|
| 1 | +## 一、Phoenix 简介 |
| 2 | + |
| 3 | +Phoenix 最早是 saleforce 的一个开源项目,后来成为 Apache 的顶级项目。 |
| 4 | + |
| 5 | +Phoenix 构建在 HBase 之上的开源 SQL 层。能够让我们使用标准的 JDBC API 去建表, 插入数据和查询 HBase 中的数据, 从而可以避免使用 HBase 的客户端 API。在我们的应用和 HBase 之间添加了 Phoenix, 并不会降低性能, 而且我们也少写了很多代码。 |
| 6 | + |
| 7 | +phoneix的本质就是定义了大量的协处理器,使用协处理器帮助我们完成HBase的操作! |
| 8 | + |
| 9 | + |
| 10 | + |
| 11 | +## 二、Phoenix 特点 |
| 12 | + |
| 13 | +将 SQL 查询编译为 HBase 扫描 |
| 14 | +确定扫描 Rowkey 的最佳开始和结束位置 |
| 15 | +扫描并行执行 |
| 16 | +将 where 子句推送到服务器端的过滤器 |
| 17 | +通过协处理器进行聚合操作 |
| 18 | +完美支持 HBase 二级索引创建 |
| 19 | +DML命令以及通过DDL命令创建和操作表和版本化增量更改。 |
| 20 | +容易集成:如Spark,Hive,Pig,Flume和Map Reduce。 |
| 21 | + |
| 22 | + |
| 23 | + |
| 24 | +## 三、Phoenix 架构 |
| 25 | + |
| 26 | +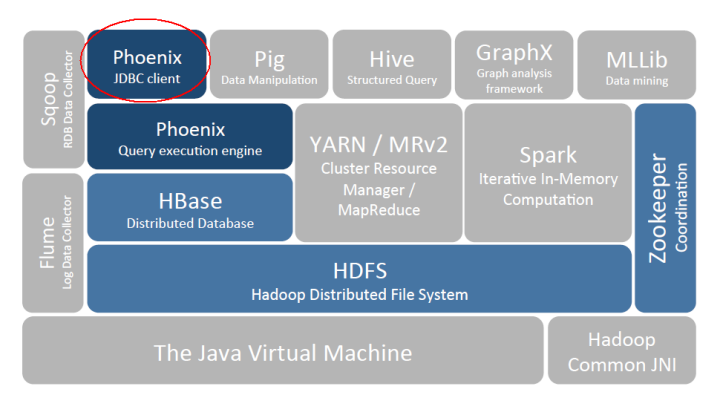 |
| 27 | + |
| 28 | + |
| 29 | + |
| 30 | +## 四、和Hbase中数据的关系映射 |
| 31 | + |
| 32 | +| 模型 | HBase | Phoneix(SQL) | |
| 33 | +| ---- | ------------------------------------ | ------------------------ | |
| 34 | +| 库 | namespace | database | |
| 35 | +| 表 | table | table | |
| 36 | +| 列族 | column Family cf:cq | 列 | |
| 37 | +| 列名 | column Quailfier | | |
| 38 | +| 值 | value | | |
| 39 | +| 行键 | rowkey(唯一) dt\|area\|city\|adsid | 主键(dt,area,city,adsid) | |
| 40 | + |
| 41 | + Phoenix 将 HBase 的数据模型映射到关系型模型中! |
| 42 | + |
| 43 | +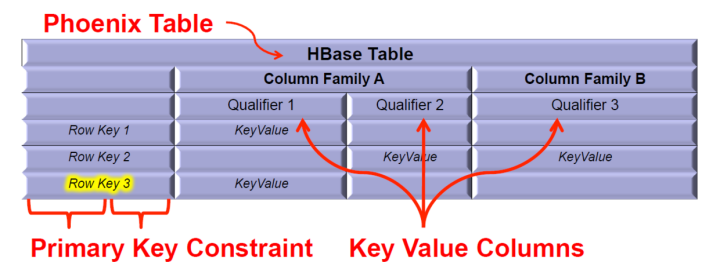 |
| 44 | + |
| 45 | +## 五、Phoenix使用场景 |
| 46 | + |
| 47 | +### 5.1 场景一:新建表 |
| 48 | + |
| 49 | +通过phoneix在hbase中创建表,通过phoneix向hbase的表执行增删改查! |
| 50 | + |
| 51 | +```sql |
| 52 | +--使用默认的0号列族 |
| 53 | +CREATE TABLE IF NOT EXISTS "us_population" ( |
| 54 | + state CHAR(2) NOT NULL, |
| 55 | + city VARCHAR NOT NULL, |
| 56 | + population BIGINT |
| 57 | + CONSTRAINT my_pk PRIMARY KEY (state, city)); |
| 58 | + |
| 59 | +--如果希望列族有意义 |
| 60 | +CREATE TABLE IF NOT EXISTS us_population ( |
| 61 | + state CHAR(2) NOT NULL, |
| 62 | + city VARCHAR NOT NULL, |
| 63 | + info.population BIGINT |
| 64 | + CONSTRAINT my_pk PRIMARY KEY (state, city)); |
| 65 | + |
| 66 | +``` |
| 67 | + |
| 68 | +默认所有的小写,都会转大写!在查询时的小写也会转大写! |
| 69 | + |
| 70 | +如果必须用小写,需要加"", 在以后操作时,都需要加"",尽量不要使用小写! |
| 71 | + |
| 72 | +### 5.2 场景二:映射Hbase中已有表 |
| 73 | + |
| 74 | +hbase中已经存在了一个表,在phoneix中建表,映射上,进行操作! |
| 75 | + |
| 76 | +在phoneix中,只读操作! 创建一个View! |
| 77 | + |
| 78 | +```sql |
| 79 | +CREATE VIEW IF NOT EXISTS "t2" ( |
| 80 | + id VARCHAR PRIMARY KEY , |
| 81 | + "cf1"."name" VARCHAR , |
| 82 | + "cf2"."age" VARCHAR , |
| 83 | + "cf2"."gender" VARCHAR |
| 84 | + ); |
| 85 | + |
| 86 | +``` |
| 87 | + |
| 88 | +在phoneix中,可读可写操作! 创建一个Table! |
| 89 | + |
| 90 | +```sql |
| 91 | +CREATE TABLE IF NOT EXISTS "t4" ( |
| 92 | + id VARCHAR PRIMARY KEY , |
| 93 | + "cf1"."name" VARCHAR , |
| 94 | + "cf2"."age" VARCHAR , |
| 95 | + "cf2"."gender" VARCHAR |
| 96 | + ) column_encoded_bytes=0; |
| 97 | +``` |
| 98 | + |
| 99 | + |
| 100 | + |
| 101 | +## 六、Phoenix使用语法 |
| 102 | + |
| 103 | +进入Phoenix客户端界面 |
| 104 | + |
| 105 | +``` |
| 106 | +[hadoop@hadoop101 phoenix]$ /opt/module/phoenix/bin/sqlline.py hadoop102,hadoop103,hadoop104:2181 |
| 107 | +``` |
| 108 | + |
| 109 | + |
| 110 | + |
| 111 | +### 1)显示所有表 |
| 112 | + |
| 113 | +``` |
| 114 | +!table 或 !tables |
| 115 | +``` |
| 116 | + |
| 117 | + |
| 118 | + |
| 119 | +### 2)创建表 |
| 120 | + |
| 121 | +``` |
| 122 | +CREATE TABLE IF NOT EXISTS us_population ( |
| 123 | + state CHAR(2) NOT NULL, |
| 124 | + city VARCHAR NOT NULL, |
| 125 | + population BIGINT |
| 126 | + CONSTRAINT my_pk PRIMARY KEY (state, city)); |
| 127 | +``` |
| 128 | + |
| 129 | +说明: |
| 130 | + |
| 131 | +- char类型必须添加长度限制 |
| 132 | +- varchar 可以不用长度限制 |
| 133 | +- 主键映射到 HBase 中会成为 Rowkey. 如果有多个主键(联合主键), 会把多个主键的值拼成 rowkey |
| 134 | +- 在 Phoenix 中, 默认会把表名,字段名等自动转换成大写. 如果要使用消息, 需要把他们用双引号括起来. |
| 135 | + |
| 136 | + |
| 137 | + |
| 138 | +### 3)插入数据 |
| 139 | + |
| 140 | +``` |
| 141 | +upsert into us_population values('NY','NewYork',8143197); |
| 142 | +upsert into us_population values('CA','Los Angeles',3844829); |
| 143 | +upsert into us_population values('IL','Chicago',2842518); |
| 144 | +说明: upset可以看成是update和insert的结合体. |
| 145 | +``` |
| 146 | + |
| 147 | +### 4)查询记录 |
| 148 | + |
| 149 | +``` |
| 150 | +select * from US_POPULATION; |
| 151 | +select * from us_population where state='NY'; |
| 152 | +``` |
| 153 | + |
| 154 | + |
| 155 | +5)删除记录 |
| 156 | + |
| 157 | +``` |
| 158 | +delete from us_population where state='NY'; |
| 159 | +``` |
| 160 | + |
| 161 | + |
| 162 | +6)删除表 |
| 163 | + |
| 164 | +``` |
| 165 | +drop table us_population; |
| 166 | +``` |
| 167 | + |
| 168 | + |
| 169 | +7)退出命令行 |
| 170 | + |
| 171 | +``` |
| 172 | +! quit |
| 173 | +``` |
| 174 | + |
| 175 | + |
| 176 | + |
| 177 | +## 七、使用JDBC连接 |
| 178 | + |
| 179 | +添加如下依赖: |
| 180 | + |
| 181 | + |
| 182 | +```xml |
| 183 | +<!-- https://mvnrepository.com/artifact/org.apache.phoenix/phoenix-core --> |
| 184 | +<dependency> |
| 185 | + <groupId>org.apache.phoenix</groupId> |
| 186 | + <artifactId>phoenix-core</artifactId> |
| 187 | + <version>5.0.0-HBase-2.0</version> |
| 188 | +</dependency> |
| 189 | + |
| 190 | +<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --> |
| 191 | +<dependency> |
| 192 | + <groupId>org.apache.hadoop</groupId> |
| 193 | + <artifactId>hadoop-common</artifactId> |
| 194 | + <version>3.1.1</version> |
| 195 | +</dependency> |
| 196 | +``` |
| 197 | + |
| 198 | +测试连接: |
| 199 | + |
| 200 | +```java |
| 201 | +import java.sql.*; |
| 202 | + |
| 203 | +public class MyPhoenix { |
| 204 | +public static void main(String[] args) throws SQLException, ClassNotFoundException { |
| 205 | + |
| 206 | + //Class.forName("org.apache.phoenix.jdbc.PhoenixDriver"); |
| 207 | + |
| 208 | + Connection connection = DriverManager.getConnection("jdbc:phoenix:hadoop102:2181"); |
| 209 | + |
| 210 | + String sql = "select * from US_POPULATION"; |
| 211 | + |
| 212 | + PreparedStatement ps = connection.prepareStatement(sql); |
| 213 | + |
| 214 | + ResultSet resultSet = ps.executeQuery(); |
| 215 | + |
| 216 | + while (resultSet.next()){ |
| 217 | + System.out.println(resultSet.getString("STATE")+" " |
| 218 | + + resultSet.getString("CITY") + " " |
| 219 | + + resultSet.getLong("POPULATION")); |
| 220 | + |
| 221 | + } |
| 222 | + |
| 223 | + resultSet.close(); |
| 224 | + |
| 225 | + ps.close(); |
| 226 | + |
| 227 | + connection.close(); |
| 228 | +} |
| 229 | +} |
| 230 | +``` |
| 231 | + |
| 232 | + |
| 233 | + |
| 234 | + |
| 235 | + |
0 commit comments