|
| 1 | +# 散列表 |
| 2 | + |
| 3 | +> 关键词: hash, 哈希表, 哈希函数 |
| 4 | +
|
| 5 | +<!-- TOC depthFrom:2 depthTo:2 --> |
| 6 | + |
| 7 | +- [1. 什么是散列表](#1-什么是散列表) |
| 8 | +- [2. 散列函数](#2-散列函数) |
| 9 | +- [3. 为什么需要散列表](#3-为什么需要散列表) |
| 10 | +- [4. 散列表的应用场景](#4-散列表的应用场景) |
| 11 | +- [5. 思考](#5-思考) |
| 12 | +- [6. 参考资料](#6-参考资料) |
| 13 | + |
| 14 | +<!-- /TOC --> |
| 15 | + |
| 16 | +## 1. 什么是散列表 |
| 17 | + |
| 18 | +散列表的英文叫“Hash Table”,我们平时也叫它“哈希表”或者“Hash 表”。 |
| 19 | + |
| 20 | +**散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表**。 |
| 21 | + |
| 22 | +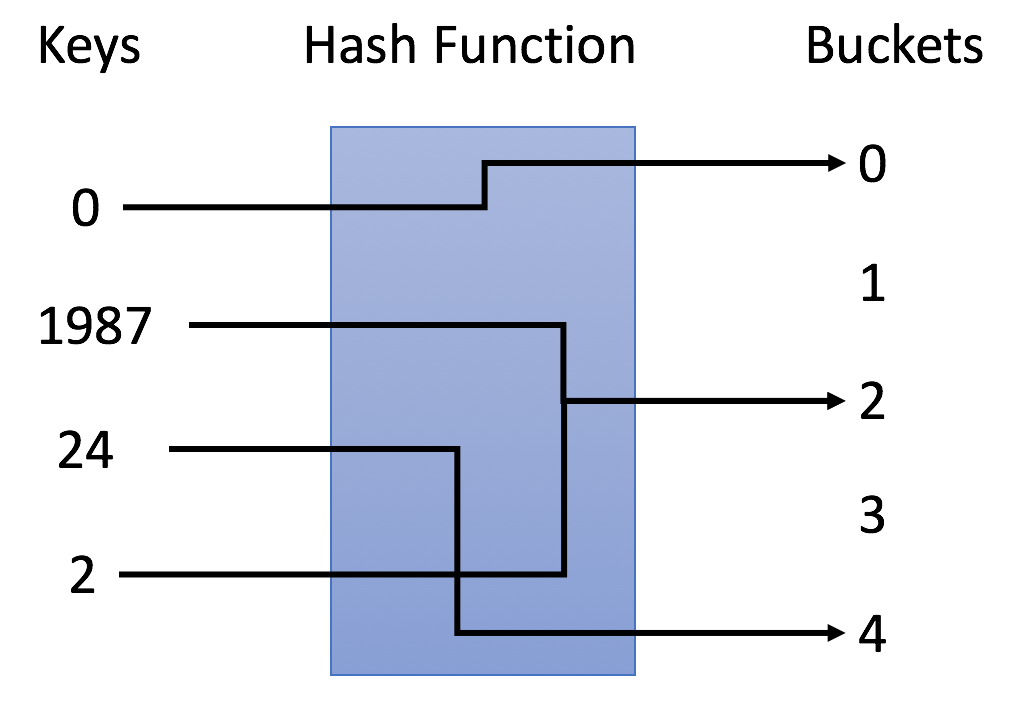 |
| 23 | + |
| 24 | +散列表通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。按照键值查询元素时,用同样的散列函数,将键值转化数组下标,从对应的数组下标的位置取数据。 |
| 25 | + |
| 26 | +有两种不同类型的哈希表:哈希集合和哈希映射。 |
| 27 | + |
| 28 | +- `哈希集合`是`集合`数据结构的实现之一,用于存储`非重复值`。 |
| 29 | +- `哈希映射`是`映射` 数据结构的实现之一,用于存储`(key, value)`键值对。 |
| 30 | + |
| 31 | +在`标准模板库`的帮助下,哈希表是`易于使用的`。大多数常见语言(如 Java,C ++ 和 Python)都支持哈希集合和哈希映射。 |
| 32 | + |
| 33 | +## 2. 散列函数 |
| 34 | + |
| 35 | +散列函数,顾名思义,它是一个函数。我们可以把它定义成 **hash(key)**,其中 key 表示元素的键值,hash(key) 的值表示经过散列函数计算得到的散列值。 |
| 36 | + |
| 37 | +哈希表的关键思想是使用哈希函数将键映射到存储桶。更确切地说, |
| 38 | + |
| 39 | +1. 当我们插入一个新的键时,哈希函数将决定该键应该分配到哪个桶中,并将该键存储在相应的桶中; |
| 40 | +2. 当我们想要搜索一个键时,哈希表将使用相同的哈希函数来查找对应的桶,并只在特定的桶中进行搜索。 |
| 41 | + |
| 42 | +散列函数将取决于 `键值的范围` 和 `桶的数量` 。 |
| 43 | + |
| 44 | +**散列函数设计的基本要求**: |
| 45 | + |
| 46 | +1. 散列函数计算得到的散列值是一个非负整数; |
| 47 | +2. 如果 key1 = key2,那 hash(key1) == hash(key2); |
| 48 | +3. 如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)。 |
| 49 | + |
| 50 | +### 散列冲突 |
| 51 | + |
| 52 | +即便像业界著名的[MD5](https://zh.wikipedia.org/wiki/MD5)、[SHA](https://zh.wikipedia.org/wiki/SHA家族)、[CRC](https://zh.wikipedia.org/wiki/循環冗餘校驗)等哈希算法,也无法完全避免这种**散列冲突**。 |
| 53 | + |
| 54 | +该如何解决散列冲突问题呢?我们常用的散列冲突解决方法有两类,开放寻址法(open addressing)和链表法(chaining)。 |
| 55 | + |
| 56 | +### 装载因子 |
| 57 | + |
| 58 | +当散列表中空闲位置不多的时候,散列冲突的概率就会大大提高。为了尽可能保证散列表的操作效率,一般情况下,我们会尽可能保证散列表中有一定比例的空闲槽位。我们用**装载因子**(load factor)来表示空位的多少。 |
| 59 | + |
| 60 | +装载因子的计算公式是: |
| 61 | + |
| 62 | +``` |
| 63 | +散列表的装载因子 = 填入表中的元素个数 / 散列表的长度 |
| 64 | +``` |
| 65 | + |
| 66 | +**装载因子越大,说明空闲位置越少,冲突越多**,散列表的性能会下降。不仅插入数据的过程要多次寻址或者拉很长的链,查找的过程也会因此变得很慢。 |
| 67 | + |
| 68 | +当装载因子过大时,就需要对散列表扩容。新申请一个更大的散列表,将数据搬移到这个新散列表中。针对数组的扩容,数据搬移操作比较简单。但是,针对散列表的扩容,数据搬移操作要复杂很多。因为散列表的大小变了,数据的存储位置也变了,所以我们需要通过散列函数重新计算每个数据的存储位置。 |
| 69 | + |
| 70 | +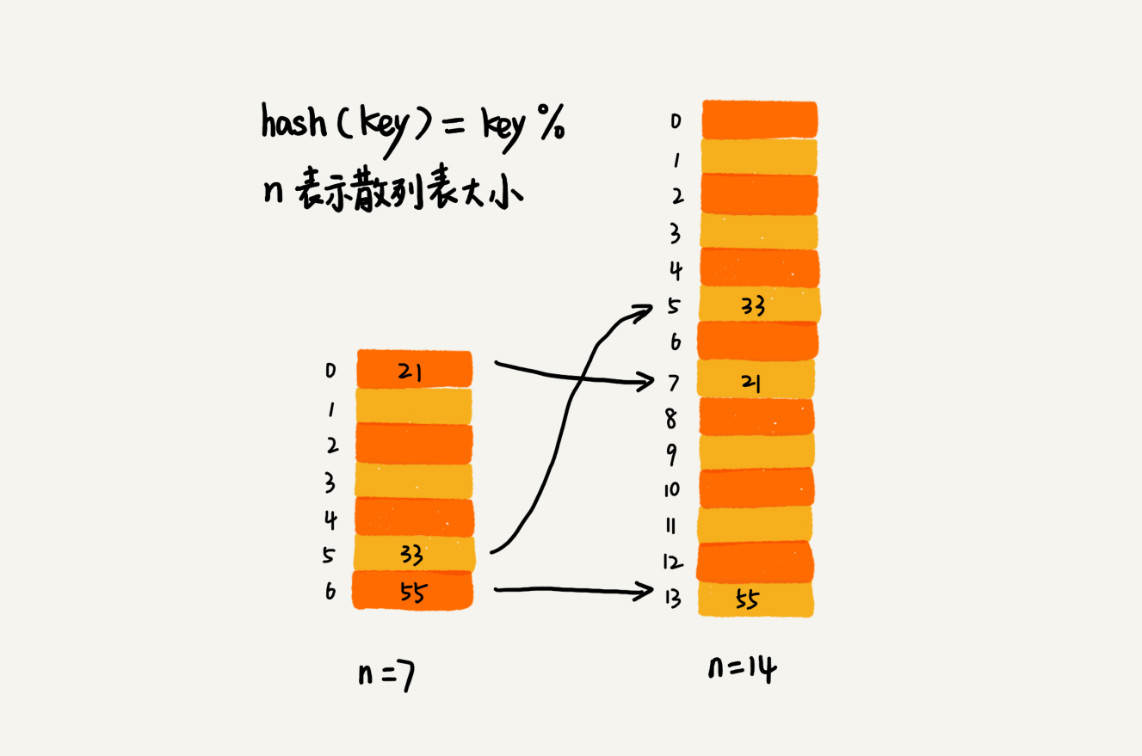 |
| 71 | + |
| 72 | +插入一个数据,最好情况下,不需要扩容,最好时间复杂度是 O(1)。最坏情况下,散列表装载因子过高,启动扩容,我们需要重新申请内存空间,重新计算哈希位置,并且搬移数据,所以时间复杂度是 O(n)。用摊还分析法,均摊情况下,时间复杂度接近最好情况,就是 O(1)。 |
| 73 | + |
| 74 | +装载因子阈值需要选择得当。如果太大,会导致冲突过多;如果太小,会导致内存浪费严重。 |
| 75 | + |
| 76 | +#### 开放寻址法 |
| 77 | + |
| 78 | +开放寻址法的核心思想是,如果出现了散列冲突,我们就重新探测一个空闲位置,将其插入。 |
| 79 | + |
| 80 | +**当数据量比较小、装载因子小的时候,适合采用开放寻址法。这也是 Java 中的 `ThreadLocalMap` 使用开放寻址法解决散列冲突的原因**。 |
| 81 | + |
| 82 | +**线性探测**(Linear Probing):当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。 |
| 83 | + |
| 84 | +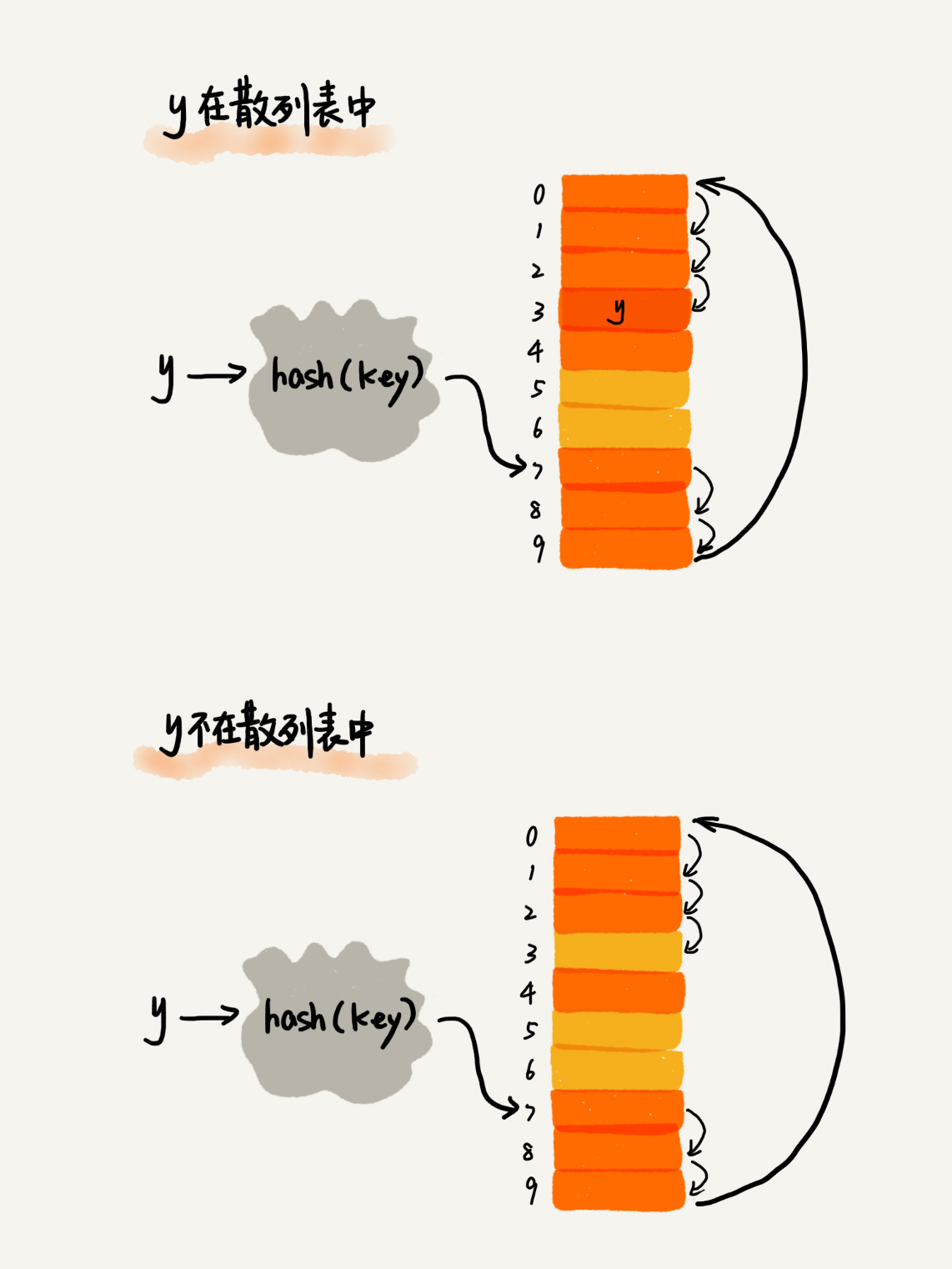 |
| 85 | + |
| 86 | +对于使用线性探测法解决冲突的散列表,删除操作稍微有些特别。我们不能单纯地把要删除的元素设置为空。这是为什么呢?在查找的时候,一旦我们通过线性探测方法,找到一个空闲位置,我们就可以认定散列表中不存在这个数据。但是,如果这个空闲位置是我们后来删除的,就会导致原来的查找算法失效。本来存在的数据,会被认定为不存在。这个问题如何解决呢? |
| 87 | + |
| 88 | +我们可以将删除的元素,特殊标记为 deleted。当线性探测查找的时候,遇到标记为 deleted 的空间,并不是停下来,而是继续往下探测。 |
| 89 | + |
| 90 | +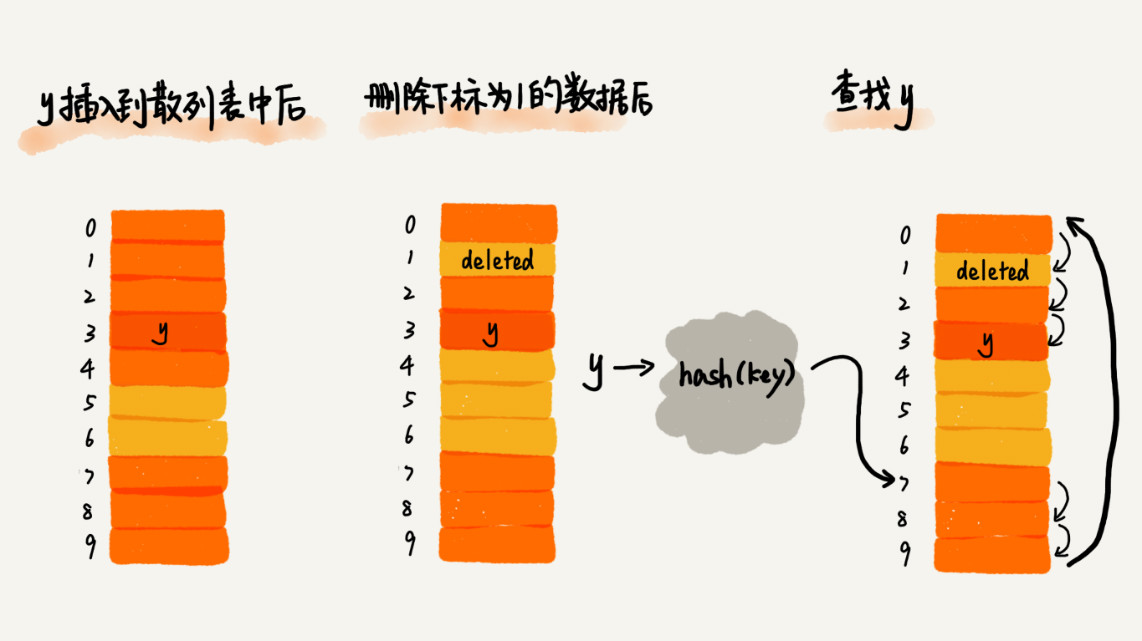 |
| 91 | + |
| 92 | +线性探测法其实存在很大问题。当散列表中插入的数据越来越多时,散列冲突发生的可能性就会越来越大,空闲位置会越来越少,线性探测的时间就会越来越久。极端情况下,我们可能需要探测整个散列表,所以最坏情况下的时间复杂度为 O(n)。同理,在删除和查找时,也有可能会线性探测整张散列表,才能找到要查找或者删除的数据。 |
| 93 | + |
| 94 | +#### 链表法 |
| 95 | + |
| 96 | +在散列表中,每个“桶(bucket)”或者“槽(slot)”会对应一条链表,所有散列值相同的元素我们都放到相同槽位对应的链表中。 |
| 97 | + |
| 98 | +链表法比起开放寻址法,对大装载因子的容忍度更高。开放寻址法只能适用装载因子小于 1 的情况。接近 1 时,就可能会有大量的散列冲突,导致大量的探测、再散列等,性能会下降很多。但是对于链表法来说,只要散列函数的值随机均匀,即便装载因子变成 10,也就是链表的长度变长了而已,虽然查找效率有所下降,但是比起顺序查找还是快很多。 |
| 99 | + |
| 100 | +**基于链表的散列冲突处理方法比较适合存储大对象、大数据量的散列表,而且,比起开放寻址法,它更加灵活,支持更多的优化策略,比如用红黑树代替链表**。 |
| 101 | + |
| 102 | +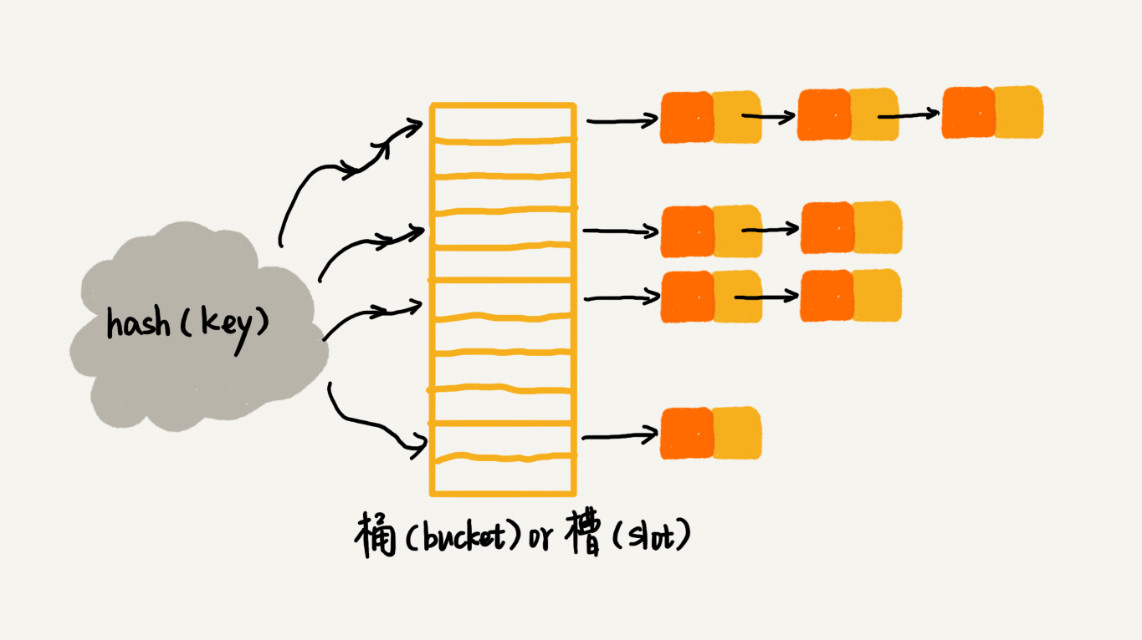 |
| 103 | + |
| 104 | +当插入的时候,我们只需要通过散列函数计算出对应的散列槽位,将其插入到对应链表中即可,所以插入的时间复杂度是 O(1)。当查找、删除一个元素时,我们同样通过散列函数计算出对应的槽,然后遍历链表查找或者删除。那查找或删除操作的时间复杂度是多少呢? |
| 105 | + |
| 106 | +实际上,这两个操作的时间复杂度跟链表的长度 k 成正比,也就是 O(k)。对于散列比较均匀的散列函数来说,理论上讲,k=n/m,其中 n 表示散列中数据的个数,m 表示散列表中“槽”的个数。 |
| 107 | + |
| 108 | +## 3. 为什么需要散列表 |
| 109 | + |
| 110 | +## 4. 散列表的应用场景 |
| 111 | + |
| 112 | +哈希算法的应用非常非常多,最常见的七个,分别是: |
| 113 | + |
| 114 | +- **安全加密**:如:MD5、SHA |
| 115 | +- **唯一标识**:UUID |
| 116 | +- 数据校验:数字签名 |
| 117 | +- **散列函数**: |
| 118 | +- **负载均衡**:会话粘滞(session sticky)负载均衡算法。**可以通过哈希算法,对客户端 IP 地址或者会话 ID 计算哈希值,将取得的哈希值与服务器列表的大小进行取模运算,最终得到的值就是应该被路由到的服务器编号。** 这样,我们就可以把同一个 IP 过来的所有请求,都路由到同一个后端服务器上。 |
| 119 | +- 数据分片 |
| 120 | +- 分布式存储:一致性哈希算法、虚拟哈希槽 |
| 121 | + |
| 122 | +### 典型应用场景 |
| 123 | + |
| 124 | +Java 的 HashMap 工具类,其 |
| 125 | + |
| 126 | +- HashMap 默认的初始大小是 16 |
| 127 | +- 最大装载因子默认是 0.75,当 HashMap 中元素个数超过 0.75\*capacity(capacity 表示散列表的容量)的时候,就会启动扩容,每次扩容都会扩容为原来的两倍大小。 |
| 128 | +- HashMap 底层采用链表法来解决冲突。即使负载因子和散列函数设计得再合理,也免不了会出现拉链过长的情况,一旦出现拉链过长,则会严重影响 HashMap 的性能。在 JDK1.8 版本中,对 HashMap 做了进一步优化:引入了红黑树。当链表长度太长(默认超过 8)时,链表就转换为红黑树。我们可以利用红黑树快速增删改查的特点,提高 HashMap 的性能。当红黑树结点个数少于 8 个的时候,又会将红黑树转化为链表。因为在数据量较小的情况下,红黑树要维护平衡,比起链表来,性能上的优势并不明显。 |
| 129 | + |
| 130 | +## 5. 思考 |
| 131 | + |
| 132 | +1. 假设我们有 10 万条 URL 访问日志,如何按照访问次数给 URL 排序? |
| 133 | +2. 有两个字符串数组,每个数组大约有 10 万条字符串,如何快速找出两个数组中相同的字符串? |
| 134 | + |
| 135 | +## 6. 参考资料 |
| 136 | + |
| 137 | +- [数据结构与算法之美](https://time.geekbang.org/column/intro/100017301) |
0 commit comments