British homes which are often much greater than equivalent values tabulated elsewhere for typical American and Canadian homes. Which could entirely be a function of local weather. The air tightness of a home where I live in Canada is probably a lot more important, especially on days when it is -30°C, than a similar home in the UK where such extremes are essentially unheard-of. Which is also putting aside the fact that commercial structures are quite different from houses and so these values may not be too representative either.
+Typical values for Canadian homes in urban areas
+| Level | +ACH | +
|---|---|
| Tight | +0.25 | +
| Average | +0.50 | +
| Leaky | +1.0 | +
Typical values for houses in the US
+| Conditions | +Tight | +Typical | +Leaky | +
|---|---|---|---|
| Mild | +0.07 | +0.1 | +0.4 | +
| Moderate | +0.2 | +0.3 | +1.0 | +
| Severe | +0.3 | +0.5 | +1.6 | +
In this model of building infiltration the ASHRAE model could be used and, with a suitable dataset of outdoor temperature and windspeeds, the ventilation rate would be a function of time. But for simplicity I am going to assume that the change in windspeed and temperature from any given hour to the next is quite small and the ventillation rate can be assumed to be a constant.
+This raises the obvious question of what impact windspeed has on the indoor concentration? At higher windspeeds the building ventilation rate is higher, and so more of what’s outside ends up inside, however at higher windspeeds there is more mixing and the outdoor concentration will generally be lower. I would expect the effect of mixing would dominate, but this might be worth investigating further.
+Armed with some ideas of the building ventilation rate, the differential equation can be solved for different outdoor concentration scenarios. When defining the problem, above, I set the outdoor concentration as generic function of time that was passed as a parameter. This ODE is simple enough that it can be solved by hand for basic cases and easily numerically integrated for any well behaved set of initial conditions and outdoor concentrations.
+For an example let’s consider a sudden pulse of a pollutant, say the outside air is 100%(vol) during the pulse and 0 otherwise, a square wave.
+function c_square(t; cmax=1, t1=5, t2=20)
+ if (t >=t1) & (t <= t2)
+ return cmax
+ else
+ return 0
+ end
+endAssuming the initial indoor concentration to be zero, and with a suitable ventillation rate, this can be solved numerically.
+The problem is defined using the ODEProblem function, which creates a problem object which the solver then solves. In this case using the Tsit5 solver, the default for non-stiff problems. The solution returned is an object that contains both a vector of solutions, and times, but can also be called like a function to return an interpolated result. This way the solution acts like a continuous function of time.
λ₀ = 0.25 # ventilation rate, 0.25 h⁻¹
+c0 = 0.0 # initial condition
+tspan = (0.0, 25.0)
+sys = f(c_square)
+
+prb = ODEProblem(sys, c0, tspan, λ₀)
+sln = solve(prb, Tsit5()) +
+Solving for the indoor concentration of pm2.5s using measured outdoor concentrations is essentially the same process, except instead of a simple square wave we have a timeseries of measured values.
+The first step is to turn that timeseries into a continuous function, in this case I am using a simple linear interpolation.
+cₒᵤₜ = LinearInterpolation(ambient_data.time, ambient_data.conc, extrapolation_bc = Interpolations.Flat())The remaining steps are the same, since the model for building infiltration is the same (with the parameter and inital conditions as defined earlier). The only difference is the timespan is the full span of the timeseries and the outdoor concentration is the linear interpolation defined above.
+tspan = (0.0, ambient_data.time[end])
+sys = f(cₒᵤₜ)
+
+prb = ODEProblem(sys, c0, tspan, λ₀)
+sln = solve(prb, Tsit5()) +
+We can see, much like in the square wave model, that the indoor concentration lags behind the outoor concentration but still rises significantly. Once the pulse in high pm2.5 ends the indoor concentration decays, but again with a delay. So there is a period after the smoke has blown over in which the pm2.5 concentration indoors can be higher than outdoors (a good time to open some windows and air the place out)
+For some context I have added Alberta’s Ambient Air Quality Objective for pm2.5s, clearly bad smoke days exceed that target but also indoor air quality can exceed it as well. Interestingly the indoor air quality may have exceeded workplace limits for airborne particulates through the whole period.
+# max outdoor concentration
+
+maximum(ambient_data.conc)867.0# max indoor concentration
+
+maximum(sln.u)501.877462902824If we assume a constant outdoor concentration, a constant ventilation rate, and an initial indoor concentration of zero, the model can be solved analytically to give
+\[ { c_i \over c_o } = 1 - e^{-\lambda t}\]
+Which leads us to ask, how long does it take for the indoor concentration to reach some fraction x of the outdoor concentration?
+\[ x = 1 - e^{-\lambda t} \]
+\[ t = { -\ln{\left( 1 - x \right)} \over \lambda } \]
+For simplicity’s sake let’s assume \(x = 0.5\).
+t_x(λ; x=0.5) = -log(1-x)/λ +
+This gives us a sense of how building tightness - the natural ventilation rate - impacts how long a shelter in place would be effective for. If the emergency is lasting for several hours then a shelter in place location would have to be highly air tight to be effective.
+A realistic shelter in place location is not going to be well mixed with the rest of the building. It will be an enclosed space that can be isolated from the building (e.g. by closing doors), and with an air handling system that can be isolated (unlike, say, a cafeteria where often the vents for clearing the air in the kitchen cannot be easily sealed). In this case the effective ventillation rate for that enclosed space, during a shelter in place, should be smaller than the ventillation rate for the building overall – when the doors are open and a single zone model is perhaps more representative.
+In this case we can use the outdoor smoke event as a test. Somewhat like a tracer test but in reverse and we are not controlling the tracer. If we knew in advance that a smoke day was coming, which given publicly available modeling such as FireSmoke is reasonable, we could close off the shelter in place location with some indoor monitoring set up in the middle of the room and watch what happens.
+If things go like they have in the past, at least where I work, the air handling system is shutdown and people try and minimize their time outdoors (and thus time spent opening and closing outside doors). By tracking the indoor concentration as well as outdoor concentrations we can compare the model to reality – does a single zone model work? do we need to incorporate weather conditions? – and estimate an effective ventilation rate by fitting the ODE to the measured data.
+At least that’s the theory. I don’t have measured indoor air data for the time in question so I am going to simulate some by assuming the model works and adding some random noise. In this case I am adding ±10% random noise to the results calculated earlier for λ=0.25.
+using DiffEqParamEstim, OptimHere I make a copy of the ambient data dataframe, df, and create a new column called cin for indoor concentration. This is the solution found earlier times a random error ±10%, then for good measure any columns with the concentration below zero are chopped off at zero since that is unphysical.
# Dummy data
+
+df = deepcopy(ambient_data)
+
+df.cin = sln.(df.time) .* ( 1 .+ 0.10*randn(size(df.time)) )
+df.cin[ df.cin .< 0 ] .= 0 +
+The model can be fit to these two sets of data, essentially taking the outdoor concentration as a given and finding the best fit curve to the indoor concentration by solving the ODE repeatedly for different values of the parameter λ.
+The major difference between this and simply solving the ODE is defining the loss function, in this case an L2 loss which is analogous to least squares, and then optimizing.
+tspan = (0, df.time[end])
+c0 = df.cin[1] # initial condition
+
+sys = f(cₒᵤₜ)
+p = [0.5] #initial guess of λ=0.5
+
+prb = ODEProblem(sys, c0[1], tspan, p)
+lossfn = L2Loss(df.time, df.cin)
+
+cost_function = build_loss_objective(prb,Tsit5(),lossfn,
+ maxiters=10000,verbose=false)The optimization is looking for the parameter that minimizes the cost function, which in this case is the least-squares difference between the model and the “measured” data for indoor concentration. The minimum is well defined and close to λ=0.25, which is what we would expect given that was how the data was generated.
+Note: the plot below is nice to look at but not something one would normally generate, since calculating each point involves solving the ODE and could be fairly resource intensive for any problem more complex than this simple model. It sort of defeats the point of using an optimization algorithm to find the minimum. It’s just a nice visualization of what is happening in the background.
+ +
+# optimize the cost function for parameters between 0 and 1
+
+result = optimize(cost_function, 0.0, 1.0)Results of Optimization Algorithm
+ * Algorithm: Brent's Method
+ * Search Interval: [0.000000, 1.000000]
+ * Minimizer: 2.363617e-01
+ * Minimum: 9.520426e+03
+ * Iterations: 27
+ * Convergence: max(|x - x_upper|, |x - x_lower|) <= 2*(1.5e-08*|x|+2.2e-16): true
+ * Objective Function Calls: 28λfit = result.minimizer[1]0.2363617224674848λfit/λ₀0.9454468898699392The best fit ventillation rate is quite close to the actual ventillation rate used to generate the data, which is what we would expect.
+With an effective ventilation rate we can generate a best fit line
+prb = ODEProblem(sys, c0[1], tspan, λfit)
+fit = solve(prb, Tsit5()) +
+For people with a background in control systems and process dynamics, an obvious alternative way of writing the problem is in term of Laplace transforms and transfer functions.
+\[ \frac{d}{dt} c = \lambda \cdot \left( c_o(t) - c \right)\]
+with the change of variables \(y = c(t) - c(0)\) and \(u = c_o\)
+\[ y^\prime = \lambda u - \lambda y \]
+Taking the Laplace transform of both sides \[ s Y = \lambda U - \lambda Y \]
+\[ Y = { \lambda \over { s + \lambda} } U \]
+This can then be solved analytically for various inputs, \(U\), or numerically for a given timeseries. In Julia this can be done with the ControlSystems.jl and ControlSystemIdentification.jl packages. This lets you define a system in terms of transfer functions and solve them that way.
I showed the more generic ODE approach at the start because this is more easily generalized to more complex models (e.g. by incorporating the functional dependence of λ on temperature and windspeed). Though the transfer function approach lends itself more simply to using different inputs to the same system, simply change \(u\) and you get a different result, whereas the generic ODE has the input as part of the system definition, which I think is sort of messy (though maybe there’s a better way of doing this that I don’t know about?).
+The building infilration model is set up by simply defining the transfer function for the system and then simulating the response to the given input (the outdoor concentration in this case)
+using ControlSystems, ControlSystemIdentificationu(x, t) = [cₒᵤₜ(t)]
+t = 0:1:ambient_data.time[end]
+
+sys = tf([λ₀], [1, λ₀])TransferFunction{Continuous, ControlSystems.SisoRational{Float64}}
+ 0.25
+-----------
+1.0s + 0.25
+
+Continuous-time transfer function modelUnlike the previous package, this returns the output, y, and time, t, as vectors with no interpolation or other information.
+y, t, x = lsim(sys, u, t) +
+ControlSystems.jl
+maximum(y)508.2191947911374The two approaches produce almost identical answers, which is not too surprising as the same ODE package and solver (Tsit5) is being used under the hood of ControlSystems.jl to solve this (I believe the only difference is one is using a variable time-step and the other a fixed time step, but I could be wrong).
For the purposes of fitting the model to the data, we note that the model is an ARX model, i.e. it is of the form
+\[ A(s) Y = B(s) U + D \]
+where \(A(s)\) and \(B(s)\) are polynomials in s, and use the ControlSystemIdentification.jl package to fit the model, generating a fitted transfer function.
In this simple approach the parameters of \(A(s)\) and \(B(s)\) are allowed to be different, and in general you could fit a variety of models and use this as a jumping off point to explore potentially better models of infiltration.
+If you are more interested in an empirical model, fitted to timeseries data, this approach can be much simpler than the model driven approach taken above with fitting the ODE to the data. Especially when incorporating other elements like windspeed and temperature.
+# generates the discrete timeseries data with a sample time of 1
+
+d = iddata(df.cin, df.conc, 1)InputOutput data of length 311 with 1 outputs and 1 inputs# finds the best fit transfer function with numerator order 1 and denominator order 1
+
+model_tf = arx(d, 1, 1)TransferFunction{Discrete{Int64}, ControlSystems.SisoRational{Float64}}
+ 0.22305776166128505
+------------------------
+1.0z - 0.738488961457766
+
+Sample Time: 1 (seconds)
+Discrete-time transfer function model# generate the best fit line
+
+y_fit, t_fit, _ = lsim(model_tf, u, t) +
+ControlSystemIdentification.jl
+A routine practice of process safety is to model scenarios for different chemical hazards present at a plant. Often there are more plausible scenarios than there is the time or resources to model at the highest level of fidelity, the more complex models take time to set up and run and often there are only so many software licenses available. There needs to be some prioritization and screening. It’s fairly typical, especially for larger companies, to have screening tools that an engineer can use which incorporate simpler models and make conservative estimates to get a first guess at the impact of a given hazard, if this crosses a preset threshold then it is escalated to a more in depth level of modelling, drilling down to more and more detailed analysis as required.
+More often than not I’ve seen these simple tools implemented as excel spreadsheets – which is fine, they do the job and everybody has excel on their computers – however overly involved spreadsheets can be rather opaque, it’s often not obvious what they are doing and what assumptions are being made in those calculations. So I am going to work through an example of how one could estimate the airborne quantity, and ultimately the consequences of, an example release of butane from a large storage sphere, while documenting the assumptions and models along the way.
+As a simple scenario suppose a leak from a butane storage sphere. These are a fairly common sight around refineries and facilities that process large quantities of hydrocarbons. This sphere is 40ft in diameter and operates under 250psig of pressure, containing primarily n-butane, which I will assume is entirely n-butane for simplicity1. As for the leak itself I am supposing a leak area equivalent to a 2in rupture2. The sphere doesn’t sit directly on the ground, it is supported 10ft above a concrete pad which has a diked area of 500ft². The leak itself at the bottom somewhere, suppose exactly at the bottom for simplicity3. Furthermore I am assuming the release occurs on a day with an ambient temperature of 25°C and that the tank contents and surroundings are at thermal equilibrium.
+1 If the vessel contained a mixture, for the purposes of screening, conservatively choosing the most volatile of the major components would be a reasonable assumption. These simplifications are suitable for screening purposes however if more in depth modeling is required then performing mixture flash calculations would have to be considered, which very quickly becomes a lot of work to set-up outside of a process simulator like Aspen
2 There are lots of ways of generating leak scenarios, from the very specific leaks from particular propagating events to simple rules of thumb. The Chemical Exposure Index gives the following rules for determining a leak scenario for a vessel:
+A rupture based on the largest diameter process pipe attached to the vessel using the following:
+3 Picking the bottom also ensures the leak occurs at the highest pressure, which gives a larger release and is most conservative. Releases at higher elevations also tend to mix more thoroughly with the air and present less of a hazard to personnel on the ground, and possibly less of an explosion hazard depending on where one supposes the ignition sources are.
Key Assumptions
+ +
+using Unitful: ustrip, @u_str
+
+ft = ustrip(u"m", 1u"ft") # unit conversion ft->m
+inch = ustrip(u"m", 1u"inch") # unit conversion inch->m
+psi = ustrip(u"Pa", 1u"psi") # unit conversion psi->Pa
+
+Dᵥ = 40ft # Diameter of the vessel, in m
+Ad = 500ft^2 # Dyked area, in m^2
+dₕ = 2inch # Diameter of the hole, in m
+hₗ = 50ft # height of liquid in the vessel
+hᵣ = 10ft # height of release point
+
+pₐ= 14.7psi # atmospheric pressure in Pa absolute
+p = 250psi + pₐ # pressure of the butane in Pa absolute
+Tᵣ= 25 + 273.15; # the release temperature in KSome relevant thermodynamic properties of butane
+# From Perry's, 8th edition
+
+R = 8.31446261815324 # universal gas constant, J/mol/K
+
+# Air
+MWₐᵢᵣ = 28.960
+ρa(T) = (pₐ*MWₐᵢᵣ)/(R*T)/1000
+μₐ(T) = (1.425e-6*T^0.5039)/(1 + 108.3/T)
+
+
+# Butane
+Mw = 58.122 # molar mass of butane, kg/kmol
+Tcr = 425.12 # critical temperature, K
+Tb = -0.6 + 273.15 # the normal boiling point of butane, K
+
+# vapour pressure in Pa, T in K
+pˢ(T) = exp(66.343 - (4363.2/T) - 7.046*log(T) + 9.4509e-6*T^2)
+
+# density in kg/m^3, T in K
+ρₗ(T) = Mw*( 1.0677/0.27188^(1+ (1-T/425.12)^0.28688) )
+
+# heat capacity in J/kmol/K, T in K
+cₚ(T) = 191030 - 1675*T + 12.5*T^2 - 0.03874*T^3 + 4.6121e-5*T^4
+
+# latent heat in J/kmol, T in K
+ΔHᵥ(T) = 3.6238e7*(1-(T/Tcr))^(0.8337 - 0.82274*(T/Tcr) + 0.39613*(T/Tcr)^2)
+
+# surface tension, N/m
+σ(T) = 0.05196*(1-(T/Tcr))^(1.2181);The vapour pressure of butane at the release temperature is below the storage pressure, so the butane in the storage sphere will be a liquid.
+pˢ(Tᵣ)<ptrueSince the vapour pressure within the vessel is below the storage pressure, at ambient temperature, the butane within the storage sphere is a liquid. In general one would have to account for flashing and two-phase flow during the release, however for very short discharge distances (<10cm) there is typically not enough time for the liquid to flash during discharge,4 over the thickness of a hole this especially true. The butane discharged from the tank will be a stream of liquid initially and the simple Bernoulli equation for a liquid jet can be used.5
+4 See AIChE/CCPS, Guidelines for Use of Vapour Cloud Dispersion Models, 2nd Ed., 1996, 37 for more of a disussion on two-phase discharge rates.
5 This is also known as Toricelli’s equation and can be derived from a mechanical energy balance and is found in a lot of references (e.g. Perry’s), the form of it I’m using here comes from AIChE/CCPS, 29 equation 4-10. This is really a function of time as the liquid height \(h_l\) will decrease as it leaks out. Using the discharge rate at the start of the leak throughout the analysis is a conservative assumption, again for the purposes of a simplified screening case. For more detailed modeling one could make this explicitly a function of time and integrate over the release.
\[ Q_l = c_d \rho_l A_h \sqrt{ 2 \left( p - p_a \over \rho_l \right) + 2gh_l } = c_d \rho_l { {\pi \over 4} d_h^2} \sqrt{ 2 \left( p - p_a \over \rho_l \right) + 2gh_l } \]
+Where \(Q_l\) is the mass flow of liquid discharged through the hole (in kg/s), \(c_d\) is the discharge coefficient which can be assumed to be 0.61,6 \(g\) is the acceleration due to gravity \(9.81 m/s^2\) and the rest are as defined earlier. I am assuming, here, that the hole is circular for simplicity.
+6 From AIChE/CCPS, Guidelines for Consequence Analysis of Chemical Releases., 1999, 27, for sharp edged orifices and Reynolds numbers greater than 30,000 the discharge coefficient approaches 0.61, and the exit velocity is independent of the hole size. For a simple screening calculation one could also use a coefficient of 1.0, though that may be excessively conservative (large over-estimates end up wasting time modeling later).
Key Assumptions
+cd = 0.61
+g = 9.81 # m/s^2
+Qₗ = cd*ρₗ(Tᵣ)*(π/4)*(dₕ^2)*√( 2*(p - pₐ)/ρₗ(Tᵣ) + 2*g*hₗ )56.31092763613714Since the butane is significantly above it’s normal boiling point, as the liquid stream exits the storage sphere it will flash. However not all of it will flash into a vapour as the quantity that can vaporize is limited by the available energy. A simplified model of flashing is to assume the process is so rapid that it is effectively adiabatic and, from a simple steady-state energy balance, one arrives at the following7
+7 This can be easily derived, but the form given here is from AIChE/CCPS, Guidelines for Use of Vapour Cloud Dispersion Models, 2nd Ed., 1996, 31, equation 4-14.
\[f_v = {Q_v \over Q_l} = { {c_p (T_r - T_b)} \over {\Delta H_v} }\]
+where \(f_v\) is the mass fraction that flashes and \(Q_v\) is the mass flow of liquid that flashes (in kg/s) and recall that the heat capacity and latent heat are functions of temperature.
+Key Assumptions
+fᵥ = cₚ(Tᵣ)*(Tᵣ-Tb)/ΔHᵥ(Tᵣ) 0.17128269541302374Qᵥ(t) = fᵥ*QₗQᵥ (generic function with 1 method)As the butane flashes into a gas, some of the liquid stream will be entrained as an aerosol. The presence of aerosolized droplets are a major contributor to the overall mass of a vapour cloud and it is important to include them. There is a wide array of methods for estimating the aerosolized fraction, from as simple as assuming it is 1-2x the flashed fraction to more detailed models that take into account the different mechanisms behind aerosolization and rain-out.
+The aerosol fraction, \(f_a\), the fraction of the liquid remaining in the cloud after flashing, in the form of aerosolized droplets.
+\[ f_a = {Q_a \over { Q_l - Q_v } }\]
+One method is to estimate the droplet size and from that determine the degree of rain out (i.e. the liquid that does not remain in the cloud) through a model of droplet settling. I am going to use the RELEASE model8 of droplet settling to determine the aerosol fraction.
+Key Assumptions
+There are three important mechanisms of drop formation, capillary breakup which occurs when sub-cooled liquids are discharged through very small holes (<2mm), aerodynamic breakup which occurs with larger holes with sub-cooled liquids or slightly super-heated liquids, and flashing breakup which occurs as super-heated liquids are discharged and flash to vapour in the form of bubbles which breakup the surrounding liquid.
+Aerodynamic breakup is correlated with the Weber number, which is the ratio of shear forces on the surface of the liquid to the surface tension.
+\[ We = { { \rho_g u_d^2 d_p } \over \sigma } \]
+Where \(\rho_g\) is the density of the gas, \(u_d\) the discharge velocity, \(d_p\) the mean droplet diameter, and \(\sigma\) the surface tension. Experimentally, droplet breakup occurs at a critical Weber number between 12 and 22, and so the mean droplet size can be estimated by rearranging9
+\[ d_p = { { \sigma We_c } \over {\rho_g u_d^2 } } \]
+and solving at the critical Weber number \(We_c = 12\), assuming \(\rho_g = \rho_a\) to be the density of ambient air, and with the discharge velocity \(u_d\) given as:
+\[ u_d = { Q_l \over { c_d A_h \rho_l} } = { Q_l \over {c_d \frac{\pi}{4} d_h^2 \rho_l} }\]
+# the cloud temperature, assumed to be the boiling point
+Tc = Tb
+
+# critical Weber number
+We = 12
+
+# release velocity, m/s
+ud = Qₗ/( cd * (π/4)*dₕ^2 * ρₗ(Tᵣ))
+
+# droplet size, m, due to aerodynamic breakup
+da = ( σ(Tc) * We)/(ρa(Tc) * ud^2) 2.188550597862162e-5The diameter of droplets from flashing breakup can be calculated from the following empirical correlation10 and the mean droplet diameter is simply the smallest of either the aerodynamic or flashing diameter11 In almost all cases that are relevant for release modelling capillary breakup is not significant.
+10 Woodward, 50.
\[ d_p = { {0.03} \over {10 + 4.0 \cdot (T - T_b) } }\]
+ +
+# droplet size, m, due to flashing breakup
+df = (0.03)/(10 + 4*(Tᵣ-Tb))
+
+dₚ = min(da, df)2.188550597862162e-5The RELEASE model uses a distribution of droplet sizes to determine, based on a simple model of settling dynamics, the fraction of droplets that remain the cloud. The model assumes droplet diameter follows a log-normal distribution and that any droplet greater than a critical diameter, determined from a balance of drag and buoyancy, will rain out. The parameters of the model were fit to experimental data of rain out events.
+The critical diameter is a function of a critical velocity which is calculated from a model of the spray jet with a tuning parameter \(\beta\) which captures the expansion of the jet. The default value for \(\beta\) is given to be 4.46°12
+\[ u_c = u_d \tan \beta \]
+# the default value given by RELEASE is 4.46°
+β = deg2rad(4.46)
+uc = ud * tan(β) # critical velocity, m/s6.197367132394693The critical diameter is found by solving the balance of buoyant and drag forces on a droplet
+\[ F_{buoyant} = F_{drag} \]
+\[ \left( \rho_l - \rho_g \right) g V_{droplet} = \frac{1}{2} C_D \rho_g u_c^2 A_{droplet} \]
+\[ \left( \rho_l - \rho_g \right) g \cdot \frac{\pi}{6} d_c^3 = \frac{1}{2} C_D \rho_g u_c^2 \cdot \frac{\pi}{4} d_c^2 \]
+\[ \left( \rho_l - \rho_g \right) g \cdot d_c - \frac{3}{4} C_D \rho_g u_c^2 = 0\]
+Where \(C_D\) is the drag coefficient, which for a solid sphere in viscous flow is given by this correlation13
+13 White, Viscous Fluid Flow. This could be an opportunity for improvement to the RELEASE model as liquid droplets and bubbles do not experience drag in the same way as solids, due to internal flows that can dissipate energy.
\[ C_D = 0.4 + {24 \over Re} + {6 \over {1 - \sqrt{Re} } } \]
+with the Reynolds number \(Re\) as
+\[ Re = { {\rho_g u_c d_c} \over \mu_a} \]
+for simplicity the gas density \(\rho_g\) can be calculated assuming an ideal gas, and \(\mu_a\) is the viscosity of air.
+This relationship will have to be solved numerically to get the critical diameter, since the Reynolds number and thus drag coefficient is a function of the critical diameter. Which is fairly straight forward and in this case I use the bounds \(0.1 \cdot d_p \le d_c \le 10 \cdot d_p\) as a very broad starting point.
+using Roots: find_zero
+
+ρg(T) = (pₐ * Mw)/(R * T)/1000 # ideal gas law, kg/m^3
+
+# the Reynold's number at the release temperature
+Re(d) = ρg(Tc) * uc * d / μₐ(Tc)
+
+# the drag coefficient
+CD(d) = 0.4 + (24/Re(d)) + 6/(1-√(Re(d)))
+
+# critical diameter
+dc = find_zero( d -> (ρₗ(Tc) - ρg(Tc))*g*d - 0.75*CD(d)*ρg(Tc) * uc^2, (0.1*dₚ, 10*dₚ))0.00014250630981793824The aerosol fraction, in the RELEASE model, is the mass fraction of droplets with a diameter less than the critical diameter:
+\[ f_a = { {F_m \left( d_c \right)} \over {F_m \left( \infty \right)} } \]
+Where \(F_m(d)\) is the cumulative mass distribution function for droplets. This is based on a log-normal distribution and is given as
+\[ F_m \left( d \right) = \left( \frac{\pi}{6} \rho_l d_p^3 \right) \int_0^t { t^2 \over {\sqrt{2 \pi} \log{\sigma_G} } } {\exp \left( -\frac{1}{2} \left( \log{t} \over \log{\sigma_G} \right)^2 \right)} dt\]
+Where \(t = d/d_p\) and \(\sigma_G\) is another tuning parameter (the default value given is 1.8).
+With a change of variables \(z = \log{t}\) and \(s = \log{\sigma_g}\) the cumulative mass distribution function can be integrated:
+\[ F_m \left( d \right) = \left( \frac{\pi}{6} \rho_l d_p^3 \right) \int_{-\infty}^z { 1 \over {\sqrt{2 \pi} s} }{\exp \left( 3z \right) \exp \left(-\frac{1}{2} \left( z \over s \right)^2 \right)} dz \]
+\[ = \left( \frac{\pi}{6} \rho_l d_p^3 \right) \frac{-1}{2} \exp \left( 9s^2 \over 2 \right) \left[ \mathrm{erf} \left( {3s^2 - z} \over {\sqrt{2} s} \right) \right]_{-\infty}^z\]
+\[= \left( \frac{\pi}{6} \rho_l d_p^3 \right) \exp \left( 9 \left( \log{\sigma_G} \right)^2 \over 2 \right) \times \frac{1}{2} \left[ 1 - \mathrm{erf} \left( {3 \left( \log{\sigma_G} \right)^2 - \log{d} + \log{d_p} } \over {\sqrt{2} \log{\sigma_G} } \right) \right] \]
+where \(\mathrm{erf}\left( x \right)\) is the error function. Finally the aerosol fraction is:14
+14 Johnson and Woodward, RELEASE - a Model with Data to Predict Aerosol Rainout in Accidental Releases, 58–60. The integration is not shown in the text, but the fortran code is included on the CD if one wants to verify the final result.
\[ f_a = { {F_m \left( d_c \right)} \over {F_m \left( \infty \right)} } = \frac{1}{2} \left[ 1 - \mathrm{erf} \left( {3 \left( \log{\sigma_G} \right)^2 - \log{d_c} + \log{d_p} } \over {\sqrt{2} \log{\sigma_G} } \right) \right]\]
+The RELEASE code uses this formula and also does a check for extreme cases, defaulting to either 1 or 0.
+using SpecialFunctions: erf
+
+function RELEASE_fa(dc, dp; σG=1.8)
+ if (dp/dc) >= exp(σG)
+ # checks for where erf(x) ~ 1
+ return 0.0
+ elseif (dc/dp) >= 15*exp(σG)
+ # checks for where erf(x) ~ -1
+ return 1.0
+ else
+ return 0.5*( 1 - erf((3*log(σG)^2 -log(dc) + log(dp)) / (√(2) * log(σG)) ))
+ end
+endRELEASE_fa (generic function with 1 method)fₐ = RELEASE_fa(dc, dₚ) # calculates the aerosol fraction using the RELEASE method0.9227949810754577Qₐ(t) = fₐ*(Qₗ - Qᵥ(t));The droplets that rain out of the cloud will form a pool and, depending on how long the release occurs, evaporation from the pool can be a significant contributor to the overall airborne quantity. In this case the liquid is assumed to be at the boiling point of butane, it cooled through evaporative cooling, and is cryogenic with respect to the ground. There are two major factors that impact the evaporation rate: the area of the pool and the heat transfer into the pool from the environment. Both of these, in general, can be quite complicated time-dependent phenomena with lots of different models capturing a wide array of scenarios.
+Since this is a simple screening calculation, I will be avoiding all of that and use some simple models for pool spread and evaporative flux.
+Key Assumptions
+A simple model of pool spread as a function of time is15
+\[ A_{pu} = \frac{\pi}{4} \sqrt{\frac{2048}{81} {Q_{p} \over \rho_l} t^3} \]
+Where \(A_{pu}\) is the unconstrained pool area in m², \(t\) is the time since the start of the release in seconds, and \(Q_{p}\) is the mass flow of liquid to the pool in kg/s (the total release rate less what was lost to flashing and entrained in the cloud as an aerosol)
+\[ Q_{p} = Q_l - Q_v - Q_a \]
+In practice the area of the pool will be limited to be at most the diked area. For large spills having a diked area is significant, both in the obvious containing of the spill, but also since it can significantly reduce the amount of pool evaporation.
+# the liquid temperature, taken to be the boiling point
+Tₗ = Tb
+
+# mass flow to the pool, kg/s
+Qₚ(t) = Qₗ - Qᵥ(t) - Qₐ(t)
+
+# unconstrained pool area, m^2
+Aₚᵤ(t) = (π/4) * √((2048/81) * (Qₚ(t)/ρₗ(Tₗ)) * t^3 )
+
+# Pool area, restricted to at most dyked area, m^2
+Aₚ(t) = min( Aₚᵤ(t) , Ad);In general the evaporation rate is derived from a heat balance accounting for the heat transfer from the ground, from the ambient air, and from solar flux, however in this case a simplifying assumption is that the majority of the heat transferred to the liquid is from the ground.
+For a cryogenic liquid spilled on land a simple model of the evaporative flux \(G_e\) in kg/s/m² is16
+\[ G_e = { {Mw} \over {\Delta H_v} } { k \left( T_s - T_l \right) \over \sqrt{\pi \alpha t} } \]
+Where \(k\) is the thermal conductivity of the surface (ground) in W/m/K, \(T_s\) is the temperature of the surface in K, \(T_l\) the temperature of the liquid in K, and \(\alpha\) the thermal diffusivity of the surface in m²/s
+The overall evaporation rate is the product of the pool area and the evaporative flux
+\[ Q_e \left( t \right) = G_e \left( t \right) \cdot A_p \left( t \right) \]
+It’s worth taking a moment to note that the evaporative flux will decrease with time. This is because the ground under the spill cools down over time. The overall evaporation rate will grow as the pool grows – in this model the pool grows \(\propto t^{3/2}\) while the flux decreases \(\propto t^{-1/2}\), so the evaporation rate should grow \(\propto t\) – but once it hits the limit of the diked area the overall evaporation rate will decrease over time.
+One thing worth noting is that the pool area equation does not take into account a mass balance. As time goes on the unconstrained pool only grows, even if the evaporation rate were to exceed the rate of new liquid being added to the pool. This limitation probably doesn’t matter for short duration leaks in which it is expected that the pool evaporation rate is strictly lower than the rate at which new liquid is added to the pool, however for long duration spills or instantaneous spills this not appropriate and a more complex model of pool growth and evaporation should be considered.
+# Thermal properties of concrete
+# A. Bejan, Kraus, A. D., Heat Transfer Handbook, John Wiley & Sons, 2003
+k = 1.28 # W/m/K
+α = 6.6e-7 # m^2/s
+
+# surface temperature, taken to be the ambient temperature
+Tₛ = Tᵣ
+
+# evaporative flux, kg/s/m^2
+Gₑ(t) = (Mw/ΔHᵥ(Tₗ)) * k * (Tₛ - Tₗ) / √(π*α*t)
+
+# evaporation rate, kg/s
+Qₑ(t) = min( Gₑ(t)*Aₚ(t), Qₚ(t));The total airborne quantity is the sum of the flashed vapour, the aerosolized droplets, and the vapour from pool evaporation. So far the calculation has been in terms of rates, but the total airborne quantity depends upon the release duration, \(t_d\). There are lots of different ways of deciding on a release duration, in general the release duration of interest is the time it would take for a vapour cloud to find an ignition source – for vapour cloud explosion scenarios – or, more optimistically, the time it would take for the plant to respond and take some action to mitigate the hazard. A common default release duration is 10 minutes17
+17 AIChE/CCPS, 22.
One common simplification is to take the vapour and aerosol rates to be a constant, and the pool evaporation rate as a constant at the final time \(t_d\), then multiply by the total duration. An alternative is to integrate over time from 0 to \(t_d\).
+\[ Q_{aq} \left( t \right) = Q_v \left( t \right) + Q_a \left( t \right) + Q_e \left( t \right)\]
+\[ m_{aq} = \int_0^{t_d} Q_{aq} \left( t \right) dt = \int_0^{t_d} Q_v \left( t \right) + Q_a \left( t \right) + Q_e \left( t \right) dt \]
+One could try to integrate this analytically, but for re-useability of code it’s a better idea to integrate numerically – then different models for each of the rates can be swapped in and out with ease.
+using QuadGK: quadgk
+
+# release duration of 10 minutes, seconds
+td = 10*60
+
+# total airborne release rate is the sum of the individual
+# mechanism release rates, in kg/s
+Qaq(t) = Qᵥ(t) + Qₐ(t) + Qₑ(t)
+
+# total airborne quantity is the integral over time
+maq, err = quadgk(Qaq, 0, td) (31737.218210630548, 0.00014433872246399915)A quick sanity check is to make sure that the total airborne quantity is less than the total quantity released, i.e. \(Q_l \cdot t_d\).
+maq <= Qₗ*tdtrueIt is often insightful to compare the airborne quantity to the case where there was no secondary containment, i.e. the pool could expand without bound.
+Qₑᵤ(t) = min( Gₑ(t)*Aₚᵤ(t), Qₚ(t))
+Qaqu(t) = Qᵥ(t) + Qₐ(t) + Qₑᵤ(t)
+
+maqu, err = quadgk(Qaqu, 0, td)(33426.49125139247, 0.0003172098610093599)With secondary containment 31.737 t
+Without secondary containment 33.426 t In this case the secondary containment reduced the overall airborne quantity by ~5%, and we wouldn’t expect it to be hugely important for this example as most of the mass of the vapour cloud came from the flashing of the liquid immediately upon release and from entrained droplets.
+There are always trade offs to be made with model accuracy, model complexity, and the shear amount of data required to run the models (often overlooked unless you’re the flunky tasked with finding all of these constants). This notebook aimed at creating a simple screening model and made several simplifications along the way. One thing I tried to avoid, though, is the use of gross “rules of thumb” and any pre-calculating of constants. I see this fairly often in older works because, likely, the calculations were being done by hand and this greatly speeds that up. I don’t think the justification for it is still valid, though, for a few reasons. For one many very rough rules of thumb were developed to avoid iterative solutions, but with modern computers there’s really no reason to, the numerical solutions in this notebook took fractions of a second to calculate on my laptop. For another much of the work collecting constants and pre-calculating things simply makes it harder to validate formulas. With a notebook like this not only can I properly typeset the formula more-or-less as presented in the reference (while keeping a consistent nomenclature) but I can also fairly transparently type that into Julia, making it very clear what the code is doing, step by step, and where those formulae came from. This should make it very easy to verify that I haven’t made a typo, for example. In my experience with some older excel tools that used a lot of pre-calculated rearranged equations, it was often entirely not obvious how the reference (if there is one given at all) lead to the final equations in the spreadsheet and verifying that the spreadsheet worked as intended without some written down derivation could take hours.
+One feature that I didn’t use, but could be a nice addition, is the unit-aware library Unitful, I included it at the beginning for some unit conversions. However it can be used to track the units for each number throughout, ensuring that results are in the appropriate units and that there are no unit mismatches. I did not use that part of things because there are quite a few correlations and figuring out the appropriate units for the various constants in those correlations such that all the units match properly can be a pain in the butt. In general, though, using Unitful is a very powerful tool when working with physical modelling.
That said, this notebook is far from perfect. Probably the biggest simplification that could be changed is the assumption that the liquid release rate is a constant and is at the highest rate. This could be made a function of time – as the vessel empties there is less hydro-static pressure – and the rates of flashing and aerosol entrainment made explicitly time dependent as well. Like all things this would take some time to implement – though not much – and would improve model performance for long duration releases. The assumption made is on the conservative side and for short duration, and large vessels, is appropriate for screening purposes. Though, like all things with code, you only have to put the effort in once…
+For re-useability the lowest hanging fruit for changes would be to link this to a database of substance properties. Probably the most tedious part of using this notebook is finding and filling in all of the correlations at the beginning for the various temperature dependent material properties. There’s no reason why a small database couldn’t be set up, containing everything in a given plant’s inventory, and some code added so the notebook can look up the properties for you.
+There are also lots of opportunities for embedding some of the decision logic into the notebook, I set up the notebook to do a liquid discharge because I knew what the scenario was. Furthermore I knew that the boiling point of butane is less than ambient and so the pool evaporation would be for a cryogenic liquid spill. There’s no reason why the logic behind those decisions, and others, couldn’t be generalized and the notebook setup to choose which model was appropriate in a clear and transparent way.
+Recently I’ve been playing around with Dynamic Mode Decomposition (DMD) and this notebook compiles my notes and julia code in one place for later reference.
+Very generally DMD is an approach to system identification problems that is well suited for high dimensional data and systems with coherent spatio-temporal structures. In particular DMD finds the “best fit” linear approximation to the dynamical system, i.e. it finds the matrix A such that
+\[ \mathbf{\dot{x} } = \mathbf{A x} \]
+Where x is the high dimensional state vector for the system. One key strength of DMD is that it allows one to calculate x(t) without explicitly calculating A. This may not seem like a particularly useful property on its face unless one notes that the matrix A is n×n and, for systems with a very large n (i.e. very high dimensionality) that can be huge. Context for huge is also important: a matrix that fits easily in memory on my laptop may be infeasibly huge for an embedded system. For control applications, such as MPC, DMD may be a good method for generating approximations that are both good and space efficient.
+As a motivating example, I am going to use the flow past a cylinder dataset from Data-Driven Science and Engineering, specifically the matlab dataset. This dataset is the simulated vorticity for fluid flow past a cylinder. The vector x in this case is the vorticity at every point in the discretized flow field at a particular time; a two dimensional array of 89,351 pixels reshaped into a column vector. The data is a sequence of equally spaced snapshots of the flow field, and ultimately we wish to generate a linear system that best approximates this.
+The MAT package allows us to import data from matlab data files directly into julia
using MAT
+
+file = matopen("data/CYLINDER_ALL.mat")
+
+# import the data set
+data = read(file, "VORTALL");
+
+# the orinal dimensions of each snapshot
+nx = Int(read(file, "nx"))
+ny = Int(read(file, "ny"))
+
+# the final dimensions of the data matrix
+n, m = size(data)(89351, 151)The data set, data, has already been processed into the form we need: each column represents a “frame” of the animation. We can walk through the matrix, taking each column and re-shaping it back into a 2D array, and recover the original flow as a movie.
 +
+The data set has the property that the number of data points at each time step, n, is much greater than the number of time steps, m. In fact n is large enough that the n×n matrix A might be unwieldy to store: If we assume it is a dense matrix of 64-bit floats, 8 bytes each, we would need ~64GB of memory just to store it.
+size_A_naive = n*n*863868809608DMD provides us a method to both find a best fit approximation for A while also being more space (and computation) efficient. To get there we first need to define what a best fit means.
+Consider the general linear system Y = AX, where Y is a n × m matrix of outputs, X is a n × m matrix of inputs and A is an n × n linear transformation matrix. We say that the best fit matrix A is the matrix that minimizes
+\[ \| \mathbf{ A X } - \mathbf{Y} \|_{F} \]
+where \(\| \cdots \|_{F}\) is the Frobenius norm.
+The solution to which is
+\[ \mathbf{A} = \mathbf{YX}^{\dagger} \]
+where X† is the Moore-Penrose pseudoinverse of X.1
+1 I think this can be shown fairly easily by starting with the definition of the Frobenius norm \(\| \mathbf{ A X } - \mathbf{Y} \|_{F}^{2} = \mathrm{Tr}\left( \left(\mathbf{ A X } - \mathbf{Y}\right)\left(\mathbf{ A X } - \mathbf{Y} \right)^{T} \right)\) and finding the matrix A that minimizes that using standard matrix calculus, and some properties of the pseudoinverse.
The conventional way of calculating the Moore-Penrose pseudoinverse is to use the Singular Value Decomposition: for a matrix X with SVD \(\mathbf{X}=\mathbf{U}\mathbf{\Sigma}\mathbf{V}^{*}\), the pseudoinverse is \(\mathbf{X}^{\dagger} = \mathbf{V} \mathbf{\Sigma}^{-1} \mathbf{U}^{*}\). Returning to the best fit matrix A we find
+\[ \mathbf{A} = \mathbf{Y} \mathbf{V} \mathbf{\Sigma}^{-1} \mathbf{U}^{*} \]
+We can calculate a projection of A onto the space of the upper singular vectors U
+\[ \tilde{ \mathbf{A} } = \mathbf{U}^{*} \mathbf{A} \mathbf{U} = \mathbf{U}^{*} \mathbf{Y} \mathbf{V} \mathbf{\Sigma}^{-1} \mathbf{U}^{*} \mathbf{U} = \mathbf{U}^{*} \mathbf{Y} \mathbf{V} \mathbf{\Sigma}^{-1} \]
+Which then allows us to reconstruct the matrix A on demand while only needing to store the matrices à and U, by the following \[ \mathbf{A} = \mathbf{U} \tilde{ \mathbf{A} } \mathbf{U}^{*} \]
+This is useful when n > > m as U is n×m and à is m×m. For this example this has reduced the memory requirement to ~108MB, a >99.8% reduction
+size_A_exact = (n*m + m*m)*8108118416size_A_exact/size_A_naive0.0016928202774340957Returning to the original problem, we have a sequence of discrete snapshots arranged in a matrix such that each column, k, is the vector xk. Our aim, then, is to find the best fit matrix A for the linear system
+\[ \mathbf{x}_{k+1} = \mathbf{A} \mathbf{x}_k \]
+for all xk in our data set. Or in other words, to find the best fit matrix A for the system
+\[ \mathbf{X}_{2} = \mathbf{A} \mathbf{X}_{1} \]
+where X1 is the matrix of all of the vectors xk and X2 is the matrix of the corresponding xk+1’s.
+Though, using DMD, we will instead calculate à and U, leaving us with
+\[ \mathbf{x}_{k+1} = \mathbf{U} \mathbf{ \tilde{A} } \mathbf{U}^{*} \mathbf{x}_k \]
+To start, we divide the data set into X1 and X2
+using LinearAlgebra# dividing into past and future states
+X₁ = data[:, 1:end-1];
+X₂ = data[:, 2:end];Then compute the SVD of X1.2
+2 The svd function in julia returns the singular values in a Vector, but for later on it will be more convenient have this as a Diagonal matrix.
# SVD
+U, Σ, V = svd(X₁)
+Σ = Diagonal(Σ);Then calculate the projection à (I am pre-computing YVΣ-1 as that will come in handy later)
+# projection
+YVΣ⁻¹ = X₂*V*Σ^-1
+Ã = U'*YVΣ⁻¹
+
+size(Ã)(150, 150)We can then calculate the predicted xk+1’s, without ever having to actually compute (or store) A
+X̂₂_exact = (U*(Ã*(U'*X₁)));As before, we can step through the matrix, extract each frame of the 2D flow field, and animate them, giving us a general sense of how well this worked
+ +
+Of course this only solves the problem in the discrete case (for control applications that may be all you need). Consider again the system \(\mathbf{\dot{x} } = \mathbf{A x}\), the solution to this differential equation is
+\[ \mathbf{x}\left( t \right) = e^{\mathbf{A}t} \mathbf{x}_{0} \]
+where x0 is the initial conditions. If the matrix A has eigendecomposition ΦΛΦ-1 then this can be written as
+\[ \mathbf{x}\left( t \right) = \mathbf{\Phi} e^{\mathbf{\Lambda}t} \mathbf{\Phi}^{-1} \mathbf{x}_{0} \]
+So it would be very convenient if we could get those eigenvalues and eigenvectors, preferably without having to actually compute A.
+Recall, by definition, the projection matrix à is unitarily similar to A, which means the eigenvalues are identical. The eigenvectors of A can also be recovered from properties of Ã: Suppose à has the eigendecomposition WΛW-1
+\[ \mathbf{ \tilde{A} } \mathbf{W} = \mathbf{W} \mathbf{\Lambda} \]
+\[ \mathbf{U}^{*} \mathbf{A} \mathbf{U} \mathbf{W} = \mathbf{W} \mathbf{\Lambda} \]
+\[ \mathbf{U} \mathbf{U}^{*} \mathbf{A} \mathbf{U} \mathbf{W} = \mathbf{U} \mathbf{W} \mathbf{\Lambda} \]
+\[ \mathbf{A} \mathbf{\Phi} = \mathbf{\Phi} \mathbf{\Lambda} \]
+where
+\[ \mathbf{\Phi} = \mathbf{U} \mathbf{W} \]
+This is what is given in the original DMD, however more recent work recommends using
+\[ \mathbf{\Phi} = \mathbf{Y} \mathbf{V} \mathbf{\Sigma}^{-1} \mathbf{W} \]
+# calculate eigenvectors and eigenvalues
+# of projection Ã
+Λ, W = eigen(Ã)
+
+# reconstruct eigenvectors of A
+Φ = YVΣ⁻¹*W;Whether or not the ultimate goal is to generate the continuous system, the eigenvectors and eigenvalues are useful to examine as they represent the dynamic modes of the system.
+ +
+I’ve played somewhat fast and loose with variables: the A for the discrete system is not the same A as the continuous system. Specifically the eigenvalues of the continuous system, ω are related to the eigenvalues of the discrete system, λ by the following
+\[ \omega_{i} = {\log{ \lambda_{i} } \over \Delta t} \]
+where Δt is the time step. The eigenvectors are the same, though. So we can generate a function x(t) pretty easily:
+# calculate the eigenvalues for
+# the continuous system
+Δt = 1
+Ω = Diagonal(log.(Λ)./Δt)
+
+# precomputing this
+Φ⁻¹x₀ = Φ\X₁[:,1]
+
+# continuous system
+x̂(t) = real( Φ*exp(Ω .* t)*Φ⁻¹x₀ ) +
+Through taking the SVD, the eigenvalue decomposition, and projections, DMD involves generating a whole bunch of matrices, which can be really unwieldy to manage without some structure. The low hanging fruit for refactoring is to introduce a struct to store those matrices.
struct DMD
+ r::Integer # Dimension
+ U::Matrix # Upper Singular Vectors
+ Ã::Matrix # Projection of A
+ Λ::Diagonal # Eigenvalues of A
+ Φ::Matrix # Eigenvectors of A
+endThen we can introduce a method that takes an input matrix X and output matrix Y and returns the corresponding DMD object. We can take advantage of multiple dispatch to to add further methods, such as for the case where we have a single data matrix X and wish to calculate the DMD on the “future” and “past” matrices.
function DMD(Y::Matrix, X::Matrix)
+ # dimension
+ r = rank(X)
+
+ # Full SVD
+ U, Σ, V = svd(X)
+ Σ = Diagonal(Σ)
+
+ # projection
+ YVΣ⁻¹ = Y*V*Σ^-1
+ Ã = U'*YVΣ⁻¹
+
+ # calculate eigenvectors and eigenvalues
+ # of projection Ã
+ Λ, W = eigen(Ã)
+ Λ = Diagonal(Λ)
+
+ # reconstruct eigenvectors of A
+ Φ = YVΣ⁻¹*W
+
+ return DMD(r,U,Ã,Λ,Φ)
+end
+
+function DMD(X::Matrix)
+ X₁ = X[:, 1:end-1]
+ X₂ = X[:, 2:end]
+ return DMD(X₂, X₁)
+endWe can check that this is doing what it is supposed to be doing by comparing with what we have already done
+d = DMD(data)
+
+# This produces the same result as before
+d.Φ == Φ && d.Λ == Diagonal(Λ)trueIf you were to build this into a larger project, it would be worthwhile to define some actual unit tests to validate that the DMD is working properly.
+Since we have a DMD type to work with, we can also refactor how discrete systems are generated. In this case I have defined a struct for the discrete system, and then added a method such that any discrete system acts as a callable xk+1=f(xk)
struct DiscreteSys
+ Ã::Matrix
+ U::Matrix
+end
+
+function DiscreteSys(d::DMD)
+ return DiscreteSys(d.Ã,d.U)
+end
+
+function (ds::DiscreteSys)(xₖ)
+ return (ds.U*(ds.Ã*(ds.U'*xₖ)))
+endds = DiscreteSys(d)
+
+# This produces the same result as before
+X̂₂_exact == ds(X₁)trueSimilarly we can refactor the generation of continuous systems, first by defining a struct for the continuous system, then by adding a method xt=f(t). This requires a little more information: we need to keep track of the initial state of the system x0 as well as the step size Δt
struct ContinuousSys
+ Φ⁻¹x₀::Vector
+ Ω::Diagonal
+ Φ::Matrix
+end
+
+function ContinuousSys(d::DMD, x₀, Δt=1)
+ Φ⁻¹x₀ = d.Φ\x₀
+ Ω = Diagonal(log.(d.Λ.diag)./Δt)
+ return ContinuousSys(Φ⁻¹x₀, Ω, d.Φ)
+end
+
+function (cs::ContinuousSys)(t)
+ return real( cs.Φ*exp(cs.Ω .* t)*cs.Φ⁻¹x₀ )
+endcs = ContinuousSys(d, X₁[:,1]);
+
+# This produces the same result as before
+x̂(150) == cs(150)trueI have been using the default tools in julia, which work well for small matrices. If you are planning on doing DMD on enormous matrices then it is worth investigating packages such as IterativeSolvers.jl, Arpack.jl, KrylovKit.jl and others to find better ways than vanilla svd and eigen. It also may be worth thinking about refactoring the problem to be matrix-free, though that is way beyond the scope of these notes.
Whenever a problem involves computing the SVD of a matrix, dimensionality reduction lurks about in the shadows, winking suggestively. By the Eckart-Young theorem we know that the best rank r approximation to a matrix X=UΣVT is the truncated SVD Xr=UrΣrVrT, i.e. the SVD truncated to the r largest singular values (and corresponding singular vectors). So an obvious step for dimensionality reduction in DMD is substitute a truncated SVD for the full SVD.
+function DMD(Y::Matrix, X::Matrix, r::Integer)
+ # full SVD
+ U, Σ, V = svd(X)
+
+ # truncating to rank r
+ @assert r ≤ rank(X)
+ U = U[:, 1:r]
+ Σ = Diagonal(Σ[1:r])
+ V = V[:, 1:r]
+
+ # projection
+ YVΣ⁻¹ = Y*V*Σ^-1
+ Ã = U'*YVΣ⁻¹
+
+ # calculate eigenvectors and eigenvalues
+ # of projection Ã
+ Λ, W = eigen(Ã)
+ Λ = Diagonal(Λ)
+
+ # reconstruct eigenvectors of A
+ Φ = YVΣ⁻¹*W
+
+ return DMD(r,U,Ã,Λ,Φ)
+end
+
+function DMD(X::Matrix, r::Integer)
+ X₁ = X[:, 1:end-1]
+ X₂ = X[:, 2:end]
+ return DMD(X₂, X₁, r)
+endOne consequence of truncation, however, is that the resulting matrix Ur is only semi-unitary, in particular
+\[ \mathbf{U}_{r}^{*} \mathbf{U}_{r} = \mathbf{I}_{r \times r} \]
+but
+\[ \mathbf{U}_{r} \mathbf{U}_{r}^{*} \ne \mathbf{I}_{n \times n} \]
+This leads to a complication as the matrix U is required to be unitary, in particular when recovering A from the projection matrix Ã, and also when recovering the eigenvalues and eigenvectors of A from Ã.
+But, supposing that this at least approximately works, we are still left with the problem of picking an appropriate value for r. One could look at the singular values and pick one based on structure. For this problem it looks like an elbow happens at r=45.
+
We can then generate a set of predictions for the reduced DMD, with r=45, and compare with the exact DMD
+ds_45 = DiscreteSys(DMD(data, 45))
+X̂₂_45 = ds_45(X₁)
+
+norm(X₂ - X̂₂_45) # Frobenius norm0.005459307491383062norm(X₂ - X̂₂_exact)0.0005597047465277092An alternative is to specify how much of the variance in the original data set needs to be captured. The singular values are a measure of the variance in the data, and so keeping the top p percent of the total variance equates to keeping the top p percent of the sum of all of the singular values.
+That is to say we calculate the r such that
+\[ { {\sum_{i}^{r} \sigma_i} \over {\sum_{i}^{m} \sigma_i} } \le p \]
+where σi is the ith singular value (in order of largest to smallest).
+function DMD(Y::Matrix, X::Matrix, p::AbstractFloat)
+ @assert p>0 && p≤1
+
+ # full SVD
+ U, Σ, V = svd(X)
+
+ # determine required rank
+ r = minimum( findall( >(p), cumsum(Σ)./sum(Σ)) )
+
+ # truncate
+ @assert r ≤ rank(X)
+ U = U[:, 1:r]
+ Σ = Diagonal(Σ[1:r])
+ V = V[:, 1:r]
+
+ # projection
+ YVΣ⁻¹ = Y*V*Σ^-1
+ Ã = U'*YVΣ⁻¹
+
+ # calculate eigenvectors and eigenvalues
+ # of projection Ã
+ Λ, W = eigen(Ã)
+ Λ = Diagonal(Λ)
+
+ # reconstruct eigenvectors of A
+ Φ = YVΣ⁻¹*W
+
+ return DMD(r,U,Ã,Λ,Φ)
+end
+
+function DMD(X::Matrix, p::AbstractFloat)
+ X₁ = X[:, 1:end-1]
+ X₂ = X[:, 2:end]
+ return DMD(X₂, X₁, p)
+endCapturing 99% of the variance, in this case, requires only keeping the first 14 singular values.
+ +
+ +
+There are also methods for finding the optimal rank for truncated SVD for a data set that involves gaussian noise which I am not going to go into here.
+So, supposing that p=0.99 works for us, how much further have we reduced the size of our matrices?
+# for p=0.99, r=14
+r = 14
+size_A_reduced = (n*r + r*r)*810008880To recover the (approximate) A matrix we only need to store 10MB, a ~91% reduction over the exact DMD
+size_A_reduced/size_A_exact0.09257331331972159and a >99.98% reduction of the naive case (recall the naive approach of storing the entire A matrix would take ~64GB)
+size_A_reduced/size_A_naive0.00015670998193688458In the above code I simply calculated the full SVD and then truncated it after the fact. If m (the rank of X) is particularly large, then this can be hilariously inefficient. In those cases it may be worth writing a method that uses TSVD.jl to efficiently calculate only the first r singular values – as opposed to calculating all m singular values and then chucking out most of them.
+Compressed DMD attempts to tackle the slowest step in the DMD algorithm: calculating the SVD. An SVD on full data is \(\mathcal{O}\left( n m^2 \right)\) if we instead compress the data from n dimensions to k dimensions then the cost of the SVD is reduced to either \(\mathcal{O}\left( k m^2 \right)\) (when k>m) or \(\mathcal{O}\left( m k^2 \right)\) (when k < m), which for large n can be a dramatic speed-up.
+Suppose we have some k×n unitary matrix C which compresses our input matrix X into the compressed input matrix Xc and our output matrix Y into the compressed output matrix Yc
+\[ \mathbf{X}_c = \mathbf{C} \mathbf{X} \\ \mathbf{Y}_c = \mathbf{C} \mathbf{Y} \]
+We suppose again that X has the SVD X=**UΣV***, then
+\[ \mathbf{X}_c = \mathbf{C} \mathbf{X} = \mathbf{C} \mathbf{U} \mathbf{\Sigma} \mathbf{V}^{*} \]
+and, since C is unitary, the SVD of Xc is
+\[ \mathbf{X}_c = \mathbf{U}_c \mathbf{\Sigma} \mathbf{V}^{*} \]
+where Uc=CU is the upper singular values of the compressed input matrix.
+The projection matrix Ãc of the compressed input matrix is
+\[ \mathbf{ \tilde{A} }_c = \mathbf{U}^{*}_c \mathbf{Y}_c \mathbf{V} \mathbf{\Sigma}^{-1} \]
+\[ = \left( \mathbf{CU} \right)^{*} \mathbf{C} \mathbf{Y} \mathbf{V} \mathbf{\Sigma}^{-1} \]
+\[ = \mathbf{U}^{*} \mathbf{C}^{*} \mathbf{C} \mathbf{Y} \mathbf{V} \mathbf{\Sigma}^{-1} \]
+\[ = \mathbf{U}^{*} \mathbf{C}^{*} \mathbf{C} \mathbf{Y} \mathbf{V} \mathbf{\Sigma}^{-1} \]
+\[ = \mathbf{U}^{*} \mathbf{Y} \mathbf{V} \mathbf{\Sigma}^{-1} = \mathbf{ \tilde{A} } \]
+and so we should recover the same eigenvalues and eigenvectors as from the uncompressed data.
+using SparseArrays
+
+function cDMD(Y::Matrix, X::Matrix, C::AbstractSparseMatrix)
+ # determining dimensionality
+ r = rank(X)
+
+ # compress the X and Y
+ Xc = C*X
+ Yc = C*Y
+
+ # singular value decomposition
+ Uc, Σc, Vc = svd(Xc)
+ Σc = Diagonal(Σc)
+
+ # projection
+ Ã = Uc'*Yc*Vc*inv(Σc)
+ U = C'*Uc
+
+ # calculate eigenvectors and eigenvalues
+ # of projection Ã
+ Λ, W = eigen(Ã)
+ Λ = Diagonal(Λ)
+
+ # reconstruct eigenvectors of A
+ Φ = Y*Vc*inv(Σc)*W
+
+ return DMD(r,U,Ã,Λ,Φ)
+end
+
+function cDMD(X::Matrix, C::AbstractSparseMatrix)
+ X₁ = X[:, 1:end-1]
+ X₂ = X[:, 2:end]
+ return cDMD(X₂, X₁, C)
+endThe giant caveat is: how do we generate a unitary compression matrix? In fact we can relax this condition if we simply want to recover the eigenvalues and eigenvectors of A. It is enough that the data is sparse in some basis and that the compression matrix is incoherent with respect to that basis.
+We can think of C as a set of k (1×n)-row vectors that project an n dimensional vector x onto a k dimensional space. There are several ways of finding the basis for this projection – e.g. a uniform random projection or a gaussian projection – but by far the simplest is to pick a random subset of k single pixels and only take the measurements from those pixels.
+function cDMD(Y::Matrix, X::Matrix, k::Integer)
+ n, m = size(X)
+ @assert k≤n
+
+ # build (sparse) compression matrix
+ C = spzeros(k, n)
+ for i in 1:k
+ C[i,rand(1:n)] = 1
+ end
+
+ return cDMD(Y, X, C)
+end
+
+function cDMD(X::Matrix, k::Integer)
+ X₁ = X[:, 1:end-1]
+ X₂ = X[:, 2:end]
+ return cDMD(X₂, X₁, k)
+endSuppose we sample at 300 randomly chosen points in the flow field to form the compression matrix
+k = 300
+
+C = spzeros(k, n)
+for i in 1:k
+ C[i,rand(1:n)] = 1
+endThat is to say we are only sampling the vorticity at the green dots. This reduces the dimensionality of the data going in to the DMD algorithm from 89351 to 300.
+
Original flow field with randomly generated sample points for compressed DMD.
+We can generate a few different compressed DMDs to get a sense of how this impacts the overall performance (in terms of the Frobenius norm) and, much like we saw with reduced DMD, there are diminishing returns.
+ +
+Using the compression matrix from above, we can generate a compressed DMD3
+3 While we can reconstruct the eigenvalues and eigenvectors quite successfully, I don’t believe we adequately reconstruct U, and so this really only works for the continuous system. The reconstruction of U strongly depends on C being unitary and I don’t think that condition can be relaxed.
 +
+The compressed DMD does not actually reduce the storage size of any of the matrices, it is more a technique to speed up the calculation of the SVD. Compressed DMD and reduced DMD can be combined: first by compressing the n×m matrix X to a k×m matrix Xc and then finding the best rank r approximation to the compressed matrix by truncating the SVD to the r largest singular values. The reduction step reduces the memory requirements and, if truncated SVD is used as well, this could significantly improve performance for enormous systems.
+There is a related approach called compressed sensing DMD, in which the full state vector is not available in the first place. A much smaller dimension set of measurements is sampled and the full state DMD generated using the same general idea as compressed DMD. It isn’t that much of a leap from what is above, just with a convex optimization step added to reconstruct the actual state matrix for a given set of measurements.
+The idea behind physics informed DMD is that the physics of the system imposes structure upon the solution, which we can build into the DMD algorithm. This way we generate results that are consistent with physical reality. Which is to say that we are not merely finding the best fit matrix A, we are finding the best fit matrix A subject to some constraints on its structure. The paper I am using as a reference gives a nice table of different types of flow problems and the sort of structure one might want to impose upon the solution,4
+ +
+Conveniently the flow past a cylinder example is on that table (that definitely wasn’t a motivating factor for choosing it as the example in the first place, nope, not at all) and what we want to impose on the solution is conservation of energy. Conservation of energy in this case equates to requiring that A be unitary, which is the standard procrustes problem
+We modify the best fit such that we are looking for the A matrix that minimizes
+\[ \| \mathbf{ A X } - \mathbf{Y} \|_{F} \]
+\[ \textrm{ subject to } \mathbf{A}^{*} \mathbf{A} = \mathbf{I} \]
+For which the standard solution is to define a matrix M
+\[ \mathbf{M} = \mathbf{Y} \mathbf{X}^{*} \]
+supposing M has SVD
+\[ \mathbf{M} = \mathbf{U}_{M} \mathbf{\Sigma}_{M} \mathbf{V}_{M}^{*} \]
+then the solution is
+\[ \mathbf{A} = \mathbf{U}_{M} \mathbf{V}_{M}^{*} \]
+Of course we can’t directly compute M in many cases for the same reason that we can’t directly compute A : it would be a n×n matrix and for large n that would be enormous. So instead we project X and Y onto the upper singular values of X and solve the procrustes problem in that smaller space:
+\[ \mathbf{X} = \mathbf{U} \mathbf{\Sigma} \mathbf{V}^{*} \]
+\[ \mathbf{ \tilde{X} } = \mathbf{U}^{*} \mathbf{X} \]
+\[ \mathbf{ \tilde{Y} } = \mathbf{U}^{*} \mathbf{Y} \]
+\[ \mathbf{ \tilde{M} } = \mathbf{ \tilde{Y} } \mathbf{ \tilde{X} }^{*} = \mathbf{U}^{*} \mathbf{Y} \mathbf{X}^{*} \mathbf{U} = \mathbf{U}^{*} \mathbf{M} \mathbf{U}\]
+since SVD is invariant to left and right unitary transformations, the SVD of the projected \(\mathbf{ \tilde{M} }\) is
+\[ \mathbf{ \tilde{M} } = \mathbf{U}_{ \tilde{M} } \mathbf{\Sigma}_{M} \mathbf{V}_{ \tilde{M} }^{*} \]
+where
+\[ \mathbf{U}_{ \tilde{M} } = \mathbf{U}^{*} \mathbf{U}_{ M } \textrm{ and } \mathbf{V}_{ \tilde{M} } = \mathbf{U}^{*} \mathbf{V}_{M} \]
+and the A matrix which solves the projected procrustes problem is
+\[ \mathbf{ \tilde{A} } = \mathbf{U}_{ \tilde{M} } \mathbf{V}_{ \tilde{M} }^{*} = \mathbf{U}^{*} \mathbf{U}_{ M } \mathbf{V}_{M}^{*} \mathbf{U} = \mathbf{U}^{*} \mathbf{A} \mathbf{U} \]
+which is exactly the projected A matrix we need to proceed with reconstructing the eigenvalues and eigenvectors as per the standard DMD algorithm.
+# this is piDMD *only* for the case where A must be unitary
+# see arXiv:2112.04307 for details on the alternative cases
+function piDMD(Y::Matrix, X::Matrix)
+ # dimension
+ r = rank(X)
+
+ # Full SVD
+ U, _, _ = svd(X)
+
+ # projection
+ Ỹ = U'*Y
+ X̃ = U'*X
+ M̃ = Ỹ*X̃'
+
+ # solve procrustes problem
+ Uₘ, _, Vₘ = svd(M̃)
+ Ã = Uₘ*Vₘ'
+
+ # calculate eigenvectors and eigenvalues
+ # of projection Ã
+ Λ, W = eigen(Ã)
+ Λ = Diagonal(Λ)
+
+ # reconstruct eigenvectors of A
+ Φ = U*W
+
+ return DMD(r,U,Ã,Λ,Φ)
+end
+
+function piDMD(X::Matrix)
+ X₁ = X[:, 1:end-1]
+ X₂ = X[:, 2:end]
+ return piDMD(X₂, X₁)
+end +
+We can compare the Frobenius norm of the actual data versus the predicted, and it’s clear the physics informed DMD does not generate as good of a fit as exact DMD. Though it could equally be the case that the exact DMD is over-fitting.
+norm(X₂ - X̂₂_pi, 2)18.35684111920036norm(X₂ - X̂₂_exact, 2)0.0005597047465277092The main reason why you would pursue physics informed DMD, though, is not necessarily to generate a better fit as much as to generate better (or more physically realistic) dynamic modes.
+Similarly to compressed DMD, physics informed DMD can also be combined with reduced DMD. In this case there are two SVD steps but only the upper singular values of X, the U matrix, needs to be truncated. The second SVD proceeds without truncation.
+While making coffee one day, I started thinking about how the coffee making process is both a perfect representation of the sorts of systems chemical engineers work on every day and also a weird edge case unlike most of the unit operations in the standard repertoire of process engineering.
+Making coffee involves heat, mass, and momentum transfer across multiple phases – pretty standard stuff for undergraduate chemical engineering curricula. On the other hand, while industrial scale leaching operations are generally designed for maximum efficiency – removing the most amount of a substance with the least amount of solvent, energy, etc. – coffee makers are specifically designed to avoid that outcome. A saturated cup of coffee would be strong, harsh, and undrinkable. Coffee making, as a unit op, aims at a managed inefficiency, which makes for an interesting design case1
+1 I am not the first person to think of this: using coffee as a basis for exploring engineering concepts is the entire premise of this book. From the reviews it sounds like it is, essentially, a lab manual for exploring chemical engineering concepts using coffee.
I claimed that making coffee is, in a sense, a deliberately inefficient process. By this I mean the goal is not to maximize extraction – defined as the mass of solids dissolved in the final cup of coffee relative to the starting mass of coffee grounds – but instead to target some middle ground. This is largely because extraction is an imperfect measure of what we actually want. Coffee releases a whole slew of flavour compounds and a good cup of coffee is a balance of all of these. However we have both limited variables to control and limited knowledge of that final composition. Even simply measuring the total dissolved solids (TDS) with a refractometer puts one well into the stratospheric heights of coffee nerd-dom. Trying to monitor all of the relevant flavour compounds would require something like a quarter-million dollar GC-MS, well out of the reach of most coffee obsessives.
+So extraction is really the best we have, as far as quantitative measures go, with the giant caveat that coffee with the same extraction, from the same beans, can taste quite different depending on the brew method. Using an indirect measurement for the actual process variable of interest is not too different from how a lot of unit operations are controlled, distillation, for example, often uses temperature as a proxy for the composition.
+ +
+The standard way of thinking about coffee extraction starts with Lockhart’s coffee control chart, this plots the concentration of solids (TDS) against total extraction. The diagonal lines represent a given dose of coffee (I typically brew 55g/L with my V60, which puts me pretty near the sweet spot). A given brew moves along the diagonal line for the given dose, moving from the bottom left to the upper right as the brew proceeds. The goal is to stop the brew once the extraction and strength (concentration) have reached the optimal level3:
+3 For a given dose of coffee, the concentration and extraction are directly proportional to one another.
+\[ \mathrm{Dose} = D = { m_{beans} \over V_{water} } \approx { m_{beans} \over V_{cup} } \]
+\[ \mathrm{Extraction} = E = { m_{cup} \over m_{beans} } = { { c_{cup} V_{cup} } \over m_{beans} } \]
+\[ c_{cup} = D \cdot E \]
+where the subscript cup means the mass/volume that ends up in the final cup of coffee. This is only approximately the case as some water is absorbed into the coffee grounds. The amount of water retained in the coffee grounds can be accounted for, giving a more accurate measure of final extraction.
For industrial scale distillation, absorption, extraction, leaching, etc. the process is usually modeled as a series of equilibrium stages, and the whole point is to maximize extraction and concentration. This leads to designs for counter-current solids extractors such as a Rotocel extractor or a Bollman extractor
+ +
+Extractors like this are, in fact, how one might decaffeinate coffee. In that case one does want to maximize the extraction of caffeine, and is free to adjust several parameters such as the solvent (with options such as supercritical CO2, dichloromethane, or ethyl acetate) that are otherwise pretty fixed for normal coffee making. At the end of the day a cup of coffee has to be made with water, a steaming cup of dichloromethane just won’t cut it.
+Coffee makers inhabit a space where the design parameters are highly restricted. Outside of espresso, the machine has to operate at atmospheric pressure and temperatures achievable with a normal kettle. The solvent must be water. The process is likely batch or semi-batch.4 The extraction happens fully within the mass-transfer dominated regime, specifically avoiding reaching equilibrium (the fundamental design assumption in most industrial extractors) as that leads to over-extracted coffee.
+4 I would love to see a fully continuous coffee maker, like the fully continuous industrial operations, and there is no reason why you couldn’t make one. Imagine going into your local coffee shop and seeing a glass fluidized bed continuously circulating grounds and hot water, that would be pretty groovy.
Perhaps the simplest method for making coffee is to put coffee grounds and water in a vessel, add heat, and let it steep for a while. This is, for example, how Turkish coffee is made as well as qahwa, bunna, and many others. A French press and other infusion brewers are a very similar idea except that the water is also the source of heat, and the pot is left to steep without any additional heat input. That’s not the only difference, of course, they differ quite substantially in grind size, whether or not the grounds are strained out at the end, and in the addition of spices or sugar during the brew. But for the purposes of building a simple model all of these methods are vessels in which coffee steeps in hot water. There are three main process variables that impact coffee extraction, and taste, for a given set of beans: brew temperature, grind size, and brew time.
+In some ways this makes these methods some of the easier ways to make good coffee. Dialing in grind size and temperature is reasonably straight forward and once set remain constant. The remaining variable, time, is relatively easy to adjust: simply wait longer.
+Modeling extraction is fairly straight forward, after some basic assumptions are made: that the brew is isothermal, that the ground coffee is uniform and with constant dimensions, and that the liquid phase is well mixed. All of these assumptions are wrong to some degree, and how wrong they are will ultimately govern how useful this model is.
+Brew temperature is an obvious variable to change, though it has wide ranging impacts and parsing out what exactly changing the temperature does is not obvious. Firstly, the solubility of the various compounds extracted from the beans is a function of temperature and in general solubility is difficult to predict, but broadly speaking solutes are more soluble at higher temperatures. Coffee is more extractable at higher temperatures. However the coffee matrix is complex and there are more than just two phases involved: flavour compounds in the coffee will partition between the solid matrix, coffee oils, and the water at different proportions depending upon the temperature. This is perhaps what is behind the notable difference in taste between cold brew versus a hot immersion brew. Even when made with the same beans, and to the same concentration, the flavour profile of cold brew is quite different.5 That said, over the range of temperatures used to brew a French press, this may not be very important.6
+Secondly, brew temperature impacts the rate of extraction. Generally speaking, diffusion coefficients are proportional to (absolute) temperature, \(\mathscr{D} \propto T\).7 At higher temperatures the various flavour compounds will diffuse more quickly through the grounds and also through the coffee, thus making the brew faster.
+To make modeling extraction simpler, we assume the brew temperature is constant. This means that, whatever the relative solubilities or rate constants turn out to be, they are constant with respect to time. The only thing varying over time is the concentration of coffee solubles in water and remaining in the grounds. For something like Turkish coffee, the system is probably close to isothermal as it is continuously heated and will remain at or near the boiling point of water the entire time. For a French press this is less true, as the press will lose heat to the environment. How much heat is lost over the course of the brew is going to depend strongly upon the press and the environment it is in. My French press is a double walled stainless steel carafe like this one and likely loses much less heat than a more typical glass carafe. It is also important to consider whether or not the French press is pre-heated. If not, the brew temperature is not going to be the temperature of the kettle. The carafe has significant thermal mass, especially if it is glass, and it will absorb a lot of heat out of the water over the course of the brew (in addition to losing heat to the environment).
+Suppose my French press starts off at 95°C and cools to 75°C – a sizable loss of heat – how much impact would that have on extraction rate? Since \(\mathscr{D} \propto T\), the percent change in the rate constant is equal to the percent change in (absolute) temperature
+\[ { { \Delta \mathscr{D} } \over \mathscr{D} } = { { \Delta T } \over T } \]
+ΔT = 20
+T = 368.15
+ΔT / T = 0.054325682466385986Even over this significant loss of heat, that translates to only a 5.4% change in the rate constants. To the exacting standards of a coffee nerd that may seem like a lot, but to chemical engineer that is really not much, it justifies the isothermal assumption (at least as a first approximation).
+Grind size is important if only for being where most of your money can get sunk when building out your home coffee set-up. A good grinder is not cheap, and a bad grinder leads to truly bad coffee. In this case what you are chasing is the ability to tune the average grind size as well as the uniformity of the size of particles produced by the grinder. A good grinder can reliably produce a consistent and suitably narrow particle size distribution.
+Why does grind size matter at all? The grind size determines the available surface area of the coffee. Mass transfer from the coffee beans (grounds) to the water is proportional to the surface area of coffee exposed to water, and so changing the grind size directly impacts the rate of extraction. The direct impact of grind-size is typically quantified through the specific area, av, which is the surface area of the particle per unit volume. For a sphere this is
+\[ a_v = {S \over V} = { {4 \pi b^2} \over { \frac{4}{3} \pi b^3} } = {3 \over b} \]
+where b is the radius of the particle. This leads immediately to the observation that, for the same dose of coffee, a finer grind leads to larger overall surface area and thus a faster rate of extraction. It also hints at why a uniform particle size distribution is important: a smaller particle has proportionately more surface area and will experience faster extraction than a larger particle, leading to the smallest particles (the fines) being over extracted while the largest particles (the boulders) are under extracted.
+Of course coffee grounds are not perfect spheres, they have a complex shape arising from the combination of cutting and brittle fracture that characterize the grinding process. The standard engineering approach is to assume that they are spheres anyways, since that is a simpler geometry to work with, and adjust for the non-sphericity with some sort of shape factor or other parameter. In the case of mass and heat transfer, typically that is the Sauter mean diameter (or Sauter mean radius), which is essentially the average diameter of the distribution of spheres that would have the same specific area as the actual particles. For an individual particle the Sauter radius is
+\[ b_{s} = {3 \over a_v } \]
+It is important to note, though, that the following model is developed for spheres and only works as well as the grounds can be approximated as spheres.
+Mass transfer problems, like this one, ultimately come down to finding good rate constants. They can be measured, estimated from a correlation, or simply tabulated in a reference, but regardless the model is only as good as the rate constants. The rate constants define, to some extent, the model itself and govern one of the key brew variables: brew time.
+In the case of coffee, and organic materials in general, there is a complex micro-scale geometry involving multiple phases: the solid ground itself, coffee oils, and water. The coffee will diffuse from the solid into the oils, into water in the interstitial spaces, and also out into the bulk liquid. All of these processes have potentially different rate constants. Additionally the solid phase is not structurally homogeneous, it is a complex arrangement of coffee bean cells, voids, pores and such. Building a model to incorporate all of this complexity is certainly possible8 but the standard approach is to treat this as a two-phase problem where all of the complexity of the solid phase, the marc, and any secondary phases (e.g. coffee oils) are all averaged together into one pseudo-homogeneous solid phase and the solvent (water) forms the liquid phase. This approximation leaves us with two mass transfer rates: the diffusion through the (pseudo-homogeneous) solid phase, within the coffee particles, and the diffusion through the solvent phase, the water outside of the coffee particles. At the interface, the solute leaves the solid phase and enters the liquid phase.
+For organic material with hard cell walls the relative diffusivity of the solid phase to the liquid phase generally falls along the range \(\frac{\mathscr{D}_s}{\mathscr{D}_l} = 0.1-0.2\),9 this allows us to estimate the (effective) diffusivity within the solid based on measured diffusivities in liquid water. It also tells us that diffusion through the solid is 5-10× slower than in the liquid phase and so, depending upon the geometry of the problem, diffusion through the solid phase may be the governing rate.
+Diffusion through the liquid phase is complicated by mixing. The diffusivity used above is the diffusivity in quiescent liquid water. In practice, in the brew vessel, the liquid will be moving and convective mass transfer will be very significant. Usually for mass transfer problems this is all rolled up into a mass transfer coefficient h which combines all of the flow complexity and geometry of the problem into a single coefficient. This is then typically estimated using correlations for the Sherwood number.
+The interface between the solid and liquid phase introduces a complication as there is some partitioning between the phases happening at the interface. If there wasn’t coffee couldn’t be made. A critical piece of the model is assuming a relationship between the concentration immediately on the solid side of the interface and the concentration immediately on the liquid side of the interface. For organic leaching it is typical to assume linear equilibrium with an equilibrium distribution coefficient
+\[ K = \frac{ q^{*} }{ c^{*} } \]
+Where q is the concentration of solute in the solid phase and c is the concentration of solute in the liquid phase. This is equivalent to assuming that there are two first order processes happening
+\[ \mathrm{coffee}_{s} \xrightarrow{k_1} \mathrm{coffee}_{l} \]
+\[ \mathrm{coffee}_{l} \xrightarrow{k_2} \mathrm{coffee}_{s} \]
+At equilibrium the rates of these two processes are equal
+\[ k_1 q^{*} = k_2 c^{*} \Leftrightarrow \frac{k_2}{k_1} = \frac{ q^{*} }{ c^{*} } = {K} \]
+Typically one assumes that at the interface, in the infintesimally thin slice of liquid on one side and the infintesimally thin slice of solid on the other, the solute is always at equilibrium (this is not the same as assuming the system is at equilibrium)
+At this point we can start defining what our specific brew is going to be: roast, grind size, dose, and water temperature. From this we can work to estimate the necessary parameters, such as the equilibrium constant, solid and liquid phase diffusivities. To an extent, these parameters then govern what specific model is used to model the brew.
+# properties of the coffee grounds
+# equilibrium parameters
+# Moroney et al. 2015
+q_sat = 118.95 # kg/m³
+c_sat = 212.4 # kg/m³
+K = q_sat/c_sat
+
+# effective diffusivity
+# Moroney et al. 2015; Schwartzberg 1987, 557
+𝒟ₗ = 2.2e-9 # m²/s
+𝒟ₛ = 0.1*𝒟ₗ
+
+# particle size
+# Moroney et al. 2015
+b = 569.45e-6 # m
+
+# density, medium roast
+# Rodrigues et al. 2002, 8
+ρₛ = 314.0 # kg/m³
+
+# dose
+# assumed, 22.5g in 500mL
+mₛ = 0.0225 # kg
+Vₛ = mₛ/ρₛ # m³
+Vₗ = 500e-6 # m³# properties of the water
+# density
+# Poling et al. 2007, 2-103
+MW = 18.015 #kg/kmol
+function ρₗ(T)
+ τ = 1 - T/647.096
+ mol_dens = 17.863 + 58.606*τ^0.35 - 95.396*τ^(2/3) + 213.89*τ - 141.26*τ^(4/3)
+ return mol_dens*MW
+end
+
+# viscosity
+# Poling et al. 2007, 2-432
+μₗ(T) = exp(-52.843 + 3703.6/T + 5.866*log(T) - 5.879e-29*T^10)
+νₗ(T) = μₗ(T)/ρₗ(T)
+
+# brew temperature
+# assumed, 95°C
+Tₗ = 95+273.15 #K
+
+# initial concentration
+c₀ = 0.0 # kg/m³
+
+# final (max) concentration
+c_max = min(q_sat*Vₛ/Vₗ + c₀, c_sat) # kg/m³These are a lot of parameters and I think it is good practice to think about how to organize them into a struct. In this case I define an InfusionBrew struct to store all of the parameters necessary for defining the brew recipe for an infusion brewer.
struct InfusionBrew{T}
+ K::T
+ q_max::T
+ c_max::T
+ Vₗ::T
+ Vₛ::T
+ mₛ::T
+ 𝒟ₛ::T
+ 𝒟ₗ::T
+ b::T
+end brew = InfusionBrew(K,q_sat,c_max,Vₗ,Vₛ,mₛ,𝒟ₛ,𝒟ₗ,b);Pulling together all of the information we have collected about coffee we can build a partial differential equation to describe the brewing process, making the following assumptions:
+We can visualize this set-up with three “phases”, the bulk liquid, a thin film around the coffee particle, and the pseudo-homogeneous solid coffee particle itself. Coffee is extracted from the particles into the thin film and from the thin film into the bulk liquid.
+ +
+There are two rates important processes governing the extraction of coffee:
+Starting with (1) the mass flux into the thin film is given by Fick’s first law (in spherical coordinates)
+\[ J_1 = - \mathscr{D}_s \left( { \partial q } \over { \partial r} \right)_{r=b} \]
+Of course the concentration in the solid, q, is a function of time (as more is extracted, there less left behind), which is given by Fick’s second law (in spherical coordinates)
+\[ { {\partial q} \over {\partial t} } = \frac{1}{r^2} { \partial \over {\partial r} } \left( r^2 \mathscr{D}_s { {\partial q} \over {\partial r} } \right) \]
+Turning to (2) the mass flux from the thin film into the bulk liquid is given by
+\[ J_2 = - h \left( c - c_s \right) \]
+Where c is the concentration in the bulk liquid and cs is the concentration at the surface.
+The change in concentration in the bulk liquid with respect to time can also be written in terms of a mass balance on the liquid phase:
+\[ V_l { { \partial c} \over {\partial t} } = a_v V_s J_2 = \frac{3}{b} V_s J_2 \]
+\[ { { \partial c} \over {\partial t} } = \frac{3}{b} \frac{V_s}{V_l} J_2 \]
+The solution to this partial differential equation depends upon which of these mass transfer processes, (1) or (2), is dominant.
+The standard approach to solving this problem is to look at the limiting cases, where the Biot number is either very large or very small10
+11 The intermediate solution is not given in Seader, Henley, and Roper, Separation Process Principles, only a reference: Schwartzberg, Henry G. and R. Y. Chao. 1982. “Solute Diffusivities in Leaching Processes.” Food Technology. 36, no. 2: 73-86, which has not been digitized and is not available from my local library, so I have no idea what it says ¯\_(ツ)_/¯
I will argue in a very hand-wavy way that the Biot number for mass transfer is likely to be large, and so the model from Carslaw and Jaeger12 is the probably the best model. First let’s start with Biot number for mass transfer, which for this situation is13
+\[ \mathrm{Bi} = { {h b} \over {K \mathscr{D}_s} } = {\mathscr{D}_l \over \mathscr{D}_s} { \mathrm{Sh} \over K }\]
+Where Sh is the Sherwood number, defined as
+\[ \mathrm{Sh} = { {h b} \over \mathscr{D}_l } \]
+Defining the Biot number in terms of the Sherwood number might, at first glance, not seem tremendously useful. However, if we suppose the Froessling equation14 for flow past a single sphere applies
+\[ \mathrm{Sh} = 2 + 0.552 \mathrm{Re}^{1/2} \mathrm{Sc}^{1/3} \]
+with Re the Reynold’s number and Sc the Schmidt number, then we have a correlation for the Biot number as a function of the Reynold’s number.
+\[ \mathrm{Bi} = {\mathscr{D}_l \over \mathscr{D}_s} { 1 \over K } \left( 2 + 0.552 \mathrm{Re}^{1/2} \mathrm{Sc}^{1/3} \right) \]
+\[ \mathrm{Bi} = { 20 \over K } + { 5.52 \over K } \mathrm{Re}^{1/2} \mathrm{Sc}^{1/3} \]
+Where \({\mathscr{D}_s \over \mathscr{D}_l}\) = 0.1 is assumed from Schwartzberg15 The Schmidt number, Sc, and equilibrium constant, K, can be calculated
+Sc = νₗ(Tₗ) / 𝒟ₗ = 139.98370415887905
+K = q_sat / c_sat = 0.5600282485875706
+
+Bi = 35.7124842370744 + 51.178588534736114 √ReUnder this model, any flow with Re > 10.3 corresponds to Bi > 200, which occurs when the velocity is
+Re = 10.3
+
+v = Re*νₗ(Tₗ)/b0.005570341094459917that is 5.6mm/s, a velocity so small that it may be achieved through the natural convection occurring within a French press (and especially so in the case of something heated from below like Turkish coffee), but is certainly the case when the French press is stirred.
+Regardless it is unlikely that \(\mathrm{Bi}<0.001\) and thus the simple exponential model is probably not a good fit, we turn instead to the model from Carslaw and Jaeger.16
+In the above I casually disregarded boundary conditions, focusing instead on refining the model. Before we move forward we should take a moment to clarify what the boundary conditions are.
+First off the coffee starts with a set of initial concentrations q0 and c0, usually these would be the max concentration in the solid phase and zero respectively but they don’t have to be. By disregarding the transfer through the thin film we impose another boundary condition: that at r = b the solid-phase concentration is at equilibrium with the concentration in the bulk liquid qr=b = K c
+It might, at first glance, appear that I have lost the thread, Carslaw and Jaeger17 is a book on heat transfer, this is a mass transfer problem. This is an example of the unreasonable effectiveness of treating transport phenomena as a unified subject. By putting the PDE into dimensionless form we find that the PDE for the equivalent heat transfer problem (a solid sphere cooling in a liquid) has already been solved and we can just use that answer.
+First step, to put the PDE in dimensionless form we make the substitutions:
+\[ \xi = {r \over b} \]
+\[ \tau = { {\mathscr{D}_s t} \over b^2} \]
+\[ u = { { q - q^{*} } \over { q_0 - q^{*} } }\]
+\[ u_f = { {c - c^{*} } \over { c_0 - c^{*} } }\]
+After which the PDE becomes
+\[ { {\partial u} \over {\partial \tau} } = \frac{1}{\xi^2} { \partial \over {\partial \xi} } \left( \xi^2 {\partial \over {\partial \xi} } \right) \]
+With boundary conditions
+And the mass transfer into the liquid bulk becomes
+\[ { {\partial u_f} \over {\partial \tau} } = -\frac{3}{\alpha} \left. { {\partial u} \over {\partial \xi} } \right|_{\xi=1} \]
+With \(\alpha = { V_l \over {K V_s} }\) and boundary condition
+This is the equivalent PDE (in dimensionless form) to the heat transfer case for a hot solid sphere cooling in a well mixed fluid,18 with the solution
+\[ u_f = 6α (α+1) \sum_{k=1}^{\infty} { \exp(-τ x_k^2 )\over { 9(α+1) + (α x_k)^2 } } \]
+Where the xk s are the roots of the equation
+\[ \tan(x) = { {3 x} \over { 3 + \alpha x^2 } } \]
+(the particular form shown here comes from Schwartzberg19)
+The first problem, when actually using this solution, is generating the roots of the equation. The original equation has a repeated singularity and, in my experience, off-the-shelf root finding algorithms have trouble with that and will find spurious zeros in the vicinity of the singularities.
+A better approach is to re-write it in a different way
+\[ \tan(x) = { \sin(x) \over \cos(x) } \]
+\[ \tan(x) - { {3 x} \over { 3 + \alpha x^2 } } = 0 \Leftrightarrow \left( 3 + \alpha x^2 \right) \sin(x) - 3 x \cos(x) = 0 \]
+This latter form is nice and continuous, with no singularities.
+using IntervalRootFinding
+using Roots
+
+α = Vₗ/(K*Vₛ)
+
+f(x) = tan(x) - 3x/(3+α*x^2)
+g(x) = (3 + α*x^2)*sin(x) - 3x*cos(x)
+
+# find the first 5 roots
+k=5
+xk = find_zeros(g, 0, (k+1/2)*π)6-element Vector{Float64}:
+ 0.0
+ 3.214656575481129
+ 6.321030394109289
+ 9.45018248676156
+ 12.585470558898335
+ 15.723260568418107Since α is fixed for a given problem we will end up using the same roots over and over again, so it would be nice to pre-calculate those roots. However, at this point, we don’t know how many we will need to get a reasonable answer. So my approach is to calculate as many as we need dynamically: if we need more roots than have already been calculated, calculate those ones and append them to the list of already calculated roots.
+function getroots(n)
+ if n ≤ length(xk)
+ return xk[2:n]
+ else
+ new_roots = find_zeros(x -> g(x), xk[end], (n+1/2)*π)
+ append!(xk, new_roots)
+ return xk[2:end]
+ end
+endThe standard approach to calculating an infinite series is to use Richardson extrapolation as this accelerates convergence and allows for an error estimate.
+using Richardson:extrapolate
+
+function u_f(τ)
+ val, err = extrapolate(1, x0=Inf) do N
+ xk = getroots(Int(N))
+ 6α*(α+1)*sum( exp.(-τ.*(xk.^2))./((9*(α+1)).+(α.*xk).^2) )
+ end
+ return val
+endNow we can put together a bulk concentration function
+function c(t)
+ τ = (𝒟ₛ*t)/b^2
+ c = (c₀ - c_max)*u_f(τ) + c_max
+ return c
+endExtraction is simply concentration over dose
+extraction(t) = c(t)*Vₗ/mₛAt this point we have enough to put together a struct to contain the parameters needed for the Carslaw and Jaeger model
struct CarslawSolution{T}
+ α::T
+ τ₁::T
+ xk::Vector{T}
+ ib::InfusionBrew{T}
+end
+
+function CarslawSolution(ib::InfusionBrew)
+ α = ib.Vₗ/(ib.K*ib.Vₛ)
+ τ₁ = ib.𝒟ₛ/ib.b^2
+ xk = find_zeros( x -> (3 + α*x^2)*sin(x) - 3x*cos(x) , 0, (10.5)*π)
+ return CarslawSolution(α, τ₁, xk, ib)
+endand update our code to add some methods for calculating the concentration and extraction based on a Carslaw and Jaeger model for the infusion brew.
+function getroots(n, model::CarslawSolution)
+ if n ≤ length(model.xk)
+ return model.xk[2:n]
+ else
+ new_roots = find_zeros(x -> (3 + model.α*x^2)*sin(x) - 3x*cos(x),
+ model.xk[end], (n+1/2)*π)
+ append!(model.xk, new_roots)
+ return model.xk[2:end]
+ end
+end
+
+function c(t, model::CarslawSolution)
+ τ = model.τ₁*t
+ α = model.α
+ u_f, err = extrapolate(1, x0=Inf) do N
+ xk = getroots(Int(N), model)
+ 6α*(α+1)*sum( exp.(-τ.*(xk.^2))./((9*(α+1)).+(α.*xk).^2) )
+ end
+ c = (c₀ - c_max)*u_f + c_max
+ return c
+end
+
+extraction(t, model::CarslawSolution) = c(t, model)*model.ib.Vₗ/model.ib.mₛsol = CarslawSolution(brew);The advantage of packaging code like this is that is now easy to explore the impact of changes to individual parameters, for example below is the impact that changing grind size has on the extraction curve. It follows our general intuition that smaller grind sizes extract faster. It also shows a major weakness of this model: there is only one particle size in the model, which is average over the range of actual particle sizes. This model works well if the grind is quite uniform, however if there is a wide range of particle sizes the actual coffee will be a mix of over extracted coffee (from the small particles) and under extracted coffee (from the large particles).
+I think this shows that making coffee can be an interesting exploration of how one would go about building a mass-transfer model for an extraction operation, and going through the stages of simplifying the model by, for example, assuming simpler geometries, limiting cases and such. I think you could also take this as an example of how very often chasing down appropriate model parameters is the limiting step when building an engineering model (at least in chemical engineering). Often the exact chemical process that you want to model has not been explored, experimentally, over the entire range of your process variables (if at all).
+The next obvious step with this model is to build some datasets and fit some of these models to actual observed extractions. This could be a jumping off point for exploring how changes in different parameters impact the overall extraction or required brew time.
+In a previous post I thought about how one might approach making coffee, in a French press, as a chemical engineering problem. The obvious next step is to look at percolation methods like espresso, which is what I am exploring here.
+The same basic principles of extraction and diffusion apply to an espresso maker as apply to a French press, and we expect the same basic parameters to be relevant: the particle size, solid phase diffusivity, etc. The major difference is that the liquid phase, water, is moving through a fixed bed of coffee particles and this significantly changes the mass transfer problem.
+In the case of the French press I made the simplifying assumption that the system was well mixed, and so I could generally ignore the flow of the fluid. In the case of the espresso maker, it is more complicated than that.
+Making espresso involves packing coffee grounds into a cylindrical puck within a portafilter then passing hot water through the grounds under pressure, up to 10 bar.1 The specific unit operation that corresponds to making espresso is packed bed leaching, in which the coffee solubles are being leached from the coffee grounds. In a lot of standard undergraduate texts on unit operations and separations, I find, this is not well explored. Especially the non-equilibrium case, which is exactly the situation when pulling a shot of espresso: one doesn’t typically fully extract the beans and stops at some point in the transient regime. That said, the basic system is the same as desorption and so a good reference for what follows is often a text on chromatography and adsorption/desorption processes.
+The espresso puck can be modelled as a perfectly cylindrical packed bed of ground coffee. Meaning both that the bed is a perfect cylinder and that the grounds are perfectly evenly distributed, i.e. has a constant porosity \(\varepsilon\). A lot of technique goes into preparing the puck, to ensure the grounds are evenly distributed in the packed bed and the distribution of water through the bed is even, so this is a reasonable assumption.
+ +
+In practice the pressure can vary over the course of the shot, but for simplicity I am only considering the case where the pressure is constant and, consequently, the flow rate of water is constant. We can simplify the flow condition more by assuming plug-flow, i.e. the velocity is a constant throughout. One final simplifying assumption is that the espresso is pulled at a constant temperature, this ensures the physical properties of water are also constant, e.g. constant density and viscosity.
+All of these assumptions, at their core, are to eliminate various partial derivatives and narrow down the governing equations to only core variables.
+Zooming in on a thin slice of the packed bed with depth, Δz, we can take a mass balance of the liquid phase.
+ +
+The mass flow into the liquid phase can be due to:
+Similarly the mass flow out of the liquid phase can be due to advection or axial diffusion out the bottom of the slice. Putting that together into a mass balance we have
+\[ { {d m_l} \over {d t} } = Q c_z - Q c_{z + \Delta z} + \varepsilon A J_z - \varepsilon A J_{z+\Delta z} + A_s J_s \]
+\[ V_l { {d c} \over {d t} } = - Q \Delta c - \varepsilon A \Delta J_z + a_s V_s J_s \]
+where as is the specific area of the coffee grounds, the surface area per unit volume. By writing the volume of the liquid phase and solid phase in terms of porosity and cross sectional area, A, we can cancel out some terms.
+\[ \varepsilon A \Delta z { {d c} \over {d t} } = - \varepsilon A v \Delta c - \varepsilon A \Delta J_z + \left( 1 - \varepsilon \right) A {\Delta z} a_s J_s\]
+\[ { {d c} \over {d t} } = - v { {\Delta c} \over {\Delta z} } - { {\Delta J_z} \over {\Delta z} } + \left( {1 - \varepsilon} \over \varepsilon \right) a_s J_s \]
+In the limit Δz → 0 this becomes
+\[ { {\partial c} \over {\partial t} } = - v { {\partial c} \over {\partial z} } - { {\partial J_z} \over {\partial z} } + \left({ 1 - \varepsilon } \over \varepsilon \right) a_s J_s \]
+Assuming axial diffusion is Fickian
+\[ { {\partial c} \over {\partial t} } = \mathscr{D}_l { {\partial^2 c} \over {\partial z^2} } - v { {\partial c} \over {\partial z} } + \left({ 1 - \varepsilon } \over \varepsilon \right) a_s J_s \]
+For the solid phase, I am assuming a uniform bed of spherical particles, all with the same radius b. Actual coffee grounds, beyond being non-spherical, are also composed of multiple phases: the solid phase, the coffee oils, and the liquid water phase within the micro-porous structure of the bean. To simplify things greatly, I am assuming an effective solid phase diffusion, wherein diffusion within the particle of coffee follows Fick’s law with an effective diffusion coefficient that combines all of that complexity into a single parameter.
+\[ { {\partial q} \over {\partial t} } = \mathscr{D}_s \nabla^2 q\]
+In spherical coordinates, this becomes
+\[ { {\partial q} \over {\partial t} } = \mathscr{D}_s \frac{1}{r^2} {\partial \over {\partial r} } \left( r^2 { {\partial q} \over {\partial r} } \right)\]
+\[ { {\partial q} \over {\partial t} } = \mathscr{D}_s \left( { {\partial^2 q} \over {\partial r^2} } + {2 \over r} { {\partial q} \over {\partial r} } \right) \]
+Where the solid phase concentration, q, is in units of mass per unit volume.
+Connecting the two phases, the liquid coffee and the solid coffee grounds, is a thin film. This is where the inter-phase mass transfer occurs, and I assume it follows a linear mass transfer relation.
+\[ J_s = h \left( c_{s} - c \right) \]
+Where h is the mass transfer coefficient and cs is the liquid concentration immediately at the solid surface. I am making the additional assumption that this concentration is in equilibrium with the solid phase concentration at the surface, and that equilibrium is linear, i.e.
+\[ K = c_{s}/q_{s} = \mathrm{constant} \]
+The initial conditions for espresso are complicated. The bed is initially full of air and the first phase of making espresso, the pre-infusion, is to saturate the bed with hot water at a lower pressure than is used during the main extraction phase. This initial step has a very complicated multi-phase flow and mass transfer which dramatically complicates the model and most papers I’ve read avoid this by making one of two simplifying assumptions:
+Basically everyone ignores pre-infusion and focuses on the main extraction phase, after the bed has been filled with water. I am going to make the second assumption, that after pre-infusion the bed is full of water that is in equilibrium with the solids. This is in part because it is a convenient initial condition for solving the partial differential equations2 and in part because the actual volume of water in the bed is small and the pre-infusion step, which can take between 5-10s, is sufficiently long enough that the water will have extracted some coffee.
+For my model, the initial conditions are:
+Several recent papers that numerically integrate the pde use some variation on the first assumption3 and this will be the major difference between my approach and some of the published literature.
+3 Cameron et al., “Systematically Improving Espresso” page 635; Moroney et al., “Modelling of Coffee Extraction During Brewing Using Multiscale Methods” page 225; Vaca Guerra et al., “Modeling the Extraction of Espresso Components as Dispersed Flow Through a Packed Bed” page 5
I am assuming the water and portafilter are isothermal and the liquid phase has the same physical properties of pure water throughout. This is not entirely true in that the system is not perfectly isothermal but also the process of extracting coffee changes the density and viscosity of the coffee. I am assuming this effect is small and can be ignored.
+using Unitful
+
+# physical properties coffee
+# assumed to be water at 90C and 10bar
+ρ = 965.34u"kg/m^3"
+μ = 0.282*0.001u"Pa*s"
+ν = μ/ρ
+ν = upreferred(ν)The most significant factors for both modelling the flow and also determining the mass transfer parameters are the features of the espresso bed itself. Primarily the porosity and the particle size. For simplicity I am taking both of these from the literature for actual espresso shots,4 but in practice these are probably the most difficult to derive for someone making espresso at home, with the sorts of tools available in a kitchen.
+4 Cameron et al., “Systematically Improving Espresso” supplemental materials.
The porosity will vary from espresso shot to espresso shot, as it is a function of the particle size distribution, the distribution within the portafilter, and also the degree of tamping. Furthermore the porosity of the dry bed will not be the same as the porosity of the bed once fully saturated with water. The coffee grounds will swell somewhat and any liquid within a particle is already accounted for in the effective solid phase mass transfer, including it in an estimate of the porosity would be double counting. One could try measuring the mass and volume of the spent puck and calculate it directly, but I’m not sure how one would account for the volume of water absorbed into the grounds while discarding the water that is only in the void space between coffee particles.
+The particle size distribution for a given coffee, grinder, and grind setting can be measured in a variety of ways, including with an app on one’s phone5 where in this case we are interested in the Sauter mean radius as we are assuming a bed of uniform spherical particles. Camera based approaches have one main weakness in that particles of coffee have microscopic pores that increase the apparent surface area but are too small to be resolved by a typical camera. Laboratory methods tend to measure the adsorption of a neutral substance, like nitrogen, to measure this. Not something one is going to be doing in the kitchen.
+The flow rate through the bed is also an important factor, I am simply taking the total volume of the shot divided by the time taken to pull a shot as the flow rate, but this is only a rough estimate. The pre-infusion phase adds water at a lower flow rate and it is only the flow after the pre-infusion has ended that is relevant to the problem. This can be measured with some higher end coffee scales that can output the time series of mass measurements during a shot. I don’t have one of these, but it’s not out of the question that I could just write down the mass and time at several points. Or take a video of my coffee scale’s screen during the actual shot and extract the data very tediously that way.
+# Cameron et al, "Systematically Improving Espresso," supplemental materials.
+
+# porosity and particle size
+ε = 1 - 0.8272
+b = 12e-6u"m"
+
+# bed size
+R_pb = 29.2e-3u"m"
+L_pb = 18.7e-3u"m"
+A_pb = π*R_pb^2
+
+# shot size
+M_shot = 0.04u"kg" # the mass of the espresso shot
+t_shot = 20u"s"
+Q_shot = (M_shot/ρ)/t_shot
+
+v_s = Q_shot/A_pb # superficial velocity, m/s
+v = v_s/εFrom the dimensions of the packed bed, assumed porosity, and assumed flow rate, I can calculate the time for the water to traverse the bed.
+(ε*A_pb*L_pb)/Q_shot4.177834449522944 sIn practice, for a lot of chemical engineering mass transfer problems, accurate mass transfer coefficients and diffusivities are hard to come by. This is equally true for the espresso system. I am going to be using a literature value for the effective solid phase diffusion, but then estimating the remainder from correlations.
+# effective solid phase diffusivity
+# Cameron et al, "Systematically Improving Espresso," 11.
+𝒟ₛ = 6.25e-10u"m^2/s"
+
+# (stagnant) liquid diffusivity
+# Schwartzberg, “Leaching – Organic Materials,” 557.
+D = 5*𝒟ₛThe thin film mass transfer coefficient is typically estimated from the Sherwood number which is a function of the Reynolds number and Schmidt number
+# Reynolds number
+Re = v_s*(2b)/ν# Schmidt number
+Sc = ν/DThe Sherwood number can be estimated using the Wilson-Geankopolis correlation for packed bed flow
+# Wilson-Geankopolis correlation
+# Hottel et al, "Heat and Mass Transfer," 5-77.
+Sh = (1.09/ε)*∛(Re*Sc)Giving the thin film mass transfer coefficient
+h = Sh*D/(2b)0.0014874874803418145 m s^-1The axial diffusion can be calculated using the Edwards-Richardson correlation
+# Edwards-Richardson correlation
+# LeVan and Carta, "Adsoprtion and Ion Exchange," 16-22.
+γ₁ = 0.45 + 0.55*ε
+γ₂ = 0.5*(1 + 13γ₁*ε/(Re*Sc))^-1
+Pe = ( γ₁*ε/(Re*Sc) + γ₂ )^-1𝒟ₗ = v*(2b)/Pe4.623616336378663e-8 m^2 s^-1I am using literature values for the saturated concentration of solubles both in the bean and in the coffee, and calculating an equilibrium constant from that.
+# saturation concentrations
+# Cameron et al, "Systematically Improving Espresso," 11.
+q_sat = 118.0u"kg/m^3"
+c_sat = 212.4u"kg/m^3"
+K = q_sat/c_sat0.5555555555555556Looking forward a little bit, I know that I will be using multiple approaches to the packed bed model and keeping track of all of the model parameters can be tricky. Especially in a notebook where everything is in the global name space. Which is why I think it is prudent to define a PackedBed data structure to contain all of the model parameters.
struct PackedBed
+ q₀
+ K
+ 𝒟ₛ
+ 𝒟ₗ
+ h
+ ε
+ b
+ c₀
+ v
+end# initial concentration
+c₀ = 0.0u"kg/m^3"pb = PackedBed(q_sat, K, 𝒟ₛ, 𝒟ₗ, h, ε, b, c₀, v);A good first approach to solving the pde is to try simplifying the mass transfer problem by eliminating some of the diffusion terms. Making the following simplifications:
+The governing equations can be reduced to
+\[ { {\partial c} \over {\partial t} } = - v { {\partial c} \over {\partial z} } + \left({ 1 - \varepsilon } \over \varepsilon \right) a_s J_s \]
+\[ { {\partial q} \over {\partial t} } = - a_s J_s \]
+with
+\[ J_s = h \left( c_{s} - c \right) \]
+This is a dramatically simpler model, eliminating much of the real complexity of the mass transfer. However an effective mass transfer coefficient, h, can be fit from measured data that combines the solid diffusion and thin film mass transfer.6 Similarly an effective mass transfer coefficient can be calculated by addition of linear mass transfer resistances. Essentially this is shifting some of the complexity out of the governing equations and into the parameters. This is a fairly common model for packed beds and was first solved, for the equivalent heat transfer case, by Anzelius and independently by Schumann.7 What follows is a general sketch of a solution.
+6 See Moroney, “Analysing Extraction Uniformity from Porous Coffee Beds Using Mathematical Modelling and Computational Fluid Dynamics Approaches” for an example of this model being used for espresso extraction.
7 Anzelius, “Über Erwärmung Vermittels Durchströmender Medien”; Schumann, “Heat Transfer”.
8 Setting the pde in dimensionless form follows Bird, Stewart, and Lightfoot, Transport Phenomena pages 753-755
The first step is to transform this pde into dimensionless form8, first by introducing a dimensionless time \(\tau = \frac{h a_s}{K} \left( t - \frac{z}{v} \right)\). Which, when substituted into the equation for the solid phase, becomes
+\[ {{\partial q} \over {\partial \tau}} = K \left( c - c_{s} \right) \]
+Further introducing a dimensionless space \(\xi = \frac{h a_s}{m v} z\) where \(m = \left({ 1 - \varepsilon } \over \varepsilon \right)\) transforms the equation for the liquid phase into
+\[ {{\partial c} \over {\partial \xi}} = c_s - c \]
+By defining a dimensionless liquid phase concentration
+\[ u = {{c - \frac{q_0}{K}} \over {c_0 - \frac{q_0}{K}}} \]
+where q0 is the initial concentration of the solid phase and c0 is the concentration in the water at z=0. We can re-write the equation for the liquid phase as
+\[ {{\partial u} \over {\partial \xi}} = {{q - q_0} \over {K c_0 - q_0}} - u \]
+Letting
+\[ y = { {q - q_0} \over {K c_0 - q_0} } \]
+the final system of equations is then
+\[ { {\partial u} \over {\partial \xi} } = y - u \]
+\[ { {\partial y} \over {\partial \tau} } = u - y \]
+Which, at this point, is just something that you can look up in Carslaw and Jaeger.9 The solution follows directly from taking the Laplace transform of \({ {\partial y} \over {\partial \tau} }\), with respect to τ, which gives
+\[ sY = U - Y\]
+\[ Y = \frac{1}{s+1}U \]
+then taking the Laplace transform of \({ {\partial u} \over {\partial \xi} }\), with respect to τ gives
+\[ { {d U} \over {d \xi} } = Y - U = \frac{-s}{s+1}U \]
+which is a differential equation that can be easily solved using the initial condition u(0) = 1 or, in the Laplace domain, U(0) = 1/s
+\[ U = \frac{1}{s} \exp\left( \frac{-s}{s+1} \xi \right) \]
+Inverting this requires a little work, though not as much as it may seem. I am departing from Bird10 since I find their approach mystifying. It is clearly designed to reverse engineer a particular form of the answer as opposed to arriving at it naturally. The approach in Carslaw and Jaeger is more intuitive11 and is what I am following here.
+11 Carslaw and Jaeger, Conduction of Heat in Solids pages 393-394; and also Goldstein, “On the Mathematics of Exchange Processes in Fixed Columns i. Mathematical Solutions and Asymptotic Expansions” pages 153-158.
First, recognize that
+\[ \frac{1}{s} \exp\left( \frac{-s}{s+1} \xi \right) = \exp\left( -\xi \right) \frac{1}{s} \exp\left( \frac{1}{s+1} \xi \right) \]
+Then, looking at a table of Laplace transforms we find12
+12 With the caveat that you need a good table of Laplace transforms, most undergraduate textbooks have a very brief one. The tables in Carslaw and Jaeger are extensive and Perry’s is also a good reference.
\[ \mathscr{L}^{-1} \left\{ \frac{1}{s} \exp\left( \frac{1}{s} x \right) \right\} = I_0 \left( 2 \sqrt{xt} \right)\]
+where I0 is the modified Bessel function of the first kind. A basic property of Laplace transforms is that
+\[ \mathscr{L}^{-1} \left\{ F(s+a) \right\} = \exp(-at)f(t) \]
+from which it follows that
+\[ \mathscr{L}^{-1} \left\{ \frac{1}{s+1} \exp\left( \frac{1}{s+1} x \right) \right\} = \exp\left( -t \right) I_0 \left( 2 \sqrt{xt} \right)\]
+Another property of Laplace transforms is that
+\[ \mathscr{L}^{-1} \left\{ \frac{1}{s} F(s) \right\} = \int_0^t f\left( \lambda \right) d\lambda \]
+which gives
+\[ \mathscr{L}^{-1} \left\{ \frac{1}{s} \frac{1}{s+1} \exp\left( \frac{1}{s+1} x \right) \right\} = \int_0^t \exp\left( -\lambda \right) I_0 \left( 2 \sqrt{x \lambda} \right) d\lambda\]
+Which is laying the groundwork for the observation that since
+\[ \frac{1}{s} - \frac{1}{s+1} = \frac{1}{s}\frac{1}{s+1} \]
+then
+\[ \frac{1}{s} = \frac{1}{s+1} + \frac{1}{s}\frac{1}{s+1} \]
+and U can be rewritten as
+\[ U = \exp\left( -\xi \right) \left[ \frac{1}{s+1} \exp\left( \frac{1}{s+1} \xi \right) +\frac{1}{s} \frac{1}{s+1} \exp\left( \frac{1}{s+1} \xi \right) \right] \]
+then by taking the inverse Laplace transform
+\[ u = \exp\left( -\xi \right) \left[ \exp\left( - \tau \right) I_0 \left( 2 \sqrt{\tau \xi} \right) + \int_0^\tau \exp\left( -\lambda \right) I_0 \left( 2 \sqrt{\lambda \xi} \right) d\lambda \right] \]
+\[ u = \exp\left( -(\tau + \xi) \right) I_0 \left( 2 \sqrt{\tau \xi} \right) + \int_0^\tau \exp\left( -(\lambda + \xi) \right) I_0 \left( 2 \sqrt{\lambda \xi} \right) d\lambda \]
+This is the solution that Schumann13 arrives at via a different means, though it is not in the form one generally sees in the standard references. To get there, we must take advantage of some properties of the Anzelius J Function (named because it is the solution to this differential equation).14
+13 This is equation 27 in Schumann, “Heat Transfer” page 409.
\[ J\left( x, y \right) = 1 - \int_0^x \exp\left( -(\lambda + y) \right) I_0 \left( 2 \sqrt{\lambda y} \right) d\lambda \]
+\[ J\left( x, y \right) + J\left( y, x \right) = 1 + \exp\left( -(x+y) \right) I_0 \left( 2 \sqrt{ x y} \right) \]
+from which we can see that
+\[ u = \exp\left( -(\xi + \tau) \right) I_0 \left( 2 \sqrt{\xi \tau} \right) + 1 - J\left( \tau, \xi \right) = J\left( \xi, \tau \right) \]
+and finally
+\[ u = 1 - \int_0^\xi \exp\left( - (\tau + \lambda) \right) I_0 \left( 2 \sqrt{\tau \lambda} \right) d\lambda \]
+Which is the form typically given in references. I think it is important to pause here and comment that this answer is not the answer, it is an answer. Both the solution above from taking the inverse Laplace transform and this solution are valid and, in fact, both are used when evaluating the Anzelius J function. It just happens to be the case that the latter result is what one tends to see in the literature.
+At this point we can calculate the dimensionless space and time for a point at the exit of the espresso bed, and at a similar point in (dimensionless) time.
+z = L_pb
+
+m = ε/(1-ε)
+aᵥ = 3/b
+ξ = (h*aᵥ*z)/(m*v)
+
+# τ = ξ
+t = (K/(h*aᵥ))*ξ + z/v
+τ = (h*aᵥ/K)*(t - z/v)
+
+@show ξ; @show τ;ξ = 7437.232219350375
+τ = 7437.232219350374It is convenient to create an AnzeliusSolution struct that takes a PackedBed and a particular point in space and generates a datatype that allows us to go back and forth between the problem in dimensionless form and the problem in actual units.
struct AnzeliusSolution{F,Q1,Q2}
+ ξ::F
+ τ₁::Q1
+ τ₂::Q2
+ pb::PackedBed
+end
+
+function AnzeliusSolution(z, pb::PackedBed)
+ m = ε/(1-ε)
+ aᵥ = 3/pb.b
+ ξ = (pb.h*aᵥ*z)/(m*pb.v)
+ τ₁ = (pb.h*aᵥ/pb.K)
+ τ₂ = τ₁*(z/pb.v)
+
+ return AnzeliusSolution(ξ, τ₁, τ₂, pb)
+endanzelius = AnzeliusSolution(z, pb);Generally the Anzelius solution is given in terms of an integral of a Bessel function that is wildly impractical to numerically integrate directly as written. For an example, Bird15 gives this as the the solution:
+\[ u = 1 - \int_0^\xi \exp\left( - (\tau + \lambda) \right) J_0 \left( i \sqrt{4\tau \lambda} \right) d\lambda \]
+where J0 in this case is the Bessel function of the first kind (not the Anzelius J function). This is correct, however, attempting to use it as written will run aground on numerical difficulties at even moderately large values of τ. The first issue with this form of the answer is that it requires one to cast everything into complex values only to cast back into floats (the answer is a real number), but the most important issue is that the integrand is the product of an exponential that decays rapidly to zero and a Bessel function that blows up rapidly to infinity. For even moderate values of τ this leads to NaN errors of the type 0*Inf.
When I was first playing around with this I attempted to integrate it as is. After that clearly didn’t work, I looked into whether or not there are scaled versions of the Bessel function. I think this is a good practice that maybe isn’t taught well in school: often functions like Bessel functions or the Gamma function explode to large numbers that would overflow, thus leading to NaN errors, consequently libraries of special functions tend to have scaled or log versions. Bessels.jl has an exponentially scaled version of I0 that works perfectly for what I need, with the exponentially scaled version being
\[ I_{x,0}(z) = \exp(-z) I_0(z) \]
+By completing the square we can rewrite
+\[ u = 1 - \int_0^\xi \exp\left( - (\tau + \lambda) \right) I_0 \left( 2 \sqrt{\tau \lambda} \right) d\lambda \]
+as
+\[ u = 1 - \int_0^\xi \exp\left( - \left( \sqrt{\tau} - \sqrt{\lambda} \right)^2 \right) \exp\left(- 2 \sqrt{\tau \lambda} \right) I_0 \left( 2 \sqrt{\tau \lambda} \right) d\lambda \]
+\[ u = 1 - \int_0^\xi \exp\left( - \left( \sqrt{\tau} - \sqrt{\lambda} \right)^2 \right) I_{x,0} \left( 2 \sqrt{\tau \lambda} \right) d\lambda \]
+Below is a figure showing a plot of the integrand for a value of τ much smaller than our particular example, just for illustration. The first curve is the original version of the solution (shifted up for visibility), which begins to fail due to NaN errors part-way up the curve (where the red X is). The second curve uses the exponentially scaled modified Bessel function and does not have this issue. The larger the τ the earlier problems arrive and by the time we get to the value of τ being used for this example the integrand doesn’t evaluate to any positive value prior to turning into NaNs.
using Bessels:besselj0, besseli0x
+
+f_orig(λ, τ) = exp(-(τ+λ))*real(besselj0(im*√(complex(4τ*λ))))
+
+fₐ(λ, τ) = exp(-(√(τ)-√(λ))^2)*besseli0x(√(4τ*λ))Now that we have a version of the integrand that we can actually calculate, the obvious approach is to integrate using a standard package for numerical integration, such as QuadGK.jl. To make things a little easier, I have made the change of variables \(x = {\lambda \over \xi}\), thus changing the bounds of integration to \(x \in [0, 1]\)
+using QuadGK: quadgk_count
+
+integrand(x) = exp(-(√(τ)-√(ξ*x))^2)*besseli0x(√(4τ*ξ*x))
+
+∫, e, N = quadgk_count(integrand,0,1)
+
+u = 1 - ξ*∫
+
+@show u; @show e; @show N;u = 0.5016355470840097
+e = 1.0518776639256381e-13
+N = 165Because of my particular choice of τ the integral stops somewhere on the curve where it is appreciably positive. There is a potential trap here when using an integration routine with automatic step-sizes like Gauss-Kronold: if the bounds of integration extend well past the peak of this curve, it is possible for the algorithm to step over it entirely and return a value of 0, when the actual integral should be ~1.
+One way of dealing with this issue is to take advantage of the symmetry of the J function and use the following rule:16
+This ensures that the numerical integration is always being taken to the left of the peak of the integrand (where ξ = τ) and thus avoids the stepping over problem.
+using QuadGK: quadgk
+
+function J_quad(x,y)
+ if x ≈ 0
+ return 1.0, 0.0
+ elseif y ≈ 0
+ return exp(-x), 0.0
+ else
+ integrand(λ) = exp(-(√(y)-√(x*λ))^2)*besseli0x(√(4y*x*λ))
+ ∫, e = quadgk(integrand,0,1)
+ J = 1.0 - x*∫
+ return J, e
+ end
+end
+
+function c_quad(t, model::AnzeliusSolution)
+ # unpack some things, calculate model parameters
+ cₛ = model.pb.q₀/model.pb.K
+ c₀ = model.pb.c₀
+ τ = model.τ₁*t - model.τ₂
+ ξ = model.ξ
+
+ # use Gause-Kronold to integrate
+ # modified integral for τ < ξ from Lassey p. 631
+ if τ < 0 || ξ < 0
+ # outside the domain of the problem
+ J = 0.0
+ elseif ξ ≤ τ
+ J, e = J_quad(ξ,τ)
+ else # τ < ξ
+ J, e = J_quad(τ,ξ)
+ J = 1 + exp(-(√(τ)-√(ξ))^2)*besseli0x(√(4τ*ξ)) - J
+ end
+
+ # return back the concentration
+ c = cₛ + (c₀ - cₛ)*J
+ return c
+endA brief review of the literature around the Anzelius J function will reveal a multitude of series representations. For example, Goldstein17 gives the following
+\[ J(x,y) = 1 - \exp\left( - \left( \sqrt{x} - \sqrt{y} \right)^2 \right) \sum_{n=1}^{\infty} \left( x \over y \right)^{n \over 2} \exp \left( -2 \sqrt{xy} \right) \mathrm{I}_{n} \left( 2 \sqrt{xy} \right) \]
+Naïvely implementing this, without the use of any techniques like Richardson acceleration, ends up requiring a large number of iterations to approach the performance of direct integration by Gauss-Kronold. Since each iteration involves calculating exponentially scaled Bessel functions of higher and higher order, this doesn’t obviously lead to any improvement over direct numerical integration.
+# Naively, just adding them up
+using Bessels:besselix
+
+function J_series(x,y,N)
+ if x ≈ 0
+ return 1.0
+ elseif y ≈ 0
+ return exp(-x)
+ else
+ α = 2√(x*y)
+ η = √(x/y)
+ partial_sum = 0.0
+ for k in 1:N
+ partial_sum += besselix(k,α)*η^k
+ end
+ J = 1 - exp(-(√(x)-√(y))^2)*partial_sum
+ return J
+ end
+end
+
+N = 900
+u = J_series(ξ,τ,N)
+
+@show u; @show N;u = 0.5016355470840961
+N = 900An alternative approach from Bac̆lić et al.18 removes the need to calculate higher order Bessel functions and, though it also requires a large number of iterations, each iteration is a simpler calculation and thus the algorithm could be faster overall. If you were going to roll out the J function in production code it would be worthwhile bench marking this against numerical integration with QuadGK.jl.
+function bac̆lić_sub_A(α₋₁,β₋₁,α₀,β₀,d₁,z,ε,max_iter)
+ αₙ₋₂, βₙ₋₂ = α₋₁, β₋₁
+ αₙ₋₁, βₙ₋₁ = α₀, β₀
+ αₙ, βₙ = 0.0, 0.0
+ dₙ = d₁
+ for n in 1:max_iter
+ αₙ = dₙ + (n/z)*αₙ₋₁ + αₙ₋₂
+ βₙ = 1 + (n/z)*βₙ₋₁ + βₙ₋₂
+
+ if βₙ > 1/ε
+ return αₙ, βₙ, n
+ else
+ dₙ = dₙ*d₁
+ αₙ₋₂, βₙ₋₂ = αₙ₋₁, βₙ₋₁
+ αₙ₋₁, βₙ₋₁ = αₙ, βₙ
+ end
+ end
+ return αₙ, βₙ, max_iter
+endfunction J_bac̆lić(x,y,ε=1e-9,max_iter=10^6)
+ if x ≈ 0
+ return 1.0
+ elseif y ≈ 0
+ return exp(-x)
+ else
+ z = √(x*y)
+ α₋₁ = 0.0
+ β₋₁ = 0.0
+ β₀ = 0.5
+ if y < x
+ α₀ = 1.0
+ d₁ = √(y/x)
+ αₙ, βₙ, N = bac̆lić_sub_A(α₋₁,β₋₁,α₀,β₀,d₁,z,ε,max_iter)
+ J = (αₙ/(2*βₙ))*exp(-(√(y)-√(x))^2)
+ else
+ α₀ = 0.0
+ d₁ = √(x/y)
+ αₙ, βₙ, N = bac̆lić_sub_A(α₋₁,β₋₁,α₀,β₀,d₁,z,ε,max_iter)
+ J = 1.0 - (αₙ/(2*βₙ))*exp(-(√(y)-√(x))^2)
+ end
+ return J, ε, N
+ end
+endu, e, N = J_bac̆lić(τ,ξ)
+
+@show u; @show e; @show N;u = 0.5016355471003766
+e = 1.0e-9
+N = 698function c_bac̆lić(t, model::AnzeliusSolution)
+ # unpack some things, calculate model parameters
+ cₛ = model.pb.q₀/model.pb.K
+ c₀ = model.pb.c₀
+ τ = model.τ₁*t - model.τ₂
+ ξ = model.ξ
+
+ if τ < 0 || ξ < 0
+ u = 0.0
+ else
+ u, err, N = J_bac̆lić(ξ,τ)
+ end
+
+ c = cₛ + (c₀ - cₛ)*u
+ return c
+endThomas19 provides an asymptotic expansion of J which forms the basis for several approximations to the J function
+19 Thomas, “CHROMATOGRAPHY” page 171. Note: Thomas gives this in terms of φ where \(J(x,y) = 1 - \exp \left( -(x+y) \right)\phi(x,y)\)
\[ J(x,y) \approx 1 - \frac{1}{2}\mathrm{erfc} \left( \sqrt{y} - \sqrt{x} \right) + \exp \left( -(x+y) \right) { \sqrt[4]{x} \over { \sqrt[4]{y} + \sqrt[4]{x} } } I_0 \left( 2\sqrt{xy} \right) + \ldots\]
+Taking the first terms of the asymptotic expansion and the limit \(I_{x,0}(z) \to \frac{1}{\sqrt{2\pi z} }\) as z → ∞20
+\[ J(x,y) \approx \frac{1}{2}\mathrm{erfc} \left( \sqrt{x} - \sqrt{y} \right) + { \exp \left( - \left( \sqrt{x} - \sqrt{y} \right)^2 \right) \over { 2\sqrt{\pi} \left( \sqrt{y} + \sqrt[4]{xy} \right) } }\]
+using SpecialFunctions: erf, erfcfunction J_approx(x,y)
+ if x ≈ 0
+ return 1.0
+ elseif y ≈ 0
+ return exp(-x)
+ else
+ return 0.5*(erfc(√(x)-√(y)) + exp(-(√(x)-√(y))^2)/(√(π)*(√(y)+(x*y)^0.25)))
+ end
+end
+
+u = J_approx(ξ,τ)
+
+@show u;u = 0.5016355333390161function c_approx(t, model::AnzeliusSolution)
+ # unpack some things, calculate model parameters
+ cₛ = model.pb.q₀/model.pb.K
+ c₀ = model.pb.c₀
+ τ = model.τ₁*t - model.τ₂
+ ξ = model.ξ
+
+ # approximate integral
+ if τ < 0 || ξ < 0
+ u = 0.0
+ else
+ u = J_approx(ξ,τ)
+ end
+
+ # return back the concentration
+ c = cₛ + (c₀ - cₛ)*u
+ return c
+endRice21 goes even further and suggests that, for \(\sqrt{xy} \gt 60\)
+\[ J(x,y) \approx \frac{1}{2}\mathrm{erfc} \left( \sqrt{x} - \sqrt{y} \right) \]
+function J_rice(x,y)
+ if x ≈ 0
+ return 1.0
+ elseif y ≈ 0
+ return exp(-x)
+ else
+ return 0.5*erfc(√(x)-√(y))
+ end
+end
+
+u = J_rice(ξ,τ)
+
+@show u;u = 0.499999999999992function c_rice(t, model::AnzeliusSolution)
+ # unpack some things, calculate model parameters
+ cₛ = model.pb.q₀/model.pb.K
+ c₀ = model.pb.c₀
+ τ = model.τ₁*t - model.τ₂
+ ξ = model.ξ
+
+ # approximate integral
+ if τ < 0 || ξ < 0
+ u = 0.0
+ else
+ u = 0.5*erfc(√(ξ)-√(τ))
+ end
+
+ # return back the concentration
+ c = cₛ + (c₀ - cₛ)*u
+ return c
+endI don’t see any great reason to use anything other than direct numerical integration, so that is the default method I am going to set going forward.
+c(t,m::AnzeliusSolution) = c_quad(t,m)That said, for this particular case, the mass transfer across the thin film is so rapid that all of the approximations are close enough as to be indistinguishable. Indistinguishable to the naked eye when staring at a plot but, more importantly, experimentally indistinguishable.
+I wouldn’t take this to mean that the simple, single term, \(\mathrm{erfc}(\ldots)\) approximation will work for modelling an actual espresso shot, though it is certainly suggestive. This approach, neglecting the solid phase diffusion entirely and neglecting axial diffusion, has lead to a very sharp moving front that is physically unrealistic. What this model is telling us is that we should expect an espresso shot to start as fully and overly extracted coffee and, after some time, transition into essentially tap water in a fraction of a second. That is not my experience, qualitatively. What this shows is that we need to increase the complexity of the model.
+Rosen22 solved the problem for the case where solid diffusion is included, but axial diffusion is still neglected, in a similar manner as above with Laplace transforms. In this case actually solving the pde is more tedious and what follows is just a loose sketch. Starting with the pde
+\[ { {\partial c} \over {\partial t} } + v { {\partial c} \over {\partial z} } = \left({ 1 - \varepsilon } \over \varepsilon \right) a_s J_s \]
+\[ { {\partial q} \over {\partial t} } = \mathscr{D}_s \left( { {\partial^2 q} \over {\partial r^2} } + {2 \over r} { {\partial q} \over {\partial r} } \right) \]
+were
+\[ J_s = h \left( c_{s} - c \right) \]
+Rosen introduced \[ { {\partial \bar{q} } \over {\partial t} } = - a_s J_s \]
+where
+\[ \bar{q} \left( z,t \right) = \frac{3}{b^3} \int_0^b q \left( r, \xi, \tau \right) r^2 dr \]
+is the volumetric average concentration in a particle. This follows directly from a mass balance.
+We can put the liquid phase equation in dimensionless form by introducing a dimensionless time, \(\tau = { { \mathscr{D} a_s} \over b} \left( t - \frac{z}{v} \right)\), and a dimensionless z-coordinate, \(\xi = { { K D a_s} \over {b m v} } z\), where \(m = { \varepsilon \over \left( 1 - \varepsilon \right) }\) and, with the same dimensionless concentrations u and y as defined above for the Anzelius solution, we have
+\[ { { \partial u} \over {\partial \xi} } = - { { \partial \bar{y} } \over {\partial \tau} } = \frac{1}{\nu} \left( y_s - u \right)\]
+where \(\nu = \frac{\mathscr{D} K}{b h}\) and ys is the dimensionless solid phase concentration at the surface of a solid particle, i.e. at r = b.
+If we further introduce a dimensionless particle radius \(\vartheta = \frac{r}{b}\) we can rewrite the solid phase diffusion equation in dimensionless form
+\[ { {\partial y} \over {\partial \tau} } = \frac{1}{3} \left( { {\partial^2 y} \over {\partial \vartheta^2} } + {2 \over \vartheta} { {\partial y} \over {\partial \vartheta} } \right) \]
+where 1/3 is 1/(asb). The solution to the solid phase diffusion problem is available in Carslaw and Jaeger23 and, with initial condition y=0 when τ=0, gives
+\[ y \left( \vartheta, \xi, \tau \right) = \frac{2}{3} \sum_{n=1}^{\infty} \left(-1 \right)^{n+1} n\pi { {\sin \left( n \pi \vartheta \right) } \over \vartheta} \int_0^{\tau} y_s \left( \xi, \lambda \right) \exp \left( -\frac{n^2 \pi^2}{3} \left( \tau - \lambda \right) \right) d\lambda\]
+This can be integrated over \(\vartheta\) to get the volume average (dimensionless) concentration
+\[ \bar{y} = 3 \int_0^1 y \vartheta^2 d \vartheta \]
+\[ \bar{y} = 2 \sum_{n=1}^{\infty} \int_0^{\tau} y_s \exp \left( -\frac{n^2 \pi^2}{3} \left( \tau - \lambda \right) \right) d\lambda \]
+since
+\[ \int_0^1 n\pi \sin \left( n \pi \vartheta \right) \vartheta d\vartheta = \left(-1 \right)^{n+1} \]
+Taking the derivative with respect to τ gives (by integration by parts)
+\[ { {\partial \bar{y} } \over {\partial \tau} } = 2 \sum_{n=1}^{\infty} \int_0^{\tau} { { \partial y_s } \over {\partial \lambda} } \exp \left( -\frac{n^2 \pi^2}{3} \left( \tau - \lambda \right) \right) d\lambda \]
+At this point we can eliminate y and ys and have an expression entirely in terms of u. First we use the expression for the liquid phase concentration to obtain an expression for ys
+\[ { { \partial u} \over {\partial \xi} } = \frac{1}{\nu} \left( y_s - u \right)\]
+\[ y_s = u + \nu { { \partial u} \over {\partial \xi} } \]
+Thus
+\[ { {\partial \bar{y} } \over {\partial \tau} } = 2 \sum_{n=1}^{\infty} \int_0^{\tau} \left[ { {\partial u} \over {\partial \lambda} } + \nu { { \partial^2 u} \over {\partial \lambda \partial \xi} } \right] \exp \left( -\frac{n^2 \pi^2}{3} \left( \tau - \lambda \right) \right) d\lambda \]
+and since \({ { \partial u} \over {\partial \xi} } = - { { \partial \bar{y} } \over {\partial \tau} }\)
+\[ { {\partial u } \over {\partial \xi} } = -2 \sum_{n=1}^{\infty} \int_0^{\tau} \left[ { {\partial u} \over {\partial \lambda} } + \nu { { \partial^2 u} \over {\partial \lambda \partial \xi} } \right] \exp \left( -\frac{n^2 \pi^2}{3} \left( \tau - \lambda \right) \right) d\lambda \]
+Rosen solves this by taking the Laplace transform, with respect to τ, with the following relations:
+\[ \mathscr{L} \left\{ \int_0^\tau f(\lambda) g(\tau-\lambda) d\lambda \right\} = F(s) G(s) \]
+\[ \mathscr{L} \left\{ { {\partial u} \over {\partial \tau} } + \nu { { \partial^2 u} \over {\partial \tau \partial \xi} } \right\} = s U + \nu s { {d U} \over {d\xi} }\]
+\[ \mathscr{L} \left\{ \exp \left( -\frac{n^2 \pi^2}{3} \tau \right) \right\} = { 1 \over {s + \frac{n^2 \pi^2}{3} } }\]
+arriving at
+\[ { {d U} \over {d\xi} } = -2 \left( s U + \nu s { {d U} \over {d\xi} } \right) \sum_{n=1}^{\infty} { s \over {s + \frac{n^2 \pi^2}{3} } } \]
+Letting
+\[ Y_D(s) = 2 \sum_{n=1}^{\infty} { s \over {s + \frac{n^2 \pi^2}{3} } } \]
+then
+\[ { {d U} \over {d\xi} } = - { Y_D \over { 1 + \nu Y_D } } U \]
+and, solving this ode with initial condition u=1, U=1/s, gives
+\[ U = \frac{1}{s} \exp \left( - { Y_D \over { 1 + \nu Y_D } } \xi \right) \]
+The final solution follows from taking the inverse Laplace transform, by way of the contour integral
+\[ u \left( \xi, \tau \right) = \frac{1}{2\pi i} \int_{\alpha - i\infty}^{\alpha + i\infty} \frac{1}{s} \exp \left( s \tau - { Y_D \over { 1 + \nu Y_D } } \xi \right) ds \]
+A major component of the integration involves first defining YD in terms of trigonometric functions. The details are tedious, but the main result is
+\[ Y_T \left( i \beta \right) = { Y_D \over { 1 + \nu Y_D } } = H_1 \left( \lambda, \nu \right) + i H_2 \left( \lambda, \nu \right) \]
+with \(\lambda = \sqrt{ \frac{3}{2} \beta}\) and
+\[ H_1 \left( \lambda, \nu \right) = { { H_{D1} + \nu \left( H_{D1}^2 + H_{D2}^2 \right) } \over { \left( 1 + \nu H_{D1} \right)^2 + \left( \nu H_{D2} \right)^2 } }\]
+\[ H_2 \left( \lambda, \nu \right) = { H_{D2} \over { \left( 1 + \nu H_{D1} \right)^2 + \left( \nu H_{D2} \right)^2 } }\]
+and
+\[ H_{D1} = \lambda { {\sinh 2\lambda + \sin 2\lambda} \over { \cosh 2\lambda - \cos 2\lambda } } - 1\]
+\[ H_{D2} = \lambda { {\sinh 2\lambda - \sin 2\lambda} \over { \cosh 2\lambda - \cos 2\lambda } } \]
+Which allows Rosen to write the integral in terms of these harmonic functions24
+24 For details of the integration see Rosen, “Kinetics of a Fixed Bed System for Solid Diffusion into Spherical Particles” pages 390-391
\[ u \left( \xi, \tau \right) = \frac{1}{2} + \frac{2}{\pi} \int_0^\infty { { \exp \left( -\xi H_1 \left( \lambda, \nu \right) \right) \sin \left( \frac{2}{3} \tau \lambda^2 - \xi H_2 \left( \lambda, \nu \right) \right) } \over \lambda } d\lambda \]
+At this point we can calculate the dimensionless space and time for a point at the exit of the espresso bed, and say at a similar point in (dimensionless) time, and proceed with calculating the integral to find the concentration.
+m = ε/(1-ε)
+aᵥ = 3/b
+
+ξ = (K*𝒟ₛ*aᵥ)/(b*m*v)*z
+
+τ = (𝒟ₛ*aᵥ/b)*(t-z/v)
+ν = (𝒟ₛ*K)/(b*h)
+
+@show ξ; @show τ; @show ν;ξ = 144.6719346388569
+τ = 144.6719346388569
+ν = 0.019452389057107278Unlike with the Anzelius case, I am not going to define a struct for the Rosen solution yet, first I am going to work through some details on how to perform the integral.
+The integral extends to infinity and so the performance of the harmonic functions at very large λ is important. The hyperbolic trig functions will blow up to infinity and, in the naïve implementation, lead to NaN errors as the numerator and denominator overflow. Rosen provides limiting behaviour, and a pre-calculated table of values, which can be used with the integrand switching from the default definition of the harmonic functions to the limiting behaviour after some λ threshold. An alternative, which I employ below, is to rewrite the hyperbolic trig functions in terms of exponentials, cancelling a exp(+4λ) from the numerator and denominator, to generate a form that handles large values of λ more gracefully.
\[ { {\sinh 2\lambda + \sin 2\lambda } \over {\cosh 2\lambda - \cos 2\lambda} } = { { 1 - \exp(-2\lambda) \left( \exp(-2\lambda) + 2 \sin 2\lambda \right) } \over {1 + \exp(-2\lambda) \left( \exp(-2\lambda) - 2 \cos 2\lambda \right) } }\]
+function HD1(λ)
+ if λ ≤ eps(0.0)
+ return 0.0
+ else
+ # λ*((sinh(2λ) + sin(2λ))/(cosh(2λ) - cos(2λ))) - 1
+ return λ*( (1 - exp(-4λ) + 2*exp(-2λ)*sin(2λ)) / (1 + exp(-4λ) - 2*exp(-2λ)*cos(2λ))) -1
+ end
+end
+
+function HD2(λ)
+ if λ ≤ eps(0.0)
+ return 0.0
+ else
+ # λ*(sinh(2λ) - sin(2λ))/(cosh(2λ) - cos(2λ))
+ return λ*( (1 - exp(-4λ) - 2*exp(-2λ)*sin(2λ)) / (1 + exp(-4λ) - 2*exp(-2λ)*cos(2λ)))
+ end
+endThe integrand can be divided into a decay component, f, that is independent of τ, and an oscillatory component, K, that is a function of τ.
+\[ f \left( \lambda; \xi, \nu \right) = { { \exp \left( -\xi H_1 \left( \lambda, \nu \right) \right) } \over \lambda }\]
+\[ \mathscr{K} \left( \lambda, \tau; \xi, \nu \right) = \sin \left( \frac{2}{3} \tau \lambda^2 - \xi H_2 \left( \lambda, \nu \right) \right) \]
+This clean division also presents an opportunity to pre-calculate the integral to an extent. With a predefined set of points { λi } then f can be entirely pre-calculated. Using prosthaphaeresis you could go further and pre-calculate parts of \(\mathscr{K}\), for some incremental improvements, though I leave that as an exercise for a more motivated individual.
+It is worth looking at the case where τ gets large as this becomes a highly oscillating integral and can be tricky to evaluate – requiring a very large number of steps for conventional numerical integration techniques like Gauss-Kronold. In this example that starts to happen near the end of the extraction, but if the bed were, say, twice as deep then much of the extraction curve would be in this regime.
+function fᵣ(λ; ξ, ν)
+ hd1, hd2 = HD1(λ), HD2(λ)
+ H1 = (hd1 + ν*(hd1^2 + hd2^2))/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ return exp(-ξ*H1)/λ
+end
+
+function 𝒦ᵣ(λ, τ; ξ, ν)
+ hd1, hd2 = HD1(λ), HD2(λ)
+ H2 = hd2/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ return sin((2/3)*τ*λ^2 - ξ*H2)
+endBy introducing the change of variables25 β = λ2, the integrand is “compressed” along β and we can take advantage of the exponential decay to truncate the integration.
+function fᵣ₂(β; ξ, ν)
+ λ = √(β)
+ hd1, hd2 = HD1(λ), HD2(λ)
+ H1 = (hd1 + ν*(hd1^2 + hd2^2))/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ return exp(-ξ*H1)/β
+end
+
+function 𝒦ᵣ₂(β, τ; ξ, ν)
+ λ = √(β)
+ hd1, hd2 = HD1(λ), HD2(λ)
+ H2 = hd2/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ return sin((2/3)*τ*β - ξ*H2)
+endQuadGK.jl can compute the improper integral directly, by making the substitution λ = t/(1-t).
+using QuadGK: quadgk_count
+
+I₁, err₁, N₁ = quadgk_count(λ -> fᵣ(λ; ξ=ξ, ν=ν)*𝒦ᵣ(λ, τ; ξ=ξ, ν=ν), 0, Inf)
+
+@show I₁; @show err₁; @show N₁;I₁ = 0.011703238397164204
+err₁ = 1.0292584595556625e-10
+N₁ = 195By making the substitution β = λ2 and truncating the integral to the range [0,2] we can achieve similar precision, with almost half as many steps.
+I_2, err_2, N_2 = quadgk_count( β -> fᵣ₂(β; ξ=ξ, ν=ν)*𝒦ᵣ₂(β, τ; ξ=ξ, ν=ν), 0, 2)
+
+@show I_2/2; @show err_2; @show N_2;I_2 / 2 = 0.01170323839564812
+err_2 = 2.183245425172356e-10
+N_2 = 105I have mentioned a few times that highly oscillating integrals can be tricky to evaluate. Gaussian quadrature will, in general, work but it will require a large number of steps. An alternative is to use Levin colocation, an example implementation is given below using ApproxFun.jl.
+Given the integral
+\[ \int_a^b \mathbf{f}(x) \cdot \mathbf{K}(x) dx \]
+if we suppose there is a function \(\mathbf{F}\) such that
+\[ \frac{d}{dx} \mathbf{F}(x) \cdot \mathbf{K}(x) = \mathbf{f}(x) \cdot \mathbf{K}(x) \]
+Then we can eliminate the integral, using the fundamental theorem of calculus
+\[ \int_a^b \mathbf{f}(x) \cdot \mathbf{K}(x) dx = \int_a^b \frac{d}{dx} \mathbf{F}(x) \cdot \mathbf{K}(x) dx = \mathbf{F}(b) \cdot \mathbf{K}(b) - \mathbf{F}(a) \cdot \mathbf{K}(a)\]
+The problem is then one of finding the function \(\mathbf{F}\).
+If we choose \(\mathbf{K}(x)\) such that \(\frac{d}{dx} \mathbf{K}(x) = \mathbf{A} \mathbf{K}(x)\), then
+\[ \frac{d}{dx} \left( \mathbf{F}(x) \cdot \mathbf{K}(x) \right) = \mathbf{F}^{\prime}(x) \cdot \mathbf{K}(x) + \mathbf{F}(x) \cdot \mathbf{A} \mathbf{K}(x) \]
+\[ \mathbf{F}^{\prime}(x) \cdot \mathbf{K}(x) + \mathbf{F}(x) \cdot \mathbf{A} \mathbf{K}(x) = \mathbf{f}(x) \cdot \mathbf{K}(x) \]
+Eliminating K(x) gives
+\[ \mathbf{F}^{\prime}(x) + \mathbf{A}^{T} \mathbf{F}(x) = \mathbf{f}(x) \]
+Solving this ode then gives the final solution.
+In this case I set K(x) to
+\[ \mathbf{K}(x) = \begin{pmatrix} \sin(h(x) \\ \cos(h(x)) \end{pmatrix} \]
+where h(x) = (2/3)τx2 - ξH2(λ), and f(x) is
+\[ \mathbf{f}(x) = \begin{pmatrix} f(x) \\ 0 \end{pmatrix} \]
+and the ode is solved for F in terms of Chebyshev polynomials.
+using ApproxFun:Interval, Fun, Derivative, Evaluation, \, I
+using LinearAlgebra: ⋅
+
+function levin(ξ, τ, ν, a, b)
+ d = Interval(a,b)
+ λ = Fun(d)
+ D = Derivative(d)
+ E = Evaluation(a)
+
+ HD1 = λ*(sinh(2λ) + sin(2λ))/(cosh(2λ) - cos(2λ)) - 1
+ HD2 = λ*(sinh(2λ) - sin(2λ))/(cosh(2λ) - cos(2λ))
+
+ H1 = (HD1 + ν*(HD1^2 + HD2^2))/((1 + ν*HD1)^2 + (ν*HD2)^2)
+ H2 = HD2/((1 + ν*HD1)^2 + (ν*HD2)^2)
+
+ h = (2/3)*τ*λ^2 - ξ*H2
+ h′ = D*h
+ w⃗ = [ sin(h); cos(h) ]
+
+ f = exp(-ξ*H1)/λ
+ f⃗ = [ 0; 0; f; 0 ]
+
+ L = [ E 0;
+ 0 E;
+ D -h′*I;
+ h′*I D ]
+
+ F = L\f⃗
+
+ return F(b)⋅w⃗(b) - F(a)⋅w⃗(a)
+endlevin(ξ, τ, ν, 0.0001, 2)0.011703248012960965This works well enough, though there is a complication in that there is a singularity at x=0, it is also rather slow.
+If the system of interest was consistently at large values of τ, where it is a highly oscillating integral throughout the main part of the problem domain, it would be worth looking at techniques to eliminate the singularity and speed it up. I include it here mostly for completeness. It is by delightful coincidence alone that I can get by solving this particular problem using more conventional numerical integration techniques.
+As I mentioned above, by splitting the integral into a function f that depends only on space and a function K that is a function of time and space, we can pre-calculate all of the space dependent components and write the integral as a weighted sum.
+\[ \int_a^b f \left(x; p\right) \mathcal{K} \left(x, t; p\right) dx \approx \sum_i^{N} w_i \mathcal{K}\left(x_i, t\right)\]
+The obvious way to do this is to use QuadGK.jl to take the weight function f and generate points that way. For example:
+pts, wts = gauss( x -> fᵣ₂(x; ξ=ξ, ν=ν), 20, 0, 2);I could not get this to work reliably, it would routinely run aground on DomainErrors close to the singularity at x=0. When I did get it to work it took a very long time to generate points, like leave my desk and go make coffee and maybe it will be done when I get back long time. I think if you really wanted to invest the time, and evaluating this integral was going to be in production code, it would be worth investigating a better quadrature rule since, when it does work, it allows you to use significantly fewer points in each integration.
The alternative, which works well enough for my purposes, is to use the gauss function to generate a set of points and weights in the truncated range \(\beta \in [0,2]\) and then pre-calculate the values of f over those points. The final integral is then the weighted sum. This involves calculating far more points for any given integral, but it is much faster than either Levin colocation or trying to have QuadGK generate the weights.
using QuadGK: gauss
+
+pts, wts = gauss(N₁, 0, 2);
+
+wts = wts .* fᵣ₂.(pts; ξ=ξ, ν=ν);
+
+I_gauss = sum( wts .* 𝒦ᵣ₂.(pts, τ; ξ=ξ, ν=ν) )/20.011703238395545075This can be packaged neatly into an IntegralTransform struct that, when constructed, generates the set of points and appropriate weights such that it only the kernel function actually needs to be evaluated for any given time.
struct IntegralTransform{T}
+ a::T
+ b::T
+ params::NamedTuple
+ numpts::Integer
+ pts::Vector{T}
+ wts::Vector{T}
+ kern::Function
+end
+
+function IntegralTransform(params, fun, kern; a=0.0, b=2.0, numpts=350)
+ pts, wts = gauss(numpts, a, b)
+ wts = wts .* fun.(pts; params...)
+ return IntegralTransform(a, b, params, numpts, pts, wts, kern)
+end
+
+function integrate(t, it::IntegralTransform)
+ return sum( it.wts .* it.kern.(it.pts, t; it.params...) )
+endOne could go further here: pre-calculating H1 and H2 as they only depend on ν and λ, splitting K into parts by prosthaphaeresis26 and pre-calculating the parts that only depend on ξ and λ. The current performance is more than good enough for me, but I think it worth highlighting that there are many opportunities for improvement.
+26 I love this word.
At this point I am finally ready to circle back and create my RosenSolution struct, one that includes the pre-calculated IntegralTransform for the particular location in the bed.
struct RosenSolution{Q1,Q2,T}
+ τ₁::Q1
+ τ₂::Q2
+ pb::PackedBed
+ it::IntegralTransform{T}
+end
+
+function RosenSolution(z, pb::PackedBed; fun=fᵣ₂, kern=𝒦ᵣ₂, a=0.0, b=2.0, numpts=200)
+ m = pb.ε/(1-pb.ε)
+ aᵥ = 3/pb.b
+ ξ = (pb.K*pb.𝒟ₛ*aᵥ*z)/(m*pb.v*pb.b)
+ ν = (pb.𝒟ₛ*pb.K)/(pb.b*pb.h)
+ τ₁ = pb.𝒟ₛ*aᵥ/pb.b
+ τ₂ = τ₁*(z/pb.v)
+
+ p = (ξ=ξ, ν=ν)
+ it = IntegralTransform(p, fun, kern; a=a, b=b, numpts=numpts)
+
+ return RosenSolution(τ₁, τ₂, pb, it)
+endThe concentration can then be obtained by calling the integrate function with the integral transform.
function c(t, model::RosenSolution)
+ # unpack some things
+ cₛ = model.pb.q₀/model.pb.K
+ c₀ = model.pb.c₀
+
+ # compute the integral
+ τ = model.τ₁*t - model.τ₂
+ I = integrate(τ, model.it)
+
+ # return back the concentration
+ u = 0.5 + I/π
+ c = cₛ + (c₀ - cₛ)*u
+ return c
+endrosen = RosenSolution(z, pb; a=0.0, b=2.0, numpts=200);Rosen27 provides an asymptotic approximation for cases where ξ is large
+\[ u = \frac{1}{2} \left[ 1 + \mathrm{erf} \left( { { \frac{\tau}{\xi} - 1} \over { 2 \sqrt{ {1 + 5\nu} \over {5 \xi} } } } \right) \right] \]
+Which is decidedly simpler to calculate.
+function c_approx(t, model::RosenSolution)
+ # unpack some things
+ cₛ = model.pb.q₀/model.pb.K
+ c₀ = model.pb.c₀
+
+ # compute the integral
+ τ = model.τ₁*t - model.τ₂
+ u = 0.5*(1 + erf( ( (τ/ξ) - 1 ) / ( 2*√((1+5ν)/(5ξ)) ) ) )
+
+ # return back the concentration
+ c = cₛ + (c₀ - cₛ)*u
+ return c
+endI briefly mentioned, above, an effective mass transfer coefficient can be derived for the Anzelius solution, one that accounts for the solid phase diffusion. This can be calculated rather simply from the linear resistance model28
+\[ \frac{1}{h_{eff} } = \frac{1}{(1-\varepsilon) h} + \frac{b}{5 K \mathscr{D}_s} \]
+Adapting the AnzeliusSolution to use a generic function to calculate the effective mass transfer coefficient allows us to reuse everything from the Anzelius case.
function AnzeliusSolution(z, h_fun, pb::PackedBed)
+ m = pb.ε/(1-pb.ε)
+ aᵥ = 3/pb.b
+ h = h_fun(pb)
+ ξ = (h*aᵥ*z)/(m*pb.v)
+ τ₁ = (h*aᵥ/pb.K)
+ τ₂ = τ₁*(z/pb.v)
+
+ return AnzeliusSolution(ξ, τ₁, τ₂, pb)
+end
+
+h_eff(pb) = 1/( 1/((1-pb.ε)*pb.h) + pb.b/(5*pb.K*pb.𝒟ₛ) )The Rosen solution is a significant departure from the pure Anzelius solution, i.e. neglecting solid diffusion, showing that for this problem the rate of solid phase diffusion is quite important. In this case ξ is large enough that the asymptotic approximation to Rosen’s integral is also a very good model and, with an appropriate effective mass transfer coefficient, the Anzelius solution also works well.
+Rasmuson and Neretnieks29 provide an exact solution for the case where axial diffusion is included. This is the original pde derived at the beginning. Their solution follows essentially the same steps as Rosen, with the main difference that the ode in the Laplace domain is second order, due to the inclusion of the \(\frac{\partial^2 c}{\partial z^2}\) term. The original paper has an detailed derivation in the appendix, if you are interested. In practice, this amounts to a relatively minor modification on what we have already put together for the Rosen solution.
+First we define the decay function, f, and kernel, K, using the same harmonic functions as Rosen.
+function f_rasmuson(λ; ν, δ, R, Pe)
+ hd1, hd2 = HD1(λ), HD2(λ)
+ H1 = (hd1 + ν*(hd1^2 + hd2^2))/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ H2 = hd2/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ a = Pe*(0.25*Pe + δ*H1)
+ b = δ*Pe*((2/3)*λ^2/R + H2)
+ return exp(0.5*Pe - √(0.5*(√(a^2 + b^2) + a)))/λ
+end
+
+function 𝒦_rasmuson(λ, y; ν, δ, R, Pe)
+ hd1, hd2 = HD1(λ), HD2(λ)
+ H1 = (hd1 + ν*(hd1^2 + hd2^2))/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ H2 = hd2/((1 + ν*hd1)^2 + (ν*hd2)^2)
+ a = Pe*(0.25*Pe + δ*H1)
+ b = δ*Pe*((2/3)*λ^2/R + H2)
+ return sin(y*λ^2 - √(0.5*(√(a^2 + b^2) - a)))
+endRasmuson and Neretnieks parameterize things slightly differently, and add some extra dimensionless groups due to the \(\mathscr{D}_L\), but the result a similar sort of integral problem as Rosen, namely integrating a highly oscillating integral that decays rapidly.
+γ = 3*𝒟ₛ*K/b^2
+δ = γ*z/(m*v)
+ν = γ*b/(3h)
+σ = 2*𝒟ₛ/b^2
+
+R = K/m
+Pe = (z*v)/𝒟ₗ
+y = σ*tThus it can be represented using the IntegralTransform type previously created.
p = (ν=ν, δ=δ, R=R, Pe=Pe)
+
+it = IntegralTransform(p, f_rasmuson, 𝒦_rasmuson; a=0.0, b=2.0, numpts=200);integrate(y, it)0.011984085774006418struct RasmusonSolution{Q,T}
+ σ::Q
+ pb::PackedBed
+ it::IntegralTransform{T}
+end
+
+function RasmusonSolution(z, pb::PackedBed; fun=f_rasmuson, kern=𝒦_rasmuson, a=0.0, b=2.0, numpts=350)
+ m = pb.ε/(1-pb.ε)
+ γ = 3*pb.𝒟ₛ*pb.K/pb.b^2
+ δ = γ*z/(m*pb.v)
+ ν = γ*pb.b/(3*pb.h)
+ σ = 2*pb.𝒟ₛ/pb.b^2
+
+ R = pb.K/m
+ Pe = (z*pb.v)/pb.𝒟ₗ
+
+ p = (ν=ν, δ=δ, R=R, Pe=Pe)
+ it = IntegralTransform(p, fun, kern; a=a, b=b, numpts=numpts)
+
+ return RasmusonSolution(σ, pb, it)
+endrasmuson = RasmusonSolution(z,pb);function c(t, model::RasmusonSolution)
+ # unpack some things
+ cₛ = model.pb.q₀/model.pb.K
+ c₀ = model.pb.c₀
+
+ # compute the integral
+ y = model.σ*t
+ I = integrate(y, model.it)
+
+ # return back the concentration
+ u = 0.5 + 2I/π
+ c = cₛ + (c₀ - cₛ)*u
+ return c
+endGoing from Rosen’s solution to Rasmuson’s solution is a less dramatic change than from Anzelius, but it is clear that axial dispersion is an important effect in this case. I haven’t shown it, since I think it should be obvious at this point, but one could generate asymptotic relations for Rasmuson, and also find effective mass transfer coefficients, h, that would bring both the Rosen and Anzelius solutions in line with the Rasmuson solution. I leave that as an exercise for the reader (hint: it is just linear mass transfer resistances).
+The more direct approach, when faced with a pde, is to integrate it by finite differences or Method of Lines. This allows one to use whatever kinetics and initial conditions one wants. The above cases are all limited by linear extraction and the initial conditions that the bed is at equilibrium. The major downside is that, for problems like this with a rather sharp moving front, the discretization needs to be very tight or another method, like moving finite element, needs to be used. Thus making the actual run time rather slow.
+The first step is to put the pde in dimensionless form, by introducing the following variables
+\[ \xi = \frac{z}{L} \]
+\[ \vartheta = \frac{r}{b} \]
+\[ \tau = \frac{t}{t_{shot} } \]
+\[ u = \frac{c}{c_{sat} }\]
+\[ y = \frac{q}{q_{0} } \]
+we can write the pde for the liquid phase concentration as
+\[ { {\partial u} \over {\partial \tau} } = { { t_{shot} \mathscr{D}_L } \over L^2 } { {\partial^2 u} \over {\partial \xi^2} } - { {t_{shot} v} \over L }{ {\partial u} \over {\partial \xi} } - { {1 - \varepsilon} \over \varepsilon } h a_s t_{shot} \left( u - y \right)\]
+and the pde for the solid phase concentration as
+\[ { {\partial y} \over {\partial \tau} } = { {t_{shot} \mathscr{D}_s} \over b^2 } \left( { {\partial^2 y} \over {\partial \vartheta^2} } + \frac{2}{\vartheta} { {\partial y} \over {\partial \vartheta} } \right) \]
+with
+\[ \left. { {\partial y} \over {\partial \tau} } \right\vert_{\vartheta=1} = { {h a_s t_{shot} } \over K} \left( u - y \right) \]
+These equations can be discretized in both spatial dimensions ξ and \(\vartheta\), turning them into an ode in τ.
+ +
+In general the bed can be divided into n cells with each cell transferring fluid to the cell below by advection and exchanging mass with the solid phase through the thin film approximation. The solid phase would then be divided into m cells per cell of the column making the overall ode an n×(m+1) vector of cells.
+As an example of the how tight the discretization needs to be, I have implemented the simple Anzelius case using an effective mass transfer coefficient. This is equivalent to the pde for the Rosen model, but with the solid phase mass transfer incorporated into the mass transfer coefficient, making the problem simpler to simulate: in this case m=1.
+I divide the bed into n cells with the first n elements in the vector u the liquid phase concentrations and the next n elements the average solid phase concentrations. The spatial derivatives are replaced with their discrete equivalents.
+using SparseArrays
+
+h_e = h_eff(pb)
+
+function parameters(n)
+ v_dm = v*t_shot/L_pb
+ h_dm = h_e*(3/b)*t_shot
+ dξ=1/(n-1)
+
+ # initial conditions
+ u0 = ones(Float64,2n)
+
+ M = spzeros(Float64,2n,2n)
+ # Liquid phase
+ # start of column, with the boundary condition that u[0]=0
+ # du[1] = -v/2dξ*(u[2] - u[0]) - h/m*(u[1] - u[n+1])
+ M[1,1] = -h_dm/m
+ M[1,2] = -v_dm/2dξ
+ M[1,1+n] = h_dm/m
+
+ # middle column
+ for i in 2:n-1
+ # du[i] = -v/2dξ*(u[i+1] - u[i-1]) - h/m*(u[i] - u[n+i])
+ M[i,i-1] = v_dm/2dξ
+ M[i,i] = -h_dm/m
+ M[i,i+1] = -v_dm/2dξ
+ M[i,i+n] = h_dm/m
+ end
+
+ # end of column
+ # du[n] = -v*(u[n]-u[n-1])/dξ - h/m*(u[n] - u[2n])
+ M[n,n-1] = v_dm/dξ
+ M[n,n] = -v_dm/dξ - h_dm/m
+ M[n,2n] = h_dm/m
+
+ # Solid phase
+ for i in n+1:2n
+ # du[i] = h/K*(u[i-n] - u[i]
+ M[i,i-n] = h_dm/K
+ M[i,i] = -h_dm/K
+ end
+
+ return u0, (0.0, 1.0), M
+endThe ode for this system is linear and is simply
+\[ { {d \mathbf{u} } \over {d \tau} } = \mathbf{M} \mathbf{u} \]
+function rhs!(du,u,M,t)
+ du .= M*u
+endWhich could presumably be solved by eigendecomposition, but more generally this would be solved using a standard ode solver.
+using OrdinaryDiffEq
+import Static
+
+sol = solve(ODEProblem(rhs!,parameters(10)...), Tsit5(thread=Static.True()))
+
+sol.retcodeReturnCode.Success = 1The liquid concentration at the exit is then extracted from the vector solution.
+# Pull out the concentration at the exit
+function c(t,sol::ODESolution)
+ n = length(sol.u[1])÷2
+ τ = t/t_shot
+ u = sol(τ)
+ return u[n]*c_sat
+endBelow is a figure showing a series of runs for increasing n. At low values of n the solution looks reasonable, but with much more diffusion than is actually warranted given the mass transfer coefficient. This is a common feature of Method of Lines when applied to pdes of this type and can, if one is not careful, lead to under-estimates of the actual effective diffusion (since much of the diffusion seen in the results is coming from the numerical method). As n increases, a spurious oscillatory behaviour appears at the end of the extraction and damping this requires increasing n > 250.
+Since I am ultimately modeling the same pde as was solved, exactly, by Anzelius I can plot the exact solution, showing that n must be quite large, >500, to start to align with the correct answer. Were we to have used the full pde, with n=m=500, this would have required a 250,500 element state vector. This approach becomes severely computationally intensive rather quickly. That said, this is mostly an issue when the moving front is very sharp.
+This can be alleviated by using a different discretization technique, such as moving finite element but, personally, there is a point where solving the pde gets complicated enough that it’s easier to just use a multiphysics program like comsol than to try implementing it yourself.
+So far I have reviewed the “conventional” approach to packed bed mass transfer, examining the solutions that are recommended in the standard texts on unit operations and leaching.30 All of these approaches over-estimate the initial concentration in the espresso because they assume the bed starts in equilibrium, though if the extraction runs for long enough these models fit the observed results better and better. An alternative approach is to assume the bed is filled with water that is not at equilibrium and the extraction only begins at t=0. This is the approach taken by much of the recent literature on modeling espresso31. The downside to this approach is that it generally underestimates the initial concentration of the espresso.
+31 Cameron et al., “Systematically Improving Espresso” page 635; Moroney et al., “Modelling of Coffee Extraction During Brewing Using Multiscale Methods” page 225; Vaca Guerra et al., “Modeling the Extraction of Espresso Components as Dispersed Flow Through a Packed Bed” page 5
Since the initial conditions are different, none of the models above are directly comparable to the approaches taken in the literature. Though it should not be a huge undertaking to change the initial conditions after taking the Laplace transform and completing the result from there. Since the Laplace transform and its inverse are linear this should equate to adding an \(\exp\left(...\right)\) term to the solution somewhere.
+I think it is also reasonable to be skeptical of the mass transfer coefficients that I estimated. These are based on correlations for packed beds with spherical packing and, while I am modeling the particles as spheres, something may have been lost in the accounting. Most of the mass transfer coefficients ultimately depend upon a good estimate for the solid phase diffusion, which in this case I obtained from literature and is comparable to what one would expect for plant matter like coffee beans.32 But an obvious next step is to compare with actual measured data.
+The model is also highly sensitive to particle size, which the figure below illustrates by successively doubling the effective diameter of the particles, while using the Rasmuson solution (all other parameters remaining equal). This diameter is also an effective parameter and not a directly measured one. It is the diameter of the sphere with an equivalent surface area to a coffee ground or, more accurately, the average of such diameters over the actual particle size distribution of the coffee grounds. This makes it somewhat difficult to determine exactly, especially if one is trying to incorporate the effects of microscopic pores on the effective surface area of coffee grounds. Rough estimates can be made using images taken of the grounds, using an app, but that will always be limited by the resolution of a camera.
+Another note of caution is in using the direct numerical integration of the Rosen and Rasmussen solutions. In this notebook I specified the (finite) bounds of integration and the number of points to sample within the interval, which were tuned more or less by eye. That does mean the code is brittle to major changes in some of the packed bed parameters, without going back and re-tuning the parameters of the numerical integration. A more robust approach would determine some of these algorithmically, especially the bounds of integration. I could just leave the upper bound of the integral as Inf, but in my experience there can be domain issues if one isn’t careful and the integrand isn’t capturing all edge cases properly.
While I focused mostly on calculating the various integrals numerically, the asymptotic and approximate forms are probably more useful if you just want to play around and explore how changing different coffee parameters changes overall extraction. They are certainly easier to calculate.
+On Monday, September 20 2021, Canadians went to the polls and ended up electing a parliament that looked very much like the one we had in August, prior to the election. Very notably so. I’m not much of a political watcher, but I did wonder was this really so notably similar? Or do we just have short memories?
+This is easy enough to answer.
+What I would like to do is take a table with the number of seats each party got in each election and calculate the change in seats from one election to the next, then add that up. I can’t simply add it up though, as the total number of seats (usually) remains constant and any party’s gain is another party’s loss: the total would always be zero. Instead I am going to add up the absolute value of the change, which effectively double counts each seat (it is counted when one party loses it and again when another party gains it). Also the total number of seats in the house of commons has not always been 338, to adjust for this I will take the absolute value of the change in percentage of seats. So, for example, if party A enters an election with 20% of the seats and leaves with 20% of the seats then this counts as no change, though if they entered with 20 seats and left with 20 seats but the overall number of seats had increased, then that counts as a change.
+I can calculate this for each election and see how much of an outlier 2021 was.
+using CSV, DataFrames, Statistics, Pipe, Plots# takes a dataframe of the form
+# | YEAR | party1 | party 2 | ... | party n |
+# |------|--------|---------|-----|---------|
+# | 1 | 100 | 50 | ... | 0 |
+# | : | : | : | : | : |
+# | m | 30 | 160 | ... | 1 |
+# and returns a length m vector with the relative change for each year
+function seat_change(df)
+
+ # the first election seat change is undefined
+ changes = [NaN]
+
+ for i in 2:nrow(df)
+ # starting with the second election
+ prev = df[i-1, Not(:YEAR)]
+ prev_total = sum(prev)
+
+ curr = df[i, Not(:YEAR)]
+ curr_total = sum(curr)
+
+ Δseats = 0
+
+ # for each party, calculate the absolute difference
+ for j in 1:length(curr)
+
+ prev_pct = prev[j]/prev_total
+ curr_pct = curr[j]/curr_total
+ Δseats += abs(curr_pct - prev_pct)
+ end
+
+ # add the change to the list
+ push!(changes, Δseats)
+ end
+
+ return changes
+endI pulled the seat count for each federal election since 1867 from wikipedia as a CSV, with a little bit of finessing in the data entry. We have had a lot of political parties in our short time as a country and many of them either never ended up with any seats or only one or two before disappearing from history – I have elected to lump these in with the independents as “Other”. We have also had several parties that merged or changed, for example the CCF ultimately became the NDP and the Reform party became part of the Canadian Alliance, I have chosen to treat those as the same party.
+Running this through the function I defined earlier gives the relative absolute seat change per election.
+data_file = "data/federal-electon-results.csv"
+
+results = @pipe data_file |>
+ CSV.File( _ ; header=1 ) |>
+ DataFrame(_) |>
+ hcat(_, seat_change(_)) |>
+ rename(_, "x1" => "Change")
+
+show(first(results, 6), allcols=true)6×14 DataFrame + + Row │ YEAR Other Liberal Conservatives CCF/NDP BQ Progressive Anti-Confederate Social Credit United Farmers Reform/Canadian Alliance Liberal Progressive Unionist Coalition Change + + │ Int64 Int64 Int64 Int64 Int64 Int64 Int64 Int64 Int64 Int64 Int64 Int64 Int64 Float64 + +─────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── + + 1 │ 1867 0 62 100 0 0 0 18 0 0 0 0 0 NaN + + 2 │ 1872 5 95 100 0 0 0 0 0 0 0 0 0 0.311111 + + 3 │ 1874 12 129 65 0 0 0 0 0 0 0 0 0 0.368932 + + 4 │ 1878 9 63 134 0 0 0 0 0 0 0 0 0 0.669903 + + 5 │ 1882 4 73 134 0 0 0 0 0 0 0 0 0 0.0802926 + + 6 │ 1887 11 80 124 0 0 0 0 0 0 0 0 0 0.116654+
Plotting the results gives us some interesting years to think about, such as 1917 when the government was composed of the Unionist Coalition, a coalition of mostly Conservatives and some Liberals and others, that basically only existed for the war in what was, apparently, one of the most bitter campaigns in Canadian history. For the next election the coalition dissolved back into it’s original parties, hence an enormous change going in and going out of that parliament. There are other large changes, like the 1993 election in which the Conservatives went into the election with 156 seats and left with 2, nearly being wiped out of parliament entirely – the largest change in history according to this metric.
+There have been periods of low change, the red-line on the plot indicates a change of less than 10%, but none as low as 2021. I do find it interesting that in the late 1800s and the early 1900s we had successive governments with very little change in overall composition but after 1908 things are a lot more variable.
+ +
+We can filter out the low-change elections and get a sense of not just the 2021 election, but the neighbourhood of low-change elections.
+lowest = filter(row -> row[:Change] < 0.10, results)
+
+sort!(lowest, [:Change]);7×9 DataFrame + + Row │ YEAR Liberal Conservatives BQ CCF/NDP Social Credit Liberal Progressive Other Change + + │ Int64 Int64 Int64 Int64 Int64 Int64 Int64 Int64 Float64 + +─────┼───────────────────────────────────────────────────────────────────────────────────────────────────── + + 1 │ 2021 158 119 34 25 0 0 2 0.0236686 + + 2 │ 1940 179 39 0 8 10 3 6 0.0653061 + + 3 │ 1965 131 97 0 21 14 0 2 0.0754717 + + 4 │ 1908 133 85 0 0 0 0 3 0.0767539 + + 5 │ 1904 137 75 0 0 0 0 2 0.0784959 + + 6 │ 1882 73 134 0 0 0 0 4 0.0802926 + + 7 │ 1891 90 118 0 0 0 0 7 0.0930233+
This is an exceptionally low change, the next lowest year (1940) had >2× as many seats change hands. Also, the last time the overall seat change was even close to this low was decades ago, the next previous year with a relative change <10% was 1965 and in that case >3× as many seats changed hands.
+This result may change, as of right now several ridings are still too-close to call without mail in ballots, but for some of those if they flip it will actually lower the overall change in seats, not increase it. For example Edmonton Center is currently undecided with the Liberal candidate ahead, but if it flips to the incumbent Conservative the overall relative change for this election would go down.
+ + +This is an interesting example that came up in conversation with another engineer related to a construction project happening at an existing facility. Imagine construction involving scaffolding and workers at an elevation that potentially puts them within the plume of an existing stack – say from an adjacent boiler. If the facility is still operating while this construction work happens then it is possible that workers will be exposed to combustion products in excess of the occupational exposure limits. The operating boiler does not have to be all that close by for the plume – which is very visible this time of year in the cold weather – to envelope a similarly tall set of scaffolding.
+So, how would one determine whether or not the operating stack presents a hazard to the workers? In practice by hiring a consultant to do detailed modelling, because safety issues like this are not the time to pencil-whip some number. But we may want to come up with a rough estimate regardless, and for that a Gaussian dispersion model of the stack can be a useful first start.
+ +
+Suppose a natural gas boiler with a rated capacity, \(W\), of 300GJ/h, stack height, \(h_s\), of 10m and diameter, \(D_s\) of 2m, and an exit temperature of 450K.
+In this case we are interested in the carbon monoxide concentrations at a work platform at the same height as the stack and 100m away, we also would like to know the concentration for a worker at ground level. I am approximately 2m tall let’s suppose the relevant height is 2m (for anyone shorter than that the concentration should be lower and thus this is conservative).
+Additionally I am assuming ambient conditions of 25°C and 1atm
+using Unitful
+
+W = uconvert(u"GJ/s", 300u"GJ/hr")
+hₛ = 10u"m" # stack height
+Dₛ = 2u"m" # stack diameter
+Tₛ = 450u"K" # stack exit temperature
+
+h₁ = hₛ # height of platform, m
+x₁ = 100u"m" # distance to platform, m
+
+pₐ = 101.325u"kPa" # ambient pressure, 1atm
+Tₐ = 298.15u"K" # ambient temperature, 25°CPrior to any dispersion modelling, the following parameters need to be collected:
+The EPA has tabulated emission factors for most combustion products in EPA AP-42 and for a natural gas boiler it is 84 lb/10^6 SCF1 with a reference higher heating value of 1020 MMBTU/10^6 SCF.
+1 EPA, “AP 42” Table 1.4-1. The emission factor is relative to the volume of natural gas consumed not the volume of stack gas emitted.
If we suppose the boiler is operating at max rates then the mass emission rate is
+\[ Q = { W \cdot EF \over HV} \]
+Where EF is the emission factor and HV the higher heating value.
+HV = uconvert(u"GJ/m^3", 1020u"btu/ft^3")
+EF = uconvert(u"kg/m^3", 84*1e-6u"lb/ft^3")
+
+Q = EF * W / HV # mass emission rate in kg/s0.002950437713234783 kg s^-1This gives a mass flow rate of carbon monoxide in the plume, but we will also need some sense of how large the plume is in general, i.e. what is the volumetric flow rate of stack gas exiting the stack?
+There are several ways the volumetric flow rate of flue gas could be estimated. One simple method is to use EPA Method 192 with the equation
+\[ V_s^o = F_w { 20.9 \over 20.9 \left( 1 - B_{wa} \right) - \%O_{2w} } \cdot W\]
+Where \(V_s^o\) is the volumetric flow of flue gas at standard conditions, \(B_{wa}\) the moisture fraction of ambient air, \(\%O_{2w}\) the percentage of oxygen on a wet basis, and the parameter \(F_w\) captures the differences in combustion stoichiometry for different fuels and is tabulated. Alternatively one could work out the volume of stack gas from the stoichiometry of combustion, this is just a shortcut.
+Fw = 2.85e-7u"m^3/J"
+pct_O2 = 4
+Bwa = 0.027
+
+Vₛᵒ = Fw * (20.9 / (20.9*(1-Bwa) - pct_O2)) * W
+
+Vₛᵒ = upreferred(Vₛᵒ)30.385903267077627 m^3 s^-1The actual volumetric flow rate can be calculated assuming the ideal gas law
+\[ { p^o V_s^o \over T^o } = { p_a V_s \over T_s } \]
+\[ V_s = { T_s \over T^o } { p^o \over p_a } V_s^o \]
+Where the standard conditions of Method 19 are \(T^o = 20 \mathrm{C}\) and \(p^o = 760 \mathrm{mm Hg}\)
+# Unitful doesn't know what "mm Hg" is
+@unit mmHg "mm Hg" MillimetersMercury 133.322387415u"Pa" false
+
+Tᵒ = uconvert(u"K", 20u"°C")
+pᵒ = uconvert(u"kPa", 760mmHg)
+
+Vₛ = (Tₛ / Tᵒ) * (pᵒ / pₐ) * Vₛᵒ46.6438970432218 m^3 s^-1This analysis is fundamentally about identifying whether a worker on the work platform would experience flue gases in excess of some concentration of interest. In this case I am supposing the Occupational Exposure Limit (OEL) for carbon monoxide alone because it is simple. In practice, since flue gas is a mixture of many substances that each have an associated OEL, one would have to look at the cumulative impact of all of these substances instead of treating them all individually3
+3 For example CCOHS recommends calculating the sum \[ \sum_i {C_i \over T_i } \] for each substance i where C is the observed concentration and T is the threshold, and this sum should be less than one.
4 From the NIOSH Handbook, using the conversion 1.15 mg/m^3 per ppm
For carbon monoxide there are three concentrations of interest worth considering4
+| Limit | +ppm | +mg/m^3 | +
|---|---|---|
| TWA | +35 | +40 | +
| Ceiling | +200 | +229 | +
| IDLH | +1200 | +1380 | +
TWA = uconvert(u"kg/m^3", 40u"mg/m^3")
+Ceil = uconvert(u"kg/m^3", 229u"mg/m^3")
+IDLH = uconvert(u"kg/m^3", 1380u"mg/m^3");We can check if the stack gas concentration at the exit exceeds the TWA. If it does not exceed the TWA then there is no reason to proceed with the calculations as a worker could work in the stack and not exceed the limits and they certainly would not exceed the limits after the plume mixed with ambient air.
+uconvert(u"mg/m^3", Q/Vₛᵒ)97.0988977125952 mg m^-3Q/Vₛᵒ > TWAtrueThe concentration in the flue gas is above the limit for long term work exposure but below the ceiling. At this point we are justified in continuing on to estimate the concentration at the work platform.
+The ambient conditions impact the release in some obvious ways and in some non-obvious ways. Obviously the wind speed impacts how far the plume is moved, through advection. Somewhat non-obviously the ambient conditions also govern how high the plume will rise due to buoyancy as well as the extent of mixing as the plume moves through the air.
+Suppose a wind speed of 1.5m/s at the stack height, just arbitrarily.
+uₛ = 1.5u"m/s"1.5 m s^-1The atmospheric stability relates to the vertical mixing of the air due to a temperature gradient, during the day air temperature decreases with elevation and this temperature gradient induces a vertical flow that leads to vertical mixing.
+ +
+This is captured by the atmospheric stability parameter \(s\) which is given by5
+\[ s = \frac{g}{T_a} { \partial \theta \over \partial z } \]
+Where \(\partial \theta \over \partial z\) is the lapse rate in K/m
+The “worst case” is the case with the least mixing and corresponds to a class F Pasquill stability, i.e. very stable, which has a corresponding default lapse rate of \({ \partial \theta \over \partial z } = 0.035 K/m\).6
+6 EPA, 2:1–9.
This isn’t entirely true. For neutrally buoyant plumes released at ground level, or in this case level with the elevated work platform, class F is likely the worst case. For buoyant plumes released at elevation the minimal vertical dispersion with stable atmospheres means the bulk of the plume will rise and be dispersed far above the ground and another class and wind speed should be considered. See Guidelines for Use of Vapour Cloud Dispersion Models, 2nd ed. section 5.8 for more details
+# acceleration due to gravity
+g = 9.80616u"m/s^2"
+
+# default lapse rate for class F
+Γ = 0.035u"K/m"
+
+# stability parameter
+s = (g/Tₐ) * Γ0.0011511507630387393 s^-2The plume rising out of the stack will rise higher than the stack height due to buoyancy – in this case because the stack gas is at a higher temperature than the ambient air – and because the stack gas is ejected with some kinetic energy. What follows is essentially a simplified version of the Brigg’s model for plume rise for stable plumes.
+As a first check, verify that stack down wash will not be relevant. For low momentum releases the effective stack height of the plume is reduced by vortices shed downwind of the stack that pull the plume downwards. This is only really relevant when \(v_s \lt 1.5 u\)
+Where \(v_s\) is the stack exit velocity and is calculated from the volumetric flow as
+\[ v_s = { V_s \over A_s} = { V_s \over \frac{\pi}{4} D^2 } \]
+vₛ = Vₛ / ((π/4)*Dₛ^2)
+
+vₛ > 1.5uₛtrueThe following assumes a stable plume rise, recall that Pasquill stability class F corresponds to very stable conditions.
+The first question that must be answered is whether or not the plume rise is dominated by buoyancy or by momentum. For buoyant plume rise to dominate the actual temperature difference – the difference between the stack exit temperature and the ambient temperature – must be greater than a critical temperature difference7
+7 EPA, 2:1–9.
\[ T_s - T_a = \Delta T \gt \left( \Delta T \right)_c = 0.019582 T_s v_s \sqrt{s} \]
+ΔTc = 0.019582u"m^-1*s^2" * Tₛ * vₛ * √(s)
+
+(Tₛ - Tₐ) > ΔTctrueIn this case buoyant plume rise is dominant, and the stable plume rise equation is8
+8 EPA, 2:1–9.
\[ \Delta h = 2.6 \left( F_b \over u_s s \right)^{1/3} \]
+where \(\Delta h\) is the increase in effective stack height due to plume rise, and \(F_b\) is the buoyancy flux parameter9
+9 EPA, 2:1–6.
\[ F_b = g v_s D_s^2 { \left( T_s - T_a \right) \over 4 T_s } \]
+Plume rise is not instantaneous and the distance to the final rise, \(x_f\) is given by10
+10 EPA, 2:1–9.
\[ x_f = 2.0715 {u_s \over \sqrt{s} } \]
+with any distance closer to the source than \(x_f\) experiencing a lesser plume rise, given by11
+11 EPA, 2:1–10.
\[ \Delta h = 1.60 \left( F_b x^2 \over u_s^3 \right)^{1/3} \]
+this can be put together into a function that calculates \(\Delta h\) as a function of distance x
+Fb = g * vₛ * Dₛ^2 * (Tₛ - Tₐ) / (4Tₛ)49.1299376393856 m^4 s^-3xf = 2.0715*uₛ/√(s)91.58199372993636 mfunction Δh(x)
+ xf = 2.0715*uₛ/√(s)
+
+ if x < xf
+ return 1.60*(Fb*x^2/uₛ^3)^(1/3)
+ else
+ return 2.6*(Fb/(uₛ*s))^(1/3)
+ end
+
+end; +
+Plume rise is impacted by the wind speed at the stack height, as the following plot shows, but with several large caveats. For one the model for plume rise given is not defined at no wind speed and for very low wind speeds the value should be treated with suspicion. Similarly for very large wind speeds the assumption of stable rise is likely quite invalid.
+ +
+As the plume is carried downwind it will mix with the ambient air and the pollutant, carbon monoxide, will be dispersed. A simple model of this is a Gaussian dispersion model, the derivation for which is sketched out as follows.
+Starting with a coordinate system centred at the top of the stack, emitting a mass flow of Q kg/s, which is assumed to be released from a point, the advection-diffusion equation for mass can be written as
+\[ {\partial C \over \partial t} = - \nabla \cdot \mathbf{D} \cdot \nabla C + \nabla \cdot \mathbf{u} C \]
+Where \(\mathbf{D}\) is the diffusivity, \(C\) the concentration of the species, and \(\mathbf{u}\) the wind speed. The diffusivity in this case is a vector and depends upon the direction, i.e. \(D_x \ne D_y \ne D_z\) and represents an eddy diffusion as opposed to a simple Fickian diffusion.
+Some simplifying assumptions can be made
+Reducing the PDE to
+\[ u {\partial C \over \partial x} = D_{y} {\partial^{2} C \over \partial y^{2} } + D_{z} {\partial^{2} C \over \partial z^{2} } \]
+Which has solutions for particular boundary conditions
+\[ C = {k \over x} \exp \left[ - \left( {y^{2} \over D_{y} } + {z^{2} \over D_{z} } \right) { u \over 4x } \right] \]
+Where k is a constant set by the boundary conditions.
+To solve for k note that Q is assumed to be constant and that mass must be conserved as it is carried downwind which has the effect that for any given x the flux through the y-z plane is Q.
+\[ Q = \int \int C u dy dz \]
+\[ Q = \int_{0}^{\infty} \int_{-\infty}^{\infty} {k u \over x} \exp \left[ - \left( {y^{2} \over D_{y} } + {z^{2} \over D_{z} } \right) { u \over 4x } \right] dy dz \]
+where the release point is assumed to be at ground level (z=0).
+Making the change of variables \(y' = {y \over \sqrt{D_{y} } }\) and \(z' = {z \over \sqrt{D_{z} } }\) gives
+\[ Q = {k u \over x} \sqrt{D_{y} D_{z} } \int_{-\infty}^{\infty} \exp \left[ - {u \over 4 x} y'^{2} \right] dy' \int_{0}^{\infty} \exp \left[ - {u \over 4 x} z'^{2} \right] dz' \]
+which are gaussian integrals that can be integrated
+\[ Q = {k u \over x} \sqrt{D_{y} D_{z} } \left( \sqrt{\pi} \over \sqrt{u \over 4x} \right) \left( \sqrt{\pi} \over 2 \sqrt{u \over 4x} \right) \]
+simplifying
+\[ Q = 2 \pi k \sqrt{D_{y} D_{z} } \]
+and solving for k
+\[ k = {Q \over 2 \pi \sqrt{D_{y} D_{z} } }\]
+Substituting k back into the model gives the gaussian dispersion model.
+\[ C = {Q \over 2 \pi x \sqrt{D_{y} D_{z} } } \exp \left[ - \left( {y^{2} \over D_{y} } + {z^{2} \over D_{z} } \right) { u \over 4x } \right] \]
+However this is more commonly expressed in terms of dispersion by letting
+\[ \sigma_{y}^{2} = {2 D_{y} x \over u}\]
+\[ \sigma_{z}^{2} = {2 D_{z} x \over u}\]
+which gives a more explicitly gaussian distribution of concentration at a given point x
+\[ C = {Q \over \pi u \sigma_{y} \sigma_{z} } \exp \left[ -\frac{1}{2} \left( {y^{2} \over \sigma_{y}^{2} } + {z^{2} \over \sigma_{z}^{2} } \right) \right] \]
+Note the parameters \(\sigma_y\) and \(\sigma_z\) have units of length.
+When solving for k, I assumed the release point was at ground level, this simplified the integration by making one of the bounds of the integral zero.
+However what we want is a generalized equation with the emissions released at some elevation h. The plume can disperse downwards but only to a distance h below the release point, at which point the mass can neither disperse further downwards (pass through the ground) nor does it just disappear. This is ground reflection.
+ +
+One way to capture this is to integrate z from \(-\infty\) to \(\infty\) (recall that the release point is at the origin) and introduce a mirror image of the stack shifted 2h below. The ground being the x-y plane at z = -h. By symmetry the portion of the mirror plume extending up above this plane is the same as the portion of the plume that, in this simple model, has extended below the ground. By adding the stack and the mirror stack together and shifting the z-coordinate so z = 0 is the ground, ground reflection is captured and the expression for a release point at elevation h is given by
+\[ C = {Q \over 2 \pi u \sigma_{y} \sigma_{z} } \exp \left[ -\frac{1}{2} \left( y \over \sigma_{y} \right)^2 \right] \]
+\[ \times \left\{ \exp \left[ -\frac{1}{2} \left( { z -h } \over \sigma_{z} \right)^2 \right] + \exp \left[ -\frac{1}{2} \left( { z + h } \over \sigma_{z} \right)^2 \right] \right\} \]
+The \(\sigma_{y}\) and \(\sigma_{z}\) are functions of the downwind distance x. In the derivation of the model they were assumed to be linear in x however in practice they are typically of the form:
+\[ \sigma_{y} = a x^{b} \]
+\[ \sigma_{z} = c x^{d} \]
+With the constants tabulated based on the Pasquill stability class criteria.
+These particular correlations come from Lees12 and are for a Pasquill stability class F
+12 Lees, Loss Prevention in the Process Industries, 15/113. There is a typo in the 4th edition of Lees’ for the \(\sigma_{z}\) corresponding to class F stability. For \(x>500\) it is given as \[ \sigma_{z} = 10^{(1.91 - 1.37 \log(x) - 0.119 \log(x)^2)} \] when it should be (note the signs) \[ \sigma_{z} = 10^{(-1.91 + 1.37 \log(x) - 0.119 \log(x)^2)} \]. I happen to have the paper version of the 2nd edition at home, which does not have the typo, whereas the standard version I use at work is the 4th edition on Knovel.
σy(x) = 0.067*x^0.90
+
+function σz(x)
+ if x < 500.0
+ return 0.057*x^0.80
+ else
+ # Note: Lee's gives the commented out form but it is wrong
+ # 10^(1.91 - 1.37*log10(x) - 0.119*log10(x)^2)
+ return 10^(-1.91 + 1.37*log10(x) - 0.119*log10(x)^2)
+ end
+end;These correlations are currently not unit-aware, so we can add that using a macro
+# this macro adds a method to handle units
+macro correl(f::Symbol, in_unit::Expr, out_unit::Expr)
+ quote
+ function $(esc(f))(x::Quantity)::Quantity
+ x = ustrip($in_unit, x)
+ res = $f(x)
+ return res*$out_unit
+ end
+ end
+end
+
+@correl σy u"m" u"m"
+@correl σz u"m" u"m"σz (generic function with 2 methods) +
+The effect of plume rise on this model is to shift from the actual stack height to an effective stack height \(h_e = h_s + \Delta h\) with \(\Delta h\) given by the plume rise model already discussed. Additionally the dispersion is adjusted by the following13
+\[ \sigma_{ze}^2 = \left( \Delta h \over 3.5 \right)^2 + \sigma_z^2 \]
+\[ \sigma_{ye}^2 = \left( \Delta h \over 3.5 \right)^2 + \sigma_y^2 \]
+and the final model of concentration is given in respect to the effective stack height
+\[ C = {Q \over 2 \pi u \sigma_{ye} \sigma_{ze} } \exp \left[ -\frac{1}{2} \left( y \over \sigma_{ye} \right)^2 \right] \]
+\[ \times \left\{ \exp \left[ -\frac{1}{2} \left( { z -h_e } \over \sigma_{ze} \right)^2 \right] + \exp \left[ -\frac{1}{2} \left( { z + h_e } \over \sigma_{ze} \right)^2 \right] \right\} \]
+function C(x, y, z)
+ hₑ = hₛ + Δh(x)
+ σyₑ = √( (Δh(x)/3.5)^2 + σy(x)^2 )
+ σzₑ = √( (Δh(x)/3.5)^2 + σz(x)^2 )
+
+ C = (Q/(2*π*uₛ*σyₑ*σzₑ)) *
+ exp(-0.5*(y/σyₑ)^2) *
+ ( exp(-0.5*((z-hₑ)/σzₑ)^2) + exp(-0.5*((z+hₑ)/σzₑ)^2) )
+
+endThere are two cases worth considering
+The first case would be very conservative and the stack plume would immediately point directly downwind, at the stack height, this is far more likely to impact the work platform and any workers on the ground, though it is also quite unrealistic.
+Note the following contour plots max out at the time weighted average concentration, shown in mg/m^3
+ +
+This clearly represents something of an extreme case, and I believe illustrates something of interest. While the work platform is ultimately below the TWA, to get even close to that concentration at the work platform the model is assuming extremely little mixing and no plume rise.
+A more realistic model would take into account the buoyant rise of hot stack gases.
+ +
+In this model the plume clearly rises significantly and, as it goes, mixes into the air column to such an extent that there is hardly any carbon monoxide at the elevations of interest downwind of the stack.
+uconvert(u"mg/m^3",C(x₁, 0u"m", h₁))0.0014282911474771348 mg m^-3C(x₁, 0u"m", h₁) > TWAfalseThis model assumed a continuous, steady-state, flow of stack gases. Boilers don’t always operate that way and the model did not, for example, consider startup or upset conditions that could lead to higher in-stack concentrations of carbon monoxide.
+The model also assumed mixing was captured by a simple Gaussian dispersion model. This model does not, for example, account for variability of wind speed either with time or spatially – wind speed typically increases with height – in this case I believe the model underestimates the degree of mixing. Nor does it account for interactions with buildings and potential down wash, which can be very significant.
+This also assumes no other sources of carbon monoxide, both at the facility surrounding the worksite but also potentially from some portable equipment.
+I think that, while modelling like this might be informative about the potential hazards, it is always good practise to develop a monitoring plan for the work area that includes the flue gases and any other potential substances to ensure workers on the scaffolding are not being exposed.
+A common thing for me to do, when using a tool developed by someone else, is to read through all the tedious details and try and understand where it all comes from and what the unstated assumptions are. While doing this recently I was motivated to ask, how do people estimate the explosive energy in a vapour cloud? It is an important question to ask when performing a hazard analysis, especially in the petrochemical industry – often the worst case scenario is some chemical release leading to a vapour cloud explosion.
+The standard references I looked at either provided an equation without giving any sense where it came from or, in one notable exception, gave an equation that (as far as I can tell) can’t possibly be right. So I thought this might be fertile ground for investigation.
+Gaussian plumes are a common first dispersion model for chemical release screening tools. They are easy to implement, especially in spreadsheets, and have convenient mathematical properties that makes calculating the parameters relevant to a hazard screening simple. The cases where either the plume is grounded1 or is free2 are particularly convenient as the plume extents can be calculated directly.
+1 emitted at ground level and perfectly reflecting off the ground plane
2 emitted high enough above the ground that the ground plane can be neglected entirely
For what follows I am going to examine a free plume – the results are very similar for a grounded plume – which is given by
+\[ \chi = { w \over {2\pi u \sigma_y \sigma_z} } \exp \left( - \frac{1}{2} \left( \left(\frac{y}{\sigma_y}\right)^2 + \left(\frac{z}{\sigma_z}\right)^2 \right) \right) \]
+Where the origin has been chosen to coincide with the release point. The standard assumptions for a Gaussian plume are:
+For a free plume it is further assumed that there is no ground plane, the z-axis extends infinitely up and down.
+To actually use this model, we need a parametrization of \(\sigma_y\) and \(\sigma_z\) for which I am going to use the simple power law \(\sigma_y = a x^b\) and \(\sigma_z = c x^d\)
+# System parameters
+w = 1 # kg/s
+u = 1 # m/s# Class D - Neutral atmospheric stability
+a = 0.128
+b = 0.905
+c = 0.20
+d = 0.76σy(x) = a*x^b
+σz(x) = c*x^dχ(x,y,z; w=w, u=u) = w*exp(-0.5*((y/σy(x))^2 + (z/σz(x))^2))/(2π*u*σy(x)*σz(x))Suppose I am interested in the region of the plume between two concentrations \(\chi_1\) and \(\chi_2\), these might be the upper flammability limit (UFL) and the lower flammability limit (LFL) (respectively). It doesn’t really matter. But further suppose that I have both the concentrations and the point along the \(x\) axis where the centerline concentration equals that concentration. This is the point where the isosurface crosses the \(x\) axis.
+This is typically the step along a hazard analysis or consequence analysis where calculating the potential explosive energy takes place.
+x₁ = 10 # m
+x₂ = 100 # mχ₁ = χ(x₁,0,0)
+χ₂ = χ(x₂,0,0)At the level of screening tools, estimating the potential explosive energy in a vapour cloud typically involves estimating the mass of explosive material in the cloud3, then calculating the energy from the specific enthalpy of combustion.
+3 How one defines the flammable mass of a vapour cloud varies significantly from author to author, depending on whether one takes it to be the entire region with a concentration greater than the LFL, some fraction of the LFL (1/2 is common), or only the region between the LFL and UFL.
The CCPS tools CHEF and RAST, the TNO Yellow Book,4 and Van Buijtenen5 give the mass of a vapour cloud as
+\[ m_e = C \frac{w}{u} x_l \]
+Where \(m_l\) is the mass of the region defined by the concentration \(\chi_l\) and \(C\) is a constant, which generally depends upon atmospheric stability. If the explosive mass is taken to be the region between two concentrations \(\chi_1\) and \(\chi_2\) with \(\chi_1 > \chi_2\) then \(m_e = m_2 - m_1\)
+| + | C | +
|---|---|
| CHEF & RAST | +1 | +
| TNO Yellow Book | +\({ {f_{z2}(L) + 1} \over {f_{z2}(L) + 2} }\) | +
| Van Buijtenen | +\({ {b + d} \over {b + d + 1 } }\) | +
Woodward6 gives the following as the rigorous method for plumes, specifically for a free plume it is
+\[ m_e = 4 \left( \chi_1 - \chi_2 \right) \int_{x_1}^{x_2} \sigma_y^2 E\left( k^2 \right) dx \]
+where \(E \left( k^2 \right)\) is the complete elliptic integral of the second kind and \(k\) is a function of \(x\) and atmospheric stability.
+The mass in the region of a Gaussian plume with a concentration greater than \(\chi_l\) is given by the volume integral
+\[ m = \iiint_V \chi dV \]
+where
+\[ V = \left\{ x,y,z \vert \chi \left(x,y,z\right) \ge \chi_l \right\} \]
+The mass in a free plume is given by
+\[ m_{free} = \iiint_V \chi dV = \int_0^{x_l} \int_{-y_l}^{y_l} \int_{-z_l}^{z_l} \chi_{free} dz dy dx \]
+By symmetry this is equal to
+\[ 2 \int_0^{x_l} \int_{-y_l}^{y_l} \int_{0}^{z_l} \chi_{free} dz dy dx \]
+Recalling that the concentration in a grounded plume is twice that of a free plume
+\[ m_{free} = 2 \int_0^{x_l} \int_{-y_l}^{y_l} \int_{0}^{z_l} \chi_{free} dz dy dx = \int_0^{x_l} \int_{-y_l}^{y_l} \int_{0}^{z_l} \chi_{grounded} dz dy dx = m_{grounded} \]
+The total mass in the plume contained between the planes \(x=0\) and \(x=x_l\) is simply the integral
+\[ m_T = \iiint_{V_T} \chi dV \]
+\[ V_T = \left\{ x,y,z \vert 0 \le x \le x_l, \chi\left(x,y,z\right) \gt 0 \right\} \]
+Which follows directly from properties of Gaussian functions
+\[ m_T = \int_0^{x_l} \int_{-\infty}^{\infty} \int_{-\infty}^{\infty} \chi dz dy dx \]
+\[ m_T = \frac{w}{u} x_l \]
+Which is the result used in CHEF v4.5 – the total mass in the plume. This also presents a useful upper bound: the mass in the flammable region of the plume must be less than the total mass of the plume.
+The isopleths for a free Gaussian plume are given by
+\[ y_l = \pm \sigma_y \sqrt{K} \]
+\[ z_l = \pm \sigma_z \sqrt{K} \]
+where \(K = 2 \log \left( w \over {2\pi u \sigma_y \sigma_z \chi_l } \right)\)
+The whole isosurface is defined by
+\[ S = \left\{ x, y, z \bigg\vert \left(\frac{y}{\sigma_y}\right)^2 + \left(\frac{z}{\sigma_z}\right)^2 = K \right\} \]
+These can be used directly, but a more general approach is to use marching squares to find the isopleth.
+ +
+ +
+For a general plume one can find the surface using marching tetrahedra. In the following the surface for \(\chi_2\) is calculated by marching tetrahedra, as shown in Figure 3.
+using Meshing: MarchingTetrahedra, isosurface
+using GeometryBasics: Mesh, Point, Vec, Triangle, TriangleFace, volumeχ_safe(x,y,z) = isnan(χ(x,y,z)) ? 0.0 : χ(x,y,z);xs = LinRange(0.0, x₂, 100)
+ys = LinRange(-7.5, 7.5, 25)
+zs = LinRange(-7.5, 7.5, 25)
+
+χfield = [ χ_safe(x,y,z) - χ₂ for x in xs, y in ys, z in zs ]
+pts,fcs = isosurface(χfield, MarchingTetrahedra(), xs, ys, zs);msh = Mesh(Point.(pts), TriangleFace.(fcs))Mesh{3, Float64, TriangleFace{Int64}}
+ faces: 43472
+ vertex position: 21740 +
+If the potential explosive energy was being determined using the volume of the cloud, well we would be done. The volume of a meshed surface can be calculated directly
+abs(volume(msh))8085.175640305937Presumably one could tetragonalize this mesh and calculate the volume integral of the mass through that. I will leave that as an exercise for the reader. For the particular case of a free plume that will be more work than is required.
+The most direct approach to calculating the explosive mass is to numerically integrate over a rectangular region containing the plume7
+\[ +m_l = \iiint_{V} \chi dV = \int_{0}^{x_l} \int_{-y_l}^{y_l} \int_{-z_l}^{z_l} \begin{cases} + \chi & \chi \ge \chi_l \\ + 0 & \chi \lt \chi_l + \end{cases} dz dy dx +\]
+This can be done directly using the trapezoidal rule in three dimensions.
+@inline χ_inbounds(x,y,z; χₗ,w,u) = χ(x,y,z; w=w,u=u)≥χₗ ? χ(x,y,z; w=w,u=u) : 0.0function mass🪤(xₗ; lower, upper, N=100, w=w, u=u)
+ y_a, z_a = lower
+ y_b, z_b = upper
+ x_a, x_b = 0.0, xₗ
+
+ Δx = (x_b - x_a)/N
+ Δy = (y_b - y_a)/N
+ Δz = (z_b - z_a)/N
+
+ χₗ, Σχ = χ(xₗ,0,0; w=w, u=u), 0.0
+ for i in 1:N, j in 1:N, k in 1:N
+ xᵢ₋₁, xᵢ = x_a + (i-1)*Δx, x_a + i*Δx
+ yⱼ₋₁, yⱼ = y_a + (j-1)*Δy, y_a + j*Δy
+ zₖ₋₁, zₖ = z_a + (k-1)*Δz, z_a + k*Δz
+
+ Σχ += ( χ_inbounds(xᵢ₋₁, yⱼ₋₁, zₖ₋₁; χₗ=χₗ, w=w, u=u)
+ + χ_inbounds(xᵢ₋₁, yⱼ₋₁, zₖ; χₗ=χₗ, w=w, u=u)
+ + χ_inbounds(xᵢ₋₁, yⱼ, zₖ₋₁; χₗ=χₗ, w=w, u=u)
+ + χ_inbounds(xᵢ₋₁, yⱼ, zₖ; χₗ=χₗ, w=w, u=u)
+ + χ_inbounds(xᵢ, yⱼ₋₁, zₖ₋₁; χₗ=χₗ, w=w, u=u)
+ + χ_inbounds(xᵢ₋₁, yⱼ₋₁, zₖ; χₗ=χₗ, w=w, u=u)
+ + χ_inbounds(xᵢ, yⱼ, zₖ₋₁; χₗ=χₗ, w=w, u=u)
+ + χ_inbounds(xᵢ₋₁, yⱼ, zₖ; χₗ=χₗ, w=w, u=u) )
+
+ end
+
+ return Σχ*Δx*Δy*Δz/8
+endm🪤 = mass🪤(x₂; lower=[-7.5,-7.5], upper=[7.5,7.5]) -
+ mass🪤(x₁; lower=[-1.5,-1.5], upper=[1.5,1.5]);The mass by trapezoidal rule is 55.77kg
+The obvious downside of this approach is that it integrates over regions that are outside the plume isosurface with the same resolution as regions within the plume. Getting a good result requires a very fine grid and calculating a great many points which are ultimately discarded.
+We can reduce the number of discards by taking advantage of what we know about the Gaussian plume: we know the vertical and crosswind isopleths. Introducing a change of variables \(\xi\), \(\zeta\) such that \(\xi \in [-1,1]\) and \(\zeta \in [-1,1]\) and
+\[ y = \sigma_y \sqrt{K} \xi \]
+\[ z = \sigma_z \sqrt{K} \zeta \]
+\[ +m_l = \iiint_{V} \chi dV = \int_{0}^{x_l} \int_{-1}^{1} \int_{-1}^{1} \begin{cases} + \sigma_y \sigma_z K \chi & \chi \ge \chi_l \\ + 0 & \chi \lt \chi_l + \end{cases} d\zeta d\xi dx +\]
+where \(K = 2 \log \left( w \over {2\pi u \sigma_y \sigma_z \chi_l } \right)\)
+This changes the domain of integration from a rectangular prism to one with a rectangular cross-section whose size is a function of \(x\). It is somewhat more efficient, and doesn’t require the user to pick a good bounding box.
+function mass🪤2(xₗ; N=100, w=w, u=u)
+ χₗ = χ(xₗ,0,0; w=w, u=u)
+ function integrand(x,ξ,ζ)
+ K = 2*log(w/(2π*u*σy(x)*σz(x)*χₗ))
+ y_lim = σy(x)*√(K)
+ z_lim = σz(x)*√(K)
+ y, z = y_lim*ξ, z_lim*ζ
+ I = y_lim*z_lim*χ_inbounds(x,y,z; χₗ=χₗ, w=w, u=u)
+ return isnan(I) ? 0.0 : I
+ end
+
+ x_a, x_b = 0.0, xₗ
+ ξ_a, ξ_b = -1.0, 1.0
+ ζ_a, ζ_b = -1.0, 1.0
+ Δx = (x_b - x_a)/N
+ Δξ = (ξ_b - ξ_a)/N
+ Δζ = (ζ_b - ζ_a)/N
+
+ Σχ = 0.0
+ for i in 1:N, j in 1:N, k in 1:N
+ xᵢ₋₁, xᵢ = x_a + (i-1)*Δx, x_a + i*Δx
+ ξⱼ₋₁, ξⱼ = ξ_a + (j-1)*Δξ, ξ_a + j*Δξ
+ ζₖ₋₁, ζₖ = ζ_a + (k-1)*Δζ, ζ_a + k*Δζ
+
+ Σχ += ( integrand(xᵢ₋₁, ξⱼ₋₁, ζₖ₋₁)
+ + integrand(xᵢ₋₁, ξⱼ₋₁, ζₖ)
+ + integrand(xᵢ₋₁, ξⱼ, ζₖ₋₁)
+ + integrand(xᵢ₋₁, ξⱼ, ζₖ)
+ + integrand(xᵢ, ξⱼ₋₁, ζₖ₋₁)
+ + integrand(xᵢ₋₁, ξⱼ₋₁, ζₖ)
+ + integrand(xᵢ, ξⱼ, ζₖ₋₁)
+ + integrand(xᵢ₋₁, ξⱼ, ζₖ) )
+
+ end
+
+ return Σχ*Δx*Δξ*Δζ/8
+endm🪤2 = mass🪤2(x₂) - mass🪤2(x₁);The mass by trapezoidal rule, with a change of variables, is 55.73kg
+This is still a very wasteful integration since it suffers from the curse of dimensionality. To come up with a somewhat reasonable answer requires evaluating the integrand \(8 \times N^3\) times. A large proportion of those evaluations are still being thrown out, as they are outside the region of interest.
+This could be sped up by parallelizing the calculations, which would allow for larger values of N to get more accurate results, but a more efficient approach is to use Monte Carlo integration.
+using MCIntegrationfunction mass🎲(xₗ; w=w, u=u)
+ χₗ = χ(xₗ,0,0; w=w, u=u)
+ function integrand(x,ξ,ζ)
+ K = 2*log(w/(2π*u*σy(x)*σz(x)*χₗ))
+ y_lim = σy(x)*√(K)
+ z_lim = σz(x)*√(K)
+ y, z = y_lim*ξ, z_lim*ζ
+ I = y_lim*z_lim*χ_inbounds(x,y,z; χₗ=χₗ, w=w, u=u)
+ return isnan(I) ? 0.0 : I
+ end
+
+ xξζ = CompositeVar(Continuous(0.0,xₗ),
+ Continuous(-1.0,1.0),
+ Continuous(-1.0,1.0))
+ res = integrate(((x, ξ, ζ), c)-> integrand(x[1],ξ[1],ζ[1]); var = xξζ)
+ return res.mean[1]
+endmass🎲 (generic function with 1 method)m🎲 = mass🎲(x₂) - mass🎲(x₁);Total iterations * blocks 160: 100%|██████| Time: 0:00:02 (17.37 ms/it)
+
+The mass by Monte Carlo, with a change of variables, is 56.36kg
+Both of these approaches have a similar relative error (spoilers!) but the Monte Carlo integration is much more efficient – in time and memory.
+using BenchmarkTools🪤res = @benchmark mass🪤2(x₂)BenchmarkTools.Trial: 1 sample with 1 evaluation per sample. + Single result which took 9.444 s (11.24% GC) to evaluate, + with a memory estimate of 9.10 GiB, over 607442648 allocations.+
🎲res = @benchmark mass🎲(x₂)BenchmarkTools.Trial: 30 samples with 1 evaluation per sample. + Range (min … max): 161.499 ms … 184.335 ms ┊ GC (min … max): 8.80% … 6.33% + Time (median): 165.566 ms ┊ GC (median): 10.62% + Time (mean ± σ): 167.251 ms ± 5.510 ms ┊ GC (mean ± σ): 10.25% ± 2.34% + ▃ ▃▃█ ▃▃▃▃ ▃ + █▁▁▇▇███▁████▇▇▇▁▁▁▇▇▁▁▇▁▁▁▇▇▁▁▁▁▇▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁█ ▁ + 161 ms Histogram: frequency by time 184 ms < + Memory estimate: 164.92 MiB, allocs estimate: 10748898.+
The only reason I included the trapezoidal rule is that I saw it suggested in an online resource that, on reflection, I think may have been AI slop and so I’m not linking to it (I was going to have a much longer diatribe here about it too, so consider yourself saved). The moral of the story is don’t use the trapezoidal rule for multidimensional integration unless you have some really compelling reason to do so.
+The advantage to the Monte Carlo approach given above is that it will work pretty much out of the box for any plume. The error will be smaller the more tightly the domain of integration can be bound around the region where \(\chi \ge \chi_l\), but it is in general pretty forgiving.
+The other standard approach for multi-dimensional integration is adaptive cubature, for example h cubature. This approach really only works well when the bounds of integration are constants (e.g. the limits \(y_l\) and \(z_l\) do not depend on \(x\)) and when the function being integrated does not have abrupt step changes. Taking the integrand from above and just running h cubature over it will be terribly inefficient.
+A better approach is to re-write the integral such that the integration is only over the region with \(\chi \ge \chi_l\), and with an integrand that is smooth and continuous throughout. Firstly we re-write the integral.
+\[m_l = \iint_V \chi dV = \int_0^{x_l} \iint_{\mathcal{E}} \chi dA dx \]
+\[ \mathcal{E} = \left\{ y, z \bigg\vert \left( y \over \sigma_y \right)^2 + \left( z \over \sigma_z \right)^2 \le K\left( x \right) \right\} \]
+ +
+Note that \(\mathcal{E}\) defines an ellipse, Figure 4, which suggests the change of variables \(\rho\), \(\theta\) such that
+\[ y = \sigma_y \sqrt{K} \rho \cos \theta \]
+\[ z = \sigma_z \sqrt{K} \rho \sin \theta \]
+and \(\rho \in [0,1]\), \(\theta \in [0, 2\pi]\)
+\[ m_l = \int_0^{x_l} \int_0^{2\pi} \int_0^1 \sigma_y \sigma_z K \chi \rho {d\rho} {d\theta} {dx} \]
+This can be integrated directly with h cubature without involving any discontinuous functions.
+using HCubature: hcubaturefunction mass📦(xₗ; w=w, u=u)
+ lower = [0.0, 0.0, 0.0]
+ upper = [1.0, 2π, xₗ]
+ χₗ = χ(xₗ,0,0; w=w, u=u)
+
+ function integrand(r)
+ (ρ,θ,x) = r
+ K = 2*(log(w) - log(2π*χₗ*σy(x)*σz(x)*u))
+ y = σy(x)*√(K)*ρ*cos(θ)
+ z = σz(x)*√(K)*ρ*sin(θ)
+ return σy(x)*σz(x)*K*χ(x,y,z; w=w, u=u)*ρ
+ end
+
+ I, err = hcubature(integrand, lower, upper)
+ return I
+endm📦 = mass📦(x₂) - mass📦(x₁);The mass by H cubature is 56.23kg
+📦res = @benchmark mass📦(x₂)BenchmarkTools.Trial: 208 samples with 1 evaluation per sample. + Range (min … max): 19.541 ms … 35.658 ms ┊ GC (min … max): 0.00% … 37.93% + Time (median): 25.003 ms ┊ GC (median): 19.48% + Time (mean ± σ): 24.127 ms ± 2.908 ms ┊ GC (mean ± σ): 13.37% ± 10.14% + ▁ ▄▂█▂ + ▄▆▇█▇▄▄▃▃▁▃▁▁▂▁▁▁▂▃▂█████▆▆▃▂▃▃▂▁▂▁▂▁▂▁▁▁▂▁▁▂▁▁▂▁▁▁▁▁▁▁▁▂▁▂ ▃ + 19.5 ms Histogram: frequency by time 34.2 ms < + Memory estimate: 23.05 MiB, allocs estimate: 1459221.+
This is both significantly more accurate (spoilers!) and a dramatic improvement in both compute time and memory useage. Though at a cost that this is not as easily adapted to other plume types. For example, a Gaussian plume at some height above the ground with ground-reflection does not have a nice clean expression for the lower plume extent and the change of variables to polar coordinates doesn’t work as nicely.
+You might get the sense now that I am leading you somewhere very specific. By choosing polar coordinates for the integration, and noting that for the Gaussian free plume the isopleths form an ellipse, it should immediately suggest that we could just…integrate this analytically. Substituting \(\rho\), \(\theta\) directly into the definition of \(\chi\) gives
+\[ m_l = \int_0^{x_l} \int_0^{2\pi} \int_0^1 \sigma_y \sigma_z K \chi \rho d\rho d\theta dx \]
+\[ = \int_0^{x_l} \int_0^{2\pi} \int_0^1 \sigma_y \sigma_z K \left( \frac{w}{2\pi u \sigma_y \sigma_z} \exp \left( -\frac{K}{2} \rho^2 \right) \right) \rho d\rho d\theta dx \]
+\[ = \int_0^{x_l} \int_0^{2\pi} \sigma_y \sigma_z \left[ \frac{w}{2\pi u \sigma_y \sigma_z} \left( 1 - \exp \left( -\frac{K}{2} \right) \right) \right] d\theta dx \]
+\[ = \int_0^{x_l} \frac{w}{u} \left( 1 - \exp \left( -\frac{K}{2} \right) \right) dx \]
+\[ m_l = \frac{w}{u} x_l - 2\pi \chi_l \int_0^{x_l} \sigma_y \sigma_z dx \]
+The last integral is a simple one dimensional integral which can be done with QuadGK.
+using QuadGK: quadgkfunction mass🔴(xₗ; w=w, u=u)
+ I, err = quadgk( t -> σy(t)*σz(t), 0, xₗ)
+ return (w/u)*xₗ - 2π*χ(xₗ,0,0; w=w, u=u)*I
+endmass🔴 (generic function with 1 method)m🔴 = mass🔴(x₂) - mass🔴(x₁);For the special case where \(\sigma_y = a x^b\) and \(\sigma_z = c x^d\) the integral can be done analytically to arrive at
+\[ m_l = { {b+d} \over {b+d+1} } \frac{w}{u} x_l \]
+Which is the result from Van Buijtenen8 given above. Similarly if we take \(\sigma_y \propto x\) and \(\sigma_z \propto x^{f_{z2}(L)}\) then
+\[ m_l = { {f_{z2}(L) +1} \over {f_{z2}(L)+2} } \frac{w}{u} x_l \]
+Which is the result from the TNO Yellow Book.9
+mₑ = (w/u)*((b+d)/(b+d+1))*(x₂ - x₁);The mass by QuadGK is 56.23kg, and the exact analytic solution is 56.23kg
+🔴res = @benchmark mass🔴(x₂)BenchmarkTools.Trial: 10000 samples with 1 evaluation per sample. + Range (min … max): 21.956 μs … 13.849 ms ┊ GC (min … max): 0.00% … 99.31% + Time (median): 29.064 μs ┊ GC (median): 0.00% + Time (mean ± σ): 29.891 μs ± 138.294 μs ┊ GC (mean ± σ): 4.60% ± 0.99% + ▁█▅▂ ▅█▇▅▂ + ▂▄▂▂▂▂▁████▆▄▃▂▂▃▃▇█████▇▅▄▃▂▂▂▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁ ▃ + 22 μs Histogram: frequency by time 43.7 μs < + Memory estimate: 24.86 KiB, allocs estimate: 1519.+
It is definitely a little bit of cheating to point out that the simple one-dimensional integral is much more performant than any of the three integrations of the whole volume, see Table 1.
+| + | Mass (kg) | +Error (%) | +Median Time (ms) | +
|---|---|---|---|
| Trapezoidal Rule | +55.73 | +0.9% | +9443.63 | +
| Monte Carlo | +56.36 | +0.23% | +165.57 | +
| H Cubature | +56.23 | +1.0e-8% | +25.0 | +
| QuadGK | +56.23 | +5.0e-10% | +0.03 | +
With a slight change, the integration over the cross-sectional area of a free plume can be modified to give us the mass in a grounded plume
+\[ m_g = \int_0^{x_l} \int_0^{\pi} \int_0^1 \sigma_y \sigma_z K_g \chi_g \rho d\rho d\theta dx \]
+where \(K_g = 2 \log \left( w \over {\pi u \sigma_y \sigma_z \chi_{g,l} } \right)\)
+\[ = \int_0^{x_l} \int_0^{\pi} \int_0^1 \sigma_y \sigma_z K_g \left( \frac{w}{\pi u \sigma_y \sigma_z} \exp \left( -\frac{K_g}{2} \rho^2 \right) \right) \rho d\rho d\theta dx \]
+\[ = \int_0^{x_l} \int_0^{\pi} \sigma_y \sigma_z \left[ \frac{w}{\pi u \sigma_y \sigma_z} \left( 1 - \exp \left( -\frac{K_g}{2} \right) \right) \right] d\theta dx \]
+\[ = \int_0^{x_l} \frac{w}{u} \left( 1 - \exp \left( -\frac{K_g}{2} \right) \right) dx \]
+\[ m_g = \frac{w}{u} x_l - \pi \chi_{g,l} \int_0^{x_l} \sigma_y \sigma_z dx = \frac{w}{u} x_l - 2 \pi \chi_{f,l} \int_0^{x_l} \sigma_y \sigma_z dx = m_f\]
+The masses within the free iso-surface and grounded iso-surface which intersect the x-axis at \(x_l\) are the same, as we expect, but the concentration which defines that iso-surface is not the same. An important distinction.
+You may have noticed the absence of the rigorous method given by Woodward in the analysis above. The rigorous method looks quite different from the previous integrations, but is similarly easy to calculate using QuadGK.
As a reminder the “rigorous” method given by Woodward for a free plume is
+\[ m_e = 4 \left( \chi_1 - \chi_2 \right) \int_{x_1}^{x_2} \sigma_y^2 E\left( k^2 \right) dx \]
+with \(k^2 = 1 - \left(\frac{\sigma_z}{\sigma_y}\right)^2\) and \(E\) the complete elliptic integral of the second kind.
+using SpecialFunctions: ellipek²(x) = 1 - (σz(x)/σy(x))^2k² (generic function with 1 method)I, err = quadgk( t -> σy(t)^2 * ellipe(k²(t)), x₁, x₂)(3522.359412198113, 4.6837135414534714e-7)m_rigorous = 4*(χ₁ - χ₂)*I;m_rigorous1853.438596397458That is far too high, it is 33.0× the exact solution and 18.5× the entire mass in the plume at x₂.
+Clearly this doesn’t work. So what’s gone wrong? Referring to the original paper by Hesse10 the mass is given as
+\[ m_e = \iiint_V \chi dV = \int_{x_1}^{x_2} \iint_{\mathcal{E}} \chi dA dx \]
+\[ \mathcal{E} = \left\{ y, z \bigg\vert K_1 \le \left(\frac{y}{\sigma_y}\right)^2 + \left(\frac{z}{\sigma_z}\right)^2 \le K_2 \right\} \]
+where \(\mathcal{E}\) is the area between the ellipses defined by \(\chi_1\) and \(\chi_2\).
+ +
+Hesse proposes that11 \[ \iint_{\mathcal{E}} \chi dA = \int_{\sigma_y \sqrt{K_1}}^{\sigma_y \sqrt{K_2}} \chi p\left( x,y \right) dy \]
+11 Hesse equation 20.
where \(p(x,y)\) is the perimeter of the elliptical isopleth in the y-z plane defined by the concentration \(\chi \left( x, y, 0 \right)\). That is to say, Hesse is integrating the cross-sectional area by treating it like a series of concentric, elliptical, rings with perimeter \(p\) and width \(dy\). For the free plume the perimeter is
+\[ p(x,y) = 4 y E \left( k^2 \right) \]
+Where \(E \left( k^2 \right)\) is the complete elliptic integral of the second kind with the elliptic modulus given by \(k^2 = 1 - \left(\frac{\sigma_z}{\sigma_y}\right)^2\), a constant with respect to \(y\) and \(z\).
+Substituting in and making the change of variables to \(\chi = \frac{w}{2\pi u \sigma_y \sigma_z} \exp \left( -\frac{1}{2} \left( \frac{y}{\sigma_y} \right)^2 \right)\)
+\[\iint_{\mathcal{E}} \chi dA = \int_{\sigma_y \sqrt{K_1}}^{\sigma_y \sqrt{K_2}} \chi p\left( x,y \right) dy \]
+\[ = 4 \int_{\sigma_y \sqrt{K_1}}^{\sigma_y \sqrt{K_2}} \chi y E \left( k^2 \right) dy \]
+\[ = 4 \int_{\chi_2}^{\chi_1} \chi y E \left( k^2 \right) { \sigma_y^2 \over {\chi y} } d\chi \]
+\[ = 4 \int_{\chi_2}^{\chi_1} \sigma_y^2 E \left( k^2 \right) d\chi \]
+\[ \iint_{\mathcal{E}} \chi dA = 4 \left(\chi_1 - \chi_2 \right) \sigma_y^2 E \left( k^2 \right) \]
+From here the remainder of the derivation follows rather obviously….Unfortunately, this doesn’t actually work as a method of integration. The problem is right at the very first step
+\[\iint_{\mathcal{E}} \chi dA \ne \int_{\sigma_y \sqrt{K_1}}^{\sigma_y \sqrt{K_2}} \chi p\left( x,y \right) dy \]
+To demonstrate this, consider the integration simply over the cross-sectional area. Hesse proposes that this relation holds
+\[ \iint_{\mathcal{E}} dA = \int_0^{a} 4 y E \left( k^2 \right) dy \]
+\[ \mathcal{E} = \left\{ y, z \bigg\vert \left(\frac{y}{a}\right)^2 + \left(\frac{z}{b}\right)^2 \le 1 \right\} \]
+\[ k^2 = 1 - \left(\frac{b}{a}\right)^2 \]
+That is, we should be able to use Hesse’s technique to recover the area of an ellipse, since he is integrating over an elliptical cross-section. However, since \(E \left( k^2 \right)\) is a constant, that’s not what we get:
+\[ A_{ellipse} = \int_0^{a} 4 y E \left( k^2 \right) dy \]
+\[ = 2 a^2 E \left( k^2 \right) \]
+But we know that the area of an ellipse is \(\pi a b\). The only case in which Hesse’s technique works is when \(a = b\), since \(E(0) = \frac{\pi}{2}\) (i.e. a circular cross-section).
+There is another glaring flaw with how this integration is being done. Even were it the case that the integration over the cross-section was correct, the axial integration is being done over the region where the cross-section is no longer well defined. The ellipse that defines the inner boundary of our cross-sectional domain of integration is not defined for \(x \gt x_1\). This is, in fact, the definition of \(x_1\) 12. The only region over which the integration even makes sense is from \(0 \le x \le x_1\), and yet the actual integration is being done over \(x_1 \lt x \lt x_2\).
+12 \(x_1\) is the point where \(K_1 = 0\), i.e. where the inner ellipse vanishes. At any point \(x \gt x_1\) there is no point in the plume where \(\chi = \chi_1\) and so the isopleth does not exist
Even if the cross-sectional integration was adjusted such that the innner ellipse is ignored, and so the problem of being undefined in the region \(x_1 \lt x \lt x_2\) is solved, it still doesn’t work because it excludes the mass in the plume between \(0 \le x \le x_1\) for which \(\chi_2 \le \chi \lt \chi_1\). Clearly from Figure 1 and Figure 2, this is not a negligible region.
+One might be tempted by the logic
+\[ m_e = m_2 - m_1 \]
+\[ = \int_{0}^{x_2} \iint_{\mathcal{E_2}} \chi dA dx - \int_{0}^{x_1} \iint_{\mathcal{E_1}} \chi dA dx \]
+\[ = \int_{x_1}^{x_2} \iint_{\mathcal{E}} \chi dA dx \]
+But that only works if \(\mathcal{E_1} = \mathcal{E_2}\), which is not the case in general.
+It is possible this was fixed in errata that did not make it into the final publication. Spicer and Havens13 also reference Hesse but note the inclusion of “important author errata distributed at the meeting where the paper was presented”. Regardless, what is published in Hesse and Woodward is wrong.
+For a screening level analysis I would use the relation
+\[ m_l = \frac{w}{u} x_l - 2\pi \chi_l \int_0^{x_l} \sigma_y \sigma_z dx \]
+to calculate the mass within an isosurface defined by \(x_l\). This gives some freedom in choice of dispersion parameters \(\sigma_y\) and \(\sigma_z\). The free plume choice is a useful simplification even when considering release points at some elevation where ground reflection is important. The free plume model, while ignoring the ground plane entirely, does capture much of the mass that would accumulate along the ground (by integrating over the region that “passes through” the ground in the free model).
+Something that may be worthwhile to explore is whether the mass within the isosurface that intersects the x-axis at \(x_l\) for a plume at some height \(h\) with ground reflection is also the same as the mass in the grounded and free plumes. One would expect the concentration along the centerline to be somwhere between that of the grounded and free plumes, so it is certainly suggestive when the mass within the two plumes is identical. I don’t seen an obvious way of doing this analytically, but it would be nice to have an answer to the question of “how wrong would I be if I just used the same \(m_l\) equation for everything?”
+ + + +November this year came in with a bang where I live: the temperature outside is currently -20°C, there is a pile of snow, and suddenly staying in and staying warm is a very important activity. At the same time, with COP27 taking place in Egypt, climate change is top of mind for everyone (Edmonton is evaluating its net zero strategy) and I thought it would be worthwhile to look at one of the largest sources of household energy use in Canada: space heating. Space heating accounts for 61.6% of household energy use, and in the province of Alberta that predominantly comes from burning natural gas. If we are going to meet our net zero goals as a municipality, we will need to address the carbon emissions that come from simply living here.
+A commonly bandied about tool for reducing household carbon emissions is hydrogen blending, such as this project in the Edmonton area. The idea is to gradually increase the hydrogen content of the natural gas and, since hydrogen burns without producing any carbon dioxide, the carbon emissions will decline. This has the obvious advantage of using the existing gas distribution infrastructure and existing appliances (e.g. people’s furnaces), thus avoiding costly retrofits.
+But is this actually a useful thing to do? A common criticism of hydrogen is its low energy density: for a given flowrate you would expect to get ~1/3 the energy from pure hydrogen than from natural gas (assuming you are combusting it). But hydrogen is also incredibly light and, since flowrate is \(\propto \frac{1}{\sqrt{\rho} }\), for the same pressure drop across a pipe you would expect a greater flowrate. So which is it? Does the energy content decrease, increase, or stay the same? Instead of just waving my hands and guessing, I thought it might be worthwhile to work through some simple calculations to get a sense of the scale of things.
+That said, it is rarely the case in engineering that decisions are clear cut. Blending hydrogen will have advantages and disadvantages, and whether the one out-weighs the other depends greatly on the particular location, its needs, infrastructure, and a host of other factors.
+The obvious place to start, and where I have found people often end, is with the heating value. For convenience I am going to use higher heating values, given here per standard cubic meter. Where standard in this case means at 15°C and 1atm.
+using Unitful
+
+# Standard State
+R = 8.31446261815324u"m^3*Pa/K/mol"
+Tᵣ = 288.15u"K"
+Pᵣ = 101325u"Pa"
+
+# Hydrogen, from the GPSA handbook, 13th ed.
+HHV_H2 = 12.109u"MJ/m^3"
+
+# Natural Gas, typical
+HHV_NG = 35.396u"MJ/m^3"We can use a simple mixing rule to determine what the heating value would be with x% hydrogen by volume.
+HHV(x) = x*HHV_H2 + (1-x)*HHV_NG +
+Which clearly shows that increasing the hydrogen content decreases the overall heating value of the fuel. At 100% hydrogen the fuel gas has lost ~66% of it’s heat content.
+Suppose you are a customer whose natural gas was transitioned entirely to hydrogen, now you are receiving about a third of the energy per unit volume than you were before. Well the obvious thing to do would be to increase the volume that you use (by a factor of three) to make up the difference. This does raise the obvious question of can you actually do that? Superficially, it looks like you are asking to triple the demand on the current infrastructure.
+The glaring omission with the previous analysis is that we know that flowrate, generally, is \(\propto \frac{1}{\sqrt{\rho} }\), and natural gas is something like 9× denser than hydrogen. So, you would expect, for the same pressure drop in the same pipes, that you would get around 3× the flow of hydrogen.
+Suppose we are only looking at the “last mile” of the distribution network, perhaps the pipe connecting your house to the main, reducing the problem to that of simple pipe flow. Assuming the flow is nearly isothermal, and an ideal gas, the mass velocity, G, of the fuel gas arriving at your house is given by:
+\[ G = \sqrt{ \rho_1 P_1 } \sqrt{ \left(1 - \left( P_2 \over P_1 \right)^2 \right) \over { K - 2\log \left( P_2 \over P_1 \right)} } \]
+Where 1 is the point just after the tee and 2 is the point just before your meter (e.g. a straight length of pipe). The volumetric flow rate, Q, at the upstream point 1, is then given by
+\[ Q_1 = {\pi \over 4} D^2 {G \over \rho_1} \]
+which, when corrected to the reference (standard) state is
+\[ Q_s = Q_1 \cdot {v_{r} \over v_1} \]
+Where v is the ideal gas molar volume (RT/P), a constant independent of the gas.
+The heat rate, q, is simply the higher heating value times the volumetric flowrate (at standard state)
+\[ q = HHV \cdot Q_s = HHV \cdot {\pi \over 4} D^2 \sqrt{P_1 \over \rho_1} \sqrt{ \left(1 - \left( P_2 \over P_1 \right)^2 \right) \over { K - 2\log \left( P_2 \over P_1 \right)} } \cdot {v_{r} \over v_1} \]
+This looks like a lot however most of that is a constant, i.e. it is a function of the system and not the gas moving through it.
+\[ q = { HHV \over \sqrt{\rho_1} } \times \textrm{a constant} \]
+So, assuming a constant pressure drop, along an identical pipe, with fully developed turbulent flow (i.e. K is constant) the ratio of heat delivered by hydrogen to that of natural gas is given by:
+\[ { q_{H_2} \over q_{NG} } = { HHV_{H_2} \over HHV_{NG} } \sqrt{ \rho_{NG} \over \rho_{H_2} } = { HHV_{H_2} \over HHV_{NG} } \sqrt{ MW_{NG} \over MW_{H_2} }\]
+# Hydrogen
+MW_H2 = 2.016e-3u"kg/mol"
+
+# Natural Gas
+MW_NG = 19.5e-3u"kg/mol"
+
+heat_ratio = (HHV_H2/HHV_NG)*√(MW_NG/MW_H2)1.0639620426132184So in total opposition to what we expected from merely looking at energy density we now expect, for the same system operating at the same pressures, to receive slightly more energy when transitioned over to pure hydrogen.
+But what about the in-between, when hydrogen is blended into natural gas? Is it just a straight line connecting these two?
+We can explore this more closely by first looking at how density, and thus volumetric flowrate, changes with the hydrogen content. I am assuming an ideal gas case and so the mixing rule is quite simple
+\[ \rho = x_{H_2} \rho_{H_2} + x_{NG} \rho_{NG} \]
+where, for an ideal gas
+\[ \rho = MW {P \over {R T} } \]
+giving
+\[ \rho = {P \over {R T} } \left( x_{H_2} MW_{H_2} + x_{NG} MW_{NG} \right)\]
+# ideal gas density
+ρ(x, T, P) = (P/(R*T))*( x*MW_H2 + (1-x)*MW_NG ); +
+So we have two competing effects: as the mole fraction increases the heating value of the gas decreases but at the same time the flowrate increases. We can explore this further by plotting the ratio of the heat rate with blended fuel gas to the heat rate with straight natural gas.
+# heat rate for blended fuel gas relative to natural gas
+q_ratio(x) = (HHV(x)/HHV_NG)*√(ρ(0,Tᵣ,Pᵣ)/ρ(x,Tᵣ,Pᵣ)); +
+Initially the loss of heating value “wins out” and increasing the hydrogen content merely decreases the energy supplied at a given pressure. But once the stream is predominantly hydrogen, the lower density takes over and the heat rate increases.
+The minimum ratio can be found by setting the derivative to zero
+using ForwardDiff: derivative
+using Roots: find_zero
+
+∂q_ratio(x) = derivative(q_ratio,x)
+xₘᵢₙ = find_zero(∂q_ratio,(0,1))
+
+xₘᵢₙ, q_ratio(xₘᵢₙ)(0.7106211503798253, 0.8839840357969662)Initially, blending hydrogen decreases the overall energy delivered, bottoming out at ~12% less, when hydrogen makes up 71% of the fuel gas. While this is not the 66% decline predicted by a naive look at energy density, neither is it nothing.
+Another important point is where the ratio becomes one: the concentration where the blended hydrogen fuel gas reattains the energy content of the original natural gas stream
+xₑᵥₑₙ = find_zero( (x)-> q_ratio(x)-1, (xₘᵢₙ,1))0.9684672945947692The system doesn’t recover the original energy supply until the hydrogen content is >96.8%, at which point a whole host of other concerns may become more relevant – burning pure and nearly pure hydrogen comes with its own issues.
+The whole point of doing this is to decrease the carbon emissions associated with space heating (plus the other uses of household natural gas, but mostly space heating). So it is worth circling back to answer the question: does this actually do that? and by how much?
+The dominant greenhouse gas associated with combustion is carbon dioxide, and the carbon dioxide emissions from combustion are fairly easy to calculate from stoichiometry, for a generic hydrocarbon the combustion equation is
+\[ C_n H_m + \left( n + {m \over 4} \right) O_2 \rightarrow n CO_2 + {m \over 2} H_2 O \]
+If we presume the natural gas is mostly methane and n≈1, then there is one mole of carbon dioxide produced per mole of natural gas delivered (assuming perfectly complete combustion). When combusting hydrogen there is no carbon dioxide produced, and so the moles of carbon dioxide produced from the combustion of a blended hydrogen fuel gas is
+\[ \dot{n}_{CO_2} = \left( 1 - x_{H_2} \right) \dot{n}_{FG} \]
+Where \(\dot{n}\) is the molar flowrate. We don’t actually know the molar flowrate of fuel gas, but we can calculate it from the ideal gas law and the volumetric flowrate at standard state Qs
+\[ \dot{n}_{FG} = {P_r \over {R T_r} } Q_s \]
+\[ \dot{n}_{CO_2} = \left( 1 - x_{H_2} \right) {P_r \over {R T_r} } Q_s \]
+What we want is the mass flowrate of carbon dioxide, so simply multiply both sides by the molar weight
+\[ \dot{m}_{CO_2} = \left( 1 - x_{H_2} \right) MW_{CO_2} {P_r \over {R T_r} } Q_s \\ = \left( 1 - x_{H_2} \right) \rho_{CO_2,r} Q_s \]
+If we assume that the users of fuel gas are using a fixed amount of energy, regardless of the actual flowrate, then what we want is the carbon intensity of the fuel: how much carbon dioxide is emitted per Megajoule of heat generated?
+\[ E = \frac{\dot{m}_{CO_2} }{q} = { {\left( 1 - x_{H_2} \right) \rho_{CO_2,r} Q_s} \over {HHV(x) Q_s} } = { { \left( 1 - x_{H_2} \right) \rho_{CO_2,r} } \over {HHV(x)} }\]
+# Carbon Dioxide
+MW_CO2 = 44.009e-3u"kg/mol"
+ρ_CO2 = MW_CO2*Pᵣ/(R*Tᵣ)
+
+E(x) = (1-x)*ρ_CO2/HHV(x) +
+So there are emissions reductions but at a cost, beyond whatever method is used to generate the hydrogen in the first place. The system must be operated at greater pressures to supply the same amount of energy, which itself takes some energy, at least until the hydrogen exceeds 96.8%. At that high level the system seems like an easy win: it takes less pressure to supply the same amount of energy and the emissions intensity is a ~8.7% that of natural gas (a ~91% reduction)
+E(xₑᵥₑₙ)/E(0)0.08690379085511468There are a few caveats with this: for one carbon dioxide is not the only significant greenhouse gas that comes from combustion, nitrous oxide is also produced and has a global warming potential ~300× that of carbon dioxide. Unlike carbon dioxide, nitrous oxide is producded when hydrogen is combusted with air because, like many other nitrogen oxides, it is generated from the high temperature reaction of the nitrogen and oxygen from the air. So burning pure hydrogen is only net zero for very particular definitions of zero, it is not net zero greenhouse gas emissions though it is net zero carbon emissions.
+So far the analysis has completely ignored the material issues that hydrogen brings. At high temperatures (such as, say, inside a furnace that is burning hydrogen) high temperature hydrogen attack is a real concern and using hydrogen as a fuel gas would eventually destroy most burners that were designed for use with natural gas. Similarly hydrogen embrittlement would be a concern for the entire system, wherever steel is used. Neither of these are insurmountable but they would require extensive retrofitting with different materials and special alloys. This dampens a lot of the advantages of hydrogen blending, namely being able to use the existing infrastructure.
+To skip over the details (I’m not a materials engineer), I think it is fair to say that the mechanical integrity of the system is strongly dependent on the hydrogen content and it likely will be a limiting factor in any hydrogen blending project.
+At the level of “back of the envelope” calculations like I have done above, it is fairly clear that blending hydrogen into the utility natural gas system is not a panacea, but then neither is it completely infeasible. I think there are several other factors that need to be considered when evaluating the possible role of hydrogen blending in the future energy mix:
+Personally I think hydrogen’s role in the future is over-hyped. A lot of people working in the fossil fuel space have pinned their industry’s future on hydrogen, which comes with a certain amount of motivated reasoning. Also hydrogen is appealing as it looks like the easy solution: swap the burning of one fuel for the burning of another, and we don’t have to make sweeping and systemic change, except that hydrogen brings its own host of issues (low energy density, material incompatibility). I think the answer will turn out not to be one silver bullet, like hydrogen, but an entire ecosystem of different technologies, often hyper specific to different locations, and what will connect them all will be the electrification of everything. That said, we have a vast, globe spanning, infrastructure and centuries of know-how in burning things and that gives hydrogen a big leg-up as a transitional solution.
+I thought I would end with a basic pipe flow example, if you wanted to look at specific numbers this is how you might start that. This is also an example of the life changing magic of solving problems with code: once you have solved them once you never have to solve them again. Since I have frequently worked out pipe flow problems with julia, I can throw together a more detailed than is at all necessary model through the magic of copying and pasting.
+We’ve already worked out the mixture density and heating value, and the next most important material property is viscosity. I don’t have a curve for natural gas, so I am just going to use methane as a proxy. I am already treating natural gas like a homogeneous substance, so this is simply an extension of that.
+using UnitfulCorrelations
+
+# Hydrogen - from Perry's, 8th ed.
+μ_H2(T) = (1.797e-7*T^0.685)/(1-0.59/T+140/(T^2));
+@ucorrel μ_H2 u"K" u"Pa*s"
+
+# Methane (Natural Gas) - from Perry's, 8th ed.
+μ_NG(T) = (5.2546e-7*T^0.59006)/(1+105.67/T);
+@ucorrel μ_NG u"K" u"Pa*s"Where I have used a macro that I wrote previously to turn correlations into correlations with units.
+At standard conditions the viscosity of hydrogen and that of natural gas (methane) are not too different, so we can get away with using a simple method for estimating the viscosity of the overall mixture.
+μ_H2(Tᵣ)/μ_NG(Tᵣ)0.8004989026814741I happen to already have Wilke’s method for a binary mixture worked out, I just need to swap in what the two components are. A more fulsome analysis would have a complete composition of natural gas (broken down into methane, ethane, propane, etc.) in which case the generalized Wilke’s method could be used as well.
+# mixture viscosity using Wilke method
+# from *The Properties of Gases and Liquids* 5th ed.
+function μ(x,T)
+ μ₁ = μ_H2(T)
+ M₁ = MW_H2
+ y₁ = x
+
+ μ₂ = μ_NG(T)
+ M₂ = MW_NG
+ y₂ = 1-x
+
+ ϕ₁₂ = ((1+√((μ₁/μ₂)*√(M₂/M₁)))^2)/√(8*(1+(M₁/M₂)))
+ ϕ₂₁ = ϕ₁₂*(μ₂/μ₁)*(M₁/M₂)
+
+ μ = (y₁*μ₁/(y₁+y₂*ϕ₁₂)) + (y₂*μ₂/(y₂+y₁*ϕ₂₁))
+ return μ
+end; +
+For the sake of having something to calculate I am just assuming a 20m length of 2in steel pipe. But you could put in really anything here.
+# Pipe dimensions
+L = 20u"m" # length
+D = 52.5u"mm" # diameter
+ϵ = 0.0457u"mm" # roughness
+
+A = 0.25*π*D^2 # cross-sectional area
+l = L/D # relative length
+κ = ϵ/D # relative roughnessThe Reynold’s number is simply a function of the mass velocity, G, the pipe diameter, D, and the mixture viscosity μ
+# Reynold's number
+Re(x,T,G) = G*D/μ(x,T);I am using my favourite correlation for the Darcy friction factor, f,
+# Churchill correlation, from Perry's
+function churchill(Re)
+ A = (2.457 * log(1/((7/Re)^0.9 + 0.27*κ)))^16
+ B = (37530/Re)^16
+ return 8*((8/Re)^12 + 1/(A+B)^(3/2))^(1/12)
+end;Since this is just a straight length of pipe, the K factor is simply fL/D, defaulting back to the Nikuradse rough pipe law for fully developed turbulent flow (i.e. very high Reynold’s numbers)
+Kf() = l/(2*log10(3.7/κ))^2 # Nikuradse
+Kf(Re) = l*churchill(Re) # ChurchillThe volumetric flowrate for an isothermal ideal gas is simply the mass velocity, G, multiplied by the cross sectional area and divided by the density GA/ρ. It is very easy to modify some code I had previously written to solve for the volumetric flowrate.
+# Isothermal ideal gas pipeflow
+function Q₁(x, T₁, P₁, P₂, K::Number)
+ ρ₁ = ρ(x, T₁, P₁)
+ v̄₁ = 1/ρ₁
+ q = P₂/P₁
+ Q₁ = A*√((v̄₁*P₁*(1-q^2))/(K-2*log(q)))
+ return upreferred(Q₁)
+end
+
+function Q₁(x, T₁, P₁, P₂, K::Function)
+ # Initialize Parameters
+ ρ₁ = ρ(x, T₁, P₁)
+ q = P₂/P₁
+
+ # Initial Guesses
+ Q₀ = Q₁(x, T₁, P₁, P₂, K())
+ G₀ = Q₀*ρ₁/A
+
+ # Numerically solve for G
+ obj(G) = (K(Re(x,T₁,G))- 2*log(q))*(G^2) - ρ₁*P₁*(1-q^2)
+ G = find_zero(obj, G₀)
+
+ return upreferred(G*A/ρ₁)
+endThis uses julia’s multiple dispatch to handle two cases: for large Reynold’s numbers where K is a constant, and for cases where K is a function of the Reynold’s number (and thus the volumetric flowrate).
+The volumetric flowrate at standard state is then the flowrate from above, corrected to the reference pressure and temperature1
+1 I have been using upreferred to force Unitful to cancel out and simplify units.
Qₛ(x, T₁, P₁, P₂) = upreferred((P₁/Pᵣ)*(Tᵣ/T₁)*Q₁(x, T₁, P₁, P₂, Kf))The heat rate is then the heating value, already worked out, times the volumetric flowrate at standard state
+q(x, T₁, P₁, P₂) = HHV(x)*Qₛ(x, T₁, P₁, P₂) +
+We see the same ordering that we expect, given the previous analysis, namely that the 0% and 100% cases are pretty close to each other, followed by the in-between hydrogen contents.
+Another way of looking at this is to pick a required heat rate and look at the pressure drop as a function of hydrogen content.
+ +
+All of this has been done assuming the ideal gas case. The next logical step is to start incorporating non-ideal gas models, say a cubic equation of state, and so on.
+Previously I evaluated hydrogen as a fuel gas from the perspective of an end user – someone who purchases utility natural gas, at pressure, for use in combustion devices like boilers and heaters. From that perspective, hydrogen is not an unreasonable conversion, with material compatibility being the primary concern. In this post I’m going to look at it from the perspective of the gas utility.
+From my previous analysis, I showed that the same piping operating at the same pressures delivers approximately the same energy, in terms of higher heating value, in systems in full hydrogen service as those in natural gas service. So, for an end user of natural gas (such as me, it’s how I heat my home) making some modifications to the fired equipment and getting a stream of hydrogen versus natural gas is a plausible pathway to low-carbon heating. That doesn’t entirely hold up for utility providing the gas, however, as there is an additional cost associated with compressing hydrogen over natural gas, which might make such systems impractically expensive to operate. At least that is the question I’m looking to answer here: is distributing hydrogen fuel gas to residential or industrial customers through a distribution network like natural gas feasible or not?
+The full economic analysis of hydrogen as a fuel gas versus some other low carbon source of energy would so strongly depend on local factors – the local cost of electricity versus hydrogen, whether that region is subject to a carbon tax and how that tax works, etc. – that I don’t think much can be generalized. The economics of hydrogen, where I live, where natural gas is abundant and widely used, export infrastructure is limited, and the carbon tax largely excludes all but the largest industrial emitters, is pretty different from a place where all natural gas is imported at large expense, or with a very different approach to carbon pricing.
+We already know that natural gas distribution systems are feasible, there is one delivering natural gas to my house right now and it is also delivering natural gas to the chemical plant I work at, the gas fired power plant that is powering my laptop right now, etc. To some extent we also already know that hydrogen distribution systems are feasible as they already exist, the longest hydrogen transmission pipeline in Europe is >1000km long and there are >700km of hydrogen pipelines in the United States.1 However those are primarily for supplying hydrogen as a feedstock to chemical and petrochemical facilities, not quite the same use case as hydrogen as a fuel gas.
+A reasonable approach to answering this question is to compare a hypothetical hydrogen transmission system to a natural gas system. This is basically what I’ve already done for pipe-flow when looking at hydrogen blending: once the hydrogen is in the pipe and at pressure, everything works from that point down. What remains to be seen is whether it is feasible to get it into the pipe and at pressure. Specifically how much more work does it take to compress hydrogen to line pressure than natural gas?
+The standard equation for determining the work, \(\dot{w}_{g}\), to compress a mass flowrate \(\dot{m}\) of gas from a pressure of \(p_1\) to \(p_2\) is234
+4 Strictly speaking this is an approximation as it neglects the change in kinetic energy of the fluid, but for small compression ratios, less than ~5, it is appropriate
\[ +\dot{w}_{g} = \dot{m} \int_{p_1}^{p_2} v dp +\]
+This is related to the isentropic work through the isentropic efficiency, \(\varepsilon_{i}\)
+\[ +\varepsilon_{i} \dot{w}_{g} = \dot{m} \int_{p_1}^{p_2} v dp \vert_{isentropic} +\]
+Where the integral of the specific volume \(v\) is taken along an isentropic path. Real compressors are not isentropic, but compressor manufacturers provide tables or figures giving the isentropic efficiency, with values of 70% - 80% being fairly typical.
+I am going to assume that whatever efficiency can be achieved for a standard natural gas compressor can also be achieved with a hydrogen compressor. They may be different compressors, but the isentropic efficiency is something of a design choice. The ratio of work for a hydrogen system to a natural gas system, \(r\), is then
+\[ +r = { {\dot{w}_{g}}_{H2} \over {\dot{w}_{g}}_{NG} } = { \left( \varepsilon_{i} \dot{w}_{g} \right)_{H2} \over \left( \varepsilon_{i} \dot{w}_{g} \right)_{NG} } = { \left( \dot{m} \int_{p_1}^{p_2} v dp \right)_{H2} \over \left( \dot{m} \int_{p_1}^{p_2} v dp \right)_{NG} } +\]
+The integrals, though, do not have to be tackled directly, recalling the differential for (specific) enthalpy
+\[ +dh = v dp + T ds +\]
+Integrating from state 1 to state 2 along an isentropic path (i.e. \(ds = 0\)) gives:
+\[ +\int_{h_1}^{h_2} dh = h_2 - h_1 = \int_{p_1}^{p_2} v dp +\]
+Thus the ratio we’re looking for is given by:
+\[ +r = { \dot{m}_{H2} \over \dot{m}_{NG} } { {\Delta h}_{H2} \over {\Delta h}_{NG} } +\]
+It is important to note that state 2 is not the same for hydrogen and natural gas. Since the integration is along an isentropic path, state 2 is at a pressure of \(p_2\) and a temperature \(T_2\) defined by \(s_1 = s_2\) and the entropy of hydrogen and natural gas are, in principle, different.
+Compressors typically don’t raise pressures all the way from, say, atmospheric pressure to the 200-1500psi working pressures of natural gas transmission lines in a single stage. For one, as gases are compressed they heat up and that large temperature rise can damage a compressor. Usually compression is accomplished with a series of stages with interstage cooling. This work ratio is really only valid for a single stage.
+Suppose we are evaluating a system that uses a multi-stage compressor to take gas at ambient conditions, in this case suppose 1bar and 15C, to a relatively high transmission line pressure of 100bar using 4 stages, Figure 1. The overall compression ratio is 100, with 3 stages this gives a per stage ratio of
+\[\begin{align} +\eta_t &= 100\;\text{ }(\text{total compression ratio}) +\\[10pt] +n &= 3\;\text{ }(\text{number of stages}) +\\[10pt] +\eta &= \eta_t^{\frac{1}{n}} +\\[10pt] +&= 100^{\frac{1}{3}} +\\[10pt] +&= 4.64 +\end{align}\]
+ +
+Suppose, for simplicity, the interstage coolers bring the gas temperature down to 15C:
+With the inlet gas to each stage being at 15C and exiting at some temperature which is determined from the energy balance and isentropic efficiency.
+The total work required to compress the gas is then
+\[ +r_{T} = { \dot{m}_{H2} \over \dot{m}_{NG} } { \left( {\Delta h}_{1 \to 2} + {\Delta h}_{3 \to 4} + {\Delta h}_{5 \to 6} \right)_{H2} \over \left( {\Delta h}_{1 \to 2} + {\Delta h}_{3 \to 4} + {\Delta h}_{5 \to 6} \right)_{NG} } +\]
+A useful first approach to most problems in life5 is to assume an ideal gas. It allows one to build some intuition about the problem and how fluid non-ideality may change the results. Starting with an ideal gas in stream 1 being isentropically compressed to stream 2,6 and equating the specific enthalpies
+5 for chemical engineers at least
\[ +s_0 + \int_{T_0}^{T_1} {c_p \over T} dT - R \log { p_1 \over p_0 } = s_0 + \int_{T_0}^{T_2} {c_p \over T} dT - R \log { p_2 \over p_0 } +\]
+Assuming \(c_p\) is a constant this simplifies to
+\[ +c_p \log{ T_2 \over T_1 } = R \log{p_2 \over p_1} +\]
+For an ideal gas \(c_p - c_v = R\), giving
+\[ +\log{T_2 \over T_1} = { {c_p - c_v} \over c_p} \log{ p_2 \over p_1} +\]
+\[ +{T_2 \over T_1} = \left( p_2 \over p_1 \right)^{1 - \frac{1}{k}} +\]
+A well known result. The enthalpy of an ideal gas with constant \(c_p\) is just \(c_p T\), so we have:
+\[ +\Delta h = c_p \Delta T = c_p \left( T_2 - T_1 \right) +\]
+\[ += c_p T_1 \left( {T_2 \over T_1} -1 \right) +\]
+\[ += c_p T_1 \left( \left( p_2 \over p_1 \right)^{1 - \frac{1}{k}} - 1 \right) +\]
+From the ideal gas law, \(T = \frac{pv}{R}\)
+\[ +\Delta h = \frac{c_p}{R} p_1 v_1 \left( \left( p_2 \over p_1 \right)^{1 - \frac{1}{k}} - 1 \right) +\]
+\[ += {k \over {k-1}} p_1 v_1 \left( \left( p_2 \over p_1 \right)^{\frac{k-1}{k}} - 1 \right) +\]
+Which allows us to write the work ratio, for a single stage, compressing an ideal gas with constant heat capacity, as:
+\[ +r = { \dot{m}_{H2} \over \dot{m}_{NG} } { {v_1}_{H2} \over {v_1}_{NG} } {C_{NG} \over C_{H2}} { { \eta^{C_{H2}} -1 } \over { \eta^{C_{NG}} - 1} } +\]
+where \(C = \frac{k-1}{k}\). From the ideal gas law the ratio of specific volumes is just the ratio of molar weights \[ +{ {v_1}_{H2} \over {v_1}_{NG} } = { MW_{NG} \over MW_{H2} } +\]
+\[ +r = { \dot{m}_{H2} \over \dot{m}_{NG} } { MW_{H2} \over MW_{NG} } {C_{NG} \over C_{H2}} { { \eta^{C_{H2}} -1 } \over { \eta^{C_{NG}} - 1} } +\]
+and, since the inlet streams are all at the same temperature
+\[ +r_T = r +\]
+Furthermore, if we assume \(k_{NG} \approx k_{H2}\) then
+\[ +r = { \dot{m}_{H2} \over \dot{m}_{NG} } { MW_{NG} \over MW_{H2} } +\]
+This is where I’ve encountered what I consider a serious error: assuming an equal mass flowrate of the two fuels. Making this assumption gives
+\[ +r = { MW_{NG} \over MW_{H2} } +\]
+using Unitful, Clapeyronideal_hydrogen = ReidIdeal(["hydrogen"])
+ideal_natural_gas = ReidIdeal(["methane"])\[\begin{align} +MW_{NG} &= 16.04\,\mathrm{kg}\,\mathrm{kmol}^{-1} +\\[10pt] +MW_{H2} &= 2.02\,\mathrm{kg}\,\mathrm{kmol}^{-1} +\\[10pt] +r &= \frac{MW_{NG}}{MW_{H2}} +\\[10pt] +&= \frac{16.04\,\mathrm{kg}\,\mathrm{kmol}^{-1}}{2.02\,\mathrm{kg}\,\mathrm{kmol}^{-1}} +\\[10pt] +&= 7.94 +\end{align}\]
+This gives a work ratio of 7.9, leading us to conclude that it will take 7.9× the power to run a hydrogen transmission system than a similar natural gas system.
+I think this is a mistake because the goal is not to deliver the same mass flowrate but the same thermal energy (combustion energy). Supposing we are seeking to deliver the same energy in terms of higher heating value
+\[ +hv_{H2} \dot{m}_{H2} = hv_{NG} \dot{m}_{NG} +\]
+\[ +{ \dot{m}_{H2} \over \dot{m}_{NG} } = { hv_{NG} \over hv_{H2} } +\]
+and so
+\[ +r = { hv_{NG} \over hv_{H2} } { MW_{NG} \over MW_{H2} } +\]
+where \(hv\) is the specific higher heating value (or gross heating value)
+\[\begin{align} +hv_{NG} &= 55.58\,\mathrm{MJ}\,\mathrm{kg}^{-1}\;\text{ }(\text{GPSA Handbook}) +\\[10pt] +hv_{H2} &= 141.95\,\mathrm{MJ}\,\mathrm{kg}^{-1}\;\text{ }(\text{GPSA Handbook}) +\\[10pt] +r &= \frac{hv_{NG}}{hv_{H2}} \cdot \frac{MW_{NG}}{MW_{H2}} +\\[10pt] +&= \frac{55.58\,\mathrm{MJ}\,\mathrm{kg}^{-1}}{141.95\,\mathrm{MJ}\,\mathrm{kg}^{-1}} \cdot \frac{16.04\,\mathrm{kg}\,\mathrm{kmol}^{-1}}{2.02\,\mathrm{kg}\,\mathrm{kmol}^{-1}} +\\[10pt] +&= 3.11 +\end{align}\]
+This gives a work ratio of 3.1, quite a bit smaller of an estimate.
+But the assumption that \(k_{H2} \approx k_{NG}\) is perhaps not a good one, so we should explore how compression effects differ even as ideal gases.
+k(gas) = isobaric_heat_capacity(gas, 1u"bar", 288.15u"K") /
+ isochoric_heat_capacity(gas, 1u"bar", 288.15u"K")\[\begin{align} +k_{H2} &= 1.41\;\text{ }(\text{Clapeyron.jl, at 1bar and 15C}) +\\[10pt] +C_{H2} &= 1 - \frac{1}{k_{H2}} +\\[10pt] +&= 1 - \frac{1}{1.41} +\\[10pt] +&= 0.29 +\\[10pt] +k_{NG} &= 1.31\;\text{ }(\text{Clapeyron.jl, at 1bar and 15C}) +\\[10pt] +C_{NG} &= 1 - \frac{1}{k_{NG}} +\\[10pt] +&= 1 - \frac{1}{1.31} +\\[10pt] +&= 0.23 +\\[10pt] +r_{ig} &= \frac{hv_{NG}}{hv_{H2}} \cdot \frac{MW_{NG}}{MW_{H2}} \cdot \frac{C_{NG} \cdot \left( \eta^{C_{H2}} - 1 \right)}{C_{H2} \cdot \left( \eta^{C_{NG}} - 1 \right)} +\\[10pt] +&= \frac{55.58\,\mathrm{MJ}\,\mathrm{kg}^{-1}}{141.95\,\mathrm{MJ}\,\mathrm{kg}^{-1}} \cdot \frac{16.04\,\mathrm{kg}\,\mathrm{kmol}^{-1}}{2.02\,\mathrm{kg}\,\mathrm{kmol}^{-1}} \cdot \frac{0.23 \cdot \left( 4.64^{0.29} - 1 \right)}{0.29 \cdot \left( 4.64^{0.23} - 1 \right)} +\\[10pt] +&= 3.25 +\end{align}\]
+This gives a work ratio of 3.25, which shows that our original approximation was reasonable: accounting for differences in isentropic expansion factor, \(k\), changes our estimate by only 5.0%.
+To account for non-ideality we need to lose some generality. The ideal gas case ultimately doesn’t depend on what the initial and final conditions are (since all of that cancels out) but for real gases how non-ideal they are depends strongly on the actual pressures and temperatures of the system.
+I am going to use a volume translated Peng Robinson cubic equation of state for both hydrogen and methane.
+real_hydrogen = PR(["hydrogen"];
+ idealmodel=ReidIdeal,
+ alpha=TwuAlpha,
+ translation=PenelouxTranslation)real_natural_gas = PR(["methane"];
+ idealmodel=ReidIdeal,
+ alpha=TwuAlpha,
+ translation=PenelouxTranslation)Clapeyron.jl does not define functions for finding the enthalpy as a function of pressure and entropy, so we will need to first find the isentropic temperature, and then calculate the enthalpy.
using Roots: find_zero
+
+function isentropic_temperature(gas, p1, T1, p2)
+ s1 = entropy(gas, p1, T1)
+ k_ig = k(gas)
+ T2_guess = T1*(p2/p1)^(1-1/k_ig)
+ T2 = find_zero( T -> entropy(gas, p2, T) - s1, T2_guess)
+ return T2
+endFirst, the specific enthalpy difference for hydrogen
+\[\begin{align} +p_{1} &= 1\,\mathrm{bar} +\\[10pt] +T_{1} &= 288.15\,\mathrm{K} +\\[10pt] +p_{2} &= 4.64\,\mathrm{bar} +\\[10pt] +T_{2H2} &= 447.3\,\mathrm{K}\;\text{ }(\text{Clapeyron.jl}) +\\[10pt] +H_{1H2} &= -283.16\,\mathrm{J}\,\mathrm{mol}^{-1}\;\text{ }(\text{Clapeyron.jl}) +\\[10pt] +H_{2H2} &= 4344.03\,\mathrm{J}\,\mathrm{mol}^{-1}\;\text{ }(\text{Clapeyron.jl}) +\\[10pt] +{\Delta}h_{H2} &= \frac{H_{2H2} - H_{1H2}}{MW_{H2}} +\\[10pt] +&= \frac{4344.03\,\mathrm{J}\,\mathrm{mol}^{-1} + 283.16\,\mathrm{J}\,\mathrm{mol}^{-1}}{2.02\,\mathrm{kg}\,\mathrm{kmol}^{-1}} +\\[10pt] +&= 2290.68\,\mathrm{kJ}\,\mathrm{kg}^{-1} +\end{align}\]
+Then the specific enthalpy difference for natural gas
+\[\begin{align} +T_{2NG} &= 404.45\,\mathrm{K}\;\text{ }(\text{Clapeyron.jl}) +\\[10pt] +H_{1NG} &= -369.79\,\mathrm{J}\,\mathrm{mol}^{-1}\;\text{ }(\text{Clapeyron.jl}) +\\[10pt] +H_{2NG} &= 4015.67\,\mathrm{J}\,\mathrm{mol}^{-1}\;\text{ }(\text{Clapeyron.jl}) +\\[10pt] +{\Delta}h_{NG} &= \frac{H_{2NG} - H_{1NG}}{MW_{NG}} +\\[10pt] +&= \frac{4015.67\,\mathrm{J}\,\mathrm{mol}^{-1} + 369.79\,\mathrm{J}\,\mathrm{mol}^{-1}}{16.04\,\mathrm{kg}\,\mathrm{kmol}^{-1}} +\\[10pt] +&= 273.41\,\mathrm{kJ}\,\mathrm{kg}^{-1} +\end{align}\]
+Finally, the work ratio of compressing hydrogen versus natural gas
+\[\begin{align} +r_{rg} &= \frac{hv_{NG}}{hv_{H2}} \cdot \frac{{\Delta}h_{H2}}{{\Delta}h_{NG}} +\\[10pt] +&= \frac{55.58\,\mathrm{MJ}\,\mathrm{kg}^{-1}}{141.95\,\mathrm{MJ}\,\mathrm{kg}^{-1}} \cdot \frac{2290.68\,\mathrm{kJ}\,\mathrm{kg}^{-1}}{273.41\,\mathrm{kJ}\,\mathrm{kg}^{-1}} +\\[10pt] +&= 3.28 +\end{align}\]
+In this case the ideal gas law estimate and the estimate using a cubic equation of state differ by only 1.0%.
+ +
+The difference does become more pronounced at higher pressures, see Figure 2, but even at stage three the work ratio for the real gases differs from the ideal gas case by only 6.0%.
+In online discussions I have seen it claimed that the difference in work – why so much more energy is required to compress hydrogen over natural gas – is due to some obscure feature of hydrogen’s phase diagram. I would say that is false. The main reason why hydrogen requires more energy to compress is simply due to its low molecular weight. That hydrogen has a high energy density, on a mass basis, offsets this greatly when hydrogen and natural gas are compared on an equivalent energy basis, though.
+There are additional effects that make hydrogen even more difficult to compress than you would expect, from a pure ideal gas analysis, but they are pretty small unless the working pressures are either huge or the compression ratio is tremendous. Neither of which are particularly relevant for a gas transmission system using normal compressors and typical pipeline pressures.
+I wrote this post to address some misconceptions that I’ve encountered regarding hydrogen7 and in particular the rhetorical device of finding one single fact about hydrogen and taking that to mean some project or another has been “debunked”. Real engineering projects are just too complex for that to be a useful exercise. Reality always depends on a great many factors.
+7 is this all just an extended response to a thread on mastodon? I mean… sort of
Is the fact that a hydrogen fuel distribution system would require >3× the energy to operate mean that such a system is impractical? That really depends. It could be that a large, continent spanning, transmission system for hydrogen such as natural gas distribution employs in North America is rendered totally infeasible by the increased power demands. But then again, why should hydrogen be so geographically constrained? Natural gas is constrained by geology but presumably one could make green hydrogen wherever there is water and renewable power. Perhaps blue hydrogen is best built on top of the existing natural gas infrastructure – send natural gas across the continent and convert it to hydrogen closer to the end use. I am doubtful that one could come up with a sweeping conclusion from all of this that would say anything beyond one’s ignorance of the specific conditions of niche industries and use cases for hydrogen versus the panoply of alternative low carbon energy sources.
+I think the dreams of existing gas fired power plants simply retrofitting to hydrogen and continuing on as before are looking increasingly like a relic from a bygone era. The price of renewables and storage continues to plumet and the economics of these schemes seem increasingly out of touch with that reality. But for other industries, with other heating demands, perhaps there is a compelling case to be made.
+I say all of this as someone who is broadly skeptical of the hype around hydrogen. I think it is being pursued mostly as a saviour of fossil fuels and not as a technology that actually best solves the problems which face us as we transition to a low carbon future. But there are also a lot of really smart engineers working on projects centered around low-carbon hydrogen, and I imagine they know what they are doing.
+Continuing on a series of posts on hydrogen of sorts, this post is on modelling hydrogen releases for risk assessment. Industry in many places, and in Alberta in particular, is looking to hydrogen as a key component of the transition to a low carbon future. This means that, suddenly, there will by hydrogen pressure equipment in a lot of process areas where it wasn’t before, as fuel gas.
+Hydrogen presents an interesting challenge for hazard analysis as it is lighter than air, rising and accumulating in places a more standard analysis would neglect. In my experience, the typical release modelling tools are for neutrally buoyant or negatively buoyant (heavier than air) gas releases, such as Gaussian plume models or dense gas models like SLAB, DEGADIS, and PHAST. They are not designed for, and may not accurately capture, the dispersion of hydrogen.
+Dense gas models typically assume cloud dynamics that are particular to denser than air clouds, with limiting behavior that brings the results in line with a neutrally buoyant release. Denser than air clouds pile up around the source, leading to dispersion upwind of the source, and have sharper cloud fronts than a more neutral cloud. These features are often written into the governing equations for plume dispersion from the outset.
+Neutral and positive buoyancy plume models typically account for buoyancy differences only through temperature as they are generally intended for hot stack gases and not low molecular weight gases. For example, the standard implementation of Brigg’s plume-rise in tools like ISC3 use only the temperature of the source to calculate the buoyant flux – implicitly assuming the molar weight of the gas is similar to that of air. The original Ooms model1 for positively buoyant plumes also only accounts for buoyancy differences due to temperature. These models would erroneously conclude that a stream of cold hydrogen gas would be heavier than air and would thus sink.
+This leaves a lot of room for integral plume models that better handle the behaviour of low molecular weight gases. One such model is incorporated into HyRAM+, from Sandia National Laboratories in the United States.2 It includes an integral plume model for positively buoyant plumes that accounts for differences in buoyancy by molar weight in addition to temperature, and was designed with hydrogen dispersion in mind.
+HyRAM+ is implemented in python, with a Windows GUI, though I will be using it directly in a jupyter notebook. Partly because I use linux at home, but also I am interested in how one would use the plume dispersion and other tools independently. I’m interested in the use case where this is integrated into an existing process safety management system and what is needed are specific values from a consequence analysis such as the explosive mass.
+Just for something to play around with, consider the case of a leak from a hydrogen cylinder into the ambient air. Suppose a cylinder containing 50kg of hydrogen at 35MPa has fallen over and the valve has broken, creating a leak from a 1/4 in. hole at essentially ground level and is oriented at 45° upwards. The hydrogen is initially at ambient temperature and the ambient air is at standard conditions and is otherwise quiescent.
+ +
+Using the HyRAM+ API we can create the ambient air, air, and hydrogen, h2, fluid models at initial conditions.
import numpy as np
+import hyram.phys.api as api
+import hyram.phys as hpTa, Pa = 288.15, 101325
+air = api.create_fluid("Air", Ta, Pa)
+
+Th2, Ph2 = Ta, 35e6
+h2 = api.create_fluid("Hydrogen", Th2, Ph2)The broken valve is initialized as an Orifice object, which has a diameter and a discharge coefficient. In this case I assume the discharge coefficient is 0.6.
d_H = 25.4e-3/4 # mm
+c_d = 0.6 # assumed
+theta = np.pi/4
+orifice = hp.Orifice(d_H, c_d)The jet is modeled, by HyRAM+, as as a steady-state jet consisting of 3 distinct zones:3
+The jet is created by initializing a Jet object, which solves the zones and integrates the governing equations to determine the plume center-line.
HyRAM+ has several internal models for solving the notional nozzle, the default is the model by Yüceil and Ötügen and is selected with the keyword parameters nn_conserve_momentum=True and nn_T='solve_energy'
jet = hp.Jet(h2, orifice, air, theta0=theta,
+ nn_conserve_momentum=True,
+ nn_T='solve_energy',
+ verbose=True)solving for orifice flow... done
+solving for notional nozzle... done.
+integrating... done.With this done, we can retrieve the mass flow-rate (in kg/s)
+jet.mass_flow_rate0.4024272255826383We can compare this to a simple ideal gas model of an adiabatic orifice5
+\[ \dot{m} = c_d A_h \sqrt{ \rho_1 p_1 k \left( 2 \over k+1 \right)^{k+1 \over k-1} } \]
+A_h = (np.pi/4)*d_H**2
+k = 1.41
+
+ideal_gas_jet = c_d*A_h*np.sqrt( h2.rho*h2.P*k*pow(2/(k+1),(k+1)/(k-1)) )
+
+ideal_gas_jet0.37797876222402915jet.mass_flow_rate/ideal_gas_jet1.0646821086315916The HyRAM+ model is estimating a ~6% greater mass flow rate through the orifice than a simple ideal gas jet model. From an end user perspective, this adds a dimension of realism to the model without requiring really anything more from the user. There are probably several opportunities to use more realistic fluid models, elsewhere in the standard literature of hazard analysis, that haven’t been realized more for reasons of tradition and laziness than anything else.
+In the past, modelling an isentropic nozzle with a real gas from scratch was a pain as there is a lot of overhead in implementing a more realistic equation of state. Especially gathering all of the relevant model parameters. With libraries like CoolProp, it really drops the barrier for incorporating more realistic fluid models into ones calculations.
For hydrogen, the hazard we are most concerned with is fires and explosions. Conveniently, we can retrieve the lower flammability limit (LFL) for hydrogen without needing to look it up ourselves.
+lfl = hp.FuelProperties(h2.species).LFLand calculate the distance, along the plume center-line, to the LFL
+streamline_dists = jet.get_streamline_distances_to_mole_fractions([lfl])
+
+streamline_dists[0]19.655324152591245similarly we can retrieve the x-y coordinates of the plume extent, out to the LFL
+mole_frac_dists = jet.get_xy_distances_to_mole_fractions([lfl])
+
+mole_frac_dists{0.04: [(0, 13.734800620965242), (0, 14.201255169630102)]}
and, finally, calculate the flammable mass in the steady-state jet.
+jet.m_flammable()0.2789535809847125The next obvious thing we want to do is plot the actual plume dispersion, to do this we retrieve the x-y coordinates and corresponding mass fraction (X), mole fraction (Y), velocity (v) and temperature (T) fields.
+x, y, X, Y, v, T = jet._contourdatawe can use matplotlib to plot the concentrations and highlight the contour corresponding to the LFL
+
Above I walked through the steps using the physics models included in HyRAM+, but if what you want is just the final plot and some basic parameters for QRA there is a much easier way: use the analyze_plume_jet model in the HyRAM+ API.
plume = api.analyze_jet_plume(air, h2,
+ orif_diam=d_H,
+ rel_angle=theta,
+ dis_coeff=c_d,
+ nozzle_model='yuce',
+ contours=lfl,
+ xmin=0.0,
+ xmax=60,
+ ymin=0.0,
+ ymax=75,
+ vmin=0,
+ vmax=2*lfl,
+ output_dir='figures',
+ filename='h2_plume_fig.png')
By default this outputs a file, instead of plotting directly into the notebook, and does not allow for as much control of the final figure. But it returns the necessary arrays if you wanted to do your own thing.
+The mass flow-rate, distance along the streamline to the LFL, and contour of the LFL are also retrievable.
+plume['mass_flow_rate']0.4024272255826383plume['streamline_dists'][0]19.655324152591245plume['mole_frac_dists']{0.04: [(0, 13.734800620965242), (0, 14.201255169630102)]}This does not return a Jet object, it returns a Dict with just the contours of the plume and some distances, so I am not entirely sure how one would get the explosive mass. This isn’t obviously exposed through the API either.
An important limitation, from a usability standpoint, is that there is no obvious way to retrieve the concentration for a given point. Suppose you have some coordinates x, y, z and you really need to know what the hydrogen concentration will be at that location specifically. HyRAM+ is not really set up to answer that question, or at least that functionality is not obviously exposed to the user. You could take the arrays of x and y points used for generating the plots, do a 2D-interpolation, and work it out from there, but that is kind of clunky.
+Another limitation of this model, if it is being used for process equipment outdoors, is that there is no accounting for wind. Ambient conditions are always assumed to be quiescent. This leads to less dispersion than you would expect were wind included, and may over-estimate the degree to which the plume will rise and disperse vertically.
+Another, more major limitation, is that there is no accounting for the ground. For large releases, near ground level, it may not be obvious that mass is being lost through the ground, and not accumulating as you would actually expect. For example, taking the above scenario and setting the release angle to 45° downward, the jet simply disappears into the earth. In reality the hydrogen should accumulate along the ground, or reflect off with some momentum. Releases near ground-level, with shallow release angles relative to horizontal, may have hazardous build-ups in areas, and that is being neglected by this model.
+plume = api.analyze_jet_plume(air, h2,
+ orif_diam=d_H,
+ rel_angle=-theta,
+ dis_coeff=c_d,
+ nozzle_model='yuce',
+ contours=lfl,
+ xmin=0,
+ xmax=60,
+ ymin=-65,
+ ymax=10,
+ vmin=0,
+ vmax=2*lfl,
+ output_dir='figures',
+ filename='h2_downward_plume_fig.png')
For integral plume dispersion models, like this one, it is typical to restrict the plume center-line such that it cannot extend below the ground, i.e. any integration step that would have a center-line with y<0 is rejected and replaced with one with y≥0. It is also common to implement ground reflection where the plume dispersion “bounces off” the ground, perfectly elastically.
+Preventing the plume from passing through the ground is strictly necessary for denser than air models, for example DEGADIS, as the plume naturally falls to ground level and rolls along it. That perhaps explains why HyRAM+ doesn’t implement this, the plume will naturally rise away from the ground due to the relative density of hydrogen. However, since HyRAM+ assumes the plume is on the ground by default, this strikes me as a significant trap for users. Shallow release angles will have non-physical results in the immediate vicinity of the jet.
+An important feature of this tool is that it allows one to easily model the accumulation of a buoyant layer along the ceiling in an enclosed space. Suppose, to continue the example, this happened in my workroom, which for the sake of simplicity is just a 4m × 4m room with 2.7m (9ft) ceiling. While the explosive mass in the steady state plume is pretty small, the lfl extent of the unconfined plume extends much further than the walls of my room. The hydrogen will hit the far wall and accumulate quite significantly.
+ +
+The blowdown of the hydrogen cylinder will take some time and the exact blowdown curve is necessary for determining how rapidly the hydrogen will accumulate in the room. Assuming the jet it at the initial steady state mass-rate throughout will be very conservative and the entire contents of the cylinder will be gone within a few seconds.
+HyRAM+ uses the governing equations for adiabatic blow-down.
+\[ \frac{dm}{dt} = -c_d A \rho v \]
+\[ \frac{du}{dt} = \frac{1}{m} \frac{dm}{dt} \left( h - u \right) \]
+where m is the mass remaining in the tank, u is the specific internal energy, h the specific enthalpy, and v the velocity through an isentropic nozzle. The thermodynamic state variables (P, T) are recovered from the fluid model and the internal energy, u, and the density ρ = m/V.
+First the cylinder is defined as a Source with an initial mass of hydrogen.
m_h2 = 50 #kg
+cylinder = hp.Source.fromMass(m_h2,h2)Then the cylinder can be blown down through the orifice previously defined. This numerically integrates the governing equations and returns the mass, pressure, temperature, and flowrate as functions of time.
A convenience function can also plot them for us.
+cylinder.empty(orifice)
+
+cylinder.plot_time_to_empty()
At this point the release is still unconfined. We need to define the room. This also includes defining the location of vents. Since no room is perfectly leak free, and for the sake of an example, I assume a similar leak area for a vent near the ceiling and one near the floor. I also define the cylinder as leaking from ground level essentially at one wall and aimed 45° upwards towards the opposite wall.
+ceiling_height = 2.7 #m
+floor_area = 16 #m^2
+release_height = 0 #m
+
+ceiling_vent = hp.Vent(A_h,2.6)
+floor_vent = hp.Vent(A_h,0.01)
+
+room = hp.Enclosure(ceiling_height, floor_area, release_height, ceiling_vent, floor_vent, Xwall=4)The release model then estimates the accumulation of a flammable layer starting at the roof and extending downwards.
+release = hp.IndoorRelease(source=cylinder,
+ orifice=orifice,
+ ambient=air,
+ enclosure=room,
+ theta0=theta,
+ nn_conserve_momentum=True,
+ nn_T='solve_energy',
+ tmax=30,
+ verbose=False)
+
+release.plot_mass()
At this point I thought, initially, that there was something wrong with the code. Why does the flammable mass suddenly disappear? Where does it go? Nowhere. HyRAM+ by default assumes the flammable mass is between the LFL and UFL. At around 15 seconds the room is essentially saturated with hydrogen and above the UFL, hence why it suddenly disappears. This can be seen by plotting the flammable layer at the ceiling.
+release.plot_layer()
By 15 seconds the layer reaches the floor and the entire room is above the UFL. Some recommend not cutting off at the UFL, this room is still quite hazardous, say if someone opened a door there would be an explosive mixture right in the door-frame that could explode and that explosion would mix with the rest of the gas and the whole mass of released hydrogen could explode.
+To consider the flammable mass to be the mixed area above the LFL and include areas that exceed the UFL, the X_lean and X_rich keyword arguments must be used.
full_release = hp.IndoorRelease(source=cylinder,
+ orifice=orifice,
+ ambient=air,
+ enclosure=room,
+ theta0=theta,
+ X_lean=lfl,
+ X_rich=1.0,
+ nn_conserve_momentum=True,
+ nn_T='solve_energy',
+ tmax=30,
+ verbose=False)
+
+full_release.plot_mass()
This whole analysis can also be accomplished using the API and the analyze_accumulation function. It outputs a series of plots into a given folder, including calculating the jet trajectories for a series of user selected times.
api.analyze_accumulation(amb_fluid=air,
+ rel_fluid=h2,
+ tank_volume=cylinder.V,
+ orif_diam=d_H,
+ rel_height=release_height,
+ enclos_height=ceiling_height,
+ floor_ceil_area=floor_area,
+ ceil_vent_xarea=A_h,
+ ceil_vent_height=2.6,
+ floor_vent_xarea=A_h,
+ floor_vent_height=0.01,
+ dist_rel_to_wall=4.0,
+ tmax=30,
+ times=[1,5,15,20,25,30],
+ orif_dis_coeff=c_d,
+ rel_angle=theta,
+ nozzle_key='yuce',
+ output_dir="figures/accumulation"){'status': 1,
+ 'pressures_per_time': array([ 388375.73527918, 3092893.44785494, 0. ,
+ 0. , 0. , 0. ]),
+ 'depths': array([1.34306015, 2.41226448, 2.45803334, 2.45809352, 2.4631503 ,
+ 2.46359848]),
+ 'concentrations': array([18.58049761, 43.85233797, 81.37521187, 89.24254417, 93.32644083,
+ 95.79735125]),
+ 'overpressure': 8136855.548411997,
+ 'time_of_overp': 11.970055170861283,
+ 'mass_flow_rates': array([0.3978773 , 0.38039983, 0.3417355 , 0.32307435, 0.30734882,
+ 0.29251744]),
+ 'pres_plot_filepath': 'figures/accumulation/pressure_plot_20240921-132132.png',
+ 'mass_plot_filepath': 'figures/accumulation/flam_mass_plot_20240921-132132.png',
+ 'layer_plot_filepath': 'figures/accumulation/layer_plot_20240921-132132.png',
+ 'trajectory_plot_filepath': 'figures/accumulation/trajectory_plot_20240921-132132.png',
+ 'mass_flow_plot_filepath': 'figures/accumulation/time-to-empty_20240921-132132.png'}




One limitation that stuck out to me, in the blowdown model, is that the blowdown is either at a constant heat flux or adiabatic (which is constant at zero). Blowdown models where the vessel is isothermal are fairly typical, especially for large (un-insulated) vessels blowing down through a small valve. For small vessels, assuming an adiabatic blowdown is reasonable, but this limits the model as the vessels get larger.
+If you are looking for a quick and easy-to-use tool for performing hazard analysis of hydrogen releases, HyRAM+ is worth checking out. I haven’t gone into it here, but the tool allows you to continue the analysis into blast over-pressure and a much more fully featured QRA. They python library allows you to split out each piece of the model, allowing you to really explore what it is doing, but also making it easier to pull out relevant pieces for comparison to other hazard analysis tools one might be using in a plant setting.
+The indoor accumulation model is worth exploring, for sites that are transitioning to hydrogen, as most “screening level” indoor accumulation models I have seen consider either a heavier-than-air layer along the ground or the entire indoor space (or zone, if it divides the area into zones) having one, fully-mixed, concentration. So it is possible that the standard plant tools for, e.g., LOPA may have blind spots for the unique hazards that hydrogen can present (e.g. accumulating as a flammable layer along the ceiling).
+For chemical plants that also operate a cogen, they may already have hydrogen venting into the air in an indoor space: large turbines (>60MW) typically use hydrogen coolant. It might be worthwhile running a HyRAM+ model for that venting just to confirm that the small quantities vented into the turbine hall are not an issue. While this may be a well known and well understood aspect of turbine operations, for people in the power business, process safety engineers tend to gasp and clutch their chests when told of routine venting of flammable and explosive gases into enclosed spaces.
+While bowling, this week, an interesting question came up: is it possible to get every score from 1 to 450 in a game of five pin bowling? Or, to flip it around, is there a score that you can never get no matter how fancy your bowling? The answer is not immediately obvious!
+Five pin bowling uses five pins but, unlike ten pin bowling, the pins are worth different amounts. Notably no pin is worth 1, and so a score of 1 is the first impossible score.
+ +
+Like ten pin bowling, if a strike or a spare is recorded in a given frame then the scores of subsequent ball(s) are counted in that frame, as well as the frame in which they were thrown. So, for example, if I throw a strike in the first frame I don’t actually know what to write on the score sheet for the first frame until the second, and possibly third, frames have been thrown. I know it is at least 15, but until I throw the next ball it could be anything up to 45. This was what initially gave me pause. It adds a layer of complexity since the possible scores for a given frame depend on what happens next.
+By symmetry, though, this way of scoring is equivalent to every strike and spare adding a multiplier to the next frame, and each frame is just scored counting whatever the pinfall is and applying the multiplier (no looking backwards). So, if I throw a strike in the first frame, then I record a 15 for the first frame and double count the next two balls. If I have thrown two strikes in a row then I triple count the first subsequent ball and double count the next one. This is a weird way of managing a score sheet, for bowlers, but makes it a lot easier to reason about the possible scores, since you don’t have to constantly be looking back two or three frames. This passing forward score sheet looks different to a regular one: The maximum score for the first frame is now 15, and for the second frame 30, and in the tenth frame it is possible to score 90 points. On a conventional score sheet the max score in any frame is 45.
+While hanging out at the lanes a few obvious impossible scores got thrown out: a 1, obviously, but also a 449 – there’s no way to throw a 14 with the last ball in the tenth frame. But the question still lingered: are there any other gaps? It was not immediately obvious, to my bowling team, how you would figure that out without checking.
+Maybe we can brute-force this and try every conceivable bowling game? However there are a lot of possible bowling games. As a first pass, there are thirty balls thrown in a game and each ball has up to fourteen possible pinfall scores (0 through 15 excluding 1 and 14). This would give 1430 possible bowling games. Even if it took a single nanosecond to evaluate each game that would take longer than the current age of the universe to work through.
+But that’s not a great upper bound, it doesn’t take into account the rules of bowling: you can only knock down up to five pins in any given frame, for example if the first ball scores a 13 then the second ball doesn’t get to choose from fourteen possibilities, it gets to chose from two: 0 and 2. Still, it is going to be a large number. The vast majority of those games are going to be completely redundant, since we are only looking for scores from 2 to 450.
+I was thinking about this some more and there is a different way of looking at this that gives a better estimate for the number of possible games.
+First let’s consider a single frame (within the first 9 frames). The order that pins are knocked down – the score per ball – matters because of the way strikes and spares are counted. So we are trying to answer the question “how many ways can 5 pins be divided into 4 categories (hit by ball 1, 2, or 3, or left standing)?” This is the sum of a multinomial and is well known, for n objects divided into m categories, the number of ways is \(m^n\): \(4^5 = 1024\)
+The tenth frame has some extra rules, so lets go through it:
+| Frame | +Number of Possibilities | +description | +
|---|---|---|
| ? ? ? | +1024 | +Any combination of the first set of 5 pins | +
| X ? ? | +35 -1 = 242 | +Every follow up to a strike except X–, which has already been counted in ??? | +
| X X ? | +25 -1 = 31 | +Every follow up to 2 strikes except XX-, which has already been counted in X?? | +
| ? \ ? | +25 × (25-1) = 992 | +Every follow up to every spare except ?\- which were counted in ??? | +
Which gives 2289 possible ways of bowling the 10th frame.
+So this gives a total count of possible 5 pin bowling games of \(2289 \times 1024^9\) which is about \(2.8 \times 10^{30}\)
+The easiest case to look at is when one never throws a strike or spare. In this case the possible scores for each frame are the same: just what you can get from knocking down any subset of the pins. This happens to be anything from 0 to 15 except 1 and 14. That’s easy enough to see just by inspection.
+This also leads to a (kinda loose) argument for why you should be able to get anything from 0 to 150 except 1 and 149:
+Suppose you are playing game with n frames and your goal is a score \(x \le 15 n\).
+If \(x \not \equiv 1 (\textrm{mod} 15)\) and \(x \not \equiv 14 (\textrm{mod} 15)\) then you can always get from a multiple of 15 to the final score in one frame.
+If \(x \equiv 1 (\textrm{mod} 15)\) or \(x \equiv 14 (\textrm{mod} 15)\) then you can’t get from a multiple of 15 to the final score in one frame, this is because you cannot score 1 or 14 in one frame. You can score 1 more than a multiple of 15 if you have two frames remaining: score a 13 in the first and a 2 in the next. Similarly you can score 1 less than a multiple of 15 if you have two frames remaining: score a 7 in the first frame and a 7 in the second.
+Since for any x such that \(1 \lt x \le 15 (n-1)\) there are \(\ge 2\) frames remaining, all of those scores can thus be achieved.
+What remains is the x such that \(15(n-1) \lt x \lt 15 n\) and \(x \equiv 14 (\textrm{mod} 15)\), this single score is not achievable in a game with no strikes and spares.
+Which is all to say there are only two impossible scores: 1 and 15n -1 or 149 in a standard ten frame game.
+I suspect that, if you wanted to put the work in, you could extend this argument to include spares and strikes, with all of the complications around how the 10th frame is scored. But an alternative is to just look through all possible scores and try and find a game that achieves it, using this general approach as a guide.
+This is pretty easy to do when only looking at the case where there are no strikes or spares: I generate a list of possible scores for a single frame (a possible move I can take towards my goal), sorted largest to smallest.
+basic_moves = [ n for n in range(16) if n not in [1,14] ]
+basic_moves.reverse()Then I define a function that recursively walks through the tree of possible games, always picking the largest viable move at each frame. If it finds an answer it returns it (in reverse order), if it exhausts the possible moves then it returns an empty list.1
+1 This code stops once it has found a single valid solution, it could be extended very easily to find every valid solution, however the space of possible games is huge.
def make_moves(cur_frame, cur_score, max_frame, target, moves=basic_moves):
+ if cur_frame == max_frame:
+ return [0] if cur_score == target else []
+ else:
+ next_frame = cur_frame + 1
+ mn, mx = min(moves), max(moves)
+ n = max_frame - next_frame
+ r = target - cur_score
+ for move in filter(lambda x: n*mn <= (r-x) <= n*mx, moves):
+ new_score = cur_score + move
+ advance = make_moves(next_frame, new_score, max_frame, target, moves)
+ if len(advance) > 0:
+ advance.append(move)
+ return advance
+ else:
+ return []Looping through all the scores: \(0 \le score \le 150\) yields the impossible to bowl scores.
+for score in range(151):
+ game = make_moves(0,0,10,score)
+ if len(game) == 0:
+ print("Score {0} is not possible".format(score))Score 1 is not possible
+Score 149 is not possibleWhich is what I expected, good news as I will be building off this general strategy for the cases where strikes and spares are included.
+Another question that comes to mind is: what if you were restricted to always hitting a pin, no gutter balls? Now you can’t get a score less than 7 (equivalent to hitting 2-2-3, the lowest pins). Does this change anything?2
+2 In five pin it is actually possible to bowl between the pins and hit nothing without it technically being a gutter ball, and you can bowl into the blank spots left by pins that were already knocked down to score zeros without putting it in the gutter. I am using the term gutter ball loosely.
Probably I could go back and look at the math again, but the nice thing about having written code is that I can just change the space of possible moves and run it again.
+no_gutters = [ n for n in range(7,16) if n != 14 ]
+no_gutters.reverse()for score in range(70,151):
+ game = make_moves(0,0,10,score,no_gutters)
+ if len(game)==0:
+ print("Score {0} is not possible, with no gutters".format(score))Score 149 is not possible, with no guttersSo nothing really changes. I mean you can’t get a score <70, obviously, but this doesn’t open up any gaps in possible scores either.
+It does mean the strategy changes, now the code takes the biggest strides it can until the remainder is a multiple of 7 then runs out the game with a string of 7s.3
+3 You may have noticed an extra “frame” at the end with a score of 0. This is because, in five pin bowling, the last frame has special rules. You always get 3 balls in the last frame, even if your first two are a strike or spare. In this case, with no strikes or spares allowed by design, that extra scoring doesn’t enter into it.
[ frame for frame in reversed(make_moves(0,0,10,100,no_gutters)) ][15, 15, 15, 13, 7, 7, 7, 7, 7, 7, 0]Adding in spares means I can’t easily track the state of each frame with an integer, like I did for the case with deadwood every frame. Now I need to track three different properties for a given frame:
+Instead of diving into the full set of scoring rules for everything, I’m going to take one baby step forward and add in a data structure to track the state of the frame and select from two sets of possibilities for the subsequent frame: was there a spare or not?
+The data structure I’m using is just a struct, tracking the score, whether it is a “special” frame and whether or not it is the end of the game.
+class SingleFrame:
+ def __init__(self, score, special=None, end=False):
+ self.score = score
+ self.special = special
+ self.end = endInstead of a list of integers for possible moves, I now need a list of possible SingleFrame objects that represent a possible frame, now including the possibility of a spare. Note the pass forward approach to scoring: a spare in a regular frame is only worth 15.
single_frame_moves = [ SingleFrame(score) for score in basic_moves ]
+single_frame_moves.insert(0, SingleFrame(15,"spare"))Now I iterate through the possible first, second, and third balls for a frame following a spare. There are more possible scores here since the first ball will be double counted. First I exhaustively generate every combination then use set() to extract only the unique elements. For this purpose it doesn’t matter how many ways you can get a given score.
spares = [ 2*f+s for f in basic_moves
+ for s in filter(lambda x: f+x==15,basic_moves)]
+
+spares = list(set(spares))
+spares.sort(reverse=True)
+
+non_spares = [ 2*f+s+t for f in basic_moves
+ for s in filter(lambda x: f+x<15, basic_moves)
+ for t in filter(lambda x: f+s+x<=15, basic_moves) ]
+
+non_spares = list(set(non_spares))
+non_spares.sort(reverse=True)Now I generate a list of moves by combining the spares and non-spares. They are arranged such that the code tries the spares first before the non-spares, going from largest to smallest. There are now 42 possible ways of scoring a frame when spares are included (versus only 14 when they aren’t).
+spare_frame_moves = [ SingleFrame(score,"spare") for score in spares ]
+spare_frame_moves += [ SingleFrame(score) for score in non_spares ]
+
+len(spare_frame_moves)42There are only two scores that are not achievable in the frame following a spare: 1 and 29
+[ s for s in range(31) if s not in [x.score for x in spare_frame_moves] ][1, 29]Adding spares has also complicated determining if a move is valid or not. Since scoring now depends on the state of a given move – is it a spare or not – this impacts the bounds of possible scores that can follow any given move. Instead of putting this all into the same function, as I did before, I have broken it out into its own function that decides, given a move, a remaining number of frames, and a remaining number of points to pick up, is the move valid.4
+4 There is an extra move at the end because of the last frame rule: A spare at the start of the last frame leads to an extra ball, but one that can only count for up to 15.
def valid_spare_moves(move, n, r, mn=0, mx=15):
+ if move.special=="spare":
+ up = (2*n + 1)*mx
+ else:
+ up = (1 + 2*max(n-1,0) + 1)*mx
+
+ return n*mn <= (r - move.score) <= upThe bulk of the main function is the same. The one exception is that it now tracks whether the previous frame was a spare (with was_spare) and uses this to determine how to finish the last frame: if the last frame was a spare, then an extra ball is thrown but with no multiplier.
def make_spare_moves(cur_frame, cur_score, max_frame, target,
+ moves=single_frame_moves, was_spare=False):
+ if cur_frame == max_frame:
+ if cur_score == target:
+ return [SingleFrame(0,False,True)]
+ elif was_spare and (target - cur_score) in basic_moves:
+ # extra ball in the last frame
+ return [SingleFrame(target-cur_score,False,True)]
+ else:
+ return []
+ else:
+ next_frame = cur_frame + 1
+ n = max_frame - next_frame
+ r = target - cur_score
+ for move in filter(lambda x: valid_spare_moves(x,n,r), moves):
+ new_score = cur_score + move.score
+ if move.special == "spare":
+ next_moves = spare_frame_moves
+ else:
+ next_moves = single_frame_moves
+
+ advance = make_spare_moves(next_frame, new_score, max_frame, target, next_moves, move.special=="spare")
+ if len(advance) > 0:
+ advance.append(move)
+ return advance
+ else:
+ return []Looping through all the scores: \(0 \le score \le 300\) yields the impossible to bowl scores, when spares are allowed.
+for score in range(301):
+ game = make_spare_moves(0,0,10,score)
+ if len(game)==0:
+ print("Score {0} is not possible, with only spares allowed".format(score))Score 1 is not possible, with only spares allowed
+Score 299 is not possible, with only spares allowedWhich is perhaps not surprising, we still can’t get 1 less than the largest multiple of 15 because we cannot bowl a 14 with the extra ball at the end of the 10th frame.
+This puts me in a good position to try a full game, I need to add the possibility of a strike. For single frame scores with nothing special before them, this just means adding a third way to score a 15. There are now 16 possible moves.
+# all the different scores for a frame following a regular frame
+
+single_frame_moves = [ SingleFrame(score) for score in basic_moves ]
+single_frame_moves.insert(0, SingleFrame(15,"spare"))
+single_frame_moves.insert(0, SingleFrame(15,"strike"))
+
+len(single_frame_moves)16Similarly the possible ways to follow a spare are the same as before, except that there is no way to “spare” with 30. Scoring a 30 after a spare requires that one throw a strike.
+# all the different scores for a frame following a spare
+
+spare_frame_moves = [ move for move in spare_frame_moves if move.score !=30 ]
+spare_frame_moves.insert(0, SingleFrame(30,"strike"))
+
+len(spare_frame_moves)42Following a single strike the rules are different: the first two balls count twice and the third counts once. Here I exhaustively generate all strikes, spares, and remaining that could follow a single strike and then trim only to the unique scores. This is a much smaller set as all spares that follow a strike must, by definition, have a score of 30.
+# all the different scores for a frame following a single strike
+
+non_spares = [ 2*f+2*s+t for f in filter(lambda x: x!=15,basic_moves)
+ for s in filter(lambda x: f+x<15, basic_moves)
+ for t in filter(lambda x: f+s+x<=15, basic_moves) ]
+
+non_spares = list(set(non_spares))
+non_spares.sort(reverse=True)
+
+single_strike_moves = [ SingleFrame(30,"strike") ]
+single_strike_moves += [ SingleFrame(30,"spare") ]
+single_strike_moves += [ SingleFrame(score) for score in non_spares ]
+
+len(single_strike_moves)30Following a double strike the rules are different again: the first ball is triple counted, the second double counted, and the third single counted.
+# all the different scores for a frame following 2 strikes
+
+spares = [ 3*f+2*s for f in filter(lambda x: x!=15,basic_moves)
+ for s in filter(lambda x: f+x==15,basic_moves)]
+
+spares = list(set(spares))
+spares.sort(reverse=True)
+
+non_spares = [ 3*f+2*s+t for f in filter(lambda x: x!=15,basic_moves)
+ for s in filter(lambda x: f+x<15, basic_moves)
+ for t in filter(lambda x: f+s+x<=15, basic_moves) ]
+
+non_spares = list(set(non_spares))
+non_spares.sort(reverse=True)
+
+double_strike_moves = [ SingleFrame(45,"strike") ]
+double_strike_moves += [ SingleFrame(score,"spare") for score in spares ]
+double_strike_moves += [ SingleFrame(score) for score in non_spares ]
+
+len(double_strike_moves)55This change in scoring, allowing for triple scoring, changes the bounds of possible scores following a given move. Now, after a strike, the next frame could count triple. But there are also potentially two more balls in the 10th frame that don’t count equally towards the upper bound on the score. The function to check for valid moves needs to be updated to reflect this.
+def valid_full_moves(move, n, r, mn=0, mx=15):
+ if move.special=="strike":
+ # max score is 3 times the max score for the remaining frames
+ # plus the multiplier for the remaining balls in the last frame
+ up = (3*n + 2 + 1)*mx
+ elif move.special=="spare":
+ # max score is 2 times the max score for the next frame
+ # 3 times the max score for the remaining frames
+ # plus the multiplier for the remaining balls in the last frame
+ up = (2 + 3*max(n-1,0) + 2 + 1)*mx
+ else:
+ up = (1 + 2*max(n-1,0) + 2 + 1)*mx
+ return n*mn <= r - move.score <= upAt this point all of the sets of moves for a regular frame contain every score except 1 and 1 less than the max score (i.e. a frame following a spare or single strike cannot score a 29 and a frame following a double-strike cannot score a 44). At this point you may expect that the only impossible scores will be 1 and 449 – this was true with the cases above. However there are two more sets of scoring possibilities just for the last frame.
+If the last frame starts with a spare, then it is the same as before: single ball, no multiplier.
+If the last frame starts with a strike, and is not preceded by one, then there are potentially two more balls left with no multipliers attached. And these do leave gaps.
+# all the different scores for the last 2 balls of the last frame
+# assuming the first ball in the last frame was a strike
+last_frame_moves = [ f+s for f in basic_moves
+ for s in filter(lambda x: f+x<=15,basic_moves) ]
+last_frame_moves += [ 15 + s for s in basic_moves ]
+last_frame_moves = set(last_frame_moves)
+
+[ s for s in range(31) if s not in last_frame_moves ][1, 16, 29]If the last frame starts with a strike and is preceded by one, then there are potentially two more balls but the first one is double counted. Again, this leaves gaps.
+# all the different scores for the last 2 balls of the last frame
+# assuming the second to last frame was a strike and the first ball
+# in the last frame was a strike
+last_frame_double_moves = [ 2*f+s for f in basic_moves
+ for s in filter(lambda x: f+x<=15,basic_moves) ]
+last_frame_double_moves += [ 30 + s for s in basic_moves ]
+last_frame_double_moves = set(last_frame_double_moves)
+
+[ s for s in range(46) if s not in last_frame_double_moves ][1, 29, 31, 44]It certainly looks now like there will be at least 4 scores that can’t be achieved because there no way to make the last step with the extra balls in the 10th frame, because the 10th frame is scored differently. This additional scoring complexity now makes it unwieldy to put all of that into the main function. I have broken it out into a separate function that just checks the last frame and either returns the last move with the remaining balls or returns an empty list if there is no possible move.
+def last_frame_rule(remaining, last_frame, max_move, mx=45):
+ if remaining == 0:
+ # hit the target, don't need any additional balls
+ return [SingleFrame(0,None,True)]
+ elif last_frame == "strike" and max_move == mx and remaining in last_frame_double_moves:
+ # two extra balls following a double strike
+ return [SingleFrame(remaining,None,True)]
+ elif last_frame == "strike" and remaining in last_frame_moves:
+ # two extra balls following a single strike
+ return [SingleFrame(remaining,None,True)]
+ elif last_frame == "spare" and remaining in basic_moves:
+ # only one extra ball
+ return [SingleFrame(remaining,None,True)]
+ else:
+ # not possible
+ return []The main function now has to track whether the last frame was a strike, to trigger the double strike rules, versus single strikes, spares, and regular frames. The logic is the same, though.
+def make_full_moves(cur_frame, cur_score, max_frame, target,
+ moves=single_frame_moves, last_frame=None):
+ if cur_frame == max_frame:
+ # max_move is used to check if the second-to-last frame was a strike
+ max_move = max( s.score for s in moves )
+ return last_frame_rule(target-cur_score, last_frame, max_move)
+ else:
+ next_frame = cur_frame + 1
+ n = max_frame - next_frame
+ r = target - cur_score
+ for move in filter(lambda x: valid_full_moves(x,n,r), moves):
+ new_score = cur_score + move.score
+ if last_frame == "strike" and move.special == "strike":
+ next_moves = double_strike_moves
+ next_last_frame = "strike"
+ elif move.special == "strike":
+ next_moves = single_strike_moves
+ next_last_frame = "strike"
+ elif move.special == "spare":
+ next_moves = spare_frame_moves
+ next_last_frame = "spare"
+ else:
+ next_moves = single_frame_moves
+ next_last_frame = None
+
+ advance = make_full_moves(next_frame, new_score, max_frame, target, next_moves, next_last_frame)
+ if len(advance) > 0:
+ advance.append(move)
+ return advance
+ else:
+ return []Looping through all the scores: \(0 \le score \le 450\) yields the impossible to bowl scores, when spares and strikes are allowed.
+for score in range(451):
+ game = make_full_moves(0,0,10,score)
+ if len(game)==0:
+ print("Score {} is not possible, full game".format(score))Score 1 is not possible, full game
+Score 434 is not possible, full game
+Score 436 is not possible, full game
+Score 449 is not possible, full gameThis conforms with our intuition, after looking at the possible last-frame moves. Of course this is entirely academic as, the way I bowl, I am in no danger of coming close to these impossible scores.
+ + +A few years ago I mused about using wildfire smoke events to measure the infiltration rate of buildings, in the context of modeling the infiltration of air pollution into buildings. Well it is wildfire season again and this past weekend saw a thick haze descend upon Edmonton, with airborne particulate concentrations, pm2.5 specifically, exceeding 440 μg/m3 in my neighbourhood.
+In anticipation I had ordered an Atmotube PRO as a relatively cheap and portable solution – something I can also hang from my backpack for when I travel. Just due to poor timing on my part, it did not arrive until part-way through the day on Saturday, May 20th, and I couldn’t use it to capture the impact of the smoke arriving as it was well and truly already here. That did not stop me from setting up two experiments, one to measure the rate of infiltration and another to demonstrate (to myself really) the effectiveness of a remedy.
+On Sunday, May 21st, I ran a very simple experiment to measure the ventilation rate in my bedroom (i.e. the rate of air infiltration). I live in an older apartment building with radiant heat, which makes my bedroom somewhat perfect: It has no vents or other connections to adjacent rooms, heat comes only from the radiators which are turned off (it’s summer). My bedroom has an older aluminum frame window, of the sort common with other apartments of the same vintage in my neighbourhood.
+The set-up was quite simple: I ran a portable HEPA filter in my bedroom, with the door closed, to maintain the particulate concentrations at a low level (more on that later) until 2:15pm. At that point I turned off the filter, left the room, and blocked off the gaps beneath the door with a wet towel. I left the atmotube sitting in the middle of the room, passively collecting at 15 minute intervals. A little over 10 hours later I returned and turned the HEPA filter back on, ending the experiment. I waited until Sunday to run the experiment as I had plans that day and knew I would be out of the apartment and thus not be tempted to go in the room for several hours.
+A house on the same block as my apartment building has a purple air outdoor air quality monitor mounted in their yard and the data is available at a 10-minute frequency through the purple air real-time air quality map. Using this and the data from the atmotube, I should be able to fit a simple building infiltration model.
+The purple air monitor can output the raw pm2.5 concentrations as a csv, which is easily imported into julia. As a first step I define when the experiment started such that I can also calculate how much time has elapsed – it is going to be easier to work with a time variable that is just a number starting at 0 when the experiment started than datetime objects. The default units of time, in julia, are milliseconds however the more convenient units for building ventilation are hours and so the time variable here is in hours.
+using CSV, DataFrames, Dates, Pipestart = DateTime(2023,5,21,14,15)2023-05-21T14:15:00The purple air monitor has dual particle count sensors, labeled in this dataset as “Purple Air A” and “Purple Air B”, for convenience I take the average of the two as the outdoor concentration.
+using Statistics: mean
+
+outdoor = @pipe "data/22_May_2023_raw-pm25-gm.csv" |>
+ CSV.read( _ , DataFrame, dateformat="yyyy-mm-dd HH:MM:SS") |>
+ transform( _ , AsTable(["Purple Air A", "Purple Air B"]) => ByRow(mean) => :pm25) |>
+ transform( _ , :DateTime => ByRow((x) -> Dates.value(x - start)/(3600*1000)) => :time);The atmotube outputs a whole bunch of stuff in one csv, including temperature, barometric pressure, VOCs, pm1, pm2.5 and pm10, I am only interested in the pm2.5s. That said, the csv has one serious issue: it implements a zero-order hold on data. There are pm2.5 values for every minute however the pm2.5 values are not sampled every minute, the atmotube holds the last value for all the minutes in between measurements. This is a problem as I am fitting a model to this data and I need the actual data at the times it was taken.
+raw_indoor = @pipe "data/C22B42153089_22_May_2023_00_43_32.csv" |>
+ CSV.read( _ , DataFrame; dateformat="yyyy-mm-dd HH:MM:SS") |>
+ sort!( _ , :Date);To retrieve only the actual measured data, and not the filled in rows, I create a new dataframe and walk through the raw data keeping a data point if it differs from the previous one or if more than 15 minutes have elapsed. Rows where the concentration value has not changed, and it has been less than 15 minutes from the last update, are assumed to be filled in rows and not “real”.
+last_good_data = raw_indoor[!, "PM2.5, ug/m3"][1]
+last_good_datetime = raw_indoor[!, :Date][1]
+
+indoor = DataFrame(datetime = DateTime[], meas = Float64[], time = Float64[])
+
+for r in eachrow(raw_indoor)
+ dt = r[:Date]
+ meas = r["PM2.5, ug/m3"]
+ time = Dates.value(dt - start)/(3600*1000)
+
+ if meas != last_good_data
+ last_good_data = meas
+ last_good_datetime = dt
+ push!(indoor, [dt, meas, time])
+ elseif Dates.value(dt - last_good_datetime) > 15*60*1000 # more than 15 minutes
+ last_good_data = meas
+ last_good_datetime = dt
+ push!(indoor, [dt, meas, time])
+ else
+ continue
+ end
+endPlotting the data looks encouraging (as far as fitting a model goes, not encouraging if one wanted to spend time in there breathing) as the particulates appear to be infiltrating with a rate proportional to the difference between the concentrations – the standard building infiltration model.
+ +
+The type of fit I am doing is quite simple: I am fitting a differential equation to the indoor concentration while taking the outdoor concentration as a parameter of the model. Thus I need the outdoor concentration as a continuous function of time and, for simplicity, I am using a linear interpolation of the measured outdoor concentration.
+using Interpolations: linear_interpolation, Flat
+
+cₒ = linear_interpolation(outdoor.time, outdoor.pm25, extrapolation_bc=Flat());To start, I define the differential equation that I am going to be fitting to the measured indoor concentration. This is the simple linear model for building infiltration
+\[ {d \over dt} c = \lambda \left( c\_o - c \right) \]
+Where c is the indoor concentration, co the outdoor concentration, and λ is the ventilation rate in units of h-1.
+using OrdinaryDiffEq
+
+# the model
+f(c, λ, t) = λ*(cₒ(t) - c)
+
+# initial condition
+c0 = indoor.meas[1]
+
+# timespan
+tspan = (0, indoor.time[end])
+
+# parameters
+p= [0.5] #initial guess of λ=0.5
+
+prb = ODEProblem(f, c0, tspan, p)Now I define the fit itself: with the cost function as the L2 loss between the measured indoor concentration and the predicted indoor concentration.
+using DiffEqParamEstim: build_loss_objective, L2Loss
+
+lossfn = L2Loss(indoor.time, indoor.meas)
+
+cost_function = build_loss_objective(prb,Tsit5(),lossfn,
+ maxiters=10000,verbose=false);Then using the Optim package to find the parameter λ which minimizes the cost function.
using Optim: optimize
+
+result = optimize(cost_function, 0.0, 1.0)Results of Optimization Algorithm
+ * Algorithm: Brent's Method
+ * Search Interval: [0.000000, 1.000000]
+ * Minimizer: 7.848374e-02
+ * Minimum: 1.517807e+03
+ * Iterations: 35
+ * Convergence: max(|x - x_upper|, |x - x_lower|) <= 2*(1.5e-08*|x|+2.2e-16): true
+ * Objective Function Calls: 36I can then retrieve the ventilation rate for my bedroom
+λfit = result.minimizer[1]0.07848373551388874prb = ODEProblem(f, c0, tspan, λfit)
+fit = solve(prb, Tsit5()); +
+I think this simple linear model works relatively well, all things considered. A more fulsome model would have treated the ventilation rate as a function of air pressure, windspeed, and the difference between indoor and outdoor temperatures.
+There are also a few weaknesses in the experimental design, beyond the quality of the sensors. For one I didn’t seal my door perfectly, and so there was some exchange with the rest of my apartment which had a much lower particulate concentration. I am also assuming that there is no deposition or adhesion of particulates when passing through the small leaks around my window. It’s possible that some particulates are being lost along the way, which would impact this. The placement of sensors could also be an issue, especially the outdoor ones: I live in a neighbourhood full of large apartment buildings and that creates complex wind patterns, I also live several stories up whereas the purple air monitor is at ground level. A better location would have been on my balcony, adjacent to the bedroom window.
+But I think as a first pass, and especially for screening potential shelter in place locations, something as simple as this could work and the time investment is very minimal. It’s major weakness is that the key variable, the outdoor concentration, is not controlled and this whole exercise is dependent upon the whims of wildfire smoke and on the individuals responsiveness to smoke forecasts.
+After all that time measuring how rapidly the particulates infiltrated a room, what is to be done? The air quality in Edmonton has been poor for several days on end. Without any sort of mitigation my bedroom would be well above the limits and would be unhealthly to be in and yet that’s where I sleep. The solution is either installing furnace air filters with a high MERV rating or, in places like mine that lack central air, using a portable fan with a HEPA filter. I picked up a portable air filter from IKEA and similar ones are available from many places, and can be made by hand. Unfortunately, dangerously high levels of pm2.5s are invisible and generally undetectable to one’s senses, so without some sort of monitoring one is left merely trusting that the system is doing what it is supposed to be doing.
+I tested my IKEA unit on Saturday night in a similar manner to the building infiltration test: I turned off the unit, closed my bedroom door, and left the space to accumulate particulates for several hours. Then, before I went to bed, I went in and turned it on. Throughout this the atmotube was located in the middle of the room collecting data. From the plot below it is clear that the air filter works: the indoor particulate concentration drops rapidly and stays at a low level throughout the night, even as the outdoor concentration rises to very high levels.
+indoor_hepa = @pipe "data/C22B42153089_21_May_2023_10_05_00.csv" |>
+ CSV.read( _ , DataFrame; dateformat="yyyy-mm-dd HH:MM:SS");
+
+outdoor_hepa = @pipe "data/21_May_2023_raw-pm25-gm.csv" |>
+ CSV.read( _ , DataFrame, dateformat="yyyy-mm-dd HH:MM:SS") |>
+ transform( _ , AsTable(["Purple Air A", "Purple Air B"]) => ByRow(mean) => :pm25); +
+Using wildfire smoke to measure the ventilation rates of different buildings, or rooms in buildings, is certainly a niche activity. I don’t imagine there are many places where it is important to screen for safe shelter-in-place locations that also experience significant wildfire smoke events regularly. That does describe the petrochemical industry in Alberta, wildfire smoke is a regular occurrence now, and perhaps locations along the west coast, but it’s not universal.
+That said I wonder if this might be a more broadly useful activity when planning for how to manage indoor air quality beyond industry. The office building I work in struggles with indoor air quality during smoke events like this one whereas my home office does not because I have invested in HEPA filters and simple air monitoring. Perhaps schools, offices, and other places could use similar techniques to screen spaces for interventions. Rooms with high ventilation rates could benefit from interventions such as better sealing around windows. Perhaps the plastic sheeting used to seal drafty windows in the wintertime could find a second use during wildfire season. In this way the air filters themselves are being used more effectively: an air filter can manage a larger space if that space has a low ventilation rate.
+Currently a lot of the advice is merely to stay indoors, with little acknowledgment that indoors is often severely polluted as well.
+ + +In previous examples I used both Gaussian plume and puff models for continuous and instantaneous releases, respectively, but what about the in-between cases? It is more commonly the case for a leak from a process vessel to be a prolonged, but finitely long, release.
+The guidance is to typically pick one or the other, depending upon the length of the release, or use a more complex model, e.g. the guidance in Lees1 is
+| \[ u \Delta t \lt 2 \sigma_x \] | +Use puff model | +
| \[ 2 \sigma_x \lt u \Delta t \lt 5 \sigma_x\] | +Neither model entirely appropriate | +
| \[ u \Delta t \gt 5 \sigma_x \] | +Use plume model | +
Where u is the wind speed, Δt the duration of the release, and \(\sigma_x\) is the downwind dispersion evaluated at \(x = \frac{u \Delta t}{2}\).2
+2 These criteria drive one to using a plume model in most cases that are not “instantaneous”. Suppose \(\sigma_x = \alpha x^\beta\) then the criteria for a puff is \(u \Delta t \lt 2 \alpha^{1 \over 1-\beta}\) which, for a class D release with windspeed of 2m/s works out to \(\Delta t \lt 5 \times 10^{-16} \mathrm{s}\). The criteria for a plume is \(u \Delta t \gt 2 \left( 2.5 \alpha \right)^{1 \over 1-\beta}\) which works out to \(\Delta t \gt 5 \times 10^{-11} \mathrm{s}\) for the same situation. So for any release of appreciable duration it will be a plume.
An alternative approach is to evaluate the downwind dispersion at a particular point of interest x1 and use the same criteria. This is much less strict than what Lees gives and is what I will do, it motivates investigating anything other than pure plume models.
+One approach in this in-between zone is to try both and pick the most conservative. But that can lead to extremely conservative results. An alternative might be to take a page from more complex models, such as INTPUFF and SCIPUFF, and treat an intermediate release as a series of smaller puff releases.
+Suppose a release from a process vessel, say a jet of gas issuing from a hole, we suppose the release is a constant rate of 1kg/s for 5s just for some nice round numbers. The release is at ground level and the ambient conditions are class D with a 2m/s windspeed. We have a point of interest 100m down-wind of the release, this could be an inhabited building or the fence-line.3
+3 We are also implicitly assuming the release is neutrally buoyant, and so a Gaussian dispersion model would be appropriate.
m = 1 #kg/s
+Δt = 5 #s
+h = 0 #m
+u = 2 #m/s
+
+x₁ = 100 #m
+t₁ = x₁/u #sThe class D dispersion parameters4 are:
+# class D puff dispersion
+
+σx(x) = 0.06*x^0.92
+σy(x) = σx(x)
+σz(x) = 0.15*x^0.70The release, at the point of interest, meets neither the criteria for a puff model nor a plume model.
+u*Δt < 2*σx(x₁)falseu*Δt > 5*σx(x₁)falseSo some other kind of model must be used.
+Recall that a single Gaussian puff is the product of 3 Gaussian distributions
+\[ c \left(x,y,z,t \right) = m \Delta t \cdot g_x(x, t) \cdot g_y(y) \cdot g_z(z) \]
+with
+\[ g_x(x,t) = {1 \over \sqrt{2\pi} \sigma_x } \exp \left( -\frac{1}{2} \left( x-u t \over \sigma_x \right)^2 \right) \]
+\[ g_y(y) = {1 \over \sqrt{2\pi} \sigma_y } \exp \left( -\frac{1}{2} \left( y \over \sigma_y \right)^2 \right) \]
+\[ g_z(z) = {1 \over \sqrt{2\pi} \sigma_z } \left[ \exp \left( -\frac{1}{2} \left( z-h \over \sigma_z \right)^2 \right) + \exp \left( -\frac{1}{2} \left( z+h \over \sigma_z \right)^2 \right) \right]\]
+where, for the sake of clarity, I’ve neglected the fact that the dispersion parameters σ are themselves all functions of t by being functions of the location of the center of the puff.
+gx(x, t) = exp((-1/2)*((x-u*t)/σx(u*t))^2)/(√(2π)*σx(u*t))
+gy(y, t) = exp((-1/2)*(y/σy(u*t))^2)/(√(2π)*σy(u*t))
+gz(z, t) = (exp((-1/2)*((z-h)/σz(u*t))^2)+exp((-1/2)*((z+h)/σz(u*t))^2))/(√(2π)*σz(u*t))c_pf(x,y,z,t; m, Δt) = m*Δt*gx(x,t)*gy(y,t)*gz(z,t)For some context we can plot the puff as a single, instantaneous, release
+ +
+Our first approximation to a release of appreciable duration is to break the release up into n intervals and release a single puff per interval.
+\[ c(x,y,z,t) = \sum_{i=0}^{n} m \frac{\Delta t}{n} \cdot g_x(x, t-\frac{i}{n}\Delta t) \cdot g_y(y) \cdot g_z(z) \]
+where we have simply taken the sum of n single puffs, each representing a fraction of the overall release, and emitting them one after the other.
+function sum_of_puffs(x,y,z,t; m, Δt, n)
+ c = 0
+ δt = Δt/n
+ for i in 0:1:n
+ t′ = t-i*δt
+ c′ = t′>0 ? c_pf(x,y,z,t′; m=m, Δt=δt) : 0
+ c += isnan(c′) ? 0 : c′
+ end
+ return c
+endWe can plot this for n=5 and we see that, while initially the individual puffs are distinct, they quickly merge into a larger more spread-out cloud.5
+5 To an extent this is a function of using a class D atmosphere. For a much more stable atmosphere, e.g. class F, the puffs remain quite distinct until a size-able number of them have been released.
 +
+If we plot the max-concentration experienced at our point of interest, x=100m, against an increasingly finely-divided release (more puffs, but each puff represents a smaller slice of time) it is clear that they are converging towards a number, and relatively quickly.
+ +
+This suggests a next step, taking the limit as \(n \to \infty\)
+Returning to our model of multiple puffs
+\[ c(x,y,z,t) = \sum_{i=0}^{n} m \frac{\Delta t}{n} \cdot g_x(x, t-\frac{i}{n}\Delta t) \cdot g_y(y) \cdot g_z(z) \]
+We can re-arrange this and take the limit as \(n \to \infty\)
+\[ c(x,y,z,t) = m\cdot g_y(y) \cdot g_z(z) \cdot \left( \lim_{n \to \infty} \sum_{i=0}^{n} g_x(x, t-\frac{i}{n}\Delta t) \frac{\Delta t}{n} \right) \]
+\[ = m\cdot g_y(y) \cdot g_z(z) \cdot \int_{t-\Delta t}^{t} g_x(x, t^{\prime}) dt^{\prime}\]
+Where we have replaced the limit with the integral.6
+6 I am assuming the dispersion parameters are constants, though they are not in practice as they are correlated to the downwind distance to the center of any given puff. I am assuming for a small enough release this is approximately constant at least.
This is an integral of a Gaussian, and so we expect the results to be in terms of the error function
+\[ \mathrm{erf}(x) = \frac{2}{\sqrt{\pi}} \int_0^x \exp \left( -t^2 \right) dt \]
+For the integral of the x component of the Gaussian puff we have
+\[ \int_{t-\Delta t}^{t} g_x(x, t^{\prime}) dt^{\prime} = \int_{t-\Delta t}^{t} {1 \over \sqrt{2\pi} \sigma_x } \exp \left( -\frac{1}{2} \left( x-u t^{\prime} \over \sigma_x \right)^2 \right) dt^{\prime}\]
+making the substitution \[\xi = { {x - u t^{\prime} } \over \sqrt{2} \sigma_x} \]
+we get7
+7 This model and the sum of puffs model both naively include contributions from releases that haven’t happened yet, e.g. at t=1 only the contribution of material released at times t≤1 should be included, but without any correction the other parts of the release would be included causing slight errors in the vicinity of the release point at t<Δt. The solution is simply to take the duration of the release to be the minimum of either the elapsed time (i.e. when the release is still “happening”) or the total release duration.
\[ \int_{t-\Delta t}^{t} g_x(x, t^{\prime}) dt^{\prime} = {-1 \over \sqrt{\pi} u} \int_{a}^{b} \exp \left( -\xi^2 \right) d\xi \]
+\[ = {-1 \over \sqrt{\pi} u} \left[ \frac{\sqrt{\pi}}{2} \mathrm{erf}(b) - \frac{\sqrt{\pi}}{2} \mathrm{erf}(a) \right] \]
+\[ = \frac{1}{2u} \left( \mathrm{erf}(a) - \mathrm{erf}(b) \right)\]
+where
+\[a = { {x - u (t-\Delta t)} \over \sqrt{2} \sigma_x }\]
+\[b = { {x - u t} \over \sqrt{2} \sigma_x } \]
+using SpecialFunctions: erf
+
+function ∫gx(x,t,Δt)
+ Δt = min(t,Δt)
+ a = (x-u*(t-Δt))/(√2*σx(u*(t-Δt)))
+ b = (x-u*t)/(√2*σx(u*t))
+ return erf(b,a)/(2u)
+end
+
+intpuff(x,y,z,t; m, Δt) = m*gy(y,x/u)*gz(z,x/u)*∫gx(x,t,Δt) +
+This release model has some convenient properties: clearly as \(\Delta t \to 0\) it becomes a Gaussian puff again, but also as \(\Delta t \to \infty\) also limits to the Gaussian plume.8
+8 This is somewhat hand-wavy but a release of infinite duration is an event that began an infinite amount of time in the past and continues an infinite amount into the future, so the term \(\frac{1}{2u} \left( \mathrm{erf}(a) - \mathrm{erf}(b) \right)\) goes in the limit to \(\frac{1}{2u} \left( \mathrm{erf}(\infty) - \mathrm{erf}(-\infty) \right) = \frac{1}{u}\) resulting in a concentration profile of \(c \left(x,y,z,t \right) = \frac{m}{u} \cdot g_y(y) \cdot g_z(z)\), which is exactly a plume model.
 +
+I’ve been casually treating the dispersion parameters, \(\sigma_x, \sigma_y, \sigma_z\), as being constants that are independent of the model and any transformations on the model. Within the context of taking sums and doing integrals it is reasonable: within a reasonable radius of the center of a given puff they are nearly constant. However, in practice, they depend upon time through their dependence on the location of the puff center and are also functions of the model itself.
+The dispersion parameters for a plume model are not the same as for a puff, and so the nice smooth curve connecting the two doesn’t really work. Not if you are strictly taking dispersion parameters as provided in standard references. It is not at all clear how to transition from the one set to the other either, in a smooth manner, to ensure that there is a smooth transition from puff to plume.
+That said, multiple puff models use the dispersion parameters for puffs and so using the puff parameters in the integrated puff model at least puts one in good company.
+There is a follow-up post that discusses the quality of these approximations in more detail.
+When I first wrote this post I could not find my final result in the literature – it wasn’t in the standard references I use, and I think I just didn’t know the right search terms. Though it seemed equally obvious to me that it must be in the literature somewhere. Since posting this, I found it: Palazzi et al.9 This is also the model used by ALOHA and the older ARCHIE models.
+The other day I was working on a project involving Gaussian puff models and I noticed that I had made a significant mistake, a mistake I have made several times without noticing, and one that invalidated a whole bunch of work I that I had done previously, so I thought this would be a good opportunity to examine my mistake and it’s consequences.
+To re-cap on what a Gaussian puff model even is: for a short duration release (strictly an instantaneous release) of a neutrally buoyant substance at ground-level, the concentration can be modeled as the product of three Gaussian distributions:
+\[ c \left(x,y,z,t \right) = \dot{m} \Delta t \cdot g_x(x, t) \cdot g_y(y) \cdot g_z(z) \]
+where
+\[ g_x(x,t) = {1 \over \sqrt{2\pi} \sigma_x } \exp \left( -\frac{1}{2} \left( x-u t \over \sigma_x \right)^2 \right) \]
+\[ g_y(y) = {1 \over \sqrt{2\pi} \sigma_y } \exp \left( -\frac{1}{2} \left( y \over \sigma_y \right)^2 \right) \]
+\[ g_z(z) = {2 \over \sqrt{2\pi} \sigma_z } \exp \left( -\frac{1}{2} \left( z \over \sigma_z \right)^2 \right) \]
+Where \(\dot{m}\) is the mass emission rate, Δt the duration of the release, and u the ambient windspeed. The coordinates are such that the release point is at the origin, the puff moves in the downwind, x, direction while spreading into the crosswind, y, and vertical, z, directions.
+The dispersion parameters, σx, σy, σz are all functions of the downwind distance and the atmospheric stability.
+# class F puff dispersion
+# x is in meters
+σx(x) = 0.024*x^0.89
+σy(x) = σx(x)
+σz(x) = 0.05*x^0.61What this generates is an instantaneous release of all of the mass in an infinitesimal point that grows as it moves downwind. This isn’t terribly realistic for releases of any appreciable duration (all of the mass is released instantly in this model), so a common approach is to break up the release into a sequence of n smaller puffs that each capture the mass released over the sub-interval \({ \Delta t \over n }\). Taking the limit as \(n \to \infty\) equates to integrating the puff model from t - Δt to t giving a nice solution in terms of the error function erf and … this is where I made the critical mistake.
+The dispersion parameters are functions of the downwind distance, but critically..to what? Taken as the downwind distance to the point being calculated, the dispersion parameters are constants (with respect to time) and the problem simplifies to integrating the Gaussian \(g_{x}(x,t)\) with respect to t, which is what I had assumed. However if the dispersion parameters are actually correlated to the downwind distance of the cloud center, which is \(x_c = u t\), they are in fact functions of time and this does not work.
+This distinction is by no means made obvious in many of the references for chemical hazard analysis. Most are either vague about it or take the dispersion parameters at the downwind distance of the point being calculated. My main reference is the CCPS Guidelines for Consequence Analysis of Chemical Releases and it does this.1 As do several workbooks I have seen. However Lees2 notes that the dispersion parameters for the Pasquill-Gifford puff model (which this is) are given by3
+3 Lees, 15/112.
\[ \sigma = { C^2 \over 2 } \left( u t \right)^{2-n} \]
+where C and n are some constants from Sutton, and in general the dispersion correlations are functions of travel time with a lot of discussion in the literature of to what power. The standard correlations for the dispersion parameters come from Slade4 which gives some details on how the measurements were actually taken. It certainly seems to me that the downwind distance was to the cloud center, i.e. the experimenters measured the cloud dimensions at the downwind point to which it had traveled. Which makes the travel time and windspeed implicit.
+I think it is a reasonable confusion as the dispersion parameters for a continuous release, a Gaussian plume model, are indeed functions of the downwind distance to the point being calculated. It is also frequently the case that examples are given for the concentration at the cloud center, in which case the downwind distance at the point being calculated is the downwind distance to the cloud center.
+How critical of a mistake is this? For regions far enough from the origin the dispersion parameters do not vary much in the neighborhood of the plume center. This is shown in the plot below where the difference is taken over the interval \([ x - \sigma_x, x + \sigma_x ]\). At distances further than a few hundred meters the difference is only a few percent. Suggesting that it might not be an unreasonable approximation to assume the dispersion parameters are constants for the purpose of the integral.
+ +
+Another way of approaching this is simply to view it as an approximation instead of an error. On the one hand this is a pretty great rhetorical trick: my answer isn’t wrong, it’s just differently true. But it could be the case that this is a useful simplification, just by eye-balling isopleths and looking at limiting behavior in the previous notebook it certainly looked reasonable.
+To make life easier, going forward, I am going to define a unit-less time \[ t = { u t^{\prime} \over L } \]
+and unit-less distances
+\[ x = {x^{\prime} \over L } \\ y = {y^{\prime} \over L } \\ z = {z^{\prime} \over L } \]
+where I am abusing notation with the \(\prime\) indicates the variable with units, and no \(\prime\) indicates it is unitless. A characteristic length, \(L\), is introduced to make everything unitless and, due to the dispersion correlations \(L = 1 \mathrm{m}\) is the most convenient.
+We can then explore the performance of different approximations to the integrated puff model by only examining the Gaussian distributions – with no dependence upon \(\dot{m}\) or u.
+g(ξ,σ) = exp(-0.5*(ξ/σ)^2)/(√(2π)*σ)
+
+gx(x, t) = g((x-t),σx(t))
+gy(y, t) = g(y,σy(t))
+gz(z, t) = 2*g(z,σz(t))
+
+pf(x,y,z,t; Δt) = gx(x,t)*gy(y,t)*gz(z,t)*ΔtThe first type of approximation is to divide the release interval into n sub-intervals and n Gaussian puffs
+function Σpf(x,y,z,t; Δt, n)
+ Δt = min(t,Δt)
+ δt = Δt/(n-1)
+ _sum = 0
+ for i in 0:(n-1)
+ t′ = t-i*δt
+ pf_i = t′>0 ? gx(x,t′)*gy(y,t′)*gz(z,t′)*δt : 0
+ _sum += pf_i
+ end
+ return _sum
+endThe next type of approximation is the one I made in the previous post wherein \(g_x(x,t)\) is integrated with respect to time, treating the σs as constants.
+There is a little sleight of hand as I include the downwind distance dependence of the σs after the integration (they aren’t actually constants)
+using SpecialFunctions: erf
+
+function ∫gx(x,t,Δt)
+ Δt = min(t,Δt)
+ a = (x-(t-Δt))/(√2*σx(t-Δt))
+ b = (x-t)/(√2*σx(t))
+ return erf(b,a)/2
+end
+
+∫pf_approx(x,y,z,t; Δt) = ∫gx(x,t,Δt)*gy(y,x)*gz(z,x)Finally, I take advantage of the QuadGK package to numerically integrate the Gaussian puff model, including the time dependence of the dispersion parameters.
using QuadGK: quadgk
+
+function ∫pf(x,y,z,t; Δt)
+ Δt = min(t,Δt)
+ integral, err = quadgk(τ -> gx(x,τ)*gy(y,τ)*gz(z,τ), t-Δt, t)
+ return integral
+endTo give a sense of how these successive approximations work, lets examine a series of slices through the cloud. The first is at a constant x on the center-line of the release, looking at how the concentration changes with time.
+Just by eye-ball the the approximate integral is very close to the numerical exact(ish) integral, as is a large enough number of puffs. Importantly, I think, the approximate integral error is of the same order of magnitude as a large number of puffs – so this is at least as good in a sense as the discrete sum of puffs method, given that we can vary the number of puffs to always make it a better/worse approximation
+ +
+In the crosswind and vertical directions the sum of discrete puffs approximation works decidedly less well, at least at this slice in the cloud, while the approximate integral still works relatively well. I would say it is still at least as good as a sum of discrete puffs for a suitably large number of puffs.
+ +
+ +
+This is, of course, very particular to that point downwind of the release. As we move closer to the origin the integral approximation gets worse, but then so does the sum of discrete puffs model. Especially for a low number of puffs: they become visibly discrete. I think this reinforces that, at least for class F stability, this approximation is in the same ball park as summing over a set discrete Gaussian puffs.
+ +
+Model error is not the only factor in deciding upon an approximation. Since QuadGK exists we have to ask ourselves, why would we not always use it? We can answer that by benchmarking the three approaches at a particular point of interest (I don’t think the choice of point impacts the calculations at all)
using BenchmarkTools: @benchmark
+
+# point of interest
+x₁ = 100
+y₁ = σy(x₁)
+z₁ = σz(x₁)
+t₁ = x₁Starting with the full numerical integration of the model, this is the time to beat. Any approximation that takes longer than ~30μs is literally pointless: it generates worse results and takes longer.
+@benchmark ∫pf(x₁,y₁,z₁,t₁; Δt=10)BenchmarkTools.Trial: 10000 samples with 1 evaluation. + Range (min … max): 28.056 μs … 57.603 μs ┊ GC (min … max): 0.00% … 0.00% + Time (median): 28.200 μs ┊ GC (median): 0.00% + Time (mean ± σ): 28.570 μs ± 1.565 μs ┊ GC (mean ± σ): 0.00% ± 0.00% + █▆▁ ▃▃ ▁▂▁▁ ▁ + ███▇▅██▇▅▄█████▆▆▆▇▆█▇▆▄▃▁▄▄▄▃▆▅▄▄▃▁▃▁▃▁▁▁▁▁▁▁▁▁▃▁▁▁▁▁▄▅▆▇▆ █ + 28.1 μs Histogram: log(frequency) by time 37.7 μs < + Memory estimate: 384 bytes, allocs estimate: 3.+
As we expect, the sequence of discrete puffs is much faster for fewer puffs, and adding an order of magnitude more puffs increases the time by an order of magnitude. At around n=100 we are no longer gaining anything over the full numerical integration. So, if the near-field matters a lot to you, then this is probably not a great approximation as the number of puffs required to approximate the full numerical integration well takes longer than just doing the integration.
+@benchmark Σpf(x₁,y₁,z₁,t₁; Δt=10, n=10)BenchmarkTools.Trial: 10000 samples with 8 evaluations. + Range (min … max): 3.746 μs … 11.498 μs ┊ GC (min … max): 0.00% … 0.00% + Time (median): 3.768 μs ┊ GC (median): 0.00% + Time (mean ± σ): 3.920 μs ± 450.991 ns ┊ GC (mean ± σ): 0.00% ± 0.00% + █ ▅ ▅▂▁▁▂ ▁ + ██▄█▇▅██████▇▆▄▄▄▃▅▄▄▂▄▄▅▃▄▅▅▆▇▇▆▆▇▇▆▆▅▅▅▅▆▅▅▅▅▄▃▅▅▄▅▅▄▄▄▂▃ █ + 3.75 μs Histogram: log(frequency) by time 5.97 μs < + Memory estimate: 16 bytes, allocs estimate: 1.+
@benchmark Σpf(x₁,y₁,z₁,t₁; Δt=10, n=100)BenchmarkTools.Trial: 10000 samples with 1 evaluation. + Range (min … max): 37.090 μs … 77.023 μs ┊ GC (min … max): 0.00% … 0.00% + Time (median): 37.199 μs ┊ GC (median): 0.00% + Time (mean ± σ): 37.760 μs ± 2.411 μs ┊ GC (mean ± σ): 0.00% ± 0.00% + █ ▂▁ ▃ ▁ + █▇▁▁▁██▃▃▁▃█▇▇▆▄▄▇█▅▄▄▄▄▄▄▃▄▄▃▁▅▁▄▃▁▁▃▃▃▃▄▇▇█▇▇▆▄▅▅▅▆▄▄▆▄▄▄ █ + 37.1 μs Histogram: log(frequency) by time 49.3 μs < + Memory estimate: 16 bytes, allocs estimate: 1.+
Finally we have the integral approximation. This takes ~1/50th the time as the full numerical integration and, by the results above, it potentially performs just as well as the discrete puff approximation. In the examples above it was doing as well as discrete puff approximations that are too large to be worthwhile.
+@benchmark ∫pf_approx(x₁,y₁,z₁,t₁; Δt=10)BenchmarkTools.Trial: 10000 samples with 189 evaluations. + Range (min … max): 534.974 ns … 988.852 ns ┊ GC (min … max): 0.00% … 0.00% + Time (median): 547.606 ns ┊ GC (median): 0.00% + Time (mean ± σ): 560.844 ns ± 40.302 ns ┊ GC (mean ± σ): 0.00% ± 0.00% + ▇▃▅█▅▅ ▅▃▄ ▃▄▁▁▁▁▁ ▂ + ██████▇█████████████▇█▇▇▆▆▆▆▅▇▇▆▅▆▇▆▆▅▅▅▅▄▄▆▅▅▅▆▆▄▅▅▂▅▄▅▄▃▅▅▅ █ + 535 ns Histogram: log(frequency) by time 770 ns < + Memory estimate: 16 bytes, allocs estimate: 1.+
I also have put no effort into optimizing any of this code, so take this with a grain of salt. Like the examination of the model error this is hardly rigorous, it is more suggestive than anything. It is possible that one could dramatically improve the discrete puff model, or re-write how the models are calculated to be more performant than I have. I prefer to write code that is easy for me to read, and re-uses things, but that does not necessarily translate into fast.
+I think it’s worth noting that calculations that take on the order of tens of microseconds, on my crappy old laptop, are fast. To make the various plots required calculating the concentration at hundreds of points and my laptop did it all in the blink of an eye. I would say the first choice, all things being equal, would be simply to use the QuadGK model and call it a day. In terms of lines of code it is certainly short, all the heavy lifting is being done by the library. It also best captures what you are trying to achieve.
If you are doing a huge number of calculations, and can tolerate some model error, then the integral approximation is a good choice. It is the fastest and can perform as well as the discrete puff model. That said, there is an elephant in the room: The two integral approaches strictly require that all of the puffs are moving along the same line, at the same speed. For a great many chemical release scenarios that is entirely the set of assumptions being made, so it works great. However, for more complex atmospheric conditions – with variable windspeed and direction – then they don’t work at all. Or, at least, it is not obvious to me how to adapt them to work. A slightly tweaked discrete puff model, tracking each puff’s individual center location and windspeed, would be quite easy to implement, giving a more flexible model overall. This is in fact the how several more complicated atmospheric dispersion modeling tools work.
+I have been interested in the Ooms plume model1 for a long time, but I haven’t really set aside the time to really play around with it because the implementation details are surprisingly sparse. A recent weekend project of mine was to sit down and work out what the actual model equations are and get it running in julia. Something which might be useful to you if you are looking to run one of the O.G. integral plume models.
+The Ooms plume model is a model of a continuous jet of fluid exiting into a crossflow. Unlike, for example, a simple Gaussian model which assumes the source has no momentum, or a free jet model which assumes there is no crossflow, the Ooms model accounts for the buoyancy and momentum of the jet as well as the crossflow without resorting empirical correlations (such as the Briggs’ model).
+However, unlike those simpler models, the Ooms model is not in the form of simple closed form expressions. It is an integral plume model which results in a system of differential algebraic equations which must be solved numerically for each particular plume. Unlike earlier integral plume models, which assumed a top hat velocity and density profile, the Ooms model assumes the plume parameters follow Gaussian profiles.
+ +
+Consider the sketch of a vertical vent shown in Figure 1. The plume starts at some point down stream of the actual vent, after the zone of flow establishment characterized by an elevation δ. The plume rises due to the buoyancy and momentum in the vent gases and bends over as it is carried along by the wind. The coordinate system is arranged such that the wind is in the positive x-direction and the center-line of the plume is within the x-z plane.
+Taking a slice through the plume, we assume it has a circular cross-section and use a local cylindrical coordinate system with s the direction along the plume axis, r the radial direction, and φ the radial angle. The overall plume radius at any point is \(\sqrt{2}b\), with b a characteristic length which is a function of distance along the center-line.
+Zooming in on a differential element of the plume, Figure 2, we take it be approximately a cylinder where flow within the plume enters and exits through the circular ends and air is entrained through the outer surface with some entrainment velocity E.
+ +
+The Ooms model comes from the conservation relations for this differential element.
+The mass exiting the differential element is equal to the mass entering through the plume plus the entrained air.
+\[ m_{out} = m_{in} + m_{ent} \]
+The mass of entrained air is simply the product of the mass flux (ρE) and the area:
+\[ m_{ent} = \rho_a E \cdot 2\pi \left( \sqrt{2} b \right) ds \]
+Giving a mass balance equation:
+\[ \frac{d}{ds} m = 2\pi \rho_a b \left( \sqrt{2} E \right) \]
+The mass passing through a surface is simply the mass flux G = ρ u integrated over the surface area:
+\[ m = \int_{A_{in}} \rho u dA = \int_0^{2\pi} \int_0^{\sqrt{2}b} \rho u r dr d\phi \] \[ m = 2\pi \int_{0}^{\sqrt{2}b} \rho u r dr \]
+Finally giving
+\[ 2\pi \frac{d}{ds} \int_{0}^{\sqrt{2}b} \rho u r dr = 2\pi \rho_a b \left( \sqrt{2} E \right) \] \[ \frac{d}{ds} \int_{0}^{\sqrt{2}b} \rho u r dr = \rho_a b E \]
+An errant \(\sqrt{2}\) has disappeared from the right hand side of the equation. It has been absorbed into the constants in E. The right hand side of the balance equations in Ooms2 appear at first blush like they were done for a top hat model of a plume with radius b, which would be a mistake. However, as the overall radius of a plume in a top hat model btop-hat = \(\sqrt{2}b_{gauss}\), when the constants are scaled by a factor of \(\sqrt{2}\) the two look the same.
+The total mass of the vented substance is conserved as the plume expands. Assuming the vent is some species i with mass concentration c:
+\[ \frac{d}{ds} m_{i} = 0 \] \[ m_i = \int_0^{2\pi} \int_0^{\sqrt{2}b} c u r dr d\phi = 2\pi \int_0^{\sqrt{2}b} c u r dr \] \[ \frac{d}{ds} \int_0^{\sqrt{2}b} c u r dr = 0 \]
+There are two equations for conservation of momentum: in the x-direction and z-direction. This is a consequence of the choice of coordinates – that the plume centerline is confined to the x-z plane and neither the jet nor the crossflow have velocity in the y-direction. In particular the coordinates were chosen such that the crossflow is entirely in the x-direction with velocity \(u_a\).
+In the x-direction the total momentum into the differential element is the mass in times the velocity component in the x direction:
+\[ p_{x,in} = \int_{A_{in}} \rho_{in} u_{in} u_{x,in} dA = \int_{A_{in}} \rho_{in} u_{in}^2 \cos\theta_{in} dA \]
+And similarly for the total momentum leaving the element
+\[ p_{x,out} = \int_{A_{out}} \rho_{out} u_{out} u_{x,out} dA = \int_{A_{out}} \rho_{out} u_{out}^2 \cos\theta_{out} dA \]
+The change in momentum is equal to the momentum added to the plume from entrainment and drag from the wind. In this case the drag force acts in the positive direction, pushing the plume along.
+\[ p_{x,out} - p_{x,in} = m_{ent} u_a + F_{d,x} \]
+Ooms notes that the drag force on the plume is only due to the component of the wind velocity which is perpendicular to the plume direction, \(u_a \sin \theta\). Drag then follows the standard relationship, with the area being the outside surface area of the cylinder.
+\[ F_{d} = \frac{1}{2} C_d A_{\perp} \rho_a v^2 = \frac{1}{2} C_d A_{\perp} \rho_a u_a^2 \sin^2 \theta \]
+The drag force in the x-direction is acting on the area perpendicular to the x-direction
+\[ F_{d,x} = \frac{1}{2} C_d \rho_a u_a^2 \sin^2 \theta 2\pi \left(\sqrt{2}b\right) | \sin \theta | ds = \pi b C_d \rho_a u_a^2 | \sin^3 \theta | ds\]
+Where the absolute value comes from the drag force being always positive.
+Giving
+\[ 2 \frac{d}{ds} \int_{0}^{\sqrt{2}b} \rho u^2 \cos \theta r dr = 2 b \rho_a u_a E + \pi b C_d \rho_a u_a^2 | \sin^3 \theta | \]
+In the z-direction the change in momentum is due to buoyant forces and drag in the z-direction. The buoyant force can be written as:
+\[ F_b = \int_V g \left(\rho_a - \rho \right) dV = 2\pi ds \int_0^{\sqrt{2}b} g \left(\rho_a - \rho \right) rdr \cdot \]
+Assuming the density within the differential element is approximately constant with s. Combining with the drag force in the z-direction gives the final momentum balance:
+\[ 2 \frac{d}{ds} \int_{0}^{\sqrt{2}b} \rho u^2 \sin \theta r dr = 2 \int_0^{\sqrt{2}b} g \left(\rho_a - \rho \right) r dr + \mathrm{sgn}\theta \cdot \pi b C_d \rho_a u_a^2 \sin^2 \theta \cos \theta \]
+Where \(\mathrm{sgn} \theta\) ensures the drag force is acting in the right direction.
+Starting from an energy balance, using the ambient temperature as the reference temperature, the enthalpy entering the differential element is:
+\[ H_{in} = \int_{A_{in}} \rho u_{in} c_p \left( T - T_{a,0} \right) dA \]
+Similarly for the enthalpy out, giving an enthalpy change over the element of:
+\[ d \left( \int_{A} \rho u_{in} c_p \left( T - T_{a,0} \right) dA \right) = d \left( 2\pi \int_0^{\sqrt{2}b} \rho u c_p \left( T - T_{a,0} \right) r dr \right) \]
+To be very abusive of notation. Where T is the temperature of the plume and Ta,0 is the reference temperature – the ambient temperature at the vent exit. The enthalpy change is assumed to come only from entrainment. The enthalpy added to the differential element from entrainment of air is:
+\[ \rho_a E c_{p,a} \left( T_a - T_{a,0} \right) \cdot 2\pi b ds \]
+Putting it all together we get the energy balance:
+\[ \frac{d}{ds} \int_0^{\sqrt{2}b} \rho u c_p \left( T - T_{a,0} \right) r dr = b \rho_a E c_{p,a} \left( T_a - T_{a,0} \right) \]
+Assuming the ideal gas law, we can make the substitution:
+\[ T = {{ P {MW} } \over {R \rho}} \]
+Furthermore, if we assume \(MW = MW_a\) and \(c_p = c_{p,a}\) then we can cancel all those constants giving:
+\[ \frac{d}{ds} \int_0^{\sqrt{2}b} \rho u \left( \frac{1}{\rho} - \frac{1}{\rho_{a,0}} \right) r dr = b \rho_a E \left( \frac{1}{\rho_a} - \frac{1}{\rho_{a,0}} \right) \]
+These seem like radical assumptions if you are coming to the Ooms plume model as a dense gas dispersion model, but the original paper is concerned with the release of stack gases from combustion equipment. For stack gases this is not unreasonable and other models such as the Briggs’ model for plume rise make similar simplifications (any model that calculates buoyant flux from plume temperature alone is making that assumption implicitly).
+Up until this point all of the plume parameters have been calculated along the plume axis. This needs to be translated into the original coordinate system to be useful, in particular the curve the plume axis takes through space is given by:
+\[ \frac{dx}{ds} = \cos \theta \] \[ \frac{dz}{ds} = \sin \theta \]
+One of the most important parts of the model is how it accounts for entrainment. Ooms considers entrainment to be the sum of three processes.
+In the immediate vicinity of the jet exit, when the jet velocity dominates, the entrainment is taken to be the same as a free jet, namely that it is proportional to the jet center line velocity. In this case we take the excess velocity:
+\[ E_1 = \alpha_1 | u - u_a \cos \theta | \]
+Where \(u_a \cos \theta\) is the component of the wind velocity parallel to the jet. The parameter \(\alpha_1\) is called the entrainment coefficient for a free jet and is independent of Reynolds’ number when \(\mathrm{Re} > 10^4\). Ooms gives this as \(\alpha_1 = 0.057\).
+At distances further down the plume axis, when \(u \approx u_a\), the entrainment is taken to be the same as a cylindrical thermal in a stagnant atmosphere, given as:
+\[ E_2 = \alpha_2 u_a | \sin \theta | \]
+Where \(\alpha_2\) is called the entrainment coefficient for a line thermal, it is similarly a constant at large Reynolds’ numbers. Ooms gives this as \(\alpha_2 = 0.5\)
+To connect these two regimes, Ooms multiplies the line thermal term by \(\cos \theta\). This doesn’t seem to have any theoretical justification, it just works to make the second term disappear when the vent is still mostly vertical. This is an important feature to note. The model is often presented such that the initial angle of the jet can be anything, but a key assumption of the entrainment model is that the jet is initially vertical.
+Finally, Ooms adds a term to entrainment due to atmospheric turbulence. Presumably if you were only interested in jets entering a crossflow where that flow was nice and laminar you would leave this out. But Ooms is specifically developing his model for vent stacks releasing plumes into the atmosphere, and the actual structure of the atmosphere and its turbulence must be accounted for. He does this by including an entrainment velocity due to turbulence \(u^{\prime}\)
+\[ E_3 = \alpha_3 u^{\prime} \]
+Where \(\alpha_3\) is the entrainment coefficient due to turbulence, which is taken to be \(\alpha_1 = 1.0\). The entrainment velocity due to turbulence can be accounted for in one of two ways:
+The total entrainment is then:
+\[ E = E_1 + E_2 \cos \theta + E_3 \]
+\[ E = \alpha_1 | u - u_a \cos \theta | + \alpha_2 u_a | \sin \theta | \cos \theta + \alpha_3 u^{\prime} \]
+or
+\[ E = \alpha_1 | u^{*} | + \alpha_2 u_a | \sin \theta | \cos \theta + \alpha_3 u^{\prime} \]
+Where \(u^{*}\) is defined in the next section.
+Earlier I mentioned that the velocity, density, and concentration in the plume are assumed to have Gaussian profiles. Though it doesn’t really have a theoretical basis, Gaussian profiles are mathematically convenient and fit observed profiles quite well. This has been experimentally validated for both free jets and bent over plumes.3
+The velocity is taken to be the component of the wind velocity parallel to the plume axis plus an excess velocity:
+\[ u = u_a \cos \theta + u^{*} \exp \left( - \left(r \over b\right)^2 \right) \]
+The plume density, similarly, is the air density plus an excess density:
+\[ \rho = \rho_a + \rho^{*} \exp \left( - \left(r \over {\lambda b} \right)^2 \right) \]
+Finally, the concentration simply follows a Gaussian profile:
+\[ c = c^{*} \exp \left( - \left(r \over {\lambda b} \right)^2 \right) \]
+Where \(\frac{1}{\lambda^2}\) is the turbulent Schmidt number. This is entirely analogous to a free jet. I’m not sure entirely why Ooms gives the Schmidt number as what I would call the inverse of the Schmidt number, but that is just a quibble of notation.
+Ooms uses a value of \(\lambda^2 = 1.35\) or \(\mathrm{Sc}_t = 0.741\), which is consistent with observations of free jets.
+The original paper does not provide the final differential algebraic equations, nor does it provide the worked out integrals, that is left as an exercise for the reader. I looked around and could not find a detailed description of the final model equations other than in the model documentation for DEGADIS.4 An earlier version of DEGADIS used the Ooms plume model for dense gas plumes with modifications to the model assumptions and, especially, the energy balance. This is a good start, but it is presented in its final matrix form with 17 model constants that are pre-calculated. It is not immediately clear where the model constants come from and how they are related to the constant λ.
+ +
+The version in DEGADIS is intended for dense gas dispersion and makes additional assumptions such as that there is no vertical change in air density. This is a reasonable assumption for dense plumes that fall back to earth and roll along the ground, but is something that would have to be corrected for large buoyant plumes rising high into the air.
+I did my own working out here because I wanted two things:
+The integrals are not difficult to work out, though they can turn into a sort of alphabet soup of variables. The integrals involving Gaussians all involve something of the form \(\int \exp(-ar^2) r dr\) which has a nice closed form solution.
+I worked out five different constants that are integrals of the Gaussian profiles and the products of them:
+\[ C_1 = 2 \int_0^{\sqrt{2}} \exp \left( - \xi^2 \right) \xi d\xi = 1 - \exp \left( -2 \right)\] \[ C_2 = 2 \int_0^{\sqrt{2}} \exp \left( - \left( \frac{\xi}{\lambda} \right)^2 \right) \xi d\xi = \lambda^2 \left( 1 - \exp \left( -\frac{2}{\lambda^2} \right) \right)\] \[ C_3 = 2 \int_0^{\sqrt{2}} \exp \left( - \xi^2 - \left( \frac{\xi}{\lambda} \right)^2 \right) \xi d\xi = \frac{\lambda^2}{\lambda^2 + 1} \left( 1 - \exp \left( -\frac{2 \left(\lambda^2 + 1\right)}{\lambda^2} \right) \right)\] \[ C_4 = \int_0^{\sqrt{2}} \exp \left( - 2\xi^2 \right) \xi d\xi = \frac{1}{4} \left( 1 - \exp \left( -4 \right) \right)\] \[ C_5 = \int_0^{\sqrt{2}} \exp \left( - 2\xi^2 - \left( \frac{\xi}{\lambda} \right)^2 \right) \xi d\xi = \frac{\lambda^2}{4\lambda^2 + 2} \left( 1 - \exp \left( -\frac{4\lambda^2 + 2}{\lambda^2} \right) \right)\]
+These are basically in the order that I encountered them when working out the integrals and could probably be cleaned up for some consistency. Throughout I made the substitution \(\xi = \frac{r}{b}\) such that every integral of a Gaussian in the model becomes \(b^2 C\) where the C corresponds to one of the above. Each of the 17 constants in the DEGADIS model correspond to one of these constants times a scaling factor. For all but \(k_1\) and \(k_2\) they are integer scaling factors, for the first two they \(\frac{1}{\lambda^2}\) times \(C_2\) and \(C_3\) respectively. Below is a table showing the concordance.
+| DEGADIS6 | +Me | +
|---|---|
| \(k_{1 }\) | +\(\frac{C_2}{\lambda^2}\) | +
| \(k_{2 }\) | +\(\frac{C_3}{\lambda^2}\) | +
| \(k_{3 }\) | +\(C_1\) | +
| \(k_{4 }\) | +\(C_2\) | +
| \(k_{5 }\) | +\(C_3\) | +
| \(k_{6 }\) | +\(2C_1\) | +
| \(k_{7 }\) | +\(2C_4\) | +
| \(k_{8 }\) | +\(2C_3\) | +
| \(k_{9 }\) | +\(2C_5\) | +
| \(k_{10}\) | +\(4C_4\) | +
| \(k_{11}\) | +\(4C_5\) | +
| \(k_{12}\) | +\(4C_1\) | +
| \(k_{13}\) | +\(3C_2\) | +
| \(k_{14}\) | +\(4C_3\) | +
| \(k_{15}\) | +\(\frac{C_2}{2}\) | +
| \(k_{16}\) | +\(\frac{C_1}{2}\) | +
| \(k_{17}\) | +\(\frac{C_3}{2}\) | +
It is decidedly easier to put everything in dimensionless form first, using the following (where a bar over the variable indicates that it is dimensionless):
+\[ \bar{s} = \frac{s}{D} \] \[ \bar{c} = \frac{c^{*}}{c_0} \] \[ \bar{b} = \frac{b}{D} \] \[ \bar{u} = \frac{u^{*}}{u_a} \] \[ \bar{\rho} = \frac{\rho^{*}}{\rho_a} \] \[ \bar{x} = \frac{x}{D} \] \[ \bar{z} = \frac{z}{D} \]
+Where D is the initial jet diameter. This is the main point where what follows diverges from DEGADIS, where the model is given in dimensional form, which makes each of the expressions much larger and makes direct comparison between the two something of a chore.
+Thusly equipped, we can work out the integrals and subsequently all the derivatives. Starting with the conservation of mass:
+\[ \int_0^{\sqrt{2}b} \rho u r dr = \int_0^{\sqrt{2}b} \rho_a u_a \left( 1 + \bar{\rho} \exp \left( - \left(r \over {\lambda b} \right)^2 \right) \right) \left( \cos \theta + \bar{u} \exp \left( - \left(r \over {b} \right)^2 \right) \right) r dr\]
+\[ = \rho_a u_a b^2 \left( \cos \theta + \bar{\rho} \cos \theta \int_0^{\sqrt{2}} \exp \left( - \left(\xi \over {\lambda } \right)^2 \right) \xi d\xi + \bar{u} \int_0^{\sqrt{2}} \exp \left( - \xi^2 \right) \xi d\xi + \bar{\rho} \bar{u} \int_0^{\sqrt{2}} \exp \left( - \xi \left(\xi \over {\lambda } \right)^2 \right) \xi d\xi \right)\] \[ = \frac{1}{2} \rho_a u_a D^2 \bar{b}^2 \left( \left( C_1 + C_3 \bar{\rho} \right) \bar{u} + \left(2 + C_2 \bar{\rho} \right) \cos \theta \right) \]
+So the balance equation is:
+\[ \frac{1}{2} \rho_a u_a \frac{d}{d\bar{s}} \bar{b}^2 \left( \left( C_1 + C_3 \bar{\rho} \right) \bar{u} + \left(2 + C_2 \bar{\rho} \right) \cos \theta \right) = b \rho_a u_a \bar{E} \] \[ \frac{d}{d\bar{s}} \bar{b}^2 \left( \left( C_1 + C_3 \bar{\rho} \right) \bar{u} + \left(2 + C_2 \bar{\rho} \right) \cos \theta \right) = b \bar{E} \]
+Where \(\bar{E} = \frac{E}{u_a}\) is the dimensionless entrainment velocity.
+Expanding out the derivatives and dividing through by b, we get:
+\[ \left( 2\cos \theta \left( 2 + C_2 \bar{\rho} \right) + 2 \bar{u} \left( C_1 + C_3\bar{\rho} \right) \right) \frac{d\bar{b}}{d\bar{s}} \] \[ + \bar{b} \left( C_1 + C_3\bar{\rho} \right) \frac{d\bar{u}}{d\bar{s}} \] \[ - \bar{b} \sin \theta \left( 2 + C_2\bar{\rho} \right) \frac{d\theta}{d\bar{s}} \] \[ + \bar{b} \left( C_2\cos \theta + C_3\bar{u} \right) \frac{d\bar{\rho}}{d\bar{s}} = 2 \bar{E}\]
+In the interests of not having this go on forever, I’m going to skip the details on the integral (they should be fairly obvious) and just give the balance equation and the final form with expanded out derivatives.
+The balance equation is:
+\[ \frac{d}{d\bar{s}} \left( \bar{c}\bar{b}^2 \left( C_2 \cos \theta + C_3 \bar{u} \right) \right) = 0 \]
+The final form is:
+\[ \bar{b} \left(C_3\bar{u} + C_2 \cos \theta \right) \frac{d\bar{c}}{d\bar{s}} \] \[ + 2 \bar{c} \left(C_3\bar{u} + C_2 \cos \theta \right) \frac{d\bar{b}}{d\bar{s}} \] \[ + C_3 \bar{c} \bar{b} \frac{d\bar{u}}{d\bar{s}} \] \[ - C_2 \bar{c} \bar{b} \sin \theta \frac{d\theta}{d\bar{s}} = 0\]
+The balance equation in the x-direction is:
+\[ \frac{d}{d\bar{s}} \left[ \bar{b}^2 \cos \theta \left( 2\bar{u}^2 \left( C_4 + C_5\bar{\rho} \right) + 2\bar{u} \cos\theta \left(C_1 + C_3 \bar{\rho} \right) + \cos^2 \theta \left( 2 + C_2 \bar{\rho} \right) \right) \right] = \bar{b} \left( 2\bar{E} + C_d | \sin^3 \theta | \right) \]
+The final form is:
+\[ 2\cos\theta \left[ 2\bar{u}^2 \left( C_4 + C_5 \bar{\rho} \right) + 2\bar{u} \cos\theta \left(C_1 + C_3 \bar{\rho} \right) + \cos^2 \theta \left( 2 + C_2 \bar{\rho} \right) \right] \frac{d\bar{b}}{d\bar{s}} \] \[ + 2\bar{b} \cos\theta \left[ 2\bar{u} \left( C_4 + C_5\bar{\rho} \right) + \cos\theta \left(C_1 + C_3 \bar{\rho} \right) \right] \frac{d\bar{u}}{d\bar{s}} \] \[ - \bar{b} \sin\theta \left[ 2\bar{u}^2 \left( C_4 + C_5 \bar{\rho} \right) + \cos \theta \left( 4\bar{u} \left(C_1 + C_3 \bar{\rho} \right) + 3\cos \theta \left( 2 + C_2 \bar{\rho} \right) \right) \right] \frac{d\theta}{d\bar{s}} \] \[ + \bar{b} \cos\theta \left[ C_2 \cos^2 \theta + 2C_3 \bar{u} \cos \theta + 2 C_5 \bar{u}^2 \right] \frac{d\bar{\rho}}{d\bar{s}} = 2 \bar{E} + C_d | \sin^3 \theta |\]
+The balance equation in the z-direction is:
+\[ \frac{d}{d\bar{s}} \left[ \bar{b}^2 \sin \theta \left( 2\bar{u}^2 \left( C_4 + C_5\bar{\rho} \right) + 2\bar{u} \cos\theta \left(C_1 + C_3 \bar{\rho} \right) + \cos^2 \theta \left( 2 + C_2 \bar{\rho} \right) \right) \right] = -C_2 \bar{b}^2 \bar{\rho} \bar{g} + \mathrm{sgn}\theta \cdot C_d \bar{b} \sin^2 \theta \cos \theta\]
+Where \(\bar{g} = \frac{Dg}{u_a^2}\) is the dimensionless gravity.
+The final form is:
+\[ 2\sin\theta \left[ 2\bar{u}^2 \left( C_4 + C_5 \bar{\rho} \right) + 2\bar{u} \cos\theta \left(C_1 + C_3 \bar{\rho} \right) + \cos^2 \theta \left( 2 + C_2 \bar{\rho} \right) \right] \frac{d\bar{b}}{d\bar{s}} \] \[ + 2\bar{b} \sin\theta \left[ 2\bar{u} \left( C_4 + C_5\bar{\rho} \right) + \cos\theta \left(C_1 + C_3 \bar{\rho} \right) \right] \frac{d\bar{u}}{d\bar{s}} \] \[ + \bar{b} \left[ 2\bar{u}^2 \cos\theta \left(C_4 + C_5 \bar{\rho} \right) + 2\bar{u} \left(\cos^2 \theta - \sin^2 \theta \right) \left( C_1 - C_3 \bar{\rho} \right) + \left(1 - 3\sin^2 \theta \right)\cos\theta \left(2 + C_2 \bar{\rho} \right) \right] \frac{d\theta}{d\bar{s}} \] \[ + \bar{b} \sin\theta \left[ C_2 \cos^2 \theta + 2C_3 \bar{u} \cos \theta + 2 C_5 \bar{u}^2 \right] \frac{d\bar{\rho}}{d\bar{s}} = -C_2 \bar{b} \bar{\rho} \bar{g} + \mathrm{sgn}\theta \cdot C_d \sin^2 \theta \cos \theta\]
+The balance equation is:
+\[ \frac{d}{d\bar{s}} \left[ \bar{b}^2 \left( 2\cos\theta + C_1 \bar{u} - \bar{\rho_a} \left( \bar{u} \left(C_1 + C_3 \bar{\rho} \right) + \cos \theta \left( 2 + C_2\bar{\rho} \right) \right) \right)\right] = 2\bar{b} \left( 1 - \bar{\rho_a} \right) \bar{E}\]
+Where \(\bar{\rho_a} = \frac{\rho_a}{\rho_{a,0}}\) is the dimensionless air density.
+The final form is:
+\[ 2\left( 2\cos\theta + C_1 \bar{u} - \bar{\rho_a} \left( \bar{u} \left(C_1 + C_3 \bar{\rho} \right) + \cos \theta \left( 2 + C_2\bar{\rho} \right) \right)\right) \frac{d\bar{b}}{d\bar{s}} \] \[ + b\left( C_1 - \bar{\rho_a} \left(C_1 + C_3 \bar{\rho} \right) \right) \frac{d\bar{u}}{d\bar{s}} \] \[ -b\sin\theta \left( 2 - \bar{\rho_a} \left( 2 + C_2\bar{\rho} \right) \right) \frac{d\theta}{d\bar{s}} \] \[ - \bar{b} \bar{\rho_a} \left( C_3 \bar{u} + C_2 \cos \theta \right) \frac{d\bar{\rho}}{d\bar{s}} = 2 \left( 1 - \bar{\rho_a} \right) \bar{E}\]
+Implementing this in julia is very straightforward, starting with the model constants
+# constants from Ooms 1972
+const λ² = 1.35
+const α₁ = 0.057
+const α₂ = 0.5
+const α₃ = 1.0
+const ϵ = 0.0
+const Cd = 0.3# integration constants
+const C₁ = 1-exp(-2)
+const C₂ = λ²*(1-exp(-2/λ²))
+const C₃ = (λ²/(λ²+1))*(1-exp(-2*(λ²+1)/λ²))
+const C₄ = (1-exp(-4))/4
+const C₅ = (λ²/(4λ²+2))*(1-exp(-(4λ²+2)/λ²))# physical constants
+const g = 9.80665 # standard gravity, m/s²
+const MWₐ = 0.0289652 # molar weight dry air, kg/mol
+const cpₐ = 1.006 # specific heat dry air, kJ/kg/K
+const ρₐ₀ = 1.2250 # standard density dry air, kg/m³The standard way of writing a differential algebraic equation is in the form of a mass matrix, M:
+\[ M \frac{d}{d\bar{s}} \mathrm{state} = f\left(\mathrm{state}, s\right) \]
+Where state is the state vector for this system. In this case M is not a constant, it is a function of the state of the system as well. Below is a function that calculates the mass matrix for a given state of the system, this is done in place to reduce the number of allocations required. The state variables are all in dimensionless form – the overbars are implied.
function ooms_matrix!(M,state,p,s)
+ # unpack variables for readability
+ c, b, u, θ, ρ, x, z = state
+
+ # calculate atmospheric conditons at centerline elevation
+ ρₐ_bar = p.rhoa_bar(z)
+
+ # species balance
+ M[1,1] = b*( C₃*u + C₂*cos(θ) )
+ M[1,2] = 2*c*( C₃*u + C₂*cos(θ) )
+ M[1,3] = C₃*c*b
+ M[1,4] = -C₂*c*b*sin(θ)
+ M[1,5] = 0
+ M[1,6] = 0
+ M[1,7] = 0
+
+ # overall mass balance
+ M[2,1] = 0
+ M[2,2] = 2cos(θ)*(2 + C₂*ρ) + 2u*(C₁ + C₃*ρ)
+ M[2,3] = b*(C₁ + C₃*ρ)
+ M[2,4] = -b*sin(θ)*(2 + C₂*ρ)
+ M[2,5] = b*(C₂*cos(θ) + C₃*u)
+ M[2,6] = 0
+ M[2,7] = 0
+
+ # x momentum balance
+ M[3,1] = 0
+ M[3,2] = 2cos(θ)*( 2u^2*(C₄ + C₅*ρ) + 2u*cos(θ)*(C₁ + C₃*ρ)
+ + cos(θ)^2*(2 + C₂*ρ))
+ M[3,3] = 2b*cos(θ)*( cos(θ)*(C₁ + C₃*ρ) + 2u*(C₄ + C₅*ρ) )
+ M[3,4] = -b*sin(θ)*( cos(θ)*( 4u*(C₁ + C₃*ρ) + 3cos(θ)*(2 + C₂*ρ) )
+ + 2u^2*(C₄ + C₅*ρ) )
+ M[3,5] = b*cos(θ)*( C₂*cos(θ)^2 + 2C₃*u*cos(θ) + 2C₅*u^2 )
+ M[3,6] = 0
+ M[3,7] = 0
+
+ # z momentum balance
+ M[4,1] = 0
+ M[4,2] = 2sin(θ)*( 2u*cos(θ)*(C₁ + C₃*ρ) + cos(θ)^2*(2 + C₂*ρ)
+ + 2u^2*(C₄ + C₅*ρ))
+ M[4,3] = 2b*sin(θ)*(cos(θ)*(C₁ + C₃*ρ) +2u*(C₄ + C₅*ρ))
+ M[4,4] = b*(2u*(cos(θ)^2 - sin(θ)^2)*(C₁ + C₃*ρ)
+ + (1-3sin(θ)^2)*cos(θ)*(2 + C₂*ρ)
+ + 2u^2*cos(θ)*(C₄ + C₅*ρ))
+ M[4,5] = b*sin(θ)*(C₂*cos(θ)^2 + 2C₃*u*cos(θ) + 2C₅*u^2)
+ M[4,6] = 0
+ M[4,7] = 0
+
+ # energy balance
+ M[5,1] = 0
+ M[5,2] = 2(2cos(θ) + C₁*u - ρₐ_bar*(u*(C₁ + C₃*ρ) + cos(θ)*(2 + C₂*ρ)) )
+ M[5,3] = b*( C₁ - ρₐ_bar*(C₁ + C₃*ρ) )
+ M[5,4] = -b*sin(θ)*( 2 - ρₐ_bar*(2 + C₂*ρ) )
+ M[5,5] = -b*ρₐ_bar*( C₂*cos(θ) + C₃*u )
+ M[5,6] = 0
+ M[5,7] = 0
+
+ # x coordinate
+ M[6,1:5] .= 0
+ M[6,6] = 1
+ M[6,7] = 0
+
+ # z coordinate
+ M[7,1:6] .= 0
+ M[7,7] = 1
+endIn dimensionless form, the only parameter of the system that is relevant to the mass matrix is \(\bar{\rho_a}\) which is a function of the (dimensionless) elevation.
+The right-hand-side of the system of equations is below, and is also in place. In this case there are three parameters: \(\bar{\rho_a}\), \(\bar{g}\) and \(\bar{u^{\prime}} = \frac{u^{\prime}}{u_a}\). These are all functions of elevation, the latter two because \(u_a\) is a function of elevation.
+function ooms_rhs!(f,state,p,s)
+ # unpack variables for readability
+ c, b, u, θ, ρ, x, z = state
+
+ # calculate atmospheric conditons at centerline elevation
+ ρₐ_bar = p.rhoa_bar(z)
+ g_bar = p.g_bar(z)
+
+ # entrainment
+ u′ = p.uprime_bar(b, z)
+ E = α₁*abs(u) + α₂*abs(sin(θ))*cos(θ) + α₃*u′
+ sgn = θ<0 ? -1 : +1
+
+ f .= [ 0 # species balance
+ 2E # overall mass balance
+ 2E + Cd*abs(sin(θ)^3) # x momentum balance
+ -C₂*b*ρ*g_bar + sign(θ)*Cd*sin(θ)^2*cos(θ) # z momentum balance
+ 2*(1-ρₐ_bar)*E # energy balance
+ cos(θ) # x coordinate
+ sin(θ)] # z coordinate
+endThe most direct way of implementing the model is as an ODE where
+\[ \frac{d}{d\bar{s}} \mathrm{state} = M^{-1} f \]
+Though instead of taking the matrix inverse a linear solve is done. This is what you might call the conventional approach, or traditional approach perhaps. People who spend a lot of time with DAEs and numerical computation will tell you not to do this – it can be unstable and fail if M is singular or near-singular – but it is also throughout the literature, especially in older code. For example, this is how DEGADIS implements the right-hand-side of the ODE.
+using OrdinaryDiffEqfunction ode_rhs!(dstate,state,p,s)
+ ooms_matrix!(p.M,state,p,s)
+ ooms_rhs!(p.f,state,p,s)
+ dstate[:] = p.M\p.f
+endInstead of allocating (and garbage collecting) a matrix M and vector f every time the right-and-side is called, I pre-allocate them and store them with the model parameters as a kind of scratch space.
+For a working example, suppose the vent is releasing into a neutral atmosphere with no density gradient and a windspeed at the stack height of 2m/s
+const dρₐdz = 0.0
+const uₐ₀ = 2.0 # m/sThe vent itself is basically air but hotter and thus at a lower density. The vent stack is 2m from the ground and 20cm in diameter, the vent is being ejected at 10m/s vertically. I am also ignoring the zone of flow establishment and having the plume start exactly at the vent exit.
+const MWⱼ = MWₐ # kg/m³
+const cpⱼ = cpₐ # kJ/kg/K
+const ρⱼ = ρₐ₀/2 # kg/m³
+const D = 0.2 # m
+const u₀ = 10.0 # m/s
+const h = 2.0 # m
+const θ₀ = π/2
+const c₀ = ρⱼThe system parameters are simply the scratch space for M and f, and the three dimensionless groups which are each functions of elevation. In this case I am further assuming that windspeed is uniform.
+params = (M = zeros(7,7),
+ f = zeros(7),
+ rhoa_bar = (z) -> 1.0 + (dρₐdz/ρₐ₀)*D*z,
+ g_bar = (z) -> (g*D)/uₐ₀^2,
+ uprime_bar = (b, z) -> ∛(ϵ*b*D)/uₐ₀)The initial state, in dimensionless form, is then
+state0 = [ 1.0 ,# c
+ 1/(2√(2)) ,# b
+ u₀/uₐ₀ ,# u
+ θ₀ ,# θ
+ (ρⱼ - ρₐ₀)/ρₐ₀ ,# ρ
+ 0.0 ,# x
+ h/D ]# zThe initial value for \(\bar{b}_{0}\) might seem strange and arbitrary, but this comes from matching the initial dimensions of the plume to the exit of the vent stack. Recall the plume radius is \(\sqrt{2}{b}\) so, if the plume initially has a radius equal to the vent \(\sqrt{2}b_0 = \frac{D}{2}\) and \(\bar{b}_0 = \frac{b}{D} = \frac{1}{2\sqrt{2}}\)
+Integrating out 100 stack diameters along the plume
+span = (0.0, 100)
+prob = ODEProblem(ode_rhs!, state0, span, params)sol = solve(prob, Tsit5())
+
+sol.retcodeReturnCode.Success = 1 +
+Nesting the linear solve step within the right-hand-side of the ODE can be dangerous if M ever becomes singular, or close to it. It is probably safer to use a DAE solver instead.
+DAE solvers expect to be solving a differential algebraic equation of the form:
+\[ f\left( \mathrm{state}^{\prime}, \mathrm{state}, s \right) = 0\]
+Using the matrix and rhs functions defined earlier this easy enough to do, in this case the function is in-place.
+function dae_lhs!(resid,dstate,state,p,s)
+ ooms_matrix!(p.M,state,p,s)
+ ooms_rhs!(p.f,state,p,s)
+ resid[:] = p.M*dstate - p.f
+endThe DAE solver also needs an initial state for all of the derivatives, which can be calculated by solving the linear system for the derivatives given the initial conditions.
+M0 = zeros(7,7)
+ooms_matrix!(M0,state0,params,0)
+
+f0 = zeros(7)
+ooms_rhs!(f0,state0,params,0)
+
+dstate0 = M0\f0diff_vars = fill(true, 7)
+daeprob = DAEProblem(dae_lhs!, dstate0, state0, span, params;
+ differential_vars = diff_vars)The DAEProblem also needs a hint as to which are differential equations, this is what is being passed by the differential_vars keyword argument. In this case they are all differential equations so I pass a vector of seven trues.
The DAE solver I am going to use is IDA from Sundials.
using Sundialsdaesol = solve(daeprob, IDA())
+
+daesol.retcodeReturnCode.Success = 1 +
+This works as well as the lazy method, slightly slower but it has not been implemented in a particularly optimal way.
+If you know anything about the universe of tools in julia for modelling differential algebraic equations you are probably yelling at your screen “use ModelingToolkit!”. In terms of getting a DAE from nothing to a working model it is by far the easiest way to do it. I deliberately put all of the working out in this blog post because it annoys me that it is so hard to find online and I want it to be somewhere. But if I didn’t care about that, ModelingToolkit is the obvious choice.
+using ModelingToolkit, Symbolics
+using ModelingToolkit: t_nounits as s, D_nounits as ∂
+
+# I would use D for derivative but I'm already using
+# that for jet diameter so I'm using ∂ insteadFirst I define the system variables, again these are in dimensionless form.
+vars = @variables c(s) b(s) u(s) θ(s) ρ(s) x(s) z(s)\[ \begin{equation} +\left[ +\begin{array}{c} +c\left( t \right) \\ +b\left( t \right) \\ +u\left( t \right) \\ +\theta\left( t \right) \\ +\rho\left( t \right) \\ +x\left( t \right) \\ +z\left( t \right) \\ +\end{array} +\right] +\end{equation} +\]
+If this wasn’t in a notebook that includes other methods of solving the DAE, I would have declared the model constants using the @constants macro. It makes the formulas look nicer for one, e.g. instead of numbers like 0.86466 there would be the appropriate constant \(C_1\).
# conservation of mass
+∫ρurdr = b^2*( (C₁ + C₃*ρ)*u + (2 + C₂*ρ)*cos(θ) )
+
+E = α₁*abs(u) + α₂*abs(sin(θ))*cos(θ) + α₃*∛(ϵ*b*D)/uₐ₀
+
+eqn1 = expand_derivatives( ∂( ∫ρurdr ) ) ~ 2*b*E\[ \begin{equation} +2 \left( u\left( t \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) + \left( 2 + 1.0431 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) \right) \frac{\mathrm{d} b\left( t \right)}{\mathrm{d}t} b\left( t \right) + \left( b\left( t \right) \right)^{2} \left( 0.5568 u\left( t \right) \frac{\mathrm{d} \rho\left( t \right)}{\mathrm{d}t} + \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \frac{\mathrm{d} u\left( t \right)}{\mathrm{d}t} + 1.0431 \frac{\mathrm{d} \rho\left( t \right)}{\mathrm{d}t} \cos\left( \theta\left( t \right) \right) - \sin\left( \theta\left( t \right) \right) \left( 2 + 1.0431 \rho\left( t \right) \right) \frac{\mathrm{d} \theta\left( t \right)}{\mathrm{d}t} \right) = 2 \left( 0.057 \left|u\left( t \right)\right| + 0.5 \left|\sin\left( \theta\left( t \right) \right)\right| \cos\left( \theta\left( t \right) \right) \right) b\left( t \right) +\end{equation} +\]
+# conservation of species
+∫curdr = c*b^2*(C₂*cos(θ) + C₃*u)
+
+eqn2 = expand_derivatives( ∂( ∫curdr ) ) ~ 0\[ \begin{equation} +2 \left( 0.5568 u\left( t \right) + 1.0431 \cos\left( \theta\left( t \right) \right) \right) c\left( t \right) \frac{\mathrm{d} b\left( t \right)}{\mathrm{d}t} b\left( t \right) + \left( b\left( t \right) \right)^{2} \left( 0.5568 u\left( t \right) + 1.0431 \cos\left( \theta\left( t \right) \right) \right) \frac{\mathrm{d} c\left( t \right)}{\mathrm{d}t} + \left( b\left( t \right) \right)^{2} \left( 0.5568 \frac{\mathrm{d} u\left( t \right)}{\mathrm{d}t} - 1.0431 \sin\left( \theta\left( t \right) \right) \frac{\mathrm{d} \theta\left( t \right)}{\mathrm{d}t} \right) c\left( t \right) = 0 +\end{equation} +\]
+# conservation of momentum
+# x-direction
+∫ρu²cosθrdr = b^2*cos(θ)*(2u*cos(θ)*(C₁ + C₃*ρ) + 2u^2*(C₄ + C₅*ρ)
+ + cos(θ)^2*(2 + C₂*ρ))
+
+eqn3 = expand_derivatives( ∂( ∫ρu²cosθrdr ) ) ~
+ b*( 2E + Cd*abs(sin(θ)^3) )\[ \begin{equation} +2 \left( 2 \left( u\left( t \right) \right)^{2} \left( 0.24542 + 0.18167 \rho\left( t \right) \right) + 2 u\left( t \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) + \cos^{2}\left( \theta\left( t \right) \right) \left( 2 + 1.0431 \rho\left( t \right) \right) \right) \frac{\mathrm{d} b\left( t \right)}{\mathrm{d}t} \cos\left( \theta\left( t \right) \right) b\left( t \right) - \left( b\left( t \right) \right)^{2} \left( 2 \left( u\left( t \right) \right)^{2} \left( 0.24542 + 0.18167 \rho\left( t \right) \right) + 2 u\left( t \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) + \cos^{2}\left( \theta\left( t \right) \right) \left( 2 + 1.0431 \rho\left( t \right) \right) \right) \sin\left( \theta\left( t \right) \right) \frac{\mathrm{d} \theta\left( t \right)}{\mathrm{d}t} + \left( b\left( t \right) \right)^{2} \left( 0.36335 \left( u\left( t \right) \right)^{2} \frac{\mathrm{d} \rho\left( t \right)}{\mathrm{d}t} + 4 u\left( t \right) \left( 0.24542 + 0.18167 \rho\left( t \right) \right) \frac{\mathrm{d} u\left( t \right)}{\mathrm{d}t} + 1.1136 u\left( t \right) \frac{\mathrm{d} \rho\left( t \right)}{\mathrm{d}t} \cos\left( \theta\left( t \right) \right) + 2 \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \frac{\mathrm{d} u\left( t \right)}{\mathrm{d}t} \cos\left( \theta\left( t \right) \right) + 1.0431 \cos^{2}\left( \theta\left( t \right) \right) \frac{\mathrm{d} \rho\left( t \right)}{\mathrm{d}t} - 2 u\left( t \right) \sin\left( \theta\left( t \right) \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \frac{\mathrm{d} \theta\left( t \right)}{\mathrm{d}t} - 2 \sin\left( \theta\left( t \right) \right) \left( 2 + 1.0431 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) \frac{\mathrm{d} \theta\left( t \right)}{\mathrm{d}t} \right) \cos\left( \theta\left( t \right) \right) = \left( 0.3 \left|\sin^{3}\left( \theta\left( t \right) \right)\right| + 2 \left( 0.057 \left|u\left( t \right)\right| + 0.5 \left|\sin\left( \theta\left( t \right) \right)\right| \cos\left( \theta\left( t \right) \right) \right) \right) b\left( t \right) +\end{equation} +\]
+# z-direction
+∫ρu²sinθrdr = b^2*sin(θ)*(2u*cos(θ)*(C₁ + C₃*ρ) + 2u^2*(C₄ + C₅*ρ)
+ + cos(θ)^2*(2 + C₂*ρ))
+
+eqn4 = expand_derivatives( ∂( ∫ρu²sinθrdr ) ) ~
+ -C₂*b^2*ρ*(g*D/uₐ₀^2) + sign(θ)*Cd*b*sin(θ)^2*cos(θ)\[ \begin{equation} +2 \left( 2 \left( u\left( t \right) \right)^{2} \left( 0.24542 + 0.18167 \rho\left( t \right) \right) + 2 u\left( t \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) + \cos^{2}\left( \theta\left( t \right) \right) \left( 2 + 1.0431 \rho\left( t \right) \right) \right) \sin\left( \theta\left( t \right) \right) \frac{\mathrm{d} b\left( t \right)}{\mathrm{d}t} b\left( t \right) + \left( b\left( t \right) \right)^{2} \left( 2 \left( u\left( t \right) \right)^{2} \left( 0.24542 + 0.18167 \rho\left( t \right) \right) + 2 u\left( t \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) + \cos^{2}\left( \theta\left( t \right) \right) \left( 2 + 1.0431 \rho\left( t \right) \right) \right) \cos\left( \theta\left( t \right) \right) \frac{\mathrm{d} \theta\left( t \right)}{\mathrm{d}t} + \left( b\left( t \right) \right)^{2} \left( 0.36335 \left( u\left( t \right) \right)^{2} \frac{\mathrm{d} \rho\left( t \right)}{\mathrm{d}t} + 4 u\left( t \right) \left( 0.24542 + 0.18167 \rho\left( t \right) \right) \frac{\mathrm{d} u\left( t \right)}{\mathrm{d}t} + 1.1136 u\left( t \right) \frac{\mathrm{d} \rho\left( t \right)}{\mathrm{d}t} \cos\left( \theta\left( t \right) \right) + 2 \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \frac{\mathrm{d} u\left( t \right)}{\mathrm{d}t} \cos\left( \theta\left( t \right) \right) + 1.0431 \cos^{2}\left( \theta\left( t \right) \right) \frac{\mathrm{d} \rho\left( t \right)}{\mathrm{d}t} - 2 u\left( t \right) \sin\left( \theta\left( t \right) \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \frac{\mathrm{d} \theta\left( t \right)}{\mathrm{d}t} - 2 \sin\left( \theta\left( t \right) \right) \left( 2 + 1.0431 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) \frac{\mathrm{d} \theta\left( t \right)}{\mathrm{d}t} \right) \sin\left( \theta\left( t \right) \right) = - 0.51149 \left( b\left( t \right) \right)^{2} \rho\left( t \right) + 0.3 \sin^{2}\left( \theta\left( t \right) \right) \cos\left( \theta\left( t \right) \right) b\left( t \right) sign\left( \theta\left( t \right) \right) +\end{equation} +\]
+# energy balance
+ρₐ_bar = 1 + dρₐdz*D*z/ρₐ₀
+
+∫ρucₚΔTrdr = b^2*(2cos(θ) + C₁*u - ρₐ_bar*( u*(C₁ + C₃*ρ)
+ + cos(θ)*(2 + C₂*ρ) ))
+
+eqn5 = expand_derivatives( ∂( ∫ρucₚΔTrdr ) ) ~ 2*b*(1 - ρₐ_bar)*E\[ \begin{equation} +2 \left( 0.86466 u\left( t \right) + 2 \cos\left( \theta\left( t \right) \right) - u\left( t \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) - \left( 2 + 1.0431 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) \right) \frac{\mathrm{d} b\left( t \right)}{\mathrm{d}t} b\left( t \right) + \left( b\left( t \right) \right)^{2} \left( 0.86466 \frac{\mathrm{d} u\left( t \right)}{\mathrm{d}t} - 0.5568 u\left( t \right) \frac{\mathrm{d} \rho\left( t \right)}{\mathrm{d}t} - 2 \sin\left( \theta\left( t \right) \right) \frac{\mathrm{d} \theta\left( t \right)}{\mathrm{d}t} + \left( -0.86466 - 0.5568 \rho\left( t \right) \right) \frac{\mathrm{d} u\left( t \right)}{\mathrm{d}t} - 1.0431 \frac{\mathrm{d} \rho\left( t \right)}{\mathrm{d}t} \cos\left( \theta\left( t \right) \right) - \sin\left( \theta\left( t \right) \right) \left( -2 - 1.0431 \rho\left( t \right) \right) \frac{\mathrm{d} \theta\left( t \right)}{\mathrm{d}t} \right) = 0 +\end{equation} +\]
+# The full system of equations
+
+eqns = [ eqn1
+ eqn2
+ eqn3
+ eqn4
+ eqn5
+ ∂(x) ~ cos(θ)
+ ∂(z) ~ sin(θ) ]Symbolics.jl has done all the derivatives and set up all the equations, what remains is to build ODESystem and solve.
@named sys = ODESystem(eqns, s)
+sys = structural_simplify(sys)\[ \begin{align} +\frac{\mathrm{d} b\left( t \right)}{\mathrm{d}t} &= \mathtt{bˍt}\left( t \right) \\ +\frac{\mathrm{d} \rho\left( t \right)}{\mathrm{d}t} &= \mathtt{{\rho}ˍt}\left( t \right) \\ +\frac{\mathrm{d} \theta\left( t \right)}{\mathrm{d}t} &= \mathtt{{\theta}ˍt}\left( t \right) \\ +\frac{\mathrm{d} u\left( t \right)}{\mathrm{d}t} &= \mathtt{uˍt}\left( t \right) \\ +0 &= 2 \left( 0.057 \left|u\left( t \right)\right| + 0.5 \left|\sin\left( \theta\left( t \right) \right)\right| \cos\left( \theta\left( t \right) \right) \right) b\left( t \right) - 2 \left( u\left( t \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) + \left( 2 + 1.0431 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) \right) b\left( t \right) \mathtt{bˍt}\left( t \right) + \left( b\left( t \right) \right)^{2} \left( - 0.5568 u\left( t \right) \mathtt{{\rho}ˍt}\left( t \right) - \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \mathtt{uˍt}\left( t \right) - 1.0431 \mathtt{{\rho}ˍt}\left( t \right) \cos\left( \theta\left( t \right) \right) + \sin\left( \theta\left( t \right) \right) \left( 2 + 1.0431 \rho\left( t \right) \right) \mathtt{{\theta}ˍt}\left( t \right) \right) \\ +0 &= - 2 \left( 0.86466 u\left( t \right) + 2 \cos\left( \theta\left( t \right) \right) - u\left( t \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) + \left( -2 - 1.0431 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) \right) b\left( t \right) \mathtt{bˍt}\left( t \right) + \left( b\left( t \right) \right)^{2} \left( - 0.86466 \mathtt{uˍt}\left( t \right) + 0.5568 u\left( t \right) \mathtt{{\rho}ˍt}\left( t \right) + 2 \sin\left( \theta\left( t \right) \right) \mathtt{{\theta}ˍt}\left( t \right) - \left( -0.86466 - 0.5568 \rho\left( t \right) \right) \mathtt{uˍt}\left( t \right) + 1.0431 \mathtt{{\rho}ˍt}\left( t \right) \cos\left( \theta\left( t \right) \right) + \sin\left( \theta\left( t \right) \right) \left( -2 - 1.0431 \rho\left( t \right) \right) \mathtt{{\theta}ˍt}\left( t \right) \right) \\ +0 &= \left( 0.3 \left|\sin^{3}\left( \theta\left( t \right) \right)\right| + 2 \left( 0.057 \left|u\left( t \right)\right| + 0.5 \left|\sin\left( \theta\left( t \right) \right)\right| \cos\left( \theta\left( t \right) \right) \right) \right) b\left( t \right) - 2 \left( 2 \left( u\left( t \right) \right)^{2} \left( 0.24542 + 0.18167 \rho\left( t \right) \right) + 2 u\left( t \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) + \cos^{2}\left( \theta\left( t \right) \right) \left( 2 + 1.0431 \rho\left( t \right) \right) \right) \cos\left( \theta\left( t \right) \right) b\left( t \right) \mathtt{bˍt}\left( t \right) + \left( b\left( t \right) \right)^{2} \left( 2 \left( u\left( t \right) \right)^{2} \left( 0.24542 + 0.18167 \rho\left( t \right) \right) + 2 u\left( t \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) + \cos^{2}\left( \theta\left( t \right) \right) \left( 2 + 1.0431 \rho\left( t \right) \right) \right) \sin\left( \theta\left( t \right) \right) \mathtt{{\theta}ˍt}\left( t \right) + \left( b\left( t \right) \right)^{2} \left( - 0.36335 \left( u\left( t \right) \right)^{2} \mathtt{{\rho}ˍt}\left( t \right) - 4 u\left( t \right) \left( 0.24542 + 0.18167 \rho\left( t \right) \right) \mathtt{uˍt}\left( t \right) - 1.1136 u\left( t \right) \mathtt{{\rho}ˍt}\left( t \right) \cos\left( \theta\left( t \right) \right) - 2 \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) \mathtt{uˍt}\left( t \right) - 1.0431 \cos^{2}\left( \theta\left( t \right) \right) \mathtt{{\rho}ˍt}\left( t \right) + 2 u\left( t \right) \sin\left( \theta\left( t \right) \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \mathtt{{\theta}ˍt}\left( t \right) + 2 \sin\left( \theta\left( t \right) \right) \left( 2 + 1.0431 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) \mathtt{{\theta}ˍt}\left( t \right) \right) \cos\left( \theta\left( t \right) \right) \\ +0 &= - 0.51149 \left( b\left( t \right) \right)^{2} \rho\left( t \right) + 0.3 \sin^{2}\left( \theta\left( t \right) \right) \cos\left( \theta\left( t \right) \right) b\left( t \right) sign\left( \theta\left( t \right) \right) - 2 \left( 2 \left( u\left( t \right) \right)^{2} \left( 0.24542 + 0.18167 \rho\left( t \right) \right) + 2 u\left( t \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) + \cos^{2}\left( \theta\left( t \right) \right) \left( 2 + 1.0431 \rho\left( t \right) \right) \right) \sin\left( \theta\left( t \right) \right) b\left( t \right) \mathtt{bˍt}\left( t \right) + \left( b\left( t \right) \right)^{2} \left( - 2 \left( u\left( t \right) \right)^{2} \left( 0.24542 + 0.18167 \rho\left( t \right) \right) - 2 u\left( t \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) + \cos^{2}\left( \theta\left( t \right) \right) \left( -2 - 1.0431 \rho\left( t \right) \right) \right) \cos\left( \theta\left( t \right) \right) \mathtt{{\theta}ˍt}\left( t \right) - \left( b\left( t \right) \right)^{2} \left( 0.36335 \left( u\left( t \right) \right)^{2} \mathtt{{\rho}ˍt}\left( t \right) + 4 u\left( t \right) \left( 0.24542 + 0.18167 \rho\left( t \right) \right) \mathtt{uˍt}\left( t \right) + 1.1136 u\left( t \right) \mathtt{{\rho}ˍt}\left( t \right) \cos\left( \theta\left( t \right) \right) + 2 \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) \mathtt{uˍt}\left( t \right) + 1.0431 \cos^{2}\left( \theta\left( t \right) \right) \mathtt{{\rho}ˍt}\left( t \right) - 2 u\left( t \right) \sin\left( \theta\left( t \right) \right) \left( 0.86466 + 0.5568 \rho\left( t \right) \right) \mathtt{{\theta}ˍt}\left( t \right) - 2 \sin\left( \theta\left( t \right) \right) \left( 2 + 1.0431 \rho\left( t \right) \right) \cos\left( \theta\left( t \right) \right) \mathtt{{\theta}ˍt}\left( t \right) \right) \sin\left( \theta\left( t \right) \right) \\ +\frac{\mathrm{d} c\left( t \right)}{\mathrm{d}t} &= \mathtt{cˍt}\left( t \right) \\ +0 &= - 2 \left( 0.5568 u\left( t \right) + 1.0431 \cos\left( \theta\left( t \right) \right) \right) c\left( t \right) b\left( t \right) \mathtt{bˍt}\left( t \right) - \left( b\left( t \right) \right)^{2} \left( 0.5568 u\left( t \right) + 1.0431 \cos\left( \theta\left( t \right) \right) \right) \mathtt{cˍt}\left( t \right) - \left( b\left( t \right) \right)^{2} \left( 0.5568 \mathtt{uˍt}\left( t \right) - 1.0431 \sin\left( \theta\left( t \right) \right) \mathtt{{\theta}ˍt}\left( t \right) \right) c\left( t \right) \\ +\frac{\mathrm{d} z\left( t \right)}{\mathrm{d}t} &= \sin\left( \theta\left( t \right) \right) \\ +\frac{\mathrm{d} x\left( t \right)}{\mathrm{d}t} &= \cos\left( \theta\left( t \right) \right) +\end{align} +\]
+In this case there are no model parameters as I inserted the equations for the dimensionless groups directly into the model.
+mtk_params = ()The initial values simply map over the initial state I worked out previously. Because ModelingToolkit generates its own internal structure and shuffles things around, a mapping needs to be provided for the initial conditions.
+initial_vals = [ c => state0[1],
+ b => state0[2],
+ u => state0[3],
+ θ => state0[4],
+ ρ => state0[5],
+ x => state0[6],
+ z => state0[7] ]mtk_prob = ODEProblem(sys, initial_vals, span)mtk_sol = solve(mtk_prob, Rodas5P())
+
+mtk_sol.retcodeReturnCode.Success = 1 +
+In terms of julia code that needed to be written, and calculus that needed to be done, this the simplest by far. Simply compare to the enormous mass matrix expression above to convince yourself of that. There are also code generation tools that can be used if you want to extract the model either as a julia script or even C code. Furthermore, if you want to go through term by term and look at the coefficients for each derivative, Symbolics.jl can do that too. I actually used Symbolics to check all of my work in the mass matrix.
+Another approach to the ODE problem is to use a matrix operator. This is a mass matrix problem with a state dependent mass matrix, which is one of the use cases for SciMLOperators.jl
+using SciMLOperatorsM = MatrixOperator(zeros(7,7); update_func! = ooms_matrix!)massprob = ODEProblem(ODEFunction(ooms_rhs!, mass_matrix=M), state0, span, params)mass_sol = solve(massprob,Rodas5P(); initializealg=BrownFullBasicInit())
+
+mass_sol.retcode┌ Warning: At t=0.0, dt was forced below floating point epsilon 5.0e-324, and step error estimate = NaN. Aborting. There is either an error in your model specification or the true solution is unstable (or the true solution can not be represented in the precision of Float64). + +└ @ SciMLBase ~/.julia/packages/SciMLBase/rvXrA/src/integrator_interface.jl:623 ++
ReturnCode.Unstable = 7I tried a bunch of different solvers and initialization algorithms, nothing could get past the first timestep. That there are two working versions of this system, in this post, using the same exact mass matrix function leads me to suspect it is not a model error, or that the solution is unstable. There is probably some aspect to how I’m supposed to be initializing this problem, or some other feature of using matrix operators, that I’m doing wrong, but I find the documentation on that to be mostly absent. I know these can work because I have used this exact method on simpler systems in the past.
+If I ever figure out what I need to do to make this work, or more definitively why it doesn’t, I’ll come back and update this. Consider this an invitation to tell me all the ways I’m doing this wrong in the comments.
+The plume solution is fundamentally in terms of the plume axis. It is not immediately obvious how to calculate the concentrations at particular points in space relative to the problem coordinate system. The way I see it, there are three related problems that involve calculating concentrations from the Ooms model.
+These all stem from the problem that for some arbitrary point not on the plume axis, it is not immediately clear which part of the plume axis is governing the concentration there. This is because the concentration profiles are not perpendicular to the x-axis, they are perpendicular to the s-axis and that curves through space.
+The easiest problem to solve is the isopleths in the plane \(y=0\). Suppose we want to calculate the isopleth for some concentration \(c = c_l\). Recalling the concentration profile:
+\[ \bar{c}_l = \bar{c}_o \exp \left( - \left( \frac{r}{\lambda b} \right)^2 \right) \]
+Where \(\bar{c}_o\) is the center line concentration at that point along the plume axis. We first solve for \(r\), the distance from the plume axis:
+\[ r = b \lambda \sqrt{ \log \left( \bar{c}_o \over \bar{c}_l \right) } \]
+Converting from cylindrical coordinates to Cartesian coordinates, \(x^{\prime}, y^{\prime}, z^{\prime}\), aligned such that \(x^{\prime}\) is aligned with the plume axis, the radius is
+\[ r^2 = \left(y^{\prime}\right)^2 + \left(z^{\prime}\right)^2 \]
+Since we are confined to the plane \(y^{\prime} = 0\), we find \(z^{\prime} = \pm r\). Then we rotate the axis to align with the problem coordinate system and translate the origin to the problem origin.
+\[ x = x_o \mp r \sin \theta \] \[ z = z_o \pm r \cos \theta \]
+Where \(x_o\) and \(z_o\) is the location of the particular point on the plume axis we were looking at. The origin relative to the point on the plume axis, hence the subscript o. The positive r gives the upper isopleth and the negative r gives the lower isopleth.
+Casal7 provides an alternative form of these isopleths:
+\[ z = z_o \pm \sqrt{ { {\lambda^2 b^2} \over { 1 + \tan^2 \theta }} \log \left(\frac{c_o}{c_l} \right) } \]
+and
+\[ {{z - z_o} \over {x - x_o}} = -\cot \theta \]
+These are actually equivalent, using the identity \(\sec^2 = 1 + \tan^2 \theta\) and the definition \(\sec \theta = \frac{1}{\cos \theta}\), the first equation can be written as:
+\[ z = z_o \pm \sqrt{ { {\lambda^2 b^2} \over { \sec^2 \theta }} \log \left(\frac{c_o}{c_l} \right) } = z_o \pm \sqrt{ \lambda^2 b^2 \cos^2 \theta \log \left(\frac{c_o}{c_l} \right) } \] \[ = z_o \pm \lambda b \sqrt{ \log \left(\frac{c_o}{c_l} \right) } \cos \theta = z_o \pm r \cos \theta\]
+The second equation can be re-written to solve for x:
+\[ {{z - z_o} \over {x - x_o}} = -\cot \theta \] \[ {z - z_o} = -\left(x - x_o\right)\cot \theta \] \[ \pm r \cos \theta = -\left(x - x_o\right)\cot \theta \] \[ \pm r \cos \theta = - \left(x - x_o\right) \frac{\cos \theta}{\sin \theta}\] \[ x = x_o \mp r \sin \theta \]
+function upper_isopleth(solution, s, c)
+ cₒ, bₒ, uₒ, θₒ, ρₒ, xₒ, zₒ = solution(s)
+
+ if c ≈ cₒ
+ return Point(xₒ,zₒ)
+ elseif c > cₒ
+ return nothing
+ else
+ r = bₒ * √(λ²*log(cₒ/c))
+ x = xₒ - r*sin(θₒ)
+ z = zₒ + r*cos(θₒ)
+ return Point(x,z)
+ end
+endfunction lower_isopleth(solution, s, c)
+ cₒ, bₒ, uₒ, θₒ, ρₒ, xₒ, zₒ = solution(s)
+
+ if c ≈ cₒ
+ return Point(xₒ,zₒ)
+ elseif c > cₒ
+ return nothing
+ else
+ r = bₒ * √(λ²*log(cₒ/c))
+ x = xₒ + r*sin(θₒ)
+ z = zₒ - r*cos(θₒ)
+ return Point(x,z)
+ end
+endFor an example, suppose we want the isopleth for \(c/c_0 = 2\%\)
+cₗ = 0.02 # c/c₀ = 2%First, I find the point along the plume axis where the concentration drops below 2%, there is no point in looking for an isopleth past this point since it doesn’t exist.
+using Roots: find_zeroi_end = findfirst(sol[1,:] .< cₗ )20s_end = find_zero( (s) -> sol(s, idxs = 1) - cₗ, sol.t[i_end])46.23790952011145Then I can calculate a series of points for the upper isopleth and the lower isopleth from the origin out to where the plume concentration has dropped below 2%.
+upper_points = [ upper_isopleth(sol, s, cₗ) for s in LinRange(0.0, s_end, 100)
+ if !isnothing(upper_isopleth(sol, s, cₗ))];
+lower_points = [ lower_isopleth(sol, s, cₗ) for s in LinRange(0.0, s_end, 100)
+ if !isnothing(lower_isopleth(sol, s, cₗ))]; +
+A somewhat more difficult problem is finding the isopleths on the plane z=a. The logic is the same: for each point along the plume axis, work out the distance r to the given concentration, then solve for y given z=a.
+function cross_isopleth(solution, s, c, a)
+ cₒ, bₒ, uₒ, θₒ, ρₒ, xₒ, zₒ = solution(s)
+
+ if c ≈ cₒ
+ return Point(xₒ,0.0)
+ elseif c > cₒ
+ # isopleth doesn't exist here
+ return nothing
+ else
+ # find the x coordinate
+ xₒ′ = xₒ*cos(θₒ) + zₒ*sin(θₒ)
+ x = (xₒ′ - a*sin(θₒ))*sec(θₒ)
+
+ # find the y coordinate
+ r² = bₒ^2 * λ²*log(cₒ/c)
+ z′² = ((a - zₒ)*cos(θₒ) - (x - xₒ)*sin(θₒ))^2
+
+ if z′² > r²
+ # the isosurface doesn't intersect z=a
+ return nothing
+ else
+ y′ = √( r² - z′²)
+ y = y′
+ return Point(x,y)
+ end
+ end
+endPicking an arbitraty height of 20 stack diameters in elevation.
+a = 20 # 20 stack diametersWe need to find the start and end of the isopleth, which not immediately obvious like it was of the isopleths in the plane y=0. But we can re-use the vertical isopleths – the start of the isopleth is the point where the upper isopleth intersects z=a and the end is where the lower isopleth intersects it. I have used the word isopleth a lot, hopefully it makes sense and has not lost all meaning.
+# the start of the isopleth
+s_start = find_zero( (s) -> upper_isopleth(sol, s, cₗ)[2] - a, 14)14.87383455152286# the end of the isopleth
+s_end = find_zero( (s) -> lower_isopleth(sol, s, cₗ)[2] - a, 33)33.55677883331305cross_points = [ cross_isopleth(sol, s, cₗ, a) for s in LinRange(s_start+1e-3, s_end, 100)
+ if !isnothing(cross_isopleth(sol, s, cₗ, a))]flipped_points = [ Point( pt[1], -1*pt[2] ) for pt in cross_points ] +
+Calculating the concentration at some arbitrary point involves first backing out where along the plume axis the concentration is coming from, then calculating the concentration using the Gaussian profile.
+To find the location on the axis that governs the concentration at the point, i.e. the location on the axis where a vector connecting it to the arbitrary point is perpendicular to the plume axis, I basically just rotate the problem coordinate system to align with the plume axis and check. Since the ODE solution includes a set of pre-calculated points, I use it to generate an initial guess of where to look and then use Newton’s method to find the exact location s.
+function find_centerline(solution,x,y,z)
+ function perp_test(s)
+ θₒ, _, xₒ, zₒ = solution(s, idxs=4:7)
+ x′ = x*cos(θₒ) + z*sin(θₒ)
+ xₒ′ = xₒ*cos(θₒ) + zₒ*sin(θₒ)
+ return x′ - xₒ′
+ end
+
+ # find initial guess
+ i0 = argmin( [ abs(perp_test(s)) for s in sol.t ] )
+ s0 = sol.t[i0]
+
+ # find the zero point
+ return find_zero(perp_test, s0)
+endThe concentration then builds on this by first finding the location along the plume axis that connects to the arbitrary point, calculating the distance r from the plume axis to the point, and finally returning the concentration.
+function concentration(solution,x,y,z)
+ # get the point on the centerline that governs this point
+ sₒ = find_centerline(solution,x,y,z)
+ cₒ, bₒ, uₒ, θₒ, ρₒ, xₒ, zₒ = sol(sₒ)
+
+ # rotate the coordinate system to the plume axis
+ y′ = y
+ z′ = (z - zₒ)*cos(θₒ) - (x - xₒ)*sin(θₒ)
+ r² = (y′)^2 + (z′)^2
+
+ # calculate concentration
+ c = cₒ*exp(-r²/(bₒ^2*λ²))
+
+ return c
+endHow do I know this is actually working? I don’t really have test data to compare against. But I do have some isopleths that I calculated independently (though using the same trig), I can check that the concentration at those points is indeed what it is supposed to be (2%).
+upper_concentrations = [ concentration(sol, pt[1], 0, pt[2]) for pt in upper_points ]
+lower_concentrations = [ concentration(sol, pt[1], 0, pt[2]) for pt in lower_points ]
+cross_concentrations = [ concentration(sol, pt[1], pt[2], a) for pt in cross_points ] +
+Indeed it does recover the concentrations as expected. There is one massive caveat though, it is assuming that there is only one location on the plume axis where a line connecting the point to the plume is perpendicular to the plume axis. If the plume is strongly curving, such as when a dense plume is emitted and bends back down to earth, this is no longer true. I think the basic assumptions of the plume itself start to break down once the plume bends back and intersects itself. I don’t think there really is a “correct” answer for how to calculate the concentration there.
+The plume model only assumes that the vent gas has a similar molar weight and heat capacity to air. It is still possible to have a negatively buoyant plume, this would be equivalent to a vent of cryogenic gas. In this case the plume will crash to the ground and…continue going. There is nothing in the Ooms model that requires z to be positive. If we assume the initial condition is \(\bar{z}_0 = \frac{h+\delta}{D}\) where h is the height of the vent stack, we can use a simple callback function to trigger once the integrator has crossed the ground plane and reflect the plume back.
+ground_check(state, s, i) = state[7] # zfunction reflect_plume!(integrator)
+ # bounce off the ground
+ integrator.u[4] = abs(integrator.u[4]) # θ
+ integrator.u[7] = 0 # z
+endground_cb = ContinuousCallback(ground_check, reflect_plume!)This makes the plume bounce along the ground. An alternative, and what DEGADIS does, is to terminate the integration once the plume contacts the ground and transition to another model.
+dense_state0 = [ 1.0 ,# c
+ 1/(2√(2)) ,# b
+ u₀/uₐ₀ ,# u
+ θ₀ ,# θ
+ 10.0 ,# ρ
+ 0.0 ,# x
+ h/D ]# zdense_prob = ODEProblem(ode_rhs!, dense_state0, span.*2, params)dense_sol = solve(dense_prob, Tsit5(); callback=ground_cb)
+
+dense_sol.retcodeReturnCode.Success = 1ModelingToolkit implements callbacks a little bit differently, as symbolic equations.
+ground = [ z ~ 0 ]
+reflect = [ θ ~ -Pre(θ) ]Which are then added to the ODESystem
@named dense_sys = ODESystem(eqns, s; continuous_events= ground => reflect)
+dense_sys = structural_simplify(dense_sys)dense_vals = [ c => dense_state0[1],
+ b => dense_state0[2],
+ u => dense_state0[3],
+ θ => dense_state0[4],
+ ρ => dense_state0[5],
+ x => dense_state0[6],
+ z => dense_state0[7] ]dense_prob_mtk = ODEProblem(dense_sys, dense_vals, span.*2)dense_sol_mtk = solve(dense_prob_mtk, Rodas5P())
+
+dense_sol_mtk.retcodeReturnCode.Success = 1 +
+I make no claims that this is a reasonable thing for the plume to do. It is mostly just for fun. If the reflect callback was changed to terminate!, then the plume would halt when the center line impacted the ground. There is also a case to be made that once the plume boundary impacts the ground, \(z - \sqrt{2}b \sin \theta = 0\), then the integration should terminate and another model used. This is basically what DEGADIS does, once the plume is at ground level it transitions to another model for grounded plumes.
It is all fine and good to say “well, those look like plausible curves,” I would like to have some validation that this is actually working as intended. For some confirmation I pulled data points from figure 3 in Ooms8 using a graph digitizer. I chose that figure since covers most of the range of the z-axis. The other two figures are squashed down, making it difficult to get good resolution on the data points.
+Unfortunately while Ooms provides most of the dimensionless groups needed to generate the plots, it is missing two important ones:
+The actual dimensions and starting location of the plume will depend on how the zone of flow establishment is calculated, and those details are missing from the paper. I assumed the initial plume dimension \(\bar{b}_{0} = \frac{1}{2\sqrt{2}}\), which corresponds to the plume starting with an identical width to the jet. Further I just picked a flow establishment of ~6.5 diameters, which is reasonable for a free jet. This recreates the curve really well.
+Putting aside basically guessing the length of the zone of flow establishment, which feels pretty sketchy, that the curve has the correct shape and reproduces figure 3 in the paper is decent validation. Adjusting the initial height simply translates the curve up and down, it doesn’t impact the result otherwise.
+I tracked down the original reference9 for the figure 3 data, and the zone of flow establishment is 6.2 diameters. Which, at the resolution of this plot, is indistinguishable from my guess of ~6.5. I think that safely puts this in the “validated” camp.
+# x/D z/D
+lfn_data = [ 16.628 19.953;
+ 43.054 29.86;
+ 46.366 32.233;
+ 61.684 36.698;
+ 84.591 42.558;
+ 109.085 48.977]lfn_prms = (M = zeros(7,7),
+ f = zeros(7),
+ rhoa_bar = (z) -> 1.0,
+ g_bar = (z) -> 4.278,
+ uprime_bar = (b,z) -> 0.0)# initial values
+lfn_state0 = [ 1.0 ,# c
+ 1/(2√(2)) ,# b
+ 8.0 ,# u
+ π/2 ,# θ
+ -0.148 ,# ρ
+ 0.0 ,# x
+ 6.5 ]# zlfn_prob = ODEProblem(ode_rhs!, lfn_state0, (0.0,150.0), lfn_prms)lfn_sol = solve(lfn_prob, Tsit5()) +
+This actually relates to one of the main difficulties in finding test data to compare against, to validate that my code is working. Results from the first version of DEGADIS are not directly applicable as DEGADIS initializes a jet using a different algorithm and the inputs into the Ooms model are not the jet parameters passed to DEGADIS. That’s assuming that I could even find DEGADIS results where the plume had the same molar weight and heat capacity as air, at which point the DEGADIS model reduces down to the original Ooms model. It has a different energy balance and for all other situations would be expected to generate different results.
+That I can recreate the figures from the original paper and that the first 4 balance equations given here are equivalent to what is given in the DEGADIS documentation (once rendered dimensionless and with the corresponding constants substituted), and the 5th equation matches in the special case of the vent gas being air and the atmosphere having no density gradient (the right hand side of the equation is zero) leaves me pretty confident that my result is correct. I also have the advantage of being able to cross-check my integrals and all those derivatives using a CAS. But it would be more satisfying if I had some unambiguous test cases to reproduce.
+I only implemented the first version of the Ooms model. There are two subsequent papers that make modifications which may be worth implementing. The first significant modification is a more complex energy balance, which is the basis for the DEGADIS implementation of Ooms, in this case the molar weight and heat capacity of the plume are calculated from the concentration in the plume. This makes the integral vastly more complex and it might make sense to try this model out while numerically integrating the balance at each step. The second significant modification is a change to the plume shape. The Ooms model assumes the plume has a circular cross-section, which is known to be incorrect for plumes dispersing in the atmosphere. The plume can be modified to an elliptical cross section in such a way as to preserve the cross-sectional area while better matching the observed shapes of real plumes. I did not implement either of these mostly because I wanted the “minimal viable plume model” first. This can be a known-working starting point on top of which these modifications can be made.
+Another obvious modification is to add ground-reflection. Once the plume has been solved, and there is a way to calculate concentrations at arbitrary points, it is not a huge challenge to add in ground-reflection. That is, managing the situation once the plume disperses into the ground. For conventional Gaussian plumes the typical assumption is that the plume simply reflects off and the concentration in this zone is the sum of the normal plume concentration and the concentration of reflected plume. Something similar could be done for Ooms as well.
+It has been a beautiful spring in Edmonton and the trees are tentatively flowering and throwing pollen to the wind. Watching the trees come back from their barren winter state left me wondering about the wind dispersal of pollen. Pollen grains must be small enough to travel quite a distance to encounter any other trees to pollinate, but they do settle out eventually. So, how far do they actually go? I’ve been wanting to play around with the mapping tools in the julia ecosystem, and this question gave me an opportunity to make some maps exploring pollen dispersal in my neighbourhood.
+I live in an older core neighbourhood in Edmonton, which has a beautiful canopy of boulevard trees. Primarily elm, but also ash, maple, and oak. The legacy of people like Gladys Reeves and the Edmonton Tree Planting Committee who, starting in 1923, defended our city green spaces and built up our urban forest. A legacy we still fight for over a century later.
+In particular I’m going to be looking at American Elm, the most common boulevard tree in my neighbourhood, and I’ll restrict myself to just here (not the whole city).
+For a lot of problems, I find it easier to work with Unitful.jl. It enforces unit consistency and inconsistent units in an answer is a good indication that I have made a math mistake somewhere. However there are two questions that I need to answer before getting too deep into things:
I could calculate the pollen concentration on a mass basis, but that seems kind of weird to me. I think the logical unit is in terms of individual pollen grains. That is not a unit that Unitful.jl is aware of and so I need to define first what a pollen grain is. It is a unit of “number”, like a mole, and in fact there are 6.022×10²³ grains in a mole of pollen.
using Unitfulbegin
+
+@unit grains "grains" Grains (1/6.02214076e23)*u"mol" true;
+Unitful.register(@__MODULE__);
+
+endCorrelations can be annoying with Unitful.jl since the various constants in a correlation are not usually given with units and figuring them all out so that units remain consistent is kind of tedious. The easiest workaround is to use a macro to strip the units off the input to a correlation function and then stick the correct units back on the output.
macro ucorrel(f::Symbol, in_unit::Expr, out_unit::Expr)
+ quote
+ function $(esc(f))(x::Quantity)::Quantity
+ x = ustrip($in_unit, x)
+ res = $(esc(f))(x)
+ return res*$out_unit
+ end
+ end
+end;For an initial sketch I’m going to consider a single tree as an elevated point source producing pollen at a constant rate P and with the wind carrying the pollen away with a constant wind speed u. Individual pollen grains settle out of the plume as they are carried downwind with velocity \(W_{set}\). The coordinate system is centred at the base of the tree with an x-axis parallel to the wind.
+ +
+There are a few things I will need to know about each elm tree in the neighbourhood:
+Neither of these are typically measured and available in data sets for urban forests. I will need to use correlations – what foresters call allometric equations. These correlate physical parameters of trees to something easier to measure, such as the diameter at breast height or DBH.
+To build an example elm tree, suppose it has a DBH of 88 cm
+# Model Elm tree
+DBH = 88u"cm" |> u"m"The crown height for an American Elm is correlated to DBH by the following equation1 for urban trees in the North climate zone
+# McPherson, van Doorn, and Peper, *Urban Tree Database*
+# Ulmus Americana, North climate zone
+crown_height(DBH) = 0.44998 + 0.55096*DBH - 0.00666*DBH^2 + 3e-5*DBH^3@ucorrel crown_height u"cm" u"m"I am going to assume this is the height at which pollen is released, that’s not particularly accurate but it is a start. A better value would be the “centre of mass” for pollen in the crown of an Elm tree, but that isn’t readily available.
+For the example tree, this predicts a height of 17.8 m which, just standing around and looking at the trees on my street seems plausible. The example elm tree should be taller than a 5 story building, and there is an elm tree at the end of my block that is about that in both diameter and height.
+The total amount of pollen in a given elm tree is given by the following equation2 where B is the tree basal area. The total pollen is based on counts of pollen per anther and an estimate of the total number of anthers per tree for urban elm trees in Ann Arbor, Michigan. Maybe not perfectly comparable to Edmonton, but it’s good enough for this exploratory work.
+# Ulmus Americana total pollen per tree
+# Katz, Morris, and Batterman, "Pollen Production," Table 2
+function total_pollen(DBH)
+ B = π/4*DBH^2
+ return exp(5.86*B + 23.11)
+end@ucorrel total_pollen u"m" u"grains"This gives a total pollen content of 384,082,918,235 grains for the model elm tree, which sounds like a lot.
+Elm trees release their pollen, in Edmonton, somewhere from the end of April to mid May and it usually lasts 1-2 weeks. As a very rough model I’m going to assume each tree releases its pollen at a constant rate over a 2 week period, and that the periods over which each of the trees are releasing overlap.
+Δt = 14u"d" |> u"s"pollen_rate(DBH) = total_pollen(DBH)/ΔtFor the example tree, this gives a pollen release rate of 317,529 grains s^-1.
+Elm pollen is relatively large and will settle out of the air. To account for this I am going to assume the pollen settles with a velocity equal to the terminal velocity given by Stokes’ Law, where each individual pollen grain is a solid sphere.
+ +
+begin
+
+# Ulmus Americana pollen
+# Brush and Brush, "Transport of Pollen," Tables 3 and 12.
+d = 31u"μm" |> u"m"
+SG = 1.1
+ρ = SG*1000u"kg/m^3"
+
+end;begin
+
+g = 9.80665u"m/s^2" # standard gravity
+ρₐ = 1.225u"kg/m^3" # density of dry air (15°C, 1atm)
+μₐ = 17.89e-6u"Pa*s" |> u"kg/m/s" # viscosity of dry air (15°C, 1atm)
+
+end;# Stokes Law
+vₜ = ((ρ - ρₐ)*g*d^2)/(18*μₐ)This gives a settling velocity for a grain of American Elm pollen in air of 3.22 cm s^-1
+We might naively consider the pollen being launched out of the tree like little cannon balls, with a velocity in the x-direction equal to the wind speed and the velocity in the z-direction equal to the terminal velocity of pollen. Assuming a wind speed of 2 m s^-1, then a pollen grain from our example tree would travel 1107 m before hitting the ground. That’s pretty far and also kind of unrealistic. It ignores all the turbulent mixing in the air column which will both loft it to much greater heights and, at times, push it towards the ground.
+The turbulent mixing in the air is captured using the dispersion parameters \(\sigma_y\) and \(\sigma_z\) which are functions of the downwind distance. This gives an average view, averaged over all of the pollen grains. In this case I will be using the Briggs’ correlations for Urban terrain.3 I am also assuming class D atmospheric stability.
+# wind speed, assumed
+u = 2u"m/s"σ_y(x) = 0.16x/√(1+0.0004x)@ucorrel σ_y u"m" u"m"σ_z(x) = 0.14x/√(1+0.0003x)@ucorrel σ_z u"m" u"m"I will be using the Ermak equation4 to model the dispersion of pollen, which results in a Gaussian-like dispersion but with the pollutant falling out and collecting on the ground. The Ermak equation is the solution to the advection diffusion equation with a constant settling velocity \(W_{set}\) and deposition velocity \(W_{dep}\)
+\[ +\frac{\partial c}{\partial r} - \frac{W_{set}}{K} \frac{\partial c}{\partial z} = \frac{\partial^2 c}{\partial y^2} + \frac{\partial^2 c}{\partial z^2} +\]
+with boundary condition at the ground
+\[ +\left( K \frac{\partial c}{\partial z} + W_{set} c \right)_{z=0} = W_{dep} c|_{z=0} +\]
+where K is the eddy diffusivity and r is defined as
+\[ +r = \frac{1}{u} \int_0^x K dx^{\prime} +\]
+and the other boundary conditions are as for the conventional Gaussian dispersion (e.g. constant mass emissions, m, at a point h above the origin, etc.). This can be solved and put in terms of \(\sigma_y\) and \(\sigma_z\) as, by definition, \(\sigma^2 = 2 r\)
+\[ +c = \frac{m}{2\pi u \sigma_y \sigma_z} \exp\left( - \frac{y^2}{2 \sigma_y^2} \right) \exp\left( { - {W_{set} (z-h)} \over {2K_z} } - { {W_{set}^2 \sigma_z^2} \over {8K_z^2} } \right) +\]
+\[ +\times \left( \exp \left( - \left(z-h\right)^2 \over {2\sigma_z^2} \right) + \exp \left( - \left(z+h\right)^2 \over {2\sigma_z^2} \right) \right. +\]
+\[ +\left. - { {\sqrt{2\pi} W_o \sigma_z} \over K_z} \exp\left( { {W_o (z+h)} \over {K_z} } + { {W_o^2 \sigma_z^2} \over {2K_z^2} } \right) \mathrm{erfc} \left( { {W_o \sigma_z} \over {\sqrt{2}K_z} } + { {z + h} \over {\sqrt{2}\sigma_z} } \right) \right) +\]
+where \(W_o = W_{dep} - \frac{1}{2}W_{set}\). In practice, relationships for \(\sigma\)s are much easier to find than Ks and the following is used to recover \(K_z\)
+\[ +K_z = \frac{1}{2} u \frac{d \sigma_z^2}{dx} +\]
+This follows from the definition of \(\sigma_z\) (and r). In this case I am going to generate the \(K_z\) using automatic differentiation with ForwardDiff.jl.
using ForwardDiff: derivative∂ₓσ_z²(x) = 2*σ_z(x)*derivative(σ_z, x)@ucorrel ∂ₓσ_z² u"m" u"m"K_z(x; u) = (1/2)*u*∂ₓσ_z²(x)Models like this, with a point source emitting mass, have nonphysical results in the vicinity of the emission source. The concentration rises sharply and there is a singularity at the source itself. There are many ways of dealing with this, but the easiest is to define a maximum concentration, usually given from a mass balance, and cut off the dispersion model at that. I don’t have any specific upper bound, so I picked a large number simply to prevent the propagation of Inf or other errors.
This is only a problem very close to the source, and I am more interested in concentrations far from the tree, so this is not a concern. A better model would calculate a “virtual origin” for the tree such that the pollen concentration in the crown of the tree was more realistic.
+max_pollen = 1e6grains/1u"m^3"using SpecialFunctions: erfcfunction ermak(x, y, z; u=u, h=crown_height(DBH), P=pollen_rate(DBH),
+ W_set=vₜ, W_dep=vₜ, p_max=max_pollen)
+
+ if x<zero(x) || z<zero(z)
+ return zero(p_max)
+ end
+
+ s_y = σ_y(x)
+ s_z = σ_z(x)
+ K = K_z(x; u)
+
+ Wₒ = W_dep - 0.5*W_set
+
+ p = (P/(2π*u*s_y*s_z))*exp(-0.5*(y/s_y)^2)*
+ exp(-0.5*W_set*(z-h)/K - 0.125*(W_set*s_z/K)^2)*(
+ exp(-0.5*((z-h)/s_z)^2) + exp(-0.5*((z+h)/s_z)^2)
+ - (√(2π)*Wₒ*s_z/K)*exp(Wₒ*(z+h)/K + 0.5*(Wₒ*s_z/K)^2)*
+ erfc((Wₒ*s_z/K + (z+h)/s_z)/√(2)) )
+
+ return isnan(p) ? zero(p_max) : min(p, p_max)
+end;Using this model, the ground level pollen concentration 100 m downwind of the example tree is 105.82 grains m^-3. As shown in the figures below, the pollen is most concentrated in an area from about 75 m to 300 m downwind of the tree. Which is about 2.5 blocks going east-west (city blocks in Edmonton are longer in the north-south direction)
+ +
+ +
+I am left with some questions about how much pollen is actually needed, in the air, for pollination to have a chance. The pollen has to end up on a corresponding flower, so there must be a point where the concentration is just too low to make this likely. Trees do put some effort into improving the odds, they typically flower and disperse pollen before their leaves have meaningfully come back, helping to remove obstructions. The branching structures of trees are both useful for light gathering and provide a large effective area over which their flowers sieve the air for pollen.
+On the other side, pollen grains are somewhat fragile too, they can dry out or be damaged by excessive UV exposure. While a single pollen grain may have the potential to make it thousands of meters away from the tree, it may not be viable by the time it gets there.
+I would guess, from these calculations, that Elm trees are getting most of their action within 300 m or less. Anything beyond that and the pollen is so dispersed that the odds of it finding a pistil are too low.
+To move from modelling a single tree to an urban forest, I will need a data structure to contain the relevant parameters of a tree. In this case I need both the map location and the location of the tree relative to the origin of the local coordinate system, \(x_o, y_o, z_o\). Each tree also has a diameter, height, pollen release rate, and terminal velocity. In this case all the trees are Elm trees, and have the same pollen, but I’m leaving it general in case I want to model something else in the future.
+begin
+
+struct Tree{G,L,P,V}
+ geopt::G
+ xₒ::L
+ yₒ::L
+ zₒ::L
+ DBH::L
+ h::L
+ P::P
+ vₜ::V
+end
+
+function Tree(geopt, xₒ, yₒ, DBH; v=vₜ)
+ h = crown_height(DBH)
+ P = pollen_rate(DBH)
+ xₒ, yₒ, zₒ, DBH, h = promote(xₒ, yₒ, zero(yₒ), DBH, h)
+ return Tree(geopt, xₒ, yₒ, zₒ, DBH, h, P, v)
+end
+
+end;elm = Tree(nothing, 0u"m",0u"m",DBH)Tree{Nothing, Quantity{Float64, 𝐋, Unitful.FreeUnits{(m,), 𝐋, nothing}}, Quantity{Float64, 𝐍 𝐓^-1, Unitful.FreeUnits{(grains, s^-1), 𝐍 𝐓^-1, nothing}}, Quantity{Float64, 𝐋 𝐓^-1, Unitful.FreeUnits{(m, s^-1), 𝐋 𝐓^-1, nothing}}}(
+ geopt = nothing
+ xₒ = 0.0 m
+ yₒ = 0.0 m
+ zₒ = 0.0 m
+ DBH = 0.88 m
+ h = 17.803579999999993 m
+ P = 317528.8675882605 grains s^-1
+ vₜ = 0.032156589905762846 m s^-1
+)I then added a method to ermak that takes a Tree object and returns the concentration of its pollen at a point x, y, and z on the local coordinate system.
function ermak(t::Tree, x, y, z; u=u)
+ x′ = x - t.xₒ
+ y′ = y - t.yₒ
+ z′ = z - t.zₒ
+ return ermak(x′, y′, z′; h=t.h, P=t.P, W_set=t.vₜ, W_dep=t.vₜ)
+end;The Ermak equation assumes the local area is a flat Euclidean plane. The earth is not that, and so a central task is going to be defining a local coordinate system that approximates my neighbourhood, Wîhkwêntôwin, as a flat plane. Then I will need to find all of the local trees and place them in this local coordinate system before adding in their individual contributions to the local Elm pollen situation.
+I arbitrarily picked a point more-or-less in the middle of the neighbourhood to act as the origin. My neighbourhood is pretty flat and so I’m going to assume everything is at the same altitude.
+using Geodesybegin
+
+latₒ, lonₒ, altₒ = 53.54100, -113.52141, 671
+Δlat, Δlon = 0.015, 0.035
+
+end;I oriented the grid such that the wind goes from west to east – which is usually the case. Another approach would be to look up the local windrose and orient the grid to the most frequent wind direction with the wind speed as the median wind speed.
+I am assuming that the area is locally flat relative to the curvature of the earth. Namely that the distance, in meters, per degree longitude is a constant across the whole neighbourhood – which I calculate from a straight line running through the origin going from the furthest west to the furthest east. Similarly for degrees latitude. This isn’t strictly true but the difference between the distance along the ellipsoid and the locally-flat distance is going to be trivially small, so I can safely ignore it.
+begin
+
+Δx = euclidean_distance(LLA(latₒ, lonₒ - Δlon/2, altₒ),
+ LLA(latₒ, lonₒ + Δlon/2, altₒ), wgs84)/Δlon
+Δy = euclidean_distance(LLA(latₒ + Δlat/2, lonₒ, altₒ),
+ LLA(latₒ - Δlat/2, lonₒ, altₒ), wgs84)/Δlat
+endfunction local_coords(lat,lon)
+ x = (lon - lonₒ)*Δx
+ y = (lat - latₒ)*Δy
+ return x, y
+endAt first glance it looks like I’m doing a lot of additional work for no reason. I ultimately want to overlay my maps on top of satellite imagery, which will require me to convert everything into Web Mercator. Why not use that as the local coordinate system? Points in Web Mercator are northing and easting in meters on a flat plane.
+Unlike UTM, where that kind of thing works out well enough for a lot of situations, there is a lot more distortion with Web Mercator. Especially closer to the poles. I’m not particularly close to the north pole, but more than close enough that the map distortion leads to significant errors when using Web Mercator naively like that.
+To demonstrate this I’m going to calculate the distance between my favourite coffee shop, stopgap, and a local park on the other side of the neighbourhood, Oliver park.
+begin
+
+stopgap = LLA(53.535618490862944, -113.5118491580413)
+oliver_park = LLA(53.54542679826651, -113.52603529325418)
+
+enddist = euclidean_distance(stopgap, oliver_park, wgs84)First I calculate the distance along the ellipsoid, which is 1441 m (the same as what Google maps tells me).
+Then I convert the coordinates to Web Mercator, which are northing and easting relative to the equator and the prime meridian.
+WM = WebMercatorfromLLA(wgs84)begin
+
+stopgap_wm = WM(stopgap)
+oliver_park_wm = WM(oliver_park)
+
+endwm_dist = √( (stopgap_wm[1] - oliver_park_wm[1])^2
+ + (stopgap_wm[2] - oliver_park_wm[2])^2 )The naive Euclidean distance using Web Mercator is 2423 m, about 68% greater than the true distance. If I set my local grid naively using the northing and easting of Web Mercator, everything would be distorted.
+Thankfully, I don’t need to wander the neighbourhood with a GPS unit and a tape measure to find all the local Elm trees and map them. The City of Edmonton has already done that. I filtered the data set to just my neighbourhood and just Ulmus Americana and downloaded it as a csv.
+using CSV, DataFramestrees_df = CSV.read("data/Ulmus_americana_wihkwentowin.csv",
+ DataFrame);describe(trees_df, :min, :max)19×3 DataFrame
+ Row │ variable min max
+ │ Symbol Any Any
+─────┼──────────────────────────────────────────────────────────────────────────────────────────────
+ 1 │ ID 155206 619701
+ 2 │ NEIGHBOURHOOD_NAME WÎHKWÊNTÔWIN WÎHKWÊNTÔWIN
+ 3 │ LOCATION_TYPE Alley Park
+ 4 │ SPECIES_BOTANICAL Ulmus americana Ulmus americana Patmore
+ 5 │ SPECIES_COMMON Elm, American Elm, American
+ 6 │ GENUS Ulmus Ulmus
+ 7 │ SPECIES americana americana
+ 8 │ CULTIVAR Brandon Patmore
+ 9 │ DIAMETER_BREAST_HEIGHT 5 110
+ 10 │ CONDITION_PERCENT 0 65
+ 11 │ PLANTED_DATE 1990/01/01 2024/09/25
+ 12 │ OWNER Parks Parks
+ 13 │ Bears Edible Fruit false false
+ 14 │ Type of Edible Fruit
+ 15 │ COUNT 1 1
+ 16 │ LATITUDE 53.5346 53.5496
+ 17 │ LONGITUDE -113.536 -113.51
+ 18 │ LOCATION (53.534594143551985, -113.510361… (53.549586375568154, -113.530880…
+ 19 │ Point Location POINT (-113.50950085882668 53.53… POINT (-113.53589639202552 53.54…What I would like is a vector of Trees. I could have added a column to the dataframe with Tree objects when it was created, but I’m not using the dataframe for anything else so I didn’t really see the point.
begin
+trees = Vector{Tree}()
+
+for row in eachrow(trees_df)
+ lat, lon = row.LATITUDE, row.LONGITUDE
+ DBH = row.DIAMETER_BREAST_HEIGHT*1u"cm" |> u"m"
+ pt = LLA(lat,lon,altₒ)
+ x, y = local_coords(lat, lon).*1u"m"
+ tree = Tree(pt,x,y,DBH)
+ push!(trees, tree)
+end
+
+endThere are 996 Elm trees in Wîhkwêntôwin alone. That’s impressive, we have a pretty great urban forest.
+trees[1]Tree{LLA{Float64}, Quantity{Float64, 𝐋, Unitful.FreeUnits{(m,), 𝐋, nothing}}, Quantity{Float64, 𝐍 𝐓^-1, Unitful.FreeUnits{(grains, s^-1), 𝐍 𝐓^-1, nothing}}, Quantity{Float64, 𝐋 𝐓^-1, Unitful.FreeUnits{(m, s^-1), 𝐋 𝐓^-1, nothing}}}(
+ geopt = LLA(lat=53.53695945675063°, lon=-113.51201340003675°, alt=671.0)
+ xₒ = 623.0131311454173 m
+ yₒ = -449.74535157065054 m
+ zₒ = 0.0 m
+ DBH = 0.2 m
+ h = 9.04518 m
+ P = 10810.758180096327 grains s^-1
+ vₜ = 0.032156589905762846 m s^-1
+)I am assuming that pollen is additive and doesn’t alter the properties of air at all. The concentration of pollen from multiple trees is just the concentration of pollen from each tree added together.
+ermak(trees::Vector{Tree}, x, y, z; u=u) =
+ sum( ermak.(trees, x, y, z; u=u) );Now that I have a set of trees and a bounding box, I need to generate some actual maps. I am going to use Tyler.jl to download the map tiles and make them plot-able in Makie. For which I need to give it a bounding box for the neighbourhood and identify a map provider. I am using the imagery from ESRI.
+using Tylerwihkwentowin = Rect2f(lonₒ - Δlon/2, latₒ - Δlat/2, Δlon, Δlat);provider = Tyler.TileProviders.Esri(:WorldImagery);I have defined a helper function to take a tree and return the appropriate Web Mercator coordinates to map on top of the ESRI imagery.
+function map_tree(tree::Tree)
+ x, y, _ = WM(tree.geopt)
+ return Point2f(x,y)
+endMapping all of the trees in the data set matches what I expected: they are mostly boulevard trees and the northwest corner of the neighbourhood is much more densely forested with Elm.
+ +
+Now I have all the tools in place to generate concentration contours for Elm pollen and plot them on top of the ESRI imagery for my neighbourhood. First, I create a helper function to convert grid points in Web Mercator to local grid coordinates, then return the concentration at that point with contributions from all 996 Elm trees.
+If I was doing this for the whole city I might want to first filter out all the Elm trees that are too distant from or downwind of the point of interest – since they won’t contribute anything.
+LLA_WM = LLAfromWebMercator(wgs84)function map_ermak(x, y)
+ lla = LLA_WM([x,y,altₒ])
+ local_x, local_y = local_coords(lla.lat, lla.lon).*1u"m"
+ return ustrip(ermak(trees, local_x, local_y, 0u"m"))
+endI then divide the neighbourhood into a grid of 10,000 points and calculate the concentration at each point.
+# defining the bounds of the grid
+
+begin
+
+xₗ, yₗ, _ = WM(LLA(latₒ - Δlat/2, lonₒ - Δlon/2, altₒ))
+xᵤ, yᵤ, _ = WM(LLA(latₒ + Δlat/2, lonₒ + Δlon/2, altₒ))
+
+end;begin
+
+xs = range(xₗ, xᵤ; length=100)
+ys = range(yₗ, yᵤ; length=100)
+
+zs = map_ermak.(xs, ys')
+
+end;Finally I overlay a contour plot on top of the ESRI imagery, showing everywhere with a pollen concentration >10 grains m^-3
+ +
+A major limitation to this style of dispersion modelling, especially in a neighbourhood like mine dominated by large apartment buildings, is that building downwash effects are not being accounted for. The Elm trees are at a similar height or shorter than the buildings around them. This model essentially ignores the buildings other than their contribution to surface roughness – reflected in the dispersion parameters \(\sigma_y\) and \(\sigma_z\). Short of doing a CFD model of the neighbourhood, I don’t think there is an easy way around that. Probably this would work better in neighbourhoods like Highlands or Ritchie which have mature Elm trees but where housing is mostly older homes, less than 2 stories, with yards spacing them out from each other.
+A limitation to this specific example is that I haven’t included all the Elm trees in adjacent neighbourhoods – Westmount in particular. This under counts the Elm pollen on the west side of Wîhkwêntôwin. I can imagine one producing maps like this, for the whole city, based on which trees are producing pollen in any given week showing where the peak pollen action is. A where not to park your car map, if you want to avoid washing your windshield every morning, or where to avoid if you are allergic to tree pollen.
+Very often, in chemical engineering, the line between problems one can solve one’s self and problems that are solved with a piece of commercial software is when ideal fluid assumptions break down. Relief valve sizing is a typical example: if the fluid is (approximately) an ideal gas then sizing is simple and often done in a spreadsheet. When this isn’t the case, if the compressiblity is <0.8 or >1.1,1 then one typically has to turn to some commercial software. Models of real fluids are complicated and extracting the relevant thermodynamic properties from them can be quite tedious when doing it all from scratch.
+Clapeyron.jl comes to the rescue here with a wide array of equations of state for real fluids. Combined with julia’s robust ecosystem of libraries for integration and optimization, solving real fluid problems becomes simple. This post walks through how to size a relief device, in gas service, starting from an ideal gas and working through various methods for real gases using equations of state.
+The general idea for sizing a relief valve is to determine the minimum area required such that the mass flow through the valve equals the mass flow required for the governing release case via the relation2
+\[ W = K A G \]
+where \(W\) is the required mass flow-rate, \(K\) is a capacity correction, \(A\) is the theoretical flow area, and \(G\) the frictionless) mass flux through the valve. Valves are sized based on the theoretical flow area.
+The general process is as follows:
+Standards, such as API-2020, give equations that combine steps 3 and 4 and absorb unit-conversions into the constants, so that the equation is in a more convenient form, but this is what is happening under the hood.
+The complications creep in through calculating \(G\), it is path-dependent and is a function of the equation of state for the fluid. For gas releases the relief device is typically treated as an isentropic nozzle, the assumption being that the flow-rate through the valve is typically large enough that any heat transfer can be neglected.
+ +
+Consider the differential form of the mechanical energy balance, along a streamline from the stagnation point, in the vessel, through the valve and out into the atmosphere, assuming no elevation change and no friction
+\[ dP + \rho u du = 0 \]
+\[ u du = -\frac{dP}{\rho} = - vdP \]
+Integrating from the stagnation point to the throat of the nozzle gives
+\[ \frac{1}{2} u_t^2 = - \int_{P_1}^{P_t} v dP \]
+Where the velocity at the stagnation point, \(u_1=0\). Putting this in terms of the mass flux \(u = v G\)
+\[ \frac{1}{2} v_t^2 G_t^2 = - \int_{P_1}^{P_t} v dP \]
+\[ G_t = \frac{1}{v_t} \sqrt{-2 \int_{P_1}^{P_t} v dP} = \rho_t \sqrt{2 \int_{P_t}^{P_1} v dP} \]
+This integral cannot be solved directly at this point as the conditions at the throat of the nozzle are not known. Solving this requires simultaneously solving for the nozzle conditions, \(P_t, T_t\).
+If we specify that the streamline follows an isentropic path, then we can construct a constrained maximization problem: the nozzle conditions are the \(P_t\) and \(T_t\) which maximizes \(G_t\) where the integration is taken along an isentropic path.
+In the case where flow is choked, i.e. the flow in the nozzle reaches sonic velocity, the maximum \(G_t\) occurs at the sonic velocity with a pressure \(P_t > P_2\). This can allow for the direct calculation of the mass flux as \(G_t = \rho_t c_t\), where \(c_t\) is the sonic velocity at the throat. No integration required.
+Consider the release of ethane from a vessel at 200 bar and 400 K, for the sake of simplicity assume the release is directly into the atmosphere at 1 bar and 288.15 K (15°C) (the flow is going to be choked, so this doesn’t actually matter).
+using Unitfulbegin
+# the vessel properties
+ P₁ = 200u"bar"
+ T₁ = 400u"K"
+
+# the ambient properties
+ P₂ = 1u"bar"
+ T₂ = 288.15u"K"
+endWe can use Clapeyron.jl to initialize a few example equations of state for ethane. In this case I’m going to use an ideal gas model (ReidIdeal is an ideal gas model that also includes correlations for the ideal gas heat capacity), a cubic equation of state (volume translated Peng Robinson), and an empirical Helmholtz model (GERG-2008).
using Clapeyronbegin
+# assorted equations of state for ethane
+ ig_ethane = ReidIdeal(["ethane"])
+ vtpr_ethane = VTPR(["ethane"]; idealmodel = ReidIdeal)
+ gerg_ethane = GERG2008(["ethane"])
+end# this is a hack, ideal models in Clapeyron do not return a
+# molar weight and so cannot return a mass density
+Clapeyron.mw(model::IdealModel) = Clapeyron.mw(vtpr_ethane)At system conditions ethane is a super critical fluid, with the temperature and pressure above the critical point, which can be modelled as a dense gas.
+Considering the choked flow case, we know that \(G_t = \frac{c_t}{v_t}\) and, for an ideal gas, the sonic velocity is given by3
+3 Tilton, “Fluid and Particle Dynamics” equation 6-113.
\[ c = \sqrt{ {k R T} \over M} = \sqrt{k P v} \]
+Combining these we have
+\[ G_t = \frac{c_t}{v_t} = { \sqrt{ k P_t v_t } \over v_t } = \sqrt{ k P_t \over v_t } \]
+It can be shown that, along an isentropic path defined by \(P v^k = \mathrm{const}\), the critical pressure ratio is4
+4 Tilton equation 6-119.
\[ {P_t \over P_1} = { P_{chk} \over P_1 } = \left(2 \over {k+1} \right)^{k \over {k-1} } \]
+Which allows us to write
+\[ P_t = P_1 {P_t \over P_1} = P_1 \left(2 \over {k+1} \right)^{k \over {k-1} } \]
+and (using \(P_1 v_1^k = P_t v_t^k\))
+\[ v_t = v_1 \left(P_1 \over P_t \right)^{1 \over k} = v_1 \left(2 \over {k+1} \right)^{-1 \over {k-1} } \]
+Substituting back into the equation for \(G_t\)5
+\[ G_t = \sqrt{ k \frac{P_1}{v_1} \left(2 \over {k+1} \right)^{k+1 \over {k-1} } } \]
+or, to put it in terms of density
+\[ G_t = \sqrt{ k P_1 \rho_1 \left(2 \over {k+1} \right)^{k+1 \over {k-1} } } \]
+where \(k\), the isentropic expansion factor for an ideal gas, is the ratio of heat capacities
+\[ k = { c_{p,ig} \over c_{v,ig} } \]
+This is the basis of API 520 Part 1 equation 9 where the following substitutions is made:
+\[ \rho = { {P M} \over {Z R T} } \]
+and the constant \(R\) and some unit conversions are rolled up into the constant 0.03948 in the expression for \(C\)
+\[ R = 8.314 { {\mathrm{m^3} \cdot \mathrm{Pa} } \over {\mathrm{mol} \cdot \mathrm{K} } } = 8,314 { {\mathrm{m^3} \cdot \mathrm{Pa} } \over {\mathrm{kmol} \cdot \mathrm{K} } } = 8,314 { {\mathrm{kg} \cdot \mathrm{m^2} } \over { \mathrm{kmol} \cdot \mathrm{s^2} \cdot \mathrm{K} } } \]
+\[ {1 \over \sqrt{8,314} } \left[ { \sqrt{ \mathrm{kmol} \cdot \mathrm{K} } \cdot \mathrm{s} } \over { \sqrt{\mathrm{kg} } \cdot \mathrm{m} } \right] \times 3600 \left[ \mathrm{s} \over \mathrm{h} \right] \times 10^{-6} \left[ \mathrm{m^2} \over \mathrm{mm^2} \right] \times 10^3 \left[ \mathrm{Pa} \over \mathrm{kPa} \right] \]
+\[ = 0.03948 \left[ \sqrt{\mathrm{kmol} \cdot \mathrm{kg} \cdot \mathrm{K} } \over { \mathrm{h} \cdot \mathrm{mm^2} \cdot \mathrm{kPa} } \right] \]
+We can use Clapeyron.jl to calculate \(k\) at any given temperature, using correlations for the ideal gas heat capacity.
function isentropic_expansion_factor(model::IdealModel, P, T; z=[1.0])
+ cₚ_ig = isobaric_heat_capacity(model, P, T; phase=:vapor)
+ cᵥ_ig = isochoric_heat_capacity(model, P, T; phase=:vapor)
+ return cₚ_ig/cᵥ_ig
+endFrom which we calculate k= 1.146.
+We can check our work by comparing with the tabulated values. At 15°C and 1 atm we calculate k= 1.193 which is the same as the tabulated value of 1.19 (given at 15°C and 1 atm).6
+6 API, 70.
function mass_flux_choked(model, P, T; z=[1.0])
+ k = isentropic_expansion_factor(model, P, T; z=z)
+ ρ = mass_density(model, P, T, z; phase=:vapor)
+ Gₜ² = k*P*ρ*(2/(k+1))^((k+1)/(k-1))
+ return √(Gₜ²)
+endThe theoretical mass flux for the ideal gas is then 38359 kg m^-2 s^-1
+The ideal gas model, when the flow is choked, calculates the mass flux directly without needing to calculate the actual conditions at the nozzle. These can be calculated easily as well.7
+7 Tilton, “Fluid and Particle Dynamics” equations 6-119 and 6-120.
nozzle_pressure_ideal(P, T, k) = P*(2/(k+1))^(k/(k-1))nozzle_temperature_ideal(P, T, k) = T*(2/(k+1))The pressure at the nozzle is 115 bar the temperature at the nozzle is 373 K, which is above the critical point. The fluid supercritical and choked when leaving the PSV.
+At the vessel conditions, the VTPR model of ethane gives a compressibility factor of 0.672 (GERG-2008 model gives a similar value of 0.69), well below 0.8 and therefore outside the range where the ideal gas model is expected to work well.
+An alternative method is to calculate what the effective isentropic expansion factor would be, for the real gas, assuming that the real fluid obeys
+\[ P_1 v_1^n = P_t v_t^n \]
+where \(n\) is a constant.
+The derivation of \(n\) follows from the definition of the speed of sound in a gas8
+\[ c = \sqrt{ \left( {\partial P} \over {\partial \rho} \right)_S} =\sqrt{ -v^2 \left( {\partial P} \over {\partial v} \right)_S} \]
+The constant entropy partial derivative can be re-written to eliminate entropy9
+\[ \left( {\partial P} \over {\partial v} \right)_S = { { \left( {\partial S} \over {\partial T} \right)_P \left( {\partial P} \over {\partial T} \right)_v } \over { \left( {\partial S} \over {\partial T} \right)_v \left( {\partial v} \over {\partial T} \right)_P } } \]
+Using the relations10
+10 Gmehling et al., Chemical Thermodynamics for Process Simulation equations C.21 and C.8 (respectively).
\[ c_p = T \left( {\partial S} \over {\partial T} \right)_P \]
+and
+\[ c_v = T \left( {\partial S} \over {\partial T} \right)_V \]
+we get
+\[ \left( {\partial P} \over {\partial v} \right)_S = {c_p \over c_v} \left( {\partial P} \over {\partial v} \right)_T \]
+and the sonic velocity is then
+\[ c = \sqrt{ -v^2 {c_p \over c_v} \left( {\partial P} \over {\partial v} \right)_T } \]
+equating this to the ideal gas case, \(c = \sqrt{n P v}\), and solving for \(n\) gives11
+\[ n = -\frac{v}{P} {c_p \over c_v} \left( {\partial P} \over {\partial v} \right)_T \]
+where \(n\) has been used to distinguish it from \(k\) (the ideal gas case). This is the version of \(n\) presented in most references, such as API 520. The derivation, however, hints at a useful shortcut to calculating \(n\) that does not require digging into the internals of Clapeyron.jl to retrieve partial derivatives:
\[ n = { c^2 \over {P v} } = { {\rho c^2} \over P } \]
+The remainder of the calculations are identical as the ideal gas case, simply substituting \(n\) wherever \(k\) appears. Unfortunately \(n\) is not actually constant and depends on the temperature and pressure, which are not actually known in the nozzle, so the temperature and pressure at the stagnation point are often used instead.
+function isentropic_expansion_factor(model, P, T; z=[1.0])
+ ρ = mass_density(model, P, T, z)
+ c = speed_of_sound(model, P, T, z)
+ n = ρ*c^2/P
+ return n
+endUsing effective isentropic expansion factors from the VTPR equation of state, the theoretical mass flux is 57811 kg m^-2 s^-1 ( 59321 kg m^-2 s^-1 from GERG-2008 ). This is quite a bit larger than the ideal case, indicating that the ideal gas law leads to a significantly over-sized PRV, 51.0% larger.
+ +
+The isentropic expansion factor method works best when \(n\) is approximately constant over the isentropic path. As the above figure shows, this breaks down in ethane for pressures greater than ~100 bar. It also shows that the different equations of state start to diverge greatly further into the supercritical regime.
+Another approach, and one I have seen more often in older references, is to perform an energy balance over the isentropic path and, assuming the flow is choked, solve for sonic velocity in the nozzle.12 Consider an energy balance starting at the stagnation point, (1), and following an isentropic path to immediately after the throat of the nozzle (t).
+\[ h_1 = h_t + \frac{1}{2} c_t^2 \]
+Where \(c_t\) is the speed of sound at the nozzle, a function of \(P_t\) and \(T_t\). The procedure is then to solve the system of equations given by the energy balance and the entropy balance, \(s_1 = s_t\), for \(P_t\) and \(T_t\), then the theoretical mass flux is given by
+\[ G_t = \rho_t c_t \]
+There are a few ways this could be done, a straight-forward way is to divide the problem into two: 1. Define the isentropic path, i.e. find the isentropic temperature for a given pressure P 2. Use the energy balance to solve for the pressure, following the isentropic path.
+A more direct way is to solve for \(P_t\) and \(T_t\) simultaneously. This is what I do next, using NonlinearSolve.jl
+# Clapeyron does not expose this by default
+molecular_weight(model,z) = Clapeyron.molecular_weight(model,z)function nozzle_balance(y, prms)
+ P, T = y
+
+ # stagnation point
+ s₁ = prms.entropy
+ h₁ = prms.enthalpy
+
+ # at throat conditions
+ s₂ = entropy(prms.model, P, T, prms.z)
+ h₂ = enthalpy(prms.model, P, T, prms.z)/prms.Mw
+ c² = speed_of_sound(prms.model, P, T, prms.z)^2
+
+ return [ s₁ - s₂
+ h₁ - h₂ - 0.5*c² ]
+endusing NonlinearSolvefunction mass_flux_choked_energy_balance(model, P, T; z=[1.0])
+ # calculate the entropy and specific enthalpy at
+ # initial conditions
+ Mw = molecular_weight(model, z)
+ s₁ = entropy(model, P, T)
+ h₁ = enthalpy(model, P, T)/Mw
+
+ # solve the choked flow energy balance for
+ # an isentropic nozzle
+ params = (model=model, entropy=s₁, enthalpy=h₁, z=z, Mw=Mw)
+ y₀ = [P; T]
+ prob = NonlinearProblem(nozzle_balance, y₀, params)
+ sol = solve(prob, NewtonRaphson())
+ Pₜ, Tₜ = sol.u
+
+ # velocity is the sonic velocity at nozzle conditions
+ ρₜ = mass_density(model, Pₜ, Tₜ, z)
+ cₜ = speed_of_sound(model, Pₜ, Tₜ, z)
+
+ return ρₜ*cₜ
+endfunction mass_flux_choked_energy_balance(model, P::Quantity, T::Quantity; z=[1.0])
+ P = ustrip(u"Pa", P)
+ T = ustrip(u"K", T)
+ return mass_flux_choked_energy_balance(model, P, T; z=z)*1u"kg*m^-2*s^-1"
+endSolving the choked flow energy balance, using VTPR equation of state, the theoretical mass flux is 54629 kg m^-2 s^-1 ( 54353 kg m^-2 s^-1 from GERG-2008 ). This is also quite a bit larger than the ideal case, 42.0% larger. Though the values for the two equations of state are closer, indicating that this method is less sensitive to model choice.
+ +
+In this case the ideal gas method and the isentropic expansion factor method bracket the more exact method of solving the energy balance directly.
+As it is written, this method would need to be modified to allow for non-choked flow. This is done by eliminating the assumption \(u_t = c_t\) and instead finding the conditions which maximize \(G_t\) (subject to the constraints of the entropy balance and the enthalpy balance). This will arrive at the same solution, in the case of choked flow, but with a little more effort.
+Direct integration is the method most commonly recommended today, as it is entirely general. It can be used to solve all flow conditions from liquids to gases as well as two-phase mixtures. As a reminder, this method constitutes finding the \(P_t\) and \(T_t\) that maximize the mass flux given by
+\[ G_t = \rho_t \sqrt{2 \int_{P_t}^{P_1} v dP} \]
+First introduce the change of variables \(\Delta P = P_1 - P\) such that the integration is from \(0\) to \(P_1 - P_2\).
+\[ \int_{P_2}^{P_1} v dP = - \int_{0}^{\Delta P} v\left( P_1 - \Delta P \right)_{s = s_1} d\left(\Delta P \right) \]
+This allows us to write the corresponding differential equation
+\[ { {d} \over {d \left(\Delta P \right)} } I = v\left(P₁ - ΔP\right) \]
+subject to the constraint
+\[ s(P_1 - \Delta P, T) = s(P_1, T_1) \]
+Which can be implemented as a differential algebraic equation using DifferentialEquations.jl
+using DifferentialEquationsfunction rhs(u, params, ΔP)
+ ∫vdP, T = u
+ model, P₁, s₁, z, Mw = params
+ P = P₁ - ΔP
+ return [ volume(model, P, T, z)/Mw
+ s₁ - entropy(model, P, T) ]
+endBut we want to stop the integration when \({ {\partial G} \over {\partial \left( \Delta P \right) } } = 0\) or, equivalently, when the velocity is sonic. We can show that these are the same by finding the stationary points of \(G^2\)
+\[ { {\partial G^2} \over {\partial \left( \Delta P \right) } } = { {\partial } \over {\partial \left( \Delta P \right) } } \left( 2 \rho_t^2 \int_0^{\Delta P_t} v d \left( \Delta P \right) \right) = 0 \]
+by applying the chain rule and cancelling \(\rho\) we get
+\[ 2 \left( {\partial \rho} \over { \partial P } \right)_S \int_0^{\Delta P_t} v d \left( \Delta P \right) - 1 = 0 \]
+recalling the definition of the speed of sound (above)
+\[ \left( {\partial \rho} \over { \partial P } \right)_S = \frac{1}{c^2} \]
+we have
+\[ 2 \int_0^{\Delta P_t} v d \left( \Delta P \right) - c^2 = 0 \]
+which is simply restating \(u_t = c_t\).
+function ∂G²_callback(u, ΔP, integrator)
+ ∫vdP, Tₜ = u
+ model, P₁, s₁, z, Mw = integrator.p
+ Pₜ = P₁ - ΔP
+ c = speed_of_sound(model, Pₜ, Tₜ, z)
+ return 2∫vdP - c^2
+endfunction mass_flux_direct_integration(model, P₁, T₁, P₂;
+ z=[1.0], solver=Rodas5P())
+ s₁ = entropy(model, P₁, T₁, z)
+ Mw = molecular_weight(model, z)
+
+ # defining the ODEFunction
+ M = [ 1 0
+ 0 0 ]
+ f = ODEFunction(rhs, mass_matrix = M)
+
+ # defining the ODEProblem
+ u0 = [0.0; T₁]
+ params = (model, P₁, s₁, z, Mw)
+ ΔP_span = (0.0, P₁ - P₂)
+ prob = ODEProblem(f, u0, ΔP_span, params)
+ cb = ContinuousCallback(∂G²_callback, terminate!)
+
+ # solving the DAE
+ sol = solve(prob, solver, callback=cb)
+
+ # unpacking the solution
+ ΔPₜ = sol.t[end]
+ ∫vdP, Tₜ = sol.u[end]
+ ρₜ = mass_density(model, P₁-ΔPₜ, Tₜ, z)
+ G = ρₜ*√(2*∫vdP)
+endfunction mass_flux_direct_integration(model, P₁::Quantity, T₁::Quantity,
+ P₂::Quantity; z=[1.0])
+ P_1 = ustrip(u"Pa", P₁)
+ P_2 = ustrip(u"Pa", P₂)
+ T_1 = ustrip(u"K", T₁)
+ return mass_flux_direct_integration(model, P_1, T_1, P_2; z=z)*1u"kg*m^-2*s^-1"
+endDirect integration of the VTPR equation of state gives a theoretical mass flux of 54629 kg m^-2 s^-1 ( 54353 kg m^-2 s^-1 from GERG-2008 ). Which is exactly the same as from solving the choked flow energy balance, as expected.
+ +
+Writing this as a differential algebraic equation was largely necessary because Clapeyron.jl does not expose any routines to calculate the volume as a function of pressure and entropy. Some libraries like CoolProps do, in which case the code could be simplified to be a one dimensional ode.
This method could be extended to include liquid and two-phase flows however, as it is currently implemented, it only handles gases. Unlike the energy balance method, though, the flow does not have to be choked. If the flow is not choked, the maximum will occur once the nozzle pressure reaches \(P_2\). This result will simply pop out without any extra effort.
+For the sake of completeness, there are two other methods that should be looked at, which are really special cases: 1. the ideal gas case, but using the real compressibility, \(Z\), at stagnation conditions, this is the API 520 standard approach for gases 2. using the isentropic expansion factor, n factor, method but calculating n at the average of the stagnation and nozzle conditions
+These two approaches do better than the basic methods I presented, but I don’t think they add enough value on their own. Given a model of the gas which can generate the compressibility, using either the energy balance method or the direct integration method produces superior results than correcting the ideal gas case. Once a viable equation of state is in hand, the simplifications are not saving any actual engineer doing their job time, they are saving fractions of a second of compute time.
+I think the choice between the first law energy balance and the direct integration technique is more a matter of taste, at least in the case of choked flow. The direct integration method is in the relevant engineering codes/standards, and that is a strong justification for using it.
+ +
+In this case the choice of equation of state did not matter strongly, just for fun I have included a few other common cubic equations of state, they all perform reasonably. However this example is for a single compound that is not strongly associating, it is the type of example where cubic equations of state should work well. The choice of equation of state will be far more important with mixtures and strongly associating substances.
+I have long been an advocate for engineering to move out of using spreadsheets for everything and to use scripting languages and notebooks like Jupyter and Pluto far more. There are large classes of problems that are easy to solve with code and hard to solve with a spreadsheet. I think almost any calculation using equations of state fit into that category. We end up beholden to commercial software suppliers for calculations that, in my view, engineers should be doing themselves.
+Presumably you could do the calculations I laid out above in Excel, at enormous effort, and making liberal use of the solver. Julia, however, has a robust ecosystem for doing all the complicated math, it only needed to be connected up. What remains, for the engineer, is assessing the physical system and picking the appropriate methods and thermodynamic models.
+When determining the required venting for above ground storage tanks it is typical to calculate normal and emergency vent rates using standards such as API 2000, which gives the venting as an equivalent flow rate of air at standard state. Most off-the-shelf vents are sized in terms of pressure drop and SCFH through it, so after calculating the required venting one can simply buy a vent with the needed characteristics.
+
+

+
It’s not uncommon, though, for tanks to have goose-neck vents constructed from piping. This is fairly normal for tanks holding water, or other nonvolatile substances, where the tank is open to atmosphere and there are no dangerous vapours that need to be managed. The goose-neck itself is merely to keep rain, and wildlife, out of the tank.
+Sizing the goose-neck to match the required venting involves performing some simple compressible flow calculations, which is fairly straightforward to set up in a generalized way such that, beyond this motivating example, it can be extended to lots of other problems. Though it isn’t at all uncommon, in this particular case, for the flow calculations to be done assuming an incompressible fluid as, over the length of the goose-neck, the pressure drop is typically slight and the compressibility of the gas (air usually) is not important.
+With that in mind, I am going to work through the problem in stages of escalating complexity, very likely the most complicated (fanno flow) is overkill for this specific example but it’s worth putting it all down as the same tools can be used for compressible flow calculations through many piping situations.
+Suppose an atmospheric storage tank with a normal venting requirement, as calculated from API 2000 or the like, of 200×10³ SCFH and a max pressure of 1 psig. We wish to design a goose-neck vent that can handle that level of venting. Suppose that the goose-neck design we have in mind is a vertical length of pipe extending up from the tank roof, two 90° bends, and an exit covered with a mesh screen (to keep birds from nesting in it, yes this is a thing). The goose-neck is a constant diameter of pipe throughout.
+For notation, the flow begins at the pipe entrance (1) and ends at the exit (2).
+ +
+For the pipe bends the bend radius to diameter ratio needs to be specified, I’m going to suppose \(r/D = 1.5\). Another important parameter is the pipe roughness, \(\epsilon\), which for commercial steel is \(\epsilon = 0.0457 \mathrm{mm}\).1 At this point I could specify a length for the straight section of pipe, a fixed height above the tank roof that is independent of the final chosen diameter of the piping, or I could fix a design and scale the whole vent up and down as required. For simplicity I am going to assume 3ft of piping.
+At this point I am going to set up the equations with no knowledge of what the final pipe diameter \(D\) will be, then numerically solve for the minimum diameter that meets the requirements. The actual diameter will be the next largest NPS size pipe.
+using Unitful: @u_str, uconvert, ustrip, upreferred
+
+# Setting up some convenient unit conversions
+SCFH = uconvert(u"m^3/s", 1u"ft^3/hr")
+psi = uconvert(u"Pa", 1u"psi")
+ft = uconvert(u"m", 1u"ft")
+inch = uconvert(u"m", 1u"inch")
+mm = uconvert(u"m", 1u"mm")
+
+# Given in the scenario, now converted to SI
+Q = 200e3SCFH
+pₐ = 14.696psi
+pₘₐₓ = 1psi + pₐ
+L = 3ft
+ϵ = 0.0457mm;I am assuming, for simplicity, that ambient conditions are standard conditions.
+# Universal gas constant to more digits than are at all necessary
+R = 8.31446261815324u"Pa*m^3/mol/K"
+
+# Standard conditions, 15°C
+Tₐ = 288.15u"K"
+
+# Some useful physical properties of air
+Mw = 0.02896u"kg/mol" # Molar weight of air, from Perry's
+k = 1.4 # Ratio of heat capacities, Cp/Cv, ideal gas
+
+# density of air, ideal gas law, kg/m^3
+ρ(p, T) = (p * Mw)/(R * T)
+
+# viscosity of air, from Perry's
+μ(T) = 1u"Pa*s"*(1.425e-6*ustrip(u"K",T)^0.5039)/(1 + 108.3/ustrip(u"K",T));Regardless of the method of performing the compressible flow calculations, the frictional head loss in the piping needs to be accounted for. I am using the K factor method as it is convenient and K factors are tabulated for most everything in references such as Crane’s TP-410. One thing to be very careful with is the difference between the Darcy and Fanning friction factors. I am using Crane’s where everything is in terms of the Darcy friction factor, which is 4× the Fanning friction factor, but Perry’s defaults to the Fanning friction factor.
+From Crane’s I have the following K factors for each piece of the goose-neck2
+Where \(f\) is the Darcy friction factor, \(f_T\) is the turbulent friction factor. I am assuming the entrance to the vent is sharp edged, and the K factors for the bends are for bends with \(r/D = 1.5\).
+For some notational convenience I am going to define the relative roughness \(\kappa = { \epsilon \over D }\) and the reduced length \(l = {L \over D}\) so that, along with the Reynolds number \(Re\), the K factors are in terms of dimensionless numbers only.
+The Darcy friction factor generally depends on which regime the flow is in, laminar, transitional, or turbulent. Since I don’t want to be referring to a Moody diagram I want to use a single equation that operates over a wide range of Reynolds numbers and potentially in laminar and transitional flow regimes since I don’t know a priori what the flow in the vent will be. There are equations like the Serghide correlation or Churchill correlation that attempt to fit a Moody diagram but in a more convenient to use manner.
+ +
+The black line conservatively takes the max of either the laminar or turbulent friction factor in the transitional region \(2100 \le Re \le 4000\). The Churchill correlation fits the general curve well for both the turbulent and laminar region, and provides reasonable values in the transitional region.
+The Churchill correlation is3
+3 Tilton, “Fluid and Particle Dynamics,” 6–11. The equation here is given in terms of the darcy friction factor.
\[ f = 8 \left( \left( \frac{8}{Re} \right)^{12} + { 1 \over {\left( A+B \right)^{3/2} } } \right)^{1/12} \]
+\[ A = \left( 2.457 \ln\left( {1 \over {\left( \frac{7}{Re} \right)^{0.9} + 0.27\kappa} } \right) \right)^{16} \]
+\[ B = \left( \frac{37530}{Re} \right)^{16} \]
+The turbulent friction factor is the friction factor at fully turbulent flow, when f is no longer dependent upon the Reynolds number.
+\[ f_T = { 0.25 \over { \left( \log \left( \kappa \over 3.7 \right) \right)^2 } } \]
+With these defined I can write a function that gives \(\sum_j K_j\) for any \(\kappa\), l, and Re
+function f(κ, Re)
+ A = (2.457 * log(1/((7/Re)^0.9 + 0.27*κ)))^16
+ B = (37530/Re)^16
+ return 8*((8/Re)^12 + 1/(A+B)^(3/2))^(1/12)
+end
+
+fT(κ) = 0.25/log10(κ/3.7)^2
+
+ΣK(κ,l,Re) = 0.5 + f(κ,Re)*l + 14*fT(κ) + 14*fT(κ) + fT(κ) + 1.0;Since the vent has a constant cross sectional area, the mass velocity, \(G\), is constant throughout
+\[ G = \frac{4 \dot{m} }{\pi D^2} \]
+Where \(\dot{m}\) is the mass flow rate in kg/s flowing through the vent, which is \[\dot{m} = Q_{std} \cdot \rho \left(p_{std}, T_{std} \right) \] with \(Q\) the flow at standard conditions and \(\rho\) the density at standard conditions.
+Note The required vent flow is given in SCFH, this is not temperature or pressure dependent and \(\dot{m}\) is a constant. If the flow given was a true volumetric flow rate, then \(\dot{m}\) would be a function of temperature and pressure in general. This is one of those things that routinely snags inexperienced engineers as a flow in terms of a standard volume looks like a volumetric flow rate, it’s in units of volume, but really isn’t one since the temperature and pressure are set to standard state by definition.
+The Reynolds number in terms of the mass velocity is
+\[ Re = \frac{G D}{\mu} \]
+The only parameter in the Reynolds number which is not a constant is the viscosity, \(\mu\), which is mostly dependent upon temperature and not pressure. So, to a very good first approximation, the Reynolds number is only a function of temperature. Which is very convenient.
+# mass flow, recall Q is at standard state so is not a function of
+# temperature or pressure
+m = Q*ρ(pₐ, Tₐ)
+
+# mass velocity
+G(D) = (4*m)/(π*D^2)
+
+# Reynold's number
+# upreferred promotes derived units to combos of base units
+# e.g. converts Pa -> kg/m/s^2
+Re(D, T) = upreferred(G(D)*D/μ(T));For problems, like this vent, where the pressure drop is expected to be small it is not unreasonable to assume the flow is approximately incompressible. This is very often what is done since, typically, it does not require any iterative methods and one can solve for incompressible flow directly. It is also useful to do even if one plans on performing a more complete compressible flow calculation, since this provides something of a sanity check and can be a good place to start compressible flow iterative calculations, i.e. the initial guess is from the incompressible case
+To check whether or not the incompressible assumption is reasonable, consider the ratio of density inside the tank (at the max allowable pressure) to the density outside the tank, assuming ambient temperature. For an ideal gas this is
+\[ { \rho_1 \over \rho_2 } = { {p_1 Mw} \over {R T_a} } { {R T_a} \over {p_2 Mw} } = \frac{p_1}{p_2} = \frac{p_{max} }{p_a}\]
+pₘₐₓ/pₐ1.0680457267283614Typically flows are considered incompressible if the density varies by less than ~5-10%, so this example (where the density varies by ~7%) is right in that range. You could justify it either way and it’s more a function of how accurate the calculations need to be. Since, ultimately, we are solving for the pipe diameter and choosing the next largest pipe size it’s probably fine to use an incompressible flow assumption. If anything the incompressible flow assumption will overestimate the pressure drop and thus lead to an oversized pipe (erring on the side of caution)
+The mechanical energy balance for an incompressible fluid is4
+4 Tilton, 6–16.
\[ p_1 - p_2 = \alpha_2 \frac{\rho v_2^2}{2} - \alpha_1 \frac{\rho v_1^2}{2} + \rho g \left( h_2 - h_1 \right) + \sum_j K_j \frac{\rho v^2}{2} \]
+With the following simplifications + given the assumption of incompressible flow and a vent with a constant cross-sectional area \(v_1 = v_2 = v\), + the flow is uniform throughout \(\alpha_1 = \alpha_2 = 1.0\) + the contribution due to hydro-static pressure is negligible as the gas density is very small, \(\rho g \left( h_2 - h_1 \right) \approx 0\)
+This becomes
+\[ p_1 - p_2 = \sum_j K_j \frac{\rho v^2}{2} \]
+Where the velocity, \(v\) is
+\[ v = \frac{Q}{A} = { Q \over { \frac{\pi}{4} D^2 } } \]
+Which can be solved algebraically for \(D\), where \(\rho\) is taken at the average pressure. That said it is easier to solve it numerically.
+using Roots: find_zero, Brent
+
+v(D) = Q / ((π/4)*D^2)
+
+Dᵢₙ(Dₗ, Dᵤ) = find_zero(
+ (D) -> pₘₐₓ - pₐ - 0.5*ΣK(ϵ/D,L/D,Re(D,Tₐ))*ρ((pₘₐₓ + pₐ)/2, Tₐ)*v(D)^2,
+ (Dₗ, Dᵤ), # Lower and upper bracket of the root
+ Brent() ) # Solve using Brent's method
+
+D0 = Dᵢₙ(4inch, 12inch)
+
+uconvert(u"inch", D0)6.497118827423374 inchAt this point one would typically stop for this example, compressible flow calculations are probably unnecessary.
+In general compressible flow situations can be very difficult to solve, since the density of the working fluid is a function of the pressure and temperature and the pressure and temperature are varying throughout, which means heat transfer must also be accounted for in some way. There are several key simplifying assumptions that take this from the sort of problem solved with CFD to something actually quite simple. The first is to assume an ideal gas, the second is to examine two extreme cases of heat transfer: isothermal flow and adiabatic flow.
+At these two extreme cases, the first where heat transfer is instantaneous and the second where it doesn’t occur at all, provide bounds on the problem.
+Isothermal compressible flow of an ideal gas is fairly straight forward. As already mentioned the Reynolds number depends only on temperature, which is constant by definition, so the Reynolds number is a constant. This means the frictional head loss is also constant throughout, and it is a simple matter to calculate the pressure drop.
+The assumption that the flow is isothermal is very reasonable in this case. We are assuming normal venting from a tank at thermal equilibrium with it’s surroundings, that is that the air flowing through the vent starts and ends in reservoirs of equal temperature. As gases expand the temperature decreases but the pressure drop across the vent is small so this effect should be negligible.
+A quick check is to estimate the ratio of temperatures at the start and end of the vent assuming a friction-less adiabatic expansion
+\[ p_1^{1-k} T_1^k = p_2^{1-k} T_2^k = \mathrm{const}\]
+\[ \frac{T_2}{T_1} = \left( p_1 \over p_2 \right)^{ {1-k} \over k}\]
+(pₘₐₓ/pₐ)^((1-k)/k)0.9813670503935878So we expect even in the most extreme case the temperature change is ~2%, justifying the assumption that the venting is isothermal.
+The isothermal flow of an ideal gas going through a length of piping is5
+5 Tilton, 6–23. This equation also neglects changes in elevation.
\[ p_{1}^{2} = G^{2} \frac{RT}{Mw} \left[ \sum \limits_{j} K_{j} + 2\ln \frac{p_{1} }{p_{2} } \right] + p_{2}^{2} \]
+If we assume the system is at thermal equilibrium with the outside air, then \(T = T_a\) and \(p_2 = p_a\)
+The only unknown is p1, which can be solved for numerically.
+pᵢₜ(G,κ,l,Re) = find_zero(
+ p -> p^2 - G^2 * (R*Tₐ/Mw) * (ΣK(κ,l,Re) + 2*log(p/pₐ)) - pₐ^2,
+ pₘₐₓ); # initial guessAt this point we can write a simple function to solve for the minimum diameter that meets our requirement that \(p_1 \le p_{max}\).
+Dᵢₜ(Dₗ, Dᵤ) = find_zero(
+ D -> pₘₐₓ - pᵢₜ( G(D), ϵ/D, L/D, Re(D, Tₐ)),
+ (Dₗ, Dᵤ), # Lower and upper bracket of the root
+ Brent() ) # Solve using Brent's method
+
+D1 = Dᵢₜ(4inch, 12inch)
+
+uconvert(u"inch", D1)6.491472166277518 inchAdiabatic flow of an ideal gas through a pipe, also called Fanno flow, is somewhat more difficult than isothermal flow – there are more steps in the iterative solution as the temperature along the length of the vent changes and thus the Reynolds number changes. The general process starts by assuming a constant friction factor, calculating the pressure and temperature changes due to the adiabatic expansion of an ideal gas, adjusting the friction factor for the temperature change, and iterating until everything converges.
+There are a few ways of setting up the calculations. We could assume the gas exits at ambient conditions – both ambient temperature and pressure – or assume the tank starts at thermal equilibrium with the environment but at a higher pressure and the gas exits at ambient pressure and some other temperature – less than ambient due to adiabatic expansion. The first set of assumptions is in some ways easier to calculate, but the second set of assumptions is more physically realistic, and consistent with the assumptions made when solving the isothermal case.
+One thing we should check before proceeding is whether or not the flow will be choked, essentially will the flow velocity reach \(Ma = 1\), the following discussion assumes flow remains subsonic, and this is easy to check. The critical pressure, at which flow becomes sonic, is given by6
+6 Tilton, 6–23.
\[ { p^o \over p_1 } = \left(2 \over k+1 \right)^{k \over {k-1} } \]
+with the criteria that flow is subsonic if
+\[ { p_2 \over p_1 } > { p^o \over p_1 } \]
+(pₐ / pₘₐₓ) > (2 / (k+1))^(k/(k-1))trueThe basic relation of Fanno flow that drives the equations is the relationship between the Fanno parameter and the Mach number7
+7 Tilton, 6–24.
\[ Fa = \left( \frac{fL^{*} }{D} \right) = \frac{1 - Ma^{2} }{kMa^{2} } + \frac{k+1}{2k} \ln \left( \frac{ \left( k+1 \right) Ma^{2} }{ 2+\left( k+1 \right) Ma^{2} } \right) \]
+Where I am defining \(Fa\) to be the Fanno parameter. The Fanno parameter is calculated from some point in the flow path through to the critical point, where flow goes sonic. The critical point can be a hypothetical point, assuming the pipe is infinite, or it can be real. In this case I am assuming the flow within the vent will remain subsonic.
+It is worth noting that elbows near the exit of a pipe may choke the flow even though the \(Ma < 1\) due to the nonuniform velocity profile in the elbow. By the design of this goose-neck we know this is the case and should keep that in mind when evaluating the results.
+For two points along a pipe, 1 and 2, the difference between their Fanno parameters is the frictional loss between those two points8
+8 Tilton, 6–24.
\[ Fa_1 - Fa_2 = \sum_{j} K_{j} \]
+Where the \(K_j\) are usually evaluated at the average temperature \({ {T_1 + T_2} \over 2}\).
+The Mach number at some point i along the pipe, for an ideal gas, is given by9
+9 Derived for an ideal gas:
+\[ G = \rho v = { {p Mw} \over {R T} } v\]
+\[ c = \sqrt{ {k R T} \over Mw } \]
+\[ Ma = { v \over c } = G { {R T} \over {p Mw} } \sqrt{ Mw \over {k R T} } = \frac{G}{p} \sqrt{ \frac{RT}{kMw} }\]
\[ Ma_{i} = \frac{v}{c} = \frac{G}{p_{i} } \sqrt{ \frac{RT_{i} }{kMw} } \]
+and the pressure can be calculated given a Mach number by rearranging
+\[ p_{i} = \frac{G}{Ma_{i} } \sqrt{ \frac{RT_{i} }{kMw} } \]
+and for any two points along the pipe the temperatures are related by10
+10 Tilton, “Fluid and Particle Dynamics” equation 6-116. Taking two points and cancelling out the stagnation temperature.
\[ T_{1} = T_{2} \frac{2 + \left( k-1 \right) Ma_{2}^{2} }{2 + \left( k-1 \right) Ma_{1}^{2} } \]
+Putting all of this together, the procedure for adiabatic ideal gas flow through piping with a given diameter \(D\) is:
+While that looks complicated, each step is fairly easy. In my experience, with subsonic flow, this converges very quickly.
+# Fanno parameter
+Fa(Ma) = ((1-Ma^2)/(k*Ma^2)) + ((k+1)/(2k))*log( ((k+1)*Ma^2) / (2 + (k+1)*Ma^2))
+
+# Mach number
+# upreferred(...) ensures units cancel appropriately and the Ma is unitless
+Ma(G, p, T) = upreferred((G/p)*√((R*T)/(k*Mw)))
+
+
+T2(T₁, Ma₁, G, p) = find_zero(
+ T -> (2 + (k-1)*Ma₁^2)*T₁ - (2 + (k-1)*Ma(G, p, T)^2)*T,
+ T₁) # Use the isothermal case as an initial guess
+
+
+function pfa(D)
+ # pre-calculating diameter dependent variables
+ Gᵢ = G(D)
+ κᵢ = ϵ/D
+ lᵢ = L/D
+
+ # initial values
+ T₂ = Tₐ
+ Ma₁ = Ma(Gᵢ, pₐ, Tₐ)
+ p₁ⁿᵉʷ = uconvert(u"Pa",(Gᵢ/Ma₁)*√((R*Tₐ)/(k*Mw)))
+
+ # loop until the error is below the given tolerance, but don't loop forever!
+ err, i = 1.0, 0
+ rtol, max_count = 1e-9, 1e5
+ while (err > rtol) && (i < max_count)
+ # Starting up
+ Tₐᵥ = 0.5*(Tₐ + T₂)
+ Reᵢ = Re(D,Tₐᵥ)
+ Ma₂ = Ma(Gᵢ, pₐ, T₂)
+
+ # Steps 3 - 6
+ Fa₂ = Fa(Ma₂)
+ Fa₁ = Fa₂ + ΣK(κᵢ,lᵢ,Reᵢ)
+ Ma₁ = find_zero(x -> Fa₁ - Fa(x), (Ma₂ + Ma₁)/2)
+ T₂ = T2(Tₐ, Ma₁, Gᵢ, pₐ)
+
+ # Check if pressure has converged
+ p₁ᵒˡᵈ = p₁ⁿᵉʷ
+ p₁ⁿᵉʷ = uconvert(u"Pa",(Gᵢ/Ma₁)*√((R*Tₐ)/(k*Mw)))
+ err = abs(p₁ⁿᵉʷ - p₁ᵒˡᵈ)/p₁ᵒˡᵈ
+ i += 1
+ end
+
+ # if the loop failed to converge, let me know
+ if i >= max_count
+ error_msg = "iterations exceeded max count, remaining error is $err"
+ error(error_msg)
+ end
+
+ return p₁ⁿᵉʷ
+end;Dfa(Dₗ, Dᵤ) = find_zero(
+ D -> pₘₐₓ - pfa(D),
+ (Dₗ, Dᵤ), # Lower and upper bracket of the root
+ Brent() ) # Solve using Brent's method
+
+D2 = Dfa(4inch, 12inch)
+
+uconvert(u"inch", D2)6.485474802835819 inchThe method given here is from Perry’s and, while it works, is an awkward way of calculating the flow from a given pressure drop. A better method, adapted from Coulson and Richardson’s is presented here.
+At this point we have solved for the minimum vent diameter in three different ways and, more or less, got the same answer three times. The minimum diameter is ~6.4in ID for all cases and the next largest standard pipe size is 8in so regardless of the method, in this particular example, one arrives at the same final answer.
+In general the incompressible model will always overestimate the pressure drop across the vent, leading to a larger vent size, and the adiabatic flow will provide an underestimate, the true minimum would be somewhere between the two. This is seen much more clearly at vent diameters less than ~5in where the pressure drop is more significant, more analogous to relief piping for a pressure vessel than venting for an atmospheric storage tank. Of course all of this is assuming flow remains subsonic, if the pressure drop leads to sonic flow then things are quite different.
+ +
+Often things like compressible flow can be intimidating since these problems, even in the simplified ideal gas case, require iterative solutions and often iterative solutions within iterative solutions. However, once the basic pieces are set up, compressible flow can be fairly simple to deal with. There are some pitfalls here that, if one wanted to create a nice generalized set of code, would have to be dealt with.
+The big one being all the find_zero() calls that rely on the initial guess being a good one, or the bracketed values actually bracketing the answer. It’s more than possible to supply a terrible initial guess, especially for pipe diameter, and have the root solver fail outright. Adding some code to check that guesses are within the domains of functions would be a start, e.g. catching attempts to take log(0) and returning -Inf or something to ensure that the root-finding algorithms respect function domains. This also presents an opportunity to generate better default values, programmatically, prior to solving. As opposed to me just picking reasonable numbers off the top of my head and having everything work out because I’m lucky.
Relatedly there is a lot of room to fiddle around with which root finding algorithm is employed.
+Recently wildfire smoke has returned and blanketed the city in haze, causing the air quality health index (AQHI) to sky rocket, and as a result I’ve been spending a lot more time inside. This feels like it is a lot more common event than it used to be, but I’m not sure if that’s true or if it merely feels true because I’m looking out at a hazy skyline.
+I would like to look into this more using air quality data and see if this truly is a recent change, or maybe Edmonton has always been like this and I’ve simply forgotten.
+Alberta has a series of air quality monitoring stations set up around the province and I can pull a data-set from the Edmonton Central station (the closest one to me) and look at airborne particulates (pm2.5) as a proxy for wildfire smoke. Though the smoke itself is more than just particulates <2.5μm in diameter, it is those particulates that cause the AQHI to rise significantly.
+However there are more sources of pm2.5 than just wildfires, vehicles are a major source for one, and in the winter atmospheric inversions can lead to really poor air quality during which time the pm2.5 concentration rises. Additionally farmers around the city often burn stubble and other stuff in the fall, leading to smoke days that have nothing to do with wildfires.
+So this is a proxy for wildfire smoke, but not a great one.
+I downloaded just the pm2.5 measurements for Edmonton Central from October 2000, the earliest reported values, through to the end of December 2020, the latest values in the database at this time, from Alberta’s Ambient Air Data Warehouse. This is a csv with 177,072 rows of data and several columns each corresponding to, I’m guessing, a different instrument. Over time the station has swapped out instruments for measuring pm2.5s and those are recorded as a different measurement type.
+using CSV, DataFrames, Dates, Pipe, Plotsdata_file = "data/Long Term pm2.5 Edmonton Central.csv"
+
+ambient_data = @pipe data_file |>
+ CSV.File( _ ;
+ dateformat="mm/dd/yyyy HH:MM:SS",
+ types=[DateTime, DateTime, Float64, Float64, Float64, Float64],
+ header=16, silencewarnings=true) |>
+ DataFrame(_);177072×6 DataFrame + +6×6 DataFrame + + Row │ IntervalStart IntervalEnd MeasurementValue MeasurementValue_1 MeasurementValue_2 MeasurementValue_3 + + │ DateTime DateTime Float64? Float64? Float64? Float64? + +─────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── + + 1 │ 2000-10-20T00:00:00 2000-10-20T00:59:00 missing missing missing 2.3 + + 2 │ 2000-10-20T01:00:00 2000-10-20T01:59:00 missing missing missing 1.8 + + 3 │ 2000-10-20T02:00:00 2000-10-20T02:59:00 missing missing missing 1.8 + + 4 │ 2000-10-20T03:00:00 2000-10-20T03:59:00 missing missing missing 1.0 + + 5 │ 2000-10-20T04:00:00 2000-10-20T04:59:00 missing missing missing 1.8 + + 6 │ 2000-10-20T05:00:00 2000-10-20T05:59:00 missing missing missing 2.0+
What I want to know is when smoke events happened and how long they were. To estimate that I am going to assume a smoke event is a period in which the hourly pm2.5 exceed the ambient air quality guideline for pm2.5s. The event starts at the first hour greater than that limit and ends on the first hour less than that limit. This has the obvious weakness that sometimes the clouds of wildfire smoke has breaks in it, so what feels like a week long smoke event would end up as a series of smaller events as the pm2.5 count might dip overnight or something. But this is a start.
+One complication is that the dataset has four columns of pm2.5 data that are full of mostly missing values since they each only correspond to the period in which the given instrument is running. So I first need to collect those measurement values, drop the missing values, and take the mean of what remains. I assume there is no overlap and so it’s the mean of one number, but I haven’t checked to see if that’s true and the mean seems like the most sensible thing to do if there is overlap.
+If there is a missing hour entirely, i.e. no instrument has a reading, then I skip it. That neither counts as the start nor the end of a smoke event and I move to the next row.
+using Statistics
+
+lim_1h = 80.0 #μg/m³ 1-hr limit
+lim_24h = 29.0 #μg/m³ 24-hr limit
+
+function exceedences(df; limit=lim_1h)
+
+ results = DataFrame(start_date = DateTime[], end_date = DateTime[], month = Int64[], year = Int64[], duration = Float64[], max_conc = Float64[])
+
+ flag = false
+ start_date = nothing
+ end_date = nothing
+ max_conc = 0.0
+
+ for r in eachrow(ambient_data)
+ measurements = [r[:MeasurementValue], r[:MeasurementValue_1], r[:MeasurementValue_2], r[:MeasurementValue_3]]
+ measurements = collect( skipmissing(measurements) )
+ conc = if (sizeof(measurements)>0) mean(measurements) else missing end
+
+ if typeof(conc) == Missing
+ # ignore missing data
+ elseif conc > limit
+ if flag == true # we are already in a sequence
+ end_date = r[:IntervalEnd]
+ max_conc = max(conc, max_conc)
+ else # we are starting a sequence
+ flag = true
+ start_date = r[:IntervalStart]
+ end_date = r[:IntervalEnd]
+ max_conc = max(conc, max_conc)
+ end
+ else
+ if flag == true # we are ending a sequence
+ flag = false
+ duration = Dates.value.(end_date - start_date)/3.6e6
+ push!(results, [start_date, end_date, month(start_date), year(start_date), duration, max_conc])
+ max_conc = 0.0
+ end
+ end
+ end
+
+ return results
+endresult_1hr = exceedences(ambient_data, limit=lim_1h)Results: 53×6 DataFrame + + + +Summary: + +6×7 DataFrame + + Row │ variable mean min median max ⋯ + + │ Symbol Union… Any Union… Any ⋯ + +─────┼────────────────────────────────────────────────────────────────────────── + + 1 │ start_date 2001-05-24T11:00:00 2019-05-31T15:00:00 ⋯ + + 2 │ end_date 2001-05-24T12:59:00 2019-05-31T15:59:00 + + 3 │ month 5.84906 1 7.0 12 + + 4 │ year 2011.15 2001 2010.0 2019 + + 5 │ duration 3.85126 0.983333 1.98333 26.9833 ⋯ + + 6 │ max_conc 135.9 80.3 93.9 867.0 + + 2 columns omitted+
Over the past 20yrs there were 53 periods with the pm2.5 concentration above the limit, these range from 1hr to 27hrs long and a max concentration observed of 867μg/m³
+A plot of the results, showing each period in excess of the hourly limit and the duration of that period, is very suggestive that these are becoming more frequent events. If we also plot the maximum hourly concentration observed it appears that the extreme smoke days are a more recent phenomenon. Though with the big caveat that the data only goes back 20 years, it could be that the period between 2000 and 2010 was an abnormally smoke-less period.
+ +
+ +
+The plots below aggregate the events by year, and it certainly seems like smoke events are becoming more frequent and lasting longer, with more time spent in haze than in the early 2000s. But there are notable years such as 2010 and 2018 which could simply be outliers. Interestingly the most notable, in the news, years for wildfires are not obvious ones here – the Slave Lake fire of 2011 and Ft. McMurray fire of 2016. I think it is often the case that the wildfire smoke in Alberta has less to do with fires in Alberta itself and more to do with smoke being carried in from neighbouring states and provinces. That is certainly true now when the major wildfires are in BC, northern Saskatchewan, and northern Manitoba.
+ +
+One thing these plots may mask is that while the median duration perhaps hasn’t changed much, it’s clear from the scatter plots that the outlier periods are more common in the last decade than the one preceding it.
+ +
+When grouped by month, we can see winter months have notable representation, which is likely those atmospheric inversions trapping pollutants near ground level, but the summer months appears to be when the hazy periods are longest and that likely corresponds to wildfire smoke.
+ +
+Filtering out only the extended periods, with a duration >5 hrs, we see that prolonged periods of excess pm2.5 appears to be a summer phenomena, especially August. Which is certainly consistent with my experience of noticeable smokey days, corresponding with wildfire season.
+ +
+An opportunity for further analysis would be to look for correlations between pm2.5 and other pollutants, say NOx, to allow one to exclude pm2.5s from vehicle emissions. That would still leave road dust, construction dust, and just farmers burning stubble, but I imagine that would go pretty far in terms of removing unrelated bad air quality days from the dataset. If one was only concerned with the most extreme cases, when the sky turns orange and visibility drops to only a few blocks, well that’s visible from space and could presumably be pulled out a dataset of satellite images, taking care to distinguish smoke from cloud cover.
+I would like to see a longer dataset. The dataset I was looking at was relatively short, only twenty years, which doesn’t allow me to answer the question of whether or not extended periods of wildfire smoke is truly a recent phenomenon versus a “return to normal”, i.e. it could be that 2000-2010 were the abnormal years and that is equally consistent with this dataset. Just looking around the air data warehouse it doesn’t look like this kind of air analysis was routine before the 2000s, but I could simply be ignorant of some other studies or datasets.
+Finally I picked pm2.5s since that is the variable responsible for the high risk AQHI levels, but there could be much better proxies for wildfire smoke that have better datasets. I can’t think of anything off the top of my head, but I’m a chemical engineer not an air quality expert.
+ + +In previous examples I discussed release scenarios involving vapour clouds spreading over a large area, carried by the wind. In those examples the momentum of the jet of fluid was not very important relative to the ambient wind conditions and could be ignored. In this example I am looking at the opposite extreme, a release from a pressure vessel inside a building where the momentum of the jet dominates.
+Consider, for an example, a leak from an acetylene cylinder inside a large building, such as in a warehouse or shop. We imagine, for convenience, that the air within the building is quiescent. For the sake of an example suppose the leak is a 1/4 in. hole, similar in diameter to a typical acetylene hose, and that the operating pressure at that point is 15psig1 We are interested in exploring the concentration distribution as the acetylene jets into the air and mixes, with our reference concentration of interest being half the LEL of 2.5%(vol).
+1 From CGA G-1 2009 the safe operating pressure of an acetylene system
using Unitful: @u_str, ustrip
+
+inch = ustrip(u"m", 1u"inch") # unit conversion inch->m
+psi = ustrip(u"Pa", 1u"psi") # unit conversion psi->Pa
+
+p₂ = 14.7psi # atmospheric pressure, Pa absolute
+T₂ = 25+273.15 # ambient temperature, K
+
+d = 0.25inch # diameter of the hole, m
+p₁ = 15psi+p₂ # pressure of the acetylene, Pa absolute
+T₁ = T₂ # the release temperature, K298.15We can look up some properties of acetylene in Perry’s2
+# universal gas constant, J/mol/K
+R = 8.31446261815324
+
+# ideal gas density, kg/m³
+ρ(p,T;MW) = (p*MW)/(R*T)/1000
+
+# gas viscosity correlation, Pa*s
+μ(T;C) = (C[1]*T^(C[2]))/(1+(C[3]/T)+(C[4]/T^2))
+
+# Properties of Acetylene
+MWⱼ = 26.037 # molar mass, kg/kmol
+LEL = 0.025 # Lower explosive limit, vol/vol
+k = 1.26 # ratio cp/cv at 15C
+μⱼ = μ(T₁;C=[1.2025e-6,0.4952,291.4,0])
+ρ₁ = ρ(p₁,T₁;MW=MWⱼ)
+
+# Properties of Air
+MWₐ = 28.960 # molar mass, kg/kmol
+ρ₂ = ρ(p₂,T₂;MW=MWₐ)1.1840386427594014We can model the release as a gas jet3 where the gas is ideal and the expansion through the jet is an isentropic process4
+4 AIChE/CCPS, Guidelines for Consequence Analysis of Chemical Releases. has a mistake in equation 2.16, the version given here is correct.
\[ G = \rho u = c_d \sqrt{ \rho_1 p_1 \left( 2 k \over k-1 \right) \left[ \left(p_2 \over p_1\right)^{2 \over k} - \left(p_2 \over p_1\right)^{k+1 \over k} \right]} \]
+for non-choked flow and
+\[ G = c_d \sqrt{ \rho_1 p_1 k \left( 2 \over k+1 \right)^{k+1 \over k-1} } \]
+for choked flow, which occurs when
+\[ \left(p_2 \over p_1 \right) \lt \left( 2 \over k+1 \right)^{k \over k-1} \]
+Where G is the mass velocity of acetylene discharged through the hole (in kg/m²/s), cd is the discharge coefficient which can be assumed to be 0.61,5 and the rest are as defined earlier. I am assuming, here, that the hole is circular for simplicity.
+(p₂/p₁) < (2/(k+1))^(k/(k-1)) trueTherefore the flow is choked and
+c_d = 0.61
+
+G = c_d * √(ρ₁*p₁*k*(2/(k+1))^((k+1)/(k-1)) )267.1556913840265The density at the orifice is reduced, through the expansion and, for an isentropic process, is related to the pressure by
+\[ {\rho_o \over \rho_1} = \left( p_o \over p_1 \right)^{1 \over k} \]
+Where subscript o indicates at the orifice. At this point, after the expansion \(p_o = p_2\) and
+\[ \rho_o = \rho_1 \left( p_o \over p_1 \right)^{1 \over k} \]
+ρₒ = ρ₁*(p₂/p₁)^(1/k)1.2307940295609565The velocity at the orifice, i.e. after the gas has expanded, is then
+\[ u_o = {G \over \rho_o} \]
+uₒ = G/ρₒ217.05962571115586To model the concentration profile I am going to assume a turbulent jet, from a circular hole, mixing with air. In this case the density of air and acetylene are similar and so a simple turbulent jet model is appropriate. If there was a significant difference in densities then a density correction would be needed, however for many applications “close” means a ratio of ambient to jet densities between6
+\[ \frac{1}{4} \le { \rho_{a} \over \rho_{j} } \le 4 \]
+Where subscript a indicates the ambient fluid and j the jet.
+Circular turbulent jets expand by entraining ambient fluid, tracing out a cone defined by a jet angle \(\alpha \approx 15-25^\circ\). The mixing layer penetrates into the jet forming the potential cone, inside is pure jet material and outside is mixed. After approximately 6 hole diameters the region is fully developed.7
+ +
+Empirical approximations of the velocity, and concentration, profiles are often given with respect to this jet angle or, equivalently, the slope of line (i.e. \(\tan \frac{\alpha}{2}\))
+Another important factor is the Reynolds number, the jet is fully turbulent when \(Re \gt 2000\), where the Reynolds number is calculated with respect to the initial jet velocity and jet diameter (i.e. the hole diameter)
+\[ Re = { \rho u d \over \mu } = { G d \over \mu }\]
+0.25 < (ρ₂/ρₒ) < 4trueRe = G*d/μⱼ
+
+Re > 2000trueThe densities are within the appropriate range and the flow is fully turbulent, so the turbulent jet model requirements are satisfied.
+There are many different empirical velocity distributions as well as velocity distributions derived from theories of turbulent mixing available in various references. Mostly of the same general type (gaussian), but parametrized slightly differently. However, in my experience, there are far fewer concentration distributions available, this is not too critical due to an interesting result in turbulent mass transfer for jets8
+\[ { C \over C_{max} } = \left( v_z \over v_{z,max} \right)^{Sc_t} \]
+That is, at a given distance z away from the hole, the concentration profile is the velocity profile raised to the power \(Sc_t\) – the turbulent Schmidt number. Experimentally this is approximately 0.7. Note also that \(C_{max}\) and \(v_{z,max}\) are taken at the centerline. Physically this means that the concentration profile, at a given downstream distance, is wider than the velocity distribution; concentration expands more.
+A similar way of capturing the same phenomenon that is often seen with empirical velocity distributions is to define a width parameter \(b\) and note that the equivalent width for the concentration profile is \(1.17b\)9 and substitute in accordingly.
+In this example I am using the empirical concentration given in Lees10 for simplicity
+\[ {C \over C_0 } = k_2 \left( d_h \over z \right) \left( \rho_z \over \rho_o \right)^{0.5} \exp \left( - \left( k_3 r \over z \right)^2 \right) \]
+Note also the ratio of densities, the density \(\rho_z\) is the density of the jet at some distance z and it is common to conservatively take this as \(\rho_a\).
+The parameters \(k_2\) and \(k_3\) are empirically derived for the particular jet and \(k_2\) is a function of Reynolds number below \(Re \lt 20000\).11 The conservative values suggested are 6 and 5 respectively.
+function C(r, z; C₀=1.0, k₂=6, k₃=5, d=d, ρz=ρ₂, ρₒ=ρₒ)
+ C = C₀ * k₂ * (d/z) * √(ρz/ρₒ) * exp(-(k₃*r/z)^2)
+endC (generic function with 1 method) +
+At this point it is worth pointing out that the model of the jet is independent of the discharge rate. The concentration profile is only a function of the hole diameter and the fluid density. The velocity in the jet, and the amount of air entrained in the jet, do depend strongly on the initial discharge rate but in such a way that the concentration does not. As the jet velocity increases proportionally more air is entrained and the concentration profile remains constant.
+ +
+Now that we have a model of the jet, showing the concentration of acetylene, the most relevant parameter we would want to know is the explosive mass such that some blast modeling could be done.
+The most obvious way to do this is to integrate over the jet, using cylindrical coordinates for convenience
+\[ m_e = \int \rho C(r,z) dV = 2\pi \rho_o \int_{0}^{\infty} \int_{0}^{\infty} C(r,z) r dr dz \]
+Except that we define the explosive mass to be the volume where \(C > \frac{1}{2} LEL\). A lazy way to do this is to define a function that equals \(C\) if it is \(\gt \frac{1}{2} LEL\) and zero otherwise.
+The potential core region is poorly described by this model, and the closer to the origin of the jet the more un-physical the results: giving concentrations greater than 100% and being undefined completely at the origin. One way of hand waving this away is to chop off any concentrations above 100%.
+function igrd(v; lim=0.5*LEL)
+ r, z = v
+
+ if z>0
+ c = C(r,z)
+ c = c<lim ? 0 : min(1,c)
+ else
+ c = 0
+ end
+
+ return r*c
+endigrd (generic function with 1 method)Integrating over some plausible bounds, taken by looking at the plots above, gives the volume of acetylene.
+using HCubature: hcubature
+
+I, err = hcubature(igrd, [0, 0], [0.25, 2.0], atol = 1e-8)(0.0008207940258726464, 9.999922827914883e-9)Which can be plugged into the equation to calculate the final explosive mass.
+mₑ = 2*π*ρₒ*I0.006347452155224944To give a sense of how much this is, the explosive mass is equivalent to ~1s of discharge at the steady state discharge rate.
+m = G*(π/4)*d^2
+
+mₑ/m0.7502356087241902Turbulent jet mixing is a much simpler model for estimating releases, especially when using empirical models, compared to models for plumes influences by buoyancy and wind. There are much fewer parameters that need to be estimated.
+One big weakness to the model as presented here is that it does not take into account the enclosed space. If the assumption is that the warehouse is large and ignition sources are numerous then that likely doesn’t matter, the acetylene leak will ignite before it has a chance to accumulate. However it will grossly underestimate the potential explosive mass that could develop as the acetylene disperses through the air of warehouse, since the model presumes the ambient air has no acetylene in it and is effectively infinite in extent.
+This limitation would, for me, motivate exploring more detailed models of gas build up in enclosed spaces
+In a previous post I worked through a chemical release modeled as a turbulent jet and while I mentioned there were several ways modeling the jet, I didn’t go into any of them. I’m taking the opportunity here to collect my notes on turbulent jets, some different ways of modeling the jets, and the relative performance of each approach.
+We are considering a submerged circular jet, issuing from a surface, with the coordinate system centered on the jet. Since it is circular, the natural coordinate system is cylindrical with a downstream distance z, radial distance r, and angular coordinate θ. The jet is fully turbulent when the Reynolds number, \(Re \gt 2000\), where the Reynolds number is calculated with respect to the initial jet velocity and jet diameter
+\[ Re = { \rho_j v_0 d_0 \over \mu_j } \]
+We are also considering the case where the densities of the two fluids are similar, where we take “similar” to mean \[ \frac{1}{4} \le { \rho_{a} \over \rho_{j} } \le 4 \]
+Where subscript a indicates the ambient fluid and j the jet. For much the experimental data the jet and ambient fluid are the same fluid, e.g. a jet of air into air or water into water.
+Turbulent jets expand by entraining ambient fluid, tracing out a cone defined by a jet angle \(\alpha \approx 15-25^\circ\). The mixing layer penetrates into the jet forming the potential core, inside is pure jet material and outside is mixed. After approximately 6 diameters the region is fully developed.
+ +
+Empirical approximations of the velocity profile are often given with respect to this jet angle or, equivalently, the slope of the line (i.e. \(\tan \frac{\alpha}{2}\)). A related way of parameterizing the jet is in terms of a width parameter b. Typically this is the width of the velocity profile at half-height \(b_{1/2}\) (though not always). With a constant jet angle and a self-similar velocity profile the width is directly proportional to the downstream distance \(b_{1/2} = \tan \left( \frac{\alpha_{1/2} }{2} \right) z = c z\).
+Where the value of c is can be found in the literature
+| c | +Reference | +
|---|---|
| 0.082 - 0.097 | +Garde1 | +
| 0.0848 | +Bird, Stewart, and Lightfoot2 | +
| 0.10 | +Rajaratnam3 | +
At this point it is common to introduce a variable \(\xi = {r \over b_{1/2} }\) or \(\xi = {r \over z }\) where we are taking advantage of the fact that \(b_{1/2} \propto z\). This is a scaled radial distance, using the width at half-height as a characteristic length. It is important to keep track of which definition of ξ is being used as they differ by a scaling factor. The reason for this change of variables is the observation that the shape of the velocity profile is the same at any downstream point, it is merely scaled down in height and wider as one travels downstream. That is \({ \bar{v}_z \over \bar{v}_{max} } = f \left( \xi \right)\) is the same for all downstream distances (in the region where the jet is fully developed).
+Another important observation is that the center-line velocity, the max velocity in the jet, decays with the inverse of the downstream distance, i.e.
+\[ \bar{v}_{max} \propto z^{-1} \]
+Putting those two observations together we expect the velocity profile to have the form
+\[ \bar{v}_z = { \mathrm{const} \over z } f \left( \xi \right)\]
+To set up our system we consider the case of a jet coming out of a point on an infinite surface into a quiescent medium, and that the jet and medium have the same density. This is a major simplification, but it makes the math easier to deal with. The coordinate system is centered at this point and all momentum in the jet ultimately comes from the origin.
+The boundary conditions for the problem are:
+Since we are concerned with turbulent flow, we can employ Reynolds decomposition to transform the velocities like so
+\[ v_z = \bar{v}_z + v^{\prime}_{z} \]
+\[ v_r = \bar{v}_r + v^{\prime}_{r} \]
+where \(\bar{v}\) is the time-smoothed velocity and \(v^{\prime}\) is an instantaneous deviation such that \(\bar{v^{\prime} } = 0\) and the time-averaging operator follows the Reynolds criteria.
+The equations of motion in terms of time-smoothed velocities are \[ \rho {D \mathbf{\bar{v} } \over D t } = - \nabla \bar{p} - \nabla \cdot \mathbf{ \bar{\tau} } + \rho \mathbf{g} \]
+Where \(\mathbf{ \bar{\tau} }\) is the turbulent stress and includes the Reynolds stresses.
+With the z component, in cylindrical coordinates4
+\[ \rho \left( {\partial \over \partial t} \bar{v}_z + \bar{v}_r {\partial \bar{v}_z \over \partial r} + {\bar{v}_\theta \over r} {\partial \bar{v}_z \over \partial \theta} + \bar{v}_z {\partial \bar{v}_z \over \partial z} \right) \]
+\[ = - {\partial \bar{p} \over \partial z} - {1 \over r} {\partial \left( r \bar{\tau}_{rz} \right) \over \partial r } - {1 \over r} {\partial \bar{\tau}_{\theta z} \over \partial \theta } - {\partial \bar{\tau}_{z z} \over \partial z } + \rho g_z\]
+Making the assumptions:
+5 The boundary layer approximation is that
+\[ { \partial^2 \bar{v}_z \over \partial z^2 } \ll { \partial^2 \bar{v}_z \over \partial r^2 } \]
+and if we suppose that
+\[ \bar{\tau}_{z z} \propto { \partial \bar{v}_z \over \partial z } \]
+and
+\[ \bar{\tau}_{r z} \propto {\partial \bar{v}_z \over \partial r} \]
+we find
+\[ { \partial \bar{\tau}_{z z} \over \partial z } \propto {\partial^2 \bar{v}_z \over \partial z^2} \ll { \partial r \bar{\tau}_{r z} \over \partial r} \propto {\partial^2 \bar{v}_z \over \partial r^2} \]
+and thus we can assume the free turbulence is dominated by \(\bar{\tau}_{r z}\) and
+\[ { \partial \bar{\tau}_{z z} \over \partial z} \approx 0 \]
The equations of motion, in the z direction, simplifies to
+\[ \bar{v}_r {\partial \bar{v}_z \over \partial r} + \bar{v}_z {\partial \bar{v}_z \over \partial z} = - {1 \over \rho r} {\partial \left( r \bar{\tau}_{rz} \right) \over \partial r } \]
+The continuity equation in terms of time-smoothed velocities is
+\[ {\partial \rho \over \partial t} + \nabla \cdot \rho \mathbf{ \bar{v} } = 0 \]
+In cylindrical coordinates6
+\[ {\partial \rho \over \partial t} + {1 \over r} {\partial \rho r \bar{v}_r \over \partial r} + {1 \over r} { \partial \rho \bar{v}_\theta \over \partial \theta} + {\partial \rho \bar{v}_z \over \partial z} = 0 \]
+Making the assumptions:
+The equation of continuity simplifies to
+\[ {1 \over r} {\partial r \bar{v}_r \over \partial r} + {\partial \bar{v}_z \over \partial z} = 0 \]
+To simplify things down to working with one dependent variable we introduce a Stokes stream function \(\psi\) defined such that
+\[ \bar{v}_z = -{1 \over r} {\partial \psi \over \partial r} \]
+and
+\[ \bar{v}_r = {1 \over r} {\partial \psi \over \partial z} \]
+This definition ensures that the equation of continuity is satisfied. Suppose that \(\psi = k z F\left(\xi\right)\), where F is a unitless function of \(\xi = \frac{r}{z}\) and \(k\) is a constant with units \([[ \mathrm{length} ]]^2 \times [[ \mathrm{time} ]]^{-1}\), then
+\[ \bar{v}_z = -{1 \over r} {\partial \xi \over \partial r} {\partial \psi \over \partial \xi} += -{1 \over r} {1 \over z} {k z F^{\prime} } \]
+\[= -{k \over z} {F^{\prime} \over \xi} = { \mathrm{const} \over z } f \left( \xi \right)\]
+Which matches what we expect from the empirical observations (which is why we supposed that form of the stream function in the first place). We can use this definition to work out some other useful terms
+\[ {\partial \bar{v}_z \over \partial z} = {k \over z^2} F^{\prime \prime} \]
+\[ {\partial \bar{v}_z \over \partial r} = -{k \over z^2} \left( { F^{\prime \prime} \over \xi} - { F^{\prime} \over \xi^2} \right) \]
+\[ \bar{v}_r = { k \over z } \left( { F \over \xi } - F^{\prime} \right) \]
+Substituting these back into the equation of motion, in the z direction, leads to
+\[ \left( k \over z \right)^2 \left[ { F F^{\prime \prime} \over \xi } - {F F^{\prime} \over \xi^2} + { \left( F^{\prime} \right)^2 \over \xi } \right] = {1 \over \rho} {\partial \over \partial r} \left( r \bar{\tau}_{rz} \right) \]
+\[ \left( k \over z \right)^2 { d \over d \xi } \left( F F^{\prime} \over \xi \right) = {1 \over \rho} {\partial \over \partial r} \left( r \bar{\tau}_{rz} \right) \]
+Which is suggestive of the overall approach to follow: find an expression for the right hand side of this differential equation, integrate both sides with respect to ξ, and solve for F(ξ)
+The initial boundary conditions of the problem were that:
+In terms of F and ξ these become:
+To determine the constant k we use a momentum balance: the momentum flux, J, in the z direction is constant. Initially the momentum flux is
+\[ J = \rho v_0^2 A_0 = \rho v_0^2 {\pi \over 4} d_0^2\]
+and at some point z downstream of the origin we have
+\[ J = \int_{0}^{2\pi} \int_{0}^{\infty} \rho \bar{v}_z^2 r dr d\theta \]
+\[ = 2 \pi \rho \int_{0}^{\infty} \bar{v}_{z,max}^2 \left( \bar{v}_z \over \bar{v}_{z,max} \right)^2 r dr \]
+\[ = 2 \pi \rho \bar{v}_{z,max}^2 \int_{0}^{\infty} \left( \bar{v}_z \over \bar{v}_{z,max} \right)^2 r dr \]
+\[ = 2 \pi \rho k^2 \int_{0}^{\infty} \left( f\left( \xi \right) \right)^2 \xi d \xi \]
+Taking the integral to be I, and equating the initial momentum flux with the momentum flux at point z7
+7 I’ve played a little fast and loose with the definition of \(\bar{v}_z\) in that I am implicitly assuming \(f(\xi) = {-F^{\prime}(\xi) \over \xi}\) which isn’t strictly true, there can be scaling factor. In practice all of these are collected together into one constant so it doesn’t matter, but that is something to be aware of as the definition of k here is really \(k\times \mathrm{const}\) where \(\mathrm{const} = {-F^{\prime}(\xi) \over \xi} \div f(\xi)\)
\[ J = \rho v_0^2 {\pi \over 4} d_0^2 = 2 \pi \rho k^2 I \]
+\[ k = \sqrt{1 \over 8 I } v_0 d_0 \]
+The Prandtl mixing length model makes the assumption that momentum transfer occurs over some “mixing length” l such that
+\[ \bar{\tau}_{rz} = -\rho l^2 \left| {\partial \bar{v}_z \over \partial r} \right| \left( {\partial \bar{v}_z \over \partial r} \right)\]
+We suppose that the mixing length is proportional to the width of the velocity profile \(b_{1/2}\), the characteristic length for the velocity profile, which we know is proportional to the downstream distance z
+\[ l \propto b_{1/2} \propto z\]
+\[ l = c z \]
+Where \(c\) is some unitless constant. Making the observation that \({\partial \bar{v}_z \over \partial r} < 0\) we can make the simplification
+\[ \bar{\tau}_{rz} = \rho c^2 z^2 \left( {\partial \bar{v}_z \over \partial r} \right)^2\]
+Recall that the equation of motion in the z direction is (in terms of the unitless function F) is
+\[ \left( k \over z \right)^2 { d \over d \xi } \left( F F^{\prime} \over \xi \right) = {1 \over \rho} {\partial \over \partial r} \left( r \bar{\tau}_{rz} \right) \]
+Substituting the expression for \(\bar{\tau}_{rz}\) we have
+\[ \left( k \over z \right)^2 { d \over d \xi } \left( F F^{\prime} \over \xi \right) = c^2 z^2 {\partial \over \partial r} \left( r \left( \partial \bar{v}_{z} \over \partial r \right)^2 \right) \]
+\[ \left( k \over z \right)^2 { d \over d \xi } \left( F F^{\prime} \over \xi \right) = c^2 z^2 \left( \left( \partial \bar{v}_{z} \over \partial r \right)^2 + 2r \left( \partial \bar{v}_{z} \over \partial r \right) \left( \partial^2 \bar{v}_{z} \over \partial r^2 \right) \right) \]
+Substituting in the expressions for \({\partial \bar{v}_z \over \partial r}\) and \({\partial^2 \bar{v}_z \over \partial r^2}\) we arrive at
+\[ \left( k \over z \right)^2 { d \over d \xi } \left( F F^{\prime} \over \xi \right) = c^2 \left(k \over z \right)^2 \left( 1 \over \xi \right)\left( F^{\prime \prime} - { F^{\prime} \over \xi } \right) \left( 2 F^{\prime \prime \prime} - 3 { F^{\prime \prime} \over \xi } + { F^{\prime} \over \xi^2 }\right) \]
+\[ { d \over d \xi } \left( F F^{\prime} \over \xi \right) = c^2 { d \over d \xi } \left( 1 \over \xi \right)\left( F^{\prime \prime} - { F^{\prime} \over \xi } \right)^2 \]
+Integrating both sides
+\[ \left( F F^{\prime} \over \xi \right) = c^2 \left( 1 \over \xi \right)\left( F^{\prime \prime} - { F^{\prime} \over \xi } \right)^2 + \mathrm{const}\]
+By applying the boundary conditions we find the constant of integration is zero, thus
+\[ F F^{\prime} = c^2 \left( F^{\prime \prime} - { F^{\prime} \over \xi } \right)^2 \]
+Making the substitution \(\phi = a^{-1} \xi\) where \(a = c^{2/3}\)
+\[ F F^{\prime} = \left( F^{\prime \prime} - { F^{\prime} \over \phi } \right)^2 \]
+\[ F^{\prime \prime} = { F^{\prime} \over \phi } + \sqrt{ F F^{\prime} } \]
+Which is in a form that can be solved numerically.
+We can solve the ODE and perform the integral needed for the momentum balance at the same time. First we define a vector u such that:
+\[ \mathbf{u} = \begin{bmatrix} u_{1} \\ u_{2} \end{bmatrix} = \begin{bmatrix} F \\ F^{\prime} \end{bmatrix}\]
+The ODE then becomes:
+\[ {d \mathbf{u} \over dt } = \begin{bmatrix} F^{\prime} \\ F^{\prime \prime} \end{bmatrix} = \begin{bmatrix} u_{2} \\ \frac{ u_{2} }{t} + \sqrt{ u_{1} u_{2} } \end{bmatrix} \]
+Which has a singularity at t=0, but one that can be easily dealt with by setting the initial value of the derivatives to8
+8 From the boundary conditions we know F’(0) = 0 but what about F’’? Taking the ratio
+\[ { \bar{v}_z \over \bar{v}_{z,max} }_{r=0} = - {F^{\prime} \over \phi }_{\phi=0} = 1 \]
+we find \({F^{\prime} \over \phi } = -1\) at φ = 0 and, from the boundary conditions,
+\[ F^{\prime \prime} = {F^{\prime} \over \phi } \]
+at φ = 0, therefore F’’(0) = -1
\[ {d \mathbf{u} \over dt }_{t=0} = \begin{bmatrix} 0 \\ -1 \end{bmatrix}\]
+Putting that together, the ODE can be integrated easily9
+9 Because of how \(\bar{v}_z\) and \(\bar{v}_r\) were defined \(-{ F^{\prime} \over \phi } \ge 0\), i.e. \({ F^{\prime} \over \phi } \le 0\). For the signs to work out, \(F \le 0\) and \(F^{\prime} \le 0\) (since \(F F^{\prime} \ge 0\))
using StaticArrays
+using DifferentialEquations: ODEProblem, Tsit5, solve, TerminateSteadyState
+
+function sys(u,p,t)
+ u₁, u₂ = u[1], u[2]
+ if t > 0.0
+ du₁ = u₂
+ du₂ = u₂/t + √(max((u₁*u₂),0))
+ else
+ du₁ = 0.0
+ du₂ = -1.0
+ end
+
+ return SA[du₁; du₂]
+end
+
+u0 = SA[0.0; 0.0]
+tspan = (0.0, 6.0)
+prob = ODEProblem(sys, u0, tspan)
+sol = solve(prob, Tsit5(), dtmax=0.1, callback=TerminateSteadyState())
+
+print(sol.retcode)Success +
+Using the solution in terms of φ we can write a function f(ξ)
+function f_pml(ξ; a=0.066)
+ ϕ = abs(ξ)/a
+
+ if ϕ >0
+ F, F′ = sol(ϕ)
+ f = -F′/ϕ
+ f = max(f, 0)
+ else
+ f = 1
+ end
+
+ return f
+endThe classic treatment of the Prandtl mixing length model is from Tollmien10 in which, instead of solving numerically in the way shown above, the ODE is further transformed and a series expansion is used to generate a table of results. More often than not it is these tabulated values, or similar ones,11 that are presented as the solution to the model.
+11 Rajaratnam, Turbulent Jets, 39. The table has an error at φ=1: the value of \({F^{\prime} \over \phi }\) should be 0.606 but is given as 0.505 (presumably a typo).
We can easily compare the result here with the tabulated values and verify for ourselves that we have indeed solved the right differential equation. Though by solving numerically in this way we can control the level of precision and easily generate smooth interpolations. In my opinion, this makes using the ODE solution far more convenient than the tabulated values.
+ +
+The width at half height, \(b_{1/2}\), is an important parameter and often velocity profiles are scaled relative to this. To compare different models on a fair basis, it is a good idea to determine what the model parameters are relative to \(b_{1/2}\). Then each model can be scaled to the same \(b_{1/2}\) and compared, apples-to-apples.
+In this case we don’t have a closed form for the velocity profile so we need to solve for φ such that f(φ)=0 numerically.
+using Roots: find_zero
+
+ϕ_half = find_zero( ϕ -> f_pml(ϕ; a=1)-0.5, (1, 1.25))1.2277665940765845and we then write the model parameter a in terms of \(b_{1/2}\)
+\[ a = \frac{1}{\phi_{1/2}} \frac{b_{1/2}}{z} = 0.814 \frac{b_{1/2}}{z} \]
+Using a default value for \({ b_{1/2} \over z } = 0.0848\) we arrive at
+b_half = 0.0848
+
+a = b_half/ϕ_half0.06906850244103516Several sources have tabulated values for a
+| a | +Reference | +
|---|---|
| 0.063 | +Tollmien12 | +
| 0.066 | +Rajaratnam13 | +
and the result of this notebook compares with those
+Now that we have completed the integration we can calculate the parameter k, using the equation derived from the momentum balance
+\[ k = \sqrt{1 \over 8 I } v_0 d_0 \]
+with the value of the integral coming directly from the ode solver
+using NumericalIntegration: integrate
+
+ϕ, F′ = sol.t, sol[2,:]
+
+# trim any unphysical values
+F′[F′.>0] .= 0.0
+
+function integrand(ϕ, F′)
+ if ϕ>0
+ return F′^2/ϕ
+ else
+ return 0
+ end
+end
+
+I = integrate(ϕ, integrand.(ϕ, F′))
+I = a^2 * I0.002573069044757039Allowing us to write the velocity profile as
+\[ \bar{v}_z = 6.97 { v_0 d_0 \over z} f(\xi) \]
+The eddy viscosity model makes the assumption that the turbulent shear stress depends on the rate of strain in a manner that is analogous to laminar flow, with the constant of proportionality being the eddy viscosity ε:
+\[ \bar{\tau}_{rz} = - \rho \varepsilon {\partial \bar{v}_z \over \partial r}\]
+Recall that the equation of motion in the z direction is (in terms of the unitless function F)
+\[ \left( k \over z \right)^2 { d \over d \xi } \left( F F^{\prime} \over \xi \right) = {1 \over \rho} {\partial \over \partial r} \left( r \bar{\tau}_{rz} \right) \]
+Substituting the expression for \(\bar{\tau}_{rz}\) we have
+\[ \left( k \over z \right)^2 { d \over d \xi } \left( F F^{\prime} \over \xi \right) = - \varepsilon {\partial \over \partial r} \left( r \left( \partial \bar{v}_{z} \over \partial r \right) \right) \]
+\[ \left( k \over z \right)^2 { d \over d \xi } \left( F F^{\prime} \over \xi \right) = - \varepsilon \left( \left( \partial \bar{v}_{rz} \over \partial r \right) + r \left( \partial^2 \bar{v}_{rz} \over \partial r^2 \right) \right) \]
+Substituting in the expressions for \({\partial \bar{v}_z \over \partial r}\) and \({\partial^2 \bar{v}_z \over \partial r^2}\) we arrive at
+\[ \left( k \over z \right)^2 { d \over d \xi } \left( F F^{\prime} \over \xi \right) = { k \varepsilon \over z^2} \left( F^{\prime \prime \prime} - { F^{\prime \prime} \over \xi } + { F^{\prime} \over \xi^2 } \right) \]
+\[ \left( k \over z \right)^2 { d \over d \xi } \left( F F^{\prime} \over \xi \right) = { k \varepsilon \over z^2} { d \over d \xi } \left( F^{\prime \prime} - { F^{\prime} \over \xi } \right) \]
+at this point we note that k and ε have the same units of \([[ \mathrm{length} ]]^2 \times [[ \mathrm{time} ]]^{-1}\) and are independent of z and ξ, so we propose that \(\varepsilon = c k\) where c is some unknown constant of proportionality.
+\[ \left( k \over z \right)^2 { d \over d \xi } \left( F F^{\prime} \over \xi \right) = c \left( k \over z \right)^2 { d \over d \xi } \left( F^{\prime \prime} - { F^{\prime} \over \xi } \right) \]
+\[ { d \over d \xi } \left( F F^{\prime} \over \xi \right) = c { d \over d \xi } \left( F^{\prime \prime} - { F^{\prime} \over \xi } \right) \]
+Integrating both sides
+\[ { F F^{\prime} \over \xi } = c \left( F^{\prime \prime} - { F^{\prime} \over \xi } \right) + \mathrm{const}\]
+By applying the boundary conditions we find the constant of integration is zero, thus
+\[ F F^{\prime} = c \left( \xi F^{\prime \prime} - F^{\prime} \right) \]
+\[{ d \over d \xi } \left( \frac{1}{2} F^2 \right) = c { d \over d \xi } \left( \xi F^{\prime} - 2 F \right) \]
+Integrating both sides
+\[ \frac{1}{2} F^2 = c \left( \xi F^{\prime} - 2 F \right) + \mathrm{const}\]
+By applying the boundary conditions we find the constant of integration is zero, thus
+\[ c \xi F^{\prime} = \frac{1}{2} F^2 + 2c F \]
+Which is separable
+\[ \int { d \xi \over \xi} = \int { c \over {\frac{1}{2} F^2 + 2c F} } dF \]
+Integrating one last time
+\[ \log \left( C_1 \xi \right) = \frac{1}{2} \log \left( F \over F + 4 c \right) \]
+Where C1 is an undetermined constant of integration. Re-arranging and solving for F we arrive at
+\[ F\left( \xi \right) = { 4 c C_1 \xi^2 \over {1 - C_1 \xi^2 } } \]
+A common substitution is \(C_1 = - \left( C_2 \over 2 \right)^2\) then
+\[ F\left( \xi \right) = { - c \left( C_2 \xi \right)^2 \over {1 + \frac{1}{4} \left( C_2 \xi \right)^2 } } \]
+What we need, for the velocity profile, is the first derivative of F, which is
+\[ F^{\prime}\left( \xi \right) = { - 2 c C_2^2 \xi \over \left( 1 + \left( C_2 \xi \over 2 \right)^2 \right)^2 } \]
+and finally
+\[ \bar{v}_z = -{k \over z} {F^{\prime} \over \xi} \]
+\[ = -{k \over z} { 1 \over \xi }{ - 2 c C_2^2 \xi \over \left( 1 + \left( C_2 \xi \over 2 \right)^2 \right)^2 } \]
+\[ = {2 \varepsilon C_2^2 \over z} \left( 1 + \left( C_2 \xi \over 2 \right)^2 \right)^{-2} \]
+\[ f \left( \xi \right) = { \bar{v}_z \over \bar{v}_{z,max} } = \left( 1 + \left( C_2 \xi \over 2 \right)^2 \right)^{-2} \]
+f_ev(ξ; C₂=15.1) = ( 1 + (C₂*ξ/2)^2 )^-2Since we have a convenient closed form for the velocity profile, we can calculate what the parameter \(C_2\) is in terms of the width at half height rather easily.
+\[ f(\xi) = \left( 1 + \left( C_2 \xi \over 2 \right)^2 \right)^{-2} \]
+\[ \frac{1}{2} = \left( 1 + \left( {C_2 \over 2} { b_{1/2} \over z }\right)^2 \right)^{-2} \]
+\[ C_2 = 2 \sqrt{\sqrt{2}-1} \frac{z}{ b_{1/2} } \]
+using the same parameterization as above we get
+C₂ = 2*√(√(2)-1)/b_half15.179109738339214Returning to the momentum balance, we need to solve the integral:
+\[ I = \int_{0}^{\infty} f\left( \xi \right)^2 \xi d \xi\\ += \int_{0}^{\infty} \xi \left( 1 + \left( C_2 \xi \over 2 \right)^2 \right)^{-4} d\xi \]
+Which can be integrated to give \[ I = {2 \over 3} C_2^{-2} \]
+and finally
+\[ k = \sqrt{ 3 \over 16 } C_2 v_0 d_0 \]
+with the velocity profile as
+\[ \bar{v}_z = 6.57 { v_0 d_0 \over z} \left( 1 + 57.6 \xi^2 \right)^{-2} \]
+Perhaps the most widely used turbulent jet model is simply an empirical gaussian fit to the data. These are easy to use – no solving of ODEs required – and fitting them to data is relatively straight forward. There is no real theoretical basis that I am aware of, merely based on the observation that a gaussian function fits the velocity profile well.
+\[ f \left( \xi \right) = \exp \left( -c \xi^2 \right) \]
+Where c is a parameter determined by fitting to a dataset.
+f_emp(ξ; c=72) = exp(-c*ξ^2)Since we have a convenient closed form for the velocity profile, we can calculate what the parameter \(c\) is in terms of the width at half height rather easily
+\[ f(\xi) = \exp \left( -c \xi^2 \right) \]
+\[ \frac{1}{2} = \exp \left( - c \left( \frac{ b_{1/2} }{z} \right)^2 \right) \]
+\[ c = \ln \left( 2 \right) \left( \frac{z}{ b_{1/2} } \right)^2 \]
+using the same parameterization as above we get
+c = log(2)/b_half^296.39039423504045Returning to the momentum balance, we need to solve the integral:
+\[ I = \int_{0}^{\infty} f\left( \xi \right)^2 \xi d \xi\\ += \int_{0}^{\infty} \xi \exp \left( -2 c \xi^2 \right) d\xi \]
+Which can be integrated to give
+\[ I = {1 \over 4 c} \]
+and finally
+\[ k = \sqrt{ c \over 2 } v_0 d_0 \]
+with the velocity profile as
+\[ \bar{v}_z = 6.94 { v_0 d_0 \over z} \exp\left( -193.0 \xi^2 \right) \]
+At this point two models of velocity were derived using different models of the free turbulent stress and one purely empirical model was introduced. Each of these models uses a different set of parameters, and have different strengths and weaknesses in terms of usability. To compare them like-for-like we can scale each to the same width at half height, which is shown below along with some measured data14
+14 Pope, Turbulent Flows, points captured from a figure using WebPlotDigitizer.
We can also calculate a Mean Square Error (MSE) and evaluate which model is a better fit to the observed velocity profile.
+ +
+Prandtl Mixing Length Model MSE 0.00051
+Eddy Viscosity Model MSE 0.00092
+Gaussian (empirical) Model MSE 0.00054Interestingly the Prandtl mixing length model works the best, though the gaussian fit is close enough as to be essentially the same given this data set. Which is convenient as a gaussian fit is easier to work with. The eddy viscosity model is the easiest to derive, however it clearly does not work as well for the outer parts of the jet.
+The above approach, the one you will most likely see in the literature, compares each model scaled to the same height and width. Which is sensible if one is planning on fitting data, and allowing that the height and width to be free parameters. However we know, from the analysis above, that the height of each model is dependent upon the width, so might be instructive to look at how that plays out in practice.
+Suppose we are looking at a velocity profile far enough downstream to be in the fully developed flow, say \(z = 7 d_0\)
+ +
+Note that in the region near the center-line the three models are no longer particularly close to one another and the eddy viscosity and prandtl mixing length models have changed places. Relative to the predicted \(v_{max}\) the the eddy viscosity model stays high when compared to the prandtl mixing length model, however the eddy viscosity model predicts a lower \(v_{max}\) such that the effect is entirely reversed.
+It’s also worth noting that the gaussian fit and the prandtl mixing length model track one another reasonably well. I have seen a gaussian fit of the Tollmien tabulated results used in some papers when a smooth interpolation of the intermediate values is required and this suggests that may not be a bad idea. Though, to me, just solving the ode is easier. On a modern machine it takes milliseconds or less and a good ode package like DifferentialEquations.jl provides a higher-order interpolation for free.
This comparison has been done with each of the model parameters set based on a shared width. However there are as many different ways of arriving at the model parameters as there are datasets to fit against. There is a wide spread in tabulated values in the literature and so the predictions of two independently arrived at models can be quite different due all of these factors coming together.
+All of this work was to determine the velocity field, which is not necessarily what anyone cares about. In a release scenario, for example, it is concentration that is most relevant. For a heat transfer application, perhaps, you may care about the temperature field instead. However, with the velocity field the concentrations, temperatures, total entrained flow, etc. can be easily derived.
+Previously I worked through the velocity profiles for turbulent jets and left off claiming that everything else of interest followed simply from those profiles. This time I am going to follow through by sketching out how to derive the concentration profile and volumetric flow rate.
+For hazard identification, among other purposes, what one often wants is not the velocity distribution of the jet, but the concentration profile. For example, suppose a vessel develops a small hole and a jet of process fluid is exiting out into the air, to determine how bad that is and what sort of hazard is presented (explosive, toxic, etc.) we first need to determine the concentration profile.
+Suppose the concentration of a species A is cA, for the sake of simplicity let this be a time-averaged concentration done in a way that is consistent with Reynolds averaging.1
+1 Note the concentration is given in units of \([[ quantity ]] \times [[length]]^{-3}\), e.g. kmol/m³
The continuity equation for species A is given by2
+\[ {\mathrm{D} \over \mathrm{D}t} c_A = - \nabla \cdot \mathbf{J}_A + r_A \]
+where J is the molar flux and r is the rate of reaction3
+3 The molar flux J is the time averaged molar flux and is the sum of both viscous and turbulent terms. \(\mathbf{J}_A = \mathbf{J}_A^{(v)} + \mathbf{J}_A^{(t)}\)
In cylindrical coordinates this is:
+\[ {\partial c_A \over \partial t} + \bar{v}_r {\partial c_A \over \partial r} + {\bar{v}_{\theta} \over r } {\partial c_A \over \partial \theta} + \bar{v}_z {\partial c_A \over \partial x} \]
+\[ = -\left[ {1 \over r} {\partial \over \partial r} \left(r J_{A,r}\right) + {1 \over r} {\partial \over \partial \theta} J_{A,\theta} + {\partial \over \partial z} J_{A,z} \right] + r_A\]
+Making the following assumptions:
+This simplifies down to
+\[ \bar{v}_r {\partial c_A \over \partial r} + \bar{v}_z {\partial c_A \over \partial z} = {-1 \over r} {\partial \over \partial r} \left( r J_{A,r} \right) \]
+We suppose that, much like the velocity profile, the concentration profile is self-similar. That is, at any given downstream distance z the profile has the same shape, just scaled and stretched.
+\[ c_A = {k_c \over z} g\left(\xi\right) \]
+where ξ is r/z and kc is some constant to be determined. From this we can work out some useful partial derivatives
+\[ {\partial c_A \over \partial r} = {k_c \over z^2} g^{\prime}\left(\xi\right) \]
+\[ {\partial c_A \over \partial z} = {-k_c \over z^2} \left[ g\left(\xi\right) + \xi g^{\prime}\left(\xi\right) \right]\]
+recalling the velocity profiles in terms of F(ξ) and substituting into the equation of continuity we arrive at
+\[{ k k_c \over z^2 } {d \over d\xi} \left(F g\right) = -{ \partial \over \partial r} \left( r J_{A,r} \right)\]
+Which gives us our path forward: find a model for \(J_{A,r}\) and substitute into the right hand side of the equation, integrate both sides and solve for g in terms of F and ξ.
+We are going to assume that the overall molar flux is proportional to the concentration gradient and some mixing length4 l, that is
+\[ J_{A,r} = -l_c^2 \left\vert \partial \bar{v}_z \over \partial r \right\vert \left(\partial c_A \over \partial r \right)\]
+we assume the mixing length is proportional to the downstream distance for the same reasons as when we derived the velocity profile and, anticipating the form of the constants from how it worked out for the velocity distribution, \(l_c = a_c^{3/2} z\)
+Putting this into the equation of continuity for A and doing some rearranging gives
+\[{ k k_c \over z^2 } {d \over d\xi} \left(F g\right) = { k k_c \over z^2 } a_c^3 {d \over d\xi}\left(g^{\prime}F^{\prime\prime} - {g^{\prime}F^{\prime} \over \xi} \right)\]
+Cancelling some terms and integrating both sides gives us
+\[ F g = a_c^3 \left(g^{\prime}F^{\prime\prime} - {g^{\prime}F^{\prime} \over \xi} \right) + \mathrm{const} \]
+Where we can see from the boundary conditions that the constant of integration is zero. We can separate F and g
+\[ {g^{\prime} \over g} = { a_c^{-3} F \over F^{\prime \prime} - {F^{\prime} \over \xi} }\]
+and integrating both sides again, we arrive at
+\[ \log{c_A \over c_{A,max} } = \log{g\left(\xi\right) \over g\left(0\right)} = a_c^{-3} \int_0^{\xi} {F \over F^{\prime \prime} - {F^{\prime} \over \xi} } d\xi\]
+Note that, when setting up the original ode, we had
+\[ F F^{\prime} = a^3 \left( F^{\prime\prime} - {F^{\prime} \over \xi} \right)^2 \]
+or
+\[ F^{\prime\prime} - {F^{\prime} \over \xi} = \sqrt{ F F^{\prime} \over a^3 } \]
+Making the substitution gives us an integral entirely in terms of F, F′ and ξ
+\[ \log{g\left(\xi\right) \over g\left(0\right)} = a_c^{-3} a^{3/2} \int_0^{\xi} {F \over \sqrt{ F F^{\prime} } } d\xi\]
+Taking the exponential of both sides gives us:
+\[ {g\left(\xi\right) \over g\left(0\right)} = \left( \exp \left(\int_0^{\xi} {F \over \sqrt{ F F^{\prime} } } d\xi \right)\right)^{ a_c^{-3} a^{3/2} } \]
+Which is something we can compute using the ode solution from last time, by importing the code for the ode from the previous notebook and running it to get the velocity distribution.
+# importing just the ODE solution
+
+using NBInclude
+
+@nbinclude("../turbulent_jet_notes/index.ipynb"; counters=[1 3])We can then perform the integration numerically, in this case the cumulative integral
+using NumericalIntegration: cumul_integrate
+
+ϕ, F, F′ = sol.t, sol[1,:], sol[2,:]
+
+# trim any unphysical values
+F[ F.>0 ] .= 0.0
+F′[F′.>0] .= 0.0
+
+
+function intgrnd(F, F′)
+ if F == 0.0
+ return 0.0
+ elseif F′ == 0.0
+ return -Inf
+ else
+ return F ./ .√(F.*F′)
+ end
+end
+
+log_g = cumul_integrate(ϕ, intgrnd.(F, F′));For some context we can plot the concentration along with the velocity, with the constants \(a_c^{-3} a^{3/2} = 1\)
+ +
+Well, that’s interesting, it looks like we have arrived at
+\[ {c_A \over c_{A,max} } = \left( \bar{v}_z \over \bar{v}_{z,max} \right)^{\mathrm{const} } \]
+Which is, in fact, the case and is generally the case – the Prandtl mixing length, eddy diffusion, and Gaussian models work out to the same conclusion.
+Consider the following derivative
+\[ {d \over d\xi} \log{f\left(\xi\right)} = {d \over d\xi} \log \left( -F^{\prime} \over \xi \right) = {1 \over F^{\prime} } \left( F^{\prime\prime} - {F^{\prime} \over \xi} \right)\]
+Recalling back to our original ode for the Prandtl mixing length velocity distribution, we had the relationship
+\[ F F^{\prime} = a^3 \left( F^{\prime\prime} - {F^{\prime} \over \xi} \right)^2 \]
+or
+\[ {F \over F^{\prime\prime} - {F^{\prime} \over \xi} } = a^3 { {F^{\prime\prime} - {F^{\prime} \over \xi} } \over F^{\prime} } \]
+and so
+\[ {d \over d\xi} \log{f\left(\xi\right)} = a^{-3} {F \over F^{\prime\prime} - {F^{\prime} \over \xi} } \]
+and recalling that the integral we originally wished to solve was
+\[ \log{c_A \over c_{A,max} } = a_c^{-3} \int_0^{\xi} {F \over F^{\prime \prime} - {F^{\prime} \over \xi} } d\xi\]
+we get
+\[ \log{c_A \over c_{A,max} } = \left(a \over a_c\right)^{3} \left[ \log \left( f\left(\xi\right) \over f\left(0\right) \right) \right] = \log \left( \bar{v}_z \over \bar{v}_{z,max} \right)^{\left(a \over a_c\right)^{3} } \]
+and finally
+\[ { c_A \over c_{A,max} } = \left( \bar{v}_z \over \bar{v}_{z,max} \right)^{\left(a \over a_c\right)^{3} }\]
+Where, rather pleasingly, the constant \({\left(a \over a_c\right)^{3} }\) works out to be the ratio of the mixing lengths, all squared5
+5 Suppose an “equivalent” eddy viscosity for the Prandtl mixing length model of
+\[\varepsilon = -l^2 \left\vert \partial \bar{v}_z \over \partial r \right\vert\]
+and eddy diffusivity of
+\[\mathscr{D}_{AB} = -l_c^2 \left\vert \partial \bar{v}_z \over \partial r \right\vert\]
+the turbulent Schmidt number is then
+\[\mathrm{Sc} = {\varepsilon \over \mathscr{D}_{AB} } = \left( l \over l_c \right)^2\]
+making the final result
+\[{c_A \over c_{A,max} } = \left( \bar{v}_z \over \bar{v}_{z,max} \right)^{Sc}\]
\[ {\left(a \over a_c\right)^{3} } = \left( l \over l_c \right)^2 \]
+We can now plot the concentration profile along with the velocity profile and see that the two profiles have a similar shape, with the concentration profile stretched to be wider. Concentration spreads out more than velocity.
+ +
+In the eddy diffusivity model we assume the molar flux is proportional to the concentration gradient with the constant of proportionality being an effective diffusivity, the eddy diffusivity. In some treatments the viscous and turbulent diffusivities are treated separately, in this model we lump it all together into one constant
+\[ J_{A,r} = -\mathscr{D}_{AB} {\partial c_A \over \partial r} \]
+where \(\mathscr{D}_{AB}\) is the eddy diffusivity for species A. Using the definition of cA we can work out the right hand side of the equation of continuity for A
+\[ -{ \partial \over \partial r} \left( r J_{A,r} \right) = {k_c \over z^2} \mathscr{D}_{AB} {d \over d\xi} \left( \xi g^{\prime} \right) \]
+putting that into the equation of continuity for A, we get
+\[{ k k_c \over z^2 } {d \over d\xi} \left(F g\right) = {k_c \over z^2} \mathscr{D}_{AB} {d \over d\xi} \left( \xi g^{\prime} \right) \]
+cancelling some terms and integrating once gives us
+\[k F g = \mathscr{D}_{AB} \xi g^{\prime} + \mathrm{const}\]
+where, by use of boundary conditions, the constant of integration is zero. This can be rearranged to isolate F and g
+\[ {g^{\prime} \over g} = {k \over \mathscr{D}_{AB} } {F \over \xi} \]
+integrating once more
+\[ \log \left( g\left(\xi\right) \over g\left(0\right) \right) = {k \over \mathscr{D}_{AB} } \int_0^{\xi} {F \over \xi} d\xi \]
+recalling that, for the eddy diffusivity model
+\[ F\left( \xi \right) = { - c \left( C_2 \xi \right)^2 \over {1 + \frac{1}{4} \left( C_2 \xi \right)^2 } } \]
+\[ \int_0^{\xi} {F \over \xi} d\xi = {c} \int_0^{\xi} { -C_2^2 \xi \over {1 + \frac{1}{4} \left( C_2 \xi \right)^2 } } d\xi = {c} \log \left(1 + \frac{1}{4} \left( C_2 \xi \right)^2 \right)^{-2} \]
+and so we have
+\[ \log \left( g\left(\xi\right) \over g\left(0\right) \right) = {k c \over \mathscr{D}_{AB} } \log \left(1 + \frac{1}{4} \left( C_2 \xi \right)^2 \right)^{-2} \]
+recalling that the constant k is related to the eddy diffusivity \(\varepsilon\) by \(\varepsilon=ck\), we have
+\[ {c_A \over c_{A,max} } = \left( g\left(\xi\right) \over g\left(0\right) \right) = \left(1 + \frac{1}{4} \left( C_2 \xi \right)^2 \right)^{-2{\varepsilon \over \mathscr{D}_{AB} } } \]
+and, looking back on the definition of f(ξ) from the eddy viscosity model, we get6
+6 The turbulent Schmidt number is defined as the ratio of the eddy viscosity to the eddy diffusivity
+\[\mathrm{Sc} = {\varepsilon \over \mathscr{D}_{AB} }\]
+making the final result
+\[{c_A \over c_{A,max} } = \left( \bar{v}_z \over \bar{v}_{z,max} \right)^{Sc}\]
\[ {c_A \over c_{A,max} } = \left( \bar{v}_z \over \bar{v}_{z,max} \right)^{\varepsilon \over \mathscr{D}_{AB} } \]
+We can plot the concentration and velocity profiles for the eddy diffusivity model as well, and it is a similar story. The shapes of the profiles are the same but the concentration profile is stretched, such that concentration “spreads out” more than velocity does.
+ +
+The standard Gaussian model was defined as
+\[ f\left(\xi\right) = \exp \left( -c \xi^2 \right) \]
+where the constant c (note: not the concentration) was found to be
+\[ c = \log{2} \left(z \over b_{1/2}\right)^2 = \log{2} \left(1 \over \beta\right)^2 \]
+where I am introducing the constant β to represent the spreading constant (i.e. the ratio of b to z) mostly to cut down on all the constants I call c given that I am also using c to represent concentrations.
+We can then write the velocity distribution as
+\[ f\left(\xi\right) = \exp \left( -c \xi^2 \right) = \exp \left( -\log{2} \left(\xi \over \beta\right)^2 \right) = \exp \left(- \log 2 \left(\xi \over \beta\right)^2 \right)\]
+The concentration distribution is similarly defined empirically in terms of a half-width, \(b_{1/2,c}\) and entirely analogously we end up with a distribution
+\[ g\left(\xi\right) = \exp \left( -\log 2 \left(\xi \over \beta_c\right)^2 \right)\]
+where βc is the spreading constant for the concentration profile. But it’s fairly easy to see that this is equivalent to
+\[ g\left(\xi\right) = \exp \left( -\log 2 \left(\xi \over \beta\right)^2 \left(\beta \over \beta_c\right)^2 \right) = f\left(\xi\right)^{\left(\beta \over \beta_c\right)^2} \]
+or7
+7 We can argue, in a manner analogous to the Prandtl mixing length theory, that the eddy viscosity is proportional to the characteristic length squared, and similarly for the eddy diffusivity and thus the turbulent Schmidt number is then
+\[\mathrm{Sc} = {\varepsilon \over \mathscr{D}_{AB} } = \left( b_{1/2} \over b_{1/2,c} \right)^2 = \left( \beta \over \beta_c \right)^2\]
+thus making the final result
+\[{c_A \over c_{A,max} } = \left( \bar{v}_z \over \bar{v}_{z,max} \right)^{Sc}\]
\[ {c_A \over c_{A,max} } = \left({\bar{v}_z \over \bar{v}_{z,max} }\right)^{\left(\beta \over \beta_c\right)^2} \]
+ +
+The dimensionless concentration profile and velocity profile, Gaussian empirical model.
+All three of the turbulent jet models looked at so far ended up with a concentration profile of
+\[{c_A \over c_{A,max} } = \left( \bar{v} \over \bar{v}_{z,max} \right)^{Sc} \]
+where I declared the constant Sc to be the turbulent Schmidt number. There are, of course, several ways of arriving at this value but literature generally gives \(Sc \approx 0.7\). This also tends to be the same value given for the turbulent Prandtl number, which is convenient.
+| Sc | +Reference | +
|---|---|
| 0.7 | +Bird, Stewart, and Lightfoot8 | +
| 0.73 | +Kaye, Khan, and Testik9 | +
Throughout all of this there has been a constant kc floating around, unaddressed. In practice this is usually a free parameter determined by fitting with experimental data. However it can also be determined by a mass balance.
+The total molar flux through any plane z=m is the same for all m (in the region of fully developed flow), which is to say
+\[ n_A = \int_0^{2\pi} \int_0^{\infty} c_A \bar{v}_z r dr d\theta = \mathrm{const} \]
+We also know what total molar flux is from the initial conditions of the jet
+\[ n_A = c_0 v_0 {\pi \over 4} d_0^2 \]
+and we can write the integral for any downstream distance z
+\[ n_A = 2\pi \int_0^{\infty} c_A \bar{v}_z r dr = 2 \pi k k_c \int_0^{\infty} \left(\bar{v}_z \over \bar{v}_{z,max} \right)^{Sc+1} \xi d\xi \]
+and so we can write kc in terms of the other parameters
+\[ k_c = { c_0 v_0 d_0^2 \over 8 k I_c } \]
+where
+\[I_c = \int_0^{\infty} \left(\bar{v}_z \over \bar{v}_{z,max} \right)^{Sc+1} \xi d\xi\]
+recalling that \(k = {v_0 d_0 \over \sqrt{8I} }\) where \[I = \int_0^{\infty} \left(\bar{v}_z \over \bar{v}_{z,max} \right)^{2} \xi d\xi\]
+we can simplify this to
+\[ k_c = \sqrt{I \over 8 I_c^2} c_0 d_0 \]
+or
+\[ {c_A \over c_0} = \sqrt{I \over 8 I_c^2} {d_0 \over z} \left(\bar{v}_z \over \bar{v}_{z,max} \right)^{Sc} \]
+These integrals can get difficult to solve analytically – except for the Gaussian case which is fairly simple – but are very easy to estimate numerically.10
+10 It is worth keeping in mind, when using the empirical constants provided in the literature, that they are often fitted parameters and as such mass and momentum conservation is not necessarily guaranteed.
As an example, suppose we wish to calculate the constant for the Prandtl mixing length model, we have already imported the solution to the ode for the velocity profile and it is a simple matter to numerically integrate (using the trapezoidal rule) the two integrals in question.
+We still need two parameters to complete the integration, the parameter a and ac or, equivalently, β and the Schmidt number Sc.
+using NumericalIntegration: integrate
+
+# solutions of the ode
+ϕ, F′ = sol.t, sol[2,:]
+
+# trim any unphysical values
+F′[F′.>0] .= 0
+
+# parameters of the model
+β = 0.0848
+a = β/1.2277667062444657
+Sc = 0.7
+f = -F′./ϕ
+ξ = a.*ϕ
+
+# momentum balance integrand
+int = (f.^2).*ξ
+int[ξ.≤0] .= 0
+
+# mass balance integrand
+int_c = (f.^(Sc+1)).*ξ
+int_c[ξ.≤0] .= 0
+
+I = integrate(ξ, int)
+I_c = integrate(ξ, int_c)
+
+k_c = √(I/(8*I_c^2))5.793131625321363The other two models could also be integrated numerically, for example the eddy diffusivity model
+using QuadGK: quadgk
+
+C₂ = 2*√(√(2)-1)/β
+f_ev(ξ) = ( 1 + (C₂*ξ/2)^2 )^-2
+
+I, err = quadgk((ξ) -> ξ*f_ev(ξ)^2, 0, Inf)
+I_c, err = quadgk((ξ) -> ξ*f_ev(ξ)^(Sc+1), 0, Inf)
+
+k_c = √(I/(8*I_c^2))5.258197856093409and the Gaussian model
+c = log(2)/β^2
+f_emp(ξ) = exp(-c*ξ^2)
+
+I, err = quadgk((ξ) -> ξ*f_emp(ξ)^2, 0, Inf)
+I_c, err = quadgk((ξ) -> ξ*f_emp(ξ)^(Sc+1), 0, Inf)
+
+k_c = √(I/(8*I_c^2))5.900934664729694In these cases I followed my convention from the previous notebook of setting each of the velocity distributions to have the same width at half height, and using the same Schmidt number for the concentration profiles. This makes it more of an “apples to apples” comparison.
+Looking at the results we see that the constant for the concentration is smaller than the velocity profiles, indicating that the centerline concentration drops off faster than the velocity. Which makes some sense as we saw above that the concentration also spreads out radially more than the velocity.
+We can combine the velocity and concentration profiles and get a sense of how the jet expands. Note that the plot is looking at the fully-developed jet, in this case ~4 diameters downstream.
+ +
+In most practical cases I’ve encountered, by far the easiest approach is to use a standard Gaussian model with parameters from literature. That said, there is a lot of variability of recommended parameters and some thought needs to go into what the model is being used for. Consider the following table giving model parameters for various gaseous jets entering into air.11
+\[ {c_A \over c_0} = k_2 {d_0 \over z} \sqrt{ \rho_a \over \rho_j} \exp \left( - \left(k_3 {r \over z} \right)^2 \right) \]
+| Jet | +Re | +\(k_2\) | +\(k_3\) | +
|---|---|---|---|
| CO₂ | +50 000 | +5.4 | +9.2 | +
| N₂ | +27 000 | +5.4 | +7.9 | +
| He | +3 400 | +4.1 | +5.3 | +
| air + 1.1% towngas | +67 000 | +5.3 | +8.8 | +
| hot air | +67 000 | +5.3 | +8.8 | +
| air + N₂O tracer | +27-57 000 | +4.5 | +7.1 | +
| hot air | +18-25 000 | +4.5 | +7.1 | +
| hot air | +30-60 000 | +5.3 | +7.8 | +
| hot air | +10-20 000 | +5.0 | +6.4 | +
| hot air | +— | +4.8 | +7.1 | +
| hot air | +— | +5.9 | +7.7 | +
Below is a plot showing the range of values this generates for the Gaussian jet model, along with the recommended parameters for use when estimating the extent of a hazardous area around a vent.12 The range of values is quite wide.
+12 Clearly the recommendation is a conservative approach, which is what you would want for a hazard analysis.
 +
+It is also worth noting that the concentration model breaks down when \(z<k_2\), it will register concentrations greater than is possible. The normal way of dealing with this is a so-called top-hat model: chop off any concentrations \(c_A > c_0\), though if the region of interest is primarily very close to the hole a different model should be used.
+The temperature profiles follow directly from the velocity profiles in an entirely analogous way to concentration. The temperature profile is given by:
+\[ {T - T_a \over T_0 - T_a} = k_T {d_0 \over z} \left( \bar{v}_z \over \bar{v}_{z,max} \right)^{Pr} \]
+Where Ta is the ambient temperature, T0 is the jet temperature, and Pr is a turbulent Prandtl number. The constant kT is then determined by an energy balance, again entirely analogously to the case for concentration.
+The volumetric flow-rate of the jet grows with the downstream distance, as the jet entrains the surrounding fluid. This can be calculated from an integral of the velocity distribution
+\[ Q = \int_0^{2\pi} \int_0^{\infty} \bar{v}_z r dr d\theta \]
+recalling the definition of \(\bar{v}_z\) in terms of the function F and making the change of variables to ξ
+\[ Q = \int_0^{2\pi} \int_0^{\infty} {-k \over z} {F^{\prime} \over \xi} (z \xi) z d\xi d\theta \]
+\[ = 2 \pi k z \int_0^{\infty} -F^{\prime} d\xi \]
+\[ = 2 \pi k z \left[ -F\left(\xi\right) \right]_{0}^{\infty} \]
+let’s define the limit
+\[ \lim_{\xi \to \infty} F\left(\xi\right) = F_{\infty}\]
+and recall that from boundary conditions F(0)=0, so
+\[ \left[ -F\left(\xi\right) \right]_{0}^{\infty} = -F_{\infty} \]
+recalling the definition of k
+\[ k = {v_0 d_0 \over \sqrt{8 I} }\]
+and putting it all together we get
+\[ Q = -{ 2 \pi \over \sqrt{8 I} } F_{\infty} v_0 d_0 z \]
+It is often more convenient to put things in in dimensionless terms, so let
+\[ Q_0 = {\pi \over 4} v_0 d_0^2 \]
+which gives us
+\[ {Q \over Q_0} = - \sqrt{8 \over I} F_{\infty} {z \over d_0} \]
+we can define a new constant kQ
+\[ k_Q = - \sqrt{8 \over I} F_{\infty} \]
+and finally
+\[ {Q \over Q_0} = k_Q {z \over d_0} \]
+Where \(k_Q\) is some constant defined by the particular model and the corresponding model parameter.
+For the Prandtl mixing length model we can compute this constant numerically
+a = β/1.2277667062444657
+
+I = integrate(ξ, int)
+F∞ = a^2*sol[1,end]
+
+k_Q = -√(8/I)*F∞0.3026722591952044For the eddy viscosity model this can be worked out analytically to be \[k_Q = {4\sqrt{3} \over C_2}\]
+C₂ = 2*√(√(2)-1)/β
+
+k_Q = 4*√3/C₂0.4564301431180997The Gaussian model can also be worked out analytically, giving \[k_Q = {4 \over \sqrt{2 c}}\]
+c = log(2)/β^2
+
+k_Q = 4/√(2*c)0.28808995465769605The literature14 gives \(k_Q = 0.32\) which compares well with the calculations above. Though it’s worth noting that the eddy viscosity model over predicts the volumetric flow rate quite noticeably, this is not surprising considering that it has fatter tails than either the Prandtl mixing length model or the Gaussian model. In the tails is where the eddy viscosity model no longer matches well with the observed data, so this is just a weakness of the model itself.
+This was just a brief tour of the different parameters that can be calculated from the velocity distribution or stream function, once it is known. In practice, very often the constants encountered along the way are treated like fitting parameters and so it is always worth keeping in mind what the model is being used for and what conditions must be strictly followed or not. For example, if one wants a very accurate fit to concentration, that may result in mass no longer being conserved because a model may not have enough degrees of freedom to fit the one and guarantee the other.
+If you are not fitting data, there is a wide range of parameters given in the literature and I think it is more important to find a set of parameters that work for the situation of interest – for whichever model they were fit, but generally it is Gaussian – than it is to fiddle around in the margins of whether or not one should use a Prandtl mixing length model versus an eddy viscosity model. Very often the answer is going to be Gaussian because that’s what the best model in the literature was fit to.
+In a previous post I worked through estimating the airborne quantity of butane due to a leak from a storage sphere. That example stopped at estimating the total quantity released, here I would like to go further into the potential for a vapour cloud explosion.
+As a recap the scenario is a leak from a butane storage sphere, the leak is 10ft above grade and results in cloud of mostly aerosolized butane that is initially below ambient temperature. The scenario parameters and results are summarized below.
+As a quick note, the whole purpose of this exercise is a sort of high-level hazard screening. Detailed enough to decide whether or not the consequences of a hazard warrant more detailed modeling.
+using Plots
+using Unitful
+using Interpolations
+using CSV
+using DataFrames
+
+gr()
+
+ft = ustrip(u"m", 1u"ft") # unit conversion ft->m
+inch = ustrip(u"m", 1u"inch") # unit conversion inch->m
+psi = ustrip(u"Pa", 1u"psi") # unit conversion psi->Pa# Scenario parameters
+hᵣ = 10ft # height of release point, m
+pₐ= 14.7psi # atmospheric pressure, Pa
+Tₐ= 25 + 273.15 # the ambient temperature, K
+td = 10*60 # release duration, 10 minutes, s
+
+# Constants
+R = 8.31446261815324 # universal gas constant, J/mol/K
+g = 9.806 # acceleration due to gravity, m/s2
+
+# Properties of Butane, from Perry's or DIPPR
+Mw = 58.122 # molar weight kg/kmol
+ρₗ(T) = Mw*( 1.0677/0.27188^(1+ (1-T/425.12)^0.28688) ) # density liquid, kg/m3
+ρg(T) = (pₐ*Mw)/(R*T)/1000 # density gas, ideal gas law, kg/m3
+ΔHc = 2657.320 # heat of combustion, kJ/mol
+LFL = 1.86e-2 # lower flammability limit, vol/vol
+
+# Properties of Air
+MWₐᵢᵣ = 28.960 # molar weight air, kg/kmol
+ρa(T) = (pₐ*MWₐᵢᵣ)/(R*T)/1000 # density of air, ideal gas law, kg/m^3
+
+# Calculated previously
+Tc = -0.6 + 273.15 # cloud temperature, K
+fᵥ = 0.17128269541302374 # flashed fraction
+fₐ = 0.9227949810754577 # aerosol fraction
+
+Qaq = 52.82002170865257 # airborne quantity, kg/sThis example focuses on a next step in a standard hazard screening, namely estimating the scale of a potential vapour cloud explosion. Typically, for flammable gases, the potential for a vapour cloud explosion is the worst case outcome of a release.
+The first step in determining the consequences of a vapour cloud explosion is to estimate the size of the vapour cloud that could take part in the explosion. This is generally done through some sort of dispersion modeling. There are many ways of defining the portion of the vapour cloud that can explode, in this case I am going to assume the flammable portion of the cloud is that with a concentration \(\ge \frac{1}{2} LFL\) .
+There is a fair bit of discussion in the literature as to whether to use the LFL or 1/2 LFL, using half the LFL is, at the very least, more conservative and given the simplified methods I am using to estimate the size of the cloud it is probably best to err on the side of an overly large cloud.
+Prior to determining the particular dispersion model some meteorological parameters must be decided upon. Atmospheric stability and the wind profile define the extent of vertical mixing, which governs how large the cloud can grow and how dispersed the butane, in this case, will get during the release. They are also important in the decision criteria for which type of dispersion model to use.
+In general, the worst case atmospheric stability is the most stable, Pasquill stability class F, for neutral to negatively buoyant clouds at ground level. This limits the degree of mixing and leads to a larger explosive mass, since we define the explosive mass as the portion of the cloud greater than half the lower flammability limit. If the cloud mixes thoroughly with the air it will be dispersed to levels well below the LFL and thus cannot explode
+For this scenario I am supposing class F stability and a moderate windspeed of 3m/s at the release point.
+There are two other important wind-speeds that will be needed, the friction velocity, \(u_{\star}\), and the wind-speed at the standard elevation of 10m, \(u_{10}\) which can be obtained from the wind profile. The wind profile can be estimated using a power law distribution parameterized based on the Pasquill stability class.
+\[ {u \over u_r} = \left( h \over h_r \right)^p \]
+Where the parameter p is tabulated1 here
+| Stability | +urban | +rural | +
|---|---|---|
| A | +0.15 | +0.07 | +
| B | +0.15 | +0.07 | +
| C | +0.20 | +0.10 | +
| D | +0.25 | +0.15 | +
| E | +0.40 | +0.35 | +
| F | +0.60 | +0.55 | +
There are several ways to estimate the friction velocity, but a simple rule of thumb used in the EPA TSCREEN model is to assume
+\[ u_{\star} = 0.06 u_{10} \]
+This is a very simplified approach and there are many alternatives to calculating the friction velocity, and parameterizing the atmospheric stability. For the purposes of this simple example this is fine but it is an opportunity for future refinement of the hazard screening.
+# wind profile
+uᵣ = 3.0 # the wind-speed at release height, m/s
+p = 0.55 # parameter, pasquill stability class F
+
+u(h) = uᵣ*(h/hᵣ)^p
+
+u₁₀ = u(10)
+
+u₊ = 0.06 * u₁₀0.3459905806850393The first important decision is whether to model the release as a continuous plume or an instantaneous puff. In reality the answer is neither but these limiting cases are easier to model and are used as first approximations.
+A simple rule of thumb is that if the distance traveled by a parcel of air over the release duration is greater than 2.5 times the distance to the point of interest, then the release can be modeled as continuous, otherwise it would be treated as instantaneous.
+\[ 2.5 \le { u_r t_d \over x^{\star} } \]
+Roughly speaking if the plume is still attached to the release point when the leading edge hits the downwind point of interest then it looks like a continuous plume to an observer at this point.
+This can be used to define a critical distance, such that any distance less than that is best modeled by a continuous release and any distance greater is best modeled by an instantaneous release. This is useful as the downwind distance is, as of yet, unknown. The distance to half the LFL concentration, which defines the extent of the cloud involved in the explosion, depends upon which model is used and is in fact one of the key parameters we need to solve for.
+x⁺ = uᵣ*td/2.5720.0From prior experience, the distance to 1/2 LFL will likely be <~200m and so a continuous release can be assumed. If after performing the calculation the downwind distance turns out to be greater than 720m then this can be re-assessed.
+The second critical factor for determining which model to use is whether or not the cloud is significantly denser than air. Dense clouds slump and hug the ground to a far greater extent than neutrally buoyant clouds and models for neutral clouds can lead to significant overestimations of the size of the vapour cloud when used on a dense cloud.
+The relevant parameter for determining if a dense gas dispersion model should be used is the Richardson number, the ratio of the potential energy from the excess density to the kinetic energy from ambient turbulence. The Richardson number for continuous releases is defined as2
+\[ \mathrm{Ri} = { { g_o V_r } \over { D_c u_{\star} } } \]
+where
+\[ g_o = g { {\rho_c - \rho_a } \over \rho_a } \]
+with \(\rho_c\) the density of the cloud and \(\rho_a\) the density of the ambient air. \(V_r\) is the volumetric release rate, and \(D_c\) a critical distance, in this case we take \(D_c\) to be the release height.
+The density of the cloud is significantly larger than the vapour density of butane as the cloud has a large fraction of aerosolized droplets, overall the cloud density can be estimated by
+\[ \frac{1}{\rho_c} = { f_v \over \rho_g } + { \left(1 - f_v \right) f_a \over \rho_l }\]
+The critical Richardson number is about 50 such that if the Richardson number is greater than 50 then a dense gas model must be used.
+ρc(T) = ((fᵥ/ρg(T)) + ((1-fᵥ)*fₐ/ρₗ(T)))^-1
+
+gₒ = g * ((ρc(Tc) - ρa(Tₐ))/ ρa(Tₐ))
+
+Vr = Qaq/ρc(Tc)
+
+Ri = (gₒ * Vr)/(hᵣ * u₊)381.8214520915426Ri > 50trueThis suggests that a dense gas model should be used, which conforms to our expectations as the vapour cloud is significantly denser than the ambient air.
+An additional check is to use the criteria from Britter and McQuaid3
+\[ \left( g_o V_r \over { u_{10}^3 D} \right)^{1/3} \ge 0.15 \]
+Where \(D\) is a critical distance defined as
+\[ D = \sqrt{ V_r \over u_{10} } \]
+D = √(Vr/u₁₀)
+
+( (gₒ * Vr) / (u₁₀^3 * D) )^(1/3) ≥ 0.15trueThe Britter-McQuaid model4 is a dense cloud dispersion model based on dimensional analysis and fitting to experimental data. It is given as a series of correlation curves for six different concentrations and the distance to the concentration of interest is interpolated from these. The concentrations represent a mean concentration over the whole cloud at that distance.
+This is one of the simpler models to use directly, and is appropriate for a screening case. Dense gas dispersion modeling is a large field with many different models that could be used and, like many things, as the models grow in detail they also grow in the number of parameters that must be provided. For the purposes of screening the limiting factor is often not computing power or model complexity per se as much as the information required to even run the models and the time needed to gather that information.
+Note the concentrations in this model are given in volume fraction and it is assumed that the in-cloud concentration of butane is 1.0 (i.e 100%) at the release point.
+The Britter-McQuaid curves can be approximated with a series of piece-wise linear functions5
+\[ \beta = m \alpha + b \]
+function piecewise(α; αs, ms, bs)
+ i = findnext(x -> x > α, αs, 1)
+ return ms[i]*α + bs[i]
+end
+
+function piecewise(; αs, ms, bs)
+ return α -> piecewise(α, αs=αs, ms=ms, bs=bs)
+end
+
+
+Britter_McQuaid_correlations = Dict{Float64, Function}(
+ 0.001 => piecewise(αs=[-0.69, -0.25, -0.13, 1.0],
+ ms=[0.00, 0.39, 0.00, -0.50],
+ bs=[2.60, 2.87, 2.77, 2.71]),
+ 0.005 => piecewise(αs=[-0.67, -0.28, -0.15, 1.0],
+ ms=[0.00, 0.59, 0.00, -0.49],
+ bs=[2.40, 2.80, 2.63, 2.56]),
+ 0.010 => piecewise(αs=[-0.70, -0.29, -0.20, 1.0],
+ ms=[0.00, 0.49, 0.00, -0.52],
+ bs=[2.25, 2.59, 2.45, 2.35]),
+ 0.020 => piecewise(αs=[-0.69, -0.31, -0.16, 1.0],
+ ms=[0.00, 0.45, 0.00, -0.54],
+ bs=[2.08, 2.39, 2.25, 2.16]),
+ 0.050 => piecewise(αs=[-0.68, -0.29, -0.18, 1.0],
+ ms=[0.00, 0.36, 0.00, -0.56],
+ bs=[1.92, 2.16, 2.06, 1.96]),
+ 0.100 => piecewise(αs=[-0.55, -0.14, 1.0],
+ ms=[0.00, 0.24, -0.50],
+ bs=[1.75, 1.88, 1.78]),
+)Dict{Float64,Function} with 6 entries:
+ 0.01 => #7
+ 0.005 => #7
+ 0.02 => #7
+ 0.001 => #7
+ 0.1 => #7
+ 0.05 => #7 +
+The correlations are given in terms of the parameters α and β, which are
+\[ \alpha = 0.2 \cdot \log \left( g_o^2 V_r u_{10}^{-5} \right) \]
+and
+\[ \beta = \log \left( x \over D \right) \]
+At first glance it is not obvious how to use these plots, or the associated piecewise functions, since, at least to me, the obvious form of a model is to compute the concentration at a given point whereas the Britter-McQuaid model does the opposite. One supplies a concentration of interest and solves for the downwind distance where the leading edge of the plume hits this concentration.
+The general procedure is:
+The function below is a convenience function that calculates the β for each concentration curve at a fixed α and returns a function that linearly interpolates to find the downwind distance for a given concentration.
+"""
+ britter_mcquaid_model(α, D; table=Britter_McQuaid_correlations)
+
+Generate the interpolation function x(c), using the Britter-McQuaid correlations.
+The system is parameterized by α and D, which are defined in the Britter-McQuaid
+model documentation.
+
+"""
+function britter_mcquaid_model(α, D; table=Britter_McQuaid_correlations)
+ interp_data = [ [conc, bfun(α)] for (conc, bfun) in table ]
+ interp_data = hcat(interp_data...)'
+ interp_data = sortslices(interp_data, dims=1)
+ linterp = LinearInterpolation(interp_data[:,1], interp_data[:,2], extrapolation_bc=Line())
+
+ return c -> 10^(linterp(c))*D
+endbritter_mcquaid_modelα = 0.2*log10( gₒ^2 * Vr * u₁₀^-5 )0.17108241842192004x = britter_mcquaid_model(α, D)#11 (generic function with 1 method)The Britter-McQuaid model assumes an isothermal case and the following correction is suggested for non-isothermal cases
+\[ C^\prime = { C \over { C + (1-C) \frac{T_a}{T_c} } }\]
+In this case the concentration of interest is half the lower flammability limit and the cloud is assumed to be well below ambient conditions.
+c = 0.5*LFL
+
+Cᵢ = c / (c + (1 - c)*(Tₐ/Tc) )0.008508269826866945The down-wind distance to half the LFL can then be estimated, and checked to ensure it is within the region for which a continuous release is a reasonable approximation.
+xᵢ = x(Cᵢ)165.85001073807788xᵢ ≤ x⁺trueThe Britter-McQuaid model also has a correlation for short distances, \(x \lt 30D\)
+\[ C = { { 306 \left( \frac{x}{D} \right)^{-2} } \over { 1 + 306 \left( \frac{x}{D} \right)^{-2} } } \]
+ +
+The Britter-McQuaid model does provide some further correlations to calculate the dimensions of the plume, though with many caveats as the model can over-estimate the width of the plume. Also I’ve noticed several sources give an obviously incorrect equation for plume height – it returns heights on the order of a few centimeters for plumes extending hundreds of meters in horizontal directions.
+ +
+Instead of that I am going to use a simple rule-of-thumb for small plumes
+\[ V_{PES} = 0.03 x_{\frac{1}{2}LFL}^3 \]
+where \(V_{PES}\) is the volume of the potential explosion site. In general this more than just the volume of a plume dispersing in open space, since buildings and equipment can confine the cloud and create multiple potential explosion sites of various sizes. This is a simple rule-of-thumb for screening purposes only
+Vₚₑₛ = 0.03 * xᵢ^3136857.23663150807There are several parameters that can be estimated to characterize explosions with the positive overpressure perhaps being the most useful for simple screening cases. Tables exist relating different levels of positive overpressure to possible damage of nearby structures.
+| psi | +kPa | +Damage | +
|---|---|---|
| 0.02 | +0.14 | +Annoying noise | +
| 0.04 | +0.28 | +Loud noise, sonic boom, glass failure | +
| 0.15 | +1.03 | +Typical pressure for glass breakage | +
| 0.4 | +2.76 | +Limited minor structural damage | +
| 1 | +6.9 | +Partial demolition of houses, made uninhabitable | +
| 2 - 3 | +13.8 - 20.7 | +Concrete or cinder block walls, not reinforced, shattered | +
| 3 | +20.7 | +Steel framed buildings distorted and pulled away from foundations | +
| 4 | +27.6 | +Cladding of light industrial buildings ruptured | +
| 5 | +34.5 | +Wooden utility poles snapped | +
| 7 | +48.2 | +Loaded train wagon overturned | +
| 10 | +68.9 | +Probable total destruction of buildings | +
It’s worth taking a moment to talk briefly about deflagrations and detonations. Deflagrations are characterized by subsonic flame propagation where the reaction zone moves through the flammable vapour by diffusion of heat and mass. Deflagrations typically result in relatively modest overpressures. A detonation, on the other hand, is characterized by a supersonic flame propagation and the reaction zone propagates by a pressure wave compressing the flammable vapour adiabatically to a temperature above the autoignition temperature. Detonations typically have significantly higher overpressures than deflagrations. Typically vapour cloud explosions in an open space with little congestion are deflagrations, however confinement and obstacles in the flame path can can accelerate a subsonic deflagration into a supersonic detonation. This is one reason why confinement and obstacles around a potential explosion site are important in the calculations.
+The simplest way of calculating the overpressure is the TNT model, where the volume previously defined is used to estimate a potential explosion energy in TNT equivalents and this is compared to blast curves for TNT. For most major vapour cloud explosion incidents the TNT equivalences have been estimated to be from 1-10% of the full energy content of the cloud.
+This is conceptually simple but can lead to very conservative estimates as vapour clouds, basically, don’t explode like TNT. These methods typically overestimate pressure close to the explosion source and underestimate it far afield. Even though the TNT method is generally not recommended, at least not in any of the references I have, it is still used in some places and it does crop up.
+A better approach is to use blast curves specifically for VCEs, in this case I am using the Baker-Strehlow-Tang curves but there are others.
+There are several ways of estimating explosive energy and all depend, in some way, on the size of the vapour cloud. Supposing the vapour cloud explosion is a deflagration and the energy in the explosion, fundamentally, comes from the combustion of the butane in the cloud then the energy can be found by estimating how much butane will combust and multiplying that by the heat of combustion of butane.
+In some references the entire volume of the cloud will be assumed butane, but that can be excessively conservative – we are assuming the edge of the cloud to be 1/2 LFL or ~0.93% (v/v) butane so assuming it to be 100% butane in that region is a serious over-estimate.
+An alternative method6 is to assume the cloud overall is at stoichiometric conditions. That is find the value of the stoichiometric concentration \(\eta\)
+\[ \eta = { \textrm{moles fuel} \over \textrm{moles fuel + air} } = { n_f \over { n_f + \frac{n_o}{f_o} } } \]
+where \(n_f\) is the moles of fuel, \(n_o\) the moles of oxygen, and \(f_o\) the mole fraction of oxygen in air, 20.946%. For the combustion of n-butane
+\[ C_{4} H_{10} + \frac{13}{2} O_{2} \longrightarrow 4 C O_{2} + 5 H_{2} O\]
+and so for \(n_f = 1\) we have \(n_o = 6.5\)
+η = 1 / (1 + 6.5/0.20946)0.031218607756809045Using the ideal gas law the total moles of gas in the cloud can be estimated
+\[ n_c = { { p_a V_{PES} } \over { R T_c } }\]
+and the explosive energy is then
+\[ E_{PES} = \eta n_c \Delta H_c \]
+nc = ( pₐ * Vₚₑₛ )/(R * Tc)
+
+Eₚₑₛ = η * nc * ΔHc5.0778644110258764e8The Baker-Strehlow-Tang model provides a series of correlation curves for different flame speeds and relates the positive overpressure to an energy scaled distance. The curves are based on spherical explosions and so it is important to include ground reflection when calculating the scaled distance.
+The positive overpressure used in the BST model is a dimensionless pressure
+\[ P = { { p - p_a } \over p_a } \]
+where \(p\) is the positive overpressure and \(p_a\) the atmospheric pressure. This is correlated to the scaled distance
+\[ R = r \cdot \left( p_a \over E \right)^{1/3} \]
+where \(E\) is the explosive energy and \(r\) the distance from the explosion epicentre. Which in this case we can take as the centre of the cloud and estimate to be half-way to \(x_i\)
+A spreadsheet with the BST curves is provided along with the AIChE/CCPS Guidelines for Chemical Process Quantitative Risk Analysis7 from which I’ve extracted just the positive overpressure curves as a csv.
+bst_curves = CSV.read("data/BST-curves.csv", DataFrame)
+
+# just show the first 5 rows
+first(bst_curves, 5)5 rows × 3 columns
| Mf | Scaled Distance | Overpressure | |
|---|---|---|---|
| Float64 | Float64 | Float64 | |
| 1 | 0.037 | 0.010179 | 0.0100961 |
| 2 | 0.037 | 0.0104867 | 0.0100271 |
| 3 | 0.037 | 0.0108027 | 0.0100993 |
| 4 | 0.037 | 0.0111287 | 0.0101009 |
| 5 | 0.037 | 0.0114646 | 0.0101025 |
 +
+The following table8 cross-references flame speed – the key parameter of the BST curves – with qualitative descriptors of fuel reactivity, density of surrounding process equipment, and degree of confinement
+
The dimensionality given is referencing the number of dimensions along which the pressure wave can travel. For example an explosion confined to a tunnel is considered one dimensional since the pressure wave can only travel along the tunnel, whereas an explosion in an open field is three dimensional since it can expand in all directions. The entries labeled DDT are where a deflagration to detonation transition may occur, due to the flame speed and potential congestion. In these cases it is recommended to use the \(Mf = 5.2\) curve, sometimes referred to as the detonation blast curve.
+| Dimension | +Description | +
|---|---|
| 3-D | +Unconfined volume, almost completely free expansion | +
| 2.5-D | +Blockage partially prevents flame in one direction, such as piperacks with tightly packed pipes, lightweight roofs, or frangible panels | +
| 2-D | +Platforms carrying process equipment, space beneath cars, open sided multistory buildings | +
| 1-D | +Tunnels, corridors, or sewage systems | +
For the storage sphere I am assuming it is standing freely on its own without any platforms or structures confining it, so the dimension is 3-D
+The density of surrounding equipment is defined qualitatively in terms of how much the surrounding area obstructs the expansion of the pressure wave. This can be defined in terms of the percentage of area in a plane occupied by obstacles.
+| Type | +Blockage Ratio | +Pitch for Obstacle Layers | +
|---|---|---|
| Low | +< 10% | +One or two layers of obstacles | +
| Medium | +10 - 40% | +Two to three layers of obstacles | +
| High | +> 40% | +Three of more fairly closely spaced obstacle layers | +
For the storage sphere suppose that there is some process equipment nearby but it is not highly confined, defaulting to medium.
+The fuel reactivity categories are defined in terms of the laminar burning velocity
+| Reactivity | +Laminar Burning Velocity | +
|---|---|
| Low | +< 45 cm/s | +
| Medium | +45 - 75 cm/s | +
| High | +> 75 cm/s | +
The best resource for finding these tabulated is Appendix D of NFPA 68.9 For butane the laminar burning velocity is 45cm/s10 and thus is medium reactivity
+Returning to the table we find that the flame speed for a medium reactivity fuel, medium obstacle density, 3D case is 0.44 (in terms of Mach number)
+Mf = 0.440.44Note the flame speeds given in the table do not correspond to the flame speeds given in the BST curves. In general one will have to double-interpolate to get the results. Find the curves that bracket the desired flame speed, interpolate to find the corresponding pair of overpressures at the given scaled distance then interpolate to find the overpressure at the desired flame speed.
+The following code sets this up in an easy way, though probably a very sub-optimal one, by doing the following:
+bst_interpsbst_interps and calculating the overpressures at each tabulated flame speed for a given distance, then interpolates for the desired flame speedbst_interps = []
+flame_speeds = unique(bst_curves[!, "Mf"])
+
+for speed in flame_speeds
+ data = bst_curves[ bst_curves."Mf" .== speed, :]
+ interp = LinearInterpolation(data[!, "Scaled Distance"],
+ data[!, "Overpressure"],
+ extrapolation_bc=Line())
+ push!(bst_interps, (speed, interp))
+end"""
+ Δp₊(r ; Mf=Mf, E=2*Eₚₑₛ, p₀=pₐ, curves=bst_interps)
+
+Calculate the positive overpressure at distance r from the explosion epicentre.
+The model parameters are the apparent flame speed, Mf, in terms of Mach number,
+the explosion energy, E, and the atmospheric pressure p₀. The units of E and p₀
+must agree, e.g. kJ and kPa.
+
+The Baker-Strehlow-Tang curves are supplied through the curves keyword.
+"""
+function Δp₊(r ; Mf=Mf, E=2*Eₚₑₛ, p₀=pₐ, curves=bst_interps)
+ E = 1000*E # Energy must be in J
+ R = r*(p₀/E)^(1/3)
+
+ Mfs = []
+ Ps = []
+
+ for (speed, interp) in bst_interps
+ push!(Mfs, speed)
+ push!(Ps, interp(R))
+ end
+
+ P = LinearInterpolation(Mfs, Ps)
+
+ return P(Mf)*p₀
+
+endΔp₊This generates a new blast curve interpolated between the curves supplied with the BST model, as shown in the plot below. Though care should be taken when the curve is used outside the range of the original curves.
+Note that the explosion energy is being multiplied by 2. This is to account for ground reflection as the BST curves are based on spherical explosions. In general the explosion energy is multiplied by a factor, which ranges from 1 to 2, to account for ground reflection where a factor of 2 is for explosions exactly at ground level and a factor of 1 is for explosions at significant elevation. The simpler and more conservative approach is to use a factor of 2.
+ +
+The explosion epicentre is assumed to be the centre of the vapour cloud, here approximated to be half way between the release point and the downwind distance to 1/2 LFL, and in this simple model the explosion is a hemispherical pressure wave expanding in all directions unobstructed. More advanced modeling will take into account buildings and equipment and their impact on shaping the pressure wave.
+The plot below shows the maximum positive overpressure experienced at that distance. Which is what is typically tabulated for different types of consequences. In general when I refer to overpressure this is what I am referring to.
+ +
+A useful question to ask at this point is how sensitive is the predicted overpressure to the parameters of the model.
+The figure below shows the impact of varying reactivity, while holding all other parameters constant. Clearly whether or not the explosion is treated as a detonation or deflagration matters hugely, the high reactivity curve corresponds to a detonation. The difference between a medium and low reactivity material is a approximately a factor of 4 in terms of max overpressure. So finding an appropriate value of reactivity while not being overly conservative is important.
+ +
+The following figure shows the impact of varying the levels of congestion. There is a fair amount of sensitivity going from low to medium but less from medium to high, which is perhaps what you would expect. I think the somewhat strange shape of the peaks is an artifact of linear interpolation.
+ +
+As is clear from the figure below the results are much less sensitive to changes in the level of confinement. At least while neglecting the one dimensional case, which should always be treated as a special case regardless.
+ +
+The last parameter worth investigating is the explosive energy, a significant portion of this exercise was in estimating the size of the vapour cloud and the consequent explosive energy. As is clear from the following figure the model is much less sensitive to changes in the explosive energy than the other parameters.
+ +
+I was thinking, recently, about how venting from vessel blowdown is modelled for screening purposes and how, more often than not, it does not take into account the blowdown curve. This is something that could easily be incorporated for simple Gaussian dispersion, which is what I examine here.
+The standard approach for assessing the consequences of a release from a pressure vessel is to:1
+The mass release rate from a vessel blowdown is taken as the max release rate (at the start of the blowdown) and generally assumed to be constant.2 While the standard references do acknowledge that the flow will decrease over time, this is typically not taken into account in the dispersion models. The one exception that I’m aware of is when modelling flaring due to vessel and pipeline blowdowns: sometimes an average flowrate is taken instead of the max, in which case the blowdown curve is used to derive that average. It is still a constant, though, for the purposes of dispersion modelling.
+However, if we think back to the development of the Palazzi model3 for short duration releases, a rather obvious path presents itself for the special case of a release of an ideal gas from an isothermal blowdown: integrate the Gaussian puff model over time with an exponentially decaying mass release rate.
+Recalling the isothermal blowdown of an ideal gas, the mass release rate, \(w\), is given by
+\[ +w\left(t\right) = w_0 \exp \left( - \frac{t}{\tau} \right) +\]
+Where4
+4 This follows from the definition of \(\tau\): \[ \tau = {m_0 \over w_0} \] \[ w_0 = {m_0 \over \tau} \] \[ w_0 = { {\rho_0 V} \over \tau }\]
\[ +w_0 = { {\rho_0 V} \over \tau } +\]
+For a blowdown through an isentropic nozzle the time constant \(\tau\) is given by
+\[ +\frac{1}{\tau} = \frac{c_D A}{V} \sqrt{ {k P_0} \over \rho_0 } \left( 2 \over {k+1} \right)^{\frac{k+1}{2 \left( k - 1 \right)} } +\]
+With:
+For a release centred at the origin with an elevation h, the concentration profile for a single Gaussian puff is given by:5
+\[ +c \left(x,y,z,t \right) = w \Delta t \cdot g_x(x, t) \cdot g_y(y) \cdot g_z(z) +\]
+Where the gs are Gaussian functions in the x, y, and z directions
+\[ +g_x(x,t) = {1 \over \sqrt{2\pi} \sigma_x } \exp \left( -\frac{1}{2} \left( x-u t \over \sigma_x \right)^2 \right) +\]
+gx(x,t,u,σx) = exp(-0.5*((x-u*t)/σx)^2)/(√(2π)*σx)\[ +g_y(y) = {1 \over \sqrt{2\pi} \sigma_y } \exp \left( -\frac{1}{2} \left( y \over \sigma_y \right)^2 \right) +\]
+gy(y,σy) = exp(-0.5*(y/σy)^2)/(√(2π)*σy)\[ +g_z(z) = {1 \over \sqrt{2\pi} \sigma_z } \left[ \exp \left( -\frac{1}{2} \left( z-h \over \sigma_z \right)^2 \right) + \exp \left( -\frac{1}{2} \left( z+h \over \sigma_z \right)^2 \right) \right] +\]
+gz(z,h,σz) = ( exp(-0.5*((z-h)/σz)^2)
+ + exp(-0.5*((z+h)/σz)^2))/(√(2π)*σz)With:
+For puff releases, the dispersion parameters are typically given in reference to the centre of the cloud,6 here I have taken some puff dispersion parameters for a class D atmospheric stability.
+# Puff dispersion parameters for Class D atmospheres
+σx(xc) = 0.06*xc^0.92
+σy(xc) = 0.06*xc^0.92
+σz(xc) = 0.15*xc^0.70I like to use Unitful to manage units. This can be a little tricky with correlations, so to make that easier I use a simple macro to add a method to each correlation function mapping the correct input units and output units.
+import Pkg
+Pkg.add(url="https://github.com/aefarrell/UnitfulCorrelations.jl")using Unitful
+using UnitfulCorrelations@ucorrel σx u"m" u"m"
+@ucorrel σy u"m" u"m"
+@ucorrel σz u"m" u"m"A good habit to get into, when developing code in julia, is to collect model parameters into structs. This is what I do here, collecting the parameters for a single Puff into a Puff struct.
struct Puff
+ m # mass
+ h # release height
+ u # velocity
+ t # release time
+endNow I create the concentration function which takes a single puff, and a location in space and time, and returns the concentration. I also check for the special case where the puff hasn’t actually been released yet, and so does not contribute to the concentration.
+Since I want this to be unit aware, both return values have to have the same units. I don’t want to hard-code this as I may also want to use this function with simple numeric types, like Float64. By using the unit function I can ensure the zero result has the same dimensions as the correct result, falling back to no units in the case where all inputs are simple numbers.
function c(p::Puff,x,y,z,t)
+ λ = t - p.t # time since release
+ xc = p.u*λ # location of cloud center
+ if λ > 0t
+ return p.m*gx(x,λ,p.u,σx(xc))*gy(y,σy(xc))*gz(z,p.h,σz(xc))
+ else # the puff hasn't been released yet
+ return 0*unit(p.m)/unit(xc)^3
+ end
+endThe single puff model assumes all of the mass is released in a single instant. This significantly over-estimates the concentration for longer duration releases, and so an alternative approach is to break up the release into several puffs and sum the result.
+\[ +c(x,y,z,t) = \sum_{i=0}^{n} w\left( t_i \right) \delta t \cdot g_x(x, t - t_i ) \cdot g_y(y) \cdot g_z(z) +\]
+Where \(\delta t\) is the duration of each puff and \(t_i\) is the time when puff i was released.
+c(ps::Vector{Puff},x,y,z,t) = sum( c.(ps, x, y, z, t) );Taking the limit \(\delta t \to 0\) takes this from a discrete sum to the corresponding integral
+\[ +c(x,y,z,t) = \int_{0}^{t} w\left( t^{\prime} \right) \cdot g_x(x, t - t^{\prime}) \cdot g_y(y) \cdot g_z(z) dt^{\prime} +\]
+For the Palazzi7 model \(w(t) = w_0 \left( H\left(t - \Delta t \right) - H\left( t \right) \right)\)8 and, assuming the \(\sigma\)s are independent of time, this can be integrated to give:
+8 \(H \left(t \right)\) being the Heaviside function
\[ +c(x,y,z,t) = \frac{w_0}{2u} \left( \mathrm{erf}\left({ {x - u (t-\Delta t)} \over \sqrt{2} \sigma_x }\right) - \mathrm{erf}\left( { {x - u t} \over \sqrt{2} \sigma_x } \right) \right) \cdot g_y(y) \cdot g_z(z) +\]
+using SpecialFunctions: erf, erfcstruct Palazzi
+ w # mass release rate
+ h # release height
+ u # velocity
+ t_f # end of release
+endfunction c(p::Palazzi,x,y,z,t)
+ Δt = min(t, p.t_f)
+ w, u = p.w, p.u
+ xa = u*(t-Δt)
+ xb = u*t
+ # n.b. erf(b,a) = erf(a) - erf(b)
+ return (w/(2u))*erf((x-xb)/(√2*σx(xb)), (x-xa)/(√2*σx(xa))) *
+ gy(y,σy(x))*gz(z,h,σz(x))
+endIt should be pretty obvious where I am going next: instead of assuming \(w(t)\) is a constant, let it be the exponential decay from an isothermal vessel blowdown. The integration is a little more tedious but it is not really any more difficult than the Palazzi case.
+\[ +c(x,y,z,t) = \int_{0}^{t} w\left( t^{\prime} \right) \cdot g_x(x, t - t^{\prime}) \cdot g_y(y) \cdot g_z(z) dt^{\prime} +\]
+\[ +c(x,y,z,t) = \int_{0}^{t} \left[ w_0 \exp\left( -{t^{\prime} \over \tau} \right) \right] \cdot \left[ {1 \over \sqrt{2\pi} \sigma_x } \exp \left( -\frac{1}{2} \left( x-u (t - t^{\prime}) \over \sigma_x \right)^2 \right) \right] \cdot g_y(y) \cdot g_z(z) dt^{\prime} +\]
+Splitting this into elements that depend on time and those that don’t \[ +c(x,y,z,t) = w_0 \left[ \int_{0}^{t} {1 \over \sqrt{2\pi} \sigma_x } \exp\left( -{t^{\prime} \over \tau} -\frac{1}{2} \left( x-u (t - t^{\prime}) \over \sigma_x \right)^2 \right) dt^{\prime} \right] \cdot g_y(y) \cdot g_z(z) +\]
+Letting everything within the integral equal \(I(x,t)\)
+\[ +c(x,y,z,t) = w_0 \cdot I(x,t) \cdot g_y(y) \cdot g_z(z) +\]
+It makes the integration a little easier to introduce \(\lambda = t-t^{\prime}\)
+\[ +I(x,t) = \int_{0}^{t} {1 \over \sqrt{2\pi} \sigma_x } \exp\left( -{{t - \lambda} \over \tau} -\frac{1}{2} \left( x-u \lambda \over \sigma_x \right)^2 \right) d\lambda +\]
+By expanding everything within the \(\exp(\dots)\), collecting terms and completing the square we arrive at:
+\[ +I(x,t) = {1 \over \sqrt{2\pi} \sigma_x } \exp \left( {\sigma_x^2 + 2 u \tau (x - u t)} \over {2 u^2 \tau^2} \right) \int_{0}^{t} \exp\left( -\left( {\sigma_x^2 + u \tau ( x - u \lambda ) } \over {\sqrt{2} \sigma_x u \tau} \right)^2 \right) d\lambda +\]
+\[ +I(x,t) = \frac{1}{2u} \exp \left( {\sigma_x^2 + 2 u \tau (x - u t)} \over {2 u^2 \tau^2} \right) \left[ \mathrm{erf}\left( {\sigma_x^2 + u \tau x} \over {\sqrt{2} \sigma_x u \tau} \right) - \mathrm{erf}\left( {\sigma_x^2 + u \tau (x - u t)} \over {\sqrt{2} \sigma_x u \tau} \right)\right] +\]
+If we evaluate the \(\sigma_x\)s at the end points then, given that \(\sigma_x \to 0\) as \(x_c \to 0\), this simplifies to:
+\[ +I(x,t) = \frac{1}{2u} \exp \left( {\sigma_x^2 + 2 u \tau (x - u t)} \over {2 u^2 \tau^2} \right) \mathrm{erfc}\left( {\sigma_x^2 + u \tau (x - u t)} \over {\sqrt{2} \sigma_x u \tau} \right) +\]
+Giving a final concentration of:
+\[ +c(x,y,z,t) = \frac{w_0}{2u} \exp \left( {\sigma_x^2 + 2 u \tau (x - u t)} \over {2 u^2 \tau^2} \right) \mathrm{erfc}\left( {\sigma_x^2 + u \tau (x - u t)} \over {\sqrt{2} \sigma_x u \tau} \right) \cdot g_y(y) \cdot g_z(z) +\]
+struct IsothermalBlowdown
+ w_0 # mass release rate
+ τ # time constant
+ h # release height
+ u # velocity
+ t_f # end of release
+endfunction c(p::IsothermalBlowdown,x,y,z,t)
+ w₀, u, τ = p.w_0, p.u, p.τ
+ xb = u*t
+ xa = t < p.t_f ? 0*xb : u*(t-p.t_f)
+ return (w₀/(2u))*
+ exp( (σx(xb)^2 + 2u*τ*(x - xb))/(2*(u*τ)^2) ) *
+ erf( (σx(xb)^2 + u*τ*(x - xb))/(√(2)*σx(xb)*u*τ),
+ (σx(xa)^2 + u*τ*(x - xa))/(√(2)*σx(xa)*u*τ) )*
+ gy(y,σy(x))*gz(z,h,σz(x))
+endNote that I have implemented a slightly different version of the model. In the case where \(t < t_f\), with \(t_f\) being the time at which the blowdown ceases, this simplifies to the model given above, where I implicitly assumed \(t_f \to \infty\).
+In the case where \(t_f\) is some finite number and \(t \ge t_f\), an extra term is added to, essentially, “turn off” the blowdown.
+Just to have something to look at, suppose an isothermal blowdown from a vessel which starts at an initial release rate of 1kg/s and the vessel contains 1000kg of an ideal gas. The vent stack is 2m above the ground and ambient windspeed is 2m/s.
+# The example case
+u = 2.0u"m/s"
+h = 2.0u"m"
+w₀ = 1.0u"kg/s"
+m₀ = 1000.0u"kg"
+τ = m₀/w₀The mass release rate, per above, is simply the exponential decay.
+w(t) = w₀*exp(-t/τ)The total mass released by time t is simply the time-integral:
+\[ +m(t) = \int_0^t w_0 \exp \left( -\frac{t^{\prime}}{\tau} \right) d t^{\prime} +\]
+\[ +m(t) = w_0 \tau \left( 1 - \exp \left( -\frac{t^{\prime}}{\tau} \right) \right) +\]
+m(t) = w₀*τ*(1 - exp(-t/τ))Suppose that after \(\tau\) time has elapsed a block-valve shuts and the release abruptly ends. This release can be modelled as a series of discrete puffs by dividing the interval \([ 0, \tau )\) into \(n\) sub-intervals and releasing a single puff at the start of each interval i with a mass \(m_i = w(t_i) \delta t\).
+function discrete_puffs(;n=100, t_0=0τ, t_f=τ)
+ δt = (t_f - t_0)/(n-1)
+ pfs = Vector{Puff}()
+ for t_i ∈ range(t_0;stop=t_f,length=n)
+ m_i = w(t_i)*δt
+ pf = Puff(m_i,h,u,t_i)
+ push!(pfs,pf)
+ end
+ return pfs
+endpfs = discrete_puffs(n=25); +
+For the purposes of illustration I chose a rather small number of puffs, as shown in Figure 1. However, if we calculate the total mass released we find that it isn’t too far off.
+m(pfs::Vector{Puff},t) = sum( pf.m for pf in pfs if pf.t < t );After time τ has elapsed, the total released mass is 632 kg, the total mass of the discrete puffs is 645 kg, an excess of only 2.1%.
+With the discrete puff case implemented, we can now compare with the approximate integral. Recall that I didn’t actually integrate the full expression, I approximated the integral as one where the \(\sigma\)s are constant (they aren’t) and integrated that. I then took that result and substituted back in the correlations for the \(\sigma\)s. The hope is that this will be close enough to the full expression that we can use it.
+For a less than rigorous approach, let us consider a point 1000m downwind of the vent stack, at the same release height as the stack. We will look at the concentration profile over time at that point.
+Another useful comparison is to the Palazzi model, we expect the concentration profile for the blowdown to be bounded between the Palazzi case with a constant mass rate \(w = w_0\) and the case with a constant mass rate \(w = w(\tau)\). Furthermore, we expect the blowdown case should connect the two curves with something resembling an exponential decay.
+bd = IsothermalBlowdown(w₀,τ,h,u,τ) +
+The results are showin in Figure 2 above, which matches our expectations. The approximate integral model developed here is virtually identical to the discrete puffs model with 100 puffs. For comparison I also included the case where the Palazzi model is used but with a time-averaged constant release rate. This will have the correct total mass in the release, but clearly underestimates the peak concentration.
+ +
+The ground level concentration also conforms to our expectations, as shown in Figure 3. The region around the vent itself, besides having some artifacts of the discretization and marching squares, is likely quite unreliable. This is the region where the fundamental assumptions, that the release has zero momentum and no buoyancy, are most egregiously violated. I think this model is still reasonable for concentrations far enough from the vent that the windspeed dominates the advection, though an effective release point would need to be used.
+It is the nature of the universe that the instant I post this I will find where this model was published in the literature. I haven’t found it yet, but I can’t imagine I am first person to come up with this. Knowing me, it is probably in one of the references I look at all the time and, somehow, failed to notice.
+If this paragraph is still here when you see this, and you know of a published reference for this model, please leave a comment.
+I was thinking, recently, about how venting from vessel blowdown is modelled for screening purposes and how, more often than not, it does not take into account the blowdown curve. This is something that could easily be incorporated for simple Gaussian dispersion, which is what I examine here.
+The standard approach for assessing the consequences of a release from a pressure vessel is to:1
+The mass release rate from a vessel blowdown is taken as the max release rate (at the start of the blowdown) and generally assumed to be constant.2 The standard approach in most modelling tools (e.g. SLAB, DEGADIS, ALOHA) is to assume the release rate is constant. Though references do acknowledge that the flow will decrease over time, this is typically not taken into account. The one exception that I’m aware of is when modelling flaring due to vessel and pipeline blowdowns sometimes an average flowrate is taken instead of the max, in which case the blowdown curve is used to derive that average. It is still a constant for the purposes of dispersion modelling.
+However, if we think back to the development of the Palazzi model3 for short duration releases, a rather obvious path presents itself for the special case of a release of an ideal gas from an isothermal blowdown: integrate the Gaussian puff model over time with an exponentially decaying mass release rate.
+Recalling the isothermal blowdown of an ideal gas, the mass release rate, \(w\), is given by
+\[ +w\left(t\right) = w_0 \exp \left( - \frac{t}{\tau} \right) +\]
+Where4
+4 This follows from the definition of \(\tau\): \[ \tau = {m_0 \over w_0} \] \[ w_0 = {m_0 \over \tau} \] \[ w_0 = { {\rho_0 V} \over \tau }\]
\[ +w_0 = { {\rho_0 V} \over \tau } +\]
+with a time constant \(\tau\) given by
+\[ +\frac{1}{\tau} = \frac{c_D A}{V} \sqrt{ {k P_0} \over \rho_0 } \left( 2 \over {k+1} \right)^{\frac{k+1}{2 \left( k - 1 \right)} } +\]
+With:
+For a release centred at the origin with an elevation h, the concentration profile for a single Gaussian puff is given by:5
+\[ +c \left(x,y,z,t \right) = w \Delta t \cdot g_x(x, t) \cdot g_y(y) \cdot g_z(z) +\]
+Where the gs are Gaussian functions in the x, y, and z directions
+\[ +g_x(x,t) = {1 \over \sqrt{2\pi} \sigma_x } \exp \left( -\frac{1}{2} \left( x-u t \over \sigma_x \right)^2 \right) +\]
+gx(x,t,u,σx) = exp(-((x-u*t)/σx)^2/2)/(√(2)*π*σx)\[ +g_y(y) = {1 \over \sqrt{2\pi} \sigma_y } \exp \left( -\frac{1}{2} \left( y \over \sigma_y \right)^2 \right) +\]
+gy(y,σy) = exp(-(y/σy)^2/2)/(√(2)*π*σy)\[ +g_z(z) = {1 \over \sqrt{2\pi} \sigma_z } \left[ \exp \left( -\frac{1}{2} \left( z-h \over \sigma_z \right)^2 \right) + \exp \left( -\frac{1}{2} \left( z+h \over \sigma_z \right)^2 \right) \right] +\]
+gz(z,h,σz) = ( exp(-((z-h)/σz)^2/2)
+ + exp(-((z+h)/σz)^2/2))/(√(2)*π*σz)With:
+# Puff dispersion parameters for Class D atmospheres
+σx(xc) = 0.06*xc^0.92
+σy(xc) = 0.06*xc^0.92
+σz(xc) = 0.15*xc^0.70struct Puff{F}
+ m::F # mass
+ h::F # release height
+ u::F # velocity
+ t::F # release time
+ c_max::F # max concentration
+end
+
+Puff(m,h,u,t,c_max) = Puff(promote(m,h,u,t,c_max)...)function c(p::Puff,x,y,z,t)
+ λ = t - p.t # time since release
+ xc = p.u*λ # location of cloud center
+ if λ < 0 # the puff hasn't been released yet
+ return 0.0
+ else
+ c = p.m*gx(x,λ,p.u,σx(xc))*gy(y,σy(xc))*gz(z,h,σz(xc))
+ return isnan(c) ? 0.0 : min(c,p.c_max)
+ end
+endThe single puff model assumes all of the mass is released in a single instant. This significantly over-estimates the concentration for longer duration releases, and so an alternative approach is to break up the release into several puffs and sum the result.
+\[ +c(x,y,z,t) = \sum_{i=0}^{n} w\left( t_i \right) \delta t \cdot g_x(x, t - t_i ) \cdot g_y(y) \cdot g_z(z) +\]
+Where \(\delta t\) is the duration of each puff and \(t_i\) is the time when puff i was released.
+c(ps::Vector{Puff},x,y,z,t) = sum( c.(ps, x, y, z, t) );Taking the limit \(\delta t \to 0\) takes this from a discrete sum to the corresponding integral
+\[ +c(x,y,z,t) = \int_{0}^{t} w\left( t^{\prime} \right) \cdot g_x(x, t - t^{\prime}) \cdot g_y(y) \cdot g_z(z) dt^{\prime} +\]
+For the Palazzi6 model \(w(t) = w_0 \left( H\left(t - \Delta t \right) - H\left( t \right) \right)\)7 and, assuming the \(\sigma\)s are independent of time, this can be integrated to give:
+7 \(H \left(t \right)\) being the Heaviside function
\[ +c(x,y,z,t) = \frac{w_0}{2u} \left( \mathrm{erf}\left({ {x - u (t-\Delta t)} \over \sqrt{2} \sigma_x }\right) - \mathrm{erf}\left( { {x - u t} \over \sqrt{2} \sigma_x } \right) \right) \cdot g_y(y) \cdot g_z(z) +\]
+It should be pretty obvious where I am going next: instead of assuming \(w(t)\) is a constant, let it be the exponential decay from an isothermal vessel blowdown. The integration is a little more tedious but it is not really any more difficult than the Palazzi case.
+\[ +c(x,y,z,t) = \int_{0}^{t} w\left( t^{\prime} \right) \cdot g_x(x, t - t^{\prime}) \cdot g_y(y) \cdot g_z(z) dt^{\prime} +\]
+\[ +c(x,y,z,t) = \int_{0}^{t} \left[ w_0 \exp\left( -{t^{\prime} \over \tau} \right) \right] \cdot \left[ {1 \over \sqrt{2\pi} \sigma_x } \exp \left( -\frac{1}{2} \left( x-u (t - t^{\prime}) \over \sigma_x \right)^2 \right) \right] \cdot g_y(y) \cdot g_z(z) dt^{\prime} +\]
+Splitting this into elements that depend on time and those that don’t \[ +c(x,y,z,t) = w_0 \left[ \int_{0}^{t} {1 \over \sqrt{2\pi} \sigma_x } \exp\left( -{t^{\prime} \over \tau} -\frac{1}{2} \left( x-u (t - t^{\prime}) \over \sigma_x \right)^2 \right) dt^{\prime} \right] \cdot g_y(y) \cdot g_z(z) +\]
+Letting everything within the integral equal \(I(x,t)\)
+\[ +c(x,y,z,t) = w_0 \cdot I(x,t) \cdot g_y(y) \cdot g_z(z) +\]
+It makes the integration a little easier to introduce \(\lambda = t-t^{\prime}\)
+\[ +I(x,t) = \int_{0}^{t} {1 \over \sqrt{2\pi} \sigma_x } \exp\left( -{{t - \lambda} \over \tau} -\frac{1}{2} \left( x-u \lambda \over \sigma_x \right)^2 \right) d\lambda +\]
+By expanding everything within the \(\exp(\dots)\), collecting terms and completing the square we arrive at:
+\[ +I(x,t) = {1 \over \sqrt{2\pi} \sigma_x } \exp \left( {\sigma_x^2 + 2 u \tau (x - u t)} \over {2 u^2 \tau^2} \right) \int_{0}^{t} \exp\left( -\left( {\sigma_x^2 + u \tau ( x - u \lambda ) } \over {\sqrt{2} \sigma_x u \tau} \right)^2 \right) d\lambda +\]
+\[ +I(x,t) = \frac{1}{2u} \exp \left( {\sigma_x^2 + 2 u \tau (x - u t)} \over {2 u^2 \tau^2} \right) \left[ \mathrm{erf}\left( {\sigma_x^2 + u \tau x} \over {\sqrt{2} \sigma_x u \tau} \right) - \mathrm{erf}\left( {\sigma_x^2 + u \tau (x - u t)} \over {\sqrt{2} \sigma_x u \tau} \right)\right] +\]
+This has the same limitations as the Palazzi model, namely that it assumes the dispersion parameters \(\sigma_x\), \(\sigma_y\), and \(\sigma_z\) are constant. This is perhaps more thoroughly violated here than in a short duration release with a constant emission rate because the blowdown never really ceases. The plume could extend out arbitrarily far from the emission source, where clearly the assumption of constant dispersion parameters would be strongly violated. However, the contribution from the later parts of the release become exponentially small. So perhaps it “cancels out” for releases with a large enough \(\tau\).
+# The example case
+u = 2.0 # m/s
+h = 10.0 # m
+c₀ = 1.0 # kg/m^3
+w₀ = 1.0 # kg/s
+m₀ = 1000.0 # kg
+τ = m₀/w₀w(t) = w₀*exp(-t/τ)\[ +m(t) = \int_0^t w_0 \exp \left( -\frac{t^{\prime}}{\tau} \right) d t^{\prime} +\]
+\[ +m(t) = w_0 \tau \left( 1 - \exp \left( -\frac{t^{\prime}}{\tau} \right) \right) +\]
+m(t) = w₀*τ*(1 - exp(-t/τ))m (generic function with 1 method)::: {#98b90fca-3aa4-40b0-99df-4af5f4f9bbbb .cell 0=‘o’ 1=‘u’ 2=‘t’ 3=‘p’ 4=‘u’ 5=‘t’ 6=‘:’ 7=‘f’ 8=‘a’ 9=‘l’ 10=‘s’ 11=‘e’ execution_count=11}
+function discrete_puffs(;n=100, t_0=0.0, t_f=τ)
+ δt = (t_f - t_0)/(n-1)
+ pfs = Vector{Puff}()
+ for t_i ∈ range(t_0;stop=t_f,length=n)
+ m_i = w(t_i)*δt
+ pf = Puff(m_i,h,u,t_i,c₀)
+ push!(pfs,pf)
+ end
+ return pfs
+enddiscrete_puffs (generic function with 1 method):::
+m(pfs::Vector{Puff},t) = sum( pf.m for pf in pfs if pf.t < t )m (generic function with 2 methods)pfs = discrete_puffs(n=100);m(pfs,τ)635.3184615206982m(τ)632.1205588285577100-element Vector{Float64}:
+ 3.5338047520570564e-222
+ 5.9945904391486026e-217
+ 8.780076906348763e-212
+ 1.1103476054378067e-206
+ 1.2123874654194069e-201
+ 1.1429987409866083e-196
+ 9.304047167478635e-192
+ 6.539128802406203e-187
+ 3.9681649546291795e-182
+ 2.0791287302864883e-177
+ 9.405781359455912e-173
+ 3.6739244027566487e-168
+ 1.2390458837143029e-163
+ ⋮
+ 4.0079999580163855e-6
+ 1.6594582580263465e-6
+ 5.932350384630131e-7
+ 1.831087476751391e-7
+ 4.879925904118141e-8
+ 1.1228951350106937e-8
+ 2.23093547634655e-9
+ 3.826984085142713e-10
+ 5.6682388145366026e-11
+ 7.248722267338629e-12
+ 8.003807184963484e-13
+ 7.630510816771475e-14 +
+pfs[1]Puff{Float64}(1.0101010101010102, 10.0, 2.0, 0.0, 1.0)using SpecialFunctions: erf, erfcA recurring task of mine is to look at some old calculations, done by some previous engineer whose identity is lost to time and organizational flux, and update them to match current reality. Depending on the state of the spreadsheet, and its lack of documentation, this can also mean going down a rabbit hole of research to find where, exactly, a given equation came from and what all the constants in it represent. This post is the result of one of those journeys, trying to track down the source of a model for depressuring a vessel.
+
+Consider the blowdown of a pressure vessel to a vent stack, where the vessel contains a gas. What we want is the time to fully depressure and the pressure curve (the blowdown curve). As a first approximation we can consider the ideal gas case and examine two limiting behaviours for the vessel: when the walls are perfect insulators (the adiabatic case) and when the walls are perfect conductors of heat (the isothermal case). Furthermore we assume the blowdown is through an isentropic nozzle.
+The adiabatic case is often a good approximation for small vessels and early in the blowdown, when the rate of energy lost from the vessel through the bulk transport of the gas is much higher than any heat gained from the environment.
+Starting with a mass balance on the vessel:
+\[ +\frac{dm}{dt} = - w +\]
+where m is the mass inside the vessel and w is the mass flow through the valve. Since the volume of the vessel is a constant, V, we can write the mass balance as
+\[ +V \frac{d \rho}{dt} = - w +\]
+We can perform a change of variables from ρ to P
+\[ +V \left( \frac{\partial \rho}{\partial P} \right)_S \frac{dP}{dt} = - w +\]
+The partial derivative is taken along an isentropic path as the adiabatic expansion within the vessel is isentropic (not because the valve is isentropic).
+We can write the mass flow through the nozzle in terms of the theoretical, friction less, mass velocity G, the discharge coefficient \(c_D\), and the flow area A.
+\[ +w = c_D A G +\]
+giving1
+\[ +\frac{dP}{dt} = - \frac{c_D A}{V} \left( \frac{\partial P}{\partial \rho} \right)_S G +\]
+Assuming the flow through the valve is choked, the velocity in the throat is the sonic velocity \(a_t\) which, for an ideal gas, is given by
+\[ +a = \sqrt{ {k R T} \over M} = \sqrt{ {k P} \over \rho} +\]
+An ideal gas undergoing an adiabatic expansion from vessel pressure to the pressure in the throat of the valve has the following relationship between density and pressure2
+2 Any physical chemistry textbook, such as Laidler, Meiser, and Sanctuary, Physical Chemistry, 79–81.
\[ +\frac{\rho_t}{\rho} = \left( \frac{P_t}{P} \right)^{\frac{1}{k} } +\]
+and, for choked flow, the pressure ratio is at maximum at3
+\[ +\frac{P_t}{P} = \left( { 2 \over {k+1} } \right)^{\frac{k}{k-1} } +\]
+putting this all together we can write G in terms of vessel conditions \(\rho\) and \(P\)
+\[ +G = \rho_t u_t = \rho_t a_t = \rho_t \sqrt{ {k P_t} \over \rho_t} = \sqrt{k \rho_t P_t} +\]
+\[ +G = \sqrt{k \rho P} \left( 2 \over {k+1} \right)^{\frac{k+1}{2 \left( k - 1 \right)} } +\]
+From thermodynamics we know
+\[ +\left( \frac{\partial P}{\partial \rho} \right)_S = a^2 = \frac{k P}{\rho} +\]
+and we can put this all together to get
+\[ +\frac{dP}{dt} = - \frac{c_D A}{V} \left( {k P} \over \rho \right) \sqrt{k \rho P} \left( 2 \over {k+1} \right)^{\frac{k+1}{2 \left( k - 1 \right)} } +\]
+At this point, it is standard to introduce a time constant \(\tau\)
+\[ +\tau = \frac{m_0}{w_0} = \frac{\rho_0 V}{c_D A \sqrt{k \rho_0 P_0} } \left( 2 \over {k+1} \right)^{-\frac{k+1}{2 \left( k - 1 \right)} } +\]
+or, more clearly,
+\[ +\frac{1}{\tau} = \frac{c_D A}{V} \sqrt{ {k P_0} \over \rho_0 } \left( 2 \over {k+1} \right)^{\frac{k+1}{2 \left( k - 1 \right)} } +\]
+Where the subscript 0 indicates the initial conditions in the vessel. This simplifies the expression to
+\[ +\frac{dP}{dt} = -\frac{k}{\tau} P \left( \frac{P}{P_0} \right)^{\frac{k-1}{2k} } +\]
+Which is separable and can be integrated to give (after some rearrangement)
+\[ +\frac{P}{P_0} = \left( 1 + \left( {k-1} \over 2 \right) \frac{t}{\tau} \right)^{\frac{2k}{1-k} } +\]
+and the depressure time is
+\[ +t = \frac{2\tau}{1-k} \left( 1 - \left( \frac{P_a}{P_0} \right)^{\frac{1-k}{2k} } \right) +\]
+Another useful thing to determine is the mass flow rate over time, which can be recovered rather easily recalling
+\[ +w = -\frac{V}{a^2} \frac{dP}{dt} = -\frac{\rho V}{k P} \frac{dP}{dt} +\]
+and
+\[ +\frac{dP}{dt} = -\frac{k}{\tau} P \left( \frac{P}{P_0} \right)^{\frac{k-1}{2k} } +\]
+we get
+\[ +w = \frac{\rho V}{\tau} \left( \frac{P}{P_0} \right)^{\frac{k-1}{2k} } = \frac{\rho_0 V}{\tau} \left( \frac{\rho}{\rho_0} \right) \left( \frac{P}{P_0} \right)^{\frac{k-1}{2k} } +\]
+By recalling the definition of \(\tau\) this simplifies to
+\[ +\frac{w}{w_0} = \left( \frac{P}{P_0} \right)^{ {k+1} \over {2k} } = \left( 1 + \left({k-1} \over 2 \right) \frac{t}{\tau} \right)^{\frac{1+k}{1-k} } +\]
+This final model, for mass flow, is the model most often given in process safety references for blowdown rates. This makes some sense as early in a blowdown the observed pressure curve tend to approximate the adiabatic curve. However (foreshadowing) the isothermal curve leads to higher predicted vessel pressures, and generally higher mass flow rates, which might be more conservative depending on the context.
+The adiabatic model is the only simple model given in Lees,4 with the recommendation to use software such as BLOWDOWN to handle more complex, multi phase, mixtures and heat transfer problems. This is also what my older copy of Perry’s gives,5 albeit with a typo.
+Perry’s gives the following
+\[ +\frac{w}{w_0} = \left( 1 + \left(\mathbf{k + 1} \over 2 \right) \frac{t}{\tau} \right)^{\frac{1+k}{1-k} } +\]
+Note the sign change, it should be k-1 not k+1, given typical values of k~1.4 this actually a huge difference.
+Perry’s only gives the mass flow, so if you wanted the pressure (and the gas density and temperature) you would need to find some other reference. Or do it yourself, it does sketch out how the equation is derived, if you have the spare time to sit down and integrate.
+There are two obvious limitations to this model: it relies on the gas being well approximated by an ideal gas and that the flow out of the vessel is always choked. The first issue I am not going to deal with right now, the second one I think can be easily dealt with by slightly modifying the governing equations.
+\[ +\frac{dP}{dt} = -\frac{c_D A}{V} a^2 G +\]
+We can solve this numerically given
+\[ +\rho = \rho_0 \left(\frac{P}{P_0}\right)^{\frac{1}{k} } +\]
+\[ +G = \sqrt{ \rho P \left( {2k} \over {k - 1} \right) \left( \left( \frac{P_t}{P}\right)^{ \frac{2}{k} } - \left( \frac{P_t}{P} \right)^{ \frac{k+1}{k} } \right) } +\]
+function isentropic_mass_flow(P, ρ; k=1.4, Pₐ=101325)
+ η = max( Pₐ/P, (2/(k+1))^(k/(k-1)))
+ G² = ρ*P*(2k/(k-1))*( η^(2/k) - η^((k+1)/k) )
+ G = G² > 0 ? √(G²) : 0
+ return G
+endfunction speed_of_sound(P, ρ; k=1.4)
+ a = √(k*P/ρ)
+ return a
+endfunction adiabatic_vessel(P, params, t)
+ c, A, V, k, ρ₀, P₀, Pₐ = params
+ ρ = ρ₀*(P/P₀)^(1/k)
+ a² = speed_of_sound(P, ρ; k=k)^2
+ G = isentropic_mass_flow(P, ρ; k=k, Pₐ=Pₐ)
+ return-c*A*a²*G/V
+endwith a callback function to terminate the integration once the vessel is fully depressured
+function depressured_callback(P, t, integrator; tol=0.001)
+ c, A, V, k, ρ₀, P₀, Pₐ = integrator.p
+ return P - (1+tol)*Pₐ
+endJust to have a real system to think about, I used to SCUBA dive when I was a teenager and had a few mishaps early on, when I was still figuring things out, accidentally opening the tank valve when the regulator yoke was not fully attached. Blasting air all over the place while I scrambled to shut it off. Typical tanks have capacities ranging from 80 cu. ft. to 100 cu. ft., with working pressures of >3000 psi. That’s a pretty high pressure for a relatively small tank. How fast could the tank blowdown if I opened the valve fully and just sat back and watched?
+# Ambient conditions
+begin
+ Pₐ = 101.325e3 # Pa
+ Tₐ = 288.15 # K
+ ρₐ = 1.21 # kg/m³
+end;I looked around online and a typical tank with a 80 cu. ft. capacity might have a “water volume” (actual internal volume) of 678 cu. in. (11.11L) and a working pressure of 3000 psi (20.68 MPa). I don’t actually know the flow area of a tank valve, I couldn’t find it easily, so I’m going to guess it’s basically a 1 mm diameter tube when fully open, with a discharge coefficient of 0.85 – all of this could be firmed up better with some real details of the valve. But this is a start.
+#Vessel conditions
+begin
+ c = 0.85
+ D = 0.001 # m
+ A = 0.25*π*D^2 # m²
+ V = 0.01111 # m³
+ P₀ = 20.68e6 # Pa
+ T₀ = Tₐ
+ ρ₀ = ρₐ*(P₀/Pₐ) # ideal gas law
+ k = 1.4
+end;I then set up the differential equation and integrate to get the blowdown curve.
+using OrdinaryDiffEq, Plotsbegin
+ params = (c, A, V, k, ρ₀, P₀, Pₐ)
+ t_span = (0.0, 12.0)
+ prob = ODEProblem(adiabatic_vessel, P₀, t_span, params)
+ sol = solve(prob, Tsit5(),
+ callback=ContinuousCallback(depressured_callback, terminate!))
+end; +
+This model has the tank blowing down pretty fast, in less than 30s. Probably my guess for the valve area is too large. I did just make it up.
+Regarding the models themselves, the adiabatic choked model is a very good approximation to the full ODE until the last few fractions of a second, at which point the models diverge. This likely to be true for any high pressure blowdowns, where the vessel pressure starts well above ~2atm, as in that case the majority of the blowdown will be entirely in the choked flow regime.
+To play around with this more, I am first going to detour into creating some helper functions and I think this is a natural point to create a struct to contain the vessel parameters.
begin
+
+struct PressureVessel{F <: Number}
+ c::F
+ A::F
+ V::F
+ k::F
+ ρ₀::F
+ P₀::F
+ Pₐ::F
+ τ::F
+end
+
+PressureVessel(c, A, V, k, ρ₀, P₀, Pₐ, τ) =
+ PressureVessel(promote(c, A, V, k, ρ₀, P₀, Pₐ, τ)...)
+
+function PressureVessel(c, A, V, k, ρ₀, P₀, Pₐ)
+ τ = 1/( (c*A/V)*√(k*P₀/ρ₀)*(2/(k+1))^((k+1)/(2*(k-1))) )
+ return PressureVessel(c, A, V, k, ρ₀, P₀, Pₐ, τ)
+end
+
+end;Where I have added a helper function to ensure all numbers are of the same type, and calculate the value of τ when the PressureVessel type is constructed.
Recreating the results from above, I start with a definition of the vessel
+vessel = PressureVessel(c, A, V, k, ρ₀, P₀, Pₐ);I would like to create some generic functions for the blowdown properties I am interested in: pressure and mass flow rate as functions of time and total blowdown time. To accommodate this I define another type to contain the VesselBlowdown solution.
abstract type Blowdown endstruct AdiabaticBlowdown{S} <: Blowdown
+ pv::PressureVessel
+ sol::S
+endHere I add some functions to make a Blowdown object act like an iterator with only a single element. This is absolutely pointless except that I just happen to like being able to generate a vector of results by using the “dot” notation, like so
my_function.(blowdown, time_vector)where I want it to broadcast over the time_vector.
Base.length(::Blowdown) = 1Base.iterate(b::Blowdown, state=1) = state > length(b) ? nothing : (b,state+1)For the simple choked model this is fairly straight forward.
+adiabatic_blowdown_choked(vessel::PressureVessel) =
+ AdiabaticBlowdown(vessel,nothing)function blowdown_pressure(bd::AdiabaticBlowdown, t)
+ P₀, k, τ = bd.pv.P₀, bd.pv.k, bd.pv.τ
+ return P₀*( 1 + 0.5*(k-1)*(t/τ))^((2*k)/(1-k))
+endfunction blowdown_mass_rate(bd::AdiabaticBlowdown, t)
+ ρ₀, V, P₀, k, τ = bd.pv.ρ₀, bd.pv.V, bd.pv.P₀, bd.pv.k,
+ bd.pv.τ
+ m₀ = ρ₀*V
+ w₀ = m₀/τ
+ P = blowdown_pressure(bd, t)
+ return w₀*(P/P₀)^((k+1)/(2k))
+endfunction blowdown_time(bd::AdiabaticBlowdown)
+ P₀, Pₐ, k, τ = bd.pv.P₀, bd.pv.Pₐ, bd.pv.k, bd.pv.τ
+ return (2τ/(1-k))*(1 - (Pₐ/P₀)^((1-k)/2k))
+endFor the full model the initial step is to integrate the differential equation. As a first guess, I calculate the blowdown time for a fully choked blowdown and set the outer-bound for the integration to 10× this. The integrator will terminate when the pressure reaches ambient and thus the last time stored will be the actual blowdown time.
+function adiabatic_blowdown_full(vessel::PressureVessel; solver=Tsit5())
+ # unpack the parameters
+ c, A, V, k, ρ₀, P₀, Pₐ = vessel.c, vessel.A, vessel.V,
+ vessel.k, vessel.ρ₀, vessel.P₀,
+ vessel.Pₐ
+ params = (c, A, V, k, ρ₀, P₀, Pₐ)
+
+ # estimate the time span needed to fully blowdown
+ τ = vessel.τ
+ t_bd = (2τ/(1-k))*(1 - (Pₐ/P₀)^((1-k)/2k))
+ t_span = (0.0, 10t_bd)
+
+ # set up the ODEProblem and solve
+ prob = ODEProblem(adiabatic_vessel, P₀, t_span, params)
+ sol = solve(prob, solver,
+ callback=ContinuousCallback(depressured_callback, terminate!))
+
+ return AdiabaticBlowdown(vessel,sol)
+endfunction blowdown_pressure(bd::AdiabaticBlowdown{<:ODESolution}, t)
+ if t < blowdown_time(bd)
+ return bd.sol(t)
+ else
+ return bd.sol.u[end]
+ end
+endfunction blowdown_mass_rate(bd::AdiabaticBlowdown{<:ODESolution}, t)
+ if t < blowdown_time(bd)
+ # unpack the parameters
+ c, A, k, ρ₀, P₀, Pₐ = bd.pv.c, bd.pv.A, bd.pv.k,
+ bd.pv.ρ₀, bd.pv.P₀, bd.pv.Pₐ
+
+ # calculate w = c*A*G
+ P = blowdown_pressure(bd, t)
+ ρ = ρ₀*(P/P₀)^(1/k)
+ G = isentropic_mass_flow(P, ρ; k=k, Pₐ=Pₐ)
+
+ return c*A*G
+ else
+ return 0.0
+ end
+endblowdown_time(bd::AdiabaticBlowdown{<:ODESolution}) =
+ bd.sol.t[end] +
+At this point I’ve built up enough machinery that playing around with all sorts of variations to the original case become quite simple. As an example, I look at the same air tank but pressured to 1.5 atm instead.
+test_vessel = PressureVessel(c, A, V, k, ρ₀, 1.5Pₐ, Pₐ); +
+Now it is clear that the fully choked model model isn’t working well, it predicts a blowdown time of 11.68s whereas numerically solving the ODE gives an answer of 20.49s, a 75.0% greater predicted blowdown.
+That said…I’m being a little coy about something: the full ODE predicts that the vessel will never blowdown. The pressure will get closer and closer to ambient but never get there. This is because G, for non-choked flow, asymptotically approaches zero as the vessel pressure approaches ambient pressure. How you define blowdown time is really a function of how close to ambient is close enough. Even if I set the tolerance in the depressured_callback function, which terminates the integration once the integrator is within tolerance of the ambient pressure, to zero it would, in reality, simply terminate at the default numerical precision of DifferentialEquations.jl. In this case I’ve said “within 0.1% of ambient is close enough,” but that’s totally arbitrary.
The other limiting case worth exploring is the isothermal case, which is equivalent to the vessel having perfectly conductive walls and remaining always at thermal equilibrium with the environment. This is often a good approximation for large vessels where the blowdown rate is small relative to the thermal mass of the gas in the vessel.
+Recalling, for the adiabatic case, we had the following
+\[ +\frac{dP}{dt} = - \frac{c_D A}{V} \left( \frac{\partial P}{\partial \rho} \right)_S G +\]
+For the isothermal case the vessel is being depressured along an isothermal path (not an isentropic path) and so we substitute the appropriate partial derivative6
+\[ +\frac{dP}{dt} = - \frac{c_D A}{V} \left( \frac{\partial P}{\partial \rho} \right)_T G +\]
+As before, the blowdown is through an isentropic nozzle and we assume that flow is choked
+\[ +G = \sqrt{k \rho P} \left( \frac{2}{k+1} \right)^{\frac{k+1}{2 \left( k-1 \right)} } = \rho \sqrt{ {k P} \over \rho} \left( \frac{2}{k+1} \right)^{\frac{k+1}{2 \left( k-1 \right)} } +\]
+From thermodynamics we can write the partial derivative as
+\[ +\left( \frac{\partial P}{\partial \rho} \right)_T = \frac{a^2}{k} = \frac{P}{\rho} +\]
+Thus
+\[ +\frac{dP}{dt} = - \frac{c_D A}{V} \frac{P}{\rho} \rho \sqrt{ {k P} \over \rho} \left( \frac{2}{k+1} \right)^{\frac{k+1}{2 \left( k-1 \right)} } +\]
+where the densities, \(\rho\), can be cancelled and, since the vessel is isothermal (i.e. \(\frac{P}{\rho}\) is a constant), the various constants can be collected to give
+\[ +\frac{dP}{dt} = -\frac{P}{\tau} +\]
+Where \(\tau\) is as defined for the adiabatic case. This can easily be integrated to give
+\[ +\frac{P}{P_0} = \exp \left( \frac{-t}{\tau} \right) +\]
+it also follows, from the ideal gas law, that
+\[ +\frac{\rho}{\rho_0} = \exp \left( \frac{-t}{\tau} \right) +\]
+and
+\[ +\frac{w}{w_0} = \exp \left( \frac{-t}{\tau} \right) +\]
+This can also be rearranged to give the blowdown time7
+7 N.B. the \(\log \left( \dots \right)\) is the natural log, this matches the convention used in julia
\[ +t = \tau \log \left( \frac{P_0}{P_a} \right) +\]
+This is the equation seen most often in references for estimating blowdown time for pipelines and compressor systems. It is also what is going on under the hood with many online calculators for vessel blowdown times. Though, in my experience, this is not always well documented and a modified form is often presented.
+The time constant, \(\tau\), can be broken up to look like this
+\[ +\tau = \frac{V}{c_D A} \sqrt{\frac{M}{M_{air} Z_0 T_0} } \sqrt{\frac{M_{air} }{kR} } \left( 2 \over {k+1} \right)^{\frac{-1}{2} \frac{k+1}{k-1} } +\]
+Where we have made the substitution \(Z_0 R T_0\) for \(R T_0\) to account for non-ideal behaviour. If the gas has a value of k ~ 1.4, we can write
+\[ +\tau = \mathrm{const} \frac{V}{c_D A} \sqrt{ \frac{SG}{Z_0 T_0} } +\]
+Where the constant is calculated entirely from the properties of air. Generally, I have found, few references describe where this constant comes from and in particular that it depends implicitly on a particular value for k. It also often has unit conversions absorbed into it, for example8
+\[ +t = 5.5 \frac{V}{c_D A} \sqrt{ \frac{SG}{Z_0 T_0} } \log \left( \frac{P_0}{P_a} \right) +\]
+with the units
+I have also found a few sources that leave the value of the constant as a mystery for the user to puzzle out.9 I was honestly surprised at the quality of the results when I first googled this and looked it up in Knovel. The highest ranked results, at the time, were cryptic to the point of uselessness or included obvious mistakes (several referred to t as the “interstitial velocity” with units of cm/s, an obvious misprint being blindly recopied in several places, including some e-books on Knovel where one would hope the quality control would be better). There are a few places with useful derivations10 but I think a good starting point is the Tank Blowdown Math set of notes. It is pretty straight forward and does not require a lot of prior knowledge of the partial derivatives of various thermodynamic state variables.
+I personally would not bother with the models that pre-calculate the constant for you. We no longer live in the age of slide-rules. The blowdown time equation for fully choked flow is well within the capabilities of excel or any competent person with a scientific calculator. I think it is easier to justify and explain, will be a better model for gases where k is not 1.4, and allows one to incorporate small levels of non-ideality through the isentropic expansion factor n.
+The isothermal fully-choked model can be implemented building on the types already created, by first creating an IsothermalBlowdown type and associated blowdown functions
struct IsothermalBlowdown{S} <: Blowdown
+ pv::PressureVessel
+ sol::S
+endisothermal_blowdown_choked(vessel::PressureVessel) =
+ IsothermalBlowdown(vessel,nothing)function blowdown_pressure(bd::IsothermalBlowdown, t)
+ P₀, τ = bd.pv.P₀, bd.pv.τ
+ return P₀*exp(-t/τ)
+endfunction blowdown_mass_rate(bd::IsothermalBlowdown, t)
+ ρ₀, V, τ = bd.pv.ρ₀, bd.pv.V, bd.pv.τ
+ m₀ = ρ₀*V
+ w₀ = m₀/τ
+ return w₀*exp(-t/τ)
+endblowdown_time(bd::IsothermalBlowdown) =
+ bd.pv.τ*log(bd.pv.P₀/bd.pv.Pₐ)In a similar vein as the adiabatic case, the requirement for fully choked flow can be relaxed and the ODE integrated numerically instead, starting with the system
+\[ +\frac{dP}{dt} = -\frac{c_D A}{V} \frac{a^2}{k} G +\]
+We can solve this numerically given that, for an isothermal system, the density is given by
+\[ +\rho = \rho_0 \left(\frac{P}{P_0}\right) +\]
+and using the definition of G given in the adiabatic case.
+function isothermal_vessel(P, params, t)
+ c, A, V, k, ρ₀, P₀, Pₐ = params
+ ρ = ρ₀*(P/P₀)
+ a² = speed_of_sound(P, ρ; k=k)^2
+ G = isentropic_mass_flow(P, ρ; k=k, Pₐ=Pₐ)
+ return-c*A*a²*G/(k*V)
+endfunction isothermal_blowdown_full(vessel::PressureVessel; solver=Tsit5())
+ # unpack the parameters
+ c, A, V, k, ρ₀, P₀, Pₐ = vessel.c, vessel.A, vessel.V,
+ vessel.k, vessel.ρ₀, vessel.P₀,
+ vessel.Pₐ
+ params = (c, A, V, k, ρ₀, P₀, Pₐ)
+
+ # estimate the time span needed to fully blowdown
+ τ = vessel.τ
+ t_bd = τ*log(P₀/Pₐ)
+ t_span = (0.0, 10t_bd)
+
+ # set up the ODEProblem and solve
+ prob = ODEProblem(isothermal_vessel, P₀, t_span, params)
+ sol = solve(prob, solver,
+ callback=ContinuousCallback(depressured_callback, terminate!))
+
+ return IsothermalBlowdown(vessel,sol)
+endfunction blowdown_pressure(bd::IsothermalBlowdown{<:ODESolution}, t)
+ if t < blowdown_time(bd)
+ return bd.sol(t)
+ else
+ return bd.sol.u[end]
+ end
+endfunction blowdown_mass_rate(bd::IsothermalBlowdown{<:ODESolution}, t)
+ if t < blowdown_time(bd)
+ # unpack the parameters
+ c, A, k, ρ₀, P₀, Pₐ = bd.pv.c, bd.pv.A, bd.pv.k,
+ bd.pv.ρ₀, bd.pv.P₀, bd.pv.Pₐ
+
+ # calculate w = c*A*G
+ P = blowdown_pressure(bd, t)
+ ρ = ρ₀*(P/P₀)
+ G = isentropic_mass_flow(P, ρ; k=k, Pₐ=Pₐ)
+
+ return c*A*G
+ else
+ return 0.0
+ end
+endblowdown_time(bd::IsothermalBlowdown{<:ODESolution}) =
+ bd.sol.t[end] +
+It is a similar story to the adiabatic case: for systems with a high initial pressure, the flow out of the valve is fully choked for almost the entire blowdown. It is only in the final fraction of a second that the full ODE system deviates from the model that assumes flow is choked all the time.
+In most practical situations, the difference would likely be swamped by two much greater problems with these models:
+Both of these assumptions will have a much greater impact on how well the model fits observed blowdowns than the slight deviation at the end of the blowdown due to non-choked flow.
+I think it might be simpler to visualize when the choked flow blowdown models will fall down by looking at the high pressure blowdown, the original example, versus the low pressure blowdown in dimensionless form. In this form, the choked flow blowdown curves (both adiabatic and isothermal) only depend on k. They are in fact the exact same curve. All that has changed is where along the curve the blowdown terminates.
+ +
+In the high pressure case the blowdown terminates much closer to \(\frac{P}{P_0}=0\) and most of the curve is fully choked.
+ +
+In the low pressure case the blowdown terminates at a much steeper part of the blowdown curve and the departure for non-choking flow is much more apparent.
+It is not immediately clear to me why the adiabatic case is all over the standard references for process safety, and the isothermal model is not. If what you care about is the pressure sustained within a vessel, the mass flow rate emitted through a blowdown stack or vent, and the duration of the blowdown, it is almost always more conservative to use the isothermal case. The isothermal (fully choked) model is also just easier to calculate, being just \(\exp \left( \frac{-t}{\tau} \right)\).
+The adiabatic case will give a better sense of how temperature changes within the vessel. I’ve largely left it out, but adiabatic blowdown does lead to a significant temperature drop and this cryogenic cooling can be a process hazard on its own. The gas exiting, and the vessel walls themselves, will get quite cold. Anyone who has gone camping in more marginal weather and watched a one-pound propane cylinder develop frost on the outside while cooking has seen this effect in action.11 But actually calculating the vessel temperature is almost entirely ignored in blowdown calculations for ideal gases, in my experience.
+11 This is also why butane cylinders are often not a good idea for early spring camping (in Canada), the cooling effect is strong enough to cause the butane inside to liquefy and the stove won’t work very well.
The isothermal model, in my review of the literature, appeared to be more commonly used in operational contexts, such as estimating the time required to blowdown a system through a blowdown vent. In this case it is likely to be the conservative answer. The two curves do cross at high \(\frac{t}{\tau}\) and so it is not always the case that the isothermal model is more conservative. Something worth noting.
+I deliberately set up the ODEs such that there is a clear path to implementing a real gas model through an equation of state. All that really needs to be done is to create functions for these three steps:
+Plugging those into the relevant steps in the adiabatic_vessel and isothermal_vessel functions changes from the ideal gas case to the real gas case. The rest of the code remains the same and operates unchanged.
In this case I think solving the full ODE for the ideal gas case alone is probably not worth the effort for most cases. The error in assuming an ideal gas, or in assuming one of the limiting heat transfer cases, is probably far larger than the error in assuming fully choked flow for all but the few cases that are near atmospheric pressure. If you are going to be estimating the blowdown for a real gas, then that’s different. If you are going to the hassle of setting up and solving the ODE, might as well have as few unnecessary assumptions as you can get away with. It really isn’t any more person effort, at that point, just more computer effort, and when the calculations happen in less than a second, how much less than a second is of little practical importance.
+Continuing on from where I left off previously, examining vessel blowdown, it is time to implement real gases. I left the ideal gas case promising that implementing a real gas was easy, well now is the time to prove it. Instead of implementing real gas equations of state myself, I am going to use Clapeyron.jl but, as a first step, it is worthwhile to consider how the problem can be divided up into sub-problems and what data structures would be the most useful. I would like to write code that is general enough that any equation of state can be used with minimal changes. With that in mind, I am going to consider the problem as being composed of three distinct subsets: the vessel, the fluid model, and the ambient conditions.
+The properties of the vessel form a natural data structure containing the valve properties, the vessel volume, and the initial conditions. It can also be divided into two distinct sub-problems: the gas expansion within the vessel and the gas expansion across the valve. The gas expansion within the vessel will be governed by the ODE or DAE for the particular expansion type – isothermal, adiabatic, &c. – whereas the expansion across the valve will always be isentropic. These sub-problems can then be solved in a way that is agnostic to the equation of state.
+An important decision must be made regarding which subset of the state variables, \(P, v, T\), will be used to define the system. The remaining variable will be defined by the equation of state. Equations of state are typically given in relation to the Helmholtz free energy, \(A\), a function of molar volume and temperature, which makes those a natural choice. The pressure vessel can then be instantiated with the total volume, total mass of material contained, and the vessel temperature. The pressure then varies with the equation of state. Alternatively, the pressure and temperature of the vessel could be chosen as the state variables. But then the total mass in the vessel depends on the particular equation of state, which strikes me as weird.
+begin
+
+struct PressureVessel{F <: Number}
+ c::F # valve discharge coefficient
+ A::F # valve flow area
+ V::F # vessel volume
+ T::F # vessel temperature
+ m::F # total mass of material
+end
+
+PressureVessel(c, A, V, T, m) =
+ PressureVessel(promote(c, A, V, T, m)...)
+
+endAbstracting the fluid properties – the P-v-T relationship, entropy, enthalpy, and the like – allows the vessel blowdown model to be re-used easily. Using Julia’s multiple dispatch no code even needs to change, just add new methods for a new fluid model and everything works. This leads naturally to a way of checking that the vessel model is working by comparing an ideal gas model to the known analytic solution. Verifying that it works with an ideal gas then gives confidence that the model is working with a real gas, for which the analytic solution is unknown.
+Collecting the ambient conditions into a data structure does not lead to any spectacular improvements or insights, it is just neat and tidy.
+begin
+
+struct Environment{F <: Number}
+ P::F
+ T::F
+end
+
+Environment(P, T) = Environment(promote(P,T)...)
+
+endFinally, a data structure for blowdown solutions is useful for dispatch.
+struct Blowdown{S}
+ pv::PressureVessel
+ env::Environment
+ sol::S
+endBase.length(::Blowdown) = 1Base.iterate(b::Blowdown, state=1) = state > length(b) ? nothing : (b,state+1)The first fluid model worth creating is the ideal gas model that corresponds to the known, analytic, solution. Specifically an ideal gas with constant heat capacities such that \(c_p - c_v = R\). Starting with the following data structure.
+begin
+
+const R = 8.31446261815324 # m³⋅Pa/K/mol
+
+struct IdealGas{F <: Number}
+ cᵥ::F # J/kg/K
+ cₚ::F # J/kg/K
+ k::F
+ R::F # J/kg/K
+ MW::F # kg/mol
+end
+
+function IdealGas(cᵥ,MW; R=R)
+ cᵥ, MW = promote(cᵥ,MW)
+ cₚ = cᵥ + R
+ k = cₚ/cᵥ
+ return IdealGas(cᵥ,cₚ,k,R,MW)
+end
+
+function IdealGas(model::Clapeyron.EoSModel;
+ P=101325, T=288.15, z=[1.])
+ MW = Clapeyron.molecular_weight(model, z) # kg/mol
+ cᵥ = Clapeyron.isochoric_heat_capacity(model, P, T, z) # J/mol/K
+ return IdealGas(cᵥ, MW)
+end
+
+endA good practice, when solving ODEs, is to use NaNMath.jl for roots, logarithms, and the like. These versions return NaN when results are outside of the function domain – for example \(\sqrt{-1}\) – instead of throwing a DomainError. Returning NaNs makes it easier for the ODE solver to detect when it has left the domain of a valid solution.
begin
+
+using NaNMath
+
+√ = NaNMath.sqrt
+log = NaNMath.log
+
+endThe equation of state is implemented as a series of high-level functions, dispatching on the fluid model and returning the relevant fluid properties. Extending the blowdown model to use a different equation of state involves merely overloading these to dispatch on a different fluid type.
+pressure(model::IdealGas, v, T) = model.R*T/vvolume(model::IdealGas, P, T) = model.R*T/Pmolecular_weight(model::IdealGas) = model.MWmolar_enthalpy(model::IdealGas, v, T) = model.cₚ*Tmolar_entropy(model::IdealGas, v, T) =
+ model.cᵥ*log(T) + model.R*log(v)molar_internal_energy(model::IdealGas, v, T) = model.cᵥ*Tspeed_of_sound(model::IdealGas, v, T) =
+ √(model.k*model.R*T/model.MW)Clapeyron.jlThe high-level functions defined above are mapped to the corresponding Clapeyron.jl functions. And that’s it. Everything is ready to use for whichever equation of state your heart desires.
+import Clapeyronpressure(model::Clapeyron.EoSModel, v, T) =
+ Clapeyron.pressure(model, v, T)volume(model::Clapeyron.EoSModel, P, T; v0=nothing) =
+ Clapeyron.volume(model, P, T; phase=:vapor, vol0=v0)molecular_weight(model::Clapeyron.EoSModel) =
+ Clapeyron.molecular_weight(model)molar_enthalpy(model::Clapeyron.EoSModel, v, T) =
+ Clapeyron.VT_enthalpy(model, v, T)molar_entropy(model::Clapeyron.EoSModel, v, T) =
+ Clapeyron.VT_entropy(model, v, T)molar_internal_energy(model::Clapeyron.EoSModel, v, T) =
+ Clapeyron.VT_internal_energy(model, v, T)speed_of_sound(model::Clapeyron.EoSModel, v, T) =
+ Clapeyron.VT_speed_of_sound(model, v, T)The vessel blowdown relies on a good model of isentropic nozzle flow. This involves finding the pressure and temperature in the throat of the nozzle which maximizes the mass flux, G, while satisfying the constraints that the path from a stagnation point in the vessel through the nozzle is isentropic and that the enthalpy is conserved. The flow is further constrained to be either sonic or subsonic, i.e. the Mach number is less than or equal to one.
+\[ +s_1 = s_t +\]
+\[ +h_1 = h(v_t, T_t) + \frac{1}{2} M u_t^2 +\]
+For almost all of the blowdown the flow will be sonic and the pressure in the throat of the nozzle will be greater than atmospheric, this is called choked flow. The entropy and enthalpy balances can be solved for the throat conditions, \(v_t, T_t\), assuming the velocity is the local speed of sound. I do this here using NonlinearSolve.jl, where the objective function, choked_nozzle_balance!, is in-place.
using NonlinearSolvefunction choked_nozzle_balance!(obj, y, prms)
+ # y = [v; T]
+ obj .= [ prms.entropy - molar_entropy(prms.model, y[1], y[2])
+ prms.enthalpy - molar_enthalpy(prms.model, y[1], y[2]) - 0.5*molecular_weight(prms.model)*speed_of_sound(prms.model, y[1], y[2])^2 ]
+ return nothing
+endchoked_nozzle_prob = NonlinearProblem(choked_nozzle_balance!, [0.0; 0.0],
+ (model=nothing, env=nothing,
+ entropy=0.0, enthalpy=0.0))In the case where the flow is subsonic, the pressure in the throat of the nozzle is atmospheric and the entropy and enthalpy balances are solved for gas velocity and temperature, \(u_t, T_t\).
+function non_choked_nozzle_balance!(obj, y, prms)
+ # y = [u; T]
+ v = volume(prms.model, prms.env.P, y[2])
+ obj .= [ prms.entropy - molar_entropy(prms.model, v, y[2])
+ prms.enthalpy - molar_enthalpy(prms.model, v, y[2]) - 0.5*molecular_weight(prms.model)*y[1]^2 ]
+ return nothing
+endnon_choked_nozzle_prob = NonlinearProblem(non_choked_nozzle_balance!,
+ [0.0; 0.0],
+ (model=nothing, env=nothing,
+ entropy=0.0, enthalpy=0.0))The most obvious and direct way of solving the entropy and energy balances is to solve the optimization problem. However, I could not get that to work reliably. Using the same constraints on entropy and enthalpy as well as constraining the Mach number to be less than or equal to one, I could get it to work but only with very good guesses of the initial conditions. Using Optimization.jl, it would either get stuck in a local maximum or, depending on the solver, sometimes return results that simply did not satisfy the constraints (but came with return code “Success”). Given that this is going to be wrapped in an ODE and executed, potentially, hundreds of times, that is not good.
My completely stupid but it works approach is to solve the choked flow nonlinear system first and, if the nozzle pressure is below atmospheric, solve the non-choked flow system instead. This works perfectly though, presumably, is not nearly as efficient as solving the optimization problem directly would be if I could get it to work properly.
+function mass_flow(model, pv, env, v, T)
+ # calculate the molar entropy and molar enthalpy
+ # at vessel conditions
+ s₁ = molar_entropy(model, v, T)
+ h₁ = molar_enthalpy(model, v, T)
+
+ # solve the choked flow energy balance for
+ # an isentropic nozzle
+ params = (model=model, env=env, entropy=s₁, enthalpy=h₁)
+ y₀ = [v; T]
+ prob = remake(choked_nozzle_prob, u0=y₀, p=params)
+ sol = solve(prob, NewtonRaphson())
+ vₜ, Tₜ = sol.u
+ Pₜ = pressure(model, vₜ, Tₜ)
+ if Pₜ > env.P
+ # flow is choked, we're done
+ uₜ = speed_of_sound(model, vₜ, Tₜ)
+ else
+ # flow is not choked, solve the non-choked problem
+ v₀ = volume(model, env.P, T)
+ y₀ = [ speed_of_sound(model, v₀, T); T ]
+ prob = remake(non_choked_nozzle_prob, u0=y₀, p=params)
+ sol = solve(prob, NewtonRaphson())
+ uₜ, Tₜ = sol.u
+ vₜ = volume(model, env.P, Tₜ)
+ end
+
+ ρₜ = molecular_weight(model)/vₜ
+ return pv.c*pv.A*ρₜ*uₜ
+endThe general adiabatic blowdown solution proceeds in the same way as the ideal gas case (solved previously). Here the isentropic path is not directly available, so the problem is rewritten as a Differential Algebraic Equation (DAE), where the vessel state is constrained to be isentropic.
+The first step is to define a basic type, PressureODE; which will allow functions like blowdown_pressure to dispatch on solution type.
struct PressureODE{S}
+ ode_sol::S
+endThe governing equations are the ODE as defined before, plus the constraints that the P-v-T behaviour follows the equation of state and the entropy is constant.
+\[ +\frac{dP}{dt} = -\frac{c_D A}{V} a^2 G +\]
+\[ +0 = v - volume(P, T) +\]
+\[ +0 = s_0 - entropy(v, T) +\]
+The equation of state does not need to be pulled into the DAE like this. It could be incorporated into the right hand side of the ODE. However, it is often convenient to have all of the state variables directly accessible in the solution.
+using OrdinaryDiffEq, DiffEqCallbacksfunction adiabatic_vessel!(dy, y, prms, t)
+ P, v, T = y
+
+ a² = speed_of_sound(prms.model, v, T)^2
+ w = mass_flow(prms.model, prms.pv, prms.env, v, T)
+
+ dy .= [-w*a²/prms.pv.V
+ v - volume(prms.model, P, T)
+ prms.init - molar_entropy(prms.model, v, T) ]
+ return nothing
+endabd_rhs = ODEFunction(adiabatic_vessel!, mass_matrix = [1 0 0
+ 0 0 0
+ 0 0 0])A callback function is used to terminate the integration once the vessel is within a given tolerance of atmospheric pressure. Without this the blowdown would continue forever, or until the limits of machine precision (whichever came first). Technically, this blowdown model predicts the pressure in the vessel will get arbitrarily close to atmospheric pressure but never actually achieve it.
+depressured_callback(y, t, I; reltol=0.001) =
+ y[1] - (1+reltol)*I.p.env.PThe entire model is packaged into a function which takes a fluid, pressure vessel, and environment and returns a Blowdown solution. By splitting the problem up like this, different fluid models, vessels or ambient conditions can be swapped around while reusing what has already been defined.
function adiabatic_blowdown(model, pv::PressureVessel,
+ env::Environment;
+ solver=Rodas5(),
+ tspan=(0.0, 600.0))
+
+ # vessel initial conditions
+ V, T₀, m = pv.V, pv.T, pv.m
+ n₀ = m/molecular_weight(model)
+ v₀ = V/n₀
+ P₀ = pressure(model, v₀, T₀)
+
+ # defining the parameters
+ s₀ = molar_entropy(model, v₀, T₀)
+ params = (model=model, pv=pv, env=env, init=s₀)
+
+ # callbacks
+ dpcb = ContinuousCallback(depressured_callback, terminate!)
+
+ # set up the ODEProblem and solve
+ y₀ = [P₀; v₀; T₀]
+ prob = ODEProblem(abd_rhs, y₀, tspan, params)
+ sol = solve(prob, solver; callback=dpcb)
+
+ return Blowdown(pv,env,PressureODE(sol))
+endFrom the ODE solution the blowdown time, pressure curve, and temperature can be recovered.
+blowdown_time(bd::Blowdown{<:PressureODE}) =
+ bd.sol.ode_sol.t[end]function blowdown_pressure(bd::Blowdown{<:PressureODE}, t)
+ bdt = blowdown_time(bd)
+ t = min(t, bdt)
+ return bd.sol.ode_sol(t; idxs=1)
+endfunction blowdown_temperature(bd::Blowdown{<:PressureODE}, t)
+ bdt = blowdown_time(bd)
+ t = min(t, bdt)
+ return bd.sol.ode_sol(t; idxs=3)
+endThe entire model, including all of the sub-models, is complicated and could easily have typos and hard to notice errors in it. An easy way to check this is to compare the results against the known analytic solution for the case where the gas is an ideal gas and the flow through the nozzle is always choked.
+struct IdealGasChoked{F <: Number}
+ P₀::F
+ k::F
+ τ::F
+endfunction adiabatic_choked_blowdown(model::IdealGas, pv::PressureVessel,
+ env::Environment)
+ # vessel parameters
+ c, A = pv.c, pv.A
+
+ # vessel initial conditions
+ V, T₀, m = pv.V, pv.T, pv.m
+ n₀ = m/molecular_weight(model)
+ v₀ = V/n₀
+ P₀ = pressure(model, v₀, T₀)
+
+ k, R, MW = model.k, model.R, model.MW
+ τ = 1/( (c*A/V)*√(k*R*T₀/MW)*(2/(k+1))^((k+1)/(2*(k-1))) )
+ return Blowdown(pv,env,IdealGasChoked(P₀,k,τ))
+endfunction blowdown_time(bd::Blowdown{<:IdealGasChoked})
+ P₀, Pₐ, k, τ = bd.sol.P₀, bd.env.P, bd.sol.k, bd.sol.τ
+ return (2τ/(1-k))*(1 - (Pₐ/P₀)^((1-k)/2k))
+endfunction blowdown_pressure(bd::Blowdown{<:IdealGasChoked}, t)
+ P₀, k, τ = bd.sol.P₀, bd.sol.k, bd.sol.τ
+ t = min(t, blowdown_time(bd))
+ return P₀*( 1 + 0.5*(k-1)*(t/τ))^((2*k)/(1-k))
+endfunction blowdown_temperature(bd::Blowdown{<:IdealGasChoked}, t)
+ T₀, P₀, k = bd.pv.T, bd.sol.P₀, bd.sol.k
+ t = min(t, blowdown_time(bd))
+ P = blowdown_pressure(bd, t)
+ return T₀*(P/P₀)^((k-1)/k)
+endThe same situation as the previous post on ideal gas blowdown is used here, a gas cylinder at 3000psia blowing down through a valve into the air. In this case the gas is nitrogen, instead of air, as having a single species is simpler than a mixture (though not by much).
+atm = Environment(101325,288.15)vessel = let
+ c = 0.85
+ D = 0.005 # m
+ A = 0.25*π*D^2 # m²
+ V = 0.01111 # m³
+ m = 2.743 # kg
+ T = 288.15 # K
+ PressureVessel(c, A, V, T, m)
+endThe real gas is modelled using a volume translated Peng-Robinson equation of state.
+using Clapeyron:PR, ReidIdeal, RackettTranslationnitrogen = PR(["nitrogen"]; idealmodel=ReidIdeal,
+ translation=RackettTranslation);ig_nitrogen = IdealGas(nitrogen);choked_model = adiabatic_choked_blowdown(ig_nitrogen, vessel, atm);ideal_gas = adiabatic_blowdown(ig_nitrogen, vessel, atm);real_gas = adiabatic_blowdown(nitrogen, vessel, atm); +
+The blowdown using an ideal gas equation of state matches the known solution for the entire domain where flow is actually choked. This gives some assurance that the general model is working properly. The real gas model, VTPR, appears to work well and is not too far from the ideal case, as expected.
+When I first played around with this I assumed flow through the nozzle was always choked (as a test) and this led to numerical difficulties near the end of the integration. I had to manually stop the integration at around 20s. Each subsequent time step would end up venting a physically unrealistic amount of material and the thermodynamic models would start to suffer from domain errors. Pleasingly, once a better model for the valve was swapped in, these problems went away.
+ +
+Another problem that can happen, depending upon the equation of state, is that the vessel may be outside the range where the equation of state can return a physically real gas. The temperature in the vessel, and especially within the nozzle, drops dramatically and in this case it drops below the boiling point of nitrogen by the time the vessel is fully depressured. This is a real result. It is not a consequence of some numerical error. It is a consequence of assuming a perfectly adiabatic vessel.
+Another way of approaching this problem is to perform a mass and energy balance. This is a more general approach and is what underlies more complex blowdown simulators (such as BLOWDOWN). Starting with a mass balance:
+\[ +\frac{dm}{dt} = -w +\]
+The energy balance is that the change in the internal energy within the vessel is equal to the rate of heat in, through the walls of the vessel, minus the rate of heat lost due to flow out of the vessel.
+\[ +\frac{dU}{dt} = Q_i - Q_o +\]
+\[ +\frac{dU}{dt} = Q_i - w \bar{h} +\]
+Where \(\bar{h}\) is the specific enthalpy, note this is at vessel conditions. The boundary for the energy balance is around the vessel, not including the valve.
+The total internal energy is the product of the mass remaining in the vessel and the specific internal energy, \(U=m \bar{u}\). Applying the chain rule:
+\[ +\frac{dU}{dt} = m \frac{d \bar{u}}{dt} + \bar{u} \frac{dm}{dt} = m \frac{d \bar{u}}{dt} - \bar{u} w +\]
+Combining these two expressions:
+\[ +\frac{d \bar{u}}{dt} = \frac{1}{m} \left( Q_i + \left(\bar{u} - \bar{h} \right) w \right) +\]
+The specific internal energy, \(\bar{u}\), is related to the molar internal energy, \(u\), by the molar weight, \(M \bar{u} = u\), similarly for the specific and molar enthalpy. Substituting and multiplying through by the molar weight gives:
+\[ +\frac{d u}{dt} = \frac{1}{m} \left( M Q_i + \left(u - h \right) w \right) +\]
+The remaining mass, \(m\), can be written in terms of the molar volume, \(v\):
+\[ +\frac{d u}{dt} = \frac{v}{M V} \left( M Q_i + \left(u - h \right) w \right) +\]
+The mass balance can also be written in terms of the molar volume:
+\[ +\frac{dv}{dt} = \frac{w v^2}{M V} +\]
+The full system of equations, in terms of \(u, v, T\) is then:
+\[ +\frac{d u}{dt} = \left( M Q_i + \left(u - h \right) w \right) \frac{v}{M V} +\]
+\[ +\frac{dv}{dt} = \frac{w v^2}{M V} +\]
+\[ +0 = u - internal\_energy(v, T) +\]
+The adiabatic case is the special case where \(Q_i = 0\).
+It is not immediately clear that this is the same model as the adiabatic pressure equation. The adiabatic pressure equation assumes the expansion within the vessel is isentropic, but that condition is not explicitly applied in the energy equation. One hint this is the same model is that the ideal gas solution can be derived from the energy balance.
+Consider an ideal gas with constant heat capacities such that \(u = c_v T\) and \(h = c_p T\). For the adiabatic case the energy balance becomes:
+\[ +c_v \frac{d T}{dt} = \frac{1}{m} \left( c_v T - c_p T \right) w +\]
+Isentropic choked flow of an ideal gas occurs with:
+\[ +w = c_d A \rho_t \sqrt{ \frac{k R T_t}{M} } +\]
+With nozzle density and temperature related to the vessel conditions by:
+\[ +\rho_t = \rho \left( 2 \over {k+1} \right)^{\frac{1}{k-1}} +\]
+\[ +T_t = T \left( 2 \over {k+1} \right) +\]
+Substituting all of this into the energy equation and dividing by \(c_v\) gives:
+\[ +\frac{dT}{dt} = \frac{c_d A}{V} \left( 1 - k \right) \left(2 \over {k+1} \right)^{\frac{k+1}{2(k-1)}} \sqrt{ \frac{k R T}{M} } T +\]
+Where \(k = \frac{c_p}{c_v}\). The time constant \(\tau\) is defined such that:
+\[ +\frac{1}{\tau} = \frac{c_d A}{V} \left(2 \over {k+1} \right)^{\frac{k+1}{2(k-1)}} \sqrt{ \frac{k R T_0}{M} } +\]
+Which simplifies the ODE to:
+\[ +\frac{dT}{dt} = \frac{1-k}{\tau} T \sqrt{\frac{T}{T_0}} +\]
+This is a separable equation and can be integrated to give:
+\[ +\frac{T}{T_0} = \left( 1 + \frac{k-1}{2} \frac{t}{\tau} \right)^{-2} +\]
+For an adiabatic expansion of an ideal gas:
+\[ +\frac{P}{P_0} = \left( \frac{T}{T_0} \right)^{\frac{k}{k-1}} +\]
+Which recovers the original solution:
+\[ +\frac{P}{P_0} = \left( 1 + \frac{k+1}{2} \frac{t}{\tau} \right)^{\frac{2k}{1-k}} +\]
+The governing equations for the vessel blowdown can be implemented as a DAE though, as the state variables, \(u, v, T\), no longer include pressure, determining when the vessel has fully depressured is slightly more complicated. The callback function must first calculate the pressure in the system. Previously, the callback function was a ContinuousCallback, which adjusts the final time step to exactly depressurize the vessel. Here the callback is a DiscreteCallback which terminates once a time step has crossed the threshold.
function energy_eqn!(dy, y, prms, t)
+ u, v, T = y
+
+ h = molar_enthalpy(prms.model, v, T)
+ w = mass_flow(prms.model, prms.pv, prms.env, v, T)
+ M = molecular_weight(prms.model)
+ V = prms.pv.V
+
+ dy .= [ (M*prms.Qᵢ(T) + (u-h)*w)*v/(M*V)
+ (w*v^2)/(M*V)
+ u - molar_internal_energy(prms.model, v, T) ]
+ return nothing
+endueqn_rhs = ODEFunction(energy_eqn!, mass_matrix = [ 1 0 0
+ 0 1 0
+ 0 0 0 ])depressured_callback_2(y, t, I; reltol=0.001) =
+ pressure(I.p.model, y[2], y[3]) < (1+reltol)*I.p.env.PTo generate the blowdown curve the pressure must be calculated, as it is no longer an output of the ODE. This could be done on demand, retrieving the molar volume and temperature for a given time and calculating the pressure. Another approach is to calculate the pressure at each time step and interpolate. This is implemented here as a SavingCallback, which calculates and saves the pressure after each time step. A cubic interpolation of the pressure is created from the results and used to generate the blowdown curve. The solution type contains two pieces: the ode solution and the pressure-time interpolation.
using DataInterpolationsstruct EnergyODE{S,I}
+ ode_sol::S
+ p_interp::I
+endfunction energy_eqn_blowdown(model, pv::PressureVessel,
+ env::Environment;
+ Qi=(T)->0.0,
+ solver=Rodas5(),
+ tspan=(0.0, 600.0))
+
+ # vessel initial conditions
+ V, T₀, m = pv.V, pv.T, pv.m
+ Mw = molecular_weight(model)
+ v₀ = Mw*V/m
+ u₀ = molar_internal_energy(model, v₀, T₀)
+
+ # defining the parameters
+ params = (model=model, pv=pv, env=env, Qᵢ=Qi)
+
+ # callbacks
+ svs = SavedValues(Float64, Float64)
+ svcb = SavingCallback((y, t, I) -> pressure(I.p.model,y[2],y[3]), svs)
+ dpcb = DiscreteCallback(depressured_callback_2, terminate!)
+ cbs = CallbackSet(svcb,dpcb)
+
+ # set up the ODEProblem and solve
+ y₀ = [u₀; v₀; T₀]
+ prob = ODEProblem(ueqn_rhs, y₀, tspan, params)
+ sol = solve(prob, solver; callback=cbs)
+
+ # set up pressure interpolation
+ pi = AkimaInterpolation(svs.saveval, svs.t)
+
+ return Blowdown(pv,env,EnergyODE(sol,pi))
+endThe methods for blowdown time, pressure, and temperature are easily implemented.
+blowdown_time(bd::Blowdown{<:EnergyODE}) =
+ bd.sol.ode_sol.t[end]function blowdown_pressure(bd::Blowdown{<:EnergyODE}, t)
+ bdt = blowdown_time(bd)
+ t = min(t, bdt)
+ return bd.sol.p_interp(t)
+endfunction blowdown_temperature(bd::Blowdown{<:EnergyODE}, t)
+ bdt = blowdown_time(bd)
+ t = min(t, bdt)
+ return bd.sol.ode_sol(t; idxs=3)
+endThe results from the energy model can be compared to the pressure model, they are functionally identical.
+ideal_gas_energybd = energy_eqn_blowdown(ig_nitrogen, vessel, atm);real_gas_energybd = energy_eqn_blowdown(nitrogen, vessel, atm); +
+ +
+I did not put a lot of effort into making exceptionally performant code. Firstly, the model for isentropic flow through the valve could be improved. Presumably this could also be incorporated into the governing equations of the ODEs, at a cost to model simplicity and reusability, which might unlock some performance opportunities.
+Given those limitations, the performance of the two models can be compared using BenchmarkTools.jl.
@benchmark adiabatic_blowdown(nitrogen, vessel, atm)BenchmarkTools.Trial: 42 samples with 1 evaluation.
+ Range (min … max): 111.588 ms … 149.424 ms ┊ GC (min … max): 0.00% … 20.45%
+ Time (median): 120.515 ms ┊ GC (median): 6.11%
+ Time (mean ± σ): 120.226 ms ± 5.882 ms ┊ GC (mean ± σ): 4.39% ± 4.00%
+
+ ▂ ██ ▅█ █
+ ▅██▁▅█▅▁▁▁▅▅███▅████▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▅ ▁
+ 112 ms Histogram: frequency by time 149 ms <
+
+ Memory estimate: 59.87 MiB, allocs estimate: 948090.The adiabatic blowdown using the energy model is about 35% faster than the pressure model. Partly this is due to the choice of terminating callbacks. Whether or not integration is terminated with a DiscreteCallback or a ContinuousCallback does not meaningfully change the performance for the pressure model. However, this choice dramatically changes the performance of the energy model. Changing to a ContinuousCallback erases the difference between the two models.
@benchmark energy_eqn_blowdown(nitrogen, vessel, atm)BenchmarkTools.Trial: 56 samples with 1 evaluation.
+ Range (min … max): 82.811 ms … 122.534 ms ┊ GC (min … max): 0.00% … 28.08%
+ Time (median): 89.420 ms ┊ GC (median): 0.00%
+ Time (mean ± σ): 89.381 ms ± 6.032 ms ┊ GC (mean ± σ): 4.05% ± 5.62%
+
+ ▂ ▂ ▂ ▂ █▂
+ █▅▅▅▁▅█▅█▅▅█▅▁▅▅██▅▁▁▁▁▁▁▁▁▁▅▁▁▁▁▅▁▁▁▁▅▅█▅██▁██▅█▁▁▅▅▁▅▁█▁▁▅ ▁
+ 82.8 ms Histogram: frequency by time 95.7 ms <
+
+ Memory estimate: 44.30 MiB, allocs estimate: 727470.The pressure model performance at the end of the blowdown is strongly dependent on whether molar volume is used as a state variable. When used as a state variable there is a major performance hit compared to moving the volume into the RHS, nearly double the compute time. Removing it as a state variable comes with a cost to the accuracy near the termination of the blowdown. It is not obvious to me why this is the case (maybe using volume as a system variable forces the solver to take smaller time steps?), but it hints that there are opportunities to improve the pressure model by tweaking how molar volume is incorporated.
+ +
+A big caveat to the kind of loose performance comparison I did here is that I did not define a metric for performance. If you wanted to more rigorously benchmark these two approaches defining what constitutes “good enough” in terms of the blowdown curve is necessary. You can always make a model faster by making it less precise.
+Extending the ideal gas blowdown to real gases using Clapeyron.jl is straightforward. Though the adiabatic case immediately calls into question the point in doing so. Even for a system as simple as a cylinder of nitrogen, the adiabatic assumption is too extreme to be plausible: it predicts the blowdown of a room temperature cylinder will result in a spray of liquid nitrogen. Really, though, the model breaks down once it results in the gas inside the vessel dropping below the boiling point while remaining a gas.
Rapid blowdowns often lead to cryogenic conditions where the assumption that the fluid in the vessel remains a gas becomes increasingly unlikely. The energy model given here can already accommodate variable heat transfer, for example \(Q = k \left( T - T_a \right)\), and it could be extended to include phase change by performing an isothermal flash calculation at each time step (and adjusting the enthalpy and internal energy calculations to account for the multiple phases). For a more realistic SCUBA tank model, this level of complexity isn’t needed, once a realistic heat transfer model is added the liquefaction problem would go away.
+Slower blowdowns, relative to the volume of the vessel, make more sense to model as always a gas. In these cases however, modelling the vessel as having no internal flow may be a serious limitation. Modelling the blowdown of pipeline segments, for example, without accounting for the frictional losses from internal flows leads to a significant error. I didn’t include an example of isothermal blowdowns here, but it is even easier to implement than the adiabatic case (for the pressure equation).
+I think there is a limited space between the pure ideal gas blowdown model and a full real fluid model with heat transfer &c. Most real situations either don’t require meticulously accounting for fluid non-ideality, and the ideal gas model works well enough, or are complex enough that a realistic model that includes phase change and heat transfer is required. However, building up from the ideal gas case step by step offers multiple points where the intermediate steps can be checked against known solutions. This is a useful exercise when building complex models, which can otherwise be difficult to test and troubleshoot.
+ + +In a previous post I modeled an example of a plume from an elevated stack. In that example I assumed very stable conditions and a low windspeed – pasquill stability class F and a windspeed of 1.5m/s – as the worst case. This was an error!
+For neutrally buoyant releases at or near ground-level that is a common “worst case”, for example when considering the potential impact due to a vapour cloud explosion. But for elevated stacks, releasing a buoyant plume, a class D stability with a moderate windspeed is often recommended. I thought it would be interesting to explore how the maximum concentration at the point of interest – an elevated work area downwind of the stack – varies with stability class and windspeed.
+I am not going to repeat all of the assumptions and working out of the previous notebook, the important results are in the source code for this post. I have also re-defined some of the functions to be a little more re-useable and to represent other stability cases not covered in the original notebook.
+As a refresher, Pasquill stability classes are a qualitative way of describing the atmospheric stability – the tendency of the atmosphere to resist or enhance vertical motion. Stability is itself related to the temperature gradient with height, wind speed, and various other things. For a simple model such as this the key model parameters are tabulated with respect to the Pasquill stability, which is why it is relevant to this discussion.
+| Stability Class | +Description | +
|---|---|
| A | +Extremely unstable | +
| B | +Unstable | +
| C | +Slightly unstable | +
| D | +Neutral | +
| E | +Slightly stable | +
| F | +Stable to extremely stable | +
In general the more stable the class the less dispersion, and thus the higher the concentration within the plume. Which is why class F is typically used for a ground level, neutrally buoyant, cloud. However plume rise is also a function of stability and, in general, more stable plumes rise without as much dispersion and thus the ground level concentration is lower than if the plume dispersed more. Furthermore the plume rise is a function of windspeed, the greater the windspeed the less the plume rises before leveling off and, again, the greater the ground level concentration.
+We can visualize the relationship between windspeed, stability class, and the concentration at the point of interest with the following plot which includes plume rise relationships for unstable, neutral, and stable atmospheres.
+
We note that, as we expect, lower stability (e.g. A or B) corresponds to a higher groundlevel concentration at low windspeed, but at high windspeed higher stability leads to a greater groundlevel concentration.
+At first blush it would appear that class F is still the worst case, however this plot naively assumes atmospheric stability is unrelated to windspeed. This is not true and roughly speaking the stability transitions towards classes C and D as the windspeed increases.
+| Windspeed (m/s) | +Strong | +Moderate | +Slight | +
|---|---|---|---|
| < 2 | +A | +A - B | +B | +
| 2 - 3 | +A - B | +B | +C | +
| 3 - 5 | +B | +B - C | +C | +
| 5 - 6 | +C | +C - D | +D | +
| > 6 | +C | +D | +D | +
| Windspeed (m/s) | +> 4/8 cloud | +< 3/8 cloud | +
|---|---|---|
| < 2 | ++ | + |
| 2 - 3 | +E | +F | +
| 3 - 5 | +D | +E | +
| 5 - 6 | +D | +D | +
| > 6 | +D | +D | +
To represent this crudely, the plots can be chopped off at the windspeed limits from the tables above. So, for example, the class F plot would end at 3m/s.
+The plots also present an obvious way of finding the worst case for a particular scenario: find the extremal point for the worst stability class. This is found rather simply by setting the derivative to zero. Something that would be complicated to do analytically but is quite straight forward when using the ForwardDiff library for automatic differentiation.
# ForwardDiff doesn't play nicely with unitful
+# so values have to be stripped of units first
+
+Fb′ = ustrip(Fb)
+x₁′ = ustrip(x₁)
+h₁′ = ustrip(h₁)
+Q′ = ustrip(Q)
+hₛ′ = ustrip(hₛ)
+
+∂Cᵤ(u) = ForwardDiff.derivative(u -> C(u, x=x₁′,
+ y=0.0,
+ z=h₁′,
+ Q=Q′,
+ h=hₛ′,
+ Δh=(x,u) -> Δhᵣ(x, u, Fb=Fb′, stable=false),
+ σy=σy("D"),
+ σz=σz("D")), float(u))∂Cᵤ (generic function with 1 method)# Find the point where ∂C/∂u = 0
+# Initial guess of 25 just by eye-ball
+
+u_worst = find_zero(∂Cᵤ, 25)
+
+C_worst = C(x₁, 0.0u"m", h₁,
+ u=u_worst*1u"m/s",
+ Q=Q,
+ h=hₛ,
+ Δh=(x,u) -> Δhᵣ(x, u, Fb=Fb, stable=false),
+ σy=σy("D"),
+ σz=σz("D"))
+
+uconvert(u"mg/m^3", C_worst)0.2753490886768969 mg m^-3
We find that the worst case is indeed class D but with quite a high windspeed, ~26.4m/s or 95kph, which would be considered a 10 on the Beaufort scale with trees being uprooted and considerable structural damage. It’s unlikely that workers would still be on the platform and it may not even be the case that the scaffolding would still be standing!
+Regardless we can look at the contour plots at the work platform elevation and vertically, along the centerline.
+Note the colours are scaled to 4mg/m^3, one tenth the occupational limit of 40mg/m^3.
+
Another interesting impact of elevated releases like this is that the worst concentration for an observer on the ground is often a significant distance downwind of the stack. Because the plume must disperse downwards.
+Below is a contour plot showing the downwind concentration at a 2m elevation – the height of a reasonably tall person. Note the scale is set to even lower concentrations. The maximum of the colour bar is 1000x lower than the occupational limit.
+
Previously, in the discussion of the occupational exposure limit I noted that, in general, one would have to account for the impact of multiple substances in the flue gas, though in that particular example I was only modeling carbon monoxide and I just moved on. I think I left the impression that one would have to model each substance separately and, at least with this simple gaussian dispersion model, that is very much not the case.
+Consider for some substance i being released with in-stack concentration \(C_{s,i}\), we can define a dimensionless “dilution” \(\chi\) as
+\[ \chi \left( x, y, z \right) = { C_i \left( x, y, z \right) \over C_{s,i} } \]
+Assuming the in-stack concentration to be simply the mass emission rate of i divided by the volumetric flow-rate1
+1 At standard state, because the concentrations given for the occupational exposure limits are given in terms of a volume at standard state. This is also a potential error in the original model as it does not correct the concentrations back to standard state, nor does it really track temperature to make that even possible, especially near the stack.
\[ C_{s,i} = { Q_i \over V_s^o } \]
+and recalling the concentration function from the gaussian dispersion model
+\[ C_i \left( x, y, z \right) = {Q_i \over 2 \pi u \sigma_{ye} \sigma_{ze} } f \left( x, y, z \right) \]
+where $ f ( x, y, z ) $ is the products of the exponentials, and is a function of x, y, z only. Putting all that together we get an expression for the dilution that does not depend upon the substance being released
+\[ \chi \left( x, y, z \right) = {V_s^o \over 2 \pi u \sigma_{ye} \sigma_{ze} } f \left( x, y, z \right) \]
+If you have already done the modeling for a particular substance then calculate \(\chi\) for the points of interest by dividing the concentrations by the in stack concentration, otherwise substitute the formula for \(\chi\) given above for the concentration and model that instead.
+Then, when evaluating multiple substances, the test2
+2 From CCOHS
\[ \sum_i {C_i \left( x, y, z \right) \over T_i } \lt 1 \]
+becomes
+\[ \chi \left( x, y, z \right) \cdot \sum_i {C_{s,i} \over T_i } \lt 1 \]
+where \(T_i\) is the relevant occupational exposure limit.
+To recap, instead of calculating the concentrations at the points of interest using a gaussian dispersion model multiple times, calculate a dimensionless dilution at the points of interest and apply that to the in stack concentrations of all of the substances of interest. Then combine those as per the relevant rules for occupational hygiene.
+Below are a series of contour plots showing the dilution \(\chi\), where colours are are from 0-5% – i.e. the concentration within the yellow region is ≥ 5% the in-stack concentration.
+Note: This is backwards to the usual way of defining dilution, where a \(\chi\) of 5% would be a 95% dilution.
+
A simple way of taking the work from a previous notebook and adding to it is just to import the notebook. This loads the results into the current notebook including any function definitions and such.
+For example
+
+using NBInclude
+@nbinclude("2020-12-05-gaussian_dispersion_example.ipynb")I didn’t do that here for two reasons:
+The second point is worth going into if one wants to build a library of worked out, generic, models as notebooks. This way an engineer can import previously defined models as needed for a particular analysis while also keeping the documentation for the models in the model. In the previous notebook I left most things in the global namespace and defined functions that used those global variables. Which is fine for that particular notebook but it means that the current workspace gets very cluttered when importing things and also those functions are not very re-usable as they were defined for a very particular example.
+It’s better, I think, to write functions that use keyword arguments for any important parameters that can then be passed as needed, instead of defining those parameters in the global namespace. Unless they are truly constants, like g the acceleration due to gravity or R the universal gas constant.
+Another point is on the use of the library Unitful. It is convenient, and a good check, to have units propagate through calculations, however Unitful does not play nicely with all libraries. This is especially the case with Plots but it can also be real hassle to use with correlations that have lots of parameters. I think this is a good opportunity to take advantage of julia’s multiple dispatch.
For example, suppose a correlation of the form \(f \left( x \right) = a \cdot x^b\), this can be written in julia very simply (supposing a and b are parameters)
+
+f(x; a, b) = a*x^bBut if we pass x with some units and don’t pass the matching units with the parameter a this will throw an error. We could tediously work out the units for each set of parameters a and b to make the units cancel out properly, or we could use multiple dispatch to manage this for us
+
+function f(x::Quantity; a, b)::Quantity
+ x′ = ustrip(u"expected input unit", x)
+ return f(x′, a=a, b=b)*1u"correlation output unit"
+endWhere we convert the input to the expected units, whatever they may be, evaluate the function in a unitless way, then tack on the expected output units at the end. Now when we use f(x) in contexts without units, for example when plotting f(x), it works as expected and if we pass a value of x with units attached we get the unit conversion/checking that we want from Unitful.
![]()
![]()
![]()
![]()
![]()
GasDispersion.jl aims to bring together several models for dispersion modelling of chemical releases with a consistent interface. Currently it implements several Gaussian dispersion models, the Britter-McQuaid dense gas dispersion model, a subset of the SLAB dense gas dispersion model, and others.
+



![]()
A collection of programs written in PicoMite BASIC for the PicoCalc.
+The programs are organized into the following categories:
+math\ BASIC code for doing mathart\ BASIC code for generating cool visualizations and artutils\ useful utilitiestoys\ little toy programs



![]()
![]()
![]()
A python module for logging data from an AtmoTube via bluetooth. Very much in development.
+PymoTube is currently just a set of helper functions and classes for taking bytearrays returned by the AtmoTube and turning it into a basic struct. The actual connection to the AtmoTube is managed by Bleak. A minimal example of connecting to an AtmoTube and logging results into an asynchronous queue is shown here
+As an example of how to use this, consider the case where you want to connect to your AtmoTube from a PC, log data from it over a pre-defined period, then exit. This will be done asynchronously and the retrieved data put into an asynchronous queue for processing.
+The first step is to create a function which connects to the AtmoTube, collects data, and then puts that data into a queue.
+from bleak import BleakClient, BleakScanner
+from atmotube import start_gatt_notifications, get_available_services
+import asyncio
+
+
+async def collect_data(mac, queue, collection_time):
+1 async def callback_queue(packet):
+ await queue.put(packet)
+
+2 device = await BleakScanner.find_device_by_address(mac)
+ if not device:
+ raise Exception("Device not found")
+
+3 async with BleakClient(device) as client:
+ if not client.is_connected:
+ raise Exception("Failed to connect to device")
+4 packet_list = get_available_services(client)
+5 await start_gatt_notifications(client, callback_queue,
+ packet_list=packet_list)
+6 await asyncio.sleep(collection_time)
+7 await queue.put(None)get_available_services function with the connected device, this generates a list of GATT services that both the atmotube library knows about and the AtmoTube device supports.
+None on the queue to indicate that the collection has ended.
+What ends up on the queue is a series of AtmoTubePacket objects representing the different types of data packets the AtmoTube returns. Each packet has an associated datetime object representing the time when the packet was received. As a somewhat silly example, this takes those packets and logs them to the logger – a more realistic thing to do might be to put the data in a database or append the data to a CSV.
from atmotube import SPS30Packet, StatusPacket, BME280Packet, SGPC3Packet
+
+import logging
+
+
+def log_packet(packet):
+1 match packet:
+ case AtmotubeProStatus():
+2 logging.info(f"{str(packet.date_time)} - Status Packet - "
+ f"Battery: {packet.battery_level}%, "
+ f"PM Sensor: {packet.pm_sensor_status}, "
+ f"Pre-heating: {packet.pre_heating}, "
+ f"Error: {packet.error_flag}")
+ case AtmotubeProSPS30():
+ logging.info(f"{str(packet.date_time)} - SPS30 Packet - "
+ f"PM1: {packet.pm1} µg/m³, "
+ f"PM2.5: {packet.pm2_5} µg/m³, "
+ f"PM4: {packet.pm4} µg/m³, "
+ f"PM10: {packet.pm10} µg/m³")
+ case AtmotubeProBME280():
+ logging.info(f"{str(packet.date_time)} - BME280 Packet - "
+ f"Humidity: {packet.humidity}%, "
+ f"Temperature: {packet.temperature}°C, "
+ f"Pressure: {packet.pressure} mbar")
+ case AtmotubeProSGPC3():
+ logging.info(f"{str(packet.date_time)} - SGPC3 Packet - "
+ f"TVOC: {packet.tvoc} ppb")
+ case _:
+ logging.info("Unknown packet type")Finally, an asynchronous event loop is created which runs the collector and then logs the data.
+ATMOTUBE = "00:00:00:00:00:00" # the mac address of the ATMOTUBE
+
+def main():
+ mac = ATMOTUBE
+ collection_time = 60 # seconds
+1 queue = asyncio.Queue()
+
+2 async def runner():
+3 collector = asyncio.create_task(
+ collect_data(mac, queue, collection_time)
+ )
+4 while True:
+ item = await queue.get()
+ if item is None:
+ break
+ log_packet(item)
+ await collector
+
+ asyncio.run(runner())
+
+
+if __name__ == "__main__":
+ logging.basicConfig(level=logging.INFO)
+ main()runner function to handle the main sequence of events
+log_packet
+![]()
A simple macro for working with empirical correlations and Unitful.
UnitfulCorrelations.jl can be installed using Julia’s built-in package manager. In a Julia session, enter the package manager mode by hitting ], then run the command
pkg> add https://github.com/aefarrell/UnitfulCorrelations.jlSuppose you have an empirical correlation \(f(x) = 0.92 x^{0.2}\), where it is given that \(x\) is in meters and \(f\) is in seconds. You could figure out the units that the constants must have to make everything work out, or write a function that uses ustrip() to manage units, but that can get tedious if there are a lot of these.
The macro @ucorrel does this for you, adding another method for the case where the function is called with units. The arguments are: function (or function block), input units, output units.
+f(x) = 0.92*x^0.2
+@ucorrel f u"m" u"s"
+
+# f(2) == 1.0568024865972723
+# f(2 u"m") == 1.0568024865972723 u"s"this can also be done with a function block
+
+@ucorrel function f(x)
+ return 0.92*x^0.2
+end u"m" u"s"
+
+# f(2) == 1.0568024865972723
+# f(2 u"m") == 1.0568024865972723 u"s"So far it only supports one dimensional correlations, because I have basically just copied over a macro that I use frequently and have not added anything to its functionality.
+ + +${missingFields[0]} field.`,
+ message: `The items being returned for this search do not include all the required fields. Please ensure that your index items include the ${missingFields[0]} field or use index-fields in your _quarto.yml file to specify the field names.`,
+ };
+ } else if (missingFields.length > 1) {
+ const missingFieldList = missingFields
+ .map((field) => {
+ return `${field}`;
+ })
+ .join(", ");
+
+ throw {
+ name: `Error: Search index is missing the following fields: ${missingFieldList}.`,
+ message: `The items being returned for this search do not include all the required fields. Please ensure that your index items includes the following fields: ${missingFieldList}, or use index-fields in your _quarto.yml file to specify the field names.`,
+ };
+ }
+ }
+}
+
+let lastQuery = null;
+function showCopyLink(query, options) {
+ const language = options.language;
+ lastQuery = query;
+ // Insert share icon
+ const inputSuffixEl = window.document.body.querySelector(
+ ".aa-Form .aa-InputWrapperSuffix"
+ );
+
+ if (inputSuffixEl) {
+ let copyButtonEl = window.document.body.querySelector(
+ ".aa-Form .aa-InputWrapperSuffix .aa-CopyButton"
+ );
+
+ if (copyButtonEl === null) {
+ copyButtonEl = window.document.createElement("button");
+ copyButtonEl.setAttribute("class", "aa-CopyButton");
+ copyButtonEl.setAttribute("type", "button");
+ copyButtonEl.setAttribute("title", language["search-copy-link-title"]);
+ copyButtonEl.onmousedown = (e) => {
+ e.preventDefault();
+ e.stopPropagation();
+ };
+
+ const linkIcon = "bi-clipboard";
+ const checkIcon = "bi-check2";
+
+ const shareIconEl = window.document.createElement("i");
+ shareIconEl.setAttribute("class", `bi ${linkIcon}`);
+ copyButtonEl.appendChild(shareIconEl);
+ inputSuffixEl.prepend(copyButtonEl);
+
+ const clipboard = new window.ClipboardJS(".aa-CopyButton", {
+ text: function (_trigger) {
+ const copyUrl = new URL(window.location);
+ copyUrl.searchParams.set(kQueryArg, lastQuery);
+ copyUrl.searchParams.set(kResultsArg, "1");
+ return copyUrl.toString();
+ },
+ });
+ clipboard.on("success", function (e) {
+ // Focus the input
+
+ // button target
+ const button = e.trigger;
+ const icon = button.querySelector("i.bi");
+
+ // flash "checked"
+ icon.classList.add(checkIcon);
+ icon.classList.remove(linkIcon);
+ setTimeout(function () {
+ icon.classList.remove(checkIcon);
+ icon.classList.add(linkIcon);
+ }, 1000);
+ });
+ }
+
+ // If there is a query, show the link icon
+ if (copyButtonEl) {
+ if (lastQuery && options["copy-button"]) {
+ copyButtonEl.style.display = "flex";
+ } else {
+ copyButtonEl.style.display = "none";
+ }
+ }
+ }
+}
+
+/* Search Index Handling */
+// create the index
+var fuseIndex = undefined;
+var shownWarning = false;
+
+// fuse index options
+const kFuseIndexOptions = {
+ keys: [
+ { name: "title", weight: 20 },
+ { name: "section", weight: 20 },
+ { name: "text", weight: 10 },
+ ],
+ ignoreLocation: true,
+ threshold: 0.1,
+};
+
+async function readSearchData() {
+ // Initialize the search index on demand
+ if (fuseIndex === undefined) {
+ if (window.location.protocol === "file:" && !shownWarning) {
+ window.alert(
+ "Search requires JavaScript features disabled when running in file://... URLs. In order to use search, please run this document in a web server."
+ );
+ shownWarning = true;
+ return;
+ }
+ const fuse = new window.Fuse([], kFuseIndexOptions);
+
+ // fetch the main search.json
+ const response = await fetch(offsetURL("search.json"));
+ if (response.status == 200) {
+ return response.json().then(function (searchDocs) {
+ searchDocs.forEach(function (searchDoc) {
+ fuse.add(searchDoc);
+ });
+ fuseIndex = fuse;
+ return fuseIndex;
+ });
+ } else {
+ return Promise.reject(
+ new Error(
+ "Unexpected status from search index request: " + response.status
+ )
+ );
+ }
+ }
+
+ return fuseIndex;
+}
+
+function inputElement() {
+ return window.document.body.querySelector(".aa-Form .aa-Input");
+}
+
+function focusSearchInput() {
+ setTimeout(() => {
+ const inputEl = inputElement();
+ if (inputEl) {
+ inputEl.focus();
+ }
+ }, 50);
+}
+
+/* Panels */
+const kItemTypeDoc = "document";
+const kItemTypeMore = "document-more";
+const kItemTypeItem = "document-item";
+const kItemTypeError = "error";
+
+function renderItem(
+ item,
+ createElement,
+ state,
+ setActiveItemId,
+ setContext,
+ refresh,
+ quartoSearchOptions
+) {
+ switch (item.type) {
+ case kItemTypeDoc:
+ return createDocumentCard(
+ createElement,
+ "file-richtext",
+ item.title,
+ item.section,
+ item.text,
+ item.href,
+ item.crumbs,
+ quartoSearchOptions
+ );
+ case kItemTypeMore:
+ return createMoreCard(
+ createElement,
+ item,
+ state,
+ setActiveItemId,
+ setContext,
+ refresh
+ );
+ case kItemTypeItem:
+ return createSectionCard(
+ createElement,
+ item.section,
+ item.text,
+ item.href
+ );
+ case kItemTypeError:
+ return createErrorCard(createElement, item.title, item.text);
+ default:
+ return undefined;
+ }
+}
+
+function createDocumentCard(
+ createElement,
+ icon,
+ title,
+ section,
+ text,
+ href,
+ crumbs,
+ quartoSearchOptions
+) {
+ const iconEl = createElement("i", {
+ class: `bi bi-${icon} search-result-icon`,
+ });
+ const titleEl = createElement("p", { class: "search-result-title" }, title);
+ const titleContents = [iconEl, titleEl];
+ const showParent = quartoSearchOptions["show-item-context"];
+ if (crumbs && showParent) {
+ let crumbsOut = undefined;
+ const crumbClz = ["search-result-crumbs"];
+ if (showParent === "root") {
+ crumbsOut = crumbs.length > 1 ? crumbs[0] : undefined;
+ } else if (showParent === "parent") {
+ crumbsOut = crumbs.length > 1 ? crumbs[crumbs.length - 2] : undefined;
+ } else {
+ crumbsOut = crumbs.length > 1 ? crumbs.join(" > ") : undefined;
+ crumbClz.push("search-result-crumbs-wrap");
+ }
+
+ const crumbEl = createElement(
+ "p",
+ { class: crumbClz.join(" ") },
+ crumbsOut
+ );
+ titleContents.push(crumbEl);
+ }
+
+ const titleContainerEl = createElement(
+ "div",
+ { class: "search-result-title-container" },
+ titleContents
+ );
+
+ const textEls = [];
+ if (section) {
+ const sectionEl = createElement(
+ "p",
+ { class: "search-result-section" },
+ section
+ );
+ textEls.push(sectionEl);
+ }
+ const descEl = createElement("p", {
+ class: "search-result-text",
+ dangerouslySetInnerHTML: {
+ __html: text,
+ },
+ });
+ textEls.push(descEl);
+
+ const textContainerEl = createElement(
+ "div",
+ { class: "search-result-text-container" },
+ textEls
+ );
+
+ const containerEl = createElement(
+ "div",
+ {
+ class: "search-result-container",
+ },
+ [titleContainerEl, textContainerEl]
+ );
+
+ const linkEl = createElement(
+ "a",
+ {
+ href: offsetURL(href),
+ class: "search-result-link",
+ },
+ containerEl
+ );
+
+ const classes = ["search-result-doc", "search-item"];
+ if (!section) {
+ classes.push("document-selectable");
+ }
+
+ return createElement(
+ "div",
+ {
+ class: classes.join(" "),
+ },
+ linkEl
+ );
+}
+
+function createMoreCard(
+ createElement,
+ item,
+ state,
+ setActiveItemId,
+ setContext,
+ refresh
+) {
+ const moreCardEl = createElement(
+ "div",
+ {
+ class: "search-result-more search-item",
+ onClick: (e) => {
+ // Handle expanding the sections by adding the expanded
+ // section to the list of expanded sections
+ toggleExpanded(item, state, setContext, setActiveItemId, refresh);
+ e.stopPropagation();
+ },
+ },
+ item.title
+ );
+
+ return moreCardEl;
+}
+
+function toggleExpanded(item, state, setContext, setActiveItemId, refresh) {
+ const expanded = state.context.expanded || [];
+ if (expanded.includes(item.target)) {
+ setContext({
+ expanded: expanded.filter((target) => target !== item.target),
+ });
+ } else {
+ setContext({ expanded: [...expanded, item.target] });
+ }
+
+ refresh();
+ setActiveItemId(item.__autocomplete_id);
+}
+
+function createSectionCard(createElement, section, text, href) {
+ const sectionEl = createSection(createElement, section, text, href);
+ return createElement(
+ "div",
+ {
+ class: "search-result-doc-section search-item",
+ },
+ sectionEl
+ );
+}
+
+function createSection(createElement, title, text, href) {
+ const descEl = createElement("p", {
+ class: "search-result-text",
+ dangerouslySetInnerHTML: {
+ __html: text,
+ },
+ });
+
+ const titleEl = createElement("p", { class: "search-result-section" }, title);
+ const linkEl = createElement(
+ "a",
+ {
+ href: offsetURL(href),
+ class: "search-result-link",
+ },
+ [titleEl, descEl]
+ );
+ return linkEl;
+}
+
+function createErrorCard(createElement, title, text) {
+ const descEl = createElement("p", {
+ class: "search-error-text",
+ dangerouslySetInnerHTML: {
+ __html: text,
+ },
+ });
+
+ const titleEl = createElement("p", {
+ class: "search-error-title",
+ dangerouslySetInnerHTML: {
+ __html: ` ${title}`,
+ },
+ });
+ const errorEl = createElement("div", { class: "search-error" }, [
+ titleEl,
+ descEl,
+ ]);
+ return errorEl;
+}
+
+function positionPanel(pos) {
+ const panelEl = window.document.querySelector(
+ "#quarto-search-results .aa-Panel"
+ );
+ const inputEl = window.document.querySelector(
+ "#quarto-search .aa-Autocomplete"
+ );
+
+ if (panelEl && inputEl) {
+ panelEl.style.top = `${Math.round(panelEl.offsetTop)}px`;
+ if (pos === "start") {
+ panelEl.style.left = `${Math.round(inputEl.left)}px`;
+ } else {
+ panelEl.style.right = `${Math.round(inputEl.offsetRight)}px`;
+ }
+ }
+}
+
+/* Highlighting */
+// highlighting functions
+function highlightMatch(query, text) {
+ if (text) {
+ const start = text.toLowerCase().indexOf(query.toLowerCase());
+ if (start !== -1) {
+ const startMark = "";
+ const endMark = "";
+
+ const end = start + query.length;
+ text =
+ text.slice(0, start) +
+ startMark +
+ text.slice(start, end) +
+ endMark +
+ text.slice(end);
+ const startInfo = clipStart(text, start);
+ const endInfo = clipEnd(
+ text,
+ startInfo.position + startMark.length + endMark.length
+ );
+ text =
+ startInfo.prefix +
+ text.slice(startInfo.position, endInfo.position) +
+ endInfo.suffix;
+
+ return text;
+ } else {
+ return text;
+ }
+ } else {
+ return text;
+ }
+}
+
+function clipStart(text, pos) {
+ const clipStart = pos - 50;
+ if (clipStart < 0) {
+ // This will just return the start of the string
+ return {
+ position: 0,
+ prefix: "",
+ };
+ } else {
+ // We're clipping before the start of the string, walk backwards to the first space.
+ const spacePos = findSpace(text, pos, -1);
+ return {
+ position: spacePos.position,
+ prefix: "",
+ };
+ }
+}
+
+function clipEnd(text, pos) {
+ const clipEnd = pos + 200;
+ if (clipEnd > text.length) {
+ return {
+ position: text.length,
+ suffix: "",
+ };
+ } else {
+ const spacePos = findSpace(text, clipEnd, 1);
+ return {
+ position: spacePos.position,
+ suffix: spacePos.clipped ? "…" : "",
+ };
+ }
+}
+
+function findSpace(text, start, step) {
+ let stepPos = start;
+ while (stepPos > -1 && stepPos < text.length) {
+ const char = text[stepPos];
+ if (char === " " || char === "," || char === ":") {
+ return {
+ position: step === 1 ? stepPos : stepPos - step,
+ clipped: stepPos > 1 && stepPos < text.length,
+ };
+ }
+ stepPos = stepPos + step;
+ }
+
+ return {
+ position: stepPos - step,
+ clipped: false,
+ };
+}
+
+// removes highlighting as implemented by the mark tag
+function clearHighlight(searchterm, el) {
+ const childNodes = el.childNodes;
+ for (let i = childNodes.length - 1; i >= 0; i--) {
+ const node = childNodes[i];
+ if (node.nodeType === Node.ELEMENT_NODE) {
+ if (
+ node.tagName === "MARK" &&
+ node.innerText.toLowerCase() === searchterm.toLowerCase()
+ ) {
+ el.replaceChild(document.createTextNode(node.innerText), node);
+ } else {
+ clearHighlight(searchterm, node);
+ }
+ }
+ }
+}
+
+function escapeRegExp(string) {
+ return string.replace(/[.*+?^${}()|[\]\\]/g, "\\$&"); // $& means the whole matched string
+}
+
+// highlight matches
+function highlight(term, el) {
+ const termRegex = new RegExp(term, "ig");
+ const childNodes = el.childNodes;
+
+ // walk back to front avoid mutating elements in front of us
+ for (let i = childNodes.length - 1; i >= 0; i--) {
+ const node = childNodes[i];
+
+ if (node.nodeType === Node.TEXT_NODE) {
+ // Search text nodes for text to highlight
+ const text = node.nodeValue;
+
+ let startIndex = 0;
+ let matchIndex = text.search(termRegex);
+ if (matchIndex > -1) {
+ const markFragment = document.createDocumentFragment();
+ while (matchIndex > -1) {
+ const prefix = text.slice(startIndex, matchIndex);
+ markFragment.appendChild(document.createTextNode(prefix));
+
+ const mark = document.createElement("mark");
+ mark.appendChild(
+ document.createTextNode(
+ text.slice(matchIndex, matchIndex + term.length)
+ )
+ );
+ markFragment.appendChild(mark);
+
+ startIndex = matchIndex + term.length;
+ matchIndex = text.slice(startIndex).search(new RegExp(term, "ig"));
+ if (matchIndex > -1) {
+ matchIndex = startIndex + matchIndex;
+ }
+ }
+ if (startIndex < text.length) {
+ markFragment.appendChild(
+ document.createTextNode(text.slice(startIndex, text.length))
+ );
+ }
+
+ el.replaceChild(markFragment, node);
+ }
+ } else if (node.nodeType === Node.ELEMENT_NODE) {
+ // recurse through elements
+ highlight(term, node);
+ }
+ }
+}
+
+/* Link Handling */
+// get the offset from this page for a given site root relative url
+function offsetURL(url) {
+ var offset = getMeta("quarto:offset");
+ return offset ? offset + url : url;
+}
+
+// read a meta tag value
+function getMeta(metaName) {
+ var metas = window.document.getElementsByTagName("meta");
+ for (let i = 0; i < metas.length; i++) {
+ if (metas[i].getAttribute("name") === metaName) {
+ return metas[i].getAttribute("content");
+ }
+ }
+ return "";
+}
+
+function algoliaSearch(query, limit, algoliaOptions) {
+ const { getAlgoliaResults } = window["@algolia/autocomplete-preset-algolia"];
+
+ const applicationId = algoliaOptions["application-id"];
+ const searchOnlyApiKey = algoliaOptions["search-only-api-key"];
+ const indexName = algoliaOptions["index-name"];
+ const indexFields = algoliaOptions["index-fields"];
+ const searchClient = window.algoliasearch(applicationId, searchOnlyApiKey);
+ const searchParams = algoliaOptions["params"];
+ const searchAnalytics = !!algoliaOptions["analytics-events"];
+
+ return getAlgoliaResults({
+ searchClient,
+ queries: [
+ {
+ indexName: indexName,
+ query,
+ params: {
+ hitsPerPage: limit,
+ clickAnalytics: searchAnalytics,
+ ...searchParams,
+ },
+ },
+ ],
+ transformResponse: (response) => {
+ if (!indexFields) {
+ return response.hits.map((hit) => {
+ return hit.map((item) => {
+ return {
+ ...item,
+ text: highlightMatch(query, item.text),
+ };
+ });
+ });
+ } else {
+ const remappedHits = response.hits.map((hit) => {
+ return hit.map((item) => {
+ const newItem = { ...item };
+ ["href", "section", "title", "text", "crumbs"].forEach(
+ (keyName) => {
+ const mappedName = indexFields[keyName];
+ if (
+ mappedName &&
+ item[mappedName] !== undefined &&
+ mappedName !== keyName
+ ) {
+ newItem[keyName] = item[mappedName];
+ delete newItem[mappedName];
+ }
+ }
+ );
+ newItem.text = highlightMatch(query, newItem.text);
+ return newItem;
+ });
+ });
+ return remappedHits;
+ }
+ },
+ });
+}
+
+let subSearchTerm = undefined;
+let subSearchFuse = undefined;
+const kFuseMaxWait = 125;
+
+async function fuseSearch(query, fuse, fuseOptions) {
+ let index = fuse;
+ // Fuse.js using the Bitap algorithm for text matching which runs in
+ // O(nm) time (no matter the structure of the text). In our case this
+ // means that long search terms mixed with large index gets very slow
+ //
+ // This injects a subIndex that will be used once the terms get long enough
+ // Usually making this subindex is cheap since there will typically be
+ // a subset of results matching the existing query
+ if (subSearchFuse !== undefined && query.startsWith(subSearchTerm)) {
+ // Use the existing subSearchFuse
+ index = subSearchFuse;
+ } else if (subSearchFuse !== undefined) {
+ // The term changed, discard the existing fuse
+ subSearchFuse = undefined;
+ subSearchTerm = undefined;
+ }
+
+ // Search using the active fuse
+ const then = performance.now();
+ const resultsRaw = await index.search(query, fuseOptions);
+ const now = performance.now();
+
+ const results = resultsRaw.map((result) => {
+ const addParam = (url, name, value) => {
+ const anchorParts = url.split("#");
+ const baseUrl = anchorParts[0];
+ const sep = baseUrl.search("\\?") > 0 ? "&" : "?";
+ anchorParts[0] = baseUrl + sep + name + "=" + value;
+ return anchorParts.join("#");
+ };
+
+ return {
+ title: result.item.title,
+ section: result.item.section,
+ href: addParam(result.item.href, kQueryArg, query),
+ text: highlightMatch(query, result.item.text),
+ crumbs: result.item.crumbs,
+ };
+ });
+
+ // If we don't have a subfuse and the query is long enough, go ahead
+ // and create a subfuse to use for subsequent queries
+ if (
+ now - then > kFuseMaxWait &&
+ subSearchFuse === undefined &&
+ resultsRaw.length < fuseOptions.limit
+ ) {
+ subSearchTerm = query;
+ subSearchFuse = new window.Fuse([], kFuseIndexOptions);
+ resultsRaw.forEach((rr) => {
+ subSearchFuse.add(rr.item);
+ });
+ }
+ return results;
+}
diff --git a/sitemap.xml b/sitemap.xml
new file mode 100644
index 0000000..d99d465
--- /dev/null
+++ b/sitemap.xml
@@ -0,0 +1,175 @@
+
+ +
+ +
+ +
+





 +
+
 +
+
 +
+

 +
+
 +
+

 +
+ +
+


 +
+ +
+


 +
+

 +
+ +
+ +
+ +
+{kind=link}